
Implementation of multiuser personal web crawler
18
Implementation of Multiuser Personal Web Crawler Ms. Swati Mali , Dr. B.B. Meshram Abstract-- The search engines many times give irrelevant searches which are based on user preferences in general. Moreover, they also maintain the user search logs and other information which is taken as privacy breach. The personal web crawlers not only magically understand precise requirements, but also they can be scheduled to automatically grab the information at regular intervals. These personal crawlers are not as fast as the commercial crawlers are, but they serve the sole purpose of getting the exact information at the desk. This paper details implementation of such an effective multiuser personal web crawler where one user can manage multiple topics of interest. The work is also supported with experimental evaluation. Index Terms—Web mining, focused crawler, personal web crawler, page relevance, Link analysis, content analysis, web page change detection I. INTRODUCTION DEFINITION: A crawler is an automated script, which independently browses the World Wide Web. It starts with a seed URL and then follows the links on each page in a Breadth First or a Depth First method. A Web Crawler searches through all the Web Servers to find information about a particular topic. However, searching all the Web Servers and the pages, is not realistic, because of the growth of the Web and their refresh rates. To traverse the web quickly and entirely is an expensive, unrealistic goal because of the required hardware and network resources. All search engines internally use web crawlers to keep the copies of data afresh. Google crawlers run on a distributed network of thousands of low-cost computers and can therefore carry out fast parallel processing. This is why and how Google returns results within fraction of seconds. Implementing a crawler isn’t an easy task. There are many issues which need to be considered while designing and implementing the same. The crawler can only download a fraction of the Web pages within a given time. It also needs to prioritize its downloads. One cant ignore the fact that by the time the crawler is downloading the last pages from a site, it is very likely that new pages have been added to the site, or that pages have already been updated or even deleted[1]. The volume and the dynamic nature of web combine to produce a wide variety of possible crawlable URLs. Considering all the above points and also considering the memory and computation limitations of personal engines, one needs to emphasize on how to identify the promising links that lead to target documents, and avoid off-topic searches. Out of all crawler architectures, the focused crawling is the only option which serves all the needs of web crawler. Moreover, it targets only at part of web, not the entire WWW. The paper starts with the introduction to the topic and is followed by literature review in section 2. Section 3 details the system
Transcript of Implementation of multiuser personal web crawler

Implementation of Multiuser Personal Web Crawler
Ms. Swati Mali , Dr. B.B. Meshram
Abstract-- The search engines many times giveirrelevant searches which are based on userpreferences in general. Moreover, they alsomaintain the user search logs and otherinformation which is taken as privacybreach. The personal web crawlers not onlymagically understand precise requirements,but also they can be scheduled toautomatically grab the information atregular intervals. These personal crawlersare not as fast as the commercial crawlersare, but they serve the sole purpose ofgetting the exact information at the desk.This paper details implementation of such aneffective multiuser personal web crawlerwhere one user can manage multiple topics ofinterest. The work is also supported withexperimental evaluation.
Index Terms—Web mining, focused crawler,personal web crawler, page relevance, Linkanalysis, content analysis, web page changedetection
I. INTRODUCTION
DEFINITION: A crawler is an automatedscript, which independently browses theWorld Wide Web. It starts with a seedURL and then follows the links on eachpage in a Breadth First or a Depth Firstmethod.
A Web Crawler searches through allthe Web Servers to find informationabout a particular topic. However,searching all the Web Servers and thepages, is not realistic, because of thegrowth of the Web and their refreshrates. To traverse the web quickly andentirely is an expensive, unrealisticgoal because of the required hardware
and network resources. All searchengines internally use web crawlers tokeep the copies of data afresh. Googlecrawlers run on a distributed network ofthousands of low-cost computers and cantherefore carry out fast parallelprocessing. This is why and how Googlereturns results within fraction ofseconds.
Implementing a crawler isn’t aneasy task. There are many issues whichneed to be considered while designingand implementing the same. The crawlercan only download a fraction of the Webpages within a given time. It also needsto prioritize its downloads. One cantignore the fact that by the time thecrawler is downloading the last pagesfrom a site, it is very likely that newpages have been added to the site, orthat pages have already been updated oreven deleted[1].
The volume and the dynamic nature ofweb combine to produce a wide variety ofpossible crawlable URLs. Considering allthe above points and also consideringthe memory and computation limitationsof personal engines, one needs toemphasize on how to identify thepromising links that lead to targetdocuments, and avoid off-topic searches.Out of all crawler architectures, thefocused crawling is the only optionwhich serves all the needs of webcrawler. Moreover, it targets only atpart of web, not the entire WWW.
The paper starts with theintroduction to the topic and isfollowed by literature review in section2. Section 3 details the system

architecture. The algorithms used forimplem- entation are listed in section4. Section 5 deals with database design.The experimental evaluation are given insections 6. The paper ends withconclusion and future scope given in thelast section, section 7.
II. LITERATURE SURVEYThe behavior of a Web crawler is
the outcome of a combination of policiesviz, a selection policy, a re-visit policy, apoliteness policy and a parallelization policyEvery crawler follows the Selectionpolicy as it marks the most relevantpages to download. Moreover, the dynamicnature of web involves many events suchas creations, updates and deletions ofthe web pages. From the search engine'spoint of view, there is a costassociated with not detecting an event,and thus having an outdated copy of aresource. This makes the implementationof revisit policy an important matter.The question of whether the page shouldbe recrawled or not can be answered bytwo properties of the page viz,freshness and age. Also, to reduce theworkload of crawler it must revisit onlythe pages those are changed since thelast visit.
Focused Crawler is defined as the Web
crawler that attempts to download pagesthat are similar to each other. It isalso called a Topic Crawler because ofits way of working. The topic vector isnothing but a set of keywords and theirassociated weights. The topic vector arewritten as[3],
T={(K1,W1), (K2,W2), (K3,W3),…….(Kn,Wn),}Where Ki is ith keyword and Wi is theassociated weight. Sum of all weightssums to 1.
Web Page Change Detection
Most of the research done to detectchange in web pages represent the pagesin tree or graph form. The nodes usedcontain some information that representsthe page structure and page contentinformation. Next time when the same URLis encountered, again a tree isconstructed for the page inconsideration and compared level bylevel for changes. The method is veryfullproof but involves too muchcomputation and memory for creatingand storing a tree for every URLencountered . Thus all the methods goingfor graph and tree representation of webpages become obsolete for personal webcrawlers[4][5][6][7][8].
Relevancy ComputationThe general methods of relevancy
computation involve representing theentire document as a vector where thevector contain some characteristicinformation of the page viz, links,images, keywords etc. This documentvector Vi is compared with anotherdocument vector Vi+1. The similaritymeasure computed in the range of [0,1]tells the similarity or dissimilarity ofthe documents. The 0 value says they aretotally different while the value 1 saysthey are completely similar. The methodslike Dice calculation, Jaquard standard,Set/Bag method, they all follow similarapproach for computing the relevancy.These methods also become impracticalfor the same reason as for the web pagechange detection methods given above[9][10][11][12][13].
III. SYSTEM ARCHITECTURE
Problem Statement: Developing anInformation Monitoring Tool to track thechanges in web information using afocused web crawler.
The idea here is to create a webbased multiuser application. Users can

create multiple topic profiles whereevery topic is a set of search stringand associated weights. The backbone isa focused crawler that accepts thoseuser defined topics as input. Itsearches the pages those are morerelevant as per the weights defined andranks them by using link analysis andthe content analysis method. It alsotakes care of the pages modified afterthe last search and checks them for thechanges. Once those pages qualify therelevancy criteria and the web pagechange criteria or one of them, thosepages are downloaded, the links areextracted from them and are added to therepository. The repository contains theinformation of metadata and the actuallinks. The database is then processedfurther with data mining algorithms toextract the precise knowledge of therelevant web pages. User can rerun thesesearches on adhoc basis or it can bescheduled to run on periodic basis. Thefocused crawler concentrates more on re-visit policy of web crawler and webchange detection policy.
Seed URL Generator
Calculate string1, string2
Discard URL
Extract content
Calculate text code
Calculate IVal
Com pare param eters
Extract URLs
URL List
Change in Text Change in Page structure
Change in im ageDeterm ine Change in pageDeterm ine Change
in page
Repository Managem ent Layer
Seed Generation Layer
Parse PageRelevance com putation layer
Link Analysis Content Analysis Com pute Relevance
Rank URLs Download PageKB
Figure 2: The Four LayerArchitecture of Multiuser Personal
Web Crawler
The four-layer architecturegenerates the seed URL frontier forevery topic. The next important URL isretrieved from the queue; it then iscompared against the database to checkwhether it was visited earlier. If thisis not a first visit, then it is checkedfor changes in structure, content andimage with the values stored in thedatabase. If the change is significantor the page the visited for the firsttime, then it gets a place in the searchresult. To decide its position in theresult domain, its relevance is computedusing link analysis and content analysisand accordingly the URLs are sorted. Inaddition, if the page is visited for thefirst time, the values for pagestructure, content, and image are storedin the database. If the URL in hand doesnot satisfy any of the criteriamentioned above, it is simply discarded.
IV. IMPLEMENTATIONA. Layer 1: Seed URL Generator
The performance of crawler alsodepends on the URL frontier. Most of theusers use search engines to get the datafrom WWW. Most of the times, even thetechnical users do not know from wherethe search should start. All these factslead to need of having a systematicmethod of generating seed URL queue.
Any user defined seed URL may not besufficient to reach all the links thosehold the data for the intended query.So, instead of relying on user’sknowledge this system uses its ownmethod for generating the URL frontieras: the search query is given as inputto three different search engines viz,Google, Yahoo and Bing. The most commonN (N<=10) results are the most relevantseed URLs to start the search with. Thissubsystem can be illustrated as,

Figure 3 : Seed Pages Fetching Sub-
System
Figure 4 : The Seed Generation Layer
Illustrated
Here the system takes resultingURLs which are common in all the threesearch engine results or common in atleast two search engine results. A URL,which is common in all three searchengines like Google, Yahoo, and Bing, itis assumed that this common searchresult URL is most relevant for thisquery. Thus, these URLs are the seedURLs, and a URL that is common in threesearch engines result by experiment,belongs to most relevant category seedURLs
B. Layer 2: Proposed Page Update criterionThe following changes are of
importance when considering changes in aweb page [1][14],
Change in page structure. Change in text contents. Change in image (Hyperlinked or as
a part of the page).
B.1 Changes in Page StructureThis method tries to capture the
changes in the structure of pages. Here by structure we mean how are the different texts and images and other
objects displayed on that page. All these objects are designed using HTML orother formatting tools. These tools use tags to define their characteristics andactual appearance on the page. Any change in structure will lead to rearrangement of tags.
The algorithm creates two strings using the tags of that page [14].
The first string will store thecharacters appearing at firstposition in the tag for all tagsin the order they appear.
The second string stores thecharacter at the last position ina tag for all tags in the orderthey appear.
In case the tag contains only oneletter, it will be repeated as itis, in the second string.
For example consider the following page,
Figure 5: Example Web Page
String1: [hhbhppp]
String2: [ldy1ppp]
The proposed method offers the followingadvantages
The traditional approaches? ofstoring the pages as a treestructure uses a lot of storagespace as well as causes a lot ofinconvenience at time of refresh,as the tree structure has to be

compared. Here only a string hasto be compared to perform thedesired operation. Even if anytag is added or deleted from thepage, the new string will recordthe change and the differencewill show in the comparison.
At the time of page updating, theclient crawler only needs tocheck these two strings todetermine a change.
If the String1 itself returns achanged value, there is no needfor comparison with the secondstring or with other changeparameters for that matter.
This method will work fordifferent pages with differentand varied formatting stylesaccurately capturing theirstructures at a given point oftime.
For most cases, a check with thefirst string should suffice. Thesecond string check is includedjust to add surety to the methodas the check for String1 may failin the unlikely case of a tagstarting with some letterreplacing another tag startingwith the same letter.
B.2 Changes in Text ContentThis is the next step to be
carried out if the first level ofdetermining changes does not find anychanges. It may be the case that thestructure of the page remains intact butthere is some definite change in theactual text content of the page. Thischange will not be captured by the abovemethod[14].
In this method, we assign a codeto all text content appearing in a page.At the time of page updating, onlycomparison will be made to the text codeof that page and if any change in thatvalue is detected for the actual copy onthe web as compared to the local copy,
the page will be refreshed or re-crawled[6]. The formula for text coding = ∑(frequency) * ASCIIsymbol / Distinct symbol countFor example, consider the following partial text content,March 26, 2007 issue - The stereotype of the"dumbjock" has never sounded right to CharlesHillman. A jock himself, he plays hockey four times aweek, but when he isn't body-checking his opponentson the ice, he's giving his mind a comparable workoutin his neuroscience and kinesiology lab at theUniversity of Illinois. Nearly every semester in hisclassroom, he says, students on the women's cross-country team set the curve on his exams. So recentlyhe started wondering if there was a vital andoverlooked link between brawn and brains—if longhours at the gym could somehow build up not justmuscles, but minds.
The ASCII sum of characters: 56652Total character count: 619Distinct character count: 43Therefore, the code for the text will be: 1317.488403
Even minute changes in above text, results in significant changes in parameters as given below.
March 26, 2007 issue - The stereotype of the "dumbjock" has never sounded right to Charles Hillman. Ajock himself, he used to play hockey five times aweek, but when he isn't body-checking his opponentson the ice, he's giving his mind a comparable workoutin his neuroscience and kinesiology lab at theUniversity of Florida. Nearly every semester in hisclassroom, he says, students on the women's cross-country team set the curve on his exams. So recentlyhe started wondering if there was a vital andoverlooked link between brawn and brains—if longhours at the gym could somehow build up not justmuscles, but minds.
The parameters are as follows,The ASCII sum of characters: 57113Total character count: 625Distinct character count: 43

Therefore, the code for the text will be: 1328.209351
The proposed method offers the followingadvantages,
It gives a unique code for alltext contents on a particularpage.
The formula is designed to besuch that even a minute change ofaddition or deletion of asingle blank space is recordedsignificantly and with pin pointaccuracy by this code.
The use of coding of text systemeliminates the need for word-by-word parsing and comparison ofeach word at the time of pageupdating.
Only the code of that page iscompared, there is no issue ofstoring the whole page as anindexed structure, hence savingon large amount of storage.
ASCII values have been used inthe formula because each symbolhas a distinct representation inASCII table leading to noambiguity.
B. 3 Change in ImageWhile the above two methods may
suffice while dealing with normal pageswhich uses tags for formatting theirstructure and text contents, they willfail for image links. In this section,we propose a method to derive a code forimages to determine whether they haveundergone a change or not. Ideally, achange in a link to an image hyperlinkwill be reflected in the label of thehyperlink for that image and the samewill be depicted by the formula proposedin step 2. However, in case the textdoes not change but the image isreplaced, it will still be leftundetected [14]. Therefore, we propose the followingmethod for image change detection,
The first step requires the imageto be scaled to a standard size ofn*n. Here n is of the form 2x,where value of x may vary from 4to 6.
Convert the image to two tone andread as an n*n array with eachvalue being either zero or one.
For each row of n elements, wewill take 24 elements at a timeand convert it to a 4 digithexadecimal number. This willresult in each row being convertedto n/24 elements from n elementswith each element being a 4 digithexadecimal number.
After doing the same operation onall the rows, we obtain an n/24*n/24 array.
Simply, by computing thedeterminant of such an array, wecan reduce the image to as singlevalue (Ival).
For each image, an Ival will bestored and at time of page updating, theclient machines without actual downloadof image will calculate this Ival.
C. Layer 3 : Relevance Score ComputationThis Layer makes the topic vectorswork to focus more on the accurateresults. For the same it uses twofoldmethod to check the relevance andaccuracy of the data viz,
Relevance score method Link analysis method
In the end, the results are passed tothe Layer 2 to decide over the revisitpolicy.The need for this layer is that, after receiving URLs , the download process must check the URLs received for the following,
As in topic specific or afocused crawler, quality of thepages to be downloaded is veryimportant,, the relevance ispredetermined by parsing thepage contents withoutdownloading and checking for the

keywords of the page andcomparing them with the relevantkeywords of the main topic orcontext for which crawling hasto be done.
If a URL is found to be relevantfor downloading purpose or incase of full web crawlingsystems, it has to be sent foractual download. But to maintainthe quality of crawling, it isdesirable that there should be amethod to determine theimportance of a page.
C.1 Relevance Computation with Content Analysis Topic vector: T is a topic and denotes thetopic vector.
T = [(k1,w1), (k2,w2), (k3,w3),…. (kl,wl),]Where j k denotes j-th keyword or phrase of topic T.
wj is the weight of the j-th keyword or phrase, denotes importance ofthe j-th keyword or phrase in the topic T, and
Σwj = 1 , 1 ≤ j ≤ l . l = |T| , is the amount of keyword or phrase of topicT.
e.g If the topic under considerationis Software TestingIn addition, we consider some exampledata as,T= {(Test case, 0.25), (test coverage, 0.40), (test suite, 0.25), (test oracle, 0.10)}
Where test case, test coverage etcrefer to keywords and the numerical figures indicate their respective weights.
Algorithm To Compute Topic Specific Relevance[15]INPUT: A Web page (P), a weight table.OUTPUT : The relevance score of the Web page (P).Step 1 Initialize the relevance score of the Web page (P) to 0. RELEVANCE_P=0.
Step 2 Select first term (T) and corresponding weight (W) from the weighttable.Step 3 Calculate how many times the term (T) occurs in the Web page P. Let the number of occurrence is calculated in COUNT.Step 4 Multiply the number of occurrence calculated at step3 with the weight W. Letcall this TERM_WEIGHT. And TERM_WEIGHT=COUNT* W.Step 5 Add this term weight to RELEVANCE_P.So new RELEVANCE_P will be, RELEVANCE_P = RELEVANCE_P + TERM_WEIGHT.Step 6 Select the next term and weight from weight table and go to step3, untilall the terms in the weight table are visited.Step 7 End.
Contribution of Web Page As DomainAlgorithm : Contribution Of Web Page As DomainStep 1 If a Web page is not relevant thengoto step2. Initialize the level value of the URL to 0.Step 2 Extract URLs from the Web page andadd to the IRRE_TABLE with level value.Step 3 Until all the IRRE_TABLE entry arevisited, take one entry from IRRE_TABLE and goto step4.Step 4 If the level value of the URL is less than or equal to the tolerance limit then goto step5 otherwise discard the URL.Step 5 Calculate relevance for the Web page.Step 6 If the page is relevant to the domain then add it to the database, elsegoto Step 7.Step 7 Increase the level value of the URL and goto step2.Definition 2: Contribution of web page as domain
Uk = (|UKk|/|UD|)*Wk denotes thecontribution of D for k-th keyword orphrase of topic T.

Where |UKk| is the frequency thatthe k-th keyword or phrase Kk of thetopic T appears in the web D.
|UD| is the amount of effectivewords in D.
wk is the weight of the k-th keyword or phrase, denotes importance ofthe k-th keyword or phrase in the topic T,
Σwj = 1,1≤ j ≤ l .
Figure 7 : Contribution Of Web Page[15]
If a web page contains Occurrencesof the relevant words as,
Test case=5 Test coverage=7 Test suite =10 Test oracle=4 Total effective words= 26
Then its relevance score is calculated as, u1= 5/26 *0.25 =0.048 u2= 7/26 * 0.4 =0.108 u3= 10/26*0.25 =0.096 u4= 4/26 *0.10 =0.015
Relevance-Score Computation Relevance-score. The relevance-
score represents the relevance-score of a page. The relevance-score of the page D is defined as follows[3],
Sim (T,D) = ∑ k=1..l uk
Where l = |T| , it is the length ofT
uk is the contribution of D for k-th keyword or phrase of topic T, and it is defined by definition 2.
Finally, following the above definition, relevance score of the page in consideration is calculated as,
Relevance score= Sim(T,D)= k=1..4 ∑uk
= 0.048+0.108+0.096+0.015
=0.267C.2 Relevance Computation With Link Analysis
The parameter used to classify URLs in the important and unimportant categories is the difference of the backward link count (BkLK) and the forward link count[3].
Pvalue = FwdLK – BkLK
This difference will be known as thePvalue (priority value) of that page. A URL having the difference between FwdLK and BkLK as the highest would be given the highest Pvalue. To calculate the values of FwdLK, the server would parse the page without downloading it for justto return the number of links in it. To estimate the number of BkLK, the server would refer to the existing database built by client crawler machines to calculate how many pages refer to this page from the point of view of current database.
Initially, the FwdLK will hold higher weight age as there will be no orvery few URLs pointing to the current URL as the database would be still in a nascent or a growing stage. But as the database of indexed pages will grow, theweight age of BkLK will gradually increase.
Obviously this will result in lower Pvalue and that page will hold lower priority. This is important since we do not want to assign high priority to download a page already downloaded and updated very frequently as indicated by the high BkLK value.
Priority Assignment

The server will sort the list of URLs received from the client according to descending order of Pvalue. It will thensend this sorted list of URLs to the clients in order to maintain quality of crawling. This method is particularly useful as it gives weightage to current database and builds a quality database of indexed web pages even when the focusis to crawl the whole of web. It works well if the database is in growing or inlow page priority
D. Layer 4: Maintain and Update RepositoryOnce the pages are marked to be
relevant, they are required to be storedsomewhere. Storing only the pages is notenough, but we also require the metadatabe maintained.
Figure 8 : Repository Structure OfThe Web Crawler
The layer 3 writes copy of relevantpage into the cache and writes metadataabout successfully downloaded pages intoan RDF database. The RDF databaseincludes page URI, date and time ofdownload, pathname in the cache, etc.the RDF is nothing but ResourceDescription Framework. it makesstatements about resources in the formof subject-predicate-object expressions.Where the subject denotes the resource,and the predicate denotes traits oraspects of the resource and expresses arelationship between the subject and theobject. RDF puts the information in a
formal way that a machine canunderstand.
The purpose of RDF is to providean encoding and interpretation mechanismso that resources can be described in away that particular software canunderstand it; in other words, so thatsoftware can access and use informationthat it otherwise couldn't use.
D. Storing Data In RepositoryIt all depends on the effective amountof text and/or web pages you intent tocrawl. A generic solution is to storedata in MySQL database.
Data AnalysisAfter a crawl job is terminated we
remain with large amounts of raw data,link graphs and RDF meta-data. This datacontains both relevant data (servicedescriptions and related documents) andirrelevant data. The data is analyzed tofilter out the relevant documents fromthe irrelevant ones and to build newarchives containing only the relevantinformation.
The analysis comprises two mainsteps,
Building unique serviceobjects and
Collecting all relateddocuments.
For retrieval, the data will be minedusing web usage mining algorithm.
V. DATABASE DESIGN
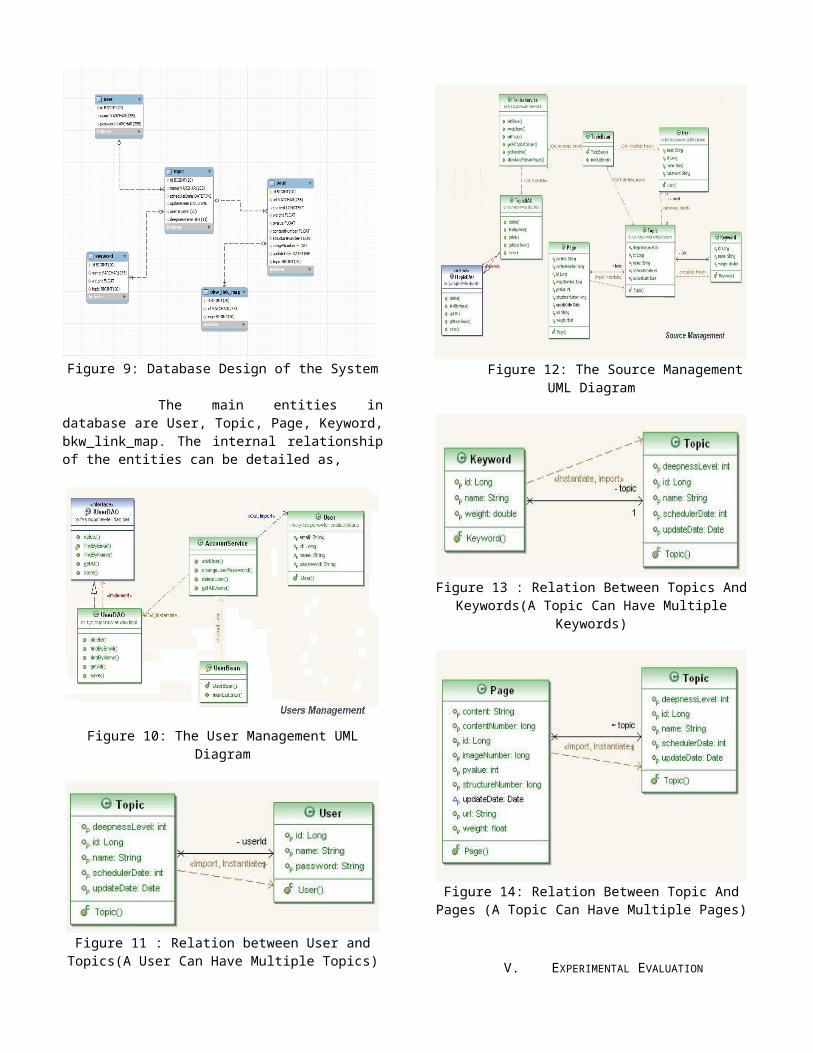
Figure 9: Database Design of the System
The main entities indatabase are User, Topic, Page, Keyword,bkw_link_map. The internal relationshipof the entities can be detailed as,
Figure 10: The User Management UML
Diagram
Figure 11 : Relation between User andTopics(A User Can Have Multiple Topics)
Figure 12: The Source ManagementUML Diagram
Figure 13 : Relation Between Topics AndKeywords(A Topic Can Have Multiple
Keywords)
Figure 14: Relation Between Topic AndPages (A Topic Can Have Multiple Pages)
V. EXPERIMENTAL EVALUATION

The deepness level assigned withevery URL tells to what level thecrawler will get trapped in every URL.For the experimental evaluation theapplication was run with the inputs as,
The StartURL: http://www.mustseeindia.com
The log file Name: crawler.log
The search string: adventure wildlife
Deepness Level: 25
Then the final output of contentanalysis was,
Crawling::http://mustseeindia.com/MunnarCrawled:: 25URLs extracted so far:: 2298
Out of these 25 URLs crawled, only 18 ofthem contained the given keywords. ThoseURLs’ content analysis result was as,
Sr.No
URL Relevance Score
1http://mustseeindia.com/tourist-places-in-india
0.35333332
2http://mustseeindia.com/places-around-bangalore
0.32068965
3http://mustseeindia.com/places-around-chennai
0.32
4http://mustseeindia.com/places-around-hyderabad
0.31652895
5http://mustseeindia.com/
0.31437126
places-around-delhi6
http://mustseeindia.com/places-around-mumbai
0.3161616
7http://mustseeindia.com/places-around-pune
0.31551722
8http://mustseeindia.com/places-around-kolkata
0.31606424
9http://mustseeindia.com/articles
0.3441281
10http://mustseeindia.com/Goa
0.35131577
11http://mustseeindia.com/Andaman
0.35307443
12http://mustseeindia.com/Shimla
0.35784614
13http://mustseeindia.com/Manali
0.36144578
14http://mustseeindia.com/Nainital
0.36309522
15http://mustseeindia.com/Darjeeling
0.36549708
16http://mustseeindia.com/Gangtok
0.36723647
17http://mustseeindia.com/Coorg
0.3679666
18http://mustseeindia.com/Munnar
0.36772487

Figure 15: Example ContentAnalysis Result
These results are sorted fortheir relevancy measure. The sorting isalso done based on Link Analysis andthen combined results are given to theuser.
The Multiuser Personal Web Crawlerwhen executed gives the topic detailsas,
Figure 16: Topic Details as Givenby Multiuser Personal Web Crawler
The figure shows details for topicnamed ‘Java Topic’. The topic vectorhere is {(java, 0.4), (J2EE, 0.6)}. Theresulting URLs with the web page accessdate and relevance score is given in thebottom pane. The results can be saved in.XML, .CSV, .XLS forms and also can bemailed directly to someone.
The web page change detectioncriteria works on the data in thedatabase. The richer the database, theresults will be more accurate. Initiallythe database will have very few entries,so almost every page will be a newlyencountered and thus will be added inthe result domain.
The weight table method isconsidered the best amongst all therelevance calculation methods. The link
analysis method supports it by tellingthe concerned URL’s position in the WWW.Still, it will face the same as theissue with web page change detectionmethod. To estimate the number of BkLK,the server would refer to the existingdatabase built by client crawlermachines to calculate how many pagesrefer to this page from the point ofview of current database.
Initially, the FwdLK will holdhigher weight age as there will be no orvery few URLs pointing to the currentURL as the database would be still in anascent or a growing stage. But as thedatabase of indexed pages will grow, theweight age of BkLK will graduallyincrease. Obviously this will result inlower Pvalue and that page will holdlower priority. This is important sincewe do not want to assign high priorityto download a page already downloadedand updated very frequently as indicatedby the high BkLK value.
VII. CONCLUSION AND FUTURE SCOPE
After all this time, shouldn't searchingfor something on the Internet be an easierprocess? Sure, it has vastly improved overthe years, but there is still asignificant element of hit-and-missinvolved. Despite the Web having been partof our lives for well over a decade now,the fundamental task of searching it forinformation remains something of alottery. Locating general information iseasy, but finding something specific canpresent a significant challenge, even tothe most experienced Internet researcher.Most searches still involve typing arcaneexpressions into a search box, applyingquotes to limit the terms, and graduallyrefining the key words in an effort tonarrow the results down to those that aremost relevant to the required material.Sometimes this approach can be effective,but at others it can seem like searchingfor a needle in a planet-sized haystack.

Over the years a large number ofsearch engines have attempted to improvethe accuracy of the search experience.From Google, who revolutionized theprocess back in the early days, right upto the newest contenders which providessegregated multimedia results, companieshave tried to find new ways of moreaccurately locating and delivering theinformation their customers need. Many ofthem have helped make our lives easier.
But despite all that, every one ofthese search engines and mechanisms isbased on the same basic technology: webspiders and crawlers of one kind oranother that travel the Web, locating andindexing information that is thenreturned in response to the searchqueries of end users. The task faced bythese crawlers is monumental. Accordingto the latest Netcraft survey, the Web asof mid 2008 consists of over 175 millionsites that contain literally billions ofpages. Between them, these pages cover arange of information too vast for asingle individual to conceive of. So justhow well can a multi-purpose searchengine with its widely targeted crawlersbe expected to meet the specializedrequirements of its individual users? Theanswer, sadly, is probably not very wellat all, as is suggested by the ongoingfrustration expressed by typical Webusers at the difficulty of findingexactly what they’re looking for.
The Information Tracking FocusedCrawler is designed for advanced web userswho want to crawl over a small part of theweb automatically for a particular topic.It isn't designed for enormous crawls likethe popular search engines. Search enginestypically use distributed crawlers runningon farms of PCs with a fat network pipeand a distributed file system or databasefor managing the crawl frontier andstoring page data. My crawler is intendedmore for personal use, to crawl perhaps ahundred or a thousand web pages. If you
want to use it for large crawls, it mayface limitations of memory andcomputation.
Merits
Rather than expecting Google orwhoever to magically understandtheir precise requirements, userscan use their own personal webcrawler to seek out theinformation they need. This has anumber of significant advantages.
Targeted information : The mainadvantage is that, unlike thoseused by the search engines, yourown web crawler can be configuredto target precisely what you need.As an example, it’s useful tothink about media researchorganizations whose business it isto seek out media reports abouttheir clients. These clients aretypically famous individuals orwell-known corporations who needto locate information aboutthemselves, usually as the basisfor commercial decision making.The Web is obviously a majorrepository for such information,but a vast amount of pointlessinformation is sure to be foundalongside the useful data: blogreferences, mentions in passing inarticles dedicated to othersubjects, and references tonamesakes are just some of thekinds of information that wouldtypically need to be filtered outto make such research worthwhile.
A personal web crawler providesone answer to this situation,since it can be configured toignore certain types ofreferences, or simply to onlysearch certain sites or types ofsites. This offers a high degreeof control over the informationthat is returned for a particular

search, vastly increasing thelikelihood that it will berelevant.
Another key advantage of thepersonal web crawler is that itcan work in the background. Unliketypical searches which must becarried out actively by typingsearch terms into the searchengine’s interface, a web crawlerwill continuously monitor the web– or at least the areas of it youspecify - and return results asthey are uncovered. This is a farmore efficient approach for thosewho seek similar types ofinformation on a regular orongoing basis.
The privacy benefits of personalcrawlers shouldn’t beunderestimated, especially inthese times of increasing concernover the amount of personal datagathered and retained by Googleand other major search engines.This data has commercial value,allowing the delivery of preciselytargeted advertising, but manyindividuals quite justifiablybelieve that what they search foron the web is nobody’s businessbut their own.
With own crawler, privacyceases to be a concern, since searchrecords are not visible beyond thelocal network. On a similar theme,and unlike public search engines,personal crawlers can not becensored, making them highly usefulin localities where web access isrestricted for political or socialreasons.
The system uses three searchengines to generate the seed URLfor each topic. This crawlfrontier is generated only once
when the topic is created. Also, Ihave not used any API to get theresults of the search engines.This prevents from having someparticular number of hits to thesearch engine site in a day.(Google search API allows onlyhundred hits in a day)
The application uses the simplestmethods for storing the pagestructure. The tree representationmethods are avoided due to reasonof need of recreating the pagetree every time the page ischanged. This helps in bridgingthe computation overhead gap.
The options like saving theresults in .CSV, .TXT formats orfacility of mailing the resultsdirectly helps in managing theresult data in better manner.
The application developed usingMVC approach. So furthermodifications would require changeonly in desired layer viz,interface layer, processing layeror the repository layer.
The two relevance computationsmethods combined together givemore accurate results than just asingle method.
Running the Crawler Workbenchinside a browser provides a fairlevel of integration betweenbrowsing and crawling, so thatcrawling tasks that arise duringbrowsing can be solved immediatelywithout changing context. Tighterintegration between browsing andcrawling would be desirable,however. For example, the usershould be able to steer a runningcrawler by clicking on links in abrowser window.

Crawler traps (e.g., calendars)may cause a crawler to download aninfinite number of pages, so thiscrawler is configured withdeepness level configured tolimit the number of dynamic pagesit crawls.
More advantages are discussed inthe table on next page thatcompares the Focused Crawler withRevisit Policy with other populararchitectures.
Limitation
The sheer scale of the Web imposesa major constraint: to crawl theentire Internet with any degree ofefficiency would require a serverfarm approaching the size ofGoogle’s, which is obviously animpossible aspiration for anindividual or small organization.For this reason, crawlers are mostsuitable when searches can beusefully restricted to veryspecific areas of the Web –newspaper and media sites forinstance, as in the above example.
There are also limits on the sheervolume of information it isreasonable to expect a personalcrawler to gather and index.Again, to attempt to index theentire web would be ridiculous aswell as meaningless. Large scalesearch engines can do that kind ofthing much more efficiently thanany individual. The core strengthof the personal crawler lies inaccurately indexing large amountsof very specific information. Usedappropriately, it can remove muchof the drudgery of this kind oftask, leaving the user free to usethe information it gathers, whichmeans that he or she won'twaste time looking for it.
Large portions of a web site maybe hidden in the deep Web. Forexample, the results page behind aweb form lies in the deep Webbecause most crawlers cannotfollow a link to the results page.My crawler doesn’t solve the issueof crawling such deep web.
Future Scope
The architecture can be modifiedeven to visit the deep web. Forthat, it must use some model togenerate the probable data thatcould be used to fill in the formsto open the doors of hidden web.
It is also possible use the samestructure with a server with thisarchitecture as a client crawler.This would increase its speed ofexecution tremendously. Only thething is, it may require somechanges so that no two clientscrawl same URL during their run.
VIII. REFERENCES1. www.wikipedia.org/web_crawler ,
accessed last Jun 12, 2011.
2. http://www.googleguide.com/ google_works.html accessed lastJuly 12, 2011
3. Zheng, Chen, “HAWK: a Focusedcrawler with content and linkanalysis”, E-business engineering,2008, ICEBE’08, IEEE internationalconference, pages 677-680, Oct2008.
4. Yuan Wang David J. DeWitt Jin-YiCai, “X-Diff: An Effective ChangeDetection Algorithm for XMLDocuments” Proceedings of 19thInternational Conference on 5-8March 2003 page(s): 519 – 530
5. Yuan Wang, David J. DeWitt, Jin-YiCai, “X-Diff: An Effective Change

Detection Algorithm for XMLDocuments”, 19th InternationalConference on Data Engineering(ICDE’03), 2003, Pages 519-530.
6. Sharma Chakravarthy andSubramanian C Hari Hara,“Automating Change detection andNotification of Web Pages”,invited paper, 2007.
7. Divakar Yadav A.K.SharmaJ.P.Gupta, “Change Detection inWeb Pages”, 10th InternationalConference on InformationTechnology, 2007, Pages 265-270.
8. H. P. Khandagale and P. P.Halkarnikar, “A Novel Approach forWeb Page Change DetectionSystem” , International Journal ofComputer Theory and Engineering,Vol. 2, No. 3, June, 2010.
9. Ling Zheng, Yang Bo, Ning Zhang,“An Improved link selectionalgorithm for vertical searchengine”, The 1st InternationalConference on Information Scienceand Engineering (ICISE2009),Pages778-781.
10. Emil Gatial, Zoltan Balogh,Michal Laclavik, Marek Ciglan andLadislav Hluchy, “Focused WebCrawling Mechanism based on PageRelevance”, invited paper, 2005.
11. P Srinivasan, G Pant, andFMenczer. A general evaluationframework for topical crawlers.Information Retrieval, 2002.
12. Cui Xiaoqing Yan Chun , “Anevolutionary relevance calculationmeasure in topic crawler”International Colloquium onComputing, Communication, Control,and Management, CCCM 2009. 8-9Aug. 2009 ,Volume: 4, On page(s):267 - 270
13. D Hati, A kumar, “AnApproach for Identifying URLsBased on Division Score and LinkScore in Focused Crawler”International Journal of ComputerApplications (0975 – 8887) Volume2 – No.3, May 2010
14. Yadav, Sharma et el,“Architecture for parallelcrawling and algorithm for changedetection in web pages”, 10thInternational Conference onInformation Technology, Pages 258-264, ICIT 2007.
15. Debajyoti Mukhopadhyay, ArupBiswas, Sukanta Sinha, “A NewApproach to Design Domain SpecificOntology Based Web Crawler”, 10thInternational Conference onInformation Technology, 2007,Pages 289-291.
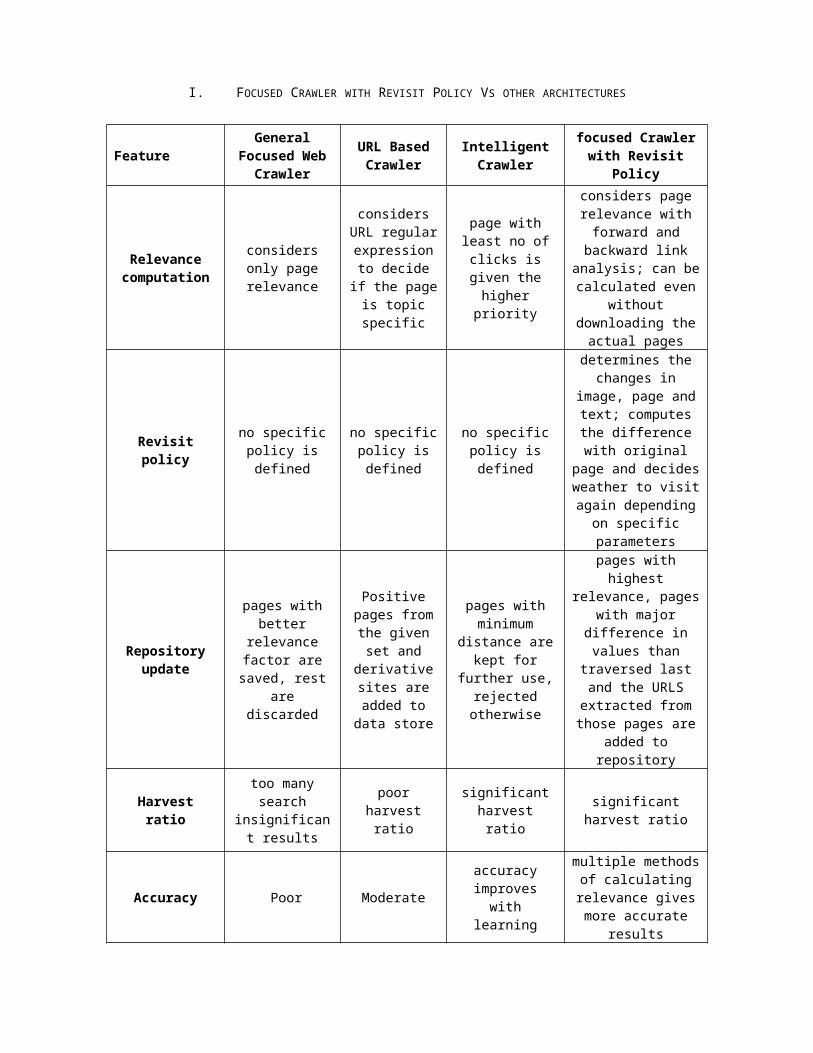
I. FOCUSED CRAWLER WITH REVISIT POLICY VS OTHER ARCHITECTURES
FeatureGeneral
Focused WebCrawler
URL BasedCrawler
IntelligentCrawler
focused Crawlerwith Revisit
Policy
Relevancecomputation
considersonly pagerelevance
considersURL regularexpressionto decideif the pageis topicspecific
page withleast no ofclicks isgiven thehigherpriority
considers pagerelevance withforward andbackward link
analysis; can becalculated even
withoutdownloading theactual pages
Revisitpolicy
no specificpolicy isdefined
no specificpolicy isdefined
no specificpolicy isdefined
determines thechanges in
image, page andtext; computesthe differencewith original
page and decidesweather to visitagain dependingon specificparameters
Repositoryupdate
pages withbetter
relevancefactor aresaved, rest
arediscarded
Positivepages fromthe givenset and
derivativesites areadded todata store
pages withminimum
distance arekept for
further use,rejectedotherwise
pages withhighest
relevance, pageswith major
difference invalues than
traversed lastand the URLSextracted fromthose pages are
added torepository
Harvestratio
too manysearch
insignificant results
poorharvestratio
significantharvestratio
significantharvest ratio
Accuracy Poor Moderate
accuracyimproveswith
learning
multiple methodsof calculatingrelevance givesmore accurate
results

Changedetection No No Slow
simple methodsto detect change
in pagestructure, and
content
Brokenlinks
doesn’trecognize
broken links
Doesn’trecognizebrokenlinks
performanceimproveswith
learning
detects brokenlinks
Performanceimprovement
withlearning
doesn’tlearn
learns; butlearningrate isvery slow
learns andimprovesbetter
doesn’t need tolearn



















