
Dynamic memory paravirtualization transparent to guest OS
12
. RESEARCH PAPERS . SCIENCE CHINA Information Sciences January 2010 Vol. 53 No. 1: 77–88 doi: 10.1007/s11432-010-0008-x c Science China Press and Springer-Verlag Berlin Heidelberg 2010 info.scichina.com www.springerlink.com Dynamic memory paravirtualization transparent to guest OS WANG XiaoLin 1 , SUN YiFeng 1 , LUO YingWei 1 ∗ , WANG ZhenLin 2 , LI Yu 1 , ZHANG BinBin 1 , CHEN HaoGang 1 & LI XiaoMing 1 1 Department of Computer Science and Technology, Peking University, Beijing 100871, China; 2 Department of Computer Science, Michigan Technological University, Houghton, MI 49931, USA Received January 13, 2009; accepted April 10, 2009 Abstract This paper introduces dynamic paravirtualization, which imitates paravirtualization and aims at reducing VM exits of full virtualization with hardware support. In dynamic paravirtualization, VMM (virtual machine monitor) dynamically monitors and replaces the hot instructions, which cause most VM exits. It is transparent to the guest OS such that the legacy OSes can benefit from this optimization. Our study focuses on reducing the overhead of memory virtualization—dynamic memory paravirtualization (DMP). We implant a new memory management mechanism in VMM such that all user-mode page faults can be handled by the guest OS directly without VM exits. We implement a prototype of dynamic memory paravirtulization based on a version of KVM using Intel VT. Our experimental results show that our technique essentially eliminates the overhead of VM exits caused by page faults. Dynamic memory paravirtualization can achieve the effectiveness of paravirtualization without changing the source code of guest OS. Keywords virtualization, virtual machine monitor, paravirtualization, dynamic paravirtualization, hot in- structions, VM exits, code implantation Citation Wang X L, Sun Y F, Luo Y W, et al. Dynamic memory paravirtualization transparent to guest OS. Sci China Inf Sci, 2010, 53: 77–88, doi: 10.1007/s11432-010-0008-x 1 Introduction Paravirtualization [1, 2] is different from full virtualization [3] when dealing with sensitive instructions consisting of privileged instructions and non-privileged instructions accessing privileged data such as page tables [4]. In full virtualization, virtual machine monitor (VMM) captures sensitive instructions in guest OS and emulates their functions. This trap-and-emulate action can cost hundreds to thousands of cycles. Paravirtualization reduces this performance overhead by changing the source code of the guest OS. It replaces the sensitive instructions with hypercalls to VMM, so VMM can take over the sensitive operations on its own initiative. Paravirtualization further provides optimizations such as combining several hypercalls into one hypercall to reduce guest OS/VMM transition cost. Intel and AMD have provided hardware extensions, Intel’s VT and AMD’s SVM, for x86 architecture to support classical full virtualization [5–8]. Intel’s VT provides two kinds of VMX mode for virtualization: VMX root mode and VMX non-root mode. VMM will run in VMX root mode and guest OS will run in ∗ Corresponding author (email: [email protected])
Transcript of Dynamic memory paravirtualization transparent to guest OS

. RESEARCH PAPERS .
SCIENCE CHINAInformation Sciences
January 2010 Vol. 53 No. 1: 77–88
doi: 10.1007/s11432-010-0008-x
c© Science China Press and Springer-Verlag Berlin Heidelberg 2010 info.scichina.com www.springerlink.com
Dynamic memory paravirtualization transparentto guest OS
WANG XiaoLin1, SUN YiFeng1, LUO YingWei1∗, WANG ZhenLin2, LI Yu1,
ZHANG BinBin1, CHEN HaoGang1 & LI XiaoMing1
1Department of Computer Science and Technology, Peking University, Beijing 100871, China;2Department of Computer Science, Michigan Technological University, Houghton, MI 49931, USA
Received January 13, 2009; accepted April 10, 2009
Abstract This paper introduces dynamic paravirtualization, which imitates paravirtualization and aims at
reducing VM exits of full virtualization with hardware support. In dynamic paravirtualization, VMM (virtual
machine monitor) dynamically monitors and replaces the hot instructions, which cause most VM exits. It is
transparent to the guest OS such that the legacy OSes can benefit from this optimization. Our study focuses
on reducing the overhead of memory virtualization—dynamic memory paravirtualization (DMP). We implant
a new memory management mechanism in VMM such that all user-mode page faults can be handled by the
guest OS directly without VM exits. We implement a prototype of dynamic memory paravirtulization based on
a version of KVM using Intel VT. Our experimental results show that our technique essentially eliminates the
overhead of VM exits caused by page faults. Dynamic memory paravirtualization can achieve the effectiveness
of paravirtualization without changing the source code of guest OS.
Keywords virtualization, virtual machine monitor, paravirtualization, dynamic paravirtualization, hot in-
structions, VM exits, code implantation
Citation Wang X L, Sun Y F, Luo Y W, et al. Dynamic memory paravirtualization transparent to guest OS.
Sci China Inf Sci, 2010, 53: 77–88, doi: 10.1007/s11432-010-0008-x
1 Introduction
Paravirtualization [1, 2] is different from full virtualization [3] when dealing with sensitive instructionsconsisting of privileged instructions and non-privileged instructions accessing privileged data such aspage tables [4]. In full virtualization, virtual machine monitor (VMM) captures sensitive instructions inguest OS and emulates their functions. This trap-and-emulate action can cost hundreds to thousands ofcycles. Paravirtualization reduces this performance overhead by changing the source code of the guestOS. It replaces the sensitive instructions with hypercalls to VMM, so VMM can take over the sensitiveoperations on its own initiative. Paravirtualization further provides optimizations such as combiningseveral hypercalls into one hypercall to reduce guest OS/VMM transition cost.
Intel and AMD have provided hardware extensions, Intel’s VT and AMD’s SVM, for x86 architecture tosupport classical full virtualization [5–8]. Intel’s VT provides two kinds of VMX mode for virtualization:VMX root mode and VMX non-root mode. VMM will run in VMX root mode and guest OS will run in∗Corresponding author (email: [email protected])

78 WANG XiaoLin, et al. Sci China Inf Sci January 2010 Vol. 53 No. 1
VMX non-root mode. Transitions from VMM to guest OS are called VM entries while transitions fromguest OS to VMM are named VM exits. A VM exit happens when a sensitive instruction in the guestOS is executed. After the instruction is emulated in VMM, the system switches back to the non-rootmode and the guest OS will continue its execution.
The hardware extensions help to implement a VMM without changing the guest OS or resortingto software binary translation. But right now, neither VT nor SVM supplies effective extensions forvirtualizing MMU (memory management unit) and I/O devices. A VMM using VT or SVM has not yetmet performance expectation and often fallen behind a VMM using binary translation [9]. One majorreason is that there still exist too many VM exits that incur significant overhead. Table 1 lists the totalnumber VM-exits and the exits caused by I/Os and page faults for a set of typical benchmarks runningin KVM-54 [10] and Xen-3.2.1 [1] with full virtualization using VT-x. The exits by page faults and I/Osare all over 56% and apparently dominant. Eliminating the overhead of these two types of exits willsignificantly reduce the overhead of full virtualization.
We further count the frequency of VM exits for different trap points in KVM-54. We find that, althoughthere are more than a thousand trap points in the guest OS, most VM exits occur in a few trap pointswith high frequency. Table 2 lists the top 10 trap points with most VM exits. For all benchmarks, theVM exits caused by the top 10 trap points account for 64 to close to 100 percent of total VM exits. Wecall a trap point with frequent VM exits frequency a hot instruction. If we can reduce the number of VMexits of hot instructions, the performance of virtualization should be improved effectively.
Learned from paravirtualization which improves performance through changing the guest OS, thispaper introduces dynamic paravirtualization aiming at reducing VM-exits of full virtualization. In dy-namic paravirtualization, VMM dynamically monitors and replaces hot instructions so as to eliminateor reduce VM exits. Similar to paravirtualization, dynamic paravirtualization needs to change the guestOS. But rather than changing the source code, we adaptively substitute new code fragments for the hotinstructions at runtime. We introduce new structures in VMM and the guest OS so that the new code
Table 1 Reason and count of VM exits
Page fault I/OTotal
count % count %
Kenerl compileKVM 7459199 83.36 768433 8.59 8948235
XEN 11219395 81.23 1247207 9.03 13812089
SpecJBBKVM 329286 2.99 6560472 59.57 11012466
XEN 352520 4.22 5000529 59.89 8350197
SpecCPUKVM 34215800 18.69 102468771 55.98 183041637
XEB 113793259 50.41 56215828 24.90 225727994
SpecWebKVM 5668822 15.50 14921351 40.79 36584589
XEN 11835408 31.46 12428086 33.04 37618375
Table 2 Top 10 trap points with high VM exits frequency in KVM-54a)
Kernel compile SpecJBB SpecCPU SpecWeb
1 21.21% (pf) 32.48% (io) 12.54% (pf) 4.65% (io)
2 26.07% (pf) 32.47% (io) 9.02% (pf) 7.46% (io)
3 3.71% (pf) 32.47% (io) 8.47% (pf) 7.46% (io)
4 2.44% (rd cr) 0.31% (io) 8.17% (ot) 7.46% (io)
5 2.44% (rd cr) 0.31% (pf) 8.01% (io) 6.08% (rd cr)
6 2.16% (pf) 0.31% (ot) 7.44% (io) 5.77% (io)
7 1.91% (pf) 0.31% (io) 7.44% (io) 5.71% (ot)
8 1.14% (pf) 0.31% (io) 7.44% (io) 5.67% (hlt)
9 0.99% (io) 0.31% (io) 4.54% (io) 5.53% (clts)
10 0.99% (io) 0.18% (ot) 2.07% (ot) 5.50% (rd cr)
Total 68.06% 99.46% 75.14% 64.30%
a) io, I/O operation; pf, page fault; rd cr, read control registers; clts and hlt, x86 instructions; ot, others.

WANG XiaoLin, et al. Sci China Inf Sci January 2010 Vol. 53 No. 1 79
fragments can achieve the functions of the hot instructions with few VM exits. Due to the high frequencyof hot instructions, even replacement of a few hot instructions can lead to a remarkable enhancement ofperformance. Considering that applications always suffer significant performance penalty by page faults,we take memory virtualization as an example to validate dynamic paravirtualization.
The rest of this paper is organized as follows. In section 2, we introduce the general design principles ofdynamic paravirtualization. Section 3 describes dynamic memory paravirtualization and its implemen-tation in KVM-54. Section 4 presents experimental results. Section 5 discusses related work and section6 concludes.
2 Dynamic paravirtualization
Dynamic paravirtualization aims at eliminating or reducing VM exits through replacing hot instructionsin guest OSes at runtime. There are three key steps in dynamic paravirtualization: detecting hot instruc-tions, generating new code fragments to replace the hot instructions, and implanting the code fragmentsinto the guest OS.
2.1 Detecting hot instructions
We instrument the VMM to intercept VM exits and the guest OS instructions incurring these exits. Abrute-force method to detect hot instructions is to collect all trap points and trap counts, and sort themafter a sampling period. Due to the large number of trap points, the efficiency of this method is low.
We use an approximate radix sort to find hot instructions with high accuracy. Using a small hashtable, we first do a simple modular arithmetic on instruction address (the value of the IP register) of eachtrap point, and the remainder indicates an entry index to the hash table. For all trap points mapped toeach hash entry, we maintain the top two points with most VM exits. Our experiments show that, with32 hash entries, the number of VM exits caused by the up to 64 hot instructions accounts for more than97 percent of all VM exits in most cases. This approximation scheme is thus simple yet effective.
2.2 Generating new code fragments to replace hot instructions
For each hot instruction, we seek new code fragment performing equivalent function so as to eliminateor reduce VM exits. The new fragment should guarantee that its overhead is smaller than ‘trap-and-emulate’. It is easy to find code replacements for some simple hot instructions. But for some otherinstructions, such as accessing page tables and accessing I/O devices, new or even complex assistantmechanisms should be introduced into VMM to make the replacement safe and possible. Section 3 willexplain how to replace the hot instructions that access page tables, along with a new memory managementmechanism, dynamic memory paravirtualization (DMP).
We usually replace hot instructions one by one. But when several hot instructions are close to eachother, we also look for the possibility to replace the code fragment including all these instructions by asingle optimized new code fragment.
2.3 Implanting new code fragments into guest OS
VMM dynamically implants the new code fragments into the running guest OS. The guest OS will executethe new code rather than the original instructions after implantation. We call this process adaptive codeimplantation. This process is reversible: new code fragments can be implanted into the guest OS whenneeded, while they can be taken out in order to restore the guest OS to the state before code implantation.Two outstanding issues remain: one is where to place the new code fragments in the guest OS; the otheris how to switch the guest OS between implanted state and non-implanted state.
We address the first issue by reserving a free kernel address space of the guest OS to place the newcode. A dependable method to reserve kernel space is to change the source code of the guest OS, or toinstall a special driver for guest OS. But this is not transparent to the guest OS. Our method is, accordingto the feature of a given guest OS, to find a rarely accessed area in the kernel space and then monitor

80 WANG XiaoLin, et al. Sci China Inf Sci January 2010 Vol. 53 No. 1
the usage of the reserved space. Once VMM finds that the guest OS needs to use the space we havereserved, it will switch the guest OS to the non-implanted state, and try to find another free space to docode implantation again.
For the second issue, our method is to implement code replacements at function level. When a hotinstruction is detected and its new code fragment is generated, we clone the whole function where theinstruction lies, and then replace it with the new code fragment. The new function will be implantedinto the guest OS by redirecting all the calls to the old function to the new function. When the guestOS needs to switch to the non-implanted state, we can restore all updated calling instructions to theiroriginal form and then remove the implanted functions.
3 Dynamic memory paravirtualization
This section first reviews two most popular memory virtualization schemes used in paravirtualization andfull virtualization, respectively. We then introduce dynamic memory paravirtualization (DMP) whichcombines the advantages of the two existing schemes.
3.1 Classical memory virtualization
Paravirtualization as taken by Xen [1] relies on changing the guest OS to avoid the overhead of virtual-ization. For memory virtualization, the guest OS in-place changes the guest frame number in each PTE(page table entry) to the corresponding host frame number so that the hardware MMU can translateguest virtual addresses to host physical addresses directly via the guest page table structure. VMMcan trap accesses to the page table so that the guest OS will not mistake a host frame number for aguest frame number. Most of those traps can be avoided when the guest OS is updated approriately.Paravirtualization requires changes to the guest OS and a legacy OS cannot operate on it directly.
Full virtualization usually uses a shadow mechanism for memory virtualization [3]. The VMM providesshadow page tables to guest OSes which are visible to the hardware MMU and are responsible fortranslation from guest virtual addresses to host physical addresses. Each guest maintains virtual pagetables that map from guest virtual addresses to guest physical addresses. The virtual page tables provideguest OSes an illusion of contiguous physical address space. The VMM has to trap accesses to the virtualpage table including validating updates and synchronizing with the shadow page table. An eminent coststems from propagating hardware updates to accessed and dirty bits.
3.2 Dynamic memory paravirtualization
3.2.1 A new memory virtualization mechanism
Our design principle is to eliminate the cost of the shadow mechanism in full virtualization. DMPintroduces a new memory virtualization mechanism, which transfers the guest OS page table to mapguest virtual addresses directly to host physical addresses. In other words, the VMM no longer needsto provide shadow tables for each guest OS and thus avoid the cost of synchronization between virtualpage tables and shadow page tables. The transferred guest page table, called direct page table, is directlyregistered with the hardware MMU. Figure 1 shows a typical direct page table structure. We furtherrefer to a process using direct page table as a paravirtualized process.
The challenge in DMP is that we still need to provide the guest OS an independent view of its ownphysical address space as used for guest OS memory management. Specifically, when the guest OSaccesses the direct page table, it expects guest physical addresses rather than host physical addresses ascurrently presented in the direct page table. We solve this issue by protecting the direct page table itselffrom guest OS accesses. We protect the direct page table by replacing all PTEs that point to the pagetable and page directory pages. We refer to these PTEs as P-PTEs (protected PTEs). The present bit ofa P-PTE is set to zero such that all accesses via P-PTE will trap to VMM. The other status bits and theframe number bits are formatted for page table recovery and distinguishing the type of the pages whichthe PTE points to.

WANG XiaoLin, et al. Sci China Inf Sci January 2010 Vol. 53 No. 1 81
Figure 1 Direct page table structure.
An access to the page table by the guest OS needs to use address translation between guest physicaland host physical. To facilitate address translation, we create two mapping tables G2H (Guest to Host)and H2G (Host to Guest) when a virtual machine (VM) is booted. G2H maps guest physical pages tohost physical pages, while H2G provides reverse translations. The two tables are mostly static unless theVMM changes the host physical memory allocation for a VM. As we will discuss in subsection 3.2.2, theOS code we implant needs direct access to G2H and H2G to eliminate VM exits. We thus link the twotables to the address space of the guest OS.
For a 32-bit machine with 4G address space, we take a simple design to create a one-to-one mappingin G2H and H2G, each of which consists of 1 M 4-byte entries. For a 64-bit machine, we plan to take amulti-level page table structure in order to reduce the physical memory requirement. Figure 2 illustratesthe content of a G2H entry. A G2H entry indexed by a guest frame number stores the corresponding hostframe number in the upper 20 bits. The protected bit denotes whether the page is protected from guestOS accessing. If the protected bit of a frame is set, the frame is used for a page table page. The presentbit tells whether the host frame is present. When a guest frame does not have a present host frame, thepresent bit is set to 0.
Figure 3 illustrates the content of an H2G entry. It consists of a guest frame number, a referencecounter, a protected bit denoting whether the page is protected from guest OS accessing, and the presentbit denoting whether the guest frame is present. We will explain the function of the reference counterlater in this section.
VMM handles a read to a PDE (page directory entry) or a regular PTE (its present bit is 1) bysearching the H2G table and returning the guest PDE or PTE it needs. A read to a P-PTE involves onelevel indirection detailed in subsection 3.2.3. An update to the page table is much more complicated.When the guest OS writes a PTE, the PTE needs to be transferred to a P-PTE if the page it points tois a direct page table page.
Figure 2 A G2H table entry.
Figure 3 A H2G table entry.

82 WANG XiaoLin, et al. Sci China Inf Sci January 2010 Vol. 53 No. 1
When the guest OS writes a new PDE, there exist four possible situations depending on whether thepages pointed by the new PDE and the PDE it overrides are present. If the old PDE is not present, thenew PDE can simply replace the old PDE. Otherwise, if old PDE is present, this override eliminates thereference of the current page table to this page. The page needs no longer to be protected if no otherpara-virtualized processes are using this page in their page tables. The page table sharing can happenwhen forking a child process which inherits the page table from the parent process with CoW (Copy onWrite) enabled. We introduce a reference counter for each page table page in the H2G table to count thenumber of references to a page table page.
• If the reference count of the page pointed by the old PTE is one, then the current process is the lastprocess using this page in its direct page table. After the new PDE replaces the old PDE, the page is nolonger a protected page table page and can be returned for regular accesses. The host frame numbers inthis page need to be transferred back to the guest frame numbers as this page might be used by a processnot paravirtualized. The P-PTE pointing to this page is now restored as a regular PTE, following thestrategy discussed in subsection 3.2.2.
• If the reference count is greater than one, suggesting that some other paravirtualized processes arestill using this page in their page tables, we simply decrease the count by one.
If the new PDE points to a new page that has not been protected, in other words, the page has notbeen used as a page table page in a paravirtualized process, the page needs to be protected by setting theprotected bit in the G2H and H2G tables. Moreover, the PTE entry pointing to this page needs to betransferred to a P-PTE. When a PTE is transferred to a P-PTE, we keep the content of the original PTEin the recovery table (RT) and create a pointer in the new P-PTE which points to the recovery tableentry (link 1 in Figure 1). We explain the function of recovery table in detail in subsection 3.2.3. If thenew PDE points to a protected page table page, suggesting that one or more processes have already usedthis page in their page tables, the reference count in the H2G entry of this page needs to be increased byone.
Write to PTE. We first check if the old PTE and the new PTE contain the same host frame number.If so, we only need to update the status bits. Note that the old PTE might be a P-PTE. In this case,its host frame number is stored in the original PTE in the recovery table and the update also goes tothe original PTE. If the frame numbers are not the same or the old PTE is not present, the new PTEwill overwrite the old PTE. When the old PTE is a regular PTE or is not present, it can be simplyoverwritten. If the old PTE is a P-PTE, the protected page it points to has already been taken care ofby PDE maintenance including related reference counts. Therefore, the P-PTE can also be overwrittenwithout additional actions. If the new PTE points to a regular page (not a direct page table page), thecontent of the new PTE directly overwrites the old PTE. Otherwise, we need to set protection for thepage the new PTE points to if the page has not yet protected. We write the corresponding P-PTE tothe entry and store the content of the new PTE in the recovery table.
3.2.2 Adaptive code implantation
Due to the protection to the direct page table, any access to the page table by the guest OS will incurtraps into the VMM, causing performance degradation even compared to the original full virtualizationscheme. We introduce adaptive code implantation to avoid the overhead caused by our new memoryvirtualization scheme and thus achieve high performance. We dynamically monitor the instructionsthat cause VM exits and replace those instructions by implanting new code that circumvents traps. Inparticular, we focus on those instructions that cause page faults and thus result in page table accesses.As noted in subsection 3.2.1, the two mapping tables, G2H and H2G, use the guest OS address space.The implanted code can thus emulate the functions of faulted instructions through translations providedby the two tables without trapping into VMM.
Due to the variety of OS hot instructions that cause VM exits, the sizes and functions of the codeused to replace these instructions differ. One hot instruction typically needs to be replaced by a set ofinstructions. Directly replacing the VM exit instruction will need to rearrange the layout the functioncontaining the hot instructions and to update the jump instructions with new offsets. Through profiling,we find that the number of hot instructions is limited and their occurrences are often independent of users’

WANG XiaoLin, et al. Sci China Inf Sci January 2010 Vol. 53 No. 1 83
applications. We thus generate a library of templates which are code fragments to substitute differenttypes of hot instructions. During system execution, when we need to eliminate a hot instruction, wereplace the whole function that contains the instruction. We first clone the function, then apply thetemplate from the library to replace the hot instruction, and finally update the jump instructions in thenew function. We track the call stack and find where the function of concern is called and change thecalling instruction to call the implanted function.
3.2.3 Recovery table
For each process, we create a one-page recovery table (RT). The recovery tables in a guest OS forman array for quick access. We make the recovery tables root from the page directory and thus directlymanageable by the MMU. In a P-PTE, we keep the index of its recovery table and its entry offset. Wecan find the original PTE in the recovery table using the index and the offset. Figure 1 illustrates thisone level indirection from a P-PTE to the original PTE (link 1). When the CPU needs to update dirtyor access bits of a P-PTE, it will trap into VMM. Through the recovery table, we can locate the originalPTE through the P-PTE that causes the trap. We then update the corresponding status bits of theoriginal PTE. As discussed in subsection 3.2.2, we can implant code in the guest OS to avoid this trapsince the recovery tables are also put in the guest OS address space. In the implanted code, the CPUdirectly sets the bits in the recovery table entry.
The recovery table also provides a mechanism for process-level recovery and OS-level recovery. In ourdesign, each recovery table costs one kernel PDE such that CPU can operate on the table as a page tablepage. The total number of kernel PDEs we can borrow is limited. Therefore, only a limited numberof processes can be paravirtualized. When the number of paravirtualized user processes is beyond alimit, we apply a process-level recovery to the least recently scheduled process following the LRU policy.This involves a traversal of the page table and translation from the host frame numbers back to guestframe numbers. For a PDE or a regular PTE, we can simply replace the host frame number by thecorresponding guest frame number looked up the H2G table. For a P-PTE, we look up the recovery tableand replace the P-PTE by the original PTE. After recovery, the recovery table page can be released forother processes to be paravirtualized.
We reserve an area of the guest OS address space for the code we adaptively implant. Although mosttimes the guest OS does not use this area, we perform an OS-level recovery when the guest OS touchesthe area. The OS-level recovery involves process-level recoveries for all paravirtualized processes followedby restoration of all calling sites we have modified.
3.3 Implementation in KVM
3.3.1 DMP architecture
We use a 32-bit Linux as guest OS and implement a DMP prototype within a full virtualization versionof KVM-54 using VT-x. We add a user-mode program, Hot instructions killer (HIK), in the host OS,and a kernel-mode module DMP engine in KVM as illustrated by Figure 4. HIK takes charge of hotinstruction analyzing, call stack tracing, and function implant generating, while the DMP engine is toturn on/off DMP, detect hot instructions, and perform code implantation.
HIK and the DMP engine cooperate to complete dynamic memory paravirtualization with the help ofIOCTL. When a VM is booted and running in the DMP mode, HIK notifies the DMP engine to start thenew memory virtualization mechanism and detecting hot instructions. After the DMP engine obtains alist of hot instructions, it will send those hot instructions to HIK which identifies page fault instructions.The DMP engine also records the call stack for each hot instruction and passes it to HIK. Through tracingthe call stack, HIK can determine the function in which a hot instruction lies and all runtime calling sitesto the function, and then return the information to the DMP engine.
Based on the structure of direct page table, we generate a library of templates which are code frag-ments to substitute different types of hot instructions accessing direct page tables. Later in subsection3.3.3, we provide a code fragment sample. HIK generates new functions to replace old functions with hot

84 WANG XiaoLin, et al. Sci China Inf Sci January 2010 Vol. 53 No. 1
Figure 4 DMP architecture.
instructions. It allocates an aligned 4 MB space in its own virtual space and stores the new functionsthere. The DMP engine will link the pages of the aligned 4 MB space to the address space of the guestOS, so the new functions is accessible to the guest OS.
When the new function is ready, HIK will ask the DMP engine to redirect all known calls to the oldfunction to the new function. The DMP engine tracks all call site replacements in a hash table so that,when we need to turn off adaptive code implantation, the DMP engine can restore the call sites.
After a hot instruction is handled, the process repeats until a sufficient number of hot instructions arekilled. Additionally, the hot instructions and the code implantation process can be recorded and savedto a disk file. Next time when the same VM starts, we can simply replay previous code implantationprocess and avoid the overhead of hot instruction detections. However, the instances of hot instructionsmay differ for different applications. Simple replay may not yield good performance.
3.3.2 Memory management for code implantation
KVM usually allocates host physical memory pages to VMs on demand. To simplify the design of theG2H and H2G tables, the DMP engine scans all host physical memory available to this VM and buildsthe mapping from guest physical page to host physical pages when a VM starts. Note that the host OSmaintains a reference count to each host page. We increase the counter of each page by one to avoidpage swapping by the host OS. After the VM is booted, the G2H and H2G tables are fixed through thelifetime of the VM unless the VMM changes the host memory allocation to this VM.
We put the G2H and H2G tables, the implanted functions, and recovery tables into the kernel space ofthe guest OS so that the guest OS can call the implanted functions which in turn access the G2H, H2G andrecovery tables. All the tables and implanted functions are linked from kernel PDEs of the guest OS. Wehack up to 24 kernel PDEs, three of which are for G2H, H2G, and implanted code, respectively. TwentyPDEs are reserved for up to twenty recovery tables. We thus can support up to twenty paravirtualizedprocesses. We create a special PDE, called the loop PDE, to help locate a P-PTE. Given an access to adirect page table page, the implanted function needs the virtual address of the P-PTE which indirectlypoints to the page of concern through the recovery table. This virtual address takes the 10-bit offset ofthe loop PDE as its upper 10 bits and the next 20 bits come from the most significant 20 bits of theoriginal virtual address. Using the new virtual address, we can locate the P-PTE following regular pagetable lookup process. The most significant 10 bits points to the page directory. The next 10 bits locatethe PDE pointing to the page containing the P-PTE. Finally, bits 3 to 12 are the offset of the P-PTE inits page.
3.3.3 A code fragment sample
This section uses an example to explain code implant generation. The instruction ‘mov %ebx, (%ebp)’

WANG XiaoLin, et al. Sci China Inf Sci January 2010 Vol. 53 No. 1 85
will cause VM exits when %ebp addresses a PTE. This instruction will be replaced by the following codefragment:
1. push %eax2. push %edx3. mov %ebx, %edx4. lea (%ebp), %eax5. call rel32 0xfa0011e0; call the implanted
function to write PTE
6. cmp $0x0, %eax7. pop %edx8. pop %eax9. jcc rel32 0xfa010227; jump to the end of the
code fragment10. mov %ebx, (%ebp)
We first save %eax and %edx in the stack (instructions 1 and 2). The value in %ebx and the addressdenoted by %ebp are assigned to %edx and %eax (instructions 3 and 4). The function 0xfa0011e0 takes%edx and %eax as parameters. It will act as explained in section 3.2 to update the PTE. If the functioncannot finish the update, it assigns 0 to %eax as the return value and returns without touching the PTE(instruction 5). The code following the function call will check the return value in %eax (instruction 6)and restore %eax and %edx. If %eax is not 0, it jumps to the end of the code fragment (instruction9). Otherwise, the original instruction should be executed to raise a VM exit for VMM to emulate theinstruction (instruction 10).
4 Evaluation
We implement DMP on KVM-54 running on an Intel workstation that supports VT-x with a Core2 Duo1.86 GHz CPU, a shared 2 MB L2 cache, and 2 GB main memory. The guest OS and native OS forKVM are Red Hat Enterprise Linux 5 with Linux kernel 2.6.18-8.el5. The host OS of KVM is Red HatEnterprise Linux 5 with Linux kernel 2.6.24.3. All OSes are configured with 512 MB host memory eitherfor both native execution and execution on VMs, if not otherwise mentioned.
We choose SpecJBB 2005, SpecInt 2006, SpecWeb 2005, kernel compilation, and a micro program,WorstCase. Kernel compilation compiles a minimal Linux2.6.18 kernel. WorstCase tests an extremecase which sequentially accesses 100 K pages where each access is an integer write. WorstCase tests theperformance of the native machine and virtual machines for handling page faults as it triggers at leastone page fault for each access. We run all SpecCPU 2006 integer benchmarks but mcf which fails on theoriginal KVM-54. We configure 752 MB physical memory, the maximum in our current implementationfor a 32-bit OS, for SpecCPU to reduce the impact of page swapping. SpecWeb causes only a smallnumber of page faults after its initialization phase, the impact of DMP is thus insignificant. We thus donot report the results for SpecWeb in the remaining sections. For all benchmarks, we eliminate top 18hot instructions with most VM exits by page faults.
4.1 Overall performance evaluation
Figure 5 shows the normalized execution times for all programs except for JBB where we use Spec scores.
Figure 5 Normalized performance. Figure 6 Normalized performance for SpecInt 2006.
86 WANG XiaoLin, et al. Sci China Inf Sci January 2010 Vol. 53 No. 1
Consistent with the percentages of page faults shown in Table 1, DMP can reduce the virtualizationoverhead for the programs with a large number of page faults. For kernel compilation, DMP improvesKVM by 32% and achieves 91% of the native performance. In SpecJBB, the top hot instructions are I/Osand as shown in Table 2, the improvement is not as imminent but still leads to 2.3% improvement. InWorstCase, DMP is able to achieve 80% of the native performance, more than doubling the performanceof KVM. The 20% gap is mostly from VMM overhead for handling timer interrupts.
On average, DMP improves 3.1% over KVM for SpecCPU integer benchmarks. It improves all butthree benchmarks. Most notable improvements are from gcc and bzip2 with 26.2% and 6.8%, respectivelyas shown in Figure 6. For gobmk. hmmer, and libquantum, we observe around 1.5% degradation byDMP over KVM. These three benchmarks have few page faults. The 1.5% degradation is the overheadof DMP.
4.2 Overhead of memory virtualization
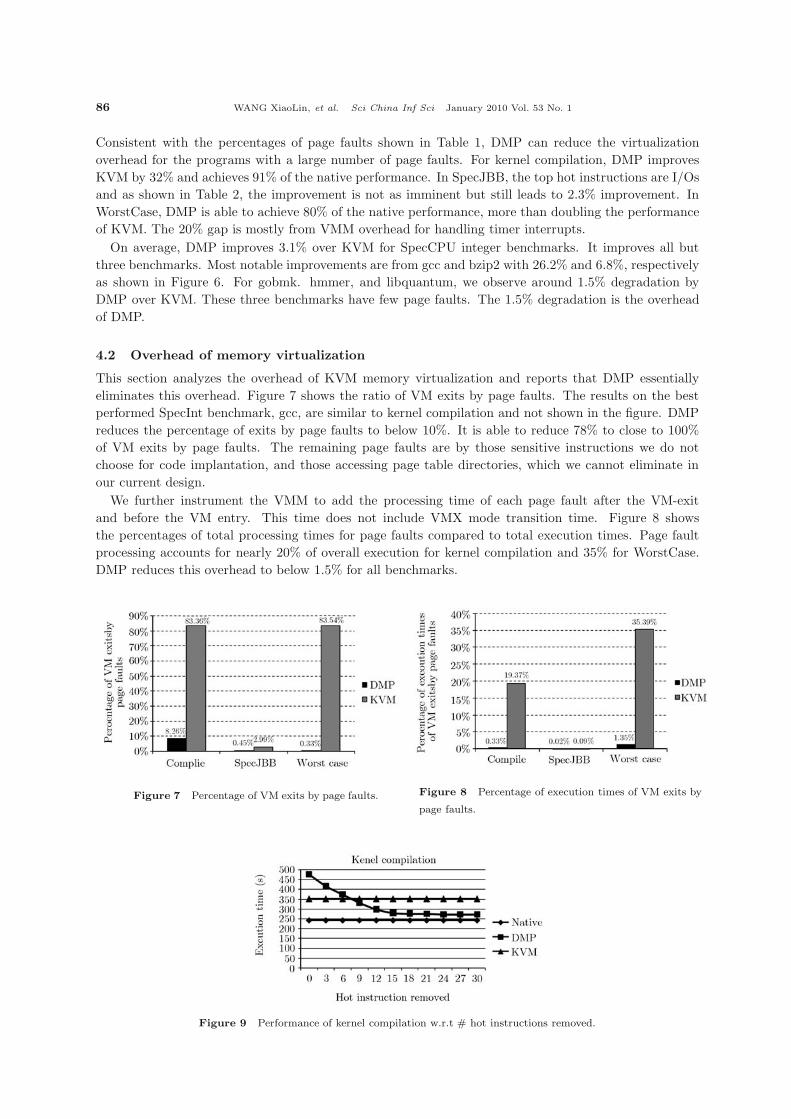
This section analyzes the overhead of KVM memory virtualization and reports that DMP essentiallyeliminates this overhead. Figure 7 shows the ratio of VM exits by page faults. The results on the bestperformed SpecInt benchmark, gcc, are similar to kernel compilation and not shown in the figure. DMPreduces the percentage of exits by page faults to below 10%. It is able to reduce 78% to close to 100%of VM exits by page faults. The remaining page faults are by those sensitive instructions we do notchoose for code implantation, and those accessing page table directories, which we cannot eliminate inour current design.
We further instrument the VMM to add the processing time of each page fault after the VM-exitand before the VM entry. This time does not include VMX mode transition time. Figure 8 showsthe percentages of total processing times for page faults compared to total execution times. Page faultprocessing accounts for nearly 20% of overall execution for kernel compilation and 35% for WorstCase.DMP reduces this overhead to below 1.5% for all benchmarks.
Figure 7 Percentage of VM exits by page faults. Figure 8 Percentage of execution times of VM exits by
page faults.
Figure 9 Performance of kernel compilation w.r.t # hot instructions removed.

WANG XiaoLin, et al. Sci China Inf Sci January 2010 Vol. 53 No. 1 87
4.3 Hot instructions and performance
Figure 9 shows the performance improvement for kernel compilation with respect to the number ofreplaced hot instructions sorted by the number of VM exits. We see similar trend for other benchmarks.DMP begins with an execution time of 474 s, with no hot instructions removed, and reaches 266 s whenthe top thirty hot instructions are replaced, which is close to the 242 s of execution time on the nativemachine. However, there is no notable improvement after 15 hot instructions and DMP becomes veryclose to native execution. It suggests that we need not remove too many hot instructions. However, DMPperforms worse than KVM until we eliminate top 7 hot instructions. We need to eliminate a sufficientnumber of hot instructions to counteract the overhead of DMP.
5 Related work
Our new memory virtualization mechanism bears a lot similarity to those used in paravirtualization,specifically Xen [1]. To avoid the cost introduced by the shadow mechanism in full virtualization [3, 10],Xen leaves most responsibility of page table management to guest OSes. The guest page table, whichregisters directly with MMU, translates guest virtual address directly to host physical address. XenVMM needs only monitor updates so as to prevent guest OSes from invalid changes. Rooted from fullvirtualization, our scheme instead switches the shadow paging mechanism on the fly to paravirtualizedpaging scheme.
Replacing an expensive instruction by one or a set of cheap instructions is a common practice in theinstruction selection phase of static compilation [11]. Binary translation and just-in-time compilationoften apply this type of optimization on the fly [9, 12, 13]. VMWare workstation uses adaptive binarytranslation to avoid traps from both privileged and non-privileged instructions [9]. Adaptive just-in-timecompilation detects hot methods and selectively recompiles them to improve the performance of Javaapplications [13].
Extended page tables (EPT) by Intel [8] and nested page tables (NPT) by AMD [6] are recent hardwareextensions that assist memory virtualization and reduce the complexity of software memory management.The hardware extensions add an additional level of address translation from guest physical addresses tohost physical addresses. Although these extensions significantly reduce the VMM intervention on addresstranslation, the two-level paging mechanism does introduce additional page table entry references andthus increase the latency. Bhargava et al. discussed a set of techniques to reduce the 2D page walkoverhead [6]. Our technique instead can work on the machines without EPT or NPT. Furthermore, theaddress translation remains one-dimensional and needs much less references than EPT and NPT.
6 Conclusions and future work
More effective hardware assistance remains a key to reduce the performance overhead of virtualization.We believe future hardware support needs to learn from the success of paravirtualization. This paperintroduced dynamic paravirtualization which plugs software solutions for paravirtualization into a fullvirtualization environment. We are able to gain the performance benefit of paravirtualization whilekeeping the applicability to the legacy OSes of full virtualization.
The code implantation does bring security concerns because the implanted code can change the pagetables. Malicious code can emulate this function to damage the system. Our implementation assumesthe trust between the guest OS and the adaptive implantation module. When the VMM or the guest OSneeds a higher security level, they can turn off dynamic paravirtualization using the recovery mechanismwe provide.
Although we focus on memory virtualization in this paper, our design leaves the interfaces for para-virtualizing I/O. The CPU I/O accesses through I/O instruction and MMIO also bring a significantnumber of VM exits. We plan to use adaptive code implantation to eliminate these exits and improvethe performance of I/O virtualization.

88 WANG XiaoLin, et al. Sci China Inf Sci January 2010 Vol. 53 No. 1
Acknowledgements
This work was supported by the National Basic Research Program of China (Grant No. 2007CB310900), the Na-
tional Natural Science Foundation of China (Grant Nos. 90718028, 60873052), the National High-Tech Research &
Development Program of China (Grant No. 2008AA01Z112), ant the MOE-Intel Information Technology Founda-
tion (Grant No. MOE-INTEL-08-09). Zhenlin Wang is also supported by NSF Career (Grant No. CCF0643664).
References
1 Barham P, Dragovic B, Fraser K, et al. Xen and the art of virtualization. In: Proceedings of the Nineteenth ACM
Symposium on Operating Systems Principles (Bolton Landing, NY, USA, October 19-22, 2003). SOSP ’03. New York:
ACM, 2003. 164–177
2 Whitaker A, Shaw M, Gribble S D. Scale and performance in the Denali isolation kernel. SIGOPS Oper Syst, 2002,
36(SI): 195–209
3 Devine S, Bugnion E, Rosenblum M. Virtualization system including a virtual machine monitor for a computer with a
segmented architecture. US Patent, 6 397 242, 1998-10
4 Smith J E, Nair R. Virtual Machines: Versatile Platforms for Systems and Processes. San Francisco: Morgan Kaufmann
Publishers, 2005
5 AMD. AMD64 Virtualization Codenamed “Pacifica” Technology: Secure Virtual Machine Architecture Reference Man-
ual, 2005
6 Bhargava R, Serebrin B, Spadini F, et al. Accelerating two-dimensional page walks for virtualized systems. In: Proceed-
ings of the 13th international Conference on Architectural Support for Programming Languages and Operating Systems
(Seattle, WA, USA, March 01-05, 2008), ASPLOS XIII. New York: ACM, 2008. 26–35
7 Intel Corp. Intel Virtualization Technology Specification for the IA-32 Intel Architecture. 2005
8 Neiger G, Santoni A, Leung F, et al. Intel virtualization technology: Hardware support for efficient processor virtual-
ization. Intel Tech J, 2006 10: 167–177
9 Adams K, Agesen O. A comparison of software and hardware techniques for x86 virtualization. In: Proceedings of the
12th international Conference on Architectural Support for Programming Languages and Operating Systems (San Jose,
California, USA, October 21-25, 2006), ASPLOS XII. New York, NY: ACM, 2006. 2–13
10 Habib I. Virtualization with KVM. Linux J, 2008, 166: 8
11 Cooper K, Torczon L. Engineering a Compiler. San Francisco: Morgan Kaufmann, 2003
12 Cramer T, Friedman R, Miller T, et al. Compiling java just in time. In: IEEE Micro 17. Los Alamitos: IEEE Computer
Society Press, 1997. 36–43
13 Arnold M, Fink S, Grove D, et al. Adaptive optimization in the Jalapeno JVM. In: Proceedings of the 15th ACM SIG-
PLAN Conference on Object-Oriented Programming, Systems, Languages, and Applications (Minneapolis, Minnesota,
United States), OOPSLA ’00. New York: ACM, 2000. 47–65




















