Initial presentation for big data anlytics graduation project
41
Big Data Analytics
-
Upload
independent -
Category
Documents
-
view
4 -
download
0
Transcript of Initial presentation for big data anlytics graduation project

Big Data Analytics

Outlines
• Big Data Overview.• Big Data Management Systems
• Hadoop• Cassandra• Datastax
• Big Data Query languauges• Hive QL• CQL

What is Big Data ?
• Big data is a popular term used to describe the exponential growth, availability and use of information, both structured and unstructured. It can serve as the basis for innovation, differentiation and growth.
Big DataIt is a collection of data sets too large and complex that it becomes difficult to process using on-hand database management tools or traditional data processing applications.

Opportunities for a New Approach to Analytics New Applications Driving Data Volume
2000’s(CONTENT & DIGITAL ASSET MANAGEMENT)
1990’s(RDBMS & DATA WAREHOUSE)
2010’s(NO-SQL & KEY/VALUE)
VOLU
ME O
F INFO
RMATIO
N
LARGE
SMALL
MEASURED INTERABYTES1TB = 1,000GB
MEASURED INPETABYTES1PB = 1,000TB
WILL BE MEASURED INEXABYTES1EB = 1,000PB

Big Data Management Systems Hadoop
Hadoop as a way to implement the MapReduce function.
Hadoop

Why Hadoop?
Answer: Big Datasets!

What do we Mean by Hadoop
• A framework for performing big data analytics– An implementation of the MapReduce paradigm
– Hadoop glues the storage and analytics together and provides reliability, scalability, and management

Structure of Apache hadoop platform (Hadoop ecosystem) cont.
consists of • JobTracker• TaskTracker • NameNode • DataNode• A slave or worker node acts as both a DataNode and TaskTracker.

Structure of Apache hadoop platform (Hadoop ecosystem) cont
• File system• MapReduce engine

Hadoop and HDFS

File System
Hadoop Distributed File SystemHDFS is a distributed, scalable, and portable file system written in Java for the Hadoop framework .Name node Data node Secondary namenodeData awareness

HDFS ArchitectureNamenode
Breplication
Rack1 Rack2Client
Blocks
Datanodes Datanodes
Client
Write
Read
Metadata ops Metadata(Name, replicas..)(/home/foo/data,6. ..
Block ops

JobTracker and TaskTracker: the MapReduce engine
• JobTracker• TaskTracker

HDFS MapReduce engine

Putting it all Together: MapReduce and HDFS
a
Task TrackerTask Tracker Task Tracker
Job Tracker
Hadoop Distributed File System (HDFS)
Client/Dev
Large Data Set(Log files, Sensor Data)
Map Job
Reduce Job
Map Job
Reduce Job
Map Job
Reduce Job
Map Job
Reduce Job
Map Job
Reduce Job
Map Job
Reduce Job2
1
3
4

MapReduce
Cat
Bat
Dog
Other Words(size:TByte)
map
map
map
map
split
split
split
split
combine
combine
combinereduce
reduce
reduce
part0
part1
part2

Hadoop cluster using visualization
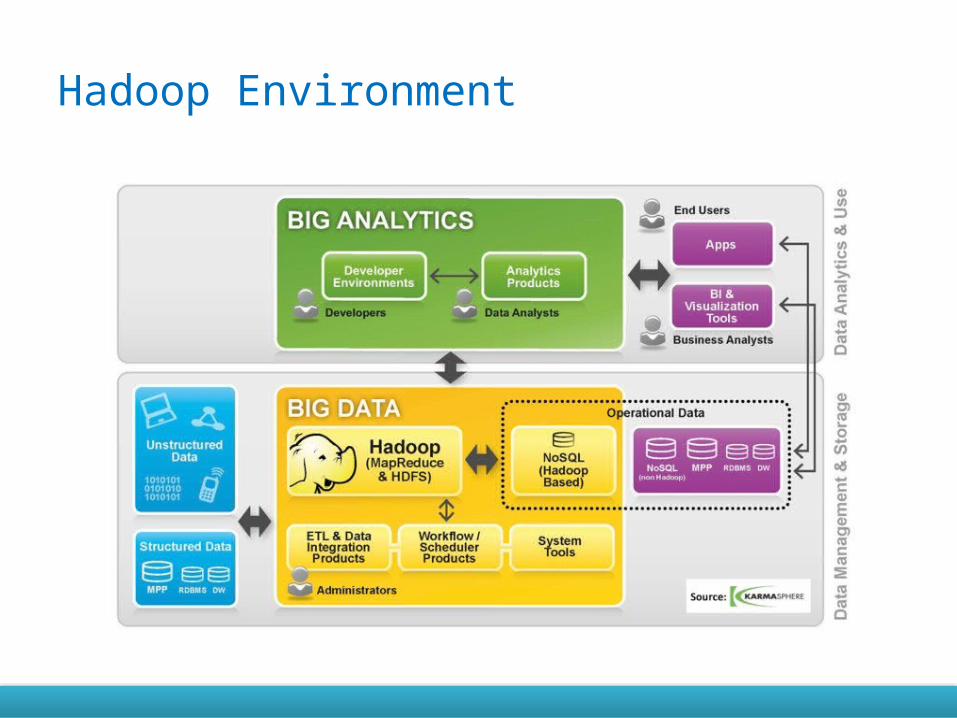
Hadoop Environment

Hadoop Environment cont.

Big Data Management Systems Apache Cassandra
Apache Cassandra is a massively scalable NoSQL database. Cassandra is architected to handle real-time big data workloads across multiple data centers with no single point of failure, providing enterprises with extremely high database performance and continuous availability.
Cassandra

Key features of Apache Cassandra
Cassandra is built for enterprise-class, real-time database deployments.Its feature set includes:• Big data scalability.• Peer-to-peer.• Fast linear performance• Elastic scalability • No single point of failure.• Multi-data center/cloud capable

Key features of Apache Cassandra cont.• Location independence.• Dynamic schema. • Tunable data consistency.• Data compression.• Cloud-ready.• SQL-like language (CQL).• Memory efficient.• Easy setup.

Cassandra data model

What is Data stax enterprise?
DataStax Enterprise is a big data platform built on Apache Cassandra that manages real-time, analytics, and enterprise search data.
DataStax Enterprise

Key Features of DataStax Enterprise• Production Certified Cassandra • No Single Point of Failure• Reserve Job Tracker • Multiple Job Trackers • Hadoop MapReduce using Multiple Cassandra File Systems.
• Analytics Without ETL • Elastic Workload Re-provisioning.

Key Features of DataStax Enterprise cont’• Streamlined Setup and Operations • Hive Support.• Pig Support.• Enterprise Search Capabilities • Migration of RDBMS data.• Runtime Logging.• Support for Mahout• Full Integration with DataStax OpsCenter

What’s Hive?
Apache Hive is a data warehousing solution which is built over Hadoop. It is powered by HiveQL which is a declarative SQL language compiled directly into Map Reduce jobs which are executed over the underlying Hadoop architecture.
Apache Hive

Advantages Of Using APACHE HIVE
• Fits the low level interface requirement of Hadoop perfectly.
• Supports external tables which make it possible to process data without actually storing in HDFS.
• It has a rule based optimizer for optimizing logical plans.
• Supports partitioning of data at the level of tables to improve performance.
• Metastore or Metadata store is a big plus in the architecture which makes the lookup easy.

Disadvantages Of Using APACHE HIVE• No support for update and delete.
• No support for singleton inserts. Data is required to be loaded from a file using LOAD command.
• No access control implementation.
• Correlated sub queries are not supported.

What's New at Hive QL
At Data Units: • Partitions• Buckets (or Clusters)Complex Types•Structs: the elements within the type can be accessed using the DOT (.) notation.
• Maps (key-value tuples)• Arrays (indexable lists)

Cassandra Query Language
Effectively a structured, Attempting to push as much server-side as possible, familiar syntax, User friendly API, SQL like query language.
CQL

CQL Advantages
• Readability• Ease of use• SQL like• Stable

CQL Disadvantages
• No joins• no ACID transactions• No Adhoc Queries• No group by• No order by

CQL (Platforms) Support
• PHP• Python• Java• Ruby

CQL (IDEs) Support
• Eclipse• Netbeans• Python

Installing Hadoop

Multi-node cluster

Multi-node cluster

R on Hadoop

END
Thanks