
Conditional access techniques for H.264/AVC and H.264/SVC compressed video
30
Conditional access techniques for H.264/AVC and H.264/SVC compressed video Enrico Magli, Member, IEEE, Marco Grangetto, Member, IEEE, Gabriella Olmo, Senior Member, IEEE Abstract Protection of video content calls for encryption of all or part of the compressed files. For the “conditional access” application, this requires to provide a video preview that is left in the clear, while the video enhancement information is encrypted. In this paper we propose four algorithms that provide the conditional access functionality. The first three algorithms are based on the idea of generating controlled drift in such a way as to obtain the desired quality level, while the fourth algorithms employs scalable coding. All four algorithms are designed so as to provide a high degree of format compliancy with H.264. We provide experimental results on several video sequences, as well as security analysis, showing that the proposed algorithms provide an effective framework to perform conditional access, with a small rate overhead with respect to an unprotected reference video, and with a high level of security. Index Terms H.264/AVC, H.264/SVC, conditional access, encryption, video coding, drift control The authors are with Dip. di Elettronica, Politecnico di Torino, Corso Duca degli Abruzzi 24 - 10129 Torino - Italy - Ph.: +39-011-5644195 - FAX: +39-011-5644099 - E-mail: enrico.magli(marco.grangetto,gabriella.olmo)@polito.it. Corresponding author: Enrico Magli.
Transcript of Conditional access techniques for H.264/AVC and H.264/SVC compressed video

Conditional access techniques for H.264/AVC
and H.264/SVC compressed videoEnrico Magli, Member, IEEE, Marco Grangetto, Member, IEEE, Gabriella Olmo, Senior
Member, IEEE
Abstract
Protection of video content calls for encryption of all or part of the compressed files. For the
“conditional access” application, this requires to provide a video preview that is left in the clear,
while the video enhancement information is encrypted. In this paper we propose four algorithms
that provide the conditional access functionality. The first three algorithms are based on the idea
of generating controlled drift in such a way as to obtain the desired quality level, while the fourth
algorithms employs scalable coding. All four algorithms are designed so as to provide a high degree
of format compliancy with H.264. We provide experimental results on several video sequences, as
well as security analysis, showing that the proposed algorithms provide an effective framework to
perform conditional access, with a small rate overhead with respect to an unprotected reference video,
and with a high level of security.
Index Terms
H.264/AVC, H.264/SVC, conditional access, encryption, video coding, drift control
The authors are with Dip. di Elettronica, Politecnico di Torino, Corso Duca degli Abruzzi
24 - 10129 Torino - Italy - Ph.: +39-011-5644195 - FAX: +39-011-5644099 - E-mail:
enrico.magli(marco.grangetto,gabriella.olmo)@polito.it. Corresponding author: Enrico Magli.

IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 1
Conditional access techniques for H.264/AVC
and H.264/SVC compressed video
I. INTRODUCTION
Multimedia security and digital rights management have become very important issues in the
deployment of multimedia content distribution systems. The ability to enforce flexible copyright
policies would allow content distributors to overcome several limitations of existing systems.
Encryption is a key enabling tecnology, as it guarantees that only the users that know a key are
going to be able to decrypt and render the multimedia content. Recent techniques such as advanced
encryption standard (AES) [1] allow to protect data communications in a reliable way, providing a
high degree of security with a reasonable computational cost. Nevertheless, encryption of a multimedia
file has to be carried out carefully. On one hand, ciphering the complete compressed file may result
in excessive computational burden and/or power consumption at the decoder. While this is not critical
for computer-based systems, it could lead to excessive battery drain on a handheld device. Even more
importantly, multimedia compressed files typically exhibit well-defined hierarchical structures that can
be exploited in several ways, e.g. for scalability, transcoding, rate shaping, and so forth. However,
these structures are not recognizable in the ciphertext, and hence become of little use.
Several authors have attempted to process the information in the compressed domain, which is more
amenable to providing enhanced functionalities. As outlined in [2], encryption can be carried out at
different stages of the compression process, namely the original pixels, the transform coefficients,
the quantization indexes, the bit-planes, the entropy coder, or the final codestream. Particular care
should be taken to select the most appropriate place to perform encryption, in order to obtain the
desired functionality. For example, encrypting data before the entropy coder may result in a coding
efficiency loss due to the modified data statistics; in [3] it has been shown that the performance
loss may be avoided by designing the compression/encryption algorithm based on distributed source
coding principles.
When employing an international standard, the issue of syntax-compliance of the encrypted file
should also be taken into account. Syntax-compliance is important because the syntax often allows
for compressed-domain processing. For example, a compressed JPEG 2000 image or video sequence
can undergo rate adaptation by simply discarding a few quality layers; this only requires parsing
the compressed file and looking for the relevant data structures. However, this cannot be done if
the compressed codestream has been encrypted using an external encryption block such as AES,

IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 2
because these structures cannot be recognized in the ciphertext. On the other hand, decrypting and
re-encrypting the information at an intermediate stage of the system considerably weakens its security,
since it makes the plaintext available in an intermediate place of the multimedia distribution system.
Moreover, it would clearly be desirable that the ciphertext could be directly decoded by a standard-
compliant decoder; for example, this is achieved in [4] using JPEG 2000. In this case, if a decoder
attempts to decode a protected file without knowing the key, it will generate a meaningless content,
but will not crash due to syntax errors. This cannot be achieved when the compressed file undergoes
encryption, because the ciphertext could violate the syntax, e.g. generating marker emulation. Syntax
compliance is typically achieved at the expenses of some performance loss (see e.g. [5]), and/or
imposing some requirements on the design of the entropy coding stage. Some hybrid solutions can
also be pursued, where the encoder first generates different codestreams (e.g., quality layers) that
are encrypted separately using e.g. AES. In this case, an external deciphering block is still necessary
before decoding, but after that the file is syntax compliant; in this way, compressed domain processing
is still possible, and security can leverage on the existing computationally secure standards.
A possible application of some of these ideas is in the field of “selective encryption”, in which
only the visually most significant information is ciphered in order to prevent display of the image
by an unauthorized user [6]. Another interesting application, namely “conditional access”, has been
proposed in [7]. In conditional access, a low-quality version of the image is left in the clear, and can
be used to preview the multimedia content; the user can purchase a key, and then decode the content
at full quality. As has been noted in [8], a few different terms have been used in the literature for the
conditional access application. Namely, the phrase “perceptual encryption” emphasizes the need of
quality control for the low- and high-quality versions of the video. The term “transparent encryption”
has also been used with reference to the fact that the encrypted data can be correctly handled by
all standard-compliant decoders, and the terms “format-compliant encryption” and “syntax-aware
encryption” have the same meaning.
These and other features can be achieved in several different ways, according to where and how
the ciphering process takes place. Although ciphering can be done directly on the image pixels, e.g.
on their least significant bit-planes as in [9], or applying a secret transform to each pixel before
compression [10], this usually leads to major compression efficiency losses. Several authors have
investigated various algorithms that operate in the transform domain or the colorspace domain. E.g.,
in [11] the signs of some wavelet coefficients are randomly changed. In [12], [13], [14] the discrete
cosine transform (DCT) coefficients of MPEG video, along with the motion vectors (MV) and color
planes, are changed; in [15], [16] the DCT coefficients are shuffled, while in [17] they are modified
adding or subtracting a constant. In [18] wavelet code-blocks are shuffled during the JPEG 2000

IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 3
encoding process. In [19] the MVs are also scrambled. In [20] different wavelet packet transforms
are used to hide the original information, whereas in [21] different wavelet filters, belonging to the
same family, are used in JPEG 2000. A few authors [2], [7] propose algorithms based on modifications
of the bit-planes of the transformed coefficients; this is particularly useful for JPEG 2000, as it allows a
high degree of flexibility in the design of the protection scheme and its functionality, since the entropy
coding is done bit-plane by bit-plane.
A large body of work has also been made with the objective of performing encryption in conjunction
with the entropy coding stage. In [22] it is suggested to map the syntactical elements to indexes in
a table, to encrypt the indexes, and to use the resulting integers as indexes of new codewords;
index mapping is also proposed in [2]. Another possible approach, which avoids any compression
performance loss, is based on the idea of encrypting fixed-length parts of entropy-coded codewords,
such as the eight-bit Huffman fields in JPEG [9], or some bits of Exp-Golomb codes [8], [13],
[23], which are used in many standard to encode all but the quantized DCT coefficients. A potential
problem with these techniques is that the encrypted codewords can be individually extracted from the
codestream, facilitating an attacker in the task of deciphering them. This can be avoided using secure
Huffman codes, [24], [25], [26]; in this case the ciphered codewords have variable lengths, and hence
cannot be straightforwardly extracted from the codestream. However, Huffman codes are memoryless,
and this facilitates possible attacks. Another option is to adopt secure arithmetic codes [4], [27], [28],
[29], [30]; the basic versions of these codes (e.g. [4]) generate a compressed file whose expected size
is the same as that of the non-encrypted file. Several researchers have also investigated the option of
encrypting the information after entropy coding. For example, in [31], [32] it is proposed to iteratively
encrypt portions of the compressed file until marker emulation is completely avoided; in [33] it is
proposed to packetize the compressed data so that encryption does not hinder further processing, e.g.
transcoding.
In light of the development of conditional access techniques for H.264/AVC and H.264/SVC, which
is the subject of this paper, the following remarks can be made. H.264 provides two entropy coding
options, i.e. context-adaptive variable length coding (CAVLC) and context-adaptive binary arithmetic
coding (CABAC). Extending either technique to a secure entropy coder would be desirable. However,
while secure variable length codes are easy to generate, their application to H.264 would require to
completely redesign the probability model used by the entropy coder, as it is this model that provides
the security features [26]. The randomized arithmetic coder [4] implies a very simple modification;
however, in order to provide conditional access, it requires the use of the data partitioning feature
of H.264. Data partitioning is necessary because, for conditional access, not all the information must
be encrypted; the capability to encrypt only selected portions of the data requires termination of the

IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 4
entropy coder as provided by data partitioning. However, data partitioning is supported in the Extended
profile, where CABAC is not allowed. This rules out a standard-compliant implementation of a
randomized arithmetic coder. As a consequence, for H.264 the security features are more conveniently
designed by modifying the quantization stage rather than entropy coding.
In this paper we address the problem of providing conditional access to video sequences within
the framework of the H.264 standard. We address the design of suitable schemes by imposing the
following requirements.
� High security level at the expenses of small compression loss.
� Syntax-compliance pursued as much as possible, at least to such an extent that the basic pro-
cessing functionalities can be carried out on the encrypted data without having to decrypt them.
Specifically, this paper provides the following contributions. We propose to employ spatial and
temporal drift as a way to generate low-quality versions of a video sequence with controlled quality
loss and small rate overhead. Although temporal drift has been implicitly used to decrease video
quality as much as possible for selective encryption applications, to our best knowledge this is the
first time it is proposed for conditional access. This latter is clearly a much difficult problem, because,
unlike selective encryption, the drift has to be completely compensated for a user that knows the key
and wants to decode the video at full quality. As an outcome, we propose three different algorithms
that employ drift control to provide conditional access, with different levels of redundancy and syntax-
compliance. Moreover, we propose a new scheme that employs the new H.264/SVC [34] scalable
extension of H.264/AVC, and encrypts all enhancement layers, leaving the base quality layer in
the clear as a low-quality video. We show that these algorithms represent feasible solutions to the
conditional access problem, with different advantages and drawbacks.
This paper is organized as follows. In Sect. II, III and IV we describe the four proposed algorithms.
In Sect. V we provide experimental results on several video sequence. In Sect. VI we analyze the
related security issues, while in VII we draw some conclusions.
II. PROPOSED TECHNIQUES - ALGORITHM 1
The first proposed algorithm is based on the concept of using drift to lower the quality of the video
for a user that does not know the key. The design of the proposed technique has been based on a
few characteristics of H.264/AVC compressed video sequences, which are discussed hereafter.
A. Design justification
A problem with scrambling techniques is that they require that the data be uncorrelated; this
guarantees that no information about the encrypted data leaks from the data that are left in the clear.

IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 5
However, transforms and prediction loops as commonly used in image and video compression are
not perfect decorrelators; as a consequence, some care must be taken in order to avoid information
leakage from non-ciphered data.
As for video sequences, besides header information, the compressed file contains the MVs, coding
modes, reference frame number, and DCT coefficients for each macroblock (MB) of each slice. Some
of this data types are not amenable to be used for conditional access. For example, the reference
frame number would be relatively easy to estimate for an attacker, given that, most of the times, the
best prediction match occurs in the previous frame. Moreover, a reference frame mismatch is not
necessarily source of a large error, especially if the motion in the sequence is slow. Similarly, the
coding modes are not so numerous, and are also amenable to attacks. For example, the coding mode
can be estimated by looking at the number of nonzero MVs in a MB, and/or at the energy of the
decoded DCT coefficients.
We believe that the most suitable data to be used to provide conditional access functionalities
are the DCT coefficients and the MVs. Since the DCT coefficients provide a frequency-based, and
hence hierarchical representation of the video content, they are amenable to differentiated encoding
for content protection purposes. Although the MVs are not so easy to use for generating lower quality
versions of the video, they should nonetheless be protected to the extent that they do not leak any
information regarding the DCT coefficients, so that an attacker will not be able to exploit them, either
for temporal or spatial error concealment, or to estimate the encrypted DCT coefficients.
Another important remark, related to H.264/AVC, is that the encoding is performed on a MB by
MB basis, also for I-frames, instead of a frame-by-frame basis as in some previous standards. The
reason lies in the fact that intra MBs are subject to spatial prediction, and hence all the previous MBs
need to be encoded before computing the prediction for the current MB. Once a MB is encoded,
its encoding parameters cannot be changed, because this would cause spatial drift. Moreover, the
rate-distortion optimization process also operates MB by MB, and mode decisions are frozen once a
MB has been coded. The problem with this approach is that frame-based scrambling algorithms for
DCT coefficients [16] are difficult to perform in H.264/AVC, while scrambling within a single MB
is not secure enough due to the low number of DCT coefficients. Therefore, other techniques have
to be used in H.264/AVC.
B. Encoding with drift control
1) DCT coefficients: H.264/AVC follows the typical structure of motion-compensated video coding
schemes, which is shown in Fig. 1; a temporal prediction loop is present, in which the prediction error
is transformed and quantized. Unlike other standards, H.264/AVC has multiple prediction loops. A

IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 6
spatial prediction loop is used to predict a MB given the previously encoded MBs; a MV prediction
loop is also employed in the motion estimation stage, in that the MV for a MB can be predicted from
other MVs of already encoded MBs in the same frame.
In the proposed algorithm, the protection is carried out for each MB separately; we process
only DCT coefficients in the luminance component, whereas the chrominance components are left
unchanged. H.264/AVC employs a 4x4 transform followed by uniform scalar quantization; for sim-
plicity, in the following we will refer to this transform as a DCT, although it is actually an integer
approximation of it. We denote as ��, with � � �� � � � � �� the quantized DCT values for a 4x4
block, ordered according to the zig-zag scan. Inside the temporal and spatial prediction loops, the
coefficients �� are left unchanged, and all quantities used for rate-distortion optimization, e.g. the
rate and distortion associated to a certain mode decision and whether a 4x4 block is nonzero, are
computed using the unchanged �� coefficients. This is very important, as it ensures that, when the
high quality video is decoded by a user that knows the key, optimal quality is achieved; on the other
hand, the mismatch between the low-precision DCT coefficients written on file and the high-precision
coefficients used for the rate-distortion optimization generates the drift which causes the video quality
to become low for a user that does not know the key.
In Fig. 1, the additional blocks that perform the video protection are shaded. The modification does
not involve all coefficients; rather, we modify only a given number of least significant bit-planes of
coefficients with index � � ����. This allows to accurately set the quality of the video preview that
all users are allowed to decode; a certain number of low-frequency coefficients are left unchanged,
whereas some bit-planes of the high-frequency ones are processed to make the detail information
unavailable to unauthorized users. Least significant bit-planes of DCT coefficients are processed only
in intra-coded MBs; the number of processed bit-planes can differ according to whether the current
MB belongs to an I or P frame, and is denoted as �� and �� respectively.
In particular, the bit-plane processing operates as follows. For each DCT coefficient of each 4x4
block coded in intra mode, if the coefficient index is larger than ����, we remove �� (or �� ) bits of
the coefficient, and then code and encrypt them separately. In particular, we remove the � � (or �� )
least significant bits of coefficients ��, with � � ����, by appropriate right-shift, and, at the same time,
we save these bits in a separate auxiliary file. The right-shift operation has two positive effects. On
one hand, these bit-planes do not need to be encoded by the H.264/AVC entropy coder; this allows to
save some bit-rate, since replacing them with zeros would still require to encode those zeros. On the
other hand, we generate an additional drift effect, since the processed DCT coefficient is smaller than
the original one due to the right-shift; hence, it will be dequantized by a standard-compliant decoder
with a dequantization error, because the decoder will use the quantization parameter of the original

IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 7
compensated
quantizationDCT +
Motion
prediction
estimationMotion
inv. quantization
inverse DCT +
DCT
processing
CAVLC
MVprocessing
4x4 block Coding
Encryption
Compressed file
Fig. 1. Block diagram of the proposed conditional access scheme.
and not the right-shifted coefficient. Note however that the security of the proposed algorithm does
not rely on this latter drift source, because this can be easily compensated for by an attacker.
All bits removed from the DCT coefficients are grouped in an auxiliary file which is compressed
using an arithmetic coder; in particular, we employ the arithmetic coder described in [35]. Subse-
quently, the compressed file is encrypted using a stream cipher, or AES in output feedback mode,
so that the encrypted file and the plaintext have the same size. If required, the resulting ciphertext
can be embedded in the compressed H.264/AVC video, for example as a supplemental enhancement
information (SEI) message.
As for the overhead incurred by this scheme, the rationale for this design is that, although we
send some additional information in the auxiliary file, we also save some rate in the encoding of the
DCT coefficients, because their energy is smaller (and zero-runs potentially longer) after the bit-plane
removal. As a consequence, the two effects are expected to balance off to some extent.
To summarize, this algorithm uses the following sources of drift to lower the quality for an
unauthorized user, whereas a user who knows the key will achieve the optimal rate and quality,
i.e. exactly the same file as if a normal rate-distortion optimized H.264/AVC encoder had been used.
� An encoded MB will potentially affect all subsequent coded MBs in the same slice due to spatial
prediction.
� An encoded MB will potentially affect all coded MBs in the next frames due to temporal
prediction.
� The decoder will amplify the error in the dequantized DCT coefficients because of quantization
parameter mismatch; this will make the two drift effects above even worse.

IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 8
Note that all the error causes above interact in such a way that just a minor modification of the
DCT coefficients will lead to a significant decrease of the video quality. This is very important,
because it makes the quality control mechanism robust towards the failure of a single cause of drift.
For example, in certain video sequences it is possible that a lot of MBs are coded in SKIP mode. In
this case, the temporal drift due to the mismatch of the prediction error with respect to the reference
MB does not take place. However, there is still some temporal drift, due e.g. to the spatial error on
a MB, generated by the spatial drift, and propagated to the next frames through the SKIP mode.
Remarkably, the interaction of these error causes also has another desirable effect, in that it will
allow to modify only a small number of coefficients, keeping the rate overhead very limited. When the
modifications are large, the overhead can increase significantly. For example, we have also attempted
to perform direct encryption of DCT coefficients, as described in [5]. Direct encryption does not
remove the bit-planes, but employs a stream cipher to encrypt �� (or �� ) least significant bit-planes
of coefficients �� with � � ���� before entropy coding. This is very appealing because no additional
auxiliary file and no external entropy coder are required; however, we have found this approach to
generate a larger rate overhead.
2) Motion vectors: Although processing the DCT coefficients provides enough flexibility in gen-
erating the desired degree of quality, an attacker could still apply error concealment techniques based
on exact knowledge of the MVs of each MB, in order to improve the quality of the decoded video.
Furthermore, an attack similar to that described in [36] could be carried out. In this attack, the
unauthorized user first attempts to estimate the first bit of the unknown data. All possible sequences
with the first bit at zero or one are generated, and decoding is carried out. The decision on the first bit
is based on the distortion of the video decoded at each attempt with respect to the low-quality video
available as preview. Once the first bit has been estimated, the same procedure can be applied to the
second bit, and so on. With enough attempts, an attacker might be able to decode the full-quality
video sequence, or at least an improved version (though this attack is more difficult for a video
sequence as opposed to an image, because of the large number of encoded pictures).
To avoid this attack, it is useful to perturb the MVs in a controlled and reversible fashion, in such a
way that there is no information leakage from the MVs regarding the DCT coefficients. In particular,
if also the MVs are perturbed, and hence a new source of drift is introduced, it has to be expected
that the distortion between the video generated during a given decoding attempt, and the low-quality
video available, will be dominated by the drift introduced by the MVs rather than by the distortion
improvement related to one bit of a DCT coefficient.
To complicate the attacker’s task even further, we perturb the MVs by employing an analog noise
signal; this makes the number of combined MV and DCT coefficients decoding attempts remarkably

IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 9
high. In particular, we modify each MV using the formula � � � � � ��� ���, where � and � �
are the horizontal/vertical components of the original and modified MVs respectively (represented as
integers), is a random variable uniformly distributed between -1 and 1, � is a constant that sets
the desired amount of MV perturbation, and ������ denotes rounding off to the nearest integer.
The choice of to be a random variable with zero mean ensures that the MV perturbation has zero
mean. This is important because, unlike the high frequency DCT coefficients, the MVs do not have
zero mean. Therefore, right-shifting the MV would generate a quick propagation of the perturbation
because of the MV prediction loop, leading to very poor and not controllable quality. The MVs are
perturbed in each and every frame of the video sequence, not only the I frames; in this way, we also
make it more difficult for the attacker to exploit information regarding the predicted frames.
Note that, as done for the DCT coefficients, the rate-distortion optimization employs the unperturbed
MV values, so as to provide exactly the same mode decisions and prediction errors as a regular
encoder.
3) Decoder: The decoder will need the key used for encrypting the auxiliary file. It will decrypt
it, decompress it, restore the removed bit-planes before inverse quantization, and restore the original
MVs as � � � ����� ���; knowledge of is ensured by the use of common randomness through
the decryption key. After that, the normal decoding process takes place.
This algorithm is perfectly standard-compliant, in that the protected bitstream can be decoded, at
a low quality level, by any standard-compliant H.264/AVC decoder, simply carrying out the standard
decoding process. In order to achieve full-quality decoding, the decoder must also perform the steps
above to reconstruct the full-precision DCT coefficients.
C. Some comments about drift control
It is worth describing in more detail the quality control mechanism on which Algorithm 1 is based,
since this mechanism is largely shared with Algorithms 2 and 3. We start with the first frame of a
group of pictures (GOP), which is always an I frame; ����, �� and �� are constants and are not
adjusted for each frame. The parameters ���� and �� are selected so that the distortion of the I frame
(on top of the source coding one) incurred by a decoder that does not know the encryption key is the
desired one, say . Note that, if the MVs are not perturbed, the quality would be roughly constant
also across the P frames of the GOP. This is due to the fact that the error introduced in a predicted
MB in the first P frame is exactly equal to the error introduced in the reference MB. If another
MB in the second P frame is predicted from this reconstructed MB, the same principle applies, i.e.
the distortion with respect to the non modified DCT coefficients would still be . This highlights
that the proposed scheme adopts an effective form of drift control. In practice, the interaction of

IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 10
the different drift sources makes the distortion variable, and a more accurate signal model should
be employed to estimate this distortion analytically. While this goes beyond the scope of this paper,
it is worth noting that, as will be seen in Sect. V, we have found experimentally that the average
distortion remains roughly constant across different predicted frames, typically within 1 dB of peak
signal-to-noise ratio (PSNR). If MV perturbation is also employed, the PSNR tends to decrease over
a GOP due to the more serious temporal error propagation.
From these remarks, it can be seen that, in order to provide conditional access functionalities, it
is not necessary to cancel or encrypt information in the MBs coded in inter mode. It is sufficient to
use the parameter �� to remove bit-planes also from the intra coded MBs in P frames, in order to
prevent any information leakage from MBs that are left in the clear.
A similar reasoning can be made for the MVs. The amount of error on the MVs can be kept under
control by making sure that the perturbation has zero-mean, and the drift in the MV intra prediction
loop turns out to be roughly constant, similarly to the case of the DCT coefficients. However, it is
difficult to employ the MV perturbation to control the decoded image quality, since even a moderate
MV error could lead to discontinuities in the decoded image, with a significant negative impact on
visual quality. Therefore, in this work we only perturb the MVs to the extent that they do not leak
any information about the DCT coefficients. More information regarding the selection of parameter
� for MV perturbation is given in Sect. V.
III. PROPOSED TECHNIQUES - ALGORITHM 2 AND 3
The next two algorithms also employ the idea of using drift to lower the video quality. However, in
these algorithms the drift is introduced by generating a double set of I frames, namely a high quality
I frame that is used in the high-quality video, and a low-quality I frame that generates drift in the
following predicted frames, whose prediction error refers to the high-quality decoded video. While
this approach is in a way similar to Algorithm 1, in that temporal drift is generated in order to obtain
a low-quality video, the drift generation process is different, and allows to use a special H.264/AVC
tool, i.e. the redundant slices, in order to achieve full compliance with the standard.
A. Algorithm 2 - redundant slices
Algorithm 2 operates as follows. We assume that the video sequence is organized as a sequence of
GOPs with periodic I frames. The quality of an I frame is essentially determined by the quantization
parameter QP, with a higher QP leading to lower quality, and vice versa. As customary in H.264/AVC,
the encoder selects a set of QPs for the intra and inter coded frames. For simplicity, in the following

IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 11
we assume that these QPs are constant for the whole sequence, and we denote them as QPI and QPP;
the algorithm can be modified straightforwardly for variable QPs.
The high-quality video sequence is generated using the prescribed set of QPs. In addition, all I
frames are encoded one more time, using a different quantization parameter, �� � � �� � �.
The increased QPI generates a lower quality version of the I frames, where the quality difference is
controlled by the integer parameter �. Then, the key step of the algorithm takes place. In particular,
the bitstream is written in such a way that the low-quality versions of the I frames are used as primary
representations of those frames. The high-quality versions are written in redundant slices, and the
payload of the redundant slice is encrypted using AES.
As for standard compliance, a compliant decoder will discard all redundant slices, since all the
corresponding primary pictures are available. However, the primary pictures are low-quality versions,
while the next frames have been predicted based on the high-quality ones. As a consequence, the
decoding process will generate temporal drift, lowering the overall quality of the video sequence to an
extent controlled through an appropriate selection of parameter �. A decoder that knows the key will
just need to preprocess the video sequence; in particular, it will discard all primary representations
of intra frames. Then, it will decrypt the redundant slices, and mark them as primary pictures of the
corresponding I frames. Finally, standard-compliant decoding will yield the high-quality video. Note
that, since the high-quality inter frames have been predicted based on the high-quality intra frames,
the encoder rate-distortion optimization provides exactly the same mode decisions and prediction
errors as a regular non-protected encoder.
This algorithm is different from Algorithm 1 in several respects.
� The drift generation process is different. In Algorithm 2 we only generate temporal drift, while
no drift is generated due to spatial prediction and dequantization.
� Unlike Algorithm 1, we only encrypt I frames, but we do not encrypt intra MBs in inter frames.
This is due to the fact that this latter option would require to use a redundant slice for each
frame, leading to a very large overhead. If one wants to also protect inter frames, it is possible
to remove some of the least significant bits of the DCT coefficients in intra MBs, as done in
Algorithm 1, though in this paper we have not done it for simplicity.
B. Algorithm 3 - redundant slices with difference information
Algorithm 3 is a modified version of Algorithm 2 aimed at reducing the rate overhead. Specifically,
in Algorithm 2, the rate overhead is generated by the redundant slices, which carry redundant (though
higher quality) information regarding the I frames. Since we provide redundant representations of I
frames, the intra period is crucial in determining the incurred amount of overhead for a given quality

IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 12
level of the preview video. As will be seen in Sect. V, if the intra period is large then the overhead is
small, but it can become significant for small intra periods. In this case, Algorithm 3 can be a viable
option to keep the overhead small.
The problem to be addressed here is that the compressed file contains two representations of I
frames, where the high-quality representation also contains all the information carried by the low-
quality one, and this duplication makes the overhead larger than necessary. To overcome this, in
Algorithm 3 we do not provide a complete representation of the high-quality frame, but only the
difference information with respect to the low-quality one. In particular, we denote as ���� and ����,
with � � �� � � � � ��, the quantized DCT coefficients of each 4x4 block of the high- and low-quality
frames respectively. Algorithm 3 is equal to Algorithm 2, except for the fact that, in the redundant
representation of I frames, before the entropy coding stage we do not write the coefficients � ��� , but
the modified coefficients ���� obtained using the following formula:
���� � ���� �
����� �� �
�
��
�
where �� denotes left-shift, and ��� denotes truncation of the fractional part. Since in H.264/AVC
the QP is such that an increase of QP by 6 doubles the quantization step size, the left-shift operation
normalizes ���� in the same range as ���� , so that ���� turns out to be the prediction error of ���� , where
the prediction is based on the low-quality version of the I frame. As a consequence, it is expected
that the overhead is reduced, since the prediction error typically has lower energy than the original
coefficient ���� because we only send the “difference” information. After reconstructing the low-
quality DCT coefficients, the decoder recovers the high-quality ones as � ��� � ���������� �� ��� �
�.
For encoding the modified coefficients ����, we investigate two different methods. In the first
method, the coefficients ���� are given as input to the CAVLC coder exactly as if they were the
original ���� coefficients. This method is expected to be suboptimal, because the statistics of the � ���
coefficients are different from those of the ���� coefficients, for which CAVLC has been designed;
however, it does not require an external entropy coder. Alternatively, we also investigate the use of
an external arithmetic coder, as is done in Algorithm 1.
IV. PROPOSED TECHNIQUES - ALGORITHM 4
The last algorithm is not based on drift control, but rather on the concept of layered coding. In
layered coding, one wants to construct a scalable bitstream that allows to decode the video at various
spatial resolutions, temporal resolutions, and quality levels. This feature provides a nice basis for
designing a conditional access scheme. It is sufficient to generate a base layer, which will be left in
the clear and used as preview, and one or more enhancement layers that will provide the full-quality

IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 13
video, which will be encrypted before transmission, and decrypted before decoding. In practice one
may complicate this considering a scenario where the layered bitstream has been generated in such
a way that the number and bit-rates of the various layers are optimized for a given application. In
this case, one can select how many layers have to be left in the clear, i.e. as many as necessary to
achieve the desired video preview quality, and to encrypt all the other layers.
In order to apply this concept to H.264/AVC, we employ the SVC extension [34], which is
currently in the final stages of the standardization process. SVC allows to generate a compressed
video with temporal, spatial and quality scalability. Temporal scalability is achieved through the use
of hierarchical B-frames, where dropping B-frames leads to reduced temporal resolution. We design
the proposed algorithm so that it can deal with any combination of temporal, spatial and quality
scalability. In particular, one selects the number of layers (the base layer plus possibly one or more
enhancement layers) that will generate the preview video, and leaves them in the clear. All the
subsequent enhancement layers are ciphered using AES.
In practice, for simplicity, we have considered two scenarios, each comprising a base layer and
an enhancement layer. In the first scenario, the base layer is a low-quality version of the original
video at full spatial and temporal resolution. This is similar to what is done in algorithms 1, 2 and
3, and allows a direct comparison of the overhead for equal distortion. In the second scenario, the
base layer contains a low spatial resolution and low temporal resolution version of the video, and the
enhancement layer improves those to full resolution. We investigate both schemes in order to assess
which one provides the best performance/redundancy trade-off.
V. EXPERIMENTAL RESULTS
We have tested the proposed techniques on several CIF video sequences, using the baseline
H.264/AVC encoder and the H.264/SVC encoder. We present results for the Mobile, Tempete and
Football sequences. The sequences have been coded with GOPs of 15 and 50 frames (one I frame
followed by P frames); more information is provided later regarding H.264/SVC encoding parameters.
CAVLC has been used as entropy coder. In order to test the algorithm under different conditions, the
sequences have been coded at different frame-rates and quality levels, as detailed in Tab. I.
We first show results for Algorithm 1. Initially, we have investigated the proper choice of parameter
� for MV perturbation. To do so, we have set �� � �, �� � �, and ���� � ��, and we have
computed the overhead and PSNR for several values of � between 0.5 and 1 (note that � � ���
has no effect whatsoever because of the rounding operation in the formula � � � � � ��� ���).
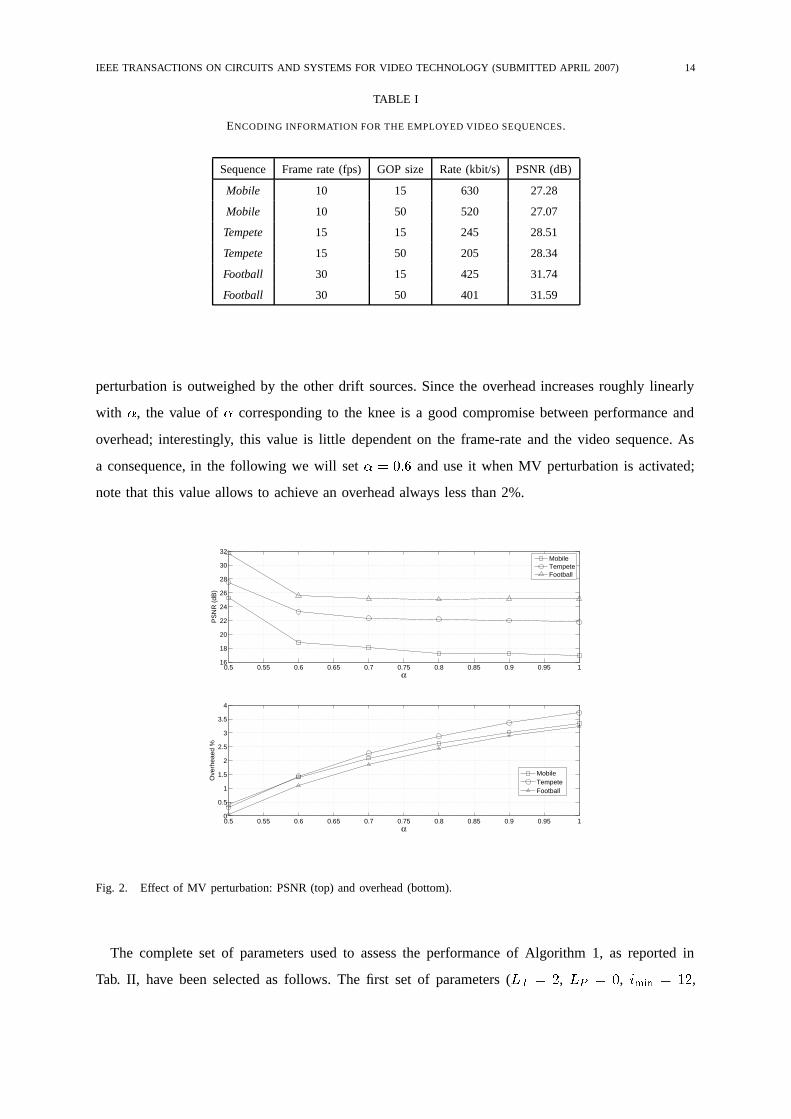
The results are shown in Fig. 2. As can be seen, for all video sequences the PSNR curve exhibits
a knee, after which the PSNR does not decrease significantly any more, because the effect of MV
IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 14
TABLE I
ENCODING INFORMATION FOR THE EMPLOYED VIDEO SEQUENCES.
Sequence Frame rate (fps) GOP size Rate (kbit/s) PSNR (dB)
Mobile 10 15 630 27.28
Mobile 10 50 520 27.07
Tempete 15 15 245 28.51
Tempete 15 50 205 28.34
Football 30 15 425 31.74
Football 30 50 401 31.59
perturbation is outweighed by the other drift sources. Since the overhead increases roughly linearly
with �, the value of � corresponding to the knee is a good compromise between performance and
overhead; interestingly, this value is little dependent on the frame-rate and the video sequence. As
a consequence, in the following we will set � � ��� and use it when MV perturbation is activated;
note that this value allows to achieve an overhead always less than 2%.
0.5 0.55 0.6 0.65 0.7 0.75 0.8 0.85 0.9 0.95 116
18
20
22
24
26
28
30
32
α
PS
NR
(dB
)
0.5 0.55 0.6 0.65 0.7 0.75 0.8 0.85 0.9 0.95 10
0.5
1
1.5
2
2.5
3
3.5
4
α
Ove
rhea
ed %
MobileTempeteFootball
MobileTempeteFootball
Fig. 2. Effect of MV perturbation: PSNR (top) and overhead (bottom).
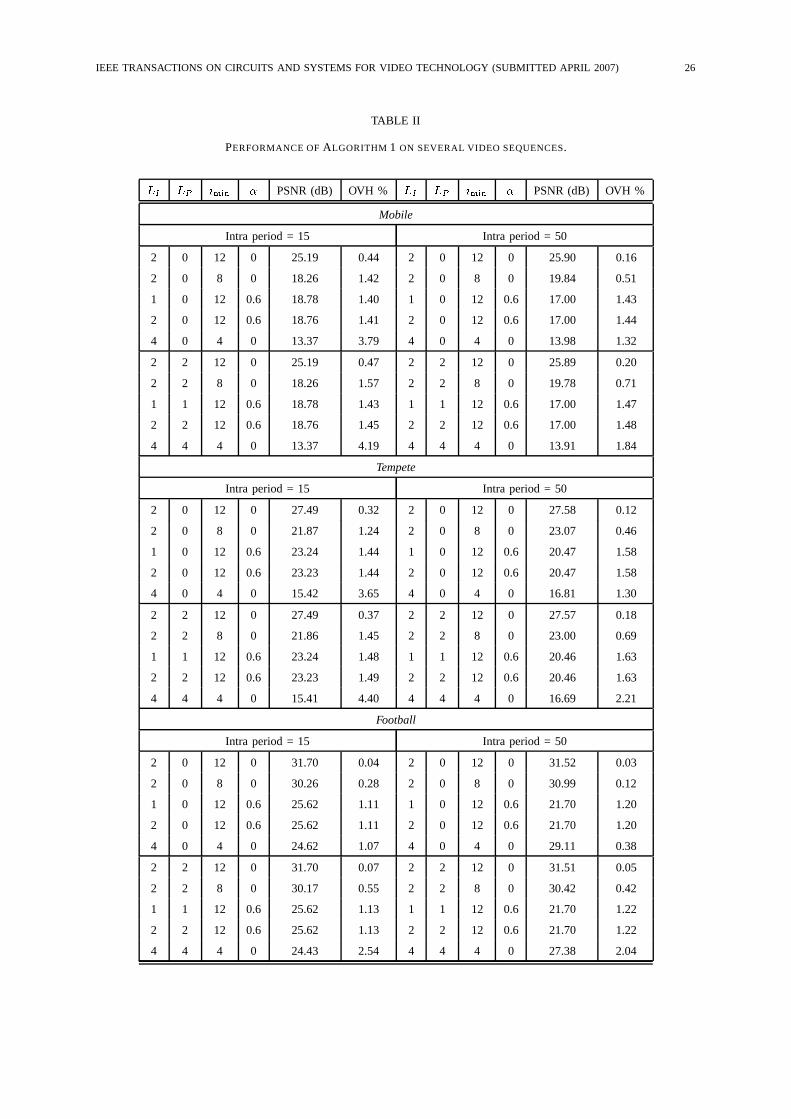
The complete set of parameters used to assess the performance of Algorithm 1, as reported in
Tab. II, have been selected as follows. The first set of parameters (�� � �, �� � �, ���� � ��,

IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 15
� � �) generates a relatively small quality decrease. The second set of parameters (� � � �, �� � �,
���� � �, � � �) allows to evaluate the effect of ���� for quality reduction. The third set of parameters
(�� � �, �� � �, ���� � ��, � � ���) allows to evaluate the effect of MV perturbation (i.e., � �� �);
in this case, we modify the DCT coefficients only slightly, and rely on the MV perturbation to lower
the quality. The fourth set of parameters (�� � �, �� � �, ���� � ��, � � ���) is very similar to
the third one; however, we set �� � � so that a direct comparison with the first parameter set is
possible. The fifth set of parameters (�� � �, �� � �, ���� � �, � � �) is designed to evaluate the
overhead incurred when the modification to the DCT coefficients is very large. These parameter sets
are replicated to comprise the case of �� � �� .
The rightmost column of Tab. II reports the overhead incurred with respect to the no protection
case. As can be seen, decreasing ���� decreases the quality obtained without the decryption key, since
more DCT coefficients undergo bit-plane cancellation. For the same value of ����, �� can be used to
fine-tune the quality control. The incurred overhead is also quite small, typically around 1-1.5%. The
overhead increases as �� and ���� increase, since more information has been cancelled and coded
separately. As anticipated, when �� is set to a value different from zero, there is no significant quality
change, since the amount of affected MBs in inter frames is very small; accordingly, the overhead
increase is also very small.
When MV perturbation is employed, i.e. � �� �, with all the other parameters being equal, the
temporal prediction drift leads to larger errors, and hence lower PSNR; the overhead is also a bit
higher because the MVs are noisier, and hence the entropy coder needs to use more bits. However,
thanks to the fact that the MV error has zero mean, the visual quality is still suitable for a video
preview. When the fourth set of parameters is used, the PSNR drops to a very low level, while the
overhead remains reasonably small. The results for intra period equal to 50 frames are very similar.
As expected, the overheads are smaller, because the refinement information for I frames is spread
over 50 as opposed to 15 frames.
The Tempete sequence has less motion with respect to Mobile, and is encoded at higher frame rate.
This leads to DCT coefficients of smaller magnitude, which generate less overhead; moreover, the
PSNR is slightly larger due to the smaller amount of temporal drift. However, for the same PSNR,
the overhead is only slightly larger than the Mobile sequence. Similar results are obtained on the
Football sequence. In general, sequences with fast motion and sequences encoded at low frame rate
require the smallest overhead for a given PSNR, because the error propagation is larger. However, a
significant quality decrease can always be obtained with an overhead no larger than 1.5%.
For comparison, Tab. III contains results for direct encryption of DCT coefficients. It can be seen
that the overhead is much higher than in the case of the proposed techniques, due to the fact that the

IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 16
modified bit-planes have poor statistical characteristics, and their encoding requires many bits.
The results obtained for Algorithm 2 and 3 are reported Tab. IV. Algorithm 3 has two different
modes, according to whether CAVLC or an external arithmetic coder (AC) are used to encode the
difference signal. Algorithm 2 always generates the largest amount of overhead. This is not surprising,
as this algorithms duplicates the information related to the I frames. When the GOP size is small, the
overhead can become very large, whereas it is between 5% and 10% for large GOP. These overheads
are significantly larger than those incurred by Algorithm 1; however, in certain applications, Algorithm
2 could be preferred because it does not need any external coding tools. For Algorithm 3, the overhead
is significantly smaller, especially when an external AC is employed to code the difference coefficients.
In this case, the overhead is similar or only slightly larger than Algorithm 1, making Algorithm 3 an
interesting option. The advantage of Algorithm 3 lies in the fact that, since every DCT coefficient of
an I frame is coded, this algorithm allows to encode the difference information in a redundant slice,
exploiting the syntactical features provided by the standard. On the other hand, Algorithm 1 requires
to send the auxiliary information separately, or in a comment marker segment.
For Algorithm 4, we have employed the Joint Scalable Video Model software version 7. One
base layer and one enhancement layer have been formed, without any fine-grain scalability layer.
Since in this experiment we are not interested in temporal and spatial scalability, a GOP has been
assumed equal to one frame1; intra frames with period 15 and 50 have been inserted. CAVLC has
been used as entropy coder; the enhancement layer is encrypted using AES. The results provided
by Algorithm 4 are shown in Tab. V. With the selected quantization parameters, the quality of the
video preview is similar to that of the other algorithms. However, it is well-known that scalable video
coders incur a performance penalty with respect to a non-scalable coder at the same target bit-rate,
due to the presence of multiple prediction loops. The overhead in Tab. V refers to the additional
rate required with respect to a non-scalable H.264/AVC coder that achieves the same quality as the
SVC enhancement layer. As can be seen, the overhead is significant. However, it should be noted
that this overhead is not a price to be paid for the conditional access functionality, but for the use
of H.264/SVC, as the encryption of enhancement layers does not increase the bit-rate. In fact, it
is known that scalable video coding is an intrinsically difficult problem, and that scalable coders
typically exhibit a rate overhead with respect to non-scalable ones for the equal PSNR of the full-
quality scene. If one decides to employ H.264/SVC instead of H.264/AVC for the sole purpose of
the conditional access functionality, the price to pay would be very high; besides the overhead, using
1In H.264/SVC, the term GOP is not related to the intra frame period, but only to the number of hierarchical B frames,
which impacts on the granularity of temporal scalability.

IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 17
H.264/SVC imposes additional requirements on the decoders, which must support SVC in addition
to AVC. On the other hand, in a communication scenario where H.264/SVC is employed e.g. for
video adaptation, the conditional access feature comes at no other cost than properly designing the
base layer for generating a low-quality video.
We also used SVC in a different way, exploiting spatial as opposed to SNR scalability. In particular,
we generated a base layer in QCIF format at 5 fps, while the enhancement layer brings the spatial
resolution to CIF, and the temporal resolution to 10 fps. The results achieved by SVC under these
conditions are significantly better, as is witnessed by the results achieved for conditional access,
which are shown in Tab. VI. As can be seen, Algorithm 4 provides a reasonable overhead, similar to
Algorithm 1 for Mobile and somewhat larger for Tempete and Football. IT can be noticed that, for
Mobile, the PSNR of the base layer is only about 3 dB smaller than that of the full-quality video. This
is due to the range limitation of the quantization parameter, which determines a minimum quality
level. While this is not a technological problem, this issue highlights the potential need to find a
workaround to this problem in order to lower the video quality to the desired level.
Fig. 3 shows a few examples of video sequences decoded without knowledge of the key. The
encoding is carried out on the Mobile sequence as described in Tab. I with intra period of 15 frames. As
can be seen, the proposed techniques exhibit distinctive visual features. Removal of DCT coefficients
leads to a very smooth image, with reasonable quality. MV perturbation leads to another kind of
artifacts, namely local image warping/distortions. H.264/SVC provides very low visual quality when
only the base layer is decoded, which is suitable for a video preview.
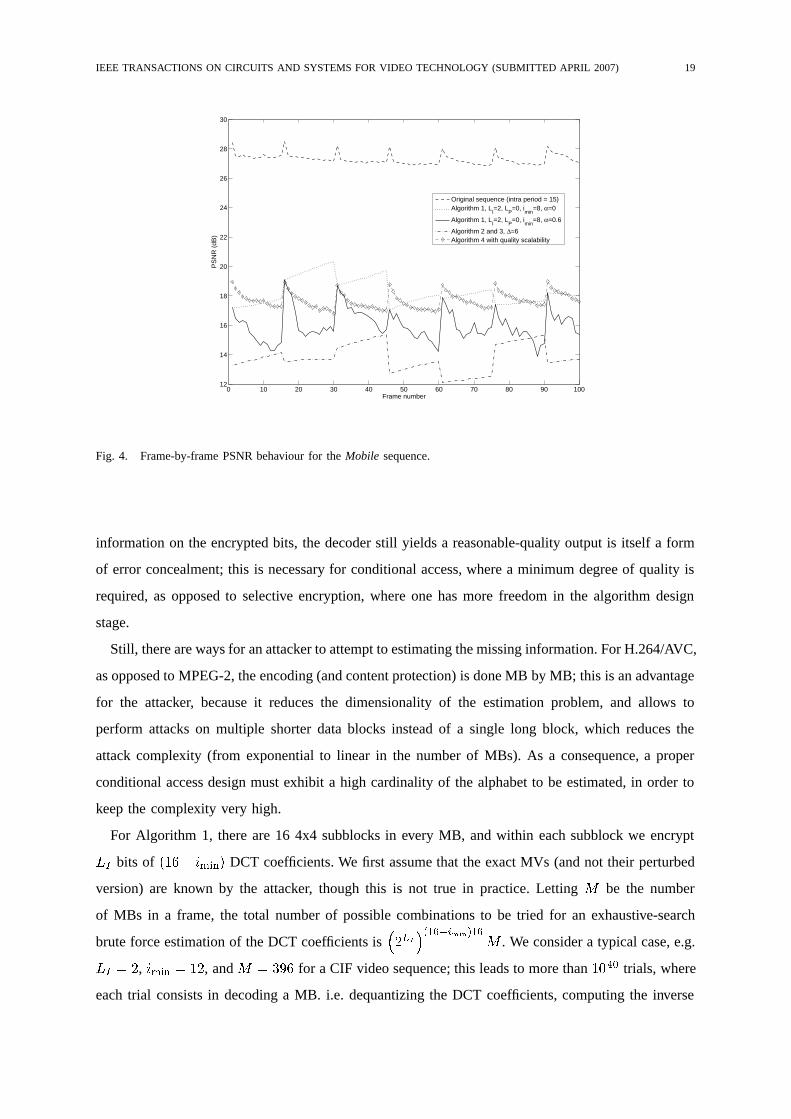
Fig. 4 shows the frame-by-frame PSNR for the different algorithms on the Mobile sequence; the
encoding is carried out as described in Tab. I with intra period of 15 frames. As can be seen, in
general the PSNR tends to drop on every I frame, and then increases slightly within a GOP (about
0.8 dB between the first and last P frame); this is consistent with the remarks in Sect. II. An exception
is given by Algorithm 1 when also the MVs are perturbed; in that case, due to the additional temporal
drift generated by the MVs, the PSNR tends to decrease during a GOP. For Algorithm 4, the behavior
is rather similar to that of the original video sequence, with the PSNR decreasing over a GOP, and
increasing in correspondence of the I frames.
VI. SECURITY ANALYSIS
In the following we discuss the security of the proposed algorithms against attacks aimed at
reconstructing the full-quality video. We focus on attacks aimed at estimating the I frames, where we
have focused the protection, because the prediction errors are of little use to the attacker if the exact
reference frames are not available to them.

IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 18
Fig. 3. Sequences decoded without knowledge of the key. Top left: Original with no protection (PSNR = 27.28 dB). Top
right: removal of DCT coefficients. Bottom left: MV perturbation. Bottom right: H.264/SVC with quality scalability. The
PSNR for the last three images is equal to about 17 dB.
A. Algorithm 1
Ciphertext-only attacks are viable against partial encryption schemes, since they do not require
knowledge of the original bits. Moreover, for conditional access applications, a low-quality preview
of the video sequence is available, which can help the attacker to estimate the encrypted information.
When a secure cipher is employed, e.g. a block cipher or a stream cipher with suitable feedback, this
cipher should be robust against ciphertext-only attacks; therefore, the attacker should not be able to
break the cipher. As pointed out in [8], suitable ciphers or key distribution systems can be chosen
so that the encryption is robust towards known/chosen-plaintext attacks. As a consequence, the main
danger lies in the estimation of the encrypted bits from the information that is left in the clear. This
is also known as “error concealment attack” [37], whereby the missing bits can be set to zero or
estimated using other available information. Note that setting to zero the missing bits does not provide
any quality improvement for the proposed algorithms; all the results presented in Sect. V have been
obtained assuming that the decoder sets to zero any unknown bit. Really, the fact that, without any
IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 19
0 10 20 30 40 50 60 70 80 90 10012
14
16
18
20
22
24
26
28
30
Frame number
PS
NR
(dB
)
Original sequence (intra period = 15)Algorithm 1, L
I=2, L
P=0, i
min=8, α=0
Algorithm 1, LI=2, L
P=0, i
min=8, α=0.6
Algorithm 2 and 3, Δ=6Algorithm 4 with quality scalability
Fig. 4. Frame-by-frame PSNR behaviour for the Mobile sequence.
information on the encrypted bits, the decoder still yields a reasonable-quality output is itself a form
of error concealment; this is necessary for conditional access, where a minimum degree of quality is
required, as opposed to selective encryption, where one has more freedom in the algorithm design
stage.
Still, there are ways for an attacker to attempt to estimating the missing information. For H.264/AVC,
as opposed to MPEG-2, the encoding (and content protection) is done MB by MB; this is an advantage
for the attacker, because it reduces the dimensionality of the estimation problem, and allows to
perform attacks on multiple shorter data blocks instead of a single long block, which reduces the
attack complexity (from exponential to linear in the number of MBs). As a consequence, a proper
conditional access design must exhibit a high cardinality of the alphabet to be estimated, in order to
keep the complexity very high.
For Algorithm 1, there are 16 4x4 subblocks in every MB, and within each subblock we encrypt
�� bits of ���� ����� DCT coefficients. We first assume that the exact MVs (and not their perturbed
version) are known by the attacker, though this is not true in practice. Letting � be the number
of MBs in a frame, the total number of possible combinations to be tried for an exhaustive-search
brute force estimation of the DCT coefficients is����
������������� . We consider a typical case, e.g.
�� � �, ���� � ��, and � � ��� for a CIF video sequence; this leads to more than �� trials, where
each trial consists in decoding a MB. i.e. dequantizing the DCT coefficients, computing the inverse

IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 20
DCT, adding the predictor from the reference frame, and computing a metric that measures how good
is the current estimate of the missing bits. This leads to the second and more serious problem that
the attacker has to cope with. Since the exact MVs are not known, there is no way for the attacker
to distinguish between good and bad estimates of the missing coefficients. It should be noted that
an attacker could in principle use a low-quality version of the video to compute the distortion for
a given set of estimated coefficients [36]. However, in the present application, although the attacker
does indeed possess the low-quality video, this video has been generated with the wrong, not the
correct DCT coefficients and MVs. As a consequence, zero distortion is obtained when the DCT
coefficients and MVs are wrong as in the received image, and not when they are correct; this is due
to the fact that the low-quality video is affected by exactly the same errors that the attacker is trying
to remove. As an example, for the Mobile sequence with intra period equal to 15, the PSNR between
the low-quality preview (decoded image when DCT coefficients and MVs are wrong) and the image
decoded with exact knowledge of the DCT coefficients is only about 11 dB. Even if the attacker
could in some way compute the PSNR with respect to the full-quality video (which he obviously
does not know), the PSNR improvement obtained through the knowledge of the DCT coefficients
would be very small (about 0.5 dB). This indicates that estimating the DCT coefficients without the
knowledge of the MVs is very time consuming, and will not lead to an improved video sequence.
Another possible strategy for an attacker is to first attempt to estimating the MVs, and then to
estimating the DCT coefficients given the exact MVs. We recall that the perturbed MVs are obtained
as � � � � � , and � ��� ���, with a random variable uniformly distributed between -1
and 1, and � a constant, e.g. � � ���. Because of the rounding operation, is a discrete random
variable that takes on integer values. The cardinality � � of its alphabet depends on �. For � � ���,
� � � �, and the MVs are never perturbed. For ��� � � � �, � � � �; for � � � � ���, � � � �,
and so on. Given the value of �, which we suppose to be known by the attacker, he/she must try
to decode the MB using all the possible combinations of MVs. Given that each MB generally has
16 MV (except for some coding modes such as SKIP), and each MV has two components, the total
number of trials for the exhaustive search is � ���, which is larger than ��� , i.e. prohibitively large,
for � � ���.
It could be argued that, because of the way the MVs are perturbed, not all values of a MV are
equally likely, because the probability that � � is always larger than or equal to the probability
of any other value of . In particular, it can be easily shown that, for ��� � � � �, the probabilities
are � � � �� � ��� and � � � �� � � � � ��� � �
�
��� �
��
�. For � � � � ���, they are
� � � �� � � � � �� � � � � ��� � ��� and � � � �� � � � � ��� � �
�
��� �
��
�. In our
example with � � ���, we have � � � �� � ����. As a matter of fact, this statistical knowledge is

IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 21
difficult to exploit, because the attacker must however try all possible combinations. The statistical
information could be used to weight the distortion for each combination of vectors by the probability
of that combination. However, this leads to the same problem as in the previous case, i.e. the lack
of a suitable low-quality image to be used as reference.
On the other hand, these remarks suggest a possible way to improve the proposed algorithm. One
could generate the perturbed MVs as � � � � � , with a discrete random variable with integer
values, whose probability mass function can be optimized for the conditional access task. The limit
of the proposed system as described above is that, in order to keep the MV perturbation reasonably
small, in order to achieve decent quality of the video preview, � cannot be too large; this leads to
small values of � �. With a design of the distribution of tailored to this application, one could
select a higher cardinality for , but assign small probabilities to the highest values. This would keep
the drift within the desired range, but complicate the attacker’s MV estimation task. We have left this
for future work, since the proposed version of the system provides an adequate degree of security.
B. Algorithms 2 and 3
Similar problems have to be faced by the attacker for Algorithms 2 and 3. In the following we
only discuss Algorithm 2, because the possible techniques are exactly the same for Algorithm 3, and
in either case the attacker has access to the same information.
The attacker’s task for Algorithm 2 is to estimate the high-quality version of an I frame based
on the low-quality version, on the previous low-quality frames, and on the prediction error of the
next frame. The problem is to understand how the attacker can do it, and if he/she has some metric
available to distinguish good from bad estimates. First, we argue that the low-quality version of the
previous frame is of no use to the attacker, because he/she might as well use the low-quality version
of the I frame. Similarly, the prediction error of the next frame is little correlated with the high-quality
version of the current frame (as a matter of fact, it is almost never used in temporal error concealment
algorithms for this very reason). Note that the attacker’s task for Algorithms 2 and 3 is more difficult
than for Algorithm 1. The reason lies in the fact that, in Algorithm 1, only a relatively small number
of coefficients are modified, and the modification has relatively small dimensionality. On the other
hand, for Algorithms 2 and 3, the dimensionality is huge, since the pixels or DCT coefficients of
the high-quality frame, as well as the MVs, can potentially take on any value. The only limitation
is given by the fixed QPs, because the quantized high-quality DCT coefficient must lie inside the
quantization interval of the low-quality one. If we take e.g. � � �, which corresponds to doubling
the step size, there are two possible values for each DCT coefficient, leading to � ����� decoding
attempts for a CIF video, under the hypothesis that the MVs of the high-quality frame were known.

IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 22
This number must be multiplied by the number of possible combinations of the MVs. Assuming that
the MV of the low-quality video is not very different from that of the high-quality video, e.g. within
�, at � -pixel resolution this leads to ������ MV combinations. besides the fact that the number
of combinations is huge, the attacker does not have any good metric for discerning good from bad
estimates, as the low-quality preview is affected by the errors that he/she is trying to correct.
C. Algorithm 4
For Algorithm 4, the attacker’s task is similar to Algorithm 2 and 3. Given that the enhancement
layers are encrypted with a secure cipher, the only possible attack is to estimate the missing informa-
tion by trial and error. Even if H.264/SVC was used without MV refinement between the base and
enhancement layers, i.e. the attacker did know the exact MVs, and even if the QP for the base layer
was equal to the QP for the enhancement layer plus 6, there would be ������ decoding attempts
required for a CIF video, which is prohibitively large. MV refinement can be employed to further
increase the dimensionality of the search, and hence the degree of security.
VII. DISCUSSION AND CONCLUSIONS
We have proposed four different algorithms for conditional access to H.264 video; Algorithms 1,
2 and 3 can be applied to H.264/AVC, whereas Algorithm 4 is designed for H.264/SVC.
The algorithm that consistently provides the smallest overhead is Algorithm 1; an overhead of
less than 2% typically yields satisfactory results. The only drawback of Algorithm 1 is that it
requires external compression tools; moreover, strictly speaking, the additional information required
to reconstruct the full-quality video should not be embedded in a redundant slice, since it is not a
complete picture representation. In practice, though, the redundant slice approach would work, since
a standard-compliant decoder would discard the redundant slice, and an enhanced decoder would use
it properly in order to enhance the picture quality.
Algorithm 2 should be used only when the intra frame period is large, in order to keep the overhead
limited. In this case, Algorithm 2 is a very attractive choice, since it does not require any external
processing tools, and the protected file is fully syntax-compliant. When the intra frame period is small,
similar results can be achieved using Algorithm 3. While Algorithm 3 is still fully syntax-compliant,
very small overheads are achieved with the aid of an external arithmetic coder, which somewhat
complicates the system design.
Algorithm 4 leverages on the powerful scalability features of H.264/SVC. One or more base layers
are left in the clear, and are hence perfectly syntax-compliant. The encrypted enhancement layers
need to be deciphered, after which they are again syntax-compliant. As a consequence, the decoder

IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 23
needs to make sure that the encrypted layers are not forwarded to the H.264/SVC decoding engine.
Performance-wise, Algorithm 4 needs to use spatial and temporal, but not quality scalability, in order
to keep the overhead small. In this case, its performance is good, especially for low-motion and
low-frame-rate sequences, while it slightly degrades for other sequences. In an application where
H.264/SVC is used for video adaptation, Algorithm 4 provides the conditional access feature with
no additional cost.
Further developments of this work will investigate other ways to exploit H.264/SVC for video
conditional access. In particular, the introduction of drift among different layers, and hence the
integration of some of the ideas of Algorithms 1, 2 and 3 into Algorithm 4, is expected to help
overcoming the issue of maximum allowed quantization parameter, by using the drift to further
decrease the video preview quality.
REFERENCES
[1] FIPS PUBS 197, 2001, Advanced Encryption Standard.
[2] Y. Mao and M. Wu, “A joint signal processing and cryptographic approach to multimedia encryption,” IEEE
Transactions on Image Processing, vol. 15, no. 7, pp. 2061–2075, July 2006.
[3] M. Johnson, P. Ishwar, P. Prabhakaran, D. Schonberg, and K. Ramchandran, “On compressing encrypted data,” IEEE
Transactions on Signal Processing, vol. 52, no. 10, pp. 2992–3006, Oct. 2004.
[4] M. Grangetto, E. Magli, and G. Olmo, “Multimedia selective encryption by means of randomized arithmetic coding,”
IEEE Transactions on Multimedia, vol. 9, no. 5, pp. 905–917, Oct. 2006.
[5] G. Olmo E. Magli, M. Grangetto, “Conditional access to H.264/AVC video with drift control,” in Proceedings of
IEEE International Conference on Multimedia and Expo (ICME), 2006.
[6] H. Cheng and X. Li, “Partial encryption of compressed images and videos,” IEEE Transactions on Image Processing,
vol. 48, no. 8, pp. 2439–2451, Aug. 2000.
[7] R. Grosbois, P. Gerbelot, and T. Ebrahimi, “Authentication and access control in the JPEG 2000 compressed domain,”
in Proceedings of the SPIE 46th Annual Meeting, 2001.
[8] S. Li, G. Chen, A. Cheung, B. Bhargava, and K.-T. Lo, “On the design of perceptual MPEG-video encryption
algorithms,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 17, no. 2, pp. 214–223, Feb. 2007.
[9] M.V. Droogenbroeck and R. Benedett, “Techniques for a selective encryption of uncompressed and compressed
images,” in Proceedings of ACIVS, 2002.
[10] M. Pazarci and V. Dipcin, “A MPEG2-transparent scrambling algorithm,” IEEE Transactions on Consumer Electronics,
vol. 48, no. 2, pp. 345–355, Feb. 2002.
[11] S. Lian, J. Sun, and Z. Wang, “Perceptual cryptography on SPIHT compressed images or videos,” in Proceedings of
IEEE International Conference on Multimedia and Expo (ICME), 2004.
[12] S. Lian, J. Sun, and Z. Wang, “Perceptual cryptography on MPEG compressed videos,” in Proceedings of IEEE
International Conference on Signal Processing (ICSP), 2004.
[13] S. Lian, Z. Liu, Z. Ren, and H. Wang, “Secure advanced video coding based on selective encryption algorithms,”
IEEE Transactions on Consumer Electronics, vol. 52, no. 2, pp. 621–629, May 2006.
[14] B.B. Zhu, C. Yuan, Y. Wang, and S. Li, “Scalable protection for MPEG-4 fine granularity scalability,” IEEE
Transactions on Multimedia, vol. 7, no. 2, pp. 222–233, Apr. 2005.

IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 24
[15] M.S. Kankanhalli and T.T. Guan, “Compressed domain scrambler/descrambler for digital video,” IEEE Transactions
on Consumer Electronics, vol. 48, no. 2, pp. 356–365, May 2002.
[16] W. Zeng and S. Lei, “Efficient frequency domain selective scrambling of digital video,” IEEE Transactions on
Multimedia, vol. 5, no. 1, pp. 118–129, Mar. 2003.
[17] C. Wang, H.-B. Yu, and M. Zheng, “A DCT-based MPEG-2 transparent scrambling algorithm,” IEEE Transactions
on Consumer Electronics, vol. 49, no. 4, pp. 1208–1213, Apr. 2003.
[18] S. Lian, J. Sun, and Z. Wang, “Perceptual cryptography on JPEG2000 compressed images or videos,” in Proceedings
of the Fourth International Conference on Computer and Information Technology, 2004.
[19] Y. Bodo, N. Laurent, and J.-L. Dugelay, “A scrambling method based on disturbance of motion vectors,” in Proceedings
of the 10th ACM International Conference on Multimedia, 2002.
[20] D. Engel and A. Uhl, “Secret wavelet packet decompositions for JPEG 2000 lightweight encryption,” in Proceedings
of IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2006.
[21] D. Engel and A. Uhl, “Security enhancement for lightweight JPEG 2000 transparent encryption,” in Proceedings of
International Conference on Information, Communication, and Signal Processing, 2005.
[22] J. Wen, M. Severa, W. Zeng, M.H. Luttrelle, and W. Jin, “A format-compliant configurable encryption framework
for access control of video,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 12, no. 6, pp.
545–557, June 2002.
[23] C. Bergeron and C. Lamy-Bergot, “Compliant selective encryption for H.264/AVC video streams,” in Proc. of IEEE
International Workshop on Multimedia Signal Processing (MMSP), 2005.
[24] A. Torrubia and F. Mora, “Perceptual cryptography of JPEG compressed images on the JFIF bitstream domain,” in
Proceedings of Dig. ICCE, 2003.
[25] X. Ruan and R.S. Katti, “A new source coding scheme with small expected length and its application to simple data
encryption,” IEEE Transactions on Computers, vol. 55, no. 10, pp. 1300–1305, Oct. 2006.
[26] C.-P. Wu and C.-C. Jay Kuo, “Design of integrated multimedia compression and encryption systems,” IEEE
Transactions on Multimedia, vol. 7, no. 5, pp. 828–839, Oct. 2005.
[27] M. Grangetto, A. Grosso, and E. Magli, “Selective encryption of JPEG 2000 images by means of randomized arithmetic
coding,” in Proceedings of IEEE International Workshop on Multimedia Signal Processing, 2004.
[28] J. Wen, H. Kim, and J.D. Villasenor, “Binary arithmetic coding with key-based interval splitting,” IEEE Signal
Processing Letters, vol. 13, no. 2, pp. 69–72, Feb. 2006.
[29] H. Kim, J. Wen, and J.D. Villasenor, “Secure arithmetic coding,” IEEE transactions on Signal Processing (to appear).
[30] R. Bose and S. Pathak, “A novel compression and encryption scheme using variable model arithmetic coding and
coupled chaotic system,” IEEE Transactions on Circuits and Systems I, vol. 53, no. 4, pp. 848–857, Apr. 2006.
[31] B.B. Zhu, Y. Yang, and S. Li, “JPEG 2000 syntax-compliant encryption preserving full scalability,” in Proceedings
of IEEE International Conference on Image Processing, 2005.
[32] Y. Wu and R.H. Deng, “Compliant encryption of JPEG2000 codestreams,” in Proceedings of IEEE International
Conference on Image Processing, 2004.
[33] S. Wee and J. Apostolopoulos, “Secure scalable streaming and secure transcoding with JPEG-2000,” in Proceedings
of IEEE International Conference on Image Processing, 2003.
[34] H. Schwarz, D. Marpe, and T. Wiegand, “Overview of the scalable H.264/MPEG4-AVC extension,” in Proceedings
of IEEE International Conference on Image Processing, 2006.
[35] A. Moffatt, R.M. Neal, and I.H. Witten, “Arithmetic coding revisited,” ACM Transactions on Information Systems,
vol. 16, pp. 256–294, 1995.

IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 25
[36] A. Said, “Measuring the strength of partial encryption schemes,” in Proc. of ICIP - IEEE International Conference
on Image Processing, 2005.
[37] J. Wen, M. Muttrell, and M. Severa, “Access control of standard video bitstreams,” in Proceedings of International
Conference on Media Future, 2001.
IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 26
TABLE II
PERFORMANCE OF ALGORITHM 1 ON SEVERAL VIDEO SEQUENCES.
�� �� ���� � PSNR (dB) OVH % �� �� ���� � PSNR (dB) OVH %
Mobile
Intra period = 15 Intra period = 50
2 0 12 0 25.19 0.44 2 0 12 0 25.90 0.16
2 0 8 0 18.26 1.42 2 0 8 0 19.84 0.51
1 0 12 0.6 18.78 1.40 1 0 12 0.6 17.00 1.43
2 0 12 0.6 18.76 1.41 2 0 12 0.6 17.00 1.44
4 0 4 0 13.37 3.79 4 0 4 0 13.98 1.32
2 2 12 0 25.19 0.47 2 2 12 0 25.89 0.20
2 2 8 0 18.26 1.57 2 2 8 0 19.78 0.71
1 1 12 0.6 18.78 1.43 1 1 12 0.6 17.00 1.47
2 2 12 0.6 18.76 1.45 2 2 12 0.6 17.00 1.48
4 4 4 0 13.37 4.19 4 4 4 0 13.91 1.84
Tempete
Intra period = 15 Intra period = 50
2 0 12 0 27.49 0.32 2 0 12 0 27.58 0.12
2 0 8 0 21.87 1.24 2 0 8 0 23.07 0.46
1 0 12 0.6 23.24 1.44 1 0 12 0.6 20.47 1.58
2 0 12 0.6 23.23 1.44 2 0 12 0.6 20.47 1.58
4 0 4 0 15.42 3.65 4 0 4 0 16.81 1.30
2 2 12 0 27.49 0.37 2 2 12 0 27.57 0.18
2 2 8 0 21.86 1.45 2 2 8 0 23.00 0.69
1 1 12 0.6 23.24 1.48 1 1 12 0.6 20.46 1.63
2 2 12 0.6 23.23 1.49 2 2 12 0.6 20.46 1.63
4 4 4 0 15.41 4.40 4 4 4 0 16.69 2.21
Football
Intra period = 15 Intra period = 50
2 0 12 0 31.70 0.04 2 0 12 0 31.52 0.03
2 0 8 0 30.26 0.28 2 0 8 0 30.99 0.12
1 0 12 0.6 25.62 1.11 1 0 12 0.6 21.70 1.20
2 0 12 0.6 25.62 1.11 2 0 12 0.6 21.70 1.20
4 0 4 0 24.62 1.07 4 0 4 0 29.11 0.38
2 2 12 0 31.70 0.07 2 2 12 0 31.51 0.05
2 2 8 0 30.17 0.55 2 2 8 0 30.42 0.42
1 1 12 0.6 25.62 1.13 1 1 12 0.6 21.70 1.22
2 2 12 0.6 25.62 1.13 2 2 12 0.6 21.70 1.22
4 4 4 0 24.43 2.54 4 4 4 0 27.38 2.04
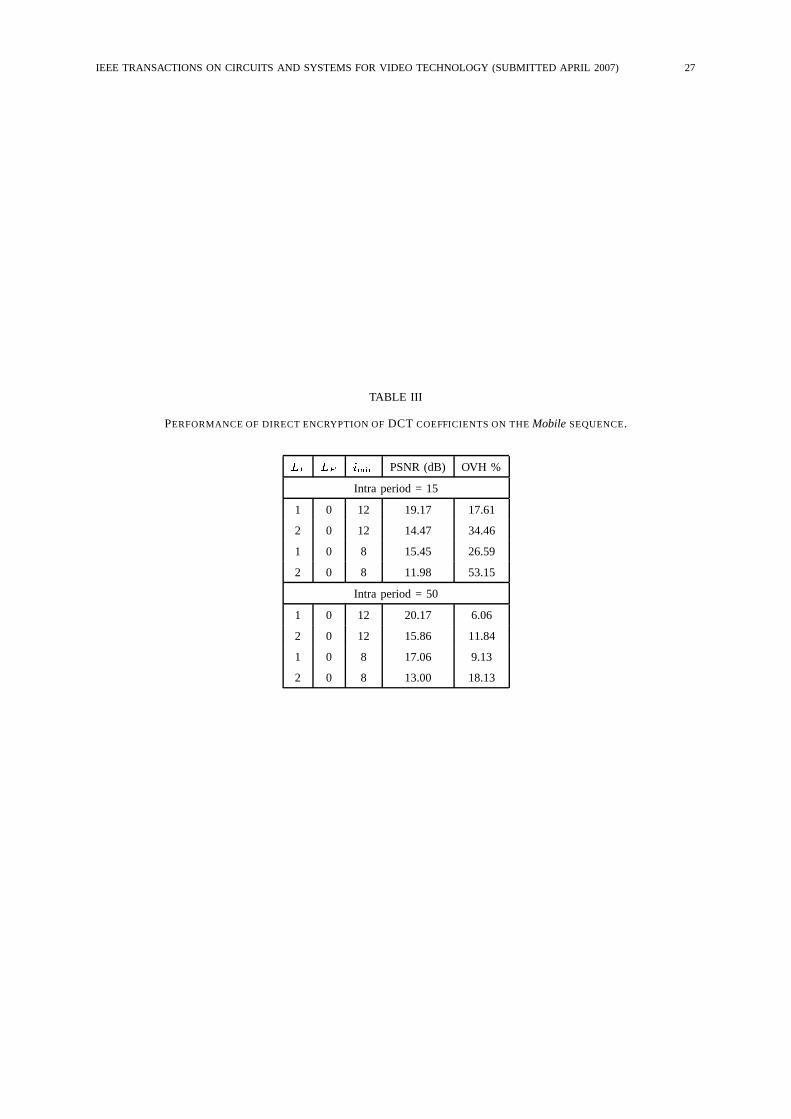
IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 27
TABLE III
PERFORMANCE OF DIRECT ENCRYPTION OF DCT COEFFICIENTS ON THE Mobile SEQUENCE.
�� �� ���� PSNR (dB) OVH %
Intra period = 15
1 0 12 19.17 17.61
2 0 12 14.47 34.46
1 0 8 15.45 26.59
2 0 8 11.98 53.15
Intra period = 50
1 0 12 20.17 6.06
2 0 12 15.86 11.84
1 0 8 17.06 9.13
2 0 8 13.00 18.13
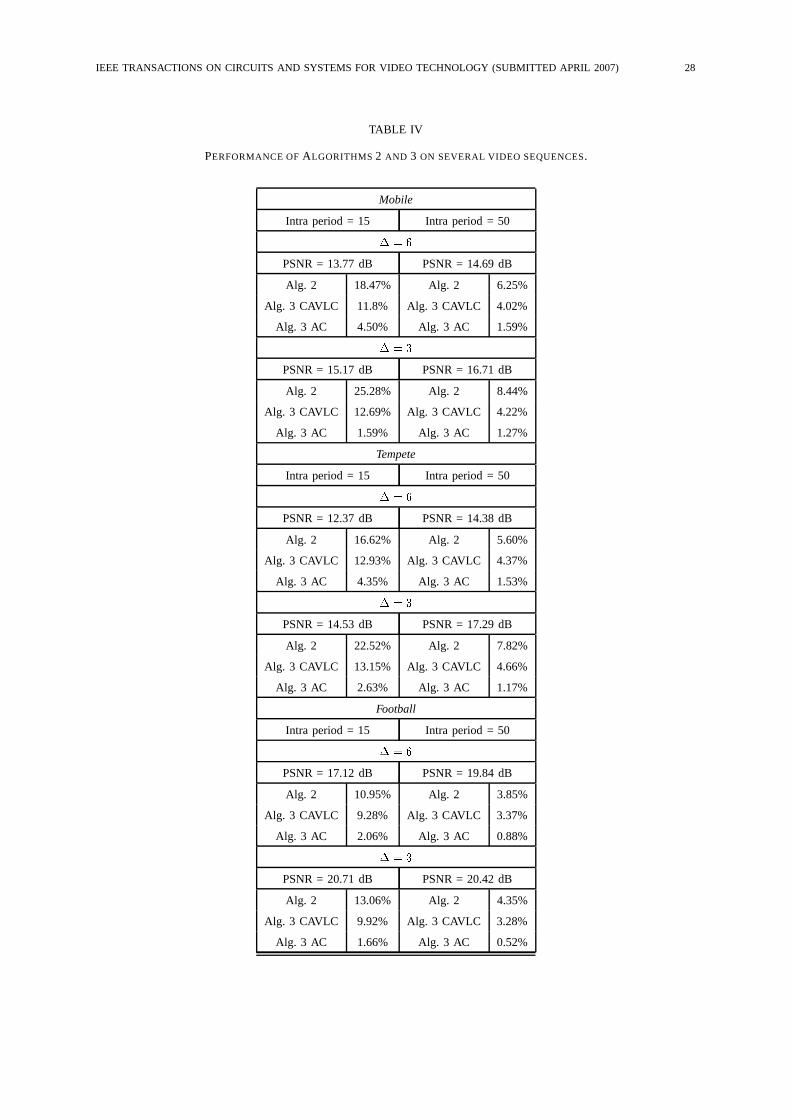
IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 28
TABLE IV
PERFORMANCE OF ALGORITHMS 2 AND 3 ON SEVERAL VIDEO SEQUENCES.
Mobile
Intra period = 15 Intra period = 50
� � �
PSNR = 13.77 dB PSNR = 14.69 dB
Alg. 2 18.47% Alg. 2 6.25%
Alg. 3 CAVLC 11.8% Alg. 3 CAVLC 4.02%
Alg. 3 AC 4.50% Alg. 3 AC 1.59%
� � �
PSNR = 15.17 dB PSNR = 16.71 dB
Alg. 2 25.28% Alg. 2 8.44%
Alg. 3 CAVLC 12.69% Alg. 3 CAVLC 4.22%
Alg. 3 AC 1.59% Alg. 3 AC 1.27%
Tempete
Intra period = 15 Intra period = 50
� � �
PSNR = 12.37 dB PSNR = 14.38 dB
Alg. 2 16.62% Alg. 2 5.60%
Alg. 3 CAVLC 12.93% Alg. 3 CAVLC 4.37%
Alg. 3 AC 4.35% Alg. 3 AC 1.53%
� � �
PSNR = 14.53 dB PSNR = 17.29 dB
Alg. 2 22.52% Alg. 2 7.82%
Alg. 3 CAVLC 13.15% Alg. 3 CAVLC 4.66%
Alg. 3 AC 2.63% Alg. 3 AC 1.17%
Football
Intra period = 15 Intra period = 50
� � �
PSNR = 17.12 dB PSNR = 19.84 dB
Alg. 2 10.95% Alg. 2 3.85%
Alg. 3 CAVLC 9.28% Alg. 3 CAVLC 3.37%
Alg. 3 AC 2.06% Alg. 3 AC 0.88%
� � �
PSNR = 20.71 dB PSNR = 20.42 dB
Alg. 2 13.06% Alg. 2 4.35%
Alg. 3 CAVLC 9.92% Alg. 3 CAVLC 3.28%
Alg. 3 AC 1.66% Alg. 3 AC 0.52%
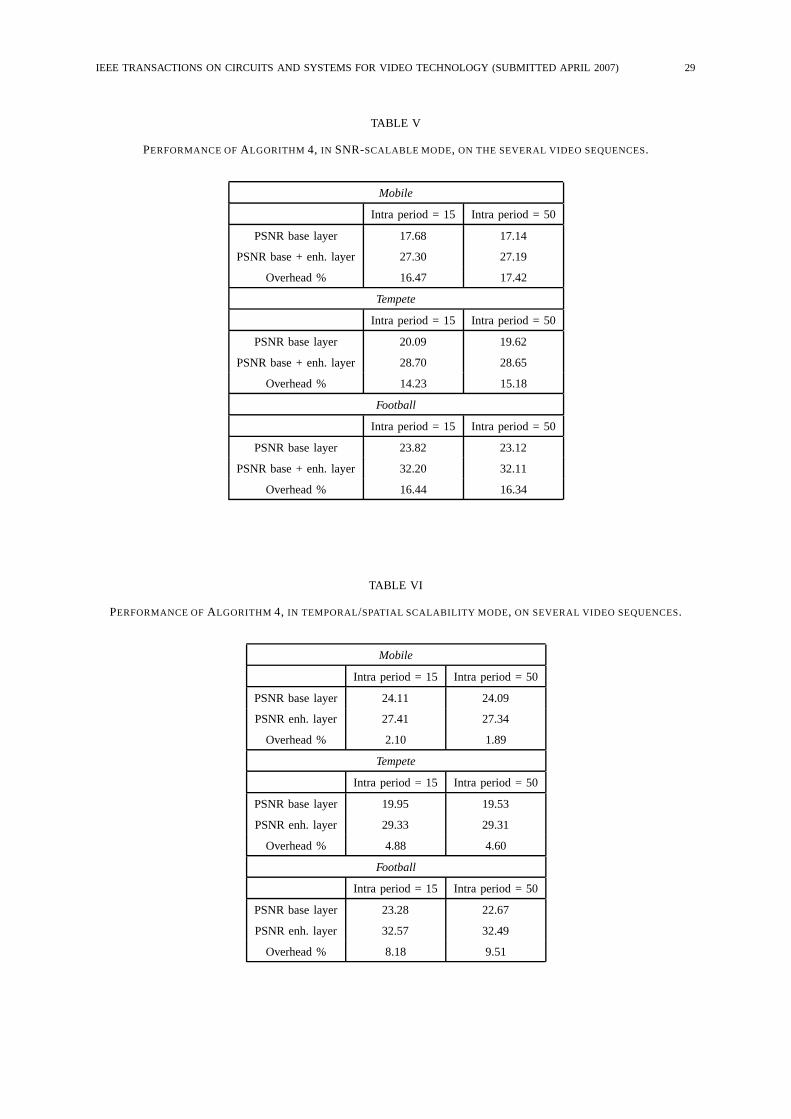
IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY (SUBMITTED APRIL 2007) 29
TABLE V
PERFORMANCE OF ALGORITHM 4, IN SNR-SCALABLE MODE, ON THE SEVERAL VIDEO SEQUENCES.
Mobile
Intra period = 15 Intra period = 50
PSNR base layer 17.68 17.14
PSNR base + enh. layer 27.30 27.19
Overhead % 16.47 17.42
Tempete
Intra period = 15 Intra period = 50
PSNR base layer 20.09 19.62
PSNR base + enh. layer 28.70 28.65
Overhead % 14.23 15.18
Football
Intra period = 15 Intra period = 50
PSNR base layer 23.82 23.12
PSNR base + enh. layer 32.20 32.11
Overhead % 16.44 16.34
TABLE VI
PERFORMANCE OF ALGORITHM 4, IN TEMPORAL/SPATIAL SCALABILITY MODE, ON SEVERAL VIDEO SEQUENCES.
Mobile
Intra period = 15 Intra period = 50
PSNR base layer 24.11 24.09
PSNR enh. layer 27.41 27.34
Overhead % 2.10 1.89
Tempete
Intra period = 15 Intra period = 50
PSNR base layer 19.95 19.53
PSNR enh. layer 29.33 29.31
Overhead % 4.88 4.60
Football
Intra period = 15 Intra period = 50
PSNR base layer 23.28 22.67
PSNR enh. layer 32.57 32.49
Overhead % 8.18 9.51




















