
Answers to Exercises
61
Answers to Exercises 1: When a software house has a popular product they tend to come up with new versions. A user can update an old version to a new one, and the update usually comes as a compressed file on a floppy disk. Over time the updates get bigger and, at a certain point, an update may not fit on a single floppy. This is why good compression is important in the case of software updates. The time it takes to compress and decompress the update is unimportant since these operations are typically done just once. 1.1: An obvious way is to use them to code the five most common strings in the text . Since irreversible text compression is a special-purpose method, the user may know what strings are common in any particular text to be compressed. The user may specify five such strings to the encoder, and they should also be written at the start of the output stream, for the decoder's use. 1.2: 6,8,0,1,3,1,4,1,3,1,4,1,3,1,4,1,3,1,2,2,2,2,6,1,1. The first two numbers are the bitmap resolution (6 x 8). If each number occupies a byte on the output stream, then its size is 25 bytes, compared to a bitmap size of only 6 x 8 bits = 6 bytes. The method does not work for small images. 1.3: RLE of images is based on the idea that adjacent pixels tend to be identical. The last pixel of a row, however, has no reason to be identical to the first pixel of the next row. 1.4: Each of the first four rows yields the eight runs 1,1,1,2,1,1,1,001. Rows 6 and 8 yield the four runs 0,7,1,001 each. Rows 5 and 7 yield the two runs 8,eol each. The total number of runs (including the eol's) is thus 44. When compressing by columns, columns 1, 3, and 6 yield the five runs 5,1,1,1,eol each. Columns 2, 4, 5, and 7 yield the six runs O,5,1 ,1,1,eol each. Column 8 gives 4,4,eol, so the total number of runs is 42. This image is thus "balanced" with respect to rows and columns.
-
Upload
khangminh22 -
Category
Documents
-
view
1 -
download
0
Transcript of Answers to Exercises

Answers to Exercises
1: When a software house has a popular product they tend to come up with newversions. A user can update an old version to a new one, and the update usuallycomes as a compressed file on a floppy disk. Over time the updates get biggerand, at a certain point, an update may not fit on a single floppy. This is whygood compression is important in the case of software updates. The time it takesto compress and decompress the update is unimportant since these operations aretypically done just once.
1.1: An obvious way is to use them to code the five most common strings in thetext. Since irreversible text compression is a special-purpose method, the user mayknow what strings are common in any particular text to be compressed. The usermay specify five such strings to the encoder, and they should also be written at thestart of the output stream, for the decoder's use.
1.2: 6,8,0,1,3,1,4,1,3,1,4,1,3,1,4,1,3,1,2,2,2,2,6,1,1. The first two numbers are thebitmap resolution (6 x 8). If each number occupies a byte on the output stream,then its size is 25 bytes, compared to a bitmap size of only 6 x 8 bits = 6 bytes.The method does not work for small images.
1.3: RLE of images is based on the idea that adjacent pixels tend to be identical.The last pixel of a row, however, has no reason to be identical to the first pixel ofthe next row.
1.4: Each of the first four rows yields the eight runs 1,1,1,2,1,1,1,001. Rows 6 and8 yield the four runs 0,7,1,001 each. Rows 5 and 7 yield the two runs 8,eol each.The total number of runs (including the eol's) is thus 44.
When compressing by columns, columns 1, 3, and 6 yield the five runs 5,1,1,1,eoleach. Columns 2, 4, 5, and 7 yield the six runs O,5,1 ,1,1,eol each. Column 8 gives4,4,eol, so the total number of runs is 42. This image is thus "balanced" with respectto rows and columns.

368 Answers to Exercises
1.5: As "11 22 90 00 00 33 44". The 00 following the 90 indicates no run, and thefollowing 00 is interpreted as a regular character.
1.6: The six characters "123ABC" have ASCII codes 31, 32, 33, 41, 42 and 43.Translating these hexadecimal numbers to binary produces "00110001 0011001000110011 01000001 01000010 01000011".The next step is to divide this string of 48 bits into 6-bit blocks. They are001100=12, 010011=19, 001000=8, 110011=51, 010000=16, 010100=20, 001001=9,000011=3. The character at position 12 in the BinHex table is "-" (position numbering starts at zero) . The one at position 19 is "6" . The final result is the string"-6) c38*$" .
1.7: Exercise 2.1 shows that the binary code of the integer i is 1 + Llog2 iJ bitslong. We add Llog2 iJ zeros, bringing the total size to 1 + 2Llog2 iJ bits.
1.8: Table Ans.1 summarizes the results. In (a), the first string is encoded withk = 1. In (b) it is encoded with k = 2. Columns (c) and (d) are the encodings of thesecond string with k = 1 and k = 2, respectively. The averages of the four columnsare 3.4375, 3.25, 3.56 and 3.6875; very similar! The move-ahead-k method usedwith small values of k does not favor strings satisfying the concentration property.
a abcdmnop 0 a abcdmnop 0 a abcdmnop 0 a abcdmnop 0b abcdmnop 1 b abcdmnop 1 b abcdmnop 1 b abcdmnop 1c bacdmnop 2 c bacdmnop 2 c bacdmnop 2 c bacdmnop 2d bcadmnop 3 d cbadmnop 3 d bcadmnop 3 d cbadmnop 3d bcdamnop 2 d cdbamnop 1 m bcdamnop 4 m cdbamnop 4c bdcamnop 2 c dcbamnop 1 n bcdmanop 5 n cdmbanop 5b bcdamnop 0 b cdbamnop 2 0 bcdmnaop 6 0 cdmnbaop 6a bcdamnop 3 a bcdamnop 3 p bcdmnoap 7 p cdmnobap 7m bcadmnop 4 m bacdmnop 4 a bcdmnopa 7 a cdmnopba 7n bcamdnop 5 n bamcdnop 5 b bcdmnoap 0 b cdmnoapb 70 bcamndop 6 0 bamncdop 6 c bcdmnoap 1 c cdmnobap 0p bcamnodp 7 p bamnocdp 7 d cbdmnoap 2 d cdmnobap 1p bcamnopd 6 p bamnopcd 5 m cdbmnoap 3 m dcmnobap 20 bcamnpod 6 0 bampnocd 5 n cdmbnoap 4 n mdcnobap 3n bcamnopd 4 n bamopncd 5 0 cdmnboap 5 0 mndcobap 4m bcanmopd 4 m bamnopcd 2 p cdmnobap 7 p mnodcbap 7
bcamnopd mbanopcd cdmnobpa mnodcpba
(a) (b) (c) (d)
Table Ans.L: Encoding with Move-Ahead-k.
1.9: Table Ans.2 summarizes the decoding steps. Notice how similar it is toTable 1.11, indicating that move-to-front is a symmetric data compression method.

Answers to Exercises 369
Code input A (before adding) A (after adding) Word
(the)(the, boy)
(boy, the, on)(on, boy, the, my)
(my, on, boy, the, right)(right, my, on, boy, the , is)(is, right, my, on, boy, the)(the, is, right, my, on, boy)(right , the , is, my, on, boy)
OtheIboy20n3my4right5is525
o(the)
(boy, the)(on, boy, the)
(my, on, boy, the)(right, my, on, boy, the)
(is, right, my, on, boy, the)(the , is, right , my, on, boy)(right, the, is, my, on, boy)(boy, right , the, is, my, on)
Table Ans.2: Decoding Multiple-Letter Words.
theboyonmyrightistherightboy
2.1: It is 1 + llog2iJ as can be shown by simple experimenting.
2.2: Two is the smallest integer that can serve as the basis for a number system.
2.3: Replacing 10 by 3 we get x = k log2 3 ~ 1.58k. A trit is thus worth about1.58 bits .
2.4: We assume an alphabet with two symbols al and a2, with probabilitiesP, and P2 , respectively. Since P, + P2 = 1, the entropy of the alphabet is-Pdog2 P, - (1 - Pd log2(1 - Pd. Table Ans.3 shows the entropies for certainvalues of the probabilities. When Pl = P2 , at least 1 bit is required to encode eachsymbol. However, when the probabilities are very different , the minimum numberof bits required per symbol drops significantly. We may not be able to develop acompression method using 0.08 bits per symbol but we know that when Pl = 99%,this is the theoretical minimum.
Pl P2 Entropy
99 1 0.0890 10 0.4780 20 0.7270 30 0.8860 40 0.9750 50 1.00
Table Ans.3: Probabilities and Entropies of Two Symbols.
2.5: It is easy to see that the unary code satisfies the prefix property, so it definitelycan be used as a variable-size code. Since its length is approximately log2n, it makessense to use it in cases were the input data consists of integers n with probabilitiespen) ~ 2-n . If the data lends itself to the use of the unary code, the entire Huffmanalgorithm can be skipped, and the codes of all the symbols can easily and quicklybe constructed before compression or decompression starts.

370 Answers to Exercises
2.6: The triplet (n, 1,n) defines the standard n-bit binary codes, as can be verifiedby direct construction. The number of such codes is easily seen to be
The triplet (0,0,00) defines the codes 0, 10, 110, 1110, which are the unary codesbut assigned to the integers 0, 1, 2,... instead of 1, 2, 3, .
2.7: The number is (230 - 21)/(21 - 1) ~ A billion.
2.8: This is straightforward. Table Ans.d shows the code. There are only threedifferent codewords since "start" and "stop" are so close, but there are many codessince "start" is large.
a= nth Number of Range ofn 1O+n ·2 codeword codewords integers
0 10 O~ 210 = lK 0-102310
1 12 lOxx...x 212 = 4K 1024-5119'--v--"
12
2 14 11xx...xx 214 = 16K 5120-21503"--v--"
14Total 21504
Table Ans.4: The General Unary Code (10,2,14).
2.9: Each part of 0 4 is the standard binary code of some integer, so it starts witha 1. A part that starts with a 0 thus signals to the decoder that this is the last bitof the code.
2.10: Subsequent splits can be done in different ways, but Table Ans.5 shows oneway of assigning Shannon-Fane codes to the 7 symbols .
Prob. Steps Final
1. 0.25 1 1 :112. 0.20 1 0 :1013. 0.15 1 0 :1004. 0.15 0 1 :015. 0.10 0 0 1 :0016. 0.10 0 0 0 0 :00017. 0.05 0 0 0 0 :0000
Table Ans.5: Shannon-Fane Example.

Answers to Exercises 371
The average size in this case is 0.25 x 2 + 0.20 x 3 + 0.15 x 3 + 0.15 x 2 + 0.10 x 3 +0.10 x 4 + 0.05 x 4 = 2.75 bits/symbols.
2.11: This is immediate -2(0.25 x log2 0.25) - 4(0.125 x log20.125) = 2.5.
2.12: Imagine a large alphabet where all the symbols have (about) the sameprobability. Since the alphabet is large, that probability will be small, resultingin long codes. Imagine the other extreme case, where certain symbols have highprobabilities (and , therefore, short codes). Since the probabilities have to add upto 1, the rest of the symbols will have low probabilities (and, therefore, long codes).We thus see that the size of a code depends on the probability, but is indirectlyaffected by the size of the alphabet.
2.13: Answer not provided.
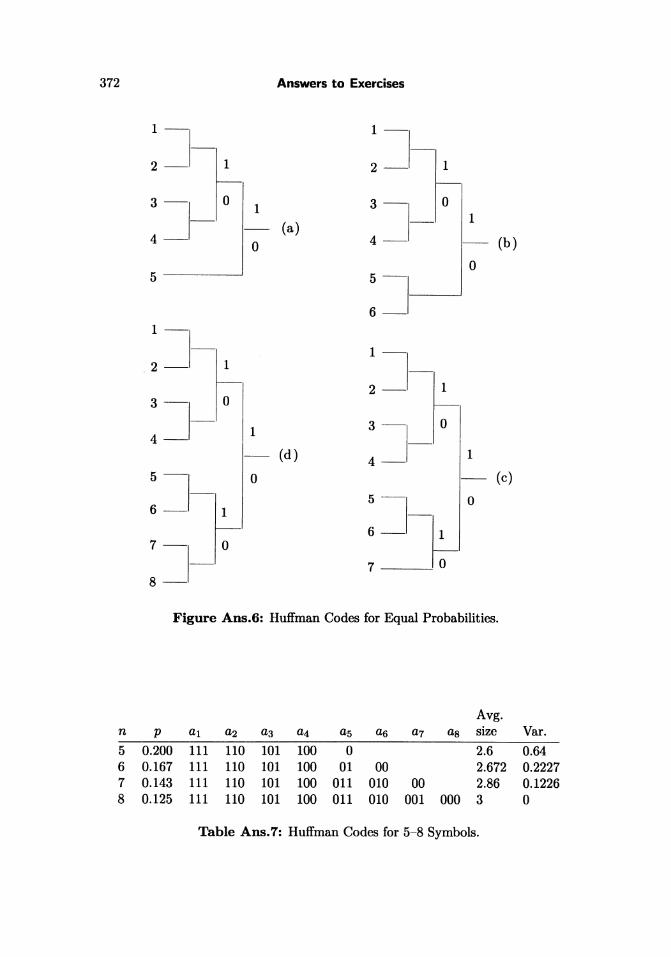
2.14: Figure Ans.6 shows Huffman codes for 5, 6, 7, and 8 symbols with equalprobabilities. In the case where n is a power of 2, the codes are simply the fixedsized ones. In other cases the codes are very close to fixed-size. This shows thatsymbols with equal probabilities do not benefit from variable-size codes. (This isanother way of saying that random text cannot be compressed.) Table Ans.7 showsthe codes, their average sizes and variances.
2.15: The number of groups increases exponentially from 28 to 28 +n = 28 X 2n .
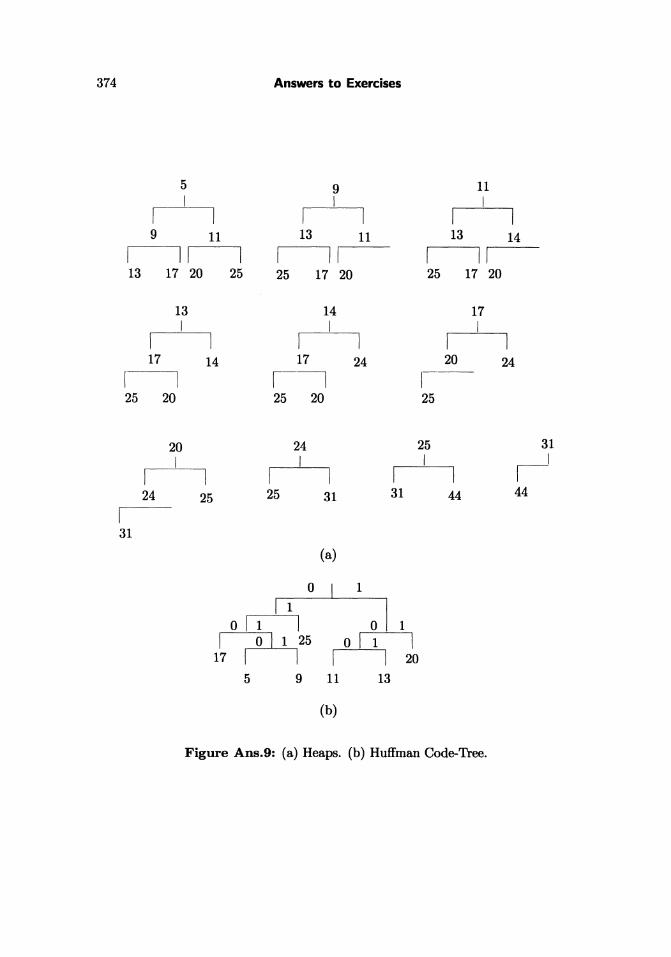
2.16: Figure Ans.8 shows how the loop continues until the heap shrinks to justone node that is the single pointer 2. Thus the total frequency (which happens tobe 100 in our example) is stored in A[2]. All other frequencies have been replacedby pointers. Figure Ans.9a shows the heaps generated during the loop.
2.17: The code lengths for the seven symbols are 2, 2, 3, 3, 4, 3, and 4 bits . Thiscan also be verified from the Huffman code-tree of Figure Ans.9b. A set of codesderived from this tree is shown in the following table:
Count:Code:Length:
25 20 13 17 9 11 501 11 101 000 0011 100 00102 2 3 3 434
2.18: A symbol with high frequency of occurrence should be assigned a shortercode. Therefore it has to appear high in the tree. The requirement that at eachlevel the frequencies be sorted from left to right is artificial. In principle it is notnecessary but it simplifies the process of updating the tree .
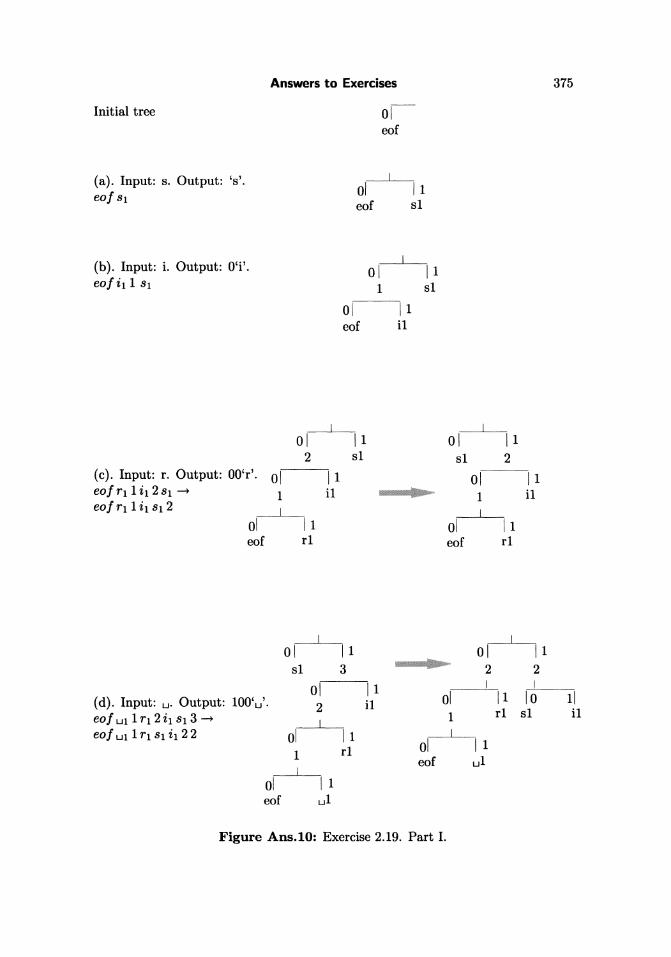
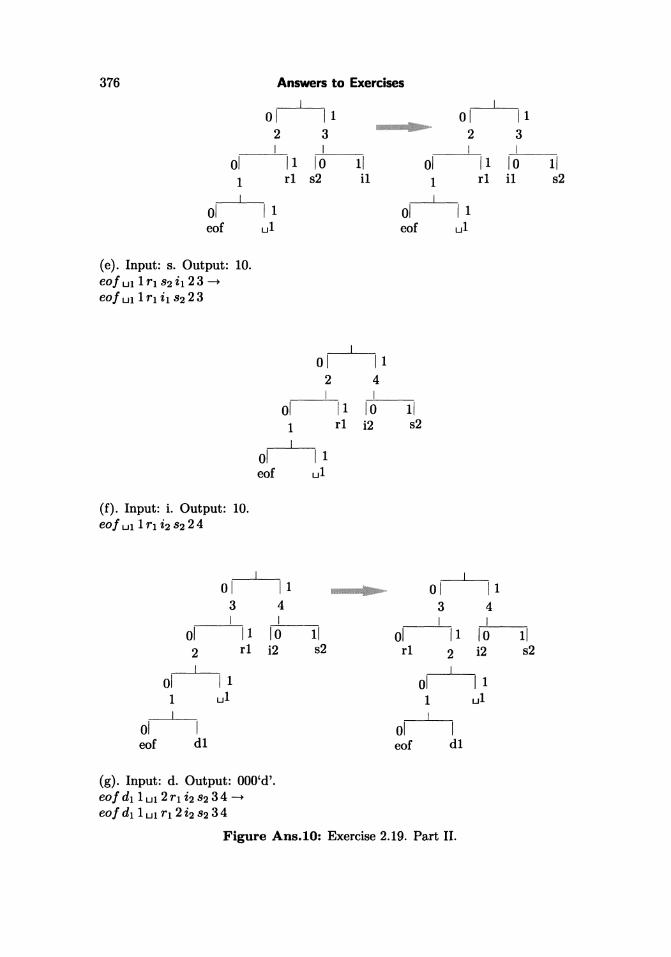
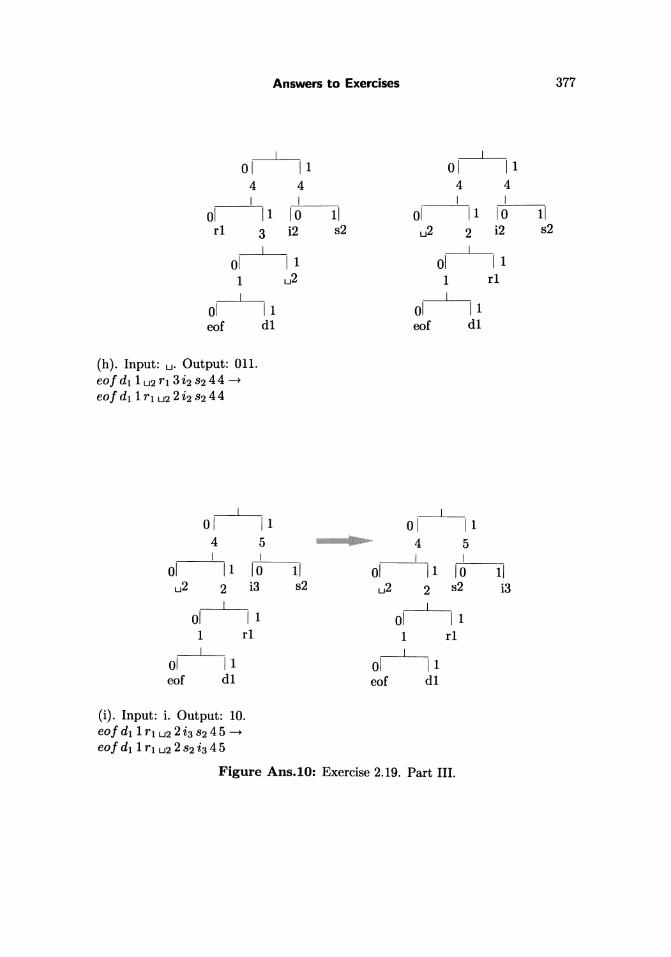
2.19: Figure Ans.lO shows the initial tree and how it is updated in the 11 steps(a) through (k). Notice how the eo! symbol gets assigned different codes all thetime, and how the differnt symbols move about in the tree and change their codes.Code 10, e.g., is the code of symbol "i" in steps (f) and (i), but is the code of "s" insteps (e) and (j). The code of a blank space is 011 in step (h), but 00 in step (k).
The final output is: "'s'O'i'OO'r'100' u'1010000'd'011101000" . A total of62 bits . The compression ratio is thus 62/88 ~ 0.7.
372 Answers to Exercises
:J-F :J-F3 -1_ 0 _1_ 3-1 0(a)
_ 1
4- 4- - (b)00
55-'
6-
:J-F :J-F3-1_0
3-1_0
4- 1(d) 4 _ 1
:J-~0 (c)
:]-~0
7-
1_07 0
8-
Figure Ans.6: Huffman Codes for Equal Probabilities.
Avg.n P al a2 a3 a4 as a6 a7 as size Var.
5 0.200 111 110 101 100 0 2.6 0.646 0.167 111 110 101 100 01 00 2.672 0.22277 0.143 111 110 101 100 011 010 00 2.86 0.12268 0.125 111 110 101 100 011 010 001 000 3 0
Table Ans.7: Huffman Codes for 5-8 Symbols.

Answers to Exercises 373
1 ~ a 1 Q Q 1 ~ ~ 10 11 12 13 14[7 11 6 8 9] 24 14 25 20 6 17 7 6 7
1 ~ a 1 Q Q 1 s ~ 10 11 12 13 14[11 9 8 6] 24 14 25 20 6 17 7 6 7
1 ~ a 1 Q Q 1 s ~ 10 11 12 13 14[11 9 8 6] 17+14 24 14 25 20 6 17 7 6 7
1 ~ a 1 Q Q 1 s ~ 10 11 12 13 14[5 9 8 6] 31 24 5 25 20 6 5 7 6 7
1 ~ a 1 Q Q 1 s ~ 10 11 12 13 14[9 6 8 5] 31 24 5 25 20 6 5 7 6 7
1 ~ a 1 Q Q 1 a ~ 10 11 12 13 14[6 8 5] 31 24 5 25 20 6 5 7 6 7
1 ~ a 1 Q Q 1 s ~ 10 11 12 13 14[6 8 5] 20+24 31 24 5 25 20 6 5 7 6 7
1 ~ a 1 Q Q 1 s ~ 10 11 12 13 14[4 8 5] 44 31 4 5 25 4 6 5 7 6 7
1 ~ a 1 Q Q 1 s ~ 10 11 12 13 14[8 5 4] 44 31 4 5 25 4 6 5 7 6 7
1 ~ a 1 Q Q 1 s ~ 10 11 12 13 14[5 4] 44 31 4 5 25 4 6 5 7 6 7
1 a a 1 Q Q 1 s ~ 10 11 12 13 14[5 4] 25+31 44 31 4 5 25 4 6 5 7 6 7
1 ~ ~ 1 Q Q 1 s ~ 10 11 12 13 14[3 4] 56 44 3 4 5 3 4 6 5 7 6 7
1 a a 1 Q Q 1 s ~ 10 11 12 13 14[4 3] 56 44 3 4 5 3 4 6 5 7 6 7
1 ~ a 1 Q Q 1 s ~ 10 11 12 13 14[3] 56 44 3 4 5 3 4 6 5 7 6 7
1 a a 1 Q Q 1 s ~ 10 11 12 13 14[3] 56+44 56 44 3 4 5 3 4 6 5 7 6 7
1 a a 1 Q Q 1 s ~ 10 11 12 13 14[2J 100 2 2 3 4 5 3 4 6 5 7 6 7
Figure ADs.8: Sifting the Heap.
374 Answers to Exercises
5 9 11I I I
I I I9 11 13 11 13 14
I II I I II I 1/13 17 20 25 25 17 20 25 17 20
13 14 17I I I
I I I17 14 17 24 20 24
r I II ,--25 20 25 20 25
20 24 25 31I I I I
I I I I I24 25 25 31 31 44 44
I31
(a)
0 I 1
I 1o Io I 1 I 1
~25 o I 1 I17 I I 20
5 9 11 13
(b)
Figure Ans.9: (a) Heaps. (b) Huffman Code-Tree.
Init ial tre e
Answers to Exercises
olear
375
(a) . Input: s. Output: 's' .eo! 8 1
(b) . Input: i. Output: O'i'.eo! i1 1 81
01ear
011
11sl
11sl
01 11ear i1
01 11 01 112 sl sl 2
(c). Input: r . Output: OO'r'. 01 11 01 11eo! r1 1 i 1 2 81 ~ 1 i1 .,
1 i1eo! r1 1 i 1 81 2 I I
01 11 01 11ear rl ear rl
0 1 11 01 11sl 3 • 2 2
01 11 I I
(d) . Input: Ll- Output: 100'u' . 2 i1 01 11 10 11
eo! U1 1r12 i 1 81 3 ~ 1 rl sl i1I
eo! U1 1r1 8 1 i 1 22 01 111 rl 01 I 1
eor u1I
01 I 1ear u1
Figure Ans.IO: Exercise 2.19. Part 1.
376 Answers to Exercises
01 11II'
01 112 3 2 3I I I I
01 11 10 11 01 11 10 11
1 rl 82 i1 1 rl i1 82
I01 I 1 01 1 1eor ul eor ul
(e). Input: 8. Output: 10.eof Ul 1 Tl 82 i 1 23 ---t
eof u1l Tl i 1 82 23
01 112 4I I
01 11 10 11
1 rl i2 82
I01 I 1eor ul
(f). Input: i. Output: 10.eofU11Tl i2 8 2 2 4
01 11 II' 01 113 4 3 4I I I I
01 11 10 11 01 11 10 112 rl i2 82 rl 2 i2 82
01 1 1 01 111 ul 1 ulI
01 1 01 Ieor dl eor dl
(g). Input: d. Output: OOO'd' .eof d1 1 Ul 2 Tl i2 82 34 ---t
eof d1l Ul T12i2 82 34
Figure Ans.lO: Exercise 2.19 . Part II .
Answers to Exercises
0 1 11 0 1 11
4 4 4 4I I I I
01 11 10 11 01 11 10 11r1 3 i2 s2 u2 2 i2 s2
I
01 1 1 01 I 1
1 u2 1 r1
I I
01 11 01 11
eof d1 eof d1
(h). Input : u. Output : OIl.eo j d1 1 u2 rl 3 iz 8244 -teoj dl 1rl u2 2i2S2 44
-----l_0 1 11 0 1 11
4 5 • 4 5I I I I
01 11 10 11 01 11 10 11u2 2 i3 s2 u2 2 s2 i3
I I
01 I 1 01 I 11 r1 1 r l
I
01 11 O[ 11eof d1 eof dl
(i). Input : i. Output: 10.eoj d1 l rl u2 2 i3 82 4 5-teoj d1 1 rl u2 2 82 i3 45
Figure Ans.lO: Exercise 2.19. Part III.
377
378 Answers to Exercises
01 11 01 115 6 .. 5 6I I I I
01 11 10 11 01 11 10 11u 3 2 s3 i3
2.s s3 i3
I I01 / 1 01 111 rl 1 rlI I
01 11 01 11eaf dl eaf dl
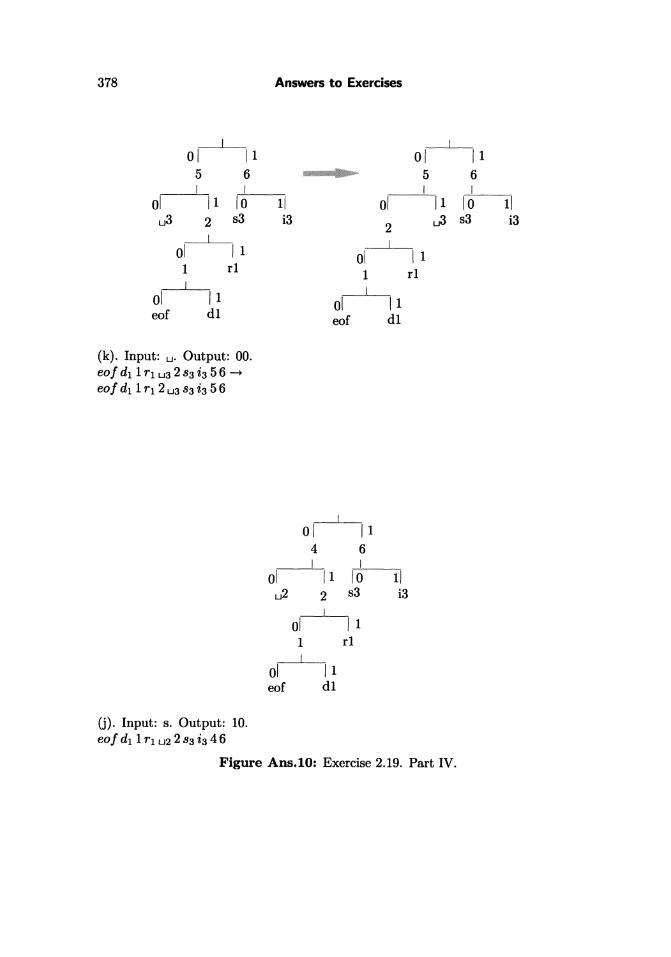
(k) . Input: u. Output: 00.eo! d1 1Tl ua 283 i3 56 --t
eo! d1 1Tl 2 u 3 83 i 3 56
01 114 6I I
01 11 10 1/u 2 2 s3 i3
01 I 11 rlI
01 /1eaf dl
(j). Input: s. Output: 10.eo! d1 1 Tl u2 283 i3 46
Figure Ans.tO: Exercise 2.19. Part IV.

Answers to Exercises 379
2.20: A simple calculation shows that the average size of a token in Table 2.25 isabout 9 bits. In stage 2, each 8-bit byte will be replaced , on the average, by a 9-bittoken, resulting in an expansion factor of 9/8 = 1.125 or 12.5%.
2.21: The decompressor will interpret the input data as "111110 0110 110000.. . ",which is the string "XRP... " .
2.22: A typical fax machine scans lines that are about 8.2 inches wide (~ 208 mm).A blank scan line thus produces 1,664 consecutive white pels.
2.23: There may be fax machines (now or in the future) built for wider paper, sothe Group 3 code was designed to accomodate them.
2.24: The code of a run length of one white pel is 000111, and that of one black pelis 010. Two consecutive pels of different colors are thus coded into 9 bits. Since theuncoded data requires just two bits (01 or 10), the compression factor is 9/2=4.5(the compressed stream is 4.5 times longer than the uncompressed one).
2.25: Figure Ans.ll shows the modes and the actual code generated from the twolines.
i i i i i i ivertical mode horizontal mode pass vertical mode horizontal mode.. .
-1 0 3 white 4 black code +2 -2 4 white 7 black
1 1 1 1 1 1 1 1 1 1 1010 1 001 1000 011 0001 000011 000010 001 1011 00011
Figure Ans.ll: Two-Dimensional Coding Example.
2.26: Table Ans.12 shows the steps in encoding the string a2a2a2a2 . Because ofthe high probability of a2 the low and high variables start at very different valuesand approach each other slowly.
a2 0.0 + (1.0 - 0.0) x 0.023162=0.0231620.0 + (1.0 - 0.0) x 0.998162=0.998162
a2 0.023162+ .975 x 0.023162=0.045744950.023162+ .975 x 0.998162=0.99636995
a2 0.04574495 + 0.950625 x 0.023162=0.067763226250.04574495 +0.950625 x 0.998162=0.99462270125
a2 0.06776322625 + 0.926859375 x 0.023162=0.089231243093750.06776322625 +0.926859375 x 0.998162=0.99291913371875

380 Answers to Exercises
2.27: If 0.999 < 1 then their average a = (1 +0.999 . . .)/2 would be a numberbetween 0.999 and 1, but there is no way to write a. It is impossible to giveit more digits than to 0.999 . . . since the latter already has an infinite number ofdigits. It is impossible to make the digits any bigger since they are already 9s. Thisis why the infinite fraction 0.999 .. . must be equal to 1.
2.28: An argument similar to the one in the previous exercise shows that there aretwo ways of writing this number. It can be written either as 0.1000.. . or 0.0111. . ..
2.29: In practice, the eof symbol has to be included in the original table of frequencies and probabilities. This symbol is the last to be encoded and the decoderstops when it detects an eof.
2.30: The encoding steps are simple (see first example on page 69). We startwith the interval [0,1) . The first symbol a2 reduces the interval to [0.4,0.9) .The second one, to [0.6,0.85), the third one to [0.7,0.825) and the eof symbol, to[0.8125,0 .8250). The approximate binary values ofthe last interval are 0.1101000000and 0.1101001100, so we select the 7-bit number 1101000 as our code.
The probability of the string "a2a2a2eof" is (0.5)3 X 0.1 = 0.0125, but since-log2 0.125 ~ 6.322 it follows that the practical minimum code size is 7 bits.
2.31: In practice, an encoder may encode texts other than English , such as aforeign language or the source code of a computer program. Even in English thereare some examples of a "q" not followed by a "u", such as in this sentence. (Theauthor has noticed that science-fiction writers tend to use non-English soundingwords, such as "Qaal," to name characters in their works.)
2.32: 2562 = 65,536, a manageable number, but 2563 = 16,777,216, perhaps toobig for a practical implementation, unless a sophisticated data structure is used, orunless the encoder gets rid of older data from time to time.
2.33: A color or gray-scale image with 4-bit pixels. Each symbol is a pixel, andthere are 16 different ones.
2.34: An object file generated by a compiler or an assembler normally has severaldistinct parts including the machine instructions, symbol table, relocation bits , andconstants. Such parts may have different bit distributions.
2.35: The alphabet has to be extended, in such a case, to include one more symbol.If the original alphabet consisted of all the possible 256 8-bit bytes, it should beextended to 9-bit symbols , and should include 257 values.
2.36: Table Ans.13 shows the groups generated in both cases and makes it clearwhy these particular probabilities were assigned .

Answers to Exercises 381
Context f 2abc-« al 1 1/20
-+ a2 1 1/20-+ a3 1 1/20-+ a4 1 1/20
Context f 2 -+ as 1 1/20abc-ex 10 10/11 -+ a6 1 1/20Esc 1 1/11 -+ a7 1 1/20
-+ as 1 1/20-+ ag 1 1/20-+ alO 1 1/20
Esc 10 10/20Total 20
Table Ans.13: Stable vs, Variable Data.
2.37: The "d" is added to the order-O contexts with frequency 1. The escapefrequency should be incremented from 5 to 6, bringing the total frequencies from19 up to 21. The probability assigned to the new "d" is therefore 1/21, and thatassigned to the escape is 6/21. All other probabilities are reduced from x/19 tox/21.
2.38: The new "d" would require switching from order-2 to order-O, sending twoescapes that take 1 and 1.32 bits. The "d" is now found in order-O with probability1/21 , so it is encoded in 4.39 bits . The total number of bits required to encode thesecond "d" is thus 1 + 1.32 + 4.39 = 6.71, still greater than 5.
2.39: The first three cases don't change. They still code a symbol with 1, 1.32, and6.57 bits, which is less than the 8 bits required for a 256-symbol alphabet withoutcompression . Case 4 is different since the "d" is now encoded with a probability of1/256, producing 8 instead of 4.8 bits. The total number of bits required to encodethe "d" in case 4 is now 1 + 1.32+ 1.93+ 8 = 12.25.
2.40: The final trie is shown in Figure Ans.14.
3.1: The size of the output stream is N[48 - 28P I = N[48 - 25.21 = 22.8N.The size of the input stream is, as before, 40N. The compression factor is thus40/22.8 ~ 1.75.
3.2: The next step matches the space and encodes the string "ue" .
sirusidlueastmanueasilyJ ::::} (4,1,"e")I sirusiduelastmanueasilYutel::::} (0,0,"a")
and the next one matches nothing and encodes the "a" .
3.3: The first two characters "CA" at positions 17-18 are a repeat of the "CA" atpositions 9-10 , so they will be encoded as a string of length 2 at offset 18 - 10 =8. The next two characters "AC" at positions 19-20 are a repeat of the string atpositions 8-9, so they will be encoded as a string of length 2 at offset 20 - 9 = 11.

382 Answers to Exercises
n,l
Ii,l
14. 'a '
Figure Ans.14: Final Trie of "assanissimassa".
3.4: The decoder interprets the first 1 of the end marker as the start of a token.The second 1 is interpreted as the prefix of a 7-bit offset. The next 7 bits are °andthey identify the end-marker as such, since a "normal" offset cannot be zero.
3.5: This is straightforward. The remaining steps are shown in Table Ans.15
Dictionary Token Dictionary Token15 "ut " (4, "t") 21 "us i" (19, "i")16 "e" (0, "e") 22 "e" (0, "c")17 "as" (8, "a") 23 "k" (0, "k")18 "es" (16, "5") 24 "use" (19,"e")19 "us" (4, "5") 25 "a1" (8, "I")20 "ea" (4, "a") 26 "s Cecf ) " (1, "(eof)")
Table Ans.15: Next 12 Encoding Steps in LZ78.
3.6: Table Ans.16 shows the last three steps.
Hashp_src 3 chars index P Output Binary output
11 "hut" 7 any-»? h 0110100012 "ut h" 5 5--+5 4,7 00001001110000011116 "ws" ws 01110111101110011
Table Ans.l6: Last Steps of Encoding "that thatch thaws".
The final compressed stream consists of 1 control word followed by 11 items (9literals and 2 copy items)000001001000000010111010010110100010110000110111010010010000010000100111000001011011000111011010001000010011100000111101110111101110011.

Answers to Exercises 383
3.7: Following the steps in the text, the output emitted by the encoder is
97 (a) , 108 (1), 102 (f) , 32 (u), 101 (e), 97 (a), 116 (t), 115 (s), 32 (u), 256 (ai),102 (f) , 265 (ali), 97 (a),
and the following new entries are added to the dictionary
(256: al.), (257: li), (258: f u), (259: ue), (260: ea) , (261: at), (262: ts),(263: su) , (264: ua) , (265: ali), (266: alia) .
3.8: The encoder inputs the first "a" into I, searches and finds "a" in the dictionary. It inputs the next "a" but finds that Ix, which is now "aa", is not in thedictionary. The encoder thus adds string "aa" to the dictionary as entry 256 andoutputs the token 97 (a). Variable I is initialized to the second "a" . The third "a"is input, so Ix is the string "aa", which is now in the dictionary. I becomes thisstring, and the fourth "a" is input. Ix is now "aaa" which is not in the dictionary.The encoder thus adds string "aaa" to the dictionary as entry 257 and outputs 256(aa). I is init ialized to the fourth "a" . Continuing this process is straightforward.
The result is that strings "aa" , "aaa" , "aaaa" ,... are added to the dictionaryas entries 256, 257, 258,.. . , and the output is
97 (a), 256 (aa), 257 (aaa), 258 (aaaa),. . .
The output consists of pointers pointing to longer and longer strings of as. The firstk pointers thus point at strings whose total length is 1 + 2 + . .. + k = (k + k2)/2.
Assuming an input stream that consists of one million as , we can find the sizeof the compressed output stream by solving the quadratic equation (k + k2)/2 =1000000 for the unknown k, The solution is k :::::J 1414. The original, 8-million bitinput is thus compressed into 1414 pointers, each at least 9-bit (and in practice,probably 16-bit) long. The compression factor is thus either 8M/(1414 x 9) :::::J 628.6or 8M/(1414 x 16) :::::J 353.6.
This is an impressive result but such input streams are rare (notice that thisparticular input can best be compressed by generating an output stream containingjust "1000000 a" , and without using LZW).
3.9: We simply follow the decoding steps described in the text. The results are :1. Input 97. This is in the dictionary so set I="a" and output "a" . String
"ax" needs to be saved in the dictionary but x is still unknown ..2. Input 108. This is in the dictionary so set J="l" and output "1". Save
"al" in entry 256. Set 1= "1".3. Input 102. This is in the dictionary so set J="f" and output "f " . Save
''If'' in entry 257. Set I="f" .4. Input 32. This is in the dictionary so set J= "u" and output "u" . Save "f u"
in entry 258. Set I="u".5. Input 101. This is in the dictionary so set J="e" and output "e". Save
"ue" in entry 259. Set 1= "e" .6. Input 97. This is in the dictionary so set J="a" and output "a". Save "ea"
in entry 260. Set 1= "a" .7. Input 116. This is in the dictionary so set J="t" and output "t". Save
"at" in entry 261. Set I="t".

384 Answers to Exercises
8. Input 115. This is in the dictionary so set J="s" and output "s". Save"t s " in entry 262. Set I="t".
9. Input 32. This is in the dictionary so set J="u" and output "u". Save "su"in entry 263. Set 1= "u" .
10. Input 256. This is in the dictionary so set J="al" and output "al" . Save"ua" in entry 264. Set 1= "al" .
11. Input 102. This is in the dictionary so set J = "f " and output "f" . Save"al f" in entry 265. Set 1= "f " .
12. Input 265. This has just been saved in the dictionary so set J="alf" andoutput "alf" . Save "f a" in dictionary entry 266. Set 1= "al f " .
13. Input 97. This is in the dictionary so set J="a" and output "a" . Save"alfa" in entry 267 (even though it will never be used). Set 1= "a" .
14. Read eof. Stop.
3.10: Assuming that the dictionary is initialized to just the two entries (1: a) and(2: b) . The encoder outputs
1 (a) , 2 (b), 3 (ab), 5(aba), 4(ba) , 7 (bab), 6 (abab) , 9 (ababa), 8 (baba), . ..
and adds the new entries (3: ab), (4: ba) , (5: aba) , (6: abab) , (7: bab), (8: baba) ,(9: ababa) , (10: ababab) , (11: babab) ,... to the dictionary. This regular behaviorcan be analyzed and the kth output pointer and dictionary entry predicted, but theeffort is probably not worth it .
3.11: The answer to exercise 3.8 shows the relation between the size of the compressed file and the size of the largest dictionary string for the "worst case" situation(input that creates the longest strings). For a IMbyte input stream, there will be1,414 strings in the dictionary, the largest of which is 1,414 symbols long.
3.12: This is straightforward (Table Ans.17) but not very efficient since only onetwo-symbol dictionary phrase is used.
Add toStep Input Output S dict . S'
swissumiss
1 s 115 s s2 w 119 w 256-sw w3 i 105 i 257-wi i4 s 115 s 258-is s5 s 115 s 259-ss s6 32 u 260-su u7 m 109 m 261-um m8 is 258 is 262-mis is9 s 115 s 263-iss s
Table Ans.lT: LZMW Compression of "swi s s miss" .

Answers to Exercises 385
Add toStep Input Output S diet. S'
yabbadabbadabbadoo
1 y 121 Y Y2 a 97 a 256-ya a3 b 98 b 257-ab b4 b 98 b 258-bb b5 a 97 a 259-ba a6 d 100 a 26Q-ad a7 ab 257 ab 261-dab ab8 ba 259 ba 262-abba ba9 dab 261 dab 263-badab dab10 ba 259 ba 264-dabba ba11 d 100 d 265-bad d12 0 111 0 266-do 013 0 111 0 267-0 0
Table Ans.18: LZMW Compression of "yabbadabbadabbadoo".
3.13: Table Ans.18 shows all the steps. In spite of the short input, the result isquite good (13 codes to compress 18-symbols) because the input contains concentrations of as and bs.
3.14: 1. The encoder starts by shifting the first two symbols "xy" to the searchbuffer, outputting them as literals and init ializing all locations of the index table tothe null pointer.
2. The current symbol is "a" (the first "a") and the context is "xy" . It ishashed to, say, 5, but location 5 of the index table contains a null pointer, so P isnull. Location 5 is set to point to the first "a" , which is then output as a literal.The data in the encoder's buffer is shifted to the left.
3. The current symbol is the second "a" and the context is "ya". It is hashedto, say, 1, but location 1 of the index table contains a null pointer, so P is null.Location 1 is set to point to the second "a", which is then output as a literal. Thedata in the encoder's buffer is shifted to the left.
4. The current symbol is the third "a" and the context is "aa" . It is hashedto , say, 2, but location 2 of the index table contains a null pointer, so P is null.Location 2 is set to point to the third "a", which is then output as a literal. Thedata in the encoder's buffer is shifted to the left.
5. The current symbol is the fourth "a" and the context is "aa". We knowfrom step 4 that it is hashed to 2, and location 2 of the index table points to thethird "a" . Location 2 is set to point to the fourth "a", and the encoder tries tomatch the string starting with the third "a" to the string starting with the fourth"a" . Assuming that the look-ahead buffer is full of as, the match length L will bethe size of that buffer. The encoded value of L will be written to the compressedstream, and the data in the buffer shifted L positions to the left.

386 Answers to Exercises
6. If the original input stream is long, more a's will be shifted into the lookahead buffer, and this step will also result in a match of length L. Ifonly n as remainin the input stream, they will be matched, and the encoded value of n output.
The compressed stream will consist of the three literals "x", "y", and "a",followed by (perhaps several values of) L, and possibly ending with a smaller value.
3.15: T percent of the compressed stream is made up of literals, some appearingconsecutively (and thus getting the flag "I" for two literals, half a bit per literal)and others with a match length following them (and thus getting the flag "01", onebit for the literal). We assume that two thirds of the literals appear consecutivelyand one third are followed by match lengths. The total number of flag bits createdfor literals is thus
A similar argument for the match lengths yields
2 1- (1 - T) x 2 + - (1 - T) x 13 3
for the total number of the flag bits. We now write the equation
which is solved to yield T = 2/3. This means that if two thirds of the items in the"compressed stream are literals, there would be 1 flag bit per item on the average.More literals would result in fewer flag bits.
3.16: The first three ones indicate six literals. The following 01 indicates a literal(b) followed by a match length (of 3). The 10 is the code of match length 3, andthe last 1 indicates two more literals ("x" and "y").
4.1: Substituting f = 0 in Equation (4.1), we get the simple expression
1 7 ((2t+l)01r) 1 1 7Go = 20 0LPt cos 16 = 2J2 Lpt
t=o t=O
= Js(ll + 22 + 33 + 44 + 55 + 66 + 77+ 88) ~ 140.
The reason for the name "DC coefficient" is that Go does not contain any sinusoidals. It simply equals some multiple of the eight pixels (rather, some multiple oftheir average) .

Answers to Exercises
4.2: The explicit expression is
387
1 7 ((2t + 1)57r)Gs = "2 CS£;Pt cos 16
1 ( (57r) (3 X 57r) (5 X 57r) (7 X 57r)="2 11cos 16 + 22cos 16 + 33cos 16 +44cos 16 +
(9 X 57r ) (l1X57r) (13X57r) (15X57r))55cos 16 + 66 cos 16 + 77cos 16 + 88 cos 16
=-2,
from which it is clear that this coefficient represents the contributions of the sinusoidals with frequencies 5t7r/16 (multiples of 57r/16). The fact that it equals -2means that these sinusoidals do not contribute much to our eight pixels.
4.3: When the following Mathematica™ code is applied to Table 4.11b it createsa data unit with 64 pixels, all having the value 140, which is the average value ofthe pixels in the original data unit 4.8.
Cr[i_]:=If[i==O, 1/Sqrt[2] , 1];IDCT[x_,y_]:={(1/4)Sum[Cr[i]Cr[j]G[[i+l,j+l]]Quant[[i+l,j+l]]*Cos[(2x+l)i Pi/16]Cos[(2y+l)j Pi/16], {i ,O,7,l}, {j,O,7,l}]};
4.4: Selecting R = 1 has produced the quantization coefficients of Table Ans.19aand the quantized data unit of Table Ans.19b. This table has 18 nonzero coefficientswhich, when used to reconstruct the original data unit, produce Table Ans.20, onlya small improvement over Table 4.9.
4.5: The zig-zag sequence is 1118,2,0, -2,0, . .. , 0, -1,0, ... (there are only four"--v--"
12nonzero coefficients).
4.6: Perhaps the simplest way is to manually figure out the zig-zag path andto record it in an array zz of structures, where each structure contains a pair ofcoordinates for the path as shown, e.g., in Figure Ans.21.
If the two components of a structure are zz. rand zz. c, then the zig-zagtraversal can be done by a loop of the form :
for (i=O; i<64; i++){row:=zz[i] .r; col :=zz[i].c... data_unit [row] [col] ... }
4.1: It is located in row 3 column 5, so it is encoded as 11101101.

388 Answers to Exercises
1 2 3 4 5 6 7 8 1118. 3 2 -1 1 0 0 02 3 4 5 6 7 8 9 -1 o 1 1 1 0 0 03 4 5 6 7 8 9 10 -3 -2 0 -2 0 0 0 04 5 6 7 8 9 1011 -1 -2 0 000005 6 7 8 9 10 11 12 0 o 0 1 0 0 0 06 7 8 9 10 11 12 13 0 o 0 o 0 0007 8 9 10 11 12 13 14 0 o 0 -1 1 0 0 08 9 10 11 12 13 14 15 0 o 0 1 0 0 0 0
(a) (b)
Table Ans.19: (a): The Quantization table 1 + (i + j) x 1. (b): QuantizedCoefficients Produced by (a).
139 139 138 139 139 138 139 140140 140 140 139 139 139 139 140142 141 140 140 140 139 139 140142 141 140 140 140 140 139 139142 141 140 140 140 140 140 139140 140 140 140 139 139 139 141140 140 140 140 139 139 140 140139 140 141 140 139 138 139 140
Table Ans.20: Restored data unit of Table 4.8.
(0,0) (0,1) (1,0) (2,0) (1,1) (0,2) (0,3) (1,2)(2,1) (3,0) (4,0) (3,1) (2,2) (1,3) (0,4) (0,5)(1,4) (2,3) (3,2) (4,1) (5,0) (6,0) (5,1) (4,2)(3,3) (2,4) (1,5) (0,6) (0,7) (1,6) (2,5) (3,4)(4,3) (5,2) (6,1) (7,0) (7,1) (6,2) (5,3) (4,4)(3,5) (2,6) (1,7) (2,7) (3,6) (4,5) (5,4) (6,3)(7,2) (7,3) (6,4) (5,5) (4,6) (3,7) (4,7) (5,6)(6,5) (7,4) (7,5) (6,6) (5,7) (6,7) (7,6) (7,7)
Figure Ans.21: Coordinates for the Zig-Zag Path.
4.8: Twelve consecutive zeros precede this coefficient, so Z = 12. The coefficientitself is found in Table 4.13 in row 1, column 0, so R = 1 and C = O. Assumingthat the Huffman code in position (R, Z) = (1,12) of Table 4.14 is 1110101, thefinal code emitted for 1 is 11101011.
4.9: This is shown by adding the largest four n-bit numbers, 11 .. . 1. Adding two'-v---'
nsuch numbers produces the n+ l -bit number 11 . .. 10. Adding two of these n+ l-bit
'-v---'n
numbers produces 11 . . . 100, an n + 2-bit number.'-v---'
n

Answers to Exercises 389
4.10: Table Ans.22 summarizes the results. Notice how a J-pixel with a contextof 00 is assigned high probability after being seen 3 times.
# Pixel Context Counts Probability New counts
5 0 10=2 1,1 1/2 2,16 1 00=0 1,3 3/4 1,47 0 11=3 1,1 1/2 2,18 1 10=2 2,1 1/3 2,2
Table Ans.22: Counts and Probabilities for Next four Pixels.
4.11: Such a thing is possible for the encoder but not for the decoder. A compression method using "fut ure" pixels in the context is useless because its outputwould be impossible to decompress.
4.12: The two previously seen neighbors of P=8 are A=1 and B=I1. P is thusin the central region, where all codes start with a zero, and L=I, H=I1. Thecomputations are straightforward:
k = Llog2(11 - 1 + I)J = 3; a = 23+1 - 11 = 5;
Table Ans.23 lists the five 3-bit codes and six 4-bit codes for the central region .The code for 8 is thus 01111.
The two previously seen neighbors of P=7 are A=2 and B=5. P is thus in theright outer region , where all codes start with 11, and L=2, H=7. We are lookingfor the code of 7 - 5 = 2. Choosing m = 1 yields, from Table 4.25, the code 11101.
The two previously seen neighbors of P=O are A=3 and B=5. P is thus in theleft outer region, where all codes start with 10, and L=3, H=5. We are looking forthe code of 3 - 0 = 3. Choosing m = 1 yields, from Table 4.25, the code 101100.
PixelP
123456789
1011
Regioncodeooooooooooo
Pixelcode000000100100011100101110111000100110101
Table Ans.23: The Codes for a Central Region.

390 Answers to Exercises
4.13: The first term can be written
n2 n2
4 - -- - --=-:-~- 2 -2n2 - 22 log n-2 .
Terms in the sequence thus contain powers of 2 that go from 0 to 210g2 n - 2,showing that there are 210g2 n - 1 terms.
4.14: Because the decoder has to resolve ties in the same way as the encoder.
4.15: Because this will result in a weighted sum whose value is in the same rangeas the values of the pixels. If pixel values are, e.g., in the range [0,15] and theweights add up to 2, a prediction may result in values of up to 31.
4.16: Each of the three weights 0.0039, -0.0351, and 0.3164 are used twice. Thesum of the weights is thus 0.5704 and the result of dividing each weight by this sumis 0.0068, -0.0615, and 0.5547. It is easy to verify that the sum of the renormalizedweights 2(0.0068 - 0.0615 + 0.5547) equals 1.
4.17: Using Mathematica™ it is easy to obtain this integral separately for negative and non-negative values of x.
{
- IVexp(~x) ,JL(V,x)dx = _1 ( 5. )V2V exP VV X ,
x ~ OJ
x < O.
4.18: An archive of static images. NASA has a large archive of images taken byvarious satellites. They should be kept highly compressed, but they never change soeach image has to be compressed only once. A slow encoder is therefore acceptablebut a fast decoder is certainly handy. Another example is an art collection. Manymuseums have digitized their collection of paintings, and those are also static.
4.19: The decoder knows this pixel since it knows the value of average p[i -1, j] =0.5(I[2i - 2, 2j] + I[2i -1, 2j +1]) and since it has already decoded pixel I[2i - 2, 2j]
4.20: When the decoder inputs the 5, it knows that the difference between p (thepixel being decoded) and the reference pixel starts at position 6 (counting fromleft) . Since bit 6 of the reference pixel is 0, that of p must be 1.
4.21: Yes, but compression would suffer. One way to apply this method is toseparate each byte into two 4-bit pixels and encode each pixel separately. Thisapproach is bad since the prefix and suffix of a 4-bit pixel may many times requiremore than 4 bits. Another approach is to ignore the fact that a byte contains twopixels, and use the method as originally described. This may still compress theimage, but is not very efficient, as the following example illustrates.
Example: The two bytes 110011101 and 111011111 represent four pixels, eachdiffering from its two immediate neighbors by its least significant bit. The fourpixels thus have similar colors (or grayscales). Comparing consecutive pixels resultsin prefixes of 3 or 2, but comparing the 2 bytes produces the prefix 2.

Answers to Exercises 391
4.22: Using a Hilbert curve produces the 21 runs 5, 1, 2, 1, 2, 7, 3, 1, 2, 1, 5, 1,2, 2, 11, 7, 2, 1, 1, 1, 6. RLE produces the 27 runs 0, 1, 7, eol, 2, 1, 5, eol, 5, 1, 2,eol, 0, 3, 2, 3, eol, 0, 3, 2, 3, eol, 0, 3, 2, 3, eol, 4, 1, 3, eol, 3, 1, 4, eol.
4.23: The string 2011.
4.24: The four-state WFA is shown in Figure Ans.24. The 14 arcs constructedare 0(0)1, 0(1)1, 0(2)1, 0(3) 1, 1(0)2, 1(1)2, 1(2)2, 1(3)2, 2(1)3, 2(2)3, 3(0)3, 3(1)3,3(2)3 and 3(3)3.
®
0,1,2,3 j
CD
0,1,2,3 j
CD
1, 2 j
Figure Ans.24: The WFA of an 8 x 8 Chessboard .

392 Answers to Exercises
4.25: Figure Ans.25 shows the six states and all 21 arcs. The WFA is morecomplex than pervious ones since this image is less self-similar.
4.26: This is a direct application of Equation (4.13).
f(OO) = IWo WoF
= (1,0) (1~2 ~) (1~2 ~) (1{2)
= (1,0) (1~4 ~) (1{2)
= (1/4,0) (1{2) = 1/8.
f(Ol) = IWOW1F
= (1,0) (1~2 ~) (1~2 1{4) (1{2)
= (1,0) (1~4 1{8) (1{2)
= (1/4,1/8) ( 1{2) = 1/8 + 1/8 = 2/8.
f(02) = f(Ol).
4.27: This is again a direct application of Equation (4.13).
f(OO . .. O) = IWoWo· .. WoF-......-.-n
= (1,0) (1~2 ~) (1~2 ~) ... (1{2)
= (1,0) C1/g )n ~) (1{2) = ((1/2) n,0) (1{2)
= (1/2) n+l -+ O.
f(33 . . . 3) = IW3W3 ••• WoF-......-.-n
= (1,0) (1~2 1{2) (1~2 1{2) . .. (1{2)
= (1,0) ( (1/02)n
(1/2)n + (1/2r-1 + ...+ 1) (1{2)
= ((1/2t , (1/2t + (1/2)n-l + ...+ 1) (1{2)
= (1/2t+l + (1/2)n + (1/2t-1 + ... + 1 -+ 1.

Answers to Exercises 393
I (2,0)-,
•
(a)
L (3,0) J
(0,2)
(2,1)
III
(0,0) (3,2). II _
•
Start state
IIIII------.-----IIIII
® '------
(3,3t ~liiiIiii[iiiiliiiiiiiiiiil(1,2) (2,3)
I CDI
1 I 3 •II (1,0) (2,2)I------.----- ...
°I
2I •I ®I
L (0,0) ~(2,0) -
I (0,0), (3,3)
IIIIII------.------IIII
(b)
0(0,0)1 0(1,0)2 0(2,2)2 0(3,2)1 1(0,0)3 1(1,0)5 1(2,5)51(3,0)6 2(0,0)4 2(2,0)2 2(3,3)4 3(3,0)3 4(0,0)4 4(2,0)45(1,2)4 5(2,1)3 5(3,2)4 6(0,2)3 6(1,2)4 6(2,3)4 6(3,3)2
Figure Ans.25: A WFA for Exercise 4.25.

394 Answers to Exercises
4.28: Using Equation (4.14) we get
(1/ 2
'I/1i(OO) = (WOWOF)i = 0
so '1/10(00) = 1/8. Also
(1/ 2
'I/1i(Ol) = (WoW1F)i = 0
so '1/10(01) = 1/4.
4.29: The transformation can be written (x,y) -+ (x, -x+y), so (1,0) -+ (1, -1),(3,0) -+ (3, - 3), (1,1) -+ (1,0) and (3,1) -+ (3, -2) . The original rectangle is thustransformed into a parallelogram.
4.30: The two sets of transformations produce the same Sierpinski triangle but atdifferent sizes and orientations.
4.31: All three transformations shrink an image to half its original size. In addition, W2 and W3 place two copies of the shrunken image at relative displacements of(0,1/2) and (1/2,0) , as shown in Figure Ans.26. The result is the familiar Sierpinskigasket but in a different orientation.
After 1ftiteration
Original
w2
wI
w3
Figure Ans.26: Another Sierpinski Gasket.

Answers to Exercises 395
4.32: There are 32 x 32 = 1,024 ranges and (256 - 15) x (256 - 15) = 58,081domains. The total number of steps is thus 1,024 x 58,081 x 8 = 475,799,552, stilla large number. PIFS is thus computationally intensive.
4.33: Suppose that the image has G levels of gray. A good measure of dataloss is the difference between the value of an average decompressed pixel and itscorrect value, expressed in number of gray levels. For large values of G (hundredsof gray levels) an average difference of 10g2 G gray levels (or fewer) is consideredsatisfactory.
5.1: Because the original string S can be reconstructed from L but not from F.
5.2: A direct application of equation (5.1) eight more times produces:
8 [10-1-2]=L[T2[I]]=L[T[T1 [I]]]=L[T[7]]=L[6]=i;8 [10-1-3] =L[T3 [I]] =L[T[T2[I]]] =L[T[6]] =L[2] =m;8[10-1-4]=L[T4[I]]=L[T[T3[I]]]=L[T[2]]=L[3]=u;
8 [10-1-5] =L[T5 [I]] =L[T[r4[I]]] =L[T[3]] =L[0] =s;8 [10-1-6] =L[T6 [I]] =L[T[T5 [I]]] =L[T [0]] =L[4] =s;8[10-1-7]=L[T7[I]]=L[T[T6[I]]]=L[T[4]]=L[5]=i;
8 [10-1-8] =L[rB [I]] =L[T[T7 [I]]] =L[T[5]] =L[1] =w;8'[10-1-9] =L[T9 [I]] =L[T[T8 [I]]] =L[T [1]] =L[9] =s;
The original string "swissumiss" is indeed reproduced in S from right to left.
5.3: Figure Ans.27 shows the rotations of S and the sorted matrix. The lastcolumn, L of Ans.27b happens to be identical to S, so S=L="sssssssssh". SinceA=(s,h), a move-to-front compression of L yields C=(l ,O ,O,O,O,O,O,O,O,I). Since Ccontains just the two values °and 1, they can serve as their own Huffman codes,so the final result is 1000000001, 1 bit per character!
ssssssssshsssssssshsssssssshsssssssshsssssssshsssssssshsssssssshsssssssshsssssssshsssssssshsssssssss
(a)
hsssssssssshsssssssssshsssssssssshsssssssssshsssssssssshsssssssssshsssssssssshsssssssssshssssssssssh
(b)
Figure Ans.27: Permutations of "sssssssssh" .

396 Answers to Exercises
5.4: The encoder starts at T[O], which contains 5. The first element of L is thusthe last symbol of permutation 5. This permutation starts at position 5 of S, so itslast element is in position 4. The encoder thus has to go through symbols S[T[i-lllfor i = 0, ... , n - 1, where the notation i-I should be interpreted cyclically (i.e.,0- 1 should be n - 1). As each symbol S[T[i-lll is found, it is compressed usingmove-to-front . The value of I is the position where T contains O. In our example,T[8]=0, so 1=8.
5.5: The first element of a triplet is the distance between two dictionary entries,the one best matching the content and the one best matching the context. In thiscase there is no content match, no distance, so any number could serve as the firstelement, 0 being the best (smallest) choice.
5.6: Because the three lines are sorted in ascending order. The bottom two linesof Table 5.13c are not in sorted order. This is why the "zz ... z" part of string Smust be preceded and followed by complementary bits.
5.7: The encoder places S between two entries of the sorted associative list andwrites the (encoded) index of the entry above or below S on the compressed stream.The fewer the number of entries, the smaller this index, and the better the compression.
5.8: All n1 bits of string £1 need be written on the output stream. This alreadyshows that there is going to be no compression . String £2 consists of n1Ik 1's, so allof it has to be written on the output stream. String L3 similarly consists of ndk2
1's, and so on. The size of the output stream is thus
for some value of m. The limit of this expression, when m -+ 00 , is n1kl(k - 1).For k = 2 this equals 2n1. For larger values of k this limit is always between n1and 2n1 '
For the curious reader , here is how the sum above is calculated. Given theseries
we multiply both sides by 11k
and subtract

Answers to Exercises 397
5.9: The input stream consists of:1. A run of three zero groups , coded as 1011 since 3 is in second position in
class 2.2. The nonzero group 0100, coded as 111100.3. Another run of three zero groups, again coded as 1011.4. The nonzero group 1000, coded as 01100.5. A run of four zero groups , coded as 01010 since 4 is in first position in class
3.6. 0010, coded as 111110.7. A run of two zero groups, coded as 1010.The output stream is thus the 30-bit string 101111100101011000100111110100.
5.10: The input stream consists of:1. A run of three zero groups , coded as R2Rl or 101111.2. The nonzero group 0100, coded as 00100.3. Another run of three zero groups, again coded as 101111.4. The nonzero group 1000, coded as 01000.5. A run of four zero groups, coded as R4 = 1001.6. 0010, coded as 00010.7. A run of two zero groups , coded as R2 = 101.The output stream is thus the 32-bit string
10111001001011101000100100010101.
5.11: The input stream consists of:1. A run of three zero groups, coded as F3 or 1001.2. The nonzero group 0100, coded as 00100.3. Another run of three zero groups, again coded as 1001.4. The nonzero group 1000, coded as 01000.5. A run of four zero groups, coded as F3F1 = 1001111.6. 0010, coded as 00010.7. A run of two zero groups, coded as F2 = 101.The output stream is thus the 32-bit string
10010010010010100010011100010101.
5.12: The LZW method, which starts with the entire alphabet stored at thebeginning of its dictionary. However, an adaptive version of LZW can be designedto compress words instead of individual characters.
5.13: Relative values (or offsets). Each (x, y) pair may specify the position ofa character relative to its predecessor. This results in smaller numbers for thecoordinates, and smaller numbers are easier to compress.
5.14: There may be such letters in other, "exotic" alphabets, but a more commonexample is a rectangular box enclosing text . The four rules comprising such a boxshould be considered a mark, but the text characters inside the box should beidentified as separate marks.
398 Answers to Exercises
5.15: Because this guarantees that the two probabilities will add up to 1.
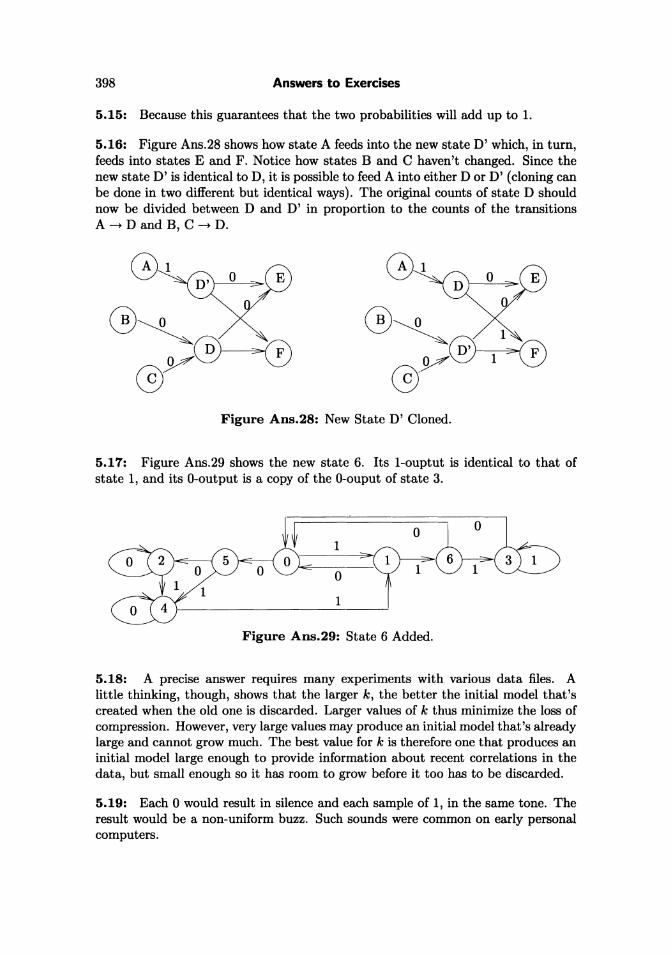
5.16: Figure Ans.28 shows how state A feeds into the new state D' which, in turn,feeds into states E and F. Notice how states Band C haven't changed. Since thenew state D' is identical to D, it is possible to feed A into either D or D' (cloning canbe done in two different but identical ways). The original counts of state D shouldnow be divided between D and D' in proportion to the counts of the transitionsA -+ D and B, C -+ D.
Q
0~ 1~
V~ 1 ~\!)
(~)
Figure Ans.28: New State D' Cloned.
5.17: Figure Ans.29 shows the new state 6. Its l-ouptut is identical to that ofstate 1, and its O-output is a copy of the O-ouput of state 3.
1
o1
Figure Ans.29: State 6 Added.
5.18: A precise answer requires many experiments with various data files. Alittle thinking, though, shows that the larger k, the better the initial model that'screated when the old one is discarded. Larger values of k thus minimize the loss ofcompression. However, very large values may produce an initial model that's alreadylarge and cannot grow much. The best value for k is therefore one that produces aninitial model large enough to provide information about recent correlations in thedata, but small enough so it has room to grow before it too has to be discarded.
5.19: Each 0 would result in silence and each sample of 1, in the same tone. Theresult would be a non-uniform buzz. Such sounds were common on early personalcomputers.

Answers to Exercises
A.l: It is a combination of "4x and "9, or "49.
399
C.l: The key is to realize that Po is a single point, and PI is constructed byconnecting nine copies of Po with straight segments . Similarly, P2 consists of ninecopies of Pll in different orientations, connected by segments (the bold segments inFigure Ans.30).
•Po
(a) (b) (c)
Figure Ans.30: The First Three Iterations of the Peano Curve.
C.2: Written in binary, the coordinates are (1101,0110). We repeat four times,each time taking 1 bit from the x coordinate and 1 bit from the y coordinateto form an (x, y) pair. The pairs are 10, 11, 01, 10. The first one yields [fromTable C.12(1)] 01. The second pair yields [also from Table C.12(1)] 10. The thirdpair [from Table C.12(1)] 11, and the last pair [from Table C.12(4)] 01. The resultis thus 01110111101 = 109.
C.3: Table C.2 shows that this traversal is based on the sequence 2114.
C.4: This is straightforward
(00,01,11 ,10) - (000,001,011,010)(100,101,111 ,110)
- (000,001,011,010)(110,111 ,101 ,100)
- (000,001,011,010,110,111,101 ,100) .
C.5: The axiom and the production rules stay the same . Only the initial headingand the turn angle change. The initial heading can be either 0 or 900
, and the turnangle either 900 or 2700
•
D.l: This is straightforward
(810 12) (-6A +B = 8 10 12 ; A - B = 0
8 10 12 6~6 ~6) jA x B = (~~6 6 90
2469114
30 )84 .138

400 Answers to Exercises
D .2: Equation (0.2) gives
T-1
= 1· 1 ~ 1 . 1 ( . .. ),
which is undefined. Matrix T is thus singular; it does not have an inverse! Thisbecomes easy to understand when we think of T as the coefficients matrix of thesystem of equations (0.1) above. This is a system of three equations in the threeunknowns x, y , and z, but its first two equations are contradictory. The first onesays that x - y equals 1, while the second one says that the same x - y equals -2.Mathematically, such a system has a singular coefficients matrix.
E.l: A direct check shows that when only a single bit is changed in any of thecodewords of codes , the result is not any of the other codewords.
E.2: A direct check shows that code, has a Hamming distance of 4, which is morethan enough to detect all 2-bit errors.
E .3: b2 is the parity of b3, b6 , b7 , blO, and bu. b4 is the parity of bs , b6 , and b7 •
b8 is the parity of bg , blO , and bu .
E.4: Table Ans.31 summarizes the definitions of the five parity bits required forthis case.
x
x x
xx x
x x x x x
x xxx x
x x x xx x x xx x x
x x x x xx x x x x
x x x
Parity Data bits _
bits 3 5 6 7 9 10 11 12 13 14 15 17 18 19 20 21
124816
Table Ans.31: Hamming Code for m = 16.
E.5: It is a variable-size code (Chapter 2). It's easy to see that it satisfies theprefix property.
H.l: Each of the 8 characters of a name can be one of the 26 letters or the tendigits, so the total number of names is 368 = 2,821,109,907,456; close to 3 trillion.
1.1: Such a polynomial depends on three coefficients A, B , and C that can beconsidered three-dimensional points, and any three points are on the same plane.
1.2:P(2/3) =(0, -9)(2/3)3 + (-4.5,13.5)(2/3)2 + (4.5, - 3.5)(2/ 3)
=(0, -8/3) + (-2,6) + (3, -7/3)
=(1,1) = P 3

Answers to Exercises 401
1.3: We use the relations sin 30° = cos 60° = .5 and the approximation cos 30° =sin 60° ~ .866. The four points are P 1 = (1,0), P 2 = (cos30°,sin300) = (.866,.5) ,P 3 = (.5, .866), and P 4 = (0,1). The relation A = N· P becomes
(8) (-4.5 13.5 -13.5 4,5) ( (1,0) )b = A = N. P = 9.0 -22.5 18 -4.5 (.866, .5)c -5.5 9.0 -4.5 1.0 (.5, .866)d 1.0 0 0 0 (0,1)
and the solutions are
8 = -4.5(1,0) + 13.5(.866, .5) - 13.5(.5, .866) + 4.5(0, 1) = (.441, -.441),
b = 19(1,0) - 22.5(.866, .5) + 18(.5, .866) - 4.5(0, 1) = (-1.485, -0.162),
c = -5.5(1,0) + 9(.866, .5) - 4.5(.5, .866) + 1(0,1) = (0.044,1.603),
d = 1(1,0) - 0(.866, .5) + 0(.5, .866) - 0(0, 1) = (1,0) .
The PC is thus P(t) = (.441, -.441)t3 + (-1.485, -0.162)t2 + (0.044, 1.603)t+ (1, 0).The midpoint is P(.5) = (.7058, .7058), only 0.2% away from the midpoint of theare, which is at (cos 45°, sin 45°) ~ (.7071, .7071).
1.4: The new equations are easy enough to set up. Using Mathematica™, theyare also easy to solve. The following code
Solve [{d==pl ,a al-3+b al-2+c al+d==p2,a be-3+b be-2+c be+d==p3,a+b+c+d==p4},{a,b,c,d}] ;ExpandAll[Simplify[%]]
(where al and be stand for a and (3, respectively) produces the (messy) solutions
P1 P 2 P 3 P 48 = - - + + + -,---------=::----=
a(3 - a 2 + a 3 + a(3 - a 2(3 a(3 - (32 - a(32 + (33 1 - a - (3+ a(3
b = P 1 (-a + a 3 + (3- a 3(3 - (33 + a(33) h + P 2 (-(3 + (33) h+ P 3 (a - ( 3) h + P 4 (a3(3 - a(33) h
c = -P1 (1 + ! +!) + (3P2
a (3 -a2 + a 3 + a(3 - a 2(3
aP3 a(3P 4+ a(3 - (32 - a(32 + (33 + 1 - a - (3+ a(3
d=P1 .
where 'Y = (-1 + a)a(-1 + (3)(3(-a + (3) .
From here, the basis matrix immediately follows
a2+a3al1 a211
- {3+113
'Y
{3
al1- 112 a112+113a-a3
'Y
al1-112-aI12+113
o1-a-l1+al1
o

402 Answers to Exercises
A direct check, again using Mathematica, for 0: = 1/3 and /3 = 2/3, produces matrixN of Equation (1.4).
1.5: The missing points will have to be estimated by interpolation or extrapolation from the known points before our method can be applied. Obviously, thefewer points are known, the worse the final interpolation. Note that 16 points arenecessary since a bicubic polynomial has 16 coefficients.
Kneading is difficult to describe in words, butmany cookbooks have pictures. The idea is to
exercise the dough and work some more flour into it.
Harry S. Delugach

Glossary
ACB
A new, very efficient text compression method by G. Buyanovsky (Section 5.3). Ituses a dictionary with unbounded contexts and contents to select the context thatbest matches the search buffer and the content that best matches the look-aheadbuffer.
Adaptive Compression
A compression method that modifies its operations and/or its parameters according to the new data read from the input stream. Examples are the adaptiveHuffman method of Section 2.9 and the dictionary-based methods of Chapter 3.(See also Semi-adaptive compression and Locally adaptive compression.)
Affine Transformations
Two-dimensional or three-dimensional geometric transformations, such as scaling, reflection, rotation, and translation, that preserve parallel lines (Section 4.15.1).
Alphabet
The set of all possible symbols in the input stream. In text compression thealphabet is normally the set of 128 ASCII codes. In image compression it is the setof values a pixel can take (2, 16, 256, or anything else). (See also Symbol.)
Archive
A set of one or more files combined into one file (Section 3.19). The individualmembers of an archive may be compressed. An archive provides a convenient wayof transferring or storing groups of related files. (See also ARC, ARJ.)
ARC
A compression/archival/cataloging program written by Robert A. Freed in themid 1980s (Section 3.19). It offers good compression and the ability to combineseveral files into an archive. (See also Archive, ARJ.)

404 Glossary
Arithmetic Coding
A statistical compression method (Section 2.14) that assigns one (normallylong) code to the entire input stream, instead of assigning codes to the individualsymbols . The method reads the input stream symbol by symbol and appends morebits to the code each time a symbol is input and processed. Arithmetic coding isslow but it compresses at or close to the entropy, even when the symbol probabilitiesare skewed. (See also Model of compression, Statistical methods.)
ARJ
A free compression/archiving utility for MS/DOS (Section 3.20), written byRobert K. Jung to compete with ARC and the various PK utilities. (See alsoArchive, ARC.)
ASCII Code
The standard character code on all modern computers. ASCII stands for American Standard Code for Information Interchange. It is a 1 + 7-bit code, meaning1 parity bit and 7 data bits per symbol. As a result, 128 symbols can be coded(Appendix A). They include the upper- and lower-case letters, the ten digits, somepunctuation marks, and control characters.
BinHex
A file format for safe file transfers, designed by Yves Lempereur for use on theMacintosh computer (Section 1.4.2).
Bits/char
Bits per character. A measure of the performance in text compression. Also ameasure of entropy.
Bits/symbol
Bits per symbol. A general measure of compression performance.
Block Coding
A general term for image compression methods that work by breaking the imageinto small blocks of pixels, and encoding each block separately. JPEG (Chapter 4)is a good example , since it processes blocks of 8 x 8 pixels.
Burrows-Wheeler Method
This method (Section 5.1) prepares a string of data for later compression. Thecompression itself is done using move-to-front method (Section 1.5), perhaps incombination with RLE. The BW method converts a string S to another string Lthat satisfies two conditions:
1. Any region of L will tend to have a concentration of just a few symbols.2. It is possible to reconstruct the original string S from L (a little more data
may be needed for the reconstruction, in addition to L, but not much) .

CALIC
Glossary 405
A context-based, lossless image compression method (Section 4.10) whose twomain features are (1) the use of three passes in order to achieve symmetric contextsand (2) context quantization, to significantly reduce the number of possible contextswithout degrading compression performance.
CCITT
The International Telegraph and Telephone Consultative Committee (ComiteConsultatif International de telegraphie et Telephonie). The old name of the ITU,the International Telecommunications Union. A United Nations organization responsible for developing and recommending standards for data communications(not just compression) . (See also ITU.)
CIE
CIE is an abbreviation for Commission Internationale de l'Eclairage (The International Committee on Illumination). This is the main international organizationdevoted to light and color. It is responsible for developing standards and definitionsin this area. (See Luminance.)
Circular Queue
A basic data structure (Section 3.2.1) that moves data along an array in circularfashion, updating two pointers to point to the start and end of the data in the array.
Codes
A code is a symbol that stands for another symbol. In computer and telecommunications applications, codes are virtually always binary numbers. The ASCIIcode is the de-facto standard, but the older EBCDIC is still used on some old IBMcomputers. (See also ASCI!.)
Compress
In the large UNIX world, compress is used virtually exclusively to compressdata. This utility uses LZW with a growing dictionary. It starts with a smalldictionary of just 512 entries and doubles its size each time it fills up, until itreaches 64K bytes (Section 3.15).
Compression Factor
The inverse of compression ratio. It is defined as
C. t: size of the input stream
ompresslOn factor = . .size of the output stream
Values> 1 mean compression and values < 1, expansion. (See also Compressionratio.)

406 Glossary
Compression Gain
This measure is defined by
10010 reference si~e .ge compressed SIze
Where the reference size is either the size of the input stream or the size of thecompressed stream produced by some standard lossless compression method.
Compression Ratio
One of several quantities that are commonly used to express the efficiency of acompression method. It is the ratio
C. . size of the output stream
ompression ratio = . f h . .Size 0 t e mput stream
A value of 0.6 means that the data occupies 60% of its original size after compression. Values> 1 mean an output stream bigger than the input stream (negativecompression) .
Sometimes the quantity 100 x (1 - compression ratio) is used to express thequality of compression . A value of 60 means that the output stream occupies 40%of its original size (or that the compression has resulted in a savings of 60%). (Seealso Compression factor.)
Context
The N symbols preceding the next symbol. A context-based model uses contextto assign probabilities to symbols.
CRC
CRC stands for Cyclical Redundancy Check (or Cyclical Redundancy Code). Itis a rule that shows how to obtain vertical check bits from all the bits of a datastream (Section 3.22). The idea is to generate a code that depends on all the bits ofthe data stream, and use it to detect errors (bad bits) when the data is transmitted(or when it is strored and then retrieved) .
Decoder
A decompression program (or algorithm).
Dictionary-Based Compression
Compression methods (Chapter 3) that save pieces of the data in a "dictionary"data structure (normally a tree). If a string of new data is identical to a piece alreadysaved in the dictionary, a pointer to that piece is output to the compressed stream.(See also LZ methods.)
Differential Image Compression
A lossless image compression method where each pixel p is compared to areference pixel, which is one of its immediate neighbors, and is then encoded in twoparts-a prefix, which is the number of most significant bits of p that are identicalto those of the reference pixel-and a suffix, which is (almost all) the remainingleast significant bits of p.

Digram
A pair of consecutive symbols.
Discrete Cosine Transform•
Glossary 407
A variant of the discrete Fourier transform (DFT) that produces just real numbers . The DCT (Section 4.2.2) transforms a set of data points from their normalspatial representation (as points in two or three dimensions) to their frequency domain. The DCT and its inverse, the mCT, are used in JPEG (Section 4.2) toreduce the image size without distorting it much, by deleting the high-frequencyparts of an image. (See also Fourier transform.)
Encoder
A compression program (or algorithm).
Entropy
The entropy of a single symbol ai is defined (in Section 2.1) as <P; log2I{where I{ is the probability of occurrence of ai in the data. The entropy of ai isthe smallest number of bits needed, on the average, to represent symbol ai. ClaudeShannon, the creator of information theory, coined the term entropy in 1948 sincethis term is used in thermodynamics to indicate the amount of disorder in a physicalsystem. (See also Information theory.)
Error-Correcting Codes
The opposite of data compression, these codes (Appendix E) detect and correcterrors in digital data by increasing the redundancy of the data. They use check bitsor parity bits , and are sometimes designed with the help of generating polynomials.
EXE Compressor
A compression program for compressing EXE files on the PC. Such a compressed file can be decompressed and executed with one command. The originalEXE compressor is LZEXE , by Fabrice Bellard (Section 3.21).
Facsimile Compression
Transferring a typical page between two fax machines can take up to 10-11minutes without compression, This is why the ITU has developed several standardsfor compression of facsimile data. The current standards (Section 2.13) are T4(Group 3) and T6 (Group 4).
FELICS
A Fast, Efficient, Lossless Image Compression method designed for grayscaleimages that competes with the lossless mode of JPEG. The principle is to codeeach pixel with a variable-size code based on the values of two of its previously seenneighbor pixels. Both the unary code and the Golomb code are used. There is alsoa progressive version of FELICS (Section 4.7). (See also Progressive FELICS.)

408
Fourier Transform
Glossary
A mathematical transformation that produces the frequency components of afunction (Appendix F). The Fourier transform shows how a periodic function can bewritten as the sum of sines and cosines, thereby showing explicitly the frequencies"hidden" in the original representation of the function. (See also Discrete cosinetransform.)
GIF
The name stands for Graphics Interchange Format. This format (Section 3.16)was developed by Compuserve Information Services in 1987 as an efficient, compressed graphics file format that allows for images to be sent between differentcomputers. The original version of GIF is known as GIF 87a. The current standardis GIF 89a.
Golomb Code
A way to generate a variable-size code for integers n (Section 2.4). It dependson the choice of a parameter b and is created in two steps.
1. Compute the two quantities
In -IJq= -- ;b
r = n - qb-l ;
2. Construct the Golomb code of n in two parts; the first is the value of q + 1,coded in unary (exercise 2.5), and the second, the binary value of r coded in eitherLlog2 bJ bits (for the small remainders) or in flOg2 bl bits (for the large ones) . (Seealso Unary code.)
GZip
A popular program that implements the so-called "deflation" algorithm (Section 3.18) that uses a variation of LZ77 combined with static Huffman coding. Ituses a 32Kbyte-Iong sliding dictionary, and a look-ahead buffer of 258 bytes. Whena string is not found in the dictionary it is emitted as a sequence of literal bytes.(See also Zip.)
Hamming codes
A type of error-correcting code for l-bit errors, where it is easy to generate therequired parity bits.
Huffman Coding
A commonly used method for data compression (Section 2.8). It assigns aset of "best" variable-size codes to a set of symbols based on their probabilities.It serves as the basis for several popular programs used on personal computers.Some of them use just the Huffman method while others use it as one step in. amulti-step compression process. The Huffman method is somewhat similar to theShannon-Fane method. It generally produces better codes and, like the ShannonFano method, it produces best code when the probabilities of the symbols are

Glossary 409
negative powers of 2. The main difference between the two methods is that ShannonFano constructs its codes top to bottom (from the leftmost to the rightmost bits) ,while Huffman constructs a code tree from the bottom up (builds the codes fromright to left) . (See also Shannon-Fano coding, Statistical methods.)
Information Theory
A mathematical theory that quantifies information. It shows how to measureinformation, so that one can answer the question: How much information is includedin this piece of data? with a precise numberl Information theory is the creation, in1948, of Claude Shannon of Bell labs. (See also Entropy.)
ISO
The International Standards Organization. This is one of the organizationsresponsible for developing standards. Among other things it is responsible (togetherwith the ITU) for the JPEG and MPEG compression standards. (See also ITU,CCITT and MPEG.)
Iterated Function Systems (IFS)
An image compressed by IFS is uniquely defined by a few affine transformations(Section 4.15.1). The only rule is that the scale factors ofthese transformations mustbe < 1 (shrinking). The image is saved in the output stream by writing the setsof six numbers that define each transformation. (See also Affine transformations,Resolution Independent Compression .)
ITU
The International Telecommunications Union; the new name of the CCITT.A United Nations organization responsible for developing and recommending standards for data communications (not just compression) . (See also CCITT.)
JBIG
A special-purpose compression method (Section 4.4) developed specifically forprogressive compression of bi-level images. The name JBIG stands for Joint BiLevel Image Processing Group. This is a group of experts from several internationalorganizations, formed in 1988 to recommend such a standard. JBIG uses multiplearithmetic coding and a resolution-reduction technique to achieve its goals.
JFIF
The full name of this method is JPEG File Interchange Format. It is a graphicsfile format (Section 4.2.8) that makes it possible to exchange JPEG-compressedimages between different computers. The main features of JFIF are the use of theYCbCr triple-component color space for color images (only one component for grayscale images) and the use of a marker to specify features missing from JPEG, suchas image resolution, aspect ratio, and features that are application-specific.

410 Glossary
JPEG
A sophisticated lossy compression method (Section 4.2) for color or gray-scalestill images (not movies). It also works best on continuous-tone images, whereadjacent pixels have similar colors. One advantage of JPEG is the use of manyparameters, allowing the user to adjust the amount of the data lost (and thus alsothe compression ratio) over a very wide range. There are two main modes: lossy(also called baseline) and lossless (which typically gives a 2:1 compression ratio).Most implementations support just the lossy mode. This mode includes progressiveand hierarchical coding.
The main idea behind JPEG is that an image exists for people to look at, sowhen the image is compressed , it is okay to lose image features for which the humaneye is not sensitive .
The name JPEG is an acronym that stands for Joint Photographic ExpertsGroup. This was a joint effort by the CCITT and the ISO that started in June1987. The JPEG standard has proved successful and has become widely used forimage presentation, especially in Web pages. (See also MPEG.)
Kraft-MacMillan Inequality
A relation (Section 2.5) that says something about unambiguous variable-sizecodes. Its first part states: given an unambiguous variable-size code, with n codesof sizes Iu, then
n
LTLi :$ 1.i=l
The second part states the opposite, namely, given a set of n positive integers(L 1 , L2 , • • • , Ln ) that satisfy Equation (2.1), there exists an unambiguous variablesize code such that L, are the sizes of its individual codes. Together, both parts saythat a code is unambiguous if and only if it satisfies relation (2.1).
L Systems
Lindenmayer Systems (or L-systems for short) were developed by the biologistAristid Lindenmayer in 1968 as a tool [Lindenmayer 681 to describe the morphologyof plants. They were initially used in computer science, in the 1970s, as a tool todefine formal languages, but have become really popular only after 1984, when itbecame apparent that they can be used to draw many types of fractals, in additionto their use in botany (Section C.5).
LHArc
This method, as well as with ICE and LHA (Section 3.20), is by HaruyasuYoshizaki. These methods use adaptive Huffman coding with features drawn fromLZSS.
Locally Adaptive Compression
A compression method that adapts itself to local conditions in the input stream,and changes this adaptation as it moves from area to area in the input. An exampleis the move-to-front method method of Section 1.5. (See also Adaptive compression,Semi-adaptive compression.)

Luminance
Glossary 411
This quantity is defined by the CIE (Section 4.2.1) as radiant power weightedby a spectral sensitivity function that 's characteristic of vision. (See also CIE.)
LZ Methods
All dictionary-based compression methods are based on the work of J. ZivandA. Lempel , published in 1977 and 1978. Today, these are called LZ77 and LZ78methods, respectively. Their ideas have been a source of inspiration to many researchers who generalized, improved, and combined them with RLE and statisticalmethods to form many commonly used, adaptive compression methods, for text,images, and sound. (See also Dictionary-based compression, Sliding-window compression.)
LZAP
The LZAP method (Section 3.11) is an LZW variant based on the idea: insteadof just concatenating the last two phrases and placing the result in the dictionary,place all prefixes of the concatenation in the dictionary. The AP stands for AllPrefixes .
LZFG
This is the name of several related methods (Section 3.6) that are hybrids ofLZ77 and LZ78. They were developed by Edward Fiala and Daniel Greene. All thesemethods are based on the following scheme. The encoder produces a compressedfile with tokens and literals (raw ASCII codes) intermixed. There are two types oftokens, a literal and a copy. A literal token indicates that a string of literals follow;a copy token points to a string previously seen in the data. (See also LZ methods.)
LZMW
A variant of LZW, the LZMW method (Section 3.10) works by: instead ofadding I plus one character of the next phrase to the dictionary, add I plus theentire next phrase to the dictionary. (See also LZW.)
LZP
An LZ77 variant developed by C. Bloom (Section 3.13). It is based on theprinciple of context prediction that says "if a certain string 'abcde' has appearedin the input stream in the past and was followed by 'f g ... ' , then when 'abcde 'appears again in the input stream, there is a good chance that it will be followedby the same 'fg... '." (See also Context.)
LZSS
This version of LZ77 (Section 3.3) was developed by Storer and Szymanski in1982 [Storer 82]. It improves on the basic LZ77 in three ways: (1) it holds thelook-ahead buffer in a circular queue , (2) it holds the search buffer (the dictionary)in a binary search tree, and (3) it creates tokens with two fields instead of three.

412 Glossary
LZW
This is a popular variant of LZ78, developed by T . Welch in 1984 (Section 3.9).Its main feature is eliminating the second field of a token. An LZW token consistsof just a pointer to the dictionary. As a result, such a token always encodes a stringof more than one symbol.
LZY
LZY (Section 3.12) is an LZW variant that adds one dictionary string per inputcharacter and increments strings by one character at a time.
MLP
A progressive compression method for grayscale images. An image is compressed in levels. A pixel is predicted by a symmetric pattern of its neighbors frompreceding levels, and the prediction error is arithmetically encoded . The Laplacedistribution is used to estimate the probability of the error. (See also ProgressiveFELICS.)
MNP5. MNP7
These have been developed by Microcom, Inc., a maker of modems, for use inits modems. MNP5 (Section 2.10) is a two-stage process that starts with run-lengthencoding, followed by adaptive frequency encoding. MNP7 (Section 2.11) combinesrun-length encoding with a two-dimensional variant of adaptive Huffman coding.
Model of Compression
A model is a method to "predict" (to assign probabilities to) the data to becompressed. This concept is important in statistical data compression. When astatistical method is used, a model for the data has to be constructed before compression can begin. A simple model can be built by reading the entire input stream,counting the number of times each symbol appears (its frequency of occurrence),and computing the probability of occurrence of each symbol. The data stream isthen input again, symbol by symbol, and is compressed using the information inthe probability model. (See also Statistical methods.)
One feature of arithmetic coding is that it is easy to separate the statisticalmodel (the table with frequencies and probabilities) from the encoding and decodingoperations. It is easy to encode, e.g., the first half of a data stream using one model,and the second half using another model.
Move-to-Front Coding
The basic idea behind this method (Section 1.5) is to maintain the alphabet Aof symbols as a list where frequently occurring symbols are located near the front .A symbol s is encoded as the number of symbols that precede it in this list. Aftersymbol s is encoded, it is moved to the front of list A.
MPEG
A standard for representing movies in compressed form. The name MPEGstands for Moving Pictures Experts Group, a working group of the ISO still atwork on this standard. (See also ISO, JPEG.)

Glossary 413
Multiresolution Image
A compressed image that may be decompressed at any resolutions. (See alsoResolution Independent Compression, Iterated Function Systems, WFA.)
Phrase
A piece of data placed in a dictionary to be used in compressing future data.The concept of phrase is central in dictionary-based data compression methods sincethe success of such a method depends a lot on how it selects phrases to be saved inits dictionary. (See also Dictionary-based compression, LZ methods.)
PKZip
A compression program for MSjDOS (Section 3.19), written by Phil Katzwho has founded the PKWare company (..http://www.pkware.com..). which alsomarkets the PKunzip, PKlite, and PKArc software.
Prediction
Assigning probabilities to symbols. (See also PPM.)
Prefix Property
One of the principles of variable-size codes. It states: once a certain bit patternhas been assigned as the code of a symbol, no other codes should start with thatpattern (the pattern cannot be the prefix of any other code). Once the string 1,e.g., is assigned as the code of all no other codes should start with 1 (i.e., they allhave to start with 0). Once 01, e.g., is assigned as the code of a2, no other codescan start with 01 (they all should start with 00). (See also Variable-size codes,Statistical methods.)
Progressive FELICS
A progressive version of FELICS where pixels are encoded in levels. Each leveldoubles the number of pixels encoded. To decide what pixels are included in acertain level, the preceding level can conceptually be rotated 45° and scaled by J2in both dimensions. (See also FELICS, MLP, Progressive image compression.)
Progressive Image Compression
An image compression method where compressed stream is made up of "layers,"such that each layer contains more detail of the image. The decoder can veryquickly display the entire image in a low-quality format and then improve the displayquality as more and more layers are being read and decompressed. A user watchingthe decompressed image develop on the screen can normally recognize most of theimage features after only 5-10% of it have been decompressed. Improving imagequality over time can be done by: (1) sharpening it, (2) adding colors, or (3) addingresolution. (See also Progressive FELICS, MLP, JBIG.)
PPM
A compression method that assigns probabilities to symbols based on the context (long or short) in which they appear. (See also Prediction, PPPM.)

414
PPPM
Glossary
A lossless compression method for grayscale (and color) images that assignsprobabilities to symbols based on the Laplace distribution, like MLP. Differentcontexts of a pixel are examined and their statistics used to select the mean andvariance for a particular Laplace distribution. (See also Prediction, PPM, MLP.)
QIC-122 Compression
An LZ77 variant that has been developed by QIC for text compression on1/4-inch data cartridge tape drives.
Quadtrees
This is a data compression method for bitmap images. A quadtree (Section 4.12) is a tree where each leaf corresponds to a uniform part of the image(a quadrant, subquadrant or a single pixel) and each interior node has exactly fourchildren .
Relative Encoding
A variant of RLE, sometimes called differencing (Section 1.3.1). It is used incases where the data to be compressed consists of a string of numbers that don'tdiffer by much, or in cases where it consists of strings that are similar to each other.The principle of relative encoding is to send the first data item al followed by thedifferences a i+l - ai. (See also RLE.)
Reliability
Variable-size codes and other codes are vulnerable to errors. In cases wherereliable transmission of codes is important, the codes can be made more reliableby adding check bits, parity bits , or CRC (Section 2.12 and Appendix E). Noticethat reliability is, in a sense, the opposite of data compression since it is done byincreasing redundancy. (See also CRC.)
Resolution Independent Compression
An image compression method that does not depend on the resolution of thespecific image being compressed. The image can be decompresed at any resolution.(See also Multiresolution, Iterated Function Systems, WFA.)
RLE
A general name for methods that compress data by replacing a run length ofidentical symbols with one code, or token, containing the symbol and the length ofthe run . RLE sometimes serves as one step in a multi-step statistical or dictionarybased method. (See also Relative encoding.)
Semi-Adaptive Compression
A compression method that uses a two-pass algorithm, where the first passreads the input stream to collect statistics on the data to be compressed, and thesecond pass does the actual compressing. The statistics (model) is included in thecompressed stream. (See also Adaptive compression , Locally Adaptive compression.)

Glossary 415
Shannon-Fano Coding
An early algorithm for finding a minimum-length variable-size code given theprobabilities of all the symbols in the data (Section 2.6). This method was later superseded by the Huffman method. (See also Statistical methods, Huffman coding.)
Sliding Window Compression
The LZ77 method (Section 3.2) uses part of the previously seen input streamas the dictionary. The encoder maintains a window to the input stream, and shiftsthe input in that window from right to left as strings of symbols are being encoded.The method is thus based on a sliding window. (See also LZ methods.)
Space-Filling Curves
A space-filling curve (Section 4.13) is a function P(t) that goes through everypoint in a given two-dimensional area, normally the unit square. Such curves aredefined recursively and are used in image compression.
Sparse Strings
Regardless of what the input data represents, text, binary, images, or anythingelse, we can think of the input stream as a string of bits. If most of the bits arezeros, the string is called sparse. Sparse strings can be compressed very efficientlyby specially designed methods (Section 5.4).
Statistical Methods
These methods (Chapter 2) work by assigning variable-size codes to symbolsin the data, with the shorter codes assigned to symbols or groups of symbols thatappear more often in the data (have a higher probability of occurrence). (See alsoVariable-size codes, Prefix property, Shannon-Fano coding, Huffman coding, andArithmetic coding.)
String Compression
In general, compression methods based on strings of symbols can be moreefficient than methods that compress individual symbols (Section 3.1).
Symbol
The smallest unit of the data to be compressed. A symbol is normally a bytebut may also be one bit, a trit {O, 1, 2}, or anything else. (See also Alphabet.)
Symbol Ranking
A context-based method (Section 5.2) where the context C of the current symbol S (the N symbols preceding S) is used to prepare a list of symbols that are likelyto follow C. The list is arranged from most likely to least likely. The position of Sin this list (position numbering starts from 0) is then written by the encoder , afterbeing suitably encoded, on the output stream.
TAR
The standard UNIX archiver. The name TAR stands for Tape ARchive. Itgroups a number of files into one file without compression. After being compressedby the UNIX compress program, a TAR file gets an extension name of TAR.Z.

416 Glossary
Textual Image Compression
A compression method for hard copy documents containing printed or typed(but not handwritten) text. The text can be in many fonts and may consist ofmusic notes, hieroglyphs , or any symbols . Pattern recognition techniques are usedto recognize text characters that are identical or at least similar . One copy of eachgroup of identical characters is kept in a library. Any leftover material is consideredresidue. The method uses different compression techniques for the symbols and theresidue. It includes a lossy option where the residue is ignored.
Token
A unit of data written on the compressed stream by some compression algorithms. A token is made of several fields that may have either fixed or variablesizes.
Unary Code
A way to generate variable-size codes in one step. The unary code of the nonnegative integer n is defined (Section 2.3.1) as n - 1 ones followed by one zero(Table 2.3). There is also a general unary code. (See also Golomb code.)
V.42bis Protocol
This is a standard, published by the ITU-T (page 62) for use in fast modems.It is based on the existing V.32bis protocol and is supposed to be used for fasttransmission rates, up to 57.6K baud. The standard contains specifications for datacompression and error-correction, but only the former is discussed, in Section 3.17.
V.42bis specifies two modes: a transparent mode, where no compression is used,and a compressed mode using an LZW variant. The former is used for data streamsthat don't compress well, and may even cause expansion. A good example is analready-compressed file. Such a file looks like random data, it does not have anyrepetitive patterns, and trying to compress it with LZW will fill up the dictionarywith short, two-symbol phrases.
Variable-Size Codes
These are used by statistical methods. Such codes should satisfy the prefixproperty (Section 2.2) and should be assigned to symbols based on their probabilities . (See also Prefix property, Statistical methods.)
WFA
A weighted finite automaton (WFA) is constructed from a bi-level image ina process similar to constructing a quadtree. The WFA becomes the compressedimage. This method uses the fact that most images of interest have a certain amountof self-similarity (i.e., parts of the image are similar, up to size, to the entire imageor to other parts). The method is lossless but can have a lossy option where auser-controlled parameter indicates the amount of loss permitted. This is a veryefficient method that can be extended to grayscale images. (See also Quadtrees,Resolution Independent Compression.)

Glossary 417
Zero-Probability Problem
When samples of data are read and analysed in order to generate a statisticalmodel of the data, certain contexts may not appear, leaving entries with zero countsand thus zero probability in the frequency table. Any compression method requiresthat such entries be somehow assigned non-zero probabilities.
Zip
A popular program that implements the so-called "deflation" algorithm (Section 3.18) that uses a variation of LZ77 combined with static Huffman coding. Ituses a 32Kbyte-Iong sliding dictionary, and a look-ahead buffer of 258 bytes . Whena string is not found in the dictionary it is emitted as a sequence of literal bytes .(See also Gzip.)
Lossy rag.
Anagram of "glossary"

Index90° rotation, 2302-pass compression, x, 50, 69, 142, 181,
205, 270, 275, 4148 1/2 (movie), 91
Abelson, Harold, 327Abish, Walter, 86ACB, 85, 251, 261-268, 403Ad hoc text compression, 3adaptive arithmetic coding, 80-84adaptive compression, xadaptive frequency encoding, 56, 412adaptive Huffman coding, x, 18, 50-56, 61,
146, 156, 403, 410, 412word-based, 275-276
ADC (analog-to-digital converter), 295Addison, Joseph (adviser), vaffine transformations, 228-232
attractor, 234, 236ALGOL60, 327alphabet (definition of), 403Alphabetical Africa (book) , 86analog-to-digital converter, see ADCAnderson, Karen, 214ARC, 150-151, 156, 403, 404archive, 150,403arithmetic coding, 21, 69-80, 187,404,409,
412,415adaptive, 80-84and move-to-front, 16and sound, 297in JPEG, 166principles of, 71
ARJ, 156, 404ASCII, 14, 157, 404, 405
code table, 301Associative coding, see ACBasymmetric compression, xi, 102, 106, 223,
269
Babbage, Charles, 348Backus, John, 327balanced binary tree, 47, 48, 81Barnsley, Michael Fielding, 228barycentric functions, 363Baudot code, 4Baudot, Jean Maurice Emile, 4Bellard, Fabrice, 156, 407Berbuizana, Manuel Lorenzo de Lizarazu
y,87Bernstein, Dan, 134Bierce, Ambrose, 161binary search, 23, 82, 84
tree, 107-110, 192, 282, 411binary tree, 47
balanced, 47, 81complete, 47, 81
BinHex, 404BinHex4, 14-16bitmap, 11bits/char, xi, 404bits/symbol, 404blending functions, 363Blinn, James F., 335block coding, 404block mode, xi, 252

420 Index
block sorting, 85, 252Bloom, Charles R., 136, 411BNF (Backus Naur Form) , 111,327bpb (bit per bit), xibpc (bits per character) , xi, 404bpp (bits per pixel), xiiBraille, 1-2Braille, Louis, 1Brailler (software), 2break even point in LZ, 110Broukhis, Leonid , 261Bunyan, John, xvBurmann, Gottlob, 87Burrows-Wheeler method, xi, 85, 251-257,
404and ACB, 263
Buyanovsky, George (Georgii)Mechislavovich, 261, 403
BWT, see Burrows-Wheeler method
Calgary Corpus, xiiCALIC, 210-213, 405Canterbury Corpus, xiiiCantor, Eddie, 162Carlyle, Thomas, xivCarroll, Lewis, 19, 116, 183CCITT, 62, 158, 165, 405, 409, 410CDC display code, 3Chomsky, Noam, 327chromaticity diagram, 167ClE, 167, 405circular queue, 106-107, 141, 156,405Cleary, John G., 85cloning (in DMC) , 290code overflow (in adaptive Huffman), 54codec, viicodes
Baudot, 4CDC, 3error-correcting, 337-348, 407error-detecting, 337-348Golomb , 30, 32, 195,200Hamming, 344, 345Hamming distance, 342-343overhead of, 341phased-in binary, 51prefix, 26-30, 146, 281SEC-DED, 346start-step-stop, 27subexponential, 30, 197-201
unary, 27-30, 117, 142variable-size, 25-30, 42, 50, 55, 56,
61-63, 69, 101, 103, 146, 371, 414unambiguous, 33, 410
voting, 339codes (definition of) , 405collating sequence, 108color images (and grayscale compression) ,
13color space, 167compaction, 2companding, vii, 298complete binary tree, 47, 81complex methods (diminishing returns),
vii, 118, 147, 186compression factor, xicompression gain, xiicompression ratio, xi, 406
in UNIX, 147known in advance, 299
compressor (definition of), viiCompuserve Information Services, 147,408computer arithmetic, 166Conan Doyle, Arthur, xviiconcordance, 268context, 406context modeling, 85
adaptive, 86order-N,87static, 85
context-based image compression, 191-194,210-213
Cormack, Gordon V., 285correlations
between phrases, 160between pixels, 40, 192between states, 290-292between words , 277
Costello, Daniel J ., 346counting argument, 36-38CRC, 151, 157-159 ,347,406Crichton, Michael, xvCrick, Francis Harry Compton, 94Culik, Karel, 219cumulative frequencies, 76, 77, 81curves
Hilbert, 218, 317Peano, 322, 325-326Sierpinski, 218, 318space-filling, 317-326

Index 421
cycles, xiicyclical redundancy check, see CRC
DAC (digital-to-analog converter) , 295Darwin, Charles, 100data compression
2-pass, x, 50, 69, 142, 181, 205, 270, 275,414
adaptive, xasymmetric, xi, 102, 106, 223, 269block mode, xi , 252block sorting, 85, 252Braille, 1-2Burrows-Wheeler, xi, 252-257, 404compaction, 2definition of, vdictionary-based methods, vii, 101-162,
406,413differential image , 214-215, 406diminishing returns, vii, 118, 147, 186EXE files, 156fax, 62-69, 279, 407
ID ,632D,66group 3, 63
FELlCS, 194-196,407fractal, 228-243, 409front , 5general law, vi, 159IFS, 228-243, 409image
color , 13differential, 214-215, 406grayscale, 13progressive, 184-186, 413resolution independent, 222, 239, 414
image (context-based), 191-194,210-213intuitive methods, 1-6irreversible, 2JBIG, 186-191 , 409JPEG, 165-182logical, xi, 101lossless, x, 3lossy, xLZ & RLE, 103, 411LZ & statistical methods, 103, 411LZ77,104-107,415LZ78, 112-115LZAP, 133-134LZFG , 27, 116-118, 411
LZMW, 131-133LZRW1, 119-122LZRW4,122LZW, 123-130,412
and UNIX, 147word-based, 276-277
LZY, 134-135,412MacWrite,6MLP, 201-209, 412MNP5,412MNP7,412model, xiii, 185, 412move-to-front, x, 16-19, 410, 412non-adaptive, xpacking, 3physical, xipointers, xivPPM, 85-100, 258, 281
exclusion, 93-94word-based, 277-278
PPPM,209-210progressive, 187progressive FELICS, 197-201, 413progressive image, 184-186, 413quadtrees, 215-219, 414reasons for, vand redundancy, vi, 289, 338and reliability, 337run length encoding, vii, 6-19, 40, 56,
61,279,412semi-adaptive, x, 50, 414small numbers, 16, 179, 181, 186, 255,
397sound, 295-299space filling, 218-219, 415sparse strings, 3, 251, 268-274, 415statistical methods, vii, 21-100, 102, 415streaming mode, xi, 252symbol ranking, 257-261symmetric, x, 102, 111textual image , 279-284unification, 159-162wavelets, 245-249word-based, 274-278
data structures, xiv, 54, 55, 106-108, 114,126, 127, 129, 405
DCT, 166,168-173,407decoder, 406
definition of, viidecompressor (definition of) , vii

422 Index
deflation, 149, 408, 417Delugach, Harry S., 401determinants, 333-335DFT,407dictionary-based methods, vii, 101-162 ,
406,413dictionaryless, 144-146and sound, 298unification with statistical methods,
159-162DIET,157differencing, 10, 130, 181, 414differential image compression, 214-215,
406digital-to-analog converter, see DACdigram, viii, 85, 86, 407
encoding, 9frequencies, 61
discrete cosine transform, see DCTdiscrete Fourier transform, see DFTdownsampling, 166, 188drawing
and JBIG, 186and sparse strings, 268
dynamic compression, see adaptivecompression
dynamic dictionary, 101GIF, 148
dynamic Markov coding, 219, 252, 285-295
EBCDIC, 405Einstein, Albert (patent examiner), 37Elias, Peter, 26Elton, John, 233encoder, 407
definition of, viiEnglish text, vi, xiv, 102
frequencies of letters, viiientropy, 25, 33, 35, 40, 69, 80, 187
definition of, 24, 407error-correcting codes, 337-348, 407error-detecting codes, 157, 337-348escape code
in adaptive Huffman, 50in Macwrite, 6in pattern substitution, 10in PPM, 90in RLE, 6in textual image, 282in word-based compression, 275
ETAOINSHRDLU (letter probabilities),viii
exclusionin ACB, 266in PPM, 93-94in symbol ranking, 258
EXE compression, 156EXE compressors, 407
facsimile compression, 62--Q9, 279, 4071D,632D,66group 3,63
FELICS, 194-196,407progressive, 197-201
Feynman, Richard Phillips, 296Fiala, Edward R., vii, 116, 411Fibonacci numbers and sparse strings,
273-274finite-state machines, 41, 219, 252, 285-288Fisher, Yuval, 228fixed-size codes, viFourier transform, 168, 245, 349-353, 407,
408Fourier, Jean Baptiste Joseph, 168, 351,
408fractal image compression, 228-243, 409Freed, Robert A., 150, 403frequencies
cumulative, 76, 77, 81of digrams, 61of pixels, 187of symbols, xiv, 25, 26, 42, 50-52, 55, 56,
58, 69, 71, 72, 187, 412in LZ77, 106
frequency of eof, 73front compression, 5functions
barycentric, 363blending, 363
fundamental frequency (of a function), 351
Gadsby (book), 86Galois fields, 346gasket (Sierpinski), 234generating polynomials, 346, 407GIF,408go (game) , 87golden ratio, 31, 231Golomb code, 30, 32, 195, 200, 407, 408

Index 423
Golomb, Solomon W., 33graphical user interface, see GUIgrayscale image compression (extended to
color images), 13, 201, 210, 214,225, 228, 241, 249
Greene, Daniel H., vii, 116, 411group 3 fax compression, 63, 407group 4 fax compression, 63, 407GUI,163gzip , 149, 408
Halmos, Paul, 335Hamming codes, 343-346, 408
16 bits, 345Hamming distance, 342-343Hamming, Richard, 342, 344Haro, Fernando Jacinto de Zurita y, 87hashing, 127, 129, 149, 192, 282, 357-360heap, 47-48Henderson, John Robert, xivHeraclitus (of Ephesus) , viiHerd, Bernd (LZH) , 105Hermite basis matrix, 363Herrera, Alonso Alcala y, 87Hertz (Hz) , 350Hilbert curve, 218-219, 317-318
traversing of, 324-325Hilbert, David, 317homogeneous coordinates, 232Horspool, R. Nigel, 285Huffman coding, 21,26, 38-42, 63, 64, 66,
69, 86, 103, 149, 156, 254, 408, 415,417
2-symbol alphabet, 40adaptive, x, 18, 50-56, 146, 156, 403, 410
word-based, 275-276canonical, 45-50code size, 43for images, 42in image compression, 214in JPEG, 166, 179in LZP, 142and move-to-front, 16, 18not unique , 39number of codes, 44-45semi-adaptive, 50and sound, 297and sparse strings, 271, 272variance, 39and wavelets, 245, 249
Huffman, David, 38
ICE, 156, 410mCT,177IFS compression, 228-243, 409
PIFS, 238image (interlaced) , 13image compression, vii, x, 6, 14, 163-249,
414hi-level , 186, 409context-based, 191-194, 210-213differential, 214-215, 406fax, 62-69, 279, 407FELICS, 194-196GIF, 147-148IFS, 228-243JPEG, 165-182LZ, 103,411LZW, 130MLP, 201-209PPPM, 209-210progressive, 184-186, 413
median, 186progressive FELICS, 197-201reasons for, 163resolution independent, 222, 239, 414RLE, 11-19, 215, 218wavelets, 245-249WFA , 219-228
imploding, 153inequality (Kraft-MacMillan), 33-34, 410information theory, 21-25, 340, 409interlacing scan rows, 13intuitive compression, 1inverse discrete cosine transform, see IDCTinverted file, 268irreversible text compression, 2ISO, 165, 409, 410, 412iterated function systems, 164, 228-243,
409ITU, 405, 407, 409ITU-R,168
recommendation BT.601, 168ITU-T, 62, 63
recommendation TA, 63, 66recommendation T.6, 63, 66, 407recommendation T .82, 187VA2bis, 148, 416
JBIG, 166, 186-191 , 409

424 Index
JFIF,182-183,409Joyce, James, 3, 162JPEG, 163-182, 404, 409, 410
and progressive image compression, 184and sparse strings, 268
Jung, Robert K., 156, 404
Kaplansky, Irving, 335Katz, Philip, 151, 413Koch snowflake curve, 327Kraft-MacMillan inequality, 33-34, 410
L Systems, 326-330, 410La Disparition (novel), 86Laertius, Diogenes, 148Langdon, Glen G., 160, 191Laplace distribution, 201, 203-209, 412,
414Lempel, Abraham, 103, 411Lempereur, Yves, 14,404lexicographic order, 107, 252LHA, 156, 410LHArc, 156, 410Life, a User's Manual (novel), 87LIFO,129Lin, Shu, 346Lindenmayer, Aristid, 326, 410lipogram, 86Littlewood, J . E., 366lockstep, 50, 124logarithm (as the information function), 23logical compression, xi, 101lossless compression, x, 3lossy compression, xluminance, 167-168LZ77, 103-107, 119, 149, 262, 264, 408,
411, 415, 417and LZRW4, 122deficiencies, 110
LZ78, 103, 110, 112-115, 264, 411, 412LZAP, 133-134LZC, 120, 147LZEXE, 156, 157, 407LZFG, 27, 116-118, 122,411LZH,105LZMW, 131-133LZP, 136-143, 161, 258, 259, 411LZRW1, 119-122 , 357LZRW4,122LZSS, 107-110, 156, 410, 411
LZW, 123-130,397,411,412,416decoding, 124-126dynamic, 151and UNIX, 147used in ARC, 151word-based, 276-277
LZY, 134-135, 412
Mackay, Alan Lindsay, xiMacWrite (data compression in) , 6Markov model, 61, 84matrices, definition and operations,
333-335Matsumoto, Teddy, 157Maugham, Somerset, 243median, definition of, 186metric, definition of, 240Microcom, Inc. , 9, 56, 412MLP, 193,201-210,412,414MMR coding, 66MNP class 5, 9, 56-60, 412MNP class 7, 61-62, 412modem, vi, 9, 24, 51, 56, 62, 148, 149, 412,
416Moffat, Alistair, 191Morley, Christopher, 366Morse code, 1, 21Morse, Samuel F. B., v, 21Motil, John Michael, xiv, 43move-to-front method, x, 16-19, 252, 254,
255, 404, 410, 412inverse of, 256and wavelets , 245, 246
MPEG, 168, 409, 412multiresolution image, 222, 413Murray, James, 19
nanometer, 167NASA,390Naur, Peter, 327negate and exchange rule , 230non-adaptive compression, xnumerical history (mists of), 366Nyquist rate, 296, 353Nyquist, Harry, 353
OCR,279Oulipo (writers' group), 87
packing, 3

Index 425
Pareto, Wilfredo, 348parity, 157
vertical, 158Pascal, Blaise, vi, 100pattern substitution, 10Peano curve, 322, 330
traversing, 325-326pel (fax compression), 63Perec, Georges, 86, 87permutation, 252phased-in binary codes, 30, 51, 147phrase, 413
in LZW, 123physical compression, xiPIFS (IFS compression) , 238Pilgrim, Mark, 2pixels , 11, 187PKArc, 151-155,413PKlite, 151, 157, 413PKunzip, 151, 413PKWare, 151, 413PKzip, 151, 413Poe , Edgar Allen , xpolynomial
parametric cubic, 362parametric representation, 362
polynomial (definition of), 159, 361Porta, Giambattista della (1535-1615) , vPPM, 84-100, 209, 258, 266, 281, 295, 413
exclusion, 93-94trie,95vine pointers, 95word-based, 277-278
PPMA,94PPMB, 94, 210PPMC, 91, 94PPPM, 209-210, 414prediction, 413prefix codes, 26-30, 146prefix property, 62, 400, 413, 416
definition of, 26probability model, xiii, 185, 412progressive compression, 187-191progressive FELICS, 197-201, 413progressive image compression, 184-186,
413FELICS, 197-201median, 186MLP, 201-209PPPM, 209-210
pyramid coding (in progressivecompression) , 184
QIC-122, 111-112, 414quadtrees, 164,215-218,220,414,416
and Hilbert curves, 219queue (data structure), 106-107,405Quinton, R. E. , 327
random data, vi, 36, 37, 40, 148, 371, 416ratio of compression, xi, 406reasons for data compression, vreducing, 152redundanc~ 25, 35, 62, 338
and data compression, vi, 289, 338definition of, 25and error-correction, 337, 343min imum, 26and reliability, 62
reflection, 229relative encoding, 10, 130, 414
in JPEG, 167reliability, 62, 337repetition finder , 144-146RGB,167Ribera, Francisco Navarrete y, 87RLE, 6-19, 63, 152, 279, 414
BinHex4, 14-16and BW method, 252, 254, 255, 404in JPEG, 166QIC-122, 111-112, 414and sound, 297and wavelets, 245, 246
rotation, 23090°,230
Rozenberg, Grzegorz, 326, 331run length encoding, vii, 6-19, 40, 56, 61,
279,412in JPEG, 177
sampling, 353Sayood, Khalid, 214scaling, 228sea (self-extracting) , 150SEC-DED code, 346self-extracting archives, 150self-similarity (in images), 220semi-adaptive compression, x, 50, 414semi-adaptive Huffman coding, 50SFX files, 150

426 Index
Shakespeare, William, 299Shannon, Claude, 24, 257, 338, 407, 409Shannon-Fano method, 21, 26, 34-35, 38,
69,408,409,415used in implode, 153
shearing, 229shrinking, 151sibling property, 52, 54Sierpinski
curve, 218, 318-322gasket, 234, 236-237, 394triangle, 233, 234, 394
Sierpinski, Waclaw, 218, 233, 234, 236, 318skewed probabilities, 72sliding window compression, 104-110, 415small numbers (easy to compress), 16, 179,
181, 186, 245, 255, 397Smith, Alvy Ray, 326Smith, Peter Desmond, xivsound compression, x, 295-299
LZ, 103,411space-filling curves, 218-219, 317-326, 415
Hilbert, 317-318Peano, 322, 330Sierpinski, 318-322
sparse strings, 3, 251, 268-274, 415stack, 129start-step-stop codes, 27static dictionary, 101, 102, 115, 147statistical methods, vii, 21-100, 102,415
context modeling, 85unification with dictionary methods,
159-162statistical model, 71, 85, 101, 187, 188, 412Stevenson, Robert Louis, 316Stewart, Ian, 249Storer, James Andrew, 107,411streaming mode, xi, 252string compression, 103-104, 415subexponential code, 30, 197-201symbol ranking, 85, 251, 257-261, 266, 415symmetric compression, x, 102, 111Szilard, Andy, 327Szymanski, T., 107, 411
TAR,415text
English, vi, viii, xiv, 102files, xnatural language, 62
random, vi, 40, 371text compression, vii, xiv, 6
LZ, 103,411QIC-122, 111-112,414RLE,6-lOsymbol ranking, 257-261
textual image compression, 279-284, 416Thomson, William, 353Tjahjono, Danu, 356token (definition of), 416transform, definition of, 349transform, Fourier, 349-353translation, 232tree
adaptive Huffman, 50-52binary search, 107-110, 411
balanced, 108, 110skewed , 108, 110
Huffman, 38, 39, 42, 50-52, 54, 371,409decoding, 54overflow, 54rebuilt , 54
LZ78,114overflow, 115
LZW, 126, 127, 129multiway, 126traversal, 38
triangle (Sierpinski), 234, 394trie
definition of, 95, 115LZW, 126
trigram, 85, 86trit (ternary digit) , 23, 326Twain, Mark, 360
Ulysses (novel), 3unary code, 27-30, 142, 195, 200, 369, 407,
408,416general, 27, 117,416
unification of statistical & dictionarymethods, 159-162
UNIXcompact, 50compress, 115, 120, 147, 149, 405
V.32,51V.32bis, 148, 416V.42bis, vii, 148-149, 416Vail, Alfred, 21Vanryper, William, 19

variable-size codes , vi, 21, 25-30, 42, 50,55, 56, 61, 101, 103, 371, 400, 413,415,416
and reliability, 62, 414and sparse strings, 270-274definition of, 25designing of, 26in fax compression, 63unambiguous, 33, 410
variance (definition of) , 206variance of Huffman codes, 39vine pointers, 95voting codes, 339
Index
Welch, Terry, 123, 412WFA, see weighted finite automataWhitman, Walt, 155Williams, Ross N., 122Wirth, Niklaus, 317Witten, Ian A., 85word-based compression, 274-278Wright, Ernest Vincent, 86, 87www (web) , 165,410
Yokko, Hidetoshi, 144Yoshizaki, Haruyasu, 156, 410
427
wavelets, 164,245-249weighted finite automata, 164, 219-228,
416
zero-probability problem, 86, 89, 185, 192,289,417
Zip, 149, 417Ziv, Jacob, 103, 411
How did he bank it up, swank it up ,the whaler in the punt, a guinea by agroat, his index on the balance and suchwealth int o the bargain , with the bogueywhich he snatched In the baggage coachahead?
- J ames Joyce, Finnegans Wake (1920)

Colophon
This book was designed by the author and was typeset by him with the 'lEX typesetting system developed by D. Knuth. The text and tables were done with Textures,a commercial 'lEX implementation for the Macintosh. The diagrams were done withSuperpaint and Adobe Illustrator, also on the Macintosh computer. The followingfeatures illustrate the amount of work that went into it:
• The book contains about 215,600 words, consisting of about 1,226,800 characters. However, the size of the auxiliary material collected in the author's computerwhile working on the book is about 10 times bigger than the entire book. This material includes articles and source codes available on the internet, as well as manypages of information collected from various sources and scanned into image files.
• The text is typeset mainly in font cmrlO, but 30 other fonts were used.
• The raw index file contained 1650 items.
• There are about 430 cross-references in the book .
• The following table shows some results of compressing a file containing theentire text of the book. The original file size is 1,227,187 bytes .
Computer
Macintosh
UNIXPC
Program
CompactorStuffit LightUNIX CompressDisk DoublerZip (deflate)GnuZipcompressWinzip (Packed mode)Winzip (Normal mode)
Compressed
445,174400,536527,671748,360390,787392,432527,295390,028395,756
Ratio
.36
.33
.43
.61
.32
.32
.43
.32
.32
Necessity is the mother of compression.
Aesop (paraphrased)




















