
conferência iadis ibero-americana - www/internet 2012
232
-
Upload
khangminh22 -
Category
Documents
-
view
0 -
download
0
Transcript of conferência iadis ibero-americana - www/internet 2012


i
CONFERÊNCIA IADIS IBERO-AMERICANA
WWW/INTERNET 2012

ii

iii
ATAS DA CONFERÊNCIA IADIS IBERO-AMERICANA
WWW/INTERNET 2012
MADRID, ESPANHA
18 – 20 OUTUBRO, 2012
Organizada por
IADIS International Association for Development of the Information Society
Co-organizada pela

iv
Copyright 2012
IADIS Press
Todos os direitos reservados
Este trabalho está sujeito a direitos de autor. Todos os direitos são reservados, no todo ou em parte, mais especificamente os direitos de tradução, reimpressão, reutilização de ilustrações, re-citação, emissão, reprodução em microfilme ou de qualquer outra forma, e armazenamento em bases de
dados. A permissão para utilização deverá ser sempre obtida da IADIS Press. Por favor contactar [email protected].
Editado por José María Gutiérrez, Flavia Maria Santoro e Pedro Isaías
Editor Associado: Luís Rodrigues
ISBN: 978-989-8533-11-1

v
ÍNDICE
PREFÁCIO ix
COMITÉ DO PROGRAMA xi
PALESTRAS CONVIDADAS xvii
ARTIGOS LONGOS
MECANISMO INFOMÉTRICO APLICADO EM UM AMBIENTE PARA GESTÃO DO CONHECIMENTO: O CASO SOCIESC Cintia Ghisi, Alcir Mário Trainotti Filho, Edicarsia Barbiero Pillon, Mehran Misaghi e Thiago Jabur Bittar
3
PREDIÇÃO DE RESULTADO DE ELEIÇÃO PARA REITOR DE UNIVERSIDADE USANDO TWEETS COMO FONTE DE PESQUISA Alessandro Kraemer, André Luiz Satoshi Kawamoto e Marco Aurélio Gerosa
11
RELAÇÕES SOCIAIS EM COMUNIDADES DE CIENTISTAS ATRAVÉS DA LENTE DA ACTOR-NETWORK THEORY: UM ESTUDO PRELIMINAR Alysson Bolognesi Prado e Maria Cecilia Calani Baranauskas
19
IDOSOS NA EAD: UMA PROPOSTA DE PARÂMETROS PARA A CONSTRUÇÃO DE OBJETOS DE APRENDIZAGEM Leticia Rocha Machado e Patricia Alejandra Behar
27
PROPOSTA DE UM CURSO EM EAD PARA FORMAÇÃO DO PROFESSOR DE ARTE COMO SER COMPLEXO Jaqueline Maissiat, Maria Cristina Villanova Biazus e Magda Bertch
35
UMA COMPARAÇÃO ENTRE O USO DE AMBIENTES VIRTUAIS DE APRENDIZAGEM E FERRAMENTAS DA WEB 2.0 NO ENSINO MÉDIO Alberto Luiz Ferreira, Carlos Fernando Araújo Junior, Juliano Schimiguel, Maria Delourdes Maciel e Tatiane Rossi Chagas
43
AMBIENTE DE APRENDIZAJE MÓVIL DE APOYO A LA EDUCACIÓN A DISTANCIA Gisela Torres de Clunie y Clifton E. Clunie T.
51
INNOVACIÓN EDUCATIVA BASADA EN PROCESOS DE EVALUACIÓN DE LA CALIDAD José Luis Castillo Sequera, Miguel A. Navarro Huerga, José A. Medina y José M. Gómez Pulido
59
BÚSQUEDAS Y ACTUALIZACIONES DE CONTENIDOS DOCENTES EN REPOSITORIOS A TRAVÉS DE AGENTES Salvador Otón, Francisco Javier Iglesias, Luis de-Marcos, Antonio García, Eva García, José María Gutiérrez, José Ramón Hilera y Roberto Barchino
67

vi
O USO DE TECNOLOGIAS DIGITAIS PARA O DESENVOLVIMENTO DE COMPETÊNCIAS TECNOLÓGICO-MUSICAIS EDUCACIONAIS Fátima Weber Rosas e Patricia Alejandra Behar
75
UM MODELO PARA NA DETECÇÃO DO INTERESSE EM AMBIENTES DE EAD ATRAVÉS DA VISUALIZAÇÃO COMPUTACIONAL Maurício José Viana Amorim, Patricia Alejandra Behar e Magda Bercht
83
APPS FRAMEWORK: UM PROCESSO CENTRADO NO USUÁRIO APLICADO PARA O DESENVOLVIMENTO DE APLICATIVOS MÓVEIS – UM ESTUDO DE CASO Awdren de Lima Fontão, Bruno Bonifácio e Angelo Nicolay
91
DESARROLLO DE MEDIOS DE COMUNICACIÓN SOCIAL Y WEB 2.0 EN LAS MAYORES CADENAS HOTELERAS María del Mar Gálvez Rodríguez, Arturo Haro de Rosario y Mª del Carmen Caba Pérez
99
EVOLUÇÃO DA FERRAMENTA ACCESSIBILITYUTIL: APOIO A PROJETOS, MODERAÇÃO DE CONTEÚDOS E VERIFICAÇÕES DE USO Thiago Jabur Bittar, Leandro Agostini do Amaral e Renata Pontin de Mattos Fortes
107
EL RETARDO DE HANDOVER EN IPV6 MÓVIL, CARACTERIZACIÓN Y DETERMINACIÓN EXPERIMENTAL DE VALORES A TRAVÉS DE LA IMPLEMENTACIÓN USAGI-PATCHED MOBILE IPV6 Juan Carlos Castillo Eraso
115
A GESTÃO DA INFORMAÇÃO CORPORATIVA NOS WEBSITES DAS CÂMARAS MUNICIPAIS PORTUGUESAS Eduardo Alfredo Cardoso Miranda e Antonio Muñoz Cañavate
123
SGEMEOS: UM GESTOR DE EVENTOS SOCIAIS BASEADO EM SERVIÇOS WEB Luiz Marcus Monteiro de Almeida Santos e Admilson de Ribamar Lima Ribeiro
131
ARTIGOS CURTOS
REPOSITÓRIO DE CONHECIMENTO ACADÊMICO: UMA PROPOSTA PARA O INSTITUTO SUPERIOR TUPY – SOCIESC Alcir Mário Trainotti Filho, Mehran Misaghi e Marcelo Macedo
141
ARQUITECTURA DE UN REPOSITORIO RDF BASADO EN CASSANDRA Jesús Bermúdez, Arantza Illarramendi, Marta González y Ana I. Torre-Bastida
147
SERVIÇO DE LOCALIZAÇÃO GEOGRÁFICA UTILIZANDO WEB SERVICE DINÂMICO Sandra Costa Pinto Hoentsch, Felipe Oliveira Carvalho, Luiz Marcus Monteiro de Almeida Santos y Admilson de Ribamar Lima Ribeiro
151
ARQUITETURA PARA GERENCIAMENTO SEGURO DE CICLO DE VIDA DE DOCUMENTOS Eduardo Henrique de Oliveira, Luís Felipe Féres Santos, Renato Lopes e Silva e Raphael Fogagnoli Tavares, Luis Fernando de Almeida
155

vii
MODELAGEM DE INTERAÇÃO NA WEB USANDO MDD COM PRINCÍPIOS DE USABILIDADE E ACESSIBILIDADE Thiago Jabur Bittar, Veríssimo Guimarães Júnior, José Aparecido Sorratini e Mehran Misaghi
161
UM AMBIENTE DE ANÁLISE PARA COMPARAR RESULTADOS DE AVALIAÇÕES DE ACESSIBILIDADE E USABILIDADE NA WEB Leandro Agostini do Amaral, Thiago Jabur Bittar e Renata Pontin de Mattos Fortes
166
A GESTÃO E VENDA ONLINE DE PRODUTOS REGIONAIS: DEFINIÇÃO DE ESTRATÉGIAS EM MODELOS DE INOVAÇÃO Luís Ascenso, Hélia Guerra, Luís Mendes Gomes e Armando Mendes
171
QUINTA DIGITAL: COMÉRCIO ELETRÓNICO DE PRODUTOS AGRÍCOLAS DO PRODUTOR AO CONSUMIDOR FINAL João Crispim Ponte, Óscar Neto, Lino Martins, Hélia Guerra, Luís Mendes Gomes e Armando Mendes
176
EVALUACION DE LA CALIDAD EN ENTORNOS VIRTUALES DE APRENDIZAJE: USO DE ONTOLOGÍAS Y AGENTES DE SOFTWARE Lilliam N. Robinson O., Clifton Clunie y Sergio Crespo
181
ELABORACIÓN DE UN AMBIENTE DE CHAT SEMÁNTICO COMO APOYO A PROCESOS DE INGENIERÍA DE SOFTWARE Y ADMINISTRACIÓN DE PROYECTOS POR MEDIO DE AGENTES DE SOFTWARE Samuel Díaz, Sergio Crespo y Clifton Clunie
187
AVALIAÇÃO DO NÍVEL DE SINAL EM UMA REDE EM MALHA SEM FIO BASEADA NO PADRÃO 802.1A Rothschild A. Antunes, Rafael B. Scarselli, Ruy de Oliveira, Valtemir E. do Nascimento, Ed’Wilson T. Ferreira e Ailton Akira Shinoda
193
SBWMX-TOOL: UNA APLICACIÓN WEB PARA EL DISEÑO DE ESTRUCTURAS MARÍTIMAS José Alfonso Aguilar, Pedro A. Aguilar y Aníbal Zaldívar
199
ARTIGO DE REFLEXÃO
BUSINESS INTELLIGENCE APLICADO NA GESTÃO ACADÊMICA Marcio Rodrigo Teixeira e Mehran Misaghi
207
AUTHOR INDEX

viii

ix
PREFÁCIO
Estas atas contêm os artigos e posters da Conferência IADIS Ibero-Americana WWW/Internet 2012, organizada pela International Association for Development of the Information Society e co-organizada pela Universidad de Alcalá, Madrid, Espanha, de 18 a 20 de outubro 2012.
A conferência IADIS Ibero-Americana WWW/Internet 2012 pretende focar os principais aspetos relacionados com a WWW e a Internet.
A WWW e a Internet tiveram um crescimento significativo nos últimos anos. As preocupações já não se centram apenas nos aspetos tecnológicos e torna-se notório o despertar para outros aspetos. Esta conferência pretende abordar ambos os aspetos, tecnológicos e não tecnológicos relacionados com este desenvolvimento:
Web 2.0: Sistemas Colaborativos, Redes Sociais, Folksonomias, Wikis e Blogs Empresariais, Mashups e Programação Web, Tags e Sistemas de Categorização do Utilizador, Jornalismo cidadão.
Web Semântica e XML: Arquiteturas, Middleware, Serviços, Agentes, Ontologias, Aplicações, Gestão de Dados e Recuperação de informação.
Aplicações e Utilizações: e-learning, e-Commerce / e-Business, e-Government, e-Health, e-Procurement, e-Society, Bibliotecas Digitais, Serviços Web/ Software como Serviço, Interoperabilidade de Aplicações, Tecnologias Multimedia para a Web.
Serviços, Arquitecturas e Desenvolvimento da Web: Internet Wireless, Internet Móvel, Computação em Cloud/Grid, Métricas Web, Web Standards, Arquiteturas da Web, Algoritmos de Rede, Arquiteturas de Rede, Computação em Rede, Gestão de Redes, Performance de Rede, Tecnologias de Distribuição de Conteúdos, Protocolos e standards, Modelos de Tráfego.
Questões de Investigação: Web Ciência, Gestão de Direitos Digitais, Bioinformática, Usabilidade e Interação Humano-Computador, Segurança e Privacidade na Web, Sistemas de Confiança e Reputação Online, Data Mining, Recuperação de Informação, Otimização de Motores de Busca.
Pratica e Experiência Industrial: Aplicações Empresariais, Casos de Estudo de Empresas, Sistemas de Informação Empresariais
A conferência IADIS Ibero-Americana WWW/Internet 2012 teve 94 submissões. Cada submissão foi avaliada por uma média de quatro revisores independentes para assegurar o elevado nível final das submissões aceites. O resultado final foi a publicação de 17 artigos longos (correspondentes a uma taxa de aceitação de 18%), sendo publicados também artigos curtos e artigo de reflexão.

x
Como sabemos, a organização de uma conferência requer o esforço de muitas pessoas. Gostaríamos de agradecer a todos os membros do Comité de Programa pelo trabalho realizado na revisão e seleção dos artigos que constam destas atas.
Estas atas resultam da contribuição de um variado número de autores. Estamos gratos a todos os autores que submeteram os seus artigos. Agradecemos igualmente ao Dr. Ignacio Asin Martinelli, Escola Politécnica da Universidade de Alcalá, Espanha (Escuela Politécnica de la Universidad de Alcalá, España) e ao Professor Luis Bengochea Martínez, Escola Politécnica da Universidade de Alcalá, Espanha (Escuela Politécnica de la Universidad de Alcalá, España) por terem aceitado dar uma palestra. Também gostaríamos de agradecer a todos os membros do comité de organização, delegados, e convidados cuja contribuição e envolvimento são cruciais para o sucesso desta conferência.
Por fim, desejamos que todos os participantes tenham uma excelente estadia em Madrid. Convidamos todos os participantes para a edição do próximo ano da conferência IADIS Ibero-Americana WWW/Internet. José María Gutiérrez, Escuela Politécnica de la Universidad de Alcalá, Espanha Flavia Maria Santoro, Universidade Federal do Estado do Rio de Janeiro (UNIRIO), Brasil Pedro Isaías, Universidade Aberta, Portugal Co-Chairs Madrid, Espanha 18 de outubro 2012

xi
COMITÉ DO PROGRAMA
CO-CHAIRS
José María Gutiérrez, Escuela Politécnica de la Universidad de Alcalá, Espanha Flavia Maria Santoro, Universidade Federal do Estado do Rio de Janeiro (UNIRIO), Brasil
Pedro Isaías, Universidade Aberta, Portugal
MEMBROS DO COMITÉ
Adelaide Bianchini, Universidad Simón Bolívar, Venezuela Adolfo Lozano-Tello, University of Extremadura, Espanha
Adriana Medeiros, Universidade Federal Fluminense (puro/uff), Brasil Adriana Soares Pereira, Universidade Federal de Santa Maria, Brasil
Alberto Cano Rojas, Universidad De Cordoba, Espanha Alberto Raposo, Puc-rio, Brasil
Alejandro Fernandez, National University Of La Plata, Argentina Alejandro Gonzalez, National University Of La Plata, Argentina
Alejandro Zunino, Tandil University, Argentina Alessandro La Neve, Centro Universitário da FEI, Brasil
Alexandra Queiros, Universidade De Aveiro, Portugal Alexandre Sztajnberg, Universidade Do Estado Do Rio De Janeiro, Brasil
Alfonso Rodriguez Rios, Universidad Del Bio-bio, Chile Álvaro Suárez Sarmiento, Las Palmas De Gran Canaria University, Espanha
Amelia Zafra Gomez, Universidad De Córdoba, Espanha Ana Guimarães, Isla Gaia, Portugal
Ana Afonso, Iscap, Portugal Ana Fernandez-Cuesta, TECNALIA, Espanha
Ana Maria Ibaños, Pontificia Universidade Catolica Do Rio Grande Do , Brasil Ana Paula Ambrosio, UFG, Brasil
Andreas Polymeris, Universidad De Concepcion, Chile Angélica Caro, Universidad del Bio-Bio, Chile
Angélica De Antonio, Universidad Politécnica De Madrid, Espanha Aníbal Zaldivar Colado , Universidad Autonoma de Sinaloa, Mexico
Annabell Del Real Tamariz, Universidade Estadual Do Norte Fluminense, Brasil Antonia Estero Botaro, Universidad De Cadiz, Espanha
Antonio Canabate, Universitat Politecnica De Catalunya, Espanha Antonio Munoz Canavate , Universidad De Extremadura, Espanha
Antonio Reyes, Universidad Politécnica De Valencia, Espana Antonio Godinho, Isla, Portugal
Antonio Paños Alvarez, Universidad De Murcia, Espanha Armando Mendes, Universidade Dos Açores, Portugal
Arnaldo Martins, Universidade De Aveiro, Portugal

xii
Arturo Mora-soto, Universidad Carlos III De Madrid, Espanha Ascension Lovillo Gil, Universidad Rey Juan Carlos, Espanha
Avanilde Kemczinski, Universidade do Estado de Santa Catarina, Brasil Barbara Neves, Universidade Técnica De Lisboa, Portugal
Beatriz Depetris, Universidad Nacional De La Patagonia, Argentina Bráulio Alturas, ISCTE-IUL, Portugal Carlos Costa, ISCTE - IUL, Portugal
Carlos Oliveira Cruz, Instituto Superior Técnico, Portugal Carlos Serrão, ISCTE-IUL, Portugal
Carlos Juiz, Universidad De Las Islas Baleares, Espanha Carlos Rabadao, Instituto Politecnico De Leiria, Portugal
Carolina Tripp, Universitat Politècnica de Catalunya (UPC) , Espanha Cedric Luiz de Carvalho, UFG, Brasil
Cesar Collazos, University Of Cauca, Colombia Cesar Guerra, Universidad Politecnica De San Luis Potosi, Mexico
César Acebal , Universidad de Oviedo, Espanha Claudia Marcos, Unicen University, Argentina
Claudia Pons, National University Of La Plata, Argentina Claudia Motta, Universidade Federal Do Rio De Janeiro, Brasil
Claudia Regina Batista, Universidade Federal de Santa Catarina - UFSC, Brasil Claudio Teixeira , Universidade De Aveiro, Portugal
Clifton Clunie, Universidad Tecnológica de Panamá, Panama Coral Calero, Universidad De Castilla-la Mancha, Espanha
Cristian Mateos, Isistan Research Institute, Argentina Cristiano Maciel, Universidade Federal de Mato Grosso - UFMT, Brasil
Daniel Diaz Palacios, Universidad De Alcala, Espana Daniela Barreiro Claro, Universidade Federal da Bahia, Brasil
David Melendi Palacio, Universidad de Oviedo, Espana David Lizcano, Universidad Politécnica De Madrid, Espanha
Debora Barbosa, Learningware Tecnologia Educacional, Brasil Denis S. Silveira, Universidade Federal de Pernambuco, Brasil
Dolores Mª Llido Escriva, Universitat Jaume I, Espanha Duncan Ruiz, Universidade Católica Do Rio Grande Do Sul, Brasil
Edna Ruckhaus, Universidad Simon Bolivar, Venezuela Eduardo Peis Redondo, Universidad De Granada, Espanha
Elaine Faria, PUCRS, Brasil Eliane Loiola, UPE/POLI, Brasil
Emanuel Peres, Universidade de Trás-os-Montes e Alto Douro, Portugal Emilio Insfran, Universitat Politècnica de València, Espanha
Erick Lopez Ornelas , Universidad Autonoma Metropolitana (uam), Mexico Eva Gibaja Galindo, Universidad De Córdoba, Espanha Eva Lorenzo Iglesias, Universidad De Vigo, Espanha
Fabio Sampaio, Nce – Ufrj, Brasil Fatima Armas, Universidade De Coimbra, Portugal
Fausto Amaro, Universidade Técnica De Lisboa, Portugal Federico Botella, Miguel Hernandez University of Elche, Espanha
Felipe Gustsack, Universidade de Santa Cruz do Sul, Brasil

xiii
Fernanda Barbosa, Universidade Nova De Lisboa, Portugal Fernanda Lima, UnB, Brasil
Fernanda Alencar , Universidade Federal De Pernambuco, Brasil Fernanda Baião, UNIRIO, Brasil Fernanda Campos, UFJF, Brasil
Fernando Ribeiro, Instituto Politecnico De Castelo Branco, Portugal Fernando De Azevedo, Universidade Federal De Santa Catarina, Brasil
Fernando Moreira, Universidade Portucalense , Portugal Flávia Bernardini, Universidade Federal Fluminense, Brasil
Francisco Cervantes, Universidad Autonoma Metropolitana, Mexico Francisco J. Garcia Penalvo, Universidad De Salamanca, Espana
Francisco Javier Martinez Mendez, Universidad De Murcia, Espanha Gabriela Aranda, Universidad Nacional Del Comahue, Argentina Georgia Gomes, Universidade Candido Mendes - Campos, Brasil
Gilberto Gutierrez, Universidad Del Bio-bio, Chile Gisela T. de Clunie, Universidad Tecnológica de Panamá, Panamá
Guillermo Feierherd, Universidad Nacional de La Patagonia, Argentina Heitor Costa, Universidade Federal de Lavras, Brasil
Helia Guerra, Universidade dos Açores, Portugal Henrique Teixeira Gil, Escola Superior De Educação De Castelo Branco, Portugal
Hermes Senger, Universidade Federal De São Carlos, Brasil Hilda Carvalho de Oliveira, Unesp - Universidade Estadual Paulista Júlio de Me, Brasil
Ignacio Marin, Fundacion CTIC, Espanha Inácio Fonseca , Isec, Portugal
Inmaculada Medina Bulo, Universidad De Cadiz, Espanha Iolanda Cláudia Sanches Catarino, Universidade Norte do Paraná - UNOPAR, Brasil
Isabel Sofia Brito, Escola Superior De Tecnologia E Gestão , Instituto, Portugal Isidro Ramos, Universidad Politécnica De Valencia, Espanha
Ismael Sanz , Universitat Jaume I, Espanha Jaime Ramírez, Universidad Politécnica De Madrid, Espanha
Javier Parra-fuente, Universidad Pontificia De Salamanca, Espanha Javier Troya Castilla, Universidad De Malaga, Espanha
Javier Cubo, Universidad De Malaga, Espanha Javier Fernandez De Canete, Universidad De Malaga, Espana
Jesus Tramullas, Universidad De Zaragoza , Espana Jesus Isidro Gonzalez Trejo, Universidad Autonoma Metropolitana, Mexico
João Bosco Sobral, Universidade Federal Da Santa Catarina, Brasil Joao Ferreira, Instituto Superior De Engenharia De Lisboa, Portugal
João Negreiros, ISEGI-UNL, Portugal João Paulo Ribeiro Pereira, Instituto Politécnico De Bragança, Portugal Joao Varajao, Universidade De Trás-os-montes E Alto Douro, Portugal
Joaquim Sousa Pinto, Universidade De Aveiro , Portugal Joice Lanzarini, Universidade De Santa Cruz Do Sul, Brasil
Jonice Oliveira, Universidade Federal do Rio de Janeiro, Brasil Jorge Barbosa, Unisinos, Brasil
Jorge Ferreira, Universidade Nova De Lisboa, Portugal Jose A. Senso, Universidad De Granada, Espanha

xiv
Jose Alfonso Aguilar Calderon, Universidad Autónoma de Sinaloa, Mexico José Cárdenas Cadierno, Universidad De Málaga, Espanha
José Eduardo Córcoles Tendero, DSI - Universidad de Castilla-la Mancha, Espanha Jose Emilio Labra Gayo, Universidad De Oviedo, Espanha
Jose Farinha, Universidade De Coimbra, Portugal Jose M. Morales Del Castillo, Universidad De Granada, Espanha
Jose Mª Luna , University Of Cordoba, Espanha José Manuel Gonçalves , Escola Superior Agrária de Coimbra, Portugal José Maria David, Universidade Federal de Juiz de Fora (UFJF), Brasil
Jose Metrolho, Instituto Politécnico De Castelo Branco, Portugal José Raúl Romero, University of Cordoba, Espanha
Josep Lluis Segu, Educaweb, Espanha Juan Rejas López, Universidad de León, Espanha
Juan Boubeta Puig, Universidad de Cadiz, Espanha Juan Carlos Guerri, Universidad Politécnica De Valencia, Espanha
Juan Jose Pardo, University Of Castilla-la Mancha, Espanha Juan Luis Olmo Ortiz, Universidad De Cordoba, Espanha
Juan M. Vara, Universidad Rey Juan Carlos, Espana Juncal Gutierrez Artacho , Universidad De Granada, Espanha
Katja Gilly, Universidad Miguel Hernandez, Espanha Leonardo Azevedo, Universidade Federal Do Estado Do Rio De Janeiro, Brasil
Leonardo Cunha de Miranda, Federal University of Rio Grande do Norte (UFRN), Brasil Leonor Teixeira, Universidade De Aveiro, Portugal
Leticia Lopes Leite, PUCRS, Brasil Liberato Perez , Esco - Escuela Superior De Comunicacion, Espanha
Lidia Oliveira Silva , Universidade De Aveiro, Portugal Lucia Giraffa, PUCRS, Brasil
Luis Martinez, Universidad De Jaen, Espana Luís Gomes, Universidade Dos Açores, Portugal
Luis Marcelino, Instituto Politécnico De Leiria, Portugal Luisa Domingues, Adetti / Iscte, Portugal
Mª Del Puerto Paule Ruiz, Universidad De Oviedo, Espanha Mª Dolores Olvera, Universidad De Granada, Espanha
Marcelo Ritzel, Universidade Feevale, Brasil Marco Aurélio Gerosa, Universidade de São Paulo (USP), Brasil
Marco Painho, Universidade Nova De Lisboa, Portugal Marco Winckler, Institute of Research on Informatics of Toulouse, France
Marcos A. F. Borges, UNICAMP, Brasil Marcus Guelpeli, Universidade Federal dos Vales do Jequitinhonha e Mucuri-UFVJM,
Brasil Margarida Almeida, Universidade De Aveiro, Portugal
Maria Ángeles Moraga, Universidad De Castilla-la Mancha, Espanha Maria Clicia De Castro, Niversidade Do Estado Do Rio De Janeiro, Brasil
Maria Esther Vidal, Universidad Simón Bolívar, Venezuela Maria Helena Braz, Ist/utl, Portugal
Maria Luque Rodriguez, Universidad De Cordoba, Espanha Maribel Sanchez Segura, Universidad Carlos Iii De Madrid, Espanha

xv
Maribel Santos, Universidade Do Minho, Portugal Marlise Geller, Universidade Luterana Do Brasil, Brasil
Marta González, Tecnalia, Espanha Mehran Misaghi, Sociesc, Brasil
Miguel Ángel Marzal, Universidad Carlos III De Madrid, Espanha Miguel Jimenez, Universidad Politécnica De Madrid, Espanha
Monica Costa, Instituto Politecnico De Castelo Branco, Portugal Nadia Gamez, Universidad De Malaga, Espanha
Nathalie Moreno, Universidad De Málaga, Espanha Neide Santos, Universidade Do Estado Do Rio De Janeiro, Brasil
Nize Pellanda, Universidade De Santa Cruz Do Sul, Brasil Nuno Fortes, Instituto Politécnico de Coimbra - ESTGOH, Portugal
Oscar Sanjuan Martinez, Universidad Carlos III, Espanha P. Pablo Garrido Abenza, Universidad Miguel Hernandez, Espanha
Pablo Munoz Martinez , Universidad De Alcala , Espana Pablo Payo, Universidade Do Porto, Portugal
Patricia Alejandra Behar, Universidade Federal Do Rio Grande Do Sul, Brasil Patricia Scherer Bassani, Universidade Feevale, Brasil
Paula Oliveira, Universidade De Trás-os-montes E Alto Douro, Portugal Paulo Loureiro, Instituto Politécnico De Leiria, Portugal
Paulo Martins, Universidade de Trás-os-Montes e Alto Douro, Portugal Paulo Rech Wagner, PUCRS, Brasil
Paulo Trigo, Instituto Superior De Engenharia De Lisboa, Portugal Paulo Urbano, Universidade De Lisboa, Portugal Pedro Hipola, Universidad de Granada, Espanha
Pedro Pina, Instituto Politécnico de Coimbra - ESTGOH, Portugal Plinio Thomaz Aquino Junior, Centro Universitario da FEI - Fund. Educ. Inaciana, Brasil
Porfírio Filipe, Instituto Superior de Engenharia de Lisboa, Portugal Rafael Repiso, Esco Escuela Superior De Comunicacion, Espanha Rafael Fernández, Universidad Politécnica De Madrid, Espanha
Ramiro Gonçalves, Universidade Trás Os Montes E Alto Douro, Portugal Regina Maria Maciel Braga, Universidade Federal De Juiz De Fora, Brasil
Remulo Alves, Universidade Federal De Lavras, Brasil Rita Suzana Maciel, Universidade Federal da Bahia, Brasil
Rocio Abascal Mena, Universidad Autonoma Metropolitana - Cuajimalpa, Mexico Rodrigo Bonacin, Centro De Tecnologia Da Informaçao Renato Archer, Brasil
Ronaldo Goldschmidt, UFRRJ - Universidade Federal Rural do Rio de Janei, Brasil Rosa Maenza, Universidad Tecnológica Nacional, Argentina
Rosana Lopez Carreño, Universidad Murcia, Espanha Ruben Gonzalez Crespo, Universidad Pontificia De Salamanca, Espanha
Sahudy Montenegro Gonzalez, Universidade Federal de São Carlos, Brasil Salvador Alcaraz, Universidad Miguel Hernandez, Espanha
Sean Siqueira, UNIRIO, Brasil Silvia B. Gonzalez Brambila, Universidad Autonoma Metropolitana, Mexico
Silvia Baldiris, University Of Girona, Espanha Silvia Castro, Universidad Nacional Del Sur, Argentina
Simone Diniz Junqueira Barbosa, PUC-Rio, Brasil

xvi
Susana Torrado Morales, Universidad De Murcia, Espanha Tanja Vos, Universidad Politécnica De Valencia, Espanha
Teresa Correia, Universidade Do Porto, Portugal Teresa Tiago, Universidade Dos Açores, Portugal
Uriel Cukierman, UTN, Argentina Vania Ulbricht, Universidade Anhembi Morumbi, Brasil
Victor M. R. Penichet, Universidad de Castilla-La Mancha, Espanha Vinicius Bezerra, Universidade Presbiteriana Mackenzie, Brasil Vitor Basto Fernandes, Instituto Politécnico de Leiria, Portugal Vitor Gonçalves, Instituto Politécnico De Bragança, Portugal Xabier Larrucea, Tecnalia Research and Innovation, Espanha
Yolanda Escudero Martin, Universidad de Alcala, Espana Adolfo Duran, Universidade Federal Da Bahia, Brasil
Zita Sampaio, Instituto Superior Técnico, Portugal

xvii
PALESTRAS CONVIDADAS
FUTURO DEL E-COMMERCE. EVOLUCIÓN EN LOS HÁBITOS DE COMPRA Y SU INCIDENCIA EN EL SECTOR TURÍSTICO
Pelo Dr. Ignacio Asin Martinelli
Escuela Politécnica de la Universidad de Alcalá, España
RESUMO
El volumen total de facturación del comercio electrónico alcanzó en el tercer trimestre de 2011 los 2.421,8 millones de euros, un 27,4% más que en el mismo periodo de 2010. Este registro supone el décimo trimestre consecutivo de crecimiento y nuevo máximo histórico, según el último Informe sobre el comercio electrónico a través de entidades de medios de pago publicado por la CMT. De este importe, más del 36% se facturó en empresas del sector turístico. Si bien las líneas aéreas abrieron el camino, en un plazo muy rápido alojamientos, agencias de viajes y tour operadores se han sumado al comercio electrónico vía internet. ¿ Qué ha cambiado en los hábitos de compra de los consumidores? En primer lugar un nuevo perfil de consumidor se ha implantado en España. Un perfil de viajero que gracias al mayor conocimiento de idiomas y mejora del poder adquisitivo, cambia sus hábitos de viaje y ocio, dejando el viaje organizado y pasando a la compra de servicios sueltos para realizar sus viajes a medida. En segundo lugar, la evolución de los perfiles de los consumidores en España con un mayor conocimiento de internet y su funcionalidad, así como el aumento de la fiabilidad en las operaciones de compra en la red, han hecho que la sociedad haya dado el paso hacia la compra no asistida de unos servicios que han pasado a ser servicios de consumo generalizado. ¿ Qué expectativas de crecimiento hay en el futuro?. ¿ Desaparecerá la venta presencial en las empresas dedicadas al turismo?. ¿Influye la distancia de los mercados de destino a la hora de realizar las compras vía internet?. ¿ ews igual en todos los subsectores turísticos?

xviii
HACIA UNA FORMACIÓN VIRTUAL INCLUSIVA Y DE CALIDAD
Pelo Professor Luis Bengochea Martínez, Escuela Politécnica de la Universidad de Alcalá, España
RESUMO
La mayor parte de los cursos que se imparten en las universidades y otras organizaciones dedicadas a la enseñanza se hace hoy día en modalidad virtual. Profesores y estudiantes comparten un espacio virtual común en una plataforma de e-learning donde se publican los contenidos, se realizan exámenes, se entregan trabajos y tareas colaborativas, se intercambian mensajes y se comparte información acerca del curso y de la materia objeto de estudio. Sin embargo, este incremento de la oferta no ha venido acompañado de un sistema normalizado que sirva para medir la calidad del servicio y poder valorar el grado de satisfacción esperado en relación con las necesidades de los estudiantes y el coste de la formación. Además, el uso intensivo de tecnologías web y multimedia en el diseño de los recusos didácticos destinados a la formación virtual, puede ocasionar una importante barrera de acceso para determinados estudiantes con alguna discapacidad, lo que hace indispensable tener presentes todos los aspectos, en algunos casos requisitos legales, relacionados con la accesibilidad del entorno y de los materiales empleados en este tipo de formación. En esta conferencia se aborda la problemática, así como las recomendaciones y normas que habría que seguir una institución u organización para lograr ofertar una formación virtual inclusiva y de calidad.

Artigos Longos


MECANISMO INFOMÉTRICO APLICADO EM UM AMBIENTE PARA GESTÃO DO CONHECIMENTO:
O CASO SOCIESC
Cintia Ghisi1, Alcir Mário Trainotti Filho1, Edicarsia Barbiero Pillon1, Mehran Misaghi1
e Thiago Jabur Bittar2 1Instituto Superior Tupy – IST/SOCIESC 2Universidade Federal de Goiás - UFG
RESUMO
O nível da globalização atualmente impulsiona as organizações a evoluírem qualitativamente seus produtos e serviços, além da necessidade de se manterem inovadoras. Além disso, o conhecimento se torna o ativo fundamental para esse processo, e as tecnologias da informação podem auxiliar a busca por maior competitividade no mercado. A Web semântica é uma das tecnologias que auxiliam o processo de explicitação do conhecimento, no entanto, a combinação com outras tecnologias pode melhorar a sua eficiência. Apresentam-se os conceitos de infometria e a gestão do conhecimento executada por meio da Web semântica, com o objetivo de desenvolver um mecanismo infométrico para a contextualização automática dos arquivos inseridos no portal acadêmico da computação do Instituto Superior Tupy - IST, e facilitar a explicitação do conhecimento. Diante da comprovação obtida pela ferramenta estatística t de Student, observou-se os benefícios imediatos trazidos, por este trabalho, à comunidade acadêmica da computação do IST.
PALAVRAS-CHAVE
Infometria. Lei de Zipf. Gestão do conhecimento.
1. INTRODUÇÃO
Atualmente a globalização é acentuada diante da competitividade comercial, o que capacita à evolução da ciência e da tecnologia. As organizações começam a avaliar a informação como o principal insumo para o desenvolvimento e a garantia de qualidade de seus produtos e serviços. Perante isso, desenvolveram-se diferentes metodologias de gestão do conhecimento e ferramentas computacionais que auxiliam os projetos administrativos para a compreensão das informações (FIGUEIREDO, 2005).
Figueiredo (2005) enuncia que a gestão do conhecimento possui diferentes ferramentas para auxiliar o processo de explicitação do conhecimento. Essas ferramentas ajudam as pessoas na busca por aprendizagem, assim como as empresas no processo de explicitação do conhecimento tangível e intangível apropriados por seus colaboradores.
Para colaborar nesse processo de disseminação do conhecimento intra-organizacional, são utilizadas ferramentas computacionais como os Podcasts, Data mining, Data Warehouse, Workflow, Business Inteligence - BI e a Web semântica. Os mecanismos semânticos são facilitadores da organização do conhecimento e atribuição de significado para as informações, o que possibilita relacioná-las dentro de um contexto específico. Ainda assim, para sustentar a gestão do conhecimento, é possível combinar diferentes tecnologias computacionais. Como exemplo tem-se a infometria, que possui a capacidade de conceder sentido aos dados e qualificá-los de forma automática para que seja atribuído um uso mais consciente em políticas de ciência e tecnologia (MACIAS-CHAPULA, 1998; ANGELONI, 2008; BREITMAN, 2005).
Esta pesquisa direciona-se ao portal acadêmico de computação do IST, que proporciona a disponibilização de informações para alunos e professores. Atualmente, este portal conta com um mecanismo semântico capaz de estruturar as informações disponibilizadas, que facilita o reaproveitamento dos conhecimentos (TRAINOTTI-FILHO, 2011).
Conferência IADIS Ibero-Americana WWW/Internet 2012
3

Nesse contexto, para o funcionamento do mecanismo semântico, é necessária a criação de um metadado para cada arquivo incluído, que é executado manualmente pelo usuário. O diferencial do mecanismo semântico é a pesquisa contextualizada, que permite a busca pelo conhecimento por meio do contexto da informação. Contudo, o campo de contexto do metadado se caracterizar em texto aberto, permite-se a adição de qualquer informação que seja relevante ou não ao documento, por consequência dos dados serem incluídos manualmente, o que reduz a confiabilidade das pesquisas e permite a inserção de informações erradas.
Diante da problemática descrita, o objetivo geral deste trabalho é desenvolver um mecanismo infométrico para a contextualização automática dos arquivos inseridos no portal acadêmico da computação. A abordagem deste tema é relevante, uma vez que a aplicação de leis infométricas, como ferramenta em um ambiente computacional, viabiliza aos softwares a contribuição para o aprendizado humano. Dessa forma, possibilita o uso das ferramentas para auxiliar a semântica no processo de explicitação do conhecimento, com a disponibilização de um ambiente inteligente para pesquisas e estudos.
Esta pesquisa está estruturada em seis seções, a primeira introduz o tema de pesquisa, apresenta a problemática e o objetivo geral do trabalho. Na próxima seção, exibe-se os conceitos de gestão do conhecimento, e adiante, a teoria sobre infometria e suas leis. Na quarta seção, apresenta-se informações sobre o ambiente estudado e o mecanismo infométrico proposto. Na seguinte seção, expõe os resultados obtidos com os testes sobre o mecanismo desenvolvido, juntamente com suas vantagens. E por fim, alegam-se as conclusões deste estudo.
2. GESTÃO DO CONHECIMENTO
A economia mundial sofreu grandes mudanças ao longo da história, o que resultou na economia atual. Essa economia se iniciou por meio da demanda acentuada por produtos personalizados e serviços modelados à necessidade dos consumidores. Essa mudança do conceito consumista fez com que as empresas sentissem a necessidade de uma economia mais racional (MOHAMED, 2011).
Perante esse cenário, percebeu-se então a importância do conhecimento para o processo de readaptação ao mercado que surgira. O conhecimento passou a ser o insumo mais importante da humanidade e por meio dele evoluiu-se tecnologicamente, socialmente e eticamente ao longo da história. Fialho et al. (2006) define o conhecimento como um conjunto de dados, informações e relações que uma pessoa possui, que a leva tomar decisões, a realizar tarefas e a criar novas informações ou novos conhecimentos. Esse conhecimento está diretamente ligado as crenças e a cultura de cada pessoa, que pode ser adquirido pelo repasse de informações ou experiências vividas.
Para as organizações aproveitarem os conhecimentos de seus funcionários, é necessário estipular uma estratégia para gerenciar esses conhecimentos. A gestão do conhecimento para Fialho et al. (2006) tem a característica de administrar o que as pessoas conhecem e aprendem no seu cotidiano, sendo gerada por meio de experiências, conversas, manuais, treinamentos ou palestras. Dessa forma, possibilita-se à organização transformar esse conhecimento tácito em explícito e facilitar a disseminação de informação.
Perante isso, a gestão do conhecimento pode ser definida sistematicamente como identificação, criação, renovação e aplicação do conhecimento, que são estratégicos na vida de uma organização. Portanto, são ativos intangíveis de uma organização, que permitem a ela saber o que realmente sabe, por intermédio de um processo de gestão bem definido (FIGUEIREDO, 2005).
No entanto, a retenção de conhecimento é o grande vilão da gestão do conhecimento. Gerenciar um ambiente baseado em conhecimento é complexo, precisa-se quebrar paradigmas e criar uma cultura menos burocrática e mais dinâmica. Os líderes possuem o papel de incentivadores e devem estimular os colaboradores a se expressarem. Para auxiliar esse processo de disseminação do conhecimento, desenvolveu-se diferentes modelos para a implantação da gestão do conhecimento nas organizações, como apresentam os pilares do conhecimento de Figueiredo (2005), o modelo atômico de Angeloni (2008), as espirais do conhecimento de Sabbag (2007) e o modelo precursor de Nonaka e Takeuchi (1997).
Além desses modelos, o avanço tecnológico computacional auxilia nos processos de explicitação, compartilhamento, interação e disponibilidade do conhecimento. Perante isso, conceitos como repositórios do conhecimento e ferramentas semânticas ganham força e se tornam aliados dos projetos de gestão do conhecimento (FALEH, HANI, KHALED, 2011; SERAFINI, HOMOLA, 2011).
ISBN: 978-989-8533-11-1 © 2012 IADIS
4

Conforme relacionado anteriormente, a web semântica é uma ferramenta definida como uma extensão da estrutura da web atual. Ela possui uma organização que possibilita a compreensão e o gerenciamento dos conteúdos, independentemente de sua forma, a partir de sua valoração semântica (SEAGARAM, EVANS e TAYLOR, 2009; RODRIGUES, ROCHA, 2011).
Essa nova arquitetura beneficia a gestão do conhecimento, bem como as indústrias e o comércio eletrônico, já que tudo o que circula na internet pode ser um conhecimento estratégico em potencial. Essa reestruturação tem o objetivo de tornar este ambiente mais colaborativo e inteligente (BERNERS-LEE, FISCHETTI e DERTOUZOS, 2000; BREITMAN, 2005).
Para manter o controle desta nova arquitetura e aplicar as melhores práticas e tecnologias na construção de um ambiente diferenciado semanticamente, criou-se o World Wide Web Consortium - W3C a partir da iniciativa de Berners-Lee (2010). Perante as ferramentas computacionais existentes, a web semântica é apenas uma opção de auxilio para a gestão do conhecimento. Para torná-la mais completa e abrangente, é possível combiná-la com diferentes tecnologias computacionais, como a infometria que será apresentada a seguir.
3. INFOMETRIA
Diferentes sistemas de pesquisas são encontrados na internet (como google, bing, yahoo search, etc.), e com a grande quantidade de dados disponível é custoso adquirir uma informação. Por meio de modelos matemáticos, booleanos, probabilísticos, linguagens de processamento e abordagens baseadas no conhecimento, a infometria estuda os documentos e grupos de dados, e têm seu foco voltado às palavras, que desenvolvem métodos e ferramentas para mensurar e analisar os aspectos cognitivos da ciência (MACIAS-CHAPULA, 1998). Noronha e Maricato (2008) complementam e relacionam a infometria com a recuperação de informações, medição de sistemas e estudo de conteúdos informativos.
Nascida da Bibliometria e da Cienciometria, e que deu origem a outros núcleos, como a mais resente Webometria, estas ciências subdividem e complementam a infometria (PINHEIRO; FERNEDA, 2007). Dentre as pioneiras, a Cienciometria se preocupa com a dinâmica da ciência e estuda diretamente as disciplinas, os assuntos específicos, as áreas e os campos científicos, por meio de métodos de análise de conjuntos que vinculam-se à produção cientifica (VANTI, 2011). Possui seu foco na organização da ciência, e tem fatores que diferenciam e identificam os domínios de interesse das subdisciplinas (NORONHA; MARICATO, 2008).
Correlacionada, a Bibliometria é apresentada por Macias-Chapula (1998) com o estudo dos livros, documentos, revistas, artigos, autores e usuários. Por intermédio de rankeamento, frequência e distribuição das palavras, observou-se que é possível vincular a gestão de bibliotecas com as bases de dados. Noronha e Maricato (2008) complementam ainda, que ela é voltada para a produção, a utilização de documentos e a organização de serviços bibliográficos.
Já para a Webometria, Macias-Chapula (1998) mostra o estudo dos domínios, dos sites, dos motores de busca, junto com o método de fator de impacto da web, densidade de links e estratégias de busca. Esta ciência se dedica a organização dos sites e a sua utilização (NORONHA; MARICATO, 2008). Sengupta (1992) concorda com Macias-Chapula (1998), Noronha e Maricato (2008) e define ainda que os termos Bibliometria, Infometria, Webometria e Cienciometria derivam da fusão do sufixo metria com bibliografia, informação, web e ciência, respectivamente por serem análogos ou próximos em sua natureza, objetivos e aplicações.
Perante as ciências apresentadas, a infometria permanece com os conceitos operacionais centrais vindos da bibliometria, como a produtividade de autores e artigos científicos (com base nas leis de Lotka e Price), o núcleo e a dispersão de artigos em periódicos científicos (lei de Bradford), e a frequência de palavras em textos longos (lei de Zipf).
Correlacionar à gestão do conhecimento ou de informações, em meios digitais ou físicos, requer o auxílio da análise bibliométrica para determinar as estratégias que devem ser tomadas. As leis Bibliométricas permitem essas análises, sendo que Santos e Kobashi (2009) conceituam-nas como:
1. Lei de Lotka, de 1926, ou lei do quadrado inverso - estuda a produtividade científica de autores, ou seja, faz referência ao cálculo de produtividade dos autores de artigos científicos. De acordo
Conferência IADIS Ibero-Americana WWW/Internet 2012
5

com esta situação tem-se, em uma especialidade científica, um número pequeno de pesquisadores altamente produtivos com uma grande quantidade de cientistas menos produtivos.
2. Lei de Bradford, de 1934, ou a lei de dispersão do conhecimento científico, relata a produtividade de periódicos que, dentre outras formas, trata-se da dispersão dos autores em diferentes publicações. Antigamente existia o interesse de determinar o núcleo de melhores periódicos em determinado tema. Esta lei propôs critérios para equilibrar a relação entre o custo e o benefício de coleções de periódicos, sendo voltada para fins gerenciais.
3. Lei de Zipf, de 1935 - propõe o modelo de distribuição e a frequência de palavras em obras. Esta lei foi extraída do princípio geral do menor esforço, que quantifica a atividade humana, e permite definir assim, o custo de utilização pequeno ou que a transmissão demande esforço reduzido em textos grandes, o que a tornou popularmente conhecida como a lei do mínimo esforço.
Por meio da Infometria e suas leis, possibilita-se a criação de ferramentas para pesquisa de palavras que indiquem a ênfase adotada por cada documento (KOS, 2001). Isso provém da abrangência de algoritmos matemáticos destinados a melhorias na recuperação das informações. Wormell (1998) considera ainda que a infometria esteja em processo de transformação para uma disciplina cientifica fortemente vinculada aos aspectos teóricos da recuperação de informação, com dimensões estatísticas e matemáticas da biblioteconomia, da documentação e da informação.
Diante da fundamentação apresenta-se a aplicação da lei de Zipf em um mecanismo de busca semântica. Porém, torna-se necessária a compreensão do conceito da Lei de Zipf, que foi criada a partir de 1935, que propõe o modelo de distribuição e a frequência de palavras em obras. Extraída do princípio geral do menor esforço, que quantifica a atividade humana, e permite definir assim, o custo de utilização pequeno ou que a transmissão demande esforço reduzido em textos grandes, o que a tornou popularmente conhecida como a lei do mínimo esforço (SANTOS; KOBASHI, 2009).
Guedes e Borschiver (2005), por sua vez, trazem a abordagem em que a Lei de Zipf relaciona-se também à frequência de ocorrência de palavras em um dado texto e liga diretamente com a representação da informação, isto é, a indexação temática automática. Em acordo com essa automatização, Luhn (1957) propôs que a indexação poderia ser derivada da análise de uma amostra representativa de documentos sobre um determinado assunto.
Dentro dessa linha de pensamento em que uma lista é confeccionada, e considerada a frequência decrescente de ocorrências e a posição das palavras nesta lista como ordem de série, ou ranking. Assim, exemplifica-se que a palavra de maior frequência de ocorrência tem a ordem de série 1, a de segunda maior frequência de ocorrência, ordem de série 2, e assim, sucessivamente. De modo geral, a lei de Zipf possui as palavras chaves dos documentos e as palavras secundárias, que representam o conceito semântico dos textos ou documentos. As ciências e as leis fundamentadas nesse capítulo, junto com os algoritmos matemáticos, permitem encontrar o conceito do documento, e com isso, alcançar um resultado efetivamente melhor na busca de informações.
4. MECANISMO INFOMÉTRICO
Este estudo tem por objetivo avaliar o ambiente Computação.sociesc (2012) e disponibilizar melhorias para o mesmo. O IST/SOCIESC é uma instituição educacional situada no norte catarinense que disponibiliza seus serviços há 50 anos. A instituição possui aproximadamente 105 cursos entre graduação e pós-graduação e destes, três graduações são voltados à área computacional. Atualmente os cursos de computação abrangem 459 alunos e 44 professores centralizados no campus Marquês de Olinda em Joinville, Santa Catarina (SOCIESC, 2012).
O portal da computação do IST foi concebido por intermédio de um CMS Joomla, desenvolvido em PHP - Hypertext Preprocessor, e projetado para disponibilizar um ambiente inteligente que atenda as necessidades de pesquisa e desenvolvimento de seus usuários. Ele é uma ferramenta de gestão de conteúdo – CMS, que disponibiliza facilidades para a construção de um repositório de informações, para facilitar o incremento, compartilhamento e manutenção da informação. Ainda assim, Trainotti Filho (2011) relaciona a construção do portal da computação do IST às teorias da gestão do conhecimento de uma maneira que permita facilitar o acesso a informação e estimular a interação do usuário com o ambiente, a fim de gerar mais sabedoria.
ISBN: 978-989-8533-11-1 © 2012 IADIS
6

Em convergência com isso, a lei de Zipf apresenta as características necessárias para otimizar o ambiente e resolver o problema encontrado, acerca da contextualização dos arquivos inseridos manualmente no metadado. O sistema proposto, que também foi projetado em PHP, seguiu alguns passos definidos para a implementação do algoritmo da Lei de Zipf. O primeiro deles foi à necessidade da leitura dos arquivos (Tratou-se como padrão apenas a leitura de arquivos PDF – Portable Document Format).
Durante o processo de desenvolvimento percebeu-se alguns empecilhos que distorciam o resultado esperado com a leitura dos arquivos. Ao efetuar a leitura dos arquivos PDF, visualizou-se que as informações estavam criptografadas. Então, aplicou-se a API XPDF Package do PHP, que Gonçalves (2009) em seu portfólio, menciona que permite a leitura de arquivos PDF como texto legível.
Adiante, o próximo passo dessa pesquisa é o tratamento do texto, com a eliminação das palavras que correspondem as regras linguísticas, pois elas não possuem significância semântica no idioma português, e com isso não devem compor o ranking de frequência que será criado para os documentos. Almeida (2008) apresenta essa listagem de palavras de ligação a serem eliminadas:
a) Artigos – que se classificam como definidos (o, a, os, as), indefinidos (um, uma , uns, umas), declináveis (do, da, no, na, ao, pelo) entre outros;
b) Adjetivos – compreendem as palavras que se referem aos substantivos e, com isso, indicam ser atributos;
c) Advérbios – utilizados para transformarem os verbos por meio de suas classes gramaticais, também modificam os adjetivos ou outros advérbios e jamais mudam substantivos.
d) Conjunção – designada a conectar as orações ou os termos de mesma função sintática, e criam entre eles uma relação de dependência ou de simples coordenação;
e) Preposição – usada para ligar dois elementos da oração, também é uma palavra invariável, e que faz subordinação entre a parte regente e a regida.
f) Pronome - empregado para substituir, ou não, um nome ou um substantivo. Diante dos conceitos apresentados por Almeida (2008), é possível aplicá-los em uma rotina de
classificação e eliminação das palavras relevantes de um documento texto. No entanto, computacionalmente o algoritmo tende a contar as palavras semelhantes perante sua representação binária, o que ocasiona divergência entre palavras que contém caracteres maiúsculos e minúsculos, mesmo que seja a mesma palavra. Outro fator gerador de análises erradas é a presença de palavras citadas no plural e no singular dentro de um mesmo texto. Essas questões devem necessariamente ser tratadas para o bom funcionamento do algoritmo da lei de Zipf.
Para a montagem do ranking foi necessário a contagem dos termos, e utilizou-se da função str_word_count() para transformar o texto em um vetor de palavras. Com isso, verificou-se que a acentuação dos vocábulos limitava o perfeito funcionamento do algoritmo. Diante disso, foi necessário desenvolver uma lógica que eliminasse todo e qualquer símbolo de acentuação, para então, contar as palavras de forma coerente.
Ao fim da implantação dessas regras, e dos ajustes para obtenção do ranking para atender a lei de Zipf, chegou-se a um resultado satisfatório da frequência das palavras contidas no texto analisado. Considera-se, com isso, que a utilização do algoritmo para a obtenção do conceito do arquivo analisado é viável, resultando na automatização da inserção dos dados semânticos compreendidos nos metadados.
5. RESULTADOS OBTIDOS
Essa pesquisa é um marco evolutivo para a automatização do portal acadêmico da computação. Isso foi possível por meio do ranking de palavras mais frequentes nos arquivos, ao considerar do quinto até o décimo segundo termo, é possível encontrar o conceito e o significado semiótico do objeto em análise automaticamente. A partir de então, elimina-se a probabilidade da inserção de arquivos que contenham seus conceitos incoerentes com a sua natureza.
Para comprovar essa situação, utilizou-se da seguinte estratégia de testes para evidenciar as melhorias no sistema de pesquisa semântico. Primeiro, considerou-se algumas sentenças definidas para testar o comportamento do portal acadêmico da computação antes da implantação do mecanismo infométrico. Na sequência, refez-se os testes com as mesmas sentenças com a implantação dos algoritmos infométricos. Para finalizar a bateria de testes comparativos, fez-se uso de uma avaliação estatística baseada no t de student,
Conferência IADIS Ibero-Americana WWW/Internet 2012
7

para provar a confiabilidade do algoritmo infométrico e comprovar matematicamente os benefícios trazidos com a sua implantação.
Analisou-se o documento, da autora Bianca Claudine Roos, que possui um trabalho relacionado ao gerenciamento de conflitos em ambiente empresarial, e envolve diretamente a participação de pessoas no desenvolvimento de projetos de tecnologia da informação. Então, ao pesquisar a palavra pessoa, o mecanismo de busca semântico não conseguiu recuperar o documento da autora e apresentou como resultado final apenas outro autor, Luiz Ricardo Uriarte, que possui um arquivo que trata sobre as palestras de intercâmbio.
Diante dos resultados obtidos e pelo insucesso com os testes, optou-se pela realização de novas pesquisas semânticas, para isso foram analisados os assuntos que geram os trabalhos de conclusão de cursos. Devido à alta participação de projetos relacionados às empresas, realizou-se a pesquisa com a palavra organização no ambiente. E em mais este teste, a pesquisa semântica evidenciou a limitação mencionada anteriormente e se mostra insuficiente para a recuperação de contextos.
No entanto, apesar da pesquisa pelo termo organizações não apresentar um resultado satisfatório no ambiente semântico, observou-se ainda a existência de uma considerável quantidade de projetos que são relacionados aos processos empresariais, e também na área de computação. Com isso, pesquisou-se pela palavra processo, que também não obteve o resultado desejado.
Diante dessa problemática, desenvolveu-se o algoritmo infométrico com a aplicação da lei de Zipf, para atender as necessidades encontradas e, assim, alimentar automaticamente o conceito semântico, evitar o erro humano e diminuir as limitações do sistema. Após a aplicação do algoritmo infométrico, as pesquisas são executadas novamente, e na mesma ordem.
Ao seguir com os testes comparativos, durante a pesquisa pela palavra pessoa, já era possível recuperar o arquivo do autor Luiz Ricardo Uriarte, e agora se complementou o resultado com a obtenção da autora Bianca Claudine Roos, devido a implantação do algoritmo infométrico.
Relatou-se anteriormente o fato de que alguns trabalhos são direcionados às organizações e o mecanismo semântico não retornava nenhum resultado para esse termo de pesquisa. Posteriormente a aplicação do algoritmo infométrico, é possível constatar um resultado significativo para esse contexto pesquisado. Da mesma forma, a palavra processo havia retornado um único documento, porém os processos de software ou até mesmo processos relacionados à infraestrutura são assuntos tratados com maior frequência na área de atuação da computação.
Esses testes comparativos são importantes para a comprovação da melhoria do sistema com a implantação do algoritmo infométrico. No entanto, para fortalecer cientificamente o benefício que essa pesquisa trouxe ao ambiente semântico, utilizou-se um método estatístico a fim de demonstrar a confiabilidade desse desenvolvimento. Esse método baseou-se em diferentes artigos científicos, que utilizaram uma ferramenta computacional para avaliação estatística de desenvolvimentos de sistemas. Essa ferramenta é o t de Student que será usada para comprovação da confiabilidade do algoritmo infométrico.
Aplicou-se o conceito da análise estatística da distribuição t de Student pareado (FREUND; SIMON, 2000), que se emprega em uma pequena amostragem de testes e permite obter o percentual de credibilidade de um sistema. Por intermédio dos resultados obtidos na aplicação da pesquisa realizada com 10 palavras diferentes, compararam-se os resultados anteriores e posteriores à aplicação do algoritmo infométrico.
De acordo com o número de graus de liberdade (gl), ou seja, a quantidade de testes realizados (n) menos 1 (constante) resultou o nível 9, já o valor t de Student calculado pela ferramenta estatística foi de 2,4. Dessa maneira, analisou-se a tabela Unicaudal que mostra a porcentagem de confiança do algoritmo infométrico, que obteve um resultado entre 97,5% e 99% de confiabilidade. Comprova-se dessa forma, a validade desse desenvolvimento e a intenção da implementação da lei de Zipf para este cenário específico, o que atribui significado ao conteúdo disponibilizado no portal da computação.
Diante dessa comprovação estatística, juntamente com a fundamentação teórica dos resultados obtidos com o algoritmo infométrico, foi possível aprimorar o sistema de pesquisa e automatizar a contextualização dos arquivos compartilhados no ambiente. Essa ação extingue o erro de procedimentos manuais, o que poderia tender à inserção de informações equivocadas no campo de contexto dos metadados do mecanismo semântico.
ISBN: 978-989-8533-11-1 © 2012 IADIS
8

6. CONCLUSÃO
Esta pesquisa apresentou um estudo abrangente sobre a infometria, aplicada em conceitos matemáticos da lei de Zipf na construção do algoritmo que auxilia a contextualização automática do conhecimento em um mecanismo semântico. A partir disso, verificou-se a importância de fundamentar os conceitos de gestão do conhecimento e suas ferramentas. Dentre as ferramentas apresentadas, tem-se a web semântica para o compartilhamento e a explicitação do conhecimento, que é utilizada no mecanismo de busca semântica, que já facilitava o compartilhamento e a recuperação das informações.
Desse modo, observou-se que a inserção de arquivos exige que o usuário complete a estrutura de metadados manualmente. Este problema se acentua ao analisar o campo de contexto dos arquivos, que é um campo de texto aberto que permite inserir qualquer informação. No entanto, esse campo é relevante para a pesquisa semântica e informações erradas diminuem a confiabilidade das informações disponibilizadas para os resultados apresentados pelo mecanismo de busca semântico.
Diante dos resultados obtidos, observa-se que o objetivo geral, de construir um mecanismo infométrico para a inserção automática da contextualização dos arquivos inseridos no portal acadêmico, foi alcançado. Com este desenvolvimento permitiu-se aumentar a confiabilidade das informações contidas no portal em mais de 98%. Ao analisar o ambiente e o problema de pesquisa encontrado, verificou-se que a lei de Zipf atende as especificações necessárias para o algoritmo candidato à resolução do problema encontrado para essa pesquisa. Santos e Kobashi (2009) apresentam que essa lei tem a capacidade de representar matematicamente a frequência de palavras em textos longos, que por ventura, representam o conceito no qual esse documento está desenvolvido.
Os conceitos da lei de Zipf permitiram a criação de rankings contendo as palavras de maior frequência dos documentos, considerou-se do quinto até o décimo segundo termo para compor o campo de contexto do metadado existente. No entanto, para o perfeito funcionamento da Lei de Zipf foi necessário identificar as regras linguísticas do idioma português, que Almeida (2008) os elenca como os plurais, os artigos, os adjetivos, os advérbios, as conjunções, as preposições e os pronomes. Diante disso, foi fundamental eliminar do cenário avaliado as palavras que atendam essas regras definidas.
No decorrer dos testes, verificou-se os benefícios que a implantação do algoritmo trouxe ao ambiente, como a abrangência de um maior universo de pesquisa, contextualizado automaticamente. Contudo, sentiu-se a necessidade de comprovar estatisticamente a eficiência do algoritmo desenvolvido e utilizou-se a estatística t de Student para comprovar a melhora de confiabilidade do mecanismo desenvolvido. O resultado obtido é expressivo e em uma amostra aleatória encontrou-se um ganho entre 97,5% e 99% (FREUND; SIMON, 2000). O resultado desse estudo, juntamente com a comprovação estatística, confirma o aprimoramento do ambiente e automatização da contextualização dos arquivos compartilhados no ambiente, que beneficiou a comunidade acadêmica da computação do IST.
REFERÊNCIAS
Almeida, N. M. de, 2008. Gramática Metódica da Língua Portuguesa. 38. ed. Saraiva, São Paulo. Angeloni, M. T, 2008. Organizações do conhecimento : infraestrutura, pessoas e tecnologia. 3. ed. Saraiva, São Paulo. Berners-lee, T.; Fischetti, M.; Dertouzos, M. L, 2000. Weaving The Web: The Original Design And Ultimate Destiny Of
The World Wide Web. Harper Paperbacks, Sabastopol, USA. Berners-lee, T, 2010. Semantic Web: Slides apresentados no congresso SML 2000. Washington, DC: [s.n.]. Disponível
em: <http://tinyurl.com/btrtsbv>. Acesso em: 04 jul. 2012. Breitman, K, 2005. Web Semântica: a internet do futuro. LTC , Rio de Janeiro. Faleh, A. A.; Hani, J. I.; Khaled, B. H., 2011. Building a knowledge repository: Linking Jourdanian Universities E-
library in an Integrated Database System. International Journal of Business and Management. Vol. 6, No 4. Fialho, F. A. P. et al., 2006. Gestão do conhecimento e aprendizagem: As estratégias competitivas da sociedade Pós-
indústrial. Visual Books, Florianópolis. Figueiredo, S. P., 2005. Gestão do conhecimento: Estratégias competitivas para a criação e mobilização do
conhecimento na empresa. 3. ed. Qualitymark, Rio de Janeiro. Freund, J. E.; Simon, G. A., 2000. trad: Farias, Alfredo Alves de. Estatística aplicada: economia, administração e
contabilidade. 9. ed. Bookman, Porto Alegre.
Conferência IADIS Ibero-Americana WWW/Internet 2012
9

Gonçalves, C., 2009. Ler PDF e Documentos Word com PHP. Artigos Ideias. Disponível em: <http://tinyurl.com/7vp5vk3>. Acesso em: 18 Jul. 2012.
Guedes, V. L. da S.; Borschiver, S., 2005. Bibliometria: uma ferramenta estatística para a gestão da informação e do conhecimento, em sistemas de informação, de comunicação e de avaliação científica e tecnológica. Diálogo Científico - Ciência da Informação. Disponível em: <http://tinyurl.com/cnae4l2>. Acesso em: 17 Jul. 2012.
Luhn, H. P., 1957. A statistical approach to mechanized encoding and searching of literary information. IBM Journal of Research and Development, v.1, n. 4, p.309-317. New York: [s.n.].
Kos, S. R., 2011. O conteúdo informacional do relatório da administração e o desempenho das empresas brasileiras do ibovespa. Dissertação de mestrado. Curitiba. Disponível em: <http://tinyurl.com/bwhnhj3>. Acesso em: 21 Jul. 2012.
Macias-chapula, C. A., 1998. O papel da informetria e da cienciometria e sua perspectiva nacional e internacional. Ciencia da Informação, v. 27, n. 2, p. 134-140. Brasília: [s.n.]. Disponível em: <http://tinyurl.com/dyt8ueh>. Acesso em: 14 ago. 2012.
Mohamed, C., 2011. The impact of knowledge-based economy on the development of the innovation in services: Case of algerian banks and insurance companie. IBIMA Publishing Review. Laboratory LAMEOR , University of Oran. Argélia. Acesso em: 31 jul. 2012. Disponível em: <http://tinyurl.com/cpq2ynh>.
Nonaka, I.; Takeuchi, H., 1997. Criação de conhecimento na empresa: como as empresas japonesas geram a dinâmica da inovação. Campus, Rio de Janeiro.
Noronha, D. P.; Maricato, J. de M., 2008. Estudos Métricos da Informação: Primeiras aprimorações. Ciencia da Informação, Florianópolis, Santa Catarina, Brasil. ISSN 1518-2924. Disponível em: <http://tinyurl.com/7rjoag9>. Acesso em: 20 Jul. 2012.
Rodrigues, R. C. R.; Rocha, F. E. L., 2011. WEBCMTOOL: Um ambiente web para facilitar a avaliação automática da aprendizagem mediada por mapas conceituais e ontologias de domínio. Conferência IADIS Ibero-Ameriaca. P.219-226.
Sabbag, P. Y., 2007. Espirais do conhecimento: Ativando indivíduos, grupos e organizações. 3. ed. Saraiva, São Paulo. Santos, R. N. M. dos; Kobashi, N. Y., 2009. Bibliometria, cienciometria, infometria: conceitos e aplicações. Ciencia da
Informação, Brasília, v.2, n.1, p.155-172. Disponível em: <http://tinyurl.com/6u4vyw8>. Acesso em: 19 Jul. 2012. Sengupta, I. N., 1992. Bibliometrics, Informetrics, scientometrics and librametrics: an overview. [S.l.: s.n.]. Libri
International Journal of Libraries Information Services, v. 42, n. 2, p. 75-98. Serafini, L.; Homola, M., 2011. Contextualized knowledge repositories for the semantic web. Web Semantics Magazine,
Science, Services and Agents on the World Wide Web. Disponível em: <http://tinyurl.com/73z4psh>. Acesso em: 04 jul. 2012.
Trainotti-Filho, A. M., 2011. Mecanismos semânticos aplicados em ambientes para a Gestão do Conhecimento: o caso SOCIESC. Trabalho de conclusão de curso (Bacharel em Engenharia de Computação) - Instituto Superior Tupy - IST/SOCIESC, Joinville. Disponível em: <http://tinyurl.com/7bgdux9>. Acesso em: 12 ago. 2012.
Wormell, I., 1998. Informetria: explorando bases de dados como instrumentos de análise. Ciência da Informação, Brasília, v. 27, n. 2, p. 210-216. Jornal da Informetria 2012. Disponível em:<http://tinyurl.com/8kqcd5l>. Acesso em: 15. jul. 2012.
Vanti, Nadia., 2011. A Cientometria Revisada à luz da Expansão da Ciência, da Tecnologia, e da Inovação. Disponível em: <http://tinyurl.com/8pk8bkd>. Acesso em: 15 jul. 2012.
ISBN: 978-989-8533-11-1 © 2012 IADIS
10

PREDIÇÃO DE RESULTADO DE ELEIÇÃO PARA REITOR DE UNIVERSIDADE USANDO TWEETS COMO FONTE DE
PESQUISA
Alessandro Kraemer1, André Luiz Satoshi Kawamoto1 e Marco Aurélio Gerosa2 1Universidade Tecnológica Federal do Paraná – UTFPR, BR 369, Km 0,5 Caixa Postal 271, Campo Mourão,
Paraná, Brasil 2Instituto de Matemática e Estatística / Universidade de São Paulo - USP
Rua do Matão, 1010, Cidade Universitária, CEP 05508-090, São Paulo, São Paulo, Brasil
RESUMO
Nos processos eletivos da Universidade Tecnológica Federal do Paraná (UTFPR) não ocorrem pesquisas eleitorais. As pesquisas eleitorais são importantes fontes democráticas de opiniões. A curiosidade em antecipar resultados é natural do ser humano, mas a principal finalidade de uma pesquisa está no contexto estratégico dos candidatos, que podem planejar ações, como mobilização para uma provável disputa de segundo turno, agradecimento aos eleitores, ou mesmo reconhecimento de uma derrota antes do resultado oficial. Para os comitês dos candidatos da UTFPR é custoso gerenciar equipes de pesquisa distribuídas geograficamente em 12 câmpus. Uma forma alternativa de fazer pesquisa eleitoral consiste em minerar dados do Twitter procurando classificar as mensagens conforme a polaridade de seus conteúdos, o que pode identificar intenções de voto. O uso desse mecanismo pode substituir a forma custosa e complexa de gerenciar equipes de pessoas distribuídas que ocorre nas pesquisas eleitorais tradicionais. Neste artigo as mensagens do Twitter são utilizadas para observar se o resultado de uma deliberação política para reitor da UTFPR corresponde aos resultados oficiais do pleito eleitoral.
PALAVRAS-CHAVE
Twitter, mineração de dados, predição de eleição.
1. INTRODUÇÃO
A predição de resultados é um processo amplamente utilizado em cenários eleitorais. Os candidatos podem utilizar o indicativo de resultado com forma de se organizarem para uma mobilização social, seja uma mobilização para um segundo turno ou para mostrar vitória, agradecer aos eleitores, entre outras formas. A predição de resultados tem forte relação com a expectativa de antecipação do público e com o planejamento estratégico de candidatos, impactando em uma série de ações estratégicas. O problema potencial em realizar pesquisa eleitoral é que esse processo exige esforço de gerenciamento de dados e de pessoas. No caso da UTFPR, onde existem 12 câmpus distribuídos geograficamente no Estado do Paraná, o esforço de gerenciamento pode também gerar custos. Uma forma alternativa de realizar pesquisa eleitoral consiste em avaliar o conteúdo de mensagens do Twitter. O conteúdo dos tweets pode ser classificado em sentimento positivo para determinado candidato, negativo, ou neutro. Esses sentimentos podem ser utilizados como indicativo de voto e representam potencialmente uma pesquisa eleitoral.
Segundo Semiocast (2012), no Brasil existem 33,3 milhões de usuários de Twitter e esse número está em processo de ascensão. Considerar o conteúdo produzido por esses usuários como se fosse um amplo repositório de dados tem sido cada vez mais importante para pesquisas de redes sociais. A UTFPR possui 23655 estudantes e 2605 servidores que são potenciais usuários do Twitter, produzindo conteúdos úteis para predição.
O uso do Twitter para influenciar pessoas ou predizer resultados são práticas que vem sendo cada vez mais utilizadas, com vários artigos científicos apontando resultados satisfatórios. Bakshy (2011), Lerman (2010), Kim (2010), Conover (2011) e Wilson (2005) tem avaliado as mensagens do Twitter como fonte sincera de opiniões de seus usuários. Diakopoulos (2010) tem observado como as pessoas reagiram ao debate
Conferência IADIS Ibero-Americana WWW/Internet 2012
11

eleitoral americano em 2008, aumentando a taxa de tweets e reweets a favor ou contra determinados candidatos. Conover (2010) prediz o alinhamento político de usuários do Twitter nas eleições americanas de 2010. Tumasjan (2010) estende esse trabalho identificando grupos de direita e de oposição. Por fim, Kwak (2010) consegue predizer com sucesso o resultado da eleição Alemã em 2010. Esses autores evidenciam o Twitter como uma importante fonte de dados para pesquisas de opinião. Por outro lado, não foram encontrados artigos que tratam da predição de eleição para reitor de universidade. Nesse cenário, os usuários precisam ser identificados pelo papel que exercem na universidade, classificado em servidor ou estudante, pois há diferença de peso desses votos.
Este artigo avalia se o conteúdo dos tweets pode predizer resultados de uma eleição para reitor de universidade no Brasil. Consideramos como cenário de estudo a eleição para Reitor da UTFPR que ocorreu em março de 2012. Os tweets que envolvem esse processo eleitoral foram capturados desde um dia antes da votação até um dia depois da divulgação do resultado oficial, totalizando 744 tweets. O processo de avaliação consiste basicamente em capturar mensagens utilizando a API do Twitter em Java, classificando-as em sentimento positivo para determinado candidato, sentimento de indecisão ou de contexto informativo.
Na Seção 2 são destacados os trabalhos que avaliam o Twitter como fonte sincera de opiniões e como ocorre a deliberação política na UTFPR. Na terceira seção são apresentados os trabalhos relacionados e as questões de pesquisa. O método desenvolvido para mineração e a classificação dos dados capturados são apresentados na quarta seção. Por fim, os resultados da predição utilizando o Twitter são confrontados com os dados oficiais divulgados pela UTFPR.
2. REFERENCIAL TEÓRICO E DELIBERAÇÃO POLÍTICA
Twitter é um serviço de microblogging no qual são enviadas mensagens de até 140 caracteres. Por esse motivo, as mensagens têm caráter objetivo e envolvem muitas abreviações de termos linguísticos. O mecanismo generalizado do Twitter consiste em enviar mensagem para um grupo de seguidores. Os seguidores podem retransmitir (retweet) ou criar novas mensagens. Para Kwak (2010), os retweets possibilitam retransmitir informações de uma forma sem precedentes, oportunizando estudos para cientistas da computação, sociólogos e outros profissionais interessados em compreender o comportamento humano, as redes sociais, e o reflexo que as ações nesse universo virtual (on-line) têm no universo real (off-line).
Para Lerman (2010), a comunicação no Twitter evidencia comportamentos, sejam comportamentos individuais ou em grupo. Kim (2010) afirma que com a divulgação de informações, usuários mais populares podem influenciar seus seguidores, mas basta ser usuário para também ser um agente influenciador. No contexto de processo eleitoral, esse é um fato positivo na conquista de votos. Essa influência para alinhamento político também foi identificada por Conover (2011). Portanto, esses autores afirmam que o conteúdo dos tweets representa a opinião verdadeira dos seus emissores e podem influenciar outras pessoas.
Wilson (2005) apresenta uma análise de sentimentos que determina se uma expressão textual é neutra ou polarizada. O sistema apresentado por Wilson é capaz de identificar automaticamente o contexto de polaridade e os resultados são significativamente satisfatórios. Para tanto, utiliza coeficiente de correlação.
A comunidade do Twitter tem comumente feito trocas de mensagens a respeito de seus candidatos em períodos de eleição. A proposta deste artigo é identificar e classificar essas mensagens procurando relações com resultados oficiais da deliberação política que ocorreu na UTFPR. A UTFPR não possui mecanismos implantados para realizar pesquisa eleitoral. Uma forma tradicional de tratar desse problema consiste em formar equipes de trabalho e entrevistar pessoas durante o período eleitoral. Considerando que a UTFPR possui 12 câmpus distribuídos geograficamente no Estado do Paraná, gerenciar essas equipes pode ser demasiadamente custoso, demandando tempo e planejamento. Uma forma alternativa para reduzir esses problemas consiste em avaliar do conteúdo dos tweets que remetem ao pleito eleitoral.
A deliberação política para reitor nas Universidades Federais brasileiras envolve servidores e estudantes de todos os câmpus. No caso da UTFPR, o voto dos servidores tem peso de 80% e 20% para os estudantes. Todos os câmpus realizam o processo de votação e contagem dos votos no mesmo dia. O resultado oficial é divulgado somente na semana seguinte à votação. Para encerrar o processo, o candidato com mais votos ponderados é indicado para o Ministério da Educação, que aceita ou não o posto de Reitor da Universidade. Portanto, a deliberação política não significa necessariamente que o candidato mais votado será o Reitor.
ISBN: 978-989-8533-11-1 © 2012 IADIS
12

3. TRABALHOS RELACIONADOS E QUESTÕES DE PESQUISA
Ifukor (2010) tem avaliado a construção linguística de mensagens durante as eleições de 2007 na Nigéria. Nesse cenário Ifukor considera 923 tweets e 254 blogs. Os tweets foram enviados para um usuário chamado Ekiti, criado especificamente para o processo de discussão eleitoral. As mensagens foram classificadas conforme o período da eleição, sendo pré-eleição, eleição e pós-eleição. A mineração feita por Ifukor ocorre de forma manual, avaliando o conteúdo semântico das mensagens. Os usuários dessas mensagens usam o Twitter como forma de se envolver nas eleições, mobilizando também outros usuários para participação política. Isso evidencia o Twitter como uma forma de motivação de usuários.
Diakopoulos (2010) observou que o debate político que ocorreu em 2008 para eleição presidencial americana alterou a taxa de mensagens no Twitter. Essas mensagens (3238) foram reações ao debate apresentado na televisão. Diakopoulos evidencia uma métrica para detectar sentimentos, anomalias e indicação de controvérsias. Para detectar sentimentos as mensagens foram classificadas em quatro tipos: positivo, negativo, mixe e neutro. Mixe compreende positivo e negativo. Neutro representa nenhum estado. Para classificação foi utilizada a correlação de Pearson com base em dicionários de termos. Com isso, Diakopoulos mostrou que o interesse por candidatos pode ser detectado avaliando mensagens do Twitter. Portanto, a estimativa de desejos pode ser feita satisfatoriamente.
O´Connor (2010) procurou medir o sentimento da opinião pública sobre política americana avaliando mensagens do Twitter entre 2008 e 2009. Isso é feito encontrando a frequências dos termos que remetem a sentimentos, previamente armazenados em dicionários de termos. Ao mesmo tempo foram capturados dados de organizações oficiais de pesquisa. Essa correlação entre o que ocorreu no Twitter e o que outras fontes de pesquisa afirmam corresponde a 80%. Essa descoberta indica que mensagens de texto têm alto potencial para sondagens, podendo substituir ou complementar as formas tradicionais de pesquisa. O´Connor utilizou o sistema OpinionFinder, que contém uma lista com 1600 e 1200 termos, positivos e negativos.
A adoção generalizada de mídias sociais para comunicação política cria oportunidades sem precedentes de monitoramento de opiniões. Conorver (2010) aborda um método para predição de alinhamento político de usuários do Twitter baseado no conteúdo de sua comunicação. Conover avaliou um conjunto de 1000 mensagens enviadas durante as eleições dos Estados Unidos em 2010. Conover conseguiu predizer a afiliação (direita ou oposição) política com 91% de certeza. Para tanto, utilizou um dicionário de palavras, busca de similaridade de Jaccard e análise no espaço vetorial usando TF-IDF.
Conover (2011) investigou como a mídia social produz redes públicas e facilita a comunicação com diferentes orientações políticas. Conover examinou duas redes de diferentes orientações políticas no Twitter, verificando 250.000 tweets durante o processo eleitoral nos Estados Unidos em 2010. A primeira forma considera os retweets, avaliando se o conteúdo é retransmitido por outros usuários. A segunda forma considera a menção do nome do usuário na elaboração de outras mensagens. Usando uma combinação de algoritmos de rede, Conover evidenciou que a rede de retweets exibe dois grupos, direita e oposição. Enquanto a simples menção do nome do usuário não consegue caracterizar a rede de grupos políticos. Portanto, retweet é para Conover a melhor forma de caracterização de usuários.
Tumasjan (2010) investigou o uso do Twitter na deliberação política da Alemanha. Para essa investigação foram avaliados 100.000 tweets contendo referências para partidos políticos ou politicagem. Para classificar as mensagens foi utilizado o sistema LIWC (Linguistic Inquiry and Word Count) de análise textual, que consegue identificar termos emocionais e cognitivos usando um dicionário psicologicamente validado por especialistas. Conclusivamente, Tumasjan mostrou que os tweets podem ser utilizados como indicativos de universos do mundo real, mas que não representam 100% do público e por isso, assim como nas pesquisas tradicionais, também são factíveis de erros. Outra informação destacada por Tumasjan é que muitas mensagens do Twitter não usam termos de dicionários regulares, com radicais e variações bem definidos. No Twitter muitas mensagens são abreviadas e isso pode comprometer a sua classificação.
Os problemas identificados por esses autores são similares aos problemas que encontramos. Entretanto, as polarizações foram identificadas semanticamente por método manual. O método manual foi necessário porque não encontramos um dicionário de termos linguísticos em português. O nosso trabalho se diferencia dos demais por encontrar nos tweets conteúdos que remetem ao local no qual os usuários trabalham ou estudam, além do tipo de usuário (servidor ou estudante). Nesse sentido, destacamos as seguintes questões:
Conferência IADIS Ibero-Americana WWW/Internet 2012
13

• Por meio das informações pessoais cadastradas em cada perfil de usuário do Twitter e de suas mensagens de relacionamento é possível obter outras informações que indiquem o tipo de usuário e onde eles atuam?
• O Twitter pode ser utilizado para predição de eleição de reitor em universidades?
4. MÉTODO E CONJUNTO DE DADOS
A avaliação de tweets tem sido abordada em diversos trabalhos científicos e tem satisfatoriamente indicado sentimento positivo, negativo, ambos e neutro. De forma geral, os mecanismos de busca de sentimentos consistem em utilizar dicionários contendo termos de sentido positivo e negativo. Os termos que aparecem nas mensagens dos usuários são organizados em uma estrutura vetorial e em seguida são feitas buscas de similaridade com os termos presentes nos dicionários. Por fim, modelos estatísticos conseguem indicar o sentido da mensagem. A análise de mensagens também pode ser feita de forma manual. Nesse processo, a sensibilidade do avaliador na análise da expressão semântica é que caracteriza o sentido das mensagens.
Os tweets analisados neste artigo foram capturados utilizando uma API Java. A busca no Twitter por meio dessa API utilizou palavras-chave que identificavam os candidatos e seus vices, assim como mensagens que continham a sigla UTFPR. Capturamos os tweets desde um dia antes até um dia depois do processo eleitoral. No total foram capturadas 744 mensagens. Para o processo de descoberta de polarização, embora exista uma diversidade de dicionários de termos de sentido positivo e negativo em língua inglesa, em português não foi encontrado algo similar. Outro fator complicador é que no Twitter as mensagens são comumente abreviadas e muitas vezes são utilizadas expressões regionais. Com isso, a classificação das mensagens ocorreu de forma manual, avaliando o sentido semântico para indicar a polarização de cada tweet.
O método manual de classificação consiste primeiramente em encontrar o câmpus universitário no qual cada usuário está relacionado. Essa classificação é importante porque no pleito eleitoral o resultado é classificado por câmpus. Assim, é possível conhecer onde determinado candidato ganhou ou perdeu votos. Para conseguir essa informação elaboramos um conjunto de passos de análise semântica. Esse processo está representado na Figura 1a. Adicionalmente, para os critérios do pleito eleitoral também é importante diferenciar usuários servidores e usuários estudantes. Cada um destes tem um peso diferente na computação dos votos. Dessa forma, ampliamos o processo de análise semântica para identificar esses usuários. A busca semântica procura relacionar termos como “prova”, “exercícios”, “a professora disse”, entre outros para identificar o perfil estudante. Para identificar o perfil servidor consideramos termos como “trabalho na UTFPR”, “aplicarei prova hoje”, “meus alunos”, entre outros. A Figura 1b representa esse processo de identificação.
ISBN: 978-989-8533-11-1 © 2012 IADIS
14

(a) (b)
Figura 1. Mecanismo de mineração manual utilizado para descoberta do câmpus universitário (a) e do tipo de usuário (b).
A etapa seguinte consiste em polarizar as mensagens por intenções de voto. Não é suficiente classificar tweets apenas pela citação do nome dos candidatos. Neste artigo identificamos as polarizações das mensagens em sentido positivo, indeterminado, informativo e irrelevante. As mensagens positivas são classificadas em pro candidato quando apresentam sentido claro da intenção do voto. As mensagens classificadas como Indeterminado não dão claramente o sentido do voto e comumente omitem nome dos candidatos. As mensagens classificadas como Informativas procuram convidar os eleitores indicando neutralidade em relação aos candidatos. Por fim, as mensagens Irrelevantes não apontam nenhum dos candidatos e não contextualizam o cenário do pleito eleitoral, mas citam a UTFPR.
5. RESULTADOS
Nesta seção analisamos os 744 tweets capturados procurando classificá-los conforme os métodos apresentados pelas Figuras 1a e 1b e suas polarizações. Os tweets capturados podem não abranger quantidade significativa em alguns câmpus, o que pode significar também que o Twitter é pouco utilizado nesses câmpus. A Tabela 1 apresenta a quantidade de tweets classificados por câmpus universitário e o resultado oficial da eleição divulgado pela UTFPR.
Conferência IADIS Ibero-Americana WWW/Internet 2012
15

Tabela 1. Quantidade total de tweets por câmpus universitário e os votos oficiais por chapa.
Sigla Câmpus Tweets Votos oficiais Chapa 1 Votos oficiais Chapa 2 AP Apucarana 13 318 44 CM Campo Mourão 36 413 692 CP Cornélio Procópio 4 795 416 CT Curitiba 404 794 2785 DV Dois Vizinhos 4 533 32 FB Francisco Beltrão 4 334 60 GP Guarapuava 0 177 7 LD Londrina 12 244 155 MD Medianeira 27 784 353 PB Pato Branco 46 852 812 PG Ponta Grossa 29 922 369 TD Toledo 3 171 283 ND Indeterminado 102 - - Outros Não UTFPR 60 - - Total - 744 6337 6008
Com base na Tabela 1, o câmpus de Curitiba (CT) é o principal representante dos tweets capturados. Os
demais câmpus não apresentam quantidade significativa para a avaliação do pleito eleitoral. O resultado das polarizações é apresentado na Tabela 2. Também foi considerado que algumas mensagens são enviadas por agências de notícias e que não representam intenções de voto, sendo apenas Informativas.
Tabela 2. Classificação dos tweets por câmpus universitário e polarização do conteúdo, totalizando 582 tweets classificados (78,22%), no qual 744=582+Indeterminado+Não UTFPR.
A Tabela 3 destaca as intenções de voto classificando as mensagens conforme o perfil do usuário: servidor, estudante, agente de notícias ou indefinido. Devido a pouca quantidade de mensagens dos câmpus do interior, a Tabela 3 destaca apenas o câmpus de Curitiba. Outra característica destacada é que não se tem dados sobre a quantidade de servidores e estudantes da UTFPR que possuem conta no Twitter. Essa informação seria importante para descobrir o percentual de participantes no universo virtual.
Tabela 3. Classificação dos tweets com base no perfil dos usuários de Curitiba e suas polarizações.
O processo de descoberta e predição setorial só foi possível porque o método de mineração conseguiu identificar os câmpus e o perfil do usuário em 78,22% dos tweets capturados. Contudo, mesmo que usuários do Twitter não preencham seu cadastro completo é possível na maioria das vezes encontrar informações
Sigla Pro Chapa 1 Pro Chapa 2 Indeterminado Informativo Irrelevante Total
AP 1 0 1 2 9 13 CM 2 2 0 2 30 36 CP 0 1 0 0 3 4 CT 38 53 25 29 259 404 DV 0 0 0 0 4 4 FB 0 0 0 0 4 4 GP 0 0 0 0 0 0 LD 0 1 0 0 11 12 MD 6 0 3 2 16 27 PB 4 1 1 2 38 46 PG 2 0 1 0 26 29 TD 0 1 0 0 2 3 Total 53 59 31 37 402 582
Classificação Pro Chapa 1 Pro Chapa 2 Indetermiando Informativo Total Estudantes 32 51 21 20 124 Servidores 6 2 0 2 10 Agentes de notícias 0 0 0 6 6 Indefinido 0 0 4 1 5 Total 38 53 25 29 145
ISBN: 978-989-8533-11-1 © 2012 IADIS
16

sobre quem esses usuários são e o que esses usuários fazem, já que podem enviar mensagens contendo informações pessoais ou utilizar outro tipo de rede social, na qual é possível obter mais informações.
A predição de eleição usando o Twitter pode ser satisfatória. Os tweets podem ser utilizados para identificar polarizações, mas dependendo do pleito eleitoral, outras redes sociais e outros mecanismos podem ser utilizados para capturar, por exemplo, informações sobre a cidade em que o usuário vota, assim como seu perfil, que pode ser ponderado diferentemente caso seja estudante ou servidor. Sem o uso dos métodos apresentadas pelas Figuras 1a e 1b, não seria possível predizer o resultado do pleito na UTFPR.
O uso somente de mecanismos de polarização não são considerados suficientes, já que um pleito pode envolver variáveis que dependem de dados de localização, determinando peso para determinadas regiões ou conforme a representação do usuário. Para tornar a predição eficiente consideramos descobrir o local onde o usuário do Twitter estuda ou trabalha. Usando o Twitter para predizer o resultado no câmpus de Curitiba, a Chapa 2 se destaca com 57,60% dos votos válidos, sem ponderações. A quantidade de votos válidos é apresentada na Figura 2, onde houve ampla vantagem dos votos dos estudantes em relação aos servidores.
Figura 2. Polarização dos tweets considerando apenas o câmpus de Curitiba e sem ponderações por tipo de usuário.
Para finalizar o processo de predição, as polarizações Pró Chapas são ponderadas com 0.8 para os votos dos servidores e 0.2 para os votos dos estudantes. Sendo assim, os estudantes de Curitiba identificados no Twitter que polarizam seus votos para a Chapa 1 representam 4,41% do total de votos no seu câmpus, enquanto a polarização para a Chapa 2 representa 7,03%. Para essa mesma classificação considerando somente os estudantes, os dados oficiais divulgados pela UTFPR indicam que a Chapa 1 conseguiu 3,29% e a Chapa 2 16,39%. Portanto, a predição usando o Twitter indicou corretamente o vencedor em Curitiba. Utilizar o nosso método de predição para o pleito completo da UTFPR pode ser eficiente desde que existam tweets suficientes. Adicionalmente, a elaboração de um dicionário de termos de polarizações e a automatização dos processos de classificação de usuários são recursos importantes que devem ser considerados em eventos com mais quantidade de mensagens. O uso desse método proporciona a virtualização das formas tradicionais de pesquisa, que consideram a entrevista pessoal do eleitor e o gerenciamento de equipes de trabalho. Ao mesmo tempo, não podemos desconsiderar que as pesquisas presenciais são eficientes e o nosso método pode atuar também como complemento dessas pesquisas.
6. CONSIDERAÇÕES FINAIS
O uso do Twitter como fonte de dados proporciona descoberta de opiniões desses usuários sobre diversos temas. Em um pleito eleitoral é natural que usuários do Twitter se expressem de forma livre. Para Bakshy (2011), Lerman (2010), Kim (2010), Conover (2011) e Wilson (2005), o conteúdo dos tweets representa a opinião verdadeira dos usuários e, portanto, podem ser úteis para diversas análises. O que foi percebido durante esse trabalho de mineração manual de dados é que embora as opiniões possam ser verdadeiras, as informações do perfil do usuário são muitas vezes falsas. Quando é necessário obter informações sobre o câmpus no qual os usuários estudam ou trabalham, ou mesmo o nome verdadeiro do usuário, uma simples consulta no perfil do usuário não é suficiente. Nesses casos podem ser desenvolvidas formas de mineração que envolvem outras redes sociais. A descoberta desses dados é importante porque o pleito eleitoral da UTFPR pondera os votos dos servidores com 0.8, enquanto o voto dos estudantes é ponderado com 0.2. Entretanto, é necessário descobrir se o usuário é estudante ou servidor.
Conferência IADIS Ibero-Americana WWW/Internet 2012
17

A análise de similaridade procurando identificar polarizações políticas tem sido usada por Conover (2011), Diakopoulus (2010), O’Connor (2010), Conover (2010) e Tumasjan (2010). Entretanto, há casos em que esses métodos não conseguem descobrir determinadas informações. Um exemplo disto ocorreu quando precisamos descobrir o câmpus com o qual um usuário se relaciona, já que o usuário pode se referir ao câmpus citando apenas o nome do curso, sem citar o próprio nome, por exemplo. Adicionalmente, não dispomos de um dicionário de termos que indiquem polarizações em português. Podemos resolver esse problema de identificação consultando o perfil do usuário no Facebook, fazendo buscas no Google ou também analisando fotos tomadas pelo Instagram. O Instagram também informa a localização geográfica e desta forma podemos obter a cidade e o câmpus do usuário. Esse processo não está automatizado.
Uma análise a priori mostrava que a predição usando o Twitter não correspondia ao resultado divulgado oficialmente sobre a deliberação política na UTFPR. Entretanto, após a identificação de que os tweets não representam todos os câmpus foi possível predizer o resultado correto classificando os tweets por localização do usuário. Portanto, a simples captura e análise de conteúdo podem não ser suficientes, também é importante compreender o processo eleitoral e identificar quais dados são necessários à predição. No caso da predição da UTFPR foi possível identificar os câmpus e o perfil dos usuários em 78,22% das vezes, o que pode ser considerado satisfatório, validando os métodos manuais de mineração que consideram outras fontes de dados complementares, como sistema acadêmico, Facebook, Google e Instagram. Na predição do câmpus de Curitiba os resultados oficiais e os que têm base no Twitter indicaram o mesmo vencedor (Chapa 2). Com isso, também percebemos que a quantidade de tweets precisa ser maior para que a predição possa ser aplicada para todos os câmpus. Com o avanço do número de usuários do Twitter, como Semiocast (2012) vem identificando, em um futuro próximo será possível encontrar mais usuários desses câmpus.
REFERÊNCIAS
Bakshy, E. et al., 2011. Everyone’s an Influencer: Quantifying Influence on Twitter. Proceedings of the fourth ACM international conference on Web search and data mining. Hong Kong, China.
Conover, M. et al., 2011. Political Polarization on Twitter. Proceedings of 5th International AAAI Conference on Weblogs and Social Media. Barcelona, Espanha.
Conover, M. D. et al., 2010. Predicting the Political Alignment of Twitter Users. Center for Complex Networks and Systems Research, School of Informatics and Computing, Indiana University, Bloomington, USA.
Diakopoulos, N. A. and Shamma, D. A., 2010. Characterizing Debate Performance via Aggregated Twitter Sentiment. Proceedings of the 28th international conference on Human factors in computing systems. Atlanta, Georgia, USA, pp. 1195-1198.
Ifukor, P., 2010. Elections or Selections? Blogging and Twittering the Nigerian 2007 General Elections. Bulletin of Science, Technology & Society, Sage Publications, Vol. 30, Nº 6, pp. 398-914.
Kim, D. et al., 2010. Analysis of Twitter Lists as a Potential Source for Discovering Latent Characteristics of Users. Workshop on Microblogging at the ACM Conference on Human Factors in Computer Systems. Atlanta, Georgia, USA.
Kwak, H. et al., 2010. Whats is Twitter, a Social Network or a News Media?. International World Wide Web Conference Committee (IW3C2). Raleigh, NC, USA, pp. 591-600.
Lerman, K. and Ghosh, R., 2010. Information Contagion: an Empirical Study of the Spread of News on Digg and Twitter Social Networks. Proceedings of 4th International Conference on Weblogs and Social Media.
O’Connor, B. et al., 2010. From Tweets to Polls: Linking Text Sentiment to Public Opinion Time Series. Proceedings of 4th International AAAI Conference on Weblogs and Social Media. Washington, DC, USA.
Semiocast, 2012. Brazil becomes 2nd country on Twitter, Japan 3rd Netherlands most active country. Available from: <http://semiocast.com/publications/2012_01_31_Brazil_becomes_2nd_country_on_Twitter_superseds_Japan> (Accessed April 2012).
Tumasjan, A. et al., 2010. Predicting Elections with Twitter: What 140 Characters Reveal about Political Sentiment. Proceedings of the 4th International AAAI Conference on Weblogs and Social Media. Washington, DC, USA, pp. 178-185.
Wilson, T. et al., 2005. Recognizing Contextual Polarity in Phrase-Level Sentiment Analysis. Proceedings of the conference on Human Language Technology and Empirical Methods in Natural Language Processing. Stroudsburg, PA, USA, pp. 347-354.
ISBN: 978-989-8533-11-1 © 2012 IADIS
18

RELAÇÕES SOCIAIS EM COMUNIDADES DE CIENTISTAS ATRAVÉS DA LENTE DA ACTOR-NETWORK THEORY:
UM ESTUDO PRELIMINAR
Alysson Bolognesi Prado e Maria Cecilia Calani Baranauskas Instituto de Computação
Universidade Estadual de Campinas, UNICAMP, Brasil
RESUMO
Compreender a web social pressupõe coletar informações sobre seus usuários atuais ou em potencial, documentar seus relacionamentos, interesses e necessidades. Uma vertente recente da sociologia, a Actor-Network Theory – ANT – propõe que as relações com elementos humanos e não-humanos são igualmente importantes na compreensão de fenômenos sociais. Este artigo investiga as possibilidades de uso da ANT na caracterização de instâncias reais de redes de relacionamentos. O papel ativo dos elementos não-humanos permite, por um lado, rastrear estas relações a partir de seus produtos materiais e por outro, explicitar pontos em que a presença computacional pode ser benéfica. O resultado deste estudo, apresentado na forma de grafos, permitiu análises de natureza tanto quantitativa como qualitativa que podem informar o design de sistemas para estas comunidades.
PALAVRAS-CHAVE
Redes sociais científicas, Teoria Ator-Rede, e-Ciência, Sociologia, Sociometria.
1. INTRODUÇÃO
Por todo o mundo, sistemas de redes sociais têm sido cada vez mais adotados como um novo mecanismo de comunicação e integração entre pessoas (Singh et al., 2012). Baseiam-se em tecnologia Web 2.0, apresentando interfaces ricas e interativas que permitem a uma grande diversidade de pessoas compartilharem ideias e informações (Pereira et al., 2010). Definições correntes desta web social são baseadas na agregação de pessoas, representadas por seus perfis públicos ou semi-públicos, através de conexões criadas por relações de amizade, comunicação ou interesse (Bae & Kim, 2009; Balbino & Anacleto, 2011; Pietilanen & Diot, 2012). A Web é estudada como um conjunto de páginas e outros conteúdos digitais interligados (Hendler et al., 2008) que funciona como meio através do qual os fenômenos sociais se desenvolvem (King et al., 2009).
Sendo uma área multidisciplinar, o estudo da web social se apoia em diversas fontes teóricas como a Psicologia, a Estatística e a Sociologia (Lubashevsky, 2010). Desta última provém a definição tradicional de que os elementos relevantes para compreensão dos fatos sociais são apenas os humanos. Por outro lado, uma vertente sociológica mais recente, a Actor-Network Theory – ANT – propõe que as relações com os elementos não-humanos têm a mesma importância na compreensão de fenômenos sociais (Latour, 2005). A atenção sobre os elementos materiais nas interações entre pessoas é compartilhada com outras fontes teóricas, como por exemplo, a teoria da cognição distribuída (Hollan et al., 2000), que estuda processos de comunicação, compreensão e aprendizado, baseada na premissa de que estes fenômenos não se limitam às habilidades intelectuais individuais, mas se estendem ao ambiente e entre pessoas e objetos.
Este artigo investiga possibilidades de uso da Actor-Network Theory na caracterização de instâncias reais de redes de relacionamentos entre cientistas, visando uma melhor compreensão das possíveis relações entre humanos através de suas associações com artefatos digitais. Partindo-se de ferramentas computacionais existentes para análise social e acrescentando-se a visão dada pela ANT, verificou-se como esta pode
Conferência IADIS Ibero-Americana WWW/Internet 2012
19

contribuir para o estudo dos grupos, suas relações internas e importância relativa de cada um de seus elementos para sua existência.
O texto está organizado da seguinte maneira: a seguir apresentaremos o referencial teórico da Actor-Network Theory utilizado neste trabalho, seguido da metodologia de análise proposta e resultados da investigação realizada em comunidades de cientistas. Por fim, discutimos os resultados obtidos e apresentamos as considerações finais e o plano de continuidade do trabalho.
2. REFERENCIAL TEÓRICO
Para a compreensão de fenômenos sociais, a sociologia clássica parte do conceito de fato social: uma manifestação humana que não faz parte dos domínios físico, biológico ou psicológico. Um fato social se reconhece pelo “poder de coerção externa que exerce ou é capaz de exercer sobre os indivíduos” (Durkheim, 2007, pág. 10) dando origem a uma estrutura que está além das pessoas e que direciona seu comportamento. Esta visão leva ao tratamento distinto entre pessoas e objetos, colocando-os em planos independentes.
A modelagem computacional do comportamento social de pessoas (King et al., 2009) parte deste mesmo princípio, aliando-se a instrumentos da estatística, algoritmos e estruturas de dados para sua representação. Com essa modelagem são estudadas as diferentes formas de interação entre pessoas na web: redes sociais, mídia social, jogos colaborativos e compartilhamento de notícias e informações. Grafos onde os vértices são pessoas e através das arestas circulam informações suportam processos de data mining e modelos matemáticos (Lubashevsky, 2010).
A Actor-Network Theory, ANT ou Teoria Ator-Rede, é um conjunto teórico-metodológico da sociologia que diverge da corrente estruturalista. Objetiva fornecer uma nova abordagem para o estudo de fenômenos sociais (Latour, 2005), equipando o observador interessado com uma “sensibilidade” para melhor captar como se desenvolvem estes fenômenos. Propõe enxergar as interações humanas como cadeias de associações distribuídas no tempo e espaço que dependem da atuação contínua de seus participantes uns sobre os outros e cuja estrutura é dinâmica, consequência desta ação conjunta.
Considera-se um ator como qualquer entidade capaz de agir alterando um determinado estado de coisas. Com esta definição ampla, permite-se que tanto elementos humanos quanto não-humanos sejam tratados conjunta e simultaneamente. Não se pretende, contudo, atribuir intencionalidade a atores não-humanos; apenas não se deve desprezar seu potencial de interação e mediação de outras relações, seja por meios físicos ou cognitivos (Law, 2009). Nem todo objeto, entretanto, é um ator. A ANT define que a capacidade de ação de um ator pode ser mais facilmente percebida em momentos específicos: quando ocorre uma inovação, quando seu modo de uso é desconhecido ou questionado ou ao ocorrerem acidentes e comportamentos inesperados.
O foco da ANT está nas associações formadas entre os atores, resultando em uma rede. O processo de construção de cada uma destas associações é chamado translação (Callon, 1986) e depende do sucesso de etapas em que um ator, frente ao desejo de alterar um determinado estado de coisas, procura outros atores cujas capacidades de atuação lhe sejam benéficas, desperta seus interesses para que se associem, define papéis e garante o cumprimento das responsabilidades assumidas. A força com que a translação se desenrola, sua estabilidade e mecanismos que garantam sua preservação definem o sucesso da rede como um todo. Se os atores se tornam conectados, as consequências de sucesso ou fracasso se propagam pela rede, de modo que há interesse mútuo que sejam bem-sucedidos. Quando a translação é eficaz, os diversos atores são levados a atuar como um só e, através dos mecanismos de controle mútuos, sua complexidade é abstraída em uma caixa-preta (Latour, 2000, pág. 217).
Aplicando ANT no estudo social de cientistas, Latour (2000) identificou que a mediação de boa parte das relações é feita através de atores não-humanos, sendo um deles a literatura técnico-científica. Quando um artigo é citado por outro, cria-se uma cadeia de associações até seus autores, pois uns dependem da boa aceitação dos resultados dos outros, enquanto os citados se beneficiam da divulgação feita pelos primeiros. Da mesma forma, autores fazem uso da infraestrutura de instituições, produzem artigos cuja quantidade se reflete em indicadores que colocam a instituição em posição mais favorável para recebimento de verbas, que melhoram sua infraestrutura. Estas são algumas relações de benefício e expectativa mútuas que circulam pelas associações da rede. Além disso, Latour mostra que fazer ciência é um processo inerentemente social, pois propor uma nova teoria depende fundamentalmente de encontrar novos aliados que lhe deem suporte
ISBN: 978-989-8533-11-1 © 2012 IADIS
20

conceitual e material, que confirmem independentemente sua validade e que, ao aplicarem seus resultados, corroboram seu conteúdo, propagam sua existência e lhe fornecem novos desafios.
Enquanto DeRoure (2010) defende que cientistas podem se beneficiar com ferramentas web 2.0 em suas atividades de pesquisa, gerando novas maneiras de pensar e colaborar, estudos de adoção destas tecnologias (Pearce, 2010) mostram que a média de uso de ferramentas como blogs e wikis entre pesquisadores fica abaixo de 10%. Gray (2007) chama atenção para a realidade de boa parte dos pesquisadores, em que o apoio computacional ainda se limita ao uso de editores de texto e planilhas eletrônicas.
Dessa maneira, a ANT se apresenta como uma alternativa para se pensar o design de ambientes de visualização e suporte a essas comunidades e seus artefatos, onde pessoas e objetos juntos constituem unidades de significação. Um estudo (Andrade & Urquhart, 2010) baseado em ANT analisou os fatores de insucesso de uma iniciativa de implantação de soluções tecnológicas em comunidades pouco informatizadas e mostrou a importância de se compreender as cadeias de associações já existentes entre os diversos tipos de atores e respeitar as relações já existentes, buscando apoiá-las e mantendo-se atento à sua evolução. Para investigar esse potencial as próximas seções apresentam metodologia e resultados de um estudo preliminar baseado em dados de conferências científicas.
3. METODOLOGIA
Para verificar como se desenrolam as relações descritas por Latour (2000) em um cenário concreto, escolhemos algumas comunidades de cientistas, representadas por suas publicações em conferências da área. Mais especificamente, pesquisadores da área conhecida como “e-science” ou “e-research”, que estuda ferramentas computacionais de suporte à ciência (Gray, 2007; Meyer & Scroeder, 2009). As conferências foram selecionadas por terem um mesmo grau de maturidade, por volta da quinta edição, pela disponibilidade na Web do texto dos artigos aceitos e por serem comunidades locais/nacionais com aproximadamente o mesmo número de artigos publicados: Workshop de e-Science da Sociedade Brasileira de Computação de 2011 (Conferência 1) e Australasian workshop on Grid computing and e-research de 2008 (Conferência 2).
Para formar a rede de atores, os artigos das conferências foram ligados a seus autores e estes às instituições a que são filiados. Os artigos também foram ligados às suas referências bibliográficas, que por sua vez se relacionam com seus respectivos autores. Estas informações foram extraídas manualmente das páginas web onde foram publicados os anais dos eventos. Não dispomos da informação de filiação dos autores das referências bibliográficas, portanto estas instituições não foram representadas. Na Figura 1 apresentamos os elementos estudados e como serão representados neste artigo, onde atores humanos e não-humanos, juntamente com suas associações, constituem grafos.
Figura 1. Atores estudados e formas de representação adotadas
A representação visual das redes foi obtida com a biblioteca Graphstream (Pigné et al., 2007) que define automaticamente o layout e disposição dos vértices a partir de um algoritmo de spring forces (Eades, 1984). Esta representação procura um equilíbrio entre os vértices, mantendo-os mais próximos quando a associação entre eles através das arestas é mais forte. Nas figuras geradas, todas as arestas tem o mesmo peso, portanto a distância depende apenas do número de conexões. Procurou-se manter o layout automático obtido pelo algoritmo, efetuando-se pequenos deslocamentos em alguns vértices apenas para aumentar a legibilidade.
Para obtermos uma dimensão da extensão da rede, aplicamos o algoritmo All Pair Shortest Path (Floyd, 1962), identificando o comprimento do caminho mais curto entre cada par de vértices e a seguir o valor máximo desta medida para cada grafo (maxAPSP). O tamanho dos vértices foi obtido pelo algoritmo de betweeness centrality (Freeman, 1977; Brandes, 2001) que indica a probabilidade de cada vértice fazer parte do caminho mais curto entre outros dois quaisquer, representando a importância que cada vértice tem na rede
Conferência IADIS Ibero-Americana WWW/Internet 2012
21

e sua influência na agregação dos demais. O código fonte em Java necessário para esta geração é apresentado a seguir, ilustrando de forma simplificada a API da biblioteca utilizada:
// building graph structure Graph g = new SingleGraph("ANT"); Node n1 = g. addNode(“n1”); Node n2 = g. addNode(“n2”); Edge e = g.addEdge(“1-2”, n1, n2); // generating all pairs shortest path APSP apsp = new APSP(); apsp.init(graph); apsp.compute();
// calculating the betweeness centrality BetweennessCentrality bc =
new BetweennessCentrality("c"); bc.init(graph); bc.compute(); // calling the visualization Viewer viewer = graph.display(false); Layout layout = new SpringBox(); viewer.enableAutoLayout(layout);
Foram localizadas as arestas de corte (Tarjan, 1974), cuja remoção aumenta o número de componentes conexas do grafo, pois destacariam pontos de potencial fragilidade da rede – foram desconsiderados os casos em que se desconectaria apenas um vértice periférico. Do ponto de vista da ANT, uma aresta de corte representaria um ponto em que a translação pode falhar, pois a escassez de caminhos alternativos entre os atores reduz as possibilidades de impor condutas e receber benefícios. Alguns vértices foram rotulados para facilitar a análise e discussão a seguir.
Para fins de comparação, também foram geradas representações das mesmas conferências considerando apenas os atores humanos, de acordo com a visão tradicional da sociologia. Os atores foram conectados quando coautores de um mesmo artigo ou afiliados a uma mesma instituição, ou seja, as relações entre os sujeitos serão inferidas a partir dos dados disponíveis, portanto chamaremos estes diagramas de sociogramas presumidos. Os autores dos artigos apresentados nas conferências estão em vermelho e os das demais referências bibliográficas em azul.
Por exemplo, suponhamos que um artigo P, cujos autores são A1, A2 e A3, será apresentado em uma das conferências. Suas referências bibliográficas incluem o artigo R1, de autoria de A1 e A4, e R2, de autoria de A5. Os autores A1 até A4 pertencem a uma mesma instituição I1, enquanto A5 pertence a I2. As representações desta rede, de acordo com as visões tradicional e a da ANT, podem ser vistas na Figura 2. Nota-se que, por terem mais relevância na manutenção da conexidade da rede, P e R2 tem dimensões maiores. Estes, juntamente com R1, são atores não-humanos que mediam as relações de interesse entre os autores humanos A1..5.
a) b)
Figura 2. a) Sociograma presumido para atores humanos e b) Rede de associações formada pelos atores humanos da Figura 2a adicionados os atores não-humanos que mediam suas relações
4. RESULTADOS
A partir da lista de publicações de cada conferência, seus autores, afiliações e suas referências bibliográficas, buscou-se reconstituir um “instantâneo” de cada uma das comunidades de cientistas. Em todos os casos as redes formadas apenas com atores humanos, mesmo tendo sido associados por artigos ou instituições em comum, apresentaram grande número de componentes conexas. Algumas componentes com menor número de vértices e que não continham autores das conferências não foram representadas.
Na Figura 3a temos a representação dos atores humanos da Conferência 1. Os autores de artigos da conferência (em vermelho) se espalham por cinco componentes isoladas, na maioria dos casos compostas também por autores de referências bibliográficas. A principal componente é a que contém o vértice “Mattoso M.”, fundamental para a aglutinação deste subgrupo de autores segundo esta representação.
Na Figura 4 vemos a rede para a mesma conferência brasileira (1), de acordo com a visão da ANT. Apresenta uma componente conexa principal capaz de interligar a maioria dos autores da conferência e duas
ISBN: 978-989-8533-11-1 © 2012 IADIS
22

menores, tendo a maior uma topologia alongada, com distância entre seus extremos maxAPSP = 14. Foram encontradas duas arestas de corte, correspondendo a prováveis pontos sensíveis de união da comunidade. Alguns vértices correspondentes a instituições (UFRJ e Unicamp) estão em destaque de acordo com a betweeness, bem como vértices correspondentes a uma referência bibliográfica (Macário 2009) e um autor (Medeiros CMB). Estes seriam os atores, humanos ou não, mais importantes para união da rede.
a) b)
Figura 3. Sociogramas presumidos relacionados às conferências brasileira (a) e australiana (b).
Figura 4. Rede de associações do workshop de e-science da Sociedade Brasileira de Computação 2011 (1).
Quanto à Conferência 2, as associações exclusivamente entre humanos também se encontram espalhadas, em sete componentes contendo os autores dos artigos ali apresentados, e também componentes formadas pelos autores das referências bibliográficas (Figura 3b). Um dos subgrafos, onde estão Foster I. e Kesselman C., não contém autores que publicaram no workshop, tratando-se portanto de um conjunto de fontes bibliográficas correlacionadas, que é importante para a comunidade mas não possui ligação direta com ela, segundo as abordagens tradicionais.
Na Figura 5 temos a representação do workshop australiano na visão da ANT. Além da componente conexa principal, existe apenas mais uma componente menor e nenhuma aresta de corte. A distância entre seus extremos é de maxAPSP = 10. A topologia assume uma forma em estrela, com os vértices centrais formados por duas referências bibliográficas e dois de seus autores (Foster I. e Kesselman C.) e os demais artigos projetando-se a partir destes. Estes vértices correspondem ao subgrafo da Figura 3b citado
Conferência IADIS Ibero-Americana WWW/Internet 2012
23

anteriormente. Desta forma a rede se apresenta mais interconectada, ao mesmo tempo em que torna claro o papel de suas regiões: um conjunto de fontes teóricas no centro, do qual partem associações para os artigos publicados na conferência, ao seu redor.
Figura 5. Rede de associações do VI Australasian workshop on Grid computing and e-research 2008 (2).
5. DISCUSSÃO
Como um estudo preliminar, o presente trabalho esboça possibilidades de uso da Actor Network Theory na compreensão e representação de fenômenos sociais. Mesmo no estágio atual, a abordagem mostrou-se promissora pelos motivos que detalharemos a seguir.
Ao adotarmos a ótica da ANT vemos que, ao seguirmos os rastros materiais produzidos por uma comunidade de cientistas na forma de artigos publicados em conferências, pode-se realçar a coerência em redes que seriam aparentemente desconexas, trazendo a tona os elementos dos quais existe mais dependência em cada uma das comunidades. Isso fica bastante claro se compararmos os resultados da Conferência 2, Figura 3b versus Figura 5, em que o número de componentes conexas se reduz drasticamente e o subgrafo formado por Foster I. e Kesselman C., desconectado e periférico quando considerados apenas os elementos humanos da rede, toma a posição central e se associa aos demais constituintes quando considerados todos os atores, segundo a ANT.
Nas duas conferências, se usássemos a visão centrada em agentes humanos dependendo apenas das relações de trabalho colaborativo (coautoria) e do provável contato interpessoal direto (mesma filiação) restringiríamos a dimensão do fenômeno estudado. A adição dos elementos não-humanos mostra que cada conferência constitui um agregado social único, com conexões que levam à maioria de seus integrantes e que pode ser estudado como um todo.
A colocação de todos os envolvidos em uma mesma estrutura permite um melhor dimensionamento da relevância de cada participante. Na Conferência 1, por exemplo, “Mattoso M.” é um autor importante para o subgrupo a que pertence, quando analisado em relação a seus contatos diretos com outros autores (Figura 3a). Entretanto quando consideramos a rede pela proposta da ANT, podemos analisar toda a comunidade de cientistas em uma única estrutura, e então a importância social daquele autor é relativizada, por haver caminhos alternativos que garantem a conexão entre seus constituintes (Figura 4).
ISBN: 978-989-8533-11-1 © 2012 IADIS
24

Os resultados vistos na rede da Conferência 2 (Figura 5) se alinham aos do estudo de Meyer e Schroeder (2009) baseado em palavras-chave de publicações de e-science, em que uma word cloud gerada com os títulos publicados na base de artigos Scopus (www.scopus.com) trouxe em destaque o conceito de grid computing, para o qual Foster e Kesselman (1998) são referências importantes. Estes resultados estão de acordo também com a visão da ciência segundo Kuhn (2009), que define uma comunidade científica como um grupo de pessoas que pesquisam um tema específico compartilhando um paradigma, ou seja, um conjunto de métodos, valores, linguagem, princípios e conceitos. A presença de autores e referências bibliográficas como elementos centrais dos grafos sugere sua importância como agregadores das comunidades. Esta visão não estaria tão clara usando apenas os sociogramas com atores humanos.
Do ponto de vista da análise de fenômenos na web social, a abordagem apoiada pela ANT demonstra resultados favoráveis, pois permite que seja feita a investigação a partir de vestígios deixados pelos atores durante a execução exclusivamente de suas atividades de interesse. Não há dependência de contatos presenciais, entrevistas ou outras abordagens diretas aos atores envolvidos. Esta característica é fundamental para o estudo de fenômenos descentralizados e em grande escala como ocorrem na Web 2.0 (Hendler et al., 2008; Pereira et al., 2011).
As diversas possibilidades de conexão para as redes vistas aqui permitem a um designer interessado em desenvolver um sistema Web 2.0 para uma destas comunidades que se inspire nos elementos fortes de algumas delas para complementar os pontos fracos de outras, como por exemplo, no uso compartilhado online de um conjunto de referências bibliográficas com os conceitos que caracterizam aquele ramo da ciência. Esta necessidade parece estar mais clara na rede da Conferência 1 (Figura 4), pois uma ferramenta Web reduziria a dependência das instituições como elementos centrais e criaria caminhos alternativos para se evitar a fragilidade da comunidade representada pelas arestas de corte. Estes atores não-humanos adicionados à rede contribuiriam para a formação de uma social machine (Hendler & Berners-Lee, 2009) em que o conjunto de atores age coordenadamente, com benefícios para todos os envolvidos.
6. CONCLUSÃO
Dada a natureza social da produção de conhecimento por cientistas, estes são potenciais candidatos ao uso de software social e, portanto, suas relações sociais devem ser mapeadas e documentadas. Entretanto, estudar grupos sociais a partir apenas das ligações entre as pessoas pode ser insuficiente em um cenário onde as relações se desenrolam através de artefatos materiais, digitais e sistemas Web 2.0.
O uso da Actor-Network Theory mostrou-se promissor por fornecer uma variação na maneira como relações sociais podem ser rastreadas, entre atores humanos ou não, abrindo espaço para elementos computacionais. Como esta abordagem produz representações em formas de grafos, dá margem para análises de natureza tanto quantitativa, baseadas em algoritmos, como qualitativa, a partir de suas representações visuais.
O trabalho aqui apresentado terá continuidade em duas frentes que se relacionam: validar o suporte da ANT à análise das comunidades, com a busca de outras associações dos atores já estudados, sua evolução ao longo do tempo e detalhamento das formas de interação; utilizar a caracterização das redes como subsídio para um processo de design para sistemas cujos potenciais usuários são os seus participantes.
AGRADECIMENTO
Este trabalho é parte do projeto Eco-web, processo CNPq 560044/2010-0. Os autores agradecem a valorosa contribuição dos revisores anônimos.
Conferência IADIS Ibero-Americana WWW/Internet 2012
25

REFERÊNCIAS
Andrade, A.D., Urquhart, C., 2010. The affordances of actor network theory in ICT for development research. Information Technology & People Vol. 23 No. 4, Emerald Insight.
Bae, J., Kim, S., 2009. A Global Social Graph as a Hybrid Hipergraph. Fifth IEEE International Joint Conference on INC, IMS and IDC.
Balbino, F.C., Anacleto, J.C., 2011. Contagious: um Framework para suporte à difusão de inovações em Sites de Redes Sociais. Workshop sobre Aspectos da Interação Humano-Computador para a Web Social.
Brandes, U., 2001. A Faster Algorithm for Betweenness Centrality, Journal of Mathematical Sociology 25:2. Callon, M., 1986. Some Elements of a Sociology of Translation: Domestication of the Scallops and the Fishermen of St
Brieuc Bay. In John Law (ed.), Power, Action and Belief: A New Sociology of Knowledge. DeRoure, D., 2010. E-Science and the Web. IEEE Computer 43 (5). Durkheim, E., 2007. As regras do método sociológico. Ed. Martins Fontes. Eades, P., 1984. A heuristic for graph drawing. Congressus Numerantium, 42:149–160. Floyd, R.W., 1962. Algorithm 97: Shortest Path. Communications of the ACM 5 (6): 345. Foster, I., Kesselman, C. (eds), 1998. The Grid: Blueprint for a New Computing Infrastructure (1st edition). San
Francisco: Morgan Kaufmann Publishers. Freeman, L., 1977. A set of measures of centrality based upon betweenness. Sociometry 40: 35–41. Gray, J., 2007. eScience: a transformed scientific method. Prefácio do livro The Fourth Paradigm. Microsoft Research. Hendler, J., Shadbolt, N., Hall, W., Berners-Lee, T., Weitzner, D., 2008. Web Science: An Interdisciplinary Approach to
Understanding the Web. Communications of ACM, v. 51, n. 7. Hendler, J., Berners-Lee, T., 2009. From the Semantic Web to social machines: A research challenge for AI on the World
Wide Web. Artificial Intelligence 174. Elsevier. Hollan, J., Hutchins, E., Kirsh, D., 2000. Distributed Cognition: Toward a New Foundation for Human-Computer
Interaction Research. ACM Transactions on Computer-Human Interaction, Vol. 7, No. 2. King, I., Li, J., Chan, K.T., 2009. A Brief Survey of Computational Approaches in Social Computing. Proceedings of the
International Joint Conference on Neural Networks – IEEE. Kuhn, T., 2009. A estrutura das revoluções científicas. Ed. Perspectiva, 9ª ed. Latour, B., 2000. Ciência em ação: como seguir cientistas e engenheiros sociedade afora. Editora da UNESP. Latour, B., 2005. Reassembling the Social: An Introduction to Actor-Network-Theory. Oxford University Press. Law, J., 2009. Actor-Network Theory and Material Semiotics. The New Blackwell Companion to Social Theory.
Blackwell Publishing Ltd. Lubashevsky, I., 2010. Towards a Description of Social Systems as a Novel Class of Physical Problems. Proceedings of
the 13th International Conference on Humans and Computers, Fukushima-ken, Japan. Meyer, E.T., Schroeder, R., 2009. Untangling the web of e-Research: Towards a sociology of online knowledge. Journal
of Infometrics 3, 246-260. Elsevier. Pereira, R.., Baranauskas, M. C. C., Silva, S.R.P., 2010. Softwares Sociais: Uma Visão Orientada a Valores. IHC 2010 –
IX Simpósio de Fatores Humanos em Sistemas Computacionais., Belo Horizonte, MG, Brazil. Pereira, R., Miranda, L.C., Baranauskas, M.C.C., Piccolo, L.S.G., Almeida, L.D.A., Reis, J.C., 2011. Interaction Design
of Social Software - Clarifying requirements through a culturally aware artifact. IEEE International Conference on Information Society.
Pearce, N., 2010. A study of technology adoption by researchers. Information, communication & society Vol. 13, no. 8. Pietilanen, A.K., Diot, C., 2012. Dissemination in opportunistic social networks: the role of temporal communities. In
Proceedings of the thirteenth ACM international symposium on Mobile Ad Hoc Networking and Computing (MobiHoc '12)
Pigné, Y., Dutot, A., Guinard, F., Olivier, D., 2007. GraphStream: A Tool for bridging the gap between Complex Systems and Dynamic Graphs. 4th European Conference on Complex Systems (ECCS'2007).
Singh, M., Dwivedi, Y., Hachney, R., Pesynski, K., 2012. Innovation in Communication: An Actor-Network Analysis of Social Websites. International Journal of Actor-Network Theory and Technological Innovation, 4(1).
Tarjan, R., 1974. A note on finding the bridges of a graph. Information Processing Letters, v.2, n.6.
ISBN: 978-989-8533-11-1 © 2012 IADIS
26

IDOSOS NA EAD: UMA PROPOSTA DE PARÂMETROS PARA A CONSTRUÇÃO DE OBJETOS DE
APRENDIZAGEM
Leticia Rocha Machado e Patricia Alejandra Behar Universidade Federal do Rio Grande do Sul, Programa de Pós-Graduação em Informática na Educação, Núcleo de
Tecnologia Digital Aplicada à Educação - Brasil
RESUMO
Com o aumento mundial da população idosa surge a necessidade de pensar sobre o processo de ensino e aprendizagem para este público na educação a distância (EAD). Desta forma, os objetos de aprendizagem (OA) podem se transformar em materiais digitais importantes para este processo. O presente artigo pretende analisar o uso de três OA utilizados em um curso de extensão voltado para idosos com 60 anos ou mais. A partir dos dados coletados são apresentados alguns aspectos e que devem ser considerados no desenvolvimento de OA para esta parcela da população. Os aspectos foram categorizados em três grandes grupos: design, conteúdo e didática. Infelizmente ainda são raras as práticas pedagógicas que usufruam do potencial de objetos com pessoas mais velhas. Desta forma entende-se que o uso deste tipo de recurso poderá atender as diversas demandas do público. Nessa perspectiva, pesquisas e discussões mais profundas sobre o tema deverão ocorrer, a fim de possibilitar o planejamento de espaços pedagógicos eficazes para os idosos.
PALAVRAS-CHAVE
Objetos de Aprendizagem, Educação a Distância, Idosos.
1. INTRODUÇÃO
A população de pessoas mais velhas encontra-se em ascensão em todo o mundo, isto se deve à reestruturação social e atenção redobrada no processo de envelhecimento. Neste processo a busca por qualidade de vida ficou mais latente, principalmente pela possibilidade de ter um envelhecimento com qualidade de vida. Uma das formas de propiciar a qualidade de vida é a participação em atividades que favoreçam o bem estar, como por exemplo, atividades educacionais. Entende-se que a Educação a Distância (EAD) pode contribuir muito para uma qualidade de vida para os idosos.
Os ambientes de aprendizagem, nas últimas décadas, vêm sofrendo transformações tanto metodológicas como tecnológicas. Com novos paradigmas, emerge a necessidade de investigar sobre o uso de tecnologias, principalmente a EAD, como uma possibilidade educativa que propicie uma efetiva participação dos idosos com potencial para uma educação continuada. Esta modalidade de educação pode proporcionar ao idoso a atualização, reflexão crítica, novas aprendizagens além da possibilidade das interações sociais que são necessárias e fundamentais nesta fase da vida.
Ao mesmo tempo em que as tecnologias estão cada vez mais presentes no cotidiano dos idosos, há a necessidade de reflexão de novas práticas pedagógicas e constituição de materiais digitais educacionais que auxiliem este processo.
Os materiais educacionais são elaborados para atender as necessidades emergentes no processo de ensino e aprendizagem, podendo ser construídos em diferentes recursos (exemplo: impresso, digital, materiais concretos). Com a incorporação das tecnologias na educação, foi adicionado mais uma palavra, sendo denominados de Materiais Educacionais Digitais (MED). Os MED, além do objetivo relacionado à aprendizagem utilizam recursos multimidiáticos e digitais, incluindo objetos de aprendizagem (OA).
Objeto de Aprendizagem pode ser considerado um tipo de material digital educacional. Portanto a elaboração de OA poderá ser uma alternativa de apresentar o conteúdo educacional de forma dinâmica e interativa.
Conferência IADIS Ibero-Americana WWW/Internet 2012
27

A possibilidade de utilização de objetos em cursos para idosos surgiu a partir das necessidades emergentes de um projeto piloto de capacitação de pessoas mais velhas para o uso dos recursos da EAD. O curso foi desenvolvido em uma Universidade no Rio Grande do Sul, Brasil. Este curso objetivou capacitar os idosos no uso das ferramentas da EAD a fim de propiciar a inclusão desta parcela da população nos cursos ofertados através desta modalidade educacional. Entre os resultados que foram coletados para o projeto, alguns apontaram a opinião dos idosos no uso dos OA desenvolvidos e aplicados.
Portanto o presente artigo pretende discutir os dados coletados sobre o uso dos objetos de aprendizagem pelos idosos. Os dados coletados na aplicação dos OA irão possibilitar uma reflexão sobre alguns aspectos que deveriam ser considerados ao se desenvolver OA para pessoas mais velhas. Para tanto, inicialmente será definido o que é um OA, seguido da metodologia adotada e análise dos dados coletados.
2. OBJETOS DE APRENDIZAGEM: DEFINIÇÃO E CARACTERÍSTICAS
Com o avanço das tecnologias Wayne Hodgins (POLSANI, 2003; MANEA, RUTLEDGE, 2007) observou a necessidade de se constituir um material para se utilizar na sala de aula, criando o termo objeto de aprendizagem em 1994 no qual utilizava as ferramentas digitais como meio de tratar os assuntos educacionais.
Ainda existem muitas discussões sobre a definição do que seria um objeto de aprendizagem. No entanto, o conceito mais comum que se encontra na literatura acadêmica foi o descrito por Wiley (2000), no qual defini como qualquer entidade, digital ou não digital, que pode ser utilizada, reutilizada ou referenciada durante a aprendizagem apoiada na tecnologia.
Behar et al (2009), Johnson (2003), Tarouco et al (2006), IEEE (2003) e Friesen (2004) consideraram um OA sendo qualquer tipo de material digital e que tenha embasamento pedagógico no seu desenvolvimento. Portanto, os OA “São destinados a situações de aprendizagem tanto na modalidade a distância quanto semipresencial ou presencialmente” (BEHAR, 2009, p.67). Existem diferentes tipos de matérias que são considerados OA, desde um texto, imagem, vídeo, música e até objetos mais complexos formados a partir de uma combinação de outros materiais. Tarouco et al (2006, p.02) escreveram que “Objetos educacionais podem ser definidos como qualquer recurso, suplementar ao processo de aprendizagem, que pode ser reusado para apoiar a aprendizagem”. Neste artigo considera-se objeto de aprendizagem sendo um material digital que possui um aporte teórico e objetivo educacional.
No contexto brasileiro, os objetos de aprendizagem estão cada vez mais presentes, principalmente no que tange à educação formal desde o ensino fundamental até a pós-graduação. Diferentes assuntos são desenvolvidos, por exemplo, sobre aleitamento materno (FERECINI, 2012), educação musical (JESUS, et al, 2010; ROSAS, BEHAR, 2012), Bioquímica celular (SILVA et al, 2011), noções algébricas (FREIRE, CASTRO FILHO, 2006), estudo de línguas (LEFFA, 2006), escrita de textos (ALVES, 2006), além de objetos voltados para formação continuada de professor (BEHAR et al, 2010a; MORESCO, BEHAR, 2009; BEHAR et al, 2010b). O aumento na utilização de objetos de aprendizagem se dá principalmente por ser um recurso que tem por objetivo organizar e estruturar materiais educacionais digitais (TAROUCO et al, 2006).
A utilização de objeto de aprendizagem remete a um novo tipo de aprendizagem apoiada pela tecnologia, no qual o professor abandona o papel de transmissor de informação para desempenhar um papel de mediador da aprendizagem favorecendo, assim, o processo de ensino e aprendizagem. O professor pode propiciar condições favoráveis às trocas e à cooperação, oferecendo ao aluno situações-problema e valorizando a produção de novos conhecimentos.
Existem alguns fatores que facilitam a utilização de OA na educação, entre eles a flexibilidade (fácil reutilização e manutenção), interoperabilidade (possibilidade de utilização em qualquer plataforma em todo o mundo) e atualização (fácil atualização e adaptação) (WILEY, 2000; MACÊDO, 2009; BEHAR et al, 2008; TORI, 2010; VAZ, 2009). Em relação aos objetos de aprendizagem, não existe definido um tamanho, ou seja, não há um parâmetro que possa dizer se o OA é muito grande para o tema proposto. Os metadados é outro fator importante na constituição da um objeto, já que se refere as informações disponibilizadas sobre o mesmo, desde o seu uso adequado, quanto a sua possibilidade de interoperabilidade ou não (GOMES, 2005).
O conjunto de suas características enfatiza as vantagens que os objetos de aprendizagem agregam à educação como um todo, já que correspondem a um recurso digital que visa auxiliar a construção do conhecimento. Complementando com Marquesi e Araújo (2009, p. 359) “Um objeto de aprendizagem pode
ISBN: 978-989-8533-11-1 © 2012 IADIS
28

ser produzido para permitir uma aprendizagem mais eficiente por meio da interação e da prática dos conceitos de um conteúdo [...]”. Nessa perspectiva, os OA convertem-se num recurso viável para enriquecer o espaço pedagógico para os idosos. Infelizmente ainda não existe muita bibliografia sobre este tema e específicos para idosos.
Cada vez mais a utilização de repositórios de objetos de aprendizagem, como RIVED– Rede Interativa Virtual de Educação (http://rived.mec.gov.br/), CESTA - Coletânea de Entidades de Suporte ao uso de Tecnologia na Aprendizagem (http://www.cinted.ufrgs.br/CESTA), MERLOT – Multimedia Educational Resources for Learning and Online Teaching (http://www.merlot.org/), estão cada vez mais presentes nas práticas pedagógicas como fonte de pesquisa.
Desta forma, foi realizada uma pesquisa nos repositórios de materiais educacionais digitais citados anteriormente e não foram localizados OA para o público mais velho. O que pode se encontrar são OA com conteúdos sobre os idosos voltados para profissionais que trabalham sobre o tema (médicos, cuidadores, enfermeiros). Este resultado negativo denota a falta de preocupação em produzir materiais para este público.
Neste sentido e, a partir da necessidade emergente, foram construídos alguns objetos de aprendizagem especificamente para idosos. Durante o decorrer da pesquisa foram desenvolvidos nove OA voltados para os idosos. Esta investigação faz parte de um projeto de pesquisa maior que envolve o oferecimento de cursos de extensão e construção de objetos voltados para os idosos na EAD. Na primeira fase da investigação foram utilizados três objetos de aprendizagem que foram analisados neste artigo.
3. METODOLOGIA: CONSTRUÇÃO DOS OBJETOS DE APRENDIZAGEM
No ano de 2009 iniciou-se uma investigação visando o oferecimento de cursos online para pessoas idosas que estivessem interessadas em realizar cursos na modalidade a distância. Durante o decorrer da pesquisa observou-se a necessidade de um aprofundamento sobre alguns recursos tecnológico para dar continuidade ao projeto por haver brechas no conhecimento técnico inicial no uso do computador. Neste contexto emergiu a necessidade de desenvolver e utilizar objetos de aprendizagem como um material auxiliar as aulas.
Desta forma foram construídos nove objetos de aprendizagem para os alunos idosos. No entanto este artigo analisa apenas três objetos de aprendizagem que foram utilizados na primeira fase da investigação:
- O Computador: histórico da informática e conceitos básicos de hardware e software; - EDITA – Edição de Arquivos: trabalha com as ferramentas de edição textual, apresentação e planilhas; -UP – Utilização do Pendrive: conceito e uso do pendrive; Para o desenvolvimento destes objetos de aprendizagem foram utilizados os passos sugeridos por Amante
e Morgado (2001): a) Concepção (o que, para quem e de que forma pretende-se desenvolver o objeto - ideias iniciais); b) Planificação (colocar em prática a primeira fase do que foi projetado, o chamado storyboard (Figura 1)- maquete do que será criado, através de seleção dos materiais e conteúdos, definir a quantidade e relevância das informações, construção de protótipos, design da interface); c) Implementação (todos os pontos planejados durante o desenvolvimento do projeto e a planificação serão colocados em prática nesta etapa de construção do produto); d) Avaliação (conjunto de procedimentos avaliados e validação do produto).
Figura 1. Storyboard dos objetos de aprendizagem construído: O computador
Conferência IADIS Ibero-Americana WWW/Internet 2012
29

Figura 2. Storyboard dos objetos de aprendizagem construídos: UP: Utilizaçaõ de Pen Drive e EDITA: Edição de Arquivos
Os objetos de aprendizagem foram desenvolvidos objetivando atender as necessidades dos idosos. Uma das atenções que se teve foi em relação à interface (Figura 3). O cuidado com a interface se teve por estudos (TORREZAN et al, 2011) que indicam que a interação do usuário com a interface pode influenciar na aprendizagem, podendo motivar ou não. Assim, foi adotado nos OA um design de fácil navegação e exploração, não necessitando de conhecimentos aprofundados ou específicos sobre os recursos informáticos para sua manipulação. Os usuários idosos puderam acessar os desafios na ordem em que foi apresentado ou aleatoriamente, de acordo com o andamento do curso e do professor.
Figura 3. Interfaces dos objetos de aprendizagem utilizados com os idosos.
Todos os OA possuem algum tipo de leituras complementares, guia de utilização, glossário e material de apoio, contando com textos, vídeos, apresentações e mapas sobre os assuntos. Também foi incluída a opção de impressão, já que os idosos, na sua maioria, ainda preferem o material impresso.
Os objetos construídos possuem também como referencia, resultados de estudos já realizados baseando-se nas necessidades dos idosos com a informática, expectativas e dificuldades encontradas pelos mesmos (KACHAR, 2011; MACHADO, 2007; SALES, 2005). Além destes aspectos, também foi considerado na construção dos objetos de aprendizagem as mudanças fisiológicas, psicológicas e cognitivas dos idosos e sua influencia no processo de ensino e aprendizagem (AZEVEDO E SOUZA, 2003; BOTH, 1999).
Portanto, a presente pesquisa foi desenvolvida em uma abordagem quantitativa-qualitativa. Este formato foi eleito pela viabilidade na complementação dos dados, a fim de auxiliar na compreensão do objeto de estudo. Em relação aos aspectos qualitativos foi utilizada uma abordagem interpretativa para auxiliar o processo de compreensão dos dados que foram coletados durante a pesquisa. A coleta de dados foi realizada
ISBN: 978-989-8533-11-1 © 2012 IADIS
30

a partir de observações participantes, questionários e entrevistas. Foram utilizados os passos sugeridos por Bardin (2004) na análise do conteúdo. Já os aspectos quantitativos foram analisados através da distribuição de frequência representada em percentuais, média e desvio padrão.Para tanto, os sujeitos que participaram da pesquisa forma 28 idosos com média de idade 70,5 anos. Os idosos são caracterizados com um índice alto de escolaridade e 20 eram do gênero feminino (Figura 4).
Figura 4. Características dos idosos participantes da pesquisa
A partir deste panorama delineado, a seguir serão analisados os dados coletados durante a pesquisa, bem como a discussão e reflexão com aporte teórico pertinente sobre os temas relacionados.
4. RESULTADO E DISCUSSÃO DOS DADOS COLETADOS
A utilização de OA durante o curso com os idosos se destacou pois propiciou uma maior autonomia aos alunos, principalmente pela grande diferença de conhecimentos e ritmo de aprendizagem entre os participantes. Os objetos aplicados com os idosos foram: UP; EDITA; O Computador (Figuras 1 e 2).
Em relação aos objetos de aprendizagem foi perguntado ao público qual o grau de satisfação no seu uso. No total de idosos, 63% relataram que estavam “Muito satisfeito”, sendo 29% “Completamente satisfeito” e 8% “Pouco satisfeito” (Figura 5).
Figura 5. Índice de satisfação dos idosos em relação aos OAs utilizados
A partir dos dados coletados, foram criadas três categorias. Estas categorias foram delineadas observando os pontos mais relevantes que deveriam ser considerados na construção de OA para idosos:
a) Design – Sugere-se que os OA para idosos possuam os pré-requisitos de usabilidade utilizados nos outros objetos, enfatizando o tamanho da fonte de letra que poderia ser maior (para auxiliar as pessoas com problema de visão), cores claras e com contrastantes (os idosos possuem a diminuição da percepção visual o que dificulta no que tange a profundidade e o contraste). Também se indica o uso de botões que remetem ao conteúdo que pretendem desenvolver link, evitando transtornos para os idosos em procurarem onde estão os materiais que desejam acessar. O uso de trilhas sonoras não agradou todos os idosos, sendo indicado o uso de comando para que seja possível o seu desligamento quando necessário. Outro ponto a ser considerado são as questões de usabilidade de acordo com W3C. O W3C - Consórcio World Wide Web é uma equipe que cria padrões de usabilidade para a internet.
Conferência IADIS Ibero-Americana WWW/Internet 2012
31

Os participantes avaliaram a interface adotada nos OA, onde foi apontado, por exemplo, como facilidade o uso de figuras para ilustrar “Consigo operar com todos, são fáceis de ler, entender e operar, fáceis de manipular”; “Como já obtive uma experiência de aprendizagem anterior achei muitos didáticos os informativos e úteis”. Em contraparte foi apontado pelos idosos algumas modificações que deveriam ser realizadas nos OA, como a trilha sonora utilizada em um objeto de aprendizagem “Mudar o fundo musical”.
Um idoso comentou sobre os objetos de aprendizagem: “Tentei usar, mas geralmente não consigo”. Esta reclamação deu-se devido à construção dos OA que foi realizado no programa Flash Cs4, sendo preciso, em alguns casos, a instalação do plugin flash no computador para que estes funcionassem, dificultando o seu acesso em alguns casos.
b) Conteúdo – Aconselha-se que os conteúdos sejam de interesse dos alunos e possuam relações, quando possível, com o passado do aluno (remeter as lembranças passadas, utilizando metáforas), estar em uma linguagem clara e objetiva e se indica que sejam mostrados em pequenos blocos. Sugere-se que os OA estejam disponíveis online (web) e em um endereço de sua localização seja de fácil memorização para o uso em suas residências.
Os participantes apontaram que o uso de OA auxiliou a sua aprendizagem, mostrando que há uma auto-avaliação constantemente “Estão atendendo perfeitamente aos meus objetivos de compreender e aprender melhor a informática na minha vida”; “Práticos que facilitam a aprendizagem”; “Reforçam os conteúdos vistos”; “É mais fácil o aprendizado: diversão”; “São muito bons a nossa aprendizagem”.
Uma alteração solicitada é em relação à linguagem que, para um idoso, era muito técnica. Esta está sendo modificada para melhor atender a eles apesar de que, em algumas situações, seja necessário o uso de uma linguagem mais técnica para explicar determinado assunto.
c) Didática – Recomenda-se a utilização de recursos visuais (imagens, vídeos) que auxiliem na compreensão dos conteúdos. Indica-se a possibilidade do aluno imprimir o material que deseja. O uso de leituras complementares é sugerido, pois com estes materiais os idosos poderão aprofundar o tema e ser autônomos na pesquisa para a realização das atividades. Aconselha-se que as atividades sejam desafiadoras e preferencialmente interativas (que seja possível de realizar no próprio OA). A combinação dos objetos de aprendizagem com ambientes virtuais de aprendizagem é recomendada, pois assim o mediador (professor/tutor) pode utilizar os recursos de comunicação síncronos e assíncronas para auxiliar no processo de ensino e aprendizagem.
Alguns idosos apontaram que o uso dos OA possibilitou uma autonomia maior na sua aprendizagem “Acho que deveria ser incentivado a utilização de tudo, porque isto ajuda muito a nossa independência”; “São eles que nos levam a praticar individualmente para aplicar em outras situações”.
Os idosos apontaram que os OA foram úteis para a sua aprendizagem e utilizaram para consulta na sua casa “É ótimo fazermos trabalhos em casa. Pesquisando se aprende muito”; “De grande utilidade e estou usando”; “Todos os objetos são muitos bons, e utilizo diariamente quando acesso no meu computador”; “Utilizo-os frequentemente”.
Portanto os objetos de aprendizagem mostraram-se ser materiais muito úteis e aprovados pelos idosos nas aulas ministradas através de cursos de extensão em uma universidade pública no Brasil. A partir das considerações dos idosos foram realizadas modificações nos outros seis OA, principalmente, em relação ao formato de construção (Flash) para evitar problemas técnicos e possibilitar uma maior acessibilidade nos seus usos.
5. CONSIDERAÇÕES FINAIS
O processo de ensino e aprendizagem na educação não deve ser desenvolvido da mesma forma para todas as faixas etárias, já que cada idade apresenta necessidades diferentes. O conhecimento precisa ser analisado, discutido e ter a sua natureza entendida.
Logo, cada vez mais recursos didáticos para uso no computador por idosos vêm sendo desenvolvidos para serem incluídos ao processo de aprendizagem, podendo ser adaptado às diferentes necessidades dos usuários. Infelizmente ainda são raras as práticas pedagógicas que usufruam do potencial de objetos de aprendizagem com as pessoas mais velhas.
ISBN: 978-989-8533-11-1 © 2012 IADIS
32

Observa-se a partir dos relatos dos idosos que os objetos de aprendizagem podem se tornar um material enriquecedor e possibilitar uma maior autonomia desta população no que tange ao uso dos recursos da informática.
A partir da falta de material sobre o tema e a experiência desenvolvida através de projetos de pesquisa que visam a construção de OA para idosos e cursos de extensão na universidade voltados para este tipo de público, foram elencados alguns aspectos na construção de OA específicos para eles. Os aspectos foram categorizados em: design, conteúdo e didática. Observa-se que há ainda muitos aspectos que devem ser considerados na construção de objetos, principalmente para o idoso, desde o layout até a forma como serão disponibilizadas as atividades (reflexão, interativas). Estes aspectos poderão auxiliar as próximas pesquisas que desejarem desenvolver objetos para o público mais velho bem como estão sendo revistos para a reestruturação dos objetos de aprendizagem citados neste artigo..
Desta forma entende-se que o uso de objetos de aprendizagem poderá atender as diversas demandas do público, a partir do conteúdo, design e didática e que poderiam ser direcionados, especificamente, para os mais velhos. Estes materiais poderão possibilitar uma maior autonomia, aprendizagem enriquecedora e lúdica. Portanto, os aspectos que são envolvidos na construção de OA devem ser repensados para o público idoso. Nessa perspectiva, deveriam ocorrer pesquisas e discussões mais aprofundadas sobre o tema, a fim de possibilitar o planejamento de novos espaços pedagógicos focados para os idosos.
REFERÊNCIAS
Amante, L.; Morgado, L., 2001. Metodologia de concepção e desenvolvimento de aplicações educativas: o caso dos materiais hipermedia. Discursos, III Série, nº especial, p.125-138.
Azevedo E Souza, V.B., 2002. A motivação do idoso para reaprender a aprender: um desafio para propostas de intervenção educativa. In: Terra, NL; Dornelles, B. Envelhecimento bem-sucedido. Porto Alegre: EDIPUCRS.
Bardin, L., 2004. Análise de Conteúdo. Lisboa, Portugal. Behar, P. A. et al, 2009. Modelos Pedagógicos em Educação a Distância. Porto Alegre, Artmed. Behar, P.A.; Bernardi, M.; Frozi, A.P., 2008. Virtual Learning Communities: a learning object integrated into a e-
learning plataform. In: Kendall, M. and Samways, B.. (Org.). Learning to live in the Knowledge society. 1 ed. New York: Springer, v. 1, p. 163-167.
Behar, Patricia Alejandra. et al., 2010b. AVALEAD: A construção de um Objeto de Aprendizagem sobre Avaliação em Educação a Distância. RENOTE: novas tecnologias na educação, v. 8, n. 3.
Behar, Patricia Alejandra. et al. , 2010a. Práticas Criativas do Professor 2.0: atendendo às demandas da ciberinfância. RENOTE: novas tecnologias na educação, v. 8, n. 2.
Both, A., 1999. Gerontogogia: educação e longevidade. Passo Fundo, Imperial. Ferecini, Geovana Magalhães, 2012. Desenvolvimento e avaliação do objeto digital de aprendizagem sobre o aleitamento
materno do prematuro. Tese (Doutorado), Escola de Enfermagem de Ribeirão Preto. Freire, Raquel Santiago; Castro Filho, José Aires De Castro Filho, 2006. Desenvolvendo conceitos algébricos no ensino
fundamental com o auxílio de um Objeto de Aprendizagem. Anais do XXVI Congresso da SBC. WIE XII Workshop de Informática na Escola. Campo Grande.
Friesen, N. T, 2004. hree objections to learning objects. Online education using learning objects. London, Routledge, p. 59-70. Disponível em http://www.learningspaces.org/n/papers/objections.html . Acesso em 22 de maio de 2012.
Gomes, Sionise Rocha et al, 2005.Objetos de Aprendizagem Funcionais e as Limitações dos Metadados Atuais. Workshop em Informática na Educação; XVI Simpósio Brasileiro de Informática na Educação, UFJF.
IEEE – Learning Technology Standards Committee. 2003 WG12: Learning Object Metadata. Disponível em: Aceso em 20 de maio de 2012.
Jesus, Elieser Ademir et al, 2010. Zorelha: Um Objeto de Aprendizagem para Auxiliar o Desenvolvimento da Percepção Musical em Crianças de 4 a 6 Anos. Revista Brasileira de Informática na Educação, Volume 18, Número 1.
Johnson, L.F., 2003. Elusive Vison:Challenges Impeding the Learning Objects Economy. Micromedia. Disponivel em: <http://www.nmc.org/pdf/Elusive_Vision.pdf>. Acesso em: 22 maio 2012.
Kachar, V., 2011. Longevidade - um novo desafio para a educação. São Paulo, Cortez. Leffa, Vilson J., 2006. Nem tudo que balança cai: Objetos de aprendizagem no ensino de línguas. Polifonia. Cuiabá, v.
12, n. 2, p. 15-45.
Conferência IADIS Ibero-Americana WWW/Internet 2012
33

Macêdo, L.N. et al., 2009. Desenvolvendo o pensamento proporcional com o uso de um objeto de aprendizagem. In: Prata, C.L.; Nascimento, A.C.A.A.. (orgs). Objetos de aprendizagem: uma proposta de recurso pedagógico. Brasília, MEC/SEED.
Machado, L.R. 2007. Metas motivacionais de idosos em inclusão digital. 2007. 116 f. [Dissertação]. Pontifícia Universidade Católica do Rio Grande do Sul. Porto Alegre.
Manea, N; Rutledge, D. A., 2007. Laboratory for Teaching Learning Objects’ Thinking for In-service Teachers. In R. Carlsen et al. (Eds.), Proceedings of Society for Information Technology & Teacher Education International Conference 2007 (pp. 1592-1599). Chesapeake, VA: AACE.
Marquesi, S.C.; Araújo Jr, C.F, 2009. Atividades em ambientes virtuais de aprendizagem: parâmetros de qualidade. In: Litto, F.M.; Formiga, M. (orgs). Educação a distancia: o estado da arte. São Paulo, Pearson.
Moresco, Silvia Ferreto da Silva; Behar, Patricia Alejandra, 2009. Objeto de aprendizagem trabalho com projetos: uma arquitetura pedagógica para a formação continuada de professores. Revista Técnico-Científi ca do IF-SC/Instituto Federal de Santa Catarina, Vol. 1, n. 1.
Polsani, P.R., 2003. Use and Abuse of Reusable Learning Objects. Journal of Digital Information, vol 3, n 4. Rosas, F.W.; Behar, P.A.; 2012. COMPMUS: um objeto de aprendizagem para auxiliar no desenvolvimento de
competências para o contexto tecnológico-musical. Renote, v.10, n.1. Sales, M.V.S., 2005. Uma reflexão sobre a produção do material didático para EAD. ABED, 2005. Disponível em:
http://www.abed.org.br/congresso2005/por/pdf/044tcf5.pdf. Acesso em 20 de março de 2011. Silva, Ítalo Esposti Poly da. et al, 2011.Desenvolvimento de objeto de aprendizagem para o estudo interativo de
Bioquímica Celular. Revista Práxis, ano III, nº 6, agosto. Tarouco, L.M.R.; Konrath, M.L.P.; Carvalho, M.J.S.; Avila, B.G., 2006. Formação de professores para produção e uso de
objetos de aprendizagem. Rev. Novas Tecnologias na Educação, v. 4 nº 1, Julho. Disponível em: http://www.cinted.ufrgs.br/renote/jul2006/artigosrenote/a20_21173.pdf. Acesso em 20 de março de 2011.
Tori, R.. 2010. Educação sem distância: as tecnologias interativas na redução de distancias em ensino e aprendizagem. São Paulo, Senac.
Torrezan, C.A.W.; Reategui, E.B.; Behar, P.A.; Costa, P.S.C., 2011. A atuação das interfaces não-convencionais na educação.Renote, v.9, n1.
Vaz, M.F.E., 2009. Os padrões internacionais para a construção de material educativo on-line. In: Litto, F.M.; Formiga, M. (orgs) Educação a distÂncia: o estado da arte. São Paulo, Pearson.
Wiley, D.A., 2000. Connecting learning objects to instructional design theory: A definition, a metaphor, and a taxonomy. In: Wiley, D.A. [ed.]. Instructional Use of Learning Objects. Association of Educational Communications and Technology. Disponível em: <http://wesrac.usc.edu/wired/bldg-7_file/wiley.pdf>. Acesso em: 04 de agosto de 2010.
ISBN: 978-989-8533-11-1 © 2012 IADIS
34

PROPOSTA DE UM CURSO EM EAD PARA FORMAÇÃO DO PROFESSOR DE ARTE COMO SER COMPLEXO
Jaqueline Maissiat, Maria Cristina Villanova Biazus e Magda Bertch Programa de Pós-Graduação em Informática na Educação, Universidade Federal do Rio Grande do Sul - UFRGS
Av. Paulo da Gama, 110 – 3º andar / s. 332 – Anexo I da Reitoria – CEP: 90040-060 – Porto Alegre/RS - Brasil
RESUMO
O presente estudo trata de uma proposta de curso, na modalidade a distância em um ambiente virtual de ensino e de aprendizagem, para professores de arte abordando a arte contemporânea e a tecnologia, com ênfase nos softwares livres e/ou gratuitos. O curso apresenta uma dinâmica metodológica inovadora, o que permite a abordagem e apropriação das ferramentas digitais, que articuladas às experiências docentes durante o seu percurso, favorece ao professor de arte o (re)conhecer-se complexo. Por entender o professor de arte enquanto um ser contemporâneo, este estudo busca propor ações que problematizem suas práticas docentes e ofereça espaços para movimentos dialógicos entre os pares. Pretende-se que os resultados obtidos sirvam como subsídios aos professores de arte, visando modificações em suas formações, e, por conseguinte, suas práticas a partir da oferta de cursos que contemplem essas problematizações, e se estenda a outras áreas de conhecimento.
PALAVRAS-CHAVE
Educação a Distância, ambiente virtual de ensino e de aprendizagem, tecnologia digital, complexidade, professor de arte.
1. INTRODUÇÃO
As tecnologias digitais, apresentando características como a interatividade, a não-linearidade e a simulação da realidade, atuam como mediadoras na construção do conhecimento (Silva, 2010), e estão cada vez mais presentes no cotidiano. Pensando no acesso, cada vez mais rápido, e em grande quantidade, de informações pelos nossos estudantes, o professor precisa estar preparado para interagir com uma geração mais atualizada e mais curiosa, como discutido por Veen e Vrakking (2009), que nomeiam a atual geração como “homo zappiens” – fazendo referência ao zapear do mouse e controles remotos, como o da televisão e do vídeo game. Pensamos então nas conexões possíveis entre tecnologia e educação.
Neste contexto, o professor de arte contemporâneo tem que atender necessidades, referentes a conteúdo e métodos, que vão além da própria estrutura curricular vigente. A arte contemporânea que, além de novas manifestações artísticas engloba a utilização de novos materiais (Barbosa, 2010; Biazus, 2001, 2009; Santaella, 2003), faz apropriação de recursos tecnológicos para sua criação. Uma possibilidade, de atender esta demanda é um curso de atualização de professores. E, para que se consiga concretizar isto de forma efetiva, trazemos a proposta do curso em educação a distância, por meio do ambiente virtual de ensino e de aprendizagem (AVEA)1.
Barbosa (2010), ao referir-se sobre o uso das novas tecnologias no ensino da arte, destaca a importância de “torna-se necessário não só aprender a ensiná-las, inserindo na produção cultural dos alunos, mas também educar para a recepção, o entendimento e a construção de valores das artes tecnologizadas, formando um público consciente” (p. 111).
Encontramos no paradigma da complexidade (Morin, 1998, 2000, 2002, 2003a, 2003b), base teórica para desenvolver estes processos, em que vislumbramos o professor como ser complexo. Morin (2002) fazendo referência ao ser complexo, o auto-geno-feno-eco-(re)organizador, coloca algumas características e ponderações que indicam quem seria este humano, que aqui contextualizamos para o campo educativo, frente
1 Estes escritos são um recorte de uma tese de doutorado, vinculada ao Programa de Pós-Graduação em Informática na Educação da Universidade Federal do Rio Grande do Sul – Porto Alegre/RS/Brasil.
Conferência IADIS Ibero-Americana WWW/Internet 2012
35

as tecnologias e o ensino da arte. No que tange ao ensino e a aprendizagem das artes visuais, cabe pensar nos aspectos que relacionam conteúdo, atualização e atuação do professor de arte.
Ao observarmos a complexidade, sob o ponto de vista da atualização, esta indica não simplesmente buscar respostas, mas também perceber os novos desafios que surgem. “É necessário que a formação transite para uma abordagem mais transdisciplinar, que facilite a capacidade de refletir sobre o que uma pessoa faz” (Barbosa, 2010, p. 97).
A seguir nos aprofundaremos nas temáticas relacionadas ao AVEA, bem como recursos digitais voltados á prática educativa no contexto da complexidade.
2. AMBIENTE VIRTUAL DE ENSINO E DE APRENDIZAGEM
O AVEA, que consiste em “cenários que habitam o ciberespaço e envolvem interfaces que favorecem a interação de aprendizes. Inclui ferramentas para atuação autônoma, oferecendo recursos para aprendizagem coletiva e individual. O foco deste ambiente é a aprendizagem” (Noronha e Vieira, 2005, p. 170), está cada vez mais sendo procurado para sediar cursos de formação (desde extensão a pós-graduação), com isto está gerando credibilidade pelos usuários e instituições, sendo que algumas destas oferecem estes ambientes como espaço complementar da sala de aula presencial.
No curso que se propôs, em um AVEA, além da utilização das tecnologias digitais para a própria formação, preocupou-se que o professor pudesse saber um mais sobre elas em si, ou seja, de como utilizá-las com seus alunos.
2.1 Recursos Digitais a Prática Educativa
Os recursos comunicacionais e informáticos estão à disposição para utilização em diversos espaços, e o educacional é um deles. Como e quando estes recursos irão compor este cenário dependerá não só de sua disponibilidade, mas também de como eles serão abordadosDestacamos a tecnologia como mediadora de aprendizagens e não como um simples reprodutor de conteúdo, não há porque fazer uso de algo novo com práticas antigas.
O professor de arte vai além de utilizar a tecnologia como meio, mas como instrumento de inventividade, necessitando de práticas pedagógicas criativas. Para tal impende a apresentação das possibilidades destes recursos, para que através destes conhecimentos, possa implementá-los em sala de aula. E nada melhor do que formar o professor para o uso da tecnologia em um ambiente tecnológico, no caso os ambientes virtuais de ensino e de aprendizagem. Porque não realizar um mural digital com obras realizadas pelos alunos, por exemplo? O criar vai surgir do experienciar a arte, que pode ser feito através de softwares de edições de áudio, vídeo e imagens. Para tal indicamos a utilização de softwares livres e/ou gratuitos, tanto por ser acessível, quanto pelo fato de transitarem por sistemas operacionais distintos.
Observando os conteúdos online disponíveis para utilização, Katz coloca que “é dentro desse contexto de crescente abertura, particularmente de dados e informações online, que a comunidade de ensino e aprendizagem deve considerar os conteúdos educativos abertos” (2012, p. 143). Mesmo aqueles que não são voltados diretamente ao campo educativo, podem vir a se tornarem grandes aliados, desde que com uma mediação voltada para este fim, como é o caso do editor de texto ou planilha eletrônica.
O Ministério da Educação do Brasil, através do Programa Nacional de Informática na Educação (Proinfo), objetiva incentivar o uso das tecnologias no ensino baseado nestas categorias de softwares. No portal do Proinfo é disponibilizado o sistema Linux Educacional, que através de download pode ser instalado nos computadores. Este sistema já tem em si um pacote de programas, tais como: Kdenlive (editor de vídeo), Audacity (editor de áudio) e Tux Paint (editor de imagens). Estes softwares podem ser acessados por todos os usuários que acessarem o Portal.
Tanto o desenvolvimento e a capacitação, para manuseio destes softwares, tem sido discutido e cada vez mais difundido. Recentemente, no VI Congresso Ibero-americano de Telemática (CITA 2011), pesquisas foram divulgadas, como a Criação de Curso voltado para professores utilizarem o Linux Educacional (Macedo, 2011) nas práticas em sala de aula (Maissiat, Silva e Biazus, 2011). A comunidade científica esta cada vez mais interessada neste tema e suas possibilidades no campo educativo.
ISBN: 978-989-8533-11-1 © 2012 IADIS
36

Alguns professores utilizavam a justificativa de não utilização dos laboratórios de informática, por falta de acesso a softwares por serem pagos. Com o advento dos softwares livres e/ou gratuitos, os professores podem ter acesso a eles. Podemos observar a diversidade e possibilidades destes softwares na internet, através de uma simples busca.
3. O SER COMPLEXO
Para que possamos aprender como aprendemos um dos requisitos necessários é que nós nos conheçamos, e que nós tenhamos consciência além da organização dos esquemas mentais, de como nós nos auto-organizamos. Morin (2002) partindo dos elementos que julga fazer parte de uma auto-organização, concebe o ser como auto-geno-feno-eco-(re)organizador (Figure 1), tendo como base os seguintes pressupostos: organização permanente de um sistema que tende a desorganizar-se pela interação com outros sers e com
objetos; reorganização permanente de si a partir da auto-referência, isto é, auto-organização; nos seres vivos, essa organização está vinculada à geratividade (organização genética que comporta o
genótipo) e à fenomenalidade (organização das atividades e comportamentos do fenótipo); organização dependente das interações com o ambiente, sob a forma de ecossistema que oferece ao
indivíduo alimento e informações para gerir sua auto-organização, que são sintetizados na fig.1. Ou seja, este esquema se apresenta num continuum como numa espiral ascendente, não necessariamente
seguiremos os esquemas conforme a organização da nomenclatura, ela pode acontecer de maneira aleatória.
Figura 1. Esquema do conceito de auto(geno-feno)eco-(re)organizador
Ao mesmo tempo em que somos autônomos somos possuídos (nossos genes ditam o nosso ritmo para continuarmos existindo). “Somos uma mistura de autonomia, de liberdade, de heteronímia e direi mesmo de possessão por forças ocultas que não são simplesmente as do inconsciente reveladas pela psicanálise” (Morin, 1998, p. 98).
Nós possuímos uma estrutura cognitiva, que mostra-se como um complexo organizado resultante dos processos cognitivos através dos quais os indivíduos adquirem, organizam, e utilizam os conhecimentos, sendo que os conceitos devem ser relevantes e inclusivos. Há, portanto, uma estrutura hierárquica dos conceitos, que comunica o significado de alguma coisa, representa uma série de características, propriedades, atributos, regularidades e/ou observações, fenômeno ou evento. E isto, pode ser contemplado em um hiperdocumento em atividades de experimentação em sala de aula.
Será através da linguagem que o ser irá se expressar e ter a possibilidade de comunicar-se com outro ser. Com isto o ser será capaz de estabelecer relações com outro ser e acabar se reconhecendo a partir dar relações oriundas destas trocas. Nisto destaca-se a importância de um espaço para conversa e troca de experiência entre os pares. Serão nestes momentos em que propostas podem ser compartilhadas, dúvidas podem surgir, ao passo que as soluções também.
Conferência IADIS Ibero-Americana WWW/Internet 2012
37

3.1 Subsídios aos Professores de Arte para tornar-se/reconhecer-se Complexo
A complexidade necessita estar presente na formação do professorado, como coloca Imbernón (2009), pois sob este prisma as ações educativas passam a ser compreendidas contrariando a linearidade do pensamento educativo, e apresenta problemáticas reais considerando a incerteza o imprevisto. Compreender o mundo sobre este prima, faz com que consigamos compreender os fenômenos que ocorrem no campo educativo e as relações surgidas daí. A introdução ao pensamento complexo, “obrigada a analisar a metodologia, os procedimentos e os pontos de vista próprios para evitar a parcialidade e o autoengano” (p. 93). Estes aspectos facilitam o processo de ensino e de aprendizagem na arte.
Entendemos a formação continuada como estimuladora da metacognição, pois nela o educador está se aperfeiçoando, revendo suas teorias e concepções. Sobre o termo ‘formação continuada’, ao pesquisá-lo na ‘Enciclopédia de Pedagogia Universitária’ esta nos diz que são: “iniciativas de formação no período que acompanham o tempo profissional dos sers” e ainda complementa dizendo que podem apresentar “formato e duração diferenciados, assumindo uma perspectiva da formação como processo. Tanto pode ter origem na iniciativa dos interessados como pode inserir-se em programas institucionais” (Cunha, 2003, p. 368).
Algumas atitudes colaborativas reduzem a incerteza do professor e aumenta sua eficiência. Litte (apud Fullan e Hargreaves, 2000) indica tipos de relações colegiadas: busca de informações e relatos de histórias; ajuda e auxílio; trocas; trabalho conjunto. A pessoa não é consumida pelos colegas, ela se vê enriquecida através deles, e isto pode ser realizado em um AVEA.
A interdependência era valorizada no sentido de se sentir parte de um grupo e do trabalho em equipe. “Na escola com uma profunda cultura de colaboração, todos os professores são líderes”. As escolas colaboradoras “não podem obter sucesso se não estabelecem relações fortes de trabalho com os pais e a comunidade” (Fullan e Hargreaves, 2000, p. 70).
O que não podemos deixar é que a balcanização impere, pois ela é “... uma cultura composta por grupos separados e, por vezes, competitivos, lutando por posições e por supremacia, (Fullan e Hargreaves, 2000, p. 71). A existência destes grupos, traz visões diferentes quanto à aprendizagem e a forma de ver: o ensino, a disciplina e o currículo.
São vários os meios e recursos para que o professor de arte possa dedicar-se a sua formação continuada. Além de visitas reais e virtuais aos Museus, eventos relacionados à arte eletrônica, (arte digital), podem atualizar o professor quanto a arte contemporânea; aqui podemos fazer uma relação direta com os recursos informáticos, tanto quanto a informática atualiza seus recursos, a arte contemporânea, que também vale-se dela, está em constante atualização. A formação continuada vai além de um saber a mais, mas sim de atualização.
Portanto, para ser entendido e entenderem-se como ser da complexidade este professor de arte irá transitar por saberes no campo da:
• metacognição: desenvolvimento da habilidade de aprender como se aprende; • resiliência: a possibilidade de reagir de maneira positiva e criativa diante situações adversas; • autonomia: ir além do que está estabelecido e proposto; • cooperação: se perceber fazendo parte de um todo, e que, com a participação de outras pessoas é
possível fazer um bom trabalho, e este tornar-se produtivo para todos; • transdisciplinaridade: observar que os conceitos e conteúdos podem estar conectados e assim
trabalhados; • criatividade: ir além, com outros olhos e outras práticas; • afetividade: o afetivo faz parte de nós, não separamos o que sentimos por local onde estamos; • subjetivação: o nosso pensar, nosso sentimento está imbricado ao nosso fazer, ou seja, é
indissociável; • flexibilidade: permitir e permitir-se flexível, cada momento é único e as pessoas que estão
envolvidas também, todos tem seu ritmo, sua velocidade e sua amplitude, a flexibilidade faz parte de um ambiente complexo.
O desenvolvimento do pensamento complexo acontece, no curso de aperfeiçoamento, a medida que cada um dos itens citados acima são explorados e reforçados na apresentação de conteúdos e utilização de recursos digitais pelos professores de arte, sempre fazendo referência ao contexto da sala de aula que se encontram.
ISBN: 978-989-8533-11-1 © 2012 IADIS
38

4. ESTRUTURA E IMPLEMENTAÇÃO DO CURSO
A criação de um curso de atualização para o professor de arte com a finalidade de fazer com que o professor se entenda e/ou se reconheça como ser complexo, necessita incorporar, em sua estrutura, os saberes citados anteriormente. Para tal, todo o conteúdo em questão e o modo como estes serão abordados necessitam perpassar por uma avaliação criteriosa que permita que toda a ação reforce um dos saberes, como é o caso da criatividade, possibilitar que o professor tenha um espaço para a criação, que ele parta de suas vivências e conhecimentos para que possa desenvolver algo. A estrutura apresentada foi o conteúdo de arte contemporânea, fazendo referência a arte criada por intermédio das tecnologias digitais.
Comumente os cursos em Ead são estruturados de forma linear, ou seja, os conteúdos são dispostos um após o outro, de forma hierárquica e sequencial do início ao fim. Há professores que mesmo tendo o curso, com esta estrutura, conseguem trabalhar de maneira diferente, fazendo ligações com temas vistos durante o curso, mas a sequencialidade continua presente, o aluno não tem autonomia para estudar o que lhe é de seu interesse maior. Quando pensamos no método que apresentamos, neste estudo, tivemos a intenção de além de favorecer estudos sobre complexidade e inter/transdisciplinaridade, a estrutura do curso seguisse esta linha de pensamento. “Mudar envolve, necessariamente, transformação na maneira de pensar e de agir no espaço educacional, impulsionando o rompimento de paradigma quanto às nossas atitudes em relação ao processo de conhecer” (Schlemmer, 2005, p. 47).
O Curso intitulado “(Re) Significando a Arte/Educação por meio dos DVDs do Arte na Escola” foi ministrado e planejado por uma equipe de professoras (Jaqueline Maissiat, Katyúscia Sosnowski, Simone Vacaro Fogazzi, sob coordenação geral da Maria Cristina Villanova Biazus) foi promovido pelo NESTA (Núcleo de Estudos em Subjetivação, tecnologia e Arte) e pelo Instituto Arte na Escola/RS. A parceria entre estas professoras com experiências em educação a distância, ensino de arte em educação a distância, tecnologia educacional e ensino da arte, permitiu a integração de saberes para que os professores aprendizes – assim os denominamos no curso – , tivessem melhor acolhimento e suporte.
O presente curso pretendeu que o(a) professor(a) possa (re)pensar seu papel, o da educação, o do aluno, sob a ótica da diferença tendo no conceito de rizoma sua principal expressão e o tornar ser complexo, de acordo com a Teoria da Complexidade (Morin). Os professores exploraram a DVDteca Arte na Escola tendo por princípio o pensamento rizomático, o que expandiu sua forma de pensar a aula, trazendo elementos constitutivos das multiplicidades de seus alunos, da escola e do mundo. A postura investigativa, criativa, foi estimulada no professor, para a criação de aulas interligadas com a realidade escolar, as singularidades dos alunos e do professor mesmo, e o acervo da DVDteca.
Este curso de atualização foi desenvolvido no Ambiente Virtual de Ensino e Aprendizagem (AVEA) Moodle Cinted (http://moodle.cinted.ufrgs.br), devido à possibilidade de acesso e disponibilidade de suporte para abertura do curso e criação de login e senha para os alunos, como curso de extensão, com carga horária de 120h, permitiu que fosse divulgado em várias mídias digitais, tal como o site do Instituto Arte na Escola (http://www.artenaescola.org.br), blog do Grupo de Pesquisa NESTA (http://gruponesta.wordpress.com) e rede social (Facebook – http://www.facebook.com).
Buscou-se a cada conteúdo e exemplos trazidos, os questionamentos de como trabalhar isto em seu fazer docente, bem como utilizar softwares que permitissem tal feito. Foram escolhidos os softwares Gimp (edição de imagens) e Audacity (edição de áudio).
O curso teve duração de 12 semanas e dividiu-se em três módulos. O primeiro deles foi para ambientação do professor aprendiz ao ambiente virtual de ensino e de aprendizagem, bem como o contato com a teoria de rizoma que perpassa nas propostas de utilização dos DVDs.
O segundo módulo teve como base os oito territórios (linguagens artísticas, patrimônio, materialidade, conexões, forma e conteúdo, processo criativo, saberes estáticos e culturais e mediação cultural), em que o professor aprendiz optou por cinco e escolheu qual o caminho a percorrer. Para que isto fosse viável, o segundo módulo deixou a disposição o conteúdo de todos os territórios. A cada semana, o aluno teve que mencionar em seu diário qual era o território escolhido e qual o motivo.
Já no terceiro módulo, todos eles se voltariam para a mesma temática, como no primeiro módulo, e percorreriam o território zarpando, que significa que a partir do que foi apropriado durante o curso, desenvolvesse um projeto que contemplasse em parte ou num todo, as temáticas escolhidas e fosse além do proposto.
Conferência IADIS Ibero-Americana WWW/Internet 2012
39

Figure 2. Esquema do Curso ‘(re)significando a arte/educação por meio dos DVDs Arte na Escola’. Fonte: Fogazzi, 2012.
Este é o mapa navegacional (Figure 2) do curso, em que os professores tinham acesso. Eles poderiam clicar nos espaços indicados pó cores (feito de pinturas em aquarelas, produzidas especialmente para o curso, para que até este espaço estivesse imerso pela arte), para ir ao território desejado. A opção por cores e a estrutura circular (sem início ou fim), foi pensada para que não se caracterizasse por uma estrutura linear ou hierárquica.
O curso foi realizado totalmente a distância, sendo sua oferta feita para 3 (três), dos 26 estados brasileiros, a saber: Rio Grande do Sul, Santa Catarina e Paraná. Teve a participação efetiva de 83 professores.
A medida que o conteúdo de arte lhes era apresentado, softwares eram indicados para utilização da entrega das atividades. E nisto, os saberes eram reforçados para que os professores se apropriassem de um novo recurso, já fazendo sua utilização. (Barbosa, 2010; Imbernón, 2009).
Ao passo em que eles incorporaram aos seus significados o que se entendia ou o que se caracterizava por arte contemporânea, estavam fazendo criações nos softwares. Todo este processo em torno de discussões relacionadas a educação, como eram seus alunos, quais eram as suas possibilidades dentro da escola para fazerem este tipo de atividade e/ou estudo.
Alguns dados que fortalecem tal utilização deste método de fazer curso em Ead: de um universo de 83 professores matriculados, tivemos apenas 7% de evasão, sendo que os
dados que o Censo Ead Brasil (2010) apresenta são de 29% em média, para cursos de extensão. Entendemos aqui como evasão aqueles que se matricularam no curso e nunca participaram e as desistências;
o curso permitiu a produção de trabalhos interdisciplinares, mesmo sendo da mesma temática (artes visuais), técnicas e linguagens artísticas puderam ser pensadas em conjunto;
ISBN: 978-989-8533-11-1 © 2012 IADIS
40

aspectos do ser complexo (metacognição, resiliência, autonomia, cooperação,transdisciplinaridade, criatividade, afetividade, subjetivação e flexibilidade) foram possíveis de serem trabalhamos durante a realização do curso, mesmo não sendo indicada bibliografia e atividades fazendo referência a tais conteúdos;
39 % dos professores de arte, não são formados na disciplina que lecionam, o que permitiu, além de uma atualização, uma formação com ênfase em recursos digitais e arte contemporânea.
5. CONCLUSÃO
A proposta deste curso teve êxito em sua finalidade, de promover uma formação de forma diferenciada, trazendo elementos da inter/transdisciplianridade tanto na sua estrutura quanto conteúdo. Seu planejamento permitiu o desenvolvimento da autonomia deste professor aprendiz, bem como compreender seus processos de aprendizagem, que isto será uma aprendizagem para toda a vida, fora todo o conteúdo envolvido da ciência arte e das tecnologias digitais. O número de alunos concluintes superou a expectativa, tivemos uma evasão de 75% a menos do que a média nacional para este tipo de curso.
O professor necessita de uma formação permanente, ou ainda continuada, em que além da própria atualização de conteúdos, que são de sua área de atuação, atenda a utilização das tecnologias digitais. Imbernón (2009), coloca que a nova tendência é que esta formação os professores deve estar aliada ao desenvolvimento do pensamento complexo.
Diante deste contexto educacional e de arte, onde há apropriações feitas das tecnologias digitais, propomos uma análise sobre o prisma da mediação tecnológica buscando atender o espaço em que a educação (sala de aula) e arte (atelier) acontecem. O interesse e os questionamentos oriundos dos professores só fez que se reforçasse a necessidade de existir cursos de aperfeiçoamento que contemplem estas temáticas e trabalhando os saberes para que se remeta a complexidade.
Na medida em que os professores, envolvidos na pesquisa, se apropriam destes materiais, e (re)visitam determinados conteúdos, eles acabam por construir novos conhecimentos, permitindo que eles utilizem destes novos conhecimentos e (re)significados em suas salas de aula. Ou seja, o professor acaba por se tornar um mediador na construção do conhecimento de seus alunos oportunizando que eles façam uso destes recursos para aprenderem, produzirem, observarem, vivenciarem a arte.
Acreditamos que teremos professores mais complexos, na medida em que oportunizarmos aos professores de arte um aperfeiçoamento, tendo previsto o uso das novas tecnologias de informação e comunicação para formação e mediação. Para tal promoveremos o exercício de estudar e compreender a contemporaneidade e sua complexidade tanto no que tange a arte quanto ao próprio ser.
AGRADECIMENTOS
Agradecemos ao Núcleo de Estudos em Subjetivação, Tecnologia e Arte por incorporar aos seus trabalhos estes estudos e ao CNPq pelo apoio financeiro para que a pesquisa pudesse se concretizar.
REFERÊNCIAS
Associação Brasileira de Educação a Distância (org.). 2010. Censo ead.br. Pearson Education do Brasil, São Paulo, Brasil.
Barbosa, A. M. (org.). 2010. Arte/Educação Contemporânea: consonâncias internacionais. 3. ed. Cortez, São Paulo, Brasil.
Biazus, M.C.V. 2001. Ambientes Digitais e Processos de Criação. Tese em Informática na Educação, Programa de Pós-Graduação em Informática na Educação, Centro Interdisciplinar de Novas Tecnologias Aplicadas a Educação, Universidade Federal do Rio Grande do Sul, Brasil.
Biazus, M.C.V. 2009. Projeto Aprendi: abordagens para uma Arte/Educação Tecnológica. Promoarte, Porto Alegre, Brasil.
Conferência IADIS Ibero-Americana WWW/Internet 2012
41

Cunha, M. I. da C. 2003. Verbete: Formação Continuada. In: Morosini, Marília Costa (org.). Enciclopédia da Pedagogia Universitária. FAPERGS/RIES, Porto Alegre, Brasil, pp. 368-375.
Fogazzi, S. 2012. Ilustração para o curso “(re) significando a arte/educação por meio dos DVDs do Arte na Escola”. Disponível em: <moodle.cinted.ufrgs.br>. Acesso em: 21 maio 2012.
Fullan, M.; Hargreaves, A. 2000. A Escola como Organização Aprendente: buscando uma educação de qualidade. 2. ed. Artmed, Porto Alegre, Brasil.
Imbernón, F, “Formação Permanente do Professorado: novas tendências”, São Paulo, Cortez, 2009. Katz, RN (ed.). 2011. The Tower and The Cloud: higher education in the Age of Cloud Computing. Disponível em:
<http://net.educause.edu/ir/library/pdf/PUB7202.pdf>. Acesso em: 07 maio 2012. Macedo, AL et al. 2011. “Linux Educacional – possibilidades práticas de aplicação em contextos educacionais”,
Cadernos de Informática, Porto Alegre, v. 6, n. 1, p. 63-69. Maissiat, J; Silva, Bruno Dorneles da; Biazus, Maria Cristina Villanova. 2011. Projeto Aprendi: aprendizagem
dinamizada por objetos. Cadernos de Informática, Porto Alegre, v. 6, n. 1, pp. 273-275, 2011. Morin, E. 2003a. Cabeça bem-feita: repensar a reforma, reformar o pensamento. 8. Ed. Bertran Brasil, Rio de Janeiro,
Brasil. Morin, E. 2003b. Educar na Era Planetária: o pensamento complexo como Método de aprendizagem no erro e na
incerteza humana. Cortez, São Paulo, Brasil. Morin, E. 2002. Ciência com consciência. 6. ed. Bertrand Brasil, Rio de Janeiro, Brasil. Morin, E. 2000. Os saberes necessários para a educação do futuro. Cortez, São Paulo, Brasil. Morin, E. 1998. O Método 4 – As ideias: habitat, vida, costumes, organização. Sulina, Porto Alegre, Brasil. Noronha, Adriana Backx e Vieira, Amanda Ribeiro. 2005. A utilização da plataforma WebCT para o desenvolvimento e
implementação de disciplinas utilizando a internet. In: Barbosa, Rommel Melgaço (org.). Ambientes Virtuais de Aprendizagem. Artmed, Porto Alegre, Brasil, pp. 169-182.
Santaella, L. 2003. Cultuas e artes do pós-humano: da cultura das mídias à cibercultura. Paulus, São Paulo, Brasil. Schlemmer, E. 2005. Metodologias para educação a distância no contexto de formação de comunidades virtuais de
aprendizagem. In: In: Barbosa, Rommel Melgaço (org.). Ambientes Virtuais de Aprendizagem. Artmed, Porto Alegre, Brasil, p. 29-49.
Silva, M. 2010. A Sala de Aula Interativa. 2. ed, Loyola, São Paulo, Brasil. Veen, W e Vrakking, B,. 2009. Homo Zappiens: educando na era digital. Artmed, Porto Alegre, Brasil.
ISBN: 978-989-8533-11-1 © 2012 IADIS
42

UMA COMPARAÇÃO ENTRE O USO DE AMBIENTES VIRTUAIS DE APRENDIZAGEM E FERRAMENTAS DA
WEB 2.0 NO ENSINO MÉDIO
Alberto Luiz Ferreira1, Prof. Dr. Carlos Fernando Araújo Junior2, Prof. Dr. Juliano Schimiguel2,
Profa. Dra. Maria Delourdes Maciel2 e Tatiane Rossi Chagas3 1Instituto Federal de Ensino Tecnológico – SP, Rua Maria Cristina, 50 - Cubatão (SP) – Brasil
2Universidade Cruzeiro do Sul, R. Galvão Bueno, 868 - São Paulo (SP) - Brasil 3Universidade Nove de Julho, Rua Guaranésia, 425 - Sao Paulo (SP) – Brasil
RESUMO
O presente artigo apresenta um estudo comparativo sobre o uso de Ambientes Virtuais de Aprendizagem e ferramentas da Web 2.0 no Ensino Médio com alunos do terceiro ano do Ensino Médio de uma escola técnica no estado de São Paulo. A comparação do rendimento e de satisfação dos alunos no uso de um ambiente virtual de aprendizagem em relação a algumas ferramentas da Web 2.0 colaboram para a escolha ou construção de novas abordagens de educação formal e não-formal dessa geração conhecida como “nativos-digitais”, que não têm dificuldades no uso da tecnologia disponível e que exigem dinamismo nas atividades educativas. O estudo utilizou uma plataforma de ensino à distância e ferramentas da Web 2.0 como o GoogleDocs e o Facebook para abordagem do tema “Células-tronco: conceitos e aplicações” com foco em Ciência, Tecnologia e Sociedade (CTS). Os resultados obtidos indicam que os alunos preferem a combinação da tecnologia das aulas à distância junto com as aulas presenciais.
KEYWORDS
Virtual Learning Environments (VLE), Collaborative Environments, Distance Learning (ODL), Stem Cells..
1. INTRODUÇÃO
Segundo (Prensky, 2006), os nativos digitais – os estudantes da atualidade, que falam naturalmente a “linguagem digital” dos computadores, videogames e internet, pensam e processam as informações de forma diferente dos professores, de gerações anteriores à deles. Portanto, os professores devem buscar inovações na área de educação que provenham recursos de interatividade, colaboracionismo, estímulo de competências e se adequem ao formato das mídias digitais. Os computadores, mais especificamente a internet, oferecem uma opção de ruptura com os modelos tradicionais de ensino. Torna-se necessário, na atualidade, trocar o foco da propagação de conteúdo curricular para a facilitação da aprendizagem do aluno por meio de métodos adequados à sua forma de agir e pensar. Um novo paradigma pode ser explorado por processos e ferramentas que disponibilizem conteúdo curricular para os alunos em um formato que permita a eles controlar o processo de aprendizagem colocando o professor como um auxiliar, tornando o aluno responsável pela construção do conhecimento. O receio de que não haja maturidade por parte do aluno para que o mesmo exerça essa autonomia é dissipado pelo fato de que tal maturidade deve ser intrínseca e presente no papel de aluno.
A utilização de Ambientes Virtuais de Aprendizagem (AVA), disponibilizados na modalidade de Ensino à Distância (EaD), através de uma plataforma Web, oferece algumas vantagens, tais como a não necessidade de deslocamentos físicos por parte do aluno, a flexibilidade dos horários de estudo, a possibilidade de obter o material necessário para os estudos para diversas formas de mídia e dispositivos.
Segundo (O’Reilly, 2011), o conceito de "Web 2.0" começou com uma conferência entre O'Reilly e a International MediaLive. Dale Dougherty, pioneiro da Web e O'Reilly, notaram que, longe de ter sido quebrada pelo colapso (a “bolha”) das empresas ditas “pontocom”, a Web assumia um papel de grande importância, com novas aplicações e sites surgindo a cada dia, podendo ser considerada um divisor de água na Internet, de tal forma que uma denominação do tipo "Web 2.0" faça sentido. Ainda há uma grande falta de
Conferência IADIS Ibero-Americana WWW/Internet 2012
43

consenso sobre o que significa Web 2.0, com algumas pessoas condenando-o como um termo de marketing sem sentido e outros aceitando-a como um novo formato da Internet.
O objetivo deste trabalho é descrever os estudos resultantes da comparação entre o uso de Ambientes Virtuais de Aprendizagem e das ferramentas da Web 2.0 no Ensino Médio, trabalhando como tema para a aula o assunto “Células-tronco”, em ambos os ambientes, apresentando-os na disciplina Ambientes Virtuais e Colaborativos, ministrada pelo Prof. Dr. Juliano Schimiguel, no curso de Mestrado Acadêmico em Educação em Ciências, para que os mesmos sirvam de referência aos professores na escolha ou utilização de um ou ambos os ambientes.
A tecnologia para a implantação de um Sistema Gerenciador do Processo de Aprendizagem ou Learning Management System (LMS) tornou-se de mais fácil acesso com a queda de preço do hardware e surgimento de propostas de software livre, até mesmo para Ambientes Virtuais de Aprendizagem. Em tais sistemas os supervisores podem disponibilizar conteúdos, rastrear e contabilizar os acessos, avaliar os alunos e gerar relatórios das atividades. Normalmente tais ambientes não proveem ferramentas de autoria de conteúdo, necessitando de outras soluções, como as providas por aplicativos de escritório, para a criação dos mesmos. Em nosso experimento foram disponibilizados conteúdos no formato do Microsoft PowerPoint, do Microsoft Word e em formato PDF. Tais sistemas tem como ponto forte a sua estruturação para a disponibilização de conteúdos e formas de acesso, com segurança e fácil navegação. Porém, apresentam-se como pontos fracos, a centralização no professor/tutor, a aparência de ambiente fechado e restrito, visto o acesso ser somente aos alunos que foram previamente cadastrados e ou convidados pelo professor/tutor e a não presença de um ambiente colaborativo e social, como o Facebook (Coutinho; Farbiarz, 2010).
Em contrapartida, as ferramentas disponíveis na Internet de compartilhamento, redes sociais e blogs, formam as chamadas ferramentas da Web 2.0. Maia (2011) cita que tais ferramentas formam o Ambiente Pessoal de Aprendizagem ou Personal Learning Environment (PLE). Tais ferramentas exploram o sentimento de posse de conteúdo e uma liberdade de ação para o aluno, visto ele se expressar de forma mais aberta nas redes sociais e blogs e de buscar conteúdos de uma forma menos burocrática em ambientes de compartilhamento. Como pontos fortes desse ambiente citam-se maior quantidade e diversidade de ferramentas, o fato de varias delas serem gratuítas e a não necessidade de uma estrutura física por parte do aluno ou instituição para hospedar a solução. O fato de não ser centrada no professor também coloca estas ferramentas como preferidas pelos alunos. A falta de um controle maior sobre as ferramentas e seus acessos, a precaria segurança desses ambientes e o grande número de opções que possam dificultar uma escolha, mostram os pontos fracos de tal solução.
A seçao 2 do artigo discorre brevemente sobre o tema da aula que serviu como “mote” utilizada para a pesquisa; a seção 3 apresenta o grupo de pesquisa participante, descrevendo a unidade de ensino e o curso a que os mesmos pertencem; os procedimentos e métodos efetuados na pesquisa são relatados na seção 4; o resultado das atividades sobre o tema da aula é descrito de forma suscinta na seção 5, bem como a avaliação feita pelos participantes das plataformas comparadas; a seção 6 encerra o artigo com as considerações finais.
2. TEMA DA AULA: AVANÇOS BIOTECNOLÓGICOS, CÉLULAS-TRONCO
Resistir aos avanços biotecnológicos é impossível. Estamos rodeados pelos impactos da tecnologia que presentemente há muito chegaram aos aspectos do desenvolvimento humano (Maia; Monteiro, 2008). Na educação, enquanto processo formador da cultura e de elementos que ensejam aspectos diretamente relacionados à cidadania e à inserção social, principalmente, (Maia; Monteiro, 2008) o ensino deve ser constantemente atualizado tanto quanto ao conteúdo a ser ensinado quanto à forma de ensinar.
Ao contrário do que muito se pensa, a ciência e a tecnologia não devem ser encaradas como propostas salvadoras dos problemas sociais e ambientais, mas sim como contribuição para a minimização ou resolução de problemáticas decorrentes da interação do homem enquanto sujeito social, com os diversos desdobramentos econômicos, culturais sociais e ambientais, sem extinguir as conseqüências de muitas de nossas escolhas nocivas (Maia; Monteiro, 2008).
Apesar de alguns dilemas éticos, é de se esperar que a sociedade recepcione quase todas as produções e descobertas científicas (Maia; Monteiro, 2008) e a pesquisa com células-tronco embrionárias é um exemplo de pesquisa e produção científica que ainda deve ser desmistificada quanto ao dilema ético do uso de
ISBN: 978-989-8533-11-1 © 2012 IADIS
44

embriões humanos e de milagre de cura. Diferenciar os tipos de células-tronco para o aluno quanto ao seu potencial biológico e à sua forma de obtenção exige alfabetização científica específica na área biológica.
As células-tronco embrionárias são as que possuem potencial para se transformar em qualquer outro tipo de célula do corpo humano. Os cientistas acreditam que a principal contribuição das células-tronco embrionárias será o conhecimento do mecanismo de diferenciação celular – transdiferenciação, sendo capazes de se transformar em variados tecidos do organismo. Além do embrião, elas são encontradas no organismo adulto e no sangue do cordão umbilical.
As células tronco-embrionárias são derivadas de embriões, mas que não são bebês ainda. No caso da espécie humana, os pesquisadores utilizam apenas células-tronco de embriões que foram obtidos a partir de óvulos fertilizados in vitro e que foram doados para fins de pesquisa científica. Os embriões dos quais as células-tronco humanas são derivados têm cerca de 4 a 5 dias e estão no estágio de blastocisto. Os blastocistos têm três estruturas: o trofoblasto que é uma camada de células que rodeia o blastocisto, a blastocele – cavidade no interior do blastocisto e a massa interna de células, com aproximadamente 30 células, localizada numa extremidade da blastocele. Durante as repetidas divisões celulares que ocorrem no zigoto unicelular transformando-o em um organismo multicelular, as células individuais sofrem diferenciação celular, isto é, tornam-se especializadas em estrutura e função. É a regulação de genes que leva a essa especialização (Dessen & Mongroni-Netto, 2007). Apesar do nome células-tronco embrionárias, os procedimentos de cultura e obtenção dessas células ocorrem em laboratório e não no útero materno.
As aplicações da Ciência e Tecnologia no contexto educacional promovem além do conhecimento, a compreensão dos anseios sociais, vinculados a interesses econômicos, certamente. Outra finalidade da abordagem Ciência-Tecnologia-Sociedade é de ensinar a compreender a atuação da ciência no contexto social. A ciência tem por finalidade encontrar explicações satisfatórias e, se possível, soluções para problemas postos (Popper, 1982 apud Maia; Monteiro, 2008).
Um grande avanço da biologia molecular vem ocorrendo nos últimos anos e, como conseqüência das modernas biotecnologias, deverá evoluir ainda mais em conhecimentos. É imprescindível que o professor da área das ciências da natureza ensine aos alunos uma ciência que está inserida em um contexto social, político, histórico, econômico, portanto, sem neutralidade e carregada de interesses pessoais dos cientistas e de grupos sociais que transformam esses conhecimentos em "bens" tecnológicos (Paduan, 2006). A alfabetização científica voltada à saúde das pessoas pode influenciar na qualidade de suas vidas assim como as demais tecnologias que devemos compreender para melhor usá-las.
3. O GRUPO DE PESQUISA
Pelo fato de um dos autores lecionar no Instituto Federal de Educação, Ciência e Tecnologia de São Paulo, campus Cubatão, houve a possibilidade de trabalhar com os alunos desta instituição, visto os mesmos não se encontrarem em fase final do respectivo ano letivo no período que a experiência foi aplicada. A instituição, conhecida regionalmente somente por “Federal de Cubatão” faz parte do campus do Instituto Federal de São Paulo. Sediada no bairro do Jardim Casqueiro, foi inaugurada em 1987, tendo como missão prover mão-de-obra técnica especializada para o pólo industrial de Cubatão.
Para o grupo participante da pesquisa foram convidados os alunos do Ensino Médio Integrado em Informática, do 3º ano. Dividido em 4 anos, com as disciplinas básicas do Ensino Médio ministradas nos 3 primeiros anos – incluindo nestes, Biologia – e disciplinas técnicas de informática ao longo dos 4 anos. Em 2011 haviam 2 turmas nesta série: uma, no período matutino, composta por 34 (trinta e quatro) alunos e 22 (vinte e dois) alunos no período vespertino. São oferecidas 80 (oitenta) vagas para ingresso no curso, anualmente. O propósito da escolha deste grupo deve-se ao fato de ser menor, apresentando uma faixa etária entre 16 e 19 anos e pelo fato de que alguns alunos vieram transferidos de outros cursos, onde tiveram anteriormente aulas de Biologia. Os 56 (cinqüenta e seis) alunos foram convidados a participar do experimento, sendo explicado para eles da não obrigatoriedade da participação, a finalidade do mesmo, os métodos a serem aplicados e os prazos e recursos disponibilizados. Deste total, 36 (trinta e seis) alunos se cadastraram no CourseSites, após o convite inicial e do cadastro manual e individual de alguns alunos que não receberam o convite por e-mail ou não conseguiram se cadastrar. Somente 48 (quarenta e oito) alunos estavam registrados no grupo criado no Facebook: o restante optou por não participar ou não tinham conta no Facebook por motivos pessoais que não foram questionados. Isto aponta a característica do amplo uso da
Conferência IADIS Ibero-Americana WWW/Internet 2012
45

rede social Facebook por parte dos adolescentes. Após a aplicação do primeiro questionário, os alunos foram convidados a participar de um segundo questionário, onde avaliaram as plataformas, disponibilizado no Google Docs. Dos que realizaram as atividades, somente 28 (vinte e oito) responderam no prazo proposto. Os demais responderam após o prazo. Os resultados da pesquisa foram, ao final, divulgados e comentados para os alunos.
4. PROCEDIMENTOS E MÉTODOS
A aula sobre células-tronco foi dividida em duas partes: a primeira abordava de modo superficial a composição e organização dos seres vivos, material genético (DNA) e a fertilização humana. Esse conteúdo foi disponibilizado aos alunos através da plataforma CourseSites, juntamente com apostilas complementares, links para acesso a blogs, vídeos e reportagens sobre células-tronco.
O CourseSites é um serviço de facilitação, criação e hospedagem de cursos on-line de forma gratuita, mantido pela Blackboard Inc. (Estados Unidos), que capacita professores do ensino fundamental e secundário, instrutores de faculdades e universidades, e educadores comunitários a adicionar componentes baseados na Web a seus cursos, ou ainda hospedar um curso completo na Internet. Uma amostra de como as atividades disponibilizadas no Coursesites eram visualizadas pelos alunos pode ser vista na figura 1.
Figura 1. Tela da plataforma CourseSites – Células-tronco: conceitos e aplicações.
A segunda parte da aula tinha como objetivo conceituar e diferenciar as células-tronco das demais células e quanto ao potencial biológico de cada tipo. Abordou-se também bioética e esclarecimentos sobre o uso de embriões humanos em pesquisas. Essa aula foi disponibilizada aos alunos no Google Docs. O Google Docs é um pacote de aplicativos do Google baseado em tecnologia de programação AJAX. Atualmente compõe-se de um processador de texto, um editor de apresentações, um editor de planilhas e um editor de formulários.
Além desses ambientes citados, os alunos contavam com um blog voltado à alfabetização científica e tecnológica que continha um post sobre o uso e pesquisa de células-tronco, disponível em http://naturalmente-blog.blogspot.com/.
A maior parte da comunicação entre os tutores e os alunos ocorreu exclusivamente pelo Facebook, na conta “Células-tronco: conceitos e aplicações”, disponível em http://www.facebook.com/#!/groups/146009598838205/. Os alunos do grupo de pesquisa foram convidados a ingressar neste grupo e após o ingresso dos primeiros, os mesmos foram convidando os demais, aumentando o grupo de forma rápida.
Após a disponibilização das aulas, em arquivo compatível com o Microsoft PowerPoint no CourseSites e visualizado através do browser, no Google Docs, foi criado e posteriormente liberado, um questionário, como atividade, no CourseSite. A atividade foi marcada no calendário do CourseSites e os alunos foram avisados por e-mail cadastrado no CourseSites e por publicação no Facebook. A atividade teve um prazo de 48 (quarenta e oito) horas para ser respondida, ficando indisponível ao final do prazo.
ISBN: 978-989-8533-11-1 © 2012 IADIS
46

5. RESULTADOS DA ATIVIDADE: QUESTIONÁRIO SOBRE O ASSUNTO CÉLULAS-TRONCO
O questionário sobre as aulas de células-tronco indicou que apesar de 100% dos participantes ouviram falar de células-tronco anteriormente, somente 17% deles ouviu sobre o assunto na escola, os demais ouviram na televisão (56%) e outros meios como internet (5%) e jornais e revistas (22%). Entre os poucos que tinham “ouvido falar” sobre células-tronco na escola, somente 11% deles tiveram aula sobre assunto e 78% dos alunos somente tinham ouvido comentários do tema em sala de aula.
Os resultados também indicaram que 94% dos alunos participantes tinham interesse em conhecer mais sobre células-tronco e que 92% dos alunos adquiriram mais conhecimento do assunto após as aulas realizadas à distância em nosso estudo. O resultado sobre a pergunta 7 do questionário (“Você entendeu durante as explicações que as células-tronco embrionárias não causam abortos ou morte de recém-nascidos?”) indicou que 11% dos participantes não entenderam que não há morte de recém-nascidos na obtenção de células-tronco embrionárias, permitindo uma conclusão a respeito de certa mistificação desse tipo de pesquisa.
5.1 Avaliação das Plataformas pelos Alunos
Para que se evidenciasse a utilização das plataformas, suas vantagens e desvantagens do ponto de vista do usuário – os alunos do grupo de pesquisa - foi criado um questionário com 10 perguntas, sendo o mesmo implementado e disponibilizado através do Google Docs. Após a criação do mesmo, foi tornado público, sendo o link de acesso fornecido somente aos alunos, por e-mail enviado da plataforma CourseSites e postado como publicação no grupo Células-tronco: conceitos e aplicações (link: https://docs.google.com/spreadsheet/viewform?formkey=dDVMUUdDMDNzbEJKdmp3OVB0emhtNnc6MQ ). Segue-se abaixo a reprodução do questionário. 1 - Qual a sua opinião sobre Ensino a distância? • Não gostei; • Nada contra, mas prefiro o ensino presencial; • Indiferente; • Serve de apoio ao ensino presencial; • Gostei: prefiro assim do que presencial. 2 - Dê uma nota para o ambiente do CourseSites utilizado: (1 - muito ruim, 2 - ruim, 3 - razoável, 4 - bom, 5 - Excelente) 3 - Do que você não gostou no ambiente do CourseSites? • Acesso; • Encontrar as atividades; • Formato do teste; • Navegação. 4 - Do que você gostou no ambiente do CourseSites? • Ser via Web; • Dos teste; • Do ambiente; • De poder acessar os textos utilizados. 5 - Você gostaria que outras disciplinas fossem disponibilizadas no Coursesites ou em um ambiente virtual de aprendizagem semelhante? • Sim; • Não.
Conferência IADIS Ibero-Americana WWW/Internet 2012
47

6 - Quanto ao documento (2ª aula) disponibilizado no Google Docs você achou: (1 - Dificil de acessar, 2 - Preferia no CourseSites, 3 - Normal, 4 - Fácil de acessar, 5 - Melhor do que no CourseSites) 7 - Você era informado das tarefas e da disponibilidade das mesmas por: • e-mail enviado pelo CourseSites; • e-mail enviado pelo professor; • Por publicação no Facebook; • Por colegas. 8 - O que você acessou nesta experiência que lhe pareceu a melhor ferramenta? • Coursesites; • E-mail; • Facebook; • Google Docs; • Blog; 9 - Em termos de teste e questionário, onde foi mais fácil respondê-los? (Não quanto às questões, mas o formato e a navegação/operação) • No formulário do Google Docs; • No teste do Coursesites; • Em ambos; • Foi difícil acessar e responder em ambos os lugares. 10 - Você acredita que o Facebook, em nossa experiência: • Foi mal utilizado; • Não fez diferença; • Foi útil; • Foi fundamental como ferramenta de apoio.
A figura 2 ilustra a interface escolhida para a apresentação do questionário, no Google Docs. O ambiente de criação de formulários do Google Docs permite a escolha do modelo de formulário dentre alguns disponíveis.
Figura 2. Tela do questionário de avaliação das plataformas, no Google Docs.
ISBN: 978-989-8533-11-1 © 2012 IADIS
48

As respostas às questões eram todas obrigatórias, incluindo a identificação, para um controle de quais alunos responderam o questionário. Dos 36 (trinta e seis) participantes da atividade sobre células-tronco, 28 (vinte e oito) responderam a este questionário, dentro do período de tempo proposto.
A primeira questão perguntava a opinião do aluno sobre Ensino a Distância. Eles tinham conhecimento da existência de plataformas de EaD, explicado nas aulas das disciplina Redes de Computadores. O resultado obtido mostrou que 71% (setenta e um) acharam que o Ensino à distância pode ser usado como apoio ao ensino presencial e ninguém respondeu que não gostou da experiência. Evidenciou-se, portanto, uma aceitação deste método de ensino por parte dos alunos integrantes da pesquisa. A 2ª, 3ª e 4ª questões eram exclusivamente sobre o ambiente virtual de aprendizagem utilizado – o CourseSites. 75% (setenta e cinco) acharam o ambiente excelente ou bom, confirmando a aceitação do mesmo como instrumento de EaD.
Quanto às funcionalidades do ambiente, os alunos não gostaram da navegação pelo site e da forma como as atividades estavam disponíveis (eles teriam que entrar na opção atividades). Por outro lado, gostaram pelo fato de ser via Web a proposta do CourseSites e pela disponibilização do conteúdo em uma só localidade. A 5ª questão mostrou que, ao serem perguntados se gostariam que outras disciplinas fossem ofertadas pelo CourseSites, houveram 2 alunos que responderam não. Ao serem questionados, na 6ª questão, sobre a 2ª parte das atividades sobre células-tronco, disponibilizada no ambiente de compartilhamento do Google Docs, obtivemos respostas com os seguintes percentuais: 39% (trinta e nove) responderam achar normal a disponibilidade de material didático através do Google Docs; 18% (dezoito) responderam ser de fácil acesso e 29% consideram-no melhor que o CourseSites. Somente cerca de 14% (quatorze) acharam difícil de acessar ou preferiam o CourseSites, nos indicando que utilização do GoogleDocs para a disponibilização de conteúdo é aceita pela maioria dos alunos.
O Facebook foi considerado, junto com o CourseSites, como a melhor ferramenta utilizada na experiência: 16 (dezesseis) alunos versus 12 (doze). Através dos percentuais apresentados, mostrou-se que pouco mais da metade – 54% (cinqüenta e quatro) considerou o Facebook útil em nossa experiência e cerca de 1/3 – 32% (trinta e dois) dos alunos o consideraram fundamental.
Quanto aos questionários – este e a atividade de avaliação sobre células-tronco – 47% (quarenta e sete) dos alunos responderam que em ambos – CourseSites e Google Docs – foi fácil responder, 14% (quatorze) responderam que acharam mais fácil o formato do questionário pelo CourseSites e 32% (trinta e dois) pelo Google Docs.
Tais números nos apontam que tanto o CourseSites quanto o Google Docs foram bem aceitos pelo grupo de pesquisa, mostrando também a importância e a forma de se utilizar o Facebook como ferramenta de comunicação com os alunos.
6. CONSIDERAÇÕES FINAIS
Esperava-se que, tendo um curso baseado em uma plataforma de EaD com um suporte eficiente de comunicação, os alunos não iriam ter a preocupação de verificar quando determinada atividade estivesse disponível, visto que os mesmos seriam avisados por e-mail, automaticamente pelo CourseSites, que dispõe de tal funcionalidade. Paralelamente, fazendo o uso do site de relacionamentos Facebook, foram feitas publicações dos mesmos avisos de disponibilidade de tarefa feitas por e-mail. 61% (sessenta e um) afirmaram tomarem conhecimento das tarefas pelo Facebook. 29% (vinte e nove) o fizeram por e-mail. Os chamados nativos digitais dão preferência a ferramentas mais atuais que o uso do e-mail. A resposta às convocações via Facebook eram respondidas em curto espaço de tempo, sendo em alguns casos até em poucos minutos.
Os novos alunos, reais nativos digitais, conseguem trabalhar de forma satisfatória em um ambiente educacional composto por novas mídias, em um formato diferente do tradicional. A comparação evidenciou que não foi necessária uma adaptação, um treinamento prévio para o aluno, para o uso do ambiente virtual de aprendizagem, muito menos do uso das ferramentas da Web 2.0 utilizadas (Google Docs e Facebook), demonstrando que o uso de ferramentas da Web 2.0 também é aceito sem restrições pelos alunos. O interesse do aluno pelas atividades e seus processos de avaliação ainda continua presente, não se alterando pelo fato de ser avaliado através de métodos não presenciais. O mecanismo de avaliação explorado, através da plataforma AVA mostrou-se eficiente, na medida em que os alunos o responderam e de que facilitou a correção e a avaliação dos resultados de aprendizagem por parte do professor/tutor.
Conferência IADIS Ibero-Americana WWW/Internet 2012
49

Como sugestão a trabalhos futuros, os autores sugerem a outros professores da instituição de ensino onde se decorreu a pesquisa, que mais temas, de diversas disciplinas, sejam trabalhadas em uma das plataformas aqui comparadas, facilitando a exploração de conteúdos e execução do plano de ensino em tempo hábil, sabendo-se que haverá uma participação favorável por parte do aluno, visto os mesmos aceitarem o uso tanto de Ambientes Virtuais de Aprendizagem como ferramentas da Web 2.0.
REFERÊNCIAS
Coutinho, M. S.; Farbiarz, A.,2010. Redes sociais e educação: uma visão sobre os nativos e imigrantes digitais e o uso de sites colaborativos em processos pedagógicos. In: 3º Simpósio Hipertexto e Tecnologias na Educação, 2010, Recife. Anais Eletrônicos do 3º Simpósio. NEHTE/ABEHTE, Recife, Brasil.
Dessen, E. M. B.; Mongroni-Netto, R. C.,2007. Desvendando as células-tronco: dos sonhos à realidade. Centro de Estudos do Genoma Humano. Universidade de São Paulo, São Paulo, Brasil.
Maia, D. P.; Monteiro, I. B., 2008. Ciência, Tecnologia e Sociedade como instrumento para formação docente. Universidade do Estado do Amazonas, Manaus, Brasil.
Maia, M. de C., 2011. Ferramentas da Web 2.0 associadas aos LMS no ensino presencial. A Educação a Distância: Estado da Arte. v. 2. Pearson, São Paulo, Brasil.
O’Reilly, T., 2011. What Is Web 2.0? Recuperado em 14 dezembro, 2011 de http://oreilly.com/web2/archive/what-is-web-20.html
Paduan, P. J., 2006. As Implicações das Novas Tecnologias no Ensino de Biologia na Escola Média. FAPIC/Uninove, São Paulo, Brasil.
Prensky. M.,2001. Digital Natives, Digital Immigrants. MCB University Press, USA.
ISBN: 978-989-8533-11-1 © 2012 IADIS
50

AMBIENTE DE APRENDIZAJE MÓVIL DE APOYO A LA EDUCACIÓN A DISTANCIA
Gisela Torres de Clunie y Clifton E. Clunie T. Universidad Tecnológica de Panamá
Ave. Ricardo J. Alfaro s/n, Apdo. 0819-07289, Panamá
RESUMEN
El desarrollo de la computación móvil y su aplicación en la educación, hizo surgir un nuevo enfoque de educación a distancia, denominado aprendizaje móvil, el cual facilita a los estudiantes el aprendizaje en cualquier momento y desde cualquier lugar. Este trabajo presenta el diseño de un ambiente de aprendizaje móvil, que facilita a los usuarios de los cursos virtuales, de la Universidad Tecnológica de Panamá, interactuar de forma eficiente, flexible y transparente en un ambiente colaborativo y personalizable de interacción y alertas, por medio de smartphones, tablets y reproductores multimedia con sistema operativo Android.
PALABRAS CLAVE
Educación a distancia, aprendizaje móvil, computación móvil, web services.
1. INTRODUCCION
El desarrollo de la computación móvil ha promovido la creación de aplicaciones móviles orientadas al campo educativo, favoreciendo el surgimiento de una nueva categoría de educación a distancia denominada “aprendizaje móvil”, conocida comúnmente como m-learning. De acuerdo con (Georgiev et al., 2004), este enfoque educativo viabiliza el aprendizaje de los estudiantes desde cualquier lugar y en cualquier momento, mediante conexiones de redes inalámbricas.
Moodle es un sistema de administración de cursos que permite a los profesores la creación de escenarios para el aprendizaje en línea. De acuerdo con (Felizardo et al., 2007), las principales fortalezas de Moodle son las herramientas de comunicación, creación y administración de objetos de aprendizaje. Mientras tanto, a pesar de las ventajas que proporciona Moodle, así como otras plataformas educativas; las mismas no brindan un ambiente colaborativo de interacción y alertas para dispositivos móviles con sistema operativo Android, lo cual constituye el principal objetivo de nuestro trabajo. Android es una plataforma de software open source, basada en Linux, creada específicamente para dispositivos móviles.
La siguiente sección describe algunos trabajos relacionados referentes para nuestra propuesta. La sección 3 describe la arquitectura del ambiente de aprendizaje móvil, que permite la integración de servicios heterogéneos en distintos escenarios de trabajo de forma flexible y aplicando reutilización; discute los componentes de la arquitectura del ambiente y define las principales funcionalidades de la misma. La sección 4, describe la implementación de los web services incorporados en el ambiente de aprendizaje. La sección 5, presenta la personalización de las alertas y la sección 6 discute el modelo de localización. Para finalizar, en la sección 7, se presentan las conclusiones y trabajos futuros.
2. TRABAJOS RELACIONADOS
Diversos artículos discuten los avances de la tecnología móvil como un complemento para la educación a distancia. Esta sección presenta una breve descripción de algunos trabajos que presentan similitud con el proyecto que estamos realizando.
Conferência IADIS Ibero-Americana WWW/Internet 2012
51

En (Colazzo, 2003), se presenta una adaptación de un sistema de administración de cursos para satisfacer las necesidades de usuarios móviles, utilizando tecnología de web services para definir la interfase de comunicación entre el CMS y sus extensiones móviles. Luego, en (Wains and Mahmood, 2008), encontramos la propuesta de un framework para la integración de un ambiente de aprendizaje móvil con un ambiente de e-learning donde, a partir de la disponibilidad de salas de chat basado en SMS, se promueve el aprendizaje de los estudiantes mediante la utilización de foros y debates para discutir sus problemas, pensamientos e ideas; se realizan llamadas de voz y transmisiones de radio y televisión. Mientras tanto, la mayor parte del contenido puede accederse a través de las conexiones a Internet de los celulares, sin ninguna adecuación de los objetos de aprendizaje.
La literatura técnica reporta algunos trabajos relativos a comunicaciones móviles y distribución de servicios. (Ibrahim and Zhao, 2009) presentan un modelo conceptual de framework para comunicación en dispositivos móviles que da soporte a la movilidad y distribución de servicios sobre múltiples dispositivos y plataformas. Muchos de los principios, entre ellos las bases de la comunicación cliente – servidor y de agentes móviles, son un referente para nuestro proyecto; pero a diferencia de nuestro trabajo, la propuesta de (Ibrahim and Zhao, 2009) está diseñada para Java Virtual Machines (JVM) y no considera un ambiente de interacción y alertas.
3. MODELO DE ARQUITECTURA DEL AMBIENTE
La Figura No.1 presenta la arquitectura del ambiente. El componente cliente representa la aplicación desarrollada para los dispositivos móviles con sistema operativo Android, mientras que el lado servidor constituye la infraestructura que realiza la integración con el ambiente Moodle.
Figura 1. Arquitectura del ambiente
En el lado servidor, un conjunto de web services actúa como interfaz de comunicación entre los clientes y el servidor, resultando responsables por ofrecer a los clientes las funcionalidades integradas. Un web service es un componente de software definido por una interfaz independiente que está disponible a través de la red. Las operaciones definidas en la interfaz, realizan funciones de negocio (Hewitt, 2009). Por medio de los web services, los clientes tienen acceso a los principales recursos de Moodle, como foro, evaluación, mensajes, chat, descarga de archivos, localización, alertas, anuncios, calificación y curso, entre otros. Al recibir una solicitud, un web service accesa la base de datos de Moodle para recuperar y/o manipular los datos necesarios para responder adecuadamente a la solicitud. En el lado cliente, la implementación está basada en el patrón de desarrollo de Android: para cada pantalla de la aplicación, existe una clase Java responsable por controlar las acciones de esa pantalla. De esta forma, para cada funcionalidad provista (por ejemplo foro,
ISBN: 978-989-8533-11-1 © 2012 IADIS
52

evaluación, mensajes, chat,…) existe un conjunto de pantallas y, por lo tanto, un conjunto de clases Java, representadas en la arquitectura mediante el uso de paquetes.
3.1 Componente Cliente
El componente cliente, es decir, la aplicación Android, utiliza el patrón de proyecto Facade (Gamma et al., 1995) para realizar la comunicación entre las pantallas y la clase responsable por invocar los web services. Cada pantalla en la aplicación Android posee una clase asociada. La clase MLEA actúa en la aplicación como una fachada para realizar la comunicación entre las clases. La Figura No. 2a, ilustra el uso de la clase MLEA, la cual es utilizada por todos los requisitos desarrollados. En la figura se puede observar que los módulos creados (por ejemplo, Curso, Foro, Mensajes) son clientes de la clase MLEA, la cual define una interfaz entre las clases ConnectionManager y SharedInfo, aislándolas del resto de la aplicación. La clase SharedInfo administra la base de datos del dispositivo móvil, donde son almacenadas las informaciones de los usuarios, tales como: datos de autenticación, identificadores de usuario conectado y de curso escogido, así como datos de caché. La figura solamente presenta algunos de los módulos desarrollados. Los módulos que conforman la arquitectura son: login, foro, evaluación, mensajes, chat, descarga de archivos, localización, alertas, anuncios, calificación, escoger curso, encuesta, evaluación del foro, estadísticas del foro y visualizar usuarios conectados.
Figura 2a. Vista del componente cliente Figura 2b. Vista del componente servidor
3.2 Servidor
El componente servidor utiliza dos patrones de diseño para responder a las solicitudes de los clientes. Primeramente, los web services utilizan el patrón de proyecto DAO (Data Access Object) (Alur et al., 2003), para acceder y manipular las informaciones en la base de datos de Moodle. Para cada tipo de dato que será utilizado, existe una interfase DAO que indica las operaciones que se pueden realizar con este tipo. La capa del modelo de la aplicación posee los siguientes tipos de datos, cada uno con una interfase DAO específica: login, foro, evaluación, mensajes, chat, descarga de archivos, localización, alertas, anuncios, calificación, escoger curso, encuesta, evaluación del foro, estadísticas del foro y visualizar usuarios conectados. Para aumentar la flexibilidad de la aplicación, las clases DAO no son instanciadas directamente por los web services; en vez de esto, es utilizada una fábrica para la construcción de las clases DAO. Esta práctica
Conferência IADIS Ibero-Americana WWW/Internet 2012
53

corresponde al uso del patrón de proyecto FacthoryMethod, el cual garantiza que toda la aplicación utilice las DAO apropiadas para la configuración escogida. La Figura No.2b presenta el uso de los patrones de diseño, donde el conjunto de web services utiliza la DaoFactory para crear instancias de las interfaces, las cuales son utilizadas para acceder y manipular las informaciones en la base de datos de Moodle.
4. IMPLEMENTACION DE WEBSERVICES
Para cada funcionalidad de la aplicación, existe una clase responsable por proveer el conjunto de web services correspondientes al requisito específico.
Figura .3. Especificación de los web services
Los web services fueron desarrollados utilizando el protocolo REST (Representational State Transfer) para web services (Allamaraju, 2010), pues Android no posee soporte nativo para otro tipo de protocolo. De esta forma, el desarrollo resultó más sencillo con el uso de las bibliotecas existentes en Android para la invocación de los servicios. REST emula el protocolo HTTP mediante la restricción de establecer la interfaz a un conjunto conocido de operaciones estándar como GET, POST o PUT. Además del HTTP, protocolo patrón utilizado por REST para la comunicación, se utilizó JSON (JavaScript Object Notation) para definir el formato de los datos, por resultar un formato liviano para el intercambio de datos computacionales, lo cual resulta en ventajas en el procesamiento de aplicaciones móviles. En la Figura No. 3, se presentan las clases implementadas, con sus respectivos web services. Por ejemplo, la clase ForumResource, contiene 4 web services: el primero que es listado, es el getForumDiscussions, este servicio recibe como parámetro los identificadores del foro, del usuario y del curso, retornando todas las discusiones que componen un foro específico.
Inicialmente, pensamos utilizar los web services de Moodle en sus versiones más recientes; sin embargo, identificamos que la cantidad de servicios disponibles por Moodle es muy poca y, de los mismos, apenas una pequeña parte sería aprovechable para los propósitos del proyecto. Frente a esta situación, optamos por desarrollar todos los web services necesarios para el funcionamiento de la aplicación.
ISBN: 978-989-8533-11-1 © 2012 IADIS
54

Tabla 1. Servicios de Moodle
Web Service Descripción
moodle_course_create_courses Crea nuevos cursos moodle_course_get_courses Recupera los cursos existentes moodle_enrol_get_enrolled_users Recupera la lista de participantes del curso
moodle_enrol_get_users_courses Recupera la lista de cursos en que un usuario participa
moodle_enrol_manual_enrol_users Registra un usuario para participar en un curso
moodle_file_get_files Navegar por los archivos de un curso moodle_file_upload Realizar el upload de un archivo moodle_group_add_groupmembers Agregar miembros a un grupo moodle_group_create_groups Crear nuevos cursos moodle_group_delete_groupmembers Excluir miembros de un grupo moodle_group_delete_groups Excluir determinado grupo
moodle_group_get_course_groups Recupera todos os grupos definidos en un curso
moodle_group_get_groupmembers Recupera los participantes de determinado grupo
moodle_group_get_groups Recupera los detalles de determinado curso
moodle_message_send_instantmessages Enviar mensajes moodle_notes_create_notes Crear notas moodle_role_assign Atribuir roles a un usuario moodle_role_unassign Remover rol de usuario moodle_user_create_users Crear usuarios moodle_user_delete_users Excluir usuarios
moodle_user_get_course_participants_by_idRecupera el perfil de los participantes de un curso
moodle_user_get_users_by_courseid Recupera los participantes de determinado curso
moodle_user_get_users_by_id Recupera un conjunto de participantes moodle_user_update_users Actualizar los usuarios
moodle_webservice_get_siteinfo Recupera algunas informaciones sobre o sitio
La Tabla No.1 presenta los servicios provistos por Moodle actualmente, destacando aquellos
aprovechables para el desarrollo de la aplicación. Sin embargo, como los servicios provistos por Moodle no resultan suficientes para atender las necesidades del ambiente de aprendizaje móvil; todos los web services utilizados por dicho ambiente fueron implementados de manera independiente de Moodle.
5. ALERTAS PERSONALIZADAS
Una contribución importante del ambiente presentado, es la oferta de una herramienta que provee alertas personalizadas a los estudiantes y a los profesores, facilitando que éstos se mantengan actualizados sobre las actividades que se realizan en los cursos. Los usuarios que desean recibir las alertas tienen a su disposición una interfase Web por medio de la cual ellos pueden definir, para cada curso, de manera individual, los eventos que les interesa recibir las alertas. Para utilizar esta facilidad de la aplicación, los usuarios requieren ser autenticados. La Figura 4, presenta la pantalla de autenticación, en la cual los usuarios deben introducir las mismas informaciones utilizadas para autenticarse en el ambiente Moodle.
Conferência IADIS Ibero-Americana WWW/Internet 2012
55

Figura 4. Pantalla de autenticación
La Figura 5, presenta la pantalla de configuración, por medio de la cual los usuarios especifican las alertas que desean recibir. Es importante destacar que los usuarios tienen a su disposición diferentes posibilidades de personalización, de acuerdo con su rol en el curso:
Figura 5. Pantalla de configuración de las alertas
Cuando se ejecutan los eventos configurados por los usuarios, éstos reciben las alertas directamente en sus teléfonos, por medio del sistema de notificación nativo del sistema operativo Android. Los teléfonos tendrán instalada una aplicación que solicitará información al servidor y, dependiendo de la respuesta, mostrará las alertas al usuario de acuerdo con las configuraciones pre-establecidas.
6. MODELO DE LOCALIZACION
El módulo de localización, cuyo diagrama presentamos en la Figura No.6, presenta un funcionamiento coherente con el funcionamiento de los otros módulos de la aplicación, presentados anteriormente. Inicialmente, es necesario descubrir la localización de los diversos usuarios. Para esto, la clase MainActivity,
ISBN: 978-989-8533-11-1 © 2012 IADIS
56

responsable de controlar la pantalla inicial de la aplicación, inicializa la clase LocationService, la cual es responsable de colectar periódicamente la localización del usuario autenticado. Entonces, cada vez que el usuario reporta una nueva localización (actual), la clase LocationService notifica a la clase MLEA, la cual utiliza la clase ConnectionManager para guardar la localización del usuario. Para esto, la clase ConnectionManager invoca el webservice apropiado, definido en la clase LocationResource. A la vez, esta clase (LocationResource), utilizará una instancia de la interfase LocationDao (en este caso la clase (DbLocationDao), la cual almacena en el banco de datos la localización recibida.
Figura 6. Modelo de Localización del ambiente móvil
Figura 7. Mapa de localización de los usuarios
Además, la clase LocationActivity es responsable por controlar la pantalla que muestra un mapa con la localización de los demás usuarios. Para esto, seguimos el mismo patrón utilizado en toda la aplicación: esta clase utiliza la clase MLEA, la cual usa la clase ConnectionManager, que a la vez invoca un web service definido en la clase LocationResource. Este web service utiliza una instancia de la interfase LocationDao, que recupera del banco de datos las localizaciones de los demás usuarios. La respuesta (es decir, la
Conferência IADIS Ibero-Americana WWW/Internet 2012
57

localización de los usuarios) sigue el recorrido inverso, hasta llegar a la clase LocationActivity, que finalmente presenta al usuario el mapa de forma apropiada (ver Figura No.7).
7. CONCLUSIONES Y TRABAJOS FUTUROS
A partir de la puesta en marcha del ambiente, se recibirán los primeros beneficios del proyecto en los diversos escenarios y sedes de la Universidad Tecnológica de Panamá. La participación de todos los actores, también nos permitirá identificar situaciones y casos que orienten hacia el mejoramiento y adecuación continua de la aplicación. Un aspecto importante a destacar es que la arquitectura desarrollada hace posible que, en el futuro, se puedan desarrollar aplicaciones clientes para diferentes sistemas operativos móviles, como por ejemplo iPhone, aprovechando gran parte de la infraestructura construida y, de esta forma, se pueda alcanzar un número mayor de usuarios.
AGRADECIMIENTOS
Este trabajo es financiado por la Secretaría Nacional de Ciencia, Tecnología e Innovación - SENACYT, en el marco de la Convocatoria Pública de Fomento a la Colaboración Internacional en I+D. Los autores expresan sus agradecimientos a SENACYT y a la Universidad Tecnológica de Panamá, en Panamá, y a la Universidade do Vale do Rio dos Sinos en Porto Alegre, Brasil, por el apoyo para el desarrollo del presente proyecto.
REFERENCIAS
Allamaraju, S.; 2010 RESTful Web Services Cookbook: Solutions for Improving Scalability and Simplicity. O`REILLY, Alur, D., et al. 2003; Core J2EE Patterns: Best Practices and Design Strategies. Prentice Hall,. Colazzo, L.; et al. 2003; Towards a multi-vendor mobile learning management system. Proceedings of e-learn
Conference. Felizardo, K.; et al. 2007; O uso do Moodle no apoio de ensino de programação para alunos iniciantes. 13º Congresso
Internacional de Educação a Distância. Gamma, E. et al. 1995; Design Patterns: Elements of Reusable Object-Oriented Software. Addison-Wesley Professional,. Georgiev, T.; et al. 2004; M-Learning – a new stage of e-learning. CompSysTech '04: Proceedings of the 5th
international conference on Computer systems, pp. 1-5. Hewitt, E. 2009; Java SOA Cookbook, 1st. Edition, O’reilly. Ibrahim, A.; and Zhao, L. 2009; Supporting the OSGi Service Platform with Mobility and Service Distribution in
Ubiquitous Home Environments. The Computer Journal. London. Vol. 52, Iss. 2, pp. 210-239. Wains, S.; and Mahmood, W., 2008; Integrating m-learning with e-learning. SIGITE '08: Proceedings of the 9th ACM
SIGITE conference on Information technology education.
ISBN: 978-989-8533-11-1 © 2012 IADIS
58

INNOVACIÓN EDUCATIVA BASADA EN PROCESOS DE EVALUACIÓN DE LA CALIDAD
José Luis Castillo Sequera, Miguel A. Navarro Huerga, José A. Medina y José M. Gómez Pulido
Universidad de Alcalá Campús Universitario s/n, 28871 Alcalá de Henares, Madrid - Spain
RESUMEN
En este artículo presentamos el desarrollo de un proceso de evaluación basado en la calidad aplicado al ámbito educativo y su aplicación práctica con TIC’s a una asignatura de grado del EEES. Se describe el modelo propuesto y su fundamentación, se detalla el caso de estudio donde se aplica dicho modelo y se analizan los resultados obtenidos, exponiéndose algunas conclusiones, así como líneas de trabajo para futuro, debido a que, la calidad educativa es un tema de sumo interés, que entra en debate con la inserción de las TIC’s en el escenario educativo. La finalidad de este trabajo es reflexionar sobre los procesos de calidad en la Educación Superior. Por ello, se hace necesaria una medida de calidad que cuantifique el impacto de los mismos y describa su desarrollo, ya que hemos pasado de metodologías basadas en clases magistrales a una composición de clases, tutorías y seguimiento online. En este trabajo, el primer paso, será el de componer un mapa de procesos que abarque toda la acción de enseñanza/aprendizaje, y luego detallar uno de los procesos estratégicos del mismo. Se analizan algunas alternativas que nos ayudan a repensar los entornos de aprendizaje desde la interacción entre los contenidos curriculares, las tecnologías y la pedagogía universitaria. El gran desafío es comprender que la calidad lleva implícita la mejora continua por lo que no debe ser solamente una intención o una finalidad, presentando con ello una propuesta de modelo de evaluación de la calidad.
PALABRAS CLAVES
Estrategias de Evaluación, Calidad, Mapa de Procesos, Mejora continua
1. INTRODUCCIÓN
La evolución de la sociedad actual se apoya, entre otros aspectos, en el desarrollo de nuevas tecnologías de información y comunicación, impulsadas por los adelantos de la informática y la telemática, que impactan en todos los ámbitos de la vida. La integración de tecnologías en los sistemas educativos es un proceso complejo, desde el potencial ofrecido a la aplicación efectiva se requiere una planificación reflexiva, implementación sostenida y mantenimiento continuo. Las Instituciones de Educación Superior no están ajenas a esta situación, y deben aprovechar al máximo el potencial de estos recursos, de manera tal de generar propuestas innovadoras y de calidad, que contribuyan a alcanzar sus objetivos.
Actualmente, nadie duda ya que el tema de la calidad ha ganado poco a poco su protagonismo para instalarse en todos los aspectos y dimensiones sujetos a evaluación en el sistema universitario. Por ello, las demandas de la universidad en la búsqueda de mejorar la calidad de la enseñanza y del sistema educativo en su conjunto hacen necesario la introducción de alternativas que promuevan flexibilizar los sistemas de enseñanza y la comunicación con los estudiantes. Hoy en día, los Entornos Virtuales de Aprendizaje forman parte de la infraestructura básica de las instituciones educativas y junto con el uso efectivo de tecnologías para la enseñanza y el aprendizaje son una cuestión clave en materia de educación superior.
En este sentido, resulta necesario que las instituciones de nivel superior fijen claramente los criterios y estándares de calidad a seguir para alcanzar sus fines teniendo en cuenta, principalmente, el papel crítico que desempeñan en la sociedad del conocimiento actual. Sin embargo, no existe un consenso acerca del concepto de calidad, y en particular en educación superior, debemos de empezar de un marco general o mapa de procesos que nos sirva de guía, que podamos luego desarrollar más al detalle para la mejora del mismo.
Conferência IADIS Ibero-Americana WWW/Internet 2012
59

Es muy común, que muchas veces, cada Universidad analiza su calidad en relación a su naturaleza y función, a sus propósitos y objetivos. Así, las diferentes propuestas y modelos sientan sus raíces en el Modelo Europeo de Calidad (EFQM) dado que focalizan su interés, especialmente, en la satisfacción de sus clientes, basando la misma en la mejora continua, medición y máxima atención a los procesos, el trabajo en equipo, y la responsabilidad de cada uno. Esto es debido a que, se define la educación como un producto o servicio, donde los alumnos son considerados sus consumidores.
Aunque, existen diferentes opiniones acerca de cómo considerar la calidad y su forma de evaluación. “Si se pone el foco, en particular en los procesos educativos”, existe una diversidad de aspectos a tener en cuenta para establecer un juicio acerca de la calidad, y la forma de analizarla. En este trabajo se presenta en primer lugar un modelo de mapa de proceso que se ha aplicado experimentalmente para la mejora de la calidad de una asignatura de grado del EEES. Con la ayuda de las TIC’s hemos desarrollado innovaciones a los procesos estratégicos presentados, centrándonos específicamente en uno de los procesos estratégicos.
El artículo se organiza de la siguiente manera: en la primera sección se aproximan los elementos correspondientes al diseño educativo, proponiendo un mapa de procesos del mismo. En la segunda sección se presenta la propuesta del proceso evaluativo para el diseño educativo tratado, haciendo uso de la plataforma virtual Blackboard y las estrategias de evaluación a aplicar. En la tercera se describen los resultados obtenidos. Finalmente en las conclusiones se incluyen algunas aportaciones que hemos recopilado de la experiencia desarrollada en el análisis de casos y los trabajos futuros.
2. MODELO EDUCATIVO BASADO EN EL MAPA DE PROCESOS
Buscar constantemente cómo aprender en forma autónoma y virtual significa probar nuevas metodologías o combinar metodologías, observar qué tipo de estrategia da mejores resultados de aprendizaje. Para ello, el profesor debe estar observando permanentemente y analizando el comportamiento de los alumnos, qué tipos de preguntas hacen, cómo participan en los foros, la profundidad de sus trabajos prácticos. Cómo hacer que la educación implemente estrategias que conlleven prácticas, que estén orientadas al trabajo, entre otras. A continuación planteamos un modelo de mapa de procesos que permita lograr este fin.
El Modelo de Procesos, está compuesto por procesos estratégicos, procesos claves y proceso de apoyo, centrándose fundamentalmente en el llamado Proceso de Enseñanza/Aprendizaje de una asignatura universitaria, con el fin de que se desarrolle cumpliendo los objetivos trazados en el modelo Bolonia.
Dicho proceso de enseñanza/aprendizaje, forma parte de un proceso más general, y se puede estructurar en tres etapas. Primeramente, la etapa de diseño y estructura el curso, luego la etapa de desarrollo y finalmente, la etapa de evaluación. Todo ello componiendo un proceso general en el que intervienen el alumno y el profesor en el marco de la institución. Este modelo de procesos ha sido utilizado como patrón para evaluar la calidad de cualquier curso universitario que se imparta, tomando como referencia una asignatura de grado de carácter obligatorio.
A continuación se describen el mapa de procesos que se ha tenido en cuenta:
ISBN: 978-989-8533-11-1 © 2012 IADIS
60

Figura 1. Modelo de Mapa de Procesos propuesto para la formación universitaria
Este modelo de procesos, utiliza sietes procesos que definen un modelo que abarca todo el proceso de Enseñanza/ Aprendizaje para el caso de la impartición de una asignatura de grado en el entorno universitario.
Existen numerosas relaciones entre los procesos de manera que unos condicionan a otros. En la siguiente figura, detallamos cada una de esas interdependencias.
Figura 2. Detalle de cada de uno de los procesos involucrados.
Como podemos apreciar, los procesos estratégicos a tener en cuenta, son: Proceso de Enseñanza/Aprendizaje, Proceso de Desarrollo del Curso y de Evaluación. Luego, los Procesos claves están
Conferência IADIS Ibero-Americana WWW/Internet 2012
61

constituidos por el proceso de estructura del curso, Apoyo al Profesorado y Apoyo al Alumno. Finalmente, el proceso de apoyo está constituido por el proceso de apoyo institucional.
El “Proceso de Enseñanza Aprendizaje” medirá todos aquellos aspectos necesarios para la realización del mismo. Desde la planificación del curso para que esté acorde al plan de estudios y al nivel exigido para los alumnos, pasando por las actividades que se desarrollen y den soporte al proceso y finalizando con la evaluación de los niveles de competencia en los que quedan reflejados los procedimientos de seguimiento con los que se mide el avance de los alumnos. Su principal objetivo es realizar eficientemente, los procesos de enseñanza/aprendizaje, con una metodología de acuerdo a los conceptos y métodos didácticos apropiados, teniendo como actores a los Alumnos, Profesores, Tutores.
El proceso de “Evaluación y Valoración” se encargará de contemplar los aspectos involucrados en la evaluación del curso: La planificación de las pruebas, la realización de las mismas, el método de evaluación y el análisis posterior que se efectúa con ellas. Su objetivo principal es describir la evaluación del proceso educativo, a través de métodos de evaluación. Dicho proceso es el que detallaremos en el siguiente apartado, a fin de validar la calidad de la propuesta presentada.
El proceso de “Desarrollo del curso” está orientada a la ejecución del propio curso, donde será necesario que se presenten a alumnos los recursos a través de una infraestructura técnica o física según la modalidad. Será necesario también que los alumnos conozcan los procedimientos para poder utilizar esos recursos y para ponerse en contacto con el profesor, tutor o administrador del sistema. Su objetivo es realizar el curso según su planificación establecida.
El proceso de “Apoyo al profesorado” cuantificará los recursos de los que debe disponer el profesor para la ejecución de sus funciones, su capacitación para el desarrollo del mismo, así como la aplicabilidad y usabilidad percibida de los mismos. El objetivo principal es describir los medios y recursos disponibles por el profesor a través del análisis de sus necesidades.
El proceso de “Estructura del Curso” contiene la definición integra del contenido del curso, su diseño, su metodología y el resto de medios necesario para colocarlos a disposición de los alumnos. Su objetivo principal es el de Estructurar detalladamente el curso.
El proceso de “Apoyo al alumno” se centra en los recursos, medios y servicios de los que dispone el alumno para la realización del proceso de Enseñanza/ Aprendizaje. Será necesario por tanto analizarlos desde el punto de vista de las necesidades del alumno, para maximizar su usabilidad y aplicabilidad. Por lo tanto, su principal objetivo es describir los medios y recursos disponibles para el alumno, a través de encuestas de Satisfacción, Estudios de usabilidad.
El proceso de “Apoyo Institucional” recoge el proceso en el que la Institución da soporte a los diferentes actores que intervienen en el curso. Su labor será poner a disposición todos los medios con garantías de funcionalidad y formar a los actores en su utilización para su mejor aprovechamiento.
3. DESARROLLO DEL PROCESO ESTRATÉGICO DE EVALUACIÓN
La estrategia de evaluación seleccionada es la evaluación continua (según la filosofía Bolonia “PEC”), basada en la evaluación de casos prácticos por grupos de trabajo, con un seguimiento continuo y retroalimentado (siguiendo las estrategias de evaluación seleccionadas previamente), con ayuda de guías de laboratorio y con la supervisión y tutoría del profesor vía la plataforma virtual, a través de foros, y email personalizados. En principio, todo el proceso, trata del desarrollo de un caso complejo, que se va trabajando incrementalmente en cada PEC, de tal forma que al finalizar todo el proceso de evaluación, se tiene construido un proyecto completo de forma integral, que permita evaluar y cubrir todas las competencias que se requieren adquirir para la asignatura.
Todo el proceso de evaluación, encaja perfectamente en el proceso de enseñanza/aprendizaje que está centrado en el alumno, tal como lo apreciamos en el siguiente diagrama:
ISBN: 978-989-8533-11-1 © 2012 IADIS
62

Figura 3. Proceso de enseñanza/aprendizaje centrado en el alumno
Es por ello, que es fundamental, que los casos estén programados de forma progresiva en un cronograma presentado al inicio de las clases, de forma que al concluir el último PEC, cada grupo haya desarrollado un proyecto informático completo y adquirido las competencias requeridas a lo largo de todo el proceso. Adicionalmente, para apoyar a los alumnos, que por diferentes circunstancias no pueden completar normalmente las sesiones preparadas, se les ofrece la posibilidad de desarrollar de manera individual trabajos de investigación relacionados a los casos de forma aplicada, de tal forma, que se pueda completar sus conocimientos y competencias y suplir algún aspecto de algún PEC desarrollado.
Los contenidos y materiales de referencia están publicados en el aula virtual (Plataforma Blackboard). Además, se propone al final de cada PEC, y a manera de retroalimentación con el profesor un proceso de Autoevaluación y Coevaluación de todo el trabajo realizado para la consecución del respectivo PEC. Dicho proceso es analizado posteriormente a fin de detectar problemas en la consecución de las metas (feedback) , y poder evaluar aspectos críticos de cada PEC.
Mediante la autoevaluación los alumnos pueden reflexionar y tomar conciencia acerca de sus propios aprendizajes y de los factores que en ellos intervienen. En la autoevaluación se contrasta el nivel de aprendizaje con los logros esperados, detectando los avances y dificultades con el fin de tomar acciones correctivas. De esta forma, el alumno aprende a valorar su desempeño con responsabilidad. La Coevaluación permite evaluar el desempeño de un alumno a través de la observación y determinaciones de sus propios compañeros de estudio, esto resulta ser realmente innovador, porque propone que sean los mismos alumnos, que aprenden, los que se coloquen en el papel del docente y evalúen los conocimientos adquiridos por sus compañeros. Con estas retroalimentaciones propuestas, se tiende a mejorar el aprendizaje, porque animará a los alumnos a que se sientan partícipes del proceso de enseñanza-aprendizaje.
Es decir, para la parte práctica se utilizó la plataforma virtual, realizándose actividades para que: • Cada alumno se autoevalúa, es decir califica su propio trabajo de laboratorio, usando los criterios de
calificación establecidos (en una escala de 0 a 10), haciendo uso de la plataforma virtual. • Cada grupo coevalua las exposiciones y trabajos de los proyectos de los otros grupos (peer review).
En donde, cada una de las preguntas establecidas para la autoevaluación y coevaluación corresponden a indicadores de calidad del aprendizaje. Finalmente, para la parte teórica, al finalizar todas las PEC’s:
• Se propuso a los alumnos que completaran una encuesta para valorar el trabajo realizado y en general de toda la asignatura, a fin de expresar la opinión sobre el proceso de innovación realizado, considerándose la última pregunta (Valoración del conocimiento adquirido), el principal indicador de todo el proceso.
A continuación, mostramos el detalle de cada una de las preguntas realizadas para el proceso de autoevaluación y Coevaluación de cada PEC.
Conferência IADIS Ibero-Americana WWW/Internet 2012
63
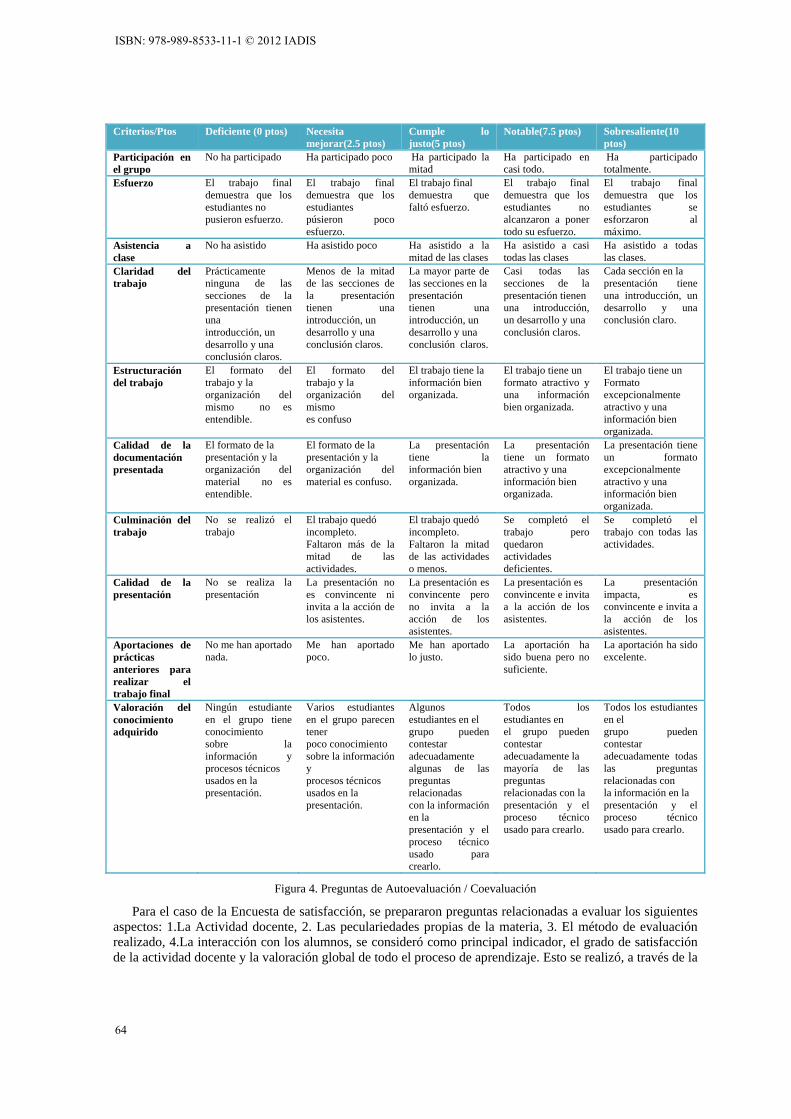
Criterios/Ptos Deficiente (0 ptos) Necesita mejorar(2.5 ptos)
Cumple lo justo(5 ptos)
Notable(7.5 ptos) Sobresaliente(10 ptos)
Participación en el grupo
No ha participado Ha participado poco Ha participado la mitad
Ha participado en casi todo.
Ha participado totalmente.
Esfuerzo El trabajo final demuestra que los estudiantes no pusieron esfuerzo.
El trabajo final demuestra que los estudiantes púsieron poco esfuerzo.
El trabajo final demuestra que faltó esfuerzo.
El trabajo final demuestra que los estudiantes no alcanzaron a poner todo su esfuerzo.
El trabajo final demuestra que los estudiantes se esforzaron al máximo.
Asistencia a clase
No ha asistido Ha asistido poco Ha asistido a la mitad de las clases
Ha asistido a casi todas las clases
Ha asistido a todas las clases.
Claridad del trabajo
Prácticamente ninguna de las secciones de la presentación tienen una introducción, un desarrollo y una conclusión claros.
Menos de la mitad de las secciones de la presentación tienen una introducción, un desarrollo y una conclusión claros.
La mayor parte de las secciones en la presentación tienen una introducción, un desarrollo y una conclusión claros.
Casi todas las secciones de la presentación tienen una introducción, un desarrollo y una conclusión claros.
Cada sección en la presentación tiene una introducción, un desarrollo y una conclusión claro.
Estructuración del trabajo
El formato del trabajo y la organización del mismo no es entendible.
El formato del trabajo y la organización del mismo es confuso
El trabajo tiene la información bien organizada.
El trabajo tiene un formato atractivo y una información bien organizada.
El trabajo tiene un Formato excepcionalmente atractivo y una información bien organizada.
Calidad de la documentación presentada
El formato de la presentación y la organización del material no es entendible.
El formato de la presentación y la organización del material es confuso.
La presentación tiene la información bien organizada.
La presentación tiene un formato atractivo y una información bien organizada.
La presentación tiene un formato excepcionalmente atractivo y una información bien organizada.
Culminación del trabajo
No se realizó el trabajo
El trabajo quedó incompleto. Faltaron más de la mitad de las actividades.
El trabajo quedó incompleto. Faltaron la mitad de las actividades o menos.
Se completó el trabajo pero quedaron actividades deficientes.
Se completó el trabajo con todas las actividades.
Calidad de la presentación
No se realiza la presentación
La presentación no es convincente ni invita a la acción de los asistentes.
La presentación es convincente pero no invita a la acción de los asistentes.
La presentación es convincente e invita a la acción de los asistentes.
La presentación impacta, es convincente e invita a la acción de los asistentes.
Aportaciones de prácticas anteriores para realizar el trabajo final
No me han aportado nada.
Me han aportado poco.
Me han aportado lo justo.
La aportación ha sido buena pero no suficiente.
La aportación ha sido excelente.
Valoración del conocimiento adquirido
Ningún estudiante en el grupo tiene conocimiento sobre la información y procesos técnicos usados en la presentación.
Varios estudiantes en el grupo parecen tener poco conocimiento sobre la información y procesos técnicos usados en la presentación.
Algunos estudiantes en el grupo pueden contestar adecuadamente algunas de las preguntas relacionadas con la información en la presentación y el proceso técnico usado para crearlo.
Todos los estudiantes en el grupo pueden contestar adecuadamente la mayoría de las preguntas relacionadas con la presentación y el proceso técnico usado para crearlo.
Todos los estudiantes en el grupo pueden contestar adecuadamente todas las preguntas relacionadas con la información en la presentación y el proceso técnico usado para crearlo.
Figura 4. Preguntas de Autoevaluación / Coevaluación
Para el caso de la Encuesta de satisfacción, se prepararon preguntas relacionadas a evaluar los siguientes aspectos: 1.La Actividad docente, 2. Las peculariedades propias de la materia, 3. El método de evaluación realizado, 4.La interacción con los alumnos, se consideró como principal indicador, el grado de satisfacción de la actividad docente y la valoración global de todo el proceso de aprendizaje. Esto se realizó, a través de la
ISBN: 978-989-8533-11-1 © 2012 IADIS
64

plataforma virtual de forma automática, en un periodo previamente establecido, y se generó los resultados estadísticos que permitieron realimentar el proceso de evaluación y validar lo realizado.
4. RESULTADOS EXPERIMENTALES
El resultado general de las autoevaluaciones y coevaluaciones, muestra que la participación en el grupo es elevada, del orden del 75 %. Comparando ambos resultados, podemos afirmar que las valoraciones coinciden y los alumnos se califican correctamente. Además, en todo momento, se consideró la valoración del profesor, a fin de validar la viabilidad de los criterios utilizados en el proceso de evaluación. Analizando los resultados, observamos que la calidad de los trabajos presentados es muy elevada, pero que al ser el proceso orientado al alumno, su esfuerzo es mucho mayor. Pese a ello, la asistencia y la finalización de los trabajos no decae para nada, y la valoración del conocimiento global adquirido es muy elevada (del orden del 75 %). Finalmente, en lo que corresponde a la encuesta de satisfacción, los indicadores de grado de satisfacción de la actividad docente es del orden de 9 y la valoración global de todo el proceso de aprendizaje es superior a 8, tal como lo mostramos en los siguientes gráficos (cuya distribución de frecuencia está expresado en decenas), que muestran algunos resultados obtenidos.
Conferência IADIS Ibero-Americana WWW/Internet 2012
65

Figura 5. Algunos resultados obtenidos.
5. CONCLUSION
Si el verdadero objetivo de la calidad es la mejora de los procesos de enseñanza aprendizaje tendríamos que garantizar que esos procesos se desarrollen en un contexto que la potencie y desarrolle. Para ello, tenemos que diseñar un entorno que produzca una interacción entre los contenidos, la tecnología y la pedagogía. Por ello, en el presente trabajo, se ha presentado un modelo de procesos, y se ha desarrollado un proceso estratégico del mismo a un caso de estudio, teniendo en cuenta esos aspectos, para conocer sus posibles fortalezas y debilidades, encontrándose resultados entre muy satisfactorios y satisfactorios, respecto de los principales indicadores requeridos. Como se ha dicho, fue aplicado de manera experimental en una asignatura de grado obligatoria (Gestión de Proyectos) de la Escuela Superior de Ingeniería en Informática de la Universidad de Alcalá, a los grados de Ingeniería en Informática e Ingeniería en Computadores, satisfactoriamente. El nucleo principal está centrado en el proceso de Enseñanza/ Aprendizaje y al aprendizaje del alumno, pudiendo ser adaptado a cualquier curso universitario de grado que se imparta con una metodología con clases presenciales y apoyo online a través de una plataforma virtual (en nuestro caso, Blackboard). Esperamos que a corto plazo lo podamos aplicar a más asignaturas universitarias y comprobár a través de sus indicadores, la bondad de la propuesta. Con este trabajo hemos contribuido a:
• Hacer explícitas las relaciones entre pedagogía, tecnología y contenido como una herramienta de auto-reflexión en toda propuesta de aprendizaje basado en la calidad de un proceso.
• Comprender que la integración de tecnologías o nuevos medios educativos conlleva necesariamente un cambio en las estructuras de contenido y en las estrategias metodologías.
• Reconocer el carácter dinámico y complejo del conocimiento docente, creando y diseñando actividades de aprendizaje que responda a las necesidades educativas de los estudiantes.
• Tener en cuenta que el poder y el potencial del uso de las TICs en la enseñanza reside en el profesorado y en el modo en cómo se genera la transposición didáctica.
• Potenciar la construcción colaborativa del conocimiento y generan la creación de redes informales y comunidades de aprendizaje virtuales a través de foros o redes sociales.
REFERENCIAS
1. Barkley, E., Cross, K. P. y Howell, C. Técnicas de aprendizaje colaborativo. Manual para el profesorado. Madrid: Morata. 2007.
2. Benavides Carlos, y Cristina Quintana “Gestión del conocimiento y calidad total”, Diaz de Santos 2003. 3. Brockbank, A. y McGill, Desarrollo de la práctica reflexiva: el diálogo del reflexivo del docente. 2002. 4. Margalef, L. y Torné, E. Estrategias de Innovación docente para favorecer el aprendizaje autónomo de los
estudiantes. UAH 2007. 5. Membrado Martinez J, “Metodologías Avanzadas para la planificación y Mejora”, Diaz de Santos, 2007. 6. Moreno F, Bailly-Bailliere M .(2002) Diseño instructivo de la formación on-line – Ariel Educación.
ISBN: 978-989-8533-11-1 © 2012 IADIS
66

BÚSQUEDAS Y ACTUALIZACIONES DE CONTENIDOS DOCENTES EN REPOSITORIOS A TRAVÉS DE AGENTES
Salvador Otón, Francisco Javier Iglesias, Luis de-Marcos, Antonio García, Eva García, José María Gutiérrez, José Ramón Hilera y Roberto Barchino
Dto. de Ciencias de la Computación Escuela Superior de Ing. Informática. Universidad de Alcalá
Alcalá de Henares (Madrid) - España
RESUMEN
En el ámbito del e-learning existen en la actualidad una gran proliferación de repositorios de objetos de aprendizaje cuyo objetivo fundamental es la reutilización del contenido docente que contienen en diversas acciones formativas. Cuando un usuario necesita confeccionar un nuevo curso realiza consultas sobre los repositorios buscando los objetos de aprendizaje que mejor se adapten a las necesidades formativas del curso. En este trabajo proponemos un sistema federado de búsqueda sobre repositorios de objetos de aprendizaje a través de agentes software que permitan almacenar los criterios de búsqueda y avisar al usuario cuando se encuentren nuevos objetos de aprendizaje o estos se hayan actualizado.
PALABRAS CLAVES
Agentes software, interoperabilidad, repositorios, e-learning.
1. INTRODUCCIÓN
Los repositorios digitales, en el sentido más amplio de la definición, se emplean para almacenar cualquier tipo de material digital. No obstante, los repositorios digitales para objetos de aprendizaje son mucho más complejos en términos de qué es necesario almacenar y cómo se almacenará. El propósito de un repositorio digital de objetos de aprendizaje no es simplemente almacenar y distribuir dichos objetos, sino permitir que los mismos sean compartidos por distintos usuarios y, sobre todo, facilitar su reutilización en diferentes actividades formativas.
Cuando los usuarios necesitan realizar una acción formativa recurren a estos repositorios para encontrar los objetos de aprendizaje que mejor se adapten a dicha formación, de esta forma confeccionarán un nuevo curso a partir de los objetos de aprendizaje encontrados en el/los repositorios a los que tenga acceso. Los objetos de aprendizaje encontrados responden a unos criterios de búsqueda que muy posiblemente el usuario estará interesado en el futuro, precisamente para realizar esta labor de mantenimiento de los criterios de búsqueda se propone un sistema basado en agentes software que mantendrá estas búsquedas a través de un sistema federado de repositorios.
2. REPOSITORIOS DE OBJETOS DE APRENDIZAJE
La gran mayoría de los procesos formativos que se realizan actualmente son ofrecidos en modalidad e-learning, dadas las amplias ventajas derivadas de su uso. Por este motivo, cada vez es más frecuente encontrar en Internet recursos electrónicos de calidad, gestionados por plataformas educativas y almacenados en repositorios de objetos de aprendizaje. Sin embargo, hasta hace relativamente poco tiempo, dichos repositorios eran en gran medida incompatibles entre sí. Es decir, no se ofrecía un sistema de búsqueda general que permitiera al usuario buscar en varios repositorios al mismo tiempo, sobre todo si los repositorios albergaban contenidos descritos utilizando diferentes estándares educativos. Como solución a este problema
Conferência IADIS Ibero-Americana WWW/Internet 2012
67

surgieron los denominados sistemas de búsqueda federada, es decir, sistemas que permitían buscar de forma simultánea en diferentes repositorios distribuidos, los describiremos con más detalle en el siguiente apartado.
Los repositorios almacenan objetos de aprendizaje que dentro del mundo del e-learning se entienden como las unidades mínimas en las que se puede organizar el material de formación. Para que su generación, catalogación y empaquetado sea efectivo, es necesario que dicho objeto se construya usando diferentes estándares o especificaciones, cuya principal característica reside en la descripción del objeto utilizando para ello metadatos generalmente basados en el estándar LOM [1].
3. SISTEMAS DE BÚSQUEDA FEDERADA EN REPOSITORIOS
Uno de los pilares básicos en la interoperabilidad entre los repositorios de objetos de aprendizaje es el poder realizar búsquedas y publicaciones de contenido docente. Actualmente los sistemas de búsqueda han evolucionado pasando de realizarse en un solo repositorio a su realización simultánea en varios repositorios distribuidos, esto se conoce como búsqueda federada.
Dentro de estos sistemas nos encontramos con una serie de especificaciones que ayudan a realizar sistemas de búsqueda que facilitan la interoperabilidad. La primera que surgió en 2003 fue la IMS DRI (Digital Repository Interoperability). Es un modelo general de referencia de acceso a diferentes repositorios, propuesto por IMS.
Sin embargo, la tecnología de búsqueda ha evolucionado mucho desde la propuesta de esta especificación por parte de IMS y hoy en día las búsquedas se han generalizado en llamadas a servicios Web que implementan los sistemas de búsqueda federada. Buena prueba de ello lo encontramos en la especificación SQI (Simple Query Interface) [2]. SQI fue definida en el 2005 por el CEN (Comité Europeo de Normalización) para tratar de garantizar la interoperabilidad entre repositorios de objetos de aprendizaje.
También es interesante mencionar la especificación SPI (Simple Publishing Interface) [3] también elaborada por el CEN. En este caso se trata de una API, también basada en servicios Web, para la publicación de datos y metadatos en un repositorio. Provee un protocolo simple y fácil de implementar y de integrar en aplicaciones ya existentes.
4. AGENTES SOFTWARE
Desde el punto de vista de las implicaciones tecnológicas y de diseño, podríamos definir un agente software como un programa autocontenido capaz de controlar su propia toma de decisiones y de actuar, basándose en la percepción de su entorno, para la consecución de uno o más objetivos [4]. Atendiendo más a la perspectiva funcional del usuario, puede definirse como una entidad software en la que se pueden delegar tareas. Esta última definición, aunque más simple, ilustra con claridad el propósito último de los agentes software: la automatización de determinadas tareas comúnmente llevadas a cabo por los usuarios.
Existen aplicaciones basadas en agentes en las que no se produce prácticamente ninguna interacción entre diferentes agentes (agentes software aislados). Por ejemplo, los servicios de búsqueda a través de Internet se basan en el lanzamiento de múltiples agentes autónomos que recorren las páginas Web y seleccionan las secciones más relevantes de la información que encuentran, la clasifican y la almacenan en una base de datos que posteriormente sirve como índice para devolver al usuario la información cuando realiza una consulta. Sin embargo, se pueden crear sociedades de agentes que se coordinen para llevar a cabo diferentes tareas. Estas sociedades son lo que se conoce como sistemas multiagente [5].
Un sistema multiagente es, pues, un sistema compuesto por agentes que se coordinan a través de las relaciones entre ellos. Estas relaciones pueden ser de cooperación, de competencia, o ser una mezcla de ambas.
ISBN: 978-989-8533-11-1 © 2012 IADIS
68

5. SISTEMA PROPUESTO
Como se comentó en la introducción cuando los usuarios necesitan realizar una acción formativa recurren a los repositorios para encontrar los objetos de aprendizaje que mejor se adapten a dicha formación y con estos confeccionar el contenido que formará parte del material formativo. Como sabemos los objetos de aprendizaje pueden variar con el tiempo, por ejemplo actualizando su contenido, o podemos encontrarnos con nuevos objetos de la misma materia de conocimiento en el que un usuario estaba interesado. Estas circunstancias hacen que un repositorio no contenga los mismos objetos de forma estática sino que evoluciona y cambia con el tiempo. Por lo tanto, es necesario encontrar un mecanismo que mantenga a los usuarios informados en aquellas materias que se actualizan o se incorporan a los repositorios y que son de su interés. Para resolver este problema planteamos un sistema federado de repositorios que integre un sistema multiagente encargado de informar al usuario de los cambios y las nuevas incorporaciones de objetos de aprendizaje que son de su interés.
Cuando un usuario realiza una búsqueda de determinados objetos de aprendizaje en un repositorio federado establece unos criterios de búsqueda generalmente basados en los campos de LOM más utilizados. El sistema que proponemos le dará la oportunidad al usuario de guardar dichos criterios de búsqueda y un histórico con los resultados obtenidos. De esta forma se establecerá un sistema de avisos que se activará en el momento en que se detecte que se ha producido o bien un cambio en alguno de los objetos ya encontrados o bien la incorporación de nuevos objetos que coincidan con los criterios de búsqueda. También es importante señalar que si se produce la incorporación de nuevos repositorios al sistema federado automáticamente se revisarán para comprobar la existencia de objetos interesantes para el usuario.
El asunto abordado está presente en la propuesta arquitectónica que IMS presentó para promover la interoperabilidad entre repositorios [6], donde se describen 5 servicios básicos que los repositorios deberían proveer, uno de ellos es Alert/Expose que en la primera fase de la especificación se dejó sin concretar, haciendo únicamente referencia a que podría estar implementado por alguna agregación de servicios al repositorio y que el uso de SMTP podría satisfacer esta función. En el presente trabajo justamente se aborda un modelo para proveer este servicio.
Algunos trabajos proponen usar OAI-PMH en un escenario federado para notificar cambios en un repositorio dentro de la federación [7]. Este modelo tiene el inconveniente de que las notificaciones no se producen en el momento de producirse un cambio, sino en el momento en que una consulta OAI-PMH, programada periódicamente en algún agente produce resultados. Esto acarrea además un tiempo de procesamiento superfluo en el caso en que en el repositorio no haya habido ninguna modificación.
Para realizar esta tarea es muy adecuado el uso de agentes software, ya que como se ha visto en su descripción tendrían un objetivo a cumplir, que sería el de cubrir las necesidades de localización de contenidos docentes de unas determinadas características. Podemos decir que el agente utilizaría, de forma preactiva los datos de búsqueda para automatizar y optimizar la localización de contenidos docentes requeridos por el usuario, de un modo más rápido y eficiente que si el usuario realizara esta labor de forma continuada.
5.1 Desarrollo del Sistema
Para implementar este sistema se necesita incorporar un agente software en cada uno de los repositorios que agrupa el sistema federado, de esta forma cada agente guardará en una base de datos: los criterios de búsqueda de los usuarios de su repositorio y los metadatos de los objetos de aprendizaje encontrados con esos criterios de búsqueda. En el momento en el que se modifican los contenidos de los objetos de aprendizaje o se incorporan nuevos objetos de aprendizaje en cualquier repositorio, el agente debe comprobar la base de datos y activar el sistema de avisos a los usuarios. Para que esto se realice correctamente se debe programar la comunicación entre los agentes de forma que se notifiquen dichos cambios en los objetos de aprendizaje de un determinado repositorio al resto de agentes de los repositorios restantes (figura 1).
Conferência IADIS Ibero-Americana WWW/Internet 2012
69

Figura 1. Sistema propuesto
Para saber si un objeto de aprendizaje se ha actualizado el agente tendrá que comprobar la modificación de dos de los campos LOM de la descripción de metadatos del objeto de aprendizaje que son “versión” y “fecha”, si se ha producido un cambio en cualquiera de estos campos debemos comprobar que ese objeto le pueda interesar a los usuarios del sistema y por tanto avisarles.
Cuando se incorpora un nuevo objeto de aprendizaje en alguno de los repositorios el agente de ese repositorio debe comprobar los criterios de búsqueda de sus usuarios para ver si alcanzan un nivel adecuado de coincidencia esperada y comunicar al resto de agentes los metadatos del nuevo objeto con el fin de que estos hagan sus comprobaciones pertinentes.
5.2 Funcionamiento del Sistema
El sistema federado está organizado como una red P2P, donde los participantes a veces actúan como clientes solicitando contenido y otras como servidores, despachando las solicitudes que les llegan.
El sistema de alertas necesita implantar en cada nodo del sistema un componente que permita difundir los eventos producidos en el repositorio local al resto de la federación y otro componente que permita procesar las alertas que lleguen desde los demás nodos de la federación. De esta forma sobre el sistema existente se va a superponer otro sistema con naturaleza P2P donde cada nodo actúa a veces difundiendo alertas y otras procesándolas. La figura 2 muestra esta primera aproximación a la arquitectura del sistema. El componente que difunde los eventos se ha llamado Despachador de Alertas (DA) y al componente que las recibe Consumidor de Alertas (CA).
Figura 2. Arquitectura simplificada del sistema
ISBN: 978-989-8533-11-1 © 2012 IADIS
70

Los eventos se producen dentro del repositorio de forma que es necesario conducirlos desde allí hasta el DA. En concreto los eventos en que estamos interesados los producen los autores de contenido, ya sea insertando nuevos objetos o modificando los existentes. Los autores utilizan algún tipo de interfaz de usuario (UI) para acceder a los servicios de publicación del repositorio. Con toda generalidad se puede pensar que una tarea de publicación de un objeto involucra, entre otras, a una capa de interfaz de usuario que suele tratarse de un componente Web, donde es posible rastrear las acciones del usuario. La labor del Consumidor de Eventos Interno (CEI) consistiría en capturar los eventos adecuados producidos en el contenedor Web y conducirlos hacia el DA para que este los distribuya entre los CA de la federación (figura 3). El diseño de este consumidor depende de la arquitectura interna de cada repositorio. En la mayor parte de los repositorios de código libre investigados es posible implantar este modelo. Por ejemplo DOOR esta implementado en PHP y en DSpace [8] y Fedora los interfaces de usuario están implementados como contenedores Web de JEE. La especificación Servlet, contenida dentro de JEE define objetos a propósito para recibir notificaciones del componente Web, los “Listener”.
Figura 3. Interacción Consumidor-DA
Para el prototipo desarrollado se ha utilizado DSpace. DSpace posee su propio sistema de eventos que posee una granularidad completamente adecuada al propósito de este trabajo: permite distinguir la creación, instalación, modificación de nuevos objetos o de sus metadatos. DSpace llama consumidores a los objetos interesados en recibir notificaciones de eventos. Un consumidor debe implementar el interfaz Consumer, que describe métodos adecuados por donde entregar el contexto del evento sucedido; el consumidor se debe registrar en el archivo de configuración de DSpace dspace.cfg.
Tanto los CA como los DA forman parte de una misma plataforma de agentes distribuidos en contenedores a través de la federación. Debe existir un contenedor al menos en cada repositorio albergando a su CA y DA. Los contenedores están coordinados por un contenedor principal donde reside un registro de los servicios de alerta desplegados en la federación.
Cuando un CA está interesado en recibir notificaciones de eventos debe empezar por contactar con el registro para localizar los DA disponibles y después suscribirse a cada uno de ellos como se muestra en la figura 4.
Conferência IADIS Ibero-Americana WWW/Internet 2012
71

Figura 4. Actividad del CA
El contenedor principal debería además notificar la aparición o supresión de nuevos contenedores o mejor aún de los DA para que el resto de contenedores pueda suscribirse a sus servicios.
Las preferencias de los clientes de cada repositorio residen en una BBDD a la que deben acceder los CA cuando reciben una notificación de los DA del repositorio. El acceso se hace mediante un DAO que expone servicios para obtener objetos representantes de las preferencias de los clientes.
6. DESARROLLO DE UN PROTOTIPO
Se ha desarrollado un prototipo que resuelve el problema planteado y que además da pie a una arquitectura para publicar eventos asociados a objetos de aprendizaje dentro de una federación de repositorios. La arquitectura propuesta permite que los repositorios de la federación pongan a disposición de la comunidad los eventos producidos en sus objetos de aprendizaje y que si es necesario un agente migre a otro repositorio para observar los eventos de su interés ahorrando en el costo de la carga de red. Se ha desarrollado un prototipo que resuelve el problema planteado al comienzo de este artículo de alertar dentro de la federación sobre la incorporación de nuevos objetos de aprendizaje o su modificación.
En la arquitectura planteada todos los repositorios están provistos de la misma infraestructura para ejecutar agentes: un contenedor de agentes que soporta los mecanismos necesarios para la creación de agentes, su registro y búsqueda, la comunicación y la migración entre contenedores. Todos los contenedores están coordinados por un contenedor principal donde se registran los agentes de cada repositorio y se coordina su ciclo de vida. El prototipo creado se ha desarrollado utilizando JADE [9].
JADE (Java Agent Development Environment) es un framework hecho en Java que facilita el desarrollo de aplicaciones de agentes. JADE cumple por completo con la especificación FIPA [10], cuyo propósito es facilitar la interoperabilidad de aplicaciones de agentes.
El entorno de ejecución de JADE ofrece un Agente Gestor de Sistema (AMS) responsable de administrar el ciclo de vida de los agentes ofreciendo además un servicio de páginas blancas, un agente o varios de ayuda de directorio (DFs) que ofrecen unos servicios de páginas amarillas, donde unos agentes pueden registrar sus servicios y otros utilizarlos y un Agente de Canal de Comunicación (ACC) encargado de intercambiar mensajes entre los agentes. Un agente se identifica por un nombre global único denominado AID. Un agente activo puede acceder a cualquier servicio ofrecido por la plataforma y ejecutar su comportamiento. Un agente puede migrar entre distintos contenedores de la misma plataforma o incluso a otra plataforma.
La comunicación entre agentes se sustenta en ACL, el estándar más ampliamente aceptado de los desarrollados por FIPA. ACL define un modelo basado en primitivas de comunicación llamadas performativas que se utilizan para provocar en el receptor una reacción.
Además JADE dispone de una serie de protocolos de comunicación que estandarizan el uso de las primitivas de comunicación según escenarios usuales. Uno de esos escenarios es el protocolo para suscribirse
ISBN: 978-989-8533-11-1 © 2012 IADIS
72

a un servicio que se usará en el prototipo implementado. En todos los protocolos de comunicación un Agente actúa como iniciador de la comunicación y el otro como agente de repuesta.
Los agentes de una plataforma JADE viven distribuidos en Contenedores, en cada uno de los cuales existe un Controlador del Contenedor con capacidad para crear nuevos agentes. Existe un contenedor especial, el primero en crearse, llamado contenedor principal donde reside el AMS y el DF. Todos los agentes de la plataforma deben registrarse en el AMS para obtener un AID valido.
6.1 Componentes del Sistema de Agentes
La arquitectura del prototipo desarrollado (figura 5) se basa en 4 componentes: 1. CEI. Consumidor de Eventos Interno 2. DA. Despachador de Alertas 3. CA. Consumidor de Alertas 4. DAO. Objetos de Acceso a la Base de Datos de Preferencias
Figura 5. Arquitectura del prototipo
6.1.1 CEI. Consumidor de Eventos Interno
El Consumidor de Eventos Interno está integrado por consumidores u oyentes (Listeners en la jerga JEE) de eventos asociados a los LO (objetos de aprendizaje) producidos en el repositorio local. Es el intermediario con el que el Contenedor de Agentes es notificado. Su finalidad es recuperar y empaquetar en formato adecuado la información asociada a los eventos que vigila y comunicársela al componente de Distribución de Alertas (DA). Si el repositorio está implementado en la especificación JEE, y la administración de eventos se hace desde un componente Web, el CEI podría estar constituido por Listeners asociados a la petición o a la sesión según convenga. De su contexto se extraería la información necesaria para comunicar el evento al siguiente eslabón, el DA, en un formato estandarizado dentro de la federación.
6.1.2 DA. Despachadores de Alertas
Este componente está compuesto por agentes que despachan alertas por la federación a aquellos otros agentes que estén suscritos a sus servicios. Se puede optar por tener un despachador especializado en un evento o gestionar todos los eventos en uno solo. En el prototipo construido existe un solo despachador, un agente JADE que actúa como un participante en el modelo de comunicación FIPA-SUSCRIBE.
Conferência IADIS Ibero-Americana WWW/Internet 2012
73

6.1.3 CA. Consumidores de Alertas
Este componente está formado por agentes suscritos a los servicios de los DA de la agencia, reciben notificaciones de los objetos publicados o modificados en la federación. Cuando se activan deben comenzar por localizar en el contenedor principal todos los DA de eventos en los que están interesados y lanzar una petición de suscripción.
Cuando llega una alerta, el agente extrae la información del objeto y lanza una comparación por cada cliente del repositorio con preferencias registradas, que obtiene con ayuda de un DAO.
6.1.4 DAO. Objetos de Acceso a la Base de Datos de Preferencias
El DAO es el componente que hace de interfaz de acceso a datos, en particular a las preferencias de los Clientes. Su principal cometido es entregar a los agentes que lo soliciten las preferencias de los clientes.
7. CONCLUSIONES
La interoperabilidad entre sistemas de e-learning y más concretamente en los repositorios de objetos de aprendizaje es uno de los problemas a resolver en la actualidad y en la que están surgiendo una gran cantidad de especificaciones y estándares. Su objetivo por lo tanto es construir sistemas de e-learning o repositorios de objetos de aprendizaje totalmente interoperables y que permitan la reutilización de los objetos de aprendizaje que contienen. Nuestro trabajo va un paso más allá resolviendo un problema habitual al componer acciones formativas como es el de su actualización. Con el uso de agentes software en sistemas federados de repositorios de objetos de aprendizaje conseguimos no solo su reutilización sino también su constante actualización y modernización.
AGRADECIMIENTOS
Al grupo de investigación TIFYC - Tecnologías de la Información para la Formación y el Conocimiento del Departamento de Ciencias de la Computación por su apoyo a este trabajo. (http://www.cc.uah.es/tifyc/).
REFERENCIAS
[1] Institute of Electrical and Electronics Engineers, 2002. IEEE Learning Object Metadata (LOM). http://ltsc.ieee.org [2] European Committee for Standardization, 2005. SQI (Simple Query Interface). ftp://ftp.cenorm.be/PUBLIC/CWAs/e-
Europe/WS-LT/cwa15454-00-2005-Nov.pdf [3] European Committee for Standardization, 2010. SPI (Simple Publishing Interface).
ftp://ftp.cen.eu/CEN/Sectors/TCandWorkshops/Workshops/CWA16097.pdf [4] Franklin, S., Graesser, A., 1996. Is it an Agent, or just a Program?: A Taxonomy for Autonomous Agents.
Proceedings of the Third International Workshop on Agent Theories, Architectures, and Languages. Springer-Verlag. [5] Wooldridge, M., 2002. Introduction to MultiAgent Systems. John Wiley & Sons. [6] IMS Global Learning Consortium (2003). Digital Repositories Specification.
http://www.imsglobal.org/digitalrepositories/ [7] Open Archives Initiative Protocol for Metadata Harvesting. http://www.openarchives.org/pmh/ [8] DSpace. http://www.dspace.org [9] JADE (Java Agent Development Environment). http://jade.tilab.com/ [10] FIPA. http://www.fipa.org.
ISBN: 978-989-8533-11-1 © 2012 IADIS
74

O USO DE TECNOLOGIAS DIGITAIS PARA O DESENVOLVIMENTO DE COMPETÊNCIAS
TECNOLÓGICO-MUSICAIS EDUCACIONAIS
Fátima Weber Rosas e Patricia Alejandra Behar Núcleo de Tecnologia Aplicada a Educação (NUTED)-Universidade Federal do Rio Grande do Sul (UFRGS)
Av. Paulo Gama, 110-Prédio 12105 – 4º andar sala 401 -90040-060-Porto Alegre (RS)- Brasil
RESUMO
A presente comunicação apresenta uma matriz de competências básicas, consideradas necessárias para o contexto tecnológico-musical na educação. Como fundamentação teórica discutem-se conceitos como o de competências e, especificamente, as relacionadas aos contextos musical e tecnológico. A construção da matriz foi realizada a partir do uso de tecnologias digitais para a composição musical como, por exemplo, o computador e softwares baseados na Web. Essas tecnologias viabilizam a composição, produção, gravação, edição e a mixagem do áudio digital. O objetivo principal do estudo foi desenvolver um mapeamento das competências necessárias para docentes e discentes atuarem no contexto tecnológico-musical. A metodologia empregada foi o estudo de caso. Para a coleta de dados foi realizado um curso de extensão na modalidade semipresencial e aplicação de dois questionários. Os resultados iniciais deste estudo são apresentados ao final deste artigo. Esta proposta é direcionada tanto para músicos como para leigos em música que almejam utilizar a música como recurso em suas aulas ou na educação musical, nas modalidades de ensino presencial e a distância.
PALAVRAS-CHAVE
Competências tecnológico-musicais, tecnologias musicais educacionais, educação a distância.
1. INTRODUÇÃO
Esta comunicação apresenta os resultados de um estudo1 que investiga as competências necessárias para o contexto tecnológico-musical educacional. Por ser uma proposta que abrange tanto a formação de músicos especialistas como leigos em música, optou-se pela utilização do computador, associado à internet como instrumento para a produção e para a composição musical digital. Por este mesmo motivo, não está prevista a utilização de softwares editores de partituras, nem a utilização de instrumentos musicais tradicionais, embora, dependendo das habilidades dos sujeitos, estes possam ser utilizados em gravações digitais junto aos softwares para composição musical que serão expostos mais adiante.
Swanwick (2003) aponta para atividades que envolvam a técnica, a execução, a composição, o estudo da literatura e a apreciação no desenvolvimento da musicalidade. Segundo ele, é preciso envolver-se com a música profundamente e não apenas escutá-la por acaso. Compreende-se a importância destas atividades para que haja um envolvimento e uma vivência musical, como também da performance no desenvolvimento das competências especializadas. Também se entende que o uso de tecnologias digitais, a exemplo do computador, não substituem a apreciação de um concerto, nem de um show ao vivo. Entretanto, com o advento destas tecnologias, acredita-se que competências para o contexto tecnológico-musical sejam necessárias para que haja uma aprendizagem mais motivadora e significativa numa sociedade cada vez mais informatizada.
No contexto atual, conhecido como Era digital, percebe-se a importância do desenvolvimento de competências tecnológicas de professores, alunos e tutores atuantes na Educação Musical. Da mesma forma, compreende-se que tais competências também são necessárias para docentes que queiram utilizar a música como recurso em suas aulas. Sendo assim, competências em TIC, alfabetização lectoescritora digital são
1 Estudo realizado junto ao Programa de Pós-Graduação em Educação da Universidade Federal do Rio Grande do Sul – Brasil.
Conferência IADIS Ibero-Americana WWW/Internet 2012
75

exemplos de competências para o contexto tecnológico constituindo os pressupostos para o contexto tecnológico-musical.
Acredita-se que o uso de tecnologias digitais dedicadas à música tenha muito a contribuir para as diferentes modalidades de ensino, desde a presencial até a totalmente a distância.
Sendo assim, na seção 2 tratar-se-á do desenvolvimento de competências para a educação e o contexto tecnológico-musical.
Na subseção 2.1 apresentar-se-á questões relacionadas ao contexto musical. Na subseção 2.2 serão abordadas questões relacionadas ao contexto tecnológico, tais como competências
em TIC e competências tecnológico-educacionais de professores. Na seção 3 será apresentada a matriz de competências para o contexto preterido a partir de um curso de
extensão e na seção 4 as conclusões.
2. O DESENVOLVIMENTO DE COMPETÊNCIAS PARA A EDUCAÇÃO: O CONTEXTO TECNOLÓGICO-MUSICAL
Conforme Zabala e Arnau (2010), uma educação voltada para o desenvolvimento de competências concebe o aluno como um todo, em todas as suas dimensões, formando-o para situações reais ao longo da vida. Uma educação focada nesta perspectiva envolve todos os atores (docentes, tutores e discentes) participantes no processo de ensino e de aprendizagem, desde a educação presencial até a totalmente a distância.
Para ser competente é indispensável dispor de conhecimentos juntamente com o domínio de procedimentos, ambos dirigidos por ações atitudinais.
Considerando as colocações de Zabala e Arnau (2010), a competência compreende a mobilização de três principais fatores interligados, sendo eles: conhecimentos (C), habilidades (H) e atitudes (A) formando a sigla CHA. Para os autores, o conhecimento implica em fatos, conceitos e sistemas conceituais, embora de nada adiantem se não houver a compreensão desses. A competência, portanto sugere a capacidade de reflexão e aplicação apoiada no conhecimento teórico.
Em consonância com Zabala e Arnau (2010) Perrenoud (2002) afirma que a competência é a capacidade para enfrentar eficazmente uma série de situações análogas. Ser competente no entendimento desse autor compreende a mobilização de múltiplos recursos cognitivos, saberes e capacidades, de maneira cada vez mais rápida, pertinente e criativa.
Nesse estudo entende-se que, tanto na educação em geral, que considera a música como recurso para atingir um fim, como na educação musical que tem como conteúdo central os aspectos musicais, uma educação voltada para o desenvolvimento de competências auxilia na aproximação entre teoria e prática. Dessa forma, acredita-se que o desenvolvimento de conhecimentos, habilidades e atitudes para o contexto tecnológico-musical seja pertinente para todos os professores ou tutores que almejam atuar em ambas as modalidades de ensino: presencial e a distância.
Contudo, ao investigar quais competências devem ser desenvolvidas por professores, alunos e tutores para o contexto tecnológico-musical educacional, faz-se necessário analisar questões relacionadas ao contexto musical. São elas: Competências musicais podem ser desenvolvidas por todos? Ou ainda, competências musicais para o contexto educacional devem ser desenvolvidas somente por músicos ou também por leigos em música? Quais competências podem ser desenvolvidas por leigos e quais por músicos?
Na seção a seguir se discutirá estas questões relacionadas ao desenvolvimento de competências no contexto musical.
2.1 O Contexto Musical
No senso comum há o mito de que a aprendizagem musical é somente para uns poucos privilegiados, dotados por uma espécie de “dom” ou talento natural. Entretanto, estudos recentes como os de (TAFURI, 2008) e (HARGREAVES, 2000) afirmam que a cultura influencia fortemente as capacidades musicais. Investigações sobre a origem da competência musical como os de (HARGREAVES, 2000), (HARGREAVES, 2005), (TAFURI, 2008) e (PERETZ, 2006) tem influenciado a compreensão sobre o fazer musical, modos de produzir e ouvir música.
ISBN: 978-989-8533-11-1 © 2012 IADIS
76

Hargreaves (2000), ao falar de competência musical é favorável à definição proposta por Stefani (2007) como sendo “[...] a capacidade de produzir sentido mediante ou através da ‘música’ no sentido lato, ou seja, em toda aquela imensa e heterogênea massa de práticas coletivas e experiências individuais que implicam o som [...]”. (STEFANI, 2007, p.01). Tanto Hargreaves (2000) quanto Stefani (2007) afirmam que a atividade musical pode ser vista como um todo e que possui características comuns.
Para Stefani (2007) a competência musical significa “[...] a habilidade de identificar e/ou estabelecer correlações adicionais ou estruturantes, assim como organizações correlatas entre eventos sonoros e seu contexto cultural.” (STEFANI, 2007, p.02). O autor refere-se à produção musical realizada por músicos e/ou à fruição de ouvintes, não fazendo uma separação, mas tratando a competência musical de maneira global, tanto para músicos como para leigos em música. Em seu Modelo de Competência Musical (MCM) há a representação simultânea tanto da competência especializada quanto da comum a todos ou geral.
Já a pesquisadora Tafuri (2008), em seus estudos sobre a musicalidade na infância diz que há uma predisposição para a música desde muito cedo, porém, é necessária a educação para que o indivíduo desenvolva essas habilidades. Segundo a autora, a maneira como o indivíduo percebe e interpreta a informação musical que chega ao seu cérebro depende dos conhecimentos, interesses, atitudes, personalidade, autoconfiança, temperamento, entre outros.
Hargreaves (2005), ao tratar de habilidades afirma que as pessoas costumam vê-las de diferentes maneiras. O pensamento positivo ou a autoconfiança é fundamental para o desenvolvimento de habilidades em qualquer área, inclusive a musical. Um aluno que se considera “não musical” devido a um comentário despercebido de um professor ou até mesmo de um colega, pode conduzir a um ciclo de “não-tentar”. O autor também afirma que habilidades de manuseio de softwares editores de áudio para gravação e mixagem são imprescindíveis para um músico na atualidade.
Semelhantemente à ideia de Stefani (2007) e Hargreaves (2000 e 2005), se é favorável que todos possuem a capacidade para desenvolver competências musicais. Entende-se que as competências especializadas são aquelas próprias de quem pretende aprofundar-se no estudo de Teoria e Percepção Musical e da performance. No presente estudo, serão enfocadas somente as competências gerais, que podem ser desenvolvidas também por leigos em música.
A seguir tratar-se-á de questões relacionadas ao desenvolvimento de competências para o contexto tecnológico.
2.2 O Contexto Tecnológico
Segundo Coll e Illera (2010) a importância das Tecnologias da Informação e Comunicação (TIC) cresce cada vez mais na sociedade atual, conhecida por sociedade da informação (SI). De acordo com esses autores, diante desse contexto o conhecimento e o domínio das TIC são necessários, pois possibilitam a aprendizagem além da sala de aula.
(GRAELLS, 2007 apud RAPOSO, 2012) acrescenta que o uso das TIC leva a novas formas de ler e escrever, ou seja, ao que ele chama de lectoescrita eletrônica, cujo conteúdo encontra-se em diversos suportes como o computador, os telefones celulares, os tocadores de mp3 digitais, etc. A principal característica destes é a leitura não linear, quase simultânea de vários textos e a possibilidade de escrita coletiva.
A partir do paralelo entre competências lectoescritoras nos suportes tradicionais e digitais, Raposo (2012) propõe o termo alfabetização lectoescritora digital como sendo “[...] o processo de aquisição de habilidades que permite aos sujeitos comunicarem-se e situarem-se de maneira eficiente no mundo digital.” (RAPOSO, 2012, p.72). Para a autora a comunicação e expressão no meio digital implicam no domínio de competências de leitura e de escrita nesses suportes.
Baseados nesses pressupostos, Coll e Illera (2010) propõem competências básicas no âmbito das TIC para a formação de adultos, conforme tabela 1.
Conferência IADIS Ibero-Americana WWW/Internet 2012
77

Tabela 1. Competências básicas em TIC. Fonte: (COLL e ILLERA, 2010, p.303).
As competências básicas em TIC na formação das pessoas adultas Dimensão: os sistemas informáticos(hardware, software e redes)
1. Conhecer os elementos básicos do computador e suas funções; 2. Instalar e desinstalar programas (seguindo as instruções da tela ou do manual);
Dimensão: o sistema operacional
3. Conhecer a terminologia básica do sistema operacional (arquivos, pastas, programas, etc.). 4. Salvar e recuperar a informação no computador e em diferentes suportes (pendrives, disco rígido, pastas, etc.); 5. Realizar atividades básicas de manutenção do sistema (antivírus, cópias de segurança, eliminar informações desnecessárias, etc.);
Dimensão: uso da internet
6. Utilizar os navegadores de internet (navegar, armazenar, recuperar, classificar e imprimir informações). 7. Utilizar os buscadores para localizar informações específicas na internet. 8. Enviar e receber mensagens de correio eletrônico, organizar a agenda de endereços e anexar arquivos. 9. Utilizar as TIC responsavelmente como meio de comunicação interpessoal em grupos (chats, fóruns, etc).
Dimensão: uso de programas básicos
10. Utilizar um editor de textos para redigir documentos, armazená-los e impirmi-los; 11. Utilizar um editor gráfico para fazer desenhos e gráficos simples e armazenar e imprimir o trabalho; 12. Utilizar uma ferramenta de apresentação para organizar e expor a informação;
Dimensão: atitudes necessárias com as TIC
13. Desenvolver uma atitude aberta, responsável e crítica frente às contribuições das tecnologias; 14. Valorizar as vantagens que a tecnologia oferece para a aprendizagem de todo tipo de conhecimentos a para a comunicação.
Segundo estudos de Palfrey e Gasser (2011), Coll e Illera (2011), Raposo (2012) e Ohler (2011), cada vez mais as tecnologias serão utilizadas em diversas áreas do conhecimento e com diversas funções na sociedade. Os futuros profissionais necessitarão de competências para atuar num mundo cada vez mais informado e informatizado.
Conforme apontam Palfrey e Gasser (2011), a geração net é compreendida pelos sujeitos nascidos depois da existência das tecnologias digitais. Palfrey e Gasser (2011), em consonância com Prensky (2001) denominam esta geração de Nativos Digitais. Para estes sujeitos, o ciberespaço apresenta oportunidades para aprenderem a criar, expressar e desfrutar novas obras de arte.
Ao falar sobre a educação para as crianças da Era digital, Ohler (2011) aponta para a existência de duas perspectivas, a do ensino para duas vidas ou para apenas uma. Segundo o autor, a perspectiva de ensinar como se os alunos tivessem duas vidas é favorável que os alunos tenham uma vida tradicional na escola, desconectada da vida digital. Nesta perspectiva as tecnologias digitais são tidas como um problema por serem caras e por distraírem. A perspectiva de ensinar como se os alunos tivessem uma vida apenas é favorável à integração das repercussões sociais, ambientais e pessoais de um estilo de vida tecnológico no currículo escolar. Os professores devem ajudar os alunos a viver uma vida integrada, incentivando-os a utilizar a tecnologia na escola, na comunidade e na sociedade de forma criativa e responsável, ensinando-os a serem cidadãos digitais. O autor afirma que algumas escolas já começaram a abordar questões acerca da “educação para a formação de um caráter digital”.2 (OHLER, 2011, p.01). Segundo o autor é preciso criar programas formais de cidadania digital que lidam com a educação para a formação de um caráter na Era digital. Para Ohler (2011) a única forma de orientar os alunos para se tornarem cidadãos digitais é incorporar as tecnologias digitais, tão familiares a eles, na escola.
2 Tradução das autoras de: “digital character education”. (OHLER, 2011, p.01).
ISBN: 978-989-8533-11-1 © 2012 IADIS
78

Diante de destas questões, entende-se que é preciso mais do que integrar e se apropriar das tecnologias na escola. É preciso orientar os alunos da Era digital para que se tornem cidadãos sociáveis, responsáveis e éticos, promovendo assim, uma cidadania digital.
Já Põldoja (et al., 2011) defende que nas últimas décadas, escolas de muitos países têm investido no emprego das TIC. O autor afirma que muitos países têm implementado a avaliação do desempenho de professores no uso das TIC através da abordagem de competências. Dentre as iniciativas apontadas pelo autor, destacam-se algumas, conforme tabela 2.
Tabela 2. Iniciativas internacionais para o desenvolvimento de competências tecnológico-educacionais, adaptado e traduzido pelas autoras.
Fonte: (PÕLDOJA, ET AL., 2011, p.122-124)
Nome Sigla Principais objetivos Internacional Computer Driving License
ICDL/ECDL Conhecimentos e conceitos básicos de Tecnologia da Informação (TI). Nível básico de alfabetização digital.
UNESCO ICT Competency Framework for Teachers
ICT-CFT Aperfeiçoamento do uso das TIC em atividades profissionais através de um modelo nacional de competência. Este modelo apresenta seis subdomínios em relação ao trabalho dos professores: visão política, currículo e avaliação, pedagogia, TIC, organização e administração e desenvolvimento profissional de professores.
National Educational Technology Standards for Teachers
NETS-T O Modelo Nacional de Tecnologia Educacional para Professores foi desenvolvido em 2008 pela Internacional Society for Technology in Education (ISTE). Seu objetivo é tornar os professores em modelos para alunos com conhecimentos e habilidades da Era digital.
Educational Technology Competency Model/ DigiMina Project
ETCM Segundo Põldoja (et al., 2011) este modelo está baseado no ISTE NETS-T/2008 e busca desenvolver competências de professores no ensino primário, secundário, profissional e superior. O modelo é composto por um núcleo com cinco áreas de competências para o contexto tecnológico educacional na Era digital: 1. Facilitar e inspirar os alunos em um ambiente digital; 2. Projetar e desenvolver experiências de aprendizagem e ambientes de aprendizagem; 3. Modelagem e concepção de ambientes de trabalho; 4. Promover a cidadania digital e a responsabilidade; 5. Engajar-se em um crescimento profissional.
Conforme Põldoja (et al., 2011) nos Países Baixos o modelo de competências em TIC para professores tem sido na linha do (NTES-T), onde as competências são agrupadas em subdomínios: currículo, pedagogia, desenvolvimento profissional, organização, políticas, ética, inovação e técnica.
No Reino Unido a avaliação das competências em TIC dos professores é mais geral, utilizando testes online como parte do exame de professores, chamado Qualified Teacher Status (QTS).
Na Estônia o modelo adotado, segundo Põldoja (et.al., 2011) foi o Educational Technology Competency Model (ETCM). O ETCM está baseado no Internacional Society for Technology in Education (ISTE) NTES-T, desenvolvido em 2008. Segundo o autor, o Projeto DigiMina engloba um software baseado na Web que avalia o desempenho de professores em suas práticas. Este software recupera informações de repositórios de aprendizagem de softwares utilizados pelos professores, avaliando as competências em diferentes níveis, diante de soluções para problemas autênticos. Ao final das interações com essa tecnologia, o DigMina apresenta um perfil de competências destes professores.
Acredita-se que o uso as tecnologias digitais a exemplo dos objetos de aprendizagem (OA), das ferramentas online, juntamente às TIC no âmbito educacional venha contribuir para uma educação motivadora e atualizada, preparando o aluno para atuar numa sociedade que se baseia na informação.
Entende-se que essas competências próprias do contexto tecnológico apresentadas nesta subseção não são específicas do contexto musical. Porém considera-se que sejam fundamentais para que o sujeito desenvolva competências tecnológico-musicais.
Conferência IADIS Ibero-Americana WWW/Internet 2012
79

Na próxima seção, tratar-se-á da composição musical digital no contexto educacional, realizada através do computador e de tecnologias digitais online como uma das maneiras de desenvolver competências para este contexto.
3. A COMPOSIÇÃO MUSICAL DIGITAL NO DESENVOLVIMENTO DE COMPETÊNCIAS TECNOLÓGICO-MUSICAIS
Segundo Fritsch (2008) no contexto tecnológico-digital destaca-se a possibilidade de utilização e criação de técnicas de processamento e transformação do áudio digital ao realizar uma composição musical. Os recursos digitais podem ser poderosos aliados no processo de ensino e de aprendizagem musical. Diante dessa realidade, acredita-se que seja necessário que professores e alunos desenvolvam competências para lidar com essas tecnologias.
Com base nos pressupostos, realizou-se um Projeto Piloto, parte da coleta de dados de uma pesquisa que consistiu num curso de extensão Universitária denominado “Composição Musical Digital para a Educação”. A metodologia adotada foi um estudo de caso, que segundo Gil (2002) consiste num estudo profundo e exaustivo de um ou poucos objetos, de maneira que permita seu amplo e detalhado conhecimento. O objetivo geral do curso foi desenvolver um mapeamento de competências para o contexto tecnológico-musical educacional a partir da produção e composição musical com o uso de tecnologias digitais gratuitas. Os objetivos secundários foram (1) investigar os conhecimentos e experiências prévias dos alunos a respeito das tecnologias musicais digitais; (2) analisar como os alunos organizam o material sonoro no contexto virtual; (3) explorar as possibilidades do objeto de aprendizagem (OA) CompMUS através de um curso de extensão.
O público-alvo do curso foi composto por estudantes de Licenciatura em Música, estudantes de Pedagogia e outras Licenciaturas, professores da Educação Básica, estudantes de Pós-Graduação, professores de música e professores dos diversos níveis de Ensino.
Um mapeamento das competências básicas para o contexto tecnológico-musical foi realizado após o término do curso, a partir da análise das composições musicais dos alunos, dos questionários e dos registros no ambiente virtual de aprendizagem (AVA) ROODA3. Na tabela 3 apresentam-se as competências para o contexto preterido, com seus três elementos essenciais: os conhecimentos, as habilidades e as atitudes.
Tabela 3. Competências para o contexto tecnológico-musical educacional a partir do uso de tecnologias digitais Fonte: (ROSAS e BEHAR, 2012, p.08)
CONHECIMENTOS (C)
HABILIDADES (H)
ATITUDES (A)
- Conhecer diferentes formatos de audio;
- Conhecer efeitos para o tratamento do áudio;
- Conhecer pressupostos históricos da música eletroacústica;
- Noções de forma e estruturação musical para escolher e organizar o material sonoro disponível nas ferramentas; - Ler e interpertar mensagens virtuais e de multimídia; - Noções de harmonia e cifragem de acordes de acordo com o sistema tonal ocidental para organizar o material sonoro na composição musical digital;
- Produzir e compor música digital de maneira coletiva/colaborativa; - Converter formatos de áudio passíveis de serem transmitidos via internet; - Configurar a placa de som de acordo com o sistema operacional e o software empegado; - Utilizar softwares e ferramentas online, principalmente as gratuitas para a composição e produção musical; - Utilizar softwares gratuitos para gravação, edição e mixagem de áudio; - Utilizar as Tecnologias de Informação e Comunicação (TIC) para
- Abertura a novas sonoridades provindas das tecnologias digitais; - Autoconfiança; - Capacidade para motivar-se e motivar os outros; - Pró-ativo (capaz de controlar a estrutura e o conteúdo na composição musical digital); - Ter flexibilidada para mudanças; - Ser responsável na utilização das TIC; - Saber trabalhar de forma autônoma; - Abertura a diversos idiomas musicais, como o popular, o erudito e o contemporâneo.
3 https://www.ead.ufrgs.br/rooda/
ISBN: 978-989-8533-11-1 © 2012 IADIS
80

as trocas sociais; - Instalar e desinstalar softwares musicais;
As composições dos alunos foram realizadas através do computador, caracterizando uma composição
musical digital, cuja sigla é CMD. A maioria dos softwares utilizados para a CMD durante o curso possuem características da Web 2.0 e seu funcionamento é baseado na Web. Neste trabalho, tais softwares são chamados de ferramentas online. Os softwares empregados durante o curso anteriormente citado foram o COoperative Music Prototype DESign4, cuja sigla é CODES, o ClubCreate/MusicLab5 e o JAMSTUDIO6.
No CODES, segundo Miletto (et al., 2005) é possível construir pequenas peças musicais chamadas de prototipações. Este software também possibilita o compartilhamento das prototipações criadas, permitindo um trabalho colaborativo.
Para a edição e mixagem das composições digitais foi empregado o software Audacity. Além das ferramentas citadas, utilizou-se um objeto de aprendizagem (OA) que deu origem ao nome do
curso Composição Musical Digital para a Educação (CompMUS)7. Este OA foi desenvolvido pela equipe interdisciplinar do Núcleo de Tecnologia Digital Aplicada a Educação (NUTED) da Universidade Federal do Rio Grande do Sul (UFRGS) e serviu como apoio teórico/didático durante o curso.
4. CONCLUSÕES
Após uma análise inicial dos dados obtidos mediante o curso de extensão Composição Musical Digital para a Educação, conclui-se que, em consonância com a afirmação de Tafuri (2008) a educação é necessária para o desenvolvimento de habilidades musicais. Um exemplo disso é a construção de noções de forma e estruturação musical e do conceito e ordenamento de cifras. Também o interesse, as atitudes, a autoconfiança, conforme apontado pela autora e por Hargreaves (2005) são fatores que fortemente levam os alunos a perseverar e a buscar soluções para as dificuldades encontradas. Observou-se também que o OA CompMUS auxiliou na superação das dificuldades, demonstrando ser fundamental como apoio didático/teórico durante o curso.
Conclui-se, portanto, que o uso de tecnologias digitais como o computador, juntamente com ferramentas para composição musical e objetos de aprendizagem quando utilizados de forma integrada, podem assessorar o mapeamento de competências tecnológico-musicais para a educação, ao mesmo tempo em que auxiliam no desenvolvimento das mesmas nos sujeitos participantes do estudo. Ao mapear tais competências, obteve-se um perfil dos sujeitos que almejam atuar neste contexto.
O uso destas tecnologias na educação justifica-se pelo fato dos estudantes da Era digital serem usuários ávidos das mesmas. Diante disso, acredita-se que os cursos de licenciatura e de formação continuada devam preparar os professores para atuarem na Educação Musical e/ou a utilizarem a música em suas aulas, desde a educação presencial até a totalmente a distância. Para isso, necessitam de formação adequada, tanto musical quanto tecnológica. Compreende-se que esta formação deva incluir o desenvolvimento de conhecimentos, habilidades e atitudes, que conforme Zabala e Arnau (2010) são os três elementos essenciais da competência.
Entende-se que as competências para o contexto tecnológico-musical educacional aqui apresentadas são iniciais e abrem perspectivas para novas pesquisas a respeito do assunto.
4 http://gia.inf.ufrgs.br/CODES3/# 5 http://remixer.clubcreate.com/v2/musiclab/launch.html 6 http://www.jamstudio.com/Studio/index.htm 7 http://www.nuted.ufrgs.br/objetos_de_aprendizagem/2011/CompMUS/#
Conferência IADIS Ibero-Americana WWW/Internet 2012
81

REFERÊNCIAS
COLL, C. e ILLERA, J. L. R., 2010. Alfabetização, novas alfabetizações e alfabetização digital: as TIC no currículo escolar. In: COLL e col. (org), Psicologia da Educação Virtual: Aprender e Ensinar com as Tecnologias da Informação e da Comunicação. Artmed, Porto Alegre-RS, Brasil. pp. 289-310.
FRITSCH, E., 2008.Música eletrônica: uma introdução ilustrada. Editora da UFRGS , Porto Alegre-RS, Brasil. GIL, A. C., 2002. Como elaborar projetos de pesquisa. São Paulo: Ed. Atlas. HARGREAVES, D., 2005. Within you without you: música, aprendizagem e identidade. Tradução de Beatriz Ilari.
Revista eletrônica de musicologia. Volume IX, Outubro. Disponível em: <http://www.rem.ufpr.br/_REM/REMv9-1/hargreaves.pdf> Acesso em: 21 abr. 2012.
HARGREAVES, D., 2000. The development of artistic and musical competence. In.: DELIEGE, Irene and SLOBODA, David. Musical Beginnings. Origins and Development of Musical Competence. Oxford: Oxford University Press. pp.145-170.
MILETTO, E. M., et al.,2005. CODES: Um Ambiente para Prototipação Musical Cooperativa Baseado na Web. In: XXV Congresso da Sociedade Brasileira de Computação – SBC. Unisinos, São Leopoldo-RS, Brasil.pp.1832-1846.
OHLER, J., 2011. Character Education for the Digital Age. In.: EL Educational Leadership, volume 68, number 5, p.01. PALFREY, J. e GASSER, U. 2011. Nascidos na era digital: entendendo a primeira geração de nativos digitais.
Tradução de Magda França Lopes. Artmed, Porto Alegre-RS, Brasil. PERETZ, I., 2000. The nature of music from biological perspective. In.: Cognition. Vol.100. pp.1-32. PERRENOUD, P.; THURLER, M. G., 2002. As competências para ensinar no século XXI: a formação dos professores e
o desafio da avaliação. Trad.:Cláudia Schilling; Fátima Murad. Porto Alegre: Artmed. PÕLDOJA, H., et al., 2011. Web-Based Selg- and Peer-Assessment of Teacher’s Educational Technology Competencies.
The 10th Internacional Conference on Web-based Learning (ICWL 2011).8-10 December. Hong Kong. China. pp.122-131.
PRENSKY, M., 2001. Digital Natives, Digital Immigrants. In: On the Horizon. NBC University Press, Vol. 9, nº5, pp.01-06.
RAPOSO, M. R., 2012. Competência digital e a EAD. In.: LITTO, F. e FORMIGA, M. (Org). Educação a distância: o estado da arte vol2. 2ª edição. São Paulo: Pearson Education do Brasil. pp.71-74.
ROSAS, F.W. e BEHAR, P.A., 2012. CompMUS: um objeto de aprendizagem para auxiliar no desenvolvimento de competências para o contexto tecnológico-musical. Revista Novas Tecnologias na Educação. Vol.10. nº1. CINTED/UFRGS. Porto Alegre-RS, Brasil.pp.01-10.
STEFANI, G., 2007. Uma teoria de Competência musical. Trad. Martha Ulhôa, Musica&Cultura [online], n.2, pp. 1-12. Disponível em: < http://www.musicaecultura.ufba.br/artigo_stefani_01.htm> Acesso em: 14 mai. 2012.
SWANWICK, K., 2003. Ensinando música musicalmente. Tradução de Alda Oliveira e Cristina Tourinho. Ed. Moderna. São Paulo-SP, Brasil.
TAFURI, J., 2008. Infant Musicality. New research for educators and parents. Graham Welch, trans. Elizabeth Hawkins. Aldershot: Sempre: Ashgate Publishing Limited.
ZABALA, A.; ARNAU, L., 2010. Como aprender e ensinar competências. Tradução de Carlos Henrique Lucas Lima. Porto Alegre: Artmed.
ISBN: 978-989-8533-11-1 © 2012 IADIS
82

UM MODELO PARA NA DETECÇÃO DO INTERESSE EM AMBIENTES DE EAD ATRAVÉS DA VISUALIZAÇÃO
COMPUTACIONAL
Maurício José Viana Amorim1, Patricia Alejandra Behar2 e Magda Bercht2 1Instituto de Informática – Instituto Federal Fluminense campus Centro, Av.Dr.Siqueira,273
– Campos dos Goytacazes – RJ – Brazil 2Programa de Pós-Graduação em Informática na Educação , Universidade Federal do Rio Grande do Sul (UFRGS)
Caixa Postal 15.064 – 91.501-970 – Porto Alegre – RS – Brasil
RESUMO
Este artigo apresenta um modelo para detecção do interesse dos alunos quando em interação com Ambientes de educação a Distância. Inicialmente são apresentados ferramentas de software criadas para obtenção das imagens. Em seguida, descreve um experimento onde trinta e um alunos foram submetidos a um Objeto de Aprendizagem com capacidade de Visualização Computacional. As imagens desta interação foram analisadas. A partir desta análise, são destacados os Movimentos Corporais Gestuais e Posturais, pré-selecionados a partir da bibliografia, que obtiveram os melhores resultados na inferência do interesse. Estes movimentos, chamados de Indicadores de Interesse. Eles servem de base para o Modelo de Inferência do Interesse, que é apresentado no presente estudo.
PALAVRAS-CHAVE
Visão Computacional, Estado Afetivo, Interesse, Tédio, Educação a Distância , Comunicação Não Verbal
1. INTRODUÇÃO
Quando se pensa numa câmera de imagens para a web, webcam, como será utilizado neste artigo, logo nos vem à cena uma pessoa conversando e visualizando o seu interlocutor através de programas de mensagens instantâneas como o MSN e Skype. Amorim & Bercht (2009) afirmam que as redes pessoais de mensagens instantâneas são as aplicações onde mais utiliza-se a webcam. Essa popularização tornou-se possível a partir do aumento da capacidade dos links com a internet e do barateamento dos valores cobrados pelas operadoras. Com links mais velozes, novas mídias podem ser utilizadas na comunicação, entre elas a voz e o vídeo. Mas os programas de mensagem instantânea não são os únicos beneficiados com esta nova realidade. A educação e principalmente, em sua vertente à distância (EAD), entra em uma nova era, onde o uso da webcam tende a ser um dos vértices tecnológicos. Este artigo aborda justamente essa tendência, o uso da Visualização Computacional em ambientes de Educação à Distância (EaD).
Na EaD, o professor e o aluno elegem um conjunto de Tecnologias da Informação e Comunicação (TICs) para que ocorra a comunicação entre ambos e a interação para aprendizagem. Essa comunicação e interação podem ocorrer através dos Ambientes Virtuais de Aprendizagem (AVAs), dos Objetos de Aprendizagem (OAs), de e-mails, de vídeo ou áudio conferência ou outras TICs. Todos meios de comunicação e interação entre os professores e os alunos são entendidas no contexto deste trabalho como ambiente de EaD1. Nestes ambientes, a comunicação muitas vezes ocorre de maneira assíncrona, onde os interagentes (professores/alunos) não estão conectados ao mesmo tempo, fato que dificulta a percepção das dificuldades e o interesse do aluno por parte do professor (Amorim, 2012).
Na aula presencial, o professor pode perceber o interesse do aluno e a partir deste, é capaz de modificar a estratégia pedagógica de forma a buscar aumentar ou manter esse nível de interesse. Boa parte dessa
1 Ambiente de Educação à Distância (EaD) abrange os Ambientes Virtuais de Aprendizagem, Objetos de Aprendizagem e as outras Tecnologias da Informação e Comunicação utilizadas durante a interação entre os alunos e os professores.
Conferência IADIS Ibero-Americana WWW/Internet 2012
83

percepção ocorre através da visão. Sendo a visão é um dos mais importantes sentidos do ser humano no apoio à detecção do interesse2, a falta deste meio de sensoriamento causa carências quando se passa para o paradigma da EaD, onde a Visualização Computacional (VC) é pouco utilizada (Prata e Nascimento, 2007).
Neste sentido, este trabalho busca indicadores que possam ser utilizados para a inferência do interesse a partir da análise de imagens de alunos em interação com ambientes de EaD e a partir deste propõe um Modelo para Inferência do Interesse.
2. FERRAMENTAS PARA OBTENÇÃO DE IMAGENS EM AMBIENTES DE EAD
No decorrer desta pesquisa foram construídos três (3) artefatos com objetivo de obtenção das imagens em ambientes de EaD. A construção deles possibilita dotar ambientes de EaD da capacidade de VC. Eles são denominados por WICFramework, QuizWebcamXML e o SQLOA e serão apresentados a seguir.
Figura 1. Detalhamento do QuizWebcamXML Fonte: o autor
O WICFramework foi detalhado em (Amorim et al, 2010). Ele é um framework para captura das imagens da câmera do usuário e direcionamento desta para um servidor devidamente preparado para recebê-las. Toda a parte de transmissão das imagens capturadas e recepção destas por parte do servidor é função deste framework. Ele é basicamente composto por dois módulos: o módulo cliente que, liga a câmera, obtém as imagens e as transmite; e o módulo servidor que recebe as imagens, ordena, nomeia e grava (vide Figura 1).
O segundo artefato construído é denominado por QuizWebcamXML (Amorim et al, 2011a). Ele é uma ferramenta abrangendo três módulos: O módulo XML é responsável por abrir o arquivo “.xml” de mesmo nome da ferramenta e extrair dele as questões, figuras, possíveis respostas e o gabarito; o módulo Quiz cuja função é montar o questionário com os parâmetros fornecidos pelo módulo XML; e por último, o módulo Webcam tem a finalidade de ligar a câmera do usuário, registrar as imagens e enviá-las para o servidor. As Figura 2 e Figura 3 exemplificam o seu funcionamento.
2 Esta premissa é baseada nos trabalhos de Pease e Pease (2005), Weil e Tompakow (2011), Cohen (2011) e Argyle (1988). Em seus trabalhos estes pesquisadores apresentam diversas características visuais que indicam a ocorrência do estado afetivo de interesse.
ISBN: 978-989-8533-11-1 © 2012 IADIS
84

Figura 2. Detalhamento do QuizWebcamXML Figura 3. Tela do QuizWebcamXML em funcionamento
Devido a sua versatilidade e parametrização, a ferramenta QuizWebcamXML pode ser utilizada para
aplicar qualquer conteúdo em qualquer disciplina. A Figura 3 mostra o QuizWebcamXML em funcionamento.
O último artefato construído foi o objeto de aprendizagem denominado de SQLOA (Amorim et al, 2011b). O SQLOA tem por objetivo apoiar o ensino da disciplina de banco de dados. Através dele o aluno identifica-se, utiliza o material didático e tem acesso aos módulos que possuem VC, no caso a vídeoaula e o questionário. Ele mantém em sua base: os dados do aluno, as respostas dos questionários executados e o histórico de utilização dos módulos.
3. COLETA DE DADOS E ANÁLISE DAS IMAGNES
Na análise das imagens, agruparam-se os alunos por desempenho. A ideia central inicial foi buscar nos vídeos da sua interação de cada grupo padrões de comportamento comuns que indicassem o grau de interesse. Esta associação de desempenho x interesse tem por base a premissa que alunos mais interessados obtêm desempenho superior aos alunos menos interessados (Chardosim, 2011).
Para o nivelamento dos alunos, foi aplicado um pré-teste. O pré-teste tinha a finalidade de eliminar os alunos cujo desempenho pudesse não condizer com o padrão de comportamento esperado pela premissa. Baseado na teoria da Aprendizagem Significativa (Ausubel et al, 1978), isso poderia ocorrer em duas situações:
• Supondo que o aluno já conhecesse o conteúdo, ele poderia demonstrar desinteresse (tédio) perante as câmeras e mesmo assim obter um bom desempenho;
• O inverso também poderia acontecer. Supondo que o aluno não conhecesse o conteúdo, ele poderia demonstrar interesse, e não ter subsunçores necessários a uma Aprendizagem Significativa. Dessa forma, apesar dos indicativos comportamentais do estado afetivo de interesse se apresentarem, seu desempenho será ruim.
Dessa forma o pré-teste foi aplicado objetivando diagnosticar e separar os indivíduos que já conhecem o conteúdo e os que não tinham subsunçores necessários à Aprendizagem Significativa dos conteúdos ensinados dos demais alunos. Segundo Ausubel (1978), a aprendizagem é dita significativa quando uma nova informação (conceito, ideia, proposição) adquire significados para o aprendiz através de uma espécie de ancoragem em aspectos relevantes da estrutura cognitiva pré-existente do indivíduo.
Ao todo trinta e um (31) alunos foram submetidos aos experimentos. Eles faziam parte de três turmas da disciplina de Administração para Banco de Dados do Curso de Sistema de Informação do Instituto Federal Fluminense, RJ. Destes, trinta (30) foram classificados como aptos. Ressalta-se o fato de todos os alunos participarem de todas as fases, mas apenas os escolhidos na fase de pré-teste tiveram as suas MCGPs analisadas (Amorim et al, 2011a).
A seguir, os alunos foram convidados a assistir à Videoaula sobre Restrições de Integridade e também a responder ao Quiz criado contendo questões sobre o assunto. Tanto a Videoaula quanto o Quiz fazem parte
Conferência IADIS Ibero-Americana WWW/Internet 2012
85

do SQLOA e através da capacidade de VC do OA, as imagens desta interação(vídeos) foram capturadas. Além dos vídeos, o desempenho obtido no Quiz foi utilizado nas conclusões.
De posse dos dados, segui-se um levantamento dos MCGPs encontrados nas imagens obtidas. A partir desse levantamento e sua associação com desempenho obtido no Quiz buscou-se os MCGPs que melhor indicavam o estado afetivo de interesse. Além deste levantamento, uma entrevista foi realizada com os alunos. Ela objetivava o detalhamento de fenômenos que contradiziam a bibliografia ou tentar explicar algum comportamento novo ainda não relatado. A Figura 4 esquematiza o processo descrito. Cujos resultados serão apresentados na próxima seção.
Figura 4. Processo metodológico
4. INDICADORES DE INTERESSE
A partir da separação da amostra em grupos, segundo o desempenho no Quiz, iniciou-se a análise das imagens. Nesta fase, os vídeos das interações dos alunos de maior e menor desempenho foram assistidos e os MCGPs encontrados foram assinalados e contabilizados em suas fichas. A Tabela 1 mostra os MCGPs encontrados nos vídeos.
Tabela 1. Principais MCGPs encontrados nos vídeos
Gestos Descrição Gestos Descrição 11 Balançar a cabeça afirmativamente 18 Piscada Longa 12 Balançar a cabeça negativamente 19 Dar de ombros 13 Bater atrás da nuca 20 Coçar a cabeça, boca, queixo, orelha ou nariz 14 Esconder a boca 21 Ajeitar-se na cadeira 15 Franzir a testa 22 Aproximar-se e voltar 16 Ajeitar a boca 23 Afastar-se e voltar 17 Olhar para o lado 24 Balançar o corpo
Além dos MCGPs descritos acima, com base na teoria sobre Comunicação Não Verbal (CNV), foram
criadas seis taxas: a taxa de foco (Jolivet, 1967), taxa de tensão aparente de (Kapoor e Picard, 2005; Argyle, 1988), taxa de apoio da cabeça (Pease e Pease, 2005), taxa de mobilidade facial aparente (Kapoor e Picard, 2005), taxa de mobilidade corporal aparente (Hakura et al, 2010; Kapoor e Picard, 2005) e taxa de piscada (Argyle, 1988; Pease e Pease, 2005).
A classificação das imagens através das taxas obedeceu à escala de 1 a 5. Amorim (2012) detalha o processo de escolha e criação desses indicadores. Dessa forma, as fichas com o levantamento quantitativo de cada aluno passaram a ter um local para anotação dessas taxas com suas respectivas métricas. A Tabela 2 apresenta as taxas criadas. Um resumo do levantamento feito é visto na Tabela 3. Nela observa-se cada aluno do grupo de maior e menor escores (Grupo 1 e Grupo 5) e suas respectivas MCGPs.
A escolha dos Indicadores de Interesse é realizada através do confronto das médias aritméticas dos MCGPs de cada grupo. Os MCGPs cuja diferença das médias for superior a 1,5 são considerados como Indicadores de Interesse.
ISBN: 978-989-8533-11-1 © 2012 IADIS
86

Casos individuais onde os MCGPs tiveram uma grande discrepância sobre a média geral foram destacados e chamados para uma entrevista, i.e., o caso do aluno 238 no indicador 18 (piscada longa). A partir destas entrevistas, outros Indicadores de Interesse foram escolhidos.
Tabela 2. Indicadores de Interesse criados
Gestos Descrição 1 Taxa de foco 2 Taxa de tensão
aparente 3 Taxa de apoio da
cabeça 4 Taxa de mobilidade
facial aparente 5 Taxa de mobilidade
corporal aparente 6 Taxa de piscada
Tabela 3. Resultados da análise dos vídeos dos grupos 1 e 5
Alunos de Grupo 1 Alunos de Grupo 5 MCGP 220 230 219 206 Média MCGP 211 209 221 238 Média
1 5 5 5 4 4,75 1 3 1 2 2 2,00 2 2 3 3 5 3,25 2 2 5 5 3 4,00 3 1 5 3 3 3,00 3 2 0 2 0 1,33 4 2 2 2 5 2,75 4 2 4 4 3 3,33 5 2 2 3 4 2,75 5 2 4 4 3 3,33 6 1 2 1 1 1,25 6 2 4 4 5 3,33 11 0 0 0 0 0,00 11 0 0 0 0 0,00 12 0 0 1 1 0,50 12 0 0 0 0 0,00 13 0 1 0 1 0,50 13 0 1 0 0 0,33 14 0 0 7 0 1,75 14 0 0 1 0 0,33 15 0 0 0 3 0,75 15 0 0 0 0 0,00 16 0 0 0 3 0,75 16 1 0 0 2 0,33 17 0 0 2 3 1,25 17 1 8 8 0 5,67 18 0 0 0 0 0,00 18 3 0 0 10 1,00 19 0 0 0 1 0,25 19 0 0 0 0 0,00 20 3 3 2 9 4,25 20 0 0 4 1 1,33 21 1 2 0 0 0,75 21 0 2 2 5 1,33 22 0 0 0 1 0,25 22 0 0 1 2 0,33 23 0 1 0 0 0,25 23 0 2 0 0 0,67 24 0 0 1 1 0,50 24 1 1 1 0 1,00 Δt 3,3 4,2 5,0 10,17 5,71 Δt 9,2 7,0 5,5 5,5 7,26
Score 9 9 9 9 9,00 Score 2 2 3 4 2,33
Os MCGPs escolhidos com indicadores de interesse foram: a Taxa de Foco, a Taxa de Apoio da Cabeça,
Forma de apoio da Cabeça, Taxa de Piscada, Piscada Longa, Atividades Dispersivas, Olhar para os lados e Mudança de Postura. Amorim (2012) realiza o detalhamento de cada um destes Indicadores.
5. MODELO PARA INFERÊNCIA DO INTERESSE
O objetivo de trabalho é a identificação do interesse do aluno a partir da análise das imagens capturadas por meio da Visualização Computacional em ambientes de EaD. Uma das etapas para esta verificação foi o levantamento dos indicadores do estado afetivo de interesse que podem ser obtidos através da VC. Esta etapa foi realizada na seção anterior. Dentre as diversas taxas e MCGPs apresentados, as taxas de foco, de apoio de cabeça e de piscada e os MCGPs “olhar para o lado”, “atividades dispersivas”, “forma de apoio da cabeça”, “piscada longa” e “mudança de postura” foram os que apresentaram os resultados mais significativos na detecção do interesse do aluno.
De posse dos indicadores e por consequência da possibilidade de inferência do interesse em ambientes EaD, surge outra questão: Como um profissional da educação pode utilizar estes indicadores para o acompanhamento do interesse do aluno?
Gatti (2003) lembra que professor tem a tarefa de acompanhar o desenvolvimento do aluno. Ele deve acompanhar o processo de desenvolvimento das atividades escolares, compreender como elas estão se concretizando, oferecer informações relevantes para o próprio desenvolvimento do ensino e para o planejamento das atividades escolares. Todo esse processo passa pelo viés afetivo em que acompanhar a motivação e o interesse do aluno é de suma importância, completa Longhi (2011).
Já Novak (1977) aponta para o papel da afetividade na regulação das relações de significação entre o professor e os estudantes e na estreita inter-relação entre predisposição para aprender e Aprendizagem Significativa. Aprender Significamente é fixar os conceitos à estrutura cognitiva existente de maneira organizada e consistente e o interesse é um fator que interfere positivamente.
Partindo desses conceitos, este trabalho propõe um Modelo para Inferência do Interesse que utiliza os Indicadores de Interessse em conjunto com um esquema denominado Esquema para Identificação do
Conferência IADIS Ibero-Americana WWW/Internet 2012
87

Interesse (EII). O modelo é retratado na Figura 5. Ele baseia-se na análise das imagens dos alunos, onde contabiliza-se os MCGPs destacados e produz se um Extrato dos Indicadores de Interesse. Os valores de cada Indicador de Interesse é submetido ao EII e que defini um valor entre 0 e 100% condizente com a taxa de interesse do aluno. Amorim (2012) mostra as fórmulas e o algoritmo do Esquema para Identificação do Interesse.
Para ilustrar o Modelo para Inferência de Interesse, a Figura 6 contém um exemplo como todo o processo ocorre. A parte pontilhada da figura destaca a parte referente ao modelo. Inicialmente, o aluno acessa o ambiente de EaD que captura os vídeos com as imagens, armazenando-as. Os vídeos são transformados em extratos contendo os identificadores de interesse dos alunos. De posse desses extratos, com auxílio do Esquema para Identificação do Interesse o professor pode obter o interesse do aluno. O professor pode utilizar o interesse para, por exemplo, modificar suas estratégicas pedagógicas, objetivando manter ou elevar o interesse do aluno ou da turma. O autor desta Tese acredita que a manutenção de bons níveis de interesse é um dos fatores norteadores para a Aprendizagem Significativa.
Figura 5. Modelo para Inferência de Interesse
Figura 6. Uso do Modelo para Inferência de Interesse
6. ESQUEMA PARA IDENTIFICAÇÃO DO INTERESSE
Uma parte importante no Modelo de Inferência de Interesse é o Esquema para Identificação do Interesse. Ele é um conjunto de procedimentos e fórmulas, para que o usuário, ao segui-lo, possa inferir com algum grau de certeza o interesse do aluno.
Para utilizar o Esquema para Identificação do Interesse, faz-se necessário possuir extratos contendo a identificação do aluno e os demais identificadores de interesse criados (vide Tabela 4). Na identificação do aluno, pode-se optar por elementos que não sejam necessariamente o seu nome, i.e., sua matrícula, seu número de chamada, etc. As outras variáveis foram aqui denominadas de i1 a i8 em referência à abreviação de identificador1 .. identificador8, cada qual correspondendo a um indicador específico. A Tabela 4 mostra os indicadores utilizados e suas variáveis correspondentes.
O Esquema para Identificação do Interesse é dividido em 6 passos (Figura 7). Os passos foram denominados de p1 a p6. Cada um dos passos possui entradas, ações, resultados parciais, pesos e resultados finais. Os valores de entrada são os Indicadores de Interesse presentes nos extratos (i1, i2,..,i8). A saída do esquema é o resultado final P(x) que é o interesse de cada passo. Depende do passo, um ou mais Indicadores de Interesse podem ser utilizados, i.e., o p3 utiliza os indicadores i3 e i5 como entrada. A Figura 7 mostra os 6 passos descritos.
ISBN: 978-989-8533-11-1 © 2012 IADIS
88

Tabela 4. Extrato dos Indicadores de Interesse
# Identificação do Aluno i1 Taxa de Foco i2 Taxa de Apoio da Cabeça i3 Taxa de Piscada i4 Forma de Apoio da Cabeça i5 Piscada Longa i6 Atividades Dispersivas i7 Olhar para os Lados i8 Mudança de Postura
Figura 7. Esquema para Identificação do Interesse
As ações são algoritmos a serem seguidos com os dados de entrada. A saída deste algoritmo será o
resultado parcial P’(x) onde x indica o passo que está sendo processado. Esta saída sempre terá como valores as constantes Interesse, Tédio ou Neutro. Neste esquema, o Interesse é uma constante de valor igual a 1. O Tédio uma constante de valor igual a 0. O Neutro uma constante de valor igual a 0,5. Os algoritmos são detalhados em (Amorim, 2012)
O Esquema para Detecção do Interesse permite que cada um dos resultados parciais obtidos P’(x) possa ter os seus valores ajustados para o cômputo do resultado final. Isso é feito pelo usuário através da atribuição de pesos distintos a cada um dos passos. O usuário pode, por exemplo, atribuir pesos maiores nos critérios que acredita serem mais adequados para a detecção do interesse.
Para o cômputo do valor do Interesse de cada passo P(x), multiplica-se cada um dos resultados parciais pelo peso de cada passo. O peso padrão de cada passo é igual a 1 (vide Equação 1).
O interesse final é o somatório dos interesses de todos os passos, divididos somatório dos pesos atribuídos em cada um dos passo, conforme Equação 2.
Equação 1. Interesse de cada passo
Equação 2.Cálculo do Interesse Final
A Tabela 5 exemplifica o cálculo do interesse para dois alunos. O aluno 220 pelo modelo obteve o
interesse de 58% e o aluno 211 obteve o interesse de 9%. Observa-se neste exemplo que o peso do passo 5 foi zerado.
Tabela 5. Exemplo de Inferência do interesse
Aluno 220 211 # peso(x) Entradas P'(x) P(x) Entradas P'(x) P(x)
p1 1 i1=97% Interesse=1,00 1,00 i1=80% Tédio=0,00 0,00 p2 1 i2=20%,i4= tripé, i5=não Neutro=0,50 0,50 i2=80%, i4=apoio, i5=sim(3) Tédio=0,00 0,00 p3 1 i3=5/min,i5=não Interesse=1,00 1,00 i3=5/min, i5=sim(3) Tédio=0,00 0,00 p4 1 i6=4 Neutro=0,50 0,50 i6=0 Tédio=0,00 0,00 p5 0 i7=0 Interesse=1,00 0,00 i7=1 Interesse=1,00 0,00 p6 1 i8=1 Neutro=0,50 0,50 i8=1 Neutro=0,50 0,50 Σ 6 3,50 0,50
Interesse: 58% Interesse: 9%
Conferência IADIS Ibero-Americana WWW/Internet 2012
89

7. CONSIDERAÇÕES FINAIS
Este trabalho mostra que é possível utilizar a Visualização Computacional em ambientes de EaD para apoio a detecção do “interesse” do aluno. Ele apresenta ferramenta para prover ambientes de EaD da capacidade de VC. Destaca os principais Movimentos Corporais, Gestuais ou Posturais que apresentaram-se mais adequados na inferência do interesse. E, por último, exibe um Modelo e um Esquema para a inferência do interesse, onde profissionais da educação, ao aplicarem o modelo, podem detectar o nível de interesse dos seus alunos.
O Modelo para Inferência do Interesse é baseado nos Indicadores de Interesse aqui apresentados.Já o Esquema para Identificação configura-se em um conjunto de passos (algoritmo) onde os extratos com os Indicadores de Interesse são aplicados e o nível de interesse do aluno é obtido. Amorim (2012) detalha cada passo com seus respectivos algoritmos.
REFERÊNCIAS BIBLIOGRÁFICAS
AMORIM, M.J.V. Visualização Computacional como apoio à identificação do interesse do aluno em ambientes de EaD. Tese de Doutorado Universidade Federal do Rio Grande do Sul CINTED/PGIE, Porto Alegre - RS - Brasil, 2012.
AMORIM, M.J.V.; BERCHT, M. ; BEHAR, P. A. Ferramenta para captura de imagens em ambientes virtuais de aprendizagem. In: Actas de la Conferência IADIS Ibero-Americana WWW/Internet Algarve, v. 1. p. 424-428. Dez, 2010a
______. QuizWebcamXML - Uma ferramenta para confecção de questionários utilizando o padrão XML e com captura de imagens. In: Actas de la Conferência IADIS Ibero-Americana WWW/Internet. Lisboa : IADIS Press Publication, 2011a. v. 1.
______. Análise do Grau de Interesse através da Visualização Computacional. In Anais do XXII Simpósio Brasileiro de Informática na Educação, Aracajú (SG), 2011b.
ARGYLE, M. The Psychology of Interpersonal Behaviour. Penguin: Harmondsworth, 1975. ______. Bodily communication. 2a ed. ISBN-0-415-051142 London and New York, 1988. AUSUBEL, D.P.; NOVAK, J.D.; HANESIAN, H.. Educational psychology. New York: Holt, Rinehart and Winston,
1978. Publicado em português pela Editora Interamericana, Rio de Janeiro, 1980. BERCHT, M.. Em Direção a Agentes Pedagógicos com Dimensões Afetivas. Instituto de Informática. UFRGS. Tese de
Doutorado. Porto Alegre. 2001. CHARDOSIM, N.M.O. Um Estudo de associação entre Desempenho Escolar e Medidas Neuropsicológicas em Alunos
da 3ª série do ensino fundamental. Monografia Universidade Federal do Rio Grande do Sul Especialização em Psicologia, Porto Alegre - RS - Brasil, 2011.
COHEN, D. A Linguagem do Corpo: o que você precisa saber. 4ª ed. Vozes, ISBN 978-85-326-3817-5, 219 p, Petrópolis, 2011.
GATTI, B.A. O Professor a avaliação em sala de aula. In: Estudos em Avaliação Educacional. n.27, jan./jun. São Paulo: Fundação Carlos Chagas, 2003, p.97-133.
HAKURA, J.; TAKAHASHI, N.; KUREMATSU, M.; FUJITA, H.; Estimating Interest Level of Person through Posture by Vision System. In: IOS PRESS, Japan, 2010.
JOLIVET, R. Tratado de Filosofia, Volume II. Agir Editora, 1967, Rio de Janeiro. traduzido por Gerardo Dantas Barretto.
KAPOOR, A.; PICARD,R.W. Multimodal Affect Recognition in Learning Environments. In MM’05 Singapore, 2005. LONGHI, M.T. Mapeamento de aspectos afetivos em um ambiente virtual de aprendizagem Tese de Doutorado
Universidade Federal do Rio Grande do Sul CINTED/PGIE, Porto Alegre - RS - Brasil, 2011. MEHRABIAN, A. Nonverbal communication. ISSN: 978-0-202-30966-8, New Jersey, USA, 226p., 2007 original 1972. NOVAK, J. A theory of education. Cornell University Press, Ithaca, N.Y., 1977. PRATA, C.; NASCIMENTO, A. Objetos de aprendizagem: uma proposta de recurso pedagógico/Organização. MEC,
SEED, Brasília 2007, 154 p.
ISBN: 978-989-8533-11-1 © 2012 IADIS
90

APPS FRAMEWORK: UM PROCESSO CENTRADO NO USUÁRIO APLICADO PARA O DESENVOLVIMENTO DE
APLICATIVOS MÓVEIS – UM ESTUDO DE CASO
Awdren de Lima Fontão, Bruno Bonifácio e Angelo Nicolay Instituto Nokia de Tecnologia - INdT
Av. Torquato Tapajós, 7200, Colônia Terra Nova. Manaus, Amazonas, Brasil
RESUMO
O crescimento sistemático no número de usuários de celular tem permitido que esses dispositivos agreguem cada vez mais recursos. Este cenário evolutivo tem estimulado a melhoria contínua de processos e metodologias que visam aumentar a produtividade e a qualidade do desenvolvimento de aplicativos. Entretanto, o sucesso no desenvolvimento de aplicativos não está somente associado as tecnologias utilizadas, mas também do processo adotado que devem focar nas expectativas do cliente. Este artigo, apresenta a aplicação de um processo de desenvolvimento para aplicativos centrado no usuário, chamado Apps Framework. Esse processo utiliza conceitos focados na experiência do usuário, para o desenvolvimento de aplicativos com maior qualidade de uso. Os resultados dessa experiência mostram que o Apps Framework pode auxiliar no desenvolvimento de aplicativos com maior qualidade e em menor tempo. Espera-se com isso incentivar a adoção de processos centrados na experiência usuário, no desenvolvimento de software em ambientes industriais.
PALAVRAS-CHAVE
Mobile, HCI, User-Centered Design Process, Experience Report.
1. INTRODUÇÃO
À medida que as tecnologias atuais evoluem é possível perceber mudanças na interação das pessoas com os dispositivos computacionais (Kappel et al. 2003). Essa evolução tem estimulado o desenvolvimento de inovações que visam aumentar a facilidade dos usuários no acesso às informações (Bonifácio et al. 2011). Neste cenário, os aplicativos (apps) móveis e dispositivos multitarefa aparecem como importante alternativa, devido às vantagens de acesso em qualquer lugar e a qualquer momento (Fling et al. 2009).
Além disso, as características do dispositivo podem tornar a experiência dos usuários mais satisfatória, uma vez que os dispositivos móveis possuem flexibilidade de personalização pelos usuários. Essas vantagens têm encorajado os usuários a incorporar cada vez mais tecnologias no seu cotidiano (Miao e Yuan, 2010).
Porém, apesar dos aplicativos facilitarem o acesso de usuários aos serviços Web, o desenvolvimento desse tipo de aplicação não é tarefa simples. Isto porque o acesso às aplicações Web em ambientes móveis possui algumas particularidades, principalmente relacionadas ao hardware, que as diferem de outras aplicações (Weiss, 2002). A maior dificuldade encontrada pelos usuários, durante a utilização dos dispositivos, está na dificuldade de uso dos aplicativos (Bonifácio et al. 2011). Para maximizar a qualidade de uso, empresas têm utilizados novas tecnologias de software que facilitem a interação dos usuários com os aplicativos. No entanto, o sucesso no desenvolvimento de software embarcado não está associado apenas as ferramentas e tecnologias utilizadas, mas também depende do processo adotado no desenvolvimento de aplicativos (Shresta, 2007). Por essa razão, métodos centrados na interação do usuário, no processo de concepção, podem apoiar o desenvolvimento bem sucedido de aplicativos.
Este artigo descreve um relato de experiência no uso de um processo de desenvolvimento de aplicativos focado no usuário, chamado Apps Framework. Este processo utiliza conceitos baseados na experiência do usuário, desde a concepção dos aplicativos até o lançamento do aplicativo e utilização pelo usuário final. Neste sentido, o objetivo deste artigo consiste em: apresentar como este processo foi aplicado, no contexto de uma empresa de desenvolvimento de aplicativos, analisando os resultados alcançados e seu custo-benefício.
Conferência IADIS Ibero-Americana WWW/Internet 2012
91

Espera-se com isso incentivar a indústria e a comunidade científica na adoção de métodos focados nas necessidades do usuário, como forma de aumentar a qualidade de uso no desenvolvimento de aplicativos.
As próximas seções deste artigo estão organizadas da seguinte forma: A Seção 2 descreve os conceitos envolvendo os aplicativos e Design Centrado no Usuário (UCD) e ainda nesta seção é apresentado o processo Apps Framework. A Seção 3 descreve a aplicação do Apps Framework no desenvolvimento de um aplicativo dentro de um ambiente industrial. A Seção 4 discute os resultados obtidos com a proposta. Por fim, a Seção 5 apresenta as conclusões e lições aprendidas.
2. DESIGN CENTRADO NO USUÁRIO E APLICATIVOS MÓVEIS
Segundo (Mikkonen, 2007), um aplicativo é definido como um trecho de software que pode ser iniciado e terminado individualmente e que executa uma tarefa específica. No entanto, essa definição tem mudado com a evolução dos aparelhos celulares. O acesso às informações da Web já não é feito essencialmente por browsers tradicionais, mas por aplicativos personalizados pelo próprio usuário (Wasserman et al. 2011).
Nesse contexto, a definição mais coerente de aplicativo em ambientes móveis é de um software, que utiliza todo o hardware disponível, para facilitar a utilização de um serviço pelo usuário em determinado contexto de uso (Florence et al. 2008). Porém, apesar da evolução tecnológica dos dispositivos móveis, muitos usuários ainda encontram dificuldades na utilização de aplicativos (Anatel, 2011). Por isso, a usabilidade dos aplicativos é um fator de grande importância para o diferencial competitivo e sucesso do produto. Por essa razão, as indústrias de desenvolvimento de aplicativos têm investindo cada vez mais em novas tecnologias e métodos centrados no usuário no processo concepção de aplicativos. Segundo (Lee et al. 2005), fatores focados em critérios específicos centrados na interação do usuário e no ambiente de uso podem influenciar na qualidade dos aplicativos.
Assim, têm-se focado em processos de desenvolvimento de software envolvendo o usuário como parte da solução. Esses processos incluem conceitos de UCD com o propósito de desenvolver produtos de software considerando as perspectivas do usuário final (e.g. usabilidade, ambiente de uso, acessibilidade, dentre outras características) como forma de identificar requisitos que possam aumentar a aceitabilidade da aplicação (Salmre, 2005).
A ISO 13407 (1999), apresenta um ciclo de desenvolvimento iterativo, conforme a Figura 1A, cujo objetivo é a identificação de requisitos específicos focados nas necessidades do usuário e no contexto de uso. Esse processo foca no entendimento das necessidades do usuário, no planejamento, desenho, construção e desenvolvimento de uma solução para essa necessidade e a disponibilização da solução ao usuário.
Figura 1. A) Ciclo UCD proposto pela (ISO 1307, 1999) B) Ciclo envolvendo as fases do Apps Framework.
Outro processo centrado no usuário, específico para aplicativos, é proposto por Guelther e Hirt (2008), considerando o contexto de interação. Porém, os resultados (Guelther e Hirt, 2008), mostraram que a rapidez no desenvolvimento de aplicativos depende da complexidade do projeto, da interação das equipes envolvidas e do tipo de dispositivo utilizado. Salmre (2005) também propôs um processo para o desenvolvimento de
ISBN: 978-989-8533-11-1 © 2012 IADIS
92

aplicativos focando nas atividades do usuário, no tempo de resposta a cada funcionalidade solicitada e no desempenho do aplicativo relacionado com as restrições.
O processo utilizado, chamado Apps Framework, utiliza o processo UCD da ISO 13407 (1999), porém considera além das necessidades do usuário, o desempenho do aplicativo independente da plataforma utilizada. O propósito do Apps Framework é detalhar as fases do ciclo proposto pela ISO 13407 (1999), focando em oportunidades de pesquisa que podem ser utilizadas para melhorar o produto final e acompanhando a experiência do usuário após sua publicação, conforme mostrado na Figura 1B. Este artigo apresenta um relato de como esse processo auxiliou no desenvolvimento de aplicativos, no contexto industrial. A Seção 2.1 descreve esse processo.
2.1 Apps Framework
A estrutura do processo do Apps Framework visa acompanhar todo o processo desde o ponto de partida, com uma solicitação de um aplicativo pelo cliente, à conceitualização ou desenvolvimento do aplicativo. O processo tem que contemplar todas as cinco etapas do ciclo de desenvolvimento UCD. Dessa forma, o processo é dividido em quatro fases, conforme a Figura 2:
• Conceito: consiste no desenvolvimento do conceito da solução e da prototipação da interface do aplicativo, feitas através das informações obtidas com o cliente. Além disso, nesta etapa é feita a validação de cada interface gerada com o cliente;
• Desenvolvimento: inicia com base nos artefatos do Conceito. Nesta etapa é adotada uma metodologia de desenvolvimento interativa e incremental para aprimoramento da solução entre designers e desenvolvedores;
• Publicação e Marketing: consiste na publicação das decisões tomadas durante processo do desenvolvimento. Esta etapa foca no entendimento das necessidades do usuário, onde serão definidas possíveis alterações feitas através do feedback dos usuários;
• Pesquisa e Cooperação: Esta etapa visa a identificação de oportunidades de pesquisa e inovação elicitadas durante a definição da solução.
Figura 2. As fases do processo de desenvolvimento do Apps Framework e os artefatos gerados em cada fase.
Essa divisão é útil para gerenciamento do processo e visando garantir melhor desempenho da equipe de desenvolvimento e apresentar ao cliente o progresso no desenvolvimento da solução solicitada. O processo de desenvolvimento descrito neste artigo é apresentado detalhadamente na Seção 3.
Conferência IADIS Ibero-Americana WWW/Internet 2012
93

3. ESTUDO DE CASO: ROCK IN RIO APP
O Instituto Nokia de Tecnologia (INdT) é um Instituto de Pesquisa sem fins lucrativos focado no desenvolvimento de serviços e soluções em software e hardware para dispositivos móveis. Diante desse cenário, o Apps Framework se mostrou útil para aprimorar o desenvolvimento de novas tecnologias de software. Um exemplo disso foi o aplicativo Rock in Rio App1. Este aplicativo, mostrado na Figura 3, surgiu diante da possibilidade de tornar a experiência dos participantes do Rock in Rio mais atrativa, uma vez que grande parte dos participantes não morava na cidade do evento. Dessa forma o aplicativo possuia características como: descrições das atrações, horários de shows, ver vídeos das atrações, locais, como chegar a cidade do rock, dentre outras.
Figura 3. Visão geral do aplicativo Rock in Rio.
Além do desafio tecnológico envolvendo o desenvolvimento deste aplicativo, a ideia seria desenvolver um aplicativo que fosse atrativo a um maior número de usuários. Dessa forma, foi feito um estudo para identificar o perfil dos usuários de web móvel. O propósito foi identificar quais os dispositivos que os usuários de celulares Nokia mais utilizavam para acessar a Web. Dessa forma, foram escolhidos os dispositivos das seguintes plataformas: Nokia S40, Nokia Belle e Windows Phone. Nas próximas seções são apresentadas cada uma das etapas do processo no desenvolvimento do Rock in Rio App.
3.1 Conceito
A fase de conceito consiste na definição do problema pelos clientes e a formulação de uma solução a ser apresentada ao cliente. Seu escopo se concentra em concretizar uma solução através da necessidade do cliente. Esta fase envolve dois passos:
Entender os anseios do cliente ou de uma oportunidade de inovação: neste passo foi realizada a coleta de informações para identificação dos requisitos e funcionalidades desejáveis entre os membros do evento e do INdT para iniciar o desenvolvimento do aplicativo. Para identificar oportunidades e requisitos, foram realizadas reuniões, com entrevista semi-estrutrada. Nessas entrevistas foram definidas questões abertas, para que o entrevistador pudesse coletar informações visando auxiliar no desenvolvimento de uma solução. Essas informações foram úteis também para geração das ideias, criação das interfaces e definição do cronograma de desenvolvimento do aplicativo. Todas as informações posteriormente armazenadas em um repositório.
A partir das entrevistas os dados foram organizados em briefings, que são documentos contendo requisitos e informações coletadas das entrevistas com o cliente (e.g. dispositivo para os quais os aplicativos serão desenvolvidos, interface, aplicativos concorrentes, público–alvo dentre outros), conforme a Figura 4. As informações coletadas no briefing, durante as reuniões, são convertidas em rascunhos da solução, inicialmente estrutural, chamados drafts. Os drafts, Figura 4, são rascunhos do aplicativo que contêm informações como: navegação, um conjunto de telas, conteúdo das telas e comportamentos de uso. Este artefato é útil para que o cliente possa visualizar as telas que irão compor o aplicativo. Como o Rock in Rio é um evento de entretenimento, a necessidade do público-alvo estava apenas em saber informações sobre as atrações e palcos do evento, a modelagem do aplicativo consistiu em integrar redes sociais (e.g. Twitter e Facebook) para alimentar a fonte e compartilhamento de informações sobre o evento.
1 http://store.ovi.com/content/128245
ISBN: 978-989-8533-11-1 © 2012 IADIS
94

Figura 4. Modelo do briefing utilizado e o draft gerado na fase de Conceito.
Após esse passo, foi iniciada a prototipação do aplicativo. Nesse passo foram feitos protótipos digitais com base nos drafts, chamados wireframes. Enquanto os drafts focam na estrutura do aplicativo, os wireframes focam nas funcionalidades do aplicativos, pois demonstram de forma direta como será o aplicativo e se está de acordo com as especificações. A ideia é auxiliar o cliente no entendimento dos requisitos sem se preocupar com a interface, conforme a Figura 5.
Figura 5. Wireframe do Rock In Rio e o Mockup gerado com especificações do dispositivo.
Através dos wireframes, o cliente pode ter uma visão geral das alternativas de interação que o público-alvo pode ter antes da implementação da interface. Após a aprovação das funcionalidades com o cliente foram gerados os mockups.
Os mockups possuem uma breve descrição do conteúdo e comportamento de cada tela. Essas informações são importantes para que o cliente possa analisar o comportamento e o visual de todas as telas antes do desenvovimento. Além disso, os mockups são importantes para analisar as características das interfaces focando na usabilidade do aplicativo, pois se aproxima das dimensões da tela do dispositivo.
Tendo o aplicativo sido conceitualmente aprovado pelo cliente através da validação do mockup e wireframe, a próxima fase foi a geração de artefatos finais para o time de desenvolvimento (imagens recortadas, fluxo de navegação, especificações de design). Esta fase consiste em repassar as equipes de desenvolvedores todas as decisões tomadas com o cliente, o escopo do aplicativo e os artefatos finais.
3.2 Desenvolvimento
A fase de Desenvolvimento consiste na codificação e validação das funcionalidades, com base nos artefatos gerados na etapa de Conceito. Para facilitar o desenvolvimento, as funcionalidades foram divididas em times de desenvolvimento e organizadas por um fluxo de telas, chamado workflow. Essa organização é útil para
Conferência IADIS Ibero-Americana WWW/Internet 2012
95

gerenciamento de projetos muito complexos, que precisem ter equipes de desenvolvimento distribuído de software. Dessa forma, o aplicativo foi dividido em módulos de desenvolvimento, considerando o fluxo de navegação para melhor visualização e entendimento do aplicativo por parte da equipe de desenvolvimento, conforme a Figura 6.
Para o desenvolvimento do Rock in Rio App, o workflow foi dividido entre quatro desenvolvedores. Como todos os requisitos foram validados com o cliente, através de reuniões, o processo de codificação tornou-se menos trabalhoso. Um cronograma foi elaborado estipulando um prazo de um mês, devido a metodologia adotada, conseguiu-se diminuir esse prazo em duas semanas, gerando nesse período duas releases, que são versões do aplicativos estáveis e prontas para entrega.
Além disso, a divisão do desenvolvimento por workflow permite que a interface de usuário seja feita de maneira independente da infra-estrutura de execução que controla o fluxo e o processamento dos dados da aplicativo. Para melhor gerenciar o tempo de desenvolvimento, cada equipe utilizou a metodologia de desenvolvimento iterativo e incremental Scrum, cada estória estava relacionada a uma tela a ser implementada, por exemplo, para a tela inicial do aplicativo: “Eu como usuário quero poder escolher inicialmente que seção desejo visitar no aplicativo Rock In Rio: Notícias, Fotos, Vídeos ou Programação”. O propósito com isso foi validar o aplicativo com o cliente e com isso diminuir os defeitos e maximizar o tempo de entrega do produto final.
Outro ponto importante na utilização dessa metodologia é a utilização de diversos ciclos de validação pelos stakeholders, tanto dos testadores quanto do cliente e os responsáveis pelo gerenciamento do projeto.
Figura 6. Workflow de tarefas do Rock in Rio App.
Após o desenvolvimento dos módulos é feita a integração entre as telas criadas por um grupo e o código gerado pelo outro grupo. Ao término dessa etapa, um pacote foi gerado e liberado para equipe de Qualidade (QA), esta etapa de QA se baseia tanto em testes funcionais quanto não-funcionais e, também, utiliza guias específicos da Loja de Aplicativos da Nokia para validação de apps. Essa equipe é responsável por realizar testes para validar o comportamento da aplicação.
Ao fim dos testes funcionais foram feitos testes de usabilidade com possíveis usuários do aplicativo, onde foram analisados itens como: usabilidade do aplicativo, familiaridade com o dispositivo, eficiência na utilização. O propósito com isso foi tornar a experiência dos usuários mais agradável possível, de forma a atender todas suas necessidades.
O pacote final foi liberado para o cliente, para aprovação do cliente. Após a aprovação, o time de Publicação e Marketing disponibilizou uma release inicial. Esses pacotes contém informações contendo todas as funcionalidades esperadas para o aplicativo. Estes pacotes são de responsabilidade da equipe de Publicação e Marketing, descritas na Seção 3.3.
ISBN: 978-989-8533-11-1 © 2012 IADIS
96

3.3 Publicação e Marketing
O escopo da fase de Publicação e Marketing está na comunicação entre os envolvidos no desenvolvimento do aplicativo, o cliente e o usuário final. Além da interação entre a equipe de desenvolvimento e cliente, esta fase é responsável pela definição do escopo das atividades desenvolvidas, bem como a entrega das releases ao cliente antes da publicação final. A publicação depende da interação com as outras fases do Apps Framework. Porém, suas fases não são interdependentes, ou seja, não precisam acontecer sempre na mesma ordem ou ao mesmo tempo, mas são todas obrigatórias.
A etapa de Publicação e Marketing envolve dois passos, primeiramente um de publicação e promoção de um aplicativo, e posteriormente manutenção e monitoramento. O passo de publicação e promoção compreende a publicação do vídeo e o lançamento do pré-release. Com esses recursos a equipe gera os roteiros para a criação do banner promocional (briefing spotlight) e para a produção do vídeo (briefing para o vídeo promocional). O passo de monitoramento e manutenção ocorre após a publicação e promoção do aplicativo. Após o desenvolvimento e validação com os clientes, o Rock in Rio App foi disponilizado na loja da Nokia, Nokia Store2, para monitoramento sobre a satisfação dos usuários e manutenção do aplicativo.
A manutenção é semelhante a uma etapa de pós-venda, são recebidos feedbacks diretos dos usuários para a solução de seus problemas através das redes sociais. Uma importante estratégia adotada para o monitoramento do Rock in Rio App foi utilizar os feedbacks dos usuários na Nokia Store. Através desse monitoramento foi possível identificar e relatar aos clientes e stakeholders a repercussão ou performance do Rock in Rio App. Além disso, o usuário utiliza escalas para o grau de satisfação ao utilizar o aplicativo com comentários que são utilizados para melhoria em novas versões ou em outros aplicativos.
3.4 Pesquisa e Cooperação
A fase de Pesquisa e Cooperação consiste na identificação de oportunidades de pesquisa através de dificuldades no desenvolvimento dos projetos de Apps do INdT. Essas oportunidades tem como escopo: Prospecção Tecnológica; Identificação, Estudo e a avaliação de oportunidades em novas plataformas de desenvolvimento de aplicativos. Estas oportunidades são identificadas durante a coleta de dados nas fases de Conceito e Desenvolvimento e armazenadas no repositório de ideias.
Além do próposito de utilizar as oportunidades identificadas, esta etapa procura realizar cooperação com universidades tanto para aprimoramento das equipes envolvidas quanto para formação de uma base de conhecimento dentro da universidade permitindo o contato de alunos de graduação e pós-graduação com o cotidiano do desenvolvimento profissional de apps, possibilitando uma experiência desde a ideia (conceito do aplicativo) até o acompanhamento (marketing & publicação) não deixando de lado a pesquisa, permitindo a contribuição dos aspectos práticos com a comunidade científica. Além disso, essa fase consiste na análise do impacto do mercado de aplicativos que possam ser desenvolvidos.
Uma das oportunidades de pesquisa identificada no desenvolvimento do Rock in Rio App, foi a criação de um novo tocador de vídeo integrado ao aplicativo para melhor performance. Esse tocador é utilizado no desenvolvimento de outros aplicativos que utilizam dados multimídia. Além disso, uma importante contribuição, adquirida com o Rock in Rio, foi a diminuição do consumo de dados da Web, visando melhorar a atualização dos dados no lado do dispositivo. Isso é importante para melhorar a experiência do usuário ao utilizar o aplicativo, uma vez que grande quantidade de informações pode gerar grande consumo de dados.
4. RESULTADOS ALCANÇADOS
A utilização do processo Apps Framework permitiu a equipe de desenvolvimento do INdT desenvolver aplicativos de forma mais ágil, através da integração com outras metodologias. Além de melhorar a qualidade dos aplicativos desenvolvidos, pois diminuiram o número de defeitos, a comunicação entre desenvolvedores, designer e cliente foi melhor integrada.
Outra importante contribuição, foi o desenvolvimento em paralelo dos módulos dos aplicativos, pois a divisão em workflow na fase de conceito permite a criação de módulos independentes do aplicativo. Podendo
2 store.nokia.com
Conferência IADIS Ibero-Americana WWW/Internet 2012
97

ainda gerar uma linha de produto mais organizada, para outros aplicativos que possam utilizar componentes em comum. Adicionalmente podemos destacar também o monitoramento da release disponibilizada na loja da Nokia, pois isso possibilita realizar melhorias no aplicativo e ainda obter feedbacks que podem ser utilizados para identificação de novas oportunidades de pesquisa e de aplicativos.
5. CONCLUSÃO E LIÇÕES APRENDIDAS
A utilização de métodos focados na interação do usuário têm sido amplamente adotados na indústria de desenvolvimento de software. Isto porque, tais métodos podem tanto auxiliar no desenvolvimento de aplicativos com mais agilidade quanto proporcionar maior qualidade de uso. Este artigo relatou a experiência do INdT no desenvolvimento de aplicativos utilizando um método centrado no usuário, o Apps Framework.
O Apps Framework tem como objetivo estar alinhado com o cenário evolutivo do desenvolvimento de aplicativos para celulares, propiciando um meio que permita tanto o desenvolvimento tecnológico quanto o científico. A ideia é que com um processo focado nas necessidades do cliente, diminuia-se o tempo de entrega dos aplicativos desenvolvidos e possibilite melhor experiência dos usuários-finais.
Como lições aprendidas podemos citar a melhor integração entre usuários, clientes, designers e desenvolvedores. Além disso, o Apps Framework permite a fácil integração com outras metodologias ágeis, o que pode tornar melhor o controle do cliente no produto a ser desenvolvido. Outro ponto observado com a adoção do Apps Framework é que a utilização de um processo centrado no usuário permite o desenvolvimento de aplicativos, onde o usuário-final é monitorado após a entrega do software. Esta abordagem permite que possamos utilizar os feedbacks dos usuários para identificar novas oportunidades de pesquisa e com isso gerar maior compartilhamento de experiência com a comunidade científica.
REFERÊNCIAS
Anatel, A.N.D.T., 2011, "Acessos móveis ultrapassam 185 milhões assinantes". In: www.anatel.gov.br/Portal/exibirPortalNoticias.do?acao=carregaNoticia&codigo=20824 Accesado em: 05.10.2012.
Bonifácio, B. et al., 2010. "UBICUA: A Customizable Usability Inspection Approach for Web Mobile Applications." In: IADIS WWW/Internet Conference, IADIS, Ed. Rio de Janeiro, RJ - Brazil: IADIS, 2011, p. 45 - 52.
Fling, B., 2009. “Mobile Design and Development - Practical concepts and techniques for creating mobile sites and web apps.” In: O'Reilly: I-XIX, San Francisco, USA, p. 69-109.
Florence B., et al., 2009. "Evaluation of User Interface Design and Input Methods for Applications on Mobile Touch Screen Devices." In: 12th International Conference on Human-Computer Interaction, Uppsala, Sweden, p. 243-246.
Guelther M. and Hirt H, 2008. “Rapid User-Centered Design for Mobile Enterprise Applications.” In: INTERACT 2008, Florence, Italy, p. 20-30.
ISO 1999. ISO 13407: Human Centered Design Process for Interactive Systems. Geneva: International Standards Organisation. Avaliable from British Standards Institute, London.
Kappel, G. P., et al, 2003. "An Introduction to Web Engineering", Web Engineering: The Discipline of Systematic Development of Web Applications, John Wiley \& Sons.
Lee, V. e Schneider, H. 2005. “Aplicações móveis: arquitetura, projeto e desenvolvimento.” Robbie Schell Mobile Business, São Paulo - Brasil.
Miao, Z. and Yuan, B., 2010. “Discussion on Pervasive Computing Paradigm. Institute of Information Science. School of Computer and Information Technology” In: IEEE TENCON 2005, Melbourne, Qld, p. 1 – 6.
Mikkonen, T. 2007. “Programming Mobile Devices. An introduction for practitioners.” Wiley & Sons, p. 61-62. Nielsen, J. 1994. "Heuristic evaluation." In: Usability Inspection Methods, John Wiley & Sons, Vol. 2, New York, USA. Salmre, I., 2005. “Writing Mobile Code: Essential Software Engineering for Building Mobile Applications.” Shrestha, S., 2007, "Mobile web browsing: usability study". In: Proceedings of the 4th international conference on mobile
technology, applications, and systems, Singapore, v. 1, p. 187-194. Wasserman, A., 2010. "Software engineering issues for mobile application development," in Proceedings of the FSE/SDP
workshop on Future of software engineering research Santa Fe, New Mexico, USA: ACM, p. 397-400. Weiss, S. 2005. "Handheld usability: design, prototyping and usability testing for mobile phones." In: 7th International
Conference on Human-Computer interaction with mobile devices and services Salzburg, Austria, p. 98 – 108.
ISBN: 978-989-8533-11-1 © 2012 IADIS
98

DESARROLLO DE MEDIOS DE COMUNICACIÓN SOCIAL Y WEB 2.0 EN LAS MAYORES CADENAS HOTELERAS
María del Mar Gálvez Rodríguez, Arturo Haro de Rosario y Mª del Carmen Caba Pérez Universidad de Almería. Departamento de Dirección y Gestión de Empresas Ctra. Sacramento s/n, La Cañada de San Urbano. 04120 Almería (España).
RESUMEN
En los últimos años se ha incrementado el desarrollo del sector hotelero. Este crecimiento ha ido acompañado de una mayor demanda de información no solo para conocer aspectos de la propia organización sino también para conocer las opiniones de los diferentes stakeholders. En este sentido, se considera que las tecnologías web 2.0 y las plataformas de comunicación social son una herramienta fundamental para la interactuar y compartir información. Bajo estos precedentes este trabajo presenta dos objetivos, por un lado conocer el grado de uso de las tecnologías web 2.0 y plataformas sociales por parte de las cadenas hoteleras y, en segundo lugar analizar la influencia de factores determinantes en el mayor uso de la web 2.0 en este sector. Como conclusiones principales cabe destacar que, el sector hotelero hasta el momento no ha sido consciente de las ventajas de las herramientas web 2.0 así como plataformas de comunicación sociales. Asimismo, se evidencia que los hoteles con mayor edad y tamaño son más proclives al uso de estas herramientas.
PALABRAS CLAVE
Cadena hotelera; Medios de comunicación social; Visibilidad; Web 2.0.
1. INTRODUCCIÓN
En los últimos años los avances de las tecnologías de la información y la comunicación (TICs) han provocado una transformación de la sociedad que ha repercutido en la organización y gestión de las empresas (Bonsón, Escobar y Flores, 2006). Así, las aplicaciones derivadas de la web 2.0 están cambiando las relaciones entre la sociedad y las empresas. Esta situación hace que cada día más clientes utilicen internet como herramienta para expresar sus experiencias con las organizaciones y que los consumidores potenciales tomen decisiones de compra, de productos o servicios, orientados por la información que encuentran en la red.
Como evolución de la web 1.0 O'Reilly (2005) creó el concepto web 2.0, basado en el uso de nuevas tecnologías como los canales RSS, el podcasting, los mashups, las folksonomías y los widgets. Además, gracias a esta base tecnológica se han desarrollado los llamados medios de comunicación social, los cuales son en definitiva aplicaciones que ofrecen servicios a las comunidades de usuarios en línea, como blogs, marcadores sociales, wikis, usos compartidos de multimedia o redes sociales que promueven la colaboración, el aprendizaje conjunto y el intercambio rápido de información entre los usuarios.
De esta forma, cualquier organización puede mejorar en gran medida su página web corporativa incorporando los servicios y las tecnologías web 2.0 (Jiang, Raghupathi, V. y Raghupathi, W., 2009), construyendo además relaciones con grupos de interés que antes, con los medios de comunicación tradicionales, eran inaccesibles o invisibles (Hearn, Foth, y Gray, 2009).
Debido a estos cambios, internet ya no es sólo un canal más de comunicación, sino que se ha convertido en un factor clave para las empresas que persiguen un mayor grado de transparencia y rendición de cuentas (Larrán y Giner, 2002), posibilitando además la interacción a través de los distintos mecanismos de participación. Sin embargo, a pesar de que las tecnologías sociales han generado un alto grado de interconectividad entre sus usuarios (Vázquez, Saldaña y Celaya, 2009), muchas organizaciones siguen ejecutando estrategias de comunicación y posicionamiento sin tener en cuenta las posibilidades de interacción que ofrece internet.
Conferência IADIS Ibero-Americana WWW/Internet 2012
99

Con respecto a los sectores que se benefician de las características de la web 2.0, Perrigot, Basset y Cliquet (2011) ponen de manifiesto que es una herramienta de ventaja competitiva para las empresas del sector servicios. Por su parte, Buhalis y Deimezi, (2004) apuntan que la utilidad de los mecanismos de interacción de la web 2.0 está revolucionando el modelo de negocio turístico.
Paton y McLaughlin, (2008) señalan la importancia de los mecanismos de interacción como un aspecto fundamental para alcanzar la excelencia del sector hotelero. En este sentido, Tiedemann, Van Birgele y Semeijn (2009) añaden que, el crecimiento de las cadenas hoteleras no va siempre acompañado del aumento de la satisfacción de los clientes ya que, en muchos casos, no se tienen en cuenta sus inquietudes ni existen instrumentos de feedback que les permitan ofrecer un servicio de mayor calidad. Ganesan y Zhai (2012) añaden que, la web 2.0 es uno de los mecanismos principales para conocer la opinión de los huéspedes.
Con respecto a las plataformas de comunicación social, Lim (2010) sostiene su gran utilidad para la interacción entre los clientes antes, durante y después de su estancia en el hotel. Además, las plataformas sociales mantienen al cliente informado y favorecen su mayor fidelidad con el hotel. Asimismo, pone de manifiesto que las redes sociales permiten mejorar la reputación y, por ende, las ventas del sector. En consecuencia, se considera que los medios sociales son una herramienta de ventaja competitiva ya que ofrecen diversas ventajas el mantenimiento de una relación directa con el cliente a un coste bajo (Hailey, 2010). Por otro lado, Paroutis y Al Saleh (2009) señalan la importancia de conocer los factores que influyen en el mayor uso de la web 2.0.
Bajo estos precedentes el presente trabajo presenta un doble objetivo. En primer lugar, análisis del uso de las herramientas de la web 2.0 y los medios de comunicación social en los hoteles y, en segundo lugar, el estudio de los posibles factores capaces de promover el desarrollo de las herramientas de la web 2.0 y los medios de comunicación social en el sector hotelero. Como muestra objeto de estudio se han tomado las 50 cadenas hoteleras más grandes del mundo según la clasificación de la revista especializada HOTELS magazine, The Magazine of the Worldwide Hotel Industry.
Respecto a la estructura del trabajo, en el apartado segundo se exponen las herramientas de la web 2.0 y los medios de comunicación social. Seguidamente, se presenta la metodología así como los resultados obtenidos. Finalmente, en el apartado cuarto se recogen las conclusiones más relevantes del estudio.
2. HERRAMIENTAS DE LA WEB 2.0 Y MEDIOS DE COMUNICACIÓN SOCIAL
En general, la cobertura mediática de la web 2.0 se centra en sus aplicaciones y servicios más comunes, tales como blogs, intercambio de videos, redes sociales o el podcasting; en definitiva en una web socialmente más conectada en la que la gente puede contribuir tanto como pueden consumir (Anderson, 2007). Sin embargo, es conveniente hacer una clara distinción entre las herramientas de la web 2.0 y los medios de comunicación social, los cuales son el resultado de aplicar la tecnología de la web 2.0 en un entorno social online.
Así, como herramientas de la web 2.0 se pueden citar las siguientes: Canal RSS (Really Simple Syndication): Se utiliza para difundir información actualizada a usuarios
que se han suscrito a la fuente de contenidos. Podcasting: consiste en la distribución de archivos de audio, generalmente en formato mp3. Vodcasting: tiene un concepto similar al podcasting, pero en vez de tener solo audio incorpora
además video. Widget: pequeña aplicación pensada para proveer de información visual y facilitar el acceso a
funciones usadas frecuentemente. Como ejemplos de widgets se pueden citar los relojes en pantalla, notas, calculadoras, calendarios, ventanas con información del tiempo en su ciudad, etc.
Facilidades para compartir, marcar y clasificar información: aplicaciones que permiten compartir la información de una web con otros usuarios así como almacenar, clasificar y compartir contenidos.
Mashup: aplicación que usa y combina datos procedentes de una o más fuentes para crear nuevos servicios. El ejemplo más conocido de mashup son las aplicaciones que utilizan Google maps.
Sistema de embebido de datos: consiste en la inclusión de contenidos en una web creados por un tercero con objeto de formar un contenido compuesto. A menudo se confunden con mashups. Por ejemplo, son habituales las aplicaciones que permiten embeber vídeos de YouTube en una web.
ISBN: 978-989-8533-11-1 © 2012 IADIS
100

Webcast: es un diseño de transmisión a tiempo real a través de Internet, similar a un programa de televisión o una emisora de radio.
Las herramientas de la web 2.0 comentadas anteriormente están presentes en casi todos los medios de comunicación social, entre los que se pueden destacar los siguientes:
Blogs: son sitios web periódicamente actualizados que recopilan cronológicamente textos o artículos de uno o varios autores. Habitualmente, los lectores pueden escribir sus comentarios y el autor darles respuesta, de forma que es posible establecer un diálogo.
Wiki: es un sitio web cuyas páginas pueden ser editadas por múltiples usuarios a través del navegador web. El ejemplo más conocido es la Wikipedia.
Plataformas de intercambio: basadas en las aplicaciones de la web 2.0 para compartir, marcar y clasificar información, estas plataformas no sólo permiten a los usuarios compartir presentaciones (Slideshare), fotografías (Flickr), documentos (Docstoc) y videos (YouTube), sino que permiten puntuar, ordenar y comentar la información disponible.
Redes sociales: Son sitios web que ofrecen servicios y funcionalidades de comunicación diversos para mantener en contacto a los usuarios de la red. Integran numerosas funciones individuales: blogs, wikis, foros, chat, mensajería, etc. en una misma interfaz y proporcionan conectividad entre los diversos usuarios de la red. Además, las principales redes sociales (Facebook, LinkedIn, MySpace, etc.) suelen permitir la interconexión entre ellas.
Twitter: es una plataforma de microblogging basada en mensajes de 140 caracteres (tweets) que no está considerada como una red social, sino como una herramienta de comunicación.
3. VISIBILIDAD ONLINE DEL SECTOR HOTELERO: ESTUDIO EMPÍRICO
3.1 Metodología
El análisis de la visibilidad de las cadenas hoteleras se estructura en dos fases. Inicialmente, se lleva a cabo un estudio descriptivo de la utilización de las herramientas de la web 2.0 y de los medios de comunicación social por parte de las cadenas hoteleras. La segunda fase consiste en analizar las causas que determinan el mayor o menor desarrollo de estas tecnologías en el sector propuesto.
Para el análisis de la utilización que las cadenas hoteleras hacen de las aplicaciones de la web 2.0, siguiendo la metodología aplicada por Elia, Margherita y Taurino (2009) y Bonsón y Flores (2011), se examina la página web oficial de cada una de ellas para localizar los siguientes ítems: 1. Blogs; 2. Podcasts; 3. Vodcasts; 4. Canales RSS; 5. Widgets; 6. Mashups; 7. Webcasts; 8. Link al canal oficial de YouTube; 9. Link a la cuenta oficial de Twitter; 10. Link a la página oficial de Facebook. Los ítems se han valorado de forma dicotómica, si el ítem está disponible se puntúa con un 1 y si no está disponible con un 0.
Respecto al estudio de los medios de comunicación social, cada uno de ellos se ha medido a través de diferentes ítems como el número de grupos, el número de seguidores o el número de visitas. Los medios de comunicación analizados han sido Twitter, Facebook, YouTube y Google blogs (también se examinaron LinkedIn y Flickr pero no se han incluido en el trabajo dados los escasos resultados obtenidos). En Twitter se verificaron los siguientes ítems: 1. Tiene cuenta oficial en Twitter; 2. Número de seguidores; 3. Número de tweets; 4. Número de páginas que está siguiendo. En Facebook se comprobaron los siguientes: 1. Tiene página oficial en Facebook; 2. Número de páginas-grupos de los que es fan la cadena hotelera; 3. Número de fans; 4. Número de visitas; 5. Número de personas que están hablando de la cadena hotelera; 6. El éxito de la página de Facebook, calculado, dividiendo el número de personas que están hablando de la cadena hotelera entre el número de fans. En YouTube se examinaron los siguientes: 1. Tiene canal oficial en YouTube; 2. Número de suscriptores; 3. Número de reproducciones de vídeo. Finalmente, en Google blogs, siguiendo la metodología aplicada por Bonsón et al. (2011), se ha chequeado el número de blogs indexados cuando se busca el nombre oficial de la cadena hotelera en Google blogs.
La segunda fase del análisis se corresponde con la parte empírica. Así, para poder analizar la influencia de factores independientes en el desarrollo de estas tecnologías en el sector hotelero, necesitamos primero cuantificar el nivel de uso de estas aplicaciones. Con este objetivo se ha clasificado cada cadena hotelera de
Conferência IADIS Ibero-Americana WWW/Internet 2012
101

acuerdo a un índice de visibilidad (IV) compuesto por los 10 ítems empleados anteriormente en el análisis la página web oficial. El IV de cada cadena hotelera se calcula como el cociente entre la suma de los ítems que estaban disponibles (se puntuaron con un 1) y el número total de ítems (10 ítems). Hay que tener en cuenta que en análisis de la web se incluyeron ítems relativos a la presencia de la cadena hotelera en YouTube, Twitter y Facebook, por lo que el IV se basa tanto en el análisis de la disponibilidad de estos ítems en la página web de las cadenas hoteleras y en la presencia de las mismas en los medios de comunicación social seleccionados.
Una vez definida la variable dependiente (IV), tomando como referencia investigaciones sobre transparencia, visibilidad, páginas web y redes sociales (Ardichvili et al., 2006; Balim y Dogerlioglu, 2011; Bertot, Jaeger y Grimes, 2010; Bonsón y Flores, 2011; Celaya et al., 2009; Claver, Andreu y Quer, 2006; Riege, 2007) se han seleccionado los posibles factores capaces de promover el desarrollo de las herramientas de la web 2.0 y los medios de comunicación social en el sector hotelero, los cuales se han testado mediante un modelo de regresión múltiple. Los factores explicativos considerados se sintetizan en la tabla 1, que indica las unidades de medida utilizadas y las relaciones esperadas con el índice de visibilidad.
Tabla 1. Factores explicativos
FACTOR MEDIDA RELACIÓN ESPERADA Tamaño (T.HAB) -Nº de habitaciones en 2010 (Log. Neperiano) Positiva Tamaño (T. HOT) -Nº de hoteles en 2010 (Log. Neperiano) Positiva Cifra de ventas (C.VENT) -Facturación en 2010 en euros (Log. Neperiano) Positiva Antigüedad (ANTI) - Nº de años en funcionamiento Positiva
Penetración de internet (P.INTER)
-Nivel de penetración de internet en el país en el que se encuentra la cadena hotelera (www.internetworldstats.com)
Positiva
Penetración de las redes sociales (P.REDES)
- Nivel de penetración de las redes sociales en el país en el que se encuentra la cadena hotelera (http://globalwebindex.net/)
Positiva
3.2 Ámbito de Estudio
La muestra del estudio comprende las 50 cadenas hoteleras más grandes del mundo, según el HOTELS´ 325 Ranking 2010 (http://www.marketingandtechnology.com/repository/webFeatures/HOTELS/2011_HOTELS _325.pdf). Concretamente, representan el 76,03% del total de habitaciones y el 80,28% del total de hoteles que suman las cadenas hoteleras de este ranking. Por lo tanto, los resultados obtenidos de este estudio podría ser un indicador de la tendencia del sector. Los datos utilizados para el análisis empírico se han extraído de los informes anuales de 2010 que figuran en la web corporativa de cada cadena hotelera.
Desde hace más de 45 años de la revista Hotels Magazine ha sido una de las principales fuentes de noticias y análisis para la industria hotelera mundial. Llegando a más de 90.000 profesionales de la hostelería en más de 160 países a través de comunicaciones impresas y en línea, Hotels Magazine proporciona información crítica sobre todos los aspectos clave de la industria hotelera a nivel mundial, incluyendo el diseño, alimentos y bebidas, finanzas, marketing y tecnología de desarrollo.
Con respecto a las regiones geográficas de las cadenas hoteleras examinadas, se observa que están más o menos uniformemente distribuidas entre América, Europa y Asia (tabla 2).
Tabla 2. Distribución geográfica y por antigüedad
CONTINENTE % ANTIGÜEDAD América 44% AÑOS % AÑOS % Europa 34% 0 - 10 14% 51 - 60 10% Asia 22% 11 - 20 12% 61 - 70 4% Oceanía 0% 21 - 30 10% 71 - 80 6% África 0% 31 - 40 12% 81 - 90 10% 41 - 50 10% 91 - 100 0% + 100 12%
ISBN: 978-989-8533-11-1 © 2012 IADIS
102

En cuanto a la edad de las mismas (ver tabla 2), la media se sitúa en torno a las seis décadas. Sin embargo, los datos presentan una desviación estándar de 56,92 años. Esta alta dispersión se debe a las cadenas hoteleras de nueva creación, que provienen recientes fusiones y adquisiciones del sector.
3.3 Análisis de los Resultados
En la tabla 3 recogemos los resultados del análisis efectuado sobre el uso de las herramientas de la web 2.0 y de las plataformas de comunicación social. En términos generales, se observa que en ambos casos es baja su utilización siendo las más aplicadas las plataformas de comunicación social.
De acuerdo con la disponibilidad de las herramientas de la web 2.0, la más utilizada es el canal RSS que alcanza el 30% de la muestra. Por el contrario, las herramientas menos utilizadas han sido los mashups (4%) seguido de los postcads y webcasts (6%). En una posición intermedia se encuentran los blogs y los vodcast con una media de 4 puntos, respectivamente.
Con respecto a las plataformas de comunicación social, se observa que las más visible es Facebook. Con seis puntos menos (40%) le sigue Twitter, mientras que solo un 20% de los hoteles analizados cuentan con un canal oficial de Youtube. Por otro lado, hemos de recordar que tal y como se indica en la metodología, además de las plataformas recogidas en la tabla 3 fueron examinadas otras plataformas tales como Linkedlin o Flirck sin embargo debido a su escasa visibilidad no fueron incluidas en este estudio.
Tabla 3. Utilización de web 2.0 y medios de comunicación social
CADENAS HOTELERAS
MEDIOS DE COMUNICACIÓN SOCIAL MEDIA
N %
Tiene cuenta oficial en Twitter (40%) 20 Blogs 4 8% Número de seguidores 32.962 Podcasts 3 6% Número de tweets 2.914
Vodcasts 4 8% Número de páginas que está
siguiendo 2.601
Canales RSS 15 30%
Tiene página oficial en Facebook (46%) 23
Widgets 3 6% Número de páginas-grupos de
los que es fan 42
Mashups 2 4% Número de fans 524.673 Webcasts 3 6% Número de visitas 332.326 Link al canal oficial de YouTube
10 20% Número de personas que están
hablando de ella 12.957
Link a la cuenta oficial de Twitter
20 40%
Éxito de la página de Facebook (2,4%)
Link a la página oficial de Facebook
23 46%
YouTube
Tiene canal oficial en YouTube (20%) 10
Número de suscriptores 6.667
Número de reproducciones de
video 5.179.818
Google Número de blogs indexados en Google blogs
279.581
En relación con las plataformas sociales utilizadas por la muestra, se observa que casi la mitad de los
hoteles analizados carece de plataforma de comunicación social siendo únicamente nueve las cadenas hoteleras que disponen de las 3 plataformas y otras nueve las que están presentes en 2 plataformas. Tal y como se observa en la tabla 3, Facebook es la plataforma con mayor número medio de suscriptores con 524.673, seguida de Twitter con un promedio de 32.962 seguidores, Sin embargo, es en Youtube donde se observa el mayor número medio de visitas con 5.179.818.Asimismo, la media de blogs indexados que se obtiene al buscar el nombre oficial de los hoteles analizados es de 279.581.
El nivel de interacción en Facebook medido según “numero medio de personas están hablando de esto” nos indica que 12,957 son el promedio de personas que han generado interacciones diversas con la página, por lo que se demuestra que Facebook está siendo de gran interés para la audiencia y que son numerosas las personas conectadas con la comunidad. Asimismo, los datos indican que el “éxito de una página” es de un 2.04%. En línea con Bonsón y Flores (2011) a partir del 5 % se considera que el éxito de la página Facebook
Conferência IADIS Ibero-Americana WWW/Internet 2012
103

de una organización es adecuado. En los hoteles analizados obtienen un 2,4% por lo que se puede considerar un nivel de éxito moderado.
De acuerdo al segundo objetivo se presentan los resultados del análisis de los factores determinantes que afectan al mayor uso de las herramientas web 2.0. Para ello, se ha utilizado un análisis de regresión múltiple, y al suponerse que las variables objeto de estudio presentan relaciones de tipo lineal, se ha seleccionado como técnica estadística la Regresión Lineal Múltiple.
Una vez comprobadas las hipótesis de partida del modelo (linealidad, homocedasticidad, normalidad, independencia y no colinealidad) se presenta la matriz de correlaciones de Pearson (ver tabla 4). Como puede comprobarse la matriz existe una moderada correlación (0,68) entre las dos variables que miden el tamaño de la organización. En menor medida, se observa una baja correlación entre el tamaño de la organización, medida por el total de habitaciones, y las variables volumen de ventas y edad de la organización. Por tanto, la inexistencia de correlaciones elevadas y significativas entre la variable dependiente y las independientes nos da una idea de los resultados de la regresión, que presumiblemente contará con un ajuste medio-bajo y pocas variables significativas.
Tabla 4. Matriz de correlaciones de Pearson
IV T.HAB T.HOT C.VENT ANTI P.INTER P.REDES IV 1 T.HAB 0,059 1 T.HOT -0,208 0,685** 1 C.VENT 0,218 0,490** 0,253 1 ANTI 0,277 0,339** 0,284* 0,227 1 P.INTER 0,169 0,132 0,083 0,205 0,088 1 P.REDES 0,156 0,224 0,202 0,207 0,034 -0,092 1 *La correlación es significativa al nivel 0,05 (bilateral). **La correlación es significativa al nivel 0,01 (bilateral).
De acuerdo al análisis efectuado (ver tabla 5), la capacidad explicativa del modelo resultante, medida a través del R cuadrado corregido, es de un 30,4% por lo que como ya se sospechaba el ajuste es moderado. En cuanto a la significatividad de las variables, solo 3 de los 6 factores independientes son significativos.
En línea con el trabajo de Paroutis y Al Saleh (2009), se observa una relación significativa y directa entre antigüedad de la organización y el uso de la web 20.0 (2,243*). Por tanto, aquellos hoteles con mayor edad son los que más se interesan en utilizar las herramientas de comunicación web 2.0. Asimismo se observa que, el tamaño afecta positivamente a un mayor uso de mecanismos de interacción de acuerdo el trabajo de Bonsón y Flores, (2011) que evidencian la relación positiva del tamaño en el mayor uso de las web de organizaciones financieras. Asimismo, los resultados coinciden con el trabajo Claver, Andreu y Quer (2006) que señalan que los hoteles de mayor tamaño son los que realizan mayores estrategias crecimiento.
Es neutra la relación entre la variable cifra de ventas y la mayor utilización de la web 2.0 por lo que en este trabajo no se comparte los resultados de Claver, Andreu y Quer (2006) que evidencian que aquellos hoteles con ingresos elevados aplican en mayor medida estrategias de crecimiento. Asimismo, no se confirma relación alguna entre las variables nivel de penetración de internet y nivel de penetración de las redes sociales en línea con el trabajo sobre entidades financieras de Bonsón y Flores (2011).
Tabla 5. Resultados de la regresión
MODELO COEFICIENTES NO ESTANDARIZADOS
COEFICIENTES TIPIFICADOS T
B ERROR TÍPICO BETA (Constante) T.HAB T.HOT C.VENT ANTI P.INTER P.REDES
-0,496 0,147 0,128 -0,006 0,001 0,100 0,121
0,383 0,051 0,032 0,016 0,000 0,081 0,076
0,832 1,046 -0,063 0,286 0,152 0,198
-1,298 2,886** 4,047** -0,410 2,243* 1,230 1,585
R R cuadrado R cuadrado corregido Error típ. de la estimación Durbin-Watson 0,624 0,389 0,304 0,152 2,025
*La correlación es significativa al nivel 0,05 (bilateral). **La correlación es significativa al nivel 0,01 (bilateral).
ISBN: 978-989-8533-11-1 © 2012 IADIS
104

4. CONCLUSIONES
De una manera cada vez más rápida, las cadenas hoteleras se están beneficiando de las nuevas tecnologías de la información y la comunicación. Por ejemplo, están empezando a usar las aplicaciones de la web 2.0 para comercializar sus productos y servicios, para recibir las reservas y para evaluar las quejas y sugerencias de los clientes. En este sentido, debido al creciente desarrollo de las redes sociales, las cadenas hoteleras también están aprovechando las oportunidades de los medios de comunicación social para aumentar su visibilidad y generar confianza y credibilidad.
Sin embargo, este proceso se encuentra todavía en una etapa inicial. De acuerdo con los resultados de nuestro estudio, la utilización por parte del sector hotelero de las herramientas web 2.0 es baja, aunque la presencia en las redes sociales está más extendida.
Una buena visibilidad para un sitio web indica que es percibido como importante por los usuarios, provee de una ventaja frente a los competidores y asegura un caudal importante de nuevos visitantes de forma sostenida. Sin embargo, las cadenas hoteleras no parece ser conscientes de estas ventajas, ya que el análisis muestra que aún queda mucho por hacer en el uso de la web 2.0 en el sector hotelero. Por otro lado, debido al impacto de la crisis mundial en el turismo, los hoteles necesitan aplicar las herramientas web 2.0 como canales mediante los que proporcionar información y servicios al público en general, y en última instancia, para tratar de aumentar el número de reservas. Por lo tanto, las cadenas hoteleras que han explorado y desarrollado los servicios y las tecnologías web 2.0 desde su inicio tienen una clara ventaja competitiva.
En cuanto a los medios de comunicación social, ante la popularización de las redes sociales, los foros de internet y los blogs, muchas empresas se han apresurado a crear una página en Facebook o han abierto una cuenta en Twitter, pero esto definitivamente es insuficiente. No es simplemente una cuestión de crear presencia y reputación, también es necesario gestionarla a través de una estrategia de medios sociales bien estructurada, de forma que se sea visible en el entorno en el que queremos promocionarnos o de cara a clientes potenciales. Los resultados sostienen que las cadenas hoteleras han empezado a reconocer los beneficios de las plataformas sociales en relación con el aumento de visibilidad, ya que el 52% de ellas tiene una cuenta oficial en alguno de los 3 medios seleccionados y los ítems y ratios que reflejan interés y la relevancia de las redes sociales así lo atestiguan.
Las cadenas hoteleras que no están presentes en las redes sociales son menos conscientes de las opiniones de sus usuarios, por lo que se están perdiendo una importante fuente de información. Incluso aunque una cadena hotelera no tenga cuenta oficial, en las redes sociales se habla de ellas, así que están desaprovechando la oportunidad de participar en conversaciones sobre ellas mismas. Por tanto, los hoteles deben incluir las redes sociales y la interacción con los clientes en el marco de una estrategia de comunicación digital, y generar contenidos de calidad, desarrollar de promociones, concursos y ofertas especiales.
Finalmente, respecto a los factores que influyen en el uso de medios de comunicación social y las herramientas de la web 2.0 en el sector hotelero, el análisis muestra que las cadenas hoteleras más antiguas se muestran más interesadas en usar estas aplicaciones. De acuerdo con esto, la edad de una empresa es a menudo considerada como un indicador de la reputación, por lo que es posible que las cadenas hoteleras más maduras estén usando estas tecnologías como mecanismos para mantener su imagen. Además de esto los hoteles más grandes son más conscientes de la utilidad de estas tecnologías. En este sentido es posible que aquellas con mayor estructura estén utilizando la web 2.0 como mecanismo para promocionar su expansión. De otra parte, a pesar de no haberse obtenido resultados concluyentes en la influencia de los factores de nivel de penetración de internet y de redes sociales, hay que tener en consideración que los usuarios de las redes sociales no son solamente las personan que viven en el país donde se ubica hotel.
REFERENCIAS
Anderson, P., 2007. What is Web 2.0? Ideas, technologies and implications for education. JISC Technology and Standards Watch, pp. 2-64.
Ardichvili, A., Maurer, M., Li, W., Wentling, T. y Stuedemann, R., 2006. Cultural influences on knowledge sharing through online communities of practice, Journal of Knowledge Management, Vol. 10, No. 1, pp. 94-107.
Beagrie, N., 2005. Plenty of room at the bottom? Personal digital libraries and collections. D-Lib magazine, Vol. 11, No. 6. Consultado el 22 de octubre de 2011, desde http://www.dlib.org/dlib /june05/beagrie/06beagrie.html
Conferência IADIS Ibero-Americana WWW/Internet 2012
105

Bertot, J.C., Jaeger, P.T. y Grimes, J.M., 2010. Using ICTs to create a culture of transparency: E-government and social media as openness and anti-corruption tools for societies. Government Information Quarterly, Vol. 27, No. 3, pp. 264-271.
Bonsón, E., Escobar, T. y Flores, F., 2006. Online transparency of the banking sector. Online information review, Vol. 30, No. 6, pp. 714-730.
Bonsón, E. y Flores, F., 2011. Social media and corporate dialogue: the response of the global financial institutions. Online Information Review, Vol. 35, No. 1, pp. 34-49.
Bonsón, E., Torres, L., Royo, S. y Flores, F., 2011. Local e-government 2.0: social media and corporate transparency in municipalities. Comunicación presentada en el XVI Congreso AECA, Granada, España.
Borgman, C., 2003. Personal digital libraries: creating individual spaces for innovation. NSF/JISC Post Digital Library Futures Workshop, 15-17. Consultado el 22 de octubre de 2011, desde http://www.sis.pitt.edu/~d lwkshop/paper_borgman.html
Buhalis D. y Deimezi , O., 2004. E-tourism developments in Greece: Information communication technologies adoption for the strategic management of the greek tourism industry. Tourism and Hospitality Research, Vol. 5, No. 2, pp. 103-130.
Celaya, J., Vázquez, J.A., Saldaña, I. y García, Y., 2009. Visibilidad de las ciudades en la Web 2.0. Grupo BPMO. CERF, V., 2007. An Information Avalanche. IEEE Computer, Vol. 40, No. 1. Claver , E. Rosario, A. y Quer, D., 2006. Growth strategies in the spanish hotel sector: Determining factors. International
Journal of Contemporary Hospitality Management, Vol. 18, No. 3, pp. 188-205. Elia, G., Margherita, A., y Taurino, C., 2009. Enhancing managerial competencies through a wiki-learning space.
International Journal of Continuing Engineering Education and Life-Long Learning, Vol. 19, No. 2-3, pp. 166-178. Ganesan, K. y Zhai, C., 2012.Opinion-based entity ranking. Information Retrieval, Vol. 15, No. 2, pp. 116-150. Hailey, L., 2010. The importance of social media marketing today. Consultado el 26 de junio de 2012, desde
http://ezinearticles.com/?The-Importance-of-Social-Media-Marketing- Today&id=3873989. Hearn, G., Foth, M., y Gray, H., 2009. Applications and implementations of new media in corporate communications: An
action research approach, Corporate Communications, Vol. 14, No. 1, pp. 49-61. Jiang, Y., Raghupathi, V., y Raghupathi, W., 2009. Content and design of corporate governance web sites. Information
Systems Management, Vol. 26, No. 1, pp. 13-27. Larrán, M. y Giner, B., 2002. The Use of the Internet for Corporate Reporting by Spanish Companies. The International
Journal of Digital Accounting Research, Vol. 2, No. 1, pp. 53-82. Lim, W., 2010. The Effects of social media networks in the hospitality industry. UNLV Theses/Dissertations/Professional
Papers/Capstones, paper 693, Consultado el 26 de junio de 2012, desde http://digitalscholarship.unlv.edu/thes esdissertations/693.
O´Really, T., 2005. What is Web 2.0: Design patterns and business models for the next generation of software. Grupo O´Really. Consultado el 22 de octubre de 2011, desde http://oreilly.com/web2/archive/what-is-web-20.html
Paroutis, S y Al Saleh A., 2009. Determinants of knowledge sharing using web 2.0 technologies. Journal of Knowledge Management, Vol. 13, No. 4, pp. 52-63.
Paton, R. y McLaughlin, S., 2008.Services innovation: Knowledge transfer and the supply chain, European Management Journal, Vol. 26, No. 2, pp. 77-83.
Perrigot, R. Basset, G. y Cliquet, G., 2011. Multi-channel communication: The case of subway attracting new franchisees in France. International Journal of Retail & Distribution Management, Vol. 39, No. 6, pp. 434-455.
Riege, A., 2007. Actions to overcome knowledge transfer barriers in MNCs. Journal of Knowledge Management, Vol. 11, No. 1, pp. 48-67.
Shadbolt, N., 2006. Problemas sociales, eticos y legales: ¿cómo afecta el aumento al acceso al conocimiento a nuestra sociedad?. Comunicación presentada en el Memories for Life: the future of our pasts, Londres.
Tiedemann, N. van Birgele, M. y Semeijn, J., 2009. Increasing hotel responsiveness to customers through information sharing. Tourism Review of AIEST - International Association of Scientific Experts in Tourism, Vol. 64, No. 4, pp. 12-26.
Vázquez, J.A., Saldaña, I. y Celaya, J., 2009. La visibilidad de los museos en la Web 2.0. Portal Cultural Dosdoce.com. Consultado el 17 de octubre de 2001, desde http://www.dosdoce.com/articulo/estudios/3071/la-visibilidad-de-los-museos-en-la-web-2-0/
ISBN: 978-989-8533-11-1 © 2012 IADIS
106

EVOLUÇÃO DA FERRAMENTA ACCESSIBILITYUTIL: APOIO A PROJETOS, MODERAÇÃO DE CONTEÚDOS E
VERIFICAÇÕES DE USO
Thiago Jabur Bittar1, 2, Leandro Agostini do Amaral1 e Renata Pontin de Mattos Fortes1 1Universidade de São Paulo – USP - ICMC
2Universidade Federal de Goiás – UFG - DCC
RESUMO
Um dos fatores que acarretam o problema de sites inacessíveis na web é a falta de conhecimento de designers e desenvolvedores, bem como a divulgação insuficiente de técnicas de implementação para garantia da acessibilidade. Nesse contexto, em 2011 foi desenvolvida a ferramenta AccessibilityUtil, que tem por objetivo compartilhar experiências de desenvolvimento de artefatos acessíveis na web, relacionando os problemas e soluções, de forma colaborativa, com diretrizes existentes. Desde sua disponibilização, tal ferramenta vem sendo melhorada constantemente e, neste artigo, são apresentadas as verificações de uso com quantidades de acesso e outras métricas, bem como evoluções realizadas em termos de funcionalidades inseridas, principalmente relacionadas à moderação de conteúdo e apoio a projetos.
PALAVRAS-CHAVE
Acessibilidade, Design Rationale (DR), Moderação de conteúdo, Colaboração, Apoio a projetos.
1. INTRODUÇÃO
Atualmente, observa-se que uma das principais causas para o contínuo problema da inacessibilidade na web é a falta de conhecimentos por designers e desenvolvedores sobre as diretrizes e a legislação existentes. Sobretudo, nota-se que a divulgação das técnicas de implementação para garantir acessibilidade é insuficiente (Sloan, 2006; Freire, Russo e Fortes, 2008).
Diante dessa problemática e com base em estudos realizados sobre diretrizes de acessibilidade, neste artigo é descrita a evolução de uma ferramenta colaborativa, chamada AccessibilityUtil, a qual proporciona um ambiente estruturado na web, visando a troca de experiências sobre o desenvolvimento de artefatos web com acessibilidade. Essa evolução tem sido desenvolvida desde o lançamento da ferramenta AccessibilityUtil, em maio de 2011, até agosto de 2012.
Tal ferramenta, descrita em outros dois trabalhos científicos (Bittar et al., 2011; Bittar, Amaral e Fortes, 2011) também foi alvo de uma apresentação com demonstração, em reconhecido evento científico de web no Brasil (Bittar et al., 2011b). A partir de sugestões recebidas e verificação das suas formas de utilização, diversas alterações para sua evolução foram incorporadas na ferramenta, principalmente em relação à moderação de conteúdo e no suporte a decisões de acessibilidade para projetos. Neste artigo, são descritos esses novos desenvolvimentos efetuados e apresentadas verificações de uso por meio de estatísticas de acesso e repercussão ocorrida desde então, proporcionando uma análise sobre sua evolução.
O restante deste artigo está organizado como segue. Na Seção 2 são apresentados os trabalhos relacionados, proporcionando uma visão geral sobre as questões tratadas nas ferramentas de apoio a garantia de acessibilidade por meio de experiências de desenvolvedores interessados, e como são tratadas essas questões pelas outras ferramentas, especialmente em relação às evoluções efetuadas. Na Seção 3 são apresentados os conceitos envolvidos na moderação de conteúdo que foi agregada na ferramenta. A Seção 4 descreve o módulo de apoio a decisões sobre acessibilidade em projetos e na Seção 5 são vistos os principais resultados obtidos com a evolução da ferramenta AccessibilityUtil. Por fim, na Seção 6, considerações finais e diretivas para trabalhos futuros são apresentadas.
Conferência IADIS Ibero-Americana WWW/Internet 2012
107

2. TRABALHOS RELACIONADOS
Ao pesquisar sobre outros trabalhos que apresentam ferramentas para apoiar o desenvolvimento de aplicações web com acessibilidade, verificou-se que a maioria se concentra em atividades relativas ao tratamento da acessibilidade de elementos já desenvolvidos, visando a realização de sua avaliação e possíveis correções. A ferramenta AccessibilityUtil almeja ser utilizada durante os processos de análise e desenvolvimento.
Dessa forma, espera-se chegar à etapa de avaliação com o menor número de erros possível; considera-se relevante a devida atenção aos custos de modificações após o desenvolvimento efetuado, que em geral é maior do que quando a correção ou o bom desenvolvimento são praticados em etapas anteriores (Martín, Cechich e Rossi, 2011).
Bailey e Pearson (2011) descrevem o desenvolvimento de uma ferramenta web de gerenciamento de conhecimento em acessibilidade, chamada “Accessibility Evaluation Assistant (AEA)1”, focada em auxiliar o processo de avaliação de acessibilidade para avaliadores novatos. Os pesquisadores relatam que as ferramentas de avaliação ainda não são facilmente compreendidas por esses usuários. Uma das causas para isso é a complexidade para o correto entendimento das diretrizes do documento WCAG (W3C, 2008) por novatos. A ferramenta AEA foi testada com bons resultados em um grupo de 38 alunos de graduação.
Uma ideia apresentada pelos autores da AEA, que merece ser destacada, é a organização dos usuários com necessidades especiais em 10 grupos: disléxicos, deficiência de aprendizagem, baixa visão, usuários de leitores de tela, deficiência motora, inglês como língua estrangeira, idosos, deficiências visuais na percepção de cores, deficiências auditivas e crises de convulsão.
A motivação para essa organização é ajudar avaliadores a reconhecerem usuários reais e encorajá-los a encontrar princípios de acessibilidade comuns, que auxiliem no processo de verificação de acessibilidade. Na ferramenta AccessibilityUtil, esse conhecimento pode ser incorporado ao longo do tempo, mas nas próprias discussões sobre as diretrizes é discorrido a qual deficiência elas em geral devem ser aplicadas.
O site “AccessibilityTips2” oferece uma coleção de dicas, guias e sugestões práticas para o desenvolvimento de sites acessíveis. Seu formato difere do trabalho desenvolvido na ferramenta AccessibilityUtil, pois é estruturado em forma de Blog, não sendo possível a colaboração entre usuários (inclusive a opção de comentários está desabilitada). Todas as postagens são, dessa forma, dos responsáveis pelo site. Outra característica que os distinguem é que não há relação das sugestões apresentadas com diretrizes oficiais do W3C. Um ponto que deve ser ressaltado é que a última postagem do site é referente ao ano de 2009, indicando desatualização e uma possível descontinuidade.
Wald et al. (2011), por sua vez, apresentam o site “web2Access3” que permite que os usuários avaliem um site em relação à WCAG 2.0 e outras diretrizes. A diferença que existe ao compará-lo com a ferramenta AccessibilityUtil é que a ideia é da avaliação de um site e não de um artefato genérico. Uma questão a se considerar na avaliação de sites é o fator temporal, pois um site pode mudar frequentemente e, com isso, as características de acessibilidade podem mudar e os dados postados na ferramenta ficarem desatualizados.
Uma ferramenta que se assemelha à proposta da ferramenta AccessibilityUtil é o “WARAU - Websites Atendendo a Requisitos de Acessibilidade e Usabilidade (Beta)4” que visa auxiliar equipes de desenvolvimento a adequarem seus sites a requisitos de acessibilidade e usabilidade por meio da disponibilização de um referencial teórico e um canal de comunicação entre seus usuários (Almeida, Santana e Baranauskas, 2008). O conteúdo é disponibilizado em tópicos de forma análoga à ferramenta AccessibilityUtil, porém a forma de interação com comentários é diferente; há também uma distinção conceitual no que se refere à integração feita com as diretrizes do W3C e uso da organização em artefatos.
Verifica-se, assim, que o trabalho desenvolvido para criação e evolução da ferramenta AccessibilityUtil apresenta inovações no sentido de relacionar discussões e comentários de desenvolvedores com diretrizes oficiais. Em todas essas ferramentas comentadas anteriormente em nenhuma foram encontrados mecanismos similares para moderação de conteúdo (com o usuário final marcando uma informação como inapropriada) e apoio a projetos específicos para gestão de decisões de acessibilidade.
1 http://arc.tees.ac.uk/aea/ 2 http://www.accessibilitytips.com/ 3 http://www.web2access.org.uk/ 4 http://warau.nied.unicamp.br/
ISBN: 978-989-8533-11-1 © 2012 IADIS
108

3. MODERAÇÃO DO CONTEÚDO
A atividade de moderação consiste em uma ação reguladora para a organização, gestão e acompanhamento das atividades de colaboração. Com a realização da moderação, é possível se ter um controle sobre a inserção de conteúdos inapropriados aos objetivos de uma aplicação, filtrando informações, que podem ser tendenciosas, erradas ou com anúncios, por exemplo (Chen, Xu e Whinston, 2011).
A moderação pode ser colaborativa, centralizada por líderes ou mista. Na moderação colaborativa, os usuários podem notificar aos líderes da colaboração sobre os conteúdos que consideram impróprios, para que haja a condução de uma avaliação das informações postadas. Esse tipo de moderação segue a premissa de que se muitas pessoas podem analisar informações e reportar erros em um conteúdo, eles serão corrigidos de forma mais barata e rápida. Já na moderação realizada por líderes, ficam esses como responsáveis por analisar os últimos conteúdos inseridos e habilitar sua visualização ou não pelos demais usuários.
Por ser incentivada uma colaboração mais aberta e informal, a moderação colaborativa contribui para que, nas discussões feitas, possa se aprender com os erros e reportar experiências, diferente de ser um repositório de diretrizes corretas ou um guia. Dessa forma, uma discussão para mostrar possíveis demonstrações equivocadas, com exemplos, partindo-se de experiências e seus resultados, se apresenta como uma base importante para compor um discurso que contribua de maneira a possibilitar a difusão de diretrizes, que se constituem como os preceitos corretos que devem ser seguidos.
Nesse contexto, a ideia proposta por trás da ferramenta AccessibilityUtil não é armazenar conteúdo irrefutável sobre um assunto, mas sim prezar pela discussão contínua e evolutiva. Entende-se que o objetivo da ferramenta não é concorrer com as bases de dados formais, que são referência para os assuntos em questão. No entanto, dentro de limites da informalidade e liberdade de expressão, pretende-se, com a devida moderação, que o conteúdo inserido na ferramenta seja correto e compreensível a todos os interessados. Assim, é necessária a moderação realizada por líderes, que corrijam e esclareçam, colaborando com a construção do conhecimento, corrigindo o raciocínio, bem como a participação de especialistas no assunto. Em contrapartida, deve-se ter cuidado durante a definição das políticas de moderação, para que seu exercício se apresente de forma equilibrada, visando não inibir a colaboração.
Dessa forma, o tipo de moderação da ferramenta AccessibilityUtil é estritamente colaborativo, no qual busca-se por discussões que agregam diferentes pontos de vistas em um meio comum, construindo um enredo dinâmico do conhecimento inserido, privilegiando a construção de conhecimento coletivo e decisões de um grupo informado para um determinado contexto. Na Figura 1 é apresentada parte de uma tela da ferramenta em questão, na qual é possível ver os links que permitem o envio de indicação de conteúdo pelo usuário.
Figura 1. Links e formulário para indicação de conteúdo a analisado por um administrador
A moderação é feita respeitando-se regras claras e públicas, todos se sentindo iguais e com os mesmos direitos em uma comunidade. Para tanto, na página inicial da ferramenta encontra-se um link para uma página que informa sobre tais regras. Dentre os conteúdos indesejados, tem-se aqueles como spam, pornografia, violação de direito autoral e propagandas.
No caso do usuário estar autenticado, ele não precisa informar seu nome e e-mail, pois são dados fornecidos na sessão. Após o envio dos dados, os administradores são notificados para analisar a indicação efetuada. Outra possibilidade de moderação incluída na ferramenta é um botão adicionado em comentários para usuários registrados marcarem se aquele conteúdo é útil, sendo que cada usuário pode fazer isso uma
Conferência IADIS Ibero-Americana WWW/Internet 2012
109

única vez para cada comentário. Assim é possível saber quais comentários foram mais úteis, de acordo com a avaliação dos outros usuários.
4. APOIO A PROJETOS COM GESTÃO DE DECISÕES SOBRE ACESSIBILIDADE
Um novo módulo incorporado à ferramenta AccessibilityUtil foi desenvolvido para permitir o gerenciamento de decisões de acessibilidade em projetos específicos, por meio de discussão de tópicos por colaboradores incluindo a sugestão de uso de diretrizes.
Os projetos podem ter um ou mais usuários colaborando entre si, ou seja, configura-se como um ambiente mais restrito para determinados grupos de usuários com suas questões de interesse. Inicialmente, um usuário criador do projeto convida outros membros para participarem inserindo questões para discussão. Os usuários podem, dessa forma, criar discussões na forma de Design Rationale (DR) (Horner e Atwood, 2006; Conklin e Burgess-Yakemovic, 1996), que são identificadas por comentários associados a um determinado tópico contendo um status, descrição e nome do criador.
Sobre um tópico, os demais usuários membros do projeto podem fazer comentários, sendo que inicialmente o tópico fica sob o status “em discussão”. Após a inserção da discussão na forma de comentários sobre o tópico, os usuários podem marcar o tópico como “concluído”. Mas um usuário pode ainda reabrir o tópico para discussão, voltando o status para “em discussão”. Um exemplo de discussão em um tópico pode ser visto na Figura 2.
Figura 2. Visualização de um tópico de um projeto e a discussão feita
Como pode ser visto na Figura 2, o apoio à gestão de discussões disponibilizado na ferramenta AccessibilityUtil, sobre um tópico de um projeto, é dividido em 4 partes principais: A) detalhes do projeto em questão e listagem de quais usuários estão colaborando; B) detalhes do tópico com seu título, descrição, palavras-chave, dados de sua criação e seu status; C) resultado da busca automática nas diretrizes pelas palavras-chave para auxiliar na discussão e D) comentários feitos no tópico, com data e autor do mesmo.
5. RESULTADOS
Além do desenvolvimento da ferramenta AccessibilityUtil, cujos estudos proporcionaram aprendizado intenso sobre questões de acessibilidade, têm-se, como resultado, expressivos frutos de colaboração com a sua adoção por parte de um significativo número de usuários, desde sua disponibilização. Assim, desde o seu
ISBN: 978-989-8533-11-1 © 2012 IADIS
110

lançamento recente em maio de 2011 até agosto de 2012, foram computados 819 acessos de usuários registrados na ferramenta, 151 usuários cadastrados e 89 artefatos em três tipos, conforme mostra a Tabela 1.
Tabela 1. Distribuição inicial dos artefatos
Tipos de artefato Quantidade
Padrões 45
Tags 22
Outros 22
Total 89
Em relação às discussões que os colaboradores inseriram durante esse período, tem-se: 602 avaliações, 71
imagens e 203 comentários adicionados em avaliações, conforme apresentado na Tabela 2.
Tabela 2. Colaborações na ferramenta
Tipos de colaboração Quantidade
Experiências 602
Imagens 71
Comentários 203
Total 876
Quanto ao módulo de projetos, criado em maio de 2012, tem-se seus números apresentados na Tabela 3.
Tabela 3. Números do módulo de projetos
Tipos de colaboração Quantidade
Projetos 13
Tópicos 58
Comentários 165
Total 236
Em relação ao número de usuários distintos colaborando em projetos, tem-se um total de 25, que
produziram 165 comentários em 58 projetos, ainda de acordo com a Tabela 3. A partir dessas informações iniciais sobre o uso e adoção da ferramenta AccessibilityUtil, constata-se um
caso de sucesso, inclusive com o feedback positivo de usuários, que traz maior confiança de que o modelo de base de dados proposto teve seu papel cumprido no sentido de proporcionar colaboração no domínio de acessibilidade na web, a qual necessita de esforços de todos para melhorar-se o quadro de inadequação de artefatos em relação às diretrizes estabelecidas.
Para se acompanhar detalhadamente os acessos e mensurar a utilização da ferramenta é utilizado o Google Analytics5. Dentre as várias informações disponibilizadas a partir desse acompanhamento, na Tabela 4, apresenta-se o resumo do relatório medido desde seu lançamento, em maio de 2011, até julho de 2012 (cerca de 14 meses).
5 http://www.google.com/analytics/
Conferência IADIS Ibero-Americana WWW/Internet 2012
111

Tabela 4. Resultados de diferentes métricas de utilização da ferramenta AccessibilityUtil
Métrica Resultado
Visitas 2.876
Visitantes únicos 1.901
Pageviews 20.520
Páginas por visita 7,13
Média de tempo de uma visita 07 minutos e 13 segundos
Porcentagem de novos visitantes 65,51%
As informações apresentadas na Tabela 4 demonstram que o conteúdo disponibilizado na ferramenta teve
uma quantidade significativa de acessos, com mais do que 20 mil páginas acessadas em 2.876 visitas. O tempo médio de permanência do usuário é expressivo, demonstrando um interesse de leitura e interação com o ferramental e conteúdos disponibilizados.
Em relação às instituições de origem dos usuários cadastrados, fez-se um levantamento manual para se conhecer melhor o perfil dos interessados, bem como a abrangência da ferramenta: dos 151 usuários 132 informaram suas instituições, sendo 37 distintas, com a configuração apresentada na Tabela 5.
Tabela 5. Número de usuários por tipo de instituição
Tipo de instituição Número de instituições Número de usuários
Instituição de ensino superior 19 113
Empresa de desenvolvimento de software 4 5
Órgão público 5 5
Instituição de ensino médio ou tecnológico 4 4
Órgão privado 3 3
Instituição de ensino superior internacional 2 2
Os dados apresentados na Tabela 5 mostram que a maioria dos usuários são ligados a instituições de
ensino superior, resultado da grande divulgação da ferramenta no meio acadêmico. A utilização da ferramenta nesse tipo de instituição é importante para auxiliar na educação tecnológica. Além disso, verifica-se a participação de usuários ligados a órgãos públicos e empresas de desenvolvimento de software, demonstrando um princípio de sua utilização no meio não acadêmico.
Uma característica relevante na ferramenta até o momento é em relação aos diferentes relatórios que podem ser gerados a partir de sua base de dados, envolvendo diferentes visões. Um exemplo disso pode visto na Figura 3, na qual se mostra uma parte do relatório de quantas avaliações cada critério de sucesso possui.
Figura 3. Número de avaliações por critério de sucesso
ISBN: 978-989-8533-11-1 © 2012 IADIS
112

De acordo com a listagem apresentada na Figura 3 é possível perceber que um critério com muitas avaliações é o “1.1.1 – Conteúdo Não Textual”, no qual 79 comentários foram feitos a respeito.
Outro ponto positivo que se destaca está relacionado com definições feitas, que não envolvem o modelo de dados, como, por exemplo, pode ser citada a escolha do domínio e nome da ferramenta: para que o projeto tivesse maior abrangência, inclusive internacional, foi escolhido o seu acesso por meio de um domínio “.com”. Essa característica permite ao projeto não ficar associado de forma restrita a um domínio de uma única instituição, já que o mesmo envolve diferentes instituições e outras poderão se associar como parceiras.
Como resultados indiretos, é possível mencionar a divulgação do tema acessibilidade na mídia a partir do desenvolvimento e disponibilização da ferramenta AccessibilityUtil. Tais divulgações ocorreram na mídia em forma de vídeos e matérias escritas. Um detalhamento dessa veiculação feita pode ser encontrado no site da ferramenta na seção “Na imprensa”6.
Um dos reconhecimentos mais relevantes para a equipe deste projeto foi a obtenção do segundo lugar no concurso “Todos@Web” - Prêmio Nacional de Acessibilidade na Web7, promovido pelo W3C Escritório Brasil. Por meio de inscrição voluntária, foi submetida a ferramenta AccessibilityUtil na categoria “Tecnologias assistivas / Aplicativos” que premiaria os melhores aplicativos e tecnologias assistivas que permitam o acesso a web por pessoas com deficiência. Com o êxito logrado na premiação do projeto, foram concedidos o valor de R$ 3.000,00, troféu e exposição do trabalho em publicação do W3C.
O evento contou com a participação de mais de 300 pessoas envolvendo autoridades como secretários do Ministério do Planejamento, equipe do Governo do Estado de São Paulo e coordenação da Associação de Assistência à Criança Deficiente (AACD). A participação honrou a todos os membros da equipe da ferramenta e proporcionou novos contatos e trocas de experiências com a sociedade e o público alvo das pesquisas realizadas.
A materialização desses contatos ficou mais evidente com a inclusão de todos os finalistas em um Grupo de Trabalho em Acessibilidade do NIC.br que mantém uma lista de discussão por e-mail bem produtiva, informando e aproximando interessados, especialistas em acessibilidade e integrantes de órgãos da área.
6. CONCLUSÃO
Neste artigo o objetivo foi apresentar a evolução do projeto, planejamento e desenvolvimento de uma ferramenta de colaboração para avaliação de artefatos quanto à acessibilidade na web.
Como lição aprendida dessa evolução dos estudos e desenvolvimento tecnológico da ferramenta, pode-se destacar que não basta apenas coletar informações e decisões de projetos para acessibilidade, existe a necessidade de organizar essas informações de acordo com as diretrizes estabelecidas.
Pela quantidade e qualidade dos acessos à ferramenta, bem como a constatação dos comentários nas discussões e avaliações realizadas, pode-se concluir o que é considerado pela equipe de desenvolvimento da ferramenta o seu ponto forte: a colaboração para ajudar os desenvolvedores a decidirem quais técnicas sobre acessibilidade usar. Almeja-se que essa contribuição possa aproximar experiências de casos reais de desenvolvimento (na forma de artefatos) às diretrizes e possibilitar a colaboração dos interessados com comentários entre desenvolvedores e stakeholders.
Como limitações no projeto da ferramenta AcessibiliyUtil, pode-se relatar a dificuldade em obter experiências para o tema de acessibilidade na Web, sendo que é um desafio a motivação de usuários para participarem com contribuições.
A ferramenta AccessibilityUtil está sendo divulgada na comunidade entre diferentes especialistas para avaliação dos inúmeros artefatos que são criados pelos próprios participantes. A partir da geração de artefatos condizentes com as diretrizes de acessibilidades, documentadas pela WCAG 2.0, pretende-se ainda em um futuro próximo, associar os artefatos a modelos, a partir da metodologia de desenvolvimento orientado a modelos. Dessa forma, busca-se um auxílio mais eficiente por meio de transformações dos artefatos em soluções de implementação de elementos de interação na web acessíveis.
Como trabalho futuro, novos conjuntos de diretrizes poderão ser adicionados à ferramenta, com o propósito de avançar nos requisitos de acessibilidade e tornar os artefatos cada vez mais compreensíveis e
6 http://www.accessibilityutil.com/press-clipping 7 http://premio.w3c.br
Conferência IADIS Ibero-Americana WWW/Internet 2012
113

acessíveis. Outra possibilidade que está sendo analisada é a de integrar os comentários sobre os artefatos em ambientes de desenvolvimento, facilitando a tarefa do desenvolvedor, que poderá visualizar recomendações e experiências práticas em modo de desenvolvimento e gerenciar de forma integrada decisões de acessibilidade em seus projetos.
AGRADECIMENTOS
Nossos sinceros agradecimentos para as universidades USP e UFG que forneceram estrutura e apoio para o desenvolvimento deste trabalho e também à agência de fomento FAPESP pelo financiamento parcial.
REFERÊNCIAS
Almeida, L. D. A., Santana, V. F. e Baranauskas M. C. C. WARAU: Uma Proposta de Apoio ao Processo de Adequação de Websites a Requisitos de Acessibilidade e Usabilidade. In: 60ª Reunião Anual da SBPC, 2008, Campinas. Anais da 60ª Reunião Anual da SBPC, 2008.
Bailey C. e Pearson E. 2011. An educational tool to support the accessibility evaluation process. In Proceedings of the 2010 International Cross Disciplinary Conference on web Accessibility (W4A '10). ACM, New York, NY, USA, Artigo 12, 4 páginas.
Bittar, T. J., Amaral, L. A. e Fortes, R. P. M. AccessibilityUtil: a tool for sharing experiences about accessibility of web artifacts. In: 29th ACM international conference on Design of Communication, 2011, Pisa. Proceedings of 29th ACM international conference on Design of Communication, 2011. v. 1. p. 17-24.
Bittar, T. J., Amaral, L. A., Lobato, L. L. e Fortes, R. P. M. AccessibilityUtil.com: uma ferramenta para colaboração de experiências de acessibilidade na Web. In: Simpósio Brasileiro de Sistemas Multimídia e Web - Webmedia 2011, Florianópolis. Anais do Simpósio Brasileiro de Sistemas Multimídia e Web - Webmedia 2011, 2011.
Bittar, T. J., Lobato, L. L., Amaral, L. A. e Fortes, R. P. M. Desenvolvimento e aplicação da ferramenta AccessibilityUtil.com: colaboração de experiências em acessibilidade na web. In: Conferência IADIS Ibero Americana WWW/INTERNET 2011, Rio de Janeiro. Actas da Conferência IADIS Ibero Americana WWW/INTERNET 2011, 2011.
Chen J., Xu H. e Whinston A. 2011. Moderated Online Communities and Quality of User-Generated Content. Journal Manage. Inf. Syst. 28, 2 (October 2011), p. 237-268.
Conklin, E. J. e Burgess-Yakemovic, K. C. (1996). A process-oriented approach to design rationale. In Moran, T. P. and Carroll, J. M. (Eds.), Design rationale: Concepts, techniques, and use, 393-427. Mahwah, NJ: Lawrence Erlbaum.
Freire, A. P., Russo, C. M. e Fortes, R. P. M. A survey on the accessibility awareness of people involved in web development projects in Brazil. In: International cross-disciplinary conference on Web accessibility (W4A), 2008, Beijing, China. Proceedings of the 2008 international cross-disciplinary conference on Web accessibility (W4A). New York, NY, USA: ACM Press, 2008. v. 1. p. 87-96.
Horner J. e Atwood M. E. 2006. Design rationale: the rationale and the barriers. In Proceedings of the 4th Nordic conference on Human-computer interaction: changing roles (NordiCHI '06), Anders M., Konrad M., Bratteteig T., Ghosh G. e Svanaes D. (Eds.). ACM, New York, NY, USA, p. 341-350.
Martín A., Cechich A. e Rossi G. 2011. Accessibility at early stages: insights from the designer perspective. In Proceedings of the International Cross-Disciplinary Conference on web Accessibility (W4A '11). ACM, New York, NY, USA, 9 páginas.
Sloan, D. 2006. The Effectiveness of the web Accessibility Audit as a Motivational and Educational Tool in Inclusive web design. PhD. Thesis, University of Dundee, Scotland. Junho, 2006.
W3C. Web Content Accessibility Guidelines (WCAG) 2.0. Dez. 2008. URL: http://www.w3.org/TR/WCAG20/. Acesso em maio de 2011.
Wald M., Draffan E. A., Skuse S., Newman R. e Phethean C. 2011. Southampton accessibility tools. In Proceedings of the International Cross-Disciplinary Conference on web Accessibility (W4A '11). ACM, New York, NY, USA, Artigo 23, 2 páginas.
ISBN: 978-989-8533-11-1 © 2012 IADIS
114

EL RETARDO DE HANDOVER EN IPV6 MÓVIL, CARACTERIZACIÓN Y DETERMINACIÓN
EXPERIMENTAL DE VALORES A TRAVÉS DE LA IMPLEMENTACIÓN USAGI-PATCHED MOBILE IPV6
Juan Carlos Castillo Eraso Grupo de Investigación Aplicada en Sistemas GRIAS
Universidad de Nariño, San Juan de Pasto (Colombia)
RESUMEN
En el contexto de las redes móviles de cuarta generación, el protocolo IPv6 móvil (MIPv6) permite a las aplicaciones que utilizan el nivel de transporte, mantener las sesiones iniciadas aún cuando las entidades involucradas cambien de subred dentro del proceso de movilidad. Para esto, MIPv6 define un conjunto de operaciones que conforman el Handover vertical. Tales operaciones introducen un retardo que afecta la calidad en el desempeño de aplicaciones sensibles al retardo como la VoIP y flujos multimedia. En el presente trabajo se realiza una caracterización de dicho retardo y se determinan de forma experimental, los valores de tiempo involucrados dentro del proceso mediante la implementación UMIP de MIPv6 parasistemas GNU/Linux y una topología de red conformada por computadores personales y enlaces WLAN. Con base en los resultados obtenidos se identifican puntos críticos dentro del proceso y se plantean las causas y posibles mejoras.
PALABRAS CLAVE
Handover, MIPv6, WLAN, UMIP, GNU/LINUX.
1. INTRODUCCIÓN
Con el fin de suministrar transparencia en cuanto a movilidad a los protocolos del nivel de transporte en una infraestructura de red soportada por IPv6, la IETF (Internet Engineering Task Force) ha propuesto el protocolo IPv6 móvil MIPv6 (Mobile IPv6) (Johnson, Perkins, &Arkko, 2004) que introduce un conjunto de operaciones y mensajes que conforman el Handover a nivel de red. Durante este proceso, las entidades en los extremos de una conexión experimentan una interrupción en el intercambio de datos y consecuentemente la posible pérdida de los mismos. La duración de dicha interrupción ó retardo de Handover, es determinante en el desempeño de las aplicaciones en los niveles superiores, más aún si son sensibles al retardo como la VoIP (Voice over IP) y flujos multimedia.
Teniendo en cuenta el incremento en la demanda de tráfico multimedia en las redes actuales y el requerimiento de movilidad de los usuarios, las soluciones a problemas del lado de la red como la escases de direcciones IPv4 mediante la implementación de IPv6, deben tener en cuenta las posibles limitaciones con el fin de diseñar soluciones que permitan un despliegue eficiente de la tecnología.
En las siguientes secciones se caracteriza el Handover en MIPv6 y las etapas involucradas, el escenario implementado para la experimentación, la metodología utilizada para las pruebas y el análisis de los resultados obtenidos.
2. TRABAJOS RELACIONADOS
Con el propósito de reducir el retardo de handover, se han planteado algunas mejoras a MIPv6 entre lasque se destacan HMIPv6 (Hierarchical MIPv6) (Soliman, Castelluccia, Malki, &Bellier, 2005) el cual requiere de la implementación de una nueva entidad del lado de la red limitando su escalabilidad a nivel global. FMIPv6
Conferência IADIS Ibero-Americana WWW/Internet 2012
115

(Fast Handovers for Mobile IPv6) (Koodli, 2005) es otra solución propuesta por IETF en la que se adicionan mensajes y operaciones a MIPv6 de tal manera que se anticipe el handover antes de establecer un vínculo definitivo con la nueva subred, dicha solución es altamente dependiente de la topología de red. Otros estudios (Han & Hwang, 2005; Kousalya, Narayanasamy, Park, & Kim, 2008; Makaya& Pierre, 2008; Oh, Yoo, Na, & Kim, 2008; Park & Kim, 2006; Petander, Perera, &Seneviratne, 2007; Rahman&Harmantzis, 2007; Viinikainen et al., 2006) presentan resultados del análisis del retardo de Handover en MIPv6 obtenidos de manera analítica ó a través de simulación y con base en ellos, se plantean mejoras encaminadas a la reducción del tiempo empleado en dicho proceso.
En este trabajo, se presenta el análisis del Handover en MIPv6 de manera experimental utilizando una topología de red operativa conformada por computadores personales interconectados a través de enlaces inalámbricos WLAN (Wireless Local Area Network) y la implementación UMIP (Aramoto, Nakamura, Sugimoto, &Takamiya, 2009) de MIPv6 según la especificación descrita en (Johnson et al., 2004), desarrollada para ser integrada a sistemas GNU/LINUX.
3. HANDOVER EN IPV6 MÓVIL
MIPv6 define tres entidades: el nodo móvil MN (Mobile Node), el agente origen HA (Home Agent) y el CN (Correspondent Node) con quien el MN realiza el intercambio de datos. La transparencia para el nivel de transporte se logra haciendo que el MN sea capaz de manipular dos direcciones IPv6, la primera se conoce como dirección de origen HoA (Home Address) la cual es asignada al MN en su red de origen. Ésta, es la dirección a través de la cual el nodo será alcanzable por otros nodos independientemente de su localización y será utilizada por las aplicaciones en nivel de transporte. La segunda dirección es conocida como dirección de asistencia CoA (Care of Address) y es configurada por el MN cuando visita otra red.
El HA es un enrutador encargado de gestionar la movilidad y la transferencia de paquetes desde y hacia el MN cuando se encuentra fuera de su red origen. Cuando el MN transita a otra red, debe informar al HA sobre su nueva ubicación a través de mensajes de actualización de localización BU (Binding Update), confirmados mediante mensajes BA (Binding Ack). Posteriormente, el intercambio de paquetes entre el MN y el CN se hace a través de un túnel bidireccional a través del HA, creado mediante encapsulamiento IPv6 en IPv6. Si el CN tiene soporte MIPv6, el MN puede registrar su CoA ante él, a través de un proceso denominado Retorno de Ruteabilidad RR (Return Routeability) (Perkins & Johnson, 1997) el cual permite que el CN y el MN intercambien paquetes directamente sin necesidad de atravesar por el HA. La Fig. 1 presenta el flujo de mensajes entre las entidades definidas por MIPv6. El AR (Access Router) corresponde a un enrutador de acceso dentro de la red visitada.
En este trabajo, las operaciones definidas en MIPv6 han sido agrupadas en tres fases: Detección de movimiento, Autoconfiguración y Actualización de localización. Además, se ha tenido en cuenta la contribución de tiempo por parte del proceso de Handover en el nivel de enlace. A continuación se describen estas etapas.
Figura 1. Secuencia de mensajes en MIPv6.
ISBN: 978-989-8533-11-1 © 2012 IADIS
116

3.1 Detección de Movimiento
El AR (Access Router) de la nueva subred, envía periódicamente anuncios de enrutador RA (Router Advertisements) que son procesados por el MN, estos mensajes contienen, entre otra información, el prefijo de la subred y el enrutador por defecto. Cuando el prefijo de la nueva subred difiere del prefijo de la HoA del MN, éste sabe que se encuentra en otra subred y de esta manera asume que se ha movido hacia ella.
3.2 Autoconfiguración
Una vez dentro de la nueva subred, el MN debe crear de la CoA, lo cual se realiza automáticamente a partir de los parámetros recibidos en los mensajes RA ó a través de un servidor DHCPv6 (si existe). Una vez creada, la CoA debe someterse a una prueba de detección de direcciones duplicadas DAD (Duplicate Address Detection) (Thomson & Narten, 2007) con el fin de garantizar que es única en la nueva subred. El proceso DAD hace uso del protocolo de descubrimiento de vecino ND (Neighbor Discovery).
3.3 Actualización de Localización
Cuando el MN dispone de conectividad IP, debe registrar su CoA ante el HA, esto lo hace mediante el envío de mensajes de actualización de vínculos BU (Binding Update). Adicionalmente, el MN inicia el procedimiento RR (Return Routability) (Johnson et al., 2004) con el fin de verificar si el CN tiene soporte de movilidad; si es así, el proceso RR se completa satisfactoriamente y el MN registra su CoA ante el CN para indicarle que puede enviar los paquetes directamente a la CoA y no a la HoA evitando el enrutamiento a través del HA optimizando la ruta RO (Route Optimization).
Durante la ejecución de estas fases, se produce un retardo y el MN no puede intercambiar paquetes con el CN.
4. METODOLOGÍA
Para el análisis del Handover en MIPv6 se ha utilizado la topología de red ilustrada en la Fig. 2 y los recursos de software y hardware presentados en la tabla 1. Las direcciones IPv6 utilizadas en la topología se han seleccionadas de manera que puedan ser fácilmente identificadas en los registros de tráfico que el sistema genera para cada interfaz.
Figura 2. Topologíautilizada en la experimentación.
Conferência IADIS Ibero-Americana WWW/Internet 2012
117

Los enlaces WLAN se configuraron para operar de acuerdo con el estándar IEEE 802.11b a una velocidad de 11Mbps. Los equipos se alojaron en un laboratorio con un área de 30 m². En la topología, se definieron 3 subredes sobre las cuales el MN se desplazará. La diferenciación de estas subredes en el nivel de enlace se hizo a través de los ESSID: HOME, INTERNET y VISITED.
Los tiempos empleados en cada una de las fases descritas anteriormente, se definieron a través de las siguientes variables:
Th2: Tiempo empleado en el proceso de Handover a nivel de enlace. Tm: Tiempo empleado en la detección de movimiento. Tc: Tiempo empelado en autoconfiguración. Ta: Tiempo empleado en actualización de localización ante el HA y el CN (si tiene soporte MIPv6)
Tabla 1. Software y hardware utilizados en la experimentación.
Nodo Software Hardware HA GNU/Linux kernel 2.6.22
UMIP 0.4 radvd-1.6
Pentium IV 3.0 GHz, 1.5 GB RAM, 60GB, 2 adaptadores de red WiFi802.11b/g D-Link DWL-54G, Ethernet Broadcom NetXtreme BCM5751
MN
GNU/Linux kernel 2.6.30 UMIP 0.4
AMD Turion 64 1.8 GHz, 2.5 GB RAM, WiFi BCM4312 802.11a/b/g, Ethernet nVidia MCP51
CN GNU/Linux kernel 2.6.22 UMIP 0.4
Pentium(R) 1.4 GHz, 1GB RAM, WiFi BCM94311 802.11/b/g, Ethernet Realtek RTL8139
AR GNU/Linux kernel 2.6.32 radvd-1.6
AMD Sempron 3500, 1GB RAM, WiFi BCM4311 802.11/b/g, Ethernet nVidia MCP51
Por lo tanto, el tiempo total empleado en el proceso de Handover en MIPv6 se puede expresar como se
muestra en la ecuación 1.
T=Th2+Tm+Tc+Ta (1) Para inducir Handovers a nivel de enlace y consecuentemente a nivel de red, se utilizó el procedimiento
presentado en el diagrama de flujo de la figura 3. El procedimiento fue implementado en el MN mediante un programa escrito en lenguaje PERL, que
invoca los comandos del sistema GNU/LINUX necesarios para forzar el cambio de asociación en la red inalámbrica mientras se desplaza dentro del área definida para el experimento.
La medición de los tiempos empleados por cada una de las fases se hizo a través del análisis de marcas de tiempo insertadas en el código fuente de UMIP del MN. Se definieron los siguientes criterios para determinar el tiempo empleado en cada fase:
Th2: Tiempo transcurrido entre la pérdida de asociación a una red y la notificación de asociación exitosa a una nueva red en el nivel de enlace. Tm: Tiempo empleado por el modulo de software que implementa el MN para detectar el cambio de
asociación en el nivel de enlace, y el envío del primer mensaje RS. Tc: Tiempo empleado por el MN para realizar el proceso de autoconfiguración. Aquí se incluye la
generación de la CoA, el procedimiento DAD y ajuste de las tablas de enrutamiento. Este tiempo se ha determinado entre el instante en que el MN detecta la presencia de un nuevo enlace y realiza los ajustes necesarios de tal manera que pueda enviar el primer mensaje BU.
Ta: Tiempo empleado en la fase de actualización de localización. Es el tiempo transcurrido entre la generación del primer mensaje BU y la recepción de su correspondiente BA.
Para estimar el retardo percibido por las aplicaciones en nivel de transporte, se utilizó un generador de tráfico (MIPv6Test) en modo cliente-servidor, el CN se configuró como servidor y el MN como cliente. El generador de tráfico hace uso de sockets tanto TCP como UDP para la transferencia de datos y es capaz de
ISBN: 978-989-8533-11-1 © 2012 IADIS
118

determinar la pérdida y recuperación de la conectividad IP y registrar los eventos y tiempos en un archivo de texto a partir del cual se realizó el análisis.
Figura 3. Procedimiento empleado para inducir Handovers a nivel de enlace.
5. RESULTADOS
La figura 4 muestra los resultados obtenidos y la tabla 2 los valores mínimo, máximo y promedio para cada variable.
Conferência IADIS Ibero-Americana WWW/Internet 2012
119

(a) (b)
(c) (d)
Figura 4. Tiempos empleados en el Handover de nivel de enlace y detección de movimiento (a). Autoconfiguración (b). Actualización de localización (c) y retardo experimentado en el nivel de transporte (d).
Tabla 2. Resultados de los tiempos empleados en cada fase.
VARIABLE MÁXIMO (segs) MÍNIMO (segs) PROMEDIO (segs)
Th2 0.1033 0.0751 0.084
Tm 0.1055 0.0779 0.086
Tc 5.7729 1.5802 3.5993
Ta 0.0261 0.0050 0.0095
TCP 6.5340 1.7040 4.1885
UDP 5.6980 1.5030 3.5107
Con el fin de lograr un mayor grado de confiabilidad en los resultados, el experimento se repitió en el
mismo escenario y con la misma metodología durante 10 días consecutivos. Los resultados fueron sometidos a un análisis de varianza ANOVA para garantizar que el promedio resulta una medida de tendencia central aceptable. La figura5 muestra los resultados obtenidos.
ISBN: 978-989-8533-11-1 © 2012 IADIS
120

Figura 5. Promedios de tiempo para cada variable en experimentos durante 10 días.
6. CONCLUSIONES
El tiempo empleado en el Handover a nivel de enlace es altamente dependiente de la tecnología inalámbrica utilizada. En este caso, el tiempo promedio es de 0.084s, el cual es un valor típico en las redes WLAN soportada por tecnología IEEE 802.11 sin hacer uso de ninguna de las mejoras al Handover a nivel de enlace como la como las descritas en (Kuran&Tugcu, 2007).
Respecto a la detección de movimiento, a pesar de que en los experimentos se modificó el tiempo de envío de los mensajes RA de acuerdo con la especificación, no se observaron diferencias significativas, por el contrario, se observó una inundación de mensajes RA en la red lo que condujo a buscar explicaciones analizando el código fuente de UMIP. En este análisis, se encontró que UMIP monitorea en tiempo real los eventos en el nivel de enlace y utiliza los cambios de estado de la interfaz de red para enviar el primer mensaje RS, el cual es inmediatamente respondido con un mensaje RA; lo que representa una mejora ya que de esta manera, se evita la espera de un mensaje RA para detectar el traspaso a una nueva subred. Esto justifica también la estrecha relación existente entre el tiempo empleado en la detección de movimiento registrada por el módulo de software del MN y el tiempo empleado en el Handover a nivel de enlace obtenido en los resultados.
La fase que más aporta tiempo al proceso, es la autoconfiguración. Los valores obtenidos en las pruebas se consideran altos puesto que en esta fase, se debe generar una nueva CoA para lo cual es necesario esperar el primer mensaje RA del nuevo AR, posteriormente se debe verificar que la dirección generada sea única mediante el DAD que utiliza el protocolo ND. Los tiempos de espera por defecto para las respuestas a mensajes ND y RS son determinantes en este aspecto. Estos tiempos se encuentran definidos en constantes tanto en la implementación UMIP como en las especificaciones del protocolo y del sistema operativo. En este sentido, el tiempo empleado en la fase de autoconfiguración es susceptible de mejoras a través de la selección cuidadosa de los valores de los umbrales de tiempo definidos para las variables antes mencionadas.
Desde la perspectiva de las aplicaciones, el retardo introducido para el tráfico TCP y UDP es bastante significativo (del orden de los segundos) ya que aplicaciones sensibles al retardo como la VoIP degradarían su desempeño debido a la interrupción prolongada de la conectividad. El retardo extremo a extremo (entre el MN y el CN) se ve afectado por el uso del túnel bidireccional para el intercambio de datos gestionado por el HA. En este sentido, la optimización de ruta RO juega un papel determinante ya que de acuerdo con los resultados obtenidos, el retardo en el intercambio de datos entre el MN y el CN sería únicamente dependiente de la topología de la red, la eficiencia del enrutamiento entre estos dos nodos y las tecnologías de acceso y transporte utilizadas.
Conferência IADIS Ibero-Americana WWW/Internet 2012
121

AGRADECIMIENTOS
El autor agradece a la Universidad de Nariño (Pasto – Colombia), especialmente al Grupo de Investigación Aplicada en Sistemas (GRIAS) del Departamento de Ingeniería de Sistemas por brindar los espacios y la infraestructura necesaria para llevar a cabo el trabajo presentado en este artículo.
REFERENCIAS
Aramoto, M., Nakamura, M., Sugimoto, S., &Takamiya, N. (2009).UMIP: USAGI-patched Mobile IPv6 for Linux. Recuperado el 12 de enero de 2010 en http://www.umip.org.
Han, Y., Hwang, S. (2005). Care-of address provisioning for efficient IPv6 mobility support. Johnson, D., Perkins, C., &Arkko, J. (2004).Mobility Support in IPv6.IETF RFC 3775.Recuperado el 10 de agosto de
2009 de http://www.ietf.org Koodli, R. (2005). Fast Handovers for Mobile IPv6.IETF RFC 4068.Recuperado el 20 de agosto de 2009 en
http://www.ietf.org Kousalya, G., Narayanasamy, P., Park, J., & Kim, T. (2008).Predictive handoff mechanism with real-time mobility
tracking in a campus wide wireless network considering ITS. Kuran, M. S., &Tugcu, T. (2007).A survey on emerging broadband wireless access technologies. Makaya, C., & Pierre, S. (2008). Enhanced fast handoff scheme for heterogeneous wireless networks. Oh, H., Yoo, K., Na, J., & Kim, C. (2008). A Robust Seamless Handover Scheme for the Support of Multimedia Services
in Heterogeneous Emerging Wireless Networks. Park, W., & Kim, B. (2006). Fast BU Process Method for Real Time Multimedia Traffic in MIPv6. Perkins, C., & Johnson, D. (1997).Route Optimization in Mobile IP.Recuperado el 19 de agosto de 2009 en
http://tools.ietf.org/id/draft-ietf-mobileip-optim-07.txt. Petander, H., Perera, E., &Seneviratne, A. (2007).Multicasting with selective delivery: a SafetyNet for vertical handoffs. Rahman, M., &Harmantzis, F. (2007).Low-latency handoff inter-WLAN IP mobility with broadband network control. Soliman, H., Castelluccia, C., Malki, K., &Bellier, L. (2005).Hierarchical Mobile IPv6 Mobility Management
(HMIPv6).IETF RFC 4140.Recuperado el 25 de agosto de 2009 en http://www.ietf.org Thomson, S., &Narten, T. (2007).IPv6 Stateless Address Autoconfiguration.IETF RFC 4862.Recuperado el 10 de agosto
de 2009 en http://www.ietf.org Viinikainen, A., Puttonen, J., Sulander, M., Hamalainen, T., Ylonen, T., &Suutarinen, H. (2006).Flow-based fast
handover for mobile IPv6 environment– implementation and analysis.
ISBN: 978-989-8533-11-1 © 2012 IADIS
122

A GESTÃO DA INFORMAÇÃO CORPORATIVA NOS WEBSITES DAS CÂMARAS MUNICIPAIS PORTUGUESAS
Eduardo Alfredo Cardoso Miranda1 e Antonio Muñoz Cañavate2 1Professor da Universidade Lusófona de Humanidades e Tecnologias - Lisboa.
2Profesor Titular. Departamento de Información y Comunicación. Facultad de Ciencias de la Documentación y la Comunicación. Universidad de Extremadura.
RESUMO
Este trabalho verte a informação eletrónica que as câmaras municipais portuguesas disponibilizam através dos seus portais, comparando-a com a do modelo da Áustria tido como o país mais evoluído neste aspecto.
PALAVRAS CHAVE
Câmaras Municipais, website, Portugal, cidadania, administração pública eletrónica, democracia eletrónica.
1. INTRODUÇÂO
As câmaras municipais1 têm vindo a assumir uma crescente relevância consubstanciada na descentralização política e financeira2 apanágio da sociedade democrática.3 Esta importância justifica-se pela relação próxima com os cidadãos e empresas com vista ao desenvolvimento da sua área jurisdicional. As redes eletrónicas municipais de informação criam uma nova forma de relação desta com os munícipes: mais barata4; menos burocratizada; mais cómoda para (cidadãos, empresas); mais transparente; etc. Esta oferta de interatividade é facilitadora de vivências, criadora do sentimento de pertença e da habituação da prática de cidadania.
1.1 Objeto de Estudo
Este estudo incide na informação eletrónica que as câmaras municipais portuguesas emanam através dos seus portais.
1Artigo 235.ºAutarquias locais. As autarquias locais são pessoas colectivas territoriais dotadas de órgãos representativos, que visam a prossecução de interesses próprios das populações respectivas. http://www.parlamento.pt/Legislacao/Paginas/ConstituicaoRepublicaPortuguesa.aspx#art235. (consultado: Agosto de 2012).
2 Artigo 237.º Descentralização administrativa. As atribuições e a organização das autarquias locais, bem como a competência dos seus órgãos, serão reguladas por lei, de harmonia com o princípio da descentralização administrativa. 2. Compete à assembleia da autarquia local o exercício dos poderes atribuídos pela lei, incluindo aprovar as opções do plano e o orçamento. Ibid.
3 “Como é conhecido, a fase constitucional do poder local em Portugal teve como marcos a aprovação da Constitucional da República em Abril de 1976 e a realização das primeiras eleições autárquicas em Dezembro de 1976.” BRANCO, Francisco. Municípios e Políticas Sociais em Portugal 1977-1989. Lisboa: Instituto Superior de Serviço Social, Departamento Editorial, 1988, p. 17.
4 “Se toda a União Europeia tivesse implementado serviços eficientes de e-government pouparia mais de 50 mil milhões de euros por ano (E. COMISSION, 2001)”. https://docs.google.com/viewer?a=v&q=cache:RGg63qI4RxwJ:marketingiscsp.files.wordpress.com/2008/11/e-government.doc+Raking+da+UE+quanto+poupa+com+o+egovernment&hl=pt-PT&pid=bl&srcid=ADGEESiVfI7UOeNl034Rg4Kuis5tV4YLF2qgnIQqHWQqQLX9gUr8zoTEUJpulNQNqZbK8VKO8jNtiwwpFXgovnCjRHUw2zbzZlwfXD0XZdhec6Khu-EGVvBSAo9TxhyVyw07NhqGkgnW&sig=AHIEtbSkuNchwI1ObaEixb3OQwxWCvMD2g (Consultado: Agosto de 2012).
Conferência IADIS Ibero-Americana WWW/Internet 2012
123

1.2 Objetivo de Estudo
Analisar, através de pesquisa direta, em cada websitio de cada câmara municipal, se a informação disponibilizada aos munícipes está em conformidade com o modelo do Livro Verde (1998)5 para a sociedade da informação. A Áustria é tida como o país mais avançado nesta área do egoverno. O portal representado abaixo é da câmara municipal do Porto onde é indicada a informação para cidadãos e para as empresas entre muita outra de interesse diverso.
Figura 1. Portal da câmara municipal da cidade do Porto.6
A sociedade da informação, da comunicação e do conhecimento é o reflexo da evolução tecnológica e desempenha um papel central na sociedade atual em todos os setores de atividade. É mais cómoda para o cidadão e mais barata quer para este quer para o Estado.
1.3 Justificação da Escolha do Modelo
"A Áustria tem sido um líder na Europa, quando se trata de iniciativas de eGovernment. Para aumentar ainda mais a popularidade do eGovernment a nível nacional, o acesso simples e fácil a 'Digital Austria Explorer' oferece aos cidadãos austríacos exatamente isso: Basta um clique e todos os serviços de governo eletrónico nacional estão disponíveis - bem apresentado e estruturado.” 7 “Áustria desde 2006 tem estado na vanguarda dos países da UE e chegou a 2009, pelo terceiro ano consecutivo, ocupando o número 1 na UE e 100 por cento para a "total disponibilidade on-line."8
5 Fuente: Instituto de Evaluación Tecnológica, Academia de Ciencias y Centro de Estudios Sociales de Austria, documento previo «Conferencia sobre la sociedad de la información: acercar la administración a los ciudadanos», noviembre de 1998 (organizada por el Centro para la Innovación Social en nombre del Foro de la Sociedad de la Información; grupo de trabajo administración pública) In Comisión Europea [COM(1998) 585] La información del sector público: un recurso clave para Europa: Livro Verde sobre la información del sector público en la sociedad de la información. http://.proyectoaporta.es/e/document_libraryYget_file?uuid=d45150-5e28-47df-ac13- ae2009bcfd50&groupId=10128 (consultado: Março de 2010).
6 http://balcaovirtual.cm-porto.pt/pt/Cidadaos/Paginas/default.aspx. (Consultado: Agosto de 2012).
7www.egov.vic.gov.au/focus-on-countries/europe/countries-europe/austria/trends-and-issues-austria/e-government-austria.html&prev=/search%3Fq%3DAustria%2Be%2Bo%2Be-government%26hl%3Dpt-PT%26biw%3D1280%26bih%3D539%26prmd%3Dimvns&sa=X&ei=BPwfULrRJqnAiQekj4GYAQ&ved=0CFsQ7gEwAQ. (Consultado: Agosto de 2012) 8 Ibid.
ISBN: 978-989-8533-11-1 © 2012 IADIS
124

1.4 Modelo de Análise da Informação Eletrónica 9
Tabela 1. Tipologia dos serviços do governo eletrónico da Áustria
Serviços de Informaçao
Serviços de Comunicação
Serviços de Transação
Vida Quotidiana Informação laboral, doméssobre educação, saúde, culttransportes, meio ambienteetc.
Debates sobre questões da vida quotidiana.
Vitrina de anúncios de tipolaboral ou doméstico.
Reserva de bilhetes, matrículas em cursos.
Administração À Distância
Direcções de serviços públicos.
Guia de procedimentos Administrativos. Registos e bases de dadospúblicos.
Contato por correio eletrónico com funcionários.
A presentação eletrónica de formulários.
Participação Política
Leis, documentos parlamentários, programas políticos, documentação de consulta Informação prévia sobre odecisório.
Debates sobre problemas políticos. Contato por correio eletrónico com políticos.
Referendos. Eleições. Sondagens.
Este documento apresenta uma estrutura de três tipos distintos de serviços: serviços de informação; serviços de comunicação e serviços de transação. E que se definem como:
Serviços de informação – disponibiliza informação ordenada e classificada (como os sítios Web). Serviços de comunicação – permite a interação entre (particulares ou empresas) ou grupos de pessoas (como o correio eletrónico ou os foros de discussão). Serviços de transação – oferece produtos ou serviços em linha (como formulários públicos ou escrutínios).
Por sua vez a dita informação eletrónica pode agrupar-se nestas três categorias: a) Aspetos relacionados com a vida quotidiana; b) Aspetos relacionados com a administração à distância; c) Aspetos relacionados com a participação política;
A combinação destes três tipos de serviços (informação, comunicação e transação) aplicados ao âmbitos da (vida quotidiana, administração à distancia e da participação política) gera nove grupos de artigos que podem ser aplicados para a avaliação de um sítio de uma seção local, como pode ser visto de maneira extensa no anexo 1.
1. Serviços de informação/Vida quotidiana 2. Serviços de comunicação/Vida quotidiana 3. Serviços de transação/Vida quotidiana. 4. Serviços de informação/Administração à distância. 5. Serev iços de comunicação/Administração à distância 6. Serviços de transação/Administração à distância. 7. Serviços de informação/Participação política. 8. Serviços de comunicação/Participação política. 9. Serviços de transação/Participação política.
Neste sentido, o “eGoverno define-se como a utilização das tecnologias da informação e das comunicações (TIC) nas administrações públicas (central e local), combinando mudanças a nível da organização e das novas aptidões do pessoal. O objectivo é melhorar os serviços públicos e reforçar os
9 Fuente: Instituto de Evaluación Tecnológica, Academia de Ciencias y Centro de Estudios Sociales de Austria, […].
Conferência IADIS Ibero-Americana WWW/Internet 2012
125

processos democráticos e de apoio às políticas públicas.”10 Os recursos humanos, por sua vez, são também um importante recurso das organizações ao nível da produção e da qualidade.
1.4.1 Síntese da Bibliografia Internacional Consultada
Tabela 2. Síntese da Revisão Bibliográfica Internacional
Autores Título Local de Publicação CARIDAD SEBASTIÃN, Mercedes (Coord.), 1999
La Sociedad de la Información Política, Tecnología de los Contenidos
Madrid
CASTELLS, Manuel; HIMANEN, Pekka, 2007
A Sociedade da Informação e o Estado-Providência: O Modelo Finlandês
Lisboa
CHAIN NAVARRO, Célia, 1997
Gestión de Información en Organizaciones
Murcia
CHAIN NAVARRO, Célia; MUÑOZ CANAVATE, Antonio; MÁS BLEDAAmália, 2008
La gestión de información en las sedes web de los ayuntamienespañoles
Revista Española de Documentación Científica, vol. 31, n.º
DEVENPORT, T. H., 1996
Reengenharia de Processos, como inovar na empresa através da Tecnologia da Informação
São Paulo
HABERMAS, Jurgen, 1984
Mudança estrutural da esfera Pública
Rio de Janeiro
HAMPTON, David, R., 1990
Administração: Processos Administrativos
São Paulo
MORAGAS, M. de, 1985 Sociología de la comunicación de masas
Barcelona
MUÑOZ CAÑAVATE, Antonio, 2005. El Web en la administración local española. Conclusiones de seis años de estudio
En IX Jornadas Españolas de Documentación. Madrid
MUÑOZ CAÑAVATE, Antonio 1997-2002 La Administración Local de Extremadura en Internet
En VII Congreso de Estudios Extremeños. Badajoz. 2006
MUÑOZ CAÑAVATE, Antonio 1997-2002 El Web como sistema de gestión de información Corpo- rativa en los ayuntamientos da Cataluña
En IX Jornadas Cata- lanas de Información y Documentación. Barcelona. 2004
MUÑOZ CAÑAVATE, Antonio 2004 Políticas de información en las Administraciones de la Comu- nidad de Madrid.
Boletín de Anabad
MUÑOZ CAÑAVATE, Antonio 2005 Políticas de información en las Administraciones de la Comu- nidad Autónoma de la Rioja
Anales de Documen- tación
MUÑOZ CAÑAVATE, Antonio CHAIN NAVARRO, C. 1997- -2002
El Web como sistema de gestión de información cor- porativa en la Administración local de Andalucía
En Actas de las III Jornadas andaluzas de Documentación. Sevilla. 2003
MUÑOZ CAÑAVATE, Antonio CHAIN NAVARRO, C. 1997- -2002
La Administración local espa- ñola en Internet: estudio cuantitativo dla evolución de los sistemas de información Web de los ayuntamientos
Ciencias de la Informa- ción (La Habana). 2004
MUÑOZ CAÑAVATE, Antonio CHAIN NAVARRO, C.; BENITEZ MORALESFrancisco 2011
La Administración local española en Internet.
Universidad de Murcia, 2011 (en prensa)
MUÑOZ CAÑAVATE, Antonio HÍPOLA-RUÍZPedro, s/d
La Administración eletrónica en España. Un recorrido desde sus inicios a la actualidad
Espanha
Elaborada pelos autores do trabalho.
10 eGoverno: a administração em linha http://europa.eu/legislation_summaries/infornation_society/124226b_pt.htm. (Consultado: Julho de 2009).
ISBN: 978-989-8533-11-1 © 2012 IADIS
126

1.4.2 Metodologia Seguida
Este estudo contemplou o universo das câmaras municipais portuguesas (308). Deste total (19) pertencem à Região Autónoma dos Açores e (11) à Região Autónoma da Madeira. A técnica utilizada para a recolha dos dados foi realizada através da observação direta em cada portal de câmara municipa (308 portais). Esta observação consistiu em aferir a informação contida em cada um dos portais, dirigida aos munícipes, e a constante no modelo de análise referido (Áustria) comparando aproximações e afastamentos da mesma. Os dados foram trabalhados quantitativamente no programa SPSS.
2. RESULTADOS (Tabela 3)
Para a Vida Quotidiana/Serviços de Informação apresenta um valor percentual de (68,47%) na vertente “existe”. Contempla a: Informação geral; Informação sobre saúde pública; Informação sobre educação; Informação sobre desportos; Informação sobre cultura; Informação sobre serviços sociais; Informação sobre transportes; Informação sobre urbanismo; Informação estatística; Informação comercial e Informação sobre segurança.
Para a Vida Quotidiana/Serviços de Comunicação (interação com os cidadãos) aduzem (64,97%) em “existe”. Esta percentagem contempla os debates sobre questões da vida quotidiana e é a vitrina de anúncios de tipo laboral ou doméstico.
Para a Vida Quotidiana/Serviços de Transação em “existe” apresenta maior percentagem (70,45%). Esta percentagem contempla a “Reserva ou compra de bilhetes sobre actividades culturais” (Teatro municipal e Eventos desportivos, matrículas).
Para a Administração à Distância/Serviços de Informação apresenta o valor percentual mais elevado (94,94%). O “existe” contempla: Directório dos serviços da Câmara; Guia de trâmites Administrativos; Serviços de Imprensa e Assembleia Municipal.
Para a Administração à Distância/Serviços de Comunicação apresenta um valor percentual de (25,95%). O “existe” contempla o contato por correio eletrónico com os funcionários da câmara.
Para a Administração à Distância/Serviços de Transação regista o valor percentual de (83,63%). O “existe” contempla a apresentação eletrónica de documentos ou solicitações de trâmites (urbanismo e habitação, veículos, comércio, indústria e consumo).
Para a Participação Política/Serviços de Informação apresenta o valor mais elevado (99,9%). O “existe” contempla: Actas de plenários; boletim municipal de informação e decretos e/ou despachos do presidente.
Para a Participação Políticao/Serviços de Comunicação apresenta (11,3%) para o “existe” que contempla: debates sobre problemas políticos; contato por correio eletrónico com políticos.
Para a Participação Política/Serviços de Transação apresenta um resultado nulo (0,00%). Aqui o “existe” contempla: referendos, eleições e sondagens.
Tabela 3. Peso médio percentual de cada um dos serviços
Serviços de Informação Serviços de Comunicação Serviços de Transação
Vida Quotidiana Existe N/Existe N/Atualizado Existe N/Existe Existe N/Existe
68,47% 31,34% 0,19% 64,97% 35,03% 70,45% 29,55%
Administração à Distância Existe N/Existe Existe N/Existe Existe N/Existe
94,94% 5,06% 25,95% 74,05% 83,63% 16,37%
Participação Política Existe N/Existe N/Atualizado Existe N/Existe Existe N/Existe
99,9% 0,1% 0,00% 11,3% 88,7% 0,00% 100%
Elaborada pelos autores do trabalho.
Conferência IADIS Ibero-Americana WWW/Internet 2012
127

3. CONCLUSÕES
A comparação dos conteúdos e serviços dos portais das câmaras municipais portuguesas apresenta:
PONTOS FORTES – nos SERVIÇOS DE INFORMACÃO no âmbito da Administração à Distância, Participação Política e nos SERVIÇOS DE TRANSAÇÃO na Administração à Distância;
MATURIDADE INTERMÉDIA - nos SERVIÇOS DE INFORMAÇÃO, SERVIÇOS DE COMUNICAÇÃO e SERVIÇOS DE TRANSAÇÃO na Vida Quotidiana;
PONTOS MUITO FRACOS - nos SERVIÇOS DE COMUNICAÇÃO na Administração à Distância e Participação Política e nos SERVIÇOS DE TRANSAÇÃO na Participação Política.
4. SUGESTÃO PARA O FUTURO
O e-governo na sua variada extensão territorial, mormente o e-local, confluem para os cidadãos e para as empresas como fundamentos da sociedade e dos mercados. O futuro impõe, naturalmente, a utilização das NTIC e a adaptação constante da informação eletrónica facilitadora de decisão, da desburocratização e da cidadania.
Como é de prever, os próximos anos serão de contenção financeira que imporá restrições a vários níveis. Será, por isso, necessário que futuramente se compare a situação aqui apresentada para equilatar se houve estagnação ou até retrocesso. Por outro lado, fica em aberto a regionalização portuguesa de que tanto se tem falado e que terá influência significativa também para esta realidade.
REFERÊNCIAS
Branco, Francisco. Municípios e Políticas Sociais em Portugal 1977-1989. Lisboa: Instituto Superior de Serviço Social, Departamento Editorial, 1988.
Castells, Manuel (2007). A Era da Informação: Economia, Sociedade e Cultura. A Sociedade em Rede. Volume I. 3.ªEdição. Lisboa: Fundação Calouste Gulbenkian.
Castells, Manuel; Himanen, Pekka (2007). A Sociedade da Informação e o Estado-Providência: O Modelo Finlandês. Lisboa: Fundação Calouste Gulbenkian,
Chain Navarro, Celia; Muñoz Cañavate, Antonio y Más Bleda, Amalia (2008). La gestión de información en las sedes web de los ayuntamientos españoles. Revista Española de Documentación Científica, vol. 31, n. 4, pp. 612-638.
eGoverno: a administração em linha http://europa.eu/legislation_summaries/infornation_society/124226b_pt.htm. La información del sector público: un recurso clave para Europa. Livro Verde sobre la información del sector público en la sociedad de la información. Comisión Europea [COM(1998) 585]
Lopes, Raul Gonçalves (1990)Planeamento Municipal e Intervenção Autárquica no Desenvolvimento Local. Dissertaçãode Mestrado em Gestão do Planeamento Regional e Urbano, Universidade Técnica de Lisboa. Lisboa: Escher, Publicações
Macedo e Sousa, Luís (2000).Onde as Coisas Acontecem: Comunicação, Sociedade, Poder, Administração Pública. Lisboa: Hugin Editores, Lda.
http://www.parlamento.pt/Legislacao/Paginas/ConstituicaoRepublicaPortuguesa.aspx#art235. https://docs.google.com/viewer?a=v&q=cache:RGg63qI4RxwJ:marketingiscsp.files.wordpress.com/2008/11/e-
government.doc+Raking+da+UE+quanto+poupa+com+o+egovernment&hl=pt- http://.proyectoaporta.es/e/document_libraryYget_file?uuid=d45150-5e28-47df-ac13-ae2009bcfd50&groupId=10128 http://balcaovirtual.cm-porto.pt/pt/Cidadaos/Paginas/default.aspx. www.egov.vic.gov.au/focus-on-countries/europe/countries-europe/austria/trends-and-issues-austria/e-government-
austria.html&prev=/search%3Fq%3DAustria%2Be%2Bo%2Be-government%26hl%3Dpt-PT%26biw%3D1280%26bih%3D539%26prmd%3Dimvns&sa=X&ei=BPwfULrRJqnAiQekj4GYAQ&ved=0CFsQ7gEwAQ.
ISBN: 978-989-8533-11-1 © 2012 IADIS
128

ANEXO 1. TÓPICOS DOS GRANDES GRUPOS DE INFORMAÇÃO
1- SERVIÇOS DE INFORMAÇÃO. VIDA QUOTIDIANA Informação Geral Dados Postais da Cidade
Informação da História da Cidade Informação Turística (monumentos) Telefones de Interesse do Município
Informação sobre Saúde Pública Sistema Sanitário (instalações) Horário das Farmácias de Serviço
Informação sobre Educação Instalações Oferta Escolar Bolsas de estudo
Informação sobre Desporto Instalações Desportivas Eventos Desportivos (agenda)
Informação sobre Cultura Museus Biblioteca Municipal Outras Bibliotecas Eventos Culturais Consulta Online
Informação sobre os Serviços Sociais Instalações para Mulheres Instalações para Jovens Instalações para Imigrantes
Informação sobre Transportes Rodoviário Metro Avião Comboio Marítimo Horários
Informação Urbanística Mapas da Cidade Mapas Interactivos da Cidade
Informação Estatística Sobre a População Sobre Dados Económicos
Informação Comercial Sobre Mercados Sobre o Comércio
Informação sobre Segurança Polícia (contatos) Bombeiros (contatos) Proteção Civil (contatos)
2. SERVIÇOS DE COMUNICAÇÃO. VIDA QUOTIDIANA Foruns de Discussão Lista de Correio Eletrónico
A través de News A través de Chat
3. SERVIÇOS DE TRANSAÇÃO. VIDA QUOTIDIANA. Reserva ou Compra de Bilhetes Teatro Municipal
Eventos Desportivos
4. SERVIÇOS DE INFORMAÇÃO. ADMINISTRAÇÃO À DISTÂNCIA.
Directório dos Serviços da Câmara Telefone Correio Eletrónico Correio Postal
Trâmites Administrativos Guia de Trâmites Administrativos (como fazer) Ordenações Fiscais Ordenações Municipais
Serviços de Imprensa Comunicados Agenda dos Atos do Presidente
Assembleia Municipal Nome do Presidente Correio Eletrónico do Presidente Nome dos Elementos Municipais Correio Eletrónico dos Elementos Municipais
5. SERVIÇOS DE TRANSAÇÃO. ADMINISTRAÇÃO À DISTÂNCIA. Apresentação Eletrónica Documentos/Solicitações/Trâmites
Conferência IADIS Ibero-Americana WWW/Internet 2012
129

População Receção de Documentos Educação Receção de Documento Território, Urbanismo e Obras Trâmites de Expediente de Obras
Consulta de Expediente Circulação, Veículos e Transportes Pagamento Imposto de Veículos Comércio, Indústria e Consumo Trâmites sobre a Abertura de Estabelecimentos
Estado do Expediente sobre Licenças/Actividade 6. SERVIÇOS DE INFORMAÇÃO. PARTICIPAÇÃO POLÍTICA.
Documentos Atas de Plenários· Boletim Municipal de Informação Decretos e/ou Despachos do Presidente
7. SERVIÇOS DE COMUNICAÇÃO. PARTICIPAÇÃO POLÍTICA.
Contato por Correio Eletrónico com os Cargos Políticos da Câmara (email)
Com o Presidente Com os outros Membros
Debates de Problemas Políticos Debates Retransmissão das Assembleias Por TV
Por voz 8. SERVIÇOS DE COMUNICAÇÃO (INTERAÇÃO COM OS CIDADÃOS). ADMINISTRAÇÃO À DISTÂNCIA.
Contato por Correio Eletrónico com os Funcionários da Câmara
Lista de Todos os Serviços Municipais Lista das áreas do Governo
9. SERVIÇOS DE TRANSAÇÃO E PARTICIPAÇÃO POLÍTICA.
Votação pela Internet Votação
ISBN: 978-989-8533-11-1 © 2012 IADIS
130

SGEMEOS: UM GESTOR DE EVENTOS SOCIAIS BASEADO EM SERVIÇOS WEB
Luiz Marcus Monteiro de Almeida Santos e Admilson de Ribamar Lima Ribeiro Departamento de Computação – Universidade Federal de Sergipe
Jardim Rosa Elze – São Cristóvão – SE – Brasil
RESUMO
A grande variedade de linguagens e plataformas para o desenvolvimento de sistemas transforma-se em problema quando surge a necessidade de compartilhamento de informações entre uma ou mais aplicações heterogêneas. Como solução, existem componentes como os serviços Web que padronizam o formato e a transmissão dos dados. Diante da possibilidade de interoperabilidade oferecida pelos serviços Web, este trabalho apresenta o SGEMEOS, um sistema gerenciador de eventos sociais no modelo cliente-servidor que faz uso destes componentes para viabilizar a troca de dados entre o servidor e os clientes de plataformas distintas.
PALAVRAS-CHAVE
Eventos sociais, Web Services, Dispositivos Móveis, Sistemas Distribuídos
1. INTRODUÇÃO
Em eventos sociais como congressos, feiras e apresentações culturais, existe uma quantidade significativa de informações a serem processadas. Nesse tipo de negócio estão inseridos dados como as inscrições dos interessados, os artigos submetidos, os horários e os locais do evento. Como soluções para a organização e manipulação desses dados foram produzidas aplicações de gerenciamento de conferências como as descritas por [Cheng et al. 2008] e [SHIH et al. 2001].
Atualmente, as ferramentas que realizam a gestão de eventos sociais podem ser desenvolvidas em diversas linguagens de programação como PHP [PHP Group 2001] ou Java [Deitel 2006] e executadas em diferentes plataformas como a Web. Essa variedade tecnológica apresenta problemas quando é necessária a troca de informações entre uma ou mais aplicações heterogêneas. Sendo assim, se um participante do evento preferir usar uma aplicação móvel para acessar seus dados pessoais que estão persistidos em um sistema Web, o recebimento deles pode ser prejudicado ou não efetuado devido às diferenças entre as plataformas.
Para que a integração entre sistemas atinjam os níveis de custo-benefício satisfatórios, é preciso que a execução desta tarefa seja padronizada. Para atender a essas especificações os Web Services [Erl 2004], ou em português, serviços Web foram desenvolvidos. Eles facilitam a troca de informações entre as aplicações através do envio e recebimento de dados no formato XML (Extensible Markup Language) [W3C 2000] via protocolos baseados em Internet. A ação dos serviços Web garante a interoperabilidade das aplicações envolvidas de modo que o fluxo de informações entre elas não dependa da tecnologia ou linguagem de programação em que cada aplicação foi desenvolvida.
Sendo uma das características dos serviços Web a transmissão de dados entre diferentes ambientes, por meio deles torna-se possível a criação de uma ferramenta de gerenciamento de eventos sociais com transmissão flexível de informações, a qual pode utilizar-se da integração entre a plataforma móvel e a Web para melhor atender as necessidades dos usuários. A essa ferramenta deu-se o nome de SGEMEOS que será discutida neste artigo.
Este artigo está organizado como segue: na seção 2, são apresentados os trabalhos relacionados; na seção 3 é descrita a metodologia usada no desenvolvimento do SGEMEOS; na seção 4, a arquitetura do SGEMEOS é exposta; na seção 5, são explicitadas algumas questões de implementação; na seção 6, são expostos os resultados encontrados através da utilização do sistema; e na seção 7 são feitas as considerações finais.
Conferência IADIS Ibero-Americana WWW/Internet 2012
131

2. TRABALHOS CORRELATOS
Como mencionado na introdução, atualmente, a maior parte de sistemas propostos para o gerenciamento de eventos sociais são voltados para uma única plataforma. Geralmente, a escolhida é a Web por motivos como acessibilidade e escalabilidade. Ferramentas como as descritas em [Cheng et al. 2008] , [Shih et al. 2001] e [Flisys, 2007] possuem como plataforma alvo a Web.
Através de [Snodgrass 1999] é possível ter acesso a uma lista ferramentas, resultantes de trabalhos científicos, que têm como objetivo comum o gerenciamento de conferências. A listagem dessas ferramentas é feita seguindo alguns critérios como suporte a envio de artigos, atribuição de revisores, submissão de revisões, inscrição de participantes e a linguagem de programação usada no desenvolvimento. A listagem conta também com a descrição de cada ferramenta.
As ferramentas apresentadas em [Snodgrass 1999], apesar de garantirem o gerenciamento das informações de um evento social, não possuem componentes que viabilizem a apresentação desses dados em plataformas distintas. Além disso, elas estão direcionadas a apenas um tipo de evento social, no caso, conferências, desse modo, não podem ser usadas em outros tipos de eventos. No SGEMEOS essas limitações foram corrigidas. O SGEMEOS permite que os dados possam ser acessados em múltiplas plataformas heterogêneas através do uso de serviços Web. Por serem suportados por várias linguagens de programação como Java e PHP, os serviços Web permitem que os desenvolvedores fiquem livres para escolherem a linguagem sobre a qual um cliente para o sistema poderá ser desenvolvido.
3. METODOLOGIA UTILIZADA
Sendo o SGEMEOS um sistema baseado em serviços Web, faz-se necessária a utilização de uma metodologia que suporte a construção de aplicações que façam uso destes componentes. Sendo assim, para a definição e construção dos serviços foi usada a metodologia de desenvolvimento de software orientado a serviços descrita em [Sommerville 2007]. Essa metodologia trata do desenvolvimento de sistemas de softwares confiáveis que usam os serviços, por conta própria ou em conjunto com outros tipos de componentes. Essencialmente, a principal preocupação é o desenvolvimento de software com reuso.
A metodologia orientada a serviços consiste, basicamente, em três estados lógicos: Identificação dos serviços candidatos: Nesta etapa são identificados os possíveis serviços que
devem ser implementados e ter seus requisitos definidos. Projeto do serviço: Nesta etapa é feito o projeto lógico e as interfaces WSDL (Web Service
Definition Language) [W3C 2001] do serviço. Ela envolve, basicamente, pensar sobre as operações do serviço e nas mensagens a serem trocadas quando o serviço for socilitado.
Implementação e implantação do serviço: Nesta fase os serviços são implementados e disponibilizados para uso. A disponibilização envolve a publicação do serviço usando UDDI (Universal Description, Discovery, and Integration) [Mckee et al. 2002] e a sua instalação em um servidor Web.
Seguindo cada etapa especificada por esta metodologia foi possível o desenvolvimento dos seguintes serviços:
Autenticação: tem por objetivo dar acesso ao sistema para o usuário. Administração: é constituído por operações ligadas a questões administrativas como o
cadastramento dos responsáveis pela organização do evento. Organização: agrega operações referentes aos dados dos organizadores do evento e suas tarefas. Exibição: possui operações relacionadas ao que será exposto no evento, como palestras e
minicursos, incluindo seu local e horário. Participação: possui operações referentes aos interessados em participar do evento social.
4. ARQUITETURA DO SGEMEOS
O SGEMEOS é um sistema distribuído no modelo cliente-servidor. O lado servidor gerencia e manipula os dados por meio de classes, sendo ele responsável também pela disponibilização dos serviços Web no formato
ISBN: 978-989-8533-11-1 © 2012 IADIS
132

WSDL através da Internet. Por sua vez, o lado cliente é uma aplicação baseada em J2ME (Java 2 Micro Editon) [Knudsen 2005], mais especificamente um MIDlet [Riggs et al. 2003], que consome os serviços, por meio de processos de requisições e respostas, à medida que lhe forem necessários. A figura 1 mostra o esquema dessa arquitetura.
Figura 1. Arquitetura do SGEMEOS.
4.1 Servidor
O servidor é o componente do SGEMEOS responsável por disponibilizar os serviços que servem como meio de transmissão de dados entre o SGBD (Sistema Gerenciador de Banco de Dados) e o cliente. Seguindo o processo definido pela metodologia orientada a serviços, antes de identificarmos os serviços, é importante que, primeiramente, sejam definidos os perfis de usuário a serem atendidos pelo SGEMEOS. Esses perfis foram definidos de modo que fossem diretamente ligados ao domínio do gerenciamento de eventos sociais. Os perfis do sistema são:
Administrador: possui como funções o cadastramento e a edição dos dados dos organizadores. Ele também tem a capacidade comandar a preparação do evento através da atribuição de atividades aos organizadores. O administrador também pode editar informações dos outros perfis.
Organizador: gerencia os participantes e os expositores, além de organizar questões relativas às exposições, como os locais e os horários. Um organizador não possui acesso aos dados do administrador nem de outros organizadores.
Expositor: acompanha os detalhes de suas exposições através da visualização dos locais e horários em quem elas serão realizadas.
Participante: esse perfil é o único que possui autonomia de registrar-se no sistema. Além disso, cada participante pode visualizar os dados das exposições disponíveis e acessar informações sobre o expositor responsável por ela. A sua participação no evento é confirmada por um organizador.
Cada serviço aloca operações que estão associadas a um perfil. Dessa forma, as operações que envolvem os dados de um participante foram atribuídas a um mesmo serviço, e assim por diante. A nomenclatura dos serviços e de suas operações também foi pensada visando facilitar o uso posterior dos serviços.
A figura 2 exibe o fragmento das operações vinculadas ao serviço Organização, o qual faz referência ao perfil organizador. Nela também é possível perceber outras informações atreladas às operações como seus dados de entrada e saída.
Figura 2. Operações do serviço Organização.
4.2 Clientes
O cliente é o componente do SGEMEOS responsável por disponibilizar as funcionalidades e dados aos usuários através do consumo de serviços Web. Ele pode ser desenvolvido em qualquer plataforma desde que
Conferência IADIS Ibero-Americana WWW/Internet 2012
133

a linguagem a ser utilizada tenha suporte a serviços Web. Em um primeiro momento um cliente móvel para a plataforma J2ME foi desenvolvido. Posteriormente, outros clientes para diferentes plataformas como Android e Web, também foram criados.
5. IMPLEMENTAÇÃO
Para a codificação do SGEMEOS a linguagem de programação Java foi escolhida. Essa escolha se deu, primeiramente, pelo fato de ela ser uma linguagem bastante difundida entre os profissionais da área de TI, o que garante um maior número de usuários, e consequentemente, um número relevante de citações. Outro motivo foi a possibilidade de desenvolver tanto para a plataforma Web quanto para móvel sem a necessidade de mudança de linguagem.
Outras tecnologias definidas para a implementação do sistema foram: o IDE NetBeans [Oracle 2011], o software Umbrello UML Modeler [Hensgen 2001] usado para a modelagem dos diversos diagramas, em UML (Unified Modeling Language) [Booch et al. 2006], necessários para a documentação do sistema, a exemplo dos diagramas de caso de uso e de classes. A persistência dos dados é de responsabilidade do SGBD (Sistema Gerenciador de Bancos de Dados) MySQL 5.5 [Oracle 2011]. Por fim, a hospedagem do sistema foi atribuída ao GlassFish 3.0 [Oracle 2011], um servidor de aplicação com suporte para linguagem Java.
5.1 Servidor
A implementação do servidor envolveu a criação de pacotes de classes Java. Cada pacote foi criado para agrupar classes que tivessem objetivos em comum. Assim, o servidor é constituído de pacotes que possuem as classes que representam os perfis, as classes que fazem comunicação com o SGBD, as classes que representam as entidades presentes no domínio do negócio e as classes que descrevem os serviços.
O pacote ufs.dcomp.sgemeos.perfis armazena as classes Administrador, Organizador, Participante e Expositor, as quais representam, respectivamente, os perfis de mesmo nome. Essas classes fazem uso da JAXB (Java Architecture for XML Binding) [Grebac 2006] para que o cliente J2ME possa receber as informações dos usuários de maneira estruturada. Além do pacote de perfis, existe o pacote que agrupa o conjunto de classes que representam as entidades presentes no domínio do negócio. Essas classes complementam os perfis para que todo o cenário do gerenciamento de eventos seja abstraído. O pacote que armazena essas classes é o ufs.dcomp.sgemeos.negocio. Nele estão presentes as classes Local, Horário, Exposição, Evento, Atividade e Autenticar.
No SGEMEOS também existem as classes que são responsáveis pela comunicação com o SGBD. Essas classes estão armazenadas no pacote ufs.dcomp.sgemeos.dao e, como o nome do pacote sugere, foram implementadas no padrão DAO (Data Access Object). Os métodos presentes nas classes desse pacote são utilizados pelos serviços Web para a manipulação dos dados. Com a base de pacotes estabelecida, foi possível criar as classes que descrevem os serviços. É nessas classes onde estão definidos os métodos que representam as operações dos serviços. Cada classe é referente a apenas um serviço.
Através dessas classes são gerados os serviços, mais especificamente, os WSDLs correspondentes. A geração dos serviços a partir das classes é feita automaticamente pelo IDE (Integrated Development Environment). O pacote que contém as classes geradoras de serviços foi nomeado de ufs.dcomp.sgemeos.servicos. A figura 3 exibe um resumo da estrutura de pacotes do SGEMEOS.
Figura 3. Resumo da estrutura de pacotes do SGEMEOS.
ISBN: 978-989-8533-11-1 © 2012 IADIS
134

5.2 Clientes
No projeto inicial do SGEMEOS foi definido que o cliente primário seria desenvolvido para a plataforma J2ME. Porém, para uma melhor avaliação da flexibilidade de plataforma do SGEMEOS, foram criados diferentes clientes, sendo um para plataforma Android e outro para Web.
5.2.1 Cliente J2ME
Consiste de um Midlet desenvolvido através da composição de formulários, listas e menus. Enquanto alguns comandos são apenas de entrada e saída de telas, outros possuem chamadas a serviços Web associadas. Porém, antes de utilizar os serviços Web é preciso que os WSDLs sejam importados para o cliente. Esse procedimento foi feito usando o IDE em conjunto com a JSR 172 [Ellis et al. 2004], onde ao ser fornecida a URL do WSDL são geradas classes Java chamadas stubs. O procedimento tem o contexto similar ao RMI (Remote Method Invocation) [Coulouris 2007]. Os stubs são classes Java que implementam o comportamento do serviço. Dessa forma, o acesso às operações dos serviços é feita por meio dos stubs. A figura 4 mostra a tela referente ao perfil administrador do cliente J2ME.
Figura 4. Tela de Administração do cliente J2ME.
5.2.2 Cliente Android
Este cliente foi construído através do uso do Android SDK [Google 2011]. Além disso, a IDE utilizada para o desenvolvimento foi o Eclipse. O Eclipse foi escolhido pelo fato de suportar o SDK que faz uso da linguagem Java em suas APIs (Application Programming Interface). A IDE também permite a emulação e a depuração da aplicação.
Como a base do SGEMEOS são seus serviços Web, fez-se necessário a integração de uma biblioteca que desse suporte a esta tecnologia no projeto. A KSoap2 [Haustein 2006] foi a API escolhida para ser a responsável por essa tarefa.
A implementação do cliente Android decorreu da mesma forma que no J2ME, ou seja, associando comandos de telas com as operações dos serviços Web. A tela de login do cliente Android é apresentada na figura 5.
Figura 5. Tela de login do cliente Android.
Conferência IADIS Ibero-Americana WWW/Internet 2012
135

5.2.3 Cliente Web
Além dos clientes voltados para plataformas móveis, foi desenvolvido também um cliente alternativo. Esse cliente foi produzido direcionado ao ambiente Web, como mostra a figura 6.
Figura 6. Tela de login do cliente Web.
No desenvolvimento deste cliente foi utilizada a linguagem de programação PHP. A escolha da PHP foi motivada pelo fato de que todos os clientes e o servidor do SGEMEOS terem sido construídos por meio da Java. Desse modo, não só a versatilidade de plataforma como também a flexibilidade com relação à linguagem de programação pôde ser testada.
6. RESULTADOS
Como o principal objetivo do SGEMEOS é gerenciar eventos sociais, o melhor cenário para sua avaliação seria a sua utilização em um ambiente real. Visando isso, o sistema foi usado para gerir a II Semana de Computação da Universidade Federal de Sergipe, a qual ocorreu entre os dias 5 e 8 de Outubro de 2011.
Ao SGEMEOS coube a responsabilidade de gerenciar as inscrições, exibir relatórios e apresentar aos inscritos as informações vinculadas ao evento como datas, locais de palestras e responsáveis pelas palestras.
Para atender as necessidades não só dos organizadores como também dos participantes ficou definido que além da implantação do servidor seriam utilizados também os clientes para a plataforma Android e para a plataforma Web. O cliente J2ME foi excluído devido à falta de serviços de Internet que proporcionassem aos usuários acesso gratuito para a visualização das informações.
O cliente Web, após ser hospedado, tornou-se acessível a partir de uma URL. Nele, os participantes podiam inscrever-se no evento, escolher quais minicursos gostariam de participar e realizar o pagamento da inscrição como mostra a figura 7.
Figura 7. Fragmento da tela de escolha de minicursos do cliente Web.
ISBN: 978-989-8533-11-1 © 2012 IADIS
136

Os organizadores ao acessarem o cliente Web tinham acesso a informações como total de inscritos no evento, total de inscritos em um determinado minicurso, locais, horários, entre outras. Além disso, era possível também alterar os inscritos de um minicurso, alterar os dados cadastrais de um inscrito e gerar listas de presença no formato PDF.
Em quanto à parte burocrática do evento podia ser resolvida por meio do cliente Web, as informações mais relevantes para os participantes eram disponibilizadas através do cliente Android. Ao entrar no cliente, o participante tinha acesso às informações associadas ao evento como horários, locais e responsáveis pelas palestras, além de saber quais palestras estavam acontecendo no momento (figura 8).
Figura 8. Tela de inicial do cliente Android com menu de opções ativo.
Como o acesso ao sistema podia ser feito em múltiplas plataformas, os participantes tinham a possibilidade de escolher do ambiente mais conveniente para a visualização das informações. Além disso, a organização, o gerenciamento e a persistência dos dados possibilitou aos responsáveis pela organização do evento uma economia de tempo nas realizações das tarefas.
A importância do gerenciamento das informações do evento feita pelo SGEMEOS ficou ainda mais evidente quando os dados quantitativos foram analisados ao final do evento. A tabela 1 mostra as estatísticas finais do evento.
Tabela 1. Tela de Administração do cliente J2ME.
Total de inscritos 410
Total de palestras 16
Total de minicursos 12
Nº de locais utilizados 5
Através das estatísticas do evento foi possível constatar que independentemente do tamanho físico, do
volume de pessoas e do tipo do evento é importante que exista um sistema de informação capaz de manipular, persistir e apresentar as informações de maneira legível e eficiente. Quando esse objetivo é alcançado e junto a ele está agregada a flexibilidade de acesso a essas informações, os organizadores ganham em eficiência nas tarefas e os participantes em qualidade de serviço.
7. CONCLUSÃO
Utilizando-se da flexibilidade oferecida pelos serviços Web, este trabalho apresenta um sistema chamado SGEMEOS direcionado ao gerenciamento de eventos sociais. O sistema foi desenvolvido no modelo de cliente-servidor, de modo que o servidor e o cliente pudessem pertencer a plataformas distintas.
A partir do sistema foram disponibilizadas funcionalidades como o cadastramento de organizadores, visualização de exposições, registro de participantes, entre outras. Essas funcionalidades foram avaliadas
Conferência IADIS Ibero-Americana WWW/Internet 2012
137

através da utilização do sistema em um evento social real. Como resultado constatou-se que o uso dos serviços Web garantiu o fluxo de dados entre plataformas distintas, de modo que os clientes do sistema pudessem acessar as informações persistidas um servidor vinculado a um ambiente heterogêneo. Além disso, a avaliação também mostrou que plataformas podem ser integradas, desde que as informações estejam estruturadas e os protocolos de transmissão sejam abertos.
No entanto, apesar de o sistema apresentado neste trabalho possuir diversas funcionalidades, existem muitas modificações e extensões que podem ser agregadas a ele. Primeiramente, visando um melhor gerenciamento dos recursos associados a um evento social e uma melhor integração entre seus participantes, seria interessante a construção e disponibilização de serviços que facilitassem a localização das pessoas no ambiente do evento (geolocalização), proporcionassem a comunicação entre usuários do sistema (chat) e minimizassem as dificuldades relacionadas à administração dos recursos financeiros (monitoramento de finanças). Além disso, o desenvolvimento de um cliente voltado para dispositivos que fazem uso do sistema operacional iOS, como o IPhone, também seria uma boa contribuição futura.
REFERÊNCIAS
BOOCH, G. et al, 2006. Uml: Guia do Usuário. Ed. 2. Rio de Janeiro, Elsevier, Campus. CHENG Z. et al, 2008. Design and implementation of a collaborative conference management system. Computer
Supported Cooperative Work in Design, 2008. CSCWD 2008. 12th International Conference on , vol., no., pp.5-10, 16-18 April 2008.
COULOURIS, G., 2007. Sistemas Distribuídos – Conceitos e Projeto. Bookman. 4a. Edição. DEITEL, H. M., DEITEL P. J., 2006. Java: Como Programar. Ed. 6. Upper Saddle River, New Jersey, Prentice Hall. ELLIS, Jon. YOUNG, Mark., 2004. JSR 172: J2ME Web Services Specification. Disponível em <
http://jcp.org/en/jsr/detail?id=172 > ERL, T., 2004. Service-Oriented Architecture: A Field Guide to Integrating XML and Web Services. Prentice Hall PTR. _______. Flisys., 2007. Disponível em < http://sourceforge.net/projects/flisys/> GOOGLE., 2011. Android SDK. Disponível em <http://developer.android.com/sdk/index.html> GREBAC, M., 2006. JSR 222: Java Architecture for XML Binding (JAXB) 2.0. Disponível em <
http://jcp.org/en/jsr/detail?id=222 > HAUSTEIN, S., 2006. KSoap2. Disponível em <ksoap2.sourceforge.net>. HENSGEN, P., 2001. Manual do Umbrello UML Modeller. Disponível em
<http://docs.kde.org/stable/pt/kdesdk/umbrello/> KNUDSEN, J.; LI S., 2005. Beginning J2ME: From Novice to Professional. Ed. 3. Apress. MCKEE, B. et al, 2002. UDDI Version 2.04 API Specification. Disponível em <
http://uddi.org/pubs/ProgrammersAPI_v2.pdf > ORACLE., 2011. Glass Fish. Disponível em: < http://glassfish.java.net/>. ORACLE., 2011. MySql. Disponível em: < http://dev.mysql.com/>. ORACLE., 2011. NetBeans. Disponível em: < http://netbeans.org/>. PHP GROUP., 2001. PHP: Hypertext Preprocessor. Disponível em:<http://www.php.net/ > RIGGS, R. et al, 2003. Programming Wireless Devices with the Java 2 Plataform, Micro Edition, Second Edition.
Addison Wesley. SHIH, T.K. et al, 2001. Virtual conference management system. Information Networking. Proceedings. 15th
International Conference on, vol., no., pp.776-781. SNODGRASS R., 1999. Summary of Conference Management Software. Disponível em
http://www.acm.org/sigs/sgb/summary.html SOMMERVILLE, I., 2007. Software Engineering. Ed. 8. Addison-Wesley. W3C., 2004. Web Services Architecture. Disponível em < http://www.w3.org/TR/ws-arch/> W3C., 2000. Extensible Markup Language (XML) 1.0 (Second Edition). W3C Recommendation. Disponível em
<http://www.w3.org/TR/2000/REC-xml-20001006> W3C., 2001. Web Services Description Language (WSDL) 1.1. Disponível em <http://www.w3.org/TR/wsdl>
ISBN: 978-989-8533-11-1 © 2012 IADIS
138

Artigos Curtos


REPOSITÓRIO DE CONHECIMENTO ACADÊMICO: UMA PROPOSTA PARA O INSTITUTO SUPERIOR
TUPY – SOCIESC
Alcir Mário Trainotti Filho, Mehran Misaghi e Marcelo Macedo Instituto Superior Tupy – IST/SOCIESC
RESUMO
O Instituto Superior Tupy - IST/SOCIESC é uma instituição de ensino do norte catarinense que possui 95 cursos entre graduação e pós graduação. Uma instituição de ensino tem como principal características a capacidade de gerar conhecimento em diferentes áreas científicas. No entanto, se a instituição não possui mecanismos para reter o conhecimento gerado que, com o passar do tempo, poderá ser perdido devido à rotatividade de alunos e professores. Nesse sentido, justifica-se a utilização de conceitos de gestão do conhecimento por meio da criação de um repositório eletrônico capaz de armazenar o conhecimento gerado e disponibilizá-lo para o aproveitamento de outras pessoas. Esta pesquisa tem como objetivo propor a criação de um repositório de conhecimento baseado no modelo de conversão do conhecimento criado por Nonaka e Takeuchi (1997) para a utilização dos cursos de graduação e pós-graduação do IST/SOCIESC. Este será um estudo descritivo sobre as características de um repositório de conhecimento e os conceitos da web semântica, para o auxilio do funcionamento deste sistema, juntamente com a análise do ambiente computacional que será envolvido neste trabalho.
PALAVRAS-CHAVE
Repositório de conhecimento. Web Semântica. Gestão do conhecimento.
1. INTRODUÇÃO
O conhecimento é um dos principais agentes propulsores do processo de desenvolvimento econômico, tecnológico e intelectual ao longo da história humana. Devido a sua magnitude, percebeu-se a importância do compartilhamento constante de informações e experiências entre as pessoas, para que elas evoluam intelectualmente (FIALHO et. al., 2006; ALVARENGA NETO, 2005).
Para auxiliar no processo de administração desse conhecimento criou-se um conceito que define sistematicamente a gestão do conhecimento como a identificação, criação, renovação, aplicação e o compartilhamento do conhecimento, que se tornam estratégicos para as organizações (FIGUEIREDO, 2005). Por sua vez, essa gestão é complexa e pode ser fragmentada em diferentes setores, como a gestão de pessoas, tecnologia e organizacional, como explicitam as dimensões do conhecimento apresentados por Angeloni (2008) e as espirais do conhecimento defendidos por Sabbag (2007) e Nonaka e Takeuchi (1998).
A gestão do conhecimento expõe diante de suas teorias que o conhecimento deve ser de livre acesso a todos os interessados em um único local. E o repositório de conhecimento tem a capacidade de retê-lo e disponibilizá-lo por meio de uma ferramenta computacional de acesso facilitado a qualquer hora do dia ou da semana (ANGELONI, 2008; FALEH, HANI, KHALED, 2011).
Esta pesquisa tem o objetivo principal de propor a criação de um repositório de conhecimento eletrônico baseado no modelo de gestão de conhecimento de Nonaka e Takeuchi (1997) para a utilização dos cursos de graduação e pós graduação do IST/SOCIESC. Esse estudo justifica-se pelo beneficio que proporcionará a comunidade acadêmica, que reterá e compartilhará o conhecimento previamente explanado por alunos e professores, que facilitará o aprendizado de todos os envolvidos.
Esse artigo esta estruturado da seguinte forma: inicialmente, exibem-se os conceitos de gestão do conhecimento e logo a seguir, os repositórios de conhecimento. A terceira seção expõe os conceitos sobre web semântica que serão utilizados para a concepção deste projeto. Na quarta seção apresentam-se as pesquisas de referência desenvolvidas que se relacionam ao objetivo deste estudo. Adiante expõe a
Conferência IADIS Ibero-Americana WWW/Internet 2012
141

arquitetura e os procedimentos necessários para a criação e o funcionamento do repositório de conhecimento. E por fim, explanam-se as considerações finais desse trabalho.
2. GESTÃO DO CONHECIMENTO
A economia mundial sofreu grandes mudanças históricas que acabaram resultando na economia atual. A base para esse novo conceito advém da demanda acentuada por produtos personalizados e serviços modelados à necessidade dos consumidores. Essa mudança consumista fez com que as empresas sentissem a necessidade de uma economia mais racional (MOHAMED, 2011).
Perante esse cenário, o conhecimento ganhou a devida importância, em virtude da necessidade de adaptação imediata das empresas com as constantes mudanças consumistas do mercado. O conhecimento passou a ser o insumo estratégico mais importante para as organizações, e por meio dele, evoluiu-se tecnologicamente, socialmente e eticamente. Diante disso, a gestão do conhecimento pode ser definida sistematicamente como identificação, criação, renovação e aplicação do conhecimento (que estão diretamente ligados as crenças e a cultura de cada pessoa) e que são estratégicos na vida de uma organização. São ativos intangíveis de uma organização, que permitem a ela saber o que realmente sabe, por intermédio de um processo de gestão bem definido (FIGUEIREDO, 2005; FIALHO, 2006).
A disseminação do conhecimento entre os colaboradores é o grande desafio para projetos dessa magnitude. Como auxilio, desenvolveram-se diferentes modelos para a implantação da gestão do conhecimento nas organizações com base no comportamento das pessoas em diferentes cenários. Dessa maneira, apresentam-se alguns modelos como os pilares do conhecimento de Figueiredo (2005), o modelo atômico de Angeloni (2008), as espirais do conhecimento de Sabbag (2007) e o precursor Nonaka e Takeuchi (2000).
Para Nonaka e Takeuchi (2000) o conhecimento dentro de uma organização apresenta um modelo de conversão. O conhecimento nasce diante das experiências e crenças de cada indivíduo que o caracteriza como tácito, e posteriormente deve ser explicitado para que outras pessoas tenham acesso, os combinem e os internalizem para gerar novos conhecimentos. A figura 1 representa esse modelo oriental de auxilio à gestão do conhecimento.
Figura 1. Modelo de conversão do conhecimento Fonte: Adaptado de Nonaka e Takeuchi (1995; p. 80-81)
A partir do modelo de conversão, Sabbag (2007) apresentou um esquema de conhecimento em espiral baseado em Nonaka e Takeuchi (1997) dentro de um ambiente acadêmico. Para Sabbag (2007), o conhecimento nasce durante o período letivo por intermédio da troca de experiências (socialização) e trabalhos dos alunos (externalização). Ele precisa ficar disponível para que outros alunos tenham acesso e criem novos conhecimentos (combinação), estimulando assim, o processo de aprendizagem (internalização). O conhecimento é fundamental para o crescimento científico de uma instituição de ensino e a espiral do conhecimento deve ser mantida sempre em operação para que o ciclo seja contínuo e traga benefícios a todos os envolvidos.
ISBN: 978-989-8533-11-1 © 2012 IADIS
142

2.1 Repositórios de Conhecimento
Um repositório de conhecimento é considerado por Fachin et. al. (2009) um sistema de informação que armazena, preserva e difunde o conhecimento. Ainda assim, Fahleh, Hani e Kahled (2011) relacionam as bibliotecas convencionais como repositórios de conhecimento clássicos. Perante a comunidade do século XXI este conceito evoluiu e permite direcionar um repositório a uma base computacional de expertises e conhecimentos, que são coletados, sumarizados e integrados com outras fontes.
É importante salientar, que as principais características de um repositório de conhecimento estão relacionadas à disponibilidade do conhecimento em um período de sete dias por semana e vinte e quatro horas por dia. Ele tem como principio básico permitir a filtragem, indexação, classificação, armazenamento e a capacidade de recuperação, juntamente com os recursos de comunicação e colaboração (KANKANHALLI, TAN e WEI, 2005).
Ainda assim, podem-se citar diferentes tecnologias que auxiliam o processo de gestão do conhecimento, bem como os repositórios, como Data warehouse, Data Mining, workflow, Business Inteligence – BI, ontologias e a web semântica. Perante isso, as combinações entre os repositórios do conhecimento e ferramentas computacionais se fortalecem e tornam-se aliados dos projetos de gestão do conhecimento (FALEH, HANI, KHALED, 2011; SERAFINI, HOMOLA, 2011). Neste artigo será abordada especificamente a combinação dos repositórios de conhecimento com princípios da web semântica para o a construção do conceito do repositório alvo.
3. WEB SEMÂNTICA
Ao avaliar o ambiente web atual, é possível visualizar diferentes limitações no ambiente como Breitman (2005) menciona em seus estudos. Estas restrições se devem a baixa inteligência na apresentação das informações, a interpretação do conteúdo é executada pelo usuário, existem problemas de localização, acesso, apresentação e manutenção dos seus dados devido ao volume excessivo de dados circulados na internet. Por estes motivos Breitman (2005) a intitula como a Web sintática e posteriormente Moura (2001) e Bonifacio e Heuser (2002) concordam com esta colocação.
Diante dessas limitações, Berners-Lee, Fischetti e Dertouzos (2000) comentam que a Web está sendo subutilizada, por efeito da falta de padronização e heterogeneização de seus usuários. Com essa linha de reflexão, Berners-Lee (1998) propõe uma nova estrutura para o ambiente Web. Composição essa, que é capaz de estruturar o conteúdo significativo das páginas e permitir que agentes de software auxiliem na pesquisa de informações. Souza e Alvarenga (2004) explicam que essa nova tecnologia prioriza a adição de inteligência nos códigos XML utilizada na confecção de páginas Web. Desta forma, aperfeiçoa-se a comunicação entre agentes de software e o uso da web se tornará mais automatizado e dinâmico para seus usuários.
Afim de padronizar os desenvolvimentos da web semântica o W3C - Worl Wide Web Consortium criou uma estrutura em camadas que formam a pirâmide das tecnologias necessárias para o desenvolvimento da web semântica. A primeira camada da pirâmide é composta pelas tecnologias Uniform Resources Identifiers - URI e Unicode que formam a base deste modelo. Elas são capazes de construir uma cadeia de caracteres única independentemente do idioma, proporcionado pelo padrão Unicode, dessa forma é possível endereçar as informações e identificar os conteúdos de forma singular por meio dos URI’s (FIALHO et al., 2006; W3.ORG, 2011).
Em complemento da camada anterior, a segunda camada se baseia no padrão Extensible Markup Language - XML. Esse padrão é capaz de tornar a informação legível para qualquer produto de software processá-la, sendo a base para a o funcionamento desse novo conceito (FIALHO et al., 2006). A web semântica começa a ganhar notoriedade a partir da terceira camada, onde os Resource Description Framework - RDF’s incumbem-se pela representação dos dados do sistema ao utilizar padrões de metadados. O seu objetivo é conceber um mecanismo apto á descrever recursos, como um metadado (SOUZA; ALVARENGA, 2004; URIARTE et al., 2010; FIALHO et al., 2006).
Para compor a quarta camada tem-se a ontologia, definida como um documento ou um arquivo que descreve formalmente as relações entre termos e conceitos, sendo então, uma especialização formal e explícita (ALVARENGA, 2004; BREITMAN, 2005). A ontologia possui papel importante para a gestão do conhecimento, ela tem a capacidade de amparar a formalização, reutilização e o compartilhamento do
Conferência IADIS Ibero-Americana WWW/Internet 2012
143

conhecimento. Ela proporciona facilidades para o processo de documentação do conhecimento, dessa forma, aumenta a confiabilidade das informações veiculadas no ambiente. Esse método é garantido por meio de regras de inferência no momento da criação da ontologia, que permite retirar inconsistências dos dados, e aperfeiçoar os mecanismos de busca por intermédio de sua implementação. (MOURA, 2001; STAAB; MAEDCHE, 2005).
Outra possibilidade é a elaboração de regras que atuem nas instâncias das classes e também sobre os recursos. Essas regras estão contidas na quinta camada, onde a lógica, prova e confiança são suas subcamadas. Elas permitem aos computadores o poder de decisão sobre o conteúdo disponível na internet, por meio de regras de inferência que capacitam agentes de software a relacionarem as informações e processá-las.
Essa estrutura em camadas representa a web semântica, que exprime a interação entre suas camadas e a inteligência funcional para o sistema é responsabilidade da semântica. A web semântica será percebida pelos usuários apenas quando representar algum valor para eles. Dessa forma será necessário, que se criem programas computacionais que apoiem e facilitem a utilização para seus usuários, como por exemplo, os repositórios de conhecimento.
4. PESQUISAS ANTERIORES COM REPOSITÓRIOS DE CONHECIMENTO EM INSTITUIÇÕES DE ENSINO
Os repositórios de conhecimentos são parte funcional para o processo de gestão do conhecimento e diversos cientistas buscam o conceito de armazenamento de informações. Tem-se como exemplo, Serafini e Homola (2011) que desenvolveram um repositório de conhecimento contextualizado. Eles abordaram os conceitos dos repositórios de conhecimento e seus benefícios juntamente com a web semântica como fonte de contextualização dos conhecimentos contidos nas bases de dados. Diante desse estudo, provou-se que é possível relacionar conhecimentos no tempo, espaço ou tema, ao se fazer uso dos conceitos da web semântica.
Pearson (2010) enfatiza seu estudo menos tecnicamente sobre as bases do conhecimento, mas apresenta de forma clara e sucinta suas vantagens para uma organização e a ferramenta Kbart para o trabalho colaborativo. Ele relaciona que a base para o desenvolvimento da ferramenta é a criação de um banco de metadados, dessa forma, é possível rotular a informação e conhecer o significado de cada dado inserido no sistema.
Ainda assim, Pérez-Pérez, Benito e Bonet (2012) utilizaram os conceitos de metadados apresentados por Pearson (2010), juntamente com ontologias e web semântica de Packer et. al. (2008) e Serafini e Homola (2011). Pérez-Pérez, Benito e Bonet (2012) apresentam o ModeloR como uma base de conhecimento de expertises disponível na internet e desenvolvida por intermédio de um modelo ontológico e uma base de metadados.
Para finalizar, Faleh, Hani e Khale (2011) indicam a importância de um repositório de conhecimento estruturado, de fácil acesso com alta disponibilidade para a evolução da comunidade acadêmica na Jordânia. Desenvolveu-se uma base de conhecimento que integra todas as universidades públicas no país e demonstram os benefícios que esse repositório trouxe para o desenvolvimento das pesquisas científicas.
Diante desses estudos, justifica-se a criação de um repositório de conhecimento que faça uso de tecnologias como ontologias e web semântica. Diferentes pesquisadores ao redor do mundo desenvolvem estudos semelhantes e obtiveram resultados positivos para a comunidade estudada. Acredita-se que com a implementação de um repositório de conhecimento o IST/SOCIESC, obterá resultados positivos para as pesquisas científicas de alunos e professores.
5. O REPOSITÓRIO DE CONHECIMENTO PROPOSTO
Esta pesquisa é desenvolvida no ambiente acadêmico do IST/SOCIESC que contém aproximadamente 36 cursos de graduação e 59 cursos de pós graduação, que dentre eles 2 cursos são Strictu Sensu. Em um ambiente acadêmico como esse, Sabbag (2007) apontou a rotatividade de alunos em uma instituição de
ISBN: 978-989-8533-11-1 © 2012 IADIS
144

ensino como um dos fatores impeditivos para o aprendizado. As teorias de Nonaka e Takeuchi (1997) convergem para o mesmo pensamento e demonstram o conhecimento como uma espiral cíclica.
Diante das teorias apresentadas, a espiral do conhecimento criada dentro da instituição não possui fluência, o que pode oprimir o aprendizado dos alunos. Isso acontece porque atualmente o conhecimento é gerado, externalizado por meio de trabalhos, artigos ou apresentações e não é compartilhado com outras pessoas, grupos ou organização. Isso impede o aproveitamento desse conhecimento prévio para alavancar outros conhecimentos.
Perante essa dificuldade de obter uma espiral do conhecimento e torná-la contínua, apresentou-se o conceito de repositório de conhecimento eletrônico. Por meio de um repositório de conhecimento é possível armazenar as produções dos alunos e torná-la acessível a qualquer outro aluno interessado. Vislumbra-se um ambiente que permita interagir entre as quatro dimensões (Socialização, Externalização, Combinação, Internalização) exploradas por Nonaka e Takeuchi (1997) em seu modelo de gestão do conhecimento. A base para essa gestão está relacionada à interação entre indivíduos dentro de uma organização e para construir um repositório baseado no modelo oriental apresentado, é necessário que exista essa interação. A socialização relaciona a criação de novos conhecimentos a partir de modelos mentais ou habilidades pessoais. Com isso, pode-se citar a utilização de ferramentas como plataformas e-learning, banco de idéias, chats e micro blogs como o twitter com características de interação entre usuários para auxiliar este processo.
A próxima dimensão menciona a externalização, que caracteriza a transformação do conhecimento tácito em explicito. Pode-se utilizar ferramentas como wikis e fóruns para o compartilhamento e construção do conhecimento explicito. A combinação é descrita como a fusão de diferentes conhecimentos para a criação de algo novo. Nesta dimensão podem-se utilizar ferramentas como os repositórios de dissertações, TCC’s, artigos e Teses, bem como eventos e congressos realizados na instituição, e também sistemas de pesquisa e mecanismos infométricos e bibliométricos para estatísticas das publicações, que fazem uso de diferentes conhecimentos para gerar outro novo.
Por fim, tem-se a internalização, que é a conversão do conhecimento explicito para o tácito. Nesta seção, relaciona-se com a experimentação, a prova de algum conceito, então, podem-se desenvolver páginas web para os projetos de pesquisa que são desenvolvidos na instituição ou projetos de extensão que retenham o conhecimento de uma experimentação desenvolvida. Este desenvolvimento entra em concordância com as teorias de gestão do conhecimento, que prevêem que a interação entre as pessoas é o principal insumo para a troca de conhecimento (PRASHANT et. al., 2010).
O repositório de conhecimento deverá ser o local, onde alunos e professores irão interagir uns com os outros, e expressar seus conhecimentos, por meio de tecnologias computacionais. Esse repositório precisa garantir as características de acessibilidade, disponibilidade e interação entre seus usuários. Com as ferramentas citadas, baseando-se no modelo de Nonaka e Takeuchi (1997), é possível criar interação entre as pessoas digitalmente, priorizar o compartilhamento e formar um movimento cíclico de criação e desenvolvimento do conhecimento.
6. CONCLUSÃO
Nesse estudo apresentou-se o ambiente acadêmico do IST/SOCIESC, e as teorias de gestão do conhecimento apresentadas por Nonaka e Takeuchi (1997) e Sabbag (2007) que se relacionam com espirais de conhecimento. Diante, disso verificou-se que além de um modelo de gestão do conhecimento é preciso de ferramentas que auxiliem nos processos de retenção e compartilhamento do conhecimento, para viabilizar prática e tecnicamente o modelo de Nonaka e Takeuchi (1997).
Perante as teorias e ferramentas disponíveis propôs-se um repositório de conhecimento para essa comunidade, que possibilite a retenção, o compartilhamento do conhecimento e a interação entre os usuários. Diante das características básicas de um repositório de conhecimento, que prevê alta disponibilidade, acessibilidade e interatividade. Diante disso, os recursos planejados para esse ambiente atendem essas expectativas e otimizam a retenção de conhecimentos explícitos e tácitos.
Essa pesquisa fundamentou-se em outros estudos para comprovar que o repositório de conhecimento e a web semântica trazem benefícios para os projetos de gestão do conhecimento. Como exibem Faleh, Hani e Khale (2011) os repositórios de conhecimento são importantes para as instituições de ensino, e diante da colaboração coletiva é possível desenvolver conhecimentos. Ainda se tratando de bases de conhecimento,
Conferência IADIS Ibero-Americana WWW/Internet 2012
145

Serafini e Homola (2011), Packer et. al. (2008), Pearson (2010), Pérez-Pérez, Benito e Bonet (2012) relacionam a web semântica e ontologia como auxilio para a construção de repositórios de conhecimento que facilitem o compartilhamento das informações de forma mais facilitada.
Diante dos estudos apresentados e das teorias de gestão do conhecimento, justifica-se a implementação do repositório de conhecimento e o estudo de ferramentas baseando-se no modelo de gestão de conhecimento empregado por Nonaka e Takeuchi (1997). Juntamente com ferramentas computacionais interconectadas com conceitos da web semântica para a retenção do conhecimento e o compartilhamento entre alunos e professores será possível disponibilizar um ambiente que facilite o aprendizado, baseado nas teorias da gestão do conhecimento.
REFERÊNCIAS
Angeloni, M. T. 2008. Organizações do conhecimento: infra-estrutura, pessoas e tecnologia. Saraiva, São Paulo. Fachin, G. R. B. et al, 2009. Perspectivas em Ciência da Informação. Gestão do conhecimento e a visão cognitiva dos
repositórios institucionais., v. 14, n. 2, p. 220-236. Disponível em: <http://tinyurl.com/7gcmdxw>. Acesso em: 05 Maio. 2012.
Faleh, A. A.; Hani, J. I.; Khaled, B. H. 2011. International Journal of Business and Management. Building a knowledge repository: Linking Jourdanian Universities E-library in an Integrated Database System. Vol. 6, No 4.
Fialho, F. A. P. et al. 2006. Gestão do conhecimento e aprendizagem: As estratégias competitivas da sociedade Pós-indústrial. Visual Books, Florianópolis.
Figueiredo, S. P. 2006. Gestão do conhecimento: Estratégias competitivas para a criação e mobilização do conhecimento na empresa. Qualitymark, Rio de Janeiro.
Kankanhalli, A.; Tan, B. C. Y.; Wei, K. 2005. Journal of the American society for information Science and technology achieve. Understanding seeking from electronic knowledge repositories: an empirical study: Special topic section on Knowledge management in Asia. Vol. 56. Issue. 11. Pag. 1156-1166.
Mohamed, C. 2011. IBIMA Publishing Review. Laboratory LAMEOR , University of Oran. Argélia. The impact of knowledge-based economy on the development of the innovation in services: Case of algerian banks and insurance companie. Acesso em: 31 mar. 2012. Disponível em: <http://tinyurl.com/cpq2ynh>.
Nonaka, I.; Takeuchi, H. 1997. Criação de conhecimento na empresa: como as empresas japonesas geram a dinâmica da inovação. Campus, Rio de Janeiro.
Packer, H. S. et al. 2008. Sixth European Workshop on Multi-agent system, University of Southampton. Envolving ontological knowledge bases through agent collaboration.
Pearson, S. 2010. ISQ Information standards quarterly Magazine. Knowledge bases and related tools (KBART): A NISO/UKSG recommended practices.
Pérez-Pérez, P. Benito, B. M., Bonet, F. J. 2012. International Journal: Experts systems with application. ModeleR: an environmetal model as knowledge base for experts. Elsevier.
Prashant, M. et. al. 2010. Building a Knowledge Repository of Educational Resources using Dynamic Harvesting. IEEE. Sabbag, P. Y. 2007. Espirais do conhecimento: Ativando indivíduos, grupos e organizações. Saraiva, São Paulo. Serafini, L.; Homola, M. 2011. Web Semantics Magazine, Science, Services and Agents on the World Wide Web.
Contextualized knowledge repositories for the semantic web. Disponível em: <http://tinyurl.com/73z4psh>. Acesso em: 04 Maio. 2012.
Uriarte, L. R. et al. 2010. Revista IST. Proposta de um ambiente colaborativo baseado em CMS com análise semântica e base ontológica: o caso da comunidade acadêmica de computação do Instituto Superior Tupy. Disponível em: <http://tinyurl.com/4yyost4>. Acesso em: 04 Maio. 2012.
ISBN: 978-989-8533-11-1 © 2012 IADIS
146

ARQUITECTURA DE UN REPOSITORIO RDF BASADO EN CASSANDRA
Jesús Bermúdez1, Arantza Illarramendi1, Marta González2 y Ana I. Torre-Bastida2 1Departamento de Lenguajes y Sistemas Informáticos, UPV-EHU, Paseo Manuel de Lardizabal,
1 Donostia, 20018 - San Sebastián 2Tecnalia Research & Innovation, Parque Tecnológico Edif 202, Zamudio, 48170 - Vizcaya
RESUMEN
La gestión de datos RDF de forma eficiente es un aspecto relevante en el entorno de la Web Semántica, y por ello requisitos como escalabilidad o eficiencia en tiempos de respuesta a preguntas referentes a dichos datos intentan resolverse desde diferentes perspectivas. Nuestra propuesta de gestión eficiente se basa en las bases de datos NoSQL, en concreto Cassandra, debido a las características que ofrece de distribución y alto rendimiento. Por lo tanto, en este artículo presentamos nuestra aproximación de un nuevo sistema de gestión RDF basado en Cassandra, describiendo su arquitectura general y mostrando los resultados preliminares obtenidos sobre el benchmark LUBM.
PALABRAS CLAVE
Web semántica, RDF, NoSQL store, SPARQL, MapReduce
1. INTRODUCCIÓN
El modelo de datos RDF1 (Resource Description Framework), promovido por el consorcio W3C en el contexto de la Web Semántica, se está convirtiendo en un estándar cada vez más utilizado para la representación e intercambio de información. La iniciativa Linked Open Data (LOD)2 pone ya a nuestra disposición una gran cantidad de conjuntos de datos, de dominios diversos como educación, ciencias de la vida, datos gubernamentales, publicaciones, geográficos y otros. Además, instituciones culturales y científicas vislumbran una gran oportunidad en la integración de la enorme cantidad de contenidos digitales que generan y que están dispuestas a compartir [González, M.et al, 2008].
El volumen de datos RDF que se necesita manejar en algunas aplicaciones ha llegado a un punto en el que aparecen problemas de rendimiento, achacables a la falta de escalabilidad de los gestores de datos utilizados [Arias, M. et al, 2011]. En este artículo presentamos una arquitectura, para un sistema de gestión de datos RDF, que precisamente se caracteriza por su alta escalabilidad, basada en la distribución de los datos y en un modelo de representación muy adecuado para los datos RDF.
El modelo de datos RDF representa la información mediante sentencias sobre recursos. Una sentencia tiene forma de triple <sujeto, predicado, objeto>, en el que se expresa que el recurso, nombrado por el sujeto, tiene como valor asociado a la propiedad, nombrada por el predicado, el recurso nombrado por el objeto. Por ejemplo, <elPrado, rdf:type, Museo>, <elPrado, localizadoEn, madrid>, <wwwInternet2012, celebradoEn, madrid>. Se puede visualizar una colección de triples como un grafo dirigido en el que los nodos son los sujetos y objetos (etiquetados con su identificador) y cada arco, que va de un sujeto a un objeto, está etiquetado con el predicado correspondiente. SPARQL3 es un lenguaje de interrogación para este modelo de datos. Una pregunta SPARQL especifica, básicamente, un grafo en el se admite que aparezcan variables en el lugar de los nodos y de los arcos, de manera que la respuesta a esa pregunta puede calcularse mediante la superposición (graph-matching) de la pregunta sobre el grafo fuente de datos. Por ejemplo, una pregunta representada por el patrón <?X, ?Y, madrid>, y evaluada en el grafo formado por los tres triples de
1 RDF - http://www.w3.org/RDF/ 2 LOD - http://richard.cyganiak.de/2007/10/lod/ 3 SPARQL 1.1 - http://www.w3.org/TR/sparql11-query/
Conferência IADIS Ibero-Americana WWW/Internet 2012
147

arriba, tendría la siguiente respuesta: (?X=elPrado, ?Y=localizadoEn) y (?X=wwwInternet2012, ?Y=celebradoEn). Una pregunta más compleja podría estar formada por varios patrones; por ejemplo <?X, rdf:type, Museo> AND <?X, localizadoEn, ?Y >, en los que la igualdad del nombre de una variable representa un equi-join. En este caso la respuesta sería (?X=elPrado, ?Y=madrid).
Aunque los triples RDF pueden almacenarse de forma simple, en una tabla con tres atributos para sujeto, predicado y objeto, se ha constatado que ese almacenamiento adolece de graves problemas de rendimiento ya que el procesamiento de consultas, en general, necesitará de muchas operaciones de auto-join y, además, tendrá problemas de escalabilidad con el crecimiento del tamaño de la tabla. Existen, además de esta, muchas otras aproximaciones para el almacenamiento de datos RDF, que se explican más en detalle en la sección 2. Entre las existentes nuestra propuesta sigue un enfoque basado en el particionamiento vertical (orientado a la columna) de los datos [Abadi, J. et al, 2009], ya que para el modelo de datos de Cassandra (orientado a la columna) es el más adecuado, además ha demostrado en general uno de los mejores rendimientos.
En Cassandra4 una columna es un par clave: valor. A una colección de columnas, ordenada por clave, se denomina fila y se accede a ella mediante una clave-de-fila. Lo expresamos así: {clave-de-fila: {clave-de-columna: valor}}. Una familia de columnas es un contenedor de filas de la misma clase. En Cassandra, cada familia de columnas recibe un nombre y queda almacenada en un fichero ordenado por clave-de-fila. Un espacio de claves es el contenedor más externo en Cassandra y es una colección de familias de columnas. Cassandra ofrece, además, una nueva estructura denominada columna compuesta (composite-column), que permite que las claves de fila y las claves de columna puedan estar compuestas de varias partes. Lo expresamos así: {[clave-de-fila1,…, clave-de-filaM]: {[clave-de-columna1,… clave-de-columnaN]: valor}}. Gracias a eso, es posible realizar búsquedas mediante índices sobre esas partes de las claves.
Las contribuciones de nuestra propuesta son, por tanto, las siguientes: Un mecanismo de persistencia de datos RDF sobre la base de datos Cassandra, manteniendo las
características de escalabilidad y distribución. Una API para desarrollar las tareas de carga, consulta y manipulación de datos sobre este
mecanismo. Los resultados obtenidos durante las pruebas de nuestro sistema en un cluster de alta
prestaciones mediante el benchmark LUBM.
2. TRABAJOS RELACIONADOS
Los sistemas de gestión de datos RDF han ido evolucionando desde simples ficheros de texto, pasando por sistemas de gestión de esquemas/datos relacionales, hasta sistemas distribuidos que gestionan elaboradas estructuras de datos basadas en representación de grafos. A continuación presentamos una clasificación de los mismos en cinco grandes grupos:
• Almacenamiento Triple store: basado en una gran tabla formada por tres columnas, correspondientes a sujeto-predicado-objeto. Muy utilizado en sistemas con persistencia mediante BD relacionales como Sesame [Broekstra, J. et al, 2002]. Otros enfoques más modernos son Hexastore[Weiss, C. et al, 2008] o RDF-3x5, que añaden estructuras de índices.
• Almacenamiento Property Table: agrupan los predicados que tienden a estar definidos sobre la misma clase de sujetos como atributos de una tabla relacional. Jena TDB6 es un ejemplo.
• Almacenamiento Vertical Partitioning: en el que se define una tabla de dos columnas, representando sujeto y objeto, por cada predicado de la fuente de datos. Este sistema fue promovido por Abadi et al [Abadi, J. et al, 2009] y es el utilizado en nuestra propuesta.
• Almacenamiento basado en grafos: basados en estructuras de datos que representan grafos, residentes en memoria principal, que aprovechan las posibilidades de compresión. Por ejemplo BitMat [Atre, M. et al, 2009].
• Aproximaciones híbridas, como puede ser Openlink Virtuoso7, que mezcla RDBMS, ORDBMS y servidores de ficheros o 4Store que es un repositorio RDF distribuido.
4 APACHE CASSANDRA - http://cassandra.apache.org/ 5 RDF-3x - http://www.mpi-inf.mpg.de/~neumann/rdf3x/ 6 Jena TDB - http://jena.apache.org/documentation/tdb/index.html 7 OpenLink Virtuoso - http://virtuoso.openlinksw.com/
ISBN: 978-989-8533-11-1 © 2012 IADIS
148

3. ARQUITECTURA Y MODELO DE DATOS
En la figura 1 mostramos la arquitectura de nuestro sistema. El elemento principal es el mecanismo de persistencia basado en un cluster de Cassandra, que es el que nos ofrece las características de distribución y escalabilidad, las cuales constituyen el principal beneficio de nuestro repositorio frente a otras opciones. Entre los nodos que lo forman, se distribuyen los diferentes triples que componen el dataset RDF a almacenar. Utilizando el modelo de datos ofrecido por Cassandra, se pueden perfilar diferentes layout de almacenamiento. En nuestro sistema, se ha optado por tres estructuras de almacenamiento formadas mediante columnas compuestas por distintos campos. Cada una de estas estructuras almacena una posible conmutación de los recursos que forman los diferentes triples (SPO, POS, OSP), se ha elegido esta forma de representación debido a que es la que mejor optimiza el rendimiento en la utilización y el acceso a las estructuras propias de Cassandra.
Estas estructuras pueden dar solución a los diferentes patrones simples de preguntas (al referirnos a un patrón simple estamos indicando un triple en el que cualquiera de sus recursos puede ser variable). En el caso de la estructura SPO, adecuado para los patrones <s ?X ?Y> y <s p ?X>, la estructura se muestra también en la figura 1, donde el sujeto es la denominada clave-de-fila, y los predicados y objetos forman la “composite-column” y tienen el papel de claves de columnas. Con esto se consigue un nivel doble de indexación, donde el sujeto es el primer índice y la combinación predicado-objeto compone un segundo índice. En la misma figura 1, describimos las estructuras POS para patrones (<?X p ?Y> y <?X p o>) y OSP para patrones (<?X ?Y o> y <s ?X o>).
Figura 1. Arquitectura Cassandra RDF y estructuras “composite-column”
Por encima del elemento de almacenamiento nos encontramos con una API que gestiona las operaciones de carga, consulta y manipulación, así como la operación de inferencia. Para esta última operación hemos integrado Hadoop (framework para la paralelización) con Cassandra y sobre él hemos ejecutado el algoritmo de inferencia descrito en [Urbani et al. 2010]. El resultado de la inferencia se materializa en las estructuras diseñadas para el almacenamiento en Cassandra. Por último nos encontramos con un módulo destinado a la optimización de las consultas, que se compone de un analizador léxico, planificador y optimizador de consultas. Este módulo está siendo diseñado y desarrollado actualmente y su objetivo es mejorar aún más los tiempos de respuesta obtenidos.
4. RESULTADOS
El entorno de ejecución de las pruebas ha sido el cluster de altas prestaciones Arina8, del que se han utilizado 6 nodos, cada uno de los cuales tiene las siguientes características: dos procesadores con 8 cores de tipo 2.4 GHz Xeon 5645, 48 GB RAM y 250 GB de disco duro. El benchmark LUBM [Guo Y. et al, 2005], esta compuesto por un generador de datos sintéticos y una batería de 14 preguntas SPARQL, ha sido elegido
8 ARINA/EHU - http://www.ehu.es/sgi/recursos/cluster-arina
Conferência IADIS Ibero-Americana WWW/Internet 2012
149

como dataset sintético por ser uno de los mas comúnmente utilizado, en él se han seleccionado dos preguntas (Q1 y Q3) entre la batería ofrecida, para la medición de tiempos de respuesta en función de la escalabilidad del dataset. Todas las medidas se encuentran en microsegundos.
Tabla 1. Resultados de Cassandra RDF con benchmark LUBM.
Tiempo de respuesta en microsegundos Dataset y nº aprox. de triples
Lubm1 (103 K )
Lubm5 (646 K)
Lubm10 (1,32 m)
Lubm20 (2,78 m)
Lubm50 (6,89 m)
Q1 Cassandra (s) 0,145760 0,364198 0,404731 0,452561 0,675441 Q3 Cassandra (s) 0,206002 0,389476 0,452258 0,509651 0,708752
Los resultados para la preguntas pueden verse en la tabla 1. En relación a las pruebas referentes a la
inferencia, podemos indicar que para un dataset de gran tamaño como es Uniprot (850 millones triples) el tiempo necesario ha sido de 20 horas y 40 minutos, duplicando la salida de la inferencia el tamaño del dataset (aprox. 1800 millones de triples inferidos). Se puede observar en las pruebas como nuestra implementación ofrece escalabilidad en un entorno distribuido, siendo capaz de dar respuesta aun tamaño cada vez mayor del dataset, viéndose los tiempos de respuesta poco afectados por el incremento en el tamaño.
5. CONCLUSIÓN Y TRABAJOS FUTUROS
En este artículo hemos presentado brevemente las posibilidades y beneficios de gestionar datos RDF usando una base de datos NoSQL, como Cassandra. Teniendo en cuenta las limitaciones que presentan los sistemas actuales que gestionan datos RDF aportamos un nuevo enfoque, integrando las ventajas de las bases de datos NoSQL a las características de los repositorios RDF ya existentes. Nuestro sistema está diseñado para gestionar datasets RDF de gran tamaño orientados a la consulta de los datos e incorpora además la posibilidad de materializar la inferencia, manteniendo un rendimiento eficiente en tiempos. Como trabajos a futuro, en primer lugar pensamos realizar una comparativa de nuestro sistema con los actuales repositorios RDF existentes en el mercado, utilizando diferentes benchmark (tanto reales como sintéticos), con el objetivo de descubrir nuevos puntos de mejora. Además ya hemos detectado la necesidad de un mecanismo de gestión de preguntas más complejo que incorpore un planificador y optimizador, para entornos en los que sea necesario trabajar con consultas analíticas muy complejas. Estos nuevos desarrollos nos permitirían, en un futuro, poder ofrecer al usuario una herramienta completa y eficiente para cualquier consulta y volumen de datos.
REFERENCIAS
Abadi, J. et al, 2009. SW-Store: a vertically partitioned DBMS for Semantic Web data management. The VLDB Journal — The International Journal on Very Large Data Bases Volume18 Issue2, Pages 385 - 406
Arias, M. et al, 2011. An empirical Study of Real-World SPARQL Queries. 1st International Workshop on Usage Analysis and the Web of Data (USEWOD2011) in the 20th International World Wide Web Conference (WWW2011). Hyderabad, India, March 28th, 2011
Atre M. et al, 2009. Bitmat: An in-core rdf graph store for join processing. Rensselaer Polytechnic Ins. Technical Report Berners-Lee T., 2006. Linked Data-Design Issues. http://www.w3.org/DesignIssues/LinkedData.html Broekstra, J. et al, 2002. Sesame: A Generic Architecture for Storing and Querying RDF and RDF Schema. The Semantic
Web — ISWC 2002.Lecture Notes in Computer Science Springer Berlin / Heidelberg González, M.et al, 2008. Semantic framework for complex knowledge domains. Proceedings of ISWC200, Germany Guo Y. et al, 2005. Lubm: A benchmark for owl knowledge base systems. Web Semantic.3:158-182, October,2005 Ladwig, G. et al, 2011. CumulusRDF: Linked Data Management on Nested Key-Value Stores. In SSWS,2011. Urbani, J. et al, 2010. OWL Reasoning with WebPIE: Calculating the Closure of 100 Billion Triples. Lecture Notes in
Computer Science, Volume 6088/2010 Weiss, C. et al, 2008. Hexastore: sextuple indexing for semantic web data management. Proceedings of the VLDB
Endowment Volume 1 Issue 1.Pages 1008-1019
ISBN: 978-989-8533-11-1 © 2012 IADIS
150

SERVIÇO DE LOCALIZAÇÃO GEOGRÁFICA UTILIZANDO WEB SERVICE DINÂMICO
Sandra Costa Pinto Hoentsch, Felipe Oliveira Carvalho, Luiz Marcus Monteiro de Almeida Santos e Admilson de Ribamar Lima Ribeiro
UFS – Universidade Federal de Sergipe Av. Marechal Rondon, Jardim Rosa Elze - São Cristóvão/SE
RESUMO
Esse artigo apresenta a proposta de site de rede social SocialNetLab que pertence ao Departamento de Computação da Universidade Federal de Sergipe e que tem como objetivos: localizar usuários e notificá-los da proximidade de um amigo independente da tecnologia de localização disponível no equipamento, fazendo uso de Web Service; servir de laboratório para pesquisas em redes sociais e promover o ensino colaborativo e a integração entre alunos, professores e pesquisadores, disponibilizando serviços e recursos educacionais da instituição em tempo integral.
PALAVRAS-CHAVE
Tecnologia de Localização, Detecção de Proximidade, Rede Social Móvel, Web Service Dinâmico.
1. INTRODUÇÃO
O crescimento do uso de dispositivos móveis, especialmente celulares e seus derivados como os smartphones, têm favorecido o aumento de serviços disponibilizados através da Internet. O site da ComputerWord publicou em fevereiro de 2011 que mais de metade dos dispositivos de informática vendidos nos próximos anos não serão computadores mas sim smartphones, tablets e netbooks (Fonseca, 2011). Segundo a revista Época publicada em maio de 2010, a média mundial de amigos virtuais é de 195 pessoas por usuário, quando no Brasil é de 365, sendo que mais de 80% dos internautas estão cadastrados em pelo menos uma rede social, classificando o Brasil como sendo o país mais sociável do mundo (Ferrari, 2010). Diante dessas considerações, percebemos a importância de realizar pesquisas em redes sociais.
O objetivo desse artigo é apresentar a rede social móvel SocialNetLab (Social Network Laboratory - Laboratório de Rede Social) que servirá de laboratório para pesquisas em redes sociais; permitirá que os usuários localizem e sejam notificados da proximidade de amigos através da tecnologia Web Service, fazendo uso de um dispositivo móvel, independente da tecnologia de localização disponível no mesmo; e disponibilizará também ferramentas voltadas ao ensino a toda comunidade acadêmica.
Além desta introdução, o artigo está dividido em mais 4 seções descritas a seguir. Na seção 2 conceituamos e descrevemos alguns sites de redes sociais e apresentamos as vantagens do SocialNetLab em relação aos demais sites de rede social. Na seção 3 abordamos o site de rede social SocialNetLab, bem como as funcionalidades e os aplicativos que irão compor o site. Na seção 4 mostramos o andamento da implementação do SocialNetLab. Na seção 5 apresentamos as considerações finais e os trabalhos futuros.
Conferência IADIS Ibero-Americana WWW/Internet 2012
151

2. SITES DE REDES SOCIAIS MÓVEIS
Os sites de rede social ou SNS (Social Network Sites) são serviços baseado na Web que permitem ao indivíduo: 1) a construção de um perfil público ou semi-público dentro do sistema; 2) gerenciar uma lista de usuários com quem o indivíduo compartilha uma conexão; 3) visualizar e pesquisar sua lista de conexões e as listas feitas por outros usuários dentro do sistema (Boyd, 2011).
Existem redes sociais on-line (Web-based), redes sociais móveis e redes sociais híbridas. Uma rede social híbrida é desenvolvida pela primeira vez como sendo on-line, e migra ou se estende a plataformas móveis mais tarde (Tong, 2008). O que diferencia uma rede social on-line de uma rede social móvel são as facilidades tecnológicas dos novos dispositivos móveis combinadas com as características das redes sociais on-line.
Na tabela 1 podemos ver um resumo de algumas redes sociais móveis com sua respectiva tecnologia de localização, bem como as principais vantagens de desvantagens de cada uma. Não foi identificada nenhuma rede social móvel que utilize Web Service Dinâmico para localizar geograficamente seus usuários.
Tabela 1. Comparação entre algumas redes sociais móveis.
Rede Social Móvel
Tecnologia de Localização
Vantagens Desvantagens
Dodgeball Celular Simplicidade; O usuário é quem informa a localização;
Facebook Places GPS, WiFi, 3G e GPRS
Preocupação com a segurança Necessidade de check-in; Não personaliza distância de notificação
FourSquare GPS, WiFi, 3G e GPRS
Atrativa – funciona como um jogo. Necessidade de check-in; Não personaliza distância de notificação
Gowalla GPS, WiFi, 3G e GPRS
Executado em aparelhos mais modestos
Necessidade de check-in; Falta de Privacidade
MSNSs Wi-Fi, GPS, GPRS Independe de Tecnologia Módulo de localização no cliente;
MySocial Wi-Fi, GPS Integração com redes sociais on-line.
Necessidade de Plugins; Ambiguidade de perfis.
Orkut GPS, WiFi, 3G e GPRS (Google Latitude)
Suporte as várias tecnologia de localização
Solução Proprietária. Não personaliza distância de notificação
A ideia de implementar uma rede social móvel própria surgiu diante da inexistência de uma rede social
móvel sem fins comerciais e de código aberto para realizarmos as pesquisas da instituição. O que diferencia o SocialNetLab dos demais SNS móveis é que, além de integrar pessoas facilitando a localização de usuários e a notificação de proximidade de amigos, fará uso de Web Service Dinâmico possibilitando atender o maior número de tecnologia de localização, servirá também de laboratório para pesquisas em redes sociais fornecendo um ambiente propício ao ensino, a pesquisa e a extensão, sem esquecer a possibilidade de integração de outras ferramentas.
3. SOCIALNETLAB
O SocialNetLab é um SNS que permitirá que um usuário localize e seja notificado da proximidade de um amigo, independente da tecnologia de localização disponível no seu equipamento e de acordo com a configuração de distância estabelecida pelo usuário.
Para fazer a localização do dispositivo móvel utilizaremos inicialmente a API (Application Programming Interface) de Geolocalização que já vem incorporada ao HTML 5 (Meyer, 2011). Essa API é uma tecnologia de posicionamento híbrido, proposta pelo grupo de trabalho Ubiquitous Web Applications1 do consórcio W3C (World Wide Web). A ideia é que a obtenção das coordenadas (latitude e longitude) ocorra no momento em que o usuário acessar um determinado site, que no caso seria o site do SocialNetLab.
A API de Geolocalização atende apenas a quatro tipos de tecnologias de localização, assim percebemos a necessidade de implementarmos outra solução que possibilite atender ao maior número de tecnologias de localização disponíveis no mercado. Numa tentativa de garantir a independência da tecnologia de localização
1 http://www.w3.org/2007/uwa/
ISBN: 978-989-8533-11-1 © 2012 IADIS
152

no dispositivo móvel é que faremos uso do Web Service Dinâmico (Murray et al, 2006), de forma que o sistema irá buscar automaticamente o serviço adequado para a tecnologia de localização disponível no equipamento. Na figura 1 podemos ver a arquitetura do SNS SocialNetLab. Nessa arquitetura um cliente com acesso a Internet acessa a aplicação SocialNetLab e sua localização e a localização de um “amigo” cadastrado na aplicação será feita via API de Geolocalização ou via Web Service Dinâmico, dependendo da disponibilidade do serviço.
Figura 1. Arquitetura do SocialNetLab
4. RESULTADOS PRELIMINARES
A rede social SocialNetLab está sendo implementada e foi dividida em três cenários conforme figura 2.
Figura 2. Cenários de implementação do SocialNetLab
O cenário 01 foi desenvolvido para dispositivos móveis com sistema operacional Android (Lecheta, 2010) e utiliza Web Service dinâmico para fazer a localização. Para que a aplicação funcione é necessária a instalação e execução do aplicativo cliente no dispositivo móvel. Essa aplicação com Web Service dinâmico foi desenvolvida utilizando a linguagem de programação Java, o protocolo SOAP (Simple Object Access Protocol), a linguagem de marcação de texto XML (eXtensible Markup Language) (Murray et al, 2006) e o banco de dados utilizado foi o MySQL (Milani, 2006). No cenário 01 estão disponíveis apenas os serviços de localização para as tecnologias GPS, Wi-Fi e 3G. A disponibilização dos serviços de localização para outras tecnologias estão em fase de estudo e de pesquisa para obtermos a solução mais adequada.
O cenário 02 está na fase final da implementação e está sendo desenvolvido para que qualquer dispositivo (móvel ou desktop) com acesso a Internet possam executar o software. O grande objetivo é implementarmos o cenário 03 com sucesso, possibilitando que, além dos dispositivos móveis com Android, todos os demais equipamentos com acesso a Internet tenham acesso aos serviços de localização dinâmico. A integração do cenário 01 com o cenário 02 poderá ser feita através da conexão A, onde o acesso ao Web Service seria feito no acesso ao browser, ou através da conexão B, onde o acesso ao Web Service seria feito no servidor. Com o término das implementações de todos os cenários daremos inicio aos testes com análise dos resultados.
Na figura 3 podemos ver a tela de “Login” e a tela de “Amigos” do SocialNetLab para Android. Além dos testes e avaliações do cenário 01, do cenário 02 e do cenário 03, faremos também uma comparação dos resultados encontrados entre o cenário 01 e o cenário 02 para verificarmos qual das duas tecnologias sozinhas é mais eficiente. Ao término dos testes é esperado que a rede social SocialNetLab esteja disponível
Conferência IADIS Ibero-Americana WWW/Internet 2012
153

para todos os alunos do departamento de computação da instituição de ensino, independente do tipo de dispositivo móvel que eles utilizem.
Figura 3. Tela de “Login” e a tela de “Amigos” do SocialNetLab para Android
5. CONSIDERAÇÕES FINAIS
A rede social móvel SocialNetLab já está funcionando para dispositivos móveis que utilizam Android. Já para os outros tipos de dispositivos (móveis ou desktop) a aplicação está na fase final de desenvolvimento, de forma que o objetivo principal da implementação é a integração entre as soluções de localização via Web Service dinâmico e via API de Geolocalização tornado a aplicação sempre disponível para o usuário e podendo ser executada em qualquer dispositivo com acesso a Internet. Por fim iremos fazer os testes e as análises dos resultados encontrados.
Como trabalho futuro sugerimos a integração de todas as ferramentas que irão compor o ambiente educacional, bem como inclusão de novas funcionalidades que agreguem valor ao SNS. As questões de privacidade e segurança também serão tratadas com mais detalhes futuramente.
REFERÊNCIAS
Boyd, D. M. e Ellison, N. B. 2011. Social network sites: Definition, history, and scholarship. Disponível em: http://jcmc.indiana.edu/vol13/issue1/boyd.ellison.html.
Ferrari, B. 2010. Onde os brasileiros se encontram. Disponível em: http://revistaepoca.globo.com/Revista/Epoca/1,,EMI143701-15224,00.html
Fonseca, P. 2011. “Boom” nos dispositivos móveis, bolha nas redes sociais. Disponível em: http://www.computerworld.com.pt/2011/02/09/boom-nos-dispositivos-moveis-bolha-nas-redes-sociais/.
Lecheta, R. R. 2010. Aprenda a Criar Aplicações Para Google Android. Novatec. São Paulo-SP.
Meyer, J. 2011. O Guia Essencial do Html 5. Ciência Moderna. São Paulo-SP
Milani, A. 2006. Mysql - Guia Do Programador. Novatec. São Paulo-SP.
Murray, G; Singh, I.; Brydon, S. 2006. Projetando Web Services com a Plataforma J2ee 1.4 - Tecnologias Jax-rpc , Soap e Xml. Ciencia Moderna, São Paulo-SP.
Tong, C. 2008. Analysis of some popular mobile social network system. Helsinki University of Technology.
ISBN: 978-989-8533-11-1 © 2012 IADIS
154

ARQUITETURA PARA GERENCIAMENTO SEGURO DE CICLO DE VIDA DE DOCUMENTOS
Eduardo Henrique de Oliveira, Luís Felipe Féres Santos, Renato Lopes e Silva, Raphael Fogagnoli Tavares, Luis Fernando de Almeida
RESUMO Nos últimos anos há uma crescente preocupação com a segurança da informação, como por exemplo, documentos de processos, e, para algumas entidades, essas informações em mãos erradas podem causar problemas. Com o alto crescimento de transações das informações na rede, surge a necessidade de se utilizar métodos que garantam a segurança e a integridade dessas informações. Neste sentido, este artigo propõe uma abordagem para controle e gerenciamento de documentos baseada na aplicação de tecnologia Smart Card, biometria e criptografia. Com a aplicação dessas tecnologias, pretende-se disponibilizar um mecanismo de compartilhamento de documentos diverso, com garantia de sua privacidade e autenticidade.
PALAVRAS-CHAVE
Segurança da Informação, Criptografia, Biometria, Chave Pública, Chave Privada.
1. INTRODUÇÃO
Nos dias de hoje, um dos grandes problemas encontrados por empresas e organizações é a falta de segurança no que diz respeito às informações enviadas e à atualização dos documentos que contém as informações. A não atualização de um documento causada pela ausência de tempo ou de visibilidade do documento dentre outros motivos, pode ser considerada um fator que pode proporcionar prejuízo financeiro para uma empresa.
Além dos problemas citados, podemos considerar as possibilidades de uma possível interceptação do e-mail ou até mesmo o acesso ao e-mail do destinatário por uma pessoa não autorizada, evitando assim o recebimento do arquivo ou também a notificação da necessidade de atualização do documento ou relatório enviado. Como solução aos problemas citados propõe-se um sistema denominado Secure Document Management (SDM) capaz de efetuar o gerenciamento do ciclo de vida de documentos digitais, desde o controle no acesso aos documentos especificando qual usuário tem permissão para apenas visualizar (read-only) ou modificar o arquivo, dificultando assim qualquer tentativa de alteração do documento por pessoas não autorizadas ou até mesmo por pessoas que devem esperar o seu período para poder modificar, até a utilização do checksum (soma de verificação utilizada para verificar a integridade dos dados) para realizar o controle de alteração do documento e de versão. A arquitetura proposta combina as tecnologias: smart cards, biometria, função hash e criptografia assimétrica.
No restante, este artigo está organizado como segue: a seção 2 aborda os conceitos básicos sobre as tecnologias aplicadas; na seção 3 é apresentado o modelo proposto; a seção 4 demonstra alguns testes realizados; e a seção 5 expõe as considerações finais do modelo proposto.
Conferência IADIS Ibero-Americana WWW/Internet 2012
155

2. FUNDAMENTAÇÃO TEÓRICA
2.1 Smart Card
Segundo Nicklous et al (2002) um smart card pode ser definido como um dispositivo portátil capaz de executar pequenas aplicações e armazenar informações de forma segura, consistindo fisicamente de um pequeno chip, com a mesma aparência de um cartão de crédito comum. Existem três tipos de cartões: com contato, sem contato e híbrido. Neste trabalho foi utilizado um smart card com contato, devido, principalmente, seu baixo custo. Dois importantes conceitos referentes a um smart card são: Answer to Reset (ATR) e Application Protocol Data Unit (APDU).
As operações de um smart card se iniciam com o envio de um sinal reset para o cartão que responde com uma cadeia de bytes chamada ATR, que tem até 33 bytes, os quais identificam alguns dados, tais como, o protocolo de transmissão, velocidade de transmissão, entre outros. Além disso, o ATR contém uma cadeia de bytes denominada history bytes que identifica o modelo do cartão e algumas outras características. Um APDU é uma mensagem que representa um comando ou uma resposta do cartão. A partir dele que é feita a comunicação com o cartão, envio e recebimento de dados e qualquer outro tipo de transação que se deseje realizar (Chen, 2000). Cada APDU é dividido em 2 partes: um cabeçalho obrigatório de 4 bytes, contendo os bytes CLA (Classe da instrução), INS (Instrução), P1 (Parâmetro 1) e P2 (Parâmetro 2), e um corpo opcional, que pode conter os bytes LC (quantidade de bytes opcionais que serão enviados), Data Field (dados opcionais) e LE (quantidade de bytes esperado como resposta).
Um APDU de resposta, também é dividido em 2 partes, tendo um campo de dados opcional, de tamanho menor ou igual a LE, e dois bytes, SW1 e SW2 que indicam o status do comando. Os valores mais comuns para os bytes de status estão indicados na norma ISO 7816-4. Na maior parte das vezes um retorno “9000” (SW1 = 90, SW2 = 00) que indica sucesso na execução do comando.
Segundo Tatara (2003), os smart cards podem ser classificados por sua forma de transmissão de dados, e são três tipos de cartões: com contato, precisa estar fisicamente em contato com um terminal de leitura; sem contato, o cartão não precisa estar fisicamente em contato com o terminal de leitura, a transmissão é feita via sinais de rádio; hbrido, são considerados híbridos todos os smart cards que possuem a tecnologia de transmissão de dados com e sem contato.
2.2 Biometria
Um método muito utilizado para identificação é por meio de senhas. Por exemplo, acessando e-mail, conta bancária e algumas outras aplicações, mais de uma senha pode ser requerida. Por outro lado, também podem ser utilizados smart cards, que permitem o acesso através de uma simples leitura. O problema desses métodos é que qualquer pessoa pode obter a senha ou o cartão. Desse modo, não há como garantir a total segurança dessas informações. Uma alternativa para este inconveniente é o uso de biometria. Diversas pesquisas demonstram que o uso de características biológicas tem se mostrado como uma idéia viável, já que cada pessoa possui características diferentes (Verna, Liu and Jia, 2012, Sluzek and Paradowski, 2012, Le, Cheung and Nguyen, 2001).
Com o uso da biometria, os riscos são menores, pois se consegue a autenticidade de uma pessoa, tendo em vista que, por exemplo, ninguém terá uma impressão equivalente a sua. Como características biométricas, podem ser citadas a íris, a retina, a impressão digital, a voz, o formato de rosto, a geometria da mão, entre outras características que poderão ser usadas no futuro, tais como o DNA e odores do corpo. Em 2006, o National Center for State Courts apresentou um modelo de comparação de sistemas biométricos, onde são analisadas diversas características dos diferentes tipos de sistemas biométricos com base no modelo proposto. A impressão digital apresentou como aspectos positivos sua precisão, capacidade de identificação e de verificação e como limitante o fator fontes de erros devido a sujeira e idade (Jain, Hong and Pankanti, 2000).
O sistema biométrico mais comum é a impressão digital devido à facilidade de acesso e o menor custo. Basicamente, consiste em capturar a formação de sulcos na pele dos dedos e das palmas das mãos de uma pessoa.
ISBN: 978-989-8533-11-1 © 2012 IADIS
156

2.3 Criptografia
De acordo com Simon (1999), criptografia é o conjunto de métodos e técnicas para cifrar ou codificar informações legíveis por meio de um algoritmo, convertendo assim um texto original em ilegível, sendo possível mediante o processo inverso recuperar as informações originais. Com os avanços da tecnologia e dos estudos na área de criptografia, ela foi dividida em criptografia de chave simétrica e criptografia de chave pública ou criptografia assimétrica.
Criptografia de chave simétrica ou de chave secreta, basicamente, consiste em um algoritmo que utiliza apenas uma chave para cifrar e decifrar a informação. Esta chave é compartilhada entre ambos interlocutores. Dentre os principais algoritmos de chave simétrica podem ser citados: AES, DES, 3DES, IDEA, Blowfish, Twofish, RC2, CAST. O AES foi adotado neste trabalho pois ele é algoritmo de criptografia simétrico mais popular nos dias de hoje desde que ele venceu o concurso do NIST (National Institute of Standards and Technology).
O método de criptografia de chave assimétrica ou chave pública utiliza um par de chaves, pública e privada, para realizar as devidas funções. A chave pública é distribuída para todos e a chave privada fica apenas com o dono da chave. O funcionamento dos algoritmos de chaves assimétricas consiste em utilizar a chave pública para cifrar a mensagem e a chave privada para decifrar. Para este tipo de método duas características são consideradas para as chaves: confidencialidade e autenticidade. Dentre os principais algoritmos de chave simétrica podem ser citados: RSA, ElGamal, Diffie-Hellman, Curvas Elípticas.
Optamos por utilizar o RSA primeiramente por ser adotado pela ICP-Brasil que é a cadeia hierárquica brasileira de confiança que viabiliza emissão de certificados digitais, também devido à facilidade na implementação e por último devido à quantidade de informações que podem ser encontradas sobre o algoritmo na literatura e nos meios digitais.
Hash é também conhecido como criptografia de caminho único, pois diferente das cifras que transformam dados de texto claro em criptograma e depois retorna em texto claro, o hash transforma um texto claro em uma espécie de assinatura representando o fluxo de dados. O hash também pode ser comparado a um selo de segurança, informando qualquer alteração efetuada no arquivo, por menor que seja. Dentre as principais funções hash, podem ser citadas: SHA-1, SHA-2, MD5, MD2, MD4.
2.4 JavaCards
JavaCards nada mais são do que smart cards capazes de executar pequenos aplicativos desenvolvidos na linguagem de programação Java. Porém, os JavaCards possuem 3 características que o diferenciam: Java Card Virtual Machine que é um subconjunto da linguagem de programação Java, porém com algumas alterações da utilizada em outros aparelhos, como por exemplo, computadores, para que possa se adequar ao tipo de aplicação aceita por um smart card; JavaCard Runtime Environment que descreve a especificação Java Card comportamento ambiente de execução. Também inclui o gerenciamento de memória, gerenciamento de aplicação, segurança e outras características de execução; JavaCard Application Programming Interface (API), que descreve o conjunto de núcleo e pacotes de extensão JavaCard e classes para programação de aplicações de cartões inteligentes. Para este trabalho foi utilizado o JavaCard por ser um cartão com uma quantidade de memória maior e por executar programas escritos em Applets Java.
3. SECURE DOCUMENT MANAGEMENT
O protótipo proposto por este trabalho é responsável por gerenciar o ciclo de vida de um documento, validar quando houver alteração no mesmo e efetuar um controle de acesso ao documento especificando quem tem permissão para alterá-lo ou somente ler e quando essa permissão é executada e ocultar as informações contidas no documento através do algoritmo de criptografia simétrica AES, além de validar a autoria de um documento utilizando o algoritmo RSA de criptografia assimétrica. O modelo de controle proposto, denominado Secure Document Management (SDM) consiste em um protótipo para controle do ciclo de vida de um documento, o qual sua elaboração consiste na participação de diversos usuários, devidamente autorizados.
Conferência IADIS Ibero-Americana WWW/Internet 2012
157

Para desenvolvimento do protótipo foi adotado o padrão de projeto Observer, conforme os conceitos propostos por Freeman, Freeman (2005), pois possibilita que a modelagem orientada a objeto seja realizada de modo a criar ligações simples entre os objetos, não comprometendo o conceito de encapsulamento e também dando maior autonomia aos mesmos. Inicialmente, utilizando um smart card devidamente inserido em uma leitora de cartões, um usuário solicita acesso ao sistema por meio de sua senha pessoal. Após validação da senha, o próximo passo consiste na autenticação do usuário por meio de sua biometria, no caso impressão digital, a ser comparada com um template contido no cartão. Este processo é descrito na Figura 1.
Figura 1. Demonstração do processo de autenticação.
Como especificado pela NBSP (2005) um sistema biométrico básico necessita que o usuário esteja previamente cadastrado em um banco de dados. No protótipo desenvolvido para se cadastrar no sistema, é necessário que o usuário cadastre as seguintes informações: nome, sobrenome, RG, CPF, endereço, bairro, cidade, UF, telefone, um login e uma senha para acesso.
No final do processo o usuário insere o seu JavaCard em uma leitora de cartão e informa a biometria em um leitor biométrico, utilizando qualquer dedo. O protótipo coleta a informação da biometria e armazena no smart card. Para armazenar a impressão digital no smart card é gerado um perfil da impressão digital do usuário, este tem tamanho bastante variado, pode ser pequeno com 300 bytes, por exemplo, ou pode passar de 1000 bytes. Para a comparação entre as impressões digital não é problema, porém, quando enviamos os dados da impressão digital para o JavaCard não é possível gravá-la por inteiro em um só espaço na memória, pois os comandos APDU’s, que são enviados para o cartão, têm um limite máximo de tamanho, 128 bytes. Então, a biometria é dividida em até 10 partes e enviada uma a uma para o cartão, e cada uma dessas partes são guardadas em diferentes vetores, pois outra limitação do smart card é não aceitar matrizes, sendo assim, é necessária a criação de um vetor para cada parte do perfil da biometria que é armazenada no cartão, em bytes. Ao adicionar um usuário novo no sistema, é criada a estrutura de diretório pessoal do mesmo, que será utilizada para armazenamento e o compartilhamento de documentos.
O processo de inserção de documentos (Figura 2) permite ao autor inserir seus documentos no sistema junto a uma chave secreta que irá criptografar o documento e mantê-lo armazenado de forma segura. No mesmo momento da inserção, também é criado um arquivo denominado Document Manager, que é um objeto único para o documento em questão que possui as seguintes informações: identificador do autor, versão do documento, caminho onde será armazenado, nome original, checksum.
Figura 2. Processo de inserção de documento.
ISBN: 978-989-8533-11-1 © 2012 IADIS
158

Figura 3. Procedimento de Assinatura Digital.
Figura 4. Processo de Compartilhamento de Documentos.
3.1 Interface Gráfica e Testes
Para demonstrar os testes e resultados obtidos serão exibidas, a seguir, imagens do protótipo desenvolvido obtendo sucesso e falha na autenticação biométrica, após a inserção do smart card e senha, e também para validar quando o arquivo sofreu alteração ou não, utilizando o algoritmo de hash. Cada usuário é autenticado na aplicação por meio de um sistema que envolve verificação por senha e biométrica, e a partir deste momento, o seu diretório pessoal é lido automaticamente e suas configurações pessoais são carregadas.
Depois de autenticado, o usuário tem disponíveis os menus que dão acesso às diferentes funções da aplicação (Figuras 5 e 6). Obrigatoriamente na primeira vez que é efetuada login no sistema, deve-se utilizar o menu de Criptografia para importar a chave pública contida dentro do smart card para um arquivo. Isso permite que o usuário a distribua a chave com outros usuários com os quais ele deseja compartilhar documentos. Não é necessário realizar esta operação novamente, pois a chave pública importada do smart card é o par da chave privada que fica armazenada dentro do cartão que não pode ser retirada por razões de segurança. O algoritmo utilizado para geração do par de chaves assimétricas foi o RSA. Também é obrigatória a geração de pelo menos uma chave AES, que será utilizada para criptografar os documentos. Esta operação pode ser realizada várias vezes de acordo com as necessidades e níveis de segurança que cada usuário desejar.
Figura 5. Menu Criptografia.
Conferência IADIS Ibero-Americana WWW/Internet 2012
159

Figura 6. Menu Documento.
As informações relacionadas ao Document Manager podem ser acessadas pelos seus usuários através da interface da aplicação, dando-se por meio do carregamento do Document Manager, ou até manualmente via qualquer software de visualização e ou edição de textos, mas as informações contidas nele não comprometem a segurança dos documentos, pois os mesmos estão protegidos pela criptografia simétrica. Se alguma informação for alterada manualmente no Document Manager, a verificação de assinatura vai falhar apontando erro autenticação.
4. CONCLUSÃO
O modelo apresentado neste trabalho propõe uma garantia de que os documentos estão sendo acessados de forma segura e pelas entidades corretas, garantindo, também, assim um maior nível de segurança em relação às informações da entidade que o está utilizando. Uma das características que pode se citar como inovação é seu funcionamento online que permite acesso aos documentos de qualquer lugar que possua conexão com a grande rede. Uma aplicação interessante para este modelo seria o controle do ciclo de vida de processos em cartórios, proporcionando que somente pessoas autorizadas possam acessar determinado processo e, adicionalmente, que se certifique que alguém receba um determinado arquivo.
REFERÊNCIAS
NIST 2001. Advanced Encryption Standard (AES), Federal Information Processing Standards Publication #197. U.S. Department of Commerce, National Institute of Standards and Technology.
Chen, Z., 2000. Java Card techonology for smart cards- architecture and programmer’s guide. Palo Alto: Addison-Wesley.
Cheung, M., Nguyen, S. 2001. Parent-child relationships in Vietnamese American families. In N. Webb (Ed.), Culturally diverse parent-child and family relationships, New York: Columbia University Press, pp. 261-282.
Freeman, E., Freeman, E., Bates, B., Sierra, K., Robsonm E., 2004. Head First Design Patterns. O'Reilly Media, 2004.
Jain, A., Hong, L., Pankanti, S. 2000. Biometric identification. Communications of the ACM , v. 43 , n. 2, pp. 90-98.
Le, T.V.; Cheung, K. Y.; Nguyen, M. H., 2001. A Fingerprint RecognizerUsing Fuzzy Evolutionary Programming. Proceedings of the 34th Hawaii International Conference on System Sciences.
Nicklous, M. S. et al., 2002. Smart Card: application development using Java. Berlim: Springer-Verlag.
NBSP. 2005. Biometric Technology Application Manual. National Biometric Security Project, v. 1, Biometrics Basics.
Simon, S. 1999. The Code Book. Anchor Books, EUA, 1999
Sluzek, A.; Paradowski, M., 2012. Visual similarity issues in face recognition. International Journal of Biometrics, v. 4, n. 1, pp. 22-37.
Vaudenay, S., 2006. A Classical Introduction to Cryptography - Applications for Communications Security. Springer Science+Business Media, Inc.
Verna A., Liu, C., Jia, J., 2012. Iris recognition based on robust iris segmentation and image enhancement. International Journal of Biometrics, v. 4, n. 1, pp. 56-76.
Tatara C. F. S2 CARD. Disponível em: <http://projetos.inf.ufsc.br/>. Acessado em: 18 de Out. 2010.
ISBN: 978-989-8533-11-1 © 2012 IADIS
160

MODELAGEM DE INTERAÇÃO NA WEB USANDO MDD COM PRINCÍPIOS DE USABILIDADE E ACESSIBILIDADE
Thiago Jabur Bittar1, 2, Veríssimo Guimarães Júnior2, José Aparecido Sorratini3 e Mehran Misaghi4
1Universidade de São Paulo – USP - ICMC 2Universidade Federal de Goiás – UFG - DCC 3Universidade Federal de Uberlândia – UFU
4SOCIESC
RESUMO
Neste artigo, é descrita a modelagem de interação na web usando o Desenvolvimento Orientado a Modelos, do inglês Modelo Driven Development (MDD), com a adoção de princípios de usabilidade e acessibilidade. O desenvolvimento de interfaces eficientes tem um custo elevado e, atualmente, requer o uso de diretrizes e padrões apropriados. Assim, é apresentada uma abordagem para o mapeamento das interações de uma forma prática e usável.
PALAVRAS-CHAVE
Interação, modelagem, desenvolvimento orientado a modelos, web, usabilidade, acessibilidade.
1. INTRODUÇÃO
O desenvolvimento de aplicações Web de qualidade envolve inicialmente a análise e o planejamento de requisitos com detalhamento das funcionalidades a serem atendidas. No entanto o resultado final não depende apenas do atendimento funcional desses requisitos, mas, sobretudo, da boa utilização e satisfação por parte do usuário que deve ter uma interação com os sistemas de forma produtiva (Bull, 2006). Tentar garantir uma boa interação deve permear todo o processo de desenvolvimento e demanda estudos específicos.
Assim, é essencial o planejamento da interação com o usuário, que se define pela modelagem prévia de tarefas, ações e feedback, compondo o projeto dos elementos de interface e ações de controle. Em síntese, é pensar e definir como o usuário irá “sentir” e “viver” o ambiente computacional, abstraindo as funções de processamento envolvidas e aproximando o sistema de seu modelo conceitual. Nesse contexto, pensando no usuário como beneficiário da tecnologia produzida, não se pode esquecer a preocupação com os diferentes perfis de usuários envolvidos, cuja especificação e modelagem também devem ser consideradas (Fischer, 2001). Em relação a isso, existem distinções cognitivas e deficiências físicas que devem ser respeitadas, tal preocupação é vista no campo da acessibilidade aos recursos oferecidos (W3C, 2008).
Com essa preocupação quanto à interação e os diversos perfis de usuário, o design e modelagem de interfaces podem ficar caros e demandar testes e correções durante todo o processo (Fischer, 2001). Para apoiar o bom design e compartilhar experiências de sucesso vê-se atualmente que muitos padrões e guidelines são desenvolvidos, mas que frequentemente não são seguidos pelo custo e tempo requeridos.
Dessa forma, este trabalho tem como objetivo propor as questões que devem compor uma metodologia que considere o planejamento de interação com verificação de requisitos de acessibilidade e usabilidade para os diversos perfis de usuários. Para tanto, propõe-se o uso de técnicas como o desenvolvimento orientado a modelos na tentativa de se englobar em camadas mais abstratas, sob a forma de meta-modelos, os princípios de interação. O desenvolvimento orientado a modelos, do inglês Model Driven Development (MDD), focaliza na construção de modelos, especificação de regras de transformação, apoio de ferramentas e geração automática de código e documentação (Cicchetti, Di Ruscio e Di Salle, 2007; Kleppe, Warmer e Bast, 2003). A Engenharia Web é um domínio concreto em que MDD pode ser útil, particularmente focalizando problemas de evolução e adaptação de software para emergir continuamente em novas plataformas e mudanças em tecnologias (Koch, 2006). A viabilidade dessa utilização é discutida neste artigo, inclusive com a adição da preocupação na modelagem da interação do usuário.
Conferência IADIS Ibero-Americana WWW/Internet 2012
161

Este artigo está organizado como segue. Na Seção 2 apresenta-se uma conceituação básica e visão geral sobre as questões envolvidas, especialmente em relação à interação do usuário. Na Seção 3 tem-se a abordagem proposta neste artigo e na 4 são vistos os principais resultados obtidos. Por fim, na Seção 5, considerações finais e trabalhos futuros são apresentados.
2. CONCEITUAÇÃO BÁSICA
A interface de usuário, chamada comumente de User Interface (UI), é formada por componentes de hardware e software que implementam um modelo de interação, ou seja, um conjunto de elementos e regras que permite ao usuário interagir com o sistema (Bull, 2006). As diversas maneiras que um usuário pode interagir com um sistema, conforme determinado pelo design da interface, caracterizam tal modelo de interação.
O modelo de interação deve compreender um conjunto de ações que o usuário pode realizar na interface. Interações simples e complexas devem ser descritas conjuntamente com a maneira como elas podem ser combinadas em estruturas que permitam o usuário interagir com o sistema. No entanto, pelas experiências de vida e conhecimentos de cada usuário tem-se uma visão da UI e do que pode ser feito em termos de regras de negócio pelo mapeamento do mundo real e domínio de aplicação aos controles de interface. Isso é sinteticamente o que se conhece por Modelo Conceitual (MC).
Verifica-se que antes de construir uma interface tem-se que haver preocupações com os requisitos funcionais e perfis de usuários que tem MCs, experiências e habilidades diferentes. Vê-se também que as técnicas de desenvolvimento de software estão evoluindo visando a boa interação para uma gama ampla de usuários de um domínio e para resolver os problemas principais que ainda afetam a construção e manutenção de sistemas: tempo, custos e menor propensão a erros (Koch, 2006).
No entanto, não existe um modelo de interação único para todas as interfaces. Cada interface implementa o modelo que foi projetado pelo seu designer. Um determinado estilo pode utilizar diferentes técnicas de interação e os sistemas devem permitir customização para que os usuários os utilizem da maneira em que acharem mais produtivo ou que hajam adaptações de interface.
2.1 Modelagem de Interação
Um importante tópico para ser analisado pela comunidade de Engenharia de Software (ES) é a modelagem de interação. Tal comunidade desenvolveu alguns métodos bem conhecidos para representar a estrutura de sistemas e suas funcionalidades de uma maneira abstrata, como o Diagrama de Classes ou de Sequência. Entretanto a comunidade de ES não desenvolveu um método amplamente aceito para representar a interação entre o usuário e o sistema.
Alguns métodos proveem um Modelo de Interação que somente representa interfaces para uma plataforma concreta como a Web. Como consequência, o processo de migração para outra plataforma (por exemplo em dispositivos móveis) é uma tarefa difícil. Alguns autores tem proposto linguagens de interface de usuário como USIXML (Vanderdonckt et al., 2004) ou modelos como UMLi (Silva e Paton, 2003).
Além do posicionamento de itens de interação deve haver a preocupação no mapeamento desses na interface visando o atendimento de atributos de usabilidade relacionados à facilidade de compreensão e aprendizado dos sistemas. Como métodos clássicos para modelagem de interação pode-se citar o TAG (task-action grammars) (Payne e Green, 1987) e o UAN (user action notation) (Hartson, Siochi e Hix, 1990).
No TAG o objetivo é integrar a tarefa mental de estabelecer objetivos e elaborar planos em forma de tarefas, isso já percebendo como será a execução física necessária em nível de interação. Já o UAN é um método que visa representar comportamentos assíncronos no processo de design de interfaces.
Já a modelagem de usuário é uma das áreas de pesquisa que intuitivamente parece merecer uma atenção especial e investimentos pelo seu potencial e retorno pela satisfação do usuário (Fischer, 2001).
Modelos de usuário são definidos como modelos que os sistemas têm dos usuários que atuam em um ambiente computacional. Eles são diferenciados por modelos mentais que os usuários possuem e de tarefas que residem dentro das mentes dos mesmos.
Tais modelos representam um mundo que está fora do ambiente computacional, envolvendo a cognição das pessoas. O mapeamento de informação externa para o modelo interno deve levar em conta quem são os potenciais usuários no domínio, suas expectativas e objetivos. Uma modelagem incorreta pode levar a
ISBN: 978-989-8533-11-1 © 2012 IADIS
162

produção de um sistema funcionalmente correto, mas para o usuário errado. Alguns questionamentos podem ser feitos nesse sentido para enfatizar a importância dessa modelagem e suas modificações.
Estudos em requisitos de usuário compartilham com a área de Interação Humano-Computador (IHC) questões, conceitos e princípios fundamentais. Ambos necessitam compreender o entendimento das pessoas e seu mundo e como representam esse entendimento.
2.2 Model Driven Development (MDD)
No desenvolvimento orientado a modelos, conhecido como Model Driven Development (MDD), os diagramas conceituais não são somente a referência que os desenvolvedores usam para produzir o código executável; os modelos se tornam artefatos “vivos”, servindo como entrada para ferramentas de geração de código.
Há histórias de sucesso de aplicação do MDD, como discutido por Fowler (2007), em que os benefícios prometidos são alcançados, mas ainda existem inúmeros desafios na área.
As metas primárias do MDD são a portabilidade, interoperabilidade e reuso pela separação arquitetural de preocupações. O MDD especifica modelos e o relacionamento entre esses durante as fases do ciclo de vida de um sistema, sendo que há a fundamentação principal em três padrões criados pelo OMG: UML (Unified Modeling Language), MOF (Meta Object Facility) e CWM (Common Warehouse Metamodel).
Para a especificação de linguagens utiliza-se o MOF, sendo que em sua terminologia alguns elementos são bastante comuns: i) Meta-dados: dados que descrevem dados; ii) Modelo: especificação ou descrição de um sistema e de seu ambiente com um determinado propósito. Um modelo é frequentemente apresentado com uma combinação de desenhos e texto; iii) Meta-modelo: definição precisa das construções e de regras necessárias para criação de modelos semânticos; e iv) Meta-meta-modelo: modelo que define a linguagem para expressar um modelo.
A modelagem tanto de interação como do usuário exerce um papel importante para se projetar e viabilizar a integração das diversas tecnologias existentes, por meio de uma modelagem independente de plataforma.
Ferramentas de MDD, como o Eclipse Modeling Framework (EMF), podem gerar protótipos funcionais de aplicações Web a partir de modelos (Budinsky et al., 2003). No entanto esses protótipos funcionais ainda são rudimentares e necessitam que sejam estendidos ou personalizados.
A questão é como se produzir interfaces Web de uma maneira automatizada calcada em modelos, o que se percebe atualmente é que os sistemas são mais efetivos quando as interfaces visuais são feitas manualmente por especialistas sob encomenda ou customizadas para usuários específicos e suas tarefas e em inúmeros refinamentos e testes. Esse processo manual é, no entanto, dependente da habilidade da equipe.
Este artigo almeja, então, indicar uma ajuda na integração do design centrado em interfaces visuais e interação para Web com o processo de MDD. Historicamente foram desenvolvidos métodos para modelar tais sistemas, como OOHDM (Schwabe e Rossi, 1998), WebML (Ceri, Fraternali e Matera, 2002) e W2000 (Baresi e Mainetti, 2005). Eles focalizam na especificação de análise e modelos de design para sistemas Web, como a construção de modelos de navegação e de adaptação.
3. ABORDAGEM MDD PARA DESENVOLVIMENTO DE INTERFACES
O design da interface do usuário ainda consome um tempo intensivo. Baseado no trabalho prévio e resultados de projetos vê-se interessante a ideia de uma abordagem orientada a modelos para gerar interfaces do usuário com propriedades de acessibilidade e usabilidade. Usando um modelo de design de interação para capturar as interações e gerar a interface do usuário, propõe-se um design de interface do usuário mais eficiente.
As regras de transformação que a partir de um modelo de discurso geram uma interface do usuário concreta têm que ser identificadas. A motivação é que atualmente muitas das interfaces são feitas: i) em nível de código pelos próprios programadores das funcionalidades ou ii) com um equipe de design separada que só faz as interfaces, mas que muita das vezes não tem total conhecimento das estruturas. Na verdade o desenvolvimento deve compreender a união de áreas: algoritmos produtivos com interfaces usáveis.
Toda plataforma precisa de uma interface do usuário dispositivo-específica. Como consequência, novas abordagens de UI tentam maximizar o reuso e qualidade de código gerando a interface do usuário automaticamente para dispositivos diferentes (por exemplo: tablets, PC e telefone móvel). O uso de uma
Conferência IADIS Ibero-Americana WWW/Internet 2012
163

Plataforma Independente de Modelos (PIM) é um elemento fundamental de MDD que permite o modelar de interações sem ter um dispositivo concreto em mente. Quando ocorre sua implementação para uma plataforma específica tem-se a PSM, Platform Specific Model.
A força motriz para atividades de pesquisa na área de geração de interfaces do usuário é a habilidade para desenvolver UIs mais rapidamente e com custo reduzido. Por permitir que especialistas possam modelar as interações e gerar as interfaces, os custos de desenvolvimento podem ser reduzidos. A geração de código pode evitar erros de codificação e, resultar em qualidade de software melhorada.
Outra motivação é de ser mais fácil de modelar interfaces para não especialistas: a habilidade para gerar interfaces do usuário para dispositivos diferentes de um modelo deveria permitir um design mais intuitivo e menos técnico de interfaces do usuário. O designer deve poder focalizar na interação entre o humano e a máquina sem ter implementação da UI detalhada em mente.
4. RESULTADOS
Como resultados inicialmente têm-se melhorias gerais pela divisão de níveis de planejamento de interação com componentes e suas ações definidas, tanto em nível mais abstrato no PIM quanto nos níveis de implementação de acordo com os dispositivos. Assim fica mais coesa a concepção de interação com o resultado mapeado por componentes que já incorporarão princípios de usabilidade e acessibilidade.
Na Figura 1 é mostrada a arquitetura desenvolvida como resultado da pesquisa.
Figura 1. Arquitetura para elementos de interação usando MDD
Figura 2. Exemplo de componentes de interação no PIM e no PSM
É possível notar que os elementos x e y permanecem da PIM para a PSM, só que agora são chamados x’ e y’ com especificidades e detalhamentos próprios da plataforma desejada. Algumas interações básicas independente do dispositivo são também elencadas: seleção, marcação, bem como entrada e saída de dados. Tais interações podem compor o PIM para a modelagem inicial e depois haveriam transformações para o dispositivo desejado. Isso flexibiliza o desenvolvimento das concepções de interações que podem ser aproveitados para inúmeros dispositivos. Na Figura 2 há um exemplo dessa flexibilização com detalhamento maior da arquitetura em que uma caixa de seleção ao se portar para o PSM fica de diferentes formas.
No caso de uma caixa de seleção no navegador Web vê-se que seu tamanho é reduzido e ela é marcada por um clique ou teclado, já em um dispositivo móvel com interação via touch screen sua aparência tem que ser maior para ser pressionado pelo toque via dedo do usuário.
Recomendações oficiais de acessibilidade como as do WCAG 2.0 (W3C, 2008) podem ser incorporadas nos componentes. Um exemplo são os cuidados com imagens para Web em que no modelo é altamente recomendado ou obrigatório o preenchimento de texto alternativo, pelo atributo “alt” na tag “<img>”.
Note que princípios de usabilidade e acessibilidade podem incorporar tanto o PIM como o PSM, mas em níveis de detalhamento diferentes. No PIM os princípios devem ser mais abstratos e genéricos, como por exemplo: em uma caixa de seleção o usuário deve poder selecionar e obter um feedback claro se está ou não marcado o controle e isso deve ser possível para uma gama ampla de usuários. Já no PSM os princípios são bem específicos da plataforma e devem seguir detalhes de boa implementação como guidelines e padrões.
Todo esse apoio de integração favorece a composição semântica dos elementos de interação, que é importante para se ter descrições completas desses de forma organizada obedecendo regras de um modelo.
ISBN: 978-989-8533-11-1 © 2012 IADIS
164

5. CONCLUSÕES
Neste artigo foram apresentadas questões com o foco no Design de Interfaces com métodos de projeto que gerem especificações de interface cuja implementação seja fiel ao projeto e proporcione ao usuário uma experiência agradável e produtiva.
Em relação à modelagem de interação para Web, foi proposta a utilização de MDD para se definir modelos e padrões de planejamento de interação, aumentando a produtividade do desenvolvimento com a utilização de componentes em um ambiente que favoreça tanto a modelagem como a geração de código.
No entanto, ainda existem muitos desafios para a utilização plena de MDD, por exemplo pela dificuldade em se desenvolver um meta-modelo que contemple a geração de código com um bom custo-benefício.
Outro ponto que deve ser considerado é que MDD também provê maior independência de plataforma. Considerando que todos os códigos sejam gerados, é possível gerar código para diferentes plataformas apenas modificando o transformador. Por meio da representação visual modelada, pode-se avaliar a arquitetura das interfaces mais facilmente e em diferentes aspectos, com uma maior validação.
Assim, as principais contribuições deste trabalho são: i) o estudo e o levantamento das principais propostas para planejamento de interação para sistemas Web e ii) identificação das informações de modelagem de tarefas e seus contextos que são pertinentes para o projeto de interação.
REFERÊNCIAS
Baresi, L. and Mainetti, L. Beyond Modeling Notations: Consistency and Adaptability of W2000 Models. In Proceedings of SAC'05, ACM Symposium on Applied Computing, Santa Fe, USA, 2005.
Bull, R. I. 2006. Integrating dynamic views using model driven development. In Proceedings of the 2006 Conference of the Center For Advanced Studies on Collaborative Research (Toronto, Ontario, Canada, October 16 - 19, 2006). CASCON '06. ACM, New York, NY, 17.
Ceri, S., Fraternali, P. and Matera, M. Conceptual Modeling of Data-Intensive Web Applications, IEEE Internet Computing 6(4), Julho/Agosto 2002.
Cicchetti, A., Di Ruscio, D., and Di Salle, A. Software customization in model driven development of Web applications. In Proceedings of the 2007 ACM Symposium on Applied Computing (Seoul, Korea, March 11 - 15, 2007). SAC '07. ACM, New York, NY, 1025-1030.
Fischer, G. 2001. User Modeling in Human–Computer Interaction. User Modeling and User-Adapted Interaction 11, 1-2 Março de 2001, 65-86.
Budinsky F., Steinberg D., Merks E., Ellersick E.,e Grose T. Eclipse Modeling Framework. Addison Wesley, 2003. Hartson, H. R., Siochi, A. C., e Hix, D. 1990. The UAN: a user-oriented representation for direct manipulation interface
designs. ACM Trans. Inf. Syst. 8, 3 (Jul. 1990), 181-203. Kleppe, A; Warmer, J. e Bast, W. MDA Explained - The Model Driven Architecture: Pratice and Promise. Addison-
Wesley, 2003 (Object Technology Series). Koch, N. Transformation techniques in the model-driven development process of UWE. In Workshop Proceedings of the
Sixth international Conference on Web Engineering (Palo Alto, Julho, 2006). ICWE '06, vol. 155. ACM, NY, 3. Object Management Group (OMG). Meta Object Facility (MOF) 2.0 Query/View/Transformation Specification Final
Adopted Specification, ptc/05-11-01. http://www.omg.org/docs/ptc/05-11-01.pdf, November 2005. Payne, S. J. e Green, T. R. 1987. Task-Action Grammars: A Model of the Mental Representation of Task Languages.
SIGCHI Bull. 19, 1 (Julho de 1987), 73. Schwabe D. e Rossi G. Developing Hypermedia Applications using OOHDM. Workshop on Hypermedia Development
Process, Methods and Models, Hypertext´98, Pittsburg, USA, 1998. Silva, P.P.D. e Paton N.W., User Interface Modeling in UMLi. IEEE Software, 2003. 20(4): p. 62-69. Vanderdonckt, J., Limbourg Q., et al. (2004). USIXML: a User Interface Description Language for Specifying
Multimodal User Interfaces. Proceedings of W3C Workshop on Multimodal Interaction WMI'2004, Sophia, Greece. W3C. Web content accessibility guidelines 2.0. W3C Recommendation, Dezembro de 2008.
Conferência IADIS Ibero-Americana WWW/Internet 2012
165

UM AMBIENTE DE ANÁLISE PARA COMPARAR RESULTADOS DE AVALIAÇÕES DE ACESSIBILIDADE E
USABILIDADE NA WEB
Leandro Agostini do Amaral1, Thiago Jabur Bittar2 e Renata Pontin de Mattos Fortes1
1Instituto de Ciências Matemáticas e de Computação, USP, São Carlos-SP, Brazil 2UFG - Catalão - GO, Brazil , USP – ICMC, São Carlos-SP, Brazil
RESUMO
A acessibilidade, tão como a usabilidade, tem grande importância no ambiente Web para absorção e criação de conteúdo. No sentido de investigar a relação entre esses dois conceitos, este artigo visa propor um planejamento objetivo para contrapor análises em ambas direções. Como resultados, são apresentadas as principais ferramentas de avaliação e a proposta de um ambiente de análise de relatórios das avaliações.
PALAVRAS CHAVES
Acessibilidade, Usabilidade, Heurísticas, Avaliação.
1. INTRODUÇÃO
O desafio da área de Acessibilidade Web é garantir que os projetos de aplicações permitam que qualquer usuário possa perceber, entender e interagir com as aplicações, bem como criar e contribuir com conteúdo. Sua importância é notória, pois visa proporcionar oportunidades iguais a todos, tendo em vista o crescente valor do conteúdo disponibilizado no ambiente online para educação, negócios, governo, comércio e lazer. Já o desafio da área de usabilidade consiste em garantir que o usuário realize com facilidade as funcionalidades disponibilizadas pela aplicação Web e, assim, muitos desenvolvedores e pesquisadores consideram que se confrontada com acessibilidade, pode se configurar um conflito de forças, pois ambas as áreas devem ser atendidas, e ao priorizar uma, a outra pode ser comprometida (LANGDON; PERSAD; CLARCKSON, 2010). Para identificar uma possível relação entre os dois conceitos, faz-se necessário o planejamento de um ambiente de análise de avaliações, que possibilite contrastar os resultados da checagem dos artefatos com os respectivos conjuntos de critérios.
Este artigo está organizado da seguinte maneira: na Seção 2 são abordados os conceitos de Acessibilidade e Usabilidade Web, bem como os diferentes meios de avaliação envolvidos para verificar o grau de observância das aplicações com os critérios pré estabelecidos. A Subseção 2.1 especifica os métodos utilizados na avaliação da usabilidade, como a avaliação heurística (2.1.1), a inspeção de recomendações ergonômicas (2.1.2) e o uso de questionários (2.1.3). A Subseção 2.2 trata da avaliação de acessibilidade, enquanto a Subseção 2.3 apresenta a linguagem de relatórios EARL. A Seção 3 apresenta os resultados, como as ferramentas semiautomáticas utilizadas na avaliação de acessibilidade (Subseção 3.1) e usabilidade (Subseção 3.2), além da representação do ambiente proposto para se obter análises objetivas de artefatos, considerando critérios de usabilidade e acessibilidade, a fim de contribuir com o estudo de correlação entre os conceitos.
2. ACESSIBILIDADE E USABILIDADE
Acessibilidade é um assunto que cresce a cada dia, porém ainda é pouco explorado, considerando sua vital importância no que concerne à equiparação de direitos na concepção e incorporação de conhecimento a todas
ISBN: 978-989-8533-11-1 © 2012 IADIS
166

as pessoas. A usabilidade, por sua vez, abrange um conteúdo mais consolidado e difundido, haja vista seu impacto direto no reflexo de qualidade das aplicações.
Alguns estudiosos colaboram com afirmações controvérsias sobre a relação existente entre os dois conceitos. Para THATCHER, J. (2006), problemas de acessibilidade afetam tão somente usuários com alguma disfunção, enquanto PETRIE, H. e KHEIR, O. (2007) afirmam que frequentemente usuários deficientes, assim como os não, encontram os mesmos problemas, porém são afetados diferentemente. A partir de um experimento objetivando identificar essa relação, SLATIN, J. e LEWIS, K. (2002) encontraram que para usuários deficientes, a aplicação de diretivas de acessibilidade melhora significativamente a experiência nos sites, enquanto usuários normais não visualizam diferenças significativas, contribuindo para a afirmação de que acessibilidade não necessariamente aumenta a usabilidade.
2.1 Avaliação de Usabilidade
Os métodos utilizados para avaliação de usabilidade consistem, grande parte, em testes empíricos com a participação de usuários e testes de inspeção. Os testes de inspeção são efetuados a partir da análise por um especialista (expert), em busca de incompatibilidades que afetem a usabilidade na aplicação, como acontece na avaliação heurística.
Já a participação de usuários se dá por meio de questionários ou pelo acompanhamento do usuário na execução de tarefas na aplicação. Nas subseções a seguir, são apresentados os métodos mais utilizados para avaliação de usabilidade.
2.1.1 Avaliação Heurística
A avaliação heurística foi criada por Nielsen e Molich (NIELSEN, 2003) e é caracterizada pela inspeção sistemática da aplicação em relação à usabilidade. Um avaliador avalia a interface de uma aplicação Web, a partir dos princípios de usabilidade denominados heurísticas.
Para aumentar a confiabilidade das avaliações e evitar vieses, é indicado que mais de um avaliador faça a verificação, individualmente, para então, ao final, apresentarem seus resultados e contrastarem com as outras avaliações. Nielsen indica o número de 3 a 5 avaliadores como o de maior custo/benefício (NIELSEN, 2003).
Durante a avaliação, que tem duração média de uma a duas horas, o próprio avaliador pode tomar nota ou esse papel pode ser atribuído a um observador, que acompanha as interações do avaliador e pode colaborar respondendo as dúvidas a respeito do protótipo. Após todos os avaliadores terem finalizado suas obrigações, os observadores têm a tarefa de reunir os resultados, que são representados em uma lista de problemas, princípios violados e as respectivas intensidades de gravidade de usabilidade, em um único documento.
2.1.2 Inspeção de Recomendações Ergonômicas
As recomendações ergonômicas, ou guidelines e checklists foram elaboradas como resultados de pesquisas em psicologia, ciência cognitiva e ergonomia. Podem ser utilizadas na concepção e avaliação da interface (WINCKLER e PIMENTA, 2002).
A inspeção consiste em um ou mais avaliadores analisando minuciosamente se as recomendações são seguidas na utilização da aplicação. Considerando a difícil aplicabilidade de algumas recomendações, ferramentas automáticas não podem contribuir e a avaliação pode exigir um conhecimento profundo por parte do condutor, para tanto, podem ser utilizadas as checklists, que são pontos objetivos a serem seguidos e requerem menos esforço para compreensão e identificação. Porém, por serem muito objetivas, podem ser constituídas por centenas de pontos a serem averiguados, contribuindo significativamente com o tédio dos inspetores. Alguns conjuntos de recomendações são: HHS Guidelines, ISO DIS 9241-151 e JISC Guidelines.
2.1.3 Questionários
Questionários são utilizados para obter informações a respeito da experiência do usuário com a aplicação, a fim de identificar seu grau de satisfação durante o uso, traçar o perfil, tanto funcional, como pessoal de cada usuário, além de contribuir na identificação de problemas encontrados, documentando-os nesse formato, possibilita a análise simultânea em inúmeros locais distintos.
Podem ser disponibilizados online, possibilitando atingir um número elevado de usuários. Porém, os resultados precisam ser cuidadosamente analisados, a fim de se obter uma conclusão a respeito da usabilidade. Isso pode despender um tempo elevado e um grande esforço por parte do avaliador.
Conferência IADIS Ibero-Americana WWW/Internet 2012
167

2.2 Avaliação de Acessibilidade
Avaliação de acessibilidade corresponde a quão bem aplicações Web podem ser utilizadas por pessoas com deficiências e, são consideradas em diferentes cenários (ABOU-ZAHRA, 2008): desenvolvedor Web objetivando confirmar a conformidade do desenvolvimento com padrões de acessibilidade requeridos; autor de conteúdo Web investigando a conformidade da informação publicada com os padrões, com o objetivo de ser compreendida pelo maior número de pessoas; webdesigner que quer aprender questões de acessibilidade em design, a fim de usá-las no processo de criação; gerente de projetos Web que deseja explorar algumas questões potenciais de acessibilidade no site, para estimar sua performance; organização que almeja determinar se suas páginas Web se encontram nos padrões, para garantir acessibilidade ou encontrar falhas nesse quesito.
Existem inúmeras ferramentas de avaliação semiautomáticas para contrapor critérios e aplicações Web. No estudo aqui exposto, o foco será as que tratem acessibilidade e usabilidade. Considerando a estagnação do conteúdo que lista as principais ferramentas de avaliação pelo W3C desde 2006, faz-se necessário um maior aprofundamento na pesquisa a fim de se obter ferramentas que tenham sido criadas desde então. Aqui se entende por semiautomática, a ferramenta que necessita de interação humana para concretizar a avaliação.
2.3 Evaluation and Report Language (EARL)
A EARL é uma linguagem que define um vocabulário para expressar resultados de testes. Ela permite a qualquer pessoa, aplicação de software ou organização, representar resultados para qualquer teste de conteúdo contra um conjunto de critérios e, seu nível de cumprimento. O conteúdo do teste é representado por um site, um usuário, ou qualquer outra entidade. O conjunto de critérios é composto por orientações de acessibilidade, gramáticas formais ou outros modelos de requisitos. Assim, a EARL é flexível, considerando o contexto ao qual pode ser aplicada (W3C, 2001).
Alguns casos de uso para a EARL (ABOU-ZAHRA, 2004), são: combinar relatórios, comparar resultados de teste, utilizar ferramentas de avaliação comparativas, facilita a mineração de dados, uso como relatórios, integração com ferramentas de autoria, interação com Web Browsers e ntegração em Search Engines. Outros usos: contrastar avaliadores e ferramentas, avaliar o progresso com o tempo e encontrar o site mais acessível. Espera-se, assim, que ela possa ser a base para outros vocabulários.
Atualmente, a EARL está em fase de desenvolvimento, porém em junho houve a última chamada para a revisão em estado Draft. Desde 2001 ela é suficiente para expressar 95% das avaliações (W3C, 2001). O documento técnico da EARL foi desenvolvido pelo grupo de trabalho em ferramentas de avaliação ERT WG, o qual forma parte do W3C e da Web Accessibility Initiative (WAI), desde 2001.
3. RESULTADOS
3.1 Ferramentas para Avaliação de Acessibilidade
Existem softwares que automatizam as avaliações contrastando o conteúdo dos sites aos critérios de acessibilidade. Dentre inúmeras ferramentas listadas pelo W3C, estão as apresentadas abaixo, das quais apenas a TAW disponibiliza testes baseados em critérios da WCAG 2.0, conjunto de diretrizes disponibilizado em 11 de dezembro de 2008.
Tabela 1. Ferramentas de avaliação de acessibilidade
Ferramenta Desenvolvedor Licença para uso EARL AccessValet WebThing Ltd Shareware Não AccMonitor HiSoftware Shareware Não AccVerify HiSoftware Shareware Sim CynthiaSays HiSoftware Freeware Não DaSilva Acessibilidade Brasil Freeware Não Hera Fundación Sidar Freeware Sim WAVE WebAIM Freeware Não
ISBN: 978-989-8533-11-1 © 2012 IADIS
168

3.2 Ferramentas para Avaliação de Usabibilidade
Existem ferramentas de avaliação, assim como acontece em acessibilidade, para avaliar automaticamente a usabilidade em um site, porém a maioria não faz análise ergonômica, que diz respeito à capacidade de trabalho perceptivo, cognitivo e motor do usuário, limitando-se à validação da sintaxe HTML. Como exemplo, pode-se citar o Boddy , Dr. Watson e o Lift.
Tabela 2. Ferramentas de avaliação de usabilidade
Ferramenta Desenvolvedor Licença para uso EARL Bobby CAST Freeware Não Dr. Watson Addy & Associates Freeware Não Lift UsableNet Freeware Não
3.3 Ambiente de Análise
Este trabalho contempla atividades e base teórica para a investigação do potencial de uma linguagem disponibilizada pelo World Wide Web Consortium (W3C), ainda em estado Draft, para representar resultados de testes de avaliações em formato padronizado, tornando-os compreensíveis por outras aplicações que podem utilizá-los para conduzir a uma experiência com maior respeitabilidade aos critérios expostos durante a avaliação. A partir de resultados nesse formato, é proposto o desenvolvimento de um ambiente de análise, a fim de investigar a correlação da usabilidade e acessibilidade.
O ambiente é ilustrado na Figura 1, a qual representa como entrada para o sistema, relatórios EARL, resultantes tanto de ferramentas automáticas de acessibilidade como também de um formulário de análise de usabilidade baseado nas recomendações de Nielsen, a fim de possibilitar a investigação da correlação entre os conceitos. O sistema possibilita o contraste dos resultados obtidos para mais de um relatório do mesmo conteúdo, gerados por ferramentas distintas.
Após submissão dos relatórios em EARL no sistema, as telas de critérios são preenchidas com ícones representativas de compatibilidade com os critérios (V), de incompatibilidade com os critérios (X) e de não conclusão (?), necessitando interação humana, a fim de investigar a validade desses.
A fim de evitar desgaste dos desenvolvedores (perfil foco do ambiente), os critérios foram minimizados na apresentação das diretrizes, podendo se estender aos níveis de conformidade a partir das recomendações de cada diretriz, posicionando o cursor do mouse sob as diretrizes, obtendo o relatório completo de conformidade.
O ambiente comporta a análise de artefatos padrões, os quais serão previamente populados no sistema. Na Figura 1, por exemplo, um accordion está sendo avaliado. Essa decisão propõe utilizar o que já foi desenvolvido em relação à acessibilidade, a partir da ferramenta de colaboração AccessibilityUtil, utilizada como base para colaboração na tomada de decisão dos desenvolvedores.
O desenvolvedor pode escolher publicar seu resultado de conformidade para ser visível e comentado por outros desenvolvedores, com o propósito de servir como base no desenvolvimento de outros usuários, como também receber contribuições por intermédio de um desenvolvimento colaborativo. Para isso, a ferramenta possibilita a inserção e visualização do código fonte do artefato em desenvolvimento.
Na tela de visualização do artefato, o desenvolvedor tem a possibilidade de analisar casos de sucesso na obtenção de altos níveis de acessibilidade e usabilidade, promovendo conhecimento necessário para aumento de cobertura das diretrizes avaliadas.
Conferência IADIS Ibero-Americana WWW/Internet 2012
169

Figura 1. Ambiente de análise entre resultados de avaliações de acessibilidade e usabilidade
4. CONCLUSÃO
A pesquisa contribui nos campos de usabilidade e acessibilidade, listando ferramentas de avaliação semiautomáticas e propondo uma solução que visa confrontar o preceito que muitos desenvolvedores tomam como premissas no desenvolvimento, que é a inviabilidade de manter sites acessíveis, sem perder a origem das funcionalidades propostas, além de contribuir significativamente com as pesquisas ao mostrar a linguagem EARL, utilizá-la como base de um estudo mais aprofundado e incentivar novas pesquisas relacionadas a ela. A partir dos resultados obtidos das avaliações semiautomáticas dispostas em relatórios EARL, será possível averiguar possíveis comportamentos repetitivos, que introduzem a uma análise de contraposição de forças, envolvendo critérios de acessibilidade e usabilidade.
AGRADECIMENTO
Agradecimento à agência de fomento FAPESP pelo financiamento na modalidade de bolsa de mestrado, sendo esse artigo um dos produtos da pesquisa.
REFERÊNCIAS
ABOU-ZAHRA, S. “Semantic web enabled web accessibility evaluation tools”. World Wide Web Consortium, 2004. ABOU-ZAHRA, S. Web Accessibility evaluation. “Web accessibility: a foundation for research”, [S.l.]: Springer, 2008.
p. 80. LANGDON, P.; PERSAD, U.; CLARCKSON, P. J. “Developing a model of cognitive interaction for analytical inclusive
design evaluation”. Interact. Comput. 22, 6 (November 2010), 510-529. LEEDY, P. D.; ORMROD, J. E. “Practical research: planning and design” (8th ed.). Upper Saddle River, NJ: Prentice
Hall, 2005. NIELSEN, J. “Usability engineering”. Boston - USA: Academic Press, 362 p., 2003. PETRIE, H.; KHEIR, O.: The relationship between accessibility and usability of websites. In: Proc. CHI 2007, pp. 397–
406. ACM, CA, 2007. SLATIN, J.; LEWIS, K.: Challenges of accessible web design: Standards, guidelines, and user testing. In: Technology
and Persons with Disabilities Conference, Los Angeles, USA. CSUN, California State University Northridge, 2002. THATCHER, J.; et. al. Web Accessibility: Web Standards and Regulatory Compliance, Friends of ED, 2006. W3C EARL – “The evaluation and report language”, 9 dez. 2001. Disponível em: <http://www.w3.org/2001/03/earl/>.
Acesso em out. 2011. WINCKLER, M.; PIMENTA, M. S. Textbook of X Escola de Informática of SBC-Sul, Sociedade Brasileira de
Computação, Porto Alegre - RS, p. 85-137, 2002.
ISBN: 978-989-8533-11-1 © 2012 IADIS
170

A GESTÃO E VENDA ONLINE DE PRODUTOS REGIONAIS: DEFINIÇÃO DE ESTRATÉGIAS EM
MODELOS DE INOVAÇÃO
Luís Ascenso1,2, Hélia Guerra1, Luís Mendes Gomes1e Armando Mendes1,2 1CMATI, Departamento de Matemática, Universidade dos Açores
2CEEAplA, Departamento de Economia e Gestão, Universidade dos Açores
RESUMO
No domínio das atividades de e-commerce, as organizações devem munir-se de capacidades dinâmicas adequadas à afirmação dos seus produtos em mercados cada vez mais competitivos, dado o impressionante ritmo de transformações tecnológicas e dos paradigmas da sociedade. Neste artigo, pretendemos desenvolver um modelo de e-commerce para a venda online de produtos regionais em que seja possível aliar a tecnologia à performance e resultados, contemplando nessa conjugação as idiossincrasias presentes nesses produtos, identitárias de uma imagem de marca e da região e a criação de valor para o cliente. Para esse efeito, será construído um espaço de interação norteado por dinâmicas de inputs-outputs geridas através de soluções inteligentes, dando expressão às ferramentas interativas da web 2.0 e da web semântica. Como base conceptual recorreremos à combinação do modelo integrado de inovação de Sarkar, com o modelo tensivo de Fontanille e Zilberberg e com a estratégia do “Oceano Azul” de Kim e Mauborgne.
PALAVRAS-CHAVE
E-commerce, inovação, web 2.0, web semântica
1. INTRODUÇÃO
Sendo uma atividade desenvolvida online, o e-commerce visa a transação de produtos por meios eletrónicos, num processo que envolve empresas, organizações e consumidores em geral (Qin et al, 2009), levando a que muitas vezes se confunda este conceito com o conceito de e-business.
O e-business, lato sensu, pressupõe, tal como o e-commerce, um processo de interação entre clientes, oferta de produtos ou serviços, acesso a processos de negócio, partilha de conteúdos e de informação (Allen, 2010). Mas enquanto no e-commerce as TIC são ferramentas orientadas unicamente no contexto transacional, do ponto de vista do e-business tornam-se um recurso para o crescimento do negócio, no sentido da obtenção de valor-cliente adicional (Andam, 2003).
Centrando-nos na perspetiva estrita do e-commerce, há dois níveis a considerar: a estrutura tecnológica e os intervenientes diretos nas transações (Tassabehji, 2003). Assume particular relevância, neste último nível, a dimensão cliente, com destaque para os papéis e os cenários que a definem (Andersen e Ritte, 2008). Com a Internet, dão-se importantes modificações nestes ambientes (Seybold, 2002), na medida em que para haver e-satisfaction, como advoga Anand (2007), é indispensável o desenvolvimento das estratégias de e-channel (Chaffey, 2009), presentes na web 2.0 (Allen, 2010; Lewis et al, 2011).
Em Valacich e Schneider (2012) são distinguidas, entre outras capacidades, a utilização da web como suporte das transações, a comunicação interativa e o suporte transacional, na medida em que permitem antecipar o desenvolvimento de uma atividade comercial online em que o utilizador/cliente é parte ativa do processo. Esta participação não depende da presença dos agentes físicos dos formatos comerciais tradicionais. Subjacente a este princípio está uma dimensão global, implícita no nível de transações a desenvolver, ao ritmo das transformações tecnológicas e de paradigmas a que assistimos atualmente. Daí que seja de colocar a inovação como um desiderato a privilegiar no desenvolvimento de uma plataforma de e-commerce.
Conferência IADIS Ibero-Americana WWW/Internet 2012
171

Como ponto de partida para o desenvolvimento de um projeto inovador, numa região, aceitamos como fundamentais as premissas estabelecidas pela teoria de inovação aberta de Chesbrough (2003). A inovação aberta pressupõe uma dinâmica na utilização de recursos, pautada por extrema flexibilidade e pelo cancelamento das linhas de fronteira da organização com o ambiente macroeconómico em que se enquadra. O valor, nesta perspetiva, é um ativo em si mesmo, intrínseco à organização, o que permite uma relação do tipo win-win (Sarkar, 2009), transformando as soluções tecnológicas desenvolvidas em produtos autónomos comercializáveis. Ou seja, torna-se um ativo capitalizável (Macedo e Camarinha-Matos, 2011), sob a forma de valor para a organização, para o cliente (Kim e Mauborgne, 2005) e para a própria sociedade (Betz, 2011). A capitalização do conhecimento através da inovação sofre um efeito de expansão, seja por meio de empresas spin-off, seja pelo reconhecimento de uma imagem de marca regional, seja pela agilização da rede de abastecimento de produtos regionais no sentido da fluidez transacional aberta a novos mercados.
Para reforçar o elo de ligação, no nosso modelo de e-commerce, entre a dimensão tecnológica, o conhecimento do cliente e a criação de riqueza para a sociedade, importámos das ciências semióticas o modelo tensivo (Pietroforte, 2008; Herbert, 2006), colocando-o ao serviço de um design organizacional através da sua acoplação ao modelo integrado de inovação de Sarkar (Sarkar 2007, 2009), em sintonia com a estratégia de “Oceano Azul”, de (Kim e Mauborgne, 2005). O elemento-chave do modelo aqui proposto será a futura criação de ontologias a partir de marcações semânticas sobre um dado cabaz de produtos regionais, estendendo a base de trabalho desta investigação da web 2.0 à web semântica.
2. O MODELO INTEGRADO DE INOVAÇÃO DE SARKAR
Dada a limitação que reconhecemos em obter a conjugação perfeita, num único canal, e em simultâneo, das propriedades correspondentes a cada um dos níveis em que nos procuramos situar: a organização, o cliente e a sociedade, recorremos ao modelo integrado de inovação de Sarkar (Sarkar, 2007; 2009).
O modelo de Sarkar está estruturado em quatro quadrantes, correspondendo a quatro dimensões distintas do comportamento do produto ou empresa, que podem ser analisadas individualmente e explicam o tipo de resposta face à pressão competitiva, a estratégia associada a essa resposta, e os resultados, medidos pela quota de mercado e pelo lucro. Obtêm-se assim o espaço de arquétipos, o espaço de estratégia, o espaço de resultados e o espaço de mercados, conforme se ilustra à esquerda na Figura 1.
Figura 1. Modelo integrado de inovação de Sarkar (adaptado de Sarkar (2007)).
O espaço dos arquétipos mede o comportamento do produto ou empresa face à ação das variáveis pressão competitiva (eixo horizontal) e inovação/diferenciação (eixo vertical), e contém implícito um dado posicionamento competitivo (vide à direita da Figura 1). O espaço de estratégia descreve a relação entre o grau de inovação/diferenciação do produto ou empresa e o seu nível de rendibilidade, representado pela quota de mercado. O espaço de resultados descreve a relação entre a variável quota de mercado e os lucros obtidos. Finalmente o espaço de mercado representa a relação entre os lucros e a pressão competitiva. Fazendo uma
ISBN: 978-989-8533-11-1 © 2012 IADIS
172

leitura no sentido oposto ao dos ponteiros do relógio, é possível perceber que a um aumento da pressão competitiva (deslocação do produto para direita e para baixo do quadrante de arquétipos) corresponde a necessidade de incrementar as estratégias de inovação/diferenciação (para a esquerda e para cima do quadrante de estratégia), sob pena de perder quota de mercado (para a esquerda e para baixo do quadrante de resultados), e obter menos rendibilidade (para a direita e para baixo do quadrante de mercados). Intervindo no espaço de estratégia através da inovação/diferenciação, dá-se uma deslocação do produto para cima e para a esquerda, repondo o nível original.
3. NOVA ABORDAGEM AO MODELO DE SARKAR
A nossa abordagem ao modelo de Sarkar (vide Figura 2) inicia-se a partir de uma reorganização do espaço de estratégia, ligando-o a uma redefinição/especificação do espaço de arquétipos. Servimo-nos do modelo tensivo introduzido nos estudos semióticos por Fontanille e Zilberberg (apud Pietroforte, 2008). Este modelo estabelece que entre duas profundidades uma define a intensidade e outra a extensidade, formando dois eixos ao longo dos quais se manifestam determinados níveis de perceção. A extensidade aponta para uma ordem de grandeza, ou uma extensão dos fenómenos no espaço ou no tempo sobre a qual se aplica a intensidade (Herbert, 2006). A combinação da intensidade e extensidade devolve-nos valências que criam as condições para a criação de valor. Existe uma correlação entre estas valências, sendo a mais comum a correlação inversa: quando a intensidade aumenta, a extensidade diminui, e vice-versa. No e-commerce, a intensidade de um produto sem extensidade corresponde à sua dimensão utilitária. A extensidade sem intensidade corresponde a uma perceção dinâmica, ou seja, o equivalente a admitir outros níveis de valor no produto além da dimensão utilitária, inclusive a aceitação de uma lógica criativa, i.e., a inovação com valor (vide Kim e Mauborgne (2005)).
Figura 2. Adaptação do modelo de Sarkar com a inclusão do modelo tensivo e o mapa PMS.
Observemos a redefinição do espaço de arquétipos proposta: os quatro arquétipos de mercado de Sarkar são substituídos por três níveis de posicionamento, na estratégia do “Oceano Azul” (Kim e Mauborgne, 2005), representado no mapa PMS (Pioneers – Migrators – Settlers): o arquétipo colonos, com maior exposição à pressão competitiva, menor propensão à diferenciação/inovação (“Oceanos Vermelhos”) e sujeito às regras de mercado; o arquétipo migradores, caracterizado por estratégias de baixo custo, mas com baixo nível de diferenciação; finalmente, o arquétipo pioneiros, caracterizado por uma elevada diferenciação, estratégias de baixo custo e de criação de valor (“Oceanos Azuis”). É orientando os produtos para os “Oceanos Azuis” que se contraria a exposição à pressão competitiva, e essa intervenção dá-se no espaço de estratégia, organizado com recurso ao modelo tensivo. O objetivo é a criação de uma ferramenta de controlo
Conferência IADIS Ibero-Americana WWW/Internet 2012
173

sobre o comportamento do produto, no sentido da sua valoração ao longo da escala tensiva. Esse comportamento expressa um conjunto de padrões de comportamento do consumidor, que resulta de uma escala emocional, desde o nível máximo de interação que é a participação em rede (sinónimo de fidelização), passando pela decisão de compra, a procura de informação, o comentário, a sugestão, entre outros. Agindo sobre o produto, agimos sobre esses padrões e criamos as condições necessárias para gerir o negócio de forma eficaz, em termos de apresentação, níveis de acesso e de informação, hierarquia de elementos de media, entre outras técnicas.
O grande desafio é o desenvolvimento de soluções inteligentes, através de ontologias que permitam ao sistema gerir de forma autónoma a interação com o cliente. Este processo é conduzido mediante a descodificação de um conjunto de predicações implícitas nos padrões semânticos, e.g., através de data mining, e que traduzem o nível de satisfação do cliente. No momento seguinte, o sistema gera novos inputs sobre a distribuição dos produtos na escala tensiva, que produzem novas respostas, e assim sucessivamente. A dinâmica deste processo inclui a coparticipação do cliente e a gestão adequada do conhecimento obtido a partir dessa coparticipação, armazenado e transformado em rendibilidade (cf. a representação do modelo integrado de inovação de Sarkar, com os quatro quadrantes em funcionamento conjunto).
Para tornar operacional esta conceptualização, assumimos um cabaz de produtos regionais em quatro classes distintas, procedendo a uma valoração inicial aleatória, representada por p1, p2, p3 e p4, consoante estamos em presença de categorias com predomínio de propriedades extensivas sobre propriedades intensivas ou vice-versa. O arquétipo ideal estará situado na zona dos “Oceanos Azuis”, onde a competição perde relevância. Um aumento de pressão competitiva tem um impacto direto no espaço de estratégia, o que reduz o potencial de valoração dos produtos e provoca alertas no sistema, desencadeados por reações do cliente, e, em resposta, uma (re)condução dos valores dos produtos ao longo da escala tensiva. O resultado será um restabelecimento do posicionamento inicial, à semelhança do que é explicado em Sarkar (2007, 2009), com o consequente ajustamento do modelo nos quadrantes inferiores.
4. CONCLUSÕES
A valoração dos componentes semânticos revela-se uma componente fundamental para a concretização deste modelo no plano operacional. Primeiro evidencia que propriedades, e com que valores, os dados processados podem representar a abstração da realidade feita por humanos, ao mesmo tempo que esta valoração possa ser percebida por máquinas e “devolvida”, sob a forma de outputs dinâmicos (Takeda, 2004). Segundo, garante a maximização das propriedades diferenciadoras dos produtos regionais, incluindo a sua extensão simbólica, orientada para o sucesso no mercado. Ao aperfeiçoarmos as técnicas multimodais que permitem maximizar a interface utilizador/máquina (Sharma, et al, 1998), criada no contexto do intercâmbio comercial, estamos a garantir maiores índices de inteligibilidade por parte da máquina dos níveis abstratos do conhecimento humano, visando ações concretas. Esta tecnologia de caráter difuso, articulada com os dispositivos móveis, permite tirar partido de funções inerentes a cada interface, como a utilização de “smart spaces” ou a exploração dos fatores de escalabilidade (Satyanarayanan e Carnegie, 2001), sem ignorar as possibilidades de realização do produto na web 2.0. É aqui que residem os principais desafios da web semântica (Yu e Hong, 2009): por um lado, especificando as regras de inferência ao nível da abstração, para garantir condições de validação e suporte de composição a utilizadores nos diferentes níveis de acesso e, por outro lado, fazendo o mapeamento das regras do nível abstrato, de modo a que seja possível a comunicação com os níveis inferiores.
REFERÊNCIAS
Allen, J.P., 2010. Internet Business Basics. Version June 1, 2010, license = Creative Commons BY-SA Anand, A, 2007. E-Satisfaction: A Comprehensive Framework. International Marketing Conference on Marketing &
Society, 8-10 April 2007, IIMK Andam, Z.R.B., 2003. E-commerce and e-business. Available at: www.apdip.net/publications/iespprimers
/eprimer_eCom.pdf
ISBN: 978-989-8533-11-1 © 2012 IADIS
174

Andersen H. e Ritte, T., 2008. Inside the Customer Universe: How to Build Unique Customer Insight for Profitable Growth and Market Leadership. John Wiley & Sons
Betz, F., 2011. Managing Technological Innovation: Competitive Advantage from Change. Hoboken: John Wiley & Sons, Inc., 3rd ed.
Chaffey, D., 2009. E-Business and E-Commerce Management: Strategy, Implementation and Practice. 4th ed., Harlow, Prentice Hall
Chesbrough, H., 2003. The Era of Open Innovation. MIT Sloan Management Review, vol. 44, nº 3 pp. 34-41. Herbert, L., 2006. Tools for Text and Image Analysis: An Introduction to Applied Semiotics. Available at:
http://www.revue-texto.net Kim, W. e Mauborgne, R., 2005. Blue Ocean Strategy: How to Create Uncontested Market Space and Make the
Competition Irrelevant. Harvard Business School Press Lewis, J., Goto, C., Gronberg, J., 2011. Evaluating Web 2.0: Innovations in E-Commerce: A Framework for Future
Development, The Tuck School at Dartmouth Macedo, P. e Camarinha-Matos, L., 2011. Value Systems Management Model for Co-innovation. In Camarinha-Matos
(ed.). Technological Innovation for Sustainability, Second IFIP WG 5.5/SOCOLNET Doctoral Conference on Computing, Electrical and Industrial Systems, DoCEIS 2011 Costa de Caparica, Portugal, February 21-23 Proceedings, pp. 11-20, Springer
Pietroforte, A., 2008. Tópicos de Semiótica: Modelos teóricos e Aplicações. São Paulo, Annablume Qin, Z. et al, 2009: Fundamentals of E-commerce. Introduction to E-commerce. pp. 3-76 Co-published by Tsinghua
University Press Sarkar, S., 2009. Empreendedorismo e Inovação. Lisboa: Escolar Editora, 2ª ed. Sarkar, S., 2007. Innovation, Market Archetypes and Outcome: An Integrated Framework. Heidelberg, Physica-Verlag Satyanarayanan, M. e Carnegie M., 2001. A Pervasive Computing: Vision and Challenges. IEEE Personal
Communications. vol. 8 issue 4, pp 10-17 : IEEE Communications Society Univ., Pittsburgh Seybold, P., 2002. Get Inside the Lives of Your Customers. Harvard Business Review on customer relationship
management. pp. 27-48 Boston: Harvard Business School Publishing Corporation Sharma, R et al, 1998. Toward Multimodal Human–Computer Interface. Proceedings of the IEEE, vol. 86, Nº. 5, May Takeda, H., 2004. Semantic Web: a Road to the Knowledge Infrastructure on the Internet. National Institute of
Informatics, New Generation Computing, 22, Ohmsha and Springer Tassabehji, R., 2003. Applying E-Commerce in Business. SAGE Publications Valacich, J., Schneider, C., 2012. Information Systems Today. Harlow: Pearson Yu H. Q., Hong Y., 2008. Graph Transformation for the Semantic Web: Queries and Inference Rules. Ehrig et al. (Eds.),
ICGT - LNCS 5214, pp. 511–513 Springer
Conferência IADIS Ibero-Americana WWW/Internet 2012
175

QUINTA DIGITAL: COMÉRCIO ELETRÓNICO DE PRODUTOS AGRÍCOLAS DO PRODUTOR AO
CONSUMIDOR FINAL
João Crispim Ponte2, Óscar Neto1, Lino Martins1 Hélia Guerra1, Luís Mendes Gomes1 e Armando Mendes1,2
1CMATI, Departamento de Matemática, Universidade dos Açores 2CEEAplA, Departamento de Economia e Gestão, Universidade dos Açores
RESUMO
A dinâmica no sector agrícola e o encarecimento dos produtos agrícolas sentido pelo consumidor final é, muitas vezes, condicionada pelos intermediários associados às grandes cadeias de distribuição. Mas, também, são conhecidas dificuldades dos pequenos e médios agricultores no acesso ao mercado para escoamento das suas produções. Neste artigo, propomos uma solução, baseada no comércio eletrónico, que designamos por Quinta Digital, a qual permite suprimir estes intermediários e estimular a comercialização direta entre produtores e consumidores finais. A este comércio é adicionada uma rede especializada cujo objetivo é fidelizar a relação entre produtores e consumidores finais. Este comércio beneficia de serviços complementares cujo objetivo é alargar e diversificar a rede mas, também, estabelecer uma relação solidária entre produtores e instituições de solidariedade social, para o aproveitamento de produtos em fim de vida.
PALAVRAS-CHAVE
E-Commerce, crowdfunding, Web 2.0, comunidade online
1. IDEIA DE NEGÓCIO
A Quinta Digital pretende ser uma forma inovadora de comércio eletrónico de produtos agrícolas, cujo primeiro objetivo é servir de único intermediário entre produtor e consumidor final. E, desta forma, suprimir os intermediários envolvidos na cadeia de valor do mercado tradicional. Esta forma de comércio proporciona um tipo de mercado virtual, permitindo a realização de transações, provenientes da comercialização direta, e a aquisição e/ou subscrição de serviços complementares.
Um destes serviços complementares é a criação de um banco de produtos agrícolas onde os produtores podem doar produtos no fim do seu ciclo de vida. Os destinatários prioritários para estas doações são instituições de solidariedade social e organizações não-governamentais. Assim, a Quinta Digital está a desempenhar as suas obrigações de responsabilidade social e, mais importante, a combater o desperdício tão frequente no negócio de produtos perecíveis. Outros serviços complementares estão relacionados com formas de proporcionar trocas diretas ou, ainda, a promover e realizar leilões online por lotes, de produtores ou associações de produtores.
A Quinta Digital está vocacionada para responder a vários segmentos de mercado, em função de unidades estratégicas de negócio, nomeadamente a consumidores finais e unidades de restauração e hotelaria. Os seus proveitos provêm, no imediato, de uma comissão por transação e na construção de uma rede de produtores e consumidores sustentável. Esta beneficia do acesso aos referidos serviços complementares que, entre outros propósitos, permite implantar um modelo de fidelização para atingir e beneficiar um mercado mais vasto e diversificado de produtores e consumidores.
Tendo em conta o quadro socioeconómico atual de Portugal, em particular do sector agrícola, não é conhecido nenhum outro negócio congénere. Apesar de esta ideia estar circunspecta ao espaço nacional, não descartamos que possa ser original, também, em outros espaços transnacionais e, possivelmente, em quadros socioeconómicos diferentes (e.g., Chen, 2002). É muito comum encontrar só páginas Web de informação
ISBN: 978-989-8533-11-1 © 2012 IADIS
176

agrícola e apoio ao agricultor, nas mais das vezes, proporcionadas por associações agrícolas ou organismos governamentais associados a este sector, sem qualquer objetivo comercial e/ou solidário.
Neste artigo, apresenta-se, sucintamente, o enquadramento socioeconómico para esta ideia de negócio associada à Quinta Digital, através da identificação de quatro fatores essenciais: dinâmicas macroeconómicas, necessidades identificadas no espaço rural, oportunidades de negócio e potencial de crescimento e expansão. Em seguida, apresentamos um modelo de negócio, baseado numa forma de taxação por cada transação, na construção de uma rede para fidelizar produtores e consumidores finais, e num modelo de financiamento que garanta o arranque e a sustentabilidade económica e financeira da Quinta Digital. Finalmente, avançamos com algumas ideias e sugestões para o desenvolvimento da implementação da infraestrutura informacional subjacente ao negócio Quinta Digital.
2. ENQUADRAMENTO SÓCIOECONÓMICO
Em Portugal, as recentes dificuldades económicas e financeiras têm revelado a necessidade de uma maior produção de bens de primeira necessidade, entre os quais destacamos os produtos agrícolas, como forma de criação de riqueza e do equilíbrio da balança comercial. Para este propósito, tem-se vindo a constatar uma necessidade estratégica emergente de modernização do sector agrícola e da sua capacidade de inovação.
Uma das principais limitações do sector agrícola está relacionada com a dificuldade de escoamento dos produtos, principalmente aqueles provenientes de pequenas explorações agrícolas, a preços justos, em consequência do excessivo poder negocial das grandes empresas de distribuição. A opção por um modelo de comércio eletrónico, para encurtar a cadeia de valor e permitir o contacto direto entre extremos: produtor e consumidor final; permite atenuar estas dificuldades e criar feedback direto, fornecendo informação essencial para ações de I&D e inovação. Esta opção resulta da intersecção de quatro fatores, que, de certa forma, deixam perspetivar a sua capacidade de rápida penetração no mercado e o seu potencial de desenvolvimento de estratégias de crescimento e expansão.
2.1 Dinâmicas Macroeconómicas
Em Portugal, desde meados da década de 1980, a agricultura perdeu mais de dois terços do seu peso total no VAB, em consequência da adoção de políticas macroeconómicas de convergência com a União Europeia. Numa avaliação das dinâmicas macroeconómicas, é possível verificar que o sector agrícola tem um grande potencial na ajuda à recuperação do equilíbrio da balança comercial e na criação de riqueza. Um dos aproveitamentos que podemos fazer deste potencial está na revitalização produtiva e comercial deste sector, num espaço inovador que estimule a sua promoção e desenvolvimento, tendo em conta o mercado local e de exportação.
2.2 Necessidades Identificadas no Espaço Rural
Existem fragilidades nas explorações e mercados agrícolas, nomeadamente na distribuição dos produtos e na capacidade para competir com a oferta das grandes superfícies comerciais.
Os pequenos produtores não conseguem volumes de produção que permitam concorrer com grandes produtores, favorecidos pelas grandes superfícies comerciais devido à estabilidade de fornecimento que oferecem. O associativismo poderia atenuar estas dificuldades mas tem funcionado de forma limitada, devido à falta de dinâmica e inovação. Os canais de distribuição das grandes superfícies comerciais permitem uma grande comodidade no processo de compra, ao passo que os pequenos produtores têm dificuldade em chegar aos consumidores explorando, ocasionalmente, os mercados locais, vendendo a condições extremamente difíceis, que passam por margens de comercialização esmagadas, prazos de pagamento alargados, exigências de quantidade e entrega impossíveis de cumprir ou, ainda, a adoção de uma postura passiva de espera pelo consumidor. A rastreabilidade é um valor acrescentado em cadeias de valor muito longas tanto em número de estádios como em distâncias percorridas pelos materiais. Tornar a cadeia de valor mais curta constitui assim uma mais-valia, permitindo consumos locais, mais facilmente rastreáveis e com menor pegada ecológica.
Conferência IADIS Ibero-Americana WWW/Internet 2012
177

É reconhecido que algumas oportunidades de desenvolvimento do espaço rural, identificadas por vários agricultores, passam pelo apoio especializado e condições para escoamento dos produtos, sem descartar o importantíssimo papel das tecnologias da informação e comunicação (Mueller, 2000).
2.3 Oportunidades de Negócio
Os produtos agrícolas são produtos de primeira necessidade o que, em geral, representa um consumo diário e rotação elevada. Este consumo pode ser doméstico ou ocorrer em unidades de restauração e hotelaria. Neste último caso pode-se atingir consumos mais elevados e com os padrões de qualidade mais exigentes. Assim, há necessidade de potenciar o associativismo para facilitar o fornecimento e distribuição em grande quantidade. Em ambos os tipos de consumidores podemos identificar algumas dificuldades: a grande maioria dos consumidores domésticos não tem disponibilidade para se deslocar ao mercado tradicional para adquirir os produtos que necessita, aproveitando as suas deslocações às grandes superfícies para comprar, também, outros produtos. Para as unidades de restauração e hotelaria a capacidade dos pequenos produtores não é suficiente para satisfazer as quantidades exigidas pelo funcionamento dos seus serviços na maior parte dos produtos.
O desenvolvimento de um serviço de intermediação direta entre produtores e consumidores representa uma efetiva oportunidade de negócio, que terá que seguir um modelo assente numa rede de parceiros e na inovação dos canais de distribuição.
2.4 Potencial de Crescimento e Expansão
A dinâmica de negócio da Quinta Digital pode passar por várias fases de desenvolvimento e de crescimento progressivo, das quais destacamos a fase inicial e os desenvolvimentos a curto e médio prazos.
No início, é expectável que seja necessário um esforço adicional na mobilização dos produtores para adesão a uma relação comercial com uma plataforma de comércio eletrónico. Um dos elementos críticos para o sucesso da iniciativa consiste em identificar produtores que sirvam de exemplo e possam demonstrar o potencial do negócio e as suas vantagens e desvantagens, decorrentes da própria experiência. O progressivo crescimento do volume de negócios desta plataforma e, por conseguinte dos produtores, será um catalisador para a atração de mais produtores e criação de uma rede alargada que diversifique a oferta disponível.
A curto prazo, existem outros produtos que poderão passar a ser oferta da Quinta Digital e que se compatibilizam com este negócio. Por exemplo, tirando proveito da designação genérica “Quinta”, a comercialização de animais, como animais domésticos, e de outros produtos de fácil manufaturação caseira, como queijo, pão, compotas ou ovos, pode garantir a contínua diversificação da oferta e a exploração de novos nichos de mercado.
E a médio prazo, com o crescimento sustentado do negócio é, também, previsível que os próprios produtores possam aumentar as suas produções e começar a desenvolver explorações com maior qualidade e diversidade. Esta situação poderá conferir a possibilidade de exportação de produtos. Poderão, assim, ser apresentados produtos de alto valor acrescentado, que valorizarão ainda mais o trabalho dos produtores e o potencial da Quinta Digital. No entanto, a sua plataforma teria que ser atualizada e devidamente preparada para uma relação comercial mais complexa.
3. MODELO DE NEGÓCIO
O modelo de negócio (e.g., Laudon, 2012) desenvolve-se em torno da necessidade dos produtores escoarem os seus produtos de forma mais eficiente e da apetência dos consumidores para comprarem estes produtos, caso estejam facilmente disponíveis e a preços baixos. O funcionamento operacional do negócio consiste na consulta aos produtores de informação a disponibilizar online sobre os produtos. Os clientes consultam a informação e escolhem os produtos que pretendem, procedendo de imediato à encomenda e ao seu pagamento. A entrega é realizada pela logística da Quinta Digital, que ganhará uma percentagem sobre o valor de venda.
ISBN: 978-989-8533-11-1 © 2012 IADIS
178

Entendemos que este negócio poderá ser sustentável através da venda de grandes quantidades de produtos com pequenas margens de lucro por unidade. Para o efeito, há que mobilizar uma rede de produtores que consiga aglomerar quantidades que satisfaçam continuamente as necessidades da exploração.
Para os consumidores a proposta de valor é a possibilidade de poderem comprar produtos de pequenos produtores de forma rápida, cómoda, segura e económica. Para os produtores, a proposta de valor consiste na visibilidade dos seus produtos no mercado global, e consequentemente na facilidade do seu escoamento, através da redução dos custos de distribuição, e consequente redução do preço de venda ou aumento das margens operacionais, e de ganhos de eficiência nos canais de distribuição.
A Quinta Digital disponibiliza informação sobre a origem, circuito de distribuição, preço e quantidade disponível de cada produto. Assim, o consumidor tem oportunidade de comparar preços entre os diversos produtores e de escolher o que considera ser o melhor. O site poderá funcionar como uma bolsa de valores, possibilitando estratégias de ajustamento de preços à procura verificada, favorecendo o comprador.
Este negócio pode ser enriquecido com alguns serviços complementares, cobrando taxas sobre as transações efetuadas. Um dos serviços consiste num sistema de leilões de cabazes de produtos ou da totalidade de produções agrícolas. É um sistema atrativo para compras antecipadas de grandes quantidades. Para os produtores, a certeza de ter a sua produção vendida e o recebimento adiantado do dinheiro compensam um eventual preço de venda mais reduzido. Outro serviço complementar consiste num sistema de vendas last minute, assente em reduções de preços unitários ou em rappel de determinados produtos, útil para o escoamento de produtos perecíveis em fim de prazo. Como fator de fidelização, é interessante disponibilizar um sistema de trocas diretas, explorado por pequenos produtores com excesso ou deficit de produtos. As recentes dinâmicas sociais, onde cada vez mais pessoas estão a procurar produzir bens deste tipo nas suas pequenas hortas, induzem a que facilmente se encontrariam boas relações de troca.
Outra forma de acrescentar valor ao negócio consiste na identificação de padrões sazonais, preferências dos consumidores e características preferenciais dos produtos transacionados, resultantes da extração de conhecimento a partir dos dados armazenados provenientes de transações, características de produtos, consumidores e produtores.
4. FINANCIAMENTO
Do planeamento já efetuado, prevemos que o financiamento para iniciar o negócio não seja elevado, adotando uma estratégia de “começar pequeno”. No entanto, uma das possibilidades mais interessantes para obter este financiamento é explorar o crowdfunding (PPL, 2012), ou seja, a recolha de pequenas contribuições financeiras de uma comunidade através de plataformas na Internet. Desta forma, estimulando, desde o início, um relacionamento próximo entre a plataforma e os produtores e/ou potenciais clientes, e incentivada por fins socialmente responsáveis. Esta forma de financiamento pode ser potenciada, através do banco de produtos agrícolas, pois levará a que os financiadores sintam que estão a contribuir para uma causa e não apenas para um negócio. Adicionalmente, podemos avançar com uma “campanha de crowdfunding” junto dos produtores que vão fornecer através da Quinta Digital os seus produtos, inovando no seu negócio e estimulando vendas.
5. CONCLUSÕES E TRABALHO FUTURO
Apresentamos uma solução baseada no comércio eletrónico para a distribuição e comercialização de produtos agrícolas, de forma a reduzir custos, impulsionar e estimular relações diretas entre produtores e consumidores finais, evitando outros intermediários na cadeia de valor. Este negócio assenta diretamente na geração de receitas através da taxação das transações e, indiretamente, através da criação de um conjunto de serviços complementares. Estes têm como objetivo implementar um modelo de fidelização para com a Quinta Digital. Sugerem-se serviços tais como a disponibilização de leilões online de lotes de produtos, gerados por um ou mais produtores, atendendo à natureza perecível destes produtos. Um serviço particularmente relevante na vertente de prestação solidária, vocacionado para instituições de solidariedade social e/ou organizações não-governamentais, pretende implementar um banco de produtos agrícolas no fim de vida.
Conferência IADIS Ibero-Americana WWW/Internet 2012
179

O projeto subjacente à Quinta Digital está envolvido na preparação de um modelo de sistema de informação, à semelhança de (Sorensen 2010), e no levantamento das ferramentas de software mais adequadas à sua implementação (vide Scobey 2012), que inclua prospeção de dados (Raghavan, 2005) e a construção de uma comunidade online especializada (Howard, 2010) para suportar e estimular o modelo de fidelização de produtores e consumidores finais.
REFERÊNCIAS
Chen, Y. et al, 2002, WTO and Agricultural E-Commerce, Proceedings of the Third Asian Conference for Information Technology in Agriculture (AFITA 2002), Beijing, China, pp. 555-558.
PPL Crowdfunding Portugal - Collective Finance, http://ppl.com.pt/, Acesso em: 27 de maio de 2012. Laudon, K. e Traver, C. 2012. E-Commerce 2012 (Eighth Edition). Pearson, United States. Howard, T. W., 2010. Design to Thrive: Creating Social Networks and Online Communities that Last. Morgan
Kaufmann, United States. Mueller, R. A. E., 2000, Emergent E-Commerce in Agriculture. AIC Issues Brief, 14, pp. 1-8. Raghavan, N. R. S., 2005. Data mining in e-commerce: A survey. Sadhana, 30 (parts 2 & 3), pp. 275-289. Scobey, P. e Lingras, P., 2012. Web Programming & Internet Technologies: An E-Commerce Approach. Jones and
Bartlett, United States. Sorensen, C. G. et al, 2010. Conceptual model of a future farm management information system. Computers and
Electronics in Agriculture, 72, 37-47. Strauss, J. e Frost, R. (2011). E-marketing (Sixth Edition), Pearson, United States.
ISBN: 978-989-8533-11-1 © 2012 IADIS
180

EVALUACION DE LA CALIDAD EN ENTORNOS VIRTUALES DE APRENDIZAJE: USO DE ONTOLOGÍAS Y
AGENTES DE SOFTWARE
Lilliam N. Robinson O.1, Clifton Clunie2 y Sergio Crespo3 1Universidad Tecnológica de Panamá, Maestría en Ciencias y Tecnología de Información y Comunicación
Panamá, Panamá 2Universidad Tecnológica de Panamá, Profesor Titular de la Facultad de Ingeniería en Sistemas Computacionales
Panamá, Panamá 3UNISINOS, Brasil, Universidade do Vale do Rio dos Sinos UNISINOS, São Leopoldo, .Brasil
RESUMEN
Este artículo presenta una propuesta para el desarrollo de una estructura de evaluación de calidad en entornos virtuales; utilizando ontologías y agentes de software como elementos de la ingeniería de software. Las ontologías permiten inferir el conocimiento que será utilizado en las evaluaciones de cursos en la plataforma Moodle, para posteriormente el conocimiento pueda ser compartido mediante protocolos de comunicación siendo los encargados de realizar esta labor, los agentes de software.
PALABRAS CLAVES
Calidad; Ontología; Agentes de Software; Entorno Virtual; Moodle.
1. INTRODUCCIÓN
La educación virtual se ha convertido en una herramienta que apoya la práctica educativa y surge por el hecho de que en la actualidad los procesos de enseñanza y aprendizaje han cambiado como resultado del desarrollo de las tecnologías de la información y comunicación.
Tomando en cuenta estos cambios y de acuerdo a (Naidu 2006) podemos definir e-learning como actividades educativas de tipo electrónico que se llevan a cabo por individuos o grupos de trabajos en líneas o sin conexión, de forma síncrona o asíncrona a través de ordenadores conectados en red o autónomos y otros dispositivos electrónicos. Este mecanismo de educación, está siendo utilizado tanto en universidades como en organizaciones de manera general. Este compromiso de uso, conlleva un compromiso de aprendizaje que dependerá además de otros factores de calidad de contenidos que estén siendo construidos y los procedimientos de mediación y seguimientos que deben ser aplicados.
La calidad es la diferencia entre lo que se espera recibir del sistema y la percepción del servicio recibido. Los estudios de calidad son particularmente importantes considerando la velocidad del crecimiento de la educación a distancia basada en internet (Correa Gorospe 2004). El desarrollo de la calidad e-learning es utilizado en áreas de formación e instituciones educativas, la calidad debe ser integrada en el proceso de desarrollo en lugar de ser aplicada después del desarrollo del producto. Los enfoques de calidad varían de acuerdo al alcance y objetivo previsto tomando en cuenta: excelencia, aptitud para el propósito, conformidad, rendimiento, satisfacción de usuario, estandarización e innovación (Dondi, Moretti et al. 2006).
Este artículo consta de siete secciones, en la siguiente sección muestra los trabajos relacionados con la temática a desarrollar. La sección 3 introduce el concepto de ontología y su funcionalidad en la ingeniería de software. La sección 4 introduce la característica de los agentes de software. En la sección 5 se expone la propuesta para el uso de agentes de software, en el desarrollo del modelo cualitativo – cuantitativo. Finalmente la sección 6 y 7 se presentan las conclusiones y referencias respectivamente.
Conferência IADIS Ibero-Americana WWW/Internet 2012
181

2. TRABAJOS RELACIONADOS.
Actualmente existen experiencias relacionados con la evaluación de calidad en entornos virtuales. En (Dondi, Moretti et al. 2006) se exploran diferentes conceptos de calidad, tomando en cuenta las diferentes visones mundiales y valores de acuerdo a su naturaleza y cultura. Este estudio permitió la creación de un marco conceptual (SEQUEEL) que es un intento de integrar una estructura con diferentes valores y criterios, que están detrás de diferentes enfoques. Este trabajo integra tres elementos de percepción, los cuales se mencionan a continuación: las fuentes de aprendizaje, proceso del núcleo de aprendizaje y el contexto de aprendizaje. Estos enfoques permitieron clasificar los criterios de evaluación que pueden ser realizados en los entornos virtuales, dependiendo del objetivo que se persigue. Por ejemplo el criterio de profesor calificado se encuentra dentro del elemento de fuentes de aprendizaje y que es enmarcado en la fase de calidad del proceso e-learning, dentro del modelo conceptual cualitativo-cuantitativo propuesto.
En (Pawlowski 2007) presenta un modelo de adaptación de calidad, identificando los pasos e instrumentos que permite a la norma ISO/IEC 19796-1 ser implementada con éxito en las instituciones educativa, considerando que un sistema de calidad en una organización educativa requiere cuatro pasos: contextualización, adaptación del modelo, implementación/adopción del modelo y desarrollo de la calidad, considerando que el modelo es genérico por lo que propone realizar más investigaciones con el objetivo de analizar y diferenciar los requisitos de adaptación para diversos países.
3. ONTOLOGIAS
En general, una ontología describe formalmente un domini, consistiendo en una lista finita de términos, y relaciones entre estos términos. Los términos denotan conceptos importantes (clases de objetos) del dominio(Antoniou and Van Harmelen 2004).
Para representar el marco ontologico utilizamos el trabajo definido en (Robinson and Clunie 2012) donde se propone el uso del Formalismo de Representación de la Ingeniería de Software-REFSENO, formalismo que permite representar ontologias en la ingeniería de software, con tablas, diagramas y textos dando como resultado una ontología semiformal (Tautz and von Wangenheim 1998), el uso de esta estructura se debe a que facilita la elaboración de las sub ontologías para las fases de de calidad del proceso e-learning, calidad del producto y calidad en uso.
El desarrollo de la ontologia esta basado en lenguajes OWL e implementada por JENA (Jena and Fuseki 2004) un marco de web semantica que permite trabajar con los lenguajes OWL, RDF entre otros además de hacer uso de SPARQL que es un protocolo y lenguaje de consulta. La importancia del uso de ontologías radica en compartir e inferir conocimiento, sin embargo se hace necesario el uso de protocolos de comunicación como agentes de software que favorezcan el intercambio de información.
4. AGENTES DE SOFTWARE.
La complejidad de los problemas en la ingeniería de software se ha incrementado, lo cual conlleva a hacer uso de metodologías, herramientas y niveles de abstracción que permitan dividir el trabajo y solucionar el problema. A través de la tecnología de agentes es posible integrar nuevos métodos de análisis y diseños sobre la forma de abordar y solucionar los problemas.
De acuerdo a (Wooldridge and Jennings 1995) e (Hipóla and Vargas 2005) un agente puede definirse como una entidad de software autónomo capaz de decidir qué acciones debe llevar acabo considerando el entorno en que se encuentra y garantizando que los objetivos establecidos sean alcanzados. Los agentes pueden clasificarse en: agentes de interface, agentes colaborativos, agentes móviles, agentes de recuperación de información y agentes deliberativos. La funcionalidad de los agentes depende de los aspectos que se coordinen para lograr una comunicación efectiva, la forma de coordinarlos está establecida por la FIPA (Hipóla and Vargas 2005) consorcio internacional fundado para desarrollar las tecnologías de agentes inteligentes considerando las especificaciones de arquitecturas, infraestructura y aplicaciones.
Entre los aspectos que deben ser considerados para una comunicación efectiva son los siguientes: la terminología utilizada en el contenido de los mensajes deben ser las ontologías, el lenguaje de codificación
ISBN: 978-989-8533-11-1 © 2012 IADIS
182

deberá estar basado en el FIPA-SL, la estructura de los mensajes está basada en el FIPA-ACL, el protocolo de intercambio de mensajes está basado en el FIPA-Protocols. El funcionamiento de los agentes está basado en JADE (de Araujo Lima, de Lima Machado et al. 2003) que es un conjunto de clases de java que permite construir un FIPA para el uso de agentes.
5. UNA ARQUITECTURA PARA LA EVALUACIÓN DE CALIDAD EN ENTORNOS VIRTUALES DE APRENDIZAJE USANDO AGENTES DE SOFTWARE Y ONTOLOGIAS
En (Clunie 2011) se propuso un modelo de evaluación que incluye aspectos cualitativos y cuantitativos, que presenta observaciones de la calidad en tres momentos diferentes: calidad del proceso, calidad del producto y calidad en uso. Este modelo busca asegurar un adecuado control de calidad durante el proceso de desarrollo de un curso virtual y garantizar la calidad del proceso y del producto final en (ROBINSON AND CLUNIE 2012) se presenta una propuesta para la integración de la ontología en este modelo, como se muestra en la Figura1.
Figura 1. Modelo Conceptual Cualitativo – Cuantitativo
• Fase 1: La calidad del proceso es realizada a través del tratamiento de un conjunto de variables y considerando los consensos creados sobre los estándares SCORM, IEEE, IMS, MECA-ODL (Metodología de la Calidad de la Formación abierta y a Distancia) y la norma ISO, basada en el Marco de Referencia para la Descripción de Calidad para el aseguramiento de la calidad del proceso. La representación de esta fase se observa en la Figura 2 y es similar a los diagramas de clases de UML. En este diagrama de conceptos se presentan los elementos contenidos dentro de la ontología que serán evaluados por el agente. Cuando el agente 1, termina de realizar la evaluación de calidad, almacena el resultado obtenido, mantiene el concentrado del resultado y envía la orden de ejecución al agente 2.
Conferência IADIS Ibero-Americana WWW/Internet 2012
183

Design Model::Ontologia_Proceso de calidad
Infra Estructura Tecnológica
Contexto Institucional
Profesores Calificados
Recursos
Equipo Multidisciplinario
Planeamiento Educativo
Características del Estudiante
Modelo PedagógicoAgente 1
1..*1
Moodle
Obtener información
Evalua las clases de ontologia
Evaluación
Almacenar Resultados BD
Evaluar
Salvar Resultados
Usuario
Solicitud de Evaluación
1
1
Figura 2. Diagrama de conceptos manejados por el agente 1- Fase 1.
• Fase 2: La calidad del producto de solución e-learning es observada considerando cinco visiones de especialidad: psicología, contenido, pedagogía, comunicación educativa e informática. En la Figura 3 muestra el diagrama de conceptos que permite observar el comportamiento de evaluación, realizado por el agente 2, evaluando las características de las visiones de los especialistas. Finalizada la evaluación de cada una de las visiones, el agente 2, almacena los resultados detallados, mantiene concentrado final del resultado obtenido y envía la orden de proceder al agente 3, para continuar con el proceso de evaluación del curso.
• Fase 3: La calidad en uso depende de un conjunto de factores como calidad del servicio, aspectos socio-culturales, accesibilidad, satisfacción, seguridad, efectividad, mediación pedagógica, aspectos legales entre otros. En esta etapa del modelo se evalúan un conjunto de variables que determinan la calidad en uso, dichas variables constan de unas series de indicadores que permitirán conocer, si todo el proceso realizado genera los resultados esperados desde la concepción del curso.
En la Figura 4, el agente 3, identifica las clases contenidas en la ontología de la calidad en uso, una vez finalizado el proceso de evaluación el agente 3 almacena los resultados en detalle y toma los datos recopilados por los otros agentes y para presentar el resultado de evaluación al usuario.
Design Model::Ontologia_Producto de Calidad
Sicología
Sistema de Información
Pedagogia
Andragogía
Especialista en ContenidoAgente 2
1..*1
Moodle
Obtener información
Evalua las clases de ontologia
Evaluación
Almacenar Resultados BD
Evaluar
Salvar Resultados
Ordena ejecución del agente 2
1
1
Agente 1
Figura 3. Conceptos manejados por el agente 2 – Fase 2.
El modelo de agente de software que se propone utilizar corresponden a agentes colaborativos y recuperación de información mencionados en la sección 4. En la Figura 5, se muestra la relación y funcionamiento que deberán tener los agentes y su relación con la ontologías, para el desarrollo de un curso inexistente en la plataforma educativa Moodle que será utilizada para las experiencias a desarrollar y validación del modelo cualitativo-cuantitativo.
ISBN: 978-989-8533-11-1 © 2012 IADIS
184

Design Model::Ontologia_Calidad en Uso
Calidad de los Servicios
Multiculturalidad
Costo Benef icio
Monitorización Y Evaluación
Cuestiones Legales
Agente 3
1..*1
Moodle
Obtener información
Evalua las clases de ontologia
Evaluación
Almacenar Resultados BD
Evaluar
Salvar Resultados
Ordena ejecución del agente 3
1
1
Agente 2
Resultado de la Evaluación<<artifact>>
Resultados
Eficacia
Mediación Pedagógica Segur idad
A ccesesibilidad
Figura 4. Conceptos evaluados por el agente 3 y presentación del resultado final – Fase 3.
En este módulo el usuario, ejecuta el agente 1, encargado del desarrollo de la fase 1, este agente realiza consultas en la plataforma sobre el curso a crear, obteniendo como resultado el formato del curso correspondiente a la fase 1 y facilitando la información al agente 2, agente 2 lleva datos ingresada por el usuario, en este punto se realiza el proceso de consulta y recuperación de información, dando lugar a la definición del formato del curso tomando en cuenta la fase 1 y 2. El agente 2 se relaciona con el agente 3. Agente encargado de la evaluación final y almacenamiento del curso dentro de la plataforma Moodle.
Figura 5. Modelo para la creación de cursos en la plataforma Moodle haciendo uso de agentes.
Figura 6. Modelo para la evaluación de cursos mediante agentes de software.
Conferência IADIS Ibero-Americana WWW/Internet 2012
185

En la Figura 6, se representa el módulo para la evaluación de calidad para cursos existentes dentro de la plataforma. En este módulo el usuario, ejecuta el agente 1, encargado de la evaluación del proceso de calidad. Este agente realiza la evaluación y almacena los resultados obtenidos. Una vez almacenados los resultados el agente da la orden de ejecución al agente 2, con la finalidad de evaluar el proceso de calidad y almacenar la información obtenida. El agente 2 ordena al siguiente agente ejecutar el proceso de evaluación de calidad en uso que corresponde a la fase 3. El agente 3 es el encargado de guardar la información y finalmente analizar los resultados obtenidos en las fases 1 y 2.
6. CONCLUSIÓN
Los cambios tecnológicos involucran el diseño de herramientas, que permitan valorizar la calidad sobre los cursos virtuales que se ofertan diariamente, con la finalidad de brindar satisfacción a quienes hacen uso del e-learning como herramienta de estudio.
Este documento forma parte de la propuesta presentada por (Clunie 2011) y (Robinson and Clunie 2012), en los cuales se presento un modelo de evaluación cualitativo – cuantitativo y la integración de las ontologías respectivamente. El objetivo de la integración de los agentes de software se debe a que son elementos autónomos capaces de tomar decisiones además permiten filtrar información, haciendo uso de los axiomas que se establecerán en las ontologías, lo que representa ganancia en tiempo de la búsqueda de información ya que por medio de la ontologia los conceptos a evaluar estan mejor organizados, facilitando la evaluación de la calidad en los entornos virtuales.
El escenario presentado en este artículo debe ser corroborado y ampliado con la aplicación del modelo presentado por (Clunie 2011) ,desarrollar las ontologías y finalmente la herramienta donde se incluyen los agentes de software, propuestos en este artículo.
REFERENCIAS
Antoniou, G. and F. Van Harmelen (2004). A semantic web primer, the MIT Press. Clunie, C. E. (2011). "MODEL FOR THE EVALUATION OF EDUCATIONAL QUALITY USING VIRTUAL
LEARNING ENVIRONMENTS." IADIS: International Association for Development of the Information Society: 5. Correa Gorospe, J. M. (2004). "¿ Calidad educativa on-line?: análisis de la calidad de la educación universitaria basada
en Internet." Pixel-Bit: Revista de medios y educación(24): 11-42. de Araujo Lima, E. F., P. D. de Lima Machado, et al. (2003). "Implementing Mobile Agent Design Patterns in the JADE
framework." Special Issue on JADE of the TILAB Journal EXP. Dondi, C., M. Moretti, et al. (2006). "Quality of e-learning: Negotiating a strategy, implementing a policy." Handbook on
quality and standardisation in e-learning: 31-50. Hipóla, P. and B. Vargas (2005). "Agentes Inteligentes: Definición y Tipología." Revista Internacional Científica y
Profesional. Jena, J. and P. Fuseki (2004). "Semantic Web Frameworks." Naidu, S. (2006). E-learning: A guidebook of principles, procedures and practices, Commonwealth Educational Media
Centre for Asia (CEMCA). Pawlowski, J. M. (2007). "The quality adaptation model: Adaptation and adoption of the quality standard ISO/IEC
19796-1 for learning, education, and training." JOURNAL OF EDUCATIONAL TECHNOLOGYAND SOCIETY 10(2): 3.
Robinson, L. and C. E. Clunie (2012). FRAMEWORK FOR EVALUATION OF EDUCATIONAL QUALITY IN VIRTUAL LEARNING ENVIRONMENT USING SOFTWARE ENGINEERING ONTOLOGIES. INTED2012 Proceedings - 6th International Technology, Education and Development Conference, Valencia, Spain.
Tautz, C. and C. G. von Wangenheim (1998). REFSENO: A representation formalism for software engineering ontologies, Fraunhofer-IESE.
Wooldridge, M. and N. R. Jennings (1995). "Intelligent agents: Theory and practice." Knowledge engineering review 10(2): 115-152.
ISBN: 978-989-8533-11-1 © 2012 IADIS
186

ELABORACIÓN DE UN AMBIENTE DE CHAT SEMÁNTICO COMO APOYO A PROCESOS DE
INGENIERÍA DE SOFTWARE Y ADMINISTRACIÓN DE PROYECTOS POR MEDIO DE AGENTES DE SOFTWARE
Ing. Samuel Díaz1, PhD. Sergio Crespo2 y PhD. Clifton Clunie1 1Universidad Tecnológica de Panamá
2Universidade do Vale do Rio dos Sinos, Brazil
RESUMEN
Este artículo tiene como finalidad la presentación de una propuesta de investigación enfocada a dar soporte a los equipos de desarrollo de proyectos de software por medio de una herramienta de chat con capacidades de inteligencia artificial. Esta herramienta busca ayudar a ampliar información y resolver dudas relacionadas a los procesos que se siguen en las etapas de la Ingeniería de Software y la Administración de Proyectos. Para la implementación se contempla el uso de las tecnologías y herramientas que ofrece la Web Semántica, entre ellas las ontologías y los agentes de software. Las ontologías se emplearan para crear las bases de conocimiento de la Ingeniería de Software y la Administración de Proyectos mediante el enfoque RUP y PMBOK respectivamente. Los agentes de software se encargarán de consultar el vocabulario propuesto por las ontologías para ampliar la información que requieren los equipos de proyecto.
PALABRAS CLAVES
Ingeniería de Software, Administración de Proyectos, Ontologías, Agentes de Software, Chat Semántico
1. INTRODUCCIÓN
La Ingeniería de Software es la disciplina encargada de ofrecer técnicas y métodos para desarrollar y mantener software de calidad (Pressman 2010 ). Esta rama de la ingeniería se implementa en conjunto con la disciplina de Administración de proyectos para lograr con éxito la realización de sistemas de software, asegurando que se cumplan los objetivos con los estándares de calidad esperados.
La administración de proyectos es una actividad fuertemente social ya que depende de la coordinación eficaz del recurso humano para lograr con éxito los requisitos del sistema a construir; por lo que la comunicación juega un rol importante en esta disciplina. Estudios realizados por DeMarco (1999) revelan que los desarrolladores de sistemas pasan el 70% del proyecto trabajando con otras personas, por otro lado Jones (1987) muestra que 85% de los costos de grandes proyectos de software están relacionados con los trabajos en equipo.
La gestión de proyectos ha evolucionado para adecuarse a la era de la globalización que es cada vez más pronunciada, surgiendo así el desarrollo de software global donde la comunicación se vuelve más compleja. El desarrollo de software global se puede ver influenciado por varios factores claves para la realización eficaz de los proyectos, entre ellos: comunicación y coordinación eficiente, unificación de conocimientos y ambientes de trabajo (Dillon 2008). Debido a estos factores es necesario tener una herramienta de comunicación lo suficientemente robusta para responder a estas eventualidades. La web es naturalmente el medio ideal para llevar a cabo este proceso.
La web se ha convertido en la principal fuente de información a nivel mundial. Sin embargo uno de los problemas que enfrenta es la obtención de contenido de calidad. Esta problemática se debe al crecimiento cada vez mas agilizado de recursos disponibles en la red. Los motores de búsqueda son cada vez más limitados al momento de ofrecer resultados de calidad en base a nuestras consultas. Esto ocurre porque la web actual no cuenta con la estructura adecuada para ser entendida de forma autónoma por sistemas de
Conferência IADIS Ibero-Americana WWW/Internet 2012
187

cómputo sin ser necesaria la intervención humana. Por esta razón surge a finales de los 90 la Web Semántica propuesta por Tim Berners Lee, como paradigma para solventar esta situación.
La web semántica se define en (Berners-Lee 2001) como una evolución de la web actual donde la información está dotada de un significado bien definido, y puede ser procesada e interpretada por las máquinas. La web semántica se apoya en diversas tecnologías para lograr su cometido, entre ellas las ontologías y los agentes de software. Las ontologías brindan el conocimiento necesario sobre un dominio específico; por su parte los agentes de software emplean facultades de inteligencia artificial para analizar este conocimiento con la finalidad de tomar decisiones en base a problemáticas y objetivos definidos.
Como es natural, los humanos tienen la tendencia de cometer errores, lo cual trae como resultado no poder lograr los objetivos deseables en el proyecto. Dichos errores pueden generarse por una comunicación deficiente, toma pobre de decisiones y falta de información útil para el proyecto. Las ontologías y los agentes de software son una alternativa ideal para facilitar la obtención de información, la comunicación y coordinación en la administración de proyectos, disminuyendo los errores para brindar resultados de calidad.
Con respecto a las bondades que ofrece en cuanto a la comunicación la web ha ido evolucionando con miras a convertirse en un gran entorno social en el que las personas están en contacto en todo momento; siendo las redes sociales la tecnología protagónica de esta evolución. El desarrollo de la web 2.0 ha contribuido al crecimiento de estas plataformas convirtiéndolas en uno de los principales medios de comunicación. Estas constituyen un recurso que puede contribuir significativamente a la interacción entre los equipos de proyectos.
El trabajo de investigación se centra en crear bases de conocimiento de los procesos de la Ingeniería de Software y la Gestión de proyectos las cuales serán analizadas por agentes de software para dar respuesta a interrogantes y problemas que enfrentan los miembros de los equipos de proyecto. Esta actividad será llevada a cabo en un ambiente de red social tipo chat por medio del cual las personas interactuaran y en base a estas interacciones los agentes buscaran y devolverán información relevante al tema de conversación.
El resto del artículo está organizado de la siguiente manera: la sección 2 describe trabajos relacionados con la temática de investigación. La sección 3 detalla el concepto de la web semántica y agentes de software. La sección 4 abarca la especificación de la propuesta de investigativo dando a conocer la arquitectura y las herramientas usadas para la implementación. La sección 5 presenta las conclusiones.
2. TRABAJOS RELACIONADOS
Han sido varios los trabajos publicados con miras a contribuir con el mejoramiento de la experiencia en los proyectos de software a partir de las bondades que ofrece la Web Semántica. Entre ellos destaca la labor realizada por Wongthongtham (2007). En la cuál se utilizan agentes de software que proporcionan información actualizada de los proyectos de software. Los agentes logran esta tarea por medio de ontologías de software que evolucionan para reflejar avances en las tareas. Por otro lado los agentes ofrecen la capacidad de recomendar soluciones frente a los conflictos que se susciten, en base a la experticia de los involucrados en el proyecto. El trabajo realizado por Seedorf (2006) hace énfasis en la ventaja de las ontologías en cada una de las etapas de la Ingeniería de Software, describiendo inconvenientes típicos en cada fase y como estos pueden ser solucionados. El proyecto explicado en (Happel 2008) presenta la creación de una ontología de proyectos de software que luego se implementa como una wiki semántica. Este entorno web puede ser editado y consultado por sus usuarios con el objetivo de documentar semánticamente los entregables del proyecto y mejorar los aspectos de administración de calidad de los mismos. Otro proyecto que se beneficia de las wikis semánticas es el expuesto en (Garcia 2010) donde el autor presenta una Web Semántica de Ingeniería de Software en la que construye un punto de acceso para desarrolladores con el objetivo de compartir conocimiento sobre los proyectos.
3. LA WEB SEMÁNTICA Y LOS AGENTES DE SOFTWARE
La web semántica es el medio por el cual la información puede ser procesada a través de herramientas automatizadas, permitiendo así el descubrimiento de recursos web en base a contenido y no por palabras clave (Guestrin 2002). Para que la web semántica pueda lograr su cometido debe existir un vocabulario
ISBN: 978-989-8533-11-1 © 2012 IADIS
188

común que sea entendible por las máquinas y que describa el dominio en particular que se desea representar. Aquí es donde entran en juego las ontologías.
La definición más aceptada es la dada por Gruber (1993) la cual establece que una ontología es una especificación formal y explícita de una conceptualización compartida. Las ontologías facilitan la definición de los conceptos presentes en los diferentes dominios, su representación jerárquica y las diferentes relaciones que existen entre los conceptos. Gracias a esto, las maquinas pueden llegar a entender la semántica asociada a los recursos web. OWL <Web Ontology Language> es el lenguaje de etiquetado semántico ideado por W3C (2009) para crear y manejar ontologías en la red. Permite definir el significado de términos en vocabularios y las relaciones entre ellos.
Un agente de software es una entidad de cómputo capaz de recolectar, filtrar y analizar información de manera autónoma (Sidnal 2006). Estas actividades hacen al agente apto para tomar decisiones y brindar respuestas en base a consultas hechas por el usuario sobre un dominio específico.
La web semántica busca enriquecer la web extendiéndola a un ambiente en donde además de existir interacción entre humanos, haya una intervención de los agentes de software. Usualmente el humano es el encargado de analizar, determinar la semántica de los datos y tomar decisiones al respecto. Los agentes están diseñados para llevar a cabo estas tareas en su totalidad de una manera más rápida y precisa (Sidnal 2010).
Para tomar sus decisiones los agentes de software consultan la base de conocimiento creadas en las ontologías. Esta actividad se realiza por medio del estándar FIPA (Kone 2000), organismo internacional que provee un conjunto de especificaciones necesarias para la comunicación e interoperabilidad efectiva de los agentes por medio del llamado Lenguaje de Comunicación de Agentes (Kone 2000). Este lenguaje brinda las reglas que requieren los agentes para interpretar el contenido de las ontologías y que permite a distintos agentes interactuar.
4. PROPUESTA DE INVESTIGACIÓN
La propuesta de investigación contempla la elaboración de un ambiente red social tipo chat. Esta herramienta tiene la finalidad de orientar a las empresas involucradas en proyectos de software y proponer soluciones a dudas que se tengan referentes a cada una de las etapas que se siguen en el proceso de requerimientos, diseño, implementación y documentación utilizando el enfoque Rational Unified Process <RUP> También tomará en consideración las etapas de administración en donde se manejan variables claves de tiempo, coste, calidad y recursos utilizados. Para la fase de gestión se escogió la metodología establecida por Project Management Body of Language <PMBOK>.
Los dominios de RUP y PMBOK se modelaran por medio de ontologías destacando los procesos a manera de conceptos, entidades y relaciones. Para el diseño de la ontología se empleará un framework denominado JENA (Apache 2011), encargado de dar soporte a la ontología para ser tratada en ambientes de programación web por medio de Java.
El proyecto será de naturaleza multi agente, ya que se emplearán varias estructuras de agentes de software que colaborarán entre sí y con el usuario. Los agentes se crearán con el framework JADE (Bellifermine 2005) también basado en Java. Las consultas a la base ontológica serán construidas utilizando el lenguaje de consultas SPARQL, debido a que provee las características RDF necesarias para la búsqueda de información dentro de la ontología. La comunicación entre agentes con las ontologías se dará siguiendo las reglas establecidas por el estándar FIPA.
El diseño de la plataforma de chat se implementará como un entorno gráfico tipo web construido en Java por medio de JSP <Java Server Pages>, tecnología que permite el desarrollo de proyectos web dinámicos. Se escoge esta herramienta para lograr un mayor grado de interoperabilidad con las ontologías y los agentes de software. Dentro de la plataforma, los miembros del equipo de software podrán intercambiar información referente al proyecto por medio de conversaciones como se aprecia en la Figura 1.
Conferência IADIS Ibero-Americana WWW/Internet 2012
189

Figura 1. Representación de intercambio de información en el ambiente chat
La interfaz permitirá a los usuarios elegir el momento que ellos consideran necesario para que el agente evalúe y amplié la información que comparten. Esta modalidad se implementara de esta manera ya que se puede dar el caso de que los usuarios del sistema comenten asuntos no relevantes al proyecto o que no necesitan la asistencia de agentes.
Los textos introducidos por los usuarios son analizados palabra por palabra por los agentes, los cuales tendrán la labor de aplicar un filtro para identificar conjuntos de palabras relevantes. Las mismas serán posteriormente consultadas en las ontologías creadas para verificar si guardan relación directa con los dominios de RUP y PMBOK. Un diagrama de esta tarea se presenta en la Figura 2.
Los filtros de palabras relevantes se realizaran programando al agente en conjunto con técnicas sintácticas y semánticas de procesamiento de lenguaje natural. Entre las técnicas a tomar en cuenta se encuentra la tokenización por medio de la cual se planea segmentar el texto en ítems para luego clasificarlo utilizando el enfoque de etiquetado POS <Part of Speech tagging>. Este enfoque tiene como objetivo catalogar las conversaciones por medio de sus estructuras gramaticales, permitiendo así filtrar términos irrelevantes a la consulta ontológica como artículos, preposiciones, signos de puntuación, entre otros. Para la implementación del filtrado se planea utilizar la herramienta de libre acceso llamada Gate <General Architecture for Text Engineering> (Cunningham ) . Gate presenta dentro de su arquitectura las técnicas de procesamiento de lenguaje natural descritas y es compatible con el ambiente de programación Java lo cual permitirá integrarla sin mayores problemas con los agentes de software.
Figura 2. Esquema representativo de análisis de la información contenida por medio de agentes de software
Una vez identificada a que ontología pertenece la información el agente de software se encargará de suministrar mayor información a los participantes del chat en las ventanas privadas de cada usuario.
Este contenido es extraído de una búsqueda semántica en la web en base a la información encontrada en la ontología como se aprecia en la Figura 3. Esta búsqueda se hará haciendo énfasis en fuentes presentadas en las wiki semánticas. Como se expone en los trabajos de Happel (2008) y García (2010 ), estas presentan la estructura correcta para ser leídas y analizadas por los agentes.
ISBN: 978-989-8533-11-1 © 2012 IADIS
190

Figura 3. Representación de la extracción de nuevos contenidos de la web
Mediante estos nuevos contenidos, los participantes del proyecto tendrán más recursos para contribuir información relevante en el chat, que los ayudará a llevar a cabo cada una de las etapas que contempla el proyecto.
Los agentes presentarán varias fuentes de información que corresponden a datos importantes del proyecto en base a las conversaciones sostenidas en el chat semántico. A medida que los usuarios van seleccionando la fuente de mayor preferencia a utilizar en el proyecto los agentes irán armando de manera interna un historial de las fuentes que los usuarios más utilizan para consultar información. Así cada vez que el agente haga la búsqueda aplicará un filtro con la finalidad de traer los resultados ordenados por orden de preferencia del usuario. Cada participante tiene de igual forma la posibilidad de ver que fuentes de información son las que más frecuenta.
A continuación se muestra la arquitectura del trabajo destacando la implementación de 4 agentes de software, los cuales se encuentran descritos en la Figura 4.
• Agente 1: monitoreará las conversaciones en el chat. Este agente se encargará de filtrar los posibles términos que sean relevantes para ser buscados en las ontologías.
• Agente 2: el agente 1 entregará la información recolectada y filtrada para que este agente analice palabra por palabra verificando la existencia de los términos dentro de las ontologías.
• Agente 3: manipulará los términos identificados dentro de la ontología y se encarga de hacer una búsqueda en la web sobre información que complemente los temas tratados. Esta se envía al agente 1 el cual la distribuirá a los usuarios pertinentes.
• Agente 4: se encargará de manipular, actualizar e interpretar el perfil del los distintos usuarios de acuerdo a la información que consultan. El agente 4 estará en contacto con el agente 1 para informarle sobre las preferencias actualizadas de la consulta de los usuarios para que en futuras búsquedas el agente de interfaz despliegue los resultados ordenados de acuerdo a estas preferencias.
Figura 4. Arquitectura de agentes para el chat semántico
Conferência IADIS Ibero-Americana WWW/Internet 2012
191

5. CONCLUSIONES
Este proyecto ha sido expuesto como una propuesta en beneficio de la implementación de proyectos de software ya que brindará un protocolo de intercambio de información inteligente que permitirá automatizar los procesos de búsqueda de información sobre interrogantes y conflictos que surgen a diario en cada una de las fases de los proyectos. Esto con el objetivo de mejorar la manera en que colaboran los equipos de trabajo.
La utilización de ontologías permitirá la representación de la información de una forma más estructurada en comparación con otras tecnologías lo cual se espera ayude a mejorar los procesos y tiempos de búsqueda, brindando resultados de mayor calidad. Por su parte con la implementación de agentes de software se tiene como expectativa la optimización de la interoperabilidad en el entorno semántico sobre todo en cuanto al minado de datos dentro de las ontologías facilitando las tareas de filtrado y selección del contenido. El diseño de la arquitectura también contempla la interacción de los agentes con el usuario con lo cual se planea que estas entidades adquieran la experticia necesaria para ofrecer soluciones de acuerdo a sus exigencias y preferencias .Como trabajo futuro se implementará el proyecto descrito generando así prototipos y artículos que detallen los avances que se van teniendo en la investigación.
REFERENCIAS
Apache 2011, Apache Jena, visitada 4 de Junio de 2012, <www.jena.apache.org> Bellifermine, F. et al, 2005. Jade-A Java Agent Development Framework. MultiAgent Programming. Vol. 15, pp 125-
147. Berners-Lee, T. et al, 2011. The Semantic Web. Scientific American. pp 29-37. Cunningham, H. et al, 2002. GATE: an Architecture for Development of Robust HLT Applications. In Recent Advanced
in Language Processing. Pp 168-175. DeMarco, T., 1999. Peopleware: productive projects and teams. Dorset House Publ., New York, EUA Dillon, T.S. et al, 2008. Ontology-Based Software Engineering-Software Engineering 2.0. Proceedings from the 19th
Australian Conference on Software Engineering. Perth, Australia, pp 13-23. García, R. et al, 2010. Semantic Wiki for Quality Management in Software Development projects. Software IET. Pp 386-
395. Gruber, T.R. , 1993. A translation Approach to Portable Ontology Specification, Knowledge Acquisition, vol. 5, No. 2, pp
199-220. Guestrin, C. et al, 2002. Coordinated Reinforcement Learning. Proceedings of the 19th International Conference on
Machine Learning. South Wales, Australia, pp 227-234. Happel, J. et al, 2008. TEAM: Towards a Software Engineering Semantic Web. Proceedings of the 2008 international
workshop on Cooperative and human aspects of software engineering. New York, Estados Unidos, pp 57-60. Jones, C., 1986, Programming Productivity, McGraw-Hill, New York, EUA. Kone, M. et al, 2000. The State of the Art in Agent Communication Languages. Knowledge and Information Systems.
Vol. 2, No. 3, pp 259-284. Pressman, R., 2010. Software engineering: a practitioner’s approach. McGraw-Hill, New York, EUA. Seedorf, S. et al, 2006. Applications of Ontologies in Software Engineering. Proceedings from the 5th International
Semantic Web Conference. Atenas, Grecia. Sidnal, N.S. et al, 2006. Agent Environment for mobile commerce. Proceedings of OBCOM International Conference on
Mobile Ubiquitous and Pervasive Computing. Vellore, India. Sidnal, N.S: et al, 2010. Service Discovery using Software Agents in Semantic Web. Proceedings from the 11th
International Conference on Control Automation Robotics & Vision. W3C, 2009. OWL Web Ontology Language , visitada 4 de Junio de 2012, < http://www.w3.org/TR/owl-features/> Wongthongtham, P. et al, 2007. Towards Social Network Based Approach for Software Engineering Ontology Sharing and Evolution. Proceedings of the OTM Confederated International Conference on On the Move to meaningful internet systems. Arlgarve, Portugal, pp 1233-1243.
ISBN: 978-989-8533-11-1 © 2012 IADIS
192

AVALIAÇÃO DO NÍVEL DE SINAL EM UMA REDE EM MALHA SEM FIO BASEADA NO PADRÃO 802.1a
Rothschild A. Antunes1, Rafael B. Scarselli1, Ruy de Oliveira1, Valtemir E. do Nascimento1, Ed’Wilson T. Ferreira1 e Ailton Akira Shinoda2
1IFMT, Cuiabá, Brasil 2UNESP, Ilha Solteira, Brasil
RESUMO
Este artigo apresenta estudo dos efeitos de variação de sinal com diferentes antenas baseados em uso de softwares e protocolos de código aberto em uma rede em malha sem fio instalada em Cuiabá. São apresentados resultados de análise de nível de sinal e largura de banda que demonstram a viabilidade da rede para acesso a internet.
PALAVRAS-CHAVE
Redes em Malha, Antenas e Propagação, Teste de Desempenho.
1. INTRODUÇÃO
As redes de computadores têm apresentado crescimento significativo nos últimos anos, sobretudo as redes sem fio. É provável que a diminuição significativa dos preços dos equipamentos tenha contribuído para esta proliferação. Além do modelo tradicional, com a existência de pontos de acesso, esta rede também suporta um modelo sob demanda ou ad hoc, como apresentado em (Johnson, 2001) e (Hauenstein, 2002).
Os dispositivos que compõe uma rede ad hoc realizam o encaminhamento de pacotes dos nós vizinhos, tornando-se uma rede cooperativa, e que disponibiliza diversos caminhos para um mesmo destino. Em alguns casos, mesmo que determinados nós deixem de funcionar, é possível que os pacotes alcancem seu destino, pois outros nós poderão suprir o roteamento que deveria ter sido executado pelos nós que deixaram de funcionar. Mesmo com estas características, a instalação e configuração destas redes são relativamente simples e rápida, por este motivo, pode ser utilizada para atender necessidades efêmeras, ou prover conectividade para acesso à Internet para uma determinada região.
A topologia em malha, sem mobilidade de nós tem tornado-se objeto de estudos de vários pesquisadores como (Saade, 2002), (Cisco Systems, 2006) e (Passos, 2006). Nesta topologia, os nós são espalhados por uma região e é permitido certo crescimento da rede, com a simples adição de novos nós. Esta topologia permite a existência de alguma mobilidade dos nós, porém o alcance ou a cobertura da rede será de acordo com o ambiente físico, existência de barreiras, e dos modelos de rádio utilizados.
As redes em malha sem fio têm sido bastante utilizadas para prover acesso à Internet, principalmente em região onde existe deficiência de serviços prestados por operadoras de telecomunicações, como mostrado em (Ribeiro Dias, 2010) e (Tecnologia Cisco Promove Inclusão Digital na histórica cidade de Tiradentes MG,2011). Enquanto este último mostra a implantação para atendimento à cidade de Tiradentes, MG, o primeiro apresenta a possibilidade de ampliação da cobertura da rede e o baixo custo dos equipamentos como as principais vantagens que incentivam a implantação de redes em malha sem fio.
A proposta deste trabalho é apresentar uma avaliação de rede em malha sem fio para provimento de acesso à Internet. Para isso, implantou-se uma rede na região central da cidade de Cuiabá, chamada Rede Stormesh. Utilizaram-se diversos aplicativos para geração, monitoramento e análise de dados. São apresentados resultados relativos de diferentes níveis de sinais entre os nós, e os resultados apresentados foram satisfatórios.
Conferência IADIS Ibero-Americana WWW/Internet 2012
193

2. TRABALHOS RELACIONADOS
Existe uma variedade de produtos comerciais na área de redes em malha no mercado, como por exemplo, a tecnologia da Cisco (Cisco Systems, 2006) que foi implantada na cidade de Tiradentes. Pelo fato da cidade ser patrimônio histórico pela UNESCO, não era possível a instalação de uma torre para instalação de rádios e antenas.
Uma proposta de protótipo de rede foi apresentada pelo MIT (Massachusetts Institute of Tecnology) através da rede Roofnet (Aguayo, 2003), onde os nós da rede eram compostos por computador de usuários equipado com duas interfaces de rede, uma rede sem fio 802.11b e foi utilizada o protocolo de roteamento SrcRR, que é baseado no DSR (Dynamic Source Routing) (Johnson, 2001).
O grupo de pesquisa da UFF (Universidade Federal Fluminense) desenvolveu um trabalho com redes em malha sem fio (Albuquerque, 2006) para prover acesso gratuito à internet nos arredores da Universidade.
A avaliação apresentada neste artigo é baseada na implementação de uma rede em malha sem fio numa área metropolitana, a Rede Stormesh. Utilizaram-se equipamentos para ambiente externo. Diferente de outras propostas semelhantes foi adotado o padrão IEEE 802.11a (IEEE Stds 802.11a, 1999), na faixa de 5.8GHz.
3. REDE STORMESH
Este trabalho é baseado na rede Stormesh, uma rede em malha sem fio instalado na cidade de Cuiabá. Sendo um ambiente urbano, a região possui alta densidade de prédios, torres de celulares e emissoras de televisão entre outras características encontradas em centros urbanos de médio porte típicos. A temperatura média em Cuiabá é elevada, atingindo 40°C em alguns meses do ano. No verão a cidade é banhada por fortes torrentes de chuva.
Os equipamentos são instalados no topo dos edifícios e interligados a rede interna do usuário através de uma interface ethernet. Atualmente, a rede possui uma conexão com a Internet identificada como Ponto A na Figura 1. A escolha dos pontos de instalação ocorreu com a disponibilização de voluntários que residem na área escolhida para implantação da rede Stormesh.
Figura 1. Localização dos pontos A, B, C, D e E da rede Stormesh. Fonte: Google Earth.
ISBN: 978-989-8533-11-1 © 2012 IADIS
194

3.1 Métodos
Para instalação da rede Stormesh, foram utilizados equipamentos de rádio Nanostation5, fabricado pela empresa Ubiquiti Networks. Sua estrutura física é preparada para ambiente externo, tornando-se dispensável a utilização de caixas herméticas.
Existe uma interface para antena externa e outra para rede UTP o qual também serve de alimentação através de módulo PoE (Power Over Ethernet). A configuração de hardware do equipamento é de 4MB de memória flash e 16MB de memória RAM, com CPU Atheros de 180MHZ.
A adoção do padrão IEEE 802.11a na faixa de freqüência 5.8GHz e modulação OFDM (IEEE Stds 802.11a, 1999) foi necessária em função da saturação do espectro na faixa de 2.4GHz (padrões IEEE 802.11b/g) na região central de Cuiabá.
O roteamento foi configurado para utilizar o OLSR (Optimized Link State Routing Protocol) (Clausen et al, 2003). Trata-se de um protocolo pró-ativo e que tem sido utilizado com sucesso em algumas implementações de rede em malha sem fio (Saade, 2002), (Passos, 2006). Além disso, o OLSR também utiliza a qualidade de enlaces de rádio como métrica no cálculo de rotas.
O firmware disponibilizado pelo fabricante do rádio não implementa o protocolo OLSR e não permite sua instalação. Para utilização do protocolo de roteamento escolhido optou-se pelo firmware denominado OpenWRT (OpenWRT Project, 2011). Trata-se de uma compilação cujo suporte é realizado por uma comunidade de usuários e é baseado em uma distribuição Linux adaptada para dispositivos embarcados sem fio. Além do OLSR, foi instalado o iPerf (iPerf Project, 2011), que permite a medição de tráfego na rede.
Conforme Figura 1, o Ponto A, gateway da rede, é o equipamento instalado no topo da caixa d'água do Instituto Federal de Mato Grosso, a 30m do solo, equipamento com uma antena omnidirecional de 12dbi, com 6° de polarização vertical. O Ponto B está instalado no topo de um edifício a 290m de distância do Ponto A e a 50m do solo, porém foi utilizado uma antena omnidirecional de 8dbi com ângulo vertical de propagação de 16°. O Ponto C foi instalado no interior do campus a 80m de distância do Ponto A, a uma altura de 14m do solo e também foi equipado com uma antena omnidirecional de 8dbi. O Ponto D, equipado com a mesma antena omnidirecional de 8dbi, está a uma distância de 174m do Ponto A e a 160m do Ponto B, a 55m do solo e finalizando com o Ponto E, a 55 metros do solo também equipado com uma antena omnidirecional de 8dbi, a uma distância de 1900 metros, do Ponto A e com visada direta para Ponto B a uma distância de 1700 metros.
Na Figura 2 é possível observar a topologia da rede, os tipos de equipamentos e serviços que podem ser avaliados na Stormesh após término de instalação e avaliação de todos os pontos, serviços como o VoIP, que necessita de uma excelente qualidade de link entre os nós da rede pois utiliza serviço de tempo real (Real Time).
Figura 2. Topologia lógica da rede Stormesh
Conferência IADIS Ibero-Americana WWW/Internet 2012
195

O Nanostation5 possui uma antena interna setorial de 14dBi de ganho, sendo 55° o ângulo de polarização horizontal e 18° o ângulo de polarização vertical, que foram utilizadas nos testes de ganho de sinal deste trabalho. É importante destacar que a todos os rádios foram acoplados antenas omnidirecionais de 8dBi.
4. RESULTADOS E DISCUSSÃO
Para avaliar o desempenho dos pontos da rede, foram estabelecidos cenários de utilização das antenas: I. Uso apenas de antenas omnidirecional em todos os pontos da rede; II. Apenas o ponto A com antena omni direcional e os demais pontos utilizando rádio no modo
adaptativo; III. Todos os rádios em modo adaptativo.
Para todos os cenários foi avaliado o nível de sinal entre os nós e o gateway (Ponto A). Existe perda significativa do sinal de transmissão entre alguns pontos da rede Stormesh como
consequência do posicionamento de ângulo vertical das antenas omnidirecionais, não percebido quando os nós da rede estão no mesmo plano horizontal ou quando não existe muita variação da altura entre os pontos (existe variação de altura entre os pontos instalados). Isso acontece, pois as antenas omnidirecionais possuem ângulo vertical que limita o plano de propagação do sinal, para antenas de 12dbi o ângulo é 6° e para as antenas de 8dbi o ângulo é 16°.
Foi realizada medição, através do software iPerf, para avaliar a largura de banda entre os nós da rede até o Ponto A, estes resultados serão discutidos na seção a seguir.
4.1 Resultados Obtidos
Nos cenários avaliados, como apresentado na seção anterior, foram realizadas medições para avaliar o ganho de sinal na rede Stormesh, em relação ao Ponto A. A Figura 3 mostra um comparativo das três opções de configuração.
Na Figura 3 pode ser avaliada a comparação entre os três cenários, onde o melhor resultado obtido foi a utilização do modo adaptativo, que utiliza ambas as antenas, direcional e omnidirecional. O software do equipamento realiza medições empregando as duas antenas, ou seja, modo adaptativo, onde seleciona a antena que apresenta melhor ganho para realização da transferência dos dados. Dessa forma foi fácil perceber que esta opção apresentou os melhores ganhos de sinal.
Figura 3. Nível de sinal (dBm) em relação ao ponto A de acordo com as configurações de antenas utilizadas
ISBN: 978-989-8533-11-1 © 2012 IADIS
196

Também foi possível medir a largura de banda passante disponível nos enlaces dos rádios para os usuários, nos três cenários através de mudanças das antenas, os resultados das medições são apresentados na Figura 4.
O software iPerf , instalado em todos os nós da rede, permitiu realizar as medições realizadas. O Ponto A foi configurado como servidor e os demais nós da rede, como clientes. Esta medição ocorreu em diferentes períodos do dia, realizados durante 1800 segundos, os resultados apresentados são procedentes da média aritmética das medições realizadas, é importante destacar que ocorreu pouca variação destes valores no transcorrer do período analisado.
É possível analisar pela Figura 4, que não houve variação significativa da largura de banda disponível para os usuários, mesmo existindo grande variação no ganho de sinal, como apresentado na Figura 3. Com isso pode-se comprovar que os equipamentos se comportam de maneira estável.
Em relação à qualidade dos enlaces disponibilizados para os usuários, com sinais próximos a -74dbm, que é a sensibilidade mínima para o funcionamento com taxa de 54mbps (Ubiquiti Networks, 2011), observa-se que o ganho mínimo para funcionamento dos equipamentos, não altera a largura de banda disponível.
Quanto ao ponto D, o resultado obtido de 3,53Mbps de largura de banda, é provável que tenha ocorrido esta redução em função do número de saltos na rede, entre este ponto e o gateway (Ponto A).
O ponto E alcançou um excelente resultado de largura de banda (ultrapassou 7,2 Mbps) no modo adaptativo, a uma distância de 1900 metros do Ponto A, e demonstrou a importância da configuração das antenas a serem instaladas nesse tipo de rede.
A largura de banda do Ponto E no modo adaptativo, que apesar de estar a uma distância de 1900 metros do Ponto A, apresentou um excelente resultado de banda passante em relação aos demais pontos que estão mais próximos, desta forma fica demonstrado que as corretas configurações de antenas são importantes na instalação de rede em malha sem fio em área metropolitana, deixando a rede com melhor desempenho e proporcionando uma rede confiável a qualquer tipo de serviço.
Através dos resultados obtidos fica evidente que o ganho de sinal tem resultado significativo para o modo adaptativo (onde o equipamento utiliza as duas antenas) e utiliza as diferentes estratégias de configuração de antenas.
Figura 4. Comparação das medições das três configurações de antenas referente à largura de banda passante em relação ao ponto A.
Conferência IADIS Ibero-Americana WWW/Internet 2012
197

Adicionalmente a altura relativa de cada nó da rede também influencia este resultado, pois o ângulo de propagação das antenas utilizadas irradiam o sinal em determinado plano, ou zona. Com isso identifica-se que o melhor cenário para utilização deste tipo de rede acontece quando as antenas estão no mesmo plano horizontal, ou com pouca variação de altura entre elas.
5. CONCLUSÕES
Com a implantação do projeto de rede em malha sem fio, a rede Stormesh, foi possível demonstrar a viabilidade deste tipo de rede para formação de um backbone em uma região metropolitana. A rede apresentou largura de banda satisfatória para tráfego de dados mesmo com a existência de diversas redes sem fio de provedores comerciais que utilizam a mesma frequência de transmissão.
Contudo, através da análise do tráfego, foi possível observar que as diferenças de largura de banda foram desprezíveis, mesmo com diferentes níveis de sinal.
Este estudo apresentou uma solução eficaz e de baixo custo para redes metropolitanas e em malha sem fio. Com os resultados aqui obtidos pode-se concluir que redes com poucos números de saltos entre os nós e serviços de acesso à Internet possuem boa qualidade, e além disso, este tipo de rede, torna-se um bom candidato para disponibilizar outros serviços como VoIP, videoconferência ou Smart Grids.
5.1 Trabalhos Futuros
Sugere-se a avaliação de QoS e implementação de VoIP na rede Stormesh. Em continuidade desta pesquisa, pode-se ainda averiguar qual modelo de monitoramento e gerenciamento é o mais adequado para a topologia utilizada. Em relação à segurança sugerem-se avaliar o funcionamento de serviços de segurança, como Sistemas de Detecção de Intrusão na rede, além de outros protocolos de roteamento. Por fim, avaliações de Smart Grids para medições de consumo de energia elétrica também podem ser executadas utilizando a Stormesh.
REFERÊNCIAS
Aguayo, Daniel et al, 2003. MIT Roofnet Implementation. Massachusetts Institute of tecnology. Cambridge, MA. Albuquerque, Célio et al, 2006. Rede Mesh de Acesso Universitário Faixa Larga Sem Fio. RNP, Brasil. Cisco Systems, 2006. Cisco Wireless Mesh Networking Solution Overview. Cisco Public Information Database, USA. Clausen, T. et al, 2003. “Optimized Link State Routing Protocol” (OLSR). IETF RFC 3626. Dias, Ribeiro, 2010. L. Internet Popular, ainda uma promessa. Revista A Rede, nº 61. Hauenstein, C. D. et al, 2002. Wireless LAN a Grande Questão: 802.11a ou 802.11b? Tese de Mestrado – UFRGS. IEEE Stds 802.11a,1999. iPerf Project, acessado em julho de 2011. Disponível em http://sourceforge.net/projects/iperf/. Johnson, D. et al, 2001. “DSR: the dynamic source routing protocol for multihop wireless ad hoc networks”, Ad Hoc
Networking, Addison-Wesley Longman Publishing Co., Boston. OpenWRT Project, acessado em julho de 2011. Disponível em http://openwrt.org/. Passos, Diego et al, 2006. Mesh Network Performance Measurements. 5th Internatinal Information and
Telecommunications Tecnologies Symposium. Cuiabá, MT, Brasil. Saade, D.C.et al, 2002. Redes em Malha: Solução de Baixo Custo para Popularização do Acesso à Internet no Brasil.
Simpósio Brasileiro de Telecomunicações. Setembro de 2007. Ubiquiti Networks, acessado em julho de 2011. Nanostation5 Complete Datasheet. Disponível em:
http://www.ubnt.com/downloads/ns5_datasheet.pdf.
ISBN: 978-989-8533-11-1 © 2012 IADIS
198

SBWMX-TOOL: UNA APLICACIÓN WEB PARA EL DISEÑO DE ESTRUCTURAS MARÍTIMAS
José Alfonso Aguilar1, Pedro A. Aguilar2 y Aníbal Zaldívar1 1Cuerpo Académico Señales y Sistemas, Facultad de Informática Mazatlán, Universidad Autónoma de Sinaloa
Ciudad Universitaria, Mazatlán, Sinaloa, México 2Escuela de Ingeniería Mazatlán, Ciudad Universitaria, Mazatlán, Sinaloa, México
RESUMEN
En este artículo presentamos la investigación y desarrollo en curso de la herramienta SBWmx-Tool, una aplicación Web para el cálculo de los factores empleados en la construcción de estructuras marítimas (rompeolas, escolleras y espigones) tales como el peso de los elementos de la estructura, coeficiente de transmisión del oleaje y el espesor de la coraza, entre otros. SBWmx-Tool ha sido ideada para auxiliar al Ingeniero Civil (Construcción) en el diseño de estructuras marítimas a través de la aplicación de distintas fórmulas, por ejemplo, la fórmula de Hudson, utilizada para la estabilidad de los elementos de la estructura en condiciones normales y de tormenta. Durante la fase inicial del proceso de desarrollo, se utilizó una aproximación orientada a objetivos para la especificación de requisitos así como el método para el desarrollo de aplicaciones Web A-OOH (Adaptive Object-Oriented Hypertext). La aproximación utilizada como sustento teórico es SBWmx (Submersible Breakwaters Approach), metodología empleada en el diseño y construcción de estructuras marítimas, desarrollada en la Facultad de Ingeniería de la UNAM (Universidad Nacional Autónoma de México).
PALABRAS CLAVE
Ingeniería Web, Ingeniería de Requisitos, A-OOH, SBWmx-Tool, Ingeniería Marítima, Aplicaciones Empresariales.
1. INTRODUCCIÓN
La complejidad y la naturaleza dinámica de la World Wide Web (WWW) demandan cada vez más su uso en distintas áreas del conocimiento gracias a las ventajas que ofrece, por ejemplo, la facilidad de acceso a datos que proveen las aplicaciones Web mediante la WWW (acceso y visualización de datos on-line). En este sentido, en el área de la construcción, específicamente en la Ingeniería Marítima, utilizar esta facilidad de acceso a datos on-line se ha convertido en una necesidad a razón de las grandes distancias de su campo de acción (mar adentro, islas, costas, etc.), por lo que es necesario el desarrollo de aplicaciones Web con la finalidad de asistir al Ingeniero durante el proceso de construcción, reduciendo el coste en tiempo y errores durante los cálculos. Sin embargo, para lograrlo, es necesaria la aplicación de la Ingeniería Web y de metodologías de desarrollo Web en el perfeccionamiento de este tipo de aplicaciones, lo que permitirá validar el desempeño de las metodologías en casos reales (detectar limitantes) y, en el mejor de los casos, verificar que el producto final corresponda cualitativamente con las expectativas del usuario.
Con la idea de paliar estas necesidades, en este trabajo describimos el procedimiento para la construcción de una aplicación Web contextualizada en la Ingeniería Marítima, el sustento teórico de la aplicación proviene de la metodología SBWmx, utilizada para la planificación y desarrollo de estructuras marítimas como los rompeolas1 en playas (Aguilar, 2011); el proceso de desarrollo de la aplicación Web, concretamente el análisis y especificación de requisitos, se establece en el argumento de las propuestas presentadas en (Garrigós, 2008), (Aguilar, 2010), (Aguilar, 2012a) y (Aguilar, 2012b) para el desarrollo de aplicaciones Web en un contexto dirigido por modelos (Model-Driven Development) (Kleppe, 2003). La idea de este trabajo radica en la importancia de la combinación de una serie de elementos para llevar aquellos trabajos (propuestas) desarrollados en la investigación a su aplicación en proyectos reales, mezclando distintas áreas
1 Un rompeolas es una estructura costera que tiene por finalidad principal proteger la costa o un puerto de la acción de las olas del mar o del clima. Son calculados, normalmente, para una determinada altura de ola con un periodo de retorno especificado (concretelayer, s.f.).
Conferência IADIS Ibero-Americana WWW/Internet 2012
199

del conocimiento como lo son la Ingeniería Civil, Ingeniería Marítima y la Ingeniería Web a través del método Web A-OOH (Adaptive Object-Oriented Hypertext) (Garrigós, 2008), con la idea de detectar sus limitantes y mejorarlas.
Por otra parte, en la Ingeniería Civil existen varios tipos de software que auxilian en el diseño de estructuras de acero (marco, viga, escaleras), concreto u hormigón (columnas, cimentaciones, trabes, pilas, losas, muros, vigas etc.) y madera (tabla-estacas, pilotes etc.), algunos ejemplos son el Stadd Pro (StaddPro, 2012), Ram Advans (Bentley, 2012) y Cypecad (Cype, 2012), lamentablemente, en el área de la Ingeniería Marítima no existe un software que considere completamente los criterios para el diseño de un rompeolas, debido a que en su gran mayoría funcionan como una herramienta para desarrollar una imagen virtual de la estructura que puede ser contrastada con diferentes cargas (Prisma, 2012). Además, ninguna de las herramientas software mencionadas aplica una metodología establecida con rigor científico para el diseño y construcción de estructuras marítimas, por lo que al final solo son aproximaciones para la esquematización de la obra civil. En este contexto, la herramienta, denominada SBWmx-Tool, permitirá la aplicación de la metodología SBWmx, asistiendo al Ingeniero durante todo el procedimiento de construcción desde las etapas iniciales de planificación hasta la etapa final de la construcción de estructuras marítimas (rompeolas, escolleras y espigones). La metodología se basa en la fórmula de Hudson (US Army, 1984), una ecuación ampliamente utilizada por los Ingenieros Marítimos para calcular la estabilidad para las estructuras de escombros bajo el ataque de condiciones de las olas de tormenta.
Cabe destacar que la propuesta que se presenta en este artículo es novedosa a razón de que el diseño y cálculo en obras marítimas de este tipo son realizados de forma manual, por lo que el tiempo en correcciones y pruebas es demasiado, lo que ocasiona un aumento en el coste-beneficio de la obra. Finalmente, al ser nuestra propuesta un trabajo en desarrollo, en este artículo nos enfocamos únicamente a la construcción del módulo rompeolas sumergible.
El resto del trabajo se estructura de la siguiente forma: en la sección 2 se introduce brevemente la metodología SBWmx para la construcción de estructuras marítimas. El diseño del módulo rompeolas es descrito en la sección 3. Finalmente, en la sección 4 se presentan las conclusiones y el trabajo futuro.
2. METODOLOGIA SBWMX
En este apartado se describe brevemente núcleo de la metodología SBWmx, es decir, se describe cómo es diseñado únicamente el rompeolas sumergible de forma manual sin asistencia de software especializado, planteado para disipar, parcial o totalmente, la energía del oleaje (Aguilar, 2011).
Para el diseño y construcción del rompeolas, se requieren estudios previos para el conocimiento del régimen de oleaje y de oleajes extraordinarios (en caso de existir) y sus características. Además, es necesaria la información sobre mareas, corrientes, vientos dominantes y reinantes así como batimetría y características del fondo marino y estratigrafía. Una vez conocidas estas variables, se selecciona el material con el que será construido. Para obtener el periodo de retorno, de vital importancia en cualquier obra a diseñar, se requirió de las Recomendaciones para Obra Marítima del Ministerio de Fomento de España.
A continuación, se presentan los cálculos necesarios (Tabla 1) para el diseño del Módulo Rompeolas Sumergible (MRS) de la herramienta SBWmx-Tool.
Tabla 1. Cálculo para el diseño del rompeolas por etapas.
ETAPA DESCRIPCIÓN 1 Determinación de la altura de la ola de diseño 2 Cálculo del peso de los elementos de la estructura 3 Cálculo del espesor de la coraza. 4 Cálculo del peso de los elementos de la capa secundaria 5 Cálculo del espesor de la capa secundaria 6 Cálculo del peso de los elementos del núcleo 7 Cálculo del coeficiente de transmisión 8 Calculo de altura de diseño del rompeolas 9 Calculo del bordo libre
10 Longitud del Rompeolas sumergible
ISBN: 978-989-8533-11-1 © 2012 IADIS
200

Una vez realizados los cálculos (Etapa 1-10), el paso siguiente consiste en dibujar a escala las secciones y planta de las dimensiones del rompeolas sumergible. Por último, se elabora una tabla con los volúmenes de obra requeridos para su construcción.
3. SBWMX-TOOL
La herramienta estará constituida por un conjunto de módulos para representar cada una de las estructuras marítimas especificadas en la metodología SBWmx, estas son: i) Módulo Rompeolas Sumergible (MRS), ii) Módulo Escolleras (MEsco) y iii) Módulo Espigones (MEspi). En este trabajo se describe el desarrollo del MRS, a razón de que fue considerado como el de mayor prioridad por el cliente.
SBWmx-Tool combina un conjunto de tecnologías para el desarrollo de aplicaciones Web open source que incluyen: i) el lenguaje de programación PHP (Nixon, 2010), ii) la plataforma Eclipse (Steinberg, 2008) y iii) MySQL (Dobois, 2008), así como herramientas y aproximaciones metodológicas desarrolladas en el ámbito de la investigación en Ingeniería Web, en donde encontramos al método Web A-OOH (Adaptive Object-Oriented Hypertext) (Garrigós, 2008), el marco de trabajo orientado a objetivos i* (Yu, 2010) y la herramienta WebREd-Tool (Aguilar, 2012b)2 .
El proceso de desarrollo de la herramienta en general se basa en MDA (Model-Driven Architecture) (Kleppe, 2003), por lo que está dividido en tres etapas, en la primera (correspondiente con el Computational Independent Model, CIM) se especificaron los requisitos de la aplicación Web por medio del marco de trabajo i* (Yu, 2010) utilizando la herramienta WebREd-Tool, como puede verse en la figura 1, el cual corresponde con el CIM en el método Web A-OOH, es importante mencionar que, a pesar de que existen otros métodos como NDT (Escalona, 2007), UWE (Koch, 2009), WebML (Stefano, 2002) y que algunos de ellos son dirigidos por modelos, pero se optó por A-OOH por el modelado de requisitos Web orientado al usuario.
Figura 2. CIM: modelado de requisitos orientado a objetivos utilizando A-OOH y WebREd-Tool.
En la segunda etapa (Platform Independent Model, PIM), se generó el modelo de dominio de la aplicación Web por medio de transformaciones model-to-model (M2M) utilizando el lenguaje ATL (Atlas Transformation Language) (ATL, 2012). En la tercera etapa (Platform Specific Model, PSM) se implementó el código fuente de la aplicación Web (incluido el código para la creación de la base de datos) mediante transformaciones model-to-text (M2T) generando código HTML y completándolo con código PHP de forma manual.
2 WebREd-Tool es una herramienta implementada en Eclipse para el desarrollo de aplicaciones Web que incluye la optimización de requisitos no-funcionales. Recientemente, WebREd-Tool ha ganado el reconocimiento como mejor Demo y Póster en la 12th International Conference on Web Engineering (ICWE) (Aguilar, 2012a).
Conferência IADIS Ibero-Americana WWW/Internet 2012
201

El funcionamiento del módulo MRS una vez codificado es el siguiente: primero el Ingeniero (usuario) selecciona el tipo de estructura marítima a diseñar, en este caso será el rompeolas sumergible, después ingresará los datos de la ola significante, la ola refractada sea para marea baja o alta, el tipo de estructura, el material a utilizar y automáticamente se generará una tabla con los valores de diseño del rompeolas sumergible (Ver Fig. 2).
Es importante mencionar que el desarrollo de los módulos restantes continúa al momento de escribir el artículo. Además, el módulo presentado en este trabajo se utilizará para la simulación en un proyecto de construcción real enfocado en la creación de un rompeolas sumergible en la playa del hotel “Faro”, ubicado en las costas del puerto de Mazatlán, Sinaloa en México.
Figura 2. Módulo MRS de la herramienta SBWmx-Tool.
4. CONCLUSION
Una herramienta llamada SBWmx-Tool ha sido presentada en este artículo. La planificación, conceptualización y desarrollo de la aplicación Web se ha llevado a cabo a través del método para el desarrollo de aplicaciones Web A-OOH y la herramienta WebREd-Tool. SBWmx-Tool continúa en etapa de construcción, al tratarse de un proyecto de desarrollo robusto, al momento de presentar este artículo se ha desarrollado uno de los módulos que la conforman (MRS). El módulo, se utilizará en la simulación de un caso real dentro del proyecto para la construcción de un rompeolas sumergible en la playa del Hotel Faro, ubicado en Mazatlán, Sinaloa, México (Océano Pacifico). El desarrollo de SBWmx-Tool a permitido la aplicación de la metodología Web en un caso real y la validación de la herramienta WebREd-Tool al momento de especificar los requisitos de la aplicación Web obteniendo resultados satisfactorios en cuanto a la agilización del proceso de desarrollo por módulos, concretamente en la especificación de requisitos y en el módulo de transformaciones ATL, gracias a esto ha surgido la necesidad de optimizar el editor gráfico de WebREd-Tool para modelar aplicaciones Web más robustas.
El trabajo futuro consistirá en la elaboración de los módulos restantes de la aplicación Web SBWmx-Tool para la aplicación de la metodología SBWmx, es decir, se contempla su adaptación para soportar el diseño de diferentes estructuras marítimas no solo para rompeolas sumergibles. En lo que respecta a la herramienta WebREd-Tool se optimizará el editor gráfico para el modelado a gran escala de aplicaciones Web robustas.
AGRADECIMIENTOS
Este trabajo ha recibido el apoyo de la Universidad Autónoma de Sinaloa a través de PROFAPI con el proyecto “Aplicación de la Ingeniería de Requisitos Orientada a Objetivos en la Ingeniería Web Dirigida por Modelos” y al Programa de Fortalecimiento Institucional (PIFI) por medio del proyecto P2011-25-116.
ISBN: 978-989-8533-11-1 © 2012 IADIS
202

BIBLIOGRAFÍA
Aguilar, J. A., Garrigos, I., Mazón, JN, Trujillo, J. 2010. An MDA Approach for Goal-oriented Requirements Analysis in Web Engineering. Journal of Universal Computer Science (JUCS), 16(17), pp. 2475-2494.
Aguilar, J. A., 2012. A Goal-oriented Approach for the Development of Web Applications. 1st ed. Saarbrücken, Germany: LAMBERT Academic Publishing.
Aguilar, J. A., Garrigos, I. Mazón, J.N., Casteleyn, S., 2012. WebREd: A Model-Driven Tool for Web Requirements Specification and Optimization. Proceedings of the 12th International Conference on Web Engineering (ICWE). Berlin, Germany, Springer-Verlag.
Aguilar, P., 2011. Restauración y Conservación de Playas con Aplicación en el Puerto de Mazatlán. México, Master Thesis. Universidad Nacional Autónoma de México (UNAM).
Atlas Transformation Language, at http://www.eclipse.org/ATL Kleppe, A., J. W. a. W. B., 2003. MDA Explained: The Model Driven Architecture(TM): Practice and Promise.
s.l.:Addison-Wesley Professional. Bentley, at: http://www.bentley.com/es-MX/Products/RAM+Advanse/ Concretelayer at: http://www.concretelayer.com/core-loc. CYPE Ingenieros at: http://cypecad.cype.es/ Steinberg, D.,. EMF: Eclipse Modeling Framework. 2nd ed. Addison-Wesley Professional. DuBois, P., 2008. MySQL. 4th ed. Addison-Wesley Professional. Prisma, at: http://www.elprisma.com/apuntes/ingenieria_civil/concretocargas/ United States Army Corps of Engineers, Coastal Engineering Research Center (U.S.)., 1984. Shore protection manual.
Cuarta edicion ed. Vicksburg: U.S. Government Printing Office. Frias, A., Moreno, G., 1988. Ingeniería de Costas. México: Editorial Limusa. Garrigós, I., 2008. A-OOH: Extending Web Application Design with Dynamic Personalization. PhD. Thesis. Alicante:
Spain. Koch, N., 2009. Patterns for the Model-Based Development of RIAs. Proceedings of the International Conference on
Web Engineering (ICWE). Springer-Verlag Nixon, R., 2010. Learning PHP, MySQL, and JavaScript: A Step-By-Step Guide to Creating Dynamic Websites. O'Reilly
Media. PHP, at: http://www.php.net/ Stadd Pro, Stadd Enginners Mumbai at: http://www.staadpro.com/. Stefano C, Piero. F., 2002. Designing Data-Intensive Web Applications. Morgan Kaufmann. Escalona, M. 2007. NDT. A Model-Driven Approach for Web Requirements. Proceedings of the IEEE Transactions on
Software Engineering. Yu, E., P. G., 2010. Social Modeling for Requirements Engineering. The MIT Press.
Conferência IADIS Ibero-Americana WWW/Internet 2012
203


Artigo de Reflexão


BUSINESS INTELLIGENCE APLICADO NA GESTÃO ACADÊMICA
Marcio Rodrigo Teixeira e Mehran Misaghi Instituto Superior Tupy (IST) / Sociedade Educacional de Santa Catarina (SOCIESC)
Campus Boa Vista, Joinville, Brasil
RESUMO
A gestão dos negócios, a competitividade, o excesso de informações e a dispersão dos dados no ambiente organizacional têm se mostrado importantes barreiras a serem superadas pelos gestores na atualidade, tanto na melhoria dos processos, quanto na tomada de decisão. Este artigo aborda o tema Business Intelligence e apresenta estudos de caso visando mostrar os benefícios de sua aplicação para ajudar Instituições de Ensino Privadas a alcançar melhores resultados na sua gestão acadêmica.
PALAVRAS-CHAVE
Gestão Acadêmica; Business Intelligence; Data Warehouse.
1. INTRODUÇÃO
Com a evolução tanto nos modelos de gestão, quanto na própria sociedade, a informação e o conhecimento passaram a serem considerados os principais patrimônios de uma organização e fatores de sucesso e diferenciação. Porém, o excesso de informações e a dispersão dos dados tem se tornado barreiras na melhoria nos processos e também na tomada de decisão. Assim sendo, podemos afirmar que a análise dos dados e informações se faz necessária, atualmente nos processos administrativos das organizações e também em um ambiente de gestão acadêmica, pois visa ajudar a tomar decisões inteligentes, mediante dados e informações recolhidas pelos diversos sistemas de informação da instituição. A seguir serão abordados temas relatando os desafios das instituições de ensino privadas, Business Intelligence, sua arquitetura e componentes, estudos de caso de aplicação dessa ferramenta em instituições de ensino.e por fim um panorama de Business Intelligence aplicado à gestão de um ambiente acadêmico privado.
2. OS DESAFIOS DAS INSTITUIÇÕES DE ENSINO PRIVADAS
As velozes transformações do mundo contemporâneo têm-se mostrado um grande e contínuo desafio para organizações incluindo as instituições de ensino. As instituições de ensino, não podem mais sentir-se excessivamente confiantes com as fatias de mercado e posições conquistadas e devem buscar a melhoria de seus serviços, redução de custos operacionais e aumento da margem de lucro.
Segundo Machado (2008), muitos outros setores já passaram pelo choque de concorrência e sobreviveram, agora chegou à vez das instituições de ensino. Ou elas aderem a um modelo de negócios mais contemporâneo e responsivo ou assistir-se-á nos próximos anos ao que nunca foi visto antes: instituições de ensino superior privadas sendo vendidas, fundidas e tendo suas portas fechadas.
3. BUSINESS INTELLIGENCE
De acordo com Filho (2010), o objetivo de BI é permitir que se identifiquem ameaças e oportunidades de negócios, para que oportunidades sejam aproveitadas em primeira mão, ameaças sejam convertidas em boas
Conferência IADIS Ibero-Americana WWW/Internet 2012
207

chances de lucro e a capacidade de resposta à mudanças seja ampliada, junto com o dinamismo característico do mercado. Para Turban, Sharda, Aronson, King (2009), os principais objetivos do BI são permitir o acesso interativo aos dados (às vezes, em tempo real), proporcionar a manipulação desses dados e fornecer aos gerentes e analistas de negócios a capacidade de realizar a análise adequada.
3.1 Arquitetura e Componentes de BI
3.1.1 Pessoas (Usuários do Negócio, Administradores, Desenvolvedores, Suporte Técnico)
As pessoas são fundamentais em uma arquitetura de Business Intelligence, além dos processos e tecnologias envolvidas. Segundo Turban, Sharda, Aronson, King (2009), o sucesso do BI depende, em parte, de quais pessoas na organização mais provavelmente fariam uso dele. Um dos aspectos mais importantes de um sistema bem-sucedido de BI é que ele deve ser vantajoso para a empresa como um todo. Isso implica em inúmeros usuários na empresa, muitos dos quais devem ser envolvidos desde o inicio de uma decisão pelo investimento em data warehouse.
A comunidade de usuário de BI é diversificada porem pode-se afirmar que a grande maioria se concentra nos níveis tático e estratégico e vale ressaltar que uns se relacionam com os outros.
3.1.2 Metadata and Master Data Management
Conforme Machado (2011), os sistemas de banco de dados necessitam de informações que são armazenadas, ou seja, precisam de dados que contenham informações sobre os dados que estão armazenados no sistema. Da mesma forma, os sistemas de data warehouse possuem um repositório de metadados, que é uma abstração dos dados, ou seja, dados de mais alto nível que descrevem os dados de níveis inferiores que compõem a estrutura do data warehouse.
Segundo Inmon, Hackathorn (1997), os metadados possuem um papel muito importante e especial no data warehouse. De acordo com Inmon, Welch, Glassey (1998), sem os metadados, o data warehouse e seus componentes associados no ambiente projetado são meramente componentes soltos funcionando independentemente e com objetivos separados.
Conforme Barbieri (2011), Master Data Management, significa gerência de dados mestres. O que são dados mestres? Os dados mestres são os dados mais importantes existentes dentro de uma organização.
O Master Data Management tem o objetivo de fornecer processos para coletar, agregar, combinar, consolidar, garantir qualidade, persistir e distribuir esses dados em toda a organização para assegurar a consistência e controle na manutenção e uso desta informação.
3.1.3 Fontes de Dados
Os dados podem possuir vários formatos e ser obtidos em várias fontes como, por exemplo: • CRM: Customer Relationship Management (CRM), conforme Serra (2002), engloba conceitos,
métricas, processos, soluções, gestão de canais, estratégias e ferramentas das áreas de marketing, vendas e serviços.
• ERP: Enterprise Resource Planning, de acordo com Filho (2010), são sistemas focados no atendimento às áreas administrativas e operacionais de uma empresa, garantindo agilidade, integridade de informações e segurança.
• Aplicações Web: são sistemas acessados através da Internet ou uma intranet. • OLTP: Online Transaction Processing, são sistemas que se encarregam de registrar todas as
transações contidas em uma determinada operação organizacional. O ERP é um dos sistemas que fazem parte desta categoria.
• Sistemas Legados: aplicações legadas são sistemas que continuam a ser usado, apesar de existir uma tecnologia mais nova ou mais métodos mais eficientes de executar a tarefa.
• Outros: existem vários outros tipos de fontes de dados além dos citados anteriormente. Estas diversas fontes de dados compõe a paisagem de inteligência analítica da empresa.
ISBN: 978-989-8533-11-1 © 2012 IADIS
208

3.1.4 Camada de Integração de Dados
A camada de integração de dados é composta pelos seguintes componentes: • Aplicação ETL: Extraction, Transformation and Load, de acordo com Turban, Sharda, Aronson,
King (2009), consiste em extração (leitura dos dados de um ou mais bancos de dados), transformação (conversão dos dados extraídos de sua forma anterior na forma em que precisam estar) e carga (colocação dos dados no data warehouse). Segundo Filho (2010), pode ser um aplicativo desenvolvido internamente, um conjunto de scripts para execução em lote ou ainda um pacote comprado de um desenvolvedor.
• Camada de Preparação de Dados: As diferentes fontes de dados que compõem as informações de negócios da empresa precisam eventualmente, ser armazenadas em um data warehouse. O ETL facilita o meio de formatação de dados de diferentes fontes para que possam ser carregados em uma estrutura de data warehouse. Conforme Machado (2011), representa um armazenamento intermediário dos dados, facilitando a integração dos dados do ambiente operativo antes de sua atualização no data warehouse.
• Data Warehouse, segundo Inmon, Hackathorn (1997), é uma coleção de dados orientados a assuntos, integrados, variáveis com o tempo, não voláteis, para suporte ao processo gerencial de tomada de decisão. Conforme Machado (2011), o data warehouse proporciona uma sólida e concisa integração dos dados da empresa, para a realização de análises gerenciais estratégicas de seus principais processos de negocio com a preocupação de integrar e consolidar as informações de fontes internas e externas, preparando-os para análises e suporte a decisão.
• Data Marts, de acordo com Serra (2002), é um pequeno data warehouse que fornece suporte a decisão de um pequeno grupo de pessoas. Segundo Primak (2008), os data marts atendem as necessidades de unidades especificas de negocio ao invés das necessidades da corporação inteira.
Através destes componentes é possível transformar os dados em informações de qualidade, úteis para toda a empresa e principalmente no processo de tomada de decisão.
3.1.5 Camada de Acesso aos Dados
A camada de acesso a dados é possui os seguintes componentes: • Cubos, referem-se a conjunto de dados correlacionados que são organizados para que os usuários
combinem atributos a fim de criar diversas visões. O cubo é usado para representar os dados ao longo de algumas medidas de interesse. Pode ter 2, 3 ou mais dimensões. Cada dimensão representa algum atributo no banco de dados e as células no cubo de dados representam a medida de interesse.
• Aplicação OLAP: De acordo com Inmon, Welch, Glassey (1998), o processamento analítico online é um método importante na arquitetura do data warehouse através do qual os dados podem ser transformados em informação. OLAP é um conjunto de funcionalidades que tenta facilitar a análise multidimensional.
• Data Mining, segundo Tan, Steinbach, Kumar (2009), é o processo de descoberta automática de informações úteis em grandes depósitos de dados. As técnicas de mineração de dados são organizadas para agir sobre grandes bancos de dados com o intuito de descobrir padrões úteis e recentes que poderiam de outra forma, permanecer ignorados.
• Aplicação de BI, são ferramentas desenvolvidas para relatar, analisar e apresentar dados. As ferramentas em geral, leem os dados que tenham sido previamente armazenados em um data warehouse ou data mart. Funções comuns de tecnologias de BI são relatórios, planilhas, processamento analítico online, análises, data mining, gerenciamento de desempenho de negócios, benchmarking, e análise preditiva.
Estes componentes permitem realizar análises empresariais com maior eficiência e eficácia e são a base para uma melhor tomada de decisão.
4. BUSINESS INTELLIGENCE APLICADO A GESTÃO DE UM AMBIENTE ACADÊMICO PRIVADO
Fornecer recursos de TI para os gestores é uma questão vital para qualquer instituição de ensino atual, portanto a aplicação de Business Intelligence é fundamental para facilitar os processos de gestão e tomada de decisão. As instituições de ensino, podem usar o BI para diferentes tarefas, como geração de relatórios relevantes, análise financeira, planejamento estratégico, monitoramento e controle de indicadores de desempenho, administração, entre outros.
Conferência IADIS Ibero-Americana WWW/Internet 2012
209

Porem existem desafios ao iniciar a aplicação em ambientes de gestão acadêmica, uma vez que se deve configurá-lo de forma diferenciada do modo tradicional, conhecido e praticado em ambientes corporativos.
Todas essas tendências são muito mais fáceis de serem observadas quando a instituição de ensino possui uma arquitetura de BI que permite atender as necessidades de informação de todos os departamentos.
Segundo Norris, Baer, Leonard, Pugliese, Lefrere (2008), algumas ações primárias são necessários para evoluir da geração atual de análise acadêmica (ferramentas, soluções e serviços) para a ação analítica:
• Foco nos processos, soluções e comportamentos, não apenas na aquisição de ferramentas. • Incorporar fatores de força de trabalho nos currículos e ofertas educacionais. • Incorporar as comparações inter-institucional e inter-setorial nas soluções. • Desenvolver novas práticas / soluções que garantam o alinhamento das metas institucionais, as
estratégias, iniciativas, intervenções, resultados e medidas em uma variedade de maneiras, incluindo o alinhamento do institucional para o acadêmico, para o departamento, para os programas.
• Desenvolver a capacidade organizacional e mudança cultural para incentivar o comportamento baseado em evidências e ação com foco em inovação para melhorar o desempenho.
Instituições de ensino privadas estão fazendo uso extensivo de inteligência analítica e modelagem preditiva em marketing, recrutamento e retenção. Utilizam análises dos dados de alunos para efetuar acompanhamento do desempenho acadêmico e retenção de aprendizado, desenvolveram suas infraestruturas de TI para alcançar esses objetivos de transformação, tendo em conta tanto “eficiência operacional” e “intimidade com o cliente.” Eles entendem as necessidades dos estudantes e empregadores e adaptam o currículo e ofertas de cursos procurando alinhar com as exigências do emprego. Muitas instituições de ensino estão implantando também a análise acadêmica, para criar modelos preditivos de inscrição, para prever e melhorar a retenção do aluno, para desenvolver um plano de aprendizagem individual ligado a sistema de alerta caso um indicador acadêmico do aluno fique abaixo da meta, além disso, o nível assertividade na tomada de decisão, planejamento e alocação de recursos, melhoria de processos tem sido observados. Análises com foco em questões relacionadas ao acesso, aprendizagem e desempenho dos alunos em todas as fases de sua vida acadêmica, permitem que os alunos assumam uma maior responsabilidade para o seu sucesso, em colaboração com os pais, professores e empregadores.
Para exemplificar uma arquitetura analítica que compreende Business Intelligence aplicado em um ambiente de gestão acadêmico, Norris, et al (2008) retrataram em seu artigo uma estrutura que pode ser descrita como de última geração, pois os dados dos sistemas ERP’s, residirão em uma "nuvem" de soluções de arquitetura aberta, que por sua vez serão acessados pela internet a partir de qualquer dispositivo, independente do sistema operacional que esteja sendo utilizado pelo usuário.
4.1 Estudos de Caso
Para ilustrar a aplicação do BI em no ambiente acadêmico a Tabela 1 apresenta dois estudos de caso, um da Microsoft (2012) e outro da IBM (2009).
Tabela 1. Business Intelligence aplicado em ambiente acadêmico
Cliente Universidade de Calgary http://www.ucalgary.ca
Universidade Sripatum http://web.spu.ac.th
Mais de 28.000 alunos estão atualmente matriculados em cursos de graduação, pós-graduação. 120.000 alunos formado Atualmente, a universidade está buscando a expansão através de um plano de investimento de US $ 1,5 bilhões para aumentar a sua capacidade e atividades de pesquisa.
A universidade Sripatum tem campi em três locais. Anualmente são aceitos mais de 5.000 novos alunos em programas de graduação, pós-graduação. A universidade quer ser a principal universidade privada da Tailândia e tem investido bastante em tecnologia da informação, incluindo redes sem fio e sistemas de e-learning.
Necessidades de Negócio
Consolidar fontes complexas e confusas de dados em informações valiosas para os tomadores de decisão.
A universidade queria otimizar relatórios para que pudessem reagir mais rapidamente às condições de mercado.
ISBN: 978-989-8533-11-1 © 2012 IADIS
210

A Universidade decidiu usar BI, para permitir que os escritórios da administração, finanças e inscrição tenham acesso a painéis de informação para a análise de previsão e monitoramento de atividades.
A universidade também queria melhorar as apresentações do seu relatório.
A universidade queria que os usuários pudessem interagir mais com os dados.
Solução/Produto IBM Cognos 8 BI Microsoft BI Benefícios Melhoria da tomada de decisão,
planejamento e modelagem preditiva, otimização de links críticos na cadeia de suprimentos; análise de métricas de custo e eficiência para a otimização de negócios sem aumentos orçamentais significativos; dashboards que permitam previsão e atividades de monitoramento
A universidade Sripatum reduziu o tempo de geração de relatórios e melhorou as suas capacidades analíticas. Utilização de painéis para monitorar indicadores-chave de desempenho (KPIs), e estão planejando hospedar materiais educativos na nuvem.
5. CONCLUSÃO
Através do estudo realizado foi possível constatar que o atual ambiente de competitividade global tem impactado inclusive o setor de educação fazendo com que as instituições de ensino procurem ajustar o seu planejamento estratégico e organizacional, promovam a inovação e o uso da tecnologia da informação para acelerar a inteligência competitiva e analítica da instituição.
Foi observado que a inteligência analítica permite que a instituição conheça suas necessidades e fraquezas, assim como, seus pontos fortes e fracos, tornando as ações estratégicas e tomadas de decisão eficazes. Para auxiliar na tomada de decisão uma das ferramentas mais importantes é o Business Intelligence que proporciona a visualização das informações em vários níveis de detalhamento, possibilitando a instituição ter um maior controle de seus negócios. O BI possui uma arquitetura que compreende tecnologias, processos e pessoas e visa auxiliar o processo de transformação dos dados em informação, informação em conhecimento e conhecimento em sabedoria, resultando em ações que beneficiam a empresa.
Várias instituições de ensino conforme exemplificado através de dois estudos de caso utilizando a ferramenta IBM Cognos e Microsoft BI nas universidades de Calgary e Sripatum estão observando o potencial da inteligência analítica e estão consequentemente adotando ferramentas de BI. O futuro dessas ferramentas tende a ser baseada em cloud computing, acessível através da Internet.
REFERÊNCIAS
Barbieri, C, 2011. BI2 – Business Intelligence: modelagem e qualidade. Elsevier, Brasil. Filho, T. L., 2010. BI – Business Intelligence no Excel. Novaterra, Brasil. IBM, 2009. Powerful business intelligence for the University of Calgary. IBM Case Study. Retrieved from http://www-
01.ibm.com/software/success/cssdb.nsf/CS/SANS-7UMHVN?OpenDocument&Site=cognos&cty=en_us Inmon, W. H., et al, 1998. Gerenciando Data Warehouse. Makron Books, Brasil. Inmon, W. H., Hackathorn, R. D., 1997. Como Usar o Data Warehouse.Infobook, Brasil. Machado, F. N., 2011. Tecnologia e Projeto de Data Warehouse. Editora Érica, Brasil. Machado, L. E., 2008. Gestão Estratégica para Instituições de Ensino Superior Privadas. Editora FGV, Brasil. Microsoft, 2012. University Speeds Reporting and Improves Data Analysis with Microsoft BI Platform. Microsoft Case
Studies. Retrieved from http://www.microsoft.com/casestudies/Microsoft-SQL-Server-2012-Enterprise/Sripatum-University/University-Speeds-Reporting-and-Improves-Data-Analysis-with-Microsoft-BI-Platform/710000001038
Norris, D., et al, 2008. Action Analytics: Measuring and Improving Performance That Matters. EDUCAUSE Review. Retrieved from http://www.educause.edu/EDUCAUSE+Review/EDUCAUSEReviewMagazineVolume43/ActionAnalyticsMeasuringandImp/162422
Primak, F. V., 2008. Decisões com B.I. (Business Intelligence). Editora Ciência Moderna ltd, Brasil. Tan, P.-N., et al, 2009. Introdução ao Data Mining. Editora Ciência Moderna ltd, Brasil. Turban, E., et al, 2009. Business Intelligence: um enfoque gerencial para a inteligência do negócio. Bookman, Brasil.
Conferência IADIS Ibero-Americana WWW/Internet 2012
211


ÍNDICE DE AUTORES Aguilar, J. ...................................................... 199 Aguilar, P. ..................................................... 199 Almeida, L. ..................................................... 155 Amaral, L. ............................................. 107, 166 Amorim, M. ..................................................... 83 Antunes, R. .................................................... 193 Araújo Junior, C. ............................................. 43 Ascenso, L. .................................................... 171 Baranauskas, M. ............................................... 19 Barchino, R. ...................................................... 67 Behar, P. ............................................... 27, 75, 83 Bercht, M. ......................................................... 83 Bermúdez, J. .................................................. 147 Bertch, M. ......................................................... 35 Biazus, M. ........................................................ 35 Bittar, T. .................................... 3, 107, 161, 166 Bonifácio, B. ................................................... 91 Caba, M. ........................................................... 99 Carvalho, F. ................................................... 151 Castillo, J. ....................................................... 115 Castillo, J. ........................................................ 59 Chagas, T. ......................................................... 43 Clunie , C. ......................................... 51, 181, 187 Crespo, S. .............................................. 181, 187 de-Marcos, L. .................................................. 67 Díaz, S. .......................................................... 187 Ferreira, A. ...................................................... 43 Ferreira, E. ...................................................... 193 Fontão, A. ........................................................ 91 Fortes, R. ................................................ 107, 166 Gálvez, M. ........................................................ 99 García, A. ......................................................... 67 García, E. ......................................................... 67 Gerosa, M. ........................................................ 11 Ghisi, C. ............................................................. 3 Gomes, L. .............................................. 171, 176 Gómez, J. .......................................................... 59 González, M. ................................................. 147 Guerra, H. .............................................. 171, 176 Guimarães Júnior,V. ....................................... 161 Gutiérrez, J. ..................................................... 67 Haro, A. ........................................................... 99 Hoentsch, S. ................................................... 151 Iglesias, F. ....................................................... 67
Illarramendi, A. .............................................. 147 Kawamoto, A. ................................................. 11 Kraemer, A. ...................................................... 11 Macedo, M. .................................................... 141 Machado, L. .................................................... 27 Maciel, M. ....................................................... 43 Maissiat, J. ...................................................... 35 Martins, L. ..................................................... 176 Medina, J. ........................................................ 59 Mendes, A. ..................................................... 171 Mendes, A. ..................................................... 176 Miranda, E. .................................................... 123 Misaghi, M. ................................ 3, 141, 161, 207 Muñoz, A. ...................................................... 123 Nascimento, V. .............................................. 193 Navarro, M. ...................................................... 59 Neto, O. ......................................................... 176 Nicolay, A. ....................................................... 91 Oliveira, E. .................................................... 155 Oliveira, R. .................................................... 193 Otón, S. ........................................................... 67 Pillon, E. ............................................................ 3 Ponte, J. ......................................................... 176 Prado, A. ......................................................... 19 Ramón, J. ........................................................ 67 Ribeiro, A. .............................................. 131, 151 Robinson, L. ................................................... 181 Rosas, F. ........................................................... 75 Santos, L. ............................................... 131, 151 Santos, L. ...................................................... 155 Scarselli, R. .................................................... 193 Schimiguel, J. ................................................... 43 Shinoda, A. ..................................................... 193 Silva, R. ......................................................... 155 Sorratini, J. .................................................... 161 Tavares, R. ..................................................... 155 Teixeira, M. ................................................... 207 Torre-Bastida, A. ............................................ 147 Torres, G. ........................................................ 51 Trainotti Filho, A. ..................................... 3, 141 Zaldívar, A. .................................................... 199




















