
An EST resource for cassava and other species of Euphorbiaceae
13
An EST resource for cassava and other species of Euphorbiaceae James V. Anderson 1, *, Michel Delseny 2 , Martin A. Fregene 3 , Veronique Jorge 2,4 , Chikelu Mba 3 , Camilo Lopez 2 , Silvia Restrepo 3 , Mauricio Soto 3 , Benoit Piegu 2 , Valerie Verdier 2 , Richard Cooke 2 , Joe Tohme 3 and David P. Horvath 1 1 USDA/ARS, Biosciences Research Laboratory, 1605 Albrecht Blvd., P.O. Box 5674, State University Station, Fargo, ND 58105, USA; 2 University of Perpignan, Genome and Plant Development Laboratory, UMR 5096 CNRS-IRD-UP, 52, Avenue Paul Alduy, 66860 Perpignan, France; 3 International Center for Tropical Agriculture (CIAT), AA6713, Cali, Colombia; (*author for correspondence; e-mail andersjv @fargo.ars.usda.gov); 4 present address: INRA, Unite Amelioration Genetique et Physiologie Forestieres, Av de la pomme de pin, BP 20619 ARDON, 45166 OLIVET Cedex, France Received 23 July 2003; accepted in revised form 2 April 2004 Key words: cassava, genomics, leafy spurge, stress Abstract Cassava (Manihot esculenta) is a major food staple for nearly 600 million people in Africa, Asia, and Latin America. Major losses in yield result from biotic and abiotic stresses that include diseases such as Cassava Mosaic Disease (CMD) and Cassava Bacterial Blight (CBB), drought, and acid soils. Additional losses also occur from deterioration during the post-harvest storage of roots. To help cassava breeders overcome these obstacles, the scientific community has turned to modern genomics approaches to identify key genetic characteristics associated with resistance to these yield-limiting factors. One approach for developing a genomics program requires the development of ESTs (expressed sequence tags). To date, nearly 23000 ESTs have been developed from various cassava tissues, and genotypes. Preliminary analysis indicates existing EST resources contain at least 6000–7000 unigenes. Data presented in this report indicate that the cassava ESTs will be a valuable resource for the study of genetic diversity, stress resistance, and growth and development, not only in cassava, but also other members of the Euphorbiaceae family. Abbreviations: BAC, bacterial amplified chromosome; bp, base pair; CAPS, cleaved amplicon polymor- phisms; CBB, cassava bacterial blight; CMD, cassava mosaic disease; EST, expressed sequence tag; PCR, polymerase chain reaction; QTLs, quantitative trait loci; RFLP, restriction fragment length polymorphism; SAGE, serial analysis of gene expression; SNP, single nucleotide polymorphisms Introduction Cassava is one of the most important crops in the tropical, inter-tropical, and sub-Saharan regions of the world for human food, because nearly 600 million people eat cassava every day. World- wide, cassava acreage is more than 16 million hectares and annually produces root yields of more than 170 million tons. The increasing importance of cassava production as a staple to the world food supply is evidenced by an increased production of more than 75% during the last 30 years. Losses in yields to cassava farmers are usually attributed to biotic and abiotic stresses such as diseases, drought, and acid soils, or from deterio- ration during the post-harvest storage of roots. To improve yields, cassava breeders are developing programs that target improved resistance to these factors. One approach is to improve yield by Plant Molecular Biology 56: 527–539, 2004. ȑ 2004 Kluwer Academic Publishers. Printed in the Netherlands. 527
Transcript of An EST resource for cassava and other species of Euphorbiaceae

An EST resource for cassava and other species of Euphorbiaceae
James V. Anderson1,*, Michel Delseny2, Martin A. Fregene3, Veronique Jorge2,4, ChikeluMba3, Camilo Lopez2, Silvia Restrepo3, Mauricio Soto3, Benoit Piegu2, Valerie Verdier2,Richard Cooke2, Joe Tohme3 and David P. Horvath11USDA/ARS, Biosciences Research Laboratory, 1605 Albrecht Blvd., P.O. Box 5674, State UniversityStation, Fargo, ND 58105, USA; 2University of Perpignan, Genome and Plant Development Laboratory,UMR 5096 CNRS-IRD-UP, 52, Avenue Paul Alduy, 66860 Perpignan, France; 3International Center forTropical Agriculture (CIAT), AA6713, Cali, Colombia; (*author for correspondence; e-mail [email protected]); 4present address: INRA, Unite Amelioration Genetique et Physiologie Forestieres, Avde la pomme de pin, BP 20619 ARDON, 45166 OLIVET Cedex, France
Received 23 July 2003; accepted in revised form 2 April 2004
Key words: cassava, genomics, leafy spurge, stress
Abstract
Cassava (Manihot esculenta) is a major food staple for nearly 600 million people in Africa, Asia, and LatinAmerica. Major losses in yield result from biotic and abiotic stresses that include diseases such as CassavaMosaic Disease (CMD) and Cassava Bacterial Blight (CBB), drought, and acid soils. Additional losses alsooccur from deterioration during the post-harvest storage of roots. To help cassava breeders overcome theseobstacles, the scientific community has turned to modern genomics approaches to identify key geneticcharacteristics associated with resistance to these yield-limiting factors. One approach for developing agenomics program requires the development of ESTs (expressed sequence tags). To date, nearly 23000ESTs have been developed from various cassava tissues, and genotypes. Preliminary analysis indicatesexisting EST resources contain at least 6000–7000 unigenes. Data presented in this report indicate that thecassava ESTs will be a valuable resource for the study of genetic diversity, stress resistance, and growth anddevelopment, not only in cassava, but also other members of the Euphorbiaceae family.
Abbreviations: BAC, bacterial amplified chromosome; bp, base pair; CAPS, cleaved amplicon polymor-phisms; CBB, cassava bacterial blight; CMD, cassava mosaic disease; EST, expressed sequence tag; PCR,polymerase chain reaction; QTLs, quantitative trait loci; RFLP, restriction fragment length polymorphism;SAGE, serial analysis of gene expression; SNP, single nucleotide polymorphisms
Introduction
Cassava is one of the most important crops in thetropical, inter-tropical, and sub-Saharan regionsof the world for human food, because nearly600 million people eat cassava every day. World-wide, cassava acreage is more than 16 millionhectares and annually produces root yields ofmore than 170 million tons. The increasingimportance of cassava production as a staple to
the world food supply is evidenced by an increasedproduction of more than 75% during the last30 years.
Losses in yields to cassava farmers are usuallyattributed to biotic and abiotic stresses such asdiseases, drought, and acid soils, or from deterio-ration during the post-harvest storage of roots. Toimprove yields, cassava breeders are developingprograms that target improved resistance to thesefactors. One approach is to improve yield by
Plant Molecular Biology 56: 527–539, 2004.� 2004 Kluwer Academic Publishers. Printed in the Netherlands.
527

limiting the impact of diseases. A major disease ofcassava is Cassava Bacterial Blight (CBB) causedby Xanthomonas axonopodis pv. manihotis(Lozano, 1986). Other important diseases resultfrom a variety of viruses including CassavaAfrican Mosaic Virus, which causes CassavaMosaic Disease (CMD) (Akano et al., 2002). Asecond target concerns starch production in theroot, which is a major source of calories for humanfood and is a valuable source for the starchindustry and its derivatives (Munyikwa et al.,1997). Other target goals include reducing lossescaused by post-harvest processing and byenvironmental factors such as dehydration- andcold-stress, and acid soils.
Unfortunately, conventional cassava improve-ment is fraught with problems of breeding a longgrowth cycle, highly heterozygous crop. Toincrease the cost-effectiveness of achieving desiredgoals, a number of resources and molecular toolshave been developed during the recent years toenhance breeding. They include construction ofgenetic maps using RFLP, isoenzymes, microsat-ellite markers (Fregene et al., 1997; Mba et al.,2001) that have already allowed the identificationof a variety of QTLs and a major gene (CMD2) forCMD resistance (Jorge et al., 2000, 2001; Akanoet al., 2002; Okogbenin and Fregene, 2002). Suchmarkers are limited in their application to breed-ing, and a more precise approach to gene mappingusing candidate genes is required. Unfortunately,relatively few genes have been identified so far incassava. In order to isolate additional genes, BAClibraries have been constructed, covering most ofthe genome (Fregene et al., 2003). However, theseBAC libraries have neither been ordered noranchored on the genetic map. As a consequence,there is an important need for additionalsequenced markers that would facilitate moredetailed genetic and physical mapping.
The era of genomics and bioinformatics hasincreased our ability to identify markers, andincreased our knowledge of plant genome struc-ture, organization, and gene function. The recentexplosion of genetic and genomic data for a widerange of plant and animal species has led to aproliferation of publicly available informationdatabases throughout the internet (http://www.ncbi.nlm.nih.gov/dbEST, http://arabidop-sis.org, http://rgp.dna.affrc.go.jp). Two completeplant genomes are available for Arabidopsis and
rice (The Arabidopsis Genome Initiative, 2000;Goff et al., 2002; Delseny, 2003). The expressedsequence tags (ESTs; which are partial sequences[200–800 bp] of expressed genes randomly pickedfrom a cDNA library) databases are currently thefastest growing and largest portion of these pub-licly available DNA sequence databases (Cookeet al., 1996; Ohlrogge and Benning, 2000). Todate, at least 20 gene indices for plants (bothdicot and monocot) that integrate data frominternational EST sequencing, genome sequenc-ing, and gene research projects are publiclyavailable (Quackenbush et al., 2001; www.tigr.org/tdb/plant.shtml). These databases are impor-tant for identifying expressed genes that arefurther used for developing DNA microarrays(Richmond and Somerville, 2000). The cDNAmicroarray technology, first developed by Schenaet al., (1995), depends on the availability of ESTs.This technology has been widely received(Duggan et al., 1999) and used in plants to iden-tify specific gene functions (Aharoni et al., 2000;Gutierrez et al., 2002), evaluate transcript profilesinduced by various physiological or environmen-tal conditions (Reymond et al., 2000; Van Halet al., 2000; Lee et al., 2002; Oztur et al., 2002;Potokina et al., 2002; Zhu et al., 2003), andevaluate transcript profiles between geneticallymodified and control species (Van Hal et al.,2000). Although these are just a few of theexcellent examples that have materialized fromgenomics initiatives, continued genome sequenc-ing projects for many important crops are stillunderway and are expected to provide futurebenefits. However, the traditional fundingcommunities have overlooked other importantplant families, having impacts on worldeconomies. In particular are members of thegenetically diverse plant family Euphorbiaceaethat includes, apart from cassava, other globallyimportant agricultural species such as: castor bean(Ricinus communis), an important oil crop;Rubber tree (Hevea brasiliensis), an importantsource of rubber; Poinsettia (Poinsettia pulcherr-ima), an important horticultural crop; leafyspurge (Euphorbia esula) an important perennialpest weed that affects range, recreational, andright of way lands in North American plains andprairies; and annual weeds such as hophornbeamcopperleaf (Acalypha ostryifolia), and endangeredspecies such as Akoka and telephus spurge.
528

Although extensive studies have been carriedout on a few model species, little is still knownabout basic physiological processes controllingcrop plant development and resistance to stress anddiseases. A significant understanding of theconservation and diversity of genes betweenmembers of the Euphorbiaceae family is alsolacking. Consequently, it is currently difficult todesign treatments or breeding programs to improvegenetic stocks of desirable species or developmethods to control the growth of undesirablespecies. Many of these problems could be solved bythe development of sequence databases andgenomic-based research strategies for members ofthis family. Several groups have realized the successof large-scale genome sequencing for developinggenomics resources and are starting to address thetask of generating ESTs from cassava and relatedspecies, such as leafy spurge, in order to preparegene catalogues that will be important for futuredevelopment of DNA arrays and virtualNortherns. Since transformation systems alreadyexist for cassava (Schopke et al., 1996), thedevelopment of an EST resource will eventuallyallow one to isolate and manipulate key genes andmetabolic pathways when they are established, andto introduce new genes when necessary. This reviewpresents resources that are being established andwill be available in the near future to the scientificcommunity. We also provide evidence to show theimportance of using these resources to understandgenetic diversity and conservation within genesequences and demonstrate potential advantages toa family-based rather than species-based genomicsapproach. We also provide data showing theeffectiveness of several high throughputapproaches to identify key genes involved in stressresponses using data generated from ESTsequencing. Finally, we will make the argumentthat these successes should be built upon and couldbe enhanced with additional sequencing efforts.Most of these data are not yet published but theaim of this article is to inform the scientific com-munity of the progress being made, preliminaryresults, and developing/planned resources.
Materials and methods
Several materials and strategies have been usedindependently, and at different international
locations to generate the present day resources.Libraries and ESTs from Euphorbia esula (leafyspurge) were generated at the Biosciences ResearchLaboratory in Fargo, North Dakota, USA.Libraries targeted to CMD were made under col-laborations between CIAT in Cali, Colombia, andthe Iwate Biotech Research Center (IBRC) inKitakami, Japan. Libraries and ESTs for analyz-ing CBB and starch metabolism resulted fromcollaborations between labs at CIAT and at theUniversity of Perpignan (France).
Plant material
Cassava plantlets, derived from meristem cultures(genotypes TME 3, TME 117, and TMS 30572),and for the development of future normalizedcDNA libraries, were initially obtained from theInternational Institute of Tropical Agriculture(IITA), Ibadan, Nigeria. TME 3 and TMS 30572comprise different sources of genetic tolerance toCMD. TME 117, a drought-tolerant variety, isdesired for its’ sweet taste and texture throughoutAfrica, even after boiling, and comprises a rela-tively low cyanide content. Individual plantletswere transferred to 4 inch, square plastic potscontaining Sunshine Mix #1. Each transplantedcassava plantlet was put inside a commerciallyavailable zip lock baggy and sealed. The plantletswere allowed to acclimate to growth chamberconditions for 3–4 weeks prior to opening the ziplock bags and allowing acclimation to continuean additional 2–3 weeks. After acclimating togrowth chamber conditions, the plants weretransferred to larger plastic pots containing 1 partSunshine Mix #1 and 2 parts sandy loam. At thisstage, the plants were transferred to greenhouseconditions. Plants grown in the greenhouse werefertilized once weekly using Prolific 20-20-20(N-P-K). Temperatures were maintained atapproximately 25 �C, 16/8 h day/night cycles withdaylight supplemented by 400 W high-pressuresodium lamps in the greenhouse or with 60 Wcool white high output fluorescent lamps supple-mented with 60 W incandescent bulbs in thegrowth chambers. Light fluencies were approxi-mately 350 lmoles m)2 s)1 in the greenhouse andapproximately 80 lmoles m)2 s)1 in the growthchambers (LiCor-185 photometer, LiCor,Lincoln, NE). Cassava plants used for the CBBand starch cDNA libraries were derived from the
529

CIAT cassava germplasm. They were grown ingreenhouse at 28/19 �C (day/night temperatures),under a 12-h day light photoperiod and 80%relative humidity. The cassava plants were grownfrom mature stem cuttings in sterile soil. Leafyspurge plant material used for growth induced,adventitious root bud cDNA libraries was grownas previously described (Anderson and Horvath,2001).
Tissue treatment
Cassava plants (2 reps) from each variety wereincubated at 25 �C (control) or 42 �C (heat shock)in an environmental growth chamber for a periodof 4 h. Plants used for the heat shock study wereobtained from the greenhouse 6–8 weeks afterbeing transferred from the growth chamber to thegreenhouse as previously described. The upper4–6 inches of the plant, including the stem andmeristem, were collected and immediately frozenin liquid N2 and pulverized prior to storage at)80 �C.
To study the effects of dehydration-stress oncassava plant tissue, water was withheld frommature plants (1 year after transferring to green-house conditions) for a period of 6 days. Youngleaf and petiole, and mature leaf, were collectedfrom all three varieties of cassava, and individuallyground in liquid N2 prior to storage at )80 �C.Cold-treated plant tissue was obtained by placingthe plants in an incubator set at 4–6 �C. After 30 hof cold-treatment, young leaf and petiole, andmature leaf were collected and processed as pre-viously described. Control tissue was collectedfrom untreated greenhouse plants.
Extraction of RNA for Northernand macroarray blotting
RNA was extracted from cassava plant materialusing the pine tree extraction method of Changet al. (1993) using modifications described byAnderson and Horvath (2001). Total RNA wasseparated on a 1% denaturing agarose gel andblotted onto a positively charged nylon membrane(Hybond-N, Amersham Pharmacia Biotech) usingstandard protocols (Sambrook et al., 1989).Northern blot hybridizations were accomplishedusing 32P radiolabeled DNA probes (Rediprime IIrandom prime labeling system; Amersham Phar-
macia Biotech) incubated in Rapid-hyb buffer(Amersham Pharmacia Biotech) at 65 �C. RNAblots were washed under high stringency(0.1 · SSC, 0.1% SDS at 65 �C) and visualized ona Packard Instant Imager with approximately 1 hof exposure and by autoradiography. All experi-ments were replicated with separate sets of treatedplants. Following visualization, filters were washedonce with boiling 0.1% (v/v) SDS solution andallowed to cool to room temperature. Filters wererinsed with 0.1% (v/v) SDS solution at roomtemperature and removal of all radioactivity wasassured by visualization of the clean filter for 1 hon the imager prior to re-probing with a newcDNA probe.
For macroarray probing, RNA was extractedas previously described above. Total RNA (30 lg)was labeled with [32P]-dCTP using reverse trans-criptase (SuperScript II, Invitrogene). With theexception of using radiolabeled dCTP vs. dATP,all labeling, hybridizations, and washes were doneusing the protocol described by Uhde-Stone et al.(2003). All arrays were visualized by autoradio-graphy. Spot intensities (radioactivity) weredetermined using a Packard Instant Imager.
cDNA library construction used for developingEuphorbiaceae EST resources
cDNA libraries for cassava bacterial blightand starch contentThe cDNA libraries have been made using aStratagene kit. For starch biosynthesis studies, twocDNA libraries were made, one from genotypeCM523-7 (a high dry matter content variety) andanother from genotype Mper183 (a low drymatter content variety). Both libraries were madefrom root material collected 6 months afterplanting. For analyzing response to Xanthomonasaxonopodis (Xam), several cDNA libraries weremade from stems using genotypes MCol1522(susceptible to Xam strain CI0151) and genotypeMBra685 (resistant to Xam strain CI0151). Leafand stem inoculations were done as previouslydescribed (Restrepo et al., 2000). Additionally,several subtracted cDNA libraries have also beenmade with genotypes SG107-35 (highly resistantto Xam strain CI0-46), MCol1522 and MBra685.Tissue was collected 6, 12, 24, 48, 72 h and 7 daysafter inoculation in order to enrich the EST data-base with genes over-expressed in inoculated
530

material. cDNA synthesized from RNA obtainedfrom either healthy or wounded stems were pooledand used as ‘‘drivers’’. The cDNA from the inoc-ulated tissues was used as ‘‘tester’’. An additionalsubtractive library was made from leaf materialcollected from genotype MBra 685. In addition, alimited number of cDNA-AFLP fragments weresequenced and included in the data set. All theselibraries are listed in Table 1.
Bacterial clones generated from these cDNAlibraries were randomly distributed in 96 wellmicrotiter plates prior to processing for plasmidisolation and sequencing using a 5¢-specific primer.Sequencing was accomplished using an ABI 3100capillary sequencing machine. Raw data werecollected and processed to evaluate the quality ofthe sequence (using Phred) and to eliminate vectorsequence. They were organized as multiFasta filesand were used to construct contigs of overlappingsequences and singletons. These data will betransferred to GenBank immediately aftersubmission of this manuscript.
cDNA libraries constructed for cassavamosaic disease resistanceA cDNA library was constructed in pYES (Invi-trogen Inc.) according to the manufacturer’sinstructions using mRNA from CMD resistantprogeny from the cassava genotype TME 3, thesource of CMD2. Two microliters of the cDNAlibrary were electroporated into 40 ll of E. coliHB101 cells (Gibco BRL) and plated on LB agarplates + ampicillin (100 lg ml)1). A total of 5000colonies were picked and placed in 70 ll of LBmedia + ampicillin (100 lg ml)1) in 384 well
plates. Plasmid isolation was done using theMONTAGE 96-well plate system (Millipore Inc).Primer designed from the 3¢ end of the multiplecloning site of pYES (Invitrogen Inc.) and 5 ll ofplasmid miniprep were used for sequencing eachclone. Sequencing reactions were accomplishedusing the ABI Prism� BigDye� Terminator CycleSequencing Ready Reaction Kit (Applied Bio-systems) on a 9600 Perkin Elmer Machine or anMJ Research DNA engine. The sequence reactionswere cleaned using the multi screen 96-well plateformat (Millipore Inc.) and analyzed on a Shima-dzu RISA 384 capillary sequencing machine.Sequences obtained were manually cleaned fromvector sequences and combined into one single textfile using a program written in Perl, running on aSunSparc Station (Sun Microsystems Inc.). Aprogram was written in Perl to perform batchBLAST (Altschul et al., 1997) similarity searchesfor sequence identification using the CIAT localBLAST site (http://gene2/BLAST/inicio.htm).Sequencing was done from the 3¢ end in order tocompare the EST sequences with a collection ofSAGE tags derived from the same material (Fre-gene, unpublished data).
cDNA libraries constructed for leafyspurge (Euphorbia esula)Construction of a cDNA library using mRNAisolated from the adventitious root buds (shootbuds below the crown) of 3-day excised plants,plasmid isolation, sequencing, and analysis of ESTswas done as previously described (Anderson andHorvath, 2001). EST sequences were submitted tothe GenBank EST database (dbEST; Boguski
Table 1. Characteristics of the libraries constructed from cassava for CBB, CMD, and starch characteristics, and from leafy spurge forgrowth-induction in underground adventitious root buds.
Cultivar Phenotype/Condition Organ Designation
CM523-7 High matter dry content Roots Starch-CM
MPer183 Low matter dry content ’’ Starch-Mper
MCol1522 Sensible/Inoculated Stem MCol-48h
Sensible/Subtracted ’’ mc_ssh
MBra685 Tolerant/Non inoculated Stem MBra
Tolerant/Not subtracted ’’ mb_nosub
Tolerant/Subtracted Leaf mb_dsc
SG107-35 Resistant/Not subtracted Stem sg_nosub
Resistant/Subtracted ’’ sg_ssh
Resistant/Subtracted ’’ sg_dsc
TME 3 Resistance to CMD/Field exposure Leaf/stem YEST
LS001 Growth-induced Root buds LS3-dgi
531

et al., 1993) where they were given GenBankaccession numbers and kept in a publicly availablearchive. Contig sets and singletons in the leafyspurge EST-database are available to the public atthe University of Minnesota, Center forComputational Genomics and Bioinformatics(http://web.ahc.umn.edu/biodata/euphorbia).
Results
Preliminary characterization of the EST resources
Characterization of ESTs obtained from cDNAlibraries targeted for CBB and StarchGood quality ESTs (11954) were obtained withan average length of 467 bp (Table 2). All werederived from the 5¢ end of mRNA. They could begrouped into 1875 contigs containing 9218 ESTs,and singletons composed of 3825 ESTs. There-fore, at this stage, a unigene set can be builtwith 5700 sequences that include the 848 cassavasequences already present in GenBank (NCBI). Afirst observation is the relatively high redundancywithin unsubtracted libraries, indicating thatsome of the analyzed tissues are highly special-ized. For example, in root libraries, we haverespectively an average of 2.9 ESTs/contig forhigh starch compared to 1.9 ESTs/contig for lowstarch. There are also more singletons in the lowstarch library.
A second characterization consists in compar-ing cassava ESTs with other sequences in publiclyavailable databases. So far, about 50% of thesingletons and contigs have significant homologywith Arabidopsis of which half correspond toArabidopsis hypothetic proteins. This data sug-gests that these hypothetic proteins are likely to bereal proteins. About 18% of the ESTs have nohomology to any known genes in available data-bases and may represent new plant genes specificof the Euphorbiaceae family. Classification ofthese ESTs into functional categories is underway.
Characterization of ESTs obtained from cassavacDNA libraries targeted for CMDThe 3¢ end sequencing of about 5000 cDNA clonesgenerated a total of 4000 ESTs (average length of481 bp). The ESTs could be organized into 1505unigenes (500 contigs, containing 2995 ESTs, and1005 singletons). Homology with known genes andproteins deposited in public databases wereobtained using the local BLAST (Altschul et al.,1997) at CIAT. The identity of about 800 unigenesequences could be ascertained with a good con-fidence level. Redundancy found in sequences ofknown functions was about 30%. The ESTs wereused for SAGE tag annotation. The annotation ofthe ESTs have been described elsewhere (Fregeneet al., 2003). The most abundant tags were easilyannotated, for example, identity of the 10 genesthat make up 5% of all expressed transcripts were
Table 2. Statistics of the EST collection for CBB and starch characterization.
Library No. of sequences generated No. of sequences analyzed Number of TCa Number of singletonb
Starch CM 5376 3608 642 555
Starch Mper 4992 3391 607 1127
MCol-48h 2304 1721 184 1178
mc_ssh 384 258 45 142
Mbra 2688 1560 158 1049
mb_nosub 384 258 22 124
mb_dsc 768 438 54 41
sg_nosub 288 128 6 95
sg_ssh 384 210 24 128
sg_dsc 768 382 29 17
Aflp 241 27 179
Genbank 848 98 534
Totalc 1875 3825
aNumber of contig was calculated as the contigs present in each library independent of other libraries.bNumber of singleton was calculated as the singleton present in each library independent of other libraries.cThe total was calculated as the number of singletons or contigs from all the libraries.
532
found by ESTs, but annotation of less abundanttags is not as efficient. This suggests that the PCRmethod of tag annotation is a more powerful routeto annotating SAGE tags compared to ESTs fromregular cDNA libraries (Fregene et al., 2003). Onthe other hand, ESTs from a normalized cDNAlibrary may be a more efficient means of tagannotation compared to non-normalized libraries.The EST data will be submitted to GenBank.
Characterization of ESTs obtained from aleafy spurge cDNA library targeted for dormancyin adventitious root budsThe average length generated from sequencingruns on 1983 isolated plasmids was 469 bases.From the 1983 sequencing reactions analyzed,quality reads were obtained for 1814 ESTs. Anal-ysis of the ESTs indicated the presence of 246contigs composed of 2 or more overlapping se-quences. In all, 642 ESTs (35%) were present inthe 246 contigs with the remaining 1172 repre-senting singletons. This data suggests a redun-dancy ratio of �25%. Approximately 28% of theESTs are classified as either unknowns or hypo-thetical proteins. Other classifications representingsignificant numbers within the EST-databaseinclude ribosomal proteins, elongation factors,
protein kinases, cell cycle proteins, heat shockproteins, aquaporins, and DNA-binding proteins(Anderson and Horvath, 2001).
Comparison of selected orthologous geneswithin cassava and leafy spurge databasesFrom the small number of accessions in GenBankfor cassava and leafy spurge, a select number oforthologous genes (Table 3) were analyzed forsimilarity and the data suggested a good proba-bility for cross-hybridization on heterologoussystems. Recent experiments using ArabidopsiscDNA microarrays have indicated that substantialcross-hybridization between species could providerelevant expression data (Horvath et al., 2003).Consequently, efforts were undertaken to use leafyspurge ESTs to produce both macro- and micro-arrays, and as direct probes for Northern blotanalysis of cassava RNA. Preliminary analysisfrom experiments done using a first round of leafyspurge microarrays, developed at the Fargo Lab,indicated that approximately 15–25% of the leafyspurge clones hybridise well to labeled target DNAfrom cassava leaf tissue (Anderson and Horvath,personal communication). Substantially higherlevels of hybridization were detected when cassavaRNA from dehydration-stressed leaf tissue was
Table 3. Comparison of sequence identities between homologues of cassava and leafy spurge.
Gene Product Spurge accession Cassava accession (%) identity Consensus length
Dna J AF239932 BI325097 78.9 152
Dna J AF239932 BI325100 69.9 216
Histone H1 AF222804 BI325218 55.4 725
Histone H3 AF239930 BI325152 53.4 696
Histone H3 AF239930 BI325185 81.9 155
Histone H3 AF239930 BI325226 79.5 215
Histone H3 AF239930 BI239930 82.5 388
Histone H4 BI946403 BI325254 68.2 320
Histone H4 BI946403 BI325167 62.4 225
Histone H4 BI946403 BI325241 65.2 157
Lhcb AF220527 BI325250 77.8 234
Lhcb AF220527 BI325141 77.2 433
Lhcb AF220527 BI325235 79.9 402
Lhcb AF220527 BI325188 56.7 236
Polyubiquitin AW944681 BI325109 60.5 208
Polyubiquitin BG345192 BI325109 68.9 148
Polyubiquitin BI975267 BI325109 71.4 139
RuBisCo BI993507 BI325191 69.3 386
RuBisCo BI975169 BI325191 67.6 283
14-3-3 AF222805 BI325181 69.1 137
Average 70 293
533
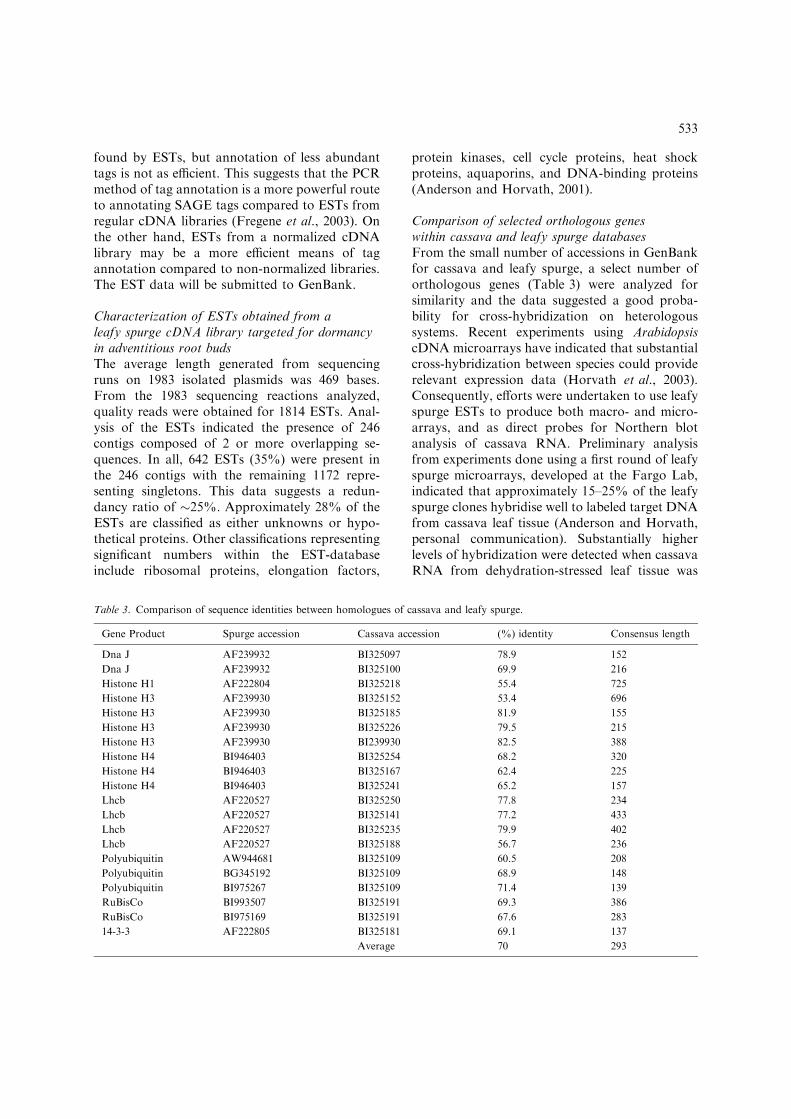
used to probe macroarrays developed from theleafy spurge EST database (Figure 1). At least35% of the leafy spurge clones showed greaterthan 2 · above background hybridization with the
dehydration-stressed cassava target sample(Figure 1).
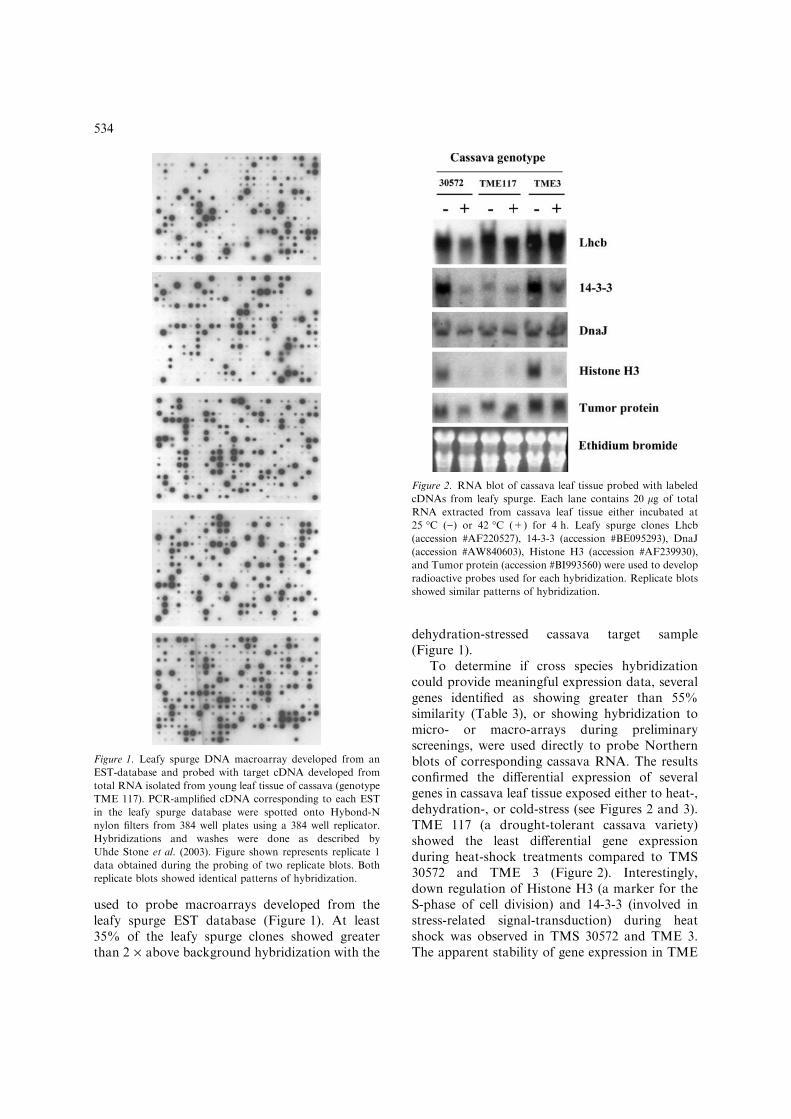
To determine if cross species hybridizationcould provide meaningful expression data, severalgenes identified as showing greater than 55%similarity (Table 3), or showing hybridization tomicro- or macro-arrays during preliminaryscreenings, were used directly to probe Northernblots of corresponding cassava RNA. The resultsconfirmed the differential expression of severalgenes in cassava leaf tissue exposed either to heat-,dehydration-, or cold-stress (see Figures 2 and 3).TME 117 (a drought-tolerant cassava variety)showed the least differential gene expressionduring heat-shock treatments compared to TMS30572 and TME 3 (Figure 2). Interestingly,down regulation of Histone H3 (a marker for theS-phase of cell division) and 14-3-3 (involved instress-related signal-transduction) during heatshock was observed in TMS 30572 and TME 3.The apparent stability of gene expression in TME
Figure 1. Leafy spurge DNA macroarray developed from an
EST-database and probed with target cDNA developed from
total RNA isolated from young leaf tissue of cassava (genotype
TME 117). PCR-amplified cDNA corresponding to each EST
in the leafy spurge database were spotted onto Hybond-N
nylon filters from 384 well plates using a 384 well replicator.
Hybridizations and washes were done as described by
Uhde Stone et al. (2003). Figure shown represents replicate 1
data obtained during the probing of two replicate blots. Both
replicate blots showed identical patterns of hybridization.
Figure 2. RNA blot of cassava leaf tissue probed with labeled
cDNAs from leafy spurge. Each lane contains 20 lg of total
RNA extracted from cassava leaf tissue either incubated at
25 �C ()) or 42 �C (+) for 4 h. Leafy spurge clones Lhcb
(accession #AF220527), 14-3-3 (accession #BE095293), DnaJ
(accession #AW840603), Histone H3 (accession #AF239930),
and Tumor protein (accession #BI993560) were used to develop
radioactive probes used for each hybridization. Replicate blots
showed similar patterns of hybridization.
534
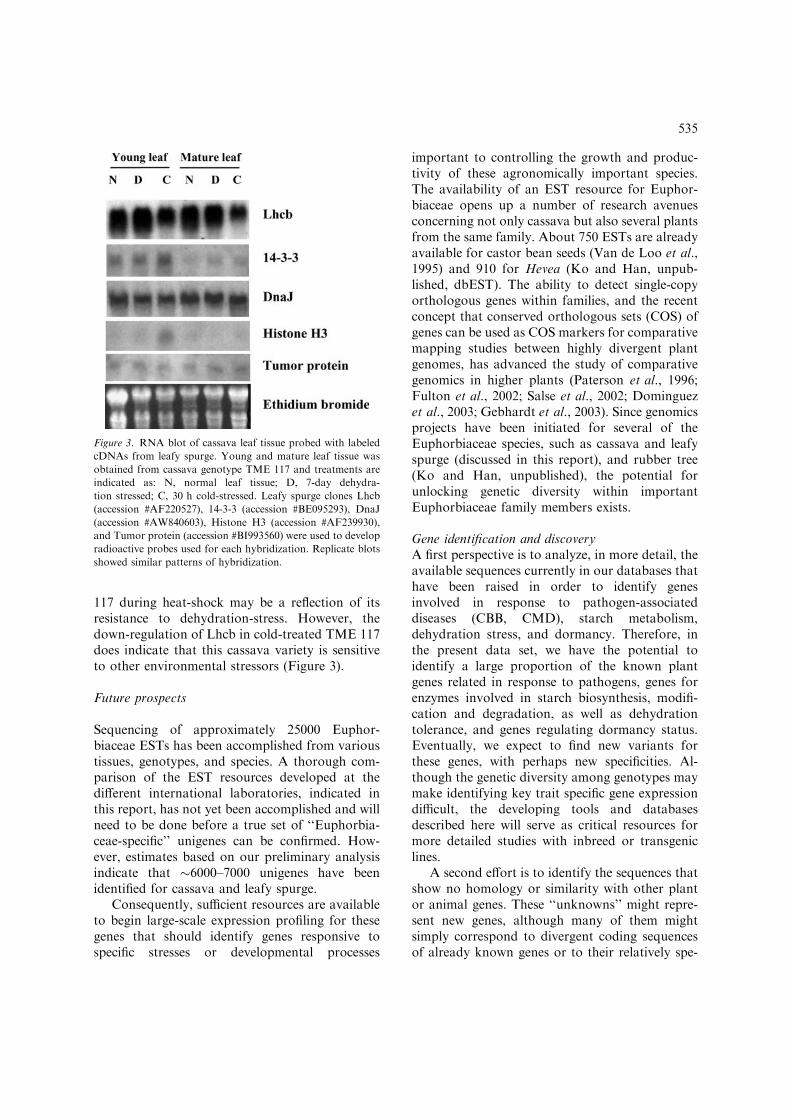
117 during heat-shock may be a reflection of itsresistance to dehydration-stress. However, thedown-regulation of Lhcb in cold-treated TME 117does indicate that this cassava variety is sensitiveto other environmental stressors (Figure 3).
Future prospects
Sequencing of approximately 25000 Euphor-biaceae ESTs has been accomplished from varioustissues, genotypes, and species. A thorough com-parison of the EST resources developed at thedifferent international laboratories, indicated inthis report, has not yet been accomplished and willneed to be done before a true set of ‘‘Euphorbia-ceae-specific’’ unigenes can be confirmed. How-ever, estimates based on our preliminary analysisindicate that �6000–7000 unigenes have beenidentified for cassava and leafy spurge.
Consequently, sufficient resources are availableto begin large-scale expression profiling for thesegenes that should identify genes responsive tospecific stresses or developmental processes
important to controlling the growth and produc-tivity of these agronomically important species.The availability of an EST resource for Euphor-biaceae opens up a number of research avenuesconcerning not only cassava but also several plantsfrom the same family. About 750 ESTs are alreadyavailable for castor bean seeds (Van de Loo et al.,1995) and 910 for Hevea (Ko and Han, unpub-lished, dbEST). The ability to detect single-copyorthologous genes within families, and the recentconcept that conserved orthologous sets (COS) ofgenes can be used as COS markers for comparativemapping studies between highly divergent plantgenomes, has advanced the study of comparativegenomics in higher plants (Paterson et al., 1996;Fulton et al., 2002; Salse et al., 2002; Dominguezet al., 2003; Gebhardt et al., 2003). Since genomicsprojects have been initiated for several of theEuphorbiaceae species, such as cassava and leafyspurge (discussed in this report), and rubber tree(Ko and Han, unpublished), the potential forunlocking genetic diversity within importantEuphorbiaceae family members exists.
Gene identification and discoveryA first perspective is to analyze, in more detail, theavailable sequences currently in our databases thathave been raised in order to identify genesinvolved in response to pathogen-associateddiseases (CBB, CMD), starch metabolism,dehydration stress, and dormancy. Therefore, inthe present data set, we have the potential toidentify a large proportion of the known plantgenes related in response to pathogens, genes forenzymes involved in starch biosynthesis, modifi-cation and degradation, as well as dehydrationtolerance, and genes regulating dormancy status.Eventually, we expect to find new variants forthese genes, with perhaps new specificities. Al-though the genetic diversity among genotypes maymake identifying key trait specific gene expressiondifficult, the developing tools and databasesdescribed here will serve as critical resources formore detailed studies with inbreed or transgeniclines.
A second effort is to identify the sequences thatshow no homology or similarity with other plantor animal genes. These ‘‘unknowns’’ might repre-sent new genes, although many of them mightsimply correspond to divergent coding sequencesof already known genes or to their relatively spe-
Figure 3. RNA blot of cassava leaf tissue probed with labeled
cDNAs from leafy spurge. Young and mature leaf tissue was
obtained from cassava genotype TME 117 and treatments are
indicated as: N, normal leaf tissue; D, 7-day dehydra-
tion stressed; C, 30 h cold-stressed. Leafy spurge clones Lhcb
(accession #AF220527), 14-3-3 (accession #BE095293), DnaJ
(accession #AW840603), Histone H3 (accession #AF239930),
and Tumor protein (accession #BI993560) were used to develop
radioactive probes used for each hybridization. Replicate blots
showed similar patterns of hybridization.
535

cific 5¢ or 3¢ untranslated sequences. BecauseCassava belongs to a poorly studied yet importantfamily, the chance of identifying genes specific forthis crop or this family is reasonably high. So far,the resources are based on the limited number ofESTs that have been sequenced from a smallnumber of tissues and biological situations. Obvi-ously, resources in the order of 6–7000 uniquegenes is small with respect to the expected numberof genes which has been estimated at �26000, orfewer, in Arabidopsis (The Arabidopsis GenomeInitiative, 2000) and �32000–50000 in rice (Goffet al., 2002; Delseny, 2003). More ESTs need to beprepared from various developmental stages inorder to successfully identify a full unigene set thatcan be used for additional studies. This will requireusing different strategies: sequencing the 3¢ ends ofthe available clones, subtraction of the presentlibraries to isolate rare clones, and preparing newlibraries from different organs and tissues in dif-ferent biological conditions. Currently, the mainefforts are being directed at increasing the numberof ESTs, and this should be considered as one ofthe goals of the Cassava Global Genome Project.As part of this goal, efforts are currently underwayin collaborations between IITA and theUSDA Agricultural Research Service to developtwo normalized cDNA libraries for cassavagenotype TME 117 (a drought-tolerant variety)that will be used to produce an additional 5000–8000 unigene set. When all these data are avail-able, bioinformatics resources will be needed forprocessing them to identify as many functions aspossible and to contig the different sequences fromall of the existing EST resources. In particular,sequencing the 3¢ ends of available clones shouldimprove the analysis of these contigs and dis-criminate sequences that have been artificiallycontiged with each other.
Finally, another resource that has still to bedeveloped is the creation of a full-length cDNAcollection. So far no real effort has been made toraise such high quality libraries. Experience inArabidopsis and rice demonstrated these resourcesare strategic both for genomic annotation andfunctional characterization of the genes by ectopicexpression (Seki et al., 2002).
Gene expression and profilingAn important application of EST programmes isglobal gene expression analysis using DNA chips
(microarrays). The first generation of DNA chipsfor cassava and leafy spurge (Euphorbiaceae) arerepresenting only part of the genome and they aremade directly by spotting amplified clones corre-sponding to each EST. Such a DNA chip is pres-ently being made at CIAT from one of the unigenesets described in this paper and will be furthercomplemented with additional resources that haveto be merged into a single unigene set when newresources are available. Nevertheless, this firstgeneration of ‘‘Euphorbiaceae-specific’’ chips willbe extremely useful for classifying unknown genesinto functional categories. The first set of experi-ments will analyze transcript responses to patho-gens, dissect starch metabolism pathways, andpathways acting in drought-tolerance, and otherimportant biotic- and abiotic-stresses. Data pre-sented in this report (Figures 1–3) already showsthe potential for using these Euphorbiaceae-specificmicro-arrays/macro-arrays to screen for differen-tially expressed genes within varieties of cassava.
Development of oligonucleotide chips will beinitiated when more information about genesequence is available in order to decrease crosshybridization interferences due to members ofmultigene families. This problem can be antici-pated from the allopolyploid nature of Cassava(Olsen and Schaal, 1999).
Mapping and comparative genomicsAs mentioned in the introduction, and this issue, agenetic map of Cassava has been developed as wellas several BAC libraries. The EST resource shouldbe invaluable to increase the density of genemarkers on the genetic map and to contribute tothe ordering of the BAC clones into a physicalmap and anchoring it on the genetic map.
ESTs can be used either as RFLP or CAPSmarkers on the mapping populations. It can beexpected that several thousand ESTs can bemapped in the coming 2 or 3 years. Meanwhilethey can be located on BAC clones even morerapidly because there is no need for polymorphismand because this can be done using highthroughput PCR strategies. We can anticipate thata number of known genes of interest will bemapped first but it is also important to randomlymap a large number of sequences. Particularlyimportant is the mapping of members of multigenefamilies because cassava is an allotetraploidgenome.
536

Another important question is when and howmany rounds of polyploidization have occurred(Wolfe, 2001; Simillion et al., 2002; Blanc et al.,2003; Bowers et al., 2003). It will be interesting tocompare the available map with that of the pre-sumed cassava ancestors. The EST resourceshould be a fantastic tool to examine evolutionaryrelationships within the Euphorbiaceae family.For example, preliminary experiments have shownthat DNA arrays constructed from the small set ofleafy spurge ESTs, described in this report, haveconsistently shown between 15 and 35% hybrid-ization 2 · above background with target DNAfrom cassava leaf tissue (Figure 1, and Andersonet al., 2001). Additionally, as already mentioned,some ESTs already exist for Ricinus and Hevea,and they can also be compared with those ofCassava. Similarly, there is already a detailedgenetic map of rubber tree (Lespinasse et al., 2002)and many ESTs from cassava cross-hybridize withHevea DNA and can be used for further mappingpurposes. Such an approach should help inestablishing syntenic regions between the differentgenomes and in facilitating positional cloning ofgenes of interest in these species. Thus, additionalhigh throughput gene discovery and sequencingprojects directed toward specific problems inEuphorbiaceae members should provide thegroundwork for unlocking genetic diversity withinthis family. Of equal importance, it should en-hance our ability to control the growth and pro-ductivity of various members of this plant familyand increase the possibility for map-based cloning.
Genetic and allelic diversityContigs available for existing ESTs alreadyrevealed a high degree of genetic diversity betweencassava genotypes. This is not unexpected becauseof the allotetraploid nature of Cassava andbecause the domestication of this crop has notbeen as intense as that of maize or rice. Generatingadditional cassava ESTs from the same cultivarsalready analyzed, and from others, should givesome indication about the distribution and diver-gence of orthologous genes and their allelicdiversity. Such knowledge should provide newtools for mapping and breeding based on the SNPdiversity that already exists.
As a conclusion, we hope that developing theseEST resources and its derivatives will contribute toa more rapid improvement of cassava breeding,
increase cassava production, unlock the geneticdiversity within the Euphorbiaceae family, andassist in our quest to regulate growth and devel-opment in undesirable species. Most of the ESTspresented in this review are already in the processof being transferred to public databases so thatthey are available for the public community.Obviously, this resource still needs to be amplified,but it already makes a significant contribution tobasic knowledge in Euphorbiaceae family mem-bers such as cassava and leafy spurge. Developingit is a strategic point of the Cassava GlobalGenome Project.
Acknowledgements
The CBB and starch EST project was funded byCGIAR through the Agropolis (Montpellier,France) platform for developing countries andbenefited from the support of the MontpellierLanguedoc-Roussillon Genopole; C Lopez wassupported by a PhD fellowship from IRD (Institutpour la Recherche et le Developpement). Fundingfor the initiation and development of normalizedcDNA libraries and EST-databases for cassavavariety TME 117 was obtained from USAID-link-age funds through the International Institute forTropical Agriculture, (IITA), Ibadan, Nigeria, incollaboration with Alfred Dixon, Ivan Ingelbrecht,and Francis Moonan. Special thanks to Dr EarnestRetzel, Center for Computational Genomics andBioinformatics, University of Minnesota, for pro-viding bioinformatics and hosting of the leafyspurge EST database. Thanks also to Ryohei Ter-auchi for help with the cDNA library for CMDresistance, and to the IBRC and JSPS for funding.
References
Aharoni, A., Keizer, L.C.P., Bouwmeester, H.J., Sun, Z.,Alvarez-Huerta, M., Verhoeven, H.A., Blaas, J., vanHouwelingen, A.M.M.L., De Vos, R.C.H., van der Voet,H., Jansen, R.C., Guis, M., Mol, J., Davis, R.W., Schena,M., van Tunen, A.J. and O’Connell, A.P. 2000. Identifica-tion of the SAAT gene involved in strawberry flavorbiogenesis by use of DNA microarrays. Plant Cell 12:647–661.
Akano, O., Dixon, A., Mba, C., Barrera, E. and Fregene, M.2002. Genetic mapping of a dominant gene conferringresistance to Cassava mosaic disease. Theor. Appl. Genet.105: 521–525.
537

Altschul, S.F., Madden, T.L., Shaffer, A.A., Zhang, J., Zhang,Z., Miller, W. and Lipman, D.J. 1997. ‘Gapped BLAST andPSI-BLAST: a new generation of protein database searchprograms’. Nucleic Acids Res. 25: 3389–3402.
Anderson, J.V., Gedil, M., Horvath, D.P. and Dixon, A. 2001.Preliminary studies directed towards the development ofEuphorbiaceae-specific microarrays. In: N.J. Taylor, F.Ogbe and C.M. Fauquet (Eds.), 5th International ScientificMeeting of the Cassava Biotechnology Network: AbstractBook Donald Danforth Plant Science Center, St. Louis,Missouri, pp. S5-02.
Anderson, J.V. and Horvath, D.P. 2001. Random sequencingof cDNAs and identification of mRNAs. Weed Sci. 49:581–589.
Blanc, G., Hokamp, K. and Wolfe, K.H. 2003. A recentpolyploidy superimposed on older large-scale duplications inthe Arabidopsis genome. Genome Res. 13: 137–144.
Boguski, M.S., Lowe, T.M. and Tolstoshev, C.M. 1993.DbEST-database for ‘‘expressed sequence tags’’. Nat. Genet.4(4): 332–333.
Bowers, J.E., Chapman, B.A., Rong, J. and Paterson, A. 2003.Unravelling angiosperm genome evolution by phylogeneticanalysis of chromosome duplication events. Nature 422:433–438.
Chang, S., Puryer, J. and Cairney, J. 1993. A simple andefficient method for isolating RNA from pine trees. PlantMol. Biol. Rep. 11: 113–116.
Cooke, R., Raynal, M., Laudier, M., Grellet, F., Delseny, M.,Morris, P.C., Guerrier, D., Giraudat, J., Quigley, F., Claba-ult, G., Li, Y.F., Mache, R., Krivitzky, M., Gy, I.J.J., Kreis,M., Lecharny, A., Parmentier, Y., Marbach, J., Fleck, J.,Clement, B., Phillips, G., Herve, C., Bardet, C., Tremousay-gue, D., Lescure, B., Lacomme, C., Roby, D., Jourjon, M.F.,Chabrier, P., Charpenteau, J.L., Desprez, T., Amselem, J.,Chiapello, H. andHofte, H. 1996. Further progress towards acatalogue of all Arabidopsis genes: analysis of a set of 5000non-redundant ESTs. Plant J. 9: 101–124.
Delseny, M. 2003. Towards an accurate sequence of the ricegenome. Curr. Opin. Plant Biol. 6: 101–105.
Dominguez, I., Graziano, E., Gebhardt, C., Barakat, A.,Berry, S., Arus, P., Delseny, M. and Barnes, S. 2003. Plantgenome archeology: evidence for conserved ancestral chro-mosome segments in dicotyledonous species. Plant Bio-technol. J. 1: 91–99.
Duggan, D.J., Bittner, M., Chen, Y., Meltzer, P. and Trent,J.M. 1999. Expression profiling using cDNA microarrays.Nat. Genet. Supplement 21: 10–14.
Fregene, M.A., Angel, F., Gomez, R., Rodriguez, F.,Chavarriaga, P., Roca, W., Tohme, J. and Bonierbale,M.W. 1997. A molecular genetic map of cassava (Manihotesculenta Crantz). Theor. Appl. Genet. 95: 431–441.
Fregene, M.A., Matsumura, H., Akano, A., and Dixon, A. andTerauchi, R. 2003. Serial analysis of gene expression (SAGE)of host plant resistance to the cassava mosaic disease(CMD). Plant Mol. Biol. (in press).
Fulton, T.M., Van der Hoeven, R., Eannetta, N.T. andTanksley, S.D. 2002. Identification, analysis, and utilizationof conserved ortholog set markers for comparative genomicsin higher plants. Plant Cell 14: 1457–1467.
Gebhardt, C., Walkemeier, B., Henselewski, H., Barakat, A.,Delseny, M. and Stuber, K. 2003. Comparative mappingbetween potato (Solanum tuberosum) and Arabidopsisthaliana reveals structurally conserved domains and ancientduplications in the potato genome. Plant J. 34: 529–541.
Goff, S.A., Rick,e D., Lan, T.-H., Presting, G., Wang, R.,Dunn, M., Glazebrook, J., Sessions, A., Oeller, P., Varma,H., Hadley, D., Hutchison, D., Martin, C., Katagiri, F.,Lange, B.M., Moughamer, T., Xia, Y., Budworth, P.,Zhong, J., Miguel, T., Paszkowski, U., Zhang, S., Colbert,M., Sun, W.-L., Chen, L., Cooper, B., Park, S., Wood, T.C.,Mao, L., Quai,l P., Wing, R., Dean, R., Yu, Y., Zharkikh,A., Shen, R., Sahasrabudhe, S., Thomas, A., Cannings, R.,Gutin, A., Pruss, D., Reid, J., Tavtigian, S., Mitchell, J.,Eldredge, G., Scholl, T., Miller, R.M., Bhatnagar, S., Adey,N., Rubano, T., Tusneem, N., Robinson, R., Feldhaus, J.,Macalma, T., Oliphant, A., and Briggs, S. 2002. A draftsequence of the rice genome (Oryza sativa L. ssp. japonica).Science 296: 92–100.
Gutierrez, R.A., Ewing, R.M., Cherry, J.M. and Green, P.J.2002. Identification of unstable transcripts in Arabidopsis bycDNA microarray analysis: rapid decay is associated with agroup of touch and specific clock-controlled genes. Proc.Natl. Acad. Sci. USA. 99(17): 11513–11518.
Horvath, D.P., Schaffer, R., West, M. and Wisman, E. 2003.Arabidopsismicroarrays identify conserved and differentially-expressed genes involved in shoot growth and developmentfrom distantly related plant species. Plant J. 34: 125–134.
Jorge, V., Fregene, M.A., Duque, M.C., Bonierbale, M.W.,Tohme, J. and Verdier, V. 2000. Genetic mapping ofresistance to bacterial blight disease in cassava (Manihotesculenta Crantz). Theor. Appl. Genet. 101: 865–872.
Jorge, V., Fregene, M.A., Velez, C.M., Duque, M.C., Tohme, J.and Verdier, V. 2001. QTL analysis of field resistance toXanthomonas axonopodis pv. manihotis in cassava. Theor.Appl. Genet. 102: 564–571.
Kohler, A., Delaruelle, C., Martin, D., Encelot, N. andMartin, F. 2003. The poplar root transcriptome: analysis of7000 expressed sequence tags. FEBS Lett. 542(1–3): 37–41.
Lee, J.M., Williams, M.E., Tingey, S.V. and Rafalski, J.A.2002. DNA array profiling of gene expression changesduring maize embryo development. Funct. Integr. Genomics2(1–2): 13–27.
Lespinasse, D., Rodier-Gout, M., Grivet, L., Leconte, A.,Legnate, H. and Seguin, M. 2002. A saturated geneticlinkage map pf rubber tree (Hevea ssp.) based on RFLP,AFLP, microsatellite and isozyme markers. Theor. Appl.Genet. 100: 975–984.
Lozano, J.C. 1986. Cassava bacterial blight: a manageabledisease. Plant. Dis. 70: 1089–1093.
Mba, R.E.C., Stephenson, P., Edwards, K., Melzer, S., Mkum-bira, J., Gullberg, U., Appel, K., Gale, M., Tohme, J. andFregene, M.A. 2001. Simple sequence repeat (SSR) markerssurvey of the cassava (Manihot esculenta Crantz) genome:towards an SSR-based molecular genetic map of cassava.Theor. Appl. Genet. 101: 21–31.
Munyikwa, T.R.I., Langeveld, S., Salehuzzaman, S.N.I.M.,Jacobsen, E. and Visser, R.G.F. 1997. Cassava starchbiosynthesis: new avenues for modifying starch quantityand quality. Euphytica 96: 65–75.
Ohlrogge, J. and Benning, C. 2000. Unravelling plant metabol-ism by EST analysis. Curr. Opin. Plant Biol. 3: 224–228.
Okogbenin, E. and Fregene, M. 2002. Genetic analysis andQTL mapping of early root bulking in an F1 populationfrom non-inbred parents in cassava (Manihot esculentaCrantz). Theor. Appl. Genet. 106: 58–66.
Olsen, K.M. and Schaal, B.A. 1999. Evidence on the origin ofCassava: phylogeography of Manihot esculenta. Proc. Natl.Acad. Sci. USA 96: 5586–5591.
538

Oztur, Z.N., Talame, V., Deyholos, M., Michalowski, C.B.,Galbraith, D.W., Gozukirmizi, N., Tuberosa, R. andBohnert, H.J. 2002. Monitoring large-scale changes intranscript abundance in drought- and salt-stressed barley.Plant Mol. Biol. 48(5–6): 551–573.
Paterson, A.H., Lan, T.H. and Reischmann, K.P. 1996.Towards a unified genetic map of higher plants transcendingthe monocot-dicot divergence. Nat. Genet. 14: 380–382.
Potokina, E., Sreenivasulu, N., Altschmied, L., Michalek, W.and Graner, A. 2002. Differential gene expression duringseed germination in barley (Hordeum vulgare L.). Funct.Integr. Genomics 2(1–2): 28–39.
Quackenbush, R.C., Cho, J., Lee, D., Liang, F., Holt, I.,Karamycheva, S., Parvisi, B., Pertea, G., Sultana, R. andWhite, J. 2001. The TIGR Gene Indices: analysis of genetranscript sequences in highly sampled eukaryotic species.Nucleic Acids Res. 29: 159–164.
Restrepo, S., Duque, M.C. and Verdier, V. 2000. Character-ization of pathotypes among isolates of Xanthomonasaxonopodis pv. manihotis in Colombia. Plant Pathol. 49:680–687.
Reymond, P., Weber, H., Damond, M. and Farmer, E.E. 2000.Differential gene expression in response to mechanicalwounding and insect feeding in Arabidopsis. Plant Cell 12:707–719.
Richmond, T. and Somerville, S. 2000. Chasing the dream:plant EST microarrays. Curr. Opin. Plant Biol. 3: 108–116.
Salse, J., Piegu, B., Cooke, R. and Delseny, M. 2002. Syntenybetween Arabidopsis thaliana and rice at the genome level: atool to identify conservation in the ongoing rice genomesequence project. Nucleic Acids Res. 30: 2316–2328.
Sambrook, J., Fritsch, E.F. and Maniatis, T. 1989. MolecularCloning – A Laboratory Manual. 2nd edn. Cold SpringHarbor Laboratory Press, New York, USA.
Schena, M., Shalon, D., Davis, R.W. and Brown, P.O. 1995.Quantitative monitoring of gene expression patterns with acomplementary DNA microarray. Science 270: 467–470.
Schopke, C., Taylor, N., Carcamo, R., N’Da,K.K.,Marmey, P.,Henshaw, G.G., Beachy, R.N. and Fauquet, C.M. 1996.Regeneration of transgenic cassava plants (Manihot esculentaCrantz) from microbombarded embryogenic suspension cul-tures. Nat. Biotechnol. 14: 731–735.
Seki, M., Narusaka, M., Kamiya, A., Ishida, J., Satou, M.,Sakurai, T., Nakajima, M., Enju, A., Akiyama, K., Oono,Y., Muramatsu, M., Hayashizaki, Y., Kawai, J., Carninci,P., Itoh, M., Ishii, Y., Arakawa, T., Shibata, K., Shinag-awa, A. and Shinozaki, K. 2002. Functional annotation ofa full-length Arabidopsis cDNA collection. Science 296:141–145.
Simillion, C., Vandepoele, K., VanMontagu, M.C., Zabeau, M.and Van de Peer, Y. 2002. The hidden duplication past ofArabidopsis thaliana. Proc. Natl. Acad. Sci. USA 15:13627–13632.
The Arabidopsis Genome Initiative. 2000. Analysis of thegenome sequence of the flowering plant Arabidopsis thaliana.Nature 408: 796–815.
Uhde-Stone, C., Zinn, K.E., Ramirez-Yanez, M., Li, A.,Vance, C.P. and Allan, D.L. 2003. Nylon filter arraysreveal differential gene expression in proteoid roots of whitelupin in response to phosphorus deficiency. Plant Physiol.131: 1064–1079.
Van de Loo, F.J., Turner, S. and Somerville, C. 1995. Expressedsequence tags from developing castor seed. Plant Physiol.108: 1141–1150.
Van Hal, N.L.W., Vorst, O., van Houwelingen, A.M.M.L.,Kok, E.J., Peijnenburg, A., Aharoni, A., van Tunen, A.J.and Keijer, J. 2000. The application of microarrays in geneexpression analysis. J. Biotech. 78: 271–280.
Wolfe, K.H. 2001. Yesterday’s polyploids and the mystery ofdiploidization. Nature Rev. Genet. 2: 333–341.
Zhu, T., Budworth, P., Chen, W., Provart, N., Chang, H.S.,Guimil, S., Su, W., Ester, B., Zou, G.Z. and Wang, X. 2003.Transcriptional control of nutrient partitioning during ricegrain filling. Plant Biotechnol. J. 1: 59–70.
539




















