
Bao cao
44
ĐẠI HỌC CÔNG NGHỆ ĐẠI HỌC QUỐC GIA HÀ NỘI BÁO CÁO MẠNG NEURAL VÀ ỨNG DỤNG Hà Nội, 04/2010 Người hướng dẫn: PGS. TS. Đỗ Năng Toàn Người thực hiện: - Bùi Hoàng Khánh - Lê Duy Hưng i
Transcript of Bao cao

ĐẠI HỌC CÔNG NGHỆĐẠI HỌC QUỐC GIA HÀ NỘI
BÁO CÁOMẠNG NEURAL VÀ ỨNG DỤNG
Hà Nội, 04/2010
Người hướng dẫn: PGS. TS. Đỗ Năng Toàn
Người thực hiện: - Bùi Hoàng Khánh- Lê Duy Hưng
i

- Hoàng Mạnh Khôi
ii

MỤC LỤC
DANH MỤC HÌNH VẼ.............................................iii
DANH MỤC BẢNG BIỂU............................................iv
CHƯƠNG 1: TỔNG QUAN VỀ MÔ HÌNH MẠNG NƠRON......................1
I. Giới thiệu về mạng nơron nhân tạo..........................1
I.1. Mạng nơron nhân tạo là gì?.............................1
I.2. Lịch sử phát triển mạng nơron..........................1
I.3. So sánh mạng nơron với máy tính truyền thống...........3
II. Nơron sinh học và nơron nhân tạo..........................3
II.1. Nơron sinh học........................................4
II.2. Nơron nhân tạo........................................5
III.3. Mô hình mạng nơron.....................................7
III.3.1. Các kiểu mô hình mạng nơron........................7
III.3.2. Perceptron.........................................9
III.3.3. Mạng nhiều tầng truyền thẳng (MLP)................10
CHƯƠNG 2: HUẤN LUYỆN VÀ XÂY DỰNG MẠNG NƠRON...................12
I. Huấn luyện mạng Nơron.....................................12
I.1. Các phương pháp học...................................12
I.2. Học có giám sát trong các mạng nơron..................13
I.3. Thuật toán lan truyền ngược...........................13
II. Các vấn đề trong xây dựng mạng MLP.......................15i

II.1. Chuẩn bị dữ liệu.....................................15
II.2. Xác định các tham số cho mạng........................17
II.3. Vấn đề lãng quên (catastrophic forgetting)...........19
II.4 Vấn đề quá khớp.......................................20
CHƯƠNG 3: ỨNG DỤNG CỦA MẠNG NƠRON.............................22
CHƯƠNG 4: THỰC NGHIỆM.........................................23
I. Giới thiệu bài toán.......................................23
I.1. Phát biểu bài toán....................................23
I.2. Mô hình mạng nơron của bài toán.......................23
II. Cài đặt chương trình.....................................24
II.1. Mô hình chương trình.................................24
II.2. Kết quả thử nghiệm...................................25
CHƯƠNG 5: KẾT LUẬN............................................28
TÀI LIỆU THAM KHẢO.............................................a
ii

DANH MỤC HÌNH VẼ
Hình 1: Cấu trúc của một nơron sinh học điển hình..............4
Hình 2: Nơron nhân tạo.........................................5
Hình 3: Mạng tự kết hợp........................................8
Hình 4: Mạng kết hợp khác kiểu.................................8
Hình 5: Mạng truyền thẳng......................................9
Hình 6: Mạng phản hồi..........................................9
Hình 7: Perceptron............................................10
Hình 8: Mạng MLP tổng quát....................................11
Hình 9: Mối liên hệ giữa sai số và kích thước mẫu.............15
Hình 10: Huấn luyện luân phiên trên hai tập mẫu...............20
Hình 11: Mô hình mạng nơron cho bài toán thực nhiệm...........22
Hình 12: Mô hình lớp của chương trình.........................23
Hình 13: Giao diện chính của chương trình.....................24
Hình 14: Kết quả huấn luyện...................................25
Hình 15: Kết quả thực nghiệm..................................26
iii

DANH MỤC BẢNG BIỂU
Bảng 1: Một số hàm truyền thông dụng...........................6
iv

CHƯƠNG 1: TỔNG QUAN VỀ MÔ HÌNH MẠNG NƠRON
I. Giới thiệu về mạng nơron nhân tạo I.1. Mạng nơron nhân tạo là gì?
Định nghĩa: Mạng nơron nhân tạo, Artificial Neural Network (ANN) gọitắt là mạng nơron, neural network, là một mô hình xử lý thông tinphỏng theo cách thức xử lý thông tin của các hệ nơron sinh học. Nóđược tạo lên từ một số lượng lớn các phần tử (gọi là phần tử xử lý haynơron) kết nối với nhau thông qua các liên kết (gọi là trọng số liênkết) làm việc như một thể thống nhất để giải quyết một vấn đề cụthể nào đó.
Một mạng nơron nhân tạo được cấu hình cho một ứng dụng cụ thể(nhận dạng mẫu, phân loại dữ liệu, ...) thông qua một quá trình họctừ tập các mẫu huấn luyện. Về bản chất học chính là quá trình hiệuchỉnh trọng số liên kết giữa các nơron.
I.2. Lịch sử phát triển mạng nơron
Các nghiên cứu về bộ não con người đã được tiến hành từ hàngnghìn năm nay. Cùng với sự phát triển của khoa học kĩ thuật đặcbiệt là những tiến bộ trong ngành điện tử hiện đại, việc con ngườibắt đầu nghiên cứu các nơron nhân tạo là hoàn toàn tự nhiên. Sựkiện đầu tiên đánh dấu sự ra đời của mạng nơron nhân tạo diễn ravào năm 1943 khi nhà thần kinh học Warren McCulloch và nhà toán họcWalter Pitts viết bài báo mô tả cách thức các nơron hoạt động. Họcũng đã tiến hành xây dựng một mạng nơron đơn giản bằng các mạchđiện. Các nơron của họ được xem như là các thiết bị nhị phân vớingưỡng cố định. Kết quả của các mô hình này là các hàm logic đơngiản chẳng hạn như “ a OR b” hay “a AND b”.
Tiếp bước các nghiên cứu này, năm 1949 Donald Hebb cho xuấtbản cuốn sách Organization of Behavior. Cuốn sách đã chỉ ra rằng các
1

nơron nhân tạo sẽ trở lên hiệu quả hơn sau mỗi lần chúng được sửdụng.
Những tiến bộ của máy tính đầu những năm 1950 giúp cho việc môhình hóa các nguyên lý của những lý thuyết liên quan tới cách thứccon người suy nghĩ đã trở thành hiện thực. Nathanial Rochester saunhiều năm làm việc tại các phòng thí nghiệm nghiên cứu của IBM đãcó những nỗ lực đầu tiên để mô phỏng một mạng nơron. Trong thời kìnày tính toán truyền thống đã đạt được những thành công rực rỡtrong khi đó những nghiên cứu về nơron còn ở giai đoạn sơ khai. Mặcdù vậy những người ủng hộ triết lý “thinking machines” (các máybiết suy nghĩ) vẫn tiếp tục bảo vệ cho lập trường của mình.
Năm 1956 dự án Dartmouth nghiên cứu về trí tuệ nhân tạo(Artificial Intelligence) đã mở ra thời kỳ phát triển mới cả tronglĩnh vực trí tuệ nhân tạo lẫn mạng nơron. Tác động tích cực của nólà thúc đẩy hơn nữa sự quan tâm của các nhà khoa học về trí tuệnhân tạo và quá trình xử lý ở mức đơn giản của mạng nơron trong bộnão con người.
Những năm tiếp theo của dự án Dartmouth, John von Neumann đãđề xuất việc mô phỏng các nơron đơn giản bằng cách sử dụng rơleđiện áp hoặc đèn chân không. Nhà sinh học chuyên nghiên cứu vềnơron Frank Rosenblatt cũng bắt đầu nghiên cứu về Perceptron. Sauthời gian nghiên cứu này Perceptron đã được cài đặt trong phần cứngmáy tính và được xem như là mạng nơron lâu đời nhất còn được sửdụng đến ngày nay. Perceptron một tầng rất hữu ích trong việc phânloại một tập các đầu vào có giá trị liên tục vào một trong hai lớp.Perceptron tính tổng có trọng số các đầu vào, rồi trừ tổng này chomột ngưỡng và cho ra một trong hai giá trị mong muốn có thể. Tuynhiên Perceptron còn rất nhiều hạn chế, những hạn chế này đã đượcchỉ ra trong cuốn sách về Perceptron của Marvin Minsky và SeymourPapert viết năm 1969.
2

Năm 1959, Bernard Widrow và Marcian Hoff thuộc trường đại họcStanford đã xây dựng mô hình ADALINE (ADAptive LINear Elements) vàMADALINE. (Multiple ADAptive LINear Elements). Các mô hình này sửdụng quy tắc học Least-Mean-Squares (LMS: Tối thiểu bình phương trungbình). MADALINE là mạng nơron đầu tiên được áp dụng để giải quyếtmột bài toán thực tế. Nó là một bộ lọc thích ứng có khả năng loạibỏ tín hiệu dội lại trên đường dây điện thoại. Ngày nay mạng nơronnày vẫn được sử dụng trong các ứng dụng thương mại.
Năm 1974 Paul Werbos đã phát triển và ứng dụng phương pháp họclan truyền ngược ( back-propagation). Tuy nhiên phải mất một vàinăm thì phương pháp này mới trở lên phổ biến. Các mạng lan truyềnngược được biết đến nhiều nhất và được áp dụng rộng dãi nhất nhấtcho đến ngày nay.
Thật không may, những thành công ban đầu này khiến cho conngười nghĩ quá lên về khả năng của các mạng nơron. Chính sự cườngđiệu quá mức đã có những tác động không tốt đến sự phát triển củakhoa học và kỹ thuật thời bấy giờ khi người ta lo sợ rằng đã đếnlúc máy móc có thể làm mọi việc của con người. Những lo lắng nàykhiến người ta bắt đầu phản đối các nghiên cứu về mạng neuron. Thờikì tạm lắng này kéo dài đến năm 1981.
Năm 1982 trong bài báo gửi tới viện khoa học quốc gia, JohnHopfield bằng sự phân tích toán học rõ ràng, mạch lạc, ông đã chỉra cách thức các mạng nơron làm việc và những công việc chúng cóthể thực hiện được. Cống hiến của Hopfield không chỉ ở giá trị củanhững nghiên cứu khoa học mà còn ở sự thúc đẩy trở lại các nghiêncứu về mạng neuron.
Cũng trong thời gian này, một hội nghị với sự tham gia của HoaKỳ và Nhật Bản bàn về việc hợp tác/cạnh tranh trong lĩnh vực mạngnơron đã được tổ chức tại Kyoto, Nhật Bản. Sau hội nghị, Nhật Bảnđã công bố những nỗ lực của họ trong việc tạo ra máy tính thế hệthứ 5. Tiếp nhận điều đó, các tạp chí định kỳ của Hoa Kỳ bày tỏ sự
3

lo lắng rằng nước nhà có thể bị tụt hậu trong lĩnh vực này. Vì thế,ngay sau đó, Hoa Kỳ nhanh chóng huy động quĩ tài trợ cho các nghiêncứu và ứng dụng mạng neuron.
Năm 1985, viện vật lý Hoa Kỳ bắt đầu tổ chức các cuộc họp hàngnăm về mạng neuron ứng dụng trong tin học (Neural Networks forComputing).
Năm 1987, hội thảo quốc tế đầu tiên về mạng neuron của Việncác kỹ sư điện và điện tử IEEE (Institute of Electrical andElectronic Engineer) đã thu hút hơn 1800 người tham gia.
Ngày nay, không chỉ dừng lại ở mức nghiên cứu lý thuyết, cácnghiên cứu ứng dụng mạng nơron để giải quyết các bài toán thực tếđược diễn ra ở khắp mọi nơi. Các ứng dụng mạng nơron ra đời ngàycàng nhiều và ngày càng hoàn thiện hơn. Điển hình là các ứng dụng:xử lý ngôn ngữ (Language Processing), nhận dạng kí tự (CharacterRecognition), nhận dạng tiếng nói (Voice Recognition), nhận dạngmẫu (Pattern Recognition), xử lý tín hiệu (Signal Processing), Lọcdữ liệu (Data Filtering),….. I.3. So sánh mạng nơron với máy tính truyền thống
Các mạng nơron có cách tiếp cận khác trong giải quyết vấn đề
so với máy tính truyền thống. Các máy tính truyền thống sử dụng
cách tiếp cận theo hướng giải thuật, tức là máy tính thực hiện một
tập các chỉ lệnh để giải quyết một vấn đề. Vấn đề được giải quyết
phải được biết và phát biểu dưới dạng một tập chỉ lệnh không nhập
nhằng. Những chỉ lệnh này sau đó phải được chuyển sang một chương
trình ngôn ngữ bậc cao và chuyển sang mã máy để máy tính có thể
hiểu được.
Trừ khi các bước cụ thể mà máy tính cần tuân theo được chỉ ra
rõ ràng, máy tính sẽ không làm được gì cả. Điều đó giới hạn khả4

năng của các máy tính truyền thống ở phạm vi giải quyết các vấn đề
mà chúng ta đã hiểu và biết chính xác cách thực hiện. Các máy tính
sẽ trở lên hữu ích hơn nếu chúng có thể thực hiện được những việc
mà bản thân con người không biết chính xác là phải làm như thế nào.
Các mạng nơron xử lý thông tin theo cách thức giống như bộ não
con người. Mạng được tạo nên từ một số lượng lớn các phần tử xử lý
được kết nối với nhau làm việc song song để giải quyết một vấn đề
cụ thể. Các mạng nơron học theo mô hình, chúng không thể được lập
trình để thực hiện một nhiệm vụ cụ thể. Các mẫu phải được chọn lựa
cẩn thận nếu không sẽ rất mất thời gian, thậm chí mạng sẽ hoạt động
không đúng. Điều hạn chế này là bởi vì mạng tự tìm ra cách giải
quyết vấn đề, thao tác của nó không thể dự đoán được.
Các mạng nơron và các máy tính truyền thống không cạnh tranhnhau mà bổ sung cho nhau. Có những nhiệm vụ thích hợp hơn với máytính truyền thống, ngược lại có những nhiệm vụ lại thích hợp hơnvới các mạng nơron. Thậm chí rất nhiều nhiệm vụ đòi hỏi các hệthống sử dụng tổ hợp cả hai cách tiếp cận để thực hiện được hiệuquả cao nhất. (thông thường một máy tính truyền thống được sử dụngđể giám sát mạng nơron)
II. Nơron sinh học và nơron nhân tạo II.1. Nơron sinh học
Qua quá trình nghiên cứu về bộ não, người ta thấy rằng: bộ nãocon người bao gồm khoảng 1011 nơron tham gia vào khoảng 1015 kết nốitrên các đường truyền. Mỗi đường truyền này dài khoảng hơn một mét.Các nơron có nhiều đặc điểm chung với các tế bào khác trong cơ thể,ngoài ra chúng còn có những khả năng mà các tế bào khác không có
5

được, đó là khả năng nhận, xử lý và truyền các tín hiệu điện hóatrên các đường mòn nơron, các con đường này tạo nên hệ thống giaotiếp của bộ não.
Hình 1: Cấu trúc của một nơron sinh học điển hình
Mỗi nơron sinh học có 3 thành phần cơ bản: • Các nhánh vào hình cây ( dendrites) • Thân tế bào (cell body) • Sợi trục ra (axon) Các nhánh hình cây truyền tín hiệu vào đến thân tế bào. Thân
tế bào tổng hợp và xử lý cho tín hiệu đi ra. Sợi trục truyền tínhiệu ra từ thân tế bào này sang nơron khác. Điểm liên kết giữa sợitrục của nơron này với nhánh hình cây của nơron khác gọi là synapse.Liên kết giữa các nơron và độ nhạy của mỗi synapse được xác địnhbởi quá trình hóa học phức tạp. Một số cấu trúc của nơron được xácđịnh trước lúc sinh ra. Một số cấu trúc được phát triển thông quaquá trình học. Trong cuộc đời cá thể, một số liên kết mới được hìnhthành, một số khác bị hủy bỏ.
6

Như vậy nơron sinh học hoạt động theo cách thức sau: nhận tínhiệu đầu vào, xử lý các tín hiệu này và cho ra một tín hiệu output.Tín hiệu output này sau đó được truyền đi làm tín hiệu đầu vào chocác nơron khác.
Dựa trên những hiểu biết về nơron sinh học, con người xây dựngnơron nhân tạo với hy vọng tạo nên một mô hình có sức mạnh như bộnão.
II.2. Nơron nhân tạo
Một nơron là một đơn vị xử lý thông tin và là thành phần cơbản của một mạng nơron. Cấu trúc của một nơron được mô tả trên hìnhdưới.
Hình 2: Nơron nhân tạoCác thành phần cơ bản của một nơron nhân tạo bao gồm: ♦ Tập các đầu vào: Là các tín hiệu vào (input signals) của nơron,
các tín hiệu này thường được đưa vào dưới dạng một vector N chiều. ♦ Tập các liên kết: Mỗi liên kết được thể hiện bởi một trọng
số (gọi là trọng số liên kết – Synaptic weight). Trọng số liên kếtgiữa tín hiệu vào thứ j với nơron k thường được kí hiệu là wkj.Thông thường, các trọng số này được khởi tạo một cách ngẫu nhiên ở
7

thời điểm khởi tạo mạng và được cập nhật liên tục trong quá trìnhhọc mạng.
♦ Bộ tổng (Summing function): Thường dùng để tính tổng của tíchcác đầu vào với trọng số liên kết của nó.
♦ Ngưỡng (còn gọi là một độ lệch - bias): Ngưỡng này thườngđược đưa vào như một thành phần của hàm truyền.
♦ Hàm truyền (Transfer function) : Hàm này được dùng để giới hạnphạm vi đầu ra của mỗi nơron. Nó nhận đầu vào là kết quả của hàmtổng và ngưỡng đã cho. Thông thường, phạm vi đầu ra của mỗi nơronđược giới hạn trong đoạn [0,1] hoặc [-1, 1]. Các hàm truyền rất đadạng, có thể là các hàm tuyến tính hoặc phi tuyến. Việc lựa chọnhàm truyền nào là tuỳ thuộc vào từng bài toán và kinh nghiệm củangười thiết kế mạng. Một số hàm truyền thường sử dụng trong các môhình mạng nơron được đưa ra trong bảng 1 .
♦ Đầu ra: Là tín hiệu đầu ra của một nơron, với mỗi nơron sẽcó tối đa là một đầu ra.
Xét về mặt toán học, cấu trúc của một nơron k, được mô tả bằngcặp biểu thức sau:
[cong thuc]
trong đó: x1, x2, ..., xp: là các tín hiệu vào; (wk1, wk2, ..., wkp)
là các trọng số liên kết của nơron thứ k; uk là hàm tổng; bk là mộtngưỡng; f là hàm truyền và yk là tín hiệu đầu ra của nơron.
Như vậy tương tự như nơron sinh học, nơron nhân tạo cũng nhậncác tín hiệu đầu vào, xử lý ( nhân các tín hiệu này với trọng sốliên kết, tính tổng các tích thu được rồi gửi kết quả tới hàmtruyền), và cho một tín hiệu đầu ra ( là kết quả của hàm truyền).
Bảng 1: Một số hàm truyền thông dụng
Hàm truyền Đồ thị Định nghĩa
8

Symmetrical Hard Limit (hardlims)
Linear (purelin)
Saturating Linear (satlin)
Log-Sigmoid (logsig)
III.3. Mô hình mạng nơron
Mặc dù mỗi nơron đơn lẻ có thể thực hiện những chức năng xử lýthông tin nhất định, sức mạnh của tính toán nơron chủ yếu có đượcnhờ sự kết hợp các nơron trong một kiến trúc thống nhất. Một mạngnơron là một mô hình tính toán được xác định qua các tham số: kiểunơron (như là các nút nếu ta coi cả mạng nơron là một đồ thị), kiếntrúc kết nối (sự tổ chức kết nối giữa các nơron) và thuật toán học(thuật toán dùng để học cho mạng).
9

Về bản chất một mạng nơron có chức năng như là một hàm ánh xạF: X → Y, trong đó X là không gian trạng thái đầu vào (input statespace) và Y là không gian trạng thái đầu ra (output state space) củamạng. Các mạng chỉ đơn giản là làm nhiệm vụ ánh xạ các vector đầuvào x ∈ X sang các vector đầu ra y ∈ Y thông qua “bộ lọc” (filter)các trọng số. Tức là y = F(x) = s(W, x), trong đó W là ma trậntrọng số liên kết. Hoạt động của mạng thường là các tính toán sốthực trên các ma trận.
III.3.1. Các kiểu mô hình mạng nơron
Cách thức kết nối các nơron trong mạng xác định kiến trúc(topology) của mạng. Các nơron trong mạng có thể kết nối đầy đủ (fullyconnected) tức là mỗi nơron đều được kết nối với tất cả các nơronkhác, hoặc kết nối cục bộ (partially connected) chẳng hạn chỉ kết nốigiữa các nơron trong các tầng khác nhau. Người ta chia ra hai loạikiến trúc mạng chính:
♦ Tự kết hợp (autoassociative): là mạng có các nơron đầu vào cũnglà các nơron đầu ra. Mạng Hopfield là một kiểu mạng tự kết hợp.
Hình 3: Mạng tự kết hợp
♦ Kết hợp khác kiểu (heteroassociative): là mạng có tập nơron đầuvào và đầu ra riêng biệt. Perceptron, các mạng Perceptron nhiềutầng (MLP: MultiLayer Perceptron), mạng Kohonen, … thuộc loại này.
10

Hình 4: Mạng kết hợp khác kiểu
Ngoài ra tùy thuộc vào mạng có các kết nối ngược (feedbackconnections) từ các nơron đầu ra tới các nơron đầu vào hay không,người ta chia ra làm 2 loại kiến trúc mạng.
♦ Kiến trúc truyền thẳng (feedforward architechture): là kiểu kiếntrúc mạng không có các kết nối ngược trở lại từ các nơron đầu ra vềcác nơron đầu vào; mạng không lưu lại các giá trị output trước vàcác trạng thái kích hoạt của nơron. Các mạng nơron truyền thẳng chophép tín hiệu di chuyển theo một đường duy nhất; từ đầu vào tới đầura, đầu ra của một tầng bất kì sẽ không ảnh hưởng tới tầng đó. Cácmạng kiểu Perceptron là mạng truyền thẳng.
Hình 5: Mạng truyền thẳng
♦ Kiến trúc phản hồi (Feedback architecture): là kiểu kiến trúcmạng có các kết nối từ nơron đầu ra tới nơron đầu vào. Mạng lưu lại
11
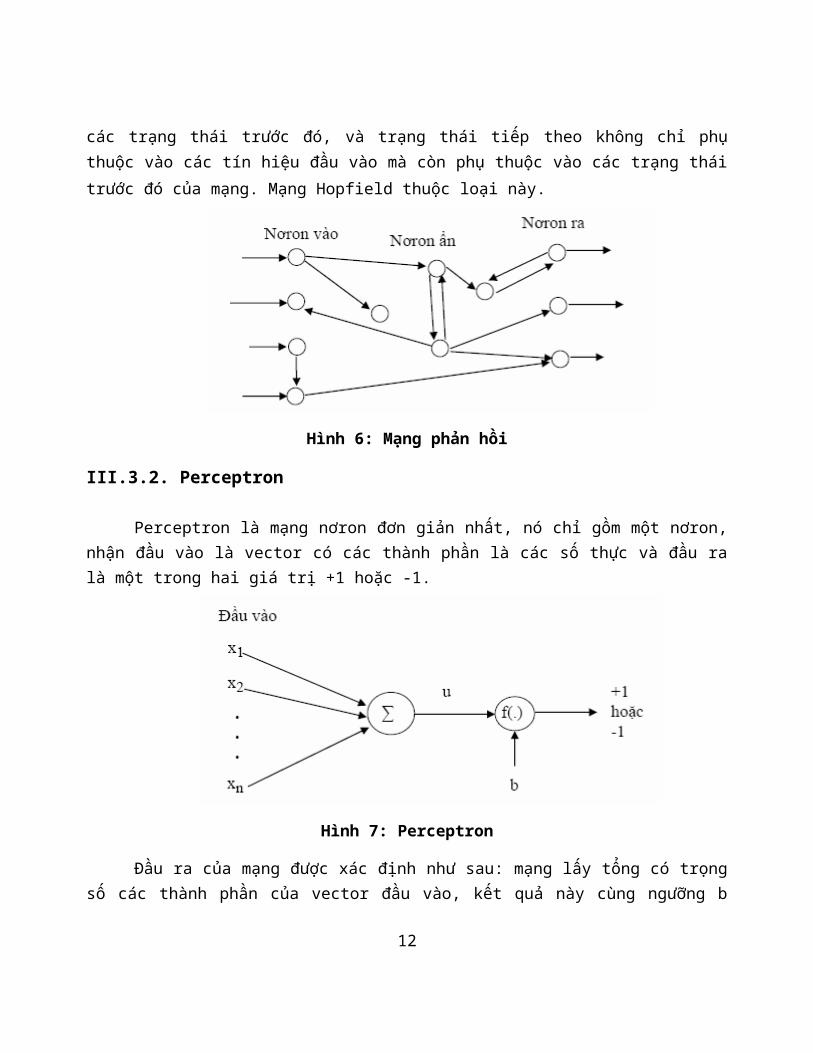
các trạng thái trước đó, và trạng thái tiếp theo không chỉ phụthuộc vào các tín hiệu đầu vào mà còn phụ thuộc vào các trạng tháitrước đó của mạng. Mạng Hopfield thuộc loại này.
Hình 6: Mạng phản hồi
III.3.2. Perceptron
Perceptron là mạng nơron đơn giản nhất, nó chỉ gồm một nơron,nhận đầu vào là vector có các thành phần là các số thực và đầu ralà một trong hai giá trị +1 hoặc -1.
Hình 7: Perceptron
Đầu ra của mạng được xác định như sau: mạng lấy tổng có trọngsố các thành phần của vector đầu vào, kết quả này cùng ngưỡng b
12

được đưa vào hàm truyền (Perceptron dùng hàm Hard-limit làm hàmtruyền) và kết quả của hàm truyền sẽ là đầu ra của mạng.
Hoạt động của Perceptron có thể được mô tả bởi cặp công thứcsau:
[Cong thuc]
và y = f(u - b) = Hardlimit(u - b); y nhận giá trị +1 nếu u -b>0, ngược lại y nhận giá trị -1.
Perceptron cho phép phân loại chính xác trong trường hợp dữliệu có thể phân chia tuyến tính (các mẫu nằm trên hai mặt đối diệncủa một siêu phẳng). Nó cũng phân loại đúng đầu ra các hàm AND, ORvà các hàm có dạng đúng khi n trong m đầu vào của nó đúng (n ≤ m).Nó không thể phân loại được đầu ra của hàm XOR.
III.3.3. Mạng nhiều tầng truyền thẳng (MLP)
Mô hình mạng nơron được sử dụng rộng rãi nhất là mô hình mạngnhiều tầng truyền thẳng (MLP: Multi Layer Perceptron). Một mạng MLPtổng quát là mạng có n (n≥2) tầng (thông thường tầng đầu vào khôngđược tính đến): trong đó gồm một tầng đầu ra (tầng thứ n) và (n-1)tầng ẩn.
Hình 8: Mạng MLP tổng quát
13

Kiến trúc của một mạng MLP tổng quát có thể mô tả như sau: ♦ Đầu vào là các vector (x1, x2, ..., xp) trong không gian p
chiều, đầu ra là các vector (y1, y2, ..., yq) trong không gian qchiều. Đối với các bài toán phân loại, p chính là kích thước củamẫu đầu vào, q chính là số lớp cần phân loại. Xét ví dụ trong bàitoán nhận dạng chữ số: với mỗi mẫu ta lưu tọa độ (x,y) của 8 điểmtrên chữ số đó, và nhiệm vụ của mạng là phân loại các mẫu này vàomột trong 10 lớp tương ứng với 10 chữ số 0, 1, …, 9. Khi đó p làkích thước mẫu và bằng 8 x 2 = 16; q là số lớp và bằng 10.
♦ Mỗi nơron thuộc tầng sau liên kết với tất cả các nơron thuộctầng liền trước nó.
♦ Đầu ra của nơron tầng trước là đầu vào của nơron thuộc tầngliền sau nó.
Hoạt động của mạng MLP như sau: tại tầng đầu vào các nơronnhận tín hiệu vào xử lý (tính tổng trọng số, gửi tới hàm truyền)rồi cho ra kết quả (là kết quả của hàm truyền); kết quả này sẽ đượctruyền tới các nơron thuộc tầng ẩn thứ nhất; các nơron tại đây tiếpnhận như là tín hiệu đầu vào, xử lý và gửi kết quả đến tầng ẩn thứ2;…; quá trình tiếp tục cho đến khi các nơron thuộc tầng ra cho kếtquả.
Một số kết quả đã được chứng minh: ♦ Bất kì một hàm Boolean nào cũng có thể biểu diễn được bởi
một mạng MLP 2 tầng trong đó các nơron sử dụng hàm truyền sigmoid. ♦ Tất cả các hàm liên tục đều có thể xấp xỉ bởi một mạng MLP 2
tầng sử dụng hàm truyền sigmoid cho các nơron tầng ẩn và hàm truyềntuyến tính cho các nơron tầng ra với sai số nhỏ tùy ý.
♦ Mọi hàm bất kỳ đều có thể xấp xỉ bởi một mạng MLP 3 tầng sửdụng hàm truyền sigmoid cho các nơron tầng ẩn và hàm truyền tuyếntính cho các nơron tầng ra.
14

CHƯƠNG 2: HUẤN LUYỆN VÀ XÂY DỰNG MẠNG NƠRON
I. Huấn luyện mạng NơronI.1. Các phương pháp học
Khái niệm: Học là quá trình thay đổi hành vi của các vật theomột cách nào đó làm cho chúng có thể thực hiện tốt hơn trong tươnglai.
Một mạng nơron được huyấn luyện sao cho với một tập các vectorđầu vào X, mạng có khả năng tạo ra tập các vector đầu ra mong muốnY của nó. Tập X được sử dụng cho huấn luyện mạng được gọi là tậphuấn luyện (training set). Các phần tử x thuộc X được gọi là các mẫuhuấn luyện (training example). Quá trình huấn luyện bản chất là sựthay đổi các trọng số liên kết của mạng. Trong quá trình này, cáctrọng số của mạng sẽ hội tụ dần tới các giá trị sao cho với mỗivector đầu vào x từ tập huấn luyện, mạng sẽ cho ra vector đầu ra ynhư mong muốn
Có ba phương pháp học phổ biến là học có giám sát (supervisedlearning), học không giám sát (unsupervised learning) và học tăng cường(Reinforcement learning):
♦ Học có giám sát: Là quá trình học có sự tham gia giám sátcủa một “thầy giáo”. Cũng giống như việc ta dạy một em nhỏ các chữcái. Ta đưa ra một chữ “a” và bảo với em đó rằng đây là chữ “a”.Việc này được thực hiện trên tất cả các mẫu chữ cái. Sau đó khikiểm tra ta sẽ đưa ra một chữ cái bất kì (có thể viết hơi khác đi)và hỏi em đó đây là chữ gì?
Với học có giám sát, tập mẫu huấn luyện được cho dưới dạng D ={(x,t) | (x,t) ∈ [IRN x RK]}, trong đó: x = (x1, x2, ..., xN) làvector đặc trưng N chiều của mẫu huấn luyện và t = (t1, t2, ..., tK)là vector mục tiêu K chiều tương ứng, nhiệm vụ của thuật toán làphải thiết lập được một cách tính toán trên mạng như thế nào đó để
15

sao cho với mỗi vector đặc trưng đầu vào thì sai số giữa giá trịđầu ra thực sự của mạng và giá trị mục tiêu tương ứng là nhỏ nhất.Chẳng hạn mạng có thể học để xấp xỉ một hàm t = f(x) biểu diễn mốiquan hệ trên tập các mẫu huấn luyện (x, t).
Như vậy với học có giám sát, số lớp cần phân loại đã được biếttrước. Nhiệm vụ của thuật toán là phải xác định được một cách thứcphân lớp sao cho với mỗi vector đầu vào sẽ được phân loại chính xácvào lớp của nó.
♦ Học không giám sát: Là việc học không cần có bất kỳ một sựgiám sát nào.
Trong bài toán học không giám sát, tập dữ liệu huấn luyện đượccho dưới dạng: D = {(x1, x2, ..., xN)}, với (x1, x2, ..., xN) làvector đặc trưng của mẫu huấn luyện. Nhiệm vụ của thuật toán làphải phân chia tập dữ liệu D thành các nhóm con, mỗi nhóm chứa cácvector đầu vào có đặc trưng giống nhau.
Như vậy với học không giám sát, số lớp phân loại chưa đượcbiết trước, và tùy theo tiêu chuẩn đánh giá độ tương tự giữa các mẫumà ta có thể có các lớp phân loại khác nhau.
♦ Học tăng cường: đôi khi còn được gọi là học thưởng-phạt(reward-penalty learning), là sự tổ hợp của cả hai mô hình trên. Phươngpháp này cụ thể như sau: với vector đầu vào, quan sát vector đầu rado mạng tính được. Nếu kết quả được xem là “tốt” thì mạng sẽ đượcthưởng theo nghĩa tăng các trọng số kết nối lên; ngược lại mạng sẽbị phạt, các trọng số kết nối không thích hợp sẽ được giảm xuống.Do đó học tăng cường là học theo nhà phê bình (critic), ngược với họccó giám sát là học theo thầy giáo (teacher).
I.2. Học có giám sát trong các mạng nơron
Học có giám sát có thể được xem như việc xấp xỉ một ánh xạ: X→Y, trong đó X là tập các vấn đề và Y là tập các lời giải tương ứngcho vấn đề đó. Các mẫu (x, y) với x = (x1, x2, . . ., xn) ∈ X, y =
16

(yl, y2, . . ., ym) ∈ Y được cho trước. Học có giám sát trong cácmạng nơron thường được thực hiện theo các bước sau:
♦ B1: Xây dựng cấu trúc thích hợp cho mạng nơron, chẳng hạn có(n + 1) nơron vào (n nơron cho biến vào và 1 nơron cho ngưỡng x0),m nơron đầu ra, và khởi tạo các trọng số liên kết của mạng.
♦ B2: Đưa một vector x trong tập mẫu huấn luyện X vào mạng ♦ B3: Tính vector đầu ra o của mạng ♦ B4: So sánh vector đầu ra mong muốn y (là kết quả được cho
trong tập huấn luyện) với vector đầu ra o do mạng tạo ra; nếu cóthể thì đánh giá lỗi.
♦ B5: Hiệu chỉnh các trọng số liên kết theo một cách nàođó sao cho ở lần tiếp theo khi đưa vector x vào mạng, vectorđầu ra o sẽ giống với y hơn.
♦ B6: Nếu cần, lặp lại các bước từ 2 đến 5 cho tới khimạng đạt tới trạng thái hội tụ. Việc đánh giá lỗi có thể thựchiện theo nhiều cách, cách dùng nhiều nhất là sử dụng lỗi tứcthời: Err = (o - y), hoặc Err = |o - y|; lỗi trung bình bìnhphương (MSE: mean-square error): Err = (o- y)2/2;
Có hai loại lỗi trong đánh giá một mạng nơron. Thứ nhất,gọi là lỗi rõ ràng (apparent error), đánh giá khả năng xấp xỉcác mẫu huấn luyện của một mạng đã được huấn luyện. Thứ hai,gọi là lỗi kiểm tra (test error), đánh giá khả năng tổng quá hóacủa một mạng đã được huấn luyện, tức khả năng phản ứng vớicác vector đầu vào mới. Để đánh giá lỗi kiểm tra chúng taphải biết đầu ra mong muốn cho các mẫu kiểm tra.
Thuật toán tổng quát ở trên cho học có giám sát trong cácmạng nơron có nhiều cài đặt khác nhau, sự khác nhau chủ yếulà cách các trọng số liên kết được thay đổi trong suốt thời
17

gian học. Trong đó tiêu biểu nhất là thuật toán lan truyềnngược.
I.3. Thuật toán lan truyền ngược
Ta sử dụng một số kí hiệu sau:
j: nơron thứ j (hay nút thứ j)
Xj: vector đầu vào của nút thứ j
Wj: vector trọng số của nút thứ j
xji: đầu vào của nút thứ j từ nút thứ i
wji: trọng số trên xji
bj: ngưỡng tại nút thứ j
oj: đầu ra của nút thứ j
tj: đầu ra mong muốn của nút thứ j
Downstream(j): Tập tất cả các nút nhận đầu ra của nút thứ
j làm một giá trị đầu vào.
η: tốc độ học
f: hàm truyền với f(x) = 1 / (1 + e-x)
Thuật toán lan truyền ngược được mô tả như sau:
Input:
- Mạng feed-forward với ni đầu vào, nh nút ẩn và no đầu
ra.
- Hệ số học η
18

- Tập dữ liệu huấn luyện D = {là vector đầu vào, là
vector đầu ra mong muốn}.
Output: Các vector trọng số
Thuật toán:
Bước 1: Khởi tạo trọng số bởi các giá trị ngẫu nhiên nhỏ.
Bước 2: Lặp lại cho tới khi thỏa mãn điều kiện kết thúc.
Với mỗi mẫu, thực hiện các bước sau:
2.1 Tính đầu ra oj cho mỗi nút j:
oj = f(d – bj) với d = Σxjiwji
2.2 Với mỗi nút k thuộc tầng ra, tính δk theo công
thức:
δk = (tk – ok)(1 – ok)ok
2.3 Với mỗi nút h thuộc tầng ẩn, tính δh theo công
thức:
δh = oh(1 – oh) Σδkwkh với k ∈ Downstream(j)
2.4 Cập nhật: wji = wji + Δwji
Trong đó Δwji = ηδkxji
II. Các vấn đề trong xây dựng mạng MLP II.1. Chuẩn bị dữ liệu
a. Kích thước mẫu Không có nguyên tắc nào hướng dẫn kích thước mẫu phải là bao
nhiêu đối với một bài toán cho trước. Hai yếu tố quan trọng ảnhhưởng đến kích thước mẫu:
19
♦ Dạng hàm đích: khi hàm đích càng phức tạp thì kích thước mẫucần tăng.
♦ Nhiễu: khi dữ liệu bị nhiễu (thông tin sai hoặc thiếu thôngtin) kích thước mẫu cần tăng.
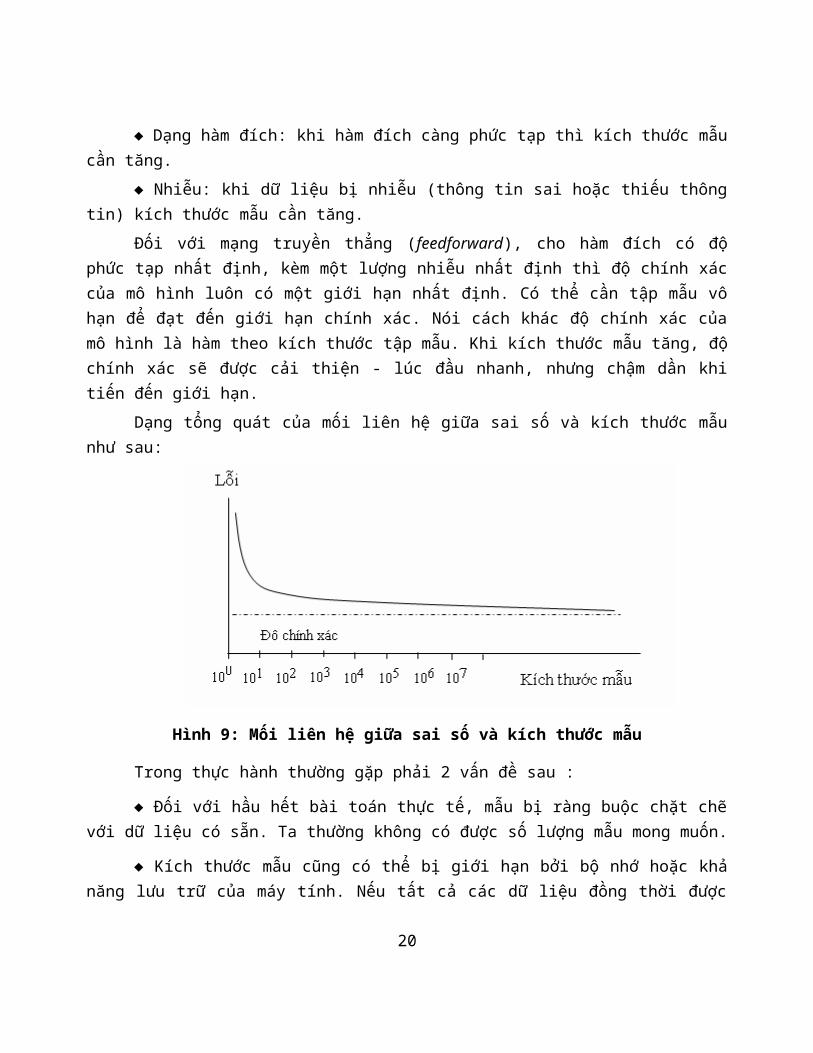
Đối với mạng truyền thẳng (feedforward), cho hàm đích có độphức tạp nhất định, kèm một lượng nhiễu nhất định thì độ chính xáccủa mô hình luôn có một giới hạn nhất định. Có thể cần tập mẫu vôhạn để đạt đến giới hạn chính xác. Nói cách khác độ chính xác củamô hình là hàm theo kích thước tập mẫu. Khi kích thước mẫu tăng, độchính xác sẽ được cải thiện - lúc đầu nhanh, nhưng chậm dần khitiến đến giới hạn.
Dạng tổng quát của mối liên hệ giữa sai số và kích thước mẫunhư sau:
Hình 9: Mối liên hệ giữa sai số và kích thước mẫu
Trong thực hành thường gặp phải 2 vấn đề sau :
♦ Đối với hầu hết bài toán thực tế, mẫu bị ràng buộc chặt chẽvới dữ liệu có sẵn. Ta thường không có được số lượng mẫu mong muốn.
♦ Kích thước mẫu cũng có thể bị giới hạn bởi bộ nhớ hoặc khảnăng lưu trữ của máy tính. Nếu tất cả các dữ liệu đồng thời được
20

giữ trong bộ nhớ suốt thời gian luyện, kích thước bộ nhớ máy tínhsẽ bị chiếm dụng nghiêm trọng.
Nếu lưu trữ trên đĩa sẽ cho phép dùng mẫu lớn hơn nhưng thaotác đọc đĩa từ thế hệ này sang thế hệ khác khiến cho tiến trìnhchậm đi rất nhiều.
Chú ý: việc tăng kích thước mẫu không làm tăng thời gianluyện. Những tập mẫu lớn hơn sẽ yêu cầu ít thế hệ luyện hơn. Nếu tatăng gấp đôi kích thước của mẫu, mỗi thế hệ luyện sẽ tốn thời giankhoảng gấp đôi, nhưng số thế hệ cần luyện sẽ giảm đi một nửa. Điềunày có nghĩa là kích thước mẫu (cũng có nghĩa là độ chính xác củamô hình) không bị giới hạn bởi thời gian luyện.
Luật cơ bản là: Sử dụng mẫu lớn nhất có thể sao cho đủ khảnăng lưu trữ trong bộ nhớ trong (nếu lưu trữ đồng thời) hoặc trênđĩa từ (nếu đủ thời gian đọc từ đĩa).
b. Mẫu con Trong xây dựng mô hình cần chia tập mẫu thành 2 tập con:
một để xây dựng mô hình gọi là tập huấn luyện (training set), vàmột để kiểm nghiệm mô hình gọi là tập kiểm tra (test set). Thôngthường dùng 2/3 mẫu cho huấn luyện và 1/3 cho kiểm tra. Điềunày là để tránh tình trạng quá khớp (overfitting).
c. Sự phân tầng mẫu Nếu ta tổ chức mẫu sao cho mỗi mẫu trong quần thể đều có
cơ hội như nhau thì tập mẫu được gọi là tập mẫu đại diện. Tuynhiên khi ta xây dựng một mạng để xác định xem một mẫu thuộcmột lớp hay thuộc một loại nào thì điều ta mong muốn là cáclớp có cùng ảnh hưởng lên mạng, để đạt được điều này ta cóthể sử dụng mẫu phân tầng. Xét ví dụ sau[1]:
Giả sử ta xây dựng mô hình nhận dạng chữ cái viết taytiếng Anh, và nguồn dữ liệu của ta có 100.000 ký tự mà mỗi ký
21

tự được kèm theo một mã cho biết nó là chữ cái nào. Chữ cáixuất hiện thường xuyên nhất là e, nó xuất hiện 11.668 lầnchiếm khoảng 12%; chữ cái xuất hiện ít nhất là chữ z, chỉ có50 lần chiếm 0,05%.
Trước hết do giới hạn của bộ nhớ máy tính, giả sử bộ nhớchỉ có thể xử lý được 1300 mẫu. Ta tạo hai dạng tập mẫu: tậpmẫu đại diện và tập mẫu phân tầng. Với tập mẫu đại diện, chữe sẽ xuất hiện 152 lần (11,67% của 1300) trong khi đó chữ zchỉ xuất hiện một lần (0,05% của 1300). Ngược lại ta có thểtạo tập mẫu phân tầng để mỗi chữ có 50 mẫu. Ta thấy rằng nếuchỉ có thể dùng 1300 mẫu thì tập mẫu phân tầng sẽ tạo ra môhình tốt hơn. Việc tăng số mẫu của z từ 1 lên 50 sẽ cải thiệnrất nhiều độ chính xác của z, trong khi nếu giảm số mẫu của etừ 152 xuống 50 sẽ chỉ giảm chút ít độ chính xác của e.
Bây giờ giả sử ta dùng máy tính khác có bộ nhớ đủ để xửlý một lượng mẫu gấp 10 lần, như vậy số mẫu sẽ tăng lên13000. Rõ ràng việc tăng kích thước mẫu sẽ giúp cho mô hìnhchính xác hơn. Tuy nhiên ta không thể dùng tập mẫu phân tầngnhư trên nữa vì lúc này ta sẽ cần tới 500 mẫu cho chữ z trongkhi ta chỉ có 50 mẫu trong nguồn dữ liệu. Để giải quyết điềunày ta tạo tập mẫu như sau: tập mẫu gồm tất cả các chữ hiếmvới số lần xuất hiện của nó và kèm thêm thông tin về chữ cónhiều mẫu nhất. Chẳng hạn ta tạo tập mẫu có 50 mẫu của chữ z(đó là tất cả) và 700 mẫu của chữ e (chữ mà ta có nhiều mẫunhất).
Như vậy trong tập mẫu của ta, chữ e có nhiều hơn chữ z 14lần. Nếu ta muốn các chữ z cũng có nhiều ảnh hưởng như cácchữ e, khi học chữ z ta cho chúng trọng số lớn hơn 14 lần. Đểlàm được điều này ta có thể can thiệp chút ít vào quá trình
22

lan truyền ngược trên mạng. Khi mẫu học là chữ z, ta thêm vào14 lần đạo hàm, nhưng khi mẫu là chữ e ta chỉ thêm vào 1 lầnđạo hàm. Ở cuối thế hệ, khi cập nhật các trọng số, mỗi chữ zsẽ có ảnh hưởng hơn mỗi chữ e là 14 lần, và tất cả các chữ zgộp lại sẽ có bằng có ảnh hưởng bằng tất cả các chữ e.
d. Chọn biến Khi tạo mẫu cần chọn các biến sử dụng trong mô hình. Có 2
vấn đề cần quan tâm: ♦ Cần tìm hiểu cách biến đổi thông tin sao cho có lợi cho
mạng hơn: thông tin trước khi đưa vào mạng cần được biến đổiở dạng thích hợp nhất, để mạng đạt được hiệu xuất cao nhất.Xét ví dụ về bài toán dự đoán một người có mắc bệnh ung thưhay không. Khi đó ta có trường thông tin về người này là“ngày tháng năm sinh”. Mạng sẽ đạt được hiệu quả cao hơn khita biến đổi trường thông tin này sang thành “tuổi”. Thậm chíta có thể quy tuổi về một trong các giá trị: 1 = “trẻ em”(dưới 18), 2 = “thanh niên” (từ 18 đến dưới 30), 3 = “trungniên” (từ 30 đến dưới 60) và 4 = “già” (từ 60 trở lên).
♦ Chọn trong số các biến đã được biến đổi biến nào sẽđược đưa vào mô hình: không phải bất kì thông tin nào về mẫucũng có lợi cho mạng. Trong ví dụ dự đoán người có bị ung thưhay không ở trên, những thuộc tính như “nghề nghiệp”, “nơisinh sống”, “tiểu sử gia đình”,… là những thông tin có ích.Tuy nhiên những thông tin như “thu nhập”, “số con cái”,… lànhững thông tin không cần thiết.
II.2. Xác định các tham số cho mạng
23

a. Chọn hàm truyền Không phải bất kỳ hàm truyền nào cũng cho kết quả như
mong muốn. Để trả lời cho câu hỏi «hàm truyền như thế nào được coi làtốt ? » là điều không hề đơn giản. Có một số quy tắc khi chọnhàm truyền như sau:
♦ Không dùng hàm truyền tuyến tính ở tầng ẩn. Vì nếu dùnghàm truyền tuyến tính ở tầng ẩn thì sẽ làm mất vai trò củatầng ẩn đó: Xét tầng ẩn thứ i:
Tổng trọng số ni = wiai-1 + bi ai = f(ni) = wf ni +bf (hàm truyền tuyến tính)
Khi đó: tổng trọng số tại tầng thứ (i + 1) ni+1 = wi+1ai + bi+1 = wi+1[wf ni +bf] + bi+1 = wi+1 [wf(wiai-1 + bi) + bf] + bi+1 = Wai-1 + b
Như vậy ni+1 = Wai-1 + b, và tầng i đã không còn giá trịnữa.
♦ Chọn các hàm truyền sao cho kiến trúc mạng nơron là đốixứng (tức là với đầu vào ngẫu nhiên thì đầu ra có phân bố đốixứng). Nếu một mạng nơron không đối xứng thì giá trị đầu rasẽ lệch sang một bên, không phân tán lên toàn bộ miền giá trịcủa output. Điều này có thể làm cho mạng rơi vào trạng tháibão hòa, không thoát ra được.
Trong thực tế người ta thường sử dụng các hàm truyền dạng– S. Một hàm s(u) được gọi là hàm truyền dạng – S nếu nó thỏamãn 3 tính chất sau:
24

– s(u) là hàm bị chặn: tức là tồn tại các hằng số C1 ≤ C2sao cho: C1 ≤ s(u) ≤ C2 với mọi u.
– s(u) là hàm đơn điệu tăng: giá trị của s(u) luôn tăngkhi u tăng. Do tính chất thứ nhất, s(u) bị chặn, nên s(u) sẽtiệm cận tới giá trị cận trên khi u dần tới dương vô cùng, vàtiệm cận giá trị cận dưới khi u dần tới âm vô cùng.
– s(u) là hàm khả vi: tức là s(u) liên tục và có đạo hàmtrên toàn trục số.
Một hàm truyền dạng - S điển hình và được áp dụng rộngrãi là hàm Sigmoid.
b. Xác định số nơron tầng ẩn Câu hỏi chọn số lượng noron trong tầng ẩn của một mạng
MLP thế nào là khó, nó phụ thuộc vào bài toán cụ thể và vàokinh nghiệm của nhà thiết kế mạng. Nếu tập dữ liệu huấn luyệnđược chia thành các nhóm với các đặc tính tương tự nhau thìsố lượng các nhóm này có thể được sử dụng để chọn số lượngnơron ẩn. Trong trường hợp dữ liệu huấn luyện nằm rải rác vàkhông chứa các đặc tính chung, số lượng kết nối có thể gầnbằng với số lượng các mẫu huấn luyện để mạng có thể hội tụ.Có nhiều đề nghị cho việc chọn số lượng nơron tầng ẩn h trongmột mạng MLP. Chẳng hạn h phải thỏa mãn h>(p-1)/(n+2), trongđó p là số lượng mẫu huấn luyện và n là số lượng đầu vào củamạng. Càng nhiều nút ẩn trong mạng, thì càng nhiều đặc tínhcủa dữ liệu huấn luyện sẽ được mạng nắm bắt, nhưng thời gianhọc sẽ càng tăng.
Một kinh nghiệm khác cho việc chọn số lượng nút ẩn là sốlượng nút ẩn bằng với số tối ưu các cụm mờ (fuzzy clusters)[8].Phát biểu này đã được chứng minh bằng thực nghiệm. Việc chọn
25

số tầng ẩn cũng là một nhiệm vụ khó. Rất nhiều bài toán đòihỏi nhiều hơn một tầng ẩn để có thể giải quyết tốt.
Để tìm ra mô hình mạng nơron tốt nhất, Ishikawa andMoriyama (1995) sử dụng học cấu trúc có quên (structural leanrningwith forgetting), tức là trong thời gian học cắt bỏ đi các liênkết có trọng số nhỏ. Sau khi huấn luyện, chỉ các noron cóđóng góp vào giải quyết bài toán mới được giữ lại, chúng sẽtạo nên bộ xương cho mô hình mạng nơron.
c. Khởi tạo trọng Trọng thường được khởi tạo bằng phương pháp thử sai, nó
mang tính chất kinh nghiệm và phụ thuộc vào từng bài toán.Việc định nghĩ thế nào là một bộ trọng tốt cũng không hề đơngiản. Một số quy tắc khi khởi tạo trọng:
♦ Khởi tạo trọng sao cho mạng nơron thu được là cân bằng(với đầu vào ngẫu nhiên thì sai số lan truyền ngược cho cácma trận trọng số là xấp xỉ bằng nhau):
|ΔW1/W1| = |ΔW2/W2| = |ΔW3/W3|
Nếu mạng nơron không cân bằng thì quá trình thay đổitrọng số ở một số ma trận là rất nhanh trong khi ở một số matrận khác lại rất chậm, thậm chí không đáng kể. Do đó để cácma trận này đạt tới giá trị tối ưu sẽ mất rất nhiều thờigian.
♦ Tạo trọng sao cho giá trị kết xuất của các nút có giátrị trung gian. (0.5 nếu hàm truyền là hàm Sigmoid). Rõ ràngnếu ta không biết gì về giá trị kết xuất thì giá trị ở giữalà hợp lý. Điều này cũng giúp ta tránh được các giá trị tháiquá.
26

Thủ tục khởi tạo trọng thường được áp dụng: – B1: Khởi tạo các trọng số nút ẩn (và các trọng số của
các cung liên kết trực tiếp giữa nút nhập và nút xuất, nếucó) giá trị ngẫu nhiên, nhỏ, phân bố đều quanh 0.
– B2: Khởi tạo một nửa số trọng số của nút xuất giá trị1, và nửa kia giá trị -1.
II.3. Vấn đề lãng quên (catastrophic forgetting)
Catastrophic forgetting là vấn đề một mạng quên những gìnó đã học được trong các mẫu trước khi đang học các mẫu mới.Nguyên nhân là do sự thay đổi các trọng số theo các mẫu mới,nếu như các mẫu cũ trong một thời gian không được đưa vàohuấn luyện. Để tránh điều này, ta thường thực hiện việc huấnluyện luân phiên giữa mẫu cũ và mẫu mới.
Hình 10: Huấn luyện luân phiên trên hai tập mẫu
Xét ví dụ mạng được huấn luyện luân phiên với hai tập mẫuA và B (hình 2-10). Tại mỗi chu kỳ mạng sẽ học tập mẫu A sauđó học tập mẫu B. Khi bước vào chu kỳ thứ hai, lỗi lúc bắtđầu học tập mẫu A cao hơn là ở chu kỳ thứ nhất khi vừa họcxong tập A. Điều này là do giữa hai lần học tập mẫu A mạng đã
27

học tập mẫu B. Tuy nhiên nếu xét trên cả chu kỳ thì lỗi huấnluyện sẽ giảm xuống. Tức là lỗi lúc bước vào chu kỳ thứ ba sẽnhỏ hơn lúc bước vào chu kỳ thứ hai.
Có nhiều phương pháp để huấn luyện dữ liệu mới. Chẳng hạnsau khi một số mẫu mới được học, một vài mẫu cũ được chọnngẫu nhiên trong số các mẫu trước đó để đưa vào học. Vấn đềsẽ khó khăn hơn khi các mẫu cũ không còn nữa. Khi đó các mẫugiả (pseudoexamples) có thể được sử dụng để lưu giữ các trọngsố càng gần các trọng số trước càng tốt.
II.4 Vấn đề quá khớp
a. Khái niệm quá khớp Vấn đề quá khớp xảy ra khi mạng được luyện quá khớp (quá
sát) với dữ liệu huấn luyện (kể cả nhiễu), nên nó sẽ trả lờichính xác những gì đã được học, còn những gì không được họcthì nó không quan tâm. Như vậy mạng sẽ không có được khả năngtổng quát hóa.
Về mặt toán học, một giả thuyết (mô hình) h được gọi làquá khớp nếu tồn tại giả thuyết h' sao cho:
1. Error train (h) < Error train (h')
2. Error test (h) > Error test (h')
b. Giải quyết quá khớp Vấn đề quá khớp xảy ra vì mạng có năng lực quá lớn. Có 3
cách để hạn chế bớt năng lực của mạng:
– Hạn chế số nút ẩn
– Ngăn không cho mạng sử dụng các trọng số lớn 28

– Giới hạn số bước luyện
Khi mạng được luyện, nó chuyển từ các hàm ánh xạ tươngđối đơn giản đến các hàm ánh xạ tương đối phức tạp. Nó sẽ đạtđược một cấu hình tổng quát hóa tốt nhất tại một điểm nào đó.Sau điểm đó mạng sẽ học để mô hình hóa nhiễu, những gì mạnghọc được sẽ trở thành quá khớp. Nếu ta phát hiện ra thời điểmmạng đạt đến trạng thái tốt nhất này, ta có thể ngừng tiếntrình luyện trước khi hiện tượng quá khớp xảy ra.
Ta biết rằng, chỉ có thể để đánh giá mức độ tổng quát hóacủa mạng bằng cách kiểm tra mạng trên các mẫu nó không đượchọc. Ta thực hiện như sau: chia mẫu thành tập mẫu huấn luyệnvà tập mẫu kiểm tra. Luyện mạng với tập mẫu huấn luyện nhưngđịnh kỳ dừng lại và đánh giá sai số trên tập mẫu kiểm tra.Khi sai số trên tập mẫu kiểm tra tăng lên thì quá khớp đã bắtđầu và ta dừng tiến trình luyện.
Chú ý rằng, nếu sai số kiểm tra không hề tăng lên, tức làmạng không có đủ số nút ẩn để quá khớp. Khi đó mạng sẽ khôngcó đủ số nút cần thiết để thực hiện tốt nhất. Do vậy nếu hiệntượng quá khớp không hề xảy ra thì ta cần bắt đầu lại nhưngsử dụng nhiều nút ẩn hơn.
29

CHƯƠNG 3: ỨNG DỤNG CỦA MẠNG NƠRON
Ngày nay, mạng nơ ron ngày càng được ứng dụng nhiều trong thựctế. Đặc biệt là các bài toán nhận dạng mẫu, xử lý, lọc dữ liệu, vàđiều khiển. Ứng dụng của mạng nơ ron được chia thành các loại sau:
- Xử lý ngôn ngữ
o Xử lý ngôn ngữ tự nhiên
- Nhận dạng mẫu
o Nhận dạng ảnh
o Nhận giọng nói
o Nhận dạng chữ viết
- Xử lý tín hiệu
o Điều khiển tự động
- Lọc và phân loại dữ liệu
o Chuẩn đoán bệnh
o Tìm kiếm
30

CHƯƠNG 4: THỰC NGHIỆM
I. Giới thiệu bài toánI.1. Phát biểu bài toán
Thực nghiệm này xây dựng một mạng nơ ron, thực hiện bài toánphân loại mẫu đơn giản sau:
Cho thông tin về học sinh, gồm họ tên, điểm các môn Văn vàToán. Xây dựng chương trình cho biết với các thông tin đấy, họcsinh có được đánh giá là Đạt hay không? Đạt ở đây được đánh giátheo tiêu chí sau:
- Trung bình cộng của điểm lớn hơn hoặc bằng 5
- Không có điểm nào bằng 0
I.2. Mô hình mạng nơron của bài toánMô hình mạng được sử dụng là mô hình mạng truyền thẳng MLP gồm
các tầng: một tầng vào, một tầng ẩn, và một tầng ra. Số nơ ron đầu vào bằng số chiều của vector đặc trưng cho mẫu, ở đây là 2 (điểm môn Toán và Văn), số nơ ron tầng ẩn có thể thay đổi linh hoạt trongquá trình huấn luyện mạng, số nơ ron đẩu ra là 1.
31
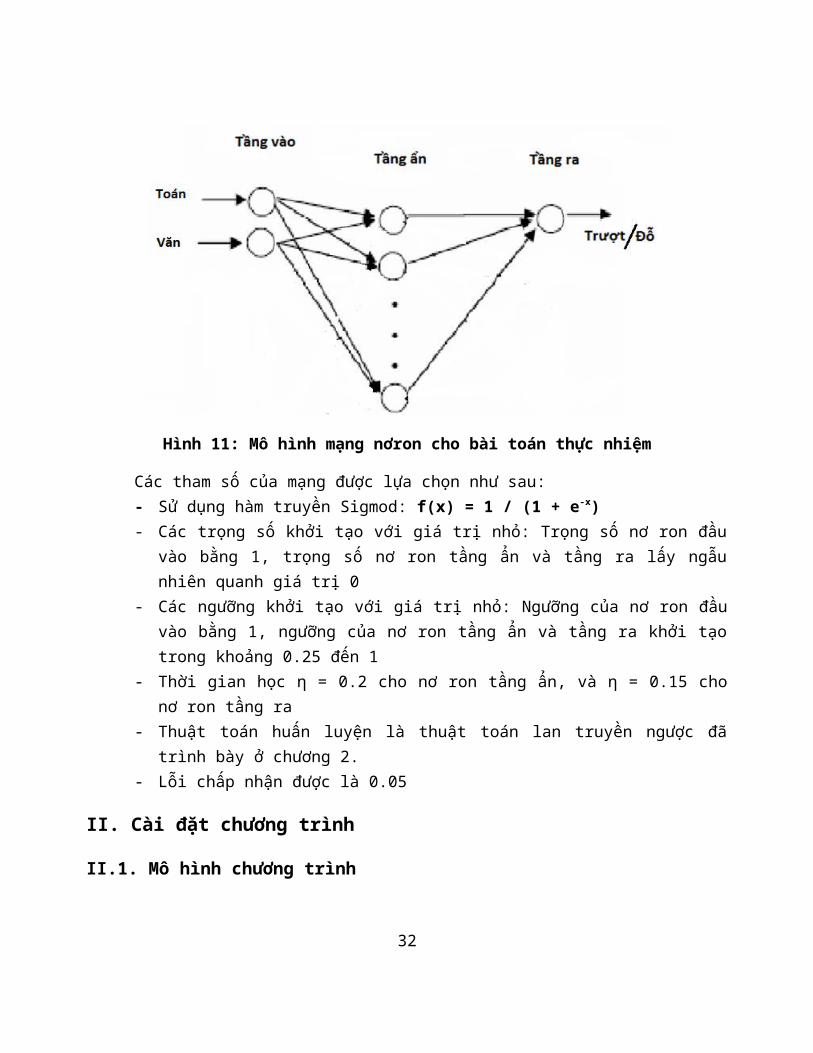
Hình 11: Mô hình mạng nơron cho bài toán thực nhiệm
Các tham số của mạng được lựa chọn như sau:- Sử dụng hàm truyền Sigmod: f(x) = 1 / (1 + e-x)- Các trọng số khởi tạo với giá trị nhỏ: Trọng số nơ ron đầu
vào bằng 1, trọng số nơ ron tầng ẩn và tầng ra lấy ngẫunhiên quanh giá trị 0
- Các ngưỡng khởi tạo với giá trị nhỏ: Ngưỡng của nơ ron đầuvào bằng 1, ngưỡng của nơ ron tầng ẩn và tầng ra khởi tạotrong khoảng 0.25 đến 1
- Thời gian học η = 0.2 cho nơ ron tầng ẩn, và η = 0.15 chonơ ron tầng ra
- Thuật toán huấn luyện là thuật toán lan truyền ngược đãtrình bày ở chương 2.
- Lỗi chấp nhận được là 0.05
II. Cài đặt chương trình
II.1. Mô hình chương trình
32
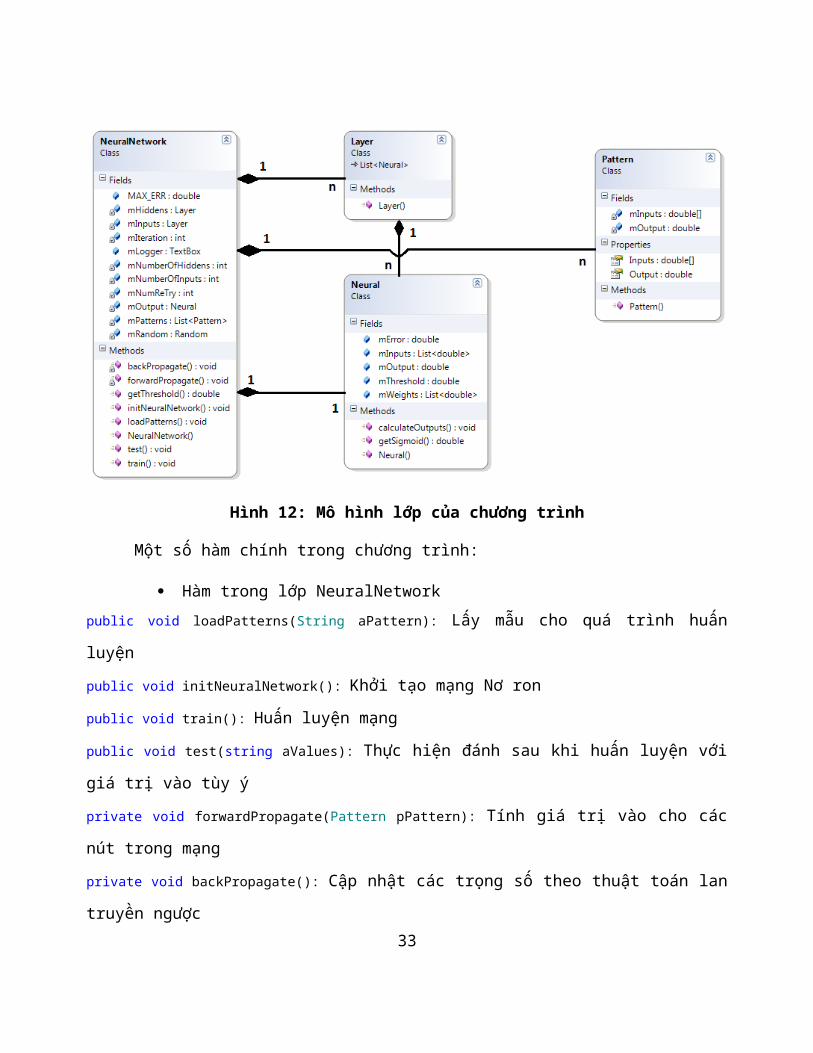
Hình 12: Mô hình lớp của chương trình
Một số hàm chính trong chương trình:
Hàm trong lớp NeuralNetworkpublic void loadPatterns(String aPattern): Lấy mẫu cho quá trình huấn
luyện
public void initNeuralNetwork(): Khởi tạo mạng Nơ ron
public void train(): Huấn luyện mạng
public void test(string aValues): Thực hiện đánh sau khi huấn luyện với
giá trị vào tùy ý
private void forwardPropagate(Pattern pPattern): Tính giá trị vào cho các
nút trong mạng
private void backPropagate(): Cập nhật các trọng số theo thuật toán lan
truyền ngược33
public double getThreshold(): Lấy giá trị ngưỡng ngẫu nhiên trong khoảng
0.25 đến 1
Hàm trong lớp Neuralpublic void calculateOutputs(): Tính giá trị ra của nơ ron
public double getSigmoid(double x): Tính giá trị theo hàm Sigmod
II.2. Kết quả thử nghiệm
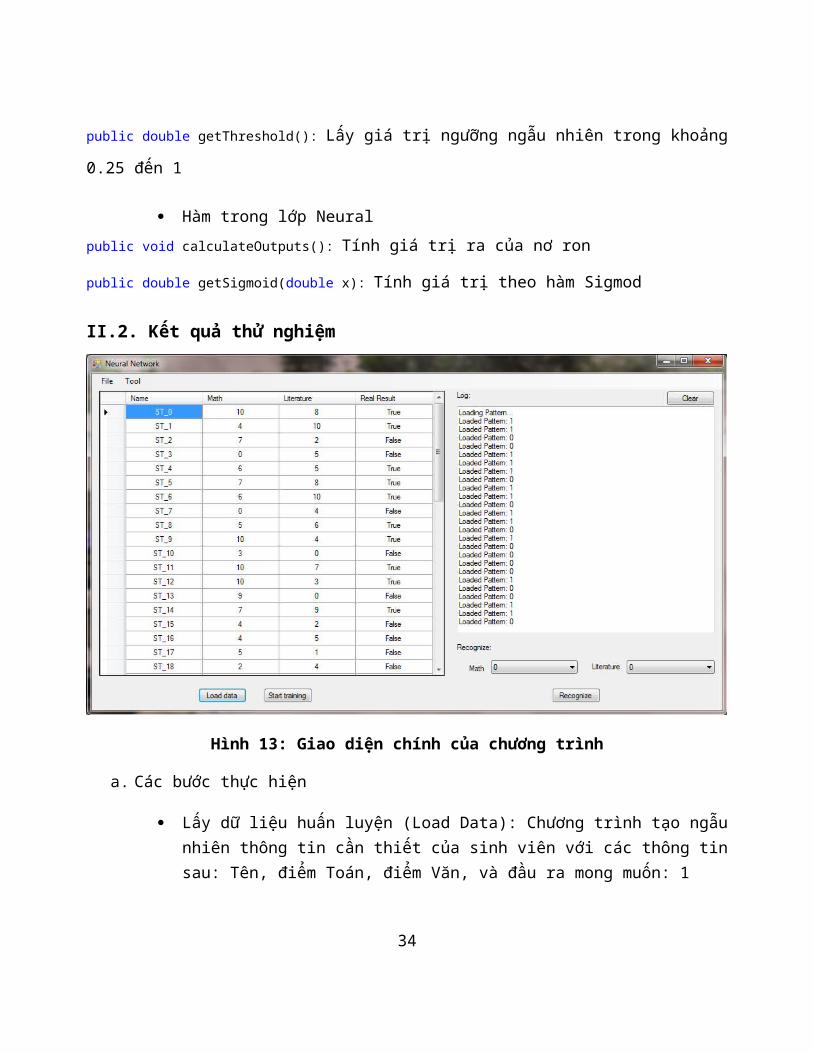
Hình 13: Giao diện chính của chương trình
a. Các bước thực hiện
Lấy dữ liệu huấn luyện (Load Data): Chương trình tạo ngẫunhiên thông tin cần thiết của sinh viên với các thông tinsau: Tên, điểm Toán, điểm Văn, và đầu ra mong muốn: 1
34
(True) là Đạt, 0 (False) là không đạt. Sau đó khởi tạo mạng nở ron
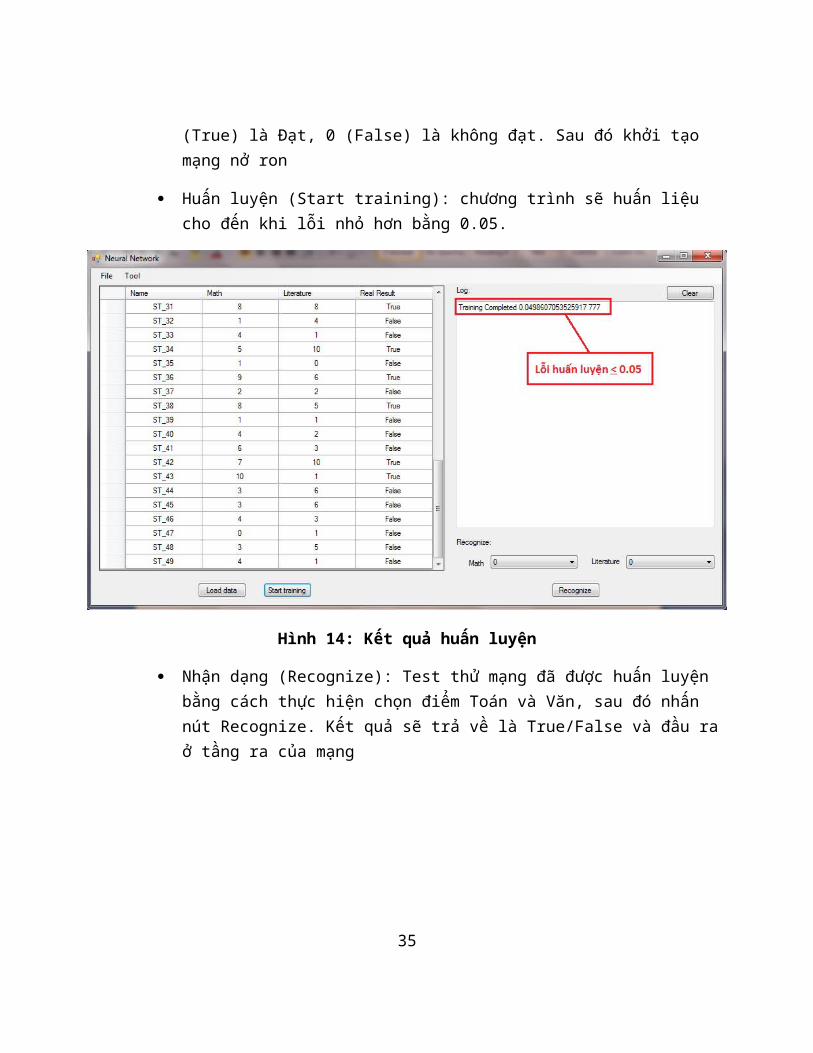
Huấn luyện (Start training): chương trình sẽ huấn liệu cho đến khi lỗi nhỏ hơn bằng 0.05.
Hình 14: Kết quả huấn luyện
Nhận dạng (Recognize): Test thử mạng đã được huấn luyện bằng cách thực hiện chọn điểm Toán và Văn, sau đó nhấn nút Recognize. Kết quả sẽ trả về là True/False và đầu ra ở tầng ra của mạng
35
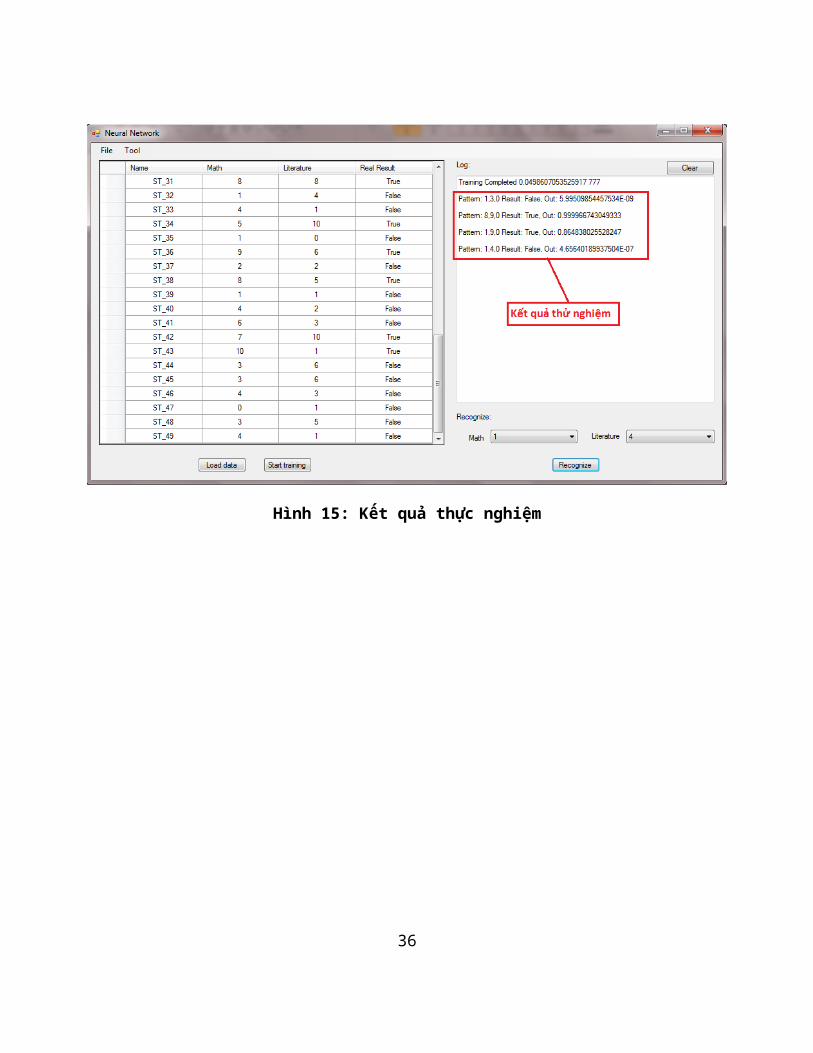
Hình 15: Kết quả thực nghiệm
36

CHƯƠNG 5: KẾT LUẬN
Báo cáo này trình bày về các vấn đề về mạng nơ ron, gồm: kháiniệm của mạng nơ ron nhân tạo, lịch sử phát triển, các mô hình mạngvà phương pháp xây dựng cũng như huấn luyện mạng. Trong đó đi sâuvào việc xây dựng một mạng nơ ron truyền thẳng MLP, và thuật tuánhuấn luyện Lan truyền ngược.
Báo cáo này cũng trình bày một thực nghiệm cho các lý thuyếtvề mạng MLP và thuật toán Lan truyền ngược đã nêu ra. Thực nghiệmxây dựng một chương trình đơn giản để phân loại mẫu (phân loại họcsinh).
Các vấn đề còn chưa có trong báo cáo, và cần nghiên cứu triểnkhai là:
- Tìm hiểu về các thuật toán huấn luyện mạng nơ ron khác, đểcó thể đưa ra các so sánh, cũng như chọn mô hình thích hợpcho các bài toán cụ thể.
- Phát triển chương trình thực nghiệm thành một chương trìnhcó ý nghĩa thực tế hơn, như nhận dạng chữ viết tay, nhậndạng ảnh, dựa trên nền tảng mạng đã xây dụng
37

TÀI LIỆU THAM KHẢO
[1]. Genevieve Orr, Nici Schraudolph and Fred Cummins http://www.willamette.edu/~gorr/classes/cs449/intro.html
[2]. Christos Stergiou and Dimitrios Siganos. Neural Networks. http://www.doc.ic.ac.uk/~nd/surprise_96/journal/vol4/cs11/report.html
[3]. Nikola K. Kasabov. Foundations of Neural Networks, Fuzzy Systems, and Knowledge Engineering. Massachusetts Institute of Technology.
a




















