
Creating Probabilistic Databases from Information Extraction Models
12
Creating Probabilistic Databases from Information Extraction Models Rahul Gupta IBM Research Lab New Delhi, India [email protected] Sunita Sarawagi Indian Institute of Technology Bombay, India [email protected] ABSTRACT 1. INTRODUCTION Permission to copy without fee all or part of this material is granted provided that the copies are not made or distributed for direct commercial advantage, the VLDB copyright notice and the title of the publication and its date appear, and notice is given that copying is by permission of the Very Large Data Base Endowment. To copy otherwise, or to republish, to post on servers or to redistribute to lists, requires a fee and/or special permission from the publisher, ACM. VLDB ‘06, September 12-15, 2006, Seoul, Korea. Copyright 2006 VLDB Endowment, ACM 1-59593-385-9/06/09 965
Transcript of Creating Probabilistic Databases from Information Extraction Models

Creating Probabilistic Databases from InformationExtraction Models
Rahul GuptaIBM Research LabNew Delhi, India
Sunita SarawagiIndian Institute of Technology
Bombay, India
ABSTRACT
1. INTRODUCTION
Permission to copy without fee all or part of this material is granted providedthat the copies are not made or distributed for direct commercial advantage,the VLDB copyright notice and the title of the publication and its date appear,and notice is given that copying is by permission of the Very Large DataBase Endowment. To copy otherwise, or to republish, to post on serversor to redistribute to lists, requires a fee and/or special permission from thepublisher, ACM.VLDB ‘06, September 12-15, 2006, Seoul, Korea.Copyright 2006 VLDB Endowment, ACM 1-59593-385-9/06/09
965

Outline
2. SETUP
2.1 Models for automatic extraction
X
P P
X X
966

0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
Pre
cisi
on o
f top
seg
men
tatio
n
Probability of top segmentation
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
Pre
cisi
on o
f top
seg
men
tatio
n
Probability of top segmentation
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
>20050-200
41-5031-40
21-3011-20
4-10321
Rel
ativ
e F
requ
ency
Number of segmentations required
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
>10050-100
41-5031-40
21-3011-20
4-10321
Rel
ativ
e F
requ
ency
Number of segmentations required
X
P
8><>:
2.2 Database representation of extraction un-certainty
2.2.1 Segmentation per row model
X
967
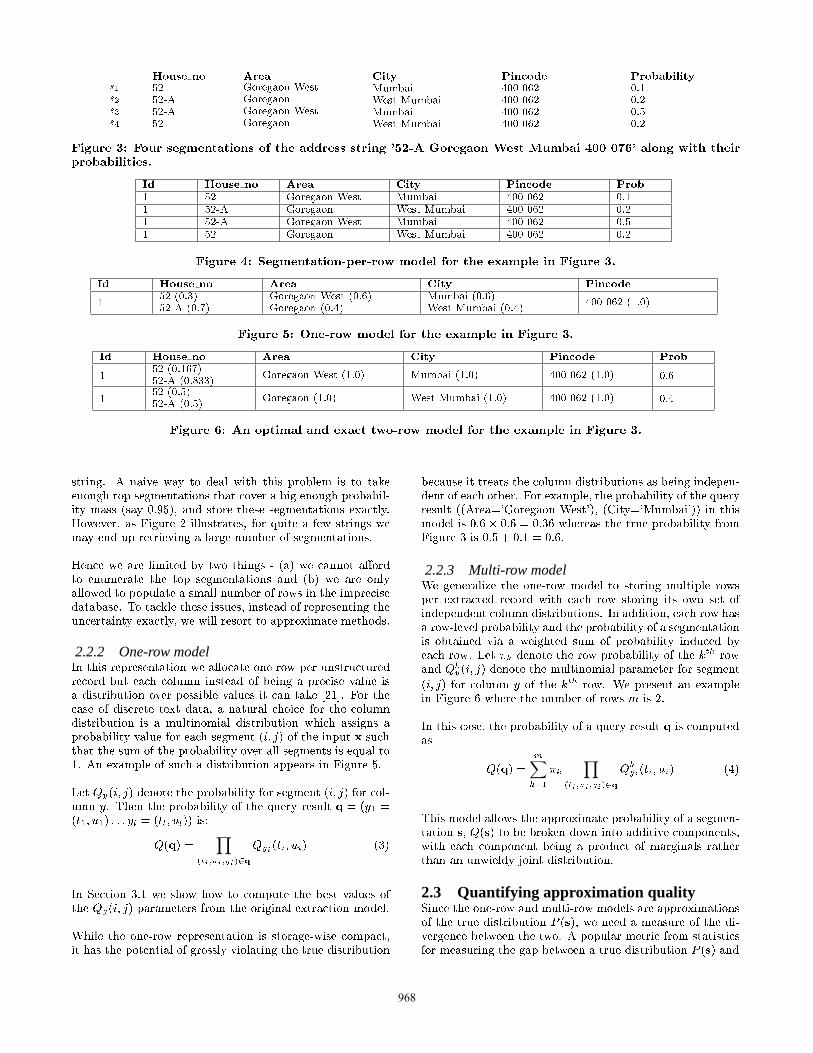
2.2.2 One-row model
Y
2.2.3 Multi-row model
X Y
2.3 Quantifying approximation quality
968

X
3. APPROXIMATIONS
3.1 One row model
X
X X
X X
X
3.1.1 Computing marginals from model
X
X X
P P
X X
P
X X
X
3.2 Multi-row model
969

X X
Q
3.3 Enumeration-based approach
X X
P
PP
X
s2
s 3
s s1 4,
A
B’West’,_
’52−A’,House_no
3.4 Structural approach
X X
X X
X X
970

X
P
P
3.5 Merging structures
PP
X
971

P
PP
P
P
P P
4. EXPERIMENTS
4.1 Datasets
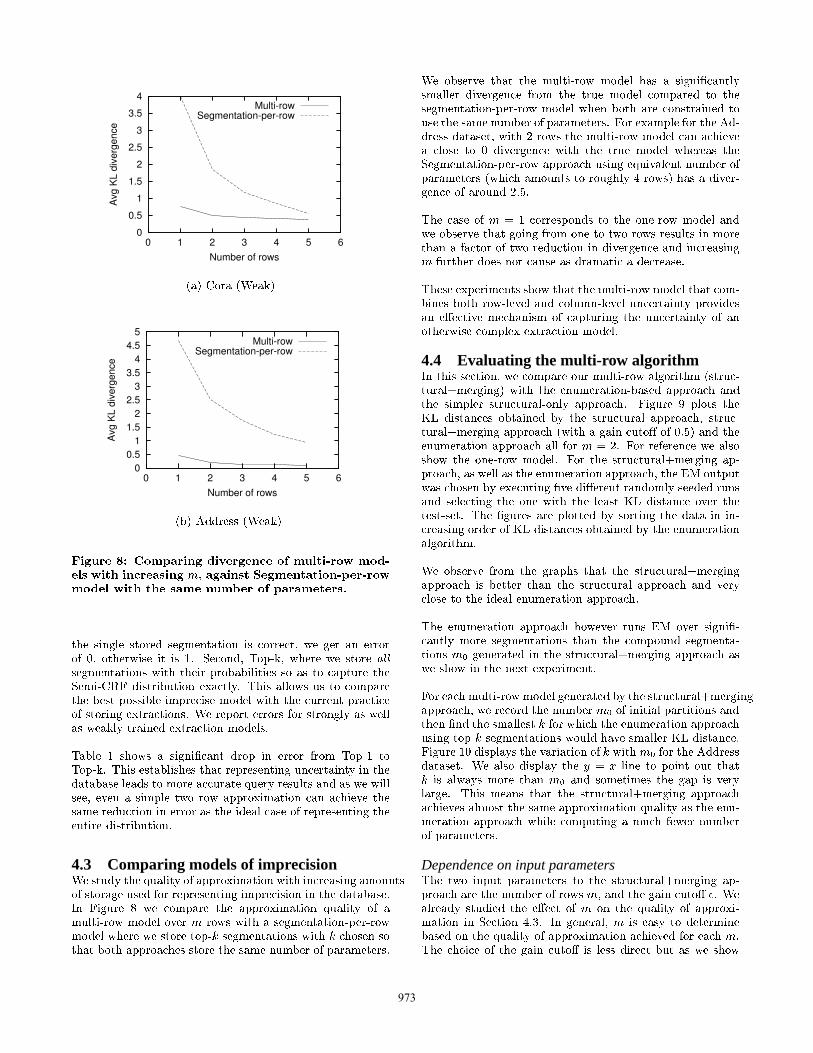
4.2 Error reduction with probabilistic data
972
0
0.5
1
1.5
2
2.5
3
3.5
4
0 1 2 3 4 5 6
Avg
KL
dive
rgen
ce
Number of rows
Multi-rowSegmentation-per-row
00.5
11.5
22.5
33.5
44.5
5
0 1 2 3 4 5 6
Avg
KL
dive
rgen
ce
Number of rows
Multi-rowSegmentation-per-row
4.3 Comparing models of imprecision
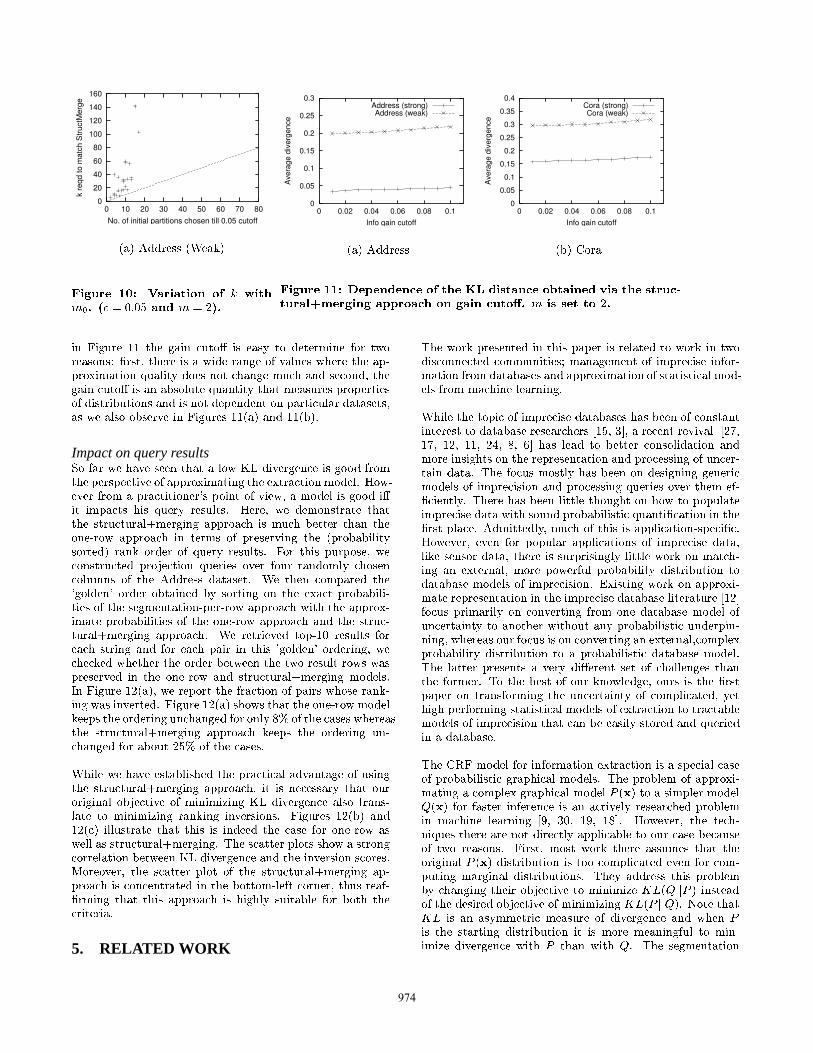
4.4 Evaluating the multi-row algorithm
Dependence on input parameters
973
0
20
40
60
80
100
120
140
160
0 10 20 30 40 50 60 70 80
k re
qd to
mat
ch S
truc
tMer
ge
No. of initial partitions chosen till 0.05 cutoff
0
0.05
0.1
0.15
0.2
0.25
0.3
0 0.02 0.04 0.06 0.08 0.1
Ave
rage
div
erge
nce
Info gain cutoff
Address (strong)Address (weak)
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0 0.02 0.04 0.06 0.08 0.1
Ave
rage
div
erge
nce
Info gain cutoff
Cora (strong)Cora (weak)
Impact on query results
5. RELATED WORK
974

0
0.05
0.1
0.15
0.2
0.25
-0.1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7
Fra
ctio
n of
str
ings
Ranking Inversions
OneRowStruct+Merge
0
0.5
1
1.5
2
2.5
0 0.1 0.2 0.3 0.4 0.5 0.6
Ran
king
Inve
rsio
ns
Divergence
OneRow
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
0 0.1 0.2 0.3 0.4 0.5 0.6
Ran
king
Inve
rsio
ns
Divergence
StructMerge
6. CONCLUSIONS
Acknowledgements
7. REFERENCES
975

0
0.5
1
1.5
2
2.5
0 50 100 150 200 250 300 350 400 450
Div
erge
nce
String Id
StructuralOne RowStruct+MergeEnumeration
0
0.5
1
1.5
2
2.5
3
0 20 40 60 80 100 120 140
Div
erge
nce
String Id
StructuralOne RowStruct+MergeEnumeration
976




















