
IMPLEMENTASI ALORITMA KMP (KNUTH MORRIS PARTT) DALAM PENCOCOKAN STRING DALAM APLIKASI PONS ASINORUM...
21
IMPLEMENTASI ALORITMA KMP (KNUTH MORRIS PARTT) DALAM PENCOCOKAN STRING DALAM APLIKASI PONS ASINORUM (JEMBATAN KELEDAI) Oleh : Candra Robiansyah 125150102111001 KEMENTRIAN PENDIDIKAN DAN KEBUDAYAAN UNIVERSITAS BRAWIJAYA PROGRAM TEKNOLOGI INFORMASI DAN ILMU KOMPUTER MALANG 2015
-
Upload
ubrawijaya -
Category
Documents
-
view
2 -
download
0
Transcript of IMPLEMENTASI ALORITMA KMP (KNUTH MORRIS PARTT) DALAM PENCOCOKAN STRING DALAM APLIKASI PONS ASINORUM...

IMPLEMENTASI ALORITMA KMP (KNUTH MORRIS PARTT)
DALAM PENCOCOKAN STRING DALAM APLIKASI PONS
ASINORUM (JEMBATAN KELEDAI)
Oleh :
Candra Robiansyah
125150102111001
KEMENTRIAN PENDIDIKAN DAN KEBUDAYAAN
UNIVERSITAS BRAWIJAYA
PROGRAM TEKNOLOGI INFORMASI DAN ILMU KOMPUTER
MALANG
2015

2
LEMBAR PENGESAHAN
Implementasi Algoritma KMP (Knuth Morris Pratt) dalam
Pencocokan String Pada Aplikasi Pons Asinorum (Jembatan
Keledai)
Bidang Keminatan Kecerdasan Buatan
CANDRA ROBIANSYAH
125150205111004
Malang, 24 April 2015
Dosen Pembimbing I, Dosen Pembimbing II,
Mengetahui
Ketua Program Studi Informatika/Ilmu Komputer,
Mardji, Drs., M.T
NIP. 19670801 199203 1 001

3
PERNYATAAN ORISINALITAS
Saya menyatakan dengan sebenar-benarnya bahwa sepanjang pengetahuan saya, di dalam naskah proposal skripsi ini tidak terdapat karya ilmiah yang pernah diajukan oleh orang lain untuk memperoleh gelar akademik di suatu perguruan tinggi, dan tidak terdapat karya atau pendapat yang pernah ditulis atau diterbitkan oleh orang lain, kecuali yang secara tertulis disitasi dalam naskah ini dan disebutkan dalam daftar pustaka.
Apabila ternyata didalam naskah skripsi ini dapat dibuktikan terdapat unsur-unsur plagiasi, saya bersedia skripsi ini digugurkan dan gelar akademik yang telah saya peroleh (sarjana) dibatalkan, serta diproses sesuai dengan peraturan perundang-undangan yang berlaku (UU No. 20 Tahun 2003, Pasal 25 ayat 2 dan Pasal 70).
Malang, 31 Mei 2015
Candra Robiansyah
NIM: 125150102111001

4
Daftar Isi
BAB I ……………………………………………………4
PENDAHULUAN ……………………………………………………4
1.1 Latar Belakang ……………………………………………………4
1.2 Rumusan Masalah ……………………………………………………6
1.3 Batasan Masalah ……………………………………………………6
1.4 Tujuan ……………………………………………………6
1.5 Manfaat ……………………………………………………7
1.6 Sistematika penulisan ……………………………………………………7
BAB II ……………………………………………………8
TINJAUAN PUSTAKA ……………………………………………………8
2.1 Tabel Kajian Pustaka ……………………………………………………8
2.2 Kompleksitas …………………………………………………..11
2.2.1 Definisi Kompleksitas …………………………………………………..11
2.3 Pencocokan String (String Matching) …………………………………………………..11
2.3.1 pengertian Pencocokan String …………………………………………………..11
2.3.2 Klasifikasi Pencocokan String …………………………………………………..12
2.4 KMP (Knuth Morris Pratt) …………………………………………………..13
BAB III …………………………………………………..15
METODOLOGI PENELITIAN …………………………………………………..15
3.1 Studi Literatur …………………………………………………..15
3.2 Pengumpulan Data …………………………………………………..16
3.2.1 Wawancara …………………………………………………..16
3.2.2 Kuisoner …………………………………………………..16
3.3 Analisa dan Perancangan …………………………………………………..16
3.3.2 Kerangka Konseptual …………………………………………………..16
3.3.1 Analisis Sistem …………………………………………………..17
3.3.2 Analisis Kebutuhan …………………………………………………..18

5
BAB I
PENDAHULUAN
1.1 Latar Belakang
Banyak anggapan bahwa ingatan manusia itu ibarat sebuah memori yang berfungsi untuk mendapatkan sebuah informasi dan melibatkan otk untuk menyimpan informasi tersebut.Ingatan tersendiri dibahas dalam ilmu psikologi dan ilmu syaraf. Pada umumnya para ahli memandang ingatan sebagai hubunggan pengalaman dan masa lampau.Apa yang pernah diingat pasti adalah hal yang mereka alami,pernah di masukkan kedalam jiwanya dan disimpan sehinga mengakar kuat didalam otak dan apabila ada hal yang bersangkut paut dengan pengalamannya tersebut makan akan secara otomatis pengalam tersebut akan dibangkitkan.ingatan merupakan kemampuan untuk menyimpan dan menimbulkan kembali apa yang pernah di simpan dan dialami dalam otak kita.
Otak juga merupakan fungsi untuk mengontrol pengendalian tubuh,bukan hanya berfikir,otak juga berinteraksi,bekerja memerintah anggota tubuh lainnya dalam suatu kegiatan.Seandainya paru-paru atau bahkan jantung anda berhenti bekerja untuk beberapa menit / detik anda masih dapat bertaha hidup.Namun apabila otak anda berhenti bekerja dalam satu detik saja,maka dapat dipastikan tubuh anda akan mati.Itulah sebabnya mengapa otak disebut sebagai organ vital.
Secara umum otak manusi terbagi menjadi 2 bagian,yaitu otak kanan dan otak kiri dan fungsi keduanya berbeda.Otak kanan sering di identikkan dengan kreatifitas yang sering halnya dimiliki oleh seorang seniman.Sedangkan otak kiri biasa di identikkan dengan kecerdasan analitik.Biasanya otak kiri ini sangat bermanfaat dalam memahami hal-hal yang kompleks dan perlu pemikiran yang mendetail.Orang yang biasanya mengandalkan otak kiri adalah seorang peneliti atau scientist.
Dengan otak yang telah diberikan oleh Yang Maha Kuasa kita bias berfikir, bersosialisasi, berkomunikasi dan menggingat segala kejadia yang telah kita lewati.Benar apa yang dikatakan oleh Albert Enstain dan para ahli yang lainnya mengenai otak manusia.Menurut mereka manusia hanya menggunakan 10% dari kemampuan otak mereka.Untuk itu keseimbangan antara otak kiri dan otak kanan sangat dibutuhkan jika kita ingin mengoptimalka kerjanya.Otak yang bekerja secara sinergis akan mempunyai kapasitas jauh lebih besar dari otak yang hanya berkembang sebelah.
Begitupun saat kita mengigat hal-hal yang tidak pernah kita lakukan maka kita akan mudah melupakannya.Ingatan alami manusia sulit untuk menerima sesuatu tidak menarik untuk diingat.Dimana pada asumsinya ingatan manusi terdiri dari ingatan Alami dan ingatan Buatan.Ingatan alami adalah ingatan manusia yang dibawah sejak dia dilahirkan dan telah menjadi kebiasaan-kebiasaan yang sering dilakukan,Sedangkan ingatan buatan bias dibangun dengan belajar dan bias di latih menggunakan teknik jembatan keledai

6
Asal mula jembatan keledai sendiri, menurut Papi Ray di majalah elektronik Papyrus,diambil dari bahasa belanda : Ezelbrug atau Ezelbruggetje. Ezel - keledai, kuldi, brug / bruggetje - jembatan / jembatan kecil. Konon kata ini diambil dari ungkapan bahas Latin yang sudah biasa dipakai di jaman pertengahan.
Pons Asinorum (jembatan para keledai) dinamakan demikian, karena menurut pengamatan, agar keledai dapat sampai ke tempat seberang dia hanya memerlukan blabag atau batang kayu yang kecil, dan dengan jembatan kecil ini dia bisa sampai ke tujuan. Dalam hal menghafalkan sesuatu, membuat kunci ingatan kepada apa yang harus diingat dapat ditolong dengan membuat "jembatan keledai ini". Istilah Inggris yang sekarang dipakai ialah mnemonic device, sarana untuk mengingat-ingat sesuatu.
Jembatan keledai bisa digunakan untuk mengingat daftar yang panjang dan sulit diingat hanya dengan ingatan alami, misalnya dalam mengingat unsur kimia, anatomi, taksonomi, tata bahasa dan rumus matematika.
Dengan jembatan keledai itu, menghafalkan sesuatu memang menjadi gampang. Tapi yang sulit justru saat kita membuatnya.

7
1.2 Rumusan Masalah
Berdasarkan uraian latar belakang diatas, maka dapat dirumuskan permasalahan pada penelitian ini yaitu sebagai berikut :
1. Bagaimana merancang aplikasi jembatan keledai yang sangat membatu kebutuhan menghafal Suatu kata yang sulit kita ingat.
2. Bagaimana membentuk kata / kalimat yang unik untuk di hafal ?
3. Bagaimana kompleksitas algoritma KMP (Knuth Morris Pratt) dalam penerapan aplikasi Jembatan Keledai
1.3 Batasan Masalah Agar permasalahan yang dirumuskan dapat lebih terfokus dan tidak meluas, maka
batasan-batasan yang ditentukan pada penelitian ini yaitu:
1. Metode yang digunakan untuk menyusun kalimat berdasarkan SPOPK (Subyek Predikat
Objek Pelengkap Keterangan).
2. Menggunakan algoritma KMP (Knuth Morris Pratt) dalam matching untuk mencocokkan huruf dalam text yang di inputkan dengan petern.
3. Inputan yang mau kita hafalkan berbentuk kata maksimal 12 kata .
4. Petern yang digunakan untuk matching menggunakan bahasa indonesia
5. Petern yang digunakan dikategorikan berdasarkan SPOPK.
6. Database yang digunakan dalam pembuatan aplikasi ini adalah mySQL.
7. Aplikasi ini dibuat berbasis Web .
1.4 Tujuan
Tujuan dari penelitian ini adalah untuk merancang aplikasi Pons Asinorum (Jembatan Keledai) Yang digunakan untuk menghafal berbasis android serta mengimplementasikan algoritma string matching yaitu KMP (Knuth Morris Pratt) .
1.5 Manfaat Penulisan penelitian ini diharapkan mempunyai manfaat yang baik dan berguna bagi
semua orang khususnya para pelajar. Adapun manfaat yang diharapkan adalah sebagai berikut:
1. Penulis dapat menerapkan ilmu yang didapatkan dalam perkuliahan untuk membantu Permasalahan pelajar khususnya.
2. Penulis dapat secara langsung mendalami materi khususnya algoritma matching

8
terutama algoritma KMP (Knuth Morris Pratt) dalam melakukan pencocokan string.
3. Mempermudah menghafal suatu kalimat yang asing bagi kita sehingga mendapatkan pola yang mudah untuk kita hafalkan.
1.6 Sistematika penulisan
Sistematika penulisan dalam skripsi ini sebagai berikut:
BAB I Pendahuluan
Memuat latar belakang, rumusan masalah, tujuan, batasan masalah, manfaat dan sistematika penulisan.
BAB II Kajian Pustaka
Menguraikan tentang dasar teori dan referensi yang mendasari pembuatan aplikasi Pons Asinorum dengan menggunakan algoritma KMP (Knuth Morris Pratt).
BAB III Metode Penelitian
Membahas metode yang digunakan dalam penelitian yang terdiri dari studi literatur, perancangan sistem perangkat lunak, implementasi sistem perangkat lunak, pengujian dan analisis, serta penulisan laporan.
9
BAB II
TINJAUAN PUSTAKA
Bab ini membahas tentang tinjauan pustaka yang meliputi kajian pustaka dan dasar teori yang diperlukan untuk penelitian. Kajian pustaka adalah membahas penelitian yang telah ada dan yang diuraikan. Dasar teori adalah membahas teori yang diperlukan untuk menyusun penelitian yang diusulkan.
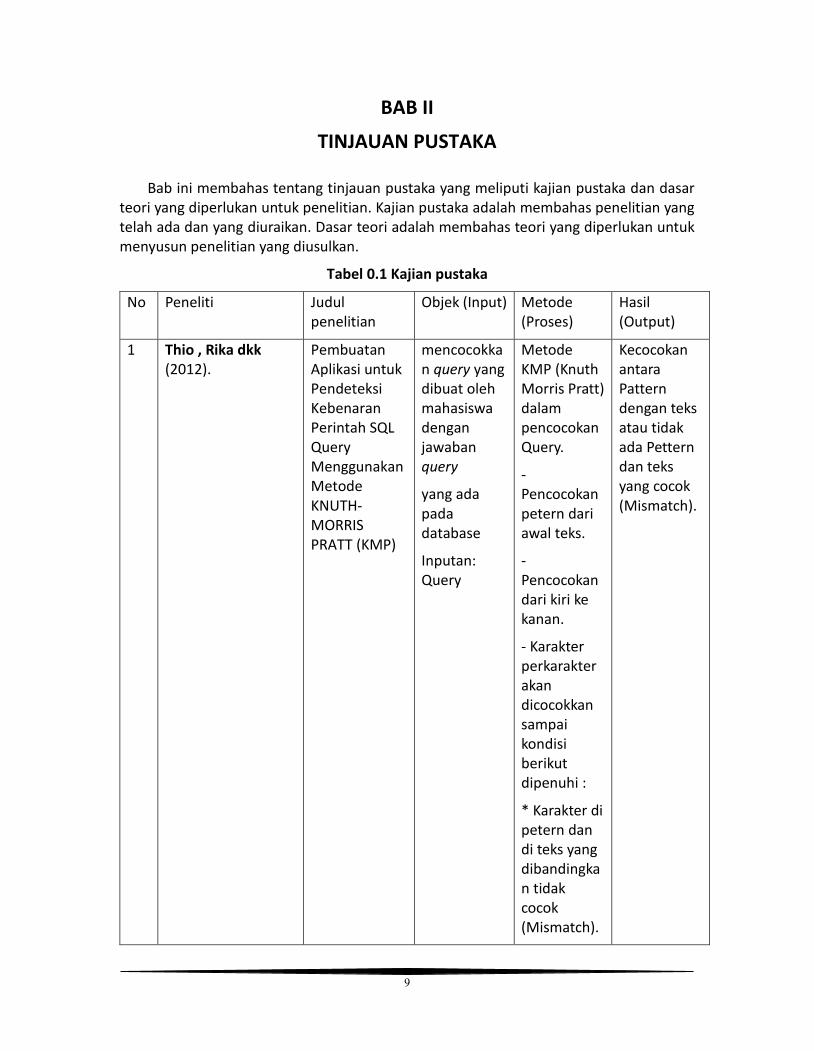
Tabel 0.1 Kajian pustaka
No Peneliti Judul penelitian
Objek (Input) Metode (Proses)
Hasil (Output)
1 Thio , Rika dkk (2012).
Pembuatan Aplikasi untuk Pendeteksi Kebenaran Perintah SQL Query Menggunakan Metode KNUTH-MORRIS PRATT (KMP)
mencocokkan query yang dibuat oleh mahasiswa dengan jawaban query
yang ada pada database
Inputan: Query
Metode KMP (Knuth Morris Pratt) dalam pencocokan Query.
- Pencocokan petern dari awal teks.
- Pencocokan dari kiri ke kanan.
- Karakter perkarakter akan dicocokkan sampai kondisi berikut dipenuhi :
* Karakter di petern dan di teks yang dibandingkan tidak cocok (Mismatch).
Kecocokan antara Pattern dengan teks atau tidak ada Pettern dan teks yang cocok (Mismatch).

10
* Semua karakter di petern cocok kemudian algoritma akan memberitahu penemuan di posisi mana.
- Algoritma kemudian menggeser paterrn berdasakan table,lalu menggulanggi langkah 2 sampai pettern berada di ujung teks.
2 Efori Buulolo (2013) Implementasi Algoritma String Matching dalam Pencaran Surat dan Ayat dalam Bible Berbasis Android
Pencarian surat dan Ayat dalam Bible.
Input : surat dan ayat
Metode Algoritma KMP (Knuth Morris Pratt) dalam Pencocokan surat dan ayat.
-Memelihara informasi yang digunakan untuk memelihara kebenaran.
-Meggunakan informasi
Surat atau ayat yang dicari.

11
hitungan ketidak cocokan Pettern dari kiri teks untuk melakukan pergeseran
3 Vita Meriati Pandiangan (2015)
Implementasi Left Corner Parser pada Perancangan Aplikasi Pemeriksaan Tata Bahasa Dalam Kalimat Bahasa Indonesia
Pemeriksaan Tata Bahasa Dalam Kalimat Bahasa Indonesia.
Input : Subjek,
Predikat Objek dan Keterangan.
Metode Left Corner Parser.
-mula-mula menerima sebuah kata, menentukan jenis constituent .
Kalimat yang sesuai dengan aturan tata
bahasa yang baku.

12
2.2 Kompleksitas
2.2.1 Definisi Kompleksitas
Komplesitas merupakan kajian atau studi terhadap sistem kompleks . kata “kompleksitas” berasal dari bahasa latin complexice yang artinya ‘totalitas’ atau ‘keseluruhan’, sebuah ilmu yang mengkaji totalitas sistem dinamik secara keseluruhan (Dimitrov, 2003)
Ada dua macam kompleksitas algoritma, yaitu : kompleksitas waktu dan kompleksitas ruang.
Kompleksitas waktu, T(n), diukur dari jumlah tahapan komputasi yang dibutuhkan untuk menjalankan algoritma sebagai fungsi dari ukuran masukan n.
Kompleksitas ruang, S(n), diukur dari memori yang digunakan oleh struktur data yang terdapat di dalam algoritma sebagai fungsi dari ukuran masukan n.
Dengan menggunakan besaran kompleksitas waktu/ruang algoritma, kita dapat menentukan laju peningkatan waktu (ruang) yang diperlukan algoritma dengan meningkatnya ukuran masukan n.
Dalam praktek, kompleksitas waktu dihitung berdasarkan jumlah operasi abstrak yang mendasari suatu algoritma, dan memisahkan analisisnya dari implementasi. Tinjau algoritma menghitung rerata pada Contoh 1. Operasi yang mendasar pada algoritma tersebut adalah operasi penjumlahan elemen-elemen ak (yaitu jumlah jumlah + ak). Kompleksitas waktu HitungRerata adalah T(n) = n.
2.3 Pencocokan String (String Matching) 2.3.1 Pengertian Pencocokan String
Pengertian string menurut Dictionary of Algorithms and Data Structures, National Institute of Standards and Technology (NIST) adalah susunan dari karakter-karakter (angka, alfabet atau karakter yang lain) dan biasanya direpresentasikan sebagai struktur data array. String dapat berupa kata, frase, atau kalimat (Efori Buulolo,2013).
Pencocokan string merupakan bagian penting dari sebuah proses pencarian string (string searching) dalam sebuah dokumen. Hasil dari pencarian sebuah string dalam dokumen tergantung dari teknik atau cara pencocokan string yang digunakan. Pencocokan string (string matching) menurut Dictionary of Algorithms and Data Structures, National Institute of Standards and Technology (NIST), diartikan sebagai sebuah permasalahan untuk menemukan pola susunan karakter string di dalam string lain atau bagian dari isi teks.

13
2.3.2 Klasifikasi Pencocokan String
Pencocokan string (string matching) secara garis besar dapat dibedakan menjadi dua yaitu:
1. Exact string matching, merupakan pencocokan string secara tepat dengan susunan karakter dalam string yang dicocokkan memiliki jumlah maupun urutan karakter dalam string yang sama. Contoh : kata step akan menunjukkan kecocokan hanya dengan kata step.
2. Inexact string matching atau Fuzzy string matching, merupakan pencocokan string secara samar, maksudnya pencocokan string dimana string yang dicocokkan memiliki kemiripan dimana keduanya memiliki susunan karakter yang berbeda (mungkin jumlah atau urutannya) tetapi string-string tersebut memiliki kemiripanbaik kemiripan tekstual/penulisan (approximate string matching) atau kemiripan ucapan (phonetic string matching). Inexact string matching masih dapat dibagi lagi menjadi dua yaitu:
a. Pencocokan string berdasarkan kemiripan penulisan (approximate string matching) merupakan pencocokan string dengan dasar kemiripan dari segi penulisannya (jumlah karakter, susunan karakter dalam dokumen). Tingkat kemiripan ditentukan dengan jauh tidaknya beda penulisan dua buah string yang dibandingkan tersebut dan nilai tingkat kemiripan ini ditentukan oleh pemrogram (programmar). Contoh: c mpuler dengan compiler, memiliki jumlah karakter yang sama tetapi ada dua karakter yang berbeda. Jika perbedaan dua karakter ini dapat ditoleransi sebagai sebuah kesalahan penulisan maka dua string tersebut dikatakan cocok.
b. Pencocokan string berdasarkan kemiripan ucapan (phonetic string matching) merupakan pencocokan string dengan dasar kemiripan dari segi pengucapannya meskipun ada perbedaan penulisan dua string yang dibandingkan tersebut. Contoh step dengan steb dari tulisan berbeda tetapi dalam pengucapannya mirip sehingga dua string tersebut dianggap cocok. Contoh yang lain adalah step, dengan steppe.
Exact string matching bermanfaat jika pengguna ingin mencari string dalam dokumen yang sama persis dengan string masukan. Tetapi jika pengguna menginginkan pencarian string yang mendekati dengan string masukan atau terjadi kesalahan penulisan string masukan maupun dokumen objek pencarian, maka inexact string matching yang bermanfaat. Beberapa algoritma exact string matching antara lain: algoritma KnuthMorris-Pratt, Bayer-Moore, dll. Beberapa algoritma phonetic string matching antara lain: soundex, metaphone, caverphone, phonex, NYSIIS, JaroWinkler, dll.
Dari contoh yang diberikan, sebenarnya phonetic string matching juga dapat dimanfaatkan untuk approximate string matching dengan batasan dua string yang dicocokkan masih memiliki kemiripan ucapan.
Phonetic string matching sering juga dimanfaatkan untuk approximate

14
string matching karena phonetic string matching lebih mudah diimplementasikan. Phonetic string matching banyak digunakan dalam bahasa Inggris karena dalam bahasa Inggris terdapat perbedaan antara penulisan dan pengucapan.
2.4 KMP (Knuth Morris Pratt)
Algoritma Knuth Morris Pratt (KMP) dikembangkan oleh D. E. Knuth, bersama dengan J. H. Morris dan V. R. Pratt. Untuk pencarian string dengan menggunakan algoritma Brute Force, setiap kali ditemukan ketidakcocokan pattern dengan teks, maka pattern akan digeser satu karakter ke kanan. Sedangkan pada algoritma KMP, kita memelihara in Formasi yang digunakan untuk melakukan jumlah pergeseran (Thio Wibowo, 2012).
Meskipun antara Knuth dan Pratt serta Morris menemukan algoritma secara sendiri-sendiri, namun mereka bertiga sepakat untuk mempublikasikannya secara bersama-sama, maka jadilah nama algoritma ini yang dikenal dengan algoritma Knuth-Morris-Pratt.Algoritma Knuth-Morris-Pratt atau yang sering disingkat KMP ini merupakan salah satu algoritma yang digunakan untuk mencari apakah suatu kata terdapat dalam suatu string atau kumpulan kata. Cara kerja algoritma ini sebenarnya cukup sederhana yakni dengan cara mencocokkan kata yang mau dicari dalam string atau kumpulan kata sampai seluruh huruf dalam kata yang dicari tadi menemui padanannya dalam kumpulan kata yang ada. Jika ada satu saja huruf dari kata yang dicari tidak cocok, maka proses pengecekan akan diulangi seperti semula tapi ke karakter selanjutnya yang masih mungkin bisa sesuai dengan karakter awal dari kata yang dicari. Untuk lebih jelasnya perhatikan contoh pergerakan dari proses pencarian kata berikut.
1) m : 01 23 456 7 8901 23 4 567 89 01 2 S : ABC ABCDAB ABCDABCDABDE W : ABCDABD i : 0 1 23 45 6
Ket : dari proses pertama ini bisa diketahui bahwa huruf D dari kata yang dicari tidak sama dengan karakter spasi, maka diproses selanjutnya pencocokkan akan dimulai dari kata kedua setelah spasi, sebab karakter spasi tidak mungkin menjadi awalan dari kata yang dicari yaitu ABCDABD.
2) m : 01 2345 67 8901 23 45 67 89 01 2 S : ABC ABCDAB ABCDABCDABDE W : ABCDABD I : 0 1 2 3 4 5 6
Ket : dari proses kedua ini kata yang dicari masih belum sepenuhnya cocok, maka proses dilanjutkan dengan ke karakter berikutnya yang masih mungkin cocok.

15
3) m : 01 2345 67 890 12 345 67 89 01 2 S : ABC ABCDAB ABCDABCDABDE W : ABCDABD i : 0 1 23 45 6
Ket : proses pencocokkan kata masih gagal atau tidak memenuhi kriteria kata yang dicari.
4) m : 01 2345 67 890 12 345 67 89 01 2 S : ABC ABCDAB ABCDABCDABDE W : ABCDABD i : 0 1 23 45 6
Ket : proses pencarian sekali lagi menunjukkan bahwa kata yang dicari belum semuanya cocok dengan string yang diberikan.
5) m : 01 2345 67 890 12 345 67 89 01 2 S : ABC ABCDAB ABCDABCDABDE W : ABCDABD i : 0 1 23 45 6
Ket : pada langkah kelima ini semua karakter atau huruf dalam kata yang dicari menemui padanannya pada kalimat atau string yang diberikan, maka proses berhenti dengan mengembalikan posisi dimana kata ditemukan.

16
BAB III
METODOLOGI PENELITIAN
Bab metodologi ini akan dibahas tentang metode yang digunakan dalam pembuatan aplikasi dengan menggunakan algoritma KMP (Knuth Morris Pratt). Metodologi penelitian yang dilakukan dalam penelitian ini melalui beberapa tahapan yaitu studi literatur, pengumpulan data,analisa dan perancangan, implementasi sistem, uji coba sistem, dan kesimpulan. Tahapan-tahapan dalam penelitian tersebut dapat diilustrasikan dengan blok metode penelitian. Gambar dibawah menunjukkan diagram blok metodologi penelitian.
3.1 Studi Literatur Tahapan penelitian ini membutuhkan studi literatur untuk merealisasikan pembuatan
Aplikasi Jembatan Keledai dengan menggunakan algoritma KMP. Informasi dan pustaka yang berkaitan dengan penelitian ini didapat dari, situs internet, jurnal, dosen pembimbing, dan rekan – rekan mahasiswa. Adapun teori-teori yang dipelajari tentang :
1. Pencocokan String (String Matching)
2. Algoritma KMP (Knuth Morris Pratt)
3. Teori tentang Pengurutan kata berdasarkan SPOK.
Studi literatur
Analisa dan perancangan
Pengumpulan data
kesimpulan
Uji coba Sistem
Implementasi sistem

17
3.2 Pengumpulan Data 3.2.1 Wawancara
Wawancara yang akan dilakukan penulis terutama ditunjukkan kepada pelajar atau mahasiswa yang kebanyakan kusilatan dalam hal menghafal.Tujuan wawancara adalah untuk mendapatkan metode-metode menghafal yang paling efektif.
3.2.2 Kuisoner
Penulis melakukan 2 kali kuisoner , pada setiap kuisoner penulis mengambil sample sebanyak 20 responden .
3.3 Analisa dan Perancangan
3.3.1 Kerangka Konseptual
Penelitian dimulai dari inputan string berupa kata dan dilakukan pemotongan kata minimal 2 karakter huruf dan maksimal 4 karakter untuk dilakukan matching dengan database SPOK menggunakan algoritma KMP dimana aturan bahasa SPOK disesuaikan dengan input user, jika pengguna melakukan banyak kata yang diinputkan maka semakin kompleks aturan SPOK yang akan digunakan sistem.
Input String
Pemotongan String
Memproses dengan algoritma KMP
Konfigurasi aturan SPOK
Output String / kalimat.

18
3.3.2 Analisis Sistem
Melakukan pemotongan pattern dengan syarat 1 < Pettern > 5 .Algoritma KMP mulai mencocokkan pattern (Sting input yang telah dilakukan pemotongan) pada awal teks yang ada pada database.Dari kiri ke kanan,algoritma ini akan mencocokkan karakter per karakter pattern dengan karakter di teks yang bersesuaian, sampai salah satu kondisi berikut dipenuhi:
Karakter di pattern dan di teks yang dibandingkan tidak cocok (mismatch).
Semua karakter di pattern cocok. Kemudian algoritma akan memberitahukan
penemuan di posisi ini.
Algoritma kemudian menggeser pattern berdasarkan tabel,lalu mengulanggi langkah 2 sampai pettern berada di ujung teks.pencocokan petern selanjutnya dan mengutamakan pencocokan pertama dilakukan di teks yang mengandung pettern pertama jika tidak ada mencari ke database dan begitu seterusnya sampai terbentuk pola kalimat / string.
Mencocokkan Pattern (String Input) pada
awal teks yang ada pada database SPOK
Pencocokan dilakukan dari kiri ke kanan
Pencocokan karakter per karakter
Mismatch / Pettern cocok
Petern berada di ujung teks
pemotongan pattern = 1 < Pettern > 5
Pembentukan kalimat SPOK.

19
3.3.3 Analisis Kebutuhan
Berdasarkan uraian system diatas kebutuhan fungsional proses sistem adalah sebagai berikut :
1. Pemotongan String. 2. Algoritma KMP (Knuth Morris Pratt). 3. Proses pembentukan kalimat berdasarkan tata bahasa SPOK.
Kebutuhan Non-fungsional sistem :
1. Kompleksitas algoritma KMP.

20
Daftar Pustaka
[1]. Siregar Ivan Michael, 2011, Mengembangkan Aplikasi Enterprise Berbasis Android, Penerbit Gava Media, Yogyakarta, Edisi I.
[2]. Syaroni M,Munir R, 2005, Pencocokan String Berdasarkan Kemiripan Ucapan(Phonetic String Matching) Dalam Bahasa Inggris, Institut Teknologi Bandung.
[3]. Hadiati Desi, 2007, Penerapan Algoritma String Matching Pada Permainan Word Search Puzzle, Institut Teknologi Bandung.
[4]. Hartoyo EG,Vebrina YG,Meilana AF, 2005, Analisis Algoritma Pencarian String(String Matching), Institut Teknologi Bandung.
[5].Tentang Alkitab di dalam Wikipedia http://id.wikipedia.org/wiki/Alkitab.htm.
[ 6]. Al-Bahra bin Ladjamudin. 2006, Analisis dan Desain Sistem Informasi. Gramedia Pustaka Utama. Jakarta. Hal: 143
[7]. Adi Nugroho. 2010. Chap.1
[8]. A.S Rosa, Salahuddin, M. 2011. Modul Pembelajaran Rekayasa Perangkat Lunak (Terstruktur dan Berorientasi Objek)
[9]. George M Scoot. 2008. Principles Of Manajement Information System. Yang diterjemahkan oleh Jogianto H.M.
[10]. Keraf Gorys. Tata Bahasa Indonesia. 1989 : 24)
[11]. Murhada, Yo Cheng Giap, Pengantar Teknologi Informasi, 2011
[12]. Utdirartatmo Firrar. 2003. Teknik Kompilasi. J&J Learning. Yogyakarta. Hal: 55
[13]. Slamet Y. 2014. Problematika Berbahasa Indonesia dan Pembelajaranya. Graha Ilmu. Yogyakarta.
[14]. Widyo. Visual Basic 2008. Cv Andi Offset. 2009. Hal: 3-22 )
[15]. http://acl.ldc.upenn.edu/E/E93/E93- 1036/jurnal.pdf , Diakses 7 Mei 2014
[16]. James Suciadi (2001) “Studi Analisis Metode-metode Parsing dan Interpretasi Semantik Pada Natural Language Processing”
[17]. http://download.portalgaruda.org/article.php? captcha=jacuaru&article=67265&val=347&ti tle=&yt0=Download%2FOpen, Diakses 7 Mei 2014
[18]. Rosalina Paramita, Dwi H.Widyantoro, Ayu Purwanrianti.” INAGP : Pengurai Kalimat Bahasa Indonesia Sebagai Alat Bantu Untuk Pengembangan Aplikasi PBA”.
[19]. Jurnal:http://www.panl10n.net/english/outputs/Indonesia/BPPT/0902/SMTFinalReport/jur
nal.pdf, Diakses 7 Mei 2014

21




















