
Analysis on multi-domain cooperation for predicting protein-protein interactions
20
BioMed Central Page 1 of 20 (page number not for citation purposes) BMC Bioinformatics Open Access Research article Analysis on multi-domain cooperation for predicting protein-protein interactions Rui-Sheng Wang †1,2 , Yong Wang †3 , Ling-Yun Wu 3 , Xiang-Sun Zhang* 3 and Luonan Chen* 2,4,5,6 Address: 1 School of Information, Renmin University of China, Beijing 100872, China, 2 Department of Electronics Information and Communication Engineering, Osaka Sangyo University, Osaka 574-8530, Japan, 3 Academy of Mathematics and Systems Science, Chinese Academy of Sciences, Beijing 100080, China, 4 Institute of Systems Biology, Shanghai University, Shanghai 200444, China, 5 ERATO Aihara Complexity Modelling Project, JST, Tokyo 151-0064, Japan and 6 Institute of Industrial Science, The University of Tokyo, Tokyo 153-8505, Japan Email: Rui-Sheng Wang - [email protected]; Yong Wang - [email protected]; Ling-Yun Wu - [email protected]; Xiang- Sun Zhang* - [email protected]; Luonan Chen* - [email protected] * Corresponding authors †Equal contributors Abstract Background: Domains are the basic functional units of proteins. It is believed that protein-protein interactions are realized through domain interactions. Revealing multi-domain cooperation can provide deep insights into the essential mechanism of protein-protein interactions at the domain level and be further exploited to improve the accuracy of protein interaction prediction. Results: In this paper, we aim to identify cooperative domains for protein interactions by extending two-domain interactions to multi-domain interactions. Based on the high-throughput experimental data from multiple organisms with different reliabilities, the interactions of domains were inferred by a Linear Programming algorithm with Multi-domain pairs (LPM) and an Association Probabilistic Method with Multi-domain pairs (APMM). Experimental results demonstrate that our approach not only can find cooperative domains effectively but also has a higher accuracy for predicting protein interaction than the existing methods. Cooperative domains, including strongly cooperative domains and superdomains, were detected from major interaction databases MIPS and DIP, and many of them were verified by physical interactions from the crystal structures of protein complexes in PDB which provide intuitive evidences for such cooperation. Comparison experiments in terms of protein/domain interaction prediction justified the benefit of considering multi-domain cooperation. Conclusion: From the computational viewpoint, this paper gives a general framework to predict protein interactions in a more accurate manner by considering the information of both multi- domains and multiple organisms, which can also be applied to identify cooperative domains, to reconstruct large complexes and further to annotate functions of domains. Supplementary information and software are provided in http://intelligent.eic.osaka-sandai.ac.jp/chenen/ MDCinfer.htm and http://zhangroup.aporc.org/bioinfo/MDCinfer . Published: 16 October 2007 BMC Bioinformatics 2007, 8:391 doi:10.1186/1471-2105-8-391 Received: 18 March 2007 Accepted: 16 October 2007 This article is available from: http://www.biomedcentral.com/1471-2105/8/391 © 2007 Wang et al.; licensee BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Transcript of Analysis on multi-domain cooperation for predicting protein-protein interactions

BioMed CentralBMC Bioinformatics
ss
Open AcceResearch articleAnalysis on multi-domain cooperation for predicting protein-protein interactionsRui-Sheng Wang†1,2, Yong Wang†3, Ling-Yun Wu3, Xiang-Sun Zhang*3 and Luonan Chen*2,4,5,6Address: 1School of Information, Renmin University of China, Beijing 100872, China, 2Department of Electronics Information and Communication Engineering, Osaka Sangyo University, Osaka 574-8530, Japan, 3Academy of Mathematics and Systems Science, Chinese Academy of Sciences, Beijing 100080, China, 4Institute of Systems Biology, Shanghai University, Shanghai 200444, China, 5ERATO Aihara Complexity Modelling Project, JST, Tokyo 151-0064, Japan and 6Institute of Industrial Science, The University of Tokyo, Tokyo 153-8505, Japan
Email: Rui-Sheng Wang - [email protected]; Yong Wang - [email protected]; Ling-Yun Wu - [email protected]; Xiang-Sun Zhang* - [email protected]; Luonan Chen* - [email protected]
* Corresponding authors †Equal contributors
AbstractBackground: Domains are the basic functional units of proteins. It is believed that protein-proteininteractions are realized through domain interactions. Revealing multi-domain cooperation canprovide deep insights into the essential mechanism of protein-protein interactions at the domainlevel and be further exploited to improve the accuracy of protein interaction prediction.
Results: In this paper, we aim to identify cooperative domains for protein interactions byextending two-domain interactions to multi-domain interactions. Based on the high-throughputexperimental data from multiple organisms with different reliabilities, the interactions of domainswere inferred by a Linear Programming algorithm with Multi-domain pairs (LPM) and anAssociation Probabilistic Method with Multi-domain pairs (APMM). Experimental resultsdemonstrate that our approach not only can find cooperative domains effectively but also has ahigher accuracy for predicting protein interaction than the existing methods. Cooperative domains,including strongly cooperative domains and superdomains, were detected from major interactiondatabases MIPS and DIP, and many of them were verified by physical interactions from the crystalstructures of protein complexes in PDB which provide intuitive evidences for such cooperation.Comparison experiments in terms of protein/domain interaction prediction justified the benefit ofconsidering multi-domain cooperation.
Conclusion: From the computational viewpoint, this paper gives a general framework to predictprotein interactions in a more accurate manner by considering the information of both multi-domains and multiple organisms, which can also be applied to identify cooperative domains, toreconstruct large complexes and further to annotate functions of domains. Supplementaryinformation and software are provided in http://intelligent.eic.osaka-sandai.ac.jp/chenen/MDCinfer.htm and http://zhangroup.aporc.org/bioinfo/MDCinfer.
Published: 16 October 2007
BMC Bioinformatics 2007, 8:391 doi:10.1186/1471-2105-8-391
Received: 18 March 2007Accepted: 16 October 2007
This article is available from: http://www.biomedcentral.com/1471-2105/8/391
© 2007 Wang et al.; licensee BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Page 1 of 20(page number not for citation purposes)

BMC Bioinformatics 2007, 8:391 http://www.biomedcentral.com/1471-2105/8/391
BackgroundMany proteins involved in signal transduction, gene regu-lation and other biological activities require interactionwith other proteins or cofactors to achieve specific proc-esses [1,2]. Elucidating protein-protein interactions canprovide deep insights into protein functions and intracel-lular signaling pathways. Owing to the recent rapidadvances in high-throughput technologies, protein-pro-tein interaction data of various species are increasinglyaccumulated from different experiments and deposited inseveral main databases such as DIP [3] and MIPS [4]. Thiscollection of protein-protein interaction data results in arich, but quite noisy and still incomplete source of infor-mation [5,6] which needs to be analyzed and completedby sophisticated computational methods.
In recent years, a number of computational algorithmshave been developed to infer protein-protein interactions,such as those methods based on gene fusion (RosettaStone) [7,8], phylogenetic profile [9], protein structure[10], and domain information [11]. In particular, infer-ring protein-protein interactions (PPI) based on domaininformation, such as association method [11], probabilis-tic method [12-14], SVM-based method [15], and LP-based approach [16], has attracted much attention due toits clear biological implication and simplicity. In additionto these methods for protein interaction prediction, infer-ring domain-domain interactions (DDI) by integratingmultiple data sources has also been investigated [17-19].
Domain-based protein interaction prediction assumesthat proteins are composed by a set of recognition ele-ments which are referred to as domains, and protein-pro-tein interactions are achieved through domaininteractions [12]. A typical procedure for these methodsincludes two steps. Firstly domain interactions areinferred from experimental protein interactions, and thennew protein interactions are predicted based on theinferred domain interactions according to either a proba-bilistic or deterministic model. The difference betweenprobabilistic and deterministic models is whether or notthey are based on the probabilistic formula describing therelations between domain interactions and protein inter-actions [12]. Most existing algorithms consider domain-domain pairs as the basic units of protein-protein interac-tions, and these domain-domain interactions are assumedto be independent. However, such an assumption is actu-ally not biologically reasonable because two or moredomains may cooperatively interact with another domain[20]. In addition, there are many superdomains wheretwo domains always appear together in individual pro-teins to mediate the interactions. Given the close relationsbetween two domains in a superdomain, the independ-ence assumption of domain-domain interactions doesnot generally hold. For example, domain 4 of RNA
polymerase Rpb1 (PF05000) and domain 1 of RNApolymerase Rpb1 (PF00623) constitute a superdomain,and they always appear together in individual proteinssuch as YOR341W, YDL140C and YOR116C, and havemany common domain interaction partners [21].
Recently, Han et al. studied domain combinations in pro-tein interactions [22,23]. In their work, the appearancefrequencies of domain combinations in a set of interact-ing and non-interacting protein pairs are counted to con-struct AP (Appearance Probability) matrices [22,23]which provide useful information about the distributionof multi-domain interactions. For example, among thelisted 300 domain combination pairs with high appear-ance probability values (top300) which are counted basedon the total 5826 protein interaction pairs in yeast, thereare 246 two-domain pairs, 44 three-domain pairs and 10four and above domain pairs. Such statistical result indi-cates that many domains are closely correlated and tendto appear in interacting protein pairs together. In addi-tion, Wang and Caetano-Anolles [24] used the occurrenceand abundance of the molecular interactome of domaincombinations to construct global phylogenic trees. Whena closely correlated domain combination appears in aninteractome, domains in this combination may mediatethe interaction simultaneously and cooperatively.
Similar to proteins in a complex which cooperatively bindto each other so as to achieve specific functions [1], thereis also such a cooperation among domains in proteininteractions. For example, Klemm and Pabo [25] foundthat two unlinked polypeptides corresponding to thePOU-specific domain and the POU homeo domain inprotein Oct-1 bind cooperatively to the octamer site.Moza et al. [20] showed that the binding energeticsbetween different hot regions consisting of interfacial res-idues in a protein-protein interaction are not strictly addi-tive. Cooperative binding energetics between distinct hotregions is significant. They pointed out that cooperativitybetween hot regions has significant implications for theprediction of protein-protein interactions. When the hotregions are distributed over different domains in proteins,the cooperativity between different hot regions is actuallyembodied by multi-domain cooperation. Hence, reveal-ing such domain cooperation may provide deep insightsinto the essential mechanism of protein interactions at thedomain level, and can also be further exploited toimprove the accuracy of protein interaction prediction.
In this paper, we firstly aim to identify cooperativedomains from protein interaction data by extending two-domain interactions to multi-domain interactions. Coop-erative domains mean that the strength of their coopera-tive interaction with some domain is stronger than thecorresponding domain-domain interactions. Then, by
Page 2 of 20(page number not for citation purposes)
BMC Bioinformatics 2007, 8:391 http://www.biomedcentral.com/1471-2105/8/391
employing the information of both multi-domains andmultiple organisms, we propose a general frameworkbased on a Linear Programming with Multi-domain pairs(LPM) and an Association Probabilistic Method withMulti-domain pairs (APMM), to predict protein interac-tions in a more accurate manner. Experimental resultsdemonstrate that our approach not only can identifycooperative domains effectively but also has a higheraccuracy for predicting protein interactions than the exist-ing methods. Cooperative domains, including stronglycooperative domains and superdomains, were detectedfrom major interaction databases, e.g. MIPS and DIP, andmany of them were verified by checking physical interac-tions from the crystal structures of protein complexes inPDB (Protein Data Bank). These crystal structures of com-plexes provide intuitive evidences for such cooperation. Inaddition, comparison experiments in terms of protein/domain interaction prediction also justified the benefit ofconsidering multi-domain cooperation.
ResultsIn this paper, we investigate domain cooperation in pro-tein interactions by extending two-domain interactions tomulti-domain interactions. We first define the types ofdomains and domain pairs, and then describe the mainresults. Assume that there are M domains D1, …, DMinvolved in the experimental interaction data. We use(Dm, Dn) to represent a two-domain pair, one domain in
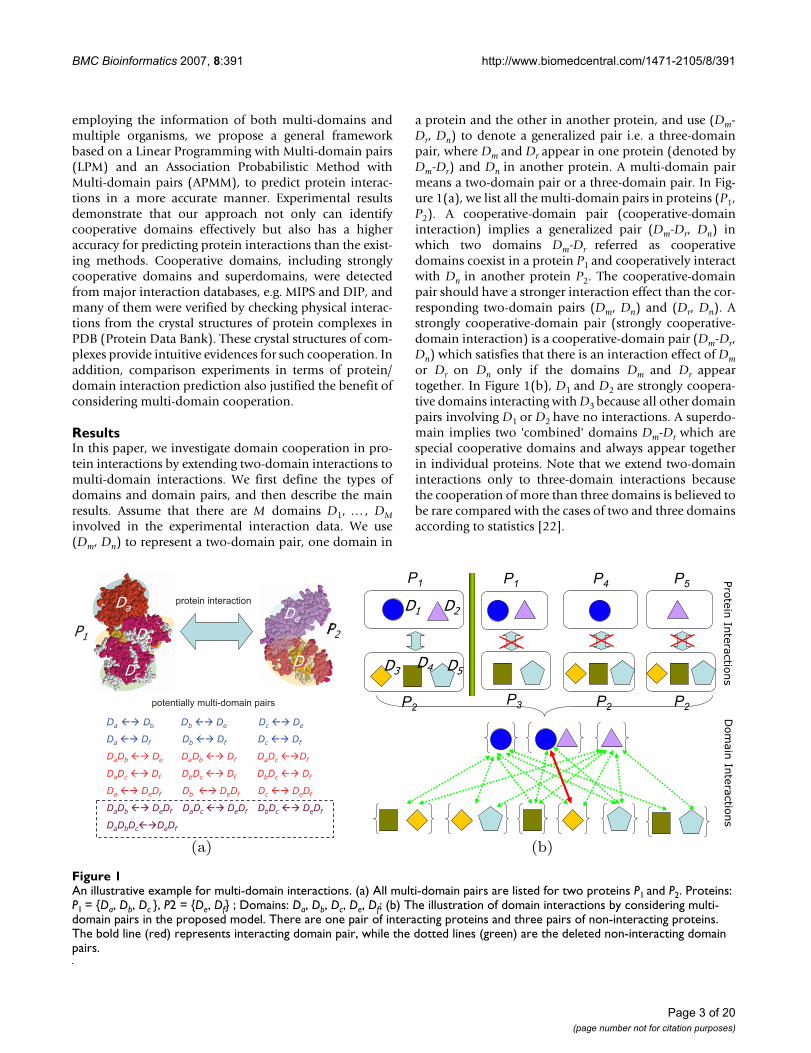
a protein and the other in another protein, and use (Dm-Dr, Dn) to denote a generalized pair i.e. a three-domainpair, where Dm and Dr appear in one protein (denoted byDm-Dr) and Dn in another protein. A multi-domain pairmeans a two-domain pair or a three-domain pair. In Fig-ure 1(a), we list all the multi-domain pairs in proteins (P1,P2). A cooperative-domain pair (cooperative-domaininteraction) implies a generalized pair (Dm-Dr, Dn) inwhich two domains Dm-Dr referred as cooperativedomains coexist in a protein P1 and cooperatively interactwith Dn in another protein P2. The cooperative-domainpair should have a stronger interaction effect than the cor-responding two-domain pairs (Dm, Dn) and (Dr, Dn). Astrongly cooperative-domain pair (strongly cooperative-domain interaction) is a cooperative-domain pair (Dm-Dr,Dn) which satisfies that there is an interaction effect of Dmor Dr on Dn only if the domains Dm and Dr appeartogether. In Figure 1(b), D1 and D2 are strongly coopera-tive domains interacting with D3 because all other domainpairs involving D1 or D2 have no interactions. A superdo-main implies two 'combined' domains Dm-Dr which arespecial cooperative domains and always appear togetherin individual proteins. Note that we extend two-domaininteractions only to three-domain interactions becausethe cooperation of more than three domains is believed tobe rare compared with the cases of two and three domainsaccording to statistics [22].
An illustrative example for multi-domain interactionsFigure 1An illustrative example for multi-domain interactions. (a) All multi-domain pairs are listed for two proteins P1 and P2. Proteins: P1 = {Da, Db, Dc }, P2 = {De, Df} ; Domains: Da, Db, Dc, De, Df; (b) The illustration of domain interactions by considering multi-domain pairs in the proposed model. There are one pair of interacting proteins and three pairs of non-interacting proteins. The bold line (red) represents interacting domain pair, while the dotted lines (green) are the deleted non-interacting domain pairs.
P2
Da
Db
Db
De
Dc
De
Da
Df
Db
Df
Dc
Df
DaDb
De
DaDb
Df
DaDc
Df
DaDc
Df
DbDc
Df
DbDc
Df
Da
DeDf
Db
DeDf
Dc
DeDf
DaDb
DeDfDaDc
DeDfDbDc
DeDf
DaDbDc
DeDf
De
Df
protein interaction
potentially multi-domain pairs
P1
Da
Dc
Db
(a)
D1 D2
D5D4D3
Protein
Interactio
ns
Dom
ain
Interactio
ns
P1
P2
P1
P3
P4
P2
P2
P5
(b)
Page 3 of 20(page number not for citation purposes)

BMC Bioinformatics 2007, 8:391 http://www.biomedcentral.com/1471-2105/8/391
The concept of cooperative domains in our work seems tobe similar to Han et al.'s "domain combination" [22,23].However, there are two fundamental differences betweenthese two concepts. Firstly, the definition of domain com-bination is not related to domain interaction strength.Each domain combination pair is considered in theirapproach, no matter what its appearance frequency is ininteracting and non-interacting protein pairs. In contrast,the definition of cooperative domains emphasizes "coop-eration" and is related to domain interaction strength. Byan elaborated variable selection strategy (see Methods),only when the interaction strength of a three-domain pair(Dm-Dr, Dn) is larger than those of the corresponding two-domain pairs (Dm, Dn) and (Dr, Dn), this three-domainpair can possibly be a cooperative-domain pair and con-sidered in the model. Secondly, there is no redundant cor-relation between different domain combinations in ourwork. For example, if a three-domain pair (Dm-Dr, Dn) isconsidered in our method according to the rules of select-ing variables (i.e. Dm, Dr are considered as cooperativedomains), the two-domain pairs (Dm, Dn) and (Dr, Dn)will not be included into the consideration as interactingdomains in the same protein pair to eliminate the redun-dancy, in contrast to the high correlation among Han etal.'s domain combinations [22,23].
In the following text, Pr(dm, n = 1) represents the probabil-ity that domain Dm interacts with Dn. Pr(dmr, n = 1) repre-sents the probability that domains Dm and Drcooperatively interact with Dn. Similarly, Pr(dm, nr = 1) rep-resents the probability that domains Dn and Dr coopera-tively interact with Dm. Our approach for detectingcooperative domains in protein-protein interactions canbe summarized as three steps. First, we extend the conven-tional probabilistic model for inferring domain interac-tions to accommodate multi-domain pairs. Then, theinteraction probabilities of multi-domain pairs are esti-mated by the proposed approach. Finally, according tothe interaction probabilities of multi-domain pairs, coop-erative domains and superdomains are detected. Thedetailed information on the methodology is given inMethods.
Identification of multi-domain cooperationIdentifying cooperative domains and superdomainsOur method is able to identify biologically meaningfulsuperdomains and putative cooperative domains. Weillustrate this feature by using MIPS data set. A cooperativedomain pair has a stronger interaction effect than theircorresponding two-domain pairs. Therefore, domains Dmand Dr are cooperative domains if Pr(dm, n = 1) <Pr(dmr, n =1) and Pr(dr, n = 1) <Pr(dmr, n = 1) from the results of LPMor APMM. From the definitions, domains in a superdo-main or in a strongly cooperative-domain pair areexpected to have similar biological functions. We applied
our approach to protein physical interaction data inMIPS1 (see Methods) to get reliable cooperative-domaininteractions.
Totally we found 5187 two-domain interactions (with no-zero interaction probability), 83 superdomains and 650cooperative-domain pairs, among which 525 pairs arestrongly cooperative domain interactions according to theabove definition. Some detected (strongly) cooperativedomains and superdomains in MIPS1 are respectivelylisted in Tables 1, 2 and 3. To investigate functional rela-tions of domains in these superdomains and cooperativedomains, we listed their Pfam descriptions and GO anno-tations. GO similarity was computed for two domainsboth with GO annotations in superdomains (Table 1).From these tables, we can see that two domains in mostsuperdomains and some cooperative domains have simi-lar GO annotations or belong to a same family, which isconsistent with our hypotheses, i.e., domains in a cooper-ative-domain interaction work cooperatively to facilitatespecific functions. For instance, two domains in superdo-mains PF05000-PF00623, PF02775-PF00205, PF02800-PF00044 or PF00488–PF05192 have identical or similarfunctions at the respective GO levels. For those superdo-mains without GO annotations, the Pfam descriptions oftwo domains in most of them are also similar, such asPF08033-PF04810, PF03953-PF0009 or PF08544-PF00288. For cooperative domains, some of them havesimilar GO annotations of functions, such as PF00806-PF00076, where PF00806 is a Pumilio-family RNA bind-ing repeat and PF00076 is a RNA recognition motif. Bothdomains are necessary for RNA binding. Some coopera-tive domains have no GO annotations but belong to samefamilies, such as PF01466–PF03931. Both PF01466(Skp1, dimerisation domain) and PF03931 (Skp1_POZ,tetramerisation domain) belong to the Skyp1 family. It isinteresting that three domains in the strongly cooperative-domain interaction (PF04998-PF00623, PF01191) arefound to have same functions, and they are all RNApolymerase domains. As another example, we identifiedcooperative domains PF00036–PF08226, and the Pfamdescription also supports the combination of PF08226(DUF1720) with PF00036 (EF hand) [21]. Such factsimply that we can infer the functions of cooperativedomains if one of them has known functions. We alsoapplied our approach to DIP data set, and the detectedsuperdomains and cooperative domains are given inTables I-III (Additional File 1)
Verifying cooperative domains by crystal structuresIn this section, we verify the detected cooperative domainsby checking their physical interactions from the crystalstructures of protein complexes in PDB and examine theessential mechanism of protein interactions at thedomain level. The complex crystal structures in PDB can
Page 4 of 20(page number not for citation purposes)
BMC Bioinformatics 2007, 8:391 http://www.biomedcentral.com/1471-2105/8/391
be regarded as a gold standard to verify protein interac-tions and domain interactions. The seq2struct webresource [26] was used to search sequence-structure links.By focusing on the protein pairs in which proteins aremapped to the same PDB IDs but possess different chainIDs, we found 50 protein pairs with crystal structures thatcontain cooperative-domain pairs identified by ourapproach (t-test value is significant by comparing withrandomly generated domain pairs).
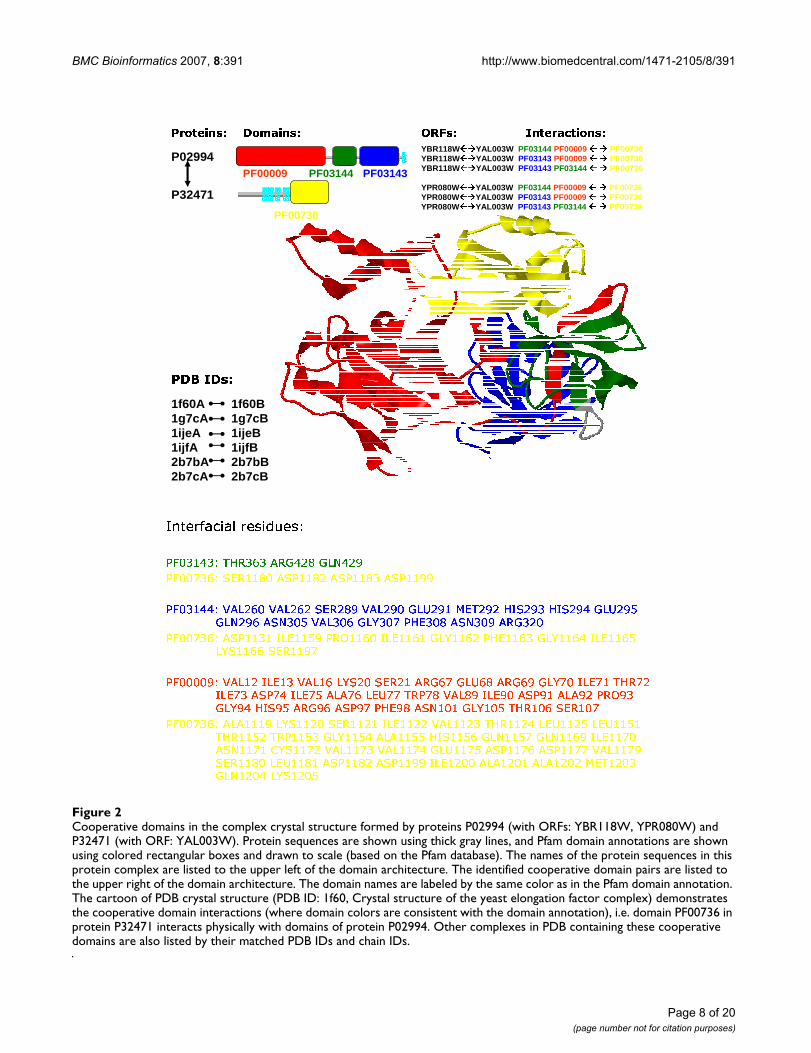
Figure 2 shows cooperative domains in a complex crystalstructure formed by physical interactions of proteinsP02994 (ORFs: YBR118W, YPR080W) and P32471 (ORF:YAL003W), where P02994 has three domains andP32471 has one domain PF00736. This complex is alsoincluded in the complex database PROTCOM [27]. Inter-acting protein pairs and their Pfam domain annotationsare described in this figure. Clearly, EF-1 guanine nucle-otide exchange domain PF00736 in P32471 has interac-tions with all of the domains in P02994. Theseinteractions are verified by the binding sites of PF00736with the domains in P02994. The cartoon of crystal struc-ture illustrates that all cooperative-domain interactions in(P02994, P32471) are correctly identified and supportedby the interfacial residues involved in the interaction. The
interfacial residues are picked out by a simple rule, i.e.their Cα atoms are within the distance threshold 10Å,which is consistent with the more accurate computationgiven in PROTCOM. This example provides an intuitiveevidence for the cooperation among domains in the inter-action of P02994 and P32471.
Furthermore we also revealed some complexes in PDBwhich are not reported by PROTCOM [27]. For example,three domains Arm, IBB and IBN_N which belong toArmadillo repeat superfamily form a cooperative-domaininteraction (PF00514–PF01749, PF03810), and suchmulti-domain cooperation leads to the complex formedby protein Q02821 (YNL189W) and P33307 (YGL238W)(PDB ID 1wa5, GTP-Binding nuclear protein RAN). Gen-erally, multiple cooperative-domain interactions in aninteracting protein pair often correspond to a more com-plicated complex. The complete list of all the verifiedcooperative domain interactions by crystal structures inPDB and more detailed information are provided on ourweb site.
Table 1: Superdomains detected by our method from MIPS protein interaction data, where GO annotations are denoted in italic
Superdomains Descriptions GO similarity
PF00488, PF05192 (1) MutS domain V, ATP binding, damaged DNA binding, mismatch repair(2) MutS domain III, DNA metabolism
2-1-2-5-11-27-1-8-102-1-2-5-11-27-1Similarity: 7
PF02775, PF00205 (1) Thiamine pyrophosphate enzyme, C-terminal TPP binding domain, catalytic activity, thiamin pyrophosphate binding(2) Thiamine pyrophosphate enzyme, central domain, magnesium ion binding, thiamin pyrophosphate binding
1-1-2-12-1-81-1-2-12-1-8Similarity: 6
PF08033, PF04810 (1) Sec23/Sec24 beta-sandwich domain(2) Sec23/Sec24 zinc finger, COPII vesicle coat, protein binding, intracellular protein transport, ER to Golgi vesicle-mediated transport
PF03953, PF00091 (1) Tubulin/FtsZ family, C-terminal domain, protein complex, GTP binding, GTPase activity, protein polymerization(2) Tubulin/FtsZ family, GTPase domain
PF07687, PF01546 (1) Peptidase dimerisation domain, hydrolase activity, protein dimerization activity(2) Peptidase family M20/M25/M40, metallopeptidase activity, proteolysis
1-1-3-161-1-3-16-18-6Similarity: 4
PF05000, PF00623 (1) RNA polymerase Rpb1, domain 4, DNA-directed RNA polymerase activity, DNA binding, transcription(2) RNA polymerase Rpb1, domain 2, nucleus, DNA-directed RNA polymerase activity, DNA binding, transcription
1-1-3-39-16-3-161-1-3-39-16-3-16Similarity: 7
PF08544, PF00288 (1) GHMP kinases C terminal(2) GHMP kinases N terminal domain, ATP binding, kinase activity, phosphorylation
PF01798, PF08060 (1) Putative snoRNA binding domain(2) NOSIC (NUC001) domain
PF02800, PF00044 (1) Glyceraldehyde 3-phosphate dehydrogenase, C-terminal domain, NAD binding, glyceraldehyde-3-phosphate dehydrogenase (phosphorylating) activity, glycolysis(2) Glyceraldehyde 3-phosphate dehydrogenase, NAD binding domain, NAD binding, glyceraldehyde-3-phosphate dehydrogenase (phosphorylating) activity, glycolysis
2-1-2-5-11-1-4-9-1-5-12-1-2-5-11-1-4-9-1-5-1Similarity: 11
PF08030, PF08022 (1) Ferric reductase NAD binding domain(2) FAD-binding domain
Page 5 of 20(page number not for citation purposes)
BMC Bioinformatics 2007, 8:391 http://www.biomedcentral.com/1471-2105/8/391
PPI prediction based on multi-domain cooperationTest on numerical PPI data setsIn addition to identifying superdomains and cooperativedomains, our approach has a higher prediction accuracyfor protein interactions by exploiting the information ofboth multi-domains and multiple organisms. In this sec-tion, we compared LPM and APMM with the existingmethods, such as association based methods (ASNM [16],ASSOC [11]), and EM method [12]. Among those existingmethods, the ASSOC and EM are developed for the binaryinteraction data whereas ASNM can be applied to experi-ment ratio data. We evaluated each method by fivefoldcross validation on Ito's experiment ratio data [28] andassessed the prediction accuracy by root-mean-squareerror (RMSE) (see Methods).
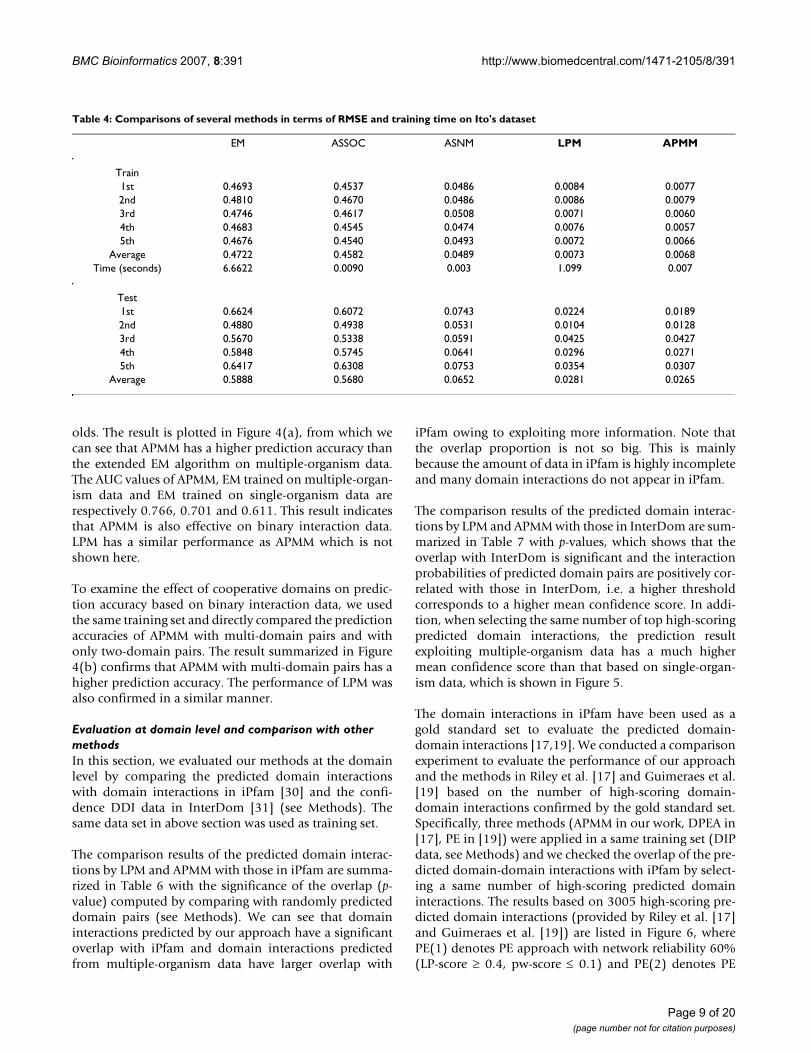
The performance of each method in terms of RMSE andelapsed training time for fivefold cross-validation is sum-marized in Table 4. In order to check the effect of cooper-ative domains on the accuracy, here we computed RMSEonly on those protein pairs containing cooperative-domain pairs. RMSE comparison results on all protein
pairs are given in Table IV and Table V (Additional file 1).From Table 4 we can see that the performances of EM andASSOC methods on experiment ratio data are not goodsince their training and testing errors are very high. ASNMwhich is an extension of ASSOC has much better resultsthan ASSOC. LPM has a lower training and testing errorthan the methods based on two-domain pairs. Table 4also indicates that APMM has the lowest error in bothtraining and testing prediction of protein interactions. Inaddition, there is no significant increase on the computa-tion time when multi-domain pairs are included.
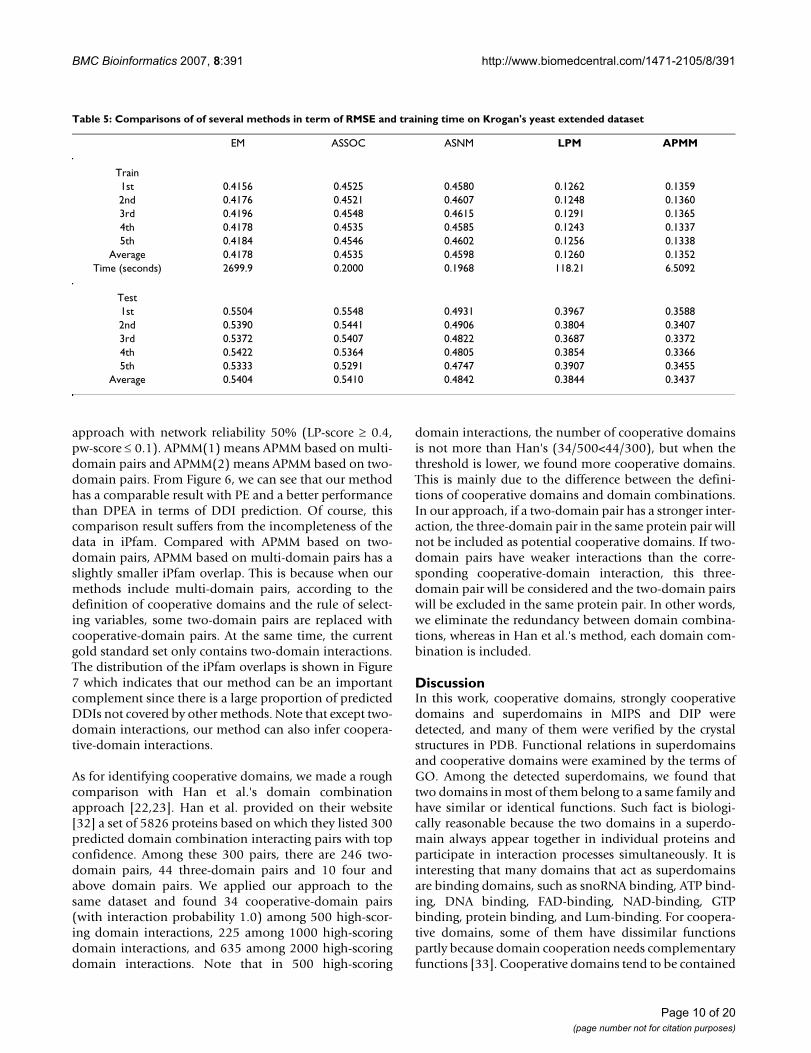
The results for Ito's dataset in five rounds are not so con-sistent because there may exist bias in five divided subsetsdue to the small size of this dataset. Another larger datasetused for cross-validation is Krogan's confidence data [29](see Methods). We used this set to test if or not variousmethods can correctly predict the interaction confidenceof protein pairs. The result is summarized in Table 5, fromwhich we can see that for the confidence prediction, ourapproach (LPM and APMM) employing multi-domainpairs again has better performance both in training and in
Table 2: Cooperative domains detected by our method from MIPS protein interaction data, where GO annotations are denoted in italic
Cooperative domains (Interactor I) Descriptions Interactor II Descriptions
PF00069, PF00786 (1) Protein kinase domain, ATP binding, protein kinase activity, protein amino acid phosphorylation(2) P21-Rho-binding domain
PF00018 SH3 domain, in a variety of proteins with enzymatic activity
PF00400, PF00646 (1) WD domain, G-beta repeat, coordinating multi-protein complex assemblies(2) F-box domain, mediating protein-protein interactions in a variety of contexts
PF01466 Skp1 family, dimerisation domain
PF00439, PF00176 (1) Bromodomain, interacting specifically with acetylated lysine(2) SNF2 family N-terminal domain, DNA binding, ATP binding
PF04433 SWIRM domain, mediating protein-protein interactions
PF00169, PF00787 (1) PH domain(2) PX domain, protein-protein interaction domain, protein binding, phosphoinositide binding, intracellular signaling cascade
PF08632 Sporulation protein Zds1 C terminal region, suppress the calcium sensitivity of Zds1 deletions
PF00069, PF00169 (1) Protein kinase domain, ATP binding, protein kinase activity, protein amino acid phosphorylation(2) PH domain
PF00018 SH3 domain, in a variety of proteins with enzymatic activity
PF00018, PF00063 (1) SH3 domain, in a variety of proteins with enzymatic activity(2) Myosin head (motor domain), myosin, ATP binding, motor activity
PF02205 WH2 motif, actin-binding motif
PF00806, PF00076 (1)Pumilio-family RNA binding repeat, DNA binding(2) RNA recognition motif
PF00501 AMP-binding enzyme, catalytic activity, metabolism
PF02985, PF03810 (1) HEAT repeat, involved in intracellular transport processes(2) Importin-beta N-terminal domain, nuclear pore, nucleus, cytoplasm, protein transporter activity, protein import into nucleus, docking
PF04096 Nucleoporin autopeptidase, nuclear pore, transport
PF02178, PF00271 (1) AT hook motif, DNA binding motifs(2) Helicase conserved C-terminal domain, ATP binding, helicase activity, nucleic acid binding
PF00249 Myb-like DNA-binding domain, nucleus, DNA binding
Page 6 of 20(page number not for citation purposes)

BMC Bioinformatics 2007, 8:391 http://www.biomedcentral.com/1471-2105/8/391
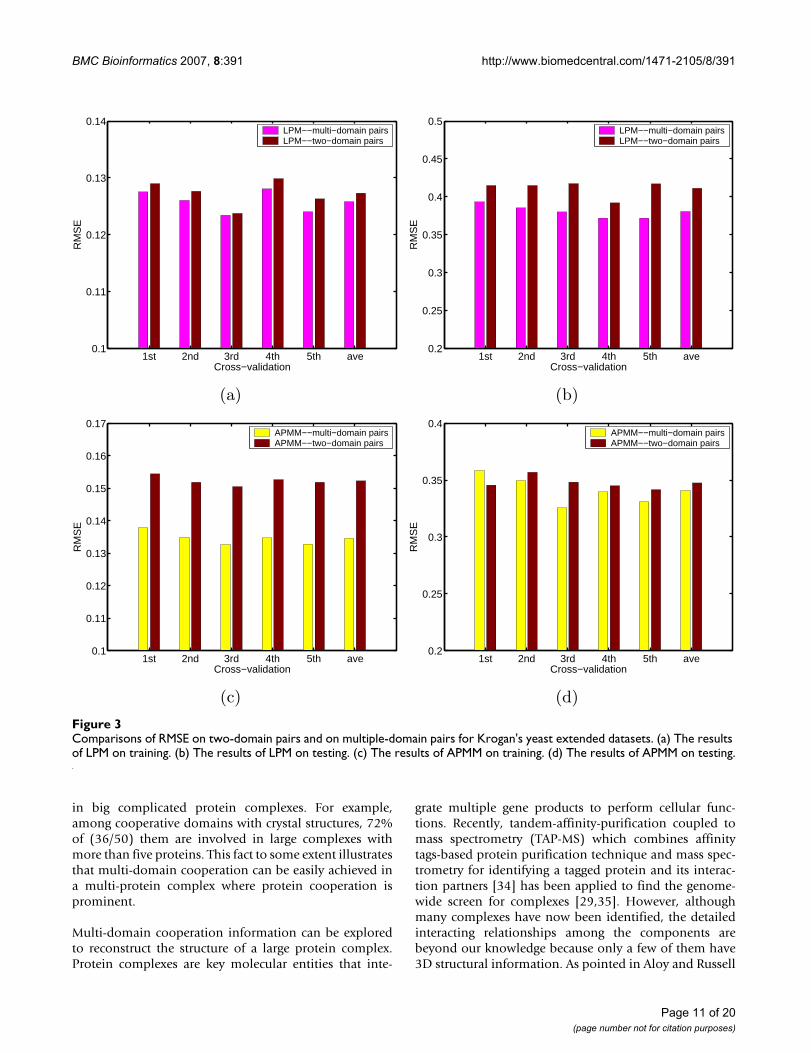
testing than other methods. LPM generally has less train-ing error than APMM but its testing error is slightly higherthan that of APMM. An example to illustrate the effect ofcooperative domains on the prediction accuracy is givenin Additional file 1. We also made a direct comparison ofour approach based on two-domain pairs and multi-domain pairs, and the results are summarized in Figure 3.We can see that LPM based on multi-domain pairs intraining and testing has less prediction error in each roundof fivefold cross validation than LPM based on only two-domain pairs. APMM also has such a tendency except thefirst round in testing. Such results further confirm the ben-efit of considering multi-domain interactions.
Test on binary PPI data sets from multiple organismsCompared with single organism, data sets from multipleorganisms can provide more information, e.g. they covermore domains. In contrast to the existing methods whichmainly use the data from single organism, LPM andAPMM can employ the data sets from multiple organismswith the consideration of their different reliabilities. Inthis section, we used binary interaction data from multi-ple organisms collected by Liu et al. [14] (see Methods) to
compare our approach with the extended EM algorithm[14] and validate the benefit of multi-domain pairs onbinary interaction data.
Based on the same test set and training set, it is convenientto compare our methods and the extended EM [14]. Thetraining sets respectively consist of protein interactionsfrom single organism (yeast) and multiple organisms.Based on yeast protein interaction dataset, we found 4556two-domain interactions (with no-zero interaction prob-ability), 94 superdomains, 652 cooperative domain pairs,among which 640 pairs are strongly cooperative-domaininteractions. In the protein interaction dataset of threeorganisms, we detected 34123 two-domain interactions(with no-zero interaction probability), 259 superdomainsand 5633 cooperative-domain interactions, where 5400are strongly cooperative. Among the cooperative-domaininteractions in yeast and three organisms, 117 pairs areyeast-specific. With these domain interactions, the predic-tion accuracy of protein-protein interactions is measuredby the receiver operating characteristic (ROC) curve,which is a plot of the true positive rate (sensitivity) againstthe false positive rate (1–specificity) for different thresh-
Table 3: Strongly cooperative domains detected by our method from MIPS protein interaction data, where GO annotations are denoted in italic
Cooperative domains (Interactor I) Descriptions Interactor II Descriptions
PF00618, PF00018 (1) Guanine nucleotide exchange factor for Ras-like GTPases; N-terminal motif, intracellular, regulation of small GTPase mediated signal transduction(2) SH3 domain, in a variety of proteins with enzymatic activity
PF00012 Hsp70 protein, involved in different cellular compartments (nuclear, cytosolic, mitochondrial, endoplasmic reticulum, etc
PF01466, PF03931 (1) Skp1 family, dimerisation domain(2) Skp1 family, tetramerisation domain
PF00646 F-box domain, mediating protein-protein interactions
PF04998, PF00623 (1) RNA polymerase Rpb1, domain 5, DNA-directed RNA polymerase activity, DNA binding, transcription(2) RNA polymerase Rpb1, domain 2, nucleus, DNA-directed RNA polymerase activity, DNA binding, transcription
PF01191 RNA polymerase Rpb5, C-terminal domain, DNA-directed RNA polymerase activity, DNA binding, transcription
PF00806, PF00076 (1) Pumilio-family RNA binding repeat, RNA binding(2) RNA recognition motif, nucleic acid binding
PF00660 Seripauperin and TIP1 family, response to stress
PF00036, PF08226 (1) EF hand, calcium ion binding(2) Domain of unknown function (DUF1720), in different combinations with cortical patch components EF hand, SH3 and ENTH
PF07651 ANTH domain, phospholipid binding
PF00443, PF00581 (1) Ubiquitin carboxyl-terminal hydro-lase, cysteine-type endopeptidase activity, ubiquitin thiolesterase activity, ubiquitin-dependent protein catabolism(2) Rhodanese-like domain
PF00611 Fes/CIP4 homology domain, regulatory processes
PF00620, PF00787 (1) RhoGAP domain, intracellular, signal transduction(2) PX domain, protein binding, phos-phoinositide binding, intracellular signaling cascade
PF08632 Sporulation protein Zds1 C terminal region, sporulation, suppress the calcium sensitivity of Zds1 deletions
PF01426, PF00439 (1) BAH domain, DNA binding, involved in protein-protein interaction(2) bromodomain, involved in protein-protein interactions
PF00076 RNA recognition motif, nucleic acid binding
Page 7 of 20(page number not for citation purposes)
BMC Bioinformatics 2007, 8:391 http://www.biomedcentral.com/1471-2105/8/391
Page 8 of 20(page number not for citation purposes)
Cooperative domains in the complex crystal structure formed by proteins P02994 (with ORFs: YBR118W, YPR080W) and P32471 (with ORF: YAL003W)Figure 2Cooperative domains in the complex crystal structure formed by proteins P02994 (with ORFs: YBR118W, YPR080W) and P32471 (with ORF: YAL003W). Protein sequences are shown using thick gray lines, and Pfam domain annotations are shown using colored rectangular boxes and drawn to scale (based on the Pfam database). The names of the protein sequences in this protein complex are listed to the upper left of the domain architecture. The identified cooperative domain pairs are listed to the upper right of the domain architecture. The domain names are labeled by the same color as in the Pfam domain annotation. The cartoon of PDB crystal structure (PDB ID: 1f60, Crystal structure of the yeast elongation factor complex) demonstrates the cooperative domain interactions (where domain colors are consistent with the domain annotation), i.e. domain PF00736 in protein P32471 interacts physically with domains of protein P02994. Other complexes in PDB containing these cooperative domains are also listed by their matched PDB IDs and chain IDs.
YBR118W YAL003W PF03144 PF00009 PF00736YBR118W YAL003W PF03143 PF00009 PF00736YBR118W YAL003W PF03143 PF03144 PF00736
YPR080W YAL003W PF03144 PF00009 PF00736 YPR080W YAL003W PF03143 PF00009 PF00736 YPR080W YAL003W PF03143 PF03144 PF00736
P02994
P32471
PF00009 PF03144 PF03143
PF00736
1f60A1g7cA1ijeA1ijfA2b7bA2b7cA
1f60B1g7cB1ijeB1ijfB2b7bB2b7cB
BMC Bioinformatics 2007, 8:391 http://www.biomedcentral.com/1471-2105/8/391
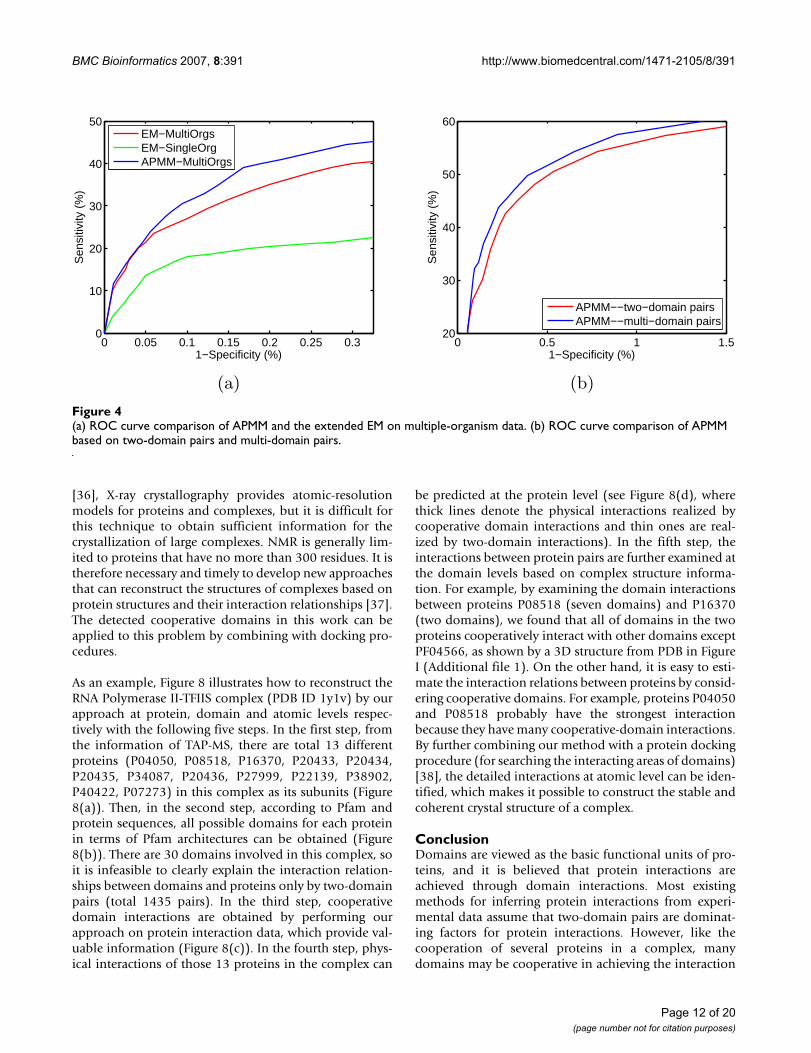
olds. The result is plotted in Figure 4(a), from which wecan see that APMM has a higher prediction accuracy thanthe extended EM algorithm on multiple-organism data.The AUC values of APMM, EM trained on multiple-organ-ism data and EM trained on single-organism data arerespectively 0.766, 0.701 and 0.611. This result indicatesthat APMM is also effective on binary interaction data.LPM has a similar performance as APMM which is notshown here.
To examine the effect of cooperative domains on predic-tion accuracy based on binary interaction data, we usedthe same training set and directly compared the predictionaccuracies of APMM with multi-domain pairs and withonly two-domain pairs. The result summarized in Figure4(b) confirms that APMM with multi-domain pairs has ahigher prediction accuracy. The performance of LPM wasalso confirmed in a similar manner.
Evaluation at domain level and comparison with other methodsIn this section, we evaluated our methods at the domainlevel by comparing the predicted domain interactionswith domain interactions in iPfam [30] and the confi-dence DDI data in InterDom [31] (see Methods). Thesame data set in above section was used as training set.
The comparison results of the predicted domain interac-tions by LPM and APMM with those in iPfam are summa-rized in Table 6 with the significance of the overlap (p-value) computed by comparing with randomly predicteddomain pairs (see Methods). We can see that domaininteractions predicted by our approach have a significantoverlap with iPfam and domain interactions predictedfrom multiple-organism data have larger overlap with
iPfam owing to exploiting more information. Note thatthe overlap proportion is not so big. This is mainlybecause the amount of data in iPfam is highly incompleteand many domain interactions do not appear in iPfam.
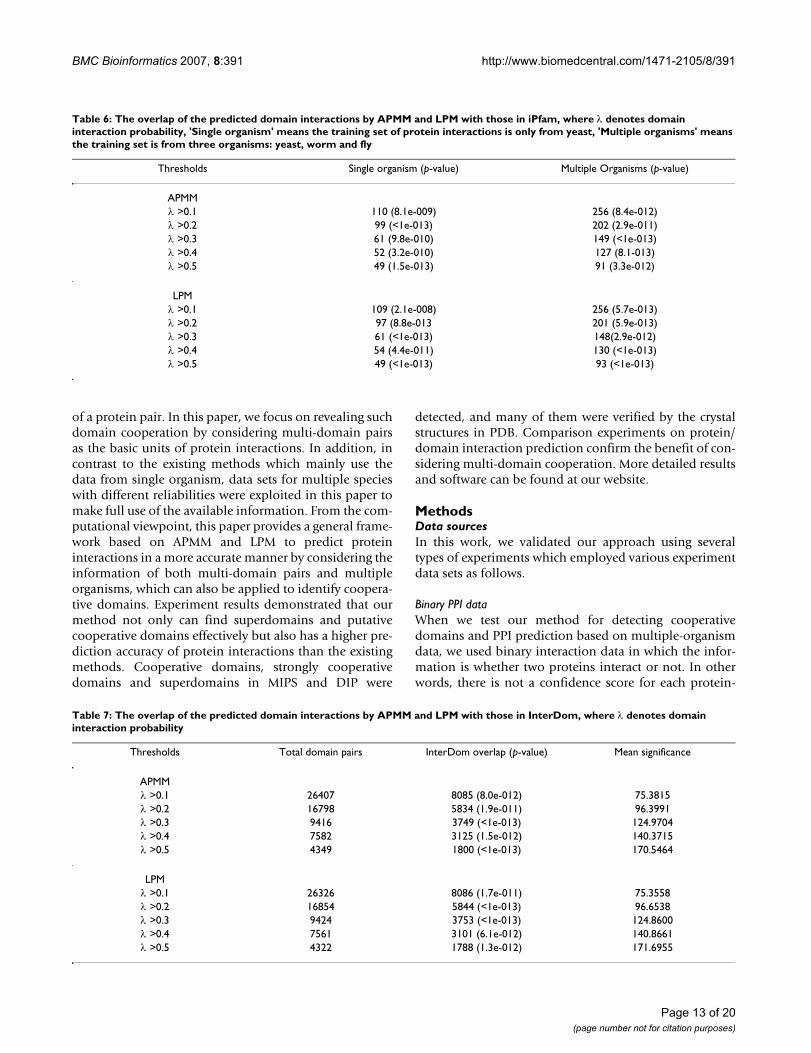
The comparison results of the predicted domain interac-tions by LPM and APMM with those in InterDom are sum-marized in Table 7 with p-values, which shows that theoverlap with InterDom is significant and the interactionprobabilities of predicted domain pairs are positively cor-related with those in InterDom, i.e. a higher thresholdcorresponds to a higher mean confidence score. In addi-tion, when selecting the same number of top high-scoringpredicted domain interactions, the prediction resultexploiting multiple-organism data has a much highermean confidence score than that based on single-organ-ism data, which is shown in Figure 5.
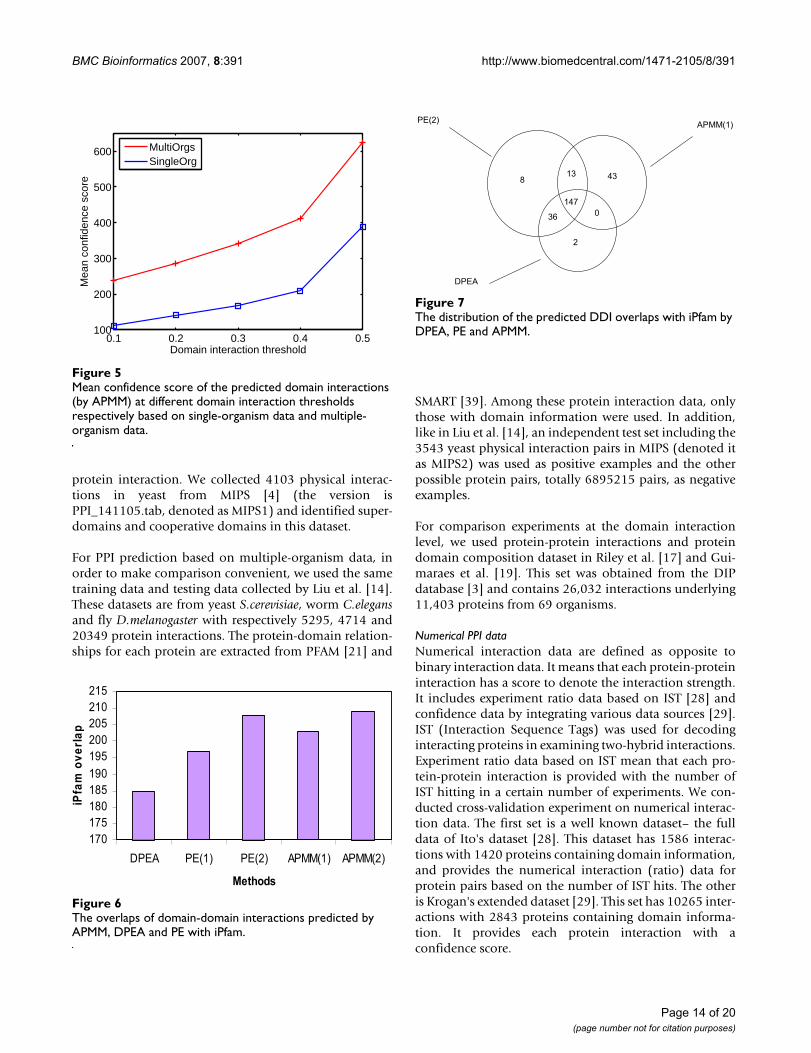
The domain interactions in iPfam have been used as agold standard set to evaluate the predicted domain-domain interactions [17,19]. We conducted a comparisonexperiment to evaluate the performance of our approachand the methods in Riley et al. [17] and Guimeraes et al.[19] based on the number of high-scoring domain-domain interactions confirmed by the gold standard set.Specifically, three methods (APMM in our work, DPEA in[17], PE in [19]) were applied in a same training set (DIPdata, see Methods) and we checked the overlap of the pre-dicted domain-domain interactions with iPfam by select-ing a same number of high-scoring predicted domaininteractions. The results based on 3005 high-scoring pre-dicted domain interactions (provided by Riley et al. [17]and Guimeraes et al. [19]) are listed in Figure 6, wherePE(1) denotes PE approach with network reliability 60%(LP-score ≥ 0.4, pw-score ≤ 0.1) and PE(2) denotes PE
Table 4: Comparisons of several methods in terms of RMSE and training time on Ito's dataset
EM ASSOC ASNM LPM APMM
Train1st 0.4693 0.4537 0.0486 0.0084 0.00772nd 0.4810 0.4670 0.0486 0.0086 0.00793rd 0.4746 0.4617 0.0508 0.0071 0.00604th 0.4683 0.4545 0.0474 0.0076 0.00575th 0.4676 0.4540 0.0493 0.0072 0.0066
Average 0.4722 0.4582 0.0489 0.0073 0.0068Time (seconds) 6.6622 0.0090 0.003 1.099 0.007
Test1st 0.6624 0.6072 0.0743 0.0224 0.01892nd 0.4880 0.4938 0.0531 0.0104 0.01283rd 0.5670 0.5338 0.0591 0.0425 0.04274th 0.5848 0.5745 0.0641 0.0296 0.02715th 0.6417 0.6308 0.0753 0.0354 0.0307
Average 0.5888 0.5680 0.0652 0.0281 0.0265
Page 9 of 20(page number not for citation purposes)
BMC Bioinformatics 2007, 8:391 http://www.biomedcentral.com/1471-2105/8/391
approach with network reliability 50% (LP-score ≥ 0.4,pw-score ≤ 0.1). APMM(1) means APMM based on multi-domain pairs and APMM(2) means APMM based on two-domain pairs. From Figure 6, we can see that our methodhas a comparable result with PE and a better performancethan DPEA in terms of DDI prediction. Of course, thiscomparison result suffers from the incompleteness of thedata in iPfam. Compared with APMM based on two-domain pairs, APMM based on multi-domain pairs has aslightly smaller iPfam overlap. This is because when ourmethods include multi-domain pairs, according to thedefinition of cooperative domains and the rule of select-ing variables, some two-domain pairs are replaced withcooperative-domain pairs. At the same time, the currentgold standard set only contains two-domain interactions.The distribution of the iPfam overlaps is shown in Figure7 which indicates that our method can be an importantcomplement since there is a large proportion of predictedDDIs not covered by other methods. Note that except two-domain interactions, our method can also infer coopera-tive-domain interactions.
As for identifying cooperative domains, we made a roughcomparison with Han et al.'s domain combinationapproach [22,23]. Han et al. provided on their website[32] a set of 5826 proteins based on which they listed 300predicted domain combination interacting pairs with topconfidence. Among these 300 pairs, there are 246 two-domain pairs, 44 three-domain pairs and 10 four andabove domain pairs. We applied our approach to thesame dataset and found 34 cooperative-domain pairs(with interaction probability 1.0) among 500 high-scor-ing domain interactions, 225 among 1000 high-scoringdomain interactions, and 635 among 2000 high-scoringdomain interactions. Note that in 500 high-scoring
domain interactions, the number of cooperative domainsis not more than Han's (34/500<44/300), but when thethreshold is lower, we found more cooperative domains.This is mainly due to the difference between the defini-tions of cooperative domains and domain combinations.In our approach, if a two-domain pair has a stronger inter-action, the three-domain pair in the same protein pair willnot be included as potential cooperative domains. If two-domain pairs have weaker interactions than the corre-sponding cooperative-domain interaction, this three-domain pair will be considered and the two-domain pairswill be excluded in the same protein pair. In other words,we eliminate the redundancy between domain combina-tions, whereas in Han et al.'s method, each domain com-bination is included.
DiscussionIn this work, cooperative domains, strongly cooperativedomains and superdomains in MIPS and DIP weredetected, and many of them were verified by the crystalstructures in PDB. Functional relations in superdomainsand cooperative domains were examined by the terms ofGO. Among the detected superdomains, we found thattwo domains in most of them belong to a same family andhave similar or identical functions. Such fact is biologi-cally reasonable because the two domains in a superdo-main always appear together in individual proteins andparticipate in interaction processes simultaneously. It isinteresting that many domains that act as superdomainsare binding domains, such as snoRNA binding, ATP bind-ing, DNA binding, FAD-binding, NAD-binding, GTPbinding, protein binding, and Lum-binding. For coopera-tive domains, some of them have dissimilar functionspartly because domain cooperation needs complementaryfunctions [33]. Cooperative domains tend to be contained
Table 5: Comparisons of of several methods in term of RMSE and training time on Krogan's yeast extended dataset
EM ASSOC ASNM LPM APMM
Train1st 0.4156 0.4525 0.4580 0.1262 0.13592nd 0.4176 0.4521 0.4607 0.1248 0.13603rd 0.4196 0.4548 0.4615 0.1291 0.13654th 0.4178 0.4535 0.4585 0.1243 0.13375th 0.4184 0.4546 0.4602 0.1256 0.1338
Average 0.4178 0.4535 0.4598 0.1260 0.1352Time (seconds) 2699.9 0.2000 0.1968 118.21 6.5092
Test1st 0.5504 0.5548 0.4931 0.3967 0.35882nd 0.5390 0.5441 0.4906 0.3804 0.34073rd 0.5372 0.5407 0.4822 0.3687 0.33724th 0.5422 0.5364 0.4805 0.3854 0.33665th 0.5333 0.5291 0.4747 0.3907 0.3455
Average 0.5404 0.5410 0.4842 0.3844 0.3437
Page 10 of 20(page number not for citation purposes)
BMC Bioinformatics 2007, 8:391 http://www.biomedcentral.com/1471-2105/8/391
in big complicated protein complexes. For example,among cooperative domains with crystal structures, 72%of (36/50) them are involved in large complexes withmore than five proteins. This fact to some extent illustratesthat multi-domain cooperation can be easily achieved ina multi-protein complex where protein cooperation isprominent.
Multi-domain cooperation information can be exploredto reconstruct the structure of a large protein complex.Protein complexes are key molecular entities that inte-
grate multiple gene products to perform cellular func-tions. Recently, tandem-affinity-purification coupled tomass spectrometry (TAP-MS) which combines affinitytags-based protein purification technique and mass spec-trometry for identifying a tagged protein and its interac-tion partners [34] has been applied to find the genome-wide screen for complexes [29,35]. However, althoughmany complexes have now been identified, the detailedinteracting relationships among the components arebeyond our knowledge because only a few of them have3D structural information. As pointed in Aloy and Russell
Comparisons of RMSE on two-domain pairs and on multiple-domain pairs for Krogan's yeast extended datasetsFigure 3Comparisons of RMSE on two-domain pairs and on multiple-domain pairs for Krogan's yeast extended datasets. (a) The results of LPM on training. (b) The results of LPM on testing. (c) The results of APMM on training. (d) The results of APMM on testing.
1st 2nd 3rd 4th 5th ave0.1
0.11
0.12
0.13
0.14
Cross−validation
RM
SE
LPM−−multi−domain pairsLPM−−two−domain pairs
(a)
1st 2nd 3rd 4th 5th ave0.2
0.25
0.3
0.35
0.4
0.45
0.5
Cross−validation
RM
SE
LPM−−multi−domain pairsLPM−−two−domain pairs
(b)
1st 2nd 3rd 4th 5th ave0.1
0.11
0.12
0.13
0.14
0.15
0.16
0.17
Cross−validation
RM
SE
APMM−−multi−domain pairsAPMM−−two−domain pairs
(c)
1st 2nd 3rd 4th 5th ave0.2
0.25
0.3
0.35
0.4
Cross−validation
RM
SE
APMM−−multi−domain pairsAPMM−−two−domain pairs
(d)
Page 11 of 20(page number not for citation purposes)
BMC Bioinformatics 2007, 8:391 http://www.biomedcentral.com/1471-2105/8/391
[36], X-ray crystallography provides atomic-resolutionmodels for proteins and complexes, but it is difficult forthis technique to obtain sufficient information for thecrystallization of large complexes. NMR is generally lim-ited to proteins that have no more than 300 residues. It istherefore necessary and timely to develop new approachesthat can reconstruct the structures of complexes based onprotein structures and their interaction relationships [37].The detected cooperative domains in this work can beapplied to this problem by combining with docking pro-cedures.
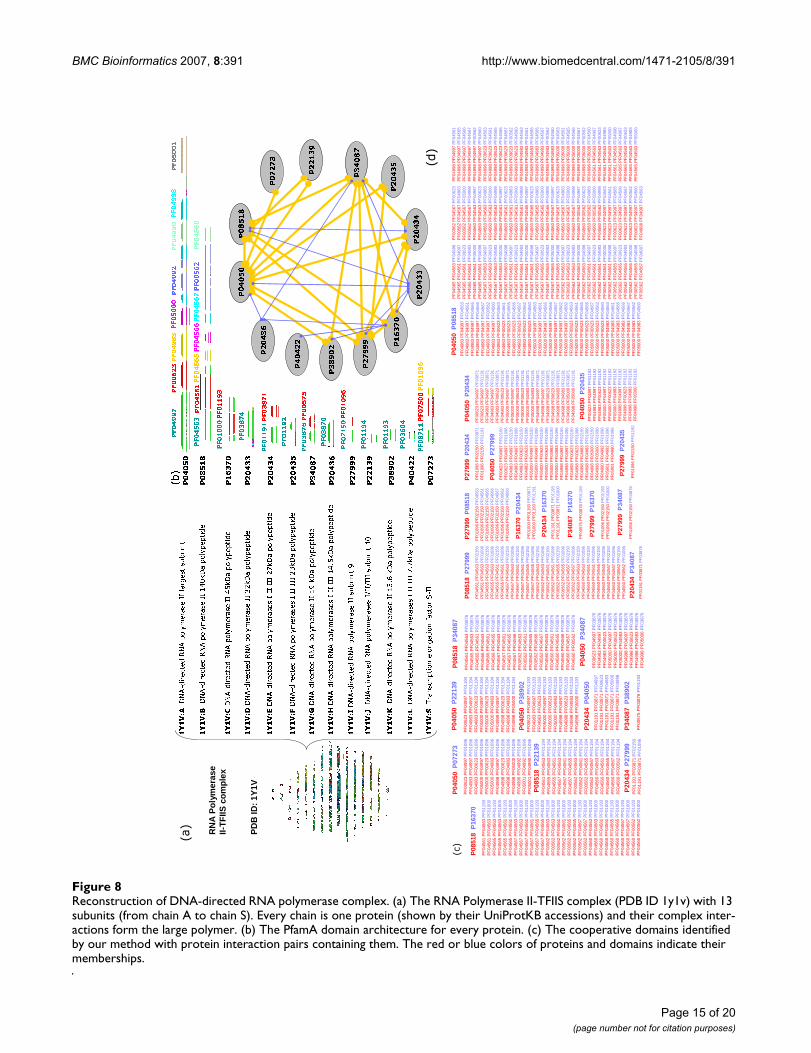
As an example, Figure 8 illustrates how to reconstruct theRNA Polymerase II-TFIIS complex (PDB ID 1y1v) by ourapproach at protein, domain and atomic levels respec-tively with the following five steps. In the first step, fromthe information of TAP-MS, there are total 13 differentproteins (P04050, P08518, P16370, P20433, P20434,P20435, P34087, P20436, P27999, P22139, P38902,P40422, P07273) in this complex as its subunits (Figure8(a)). Then, in the second step, according to Pfam andprotein sequences, all possible domains for each proteinin terms of Pfam architectures can be obtained (Figure8(b)). There are 30 domains involved in this complex, soit is infeasible to clearly explain the interaction relation-ships between domains and proteins only by two-domainpairs (total 1435 pairs). In the third step, cooperativedomain interactions are obtained by performing ourapproach on protein interaction data, which provide val-uable information (Figure 8(c)). In the fourth step, phys-ical interactions of those 13 proteins in the complex can
be predicted at the protein level (see Figure 8(d), wherethick lines denote the physical interactions realized bycooperative domain interactions and thin ones are real-ized by two-domain interactions). In the fifth step, theinteractions between protein pairs are further examined atthe domain levels based on complex structure informa-tion. For example, by examining the domain interactionsbetween proteins P08518 (seven domains) and P16370(two domains), we found that all of domains in the twoproteins cooperatively interact with other domains exceptPF04566, as shown by a 3D structure from PDB in FigureI (Additional file 1). On the other hand, it is easy to esti-mate the interaction relations between proteins by consid-ering cooperative domains. For example, proteins P04050and P08518 probably have the strongest interactionbecause they have many cooperative-domain interactions.By further combining our method with a protein dockingprocedure (for searching the interacting areas of domains)[38], the detailed interactions at atomic level can be iden-tified, which makes it possible to construct the stable andcoherent crystal structure of a complex.
ConclusionDomains are viewed as the basic functional units of pro-teins, and it is believed that protein interactions areachieved through domain interactions. Most existingmethods for inferring protein interactions from experi-mental data assume that two-domain pairs are dominat-ing factors for protein interactions. However, like thecooperation of several proteins in a complex, manydomains may be cooperative in achieving the interaction
(a) ROC curve comparison of APMM and the extended EM on multiple-organism dataFigure 4(a) ROC curve comparison of APMM and the extended EM on multiple-organism data. (b) ROC curve comparison of APMM based on two-domain pairs and multi-domain pairs.
0 0.05 0.1 0.15 0.2 0.25 0.30
10
20
30
40
50
1−Specificity (%)
Sen
sitiv
ity (
%)
EM−MultiOrgsEM−SingleOrgAPMM−MultiOrgs
(a)
0 0.5 1 1.520
30
40
50
60
1−Specificity (%)
Sen
sitiv
ity (
%)
APMM−−two−domain pairsAPMM−−multi−domain pairs
(b)
Page 12 of 20(page number not for citation purposes)
BMC Bioinformatics 2007, 8:391 http://www.biomedcentral.com/1471-2105/8/391
of a protein pair. In this paper, we focus on revealing suchdomain cooperation by considering multi-domain pairsas the basic units of protein interactions. In addition, incontrast to the existing methods which mainly use thedata from single organism, data sets for multiple specieswith different reliabilities were exploited in this paper tomake full use of the available information. From the com-putational viewpoint, this paper provides a general frame-work based on APMM and LPM to predict proteininteractions in a more accurate manner by considering theinformation of both multi-domain pairs and multipleorganisms, which can also be applied to identify coopera-tive domains. Experiment results demonstrated that ourmethod not only can find superdomains and putativecooperative domains effectively but also has a higher pre-diction accuracy of protein interactions than the existingmethods. Cooperative domains, strongly cooperativedomains and superdomains in MIPS and DIP were
detected, and many of them were verified by the crystalstructures in PDB. Comparison experiments on protein/domain interaction prediction confirm the benefit of con-sidering multi-domain cooperation. More detailed resultsand software can be found at our website.
MethodsData sourcesIn this work, we validated our approach using severaltypes of experiments which employed various experimentdata sets as follows.
Binary PPI dataWhen we test our method for detecting cooperativedomains and PPI prediction based on multiple-organismdata, we used binary interaction data in which the infor-mation is whether two proteins interact or not. In otherwords, there is not a confidence score for each protein-
Table 6: The overlap of the predicted domain interactions by APMM and LPM with those in iPfam, where λ denotes domain interaction probability, 'Single organism' means the training set of protein interactions is only from yeast, 'Multiple organisms' means the training set is from three organisms: yeast, worm and fly
Thresholds Single organism (p-value) Multiple Organisms (p-value)
APMMλ >0.1 110 (8.1e-009) 256 (8.4e-012)λ >0.2 99 (<1e-013) 202 (2.9e-011)λ >0.3 61 (9.8e-010) 149 (<1e-013)λ >0.4 52 (3.2e-010) 127 (8.1-013)λ >0.5 49 (1.5e-013) 91 (3.3e-012)
LPMλ >0.1 109 (2.1e-008) 256 (5.7e-013)λ >0.2 97 (8.8e-013 201 (5.9e-013)λ >0.3 61 (<1e-013) 148(2.9e-012)λ >0.4 54 (4.4e-011) 130 (<1e-013)λ >0.5 49 (<1e-013) 93 (<1e-013)
Table 7: The overlap of the predicted domain interactions by APMM and LPM with those in InterDom, where λ denotes domain interaction probability
Thresholds Total domain pairs InterDom overlap (p-value) Mean significance
APMMλ >0.1 26407 8085 (8.0e-012) 75.3815λ >0.2 16798 5834 (1.9e-011) 96.3991λ >0.3 9416 3749 (<1e-013) 124.9704λ >0.4 7582 3125 (1.5e-012) 140.3715λ >0.5 4349 1800 (<1e-013) 170.5464
LPMλ >0.1 26326 8086 (1.7e-011) 75.3558λ >0.2 16854 5844 (<1e-013) 96.6538λ >0.3 9424 3753 (<1e-013) 124.8600λ >0.4 7561 3101 (6.1e-012) 140.8661λ >0.5 4322 1788 (1.3e-012) 171.6955
Page 13 of 20(page number not for citation purposes)
BMC Bioinformatics 2007, 8:391 http://www.biomedcentral.com/1471-2105/8/391
protein interaction. We collected 4103 physical interac-tions in yeast from MIPS [4] (the version isPPI_141105.tab, denoted as MIPS1) and identified super-domains and cooperative domains in this dataset.
For PPI prediction based on multiple-organism data, inorder to make comparison convenient, we used the sametraining data and testing data collected by Liu et al. [14].These datasets are from yeast S.cerevisiae, worm C.elegansand fly D.melanogaster with respectively 5295, 4714 and20349 protein interactions. The protein-domain relation-ships for each protein are extracted from PFAM [21] and
SMART [39]. Among these protein interaction data, onlythose with domain information were used. In addition,like in Liu et al. [14], an independent test set including the3543 yeast physical interaction pairs in MIPS (denoted itas MIPS2) was used as positive examples and the otherpossible protein pairs, totally 6895215 pairs, as negativeexamples.
For comparison experiments at the domain interactionlevel, we used protein-protein interactions and proteindomain composition dataset in Riley et al. [17] and Gui-maraes et al. [19]. This set was obtained from the DIPdatabase [3] and contains 26,032 interactions underlying11,403 proteins from 69 organisms.
Numerical PPI dataNumerical interaction data are defined as opposite tobinary interaction data. It means that each protein-proteininteraction has a score to denote the interaction strength.It includes experiment ratio data based on IST [28] andconfidence data by integrating various data sources [29].IST (Interaction Sequence Tags) was used for decodinginteracting proteins in examining two-hybrid interactions.Experiment ratio data based on IST mean that each pro-tein-protein interaction is provided with the number ofIST hitting in a certain number of experiments. We con-ducted cross-validation experiment on numerical interac-tion data. The first set is a well known dataset– the fulldata of Ito's dataset [28]. This dataset has 1586 interac-tions with 1420 proteins containing domain information,and provides the numerical interaction (ratio) data forprotein pairs based on the number of IST hits. The otheris Krogan's extended dataset [29]. This set has 10265 inter-actions with 2843 proteins containing domain informa-tion. It provides each protein interaction with aconfidence score.
The distribution of the predicted DDI overlaps with iPfam by DPEA, PE and APMMFigure 7The distribution of the predicted DDI overlaps with iPfam by DPEA, PE and APMM.
PE(2)
DPEA
APMM(1)
8
147
2
036
13 43
Mean confidence score of the predicted domain interactions (by APMM) at different domain interaction thresholds respectively based on single-organism data and multiple-organism dataFigure 5Mean confidence score of the predicted domain interactions (by APMM) at different domain interaction thresholds respectively based on single-organism data and multiple-organism data.
0.1 0.2 0.3 0.4 0.5100
200
300
400
500
600
Domain interaction threshold
Mea
n co
nfid
ence
sco
re
MultiOrgsSingleOrg
The overlaps of domain-domain interactions predicted by APMM, DPEA and PE with iPfamFigure 6The overlaps of domain-domain interactions predicted by APMM, DPEA and PE with iPfam.
170
175
180
185
190
195
200
205
210
215
DPEA PE(1) PE(2) APMM(1) APMM(2)
Methods
iPfa
m o
verla
p
Page 14 of 20(page number not for citation purposes)
BMC Bioinformatics 2007, 8:391 http://www.biomedcentral.com/1471-2105/8/391
Page 15 of 20(page number not for citation purposes)
Reconstruction of DNA-directed RNA polymerase complexFigure 8Reconstruction of DNA-directed RNA polymerase complex. (a) The RNA Polymerase II-TFIIS complex (PDB ID 1y1v) with 13 subunits (from chain A to chain S). Every chain is one protein (shown by their UniProtKB accessions) and their complex inter-actions form the large polymer. (b) The PfamA domain architecture for every protein. (c) The cooperative domains identified by our method with protein interaction pairs containing them. The red or blue colors of proteins and domains indicate their memberships.
RN
A P
oly
mer
ase
II-T
FIIS
co
mp
lex
PD
B ID
: 1Y
1V
(a)
(d)
P08
518
P16
370
PF
0456
1 P
F04
563
PF
0119
3P
F04
561
PF
0456
3 P
F01
000
PF
0456
5 P
F04
563
PF
0119
3P
F04
565
PF
0456
3 P
F01
000
PF
0456
5 P
F04
561
PF
0119
3P
F04
565
PF
0456
1 P
F01
000
PF
0456
7 P
F04
563
PF
0119
3 P
F04
567
PF
0456
3 P
F01
000
PF
0456
7 P
F04
561
PF
0119
3 P
F04
567
PF
0456
1 P
F01
000
PF
0456
7 P
F04
565
PF
0119
3P
F04
567
PF
0456
5P
F01
000
PF
0056
2 P
F04
563
PF
0119
3 P
F00
562
PF
0456
3 P
F01
000
PF
0056
2 P
F04
561
PF
0119
3P
F00
562
PF
0456
1 P
F01
000
PF
0056
2 P
F04
565
PF
0119
3P
F00
562
PF
0456
5 P
F01
000
PF
0056
2 P
F04
567
PF
0119
3P
F00
562
PF
0456
7 P
F01
000
PF
0456
0 P
F04
563
PF
0119
3P
F04
560
PF
0456
3 P
F01
000
PF
0456
0 P
F04
561
PF
0119
3P
F04
560
PF
0456
1 P
F01
000
PF
0456
0 P
F04
565
PF
0119
3P
F04
560
PF
0456
5 P
F01
000
PF
0456
0 P
F04
567
PF
0119
3P
F04
560
PF
0456
7 P
F01
000
PF
0456
0 P
F00
562
PF
0119
3P
F04
560
PF
0056
2 P
F01
000
P04
050
P07
273
PF
0456
1 P
F04
563
PF
0119
4P
F04
565
PF
0456
3 P
F01
194
PF
0456
5 P
F04
561
PF
0119
4P
F04
567
PF
0456
3 P
F01
194
PF
0456
7 P
F04
561
PF
0119
4P
F04
567
PF
0456
5 P
F01
194
PF
0056
2 P
F04
563
PF
0119
4P
F00
562
PF
0456
1 P
F01
194
PF
0056
2 P
F04
565
PF
0119
4P
F00
562
PF
0456
7 P
F01
194
PF
0456
0 P
F04
563
PF
0119
4P
F04
560
PF
0456
1 P
F01
194
PF
0456
0 P
F04
565
PF
0119
4P
F04
560
PF
0456
7 P
F01
194
PF
0456
0 P
F00
562
PF
0119
4
P08
518
P22
139
PF
0062
3 P
F04
997
PF
0109
6P
F04
983
PF
0499
7 P
F01
096
PF
0498
3 P
F00
623
PF
0109
6P
F05
000
PF
0499
7 P
F01
096
PF
0500
0 P
F00
623
PF
0109
6P
F05
000
PF
0498
3 P
F01
096
PF
0499
8 P
F04
997
PF
0109
6P
F04
998
PF
0062
3 P
F01
096
PF
0499
8 P
F04
983
PF
0109
6P
F04
998
PF
0500
0 P
F01
096
PF
0499
0 P
F04
992
PF
0109
6P
F05
001
PF
0499
2 P
F01
096
PF
0500
1 P
F04
990
PF
0109
6
P08
518
P34
087
PF
0456
1 P
F04
563
PF
0387
6P
F04
565
PF
0456
3 P
F03
876
PF
0456
5 P
F04
561
PF
0387
6P
F04
566
PF
0456
3 P
F03
876
PF
0456
6 P
F04
561
PF
0387
6P
F04
566
PF
0456
5 P
F03
876
PF
0456
7 P
F04
563
PF
0387
6P
F04
567
PF
0456
1 P
F03
876
PF
0456
7 P
F04
565
PF
0387
6P
F04
567
PF
0456
6 P
F03
876
PF
0056
2 P
F04
563
PF
0387
6P
F00
562
PF
0456
1 P
F03
876
PF
0056
2 P
F04
565
PF
0387
6P
F00
562
PF
0456
6 P
F03
876
PF
0056
2 P
F04
567
PF
0387
6P
F04
560
PF
0456
3 P
F03
876
PF
0456
0 P
F04
561
PF
0387
6P
F04
560
PF
0456
5 P
F03
876
PF
0456
0 P
F04
566
PF
0387
6P
F04
560
PF
0456
7 P
F03
876
PF
0456
0 P
F00
562
PF
0387
6
P20
434
P27
999
PF
0119
1 P
F03
871
PF
0215
0P
F01
191
PF
0387
1 P
F01
096
P04
050
P22
139
PF
0062
3 P
F04
997
PF
0119
4P
F04
983
PF
0499
7 P
F01
194
PF
0498
3 P
F00
623
PF
0119
4P
F05
000
PF
0499
7 P
F01
194
PF
0500
0 P
F00
623
PF
0119
4P
F05
000
PF
0498
3 P
F01
194
PF
0499
8 P
F04
997
PF
0119
4P
F04
998
PF
0062
3 P
F01
194
PF
0499
8 P
F04
983
PF
0119
4P
F04
998
PF
0500
0 P
F01
194
P04
050
P38
902
PF
0062
3 P
F04
997
PF
0119
3P
F04
983
PF
0499
7 P
F01
193
PF
0498
3 P
F00
623
PF
0119
3P
F05
000
PF
0499
7 P
F01
193
PF
0500
0 P
F00
623
PF
0119
3P
F05
000
PF
0498
3 P
F01
193
PF
0499
8 P
F04
997
PF
0119
3P
F04
998
PF
0062
3 P
F01
193
PF
0499
8 P
F04
983
PF
0119
3P
F04
998
PF
0500
0 P
F01
193
P20
434
P04
050
PF
0119
1 P
F03
871
PF
0499
7P
F01
191
PF
0387
1 P
F00
623
PF
0119
1 P
F03
871
PF
0498
3P
F01
191
PF
0387
1 P
F05
000
PF
0119
1 P
F03
871
PF
0499
8
P04
050
P34
087
PF
0062
3 P
F04
997
PF
0387
6P
F04
983
PF
0499
7 P
F03
876
PF
0498
3 P
F00
623
PF
0387
6P
F05
000
PF
0499
7 P
F03
876
PF
0500
0 P
F00
623
PF
0387
6P
F05
000
PF
0498
3 P
F03
876
PF
0499
8 P
F04
997
PF
0387
6P
F04
998
PF
0062
3 P
F03
876
PF
0499
8 P
F04
983
PF
0387
6P
F04
998
PF
0500
0 P
F03
876
P34
087
P38
902
PF
0057
5 P
F03
876
PF
0119
3
(c)
P04
050
P20
435
PF
0456
1 P
F04
563
PF
0215
0P
F04
561
PF
0456
3 P
F01
096
PF
0456
5 P
F04
563
PF
0215
0P
F04
565
PF
0456
3 P
F01
096
PF
0456
5 P
F04
561
PF
0215
0P
F04
565
PF
0456
1 P
F01
096
PF
0456
7 P
F04
563
PF
0215
0P
F04
567
PF
0456
3 P
F01
096
PF
0456
7 P
F04
561
PF
0215
0P
F04
567
PF
0456
1 P
F01
096
PF
0456
7 P
F04
565
PF
0215
0P
F04
567
PF
0456
5 P
F01
096
PF
0056
2 P
F04
563
PF
0215
0P
F00
562
PF
0456
3 P
F01
096
PF
0056
2 P
F04
561
PF
0215
0P
F00
562
PF
0456
1 P
F01
096
PF
0056
2 P
F04
565
PF
0215
0P
F00
562
PF
0456
5 P
F01
096
PF
0056
2 P
F04
567
PF
0215
0P
F00
562
PF
0456
7 P
F01
096
PF
0456
0 P
F04
563
PF
0215
0P
F04
560
PF
0456
3 P
F01
096
PF
0456
0 P
F04
561
PF
0215
0P
F04
560
PF
0456
1 P
F01
096
PF
0456
0 P
F04
565
PF
0215
0P
F04
560
PF
0456
5 P
F01
096
PF
0456
0 P
F04
567
PF
0215
0P
F04
560
PF
0456
7 P
F01
096
PF
0456
0 P
F00
562
PF
0215
0P
F04
560
PF
0056
2 P
F01
096
P08
518
P27
999
P27
999
P08
518
PF
0109
6 P
F02
150
PF
0456
3P
F01
096
PF
0215
0 P
F04
561
PF
0109
6 P
F02
150
PF
0456
5P
F01
096
PF
0215
0 P
F04
566
PF
0109
6 P
F02
150
PF
0456
7P
F01
096
PF
0215
0 P
F00
562
PF
0109
6 P
F02
150
PF
0456
0
P16
370
P20
434
PF
0100
0 P
F01
193
PF
0387
1P
F01
000
PF
0119
3 P
F01
191
P20
434
P16
370
PF
0119
1 P
F03
871
PF
0119
3P
F01
191
PF
0387
1 P
F01
000
P34
087
P16
370
PF
0057
5 P
F03
876
PF
0119
3
P27
999
P16
370
PF
0109
6 P
F02
150
PF
0119
3P
F01
096
PF
0215
0 P
F01
000
P20
434
P34
087
PF
0119
1 P
F03
871
PF
0387
6
P27
999
P20
434
PF
0109
6 P
F02
150
PF
0387
1P
F01
096
PF
0215
0 P
F01
191
P04
050
P20
434
PF
0062
3 P
F04
997
PF
0387
1P
F00
623
PF
0499
7 P
F01
191
PF
0498
3 P
F04
997
PF
0387
1P
F04
983
PF
0499
7 P
F01
191
PF
0498
3 P
F00
623
PF
0387
1P
F04
983
PF
0062
3 P
F01
191
PF
0500
0 P
F04
997
PF
0387
1P
F05
000
PF
0499
7 P
F01
191
PF
0500
0 P
F00
623
PF
0387
1P
F05
000
PF
0062
3 P
F01
191
PF
0500
0 P
F04
983
PF
0387
1P
F05
000
PF
0498
3 P
F01
191
PF
0499
8 P
F04
997
PF
0387
1P
F04
998
PF
0499
7 P
F01
191
PF
0499
8 P
F00
623
PF
0387
1P
F04
998
PF
0062
3 P
F01
191
PF
0499
8 P
F04
983
PF
0387
1P
F04
998
PF
0498
3 P
F01
191
PF
0499
8 P
F05
000
PF
0387
1P
F04
998
PF
0500
0 P
F01
191
P27
999
P34
087
PF
0109
6 P
F02
150
PF
0387
6
P04
050
P27
999
PF
0062
3 P
F04
997
PF
0215
0P
F00
623
PF
0499
7 P
F01
096
PF
0498
3 P
F04
997
PF
0215
0P
F04
983
PF
0499
7 P
F01
096
PF
0498
3 P
F00
623
PF
0215
0P
F04
983
PF
0062
3 P
F01
096
PF
0500
0 P
F04
997
PF
0215
0P
F05
000
PF
0499
7 P
F01
096
PF
0500
0 P
F00
623
PF
0215
0P
F05
000
PF
0062
3 P
F01
096
PF
0500
0 P
F04
983
PF
0215
0P
F05
000
PF
0498
3 P
F01
096
PF
0499
8 P
F04
997
PF
0215
0P
F04
998
PF
0499
7 P
F01
096
PF
0499
8 P
F00
623
PF
0215
0P
F04
998
PF
0062
3 P
F01
096
PF
0499
8 P
F04
983
PF
0215
0P
F04
998
PF
0498
3 P
F01
096
PF
0499
8 P
F05
000
PF
0215
0P
F04
998
PF
0500
0 P
F01
096
PF
0499
0 P
F04
992
PF
0109
6P
F05
001
PF
0499
2 P
F01
096
PF
0500
1 P
F04
990
PF
0109
6
P27
999
P20
435
PF
0109
6 P
F02
150
PF
0119
2
PF
0062
3 P
F04
997
PF
0119
2P
F04
983
PF
0499
7 P
F01
192
PF
0498
3 P
F00
623
PF
0119
2P
F05
000
PF
0499
7 P
F01
192
PF
0500
0 P
F00
623
PF
0119
2P
F05
000
PF
0498
3 P
F01
192
PF
0499
8 P
F04
997
PF
0119
2P
F04
998
PF
0062
3 P
F01
192
PF
0499
8 P
F04
983
PF
0119
2P
F04
998
PF
0500
0 P
F01
192
PF
0456
5 P
F04
563
PF
0499
8P
F04
565
PF
0456
1 P
F04
997
PF
0456
5 P
F04
561
PF
0062
3P
F04
565
PF
0456
1 P
F04
983
PF
0456
5 P
F04
561
PF
0500
0P
F04
565
PF
0456
1 P
F04
998
PF
0456
7 P
F04
563
PF
0499
7P
F04
567
PF
0456
3 P
F00
623
PF
0456
7 P
F04
563
PF
0498
3P
F04
567
PF
0456
3 P
F05
000
PF
0456
7 P
F04
563
PF
0499
8P
F04
567
PF
0456
1 P
F04
997
PF
0456
7 P
F04
561
PF
0062
3P
F04
567
PF
0456
1 P
F04
983
PF
0456
7 P
F04
561
PF
0500
0P
F04
567
PF
0456
1 P
F04
998
PF
0456
7 P
F04
565
PF
0499
7P
F04
567
PF
0456
5 P
F00
623
PF
0456
7 P
F04
565
PF
0498
3P
F04
567
PF
0456
5 P
F05
000
PF
0456
7 P
F04
565
PF
0499
8P
F00
562
PF
0456
3 P
F04
997
PF
0056
2 P
F04
563
PF
0062
3P
F00
562
PF
0456
3 P
F04
983
PF
0056
2 P
F04
563
PF
0500
0P
F00
562
PF
0456
3 P
F04
998
PF
0056
2 P
F04
561
PF
0499
7P
F00
562
PF
0456
1 P
F00
623
PF
0056
2 P
F04
561
PF
0498
3P
F00
562
PF
0456
1 P
F05
000
PF
0056
2 P
F04
561
PF
0499
8P
F00
562
PF
0456
5 P
F04
997
PF
0056
2 P
F04
565
PF
0062
3P
F00
562
PF
0456
5 P
F04
983
PF
0056
2 P
F04
565
PF
0500
0P
F00
562
PF
0456
5 P
F04
998
PF
0056
2 P
F04
567
PF
0499
7
PF
0499
8 P
F04
997
PF
0456
1P
F04
998
PF
0499
7 P
F04
565
PF
0499
8 P
F04
997
PF
0456
6P
F04
998
PF
0499
7 P
F04
567
PF
0499
8 P
F04
997
PF
0056
2P
F04
998
PF
0499
7 P
F04
560
PF
0499
8 P
F00
623
PF
0456
3P
F04
998
PF
0062
3 P
F04
561
PF
0499
8 P
F00
623
PF
0456
5P
F04
998
PF
0062
3 P
F04
566
PF
0499
8 P
F00
623
PF
0456
7P
F04
998
PF
0062
3 P
F00
562
PF
0499
8 P
F00
623
PF
0456
0P
F04
998
PF
0498
3 P
F04
563
PF
0499
8 P
F04
983
PF
0456
1P
F04
998
PF
0498
3 P
F04
565
PF
0499
8 P
F04
983
PF
0456
6P
F04
998
PF
0498
3 P
F04
567
PF
0499
8 P
F04
983
PF
0056
2P
F04
998
PF
0498
3 P
F04
560
PF
0499
8 P
F05
000
PF
0456
3P
F04
998
PF
0500
0 P
F04
561
PF
0499
8 P
F05
000
PF
0456
5P
F04
998
PF
0500
0 P
F04
566
PF
0499
8 P
F05
000
PF
0456
7P
F04
998
PF
0500
0 P
F00
562
PF
0499
8 P
F05
000
PF
0456
0P
F04
561
PF
0456
3 P
F04
997
PF
0456
1 P
F04
563
PF
0062
3P
F04
561
PF
0456
3 P
F04
983
PF
0456
1 P
F04
563
PF
0500
0P
F04
561
PF
0456
3 P
F04
998
PF
0456
5 P
F04
563
PF
0499
7P
F04
565
PF
0456
3 P
F00
623
PF
0456
5 P
F04
563
PF
0498
3P
F04
565
PF
0456
3 P
F05
000
PF
0498
3 P
F04
997
PF
0456
3P
F04
983
PF
0499
7 P
F04
561
PF
0498
3 P
F04
997
PF
0456
5P
F04
983
PF
0499
7 P
F04
566
PF
0498
3 P
F04
997
PF
0456
7P
F04
983
PF
0499
7 P
F00
562
PF
0498
3 P
F04
997
PF
0456
0P
F04
983
PF
0062
3 P
F04
563
PF
0498
3 P
F00
623
PF
0456
1P
F04
983
PF
0062
3 P
F04
565
PF
0498
3 P
F00
623
PF
0456
6P
F04
983
PF
0062
3 P
F04
567
PF
0498
3 P
F00
623
PF
0056
2P
F04
983
PF
0062
3 P
F04
560
PF
0500
0 P
F04
997
PF
0456
3P
F05
000
PF
0499
7 P
F04
561
PF
0500
0 P
F04
997
PF
0456
5P
F05
000
PF
0499
7 P
F04
566
PF
0500
0 P
F04
997
PF
0456
7P
F05
000
PF
0499
7 P
F00
562
PF
0500
0 P
F04
997
PF
0456
0P
F05
000
PF
0062
3 P
F04
563
PF
0500
0 P
F00
623
PF
0456
1P
F05
000
PF
0062
3 P
F04
565
PF
0500
0 P
F00
623
PF
0456
6P
F05
000
PF
0062
3 P
F04
567
PF
0500
0 P
F00
623
PF
0056
2P
F05
000
PF
0062
3 P
F04
560
PF
0500
0 P
F04
983
PF
0456
3P
F05
000
PF
0498
3 P
F04
561
PF
0500
0 P
F04
983
PF
0456
5P
F05
000
PF
0498
3 P
F04
566
PF
0500
0 P
F04
983
PF
0456
7P
F05
000
PF
0498
3 P
F00
562
PF
0500
0 P
F04
983
PF
0456
0
PF
0056
2 P
F04
567
PF
0062
3P
F00
562
PF
0456
7 P
F04
983
PF
0056
2 P
F04
567
PF
0500
0P
F00
562
PF
0456
7 P
F04
998
PF
0456
0 P
F04
563
PF
0499
7P
F04
560
PF
0456
3 P
F00
623
PF
0456
0 P
F04
563
PF
0498
3P
F04
560
PF
0456
3 P
F05
000
PF
0456
0 P
F04
563
PF
0499
8P
F04
560
PF
0456
1 P
F04
997
PF
0456
0 P
F04
561
PF
0062
3P
F04
560
PF
0456
1 P
F04
983
PF
0456
0 P
F04
561
PF
0500
0P
F04
560
PF
0456
1 P
F04
998
PF
0456
0 P
F04
565
PF
0499
7P
F04
560
PF
0456
5 P
F00
623
PF
0456
0 P
F04
565
PF
0498
3P
F04
560
PF
0456
5 P
F05
000
PF
0456
0 P
F04
565
PF
0499
8P
F04
560
PF
0456
7 P
F04
997
PF
0456
0 P
F04
567
PF
0062
3P
F04
560
PF
0456
7 P
F04
983
PF
0456
0 P
F04
567
PF
0500
0P
F04
560
PF
0456
7 P
F04
998
PF
0456
0 P
F00
562
PF
0499
7P
F04
560
PF
0056
2 P
F00
623
PF
0456
0 P
F00
562
PF
0498
3P
F04
560
PF
0056
2 P
F05
000
PF
0456
0 P
F00
562
PF
0499
8P
F00
623
PF
0499
7 P
F04
563
PF
0062
3 P
F04
997
PF
0456
1P
F00
623
PF
0499
7 P
F04
565
PF
0062
3 P
F04
997
PF
0456
6P
F00
623
PF
0499
7 P
F04
567
PF
0062
3 P
F04
997
PF
0056
2P
F00
623
PF
0499
7 P
F04
560
PF
0499
8 P
F04
997
PF
0456
3
P04
050
P08
518

BMC Bioinformatics 2007, 8:391 http://www.biomedcentral.com/1471-2105/8/391
Domain sources and DDI dataThe domain information for proteins was extracted fromPfam 14.0 [21]. For MIPS1, there are total 1483 Pfamdomains involved in 2477 proteins. iPfam database [30]contains domain-domain interactions confirmed by PDBcrystal structures. It has been used as a gold standard setfor evaluating predicted domain-domain interactions[17,19]. In this work, 3034 domain interactions in iPfam(December 2005 version) were used for evaluatingdomain interaction prediction. In addition, InterDom(version 1.2) [31] was also used for this purpose. It is adatabase of putative interacting domains derived frommultiple data sources, ranging from domain fusions(Rosetta Stone), protein interactions (DIP and BIND),protein complexes (PDB), to scientific literature(MEDLINE). InterDom 1.2 has 30038 putative domaininteractions with different confidence scores.
Protein complex and crystal structure databaseCooperative domains were confirmed using structuraldata of protein complexes from PDB and PROTOCOM.Protein sequences were mapped from Swiss-Prot/TrEMBLdatabase to their corresponding structure files using theseq2struct web resource [26]. PROTOCOM [27] is a col-lection of protein-protein transient complexes anddomain-domain structures. It provides the detailed infor-mation about protein interactions by identifying the con-tacted residues, presenting the number of residues on theinterface and the list of interfacial residues.
Probabilistic model with multi-domain pairsIn this section, we describe an improved probabilisticmodel for protein interactions by considering the multi-domain pairs, which is the essential basis of our method.
Assume that in the protein interactions of K species (ordata sets), there are Nk proteins in dataset k respectively
denoted by , …, k = 1, …, K, with M domains in
all of these proteins represented by D1, …, DM . Let
also denote a set of domains in the protein i of dataset k.
Define to represent a protein pair ( , ) and Dm, n
to represent a domain pair (Dm, Dn). We also introduce a
symbol Dm, rn for a cooperative-domain pair (Dm - Dr, Dn)
to represent the case that domains Dm and Dr in protein
cooperatively interact with domain Dn in protein .
Dm, rn has a similar implication. In our probabilistic
model, is also used to represent the set of domain
pairs including all multi-domain pairs in , and i.e.,
Let the interaction between and (between Dm and
Dn) be represented by a random variable (dm, n).
Accordingly we introduce random variables dmr, n to
denote whether domains Dm and Dr cooperatively interact
with domain Dn or not. The probabilistic model [12,13]
for inferring protein interactions has two basic assump-tions. One is that domain interactions in each protein pairare independent. The other is that two proteins interact ifand only if there is at least one interacting domain pair inthis protein pair. In the improved model, we also makethese assumptions, but extend two-domain interactionsto multi-domain interactions. Therefore, the interaction
probability of and is given by
where Pr( = 1) represents the interaction probability of
proteins and in dataset k, and Pr(dm, n = 1) repre-
sents the probability that domain Dm interacts with Dn.
Pr(dmr, n = 1) represents the probability that domains Dm
and Dr cooperatively interact with Dn. Pr(dm, nr = 1) has a
similar meaning. For each protein pair in (1), if there is acooperative interaction of domains Dm - Dr with domain
Dn in the second multiplying term, then (Dm, Dn) and (Dr,
Dn) must be excluded from the first multiplying term in
order to maintain the independence assumption; other-wise, (Dm - Dr, Dn) should be deleted. The third multiply-
ing term for (Dm, Dr - Dn) should be checked in the same
way. Clearly, the first multiplying term represents theeffect of two-domain pair interactions while the secondand third multiplying terms stand for the effects of coop-erative-domain interactions. In next section, we will showhow to determine those independent variables.
Note that we extend two-domain interactions only tothree-domain interactions because the cooperationinvolving more than three domains is believed to be rarecompared with cases of two and three domains, thoughtheoretically model (1) can be further extended to four-domain pair and above but with the sacrifice of the com-putational efficiency. Figure 1(b) gives an example forinferring domain interactions from protein interactionand non-interaction data. It indicates that the classical
PK1 PN
kk
Pik
Pijk Pi
k Pjk
Pik Pj
k
Pijk
Pik Pj
k
P D D P D P D D D P D P Dijk
m n m ik
n jk
mr n m r ik
n jk
m nr= ∈ ∈ ∈ ∈{ | , } { | , , } { |, , ,∪ ∪ DD P D D Pm ik
n r jk∈ ∈, , }.
Pik Pj
k
pijk
Pik Pj
k
Pr( ) ( Pr( )) ( Pr( )) ( Pr(, ,
,
p d dijk
m nD P
mr n
m n ijk
= = − − = − = −∈
∏1 1 1 1 1 1 1 ddm nrD PD P m nr ij
kmr n ij
k, ))
,,
=∈∈
∏∏ 1
(1)
pijk
Pik Pj
k
Page 16 of 20(page number not for citation purposes)

BMC Bioinformatics 2007, 8:391 http://www.biomedcentral.com/1471-2105/8/391
probabilistic model fails to give the correct result for thiscase while our model can do it by considering multi-domain interactions.
Selection of independent variablesIn order to make the variables of model (1) independentwith each other, we will delete dependent variablesamong dm, n, dmr, n and dr, n according to the following strat-egy. Define
where Imn is the number of interacting protein pairs in thetraining set that contain domain pair Dm, n, and Nm, n is thetotal number of protein pairs in the training set that con-tain Dm, n. Rmr, n and Rr, n are similarly defined. For variablesdm, n, dmr, n and dr, n, the variable deletion strategy isdescribed by the following procedure.
1. If Rmr, n< Rm, n or Rmr, n< Rr, n, it indicates that the appear-ance frequency of domain pair Dmr, n in interacting proteinpairs is not higher than those of Dm, n and Dr, n. We con-sider that there is no cooperation between Dm and Dr intheir interacting with Dn, so we keep the variables dm, n, dr,
n and delete the variable dmr, n in (1).
2. If Rmr, n ≥ Rm, n and Rmr, n ≥ Rr, n, for Dm, n
• when Rmr, n> Rm, n and Imr, n = Im, n, the appearance fre-quency of domain pair Dmr, n in interacting protein pairs ishigher than those of Dm, n and Dr, n, and furthermore, Dm,
n does not appear in any other interacting protein pairwithout Dr. Hence, we consider that Dm and Dr are coop-erative when interacting with Dn, and thereby the variabledm, n is deleted, but the variable dmr, n is kept in (1);
• when Rmr, n = Rm, n and Imr, n = Im, n, it means that Dm andDr always appear together in individual proteins. Hence,Dm and Dr are considered as a superdomain and can bemerged to one. For such a case, we delete variable dm, n butkeep the cooperative-domain pair dmr, n.
The operations are performed in the same way for Dr, n.For the case of Figure 1(b), variables for all domain pairsexcept (D1 - D2, D3) are deleted based on this procedure.
Obviously, the above operations do not cover the case Rmr,
n ≥ Rm, n and Imr, n< Imn. For this case, we cannot determineif or not there is a cooperative effect of domains Dm and Dron their interacting with domain Dn since Dm, n alsoappears in the interacting pairs without Dr, thereby wekeep all of them. This may affect the assumption of inde-pendence, but there are few such cases. For example, forthe date set MIPS1, among 22325 multi-domain pairs,
there are only 85 such cases. Hence, by the above variabledeletion operations, the assumption can be primarily sat-isfied. In the following formulation, all the variablesappearing in the formula are those kept after the deletingstrategy, whereas the probabilities of all deleted variablesare set to be zero. Note that, in contrast to the appearancefrequency or interaction strength for selecting cooperativedomains, the two domains in a superdomain are deter-mined based on their co-occurrence, and the cooperativityare also indirectly confirmed by their identical or similarfunctions from GO annotations.
Inference of domain interactionsLinear programming with multi-domain pairs
Before predicting protein interactions, we need firstly toinfer domain interactions from multiple datasets. Owingto experiment noises, each protein interaction dataset hasa false positive rate fpk and a false negative rate fnk·fpk =
Pr( = 1| = 0), fnk = Pr( = 0| = 1). where = 1
if the interaction between proteins and is observed
in the dataset and = 0 otherwise. Thus the probability
that proteins and in dataset k are observed to be
interacting in the experiments is related with the realinteraction probability in the following way:
The parameters fpk and fnk can be estimated from experi-mental data in a similar way as that in Liu et al. [14].
With the basic probabilistic model (1) and the formula(3), we have
Pr( = 1) when two proteins ( , ) interact and 0
otherwise in the binary PPI data. For numerical interac-
tion data we can set Pr( = 1)as the ratio of interactions
between proteins and in a series of experiments.
Note that the left side may be greater than 1 due to theincomplete interaction information in binary experimentdata. For such a case we can normalize them first. Let xm, n
= ln(1- Pr(dm, n = 1)), xmr, n = ln(1 - Pr(dmr, n = 1)), xm, nr =
RI
Nm nm n
m n,
,
,,= (2)
oijk pij
k oijk pij
k oijk
Pik Pj
k
oijk
Pik Pj
k
Pr( ) Pr( )( ) ( Pr( )) .o p fn p fpijk
ijk k
ijk k= = = − + − =1 1 1 1 1
(3)
Pr( )( Pr( )) ( Pr(,
,
o fp
fn fpd d
ijk k
k k m nD P
m
m n ijk
= −
− −= − − = −
∈∏
1
11 1 1 1 rr n
D Pm nr
D Pmr n ijk
m nr ijk
d, ,)) ( Pr( ))
, ,
= − =∈ ∈
∏ ∏1 1 1
(4)
oijk Pi
k Pjk
oijk
Pik Pj
k
Page 17 of 20(page number not for citation purposes)

BMC Bioinformatics 2007, 8:391 http://www.biomedcentral.com/1471-2105/8/391
ln(1 - Pr(dm, nr = 1)) and . By
the similar technique adopted in Hayashida et al. [16],then the above equalities can be written as
This is a set of linear equalities. If we can find xm, n, xmr, nand xm, nr (xm, n ≤ 0, xmr, n ≤ 0 and xm, nr ≤ 0) satisfying (5) forall observed protein interaction data, the domain interac-tion probabilities Pr(dm, n = 1), Pr(dmr, n = 1) and Pr(dm, nr =1) fully consistent with the training data can be obtained.However, it is usually impossible to satisfy all constraintsowing to the noise and incompleteness of experimentaldata. In such a case it is natural and reasonable to mini-mize the total error with respect to L1 norm. Therefore wecan obtain the following Linear Programming with Multi-domain pairs (LPM):
where is the error for each equality of (5). Model (6)
can be solved by any standard LP technique (see Addi-tional file 1).
Solving (6), we can obtain a set of interaction probabili-ties for domain pairs. Then, new protein interactions canbe predicted by these inferred domain interactionsthrough the probabilistic model (1).
Association probabilistic method with multi-domain pairsNumerical experiments show that LPM performs well, butis computationally expensive for large scale problems.Therefore, we introduce a faster probabilistic methodbased on statistics. This method is based on a generaliza-tion of Association Probabilistic Method [13] with multi-domain pairs (APMM). It estimates the interaction proba-bilities of multi-domain pairs in the following way:
where | | represents the number of multi-domain pairs
in , and is the observed interaction probability
between and in the experimental data after consid-
ering the false positive and false negative rates. Note thatthe deleted variables are not counted. From these formula,we can see that all domain pairs have an equal opportu-
nity to contribute the interactions between and for
| | > 1 under the independence assumption for domain
interactions. With these interaction probabilities ofdomain pairs, we can predict whether a pair of proteinsinteract or not by the formula (1). The computation ofthis method is much simple and thus highly efficient. Inaddition, it does not require any parameter tuning.
Evaluation measuresWe validated our method using several types of experi-ments with different criteria. For computing the similarityof GO annotations [40], we adopted a simple methodused successfully in Chen et al. [41] and Wu et al. [42]. Inthis method, known proteins are assigned with functionalannotations by a GO Identification (ID). According to thehierarchical structure of GO annotations, each GO termcorresponds to a numerical GO INDEX. The moredetailed level of the GO INDEX, the more specific is thefunction assigned to a protein. The maximum level of GOINDEX is 14. The function similarity between proteins Pxand Py is defined by the maximum number of index levelsfrom the top shared by Px and Py. The smaller the value offunction similarity, the broader is the functional categoryshared by the two proteins. The details can be found inChen et al. [41].
For protein interaction prediction on numerical PPI data,we use root-mean-square error (RMSE) to measure the dif-ference between the observed probability values and thepredicted probability values:
βijk ij
k k
k k
o fp
fn fp= −
= −
− −ln(
Pr( ))1
1
1
x x xm nD P
mr nD P
m nr ijk
D Pm n ijk
mr n ijk
m nr ijk
, , ,
, , ,
.∈ ∈ ∈
∑ ∑ ∑+ + = β
(5)
min
. .
,
, , ,
, ,
εε
xijk
P
m nD P
mr nD P
m nr
ijk
m n ijk
mr n ijk
s t x x x
∑
∑ ∑∈ ∈
+ + = ββ εijk
ijk
ijk
D P
m n mr n m nr
P
x x xm nr ij
k
−
≤ ≤ ≤∈
∑ for all ,
, , ,,
, , ,0 0 0
ii j N k Kk, { ,..., }, , ,∈ =1 1
(6)
εi jk,
Pr( )[ ( ) ]
,
Pr(
,
| |{ | }
,
,
,dN
d
m n
ijk P
P D P
m n
mr
ijk
ijk
m n ijk
= =− −∈∑
11 1 ρ
nn
ijk P
P D P
mr n
m nr
ijk
ijk
mr n ijk
N
d
= =− −
=
∈∑1
1 1
1
)[ ( ) ]
,
Pr(
| |{ | }
,
,
,ρ
))[ ( ) ]
,
| |{ | }
,
,=− −∈∑ 1 1 ρij
k PP D P
m nr
ijk
ijk
m nr ijk
N(7)
Pijk
Pijk ρij
k
Pik Pj
k
Pik Pj
k
Pijk
Page 18 of 20(page number not for citation purposes)

BMC Bioinformatics 2007, 8:391 http://www.biomedcentral.com/1471-2105/8/391
where P denotes a set of protein pairs (training set or test-ing set) including interactions and non-interactions. Non-interacting protein pairs may be those not appearing inthe observed interaction data or those whose interactionprobabilities are below a threshold.
For protein interaction prediction on binary PPI data, weuse sensitivity and specificity to evaluate the performanceof a method. Specifically, given a set of interacting proteinpairs as positive set and a non-interacting protein pair setas negative set, sensitivity and specificity (denoted by SNand SP) are respectively defined as
where the number of true positives (TP), true negatives(TN), false positives (FP) and false negatives (FN) are esti-mated with respect to the given test set.
The evaluation of the predicted domain interactions inthis work is based on the overlap with the gold standardset iPfam. We adopted binomial cumulative distributionfunction to compute the significance of the overlap (p-value) by comparing with randomly predicted domainpairs:
where n denotes the total number of the predicteddomain interactions and N denotes the overlap of the pre-dicted domain interactions with the gold standard set. prepresents the probability that a randomly predicteddomain pair is in the gold standard set. This measure char-acterizes the significance of an overlap.
AbbreviationsPPI: Protein-Protein Interaction;
DDI: Domain-Domain Interaction;
LPM: Linear Programming with Multi-domain pairs;
APMM: Association Probabilistic Method with Multi-domain pairs;
EM: Expectation Maximization;
LP: Linear Programming;
ASNM: Association Numerical Method;
RMSE: Root Mean Square Error;
IST: Interaction Sequence Tags;
AUC: Area Under Curve.
Authors' contributionsRSW and YW designed and implemented the algorithm.LYW and XSZ gave some helpful suggestions on the exper-iments. LC proposed the main idea and gave many help-ful suggestions for the manuscript. All authors wrote andapproved the manuscript.
Additional material
AcknowledgementsThe authors are grateful to the anonymous referees for their valuable com-ments and suggestions in improving the presentation of the earlier version of the paper. This research work is supported by JSPS under JSPS-NSFC collaboration project, the National Nature Science Foundation of China (NSFC) under grant No.10701080 and the Ministry of Science and Technol-ogy, China, under grant No.2006CB503905.
References1. Eisbacher M, Holmes M, Newton A, Hogg P, Khachigian L, Crossley
M, Chong B: Protein-protein interaction between Fli-1 andGATA-1 mediates synergistic expression of megakaryocyte-specific genes through cooperative DNA binding. Mol Cell Biol2003, 23:3427-3441.
2. Labalette C, Renard C, Neuveut C, Buendia M, Wei Y: Interactionand functional cooperation between the LIM protein FHL2,CBP/p300, and β-Catenin. Mol Cell Biol 2004, 24:10689-10702.
3. Salwinski L, Miller C, Smith A, Pettit F, Bowie J, Eisenberg D: Thedatabase of interacting proteins: 2004 update. Nucl Acids Res2004, 32:D449-451.
4. Mewes H, Frishman D, Mayer K, Munsterkotter M, Noubibou O,Pagel P, Rattei T, Oesterheld M, Ruepp A, Stumpflen V: MIPS: anal-ysis and annotation of proteins from whole genomes in 2005.Nucl Acids Res 2006, 34:D169-172.
5. Deng M, Sun F, Chen T: Assessment of the reliability of protein-protein interactions and protein function prediction. PacSymp Biocomput 2003:140-51.
6. von Mering C, Krause R, Snel B, Cornell M, Oliver S, Fields S, Bork P:Comparative assessment of large-scale data sets of prote-protein interactions. Nature 2002, 417:399-403.
RMSE = = −∈
∑ (Pr( ) ) )/P Pijk
ijk
P Pijk
1 ρ (8)
SNTP
TP FN=
+, (9)
SPTN
TN FP=
+, (10)
Pn
kp p
k
Nk n k= −
⎛
⎝⎜
⎞
⎠⎟ −
=
−∑1 10
( ) (11)
Additional file 1This additional file contains the detected superdomains and cooperative domains from DIP (Tables I-III), cooperative-domain interactions veri-fied by PDB crystal structure (Figure I), RMSE comparison results on all protein pairs (Table IV, Table V), and the additional information on the LP model.Click here for file[http://www.biomedcentral.com/content/supplementary/1471-2105-8-391-S1.pdf]
Page 19 of 20(page number not for citation purposes)

BMC Bioinformatics 2007, 8:391 http://www.biomedcentral.com/1471-2105/8/391
Publish with BioMed Central and every scientist can read your work free of charge
"BioMed Central will be the most significant development for disseminating the results of biomedical research in our lifetime."
Sir Paul Nurse, Cancer Research UK
Your research papers will be:
available free of charge to the entire biomedical community
peer reviewed and published immediately upon acceptance
cited in PubMed and archived on PubMed Central
yours — you keep the copyright
Submit your manuscript here:http://www.biomedcentral.com/info/publishing_adv.asp
BioMedcentral
7. Enright AJ, Iliopoulos KNOC I: Protein interaction maps forcomplete genomes based on gene fusion events. Nature 1999,402:86-90.
8. Marcotte E, Pellegrini M, Ng H, Rice D, Yeates T, Eisenberg D:Detecting protein function and protein-protein interactionsfrom genome sequences. Science 1999, 285:751-753.
9. Pellegrini M, Marcotte E, Thompson M, Eisenberg D, Yeates T:Assigning protein functions by comparative genome analy-sis: Protein phylogenetic profiles. Proc Natl Acad Sci 1999,96:4285-4288.
10. Szilagyi A, Grimm V, Arakaki A, Skolnick J: Prediction of physicalprotein-protein interactions. Phys Biol 2005, 2:S1-S16.
11. Sprinzak E, Margalit H: Correlated sequence-signatures asmarkers of protein-protein interaction. J Mol Biol 2001,311:681-692.
12. Deng M, Mehta S, Sun F, Chen T: Inferring domain-domain inter-actions from protein-protein interactions. Genome Res 2002,12:1540-1548.
13. Chen L, Wu L, Y W, Zhang X: Inferring protein interactionsfrom experimental data by association probabilistic method.Proteins 2006, 62:833-837.
14. Liu Y, Liu N, Zhao H: Inferring protein-protein interactionsthrough high-throughput interaction data from diverseorganisms. Bioinformatics 2005, 21:3279-3285.
15. Dohkan S, Koike A, Takagi T: Support vector machines for pre-dicting protein-protein interactions. Genome Inform 2003,14:502-503.
16. Hayashida M, Ueda N, Akutsu T: Inferring strengths of proteinprotein interactions from experimental data using linearprogramming. Bioinformatics 2003, 19(Suppl 2):ii58-65.
17. Riley R, Lee C, Sabatti C, Eisenberg D: Inferring protein domaininteractions from databases of interacting proteins. GenomeBiol 2005, 6:R89.
18. Lee H, Deng M, Sun F, Chen T: An integrated approach to theprediction of domain-domain interactions. BMC Bioinformatics2006, 7:269.
19. Guimaraes K, Jothi R, Zotenko E, Przytycka T: Predicting domain-domain interactions using a parsimony approach. Genome Biol2006, 7:R104.
20. Moza B, Buonpane R, Zhu P, Herfst C, Rahman A, McCormick J,Kranz D, Sundberg E: Long-range cooperative binding effects ina T cell receptor variable domain. Proc Natl Acad Sci 2006,103:9867-9872.
21. Bateman A, Coin L, Durbin R, Finn R, Hollich V, Griffiths-Jones S,Khanna A, Marshall M, Moxon E, Sonnhammer S 1, Studholme D,Yeats C, Eddy S: The Pfam protein families database. Nucl AcidsRes 2004, 32:D138-D141.
22. Han D, Kim H, Seo J, Jang W: A domain combination basedprobabilistic framework for protein-protein interaction pre-diction. Genome Inform 2003, 14:250-259.
23. Han D, Kim H, Jang W, Lee S, Suh J: PreSPI: a domain combina-tion based prediction system for protein-protein interaction.Nucl Acids Res 2004, 32:6312-6320.
24. Wang M, Caetano-Anolles G: Global phylogeny determined bythe combination of protein domains in proteomes. Mol BiolEvol 2006, 23:2444-2454.
25. Klemm J, Pabo C: Oct-1 POU domain-DNA interactions: coop-erative binding of isolated subdomains and effects of cova-lent linkage. Genes Dev 1996, 10:27-36.
26. Via A, Zanzoni A, Helmer-Citterich M: Seq2Struct: a resource forestablishing sequence-structure links. Bioinformatics 2005,21:551-553.
27. Kundrotas P, Alexov E: PROTCOM: searchable database ofprotein complexes enhanced with domain-domain struc-tures. Nucl Acids Res 2006, 35:D575-9.
28. Ito T, Chiba T, Ozawa R, Yoshida M, Hattori M, Sakaki Y: A compre-hensive two hybrid analysis to explore the yeast proteininteractome. Proc Natl Acad Sci 2001, 98:4569-4574.
29. Krogan N, Cagney G, Yu H, Zhong G, Guo X, Ignatchenko A, Li J, PuS, Datta N, Tikuisis A, Punna T, Peregrin-Alvarez J, Shales M, ZhangX, Davey M, Robinson M, Paccanaro A, Bray J, Sheung A, Beattie B,Richards D, Canadien V, Lalev A, Mena F, Wong P, Starostine A, Can-ete M, Vlasblom J, Wu S, Orsi C, Collins S, Chandran S, Haw R,Rilstone J, Gandi K, Thompson N, Musso G, St Onge P, Ghanny S,Lam M, Butland G, Altaf-Ul A, Kanaya S, Shilatifard A, O'Shea E,Weissman J, Ingles C, Hughes T, Parkinson J, Gerstein M, Wodak S,
Emili A, Greenblatt J: Global landscape of protein complexes inthe yeast Saccharomyces cerevisiae. Nature 2006,440:637-643.
30. Finn R, Marshall M, Bateman A: iPfam: visualization of protein-protein interactions in PDB at domain and amino acid reso-lutions. Bioinformatics 2005, 21:410-412.
31. Ng S, Zhang Z, Tan S, Lin K: InterDom: a database of putativeinteracting protein domains for validating predicted proteininteractions and complexes. Nucl Acids Res 2003, 31:251-254.
32. PreSPI [http://prespi.icu.ac.kr]33. Apic G, Gough J, Teichmann S: An insight into domain combina-
tions. Bioinformatics 2001, 17:S83-S89.34. Shevchenko A, Schaft D, Roguev A, Pijnappel WWMP, Stewart A,
Shevchenko A: Deciphering protein complexes and proteininteraction networks by tandem affinity purification andmass spectrometry. Mol Cell Proteomics 2002, 1:204-212.
35. Gavin A, Aloy P, Grandi P, Krause R, Boesche M, Marzioch M, Rau C,Jensen L, Bastuck S, Dümpelfeld B, Edelmann A, Heurtier M, HoffmanV, Hoefert C, Klein K, Hudak M, Michon A, Schelder M, Schirle M,Remor M, Rudi T, Hooper S, Bauer A, Bouwmeester T, Casari G,Drewes G, Neubauer G, Rick J, Kuster B, Bork P, Russell R, Superti-Furga G: Proteome survey reveals modularity of the yeast cellmachinery. Nature 2006, 440:631-636.
36. Aloy P, Russell R: Structural systems biology: modelling pro-tein interactions. Nat Rev Mol Cell Biol 2006, 7:188-197.
37. Aloy P, Bottcher B, Ceulemans H, Leutwein C, Mellwig C, Fischer S,Gavin A, Bork P, Superti-Furga G, Serrano L, Russell R: Structure-based assembly of protein complexes in yeast. Science 2004,303:2026-2029.
38. Schneidman-Duhovny D, Inbar Y, Nussinov R, Wolfson H: Patch-Dock and symmDock: servers for rigid and symmetric dock-ing. Nucl Acids Res 2005, 33:W363-367.
39. Letunic I, Copley R, Schmidt S, Ciccarelli F, Doerks T, Schultz J, Pon-ting C, Bork P: SMART 4.0: towards genomic data integration.Nucl Acids Res 2004, 32:D142-144.
40. Gene Ontology Database [http://www.geneontology.org]41. Chen Y, Xu D: Global protein function annotation through
mining genome-scale data in yeast Saccharomyces cerevi-siae. Nucl Acids Res 2004, 32:6414-6424.
42. Wu H, Su Z, Mao F, Olman V, Xu Y: Prediction of functionalmodules based on comparative genome analysis and GeneOntology application. Nucl Acids Res 2005, 33:2822-2837.
Page 20 of 20(page number not for citation purposes)
http://www.ncbi.nlm.nih.gov/entrez/query.fcgi?cmd=Retrieve&db=PubMed&dopt=Abstract&list_uids=8557192
http://www.ncbi.nlm.nih.gov/entrez/query.fcgi?cmd=Retrieve&db=PubMed&dopt=Abstract&list_uids=8557192




















