
Detecção de pedestres em cruzamentos utilizando características Haar
31
Suellen Jaccon Shimabukuro e Victor de Sousa Detecção de pedestres em cruzamentos utilizando características Haar Curitiba - PR, Brasil Agosto de 2011
Transcript of Detecção de pedestres em cruzamentos utilizando características Haar

Suellen Jaccon Shimabukuro e Victor de Sousa
Detecção de pedestres em cruzamentos utilizandocaracterísticas Haar
Curitiba - PR, Brasil
Agosto de 2011

Suellen Jaccon Shimabukuro e Victor de Sousa
Detecção de pedestres em cruzamentos utilizandocaracterísticas Haar
Trabalho de Graduação apresentado paraobtenção do Grau de Bacharel em Ciênciada Computação pela Universidade Federal doParaná.
Orientador:
Eduardo Todt
DEPARTAMENTO DE INFORMÁTICA
SETOR DECIÊNCIAS EXATAS
UNIVERSIDADE FEDERAL DO PARANÁ
Curitiba - PR, Brasil
Agosto de 2011

Trabalho de Graduação sob o título“Detecção de pedestres em cruzamentos utilizando
características Haar”, defendida por Suellen Jaccon Shimabukuro e Victor de Sousae aprovada
em Agosto de 2011, em Curitiba, Estado do Paraná, pela banca examinadora constituída pelos
professores:
Prof. Dr. Eduardo TodtOrientador
Prof.Universidade Federal do Paraná
Prof.Universidade Federal do Paraná

Resumo
A detecção de pedestres tem se mostrado vital para os Sistemas de Apoio ao Motorista àmedida que pode alertar e auxiliar na prevenção de colisões entre veículos e pessoas, além deapoiar sistemas de segurança detectando a presença de humanos em locais restritos.
Neste trabalho realizamos o estudo das principais técnicasde detecção de pedestres, emparticular de um método que se utiliza de características Haar para encontrar os objetos deinteresse. Foi implementado um sistema detector de pedestres em cruzamentos de ruas, examinandoo comportamento e acurácia do método. O sistema valeu-se de uma etapa de aprendizadobaseado no algoritmoAdaBoostcom imagens retiradas de cenas reais e obteve um desempenhodentro do esperado, reconhecendo 57,04% dos 1080 pedestrespresentes nas imagens de testesapós o tratamento das imagens e detecção de movimento.
Palavras-chaves: Detecção de Pedestre, Características Haar, Classificador de Regras, CascataHaar.

Dedicatória
Oferecemos essa vitória aos nossos pais, Gilda Mari Jaccon Shimabukuro, Paschoal Shimabukuro,
Danielle Castilho de Sousa e Luiz Carlos de Sousa. Vocês são nossos heróis, exemplo de
dedicação, superação, força e coragem.
Aos nossos irmãos, familiares, amigos e amores pela cumplicidade e compreensão pela
ausência em suas vidas, muitas vezes necessárias para a realização deste sonho.
Todo o nosso carinho e reconhecimento!

Agradecimentos
Primeiramente a Deus, que sempre esteve ao nosso lado, nos dando força, paciência e
iluminando os nossos passos para que pudéssemos superar cada obstáculo.
Ao nosso Professor Eduardo Todt, que com sua experiência nosorientou para que a realização
deste trabalho fosse possível.
E por fim, à Michelle Shimabukuro Zanolla que com seu conhecimento nos possibilitou
compor este documento de forma mais fácil e descomplicada.
O nosso muito obrigado!

Sumário
Lista de Figuras
Lista de Tabelas
1 Introdução p. 9
1.1 Objetivo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 10
1.2 Justificativa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 11
1.3 Metodologia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p.11
1.4 Estrutura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p.12
2 Trabalhos Relacionados p. 13
3 Implementação p. 15
3.1 Características Haar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. p. 15
3.2 Aprendizado Adaboost e o Classificador em Cascata . . . . . . . .. . . . . p. 18
3.3 Tratamento das imagens . . . . . . . . . . . . . . . . . . . . . . . . . . . .p. 20
3.4 Detecção de pedestres em cruzamentos . . . . . . . . . . . . . . . .. . . . . p. 21
4 Experimentos e Resultados p. 24
5 Discussão e Conclusão p. 27
5.1 Conclusões . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 27
5.2 Trabalhos Futuros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .p. 28
Referências Bibliográficas p. 29

Lista de Figuras
3.1 Características Haar [Paul Viola e Michael Jones 2001] . .. . . . . . . . . . p. 15
3.2 Médias de intensidade em tons de cinza [Michael Oren et al. 1997] . . . . . p. 17
3.3 (a) Valor da Imagem Integral no ponto(x,y) é a soma das intensidades de
todos os pixels acima e à esquerda do ponto. (b) Cálculo da somada intensidade
dos pixels do retângulo D. [Paul Viola e Michael Jones 2001] .. . . . . . . p. 18
3.4 Quadros de imagens presentes na base [CVC02 2010] . . . . . . . .. . . . p. 21
3.5 Imagem de fundo (estática) à esquerda e quadro de detecção (dinâmico) à
direita [CVC02 2010] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 22
4.1 Exemplo de detecção de 2 pedestres e a presença de um falsopositivo e de
um falso negativo (com oclusão parcial) com imagem do conjunto 1. Imagem
de [CVC02 2010] e marcação produzida pelo sistema implementado. . . . . p. 25
4.2 Exemplo de detecção de 2 pedestres e 2 falsos negativos (um deles com
oclusão parcial) com imagem do conjunto 6. Imagem de [CVC02 2010]
e marcação produzida pelo sistema implementado. . . . . . . . . .. . . . . p. 25
4.3 Porcentagem de acertos, de falsos positivos e de falsos negativos em cada
conjunto de teste. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 26

Lista de Tabelas
1.1 Causas de acidentes [DPRF 2007] . . . . . . . . . . . . . . . . . . . . . . .p. 11
3.1 Intensidade média (imagem negativa) [Michael Oren et al. 1997] . . . . . . p. 16
3.2 Intensidade média (imagem positiva) [Michael Oren et al. 1997] . . . . . . . p. 17
4.1 Resultados por conjunto de imagens . . . . . . . . . . . . . . . . . . .. . . p. 26

9
1 Introdução
O reconhecimento de objetos tem sido amplamente estudado naárea de Visão Computacional,
com destaque para o reconhecimento de pessoas [Paul Viola e Michael Jones 2001] [Michael
Oren et al. 1997] [S. Munder e D.M. Gavrila 2006] [Bastian Leibe et al. 2002] [S. Alvarez et al.
2009] [Navneet Dalal e Bill Triggs 2005] [Xiaoyu Wang, Tony X.Han e Shuicheng Yan 2009].
O seu uso pode ser observado em diversas aplicações de vigilância, em sistemas de contagem e
controle de fluxo de pessoas e nos sistemas de auxílio ao motorista.
A detecção de pedestres consiste na constatação da presençade um pedestre em uma
imagem e, posteriormente, na localização de sua posição relativa na imagem. A detecção de
pessoas de forma genérica enfrenta alguns desafios inerentes à sua natureza. Pessoas possuem
formas e tamanhos diferentes, utilizam roupas com cores e texturas muito variadas, além da
presença de acessórios (bonés, bolsas, dentre outros). No contexto de pessoas em trânsito,
somam-se a esses desafios a complexidade dos cenários, a grande variação de iluminação e
escala, a oclusão parcial ocasionada por outros elementos do cenário e a variedade de posições
que os pedestres podem assumir.
Segundo estudos recentes do grupo Transportation For America (TFA), aproximadamente
47 mil pedestres morreram e mais de 688 mil ficaram feridos entre 2000 e 2010 somente nos
Estados Unidos [Transportation For America 2011]. Este estudo mostra ainda que a maioria
das mortes aconteceu nas vias arteriais, as quais, em geral,são projetadas para agilizar o tráfego
de veículos em detrimento de estruturas seguras para pedestres, ciclistas e cadeirantes.
Recentemente surgiu na Europa a preocupação com a segurança dos pedestres na manufatura
dos carros. O instituto Euro NCAP avalia as questões de segurança de um veículo, mensurando
possíveis colisões frontais, laterais e contra pedestres através de rígidos testes e simulações
[EURONCAP 2011]. De acordo com o instituto, os consumidores estão cada vez mais preocupados
com a segurança dos ocupantes do veículo e dos demais usuários da via, como os pedestres,
considerando o potencial das tecnologias avançadas de assistência ao motorista. Para a América
Latina há o Instituto Latim NCAP, que tem feito testes de colisões e avaliado o impacto sobre

1 Introdução 10
os ocupantes dos veículos utilizados nos países da América Latina [LATIMNCAP 2011].
O automóvel desde o início da sua invenção, vem sofrendo inúmeras inovações. Muitas
delas completamente despercebidas ao condutor. No início,o automóvel se resumia a um motor,
um chassis, quatro rodas, um volante e um sistema de iluminação. O automóvel dos nossos dias
continua a ter essas mesmas características, porém evoluiude uma máquina completamente
dependentes de ações humanas à um sistema informatizado, que atende cada vez mais às
necessidades e desejos de seus usuários. Tal é essa evoluçãoque temos ao nosso alcance
dispositivos desde travas automáticas à sistemas de auto-estacionamento e frenagem autônoma
[Todt 2009].
Observando a evolução que os automóveis vem sofrendo ao longo dessas décadas, e sabendo
da necessidade de reduzir os altos índices de atropelamento, é importante investir em pesquisas
direcionadas ao desenvolvimento não só de tecnologias voltadas ao conforto, mas também de
inovações focadas na segurança do condutor e de pessoas que estão a sua volta.
Um automóvel, como qualquer outra máquina, exige que o usuário esteja qualificado tecnicamente
para operá-lo de forma segura, porém somente a parte técnicanão garante a total segurança do
condutor e das pessoas que estão à sua volta.
O ser humano ainda é fundamental para guiar o veículo, contudo sabemos que faz parte
da nossa natureza errar. Fatores como cansaço, desatenção,consumo de drogas, desrespeito às
regras de trânsito são alguns dos erros cometidos pelos motoristas e que, segundo relatório
da Polícia Federal, estão entre as principais causas de acidentes nas rodovias como segue
abaixo [DPRF 2007]:
Tabela 1.1: Causas de acidentes [DPRF 2007]NACIONAL - Ano: 2007 - Mês: TODOSCausa Acidentes Índice MortosFalta de atenção 42509 52% 1626Não guardar distância de segurança 8145 10% 71Velocidade incompatível 6027 7% 540Defeito mecânico em veículo 5406 7% 121Animais na pista 4207 5% 102Desobediência a sinalização 4063 5% 289Sono 3367 4% 223Ingestão de álcool 3135 4% 188Ultrapassagem indevida 2843 3% 517Defeito na via 2347 3% 71TOTAL 82049 3748
Com isso, pode-se perceber a importância de pesquisas realizadas com o intuito de agregar

1.1 Objetivo 11
tecnologias avançadas, para promover uma maior segurança na utilização destas máquinas e
assim diminuir a incidência de acidentes envolvendo pedestres.
1.1 Objetivo
O objetivo principal deste trabalho é apresentar os conceitos essenciais que norteiam a
detecção apoiada por característicasHaar, bem como propor um sistema de detecção de pedestres
em cruzamentos para adquirir experiência com o tema, entender as abordagens possíveis e
dificuldades relacionadas.
1.2 Justificativa
Tendo como base os dados apresentados na tabela 1.1, percebe-se que as principais causas
de acidentes estão relacionadas a erros humanos, como por exemplo a falta de atenção, considerado
o maior índice gerador de acidentes, representado com 52% das causas.
Tendo a tecnologia ao nosso alcance, pode-se tentar reduzira incidência de acidentes
envolvendo pedestres utilizando sistemas inteligentes, para que, em meio a uma falha humana,
haja uma intervenção do sistema evitando um possível atropelamento.
1.3 Metodologia
Uma das primeiras dificuldades encontradas no desenvolvimento de um sistema detector de
pedestres é a obtenção de imagens que são necessárias para o treinamento de um classificador
e para a verificação da acurácia do detector. Em geral, as bases de imagens padronizadas são
fechadas, e quando abertas não contém uma quantidade suficientemente grande de exemplos.
Dentre as bases abertas de imagens específicas para pedestres pode-se citar obenchmarkda
Daimler-Chryslere a base CVCVirtual Pedestrian Datasetque inova ao apresentar bons resultados
utilizando imagens geradas em um ambiente virtual.
Para o desenvolvimento do classificador e do conjunto de testes deste trabalho foi utilizada a
base CVC02 doComputer Vision Centerda Universidade Autônoma de Barcelona [CVC02 2010].
Esta base contém 7666 imagens para treinamento, sendo 1016 imagens de pedestres, ditas
positivas, e 6650 imagens que não apresentam nenhum pedestre e são chamadas imagens negativas.
Além disso, há 15 sequências de 4364 quadros de vídeos capturados com uma câmera de lente
focal 6mm nos arredores de Barcelona, Espanha. Essas imagenscontém 7983 pedestres em

1.4 Estrutura 12
variadas posições e escala e alguns de seus subconjuntos foram escolhidos para a realização dos
testes deste trabalho.
O treinamento foi feito através de uma adaptação do algoritmo de Aprendizado de Máquina
AdaBoostproposto por [Paul Viola e Michael Jones 2001] utilizando o utilitário opencv-training
e tendo como entrada 1016 imagens positivas e 4916 imagens negativas.
O sistema detector proposto varre a imagem procurando por característicasHaar em janelas
inicialmente de tamanho 12x24 pixels e que variam sua escalaem 10 por cento até encontrar
objetos de interesse, caso eles existam. Ao final do processo, os pedestres presentes na imagem
são marcados com um retângulo colorido.
O funcionamento do sistema foi validado por meio de um processo manual de contagem
de pedestres. As imagens de teste foram segredadas daquelasutilizadas no treinamento e
rotuladas com o número de pedestres presentes. Após a execução do programa, as imagens de
teste marcadas foram armazenadas e então verificadas manualmente quais marcações estavam
corretas.
1.4 Estrutura
Este documento convenientemente foi dividido em 5 partes: (1) Apresentação do Tema; (2)
Trabalhos Relacionados; (3) Implementação; (4) Experimentos e Resultados; (5) Discussão e
Conclusão.

13
2 Trabalhos Relacionados
Este capítulo mostra o trabalho de alguns pesquisadores da Visão Computacional, na área
de detecção de pedestres, conforme encontrado na literatura em pesquisas noWeb of Science,
IEEE XploreeACM Digital Library.
Existem várias tentativas de resolver o problema da detecção de objetos no contexto da
Visão Computacional. Há abordagens apoiadas por dispositivos a laser e outros sensores que
têm produzido resultados significativos [Beckwith 1997], contudo, neste trabalho, as pesquisas
estarão voltadas para a detecção de pedestres através do espectro visível, isto é, que pode ser
capturado pelo olho humano.
No campo de estudo baseado em visão monocular, a abordagem mais simples consiste em
percorrer uma imagem pixel a pixel casando padrão com uma imagem modelo preexistente.
Obviamente essa técnica ingênua é inviável no contexto de detecção de pedestres em sistemas
de transporte, por causa das variações na escala, posição, iluminação e, principalmente, por que
o tempo computacional necessário para tal atividade seria elevado e extremamente dependente
do tamanho da imagem de entrada, o que tornaria inviável a incorporação em um sistema de
assistência ao motorista, no qual existe a necessidade da detecção de pedestres em tempo real e
em diversas imagens com variações de escala, iluminação e posição.
Recentemente têm surgido diversos trabalhos baseados em rastreamento [Bastian Leibe
et al. 2002] e em movimento, previamente observado por meio de técnicas de segmentação
de fundo como subtração de imagens, estatísticas ou ainda através da análise de gradientes
resultantes da detecção de bordas [S. Alvarez et al. 2009].
Além disso, há abordagens que utilizam classificadores baseados em histogramas orientados
[Navneet Dalal e Bill Triggs 2005] e [Xiaoyu Wang, Tony X. Han eShuicheng Yan 2009] da
imagem e combinações com outras técnicas, como co-ocorrência [Yuji Yamauchi et al. 2008].
A detecção de objetos através de característicasHaar vem consolidando sua importância
para os sistemas de apoio ao motorista desde que foi propostapor [Michael Oren et al. 1997]no
final da década de 90. Isso deve-se ao seu baixo custo de tempo computacional e à precisão

2 Trabalhos Relacionados 14
dos resultados obtidos, o que é essencial em sistemas de trânsito, nos quais a detecção deve
ser feita em tempo real. A abordagem baseada em característicasHaar foi aprimorada por
[Paul Viola e Michael Jones 2001] através de uma representação intermediária da imagem, chamada
"Imagem Integral", da adaptação de um algoritmo de aprendizado AdaBooste de um método
que combina classificadores em uma cascada.
Pode-se citar ainda as abordagens que são baseadas em componentes de pedestres, como
partes do corpo [Amnon Shashua, Yoram Gdalyahu e Gaby Hayun 2004] e formatos anatômicos
segregados geometricamente [Mykhaylo Andriluka, Stefan Roth e Bernt Schiele 2008].
Outros autores têm trabalhado com combinações de vários métodos [S. Munder e D.M.
Gavrila 2006], [Markus Enzweiler et al. 2010] e [Paul Viola,Michael J. Jones e Daniel Snow
2003], a fim de aproveitar as vantagens de cada um e de mensurara precisão de detecção das
diversas técnicas [Piotr Dollar et al. 2009].
Tendo em vista a ampla gama de opções diferentes encontradasna literatura, optou-se
pelas característicasHaar, que é uma das abordagens mais simples e que tem produzido bons
resultados [Paul Viola e Michael Jones 2001], combinadas com a detecção de movimento [S.
Alvarez et al. 2009] [Bastian Leibe et al. 2002] na tentativa de reduzir falsos positivos.

15
3 Implementação
Este capítulo descreve o sistema piloto implementado, bem como as características empregadas
na detecção.
3.1 Características Haar
As característicasHaar são a base da detecção de pedestres utilizada neste trabalho. Ela
consiste na diferença de intensidade entre regiões retangulares de uma imagem. As relações
entre as diferentes regiões são expressas como restrições sobre os valores dos coeficientes.
Essas características foram baseadas no trabalho do matemático húngaro Alfred Haar de 1909,
a Transformada de Haar, que pode ser utilizada na representação de uma função.
Figura 3.1: Características Haar [Paul Viola e Michael Jones2001]
Dentre as vantagens do uso das característicasHaar pode-se citar a eficiência computacional,
a independência de escala e cor, a baixa variedade intra-classes, a alta variação inter-classes e o
fato de ser orientada a diferença de intensidades locais. Asrelações mútuas de intensidade de
várias regiões pouco varia à medida que a intensidade absoluta de diferentes regiões da imagem
muda drasticamente [Michael Oren et al. 1997].

3.1 Características Haar 16
As diferenças de intensidades entre regiões da imagem podemser computadas facilmente
utilizando-se as característicasHaar descritas na figura 3.1. A aplicação de uma função que
calcule a diferença entre regiões pode mostrar certos padrões de mudança nas subregiões da
imagem, indicando que há uma mudança drástica (bordas) ou que a região é uniforme. Imagens
que representam ambientes não controlados aleatórios, isto é, sem a presença de pedestres,
tendem a apresentar um padrão desordenado nas médias calculadas pela funçãoHaar, enquanto
que imagens que contém pedestres, apresentam um certo padrão, criado principalmente pelo
contraste do corpo do pedestre com o fundo do cenário e pela consistência das regiões internas
ao corpo humano como pode ser observado nas tabelas 3.1 e 3.2.
Tabela 3.1: Intensidade média (imagem negativa) [Michael Oren et al. 1997]1.18 1.14 1.16 1.09 1.111.13 1.06 1.11 1.06 1.071.07 1.01 1.05 1.03 1.051.07 0.97 1.00 1.00 1.051.06 0.99 0.98 0.98 1.041.03 0.98 0.95 0.94 1.010.98 0.97 0.96 0.91 0.980.98 0.96 0.98 0.94 0.991.01 0.94 0.98 0.96 1.011.01 0.95 0.95 0.96 1.000.99 0.95 0.92 0.93 0.981.00 0.94 0.91 0.92 0.961.00 0.92 0.93 0.92 0.96
Tabela 3.2: Intensidade média (imagem positiva) [Michael Oren et al. 1997]0.62 0.74 0.60 0.75 0.660.76 0.92 0.54 0.88 0.811.07 1.11 0.52 1.04 1.151.38 1.17 0.48 1.08 1.471.65 1.27 0.48 1.15 1.711.62 1.24 0.48 1.11 1.631.44 1.27 0.46 1.20 1.441.27 1.38 0.46 1.34 1.271.18 1.51 0.46 1.48 1.181.09 1.54 0.45 1.52 1.080.94 1.38 0.42 1.39 0.930.74 1.08 0.36 1.11 0.720.52 0.74 0.29 0.77 0.50
Esses padrões podem ser melhor observados na figura 3.2, adaptada de [Michael Oren et al.
1997], na qual (a) representa os coeficientes verticais de uma imagem negativa e (b), (c) e (d)

3.1 Características Haar 17
representam os coeficientes obtidos da aplicação de característicasHaar vertical, horizontal e
de cantos em uma imagem positiva dimensionada para 16 x 16.
Figura 3.2: Médias de intensidade em tons de cinza [Michael Oren et al. 1997]
Tendo em vista o grande custo computacional de varrer uma imagem aplicando vários tipos
de característicasHaar em diversas escalas, [Paul Viola e Michael Jones 2001] criaram uma
representação intermediária da imagem, chamada de Imagem Integral, que pode ser computada
através de poucas operações por pixel e, uma vez calculada, pode ser obtida em qualquer escala
em tempo constante.
Para o cálculo da imagem integral, considere um ponto (x,y) qualquer em uma imagem
arbitrária relaciona-se com seu valor na imagem integral através do somatório de todos os pixels
acima e à esquerda de (x,y), incluindo o próprio ponto. Destaforma, os valores dos coeficientes
da imagem integral podem ser calculados com uma simples varredura na imagem original.
Segundo [Paul Viola e Michael Jones 2001], é possível calcular o valor de intensidade de um
pixel da imagem integralI(x,y) sendo: I(x,y) = o(x,y) + I(x-1,y) + I(x,y-1) - I(x-1,y-1), onde
o(x,y)é o pixel na imagem original.
A figura 3.3(b), extraída de [Paul Viola e Michael Jones 2001], mostra que é possível calcular
o valor da intensidade dos pixels interiores do retângulo D como 4 + 1 - (2 + 3), uma vez que 1
é a soma dos pixels que estão dentro do retângulo A, 2 é A + B, 3 é A +C e 4 é A + B + C + D.
Com isso, obtém-se uma forma rápida e eficiente do ponto de vista computacional de calcular
as característicasHaar de uma imagem.

3.2 Aprendizado Adaboost e o Classificador em Cascata 18
Figura 3.3: (a) Valor da Imagem Integral no ponto(x,y) é a soma das intensidades de todos ospixels acima e à esquerda do ponto. (b) Cálculo da soma da intensidade dos pixels do retânguloD. [Paul Viola e Michael Jones 2001]
3.2 Aprendizado Adaboost e o Classificador em Cascata
Uma vez de posse de um conjunto robusto de características é preciso utilizar um algoritmo
de aprendizado que seja capaz de reconhecer as característicasHaar em uma imagem. O
algoritmo AdaBoost (Adaptive Boosting), que dispõe de um conjunto de classificadores pré-
treinados e um conjunto de avaliação, retro-alimenta os pesos de avaliação dos classificadores
já existentes, atualizando a probabilidade da ocorrência de um evento. O algoritmo realiza essa
tarefa combinando regras simples de treinamento [Freund e Schapire 1995].
O propósito original do algoritmo AdaBoost é de refinar o desempenho de um outro algoritmo
de classificação mais simples, selecionando um pequeno número de características que sejam
significativamente variadas para que possam representar o conjunto todo.
Durante o processamento, em uma janela qualquer da imagem analisada, pode haver muitas
característicasHaar. O número de características é, em geral, bem maior que o número de
pixels daquela região. Então, faz-se necessária uma seleção prévia das características mais
importantes por parte do classificador, denominado classificador fraco, que relaciona-se com
uma única característica e concentra-se na mesma. Os pesos de classificação são ajustados para
que os classificadores posteriores possam analisar os resultados anteriores e classificar de forma
mais refinada.
Com o intuito de reduzir o tempo computacional e melhorar o desempenho da detecção,
[Paul Viola e Michael Jones 2001] propuseram um modelo de classificadores em cascata, no
qual, classificadores mais simples avaliam sub-janelas da imagem, rejeitando aquelas que são
explicitamente negativas, isto é, sem a presença de um elemento que possa vir a ser um pedestre.
Posteriormente, os classificadores mais especializados e,portanto, mais complexos, avaliam a
presença de um pedestre somente nas sub-janelas não negativas da imagem, que são previamente

3.2 Aprendizado Adaboost e o Classificador em Cascata 19
conhecidas.
Esta idéia está baseada na pequena amostragem de sub-janelas positivas de uma imagem.
Portanto, é razoável que classificadores simples descartemessas regiões precocemente. O
classificador de um nível posterior é treinado para reconhecer todas as características dos níveis
anteriores, logo, sua tarefa é mais complexa e demanda mais tempo computacional que o
classificador anterior. Desta forma, os classificadores de níveis profundos analisam menos
regiões, uma vez que as regiões negativas são descartadas noinício do processo pelos classificadores
anteriores. Um efeito colateral desse procedimento é que osclassificadores em cascata muito
profundos têm uma taxa de falsos positivos equivalentemente alta.
Para realizar o aprendizado com as imagens deste trabalho foi utilizada a ferramentaopencv-
haartraining, distribuída juntamente com a bibliotecaOpenCV. Para o treinamento foram utilizados
1016 amostras de pedestres dimensionados em imagens de 12 x 24 pixels espelhadas simetricamente
e 3000 imagens aleatórias de dimensões variadas e que não continham pedestres. Os seguintes
parâmetros foram aplicados:
opencv-haartraining -data Haarcascade -vec samples.vec -bg negatives.dat -nstages 18 -
minhitrate 0.999 -maxfalsealarm 0.5 -npos 2032 -nneg 3000 -w 64 -h 128 -nonsym -mem 768
-mode ALL
Significando:dataé o diretório de trabalho onde as informações classificador ficarão armazenadas;
samples.vecé o arquivo que contém as amostras positivas simétricas agrupadas pelo aplicativo
opencv-createsamples, também disponibilizado juntamente com a bibliotecaOpenCV; negatives.dat
é o arquivo que contém informações das imagens negativas, como sua localização e dimensão;
nstagesé o número máximo de estágios do classificador, que não será atingido caso todas as
amostras sejam rejeitadas em um estágio intermediário ou ainda se ultrapassou o índice de
acerto mínimo desejado (minhitrate); maxfalsealarmé a taxa máxima de alarmes falsos;npose
nnegsão a quantidade de imagens positivas e negativas, respectivamente;w eh são as dimensões
das imagens positivas; a opçãononsymé utilizada quando não há simetria vertical entre as
classes de objeto;memé a quantidade de memória principal em Megabytes disponível; a opção
mode ALLusa o conjunto completo de característicasHaar, inclusive as rotacionadas em 45
graus.
No presente trabalho, a técnica do classificador em cascata éutilizada com um parâmetro de
18 níveis de classificadores, segundo sugestão de [Paul Viola e Michael Jones 2001], por dois
motivos. O primeiro deles é o tempo computacional necessário para construir um classificador
eficiente com o número de amostragem de pedestres disponível. O treinamento desse classificador,
feito com 1016 imagens espelhadas, totalizando 2032 imagens positivas e 3000 imagens negativas,

3.3 Tratamento das imagens 20
levou cerca de 72 horas para terminar, executando em uma máquina com processador Intel i3
64 bits 2.27GHz, 4GB de memória e sistema operacional Ubuntu10.04. Além disso, o tempo
computacional na detecção de pedestres tende a aumentar proporcionalmente a profundidade
de cascata. O segundo motivo foi um balenceamento empírico na taxa de falsos positivos, uma
vez que esta cresce à medida que o número de níveis aumenta.
3.3 Tratamento das imagens
Como mencionado na seção que apresenta a metodologia, este trabalho utilizou 7666 imagens
da base CVC02 para testes de detecção e 1016 para o desenvolvimento de um classificador
eficiente. Essas imagens foram obtidas na cidade de Barcelona, Espanha, em ambientes urbanos
não-controlados, isto é, desordenados. Com isso, deseja-seobter uma detecção próxima dos
ambientes reais encontrados numa situação típica de um sistema de apoio ao motorista.
As imagens positivas utilizadas no treinamento do classificador foram todas redimensionadas
para 12x24 enquanto as imagens negativas possuíam tamanhosaleatórios. Uma vez que as
característicasHaar são invariantes à cor, todas as imagens foram transformadaspara tons de
cinza para efeitos de treinamento. Nos testes de detecção asimagens de entrada são coloridas,
contudo, posteriormente elas são convertidas para escala de cinza para facilitar a detecção e,
uma vez detectados os pedestres, estes são marcados na imagem colorida correspondente, que
é a imagem de saída.
O conjunto de imagens de teste contém 1016 pedestres nas maisvariadas posições, vestidos
com roupas e acessórios distintos e de cores variadas. As condições de iluminação e posição
também varia bastante nas imagens, a fim de representar fielmente um ambiente real. Essas
imagens foram espelhadas com o intuito de variar ainda mais aposição dos pedestres e o
resultado foi um conjunto de 2032 imagens positivas simétricas dimensionadas para o padrão
de janela que seria usado na fase de detecção.
As imagens de teste de detecção estavam todas no formato PNG (Portable Network Graphics),
eram coloridas e tinham 640 pixels de largura por 480 de altura. As imagens retratam cenas
reais de tráfego urbano capturadas por um carro em movimento. Apenas as imagens que
representavam o momento de parada de um veículo em um cruzamento foram analisadas. Com
isso, foi possível aplicar uma técnica de detecção de movimento para reduzir ainda mais o
escopo de busca de pedestres na imagem.
A remoção do fundo é utilizada para este fim. Essa técnica foi simplificada para não
interferir negativamente no tempo computacional da detecção de pedestres, uma vez que é feito

3.4 Detecção de pedestres em cruzamentos 21
Figura 3.4: Quadros de imagens presentes na base [CVC02 2010]
um pré-processamento on-line de cada quadro da imagem. Essaremoção se dá pela subtração
de cada quadro da imagem de fundo original e estática. Tanto as imagens individuais de cada
quadro como a imagem estática de fundo são convertidas para escala de cinza e suavizadas
por meio de de um filtro Gaussiano. À imagem resultante dessa subtração pixel a pixel é
aplicado uma operação morfológica conhecida como erosão e uma binarização por meio das
funçõescvErode()e cvThreshold(), respectivamente, da biblioteca OpenCV. Com isso, tem-se
uma imagem uniforme que representa objetos em movimento no cenário.
3.4 Detecção de pedestres em cruzamentos
Uma vez que esse trabalho tem o objetivo de detectar pedestres em cruzamentos e se
propõe a fazê-lo de forma rápida, a área de busca por objetos positivos, isto é, por pedestres,
é reduzida significativamente nas imagens por meio do processo de remoção do fundo e de
homogeneização da imagem.
Para isso, são fornecidas uma imagem de entrada que representa o cenário estático do

3.4 Detecção de pedestres em cruzamentos 22
cruzamento e uma sequência de imagens, ou um vídeo, nas quaisserão detectados e marcados os
pedestres. Ainda é necessário passar como parâmetro o arquivo xml que contém o classificador
em cascata produzido no processo de aprendizado. As imagensde entrada sofrem as transformações
descritas na seção de tratamento das imagens, como conversão para escala de cinza, suavização
e remoção do fundo.
Figura 3.5: Imagem de fundo (estática) à esquerda e quadro dedetecção (dinâmico) à direita[CVC02 2010]
As diversas regiões homogêneas que representam os objetos em movimento na imagem são
obtidas no processo de remoção do fundo. Isso reduz o espaço de busca consideravelmente e,
portanto, diminui o tempo de processamento. O sistema transforma essas regiões homogêneas
em retângulos através da funçãocvFindContours()da bibliotecaOpenCV. Os pedestres serão
procurados somente nos espaços que correspondem às áreas internas desses retângulos homogêneos.
Os retângulos pequenos, isto é, menores que 12 x 24, são eliminados por serem considerados
ruído de um fenômeno conhecido como "salt and pepper".
Uma sub-janela com 12 pixels de largura e 24 pixels de altura éajustada no canto superior
esquerdo de cada retangulo representante da região homogênea previamente calculada. A
função da bibliotecaOpenCV cvhaarDetectObjects()procura por característicasHaar na sub-
janela especificada - que é incrementada por um fator de 10% nas avaliações subsequentes.
Segundo [Paul Viola e Michael Jones 2001], dimensionar a janela de busca de características é
mais eficiente do que reescalar toda a imagem para localizar objetos em diferentes escalas.
Ainda é usado uma técnica que diminui ainda mais a carga computacional, a poda Canny,
que evita regiões negativas por meio da aplicação de um filtrode bordas. A janela se move
através das regiões homogêneas da imagem, da esquerda para adireita e de baixo para cima, até
percorrer toda a região homogênea. Após uma varredura completa, a janela tem seu tamanho
incrementado em 10% e o processo é repetido.
Quando é encontrada alguma característica, a região é guardada para posterior avaliação e
marcação do pedestre. Ao final do processo, as diversas regiões ditas positivas são agrupadas,

3.4 Detecção de pedestres em cruzamentos 23
incluindo aquelas que estão sobrepostas. Um retângulo colorido é desenhado na imagem de
saída na região correspondente ao pedestre encontrado.

24
4 Experimentos e Resultados
Este capítulo descreve os experimentos realizados com o sistema detector de pedestres e
aponta os resultados de desempenho obtidos.
Para a realização dos experimentos primeiramente foi realizada a etapa de aprendizado
do classificador. Segundo [Tutorial OpenCV 2006], são necessárias 5000 imagens positivas,
ou seja, no caso deste experimento imagens contendo somentepedestres, e 3000 imagens
negativas. Devido ao tempo e a dificuldade para coletar e tratar as imagens e, pricipalmente
para produzir um classificador eficiente, utilizou-se para fins de experimento somente 2032
imagens positivas, encontradas na base de imagens CVC02 citada anteriormente.
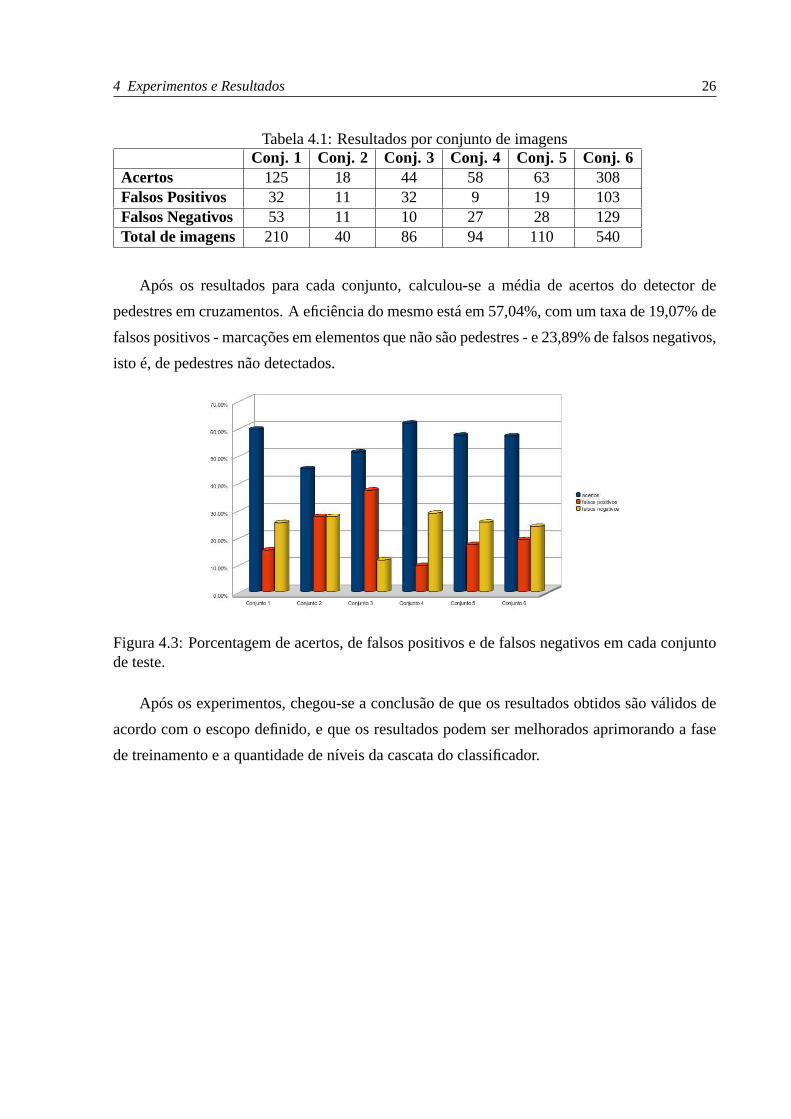
Percebe-se no gráfico da figura 4.3 que a redução de imagens para a etapa de treinamento
gera um impacto significativo na segunda etapa, a de detecçãodos objetos de interesse nas
imagens testadas, mais especificamente nos índices de acerto e nos índices de falsos negativos
obtidos, devido ao classificador não conter informações suficientes para a tarefa de detectar um
padrão em meio aos pixels da imagem.
Outro ponto relevante é quanto ao número de estágios do classificador, que impacta diretamente
nas porcentagens de falsos positivos. Quanto maior o númerode estágios, maior também será
a quantidade proporcional de falsos positivos gerada pelo classificador, que não produzirá bons
resultados. Como apresentado na seção 3.2, utilizou-se uma cascata de 18 níveis, por questões
de tempo computacional e de desempenho. A escolha da quantidade de níveis teve também
como base a análise dos índices de acerto, falsos positivos efalsos negativos, com a finalidade de
alcançar o melhor resultado, tendo em vista a fase de treinamento do classificador ter recebido
um número de imagens insuficientes.
Pode-se observar os resultados apresentados através das figuras 4.1 e 4.2. Na figura 4.1
houve uma taxa de acerto de 66% pois foram detectados 2 dos 3 pedestres presentes na imagem.
Já na figura 4.2 obtivemos um índice de 50% de acerto, pois dentre os quatro pedestres presentes
na imagem, o classificador obteve sucesso em localizar dois deles. Observa-se também que
neste exemplo há uma marcação considerada falso positivo, logo acima do carro e dois casos de

4 Experimentos e Resultados 25
falso negativo, no canto direito.
Figura 4.1: Exemplo de detecção de 2 pedestres e a presença deum falso positivo e de umfalso negativo (com oclusão parcial) com imagem do conjunto1. Imagem de [CVC02 2010] emarcação produzida pelo sistema implementado.
Figura 4.2: Exemplo de detecção de 2 pedestres e 2 falsos negativos (um deles com oclusãoparcial) com imagem do conjunto 6. Imagem de [CVC02 2010] e marcação produzida pelosistema implementado.
Para a avaliação dos resultados foram escolhidos 6 conjuntos de imagens da base de dados.
Os conjuntos continham, respectivamente, 210, 40, 86, 94, 110 e 540 quadros de imagens.
Todos os conjuntos representavam cenas de pedestres em um cruzamento. Nota-se um aumento
na taxa de falsos positivos naqueles conjuntos onde há abundância de estruturas verticais (postes,
árvores, entre outros). Já as altas taxas de falsos negativos podem ser observadas nos conjuntos
em que a apresentação de pedestres se dá em meio a oclusões parciais ou quando os pedestres
estão distantes, ocasionando uma baixa resolução da regiãohomogênea.
4 Experimentos e Resultados 26
Tabela 4.1: Resultados por conjunto de imagensConj. 1 Conj. 2 Conj. 3 Conj. 4 Conj. 5 Conj. 6
Acertos 125 18 44 58 63 308Falsos Positivos 32 11 32 9 19 103Falsos Negativos 53 11 10 27 28 129Total de imagens 210 40 86 94 110 540
Após os resultados para cada conjunto, calculou-se a média de acertos do detector de
pedestres em cruzamentos. A eficiência do mesmo está em 57,04%, com um taxa de 19,07% de
falsos positivos - marcações em elementos que não são pedestres - e 23,89% de falsos negativos,
isto é, de pedestres não detectados.
Figura 4.3: Porcentagem de acertos, de falsos positivos e defalsos negativos em cada conjuntode teste.
Após os experimentos, chegou-se a conclusão de que os resultados obtidos são válidos de
acordo com o escopo definido, e que os resultados podem ser melhorados aprimorando a fase
de treinamento e a quantidade de níveis da cascata do classificador.

27
5 Discussão e Conclusão
Este capítulo trata das conclusões e das melhorias e incorporações futuras que poderão ser
feitas no sistema.
5.1 Conclusões
O tema é extremamente complexo. Entendemos que este trabalho é um ponto de partida
para um estudo mais profundo envolvendo técnicas mais eficientes. A realização deste projeto
possibilitou não somente o aprendizado da técnica aplicada, Cascata Haar, mas também pôde-
se observar a importância do tema principal, que é a Detecçãode Pedestres. Um sistema de
bordo que auxilie o motorista de tal forma a diminuir os erroscometidos pelo mesmo, pode sim
reduzir a incidência de acidentes, garantindo a segurança tanto de pedestres quanto das pessoas
que estão no veículo.
A maior dificuldade neste projeto foi a etapa de treinamento da cascata de classificadores.
Para que o classificador tenha uma precisão ótima é necessário o treinamento com mais imagens,
o que ocasiona um aumento no tempo do processamento para a criação da cascata. Como
consequência à essa redução, obteve-se um classificador coma acurácia não tão elevada.
Outro motivo para o qual obteve-se esses resultados, refere-se tanto à qualidade das imagens
utilizadas, quanto ao tamanho empregado na etapa de treinamento. Foram realizadas várias
tentativas de redimencionamento do tamanho da imagem afim deque a fase de treinamento
pudesse ser concluída. As imagens positivas, que já não eramtão nítidas, foram redimensionadas
para o tamanho 12x24, ocasionando uma perda significativa deinformações que poderiam ser
úteis ao classificador.
Apesar dos empecilhos encontrados, obtivemos êxito no objetivo definido anteriormente.
Realizou-se um estudo mais a fundo dos conceitos essenciais ao tema Detecção de Pedestres,
bem como a implementação do sistema proposto, baseado em CaracteríscasHaar.

5.2 Trabalhos Futuros 28
5.2 Trabalhos Futuros
Devido aos problemas encontrados principalmente na etapa de apredizado do classificador,
uma forma de aprimoar a robustez do sistema é focar principalmente nas imagens que o treinamento
utiliza para a formação das cascatas.
Uma possibilidade seria incluir uma etapa de coleta das imagens necessárias, ao invés de
realizar uma busca nas bases de imagens existentes. Nesta fase, deve-se considerar locais
apropriados e equipamentos de qualidade, para que as imagens capturadas sejam adequadas
ao estudo em questão.
Um dos pontos que neste trabalho tornou-se negativo para a obtenção de um classificador
eficiente, foi com relação ao tamanho das imagens positivas utilizadas na fase de treinamento.
Para processar imagens de tamanhos mais adequados, é necessário um computador com maior
poder de processamento. Assim, o classificador poderá retirar mais informações das imagens,
melhorando então o seu desempenho.
Um sistema de detecção de pedestres deve ser um sistema de processamento em tempo
real. Portanto, após as melhorias propostas ao sistema, e a realização dos devidos testes em
imagens estáticas, como vem-se fazendo neste estudo, pretende-se realizar a implementação de
um sistema mais completo, composto também por uma câmera, para que este seja realmente
utilizado. A idéia é que um sistema aprimorado seja incorporado a um veículo para detecção
on-line de pedestres ao aproximar-se de um cruzamento, emitindo um alerta ao condutor com o
objetivo de auxiliar a prevenir a principal causa dos acidentes, que é a falta de atenção.

29
Referências Bibliográficas
[Amnon Shashua, Yoram Gdalyahu e Gaby Hayun 2004]Amnon Shashua; Yoram Gdalyahu;Gaby Hayun. Pedestrian Detection for Driving Assistance Systems: Single-frameClassification and System Level Performance.IEEE Intelligent Vehicles Symposium, 2004,2004.
[Bastian Leibe et al. 2002]Bastian Leibe et al. Pedestrian Detection in Crowded Scenes.Multimodal Interactive Systems, TU Darmstadt, Germany, 2002.
[Beckwith 1997]BECKWITH, D. M. Passive Pedestrian Detection atUnsignalized Crossing.Transportation Research Institute, 1997.
[CVC02 2010]CVC02. 2010. Disponível em: <http://www.cvc.uab.es/adas/>. Acessado em: 29de novembro de 2010.
[DPRF 2007]DPRF. 2007. Disponível em: <http://www.dprf.gov.br/PortalInternet/estatistica.faces>.Acessado em: 22 de maio de 2011.
[EURONCAP 2011]EURONCAP. 2011. Disponível em: <http://www.euroncap.com/home.aspx>.Acessado em: 20 de maio de 2011.
[Freund e Schapire 1995]FREUND, Y.; SCHAPIRE, R. E.A Decision-TheoreticGeneralization of on-Line Learning and an Application to Boosting. 1995.
[LATIMNCAP 2011]LATIMNCAP. 2011. Disponível em: <http://www.latinncap.com/>.Acessado em: 20 de maio de 2011.
[Markus Enzweiler et al. 2010]Markus Enzweiler et al. Multi-Cue Pedestrian ClassificationWith Partial Occlusion Handling.IEEE Conference on Computer Vision and PatternRecognition (CVPR), 2010, 2010.
[Michael Oren et al. 1997]Michael Oren et al. Pedestrian Detection Using Wavelet Templates.Computer Vision and Pattern Recognition 1997, 1997.
[Mykhaylo Andriluka, Stefan Roth e Bernt Schiele 2008]Mykhaylo Andriluka; Stefan Roth;Bernt Schiele. People-Tracking-by-Detection and People-Detection-by-Tracking.IEEE Conf.on Computer Vision and Pattern Recognition 2008, 2008.
[Navneet Dalal e Bill Triggs 2005]Navneet Dalal; Bill Triggs.Histograms of OrientedGradients for Human Detection.International Conference on Computer Vision and PatternRecognition 2005, 2005.
[Paul Viola e Michael Jones 2001]Paul Viola; Michael Jones.Robust Real-time ObjectDetection.Second International Workshop on Statical and Computacional Theories of Vision- Modeling, Learning, Computing and Sampling, 2001.

Referências Bibliográficas 30
[Piotr Dollar et al. 2009]Piotr Dollar et al. Pedestrian Detection: A Benchmark.IEEEConference on Computer Vision and Pattern Recognition, 2009, 2009.
[S. Alvarez et al. 2009]S. Alvarez et al. Vehicle and Pedestrian Detection in esafetyApplications.Proceedings of the World Congress on Engineering and ComputerScience2009, 2009.
[Todt 2009]TODT, E. Vehicular safety technologies and trends. Transportation:Theory and Application, v. 1, n. 1, 2009. ISSN 1946-3111. Disponível em:<http://www.inghum.com/ojs2/index.php/TTAP/article/view/8/29>.
[Transportation For America 2011]TRANSPORTATION For America. 2011. Disponível em:<http://t4america.org/blog/2011/05/24/new-report-and-map-chronicles-the-visceral-reality-of-47000-preventable-pedestrian-deaths/>. Acessado em: 28 de maio de 2011.
[Tutorial OpenCV 2006]TUTORIAL OpenCV. 2006. Disponível em:<http://note.sonots.com/SciSoftware/haartraining.html>. Acessado em: 22 de fevereirode 2011.
[Xiaoyu Wang, Tony X. Han e Shuicheng Yan 2009]Xiaoyu Wang; Tony X. Han; ShuichengYan. An hog-lbp human detector with partial occlusion handling. IEEE 12th InternationalConference on Computer Vision 2009, 2009.
[Yuji Yamauchi et al. 2008]Yuji Yamauchi et al. People Detection Based on Co-occurrenceof Appearance and Spatiotemporal Features.ICPR 2008. 19th International Conference onPattern Recognition 2008, 2008.




















