
Design and Performance of Configurable Endsystem Scheduling Mechanisms
12
Design and Performance of Configurable Endsystem Scheduling Mechanisms Tejasvi Aswathanarayana and Douglas Niehaus Venkita Subramonian and Christopher Gill tejasvi,niehaus @ittc.ku.edu venkita,cdgill @cse.wustl.edu Computer Science and Engineering Computer Science and Engineering University of Kansas, Lawrence, KS Washington University, St. Louis, MO Abstract This paper describes a scheduling abstraction, called group scheduling, that emphasizes fine grain configurabil- ity of system scheduling semantics. The group scheduling approach described and evaluated in this paper provides an extremely flexible framework within which a wide range of scheduling semantics can be expressed, including famil- iar priority and deadline based algorithms. The paper de- scribes both OS and middleware based implementations of the framework, and shows through evaluation that they can produce the same behavior for a non-trivial set of appli- cation computations. We also show that the framework can support application-specific scheduling constraints such as progress, to improve performance of applications whose scheduling semantics do not match those of traditional scheduling algorithms. 1. Introduction Distributed real-time and embedded (DRE) systems are increasingly common across a wide range of application do- mains. Constraints on application behavior in DRE systems are becoming ever more detailed and diverse as the applica- tions become more complex. This trend is illustrated by the range of constraints associated with several application do- mains we have examined recently, including industrial au- tomation, military command and control, and life science laboratory experiment control/management. A key challenge these systems pose for application de- signers is the increasing complexity of the application se- mantics and the resulting difficulty of expressing those se- mantics in terms of commonly available programming mod- els. The scheduling model in particular provides a promi- nent example of this difficulty. The challenge addressed by This work was supported in part by DARPA PCES contract F33615- 03-C-4111 and by NSF EHS contract CCR-0311599. this paper, which is faced by both application and system designers, is that no single scheduling model is adequate for expressing the full range of scheduling semantics for all DRE endsystems. We use the term “DRE endsystem” to re- fer to an individual computational node within a (possibly distributed) DRE system. Traditional DRE endsystem designs generally assume that the underlying OS provides a single scheduling model; typically some form of priority scheduling. DRE endsystem designers have tended to provide a single scheduling model for three major reasons. First, priority scheduling is rela- tively simple to understand and to implement. Second, the execution semantics of many DRE applications are appro- priately expressed in terms of priorities. Third, the range of application semantics for which priority scheduling can be used has been extended by the development of theories for mapping application semantics to priority assignments. Ex- amples of this approach include: rate monotonic [12], ear- liest deadline [12], maximum urgency [19], and least lax- ity [13, 19] schemes. The flexibility of priority scheduling makes it suit- able for the design of many DRE systems. However, endsystem designers have continued to provide this prior- ity scheduling model even when it places an undue burden on the application designers to map application seman- tics directly into priority assignments. For example, Linux by default provides a dynamic priority scheme fairly typ- ical of general purpose systems. It also provides a fixed priority (SCHED FIFO) scheme for use by computa- tions that take precedence over computations within the default scheduling class. While this endsystem schedul- ing model is appropriate for a fairly wide range of appli- cations, priorities are not adequate to express important classes of DRE application semantics such as coordi- nated progress of multiple independently time-varying computations. Endsystem scheduling frameworks have historically in- creased their flexibility by increasing the configurability of low level resource control mechanisms, rather than focus-
-
Upload
independent -
Category
Documents
-
view
1 -
download
0
Transcript of Design and Performance of Configurable Endsystem Scheduling Mechanisms

Design and Performance of ConfigurableEndsystem Scheduling Mechanisms
�
Tejasvi Aswathanarayana and Douglas Niehaus Venkita Subramonian and Christopher Gill�tejasvi,niehaus � @ittc.ku.edu
�venkita,cdgill � @cse.wustl.edu
Computer Science and Engineering Computer Science and EngineeringUniversity of Kansas, Lawrence, KS Washington University, St. Louis, MO
Abstract
This paper describes a scheduling abstraction, calledgroup scheduling, that emphasizes fine grain configurabil-ity of system scheduling semantics. The group schedulingapproach described and evaluated in this paper providesan extremely flexible framework within which a wide rangeof scheduling semantics can be expressed, including famil-iar priority and deadline based algorithms. The paper de-scribes both OS and middleware based implementations ofthe framework, and shows through evaluation that they canproduce the same behavior for a non-trivial set of appli-cation computations. We also show that the framework cansupport application-specific scheduling constraints such asprogress, to improve performance of applications whosescheduling semantics do not match those of traditionalscheduling algorithms.
1. Introduction
Distributed real-time and embedded (DRE) systems areincreasingly common across a wide range of application do-mains. Constraints on application behavior in DRE systemsare becoming ever more detailed and diverse as the applica-tions become more complex. This trend is illustrated by therange of constraints associated with several application do-mains we have examined recently, including industrial au-tomation, military command and control, and life sciencelaboratory experiment control/management.
A key challenge these systems pose for application de-signers is the increasing complexity of the application se-mantics and the resulting difficulty of expressing those se-mantics in terms of commonly available programming mod-els. The scheduling model in particular provides a promi-nent example of this difficulty. The challenge addressed by
� This work was supported in part by DARPA PCES contract F33615-03-C-4111 and by NSF EHS contract CCR-0311599.
this paper, which is faced by both application and systemdesigners, is that no single scheduling model is adequatefor expressing the full range of scheduling semantics for allDRE endsystems. We use the term “DRE endsystem” to re-fer to an individual computational node within a (possiblydistributed) DRE system.
Traditional DRE endsystem designs generally assumethat the underlying OS provides a single scheduling model;typically some form of priority scheduling. DRE endsystemdesigners have tended to provide a single scheduling modelfor three major reasons. First, priority scheduling is rela-tively simple to understand and to implement. Second, theexecution semantics of many DRE applications are appro-priately expressed in terms of priorities. Third, the range ofapplication semantics for which priority scheduling can beused has been extended by the development of theories formapping application semantics to priority assignments. Ex-amples of this approach include: rate monotonic [12], ear-liest deadline [12], maximum urgency [19], and least lax-ity [13, 19] schemes.
The flexibility of priority scheduling makes it suit-able for the design of many DRE systems. However,endsystem designers have continued to provide this prior-ity scheduling model even when it places an undue burdenon the application designers to map application seman-tics directly into priority assignments. For example, Linuxby default provides a dynamic priority scheme fairly typ-ical of general purpose systems. It also provides a fixedpriority (SCHED FIFO) scheme for use by computa-tions that take precedence over computations within thedefault scheduling class. While this endsystem schedul-ing model is appropriate for a fairly wide range of appli-cations, priorities are not adequate to express importantclasses of DRE application semantics such as coordi-nated progress of multiple independently time-varyingcomputations.
Endsystem scheduling frameworks have historically in-creased their flexibility by increasing the configurability oflow level resource control mechanisms, rather than focus-

ing on direct support for the application level resource con-trol requirements. However, this places an undue burden onapplication developers who are then made responsible forexpressing the application-level resource requirements interms of low level mechanisms whose semantics may dif-fer considerably from those of the application.
In this paper we focus on providing an endsys-tem scheduling framework within which we can maximizethe correspondence between the application scheduling se-mantics and the semantics of the endsystem schedulingmodel supporting the application. We call our frame-work “Group Scheduling” (GS) because it emphasizesrepresentation of the groups of computation compo-nents comprising an application. Furthermore, it recog-nizes the diversity of scheduling semantics by permittingeach group to use the scheduling algorithm most appro-priate to the set of components it controls. The DREsystem designer then constructs a scheduler for the sys-tem as a whole through hierarchic composition of groups.
Group Scheduling thus provides an extremely flexiblemodel that can be used to express a wide range of ap-plication and endsystem scheduling semantics. The groupscheduling model emphasizes the ease and clarity withwhich developers can express the scheduling semantics ofthe application in operational terms. Also, as we demon-strate in this paper, the group scheduling model can be im-plemented at both the OS and Middleware levels.
Implementation of the group scheduling model raises anumber of important systems research issues, including: (1)the fidelity with which application resource requirementscan be expressed and enforced, (2) the portability of theframework and its enforcement capabilities across a rangeof OS platforms, and (3) the degree of augmentation ofcommonly available system capabilities required to supportapplication semantics in particular contexts. We addressthese issues in the rest of the paper. However, it is also im-portant to note that in a DRE system, each endsystem mustnot only control access to its local resources, it must alsoparticipate in end-to-end resource allocations for distributedapplication computations crossing endsystem boundaries.In collaboration with colleagues at URI and Ohio Univer-sity, we have developed and evaluated a multi-level schedul-ing and resource management architecture within which ourgroup scheduling framework will be integrated [3].
The rest of this paper first discusses the motivations andchallenges of our work in Section 2, and the essential as-pects of the group scheduling framework in Section 3. Wethen describe details of our middleware group schedulingimplementation in Section 4. Section 5 presents experimen-tal results demonstrating the validity of the claims we havemade about our approach. We then discuss related work inSection 6, and Section 7 presents our conclusions and dis-cusses future work.
2. Motivation and Challenges
Many DRE systems involve a non-trivial number ofcomputations whose activities must be coordinated. Onecommon scenario is sets of computations operating on oneor more streams of data. Each computation can often beviewed as a pipeline of computation components. Examplesof such systems to which the work described here is relevantinclude: multi-channel sensor fusion for DRE systems suchas sensor nets or laboratory science, multi-channel audiodata mixing, or time-critical military applications. Theseand similar classes of applications have a number of com-mon characteristics that we have abstracted into a represen-tative application architecture, which we used in the designand evaluation of our OS and middleware group schedul-ing implementations.
In the rest of this paper we focus on an example,drawn from a canonical video processing challenge prob-lem, which exhibits characteristics emphasizing the needfor flexible scheduling support for many DRE applica-tion areas:
1. Each computation is implemented as a pipeline ofcomputation components operating on a stream of dataelements. These sets of computation components maybe supported on a single computer, or by several com-puters in a distributed system. For the results reportedhere we have concentrated on computations supportedby a single endsystem.
2. Data elements, called frames, move through thepipelines as they are processed.
3. Processing of a frame by a computation componentcan require widely varying CPU time. This is true ofmany applications, but is particularly characteristic ofvideo processing applications.
4. Multiple pipeline computations are supported by theDRE system as a whole. This is an important prop-erty for our experimental evaluations because it makesthe scheduling problem both realistic and sufficientlycomplex to show that priority driven and other popu-lar scheduling algorithms have important limitations.
5. Balanced progress by multiple computations can bean important application requirement. This is trueof many applications which fuse data from sev-eral sources, but is particularly relevant to support-ing multiple video streams that are meant to be viewedconcurrently.
Three kinds of resource contention must be resolved bythe scheduling policies on each DRE endsystem: (1) con-flict between computation components, (2) conflict betweencomputations, and (3) conflict between DRE applicationcomputations and other computations on a given endsys-tem. The group scheduling framework allows DRE system

designers to address these types of conflicts using separategroup representations, and provide an individual schedul-ing policy for each group.
���
���
���������
���������
���
���
���
���
���
���
���
generatestimuli
Threads
Active Objects as computation nodes
using RT−CORBAInput threads
Non−CRITICAL
CRITICAL
Figure 1. Computation pipelines
Our example application consists of a collection of com-putation pipelines as shown in Figure 1. The urgency ofcomputations performed by a pipeline determines the criti-cality of that pipeline. For example, each pipeline could rep-resent a series of image processing computations on an im-age sent by an unmanned aerial vehicle to a shipboard com-puter. If a particular pipeline is identified as containing asensitive image like an enemy battle-tank, that pipeline isdesignated as critical.
There are several interesting performance metrics for thisapplication. First, streams are divided into critical and non-critical classes, with execution of critical class memberstaking strict precedence over that of non-critical streams.Second, the processing of streams within each class must bebalanced in terms of their progress on a stream of frames.This is important for a number of sensor fusion situations,such as when several streams of video will be viewed to-gether. Third, we are interested in the overall frame through-put of the application. Finally, we are also interested in howwell the scheduling framework can partition the CPU re-source used by the pipeline computations from that of othercomputations on the system.
Each pipeline is implemented as a set of active ob-jects [11] under the ACE ORB (TAO)[4]. Each active ob-ject provides a worker thread and a queue on which thework items are placed. The set of frames processed by eachpipeline is created by a thread executed periodically on an-other machine, which is not a member of the set of com-putations under group scheduling control. It is important tonote that a thread within the TAO middleware receives thestream of frames, and must be included in the group thatcontrols the execution of the pipeline to properly controleach computation. We use the RTCORBA features in TAO,including thread-pools [16], to achieve individual control ofeach pipeline. We define a computation stream as a combi-nation of an RTCORBA thread and a pipeline of computa-tion nodes. Thus, a computation stream contains a message
receiver RTCORBA thread and a set of pipeline threads thatprocess each frame. Each frame is received by the compu-tation stream’s RTCORBA thread which waits on a socketthat is used by the frame generating thread for the stream.The nature of the TAO implementation dictates that thesending of a frame by the source thread, through the en-queuing of the frame at the input of the first pipeline stageand the return to the source thread, completes the TAO mes-sage exchange operation. This then permits TAO to startthe execution of the active objects that will pass the framethrough the pipeline.
Note that the example application’s combination of bal-anced progress constraints and variable execution timeis particularly difficult for traditionally popular schedul-ing algorithms to satisfy. For this example application, thegroup scheduling framework allows us to explicitly rep-resent multi-level computation structures as hierarchicallydefined groups and to associate appropriate scheduling de-cision functions with each group. This in turn enablesus to create a representation of the application seman-tics that is both easy to understand and effective duringexecution.
3. Group Scheduling Model
The group scheduling model used to describe thescheduling semantics in this paper is a simple, but im-portant, variation on hierarchical descriptions of schedul-ing that have been developed by several other re-searchers [18, 17, 9]. What distinguishes the groupscheduling framework is (1) an emphasis on group-ing of computation components to represent applicationcomputations, (2) the association of an arbitrary schedul-ing decision function with each group to produce an ex-tremely flexible scheduling framework capable of clearlyand easily expressing a wide range of scheduling seman-tics, and (3) efficient OS and middleware implementationsof the framework in the popular open source Linux plat-form.
3.1. Group Scheduling Implementation Core
A group is defined as a collection of computation com-ponents with an associated scheduling decision function(SDF) that selects from among the group members wheninvoked. Each member of a group can have information as-sociated with it, as required by the SDF. Groups can alsobe members of other groups, thus supporting hierarchicalcomposition of more complex SDFs, culminating in the cre-ation of an SDF for the system as a whole, the system SDF(SSDF). A subset of the computations on a system can beplaced explicitly under SSDF control because both the OSand middleware group scheduling implementations permit

the default OS scheduler to make a decision if the SSDFdoes not make a choice. Computations can be placed un-der exclusive control of the SSDF or under joint control ofthe SSDF and the default OS scheduler.
The group scheduling framework emphasizes modular-ity of the SDF implementations and thus makes it rela-tively easy for users to implement their own SDFs if a li-brary of available functions does not include one matchingthe scheduling semantics they desire. The group schedul-ing framework can subsume many of the popular schedulingmodels by providing matching SDFs (e.g. RMS or EDF).However, it can also support application specific schedul-ing semantics with equal ease, as illustrated by the frame-progress scheduler used to control frame processing bypipelines in Scenario 3 described in Section 5.
The semantics of the OS and middleware implementa-tions of the group scheduling model are the same in mostways, but differ in some important aspects that are describedin the remainder of this section. For example, the applica-tion based specialization of the frame-progress schedulerdepends on information from the application about progresssupplied to the SSDF in a variety of ways. The OS levelgroup scheduling implementation has direct access to muchof the progress information directly, while the middlewarelevel group scheduling implementation requires additionalmechanisms to transmit progress information from the ap-plication to the scheduler.
3.2. OS Level Group Scheduling
The OS level implementation of group scheduling en-joys several advantages over the middleware version. First,it offers direct integrated control over all computation com-ponents in the Linux system, including hardware interrupthandlers, soft interrupt (Soft-IRQ) handlers, tasklets andbottom halves [7]. In contrast, the middleware implementa-tion can only control threads. Second, the overhead of per-forming context switches is lower in the OS implementa-tion because the scheduling decision made by the SSDF andthe actual context switch both occur in the OS context. Themiddleware version must use an indirect mechanism basedon priority manipulation and signals to accomplish the sameobjective. Third, the SDFs have a much wider range of com-putation and system state information available at minimalcost, again because the SSDF executes in OS context.
These advantages enjoyed by the OS implementation arereal but not definitive for the frame processing example im-plementation discussed in this paper. However, other appli-cations involving, for example, integrated group schedul-ing control of interrupt handlers and network protocol pro-cessing, have semantics that can only be implemented un-der the OS group scheduling implementation. One disad-vantage of the OS group scheduling implementation is that
it requires access to the source of the OS, and involves sub-tle modifications to how the OS manages computation com-ponents to produce a unified scheduling framework. To ad-dress these issues, we have also implemented our groupscheduling framework at the middleware level, as we de-scribe next.
3.3. Middleware Level Group Scheduling
The group scheduling API is consistent across mid-dleware and OS implementations, but the mechanismsdiffer because the middleware version requires several util-ity threads, of which the most important are the schedul-ing thread which evaluates the SSDF, and the blockcatcher thread which helps detect state changes of the con-trolled threads. In contrast, these mechanisms are implicitparts of the OS level group scheduling implementa-tion. The API which application code can use to pro-vide scheduler-specific parameters and to constructthe SSDF are based on shared-memory in the middle-ware implementation, as opposed to ioctl based callsin the OS implementation. The most significant limita-tion of the middleware version is that it lacks the easy ac-cess to computation state (RUNNABLE, BLOCKED, etc.)enjoyed by the OS version. Instead the middleware ver-sion must go to some lengths, described in Section 4,to track computation state changes. As shown in Sec-tion 5, the behavior of the application controlled by themiddleware scheduler closely matches that of the applica-tion under OS scheduler control. The middleware versionpays a price in context switch overhead but enjoys the ad-vantage of greater portability since it only depends oncommonly available OS capabilities.
4. Middleware Implementation
This section describes details of the middleware levelgroup scheduling implementation, which are relevant forunderstanding our experimental results for the example ap-plication described in Section 5. In the following discus-sion, we refer to threads under the control of the middlewaregroup scheduler as controlled threads. We used the nativeOS priority model as an enforcement mechanism for the de-cisions made by the SSDF. To achieve this, we used five dif-ferent priority levels as shown in Table 1. MAX PRIO is themaximum priority in the SCHED FIFO scheduling class.
Other than the controlled threads, the group scheduleruses 4 internal threads, listed in Table 1, for its own func-tioning. The Reaper thread helps in shutting down and gain-ing control of the system in case of a faulty group schedul-ing hierarchy. Scheduling is done in the context of the Sys-tem Scheduler Decision Thread (SSDT). The Block Catcherthread helps detect blocking of a controlled task by running

immediately after a controlled task blocks. Requests to thegroup scheduler are handled by an API thread to decouplescheduling data update and scheduling decision execution.
Reaper thread MAX PRIOBlocked Controlled threads MAX PRIO-1GS threads (SSDT and API) MAX PRIO-2Currently Scheduled thread MAX PRIO-3Block Catcher thread MAX PRIO-4Other Controlled threads MAX PRIO-5
Table 1. Middleware GS priority levels
Figure 2. A controlled task blocks
Figures 2 and 3 illustrate the sequence of events that takeplace during blocking and unblocking of a thread. A con-trolled thread is about to make a system call that may causethe thread to block (1). Since we are using the ACE toolkitthat provides a wrapper layer for all system calls, thesechanges were localized and hence this approach is highlyscalable. All system calls that may block are wrapped asfollows.
wrapped_system_call(){before_system_call_hook()system_call()after_system_call_hook()
}
The before system call hook sets the status of the call-ing thread to MAY BLOCK (2). This is to explicitly assistthe scheduler with information about possible blocking. Ifthe thread really blocks, the block catcher thread wakesup, changes the status of the blocked thread to BLOCKED(3). and increases the priority of the blocked thread toMAX PRIO-1 as shown in Table 1. The block catcherthread then wakes up the scheduler thread (4), and thescheduler thread calls the SSDF which picks up the mosteligible thread to run.
After a (possibly blocking) system call returns, its con-trolled thread calls the after system call hook function (5).
Figure 3. A controlled task unblocks
This function ascertains whether or not the thread actuallyblocked on the system call. If the thread had not blocked onthe system call it simply changes its status to RUNNABLEand continues to run. If it did block, it changes its statusfrom BLOCKED to UNBLOCKED, and awakens the sched-uler thread (6) to make a new scheduling decision. Thescheduler then changes the status of the (possibly multi-ple) UNBLOCKED threads to RUNNABLE, so that they areall considered for scheduling. The scheduler then againchooses the most eligible thread to run (7).
aware of unblockingscheduler becomes
did not blockon system call
aware of blockingMAY_BLOCK
RUNNABLE
BLOCKED
UNBLOCKED
thread unblockssystem call
thread really blocksscheduler becomes
Figure 4. State transitions for threads
Figure 4 summarizes the different states of a controlledthread. A thread is in the RUNNABLE state if it is ready torun and is thus an eligible candidate that could be pickedto run by the SSDF. The execution of these threads is con-trolled by sending SIGSTOP and SIGCONT signals. A con-trolled task that is about to make a system call that couldblock, makes a state transition to the MAY BLOCK state. Ifa controlled task really blocked after making a system call,then its state is marked as BLOCKED. Once the system callunblocks the controlled thread starts running again chang-ing its state to UNBLOCKED. The scheduler is informed im-mediately about the unblocking and changes the controlledthread’s state to RUNNABLE again.
5. Evaluation
We now proceed to evaluate our implementation de-scribed in Section 4 in the context of the challenges pro-

vided by the motivating application described in Section 2.The goal of our evaluation is to demonstrate the following:
� the necessity and sufficiency of the group schedulingparadigm;
� that applications may require simple policies whichare nonetheless difficult to express in terms of exist-ing lower level scheduling policies;
� that group scheduling raises the level of abstraction forspecifying application policies so that applications candirectly express their policies in terms of the compu-tation hierarchy offered by the group scheduling pro-gramming model; and
� that efficient implementation of group scheduling mid-dleware is possible, making our solution directly appli-cable to a wide variety of platforms and operating sys-tems.
For this evaluation, we used a random payload to repre-sent an image frame that is being sent by an image source.We state a simple but realistic set of application policy goals(APG) for our example application:
1. preference of critical streams over non-criticalstreams;
2. a computation pipeline is drained as fast as possible;
3. receiving an input frame has preference over frameprocessing in a pipeline; and
4. balanced progress is desired, in terms of the numberof frames processed, among the non-critical streams inthe face of variable computation times for frames pass-ing through the pipeline.
5.1. Qualitative Evaluation
Expressing the above high-level application policies us-ing existing low-level scheduling policies and priority as-signments can be tedious and error-prone. Moreover, staticpolicies are inadequate to express the notion of balancedprogress due to lack of a priori knowledge of varying exe-cution times on the computation nodes.
Group scheduling is a generalization of conventionalscheduling paradigms and is hence sufficient to express ex-isting low-level scheduling policies like FIFO and round-robin. Moreover, it enables us to let application-specificpolicies be directly expressed as SDFs, thus closing the gapbetween higher level application policies and lower levelscheduling policies for computation elements. Not onlydoes this raise the level of abstraction for the applicationdeveloper, but it is also necessary for several classes of ap-plications whose desired scheduling semantics do not mapreliably onto conventional scheduling semantics.
We now demonstrate the sufficiency of group schedulingto express our application-specific policies using the com-putational model described in Section 3. In the course of do-ing this, we show the inadequacy of existing low-level poli-cies to capture APG-4 which then demonstrates the neces-sity of group scheduling for many applications.
Figure 5. Group hierarchy for scenario 1
5.1.1. Scenario 1 – Non-critical Streams Outside GSControl: In this scenario, we try to map the four desiredapplication policies to existing lower-level scheduling poli-cies expressed within the group scheduling computationalmodel. The group scheduling model allows us to specifyeach of the policies intuitively. To express APG-1 we wantthe scheduler to give preference to the critical stream overall other threads in the system including threads in the non-critical stream. The SSDF, shown in Figure 5 is used tospecify this policy. A Critical Stream group is created torepresent a critical stream. The SSDF is consulted beforethe default Linux scheduler whenever a scheduling decisionis required. The default Linux scheduler is invoked only ifno threads controlled by the SSDF are in the RUNNABLEstate. This is indicated in Figure 5 by the arrow marked “Im-plicit choice”.
To specify APG-3, we intuitively divide the process-ing of a frame in two computational parts: (1) input pro-cessing of a frame (by an RTCORBA thread) and (2) thepipeline computation. The computation threads in the criti-cal pipeline are represented by the Pipeline Threads group.Between these two computations, the input processing andhence the RTCORBA thread has to be given preference, asper APG-3. Hence a sequential scheduling policy is cho-sen for the Critical Stream group which checks to see ifthe RTCORBA thread can run before it checks the PipelineThreads group.
To specify APG-2, we choose a static priority scheduler,with priorities increasing across the pipeline stages with thelast stage having the highest priority. This ensures that amessage flows across the pipeline before a new message

will be processed. For APG-4, in this scenario, we relyon the default policy of the default OS scheduler since allthe non-critical stream threads are under its control.
5.1.2. Scenario 2 – Non-critical Streams Under RR SDFControl: This scenario attempts to address APG-4, whichwe left to the control of the default OS scheduler in Scenario1. To this end, the non-critical streams are also brought un-der the control of the group scheduler. Intuitively, we di-vide the different non-critical streams into groups as shownin Figure 6, with each stream supported by a PipelineThreads group similar to that in Scenario 1. The criti-cal stream is again given preference over this collectionof non-critical streams. To express this policy, the non-critical stream groups are all grouped together under theNon-critical Streams group and this group gets lower pref-erence than the Critical Streams group.
To address balanced frame progress (APG-4), we try tomap this policy in terms of a round-robin scheduling policyfor the Non-critical streams group. This would achieve bal-anced progress if the computation times were equal for eachframe and each stream, but they are not. Note that Figure 6shows the group hierarchy for both Scenarios 2 and 3. Sce-nario 2 uses the Round-Robin(RR) SDF for the Non-criticalstreams group, while Scenario 3 uses the Frame ProgressSDF.
Figure 6. Group hierarchy for scenarios 2 and3
5.1.3. Scenario 3 – Non-critical Streams Under FrameProgress Control: The requirement of balanced progressis very often a feature of the kinds of applications discussedin Section 2. Hence it is necessary for those applicationsto be able to specify scheduling policies in terms of higherlevel programming models within which alternative SDFscan be expressed.
If the computation times on a pipeline node can varybased on the type of frame that it is processing, then theRR approach used in Scenario 2 can lead to an imbalancein the number of frames that can be processed by different
pipelines within the same time duration. Scenario 3 there-fore uses a Frame Progress SDF for the Non-critical streamsgroup. The group scheduling hierarchy for Scenario 3 isalso shown in Figure 6, and is similar to the hierarchy forScenario 2, except for the scheduling policy that is associ-ated with the Non-critical Streams group.
The aim of our application-specific Frame ProgressSDF is to maintain a balance of progress across mul-tiple pipelines. In the Frame Progress SDF, a speci-fied quantum of time is allotted for each non-criticalstream, to balance the progress among the differentstreams. The Frame Progress SDF also ensures that nonon-critical stream gets more than N frames ahead of theother non-critical streams, where N is an application de-fined constant (or in some cases could even be a function).This effect can be shown visually as described in Sec-tion 5.2.
5.2. Instrumentation, Logging and Visualization
Having demonstrated an intuitive style for specifying ap-plication policies in the group scheduling model, we nowdemonstrate that our group scheduling implementation in-deed can enforce the application policies. We use a com-bination of visualization tools and quantitative analysis forthis purpose.
We used the DataStream Kernel Interface (DSKI) andDatastream User Interface (DSUI) logging framework andpost-processing tools to instrument our example applica-tion, the group scheduler, and the Linux kernel [15]. Weused the visualizer tool to generate execution interval di-agrams, like the one shown in Figure 7, to examine qual-itatively how well our group scheduling implementationsenforced the application specified policies discussed previ-ously. For example, Figure 7 shows the visualizer tool dis-playing information mined via post-processing tools fromthe DSUI and DSKI event logs for an experimental run ofScenario 3 using the middleware group scheduler imple-mentation.
The execution time-line depicted in Figure 7 clearly ver-ifies the desired behavior. The visualizer has been config-ured to show the execution time-lines for all the pipelines.In our experiment, as seen in Figure 7, we chose messageswith lower processing times to be passed through pipelines3 and 5, although this is configurable in our experimentalsetup.
A non-critical pipeline, when chosen to run, runs until itprocesses a frame completely, i.e. the frame passes throughall stages of the pipeline, before any other pipeline startsprocessing its own frames. This is also confirmed by thevisualizer, as none of the non-critical pipeline executionsoverlap. Arrival of a frame for the critical stream causes thethreads related to the critical stream to run. As seen in the

Figure 7. Scenario 3 execution (MW GS)
visualizer, Pipeline 1 was processing a frame when a framefor the critical stream arrived, as indicated by an event in theSTART-END cycle row of the visualizer. This event causedcontrol to shift to the tasks in the critical stream.
The group scheduling thread and the block catcherthread seen in the last two rows of the visualizer in-cur context switch overhead in the middleware implemen-tation as opposed to the kernel-based implementation ofthe group scheduler, which does not have this extra over-head. The execution of the group scheduling thread isvery frequent, as shown by the visualizer. This is be-cause the group scheduling task is run at least once everytime quantum, which is set to 10 msec in our implemen-tation, equal to the Linux system heartbeat frequency inthe 2.4 kernel series. This is a tunable system parame-ter affecting context switching overhead in the middlewareimplementation.
5.3. Quantitative Evaluation
We also evaluated our kernel and middleware groupscheduling implementations in the face of background loadcompeting with the application, in the face of non-criticalcomputations competing with critical computations, andthe interference of the non-critical computations with eachother. We ran Scenario 3 under two experimental condi-tions: without any competing load, and with a competingload of two kernel compilations - one on the local parti-tion, while the other was on a NFS mounted partition - anda CPU-intensive background task. Tables 2 and 3 summa-rize the results of our evaluation.
5.3.1. Effect of Background Load: The results in Table 2show the CPU utilization of the different threads in the ap-plication. Each entry prefixed with “Pipe” in the table showthe total utilization of all threads in that pipeline. The re-sults of our experiments show that the competing load did
Kernel Middlewarevalues in % L NL L NLApp 78.5 78.4 79.1 79.1Total 99.0 78.5 98.9 79.1RTCORBA 0.2 0.2 0.2 0.2Pipe1 7.8 7.8 7.9 7.9Pipe2 15.3 15.3 15.3 15.3Pipe3 8.3 8.3 8.2 8.3Pipe4 3.2 3.2 3.2 3.2Pipe5 15.8 15.8 15.8 15.8Pipe6 15.6 15.6 15.7 15.7Pipe7 12.0 12.0 12.0 12.0Scheduler NA NA 0.427 0.424Block Catcher NA NA 0.063 0.065CPU bound task 14.5 NA 14.7 NAFrame source 0.3 0.3 0.3 0.3Idle task 0.0 21.4 0.0 20.8
Table 2. CPU utilization with load (L) and withno load (NL)
not affect the application pipelines, which ran exactly asthough there was no other load on the machine, with a con-sistent utilization of around 79% (entry “App”). With back-ground load (L), the total utilization (entry “Total”) wasaround 99% whereas with no load (NL) the total utiliza-tion was very close to the CPU utilization of the appli-cation. In spite of background load that causes a signifi-cant number of disk interrupts, network interrupts and in-tensive demand for CPU, the CPU utilization of the indi-vidual pipelines did not vary meaningfully between the twoexperiments or between the middleware and kernel imple-mentations. This shows that both the kernel and middlewareschedulers provide robust resource partitioning in the faceof CPU, disk I/O, and network I/O bound background loads.
These results also demonstrate that our group schedulingimplementation does not preclude the scheduling of compu-tations that are not under the purview of group scheduling.For example, in Table 2, the CPU bound background taskgets around 14% of the CPU, since the application utilizesonly around 79%. There is also some minimal utilization(0.3%) by the client tasks (entry “Frame Source”) that areresponsible for periodically supplying frames to the compu-tation streams. The remaining utilization can be attributedto the 2 background kernel compilations, which we havenot shown here.
5.3.2. Middleware Scheduler Overhead: The middle-ware scheduler incurs overhead for maintaining two threadsto control scheduling - the scheduler and block catcherthreads. The overhead in terms of context switches is no-table in the case of the middleware implementation.

Kernel Middlewarevalues in % L NL L NLScheduler NA NA 6.6 27.2Block Catcher NA NA 2.2 9.1
Table 3. Context switch overhead
Table 3 shows the percentage of the total number of con-text switches during the experiment that are attributed tothe scheduler and block catcher threads. This occurs be-cause of the extra context switches involved in switch-ing to the scheduler and block catcher threads, when athread other than the currently running controlled thread be-comes potentially eligible to run. Though the number ofcontext switches is higher in the middleware implemen-tation, the CPU time taken by these additional threadsis insignificant, as shown by the utilization values in Ta-ble 2. For the kernel implementation, there are no addi-tional context switches involved since the scheduling de-cision is made in the kernel itself. Moreover there is noneed for the scheduler and block catcher threads in the ker-nel implementation and hence no data are shown in thetables for these entries.
5.3.3. Balanced Progress of Non-critical Streams: Wenow proceed to analyze the interference among the non-critical pipelines. To do this, we modified our experimen-tal parameters so that the pipelines are kept busy by adjust-ing the send rate of the frame and the computation times ofthe messages. Pipelines 3 and 5 were chosen to have rela-tively lower message computation times when compared toother pipelines.
When the frame processing time varies for differentframe types as shown in Figure 7, it becomes difficult toexpress policy goal APG-4 in terms of existing low-levelscheduling policies, though we do attempt to do such map-pings in Scenario 1 and Scenario 2. We now demonstratethat this approach fails, and hence we need to be able tospecify the application policy directly as in Scenario 3.
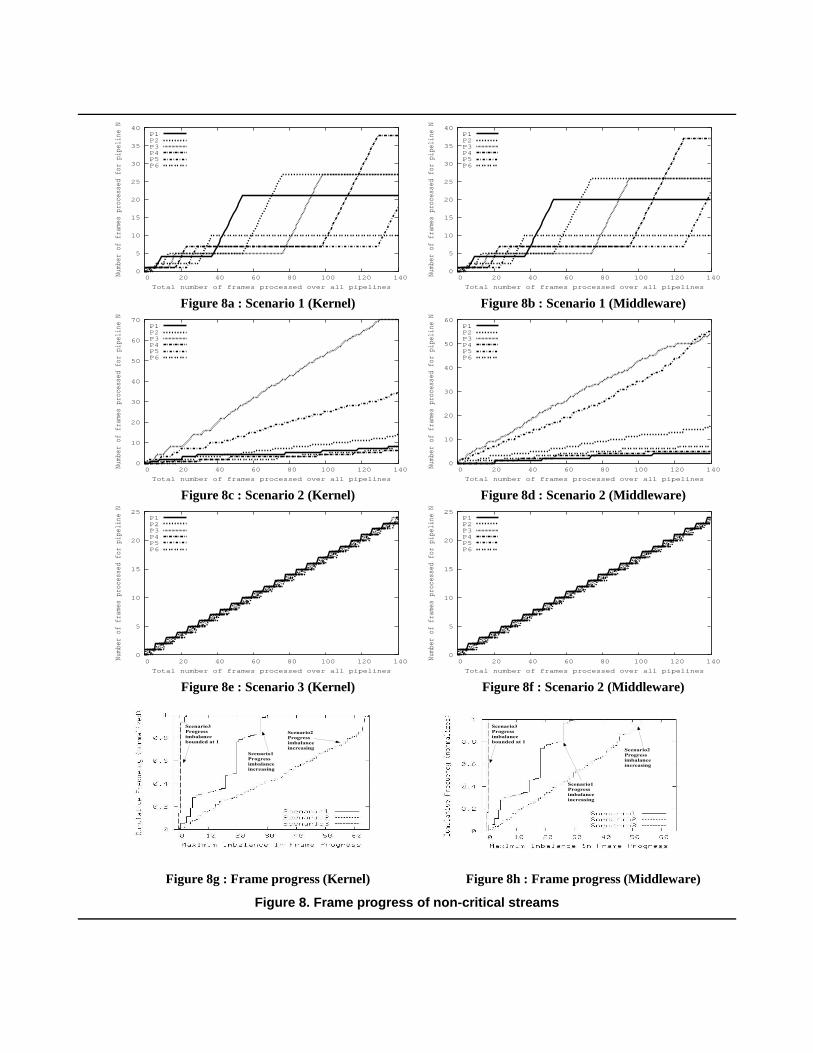
We desire balanced progress for each of the non-criticalstreams in terms of the number of frames processed overa period of time. We plotted the number of frames pro-cessed by each non-critical pipeline against the total numberof frames processed by all the non-critical pipelines. Plotsfor the three scenarios are shown in Figures 8a-8f.
Figures 8a and 8b show the frame progress for each non-critical pipeline under Scenario 1 with kernel and middle-ware group scheduling implementations respectively. Hereonly the critical stream is under group scheduling controland all the non-critical streams are under the control of theLinux scheduler. Even though none of the pipelines expe-riences starvation, there is a lot of jitter and divergence inthe streams’ relative frame progress, which violates applica-
tion policy goal APG-4. The middleware and kernel basedgroup scheduling implementations show similar behavior,although it should be noted that Scenario 1 is not affectedby the group scheduler implementation as far as the non-critical streams as concerned, since they are under the con-trol of the Linux scheduler rather than the group schedulerand hence have no influence over the scheduling decisionsof the Linux scheduler.
Figures 8c and 8d show the respective kernel and mid-dleware scheduled frame progress for each non-criticalpipeline under Scenario 2. Here all the non-criticalstreams are under the control of the group scheduler. Around-robin policy with a fixed time quantum was cho-sen for scheduling the non-critical pipelines. As seen inFigure 7, we set up our experiment so that the frames pass-ing through pipelines 1 and 3 cause lesser computationtimes, when compared to the other pipelines. The re-sult is that these two pipelines get to process more framesin a specified period of time due to the round-robin pol-icy and the lower computation times. Clearly this is also aviolation of application policy goal APG-4.
Figures 8e and 8f show the Scenario 3 non-criticalpipeline frame progress. All non-critical pipelines are un-der control of an application-specific group schedul-ing SDF. Feedback data, the number of frames processedby a pipeline, is made available to the application-specificSDF as each pipeline completes processing of a frame. Theapplication-specific SDF considers the number of framesprocessed by each pipeline when making a scheduling de-cision. The graphs show that the application policy ofbalanced progress is satisfied very well.
The variable execution times for a message in the differ-ent stages of the pipeline make it difficult to choose a pri-ori a static scheduling policy that will let us maintain bal-anced progress. Our frame progress based scheduler main-tained balance by ensuring that no non-critical pipeline ismore than one frame ahead of the other non-critical streams.
The cumulative distributions in Figures 8g and 8h sum-marize the balanced frame progress for Scenario 3 and theimbalance in frame progress for the other scenarios. We cal-culated the maximum frame progress imbalance, i.e., thedifference between the number of frames processed by thepipeline that has processed the most frames, and by thepipeline that has processed the least frames. Moreover, inScenario 3 this balance is maintained over time, whereas forthe other scenarios the imbalance increases over time. Themaximum imbalance for Scenario 3 is 1. There is one in-stance of an imbalance of 2 for Scenario 3 at the top of thecurve. We verified this to be an artifact of experiment ter-mination where one thread processed one more frame whenall the other pipeline threads were shutting down.
5.3.4. End-to-End Response Times: We also measuredthe end-to-end response time for processing each frame.
0
5
10
15
20
25
30
35
40
0 20 40 60 80 100 120 140Number of frames processed for pipeline N
Total number of frames processed over all pipelines
P1P2P3P4P5P6
0
5
10
15
20
25
30
35
40
0 20 40 60 80 100 120 140Number of frames processed for pipeline N
Total number of frames processed over all pipelines
P1P2P3P4P5P6
Figure 8a : Scenario 1 (Kernel) Figure 8b : Scenario 1 (Middleware)
0
10
20
30
40
50
60
70
0 20 40 60 80 100 120 140Number of frames processed for pipeline N
Total number of frames processed over all pipelines
P1P2P3P4P5P6
0
10
20
30
40
50
60
0 20 40 60 80 100 120 140Number of frames processed for pipeline N
Total number of frames processed over all pipelines
P1P2P3P4P5P6
Figure 8c : Scenario 2 (Kernel) Figure 8d : Scenario 2 (Middleware)
0
5
10
15
20
25
0 20 40 60 80 100 120 140Number of frames processed for pipeline N
Total number of frames processed over all pipelines
P1P2P3P4P5P6
0
5
10
15
20
25
0 20 40 60 80 100 120 140Number of frames processed for pipeline N
Total number of frames processed over all pipelines
P1P2P3P4P5P6
Figure 8e : Scenario 3 (Kernel) Figure 8f : Scenario 2 (Middleware)
Figure 8g : Frame progress (Kernel) Figure 8h : Frame progress (Middleware)
Figure 8. Frame progress of non-critical streams
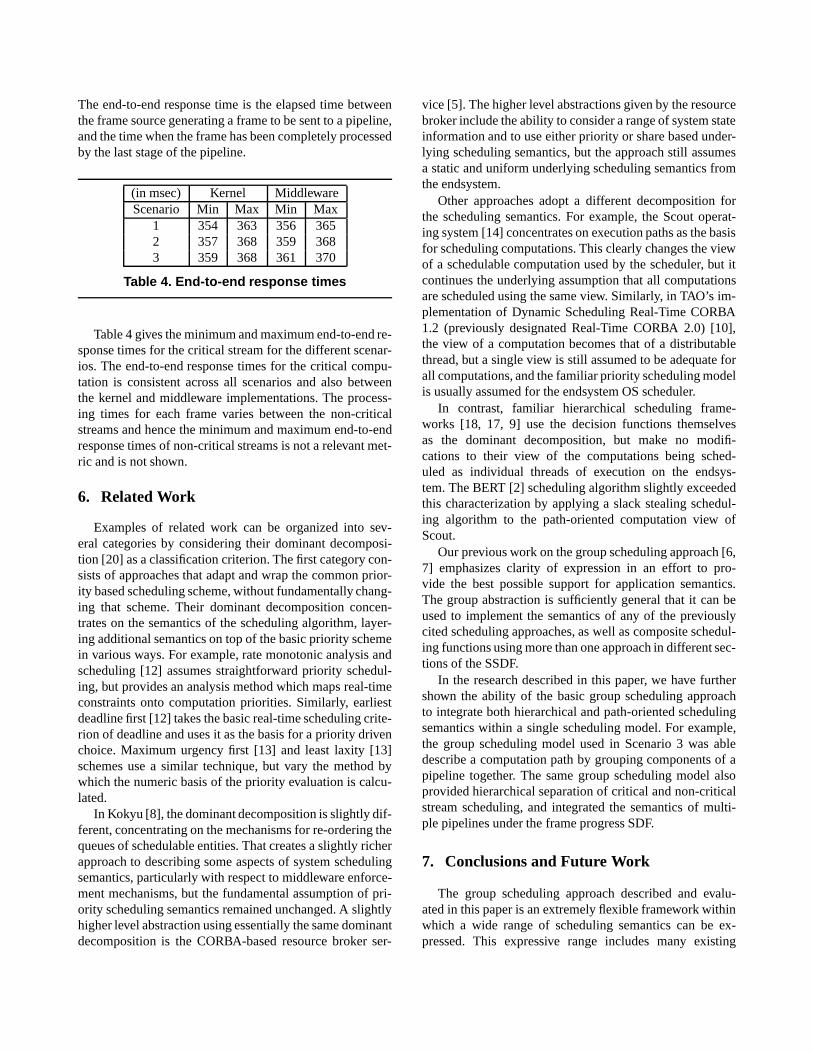
The end-to-end response time is the elapsed time betweenthe frame source generating a frame to be sent to a pipeline,and the time when the frame has been completely processedby the last stage of the pipeline.
(in msec) Kernel MiddlewareScenario Min Max Min Max
1 354 363 356 3652 357 368 359 3683 359 368 361 370
Table 4. End-to-end response times
Table 4 gives the minimum and maximum end-to-end re-sponse times for the critical stream for the different scenar-ios. The end-to-end response times for the critical compu-tation is consistent across all scenarios and also betweenthe kernel and middleware implementations. The process-ing times for each frame varies between the non-criticalstreams and hence the minimum and maximum end-to-endresponse times of non-critical streams is not a relevant met-ric and is not shown.
6. Related Work
Examples of related work can be organized into sev-eral categories by considering their dominant decomposi-tion [20] as a classification criterion. The first category con-sists of approaches that adapt and wrap the common prior-ity based scheduling scheme, without fundamentally chang-ing that scheme. Their dominant decomposition concen-trates on the semantics of the scheduling algorithm, layer-ing additional semantics on top of the basic priority schemein various ways. For example, rate monotonic analysis andscheduling [12] assumes straightforward priority schedul-ing, but provides an analysis method which maps real-timeconstraints onto computation priorities. Similarly, earliestdeadline first [12] takes the basic real-time scheduling crite-rion of deadline and uses it as the basis for a priority drivenchoice. Maximum urgency first [13] and least laxity [13]schemes use a similar technique, but vary the method bywhich the numeric basis of the priority evaluation is calcu-lated.
In Kokyu [8], the dominant decomposition is slightly dif-ferent, concentrating on the mechanisms for re-ordering thequeues of schedulable entities. That creates a slightly richerapproach to describing some aspects of system schedulingsemantics, particularly with respect to middleware enforce-ment mechanisms, but the fundamental assumption of pri-ority scheduling semantics remained unchanged. A slightlyhigher level abstraction using essentially the same dominantdecomposition is the CORBA-based resource broker ser-
vice [5]. The higher level abstractions given by the resourcebroker include the ability to consider a range of system stateinformation and to use either priority or share based under-lying scheduling semantics, but the approach still assumesa static and uniform underlying scheduling semantics fromthe endsystem.
Other approaches adopt a different decomposition forthe scheduling semantics. For example, the Scout operat-ing system [14] concentrates on execution paths as the basisfor scheduling computations. This clearly changes the viewof a schedulable computation used by the scheduler, but itcontinues the underlying assumption that all computationsare scheduled using the same view. Similarly, in TAO’s im-plementation of Dynamic Scheduling Real-Time CORBA1.2 (previously designated Real-Time CORBA 2.0) [10],the view of a computation becomes that of a distributablethread, but a single view is still assumed to be adequate forall computations, and the familiar priority scheduling modelis usually assumed for the endsystem OS scheduler.
In contrast, familiar hierarchical scheduling frame-works [18, 17, 9] use the decision functions themselvesas the dominant decomposition, but make no modifi-cations to their view of the computations being sched-uled as individual threads of execution on the endsys-tem. The BERT [2] scheduling algorithm slightly exceededthis characterization by applying a slack stealing schedul-ing algorithm to the path-oriented computation view ofScout.
Our previous work on the group scheduling approach [6,7] emphasizes clarity of expression in an effort to pro-vide the best possible support for application semantics.The group abstraction is sufficiently general that it can beused to implement the semantics of any of the previouslycited scheduling approaches, as well as composite schedul-ing functions using more than one approach in different sec-tions of the SSDF.
In the research described in this paper, we have furthershown the ability of the basic group scheduling approachto integrate both hierarchical and path-oriented schedulingsemantics within a single scheduling model. For example,the group scheduling model used in Scenario 3 was abledescribe a computation path by grouping components of apipeline together. The same group scheduling model alsoprovided hierarchical separation of critical and non-criticalstream scheduling, and integrated the semantics of multi-ple pipelines under the frame progress SDF.
7. Conclusions and Future Work
The group scheduling approach described and evalu-ated in this paper is an extremely flexible framework withinwhich a wide range of scheduling semantics can be ex-pressed. This expressive range includes many existing

scheduling approaches that are normally considered dis-joint, and permits the use of different approaches withindifferent portions of composite system scheduling deci-sion functions. Moreover, we have shown that both OSbased and middleware based implementations of the frame-work can support the same semantics, with few limitations.The middleware implementation does incur an unavoid-able increase in context switching overhead, but this isalso essentially the minimum overhead possible giventhe need for a user-level scheduling thread. Further-more, the middleware implementation is not able to includeinterrupt handler or other OS computation components un-der its control as the OS implementation does, but this isalso to be expected. The greatest limitation of the mid-dleware implementation is the need for a mechanism bywhich the scheduling thread can be notified when a con-trolled thread becomes unblocked. We demonstrated amechanism requiring a wrapper for each potentially block-ing system call. Alternately, some form of OS supportsimilar to scheduler activations [1] can be used.
Our future work includes investigation of how groupscheduling may be used in a wider range of contexts, in-cluding: time division multiplexing of Ethernet to imple-ment reliable real-time communication, extensions of thegroup scheduling approach to manage distributed computa-tions, and its use for supporting a wider range of applica-tions requiring nuanced real-time QoS assurances.
References
[1] Anderson, Bershad, Lazowska, and Levy. Scheduler acti-vations: effective kernel support for the user-level manage-ment of parallelism. ACM Trans. Comput. Syst., 10(1):53–79, 1992.
[2] Bavier, Peterson, and Mosberger. BERT: A Scheduler forBest Effort and Realtime Tasks. Technical Report TR-602-99, Princeton University, 1999.
[3] Kevin Byran, David Fleeman, Matthew Murphy, JiangyinZhang, Lisa DiPippo, Victor Fay Wolfe, David Juedes,Chang Liu, , Lonnie Welch, Douglas Niehaus, and Christo-pher Gill. Integrated corba scheduling and resource man-agement for distributed real-time embedded systems. In11th IEEE Real-time Technology and Application Sympo-sium (RTAS), San Fransisco,CA, March 2005. IEEE.
[4] Center for Distributed Object Computing. The ACE ORB(TAO). www.cs.wustl.edu/ � schmidt/TAO.html, WashingtonUniversity.
[5] D. Fleeman and et. al. Quality-based adaptive resource man-agement architecture (qarma): A corba resource manage-ment service. In 12th International Workshop on Paralleland Distributed Real-Time Systems, Santa Fe, NM, apr 2004.
[6] M. Frisbie. A unified scheduling model for precise compu-tation control. Master’s thesis, University of Kansas, June2004.
[7] M. Frisbie, D. Niehaus, V. Subramonian, and ChristopherGill. Group scheduling in systems software. In Workshop onParallel and Distributed Real-Time Systems, Santa Fe, NM,apr 2004.
[8] Gill, Schmidt, and Cytron. Multi-Paradigm Scheduling forDistributed Real-Time Embedded Computing. IEEE Pro-ceedings, Special Issue on Modeling and Design of Embed-ded Software, 91(1), January 2003.
[9] Goyal, Guo, and Vin. A Hierarchical CPU Scheduler forMultimedia Operating Systems. In
�����Symposium on Op-
erating Systems Design and Implementation. USENIX, Oc-tober 1996.
[10] Krishnamurthy, Pyarali, Gill, and Wolfe. Design and Imple-mentation of the Dynamic Scheduling Real-Time CORBA2.0 Specification in TAO. In OMG Workshop on Real-timeand Embedded Distributed Object Computing, Alexandria,VA., July 2003. OMG.
[11] R. Greg Lavender and Douglas C. Schmidt. Active Object:an Object Behavioral Pattern for Concurrent Programming.In Proceedings of the
� ���Annual Conference on the Pat-
tern Languages of Programs, pages 1–7, Monticello, Illinois,September 1995.
[12] C.L. Liu and J.W. Layland. Scheduling Algorithms for Mul-tiprogramming in a Hard-Real-Time Environment. JACM,20(1):46–61, January 1973.
[13] Jane W. S. Liu. Real-Time Systems. Prentice Hall, New Jer-sey, 2000.
[14] Mosberger and Peterson. Making Paths Explicit in the ScoutOperating System. In ���
�Symposium on Operating Systems
Design and Implementation. USENIX Association, October1996.
[15] D. Niehaus. Improving support for multimedia system ex-perimentation and deployment. In Workshop on Parallel andDistributed Real-Time Systems, San Juan, Puerto Rico, April1999. Also appears in Springer Lecture Notes in ComputerScience 1586, Parallel and Distributed Processing, ISBN 3–540–65831–9, pp 454–465.
[16] Irfan Pyarali, Marina Spivak, Ron K. Cytron, and Douglas C.Schmidt. Optimizing Threadpool Strategies for Real-TimeCORBA. In Proceedings of the Workshop on Optimization ofMiddleware and Distributed Systems, pages 214–222, Snow-bird, Utah, June 2001. ACM SIGPLAN.
[17] Regehr, Reid, Webb, Parker, and Lepreau. Evolving real-time systems using hierarchical scheduling and concurrencyanalysis. In
�� ��IEEE Real-Time Systems Symposium, Can-
cun, Mexico, December 2003.[18] Regehr and Stankovic. HLS: A Framework for Composing
Soft Real-Time Schedulers. In�������
IEEE Real-Time Sys-tems Symposium, London, UK, December 2001.
[19] David B. Stewart and Pradeep K. Khosla. Real-TimeScheduling of Sensor-Based Control Systems. In W. Ha-lang and K. Ramamritham, editors, Real-Time Programming.Pergamon Press, Tarrytown, NY, 1992.
[20] Tarr, Harrison, Ossher, Finkelstein, Nuseibeh, and Perry.Mdscse workshop description. In ICSE 2000 Workshop onMulti-Dimensional Separation of Concerns in Software En-gineering, Limerick, Ireland, June 2000.



















