
Hybrid In-Network Query Processing Framework for Wireless Sensor Networks
6
Hybrid In-network Query Processing Framework for Wireless Sensor Networks Shaila Pervin, Joarder Kamruzzaman, Gour Karmakar, A K M Azad Gippsland School of IT, Monash University, VIC 3842, Australia Email: {shaila.pervin, joarder.kamruzzaman, gour.karmakar, akm.azad}@monash.edu Abstract - Existing in-network query processing techniques are categorized as approximation and aggregation based approaches, where the former achieves lower network traffic at the expense of query response accuracy, whereas the later reduces query response inaccuracy by executing queries at the actual sensor nodes which necessitates the overhead of query specific sensor selection mechanism. In this paper, we propose a hybrid query processing framework that combines the advantages of both the approximation and aggregation based techniques and avoids their limitations. In our approach, we construct a hierarchical probabilistic data model representing the overall sensor data characteristics across the network, which is query independent and is later used for selecting sensor nodes to process user queries. Experimental results illustrate the efficacy of the proposed framework compared to contemporary approximation and aggregation based query processing techniques. I. INTRODUCTION Recent advances in Micro Electro-Mechanical Systems (MEMS) have made possible the construction of tiny and low- cost sensor nodes containing on-board sensing, signal processing and wireless communication capabilities [1]. A wireless sensor network (WSN) is a collection of such sensor nodes spatially deployed in an ad hoc fashion that performs distributed sensing tasks in a collaborative manner without relying on any underlying infrastructure support [2]. Networking such unattended sensors in an ad hoc manner would have significant impact on a wide range of military and civil applications such as environmental monitoring, disaster management system, target tracking, battle field monitoring, emergency navigation, traffic management etc. In WSNs, sensor nodes have been usually treated as passive elements [3-4] where they measure some physical phenomena periodically or detect some events, and then send the data generated to the sink. Another kind of application is emerging where, instead of serving as passive information gathering mechanisms only, sensors can actively process and respond to user queries to report the sensed data on demand [5-6]. Based on the selection criteria, queries are categorized as spatial queries (data from spatially specific sensors) or range queries (data from sensors having particular value range); and based on the duration of execution, as continuous queries (data from sensors over a time window) or snapshot queries (data from sensors at a specific moment) [7]. Also a hybrid of the aforementioned query types may present in an application. Irrespective of the query type, in query-based WSNs, high level user queries are received at the sink which are then rewritten and forwarded to the relevant sensors. Sensor nodes process the queries and return the query results to the sink. Such paradigm to push query processing towards the origin of the data is usually known as in-network query processing [8]. Existing in-network query processing techniques vary in terms of their sensor selection and data retrieval strategies, and are broadly categorized into approximation and aggregation based techniques. To reduce the overall query dissemination and response traffic, in approximation based techniques, instead of sending user queries to sensor nodes, a query result is generated with certain probabilistic confidence based on some statistical model derived by exploiting the spatial and temporal correlation among sensor data [9-10]. For example, Meliou et al. introduced the probabilistic model-based approach [10] based on carefully designed in-network spanning tree to minimize the communication overhead required to return a reliable estimate of the value reported by all sensors in the network. The tree is rooted at the sink and each node in the tree stores one Gaussian model generated by merging Gaussian models stored in its child nodes. Queries are answered by traversing to a depth in the tree where the summaries provide sufficient information to answer a query within a specified window of accuracy. Although the study opens a door for probabilistic estimation based data modeling for WSNs, their underlying assumptions about the network architecture and query processing methodology do not fit for sensor query, which requires data from a subset of sensors satisfying given spatial and/or range predicate(s). In general, approximation based query processing techniques reduce the data traffic in the networks, which leads to a better energy efficiency and latency at the expense of certain inaccuracy in the query result. In aggregation based techniques [11-14], user queries are disseminated to the sensor nodes based on their selection predicates, and each query is executed on the actual sensor data unlike approximation based techniques. Aggregation based query processing technique introduces a new challenge to select an appropriate set of sensors where a query would be executed, and depending on the selection predicates in the user queries such set would be query wise different. For example, Connected Sensor Cover [15] is one such sensor node selection approach for spatial query execution where, in response to a query, the network is self-organized into a topology that involves only a small subset of the sensors sufficient to process the query and thereby the query is then 978-1-61284-231-8/11/$26.00 ©2011 Crown This full text paper was peer reviewed at the direction of IEEE Communications Society subject matter experts for publication in the IEEE ICC 2011 proceedings
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of Hybrid In-Network Query Processing Framework for Wireless Sensor Networks

Hybrid In-network Query Processing Framework for Wireless Sensor Networks
Shaila Pervin, Joarder Kamruzzaman, Gour Karmakar, A K M Azad
Gippsland School of IT, Monash University, VIC 3842, Australia Email: shaila.pervin, joarder.kamruzzaman, gour.karmakar, [email protected]
Abstract - Existing in-network query processing techniques are categorized as approximation and aggregation based approaches, where the former achieves lower network traffic at the expense of query response accuracy, whereas the later reduces query response inaccuracy by executing queries at the actual sensor nodes which necessitates the overhead of query specific sensor selection mechanism. In this paper, we propose a hybrid query processing framework that combines the advantages of both the approximation and aggregation based techniques and avoids their limitations. In our approach, we construct a hierarchical probabilistic data model representing the overall sensor data characteristics across the network, which is query independent and is later used for selecting sensor nodes to process user queries. Experimental results illustrate the efficacy of the proposed framework compared to contemporary approximation and aggregation based query processing techniques.
I. INTRODUCTION
Recent advances in Micro Electro-Mechanical Systems (MEMS) have made possible the construction of tiny and low-cost sensor nodes containing on-board sensing, signal processing and wireless communication capabilities [1]. A wireless sensor network (WSN) is a collection of such sensor nodes spatially deployed in an ad hoc fashion that performs distributed sensing tasks in a collaborative manner without relying on any underlying infrastructure support [2]. Networking such unattended sensors in an ad hoc manner would have significant impact on a wide range of military and civil applications such as environmental monitoring, disaster management system, target tracking, battle field monitoring, emergency navigation, traffic management etc.
In WSNs, sensor nodes have been usually treated as passive elements [3-4] where they measure some physical phenomena periodically or detect some events, and then send the data generated to the sink. Another kind of application is emerging where, instead of serving as passive information gathering mechanisms only, sensors can actively process and respond to user queries to report the sensed data on demand [5-6]. Based on the selection criteria, queries are categorized as spatial queries (data from spatially specific sensors) or range queries (data from sensors having particular value range); and based on the duration of execution, as continuous queries (data from sensors over a time window) or snapshot queries (data from sensors at a specific moment) [7]. Also a hybrid of the aforementioned query types may present in an application. Irrespective of the query type, in query-based WSNs, high level user queries are received at the sink which are then rewritten and forwarded to the relevant sensors. Sensor nodes
process the queries and return the query results to the sink. Such paradigm to push query processing towards the origin of the data is usually known as in-network query processing [8]. Existing in-network query processing techniques vary in terms of their sensor selection and data retrieval strategies, and are broadly categorized into approximation and aggregation based techniques.
To reduce the overall query dissemination and response traffic, in approximation based techniques, instead of sending user queries to sensor nodes, a query result is generated with certain probabilistic confidence based on some statistical model derived by exploiting the spatial and temporal correlation among sensor data [9-10]. For example, Meliou et al. introduced the probabilistic model-based approach [10] based on carefully designed in-network spanning tree to minimize the communication overhead required to return a reliable estimate of the value reported by all sensors in the network. The tree is rooted at the sink and each node in the tree stores one Gaussian model generated by merging Gaussian models stored in its child nodes. Queries are answered by traversing to a depth in the tree where the summaries provide sufficient information to answer a query within a specified window of accuracy. Although the study opens a door for probabilistic estimation based data modeling for WSNs, their underlying assumptions about the network architecture and query processing methodology do not fit for sensor query, which requires data from a subset of sensors satisfying given spatial and/or range predicate(s). In general, approximation based query processing techniques reduce the data traffic in the networks, which leads to a better energy efficiency and latency at the expense of certain inaccuracy in the query result.
In aggregation based techniques [11-14], user queries are disseminated to the sensor nodes based on their selection predicates, and each query is executed on the actual sensor data unlike approximation based techniques. Aggregation based query processing technique introduces a new challenge to select an appropriate set of sensors where a query would be executed, and depending on the selection predicates in the user queries such set would be query wise different. For example, Connected Sensor Cover [15] is one such sensor node selection approach for spatial query execution where, in response to a query, the network is self-organized into a topology that involves only a small subset of the sensors sufficient to process the query and thereby the query is then
978-1-61284-231-8/11/$26.00 ©2011 Crown
This full text paper was peer reviewed at the direction of IEEE Communications Society subject matter experts for publication in the IEEE ICC 2011 proceedings

executed using only the sensors in the constructed topology. In general, aggregation based query processing techniques process query results from original sensor data and thereby, reduce query response inaccuracy at the overhead cost of selecting appropriate set of sensors.
In this paper, we propose a hybrid query processing framework by combining the strengths of both the approximation based and the aggregation based query processing techniques. Here, like approximation based techniques, a statistical model representing sensor data would be developed, but instead of using approximated values as query results, such model would be used for appropriate sensor selection to execute queries at the selected sensors like aggregation based techniques. The statistical data model would be query independent and used to extract the proper set of sensors for executing any query rather than applying query specific sensor selection methodology for each query and thereby, the sensor selection process would be faster than the conventional aggregation based query processing techniques. Also the methodology would yield query results with higher accuracy compared to approximation based query processing techniques as in our method query would be executed at the original data of selected sensors as stated above. To the best of our knowledge, this is the first initiative to merge the benefits of approximation and aggregation based techniques into a single hybrid in-network query processing framework. The main contributions are as follows:
1. Development of a hierarchical probabilistic sensor data model representing sensor data characteristics which is independent of user queries,
2. Introduction of a query specific sensor selection technique based on the developed data model, and
3. Formulation of query result accuracy based on a threshold used for merging sensor and fusion node level probabilistic data models.
II. PROPOSED QUERY PROCESSING FRAMEWORK
A. The Network Model We consider a large number of sensor nodes and a relatively
small number of fusion nodes randomly and uniformly deployed in a wireless sensor network, and the whole network area is divided into polygonal regions around the fusion nodes as shown in Fig. 1(a) where the fusion nodes hold sensor data characteristics summary of the respective regions. Let and
be the number of sensors and fusion nodes deployed over the whole network. We denote by , , … , the set of all fusion nodes and by , , … , the set of regions where the polygonal region around the fusion node is . Let , , … , be the set of all sensor nodes, where , , , , … , , is the set of sensor nodes located within the region . The overall network forms a 3-tier architecture as shown in Figure 1(b), where sensor nodes, fusion nodes and a single sink node make the bottom, middle
and top level in the network hierarchy. A sensor node senses the surrounding environment to measure certain physical phenomena periodically, stores data generated thereby, and based on the measured data, it generates (or updates) a probability distribution function (pdf) representing its sensed data over a certain number of previous sense cycles. Each sensor is assigned to its nearest fusion node and the pdf generated at a sensor is sent to the fusion node if the newly calculated pdf varies significantly (more than a threshold measure) from the last sent pdf. On receiving new pdfs from its sensor nodes, a fusion node merges the sensor level pdfs and generates one or more number of fusion node level pdfs that act as the representative(s) for all sensor data in that region. The fusion node level pdfs are then sent to the sink node, which merges the pdfs received from all fusion nodes and generates a small number of resultant sink level pdfs representing the sensor data over the whole network. The detail of how to determine and update pdf in each sensor node and merge pdfs at the fusion nodes and sink are discussed next.
B. Probabilistic Sensor Data Model In this section, we discuss how a sensor node determines the
probabilistic data model representing its sensed data over a certain period. We assume that sampled data value of individual sensor node follows Normal distribution. Let , , be the pdf for sensor , at -th sense cycle over its recent sensed data having mean , , and variance
, , respectively. The value of depends on the storage capacity of the node. Then,
, , ∑∑ and
, , ∑ , ,∑
where is the sensed data at the -th sense cycle of sensor , and is the weight assigned for it, which would be used to change emphasis on recent and old sensed data [16]. A sensor sends the newly generated pdf to its nearest fusion node
Figure 2: Two normal distributions overlapping (a) 10% (b) 90%. (a) (b)
Sink Level
Fusion Node Level
Sensor Level
Region
Fusion Node
(a) (b) Figure 1: (a) Dividing a WSN into polygonal regions around fusion nodes and (b) 3-tier architecture of a WSN.
Sensor
This full text paper was peer reviewed at the direction of IEEE Communications Society subject matter experts for publication in the IEEE ICC 2011 proceedings

iff the mean varies more that a threshold value from the previously sent pdf.
C. Query Independent Hierarchical Probabilistic Sensor Data Model at Fusion Node and Sink
A hierarchical probabilistic data model of WSN is generated following the bottom-up approach; firstly, by merging the sensor node level pdfs into fusion node level pdfs and then merging the fusion node level pdfs into sink level pdfs. In merging pdfs, at both fusion node and sink levels, our strategy is to merge two distributions iff they overlap each other by at least a minimum predefined threshold and thus only close enough distributions are merged into one distribution retaining the original characteristic of the sensed data. For example, with the threshold set at 80%, two distributions overlapping each other by at least 80% will be merged. Figures 2(a)-(b) show two cases with varied degree of overlaps, where the distributions in Fig. 2(b) satisfy the threshold for merging, and thereby would be merged into one distribution. Now, in order to minimize the number of resultant merged distributions it is important to detect similar set of distributions that will be merged together based on the merging threshold. We use quality threshold clustering algorithm [17] to divide a set of distributions into a number of groups where each member of a group overlap by at least the threshold amount with each of the remaining members. Finally, the distributions of each group are merged together into one single distribution according to Gaussian mixture model [18]. A detailed example of merging distributions is shown in Fig. 3.
PDFs Merging at a Fusion Node: Since , , is the pdf for sensed data of sensor , , at -th sense cycle the set of pdfs of all sensors in region is , , , , … , , which would be merged at the corresponding fusion node . We denote by the merging threshold for merging sensor level pdfs at the fusion node, and by , , , , … , , the set of merged pdfs generated at the fusion node from the
sensor level pdfs in set , where is the number of resultant merged pdfs generated at and . We also define by Γ Γ , , Γ , , … , Γ , a set, where Γ , is the set of sensors whose corresponding pdfs are merged together and give the fusion node level pdf Y , , Γ , , 1 and Γ ,Γ , for . Figure 4 illustrates the development of fusion node level merged pdfs.
PDFs Merging at the Sink: As discussed earlier, fusion node generates a set of merged pdfs , , , , … , , from the sensor level pdfs , , , , … , , , which is then sent to the sink. Likewise, sink merges the fusion node level pdfs and generates a set of sink level pdfs that represent the probabilistic distribution of sensor data across the whole network. Similar to , let be the threshold for merging two fusion level pdfs at the sink, and , , … , be the set of merged pdfs generated at the sink from the fusion node level pdfs in sets s (1 ), where is the number of sink level merged pdfs generated at the sink from the ∑ number of fusion level pdfs received at the sink from the number of fusion nodes present in the network. We also define a set ψ ψ , ψ , … , ψ , where ψ is the set of fusion node level pdfs which are merged together and give the sink level pdf Z , , 1 and ψ ψ for
. Figure 5 illustrates the scenario of fusion node level pdf merging at the sink.
D. Query Processing using Probabilistic Hierarchical Sensor Data Model
From Sections II-B and II-C, it is to be noted that the hierarchical probabilistic sensor data model generated at sensor, fusion node and sink levels is query independent, which would be used for selecting the appropriate sets of fusion nodes and sensors for processing user query. In our approach, a query with predicate , is received at the sink, then based on the query predicate sink selects appropriate sink level pdfs which overlap fully or partially with the query predicate as described below:
Full overlap: 3 3 or 3 3 Partial overlap: 3 3 or 3 3 Figure 4: The similar sensor pdfs of region are merged and the merged
pdfs along with the information of their source sensors are stored on the fusion node .
PDF Source
Merging of sensor level PDFs at iF
iF
,1iX ,1is ,2iX
,2is , ii ns , ii nX
,1iY ,2iY , ii uY
,1iΓ
, ii uΓ
,2iΓ
(a)
Figure 3: (a) Six original distributions to be merged, (b) three groups of similar distributions, and (c) three merged distributions each for one group.
(b) (c)
Figure 5: The similar merged pdfs of regions are merged and the final merged pdfs along with their source pdf information are stored at the sink.
1ψ 2ψ vψ Sink 1Z 2Z vZ
1F FNF
Source
Merging of fusion node level PDFs at sink
1,1Y 11,uY 2,1Y
22,uY ,1FNY ,F NFN uY 2F
This full text paper was peer reviewed at the direction of IEEE Communications Society subject matter experts for publication in the IEEE ICC 2011 proceedings
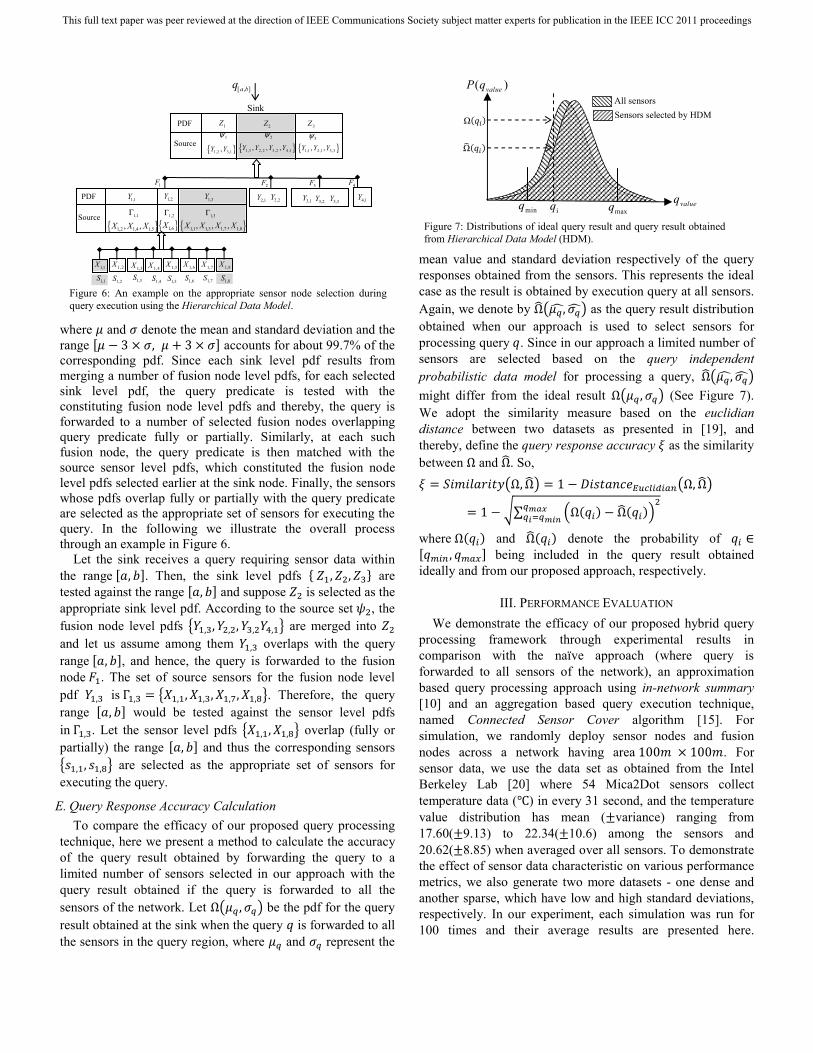
where and denote the mean and standard deviation and the range 3 , 3 accounts for about 99.7% of the corresponding pdf. Since each sink level pdf results from merging a number of fusion node level pdfs, for each selected sink level pdf, the query predicate is tested with the constituting fusion node level pdfs and thereby, the query is forwarded to a number of selected fusion nodes overlapping query predicate fully or partially. Similarly, at each such fusion node, the query predicate is then matched with the source sensor level pdfs, which constituted the fusion node level pdfs selected earlier at the sink node. Finally, the sensors whose pdfs overlap fully or partially with the query predicate are selected as the appropriate set of sensors for executing the query. In the following we illustrate the overall process through an example in Figure 6.
Let the sink receives a query requiring sensor data within the range , . Then, the sink level pdfs , , are tested against the range , and suppose is selected as the appropriate sink level pdf. According to the source set , the fusion node level pdfs , , , , , , are merged into and let us assume among them , overlaps with the query range , , and hence, the query is forwarded to the fusion node . The set of source sensors for the fusion node level pdf , is Γ , , , , , , , , . Therefore, the query range , would be tested against the sensor level pdfs in Γ , . Let the sensor level pdfs , , , overlap (fully or partially) the range , and thus the corresponding sensors , , , are selected as the appropriate set of sensors for executing the query.
E. Query Response Accuracy Calculation To compare the efficacy of our proposed query processing
technique, here we present a method to calculate the accuracy of the query result obtained by forwarding the query to a limited number of sensors selected in our approach with the query result obtained if the query is forwarded to all the sensors of the network. Let Ω , be the pdf for the query result obtained at the sink when the query is forwarded to all the sensors in the query region, where and represent the
mean value and standard deviation respectively of the query responses obtained from the sensors. This represents the ideal case as the result is obtained by execution query at all sensors. Again, we denote by Ω , as the query result distribution obtained when our approach is used to select sensors for processing query . Since in our approach a limited number of sensors are selected based on the query independent probabilistic data model for processing a query, Ω , might differ from the ideal result Ω , (See Figure 7). We adopt the similarity measure based on the euclidian distance between two datasets as presented in [19], and thereby, define the query response accuracy as the similarity between Ω and Ω. So, Ω, Ω 1 Ω, Ω
1 ∑ Ω Ω
where Ω and Ω denote the probability of , being included in the query result obtained ideally and from our proposed approach, respectively.
III. PERFORMANCE EVALUATION
We demonstrate the efficacy of our proposed hybrid query processing framework through experimental results in comparison with the naïve approach (where query is forwarded to all sensors of the network), an approximation based query processing approach using in-network summary [10] and an aggregation based query execution technique, named Connected Sensor Cover algorithm [15]. For simulation, we randomly deploy sensor nodes and fusion nodes across a network having area 100 100 . For sensor data, we use the data set as obtained from the Intel Berkeley Lab [20] where 54 Mica2Dot sensors collect temperature data ( ) in every 31 second, and the temperature value distribution has mean ( variance) ranging from 17.60( 9.13) to 22.34( 10.6) among the sensors and 20.62( 8.85) when averaged over all sensors. To demonstrate the effect of sensor data characteristic on various performance metrics, we also generate two more datasets - one dense and another sparse, which have low and high standard deviations, respectively. In our experiment, each simulation was run for 100 times and their average results are presented here.
Figure 6: An example on the appropriate sensor node selection during query execution using the Hierarchical Data Model.
2,1Y 2,2Y 3,1Y 3,2Y 3,3Y 4,1Y
Source 1ψ 2ψ
3ψ
Sink
1Z 2Z 3Z
1,2 3,1,Y Y 1,3 2,2 3,2 4 ,1, , ,Y Y Y Y 1,1 2,1 3,3, ,Y Y Y
2F 3F 4F PDF
Source 1,1Γ 1,2 1,4 1,5, ,X X X 1,6X 1,1 1,3 1,7 1,8, , ,X X X X
1,1Y 1,2Y 1,3Y
1,2Γ 1,3Γ
1,1X 1,2X
1,1S1,3X 1,4X 1,5X 1,6X 1,7X 1,8X
1F
1,2S 1,3S1,4S 1,5S 1,6S 1,7S 1,8S
[ , ]a bq
Figure 7: Distributions of ideal query result and query result obtained from Hierarchical Data Model (HDM).
minq maxq iq
Ω
Ω
valueq
( )valueP q
All sensors Sensors selected by HDM
This full text paper was peer reviewed at the direction of IEEE Communications Society subject matter experts for publication in the IEEE ICC 2011 proceedings
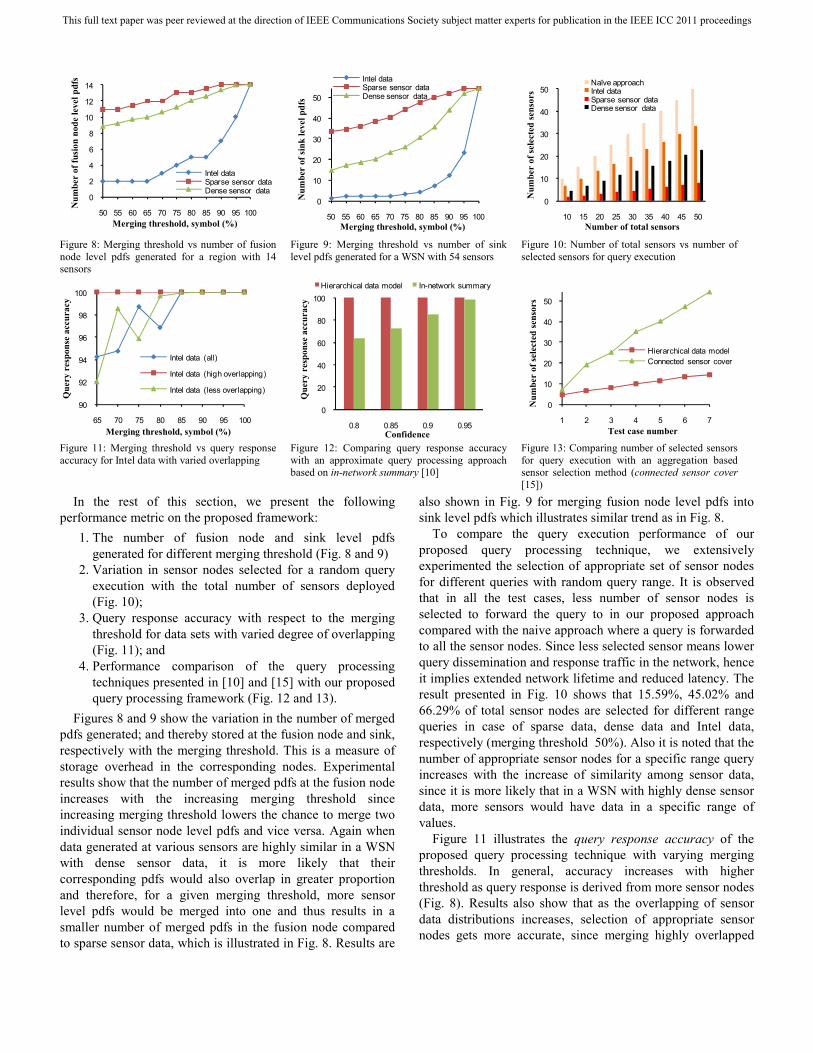
Figure 8: Merging threshold vs number of fusion node level pdfs generated for a region with 14 sensors
Figure 9: Merging threshold vs number of sink level pdfs generated for a WSN with 54 sensors
Figure 10: Number of total sensors vs number of selected sensors for query execution
Figure 11: Merging threshold vs query response accuracy for Intel data with varied overlapping
Figure 12: Comparing query response accuracy with an approximate query processing approach based on in-network summary [10]
Figure 13: Comparing number of selected sensors for query execution with an aggregation based sensor selection method (connected sensor cover [15])
In the rest of this section, we present the following performance metric on the proposed framework:
1. The number of fusion node and sink level pdfs generated for different merging threshold (Fig. 8 and 9)
2. Variation in sensor nodes selected for a random query execution with the total number of sensors deployed (Fig. 10);
3. Query response accuracy with respect to the merging threshold for data sets with varied degree of overlapping (Fig. 11); and
4. Performance comparison of the query processing techniques presented in [10] and [15] with our proposed query processing framework (Fig. 12 and 13).
Figures 8 and 9 show the variation in the number of merged pdfs generated; and thereby stored at the fusion node and sink, respectively with the merging threshold. This is a measure of storage overhead in the corresponding nodes. Experimental results show that the number of merged pdfs at the fusion node increases with the increasing merging threshold since increasing merging threshold lowers the chance to merge two individual sensor node level pdfs and vice versa. Again when data generated at various sensors are highly similar in a WSN with dense sensor data, it is more likely that their corresponding pdfs would also overlap in greater proportion and therefore, for a given merging threshold, more sensor level pdfs would be merged into one and thus results in a smaller number of merged pdfs in the fusion node compared to sparse sensor data, which is illustrated in Fig. 8. Results are
also shown in Fig. 9 for merging fusion node level pdfs into sink level pdfs which illustrates similar trend as in Fig. 8.
To compare the query execution performance of our proposed query processing technique, we extensively experimented the selection of appropriate set of sensor nodes for different queries with random query range. It is observed that in all the test cases, less number of sensor nodes is selected to forward the query to in our proposed approach compared with the naive approach where a query is forwarded to all the sensor nodes. Since less selected sensor means lower query dissemination and response traffic in the network, hence it implies extended network lifetime and reduced latency. The result presented in Fig. 10 shows that 15.59%, 45.02% and 66.29% of total sensor nodes are selected for different range queries in case of sparse data, dense data and Intel data, respectively (merging threshold 50%). Also it is noted that the number of appropriate sensor nodes for a specific range query increases with the increase of similarity among sensor data, since it is more likely that in a WSN with highly dense sensor data, more sensors would have data in a specific range of values.
Figure 11 illustrates the query response accuracy of the proposed query processing technique with varying merging thresholds. In general, accuracy increases with higher threshold as query response is derived from more sensor nodes (Fig. 8). Results also show that as the overlapping of sensor data distributions increases, selection of appropriate sensor nodes gets more accurate, since merging highly overlapped
0
2
4
6
8
10
12
14
50 55 60 65 70 75 80 85 90 95 100
Intel dataSparse sensor dataDense sensor data
0
10
20
30
40
50
50 55 60 65 70 75 80 85 90 95 100
Intel dataSparse sensor dataDense sensor data
0
10
20
30
40
50
10 15 20 25 30 35 40 45 50
Naïve approachIntel dataSparse sensor dataDense sensor data
90
92
94
96
98
100
65 70 75 80 85 90 95 100
Intel data (all)
Intel data (high overlapping)
Intel data (less overlapping)
0
20
40
60
80
100
0.8 0.85 0.9 0.95
Hierarchical data model In-network summary
0
10
20
30
40
50
1 2 3 4 5 6 7
Hierarchical data modelConnected sensor cover
Merging threshold, symbol (%) Merging threshold, symbol (%) Number of total sensors
Merging threshold, symbol (%) Confidence
Num
ber
of fu
sion
nod
e le
vel p
dfs
Num
ber
of si
nk le
vel p
dfs
Num
ber
of se
lect
ed se
nsor
s
Que
ry r
espo
nse
accu
racy
Que
ry r
espo
nse
accu
racy
Test case number
Num
ber
of se
lect
ed se
nsor
s
This full text paper was peer reviewed at the direction of IEEE Communications Society subject matter experts for publication in the IEEE ICC 2011 proceedings

distributions represent the characteristics of original distributions more accurately. The results also show the effect of data characteristics on query response accuracy, where one set of data is the Intel dataset [20], the second and third sets are the highly overlapped and less overlapped data extracted from the first set.
Next, the query response accuracy of our proposed model is compared with an approximation based query processing approach using in-network summary [10], where a query with accuracy window , confidence and cardinality , requires that on expectation of the reported values will fall within
of the actual values. For random values of and four values of (0.8, 0.85, 0.9, and 0.95), we first construct the spanning tree with in-network compressed summary of sensor data for each given set of and using the method described in [10]. We then apply random range queries over the nodes in the generated tree, collect query response and compute the query response accuracy as described in Section II-E. On the other hand, using the same sensor dataset and same set of range queries, we use our proposed method and compute the query response accuracy. The comparison of accuracy between the methods is presented in Fig. 12, which demonstrates significantly improved accuracy in our approach.
We also compare the sensor node selection performance of our proposed hierarchical probabilistic data model with an aggregation based sensor selection method named Connected Sensor Cover [15], which selects minimum number of connected sensors covering the geographic region specified in the spatial query and then forwards the query to all the selected sensor nodes. We consider circular query regions with 10 radius for 1,2, … ,7 located in different random locations (one region of specified radius generated in each trial) on the deployed sensor region for spatial queries and first select appropriate set of sensors using Connected Sensor Cover over the region. Since this method is region specific, a direct comparison with our method which selects sensors over the whole deployed region cannot be made. So to make the comparison meaningful, we apply random range queries (for example, “select all sensors having temperature value within 15 20 ”) on the sensors over the corresponding region and select proper sensors satisfying the query predicate using our method. A comparison between the numbers of selected sensor nodes is shown in Fig. 13 where our proposed model always selects less number of sensor nodes and thus forward the query to only the selected sensors rather than sending the query to all of the connected sensors located in that particular region as selected by the method presented in [15].
IV. CONCLUSION
In this paper, we propose a hybrid in-network query processing framework by combining the benefits of traditional approximation and aggregation based query processing techniques. In particular, we develop a query independent
hierarchical probabilistic data model representing the data characteristics of the whole sensor network and exploit that model to choose appropriate set of sensors satisfying user query requirements. Then collecting actual data from the selected sensors, query results are processed with high accuracy. Simulation results confirm that the proposed framework is able to meet high accuracy requirements with a much smaller set of selected sensors rather than sending user queries to all the sensors of the network. In our future work, the data model would potentially be augmented with pdf update with time rather than using static sensor data and the query processing framework would be customized to achieve user defined level of accuracy.
REFERENCES [1] F. Zhao and L. Guibas, “Wireless sensor networks: an information
processing approach,” Morgan Kaufmann, Los Altos, CA, 2004. [2] D. Culler, D. Estrin, and M. Srivastava, “Overview of sensor networks,”
IEEE Computer, vol. 37, no. 8, pp. 41-49, 2004. [3] H. Saito, O. Kagami, M. Umehira, and Y. Kado, “Wide area ubiquitous
network: the network operator’s view of a sensor network,” IEEE Communications Magazine, vol. 46, no. 12, pp. 112-120, 2008.
[4] L. Yonghe and S.K. Das, “Information-intensive wireless sensor networks: potential and challenges,” IEEE Communications Magazine, vol. 44, no. 11, pp. 142-147, 2006.
[5] C. Efthymiou, S. Nikoletseas, and J. Rolim, “Energy balanced data propagation in wireless sensor networks,” Wireless Networks, vol. 12, no. 6, pp. 691-707, 2006.
[6] W. Choi and S. K. Das, “A novel framework for energy-conserving data gathering in wireless sensor networks,” Proc. of the IEEE INFOCOM, pp. 1985-1996, 2005.
[7] K. Park, R. Elmasri, "Query classification and storage evaluation in wireless sensor networks", Proc. of the 22nd International Conference on Data Engineering Workshops, pp. 35, 2006.
[8] M. Demirbas, L. Xuming, and P. Singla, “An in-network querying framework for wireless sensor networks,” IEEE Trans. on Parallel and Distributed Systems, vol. 20, no. 8, pp., 1202-1215, 2009.
[9] A. Deshpande, C. Guestrin, S. R. Madden, J. M. Hellerstein, "Model-driven data acquisition in sensor networks," Proc. of VLDB, 2004.
[10] A. Meliou, C. Guestrin, and J.M. Hellerstein, "Approximating sensor network queries using in-network summeries," Proc. of IPSN, pp. 229-240, 2009.
[11] Y. Yao and J. Gehrke, “The Cougar approach to in-network query processing in sensor networks,” SIGMOD, vol. 31, no. 3, pp. 9-18, 2002.
[12] S. Madden, M.J. Franklin, J.M. Hellerstein, and W. Hong, “TinyDB: an acquisitional query processing system for sensor networks,” ACM Transactions on Database Systems, vol. 30, no. 1, pp. 122–173, 2005.
[13] M. A. Sharaf, J. Beaver, A. Labrinidis, and P. K. Chrysanthis, “TiNA: A scheme for temporal coherency-aware in-network aggregation,” Proc. of the ACM MobiDE, pp. 69-76, 2003.
[14] D. J. Abadi, S. Madden, and W. Lindner, “REED: Robust, efficient filtering and event detection in sensor networks,” VLDB, 2005.
[15] H. Gupta, Z. Zhou, S.R. Das, Q. Gu, “Connected sensor cover: self-organization of sensor networks for efficient query execution,” IEEE ACM Transactions on Networking, Volume: 14, Issue: 1, pp. 55-67, 2006.
[16] D. H. D. West, “Updating mean and variance estimates: an improved method,” Communications of the ACM, 1979.
[17] Quality threshold clustering : http://en.wikipedia.org/wiki/Cluster_analysis
[18] Gaussian mixture model: www.cs.cmu.edu/afs/cs/Web/People/awm/tutorials/gmm.html
[19] Yingying Tao, M. Tamer Özsu, “Mining data streams with periodically changing distributions,” International Conference on Information and Knowledge Management (CIKM), 2009.
[20] Intel lab data: http://db.csail.mit.edu/labdata/labdata.html
This full text paper was peer reviewed at the direction of IEEE Communications Society subject matter experts for publication in the IEEE ICC 2011 proceedings




















