
Development of speech corpora for speaker recognition research and evaluation in Indian languages
16
Int J Speech Technol (2008) 11: 17–32 DOI 10.1007/s10772-009-9029-5 Development of speech corpora for speaker recognition research and evaluation in Indian languages Hemant A. Patil · T.K. Basu Received: 9 February 2009 / Accepted: 15 April 2009 / Published online: 19 May 2009 © Springer Science+Business Media, LLC 2009 Abstract Automatic Speaker Recognition (ASR) refers to the task of identifying a person based on his or her voice with the help of machines. ASR finds its potential applica- tions in telephone based financial transactions, purchase of credit card and in forensic science and social anthropology for the study of different cultures and languages. Results of ASR are highly dependent on database, i.e., the results ob- tained in ASR are meaningless if recording conditions are not known. In this paper, a methodology and a typical exper- imental setup used for development of corpora for various tasks in the text-independent speaker identification in differ- ent Indian languages, viz., Marathi, Hindi, Urdu and Oriya have been described. Finally, an ASR system is presented to evaluate the corpora. Keywords Speaker recognition · Dialectal zones in Maharashtra and Orissa · Data collection · Corpus design · LP cepstrum · Mel cepstrum · Polynomial classifier 1 Introduction Automatic Speaker Recognition can be categorized as auto- matic speaker identification (ASI), automatic speaker veri- fication (ASV) and automatic speaker classification (ASC). H.A. Patil ( ) Dhirubhai Ambani Institute of Information and Communication Technology (DA-IICT), Gandhinagar, Gujarat, India e-mail: [email protected] T.K. Basu Department of Electrical Engineering, Indian Institute of Technology, Kharagpur 721302, India e-mail: [email protected] ASI refers to the task of identification of a person’s voice from a population of speakers whose voices are stored in the machine and ASV refers to the task of verifying a per- son’s claimed identity. It is a complementary task of ASI. The problem of ASC can be defined in several ways. We define ASC as a grouping of the speakers based on simi- lar acoustical characteristics of their dialectal zone (speak- ers residing in a particular dialectal zone speak in a similar manner). This is also referred to as dialect recognition and it has applications in the area of automatic speech recognition. ASR is a data driven field, i.e., the performance of ASR is dependent on the database. The factors affecting the per- formance are recording conditions, gender type used in pop- ulation, speaker characteristics, etc. Success rates obtained in an ASR system are meaningless if the recording condi- tions are not known. The use of standard speech corpora for evaluation of ASR is the most crucial task in speech and speaker recognition systems (Reynolds 2002). In this paper, a methodology and the typical experimental setup used for building up speech corpora for text-independent ASR sys- tem is presented. To the best of the authors’ knowledge, there is no publicly available corpus in Indian languages, i.e., Marathi, Hindi, Urdu, Oriya, etc., for ASR in real life settings, so it was decided to design and develop a suitable corpus for this purpose. 2 Objectives of the corpus The purpose of this work is to build speech corpora con- taining recordings from a large number of speakers from phonologically distinct dialect zones in the Indian states of Maharashtra, Uttar Pradesh and Orissa for use in speaker classification and identification. Speaker identification has been an important topic of research mostly in American
-
Upload
independent -
Category
Documents
-
view
3 -
download
0
Transcript of Development of speech corpora for speaker recognition research and evaluation in Indian languages

Int J Speech Technol (2008) 11: 17–32DOI 10.1007/s10772-009-9029-5
Development of speech corpora for speaker recognition researchand evaluation in Indian languages
Hemant A. Patil · T.K. Basu
Received: 9 February 2009 / Accepted: 15 April 2009 / Published online: 19 May 2009© Springer Science+Business Media, LLC 2009
Abstract Automatic Speaker Recognition (ASR) refers tothe task of identifying a person based on his or her voicewith the help of machines. ASR finds its potential applica-tions in telephone based financial transactions, purchase ofcredit card and in forensic science and social anthropologyfor the study of different cultures and languages. Results ofASR are highly dependent on database, i.e., the results ob-tained in ASR are meaningless if recording conditions arenot known. In this paper, a methodology and a typical exper-imental setup used for development of corpora for varioustasks in the text-independent speaker identification in differ-ent Indian languages, viz., Marathi, Hindi, Urdu and Oriyahave been described. Finally, an ASR system is presented toevaluate the corpora.
Keywords Speaker recognition · Dialectal zones inMaharashtra and Orissa · Data collection · Corpus design ·LP cepstrum · Mel cepstrum · Polynomial classifier
1 Introduction
Automatic Speaker Recognition can be categorized as auto-matic speaker identification (ASI), automatic speaker veri-fication (ASV) and automatic speaker classification (ASC).
H.A. Patil (�)Dhirubhai Ambani Institute of Information and CommunicationTechnology (DA-IICT), Gandhinagar, Gujarat, Indiae-mail: [email protected]
T.K. BasuDepartment of Electrical Engineering, Indian Instituteof Technology, Kharagpur 721302, Indiae-mail: [email protected]
ASI refers to the task of identification of a person’s voicefrom a population of speakers whose voices are stored inthe machine and ASV refers to the task of verifying a per-son’s claimed identity. It is a complementary task of ASI.The problem of ASC can be defined in several ways. Wedefine ASC as a grouping of the speakers based on simi-lar acoustical characteristics of their dialectal zone (speak-ers residing in a particular dialectal zone speak in a similarmanner). This is also referred to as dialect recognition and ithas applications in the area of automatic speech recognition.
ASR is a data driven field, i.e., the performance of ASRis dependent on the database. The factors affecting the per-formance are recording conditions, gender type used in pop-ulation, speaker characteristics, etc. Success rates obtainedin an ASR system are meaningless if the recording condi-tions are not known. The use of standard speech corpora forevaluation of ASR is the most crucial task in speech andspeaker recognition systems (Reynolds 2002). In this paper,a methodology and the typical experimental setup used forbuilding up speech corpora for text-independent ASR sys-tem is presented. To the best of the authors’ knowledge,there is no publicly available corpus in Indian languages,i.e., Marathi, Hindi, Urdu, Oriya, etc., for ASR in real lifesettings, so it was decided to design and develop a suitablecorpus for this purpose.
2 Objectives of the corpus
The purpose of this work is to build speech corpora con-taining recordings from a large number of speakers fromphonologically distinct dialect zones in the Indian states ofMaharashtra, Uttar Pradesh and Orissa for use in speakerclassification and identification. Speaker identification hasbeen an important topic of research mostly in American

18 Int J Speech Technol (2008) 11: 17–32
English since the 1960’s. The first study on identificationand verification of speakers was reported by Kersta (1962a,1962b, 1965, 1966, 1970), Kersta and Colangelo (1970),and Bricker and Pruzansky (1966), Li et al. (1966), Li andWrench (1983) respectively. Dialect variation, both zonaland social in origin, has been an important topic of researchin American English since 1930’s (Cassidy 1993). The firststudies were primarily concerned with zonal variation, fo-cusing on differences in lexical items produced by oldermales from rural areas (Chambers 1993). More recently, di-alect research has been extended to include studies on so-cial and ethnic variation and phonological variation in thevowel systems (Wolfram and Schilling-Estes 1998). Suchtype of work is mostly done in American English and veryless amount of such work is done to document the acousticalproperties of speech or to study their perceptual correlatesby playback experiments in Indian languages, viz., Marathi,Hindi, Urdu, Oriya, etc. India being a multilingual country,where there are 22 major languages and more than 3000partly developed dialects or native languages (according to1991 census) with at least 10,000 people for each dialect;where majority of the people have command over multiplelanguages especially at the border areas, study of ASR per-formance for different Indian languages is worth pursuing.Moreover, at finer levels, criminals often move from one di-alectal zone to another in a state and switchover to the nativelanguages of that zone. So, in such situations, it is clear thatASR system needs to deal with speaker classification exper-iments in closed and open set mode. Recently, linguistic dataconsortium for Indian language (LDC-IL) has taken up aninitiative to build speech corpora for all Indian language inthe area of speech recognition (Linguistic Data Consortium2008).
Finally, to facilitate future research efforts to improve theASR system’s capability, the needed work includes (espe-cially in Indian context): (1) collect multilanguage or multi-dialect and multimodal (cross channel) corpora, (2) dissem-inate corpora to relevant sites, (3) improve system perfor-mance with the new corpora, and finally, (4) evaluate sys-tem performance. The proposed study in this paper is a steptowards feeling up this gap.
3 Ideal characteristics of a corpus
Following are some of the criteria that one may considerfor building up a speech corpus for text-independent ASRapplications. However, some of them may also be useful tobuild speech corpora for a text-dependent ASR task:
1. Depth and breadth of the coverage- we must haveenough speech from enough speakers in order to vali-date an experiment under study (Reynolds 2002). Also,data in a particular language should be collected in allpossible dialects in order to track all possible variationin pronunciation in that language.
2. Speakers of wide ranging age should be considered tostudy the effects of age on pronunciation.
3. Corpus should contain equal numbers of males and fe-males to perform the experiments exclusively on maleor female or both (Doddington et al. 2000).
4. Corpus should be designed for closed set and open setASR experiments (Reynolds 2002).
5. Speakers of varying educational backgrounds should beconsidered in order to track the effects of speech effortlevel and speaking rate, intelligence level, speaker’s ex-perience, Lombard effect, etc. (Kersta 1965; Lombard1911; Junqua et al. 1999).
6. It has been observed that text material affects ASR per-formance to a great extent (Li et al. 1966). Text mate-rial should be phonetically balanced such that it con-tains all possible vowels, nasal consonants, fricativesand nasal-to-vowel coarticulation, etc. (Sambur 1975;Su et al. 1974; Wolf 1972). It should contain question-answer sessions to know the speaker’s personal infor-mation such as his or her name, age, sex, professionand qualification and his or her spontaneous reactionto these questions, isolated words, digits, combination-lock phrases, read sentences and contextual speech ofconsiderable duration or familiar expressions (Li et al.1966; Reynolds 2002). The contextual speech may bea paragraph from newspapers or any topic of speaker’sinterests such as description of his or her job or familylife or any memorable event or experience in his or herlife (Markel and Davis 1979). The vocabulary shouldcontain at least four syllables, begin with a vowel or avoiceless plosive, it should not have any plosive soundsexcept at the initial stage, it should have a wide range offormant movements, the stress of the first word must beon the first syllable (Li et al. 1966).
7. Data should be collected in wide ranges of acoustic en-vironments such as home or office or telephone boothor roads or cars or van or noisy conditions or worksta-tions or remote villages, etc. in order to make the ASRsystem more realistic.
8. Data should be collected with different types of micro-phones and transmission channels such as carbon but-ton, electrets or mobile phones (Norton 2002), in orderto track the effect of microphone variability on ASRperformance (Reynolds et al. 1995; Reynolds 1996,1997).
9. Data should be collected with multiple training and test-ing sessions in order to track the effects of interses-sion variability on ASR performance (Reynolds 2002;Gish and Schmidt 1994).
10. A corpus should be designed to evaluate a system’s per-formance against mimicry (referred to as analysis of at-tacks in voice biometrics) such as those based on phys-iological characteristics (e.g., identification of profes-

Int J Speech Technol (2008) 11: 17–32 19
sional mimics) or those based on physiological charac-teristics (e.g., identification of identical twins) (Rosen-berg 1976). Authors have reported a detailed studyon speaker identification of professional mimics in In-dian languages in a companion paper (Patil and Basu2009).
11. In a multilingual country like India, data should becollected from each speaker in different languagesfor cross-lingual (i.e., language-independent ASR) andmultilingual experiments. For example, in India Hindilanguage is spoken in many states or parts of the coun-try; so for each speaker, Hindi language should bekept as a default language and any one or two fromother languages such as Marathi, Bengali, Urdu, Oriya,Assamese, Tamil, Telugu, Gujarati, etc. as native lan-guages.
Practically, it is very difficult, if not impossible to preparea corpus which will satisfy all of the above requirements fora problem of study. So, one may prepare a corpus accordingto the problem of study at hand.
4 Distinct dialect zones for Marathi, Urdu and Oriya
In this section, details of different dialect zones for Marathi,Urdu and Oriya languages are discussed. Figure 1 showsthe dialectal map of Maharashtra state which can be broadlyclassified into six major dialect zones, viz., Khandesh, Pune(Western Maharashtra), Kolhapur, Konkan, Marathwada and
Vidharbh where majority of the people speak Marathi astheir native language and Hindi as the non-native language.
The rounded regions in the map indicate the places se-lected for data collection. The Northern part of Maharash-tra is surrounded by Gujarat and Madhya Pradesh whereasits southern part is surrounded by Karnataka and AndhraPradesh. Similarly, the eastern part of Maharashtra is sur-rounded by Chattisgarh and the Western part (coastal zoneof Konkan) is surrounded by the Arabian sea. Because ofthese geographical conditions, the Marathi language is in-fluenced by Gujarati (Nandurbar district), Hindi (Nagpurdistrict), Kannada (Latur district), Konkani (Sindhudurg dis-trict), etc. Table 1 shows the distinct native languages spo-ken in different dialectal zones of Maharashtra. There aredistinct dialect differences in the spoken form of Marathiin these zones. The factors which are responsible for thesedifferences are diction, semantics, pronunciations, idiosyn-crasies, intonation, and rhythm. One of the most impor-
Table 1 Native languages (dialects) in Maharashtra state
Dialectal region Native language
Khandesh Ahirani
Marathwada Marathwadi
Pune Puneri
Kolhapur Kolhapuri
Vidharbh Varhadi
Konkan Konkani
Fig. 1 Dialectal map ofMaharashtra.http://www.mapsofworld.com/india/maharashtra/maharashtra-map.html

20 Int J Speech Technol (2008) 11: 17–32
Fig. 2 Two dialectal zonesselected for Urdu. Map of India.http://www.mapsofindia.com/maps/india/indiastateandunion.htm
tant factors affecting dialect differences are the geograph-ical barriers creating isolation of zones making intermix-ing of people less probable. For example, the Kolhapur andKonkan zones, though adjacent, are separated by ‘PhondaGhat’ (a natural barrier of mountain and hills) and henceshow different dialectal features in the pronunciations of therural subjects.
In India, there are several dialect variations in spo-ken form of Urdu, such as the one spoken at Lucknow(Uttar Pradesh), Balia, Patna (Bihar), Mumbai (Maha-rashtra), Hyderabad (Andhra Pradesh), Bhopal (MadhyaPradesh), Jammu and Kashmir (J&K), Kolkata (West Ben-gal), Palanpur (Gujarat), etc. The usage of Urdu languageis also found in Hindi Cinema or movies (e.g., dialogs,songs, etc). In this work, data for the Urdu language iscollected from two distinct dialectal zones (as shown inFig. 2), viz., A) central Uttar Pradesh (UP state) zone(around Allahabad) and B) Kolkata (West Bengal state)zone.
Figure 3 shows the dialectal map of the Orissa state,which can be broadly classified into three major dialectzones, viz., central dialect zone or Cuttack zone, southern di-alect zone or Berhampur zone and North-West dialectal zoneor Sambalpur zone. From an ASR point of view, the Oriyalanguage is inherently rich in conveying speaker-specific in-formation as it contain various nasal-to-vowel coarticulation(e.g. ‘aasanti (coming)’, ‘naahanti (not there)’, ‘jauchanti(going)’, ‘aasanto (welcome)’, etc.). It has different longand short vowels (e.g. ‘aauu (and)’, ‘jaauuchee (coming)’,‘muhoo (me)’, ‘aapanno (you)’, etc.). Orissa is a coastalstate surrounded by West Bengal (W.B.), Jharkhand andAndhra Pradesh (A. P.) and Chattisgarh. Because of this,Orissa can be broadly classified into three distinct dialec-tal zones. Amongst these zones, Cuttack is the most wide-spread and chaste Oriya is spoken here. The Cuttack zonehas West Bengal as a neighboring state and hence there isan influence of Bengali in some districts such as Baleshwar(Balasore), Mayurbhanj, etc. Moreover, Orissa has nearly700 km of coastal lines along the Bay of Bengal out of
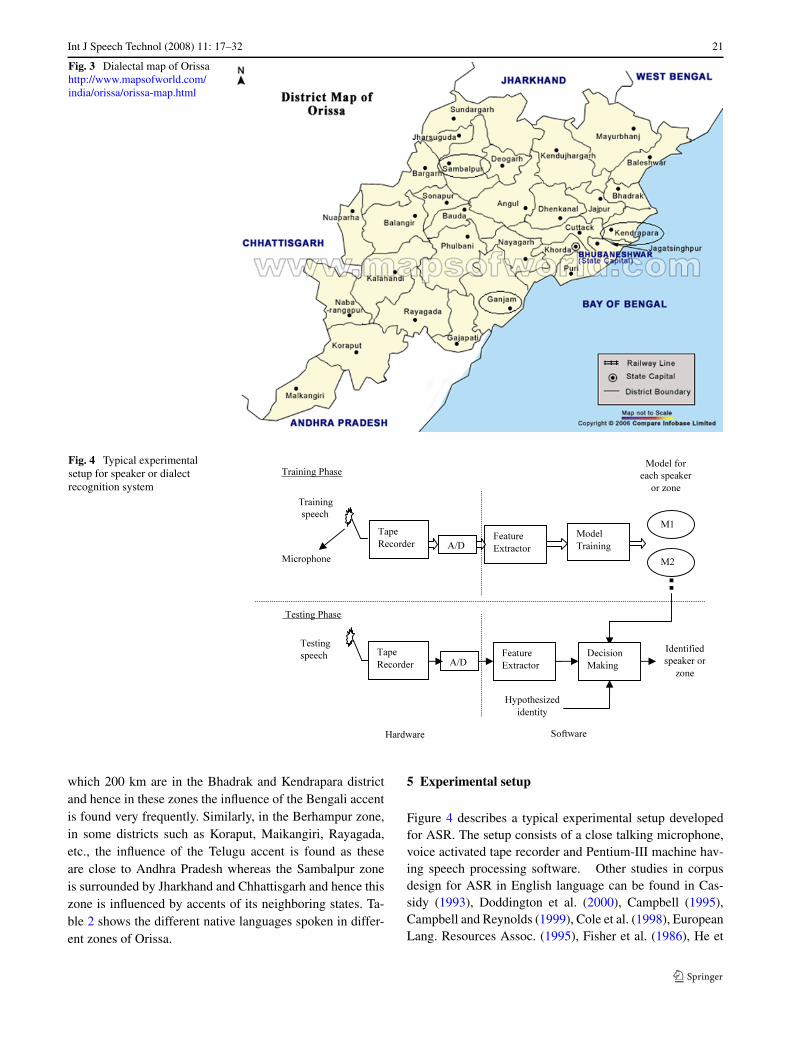
Int J Speech Technol (2008) 11: 17–32 21
Fig. 3 Dialectal map of Orissahttp://www.mapsofworld.com/india/orissa/orissa-map.html
Fig. 4 Typical experimentalsetup for speaker or dialectrecognition system
which 200 km are in the Bhadrak and Kendrapara districtand hence in these zones the influence of the Bengali accentis found very frequently. Similarly, in the Berhampur zone,in some districts such as Koraput, Maikangiri, Rayagada,etc., the influence of the Telugu accent is found as theseare close to Andhra Pradesh whereas the Sambalpur zoneis surrounded by Jharkhand and Chhattisgarh and hence thiszone is influenced by accents of its neighboring states. Ta-ble 2 shows the different native languages spoken in differ-ent zones of Orissa.
5 Experimental setup
Figure 4 describes a typical experimental setup developedfor ASR. The setup consists of a close talking microphone,voice activated tape recorder and Pentium-III machine hav-ing speech processing software. Other studies in corpusdesign for ASR in English language can be found in Cas-sidy (1993), Doddington et al. (2000), Campbell (1995),Campbell and Reynolds (1999), Cole et al. (1998), EuropeanLang. Resources Assoc. (1995), Fisher et al. (1986), He et

22 Int J Speech Technol (2008) 11: 17–32
al. (1997), Jankowski et al. (1990), Linguistic Data Consor-tium (1992). Table 3 shows different available corpora alongwith their advantages and limitations.
Table 2 Native languages (dialects) in Orissa state
Dialectal zone Native language
Cuttack Cuttacki
Sambalpur Sambalpuri
Berhampur Berhampuri
5.1 Data collection
A database of 200 speakers in Marathi, 180 speakers inHindi, 150 speakers in Oriya and 70 speakers in Urdu isprepared for major studies from Maharashtra, Orissa, Ut-tar Pradesh and West Bengal. A database of Marathi andHindi is prepared from the six distinct dialectal regions ofMaharashtra with the help of voice activated (VAS) taperecorders (Sanyo model no. M-1110C and Aiwa modelno. JS299) with microphone input and close talking mi-crophones (viz., Frontech and Intex), whereas the data-base of Oriya is prepared from three distinct dialectal
Table 3 Available corpora for ASR systems
SN Corpus Advantages Limitations
1 TIMIT (Reynolds 1996; Fisher et al. 1986;Linguistic Data Consortium 1992)
Large population No intersession dataText material is limited to only read sen-tencesData recorded in sound booth
2 SIVA (ELVA) (Campbell and Reynolds1999; European Lang. Resources Assoc.1995)
Large populationLarge number of sessions per speakerPhonetically balanced text material
Acoustic environment is limited to office andhome only
3 PolyVar (ELRA) (Campbell and Reynolds1999; European Lang. Resources Assoc.1995)
Large number of sessions per speakerWide range of text material such as read andprompted digits, word and sentences, andspontaneous speech
Acoustic environment is limited to office andhome only
4 POLYCOST (ELRA) (European Lang. Re-sources Assoc. 1995; Petrovska et al. 1998)
Different European languages in the corpusallow for experimentation on the effect oflanguage on ASR performance
Less number of sessions per speakerAcoustic environment is limited to office andhome only
5 KING (LDC) (Reynolds et al. 1995; Lin-guistic Data Consortium 1992; Reynolds1994)
Spontaneous speech in text material Only male subjects are consideredData recorded in sound boothRelatively small population size
6 YOHO (Campbell 1995; Linguistic DataConsortium 1992)
Suitable for text-dependent speaker verifi-cationLarge number of enrollment and verifica-tion session
Text material is limited to only promptedphrasesAcoustic environment is limited to officeonly
7 Switchboard I-II including NIST evaluationsubsets (LDC)(Campbell and Reynolds 1999; LinguisticData Consortium 1992; Godfrey et al. 1992;Martin and Przybocki 2001)
Large number of sessions/speakerSpontaneous speech as text material
Acoustic environment is limited to office andhome only
8 OGI speaker recognition corpus (Cole et al.1998; Oregon Graduate Institute 1975)
Intersession interval spans over months-2years
Acoustic environment is limited to office andhome only
9. Call friend corpus(Linguistic Data Consortium 1992; Torres-Carrasquillo et al. 2002a, 2002b, 2004)
12 languages are usedRecorded over domestic telephone lines
Less number of dialects is considered
AHUMADA-III (Ramos et al. 2008) Suitable for real forensic conditions Database is only for Spanish
10. Mixer corpus (2004–2006) (Campbell et al.2004; Przybocki et al. 2007; Cieri et al.2007).
Suitable for forensic ASRCross-channel and language independentcorporaLarge population
Limited to bilingual subjects only

Int J Speech Technol (2008) 11: 17–32 23
zones of Orissa (where a sizable population of Bengalispeaking migrants have settled), viz., Cuttack, Sambalpurand Berhampur. The database of 70 speakers is preparedfrom Allahbad (Uttar Pradesh State) and Kolkata (WestBengal State) in Urdu with the help of tape recorders(Panasonic model no. RQ-L11 and Sanyo model no. M-1110C). The data is recorded on Sony high fidelity voiceand music recording cassettes (C-90HFB). For minor stud-ies, a database of 7 female speakers in Bengali, Tamil,Telugu is prepared from Jamshedpur, Chennai, Kolkataand Kharagpur. Some subjects especially college studentschose English language for recording. A list consistingof five questions, isolated words, digits, combination-lockphrases, read sentences and a contextual speech of consider-able duration was prepared in the Marathi, Hindi, Oriya,Urdu and English languages. The text material in Eng-lish was prepared by referring to the work reported inWolf (1972), Arslan and Hansen (1996). The contextualspeech consisted of a description of a nature or memo-rable events etc. of community or family life of the speaker.The topics generally allowed each speaker to think in-stantaneously and the speech was usually conversationaland quite varied. The interview was started with somequestions to know about the personal information of thespeaker such as his or her name, age, education, pro-fession, etc. After that the list was given to the speakerto read in his or her own way. The data was recordedwith 10 repetitions except for the contextual speech. Sincethe present work deals with text-independent ASR prob-lem exclusively, the database collection demands a largeamount of variations in pronunciations with all possiblephonemes in a particular language. The text material usedfor recording consisted of isolated words, read sentences,digits, combination-lock phrases, contextual or spontaneousspeech of considerable duration. Since speech is a per-forming art and each performance is unique, we wantedto get all possible variations in pronunciation for a par-ticular text material and so we have recorded data withrepetitions. During recording, we observed that at ini-tial repetitions subjects speak sometimes loudly or differ-ently and at the last repetition subjects try to speak fastin order to complete it as early as possible and hencewe kept 10 repetitions to track all theses possible varia-tions.
5.2 Data acquisition
The recorded voice is played back into the computer throughthe sound card of the computer (P3-833 MHz, 256 MBRAM) (Das and Mohn 1971). The communication betweenthe headphone output from the VAS and the sound cardwas made with the help of EP-EP pin. The speech files
were stored into the ‘wav’ files with the help of sound edit-ing software with a 22050 Hz sampling frequency and 16-bit depth. The dc level is adjusted in the software in or-der to eliminate the dc offset produced by the audio hard-ware, i.e., when the recording hardware such as a soundcard adds a dc offset to the voice signal, which may pro-duce glitches and other unexpected results, if not prop-erly compensated. Once the magnetic tape was playedinto the computer, the speaker’s voice was played againto check the editing errors. The interviewer’s voice wasdeleted from the speech file so that the models of the ac-tual speaker can be made. The automatic silence detec-tor was employed to remove the silence periods in thespeech recordings to get only the models of the speakerand not the background noise and silence interval. Also,each speaker’s voice was normalized by the peak value sothat the speech amplitude level is constant for all the speak-ers.
5.3 Corpus design
Using a corpus to perform any experiment for speaker recog-nition requires the definition of an evaluation procedure thatspecifies, among other things, the partitioning of a corpusinto training and testing data sets (Reynolds 2002). Exam-ination of system performance for specific conditions suchas intersession variability, microphone variability, mimic re-sistance based on physiological characteristics (e.g., iden-tification of identical twins) and behavioral characteristics(e.g., identification of professional mimics) requires that thecorpus should have enough speech from enough speakersfor the condition of interest to construct a valid experiment.In addition, for speaker verification experiments, a corpusis required to be sufficiently large so that two different setsof speakers can be used for training and testing (Campbelland Reynolds 1999). The present corpus is designed intotraining segments of 30 s, 60 s, 90 s and 120 s durationsand testing segments of 1 s, 3 s, 5 s, 7 s, 10 s, 12 s and15 s durations in order to find the performance of the sys-tem for various training and testing durations. Table 4 showsthe summary of the data collection procedure and corpusplan.
5.4 Features of the corpus
Even though there are many publicly available corpora forASR research, they are mainly in American English or Euro-pean languages with certain advantages and limitations (asshown in Table 3). But, this has not been done for manynon-European languages (e.g., languages spoken in India).Hence a major effort is done for development of new data-bases for Indian languages. The following are some of thedistinct features of the corpora developed in this work:

24 Int J Speech Technol (2008) 11: 17–32
Table 4 Database description
Item Details
No. of speakers 200 Marathi, 180 Hindi,150 Oriya, 70 Urdu (∼50% M & ∼50% F)
No. of sessions 2 for Marathi and Hindi, 1 for Urdu, 1 for Oriya
Intersession interval Hours-days-weeks
Data type Speech
Sampling rate 22,050 Hz
Sampling format 1-channel, 16-bit resolution
Type of speech Read sentences, isolated words and digits, combination-lock phrases, questions,contextual speech of considerable duration
Application Text-independent ASR system
Training language Marathi, Hindi, Urdu, Oriya
Testing language Marathi, Hindi, Urdu, Oriya
No. of repetitions 10 except for contextual speech
Training segments 30 s, 60 s, 90 s, 120 s
Test segments 1 s, 3 s, 5 s, 7 s, 10 s, 12 s, 15 s
Microphone Close talking microphone
Recording equipment Sanyo Voice Activated System (VAS), Aiwa, Panasonic magnetic tape recorders
Magnetic tape Sony High-Fidelity (HF) Voice and music recording cassettes
channels EP to EP Wire
Acoustic environment Road/home/office/slums/college/trains/hills/valleys/remote
villages/research labs/farms
1. Two languages, viz., Marathi and Hindi were used forcross-lingual experiments. So the data is completely pho-netically independent.
2. Four languages, viz., Marathi, Hindi, Oriya and Urduwere used for multilingual ASR and language identifi-cation experiments.
3. Speech units including specific vocabularies, e.g., iso-lated words, digits, combination-lock phrases, read sen-tences, question-answer session, and contextual speechof considerable duration with varying topics were con-sidered in the recording.
4. Wide varieties of acoustic environments were consid-ered during recording ranging from office-roads-train, tonoisy workstations, etc. which added realistic noise (e.g.,crosstalk, burst, spurious noise activity) to the voice data.
5. Data is not recorded in closed booth (research lab), wherethe speaker may not feel free.
6. Speakers of wide ranging ages (5–85 years) and a varietyof educational backgrounds (from illiterate to universitypost graduates) have been considered in the corpus.
7. Database is prepared from non-paid subjects and hencetheir natural mode of excitation was not altered and onlythose subjects who were ready to volunteer for this studywere considered.
6 Efforts and experiences during corpora building
The following are some of our efforts and experiences dur-ing the data collection phase which may be of considerableimportance in practical situations (Patil and Basu 2004a,2004b, 2004c, 2004d; Patil 2005).
1. Initially in every village the interviewer went, a meetingwas held wherein the Sarpanch or Police Patil of the vil-lage (village head of local self government) used to callthe native speakers and the purpose of the project wasexplained allaying any apprehension about the misuseof the voice documents, and recording was carried outat a central place in the village.
2. Many native speakers were initially shy and reluctant torecord their voices. So, initially an informal discussionwas carried out to overcome this reluctance and record-ing was done after some time.
3. For recording children’s speech, parents were asked tosit along with the speakers to help them overcome ner-vousness.
4. For recording of illiterate speakers, i.e., those who werenot able to read the text material given in the list,the interviewer was helping the speakers to read or insome cases, the interviewer was reading the text and thespeaker was following it.

Int J Speech Technol (2008) 11: 17–32 25
5. It has been observed that the pronunciations of digits(single and two digit numbers) and combination-lockphrases were highly dependent on the educational back-ground of the subjects. Some speakers were not able tospeak combination-lock phrases. In such cases, an ini-tial training was given to the speakers and then record-ing was done. Finally, if a speaker was not able to speakthese phrases then he or she was asked to speak onlysome single digit or two digit numbers (between 10and 19), which are not combination-lock ones.
6. During recording of the contextual speech, the inter-viewer asked some questions to speaker in order to mo-tivate him or her to speak on his or her chosen topic.This also helps the speaker to overcome the initial ner-vousness and come to his or her natural mode so thatthe acoustic characteristics of subjects’ speeches aretracked precisely. The speaker’s voice and interviewer’svoice were recorded on the same track. After the record-ing was done for each speaker, a speaker informationform was prepared to know historical details of thespeaker such as his or her name, age, sex, place of birth,native place, social status, education, profession, num-ber of children if married, mother tongue, languagesknown, etc.
7. It has been observed that the dialect variations ap-pear in speech styles more frequently in casual con-versation or in specific situational contexts, or onlywith other members of the same dialect communityand not with the reading text material (identical to thatmentioned in Clopper et al. 2000). For speaker clas-sification, spontaneous speech recording is desirable,whereas for speaker identification or verification, thereis no such constraint.
8. The presence of the observer (the observer being an ex-perimenter, recording equipment, or any other tool ofmeasurement) affects the acoustical characteristics ofspeech produced by members of a dialect communityof interest. Thus, intrusion of an experimenter from out-side the dialect community and the effect of recordingequipment on the formality of the conversational settingare perceived as barriers to the elicitation of the “deep-est” form of the dialect in question, which is just identi-cal to that of Labov’s “observer’s paradox” (reported inClopper et al. 2000, Wolfram and Schilling-Estes 1998)which states that, “the aim of linguistic research in thecommunity must be to find out how people talk whenthey are not being systematically observed yet we canonly obtain this data by systematic observation”.
9. It has been observed that the subject involuntarily raiseshis or her vocal intensity in the presence of high levelsof sound or microphone. This is referred as Lombardeffect (Lombard 1911; Junqua et al. 1999).
10. Even though data is recorded in Marathi, there was in-fluence of native languages of dialect zones such as
Ahirani, Marathwadi, Puneri, Kolhapuri, Varhadi andKonkani on the pronunciations of the speakers fromother zones’ identical words in the text material, i.e.,subjects often tend to use the dialect-specific words es-pecially in recording of contextual speech. Similarly forOriya, there was influence of zonal dialects such as Cut-tacki, Sambalpuri and Berhampuri on the pronuncia-tions of the native people from different dialectal zonesof Orissa.
11. While entering each of the dialectal zones, extensivecare has been taken about the geographical conditions,culture, food habits, etc. of the respective zones in orderto establish a close interaction with the native commu-nities and avoid any misunderstanding between inter-viewer and villagers, especially during the recordingsof female speakers.
12. While recording the speech for a secondary language(i.e., Hindi), some initial resistance was experiencedfrom a small section of speakers.
13. Some speakers caught a cold during recording of eitherthe first or second session. However, all of these caseswere recorded in a normal fashion and no manual edit-ing or deletion of any data was performed. This allowsthe problem to be applicable in realistic situations.
14. Speakers occasionally became bored or distracted, andlowered their voice intensity or turned their heads awayfrom the microphone.
15. Speakers sometimes felt emotionally involved while de-scribing personal experiences on their chosen topic andthus due to the breath bursts (A breath burst is a vio-lent exhalation of air without vibration of vocal cords,e.g., in the pronunciation of p, s, or Indian phonemeslike ‘ph’, ‘bh’ unlike ‘f ’ or ‘v’ or air exhaled duringbreathing process), the frequency response of the mi-crophone was substantially lowered.
16. There was stammering, laughter, throat clearing, titter-ing and poor articulation. All these cases were recordedin normal fashion.
17. Because of differences in the time of availability ofspeakers for recording, it is not practicable to maintainthe same time of recording for all speakers; recordingswere made at different times of the day.
7 Database organization
The speech corpora are divided into several subsets accord-ing to the problem at hand, such as speaker identification,speaker classification and evaluation of the system’s robust-ness against mimicry, etc. Figure 5 shows the corpora plansfor performing experiments on different ASR problems. Forspeaker identification, the corpus is divided into several sub-sets for monolingual, cross-lingual and multilingual experi-

26 Int J Speech Technol (2008) 11: 17–32
Fig. 5 Speech corporaorganization for different ASRtasks in Indian languages
Table 5 Corpora details (speaker classification-closed set)
Criteria Agewise distributions Genderwise Dialectwise distributionsb
5–20 20–40 40–60 60–85 distributionsa KN MW V K P KL
M F
Mc
−−→ TR & TE 10 38 19 23 49 41 15 15 15 15 15 15
aM = Male, F = FemalebKN = Konkan, MW = Marathwada, V = Vidharbh, K = Khandesh, P = Pune, KL = KolhapurcM = Marathi, TR = speaker used during training and TE = speakers used during testing
ments in Marathi, Hindi, Oriya and Urdu. For speaker clas-sification, the corpus is divided into the different subsets forclosed set experiments in Marathi, Oriya and Urdu and openset experiments in Marathi and Oriya only. For evaluationof robustness of ASR against mimicry, corpora are dividedinto corpora for twins (for mono-lingual, cross-lingual andmultilingual ASR experiments) and corpora for identifica-tion of professional mimics in Marathi and Hindi (detailedanalysis for ASR of mimics is reported in a companion pa-per of Patil and Basu 2009). Tables 5–9 show details (suchas age, gender, sex type and dialect) of some of the corporaused for speaker classification (closed set and open set), twinidentification and professional mimics in Marathi and Hindi,respectively.
8 Development of ASR system for Indian languages
In this section, brief description of experimental results fordevelopment of ASR system in Indian languages is pre-sented in mono-lingual, cross-lingual and multilingual en-vironments. Three different features, viz., Linear Predic-tion Coefficients (LPC), Linear Prediction Cepstral Coeffi-cients (LPCC) (Atal 1974), Mel frequency cepstral coeffi-cients (MFCC) (Davis and Mermelstein 1980) are employedin ASR system for various tasks and operating modes. Forall the experiments, the dimension of the feature vector iskept as 12. Feature analysis was performed using a set offrames, each of 23.2 ms duration with an overlap of 50%.A Hamming window was applied to each frame and sub-sequently, each frame was pre-emphasized with the filter

Int J Speech Technol (2008) 11: 17–32 27
Table 6 Corpora details (speaker classification- open set)
Criteria Agewise distributions Genderwise Dialectwise distributionsb
5–20 20–40 40–60 60–90 distributionsa KN MW V K
M F
Mc
−−→ TR 02 48 15 19 53 31 21 21 21 21
TE 00 34 29 21 44 40 21 21 21 21
aM = Male, F = FemalebKN = Konkan, MW = Marathwada, V = Vidharbh, K = KhandeshcM = Marathi
Table 7 Corpora details (identical twins in Marathi, Hindi and Urdu)
Criteria Agewise distributions Genderwise Dialectwise distributionsb
5–20 20–35 35–50 50–65 distributionsa KL KN MW V K UN UM Kal.
M F M + F
No. of M 12 7 0 2 14 5 2 5 5 4 5 2 – – –Twinsc−−−−→ H 11 6 0 2 13 5 1 4 5 4 3 2 – – –
U 3 0 1 0 2 1 1 – – – – – 01 02 01
aM = Male, F = Female, M + F = one male and one femalebKL = Kolhapur, KN = Konkan, MW = Marathwada, V = Vidharbh, K = Khandesh, UN = Unanao, UM = Umri, and KAL = KolkatacM = Marathi, H = Hindi, U = Urdu
Table 8 Corpora details (identical twins in Oriya)
Criteria Agewise distributions Genderwise distributionsa Dialectwise distributionsb
5–20 20–35 35–50 50–65 M F M + F C B S
No. of O 15 3 – – 8 8 2 12 02 04Twinsc−−−−→aM = Male, F = Female, M + F = one male and one femalebC = Cuttack, B = Berhampur, and S = SambalpurcO = Oriya
Table 9 Corpora details(professional mimics)
aM = Marathi and H = HindibIC = Imaginary characters,ATS = Actual target speakers
Criteria Approx. age Gender Place Target speakersb
Languagea
−−−−−−→ M 45–50 Male Aurangabad 21 (IC)
H 35–45 Male Mumbai 22 (IC) and 7 (ATS)
(1 − 0.97z−1). Pre-emphasis is a smooth high pass filter-ing process applied to each speech frame, which empha-sizes high frequency components and de-emphasizes lowfrequency components, i.e., sharp or sudden changes in ar-ticulation are boosted up. This is also used to reduce theeffect of the transfer function of the glottis and thereby trackchanges solely related to the vocal tract. Thus, pre-emphasishelps one to concentrate on articulator dynamics in speech
frames and hence it is useful for tracking the manner inwhich the speaker pronounces a word. The experimentswere performed for different durations of training such as30 s, 60 s, 90 s and 120 s which corresponds to 2582, 5164,7746, and 10328 speech frames for 22050 Hz sampling fre-quency. No data reduction technique or averaging was done.For all of the experiments, polynomial classifier of 2nd or-der approximation is employed for preparation of speaker

28 Int J Speech Technol (2008) 11: 17–32
models and finally the recognition process (Campbell et al.2002). Hence, the sizes of the training vectors fed to the clas-sifier were approximately 12 × 2582 (for 30 s training dura-tions), 12×5164 (for 60 s training durations), 12×7746 (for90 s training durations), and 12 × 10328 (for 120 s trainingdurations). The computational details of different featuressets (such as LPC, LPCC and MFCC) and polynomial, clas-sifier, are given in a companion paper (Patil and Basu 2009).In this paper, the majority of the experiments are performedover two major evaluation factors, viz., training (TR) speechdurations (ranging from 30 s, 60 s, 90 s and 120 s) and test-ing (TE) speech durations (ranging from 1 s, 3 s, 5 s, 7 s,10 s, 12 s and 15 s). Success rates (defined in a compan-ion paper of Patil and Basu 2009) are computed over testingspeech durations and overall average success rates are com-puted as average over testing speech duration followed bytraining speech durations. In the following subsections, dif-ferent ASR experiments are presented.
8.1 Mono-lingual experiments
Database of 60 speakers in each of four Indian languages,viz., Marathi, Hindi, Urdu and Oriya is considered formonolingual speaker identification experiments. The pop-ulation size is kept constant to make relative comparisonof the performance of ASI for different languages. Train-ing and testing was done with the same microphones forall the languages except for Oriya. Table 10 shows the re-sults on monolingual speaker identification experiments forMarathi over different testing and training speech durationsfor LPC whereas Table 11 shows average success rates formonolingual speaker identification experiments in Marathi(M), Hindi (H), Urdu (U) and Oriya (O) for LPC. Finally,Table 12 shows the overall average success rates for Marathi,Hindi, Urdu and Oriya with LPC, LPCC and MFCC.
Some of the observations from the results are as follows:
Table 10 (ASR for Marathi) Success rates (%) for LPC
TE TR
30 s 60 s 90 s 120 s
1 s 51.66 51.66 56.66 55
3 s 55 58.33 56.66 66.66
5 s 56.66 61.66 61.66 65
7 s 55 58.33 61.66 66.66
10 s 56.66 61.66 66.66 68.33
12 s 61.66 61.66 66.66 73.33
15 s 58.33 70 70 80
Av 56.42 60.47 62.85 67.85
TR = Training speech duration
TE = Testing speech duration
1. The success rates are rather low for very short durationsof testing utterances (such as 1 s to 7 s); this is quite ex-pected, because of the fact that the speaker-specific in-formation is not tracked properly in a very short testingutterance (Table 10).
2. The general trend in success rates is found to be increas-ing with respect to increase in training speech durations(Tables 10 and 11).
3. In the majority of the cases, MFCC performed better thanother feature sets (Table 12).
4. Results are better for Marathi as compared to Hindi. Thismay be due to the fact that the Hindi data was recordedfrom rural subjects from Maharashtra having Marathi astheir native language and Hindi as a non-native languageand hence subjects might have some difficulty in pro-nouncing the text material in Hindi as compared to thatin Marathi (Table 12).
5. Performance of ASR in Urdu was also found satisfactoryas compared to Hindi, since the Urdu data is recordedfrom native speakers in Urdu (Table 12).
6. Because of the use of different microphones for testingand training, degradation in the performance for Oriyacannot be ruled out (Table 12).
7. On the whole, the performance of LPC is poorer thanLPCC and MFCC. This may be due to the fact that thedistances between training and testing LP feature vectorscorrelate poorly with spectral envelope distance.
8.2 Cross-lingual experiments
In this section, ASR experiment is conducted for 17 pairsof identical twins (i.e., 34 speakers) in cross-lingual mode
Table 11 Average success rates (%) for LPC
L TR
30 s 60 s 90 s 120 s
M 56.42 60.47 62.85 67.85
H 44.75 46.42 47.37 56.18
U 57.14 55.23 55.71 56.90
O 39.04 42.61 42.14 44.75
Table 12 Overall average success rates (%)
L FS
LPC LPCC MFCC
M 61.89 66.72 73.62
H 48.68 50.17 64.69
U 56.24 60.44 67.25
O 42.13 38.56 49.75
L = language, M = Marathi, H = Hindi, U = Urdu, O = Orirya

Int J Speech Technol (2008) 11: 17–32 29
Table 13 Average success rates for cross-lingual speaker identifica-tion of twins (TR = Hindi and TE = Marathi)
FS TR
30 s 60 s 90 s
LPC 36.13 (53.35) 33.61 (47.89) 30.25 (49.57)
LPCC 41.17 (67.64) 44.11 (65.96) 47.89 (67.22)
MFCC 37.81 (58.40) 46.63 (67.22) 42.43 (63.86)
Table 14 Average success rates for cross-lingual speaker identifica-tion of twins (TR = Marathi and TE = Hindi)
FS TR
30 s 60 s 90 s
LPC 31.51 (55.88) 28.99 (52.52) 30.67 (49.16)
LPCC 31.09 (50.41 53.78 (54.62) 39.91 (51.68)
MFCC 34.87 (59.66) 42.01 (64.70) 42.43 (64.28)
FS = Feature sets, viz., LPC, LPCC and MFCC
Results in the brackets indicate the sub-optimal success rates
(Patil and Basu 2004e). Table 13 shows the average successrates when training (TR) is done in Hindi and testing (TE)is done in Marathi whereas Table 14 shows the results whentraining is done in Marathi and testing is done in Hindi.
Some of the observations from the results are as follows:
1. MFCC outperformed LPC and LPCC when training isdone with Marathi and testing is done with Hindi in al-most all the cases of training durations (Table 14).
2. The success rates are dependent on the closeness of thetesting language to the mother tongue of the speaker thanthe training language (Tables 13 and 14).
3. It has been observed that the results are better for mono-lingual experiments (almost 70%) than the cross-lingual.Thus language consistency matters for speaker recogni-tion and for cross-lingual ASR experiments; the system isdoing language recognition as much as it is doing speakerrecognition (Przybocki et al. 2007). This may be due tothe fact that during training, we train and build poly-nomial models for each speaker with one language (sayMarathi) having particular set of sound units. Now dur-ing testing with another language (say Hindi), the fea-ture vector falls into different zone of feature space be-cause training feature vectors distribution has differentlanguage-specific features
4. For LP-based features, comparison of the success ratesalso reveals that if the testing language is Marathi(mother tongue), the performance is better. This may bedue to the fact that LP-based features are known to bedependent on text material used for the recording andpronunciations (Atal and Hanuaer 1971). As discussedabove, Marathi being the native language of the sub-
Table 15 Average success rates for multilingual ASR TASK (M, H,U and O) population size = 240 speakers
FS TR
30 s 60 s 90 s 120 s
LPC 31.06 30.41 32.85 34.64
LPCC 32.55 33.80 34.52 34.63
MFCC 48.09 48.26 48.452 49.22
Table 16 Confusion matrix LPC with TR = 120 s and TE = 15 s
Act. Ident.
M H U O
M 70 21.66 1.66 6.66
H 3.33 93.33 3.33 0
U 0 3.33 96.66 0
O 6.66 5 0 88.33
jects, speaker specific information is better tracked byLP-based features when Marathi is used as the testinglanguage (Tables 13 and 14).
5. It has been observed that the chances of misclassificationgo up when more than one set of twins is taken from thesame dialectal zone in a particular language.
6. It has been observed that in the case of misidentifica-tion, most of the time, a twin is misidentified as its twinbrother or sister rather than another twin in the data-base. This reduces the search space for misidentification.This motivated the authors to introduce a new perfor-mance measure, viz., sub-optimal success rate (SOSR)(shown in the brackets in Tables 13 and 14), which willtake care of misidentification between twins. If a twinspeaker is misidentified as his or her brother or sister, i.e.,misidentification is occurring amongst a twin pair, wecount this event to be partially successful since the iden-tified speaker is closely related to the original speaker.So the actual and partial successes taken together arecounted as sub-optimal cases. It is evident from Tables 13and 14 that the proposed performance measure improvesthe ASR performance.
8.3 Multilingual experiments
In this subsection, results on multilingual speaker identifica-tion for population size 240 speakers (60 speakers in each ofMarathi, Hindi, Urdu and Oriya) are discussed (Patil 2005).Table 15 shows the average success for LPC, LPCC andMFCC with various training durations, viz., 30 s, 60 s, 90 s,and 120 s. Tables 16–18 show confusion matrices (diagonalelements indicate % correct identification in a particular lin-guistic group and off-diagonal elements show the misiden-tification) for Marathi (M), Hindi (H), Urdu (U) and Oriya

30 Int J Speech Technol (2008) 11: 17–32
Table 17 Confusion matrix LPCC with TR = 120 s and TE = 15 s
Act. Ident.
M H U O
M 71.66 26.66 1.66 0
H 11.66 88.33 0 0
U 0 0 100 0
O 18.33 1.66 0 80
Table 18 Confusion matrix MFCC with TR = 120 s and TE = 15 s
Act. Ident.
M H U O
M 88.33 8.33 0 3.33
H 8.33 91.66 0 0
U 0 1.66 98.33 0
O 8.33 5 0 86.66
(O). In Tables 16–18, ACT represents the actual language ofthe speaker and IDENT represents the identified language ofan unknown speaker.
Some of the observations from the results are:
1. In the majority of the cases, MFCC performed better thanLPC and LPCC (Tables 15 and 16).
2. Overall results are low since 60 speakers in Oriya aretrained and tested with different microphones.
3. Confusion matrix for MFCC is better than those for LPCand LPCC indicating that MFCC can capture speaker-specific information better than LP-based features.
4. Confusion matrices for all the feature sets show that aMarathi speaker is misidentified more often as a Hindispeaker rather than Urdu. Also, Oriya speakers aremisidentified with Marathi to a larger extent rather thanwith Hindi or Urdu.
8.3.1 Analysis of attacks in ASR
Authors have investigated effectiveness of different speechfeatures for identification of professional mimics in Indianlanguages. It has been observed that LP-based features per-form better than filterbank-based features (e.g. MFCC) forthis problem. This may be due to the fact that LPC modelrepresents the combined effect of vocal tract (formant fre-quencies and their bandwidths and thus in turn emphasizesthe formant structure more dominantly), glottal pulse and ra-diation model and in turn the physiological characteristicsof mimic’s vocal tract. So even if mimic is imitating otherperson’s voice to fool human perception process (so to thefeatures based on it, viz., MFCC, he cannot change his orher physiological characteristics of the vocal tract which areknown to be nicely tracked by LP-based features. So, in the
testing phase, LP-based features track these properties dom-inantly as compared to filterbank-based features and henceoutperform MFCC feature set in the identification process.The detailed analysis of these results is presented in com-panion paper (Patil and Basu 2009).
9 Summary and conclusions
In this paper, the methodology and a typical experimentalsetup are presented to build up speech corpora for ASRsystems in Indian languages, viz., Marathi, Hindi, Urduand Oriya. Different ideal characteristics of a speech cor-pus are discussed along with advantages and limitations ofthe other publicly available corpora (which are mostly inAmerican English and European languages) and the featuresof the present corpora. Efforts and experiences during cor-pora building are discussed along with the details of corporaplans for performing experiments on different ASR prob-lems are given followed by details of some of the major cor-pora given in tabular form. Finally, an ASR system is pre-sented to demonstrate the results on speaker identificationexperiments in mono-lingual, cross-lingual and multilingualmodes, etc.
It should be noted that the speech corpora building is themost crucial task in speaker recognition systems in orderto employ an ASR system in realistic situations. Moreover,the results obtained in ASR are meaningless if the detailsof the corpora preparation (especially details of speaker-education, socio-economic status, etc. recording conditions-microphone type, channels, etc.) are not known. In additionto this, from the results presented in this paper and a com-panion paper, it is evident that no particular feature set (e.g.LPC, LPCC, MFCC, T-MFCC, etc.) can be recommendedas a versatile feature in ASR for all the tasks. This maybe due to the fact that for ASR of mimics, LP-based fea-tures perform better whereas for normal speaker recognition,filterbank-based feature such as MFCC perform better.
Acknowledgement The authors would like to thank those people ofIndia who have given their kind support and cooperation in data collec-tion phase. They would also like to thank the authorities of DA-IICTGandhinagar and IIT Kharagpur for their kind support to carry out thisresearch work. They would also like to thank Mr. Tauseef Ahmad, Mr.Bikas Kar, Mr. Debee Prakash and Mr. Bishnu Bhatta for their helpduring corpus preparation.
References
Arslan, L. M., & Hansen, J. H. L. (1996). Language accent classifica-tion in American English. Speech Communications, 18, 353–367.
Atal, B. S. (1974). Effectiveness of linear prediction of the speech wavefor automatic speaker identification and verification. Journal ofthe Acoustical Society of America, 55(6), 1304–1312.

Int J Speech Technol (2008) 11: 17–32 31
Atal, B. S., & Hanuaer, S. L. (1971). Speech analysis and synthesisby linear prediction of the speech wave. Journal of the AcousticalSociety of America, 50, 637–655.
Bricker, P. D., & Pruzansky, S. (1966). Effects of stimulus content andduration on talker identification. Journal of the Acoustical Societyof America, 40(6), 1441–1449.
Campbell, J. P. Jr. (1995). Testing with The YOHO CD-ROM voiceverification corpus. In Proceedings of the international confer-ence on acoustics, speech and signal processing, ICASSP’95,Detroit (pp. 341–344). http://www.biometrics.org/REOROTS/ICASSP95.html.
Campbell, J. P. Jr., & Reynolds, D. A. (1999). Corpora for the eval-uation of speaker recognition systems. In Proceedings of inter-national conference on acoustics, speech and signal processing,ICASSP’99 (Vol. 2, pp. 829–832), 15–19 March 1999.
Campbell, W. M., Assaleh, K. T., & Broun, C. C. (2002). Speakerrecognition with polynomial classifiers. IEEE Transactions onSpeech and Audio Processing, 10(4), 205–212.
Campbell, J. P., Nakasone, H., Cieri, C., Miller, D., Walker, K., Martin,A. F., & Przybocki, M. A. (2004). The MMSR bilingual and crosschannel corpora for speaker recognition research and evaluation.In The speaker and language recognition workshop, Odyssey’04,Toledo, Spain (pp. 29–32), 31 May–3 June 2004.
Cassidy, F. G. (1993). Area lexicon: The making of DARE. In D. R.Preston (Ed.), American dialect research (pp. 93–106). Philadel-phia: Benjamin.
Center for Spoken Language Understanding (CSLU) at Oregon Grad-uate Institute (OGI). (1975). http://cslu.cse.ogi.edu/.
Chambers, J. K. (1993). Sociolinguistic dialectology. In D. R. Pre-ston (Ed.), American dialect research (pp. 133–164). Philadel-phia: Benjamin.
Cieri, C., Corson, L., Graff, D., & Walker, K. (2007). Resources fornew research directions in speaker recognition: The mixer 3, 4 and5 corpora. In Proceedings of Interspeech (pp. 950–953), Antwerp,Belgium, 27–31 August 2007.
Clopper, C. G. et al. (2000). A multi-talker dialect corpus of spokenAmerican English: an initial report. Research on spoken languageprocessing, progress report (no. 24, pp. 409–413), Speech Re-search Laboratory, Indiana University, Bloomington, IN.
Cole, R., Noel, M., & Noel, V. (1998). The CSLU speaker recogni-tion corpus. In Proceedings of international conference on spokenlanguage processing, ICSLP’98, Sydney, Australia, 30 November,1998.
Das, S. K., & Mohn, W. S. (1971). A scheme for speech processing inautomatic speaker verification. IEEE Transactions on Audio andElectroacoustics, 19, 32–43.
Davis, S. B., & Mermelstein, P. (1980). Comparison of parametric rep-resentations for monosyllabic word recognition in continuouslyspoken sentences. IEEE Transactions on Acoustics, Speech andSignal Processing, 28(4), 357–366.
Doddington, G. R., Przybocki, M. A., Martin, A. F., & Reynolds,D. A. (2000). The NIST speaker recognition evaluation overview:methodology systems, results, perspective. Speech Communica-tions, 31, 225–254.
European Lang. Resources Assoc. (1995). http://www.icp.grenet.fr/ELRA/.
Fisher, W. M., Doddington, G. R., & Gaudic-Marshall, K. M. (1986).The DARPA speech recognition research database: specificationsand status. In Proceedings of DARPA workshop on speech recog-nition (pp. 93–99), February 1986.
Gish, H., & Schmidt, M. (1994). Text-independent speaker identifica-tion. IEEE Signal Processing Magazine, 11(4), 18–32.
Godfrey, J. J., Holliman, E. C., & McDaniel, J. (1992). Switch-board: telephone speech corpus for research and development.In Proceedings of international conference on acoustics, speech,and signal processing, ICASSP’92 (Vol. 1, pp. 517–520), March1992.
He, H. et al. (1997). European speech database for telephone appli-cations. In Proceedings of international conference on acoustics,speech, and signal processing, ICASSP’97 (Vol. 3, pp. 1771–1774), 21–24 April 1997.
Jankowski, C., Kalaynswamy, A., Basson, S., & Spitz, J. (1990).NTIMIT: A phonetically balanced, continuous speech telephonebandwidth speech database. In Proceedings of international con-ference on acoustics, speech, and signal processing, ICASSP’90(pp. 109–112), April 1990.
Junqua, J. C., Fincke, S. C., & Field, K. (1999). The Lombard effect:a reflex to better communicate with other in noise. In Proceed-ings of international conference on acoustics, speech, and signalprocessing, ICASSP’99 (Vol. 4, pp. 2083–2086).
Kersta, L. G. (1962a). Voiceprint identification. Nature, 196(4861),1253–1257 (29 December).
Kersta, L. G. (1962b). Voiceprint-identification infallibility. Journal ofthe Acoustical Society of America (A), 38, 1978.
Kersta, L. G. (1965). Voiceprint classification, part 2. Journal of theAcoustical Society of America (A), 37, 1217.
Kersta, L. G. (1966). Voiceprint classification for an extended popula-tion. Journal of the Acoustical Society of America (A), 39, 1239.
Kersta, L. G. (1970). Progress report on automated speaker-recognitionsystems. Journal of the Acoustical Society of America (A), 139.
Kersta, L. G., & Colangelo, J. A. (1970). Spectrographic speech pat-terns of identical twins. Journal of the Acoustical Society of Amer-ica, 47, 58–59.
Li, K. P., & Wrench, E. H. Jr. (1983). Text-independent speaker recog-nition with short utterances. In Proceedings of international con-ference on acoustics, speech, and signal processing, ICASSP’83,Boston, MA (pp. 555–558).
Li, K. P., Dammann, J. E., & Chapman, W. D. (1966). Experimentalstudies in speaker verification using an adaptive system. Journalof the Acoustical Society of America, 40(5), 966–978.
Linguistic Data Consortium. (1992). http://www.ldc.upenn.edu/.Linguistic Data Consortium for Indian Languages. (2008).
http://www.ldcil.org.Lombard, E. (1911). Le signe de l’élévation de la voix. Annales de
Maladies Oreille, Larynx, Nez, Pharynx, 37, 101–119.Markel, J. D., & Davis, S. B. (1979). Text-independent speaker
recognition from a large linguistically unconstrained time-spaceddata base. IEEE Transactions on Acoustics, Speech and SignalProcessing, 27(1), 74–82.
Martin, A. F., & Przybocki, M. A. (2001). The NIST speaker recog-nition evaluations: 1996–2001. In A speaker Odyssey, a speakerrecognition workshop, December 2001.
Norton, R. (2002). The evolving biometric marketplace to 2006. Bio-metric Technology Today, 10(9), 7–8.
Patil, H. A. (2005). Speaker recognition in Indian languages: a featurebased approach. Ph.D. thesis, Department of Electrical Engineer-ing, IIT Kharagpur, India.
Patil, H. A., & Basu, T. K. (2004a). Speech corpus for text or language-independent speaker recognition in Indian languages, Addendumto the lecture compendium. In Proceedings of national sympo-sium on morphology, phonology and language engineering, SIM-PLE’04, IIT Kharagpur, India, pp. A1–A4, March 19–21 2004.
Patil, H. A., & Basu, T. K. (2004b). Multilingual speech corpus de-sign for speaker identification in Indian languages. In Interna-tional workshop on standardization of speech database, orientalCOCOSDA’04, Noida, Delhi, India, 17–19 November 2004.
Patil, H. A., & Basu, T. K. (2004c). Designing speech corpus fortwin identification experiments in Indian languages. In Proceed-ings of international conference on natural language processing,ICON’04, IIIT Hyderabad, 19–22 December 2004.
Patil, H. A., & Basu, T. K. (2004d). Speech corpora for speaker clas-sification experiments in Indian languages. In Proceedings of in-ternational conference on emerging technology, ICET’04, Allied,KIIT Orissa, India (pp. 71–78), 22–24 December 2004.

32 Int J Speech Technol (2008) 11: 17–32
Patil, H. A., & Basu, T. K. (2004e). Detection of bilingual twins by Tea-ger energy based features. In Proceedings of international confer-ence on signal processing and communication, SPCOM’04, IISc,Bangalore, India (pp. 32–36), 11–14 December 2004.
Patil, H. A., & Basu, T. K. (2009). LP Spectra vs. MelSpectra for identification of professional mimics in In-dian languages. International Journal of Speech Technology.doi:10.1007/s10772-009-9031-y.
Petrovska, D. et al. (1998). POLYCOST: a telephone speech data-base for speaker recognition (pp. 211–214), RLA2C, Avignon,France, 20–23 April 1998. http://www.speech.kth.se/~melin/papers/rla2c_ply.ps.
Przybocki, M. A., Martin, A. F., & Le, A. N. (2007). NIST speakerrecognition evaluations utilizing the mixer corpora—2004, 2005,2006. IEEE Transactions on Audio, Speech, and LanguageProcessing, 15(7), 1951–1959.
Ramos, D., Gonzalez-Rodriguez, J., Gonzalez-Dominguez, J., &Lucena-Molina, J. J. (2008). Addressing database mismatch inforensic speaker recognition with AHUMADA III: a public realcasework database in Spanish. In Proceedings of Interspeech(pp. 1493–1496), Brisbane Australia, 22–26 September 2008.
Reynolds, D. A. (1994). Experimental evaluation of features for robustspeaker identification. IEEE Transactions on Speech and AudioProcessing, 2, 639–643.
Reynolds, D. A. (1996). The effects of handset variability on speakerrecognition performance: Experiment on the Switchboard corpus.In Proceedings of international conference on acoustics, speech,and signal processing, ICASSP’96 (pp. 113–116), May 1996.
Reynolds, D. A. (1997). HTIMIT and LLHDB: Speech corpora forthe study of handset transducer effects. In Proceedings of inter-national conference on acoustics, speech, and signal processing,ICASSP’97 (pp. 1535–1538), Munich, Germany.
Reynolds, D. A. (2002). An overview of automatic speaker recogni-tion technology. In Proceedings of international conference onacoustics, speech and signal processing, ICASSP’02 (Vol. IV,pp. 4072–4075), 13–17 May 2002.
Reynolds, D. A., Zissman, M. A., Quateri, T. F., O’Leary, G. C., &Carlson, B. (1995). The effects of telephone transmission degra-dations on speaker recognition performance. In Proceedings of in-ternational conference on acoustics, speech, and signal process-ing, ICASSP’95 (pp. 329–332), May 1995.
Rosenberg, A. E. (1976). Automatic speaker verification: a review.Proceedings of IEEE, 64, 475–487.
Sambur, M. R. (1975). Selection of acoustic features for speaker iden-tification. IEEE Transactions on Acoustics, Speech and SignalProcessing, 23, 176–182.
Su, L. B., Li, K. P., & Fu, K. S. (1974). Identification of speakers byuse of nasal co-articulation. Journal of the Acoustical Society ofAmerica, 56, 1876–1882.
Torres-Carrasquillo, P. A., Reynolds, D. A., & Deller, J. R. Jr. (2002a).Language identification using Gaussian mixture model tokeniza-tion. In Proceedings of international conference on acoustics,speech, and signal processing, ICASSP’02, Orlando, FL (Vol. I,pp. 757–760), 13–17 May 2002.
Torres-Carrasquillo, P. A., Singer, E., Kohler, M. A., Greene, R. J.,Reynolds, D. A., & Deller, J. R. Jr. (2002b). Approaches to lan-guage identification using Gaussian mixture models and shifteddelta cepstral features. In Proceedings of international confer-ence on spoken language processing, ICSLP’02, ISCA, Denver,CO (pp. 33–36), September 2002.
Torres-Carrasquillo, P. A., Gleason, T. P., & Reynolds, D. A. (2004).Dialect identification using Gaussian mixture models. In Proceed-ings of Odyssey: the speaker and language recognition workshopin Toledo, Spain, ISCA (pp. 297–300) 31 May–3 June 2004.
Wolf, J. J. (1972). Efficient acoustic parameters for speaker recog-nition. Journal of the Acoustical Society of America, 51, 2030–2043.
Wolfram, W., & Schilling-Estes, N. (1998). American English.Malden: Blackwell.




















