
A novel framework for supporting the exponential worldwide adoption of electronic transactions
8
A Novel Framework for Supporting the Exponential Worldwide Adoption of Electronic Transactions Rodrigo da Rosa Righi, Vinicius Facco Rodrigues, Cristiano Andr´ e da Costa, Leonardo Chiwiacowsky Applied Comp. Grad. Program/Unisinos - Brazil Email: {rrrighi,vrodrig,cac,ldchiwiacowsky}@unisinos.br Diego Luis Kreutz LaSIGE/FCUL - Portugal Email: [email protected] Alexandre Andrade GetNET EFT Company - Brazil Email: [email protected] Abstract—Electronic transactions have become the main- stream mechanism for performing commerce activities in our daily lives. Aiming at processing them, the most common ap- proach addresses the use of a switch that dispatches transactions to processing machines using the so-called Round-Robin sched- uler. Considering this electronic funds transfer (EFT) scenario, we developed a framework model denoted GetLB which comprises not only a new and efficient scheduler, but also a cooperative communication infrastructure for handling heterogeneous and dynamic environments. The GetLB scheduler uses a scheduling heuristic that combines static data from transactions and dynamic information from the processing nodes to overcome the limitations of the Round-Robin based scheduling approaches. Scheduling efficiency takes place thanks to the periodic interaction between the switching node and processing machines, enabling local deci- sion making with up-to-date information about the environment. Besides the description of the aforementioned model in detail, this article also presents a prototype evaluation by using both traces and configurations obtained with a real EFT company. The results show improvements in transaction makespan when comparing our approach with the traditional one over homogeneous and heterogeneous clusters. I. I NTRODUCTION In the last few years, electronic medias for payment op- erations have become mainstream, instead of using money in currency paper and check [1]. For example, paper checks require staff time to open, internally process, and deliver checks to the bank, or payments for lock-box services.Thus, besides convenience for consumers, the use of credit cards benefits trade institutions and eases the access to applications and services on the Internet. Typically, an electronic transaction is related to either a purchase or balance requisition and runs through a round-trip path from one terminal up to a processing center [2]. Point of Sale (POS), Electronic Funds Transfer (EFT), Automatic Teller Machine (ATM) and mobile devices are examples of the most used terminals [3]. After arriving in the service provider company, transactions are received by a switch that acts as a scheduler responsible for assigning them to processing machines (PMs). Both resource management and scheduling are key services for getting efficiency when addressing the observed growing of transactions per second (TPS) on processing companies [4]. The standard mechanism for mapping transactions to PMs is based on the Round-Robin algorithm, which schedules a list of resources in a circular fashion [5], [6]. As illustrated in Figure 1(a), this method represents an easy way to achieve an optimal scheduling when both sets of transactions and PMs are characterized by a homogeneous system [7]. For instance, all transactions present a single type, with the same CPU and I/O requirements among themselves, and PMs are built with the same pieces of hardware and present the same software configuration. Nevertheless, the Round-Robin scheduling ap- proach may not be the best alternative when either dynamic or heterogeneous systems are involved. Particularly, electronic transactions systems can be encompassed on both classifica- tions since the time interval between arrivals is not constant and different types of transactions such as deposit, withdraw, balance, undo and prepaid phone charge should be processed. Since the transactions are heterogeneous, Round-Robin al- gorithm could distribute them for processing on highly-loaded machines, leaving others with moderated-loaded idle. More- over, this strategy restricts the use of computational resources with specialized features, such as those with hardware-assisted cryptography or image (de)coding capabilities. In spite of the disadvantages explained earlier, many transaction processing companies still use a Round-Robin-based scheduling. The main reason of using this limited scheduling policy is because it is not time consuming, even if it may not offering a good scheduling [4], [8]. Figure 1(b) depicts this situation. All PMs are homogeneous and located in the same data center. In addition, all subsystems (information security, terminal configuration, databases and fraud prevention) required by PMs are present in the same network. Instead of using a circular approach for mapping transaction T5 to PM1, an efficient scheduling could map it to PM2 or PM3 for reducing the workload time as a whole. To allow electronic transaction processing providers for better using their computational resources, and so improving the user experience on using such systems, we propose an innovative load balancing framework called GetLB. GetLB acts as an alternative of employing the Round-Robin method and presents the following structure: (i) cooperative commu- nication; (ii) scheduling and; (iii) notification. The first topic concerns the efficient and cooperative interaction between the switch and PMs for collecting scheduling data. In its turn, the scheduler uses predefined data about the transactions to assign them in accordance with their requirements (CPU, network, memory and disk) and data dynamism regarding PMs and network status. Notifications are useful for increasing or decreasing the number of PMs without loosing system availability. The management of both scheduling and notifi- cation allows to GetLB a proactive behavior on dealing with heterogeneous and dynamic resources. Besides the GetLB model itself, this article also describes the implementation of a prototype and its evaluation using in- frastructures with homogeneous and heterogeneous resources. The input workload was based on traces obtained with a real
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of A novel framework for supporting the exponential worldwide adoption of electronic transactions

A Novel Framework for Supporting the ExponentialWorldwide Adoption of Electronic Transactions
Rodrigo da Rosa Righi, Vinicius Facco Rodrigues,Cristiano Andre da Costa, Leonardo Chiwiacowsky
Applied Comp. Grad. Program/Unisinos - BrazilEmail: {rrrighi,vrodrig,cac,ldchiwiacowsky}@unisinos.br
Diego Luis KreutzLaSIGE/FCUL - Portugal
Email: [email protected]
Alexandre AndradeGetNET EFT Company - BrazilEmail: [email protected]
Abstract—Electronic transactions have become the main-stream mechanism for performing commerce activities in ourdaily lives. Aiming at processing them, the most common ap-proach addresses the use of a switch that dispatches transactionsto processing machines using the so-called Round-Robin sched-uler. Considering this electronic funds transfer (EFT) scenario, wedeveloped a framework model denoted GetLB which comprisesnot only a new and efficient scheduler, but also a cooperativecommunication infrastructure for handling heterogeneous anddynamic environments. The GetLB scheduler uses a schedulingheuristic that combines static data from transactions and dynamicinformation from the processing nodes to overcome the limitationsof the Round-Robin based scheduling approaches. Schedulingefficiency takes place thanks to the periodic interaction betweenthe switching node and processing machines, enabling local deci-sion making with up-to-date information about the environment.Besides the description of the aforementioned model in detail, thisarticle also presents a prototype evaluation by using both tracesand configurations obtained with a real EFT company. The resultsshow improvements in transaction makespan when comparingour approach with the traditional one over homogeneous andheterogeneous clusters.
I. INTRODUCTION
In the last few years, electronic medias for payment op-erations have become mainstream, instead of using moneyin currency paper and check [1]. For example, paper checksrequire staff time to open, internally process, and deliverchecks to the bank, or payments for lock-box services.Thus,besides convenience for consumers, the use of credit cardsbenefits trade institutions and eases the access to applicationsand services on the Internet. Typically, an electronic transactionis related to either a purchase or balance requisition and runsthrough a round-trip path from one terminal up to a processingcenter [2]. Point of Sale (POS), Electronic Funds Transfer(EFT), Automatic Teller Machine (ATM) and mobile devicesare examples of the most used terminals [3]. After arriving inthe service provider company, transactions are received by aswitch that acts as a scheduler responsible for assigning themto processing machines (PMs).
Both resource management and scheduling are key servicesfor getting efficiency when addressing the observed growingof transactions per second (TPS) on processing companies [4].The standard mechanism for mapping transactions to PMs isbased on the Round-Robin algorithm, which schedules a listof resources in a circular fashion [5], [6]. As illustrated inFigure 1(a), this method represents an easy way to achieve anoptimal scheduling when both sets of transactions and PMsare characterized by a homogeneous system [7]. For instance,all transactions present a single type, with the same CPU and
I/O requirements among themselves, and PMs are built withthe same pieces of hardware and present the same softwareconfiguration. Nevertheless, the Round-Robin scheduling ap-proach may not be the best alternative when either dynamicor heterogeneous systems are involved. Particularly, electronictransactions systems can be encompassed on both classifica-tions since the time interval between arrivals is not constantand different types of transactions such as deposit, withdraw,balance, undo and prepaid phone charge should be processed.
Since the transactions are heterogeneous, Round-Robin al-gorithm could distribute them for processing on highly-loadedmachines, leaving others with moderated-loaded idle. More-over, this strategy restricts the use of computational resourceswith specialized features, such as those with hardware-assistedcryptography or image (de)coding capabilities. In spite of thedisadvantages explained earlier, many transaction processingcompanies still use a Round-Robin-based scheduling. Themain reason of using this limited scheduling policy is becauseit is not time consuming, even if it may not offering a goodscheduling [4], [8]. Figure 1(b) depicts this situation. AllPMs are homogeneous and located in the same data center.In addition, all subsystems (information security, terminalconfiguration, databases and fraud prevention) required byPMs are present in the same network. Instead of using acircular approach for mapping transaction T5 to PM1, anefficient scheduling could map it to PM2 or PM3 for reducingthe workload time as a whole.
To allow electronic transaction processing providers forbetter using their computational resources, and so improvingthe user experience on using such systems, we propose aninnovative load balancing framework called GetLB. GetLBacts as an alternative of employing the Round-Robin methodand presents the following structure: (i) cooperative commu-nication; (ii) scheduling and; (iii) notification. The first topicconcerns the efficient and cooperative interaction between theswitch and PMs for collecting scheduling data. In its turn,the scheduler uses predefined data about the transactions toassign them in accordance with their requirements (CPU,network, memory and disk) and data dynamism regardingPMs and network status. Notifications are useful for increasingor decreasing the number of PMs without loosing systemavailability. The management of both scheduling and notifi-cation allows to GetLB a proactive behavior on dealing withheterogeneous and dynamic resources.
Besides the GetLB model itself, this article also describesthe implementation of a prototype and its evaluation using in-frastructures with homogeneous and heterogeneous resources.The input workload was based on traces obtained with a real

T1
T2
T3
T4
T5
PM1
PM2
PM3
PM4
T1
T2
T3
T4
T5
HomogeneousTransactions (T)
HomogeneousProcessing
Machines (PM)Optimal
Scheduling withRound-Robin
PM1
PM2
PM3
PM4
T1
T2
T3
T4
T5
GetLBScheduling
500 flops
1 GHz
T1 T5. . .
PM1 PM4. . .
T1 T4
T2 T3 T5
PM1 PM3
PM2 PM4
500 flops
1 GHz
1000 flops
500 MHz
(a)
(c)
Legend
Legend
Scheduler
T1
T2
T3
T4
T5
1 GHzPM1 PM4. . .
(b)
T1 T4
T2 T3 T5 500 flops
1000 flops
Legend
T1
T2
T3
T4
T5
HeterogeneousTransactions (T)
T1
T2
T3
T4
T5
Round-RobinScheduling
HomogeneousProcessing
Machines (PM)
PM1
PM2
PM3
PM4
HeterogeneousTransactions (T)
HeteroogeneousProcessing
Machines (PM)
Scheduler
Scheduler
Fig. 1. Examples of electronic transaction scheduling: (a) Round-Robinachieves optimal scheduling when both transactions and PMs represent anhomogeneous system; (b) Common situation on EFT processing companies,in which Round-Robin may not provide an optimal scheduling; (c) Expectedresults with GetLB when considering heterogeneity for transactions and PMs.
Brazilian service provider company. The tests with a dataset of 8168 transactions, obtained from a period close to2011 Christmas, revealed GetLB as a viable approach for theincreasingly demand on transactions processing.
The remainder of this article will first introduce the relatedwork in Section II. Sections III and IV show the proposedmodel and its prototype, respectively. Section V describes theevaluation methodology. Section VI presents and discussesabout the results by comparing GetLB and Round-Robin indifferent situations. We conclude the paper in Section VII,summarizing the main contributions and achievements, as wellas introducing open avenues for future work.
II. RELATED WORK
Electronic payment has been increasingly adopted owing tothe current technological improvement in information technol-ogy. This transition can be observed in banks, e-commerce sys-
tems, e-governance, entertainment and healthcare industries,mobile devices and applications, and so forth [9]. The moststudied topic in electronic transactions systems considers thesecurity of information [2], [10], [11]. Considering particularlythe modeling of electronic funds transfer (EFT) systems, Sousaet al. [4] present a stochastic model for performance evaluationand resource planning. These authors developed a study ofthe performance, considering characteristics of dependability,such as availability, reliability, scalability and security. Theyaffirm that these parameters are important for maintainingthe service level agreement (SLA) with customers. Araujo etal. [3] report that the analysis of performance should observealways the worst-case scenario for the volume of transactionswhen evaluating reliability of processing centers. The authorsadopted Petri Nets and make use of access time and diskstorage data, in addition to the arrival time of the transactionalvolume.
Besides the experimental approach [4], [3], a formal per-formance analysis is applied on different segments of paralleland distributed computing. Desnoyers et al. [12] developeda system called Modellus, which allows modeling the useof data centers around the Internet automatically. Modellususes queuing theory to derive predictive models of resourceusage by applications. Considering the EFT context, queuingtheory is not the best approach for observing the real situationof processing centers since it does not deal with demandpeaks and dynamism of processing machines. Mathematicalmodels of queuing theory can only be applied to systems thatreached their equilibrium state or permanent regimen, i.e.,systems in which we can verify a standard behavior for along period of time. Other work includes the evaluation ofstrategies for scheduling in computational grids using tracesof real workloads [6]. Formal analysis allows observing theefficiency of the algorithms and the average waiting time forcompletion of each job. The article written by Tchrakian, Basuand Mahony [5] emphasize the importance of the time intervalon scheduling reactivity. Particularly, a large interval cannotbe applied to EFT systems, because of it can both disregarda given peak of arrival of transactions and deal with outdatedinformation about PMs.
Scheduling is a so-called task in cooperative and distributedsystems. Besides being employed to process transactions indata centers, scheduling must also be analyzed in cloudcomputing scenarios for mapping virtual machines to physicalnodes. Scalability, energy saving and elasticity depend on anefficient scheduling policy on cloud environments [13]. Inthis context, cloud providers, such as Amazon EC2, Nimbus,Eucalyptus and OpenNebula present a Round-Robin schedulerfor assigning virtual to physical machines [14]. The lastthree systems work with this technique as a default one fortheir cloud environments. Thus, our scheduling proposal canbe employed on different branches of distributed computing.Middlewares like OpenNebula present a framework that offersto users the possibility to implement their own load balancers.
III. GETLB: A LOAD BALANCING FRAMEWORK FOREFT SYSTEMS
The traditional infrastructure of EFT processing centersconsists in a scheduler that dispatches transactions in ac-cordance with the Round-Robin approach. Each PM has its

own incoming queue and may use one or more subsystemsfor processing a transaction. Since Round-Robin does notconsider the PM’s load or transactions characteristics, it is notuncommon to overload some machines and to observe trans-action loss. Thus, GetLB was structured with the followingdesign decisions in mind: (i) the switch module must workwith up to date information regarding the PMs for schedulingcalculus; (ii) the scheduling of transactions must combinerelevant data in order to compose an efficient heuristic forthe concept of load; (iii) PMs must be capable to notifythe switch when occurring events; (iv) the framework mustdeal with heterogeneous resources at both communication andcomputing levels. Considering item (i), PMs update their owndata by sending updates through the netowrk to the switchmodule periodically. Concurrently, this last entity can receivetransactions and use the most recent in-memory data frommachines for mapping decisions.
A. Extensible Architecture
First of all, it is important to describe the traditionalarchitecture to process electronic transactions [4]. It presentsa switch that dispatches transactions to homogeneous PMs ina Round-robin fashion. Moreover, the switch, the PMs andthe internal subsystems are all organized in the local networkbelonging to the provider’s data center. The first differencewhen comparing GetLB to the traditional approach comprisesthe network. The proposed architecture can be seen in Figure 2.In GetLB, the disposition of the elements in the same networkis not mandatory. The only prerequisite consists in the fact thateach element should be accessed through an IP address. Takinginto account the switch perspective, the time for accessingone PM should not be the same for another one. The samecan be applied for communications from PM components tointernal subsystems. Although the Internet offers a networklatency often 1000 times greater than local area networks [15],the flexibility offered by GetLB brings the following benefits:(i) given that the resources of an institution are limited, it ispossible to include additional ones from business partners inorder to support a specific demand; (ii) it helps the growthof the enterprise, since some countries like Chile presentstrong regulations that claim electronic transactions must beprocessed by machines located in national territory.
Other relevant aspect of GetLB architecture concerns theheterogeneity management. Besides the exploration of thisfeature at network level (using different local area networksconnected through the Internet), GetLB also deals with PMsthat present different features such as CPU clock, accesstimes to the switch and subsystems, as well as differentconfigurations of primary and secondary memories. Figure 3illustrates the composition of a processing machine. Each PMstores network data because the use of a local area networkis not mandatory, so the latency for accessing the switch andeach subsystem can change along the time. CPU, RAM anddisk data are dynamic and present a direct impact on the PMchances for receiving transactions.
The switch works with a vector that contains informationof all PMs. We designed a pull-based interaction between theswitch and PMs, where each processing machine updates itspart on the remote vector periodically. Technically, each PMsends the information indicated within GetLB Data frame in
ProcessingMachine 1POS
ATM
X.25➝IP
Incomming Transactions
Switch
Cards
Cellphone Prepaid
Transport cards
Terminal Configuration
Information Security
Fraud Prevention
Internal Subsystems
DB DB DB DBAuxiliary Systems
EFT
ProcessingMachine 2
ProcessingMachine n
Notifications and Scheduling Data
LocalAreaNetwork 1
LocalAreaNetwork 2
LL Scheduler
Fig. 2. Example of the GetLB architecture, emphasizing network decouplingand “PMs→switch” interaction besides the traditional one for transactiondispatching in opposite direction. Here, the size of each PM represents itsCPU capacity, while the arrows’ width means different latencies on networkcommunication. In this example, the interactions between the PM n and theSwitch occurs through the Internet.
CPUData
DiskData
RAM Data
Access Time to Sub-systems
Processing Machine
Reception of Transactions
Execution of Transactions
Communication with Output Systems
Transactions Queue
GetLB data
Access Timeto the Switch
Fig. 3. Composition of a Processing Machine.
Figure 3 to the switch in accordance with a preconfigured pa-rameter. This organization allows the switch to decide the des-tination of an incoming transaction without spending time withnetwork communication for scheduling purposes. Therefore,the interaction among the architecture elements enables switchto act only with in-memory data for performing schedulingcalculus. The updating period will inform how recent is dataregarding CPU, memory and network from the processingmachines. Unlike this approach, notification causes the switchto be notified regarding a particular event asynchronously.Notifications will not be covered in this article in detail.Basically, GetLB works with traffic shaping, maintenanceand overload notifications. While maintenance is launched bythe administrator, overload notifications are triggered by theown machine that has not enough resources for processingtransactions. Traffic shaping is used for either denying orallowing the reception of a specific type of transaction.
B. Transaction Scheduling
Before running the scheduler, we are assuming that theSwitch knows a pre-mapping of the types and the resourcesrequired by each transaction. This data is not moldable alongthe system functioning. Hence, the switch module identifies

the type of a transaction, which has its own CPU and I/Orequirements, and finds the most suitable target for its pro-cessing. Considering a modeling where transactions and PMsare heterogeneous and PMs can be also seen as a dynamicenvironment, we developed a scheduling heuristic called LL(Load Level). LL can be viewed as a decision function LL(i, j)where i means a specific type of transaction while j = 1, . . . , ndenotes a candidate target PM for receiving transaction i. Thus,for each new transaction i, the switch will calculate n values ofLL(i, j), where n means the number of processing machines.In this way, the lowest result will inform the target that willreceive a specific transaction. The value of LL(i, j) can beobtained by computing Equation (1). We opted here to explainLL in a top-down style, first presenting our final objective andthen the auxiliary functions and parameters for achieving it.
LL(i, j) = Recv(i, j) + Proc(i, j) , (1)
where
Recv(i, j) = bytes(i)× transfer(j) , (2)
and
Proc(i, j) = transaction(i, j) +
m−1∑z=0
transaction(z, j) ,
(3)
such that
transaction(i, j) =instructions(i)
clock(j)× [1− load(j)]+
+RAM(i)× serviceRAM(j)
freeRAM(j)+
+HD(i)× serviceHD(j)
freeHD(j)+
+ sub(i, j) , (4)
and
sub(i, j) =
x−1∑y=0
[2 suba(y, j) + subc(y)]× subr(i, y) . (5)
The value of LL(i, j) is obtained by calculating the timerequired for receiving and processing a given transaction iin a target machine j. So, the term Recv(i, j) considers thetime required to transfer all bytes of the transaction from theswitch to the PM. For that, transfer(j) comprises the time tosend 1 byte between both communication entities. Equation (2)can represent the most significant term on LL equation owingto this be the most onerous portion for accessing processingmachines around the Internet. The term Proc(i, j) correspondsto the processing time of all transactions mapped to machinej, including the candidate transaction i. Thus, Equation (3) canbe divided in two portions: (i) a prediction of computation timefor transaction i on PM j; (ii) a prediction of all m transactionsthat have already mapped to PM j previously and remain onits input queue.
Equation (4) is used for measuring the execution time ofa transaction i on PM j. It can be divided in four terms:the first denotes CPU operations, the second and the thirdI/O operations and the fourth refers to subsystems. Eachtransaction is defined by the following parameters: (i) numberof instructions; (ii) number of RAM operations; (iii) numberof HD operations; (iv) which subsystems are necessary forcomputing a transaction and the number of interactions witheach one; (v) access time to each subsystem. Consideringthat the use of local area network is not mandatory, theaforementioned parameter (v) is useful to add a delay for usingsubsystems distributed along different Internet domains. InEquation (4), serviceRAM(j) and serviceHD(j) denote theaverage I/O time for performing a single instruction of write inmemory and disk, respectively. The parameters freeRAM(j)and freeHD(j) are percentages that indicate the availabilityof each I/O resource in a specific moment.
The time involving the subsystems is computed by sub(i, j)in accordance with Equation (5). Each type of transaction imust access x subsystems. Thus, suba(y, j) considers the timespent by PM j for accessing the particular subsystem y throughnetwork interaction. This time is multiplied by 2 in orderto consider a round-trip evaluation. The term subc(y) refersto the service time of the subsystem y. The term subr(i, y)is used as the number of times that subsystem y is calledfor the complete computation of transaction i. Finally, theswitch has two tables for helping the scheduling process: (i)types of transactions with requirements; (ii) subsystems withcomputation times. Therefore, data needed for the functionsbytes(i), instructions(i), RAM(i), HD(i), subc(y) andsubr(i, y) are fixed (static) and taken by querying these tables.
IV. GETLB PROTOTYPE
GetLB was tested with an experimental prototype insteadof using a real production environment for processing trans-actions. However, the input workload was captured from realtraces of a production system. The prototype implements adistributed system with full-duplex communications betweenthe switch and PM machines. The interaction “PM→Switch”is used by processing machines for updating their data (seeFigure 3) to the switch, as well as for sending notifications. The“Switch→PM” is used for transaction dispatching. Consideringthese communication requirements, we developed an RMI(Remote Method Invocation) system with remote objects asillustrates Figure 4. Although Java is not a high performance-driven programming language [16], its employment in this con-text was pertinent to analyze possible gains and the overheadwhen using GetLB for routing electronic transactions.
The switch creates a collection of n remote objects (wheren is the number of processing machines), each one for storinginformation regarding a specific PM. Each processing machineis responsible for creating a single remote object that willhandle requests queuing. Logically, there is a complementaryproxy object for each remote one in the opposite side. Thearrangement of the remote and proxy objects is centeredon efficiency, since the scheduling calculation does not needto capture up to date information across the network. Eachremote object in the switch side maintains a table with dataabout CPU, disk, network time, memory as well as the accesstimes between a specific processing and each subsystem. We

Switch
RMI Client
Processing Machine 0
TransactionsQueue 0
TransactionsQueue n-1
RMI ServerMachineData 0
MachineData n-1
RMI Client
MachineData 0
RMI Server
TransactionsQueue 0
RMI Registry
RMI Registry
Processing Machine n-1
RMI Client
MachineData n-1
RMI Server
TransactionsQueue n-1
RMI Registry
Thread for UpdatingMachine
Data
Thread for UpdatingMachine
Data
Datacenter
IncomingTransactions
Transactions dispatching
Updating of ProcessingMachine data
Fig. 4. GetLB prototype using Java RMI with remote objects in both sides: Processing Machines and Switch.
modeled a thread on each PM called Machine Thread, whichis created when instantiating an object (constructor part) thatdescribes a PM. This thread captures up-to-date informationabout the PM periodically, calling the remote object for passingdata to the switch side. Each PM implements a FIFO mecha-nism for consuming transaction from its incoming queue.
When starting the system, the switch receives two text filesas input data: (i) transaction to be processed; (ii) description ofthe current PMs in the system. The first file has a collectionof lines, where each one presents the transaction’s type andthe related arrival time. The machine file, in its turn, has thename of each PM, IP addresses, clock frequencies, total ofmemory of each machine and maximum size of the transac-tions queue. Besides RMI, the prototype also uses the returnof the command “top” from the Linux operating system forgetting data about CPU and memory load on each PM. Thecurrent implementation of the prototype does not considerdisk data, as stated in the GetLB’s modeling part. In theprototype, both implementations of LL and Round-Robin (RR)scheduling schemes are presented in the switch module. Inprocessing machine view, RR algorithm does not use the ideaof updating data from the machine in the switch side, since RRestablishes a strictly scheduling mechanism based on a circulardispatching list.
V. EVALUATION METHODOLOGY
Each transaction type has its own peculiarities regarding theuse of CPU and RAM memory, size and timing for accessinginternal subsystems. Table I shows the transactions’ types thatwe are using in the tests. Data were obtained from GetNetcompany1 that operates in the field of electronic transactionprocessing. Transaction’s size is the amount in bytes that is sentby the switch to a specific PM. Transactions used in the testswere captured by the company GetNet preserving sensitive
1https://www.getnet.com.br
data, credit card numbers and values. Data were obtainedon 23rd December, 2011, in the range between 13:30 and22:30, summing 8168 transactions. This amount is classifiedas follows: 1916 Purchasing, 41 Purchasing Canceling, 36Transaction Reverting, 5303 related to Prepaid Telephony and872 are Administrative transactions. Figure 5 shows arrivalsequence of the 8168 transactions.
The tests rely on a machine that acts in the role of aswitch (Xeon 2.4 GHz) that dispatches transactions to a clusterof homogeneous or heterogeneous processing machines. Thehomogeneous cluster is formed by six machines Xeon 2.4GHz with 2 GB of RAM, while the heterogeneous one hasfour machines with this configuration and two machines of1.2 GHz and with 2 GB of RAM. In both systems, our setof transactions was evaluated with the GetLB (LL scheduler)and Round-Robin (RR) prototypes. Both were implemented inJava, version 1.7.
The transaction dispatching algorithm is illustrated in Fig-ure 6. This sequence of steps is performed by the switch whichuses a file that describes a single transaction on each row. Line17 presents a function that waits for completing all transactionson each machine. Locally, this function captures end of workfor each machine and completes a vector of processing timesfor each one by using time t1. The completion time of theworkload is obtained in line 18. In scheduling literature, thismeasure is also known as makespan [17]. The dispatchingmethod (line 15) has an asynchronous capability, being respon-sible for sending a message over the network to the input queueof the target machine. On the other hand, the method presentedin line 17 is synchronous, i.e., it has a blocking behavior upto concluding all transactions properly. The difference betweent3 and t2 reports the time spent in the scheduling algorithm,RR or LL.

TABLE I. TRANSACTIONS’ TYPES DEFINITION AND THEIR CHARACTERISTICS.
TypeAveragesize(bytes)
Memoryusage
Clock cy-cles
Subsystems (mil-liseconds) Description of accessed subsystems
Purchasing 1322 12300 107 1140 Cards system (3 accesses), Cryptography system (1 access), Fraud Preventionsystem (1 access), Management system (1 access)
Purchasing cancellation 1212 12250 102 1100 Card system (3 accesses), Fraud Prevention system (1 access), Managementsystem (1 access)
Transaction reverting 348 1140 83 400 Card system or Recharge system (1 access), Management system (1 access)
Prepaid telephony 1146 2000 42 1150 Recharge system (3 accesses), Fraud Prevention system (1 access), Managementsystem (1 access)
Administrative 6700 7000 30 1350 Configuration system (1 access), Cards system (1 access), Fraud Preventionsystem (1 access)
0 2000 4000 6000 80000
1
2
3
4
5
Identificação das Transações
Tipo
da
Tran
saçã
oTy
pe o
f Tra
nsac
tion
Transaction's Identification
Fig. 5. Arrival and classification of 8168 transactions. Types: 1-Administrative; 2-Recharge; 3-Purchasing; 4-Purchasing canceling; 5-Transaction reverting.
01. t1 = get_time();02. Iteration in the number of transactions03. {04. transaction = transaction_capturing(file);05. t2 = get_time();06. if algorithm is Round Robin07. {08. processing_machine = machine_capturing_rr();09. }10. else11. {12. processing_machine = machine_capt_ll(transaction);13. }14. t3 = get_time();15. dispatching(transaction, processing_machine);16. }17. vector[] v = wait_transactions_conclusion(t1);18. makespan = get_max_time(v);
Fig. 6. Algorithm for dispatching transactions.
VI. EVALUATION RESULTS
Figures 7 and 8 present the results when using the ho-mogeneous cluster. A balance on distributing transactionswith RR scheme can be observed, but this fact does notimply on better performance regarding the processing timeperspective. Although the machines are homogeneous, the setof transactions is not, and RR algorithm maps them to re-sources cyclically without observing their characteristics. Sucha situation was illustrated previously in Figure 1(b). Each barin Figure 8 represents the time of a PM when using either RRor GetLB (using LL algorithm). This time denotes the periodfrom the beginning of the program until the last processedtransaction. GetLB scheduler was responsible for obtaining atotal processing time lower than that obtained with the RR.Respectively, 05:21 (with a notation of minutes:seconds) and06:26 measurements were responsible for this observation.
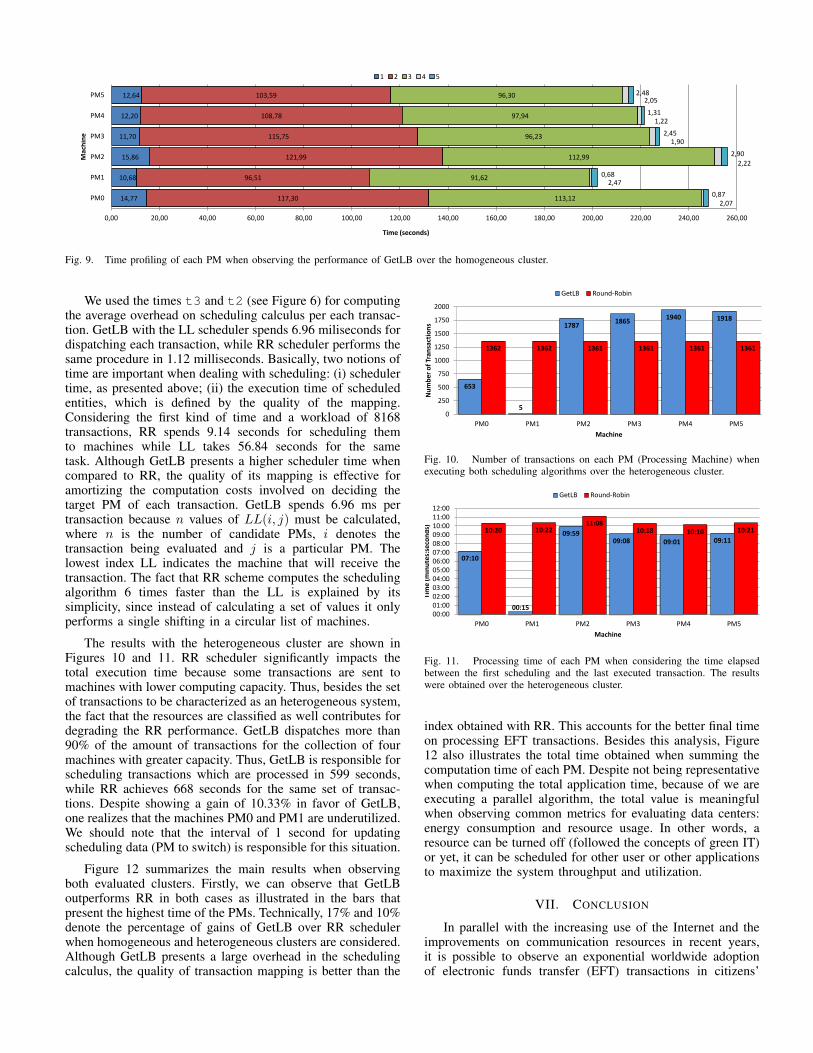
Figure 9 depicts the processing time spent on each machinefor computing a particular transaction type when using GetLB
over the homogeneous cluster. Load balancing serves to bal-ance the amount of processing performed on each machine.When summing the time of each PM, the highest value wasattained by PM2, while the lowest number was provided byPM1. The respective achieved values were 255.19 seconds and201.96 seconds. In this way, an average of 228.78 seconds anda standard deviation of 12.20 were obtained.
1470
1192
1467 1365 1377
1297 1362 1362 1361 1361 1361 1361
0
250
500
750
1000
1250
1500
1750
2000
PM0 PM1 PM2 PM3 PM4 PM5
Nu
mb
er
of
Tran
sact
ion
s
Machine
GetLB Round-Robin
Fig. 7. Number of transactions on each PM (Processing Machine) whenexecuting both scheduling algorithms over the homogeneous cluster.
04:45 04:47 05:21
04:46 04:38 04:06
05:51 05:52 06:26
05:52 05:44 05:27
00:00 01:00 02:00 03:00 04:00 05:00 06:00 07:00 08:00 09:00 10:00 11:00 12:00
PM0 PM1 PM2 PM3 PM4 PM5
Tim
e (
min
ute
s:se
con
ds)
Machine
GetLB Round-Robin
Fig. 8. Processing time of each PM when considering the first and the lastexecuted transaction. The results were obtained over the homogeneous cluster.
14,77
10,68
15,86
11,70
12,20
12,64
117,30
96,51
121,99
115,75
108,78
103,59
113,12
91,62
112,99
96,23
97,94
96,30
0,87
0,68
2,90
2,45
1,31
2,48
2,07
2,47
2,22
1,90
1,22
2,05
0,00 20,00 40,00 60,00 80,00 100,00 120,00 140,00 160,00 180,00 200,00 220,00 240,00 260,00
PM0
PM1
PM2
PM3
PM4
PM5
Time (seconds)
Mac
hin
e
1 2 3 4 5
Fig. 9. Time profiling of each PM when observing the performance of GetLB over the homogeneous cluster.
We used the times t3 and t2 (see Figure 6) for computingthe average overhead on scheduling calculus per each transac-tion. GetLB with the LL scheduler spends 6.96 miliseconds fordispatching each transaction, while RR scheduler performs thesame procedure in 1.12 milliseconds. Basically, two notions oftime are important when dealing with scheduling: (i) schedulertime, as presented above; (ii) the execution time of scheduledentities, which is defined by the quality of the mapping.Considering the first kind of time and a workload of 8168transactions, RR spends 9.14 seconds for scheduling themto machines while LL takes 56.84 seconds for the sametask. Although GetLB presents a higher scheduler time whencompared to RR, the quality of its mapping is effective foramortizing the computation costs involved on deciding thetarget PM of each transaction. GetLB spends 6.96 ms pertransaction because n values of LL(i, j) must be calculated,where n is the number of candidate PMs, i denotes thetransaction being evaluated and j is a particular PM. Thelowest index LL indicates the machine that will receive thetransaction. The fact that RR scheme computes the schedulingalgorithm 6 times faster than the LL is explained by itssimplicity, since instead of calculating a set of values it onlyperforms a single shifting in a circular list of machines.
The results with the heterogeneous cluster are shown inFigures 10 and 11. RR scheduler significantly impacts thetotal execution time because some transactions are sent tomachines with lower computing capacity. Thus, besides the setof transactions to be characterized as an heterogeneous system,the fact that the resources are classified as well contributes fordegrading the RR performance. GetLB dispatches more than90% of the amount of transactions for the collection of fourmachines with greater capacity. Thus, GetLB is responsible forscheduling transactions which are processed in 599 seconds,while RR achieves 668 seconds for the same set of transac-tions. Despite showing a gain of 10.33% in favor of GetLB,one realizes that the machines PM0 and PM1 are underutilized.We should note that the interval of 1 second for updatingscheduling data (PM to switch) is responsible for this situation.
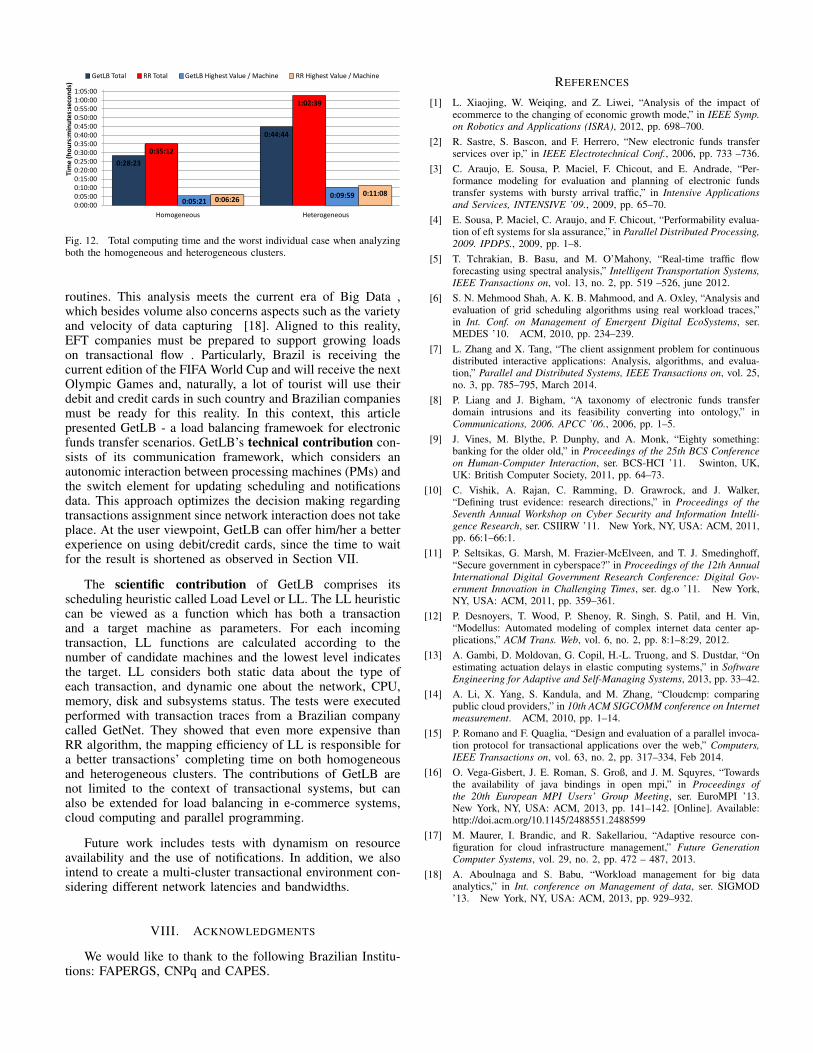
Figure 12 summarizes the main results when observingboth evaluated clusters. Firstly, we can observe that GetLBoutperforms RR in both cases as illustrated in the bars thatpresent the highest time of the PMs. Technically, 17% and 10%denote the percentage of gains of GetLB over RR schedulerwhen homogeneous and heterogeneous clusters are considered.Although GetLB presents a large overhead in the schedulingcalculus, the quality of transaction mapping is better than the
653
5
1787 1865
1940 1918
1362 1362 1361 1361 1361 1361
0
250
500
750
1000
1250
1500
1750
2000
PM0 PM1 PM2 PM3 PM4 PM5 N
um
be
r o
f Tr
ansa
ctio
ns
Machine
GetLB Round-Robin
Fig. 10. Number of transactions on each PM (Processing Machine) whenexecuting both scheduling algorithms over the heterogeneous cluster.
07:10
00:15
09:59 09:08 09:01 09:11
10:20 10:22 11:08
10:18 10:10 10:21
00:00 01:00 02:00 03:00 04:00 05:00 06:00 07:00 08:00 09:00 10:00 11:00 12:00
PM0 PM1 PM2 PM3 PM4 PM5
Tim
e (
min
ute
s:se
con
ds)
Machine
GetLB Round-Robin
Fig. 11. Processing time of each PM when considering the time elapsedbetween the first scheduling and the last executed transaction. The resultswere obtained over the heterogeneous cluster.
index obtained with RR. This accounts for the better final timeon processing EFT transactions. Besides this analysis, Figure12 also illustrates the total time obtained when summing thecomputation time of each PM. Despite not being representativewhen computing the total application time, because of we areexecuting a parallel algorithm, the total value is meaningfulwhen observing common metrics for evaluating data centers:energy consumption and resource usage. In other words, aresource can be turned off (followed the concepts of green IT)or yet, it can be scheduled for other user or other applicationsto maximize the system throughput and utilization.
VII. CONCLUSION
In parallel with the increasing use of the Internet and theimprovements on communication resources in recent years,it is possible to observe an exponential worldwide adoptionof electronic funds transfer (EFT) transactions in citizens’
0:28:23
0:44:44
0:35:12
1:02:39
0:05:21 0:09:59
0:06:26 0:11:08
0:00:00 0:05:00 0:10:00 0:15:00 0:20:00 0:25:00 0:30:00 0:35:00 0:40:00 0:45:00 0:50:00 0:55:00 1:00:00 1:05:00
Homogeneous Heterogeneous
Tim
e (
ho
urs
:min
ute
s:se
con
ds)
GetLB Total RR Total GetLB Highest Value / Machine RR Highest Value / Machine
Fig. 12. Total computing time and the worst individual case when analyzingboth the homogeneous and heterogeneous clusters.
routines. This analysis meets the current era of Big Data ,which besides volume also concerns aspects such as the varietyand velocity of data capturing [18]. Aligned to this reality,EFT companies must be prepared to support growing loadson transactional flow . Particularly, Brazil is receiving thecurrent edition of the FIFA World Cup and will receive the nextOlympic Games and, naturally, a lot of tourist will use theirdebit and credit cards in such country and Brazilian companiesmust be ready for this reality. In this context, this articlepresented GetLB - a load balancing framewoek for electronicfunds transfer scenarios. GetLB’s technical contribution con-sists of its communication framework, which considers anautonomic interaction between processing machines (PMs) andthe switch element for updating scheduling and notificationsdata. This approach optimizes the decision making regardingtransactions assignment since network interaction does not takeplace. At the user viewpoint, GetLB can offer him/her a betterexperience on using debit/credit cards, since the time to waitfor the result is shortened as observed in Section VII.
The scientific contribution of GetLB comprises itsscheduling heuristic called Load Level or LL. The LL heuristiccan be viewed as a function which has both a transactionand a target machine as parameters. For each incomingtransaction, LL functions are calculated according to thenumber of candidate machines and the lowest level indicatesthe target. LL considers both static data about the type ofeach transaction, and dynamic one about the network, CPU,memory, disk and subsystems status. The tests were executedperformed with transaction traces from a Brazilian companycalled GetNet. They showed that even more expensive thanRR algorithm, the mapping efficiency of LL is responsible fora better transactions’ completing time on both homogeneousand heterogeneous clusters. The contributions of GetLB arenot limited to the context of transactional systems, but canalso be extended for load balancing in e-commerce systems,cloud computing and parallel programming.
Future work includes tests with dynamism on resourceavailability and the use of notifications. In addition, we alsointend to create a multi-cluster transactional environment con-sidering different network latencies and bandwidths.
VIII. ACKNOWLEDGMENTS
We would like to thank to the following Brazilian Institu-tions: FAPERGS, CNPq and CAPES.
REFERENCES
[1] L. Xiaojing, W. Weiqing, and Z. Liwei, “Analysis of the impact ofecommerce to the changing of economic growth mode,” in IEEE Symp.on Robotics and Applications (ISRA), 2012, pp. 698–700.
[2] R. Sastre, S. Bascon, and F. Herrero, “New electronic funds transferservices over ip,” in IEEE Electrotechnical Conf., 2006, pp. 733 –736.
[3] C. Araujo, E. Sousa, P. Maciel, F. Chicout, and E. Andrade, “Per-formance modeling for evaluation and planning of electronic fundstransfer systems with bursty arrival traffic,” in Intensive Applicationsand Services, INTENSIVE ’09., 2009, pp. 65–70.
[4] E. Sousa, P. Maciel, C. Araujo, and F. Chicout, “Performability evalua-tion of eft systems for sla assurance,” in Parallel Distributed Processing,2009. IPDPS., 2009, pp. 1–8.
[5] T. Tchrakian, B. Basu, and M. O’Mahony, “Real-time traffic flowforecasting using spectral analysis,” Intelligent Transportation Systems,IEEE Transactions on, vol. 13, no. 2, pp. 519 –526, june 2012.
[6] S. N. Mehmood Shah, A. K. B. Mahmood, and A. Oxley, “Analysis andevaluation of grid scheduling algorithms using real workload traces,”in Int. Conf. on Management of Emergent Digital EcoSystems, ser.MEDES ’10. ACM, 2010, pp. 234–239.
[7] L. Zhang and X. Tang, “The client assignment problem for continuousdistributed interactive applications: Analysis, algorithms, and evalua-tion,” Parallel and Distributed Systems, IEEE Transactions on, vol. 25,no. 3, pp. 785–795, March 2014.
[8] P. Liang and J. Bigham, “A taxonomy of electronic funds transferdomain intrusions and its feasibility converting into ontology,” inCommunications, 2006. APCC ’06., 2006, pp. 1–5.
[9] J. Vines, M. Blythe, P. Dunphy, and A. Monk, “Eighty something:banking for the older old,” in Proceedings of the 25th BCS Conferenceon Human-Computer Interaction, ser. BCS-HCI ’11. Swinton, UK,UK: British Computer Society, 2011, pp. 64–73.
[10] C. Vishik, A. Rajan, C. Ramming, D. Grawrock, and J. Walker,“Defining trust evidence: research directions,” in Proceedings of theSeventh Annual Workshop on Cyber Security and Information Intelli-gence Research, ser. CSIIRW ’11. New York, NY, USA: ACM, 2011,pp. 66:1–66:1.
[11] P. Seltsikas, G. Marsh, M. Frazier-McElveen, and T. J. Smedinghoff,“Secure government in cyberspace?” in Proceedings of the 12th AnnualInternational Digital Government Research Conference: Digital Gov-ernment Innovation in Challenging Times, ser. dg.o ’11. New York,NY, USA: ACM, 2011, pp. 359–361.
[12] P. Desnoyers, T. Wood, P. Shenoy, R. Singh, S. Patil, and H. Vin,“Modellus: Automated modeling of complex internet data center ap-plications,” ACM Trans. Web, vol. 6, no. 2, pp. 8:1–8:29, 2012.
[13] A. Gambi, D. Moldovan, G. Copil, H.-L. Truong, and S. Dustdar, “Onestimating actuation delays in elastic computing systems,” in SoftwareEngineering for Adaptive and Self-Managing Systems, 2013, pp. 33–42.
[14] A. Li, X. Yang, S. Kandula, and M. Zhang, “Cloudcmp: comparingpublic cloud providers,” in 10th ACM SIGCOMM conference on Internetmeasurement. ACM, 2010, pp. 1–14.
[15] P. Romano and F. Quaglia, “Design and evaluation of a parallel invoca-tion protocol for transactional applications over the web,” Computers,IEEE Transactions on, vol. 63, no. 2, pp. 317–334, Feb 2014.
[16] O. Vega-Gisbert, J. E. Roman, S. Groß, and J. M. Squyres, “Towardsthe availability of java bindings in open mpi,” in Proceedings ofthe 20th European MPI Users’ Group Meeting, ser. EuroMPI ’13.New York, NY, USA: ACM, 2013, pp. 141–142. [Online]. Available:http://doi.acm.org/10.1145/2488551.2488599
[17] M. Maurer, I. Brandic, and R. Sakellariou, “Adaptive resource con-figuration for cloud infrastructure management,” Future GenerationComputer Systems, vol. 29, no. 2, pp. 472 – 487, 2013.
[18] A. Aboulnaga and S. Babu, “Workload management for big dataanalytics,” in Int. conference on Management of data, ser. SIGMOD’13. New York, NY, USA: ACM, 2013, pp. 929–932.




















