
Content aware delivery of visual attention based scalable multi-view video over P2P
6
Content Aware Delivery of Visual Attention based Scalable Multi-View Video over P2P Erhan Ekmekcioglu, Hemantha Kodikara Arachchi, Ahmet Kondoz I-Lab, University of Surrey Guildford, GU2 7XH, United Kingdom {Erhan.Ekmekcioglu, H.Kodikaraarachchi, A.Kondoz}@surrey.ac.uk C. Goktug Gurler, S. Sedef Savas Department of Electrical and Electronics Engineering Koc University 34450 Sariyer, Istanbul, Turkey {cgurler, ssavas}@ku.edu.tr Abstract—3D media applications have become widespread thanks to the intense research being conducted on 3D enabling technologies, commercial products being released and service providers. There is also a huge potential for IP network to become a major means for delivering 3D video services, being highly flexible and allowing much custom and scalable applications to take up. Peer-to-Peer (P2P) video streaming, which offers high scalability in the presence of many media consuming peers, is suitable for multi-view video applications with significantly higher bandwidth requirements. To exploit flexible streaming and also serve a range of displays, P2P networking should be combined with scalable coded multi-view video that offers a useful bit-rate and maximum viewpoint adaptation range. However, since maintaining users’ Quality of Experience (QoE) is a primary target, scalable coded video should ensure that perceptually sensible visual data is delivered with high accuracy at all times to users, even under severe network conditions. Hence, content-based visual attention models provide a suitable means for letting salient video data be delivered at all times to users. With the utilization of appropriate adaptation decision making process in users’ equipment, the P2P protocol can adaptively stream the scalable 3D media. Work presented in this paper explains such a delivery framework over P2P networks. Keywords - multi-view video, scalable video coding, 3D media streaming, adaptation, P2P overlay networks I. INTRODUCTION 3D video, in its most conventional form of stereoscopic 3D (e.g. left and right eye views), has been on demand and a major point of attraction in many multimedia based applications. 3D movies have gained considerable success during the last decade, and especially with the spread of Blu-ray technology, such bandwidth consuming 3D media can be stored easily and enjoyed at home on 3D-TV sets. In addition to that, stereoscopic 3D TV broadcast has been researched in a number of projects, and broadcast services have already been launched in a number of countries. For example Sky (the British broadcaster) has been serving their subscribers a 3D channel over DVB-S2 since 2010, where users having compatible set- top boxes can decode 3D video and render them on their 3D compatible (3D-ready or Full-3D) TV sets. 3D broadcast services and 3D media on Blu-ray discs have encouraged consumers to buy new 3D-TV sets, which have been manufactured by mainstream consumer electronics companies. The trend has even reflected itself on amateur, or semi- professional content production, by the introduction of many 3D capturing enabled cameras (e.g. by Sony and JVC), where dual lens technology is widely used for stereoscopic video capture. Nevertheless, 3D video services have started to shift towards more immersive applications. Free-viewpoint video, where users are free to navigate in the 3D scene, is the most prominent 3D video application enabled by multi-view video and multi-view plus depth (MVD) [1] format. This usually involves more than the stereoscopic video (i.e. two views), where the transmission bandwidth becomes a major bottleneck in the pipeline. Hence, broadcasters are not tending to allocate multi-view services over their spectra that involve more than stereoscopic 3D video, since it is too costly and the number of such channels would be restricted. Even compression standards dedicated to efficiently encode multiple viewpoints by exploiting inter-view redundancies, such as MVC, are not able to restrict the total bit-rate and the total bit-rate is almost linearly proportional to the number of cameras inside the multi- view set. This necessitates the utilization of more flexible and potentially more bandwidth supplying delivery networks, such as IP. It also necessitates scalable 3D media that would lead to adaptation depending on dynamic network conditions without giving rise to disruptions in the service or loss in the Quality of Experience (QoE), and also serve a variety of display types with different input requirements (by scaling the number of views). Taking into consideration a high population of users who would like to concurrently watch a 3D video that is on high demand, client-server based streaming solutions become a problem due to server upload capacity. On the other hand, P2P approach is a promising solution as it distributes the burden of data transmission over users (used interchangeably with “peers” from this point), effectively utilizing their upload capacity. This paper focusses on a multi-view video streaming use- case for realizing high quality 3D video reconstruction from users’ preferred viewpoint. For this, it is proposed to exploit scalable multi-view video coding (using SVC [2]) with multiple quality layers for each viewpoint. Furthermore, to This work is supported by the DIOMEDES project (grant agreement number: 247996), which was funded by the European Union’s FP7 ICT collaborative research program. Proceedings of 2012 IEEE 19th International Packet Video Workshop May 10-11, 2012, Munich, Germany 978-1-4673-0301-9/12/$31.00 ©2012 IEEE PV 2012 71
-
Upload
lborolondon -
Category
Documents
-
view
1 -
download
0
Transcript of Content aware delivery of visual attention based scalable multi-view video over P2P

Content Aware Delivery of Visual Attention based Scalable Multi-View Video over P2P
Erhan Ekmekcioglu, Hemantha Kodikara Arachchi, Ahmet Kondoz
I-Lab, University of Surrey Guildford, GU2 7XH, United Kingdom
{Erhan.Ekmekcioglu, H.Kodikaraarachchi, A.Kondoz}@surrey.ac.uk
C. Goktug Gurler, S. Sedef Savas
Department of Electrical and Electronics Engineering Koc University
34450 Sariyer, Istanbul, Turkey {cgurler, ssavas}@ku.edu.tr
Abstract—3D media applications have become widespread thanks to the intense research being conducted on 3D enabling technologies, commercial products being released and service providers. There is also a huge potential for IP network to become a major means for delivering 3D video services, being highly flexible and allowing much custom and scalable applications to take up. Peer-to-Peer (P2P) video streaming, which offers high scalability in the presence of many media consuming peers, is suitable for multi-view video applications with significantly higher bandwidth requirements. To exploit flexible streaming and also serve a range of displays, P2P networking should be combined with scalable coded multi-view video that offers a useful bit-rate and maximum viewpoint adaptation range. However, since maintaining users’ Quality of Experience (QoE) is a primary target, scalable coded video should ensure that perceptually sensible visual data is delivered with high accuracy at all times to users, even under severe network conditions. Hence, content-based visual attention models provide a suitable means for letting salient video data be delivered at all times to users. With the utilization of appropriate adaptation decision making process in users’ equipment, the P2P protocol can adaptively stream the scalable 3D media. Work presented in this paper explains such a delivery framework over P2P networks.
Keywords - multi-view video, scalable video coding, 3D media streaming, adaptation, P2P overlay networks
I. INTRODUCTION
3D video, in its most conventional form of stereoscopic 3D (e.g. left and right eye views), has been on demand and a major point of attraction in many multimedia based applications. 3D movies have gained considerable success during the last decade, and especially with the spread of Blu-ray technology, such bandwidth consuming 3D media can be stored easily and enjoyed at home on 3D-TV sets. In addition to that, stereoscopic 3D TV broadcast has been researched in a number of projects, and broadcast services have already been launched in a number of countries. For example Sky (the British broadcaster) has been serving their subscribers a 3D channel over DVB-S2 since 2010, where users having compatible set-top boxes can decode 3D video and render them on their 3D compatible (3D-ready or Full-3D) TV sets. 3D broadcast services and 3D media on Blu-ray discs have encouraged
consumers to buy new 3D-TV sets, which have been manufactured by mainstream consumer electronics companies. The trend has even reflected itself on amateur, or semi-professional content production, by the introduction of many 3D capturing enabled cameras (e.g. by Sony and JVC), where dual lens technology is widely used for stereoscopic video capture.
Nevertheless, 3D video services have started to shift towards more immersive applications. Free-viewpoint video, where users are free to navigate in the 3D scene, is the most prominent 3D video application enabled by multi-view video and multi-view plus depth (MVD) [1] format. This usually involves more than the stereoscopic video (i.e. two views), where the transmission bandwidth becomes a major bottleneck in the pipeline. Hence, broadcasters are not tending to allocate multi-view services over their spectra that involve more than stereoscopic 3D video, since it is too costly and the number of such channels would be restricted. Even compression standards dedicated to efficiently encode multiple viewpoints by exploiting inter-view redundancies, such as MVC, are not able to restrict the total bit-rate and the total bit-rate is almost linearly proportional to the number of cameras inside the multi-view set. This necessitates the utilization of more flexible and potentially more bandwidth supplying delivery networks, such as IP. It also necessitates scalable 3D media that would lead to adaptation depending on dynamic network conditions without giving rise to disruptions in the service or loss in the Quality of Experience (QoE), and also serve a variety of display types with different input requirements (by scaling the number of views). Taking into consideration a high population of users who would like to concurrently watch a 3D video that is on high demand, client-server based streaming solutions become a problem due to server upload capacity. On the other hand, P2P approach is a promising solution as it distributes the burden of data transmission over users (used interchangeably with “peers” from this point), effectively utilizing their upload capacity.
This paper focusses on a multi-view video streaming use-case for realizing high quality 3D video reconstruction from users’ preferred viewpoint. For this, it is proposed to exploit scalable multi-view video coding (using SVC [2]) with multiple quality layers for each viewpoint. Furthermore, to
This work is supported by the DIOMEDES project (grant agreementnumber: 247996), which was funded by the European Union’s FP7 ICT collaborative research program.
Proceedings of 2012 IEEE 19th International Packet Video Workshop May 10-11, 2012, Munich, Germany
978-1-4673-0301-9/12/$31.00 ©2012 IEEE PV 201271

improve the users’ quality of experience during severe network conditions, where the streaming data rate needs to be dropped and content bit-streams needs scaling down, content specific visual attention model is utilized during encoding process. This way, it is aimed to preserve the most visually salient features more precisely all times. It is achieved by selectively assigning quantization parameter (QP) values to each macroblock in base and quality enhancement layers. An adaptation decision taking strategy is employed in clients’ terminal equipment that takes into account layers’ hierarchy, user’s preferences and QoE. It is combined with a pull-based P2P streaming protocol, where adaptation is carried out based on the taken adaptation decisions in fluctuating network conditions.
The rest of the paper is follows: Section II gives the state-of-the-art in 3D video streaming and broadcasting approaches with the underlying coding schemes, Section III explains the utilized visual attention based scalable multi-view coding scheme and Section IV gives the details of the adaptation process as well as the pull-based P2P streaming approach. Section V outlines the streaming test results and finally Section VI concludes the paper.
II. STATE-OF-THE-ART
A. 3D Video coding techniques
Based on different 3D video representation formats for stereoscopic and multi-view videos, different coding schemes have evolved over time. Video-only (e.g. stereo or multi-view) or video-plus-depth (e.g. colour-plus-depth or Multi-View-plus-Depth) based formats are usually compressed using the legacy block based coding standards, such as MPEG-4 Part 10/ H.264 AVC [3], or its extensions, such as Scalable Video Coding (SVC) or Multi-View Coding (MVC) [4]. SVC is used to provide a universal media stream that can be decoded by multiple terminals with different network and resource capacities. SVC also provides dynamic adaptation to a diverse network conditions, terminals and formats. MVC amendment exploits both temporal and inter-view redundancy in order to compress multiple camera views with a typical 20% to 50% lesser overhead compared to simultaneous encoding using AVC. With MVC, most of the stream syntax remains identical with respect to AVC and SVC.
Simultaneous encoding of multiple camera views using AVC (usually referred to as simulcasting) is the most computationally efficient and fast way of encoding 3D videos, but it is not bandwidth efficient. Asymmetric coding techniques can be deployed in the context of 3D video coding to save bandwidth without sacrificing the perceived 3D video quality. Other than that, AVC defines Frame Packing Arrangement SEI message [5] telling the decoder that the left and right view frames are packed into a single 2D high-resolution video frame (e.g. HD frame compatible) either in a top-to-bottom, side-by-side, checkerboard, or any other arrangement. This format is currently widely used in 3D broadcasting over DVB. Stereo High Profile of AVC [5] allows coding two views in a stereo video using inter-view prediction for one of the views. The other view is encoded independent of the other. MVC standard employs the same idea and offers the same profile in addition to another multi-view high profile.
Multi-view video coding with adaptive inter-view prediction can yield remarkably better rate-distortion performance compared to independent (e.g. simulcast) coding. Especially if the disparity range is sufficiently small, the efficiency of the inter-view prediction can lead to bit-rate savings up to 50% with respect to simulcast stereo video coding. However, the encoding efficiency of MVC is primarily affected by illumination misbalances and poor rectification. As the disparity among views increases, the gain from dependent coding may become marginal. The lack of quality scalability support for individual camera streams is also a major disadvantage of MVC. On the other hand, SVC simulcast coding of multiple views allows quality, temporal or spatial scalability. Since views are encoded independently, view scalability is inherent. Hence, SVC provides flexible adaptation possibilities and is more suitable for supporting multiple users with different displays types. Especially when QoE of users under varying network conditions is considered and prioritised coding techniques are incorporated within SVC quality layers to favour visually salient information, a better overall coding performance is attained.
B. 3D Video broadcasting and streaming approaches
3D media is widely delivered to end-users via different channels. The two mostly used means are broadcasting and the internet, where these two are usually used separately. There have only recently been initiatives on joint/ hybrid usage of internet broadband and conventional broadcast systems (e.g. Hbb-TV [6]), as well as new research projects (e.g. EU-FP7 DIOMEDES [7]) Users can receive the 3D media over DVB (e.g. DVB-T2/S2) [8], [9], or over their internet connection by their service and content providers. DVB-T2 offers higher bit-rates than DVB-T and is suitable for HD video services, whereas broadcasters around world use DVB-S2 to broadcast 3D media (e.g. SKY in Germany, UK, Italy, Freesat in Ireland and DirectTV in USA).
Main P2P 2D/3D multimedia approaches are tree and mesh based approached, which is based on the formation of the links between peers. Tree based solutions can be efficient in terms of message traffic, but the real-time media delivery can easily get interrupted in case of arbitrary peer churns (exit). Also, this approach assumes that peers have symmetric network connections. However, since many consumers currently have only access to asymmetric connections, with fast downlink and much slower uplink, a tree-based P2P distribution system is not realistic for sharing multi-view video between consumers. Tree-based solutions are also susceptible to free-riders (i.e., peers that are not contributing to distribution). On the other hand, in a mesh based approach, peers form self-organized and loosely coupled overlay networks. Among mesh based approaches, the BitTorrent protocol [10] has become one of the most successful ones, which is ideally designed for sharing large sized files (of any kind of data) without timeliness consideration. This is not suitable for real-time multimedia distribution. In BitTorrent, files are partitioned into chunks, and chunks are exchanged between peers. A peer that has all chunks is called a seeder, whereas peers with missing chunks are called leechers. They together form P2P swarms. To enable real-time multimedia delivery using BitTorrent, a temporal
72

windowing mechanism can be used, in which peers can only schedule chunks (i.e., request from other peers) whose play-out time is in near future, in a random or rarest-first order. This comes at the expense of increased pre-buffering delay in user terminal before media playback starts.
P2P-Next is a software that is developed in the P2P-Next project [11]. It supports SVC by segmenting the payload to layered chunks; allowing selective discarding. MPEG-TS encapsulation format is adopted in P2P-Next’s approach. LayerP2P approach described in [12] similarly supports SVC but with a different peer protocol. It differentiates peers as initiators and receptors based which side initiates the connection; easing struggle against free-riders. Another projects funded under EU Framework Programme 7, called NAPA-WINE [13], focuses on 2D multimedia sharing, whereas more recent projects, like DIOMEDES and ROMEO [14] target real-time distribution of multi-view 3D media using P2P along with DVB broadcasting.
III. VISUAL ATTENTION BASED SCALABLE MULTI-VIEW
CODING
As mentioned in the introduction, it is aimed at incorporating visual saliency adaptive bit-rate allocation in scalable video layers to boost up the adaptation performance of the targeted P2P distribution platform, where users’ QoE is maintained under fluctuating network conditions.
A. Visual attention model computation
Human visual attention is a complex but automatic (involuntary) process. Feature Integration theory by Treisman [15] divides the visual attention process into the pre-attentive level and attentive level stages, where pre-attentive stage consists of pointing out features like colour, shape, size, orientation, depth, and the attentive level stage consists of scanning the features to combine them into groups. Attentive level stage involves learning and previous knowledge. Guided Search approach by Wolfe [16] on top of Treisman’s theorem uses top-down input to enhance bottom-up feature extraction. The model applied in this work uses a combination of both.
The deployed model consists of feature extraction, feature map processing, object rating and clustering stages. The source is the individual camera viewpoints and corresponding depth maps. The output of this processing chain is a custom file depicting the saliency level of each macroblock in each frame, which is understandable by the scalable video encoder described in the next section. Feature extraction focuses on identifying motion activity, distinct colour levels and different structures. Depth map info is utilised in 3D scene model extraction with the detected features. Motion is detected using a global motion detection and compensation framework, in which a transform matrix is calculated by matching the feature points (e.g. noticeable corners) to yield the homography in between consecutive images. Lucas-Kanade algorithm [17] in combination with RANSAC is used. All detected features are combined in a single representation and an initial saliency map is produced by normalising the detected features. Features of common characteristics are then combined into object groups of interest according to size, shape as well as relative depth.
Figure 1. Sample visual attention map depicted on the right, of the corresponding video frames depicted on the left.
Figure 2. Saliency level adaptive quantisation parameter (QP) assignement process in scalable video coding.
To calculate the rating of them, predefined target values and deviations according to the analysed content are used. Target values are defined for specific content types based on previous content analysis. Figure 1 shows a sample video frame and the computed visual attention map (illustrated as a grey-scale graph).
B. Visual attention based scalable multi-view coding
The strategy in utilising the visual attention model described in Section III-A is to distribute the available bit-rate between the base quality layer and the enhancement quality layers of the SVC camera viewpoints, such that the perceived drop in quality between successive layers at times of adaptation is minimised. Bit-rate is allocated unequally for a particular quality enhancement layer (or base quality layer), such that the pixels of visually salient frame regions are reconstructed with higher precision in that particular layer. As a result, most salient visual features are delivered with higher quality even in the base layer and lesser salient features’ quality is enhanced gradually with the extra decoded quality enhancement layers. Figure 2 depicts this procedure. As seen, each video frame is categorised into sub-frame regions that have different visual importance. SL 1 is denoted as the most visually salient collection of pixels in the video frame. However, since SVC is
73
a block based encoder, the boundaries between discrete saliency regions are aligned with macroblock boundaries. In the modified SVC encoder, for the base quality layer and for coarse grain quality scalability (CGS) layers, more than one Quantisation Parameter (QP) values are employed based on the visual saliency value of each processed macroblock (MB). The amount of the generated quality enhancement layers, as well as the step size between the QP values of two adjacent quality enhancement layers is primarily a matter of how the network adaptation will work. The selection of these two factors affects the bandwidth adaptation range and the granularity of adaptation to dynamic network state. The applied modification on coding affects the assignment of the actual QP value used for the coding mode decision of an MB in slice encoding stage. Unless the specifically indicated QP value is assigned to a particular macroblock, the reference encoder enforces the base QP value in the encoded slice header to be assigned as the MB QP value. The implicit referral of the visual attention map value in assigning different QPs does not necessitate encoding extra control information for the decoder. Because, the syntax element called mb_qp_delta, which depicts the difference between the QP value of a particular macroblock and the other syntax element slice_qp_delta, is coded to a non-zero value and can be decoded in the decoder to apply inverse quantisation process correctly.
TABLE I. OPERTING POINT BIT-RATES FOR THE TEST STEREOSCOPIC
VIDEO SEQUENCES
Test Video Anchor SVC Visual Attention
adaptive SVC
Band 4.4 – 8.3 Mbps 4.5 Mbps – 8.3 Mbps
Café 3.8 – 6 Mbps 3.9 Mbps – 6.2 Mbps
Street 3.4 – 7.1 Mbps 3.4 Mbps – 6.9 Mbps
Music 3.6 – 7.2 Mbps 3.7 Mbps – 7.3 Mbps
Lecture 3.4 – 6.5 Mbps 3.3 Mbps – 6.4 Mbps
To test the efficiency of the proposed visual attention based
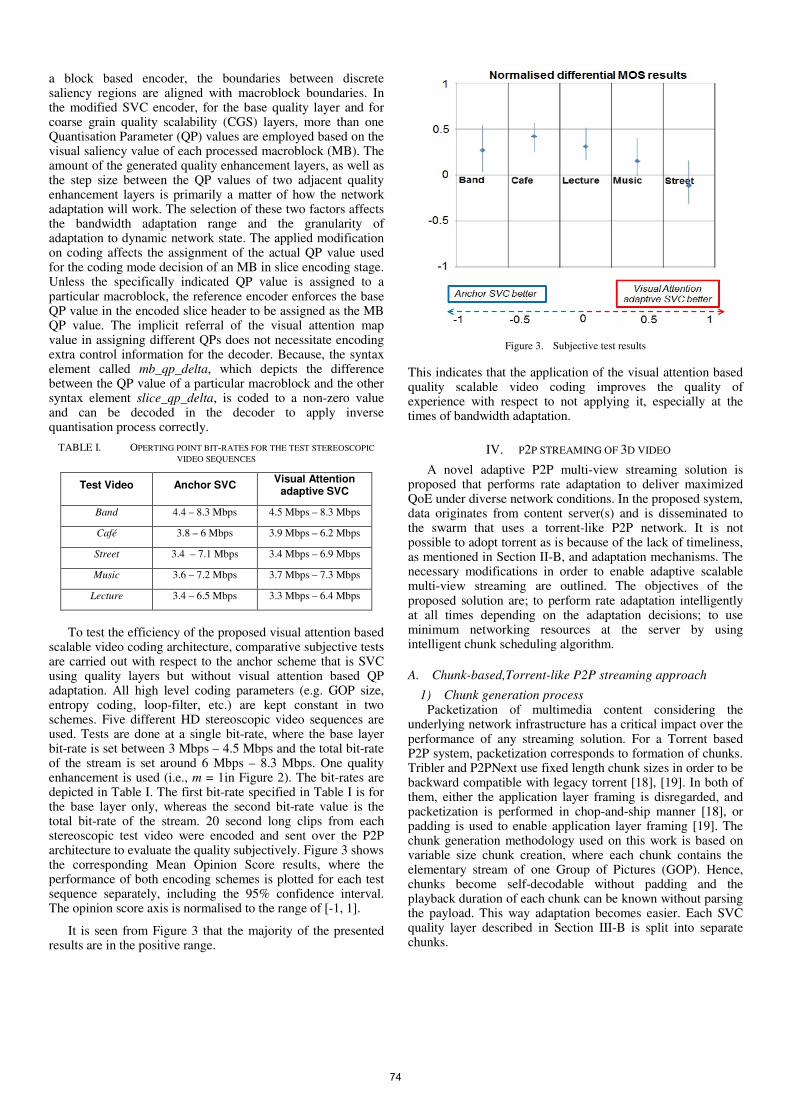
scalable video coding architecture, comparative subjective tests are carried out with respect to the anchor scheme that is SVC using quality layers but without visual attention based QP adaptation. All high level coding parameters (e.g. GOP size, entropy coding, loop-filter, etc.) are kept constant in two schemes. Five different HD stereoscopic video sequences are used. Tests are done at a single bit-rate, where the base layer bit-rate is set between 3 Mbps – 4.5 Mbps and the total bit-rate of the stream is set around 6 Mbps – 8.3 Mbps. One quality enhancement is used (i.e., m = 1in Figure 2). The bit-rates are depicted in Table I. The first bit-rate specified in Table I is for the base layer only, whereas the second bit-rate value is the total bit-rate of the stream. 20 second long clips from each stereoscopic test video were encoded and sent over the P2P architecture to evaluate the quality subjectively. Figure 3 shows the corresponding Mean Opinion Score results, where the performance of both encoding schemes is plotted for each test sequence separately, including the 95% confidence interval. The opinion score axis is normalised to the range of [-1, 1].
It is seen from Figure 3 that the majority of the presented results are in the positive range.
Figure 3. Subjective test results
This indicates that the application of the visual attention based quality scalable video coding improves the quality of experience with respect to not applying it, especially at the times of bandwidth adaptation.
IV. P2P STREAMING OF 3D VIDEO
A novel adaptive P2P multi-view streaming solution is proposed that performs rate adaptation to deliver maximized QoE under diverse network conditions. In the proposed system, data originates from content server(s) and is disseminated to the swarm that uses a torrent-like P2P network. It is not possible to adopt torrent as is because of the lack of timeliness, as mentioned in Section II-B, and adaptation mechanisms. The necessary modifications in order to enable adaptive scalable multi-view streaming are outlined. The objectives of the proposed solution are; to perform rate adaptation intelligently at all times depending on the adaptation decisions; to use minimum networking resources at the server by using intelligent chunk scheduling algorithm.
A. Chunk-based,Torrent-like P2P streaming approach
1) Chunk generation process Packetization of multimedia content considering the
underlying network infrastructure has a critical impact over the performance of any streaming solution. For a Torrent based P2P system, packetization corresponds to formation of chunks. Tribler and P2PNext use fixed length chunk sizes in order to be backward compatible with legacy torrent [18], [19]. In both of them, either the application layer framing is disregarded, and packetization is performed in chop-and-ship manner [18], or padding is used to enable application layer framing [19]. The chunk generation methodology used on this work is based on variable size chunk creation, where each chunk contains the elementary stream of one Group of Pictures (GOP). Hence, chunks become self-decodable without padding and the playback duration of each chunk can be known without parsing the payload. This way adaptation becomes easier. Each SVC quality layer described in Section III-B is split into separate chunks.
74

Figure 4. Chunk generation using one GOP of an SVC stream per chunk
Figure 5. Downloading window with two layers
This way, discardable chunks are produced, where enhancement layer chunks can be truncated at severe network conditions (see Figure 4). Multiple streams exist in a multi-view video that have separate base layer and enhancement layer chunks. These are prioritized by an adaptation decision engine that has knowledge on content, and also takes into consideration user’s viewing preferences, as well as QoE.
2) Chunk scheduling
a) Sliding window
As mentioned beforehand, default rarest-first approach of torrent based file sharing systems does not meet the requirements of delivering time sensitive multimedia. Most solutions have offered a windowing mechanism [12]. Windowing both provides timely delivery by restricting scheduling for chunks inside the window and also enables differentiation among chunks scheduled by different peers to enable chunk exchange among them [20]. The windowing mechanism used in this work has two additional dimensions as depicted in Figure 5. The first dimension is the number of views, meaning that there are separate windows for each view’s stream. The second dimension represents the discardibility of the chunks. For scalable views, all base layer chunks are supposed to be acquired prior to requesting enhancement layer chunks. By this way, the scheduling mechanism tries to ensure uninterrupted video playback and provides high quality whenever possible. The prioritization among views is described in the following subsection.
b) Adaptation process
Once a streaming session is initiated, peers request chunks of all layers to deliver at the highest possible quality. Once the window is downloaded, it advances its window in time to schedule new chunks. Meanwhile, the player starts to consume
downloaded multimedia when the buffer reaches to a certain level. Adaptations are based on the streams’ prioritization order determined by the adaptation decision engine (described in Section IV-B). The number of streams to be scheduled is updated each time the window slides. If the buffer duration is below a certain threshold, the number of downloaded streams is reduced by discarding the stream that is at the bottom of the prioritization order. In the opposite case, if the data in the buffer is large, unscheduled streams are added to the queue. Once the number of streams has been updated, chunks can be scheduled for the new window.
Chunk scheduling is performed in two steps. First, different downloading weights are given to the streams based on their prioritization orders, and a particular stream is scheduled according to the assigned weighting. The second step is to determine the chunk request order for the selected stream. The criterion here is whether the buffer is short, or long. If it is short, chunks are requested in a weighted random order that gives higher chance to the chunks close to the play-out deadline to be scheduled first. If the buffer is long, chunks that are available in the swarm are scheduled first. If no chunks are available in the swarm, then they are selected randomly within the window. Randomization increases the diversity among the peers and augments the P2P communication, which decreases the overall bit-rate requirements on the server.
B. Adaptation decision engine
The adaptation decision engine’s aim is to assign priorities to different parts of the overall 3D video stream from the perspective of the media consumer, as well as taking into account encoded content’s characteristics. The priority of base and enhancement quality layers and the depth maps (if exists) of each viewpoint are ordered in the same list, where the P2P client makes use of this list to perform the necessary video adaptation operations. In a viewpoint adaptation scenario, the camera streams that do not contribute to the synthesis of the user preferred viewpoint are primarily discarded from the priority list. Knowing that the video is encoded using SVC standard, adaptation decision engine never prioritizes enhancement layer chunks over corresponding base layer chunks. Depth map chunks are also prioritized over enhancement layer chunks, since the depth image based rendering necessitates the correct reception of depth values. If QoE related key performance indices are embedded in the delivered chunks, adaptation decision engine dynamically incorporates them in estimating the overall QoE and can change views’ priority order to maximize the estimated QoE.
C. P2P networking tests
1) Test conditions The P2P 3D video streaming tests are run with the above
mentioned features and on the PlanetLab [21] test-bed, to evaluate the performance of the proposed chunk based and torrent-like streaming solution in the existence of multiple peers. Throughout the tests, the traffic over the content server and the state of all peers are monitored. Tests are done using a double stream (base layer and one quality enhancement layer) single view, to be able to clearly observe the uploading burden on the server. The mentioned stream has been coded using the
75

Figure 6. Server load over time
TABLE II. AVERAGE BUFFERING DURATION AND SERVER LOAD
# Peers Buffer Duration (sec) Server Load (Mbps)
5 2,53 3,71
10 4,67 5,36
15 6,76 6,80
scalable video coding approach at 1.2 Mbps. Base quality layer is encoded at 620 Kbps with a PSNR value of 33.5 dB, and the enhancement quality layer is encoded at 580 Kbps with a PSNR value of 36.5 dB. The bit-rate is divided almost equally among the two layers to increase the efficiency of bit-rate adaptation at network congestion times.
2) Test results Based on the networking test results depicted in Table 2
and Figure 6, the followings are observed:
• The increase rate of the average server load is not linearly proportional to the increase rate of peers, which indicates that the proposed streaming architecture is scalable.
• The peak load at the server side occurs at the initial stage, in which peers are unable to exchange data.
On the average, only a few peers have received the content at the base quality. Almost all of the peers could deliver at least the base quality layer chunks, meaning that they were guaranteed smooth and uninterrupted service. The average ratio of receiving enhancement layer chunks was observed to be about 50%. The experimental results validate that the proposed adaptation strategy ensures smooth playback by prioritizing transmission of the base layer chunks and augments the video quality when additional bit-rate is available.
V. CONCLUDING REMARKS
This paper has outlined the current research outcomes regarding a scalable 3D multimedia streaming approach over novel torrent-like P2P networks. Both the details of a visual attention model adaptive multi-quality layer scalable video coding approach and a novel chunk-based torrent-like P2P multimedia delivery framework are given. The indicative results enclosed within the sections prove that the underlying
techniques are well suited to a real-time IP based 3D multimedia delivery scenario, where a vast majority of users’ QoE is maintained under varying network conditions by exploiting advanced adaptation options.
ACKNOWLEDGMENT
In addition to the listed authors, the following individuals led the research activities in visual attention model computing: Norbert Just, Peter tho Pesch and Dagmar Driesnack from Institut für Rundfunktechnik (IRT), Germany.
REFERENCES
[1] P. Merkle, et. al., "Multi-View Video Plus Depth Representation and Coding," IEEE International Conference on Image Processing , vol.1, no., pp.I-201-I-204, Oct. 2007.
[2] H. Schwarz, D. Marpe, and T. Wiegand, “Overview of the scalable video coding extension of the H.264/AVC standard”, IEEE Trans. Circuits Syst. Video Technol., vol. 17, no. 9, pp. 1103–1120, Sep. 2007.
[3] ITU-T and ISO/IEC JTC 1, “Advanced video coding for generic audio-visual services,” ITU-T Recommendation H.264 and ISO/IEC 14496-10 (MPEG-4 AVC), 2010.
[4] A. Vetro, P. Pandit, H. Kimata, A. Smolic, and Y.-K. Wang, “Joint draft 8 of multi-view video coding”, Hannover, Germany, Joint Video Team (JVT) Doc. JVT-AB204, Jul. 2008.
[5] G. J. Sullivan, A. M. Tourapis, T. Yamakage, and C. S. Lim, “Draft AVC amendment text to specify constrained baseline profile, stereo high profile, and frame packing SEI message”, London, UK, Joint Video Team (JVT) Doc. JVT-AE204, Jul. 2009.
[6] http://www.hbbtv.org/
[7] http://www.diomedes-project.eu/
[8] http://www.dvb.org/technology/dvbt2
[9] http://dvb.org/technology/fact_sheets/DVB-S2_Factsheet.pdf
[10] B. Cohen, "The BitTorrent Protocol Specification", Jan. 2008 (can be found online at http://www.bittorrent.org/beps/bep_0003.html).
[11] N. Capovilla, et. al., “An Architecture for Distributing Scalable Content over Peer-to-Peer Networks”, in Proc. of International Conferences on Advances in Multimedia (MMEDIA’10), Athens, Greece, Jun. 2010.
[12] Z. Liu, et. al., "Layerp2p: using layered video chunks in p2p live streaming," IEEE Trans. on Multimedia, vol. 11, no. 7, pp. 1340-1352, 2009.
[13] http://www.napa-wine.eu
[14] http://www.ict-romeo.eu
[15] A. Treisman, “Features and objects in visual processing”, Scientific American Inc. Scientific American, vol. 254, 5, pg. 114-125. Nov. 1986.
[16] J. Wolfe, “Guided Search 2.0.”, [ed.] Psychonomic Bulletin & Review, vol. 1, pp. 202-238, 1994.
[17] B. Lucas, T. Kanade, “An Iterative Image Registration Technique with an Application to Stereo Vision”, Proc. of 7th International Joint Conference on Artificial Intelligence (IJCAI), pp. 674-679, 1981.
[18] Tribler Protocol Specification, Jan. 2009. (available online: http://svn.tribler.org/bt2-design/proto-spec-unified/trunk/proto-spec-current.pdf)
[19] M. Eberhard et al., “Knapsack problem-based piecepicking algorithms for layered content in peer-to-peer networks,” in ACM Workshop on Advanced Video Streaming Techniques for P2P Networks and Social Networking, 2010, pp. 71–76.
[20] S. Savas, G. Gurler, M. Tekalp, E. Ekmekcioglu, S. Worrall, A. Kondoz, “Adaptive streaming of multi-view video over P2P networks,” in Proc. Journal of Signal Processing: Image Communications, Special issue on Advances in video streaming for P2P networks, in press.
[21] Open platform for developing, deploying and accessing planetary-scale services (http://www.planet-lab.org/)
76




















