
El tiempo social de trabajo: (aspectos metódicos de su análisis)
Upload
independentCategory
view
0download
0
Análisis de Series de Tiempo
96
Note que dada la estructura de n , diferenciar la función de verosimilitud es muy
complicado y por tanto difícil de optimizar. En estos casos, se aplican métodos numéricos con
estimadores iniciales dados en la estimación preliminar.
Podemos transformar la distribución conjunta usando las innovaciones jj XX ˆ y sus
respectivas varianzas 1j calculadas recursivamente por el algoritmo de Innovaciones.
Recordemos que por el algoritmo de innovaciones, se tiene la igualdad:
)ˆ(n nnn XXCX
Por otra parte, sabemos que las innovaciones son no correlacionadas, por lo tanto la
matriz de covarianzas de las innovaciones es la matriz diagonal Dn siguiente:
},...,,{ 110 nn diagD
Por la igualdad anterior y la matriz D, se tiene que:
'
nnnn CDC
Usando las igualdades anteriores, podemos ver que la forma cuadrática nnn XX 1' está
dada por: n
j
jjjnnnnnnnn XXXXDXXXX1
1
211'/)ˆ()ˆ()'ˆ(
Recordemos, también, que Cn es una matriz triangular con elementos en la diagonal
igual a uno, por lo tanto su determinante es uno. De donde:
110
2' ... nnnnnnnn DDCCDC
Sustituyendo, la función de distribución conjunta inicial se reduce a:
}/)ˆ(2
1exp{
...)2(
1)(
1
1
2
110
n
j
jjj
n
nn XXL
Si n puede ser expresada en términos de un número finito de parámetros
desconocidos, como es el caso de un proceso ARMA(p,q), entonces los estimadores de
Máxima Verosimilitud de los parámetros son los valores que maximizan la función L para el
conjunto de datos dado.
La verosimilitud para los datos de un proceso ARMA(p,q) puede ser calculada
recursivamente por el algoritmo de innovaciones.

Análisis de Series de Tiempo
97
Así, el predictor de Xn+1, como su error cuadrado medio están dados por:
nnnjnjn
n
j
jnjnnjpnpn
n
j
jnjnnj
n
rWWEXXE
y
mnXXXX
mnXX
X
22
11
22
11
1
1111
1
11
1
)ˆ()ˆ(
, )ˆ(....
1 , )ˆ(
ˆ
donde θnj y rn son determinados por el algoritmo de innovaciones y m=max(p,q). De esta
forma, la función de verosimilitud para el proceso ARMA(p,q) es:
})ˆ(
2
1exp{
...)2(
1),,(
1 1
2
2
110
2
2n
j j
jj
n
n r
XX
rrrL
Derivando parcialmente el logaritmo de L con respecto a la varianza del ruido blanco y
teniendo que jX y rj son independientes de
2, encontramos los estimadores de máxima
verosimilitud.
n
j
j
n
j
jjj
rnSnl
y
rXXS
n
S
1
1
11
1
1
2
2
)ln()),(ln(),(
minimizan que valoreslosson ˆ,ˆ
/)ˆ()ˆ,ˆ(
donde
)ˆ,ˆ(ˆ
El criterio de selección del orden del modelo es la minimización del AICC. Este
criterio consiste en escoger p, q, p
y q que minimicen la cantidad:
)2/()1(2)/),(,,ln(2 qpnnqpnSAICC qpqp
Una de las opciones del programa ITSM es un “autoajuste” del modelo. Esto se lleva a
cabo seleccionando Model>Estimation>Autofit. La selección de esta opción nos permite
especificar un rango de los valores de p y de q (el rango máximo es de 0 a 27 para ambos, p y
q). El modelo elegido es el que tenga mínimo AICC y una vez que el modelo ha sido
determinado, debe ser estimado por máxima verosimilitud. Más adelante se ejemplificará la
teoría. En S-PLUS la función de estimación por máxima Verosimilitud es: arima.mle(x,
model, n.cond=<< >>, xreg=NULL, ...)

Análisis de Series de Tiempo
98
Para hacer inferencia sobre los parámetros se usan resultados asintóticos, es decir, se
suponen muestras “grandes”. En este caso, consideremos el vector de parámetros )'ˆ,ˆ(ˆ ,
entonces para una muestra grande:
))(,(ˆ 1VnN
donde )(V es la matriz Hessiana definida por:
qp
jiji
lV
1,
2 )()(
Si se quiere probar la hipótesis H0: parámetro=0, la prueba se lleva a cabo calculando
el cociente:
)(*96.1 parámetroEE
parámetro
La regla de decisión es rechazar H0 si el cociente anterior se encuentra fuera del
intervalo [-1,1].
Ejemplo V.2.1. Consideremos los datos del nivel del Lago Hurón (ver ejemplo V.1.2) y
ajustemos un modelo por máxima verosimilitud.
Solución.
Recordemos que en la estimación preliminar se encontró que el mejor modelo ajustado
(mínimo AICC) a los datos corregidos por la media fue el modelo ARMA(1,1):
X(t) = Y(t) - 9.0041
Method: Innovations
ARMA Model:
X(t) - .7234 X(t-1) = Z(t) + .3596 Z(t-1)
WN Variance = .475680
AICC = .212894E+03
El siguiente paso es ajustar el modelo por máxima verosimilitud usando como
estimación preliminar el modelo ARMA(1,1). Usando la función arima.mle de S-PLUS
obtenemos:
Coefficients:
AR : 0.75544 MA : -0.30721
Variance-Covariance Matrix:
ar(1) ma(1)
ar(1) 0.005949613 0.004373168
ma(1) 0.004373168 0.012550728

Análisis de Series de Tiempo
99
Optimizer has converged
Convergence Type: relative function convergence
AIC: 207.81105
Los resultados anteriores se obtienen escribiendo las instrucciones:
Lake.corr<-Lake-mean(t(Lake))
mod<-list(ar=-0.7234,ma=0.3596)
arima.mle(Lake.corr, model=mod)
donde “Lake” es el nombre del Dataset con la serie del Lago Hurón.
En los resultados también se obtienen las varianzas de los parámetros, con lo cual
podemos establecer los siguientes intervalos de confianza al 95% como sigue:
)0876.0,5268.0(01255.0*96.13072.0:
)9066.0,6042.0(0059.0*96.17554.0:
[Hamilton (1994)] desarrolla la estimación de Máxima Verosimilitud usando
distribuciones condicionales. Esto es, parte de:
1,...,
21/
1,
2/
31/
21,...,
2,
1Y
nY
nY
nYYYYYYY
nYYY fffff
Por ejemplo, para el proceso AR(1) dado por ttt ZYY 1 y dados Y1, Y2 y Y3, se
tiene:
)1/(2
)]1/([exp
)1/(2
122
2
1
221
yfY
ya que )1/()(y )1/()( 22
11 YVYE . Además,
2
2
23
21,
2/
3
2
2
12
21/
2
2
][exp
2
1
y
2
][exp
2
1
yyf
yyf
YYY
YY
Por lo tanto, la distribución conjunta está dada por:
3
1
11
/
2
321),/()|,,(
t
ttt
Yt
YYYY yyfyLf

Análisis de Series de Tiempo
100
Como puede observarse en los argumentos de la función exponencial, el numerador
corresponde a las Innovaciones. Esta es la similitud entre el procedimiento de Hamilton y el
que se presenta en este trabajo. El procedimiento de Hamilton se puede extender para
cualquier modelo ARMA(p,q).
V.3. PRUEBAS DE BONDAD DE AJUSTE
El paso final en el proceso de ajuste de modelos de series de tiempo es verificar qué tan
“bueno” es el modelo. Esto se consigue mediante las pruebas de bondad de ajuste. Tales
pruebas consisten en verificar que los supuestos de los residuales se cumplan, es decir, que
forman un proceso de Ruido Blanco.
Enseguida se mencionarán algunas de las pruebas que se utilizan para probar los
supuestos iniciales (de los residuales). Cabe mencionar que no son las únicas, algunas otras se
pueden consultar en [Brockwell y Davis (2002) pp. 35-38].
V.3.1. La función de autocorrelación de residuales
Si {Zt} forma un proceso de Ruido Blanco, entonces las autocorrelaciones de las
innovaciones (errores) deben ser estadísticamente iguales con cero. Es decir, con el 95% de
confianza, se debe cumplir:
1,2,3,.... )/96.1,/96.1()( hnnhtZ
Si calculamos las correlaciones muestrales para más de 40 observaciones y
encontramos que más de dos valores caen fuera del intervalo de confianza, entonces
rechazaremos la hipótesis de que los errores son independientes. Las bandas n/96.1
son graficadas automáticamente cuando se grafica la función de autocorrelación en el
programa ITSM.
En la siguiente gráfica se muestran las funciones de autocorrelación y autocorrelación
parcial de los residuales después de haber ajustado un modelo ARMA(1,1) a los datos del
Lago Hurón. Podemos ver que ningún valor cae fuera de las bandas de confianza, por lo que
podemos concluir que los residuales, en efecto, son independientes.
La gráfica se logra de la siguiente forma: En el Dataset “Lake”, seguimos Data>
Transform y en el cuadro Expression escribimos Lake-mean(t(Lake)). Esto creará una nueva
columna de datos corregidos por la media. Enseguida, ajustamos el modelo ARMA(1,1)
siguiendo Statistics> Time Series> ARIMA Models y especificamos 1 en Autorregresive (p) y
1 en Moving Avg. (q). Finalmente, en la pestaña Diagnostics marcamos Autocorrelation of
Residuals y Plot Diagnostics.

Análisis de Series de Tiempo
101
Gráfica24. ACF y PACF de los residuales después de ajustar un modelo
ARMA(1,1) a la serie nivel del lago Hurón.
ACF Plot of Residuals
ACF
0 5 10 15 20
-1.0
-0.5
0.0
0.5
1.0
PACF Plot of Residuals
PAC
F
5 10 15 20
-0.2
-0.1
0.0
0.1
0.2
ARIMA Model Diagnostics: Lake$V1
ARIMA(1,0,1) Model with Mean 0 V.3.2. Prueba de puntos cambiantes (turning points)
Esta prueba consiste en determinar si los residuales forman un patrón aleatorio.
Supongamos que tenemos una muestra aleatoria nyy ,...,1 . Se dice que la i-ésima
observación es un punto cambiante si:
1111 y o y iiiiiiii yyyyyyyy
Si definimos a T como el número de puntos cambiantes en una sucesión de variables
aleatorias iid de tamaño n, entonces, dado que la probabilidad de que haya un punto cambiante
en el tiempo i es 2/3, el valor esperado de T es:
3/)2(2)( nTET
También, la varianza de T es:
90/)2916()(2 nTVarT
Por otro lado, para una muestra iid “grande”, puede mostrarse que:
)1,0(NT
TT
Tp
Con esto, podemos llevar a cabo la prueba de hipótesis de que los residuales son
aleatorios, usando el criterio de decisión:

Análisis de Series de Tiempo
102
Rechazar H0: La muestra es aleatoria, al nivel de significancia α si 2/1ZTp , donde
2/1Z es el cuantil 1- α/2 de la distribución Normal estándar.
V.3.3. Prueba de signo (difference-sign)
En esta prueba se cuenta el número de observaciones i tales que niyy ii 1,..., ,1 .
Definimos a S como el total de tales observaciones. Entonces, bajo el supuesto de muestra
aleatoria, se tiene que:
12/)1()(
2/)1()(
2 nSVar
y
nSE
S
S
De la misma forma que para T, para un valor grande de n, se tiene que:
)1,0(NS
SS
S
p
Un valor grande, en valor absoluto, de SS indicaría la presencia de un incremento
(o decremento) en la tendencia de los datos. De aquí que, rechazaremos la hipótesis de
tendencia en los datos al nivel α de significancia si 2/1ZS p , donde 2/1Z es el cuantil 1-
α/2 de la distribución Normal estándar.
Las tres pruebas mencionadas, entre otras, son calculadas por el programa ITSM
usando la opción Statistics>Residual Analysis>Test of Randomness. S-PLUS sólo ofrece la
estadística de Ljung-Box que se distribuye como Ji-Cuadrada. Para obtenerla, en el cuadro
de diálogo que aparece después de Statistics> Time Series> ARIMA Models, en la pestaña
Diagnostics marcamos la opción Portmanteau Statistics.
Es claro que, si no se ha ajustado algún modelo a los datos, los residuales son los
mismos que las observaciones. Esto significa que podemos llevar a cabo las pruebas para las
observaciones (cuando no se ha ajustado algún modelo), como para los residuales.
Ejemplo V.3.1. Consideremos los datos del archivo SIGNAL.TXT. Veremos las opciones que
ofrecen ambos programas, ITSM-2000 y S-PLUS, para llevara cabo las pruebas de bondad de
ajuste.

Análisis de Series de Tiempo
103
Gráfica25. Valores simulados de la serie X(t)=cos(t) +N(t), t=0.1,0.2,…,20, donde
N(t) es WN(0,0.25).
30 80 130 180
-3
-2
-1
0
1
2
3
signa
l
En primer lugar, veremos la gráfica de la función de autocorrelación.
Gráfica26. ACF de la serie X(t)=cos(t) + N(t), t=0.1,0.2,…,20, donde N(t) es
WN(0,0.25).
Lag
ACF
0 5 10 15 20
0.00.2
0.40.6
0.81.0
Series : signal$signal
Las gráficas 25 y 26 son resultado de las instrucciones:
guiPlot(PlotType="Y Series Lines", Columns=1, DataSet="signal")
acf(x = signal$signal, type = "correlation")
donde “signal” es el Dataset con los datos de la serie simulada.
Note que algunas observaciones (más de dos) salen de las bandas de confianza, por
tanto rechazaremos la hipótesis de que la serie es independiente. La estimación preliminar de
Yule-Walker sugiere ajustar un modelo AR(7) a los datos corregidos por la media. Ajustando
este modelo, podemos verificar si los residuales cumplen con las pruebas de bondad de ajuste.
En ITSM se obtienen mediante Statistics>Residual Analysis> Test of Randomness.
Los resultados son:
============================================
ITSM::(Tests of randomness on residuals)
============================================
Ljung - Box statistic = 16.780 Chi-Square ( 20 ), p-value = .66719

Análisis de Series de Tiempo
104
McLeod - Li statistic = 25.745 Chi-Square ( 27 ), p-value = .53278
# Turning points = .13600E+03~AN(.13200E+03,sd = 5.9358), p-value = .50039
# Diff sign points = .10300E+03~AN(99.500,sd = 4.0927), p-value = .39245
Rank test statistic = .10083E+05~AN(.99500E+04,sd = .47315E+03), p-value = .77864
Jarque-Bera test statistic (for normality) = 3.8175 Chi-Square (2), p-value = .14826
Order of Min AICC YW Model for Residuals = 0
El programa ITSM nos da el p-value. La regla es rechazar la hipótesis nula al nivel de
significancia α si α > p-value. Si establecemos un nivel de significancia del 5%, podemos ver
que, utilizando cualquier estadística, no se rechaza la hipótesis nula de que los residuales
forman una serie iid.
En S-PLUS seleccionamos la opción Statistics> Time Series> ARIMA Models,
especificamos 7 en Autorregresive (p), y marcamos las opción Portmanteau Statistics y Plot
Diagnostics en la pestaña Diagnostics. Obteniendo:
P-values of Ljung-Box Chi-Squared Statistics
Lag
p-va
lue
8.0 8.5 9.0 9.5 10.0
0.0
0.2
0.4
0.6
ARIMA Model Diagnostics: signal$V2
ARIMA(7,0,0) Model with Mean 0 En conclusión, el modelo propuesto para los datos corregidos por la media, AR(7),
resulta “bueno”, pues los residuales cumplen satisfactoriamente con las pruebas de bondad de
ajuste.

Análisis de Series de Tiempo
105
CAPITULO VI. MODELOS NO-ESTACIONARIOS
En la mayoría de los casos, las observaciones no son generadas por series de tiempo
necesariamente estacionarias, por lo que en este capítulo este tipo de conjunto de datos será
nuestro objetivo de estudio.
El tipo de modelo que analizaremos en la siguiente sección serán los modelos ARIMA
(Autorregresivo Integrado de Promedio Móvil).
VI.1. MODELOS ARIMA PARA SERIES NO-ESTACIONARIAS
Cuando ajustamos un modelo ARMA a una serie diferenciada, en realidad estamos
ajustando un modelo ARIMA a los datos originales. Es decir, un modelo ARIMA es un
proceso que se reduce a un proceso ARMA cuando diferenciamos un número finito de veces.
Definición VI.1.1. [Modelo ARIMA(p,d,q)].- Si d es un entero no-negativo, entonces
}{ tX es un proceso ARIMA(p,d,q) si t
d
t XBY )1( es un proceso ARMA(p,q) causal.
Esto significa que:
tt
tt
d
tt
ZBXB
ZBXBB
ZBYB
)()(
)()1)((
)()(
*
Note que el proceso }{ tX es estacionario si y solo si d=0. Si es el caso, entonces el
proceso se reduce a un ARMA(p,q).
Ejemplo VI.1.1. Supongamos que }{ tX es un proceso ARIMA(1,1,0).
Podemos escribir el modelo como:
1
1
01111
0111
0122122
011011
n
j
jnnnnnn
nnnnnn
YXYXXXXY
XYYYXXXY
XYYXXXY
XYXXXY
Esto significa que, para predecir al proceso }{ tX , primero podemos predecir el
proceso }{ tY y agregar la observación inicial. Esto es,

Análisis de Series de Tiempo
106
111
1
1
01
)( nnnnnnnn
n
j
jnnn
YPXYXPXP
o
YPXXP
Asumiendo que el proceso }{ tX satisface t
d
t XBY )1( . Podemos reescribirlo
como:
d
j
jt
j
tt Xj
dYX
1
)1(
De aquí que, el procedimiento de predicción se puede generalizar, de modo que, para
un proceso ARIMA(p,d,q), se tiene:
d
j
jhnn
j
hnnhnn XPj
dYPXP
1
)1(
donde }{ tY es un proceso ARMA(p,q) causal.
Con respecto al Error Cuadrado Medio. Tenemos que, para cualquier h:
d
j
jhn
j
hn
d
j
jhnn
j
hnnhnhnn Xj
dYXP
j
dYPXXP
11
)1()1(
Para h=1, la expresión se reduce a:
11
1
11
1
1111
)1()1(
nnn
d
j
jn
j
n
d
j
jnn
j
nnnnn
YYP
Xj
dYXP
j
dYPXXP
Por lo tanto,
11
2
11
2
11
nn
nnnnnn
YECMXECM
YYPEXXPE
Hemos llegado a una expresión que nos dice que, para h=1, el ECM de la predicción de
la observación no estacionaria es igual al ECM de la estacionaria.
Por otra parte, sabemos que, bajo el supuesto de causalidad en }{ tY ,

Análisis de Series de Tiempo
107
0
*
0
0
)1(
)(
)()1(
j
jtjt
tdt
t
j
jtjt
d
j
jtjt
ZX
ZB
BX
ZBZXB
ZY
Note que, según la expresión anterior, podemos expresar la serie no estacionaria como
un proceso lineal en términos de los coeficientes lineales de la serie estacionaria.
Ejemplo VI.1.2. Consideremos los datos del Índice de Utilidad Dow Jones (del 28 de Agosto
al 18 de Diciembre de 1972). El archivo es DOWJ.TXT.
Recordemos que para esta serie de datos se tuvo que diferenciar una vez a distancia
uno para tener una serie estacionaria. Así mismo, se ajustó un modelo AR(1) para los datos
corregidos por la media (ver ejemplo V.1.1), teniendo como resultados aplicando Máxima
Verosimilitud:
> media
[1] 0.1336364
$var.pred:
[,1]
[1,] 0.1518409
Coefficients:
AR : 0.4483
Variance-Covariance Matrix:
ar(1)
ar(1) 0.01051349
Las instrucciones son:
dif.DJ<-diff(DOWJ,1,1)
media<-mean(t(dif.DJ))
dif.DJcorr<-dif.DJ-media
mod<-list(ar=0.4218786)
media
arima.mle(dif.DJcorr, model=mod)
donde “DOWJ” es el Dataset con la serie del Índice de utilidad Dow Jones.
Note que el ajuste anterior es para la serie 1336.01ttt DDX . En consecuencia,
el modelo para }{ tD es:

Análisis de Series de Tiempo
108
)1518.0,0( Z , 1336.0)1(4483.01 t WNZDBB tt
Note que, de acuerdo a la definición VI.1.1, {Dt} es un proceso ARIMA(1,1,0).
Sabemos que para un proceso AR(1), el mejor predictor lineal está dado por
n
h
hnn YYP . Así, la predicción para Dt+1 quedaría como:
11
11
1
4483.04483.10737.0
1336.04483.01336.0
4483.0
ttt
tttt
tt
DDD
DDDD
XX
El ECM se obtiene de la misma manera que antes para un modelo AR(1).
En este ejemplo se mostró la estrategia de predicción para un modelo (sencillo)
ARIMA(1,1,0); Sin embargo, el procedimiento es similar para modelos más generales
ARIMA(p,d,q).
VI.1.1 Identificación y estimación de modelos
Cuando tenemos una serie {Xt} con media cero (o corregida por la media), nos
enfrentamos al problema de encontrar un modelo ARMA(p,q) que represente nuestra serie. Si
los valores de p y q son conocidos, tenemos una gran ventaja. Sin embargo, no siempre es el
caso, por lo que necesitamos de técnicas que nos den una aproximación de p y q. Como hemos
comentado, nosotros basamos el criterio de selección de p y q en base al mínimo AICC,
definido por:
)2/()1(2)/),(,,ln(2 qpnnqpnSAICC qpqp
discutido en el capítulo V.
La estimación e identificación de modelos se resume en los siguientes pasos:
1. Después de transformar nuestra serie (si es necesario) para tener una serie estacionaria,
examine las gráficas de las funciones FAC y PACF para tener una idea de los valores
de p y q. Después de esto, podemos obtener la estimación preliminar por alguno de los
métodos descritos en el capítulo V.
2. Cuando introduzcamos la función (en S-PLUS) de estimación preliminar, ya sea por el
algoritmo de Yule-Walker o Burg, debemos agregar la condición aic=T. Esto nos
garantizará modelos con p y q, tales que el AICC sea mínimo. Por ejemplo, debemos
escribir: ar.burg(x, aic=T).
3. Examinar los valores de los coeficientes calculados y los errores estándar. Esto nos
ayudará a concluir que algunos coeficientes son estadísticamente igual con cero. Si es

Análisis de Series de Tiempo
109
así, podemos ajustar un “nuevo” modelo a la serie mediante la opción Model>
Estimation>Max Likelihood, dar clic en la opción Constrain Optimization y
especificar cuales valores son iguales con cero en ITSM y especificando los valores
diferentes de cero en la opción “model” de la función arima.mle(x, model) de S-PLUS.
4. Ya hemos discutido que no existe unicidad en el ajuste de un modelo a una serie de
tiempo, por lo que una vez que tenemos varios candidatos, tenemos que ver cuáles de
ellos cumplen con las pruebas de bondad de ajuste (capítulo V).
VI.2. MODELOS SARIMA
Ya hemos visto que para eliminar el componente estacional de periodo s de una serie
es necesario diferenciar, justamente, a distancia s. Si ajustamos un modelo ARMA(p,q) a la
serie diferenciada a distancia s, entonces el modelo ajustado a la serie original es un caso de un
proceso ARIMA estacional o también llamado SARIMA.
Para tener una idea de qué es lo que estudiaremos en esta sección, supongamos que
tenemos mediciones mensuales de algún fenómeno. Es decir, tenemos una colección de 12
series por año, a las cuales les podemos ajustar un modelo ARMA(p,q).
Definición VI.2.1. [Modelo SARIMA(p,d,q) x (P,D,Q)s].- Si d y D son enteros no-negativos,
entonces }{ tX es un proceso SARIMA(p,d,q) x (P,D,Q)s con periodo s, si la serie diferenciada
t
Dsd
t XBBY )1()1( es un proceso causal ARMA definido por:
tt
t
s
t
s
ZBYB
ZBBYBB
)()(
)()()()(
**
Supongamos que:
ssss BBBB
BBBB
1)( , 1)(
1)( , 1)(
Sustituyendo en la definición, tenemos:
1*
1*
1)1)(1()(
1)1)(1()(
sss
sss
BBBBBB
BBBBBB
Podemos ver que, la diferencia fundamental entre un modelo cualquiera estacional y un
modelo SARIMA es la restricción que existe en los parámetros del modelo y, además, para
varios valores de t los parámetros tienen un valor igual con cero.
Los pasos para identificar un modelo SARIMA para un posible conjunto de datos son
los siguientes:
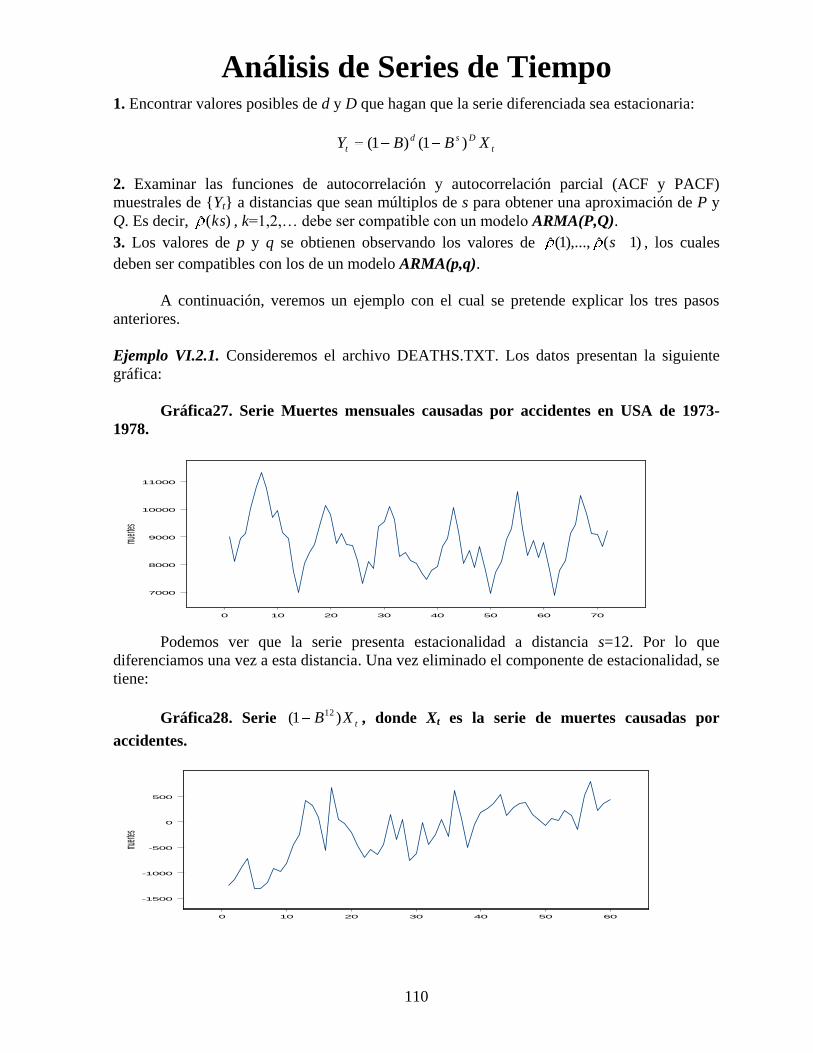
Análisis de Series de Tiempo
110
1. Encontrar valores posibles de d y D que hagan que la serie diferenciada sea estacionaria:
t
Dsd
t XBBY )1()1(
2. Examinar las funciones de autocorrelación y autocorrelación parcial (ACF y PACF)
muestrales de {Yt} a distancias que sean múltiplos de s para obtener una aproximación de P y
Q. Es decir, )(ˆ ks , k=1,2,… debe ser compatible con un modelo ARMA(P,Q).
3. Los valores de p y q se obtienen observando los valores de )1(ˆ),...,1(ˆ s , los cuales
deben ser compatibles con los de un modelo ARMA(p,q).
A continuación, veremos un ejemplo con el cual se pretende explicar los tres pasos
anteriores.
Ejemplo VI.2.1. Consideremos el archivo DEATHS.TXT. Los datos presentan la siguiente
gráfica:
Gráfica27. Serie Muertes mensuales causadas por accidentes en USA de 1973-
1978.
0 10 20 30 40 50 60 70
7000
8000
9000
10000
11000
muert
es
Podemos ver que la serie presenta estacionalidad a distancia s=12. Por lo que
diferenciamos una vez a esta distancia. Una vez eliminado el componente de estacionalidad, se
tiene:
Gráfica28. Serie tXB )1( 12, donde Xt es la serie de muertes causadas por
accidentes.
0 10 20 30 40 50 60
-1500
-1000
-500
0
500
muert
es
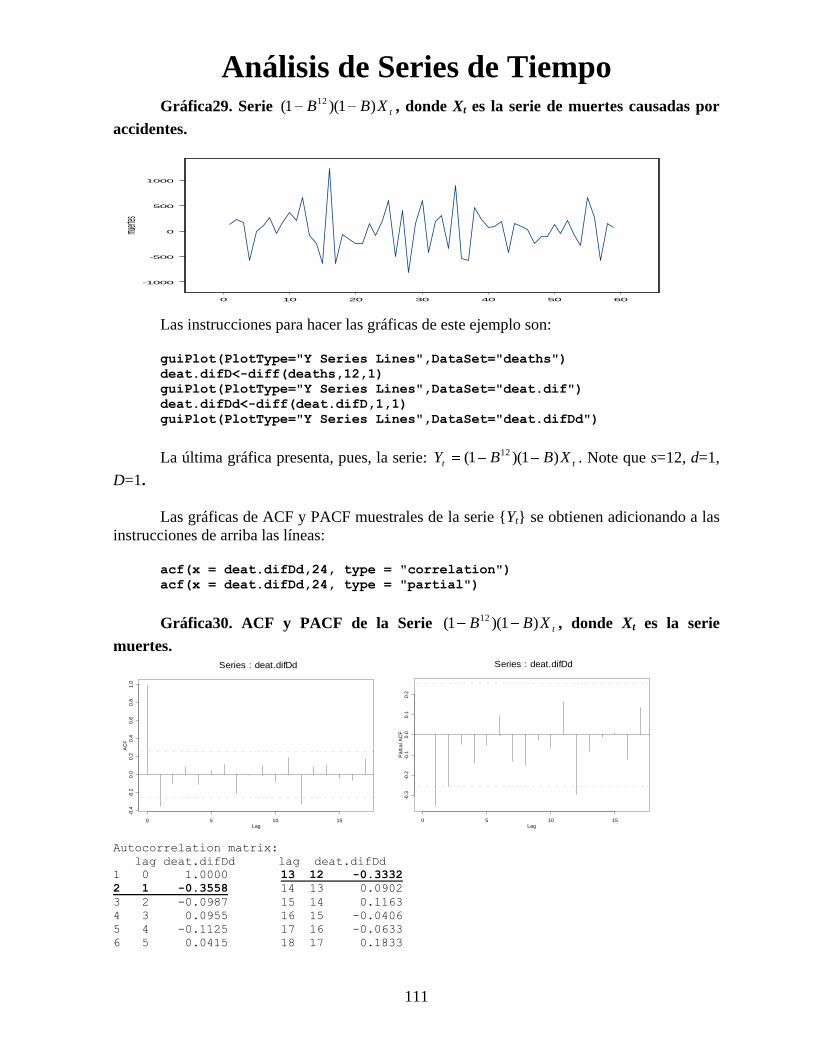
Análisis de Series de Tiempo
111
Gráfica29. Serie tXBB )1)(1( 12, donde Xt es la serie de muertes causadas por
accidentes.
0 10 20 30 40 50 60
-1000
-500
0
500
1000
muerte
s
Las instrucciones para hacer las gráficas de este ejemplo son:
guiPlot(PlotType="Y Series Lines",DataSet="deaths")
deat.difD<-diff(deaths,12,1)
guiPlot(PlotType="Y Series Lines",DataSet="deat.dif")
deat.difDd<-diff(deat.difD,1,1)
guiPlot(PlotType="Y Series Lines",DataSet="deat.difDd")
La última gráfica presenta, pues, la serie: tt XBBY )1)(1( 12. Note que s=12, d=1,
D=1.
Las gráficas de ACF y PACF muestrales de la serie {Yt} se obtienen adicionando a las
instrucciones de arriba las líneas:
acf(x = deat.difDd,24, type = "correlation")
acf(x = deat.difDd,24, type = "partial")
Gráfica30. ACF y PACF de la Serie tXBB )1)(1( 12, donde Xt es la serie
muertes.
Lag
AC
F
0 5 10 15
-0.4
-0.2
0.0
0.2
0.4
0.6
0.8
1.0
Series : deat.difDd
Lag
Pa
rtia
l A
CF
0 5 10 15
-0.3
-0.2
-0.1
0.0
0.1
0.2
Series : deat.difDd
Autocorrelation matrix:
lag deat.difDd lag deat.difDd
1 0 1.0000 13 12 -0.3332
2 1 -0.3558 14 13 0.0902
3 2 -0.0987 15 14 0.1163
4 3 0.0955 16 15 -0.0406
5 4 -0.1125 17 16 -0.0633
6 5 0.0415 18 17 0.1833

Análisis de Series de Tiempo
112
7 6 0.1141 19 18 -0.1929
8 7 -0.2041 20 19 0.0242
9 8 -0.0071 21 20 0.0496
10 9 0.1001 22 21 -0.1201
11 10 -0.0814 23 22 0.0411
12 11 0.1952 24 23 0.1631
25 24 -0.0989
Los valores 0126.0)36(ˆ,0989.0)24(ˆ,333.0)12(ˆ sugieren un modelo
MA(1) para los datos anuales, pues después de )12(ˆ , los valores de )(ks para k=2,3… son
estadísticamente igual con cero. Es decir, P=0 y Q=1.
Por otra parte, )1(ˆ es el único término de correlación de los 11 primeros
significativamente diferente de cero. Por lo que escogemos un modelo MA(1) para los datos
mensuales. Es decir, p=0 y q=1.
De acuerdo a lo anterior, tenemos que:
1312*
131212*
1)1)(1()(
1)1)(1()(
BBBBBB
BBBBBB
s
Hemos visto, pues, que el modelo adecuado para la serie {Xt} corregida por la media es
un proceso SARIMA(0,1,1) x (0,1,1)12. El ajuste se llevó a cabo con el paquete R. Una vez
que tenemos nuestros datos en un vector, usamos la función arima0. Es decir,
> deat
[1] 9007 8106 8928 9137 10017 10826 11317 10744 9713 9938 9161 8927
[13] 7750 6981 8038 8422 8714 9512 10120 9823 8743 9129 8710 8680
[25] 8162 7306 8124 7870 9387 9556 10093 9620 8285 8433 8160 8034
[37] 7717 7461 7776 7925 8634 8945 10078 9179 8037 8488 7874 8647
[49] 7792 6957 7726 8106 8890 9299 10625 9302 8314 8850 8265 8796
[61] 7836 6892 7791 8129 9115 9434 10484 9827 9110 9070 8633 9240
> deatD<-diff(deat,12,1)
> deatDd<-diff(deatD,1,1)
> fit<-arima0(deat,order=c(0,1,1),seasonal=list(order=c(0,1,1),period=12),method="ML")
> mean(deatDd)
[1] 28.83051
> fit
Call:
arima0(x = deat, order = c(0, 1, 1), seasonal = list(order = c(0, 1, 1), period = 12),
method = "ML")
Coefficients:
ma1 sma1
-0.4277 -0.5546
s.e. 0.1229 0.1715
sigma^2 estimated as 99797: log likelihood = -425.54, aic = 857.08

Análisis de Series de Tiempo
113
Por lo que el modelo ajustado para {Xt} (la serie original) es un proceso
SARIMA(0,1,1) x (0,1,1)12, dado por:
)99797,0( Z, )5546.01)(4277.1(8305.28 t
12
12 WNZBBX tt
Ejemplo VI.2.2. Consideremos el archivo VIAJEROS.TXt. Esta serie la vimos en el capítulo
2, y recordemos que fue necesario diferenciar a distancia 12 y a distancia uno, es decir s=12,
D=1 y d=1. Con lo que obtuvimos:
Gráfica31. Serie tXBB )1)(1( 12, donde Xt es la serie de viajeros.
0 50 100 150 200 250 300
-500
0
500
1000
Viaj
El paso siguiente es analizar las gráficas de ACF y PACF para obtener los valores de
P, Q, p y q. Las gráficas son:
Gráfica32. ACF y PACF de tXBB )1)(1( 12, donde Xt es la serie de viajeros.
Lag
AC
F
0 5 10 15 20
-0.5
0.0
0.5
1.0
Series : viaj.difDd
Lag
Pa
rtia
l A
CF
0 5 10 15 20
-0.4
-0.3
-0.2
-0.1
0.0
0.1
0.2
Series : viaj.difDd
Las gráficas anteriores las obtenemos, en S-PLUS, mediante:
guiPlot(PlotType="Y Series Lines",DataSet="viajeros")
viaj.difD<-diff(viajeros,12,1)
guiPlot(PlotType="Y Series Lines",DataSet="viaj.difD")
viaj.difDd<-diff(viaj.difD,1,1)
guiPlot(PlotType="Y Series Lines",DataSet="viaj.difDd")
acf(x = viaj.difDd,24, type = "correlation")
acf(x = viaj.difDd,24, type = "partial")

Análisis de Series de Tiempo
114
De acuerdo a la ACF, podemos ver que después de h=12, la ACF es estadísticamente
igual con cero, por lo que Q=1. Para h=1,…,11, la ACF toma varios valores distintos de cero,
sin embargo, usaremos solo el primero, es decir, q=1. De la gráfica de la PACF, como lo
hicimos con la ACF, podemos obtener P=1 y p=1. Así, el modelo que ajustaremos a la serie de
viajeros será un modelo SARIMA(1,1,1) x (1,1,1)12.
El ajuste lo hicimos en con el paquete R y, específicamente, con la función arima0.
fit<-arima0(viaj,order=c(1,1,1),seasonal=list(order=c(1,1,1),period=12),method="ML")
> media<-mean(viaj)
Obteniendo:
Coefficients:
ar1 ma1 sar1 sma1
0.4074 -0.9156 0.0125 -0.8349
s.e. 0.0525 0.2583 0.0690 0.0422
sigma^2 estimated as 13377: log likelihood = -1969.67, aic = 3949.33
> media
[1] 785.8164
Por lo que el modelo ajustado para la serie original es un proceso SARIMA(1,1,1) x
(1,1,1)12, dado por:
)13377,0( Z
, )835.01)(916.01()012.01)(407.01(8.785
t
1212
12
WN
ZBBXBBX ttt
VI.2.1 Predicción con Modelos SARIMA
El proceso de predicción en los procesos SARIMA es análogo al presentado en los
procesos ARIMA. El proceso consiste en desarrollar los binomios usados para volver
estacionaria la serie. Es decir, desarrollar el término Dsd BB )1()1( , el cual está dado por:
)2..(....................)()1()1(
)1........(....................)()1()1(
0
0
VIBj
DB
VIBk
dB
jDsjD
j
Ds
kdkd
k
d
El producto de estas dos expresiones resulta un polinomio de orden Ds+d, que se
puede expresar como un solo polinomio )(B . Por lo que podemos escribir:

Análisis de Series de Tiempo
115
t
dDs
j
jtjt
tt
t
Dsd
t
YXaX
YBX
YBBX
1
)(
)1()1(
donde el término aj expresa el producto de signos y combinatorias de los términos dados en
(VI.1) y (VI.2).
Para t=n+h, despejando Xn+h, obtenemos:
dDs
j
jhnjhnhn XaYX1
,
y dado que el predictor es un operador lineal, la predicción de Xn+h, hnn XP , queda como:
dDs
j
jhnnjhnnhnn XPaYPXP1
Note que el primer término de la derecha es la predicción de un proceso ARMA, el cual
ya hemos estudiado en capítulos anteriores. El segundo término se calcula recursivamente
partiendo del resultado 1. para , 11 jXXP jnjnn
Con respecto al ECM, tenemos que encontrar una expresión análoga a la que
encontramos para el proceso ARIMA. Esto es, una expresión de la forma
0
*
j
jtj Z .
Para esto, tal como lo hicimos para el proceso ARIMA, partimos de la igualdad:
tt
tDsds
s
t
t
s
t
Dsds
t
s
t
s
ZBX
ZBBBB
BBX
ZBBXBBBB
ZBBYBB
)(
)1()1)(()(
)()(
)()()1()1)(()(
)()()()(
*
De esta forma, para un número de observaciones, n, “grande”, podemos usar la
aproximación:
1
0
2*2)ˆ(h
j
jhnXECM ,

Análisis de Series de Tiempo
116
donde
0
1 , )1()1)(()(
)()()(
jDsd
sj
j zzzzz
zzzz
Ejemplo VI.2.2. Consideremos, nuevamente, el archivo DEATHS.TXT.
Una vez ajustado el modelo como en el ejemplo V.2.1, podemos predecir los siguientes
valores de la serie. En este ejemplo, vamos a estimar los siguientes seis valores (de la
observación 73 a la 78). Para esto, nuevamente usando el paquete R, usamos la función
predict. Así, adicionamos la línea siguiente a las líneas con las que ajustamos el proceso del
ejemplo V.2.1:
> forecast<-predict(fit,n.ahead=6,se.fit=TRUE)
> forecast
$pred
Time Series:
Start = 73
End = 78
Frequency = 1
[1] 8336.999, 7533.183, 8317.035, 8589.337, 9490.938, 9860.644
$se
Time Series:
Start = 73
End = 78
Frequency = 1
[1] 315.8686 363.8916 406.2772 444.6406 479.9473 512.8289
En la primera línea en negritas de los resultados se tienen las estimaciones y en la
segunda su correspondiente raíz del ECM.
Al final del capítulo aparece una tabla, extraída de [Box, Jenkins y Reinsel (1994)] en
la que se resumen algunos modelos estacionales, junto con su función de autocovarianzas y
algunas propiedades importantes.
VI.3. REGRESIÓN CON ERRORES ARMA(p,q)
Como tarea importante en la generalización de la técnica de regresión tradicional, se
presenta el caso donde los errores del modelo de regresión siguen un proceso ARMA(p,q), en
vez de suponer que son independientes e idénticamente distribuidos (iid). Esta generalización
es muy útil ya que en muchos casos prácticos, la suposición de independencia no se cumple.
Enseguida daremos un breve resumen de las técnicas de estimación del Análisis de
Regresión.

Análisis de Series de Tiempo
117
VI.3.1 Mínimos Cuadrados Ordinarios (MCO)
Consideremos el modelo de regresión simple en forma matricial:
XY
Este método consiste en escoger el valor de ˆ que minimice la suma de cuadrados de
las desviaciones de las observaciones respecto a su valor esperado, es decir, el valor que
minimiza:
)()'()]([1
2 XYXYyEyN
i
ii
donde N es el número de observaciones.
El estimador resultante, MCO
ˆ , es el siguiente:
YXXXMCO
')(ˆ 1'
VI.3.2 Mínimos Cuadrados Generalizados (MCG)
Cuando asumimos que conocemos la matriz de varianzas-covarianzas del vector de
errores, es decir, suponemos VCov )( , podemos minimizar, respecto a , la cantidad:
)()'( 1 XYVXY
El estimador resultante, MCG
ˆ , es el siguiente:
YVXXVXMCG
1'11' )(ˆ
Note que si IV 2, tenemos el caso de MCO. Para más detalles revisar [Searle S.R.
Linear Models (1997)].
En el Análisis de Regresión Estadístico, generalmente, se supone que los errores son
independientes e idénticamente distribuidos (iid). Sin embargo, en la práctica este supuesto no
se cumple. Esto se puede corroborar examinando los residuales del modelo ajustado y su
autocorrelación muestral.
Por lo anterior, una aplicación del análisis de Series de Tiempo en el Análisis de
Regresión es considerar que los errores {Wt} siguen un proceso causal ARMA(p,q) con media
cero dado por ),0(con , )()( 2WNZZBWB ttt .
Consideremos el modelo de regresión simple:

Análisis de Series de Tiempo
118
0]E[Wcon ),( donde , t
' qpARMAWWxY tttt , t=1,…,n
Dicho de otra forma, {Wt} satisface:
),0(con , )()( 2WNZZBWB ttt
El modelo lo podemos expresar en forma matricial como:
WXY
donde )',...,,( 21 nYYYY , X es la matriz diseño cuya i-ésima hilera está dada por los valores
que toman las variables explicatorias en el tiempo t, ),...,,,1( 1
'
tktktt xxxx , k es el número de
variables explicatorias, es decir, X es de orden n x (k+1) y )',...,,( 21 nWWWW es el vector de
errores. También, definimos los vectores de parámetros asociados al proceso {Wt},
),...,( 1 p y )',...,( 1 q .
El problema que abordaremos será ¿cómo estimar este modelo? Es decir, identificar el
proceso que sigue {Wt} y estimar el vector de regresión, . Para esto, debemos recurrir a
estrategias que nos permitan tener valores iniciales de los parámetros en cuestión.
Tomemos como estimador inicial de al estimador de regresión por MCO
YYW
XY
YXXX
ˆˆ
ˆˆ
)(ˆ
)0(
)0()0(
'1')0(
Una vez que conocemos la primera estimación de W , podemos conocer su matriz de
varianzas-covarianzas. Sea ]'[ WWEn dicha matriz. Así, se puede obtener la matriz de
covarianzas de )0(
ˆ , la cual está dada por:
1''1')0(
)()()ˆ( XXXXXXCOV n
Ahora, teniendo )0(
W , podemos identificar qué proceso sigue. Es decir, podemos
ajustar un modelo de la forma ),0(con , )()( 2WNZZBWB ttt .
El siguiente paso es refinar la estimación del vector por el método de MCG
considerando que conocemos la matriz de covarianzas de los errores, ]'[ WWEn . Así,

Análisis de Series de Tiempo
119
)1()1(
)1()1(
1'11')1(
ˆˆ
ˆˆ
)(ˆ
YYW
XY
YXXX nn
Ahora el nuevo vector de parámetros )1(
ˆ tiene matriz de Covarianzas:
11'
11'11'11')1(
)(
)()()ˆ(
XX
XXXXXXCOV
n
nnnnn
Cabe mencionar que para efectuar esta estimación es necesario conocer los vectores
y .
Se puede mostrar que,
)()()0(')1('
cVARcVAR
Usando )1(
ˆ se vuelven a estimar los residuales )1(
W , a los cuales se les ajusta un
nuevo modelo ARMA(p,q) con el fin de refinar los vectores y . El proceso es iterativo y
termina cuando los parámetros convergen.
El proceso de estimación nos conducirá a la convergencia
(i)
)(
ˆy
ˆ
ˆ
i
MCG
Cabe destacar que el proceso ARMA(p,q) ajustado en cada iteración i > 0 actualiza los
valores de y del proceso inicial.
Lo anterior se resume en el siguiente diagrama:

Análisis de Series de Tiempo
120
Figura4. Proceso de ajuste de un modelo de regresión con errores siguiendo un
proceso ARMA(p,q).
WXY : Modelo Inicial.
YXXX '1')0()(ˆ : Se estima con MCO.
)0()0( ˆˆ XYW : Se genera el proceso {Wt} de residuales como
)0(W .
Ajustar un proceso ARMA a )0(
ˆi
W
n
)0()0(implican y
ii
YXXX nn
i 1'11')1()(ˆ
)1()1( ˆˆ
iiXYW
Ejemplo VI.3.1. Consideremos la serie de 57 mediciones de la cantidad de gasolina en un
tanque estacionario. El archivo es OSHORTS.TXT.
El modelo propuesto para el stock de gasolina en el tanque es:
tt WY
Donde –β es interpretado como la merma diaria en el tanque de gasolina y {Wt} un
proceso MA(1). Esto es, {Wt} cumple:
),0( , 2
1 WNZZZW tttt

Análisis de Series de Tiempo
121
Para ajustar el modelo, en ITSM, seleccionamos la opción Regression>Specify y
marcamos la opción Include Intercept term, luego seleccionamos la opción
Regression>Estimation>Least Squares.
El siguiente paso es ajustar un modelo ARMA a la serie {Wt}. Para ello, seguimos los
pasos Model>Estimation>Autofit (seleccionará el modelo ARMA con mínimo AICC):
Method: Maximum Likelihood
Y(t) = M(t) + X(t)
Based on Trend Function: M(t) = - 4.0350877
ARMA Model: X(t) = Z(t) - .8177 Z(t-1)
WN Variance = .204082E+04
Con esto, podemos obtener una nueva estimación para el modelo de regresión por el
método de MCG. Para ello, seleccionamos la secuencia (en ITSM) Regression> Estimation>
Generalized LS y los resultados aparecerán en la ventana Regression Estimates.
Method: Generalized Least Squares
Y(t) = M(t) + X(t)
Trend Function: M(t) = - 4.7449426
ARMA Model: X(t) = Z(t) - .8177 Z(t-1)
WN Variance = .204082E+04
Como vimos en el desarrollo de la teoría, el proceso es iterativo, por lo que tenemos
que ajustar nuevamente el modelo para los errores. Esto se logra en ITSM presionando el
botón azul superior MLE:
Method: Generalized Least Squares
Trend Function: M(t) = - 4.7799300
ARMA Model: X(t) = Z(t) - .8475 Z(t-1)
WN Variance = .201992E+04
Después de 4 iteraciones el proceso converge como se puede ver en el siguiente cuadro
resumen:
Cuadro3. Resumen del ejemplo regresión con errores ARMA.
Iteración i )(ˆ i )(ˆ i
1 0 - 4.0350877
2 - .8177 - 4.7449426
3 - .8475 -4.77992996
4 - .8475 -4.77992996
En S-PLUS se usan, iterativamente, las instrucciones:

Análisis de Series de Tiempo
122
media<-mean(t(oshorts$stock))
mco<-lm(oshorts$stock ~ oshorts$stock)
resid<-oshorts$stock-media
ajuste.res<-arima.mle(resid,list(ma=0))
mcg<-lm(oshorts$stock ~ oshorts$stock + resid)
mco
ajuste.res
mcg
Obteniendo como primera iteración:
Coefficients:
(Intercept)
-4.035088
Method: Maximum Likelihood
Model : 0 0 1
Coefficients:
MA : 0.81763
Variance-Covariance Matrix:
ma(1)
ma(1) 0.005815465
Coefficients:
(Intercept) resid
-4.035088 1
VI.4. RAICES UNITARIAS EN SERIES DE TIEMPO
El problema de las raíces unitarias surge cuando los polinomios Autorregresivos o de
Promedio Móvil de un proceso ARMA tienen una raíz igual con 1. Las consecuencias de este
problema estriban en las diferenciaciones. Si encontramos que el polinomio Autorregresivo
tiene una raíz unitaria, entonces significa que la serie no es estacionaria y en consecuencia,
requiere ser diferenciada; mientras que, si encontramos una raíz unitaria en el polinomio de
Promedio Móvil, significa que la serie está sobrediferenciada.
VI.4.1 Raíces Unitarias en el polinomio Autorregresivo
El grado de diferenciación en una serie {Xt}, como vimos, está determinado por la
aplicación del operador de diferencia repetidamente hasta que la gráfica de la función de
autocorrelación muestral de la serie diferenciada, ACF, decae rápidamente. De aquí que, el
modelo ARIMA(p,d,q) tiene un polinomio autorregresivo con d raíces en el círculo unitario.
En esta sección discutiremos las pruebas básicas de raíces unitarias para decidir si
tenemos o no que diferenciar la serie.
Supongamos que {Xt} sigue un proceso AR(1) con media μ, es decir:
),0( , )( 2
11 WNZZXX tttt

Análisis de Series de Tiempo
123
Por otra parte, sabemos que, para un número de observaciones n, grande, el estimador
de máxima verosimilitud de 1 tiene la propiedad: )/)1(,(ˆ 2
111 nN .
La prueba de hipótesis de raíz unitaria en este modelo consiste en establecer:
1: v.s1: 1110 HH
Para construir la estadística de prueba, escribimos el modelo AR(1) como sigue:
1
)1(
donde
1
*
1
1
*
0
1
*
1
*
0
1
tt
ttt
ZX
XXX
Note que esta representación es análoga al modelo de análisis de regresión expuesto en
la sección VI.3. En este caso, la variable dependiente es tX y la independiente es Xt-1.
Si *
1 es el estimador de MCO de *
1 , entonces su correspondiente Error Estándar
muestral (EE) está dado por:
2/1
2
2
1
*
1
)(
)ˆ(ˆn
t
t XX
SEE
n
t
t
n
t
tt
Xn
X
nXXS
2
1
2
2
1
*
1
*
01
2
1
1
)3/(ˆˆ
donde
Dickey y Fuller (1979), bajo el supuesto de raíz unitaria, derivaron la distribución
asintótica (n grande) para la prueba de hipótesis propuesta. Dicha estadística de prueba es la
razón dada por:
)ˆ(ˆ
ˆˆ
*
1
*
1
EE
Los valores críticos para tres diferentes niveles de significancia se muestran en la tabla
siguiente:

Análisis de Series de Tiempo
124
Cuadro4. Valores críticos de Dicky-Fuller.
α D/Fα t-student
0.01 -3.43 -2.33
0.05 -2.86 -1.96
0.10 -2.57 -1.65
La regla de decisión es:
0
0
Rechazar No /
Rechazar /
HFD
HFD
Note que es menos probable rechazar la hipótesis de raíz unitaria usando la
distribución límite de Dickey-Fuller que usando la aproximación a la distribución t-Student.
El procedimiento de prueba anterior se puede extender al caso de un proceso AR(p)
con media μ dado por:
),0( , )()( 2
11 WNZZXXX ttptptt
Siguiendo la misma idea que en el AR(1), el modelo AR(p) lo podemos escribir como:
tptpttt ZXXXX 1
*
1
*
21
*
1
*
0
p,...,2j ,
1
)1(
:donde
1
*
1
*
1
1
*
0
p
i
ij
p
i
i
p
La prueba de raíz unitaria, como en el AR(1), es equivalente a probar 0*
1 . La
estadística de prueba y la regla de decisión son las mismas que en el caso del proceso AR(1).
Ejemplo VI.4.1. Consideremos la serie de datos del Lago Hurón. El archivo es LAKE.TXT.
La gráfica de esta serie se encuentra en la gráfica22 y las gráficas de las funciones de
autocorrelación y autocorrelación parcial en la gráfica23.
La PACF muestral sugiere ajustar un modelo AR(2). Sin embargo, para ejemplificar la
teoría descrita, propondremos un modelo AR(1).

Análisis de Series de Tiempo
125
Para llevar a cabo el ajuste del modelo de regresión de tX sobre Xt-1 en S-PLUS
seguimos: En el Dataset “Lake”, seleccionamos Data> Transform y en el cuadro de diálogo
que aparece escribimos la Expression: diff(Lake,1,1), esto creará una nueva columna (llamada
V1) con las diferenciaciones a distancia 1. Enseguida seleccionamos Statistics> Regression>
Linear y en la opción Variable Dependent seleccionamos “V1” y en Independent elegimos
“lake”. Obteniendo:
Cuadro5. Parámetros estimados de la regresión de tX sobre Xt-1.
Coefficients:
(Intercept)
lake
Value
1.4670
-0.1636
Std. Error
0.5061
0.0557
t value
2.8986
-2.9381
Pr(>|t|)
0.0047
0.0041
Note que la columna t value muestra la estadística de prueba de Dickey-Fuller. Es
decir:
94.205568.0
16359.0ˆ
De acuerdo a la regla de decisión de Dickey Fuller, a un nivel de significancia del 1%,
no se rechaza la hipótesis de raíz unitaria, pues -3.43)(-2.94 /ˆ 01.0FD . Esto permite
concluir que existe raíz unitaria en el polinomio autorregresivo y esto, a su vez, implica que la
serie no está suficientemente diferenciada, como lo mencionamos anteriormente en base a la
gráfica de la PACF muestral. Nótese, también, que si usamos la aproximación a la distribución
t-Student, la hipótesis nula se rechazaría al nivel de significancia del 1%, pues es mayor al p-
value=0.41%.
Veamos ahora que pasa si proponemos un modelo AR(2). Esto implica llevar a cabo la
regresión de tX sobre Xt-1 y 1tX para t=3,…,98. El procedimiento es similar al anterior
con la novedad de que ahora se agrega una nueva variable independiente, a saber 1tX .
Cuadro6. Parámetros estimados de la regresión de tX sobre Xt-1 y 1tX .
Coefficients:
Value Std. Error t value Pr(>|t|)
(Intercept) 1.9196 0.5023 3.8217 0.0002
lake -0.2158 0.0554 -3.8977 0.0002
V1 0.2376 0.0971 2.4457 0.0163
donde: V1:= 1tX ;
lake:= Xt-1,
t=3,…,98.
De los resultados podemos ver que:
9.305538.0
21584.0ˆ

Análisis de Series de Tiempo
126
De acuerdo a la regla de decisión de Dickey Fuller, a un nivel de significancia del 1%,
se rechaza la hipótesis de raíz unitaria, pues -3.43)(-3.9 /ˆ 01.0FD . Con esto,
concluimos que ajustando un AR(2) no existe raíz unitaria.
VI.4.2 Raíces Unitarias en el polinomio de Promedio Móvil
La interpretación de la existencia de raíces unitarias en el polinomio de promedio
móvil depende de la aplicación del modelo. Una de ellas es, como ya se mencionó, que la serie
está sobrediferenciada. Supongamos que {Xt} sigue un proceso ARMA(p,q) invertible, por lo
que satisface:
),0( Z, )()( 2
t WNZBXB tt
Entonces, la serie diferenciada tt XY es un proceso ARMA(p,q+1) no invertible
con polinomio de promedio móvil dado por: )1)(( zz . De aquí que, probar la existencia de
raíz unitaria es equivalente a probar que la serie está sobrediferenciada.
En la presente, nos limitaremos al caso de raíces unitarias en procesos MA(1).
Supongamos que {Xt} forma un proceso MA(1):
),0( Z, 2
t1 IIDZZX ttt
Supongamos, también, la existencia de raíz unitaria (z=1), por lo que el polinomio de
promedio móvil 01z implica que 1. Esta última igualdad es, de hecho, la hipótesis
por probar. Bajo esta hipótesis, [Davis y Dunsmuir (1995)] mostraron que n( ˆ +1), donde ˆ
es el estimador de Máxima Verosimilitud de θ, tiene la propiedad de converger en
distribución. Lo anterior se resume en probar el juego de hipótesis:
1: v.s1: 10 HH
La regla de decisión es: Si
0
0
Rechazar No /1ˆ
Rechazar /1ˆ
HnC
HnC
donde C es el (1-α) cuantil de la distribución límite de n( ˆ +1). Los valores críticos de esta
distribución se muestran en el siguiente cuadro para tres niveles de significancia, los cuales
fueron extraídos de la tabla 3.2 de [Davis, Chen y Dunsmuir (1995)]:
Cuadro7. Valores críticos de la estadística Cα.
α Cα
0.01 11.93
0.05 6.80
0.10 4.90

Análisis de Series de Tiempo
127
Note que la desigualdad de la regla de decisión es resultado de la desigualdad
Cn )1ˆ( .
Cabe mencionar que existe otra estadística de prueba para probar el mismo juego de
hipótesis (de raíz unitaria) que consiste en la prueba de Razón de Verosimilitud. Para más
detalles consultar [Brockwell y Davis (2002) pp. 197].
Ejemplo VI.4.1. Consideremos la serie de datos del ejemplo VI.3.1 (57 observaciones de
cantidad de gasolina en un tanque estacionario).
Recordemos que el modelo ajustado para los datos corregidos por la media fue:
ARMA Model:
X(t) = Z(t) - .8177 Z(t-1)
WN Variance = .204082E+04
De acuerdo a la regla de decisión descrita arriba, al 5% de significancia, tenemos que:
nC
nC
/1ˆ
881.057/8.61/1
8177.0ˆ
05.0
05.0
Rechazar la hipótesis de raíz unitaria en el polinomio de promedio móvil.
Nótese que en este ejemplo consideramos que la media es conocida. En la práctica, la
prueba debe ser ajustada por el hecho de que la media también debe ser estimada.

Análisis de Series de Tiempo
128
Cuadro8. Autocovarianzas de algunos modelos estacionales.
Modelo (Autocovarianza de Xt)/σ2 Algunas características
3
)1)(1(
11
s
ZZZZ
ZBBX
ststtt
t
s
t
ceroson demás Las
)1(
)1(
)1)(1(
11
2
1
2
1
22
0
ss
s
s 111
11
)(
)(
sss
ss
b
a
3
)1)(1()1(
11
s
ZZZZXX
ZBBXB
ststttstt
t
s
t
s
ceroson ,...,, 4,s Para
2,
1
)()1(
1
)(
1
)(1
1
)(1)1(
232
11
2
22
2
2
1
2
2
1
2
22
0
s
sjj
ss
s
s
sj
2, )(
)( 11
sjb
a
sjj
ss

Análisis de Series de Tiempo
129
Modelo (Autocovarianza de Xt)/σ2 Algunas características
5
)1)(1(
2222122122212
11112211
2
21
2
21
s
ZZZZ
ZZZZZ
ZBBBBX
stststst
ststttt
t
ss
t
)1)(1(
)1)(1(
)1(
)1(
)1)(1(
)1)(1(
2
2
2
2
2
11
2
22111
2
2122
2
2
2
122
2
2
2
1211
2
2
2
1
2
2
2
10
s
s
s
1212
2222
11
22
)(
)(
)(
)(
ss
ss
ss
ss
d
c
b
a
cero a igualson resto El
)1(
)1(
2222
1212
2
2
2
122
22112
2222
22
11
ss
ss
s
s
s
ss
ss

Análisis de Series de Tiempo
130
Modelo (Autocovarianza de Xt)/σ2 Algunas características
3
)1(
1111
1
11
s
ZZZZ
ZBBBX
stsststt
t
s
s
s
st
11
11
11
111
2
1
22
10 1
ss
sss
ss
ss
ss
11
11
general,En )(
ss
ss
a
3
)1()1(
1111
1
11
s
ZZZZXX
ZBBBXB
stsststtstt
t
s
s
s
st
s
ceroson ,...,, 4,s Para
2,
1
)(1)(
1
)()(
1
)(1)(
1
)()(
1
))((
1
)(
1
)(1
232
2111
2
11
111
2
2
11
11
2
11
11
2
2
11
2
2
2
10
s
sjj
s
ss
s
s
s
ss
s
ss
ss
ss
sj
2, )(
)( 11
sjb
a
sjj
ss

Análisis de Series de Tiempo
131
CAPITULO VII. SERIES DE TIEMPO MULTIVARIADAS
El análisis de series de tiempo multivariadas consiste, esencialmente, en analizar varias
series de tiempo a la vez. Este análisis es justificable, puesto que en la práctica es difícil que
una variable actúe por si misma. Es decir, muchas veces hay una interdependencia entre varias
variables.
Supongamos dos series {Xt1} y {Xt2}. Cada una de ellas las podemos analizar por
separado como series univariadas, sin embargo puede que exista algún tipo de dependencia
entre ambas variables y tal dependencia puede ser de gran importancia cuando se tenga interés
en predicciones futuras de las variables.
Sin perdida de generalidad se dará el caso de dimensión 2, ya que su extensión a
dimensión k es muy sencilla. Consideremos la serie bivariada '
21 ),( ttt XXX . Definimos la
función vectorial promedio como sigue:
2
1
t
t
t EX
EX
y la función matricial de covarianzas como:
),cov( ),cov(
),cov( ),cov(),(),(
22,12,
21,11,
thttht
thttht
thtXXXX
XXXXXXCovtht
Cuando la función vectorial promedio y la función matricial de covarianzas de la serie
bivariada '
21 ),( ttt XXX no depende de t, se dice que es estacionaria en sentido débil, en
cuyo caso usamos la notación:
2
1
t
t
EX
EX
y
)( )(
)( )(),()(
2221
1211
hh
hhXXCovh tht
Note que los elementos de la diagonal de la matriz de covarianzas son las funciones de
autocovarianzas univariadas de cada serie. Mientras que, los elementos fuera de la diagonal
son las covarianzas cruzadas. Es decir: )()( hh Xiii . Más adelante enumeraremos algunas
de las propiedades de )(h para las series multivariadas.
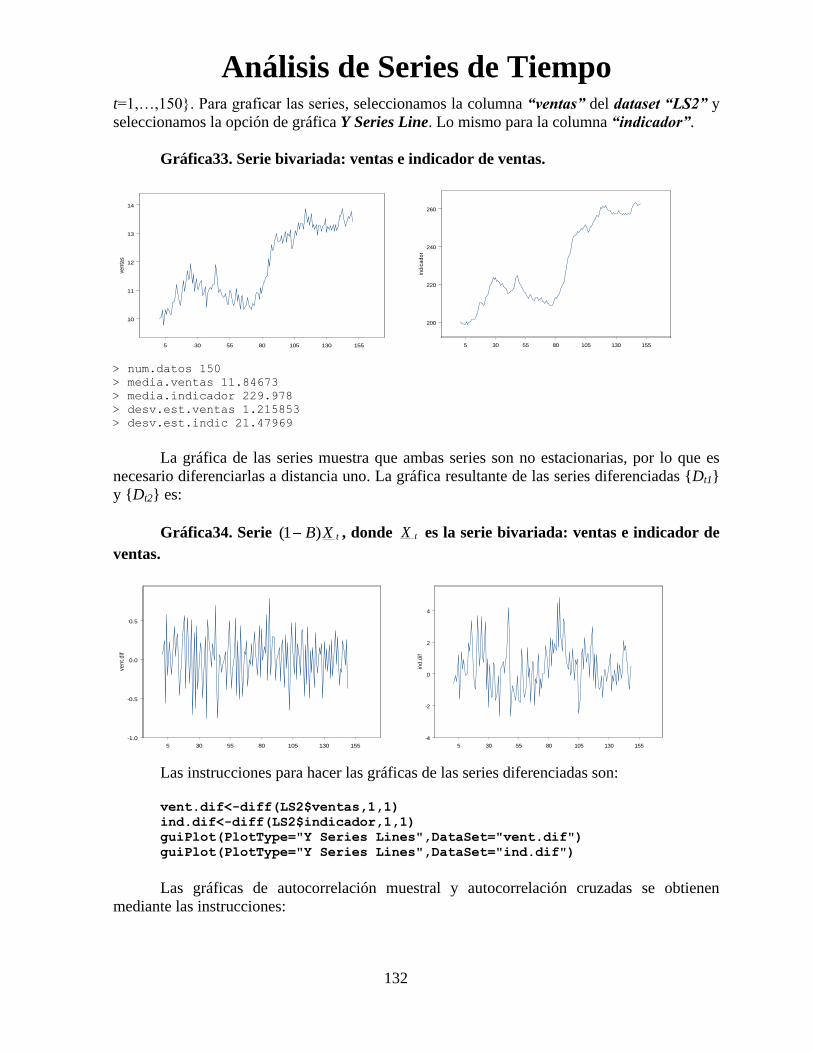
Ejemplo VII.1. Consideremos el archivo LS2.TXT. Los datos de la serie uno corresponden a
ventas {Yt1, t=1,…,150}; la segunda serie muestra un indicador de dirección de ventas, {Yt2,
Análisis de Series de Tiempo
132
t=1,…,150}. Para graficar las series, seleccionamos la columna “ventas” del dataset “LS2” y
seleccionamos la opción de gráfica Y Series Line. Lo mismo para la columna “indicador”.
Gráfica33. Serie bivariada: ventas e indicador de ventas.
5 30 55 80 105 130 155
10
11
12
13
14
ven
tas
5 30 55 80 105 130 155
200
220
240
260
ind
ica
do
r
> num.datos 150
> media.ventas 11.84673
> media.indicador 229.978
> desv.est.ventas 1.215853
> desv.est.indic 21.47969
La gráfica de las series muestra que ambas series son no estacionarias, por lo que es
necesario diferenciarlas a distancia uno. La gráfica resultante de las series diferenciadas {Dt1}
y {Dt2} es:
Gráfica34. Serie tXB)1( , donde tX es la serie bivariada: ventas e indicador de
ventas.
5 30 55 80 105 130 155
-1.0
-0.5
0.0
0.5
ven
t.d
if
5 30 55 80 105 130 155
-4
-2
0
2
4
ind
.dif
Las instrucciones para hacer las gráficas de las series diferenciadas son:
vent.dif<-diff(LS2$ventas,1,1)
ind.dif<-diff(LS2$indicador,1,1)
guiPlot(PlotType="Y Series Lines",DataSet="vent.dif")
guiPlot(PlotType="Y Series Lines",DataSet="ind.dif")
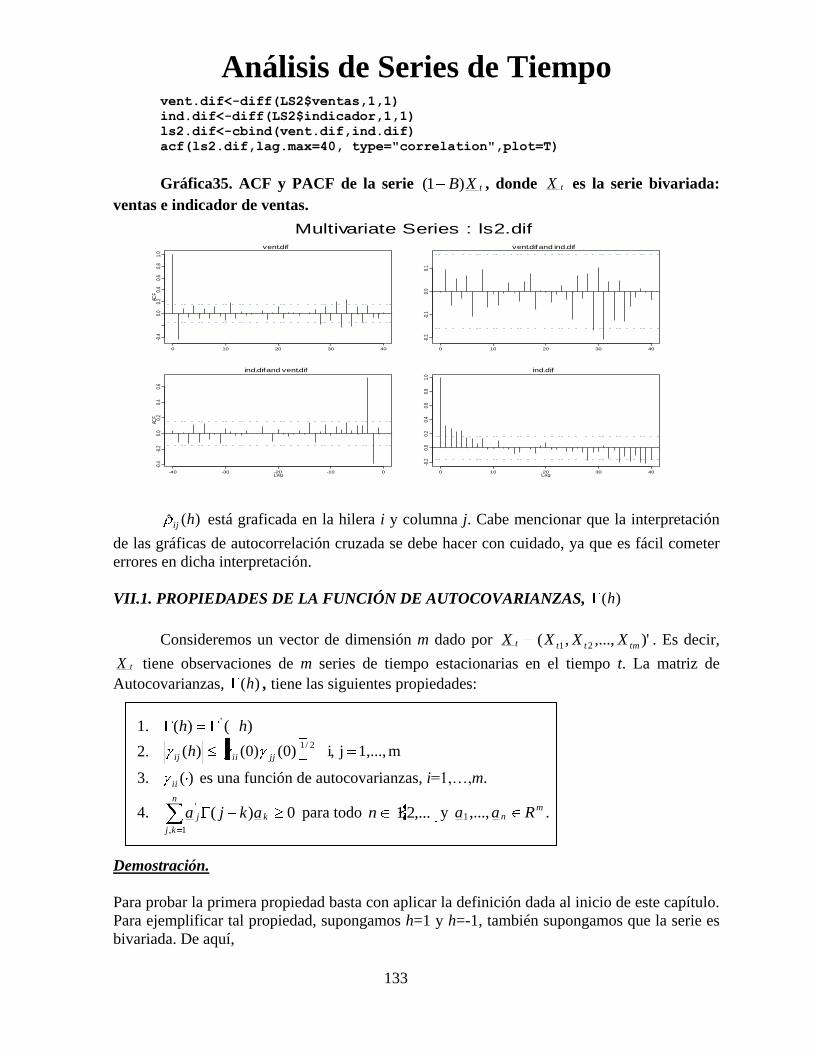
Las gráficas de autocorrelación muestral y autocorrelación cruzadas se obtienen
mediante las instrucciones:
Análisis de Series de Tiempo
133
vent.dif<-diff(LS2$ventas,1,1)
ind.dif<-diff(LS2$indicador,1,1)
ls2.dif<-cbind(vent.dif,ind.dif)
acf(ls2.dif,lag.max=40, type="correlation",plot=T)
Gráfica35. ACF y PACF de la serie tXB)1( , donde tX es la serie bivariada:
ventas e indicador de ventas.
vent.dif
ACF
0 10 20 30 40
-0.4
0.0
0.2
0.4
0.6
0.8
1.0
vent.dif and ind.dif
0 10 20 30 40
-0.2
-0.1
0.0
0.1
ind.dif and vent.dif
Lag
ACF
-40 -30 -20 -10 0
-0.4
-0.2
0.0
0.2
0.4
0.6
ind.dif
Lag0 10 20 30 40
-0.2
0.0
0.2
0.4
0.6
0.8
1.0
Multivariate Series : ls2.dif
)(ˆ hij está graficada en la hilera i y columna j. Cabe mencionar que la interpretación
de las gráficas de autocorrelación cruzada se debe hacer con cuidado, ya que es fácil cometer
errores en dicha interpretación.
VII.1. PROPIEDADES DE LA FUNCIÓN DE AUTOCOVARIANZAS, )(h
Consideremos un vector de dimensión m dado por )',...,,( 21 tmttt XXXX . Es decir,
tX tiene observaciones de m series de tiempo estacionarias en el tiempo t. La matriz de
Autocovarianzas, )(h , tiene las siguientes propiedades:
1. )()( ' hh
2. m1,...,ji, )0()0()(2/1
jjiiij h
3. )(ii es una función de autocovarianzas, i=1,…,m.
4. n
kj
kj akja1,
'0)( para todo ,...2,1n y m
n Raa ,...,1 .
Demostración.
Para probar la primera propiedad basta con aplicar la definición dada al inicio de este capítulo.
Para ejemplificar tal propiedad, supongamos h=1 y h=-1, también supongamos que la serie es
bivariada. De aquí,

Análisis de Series de Tiempo
134
)1()1(
)1( )1(
)1( )1(
)1( )1(
)1( )1(
),cov( ),cov(
),cov( ),cov()1(
)1( )1(
)1( )1(
),cov( ),cov(
),cov( ),cov()1(
'
2212
2111
2221
1211
22,112,1
21,111,1
2221
1211
22,112,1
21,111,1
tttt
tttt
tttt
tttt
XXXX
XXXX
XXXX
XXXX
De las igualdades anteriores, concluimos la primera propiedad.
Para probar la segunda igualdad usamos la definición de correlación y el hecho de que esta no
puede ser mayor a 1 en valor absoluto. Es decir:
2/1
2/1ij
)0()0()(
1)0()0(
)()(
jjiiij
jjii
ij
h
hh
La tercera propiedad no es más que una observación de la diagonal de la matriz de
autocovarianzas. Esto es, podemos ver que )(ii es la función de autocovarianzas de la serie
estacionaria {Xti, i=1,…,m}.
Para probar la propiedad 4 consideremos la variable:
)()()('
2'21
'1 nn XaXaXaW
Cuya varianza está dada por:
n
kj
kjk
n
kj
kjj akjaaXXaWVar1,
'
1,
')()cov()cov()(
La última expresión es la que nos interesa y es mayor o igual a cero ya que sabemos que,
siendo una varianza, no puede ser un valor negativo. De esta forma, quedan probadas las
cuatro propiedades de la matriz de Covarianzas.
///
Definición VII.1.1. [Ruido Blanco Multivariado].- El proceso }{ tZ de dimensión m
es llamado Ruido Blanco Multivariado con vector de medias cero y matriz de covarianzas Σ si
}{ tZ es estacionario con vector promedio 0 y tiene matriz de covarianzas definida por:
modo otro de 0
0 si )(
m
hh

Análisis de Series de Tiempo
135
Se usa la notación: ),0(WNZ t ; 0 es el vector cero de dimensión m; m0 es la matriz cero
de dimensión m x m.
Nótese que la definición no indica independencia entre las componentes de }{ tZ , sino
entre las observaciones de }{ tZ .
Recordemos que en las series de tiempo univariadas definimos un proceso lineal a
partir de la definición de proceso de Ruido Blanco. Para el caso multivariado, también existe
este concepto. La diferencia se halla en que ahora los coeficientes del proceso }{ tZ son
matrices. A continuación damos la definición de proceso lineal multivariado.
Definición VII.1.1. [Proceso Lineal Multivariado].- La serie m-variada }{ tX es un
proceso lineal si tiene la representación:
j
jtjt ZCX con ),0(WNZ t
donde {Cj} es una secesión de matrices m x m cuyos componentes son absolutamente
sumables.
Esta definición la usaremos más adelante para introducir el concepto de causalidad en
series multivariadas. También, a partir de ella, se tiene el resultado siguiente, el cual nos ayuda
a determinar la función de autocovarianzas )(h para }{ tX .
RESULTADO VII.1.- Si }{ tX es un proceso lineal de dimensión m, entonces )(h se puede
escribir como:
j
jhj CCh ')(
Demostración.
Dado que }{ tX es un proceso lineal, tiene la propiedad: j
jtjt ZCX con
),0(WNZ t . Partiendo de esto y la definición de covarianza, tenemos:
hthtthht
j
jtj
j
jhtjtht
ZCZCZCZCCOV
ZCZCCOVXXCOV
00
00
,
,),(
Como }{ tZ es un proceso de Ruido Blanco, ),( tht ZZCOV para h=0 y m0 de otro modo.
Así,

Análisis de Series de Tiempo
136
0
'
0
'
'
1111
'
0
'
1111
'
110
'
0
'
00
),(
),(),(
),(),(
),(),(),(
j
jhj
j
jjtjthj
tthtth
tththt
tththttht
CCΓ(h)
CZZCOVC
CZZCOVCCZZCOVC
CZZCOVCCZZCOVC
CZZCOVCCZZCOVCXXCOV
Con lo queda demostrado el resultado.
///
Ejemplo VII.1.1. Consideremos el modelo estacionario bivariado siguiente: ttt ZXX 1
con ),0(WNZ t . Explícitamente, tenemos:
2
1
2,1
1,1
2221
1211
2
1
t
t
t
t
t
t
Z
Z
X
X
X
X
Encontremos una expresión de }{ tX como proceso lineal. Esto se logra iterando el
modelo como sigue:
)(
)(
122
33
1232
122
121
tttttttt
ttttttttt
ZZZXZZZX
ZZXZZXZXX
Aplicando el proceso repetidamente, llegamos a la expresión:
0j
jtj
t ZX
De esta forma, usando el resultado VII.1 podemos encontrar una expresión de la
función de Covarianzas )(h del proceso:
0
')(j
jhjh
VII.2. ESTIMACIÓN DEL VECTOR PROMEDIO Y LA FUNCIÓN DE COVARIANZAS
En esta sección introduciremos los estimadores de los componentes ijy , ijj de una
serie estacionaria m-variada }{ tX . También examinaremos las propiedades de los estimadores
cuando se tienen muestras “grandes”.

Análisis de Series de Tiempo
137
VII.2.1. Estimación del vector promedio,
Como mencionamos anteriormente, el estimador natural del vector de medias basado
en n observaciones nXX ,...,1 es el vector de medias muestrales:
n
t
tn Xn
X1
1ˆ
El estimador resultante de la media de la j-ésima serie de tiempo es, entonces, la
univariada media muestral n
t
tjXn1
/1 .
En seguida daremos un resultado que involucra la varianza del vector de medias,
análogo al resultado IV.1 para series univariadas.
RESULTADO VII.2.- Si }{ tX es una serie de tiempo estacionaria m-variada con vector
promedio y función de covarianzas )(h , entonces conforme n :
0)()'( nn XXE , si minii 1 0)( ,
y
h
m
i
iinn hXXnE1
)()()'( si h
ii h |)(|
Bajo supuestos más restrictivos, se puede mostrar que el proceso }{ tX es distribuido
aproximadamente Normal cuando el número de observaciones es suficientemente grande. Este
hecho nos permite hacer inferencia sobre las medias de las series de tiempo.
VII.2.2. Estimación de la función de Covarianzas, )(h
El estimador natural de la función de autocovarianzas para un proceso estacionario
}{ tX , )')(()( tht XXEh , es:
01 para )(ˆ
10 para ))((1
)(ˆ
'
1
'
h-nh
n-hXXXXnh
hn
t
ntnht
En consecuencia, el estimador de las correlaciones cruzadas es:
,...,mi,jh
hjjii
ij
ij 1 , )0(ˆ)0(ˆ
)(ˆ)(ˆ
2/1

Análisis de Series de Tiempo
138
Para el caso i=j, la expresión anterior se reduce a la función de autocorrelación
muestral de la i-ésima serie.
Enseguida damos un resultado muy útil al momento de probar independencia entre dos
series.
RESULTADO VII.3.- Sea }{ tX una serie bivariada cuyos componentes están definidos
como:
)IID(0,}{Z ,
y
)IID(0,}{Z ,
2
2t22,2
2
1t11,1
k
ktkt
k
ktkt
ZX
ZX
donde las secuencias }{ 1tZ y }{ 2tZ son independientes. Entonces, para todo entero h y k con
kh , las variables aleatorias )(ˆ12 hn y )(ˆ12 kn se distribuyen, conjuntamente,
aproximadamente como Normal Bivariada con parámetros:
jj
jj
jjhkjj
hkjjjj
Nkn
hn
)()()()(
)()()()(
, 0
0
)(ˆ
)(ˆ
22112211
22112211
12
12
Para llevar a cabo inferencia sobre las medias y las correlaciones debemos conocer sus
propiedades distribucionales. Recordemos que en el caso univariado, para llevar a cabo
inferencia sobre las autocorrelaciones, usamos la Fórmula de Barttlet considerando un número
de observaciones “grande”. En el caso multivariado existe una versión bivariada de esta
fórmula que enunciamos enseguida.
RESULTADO VII.4.- (FÓRMULA DE BARTTLET BIVARIADA). Si }{ tX es una serie de
tiempo bivariada (Gaussiana) con covarianzas tales que 1,2. , |)(| i,jhh
ij Entonces:
])()(2
1)()(
2
1)()(
)()()()()(-
)()()()()(-
)()()()([)(ˆ),(ˆ lim
21
2
22
2
12
2
111212
2122121112
2122121112
211222111212
jjjjkh
hjjhjjk
kjjkjjhn
hjkjhkjjkhnCOVj

Análisis de Series de Tiempo
139
Note que, al igual que el Resultado VII.2, la fórmula no asume independencia entre las
series {Xt1} y {Xt2}.
El siguiente resultado es un corolario de la fórmula de Barttlet. El supuesto adicional es
que una de las series sigue un proceso de Ruido Blanco.
RESULTADO VII.5.- Si }{ tX satisface las condiciones de la fórmula de Barttlet, y si {Xt1} o
{Xt2} es un proceso de Ruido Blanco y si 0)(12 h , entonces:
n
hnVar 1)(ˆ lim 12
Con lo anterior, podemos establecer la hipótesis: 0)(: 120 hH . Tal hipótesis
establece que las series están no correlacionadas. La prueba de hipótesis se puede llevar a cabo
con un intervalo de confianza usando aproximación Normal. Tal prueba consiste en verificar si
el valor cero se encuentra en el intervalo:
))(ˆ(96.1)(ˆ 1212 hVarh
si es así, no se rechaza H0 con un nivel de significancia del 5%.
VII.3. PROCESOS ARMA MULTIVARIADOS
Como en el caso univariado, definiremos un tipo de procesos estacionarios
multivariados que son muy usuales, los procesos ARMA multivariados. Como veremos, la
definición está basada en la definición de Ruido Blanco multivariado.
Definición VII.3.1. [Proceso ARMA(p,q) Multivariado].- }{ tX es un proceso
ARMA(p,q) multivariado si }{ tX es estacionario y si para cada t se cumple:
),0( donde , 1111 WNZZZZXXX tqtqttptptt
donde ,...,qj,...,pi ji 1 , y 1 , son matrices m x m.
Muchas veces usaremos la notación simplificada siguiente del modelo ARMA, usando
el operador B:
tt ZBXB )()(
donde p
p BBB 11)( y q
q BBB 11)(

Análisis de Series de Tiempo
140
Note que en la definición se asume 0 . Cuando es diferente de cero, entonces
}{ tX es un proceso ARMA(p,q) multivariado con media si }{ tX es un proceso
ARMA(p,q) multivariado.
Ejemplo VII.3.1. Sustituyendo p=1 y q=0 en la definición VII.3.1, obtenemos el proceso
AR(1) multivariado:
ttt ZXX 1 con ),0(WNZ t .
Como vimos en el ejemplo VII.1.1, podemos escribir tal proceso como proceso lineal:
0j
jt
j
t ZX
Tal representación sólo existe bajo la condición: 0zI 1 que talC zz .
El planteamiento anterior no es más que el concepto de causalidad. En seguida
exponemos formalmente tal concepto. Para modelos univariados definimos este concepto en la
sección III.6.
Definición VII.3.1. [Causalidad].- Un proceso ARMA(p,q) multivariado }{ tX es
causal o una función causal de }{ tZ , si existen matrices }{ j con componentes
absolutamente sumables, tales que:
. todopara 0
tZXj
jtjt
La Causalidad es equivalente a la condición: 0zI 1 que talC zz .
RESULTADO VII.6.- Las matrices }{ j de la definición de causalidad se encuentran
recursivamente de:
0 para 0
para 0
para 0
;
con
0,1,... ,
j
j
j
0
1
j
pj
qj
I
j
m
m
m
k
kjkjj

Análisis de Series de Tiempo
141
Ejemplo VII.3.2. Consideremos el modelo AR(1) multivariado del ejemplo VII.3.1.
Aplicando el resultado anterior, podemos verificar que existen las matrices }{ j
necesarias para expresar a }{ tX como proceso lineal y por lo tanto el proceso es causal.
El modelo es ttt ZXX 1 . Note que mj 0 para todo j y mj 0 para j > 1.
j
jjj
I
12211
2
102112
1011
0
Note que este resultado ya lo habíamos encontrado en el ejemplo VII.1.1 por otra vía.
NOTA1: Consideremos el modelo AR(1) bivariado con:
00
0 12
Podemos verificar que m
j 0 para j > 1 y por el resultado del ejemplo VII.3.2, se sigue que
mj 0 para j > 1. Sustituyendo }{ j en la expresión de proceso lineal, llegamos a que:
11
11110
0
tt
tttt
j
jtjt
ZZ
ZIZZZ
ZX
Observe que esta expresión corresponde a un modelo MA(1). Hemos partido de un modelo
AR(1) y llegamos a que tiene una representación alternativa como MA(1). Este ejemplo
muestra que no siempre es posible distinguir modelos ARMA multivariados de diferente
orden. Este fenómeno de no-distinción entre modelos se conoce como Dualidad. Muchos
autores evitan este problema enfocándose solo en modelos Autoregresivos. En el presente
trabajo, adoptaremos este enfoque.
VII.3.1. Función de Covarianzas de un proceso ARMA causal, )(h
Si suponemos causalidad en un modelo ARMA(p,q) m-variado sabemos, por la definición
VII.3.1, que: . todopara 0
tZXj
jtj
t donde las matrices }{ j son calculadas de

Análisis de Series de Tiempo
142
acuerdo al resultado VII.6. Entonces, por el resultado VII.1, la función de Covarianzas
podemos calcularla como:
0
')(j
jhjh
Cabe mencionar que esta expresión es fácil de aplicar cuando es “sencillo” encontrar
las matrices }{ j ; sin embargo, esto no siempre ocurre, por lo que se deben tener estrategias
alternativas para calcular la función de Covarianzas.
Una técnica alternativa para calcular la función de Covarianzas consiste, como en el
caso univariado, en resolver las ecuaciones multivariadas de Yule-Walker. El método consiste
en post-multiplicar ambos lados de la igualdad de la definición de proceso ARMA
multivariado dado en la definición VII.3.1 por '
jtX y tomar valor esperado. El resultado se
resume en la expresión siguiente (ecuaciones multivariadas):
,...2,1,0 , )()(
r
1
hrhhqrh
hr
p
r
r
Para el caso de un proceso AR(p) en donde I0 y mj 0 para j > 0, y haciendo
uso de la propiedad 1 de la función )(h , se tiene el sistema:
mp
mp
mp
mp
p
pp
pp
p
p
p
0)1()()1(
0)0()1()(
0)2()1()2(
0)1()0()1(
)()1()0(
1
1
1
1
1
Resolviendo las primeras p+1 ecuaciones tendremos la solución de )(),...,0( p . El
resto de ecuaciones nos permitirá obtener ),...2(),1( pp de forma recursiva.
VII.4. EL MEJOR PREDICTOR LINEAL
Sea )',....,,( 21 tmttt XXXX una serie de tiempo m-variada con vector promedio
ttXE )( y función de covarianzas dada por las matrices de orden m x m:
''
),(jiji XXEji

Análisis de Series de Tiempo
143
El problema de encontrar el mejor predictor lineal consiste en encontrar una
proyección de hnX en función de nXX ,...,1 . Es decir, en encontrar las matrices Aj tales que:
)()()(
ˆ
111121 XAXAXA
XPX
nnnnn
hnnhn
Las matrices tienen que cumplir la condición de ortogonalidad siguiente:
,...,niXXPX inhnnhn 1 , ˆ 1
Un caso especial de lo anterior surge cuando nos enfrentamos a una serie que tiene
como vector promedio al vector cero. En tal caso, el mejor predictor lineal de 1nX en función
de nXX ,...,1 , está dado por:
11211ˆ XXXX nnnnnnn
donde los coeficientes nj , j=1,…,n, son tales que '
11'
11ˆ inninn XXEXXE , i=1,…,n
(condición de ortogonalidad). Es decir, se tiene el sistema de ecuaciones:
,...,niinninjnn
j
nj 1 , )1,1()1,1(1
En el caso que )',....,,( 21 tmttt XXXX es estacionario con )(),( jiji , el
sistema de ecuaciones de predicción anterior se reduce a:
,...,niijin
j
nj 1 , )()(1
Los coeficientes }{ nj se obtienen recursivamente del sistema anterior. Tal
procedimiento es una versión multivariada del Algoritmo de Durbin-Levinson dado por
Whittle (1963). Las ecuaciones recursivas de Whittle también permiten obtener el Error
Cuadrado Medio de la predicción (Matrices de covarianzas). Ver [Brockwell y Davis (1991)].
Ejemplo VII.4.1. Para que quede claro qué coeficientes debemos calcular en el predictor,
supongamos un proceso bivariado estacionario con media cero y n=2. Estamos interesados en
predecir la siguiente observación, 3X . En este caso, el mejor predictor lineal estaría dado por:
12
11
)2(2221
1211
22
21
)1(2221
1211
32
31
12213
ˆ
ˆ
ˆ
X
X
aa
aa
X
X
aa
aa
X
X
XAXAX

Análisis de Series de Tiempo
144
Por lo que debemos calcular las matrices A1 y A2.
NOTA2: Al igual que el Algoritmo de Durbin-Levinson, el Algoritmo de Innovaciones
también tiene una versión multivariada que puede ser usada en predicción. Tal algoritmo es,
prácticamente, igual al univarido (descrito en capítulos anteriores), solo que ahora en lugar de
trabajar con escalares, se trabaja con matrices. Ver [Brockwell y Davis (1991)].
NOTA3: Aunque nuestro enfoque es meramente para modelos AR(p), existe toda una teoría
para modelos generales ARMA(p,q) multivariados. Para llevar a cabo la predicción en estos
modelos se usa el Algoritmo de Innovaciones multivariado. Ver [Lüthkepohl (1993)],
[Brockwell y Davis (1991)] o [Reinsel (1997)].
VII.5. MODELACIÓN Y PRONÓSTICO CON MODELOS AR MULTIVARIADOS
La modelación de series de tiempo multivariadas, como lo hicimos en series
univariadas, se lleva a cabo mediante métodos de estimación tanto preliminar (algoritmo de
Whittle o Burg multivariado) como optimizada (máxima verosimilitud).
VII.5.1. Estimación Preliminar de Whittle (Yule-Walker multivariado)
Si }{ tX es un proceso AR(p) multivariado causal definido por:
),0( donde , 11 WNZZXXX ttptptt
O bien,
),0( donde , 11 WNZZXXX ttptptt
Entonces podemos aplicar el método de Yule-Walker multivariado al proceso para
obtener una estimación preliminar. Es decir, post-multiplicamos por '
jtX para j=0,1,…,p, y
tomar el valor esperado. Obteniendo las ecuaciones:
,...,pijii
j
p
j
j
p
j
j
1 , )()(
)()0(
1
1
El procedimiento consiste en reemplazar las )( j por las )(ˆ j (estimadas) en las
últimas p ecuaciones y resolverlas simultáneamente para así encontrar los estimadores
pˆ,...,ˆ
1 . Luego, sustituirlos en la primera ecuación y encontramos la matriz de covarianzas
del ruido estimada, ˆ .

Análisis de Series de Tiempo
145
VII.5.2. Máxima Verosimilitud
Supongamos una serie }{ tX con vector promedio igual a cero. De los resultados de la
sección VII.4 y del hecho de que las innovaciones estiman un proceso de Ruido Blanco,
tenemos:
kjXXXXE mkkjj para 0ˆˆ'
Si además suponemos que }{ tX es un proceso Gaussiano (Normal), entonces la
correlación cero de las innovaciones jjj XXU ˆ , j=1,…,n, implica independencia.
También sabemos que las innovaciones tienen como matrices de covarianzas V0,…,Vn-1,
respectivamente. En consecuencia, la distribución conjunta de las jU no es más que el
producto de las distribuciones individuales:
n
j
jjj
n
j
nm
n
un
uVuV
fuufj
1
1
1
'
2/1
1j
1
2/
1j
1
2
1exp)2(
),...,(
Si suponemos que }{ tX sigue un proceso AR(p) multivariado (vector promedio cero)
con coeficientes las matrices },...,{ 1 p y Σ la matriz del Ruido Blanco, entonces
podemos expresar la verosimilitud de las observaciones nXX ,...,1 como:
n
j
jjj
n
j
nm UVUVL1
1
1
'
2/1
1j
1
2/
2
1exp)2(),(
donde jjj XXU ˆ , j=1,…,n. jX es calculado con el Algoritmo de Whittle de la sección
VII.4 descrito antes.
La maximización de la verosimilitud multivariada resulta más complicada que el caso
univariado porque incluye un gran número de parámetros. Para el caso que estamos estudiando
(procesos AR(p)), el Algoritmo de Whittle o de Burg multivariado (desarrollado por Jones
(1978)) dan buenas estimaciones preliminares. Las opciones de estos algoritmos en el software
S-PLUS las encontramos en las mismas funciones que utilizamos para el caso univariado. Es
decir, con las funciones ar.burg(x, aic=T, order.max=” ”) o ar.yw(x, aic=T, order.max=” “).
La selección del orden de un modelo Autorregresivo multivariado (valor de p) se basa
en la minimización del valor AICC, análogo al caso univariado:
2
)1(2),,...,(ln2
2
2
1pmnm
nmpmLAICC p
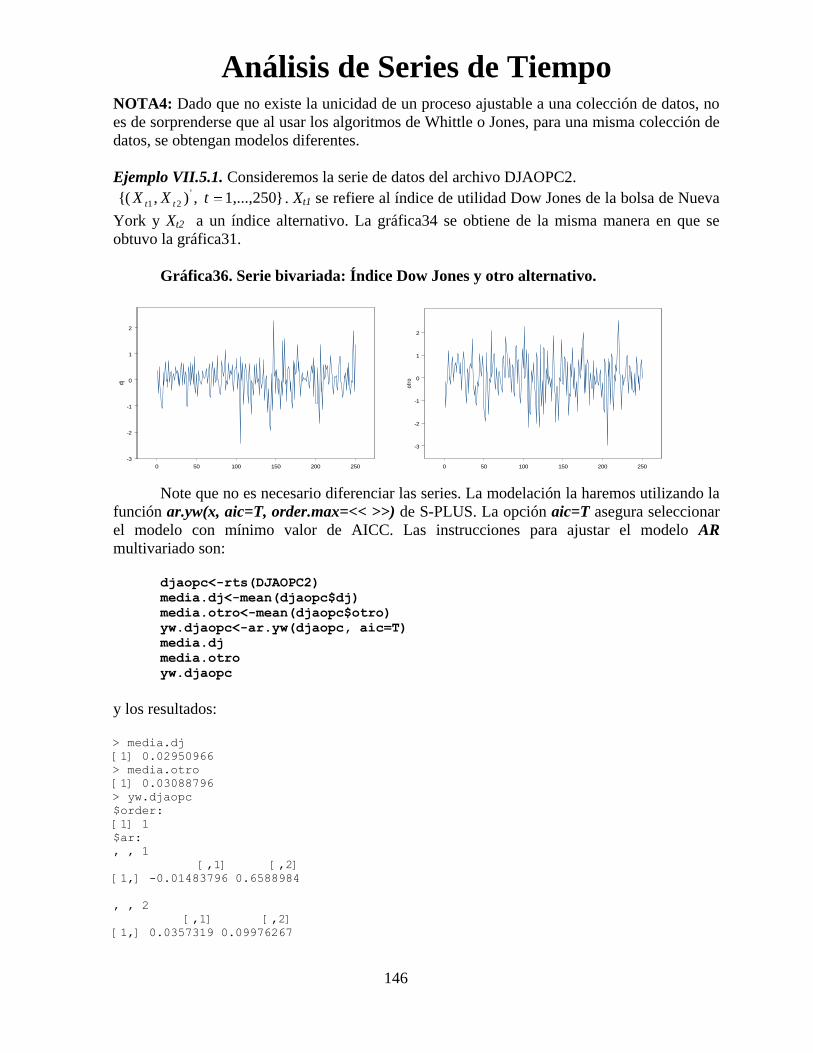
Análisis de Series de Tiempo
146
NOTA4: Dado que no existe la unicidad de un proceso ajustable a una colección de datos, no
es de sorprenderse que al usar los algoritmos de Whittle o Jones, para una misma colección de
datos, se obtengan modelos diferentes.
Ejemplo VII.5.1. Consideremos la serie de datos del archivo DJAOPC2.
}1,...,250 ,),{( '
21 tXX tt . Xt1 se refiere al índice de utilidad Dow Jones de la bolsa de Nueva
York y Xt2 a un índice alternativo. La gráfica34 se obtiene de la misma manera en que se
obtuvo la gráfica31.
Gráfica36. Serie bivariada: Índice Dow Jones y otro alternativo.
0 50 100 150 200 250
-3
-2
-1
0
1
2
dj
0 50 100 150 200 250
-3
-2
-1
0
1
2
otr
o
Note que no es necesario diferenciar las series. La modelación la haremos utilizando la
función ar.yw(x, aic=T, order.max=<< >>) de S-PLUS. La opción aic=T asegura seleccionar
el modelo con mínimo valor de AICC. Las instrucciones para ajustar el modelo AR
multivariado son:
djaopc<-rts(DJAOPC2)
media.dj<-mean(djaopc$dj)
media.otro<-mean(djaopc$otro)
yw.djaopc<-ar.yw(djaopc, aic=T)
media.dj
media.otro
yw.djaopc
y los resultados:
> media.dj
[1] 0.02950966
> media.otro
[1] 0.03088796
> yw.djaopc
$order:
[1] 1
$ar:
, , 1
[,1] [,2]
[1,] -0.01483796 0.6588984
, , 2
[,1] [,2]
[1,] 0.0357319 0.09976267

Análisis de Series de Tiempo
147
$var.pred:
[,1] [,2]
[1,] 0.37119901 0.02275335
[2,] 0.02275335 0.61140382
Explícitamente, el modelo ajustado es un AR(1) multivariado dado por:
6114.00227.0
0227.03712.0 ,
0
0
donde
0997.06589.00083.0
0357.00148.00288.0
099763.0658898.0
035732.0014838.0
008363.0
028844.0
0309.0
0295.0
099763.0658898.0
035732.0014838.0
0309.0
0295.0
2
1
22,11,12
12,11,11
2
1
2,1
1,1
2
1
2
1
2
1
2
1
WNZ
Z
ZXXX
ZXXX
Z
Z
X
X
X
X
Z
Z
X
X
X
X
t
t
tttt
tttt
t
t
t
t
t
t
t
t
t
t
t
t
De la matriz 1 podemos observar que el índice Dow Jones ayuda mucho en la
predicción del rendimiento del índice alternativo (0.6589); Mientras que el índice alternativo
no es muy significante en la predicción del Dow Jones (0.0357).
Ejemplo VII.5.2 Consideremos la serie de datos LS2.TXT. Esta serie la vimos en el
ejemplo VII.1).
Como vimos en el ejemplo VII.1, la serie es no-estacionaria, por lo que es necesario
diferenciar a distancia 1. Una vez diferenciada la serie (estacionaria) ya podemos ajustar un
modelo a los datos. Como en el ejemplo anterior, usaremos la misma función de S-PLUS para
ajustar el modelo autorregresivo a la serie diferenciada y corregida por la media con mínimo
AICC. Las instrucciones son:
vent.dif<-diff(LS2$ventas,1,1)
ind.dif<-diff(LS2$indicador,1,1)
ls2.dif<-cbind(vent.dif,ind.dif)
media.vent.dif<-mean(vent.dif)
media.ind.dif<-mean(ind.dif)
yw.ls2.dif<-ar.yw(ls2.dif, aic=T)
media.vent.dif
media.ind.dif
yw.ls2.dif
acf(yw.ls2.dif$resid)
Obteniendo:

Análisis de Series de Tiempo
148
> media.vent.dif
[1] 0.02275168
> media.ind.dif
[1] 0.4201342
> yw.ls2.dif
$order:
[1] 5
$ar:
, , 1
[,1] [,2]
[1,] -0.51704335 -0.01908753
[2,] -0.19195479 0.04683970
[3,] -0.07332958 4.67775106
[4,] -0.03176252 3.66434669
[5,] 0.02149335 1.30010366
, , 2
[,1] [,2]
[1,] 0.024091702 -0.050628599
[2,] -0.017620379 0.249683127
[3,] 0.010014648 0.206463397
[4,] -0.008762498 0.004438486
[5,] 0.011381958 0.029279621
$var.pred:
[,1] [,2]
[1,] 0.082490996 -0.002794969
[2,] -0.002794971 0.103457905
Las matrices del modelo autorregresivo son:
PHI(1) PHI(2) PHI(3)
-.517043 .024092 -.191955 -.017620 -.073332 .010014
-.019088 -.050621 .046840 .249683 4.677751 .206463
PHI(4) PHI(5)
-.031762 -.008763 .021493 .011382
3.664346 .004438 1.300103 .029280
El ajuste usando el Algoritmo de Burg da como resultado un modelo AR(8). Sin
embargo el valor del AICC es prácticamente el mismo que el obtenido por el Algoritmo de
Yule-Walker. Como mencionamos antes, no existe unicidad en el ajuste de modelos para los
mismos datos usando diferentes algoritmos.
La gráfica de la ACF y PACF de los residuales es resultado de la línea:
acf(yw.ls2.dif$resid)
La gráfica muestra que el ajuste es “bueno”, pues todas las correlaciones caen dentro
de las bandas de confianza n/96.1 , n=150.

Análisis de Series de Tiempo
149
Gráfica37. ACF y PACF de los residuales después de ajustar un modelo
multivariado AR(5) a la serie diferenciada de ventas.
vent.dif
ACF
0 5 10 15
-0.2
0.0
0.2
0.4
0.6
0.8
1.0
vent.dif and ind.dif
0 5 10 15
-0.1
0.0
0.1
ind.dif and vent.dif
Lag
ACF
-15 -10 -5 0
-0.1
5-0
.05
0.0
0.05
0.10
0.15
ind.dif
Lag0 5 10 15
-0.2
0.0
0.2
0.4
0.6
0.8
1.0
Multivariate Series : yw.ls2.dif$resid
VII.5.3. Pronóstico con modelos Autoregresivos Multivariados
Una vez que hemos ajustado un modelo multivariado a nuestros datos, podemos llevar
a cabo la predicción de observaciones futuras (pronóstico) usando el mejor predictor lineal.
Supongamos una serie }{ tX estacionaria con vector promedio y función de Covarianzas
)(h . El Algoritmo de Whittle determina las matrices coeficiente }{ nj en la expresión:
)()()(ˆ 11211 XXXX nnnnnnn
Si }{ tX es un proceso AR(p) causal, la expresión anterior se reduce a:
pnpnnn XXXX 11211ˆ
Las }{ j para j > p son cero porque el modelo requiere, por definición, solo de p
matrices .
Para verificar que esto es suficiente, basta con observar que el error de predicción
11121111 ˆ npnpnnnnn ZXXXXXX
es ortogonal a nXX ,...,1 , es decir, se cumple la condición de ortogonalidad pedida en el
algoritmo de Whittle. De esta forma, es claro que la matriz de covarianzas del error de
predicción es Σ:

Análisis de Series de Tiempo
150
'11
'
1111 ˆˆ nnnnnn ZZEXXXXE
El cálculo de la predicción a distancia h teniendo n observaciones, nXX ,...,1 , consiste
en aplicar el mismo proceso recursivamente. Esto es, se obtiene el predictor de knX para
k=1,…,h. Con esto obtenemos:
phnphnhnhn XXXX 1211ˆ
En este caso, el ECM se calcula usando el hecho de que }{ tX se puede expresar como
proceso lineal. Es decir:
0j
jhnjhn ZX
donde las matrices }{ j se calculan usando el resultado VII.4 con q=0.
Aplicando el predictor lineal a hnX expresado como proceso lineal, encontramos que
para pn :
hj
jhnj
j
jhnnjhnn ZZPXP0
Para calcular el error de predicción a distancia h, hacemos la resta de las expresiones
anteriores:
1
00
h
j
jhnj
hj
jhnj
j
jhnjhnnhn ZZZXPX
Con esta última expresión resulta más fácil calcular el Error Cuadrado Medio de la
predicción a distancia h. Además, sabemos que }{ tZ forma un proceso de Ruido Blanco, por
lo que las observaciones están no-correlacionadas:
'
11
'
00
'
1111
'
00
'1
0
1
0
'
),(),(
hh
hnnhhnhn
h
j
jhnj
h
j
jhnjhnnhnhnnhn
ZZCOVZZCOV
ZZEXPXXPXE
Es decir, el Error Cuadrado Medio está dado por:
1
0
''h
j
jjhnnhnhnnhn XPXXPXE

Análisis de Series de Tiempo
151
Ejemplo VII.5.3. Consideremos, nuevamente, la serie LS2.TXT.
Recordemos que la serie fue diferenciada a distancia 1. Por otra parte, supongamos que
el modelo ajustado a la serie }1,...,149 , { tY t en el ejemplo VII.5.2 es correcto. Es decir:
5
51ˆˆ)(
1,...,149 , )'420.0 , 0228.0()1(
donde
)ˆ,0(}{ , )(
BBIB
tYBX
WNZZXB
tt
ttt
El modelo ajustado fue un AR(5). Las matrices ˆ,ˆ,...,ˆ51 fueron calculadas en el
ejemplo VII.5.2. Podemos predecir las siguientes dos observaciones de }{ tX en base a las
expresiones obtenidas en la sección VII.5.2, h=1,2:
816.0
027.0ˆˆ
217.0
163.0ˆ
14651501151
14551491150
XXX
XXX
Note que en la predicción de 151X usamos el valor predicho de 150X .
La matriz de covarianzas Σ, encontrada en el ejemplo VII.5.2, es:
$var.pred:
[,1] [,2]
[1,] 0.082490996 -0.002794969
[2,] -0.002794971 0.103457905
Así, los correspondientes Errores Cuadrados Medios están dados por:
0.0950.002-
0.002-0.096
2
0.103450.00279-
0.00279-0.0825
1
'
11
'
11
'
00
'12
0
2
'
00
'11
0
1
j
j
j
j
j
j
ECMh
ECMh
El procedimiento de pronóstico con el software ITSM consiste en: una vez ajustado el
modelo apropiado a la colección de datos, seleccionar la secuencia Forecasting>AR Model.

Análisis de Series de Tiempo
152
Aparecerá una ventana con diferentes opciones, entre ellas, el número de observaciones
posteriores que desea calcular, si desea calcular las predicciones para los datos
diferenciados o para los datos originales y si desea graficar bandas de confianza para los
valores predichos. Cuando dé clic en OK aparecerá la gráfica de los datos originales y los
predichos, para ver los valores calculados dé clic en la gráfica con el botón derecho del ratón
y elija la opción INFO.

Análisis de Series de Tiempo
153
CAPITULO VIII. MODELOS ESPACIO-ESTADO
Los modelos de espacio-estado, junto con las recursiones de Kalman, ofrecen una
alternativa del análisis de series de tiempo. Estos modelos han tenido un gran impacto en
muchas áreas relacionadas con las series de tiempo, como lo son el control de sistemas
lineales.
El análisis de estos modelos se basa, principalmente, en la representación de los
componentes de la serie (tendencia, estacionaridad y ruido) en dos ecuaciones, una de ellas
dada por las observaciones y la otra por el proceso que forma.
Veremos que los modelos ARMA(p,q) son un caso particular de los modelos espacio-
estado. Esto significa que el análisis de modelos espacio-estado puede incluir modelos más
generales que los ARMA(p,q) que analizamos en capítulos anteriores.
VIII.1. REPRESENTACIÓN DE LOS MODELOS ESPACIO-ESTADO
Consideremos la serie de tiempo multivariada }1,2,... , { tY t . El modelo de espacio-
estado para esta serie consiste en dos ecuaciones. La primera expresa a }{ tY en función de
una variable estado }{ tX . La segunda ecuación determina el estado 1tX en el tiempo t+1 en
términos de los estados previos tX . Algebraicamente, el modelo general espacio-estado está
dado por:
s,tVWE
v x vF
w x vG
QWNV
RWNW
vX
wY
tVXFX
tWXGY
st
t
t
tt
tt
t
t
tttt
tttt
0)(
matrices de secuencia :}{
matrices de secuencia :}{
}){,0(
}){,0(
dimensión de variable:
dimensión de datos de serie :
:donde
estado) de(Ecuación 1,2,... ,
n)observació de(Ecuación 1,2,... ,
'
1
En muchos casos particulares, como en los modelos ARMA(p,q), se asume que las
matrices Gt, Ft, Rt y Qt no dependen del tiempo en que se observan. En ese caso, no es
necesario el subíndice t.
Definición VIII.1.1. [Representación espacio-estado].- Una serie de tiempo
}1,2,... , { tY t tiene una representación espacio-estado si existe un modelo espacio-estado
para la serie dado por las ecuaciones generales de observación y estado.

Análisis de Series de Tiempo
154
Ejemplo VIII.1.1. Consideremos el modelo AR(1) causal univariado dado por: ttt ZYY 1
con ),0(}{ 2WNZ t . La representación espacio-estado para este modelo es sencilla.
Consideremos la secuencia de variables estado:
ttt ZXX 1 (Ecuación de estado)
Entonces, la ecuación de observación está dada por:
tt XY (Ecuación de observación)
Note que, para este modelo, Gt=1, Wt=0, tF y 2
tQ .
Ejemplo VIII.1.2. Consideremos el modelo ARMA(1,1) causal univariado dado por:
tttt ZZYY 11 con ),0(}{ 2WNZ t . Veamos si se puede representar como un
modelo espacio-estado.
Consideremos la variable de estado }{ tX dada por:
1
1
1
0
0
10
tt
t
t
t
ZX
X
X
X (Ecuación de estado)
Entonces, si planteamos la ecuación de observación como:
t
t
tX
XY
11 (Ecuación de observación)
sustituyendo la variable de estado y desarrollando, obtenemos:
ttt
tt
t
tt
t
t
t
t
ZXX
ZX
X
ZX
X
X
XY
11
1
1
1
211
0
0
1011
En conclusión, el modelo ARMA(1,1) se puede representar como un modelo espacio-
estado.
Ejemplo VIII.1.3. Consideremos el modelo MA(1) causal univariado dado por: ttt ZYY 1
con ),0(}{ 2WNZ t . La representación de este modelo en forma espacio-estado consiste en
considerar la ecuación de estado:

Análisis de Series de Tiempo
155
11 0
1
t
t
t
t
Z
Z
X
X (Ecuación de estado)
Si consideramos la ecuación de observación siguiente:
t
t
tX
XY
101 (Ecuación de observación)
sustituyendo, llegamos a:
tt
t
tt
t
t
t
t
t
ZZ
Z
ZZ
Z
Z
X
XY
1
11101
0
10101
La igualdad permite concluir que el modelo MA(1) tiene una representación como
modelo espacio-estado.
Más adelante veremos la representación de modelos generales ARIMA como modelos
espacio-estado.
NOTA1: La representación de los modelos ARMA(p,q) como modelos espacio-estado no es
única. El lector puede comprobarlo proponiendo diferentes matrices en las ecuaciones
generales del modelo espacio-estado en los ejemplos anteriores.
VIII.2. EL MODELO ESTRUCTURAL BÁSICO
El concepto de modelo estructural estriba en que, en su definición, sus componentes
pueden ser modelados mediante un proceso propio. Un ejemplo de estos modelos es nuestro
modelo clásico de series de tiempo, el cual está definido por tres componentes, que son
tendencia, estacionaridad y ruido. Considerar como deterministicos los componentes de
tendencia y estacionaridad, en la descomposición del modelo, restringe la aplicación de dichos
modelos. Así, se justifica que permitiremos que los componentes mencionados se modelen
mediante un proceso aleatorio propio.
Para entrar en materia de lo que es un modelo estructural, consideremos el siguiente
ejemplo.
Ejemplo VIII.2.1. Consideremos el proceso de Caminata Aleatoria con un componente de
ruido, dado por:
)WN(0,}{ , V
donde
)WN(0,}{ ,
2
Vt1
2
w
ttt
tttt
VMM
WWMY

Análisis de Series de Tiempo
156
Note que haciendo analogía con la representación espacio-estado, en el modelo anterior
F=1 y G=1;
Veamos que sucede con las diferenciaciones de la caminata aleatoria, es decir con:
11
1111
)(
ttt
tttttttttt
WWV
WWMMWMWMYD
Podemos ver que las diferenciaciones son una suma de ruidos y por propiedad de este
proceso, también es un proceso de ruido y, además, estacionario. Tal proceso (de las
diferenciaciones) tiene como función de autocovarianzas y autocorrelación dadas por:
2 para 0
1 para 2)(
2 para 0
1 para
0 para 2
)(
22
2
2
22
h
hh
h
h
h
h
VW
W
D
W
VW
D
Para llegar a las expresiones anteriores basta aplicar la definición de función de
autocovarianzas y el hecho de que las series }{ tW y }{ tV son no correlacionadas para todo t.
Esto es:
2
W
111
2
W
2
V
2
W
2
W
2
V
111111
1111
)(),(
1
2
)()()(),(
),()(
ttttttt
ttttttttt
hththttttD
WCovWWVWWVCov
h
WCovWCovVCovWWVWWVCov
oh
WWVWWVCovh
Dado que {Dt} está correlacionado solo a distancia uno, podemos concluir que forma
un proceso MA(1). En consecuencia, {Yt} forma un proceso ARIMA(0,1,1).
El modelo anterior lo podemos extender agregando un componente de tendencia. Esto
es, considerar el modelo:

Análisis de Series de Tiempo
157
)WN(0,}{ , 2
wtttt WWMY
)WN(0,}{ ,
)WN(0,}{ , V
donde
2
U11
2
V1-t11
tttt
tttt
UUBB
VBMM
Para expresar el modelo anterior como modelo espacio-estado, consideremos el
vector )'( ttt BMX . Entonces:
ttt WXY 01 (Ecuación de observación)
donde
1
1
1
11
10
11
t
t
t
t
t
tt
U
V
B
M
B
MX (Ecuación de estado)
Suponiendo que las variables involucradas en esta representación están no
correlacionadas, las ecuaciones anteriores constituyen la representación espacio-estado de la
serie {Yt}. Recordemos que la serie {Yt} representa datos con componente de tendencia
aleatorio más un componente de ruido.
Ejemplo VIII.2.2. Hemos representado un modelo con tendencia aleatoria en forma de modelo
espacio-estado. El paso siguiente es llevar a cabo esta representación, pero ahora de un modelo
con componente estacional aleatorio. De la definición de estacionalidad de periodo d, se
cumple st=st+d y s1+…+sd=0.
El modelo en cuestión es:
211
2
w
donde
)WN(0,}{ ,
dtttt
tttt
ssss
WWsY
Sustituyendo recursivamente el componente de estacionalidad, se puede llegar a la
expresión:
1,2,... 21 tSYYY tdttt
Para encontrar la representación espacio-estado de {Yt} introduciremos el vector tX
siguiente: )',...,,( 21 dtttt YYYX . Así:

Análisis de Series de Tiempo
158
ttt WXY 001 (Ecuación de observación)
donde
0
0
0
0 1 0 0
0 0 10
0 0 01
1 1- 11 1
1
t
tt
S
XX (Ecuación de estado)
Por tanto, el modelo clásico con componente estacional aleatorio, también se puede
representar como modelo espacio-estado.
La pregunta que surge en este momento es ¿se puede representar como modelo
espacio-estado el modelo estructural básico? Es decir, ¿podemos representar el modelo clásico
como modelo espacio-estado si incluimos componentes de tendencia y estacionalidad
aleatorios? La respuesta es sí. Solo basta “agrupar” las ecuaciones de estado de los ejemplos
anteriores (VIII.2.1 y VIII.2.2). Para más detalles ver [Brockwell y Davis (2002) pp. 267].
VIII.3. REPRESENTACIÓN ESPACIO-ESTADO DE MODELOS ARMA
En ejemplos anteriores representamos modelos ARMA específicos como el AR(1), el
MA(1) y el ARMA(1,1). En esta sección generalizaremos la representación para el modelo
general ARMA(p,q).
Como mencionamos en la NOTA1, la representación espacio-estado no es única. Aquí
presentamos una de ellas para un proceso ARMA(p,q) causal. Consideremos el proceso
ARMA(p,q) causal definido por:
tt ZBYB )()( donde ),0(}{ 2WNZ t
Sean r=max(p,q+1); j =0 para j > p; j =0 para j > q; y θ0=1. Si {Xt} sigue un proceso
causal AR(p) dado por tt ZXB)( , entonces tt XBY )( . Esta conclusión se recoge del
hecho de que: tttt ZBXBBXBBYB )()()()()()( . Es decir, si sustituimos
tt XBY )( , se satisface el modelo ARMA(p,q) original.
En consecuencia, apoyándonos del ejemplo VIII.1.2 [representación para el modelo
ARMA(1,1)], tenemos la representación espacio-estado del modelo ARMA(p,q):

Análisis de Series de Tiempo
159
trrt XY 121 (Ecuación de observación)
donde
1
1
1
1211
1
2
1
0
0
0
1000
0100
0010
tt
t
rt
rt
rrrt
t
rt
rt
t
ZX
X
X
X
X
X
X
X
X
(Ecuación de estado)
Se puede probar que usando esta expresión, la representación del modelo ARMA(1,1)
es la misma que encontramos en el ejemplo VII.1.2.
Existe una forma general para representar a los modelos ARIMA(p,d,q) como modelos
espacio-estado. Está basada, esencialmente, en el hecho de que la serie diferenciada a distancia
d sigue un proceso ARMA(p,q), la cual ya expresamos arriba. Para más detalles, ver
[Brockwell y Davis (2002) pp.269-271].
VIII.4. RECURSIONES KALMAN
Los principales problemas que enfrentan los modelos espacio-estado definidos en la
sección VIII.1 son tres. Todos ellos consisten en encontrar el mejor predictor lineal del vector
de estado tX en términos de las observaciones ,..., 21 YY y un vector aleatorio 0Y ortogonal a
tV y tW . Las estimaciones de interés de tX son las siguientes:
Predicción: tt XP 1
Filtrado: tt XP
Suavización: tn XP , n > t.
Los tres problemas pueden ser resueltos usando, apropiadamente, un conjunto de
recursiones. Tales recursiones se conocen como recursiones de Kalman.
Definición VIII.1.1. [Mejor predictor lineal].- Para el vector aleatorio
)',...,( 1 vXXX se define el mejor predictor lineal como:
))'(),...,(()( 1 Vttt XPXPXP
donde ),...,,|()( 10 tiit YYYXPXP es el mejor predictor lineal de iX en términos de todos
los componentes tYYY ,...,, 10 .
El mejor predictor lineal de la definición tiene, bajo ciertas restricciones, las siguientes
propiedades:

Análisis de Series de Tiempo
160
1. )()( XAPXAP tt
2. )()()( VPXPVXP ttt
3.
)'( de dageneraliza inversa es )]'([ .)]'()['(
donde
)|(
YYEYYEYYEYXEM
YMYXP
Con la definición y las propiedades, enunciamos en seguida el algoritmo de predicción
de Kalman.
RESULTADO VIII.1.- [Predicción de Kalman].- Considere el modelo espacio-estado de la
sección VIII.1. Es decir, supongamos que tttt WXGY con tttt VXFX 1 donde
}){,0( tt RWNW y }){,0( tt QWNV . Entonces los predictores a un paso )(ˆ1 ttt XPX y
sus matrices de error ])'ˆ)(ˆ[( ttttt XXXXE son únicos y están determinados por la
condición inicial:
)|(ˆ 011 YXPX con ])'ˆ)(ˆ[( 11111 XXXXE
y las recursiones para t=1,…
'
'
''
1
1 )ˆ(ˆˆ
tttt
ttttt
tttttttt
tttttttt
GF
RGG
donde
QFF
XGYXFX
t es la inversa generalizada de t .
Demostración.
Para llevar a cabo la demostración haremos uso del concepto de innovaciones, tI , con 01 YI
y
1,2,... )ˆ(ˆ1 tWXXGXGYYPYI ttttttttttt
Por otra parte, se tiene la igualdad )|()()( 1 ttt IPPP . Usando las propiedades 1, 2 y 3
enunciadas arriba, encontramos que:

Análisis de Series de Tiempo
161
'
ttt
'
t
'tttt
't
'
t
'ttttt
'ttt
ttttttt
ttttt
tttttttt
-'tt
'ttttttt
ttttt
GΩF
G)XX)(X(EFWG)XX(VXFEIXEΘ
XGYXF
IXF
IVPXPF
]II]E[IXE[MIMVXFP
IXPXPX
]ˆ[ˆ][
donde
)ˆ(ˆ
ˆ
)()(
donde )(
)|()(ˆ
1
11
11
1111
tttt
tttttttt
tttttttt
RGG
WWEGXXXXEG
WGXXWXXGE
'
''
''''ttt
)(])'ˆ)(ˆ[(
)ˆ()ˆ(]IIE[
Para encontrar el error cuadrado medio para t > 1, basta con aplicar la definición de la matriz
de error. Esto es:
''
''''''
'''''''
''
'
11'
11
'
11111
ˆˆ
ˆˆ
ˆˆ
ˆˆ
ˆˆ
ttttttt
ttttttttttttt
tttttttttttttttt
tttttttttttttttt
tttt
ttttt
QFF
FXXEFVVEFXXEF
IFXIXFEVFXVXFE
IXFIXFEVXFVXFE
XXEXXE
XXXXE
Las matrices tt y son las mismas que se definieron en el resultado VIII.1.
///
Para llevar a cabo la predicción a distancia h usaremos la predicción de Kalman a un
paso. Como veremos, la predicción consiste en aplicar recursivamente las propiedades del
mejor predictor lineal y la ecuación de estado definida en la representación espacio-estado
original.
)(
)(
)(
1121
221
2221
11111
111
ttththt
htththt
hththttht
htththtthttht
hththtthtt
XPFFF
XPFF
VXFPF
XPFVPXPF
VXFPXP

Análisis de Series de Tiempo
162
)ˆ(ˆ121 tttttttthththtt XGYXFFFFXP
También se tiene la predicción para la variable de observación:
htthtththtthtt XPGWXGPYP
El paso siguiente es encontrar la matriz de error de predicción a distancia h.
'11
'
1
'11111
'11111111
')(
1111
11111
hthththtththtththt
hthtththththtththt
htththtthth
t
hthtththt
htthththththttht
VVEFXPXXPXEF
VXPXFVXPXFE
XPXXPXE
VXPXF
XPFVXFXPX
1
'
1
)1(
1
)( htht
h
tht
h
t QFF
El proceso se aplica recursivamente para h=2,3,… partiendo de la igualdad inicial
1
)1(
tt . Además, para la variable de observación se tiene:
'''
'
')(
hthththtththtththt
hthtththththtththt
htththtthth
t
hthtththt
htthththththttht
WWEGXPXXPXEG
WXPXGWXPXGE
YPYYPYE
WXPXG
XPGWXGYPY
htht
h
tht
h
t RGG ')()(
Con esto terminamos la solución del problema de predicción de Kalman.
RESULTADO VIII.2.- [Filtrado de Kalman].- Considere el modelo espacio-estado de la
sección VIII.1. Es decir, supongamos que tttt WXGY con tttt VXFX 1 donde
}){,0( tt RWNW y }){,0( tt QWNV . Entonces las estimaciones filtradas )(/ tttt XPX y
sus matrices de error ])')([( /// tttttttt XXXXE están determinadas por la relación:

Análisis de Series de Tiempo
163
)ˆ()( '
1/ tttttttttt XGYGXPX
con
''
/ tttttttt GG
t , la inversa generalizada de t , y t se calculan como en la predicción de Kalman.
Demostración.
La demostración consiste en usar, nuevamente, el concepto de innovaciones, tI , con 01 YI
1,2,... )ˆ(ˆ1 tWXXGXGYYPYI ttttttttttt
También consideraremos la igualdad )|()()( 1 ttt IPPP . De esta forma:
ttt
ttttt
tttttt
tttttt
-'tt
'tt
ttt
tttt
tttt
G
GXXXE
WGXXXE
WXXGXE
IIEIXEM
IMXP
IXPXP
XPX
'
''
'''
'
1
1
/
)ˆ(
)ˆ(
)ˆ(
][][
donde
)(
)|()(
)(
Para encontrar la expresión de la matriz de error partimos de:
tttt
tttttttttt
tttttttttt
IMXPX
XPXPXPXXPX
XPXPIMIMXPXP
&
11
11

Análisis de Series de Tiempo
164
''
/
''
/
''
/
'
/
'''
'
'
11
'][
tttttttt
ttttttt
ttttttttt
tttt
tttttttt
tttttttt
ttttttt
GG
GG
GG
MIIME
MIIMEXPXXPXE
IMXPXIMXPXE
XPXXPXE
De esta forma queda demostrada la proposición del filtrado de Kalman.
///
Por último, presentaremos la técnica de suavización. El concepto de suavización radica
en sustituir observaciones aberrantes en un conjunto de datos por otra estimación “suave”
basada en las n observaciones.
RESULTADO VIII.3 [Suavización de Kalman].- Considere el modelo espacio-estado de la
sección VIII.1. Es decir, supongamos que tttt WXGY con tttt VXFX 1 donde
}){,0( tt RWNW y }){,0( tt QWNV . Entonces las estimaciones suavizadas )(/ tnnt XPX
y sus matrices de error ])')([( /// nttnttnt XXXXE están determinadas, para un t fijo,
por las recursiones, las cuales pueden resolverse sucesivamente para n=t, t+1,…:
)ˆ()( '
,1/ tnnnnnttnnt XGYGXPX
con
'
,
'
,1//
'
,1,
ntnnnntntnt
ttnnntnt
GG
GF
y las condiciones iniciales
ttttt
ttt XXP
1/,
1ˆ
t , la inversa generalizada de t , y t se calculan como en la predicción de Kalman.
Demostración.
Tenemos las siguientes igualdades:
1,2,... )ˆ(ˆ1 tWXXGXGYYPYI ttttttttttt y )|()()( 1 ttt IPPP

Análisis de Series de Tiempo
165
Así,
'
,
'
,
''
'''
'
1
1
/
ˆˆ
con
)ˆ(
)ˆ(
)ˆ(
][][
donde
)(
)|()(
)(
nnttnt
ttnt
nnnnt
nnnnnt
nnnnnt
-'nn
'nt
ntn
nttn
tnnt
XXXXE
G
GXXXE
WGXXXE
WXXGXE
IIEIXEM
IMXP
IXPXP
XPX
Para encontrar la segunda expresión de la estimación de suavización partimos de la ecuación
de estado y de la expresión del predictor de Kalman. Esto es:
nnnnnnnnn
nnnnnn
nnnn
VIXXFXX
IXFX
VXFX
ˆˆ
ˆˆ
&
11
1
1
'
,1,
'
,
'
,
''
,
'
,
'''
''''
'''
'
'
111,
)(
0)(0)(
ˆ )(ˆ
)(ˆˆˆˆ
))ˆ((ˆˆˆ
)ˆ(ˆ
ˆˆ
nnnnntnt
nnnntnnt
nnnnnntnnt
nttnnntt
nnnnnttnnntt
nnnnnnnttnnntt
nnnnnnntt
nnttnt
GF
GF
GF
VXXEWXXE
GXXXXEFXXXXE
VWXXGXXEFXXXXE
VIXXFXXE
XXXXE
Solo nos resta encontrar la expresión para la matriz de error. Para ello utilizamos la expresión:

Análisis de Series de Tiempo
166
'
,
'
,1//
'
,
'
,1/
'
,
'
,1/
'
1/
'''
11
'
11
'
/
1
1
'][
ntnnnntntnt
ntnnnntnt
ntnnnnnntnt
nnnt
nntnttnt
ntntntnt
tnttntnt
ntnttnt
ntntn
GG
GG
GG
MIIME
MIIMEXPXXPXE
IMXPXIMXPXE
XPXXPXE
IMXPXXPX
MIXPXP
Así, queda demostrado el resultado de suavización de Kalman.
///
El siguiente ejemplo ilustra la forma iterativa en que funciona la suavización de
Kalman. Como veremos, no solo haremos uso del resultado VIII.3, sino, en general, de los tres
resultados de las recursiones Kalman.
Ejemplo VIII.4.1. Consideremos el modelo AR(1). Supongamos 5 observaciones y1, y2, y3, y4
y y5 y suavizaremos la observación 2.
El modelo espacio-estado para este proceso, como vimos en el ejemplo VIII.1.1, está
dado por:
,1 ttt
tt
ZXX
XY
Con ),0(}{ 2WNZ t
Pero dado que no contamos con “información completa”, es decir, no utilizaremos la
observación 2, planteamos el modelo:
ttt
tttt
ZXX
WXGY
1
***
Note que, de acuerdo a la representación espacio-estado, tenemos que:

Análisis de Series de Tiempo
167
2 si 1
2 si 0
2 si 0
2 si 1
*
2
*
t
tR
Q
t
tG
F
t
t
t
t
Partimos de las condiciones iniciales:
0ˆ110 XXP , )1/()0()( 22
111 XXE
Así,
, ],[
,1 ,00
11
,1
,1
222
33333
222
3333
222
2
1
2222223
22222
2
2222
2
2
222
2
22
1
1
1111112
2
2
111112
2
1111
RGGGF
QFF
RGGGF
QFF
RGGGF
)1/(
)1/(0)1/(
)1/()/(
0
0
0][][
]0[][
22
5|2
2222
4,24
1
444,23|24|2
22222422
3,23
1
333,22|23|2
22
2,22
1
222,21|22|2
2
2,21|2
5,2
2
3
1
3333,24,2
22
2
1
2222,23,2
2
22,2
GG
GG
GG
GF
GF
Nos resta calcular la suavización de la observación 2.

Análisis de Series de Tiempo
168
)1/()ˆ(
)1/(0)1/()ˆ(
)1/()/()0()ˆ(
0)ˆ(
)0(0)ˆ(
2
31555
1
555,22425
2
31
2
31444
1
444,22324
2
31
222
3
2
1333
1
333,22223
11222
1
222,22122
11111
1
111,22021
YYXGYGXPXP
YYYYXGYGXPXP
YYYYXGYGXPXP
YYXGYGXPXP
YYXGYGXPXP
En resumen, el valor suavizado de la observación dos está dado por:
)1/( 2
3125 YYXP
Con correspondiente error cuadrado medio:
)1/( 22
5|2
VIII.5. EL ALGORITMO EM
El algoritmo de Esperanza-Maximización (EM), propuesto por [Dempster, Laird y
Rubin (1977)] es un procedimiento iterativo útil para calcular estimadores de máxima
verosimilitud cuando contamos sólo con una parte disponible de la colección de datos, por
ejemplo, cuando existen datos perdidos. La construcción y convergencia del algoritmo se
pueden consultar en [Wu (1983)].
Denotemos por Y al vector de datos observados, por X al vector de datos no-
observados y a XYW como el vector de datos “completos”. A manera de analogía con
los modelos espacio-estado, podemos decir que Y consiste de los vectores observados
nYY ,...,1 y X de los vectores de estado (no observables) nXX ,...,1 . Los datos X pueden
considerarse como una variable aleatoria cuya distribución de probabilidad depende de los
parámetros θ que deseamos estimar y de los datos observados Y . Dado que W depende de
X , es a su vez, una variable aleatoria.
Cada iteración del algoritmo EM consiste en dos pasos: E y M. E se refiere a obtener la
esperanza ]|),;([)( YYXlE i . Tomar el valor esperado se justifica en el sentido de que existen
datos no observados, X , por lo que se deben considerar todos los posibles valores de X ,
ponderados según su probabilidad; y M se refiere a la maximización de la verosimilitud del
parámetro θ.
En general, el algoritmo EM repite la pareja de pasos siguientes en la iteración (i+1)
hasta obtener convergencia, partiendo de que )(i denota el valor estimado de θ en la iteración
i.

Análisis de Series de Tiempo
169
Paso-E. Calcular )|( )(iQ utilizando los datos observados Y . Esto es, calcular:
YYXlEQ i
i |),;()|( )(
)(
donde:
);,(ln),;( θyxfyxl ;
YE i |)( denota la esperanza condicional relativa a la densidad condicional
);(
);,();|(
)(
)(
)(
i
i
i
yf
yxfyxf .
Paso-M. Maximizar )|( )(iQ con respecto a θ.
Note que al maximizar el logaritmo de la distribución, se está maximizando la
verosimilitud.
Observemos que:
YldxYxfYxf
YfdxYxfYxf
dxyxfYfdxyxfYxf
dxYxfYfYxf
dxYxfYxfYxfYxl
YYxlEQ
yfyxfyxfyf
yxfyxf
i
i
ii
i
ii
i
iii
i
i
i
i
;);|();|(ln
)1();(ln);|();|(ln
);|();(ln);|();|(ln
);|();(ln);|(ln
);|();,(ln);|(),;(
|),;()|(
);(ln);|(ln);,(ln);(
);,();|(
)(
)(
)()(
)(
)()(
)(
)()()(
)(
)(
)(
)(
Derivando la función Q con respecto a θ, encontramos que:
);();|();|(
);|(
;);|();|(ln)|(
')(
)()('
YldxYxfYxf
Yxf
YldxYxfYxfQ
i
ii
Si reemplazamos por )1(i y si i (recordemos que el proceso es convergente),
tenemos que )1()(ˆ ii y 0)|( )()1(' iiQ . Esto es,

Análisis de Series de Tiempo
170
0);ˆ(
0);ˆ()1(
0);ˆ()ˆ;|(
0);ˆ()ˆ;|(
0);ˆ();|();|(
)ˆ;|(
)|(
'
'
'
'
')(
)1(
)()1('
Yl
Yl
YldxYxf
YldxYxf
YldxYxfYxf
Yxf
Q i
i
ii
La igualdad anterior muestra que si )(i converge a ˆ , entonces ˆ es una solución de
la ecuación de verosimilitud 0);ˆ(' Yl .
Como mencionamos al inicio de esta sección, el algoritmo EM es útil cuando la
colección de datos es incompleta (datos perdidos). A continuación desarrollamos el método de
estimación.
Supongamos que la colección de datos comprende nYY ,...,1 , de los cuales r son
observados y n-r son perdidos. Definamos )',...,( 1 iri YYY como el vector de datos observados
y )',...,( ,1 rnjj XXX como el vector de datos perdidos. Por otra parte, supongamos que
)'','( YXW se distribuye Normal( ,0 ), donde Σ depende del parámetro θ. Es decir, el
logaritmo de la verosimilitud de los datos completos (W ) está dada por:
WWn
Wl
WWWfn
1
1
)2/1(2/
´2
1)ln(
2
1)2ln(
2);(
´2
1exp
2
1);(
Hagamos la partición conformable con X e Y siguiente:
2221
1211
De acuerdo a los resultados de la sección II.2 de la Normal Multivariada (Propiedad5),
tenemos que:
YX 1
2211ˆ y 21
1
2212112|11 )(
Entonces, la distribución de W dado Y requerida en el paso E es:

Análisis de Series de Tiempo
171
00
0)(,
0
ˆ2|11X
NMV
Usando el resultado ''
)(AtrazaXAXE , podemos ver que:
WWtraza
YXYXEYWWE
i
iii
ˆ)('ˆ)()(
)','ˆ)(()'','ˆ(|ˆ)('ˆ
11
2|11
)(
2|11
)(1
2|11
1
2|11 )()(
De aquí que,
)()(2
1)ˆ;(
ˆ)('ˆ)ˆ;(
|)ˆ;()|(
1
2|11
)(
2|11
1
2|11
)(
)(
)(
i
i
trazaWl
WWEWl
YWlEQ
i
i
Note que )ˆ;( Wl es el logaritmo de la verosimilitud de los datos completos en los que
X es reemplazado por su estimación, X .
Dado que el proceso converge, en la práctica se usa la expresión (reducida):
)ˆ;()|(~ )( WlQ i
El paso M restante del algoritmo EM consiste en maximizar la verosimilitud. Es decir,
maximizar )ˆ;( Wl .
Ejemplo VIII.5.1.- Consideremos el conjunto de datos DOWJ.TXT. Para ejemplificar el
algoritmo EM, eliminaremos las observaciones 10, 20 y 30.
El modelo ajustado en el ejemplo V.1.1 para los datos diferenciados a distancia uno y
corregidos por la media fue un AR(1):
X(t) = .4219 X(t-1)+ Z(t)
WN variance estimate (Yule Walker): .147897
La primera iteración se inicia con 0ˆ )(o y dado que estamos suponiendo Ruido
Blanco, el paso E del algoritmo EM consiste en sustituir 0ˆˆˆ302010 XXX , donde Xt
representa los datos diferenciados a distancia uno y corregidos por la media. Una vez
reemplazadas las observaciones “perdidas”, ajustamos un modelo AR(1) por máxima
verosimilitud a este nuevo conjunto de datos, obteniendo:
ARMA Model:
X(t) = .4153 X(t-1) + Z(t)

Análisis de Series de Tiempo
172
Es decir, tenemos 4153.0ˆ )1( . El paso M consiste en minimizar con respecto a Xt la
expresión de error:
2)1(
1
2
1
)1(1
0
2
1
)1( )ˆ()ˆ()ˆ( tttt
j
jtjt XXXXXX
Derivando e igualando con cero, encontramos que:
11
)1(
1
)1(
1
)1(2)1(
)1(
1
)1(
1
)1(
ˆˆˆ)ˆ(1
0)ˆ(ˆ2)ˆ(2
ttttt
tttt
XXXXX
XXXX
2)1(
11
)1(
)ˆ(1
ˆˆ tt
t
XXX
Con la última expresión podemos estimar los datos perdidos 10, 20 y 30.
3426.0)4153.0(1
4153.0ˆ
2
911
10
XXX , etc.
Con estas estimaciones, ajustamos un “nuevo” modelo AR(1). Obteniendo:
ARMA Model:
X(t) = .4377 X(t-1) + Z(t)
Es decir, 4377.0ˆ )2( .
El proceso itera hasta converger (en i=3). En el siguiente cuadro se resumen los
resultados:
Cuadro9. Estimación de valores “perdidos” de la serie del Índice Dow Jones
Iteración i X10 X20 X30
0 0 0 0 0
1 -0.36 0.01 -0.03 0.4153
2 -0.36 0.01 -0.03 0.4377
3 -0.36 0.01 -0.03 0.4377
Es decir, el modelo ajustado considerando las observaciones 10, 20 y 30 como perdidas
es:
ARMA Model:
X(t) = .4377 X(t-1) + Z(t)
WN Variance = .143922

Análisis de Series de Tiempo
173
CAPITULO IX. COINTEGRACIÓN
Recordemos que una serie de tiempo es estacionaria si su distribución es constante a lo
largo del tiempo; para muchas aplicaciones prácticas es suficiente considerar la llamada
estacionaridad débil, esto es, cuando la media y la varianza de la serie son constantes a lo
largo del tiempo. Muchas de las series de tiempo que se analizan en la práctica no cumplen
con esta condición cuando tienen una tendencia. Cuando no se cumple esta suposición se
pueden presentar problemas serios, consistentes en que dos variables completamente
independientes pueden aparecer como significativamente asociadas entre sí en una regresión,
únicamente por tener ambas una tendencia y crecer a lo largo del tiempo; estos casos han sido
popularizados por [Granger y Newbold (1974)] con el nombre de “regresiones espurias”.
El problema de las regresiones espurias aparece frecuentemente cuando se halla la
regresión entre series afectadas por tendencias comunes, lo que lleva a encontrar un valor de
R2 elevado, sin que exista realmente una relación de causa-efecto. Cuando se lleva a cabo una
regresión espuria, suele aparecer un valor pequeño del estadístico de Durbin-Watson,
indicando que los errores de la ecuación están correlacionados positivamente. Esto implica no
sólo que los estimadores de mínimos cuadrados de los coeficientes son ineficientes, sino que
son inconsistentes, lo que lleva a incurrir en serios problemas de especificación.
Recientemente se ha dedicado mucho esfuerzo al análisis de las propiedades de
ecuaciones de regresión con variables más generales que las estacionarias, pero con algún tipo
de restricción a su distribución. Un caso particular de las variables no estacionarias es el de las
llamadas variables integradas. Este tipo de variables será de gran importancia en el
desarrollo de la teoría de Cointegración que se presenta en el presente capítulo.
IX.1. DEFINICIONES Y PROPIEDADES
Cuando en el proceso que sigue un vector de observaciones se tienen raíces unitarias,
se dice que tal proceso es Cointegrado. El concepto de cointegración se debe a [Engle y
Granger (1987)].
Además de las variables integradas, que ya se mencionaron, otro concepto clave en el
que se basa la teoría de la cointegración es la representación de corrección de error, que
definiremos más adelante.
Una correlación alta entre dos variables, Y y X, puede deberse a tres tipos de relaciones
causa efecto:
a) que X sea la causa de la variable Y.
b) que Y sea la causa de los cambios en X.
c) que cada una de ellas sea a la vez causa y efecto de la otra.
Como en todo desarrollo de teoría, será necesario definir algunos conceptos clave que
manejaremos en este capítulo.

Análisis de Series de Tiempo
174
Definición IX.1.1. [Causalidad en el sentido de Granger].- X causa a Y, en el sentido
de Granger, )( YX , si Y se puede predecir con mayor exactitud utilizando valores pasados
de X que sin usarlos, manteniendo igual el resto de la información. Véase [Granger (1969)].
Cuando se dice que )( YX se está expresando que los valores de X “preceden” a los
de Y, en el sentido de que anteceden siempre a los de Y y sirven para predecirlos, pero no que
necesariamente los valores de X “originen” los valores de Y. Es posible que, por ejemplo, una
tercera variable Z produzca los cambios en Y, y posiblemente también en X, sin embargo,
)( YX . Por lo que sería más apropiado hablar de precedencia.
Definición IX.1.2. [Serie de Tiempo Integrada].- Se dice que una serie de tiempo
{Xt} es integrada de orden d, denotada por )(dIX t , si puede expresarse como:
tt
d ZBXBB )()()1(
donde
qtqttt
ptpttt
ZZZZB
XXXXB
11
11
)(
)(
Otro modo de definir una serie integrada es decir que {Xt} es ARIMA(p,d,q) con un
proceso {Zt} estacionario e invertible. En estas condiciones la menor raíz en valor absoluto de
la parte autorregresiva es la unidad y se dice que la serie tiene d raíces unitarias o que es I(d); a
manera de ejemplo, una serie estacionaria es I(0) y una “caminata aleatoria” es I(1).
También, la suma o combinación lineal de procesos de distintos ordenes de integración
es del mismo orden que el proceso de orden mayor. Es decir, si:
)(
)(
dIY
eIX
con
YXZ
t
t
ttt
entonces )),(max( deIZ t
En términos similares, la combinación lineal de dos procesos con el mismo orden de
integración es, en general, de ese orden de integración.
NOTA1: En particular, combinaciones lineales de series I(0) son I(0); combinaciones lineales
de series I(1) son en general I(1), con una excepción muy importante, la de las series
cointegradas que son I(0) y que veremos en detalle más adelante. Esto también muestra que
una serie integrada no puede ser representada adecuadamente por series estacionarias; del
mismo modo, una serie estacionaria no puede, en general, representarse como función de
series integradas.

Análisis de Series de Tiempo
175
NOTA2: Cabe mencionar que el análisis de cointegración involucra conceptos de Análisis de
Regresión (multicolinealidad y estadístico de Durbin-Watson, principalmente) y de Raíces
Unitarias (vistas en el capítulo VI), por lo que se recomienda que el lector esté familiarizado
con estos tópicos.
NOTA3: Un síntoma de Cointegración entre variables es un valor alto del coeficiente de
determinación de la regresión entre ellas, R2, acompañado de valores no muy bajos del
estadístico de Durbin - Watson.
Estudios hechos recientemente muestran que una gran proporción de las series
económicas no estacionarias son I(d), y en especial muchas de ellas I(1). Esto ha inducido una
gran cantidad de investigaciones sobre las propiedades estadísticas de series I(d). Y
particularmente en la búsqueda de combinaciones lineales estacionarias de series integradas, lo
que se llama Cointegración en series.
Supóngase dos variables no estacionarias Yt y Xt, entre las que se cree que existe una
relación de dependencia. Cabe esperar que, bajo tal supuesto, los residuos de la regresión que
explica a Yt en función de Xt sean estacionarios, a pesar de que ninguna de las dos variables
del modelo lo sean. Esta es la idea de Cointegración, y a continuación se da la definición.
Definición IX.1.3. [Serie Cointegrada].- Se dice que una series de tiempo { tY } m-
variada es cointegrada de orden (d,b), denotada por ),( bdCIY t , si siendo todas las series
del vector I(d), existe un vector de coeficientes no nulo tal que )('
bdIYz tt , con b
> 0. La relación tt Yz'
se denomina relación de cointegración y el vector vector de
cointegración. [Engle y Granger (1987)].
Supongamos la serie bivariada '),( ttt xyY . Si suponemos que hay una relación entre
las componentes del vector, conocida como relación de equilibrio, entonces esta relación se
puede expresar como una relación lineal como la siguiente:
tt xy 10
*
De acuerdo con ello, hay equilibrio en el periodo t si 0*
tt yy , es decir, si
0)( 00 tt xy . Ahora bien, como yt será, en general, distinto del valor de equilibrio,
podemos agregar un término de error o desviación, ut, quedando:
ttt uxy )( 10
Agrupando términos, podemos escribir la ecuación como: ttt uxy 01 . Así,
podemos ver que no es más que la relación de cointegración del vector tY , donde:

Análisis de Series de Tiempo
176
tt
ttt
uz
xyY
0
1
'
'
),1(
,),(
Cointegración significa que, aunque haya fuerzas que causen cambios permanentes en
los elementos individuales del vector tY , existe una relación de equilibrio a largo plazo que
los une, representada por la combinación lineal tt Yz'
.
De la definición de cointegración podemos deducir algunas observaciones:
1. El coeficiente de la variable independiente siempre es 1, por lo que el vector de
cointegración, , aparece normalizado.
2. Basta multiplicar el vector por un escalar no nulo para obtener un nuevo vector de
cointegración, por lo que el vector de cointegración no será único.
3. El número máximo de vectores de cointegración linealmente independientes que puede
haber entre m variables integradas del mismo orden es m−1. Al número de vectores de
cointegración linealmente independientes se le denomina rango de cointegración.
4. Dos series no pueden ser cointegradas si no son integradas del mismo orden. Así, por
ejemplo, si )1(Iyt y )0(Ixt , entonces )1(Izt y las variables yt y xt no son
cointegradas.
5. Cuando se relacionan dos series cada una integrada de orden cero, no tiene sentido
hablar de cointegración.
6. Cuando se consideran más de dos series de tiempo la situación se puede complicar, ya
que, al contrario de lo que la observación 4 parece implicar, puede que exista
cointegración sin que todas las variables sean integradas del mismo orden. Por
ejemplo, supóngase que )1(Iyt , )2(Ixt y )2(Ivt . Si )1,2(],[ CIvx tt ,
entonces, existirá una relación lineal entre la relación de cointegración de xt con vt y yt.
El caso más sencillo e interesante de cointegración es cuando d = b, es decir cuando
)0(Izt , ya que entonces es cuando se pueden identificar los parámetros del vector de
cointegración con los coeficientes de una relación a largo plazo entre las variables y aplicar el
análisis de la regresión. Este caso es en el que se centrará el análisis del capítulo.
Enseguida se expone el concepto de Representación de Corrección de Error que, como
se mencionó anteriormente, es de gran importancia en el análisis de cointegración, en el
sentido de que series cointegradas tienen una representación de corrección de errores, e
inversamente, una representación de corrección de errores genera series cointegradas
IX.2. REPRESENTACIÓN DEL MECANISMO DE CORRECCIÓN DE ERROR (MCE)
El Mecanismo de Corrección de Error (MCE) consiste en representar modelos
dinámicos. Su aplicación se debe, principalmente, al trabajo de [Davidson, Hendry, Srba y
Yeo (1978)]. Los modelos MCE permiten modelar tanto las relaciones a largo plazo como la
dinámica a corto de las variables. La denominación de MCE se debe a la especificación del

Análisis de Series de Tiempo
177
modelo en la cual las desviaciones de la relación del largo plazo entre los niveles de las
variables funcionan como un “mecanismo” que impulsa a los cambios de las variables a
acercarse a su nivel de equilibrio cuando se han alejado de este. Es decir, se corrigen los
errores de equilibrio de periodos anteriores de forma gradual.
Aunque el procedimiento puede extenderse a m variables, sólo consideramos un
modelo dinámico de dos variables yt y xt, entre las cuales existe algún tipo de correlación. El
modelo dinámico se expresa como:
tttt uyBaxBy )](1[)(
en donde las raíces de a(B) = 0 caen fuera del círculo de radio unitario, como condición de
estacionaridad. a(B) y )(B son los siguientes polinomios en el operador de rezago
mtmttt
ntnttt
xxxxB
yyyyBa
110
11
)(
)(
Desarrollando los polinomios, sumando y restando términos, se obtiene:
1
1
1 1
0
121
1
1 1
0
121
1
3243
2132
10
110
)1(
)(
)(
)(
))((
))((
)(
)(
t
m
j
jt
m
jk
kt
tm
m
j
jt
m
jk
kt
tm
mtmtm
ttm
ttm
tt
mtmttt
xxx
xxx
x
xx
xx
xx
xx
xxxxB
Análogamente, se obtiene
1
1 1
1]11[]1[n
j
jt
n
jk
kt-t yy)-a(y-a(B)
donde na 21)1(
Con esto, el modelo dinámico original puede escribirse en la forma siguiente:

Análisis de Series de Tiempo
178
t
n
j
jt
n
jk
kt
t
m
j
jt
m
jk
ktt
uyyA
xxxy
1
1 1
1
1
1 1
0
)]1(1[
)1(
Restando yt-1 en los ambos miembros de la igualdad, se tiene:
ttt
n
j
jt
n
jk
k
m
j
jt
m
jk
ktt uxAA
yAyxxy)1(
)1(
)1()1( 1
1
1 1
1
1 1
0
Esta última expresión es la forma general del modelo de MCE para el caso de dos
variables. El cociente Ω(1) / A(1) se conoce como multiplicador total.
Definición IX.2.1. [Representación MCE].- Se dice que un vector m-variado Y
admite la representación MCE si se puede expresar como:
ttt YYBA 1)(
donde t es un vector error estacionario; A(B) es una matriz m x m, con A(0)=Im; y es una
matriz m x m diferente de la nula.
El análisis e interpretación del modelo MCE se reducirá a un vector bivariado,
)',( ttt xyY , en donde cada una de las componentes son I(1). Dicho esto, el MCE para el
caso de dos variables está dado por:
tttttt
tttttt
t
t
tttt
tttt
t
t
xyxByBx
xyxByBy
xyxByB
xyxByB
x
y
211212122
111111111
2
1
1121212
1111111
2
1
)()()(
)()()(
)()()(
)()()(
Con las siguientes condiciones:
1. El vector de cointegración )',1( es el mismo para ambas ecuaciones.
2. Los polinomios )(Bi y )(Bi para i=1,2, tienen todas sus raíces fuera del círculo
unitario (condición de estacionaridad).
3. Al menos uno de los parámetros i , i=1,2 no es nulo. Estos parámetros se conocen
como parámetros de velocidad de ajuste.
De las ecuaciones podemos ver que, los términos entre paréntesis involucran la
relación a largo plazo de las variables involucradas. Esto no es más que la relación de

Análisis de Series de Tiempo
179
cointegración. El término en cuestión se conoce como “corrector del error”, en el sentido
que será distinto de cero únicamente cuando haya alejamiento del valor de equilibrio. Si por
ejemplo, en el momento t se da que tt xy < 0, es decir, que yt está por debajo del valor de
equilibrio que mantiene respecto a xt, entonces el término de corrección de error provocará un
aumento superior de 1ty a fin de corregir la brecha en la relación de equilibrio. Los i ’s
reciben el nombre de “parámetros de velocidad del ajuste” porque cuanto mayor sea su valor
más rápidamente se corregirán los desequilibrios.
A continuación enunciamos un teorema de gran importancia que involucra la relación
entre el Mecanismo de Corrección de Error y Cointegración.
TEOREMA. [Representación de Granger]. Si las m componentes de una serie de tiempo
multivariada }{ tX son CI(1,1) de rango de cointegración r, entonces existe una representación
Mecanismo de Corrección de Error para el Proceso Generador de Datos (PGD). Por otra parte,
si el PGD de un conjunto de variables admite una representación MCE, entonces las variables
están cointegradas.
Demostración. Ver [Engle y Granger (1987)].
///
Mediante el teorema anterior se puede mostrar que existe un isomorfismo de
representaciones para variables cointegradas. Tales representaciones son: Vectores
Autorregresivos (VAR), MCE y Promedios Móviles Multivariados.
IX.3. ESTIMACIÓN Y CONTRASTE DE RELACIONES DE COINTEGRACIÓN
El proceso de estimación de la relación de cointegración es un poco complicado dada
la relación mostrada entre cointegración y modelos de MCE del Teorema de Representación
de Granger. Es decir, tenemos que estimar la relación de cointegración y el MCE.
La vía tradicional de estimación y contraste de relaciones de cointegración ha sido
estimar directamente la relación de cointegración y, posteriormente, se modela el MCE. En
seguida desarrollamos el procedimiento.
IX.3.1. Estimación en dos etapas de Engle y Granger
La estimación en dos etapas de los modelos que involucran variables cointegradas
propuesta por [Engle y Granger (1987)] consiste en estimar en un primer paso la relación de
cointegración realizando la regresión estática de las variables en niveles y, en el segundo paso
se estima el MCE introduciendo los residuos de la relación de cointegración estimada en el
primer paso, diferenciados un periodo. Puede mostrarse que los resultados son consistentes
para todos los parámetros. En particular, los estimadores de los parámetros en el primer paso
convergen en probabilidad a una tasa n; mientras que en el segundo paso, los elementos del
vector de los términos de corrección de error, convergen asintóticamente a la tasa usual de
n . Esto se puede ilustrar proponiendo un modelo simple de MCO sin ordenada al origen.

Análisis de Series de Tiempo
180
Supongamos que existe alguna relación entre las series con media cero )1(, Iyx tt , y
que estas dos series están cointegradas. Entonces, la regresión estática sin ordenada al origen
de ty sobre tx está dada por:
ttt xy
Note que, el término de error, t , contiene toda la dinámica omitida y además,
)0(}{ It bajo el supuesto de cointegración. Así, es estimada consistentemente por la
regresión a pesar de la omisión de toda la dinámica. Tal estimación está dada por:
n
t
t
n
t
tt
n
t
t
n
t
tt
n
t
t
n
t
t
n
t
ttt
n
t
t
n
t
tt
x
x
x
xx
x
xx
x
yx
1
2
1
1
2
11
2
1
2
1
1
2
1
)(
ˆ
Podemos ver que a medida que t tiende a infinito, n
t
tx1
2también tiende a infinito y, en
consecuencia, ˆ tiende a independientemente de n
t
ttx1
, que se ve superado por el
crecimiento de n
t
tx1
2, a una tasa de n y no a la tasa usual de n .
Esto significa que los parámetros convergen al valor poblacional a una velocidad
superior, conforme aumenta la muestra, a las estimaciones con variables estacionarias. Este
hecho se debe a que para el verdadero valor , los residuales son estacionarios.
Este resultado es llamado teorema de superconsistencia de [Stock (1987)] y es usado
por Engle y Granger como base de la estimación. Enseguida enunciamos el Teorema de Engle
y Granger, el cual establece la distribución límite de la relación de cointegración en dos
etapas.
TEOREMA. (de Engle y Granger). La estimación en dos etapas de una ecuación de un
sistema de corrección de error con un vector de cointegración obtenido al tomar la estimación
ˆ de de la regresión estática, en lugar del verdadero valor, para estimar el MCE en la
segunda etapa, tiene la misma distribución límite con el estimador de máxima verosimilitud
que usando el verdadero valor de . El método de mínimos cuadrados en la segunda etapa
proporciona estimadores consistentes del error estándar.
Demostración. Ver [Engle y Granger (1987)].
///
Como hemos mencionado, la estimación tradicional de relaciones de cointegración
consiste en dos etapas. La primera consiste en estimar directamente la relación de
cointegración y la segunda en estimar el MCE introduciendo los residuos de la relación de
cointegración estimada en el primer paso.

Análisis de Series de Tiempo
181
IX.3.1a. Estimación Directa de la Relación de Cointegración
Cuando se estima una relación entre variables integradas, podemos caer en una
regresión espuria, es decir, obtener residuos que no son estacionarios, un R2 elevado y aceptar
como significativo el parámetro asociado al regresor. En cambio, si un conjunto de variables
están cointegradas, al obtenerse unos residuos estacionarios, puede realizarse la regresión por
MCO. Esto pone de manifiesto la utilidad de la teoría de cointegración a la hora de discriminar
entre relaciones espurias y relaciones reales entre variables.
Como hemos dicho antes, solo consideramos el caso bivariado para una mayor
simplicidad. Así, si )1(, Iyx tt y se puede plantear la regresión:
ttt xy
entonces la estimación por MCO, al minimizar la varianza residual, estimará consistentemente
este único parámetro de cointegración, , que conduce a unos residuos estacionarios.
De acuerdo a los supuestos, en la expresión anterior, aunque estén involucradas
variables I(1), no se trata de una relación espuria puesto que los residuales son estacionarios
para un determinado valor de y, por tanto, el estadístico Durbin-Watson (DW) será
significativamente distinto de cero al no haber una raíz unitaria en { t }.
Enseguida enunciamos algunas de las características que presenta la estimación por
MCO de la regresión de cointegración: ttt xy .
La estimación del parámetro es sesgada, principalmente cuando tenemos muestras
pequeñas. Esto se debe a la autocorrelación que presenta t [Phillips (1988)]. Este
sesgo no tiene una distribución normal ni media cero, pero desaparece cuando el
tamaño muestral tiende a infinito.
La estimación por MCO no es completamente eficiente, pues recordemos que no
estamos considerando el resto de información disponible, es decir, todo el MCE.
En la regresión estática suele haber una considerable autocorrelación residual, lo que
lleva a la inconsistencia de la estimación de los errores estándar de los parámetros.
Esto implica que los valores de t (estadística de prueba) de los parámetros del vector de
cointegración están sesgados y son inconsistentes. Por tanto, la inferencia sobre los
parámetros estimados no se puede hacer de manera tradicional.
Si las variables implicadas en la relación de cointegración son más de tres, se espera
una fuerte colinealidad entre las variables explicativas. Ello sucede porque, para que
haya una relación de cointegración, las variables han de evolucionar conjuntamente a
largo plazo. La eliminación de una de las variables explicativas en la regresión de
cointegración, a fin de reducir la multicolinealidad, conducirá a resultados
inconsistentes al no poder obtener residuos estacionarios. Con ello se constata que la
multicolinealidad, más que un problema, es una característica inherente a las variables
cointegradas.

Análisis de Series de Tiempo
182
En resumen, se podría decir que la estimación por MCO de la regresión de
cointegración proporciona, de forma sencilla, unos parámetros superconsistentes, aunque
sesgados y no eficientes, sobre los que no se puede hacer inferencia, pero que permitiría
contrastar si existe una raíz unitaria en los residuos estimados (que son consistentes).
IX.3.1b. Estimación del Mecanismo de Corrección de Error (MCE)
Una vez estimado por MCO el vector de cointegración (regresión estática) en el paso
uno, los resultantes parámetros del MCE pueden ser estimados consistentemente introduciendo
los residuales de la regresión estática del paso uno rezagados un periodo, es decir, 1t ,en el
MCE. Así, en la segunda etapa del proceso de estimación y contraste de relaciones de
cointegración, se estimará el MCE introduciendo 1t en lugar del vector de cointegración.
[Engle y Granger (1987)].
Existe una versión de estimación que consiste en tres etapas, es decir, se agrega una a
las dos anteriores. El supuesto en el que se basa esta versión es la existencia de un único
vector de cointegración. El procedimiento de estimación en tres etapas fue desarrollado por
[Engle y Yoo (1987)].
Otro método alternativo de estimación es propuesto por Johansen y está basado en el
concepto de máxima verosimilitud.
IX.3.2. Estimación de Johansen
El procedimiento basado en Máxima Verosimilitud con información completa tiene
una serie de ventajas frente a los restantes métodos, como son: contrastar simultáneamente el
orden de integración de las variables y la presencia de relación de cointegración y estimar
todos los vectores de cointegración, sin imponer a priori que únicamente hay uno. Por estos
motivos, se convierte en una alternativa cada vez más utilizada frente a otros métodos de
estimación y contraste como el de dos etapas de Engle y Granger. No obstante, el
procedimiento de Johansen también impone algunos supuestos. [Johansen (1988)].
El procedimiento parte de la modelación de vectores autoregresivos en la que todas las
variables se consideran endógenas (dependientes). Formalmente, supongamos el modelo
autorregresivo multivariado de orden p, VAR(p):
tptptt YYY 11
donde tY es un vector de orden m; m es el número de variables del modelo; es un vector de
constantes, y t es un vector de perturbaciones aleatorias tal que ),0(iidt .
Se puede mostrar (mediante algebra) que el modelo puede escribirse de la siguiente
forma:
tptptptt YYYY 1111

Análisis de Series de Tiempo
183
I
piI
p
ii
1
1 1,...,1,
donde
La matriz es conocida como matriz de impactos, pues contiene toda la
información sobre la relación a largo plazo. Note que esta última expresión del modelo es la
de un MCE en forma matricial.
Por otro lado, si recoge la relación de cointegración, entonces }{ ptY será I(0).
Esto garantiza que el modelo esté equilibrado.
Si r es el rango de , pueden presentarse los siguientes casos:
1. r=0.
En este caso, tendríamos que es una matriz nula. Esto implica que el modelo presente solo
variables diferenciadas y, en consecuencia, las variables del vector tY serán I(0). Es decir, no
existiría ninguna relación de cointegración.
2. 0 < r < m.
En este caso habrá r relaciones de cointegración. El rango de será el número de columnas
linealmente independientes de la matriz (vectores de cointegración).
3. r = m.
En este caso, el proceso multivariado { tY } será estacionario. Como mencionamos antes,
intuitivamente, esto se debe a que entre m variables sólo puede haber como máximo m − 1
vectores de cointegración linealmente independientes. Tendríamos que, si A es la matriz de
vectores de cointegración, )0(' IYA t , donde todas las variables de tY son I(1). En
conclusión, tY será estacionario solo si es de rango m, ya que esta matriz recoge las
relaciones (vectores) de cointegración (relaciones a largo plazo).
La idea intuitiva que hay detrás del procedimiento de estimación por Máxima
Verosimilitud de Johansen es que se deben encontrar las combinaciones lineales del vector tY
que estén correlacionadas al máximo con las diferencias tY . La secuencia de pruebas de
hipótesis sería empezar planteando H0: r=0 (no cointegración) frente una alternativa de r=1.
En caso de rechazar H0, se contrastaría la nueva hipótesis H0: r = 1 frente a la alternativa de
r=2, y así sucesivamente hasta el momento en que no se rechace H0, o bien hasta aceptar que
todas las variables son estacionarias, en tal caso, tendríamos r = m.
El proceso de estimación de Johansen se basa en el concepto de Máxima
Verosimilitud, por lo que debemos suponer alguna distribución (Normal Multivariada).
Supongamos que la expresión tptptptt YYYY 1111 es el MCE,
0 , 0 < r < m, 0,...,YY pt son datos conocidos y ),0(NMt e independientes. Bajo
estos supuestos, podemos obtener la estimación por Máxima Verosimilitud siguiendo los
siguientes pasos:

Análisis de Series de Tiempo
184
1. Estimar por MCO los sistemas de ecuaciones:
tptptpt
tptptt
rYYY
rYYY
111,1111
011,0101
De esta forma, podemos obtener los vectores residuales tr 0 y tr1 .
2. Calcular los momentos de segundo orden de los residuales. Es decir, calcular la cantidad:
1,0, ,1
'
jin
rr
S
n
t
jtit
ij
Note que Sij es una matriz cuadrada de orden m × m.
3. La estimación de máxima verosimilitud de la matriz de vectores de cointegración, A, bajo la
restricción de normalización IASA 11
' , se obtiene a partir del cálculo de los valores propios
de 01
1
0010 SSS respecto a 11S . Es decir, las i , i = 1, . . . ,m, son tales que:
001
1
001011 SSSS
Las lambdas obtenidas serán: m21 .
4. Para probar la hipótesis nula de que hay como máximo r vectores de cointegración frente a
la alternativa de que hay m, r < m, la estadística de prueba de razón de verosimilitud está dada
por: m
ri
itraza nQr1
)1(ln2)(
la cual sigue una distribución (asintótica) 2
)( fc , donde c = 0,85 − 0,58/f , 2
)( f es la
distribución Ji-Cuadrada con f = 2(m − r)2 grados de libertad. Esta estadística se denomina
estadística de la traza.
5. Teniendo el rango de cointegración, podemos pensar en la estimación de la matriz A. Las
columnas de A serán los vectores propios asociados a cada i . De esta forma, la i-ésima
columna de la matriz A, Ai, se estima a partir de la expresión:
iii ASASSS ˆˆ1101
1
0010 i=1,…,r
6. Una estimación consistente de las matrices , y se obtiene de:

Análisis de Series de Tiempo
185
'
00
01
ˆˆˆ
ˆˆˆ
ˆˆ
S
A
AS
IX.3.3. Contrastes de Cointegración sobre los Residuales
Una forma sencilla de contrastar una relación de cointegración entre variables consiste
en analizar si los residuos de la regresión de cointegración presentan un orden de integración
menor que el de las variables involucradas. A manera de ejemplo, para el caso de variables
I(1), el contraste consistirá en determinar si los residuos presentan una raíz unitaria (no
cointegración) o, lo que es lo mismo, determinar si son o no estacionarios. Para ello se pueden
utilizar los contrastes de raíces unitarias presentadas anteriormente (Dickey - Fuller).
Mostramos dos contrastes propuestos en [Engle y Granger (1987)] de los que existen
valores críticos tabulados: el basado en el Durbin-Watson de la regresión estática y el Dickey
- Fuller Aumentado sobre los residuos de dicha regresión. En ambos la hipótesis nula es:
)1(:0 IH t (H0: no cointegración)
Si no se rechaza la hipótesis de no cointegración entre las variables integradas
utilizadas en la regresión estática, debemos concluir que la relación estimada es de tipo
espurio.
IX.3.3a. Contraste Durbin-Watson sobre los Residuales de Cointegración (DWRC)
El DWRC, se calcula de la misma forma que el estadístico Durbin-Watson y está dado
por:
n
t
t
n
t
tt
DWRC
1
2
2
2
1
ˆ
ˆˆ
tˆ denota los residuales de la regresión de cointegración estimada por MCO.
La hipótesis nula que se plantea en la estimación ttt xy es 0:0 DWRCH
(no cointegración). Si el estadístico DWRC es significativamente mayor que cero, entonces
aceptaremos la existencia de una raíz unitaria en los residuos. El valor DWRC se compara con
los valores críticos de las tablas que aparecen en [Engle y Granger (1987)] para el caso de dos
variables. De manera usual, si el DWRC estimado es inferior a los valores críticos tabulados
no se podrá rechazar la H0.
Como todo procedimiento, este tiene ventajas y desventajas. Una ventaja de este
contraste es que es invariante frente a la posible inclusión de constantes y tendencias en el
modelo, sin que por ello varíen sus valores críticos. El problema de este contraste es que

Análisis de Series de Tiempo
186
generalmente { t } sigue un esquema AR(p) y el contraste DWRC considera únicamente un
esquema AR(1).
IX.3.3b. Contraste Dickey-Fuller sobre los Residuales de Cointegración (DFRC)
El contraste del tipo Dickey-Fuller (DF) o Dickey-Fuller Aumentado (DFA) sobre la
regresión de cointegración, consiste en estimar por MCO la regresión:
p
i
ttitt e1
11 ˆˆˆ
donde tˆ denota los residuos de la regresión de cointegración estimada por MCO, y el número
de retardos p se escoge suficientemente grande como para que { te } forme un proceso de ruido
blanco. Como sugieren Phillips y Oularis, el valor de p debe aproximarse por el valor 3 n
cuando las variables siguen un proceso ARIMA(p,1,q). La introducción de los retardos de los
residuos diferenciados en el modelo se justifica de la necesidad de eliminar la autocorrelación
que presenten los residuos.
Cabe señalar que si se utilizan los valores críticos de los contrastes DF o DFA para este
caso, se rechazará la hipótesis nula de no estacionaridad con demasiada frecuencia. Para evitar
este sesgo los valores críticos deben aumentarse ligeramente.
IX.4. PRONÓSTICO EN SISTEMAS COINTEGRADOS
En los procesos de predicción se tiene la característica de que la varianza del error de
pronóstico crece a medida que el horizonte de pronóstico lo hace (h crece). El proceso de
pronóstico de sistemas cointegrados también tiene esta característica.
Por otra parte, según [Engle y Yoo (1987)], el pronóstico a largo plazo viene dado
exactamente por el vector de cointegración. Así por ejemplo, dada una representación por
MCE con una relación de cointegración tt Xy'
, la mejor predicción a largo plazo hecha en
el momento t de hty (con t suficientemente grande) condicionada a htX es htht Xy'
ˆ , la
cual tendrá varianza finita aunque h tienda a infinito.
Sin embargo, el hecho de que la varianza de los errores del pronóstico (ECM) de la
combinación de cointegración se mantiene finita no resuelve el problema del pronóstico a
largo plazo con variables integradas. El siguiente ejemplo ilustra la dificultad.
Consideremos el proceso
ttt xx 10
con 1. Entonces, haciendo repetidas sustituciones, se puede llegar a que el pronóstico a h
pasos en el tiempo t, denotado por thtx ||ˆ está dado por:

Análisis de Series de Tiempo
187
t
h
h
tht xx1
)1(ˆ
0
|
Es fácil observar que cuando h tiende a infinito, la predicción en cuestión tiende a la
cantidad 1
0 )1( , que no es más que la media no condicional del proceso. Este argumento,
implica que el sistema de ecuaciones, si se reescribe enteramente en términos de variables I(0),
pierde la capacidad de pronosticar los valores futuros basados en el pasado observado.
Cuando el horizonte de pronóstico aumente (aumente h), el mejor pronóstico, como vimos con
el ejemplo, es la media no condicional.
En el siguiente ejemplo llevamos a cabo la estimación de la relación entre el índice
general de inflación y el índice subyacente de inflación (desglosado como mercancías y
servicios) [fuente: www.banxico.org.mx]. Se piensa que el índice subyacente determina en
gran medida el índice general, lo cual se prueba al ver en el mismo plano la gráfica de la serie
original y la serie estimada.
El análisis fue hecho con el paquete Eviews5 que ofrece las opciones de estimación del
vector de cointegración como las pruebas de raíz unitaria.
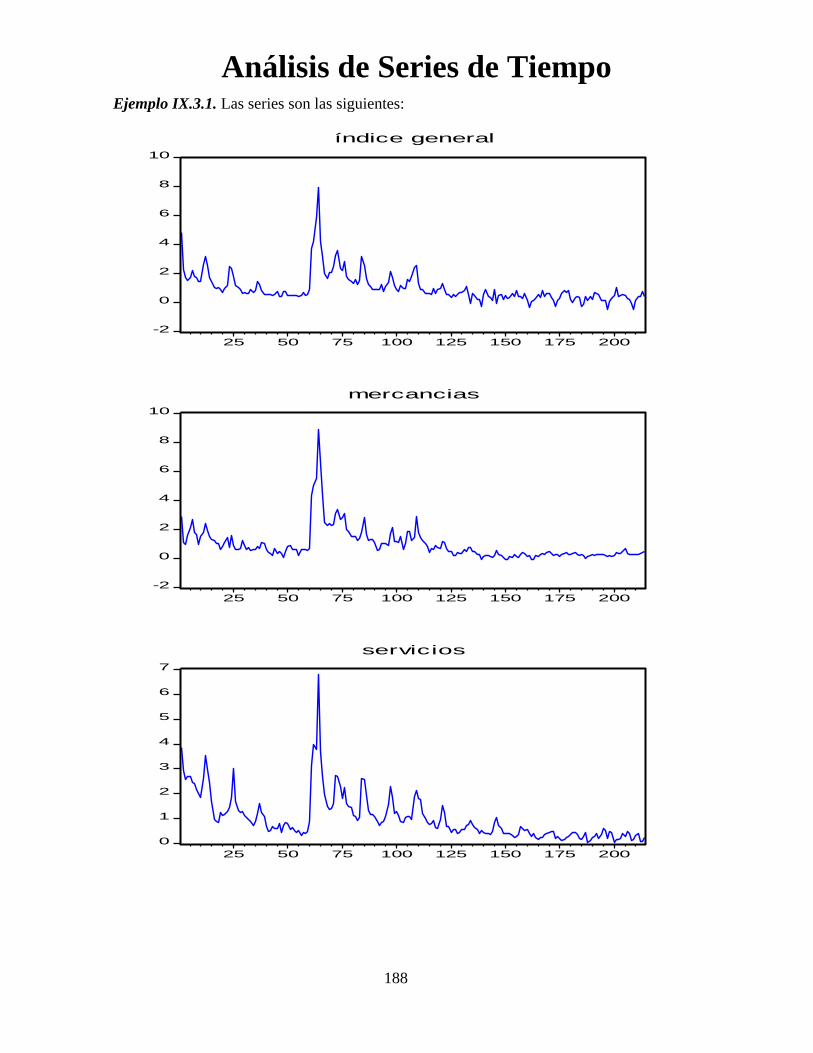
Análisis de Series de Tiempo
188
Ejemplo IX.3.1. Las series son las siguientes:
-2
0
2
4
6
8
10
25 50 75 100 125 150 175 200
índice general
-2
0
2
4
6
8
10
25 50 75 100 125 150 175 200
mercancias
0
1
2
3
4
5
6
7
25 50 75 100 125 150 175 200
servicios

Análisis de Series de Tiempo
189
Para manejar mejor las tres series, las ponemos en un “grupo” que llamamos
“inflaciones”.
Primero llevamos a cabo la regresión del índice general con los índices de mercancías
y servicios mediante la opción:
LS gral merc serv
Obteniendo:
Dependent Variable: GRAL
Method: Least Squares
Sample: 1 214
Included observations: 214
Variable Coefficient Std. Error t-Statistic Prob.
MERC 0.467194 0.043189 10.81736 0.0000
SERV 0.544799 0.046384 11.74533 0.0000
R-squared 0.892442 Mean dependent var 1.019811
Adjusted R-squared 0.891934 S.D. dependent var 1.048576
S.E. of regression 0.344702 Akaike info criterion 0.717029
Sum squared resid 25.18973 Schwarz criterion 0.748487
Log likelihood -74.72210 Durbin-Watson stat 1.280057
Procedemos a generar la serie de residuales siguiendo Proc > Make Residual Series y
llevar a cabo la prueba de raíz unitaria en esta serie mediante View > Unit Root Test.
Obteniendo:
Null Hypothesis: RESIDUALES has a unit root
Exogenous: Constant
Lag Length: 5 (Automatic based on SIC, MAXLAG=14) t-Statistic Prob.*
Augmented Dickey-Fuller test statistic -9.061679 0.0000
Test critical values: 1% level -3.461783
5% level -2.875262
10% level -2.574161
*MacKinnon (1996) one-sided p-values.
Podemos ver que se rechaza la hipótesis de existencia de raíz unitaria en la serie de
residuales al 1% de significancia, por lo que concluimos que hay existencia de cointegración.
Esto confirma la hipótesis a priori.
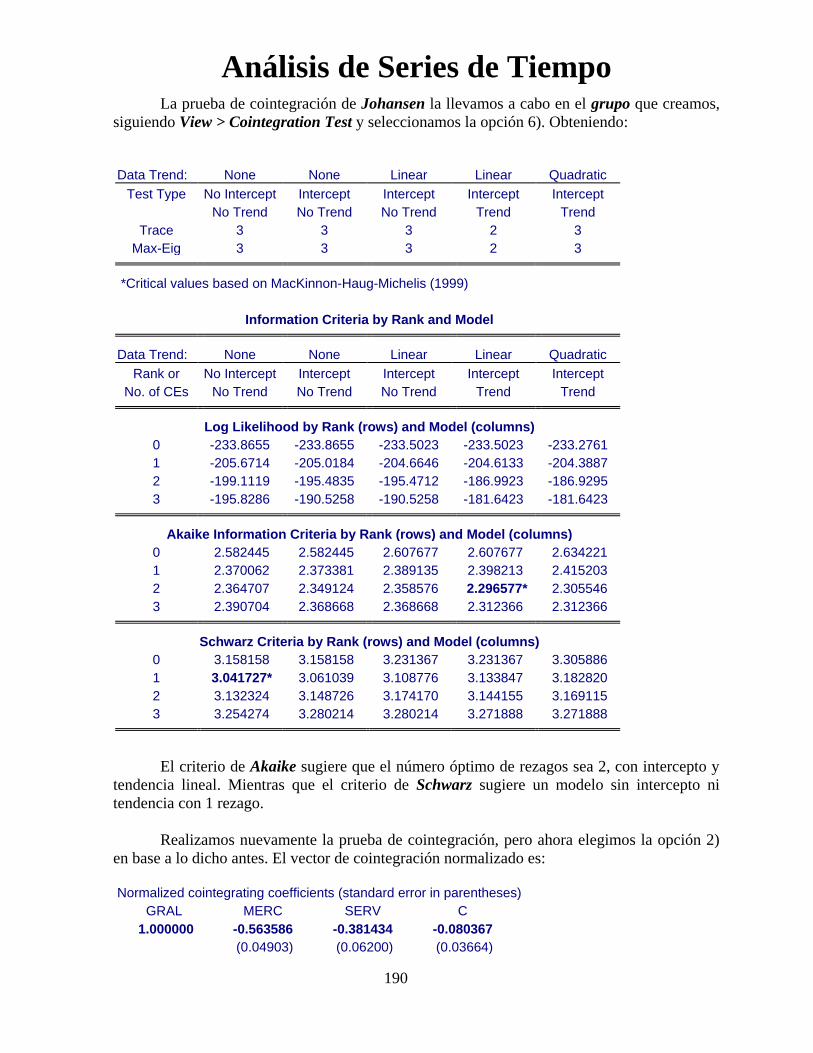
Análisis de Series de Tiempo
190
La prueba de cointegración de Johansen la llevamos a cabo en el grupo que creamos,
siguiendo View > Cointegration Test y seleccionamos la opción 6). Obteniendo:
Data Trend: None None Linear Linear Quadratic
Test Type No Intercept Intercept Intercept Intercept Intercept
No Trend No Trend No Trend Trend Trend
Trace 3 3 3 2 3
Max-Eig 3 3 3 2 3
*Critical values based on MacKinnon-Haug-Michelis (1999)
Information Criteria by Rank and Model
Data Trend: None None Linear Linear Quadratic
Rank or No Intercept Intercept Intercept Intercept Intercept
No. of CEs No Trend No Trend No Trend Trend Trend
Log Likelihood by Rank (rows) and Model (columns)
0 -233.8655 -233.8655 -233.5023 -233.5023 -233.2761
1 -205.6714 -205.0184 -204.6646 -204.6133 -204.3887
2 -199.1119 -195.4835 -195.4712 -186.9923 -186.9295
3 -195.8286 -190.5258 -190.5258 -181.6423 -181.6423 Akaike Information Criteria by Rank (rows) and Model (columns)
0 2.582445 2.582445 2.607677 2.607677 2.634221
1 2.370062 2.373381 2.389135 2.398213 2.415203
2 2.364707 2.349124 2.358576 2.296577* 2.305546
3 2.390704 2.368668 2.368668 2.312366 2.312366
Schwarz Criteria by Rank (rows) and Model (columns)
0 3.158158 3.158158 3.231367 3.231367 3.305886
1 3.041727* 3.061039 3.108776 3.133847 3.182820
2 3.132324 3.148726 3.174170 3.144155 3.169115
3 3.254274 3.280214 3.280214 3.271888 3.271888
El criterio de Akaike sugiere que el número óptimo de rezagos sea 2, con intercepto y
tendencia lineal. Mientras que el criterio de Schwarz sugiere un modelo sin intercepto ni
tendencia con 1 rezago.
Realizamos nuevamente la prueba de cointegración, pero ahora elegimos la opción 2)
en base a lo dicho antes. El vector de cointegración normalizado es:
Normalized cointegrating coefficients (standard error in parentheses)
GRAL MERC SERV C
1.000000 -0.563586 -0.381434 -0.080367
(0.04903) (0.06200) (0.03664)

Análisis de Series de Tiempo
191
El último paso es graficar el índice general y el índice general estimado por la relación
de cointegración, esto lo hacemos mediante:
PLOT gral 0.080367+0.563586*merc+0.381434*serv
-2
0
2
4
6
8
10
25 50 75 100 125 150 175 200
GRAL0.080367+0.563586*MERC+0.381434*SERV
Como podemos observar, esta estimación logra un buen ajuste, dado que capta la
tendencia histórica de la serie.
Es interesante observar, la diferencia entre la estimación de la relación de
cointegración y la estimación de un vector autorregresivo, es decir, un modelo AR
multivariado. El ajuste del modelo AR multivariado se logra, en Eviews5, como sigue: en el
grupo creado anteriormente llamado “inflaciones”, seguimos la secuencia Proc> Make Vector
Autoregression y seleccionamos la opción Unrestricted VAR. Con esto aparecerán los
primeros resultados del modelo AR. En la ventana resultante seleccionamos la opción Views>
Lag Structure> Lag lenght criteria, esto nos informará una serie de criterios para elegir el
número de rezagos necesarios, que para este ejemplo es 7.
VAR Lag Order Selection Criteria
Endogenous variables: GRAL MERC SERV
Exogenous variables: C
Sample: 1 214
Included observations: 206
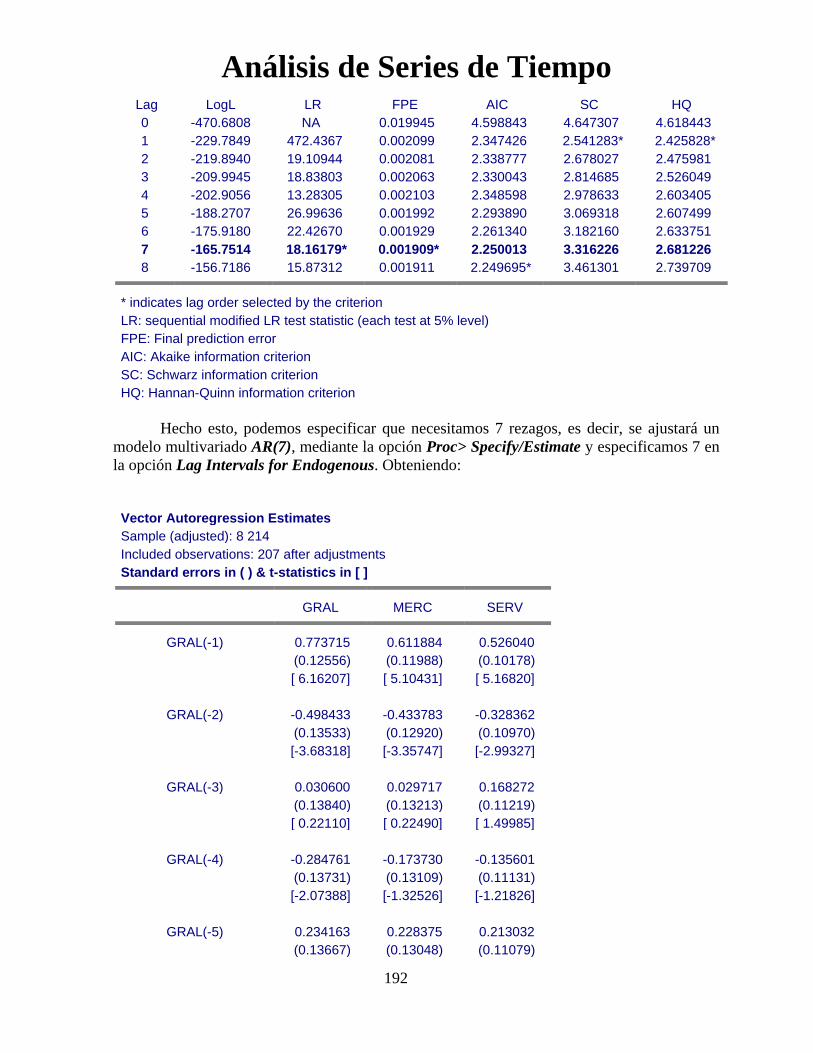
Análisis de Series de Tiempo
192
Lag LogL LR FPE AIC SC HQ
0 -470.6808 NA 0.019945 4.598843 4.647307 4.618443
1 -229.7849 472.4367 0.002099 2.347426 2.541283* 2.425828*
2 -219.8940 19.10944 0.002081 2.338777 2.678027 2.475981
3 -209.9945 18.83803 0.002063 2.330043 2.814685 2.526049
4 -202.9056 13.28305 0.002103 2.348598 2.978633 2.603405
5 -188.2707 26.99636 0.001992 2.293890 3.069318 2.607499
6 -175.9180 22.42670 0.001929 2.261340 3.182160 2.633751
7 -165.7514 18.16179* 0.001909* 2.250013 3.316226 2.681226
8 -156.7186 15.87312 0.001911 2.249695* 3.461301 2.739709
* indicates lag order selected by the criterion
LR: sequential modified LR test statistic (each test at 5% level)
FPE: Final prediction error
AIC: Akaike information criterion
SC: Schwarz information criterion
HQ: Hannan-Quinn information criterion
Hecho esto, podemos especificar que necesitamos 7 rezagos, es decir, se ajustará un
modelo multivariado AR(7), mediante la opción Proc> Specify/Estimate y especificamos 7 en
la opción Lag Intervals for Endogenous. Obteniendo:
Vector Autoregression Estimates
Sample (adjusted): 8 214
Included observations: 207 after adjustments
Standard errors in ( ) & t-statistics in [ ] GRAL MERC SERV
GRAL(-1) 0.773715 0.611884 0.526040
(0.12556) (0.11988) (0.10178)
[ 6.16207] [ 5.10431] [ 5.16820]
GRAL(-2) -0.498433 -0.433783 -0.328362
(0.13533) (0.12920) (0.10970)
[-3.68318] [-3.35747] [-2.99327]
GRAL(-3) 0.030600 0.029717 0.168272
(0.13840) (0.13213) (0.11219)
[ 0.22110] [ 0.22490] [ 1.49985]
GRAL(-4) -0.284761 -0.173730 -0.135601
(0.13731) (0.13109) (0.11131)
[-2.07388] [-1.32526] [-1.21826]
GRAL(-5) 0.234163 0.228375 0.213032
(0.13667) (0.13048) (0.11079)

Análisis de Series de Tiempo
193
[ 1.71338] [ 1.75027] [ 1.92289]
GRAL(-6) -0.340303 -0.064444 -0.092300
(0.13934) (0.13304) (0.11296)
[-2.44217] [-0.48441] [-0.81712]
GRAL(-7) -0.160788 -0.002166 -0.006777
(0.12298) (0.11742) (0.09970)
[-1.30738] [-0.01844] [-0.06798]
MERC(-1) 0.149463 0.446264 -0.058824
(0.11950) (0.11409) (0.09687)
[ 1.25075] [ 3.91157] [-0.60725]
MERC(-2) 0.175719 0.110649 -0.040811
(0.12686) (0.12112) (0.10284)
[ 1.38511] [ 0.91356] [-0.39684]
MERC(-3) 0.276499 0.248867 0.259067
(0.12715) (0.12139) (0.10307)
[ 2.17459] [ 2.05009] [ 2.51346]
MERC(-4) -0.351215 -0.179395 -0.307971
(0.12847) (0.12265) (0.10414)
[-2.73391] [-1.46267] [-2.95731]
MERC(-5) 0.127126 0.135534 -0.009963
(0.13163) (0.12567) (0.10670)
[ 0.96582] [ 1.07852] [-0.09338]
MERC(-6) 0.000569 -0.155819 -0.062932
(0.12802) (0.12223) (0.10378)
[ 0.00444] [-1.27482] [-0.60639]
MERC(-7) 0.369230 0.213162 0.143973
(0.10779) (0.10291) (0.08738)
[ 3.42535] [ 2.07129] [ 1.64765]
SERV(-1) 0.079826 0.103354 0.483039
(0.14824) (0.14153) (0.12017)
[ 0.53849] [ 0.73026] [ 4.01963]
SERV(-2) 0.259422 0.137790 0.262735
(0.15910) (0.15189) (0.12897)
[ 1.63060] [ 0.90715] [ 2.03720]
SERV(-3) -0.261119 -0.194021 -0.264887

Análisis de Series de Tiempo
194
(0.15930) (0.15209) (0.12913)
[-1.63916] [-1.27572] [-2.05126]
SERV(-4) 0.170856 0.102134 0.057375
(0.15929) (0.15208) (0.12913)
[ 1.07261] [ 0.67159] [ 0.44433]
SERV(-5) -0.073163 -0.236756 -0.036869
(0.15853) (0.15135) (0.12851)
[-0.46151] [-1.56427] [-0.28689]
SERV(-6) 0.299068 0.055199 0.190894
(0.15821) (0.15105) (0.12825)
[ 1.89028] [ 0.36543] [ 1.48841]
SERV(-7) -0.130125 -0.070010 -0.072713
(0.13697) (0.13076) (0.11103)
[-0.95005] [-0.53539] [-0.65490]
C 0.176391 0.076452 0.094600
(0.06472) (0.06179) (0.05246)
[ 2.72556] [ 1.23735] [ 1.80321]
R-squared 0.792219 0.845141 0.813005
Adj. R-squared 0.768633 0.827563 0.791778
Sum sq. resids 44.54642 40.60384 29.27260
S.E. equation 0.490705 0.468487 0.397782
F-statistic 33.58860 48.07803 38.30139
Log likelihood -134.7249 -125.1337 -91.26735
Akaike AIC 1.514250 1.421581 1.094371
Schwarz SC 1.868452 1.775783 1.448573
Mean dependent 0.976294 0.934256 0.970930
S.D. dependent 1.020164 1.128190 0.871729
Determinant resid covariance (dof adj.) 0.001389
Determinant resid covariance 0.000992
Log likelihood -165.3557
Akaike information criterion 2.235321
Schwarz criterion 3.297927
Muchos de los coeficientes en el modelo AR no son significativos. Para ello, podemos
llevar a cabo la regresión de la variable general con los 7 rezagos de las variables general,
mercancías y servicios. Una vez hecha la regresión, podemos ver que los resultados son los
mismos que los obtenidos anteriormente. La regresión es:
LS gral gral(-1) gral(-2) gral(-3) gral(-4) gral(-5) gral(-6) gral(-7) merc(-1) merc(-2) merc(-3) merc(-4) merc(-5) merc(-6) merc(-7) serv(-1) serv(-2) serv(-3) serv(-4) serv(-5) serv(-6) serv(-7) C
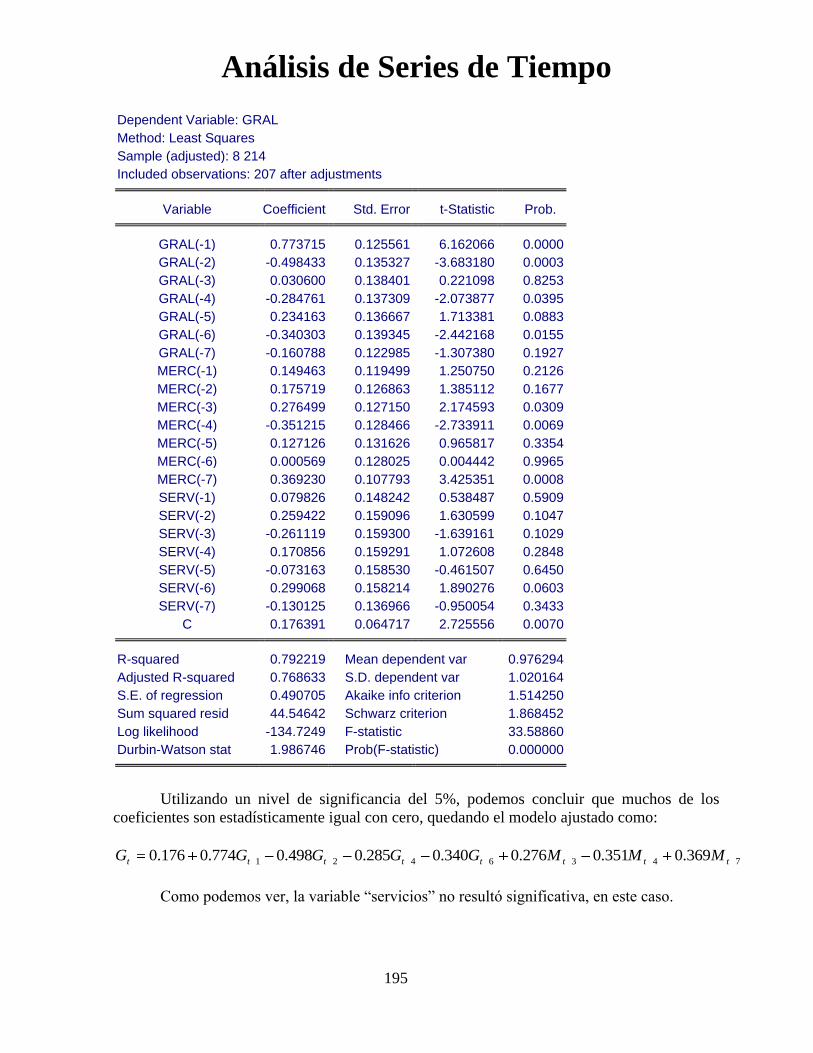
Análisis de Series de Tiempo
195
Dependent Variable: GRAL
Method: Least Squares
Sample (adjusted): 8 214
Included observations: 207 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
GRAL(-1) 0.773715 0.125561 6.162066 0.0000
GRAL(-2) -0.498433 0.135327 -3.683180 0.0003
GRAL(-3) 0.030600 0.138401 0.221098 0.8253
GRAL(-4) -0.284761 0.137309 -2.073877 0.0395
GRAL(-5) 0.234163 0.136667 1.713381 0.0883
GRAL(-6) -0.340303 0.139345 -2.442168 0.0155
GRAL(-7) -0.160788 0.122985 -1.307380 0.1927
MERC(-1) 0.149463 0.119499 1.250750 0.2126
MERC(-2) 0.175719 0.126863 1.385112 0.1677
MERC(-3) 0.276499 0.127150 2.174593 0.0309
MERC(-4) -0.351215 0.128466 -2.733911 0.0069
MERC(-5) 0.127126 0.131626 0.965817 0.3354
MERC(-6) 0.000569 0.128025 0.004442 0.9965
MERC(-7) 0.369230 0.107793 3.425351 0.0008
SERV(-1) 0.079826 0.148242 0.538487 0.5909
SERV(-2) 0.259422 0.159096 1.630599 0.1047
SERV(-3) -0.261119 0.159300 -1.639161 0.1029
SERV(-4) 0.170856 0.159291 1.072608 0.2848
SERV(-5) -0.073163 0.158530 -0.461507 0.6450
SERV(-6) 0.299068 0.158214 1.890276 0.0603
SERV(-7) -0.130125 0.136966 -0.950054 0.3433
C 0.176391 0.064717 2.725556 0.0070
R-squared 0.792219 Mean dependent var 0.976294
Adjusted R-squared 0.768633 S.D. dependent var 1.020164
S.E. of regression 0.490705 Akaike info criterion 1.514250
Sum squared resid 44.54642 Schwarz criterion 1.868452
Log likelihood -134.7249 F-statistic 33.58860
Durbin-Watson stat 1.986746 Prob(F-statistic) 0.000000
Utilizando un nivel de significancia del 5%, podemos concluir que muchos de los
coeficientes son estadísticamente igual con cero, quedando el modelo ajustado como:
7436421 369.0351.0276.0340.0285.0498.0774.0176.0 tttttttt MMMGGGGG
Como podemos ver, la variable “servicios” no resultó significativa, en este caso.

Análisis de Series de Tiempo
196
5. CONCLUSIONES
En primer lugar, es sano mencionar que el campo de estudio del Análisis de Series de
Tiempo es mucho más amplio que los temas que se exponen en el presente trabajo; Sin
embargo, de acuerdo al objetivo que se planteó al inicio, que era elaborar apuntes para las
materias de Series de Tiempo I y II que se imparten en la Licenciatura en Estadística de la
UACh, podemos decir que el objetivo principal se ha cumplido satisfactoriamente, pues se
reúnen todos los temas del plan de estudios de las materias mencionadas.
El ajuste de modelos de series de tiempo se llevó a cabo, principalmente, con el
paquete estadístico S-PLUS y con R. No obstante, se da un ejemplo de ajuste de modelo a una
serie univariada con ITSM-2000 en el Anexo, como se planteó en los objetivos. Además de
usar el paquete Eviews5 para el ejemplo de cointegración.
Aunque el modelo ajustado a las ventas de automóviles en el Anexo es bueno, este no
era el objetivo, sino ilustrar la rutina de ajuste de modelos con el paquete ITSM.
Estamos seguros que será una buena guía para quienes gusten del Análisis de Series de
Tiempo, y principalmente, para gente “principiante”, pues los ejemplos desarrollados están
resueltos con detalles. Además de que se manejaron ejemplos con datos de series de tiempo
reales.
Finalmente, como todo trabajo, estamos conscientes que la presente tesis está sujeta a
críticas y, desde luego, serán bienvenidas y agradecidas.

Análisis de Series de Tiempo
197
6. BIBLIOGRAFÍA
Box, G.E.P y Cox, D.R. (1964). An analysis of transformations. J. R. Stat. Soc.
Box, G.E.P, Jenkins, G.M y Reinsel, G.C (1994). Time Series Analysis, 3ra edición.
Prentice-Hall.
Brockwell P.J y Davis, R.A (1991). Time Series: Theory and Methods, 2da Edición.
Springer-Verlag.
Brockwell, P.J y Davis, R.A (2002). Introduction to Time Series and Forecasting.
Springer.
Davidson, J.H., Hendry, D.H., Srba, F. y Yeo, S (1978). Econometric Modelling of the
Aggregate Time-Series “Relationship between Consumers” Expenditure and Income in
the United Kingdom. The Economic Journal.
Davis, R.A, Chen, M y Dunsmuir, W.T.M (1995). Inference for MA(1) processes whit
a root on or near the unit circle. Probability and Mathematical Statistics 15.
Dempster, A.P, Laird, N.M y Rubin, D.B (1977). Maximum Likelihood from
incomplete data via the EM algorithm. J. R. Stat. Soc.
Durbin, J, A. (1960). The Fitting of Time Series Models. International Statist Inst, 28.
Engle, R.F y Granger, C.W.J (1987). Cointegration and error correction:
representation, estimation and testing. Econometrica 55.
Engle, R.F y B.S. Yoo (1987). Forecasting and Testing in Cointegrated Systems.
Journal of Econometrics 35.
Granger, C.W.J (1969). Investigating Causal Relations by Econometric Models and
Cross-Spectral Methods. Econometrica.
Graybill,F.A (1983). Matrices whit Applications in Statistics. Wadsworth.
Hamilton, J.D (1994). Time Series Analysis. Princeton University Press.
Hernández, A.R (2002). Tesis: Análisis de Cointegración. UNAM.
John E. Hanke, Arthur G. Reitsch. Pronósticos en los negocios. Prentice-Hall.
Jones, R.H (1978). Multivariate autorregression estimation using residuals. Academic
Press.
Loría, E. Econometría con aplicaciones. Prentice-Hall.
Lütkepohl, H (1993). Introduction To Multiple Time Series Analysis, 2da. Edición.
Springer-Verlag.
Mood, et. al (1974). Introduction to the Theory of Statistics. McGraw-Hill.
Phillips, P.C.B (1988). Time Series Regression whit a Unit Root. Econometrica 55.
Searle S.R (1997). Linear Models. John Wiley and Sons, Inc.
Stock, J.H (1987). Asymptotic Properties of Least Squares Stimators of Cointegrating
Vectors. Econometrica 55.
Wu, C.F.J (1983). On the convergence of the EM algorithm. Ann. Stat. 11.
Zivot, E y Wang, J (2003). Modeling Financial Time Series whit S-PLUS. Springer.
http://www.gestiopolis.com/recursos/documentos/fulldocs/ger1/serietiempo.htm#bi
http://www.gestiopolis.com/recursos2/documentos/fulldocs/eco/metrauni.htm
http://ciberconta.unizar.es
http://www.gestiopolis.com/recursos/documentos/fulldocs/ger1/serietiempo
http://www.banxico.org.mx
http://www.inegi.gob.mx
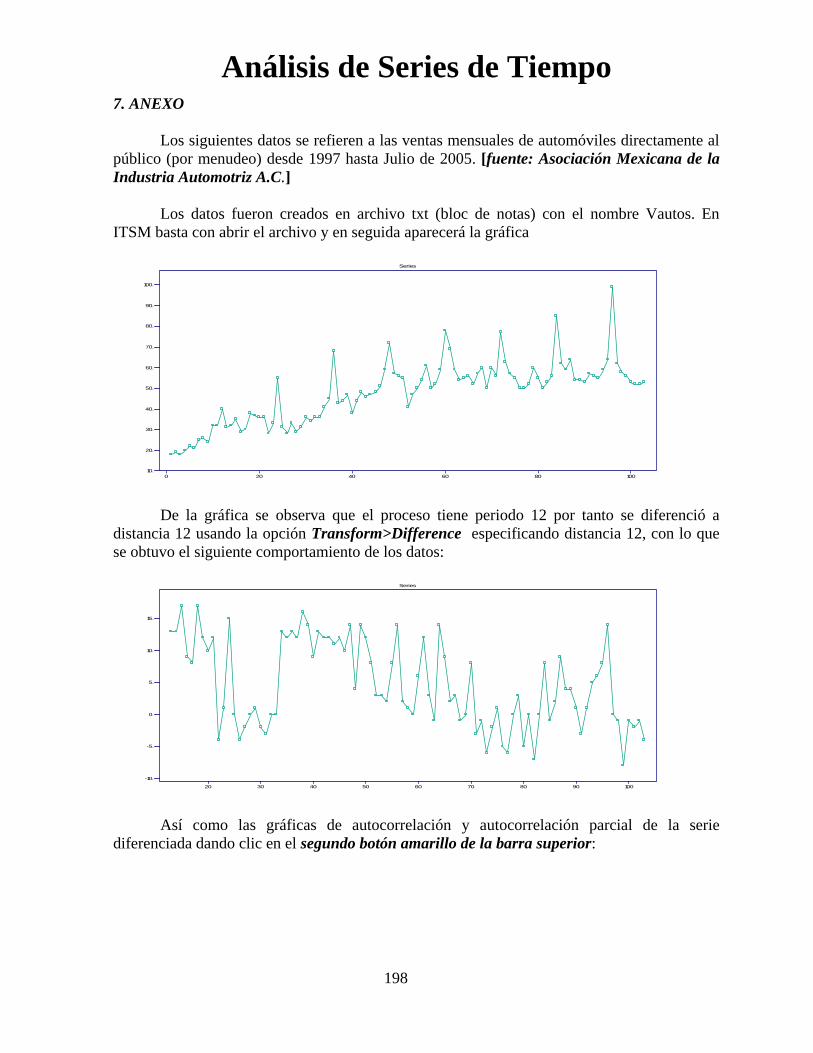
Análisis de Series de Tiempo
198
7. ANEXO
Los siguientes datos se refieren a las ventas mensuales de automóviles directamente al
público (por menudeo) desde 1997 hasta Julio de 2005. [fuente: Asociación Mexicana de la
Industria Automotriz A.C.]
Los datos fueron creados en archivo txt (bloc de notas) con el nombre Vautos. En
ITSM basta con abrir el archivo y en seguida aparecerá la gráfica
10.
20.
30.
40.
50.
60.
70.
80.
90.
100.
0 20 40 60 80 100
Series
De la gráfica se observa que el proceso tiene periodo 12 por tanto se diferenció a
distancia 12 usando la opción Transform>Difference especificando distancia 12, con lo que
se obtuvo el siguiente comportamiento de los datos:
-10.
-5.
0.
5.
10.
15.
20 30 40 50 60 70 80 90 100
Series
Así como las gráficas de autocorrelación y autocorrelación parcial de la serie
diferenciada dando clic en el segundo botón amarillo de la barra superior:
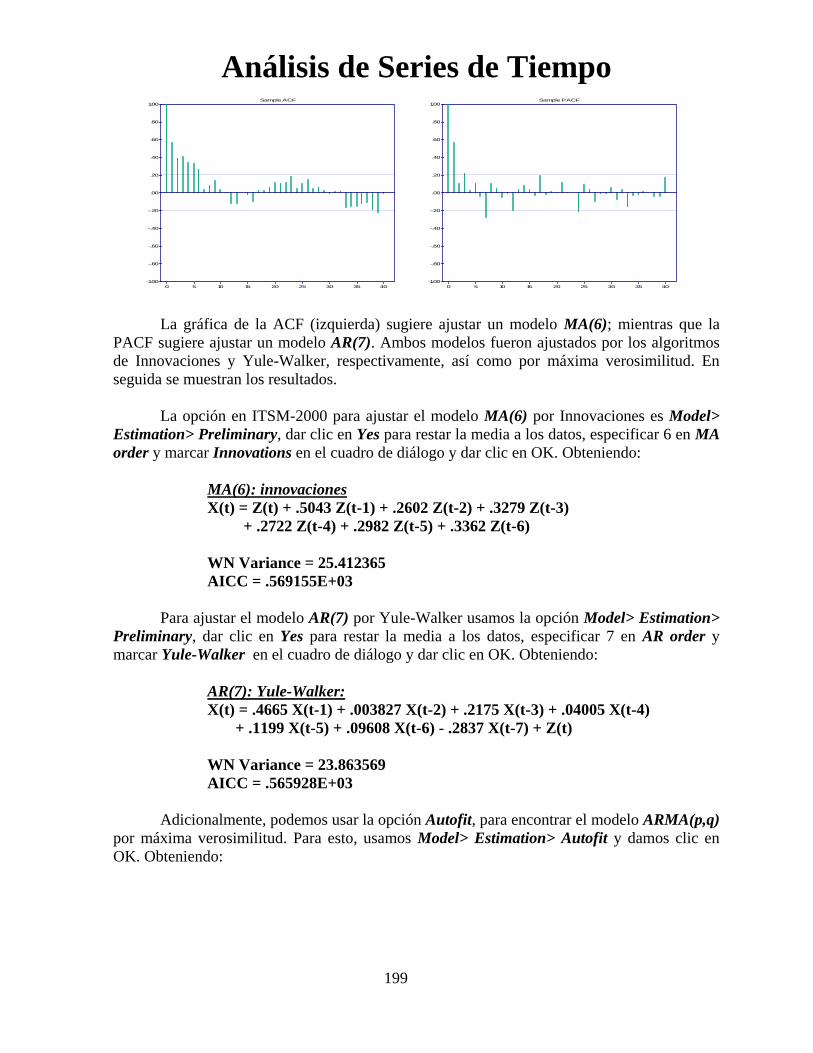
Análisis de Series de Tiempo
199
-1.00
-.80
-.60
-.40
-.20
.00
.20
.40
.60
.80
1.00
0 5 10 15 20 25 30 35 40
Sample ACF
-1.00
-.80
-.60
-.40
-.20
.00
.20
.40
.60
.80
1.00
0 5 10 15 20 25 30 35 40
Sample PACF
La gráfica de la ACF (izquierda) sugiere ajustar un modelo MA(6); mientras que la
PACF sugiere ajustar un modelo AR(7). Ambos modelos fueron ajustados por los algoritmos
de Innovaciones y Yule-Walker, respectivamente, así como por máxima verosimilitud. En
seguida se muestran los resultados.
La opción en ITSM-2000 para ajustar el modelo MA(6) por Innovaciones es Model>
Estimation> Preliminary, dar clic en Yes para restar la media a los datos, especificar 6 en MA
order y marcar Innovations en el cuadro de diálogo y dar clic en OK. Obteniendo:
MA(6): innovaciones
X(t) = Z(t) + .5043 Z(t-1) + .2602 Z(t-2) + .3279 Z(t-3)
+ .2722 Z(t-4) + .2982 Z(t-5) + .3362 Z(t-6)
WN Variance = 25.412365
AICC = .569155E+03
Para ajustar el modelo AR(7) por Yule-Walker usamos la opción Model> Estimation>
Preliminary, dar clic en Yes para restar la media a los datos, especificar 7 en AR order y
marcar Yule-Walker en el cuadro de diálogo y dar clic en OK. Obteniendo:
AR(7): Yule-Walker:
X(t) = .4665 X(t-1) + .003827 X(t-2) + .2175 X(t-3) + .04005 X(t-4)
+ .1199 X(t-5) + .09608 X(t-6) - .2837 X(t-7) + Z(t)
WN Variance = 23.863569
AICC = .565928E+03
Adicionalmente, podemos usar la opción Autofit, para encontrar el modelo ARMA(p,q)
por máxima verosimilitud. Para esto, usamos Model> Estimation> Autofit y damos clic en
OK. Obteniendo:
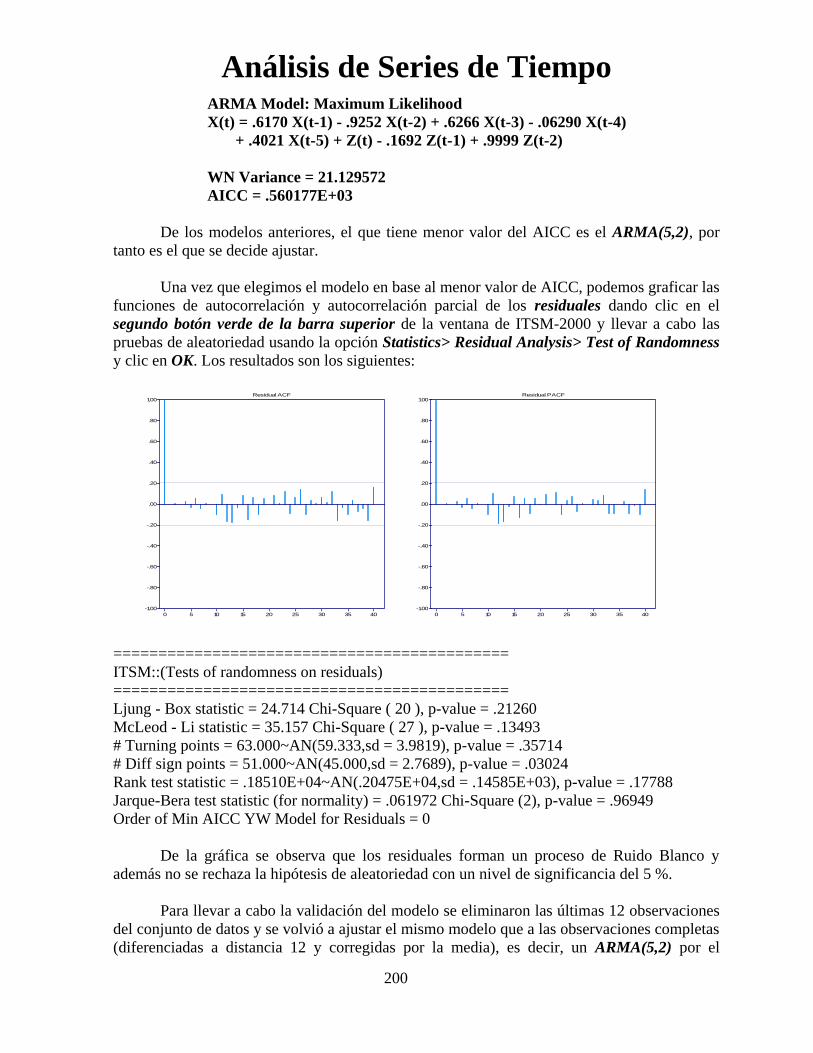
Análisis de Series de Tiempo
200
ARMA Model: Maximum Likelihood
X(t) = .6170 X(t-1) - .9252 X(t-2) + .6266 X(t-3) - .06290 X(t-4)
+ .4021 X(t-5) + Z(t) - .1692 Z(t-1) + .9999 Z(t-2)
WN Variance = 21.129572
AICC = .560177E+03
De los modelos anteriores, el que tiene menor valor del AICC es el ARMA(5,2), por
tanto es el que se decide ajustar.
Una vez que elegimos el modelo en base al menor valor de AICC, podemos graficar las
funciones de autocorrelación y autocorrelación parcial de los residuales dando clic en el
segundo botón verde de la barra superior de la ventana de ITSM-2000 y llevar a cabo las
pruebas de aleatoriedad usando la opción Statistics> Residual Analysis> Test of Randomness
y clic en OK. Los resultados son los siguientes:
-1.00
-.80
-.60
-.40
-.20
.00
.20
.40
.60
.80
1.00
0 5 10 15 20 25 30 35 40
Residual ACF
-1.00
-.80
-.60
-.40
-.20
.00
.20
.40
.60
.80
1.00
0 5 10 15 20 25 30 35 40
Residual PACF
============================================
ITSM::(Tests of randomness on residuals)
============================================
Ljung - Box statistic = 24.714 Chi-Square ( 20 ), p-value = .21260
McLeod - Li statistic = 35.157 Chi-Square ( 27 ), p-value = .13493
# Turning points = 63.000~AN(59.333,sd = 3.9819), p-value = .35714
# Diff sign points = 51.000~AN(45.000,sd = 2.7689), p-value = .03024
Rank test statistic = .18510E+04~AN(.20475E+04,sd = .14585E+03), p-value = .17788
Jarque-Bera test statistic (for normality) = .061972 Chi-Square (2), p-value = .96949
Order of Min AICC YW Model for Residuals = 0
De la gráfica se observa que los residuales forman un proceso de Ruido Blanco y
además no se rechaza la hipótesis de aleatoriedad con un nivel de significancia del 5 %.
Para llevar a cabo la validación del modelo se eliminaron las últimas 12 observaciones
del conjunto de datos y se volvió a ajustar el mismo modelo que a las observaciones completas
(diferenciadas a distancia 12 y corregidas por la media), es decir, un ARMA(5,2) por el
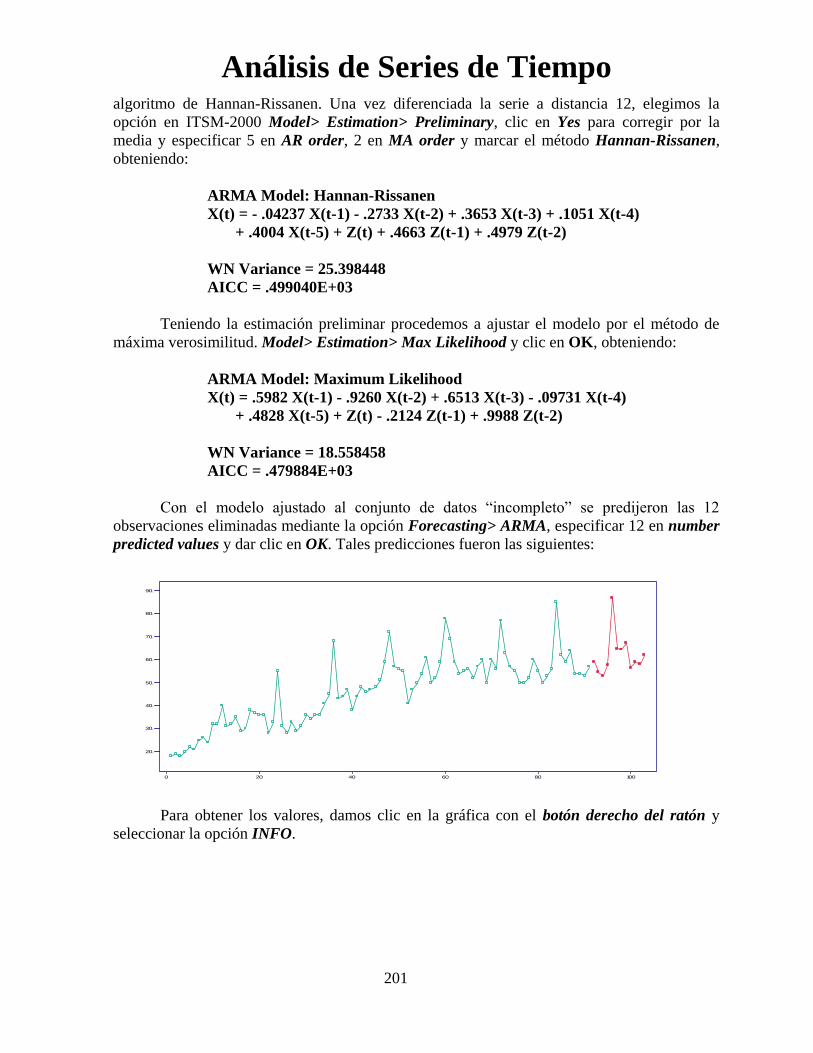
Análisis de Series de Tiempo
201
algoritmo de Hannan-Rissanen. Una vez diferenciada la serie a distancia 12, elegimos la
opción en ITSM-2000 Model> Estimation> Preliminary, clic en Yes para corregir por la
media y especificar 5 en AR order, 2 en MA order y marcar el método Hannan-Rissanen,
obteniendo:
ARMA Model: Hannan-Rissanen
X(t) = - .04237 X(t-1) - .2733 X(t-2) + .3653 X(t-3) + .1051 X(t-4)
+ .4004 X(t-5) + Z(t) + .4663 Z(t-1) + .4979 Z(t-2)
WN Variance = 25.398448
AICC = .499040E+03
Teniendo la estimación preliminar procedemos a ajustar el modelo por el método de
máxima verosimilitud. Model> Estimation> Max Likelihood y clic en OK, obteniendo:
ARMA Model: Maximum Likelihood
X(t) = .5982 X(t-1) - .9260 X(t-2) + .6513 X(t-3) - .09731 X(t-4)
+ .4828 X(t-5) + Z(t) - .2124 Z(t-1) + .9988 Z(t-2)
WN Variance = 18.558458
AICC = .479884E+03
Con el modelo ajustado al conjunto de datos “incompleto” se predijeron las 12
observaciones eliminadas mediante la opción Forecasting> ARMA, especificar 12 en number
predicted values y dar clic en OK. Tales predicciones fueron las siguientes:
20.
30.
40.
50.
60.
70.
80.
90.
0 20 40 60 80 100
Para obtener los valores, damos clic en la gráfica con el botón derecho del ratón y
seleccionar la opción INFO.
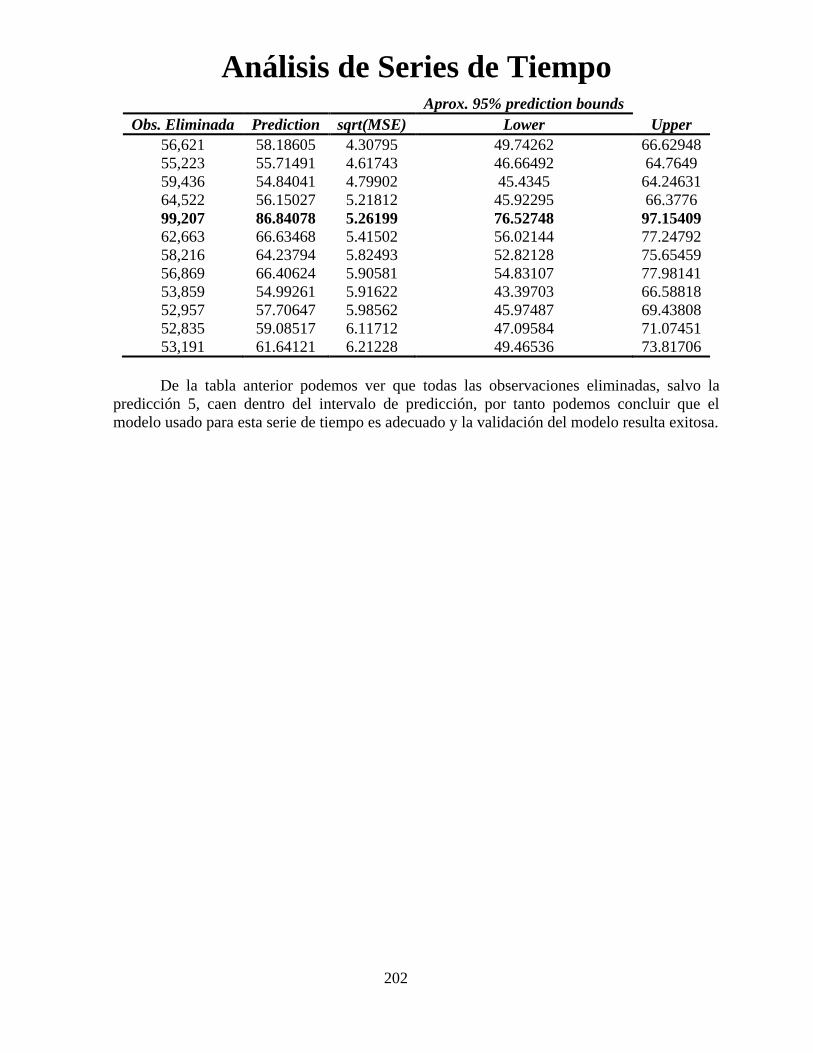
Análisis de Series de Tiempo
202
Aprox. 95% prediction bounds
Obs. Eliminada Prediction sqrt(MSE) Lower Upper
56,621 58.18605 4.30795 49.74262 66.62948
55,223 55.71491 4.61743 46.66492 64.7649
59,436 54.84041 4.79902 45.4345 64.24631
64,522 56.15027 5.21812 45.92295 66.3776
99,207 86.84078 5.26199 76.52748 97.15409
62,663 66.63468 5.41502 56.02144 77.24792
58,216 64.23794 5.82493 52.82128 75.65459
56,869 66.40624 5.90581 54.83107 77.98141
53,859 54.99261 5.91622 43.39703 66.58818
52,957 57.70647 5.98562 45.97487 69.43808
52,835 59.08517 6.11712 47.09584 71.07451
53,191 61.64121 6.21228 49.46536 73.81706
De la tabla anterior podemos ver que todas las observaciones eliminadas, salvo la
predicción 5, caen dentro del intervalo de predicción, por tanto podemos concluir que el
modelo usado para esta serie de tiempo es adecuado y la validación del modelo resulta exitosa.
Copyright © 2022 FDOKUMEN




















