
Acquiring Knowledge from Digital Libraries - CiteSeerX
35
Beyond Information Searching and Browsing: Acquiring Knowledge from Digital Libraries ? Ling Feng a,1 Manfred A. Jeusfeld b Jeroen Hoppenbrouwers b a Department of Computer Science, University of Twente, PO Box 217, 7500 AE Enschede, The Netherlands b Infolab, Tilburg University, PO Box 90153, 5000 LE Tilburg. The Netherlands Abstract Digital libraries (DLs) are a resource for answering complex questions. Up to now, such systems mainly support keyword-based searching and browsing. The mapping from a research question to keywords and the assessment whether an article is rel- evant for a research question is completely with the user. In this paper, we present a two-layered digital library model. The aim is to enhance current DLs to sup- port different levels of human cognitive acts, thus enabling new kinds of knowledge exchange among library users. The low layer of the model, namely, the tactical cog- nition support layer, provides users with requested relevant documents, as searching and browsing do. The upper layer of the model, namely, the strategic cognition sup- port layer, not only provides users with relevant documents but also directly and intelligently answers users’ cognitive questions. On the basis of the proposed model, we divide the DL information space into two subspaces, i.e., a knowledge subspace and a document subspace, where documents in the document subspace serves as the justification for the corresponding knowledge in the knowledge subspace. De- tailed description of the knowledge subspace and its construction, as well as query facilities against the enhanced DLs for users’ knowledge sharing and exchange, are particularly discussed. Key words: Digital libraries, Tactical support, Strategic support, Document subspace, Knowledge subspace ? An earlier version of the paper was presented at the ICADL’02 Conference. Email addresses: [email protected] (Ling Feng), [email protected] (Manfred A. Jeusfeld), [email protected] (Jeroen Hoppenbrouwers). URLs: http://www.cs.utwente.nl/ ling (Ling Feng), http://infolab.uvt.nl/people/jeusfeld/ (Manfred A. Jeusfeld), http://infolab.uvt.nl/people/hoppie/ (Jeroen Hoppenbrouwers). 1 Corresponding author. Tel: +31 53 489 3772 Fax: +31 53 489 2927 Preprint submitted to Elsevier Science 4 October 2004
-
Upload
khangminh22 -
Category
Documents
-
view
0 -
download
0
Transcript of Acquiring Knowledge from Digital Libraries - CiteSeerX

Beyond Information Searching and Browsing:
Acquiring Knowledge from Digital Libraries ?
Ling Feng a,1 Manfred A. Jeusfeld b Jeroen Hoppenbrouwers b
aDepartment of Computer Science, University of Twente, PO Box 217, 7500 AE
Enschede, The Netherlands
bInfolab, Tilburg University, PO Box 90153, 5000 LE Tilburg. The Netherlands
Abstract
Digital libraries (DLs) are a resource for answering complex questions. Up to now,such systems mainly support keyword-based searching and browsing. The mappingfrom a research question to keywords and the assessment whether an article is rel-evant for a research question is completely with the user. In this paper, we presenta two-layered digital library model. The aim is to enhance current DLs to sup-port different levels of human cognitive acts, thus enabling new kinds of knowledgeexchange among library users. The low layer of the model, namely, the tactical cog-
nition support layer, provides users with requested relevant documents, as searchingand browsing do. The upper layer of the model, namely, the strategic cognition sup-
port layer, not only provides users with relevant documents but also directly andintelligently answers users’ cognitive questions. On the basis of the proposed model,we divide the DL information space into two subspaces, i.e., a knowledge subspace
and a document subspace, where documents in the document subspace serves asthe justification for the corresponding knowledge in the knowledge subspace. De-tailed description of the knowledge subspace and its construction, as well as queryfacilities against the enhanced DLs for users’ knowledge sharing and exchange, areparticularly discussed.
Key words: Digital libraries, Tactical support, Strategic support, Documentsubspace, Knowledge subspace
? An earlier version of the paper was presented at the ICADL’02 Conference.Email addresses: [email protected] (Ling Feng), [email protected]
(Manfred A. Jeusfeld), [email protected] (Jeroen Hoppenbrouwers).URLs: http://www.cs.utwente.nl/ ling (Ling Feng),
http://infolab.uvt.nl/people/jeusfeld/ (Manfred A. Jeusfeld),http://infolab.uvt.nl/people/hoppie/ (Jeroen Hoppenbrouwers).1 Corresponding author. Tel: +31 53 489 3772 Fax: +31 53 489 2927
Preprint submitted to Elsevier Science 4 October 2004

1 Introduction
In todays’ networked environment, people demand new evolutionary tech-nology for information retrieval and intellectual exchange. DLs serve as anincreasingly important channel to a vast array of information sources and ser-vices. They provide new opportunities to assemble, organize and access largevolumes of information from multiple repositories, while making distributedheterogeneous resources spread across the network appear to be a single uni-form federated source (Schatz and Chen, 1999). Under the assistance of DLsystems, users can move from source to source, seeking and linking informa-tion automatically or semi-automatically to solve their various informationproblems.
Traditionally, when people retrieve information, their activities are classifiedinto two broad categories: searching and browsing. Searching implies that theuser knows exactly what to look for, while browsing should assist users navi-gating among correlated searchable terms to look for something new or inter-esting. Currently, most of the major work on DL systems focus on supportingthese two kinds of activities. However, with more DLs built up to handleusers’ information requests, we ask questions: Are the existing informationtechnologies powerful enough to facilitate DL users’ problem solving? Or whattechnologies do we still need to help users better do their work? Compared totraditional physical libraries, are there any important features missing from thecurrent DL systems? To answer these questions, let’s first look at a scenarioon the use of a DL system.
Kooper works in a city plan & management office. He is investigating the pre-
caution policy against flood this year. If there will be a flood in the coming sum-
mer, necessary actions (e.g., strengthing the embankment, resource allocation,
etc.) must be taken now to prevent the city from sustaining losses. According to
Kooper’s previous experience, it seems that “A wet winter might cause flood in
summer.” To confirm this pre-conceived hypothesis, he rewords a DL system to
request information talking about the reasons of flood. The DL system returns
a number of articles. He browses through the returned article list and selects
three articles that look most relevant. All of the three articles mention that “A
precursor to the flooding in summer is a wet winter.” To assure this information
is also valid for the area where Kooper lives, he accesses the DL again to ask for
documents reporting river floods in the city before. ¿From the articles returned,
he gets to know the latest 3 severe floods that happened in 1986, 1995, 1997,
respectively, in the city. He then navigates to the meteorological repository of the
DL, and accesses the weather information of the city during the winter time of
these three years. He notes a tight correlation between wet winter and summer
flood. Based on the information obtained from the DL, Kooper is pretty sure now
about his prior flood prediction assumption for the city. He logs off the system.
2

Having experienced a very wet winter this year, Kooper decides to draw up a city
flood precaution plan immediately.
This scenario shows us a few shortcomings that exist in current DLs. Belowwe outline some of the problems and propose our work to solve them.
1) Inadequate strategic level cognition support. The aim of DL sys-tems is to empower users to find useful information to solve their problems.When a person goes into a library to look for something, s/he usually has cer-tain purposes in mind. For example, s/he may want to read a specific articlewritten by a certain author. In this situation, the target of the user is pre-cise and clear. Sometimes, the user wishes to explore the available resourcesfirst before exploiting them. This exploration may be targeted at refining aprior understanding of a certain information context, or formulating a furtherconcrete requirement for specific documents. Most efforts of the current DLsystems aim to support these two kinds of users’ activities, namely, searchingand browsing.
However, besides simply entertaining users with documents located by search-ing and browsing, DL systems also should consider supporting human’s strate-gic level cognitive work which can directly enable correct actions and problemsolving. Typically, users have already some prior domain-specific knowledgeor pre-conceived hypotheses. They may expect the library systems to con-firm/deny their existing concepts, or to check whether there is some excep-tional/contradictory evidence against pre-existing notions, or to provide somepredictive information so that users can take effective actions. Under this cir-cumstance, the users’ information needs are not only for relevant documents,but also for intelligent answers to their questions together with supporting lit-erature for justification and explanation, as illustrated in the above scenario.To distinguish this kind of information need from traditional searching andbrowsing requests, we categorize traditional users’ information searching andbrowsing activities into tactical level cognition act and the latter into strategiclevel cognition act.
As (Checkland and Holwell, 1998) says, “The nature of an information systemis to provide informational support to people as they carry out their intentionaltasks.” Developing one of the most complex and advanced forms of informa-tion systems, DL system designers must have a comprehensive understandingof users’ information needs and their purposes for using DLs. In the aboveexample, if the DL system could automate user’s rational exploration fromthe knowledge space, consisting of propositions and assertions, to the corre-sponding justification/explanation space, consisting of data sources in variousforms like textual articles, reports, databases, etc., the information role of theDLs in helping users derive effective decisions will be greatly enforced. Un-fortunately, such high-order cognition support and its impact on users’ work
3

have not received much exploration in current DL systems.
2) Inadequate knowledge sharing facilities. Traditional libraries are apublic place where a large extent of mutual learning, knowledge sharing andexchange can happen. A user may ask a librarian for search assistance. Librar-ians themselves may collaborate in the process of managing, organizing anddisseminating information, or share experiences in using consistently-emergingnew systems and tools to tackle users’ search questions. Users may communi-cate and learn from each other by observing how others use library’s resources,or by asking for help. With paper sources digitalized and physical librariesmoving to virtual DLs, these valuable features of traditional libraries shouldbe retained. We believe DLs of the future should not just be simple storageand archival systems. To be successful, DLs must become a knowledge placewhere knowledge acquisition, sharing and propagation take place. For exam-ple, if the DL in the above scenario could make readily available expertiseand answers to strategic level questions, which might require time-consumingsearch or consultation with experts, it can help users to better exploit the DLand improve working effectiveness. Also, as computerized knowledge does notdeteriorate with time as that human knowledge does, for long-term retention,DLs offer ideal repositories for the knowledge in the world, and make it univer-sally accessible. Currently, there are some DL efforts aiming in this direction,see (Marshall et al., 2003) for good reference.
Our work. We propose a two-layered DL functional model to support bothtactical level and strategic level cognitive tasks of users according to theirinformation needs. The model moves beyond simple searching and browsingacross multiple correlated repositories, to acquisition of knowledge. On thebasis of the proposed functional model, we further divide the DL informationspace into two subspaces, i.e., a knowledge subspace and a document subspace.Documents in the document subspace serve as the justification for the corre-sponding knowledge in the knowledge subspace. We give a detailed descriptionof the DL knowledge subspace, as well as query facilities against such enhancedDLs. Further issues regarding the construction of the knowledge subspace andits linkage with the document subspace also are addressed in the paper.
The remainder of the paper is organized as follows. In section 2, we review someclosely related work. A two-layered DL model, consisting of a tactical cognitionsupport layer and a strategic cognition support layer, is presented in section 3.A formal description of the DL knowledge subspace and query facilities againstthe enhanced DLs are presented in section 4 and section 5, respectively. Twomechanisms for the construction of a DL’s knowledge subspace and its linkageto the document subspace are described in section 6. One of them is based onthe manual input from experienced users. Another approach addresses (semi-)automatic knowledge acquisition by correlating and analyzing data sourcesfrom multiple repositories in DLs. Section 7 discusses the fundamental differ-
4

ences between such an enhanced DL system and traditional knowledge-basedinformation systems. A number of issues are meanwhile pointed out for futurework.
2 Related work
DLs integrate a variety of information technologies, calling for multi-disciplinarycooperation in information science. In this section, we provide a brief reviewof relevant work in different fields, including ontologies and lexical relations,knowledge representation, information retrieval and multi-source integrationin DLs.
Ontologies and Lexical Relations
The Oxford English Dictionary defines ontology as the “the science or studyof being”. In philosophy, the word ontology refers to a systematic descriptionof a minimal set of concepts that a language needs to express all its otherconcepts (Hoppenbrouwers, 1997). In linguistic and lexicographic contexts, anontology is a specification of the concepts and their relationships that exist fora community of people or automated agents. Its purpose is to enable knowl-edge sharing and reuses (Gruber, 1993). To reflect cognitive relations amongthe concepts as expressed by or embodied in words in natural languages, thetheory of lexical relations was developed (Kiefer, 1969), where information isrepresented as a collection of nodes connected by labeled arcs that expresslinks or relationships between the nodes. These links may represent seman-tic and syntactic relationships among concepts, and can be used to reflect notonly major aspects of word meaning, but also their morphological relationshipsand implicatures (Kiefer, 1969; Evens and Smith, 1979; Nutter et al., 1990;Markowitz et al., 1992; Nutter, 1989). The most widely recognized relation-ships include is-a, synonym, antonym, and so on. In the literature, a link canbe denoted using either a labeled arc or a proposition node (et al., 1978; Find-ler, 1979; Cercone and McCalla, 1987). Further, a methodology for identifying,evaluating and describing different relationships, along with their logical prop-erties in modeling human reasoning, was presented (Markowitz et al., 1992).It begins with a study of dictionary and folk definitions to obtain the linguis-tic formulae used to express the link in question. Then it discovers how thislink appears in anthropology, linguistics, philosophy and psychology, and theway it interacts with other links and the way it is used in conceptual informa-tion processing. A hierarchy of lexical-semantic relations is thus constructedwhich contains both basic and non-basic semantic relations as well as a largenumber of lexical relations. Many (but not all) of the lexical relations so faridentified can be extracted automatically from dictionary definitions (Nutteret al., 1990). CYC (Lenat, 1995) aims to build a common sense knowledge base
5

consisting of roughly 100,000 general concepts spanning all aspects of humanreality. WordNet is another remarkable and widely used lexicon, which groupsthe words together by means of synonym sets. It aims to provide an aid tosearch in a lexicon in a conceptual rather than an alphabetical way (Milleret al., 1993).
Knowledge Representation
Knowledge is an important element of any AI application. A number of knowl-edge representation schemas are designed in the AI field so that the knowledgecan be applied in the reasoning process to solve problems. These techniquescan be roughly categorized as either declarative methods, in which most ofthe knowledge is represented as a static collection of facts accompanied by asmall set of general procedures for manipulating them; or procedural methods,in which the bulk of the knowledge is represented as procedures for using it(Anderson, 1992; Rich, 1983; Garnham, 1988). Typical declarative methodsinclude predicate logic, semantic nets, frames and scripts. 1) Predicate logicinvolves using standard forms of logical symbolism to represent real-worldfacts as statements, written as well-formed formulae, which are made up ofpredicates, constant terms, variables, logical connectives, and quantifiers. 2)Semantic nets take the complex structure of the world into consideration,where information is represented as a set of nodes connected to each otherby a set of labeled arcs, representing relationships among the nodes (Minsky,1968a,b). Both 3) frames and 4) scripts serve as general-purpose knowledgestructures that represent some common features of things or sequence of eventsin a particular context. Some procedural knowledge representation methodsinclude procedures and production rules.
In our study, we explore the use of predicate logic and semantic networkmechanisms to represent hypotheses and their inter-relationships in the DLknowledge subspace.
Information Retrieval
To support efficient information searching and browsing activities, many ef-forts have been made in developing retrieval models, building document andindex spaces, or extending and refining queries for information retrieval sys-tems (Fidel, 1994; Frakes and Baeza-Yates, 1992; Crestani et al., 1998). Athree-dimensional model of information exploration is presented in (Water-worth and Chignell, 1991), with the attempt to clarify the respective rolesof the human and the system in browsing and information retrieval, and tocharacterize alternative interaction styles to maximize retrieval effectiveness.In (Dunlop and van Rijsbergen, 1993), index terms are automatically ex-tracted from documents and a vector-space paradigm is exploited to measurethe matching degrees between queries and documents. Indexes and metadata
6

also can be created manually, from which semantic relationships are captured(Beard and Sharma, 1997; Dao, 1998). Besides, the large collection of docu-ments can be semantically partitioned into different clusters, so that queriescan be evaluated against relevant clusters (Willett, 1988). To improve queryrecall and precision, several query expansion and refinement techniques basedon relational lexicons/thesauri or relevance feedback have been explored (Velezet al., 1997; Efthimiadis, 1993; Jones et al., 1995). (Ingwersen, 1994) appliesa cognitive polyrepresentation of information needs to information retrievalsystems, aiming to improve the intellectual access to information sources onan enriched contextual platform. (Beaulieu and Jones, 1998) investigates theinterface design issues for a highly interactive information retrieval systembased on a probabilistic retrieval model with relevance feedback. (Belkin andMarchetti, 1990) proposes a method for specifying the functionality of an in-telligent interface to large-scale information retrieval systems, and for imple-menting those functions in an operational environment. Furthermore, (Chen,1992) outlines a theoretical framework for understanding the information stor-age and retrieval process in terms of the “agents” involved in the indexing andsearching processes. It shows how human agents are involved in the retrievalprocesses, the types of knowledge these agents possess, and the observed char-acteristics of their indexing and searching behaviors. A recent work incor-porates knowledge about the document structures into information retrieval,and the presented query language allows the assignment of structural rolesto individual query terms (Wolff et al., 2000). Individual differences in usinginformation retrieval systems also have been extensively studied in (Borgman,1987; McKnight et al., 1989; Belkin et al., 1994; Spink and Saracevic, 1998;Dumais, 1999).
Multi-Source Integration in DLs
The emerging field of DLs brings together participants from many existing re-search areas (Fox and Marchionini, 1998, 2001). ¿From a database or informa-tion retrieval perspective, DLs may be seen as a form of federated databases,since a DL usually contains lots of distributed and heterogeneous repositorieswhich may be autonomously managed by different organizations. To facili-tate users’ easy access to diverse sources, many efforts have been engagedin handling various structural and semantics variations and providing userswith a coherent view of a massive amount of information. Currently, the in-teroperability problem has sparked vigorous discussions in the DL community(Schatz and Chen, 1999; Schatz et al., 1999; Schatz, 1998, 1996; Chen, 1999;Payette et al., 1999; Paepcke et al., 1998). The concept extraction, mappingand switching techniques, developed in (Bennett et al., 1999; Mead and Gay,1995; Chen et al., 1997), enable users in a certain area to easily search thespecialized terminology of another area. A dynamic mediator infrastructure(Melnik et al., 2000) allows mediators to be composed from a set of modules,each implementing a particular mediation function, such as protocol trans-
7

lation, query translation, or result merging (Paepcke et al., 2000). (Payetteand Lagoze, 1999; Jr and Lagoze, 1997) present an extensible digital objectand repository architecture FEDORA, which can support the aggregation ofmixed distributed data into complex objects, and associate multiple contentdisseminations with these objects. (Kahn and Wilensky, 1995; Paepcke et al.,1996; Paepcke and Hassan, 1996) employ the distributed object technologyto cope with interoperability among heterogeneous resources. According totopic areas, a distributed semantic framework is proposed to contextualizethe entire collection of documents in a DL for efficient large-scale searching(Papazoglou and Hoppenbrouwers, 1999). Experiences in designing and im-plementing DLs, including the archival repository architecture, user interface,cross-access mechanism, and intellectual property protection, etc., are substan-tially presented in (Bates, 2002; Hoppenbrouwers and Paijmans, 2000; Crespoand Garcia-Molina, 2000; Cooper et al., 2000; House et al., 1996; House, 1995;Phelps and Wilensky, 1997; Beard and Sharma, 1997; Buttenfield and Larsen,1997). Recommendations for DL evaluation from both a longitudinal and mul-tifaceted viewpoint are provided in (Marchionini, 2000; Kantor, 1998).
On the other hand, applying AI to library science, many library-oriented ex-pert systems have been developed (Lancaster and Smith, 1990; Lancaster andSandore, 1997). However, most of these systems essentially aid in carrying outthe support operations of libraries, such as descriptive cataloging, collectiondevelopment, disaster planning and response, database searching, documentdelivery, etc. (Lancaster and Smith, 1990; Lancaster and Sandore, 1997). Thereis a fundamental difference from the work reported in this paper, whose in-tention is to answer library users’ strategic questions.
3 A Two-Layered DL Function Model
Supporting users’ information searching and browsing has been the focus ofDL research for a long time. However, as social humans, their informationexpectations for a DL are more than pure searching and browsing. In thissection, we extend the traditional role of DLs from information provider toinformation & knowledge provider. Figure 1 illustrates a two-layered DL func-tional model, consisting of a tactical cognition support layer and a strategiccognition support layer.
3.1 Tactical Level vs. Strategic Level Cognition Support
Tactical level cognition support. We view traditional DL searching andbrowsing as tactical level cognitive acts. The target of searching is towards
8

correlated concept spacewith relevant documentsuseful documents
look for "potentially"
answer to a research questionbased on knowledge andsupporting documents
KnowledgeInquiry
InformationBrowsing
InformationSearching
Cognition Support
Tactical Level Cognition Support
requested documents
look for "hypothesis" knowledge with/withoutjustifications
look for "specific"documents
Strategic Level
User’s RequestFunction Modules
DL’s Cognitive DL’s Result
Fig. 1. A two-layered DL functional model
certain specific documents. One searching example is “Look for the articlewritten by John Brown in the proceedings of VLDB88.” As the user’s requestcan be precisely stated beforehand, identifying the target repository wherethe requested document is located is relatively easy. Primarily, the ability tosearch indexes of repositories can support this kind of searching activities.In comparison to searching whose objective is well-defined, browsing aimsto provide users with a conceptual map, so that users can navigate amongcorrelated items to hopefully find some potentially useful documents, or toformulate a more precise retrieval request further. For instance, a user readsan article talking about a water reservoir construction plan in a certain region.S/he wants to know the possible influence on ecological balance. By followingsemantic links for the water reservoir plan in the DL, s/he navigates to therelated “ecological protection” theme, under which a set of searchable termswith relevant documents are listed for selection. To facilitate browsing, DLsmust integrate diverse repositories to provide users with a uniform searchingand retrieval interface to a coherent collection of materials. The capabilitythat enables navigation among a network of inter-related concepts, plus thesearching capability on each individual repository, constitute the fundamentalsupport to browsing activities.
As the techniques of searching and browsing have been extensively studiedand published in the literature, we will not discuss these any further here.
Strategic level cognition support. In contrast to tactical level cognitionsupport which intends to provide users with requested documents, strategiclevel cognition support not only provides relevant documents but also intelli-gently answers high-order cognitive questions, and meanwhile provides justi-fications and evidences. Taking the scenario in section 1 as an example, thepurpose of Kooper on the use of the DL is to confirm his prior knowledgeabout “Wet winter causes summer flood”. Instead of retrieving documents us-ing keywords like wet winter, summer flood, cause, etc., the user would preferto pose a direct question Q1 as follows, and expect a direct confirmed/deniedanswer from the DL system rather than a list of articles lacking explanatorysemantics and waiting for his assessment.
9

Q1: “Tell me whether a wet winter will cause summer flood.”
Other high-order cognitive request examples are like:
Q2: “Tell me what will possibly cause summer flood. Give me referent articlesthat talk about this.”
Q3: “Give me articles which state the necessary influences of wet winter.”
In response to different questions as described above, it is desirable for DLsto provide knowledge-level answers, together with the justifications for theseanswers. For example, the justification for Q1 is a series of articles talkingabout “wet winter causes flood in summer”, as well as evidence articles whichtalk about, respectively, wet winter in certain years and summer flood in thenext years in certain particular regions.
The provision of strategic level cognition support adds values to DLs beyondsimply providing document access. It reinforces the exploration and utilizationof information in DLs, and advocates a more close and powerful interactionbetween users and DL systems. With this high-order cognitive assistance, DLusers will be able to find things to solve their real information problems them-selves. ¿From the viewpoint of DLs, to realize such a strategic level cognitionfunction, substantial information analysis and abstraction need to be done.This inevitably involves the navigation and correlation of information itemsacross multiple repositories in DLs, and production of intelligent knowledgein answering users’ strategic questions.
3.2 An Enlarged DL Information Space
In order to support the two kinds of cognitive acts, we further divide theDL information space into two subspaces, i.e., a knowledge subspace and adocument subspace, as shown in Figure 2. Note that in this figure, we onlyillustrate the organization of documents for knowledge justification purpose.Documents in a DL are in fact also indexed and clustered based on the ontologyand specific topics.
The knowledge subspace. The basic constituent of the knowledge subspaceis knowledge, such as hypothesis, rule, belief, etc. 2 Each hypothesis describesa certain relationship among a set of concepts. For example, the hypothesis“H2 : wet winter causes summer flood” explicates a causal relationship be-tween a cause wet winter and the effect summer flood it has. Considering thatthe DL knowledge subspace is for users to retrieve strategical level knowledge,
2 In this initial study, we focus on hypothesis knowledge in empirical sciences.
10

articles on H3
articles on H2
KnowledgeSubspace
represents a hypothesis
represents an opposite relationship between two hypotheses
represents a specification relationship between two hypotheses
articles on H1 articles
on H4
DocumentSubspace
....H1:
summer-flood and
......
H3:
relate (winter|*,river-behavior|*)
H2: cause (wet-winter|*,summer-flood|*)
cause (wet-winter|*,
hot-summer|*)H4: summer-flood and
cause (wet-winter|*,
cool-summer|*)
......
(for justification)
Fig. 2. An enlarged DL information space
it will inevitably be subject to the classical information retrieval’s vocabu-lary (synonymy and polysemy) problem. Previous research (Bates, 1986; Chenet al., 1993) demonstrated that different users tend to use different terms toseek identical information. Furnas et al. (Furnas et al., 1987) showed that theprobability of two people using the same term to classify an object was lessthan 20%. To enable knowledge exchange and reusability, we formulate variousrelationships including equivalence, specification/generalization and oppositionover the hypotheses knowledge, expanding a single user’s hypothesis into anetwork of related hypotheses. For example, a more general hypothesis withrespect to H2 is “H1: wet winter is related with river behavior”. Section 4 givesa detailed description of the knowledge subspace. A query language againstthe enhanced DLs is provided in Section 5.
The document subspace. Under each hypothesis is a justification set, giv-ing reasons and evidences for the knowledge. These justifications, made up ofarticles, reports, etc., constitute the document subspace of the DL informationspace. Taking the above hypothesis H2 for example, the articles mentioningexactly that “wet winter is an indicator of summer flood.” constitute the justi-fication for that hypothesis. Returning to the previous example questions Q1,Q2 and Q3, the DL system can provide not only intelligent answers accordingto the hypothesis, but also a series of links to the justifying articles for users’reference.
It is worth notice here that the document subspace challenges traditional DLson literature organization, classification, and management. For belief justi-fications, we must extend the classical keyword -based index schema, whichis mainly used for information searching and browsing purposes, to knowl-
11

edge-based index schema, in order that the information in DLs can be easilyretrieved by both keywords and knowledge. Two mechanisms for construct-ing the knowledge subspace and its linkage with the document subspace aredescribed in Section 6.
4 A Formal Description of DL Knowledge Subspace
In this section, we define the basic constituent of the DL knowledge subspace- hypothesis, starting with its two constructional elements, i.e., concept termsand relation terms. Different concept-term-based and relation-term-based rela-tionships are then defined. They form the base for the definitions of hypothesesand the equivalence, specification/generalization and opposition relationshipsof hypotheses. Throughout the discussion, we assume the following notationis used.
• A finite set of entity concepts EConcept = {e1, e2, . . . , et}.• A finite set of relation concepts RConcept = {r1, r2, . . . , rs}.• A finite set of concepts Concept, where Concept = EConcept ∪ RConcept.• A finite set of contextual attributes Att = {a1, a2, . . . , am}.
The domain of ai ∈ Att is denoted as Dom(ai).• A finite set of concept terms CTerm = {n1, n2, . . . , nu}.• A finite set of relation terms RTerm = {m1,m2, . . . ,mv}.• A finite set of hypotheses Hypo = {H1, H2, . . . , Hw}.
4.1 Concepts
Concepts represent real-world entities, relations, states and events. Here, weclassify concepts into two categories, i.e., entity concepts and relation con-cepts, according to the roles they play in representing knowledge, which willbe addressed in this section. Entity concepts are used to describe conceptterms, including attributes. They are similar to entities in classical Entity-Relationship (ER) diagrams. Some entity concept examples are dog, animal,traffic-jam, wet-winter, summer-flood, etc. In contrast, relation concepts aremainly for presenting various relationships among concept terms. They thuslook like relationships in ER diagrams. For example, the causal relation be-tween a wet-winter in the north and a consequence summer-flood in the southcan be expressed with the relation concept cause.
Concepts are the building blocks of a sentence. They convey the most funda-mental cognitive knowledge in human society. Based on the substantial workon lexicography and ontology (Sowa, 1984; Kiefer, 1969; Evens and Smith,
12

1979; Nutter et al., 1990; Gruber, 1993; Guarino and Welty, 2000), three typi-cal primitive relationships between concepts can be established. They are Is-A,Synonym, and Opposite, each of which is denoted using a binary predicate.For example, Is-A (summer-flood, river-behavior) represents the notion thatsummer-flood is a river-behavior, Opposite (wet-winter, dry-winter) repre-sents a pair of antonym concepts, wet-winter and dry-winter, and Is-A (cause,relate) specifies a more general relation concept relate with respect to cause.
Property 1 The three primitive relationships of concepts (which can be eitherentity concepts or relation concepts) have the following properties: 1) Is-A isreflexive and transitive. 2) Synonym is reflexive, transitive and symmetric. 3)Opposite is symmetric. 2
4.2 Concept Terms
Observing that real-world users’ investigation and understanding of conceptsare usually under certain specific contexts, in this study, we associate each en-tity concept with a conceptual context to denote the circumstance under whichthe entity concept is considered. Basically, we can declare a conceptual contextby a set of attributes called contextual attributes, each of which represents adimension in the real world. Typical contextual attributes include time, space,temperature, and so on. Note that the contextual attributes could be of anykind as long as they are meaningful and make commitment to the existence ofentity concepts. For example, the context for the entity concepts wet-winterand summer-flood could be constructed by two contextual attributes, Periodand Region, indicating the time and place for the occurrences of wet-winterand summer-flood. The context of an entity concept can be further instanti-ated by assigning concrete values to its constructional attributes. For example,we can restrict the contextual Region and Year of the wet-winter concept tothe north and south areas in 2000 by setting Region:={“north”, “south”}and Y ear:={“2000”}. Region := Dom(Region) assigns all applicable regions(“south”, “north”, “east”, and “west”) to contextual attribute Region.
In this paper, we view an entity concept and its associated context as anintegral unit, where the context spans the universe of discourse for that entityconcept. To distinguish it from the traditional notion of entity concept, wename it as a concept term.
Definition 1 A concept term n ∈ CTerm is of the form n = e |AV , wheree ∈ EConcept and AV = {a := Va | (a ∈ Att) ∧ (Va ⊆ Dom(a))}.
Let Att = {a1, a2, . . . , am} be a set of contextual attributes which constitutethe context under consideration. The default setting for attribute ai (whereai ∈ Att) is the whole set of applicable values in the domain of ai, i.e., ai :=
13

Dom(ai). AV = {a1 := Dom(a1), a2 := Dom(a2), . . . , am := Dom(am)}depicts a universe context, covering all possible values for every constructionalattribute. A simple and equivalent representation of a universe context is AV =∗. 2
Example 1 Suppose the context under consideration is comprised of two at-tributes Region and Y ear. wet-winter |{Region:={“north”,“south”}, Y ear:={“2000”}} isa concept term, denoting a wet-winter entity concept in the north or south in2000. The concept term wet-winter |{Y ear:={“2000”}} implies a wet-winter con-cept in 2000 in all regions, including “north”, “south”, “west” and “east”. Thecontext in wet-winter |{Region:=Dom(Region), Y ear:=Domain(Y ear)} spans the uni-verse of discourse, equivalent to the expression wet-winter |∗ according to Def-inition 1. 2
Different relationships of concept terms can be identified based on their entityconcepts and associated contexts. Before giving the formal definitions, we firstdefine three relationships between two conceptual contexts.
Definition 2 Let AV1 and AV2 be two instantiated contexts.
• AV1 ≤a AV2 (or AV2 ≥a AV1), iff ∀(a := V2) ∈ AV2 ∃(a := V1) ∈ AV1
(V1 ⊆ V2).• AV1 =a AV2, iff AV1 ≤a AV2 and AV2 ≤a AV1.• AV1 <a AV2 (or AV2 >a AV1), iff (AV1 ≤a AV2 ∧ AV1 6=a AV2).
According to Definition 1, for any instantiated context AV , we have AV ≤a ∗.2
The =a relationship between two instantiated contexts AV1 and AV2 indicatesthat they both have exactly the same contextual attributes with the sameattribute values. AV1 ≤a AV2 implies a broader contextual scope of AV2 whichembodies the contextual scope of AV1.
Example 2 Assume we have four instantiated contexts: AV1 = ∗,AV2 = {Y ear := {“1999”, “2000”, “2001”}},AV3 = {Region := {“north”}, Y ear := {“2000”}}, andAV4 = {Region := {“south”}, Y ear := {“2000”}}. Following Definition 2,AV2 <a AV1, AV3 <a AV1, AV4 <a AV1, AV3 <a AV2, and AV4 <a AV2. 2
Property 2 The four context-based relationships defined above have the fol-lowing properties:1) ≤a (or ≥a) is reflexive and transitive.2) =a is reflexive, transitive and symmetric.3) <a (or >a) is transitive. 2
Based on the primitive relationships of concepts (Is−A, Synonym,Opposite),
14

as well as their contexts (≤a, =a, <a), we declare the following three concept-term-based relationships, i.e., equivalence EQct, specification SPECct, andopposition OPSIct. Assume n1 = e1 |AV1
and n2 = e2 |AV2are two concept
terms in the following definitions, where n1, n2 ∈ CTerm.
Definition 3 Equivalence EQct (n1, n2). n1 is equivalent to n2, iff thefollowing two conditions hold: 1) (e1 = e2) ∨ Synonym(e1, e2); 2) (AV1 =a
AV2). 2
Example 3 Given two concept terms: n1 = wet-winter |∗ andn2 = high-rainfall-winter |{Region:=Dom(Region)},EQct(n1, n2) since Synonym (wet-winter, high-rainfall-winter). 2
Definition 4 Specification SPECct (n1, n2). n1 is a specification of n2
(conversely, n2 is a generalization of n1), iff the following two conditionshold: 1) (e1 = e2) ∨ Is-A(e1, e2) ∨ Synonym(e1, e2); 2) (AV1 ≤a AV1).
2
Example 4 Given three concept terms:n1 = wet-winter |{Region:={“north”},Y ear:={“2000”}}, n2 = wet-winter |{Y ear:={“2000”}}
, and n3 = winter |∗, we have SPECct(n1, n2), SPECct(n1, n3) andSPECct(n2, n3), since {Region:={“north”}, Year:={“2000”}} <a
{Year:={“2000”}}, {Region:={“north”}, Year:={“2000”}} <a *,{Year:={“2000”}} <a *, and Is-A ( wet-winter, winter). 2
Definition 5 Opposition OPSIct(n1, n2). n1 is opposite to n2, iff thefollowing two conditions hold 1) Opposite(e1, e2); 2) (AV1 =a AV2). 2
Example 5 Let n1 = wet-winter |{Region:={“north”}} andn2 = dry-winter |{Region:={“north”}} be two concept terms, we have OPSIct(n1, n2)since Opposite (wet-winter, dry-winter). 2
To facilitate the description of hypothesis-based inter-relationships in Sub-section 4.4, we further extend the three relationships (i.e., EQct, SPECct
and OPSIct) defined over a pair of concept terms to the relationships (i.e.,EQCT , SPECCT and OPSICT ) over a pair of concept term sets. Let N1 andN2 be two concept term sets, where N1, N2 ⊆ CTerm.
Definition 6 Equivalence EQCT (N1, N2). N1 is equivalent to N2, iff∀n1 ∈ N1 ∃n2 ∈ N2 EQct(n1, n2) ∧ ∀n2 ∈ N2 ∃n1 ∈ N1 EQct(n2, n1). 2
Definition 7 Specification SPECCT (N1, N2). N1 is specification ofN2, iff ∀n2 ∈ N2 ∃n1 ∈ N1 SPECct(n1, n2). 2
Definition 8 Opposition OPSICT (N1, N2). N1 is opposite to N2, iff∃n1 ∈ N1 ∃n2 ∈ N2 OPSIct(n1, n2) ∨ ∃n2 ∈ N2 ∃n1 ∈ N1 OPSIct(n2, n1).
15

2
As long as there exists a pair of opposite concept terms in the two conceptterm sets, we declare they are opposite.
Property 3 The three relationships (EQCT , SPECCT and OPSICT ) definedabove have the following properties: 1) EQCT is reflexive, transitive and sym-metric. 2) SPECCT is reflexive and transitive. 3) OPSICT is symmetric. 2
4.3 Relation Terms
A conceptual relation explicates a certain correlation among a set of concep-tual terms. Unlike entity concepts, a relation concept can be affiliated withdifferent kinds of modals like necessity, possibility, permission, etc. to qualifythe truth of the relationship. Reword we explore the use of well-establishedmodal logic (Chellas, 1980) to our conceptual relation study. Modal logic,as mentioned in the Stanford Encyclopedia of philosophy (Garson, 2001), is,strictly speaking, the study of deductive behavior of the expressions “it isnecessary that” and “it is possible that”. Here, by prefixing a relation conceptr with the symbol 2 or 3, we can achieve different levels of ascertainabilityregarding relation r. For example, 2cause implies a definite causal relation,while 3cause implies a possible cause relation.
Definition 9 A relation term m ∈ RTerm is of the form m = δr, wherer ∈ RConcept, and δ could be 2, 3, or omitted representing an empty modal.
2
Definition 10 According to modal logic, we define the order “2” < “ ” <“3” for symbols 2, empty modal, and 3. 2
The three relation-term-based relationships can be defined using the samenames (i.e., EQ,SPEC and OPSI) as concept-term-based relationships butwith a different subscript flag “rt” to make the difference.
Definition 11 Equivalence EQrt (δ1r1, δ2r2). δ1r1 is equivalent to δ2r2,iff the following two conditions hold: 1) (r1 = r2) ∨ Synonym(r1, r2); 2)(δ1 = δ2). 2
Definition 12 Specification SPECrt (δ1r1, δ2r2). δ1r1 is a specification
of δ2r2 (conversely, δ2r2 is a generalization of δ1r1), iff the following twoconditions hold:1) (r1 = r2) ∨ Is-A(r1, r2) ∨ Synonym(r1, r2); 2) (δ1 = δ2) ∨ (δ1 < δ2).
2
16

Definition 13 Opposition OPSIrt(δ1r1, δ1r2). δ1r1 is opposite to δ2r2,iff the following two conditions hold: 1) Opposite(r1, r2); 2) (δ1 = δ2 6=“3”). 2
Example 6 EQrt(3cause, 3lead-to), SPECrt(2cause, 3cause),SPECrt(cause, relate), OPSIrt(2relate, 2unrelate). 2
The three relation-term-based relationships defined above have the same prop-erties as their corresponding concept-term-based relationships.
4.4 Hypotheses
A hypothesis communicates a human’s cognitive idea or thinking about thingsin existence, such as the causal connection of situations, the sequential occur-rence of events, etc. Here, we view each piece of hypothesis as a conceptualrelation (situated at the intermediate of Figure 3) which correlates a set ofinput concept terms to a set of output concept terms. For example, the hypoth-esis “wet winter in the north causes summer flood in the south and hot sum-mer in the east” causally relates concept term wet-winter |{Region:={“north”}} tosummer-flood |{Region:={“south”}} and hot-summer |{Region:={“east”}}.
1n
n 2
n un’v
concept terms concept terms
Input Output
relation termm...
....n’1
Fig. 3. A schematic view of a hypothesis
Definition 14 A hypothesis H ∈ Hypo is of the form H = δr(IN , ON),where δr ∈ RTerm, IN ⊆ CTerm, and ON ⊆ CTerm. A hypothesis H also
can be pictorially denoted as “H : INδr
=⇒ ON”. 2
Various hypothesis-based inter-relationships can be established based on theircomponent relationships, i.e., concept term sets and relation terms. Assume
that H1 : IN1
δ1r1=⇒ ON1and H2 : IN2
δ2r2=⇒ ON2are two hypotheses in Hypo.
Definition 15 H1 is equivalent to H2, written as H1 ≡h H2, iffEQrt(δ1r1, δ2r2) ∧ EQCT (IN1
, IN2) ∧EQCT (ON1
, ON2). 2
For two equivalent hypotheses, they must have equivalent relation terms, aswell as equivalent input and output concept term sets.
17

Definition 16 H1 is a specification of H2 (conversely, H2 is a general-
ization of H1), written as H1 ¹h H2 (H2 ºh H1), iffSPECrt(δ1r1, δ2r2) ∧ SPECCT (IN1
, IN2) ∧ SPECCT (ON1
, ON2).
We call H1 a strict specification of H2 (conversely, H2 a strict general-
ization of H1), written as H1 ≺h H2 (H2 Âh H1), iff (H1 ¹h H2) ∧ (H1 6≡h
H2).
If H1 is a specification of H2 and a specification of H3, then H1 is a common
specification of H2 and H3. Conversely, if H1 is a generalization of H2 anda generalization of H3, then H1 is a common generalization of H2 andH3. 2
Example 7 Given the following three hypotheses:H1 : {wet-winter |{Region:={“north”}}, warm-winter |{Region:={“north”}}}
2cause=⇒
{summer-flood |{Region:={“south”}}},
H2 : {wet-winter |{Region:={“north”}}}3cause=⇒ {summer-flood |{Region:={“south”}}
},H3 : {wet-winter |{Region:={“north”}}}
3cause=⇒ {river-behavior |∗}.
H1 is more specific than H2 and H3, and H2 is also more specific than H3
(i.e., H1 ¹h H2, H1 ¹h H3, and H2 ¹h H3). Besides, all of them are strictspecifications. H1 is a common specification of H2 and H3, and H3 is a commongeneralization of H1 and H2. 2
Definition 17 H1 is opposite to H2, written as H1 ∝h H2, iff either of thefollowing conditions holds:1)OPSIrt(δ1r1, δ2r2) ∧ EQCT (IN1
, IN2) ∧ EQCT (ON1
, ON2); or
2)EQrt(δ1r1, δ2r2) ∧ EQCT (IN1, IN2
) ∧ OPSICT (ON1, ON2
). 2
For two opposite hypotheses, they may have equivalent input/output conceptterm sets but with opposite relation terms (Case 1 of the definition), or theymay have equivalent relation terms and input concept term sets, but with atleast one opposite output concept term pair (Case 2 of the definition).
Example 8 Given the following three hypotheses:
H1 : {wet-winter |∗}2relate=⇒ {summer-flood |∗, hot-summer |∗},
H2 : {wet-winter |∗}2unrelate
=⇒ {summer-flood |∗, hot-summer |∗}, and
H3 : {wet-winter |∗}2relate=⇒ {cool-summer |∗},
we have (H1 ∝h H2) and (H1 ∝h H3), since OPSIrt(2relate, 2unrelate) andOPSICT (hot-summer |∗, cool-summer |∗). 2
Property 4 The relationships defined on hypotheses have the following prop-erties: 1) Equivalence ≡h is reflexive, transitive and symmetric. 2) Specifica-tion ¹h is reflexive and transitive. 3) Strict specification ≺h is transitive. 4)
18

Opposition ∝h is symmetric. 2
4.5 The Knowledge Subspace
Hypotheses and their inter-relationships constitute a DL knowledge subspace.At an abstract level, a knowledge subspace can be viewed as an oriented dia-gram consisting of a series of nodes (each representing a hypothesis) that areconnected to each other through directed labeled edges (representing variousrelationships between hypotheses), as shown in the upper part of Figure 2. Tomake the diagram connected, we introduce two special hypotheses to Hypo:the universal hypothesis > that is a generalization of all other hypothesis ,and the absurd hypothesis ⊥ that is a specification of all other hypotheses.
Definition 18 A DL knowledge subspace KSpace = (Node, Edge) iscomposed of a set of nodes representing hypotheses in Hypo, and a set of di-rected edges representing relationships of equivalence ≡h, (strict) specification(≺h) ¹h, and opposition ∝h among the hypotheses. 2
The DL knowledge subspace provides users with a huge exploratory space,where knowledge acquisition, navigation and deduction can be performed. Ifa user’s inquiry has the form of a hypothesis, the above relationships likeequivalence, specification/generalization, opposition can be explored to findmatching hypotheses in the knowledge subspace. The hypotheses togetherwith the backing documents, serving as the justification of hypotheses, arereturned to the user as a part of the answer to his/her strategical request.
4.6 The Linkage Between the Knowledge Subspace and Document Subspace
The DL document subspace accommodates all the documents in a library.They are the sources for answering users’ information searching and brows-ing requests. In addition, for an enhanced DL system proposed in this paper,documents in the DL document subspace also serve as the justification forthe corresponding knowledge in the knowledge subspace. That is, under eachhypothesis is a justification, giving reasons and evidences for that knowledge.This justification comes from articles, reports, and so on. Taking the hypoth-esis H : {wet-winter |∗}
2cause=⇒ {summer-flood |∗} for example, its supporting
documents are those which state exactly that “wet winter is an indicator ofsummer flood.” Let Doc denote the whole set of documents in a DL. All thedocuments in the DL that support a hypothesis constitute the referent forthat hypothesis.
Definition 19 Let H ∈ Hypo be a hypothesis in the knowledge subspace. The
19

referent of H, written as ΨH, is the set of all documents in the library thatsupport H.For the two special hypotheses, we assume Ψ⊥ = ∅ and Ψ> = Doc. 2
The defined relationships (i.e.,equivalent, specific/general and opposite) amonghypotheses lead us to the following axiom and theorem.
Axiom 1 , Let H1, H2 be two hypotheses in Hypo.
• If H1 is a (strict) specification of H2 (i.e., H1 ≺h H2 or H1 ¹h H2), thenΨH1 ⊆ ΨH2.
• If H1 is equivalent to H2 (i.e., H1 ≡h H2), then ΨH1 = ΨH2.• H1 is opposite to H2 (i.e., H1 ∝h H2), then ΨH1 ∩ ΨH2 = ∅.
2
Using Definition 16 of speciality/generality between hypotheses, we can besure that if a hypothesis is consistent with a set of documents, any general-ization of it also will be consistent with this document set. In contrast, if adocument does not conform to a hypothesis, it cannot conform to any spe-cialization of that hypothesis either. For any hypothesis H ∈ Hypo where(⊥ ¹h H ¹h >), it is obvious that ∅ = Ψ⊥ ⊆ ΨH ⊆ Ψ> = Doc.
Theorem 1 Let H1, H2, H3 be three hypotheses in Hypo, where H1 is a com-mon generalization of H2 and H3, i.e., (H2 ¹h H1) and (H3 ¹h H1). We have(ΨH2 ∪ ΨH3) ⊆ ΨH1. 2
Proof 1 Since (H2 ¹h H1), according to Axiom 1, (ΨH2 ⊆ ΨH1). Similarly,(ΨH3 ⊆ ΨH1) because of (H3 ¹h H1). Thus, (ΨH2 ∪ ΨH3) ⊆ ΨH1. 2
5 Queries Against the Enhanced DLs
With the proposed two-layered DL information space, users can pose to DLsvarious strategic level questions which involve knowledge elements like “whatwill cause a summer-flood in the south?” “Does mobile phone cause braincancer? If so, give me documents to prove that.” To express this kind of in-formation requests, we present a query language against the enhanced DLs,using a syntax similar to logical expressions.
20

5.1 Query Constructors
Basically, a DL query consists of a single head and a single tail separated bythe | symbol, 〈head〉 | 〈tail〉. The tail describes the query condition, while thehead describes the query result, which can be knowledge (i.e., either a completehypothesis or part of a hypothesis) with/without justification documents, ora boolean indicating whether the knowledge is true or false.
A query tail is a list of predicates connected by logical connectives AND (∧),OR (∨), or NOT (¬), where each predicate falls into any of the following threecategories:
• an element binding constraint Func(e)/Func(e, E)• a hypothesis of a binary predicate form t(IN , ON);• a comparison constraint between two expressions
〈expression〉 〈opcomp〉 〈expression〉.
An element in a query tail can be either a variable or a constant. It canrepresent a hypothesis, a hypothesis component (which can be a concept term,a contextual attribute, a contextual attribute value, a relation term or a modalsymbol), or a referent document of a hypothesis, i.e.,
〈element〉 ::= 〈hypothesis〉 | 〈hypothesis component〉 |
〈referent-document〉
〈hypothesis component〉 ::= 〈concept-term〉 | 〈contextual-attribute〉 |
〈contextual-attribute-value〉 |
〈relation-term〉 | 〈modal〉
We use different constraint functions of the form Func(e) or Func(e, E) tobind an element to the corresponding category.
• Hypo (e) - e denotes a hypothesis;• Ref (e, H) - e denotes a referent document of hypothesis H;• CTerm (e, H) - e denotes a concept term in hypothesis H;• Att (e, H) - e denotes a contextual attribute in hypothesis H;• V al (e, a) - e denotes a value of the contextual attribute a;• RTerm (e, H) - e denotes a relation term in hypothesis H;• Modal (e, H) - e denotes a modal in hypothesis H.
An expression in a comparison constraint 〈expression〉 〈opcomp〉 〈expression〉can be an element or an arithmetic expression involving single-value-orientedoperators {+, -, *, /} or set-value-oriented operators {∩, ∪}. That is,
21

〈expression〉 ::= 〈element〉 | 〈element〉 〈opmath〉 〈expression〉
〈opmath〉 ::= + | − | ∗ | / | ∩ | ∪
To query the knowledge in a DL, we expand the traditional comparison op-erators to include the hypothesis-based comparison operators {≺h,¹h,Âh,ºh
,≡h, 6≡h,∝h} defined in the previous section, i.e.,
〈opcomp〉 ::= < | ≤ | = | 6= | > | ≥ | ⊂ | ⊆ | ⊃ | ⊇ |
≺h | ¹h | ≡h | 6≡h | ∝h | Âh | ºh.
Within a query (tail and head), we use e to indicate a single element, andbrace {e} to indicate a set of elements.
5.2 Query Examples
We illustrate the usage of the presented query constructors through a setof examples. In this subsection, we formulate our descriptions according todifferent types of query outputs.
1) Query the tenability of an input knowledge (e.g., hypothesis)
Q1: Tell me whether wet winter will cause summer flood.
| cause ({wet-winter |∗}, {summer-flood |∗}).
An empty query head merely inquires the tenability of the input knowledge.If it holds, the query returns true, and otherwise, false.
2) Query the referent documents of a hypothesis
Q2: Give me documents which talk about the causal relation between wet winterand summer flood.
{d} | Hypo(H) ∧ Ref(d, H) ∧
H ≡h cause ({wet-winter |∗}, {summer-flood |∗}).
Some intermediate variables with corresponding binding constraints (e.g., Hin this query example) can be employed for the ease of query expressions.
3) Query the hypotheses and their referent documents
Q3: Tell me all hypotheses in contrast to the one “wet winter will cause summer
22

flood”. Give me all the referent documents.
{H, {d}} | Hypo(H) ∧ Ref(d, H) ∧
H ∝h cause ({wet-winter |∗}, {summer-flood |∗}).
The result is a set whose element is made up of two fields, a hypothesis and aset of supporting documents.
4) Query the concept terms in a hypothesis
Q4: Tell me what factor(s) will possibly cause a summer flood. Give me thereferent documents.
{n}, {d} | Hypo(H) ∧ CTerm(n, H) ∧ Ref(d, H) ∧
H ≡h 3 cause (n, {summer-flood |∗}).
5) Query the relation term in a hypothesis
Q5: Tell me whether there is a relation between wet winter and summer flood.Give me the referent documents.
m, {d} | Hypo(H) ∧ RTerm(r, H) ∧ Ref(d, H) ∧
H ≡h m ({wet-winter |∗}, {summer-flood |∗}).
6) Query the modal of a relation term in a hypothesis
Q6: Tell me whether wet winter will necessarily or possibly cause summer flood.
δ | Hypo(H) ∧ Modal(δ, H) ∧
H ≡h δ cause ({wet-winter |∗}, {summer-flood |∗}).
The query answer will be 2, 3 or empty.
7) Query the contextual values in a hypothesis
Q7: Tell me which region(s) will have summer flood due to the wet winter inthe south. Give me the referent documents.
{v}, {d} | Hypo(H) ∧ V al(v, Region) ∧ Ref(d, H) ∧
H ≡h cause ({wet-winter |Region:={v}}, {summer-flood |Region:={south}}).
8) Query the contexts (attribute-value pairs) in a hypothesis
23

Q8: Tell me the contexts under which wet winter will cause summer flood.
{a := {va}}, {b := {vb}} | Hypo(H) ∧ Att(a, H) ∧ V al(va, a) ∧
Att(b, H) ∧ V al(vb, b) ∧
H ≡h cause ({wet-winter |{a:={va}}}, {summer-flood |{b:={vb}}}).
6 The Construction of DL Knowledge Subspace
The construction of the DL knowledge subspace and its linkage to the asso-ciated justification (document) subspace can be done in two ways: 1) human-centered knowledge acquisition. Experienced humans input hypothesis knowl-edge manually, based on which justifying articles are collected by performingsearching and browsing on DL systems; 2) machine-centered knowledge ac-quisition. Under the assistance of users, DL systems automatically deducehypothesis knowledge by correlating and analyzing data sources. We discussthese two methods in detail in the following subsections.
6.1 Human-Centered Knowledge Acquisition
The central problem in all attempts to leverage a digital library by addingknowledge to mainly symbolic data (either in the form of raw data or documentcollections) is to understand the data. Currently, machines hardly extractproper knowledge from data alone. Therefore, any practical application ofthe techniques described in this paper involves human knowledge acquisitionefforts.
The sheer amount of data available through current DLs, including the Web,prevents “charting of the knowledge space,” as traditionally done by librariansand other knowledge workers. Their efforts are still invaluable, as all “portals”on the Internet prove: few true search engines without human knowledge chartssurvive to date. However, humans alone on the knowledge provider side cannotproperly chart all documents and data that become, or already are, availableto (potential) knowledge consumers.
What is needed is a human input from the consumer side. As even detailed logsof search engines prove, these logs (taken at the tactical level of informationseeking) only reveal attempts of users to find what they want using coarseand/or dumb tools. It is like attempting to reconstruct the history of the greatpyramids in Egypt by looking only at the cuts the tools of the stone carversmade on the sand stone blocks. What is totally missing from search engine
24

query logs is the actual strategic intention of the user behind the keyboard.
Acquiring this strategic intention is difficult. Few users will volunteer a semi-formal description of their intentions when there is no single form of short-term reward for their efforts. Users will never take the time to learn a formallanguage to express their strategic targets, and any user interface trying toguide them will likely become either too complex to understand or too coarseto be of use.
In order to overcome at least some of these problems and to be able to run someexperiments on strategic user intention acquisition, we intend to concentrateon a very limited subset of knowledge acquisition (hypothesis support/denial).Such a limited goal can be pursued with limited tools, making it suitable fora small group of users with a well-defined type of knowledge need. On top ofthe limited, but understandable and simple strategic intention acquisition tool,we intend to implement some kind of immediate reward system that makes itattractive for users to specify their strategic intentions to the system beforeembarking on their traditional, tactical search effort. Currently, we think ofa system that extends the user’s quota for certain activities, typically inter-library loans or other kinds of priced assets that are required for the work, butare in short supply due to the costs involved. Users who are active in supplyingproper strategic targets are rewarded by increasing quota for related activities,facilitating their work. Existing systems which use this “return on investment”policy have showed that such a policy has a self-regulating property 3 , andindeed may lead to a coarse but useful filtering of data items (documents)useful to support a strategic goal.
One of our future work will concentrate on finding a proper test case for such asystem, and to gather data on the success of a “return on investment” policy,the collected strategic knowledge targets in respect to the retrieved documents,and the re-usability of these targets and the document result sets for otherusers with comparable information needs.
6.2 Machine-Centered Knowledge Acquisition
On the other hand, with more and more digital information in a wide varietyof disciplines accumulated in DLs today, the automatic and/or user-assistedsemi-automatic extraction of inherent knowledge from such a large volumeof data becomes indispensable. In this subsection, we outline a frameworkfor machine-centered knowledge discovery across multiple repositories in DLs.Basically, it proceeds in six steps: 1) set up knowledge discovery targets, 2)
3 http://www.slashdot.org
25

identify relevant resources, 3) filter out interesting concepts from identified re-sources, 4) correlate concepts according to contextual information, 5) extractknowledge and justifications from correlated concepts, and 6) evaluate the dis-covered knowledge and justifications.
Phase-1: Set Up Knowledge Discovery Tasks
Before extracting knowledge and associated justifications, we need to knowwhat kind of knowledge and justifications are expected from users. Does theuser want to know the inherent associations of some of concepts in certainareas? Or does the user want to obtain some knowledge on classifying ordiscriminating objects? Or is the user interested in the sequential evolutionof certain objects in order to make predictions? Here, a friendly user inter-face is important to the natural and accurate specification of such knowledgeacquisition targets.
Phase-2: Identify Relevant Resources
Confronted with a huge collection of data sources scattered in heaps of repos-itories, we must identify repositories which contain the most likely relevantresources in response to a given knowledge request. Otherwise, the followingknowledge discovery process will be lengthy, aimless and inefficient. To dothis, we must categorize the information content in each repository. By query-ing the concepts, which are elicited from the user’s request and background,against these meta-data catalogs, we may identify relevant data sources. Forexample, if a user is interested in the correlations between “summer flood”and “meteorological factors”, the meteorological repository in the observatoryheadquarters, and the repository in the river management office, will be iden-tified as mostly relevant.
Phase-3: Filter Out Interesting Concepts from Identified Resources
The identified resources from Phase-2 could be in various formats. They canbe unstructured articles, multimedia documents, formatted reports, databaserecords, semi-structured files, or hypertexts, etc. To make knowledge discoveryacross multiple heterogeneous repositories possible, we need to transform theoriginal data sources into a uniform format. A record structure consistingof a set of keywords can be exploited to describe each documental entity.These keywords explicate the major concepts conveyed by the correspondingdocuments. For example, from a textual article which mentions “high rainfallamounts in November and December in 1996”, we can filter out “wet winter”concept “in 1996”. Here, the transformation from heterogeneous resources intokeyword-based records solicits a wide range of techniques, including naturallanguage processing, information analysis, categorization and summarization,textual and multimedia data mining, etc.
26
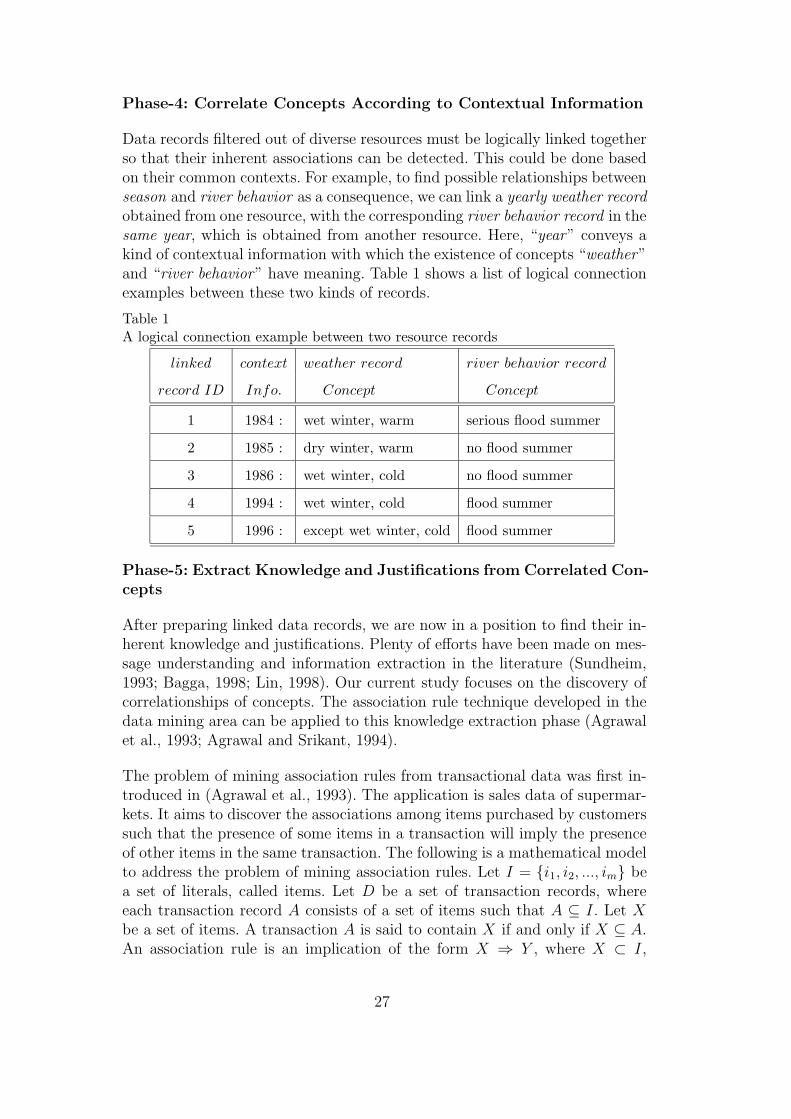
Phase-4: Correlate Concepts According to Contextual Information
Data records filtered out of diverse resources must be logically linked togetherso that their inherent associations can be detected. This could be done basedon their common contexts. For example, to find possible relationships betweenseason and river behavior as a consequence, we can link a yearly weather recordobtained from one resource, with the corresponding river behavior record in thesame year, which is obtained from another resource. Here, “year” conveys akind of contextual information with which the existence of concepts “weather”and “river behavior” have meaning. Table 1 shows a list of logical connectionexamples between these two kinds of records.
Table 1A logical connection example between two resource records
linked context weather record river behavior record
record ID Info. Concept Concept
1 1984 : wet winter, warm serious flood summer
2 1985 : dry winter, warm no flood summer
3 1986 : wet winter, cold no flood summer
4 1994 : wet winter, cold flood summer
5 1996 : except wet winter, cold flood summer
Phase-5: Extract Knowledge and Justifications from Correlated Con-cepts
After preparing linked data records, we are now in a position to find their in-herent knowledge and justifications. Plenty of efforts have been made on mes-sage understanding and information extraction in the literature (Sundheim,1993; Bagga, 1998; Lin, 1998). Our current study focuses on the discovery ofcorrelationships of concepts. The association rule technique developed in thedata mining area can be applied to this knowledge extraction phase (Agrawalet al., 1993; Agrawal and Srikant, 1994).
The problem of mining association rules from transactional data was first in-troduced in (Agrawal et al., 1993). The application is sales data of supermar-kets. It aims to discover the associations among items purchased by customerssuch that the presence of some items in a transaction will imply the presenceof other items in the same transaction. The following is a mathematical modelto address the problem of mining association rules. Let I = {i1, i2, ..., im} bea set of literals, called items. Let D be a set of transaction records, whereeach transaction record A consists of a set of items such that A ⊆ I. Let Xbe a set of items. A transaction A is said to contain X if and only if X ⊆ A.An association rule is an implication of the form X ⇒ Y , where X ⊂ I,
27

Y ⊂ I and X ∩ Y = φ. The rule X ⇒ Y holds in the transaction set D withconfidence c if c% of transactions in D that contain X also contain Y . Therule has support s if s% of transactions in D contain X ∪ Y .
Applying the concept of association rules in transactional data to our linkedrecords illustrated in Table 1, we can find the correlationship of concept termslike “wet-winter ⇒ summer-flood”. Since among the total 5 records in thissmall database, 3 of them contain {wet-winter, summer-flood}, thus support =3/5 = 60%. Within the 4 records stating wet winter, 3 of them also statesummer flood. Therefore, we have confidence = 3/4 = 75%. These supportingrecords, together with the support and confidence measurement values, canserve as the justifications for the extracted knowledge.
Phase-6: Evaluate the Discovered Knowledge and Justifications
Obtaining a set of knowledge and justifications is not the end. Besides usingstatistical indicators such as support and confidence to measure the strengthof discovered knowledge, we may also incorporate subjective measurements toevaluate and rank their significance with respect to users’ cognitions and theirreal-life problems.
7 Conclusion
Information is a basic human need. DLs contain a set of information resourcescollected and organized in a way that accommodates the actual tasks andactivities that people engage in when they create, seek, and use informationsources. Motivated by the problems - (i) inadequate strategical level cognitionsupport; (ii) inadequate knowledge sharing facilities - with the present-dayDLs, we first introduce a two-layered DL functional model to support differ-ent levels of human cognitive acts. The tactical level cognition support aims toprovide users with requested relevant documents, as searching and browsingdo, while strategic level cognition support can provide not only documents butalso intelligent answers to users’ high-order cognitive questions. Second, to ad-dress users’ high-order cognitive requests, we propose an enlarged informationspace comprised of a knowledge subspace and a document subspace. A formaldescription of the knowledge subspace, as well as query facilities against theenhanced DLs for knowledge sharing and propagation among DL users, aredescribed.
Compared with traditional knowledge-based systems, enhanced DL systemswith knowledge elements have the following distinguished features.
• A cognitive function. A knowledge-based system is usually designed to apply
28

logical inference rules to make judgements in processing business routinesor come up with a conclusion to a certain pre-defined problem. The missionof a DL system equipped with a knowledge subspace is to make expertiseknowledge widely available to the public. ¿From such DLs, users can obtainnot only requested documents, but also intelligent answers to their strategiclevel questions.
• A broad scope. A knowledge-based system intends to solve problems in anarrow domain, e.g., company delivery charge, heart disease diagnosis, etc.The rules stored in its knowledge bases are thus limited to a particular field.On the contrary, the scope of the DL knowledge subspace is broad, coveringa wide spread of scientific and enginering disciplines.
• An extensive content. DLs collect a huge body of documents, which canserve as knowledge justifications. Comparatively, knowledge-based systemscontain a limited amount of rules and facts in a particular field of expertise.
The major contributions of the paper are twofold. First, the presented DL in-formation space extends the traditional role of DLs from information providerto information & knowledge provider. Second, the traditional simple keyword-based index schema is expanded to the strategic knowledge-based level, con-sisting of inter-related hypotheses that are backed by documents. One cansay that the essence of the documents is reconstructed in the DLs’ knowledgelevel.
The work reported here is a first step towards knowledge-based DLs. For fu-ture work, a lot of issues deserve investigation. 1) One immediate work is tobuild up the knowledge subspace and link it to the document subspace. 2) Tofacilitate strategic level cognitive activities, efficient storage and managementof the knowledge and document subspaces is very important and must be care-fully planned. This demands effective indexing strategies for both knowledgeand justifying documents. 3) Efficient query evaluation and knowledge navi-gation mechanisms must be built to help users make the best of informationand knowledge assets in solving their problems. 4) Our eventual goal is to de-velop a practical DL system, which can empower humans with real actionableknowledge in solving their information problems.
Acknowledge
The authors would like to thank the guest editors Edward Fox and Elisa-beth Logan, and the referees for their insightful comments which have greatlyhelped to improve the paper.
29

References
Agrawal, R., Imielinski, T., Swami, A., May 1993. Mining association rulesbetween sets of items in large databases. In: Proc. of the 1993 ACM SIG-MOD International Conference on management of data. Washington D.C.,USA, pp. 207–216.
Agrawal, R., Srikant, R., September 1994. Fast algorithms for mining asso-ciation rules. In: Proc. of the 20th Intl. Conf. on Very Large Data Bases.Santiago, Chile, pp. 478–499.
Anderson, R., 1992. Information and Knowledge Based Systems: an Introduc-tion. Prentice Hall, Inc., New York.
Bagga, A., 1998. Analyzing the complexity of a domain withrespect to an information extraction task. In: Proc. of theseven Message Understanding Conference. Virginia, USA,http://www.itl.nist.gov/iaui/894.02/related projects/muc/ proceed-ings/muc 7 toc.html#infoextract.
Bates, M., 1986. Subject access in online catalogs: A design model. Journal ofthe American Society for Information Science 37 (6), 357–376.
Bates, M., 2002. The cascade of interactions in the digital library interface.Information Processing and Management 38 (3), 381–400.
Beard, K., Sharma, V., 1997. Multidimensional ranking for data in digitalspatial libraries. Journal on Digital Libraries 1 (2), 153–160.
Beaulieu, M., Jones, S., 1998. Interactive searching and interface issues in theOkapi best match probabilistic retrieval system. Interacting with Computers10, 237–248.
Belkin, N., Borgman, C., Dumais, S., M.H-Beaulieu, July 1994. Evaluatinginteractive retrieval systems. In: Proc. of the 17th Intl. Conf. on Researchand Development in Information Retrieval. Dublin, Ireland, p. 361.
Belkin, N., Marchetti, P., September 1990. Determining the functionality andfeatures of an intelligent interface to an information retrieval system. In:Proc. of the 13th Intl. Conf. on Research and Development in InformationRetrieval. Brussels, Belgium, pp. 151–177.
Bennett, N., He, Q., Chang, C., Schatz, B., April 1999. Concept extraction inthe interspace prototype. Tech. Rep. UIUCDCS-R-99-2095, Dept. of Com-puter Science, University of Illinois at Urbana-Champaign.
Borgman, C., June 1987. Individual differences in the use of information re-trieval systems: Some issues and some data. In: Proc. of the 10th Intl. Conf.on Research and Development in Information Retrieval. New Orleans, USA,pp. 61–71.
Buttenfield, B., Larsen, S., October 1997. Building a digital library for earthsystem science: The Alexandria project. In: Proc. of Annual Meeting of theGeoscience Information Society. USA, pp. 23–26.
Cercone, N., McCalla, G. (Eds.), 1987. The Knowledge Frontier. Springer-Verlag, New York, Ch. SNePS considered as a fully intensional propositionalsemantic network (S.C. Shapiro and W.J. Rapaport).
30

Checkland, P., Holwell, S., 1998. Information, Systems and Information Sys-tems - making sense of the field. John Wiley & Sons, Inc., New York.
Chellas, B., 1980. Modal Logic: An Introduction. Cambridge University Press,Cambridge.
Chen, H., 1992. Knowledge-based document retrieval: framework and design.Journal of Information Science 18, 293–314.
Chen, H., 1999. Semantic research for digital libraries. D-Lib Magazine 5 (10),http://www.dlib.org/dlib/october99/chen/10chen.html.
Chen, H., Lynch, K., Basu, K., Ng, T., 1993. Generating, integrating, and ac-tivating thesauri for concept-based document retrieval. IEEE Expert 8 (2),25–34.
Chen, H., Smith, T., Ng, T., July 1997. Geoscience self-organizing map andconcept space. In: Proc. of 2nd ACM Intl. Conf. on Digital Libraries.Philadelphia, USA, p. 257.
Cooper, B., Crespo, A., Garcia-Molina, H., September 2000. Implementinga reliable digital object archive. In: Proc. of the fourth European Confer-ence on Research and Advanced Technology for Digital Libraries. Lisbon,Portugal, pp. 128–143.
Crespo, A., Garcia-Molina, H., September 2000. Modeling archival repositoriesfor digital libraries. In: Proc. of the fourth European Conference on Researchand Advanced Technology for Digital Libraries. Lisbon, Portugal, pp. 190–205.
Crestani, F., Lalmas, M., van Rijsgergen, C., Campbell, I., 1998. ‘is this docu-ment relevant? ... probably’: A survey of probabilistic models in informationretrieval. ACM Computing Surveys 30 (4), 528–552.
Dao, T., April 1998. An indexing model for structured documents to supportqueries on content, structure and attributes. In: Proc. of the IEEE Forumon Research and Technology Advances in Digital Libraries. California, USA,pp. 88–97.
Dumais, S., May 1999. Beyond content-based retrieval: Modeling domains,users, and interaction. In: Proc. of the IEEE Advanced in Digital Libraries.Maryland, USA, pp. 144–145.
Dunlop, M., van Rijsbergen, C., 1993. Hypermedia and free text retrieval.Information Processing and Management 29 (3), 287–298.
Efthimiadis, E., June 1993. A user-centered evaluation of ranking algorithmsfor interactive query expansion. In: Proc. of the 16th Intl. Conf. on Researchand Development in Information Retrieval. Pittsburgh, PA, pp. 146–159.
et al., R. B., 1978. KL-ONE reference manual. Tech. rep., Bolt Beranek andNewman Inc. BBN Report No. 3848, Cambridge, MA.
Evens, M., Smith, R., 1979. A lexicon for a computer question-answering sys-tem. American Journal of Computational Linguistics 83, 1–93.
Fidel, R., 1994. User-centered indexing. Journal of the American Society forInformation Science 45 (8), 572–576.
Findler, N. (Ed.), 1979. Associative Networks: The Representation and Useof Knowledge by Computers. Academic Press, New York, Ch. The SNePS
31

semantic network processing system (S.C. Shapiro).Fox, E., Marchionini, G., 1998. Toward a world wide digital library. Commu-
nications of the ACM 41 (4), 28–32.Fox, E., Marchionini, G., 2001. Digital libraries: Introduction. Communica-
tions of the ACM 44 (5), 30–32.Frakes, W., Baeza-Yates, R., 1992. Information Retrieval: Data Structures and
Algorithms. Prentice Hall, Inc., New Jersey.Furnas, G., Landauer, T., L.M.Gomex, Dumais, S., 1987. The vocabulary
problem in human-system communication. Communications of the ACM30 (11), 964–971.
Garnham, A., 1988. Artificial Intelligence: An Introduction. Routledge &Kegan Paul, Inc., London.
Garson, J., 2001. The Stanford Encyclopedia of Philosophy, winter 2001 edi-tion, edward n. zalta ed. Edition. http://plato.stanford.edu/archives/, Ch.Modal Logic.
Gruber, T., 1993. A translation approach to portable ontologies. KnowledgeAcquisition 5 (2), 199–220.
Guarino, N., Welty, C., October 2000. Ontological analysis of taxonomic re-lationships. In: Proc. of the 19th International Conference on ConceptualModeling. Salt Lake City, Utah, USA, pp. 210–224.
Hoppenbrouwers, J., 1997. Conceptual Modeling and the Lexicon. PhD Thesis,Tilburg University, The Netherlands.
Hoppenbrouwers, J., Paijmans, H., May 2000. Invading the fortress: How tobesiege reinforced information bunkers. In: Proc. of the IEEE Advanced inDigital Libraries. Washington D.C., USA, pp. 27–35.
House, N. V., June 1995. User needs assessment and evaluation for the UCberkeley electronic environmental library project. In: Proc. of the 2ndIntl. Conf. on the Theory and Practice of Digital Libraries. Texas, USA,http://csdl.tamu.edu/DL95/.
House, N. V., Butler, M., Ogle, V., Schiff, L., 1996. User-centered iterativedesign for digital libraries: The Cypress experience. D-Lib Magazine 2 (2),http://www.dlib.org/dlib/february96/02vanhouse.html.
Ingwersen, P., July 1994. Polyrepresentation of information needs and seman-tic entities: Elements of a cognitive theory for information retrieval interac-tion. In: Proc. of the 17th Intl. ACM SIGIR Conf. on Research and Devel-opment in Information Retrieval. Dublin, Ireland, pp. 101–110.
Jones, S., Gatford, M., Robertson, S., H-Beaulieu, M., Secker, J., Walker, S.,1995. Interactive thesaurus navigation: Intelligence rules OK? Journal ofthe American Society for Information Science 46 (1), 52–59.
Jr, R. D., Lagoze, C., 1997. Extending the warwick framework: Frommetadata containers to active digital objects. D-Lib Magazine 3 (11),http://www.dlib.org/dlib/november97/daniel/11daniel.html.
Kahn, R., Wilensky, R., 1995. A framework for distributed digi-tal object services. Corporation for National Research Initiatives,http://www.cnri.reston.va.us/home/cstr/arch/k-w.html.
32

Kantor, P., 1998. Observation and measurement in evaluating digital libraries.http://www.canis.uiuc.edu/seminar.html.
Kiefer, F. (Ed.), 1969. Studies in Syntax and Semantics. Dordrecht - Hol-land, Ch. Semantics and Lexicography: Towards a New Type of UnilingualDictionary (Y.D. Apresyan, I.A. Melcuk and A.K. Zolkovsky).
Lancaster, F., Sandore, B., 1997. Technology and management in library andinformation services. University of Illinois Graduate School of Library andInformation Science.
Lancaster, F., Smith, L. (Eds.), 1990. Artificial Intelligence and expert sys-tems: will they change the library? The Board of Trustees of the Universityof Illinois, Ch. Artificial Intelligence: What will they think of next? (D.P.Metzler), pp. 2–49.
Lenat, D., 1995. CYC: a large-scale investment in knowledge infrastructure.Communications of ACM 13 (11), 32–38.
Lin, D., 1998. Using collocation statistics in information extraction.In: Proc. of the seven Message Understanding Conference. Virginia,USA, http://www.itl.nist.gov/iaui/894.02/related projects/muc/ proceed-ings/muc 7 toc.html#infoextract.
Marchionini, G., 2000. Evaluating digital libraries: A longitudinal and multi-faceted view. Library Trend 49 (2), 304–333.
Markowitz, J., Nutter, J., Evens, M., 1992. Beyond is-a and part-whole: Moresemantic network links. Journal of Computers and Mathematics with Ap-plications 23 (6-9), 377–390.
Marshall, B., Zhang, Y., Chen, H., Lally, A., Shen, R., Fox, E., Cassel, L., May2003. Convergence of knowledge management and E-learning: the GetSmartexperience. In: Proc. of the third Joint ACM/IEEE-CS International Con-ference on Digital Libraries. Houston, pp. 135–146.
McKnight, C., Dillon, A., Richardson, J., 1989. Problems in hyperland? ahuman factors perspective. Hypermedia 1 (2), 167–178.
Mead, J., Gay, G., December 1995. Concept mapping: An innovative approachto digital library design and evaluation. ACM SIGOIS Bulletin 16 (2), 10–14.
Melnik, S., Garcia-Molina, H., Paepcke, A., 2000. A mediation infrastructurefor digital library services. Tech. rep., Stanford University.
Miller, G., Beckwith, R., Fellbaum, C., Gross, D., Miller, K.,1993. Introduction to wordnet: an on-line lexical database.http://www.cogsci.princeton.edu/ wn/5papers.pdf.
Minsky, M. (Ed.), 1968a. Semantic Information Processing. MIT Press, Cam-bridge, Mass., Ch. Semantic Memory (R. Quillian).
Minsky, M. (Ed.), 1968b. Semantic Information Processing. MIT Press, Cam-bridge, Mass., Ch. A Computer Program for Semantic Information Retrieval(B. Raphael).
Nutter, J., 1989. Representing knowledge about words. In: Proc. of the SecondNational Conference of AI and Cognitive Science. London, pp. 313–328.
Nutter, J., Fox, E., Evens, M., 1990. Building a lexicon from machine-readable
33

dictionaries for improved information retrieval. Journal of Literary and Lin-guistic Computing 5 (2), 129–137.
Paepcke, A., Brandriff, R., Janee, G., Larson, R., Ludaescher, B.,Melnik, S., Raghavan, S., 2000. Search middleware and the sim-ple digital library interoperability protocol. D-Lib Magazine 6 (3),http://www.dlib.org/dlib/march00/paepcke/03paepcke.html.
Paepcke, A., Chang, C., Garcia-Molina, H., Winograd, T., 1998. Interoper-ability for digital libraries worldwide. Communications of the ACM 41 (4),33–43.
Paepcke, A., Cousins, S., Garcia-Molina, H., Hassan, S., Ketchpel, S.,Roscheisen, M., Winograd, T., May 1996. Using distributed objects for dig-ital library interoperability. IEEE Computer 29 (5), 61–68.
Paepcke, A., Hassan, S., June 1996. Combining CORBA and the World-Wide Web in the stanford digital library project. In: Proc. of the OMG’sWWW/CORBA workshop.
Papazoglou, M., Hoppenbrouwers, J., 1999. Contextualizing the informationspace in federated digital libraries. SIGMOD Record 28 (1), 40–46.
Payette, S., Blanchi, C., Lagoze, C., Overly, E., 1999. Interoperability for dig-ital objects and repositories: The Cornell/CNRI experiments. D-Lib Maga-zine 5 (5), http://www.dlib.org/dlib/may99/payette/05payette.html.
Payette, S., Lagoze, C., September 1999. Flexible and extensible digital objectand repository architecture (FEDORA). In: Proc. of the 2nd European Con-ference on Research and Advanced Technology for Digital Libraries. Crete,Greece, pp. 41–59.
Phelps, T., Wilensky, R., September 1997. Multivalent annotations. In: Proc.of the 1st European Conf. on Research and Advanced Technology for DigitalLibraries. Pisa, Italy, pp. 287–303.
Rich, E., 1983. Artificial Intelligence. McGraw-Hill, Inc., Singapore.Schatz, B., June 1996. Information analysis in the net: The in-
terspace of the twenty-first century. In: Proc. of the 7thWorkshop on Digital Libraries. Tsukuba Science City, Japan,http://www.canis.uiuc.edu/archive/talks/plenary.pdf.
Schatz, B., July 1998. High-performance distributed digital libraries: Buildingthe interspace on the grid. In: Proc. of 7th IEEE Intl. Symposium on High-Performance Distributed Computing. pp. 224–234.
Schatz, B., Chen, H., 1999. Digital libraries: Technological advances and socialimpacts. IEEE Computer 32 (2), 45–50.
Schatz, B., Mischo, W., Cole, T., Bishop, A., Harum, S., Johnson, E., Neu-mann, L., Chen, H., Ng, D., 1999. Federated search of scientific literature.IEEE Computer 32 (2), 51–59.
Sowa, J., 1984. Conceptual Structures: Information Processing in Mind andMachine. Addison-Wesley Longman, Inc., Boston.
Spink, A., Saracevic, T., 1998. Human-computer interaction in information re-trieval: Nature and manifestations of feedback. Interacting with Computers10 (3), 249–267.
34

Sundheim, B., 1993. Tipster/MUC-5 information extraction system evalua-tion. In: Proc. of the fifth Message Understanding Conference. San Mateo,USA, pp. 27–44.
Velez, B., Weiss, R., Sheldon, M., Gifford, D., July 1997. Fast and effectivequery refinement. In: Proc. of the 20th Intl. ACM SIGIR Conf. on Researchand Development in Information Retrieval. Philadelphia, USA, pp. 6–15.
Waterworth, J., Chignell, M., 1991. A model for information exploration. Hy-permedia 3 (1), 35–58.
Willett, P., 1988. Recent trends in hierarchical document clustering: A criticalreview. Information Processing and Management 24 (5), 577–597.
Wolff, J., Florke, H., Cremers, A., May 2000. Searching and browsing collec-tions of structural information. In: Proc. of the IEEE Advances in DigitalLibraries. Washington D.C., USA, pp. 141–150.
35




















