
An Exploration of the Effects of State Granularity through (m, k) Real-Time Streams
15
An Exploration of the Effects of State Granularity through ðm; kÞ Real-Time Streams Yingxin Jiang, Student Member, IEEE, and Aaron Striegel, Member, IEEE Abstract—Real-time media servers are becoming increasingly important as the Internet supports more and more multimedia applications. In order to meet these ever increasing demands, real-time media servers will be responsible for supporting a large number of clients with a wide range of QoS requirements. While techniques to aggregate state information for scalability have been proposed in the literature such as with Differentiated Services; the per-stream effects of such aggregation are poorly understood. Based on the ðm; kÞ-firm model to schedule loss-tolerant streams, we explore the effects of aggregated state information in this paper and describe our scheme, called Granularity Aware ðm; kÞ Queue Management (GAQM). GAQM improves control over the tradeoff between scalability and per-stream QoS performance. Specifically, we identify the necessity of balancing aggregation groups according to characteristics such as relative deadlines. Another key finding of this work is that with proper biasing, the inaccuracy of aggregate state lends itself to burst scheduling rather than simply extending traditional scheduling mechanisms. This finding is profound in that the result is counterintuitive: less frequent scheduling leads to increased per-stream performance. We present detailed examples of GAQM and evaluate our work through simulation studies and Markov chain analysis. Index Terms—Real-time systems, dynamic failure, deadline-constraint scheduling, (m, k)-firm task scheduling, queue management. Ç 1 INTRODUCTION W ITH the proliferation of multimedia content on the Internet, a critical aspect of the user experience is the quality of service (QoS) delivered by the content infra- structure. Notably, the multimedia content possesses several common qualities in which data are often timely (must be delivered in a certain amount of time) [2], [3] and loss tolerant (a loss may not produce a noticeable quality drop) [4], [5]. The fundamentals of real-time scheduling offer important insight as QoS characteristics are easily mapped to their real-time counterparts. As the system load increases, the scheduling mechan- ism becomes critical to balance the loss between applica- tions as tolerated by their QoS requirements. For instance, an audio signal may miss vital portions of a talkspurt if a block of consecutive packets are dropped, but may perform satisfactorily if losses are adequately spaced. A loss-tolerant stream is said to experience dynamic failure when the number of lost packets over a window exceeds the maximum tolerable value [6]. In its simplest form, the goal of the scheduler is to minimize the dynamic failure or conversely maximize the received quality of service. A wide variety of schemes have been proposed in the literature to address the problem of scheduling loss tolerant multimedia streams [6], [7], [8], [9], [10], [11]. In this paper, we refer to scalability as outlined in [12], where scalability (specifically load scalability) indicates the ability of a system to handle growing traffic gracefully. In practice, the issue of scalability is to provide the maximum client load with satisfied QoS as excess capacity is immaterial if QoS is sacrificed. For many real-time media servers, the usage of a lightweight state mechanism such as DWCS [8] is sufficient. In contrast, when addressing the Internet where the scale can be considerably higher (millions or billions of flows), the amount of state dominates the scalability issue. Despite the fact that techniques for reducing state (fixed number of classes, etc.) are well known, such as Differentiated Services [13], the effects on per-stream quality are not well under- stood. Rather, such work on scalability has typically focused on the average performance of the class or group [14], [15], [16]. This encourages us to explore the following questions: what are the underlying properties that cause aggregation-based schemes to inefficiently schedule versus stream-based schemes? Furthermore, can these properties be ameliorated through how streams are aggregated, scheduled, and/or maintained? The issue of state aggregation and improving per-stream quality provides the motivation for this paper. While the application of this work to the network with its consider- able intricacies is the end goal, the real-time server provides an excellent controlled environment from which to observe the effects of state aggregation. Furthermore, loss-tolerant multimedia streams offer an ideal test case for exploring the impact of aggregated state information. To that end, this paper investigates the effects of state granularity on a real-time media server. Specifically, we propose a new queue management scheme, Granularity Aware ðm; kÞ Queue Management (GAQM), which offers novel insights regarding the importance of group organiza- tion and consideration for state imprecision. 784 IEEE TRANSACTIONS ON COMPUTERS, VOL. 58, NO. 6, JUNE 2009 . The authors are with the Department of Computer Science and Engineering, University of Notre Dame, 384 Fitzpatrick Hall, Notre Dame, IN 46556. E-mail: {yjiang3, striegel}@nd.edu. Manuscript received 4 Apr. 2008; revised 17 Oct. 2008; accepted 5 Nov. 2008; published online 18 Dec. 2008. Recommended for acceptance by S.H. Son. For information on obtaining reprints of this article, please send e-mail to: [email protected], and reference IEEECS Log Number TC-2008-04-0144. Digital Object Identifier no. 10.1109/TC.2008.225. 0018-9340/09/$25.00 ß 2009 IEEE Published by the IEEE Computer Society
-
Upload
independent -
Category
Documents
-
view
1 -
download
0
Transcript of An Exploration of the Effects of State Granularity through (m, k) Real-Time Streams

An Exploration of the Effects of StateGranularity through ðm; kÞ Real-Time Streams
Yingxin Jiang, Student Member, IEEE, and Aaron Striegel, Member, IEEE
Abstract—Real-time media servers are becoming increasingly important as the Internet supports more and more multimedia
applications. In order to meet these ever increasing demands, real-time media servers will be responsible for supporting a large
number of clients with a wide range of QoS requirements. While techniques to aggregate state information for scalability have been
proposed in the literature such as with Differentiated Services; the per-stream effects of such aggregation are poorly understood.
Based on the ðm; kÞ-firm model to schedule loss-tolerant streams, we explore the effects of aggregated state information in this paper
and describe our scheme, called Granularity Aware ðm; kÞ Queue Management (GAQM). GAQM improves control over the tradeoff
between scalability and per-stream QoS performance. Specifically, we identify the necessity of balancing aggregation groups
according to characteristics such as relative deadlines. Another key finding of this work is that with proper biasing, the inaccuracy of
aggregate state lends itself to burst scheduling rather than simply extending traditional scheduling mechanisms. This finding is
profound in that the result is counterintuitive: less frequent scheduling leads to increased per-stream performance. We present detailed
examples of GAQM and evaluate our work through simulation studies and Markov chain analysis.
Index Terms—Real-time systems, dynamic failure, deadline-constraint scheduling, (m, k)-firm task scheduling, queue management.
Ç
1 INTRODUCTION
WITH the proliferation of multimedia content on theInternet, a critical aspect of the user experience is the
quality of service (QoS) delivered by the content infra-structure. Notably, the multimedia content possessesseveral common qualities in which data are often timely(must be delivered in a certain amount of time) [2], [3] andloss tolerant (a loss may not produce a noticeable qualitydrop) [4], [5]. The fundamentals of real-time schedulingoffer important insight as QoS characteristics are easilymapped to their real-time counterparts.
As the system load increases, the scheduling mechan-
ism becomes critical to balance the loss between applica-
tions as tolerated by their QoS requirements. For instance,
an audio signal may miss vital portions of a talkspurt if a
block of consecutive packets are dropped, but may
perform satisfactorily if losses are adequately spaced. A
loss-tolerant stream is said to experience dynamic failure
when the number of lost packets over a window exceeds
the maximum tolerable value [6]. In its simplest form, the
goal of the scheduler is to minimize the dynamic failure or
conversely maximize the received quality of service.A wide variety of schemes have been proposed in the
literature to address the problem of scheduling loss tolerant
multimedia streams [6], [7], [8], [9], [10], [11]. In this paper,
we refer to scalability as outlined in [12], where scalability
(specifically load scalability) indicates the ability of a system
to handle growing traffic gracefully. In practice, the issue of
scalability is to provide the maximum client load with
satisfied QoS as excess capacity is immaterial if QoS is
sacrificed. For many real-time media servers, the usage of a
lightweight state mechanism such as DWCS [8] is sufficient.
In contrast, when addressing the Internet where the scale
can be considerably higher (millions or billions of flows),
the amount of state dominates the scalability issue. Despite
the fact that techniques for reducing state (fixed number of
classes, etc.) are well known, such as Differentiated Services
[13], the effects on per-stream quality are not well under-
stood. Rather, such work on scalability has typically focused
on the average performance of the class or group [14], [15],
[16]. This encourages us to explore the following questions:
what are the underlying properties that cause aggregation-based
schemes to inefficiently schedule versus stream-based schemes?
Furthermore, can these properties be ameliorated through how
streams are aggregated, scheduled, and/or maintained?
The issue of state aggregation and improving per-stream
quality provides the motivation for this paper. While the
application of this work to the network with its consider-
able intricacies is the end goal, the real-time server provides
an excellent controlled environment from which to observe
the effects of state aggregation. Furthermore, loss-tolerant
multimedia streams offer an ideal test case for exploring the
impact of aggregated state information.To that end, this paper investigates the effects of state
granularity on a real-time media server. Specifically, we
propose a new queue management scheme, Granularity
Aware ðm; kÞ Queue Management (GAQM), which offers
novel insights regarding the importance of group organiza-
tion and consideration for state imprecision.
784 IEEE TRANSACTIONS ON COMPUTERS, VOL. 58, NO. 6, JUNE 2009
. The authors are with the Department of Computer Science andEngineering, University of Notre Dame, 384 Fitzpatrick Hall, NotreDame, IN 46556. E-mail: {yjiang3, striegel}@nd.edu.
Manuscript received 4 Apr. 2008; revised 17 Oct. 2008; accepted 5 Nov. 2008;published online 18 Dec. 2008.Recommended for acceptance by S.H. Son.For information on obtaining reprints of this article, please send e-mail to:[email protected], and reference IEEECS Log Number TC-2008-04-0144.Digital Object Identifier no. 10.1109/TC.2008.225.
0018-9340/09/$25.00 � 2009 IEEE Published by the IEEE Computer Society

Further details on the contributions of this work can befound below:
. This paper identifies group organization (aggregatedstate) as most critically affected by variations indeadline. Unless specifically stated, the term deadlinein the paper means relative deadline. Then, the groupbalancing mechanism is proposed to reduce theimbalance in deadline variation among aggregations.Further, the maximum variation can be boundedthrough the usage of the Deadline Tolerance parameter.
. The burst sending mechanism is proposed to reducethe gap between per-group performance and per-stream performance. The finding of burst sending isprofound in that the result is counterintuitive: lessfrequent scheduling leads to increased per-streamperformance. In the simulation studies, we also showthat the burst sending mechanism becomes moreeffective as the system scales.
. This paper employs Markov chains to analyze whyaggregation-based schemes decrease per-streamperformance. In addition, the concept of HiddenFailure State is defined to capture the inaccuracy ofaggregation-based schemes.
. Simulation studies validate the effectiveness ofGAQM along with analytical results. Experimentalstudies also show the efficacy of GAQM.
The rest of the paper is structured as follows. Section 2details the related work to this paper. Next, Section 3describes the GAQM model with detailed schedulingexamples. Section 4 analyzes the gap between groupwiseperformance and streamwise performance for aggregation-based schemes and why burst sending can reduce theperformance gap. Then, Section 5 compares the perfor-mance of GAQM to other schemes for loss-tolerant applica-tions in a number of simulations. Finally, in Section 6, wepresent conclusions and discuss future research directions.
2 RELATED WORK
2.1 Per-Stream Loss-Tolerant Scheduling
In the literature, many fair queuing schemes have beendeveloped to ensure that each stream has fair access tonetwork resources, such as Generalized Processor Sharing[17], Fair Queueing [18], Weighted Fair Queueing [19], andStochastic Fairness Queueing [20]. However, in the case ofloss-tolerant applications, loss tolerance may be exploitedby the scheduler to improve performance. In short, a losstolerant aware scheduler spaces losses in an individualstream appropriately to preserve the loss-tolerance windowand avoid dynamic failure, i.e., violation of the loss toleranceand end user QoS.
One of the earlier loss-tolerant schemes developed is theDistance-Based Priority (DBP) scheme [6]. DBP capturesloss tolerance using the ðm; kÞ model and uses the notion ofdistance (state transitions to dynamic failure) to prioritizestreams. A stream in the ðm; kÞ model with m andk parameters states the following QoS requirement: forevery k consecutive packets in the stream, at least m packetsmust meet their deadlines. When the number of droppedpackets over k exceeds k�m, a condition known as dynamic
failure occurs. In the DBP scheme, a state is maintained foreach stream, and at any time, the packet from the streamwith the shortest distance to a failing state is selected fortransmission. The ðm; kÞ nature of the loss tolerance iscaptured via a k bit history requiring OðNkÞ memory,where N is the number of streams.
In [21], the authors mathematically analyzed the dy-namic failure rate for the DBP and the single priorityschemes. A further extension, EDBP (Enhanced DBP), wasstudied in [7] to let the scheduler discern the levels ofdynamic failure between different streams. Based on theDBP scheme, other approaches have been proposed for thescheduling problem in overloaded systems [22], [23]. Thework in [24], [25] studied the schedulability of task setswith (m, k) constraints and concluded that the resourcereservation to schedule such task sets in the worst case hasto be the same as the one without (m, k) constraints. Toreduce resource requirement, the relaxed (m, k)-firmconstraint model which considers the global transmissiondelay of at least m out of any k consecutive packets wasproposed in [26], [27]. In addition, the Double Leaks Bucket(DLB) mechanism is presented in [27] to guarantee relaxed(m, k)-firm constraints in networks.
In contrast to DBP, the later work of the DynamicWindow-Constrained Scheduling (DWCS) scheme [8] uti-lized the concept of the ðx; yÞ model where ðx; yÞ ¼ðk�m; kÞ. Through streamlined priority rules borrowingconcepts from EDF and the simplified integer statevariables of x and y, DWCS significantly improved thescalability of capturing per-stream loss tolerance. Hence,while DBP required significant space overhead for per-stream state, the space overhead of DWCS is reasonable,Oð2NÞ. Extensions to DWCS have been proposed in [10]and [11]. Due to the per-stream characteristic, the schedul-ing overhead for both DBP and DWCS schemes depends onthe number of existing streams in the system.
2.2 Aggregation-Based Loss-Tolerant Scheduling
Although DWCS possesses relatively lightweight scalingcosts, it still requires per-stream state cost. In contrast,most highly scalable schemes (Rate Monotonic Scheduling[28], [29], Earliest Deadline First, Class-Based Scheduling[30], [31], [32], [33]) ignore streamwise information andachieve scalability at the cost of per-stream performance.To examine the initial tradeoffs between scalability andper-stream QoS, the Dynamic Class-Based Queue Manage-ment model (DCQM) was proposed in [9].
The DCQM model uses the concept of a group to allowflexibility between the two extremes of per-stream QoS andper-class QoS by varying the number of streams that can bemultiplexed into one group.1 Fig. 1 shows the DCQM model.State information is maintained on a per-group basis withthe DBP or DWCS scheduler applied on the basis of groupstate. At any time, the packet from the group with either thehighest DBP or DWCS priority is selected for transmission.As groups are limited to a maximum size of G to controlaggregation, a proportional reduction of state would beachieved, yielding memory requirements of OðNkG Þ for DBP
JIANG AND STRIEGEL: AN EXPLORATION OF THE EFFECTS OF STATE GRANULARITY THROUGH ðm; kÞ REAL-TIME STREAMS 785
1. In this paper, we use term “aggregation based” and “group based”interchangeably.

andOð2NG Þ for DWCS. Thus, compared with DBP/DWCS, theDCQM scheme has less scheduling overhead as well.
As the number of streams multiplexed into the samegroup increases, the accuracy of the per-group statedecreases. Thus, although a given group may meet itsQoS requirements, the individual streams multiplexed intothis group may not meet their QoS requirements. Thisoccurs because the QoS received by the group does notrepresent the QoS received by the individual streamsthemselves. As a result, the more streams a group holds,the more the streamwise state information is hidden; hence,the higher dynamic failure rate the system receives. Figs. 2and 3 present the performance of DCQM whose simulationsetup is described in Section 5.2.2
In Fig. 2, which shows the effect of G (the number ofstreams a group can hold) on the dynamic failure rate forthe DCQM scheduler, we can see that the DCQM scheduleroffers minimal control on the tradeoff between scalability/granularity and QoS performance, even when G is small.For example, since the scalability for G ¼ 8 is worse thanthe scalability for G ¼ 50, the dynamic failure rate for G ¼ 8should be lower than the one for G ¼ 50. However, in theDCQM model, they receive a similar QoS performance. Oneof the reasons for this ineffective tradeoff control betweenscalability/granularity and QoS performance lies in the fact
that streams are multiplexed into groups blindly, withoutconsideration for their characteristics.
Fig. 3 shows the standard deviation of deadlines of per-group streams with the increase of G in the DCQM model:after G is greater than 8, the standard deviation of thedeadlines of per-group streams is quite high. If the streamsmultiplexed into the same group have significantly differ-ent deadlines, the streams with lax deadlines will havebetter performance than the streams with tight deadlineswhen FIFO is used inside of a group. After dropping thetight-deadline packets, the packets with lax deadlines willstay at the head of the queue. Thus, each time the schedulerchooses the packet from the queue of the group to transmit,the packets with lax deadlines will have a higher prob-ability of being at the head of the queue. Since the stateinformation of the streams is mapped into a single piece ofgroup state information, the group cannot differentiatewhich kind of performance is received by an individualstream belonging to it.
3 GAQM (GRANULARITY AWARE ðm; kÞ QUEUE
MANAGEMENT) OVERVIEW
To study the effects of state aggregation on per-stream QoSperformance and improve per-stream performance, wepropose the model of GAQM (Granularity Aware ðm; kÞQueue Management) which is based on DCQM shown inFig. 4. Within a given loss class i, streams of class i aresubdivided into groups limited by a maximum size of G. Byvarying G from 1 to 1, the scheduler can change from apure stream-wise DBP/DWCS to pure class-based schedul-ing. For simplicity in the paper, we assume that only a singleclass exists and that only streams with the same ðm; kÞ valuewould be assigned to one group whose ðm; kÞ value is set tobe the same as its streams. The overarching scheduler (DBP,DWCS) is presented with the groups for which state(history) is maintained on a groupwise basis. Compared toDCQM, GAQM incorporates the following aspects:
. Group balancing: The group balancing algorithm isinvoked on a stream join to correct any unbalanced
786 IEEE TRANSACTIONS ON COMPUTERS, VOL. 58, NO. 6, JUNE 2009
2. In Section 5.2, Figs. 16 and 18 compare DCQM with GAQM under thesame simulation setup.
Fig. 1. DCQM model proposed in [9].
Fig. 2. Dynamic failure rate of the DCQM-based scheduler.
Fig. 3. Standard deviation of deadlines for per-group streams in the
DCQM model.

stream distributions among groups. Imbalance ofgroups include both cardinality imbalance (groupsize) and characteristic imbalance (deadline).
. Deadline tolerance (DT ): Deadline Tolerance is used torestrict deviation in deadlines for streams multi-plexed into the same group. By restricting thedeviation in deadlines, a quasi-deadline ordering isachieved despite using an FIFO queue.
. Burst sending: To further offset the inaccuracy ofgroup states, the burst sending mechanism is invokedafter the DBP/DWCS scheduler selects the groupwith the highest priority for transmission. By trans-mitting multiple packets from the sending groupconsecutively, this mechanism gives multiple streamsinside one group an opportunity to send packet.
3.1 Scheduling
Scheduling in GAQM is similar to the one in the original
DCQM model [9]. Streams are aggregated into groupsn and
history (DBP or DWCS) is maintained on a groupwise basis.
Scheduling is performed from the perspective of groups,
and each group has an FIFO queue to store packets that
belong to it. As packets are scheduled or dropped from a
group, the groupwise history is updated appropriately. Ties
in groupwise DBP/DWCS priority are resolved by choos-
ing the group where the deadline of the first packet in its
FIFO queue is earliest.While GAQM conceptually operates similar to DCQM,
one of the key differences occurs in how groups are selected
for individual streams. Unlike DCQM, GAQM does not
assign streams to groups simply based on similar loss
tolerances. Rather, GAQM applies stream join and group
balance techniques that significantly reduce the penalty
associated with groupwise state aggregation.
3.2 Stream Joining
When a new stream S begins to send packets in a media
server, GAQM will select a group for the stream within the
QoS class of S. If there are open groups3 existing within the
class, the GAQM scheduler finds the group Gopen, which has
the closest average deadline to the new stream. The newstream S is allocated to Gopen, if
jdðGopenÞ � dðSÞj � DT;
where dðGopenÞ, the deadline of group Gopen, is the averagedeadline for streams belonging to Gopen, dðSÞ is the deadlineof stream S, and DT is defined as the Deadline Toleranceparameter. Otherwise, a new group will be created forstream S.
After S joins a group, to decrease the intergroupimbalance (group size) and the intragroup imbalance(deadline), the group balancing algorithm is invokedbetween the group holding S and the group with the mostsimilar deadline to S in the same class. The number ofgroups depends on the number of streams, G (group size),and DT (deadline tolerance). Fig. 5 details the algorithm forstream joining.
For each group in GAQM, an FIFO queue is employed tominimize queue insertion cost. While a more intelligentqueue order scheme such as EDF could offer betterperformance, the insertion cost incurs significant overhead.Notably, schemes such as DBP and DWCS can employ anFIFO scheme without penalty as queues are maintained ona per-stream basis, thus implying a de facto ordering ofrelative deadline provided that the relative deadline is aconsistent stream characteristic.
To balance the effect of the FIFO queue, DT is used tocontrol the deviation of deadlines for streams that share thesame group, and hence, share the same queue. If DT is toolarge, stream deadlines can vary considerably, resulting inthe potential for significant order inaccuracies, i.e., packetswith a later deadline are served first. The net effect is asignificant increase in dynamic failure rate as additionalstreams are multiplexed into the group.
By limiting DT , a quasi-deadline ordering is imposed onthe queue such that arrival time ordering of packets willhave a strong probability of implying deadline ordering.Stated formally, given two packets Px and Py belonging to a
JIANG AND STRIEGEL: AN EXPLORATION OF THE EFFECTS OF STATE GRANULARITY THROUGH ðm; kÞ REAL-TIME STREAMS 787
Fig. 4. GAQM model.
Fig. 5. Stream joining algorithm in GAQM.
3. A group is an open group if the number of streams in this group is lessthan G. A group is a closed group if the number of streams that this group isholding equals G.

stream or streams that share the same group and given thatPy arrives after Px, the following relationship should hold:
limDT!0
ProbðdðPxÞ < dðPyÞÞ ¼ 1;
where dðPxÞ is the deadline of packet Px and dðPyÞ is thedeadline of packet Py. In short, as DT is tightened, theordering of the queue will approach that of relativedeadline. An appropriate DT value will ensure that if agroup is selected for scheduling, the packet at the head ofthe queue will be the packet with the lowest deadline.
However, while a low DT value will ensure an implicitdeadline ordering without the insertion cost, a value of DTthat is too low will prevent stream aggregation fromoccurring, thus defeating the entire purpose of streamaggregation. When the number of streams becomes larger,the importance of DT decreases as the group balancingmechanism has minimized the intragroup imbalance.
3.3 Group Balancing
As explained in Section 3.2, if the streams multiplexed intoone group have significantly different deadlines, thepackets in the groupwise FIFO queue have an increasedchance of being out of deadline order. The following showshow a DBP-based scheduler4 works when the streams withdifferent deadlines are multiplexed into one group.
Example 1. Consider a real-time application with twogroups, G0 and G1 (G ¼ 2) and four periodic streams, S0,S1, S2, and S3. The streams and the groups have the sameðm; kÞ value (2,3). The periods of S0, S1, S2, and S3 are 2,2, 3, and 3, respectively. The deadlines of S0, S1, S2, andS3 are 3, 8, 3, and 8, respectively. Streams S0 and S1
belong to G0; S2 and S3 belong to G1.
Fig. 6 shows the resulting schedule of this DBP-basedscheduler. At t ¼ 0, the DBP values5 of G0 and G1 are equal
to 0 since both groups are experiencing a dynamic failure.Until t ¼ 19, the number of dynamic failures in G0 and G1
are 0 and 1, respectively. However, the actual number ofdynamic failures in S0, S1, S2, and S3 are 2, 0, 4, and 0.6
Note, the DBP values for streams in Fig. 6 are not used bythe scheduler but to indicate the instantaneous ðm; kÞ statefor individual streams. In group G0, since S1 has a more laxdeadline than S0, more packets belonging S0 are dropped.In addition, there are several transmitted packets of S1
which are unnecessarily scheduled since the servicerequirement of S1 is (2,3). Most importantly, the exampleillustrates how the state information of group G0 representsthe average service received by its members, not the actualservices received by the individual streams. The cause ofthe intragroup imbalance can be directly attributed to thedifferences in deadlines of S0 and S1. Similarly, in group G1,because S3 has a more lax deadline than S2, S3 receives abetter performance than S2 as well.
In GAQM, the group balancing algorithm is used tobalance groups that belong to the same class. We consider twogroups, G0 and G1, to do the group balancing. G0 containsn streams S01, S02; . . . ; S0n with deadlines d01, d02; . . . ; d0n,respectively; G1 contains m streams S11, S12; . . . ; S1m withdeadlines d11, d12; . . . ; d1m, respectively.
The group balancing algorithm first increasingly sorts allstreams belonging to G0 and G1 by their deadlines andproduces d1, d2; . . . ; dmþn, where di � dj if i < j. Next,streams Sðd1Þ; . . . ; Sðdbmþn2 cÞ are allocated to G0; streamsSðdbmþn2 þ1cÞ; . . . ; SðdmþnÞ are allocated to G1. The deadlines ofG0 and G1 can be computed as
dðG0Þ ¼Xbmþn2 c
i¼1
di
0@
1A� mþ n
2
j k� �;
dðG1Þ ¼Xmþn
i¼bmþn2 cþ1
di
0@
1A� mþ n
2
l m� �:
Note that the packets for moved streams are not copied,only the queue routing information for those streams ischanged. Example 2 shows how the DBP-based schedulerworks when the group balancing mechanism is employedwith the same scenario as Example 1.
Example 2. In contrast to DCQM, the GAQM model attemptsto put the streams with similar deadlines into the samegroup through the group balancing algorithm when S0,S1, S2, and S3 are added into the server: S0 and S2 aremultiplexed into G0; S1 and S3 are multiplexed into G1.
Fig. 7 shows the resulting schedule of this scheme. Untilt ¼ 19, the number of dynamic failures in G0 and G1 are 0and 2, respectively. The number of dynamic failures in S0,S1, S2, and S3 are 0, 2, 0, and 0, respectively. Since thestreams multiplexed into one group have similar dead-lines, the state information of a group reflects the stateinformation of its streams more accurately. In other words,because the packets waiting in the queue of a group to betransmitted have similar deadlines no matter which
788 IEEE TRANSACTIONS ON COMPUTERS, VOL. 58, NO. 6, JUNE 2009
Fig. 6. Schedule for Example 1.
4. This scheduler is, in fact, the DCQM scheduler where streams can beadded into any open group with the same ðm; kÞ setting.
5. The DBP value captures loss tolerance by using the notion of distancefrom current state to dynamic failure state. For example, DBP ðGÞ0 ¼ 0means group G0 is experiencing a dynamic failure; DBP ðGÞ0 ¼ 1 meansgroup G0 will have a dynamic failure if next packet is dropped.
6. For a stream or a group, the dynamic failure rate is not counted untilthere are at least m packets transmitted.

streams they belong to, every stream in one group has asimilar opportunity to transmit packets which results in abetter QoS performance.
3.4 Burst Sending
Although group balancing decreases intragroup imbalancein terms of stream deadline, the scheduler cannot achievethe optimal per-stream performance as it focuses onminimizing the dynamic failure rates for groups ratherthan streams. To further offset inaccuracy in group states,we propose the burst sending mechanism shown in Fig. 8. Inthis mechanism, when a group is selected to send packets,unlike the original group-based schemes where only onepacket is sent, the burst sending algorithm sends multiplepackets from this group consecutively without updating theðm; kÞ state for any group. The maximum number ofpackets that can be transmitted at one time is defined asthe Burst Window parameterB. The default value of B isequal to the actual number of streams in the sending group.
The intuition behind a burst sending of B ¼ jGxj packets7
is that since consecutive packets in the FIFO queue of onegroup may not belong to the same stream after groupbalancing, transmitting B packets at one time from thesending group may give multiple streams an opportunity tosend packets, which offsets the stream state inaccuracy ingroup states. In Section 5, simulation studies will show thatthe burst sending mechanism achieves a significant im-provement in scalability together with an increase in per-stream performance. Interested readers can refer to [34] forexperimental studies. Next, we expand the previous exam-ples to demonstrate the effectiveness of the burst sendingmechanism.
Example 3. Consider the same scenario of Example 2 withthe burst sending mechanism. The scheduling result isshown in Fig. 9. Since burst sending algorithm does noteffect the way of grouping streams in GAQM, in thisexample, S0 and S2 still belong to G0; S1 and S3 belong toG1. Until t ¼ 19, although the number of dynamic
failures on group G0 and G1 are 2 and 1, respectively,there are no dynamic failures for individual streams. TheDBP values of groups/streams in Fig. 9 are not generatedby the GAQM scheme, but to show the instantaneousðm; kÞ state of individual groups/streams. For example,at t ¼ 12 and t ¼ 13, packets P5 and P6 of stream S0 aresent consecutively through burst sending. Although theDBP state of G0 and G1 are not updated by GAQM dueto burst sending, DBP ðGÞ1 is changed from 2 to 1 att ¼ 12 to reflect the loss of packet P2 in stream S1.
4 ANALYZING AGGREGATED GROUP STATE
In aggregation-based schemes, the state presented to thescheduler represents the cumulative performance of theaggregate rather than the performance of individualstreams. Hence, per-stream accuracy is lost and thescheduler receives a coarser view of choices for schedul-ing. This section analyzes why traditional aggregation-based schemes cannot achieve the optimal per-stream
JIANG AND STRIEGEL: AN EXPLORATION OF THE EFFECTS OF STATE GRANULARITY THROUGH ðm; kÞ REAL-TIME STREAMS 789
Fig. 7. Schedule for Example 2 with group balancing. Fig. 8. Burst sending algorithm in GAQM.
Fig. 9. Schedule for Example 3 with group balancing and burst sending.
7. jGxj is the actual number of streams in the sending group Gx.

performance. Then, through examples, it explains thereason for the improvement of the burst sending mechan-ism on per-stream performance.
To better illustrate the inaccuracy of aggregated states,we first examine the direct effect of aggregation throughsimple examples. Consider a simple example, as shown inFig. 10a, where two streams, S0 and S1, with the sameperiod and deadline belong to group G0. S0, S1, and G0
have the ðm; kÞ value ð1; 2Þ. Suppose the service rate for G0
is 0.5 such that half of packets in G0 will be dropped. As theaggregation-based scheduler cannot distinguish S0’s pack-ets from S1’s, to satisfy the ð1; 2Þ constraint for G0, thescheduler drops every other packet from G0. However,from the perspective of streams, this scheduling is notoptimal as all packets from S0 are transmitted, which is notnecessary, and all packets from S1 are dropped. Thus, theaverage dynamic failure rate for streams is 50 percent. Inthis simple scenario, streams in the same group have staticpriorities to transmit packets. For example, if S1 arrives atG0 before S2, packets from S1 always have higher prioritiesto transmit than the ones from S2 with the same generationtime. In Section 5, we will show the simulation results,where packets are enqueued randomly to break ties.
In contrast, consider another scheduling mechanism, theburst sending mechanism, whose scheduling is shown inFig. 10b. WhenG0 has the highest priority to transmit packets,rather than just sending one packet, the scheduler sends twopackets from G0 without invoking DBP/DWCS schedulerand state update on each packet. Although this methodincreases the perceived dynamic failure rate for G0 from0 percent to 25 percent, there is no actual dynamic failure inS0
and S1. Since the ultimate objective is to minimize per-streamdynamic failure rate, the latter method achieves betterperformance.
We have described the burst sending mechanism whichwas used in Fig. 10b in Section 3.4. In this section, wemainly focus on analyzing the reason why the originalaggregation-based schemes cannot provide the optimalperformance for streams in simple cases where streams inthe same group have the same period/deadline. Then, in
Section 5, we will show the simulation results for more
general cases, where streams with different periods/dead-
lines are combined together. As with many loss-tolerant
applications, the interval of two consecutive packets from
the same stream determines the deadline by which the
previous packet must be serviced. In line with existing
literature [35], [36], we assume that the period and deadline
parameters for the same stream have the same value.Consider a simple scenario where two streams, S0 and S1,
with the same period/deadline are aggregated into the same
group G0, both streams and group have the same ðm; kÞvalue ð1; 2Þ (examples in Fig. 10 are specific cases of this
scenario with the service rate for G0 being 0.5). Since the
states of streams follow the Markov chain in the DBP scheme
[21], the states of groups follow the Markov chain as well.
Fig. 11 shows the Markov chain for groupG0, which consists
of four states, MM, Mm, mM and mm, where mm is the
failure state. The IDs of states are listed beside the states. pi is
the probability of a packet at state i, missing its deadline
such that the group transits to another state. 1� pi is the
probability of a packet at state i meeting its deadline. For
example, when the group is in stateMm, p2 is the probability
that the next packet misses its deadline and enters state mm.
The transition probability matrix can be stated as
P ¼
1� p1 p1 0 00 0 1� p2 p2
1� p3 p3 0 00 0 1� p4 p4
0BB@
1CCA: ð1Þ
Since two streams in G0 have the same parameters, by
enlarging G0’s states to include one more packet, we can
derive the probability of failure state mm for individual
streams. We use �1, �2, �3, and �4 to express the steady-state
distribution of the Markov chain shown in Fig. 11. As the
probability of steady state MM of G0 is �1 and the
probability for G0 sending another packet with state MM
is 1� p1, the probability for G0 to have state MMM is equal
to �1 � ð1� p1Þ. Similarly, by combining the steady-state
distribution of G0 and the transition probability matrix (1),
we can derive the probabilities for enlarged steady states
with three consecutive packets in G0, as shown in Table 1.
790 IEEE TRANSACTIONS ON COMPUTERS, VOL. 58, NO. 6, JUNE 2009
Fig. 10. Two different methods for scheduling.
Fig. 11. Markov chain for the group with ðm; kÞ equal to ð1; 2Þ.

As streams S1 and S2 have the same period, in eachenlarged state, the first and third packets belong to the samestream. Thus, to compute the probability of failure state forstreams, we need to compute the probability for enlargedstates mMm and mmm. In these two states, both the firstand the third packets fail to meet their deadlines whichcauses individual streams to enter failure state mm. There-fore, the probability of the failure state for streams is
Pfail ¼ �3 � p3 þ �4 � p4: ð2Þ
Aggregation-based scheduling tends to minimize �4 withoutconsidering the value of �3 since �4 is the probability of thefailure state on groupwise basis. Thus, scheduling to minimizedynamic failure rates for groups may cause large dynamic failurerates for streams. We call mM the hidden failure state, which isnot a failure state for groups but provides the possibility ofcausing individual streams into failures.
Similarly, by computing the probabilities for enlargedsteady states with four consecutive packets on the Markovchain of one group, we can derive the probability of streamfailure states for G ¼ 3:
Pfail ¼ �3 � ð1� p3Þ � pi þ �3 � p3 � pjþ �4 � ð1� p4Þ � pk þ �4 � p4 � pl;
ð3Þ
where pi, pj, pk, and pl are the probabilities of missingpackets at steady state mMM, mMm, mmM, and mmm,respectively, when the steady states of groups are enlargedto include three consecutive packets. Although the compu-tations of Pfail in equations (3) and (2) are different, both �4
(failure probability) and �3 (hidden failure probability) areneeded.
To validate the analysis, we use equation (2) to computethe per-stream dynamic failure rate for the example inFig. 10a, which tries to achieve the optimal performance ongroup basis (no burst sending). Since every other packet isdropped, there are no states MM and mm. The Markovchain for the group is shown in Fig. 12, where p3 ¼ 1 and�3 ¼ 0:5. Thus, the per-stream dynamic failure rate is equalto �3 � p3 þ �4 � p4 ¼ 0:5� 1 ¼ 0:5.
Similarly, we use (2) to compute the per-stream dynamicfailure rate for the example in Fig. 10b, where the burstsending mechanism is employed. Since the service rate ofG0
is 0.5, half of its packets will be dropped. When group G0 ischosen as the sending group, two packets are sent from G0.Then, the next two packets miss their deadlines and aredropped. The Markov chain for groupG0 is shown in Fig. 13,where p1 ¼ p2 ¼ 1 and p3 ¼ p4 ¼ 0. The steady-state dis-tribution of this Markov chain is �1 ¼ �2 ¼ �3 ¼ �4 ¼ 0:25.By using (2) to compute the per-stream dynamic failure rate,we have �3 � p3 þ �4 � p4 ¼ 0� 0:25þ 0� 0:25 ¼ 0. Thus,compared with the original group-based scheme shown inFig. 10a, burst sending in this example achieves betterperformance for streams.
While we concur that the Markov analysis is quiterestrictive, the purpose of the analysis was to shed light onwhy optimal scheduling on a group basis does not result inan optimal scheduling for individual streams, and further-more, why burst sending can improve streamwise perfor-mance. Since the computation of the dynamic failure ratefor aggregated streams depends on G and (m, k), it isnontrivial to do the analysis on general cases, which is anopen topic for future work.
5 SIMULATION STUDIES
In the simulation studies, first we validate the derivation ofper-stream performance for aggregation-based schedulingin the simple scenario. Then, we evaluate the performanceof the proposed mechanisms in GAQM in a more generalscenario. The dynamic failure rate is used as the performancemetric with the goal to decrease the dynamic failure rate aslow as possible in the presence of aggregation-oriented
JIANG AND STRIEGEL: AN EXPLORATION OF THE EFFECTS OF STATE GRANULARITY THROUGH ðm; kÞ REAL-TIME STREAMS 791
TABLE 1Probabilities of Enlarged Steady States for G0
Fig. 12. Markov chain for the example in Fig. 10a. Fig. 13. Markov chain for the example in Fig. 10b.
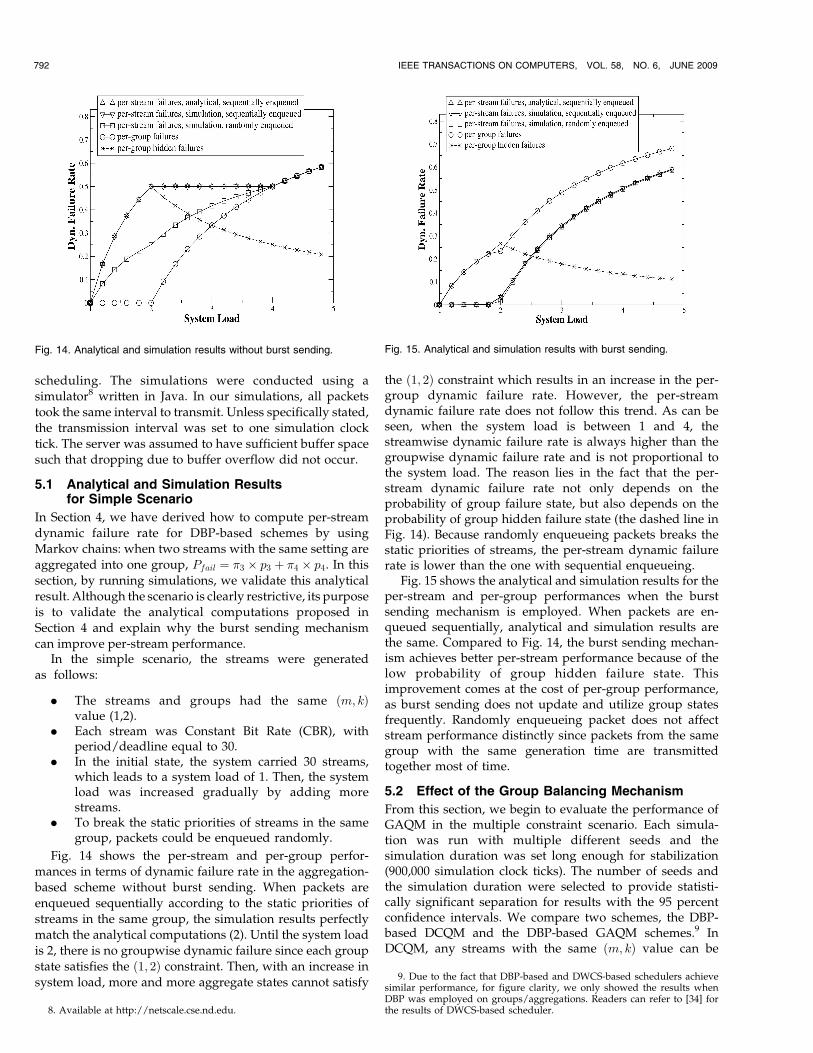
scheduling. The simulations were conducted using asimulator8 written in Java. In our simulations, all packetstook the same interval to transmit. Unless specifically stated,the transmission interval was set to one simulation clocktick. The server was assumed to have sufficient buffer spacesuch that dropping due to buffer overflow did not occur.
5.1 Analytical and Simulation Resultsfor Simple Scenario
In Section 4, we have derived how to compute per-streamdynamic failure rate for DBP-based schemes by usingMarkov chains: when two streams with the same setting areaggregated into one group, Pfail ¼ �3 � p3 þ �4 � p4. In thissection, by running simulations, we validate this analyticalresult. Although the scenario is clearly restrictive, its purposeis to validate the analytical computations proposed inSection 4 and explain why the burst sending mechanismcan improve per-stream performance.
In the simple scenario, the streams were generatedas follows:
. The streams and groups had the same ðm; kÞvalue (1,2).
. Each stream was Constant Bit Rate (CBR), withperiod/deadline equal to 30.
. In the initial state, the system carried 30 streams,which leads to a system load of 1. Then, the systemload was increased gradually by adding morestreams.
. To break the static priorities of streams in the samegroup, packets could be enqueued randomly.
Fig. 14 shows the per-stream and per-group perfor-mances in terms of dynamic failure rate in the aggregation-based scheme without burst sending. When packets areenqueued sequentially according to the static priorities ofstreams in the same group, the simulation results perfectlymatch the analytical computations (2). Until the system loadis 2, there is no groupwise dynamic failure since each groupstate satisfies the ð1; 2Þ constraint. Then, with an increase insystem load, more and more aggregate states cannot satisfy
the ð1; 2Þ constraint which results in an increase in the per-group dynamic failure rate. However, the per-streamdynamic failure rate does not follow this trend. As can beseen, when the system load is between 1 and 4, thestreamwise dynamic failure rate is always higher than thegroupwise dynamic failure rate and is not proportional tothe system load. The reason lies in the fact that the per-stream dynamic failure rate not only depends on theprobability of group failure state, but also depends on theprobability of group hidden failure state (the dashed line inFig. 14). Because randomly enqueueing packets breaks thestatic priorities of streams, the per-stream dynamic failurerate is lower than the one with sequential enqueueing.
Fig. 15 shows the analytical and simulation results for theper-stream and per-group performances when the burstsending mechanism is employed. When packets are en-queued sequentially, analytical and simulation results arethe same. Compared to Fig. 14, the burst sending mechan-ism achieves better per-stream performance because of thelow probability of group hidden failure state. Thisimprovement comes at the cost of per-group performance,as burst sending does not update and utilize group statesfrequently. Randomly enqueueing packet does not affectstream performance distinctly since packets from the samegroup with the same generation time are transmittedtogether most of time.
5.2 Effect of the Group Balancing Mechanism
From this section, we begin to evaluate the performance ofGAQM in the multiple constraint scenario. Each simula-tion was run with multiple different seeds and thesimulation duration was set long enough for stabilization(900,000 simulation clock ticks). The number of seeds andthe simulation duration were selected to provide statisti-cally significant separation for results with the 95 percentconfidence intervals. We compare two schemes, the DBP-based DCQM and the DBP-based GAQM schemes.9 InDCQM, any streams with the same ðm; kÞ value can be
792 IEEE TRANSACTIONS ON COMPUTERS, VOL. 58, NO. 6, JUNE 2009
Fig. 14. Analytical and simulation results without burst sending. Fig. 15. Analytical and simulation results with burst sending.
8. Available at http://netscale.cse.nd.edu.
9. Due to the fact that DBP-based and DWCS-based schedulers achievesimilar performance, for figure clarity, we only showed the results whenDBP was employed on groups/aggregations. Readers can refer to [34] forthe results of DWCS-based scheduler.

aggregated into one group [9]. In GAQM, only streamswith the same (m, k) value can be aggregated into thesame group.
In the multiple constraint scenario, the streams for thesimulations were generated as follows:
. The ðm; kÞ value of each stream equaled (4,6) or(7,10) with the ratio of 1:1.
. Streams were CBR. Each stream was characterizedby the stream duration and the stream period (pi)which was equal to its relative deadline. The arrivalof the streams followed Poisson distribution with amean interarrival time of 50.
. For an individual stream, the period of generatingpackets were exponentially distributed with a meanof 110. The duration of a stream followed exponen-tial distribution with a mean of 4,000.
Fig. 16 shows the stream dynamic failure rate of theDBP-based DCQM scheduler and the DBP-based GAQMscheduler with the group balancing mechanism beingeffective. To isolate the effect of group balancing, DT ¼ 1(Deadline Tolerance) and the bursting sending mechanismwas not employed. With an increase of the group size inFig. 16, the dynamic failure rate increases in both theDCQM and the GAQM models. The change in dynamicfailure rate as the group size G increases can be explainedby the variation in the number of groups, as shown inFig. 17. As G increases, the number of groups decreases,thus yielding a decrease in QoS granularity, and hence, anincrease in the dynamic failure rate. When G equals 1, bothDCQM and GAQM perform as a DBP scheduler since thehistory for a group is the same as the history for a stream.
Fig. 16 also shows that with an increase in G, the GAQMmodel achieves a better QoS performance than the DCQMmodel does. As explained in Section 3.2, if the deadlines ofper-group streams vary significantly, the QoS performancedecreases. By aggregating streams with close deadlinestogether, the group balancing mechanism of GAQMdecreases the intragroup imbalance in terms of streamdeadlines. The standard deviation of deadlines for per-group streams is shown in Fig. 18, where the variance of
per-group stream deadlines in the DCQM model is always
larger than the one in GAQM.
5.3 Effect of the Deadline Tolerance Parameter
Figs. 19, 20, and 21 show the simulation results of the DBP-
based GAQM scheduler with different values for the
deadline tolerance parameter DT when G was equal to
30. The deadline tolerance parameter is used to control the
deviation of deadlines for per-group streams. As shown in
Fig. 20, with an increase in the value of the deadline
tolerance parameter, streams with highly different dead-
lines can be multiplexed into the same group. Thus, the
probability of packets being out of deadline order in a
group’s FIFO queue increases, which causes the increase in
per-stream dynamic failure rate (see Fig. 19).The change in the dynamic failure rate as the value of the
deadline tolerance increases can be explained also by the
variation in the number of groups shown in Fig. 21. As
the value of the deadline tolerance parameter increases, the
number of groups decreases, thus yielding a decrease in
QoS granularity, and hence, an increase in per-stream
dynamic failure rate.
JIANG AND STRIEGEL: AN EXPLORATION OF THE EFFECTS OF STATE GRANULARITY THROUGH ðm; kÞ REAL-TIME STREAMS 793
Fig. 16. Dynamic failure rate for the DBP-based DCQM scheduler and
the DBP-based GAQM scheduler.Fig. 17. Effect of group size on number of groups.
Fig. 18. Standard deviation of deadlines for per-group streams in the
DBP-based DCQM scheduler and the DBP-based GAQM scheduler.
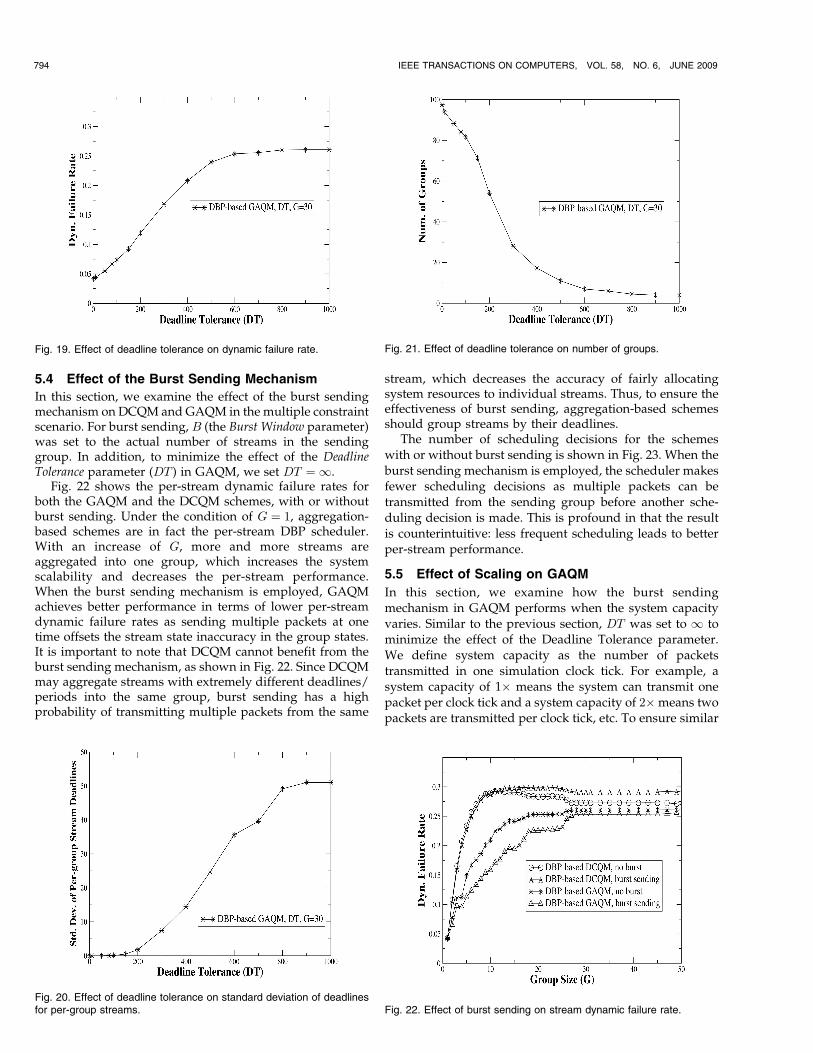
5.4 Effect of the Burst Sending Mechanism
In this section, we examine the effect of the burst sendingmechanism on DCQM and GAQM in the multiple constraintscenario. For burst sending, B (the Burst Window parameter)was set to the actual number of streams in the sendinggroup. In addition, to minimize the effect of the DeadlineTolerance parameter (DT ) in GAQM, we set DT ¼ 1.
Fig. 22 shows the per-stream dynamic failure rates forboth the GAQM and the DCQM schemes, with or withoutburst sending. Under the condition of G ¼ 1, aggregation-based schemes are in fact the per-stream DBP scheduler.With an increase of G, more and more streams areaggregated into one group, which increases the systemscalability and decreases the per-stream performance.When the burst sending mechanism is employed, GAQMachieves better performance in terms of lower per-streamdynamic failure rates as sending multiple packets at onetime offsets the stream state inaccuracy in the group states.It is important to note that DCQM cannot benefit from theburst sending mechanism, as shown in Fig. 22. Since DCQMmay aggregate streams with extremely different deadlines/periods into the same group, burst sending has a highprobability of transmitting multiple packets from the same
stream, which decreases the accuracy of fairly allocatingsystem resources to individual streams. Thus, to ensure theeffectiveness of burst sending, aggregation-based schemesshould group streams by their deadlines.
The number of scheduling decisions for the schemeswith or without burst sending is shown in Fig. 23. When theburst sending mechanism is employed, the scheduler makesfewer scheduling decisions as multiple packets can betransmitted from the sending group before another sche-duling decision is made. This is profound in that the resultis counterintuitive: less frequent scheduling leads to betterper-stream performance.
5.5 Effect of Scaling on GAQM
In this section, we examine how the burst sendingmechanism in GAQM performs when the system capacityvaries. Similar to the previous section, DT was set to 1 tominimize the effect of the Deadline Tolerance parameter.We define system capacity as the number of packetstransmitted in one simulation clock tick. For example, asystem capacity of 1� means the system can transmit onepacket per clock tick and a system capacity of 2�means twopackets are transmitted per clock tick, etc. To ensure similar
794 IEEE TRANSACTIONS ON COMPUTERS, VOL. 58, NO. 6, JUNE 2009
Fig. 19. Effect of deadline tolerance on dynamic failure rate.
Fig. 20. Effect of deadline tolerance on standard deviation of deadlinesfor per-group streams.
Fig. 21. Effect of deadline tolerance on number of groups.
Fig. 22. Effect of burst sending on stream dynamic failure rate.

workloads for different system capacities, the traffic load
was changed accordingly. The multiple constraint scenario
described in Section 5.2 was used to generate streams for
the system capacity of 1�. By varying the mean of the
stream interarrival time in the multiple constraint scenario,
we can get different traffic loads. For example, since the
original stream interarrival time was equal to 50, a value of
25 for the stream interarrival time would make the traffic
load doubled. And this doubled traffic load was the input
for the system capacity of 2�. Fig. 24 shows the number of
active streams for different system capacities. When the
system capacity increases, more active streams exist in the
system to ensure a similar workload.Fig. 25 shows the per-stream dynamic failure rate for
different system capacities with or without burst sending.
When the burst sending mechanism was employed, B (the
Burst Window parameter) was set to the actual number of
streams in the sending group. Without burst sending, since
the traffic load has changed according to the system capacity,
the systems with different capacities achieve similar perfor-
mance. For figure clarity, we only showed the no burst
sending case with the system capacity being 1� and 2�.
With burst sending, however, the performance fordifferent system capacities varies. Basically speaking, for aspecified value of G, the larger the system capacity, thelower the dynamic failure rate. The reason lies in the factthat for a large system capacity, which means the trafficload is large as well, more active streams exist in the system.Thus, for a certain group size G, with the increase in thetraffic load, the variance of per-group stream deadlinesdecreases through group balancing, as shown in Fig. 26.Since the burst sending mechanism works most efficientlywhen the streams in one group have similar deadlines/periods, a system with larger capacity achieves betterperformance. In Fig. 25, when G is small, the receivedper-stream dynamic failure rate fluctuates, which webelieve implies a more complicated relationship betweenscalability and per-stream QoS performance than capturedby our model. While we believe that it may be possible touse a Markov-based analysis to predict the optimal value ofG (small G) for minimizing the per-stream dynamic failurerate, the focus of the paper is improving performance withincreasing G values rather than dynamically deriving anoptimal G value. The analysis of an optimal G derivation is
JIANG AND STRIEGEL: AN EXPLORATION OF THE EFFECTS OF STATE GRANULARITY THROUGH ðm; kÞ REAL-TIME STREAMS 795
Fig. 23. Effect of burst sending on the number of scheduling decisions.
Fig. 24. Number of active streams for different system loads
Fig. 25. Per-stream dynamic failure rate for different system loads.
Fig. 26. Standard deviation of stream deadlines in one group for different
system loads.
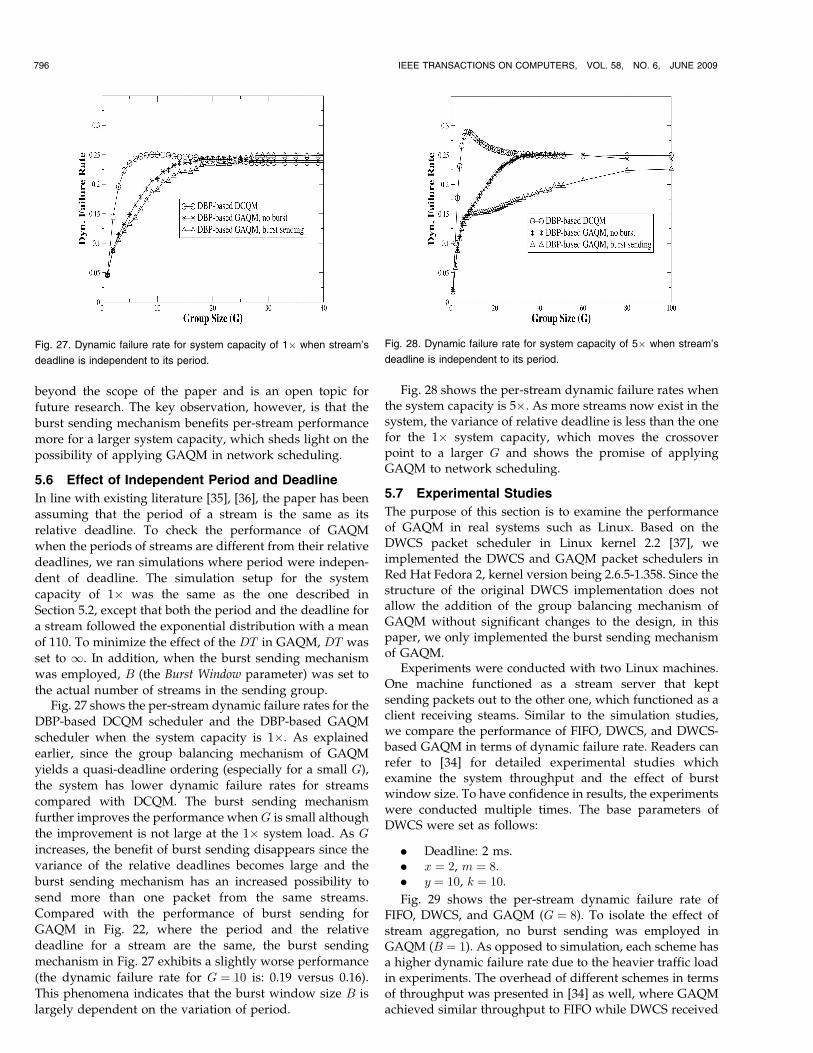
beyond the scope of the paper and is an open topic for
future research. The key observation, however, is that the
burst sending mechanism benefits per-stream performance
more for a larger system capacity, which sheds light on the
possibility of applying GAQM in network scheduling.
5.6 Effect of Independent Period and Deadline
In line with existing literature [35], [36], the paper has been
assuming that the period of a stream is the same as its
relative deadline. To check the performance of GAQM
when the periods of streams are different from their relative
deadlines, we ran simulations where period were indepen-
dent of deadline. The simulation setup for the system
capacity of 1� was the same as the one described in
Section 5.2, except that both the period and the deadline for
a stream followed the exponential distribution with a mean
of 110. To minimize the effect of the DT in GAQM, DT was
set to 1. In addition, when the burst sending mechanism
was employed, B (the Burst Window parameter) was set to
the actual number of streams in the sending group.Fig. 27 shows the per-stream dynamic failure rates for the
DBP-based DCQM scheduler and the DBP-based GAQM
scheduler when the system capacity is 1�. As explained
earlier, since the group balancing mechanism of GAQM
yields a quasi-deadline ordering (especially for a small G),
the system has lower dynamic failure rates for streams
compared with DCQM. The burst sending mechanism
further improves the performance when G is small although
the improvement is not large at the 1� system load. As G
increases, the benefit of burst sending disappears since the
variance of the relative deadlines becomes large and the
burst sending mechanism has an increased possibility to
send more than one packet from the same streams.
Compared with the performance of burst sending for
GAQM in Fig. 22, where the period and the relative
deadline for a stream are the same, the burst sending
mechanism in Fig. 27 exhibits a slightly worse performance
(the dynamic failure rate for G ¼ 10 is: 0.19 versus 0.16).
This phenomena indicates that the burst window size B is
largely dependent on the variation of period.
Fig. 28 shows the per-stream dynamic failure rates whenthe system capacity is 5�. As more streams now exist in thesystem, the variance of relative deadline is less than the onefor the 1� system capacity, which moves the crossoverpoint to a larger G and shows the promise of applyingGAQM to network scheduling.
5.7 Experimental Studies
The purpose of this section is to examine the performanceof GAQM in real systems such as Linux. Based on theDWCS packet scheduler in Linux kernel 2.2 [37], weimplemented the DWCS and GAQM packet schedulers inRed Hat Fedora 2, kernel version being 2.6.5-1.358. Since thestructure of the original DWCS implementation does notallow the addition of the group balancing mechanism ofGAQM without significant changes to the design, in thispaper, we only implemented the burst sending mechanismof GAQM.
Experiments were conducted with two Linux machines.One machine functioned as a stream server that keptsending packets out to the other one, which functioned as aclient receiving steams. Similar to the simulation studies,we compare the performance of FIFO, DWCS, and DWCS-based GAQM in terms of dynamic failure rate. Readers canrefer to [34] for detailed experimental studies whichexamine the system throughput and the effect of burstwindow size. To have confidence in results, the experimentswere conducted multiple times. The base parameters ofDWCS were set as follows:
. Deadline: 2 ms.
. x ¼ 2, m ¼ 8.
. y ¼ 10, k ¼ 10.
Fig. 29 shows the per-stream dynamic failure rate ofFIFO, DWCS, and GAQM (G ¼ 8). To isolate the effect ofstream aggregation, no burst sending was employed inGAQM (B ¼ 1). As opposed to simulation, each scheme hasa higher dynamic failure rate due to the heavier traffic loadin experiments. The overhead of different schemes in termsof throughput was presented in [34] as well, where GAQMachieved similar throughput to FIFO while DWCS received
796 IEEE TRANSACTIONS ON COMPUTERS, VOL. 58, NO. 6, JUNE 2009
Fig. 27. Dynamic failure rate for system capacity of 1� when stream’s
deadline is independent to its period.
Fig. 28. Dynamic failure rate for system capacity of 5� when stream’s
deadline is independent to its period.

a substantially lower throughput (35 percent less). Fig. 30presents the effect of the Burst Window parameter ðBÞ inGAQM when G was equal to 8. With the increase in B, theper-stream dynamic failure rate decreases until B is close toG, where the GAQM scheme exhibits the optimal perfor-mance.
6 CONCLUSIONS
In this paper, we described a Granularity Aware ðm; kÞQueue Management (GAQM) which consists of the algo-rithms for stream joining, group balancing, and burstsending. Then, we analyzed the reason why aggregation-based loss-tolerant schemes may downgrade per-streamperformance and why the burst sending mechanism mayreduce this downgrade.
By coupling the group balancing algorithm with thestream join algorithm, we successfully decreased theintragroup imbalance which is introduced by the signifi-cantly different deadlines of per-group streams. The burstsending mechanism improved the system performancefurther by sending multiple packets consecutively. Thekey finding of burst sending is that with proper biasing, theinaccuracy of aggregate state lends itself to burst schedulingrather than simply extending traditional scheduling me-chanisms. This finding is profound in which the result iscounterintuitive: less frequent scheduling leads to increasedperformance. The simulation studies have shown thatGAQM can more effectively control the tradeoff betweenscalability and per-stream QoS performance.
While this work offers interesting insight on the interplayof group state and group scheduling, there are severaltopics open for future work. First, explorations can be
conducted regarding the generalization of extracting hidden
failure state from arbitrary ðm; kÞ and G values. Second, the
issue of blending streams with different ðm; kÞ values merits
further attention. Finally, there is ample opportunity for
future work in relaxing the scheduling constraints with
regards to only deadlines and generalizing the results for
network scheduling.
ACKNOWLEDGMENTS
The authors would like to thank Dr. Christian Poellabauer,
the RTAS reviewers, the journal reviewers, and the area
editor for their insightful and helpful comments. This work
was partially supported by the US National Science
Foundation Grant CNS03-47392. This paper is based on
our previous work GAQM (Granularity Aware ðm; kÞQueue Management) which was presented at RTAS ’06 [1].
REFERENCES
[1] Y. Jiang and A. Striegel, “Granularity-Aware (m,k) QueueManagement for Real-Time Media Servers,” Proc. 12th IEEEReal-Time and Embedded Technology and Applications Symposium(RTAS), pp. 103-112, Apr. 2006.
[2] C.M. Aras, J.F. Kurose, D.S. Reeves, and H. Schulzrinne, “Real-Time Communication in Packet-Switched Networks,” Proc. IEEE,vol. 82, no. 1, pp. 122-139, Jan. 1994.
[3] J.M. Peha and F.A. Tobagi, “A Cost-Based Scheduling Algorithmto Support Integrated Services,” Proc. IEEE INFOCOM ’91,pp. 741-753, 1991.
[4] J.M. Boyce and R.D. Gaglianello, “Packet Loss Effects on MPEGVideo Sent Over the Public Internet,” Proc. Sixth ACM Int’l Conf.Multimedia, pp. 181-190, Sept. 1998.
[5] A. Koubaa and Y.-Q. Song, “Loss-Tolerant QoS Using FirmConstraints in Guaranteed Rate Networks,” Proc. 10th IEEE Real-Time and Embedded Technology and Applications Symp. (RTAS ’04),pp. 526-533, May 2004.
[6] M. Hamdaoui and P. Ramanathan, “A Dynamic Priority Assign-ment Technique for Streams with (m,k)-Firm Guarantees,” IEEETrans. Computers, vol. 44, no. 12, pp. 1443-1451, Dec. 1995.
[7] A. Striegel and G. Manimaran, “Best-Effort Scheduling of (m, k)-Firm Real-Time Streams in Multihop Networks,” Computer Comm.,vol. 23, no. 13, pp. 1292-1300, July 2000.
[8] R. West, Y. Zhang, K. Schwan, and C. Poellabauer, “DynamicWindow-Constrained Scheduling of Real-Time Streams in MediaServers,” IEEE Trans. Computers, vol. 53, no. 6, pp. 744-759, June2004.
[9] A. Striegel and G. Manimaran, “Dynamic Class-Based QueueManagement for Scalable Media Servers,” J. Systems and Software,vol. 66, no. 2, pp. 119-128, May 2003.
[10] Y. Zhang, R. West, and X. Qi, “A Virtual Deadline Scheduler forWindow-Constrained Service Guarantees,” Proc. 25th IEEE Real-Time Systems Symp. (RTSS), pp. 151-160, Dec. 2004.
[11] Y. Zhang and R. West, “End-to-end Window-ConstrainedScheduling for Real-Time Communication,” Proc. 10th Int’l Conf.Real-Time and Embedded Computing Systems and Applications(RTCSA ’04), Aug. 2004.
[12] A.B. Bondi, “Characteristics of Scalability and Their Impact onPerformance,” Proc. Second Int’l Workshop Software and Performance,pp. 195-203, 2000.
[13] K. Nichols, S. Blake, F. Baker, and D. Black, “Definition of theDifferentiated Services Field (DS Field) in the IPv4 and IPv6Headers,” IETF RFC 2474, Dec. 1998.
[14] J. Heinanen, F. Baker, W. Weiss, and J. Wroclawski, “AssuredForwarding PHB Group,” IETF RFC 2597, June 1999.
[15] C. Dovrolis and P. Ramanathan, “A Case for Relative Differ-entiated Services and the Proportional Differentiation Model,”IEEE Network, pp. 26-34, Sept./Oct. 1999.
[16] C. Dovrolis, D. Stiliadis, and P. Ramanathan, “ProportionalDifferentiated Services: Delay Differentiation and Packet Schedul-ing,” IEEE/ACM Trans. Networking, vol. 10, no. 1, pp. 12-26, Feb.2002.
JIANG AND STRIEGEL: AN EXPLORATION OF THE EFFECTS OF STATE GRANULARITY THROUGH ðm; kÞ REAL-TIME STREAMS 797
Fig. 29. Dynamic failure rate for FIFO, DWCS, and GAQM in Linux 2.6.
Fig. 30. Effect of the burst window size in Linux 2.6.

[17] A.K. Parekh and R.G. Gallager, “A Generalized Processor SharingApproach to Flow Control in Integrated Services Networks: TheSingle-Node Case,” IEEE/ACM Trans. Networking, vol. 1, no. 3,pp. 344-357, June 1993.
[18] J. Nagle, “On Packet Switches with Infinite Storage,” IEEE Trans.Comm., vol. 35, no. 4, pp. 435-438, Apr. 1987.
[19] A. Demers, S. Keshav, and S. Shenker, “Analysis and Simulationof a Fair Queueing Algorithm,” Proc. ACM SIGCOMM ’89,pp. 1-12, 1989.
[20] P. McKenney, “Stochastic Fairness Queueing,” Internetworking:Research and Experience, vol. 2, pp. 113-131, Jan. 1991.
[21] M. Hamdaoui and P. Ramanathan, “Evaluating Dynamic FailureProbability for Streams with (m, k)-Firm Deadlines,” IEEE Trans.Computers, vol. 46, no. 12, pp. 1325-1337, 1997.
[22] E. Poggi, Y. Song, A. Koubaa, and Z. Wang, “Matrix-DBP forðm; kÞ-Firm Real-Time Guarantee,” Proc. Real-Time and EmbeddedSystem, pp. 457-482, Apr. 2003.
[23] W. Lindsay and P. Ramanathan, “DBP-M: A Technique forMeeting End-to-End ðm; kÞ-Firm Guarantee Requirements inPoint-to-Point Networks,” Proc. 22nd Ann. IEEE Conf. LocalComputer Networks, pp. 294-303, Nov. 1997.
[24] G. Quan and X. Hu, “Enhanced Fixed-Priority Scheduling with(m, k)-Firm Guarantee,” Proc. 21st IEEE Real-Time Systems Symp.,pp. 79-88, Nov. 2000.
[25] A.K. Mok and W. Wang, “Window-Constrained Real-TimePeriodic Task Scheduling,” Proc. IEEE Real-Time Systems Symp.,pp. 15-24, 2001.
[26] L. Jian and S. Ye-Qiong, “Relaxed (m, k)-Firm Constraint toImprove Real-Time Streams Admission Rate under Non Pre-Emptive Fixed Priority Scheduling,” Proc. IEEE Conf. EmergingTechnologies and Factory Automation (ETFA ’06), pp. 1051-1060,2006.
[27] J. Li and Y. Song, “Dlb: A Novel Real-Time QoS ControlMechanism for Multimedia Transmission,” Proc. Advanced Infor-mation Networking and Applications, pp. 185-190, 2006.
[28] J. Lehoczky, L. Sha, and Y. Ding, “The Rate-Monotonic SchedulingAlgorithm: Exact Characterization and Average Case Behaviour,”Proc. IEEE Real-Time Systems Symp., pp. 166-171, 1989.
[29] A. Atlas and A. Bestavros, “Statistical Rate Monotonic Schedul-ing,” Proc. 19th IEEE Real-Time Systems Symp., pp. 123-132, 1998.
[30] S. Floyd and V. Jacobson, “Link-Sharing and Resource Manage-ment Models for Packet Networks,” IEEE/ACM Trans. Networking,vol. 3, no. 4, pp. 365-386, 1995.
[31] J. Mao, W.M. Moh, and B. Wei, “PQWRR Scheduling Algorithm inSupporting of DiffServ,” Proc. Int’l Conf. Comm. 2001, vol. 3,pp. 679-684, 2001.
[32] V. Jacobson, K. Nichols, and K. Poduri, “An Expedited Forward-ing PHB Group,” IETF RFC 2598, June 1999.
[33] M. Song and M. Alam, “Two Scheduling Algorithms for Input-Queued Switches Guaranteeing Voice QoS,” Proc. IEEEGLOBECOM 2001, pp. 92-96, 2001.
[34] Y. Jiang, X. Li, and A. Striegel, Experimental Studies of GranularityAware (m,k) Scheduling for Real-Time Media Servers, TechnicalReport TR-2008-01, ND CSE, 2008.
[35] R. West and C. Poellabauer, “Analysis of a Window-ConstrainedScheduler for Real-Time and Best-Effort Packet Streams,” Proc.21st IEEE Real-Time Systems Symp. (RTSS), pp. 239-248, 2000.
[36] P. Ramanathan, “Overload Management in Real-Time ControlApplications using m,k ðm; kÞ-Firm Guarantee,” IEEE Trans.Parallel and Distributed Systems, vol. 10, no. 6, pp. 549-559, June1999.
[37] http://cs-pub.bu.edu/fac/richwest/dwcs.html, 2009.
Yingxin Jiang received the BS and MS degreesfrom Jilin University, China, in 1999 and 2002,respectively. and the PhD degree in February2007 with an expected graduation date of Spring2009. She is currently a graduate student in theDepartment of Computer Science and Engineer-ing, University of Notre Dame. Her researchareas include networking (QoS) and real-timesystems. She is a student member of the IEEE.
Aaron Striegel received the PhD degree incomputer science in December 2002 from IowaState University under the direction of Dr. G.Manimaran. He is currently an assistant pro-fessor in the Department of Computer Scienceand Engineering, University of Notre Dame. Hisresearch interests include networking (band-width conservation, QoS), computer security,grid computing, and real-time systems. He hasreceived research and equipment funding from
US National Science Foundation (NSF), US Defense AdvancedResearch Projects Agency (DARPA), Sun Microsystems, and Intel.He was the recipient of an NSF CAREER Award in 2004. He is amember of the IEEE.
. For more information on this or any other computing topic,please visit our Digital Library at www.computer.org/publications/dlib.
798 IEEE TRANSACTIONS ON COMPUTERS, VOL. 58, NO. 6, JUNE 2009




















