
Processing interactions between phonology and melody: Vowels sing but consonants speak

Redistr
Effects of consonantal context on perceptual assimilationof American English vowels by Japanese listeners
Winifred Strangea)
Speech & Hearing Sciences, The City University of New York Graduate School and University Center,New York, New York 10016
Reiko Akahane-Yamada and Rieko KuboInformation Sciences Division, Advanced Telecommunications Research Institute International, Kyoto 619-0288, Japan
Sonja A. Trent and Kanae NishiDepartment of Psychology, University of South Florida, Tampa, Florida 33620
~Received 13 April 1999; revised 25 September 2000; accepted 1 December 2000!
This study investigated the extent to which adult Japanese listeners’perceived phonetic similarityofAmerican English~AE! and Japanese~J! vowels varied with consonantal context. Four AE speakersproduced multiple instances of the 11 AE vowels in six syllabic contexts /b-b, b-p, d-d, d-t, g-g, g-k/embedded in a short carrier sentence. Twenty-four native speakers of Japanese were asked tocategorize each vowel utterance as most similar to one of 18 Japanese categories@five one-moravowels, five two-mora vowels, plus/ei, ou/ and one-mora and two-mora vowels in palatalizedconsonant CV syllables, Cja~a!, Cju~u!, Cjo~o!#. They then rated the ‘‘category goodness’’ of the AEvowel to the selected Japanese category on a seven-point scale. None of the 11 AE vowels wasassimilated unanimously to a single J response category in all context/speaker conditions;consistency in selecting a single response category ranged from 77% for /e(/ to only 32% for /,/.Median ratings of category goodness for modal response categories were somewhat restrictedoverall, ranging from 5 to 3. Results indicated that temporal assimilation patterns~judged similarityto one-mora versus two-mora Japanese categories! differed as a function of the voicing of the finalconsonant, especially for the AE vowels, /i, u,(, }, #, */. Patterns of spectral assimilation~judgedsimilarity to the five J vowel qualities! of /(, }, ,, #/ also varied systematically with consonantalcontext and speakers. On the basis of these results, it was predicted that relative difficulty in theidentification and discrimination of AE vowels by Japanese speakers would vary significantly as afunction of the contexts in which they were produced and presented. ©2001 Acoustical Society ofAmerica. @DOI: 10.1121/1.1353594#
PACS numbers: 43.71.An, 43.71.Es, 43.71.Hw@JMH#
eifi
edi
terivveph
th
ere
arn-
geg-
per--nts
ticl-at aap-boutherentsand
thebyss-the
I. INTRODUCTION
Early research in cross-language speech perception donstrated that adult listeners had difficulty perceptually dferentiating phonetic contrasts that were not distinctivetheir native language~see Strange, 1995, for review!. Theselearned, language-specific patterns of perception have bcited as a major contribution to adult language learners’ficulty in acquiring a second-language~L2! phonology.However, research over the last several years has shownthere is considerable variability in second-language learnperceptual difficulties with non-native contrasts, and relatperceptual difficulty is often not predictable from contrastianalyses based on comparisons of native and non-nativeneme inventories or phonological features~Kohler, 1981!.Some distinctions between non-native segments are raeasily perceived with no prior [email protected]., Farsi velarversus uvular stops by English listeners~Polka, 1992!; voic-ing and place contrasts in Zulu clicks by English listen~Bestet al., 1988!#. In other cases, contrasts which are ‘‘thsame’’ as native contrasts in terms of~abstract! phonological
a!Electronic mail: [email protected]
1691 J. Acoust. Soc. Am. 109 (4), April 2001 0001-4966/2001/109
ibution subject to ASA license or copyright; see http://acousticalsociety.org
m--n
enf-
hats’e
o-
er
s
features are nevertheless difficult for second-language leers to differentiate [email protected]., French /i-e/ by EnglishL2 learners of French~Gottfried, 1984!#.
Two current theories of second-language~L2! phono-logical acquisition hypothesize that difficulties in learninboth to produce and to perceive non-native phonetic sments are predictable in large part on the basis of theceivedphoneticsimilarities and dissimilarities between native language~L1! segments and the to-be-learned segme~Best, 1994, 1995; Flege, 1992, 1995!. In both of these theo-ries, phonetic similarity is defined in terms of the acousand/or articulatory characteristics of the linguistically reevant speech sounds. That is, both theorists argue thcontext-free phonemic level of analysis is too abstract to cture the details needed to make precise predictions across-language perceptual patterns. However, to date, tare limited data describing the phonetic details of segmein cross-language comparisons of phoneme inventorieslittle is known about how cross-language differences inphonetic realization of segments affect their perceptionnon-native listeners. Most studies which examine crolanguage perception utilize stimulus materials in which
1691(4)/1691/14/$18.00 © 2001 Acoustical Society of America
/content/terms. Download to IP: 192.88.142.253 On: Fri, 19 Sep 2014 13:47:21

iheteapts
ticmica
,er
uas
segne
idgn
owt
s-elan
nen
m
o
pro
lsn-
eetiv’r
ted-
te
st-atnts
s-i-
fthetivedif-
veentspleed-
hecep-pa-ary-
el
aare
a-ly
h-
h-h-alnn,
n-at-
lsa-
hkis,
c-
Redistr
target segments are presented in very limited~often single!phonetic and phonotactic contexts, and most oftencitation-form monosyllables or even in isolation. Since tphonetic/phonotactic context and the larger prosodic consignificantly affect the phonetic realization of phonologicsegments, evidence from these studies of cross-languageceptual patterns cannot be generalized beyond the contexwhich the target segments were examined.
Support for the necessity of considering phonephonotactic variables in cross-language perception cofrom studies showing that Japanese L2 learners of AmerEnglish ~AE! have significantly more difficulty learning toperceive the /[/-/l/ contrast in prevocalic contexts~especiallyinitial consonant clusters! than in postvocalic contexts~e.g.,Mochizuki, 1981; Livelyet al., 1993; Yamada and Tohkura1992a, b! and that vowel context also seems to affect pceptual difficulty~Sheldon and Strange, 1982!. Other studieshave documented context-specific patterns of cross-langperception of voicing contrasts between stop consonantinitial position ~cued by voice onset time! and in final posi-tion ~cued by vowel duration, closure ‘‘murmur’’ and releabursts! ~cf. Flege and Hillenbrand, 1987; Flege and Eeftin1987!, although seldom in the same study. Morosan aJamieson~1989! also reported that French speakers trainto perceive English /Z-Y/ in syllable-initial position failed togeneralize to new syllable positions. More recently, Schm~1996! reported effects of vowel context on cross-languaperceptual similarity judgments of Korean and American Eglish consonants by Korean L2 learners of English.
Previous cross-language studies of vowels have shthat L2 learners may have persistent difficulties learningperceptually differentiate some non-native vowel contra~cf. Gottfried, 1984; Flege, 1995!. Other studies have reported relatively accurate perception of non-native voweven by listeners with no previous experience with the lguage~Polka, 1995; Bestet al., 1996!. Further studies havedemonstrated that the acoustic cues upon which L2 learbase their perceptual judgments may vary from those oftive speakers~cf. Bohn, 1995; Gottfried and Beddor, 1988!.These and other studies have usually employed stimulusterials in which vowels are produced~or synthesized! in iso-lation ~e.g., Kuhl et al., 1992! or in citation-form syllableswith a single consonantal context~e.g., Flege, 1995!; thus,little is known about contextual influences on perceptionnon-native vowels. The Gottfried~1984! study of L2 learnersof French is of particular interest here because he testedception of the same vowel contrasts when they were pduced ~and presented! as isolated utterances~#V#! and incitation-form /tVt/ syllables, and found that some vowewere significantly more difficult to discriminate in consonatal context than in isolation~e.g., 86% correct for /y-Ö/, 65%correct for /tyt-tÖt/; chance550%!.
According to the perceptual assimilation model~PAM!~Best, 1994, 1995!, relative difficulty in perception of non-native contrasts is predictable from listeners’ patterns of pceptual assimilation of non-native vowels to native vowcategories. Non-native vowels may be assimilated to navowel categories on a continuum from ‘‘good’’ to ‘‘poor’instances of a native category, or perhaps as ‘‘uncatego
1692 J. Acoust. Soc. Am., Vol. 109, No. 4, April 2001
ibution subject to ASA license or copyright; see http://acousticalsociety.org
n
xtler-in
/esn
-
gein
,dd
te-
nots
s-
rsa-
a-
f
er--
r-le
iz-
able’’ segments. If two non-native segments are assimilato a single native vowel category as equally ‘‘good’’ instances, then they will be very difficult to discrimina~single category pattern!. If one non-native vowel is judgedto be a ‘‘good’’ instance of a native category and a contraing non-native vowel is considered a ‘‘poor’’ instance of thsame category or ‘‘uncategorizable,’’ then the two segmewill be easier to perceptually differentiate~category good-ness pattern!. If two non-native vowels are perceptually asimilated to different native categories, they will be discrimnated most accurately~two category pattern!.
In order to predict the relative perceptual difficulty onon-native vowels, then, it is important to understandpatterns of perceptual assimilation of those vowels to nalanguage categories and how those assimilation patternsfer as a function of the context in which the non-natiphones occur. To this end, we have conducted experimin which listeners are asked directly to categorize multiinstances of each L2 vowel as being ‘‘most similar’’ to onof their L1 vowel classes and to judge the ‘‘category gooness’’ of the L2 vowel with respect to that L1 category. Tpresent study reports results of an experiment on the pertual assimilation of AE vowels by native speakers of Janese when the vowels were produced and presented in ving CVC syllables imbedded in a fixed sentence context.
The Japanese vowel inventory consists of five vow‘‘qualities’’ ~which we refer to as spectral categories! /i, e, a,o, u/ which have phonologically distinctive short~one-mora!and long ~two-mora! cognates. Both one- and two-morvowels are produced as monophthongs, and long vowelsoften described as ‘‘double’’ vowels, implying that the durtion ratio of two-mora to one-mora vowels is approximate2:1. In Standard~Kanto! dialect, the high back vowel /u/ isphonetically realized as unrounded@%#, while in westerndialects~Kansai! it is more rounded. The American Englis~AE! vowel inventory consists of 11 spectrally distinct vowels /i, (, e,}, ,, Ä, Å, #, o, *, u/, plus the rhotic vowel /É/ andthe ‘‘true’’ diphthongs. In stressed syllables, /e, o/ are dipthongized@e(̂, o*̂] and many of the other so-called monopthongs display considerable ‘‘vowel-intrinsic spectrchange’’~Andruski and Nearey, 1992; Nearey and Assma1986; Hillenbrandet al., 1995!. In many dialects of AE, the/Ä-Å/ distinction is neutralized to a single vowel@"#. Whilevowel length is considered phonologically redundant in Eglish, phonetically AE vowels can be divided into three cegories: four intrinsically short vowels@(, }, #, *#, two inter-mediate vowels@ib, ub#, and five long vowels@e(̂, ,b, Äb, Åb,o*̂] ~Peterson and Lehiste, 1960!.
Both temporal and spectral properties of AE vowevary systematically with contextual variables. Vocalic durtions differ as a function of phonetic context~e.g., voicing ofthe following consonant!, phonotactic context~e.g., structureand number of syllables!, prosodic structure~lexical stress,sentence focus, phrase boundaries!, and the rate of speec~Crystal and House, 1988a, 1988b; Klatt, 1976; Foura1991!. The spectral characteristics of vowels~F1/F2/F3 for-mant values or ratios! have been shown to differ as a funtion of consonantal context~Stevens and House, 1963!, dia-lect ~Wolfram, 1991!, speaking rate and style~Moon and
1692Strange et al.: Perceptual assimilation of vowels
/content/terms. Download to IP: 192.88.142.253 On: Fri, 19 Sep 2014 13:47:21

-
icrt
itybbt
cuss
ct
-
xtllat
e
ioin
ncarsnatalwtw
r-piorpa
licbubth
iodo
cuo,
iced
fore,ext
to
ofinerecat-tion
e-ho-
o-ex-
ts
byt in
adshar-
ms,allral
blytinge.-
oplesese
on-totill
ys-ss
byg
AEetoer,’’ble.me-tem-sid-echcific
Redistr
Lindblom, 1994; Huang, 1991!, and individual speaker characteristics such as gender, age, and physiognomy~Petersonand Barney, 1952; Hillenbrandet al., 1995!. While some ofthese causes of acoustic variability are due to physiologconstraints of the human vocal system, and are thus univeacross languages, other sources of variability are part oflinguistic codes of the language.
In the case of language-specific patterns of variabilperceivers must learn to compensate for the variabilityforming equivalence classes appropriate to the languageing acquired. Developmental research has demonstratedlanguage-specific patterns of equivalence classificationvowels are evident very early in L1 acquisition~Kuhl et al.,1992; but see Polka and Bohn, 1996!. For the L2 learner,then, part of learning to perceive non-native vowels acrately involves establishing new rules for equivalence clafication ~Flege, 1992, 1995! by which discriminable differ-ences between instances of L2 vowels are correpartitioned into within-L2-category variations~i.e., allo-phonic, stylistic, or free variations! versus across-L2category variations~distinctive or phonemic variations!. Be-fore such new equivalence classes are acquired, contevariations in the realization of an L2 vowel may very welead to its being perceptually assimilated to different L1 cegories~and with different category goodness! when heard indifferent contexts.
In a previous study~Strangeet al., 1998! we reportedthat Japanese listeners’ perceptual assimilation of AE vowto native categories~and their judged category goodness! dif-fered when vowels were produced and presented in citatform /hVba/ bisyllables versus /hVb/ syllables imbeddedthe sentence, ‘‘I say the /hVb/ on the tape.’’ In the sentecondition, the intermediate and long AE vowels were heas similar to two-mora Japanese vowels much more contently than for the citation-form bisyllables. In both citatioand sentence contexts, the short AE vowels were assimilto one-mora categories; thus, assimilation patterns revebetter temporal differentiation of long versus short AE voels in the sentence condition. This was true, even thoughrelative durations of intermediate/long versus short AE voels ~mean ratio51.3! in citation-form and sentence utteances did not differ significantly, and were smaller than tycally found for Japanese two-mora versus one-mcognates. Assimilation of the 11 AE vowels to the five Janese spectral categories~disregarding length! also variedwith context. Four of the eleven vowels@(, ,b, Åb, o*̂], wereactually assimilated most often todifferentJapanese spectracategories in citation and sentence conditions. Acoustanalysis of the AE vowel stimuli suggested that some,not all, variations in spectral assimilation patterns couldaccounted for by differences in speakers’ productions ofvowels in the different contexts.
In summary, both temporal and spectral assimilatpatterns of AE vowels by Japanese listeners were founvary with prosodic context. In that study, the immediate phnetic context was chosen in order to minimize the coartilatory influence of preceding and following consonantsthe formant structure of the vowels~Stevens and House1963!, and to precludevariation in spectral structure and
1693 J. Acoust. Soc. Am., Vol. 109, No. 4, April 2001
ibution subject to ASA license or copyright; see http://acousticalsociety.org
alsalhe
,ye-
hatof
-i-
ly
ual
-
ls
n-
edis-
eded-he-
-a-
altee
nto--
n
vocalic duration within each condition that was not intrinsto the vowel. In the present study, AE vowels were producin CVC syllables in the same carrier sentence as used bewhile the preceding and following stop consonant contwas varied. The voicing of the final consonant was variedinvestigate howcontextualvariation in vocalic duration af-fected temporal assimilation patterns. Place-of-articulationpreceding and following consonants was varied to examthe effects of coarticulatory variations in formant structuon patterns of spectral assimilation to Japanese vowelegories. Thus, systematic variation in perceptual assimilaof AE vowels by Japanese listeners as a function of immdiate phonetic context was examined, while holding the pnotactic and prosodic context constant.
Although there are few systematic studies of the phnetic variability of Japanese vowels as a function of conttual variables, phonetic descriptions state that~1! the high-back vowel@%# is fronted in coronal consonantal contex~Homma, 1992; Shibatani, 1990!, and~2! the high vowel /i/and /u/ are ‘‘devoiced’’ when preceded and followedvoiceless consonants or following a voiceless consonanword final position~Sugito, 1996!. Although the nature ofthe devoicing process is controversial, acoustically this leto a change in both source characteristics and temporal cacteristics of these vowels~Beckman, 1982!. Keating andHuffman ~1984! reported acoustical data from citation-forutterances and continuous~read! speech of seven speakershowing considerable variation in the formant structure offive one-mora vowels, with the overall spread in spectvalues greatest for /a/ and /%/. In continuous speech,F1/F2values for the five one-mora vowels overlapped consideraeven within an individual speaker’s utterances, suggessignificant coarticulatory effects on formant structurFitzgerald~1996! reported vowel centralization and systematic coarticulatory effects of preceding and following stconsonants for one-mora vowels produced in CVC syllabin a short carrier sentence. Temporal patterning of Japanvowels also varies with speaking style and context. In ctinuous speech contexts, the duration ratio of two-moraone-mora vowels is reduced, but two-mora vowels are sover 50% longer than one-mora vowels~Campbell and Sag-isaka, 1991!. Vowels before voiced consonants are not stematically longer in duration than vowels before voiceleconsonants~Fitzgerald, 1996! and, in general, allophonicvariation in vowel duration is said to be more conditionedpreceding~tautomoraic! consonants than by the followinconsonants~Homma, 1981!.
In the present study, four speakers produced the 11vowels in six contexts: /b-b, b-p, d-d, d-t, g-g, g-k/ in thsentence, ‘‘I say the /CVC/ on the tape,’’ with instructionsproduce the sentences ‘‘as if speaking to a native speakwith no pauses or special emphasis on the target syllaThus, their rate and style of speech was thought to be sowhere between careful and casual speech styles and theporal and spectral characteristics of the vowels were conered to be closer to those found in continuous speutterances than are citation-form utterances. The spequestions asked were as follows:
1693Strange et al.: Perceptual assimilation of vowels
/content/terms. Download to IP: 192.88.142.253 On: Fri, 19 Sep 2014 13:47:21

se
ce
llseth
-esa
erne
Em
llyea
llye
atea
ss
xtchthat iit
s
aaninaohrc
S
sandl inst’’
fromwsub-nsthe
et8
achcon-rialdr atal
r-ted
ls,ctlyl
ddtheels
ersas
share
-tro-a-the
the
siss
0%,in-
Redistr
A. Temporal assimilation patterns
~a! Are intermediate and long AE vowels consistently asimilated to two-mora J categories and the short vowto one-mora J categories~as in the previous study! ordoes contextual variation in vocalic duration reduconsistency in temporal assimilation of AE vowels?
~b! Do temporal assimilation patterns vary systematicawith the voicing of the following consonant? BecauJapanese vowels do not vary systematically withfinal consonant voicing, it was predicted that AE vowels would be assimilated more to two-mora Japancategories when followed by voiced consonants thby voiceless consonants.
~c! To what extent does vocalic duration alone predict pceptual assimilation to two-mora as opposed to omora Japanese categories?
B. Spectral assimilation patterns
~a! Do patterns of perceptual assimilation of the 11 Avowels to the five J spectral categories differ systeatically with the place-of-articulation~and voicing! ofthe preceding and following consonants? Specificaare vowels that have no close counterpart in Japanassimilated todifferentJapanese vowel categories asfunction of consonantal context?
~b! If spectral assimilation patterns vary systematicawith consonantal context, to what extent do differencin formant structure predict those variations?
II. METHOD
A. Stimulus materials
Four male monolingual speakers of AE~25–36 yearsold! produced the corpus.@These were the same speakersin Strangeet al. ~1998!; stimulus materials for the presenstudy and for that study were recorded at the same tim#None of the men spoke with a strong regional accent andfour maintained the@Ä-Å# contrast in their spontaneouspeech. There were, however, some noticeable variationthe phonetic realization of these vowels and of /,, */. Eachspeaker produced the 11 AE vowels in six CVC conte/b-b, b-p, d-d, d-t, g-g, g-k/ in blocks of 12 sentences eawithin which the vowels were randomly sequenced, butconsonant context was constant.~The 12th sentence wasrepetition of the first, and was not used in the experimenorder to control for any changes in intonation associated wthe last utterance of the list.! Four such blocks of 11 vowelin each consonantal context were recorded.
The first author monitored the recording sessions offour speakers and asked the speaker to repeat any utterwhich were obviously misproduced, or which containedconsistencies in intonation, rate, or voice quality. The speers were familiar with phonetic transcription, but were ntrained speakers. Speaker JM was recorded in an anecchamber at ATR Human Information Processing ReseaLaboratories, using a DAT~SONY PCM 2500, B! recorderand condenser microphone~SONY ECM-77!. The remainingthree speakers were recorded in an IAC chamber at U
1694 J. Acoust. Soc. Am., Vol. 109, No. 4, April 2001
ibution subject to ASA license or copyright; see http://acousticalsociety.org
-ls
y
e
en
--
-
,se
s
s
.ll
in
s,
e
nh
llces-k-toich
F
Speech Perception Laboratory using a DAT~SONY TDC-D10! recorder and dynamic microphone~Panasonic WM-1325!.
The stimuli were digitally transferred to computer fileand downsampled to 22.05 kHz for storage, analysis,presentation to subjects. Three utterances of each voweeach context were chosen by the first author as the ‘‘beinstances of the vowel. In most cases, these were takenblocks 2–4 of the original recordings. However, in a fecases, the first repetition was considered better and wasstituted. In the judgment of the first author, all productiowere good instances of the intended vowels except incase of JM’s productions of@e(̂# in the /g-g/ context. In thiscontext, the contrast between@e(̂-}# was reduced so that onof the three ‘‘best’’ @e(̂# tokens was still heard by the firsauthor as@}#-like. The final stimulus corpus consisted of 19utterances for each speaker: 11 vowels36 contexts33 rep-etitions. Separate listening tests were constructed for espeaker’s utterances. Within each speaker condition, thesonantal context and the vowels varied randomly from tto trial within the block of 198 trials. Each listener completethree such blocks of 198 items from a single speaker, fototal of nine judgments of each vowel in each consonancontext.1
A group of 16 native AE speakers who were undegraduates at the University of South Florida were presenthe listening tests for identification. Pooling over all vowecontexts, and speakers, the vowels were identified corre94% of the time~where ‘‘correct’’ is defined as the voweintendedby the speaker!. Seven vowels /i,(, }, ,, #, o*̂, u/were identified with>98% accuracy over all speakers ancontexts. The vowels /Ä/ and /Å/ were sometimes confusewith each other, reflecting the dialect patterns of some oflisteners. Overall correct identification rates for these vowwere 81% and 83%, respectively~98% and 100% when /Ä-Å/confusions were not counted as errors!. JM’s productions of/e/ in /g-g/ context were often misidentified as /}/; correctidentification of /e/ in this context averaged across speakwas 88%. In all other contexts, correct identification w>90% for all four speakers. Finally, the vowel /*/ was some-times misidentified as /#/, especially in labial contexts; theoverall correct identification rate was 85%.
B. Acoustical analysis procedures
Digitized stimuli were analyzed on a Power Macintocomputer using Soundscope/16 speech analysis softw~GW Instruments!. Vocalic duration was determined by inspection of time-aligned waveform and broadband specgraphic displays~300 Hz, 1024 FFT points, 6 dB preemphsis!. Vocalic duration was defined as the interval betweenonset of voicing~the first full glottal pulse following theplosive burst! and the beginning of consonant closure~indi-cated by a rapid decrease in waveform amplitude andcessation of energy in upper formants!. Frequencies of thefirst three formants were measured using LPC analy~autocorrelation—28 coefficients!. LPC spectral envelopewere superimposed on narrow-band power spectra~FFT!computed at three temporal locations centered 25%, 5and 75% through the vocalic duration of the syllable. W
1694Strange et al.: Perceptual assimilation of vowels
/content/terms. Download to IP: 192.88.142.253 On: Fri, 19 Sep 2014 13:47:21

n-
che
ue
-thsa
heie
FFe
ce
ws
yning
llsk
yese
ter
ercoen
S
g
cg
e-
pls
sothor
ionbject
to 7’’
onsedo-m-
er’sh ofertedas-dianeachfingsom-cs inools tolis-er-
r dif-pat-
ers,ror
ereare
thedic-ak-ngeson-el,ctlywasas-ntaldnsesd tothense
inrror,ntall re-
n asthat-
Redistr
dow width for the 50% point was 25 ms, while 10-ms widows were used for 25% and 75% measurements, sincelatter locations included portions of the syllable in whiformant transitions associated with the consonants wpresent, especially for the short vowels. Numerical valgiven by the LPC analysis were used unless clear errors~spu-rious formants or missed formants! were evident. To determine this, LPC formant tracks were superimposed onbroadband spectrographic display of the target syllableassess formant continuity, and LPC spectral envelopesFFT power spectra were compared. In those cases wLPC values were judged to be incorrect, formant frequencwere determined by manual measurement of smoothedpower spectra. All measurements were made by two expmenters, working separately, and discrepancies~8 ms for du-ration, 50 Hz forF1, 150 Hz forF2, 250 Hz forF3! wereresolved through additional analysis by the most experienresearch assistant or the first author.
C. Listeners and procedures
Native speakers of Japanese~18 to 24 years old! residingin the Kansai area volunteered to serve as subjects andpaid for their participation. Six listeners were randomly asigned to each speaker for a total of 24 subjects~13 malesand 11 females! in all. All were college students at nearbuniversities and had received the ‘‘standard’’ English laguage training, which consists of six years of instructionjunior and senior high school, and some classes in colleEnglish instruction emphasized reading and writing skiwith little or no experience listening to native English speaers. None of the subjects had lived or traveled extensivelan English-speaking country. A language-background qutionnaire revealed that 19 listeners were from the Kanregion, while the remaining five listeners were from othregions of Japan~Tokyo, Nagoya, Kyushu, and Hokuriku!.
All subjects were tested individually in sound-attenuachambers at ATR Human Information Processing ReseaLaboratories~Kyoto, Japan! by Japanese experimenters. Pceptual assimilation and goodness ratings tasks wereducted using a NeXT cube workstation for stimulus prestation and response acquisition. Stimuli were convertedanalog signals and low-pass filtered using the NeXT Dboard, and presented binaurally through earphones~Stax SRSignature Professional! at a preset comfortable listeninlevel.
A trial consisted of two presentations of each utteranin succession. After the first presentation, the subject caterized the target syllable as ‘‘most similar’’ to 1 of 18 J rsponse alternatives, by selecting 1 of 18katakanacharactersdisplayed on the computer screen. The 18 characters resented CV syllables containing the five one-mora vowe@a, i, u, e, o#, the five two-mora vowels@aa, ii, uu, ee, oo#,2
the palatalized consonant1vowel combinations@ ja, ju, jo]~1-mora syllables!, the palatalized consonant1two-moravowels@ jaa,juu, joo], and the two-mora vowel combination@ou, ei#.3 Thekatakanasymbols changed from trial to trial sthat they represented the appropriate initial consonant;the listeners knew the identity of the initial consonant befresponding, but not whether the final consonant~with the
1695 J. Acoust. Soc. Am., Vol. 109, No. 4, April 2001
ibution subject to ASA license or copyright; see http://acousticalsociety.org
the
res
etondresT
ri-
d
ere-
-
e.,-ins-air
dch-n--
toP
eo-
re-,
use
same place of articulation as the initial consonant! wasvoiced or voiceless. Following the subject’s categorizatresponse, the same utterance was repeated and the surated the vowel’s category goodness on a scale from 1(75best fit!. The endpoints were labeled ‘‘Japanese-like~7! and ‘‘not Japanese-like’’~1!. Subjects were permitted torepeat an utterance or change their categorization respafter the second presentation, but were discouraged froming so. A new trial began after the rating response was copleted; thus, all testing was subject paced.
D. Perceptual data analysis
Categorization responses were tallied for each speakvowels in each consonantal context. Frequencies of eacthe 18 responses were summed over listeners and convto percentages of total opportunities. Goodness ratingssigned to each response category were tallied and the meresponse, summed over listeners, was computed. Forvowel, overall response patterns~frequencies of selection oeach response category and overall median goodness rat!summed over all four listener/speaker groups were also cputed and are presented as summary descriptive statistitables shown later in this work. These overall data thus presponses both within and across listener/speaker groupobtain reliable estimates of how the ‘‘average’’ Japanesetener perceptually assimilates the AE vowels of the ‘‘avage’’ ~male! AE speaker.
To assess the effects of consonantal context, speakeferences, and their interaction on perceptual assimilationterns, percentages of selection of the modal~most frequent!response category for each vowel, summed over listenwere analyzed using the proportion of reduction in er~PRE! procedure~Reynolds, 1984; Wickens, 1989!. This is anonparametric procedure for use with categorical data whthe effect-size measures employed with continuous datanot appropriate. If there issystematicvariation in the assimi-lation pattern across different contexts and speakers,overall modal response category will not be the best pretor of assimilation patterns across all conditions and speers. The PRE analysis quantifies these systematic chaacross conditions in the native category to which the nnative vowel is most often assimilated. For each AE vowthe proportion of obtained responses not predicted correby the overall modal response—the base rate of error—computed. To establish the effect of context on modalsimilation patterns, the modal response for each consonacondition~summed over speakers! was used as the predicteresponse; then the number of incorrectly predicted respowas determined, and the reduction in error was convertea proportion of the base rate of error. In the same way,speaker effect was computed by using the modal respofor each vowel in each speaker condition~summed over con-sonantal contexts! as the predicted response; the reductionerrors, expressed as a proportion of the base rate of ewas computed. Finally, the interaction between consonacontext and speakers was assessed by using the modasponse categories for each speaker/context combinatiothe predicted responses for the AE vowel. To the extentthe proportion of errors isfurther reduced over the reduc
1695Strange et al.: Perceptual assimilation of vowels
/content/terms. Download to IP: 192.88.142.253 On: Fri, 19 Sep 2014 13:47:21

nd four
1696 J. Acoust. S
Redistribution subject to ASA
TABLE I. Overall perceptual assimilation patterns, pooling responses over six consonantal contexts aspeakers. See text for details.
AEvowel
Modal assimilation response Second most frequent response
Japanesecategory
Consistency~%!
Goodness~median!
Japanesecategory
Consistency~%!
Goodness~median!
ib ii 71 5 i 26 6e(̂ ei 77 5 ee 13 5Äb aa 60 5 a 21 3o*̂ ou 57 5 oo 17 5ub uu 73 5 u 26 5
,b aa 32 3 a 17 1Åb oo 46 4 ou 26 4
( i 45 5 e 31 5} e 37 5 a 22 3# a 44 5 o 25 4* u 50 4 uu 32 4
cioersitio
dthecos
asfo
s othailake
xtc
w
seac
wiriannA
s
-n-
ir
ameither
elyoverpat-e J
toelsof
w
ow-ed
ost
gh-ions
Inid-the
for
tions attributable to contexts and speakers separately, itbe concluded that the variation in perceptual assimilatpattern across contexts was different for different speakAs in the previous study, a PRE of at least 0.10 was conered to reflect systematic variation in perceptual assimilapatterns.@See Strangeet al. ~1998! for further details of thelogic behind these analyses and reliability estimates.# That is,when context/speaker specific response categories usepredict assimilation responses led to a 10% improvemen‘‘fit’’ to obtained response patterns over the use of tcontext/speaker independent predicted response, wecluded that there were systematic context/speaker effectperceptual assimilation patterns.
III. RESULTS
In this section, we first present descriptive data onsimilation patterns, pooled over speakers and contexts,lowed by the PRE analysis of context and speaker effectmodal response patterns. Following this overall analysis,effect of consonantal context on temporal assimilation pterns is examined in more detail. Finally, spectral assimtion patterns and how they varied with contexts and speaare presented.
A. Overall perceptual assimilation patterns
After pooling the data across all consonantal conteand speaker/listener groups, the overall modal J responseegory and the second most frequent J response categorydetermined for each AE vowel, as shown in Table I~columns2 and 5!. Frequencies of selection of these two responwere converted to percentages of total opportunities andpresented in columns 3 and 6 of the table. These valuesbe considered measures of the overall consistencywhich the listeners assimilated each AE vowel to particulacategories, independent of context. In addition, the medratings assigned to these responses are given in columand 7; these values indicate the perceived category goodof the AE vowel as an instance of the selected J category.vowels are grouped such that the five~intermediate and long!vowels which are phonetically most ‘‘similar’’ to J vowel
oc. Am., Vol. 109, No. 4, April 2001
license or copyright; see http://acousticalsociety.org
anns.d-n
toin
n-on
-l-net--rs
sat-ere
sreanthJn
s 4essE
are presented in the top rows, the two ‘‘new’’ long AE vowels ~those with no clear phonetic counterpart in the J invetory! are presented next, and the four short vowels~also con-sidered ‘‘new’’! are presented in the bottom rows.
As the modal response percentages indicate,no AEvowel was assimilated to asingleJ category in all contextsfor all speakers with extremely high consistency~valuesranged from 32% to 77%!. As expected, the five similar AEvowels@ib, e(̂, Äb, o*̂, ub# were assimilated most often to theanalogous two-mora J categories@ii, ei, aa, ou, uu#, withrelatively better consistency~57% to 77%! than new vowels,and relatively high goodness ratings (median55). Note thatthe modal responses for the diphthongized@e(̂, o*̂] were thetwo-mora vowel combinations@ei, ou#. For these five AEvowels, the second most frequent responses were the sspectral J categories as the modal responses, but were ethe one-mora cognates~for @ib, Äb, ub#! or the two-moramonophthongal vowels@ee, oo#.3 With the exception of J@a#for AE @Äb#, the judged category goodness was also relativhigh for the second most frequent responses. Collapsingthese variations in perceived temporal and diphthongalterns, these five AE vowels were assimilated to the fivspectral categories with consistencies ranging from 78%99% and median ratings of 5. In general, then, these vowwere perceived as relatively good to excellent instancesnative categories.
In contrast, the two new long vowels and the four neshort vowels were assimilated less consistently~32% to50%! and had lower median goodness ratings for some vels ~3–5!. That is, none of these vowels was categorizmore than half the time~over speakers and contexts! as mostsimilar to a single J vowel category. When the second mfrequent responses are included, it is clear that@Åb# and @*#were more consistently assimilated to mid-back and hiback spectral categories, respectively, disregarding variatin perception of temporal and diphthongal parameters.terms of vowel quality then, these vowels were also consered relatively good instances of Japanese vowels. Forremaining three short vowels and@,b#, there were clear in-consistencies in spectral assimilation patterns. For@,b#, two-and one-mora J@a~a!# responses, combined, accounted
1696Strange et al.: Perceptual assimilation of vowels
/content/terms. Download to IP: 192.88.142.253 On: Fri, 19 Sep 2014 13:47:21

oco
t
ia
e-a
eaE
ararrroxPi
ryicons
tei
-on
aanlit
n-k
igk
tail
rtextn.m-
in-els
res inre-
ings
eseralort,a Jora
shwelge,
ora
riesurw-
els
as-geseic
ndso-nd
nso-forls
n inxts.ofelsces
o-out
Redistr
just less than half of the total responses~49%!, and wereassigned very low goodness ratings~1–3!. Other responseswere distributed across palatalized J categories@ jaa,ja#~23%; median ratings52 to 3! and mid-front J categories@ei,ee, e# ~26%; median ratings 2 to 3!. The overall responsepatterns for@(, }, ## placed them as perceptually between twadjacent J categories. Surprisingly, when pooling acrosstexts and conditions, the judged category goodness tomodal category~median ratings55! were not any lower forthese three short vowels than for the five similar intermedand long vowels.
To ascertain how much of the variability in modal rsponse consistency was systematically related to contextspeaker differences, PRE analyses were completed forof the 11 AE vowels. Table II displays the results; again, Avowels are arranged such that the five similar vowelsgrouped above, while the new long and short vowelslisted below. The second column lists the base rates of ethe next three columns give the PRE values for contespeaker, and context/speaker analyses, respectively.values exceeding the criterial value of 0.10 are printedboldface.
Modal responses for the five similar vowels did not vasystematically with consonantal context, speaker, or partlar context/speaker combinations, except for the high frvowel @ib#. For this vowel, assimilation to two-mora versuone-mora high front J categories did change across confor two of the four speakers. Variations in temporal assimlation of @ub# approached thea priori value set for a meaningful variation, again for the same two speaker/context cditions as for@ib# (speaker3context PRE50.091). Thus, forthese five similar vowels, the PRE analysis showed thatsimilation patterns were quite stable across contextsspeakers, with only weak evidence of systematic variabiin temporal assimilation~discussed further in Sec. III B!.
Variability in modal responses for five of the six remaiing AE vowels was attributable, in part, to particular speaers, contexts, or their interaction. For@*#, the variability inperceptual assimilation to two-mora versus one-mora J hback categories was due to an interaction between spea
TABLE II. Results of proportion of reduction of error~PRE! analysis per-formed on modal responses for each AE vowel. Meaningful effects~.0.10!are indicated in boldface.
AE vowelBase rate of
errorContenteffects
Speakereffects
Context3speaker
interaction
ib 28.63 0.000 0.000 0.119e(̂ 23.07 0.000 0.000 0.047Äb 40.20 0.000 0.000 0.006o*̂ 42.67 0.000 0.000 0.040ub 27.77 0.000 0.000 0.091
,b 67.98 0.091 0.023 0.135Åb 54.39 0.000 0.000 0.057
( 54.63 0.133 0.052 0.234} 63.04 0.042 0.114 0.229# 56.48 0.000 0.112 0.145* 50.23 0.063 0.054 0.204
1697 J. Acoust. Soc. Am., Vol. 109, No. 4, April 2001
ibution subject to ASA license or copyright; see http://acousticalsociety.org
n-he
te
ndch
eer;t,REn
u-t
xts-
-
s-d
y
-
hers
and contexts.~These results are also described in more dein Sec. VII B.! The remaining three short vowels and@,b#produced very complex spectral assimilation patterns~dis-cussed further in Sec. III C!. For @,b#, the context/speakePRE of 0.135 was not 0.10 greater than the main coneffect (PRE50.091), but did exceed the 0.10 criterioThus, we can interpret this result as primarily due to systeatic variation with context~see Sec. III C!.
In summary, then, the PRE analyses confirmed thatconsistant assimilation patterns for 5 of the 11 AE vowcould be attributed tosystematic differencesin perceivedsimilarity as a function of consonant context for one or mospeakers’ utterances. In order to examine these variationmore detail, further analyses were conducted in whichsponse categories were partitioned into temporal group~presented in Sec. III B! and spectral groupings~presented inSec. III C!.
B. Effects of context on temporal assimilationpatterns
For this analysis, the first question was whether Japanlisteners distinguished AE vowels in terms of their tempostructure, as evidenced by differential assimilation of shintermediate, and long vowels to one-mora and two-morcategories. Thus, responses were partitioned into one-mresponses@i, e, a, o, u,ja,ju, jo# versus two-mora response@ii, ee, aa, oo, uu, ei, ou,jaa,juu,joo# and percentages of eactype of temporal response were computed for each AE voin each context within each speaker condition. On averathe five long vowels were heard as most similar to two-mJ vowels 79% of the time~range 61% to 92%!, while the twointermediate vowels were assimilated to two-mora catego74% and 73% of the time, respectively. In contrast, the foshort vowels were heard as most similar to two-mora J voels on only 27% of the trials~range 19% to 37%!. Thus, on76% of the trials, long/intermediate versus short AE vowwere ‘‘correctly’’ differentiated as~most similar to! two-mora versus one-mora J categories, respectively.
A second question was whether patterns of temporalsimilation differed systematically as a function of the voicinof the following consonant, as would be expected if Japanlisteners did not ‘‘compensate’’ for non-native allophonvariation in vocalic duration. In Fig. 1~a!, percentages oftwo-mora responses for the five long, two intermediate afour short AE vowels in final voiced versus voiceless connant contexts~pooled over repetitions, vowels, speakers, aplace-of-articulation of consonants! are plotted. For all fourspeakers’ utterances, there was a clear effect of final conant voicing on temporal assimilation patterns, especiallythe short and intermediate vowels. All four short vowewere assimilated to two-mora J vowel categories less oftevoiceless final consonant contexts than in voiced conteThe effect of voicing context on temporal assimilationintermediate vowels appeared similar to that for short vowfor three speakers’ utterances, but smaller for the utteranof JM. Finally, the five long vowels were assimilated to twmora response categories in both voicing contexts at abthe same levels.
1697Strange et al.: Perceptual assimilation of vowels
/content/terms. Download to IP: 192.88.142.253 On: Fri, 19 Sep 2014 13:47:21
ra
orco
of
s
lefte
ion
raedechetht
de
he
nnt20h
veo
im
s intich
-wasmi-
sta-
for
ionort,ker.ls;ols.enlsoof-
ven
se,
ra-ilar
keexd
abi
bols.ntxts.longow-
ence
Redistr
To assess the reliability across listeners of these ovetrends, a repeated measures analysis of variance~ANOVA !with vowels~11! and contexts~6! nested within speaker~lis-tener! groups was performed, using the number of two-mresponses as the score. The main effects of vowels andtexts were both highly significant,F(10,200)576.360 andF(5,100)516.287, respectively, bothp,0.001. While themain effect of speakers was not significant@F(3,20)50.801#, there were small but significant interactionsspeakers3contexts@F(15,100)52.219, p,0.02], Speakers3vowels @F(30,200)51.804, p,0.01], and speaker3vowels3contexts @F(150,1000)52.022, p,0.01]. Thevowels3contexts interaction was also highly reliab@F(50,1000)53.607, p,0.01]. A planned comparison othe three voiced contexts versus the three voiceless conalso yielded a statistically significant result,F(1,100)568.842,p,0.001.
To summarize, the patterns of temporal assimilatshown in Fig. 1~a! were highly reliable across listeners. Oaverage, vowels were judged as less similar to two-mocategories in voiceless contexts, especially for the intermate and short vowels. The extent of this contextual effvaried somewhat across speakers. However, despite tcontext/speaker effects, the four short vowels were neverless most often assimilated to one-mora categories, whileintermediate and long vowels were most often assimilatetwo-mora categories for all speakers’ vowels in both voicand voiceless final consonant contexts.
Figure 1~b! presents the vocalic duration data for tfour short, two intermediate, and five long vowels~averagedover tokens, vowels, speakers, and place-of-articulationthe consonants!. For all three sets of vowels, vocalic duratiovaried systematically with the voicing of the final consonaOn average, vowels preceding voiced consonants werelonger than vowels preceding voiceless consonants. Svowels in voiced contexts averaged 18 ms longer, intermdiate vowels averaged 22 ms longer, and long vowels aaged 26 ms longer than their counterparts in voiceless ctexts.
In order to assess the extent to which temporal ass
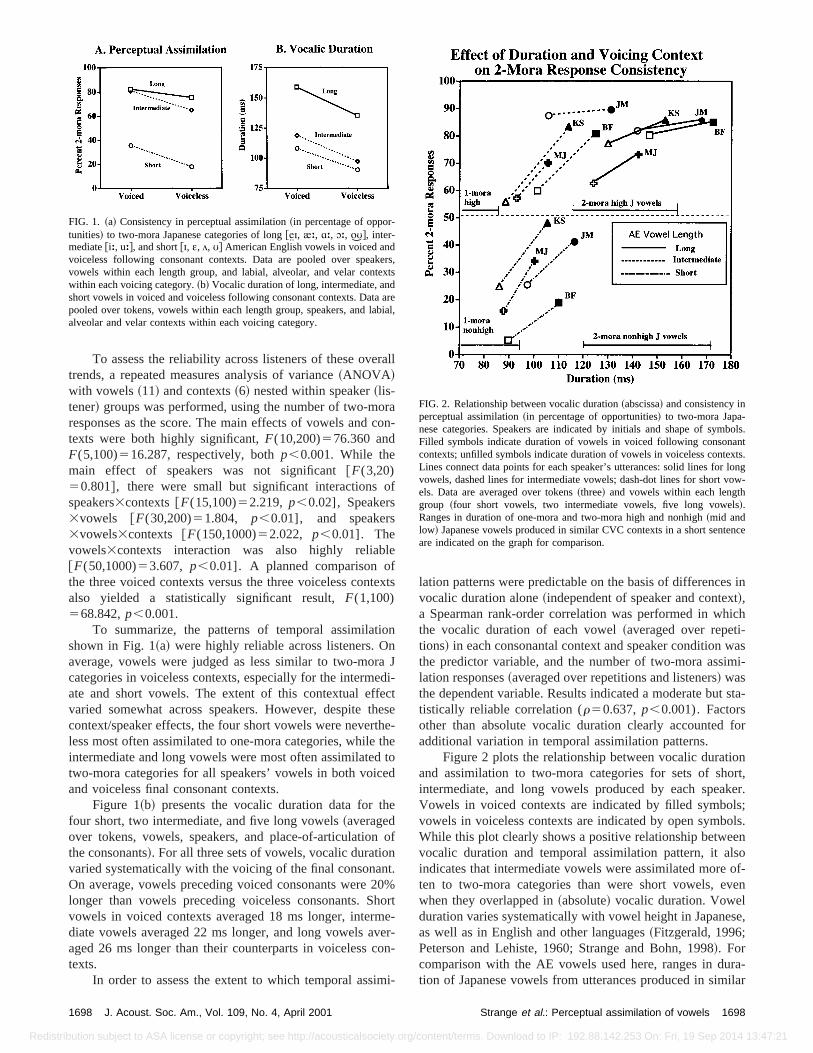
FIG. 1. ~a! Consistency in perceptual assimilation~in percentage of oppor-tunities! to two-mora Japanese categories of long@|P(, ,b, Äb, Åb, Ç*̂#, inter-mediate@ib, ub#, and short@(, }, #, *# American English vowels in voiced andvoiceless following consonant contexts. Data are pooled over speavowels within each length group, and labial, alveolar, and velar contwithin each voicing category.~b! Vocalic duration of long, intermediate, anshort vowels in voiced and voiceless following consonant contexts. Datapooled over tokens, vowels within each length group, speakers, and laalveolar and velar contexts within each voicing category.
1698 J. Acoust. Soc. Am., Vol. 109, No. 4, April 2001
ibution subject to ASA license or copyright; see http://acousticalsociety.org
ll
an-
xts
n
Ji-tse
e-hetod
of
.%
orte-r-n-
i-
lation patterns were predictable on the basis of differencevocalic duration alone~independent of speaker and contex!,a Spearman rank-order correlation was performed in whthe vocalic duration of each vowel~averaged over repetitions! in each consonantal context and speaker conditionthe predictor variable, and the number of two-mora assilation responses~averaged over repetitions and listeners! wasthe dependent variable. Results indicated a moderate buttistically reliable correlation (r50.637,p,0.001). Factorsother than absolute vocalic duration clearly accountedadditional variation in temporal assimilation patterns.
Figure 2 plots the relationship between vocalic duratand assimilation to two-mora categories for sets of shintermediate, and long vowels produced by each speaVowels in voiced contexts are indicated by filled symbovowels in voiceless contexts are indicated by open symbWhile this plot clearly shows a positive relationship betwevocalic duration and temporal assimilation pattern, it aindicates that intermediate vowels were assimilated moreten to two-mora categories than were short vowels, ewhen they overlapped in~absolute! vocalic duration. Vowelduration varies systematically with vowel height in Japaneas well as in English and other languages~Fitzgerald, 1996;Peterson and Lehiste, 1960; Strange and Bohn, 1998!. Forcomparison with the AE vowels used here, ranges in dution of Japanese vowels from utterances produced in sim
rs,ts
real,
FIG. 2. Relationship between vocalic duration~abscissa! and consistency inperceptual assimilation~in percentage of opportunities! to two-mora Japa-nese categories. Speakers are indicated by initials and shape of symFilled symbols indicate duration of vowels in voiced following consonacontexts; unfilled symbols indicate duration of vowels in voiceless conteLines connect data points for each speaker’s utterances: solid lines forvowels, dashed lines for intermediate vowels; dash-dot lines for short vels. Data are averaged over tokens~three! and vowels within each lengthgroup ~four short vowels, two intermediate vowels, five long vowels!.Ranges in duration of one-mora and two-mora high and nonhigh~mid andlow! Japanese vowels produced in similar CVC contexts in a short sentare indicated on the graph for comparison.
1698Strange et al.: Perceptual assimilation of vowels
/content/terms. Download to IP: 192.88.142.253 On: Fri, 19 Sep 2014 13:47:21

ories,ll
1699 J. Acoust. S
Redistribution subject to ASA
TABLE III. Overall pattern of perceptual assimilation of AE vowels to the five Japanese spectral categdisregarding length and palatalization. Data~percent of opportunities! are pooled over all six contexts and afour speakers.
AE vowel
Japanese response categories
High-fronti, ii
Mid-fronte, ee, ei
Lowa, aaja, jaa
Mid-Backo, oo, ou,jo, joo
High-backu, uu, ju, juu
ib 98 2( 51 44 1 4e(̂ 5 95} 2 53 44 ,1 ,1,b 1 26 73Äb 1 81 16 2# ,1 1 51 39 8Åb 13 82 5o*̂ ,1 ,1 79 20* 3 15 82ub ,1 99
rae
spig
hac
w-eit,
ene
thuro
paidinb
re
sleonumac
yls
rsi-rao
rs,
ncy
enec-bil-
c-or
t
i-rall
over
c-extsr theAsing-tral
achs-
ider-ofer-rees-
own
aker
sentential and consonantal contexts are marked on the g~Fitzgerald, 1996!. High J vowels are indicated above th50% point of the ordinate; mid and low~nonhigh! J vowelsare indicated above the 0% point. Note the differences ecially in upper boundaries of the ranges for Japanese hversus nonhigh vowels. Japanese listeners appear toconsidered L1 phonetic variation in vocalic duration assoated with vowel height when judging AE mid and short voels as more similar to two-mora or one-mora vowels. Thdid not appear to have attributed any part of the variationvocalic duration to the voicing of the following consonansince such allophonic variation in vowel length is not presin Japanese. Thus, for short and intermediate AE vow~whose durations were ambiguous in comparison withvowels!, assimilation responses differed significantly wivoicing context and the relationship between absolute dtion and percentage of two-mora responses appeared tquite linear.
C. Effects of context on spectral assimilationpatterns
For this analysis, the 18 response alternatives weretitioned into the five spectral categories: high-front, mfront, low, mid-back, and high-back. That is, differencestemporal assimilation were ignored, as were differencestween two-vowel sequences@ei, ou# versus double vowels@ee, oo# and palatalized versus nonpalatalized vowelsponses@a~a!, o~o!, u~u!# versus@ ja~a!, jo~o!, ju~u!#. Table IIIpresents the overall distribution of assimilation responsethese five categories for each AE vowel. Data were pooover all six contexts and all four speaker conditions and cverted to percentages of opportunities. The boldfaced nbers highlight the overall modal response choices for evowel.
As these data show, there was considerable variabilitthe overall consistency with which particular AE vowewere assimilated to particular J spectral categories. TheAE vowels can be grouped into three clusters. The figroup—@ib, e(̂, ub#—were assimilated to their spectrally simlar J counterparts with greater than or equal to 95% oveconsistency. Consistency in spectral assimilation varied fr
oc. Am., Vol. 109, No. 4, April 2001
license or copyright; see http://acousticalsociety.org
ph
e-hve
i-
yn
tlsJ
a-be
r--
e-
-
tod--h
in
11t
llm
89% to 100% across the six contexts~pooling across speakeconditions!. Within particular speaker/context conditionpercentages ranged from 89% to 100% for@i, u# while theywere slightly more variable for@e(̂# ~74% to 100%!.
The second group of vowels@,b, Äb, Åb, o*̂, *# wereassimilated to J spectral categories with overall consistebetween 73% and 82%. Across contexts~pooling over speak-ers! consistency ranged from 65% to 93%. However, whindividual speaker/context conditions were considered, sptral assimilation patterns showed considerably more variaity for these vowels than for the first group~range 31% to100%!. For @,b, Äb, o*̂, *#, the modal spectral response atually differed from the overall modal response in onemore speaker/context conditions.
The third group of vowels@(, }, ## showed the leasoverall consistency~51% to 53%! and the greatest variabilityin spectral assimilation patterns across contexts~rangingfrom 29% to 74%!. When individual speaker/context condtions were considered, the range in selection of the ovemodal response was even greater~4% to 96%!. For thesevowels, then, no single spectral J category was chosen50% of the time for every speaker~pooling over contexts! orfor every context~pooling over speakers!.
To quantify the extent to which these variations in spetral assimilation patterns were systematic across contand/or speakers, new PRE analyses were conducted foeight vowels showing less than 95% overall consistency.before, a PRE of 10% or greater was considered a meanful effect. These analyses indicated that variations in specassimilation patterns for the@,b, Äb, Åb, o*̂, *# were notrelated sufficiently to context and speaker variables to rea priori levels of reduction in errors. That is, while consitency ~and sometimes modal response choice! did changeacross context/speaker conditions, there was also consable variability within conditions, such that predictionsassimilation patterns were not much improved by considation of the context and the speaker. However, for the thshort vowels@(, }, ## the PRE analyses revealed clear sytematic effects of context for one or more speakers, as shin Table IV~a!. Here again, base rates of error~column 2!and PRE values for context, speaker, and context/spe
1699Strange et al.: Perceptual assimilation of vowels
/content/terms. Download to IP: 192.88.142.253 On: Fri, 19 Sep 2014 13:47:21

ld
a-the
tice
n
n
ns
ththitllth
inercela
l.
lere
a
-i-d
n
are
ernAE
e-
n-
enla-
forted
re-
or-cat-lallyntlysetal-nsi-es-stic
at-
gre-ngh-ts oftral
bout
nsandions
se
en-
Redistr
interactions are given, with values exceeding 0.10 in boface.
While the PRE analysis of the spectral assimilation pterns for AE@,b# did not reveal a meaningful effect of context and/or speaker, an inspection of the data indicatedthe proportion of assimilation responses indicating the pception of a syllable with changing spectral characteris~i.e., assimilation to palatalized J categories or two-vowsequences! appeared to vary systematically with contexts aspeakers. Thus, an additional analysis was performedwhich J responses to this vowel were partitioned into ‘‘nomovement’’ J response categories@a, aa, e, ee# versus‘‘movement’’ J response categories@ ja, jaa, ei]. The resultsof a PRE analysis based on this partitioning of J respocategories is shown in Table IV~b!. The significant reductionin errors associated with the main effect of context andspeaker/context interaction support the conclusion thatperceptual assimilation pattern varied systematically wcontext for three of the speakers’ utterances. Specificamore movement assimilation responses were given tovowel in velar consonant contexts.
To determine the extent to which systematic variationspectral assimilation pattern as a function of speakcontexts could be accounted for by production differen@(, }, ##, multiple regression analyses were performed reing formant values and modal response consistency~acrosslisteners and trials/listener! for the 72 tokens of each voweFor each analysis, the independent variables wereF1 fre-quency, F2 frequency, andF1/F2 frequencies combined~values measured at the 50% duration point in each syllab!,while the dependent variable was the number of modalsponses~out of 18 possible; 6 listeners33 trials! for eachvowel token. Table V presents the multipleR and adjustedR-squared values for each combination of independent vables. For AE@(#, assimilation to high~as opposed to mid!front J vowels correlated significantly with formant frequency, especiallyF1; however, less than 24% of the varance in perceptual assimilation responses was accounteby spectral variation. For@}#, F1 andF2 frequencies, bothalone and in combination, showed significant correlatiowith perceptual assimilation to mid~as opposed to low! Jvowels; together, they accounted for about 59% of the vance. Thus, vowel height of AE short front vowels, as cuby F1 frequency~and to a lesser extentF2 frequency!, ac-
TABLE IV. ~a! Results of proportion of reduction of error~PRE! analysisfor spectral assimilation response patterns for /(, }, #/. ~b! Results of PREanalysis for ‘‘movement’’ versus ‘‘nonmovement’’ assimilation responpatterns for /,/. See text for details.
AE vowelBase rate of
errorContexteffects
Speakereffects
Context3speaker
interaction
~a!( 48.69 0.185 0.147 0.357} 47.45 0.115 0.280 0.380# 48.69 0.060 0.260 0.281
~b!,b 30.40 0.193 0.000 0.391
1700 J. Acoust. Soc. Am., Vol. 109, No. 4, April 2001
ibution subject to ASA license or copyright; see http://acousticalsociety.org
-
t-
atr-sl
din-
e
ee
hy,e
s/st-
-
ri-
for
s
i-d
counted for some of the differences in assimilation pattacross speakers and contexts. Mid-high and mid-lowvowels with higherF1 values and lowerF2 values weremore likely to be assimilated to mid and low J vowels, rspectively. For AE@##, assimilation to low~as opposed tomid! back J vowels showed a significant, but weak relatioship to formant frequencies;F1 andF2 combined accountedfor only 21% of the variance.
A final analysis investigated the relationship betwe‘‘vowel-intrinsic spectral change’’ and perceptual assimition to palatalized and two-vowel J responses categoriesAE @,b#. A Spearman rank-order correlation was compuin which the predictor variable was change inF1/F2 values~Euclidean distance inF1/F2 bark space! across the middlehalf of each syllable~from 25% to 75% durational points!.The dependent variable was the number of assimilationsponses to ‘‘movement’’ categories (Cja,Cjaa,Cei). Therewas no overall significant relationship between extent of fmant movement and assimilation to movement responseegories~r520.083, p50.492!. Thus, although perceptuaassimilation to J movement categories was systematicgreater in velar consonant contexts, this was not significarelated to greater diphthongization of this vowel in thecontexts. It might be that perceptual assimilation to palaized categories was associated with slower formant trations of velar consonant-to-vowel opening and closing gtures, but this hypothesis was not testable with the acoumeasurements available for these stimuli.
In summary, the analysis of spectral assimilation pterns revealed that the short AE vowels@(, }, ## were percep-tually assimilated todifferent spectral categories dependinupon the context in which the vowel was produced and psented. An analysis of the pattern of assimilation of the loAE vowel @,b# to palatalized and two-vowel versus monopthongal J vowel categories also revealed systematic effeccontext for three of the four speakers’ utterances. Specassimilation of the other new vowels@Åb, *# was more stableacross contexts and speakers, with overall consistency aequal to AE vowels@Äb, o*̂] which are considered moresimilar to J vowels in phonological analyses. Correlatiobetween formant cues associated with vowel heightspectral assimilation patterns showed only weak associat
TABLE V. Results of multiple regression analysis relating formant frequcies to Japanese spectral category assimilation responses~percent assimi-lated to modal spectral category!.
AEvowel
Modal Jcategory
Predictor variables~formant values!
MultipleR
AdjustedR2 p value
/(/ /i, ii/ F1 0.475 0.226 ,0.001F2 0.212 0.031 50.074F1 andF2 0.498 0.236 ,0.001
/}/ /e, ee/ F1 0.772 0.591 ,0.001F2 0.538 0.279 ,0.001F1 andF2 0.773 0.586 ,0.001
/#/ /a, aa,ja, jaa/ F1 0.333 0.098 50.004F2 0.314 0.086 50.007F1 andF2 0.482 0.211 ,0.001
1700Strange et al.: Perceptual assimilation of vowels
/content/terms. Download to IP: 192.88.142.253 On: Fri, 19 Sep 2014 13:47:21

l a
erscengcrJ
co
ir
er
e
o
no
tet’e
ae
a
eevla
oVl-ecaaon-
or
wco
ish
ntia
icalles
ot
icion-2,-
os ofent
ith
es,pec-
r tovedtend to
sedisren-k
-
lis-ardh-
ldednc-
toon-as-
s the
-on-ore
textor-tal
ten-not
Redistr
between production variations and J listeners’ perceptuasimilation patterns.
IV. DISCUSSION
A. Summary of results
The results of this study have shown that the 11 vowof AE, when produced and presented to Japanese listeneCVC syllables embedded in a carrier sentence, were pertually assimilated to native J vowel categories with varyidegrees of category goodness, as measured by consistenassignment to a particular native category and goodnessings. No vowelwas perceptually assimilated to a singleresponse category consistently across all consonantaltexts. As might be predicted from~abstract! linguistic de-scriptions of the two vowel inventories, the AE vowels@ib,e(̂, Äb, o*̂, ub# were most consistently assimilated to thespectrally similar counterparts in Japanese@ii, ei, aa, ou,%%#, with relatively little variation across context/speakconditions. However, there were systematic differencestemporal assimilation patterns especially for@ib, ub# as afunction of the voicing of the following consonant. For fivof the six ‘‘new’’ AE vowels @(, }, ,b, #, *#, spectral and/ortemporal assimilation patterns varied systematically acrcontext/speaker conditions.
Temporal assimilation patterns indicated that long aintermediate AE vowels were most often assimilated to twmora J categories, while short AE vowels were more ofassimilated to one-mora categories, with overall ‘‘correctemporal differentiation on 76% of the trials. This is somwhat lower than reported in our earlier study~Strangeet al.,1998! which investigated Japanese listeners’ perceptualsimilation of vowels produced in /hVb/ syllables in the samcarrier sentence~84% ‘‘correct’’ temporal assimilation!.However, temporal differentiation was superior to thshown for citation-form /hVbÄ/ bisyllables~53% ‘‘correct’’!,suggesting that sentence context helps L2 listeners perctemporal cues associated with segmental contrastswhen those cues are more subtle than in their nativeguage.
The greater variability in assimilation of AE vowels tone-mora versus two-mora J categories in this mixed Cstudy, in comparison with our earlier findings for /hVb/ sylables in sentences, was due primarily to the short vowbeing assimilated more often to two-mora J responsesegories when they were produced in final voiced consoncontexts~36% responses versus 17% in voiceless final csonants; 17% for /hVb/!, and to the intermediate vowels being assimilated more often to one-mora J response categin voiceless final consonant contexts~44% vs 19% in voicedfinal consonant contexts; 15% for /hVb/!. The long vowelswere also assimilated somewhat less consistently to tmora J response categories in voiceless final consonanttexts~76% vs 82% in voiced contexts; 85% for /hVb/!. Thissupports the prediction that the allophonic rule in Englwhereby vocalic duration differences are attributed~in part!to the voicing status of final consonants would not be ‘‘hoored’’ by the Japanese listeners. The moderate correlafound between absolute vocalic duration and perceptual
1701 J. Acoust. Soc. Am., Vol. 109, No. 4, April 2001
ibution subject to ASA license or copyright; see http://acousticalsociety.org
s-
lsin
p-
y ofat-
n-
in
ss
d-n’-
s-
t
iveenn-
C
lst-
nt-
ies
o-n-
-ons-
similation to two-mora responses suggests that both physduration and native-language phonetic realization ru~variation in vocalic duration with vowel height! contributedto judged temporal similarity. That is, J listeners did njudge L2 vowel length on the basis of a very abstract~voweland context-independent! characterization such as moracount, nor on the basis of surface level acoustic durat~utterance-specific!, but rather made L1/L2 phonetic similarity judgments which were consistent with L1, but not Lphonetic realization rules~vowel-height-specific, but independent of following consonant context!.
Spectral assimilation of the six ‘‘new’’ AE vowels alsrevealed differences in their judged goodness as instancenative categories not predictable from a context-independand very abstract characterization. AE@Åb, *# were assimi-lated to J mid- and high-back categories, respectively, wabout the same consistency as the similar AE vowels@Äb#and@o*̂# were assimilated to J low and mid-back categoriand did not show systematic context/speaker effects in stral assimilation patterns. It is interesting to note that AE@Äb#and @Åb# were heard by Japanese as perceptually similadifferent native categories, perhaps due to the perceirounded quality of the latter. Thus, while AE speakers ofconfuse these two vowels, J L2 learners might be expecteconfuse@Åb# and @o*̂# more often.@However, some dialectsof Japanese are said to contrast /Å/ and /o/ ~Sugito, 1996!#.Likewise, AE @*#, which was sometimes confused with@##by native speakers of AE, would be expected to be confumore with AE @ub# by Japanese learners of English. Thisespecially the case because of the reduced temporal diffetiation of @*-ub# by J listeners. In addition, the mid-high bacAE @*# has a relatively highF2, especially in alveolar contexts. Thus, it is similar acoustically to the unrounded@%# ofStandard~Kanto! Japanese. While most of our Japaneseteners were from the Kansai region, they apparently heAE @*# as quite similar to the Standard variant of the J higback vowel.
The remaining new vowels@(, }, #, ,b# were consideredpoor instances of any one J spectral category and yielarge differences in spectral assimilation patterns as a fution of context. J listeners assimilated AE@,b# in velar con-texts more often to palatalized J syllables, but more oftennonpalatalized categories when in labial and alveolar ctexts. The very low consistency in the overall spectralsimilation pattern for AE@(, }, ## was attributable, in part, tosystematic contextual effects on the J category chosen amost similar. AE@(# was assimilated to J@i# more often inalveolar contexts, but to J@e# in labial and velar contexts. AE@}# was assimilated to J@e# most often in voiced velar contexts, and less consistently in voiced labial and alveolar ctexts, whereas in voiceless contexts, it was assimilated mto J @a#. AE @## was assimilated more often to J@a# in voice-less contexts~especially g-k!, but more often to J@o# invoiced labial and velar contexts. These systematic coneffects were only weakly associated with differences in fmant structure associated with coarticulatory and idiolecvariation in the production of these vowels.
In general, the data presented here indicate that J lisers’ patterns of perceptual assimilation of AE vowels are
1701Strange et al.: Perceptual assimilation of vowels
/content/terms. Download to IP: 192.88.142.253 On: Fri, 19 Sep 2014 13:47:21

s
atgeveioenss, uen
net
ernteshefi-re
thelr-
oo
s,ryzetsd
nd
e’’
ldthon-:
f Jrnston-thislory
od
e a
n-ionbee-elsinn inn inery
s
ion
mi-rs
ackr-
as
ernsiated-ld
in
eyAE
l
e
alea
Redistr
highly predictable either from cross-language descriptionthe abstract ~context-independent! phonological featurelevel, nor from surface level acoustic parameters associwith vowel identity. Thus, we will argue that cross-languaphonetic similarity must be defined at an intermediate leof abstraction, in which context-specific phonetic realizatrules in L1 are brought to bear on cross-language judgmof similarity. The most accurate way of establishing crolanguage perceptual similarities is by direct assessmenting stimulus materials in which phonetic variation is presand tasks such as the ones employed here.
Current theories of L2 speech learning are concerwith how perceptual assimilation patterns might be usedpredict better the perceptual difficulties adult L2 learnface in acquiring new phonetic contrasts. The data presehere might be used to predict relative difficulties of Japanlearners acquiring AE vowel distinctions. Specifically, tresults indicate that perceptual difficulties will vary signicantly with the phonetic context in which the vowel pairs apresented.
B. Predicted perceptual difficulty of AE vowel pairsfor Japanese listeners
Using Best’s perceptual assimilation model~1994,1995!, the perceptual assimilation patterns revealed inpresent study would predict that seven pairs of AE vowwill be difficult for Japanese listeners to perceptually diffeentiate because they reflect single category or category gness assimilation patterns in at least some contexts: /i-(, u-*,e-}, o-Å, ,-Ä, Ä-#, (-}/. However, all but one of these pair/o-Å/, include an AE vowel which differed in modal categoassignment as a function of context. Table VI summarithe spectral assimilation data across contexts for five sevowels which, in some contexts, at least, were assimilatethe same native category.
TABLE VI. Consistency~in percent! of assimilation to Japanese spectrcategories as a function of consonantal context, pooled over all four spers. Entries for@,b# indicate only nonpalatalized responses.
AE vowelJ spectralcategory
Consonant context
Labial Alveolar Velarb-b b-p d-d d-t g-g g-k
ib Highfront/i, ii/
100 100 94 95 99 99
( 49 38 73 70 50 29
ub Highback/u, uu/
100 100 96 99 100 100
* 81 71 91 91 83 72
e(̂ Midfront/e, ee, ei/
100 100 89 91 97 94
} 56 44 57 45 74 39
o* Midback/o, oo, ou/
77 81 71 66 93 88
Åb 83 86 77 74 87 88
,bLow central/a, aa/
60 65 64 60 25 20Äb 75 78 77 81 84 93# 39 52 50 54 45 67
1702 J. Acoust. Soc. Am., Vol. 109, No. 4, April 2001
ibution subject to ASA license or copyright; see http://acousticalsociety.org
at
ed
lnts-s-t
dosede
es
d-
softo
Consider first the two vowel contrasts between high amid-high AE vowels:@ib-(# and@ub-*#, shown in the first twoboxed rows. While these two pairs constitute the ‘‘samnon-native phonological feature contrast~height or, alterna-tively, tenseness!, the perceptual assimilation data woupredict differences in relative perceptual difficulty bowithin and across pairs of vowels. Overall, these pairs cstitute a category goodness~CG!-type assimilation patternthe high AE vowels are excellent~spectral! exemplars,whereas the mid-high AE vowels are poorer exemplars ohigh vowels. However, context-specific assimilation pattepredict that both pairs of vowels would be more difficultdifferentiate in alveolar context than in labial and velar cotexts, at least for the AE speakers’ utterances used instudy. Indeed, for@ub-*# in alveolar contexts, the spectraassimilation pattern may be considered a single categ~SC! type, with both AE vowels being considered very goinstances of J@u~u!#. For the front vowel pair in labial andvelar contexts, the spectral assimilation pattern is mortwo-category~TC! type, with AE @(# being more often as-similated to J@e#, whereas the back vowel pair in these cotexts reflect a CG pattern in these contexts. Differentiaton the basis of temporal assimilation pattern would alsodifficult for both these vowel pairs, since assimilation to onmora versus two-mora categories for all four of these vowdiffered significantly with consonantal context. Thus,Best’s taxonomy, this feature contrast shows a TC pattersome contexts, a CG pattern in others, and a SC patterstill other contexts. Difficulty in learning to differentiatthese vowels, then, would be predicted to vary from veeasy to quite difficult, depending upon context.
Consider next the two mid/mid-low AE vowel pair@e(̂-}# and@ob-Åb# ~shown in the next two rows of Table VI!.The front pair constitutes a CG-type spectral assimilatpattern~/e( /an excellent exemplar of J/ei/ or /ee/, /}/ a poorexemplar of J/e~e!/! or a TC pattern~/}/ an exemplar of J/a/!,depending upon context. Again, differential temporal assilation patterns would be of only marginal help to J listenein mixed consonantal contexts, since@}# was often assimi-lated to two-mora categories in voiced contexts. The bpair would be predicted to be even more difficult to diffeentiate in all contexts. Both@o*̂# and @Åb# were assimilatedprimarily to two-mora native categories and were heardgood exemplars of mid-back J vowels@oo,ou#; i.e., the pairconstitutes a SC-type pattern. However, response pattdid suggest that Japanese listeners perceptually differentthe diphthongal pattern in@o*̂# from the monophthongal pattern of @Åb#. If this were the case, then discrimination woube predicted to be easier for these vowels in contextswhich the AE mid vowels are more diphthongized~e.g., pre-ceding voiced consonants and in open syllables!.
The low and mid-low AE vowels@,b, Äb, ## were allassimilated most often to the low J vowels; however, thdiffered considerably in perceived category goodness.@Äb# was judged a relatively good exemplar of J@a~a!#, espe-cially in velar contexts, while@## was judged a marginaexemplar in voiceless contexts and more like J@o~o!# invoiced labial and velar contexts. AE@,b# was a poor exem-plar of J a~a! in labial and alveolar contexts and more lik
k-
1702Strange et al.: Perceptual assimilation of vowels
/content/terms. Download to IP: 192.88.142.253 On: Fri, 19 Sep 2014 13:47:21

eiodn
bore
he
AEgefooeratun
pradtslet aL2e-ethtuhen
-evfi
wlsicarb
icreeps
irH.fos
su
toci-
ures
hatdent
cep-n theever,
fouruli
ted
b/
o-
u-
ords
p-ss-
oc.
dis-
n-c
eder-
gs,in
f
Redistr
gja~a! in velar contexts. Thus, the@Äb-,b# contrast constitutesa CG-type pattern in labial and alveolar contexts~or possiblycategorizable-uncategorizable!, but a TC pattern in velarcontexts. The@Äb-## contrast constitutes a CG type in somcontexts and a TC type in others; furthermore, differentiatwould be expected to be helped by perceived temporalferences. Thus,@Äb-## should be easier to discriminate tha@Äb-,b# except in velar contexts.
Finally, the AE pair@(-}# ~not shown in adjacent rows inTable VI! were both assimilated to the J@e# category in somecontexts for some speakers. Since these vowels wereheard as most similar to one-mora J vowels, we would pdict on the basis of spectral assimilation patterns that twould be most difficult to differentiate in labial contexts~CGpattern! and easiest in alveolar contexts~TC pattern! for theutterances used in this study.
The patterns of temporal and spectral assimilation ofvowels to native J vowel categories reported above suggenerally that all 11 AE vowels are perceptually distinctJapanese L2 learners of English in at least some CVC ctexts. That is, it was never the case that two vowels wequally well assimilated to the same J vowel category incontext/speaker conditions. However, predicted percepdifficulties based on the overall assimilation patterns, or aparticular context condition, would not be as accurate asdictions which take contextual variables into account. Indition to differences which can be attributed to task effecL2 experience effects, and other methodological variabcontext effects such as those demonstrated here mighcount for the lack of consistency in previous studies ofvowel perception outlined in the introduction. In future rsearch on cross-language vowel perception, it will be necsary to consider the prosopic and allophonic details ofstimulus materials in interpreting the outcomes of percepassimilation and L2 discrimination performance. On tpractical side, results such as the ones reported here caused to generate ‘‘graded’’ stimulus materials~Jamieson andMorosan, 1986! for training studies of non-native vowel contrasts. Finally, the results reported here supply additionaldence that an adequate description of the effects of thelanguage phonology on the perception~and production! ofL2 phonetic segments by adult second language learnersrequire cross-language comparisons of the phonetic detaiboth L1 and L2 systems. Neither very abstract phonologdescriptions of phoneme inventories nor acoustic compsons of specific realizations of phoneme categories willadequate in predicting cross-languageperceptualsimilari-ties. Rather, an intermediate level of abstraction, in whlanguage-specific ‘‘rules’’ about phonetic variation abrought to bear on categorization processes, appears to bappropriate level of analysis of L1/L2 phonetic relationshi
ACKNOWLEDGMENTS
The authors wish to express their thanks to TakahAdachi for programming the experiments, to DavidThornton, Robin L. Rodriguez, and Amanda Graingertheir assistance in data analysis, and to James J. Jenkinhis comments on the manuscript. This research was
1703 J. Acoust. Soc. Am., Vol. 109, No. 4, April 2001
ibution subject to ASA license or copyright; see http://acousticalsociety.org
nif-
th-y
strn-ellalye--,s,c-
s-eal
be
i-rst
illof
ali-e
h
the.
o
rforp-
ported by a grant to the first author from the NIH~Grant No.NIDCD-00323!. Requests for reprints should be addressedthe first author: PhD Program in Speech and Hearing Sences, CUNY-Graduate School.
1In this study, it was impractical to use a completely repeated measdesign, because of the large number of trials. In the previous study~Strangeet al., 1998! using subjects drawn from the same population, we found tperceptual assimilation patterns were quite stable across indepengroups of listeners. In contrast, we found systematic differences in pertual assimilation patterns across speakers for the same listeners. Ipresent study, speakers and listeners are confounded variables. Howthe main variable of interest~i.e., consonantal context! was a within-listeners variable. Thus, one can think of this design as consisting ofreplications of an investigation of context effects, using different stim~speakers! and different listeners.
2In this article, two-mora monophthongal Japanese vowels will be indicain IPA transcriptions by two identical symbols
3There is some ambiguity with respect to whether the Katakana symbols@ei#and@ou# represent a two vowel sequence. In Hiragana~the syllabary whichis used for words of Japanese origin, as opposed to loan words! themonophthongal two-mora vowels@ee# and@oo# are often written as@ei# and@ou#, respectively.
Andruski, J. E., and Nearey, T. M.~1992!. ‘‘On the sufficiency of com-pound target specifications of isolated vowels and vowels in /bVsyllables,’’ J. Acoust. Soc. Am.91, 390–410.
Beckman, M.~1982!. ‘‘Segment duration and the ‘mora’ in Japanese,’’ Phnetica39, 1113–135.
Best, C. T.~1994!. ‘‘The emergence of native-language phonological inflences in infants: A perceptual assimilation model,’’ inThe Development ofSpeech Perception: The Transition from Speech Sounds to Spoken W,edited by J. Goodman and H. C. Nusbaum~MIT, Cambridge, MA!, pp.167–224.
Best, C. T.~1995!. ‘‘A direct realist view of cross-language speech percetion,’’ in Speech Perception and Linguistic Experience: Issues in CroLanguage Research, edited by W. Strange~York, Timonium, MD!, pp.171–204.
Best, C. T., Faber, A., and Levitt, A.~1996!. ‘‘Assimilation of non-nativevowel contrasts to the American English vowel system,’’ J. Acoust. SAm. 99, 2602~abstract!.
Best, C. T., McRoberts, G. W., and Sithole, N. M.~1988!. ‘‘Examination ofperceptual reorganization for nonnative speech contrasts: Zulu clickcrimination by English speaking adults and infants,’’ J. Exp. Psychol.14,345–360.
Bohn, O.-S.~1995!. ‘‘Cross-language speech perception in adults: First laguage transfer doesn’t tell it all,’’ inSpeech Perception and LinguistiExperience: Issues in Cross-Language Research, edited by W. Strange~York, Timonium, MD!, pp. 279–304.
Campbell, W. N., and Sagisaka, Y.~1991!. ‘‘Moraic and syllable-level ef-fects on speech timing,’’ Technical Report of IEICESP90-107, pp. 35–40.
Crystal, T. H., and House, A. S.~1988a!. ‘‘Segmental duration inconnected-speech signals: Current results,’’ J. Acoust. Soc. Am.83,1553–1573.
Crystal, T. H., and House, A. S.~1988b!. ‘‘Segmental duration inconnected-speech signals: Syllabic stress,’’ J. Acoust. Soc. Am.83, 1574–1585.
Fitzgerald, B. H.~1996!. ‘‘Acoustic analysis of Japanese vowels producin multiple consonantal contexts,’’ unpublished Master’s thesis, Univsity of South Florida.
Flege, J. E.~1992!. ‘‘Speech learning in a second language,’’ inPhonologi-cal Development: Models, Research, and Applications, edited by C. Fer-guson, L. Menn, and C. Stoel-Gammon~York, Timonium, MD!, pp. 565–604.
Flege, J. E.~1995!. ‘‘Second language speech learning: Theory, findinand problems,’’ inSpeech Perception and Linguistic Experience: IssuesCross-Language Research, edited by W. Strange~York, Timonium, MD!,pp. 233–277.
Flege, J. E., and Eefting, W.~1987!. ‘‘The production and perception oEnglish stops by Spanish speakers of English,’’ J. Phonetics15, 67–83.
1703Strange et al.: Perceptual assimilation of vowels
/content/terms. Download to IP: 192.88.142.253 On: Fri, 19 Sep 2014 13:47:21

h
n
of
-
n
nti
s-
-
B.6
ntst
-
-Am
wo
l
ic,
ri-
e
lst.
rt
ecede
Res.
is-
Soc.
nd-
ech
o-
d.
ese
Redistr
Flege, J. E., and Hillenbrand, J.~1987!. ‘‘Differential use of closure voicingand release burst as cues to stop voicing by native speakers of FrencEnglish,’’ J. Phonetics15, 203–208.
Fourakis, M. ~1991!. ‘‘Tempo, stress, and vowel reduction in AmericaEnglish,’’ J. Acoust. Soc. Am.90, 1816–1827.
Gottfried, T. L. ~1984!. ‘‘Effects of consonant context on the perceptionFrench vowels,’’ J. Phonetics12, 91–114.
Gottfried, T., and Beddor, P. S.~1988!. ‘‘Perception of temporal and spectral information in French vowels,’’ Lang. Speech31, 57–75.
Hillenbrand, J., Getty, L. A., Clark, M. J., and Wheeler, K.~1995!. ‘‘Acous-tic characteristics of American English vowels,’’ J. Acoust. Soc. Am.97,3099–3111.
Homma, Y. ~1981!. ‘‘Durational relationship between Japanese stops avowels,’’ J. Phonetics9, 273–281.
Homma, Y.~1992!. Acoustic Phonetics in English & Japanese~Yamaguchi,Kyoto, Japan!.
Huang, C.~1991!. ‘‘An acoustic and perceptual study of vowel formatrajectories in American English,’’ Report 563, Research LaboratoryElectronics, MIT, Cambridge, MA.
Jamieson, D. G., and Morosan, D. E.~1986!. ‘‘Training non-native speechcontrasts in adults: Acquisition of the English /Z/-/Y/ contrast by franco-phones,’’ Percept. Psychophys.40, 205–215.
Keating, P. A., and Huffman, M. K.~1984!. ‘‘Vowel variation in Japanese,’’Phonetica41, 191–207.
Klatt, D. ~1976!. ‘‘Linguistic uses of segmental duration in English: Acoutic and perceptual evidence,’’ J. Acoust. Soc. Am.59, 1208–1221.
Kohler, K. J. ~1981!. ‘‘Contrastive phonology and the acquisition of phonetic skills,’’ Phonetica38, 213–226.
Kuhl, P. K., Williams, L. A., Lacerda, F., Stevens, K. N., and Linblom,~1992!. ‘‘Linguistic experience alters phonetic perception in infants bymonths of age,’’ Science255, 606–608.
Lively, S. E., Logan, J. S., and Pisoni, D. B.~1993!. ‘‘Training Japaneselisteners to identify English /r/ and /l/ II: The role of phonetic environmeand talker variability in learning new perceptual categories,’’ J. AcouSoc. Am.94, 1242–1255.
Mochizuki, M. ~1981!. ‘‘The identification of /r/ and /l/ in natural and synthesized speech,’’ J. Phonetics9, 283–303.
Moon, S-J., and Lindblom, B.~1994!. ‘‘Interaction between duration, context, and speaking style in English stressed vowels,’’ J. Acoust. Soc.96, 40–55.
Morosan, D. E., and Jamieson, D. G.~1989!. ‘‘Evaluation of a technique fortraining new speech contrasts: Generalization across voices, but notposition or task,’’ J. Speech Hear. Res.32, 501–511.
Nearey, T., and Assmann, P.~1986!. ‘‘Modeling the role of inherent spectrachange in vowel identification,’’ J. Acoust. Soc. Am.80, 1297–1308.
Peterson, G. E., and Barney, H. L.~1952!. ‘‘Control methods used in thestudy of vowels,’’ J. Acoust. Soc. Am.24, 175–184.
1704 J. Acoust. Soc. Am., Vol. 109, No. 4, April 2001
ibution subject to ASA license or copyright; see http://acousticalsociety.org
and
d
n
.
.
rd
Peterson, G. E., and Lehiste, I.~1960!. ‘‘Duration of syllable nuclei inEnglish,’’ J. Acoust. Soc. Am.32, 693–703.
Polka, L. ~1991!. ‘‘Cross-language speech perception in adults: Phonemphonetic, and acoustic factors,’’ J. Acoust. Soc. Am.89, 2961–2977.
Polka, L. ~1992!. ‘‘Characterizing the influence of native language expeence on adult speech perception,’’ Percept. Psychophys.52, 37–52.
Polka, L. ~1995!. ‘‘Linguistic influences in adult perception of non-nativvowel contrasts,’’ J. Acoust. Soc. Am.97, 1286–1296.
Polka, L., and Bohn, O-S.~1996!. ‘‘A cross-language comparison of voweperception in English-learning and German-learning infants,’’ J. AcouSoc. Am.100, 577–592.
Reynolds, H. T.~1984!. Analysis of Nominal Data (Second Edition)~Sage,Beverly Hills!.
Schmidt, A. M. ~1996!. ‘‘Cross-language identification of consonants: Pa1. Korean perception of English,’’ J. Acoust. Soc. Am.99, 3201–3211.
Sheldon, A., and Strange, W.~1982!. ‘‘The acquisition of /r/ and /l/ byJapanese learners of English: Evidence that speech production can prspeech perception,’’ Appl. Psycholing.3, 243–261.
Shibatani, M.~1990!. The Languages of Japan~Cambridge U. P., Cam-bridge, UK!.
Stevens, K. N., and House, A. S.~1963!. ‘‘Perturbation of vowel articula-tions by consonantal context: An acoustical study,’’ J. Speech Hear.6, 111–128.
Strange, W.~1995!. ‘‘Cross-language studies of speech perception: A htorical review,’’ in Speech Perception and Linguistic Experience, editedby W. Strange~York, Timonium, MD!, pp. 3–45.
Strange, W., and Bohn, O-S.~1998!. ‘‘Dynamic specification of coarticu-lated German vowels: Perceptual and acoustical studies,’’ J. Acoust.Am. 104, 488–504.
Strange, W., Akahane-Yamada, R., Kubo, R., Trent, S. A., Nishi, K., aJenkins, J. J.~1998!. ‘‘Perceptual assimilation of American English vowels by Japanese listeners,’’ J. Phonetics26, 311–344.
Sugito, M. ~1996!. Nihongo onsei no kenkyuu (Studies of Japanese spesounds). Series 3, Nohongo no Otto (Japanese Speech Sounds).
Wickens, T. D.~1989!. Multiway Contingency Tables Analysis for the Scial Sciences~Erlbaum, Hillsdale, NJ!.
Wolfram, W. ~1991!. Dialects of American English~Prentice–Hall, Engle-wood Cliffs, NJ!.
Yamada R. A., and Tohkura Y.~1992a!. ‘‘Perception of English /r/ and /l/by native speakers of Japanese,’’ inSpeech Perception, Production anLinguistic Structure, edited by Y. Tohkura, E. Vatikiotis-Bateson, and YSagisaka~OHM, Tokyo, Japan!, pp. 155–174.
Yamada, R. A., and Tohkura, Y.~1992b!. ‘‘The effect of experimentalvariables on the perception of American English /r/ and /l/ by JapanListeners,’’ Percept. Psychophys.52, 376–392.
1704Strange et al.: Perceptual assimilation of vowels
/content/terms. Download to IP: 192.88.142.253 On: Fri, 19 Sep 2014 13:47:21
Copyright © 2022 FDOKUMEN




















