
Analisis Deteksi Outlier Menggunakan CLARANS
58
i Abstrak Klastering merupakan salah satu metode data mining yang digunakan untuk mengelompokkan sejumlah obyek ke dalam klaster berdasarkan kesamaan karakteristik yang dimiliki obyek. Pada dataset yang memiliki banyak objek dimungkinkan adanya beberapa obyek yang memiliki perbedaan karakteristik dengan yang lainnya, obyek ini disebut outlier. Jumlah outlier yang sedikit dari banyaknya obyek menyebabkan outlier sulit untuk terdeteksi. Sedangkan tidak jarang ada informasi penting yang dapat digunakan dari keanomalian tersebut. Klastering dapat digunakan untuk mendeteksi keberadaan outlier. Pada pembahasan tugas akhir ini, outlier didapatkan dari teknik postprocessing dari hasil klastering oleh algoritma CLARANS (Clustering Large Application based on RANdomized Search). CLARANS menerapkan prinsip k- medoid dan melakukan pengkombinasian teknik sampling dengan PAM (Partitioning Around Medoid) untuk menemukan medoid terbaik dari tiap klaster. Dikarenakan klastering CLARANS belum dapat mendeteksi outlier, maka diperlukan teknik postprocessing setelah klastering. Teknik postprocessing yang digunakan ada 2, yaitu Clustering Outlier Removal (COR) dan Separation. Hasil pengujian sistem menghasilkan akurasi pendeteksian outlier hasil klastering CLARANS yang lebih baik oleh teknik COR dengan kondisi jumlah klaster yang ideal. Sedangkan pada teknik separation, nilai akurasi dipengaruhi oleh jumlah klaster dan model persebaran dataset. Kata kunci : klastering, deteksi outlier, k-medoid, CLARANS, clustering outlier removal, separation.
-
Upload
telkomuniversity -
Category
Documents
-
view
3 -
download
0
Transcript of Analisis Deteksi Outlier Menggunakan CLARANS

i
Abstrak
Klastering merupakan salah satu metode data mining yang digunakan untuk
mengelompokkan sejumlah obyek ke dalam klaster berdasarkan kesamaan
karakteristik yang dimiliki obyek. Pada dataset yang memiliki banyak objek
dimungkinkan adanya beberapa obyek yang memiliki perbedaan karakteristik
dengan yang lainnya, obyek ini disebut outlier. Jumlah outlier yang sedikit dari
banyaknya obyek menyebabkan outlier sulit untuk terdeteksi. Sedangkan tidak
jarang ada informasi penting yang dapat digunakan dari keanomalian tersebut.
Klastering dapat digunakan untuk mendeteksi keberadaan outlier. Pada
pembahasan tugas akhir ini, outlier didapatkan dari teknik postprocessing dari
hasil klastering oleh algoritma CLARANS (Clustering Large Application based
on RANdomized Search). CLARANS menerapkan prinsip k-medoid dan
melakukan pengkombinasian teknik sampling dengan PAM (Partitioning Around
Medoid) untuk menemukan medoid terbaik dari tiap klaster. Dikarenakan
klastering CLARANS belum dapat mendeteksi outlier, maka diperlukan teknik
postprocessing setelah klastering. Teknik postprocessing yang digunakan ada 2,
yaitu Clustering Outlier Removal (COR) dan Separation.
Hasil pengujian sistem menghasilkan akurasi pendeteksian outlier hasil
klastering CLARANS yang lebih baik oleh teknik COR dengan kondisi jumlah
klaster yang ideal. Sedangkan pada teknik separation, nilai akurasi dipengaruhi
oleh jumlah klaster dan model persebaran dataset.
Kata kunci : klastering, deteksi outlier, k-medoid, CLARANS, clustering outlier
removal, separation.

ii
Abstract
Clustering is one of data mining’s methods that used to grouped a set of
objects into a cluster based on the similarity of its characteristics. In a large
dataset, there is a possibility that one or more objects have difference
characteristic with another, this object called outlier. The small number of outlier
from a lot of objects causes the outlier difficult to detect. It is oftenly there are
some important information can used from that anomaly.
Clustering can used to detect the existence of outlier. In this study of final
task, outlier get from postprocessing technique of result by CLARANS
(Clustering Large Application based on RANdomized Search) algorithm.
CLARANS applying principle of k-medoid and combining the sampling
technique with PAM to find the best medoid from each cluster. Because of
clustering CLARANS disable to detect the outlier, then it need postprocessing
technique after clustering. There are two postprocessing techniques, Clustering
Removal Outlier (COR) and Separation.
Result of system obtain that accuration of detection outlier from clustering
CLARANS is more better by COR in condition ideal number of cluster. Whereas
in separation technique, value of accuracy influenced by number of cluster and
distribution model of data.
Keywords: clustering, outlier detection, k-medoid, CLARANS, clustering outlier
removal, separation.

iii
Lembar Persembahan
Tentunya dalam penyusunan tugas akhir ini tidak pernah terlepas dari bantuan
segenap pihak di sekitar penulis,
1. Allah SWT, Yang Maha Pengasih, Maha Penyayang, yang telah
memberikan segala kebaikan dan nikmat yang tak henti-hentinya kepada
penulis dan memberikan penulis sebuah hikmah yang berharga di bulan
Ramadhan tahun ini. Segala puji syukur hanya untuk-Mu, Ya Rabb…
2. Rasulullah SAW, shalawat atasnya, yang telah membawa penerang,
risalah Al Islam ke hati umatnya hingga sekarang…qudwah terbaik
dalam hidup penulis…
3. Orangtuaku tercinta, Ayah : Terimakasih atas semangat dan nasihat yang
tak bosan-bosannya kau berikan, dan Mama : Terimakasih atas
pengertian dan perhatian yang selalu kau curahkan. Semoga dengan
selesainya tugas akhir ini dapat mengukir senyum bangga dan bahagia
kalian. Adik-adikku tersayang : Sarah, Yaya, Icha. Terimakasih atas
support dan doa buat Mbak. Kalian harus bisa menjadi lebih baik dari
Mbak ya dek.
4. Pak Dhinta Darmantoro, ST., MSCS dan Pak Moch. Arif Bijaksana, Ir.,
MTech, selaku dosen pembimbing I dan II, penulis mengucapkan
terimakasih atas kesabaran dan keluasan ilmunya yang telah mau
membimbing dan membantu penulis untuk menyelesaikan amanah tugas
akhir ini guna melengkapi kelulusan dari kampus.
5. Rekan-rekan sekelas IF-27-03, terimakasih atas kebersamaan penuh suka
dan duka selama 4 tahun ini. Tanpa kalian, hari-hari di kampus akan
terasa melelahkan, teman.
6. Keluarga Besar LDK SKI STT Telkom, DKMSU, BMT, BKM Al Amin,
KAMMI. Dari sini penulis mendapatkan pelajaran berharga tentang
indahnya Islam dan ukhuwah islamiyah. Sungguh, tanpa kalian, hari-hari
ini tidak akan penuh makna akan perenungan kehidupan.
7. Saudari-saudariku, Erna, Dia, Nhita, Firah, Acit, Rey, Atik, Nana, Anggi,
Mega, Fika, Ufo, Titis (for the laptop and all...syukron ya ukh), Linda,
Nita, dan yang lainnya. Ukhti, karena kalianlah beban dan lelah dalam
menyusun tugas akhir ini dapat sirna hanya dengan mendengar tawa dan
ucapan tausiyah. Jazakillah.
8. Adik-adik angkatan 2004,2005,dan 2006 - Manda, Nia, Risti, Inda, Nina,
Wuri, Dhita, Fitri, dll - yang selalu mendukung dan tak bosan-bosan
menanyakan kabar perkembangan tugas akhir ini hingga penulis
termotivasi terus untuk menyelesaikannya.Terimakasih, hanya Allah
yang dapat membalas kebaikan kalian semuanya.
9. Untuk keluarga ’kedua’ penulis selama di Bandung, Ibu Ucah, Mba
Neng, Umi Wafa, Teh Elin, Ibu Ani, Mama Rendy, Mama Tenti, Kak
Azwan, dan adik-adikku, Wafa, Rendy, Harry dan Rofi. Tanpa kalian, tak
akan ada tempat senyaman seperti di rumah selama di Bandung ini.
10. Dan terakhir,untuk semua pihak yang telah membantu, DMC’ers, Aji,
Rahmi, Raudah, Desiyana, Desty, Lab Basdat, dll yang tak bisa
disebutkan satu per satu. Terimakasih atas bantuan dan dukungannya.

iv
Kata Pengantar
Klastering yang merupakan salah satu teknik data mining dapat digunakan
untuk mendeteksi keberadaan outlier. Sedangkan keberadaan outlier tak jarang
menyimpan informasi penting yang dapat digunakan dalam beberapa
permasalahan seperti fraud detection, fault detection, atau deteksi keanomalian
data. Oleh karena itu diperlukan metode untuk mendeteksi keberadaannya.
Karenanya pada penelitian tugas akhir ini, penulis memilih topik deteksi outlier
yang diharapkan dapat bermanfaat untuk pendeteksian outlier pada data. Fokus
penelitian ini dikhususkan untuk menganalisis kemampuan CLARANS
membentuk klastering serta teknik postprocessing-nya dalam mendeteksi outlier.
Penulis sangat berharap adanya masukan-masukan yang bersifat
membangun sehingga penelitian ini dapat terus dikembangkan untuk penelitian di
masa mendatang.
Wassalam,
Penulis

v
Daftar Isi
ABSTRAK .......................................................................................................... I
ABSTRACT ...................................................................................................... II
LEMBAR PERSEMBAHAN ......................................................................... III
KATA PENGANTAR ...................................................................................... IV
DAFTAR ISI ..................................................................................................... V
DAFTAR TABEL ......................................................................................... VIII
DAFTAR ISTILAH ......................................................................................... IX
1. PENDAHULUAN ........................................................................................ 1
1.1 LATAR BELAKANG ................................................................................... 1
1.2 PERUMUSAN MASALAH ............................................................................ 2
1.3 TUJUAN ................................................................................................... 2
1.4 METODOLOGI PENYELESAIAN MASALAH ................................................... 2
2. DASAR TEORI ........................................................................................... 3
2.1 DATA MINING.......................................................................................... 3
2.1.1 Klastering ......................................................................................... 3
2.1.2 Preprocessing Dataset ...................................................................... 4
2.2 DETEKSI OUTLIER .................................................................................... 4
2.2.1 Clustering Outlier Removal (COR) ................................................... 6
2.2.2 Separation ........................................................................................ 7
2.3 K-MEDOID .............................................................................................. 7
2.3.1 Partitioning Around Medoid (PAM).................................................. 7
2.3.2 CLARANS ......................................................................................... 9
2.4 VALIDASI KLASTERING DAN DETEKSI OUTLIER ....................................... 10
2.4.1 Silhouette Coefficient ...................................................................... 10
2.4.2 Absolute-Error Criterion ................................................................ 11
2.4.3 Precision, Recall, dan F-measure ................................................... 12
3. ANALISIS DAN PERANCANGAN PERANGKAT LUNAK ................. 13
3.1 GAMBARAN UMUM SISTEM .................................................................... 13
3.2 ANALISA KEBUTUHAN SISTEM ............................................................... 13
3.2.1 Kebutuhan Perangkat Lunak........................................................... 13
3.2.2 Analisis Perangkat Lunak ............................................................... 14
3.2.3 Analisis Perangkat Keras ............................................................... 14
3.3 PERANCANGAN SISTEM .......................................................................... 14
3.3.1 Diagram Aliran Data (DAD) .......................................................... 14
3.3.1.1 DAD Level 0 ................................................................................ 15
3.3.1.2 DAD Level 1 ................................................................................ 15
3.3.1.3 DAD Level 2 proses 1 .................................................................. 15
3.3.1.4 DAD Level 2 proses 2 .................................................................. 16
3.3.1.5 DAD Level 3 proses 2.2 ............................................................... 16
3.3.1.6 DAD Level 3 proses 2.3 ............................................................... 16

vi
3.3.1.7 Kamus Data ................................................................................ 17
3.3.1.8 Spesifikasi Proses ........................................................................ 18
4. IMPLEMENTASI DAN ANALISIS PENGUJIAN ................................. 22
4.1 IMPLEMENTASI SISTEM .......................................................................... 22
4.1.1 Implementasi Perangkat Keras ....................................................... 22
4.1.2 Implementasi Perangkat Lunak ....................................................... 22
4.2 KEBUTUHAN PENGUJIAN ........................................................................ 22
4.2.1 Dataset ........................................................................................... 22
4.2.2 Skenario Pengujian......................................................................... 24
4.3 PENGUJIAN DAN ANALISIS HASIL ........................................................... 24
4.3.1 Pengujian dan Analisis Klastering dengan CLARANS .................... 24
4.3.2 Pengujian dan Analisis Pengaruh Maxneighbor dan Numlocal
Terhadap Hasil Klastering .......................................................................... 28
4.3.3 Pengujian dan Analisis Pengaruh Maxneighbor dan Numlocal
Terhadap Waktu Eksekusi ........................................................................... 29
4.3.4 Pengujian dan Analisis Teknik COR Dalam Mendeteksi Objek
Outlier ....................................................................................................... 30
4.3.5 Pengujian dan Analisis Teknik Separation Dalam Mendeteksi
Klaster Outlier ............................................................................................ 33
5. KESIMPULAN DAN SARAN .................................................................. 36
5.1 KESIMPULAN ......................................................................................... 36
5.2 SARAN ................................................................................................... 37
DAFTAR PUSTAKA ....................................................................................... 38
LAMPIRAN A: DATA PENGUJIAN ............................................................. 39

vii
Daftar Gambar
Gambar 2-1 Ilustrasi Clustering-Based................................................................. 5
Gambar 2-2 Separation ........................................................................................ 7
Gambar 2-3 Kasus Kemungkinan untuk Fungsi Cost............................................ 9
Gambar 2-4 Ilustrasi Algoritma CLARANS ......................................................... 9
Gambar 2-5 Ilustrasi a(x) dan b(x) ..................................................................... 10
Gambar 3-1 Skema Deteksi Outlier pada Sistem ................................................ 13
Gambar 3-2 Diagram Aliran Data level 0 ........................................................... 15
Gambar 3-3 Diagram Aliran Data level 1 ........................................................... 15
Gambar 3-4 Diagram Aliran Data level 2 proses CLARANS ............................. 15
Gambar 3-5 Diagram Aliran Data level 2 proses Deteksi Outlier ....................... 16
Gambar 3-6 Diagram Aliran Data level 3 proses COR ....................................... 16
Gambar 3-7 Diagram Aliran Data level 3 proses Separation .............................. 16
Gambar 4-1 Hasil Klastering CLARANS Data Nilai Mahasiswa 3 klaster.......... 24
Gambar 4-2 Hasil Klastering CLARANS Data Sintesis1 5 klaster ...................... 25
Gambar 4-3 Grafik Pengaruh Parameter CLARANS pada 5 Dataset .................. 28
Gambar 4-4 Grafik Pengaruh Penambahan Parameter CLARANS terhadap Waktu
Eksekusi pada Data Bayi (kiri) dan Data Balon (kanan) ............................... 29
Gambar 4-5 Model Persebaran Data Balon (kiri atas), Data Sintesis_1 (kanan
atas), dan Data Bayi 3 Dimensi (kiri dan kanan bawah) ............................... 33

viii
Daftar Tabel
Tabel 2-1 Silhouette Objek ................................................................................. 11
Tabel 2-2 Silhouette Width ................................................................................ 11
Tabel 4-1 Outlier Data Balon ............................................................................. 22
Tabel 4-2 Outlier Data Bayi ............................................................................... 23
Tabel 4-3 Outlier Data Nilai Mahasiswa ............................................................ 23
Tabel 4-4 Outlier Data Sintesis 1 ....................................................................... 23
Tabel 4-5 Outlier Data Sintesis 2 ....................................................................... 23
Tabel 4-6 Silhouette Outlier pada Data Sintesis_1 .............................................. 25
Tabel 4-7 Silhouette Outlier pada Data Bayi ...................................................... 27
Tabel 4-8 Hasil Pengukuran Akurasi F-measure Data Sintesis_1 ....................... 30
Tabel 4-9 Hasil Pengukuran Akurasi F-measure Data Sintesis_2 ....................... 31
Tabel 4-10 Hasil Pengukuran Akurasi F-measure Data Bayi .............................. 31
Tabel 4-11 Hasil Deteksi Outlier dengan Separation pada Data Balon............... 34
Tabel 4-12 Hasil Deteksi Outlier dengan Separation pada Data Bayi ................ 34
Tabel 4-13 Hasil Deteksi Outlier dengan Separation pada Data Sintesis 1 ......... 34
Tabel A-1 Hasil Pengujian Parameter CLARANS pada Data Sintesis_2 ............ 39
Tabel A-2 Hasil Pengujian Parameter CLARANS pada Data Balon ................... 39
Tabel A-3 Hasil Pengujian Parameter CLARANS pada Data Bayi ..................... 39
Tabel A-4 Hasil Pengujian Parameter CLARANS pada Data Nilai .................... 40
Tabel A-5 Hasil Pengujian Parameter CLARANS pada Data Sintesis_1 ............ 40
Tabel A-6 Hasil Pengujian Klastering 5 klaster Data Sintesis_1, MN 9 NL 2 ..... 41
Tabel A-7 Hasil Pengujian Klastering 2 Klaster Data Bayi, MN 6 NL 2 ............. 42
Tabel A-8 Hasil Pengujian Akurasi Deteksi Outlier Data Sintesis_1 2 klaster .... 46

ix
Daftar Istilah
DAD Diagram aliran data yang menggambarkan aliran data
pada suatu sistem.
Klaster Kelompok data yang terdiri dari beberapa objek yang
memiliki tingkat kesamaan yang tinggi.
Stand-alone tool Perangkat yang berdiri sendiri.
Human error Kesalahan teknis yang dilakukan oleh manusia
Klaster outlier Kelompok data yang biasanya berukuran kecil dan
diindikasikan sebagai kelompok objek pencilan
Threshold Nilai ambang
Sampling Penarikan contoh, teknik pada algoritma CLARANS
Postprocessing Proses yang dilakukan setelah proses utama
Medoid Objek representatif klaster yang letaknya dekat dengan
pusat klaster Anomali Ketidaknormalan, kondisi abnormal

1
1. PENDAHULUAN
1.1 Latar belakang
Data merupakan kumpulan objek beratribut. Dengan data mining, data
tersebut dapat digunakan untuk memperoleh informasi penting yang tersimpan di
dalamnya. Namun, terkadang ada objek yang tidak termasuk ke dalam kelas
objek-objek lainnya. Dan jumlah objek ini umumnya sedikit sekali dari sekian
banyak objek, sehingga sulit terdeteksi keberadaannya. Objek ini dikenal dengan
outlier. Outlier adalah objek yang memiliki karakteristik berbeda jika
dibandingkan dengan objek yang lain yang ada di data set (abnormal data) [6].
Biasanya outlier ini menyimpan informasi yang dapat digunakan untuk
mendeteksi ke-abnormalan suatu masalah, seperti deteksi penggunaan tidak biasa
dari credit card, analisis medis untuk menemukan respon tidak biasa pada medical
treatment yang dilakukan, kesalahan sistem, deteksi fraud, human error, intrusion
detection, dan deteksi perilaku abnormal pelanggan [6]. Oleh karena itu,
keberadaan outlier penting untuk diketahui.
Pada data mining, salah satu teknik yang digunakan untuk mendeteksi
outlier yaitu dengan teknik klastering, dimana objek data dikelompokkan ke
dalam klaster-klaster berdasarkan kesamaan karakteristik yang dimiliki objek
tersebut [7]. Objek yang membentuk klaster berukuran kecil dan berada jauh
dibandingkan klaster lain atau objek yang memiliki perbedaan karakteristik yang
paling besar dalam klaster tersebut dapat dikatakan sebagai outlier.
Teknik klastering memiliki banyak algoritma untuk pengelompokan objek.
Namun tidak semuanya cocok diimplementasikan untuk deteksi outlier.
Algoritma yang dapat mendeteksi outlier adalah DBSCAN, BIRCH, dan CURE
[2]. Sedangkan dalam penelitian ini dipilih algoritma CLARANS yang merupakan
varian algoritma dari metode k-Medoid (algoritma PAM , Partitioning Around
Medoid) yang dikembangkan untuk data set yang berjumlah banyak (lebih dari
1000 record) [9] dan tidak bisa menangani dimensi tinggi. K-medoid sendiri
merupakan perbaikan dari algoritma k-means yang tidak dapat mendeteksi
keberadaan outlier. Jika dibandingkan dengan k-means, k-medoid lebih kuat
menangani keberadaan outlier. Sehingga algoritma yang mengimplementasikan
metode k-medoid bisa dikatakan memungkinkan mendeteksi outlier.
CLARANS juga dikatakan memungkinkan untuk menangani atau
mendeteksi outlier dan memiliki performansi yang lebih baik dari sisi penanganan
jumlah objek yang besar dibandingkan algoritma k-Medoid sebelumnya, karena
CLARANS mengkombinasikan teknik sampling dengan PAM [4]. CLARANS
melakukan klastering berdasarkan pencarian random medoid (randomized
search). Dari eksperimen yang telah dilakukan menunjukkan bahwa CLARANS
lebih efektif daripada PAM dan CLARA (algoritma perbaikan dari PAM dengan
teknik sampling) [4]. Namun, belum ada penelitian khusus yang menjelaskan
secara jelas bagaimana outlier mungkin terdeteksi dengan CLARANS ini.

2
1.2 Perumusan masalah
Adapun perumusan masalah yang diteliti dalam penelitian ini adalah :
1. apakah data dapat terpartisi dengan baik jika menggunakan CLARANS,
sehingga satu objek tepat berada di dalam satu klaster, kecuali outlier?
2. apakah outlier dapat dideteksi oleh CLARANS?
3. bagaimana cara outlier dideteksi dengan CLARANS?
4. pada kondisi seperti apa outlier dapat dideteksi oleh CLARANS?
5. bagaimana meningkatkan akurasi CLARANS dalam mendeteksi outlier?
Dan agar pembahasan dapat fokus, maka batasan masalah pada penelitian
ini adalah :
1. data set yang digunakan adalah data dengan variabel numerik dan data
pre-processing untuk data berdimensi tinggi, karena CLARANS tidak
mampu menangani data berdimensi tinggi, maksimal 5 dimensi.
2. tidak membahas terlalu mendalam algoritma klastering selain CLARANS,
kecuali untuk perbandingan dalam mendeteksi outlier.
3. tidak menangani eliminasi outlier setelah terdeteksi.
4. tidak ada pembobotan yang mempengaruhi pada dimensi-dimensi dataset
yang dipilih.
1.3 Tujuan
Dan tujuan dari penelitian ini adalah :
1. mempelajari proses deteksi outlier dengan algoritma CLARANS.
2. membuktikan CLARANS dapat atau tidak dapat menangani objek outlier.
3. mencari tahu faktor-faktor yang mempengaruhi kemampuan CLARANS
dalam mendeteksi outlier.
4. membangun perangkat lunak yang mengimplementasikan algoritma
CLARANS.
5. mendapatkan hasil akhir klastering yang terpartisi dengan baik, satu objek
tepat berada di satu klaster.
1.4 Metodologi penyelesaian masalah
Untuk menyelesaikan permasalahan pada penelitian ini, maka metodologi
penyelesaian yang akan dilakukan adalah :
1. Melakukan studi literatur terkait deteksi outlier, algoritma CLARANS,
dan algoritma pendukung.
2. Mengumpulkan data set yang memiliki objek outlier.
3. Melakukan pre-processing sehingga dataset yang digunakan sesuai untuk
inputan aplikasi yang dibangun..
4. Membangun perangkat lunak untuk implementasikan algoritma
CLARANS pada dataset tersebut untuk mendeteksi outlier.
5. Melakukan testing dengan data set yang ada.
6. Melakukan analisis terhadap hasil klastering yang dihasilkan.
7. Kesimpulan akhir dan pembuatan laporan akhir.

3
2. DASAR TEORI
2.1 Data Mining
Data mining merupakan proses menggali atau mengekstrak sejumlah data
yang ada untuk mendapatkan informasi yang penting di dalamnya. Data mining
juga dikenal sebagai Knowledge Discovery in Database (KDD) [1].
Ada beberapa tahapan yang dilakukan dalam data mining,yaitu :
1. Data cleaning, merupakan proses pembersihan data dari noise dan data
inkonsisten.
2. Data integration, penggabungan beberapa data.
3. Task relevant data, data yang telah digabungkan, ditaransformasi ke
bentuk yang sesuai agar bisa di-mining.
4. Data mining, proses penggalian data dilakukan.
5. Pattern evaluation, kemudian dilakukan evaluasi terhadap pola yang
dihasilkan dari data mining.
6. Barulah didapatkan knowledge atau presentasi pengetahuan dengan
visualisasi.
Di dalam data mining terdapat metode yang dibagi secara umum menjadi
dua yaitu predictive methods dan descriptive methods. Pada predictive methods
menggunakan beberapa variabel untuk memprediksi nilai dari variabel yang
lainnya. Yang termasuk metode ini adalah klasifikasi dan regresi. Sedangkan pada
descriptive methods dengan cara menemukan terlebih dahulu pola yang dibuat
berdasarkan interpretasi manusia terhadap data-data. Dan yang termasuk metode
ini adalah klastering, association rule mining, sequential pattern mining, dan
subgraph mining.
2.1.1 Klastering Klastering termasuk ke dalam descriptive methods, dan juga termasuk
unsupervised learning dimana tidak ada pendefinisian kelas objek sebelumnya.
Sehingga klastering dapat digunakan untuk menentukan label kelas bagi data-data
yang belum diketahui kelasnya. Konsep dasar dari klastering adalah
mengelompokkan sejumlah objek ke dalam klaster dimana klaster yang baik
adalah klaster yang memiliki tingkat kesamaan atau similarity yang tinggi antar
objek di dalam satu klaster dan tingkat ketidaksamaan atau dissimilarity yang
tinggi dengan objek klaster yang lainnya. Aplikasi klastering bisa dibangun
sebagai stand-alone tool atau sebagai preprocessing algoritma lainnya, misalnya
untuk algoritma pendeteksian outlier. Aplikasi clustering bisa dibangun sebagai
stand-alone tool atau sebagai preprocessing algoritma lainnya, misalnya untuk
algoritma pendeteksian outlier dalam pembahasan ini. Aplikasi clustering juga
dapat diimplementasikan untuk pattern recognition, spatial data analysis, image
processing, klasifikasi dokumen, dan market research.
Terdapat banyak algoritma klastering yang dalam penggunaannya
tergantung pada tipe data yang akan dikelompokkan dan apa tujuan dari
pembuatan aplikasinya. Dalam pembahasan di sini, algoritma klastering
digunakan untuk mengelompokkan objek ke dalam klaster-klaster, kemudian dari

4
hasil klastering akan dideteksi keberadaan outlier dalam data tersebut. Sedangkan
data yang digunakan bertipe data numerik.
Algoritma klastering diklasifikasikan ke dalam 5 kategori, yaitu :
1. Partitioning methods
Pengelompokkan objek dimana tiap objek terpartisi dengan tepat, yang
berarti 1 objek dimiliki oleh 1 klaster. Yang termasuk ke dalam metode ini
adalah algoritma k-means, k-medoid atau PAM, CLARA, dan CLARANS.
2. Hierarchical methods
Pengelompokan objek dapat dilakukan dengan 2 cara, agglomerative yang
dimulai dengan menggabungkan beberapa klaster hingga menjadi satu,
atau divisive yang dimulai dengan klaster yang sama kemudian dipecah
menjadi beberapa klaster yang lebih kecil. Yang termasuk ke dalam
metode ini adalah algoritma CURE, BIRCH, dan Chameleon.
3. Density-based methods
Pengelompokkan objek berdasarkan tingkat kerapatan objek atau densitas.
Yang termasuk ke dalam metode ini adalah algoritma DBSCAN,
DENCLUE, dan OPTICS.
4. Grid-based methods
Pengelompokan objek dengan menggunakan struktur data grid
multiresolusi. Mampu untuk menangani data berdimensi tinggi. Yang
termasuk ke dalam metode ini adalah algoritma CLIQUE, WaveCluster,
dan STING.
5. Model-based methods
Pengelompokan objek dengan memodelkan tiap klaster , dan mencoba
mengoptimasikan kesesuaian data dengan model matematika. Yang
termasuk ke dalam metode ini adalah algoritma COBWEB.
2.1.2 Preprocessing Dataset
Preprocessing merupakan salah satu tahapan awal dalam data mining,
yang terdiri dari proses pembersihan data, transformasi data, dan reduksi data.
Tujuan dari preprocessing adalah agar data yang digunakan untuk aplikasi data
mining mudah diinterpretasikan untuk dianalisis. Selain itu, agar data yang
digunakan sesuai atau relevan dengan kebutuhan aplikasi yang dibangun,
sehingga tentunya hasil yang dikeluarkan juga sesuai dan optimal.
Dan untuk algoritma CLARANS yang memiliki keterbatasan dalam
menangani data yang berdimensi tinggi, maka dilakukan preprocessing manual,
yaitu dengan memilih dimensi data yang akan diklastering dan dideteksi. Dimensi
yang dipilih haruslah bertipe numerik dan maksimal berjumlah 5 dimensi.
Peningkatan jumlah dimensi dalam klastering menimbulkan dampak kurang
berpengaruhnya perhitungan jarak antara 2 objek [5] sehingga juga mempengaruhi
klastering yang dihasilkan.
2.2 Deteksi Outlier
Deteksi outlier dikenal juga dengan deteksi anomali, yang merupakan
teknik untuk mencari atau menemukan objek yang memiliki karakteristik yang
berbeda daripada objek lainnya, objek ini disebut outlier. Permasalahan yang ada
pada deteksi outlier adalah bagaimana mendefinisikan objek sebagai outlier dan
menemukan outlier tersebut dalam berbagai kondisi dataset. Penyebab munculnya

5
objek outlier bisa disebabkan karena kesalahan pengukuran atau perhitungan,
human error, variasi nilai data, dan lain-lain. Banyak algoritma data mining yang
mencoba meminimalisasi dampak atau pengaruh dari keberadaan outlier ini,
bahkan dimungkinkan juga untuk mengeliminasi outlier sekaligus untuk
meminimasi error.
Terdapat beberapa pendekatan deteksi outlier antara lain :
1. Statistical-distribution based outlier detection
Pendekatan ini mengasumsi model persebaran atau probabilitas untuk data
set yang diberikan dan mengidentifikasi outlier dengan model
menggunakan discordancy test.
2. Distance-based outlier detection
Pendekatan ini muncul karena kekurangan dari pendekatan statistik dalam
mendeteksi outlier. Distance-based outlier adalah objek yang tidak
memiliki tetangga cukup banyak. Pengukuran jarak yang digunakan
biasanya menggunakan perhitungan Euclidean distance.
3. Density-based local outlier detection
Metode density-based mengantisipasi kesulitan ketika persebaran data
terjadi perbedaan densitas atau kerapatan. Di sini kita menggunakan notasi
local outlier.
4. Deviation-based outlier detection
Pendekatan ini memeriksa karakteristik utama dari objek-objek di dalam
grup atau klaster. Objek yang deviate atau menyimpang dari deskripsi
tersebut dipertimbangkan sebagai outlier.
5. Clustering-based outlier detection
Pendekatan ini menggunakan klastering untuk mendeteksi outlier. Klaster
yang berukuran kecil dan letaknya jauh dapat diindikasikan sebagai klaster
outlier. Ide dasar untuk mendeteksi outlier sebagai berikut [3]:
1. kelompokkan data ke dalam kelompok-kelompok berdasarkan
densitasnya.
2. Pilih titik-titik yang ada di dalam klaster yang kecil, sebagai kandidat
outlier
3. Hitung jarak antara kandidat outlier dengan klaster non-kandidat
lainnya.
4. Jika kandidat outlier letaknya jauh dari semua klaster non-kandidat
lainnya, maka kandidat outlier itu disebut outlier.
Gambar 2-1 Ilustrasi Clustering-Based

6
Terdapat 2 cara umum dalam mendeteksi keberadaan outlier pada
distribusi data. Pertama, dengan implementasi algoritma klastering yang
keluarannya langsung dihasilkan klaster outlier ataupun objek outlier. Salah satu
contohnya adalah dengan algoritma DBSCAN atau k-nearest neighbor. Dengan
DBSCAN keberadaan outlier dapat diketahui dengan mengukur tingkat kerapatan
atau densitas klaster. Sebuah objek dikatakan outlier jika dalam radius yang telah
ditentukan (Eps) tidak terdapat objek lainnya atau jika pun ada, kurang dari
jumlah minimum objek (MinPts) yang ditentukan sebelumnya. Sedangkan cara
kedua, dimana proses deteksi merupakan tahapan post-processing dari
implementasi algoritma klastering, karena pendeteksian outlier dilakukan setelah
klaster-klaster terbentuk, dengan kata lain dalam hal ini, algoritma klastering tidak
berperan secara langsung dalam mendeteksi outlier. Sehingga diperlukan metode
atau algoritma tambahan untuk mendeteksi keberadaan outlier.
Dan pada pembahasan tugas akhir, CLARANS memungkinkan
mendeteksi outlier yang mana dihasilkan dari produk atau hasil proses klastering
[6]. Sehingga diperlukan teknik post-processing untuk dapat menemukan outlier,
dan dalam pembahasan tugas akhir ini dipilih 2 metode yaitu algoritma Clustering
Outlier Removal (COR) dan Separation.
2.2.1 Clustering Outlier Removal (COR)
Teknik Clustering Outlier Removal atau COR dikembangkan oleh
Svetlana Cherednichenko pada tesisnya di tahun 2005. Dalam penelitiannya,
algoritma klastering yang digunakan adalah k-means [14]. Dan dalam pembahasan
tugas akhir ini, CLARANS akan menggantikan k-means sebagai algoritma
klastering yang digunakan.
COR terdiri dari 2 tahap dalam implementasinya. Tahap pertama adalah
implementasi algoritma klastering, kemudian tahap kedua yaitu secara iterative
mengimplementasikan algoritma outlier removal untuk menemukan objek outlier,
dan akan berhenti sampai pencacah iterasi terpenuhi atau kondisi threshold
terpenuhi. Outlier di sini didefinisikan sebagai titik atau objek yang jaraknya
relatif jauh objek-objek yang lainnya. Teknik ini bergantung pada 2 variabel, yaitu
threshold dan distortion. Threshold adalah parameter yang diinputkan oleh
pengguna, yang berkisar antara nilai 0 sampai dengan 1, sedangkan distortion
adalah perbandingan antara jarak objek terdekat dari centroid klaster dan jarak
terjauh dari centroid klaster dalam satu klaster [14]. Distortion dihitung untuk
mengetahui seberapa jauh sebuah objek yang terjauh jika dibandingkan dengan
objek yang terdekat dengan centroid.
maxmin ddDistortion (2.1)
Sebuah objek dikatakan outlier jika menemui kondisi distortion lebih
rendah daripada threshold yang diinputkan, maka objek terjauh dari klaster
tersebut dapat dipertimbangkan sebagai objek outlier. Namun dampak dari teknik
ini adalah belum diketahui secara pasti nilai threshold yang mengindikasikan
outlier, karena tiap bentuk klaster yang dihasilkan memungkinkan memiliki
perbedaan nilai threshold.

7
2.2.2 Separation
Separation merupakan ukuran seberapa berbeda atau jauh terpisah sebuah
klaster dengan klaster lainnya. Separation biasanya digunakan untuk mengukur
validitas klaster. Dalam pembahasan tugas akhir ini, selain sebagai salah satu
variabel pengukuran validitas klaster, separation akan digunakan untuk
menemukan klaster outlier dari klaster-klaster hasil klastering dengan
CLARANS. Perhitungan separation bisa didapatkan dari 2 pendekatan, yaitu
graph-based dan prototype-based. Perbedaannya bisa dilihat pada gambar di
bawah ini :
(a) Graph-based (b) Prototype-based
Gambar 2-2 Separation
Persamaan separation dituliskan sebagai berikut :
a. Graph-based
i jCx Cy
ji yxproximityCCSeparation ,, (2.2)
b. Prototype-based
jiji ccproximityCCSeparation ,, (2.3)
Nilai proximity yang digunakan adalah Euclidean Distance. Persamaan
Euclidean cocok untuk data bertipe numerik dan mengutamakan perbedaan jarak
antar keduanya [5]. Persamaan Euclidean dihitung dengan persamaan berikut :
l
k
jkik xxjiDist1
2)(),( (2.4)
Sebuah objek dikatakan objek outlier jika berada di dalam klaster outlier.
Klaster dikatakan sebagai klaster outlier ketika size atau ukuran klaster kecil atau
1 dan nilai separation tinggi.
2.3 K-Medoid
K-medoid mengelompokkan objek-objek dengan terlebih dahulu
menemukan objek yang mewakilkan objek lainnya, yang disebut medoid, yang
secara letaknya berada di tengah-tengah klaster. K-medoid juga dikenal sebagai
PAM.
2.3.1 Partitioning Around Medoid (PAM)
Algoritma pertama yang menerapkan k-medoid adalah PAM (partitioning
around medoid). PAM dikembangkan oleh Kaufmann dan Rousseeuw [4]. Untuk
menemukan k-klaster, PAM melakukan pendekatan dengan menentukan objek
mana yang mewakilkan setiap klaster yang ada. Objek representatif ini disebut
dengan medoid, yang secara umum letaknya di tengah-tengah klaster. Sekali

8
medoid terpilih, objek yang bukan medoid atau non-medoid akan dikelompokkan
dengan medoid yang paling mirip.
Sebagai gambaran, sebuah dataset memiliki n buah objek. Kemudian
medoid akan terpilih secara acak sejumlah k objek, dimana k sama dengan jumlah
klaster yang ingin dibentuk. K-medoid ini dianggap sebagai objek yang terpilih Oj
dan objek selain medoid dianggap objek non-medoid Oh. Oh termasuk ke dalam
klaster yang direpresentasikan oleh Oj jika dissimilarity atau jarak antara Oh dan
Oj merupakan minimum dari semua medoid Om. Dalam notasi dinyatakan dengan
d(Oh,Oj) = min(Oh,Om). Kemudian dilakukan swapping atau pertukaran antara Oj
dengan Oh pada tiap tahap.
Algoritma PAM dapat diurutkan sebagai berikut :
1. pilih k objek secara sembarang.
2. hitung fungsi cost TCjh untuk setiap pasangan objek Oj dan Oh, dimana Oj
adalah objek terpilih dan Oh adalah objek yang tidak terpilih.
3. pilih pasangan Oj,Oh yang menghasilkan TCjh = min(Oj,Oh). Jika nilai
minimum TCjh negatif, maka ganti Oj dengan Oh dan selanjutnya kembali
ke langkah 2.
4. sebaliknya, untuk setiap objek tidak terpilih, temukan medoid yang paling
mirip dengan objek tidak terpilih tersebut.
Dalam perhitungan fungsi cost, ada 4 kasus kemungkinan yang terjadi saat
pertukaran medoid, yaitu :
1. P sebelumnya milik medoid Oj, jika Oj digantikan oleh Oh sebagai medoid
dan P lebih dekat ke salah satu dari Oi, i ≠ j, maka P di-assign kembali ke
Oi. Dimana d(P, Oh) ≥ d(P, Oi). Fungsi cost :
jipjh OPdOPdC ,, (2.5)
2. P sebelumnya milik medoid Oj, jika Oj digantikan oleh Oh sebagai medoid
dan P lebih dekat ke Oh, maka P di-assign kembali ke Oh. Dimana d(P, Oh)
< d(P, Oi). Fungsi cost :
jhpjh OPdOPdC ,, (2.6)
3. P sebelumnya milik medoid Oi, i ≠ j, jika Oj digantikan oleh Oh sebagai
medoid, dan P masih tetap dekat ke Oi, maka tidak ada perubahan.
Fungsi cost :
0pjhC (2.7)
4. P sebelumnya milik medoid Oi, i ≠ j, jika Oj digantikan oleh Oh sebagai
medoid dan P lebih dekat ke Oh, maka P di-assign kembali ke Oh.
Fungsi cost :
ihpjh OPdOPdC ,, (2.8)
Sehingga dari 4 kasus di atas dapat diakumulasikan perhitungan cost oleh
persamaan Total Cost berikut :
p
pjhjh CTC (2.9)

9
(1) (2) (3) (4)
Gambar 2-3 Kasus Kemungkinan untuk Fungsi Cost
2.3.2 CLARANS
Algoritma CLARANS atau Clustering Large Application based on
RANdomized Search merupakan algoritma varian algoritma dari k-medoid. Dan
juga merupakan pengembangan dari algoritma-algoritma sebelumnya yang
menerapkan k-medoid, seperti PAM (Partitioning Around Medoid) dan CLARA
(Clustering Large Application) untuk menangani jumlah data yang lebih besar.
CLARANS mengkombinasikan teknik sampling dengan PAM. Yang dimaksud
menggunakan pengkombinasian kedua teknik di atas yaitu CLARANS mengambil
secara random sejumlah objek yang dianggap medoid yang merupakan sampling
dari objek-objek yang lain, kemudian mengimplementasikan teknik PAM pada
setiap sampling.
Sebagai awal penggambaran, CLARANS memulai proses dengan
mengambil secara random beberapa objek dari n objek yang sebelumnya
dijabarkan sebagai sebuah graph, Dinotasikan dengan Gn,k.. Objek random
tersebut dianggap sebagai medoid pada suatu node. Jadi sebuah node pada graph
berisikan k-medoid, dimana k merupakan jumlah klaster yang diinginkan. Sebuah
node memiliki neighbor, dan dua buah node dapat dikatakan bertetanggaan jika
perbedaan anggota medoid mereka hanya 1 objek saja. Dengan kata lain, jika ada
k buah medoid pada tiap node, maka perbedaan antara 2 node hanya (k-1) objek
medoid, sehingga dapat disimpulkan bahwa 1 node memiliki k(n-k) neighbor. Dan
dari node inilah akan dihitung persamaan total cost dengan menghitung
dissimilarity antara medoid dengan tiap objek.
Gambar 2-4 Ilustrasi Algoritma CLARANS

10
CLARANS memiliki 2 parameter utama, yaitu maxneighbor dan
numlocal. Maxneighbor adalah jumlah maksimal neighbor dari sebuah node yang
akan dicek, sedangkan numlocal adalah jumlah maksimal local minimum yang
menentukan berapa kali node dicek. Pada referensi [12], berdasarkan eksperimen
yang dilakukan sebelumnya, nilai numlocal yang telah diuji sama dengan 2 dan
maxneighbor yang telah diuji berkisar antara 1,25% s/d 1,5% * k(n-k), dimana k
adalah jumlah klaster yang diinginkan, dan n adalah jumlah objek pada dataset.
Berikut langkah-langkah dalam algoritma CLARANS :
1. inputkan parameter numlocal dan maxneighbor. Inisialisasi i=1 dan
mincost = large number
2. set current node di graph G.
3. set j = 1
4. pilih secara random neighbor (S) dari current node. Hitung selisih cost
dari 2 node (current dan S) berdasarkan persamaan (2.9).
5. jika S punya cost lebih rendah, maka set current node = S, dan balik ke
langkah (3).
6. sebaliknya, jika S > current node , maka increment j j = j + 1. lalu cek
jika j <= maxneighbor, kembali ke langkah (4).
7. sebaliknya jika j > maxneighbor , bandingkan cost antara S dengan
mincost. Jika S << mincost, maka mincost = cost S dan bestnode = S.
8. lalu increment i i = i+1. jika i > numlocal, maka output = best node dan
proses berhenti. Jika i < numlocal, kembali ke langkah (2). Proses berhenti
jika nilai numlocal telah terpenuhi.
2.4 Validasi Klastering dan Deteksi Outlier
2.4.1 Silhouette Coefficient
Silhouette Coefficient dikembangkan pertama kali oleh Kaufman dan
Rousseeuw [15]. Silhouette coefficient mengkombinasikan ide cohesion dan
separation untuk validasi hasil klastering. Cohesion digunakan untuk mengukur
seberapa dekat hubungan objek-objek pada klaster yang sama. Sedangkan
separation digunakan untuk mengukur seberapa berbeda atau terpisahnya sebuah
klaster dari klaster lainnya. Sedangkan silhouette coefficient sendiri digunakan
untuk mengukur kualitas klaster yang dihasilkan sekaligus mengindikasikan
derajat kepemilikan setiap objek yang berada di dalam klaster.
Nilai silhouette dari sebuah objek Oj berada pada rentang antara -1 sampai
dengan 1. Semakin dekat nilai silhouette objek Oj ke 1, maka semakin tinggi
derajat Oj di dalam klaster. Berdasarkan penggunaannya, berikut akan dijelaskan
cara untuk menentukan silhouette coefficient dari klaster :
Gambar 2-5 Ilustrasi a(x) dan b(x)
Diberikan sebuah titik x di klaster A, lalu a(x) adalah jarak rata-rata antara
titik x dengan titik lain di klaster A, dan b(x) adalah jarak rata-rata antara titik x

11
dan titik-titik di klaster kedua yang terdekat dengan A, yaitu klaster B. Kemudian
hitung nilai silhouette setiap objek dengan persamaan :
xbxa
xaxbxS
,max
(2.10)
Pada referensi [15], nilai silhouette akan mengindikasikan derajat
kepemilikan tiap objek sebagai berikut :
Tabel 2-1 Silhouette Objek
Silhouette Interpretasi
S(x)= -1 menunjukkan overlapping struktur yang tinggi, bahwa x berada
dekat dengan objek lain di klaster B, bukan A, klaster sebelumnya. Atau bisa dikatakan x seharusnya tidak berada di
dalam klaster A.
S(x)=0 menunjukkan x sama-sama similar untuk klaster A dan B.
S(x)= 1 Menunjukkan x memang milik klaster A.
Setelah mendapatkan nilai silhouette tiap objek dalam klaster, kita dapat
menentukan silhouette width untuk klaster tersebut, yaitu dengan menghitung
rata-rata nilai silhouette semua objek yang berada dalam klaster. Dan berdasarkan
eksperimen pada referensi [15] yang mengemukakan interpretasi terhadap nilai
silhouette width untuk klaster sebagai berikut :
Tabel 2-2 Silhouette Width
Silhouette Width Interpretasi
0.71 – 1 Strong klaster
0.51 – 0.7 Reasonable klaster
0.26 – 0.5 Weak atau artificial klaster
≤ 0.25 No klaster found
Dari nilai silhouette width klaster, dapat dihitung nilai rata-rata silhouette
width untuk k-klaster sehingga didapatkan nilai silhouette coefficient klastering
yang mengindikasikan kualitas klastering.
2.4.2 Absolute-Error Criterion
Absolute-Error Criterion atau AEC digunakan sebagai prinsip minimasi
total dissimilarities antara tiap objek dengan representatif objeknya. Dalam
CLARANS digunakan untuk menghitung cost pada proses klasteringnya.
Semakin kecil nilai AEC maka hasil klastering juga semakin baik.
Berikut persamaan yang digunakan :
k
j Cp
j
j
opE1
(2.11)

12
2.4.3 Precision, Recall, dan F-measure
Sedangkan untuk mengukur ketepatan deteksi outlier, digunakan perhitungan
precision, recall, dan f-measure terhadap objek yang termasuk kelas outlier
(kelas O). Berikut persamaan-persamaan yang digunakan :
1. Precision (i,j) : iijij mmp / (2.12)
2. Recall (i,j) : jij mm / (2.13)
3. F-measure (i,j) : rp
pr
2 (2.14)
Semakin besar nilai f-measure yang dihasilkan, semakin baik hasil deteksi.
Dimana :
mi= jumlah record pada klaster ke-i
mij= jumlah record dari class ke-j yang ada pada klaster ke-i
pij= precision dari klaster ke-i dan class ke-j
m=jumlah semua record pada data
mj= jumlah record pada class ke-j

13
3. Analisis dan Perancangan Perangkat Lunak
3.1 Gambaran Umum Sistem
Perangkat lunak yang dibangun merupakan implementasi algoritma
klastering, yaitu CLARANS, dalam mendeteksi keberadaan outlier di dalam
sebuah dataset. Perangkat lunak ini terdiri dari 2 proses utama, yaitu klastering
dan deteksi outlier dari hasil klastering tersebut.
Secara umum proses deteksi outlier pada sistem adalah sebagai berikut :
Gambar 3-1 Skema Deteksi Outlier pada Sistem
Data preprocessing merupakan tahapan awal untuk mempersiapkan
dataset agar dapat digunakan dan sesuai dengan kebutuhan perangkat lunak.
Dalam perangkat lunak ini proses preprocessing tidak dibangun
fungsionalitasnya.
3.2 Analisa Kebutuhan Sistem
Sistem yang dibuat dalam tugas akhir ini merupakan sebuah perangkat
lunak yang memiliki 2 proses utama, yaitu klastering data dan setelah itu
melakukan proses deteksi outlier dari hasil klaster tersebut. Pada saat
pengoperasian sistem ini dapat dilakukan dengan memperhatikan hal – hal
berikut ini :
File tabel yang dijadikan inputan dalam aplikasi ini berada di dalam 1
database dataset yang bertipe *.mdb
File tabel harus beratribut numerik ,kecuali kolom id_record yang harus
berada di kolom pertama tabel.
Berdasarkan analisis kebutuhan sistem ini maka terdapat beberapa
kebutuhan yang nantinya akan menjadi masukan dalam proses perancangan
sistem.
3.2.1 Kebutuhan Perangkat Lunak
Di dalam perangkat lunak ini terdapat beberapa kebutuhan fungsional,
yaitu :
1. memilih tabel dari database dataset.mdb yang ingin diklastering dan
dideteksi keberadaan outlier pada dataset tersebut.
2. melakukan proses klastering kemudian pendeteksian outlier.
3. menampilkan visualisasi dalam 2D hasil proses klastering dan deteksi
outlier pada chart.
4. menyimpan hasil klastering dan deteksi outlier berupa file *.txt dan *.bmp
untuk hasil visualisasi.
Dataset Data
preprocessing Deteksi outlier
Data outlier
Klastering data

14
3.2.2 Analisis Perangkat Lunak
Dalam pembangunan sistem ini memerlukan beberapa perangkat lunak,
sebagai berikut :
1. sistem operasi Microsoft Windows XP Profesional version 2002.
2. database Microsoft Access 2003
3. bahasa pemrograman Borland Delphi 7
3.2.3 Analisis Perangkat Keras
Dan juga diperlukan spesifikasi perangkat keras di dalam pembangunan
perangkat lunak ini, yaitu :
1. Processor AMD Athlon™ - 1.24 GHz.
2. RAM 256 MB
3. Harddisk 40 GB
4. VGA Card
5. Monitor LG 15’
6. Keyboard dan mouse
3.3 Perancangan Sistem
3.3.1 Diagram Aliran Data (DAD)
Dari analisis sistem di atas, maka dibuat perancangan sistem dengan
Diagram Aliran Data (DAD) yang terdiri dari beberapa level yang setiap levelnya
menjelaskan proses di dalam sistem. Keterangan mengenai simbol-simbol yang
digunakan pada Diagram Aliran Data dapat dilihat pada tabel dibawah ini :
Tabel 3.1 Simbol Diagram Aliran Data
Simbol Arti
Proses
Subyek/obyek (entity luar ) yang berinteraksi dengan
proses
Tempat penyimpanan data ( database)
Arah aliran data

15
3.3.1.1 DAD Level 0
user0.
Sistem Deteksi
Outlier
nama_database , nama_tabel, jumdim, jumclust,
Index_metode
Outlier_point, Cluster_outlier,
Visual_2D
Gambar 3-2 Diagram Aliran Data level 0
3.3.1.2 DAD Level 1
user
1.
CLARANS
2.
Deteksi
Outlier
Nama_database, nama_tabel,
Jumdim, jumclust
Outlier_point,
Cluster_outlier
Best_medoid,
Cluster_member
Index_metode
3.
VisualisasiVisual_2D
Outlier_point,
Cluster_outlier
Gambar 3-3 Diagram Aliran Data level 1
3.3.1.3 DAD Level 2 proses 1
Dataset
1.1
Load Tabel
Nama_database,
Nama_tabel
List_tabel
1.2
Generate
parameter
Jumdim, jumclust,
jumrec
1.3
Select
random
medoid
Maxneighbor,
numlocal
1.5
Compare
TotalCost
1.4
Select
random
neighbor
Maxneighbor,
numlocal
Current_nodeNeighbor_node
1.6
Select
Medoid
Best_nodeBest_medoid,
Cluster_member
Gambar 3-4 Diagram Aliran Data level 2 proses CLARANS

16
3.3.1.4 DAD Level 2 proses 2
2.1
Choose MethodIndex_metode
2.2
COR
2.3
Separation
Metode_COR
Metode_separation
Outlier_point
Cluster_outlier
Gambar 3-5 Diagram Aliran Data level 2 proses Deteksi Outlier
3.3.1.5 DAD Level 3 proses 2.2
2.2.1
Nearest and
Furthest Object
Threshold, Iterasi
Best_medoid,
Cluster_member
2.2.2
Distortion
2.2.3
Compare
Threshold and
Distortion
Dist_min,
Dist_maxDistorsi
User
Outlier_point
Gambar 3-6 Diagram Aliran Data level 3 proses COR
3.3.1.6 DAD Level 3 proses 2.3
2.3.1
Cluster
Diameter
Best_medoid,
Cluster_member
2.3.2
Find Biggest
Separation
Diameter_cluster Cluster_outlier
Dataset
Size_cluster
Gambar 3-7 Diagram Aliran Data level 3 proses Separation

17
3.3.1.7 Kamus Data
Dan elemen-elemen yang digunakan pada Diagram Aliran Data di atas
adalah sebagai berikut :
Elemen data Jenis Data Keterangan
Nama_database File *.mdb Nama database yang digunakan yang berisi kumpulan tabel
Nama_tabel String Nama tabel dataset yang akan digunakan
JumDim Numerik Jumlah dimensi yang dipilih dari tabel dataset
JumClust Numerik Jumlah klaster yang ingin dibentuk
JumRec Numerik Jumlah record dataset
Outlier_point Array of Tcluster Hasil deteksi berupa objek outlier
*TCluster = record
jum_member = integer rec = array of Trecord*
Cluster_outlier Array of Tcluster Hasil deteksi berupa klaster outlier
*TCluster = record
jum_member = integer rec = array of Trecord*
Index_metode 1 | 2 Index metode yang dipilih oleh user. Nilai (1)
jika postprocessing dengan COR, dan (2) jika postprocessing dengan separation.
Best_medoid Array of TRecord Hasil akhir klastering CLARANS berupa objek
medoid setiap klaster.
*Trecord = record id = string;
dim = array of double*
Cluster_member Numerik Jumlah anggota tiap klaster.
Dataset Data store Menyimpan kumpulan dataset
List_Tabel String Nama tabel-tabel dataset yang ada di dalam
database *.mdb
Maxneighbor Numerik Nilai parameter yang digenerate atau diinput
user
Numlocal Numerik Nilai parameter yang digenerate atau diinput
user
Current_node Array of TRecord Node yang dipilih random di awal proses
klastering *Trecord = record
id = string;
dim = array of double*
Neighbor_node Array of TRecord Node neighbor yang dipilih random di awal proses klastering
*Trecord = record
id = string; dim = array of double*
Best_node Array of TRecord Node terpilih dari proses perbandingan total
cost
*Trecord = record id = string;
dim = array of double*

18
Metode_COR Numerik Output pilihan index metode
Metode_separation Numerik Output pilihan index metode
Dist_min Numerik Nilai jarak antara objek medoid dengan objek
terdekatnya dalam satu klaster.
Dist_max Numerik Nilai jarak antara objek medoid dengan objek terjauhnya dalam satu klaster.
Distorsi Numerik Nilai rasio jarak terdekat dengan jarak terjauh.
Threshold Numerik Nilai ambang untuk menentukan objek outlier
atau bukan
Iterasi Numerik Pencacah metode COR
Diameter_cluster Numerik Ukuran diameter klaster
Size_cluster Numerik Jumlah anggota klaster
Visual_2D Chart Hasil visualisasi klastering dan deteksi outlier
3.3.1.8 Spesifikasi Proses
Proses 1.1 Load Tabel
Deskripsi Memilih tabel dataset yang ingin digunakan
Input Nama_database, list_tabel, nama_tabel
Output JumDim, JumClust, JumRec
Logika Proses ADOConnection1.GetTableNames(nama_tabel);
ADOTable1.Active false
ADOTable1.TableName nama_tabel
ADOTable1.Active true
ADOTable1.GetFieldNames(list_tabel)
Proses 1.2 Generate Parameter
Deskripsi Membangkitkn nilai maxneighbor dan numlocal awal
Input jumdim,jumclust,jumrec
Output Maxneighbor, numlocal
Logika Proses Maxneighbor 0.0150*jumclust*(jumrec-jumclust)
numlocal 2
Proses 1.3 Select Random Medoid
Deskripsi Memilih current node secara acak sebagai k-medoid
Input Maxneighbor, numlocal
Output Current_node
Logika Proses Randomize
Sim Random(jumrec-1);
current_node rec[sim];

19
Proses 1.4 Select Random Neighbor
Deskripsi Memilih neighbor dari node secara acak
Input Maxneighbor, numlocal
Output Neighbor
Logika Proses Randomize
temp random(jumclust-1)
for k 0 to (jumclust-1) do begin
if (k ≠ temp) then neighbor[k] current_node[k]
else
repeat
randomize
neighbor[k] rec[random(jumrec-1)];
if (neighbor[k]=current_node[k] then
select_random_neighbor
endif
until (neighbor[k]≠current_node[k] )
endif
endfor
Proses 1.5 Compare Total Cost
Deskripsi Membandingkan total cost current_node dengan neighbor
Input Current_node, neighbor
Output Best_node
Logika Proses Hitung = 1
repeat
num num+1
repeat
if (TotalCost(current_node) < TotalCost(neighbor)) then
hitung hitung+1
else
hitung 1
current_node neighbor
endif
select_random_neighbor
until (hitung > maxneighbor);
if (mincost < TotalCost(current_node)) then
best_nodebest_node
else
best_node current_node
mincost TotalCost(current_node);
endif
select_random_medoid
select_random_neighbor
until (num > numlocal)

20
Proses 1.6 Select Medoid
Deskripsi Mengelompokkan objek non-medoid ke dalam klaster dengan
medoid yang termirip
Input Best_node
Output Best_medoid, cluster_member
Logika Proses cluster_member 0
if (best_node = node_select) then
cluster.rec[cluster_member] rec[i]
endif
best_medoid best_node
cluster_member cluster_member + 1
Proses 2.1 Choose Method
Deskripsi Memilih teknik postprocessing untuk mendeteksi outlier
Input Index_metode
Output metode_COR, metode_separation
Logika Proses If index_metode = 1 then
metode_COR
else
metode_Separation
endif
Proses 2.2.1 Nearest and Furthest Object
Deskripsi Mencari objek terdekat dan terjauh dari medoid dalam klaster
yang sama
Input Best_medoid, cluster_member
Output Dist_min, dist_max
Logika Proses for i0 to (cluster_member-1) do
temp temp + (sqr(best_medoid-cluster.rec[i]));
endfor
distance[i] sqrt(temp);
if (init_dist_max < distance[i]) then
init_dist_max distance[i]
endif
if (distance[i] ≠ 0) then
if (init_dist_min > distance[i]) then
init_dist_min distance[i]
endif
endif
endfor
dist_max init_dist_max;
dist_min init_dist_min;

21
Proses 2.2.2 Distortion
Deskripsi Menghitung distorsi klaster
Input Dist_min, dist_max
Output Distorsi
Logika Proses Distortion dist_min / dist_max;
Proses 2.2.3 Compare Threshold and Distortion
Deskripsi Membandingkan antara threshold dan distorsi
Input Distorsi, threshold, iterasi
Output Outlier_point
Logika Proses repeat
for i0 to cluster_member-1 do
if (distortion < threshold ) or (distortion=1) then
outlier_point cluster.rec[i];
cluster_member cluster_member-1
endif
endfor
until (iterasi terpenuhi)
Proses 2.3.1 Cluster Diameter
Deskripsi Menghitung diameter klaster
Input Best_medoid, cluster_member
Output Diameter_cluster
Logika Proses for i0 to cluster_member-1 do begin
for k0 to cluster_member-1 do begin
temp temp + sqr(cluster.rec[i]-cluster.rec[k]);
endfor
endfor
diameter_cluster sqrt(temp / (n*(n-1)))
Proses 2.3.2 Find Biggest Separation
Deskripsi Menghitung dan mencari separation klaster
Input Diameter_cluster, size_cluster
Output Cluster_outlier
Logika Proses for k0 to jumclust-1 do
for l0 to jumclust-1 do begin
temptemp + (sqr(cluster[k].rec-cluster[l].rec))
{jumlahkan jarak antar titik}
sum_distsum_dist + sqrt(temp)
dist_clust dist_clust + sum_dist;
endfor
separation[k] dist_clust;
endfor
if ((min_size = size_cluster) and(max_sep = separation[k]))
then cluster_outlier cluster[k]
endif

22
4. Implementasi dan Analisis Pengujian
4.1 Implementasi Sistem
4.1.1 Implementasi Perangkat Keras
Perangkat keras yang digunakan untuk implementasi adalah perangkat
keras dengan spesifikasi sebagai berikut :
1. Processor AMD Athlon™ - 1.24 GHz.
2. RAM 256 MB
3. Harddisk 40 GB
4. VGA Card
5. Monitor LG 15’
6. Keyboard dan mouse
4.1.2 Implementasi Perangkat Lunak
Perangkat lunak yang digunakan untuk implementasi adalah perangkat
lunak dengan spesifikasi sebagai berikut :
1. sistem operasi Microsoft Windows XP Profesional version 2002.
2. database Microsoft Access 2003
3. bahasa pemrograman Borland Delphi 7
4.2 Kebutuhan Pengujian
4.2.1 Dataset
1. Data Balon
Data ini berasal dari UCI repositary, terdiri dari 1800 record dan 2 dimensi
dengan kolom id berisi id_balon. Jumlah klaster tidak diketahui ,terdapat 10 objek
outlier, yaitu nilai raw dan residual yang rendah jika dibandingkan dengan objek
lainnya. Struktur tabel data balon beserta data outlier-nya adalah sebagai berikut :
Tabel 4-1 Outlier Data Balon
id_balon raw residual
90 1 -0,944
333 0,72 -1,306
707 0,82 -1,299
967 1,08 -1,089
970 0,64 -1,530
1026 0,78 -1,400
1042 0,58 -1,600
1400 0,72 -1,512
1454 0,76 -1,478
1511 0,78 -1,458
2. Data Bayi
Data ini terdiri dari 211 record dan 3 dimensi dengan kolom id berisi
nama_bayi. Jumlah klaster tidak diketahui sebelumnya dan terdapat 10 objek
outlier. Struktur tabel data bayi beserta data outlier-nya adalah sebagai berikut :
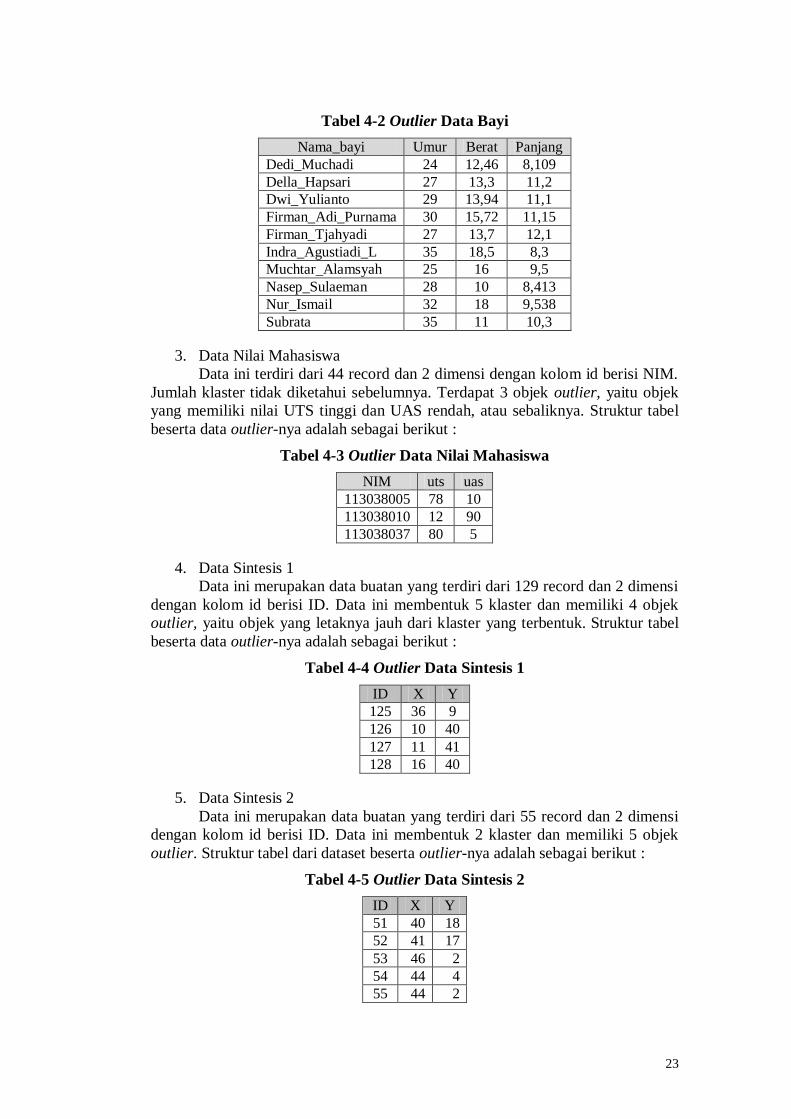
23
Tabel 4-2 Outlier Data Bayi
Nama_bayi Umur Berat Panjang
Dedi_Muchadi 24 12,46 8,109
Della_Hapsari 27 13,3 11,2
Dwi_Yulianto 29 13,94 11,1
Firman_Adi_Purnama 30 15,72 11,15
Firman_Tjahyadi 27 13,7 12,1
Indra_Agustiadi_L 35 18,5 8,3
Muchtar_Alamsyah 25 16 9,5
Nasep_Sulaeman 28 10 8,413
Nur_Ismail 32 18 9,538
Subrata 35 11 10,3
3. Data Nilai Mahasiswa
Data ini terdiri dari 44 record dan 2 dimensi dengan kolom id berisi NIM.
Jumlah klaster tidak diketahui sebelumnya. Terdapat 3 objek outlier, yaitu objek
yang memiliki nilai UTS tinggi dan UAS rendah, atau sebaliknya. Struktur tabel
beserta data outlier-nya adalah sebagai berikut :
Tabel 4-3 Outlier Data Nilai Mahasiswa
NIM uts uas
113038005 78 10
113038010 12 90
113038037 80 5
4. Data Sintesis 1
Data ini merupakan data buatan yang terdiri dari 129 record dan 2 dimensi
dengan kolom id berisi ID. Data ini membentuk 5 klaster dan memiliki 4 objek
outlier, yaitu objek yang letaknya jauh dari klaster yang terbentuk. Struktur tabel
beserta data outlier-nya adalah sebagai berikut :
Tabel 4-4 Outlier Data Sintesis 1
ID X Y
125 36 9
126 10 40
127 11 41
128 16 40
5. Data Sintesis 2
Data ini merupakan data buatan yang terdiri dari 55 record dan 2 dimensi
dengan kolom id berisi ID. Data ini membentuk 2 klaster dan memiliki 5 objek
outlier. Struktur tabel dari dataset beserta outlier-nya adalah sebagai berikut :
Tabel 4-5 Outlier Data Sintesis 2
ID X Y
51 40 18
52 41 17
53 46 2
54 44 4
55 44 2

24
4.2.2 Skenario Pengujian
Sistem ini memiliki 2 tahap utama sebelum sampai pada tujuannya
mendeteksi outlier yaitu membentuk klaster dengan CLARANS dan melanjutkan
dengan mendeteksi outlier dari hasil klaster yang dihasilkan.
Skenario pengujian yang akan dilakukan adalah sebagai berikut :
1. Melakukan proses klastering dengan mengubah nilai parameter
CLARANS, yaitu maxneighbor dan numlocal. Pengujian ini bertujuan
untuk :
a) Menganalisis proses klastering untuk deteksi outlier.
b) Melihat pengaruh parameter maxneighbor dan numlocal terhadap hasil
klastering.
c) Melihat pengaruh parameter maxneighbor dan numlocal terhadap
waktu eksekusi.
2. Melakukan proses deteksi outlier dari hasil klastering CLARANS dengan
teknik COR dan separation. Pengujian ini bertujuan untuk :
a) Melihat pengaruh hasil klastering yang dipengaruhi jumlah klaster,
maxneighbor, dan numlocal oleh CLARANS terhadap ketepatan
deteksi outlier dengan teknik COR.
b) Melihat pengaruh hasil klastering yang dipengaruhi jumlah klaster,
maxneighbor, dan numlocal oleh CLARANS terhadap ketepatan
deteksi outlier dengan teknik separation. Pengujian dilakukan dengan
mengubah nilai jumlah klaster dari 3 hingga 20.
c) Melihat teknik mana yang cocok digunakan untuk CLARANS.
4.3 Pengujian dan Analisis Hasil
4.3.1 Pengujian dan Analisis Klastering dengan CLARANS
Untuk melihat CLARANS melakukan partisi terhadap dataset, berikut
hasil klastering dengan aplikasi untuk data nilai 2-dimensi 3-klaster dan data
síntesis_1 2-dimensi 5-klaster.
Nilai uts
Gambar 4-1 Hasil Klastering CLARANS Data Nilai Mahasiswa 3 klaster

25
Nilai X
Gambar 4-2 Hasil Klastering CLARANS Data Sintesis1 5 klaster
Pada gambar 4.1 di atas, dengan kasat mata dapat dilihat terdapat 3 outlier
dan 3 klaster yang divisualisasikan dengan warna yang berbeda. Medoid tiap
klaster digambarkan dengan titik berwarna biru. Namun oleh CLARANS, outlier
tersebut tetap dimasukkan ke dalam salah satu klaster. Begitu juga dengan gambar
4.2, pada data sintesis_1 dapat juga dilihat terdapat 4 outlier, dan outlier juga
masuk ke dalam salah satu klaster. Setelah dilakukan analisa, hal ini disebabkan
pada langkah-langkah algoritma CLARANS, tidak terdapat parameter yang
mampu mengindikasikan sebuah objek termasuk outlier. Tidak seperti algoritma
CLAD yang memiliki parameter W atau lebar klaster yang digunakan untuk
mencari ketetanggaan terdekat dari pusat klaster dengan obyek data yang
berdekatan dan atribut tambahan untuk menentukan klaster outlier atau bukan,
sehingga semua klaster memiliki nilai anomaly score yang mengindikasikan
sebuah klaster merupakan klaster outlier.
Sedangkan CLARANS melakukan proses klastering dengan hasil akhir
menemukan best node. Kemudian tiap titik akan dihitung jarak yang paling dekat
dengan medoid, termasuk objek yang seharusnya outlier dan outlier akan masuk
ke dalam klaster dengan medoid yang paling mirip. Namun, dengan bantuan
validasi klastering yaitu silhouette coefficient yang merupakan parameter kualitas
hasil klastering yang didapat dari rata-rata nilai silhouette setiap objek,
memungkinkan untuk menemukan objek-objek mana yang memiliki derajat
kepemilikan terendah terhadap klaster. Nilai silhouette ini dimiliki oleh setiap
objek pada dataset. Dengan kata lain, nilai silhouette setiap objek bisa digunakan
untuk mempertimbangkan apakah sebuah objek pada klaster merupakan pencilan
dari klaster tersebut atau mungkin objek tersebut seharusnya tidak berada di
klaster tersebut. Berikut contoh silhouette dari hasil klastering pada dataset nilai
mahasiswa yang memiliki 3 outlier :
Tabel 4-6 Silhouette Outlier pada Data Sintesis_1
k NL MN Silhouette Clustering Silhouette objek
5 2 9 0,884835327924406
Sampel Non-outlier :
72 : 0,922036739517197

26
k NL MN Silhouette Clustering Silhouette objek
Silhouette terendah :
125 : 0,16265065154186
126 : 0,0763134936188689 128 : 0,0761549776003032
127 : 0,0258511559654865
75 : 0,922035927612999
88 : 0,922035927612999
75 : 0,922035927612999 Outlier :
125 : 0,16265065154186
126 : 0,0763134936188689 128 : 0,0761549776003032
127 : 0,0258511559654865
5 2 500 0,885473914537399
Silhouette terendah :
127 : 0,166407111030104
126 : 0,119076642743177 128 : 0,112906237664813
125 : 0,18426020038592
Sampel Non-outlier :
18 : 0,94064547126106 7 : 0,940042060046984
3 : 0,938330000320539
19 : 0,938330000320539 Outlier :
127 : 0,166407111030104
126 : 0,119076642743177
128 : 0,112906237664813 125 : 0,18426020038592
4 2 8 0,786700416694776
Silhouette terendah :
125 : 0,250092725244475
127 : 0,166407111030104
126 : 0,119076642743177 128 : 0,112906237664813
Sampel Non-outlier :
31 : 0,948163384696378 43 : 0,948163384696378
31 : 0,948163384696378
43 : 0,948163384696378
Outlier : 125 : 0,250092725244475
127 : 0,166407111030104
126 : 0,119076642743177 128 : 0,112906237664813
4 2 500 0,828850095858605
Silhouette terendah : 127 : 0,166407111030104
126 : 0,119076642743177
128 : 0,112906237664813 125 : 0,18426020038592
Sampel Non-outlier :
62 : 0,951363807947666
59 : 0,95109133815507 58 : 0,948783369732665
61 : 0,945632567028764
Outlier : 127 : 0,166407111030104
126 : 0,119076642743177
128 : 0,112906237664813
125 : 0,18426020038592
Dari tabel 4.6, dapat dilihat bahwa dengan berbagai kondisi jumlah klaster,
maxneighbor, dan numlocal yang berbeda akan menghasilkan nilai silhouette
klastering yang berbeda juga, 4 objek yang sudah diketahui sebagai outlier (125,
126, 127, 128) memiliki silhouette terendah jika dibandingkan objek lainnya.
Dengan kata lain, derajat kepemilikan objek-objek tersebut terhadap klasternya
rendah dan dapat dipergunakan untuk mempertimbangkan objek sebagai outlier
atau pencilan dari klaster tersebut.
Tapi pada data yang berbeda, hasil silhouette dapat berbeda, nilai
silhouette objek outlier tidak selalu yang terendah pada setiap klaster yang
terdapat outlier, seperti pada data bayi dengan 2 dan 5 klaster berikut :

27
Tabel 4-7 Silhouette Outlier pada Data Bayi
k NL MN Silhouette Clustering Silhouette objek
2 2 6 0,489051615023538
Silhouette terendah :
Sahat_Marihot 0,0321892106364
Irma_Ratnasari 0,0085435873418
Sampel Non-outlier : Erlin_Febriwahyuni 0,6870551679757
Teddy_Rinaldi 0,6821191400754
Muhammad_Lutfi 0,6465003735594
Febi_Ari_Pribadi 0,6460161158362 Sampel Outlier :
Muchtar_Alamsyah 0,5549979256724
Firman_Tjahyadi 0,4292767010334 Nasep_Sulaeman 0,3721635458871
Nur_Ismail 0,4447329924952
2 2 500 0,492980187381116
Silhouette terendah :
Yuli_Alia -0,2196761684918
Vitri_Widalabardi -0,24589049036
Sampel Non-outlier :
Yuliani_Agustina 0,7116859011689 Erlin_Febriwahyuni 0,7099197223330
Amvira 0,6240116471826
Adriansyah 0,6229980141389 Sampel Outlier :
Nur_Ismail 0,4562990077698
Firman_Tjahyadi 0,3920981808082 Nasep_Sulaeman 0,3384414863383
Muchtar_Alamsyah 0,5645733719820
5 2 15 0,316046313919163
Silhouette terendah :
Teddy_Rinaldi 0,08910573385299
Hendra_Ferdian -0,199838206298
Sampel Non-outlier :
Rendhy_Aprialy 0,565404493929106 Erwin_Ginanjar 0,547715657198734
Dery_Maulina 0,599853941840216
Renol_Darmawan 0,5440652161137
Sampel Outlier : Muchtar_Alamsyah 0,2591504007335
Firman_Tjahyadi 0,1756493081256
Nasep_Sulaeman 0,2495797489160 Nur_Ismail 0,1403701396455
5 2 500 0,363177628326685
Silhouette terendah : Rusdhi_Anggoro 0,162494474085
Dwi_Yulianto -0,0082616091555
Sampel Non-outlier :
Rendhy_Aprialy 0,6122185276648
Erwin_Ginanjar 0,5928222841949 Amvira 0,5451642801174
Hendra_Ferdian 0,4952023100560
Sampel Outlier : Muchtar_Alamsyah 0,263325455581
Firman_Tjahyadi 0,203431408730
Nasep_Sulaeman 0,184702199953 Nur_Ismail 0,291249037981
Pembentukan klaster sangat tergantung pada medoid terpilih. Berbeda
medoid maka akan berbeda pula bentuk klaster-klaster yang dihasilkan. Parameter
maxneighbor dan numlocal berfungsi sebagai penentu bagaimana akhir
terpilihnya k-medoid, dan kedua parameter ini tidak mampu mencapai tujuan
mendeteksi outlier. Sehingga dapat disimpulkan bahwa CLARANS dalam
pembahasan tugas akhir ini tidak dapat mendeteksi outlier sebagai stand-alone
tools, sehingga untuk mencapai tujuan tersebut, dibutuhkan teknik tambahan
sebagai postprocessing klastering CLARANS.

28
4.3.2 Pengujian dan Analisis Pengaruh Maxneighbor dan Numlocal
Terhadap Hasil Klastering
Dalam subbab ini akan dilakukan pengujian nilai maxneighbor = nilai
yang digenerate,50,100,250,500,1000. Sedangkan untuk numlocal = 2,3,4.
Dikarenakan pencarian medoid pada CLARANS berdasarkan prinsip randomized
search, maka hasil pengujian klastering merupakan nilai relatif atau rata-rata dari
Absolute-Error Criterion (AEC) yang dihasilkan dari pengujian dengan random
current_node pertama kali yang berbeda-beda sebanyak 10 kali. Berikut hasil
pengujian pada 5 dataset :
0,0
50,0
100,0
150,0
200,0
250,0
300,0
54 100 250 500 1000
Maxneighbor
Avera
ge A
EC
nl 2nl 3nl 4
470,0
475,0
480,0
485,0
490,0
495,0
500,0
505,0
6 50 100 250 500 1000
maxneighbor
avera
ge A
EC
nl 2
nl 3nl 4
(a) Data Balon (b) Data Bayi
640,0
660,0
680,0
700,0
720,0
740,0
760,0
780,0
800,0
2 50 100 500 1000
Maxneighbor
avera
ge A
EC
nl 2
nl 3
nl 4
0,0
100,0
200,0
300,0
400,0
500,0
600,0
700,0
800,0
9 50 100 250 500 1000
maxneighbor
ave
rag
e A
EC
nl 2nl 3nl 4
(c) Data Nilai (d) Data Sintesis 1
400
410
420
430
440
450
460
470
480
490
500
2 50 100 250 500 1000
maxneighbor
ave
rag
e A
EC
nl 2nl 3nl 4
(d) Data Sintesis 2
Gambar 4-3 Grafik Pengaruh Parameter CLARANS pada 5 Dataset
Dari kelima grafik hasil pengujian, grafik terlihat cenderung menurun
seiring dengan meningkatnya maxneighbor dan numlocal. Numlocal menentukan
berapa banyak node yang diperiksa dalam sekali proses pencarian dan merupakan
jumlah lokal minimum yang dihasilkan. Pada numlocal 2, bisa dilihat nilai rata-
rata AEC lebih besar jika dibandingkan numlocal 3 dan 4, ini dikarenakan dalam
pencarian lokal minimum, peluang untuk menemukan lokal minimum yang lebih

29
0
100
200
300
400
500
600
700
800
6 50 100 250 500 1000
maxneighbor
run
tim
e (
ms)
nl 2nl 3nl 4
0
1000
2000
3000
4000
5000
6000
54 100 250 500 1000
maxneighbor
run
tim
e (
ms)
nl 2
nl 3
nl 4
baik adalah 1 dari 2 pencarian (50%). Sedangkan untuk numlocal 3, peluangnya
lebih besar, yaitu 2 dari 3 pencarian (66,67%) dan untuk numlocal 4 peluangnya 3
dari 4 pencarian (75%). Sehingga jika jumlah node yang diperiksa lebih dari satu,
maka kualitas klastering yang dihasilkan juga dapat lebih baik, karena peluang
untuk menghasilkan lokal minimum yang baik lebih besar.
Maxneighbor menjadi parameter penting karena untuk menentukan
medoid terbaik diperlukan perbandingan total cost antara current node dengan
neighbornya, dan maxneighbor menentukan jumlah maksimum neighbor yang
dapat diperiksa. Sebuah node memiliki k(n-k) neighbor. Misal pada data
sintesis_2 dengan 55 record dan 2 klaster, maka maksimum neighbor yang
dimiliki oleh sebuah node adalah 2(55-2) = 106. Jika jumlah neighbor yang
diperiksa semakin banyak, maka peluang menemukan medoid terbaik semakin
besar. Namun, ada kemungkinan neighbor yang sama pada sebuah node bisa
diperiksa lebih dari satu kali jika nilai maxneighbor di set lebih dari k(n-k).
Sedangkan prinsip dasar CLARANS yang menggunakan teknik random
dalam pencariannya menyebabkan variasi letak medoid yang berbeda, sehingga
dalam 10 kali pengujian pada 1 dataset dengan 1 kondisi, nilai rata-rata AEC ada
kalanya naik meski maxneighbor bertambah, seperti pada gambar 4-3 grafik data
bayi maxneighbor 100 numlocal 2 dan grafik data nilai maxneighbor 500
numlocal 3 dan 4.
4.3.3 Pengujian dan Analisis Pengaruh Maxneighbor dan Numlocal
Terhadap Waktu Eksekusi
Pada subbab ini akan dilihat pengaruh penambahan nilai parameter
CLARANS terhadap waktu eksekusi. Berikut hasil pengujian dalam bentuk grafik
dari 2 dataset yang telah dilakukan :
Data Bayi (211 record) dan Data Balon (1800 record)
Gambar 4-4 Grafik Pengaruh Penambahan Parameter CLARANS terhadap
Waktu Eksekusi pada Data Bayi (kiri) dan Data Balon (kanan)
Pada grafik 2 contoh dataset di atas, terlihat jelas pengaruh penambahan
nilai maxneighbor dan numlocal terhadap waktu eksekusi. Semakin banyak
neighbor yang diperiksa, maka waktu eksekusi pun semakin besar. Begitu juga
dengan numlocal ,semakin besar nilai numlocal, maka semakin banyak waktu
eksekusi yang dibutuhkan. Sehingga peningkatan nilai parameter, berbanding
lurus dengan peningkatan waktu eksekusi. Selain itu perbedaan jumlah record

30
juga berpengaruh, semakin banyak jumlah record, semakin banyak waktu
eksekusi yang diperlukan.
4.3.4 Pengujian dan Analisis Teknik COR Dalam Mendeteksi Objek Outlier
Pengujian dilakukan pada 3 dataset untuk melihat pengaruh parameter
CLARANS dalam mendeteksi outlier. Setiap dataset di klastering dengan kondisi
jumlah klaster 2, 3, dan 5 klaster, maxneighbor generate, 50,100,250,500, dan
1000, numlocal 2 dan 4. Dataset yang digunakan untuk pengujian ini adalah data
sintesis 1, data sintesis 2, dan data bayi. Berikut hasil pengujian yang diambil
threshold dengan nilai f-measure tertinggi di tiap kondisi parameter CLARANS
yang berbeda :
Tabel 4-8 Hasil Pengukuran Akurasi F-measure Data Sintesis_1
K-klaster Numlocal Maxneighbor Threshold Iterasi F-measure
2 2 4 0.05 10 0,083
2 2 50 0.05 5 0,143
2 2 100 0.05 5 0,182
2 2 250 0.05 5 0,143
2 2 500 0.2 10 0,250
2 2 1000 0.05 5 0,143
2 4 4 0.05 5 0,143
2 4 50 0.05 5 0,615
2 4 100 0.15 5 0,286
2 4 250 0.2 10 0,250
2 4 500 0.05 5 0,143
2 4 1000 0.2 10 0,250
3 2 6 0.05 5 0,615
3 2 50 0.05 5 0,133
3 2 100 0.05 5 0,571
3 2 250 0.05 5 0,615
3 2 500 0.05 5 0,316
3 2 1000 0.05 5 0,615
3 4 6 0.05 5 0,615
3 4 50 0.05 5 0,615
3 4 100 0.05 5 0,615
3 4 250 0.05 5 0,615
3 4 500 0.05 5 0,615
3 4 1000 0.05 5 0,615
5 2 9 0.05 5 1,000
5 2 50 0.05 5 1,000
5 2 100 0.05 5 1,000
5 2 250 0.05 5 1,000
5 2 500 0.05 5 1,000
5 2 1000 0.05 5 1,000
5 4 9 0.05 5 1,000
5 4 50 0.05 5 1,000
5 4 100 0.05 5 1,000
5 4 250 0.05 5 1,000
5 4 500 0.05 5 1,000
5 4 1000 0.05 5 1,000

31
Tabel 4-9 Hasil Pengukuran Akurasi F-measure Data Sintesis_2
K-klaster Numlocal Maxneighbor Threshold iterasi F-measure
2 2 2 0.10 5 0,769
2 2 50 0.10 5 0,769
2 2 100 0.10 5 1,000
2 2 250 0.10 5 1,000
2 2 500 0.10 5 1,000
2 2 1000 0.10 5 1,000
2 4 2 0.05 5 1,000
2 4 50 0.10 5 1,000
2 4 100 0.10 5 1,000
2 4 250 0.10 5 1,000
2 4 500 0.10 5 1,000
2 4 1000 0.10 5 1,000
3 2 2 0.10 5 1,000
3 2 50 0.15 5 0,333
3 2 100 0.15 5 0,364
3 2 250 0.15 5 0,364
3 2 500 0.15 5 0,571
3 2 1000 0.10 5 1,000
3 4 2 0.10 5 1,000
3 4 50 0.15 5 0,400
3 4 100 0.15 5 0,571
3 4 250 0.15 5 0,400
3 4 500 0.15 5 0,250
3 4 1000 0.15 5 0,571
5 2 4 0.15 5 0,833
5 2 50 0.15 5 0,571
5 2 100 0.15 5 0,444
5 2 250 0.15 5 0,571
5 2 500 0.15 5 0,333
5 2 1000 0.15 5 0,571
5 4 4 0.10 5 0,444
5 4 50 0.15 5 0,444
5 4 100 0.15 5 0,444
5 4 250 0.15 5 0,571
5 4 500 0.15 5 0,444
5 4 1000 0.15 5 0,571
Tabel 4-10 Hasil Pengukuran Akurasi F-measure Data Bayi
Klaster Numlocal Maxneighbor Threshold iterasi F-measure
2 2 6 0.10 5 0,286
2 2 50 0.10 5 0,421
2 2 100 0.15 5 0,211
2 2 250 0.10 5 0,400
2 2 500 0.10 5 0,476
2 2 1000 0.10 5 0,381
2 4 6 0.05 10 0,273
2 4 50 0.15 5 0,381

32
Klaster Numlocal Maxneighbor Threshold iterasi F-measure
2 4 100 0.10 10 0,323
2 4 250 0.10 10 0,387
2 4 500 0.15 5 0,571
2 4 1000 0.15 5 0,476
3 2 9 0.20 5 0,522
3 2 50 0.15 5 0,522
3 2 100 0.25 5 0,462
3 2 250 0.15 5 0,538
3 2 500 0.10 5 0,476
3 2 1000 0.10 5 0,500
3 4 9 0.10 5 0,444
3 4 50 0.05 10 0,364
3 4 100 0.05 5 0,353
3 4 250 0.15 5 0,615
3 4 500 0.15 10 0,439
3 4 1000 0.15 10 0,545
5 2 15 0.20 5 0,606
5 2 50 0.10 5 0,611
5 2 100 0.10 10 0,552
5 2 250 0.15 5 0,333
5 2 500 0.01 5 0,533
5 2 1000 0.10 5 0,444
5 4 15 0.15 5 0,606
5 4 50 0.05 5 0,533
5 4 100 0.05 5 0,588
5 4 250 0.10 5 0,667
5 4 500 0.10 5 0,533
5 4 1000 0.10 5 0,471
Pada tabel 4.7, nilai threshold untuk setiap kondisi cenderung tetap yaitu
0,05 pada iterasi 5, yang berbeda adalah nilai f-measure. Pada tiap kenaikan
jumlah maxneighbor dan numlocal, nilai f-measure relatif meningkat. Kondisi ini
terjadi pada jumlah klaster 2 dan 3. Namun pada kondisi jumlah klaster 5, nilai f-
measure sudah mencapai nilai tertinggi yaitu 1,000. Itu berarti outlier telah
ditemukan semuanya.
Pada tabel data sintesis_2, nilai threshold pada jumlah klaster 2 cenderung
tetap pada 0,10 iterasi 5, meningkatnya jumlah maxneighbor dan numlocal pada 2
klaster meningkatkan f-measure. Dapat dilihat pada nilai maxneighbor 50 ke 100
pada numlocal 2, nilai f-measure meningkat dari 0,769 ke 1,000 dan stabil
seterusnya. Sedangkan pada kondisi jumlah klaster 3 dan 5, nilai threshold
berkisar pada 0,15 iterasi 5. Dan nilai f-measure yang dihasilkan tidak seperti
pada 2 klaster, tidak stabil. Namun pada 3 klaster, nilai f-measure 1,000 masih
mampu tercapai pada kondisi numlocal 2 maxneighbor 2 dan 1000, juga numlocal
4 maxneighbor 2.
Dan pada data bayi, nilai threshold berkisar antara rentang 0,05 sampai
0,25 pada iterasi 5 mau pun 10, dan nilai f-measure dihasilkan juga berbeda-beda.
Hasil ini berbeda dengan 2 dataset sebelumnya. Hal ini dikarenakan pengaruh
jumlah klaster. Seperti diketahui, data bayi tidak diketahui jumlah klasternya,
sehingga hasil rentang pengujian jumlah klaster 2,3, dan 5 belum ditemukan nilai

33
residual
raw
_d
ata
0
10
20
30
40
50
60
70
80
90
0 20 40 60 80
X
Y
8
10
12
14
16
18
23 25 27 29 31 33 35 37umur
bera
t
7
8
9
10
11
12
13
23 25 27 29 31 33 35 37umur
pa
nja
ng
f-measure terbaiknya. Karena itu juga, pengaruh parameter maxneighbor dan
numlocal tidak terlihat secara signifikan.
Dari ketiga hasil pengujian di atas, secara keseluruhan nilai f-measure
akan lebih baik pada jumlah klaster yang ideal. Jumlah klaster yang ideal, akan
menunjukkan nilai silhouette coefficient yang mengindikasikan strong klastering
atau di atas nilai 0,7. Dengan kata lain, hasil akurasi menjadi tergantung kepada
hasil klastering yang dihasilkan, jika medoid yang terpilih merupakan medoid
dengan total cost kecil, letak medoid akan mendekati di tengah klaster, namun
jika medoid yang terpilih posisinya kurang tepat, maka akan mempengaruhi
perhitungan jarak antara medoid tersebut dengan objek-objek lainnya dalam satu
klaster. Dan untuk dapat menghasilkan hasil klastering lebih baik, dapat dilakukan
dengan menambah nilai parameter CLARANS. Sehingga juga dapat mendeteksi
outlier lebih baik. Hanya saja dengan jumlah maxneighbor dan numlocal yang
lebih besar, maka jumlah waktu yang diperlukan lebih banyak.
Sedangkan nilai threshold untuk menemukan outlier berbeda-beda,
tergantung pada bentuk klaster yang dihasilkan. Karena tiap klaster akan
menghasilkan distorsi yang berbeda-beda. Jika pada klaster nilai jarak objek
terjauh semakin jauh, maka derajat kepemilikan terhadap klaster semakin rendah
dan nilai distorsi akan lebih kecil sehingga terlingkupi oleh threshold yang di set
tidak terlalu besar. Dari pengujian di atas, disarankan untuk memulai dengan nilai
threshold 0,05 dan iterasi 5.
4.3.5 Pengujian dan Analisis Teknik Separation Dalam Mendeteksi Klaster
Outlier
Pada subbab ini, dataset yang digunakan adalah data balon, data bayi, dan
data sintesis 1.Berikut model persebaran data ketiga dataset yang digunakan :
Gambar 4-5 Model Persebaran Data Balon (kiri atas), Data Sintesis_1
(kanan atas), dan Data Bayi 3 Dimensi (kiri dan kanan bawah)

34
Dan berikut hasil pengujiannya :
Tabel 4-11 Hasil Deteksi Outlier dengan Separation pada Data Balon
Klaster AEC Size Outlier Separation
3 145,724179 272 10 0,879372181
4 130,5057647 278 10 1,426681627
5 113,4829018 51 10 3,454194775
6 104,719524 47 10 4,17234362
7 97,18401155 28 10 6,345046343
8 93,06906189 40 10 6,455463494
9 83,24452379 10 10 16,88245195
10 78,96600049 10 10 18,83264455
11 75,96144412 9 9 23,18651327
12 72,91840194 9 9 24,02667077
13 67,34583576 10 10 22,14011995
14 63,65885337 9 9 25,74101385
15 61,74592666 10 10 27,72782795
16 60,59865708 10 10 29,04813153
17 59,1342982 8 8 35,07785517
18 57,75838358 8 8 34,88479035
19 54,12990197 10 10 30,96093111
20 52,17135229 10 10 37,49658913
Tabel 4-12 Hasil Deteksi Outlier dengan Separation pada Data Bayi
Klaster AEC Size Outlier Separation
3 487,1547637 91 5 13,00844587
4 383,4982109 - - -
5 346,4192044 - - -
6 316,797304 25 1 36,89553983
7 281,9573623 - - -
8 269,6540692 - - -
9 259,3003581 - - -
10 238,5941327 - - -
11 224,6795375 10 1 65,84362393
12 223,1730598 - - -
13 205,155586 - - -
14 203,4120031 - - -
15 202,6397876 - - -
16 190,148445 - - -
17 180,2509551 8 1 123,987653
18 176,3037783 - - -
19 168,3233987 - - -
20 165,8148442 - - -
Tabel 4-13 Hasil Deteksi Outlier dengan Separation pada Data Sintesis 1
Klaster AEC Size Outlier Separation
3 2881,431155 - - -
4 1214,228884 - - -
5 510,0316176 - - -

35
Klaster AEC Size Outlier Separation
6 477,6682313 - - -
7 407,7453889 1 1 306,5409826
8 438,3234972 - - -
9 332,4054549 - - -
10 390,7966855 - - -
11 260,6162446 1 1 558,6606756
12 356,3506023 - - -
13 264,2740534 - - -
14 227,4667876 1 1 794,9726862
15 224,9922049 1 1 843,4893694
16 197,7938708 1 1 830,0896271
17 219,6740055 - - -
18 214,0127729 1 1 1032,099617
19 251,9311787 - - -
20 189,3984567 - - -
Pada tabel 4.10 di atas, saat k=3, 10 outlier berada di dalam salah satu
klaster. Namun kondisi ini belum tepat dalam mendeteksi klaster outlier. Klaster
outlier yang lebih tepat dihasilkan pada saat k=9 sampai seterusnya. Sedangkan
pada tabel 4.11, klaster outlier ditemukan k=3,6,11, dan 17. Tapi hasil klaster
outlier ini juga tidak tepat, karena dalam klaster yang dipertimbangkan sebagai
klaster outlier tersebut, jumlah objek non outlier yang seharusnya tidak terdeteksi
lebih banyak dari jumlah outlier. Dan pada tabel 4.12, klaster outlier ditemukan
pada k = 7,11,14,15,16, dan 18. hasil klaster outlier lebih tepat jika dibandingkan
dengan hasil data bayi, meskipun masih lebih baik hasil pada data balon.
Perbedaan hasil ini dipengaruhi oleh jumlah klaster k dan model
persebaran data. Peningkatan jumlah k menyebabkan terbentuknya klaster-klaster
yang lebih banyak dan memiliki ukuran (size) yang lebih kecil. Pada teknik
separation, klaster outlier ditemukan pada klaster dengan nilai separation terbesar
dan ukurannya yang kecil atau 1. Dengan model persebaran data yang berbentuk
diagonal pada data balon, klaster outlier mudah ditemukan, karena outlier pada
dataset terkumpul di diagonal bawah, sehingga dapat membentuk klaster sendiri.
Penggunaan teknik separation tepat digunakan untuk model persebaran data
seperti ini. Sedangkan pada data bayi, model data berbentuk bola atau spherical
dengan 3 dimensi, outlier berada di sisi-sisi luar. Model data seperti ini
menyulitkan pembentukan klaster outlier yang tepat. Sama seperti data sintesis 1,
model data berbentuk 5 klaster dimana outlier terdapat di antara 5 klaster tersebut.
Meski ditemukan klaster berukuran kecil, tapi nilai separationnya tidak signifikan
besar jika dibandingkan dengan 5 klaster yang lainnya. Sehingga ini juga
menyulitkan pembentukan klaster outlier yang tepat.

36
5. Kesimpulan dan Saran
5.1 Kesimpulan
1. CLARANS murni belum dapat mendeteksi outlier sebagai stand-alone
tool. Ini disebabkan karena tidak adanya parameter CLARANS yang
mampu mengindikasikan sebuah objek menjadi outlier dan pada prosesnya
tiap titik akan dihitung jarak yang paling dekat dengan medoid, termasuk
objek yang seharusnya outlier, sehingga outlier tidak mampu terdeteksi.
Oleh karena itu dibutuhkan teknik tambahan untuk mencapai tujuan
mendeteksi outlier, yaitu teknik Clustering Outlier Removal (COR) dan
separation.
2. Dari analisis hasil klastering, didapatkan pada data nilai mahasiswa, 3
outlier ditemukan dengan silhouette terendah, dimana nilai silhouette
objek ini bisa membantu mengindikasikan objek yang memiliki derajat
kepemilikan rendah terhadap klasternya sehingga dapat dipertimbangkan
sebagai outlier klaster tersebut, tetapi pada data bayi, 4 outlier nilai
silhouettenya bukan yang terendah dalam klasternya, sehingga nilai
silhouette pada data yang berbeda belum cukup untuk mendeteksi
keberadaan outlier.
3. Pada teknik COR, nilai akurasi akan lebih baik pada jumlah klaster yang
ideal. Dari hasil analisis data sintesis_1 dengan 5 klaster, nilai f-measure
1,000 pada threshold 0.05 iterasi 5 stabil dari kondisi maxneighbor 9
numlocal 2 hingga maxneighbor 1000 numlocal 4.
4. Pada teknik separation, nilai akurasi dipengaruhi oleh jumlah klaster dan
model persebaran dataset.
5. Teknik COR lebih sesuai dalam menemukan outlier dari hasil klastering
CLARANS, karena tidak terpengaruh model persebaran data seperti
separation. Dan proses menemukan outlier erat terkait dengan letak
medoid yang dipengaruhi parameter CLARANS, sehingga keduanya
saling mempengaruhi dalam mendeteksi outlier.
6. Untuk meningkatkan akurasi deteksi pada COR, dengan menemukan
terlebih dahulu jumlah klaster yang baik yang diindikasikan dengan nilai
silhouette coefficient clustering.

37
5.2 Saran 1. Proses klastering CLARANS sangat dipengaruhi perhitungan jarak
Euclidean, untuk menghasilkan tingkat dissimilarity antar objek yang
lebih baik dapat dilakukan pengembangan dengan rumus jarak selain
Euclidean.
2. Untuk teknik separation yang dipengaruhi model persebaran data, dapat
diteliti lebih jauh, melihat keberagaman model persebaran data yang ada
dalam kondisi real.
3. Keterbatasan CLARANS terhadap data dimensi tinggi merupakan hal yang
cukup menarik untuk diteliti lebih lanjut dengan menerapkan teknik
preprocessing sehingga data dapat diklastering dengan CLARANS.

38
Daftar Pustaka
[1] A. K. Jain and R. C. Dubes, 1988, Algorithms for Clustering Data, Prentice
Hall.
[2] Berkhin, Pavel, Survey of Clustering Data Mining Technique, Accrue
Software, Inc. CA.
[3] Bijaksana, M.Arif, 2006, CSE 881:Data Mining, Lecture 24: Anomaly
Detection, STT Telkom, Bandung.
[4] Han, J. and M. Kamber, 2000, Data Mining : Concepts and Technique. The
Morgan Kaufmann Series in Data Management Systems, Jim Gray, Series
Editor Morgan Kaufmann Publishers.
[5] Handriyadi, Dedy, 2006, Analisis Perbandingan Clustering-Based, Distance-
Based, dan Density-Based Dalam Mendeteksi Outlier, Teknik Informatika,
STT Telkom, Bandung.
[6] Hodge, J.V and Austin, J., 2004, A Survey of Outlier Methodologies, Dept.
of Computer Science, University of York.
[7] J. A. Hartigan, 1975, Clustering Algorithms, John Wiley & Sons.
[8] L. Kaufman and P. J. Rousseeuw, 1990, Finding Groups in Data: an
Introduction to Cluster Analysis, John Wiley & Sons.
[9] M. Ester, H.-P. Kriegel, and X. Xu, 1995, Knowledge discovery in large
spatial databases: Focusing techniques for efficient class identification. In
Proc. 1995 Int. Symp. Large Spatial Databases (SSD'95),pages 67{82,
Portland, Maine.
[10] Mercer, D. P., 2003, Clustering Large Datasets, Linacre College.
[11] P. Arabie, L. J. Hubert, and G. De Soete, 1996, Clustering and Classification.
World Scientific.
[12] R. Ng and J. Han, 1994, CLARANS : Efficient and effective clustering method
for spatial data mining. In Proc. 1994 Int. Conf. Very Large Data Bases
(VLDB'94), pages 144{155, Santiago, Chile.
[13] Tan. Pang-Ning, Steincbach. Michael, Kumar.Vipin, 2006, Introduction to
Data Mining, Pearson Education Inc.
[14] Cherednichenko, Svetlana. 2005.Outlier Detection in Clustering. Department
of Computer Science, University of Joensuu
[15] L.kaufmann and PJ Roussew, Finding groups in data: an introduction to
Cluster analysis dan HJ Miller and J Han, geographic data mining &
knowledge Discovery.

39
Lampiran A: Data Pengujian
Tabel A-1 Hasil Pengujian Parameter CLARANS pada Data Sintesis_2
NL MN Rata-rata AEC Min AEC Max AEC Rata-rata SC rTime
2 2 488,81233550 458,49946511 536,63916490 0,808428696202973 21,9
2 50 466,69021451 425,23979810 523,22142938 0,808362862681082 40,6
2 100 436,96211194 420,73327968 462,33631453 0,808362862681082 53,1
2 250 443,52497446 425,00566329 479,85996313 0,808428696202973 123,6
2 500 438,28372405 420,73327968 467,20458437 0,808362862681082 178,1
2 1000 439,91431127 420,73327968 458,49946511 0,808362862681082 309,5
3 2 449,75582139 432,03024799 470,67753420 0,808584044941175 28,1
3 50 448,07950044 420,96741449 507,72237401 0,808395779442028 56,3
3 100 440,42778280 420,73327968 461,45598578 0,808362862681082 76,7
3 250 440,44977886 420,73327968 477,30850590 0,808362862681082 140,7
3 500 436,83179149 420,73327968 472,62614588 0,808395779442028 209,2
3 1000 437,80565413 420,73327968 502,07950999 0,808362862681082 389
4 2 449,39409277 428,57456383 476,51278670 0,808395779442028 26,5
4 50 434,32959127 420,73327968 503,01542632 0,808395779442028 64
4 100 436,86321430 420,73327968 458,49946511 0,808395779442028 84,3
4 250 434,20969198 420,96741449 454,50578479 0,808395779442028 160,9
4 500 431,73628416 420,733279681 446,86786151 0,808362862681082 282,8
4 1000 433,08205012 420,733279681 462,33631453 0,808362862681082 550
Tabel A-2 Hasil Pengujian Parameter CLARANS pada Data Balon
NL MN Rata-rata AEC Min AEC Max AEC Rata-rata SC rTime
2 54 240,58159655 188,46379641 662,76326928 0,379194714420676 917,5
2 100 242,31336058 186,95596177 682,09500464 0,394939969666585 1031
2 250 207,39748192 189,60868022 245,99901827 0,407961042344279 1296,8
2 500 206,44300350 186,65692729 309,99489526 0,394363453062350 2543,8
2 1000 192,54055737 186,64559394 215,04368154 0,400985552010731 3733
3 54 240,40404555 188,37783952 676,80734695 0,393733009747280 942,2
3 100 196,27107806 189,63771301 201,96020196 0,397272604395426 1028,2
3 250 193,53639892 186,44446748 209,86386890 0,402130554489698 1723,5
3 500 191,70478767 186,65884307 211,14329169 0,405228098852444 3129,6
3 1000 209,93266261 186,95596177 330,69828742 0,399299463436023 3992,2
4 54 190,25744524 188,10039359 192,54384738 0,405745862211540 1182,6
4 100 196,70835136 188,29564133 236,11360587 0,404646871421163 1267,3
4 250 192,64978155 186,95414204 201,60712280 0,400775605668429 1832,9
4 500 193,62099745 186,95414204 200,70986866 0,401579842193075 2810,7
4 1000 205,96138523 186,72735549 263,65779085 0,403272030482102 4914,3
Tabel A-3 Hasil Pengujian Parameter CLARANS pada Data Bayi
NL MN Rata-rata AEC Min AEC Max AEC Rata-rata SC rTime
2 6 502,60994235 477,64488316 551,18749197 0,485756654435304 65,6
2 50 493,70786008 456,80058959 546,66888813 0,495538273293353 87,3
2 100 500,04203391 456,50678791 572,86422664 0,499815377675916 109,2
2 250 496,12198063 455,98061926 576,35746761 0,494034616401584 178
2 500 491,46504084 460,81148890 533,99239222 0,492462444435568 285,8
2 1000 486,37460562 455,59903804 517,15110887 0,492031257285944 400,1
3 6 488,52893899 458,68141685 535,74581343 0,499551545265781 70,5
3 50 487,64078023 459,44904863 524,07688940 0,496494356972982 103,1

40
NL MN Rata-rata AEC Min AEC Max AEC Rata-rata SC rTime
3 100 488,62919281 455,47577453 537,45364928 0,499866211388173 126,6
3 250 489,04063563 455,98061926 552,64124664 0,496744446271363 229,5
3 500 490,23879350 455,98061926 523,94297207 0,498080280631796 342,1
3 1000 481,42841531 454,22828971 531,46055740 0,494727999307751 540,5
4 6 484,07613641 457,32304357 537,77216091 0,489642039417577 71,7
4 50 485,63213223 457,32304357 537,77785538 0,494100060722299 114,1
4 100 486,54061106 454,22828971 533,79910577 0,493621359964794 151,6
4 250 487,08349774 460,81148890 511,02892773 0,493856663853446 236
4 500 480,89114478 455,98061926 528,26862843 0,493907490906754 396,9
4 1000 480,27971982 456,80772458 523,39485335 0,493600479290885 746,9
Tabel A-4 Hasil Pengujian Parameter CLARANS pada Data Nilai
NL MN Rata-rata AEC Min AEC Max AEC Rata-rata SC rTime
2 2 772,56974771 723,20587729 867,07909147 0,515220255120050 15,8
2 50 691,36020608 657,67412227 728,00044714 0,533277662520407 28,1
2 100 695,36858695 659,07303585 783,25039668 0,508168353602353 45,2
2 500 692,87822602 656,65416533 749,05581445 0,509503236506256 150
2 1000 682,74757335 648,36542865 798,85903253 0,522907090239439 218,8
3 2 776,62386011 730,65232763 827,24368674 0,482297118068845 26,5
3 50 684,17326801 660,09299278 749,40911038 0,526439804801883 47
3 100 666,49273551 656,65416533 682,47420850 0,523100179219359 71,8
3 500 686,02791166 656,65416533 793,20894981 0,542924407000030 190,8
3 1000 690,27001884 648,36542865 755,96121895 0,511068076777512 384,4
4 2 726,40809926 672,34319829 759,97736799 0,524220821085121 22
4 50 670,61367364 656,65416533 716,82681916 0,530671195057740 61
4 100 676,05882928 656,65416533 729,61908214 0,523608064398395 84,6
4 500 692,68428475 656,65416533 788,29153742 0,521328227206221 261
4 1000 688,65132346 657,67412227 757,67879821 0,518460039265831 407,7
Tabel A-5 Hasil Pengujian Parameter CLARANS pada Data Sintesis_1
NL MN Rata-rata AEC Min AEC Max AEC Rata-rata SC rTime
2 9 738,73867386 499,40900099 1331,20309809 0,820420506747773 56,3
2 50 501,63243707 461,62060206 557,36473819 0,883035232422312 81,4
2 100 513,26266520 469,81125559 556,30962723 0,883571512414824 110,6
2 250 506,73350788 466,41629015 652,35572241 0,885346197214800 189
2 500 494,63074631 462,55673728 557,61526985 0,885006936721402 337,5
2 1000 487,21063102 463,82488702 524,61639971 0,885346197214800 550,1
3 9 569,07184209 470,07162721 1208,95276066 0,853341701221893 61,2
3 50 573,51900674 475,04802662 1093,26082078 0,880920921248168 75,1
3 100 512,93206582 465,29748929 563,70690631 0,884038490230820 129,8
3 250 482,81049795 464,90098788 508,58047315 0,884667676228004 365,4
3 500 486,57886059 463,76920609 572,30869005 0,885070795382701 379,6
3 1000 487,02181729 463,56013607 529,08969656 0,884731534889303 817,4
4 9 525,84324611 489,48111244 586,00501266 0,884653152556318 68,6
4 50 496,11525666 463,40663944 534,26105307 0,883635371076123 99,9
4 100 494,74632704 467,59448242 586,49075425 0,885006936721402 157,7
4 250 481,65918275 465,83797748 540,25932117 0,884392274395905 292
4 500 496,04212748 459,32563197 523,37476373 0,884328415734606 526,3
4 1000 491,21555753 463,56013607 552,23976272 0,884667676228004 732,8

41
Tabel A-6 Hasil Pengujian Klastering 5 klaster Data Sintesis_1, MN 9 NL 2
Klaster Medoid Anggota Klaster
[1] 80 72 --- 0,922036739517197
75 --- 0,922035927612999
88 --- 0,922035927612999
76 --- 0,916564456664282
93 --- 0,915947064459087 77 --- 0,915947064459087
89 --- 0,915947064459087
74 --- 0,915568421196201
73 --- 0,913224720298766
84 --- 0,91139818264322
97 --- 0,904584358438706
87 --- 0,90173513086136
90 --- 0,899046858124729
92 --- 0,893205565337292
85 --- 0,891311259369068
86 --- 0,891172266649799
95 --- 0,891172266649799
83 --- 0,888249330610586 78 --- 0,886793761797154
80 --- 0,881144553743418
79 --- 0,880218323672086
81 --- 0,877171802830594
91 --- 0,875325029977362
94 --- 0,875325029977362
98 --- 0,860091199313264
96 --- 0,832159950797807
[2] 108 103 : 0,961195420223131
104 : 0,959806736730392
109 : 0,959369332776816
115 : 0,958375425224202 121 : 0,958375425224202
102 : 0,956115850312723
105 : 0,956115850312723
108 : 0,955395900580226
117 : 0,955395900580226
101 : 0,953188345095002
106 : 0,953188345095002
123 : 0,953188345095002
101 : 0,953188345095002
111 : 0,948289582833959
113 : 0,947753174407487
100 : 0,947520105370276
116 : 0,944597939897219
122 : 0,944597939897219 119 : 0,943702915987312
118 : 0,942970774260655
110 : 0,941631567883329
124 : 0,941631567883329
99 : 0,93638808682515
107 : 0,934007426218906
112 : 0,927826133239563
114 : 0,918962935073752
120 : 0,918962935073752
[3] 129 7 --- 0,893317985888256
18 --- 0,892775617506792 3 --- 0,891862382500568
19 --- 0,891862382500568
82 --- 0,89004499750954
129 --- 0,889995235420284
20 --- 0,889995235420284
14 --- 0,889846445822075
6 --- 0,888207899463155
16 --- 0,88638921239171
13 --- 0,884923072329044
17 --- 0,883977148059346
21 --- 0,882706208642816
2 --- 0,88221461488941
22 --- 0,882205686595245
5 --- 0,879517445724467 1 --- 0,877603881824199
9 --- 0,877101790417494
8 --- 0,876240659961813
15 --- 0,875829624707286
10 --- 0,869985976530013
4 --- 0,869754407152052
11 --- 0,869427997535723
12 --- 0,868958487228679
125 --- 0,16265065154186
126 --- 0,0763134936188689
128 --- 0,0761549776003032
127 --- 0,0258511559654865
[4] 39 31 : 0,918886991007404 43 : 0,918886991007404
30 : 0,913973125325865
40 : 0,913973125325865
45 : 0,913973125325865
25 : 0,913420801745023
37 : 0,912970705304231
33 : 0,905987656019031
23 : 0,905024264181789
39 : 0,90344548498983
27 : 0,900558153351506
35 : 0,895839984733681
32 : 0,893791136422344 46 : 0,891848677504703
42 : 0,890156410170994
28 : 0,889692275506818
38 : 0,885986330086442
44 : 0,879988605530093
26 : 0,878055125498707
29 : 0,874538685195475
34 : 0,873181437604588
41 : 0,871882742382979
24 : 0,817153256662305
36 : 0,812779140123532

42
Klaster Medoid Anggota Klaster
[5] 48 49 : 0,939978959603106
53 : 0,934704055927666
59 : 0,93449826130332
66 : 0,93449826130332
48 : 0,934477307724963
62 : 0,934477307724963
51 : 0,933270383157075
70 : 0,933270383157075
58 : 0,931834658060986
61 : 0,926304948361934
65 : 0,924406028469332 55 : 0,924284747733083
64 : 0,920190601569799
50 : 0,919573543883813
69 : 0,919573543883813
50 : 0,919573543883813
69 : 0,919573543883813
57 : 0,919253128708187
56 : 0,918184366076264
68 : 0,918184366076264
60 : 0,91718539041339
67 : 0,91718539041339
54 : 0,909422195141223
63 : 0,904908765868831
52 : 0,898190156904562 71 : 0,898190156904562
47 : 0,897352803991085
Tabel A-7 Hasil Pengujian Klastering 2 Klaster Data Bayi, MN 6 NL 2
Klaster Medoid Anggota Klaster
[1] Siti_Yaroh Erlin_Febriwahyuni : 0,687055167975702
Teddy_Rinaldi : 0,682119140075413
Nur_Indah_Utami : 0,680539101891618
Yuliani_Agustina : 0,674878201817136 Teni_Amarini : 0,673445758335719
Dony_Eko_S : 0,672480011234116
Ilman_Indaloh : 0,670873498671536
Hadi_Supriyadi : 0,670538776306263
Aya_Dewi : 0,670131225168854
Teddy_Lakoni : 0,666226059758137
Haerlina_Sugiarty : 0,664671248822343
Sendy_Carolina : 0,662735970236823
Eli_Saparyah : 0,662529571227874
Ratna_Juwita : 0,662489814802725
Miradina : 0,662419485416146 Dewi_Mulyani : 0,66155854520656
Ravelina_Dona_S : 0,661491708290982
Heti_Taryati : 0,660613851239201
Yuliawati : 0,659399651695053
Dewi_Silalahi : 0,659244040959705
Muharromi : 0,659001059350308
Frista_D : 0,657964293493547
Reza_Wediansyah : 0,654883460545041
Irma_Mentariana : 0,653431985408782
Resna_Herliana : 0,651014022203573
Rahmat_Solihin : 0,649877516382226
Rusdhi_Anggoro : 0,648512931953583 Mim_Talhisi_R : 0,646651915352406
Renol_Darmawan : 0,646440380995596
Irma_Mardiana : 0,645213302452253
Elis_Herlina : 0,637161295785751
Indri_ : 0,636362376783525
Isa_Salman_A : 0,635236016569764
Rendhy_Aprialy : 0,63442880322949
Dian_Riana : 0,629426445046396
Hadi_Roshadi : 0,624843897798856
Fitri_Gusmayanti : 0,623191475046964
Erwin_Ginanjar : 0,622634571844923

43
Klaster Medoid Anggota Klaster
Andri_F : 0,622130425083655
Riki_Yustiawan : 0,621129033061719
Rendy_Dharmanto : 0,62056414222669
Yoga_Ivandiyanto : 0,620541321301867
Novie_Setiawati : 0,620272900196106
Dedi_Muchadi : 0,612580216764515
Winda_Eka_Putri : 0,612014074008559
Vina_Agustina : 0,611767014211805
Neni_Yulianti : 0,611475737464706
Devid_Gustri_A : 0,607734436151407
Wisda_Ningsih_S : 0,607189049607557 Moh._Decky_E : 0,606719885872451
Nunun_Nurjannah : 0,605688943535992
Dadang_A : 0,605668722789087
Asep_Jatnika_Indrawa : 0,59925819926789
Yan_Apsari : 0,594533058706598
Giantry_Rizky_Wuland : 0,580382492532517
Asep_Tommi : 0,569121470834205
Hendra_Ferdian : 0,560858623979933
Sri_Artanty : 0,560006317901395
Mila_Karmila : 0,556759385135549
Tuti : 0,556528941340334
Muchtar_Alamsyah : 0,554997925672379 Eryca_Mery_Kristiana : 0,553612279615123
Heni_Hasanah : 0,552249251307138
Siti_Yaroh: 0,550087585187613
Rully_Agustine : 0,549636189958837
Mutiara_Maulida : 0,53230535639213
Nifa_Handiani : 0,531930557363625
Lisnawati : 0,531228602253731
Ina_Mutmainnah : 0,523967674102862
Yusep_Hikmat : 0,520058869994604
Dianti_F : 0,519730998843049
Dian_Marliani : 0,518716788260251 Deasy_Diaswati : 0,518209657805741
Della_Hapsari : 0,511720958174097
Nita_Naritawati : 0,497570081980145
Meizia_Sufina : 0,497029837716649
Dodi_Hermawan : 0,486077802366371
Fini_Farlianti_Hatoa : 0,470388306882051
Mulyana : 0,463197875242832
Cipta_Riadi : 0,453879697587561
Rahmi_Puspita_Iha : 0,439954460673392
Devie_Siswanti : 0,437205446448189
Firman_Tjahyadi : 0,429276701033365
Nasep_Sulaeman : 0,372163545887123 Eka_Dalu_K : 0,338132579631811
Vitri_Widalabardi : 0,332072344969126
Adek_Andriany : 0,330973863758793
Yuli_Alia : 0,330411521338195
Rizki_Hadi : 0,327150011493907
Didong : 0,322168233729452
Nandi_Syafiek : 0,314836131563638
Dadan_M_R : 0,284058555665177
Dadan_Gandara : 0,253625332159304
Teguh_Hermawan : 0,245241278618955
Ratu_Dinar_Ayuningbi : 0,223231210990491

44
Klaster Medoid Anggota Klaster
Fauziah : 0,220933150778488
Dwi_Yulianto : 0,214705520172241
Fenni_Mindawati : 0,191954196515671
Rina_Triyani : 0,18101549546673
Beny_Ramdani : 0,167712127979728
Adam_Supriyatna : 0,162747756065249
Melati_Indah_P. : 0,0492638810751139
Tubagus_Fikri : 0,0327713269736531
Sahat_Marihot_A. : 0,0321892106364351
[2] Nia_K Muhammad_Lutfi : 0,646500373559436
Febi_Ari_Pribadi : 0,646016115836171
Prima_Kurniawan : 0,645748967521397 Ratih_Juwita : 0,642883495463642
Mela_Winaningsih : 0,642684194229469
Eva_Rahmawati : 0,639738654049574
Amvira : 0,639509838738111
Lidya_Puspita : 0,638514117090013
Sanmarliyanto : 0,638054002913735
Adriansyah : 0,635578796244005
Ane_Dewi : 0,633403233646858
Sandra_F : 0,632988228986565
Apriliani : 0,632888050070967
Imas_Noni : 0,632502044724504
Dewi_Pusfita_Sari : 0,629861496581962 Lia_Frizka : 0,628680915067365
Ritta_Yoana : 0,627771489134819
Septina_R._Hasanah : 0,626443502242036
Ivan_Fandikha : 0,624844435798538
Dian_Septiani : 0,620293373299099
Putri_Indah : 0,619276655023133
Sri_Ratna : 0,619054715893844
Olva_Ratriani : 0,607926993199917
Anggia_Bonyta : 0,607628552262066
Eko_Andri : 0,607491646664492
Nashadi_Susanto : 0,606159415209143 Shynta_Dewi : 0,605835318190494
Riski_Farendra : 0,603324791074127
Vina_Indayani : 0,603177516114654
Tika_Mustika : 0,600076351123382
Santi_Rostikasari : 0,597686036816305
Rika_Heryani : 0,593951803538431
Dewi_Susilawati : 0,593378369255624
Erik_Sulistiawan : 0,589889223628948
Henry_Hermawan : 0,587203678724957
Dery_Maulina : 0,586388905879771
Vita_Hapsari : 0,585547785295047
Kiki_Indriasari : 0,584480123005221 Pitriyani : 0,584339029246855
Kim_Paul_Tomozoy : 0,583748050203851
Pipit_Fitriani : 0,582541569452801
Wihartini : 0,580211596136347
Anita_Pujiastuti : 0,578726225080121
Agus_Supriyatna : 0,578293785370906
Irma_Febriani : 0,577104086707393
Catur_Putri_S : 0,576794873994987
Rendy_Anggaswara : 0,569501312095316
Jeria_Handayani : 0,567062194506071

45
Klaster Medoid Anggota Klaster
Gira_Garmira : 0,566065511322585
Abu_Bakar : 0,558486952030805
Enggria_Wulandari : 0,557677144672371
Desi_Setiowati : 0,553942508506453
Syali_Diani_Dewi : 0,551746661195603
Seshi_Y : 0,549012831358317
Fitrah_Agustian : 0,548991755992539
Fika_Fidayyah : 0,544283310853518
Astri_Kurniati : 0,537087642641065
Denri_Ramza_Fadila : 0,529314279428328
Hery_S : 0,523621397747581 Mario_Randi : 0,519608311650086
Indra_Agustiadi_L : 0,500388548768431
Yohanes_Halomoan : 0,480397954965361
Tuti_Haryati : 0,445943892863267
Nur_Ismail : 0,444732992495176
Yati_Novianti : 0,439138576558789
Viviet_Safitri : 0,42817446560742
Astri_Tresnawaty : 0,428028954772558
Nurul_Emily : 0,424355890730303
Firzania_Novita_Bahr : 0,424272896253263
Nia_K : 0,423604076308886
Winarni : 0,421689428649277 Nur_Yatnikasari : 0,421628154419162
Rulianti : 0,420498524079624
Subrata : 0,414765375564591
Asti_Ambarwati : 0,413880260037605
Karina : 0,412707333717159
Tessa : 0,400035752724307
Henny_Anggraeni : 0,399075395271894
Silvie_Meilia : 0,388277505805055
Endah_Sekar_Mawar : 0,374100654761201
Dwi_Ely_Pradinayanti : 0,37219504003629
Susilawaty : 0,3347355376094 Emil_Mirnawati : 0,329891316955783
Donny_Firdaus : 0,289425133444104
Indri_Dewi_Kartika_W : 0,283356213973341
Rico_Siregar : 0,266125145787517
Welly_F._Nugraha : 0,191552069677136
Dede_Rikayanti : 0,190898228035777
Erlin_Puspakania : 0,186135524555337
Liesdya_N. : 0,174735122749533
Ade_Vita_Fadilah : 0,163261457828513
Firman_Adi_Purnama : 0,160272231833341
Adhitya_Setiartha : 0,158653551142894
Isti_Agustianti : 0,146506435870641 Fitri_Handayani : 0,146363896094964
Andriani_Sabaryati : 0,14144917853083
Aryana_Wirawardana : 0,1125201197591
Nur_Permana : 0,0780982419842938
Amigia_Rustanti : 0,0753437332052438
Wita_Rahmalia : 0,0746468461837326
Rahayu_B. : 0,0611149082060729
Shannita_Simbolon : 0,0574183118998889
Rita_Komala : 0,0326798560785388
Rina_Triana : 0,0239789242970347
Irvan_ : 0,0221411666040298

46
Klaster Medoid Anggota Klaster
Desya_Natalia : 0,0161443759587199
Irma_Ratnasari : 0,0085435873418248
Tabel A-8 Hasil Pengujian Akurasi Deteksi Outlier Data Sintesis_1 2 klaster
NL MN it th detect TP FP FN TN Precision Recall f-measure
2 4 5 0,01 0 0 0 4 125 0 0 0
0,05 10 0 10 4 115 0,000 0 0
0,1 10 0 10 4 115 0,000 0 0
0,15 10 0 10 4 115 0,000 0 0
0,2 10 0 10 4 115 0,000 0 0
0,25 10 0 10 4 115 0,000 0 0
0,3 10 0 10 4 115 0,000 0 0
10 0,01 0 0 0 4 125 0 0 0
0,05 20 1 19 3 106 0,050 0,25 0,083
0,1 20 1 19 3 106 0,050 0,25 0,083
0,15 20 1 19 3 106 0,050 0,25 0,083
0,2 20 1 19 3 106 0,050 0,25 0,083
0,25 20 1 19 3 106 0,050 0,25 0,083
0,3 20 1 19 3 106 0,050 0,25 0,083
2 50 5 0,01 0 0 0 4 125 0 0 0
0,05 10 1 9 3 116 0,100 0,25 0,143
0,1 10 1 9 3 116 0,100 0,25 0,143
0,15 10 1 9 3 116 0,100 0,25 0,143
0,2 10 1 9 3 116 0,100 0,25 0,143
0,25 10 1 9 3 116 0,100 0,25 0,143
0,3 10 1 9 3 116 0,100 0,25 0,143
10 0,01 0 0 0 4 125 0 0 0
0,05 20 1 19 3 106 0,050 0,25 0,083
0,1 20 1 19 3 106 0,050 0,25 0,083
0,15 20 1 19 3 106 0,050 0,25 0,083
0,2 20 1 19 3 106 0,050 0,25 0,083
0,25 20 1 19 3 106 0,050 0,25 0,083
0,3 20 1 19 3 106 0,050 0,25 0,083
2 100 5 0,01 0 0 0 4 125 0 0 0
0,05 7 1 6 3 119 0,143 0,25 0,182
0,1 7 1 6 3 119 0,143 0,25 0,182
0,15 7 1 6 3 119 0,143 0,25 0,182
0,2 7 1 6 3 119 0,143 0,25 0,182
0,25 7 1 6 3 119 0,143 0,25 0,182
0,3 7 1 6 3 119 0,143 0,25 0,182
10 0,01 0 0 0 4 125 0 0 0
0,05 12 1 11 3 114 0,083 0,25 0,125
0,1 12 1 11 3 114 0,083 0,25 0,125
0,15 20 2 18 2 107 0,100 0,5 0,167
0,2 20 2 18 2 107 0,100 0,5 0,167
0,25 20 2 18 2 107 0,100 0,5 0,167
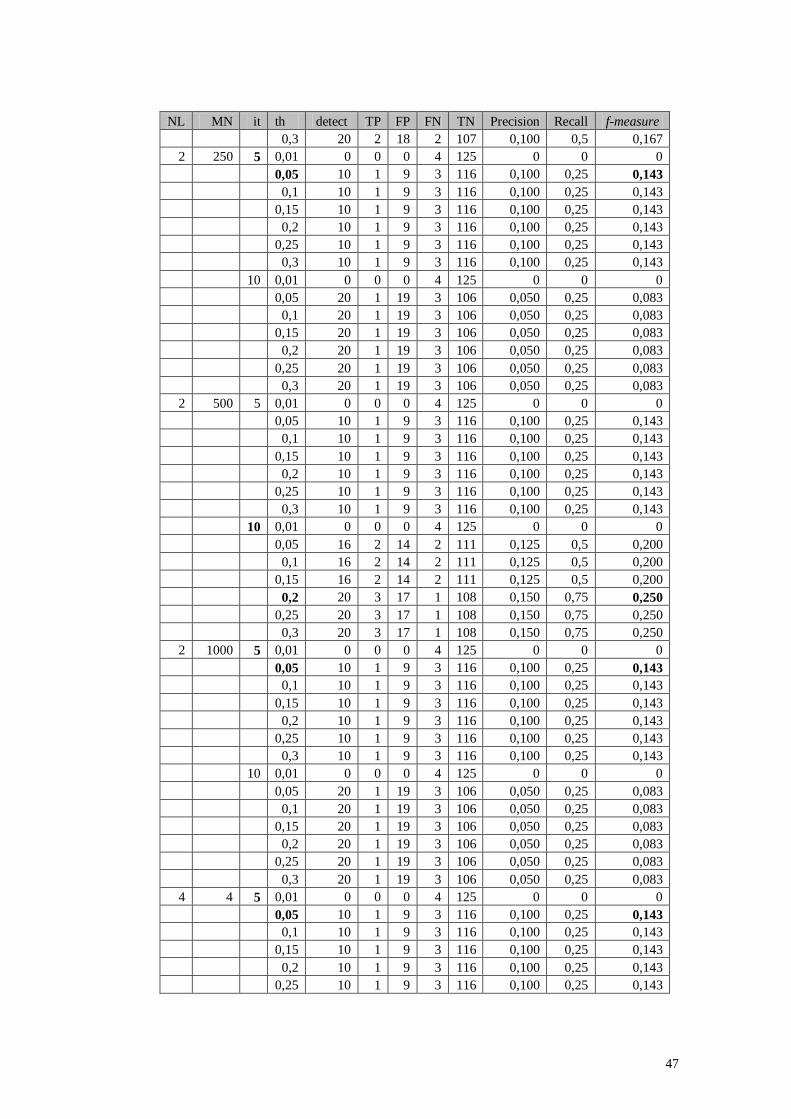
47
NL MN it th detect TP FP FN TN Precision Recall f-measure
0,3 20 2 18 2 107 0,100 0,5 0,167
2 250 5 0,01 0 0 0 4 125 0 0 0
0,05 10 1 9 3 116 0,100 0,25 0,143
0,1 10 1 9 3 116 0,100 0,25 0,143
0,15 10 1 9 3 116 0,100 0,25 0,143
0,2 10 1 9 3 116 0,100 0,25 0,143
0,25 10 1 9 3 116 0,100 0,25 0,143
0,3 10 1 9 3 116 0,100 0,25 0,143
10 0,01 0 0 0 4 125 0 0 0
0,05 20 1 19 3 106 0,050 0,25 0,083
0,1 20 1 19 3 106 0,050 0,25 0,083
0,15 20 1 19 3 106 0,050 0,25 0,083
0,2 20 1 19 3 106 0,050 0,25 0,083
0,25 20 1 19 3 106 0,050 0,25 0,083
0,3 20 1 19 3 106 0,050 0,25 0,083
2 500 5 0,01 0 0 0 4 125 0 0 0
0,05 10 1 9 3 116 0,100 0,25 0,143
0,1 10 1 9 3 116 0,100 0,25 0,143
0,15 10 1 9 3 116 0,100 0,25 0,143
0,2 10 1 9 3 116 0,100 0,25 0,143
0,25 10 1 9 3 116 0,100 0,25 0,143
0,3 10 1 9 3 116 0,100 0,25 0,143
10 0,01 0 0 0 4 125 0 0 0
0,05 16 2 14 2 111 0,125 0,5 0,200
0,1 16 2 14 2 111 0,125 0,5 0,200
0,15 16 2 14 2 111 0,125 0,5 0,200
0,2 20 3 17 1 108 0,150 0,75 0,250
0,25 20 3 17 1 108 0,150 0,75 0,250
0,3 20 3 17 1 108 0,150 0,75 0,250
2 1000 5 0,01 0 0 0 4 125 0 0 0
0,05 10 1 9 3 116 0,100 0,25 0,143
0,1 10 1 9 3 116 0,100 0,25 0,143
0,15 10 1 9 3 116 0,100 0,25 0,143
0,2 10 1 9 3 116 0,100 0,25 0,143
0,25 10 1 9 3 116 0,100 0,25 0,143
0,3 10 1 9 3 116 0,100 0,25 0,143
10 0,01 0 0 0 4 125 0 0 0
0,05 20 1 19 3 106 0,050 0,25 0,083
0,1 20 1 19 3 106 0,050 0,25 0,083
0,15 20 1 19 3 106 0,050 0,25 0,083
0,2 20 1 19 3 106 0,050 0,25 0,083
0,25 20 1 19 3 106 0,050 0,25 0,083
0,3 20 1 19 3 106 0,050 0,25 0,083
4 4 5 0,01 0 0 0 4 125 0 0 0
0,05 10 1 9 3 116 0,100 0,25 0,143
0,1 10 1 9 3 116 0,100 0,25 0,143
0,15 10 1 9 3 116 0,100 0,25 0,143
0,2 10 1 9 3 116 0,100 0,25 0,143
0,25 10 1 9 3 116 0,100 0,25 0,143

48
NL MN it th detect TP FP FN TN Precision Recall f-measure
0,3 10 1 9 3 116 0,100 0,25 0,143
10 0,01 0 0 0 4 125 0 0 0
0,05 20 1 19 3 106 0,050 0,25 0,083
0,1 20 1 19 3 106 0,050 0,25 0,083
0,15 20 1 19 3 106 0,050 0,25 0,083
0,2 20 1 19 3 106 0,050 0,25 0,083
0,25 20 1 19 3 106 0,050 0,25 0,083
0,3 20 1 19 3 106 0,050 0,25 0,083
4 50 5 0,01 0 0 0 4 125 0 0 0
0,05 9 4 5 0 120 0,444 1 0,615
0,1 9 4 5 0 120 0,444 1 0,615
0,15 10 4 6 0 119 0,400 1 0,571
0,2 10 4 6 0 119 0,400 1 0,571
0,25 10 4 6 0 119 0,400 1 0,571
0,3 10 4 6 0 119 0,400 1 0,571
10 0,01 0 0 0 4 125 0 0 0
0,05 14 4 10 0 115 0,286 1 0,444
0,1 14 4 10 0 115 0,286 1 0,444
0,15 15 4 11 0 114 0,267 1 0,421
0,2 15 4 11 0 114 0,267 1 0,421
0,25 15 4 11 0 114 0,267 1 0,421
0,3 15 4 11 0 114 0,267 1 0,421
4 100 5 0,01 0 0 0 4 125 0 0 0
0,05 7 1 6 3 119 0,143 0,25 0,182
0,1 7 1 6 3 119 0,143 0,25 0,182
0,15 10 2 8 2 117 0,200 0,5 0,286
0,2 10 2 8 2 117 0,200 0,5 0,286
0,25 10 2 8 2 117 0,200 0,5 0,286
0,3 10 2 8 2 117 0,200 0,5 0,286
10 0,01 0 0 0 4 125 0 0 0
0,05 12 1 11 3 114 0,083 0,25 0,125
0,1 12 1 11 3 114 0,083 0,25 0,125
0,15 20 2 18 2 107 0,100 0,5 0,167
0,2 20 2 18 2 107 0,100 0,5 0,167
0,25 20 2 18 2 107 0,100 0,5 0,167
0,3 20 2 18 2 107 0,100 0,5 0,167
4 250 5 0,01 0 0 0 4 125 0 0 0
0,05 10 1 9 3 116 0,100 0,25 0,143
0,1 10 1 9 3 116 0,100 0,25 0,143
0,15 10 1 9 3 116 0,100 0,25 0,143
0,2 10 1 9 3 116 0,100 0,25 0,143
0,25 10 1 9 3 116 0,100 0,25 0,143
0,3 10 1 9 3 116 0,100 0,25 0,143
10 0,01 0 0 0 4 125 0 0 0
0,05 16 2 14 2 111 0,125 0,5 0,200
0,1 16 2 14 2 111 0,125 0,5 0,200
0,15 16 2 14 2 111 0,125 0,5 0,200
0,2 20 3 17 1 108 0,150 0,75 0,250
0,25 20 3 17 1 108 0,150 0,75 0,250

49
NL MN it th detect TP FP FN TN Precision Recall f-measure
0,3 20 3 17 1 108 0,150 0,75 0,250
4 500 5 0,01 0 0 0 4 125 0 0 0
0,05 10 1 9 3 116 0,100 0,25 0,143
0,1 10 1 9 3 116 0,100 0,25 0,143
0,15 10 1 9 3 116 0,100 0,25 0,143
0,2 10 1 9 3 116 0,100 0,25 0,143
0,25 10 1 9 3 116 0,100 0,25 0,143
0,3 10 1 9 3 116 0,100 0,25 0,143
10 0,01 0 0 0 4 125 0 0 0
0,05 20 1 19 3 106 0,050 0,25 0,083
0,1 20 1 19 3 106 0,050 0,25 0,083
0,15 20 1 19 3 106 0,050 0,25 0,083
0,2 20 1 19 3 106 0,050 0,25 0,083
0,25 20 1 19 3 106 0,050 0,25 0,083
0,3 20 1 19 3 106 0,050 0,25 0,083
4 1000 5 0,01 0 0 0 4 125 0 0 0
0,05 10 1 9 3 116 0,100 0,25 0,143
0,1 10 1 9 3 116 0,100 0,25 0,143
0,15 10 1 9 3 116 0,100 0,25 0,143
0,2 10 1 9 3 116 0,100 0,25 0,143
0,25 10 1 9 3 116 0,100 0,25 0,143
0,3 10 1 9 3 116 0,100 0,25 0,143
10 0,01 0 0 0 4 125 0 0 0
0,05 16 2 14 2 111 0,125 0,5 0,200
0,1 16 2 14 2 111 0,125 0,5 0,200
0,15 16 2 14 2 111 0,125 0,5 0,200
0,2 20 3 17 1 108 0,150 0,75 0,250
0,25 20 3 17 1 108 0,150 0,75 0,250
0,3 20 3 17 1 108 0,150 0,75 0,250




















