
Memory retrieval processing: Neural indices of processes supporting episodic retrieval






Acknowledgments
First of all, I would like to thank Allah, Allah the Almighty, who gave me the
Strength to finish this thesis. My sincere thanks go to my supervisor Dr.
Mamoun Al-Rababaa for support and guidance during the research.
I would like also to express my appreciation and deep gratitude to Dr. Essam
Hanandeh and Dr. Mofleh Aldyabat
I would like to thank from the deepest of my heart my grandparents and my
parents who supported me morally and encouraged me in all my way in my
study. They were lighting my way by their words and their smiles.
accepting to come and discuss my thesis. Finally, I hope this work may
contribute in developing the knowledge in this field. And I pray to Allah to
dedicate me to serve my country under the governance of His Majesty King
Abdullah II Bin Al-Hussein
All praises to Allah
Laith aboaliqa

Dedication
To the Soul of my grandfather
To my beloved, father, mother, brothers and sisters
Laith aboaliqa

Table of Contents
List of Tables........................................................................................................................... G
.. I
List of ... . J
Abstract .........................................K
______________________________________________________________________________
Chapter 1: Introduction
1.1 Background ......................................................................................................................
1.2 Information Retrieval Systems (IRS)..............................................................................
3
1.4 The Statement of the Problem....................................................................................................4
1.5 The Objectives of the Study.................................................................................. 5
1.6 Organization of the Thesis.........................................................................................................5
______________________________________________________________________________
Chapter 2: Theoretical concept
2.1Information R ....................................................................................................6
2.2 Basic Processes of Information Retrieval..................... ............................................6
2.3 Information Retrieval (IR) Models .......................................................................................7
2.4 Document and Query Representation......................................................................................10

2.5 Example Cosine Similarity Measures......................................................................................12
2.6 Evaluation of Information Retrieval Systems..........................................................................15
2.7 Overview of Genetic Algorithm..............................................................................................16
2.7.1 Genetic Algorithm Approach................................................................................................17
2.7.2 Adaptive genetic algorithm...................................................................................................20
Chapter 3: Literature Review.................................................................................................24
______________________________________________________________________________
Chapter 4: Methodology
4.1 Introduction..................................................................................................................... .........28
4.2 Data Collection .........29
4.3 Preprocessing Steps.................................................................................................................30
4.4 Proposed Algorithm.................................................................................................................36
4.5 Pseudocode of Proposed Adaptive Genetic Algorithm..........................................................37
______________________________________________________________________________
Chapter 5: Experimental results
5.1 Results .....................................................................................................................................39
5.2 Average Precision using VSM with Cosine.............................................................................45
.........................................................................46
5.4 Average Precision using EBM with Cosine.............................................................................47
5.5 Average Precision using EBM with Cosine.............................................................................48
5.6 Result of Precision for (VSM).................................................................................................49

5.7 Result of Precision for (EBM).................................................................................................50
5.8 Comparison between Proportions Improvement.....................................................................51
______________________________________________________________________________
Chapter 6: Conclusion, recommendations and future work
6.1 Introduction 52
6.2 Conclusion ..................................52
6.3 Future work 53
______________________________________________________________________________
References.......................................................................................................................54
Abstract in Arabic languages ....................................................................................57

List of Tables
Table (2.1) Document and term query frequency..........................................................................12
Table (2.2) Max frequency and document ID................................................................................13
Table (2.3) Inverse document frequency.......................................................................................13
Table (2.4) Compute frequency and weights.................................................................................14
Table (2.5) Weights of term...........................................................................................................14
Table (4.1) representation chromosome........................................................................................32
Table (5.1) value of precision and Recall for query number1 by using (VSM) with (AGA)
using cosine fitness function..........................................................................................................39
Table (5.2) value of precision and Recall for query number1 by using (VSM) with (AGA)
using proposed cosine fitness function..........................................................................................40
Table (5.3) value of precision and Recall for query number1 by using (VSM) with (AGA)
using jaccard's fitness function......................................................................................................41
Table (5.4) value of precision and Recall for query number1 by using (VSM) with (AGA)
using proposed jaccard's fitness function.......................................................................................41
Table (5.5) value of precision and Recall for query number1 by using (EBM) with (AGA)
using cosine fitness function..........................................................................................................42
Table (5.6) value of precision and Recall for query number1 by using (EBM) with (AGA)
using proposed cosine fitness function..........................................................................................43
Table (5.7) value of precision and Recall for query number1 by using (EBM) with (AGA)
using jaccard's fitness function......................................................................................................43

Table (5.8) value of precision and Recall for query number1 by using (EBM) with (AGA)
using proposed jaccard's fitness function.......................................................................................44
Table (5.9) Average value of precision for all queries using VSM with cosine............................45
Table (5.10) Average value of precision for all queries .....................46
Table (5.11) Average value of precision for all queries using EBM with cosine..........................47
Table (5.12) Average value of precision for all queries using EBM with jaccard's......................48
Table (5.13) Using vector space model with fitness function option............................................49
Table (5.14) Using extended Boolean model with fitness function option...................................50
Table (5.15) Compare between improvements..............................................................................51

List of Figures
Figure (2.1) Data flow for the traditional genetic algorithm.........................................................17
Figure (4.1) Data flow for proposed algorithms............................................................................38
Figure (5.1): Average value of precision for all queries using VSM-cosine.................................45
Figure (5.2): Average value of precision for all queries using VSM-jaccard's.............................46
Figure (5.3): Average value of precision for all queries using EBM-cosine.................................47
Figure (5.4): Average value of precision for all queries using EBM- .............................48
Figure (5.5): Using VSM with fitness function option..................................................................49
Figure (5.6): Using EBM with fitness function.............................................................................50

List of abbreviations
IRS :--------------------------------- information retrieval system
AGA:-------------------------------- adaptive genetic algorithm
GA:---------------------------------- genetic algorithm
IR: -----------------------------------information retrieval
P: -------------------------------------precision
R: -------------------------------------recall
Doc Id:-------------------------------document identifier
F: -------------------------------------fitness value
Q: ------------------------------------query
TF:----------------------------------- term frequency
TF-IDF: -----------------------------term frequency- inverse document frequency
VSM: --------------------------------vector space model
EBM: --------------------------------extended Boolean model
Pm:----------------------------------- mutation probability
Pc: ------------------------------------crossover probability

Abstract:
Keywords: Information Retrieval, Adaptive genetic Algorithm, Extended Boolean Model, Vector space model.

Chapter one
Introduction
1.1 Background
After the increase number of information and documents on the Internet, provide a
huge number of information and documents, created by millions of authors and
organizations. As users, we can have this information through using the process of
information retrieval system. But still the users may encounter several problems in the
process of information retrieval system. Thus, there are several researches that are
tackling these problems that have an effect on the accuracy of the system in order to
find the best solutions. The researcher will attempt to increase the efficiency and
accuracy of the system [21].
The researcher reaches to some results from this study, which showed some
improvements in information retrieval system performance using adaptive genetic
algorithms, through implementing some queries using several methods in order to
obtain the relevant information through sorting and ranking based on the similarity
measure [21].
The objectives of the study were identified in order to solve the problems of
information retrieval system and to facilitate this process so that the user will obtain
the information he needs accurately through adaptive genetic algorithms and
implement it in an information retrieval system. The best solution was obtained with
the information retrieval system through achieving more accuracy after the
improvements from applying genetic algorithms [1] [21].

Genetic algorithms were used in many traditional areas such as information
retrieval system to meet the user need through entering the query, Neural networks to
get the best solution through the sorting of node, and artificial intelligence which has
become very common recently on the development of a genetic algorithm through
proposing adaptive fitness function and adaptive mutation operator [1] [10].
As is should be clear now that the study aims at investigating the information
retrieval models that are used to find the similarity between the query and documents.
In this study, the researcher used two models: vector space model and extended
Boolean model to compute the similarity between the query and documents [5].
The researcher also proposed two fitness functions: cosine and j
used variable ratio of mutation operators in order to have better results through
comparing first fitness function (Cosine) with variable probability mutations and
variable probability crossover and comparing
with variable probability mutations and variable probability crossover [5].
The corpus of the study consists of 1400 English documents in Mathematics and
255 queries to evaluate the effectiveness of the results according to the precision and
recall measures [4] [7].
1.2 Information Retrieval Systems (IRS)
In order to facilitate the task of the user in searching for information from a collection
of available documents through entering the query linked with user need, the
information retrieval systems work to rank documents in order, based on cosine
similarity, and identify documents that contain a relationship (relevant) with user
needs [1].

1.3 Genetic Algorithm
Genetic algorithm is represented by chromosome and the chromosome is represented
in several ways: figures of the percentage of decimal places, groups or binary system,
and conversion can be carried out on the basis of the fitness function. Through the
work of the algorithm in the process of retrieving the genetic information, each
chromosome is divided into several genes and each gene represents a term for the
query entered [7].
Genetic algorithms can work in several adaptations, such as adaptive fitness function,
adaptive crossover and mutation operators to improve the performance of the genetic
algorithm in information retrieval and having a better generation of the population
[17].
Genetic algorithm focuses on population to start the evaluation of process in genetic
algorithm and the population will be taken from the results of information retrieval
system when finishing the process [2].
The process of information retrieval systems is based on the degree of similarity
between the query and documents in the corpus and it is calculated according to the
degree of efficiency and accuracy using precision and recall measures [1][4].
Several models have been used in information retrieval to represent the document
and query to compute the similarity between them such as the vector space model,
Boolean model, language model and fuzzy model. But, in our study, the researcher
just used vector space model and extended Boolean model [10].

The researcher used adaptive genetic algorithm in order to have the best solution from
the results of information retrieval system [1].
Genetic algorithms used several principles in their operations such as a selection
method of the initial population. In our study, the researcher used the top ranked
documents retrieval in the selection process and used the documents retrieved from
the entry of a single query as initial population [2].
There are also several probability ratios of mutations and crossover in genetic
algorithms that can be taken from a range of mutation probability. Each ratio may flip
the chromosomes or may not, and has a ratio of crossover that may flip also the
chromosomes or may not for having best solution [5].
Mutation is an important strategy to study genetic algorithm for the optimization
process to get better results and to seek the best solution in the genetic algorithm
when retrieving information. There are several types of mutation operator and every
type uses certain probability with specific range to get a great number of Mutations
[3].
1.4 The Statement of the Problem
A large number of documents retrieved by the users
,
the

1.5 The Objectives of the Study
The aims to achieve the following goals:
1- Proposing adaptive fitness function through the use of two equations (Cosine, and
Jaccard) which have been used recently for having accurate results and improving the
GA performance.
2- Proposing adaptive crossover and mutation operators through the use of more
points within the domain of crossover equations that have been used recently for
having accurate results and improving the GA performance.
3- Finding the right number of generations for the user to save time in genetic
algorithms.
1.6 Organization of the Thesis
1. Chapter one : an introduction
2. Chapter two : theoretical concept
3. Chapter three : literature review
4. Chapter four : methodology and data collection
5. Chapter five : experimental results
6. Chapter six : conclusions, recommendations and future work

Chapter two
Theoretical concept
2.1 Information Retrieval
There are fundamental processes in information retrieval systems to get the
information that meets the needs of the user by finding the similarity between the
query and the existing documents. In this chapter, we shall show some of the basic
processes of matching the query with documents [9], based on Vector Space Model
(VSM) in which both documents and queries are represented as vectors, and used
extended Boolean model (EBM) [10].
2.2 Basic Processes of Information Retrieval
There are several processes of information retrieval system as following:
1- Removing the punctuation marks from each document.
2- Removing stop words from each document, such as prepositions, articles and
other words that appear frequently in the document without adding any
meaning to it [7] [8].
3- Stemming the words using the porter stemmer that is the most commonly used
[8].
4- Inverted index, give each document a unique serial number, known as the
document identifier and connecting which element in any document appeared
(doc ID) [7].

2.3 Information Retrieval (IR) Models
A range of different models has been proposed in the information retrieval literature,
based upon different notions of what it means for a document to be relevant to a
query. While some models, such as Boolean model, have been important historically,
the most common form of information retrieval today is ranked retrieval. A query is
treated as an unordered set of Keywords.
There are models of information retrieval system as follow:
1- The Extended Boolean model was described in a Communications of the
ACM article appearing in 1983, by Gerard Salton, Edward A. Fox, and Harry
Wu. The goal of the Extended Boolean model is to overcome the drawbacks of
the Boolean model that has been used in information retrieval. The Boolean
model doesn't consider term weights in queries, and the result set of a Boolean
query is often either too small or too big.
The idea of the extended model is to make use of partial matching and term
weights as in the vector space model. It combines the characteristics of the
Vector Space Model with the properties of Boolean algebra and ranks the
similarity between queries and documents. This way a document may be
somewhat relevant if it matches some of the queried terms and will be
returned as a result, whereas in the Standard Boolean model [From Wikipedia].
Extended Boolean model (EBM): it is a simple model that works on the basis
of the binary system [20]. The logical model to calculate the similarity
between the query and the documents where the logic (or, and, not) are
calculated according to the equations given to retrieve all documents that
contain terms through using (or) in this model [10] [18]. We used equation (1)
to rank documents in (EBM).


2- Vector Space Model (VSM): This model is characterized by the use of very
little binary weight. Instead, it deals with a model that has partial matching.
When the weight is given to the index terms in queries, these weights are used
to calculate the degree of similarity of each file in the system and the user
queries through a descending arrangement after calculating the degree of
similarity. Then, they are arranged in a descending way [7] [10].
Vector Space Model: The researcher used cosine equations from some
measure to compute the similarity between query and document because the
cosine similarity in recent research given good results. The document and
query are represented to compare each term query with each term document
when matching term query and term document in order to compute the weight
to compute similarity as following [10].
Each dimension corresponds to a separate term. If a term occurs in the
document, its value in the vector is non-zero. Several different ways of
computing these values, also known as (term) weights, have been developed.
One of the best known schemes is TF-IDF weighting (see the example below).
Example documents and queries are represented as vectors
Q= (W1,q , W2,q ,... Where x num of index term ,Q=term query
num of doc, D=documents
The definition of term depends on the application. Typically terms are single
words, keywords, or longer phrases. If the words are chosen to be the terms,
the dimensionality of the vector is the number of words in the vocabulary (the
number of distinct words occurring in the corpus) [From Wikipedia].




Table (2.2) shows the identity (ID) documents and max frequencies for each
document.
Table (2.2) Max frequency and document ID
Max frequency Document ID
15 1
17 2
12 3
11 4
Table (2.3) shows the number of documents in which the index term appears in them
(ni), and compute the inverse document frequency (Idfi) using an equation number
(4).
Table (2.3) Inverse document frequency
Idfi = log(N/ni) ni Term ID Words
log10 4/4 = 0 4 1
log10 4/4 = 0 4 2
log10 4/2 = 0.301 2 3
log10 4/3 = 0.125 3 4
log10 4/2 = 0.301 2 5



2.7 Overview of Genetic Algorithm
Genetic algorithm is an important technique in random search in the best solution or
the best among a group of solutions in the available data [8].In the computer science
field of information retrieval system, genetic algorithm (GA) is a search heuristic that
mimics the process of natural selection. This heuristic (also sometimes called a met
heuristic) is routinely used to generate useful solutions to optimization and search.
Genetic algorithms belong to the larger class of evolutionary algorithms (EA), which
generate solutions to optimization problems using techniques inspired by natural
evolution, such as mutation, selection, and crossover.
In a genetic algorithm, a population of candidate solutions to an optimization problem
is evolved toward better solutions. Each candidate solution has a set of properties (its
chromosomes) which can be mutated and altered; traditionally, solutions are
represented in binary as strings of 0s and 1s, but other encodings are also possible.[2]
The evolution usually starts from a population of randomly generated individuals, and
is an iterative process, with the population in each iteration called a generation. In
each generation, the fitness of every individual in the population is evaluated; the
fitness is usually the value of the objective function in the optimization problem being
solved. The more fit individuals are stochastically selected from the current
population, and each individual's gene is modified (recombined and possibly
randomly mutated) to form a new generation. The new generation of candidate
solutions is then used in the next iteration of the algorithm. Commonly, the algorithm
terminates when either a maximum number of generations has been produced, or a
satisfactory fitness level has been reached for the population.

Genetic algorithm operates on the encoded representation of the solutions, equivalent
to those chromosomes of the individuals in nature. It is assumed that a potential
solution to a problem may be represented as encoded as a chromosome. The
researcher used chromosome depends on converting the documents chosen from IRs
to the chromosome in genetic algorithm represented by the binary system to
implement it in genetic algorithms, can see in the next page [7]. The researcher will
compare between the works of the system using the adaptive genetic algorithm with a
traditional genetic algorithm.
2.7.1 Genetic Algorithm ApproachData flow for traditional genetic algorithm as following:
Yes
No
Figure (2.1) Data flow for the traditional genetic algorithm.
Representation of chromosome
Initial population
Fitness evaluation
Got betterresult
Result
Selection method
Crossover
Mutation

The process of the genetic algorithms
Representation of the chromosomes: These chromosomes are represented using
the binary system to express them. They represent a group of genes depending on
the degree of similarity between the query and documents.
The researcher chooses 30 documents were selected from information retrieval
system as initial population, The researcher chooses this number of documents as
chromosome because this number is good for average research, and a document
was transformed to a binary system.
The researcher compares between the query term and term document. If the first
term query exists in term document, set the first bit 1, otherwise set 0. This can be
done with the rest of the bits of chromosomes. The length of the chromosome is
ten.
Fitness Function: an approach used to compute system performance. It evaluates
the solution whether it was effective or not. Adaptive Genetic algorithm in my
thesis used two proposed fitness function cosine, and jaccard's with some
modification (add addition equation at fitness function cosine and to
find the similarity between the chromosomes and identify the chromosomes that
have better value.
The researcher used two fitness functions to get better results during measuring.
Then, the researcher will work to change the equation of fitness and seeks to get
the best results. The researcher s as fitness function
because this has been used recently in many research and taking good results so
used this two measure in case and modification this measure in another case to
get the best case.

Selection Method: The researcher used in the genetic algorithm the selection
mechanism that is a simple random sampling for the application of operations.
This consists of the construction based on selecting randomly chromosome. The
researcher chosen were selected randomly model because takes all chromosomes
chance to apply operator of genetic algorithm to get the best result from all
chromosomes.
After choosing two chromosomes the researcher applies operators of genetic
algorithm to achieve get a new two chromosomes better the old two chromosomes
have been selected. When get two chromosomes better the researcher made
swapping between the original chromosomes, then put the better chromosome
instead two chromosomes is bad, evaluated based fitness function [7].
Operators :
In a genetic algorithm approaches, the researcher uses two GA operators to
produce offspring chromosomes, which are:
Crossover: the genetic operator that mixes two chromosomes together to form a
new offspring. On adaptive probability, the researcher apply two points crossover
through using many probability ratio crossover, to get better value, the researcher
chosen two point crossover mechanism because takes chromosomes more chance
for chromosome change [7] [10].
Mutation: the second operator used in our genetic algorithm systems, involves a
mutation to modify the values of the gene; under slight change, changing the
values of chromosomes that appear different breeds, the goal of the mutation is to
restore the lost and explore a variety of data. The researcher used adaptive many
ratio probabilities to get a better ratio mutation, based on applying one point
randomly [6] [10].

2.7.2 Adaptive genetic algorithm
Genetic algorithms with adaptive parameters (adaptive genetic algorithms, AGAs) is
another significant and promising variant of genetic algorithms. The probabilities of
crossover (pc) and mutation (pm) greatly determine the degree of solution accuracy
and the convergence speed that genetic algorithms can obtain. Instead of using fixed
values of pc and pm, AGAs utilize the population information in each generation and
adaptively adjust the pc and pm in order to maintain the population diversity as well
as to sustain the convergence capacity.
In adaptive genetic algorithm, the adjustment of pc and pm depends on the fitness
values of the solutions. In CAGA (clustering-based adaptive genetic algorithm),
through the use of clustering analysis to judge the optimization states of the
population, the adjustment of pc and pm depends on these optimization states. It can
be quite effective to combine GA with other optimization methods.GA tends to be
quite good at finding generally good global solutions, but quite inefficient at finding
the last few mutations to find the absolute optimum Genetic algorithms with adaptive
parameters (adaptive genetic algorithms, AGAs) is another significant and promising
variant of genetic algorithms.
The probabilities of crossover (pc) and mutation (pm) greatly determine the degree of
solution accuracy and the convergence speed that genetic algorithms can obtain.
Instead of using fixed values of pc and pm, AGAs utilize the population information
in each generation and adaptively adjust the pc and pm in order to maintain the
population diversity as well as to sustain the convergence capacity. In AGA (adaptive
genetic algorithm), the adjustment of pc and pm depends on the fitness values of the
solutions. GA tends to be quite good at finding generally good global solutions, but
quite inefficient at finding the last few mutations to find the absolute optimum.




Chapter three
Literature Review
The researcher have studied a range of scientific papers published in scientific
journals, to benefit from them and to know where the researchers are in this
field in order to enhance our work on genetic algorithms, and to find better
solutions through this study.
It should be noted that many scholars have studied and worked in this field.
The researcher will mention some of the studies on genetic algorithms in this
section.
(2013), Wafa Zaal: In this paper, worked on the adaptation in genetic
algorithm using some model as the vector space model, the logical model and
the language model. She used crossover and mutation probability variable
instead of using a fixed value in traditional genetic algorithms. And she is
expanding both crossover and Mutation to get best results. This thesis used
Arabic corpus. Her study has shown that using the model space model with
cosine similarity was the best solution and the improvement rate was 13.0%
[10].
(2013), Mohammad Thangamani: In this paper, the focus was on the
retrieval of the most relevant information. The author used the genetic
algorithm to improve the information retrieval systems. The author studied,
the fitness function based on the frequency of words in the document. He had
concluded that a genetic algorithm with information retrieval gives better
results than conventional systems in addition to efficiency of documents
recovered in this search [16].

(2013), Priya Borkar and Leena Patil: In this paper, they worked on a model
of hybrid genetic algorithm particles. They also worked on the expansion of
keywords to produce new keywords related to the needs of the user. In this
recent study, they worked on the development of the algorithm in order to help
improve the search results that are relevant to the user needs, and used the
fitness function, which is represented by the equation that gives more
sophisticated operating results to find similarities between the needs of the
user and feedback documents. They also gave a briefing on the working
principle with an adaptive genetic algorithm which can be put in the query
expansion [1].
(2013), Korejo and Khuhro: In this paper, the author studied adaptive
mutation and proposed four operators in the genetic algorithm to determine the
operator mutation despite the difficulty of the matter in the application
process. The author proposed solution to the problem by adapting the mutation
percentage of mutation. He chose each operator mutation based on the
behavior of the initial Population of each generation. Finally, this study has
shown that the work of adaptation mutation gave the best result at work [2].
(2012), Firas Alabsi and Reyadh Naoum: In this paper, multiple systems in
the process of detecting the sequence were used, and types of value were used
to assess the population size and encoding. The author mentioned several
types of crossover used to determine the best type of this species, and
mentioned types of surge and compare them to find the best kind of boom. He
also studied the behavior of a genetic algorithm with the different types as
mentioned in this research to compare different types of genetic processes to
determine the best one to use [17].

(2012), Ammar Sami: In this paper, he proposed a research method based that
is on genetic algorithm to improve information retrieval system from websites
online, and apply information retrieval using a genetic algorithm and divided
the work into two units, first unit document indexing, the second unit genetic
algorithm used crossover and mutation operator and specialize of fitness
function and finally was obtained an improvement in the results of up to 90%
[21].
(2011), Mohammad Nassar and Feras AL Mshagba and Eman AL
mshagba: In this paper, genetic algorithm was used to improve the retrieval of
data by finding better inquiry through optimization. Arabic texts were used in
this study. The query was improved by using genetic algorithm through the
use of different functions, fitness, and different mutation strategies to get the
best result through the use of a logical model when data collection is in
Arabic. Finally, the study has shown that the best strategy is to use a genetic
algorithm and logic models (M2, Precision) method [4].
(2009), Noha Marwan: In this paper, she worked on the use of four different
Islands in the retrieval of data, and used the fitness function through Jaccard's
and Ochiai's. She applied each measure on the islands independently. She used
expanded query and show the results using the expanded query and the results
without the use of expansion query, she compared the results of the four
islands with the use of expansion and without the use of expansion. She points
out that the use of expansion improved the search results in accordance with
the user needs and showed that Jaccard's is better than Ochiai's when using
random selection and Ochiai's is better than Jaccard's when using unbiased
model tournament selection [14].

(2008), Ahmed Radwan and Bahgat Abdel Latef and Abdel Ali and
Osman Sadek: In this paper, the authors studied the use of genetic algorithm
in information retrieval. They used three Corpuses. Documents retrieved were
amended for users in genetic modification. In this paper, new jobs for fitness
were provided for approximate information. The result was very fast recovery
and very flexible through the use of cosine similarity function fitness. Finally,
the results showed that the use of new job fitness gives a more sophisticated
results and he pointed out that it is more accurate than the other two
approaches [7].
(2007), Detelin Luchev: In this paper, the author studied the use of genetic
algorithms in information retrieval for having improvements on the user
queries in information retrieval systems. The author used genetic modification
to have accurate information retrieval through improving the efficiency of the
system. The aim of the study was to retrieve relevant documents with a
smaller number of documents that are relevant with respect to the query input
by the user in retrieval system information using genetic algorithm. The result
has shown that when using a genetic algorithm, the results are more
sophisticated and more accurate than IR System classic in groups selected,
since the use of genetic algorithm gives more accurate output in terms to adapt
the weights of query terms to get high precision results in the query [8].
(2004), Sanem Sariel: In this paper, the focus was on the retrieval of the most
relevant information. The author used genetic algorithms to improve the
information retrieval systems. The author studied how adaptive mutation
based on the feedback of the population through changing, job fitness through
the work of a genetic algorithm to obtain the best solutions [11].

Chapter Four
Methodology
4.1 Introduction
Because of the large amount of documents and information that are related to each
other in the current time, particularly on the Internet, the users may encounter
problems in the process of information retrieval systems.
Indeed, in the process of retrieval of information, there are several key stages in the
building of information retrieval systems such as tokens, stems and inverted index. In
our study, the researcher used the adaptive genetic algorithm in the research in order
to have the best results in the process of recovery through the use of information
retrieval system (IRs) by an adaptive genetic algorithm (AGA) to get the best solution
among all solutions.
The researcher seeks to improve and enhance the genetic algorithm by applying
information retrieval systems to get more accurate results compared with previous
work. We also try to work on the adaptation fitness function through modification on
the two equations of fitness function (Cosine, Jaccard's) used in this research to
modify the equations used to find out the best solutions.
The researcher seeks to obtain a good result by applying the proposed equations of
change on the fitness function to have accurate and results. The significance of our
work stems from being an original measure compared with adaptive fitness function
and conditioning through a functional modification.

As it obvious, in the first act of the equations, The researcher want to get the best
results in the retrieval of information using the (Cosine) as a function of fitness based
on previous work [14], while in the other part of work, the equations The researcher
wants to get the best results in the use of information retrieval in (Jaccard's) as a
fitness function based on compare with previous researched [10]. Then the researcher
will compare our equations that are used after adjustment with common equations to
access the best res ) that
the researcher used in our study.
The research focused on our work on the use of model space vector (VSM) because it
is considered the best model and Extended Boolean model (EBM) proved by previous
studies in [8] [10]. The researcher used two equations to calculate the fitness function,
and work on adapting the mutation to find a better priority because of our work of the
crossover adjustment [19]. Finally, the researcher work on finding the best number of
generations from applying genetic algorithms.
4.2 Data collection
To achieve the purpose of the study, The researcher chose Cranfield English Corpus
test collection that Contain information on mathematics, which was conducted by
Cyrial Cleverdon and used at the University of Cranfield in 1960 .It contains 1400
document collection, and 225 queries collection for simulation purposes. Used in
order to evaluate the 2009 Cambridge University Press, Goteborgs University by
Karin Friberg Heppin (2002), and used in wright state university (2014), through
using Precision and Recall measure to evaluate the system.

4.3 Preprocessing steps
Before implementing the IRs, there are many steps to prepare Corpus as following:
1- The corpus of Cranfield English Corpus that contain information on mathematical
conducted by Cyrial Cleverdon and his colleagues at the University of Cranfield.
2- Conduct some operations on the texts for the processing of data retrieval systems to
take the terms of the documents (phase one preparing documents) as follows:
Tokenizing: Finding the terms of the documents.
Elimination of all the stop-words [7].
Stemming the remaining words: extracting prefixes and suffixes of each word to
get the root to facilitate the process of comparing the words and get similar
results, depending on the root, using the porter stemmer [8].
3- Building information retrieval system as following:
Inverted index: referring to each term stated in the documents, in addition to the
number of repeated terms in each document such as a table (2-4) in chapter two.
Assigning weight for each term taken from documents using IR models [7] [9].
Calculate the degree of weight for each of the terms in the inquiry and documents
using information retrieval models (VSM, EBM) Then, calculating the degree of
similarity by equalizing cosine similarity based on the weight of each of the terms
to give a degree of similarity between the inquiry and documents [10].

Using vector space model (VSM): a strategy to build an inverted index
file. Each query is compared to the input documents in the system to
produce the degree of similarity between the query and documents, and
then put in order of ascending degrees the similarity to rank the closest
degree of similarity that is based on recall and precision [10][12].
Extended Boolean model (EBM): It is a simple model used in the past in
information retrieval systems to represent terms. It works on the basis of
the binary system.
Extended Boolean Model (EBM): working when made similarity between
documents and queries, take a term from a query by query if the term
taking from query existing in document get the weights and division based
number of terms existing in a document by document [20].
The logical model to calculate the similarity between the query and the
documents where the logic (or, and, not) is calculated according to
equations in chapter two given to retrieve all documents containing
anything from terms, The researcher used logical or to apply extended
Boolean model to get the similarity between term queries and documents,
using or in this strategy that meaning take weight for each term query
found in query or found in documents [10] [18].

4- Building Genetic Algorithm
Representation of the chromosomes: Initial population in genetic
algorithms is represented by the chromosome. Each chromosome consists
of several genes and each chromosome is calculated based on the number
of query terms that the researcher considers 10 bits which represents the
number of maximum terms queries. If the term query exists in the
document, it is represented as 1, and if not, represented as 0.
Example of representation chromosome as follow:
Table (4.1) representation chromosome
Chromosome number from
1 to 30
Representation chromosomes 10
bit
Document1 - Chromosome 1 0101101000
Document2 - Chromosome 2 1010111010
Document3 - Chromosome 3 1010011010
In the above example, document1=chromosome 1 =0101101000
D1= made, Answer, arrive, ask, become, break, believe, build, buy, call,
welcome, tomorrow, today, yesterday, man, accident, improve, car, bus.
Q1= dad, answer, special, call, ask, differ, call, mum.
To represent chromosome1 as binary system made mach between
document and query, first term query not found in document1, gene1 =0.
Second term query finds in document1, gene2 =1. Third term query not
found in document1, etc. When term queries less than 10, then genes must
complete zeros, to impose the complemented terms query not found in
document.

The system snapped the first 30 documents retrieved by the system and
take these documents to be in the initial population the adaptive genetic
algorithm.
Evaluation the fitness function: valuing each chromosome in the
population. The researcher used two adaptive fitness functions (Cosine and
Jaccard) with the following modifications in chapter two (7) (8).
Selection method: The selection process consists of selecting two parent
chromosomes on the basis of randomly fitness function to get a better
owner of Fitness and the greatest opportunity to choose.
5- Genetic Operation:
In our GA approaches, the researcher uses two GA operators to produce
offspring chromosomes, which are:
Crossover: The process of mixing the two chromosomes to get new two
chromosomes as offspring used in genetic algorithm. The researcher uses
two points of crossover to get better chromosome. When trying again,
accurate results are obtained through an adaptive genetic algorithm [19].
The proposed algorithm used the two points crossover operator in the
range of probability, and crossover usually used the value of probability
(0.5, 0.9) as initial value to the equation (9) in chapter two to take a
random number and compare it with the possibility of crossover to find out
the number of bits to be applied by the crossover.

Examples of crossover
In this example the researcher applies crossover after second gene
using two point crossover with (0.6) probability of crossover .
1010101011 parent1 (chromosome 1 chosen by selecting method )
1001100101 parent2 (chromosome 2 chosen by selecting method )
----------------------- The researcher swap the bits in bold color
1001100111 children1 (chromosome 1 Produced by crossover)
1010101001 children2 (chromosome 2 Produced by crossover )
Mutation: The process of changing one bit based on a random
selection of these bits to get better chromosome. Trying to gain access
to more accurate results in the work of adaptive genetic algorithm, if
bit 1 becomes 0, and bit 0 becomes 1 [19], the probability of mutation
that is usually used (0.2, 0.001) because The researcher made many
appearances to get the best ratio.
The researcher uses random one point mutation operator in range of
probability, but the value of the probability mutation (0.001, 0.2) are
usually used with adaptive based on equation (10) in chapter two. The
researcher takes a random number and compare it with the possibility
of mutation if the number is smaller or equal to the probability, The
researcher applies mutation operator if the random number applied is
greater than the probability of mutation, then when the random number
applied is smaller than the probability of mutation, The researcher

Example of mutation operator. If choose 3rd gene
In this example the researcher applies mutation operator in a third gene
using one point mutation with (0.01) probability of mutation.
1001100111 children1 (chromosome 1 Produced by crossover)
1010101001 children2 (chromosome 2 Produced by crossover)
------------------------- The researcher flip one bit in bold color
1011100111 new chromosom1 (chromosome 1 Produced by mutation )
1000101001 new chromosom2 (chromosome 2 Produced by mutation )
6- Evaluation fitness function: used method based fitness functions to end
genetic algorithm based on the 70 generations because the researcher made
many experiences to get this better number to get the optimal solution. We
try to find the best number of generations.
7- Evaluating the retrieved document using average (Recall and precision)
[20], the most commonly used measurements of retrieval performance are
precision and recall. Precision measures the ability of the system to
retrieve only the documents that are relevant to a query [7] [13].
8- Comparing between the use of traditional cosine and jaccard's efficiency
of the fitness function in genetic algorithm, and use of the proposed
adaptive fitness function.
9- Comparing the efficiency between using of crossover and mutation
probability in the adaptive genetic algorithm.
10- Comparing between the use of two models (VSP, EBM).

4.4 Proposed Algorithm
The overall steps of our proposed algorithm are as follows:-
Step 1: Tokenizing (to get the word form documents).
Step 2: Elimination all the stop-word.
Step 3: Stemming (to get the root of word based on porter stemmer).
Step 4: Inverted index (to represent frequencies of term and where it can be
found).
Step 5: Assigning weight for each term taken form document (to give each
term weight to compute a similarity measure using equation (8).
Step 6: using two models: vector space model (VSP), extended Boolean model
(EBM) (used to describe document contents in corpus and compute similarity
between query and documents.).
Step 7: compute similarity between documents and query (to get similarity
between documents and query using the cosine measure).
Step 8: The system snapped the first 30 documents retrieved by the system and
take these documents (to be initial population).
Step 9: Representation of the chromosome (to represent each individual
population in binary presentation).
Step 10: Evaluation the fitness (compute fitness function to get better
population using adaptive cosine fitness and adaptive jaccard's fitness).
Step 11: Selection method (method used to choose two chromosomes to apply
some operator based on randomly selection).
Step 12: Crossover (the method used to attend new better solution based on
two points after second gene ) .
Step 13: Mutation operator (oprator used to attend new better solution based
on one point randomly).
Step 14: Evaluation (evaluation two chromosomes Produced by mutation with
two chromosomes chosen by a select method to choose better two
chromosomes among them).
Can see data flow of the proposed algorithm in Figure (4.1) in next pages.

4.5 Pseudocode of Proposed Adaptive Genetic Algorithm
The pseudcode adaptive genetic algorithm process is expressed as follows:
1. [Start] Genetic initial population top 30 chromosome as sample
2. [Fitness] Evaluate the fitness (co of each individual in the
population
3. [New population] Create a new population by rebeating the following step
until the end condition
A. [Selection] Select two parents from a population according to their
fitness randomly
B. [Crossover rate] Calculate the genetic crossover to find the best rate
for individual according to the fitness using two point crossover
C. [Crossover] Crossing of two individual by using the parameter of the
individual with best fitness to from new offspring
D. [Mutation rate] Calculate the genetic mutation to find the best rate for
individual according to the fitness
E. [Mutation] Mutation of new offspring at each random position in
coromosome by using the best parameter
F. [Accepting] place new offspring in new population
G. [Parameter evaluation] Create a new set of parameter for each
individual in population
a. [Selection] Select two parameter settings from apopulation
according to their reinforcement position
b. [Crossover] Crossing of two parameter sets by using the
parameter of individual
c. [Mutation] Mutation of new offspring by using the parameter
of the individual
d. [Accepting ] Place new offspring in the new sets parameter
population
4. [Replace] Use newly generated population for a further run of the
algorithm
5. [Test] If the end condition is satisfied, and return the optimized query
6. [Loop] Go to step 2

Figure (4.1) Data flow for proposed algorithms.
Tokenized
Stemming
Inverted index
Calculate the terms weight for each document
Vector Space Model
Taking documents ranking from IRS
Extended Boolean Model
Used cosine and proposed cosine
Representation of chromosomeRepresentation of chromosome
Evaluation
Initial population
Evaluation the fitness
Stop
Selection method
Crossover
Mutation
Initial population
Evaluation the fitness
Selection method
Crossover
Mutation
Evaluation

Chapter five
Experimental results
5.1 Results
The researcher used in this study ten queries and every query has 8 states. In other
words, the researcher had 80 results. After obtaining the results, the researcher
analyzed them through using evaluation criteria. The researcher chose to show the
results of query number one.
Table (5.1) shows the adaptive genetic algorithm (AGA) is used in information
retrieval system (IRs), using the vector space model (VSM) with the cosine fitness
function. It has shown relevant documents in order, but this result bad case when
used cosine because the next case in table (5.2) when used proposed cosine with
VSM better than this table, and can see when increasing recall the precision
decrease in all cases because increasing the number of samples.
Table (5.1) value of precision and Recall for query number1 by using (VSM)with (AGA) using the cosine fitness function.
Recall Precision (%)0.1 850.2 750.3 720.4 640.5 500.6 380.7 320.8 220.9 20

Table (5.2) shows the adaptive genetic algorithm (AGA) is used in information
retrieval system (IRs), using the vector space model (VSM) and cosine fitness
function. It has shown relevant documents in order; the researcher got better
results in the evaluation and better degree of similarity and has average precision
greater than traditional cosine. But, this case has topped precision result, 91%
when recall 0.1 because the AGA give more weight to term query, and get better
crossover and mutation probability.
Table (5.2) value of precision and Recall for query number1 by using (VSM)with (AGA) using the proposed cosine fitness function.
Recall Precision (%)0.1 910.2 850.3 790.4 650.5 540.6 450.7 390.8 280.9 22
Table (5.3) shows the adaptive genetic algorithm (AGA) is used in information
retrieval system (IRs), using the vector space model (VSM) with jaccard's fitness
function. The researcher gets better result in the next table (5.4) when used
And, in this table can see when increase recalls the
precision decrease in all cases. But in this case has bad result, 80% for all result
when recall 0.1 compares with the next case.

Table (5.3) value of precision and Recall for query number1 by using (VSM)with (AGA) using the jaccard's fitness function.
Recall Precision (%)0.1 800.2 700.3 600.4 580.5 430.6 330.7 290.8 210.9 19
Table (5.4) shows the adaptive genetic algorithm (AGA) is used in information
retrieval system (IRs), using the vector space model (VSM) and proposed
jaccard's fitness function .Here when used the proposed jaccard's fitness function,
the researcher got better results in evaluation and better degree of similarity, when
the researcher got more average
, the best case among the four cases in
(VSM) is when using proposed cosine.
Table (5.4) value of precision and Recall for query number1 by using (VSM)with (AGA) using proposed the jaccard's fitness function.
Recall Precision (%)0.1 870.2 760.3 710.4 640.5 500.6 350.7 300.8 250.9 21

Table (5.5) shows the adaptive genetic algorithm (AGA) is used in information
retrieval system (IRs), using extended Boolean model (EBM) with the cosine
fitness function. In this case the researcher gets bad result comparing with next
result in table (5.6) because when used proposed cosine with VSM has good result
because used adaptive genetic algorithm from there, the researcher got better
crossover and mutation probability and got better fitness function through giving
terms queries more weights.
Table (5.5) value of precision and Recall for query number1 by using (EBM)with (AGA) using the cosine fitness function.
Recall Precision (%)0.1 820.2 720.3 620.4 600.5 480.6 350.7 300.8 200.9 19
Table (5.6) shows the adaptive genetic algorithm (AGA) is used in information
retrieval system (IRs), using Extended Boolean model (EBM) and proposed
cosine fitness function. In this case when used proposed cosine with VSM has
better results for all cases, used VSM that meaning gave terms queries more
weight in a fitness function query that effectively taking better results than before.

Table (5.6) value of precision and Recall for query number1 by using (EBM)with (AGA) using the proposed cosine fitness function.
Recall Precision (%)0.1 890.2 790.3 750.4 650.5 520.6 410.7 350.8 250.9 20
Table (5.7) shows the adaptive genetic algorithm (AGA) is used in information
retrieval system (IRs), using extended Boolean model (EBM) with jaccard's
fitness function. In this case the result is worse than using proposed jaccard
the
next table (5.8), and can see when increase recall the precision decrease in all
cases, because when increase recall taking a larger sample of the documents.
Table (5.7) value of precision and Recall for query number1 by using (EBM)with (AGA) using the jaccard's fitness function.
Recall Precision (%)0.1 750.2 680.3 600.4 550.5 400.6 300.7 250.8 210.9 18
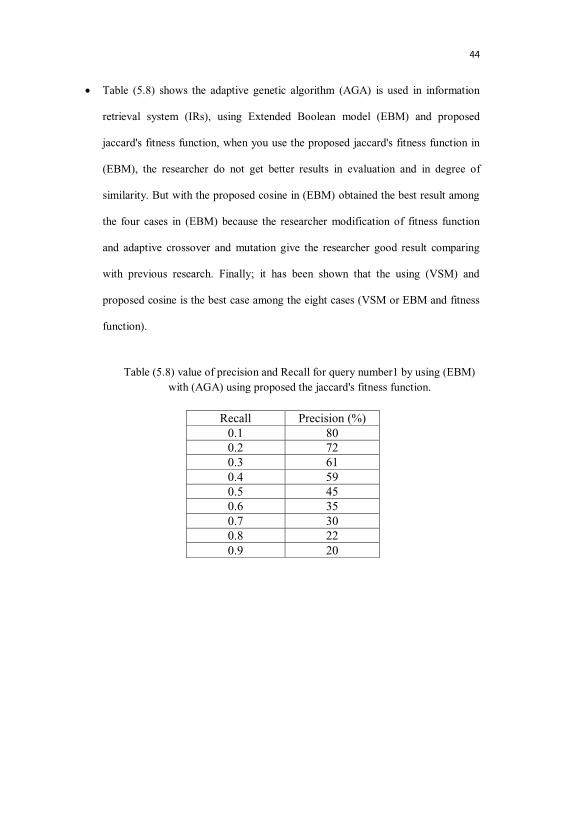
Table (5.8) shows the adaptive genetic algorithm (AGA) is used in information
retrieval system (IRs), using Extended Boolean model (EBM) and proposed
jaccard's fitness function, when you use the proposed jaccard's fitness function in
(EBM), the researcher do not get better results in evaluation and in degree of
similarity. But with the proposed cosine in (EBM) obtained the best result among
the four cases in (EBM) because the researcher modification of fitness function
and adaptive crossover and mutation give the researcher good result comparing
with previous research. Finally; it has been shown that the using (VSM) and
proposed cosine is the best case among the eight cases (VSM or EBM and fitness
function).
Table (5.8) value of precision and Recall for query number1 by using (EBM)with (AGA) using proposed the jaccard's fitness function.
Recall Precision (%)0.1 800.2 720.3 610.4 590.5 450.6 350.7 300.8 220.9 20

5.2 Average Precision using VSM with Cosine
In this case, the researcher compares between the usages of vector spacemodel with cosine and proposed cosine.
Table (5.9) Average value of precision for all queries using VSM withcosine
RecallAverage precision
Cosine (%)Average precisionproposed cosine
(%)
AGAImprovement
(%)0.1 85 92 70.2 76 85 90.3 72 80 80.4 65 68 30.5 51 55 40.6 39 45 60.7 33 38 50.8 23 28 50.9 20 23 3
average 51.5 57.1 5.6
Figure (5.1): Average value of precision for all queries using VSM-cosine
In this case, vector space model is used with cosine and proposed cosine. As can
be seen, the average of precision when using proposed cosine is greater than
cosine and when increasing the recall the precision is decreasing. Moreover, the
degree of improvement is good when the top recall because taking a small sample,
average precision when recall 0.1 is good for all queries, but recall 0.9 is bad. This
good result because the modification of fitness function more gave weight to each
term query and gets better ratio probability using adaptive crossover and mutation,
but shown in this figure (5.1) when using VSM with cosine the researcher have

5.3 Average Precision
In this case, the researcher compares the usages of vector space model withjaccard's and
Table (5.10) Average value of precision for all queries using VSM
Recall Average precision Jaccard's (%)
Average precisionproposed Jaccard's
(%)
AGAImprovement
(%)0.1 80 87 70.2 71 76 50.3 62 70 80.4 57 65 80.5 42 47 50.6 32 35 30.7 30 31 10.8 21 25 40.9 19 20 1
average 46 50.6 4.6
Figure (5.2): Average value of precision for all queries using VSM-jaccard's
In this case, vector space model with jacc
used. As can be seen the average
is greater than and when increasing the recall, the precision is
decreasing, and the degree of improvement is good when the top recall and
the average precision when recall 0.1 is good for all queries, whereas
recall 0.9 is bad. This result is good because of the modification on fitness
function and usage of adaptive crossover and mutation. But when using
VSM with cosine, the researcher has

5.4 Average Precision using EBM with Cosine
In this case, the researcher compares between the usages of extended Booleanmodel with cosine and proposed cosine.
Table (5.11) Average value of precision for all queries using EBMwith cosine
Recall Average precision Cosine (%)
Average precisionproposed cosine
(%)
AGAImprovement
(%)0.1 79 89 100.2 70 75 50.3 61 70 90.4 59 65 60.5 44 49 50.6 33 36 30.7 30 32 20.8 21 25 40.9 19 21 2
average 46.2 51.3 5.1
Figure (5.3): Average value of precision for all queries using EBM-cosine
In this case, extended Boolean model with cosine and proposed cosine are
used. As can be seen the average precision when using proposed cosine is
greater than cosine, The researcher can see when increasing recall, the
precision is decreasing and the degree of improvement is good when the
top recall. So the average precision when recall 0.1 is good for all queries,
but recall 0.9 is bad, this good result is because of the modification of
fitness function and the use of adaptive crossover and mutation, but the
degree of improvement EBM is worse than VSM.

5.5 Average Precision using EBM with Cosine
In this case, the researcher compares between usages the extended Booleanmodels with jaccard's and proposed jaccard's.
Table (5.12) Average value of precision for all queries using EBMwith jaccard's
Recall Average precision jaccard's (%)
Average precisionproposed jaccard's
(%)
AGAImprovement
(%)0.1 82 89 70.2 73 77 40.3 64 75 90.4 59 64 50.5 47 53 60.6 36 41 50.7 31 36 50.8 21 23 20.9 19 20 1
average 48 52.8 4.8
Figure (5.4): Average value of precision for all queries using VSM-
In this case, extended Boolean model with jacc
used. As can be seen the average precision when using
, the researcher can see when
increasing recall the precision is decreasing, and the degree of
improvement is good when the top recall. The average precision when
recall 0.1 is good for all query, but recall 0.9 is bad, this good result is
because of the modification of fitness function and the use of adaptive
crossover and mutation.

5.6 Result of precision for (VSM)
Calculating the average precision by dividing the total Precision inquiries on the 9
(value of Recall) and the calculation of the average precision using the Vector
Space Model.
Table (5.13) used vector space model with fitness function option.
option Cosine Proposed
cosine
Jaccard's Proposed
Jaccard's
Average
Precision(%)
51.5 57.1 46 50.6
Figure (5.5): Using VSM with function fitness option
Here, the researcher can see that proposed cosine has a degree in a flowchart; the
second score proposed jaccard's, third degree cosine and fourth score jaccard's.
This means the researcher got the best solution when modifying fitness functions
and using probability crossover and mutation operator.

5.7 Result of precision for (EBM).
Calculating the arithmetic mean by dividing the total Precision inquiries on the 9
(value of Recall) and the calculation of the arithmetic mean for them using
Extended Boolean Model.
Table (5.14) Using extended Boolean model with fitness function option.
options cosine Proposed
cosine
Jaccard's Proposed
Jaccard's
Average
Precision(%)
46.2 51.3 48 52.8
Figure (5.6): Using EBM with function fitness
Here, the researcher can see that proposed jaccard's has a high degree in the
flowchart, second degree proposed cosine, third degree jaccard's and fourth score
cosine. This means that proposed cosine is the best solution when comparing all
cases (VSM-proposed cosine); the researcher can have the best result.
This means the researcher got the best solution when modifying fitness function
and the usage of probability crossover and mutation operator when modifying
fitness function to compute similarity, the researcher have the best result by
using precision evaluation between these results, the researcher can have the best
solution.

5.8 Comparison between proportions improvement
In table (5.15) show the comparison between improvement strategies andshow a degree of improvements for each IR model with each one fitness
function.
Table (5.15) Compare between improvements.
Average ImprovementProposed cosine (%)
Average ImprovementProposed jaccard's (%)
VSM 5.6 4.6EBM 5.1 4.8
Degree of improvement in proposed cosine and cosine with VSM and EBM is
adaptive genetic algorithm given more accuracy in a working system.
After got the results. The best result in improvement when used VSM with proposed cosine because
used adaptive genetic algorithm. Can see the degree of improvement in all cases
through use information retrieval model (VSM, EBM) with all fitness functions as
following:
A. VSM with proposed Cosine (5.6%)B. EBM with proposed Cosine (5.1%)C. VSM with proposed Jaccard's (4.8%)D. EBM with proposed Jaccard's (4.6%)
Rank of the result based on average precision.The best result in ranking when used VSM with proposed cosine because used
adaptive genetic algorithm. Can see average precision for all cases through use
information retrieval model (VSM, EBM) with all fitness functions as following:
A. (VSM)- proposed Cosine (57.1%). B. (EBM)- proposed Jaccard's (52.8%). C. (VSM)- Cosine (51.5%). D. (EBM)- proposed Cosine (51.3%)E. (VSM)- proposed Jaccaed's (50.6%). F. (EBM)- Jaccard's (48%).
G. (EBM)- Cosine (46.2%). H. (VSM)- Jaccard's (46%).

Chapter six
Conclusion, recommendations and future work
6.1 Introduction
In this thesis, The researcher proposed adaptive genetic algorithm (AGA) to
enhance information retrieval systems (IRs) using several fitness functions
(cosine, proposed cosine, jaccard's, proposed jaccard's) on the vector space
model (VSM) and extended Boolean model (EBM).
6.3 Conclusion
In this thesis, the researcher concluded several conclusions the following: 1. When using adaptive crossover and mutation operator with VSM-proposedcosine to retrieve relevant document, we have the best result, when averageprecision (57.1%).2. Having a better generation of initial population is the best result to retrieverelevant documents. 3. When using VSM-proposed cosine, the researcher got high degree ofsimilarity for each relevant document. 4. Using adaptive crossover and mutation with EBM-proposed cosine toretrieval relevant document is the second best result when average precision(51.3%).5. The best result when using VSM is when using proposed cosine whenaverage precision (57.1).6. The best result when using EBM is when using proposed jaccard's whenaverage precision (52.8%).7. When comparing between the uses of cosine when average precision(51.5%) and the propose cosine when average precision (57.1%) with VSM, the best result is when using proposed cosine with improve 5.6%.8. When comparing between the uses of cosine when average precision (46%)and proposed cosine when average precision (51.3%) with EBM, withimprove 5.1%.9. When comparing between the use of jaccard's when average precision(46%) and jaccard's addition when average precision (50.6%) with VSM, thebest result is when using proposed jaccard's with improve 4.6%.10. When comparing between the uses of jaccard's when average precision
when average precision (52.8%) withEBM, the best result is when using proposed jaccard's with improve (4.8%). 11. The highest rate of improve is when using VSM with proposed cosine5.6%.

6.3 Future work
After finishing the study which mainly aims at improving information retrieval
using genetic algorithm and adaptive, The researcher have the following
suggestions:
1. In our study, the researcher used two models: Vector Space Model and
Extended Boolean Model. In the future work, Probability Model Language
Model and Fuzzy Model may be used.
2. In our study, the researcher used two fitness functions: cosine fitness function
and jaccard's fitness function. In the future work, horng & yeh formula fitness
function and ochiai's may be used.
3. In our study, the researcher has adaptive crossover and adaptive mutation. In
the future work, another manner can be used.
4. In this study, the researcher has an adaptive cosine fitness function and
adaptive jaccard's fitness function. In the future work, another manner in
adaptive can be used.
5. In our study, the researcher use random selection models, two points as a type
of crossover and randomly mutation. In future work, other types of selection as
Roulette Wheel Selection, Elitism Selection and rank selection can be used.
Furthermore, other types of crossover as a single point and uniform can be used.
Finally, other types of mutation as uniform can be used.

References
[1] Priya Borkar and Leena Patil, "Web Information Retrieval Using Geneticalgorithm Particle Swarm Optimization", international Journal of Future Computer
and Communication, Vol. 2, No. 6, pp 595-599, (2013).
[2] Korejo and Khuhro, "Genetic Algorithm Using an Adaptive MutationOperator for Numerical Optimization Functions", University of Sindh, Vol.45, pp
41- 48, (2013).
[3] Taisir Eldos, "Mutative Genetic Algorithms", Journal of Computations &Modelling, Vol.3, No. 2 , pp111-124, (2013).
[4] Mohammad Nassar , Feras AL Mshagba , Eman AL mshagba ,"Improving theUser Query for the Boolean Model Using Genetic Algorithms", IJCSIInternational Journal of Computer Science Issues, Vol. 8, Issue 5, No. 1 , pp66-70,
(2011).
[5] Imtiaz Korejo, Shengxiang Yang, and ChangheLi, "A Comparative Study ofAdaptive Mutation Operators for Genetic Algorithms", The VIII Metaheuristics
International Conference, (2009).
[6] Huifang Cheng , Handan, China ,"Improved Genetic Programming algorithm", International Asia Symposium on Intelligent Interaction and Affective Computing ,
ieee, pp168-177, (2009).
[7] Ahmed Radwan and Bahgat Abdel Latef and Abdel Ali , Osman Sadek, "UsingGenetic Algorithm to Improve Information Retrieval Systems", World Academy
of Science, Engineering and Technology, pp1021-1027, (2008).
[8] Detelin Luchev, "APPLYING GENETIC ALGORITHM IN QUERYIMPROVEMENT PROBLEM", International Journal "Information Technologies
and Knowledge", Vol.1,No. 1, pp309-216, (2007).

[9] NIR OREN, "Reexamining tf.idf based information retrieval with GeneticProgramming", University of the Witwatersrand, paper, pp1-10, (2002).
[10] Wafa. Maitah, Mamoun. Al-Rababaa and Ghasan. Kannan, "IMPROVINGTHE EFFECTIVENESS OF INFORMATION RETRIEVAL SYSTEM USINGADAPTIVE GENETIC ALGORITHM", International Journal of Computer
Science & Information Technology (IJCSIT), Vol 5, No. 5 , pp91-105, ( 2013).
[11] Sima Uyar, Sanem Sariel, and Gulsen Eryigit, "A Gene Based AdaptiveMutation Strategy for Genetic Algorithms", Istanbul Technical University, Electrical and Electronics Faculty, Department of Computer Engineering, LNCS
3103, pp 271 281, (2004).
[12] Sima Etaner and Gulsen Cebiroglu, "An Adaptive Mutation Scheme in GeneticAlgorithms for Fastening the Convergence to the Optimum", Istanbul Technical
University, Computer Engineering Department, (2005).
[19] BANGORN KLABBANKOH, "APPLIED GENETIC ALGORITHMS ININFORMATION RETRIEVAL", Faculty of Information Technology King
paper, (2009).
[13] Noha Mezyan, "web mining based on island genetic algorithm", al albaytuniversity, (2009).
[14]"Informationretrieval"http://www.dsoergel.com/NewPublications/HCIEncyclopediaIRShortEForDS, pdf, pp1-11.
[15] Kalayanasaravan and Thangamani, "Document Retrieval System using GeneticAlgorithm", Kongu Engineering College, Perundurai, Vol. 2, No.10, pp 943-946,
(2013).
[16] Firas Alabsi and Reyadh Naoum ," Comparison of Selection Methods andCrossover Operations using Steady State Genetic Based Intrusion DetectionSystem", Middle East University, Vol. 3, No.7, (2012).

[17] Desjardins, "Performance of Information Retrieval Models Using Term Co-occurrences University of Quebec in Montreal, research, Canada, (2012).
[18] Aijun Li," The Operator of Genetic Algorithms to Improve its Properties",Tianjin University of Technology and Education, Vol. 4, No. 3, pp 60-62, (2010).
[19] Pragati Bhatnagar, "A Combined Matching Function based EvolutionaryApproach for development of Adaptive Information Retrieval System", India, Vol. 2, No. 6 , pp249-256, (2012).
[20] ammar s al-dallal "ENHANCING RECALL AND PRECISION OF WEBSEARCH USING GENETIC ALGORITHM", paper, Brunel University, (2012).






Copyright © 2022 FDOKUMEN




















