
صورة األرض املؤلف: حممد بن حوقل البغدادي املوصلي - Quranic ...
Upload
teknologimalaysiaCategory
view
2download
0
#20
A Novel Dataset for Quranic Words Identificationand Authentication
1Thabit Sabbah, 2Ali SelamatUniversiti Teknologi Malaysia (UTM)
[email protected], [email protected]
Abstract— Quran is the holy book for all Muslims around theworld. During hundreds of years, it was preserved in all possibleways from distortion. The huge increment and spread of digitalmedia and internet usage, leaded to many organizational andindividual websites, services, and applications are beingintroduced to spread the knowledge related to Quran as well asQuranic Verses, Translations, Explanations with the Tafseer andother Quranic sciences in its digital formats, some of theseservices are less authentic. The first step of authentication is thecorrect detection and identification of Quranic words among thetext. In this paper, we introduce a novel dataset for Quranicwords identification and Authentication. The proposed datasetcontains more than 93000 samples with 64 features for eachsample extracted in numerical form. Samples are categorizedinto two labeled classes; “Quranic” and “non-Quranic”,Validation tests of our dataset show a high accuracy average.
Keywords: Quranic words detection, Quranic words Dataset,Arabic words classification, Arabic Diacritic Words;
I. INTRODUCTIONQuranic words identification can be defined as determining
which words of the text belongs to Holy Quran and is writtenexactly as it is written in holy Quran1. Consecutive wellorderedQuranic words forms a verse. In common, Quran is writtenwith diacritics. Originally, diacritics are used in Arabic todistinguish the vocal pronunciation of words and represents thevowel sounds [1]; In ordinary Arabic writing few diacritics arecommonly used as shown in Table I. However, in Quranic textwriting there are many other diacritics and special symbolsused to give the reader other sorts of reading guidance, we willcall all of these diacritics and special symbols as diacritics forabbreviation.
TABLE I. COMMON DIACRITICS USED IN ARABIC WRITING
1 Based on standard Quranic writing style known as (Uthmani).
Muslims a round world use verses in their daily life formany reasons such as support decision making, deducesolutions deduce solutions for their social and religiousproblems or to analyze many issues. Most of Muslim authorsquote verses as an evidence to support their conclusions andtheir analysis of events [2]. Quotation is not only used inwritten publications, but also it is common in speeches,conversations, dialogs and discussions. This scientific methodis popular in Islamic societies in general and Arabs inparticular [3]. According to this method, in written works, thequoted verses are distinguished among the text by many wayssuch as surrounded by brackets, written in standardQuranicstyle (known as Uthmani) with full diacritics, andmany other techniques. On the other hand, Quranic verses isdistinguished in oral works by reciting these verses accordingto the standard Quranic recitation rules or by adding thecommon phrases used to indicate the starting and the ending ofthe quoted verse, as well many other vocal techniques are usedto distinguish verses in oral works. In Islamic multimediaworks many advanced graphics and sound effects techniquesare utilized to distinguish verses among other multimediacontent. However in much other less authentic worksespecially online recourse such as forums, social networks,blogs, personal websites, users occasionally use the scientificmethod of quoting and citing Quranic verses, this case make ithard not only for a reader to distinguish the Quranic verses(words) but also it become harder for the automatic textprocessing and natural language processing techniques such asInformation Retrieval Systems (IRS) and KnowledgeManagement Systems (KMS) to work efficiently on Arabictext in general and religious content in particular.
In this paper we propose a novel dataset for Quranic wordsidentification and authentication; the proposed dataset contains93161 sample with 64 features for each sample. Samples arecategorized into two categories; “Quranic” and “non-Quranic”.The “Quranic” labeled samples of the dataset were collectedfrom highly trusted resource, while the “non-Quranic” labeledsamples were collected from thousands of Arabic postdownloaded from one of the biggest Arabic religious forum onthe web. In the rest of this paper, section II highlights ourmotivation by focusing on previous works related to Quranicverse detection. Section III explains our framework in
263

264

265

266

267
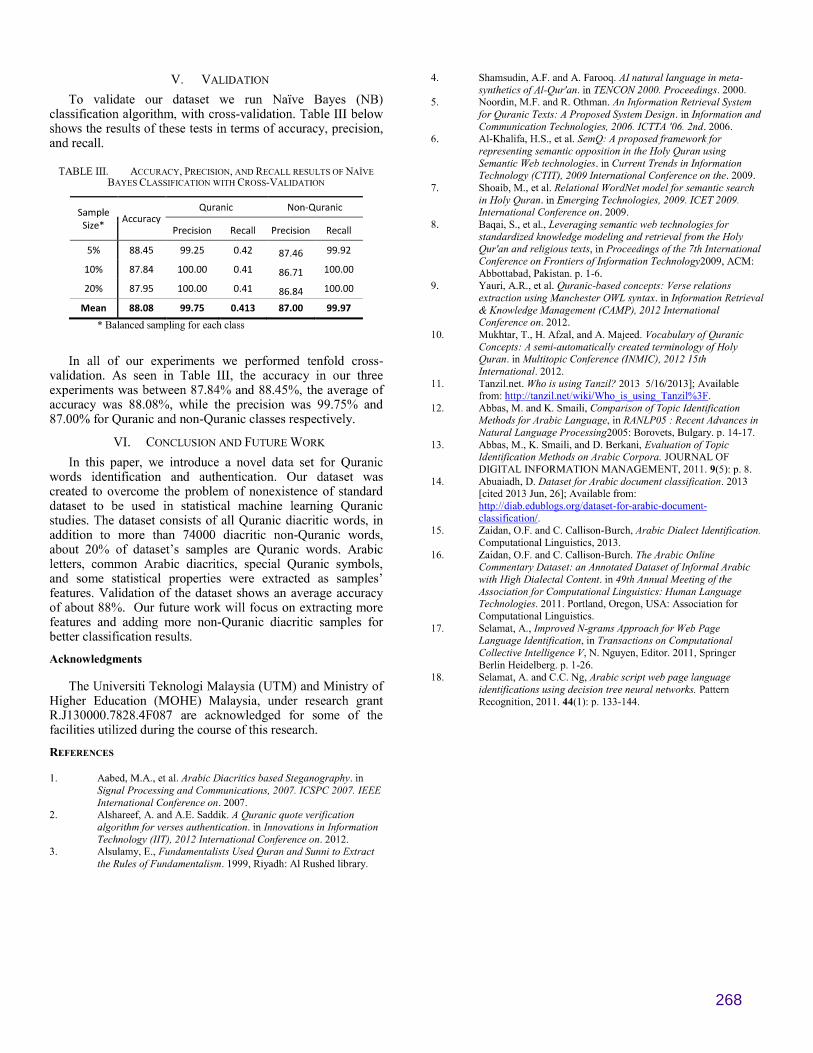
268
Copyright © 2022 FDOKUMEN




















