
Avoiding an Andragogy of Poverty: Holding In-service Educators Accountable
Upload
khangminh22Category
view
0download
0
A NEGOTIATION PROTOCOL
FOR ACCOUNTABLE RESOURCE
SHARING IN E-SCIENCE
COLLABORATIONS
A thesis submitted to the University of Manchester
for the degree of Doctor of Philosophy
in the Faculty of Sciences & Engineering
2018
By
Zeqian Meng
Computer Science

2

Contents
List of Tables 9
List of Figures 11
Abstract 15
Declaration 19
Copyright 21
Acknowledgements 23
Definitions 25
1 Introduction 27
1.1 Setting the Scene . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
1.2 e-Science Resource Provision Introduction . . . . . . . . . . . . . 30
1.3 Negotiation Entities for e-Science Resource Provision . . . . . . . 32
1.4 Research Motivations and Challenges . . . . . . . . . . . . . . . . 33
1.5 Research Hypothesis and Objectives . . . . . . . . . . . . . . . . . 34
1.6 Methodology and Approach . . . . . . . . . . . . . . . . . . . . . 35
1.7 Research Contributions . . . . . . . . . . . . . . . . . . . . . . . . 37
1.8 Publications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
1.9 Thesis Organisation . . . . . . . . . . . . . . . . . . . . . . . . . . 41
2 Background 43
2.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
2.2 Current e-Science Enabling Models and Lifecycle . . . . . . . . . 44
2.2.1 The Grid Model . . . . . . . . . . . . . . . . . . . . . . . . 45
3

2.2.2 The Cloud Model . . . . . . . . . . . . . . . . . . . . . . . 52
2.2.3 The Cluster Model . . . . . . . . . . . . . . . . . . . . . . 55
2.2.4 The Alliance Model . . . . . . . . . . . . . . . . . . . . . . 57
2.3 Current e-Science Authentication and Authorisation . . . . . . . . 59
2.3.1 VOMS and Proxy Certificates with Attributes . . . . . . . 60
2.3.2 Proxy Certificates and Shibboleth: GridShib . . . . . . . . 61
2.3.3 A Cooperative Access Control Model for Ad-hoc User Col-
laborations in Grids . . . . . . . . . . . . . . . . . . . . . . 62
2.3.4 Lightweight Credentials and Shibboleth: The EGI CheckIn
Service . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
2.3.5 AWS Identity and Access Management for Ad-hoc User
Collaborations . . . . . . . . . . . . . . . . . . . . . . . . . 64
2.3.6 Further Discussion . . . . . . . . . . . . . . . . . . . . . . 64
2.4 Current e-Science Resource Management: A Semantic View . . . 66
2.4.1 User Requirements: Job Description Languages . . . . . . 69
2.4.2 Resource Management: GLUE 2.0 . . . . . . . . . . . . . . 72
2.4.3 Accounting: Usage Record and Compute
Accounting Record . . . . . . . . . . . . . . . . . . . . . . 79
2.5 A Way Forward . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
2.6 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
3 A Collaboration Model: The Alliance2 Model 85
3.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
3.2 Use Case Studies . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
3.2.1 Interactive Computational Steering . . . . . . . . . . . . . 87
3.2.2 VO Group Dynamic Collaborations . . . . . . . . . . . . . 90
3.2.3 Dynamic Resource Supply for FedCloud . . . . . . . . . . 91
3.3 The Alliance2 Model . . . . . . . . . . . . . . . . . . . . . . . . . 92
3.4 Alliance2 Model Analysis . . . . . . . . . . . . . . . . . . . . . . . 95
3.4.1 Features of the Alliance2 Model . . . . . . . . . . . . . . . 95
3.4.2 Comparison with Other Enabling Models and Approaches 100
3.5 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
4 A Resource Management Model: The Alliance2 Resource Man-
agement Model 109
4.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
4

4.2 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
4.3 Introduction to Ontologies . . . . . . . . . . . . . . . . . . . . . . 115
4.4 Overall Ontology Deployment Architecture . . . . . . . . . . . . . 118
4.5 GLUE 2.0 Extensions and Implementation . . . . . . . . . . . . . 120
4.5.1 Base Ontology: Accounting Property Extensions . . . . . . 120
4.5.2 ComputingShare Class Extensions and Ontology Instance . 125
4.5.3 MappingPolicy Class Extensions and Ontology Instance . . 128
4.5.4 ComputingService Class Extensions and Ontology Instance 128
4.5.5 Ontology Analysis . . . . . . . . . . . . . . . . . . . . . . 129
4.6 Resource Discovery and Aggregation . . . . . . . . . . . . . . . . 131
4.6.1 Reasoning Procedures among Ontologies . . . . . . . . . . 132
4.6.2 Ontology Resource Discovery for Single Jobs . . . . . . . . 135
4.6.3 Ontology Resource Discovery for Workflow Jobs . . . . . . 137
4.6.4 Access Control for Resource Sharing . . . . . . . . . . . . 139
4.6.5 Accounting for Resource Sharing and Provisioning . . . . . 140
4.7 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140
4.7.1 Functionality and Performance Evaluation . . . . . . . . . 140
4.7.2 Further Analysis . . . . . . . . . . . . . . . . . . . . . . . 146
4.8 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
5 A Negotiation Protocol: The Alliance2 Protocol 149
5.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149
5.2 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
5.3 A Novel Idea for the Alliance2 Protocol . . . . . . . . . . . . . . . 155
5.4 Protocol Design Methodology . . . . . . . . . . . . . . . . . . . . 155
5.5 Preliminaries . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 158
5.5.1 Terminology . . . . . . . . . . . . . . . . . . . . . . . . . . 158
5.5.2 Assumptions . . . . . . . . . . . . . . . . . . . . . . . . . . 160
5.6 A High-Level State Machine . . . . . . . . . . . . . . . . . . . . . 161
5.7 Alliance2 Protocol Specification . . . . . . . . . . . . . . . . . . . 162
5.7.1 Pre-negotiation . . . . . . . . . . . . . . . . . . . . . . . . 165
5.7.2 Access Negotiation . . . . . . . . . . . . . . . . . . . . . . 165
5.7.3 Resource Negotiation . . . . . . . . . . . . . . . . . . . . . 166
5.7.4 Revocation . . . . . . . . . . . . . . . . . . . . . . . . . . 168
5.7.5 Contract Termination . . . . . . . . . . . . . . . . . . . . . 169
5.7.6 Race Conditions and Solutions . . . . . . . . . . . . . . . . 169
5

5.8 Protocol Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . 172
5.8.1 Job Submission in Grids . . . . . . . . . . . . . . . . . . . 172
5.8.2 Further Analysis of Related Work . . . . . . . . . . . . . . 174
5.8.3 Enabling Co-Allocation with Alliance2 Protocol . . . . . . 178
5.8.4 Enabling Alliance2 Protocol for Interoperation . . . . . . . 179
5.9 Formal Protocol Verification . . . . . . . . . . . . . . . . . . . . . 180
5.9.1 Spin Model Checker . . . . . . . . . . . . . . . . . . . . . 181
5.9.2 Implementation . . . . . . . . . . . . . . . . . . . . . . . . 183
5.9.3 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . 188
5.10 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189
6 Testbed-Based Protocol Evaluation 191
6.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191
6.2 Preliminaries . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192
6.2.1 Application Hosting Environment 3 . . . . . . . . . . . . . 192
6.2.2 Design Principles . . . . . . . . . . . . . . . . . . . . . . . 193
6.2.3 Use Cases . . . . . . . . . . . . . . . . . . . . . . . . . . . 197
6.2.3.1 Use Case 1: SWDS on AWS . . . . . . . . . . . . 197
6.2.3.2 Use Case 2: Local Cluster Resource Sharing Man-
agement . . . . . . . . . . . . . . . . . . . . . . . 197
6.3 Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 199
6.3.1 Testbed Architecture . . . . . . . . . . . . . . . . . . . . . 199
6.3.2 Use Case Implementation . . . . . . . . . . . . . . . . . . 201
6.3.2.1 Use Case 1 Implementation with Client Service . 201
6.3.2.2 Use Case 2 Implementation . . . . . . . . . . . . 203
6.3.3 Service Broker . . . . . . . . . . . . . . . . . . . . . . . . . 206
6.3.3.1 Negotiation and Accounting . . . . . . . . . . . . 208
6.3.3.2 Job Management . . . . . . . . . . . . . . . . . . 214
6.3.3.3 Resource Accounting Strategies . . . . . . . . . . 214
6.4 Evaluation and Results . . . . . . . . . . . . . . . . . . . . . . . . 215
6.4.1 Negotiation and Accounting Functionality Evaluation . . . 216
6.4.2 Automatic Negotiation Performance Evaluation . . . . . . 221
6.4.2.1 Negotiation Performance Evaluation without Net-
work . . . . . . . . . . . . . . . . . . . . . . . . . 222
6.4.2.2 Negotiation Performance Evaluation with Internet 225
6.4.3 Further Analysis . . . . . . . . . . . . . . . . . . . . . . . 227
6

6.4.3.1 Dealing with Exceptions . . . . . . . . . . . . . . 227
6.4.3.2 Scalability . . . . . . . . . . . . . . . . . . . . . . 228
6.4.3.3 Implementation Constraints . . . . . . . . . . . . 229
6.4.3.4 Comparison with Other Approaches . . . . . . . 230
6.5 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 233
7 Conclusion 235
7.1 Research Contributions . . . . . . . . . . . . . . . . . . . . . . . . 235
7.2 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 237
Bibliography 243
A Testbed Experiment Screenshots 263
Word Count: 83080
7

8

List of Tables
2.1 Access and accounting mechanisms in e-Science-enabling models . 58
2.2 Semantic comparison: GLUE 2.0 and job description languages . 71
2.3 Standards adoptions for resource management and accounting in
Grids . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
2.4 Application execution properties semantic mapping: GLUE 2.0 &
UR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
4.1 Details of the applied AWS instances . . . . . . . . . . . . . . . . 143
4.2 AWS single job ontology matchmaking evaluation . . . . . . . . . 145
4.3 AWS job matchmaking performance . . . . . . . . . . . . . . . . . 145
5.1 Summary of negotiation protocols . . . . . . . . . . . . . . . . . . 177
5.2 Negotiation end states . . . . . . . . . . . . . . . . . . . . . . . . 185
5.3 Negotiation simulation modelling with Spin . . . . . . . . . . . . 186
6.1 Automatic negotiation performance without Internet . . . . . . . 223
6.2 Automatic negotiation performance with Internet . . . . . . . . . 226
6.3 e-Science tools functionality comparison . . . . . . . . . . . . . . 231
9

10

List of Figures
1.1 Research motivations . . . . . . . . . . . . . . . . . . . . . . . . . 34
1.2 A reader’s guide to the thesis structure and dependencies . . . . . 42
2.1 Classification of VOs . . . . . . . . . . . . . . . . . . . . . . . . . 48
2.2 Pipeline of computational steering [Linxweiler et al., 2010] . . . . 50
2.3 Traditional computational fluid dynamics process [Linxweiler et al.,
2010] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
2.4 Authentication and authorisation in VOMS . . . . . . . . . . . . 61
2.5 Authentication and authorisation in GridShib . . . . . . . . . . . 62
2.6 Authentication and authorisation in EGI CheckIn service . . . . . 63
2.7 Open standards in Grids with their different technical areas [Riedel,
2013] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
3.1 Argus authorization service framework [CERN, 2018] . . . . . . . 91
3.2 Alliance2 Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
3.3 Authorisation in Alliance2 . . . . . . . . . . . . . . . . . . . . . . 98
4.1 The deployed ontologies’ architecture . . . . . . . . . . . . . . . . 119
4.2 Extended entities and relationships for the Main Entities . . . . . 121
4.3 The maxCpuTime property extension . . . . . . . . . . . . . . . . 123
4.4 Properties in the ComputingShare class . . . . . . . . . . . . . . . 127
4.5 Reasoning logics among ontologies . . . . . . . . . . . . . . . . . . 133
5.1 The evolution of resource management lifecycle in e-Science . . . 157
5.2 The high-level state machine for each participant for a complete
resource provisioning lifecycle . . . . . . . . . . . . . . . . . . . . 161
5.3 The Alliance2 negotiation protocol for negotiation scenario 2 . . . 164
11

5.4 A race condition example between Resource Requester and Re-
source Provider . . . . . . . . . . . . . . . . . . . . . . . . . . . . 170
5.5 A high-level state machine for each participant during contract
negotiation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171
5.6 Some race conditions caused by RevokeReq . . . . . . . . . . . . . 172
5.7 Resource co-allocation based on the Alliance2 negotiation protocol 178
5.8 Negotiation with independent providers . . . . . . . . . . . . . . . 181
6.1 Testbed architecture . . . . . . . . . . . . . . . . . . . . . . . . . 200
6.2 Architecture of Service Broker . . . . . . . . . . . . . . . . . . . . 207
6.3 Data-driven steering enabled by negotiation . . . . . . . . . . . . 211
6.4 Negotiation performance . . . . . . . . . . . . . . . . . . . . . . . 224
7.1 Negotiation with Argus and a VO . . . . . . . . . . . . . . . . . . 238
7.2 Negotiation enabled on a VO as a new provider . . . . . . . . . . 239
A.1 Screenshot: negotiation in Service Broker . . . . . . . . . . . . . . 264
A.2 Screenshot: procedures when Service Broker received contract
acknowledgement . . . . . . . . . . . . . . . . . . . . . . . . . . . 265
A.3 Screenshot: the deadline specified detected by Service Broker . . . 265
A.4 Screenshot: Service Broker verified the completion of the job . . . 265
A.5 Screenshot: balance updates for resource consumption in Use Case 1266
A.6 Screenshot: Service Broker detected that the specified deadline
approached . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 266
A.7 Screenshot: Service Broker updated the contract state to reqTer-
minated . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 266
A.8 Screenshot: the contract formation procedures in Service Broker . 267
A.9 Screenshot: first contract formation in the re-negotiation scenario 268
A.10 Screenshot: reasoning procedures in the re-negotiation scenario . . 268
A.11 Screenshot: the returned Quotes by Service Broker during re-
negotiation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 269
A.12 Screenshot: balance updates for the first contract completion in
Service Broker . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 269
A.13 Screenshot: balance updates for the second contract completion in
Service Broker . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 269
A.14 Screenshot: balance updates for the third contract completion in
Service Broker . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 270
12

A.15 Screenshot: insufficient balance for the group for the required re-
source . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 270
A.16 Screenshot: insufficient balance of the requester . . . . . . . . . . 271
A.17 Screenshot: the requester had no privilege to use the required re-
source . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 271
A.18 Screenshot: successful negotiation for the termination scenario . . 272
A.19 Screenshot: successful termination of the required Offer . . . . . . 272
A.20 Screenshot: the stop request was received, and balances were up-
dated in Service Broker . . . . . . . . . . . . . . . . . . . . . . . . 273
A.21 Screenshot: successful contract formation for the user-stop scenario 273
A.22 Screenshot: the maximum CPU time reached, and the contract
state was updated in Service Broker . . . . . . . . . . . . . . . . . 274
A.23 Screenshot: successful contract formation for the manager-stop
scenario . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 274
13

14

Abstract
A Negotiation Protocolfor Accountable Resource Sharing in e-Science
Collaborations
Zeqian MengA thesis submitted to the University of Manchester
for the degree of Doctor of Philosophy, 2018
The e-Science community is entering an age where: (i) resources can be sup-
plied from various infrastructures to meet dynamic and customised resource pro-
visioning demands; and (ii) no centralised management is required between an
e-Scientist collaboration (i.e., a research group) and infrastructures. The in-
dependence between research groups and infrastructures for dynamic and cus-
tomised resource provisioning raises two new issues. First, how to enable an
e-Scientist or a research group to reach an agreement dynamically with an infra-
structure for customised resource provisioning? Such dynamic resource provision-
ing agreement would require to be formed in a lightweight manner. Second, how
to manage resource sharing for e-Scientists who are members of a research group
for such dynamic resource provision? In this scenario, a research group may pay
for resources consumed by members and require fine-grained rules followed by the
resource provisioning.
Previous research proposed negotiation protocols for dynamic and customised
resource provisioning to support e-Scientists’ computational experiments. How-
ever, these protocols assumed that: (i) a research group and an infrastructure
are in the same virtual administrative domain, where the infrastructure acts as a
resource provider; and (ii) resource sharing management (i.e. resource provision-
ing based on resource sharing rules within the group and accounting for resource
15

consumption by e-Scientists) is conducted entirely within the provider domain.
As a result, resource sharing management available for research groups is coarse-
grained. Furthermore, existing protocols consider only negotiation between an e-
Scientist and a resource provider, and do not consider communication between a
research group and resource provider to inform resource usage by group members.
These assumptions are not valid for dynamic resource provisioning collaborations
where no virtual administrative domain exists to centrally manage a resource
provider and research group. Thus, the approach for resource management must
be reconsidered by addressing resource sharing management for a research group
and resource provisioning management for resource providers. It should also in-
corporate a complete resource provisioning lifecycle between independent entities.
In this thesis, we propose the Alliance2 protocol, which considers these re-
quirements and offers a solution. The protocol is established upon a novel e-
Science collaboration model proposed in this thesis, Alliance2, which re-identifies
the involved entities’ demands and restructures the resource provisioning life-
cycle. The idea of the Alliance2 model is to shift resource sharing management
including accounting for group members to research groups to enable fine-grained
management. Based on this idea, the Alliance2 protocol: (i) regulates the pro-
cedures of negotiation among the engaged entities to reach effective agreements
for resource provisioning; and (ii) manages a complete the resource provision-
ing lifecycle between independent research groups and resource providers. This
thesis formally verifies the correctness of the proposed protocol and analyses the
features of the protocol via a comparison with related protocols. Furthermore,
a testbed is built to evaluate functionalities and negotiation performance of the
Alliance2 protocol. This testbed implements production use cases that require
dynamic and customised resource provisioning to meet e-Scientists’ demands for
computational experiments as well as fine-grained resource sharing management
for a research group. The evaluated functionalities are derived from the de-
mands of the use cases. That is dynamic and customised resource provisioning
required by group members can be managed by a research group on a per job
basis via the Alliance2 protocol. The functionality evaluation demonstrates that
the Alliance2 protocol can facilitate dynamic resource provisioning to support
e-Scientists’ customised demands while enabling fine-grained resource sharing for
a research group. The performance evaluation of the testbed shows that the ne-
gotiation procedures developed will not extend resource provisioning lifecycles of
16

computational experiments significantly.
To enable a common understanding among negotiating entities for resource
provision and sharing, this research also develops a resource management model
based on the Alliance2 model. The Alliance2 resource management model is es-
tablished semantically with ontologies and practically with software, which are
utilised by the testbed for resource matchmaking and accounting purposes. With
this resource management model, the entities involved can communicate and
negotiate with resource provisioning details. The evaluation of the developed on-
tologies and software shows that: (i) the Alliance2 resource management model
can manage fine-grained resource sharing for research groups and coarse-grained
resource provisioning for resource providers; and (ii) the time consumed by the
enabled matchmaking is very short, compared to computational experiment dur-
ation.
17

18

Declaration
No portion of the work referred to in this thesis has been submitted in support of
an application for another degree or qualification of this or any other university
or other institute of learning.
19

20

Copyright
i. The author of this thesis (including any appendices and/or schedules to this
thesis) owns certain copyright or related rights in it (the “Copyright”) and s/he
has given The University of Manchester certain rights to use such Copyright, in-
cluding for administrative purposes.
ii. Copies of this thesis, either in full or in extracts and whether in hard or
electronic copy, may be made only in accordance with the Copyright, Designs
and Patents Act 1988 (as amended) and regulations issued under it or, where
appropriate, in accordance with licensing agreements which the University has
from time to time. This page must form part of any such copies made.
iii. The ownership of certain Copyright, patents, designs, trade marks and other
intellectual property (the “Intellectual Property”) and any reproductions of copy-
right works in the thesis, for example graphs and tables (“Reproductions”), which
may be described in this thesis, may not be owned by the author and may be
owned by third parties. Such Intellectual Property and Reproductions cannot
and must not be made available for use without the prior written permission of
the owner(s) of the relevant Intellectual Property and/or Reproductions.
iv. Further information on the conditions under which disclosure, publication
and commercialisation of this thesis, the Copyright and any Intellectual Property
and/or Reproductions described in it may take place is available in the University
IP Policy (see http://documents.manchester.ac.uk/DocuInfo.aspx?DocID=
24420), in any relevant Thesis restriction declarations deposited in the Univer-
sity Library, The University Library’s regulations (see http://www.library.
manchester.ac.uk/about/regulations/) and in The University’s policy on pre-
sentation of Theses.
21

22

Acknowledgements
First, I would like to thank my former supervisor Dr John Brooke for his super-
vision, patient and valuable guidance, and push during my PhD. He provided me
with every opportunity that a PhD student can wish for. To Dr Rizos Sakellariou,
my current supervisor, thank you for guiding me through the last phase of this
journey and guiding me to be a good researcher.
I also like to thank Junyi, who I collaborated with for a use case (i.e. data-
driven computational steering) in my testbed, for his valuable contributions and
support. To express my sincere thanks to George Leaver for help in using the
local Cluster in the University of Manchester, and Stefan Zasada for helping me
with the Grid gateway, Application Hosting Environment 3.
I would like to express my sincere thanks to my loving families for their support
throughout my PhD, morally and financially. Their love, care, trust, encourage-
ment, and patience are the sources of power to keep me moving further. Giant
thanks go to my dear boyfriend, Lasse, for his love, understanding, encourage-
ment, and support. He makes this journey more pleasant and enjoyable.
Further, thanks to the School of Computer Science for an offer of partial
funding for my PhD. Finally, thanks go to eScience 2014 conference committees
for a conference scholarship, UK-USA HPC collaboration for an SC14 travel
award, and Netherlands eScience Center for a conference scholarship for eScience
2015.
23

24

Definitions
e-Scientist: A user of resources to conduct computational experiments. Com-
puting software for e-Scientists includes user access points, i.e. software running
on the individual machines used by e-Scientists.
Research group: A collaboration of e-Scientists and a group manager to achieve
research targets.
Resource provider: An entity that provides local resources to external users,
such as a computing infrastructure that allows e-Scientists to access and utilise
local resources via network connections.
Infrastructure: A combination of interworking digitally-based technologies (hard-
ware and software), resources (data, services, and digital libraries), communica-
tions (protocols, access rights, and networks), and people that can be a resource
provider for local resources to external e-Scientists via established interfaces.
Group manager: A manager of a research group using resource sharing manage-
ment among group members who can be e-Scientists from different universities,
organisations, or companies. Computational resource sharing management soft-
ware manages resource distribution and allocation among group members and
mediates resource provision from infrastructures as resource providers.
e-Science collaboration: A collaboration for resource provision formed between
a research group and a resource provider.
e-Science collaboration lifecycle: A process containing the following pro-
cedures: (i) e-Scientists and a group manager form a research group; (ii) a group
25

manager establishes a collaboration with a resource provider; (iii) e-Scientists
request resources to be supplied by the resource provider; and (iv) the research
group and resource provider terminates the collaboration.
Dynamic resource provisioning collaboration: A collaboration formed between
an e-Scientist and a resource provider for resource provision of a single job.
Dynamic resource provisioning collaboration lifecycle: The same pro-
cedures as the e-Science collaboration lifecycle, excluding the first and final steps.
e-Science resource sharing: When resources are shared among group mem-
bers of a research group, which is managed by a group manager.
Fine-grained accountable resource provisioning: When resource provision-
ing from a resource provider is managed by fine-grained policies defined by a
group manager through the resource provisioning lifecycle.
Customised resource provisioning: When resources satisfying the features
as required by an e-Scientist are provided.
Dynamic resource provisioning: Resources are provisioned for an e-Scientist
on demand.
26

Chapter 1
Introduction
1.1 Setting the Scene
E-Science is a collaborative, computationally- or data-intensive research activ-
ity spanning all disciplines and is facilitated by infrastructures [Jirotka et al.,
2013]. E-Science collaboration occurs throughout the research lifecycle. As a
collaboration, e-Science inherently enables users to share computing resources
to conduct computational experiments, storage resources, data, and expertise.
These resources are supplied by infrastructures and can be accessed via Internet
connections [RCUK, 2018]. The users are often researchers from different uni-
versities, organisations, or companies who have interests in a specific research
area, such as astronomy, physics, or biology [Jirotka et al., 2013]. Such users are
referred to as e-Scientists in this thesis, which represents researchers who utilise
resources to conduct their computational experiments. These resources can be
provided by different infrastructures, e.g. Clouds, Grids, or local Clusters, which
require organisational structures to support resource provisioning to e-Scientists.
The following three scenarios are identified as collaborations that enable e-
Science computational experiments:
• Scenario 1: a collaboration of e-Scientists interested in a research area in
the form of a research group.
• Scenario 2: a collaboration formed between a research group (Scenario 1)
and an infrastructure or between an e-Scientist and an infrastructure [David
and Spence, 2003] for resource provisioning.
27

28 CHAPTER 1. INTRODUCTION
• Scenario 3: a collaboration of infrastructures [Riedel et al., 2009] to support
computational requirements.
In this thesis, collaboration refers to Scenario 2 exclusively. The reason is
Scenario 2 focuses on provisioning resources to e-Scientists’ computational ex-
periments, while Scenario 1 and 3 concern collaborations of e-Scientists and in-
frastructures, respectively. However, the principles developed for Scenario 2 also
apply to Scenarios 1 and 3. E-Science collaborations enable resource sharing,
which can shorten the research lifecycle and contribute to productive research.
Resource sharing is defined in this thesis as a pool of available resources being
shared among members of an e-Scientist collaboration (i.e. a research group). Re-
source sharing management refers to managing resource provision and consump-
tion (i.e. accounting) among members of a research group. A different resource
sharing scenario that can be considered is an e-Scientist publishing available re-
sources, creating a group, and defining policies for other e-Scientists to access
and utilise the published resources. Computational experiment resources include
the computing facility, storage facility, service, data, software, middleware, and
expertise. The resources considered primarily in this thesis are the computing fa-
cility resources. However, the concepts developed for computing facility resources
can be applied to other resources.
The processes to fulfil requirements for resource sharing and provisioning are
defined as the procedures of the e-Science collaboration lifecycle:
1. E-Scientists form a research group with a group manager who establishes
rules for resource sharing within the group.
2. The group manager or an e-Scientist collaborates with an infrastructure
for resource provision, and the resources may be shared among the group
members. The group of e-Scientists represents a collaboration that lasts
longer than a single resource provisioning collaboration.
3. E-Scientists from the group request and consume resources supplied by the
infrastructure. Simultaneously, a resource management layer controls access
to the resources available in the infrastructure’s local domain with rules for
resource sharing among group members.
4. Accounting for the resources consumed by the e-Scientists is conducted, and
resource management information should be updated accordingly.

1.1. SETTING THE SCENE 29
5. The collaboration between the research group or e-Scentist and the infra-
structure terminates according to agreed conditions.
Procedures 2 through 5 are defined as the resource provisioning lifecycle and
focus on the procedures required to form a resource provisioning collaboration
between a resource requester and provider. The resource requester can be an
e-Scientist or a group manager, while the resource provider is the infrastructure.
Procedure 1 will be discussed briefly to provide a complete picture of the e-Science
collaboration lifecycle.
Resource provisioning that follows the rules defined and enforced by a research
group is referred to as accountable resource provisioning. Such rules can be rules
for resource sharing management among members of the group. Accounting for
resource consumption on a per job basis is referred to as fine-grained accounting.
Fine-grained accounting in this thesis indicates accounting capability enabled for
a research group. It indicates that a research group is aware of the number of
resources to be provided and actually consumed by a job submitted by a group
member. Fine-grained accounting should also be considered for dynamic resource
provisioning in the interoperability scenario, where resources can be supplied from
any infrastructure via open standards. The reasons are that without centralised
resource management between a research group and an infrastructure: (i) every
execution should be advised to the research group for resource sharing manage-
ment purposes; and (ii) in a commercial resource provisioning scenario, payment
may be made between the research group and the infrastructure.
The scale of e-Science collaborations vary and are supported by infrastruc-
tures based on different enabling models. For instance, the Worldwide Large
Hadron Collider Computing Grid (WLCG) is a global collaboration of more than
170 computing centres in 42 countries and links national and international Grid
infrastructures. The WLCG project has gathered over 8,000 physicists to take
advantage of its distributed global computing resource to store, distribute, and
analyse a vast amount of generated data since 2002 [Shiers, 2007]. In contrast to
such large-scale and long-term collaborations, small- and medium-scale e-Science
collaborations may incorporate dozens or hundreds of e-Scientists formed for spe-
cific projects or events. They may require fine-grained access control and resource
consumption accounting for resource sharing among the members because of lim-
ited resources or budget, especially when resources are provided from different
infrastructures for an application execution request. Also, they may not last as

30 CHAPTER 1. INTRODUCTION
long as the large-scale collaborations. For these smaller collaborations, efficient
and lightweight approaches with infrastructures for resource provisioning are es-
sential. For instance, professional astronomers and citizen scientists in related
scientific projects will be interested in collaborating to share expertise and data
during important galaxy transient events. Such collaborations would require re-
sources from different infrastructures to store and process data, respectively. For
such small-scale and short-term collaborations: (i) access control can be of great
concern for data and budget control while using the resources; and (ii) lightweight
approaches to form collaborations with infrastructures for resource provisioning
and manage resources from different infrastructures would be required. A light-
weight approach indicates the software representation of a collaboration can be
easy to deploy and install with minimal but sufficient functionality for the user
requirements [Chin and Coveney, 2004] along with minimal external dependen-
cies [Hayes et al.]. Also, lightweight collaborations require lightweight credentials
for e-Scientists to access resources and lightweight tools for group managers to
manage resource sharing.
Computational experiments are conducted through computational applica-
tions, and e-Scientists execute these in the form of jobs (or web services as is
for Bioinformaticians [Bazinet et al., 2014, Shahand et al., 2012]). Jobs are sub-
mitted to infrastructures for execution using the provided resources. Typically,
single job and workflow job types are supported. As demonstrated in [Yu and
Buyya, 2005], a workflow job can represent the data and job execution manage-
ment for application execution. This thesis alternatively considers a workflow
job as a computational job that consists of more than one application or task, as
described in [Deelman et al., 2009, Mattoso et al., 2013].
1.2 e-Science Resource Provision Introduction
Small- and medium-scale e-Science collaborations may not last as long as large-
scale collaborations and may require a customised application execution environ-
ment. Once established, for these collaborations to then customise an execution
environment with a Grid or Cluster requires too much effort relative to the pos-
sible benefits. This barrier leads small- and medium-scale research groups to
investigate commercial Cloud services.
Cloud computing has been increasingly utilised for e-Science computational

1.2. E-SCIENCE RESOURCE PROVISION INTRODUCTION 31
experiments to satisfy the demands of dynamic and customised resource provision.
Open markets, such as the Helix Nebula Science Cloud (HNSciCloud) [Gasthuber
et al., 2017] and European Grid Infrastructure (EGI) Marketplace [EGI, 2018f],
are established for the commercialisation of Cloud platforms to conduct high-
performance computing for scientific experiments. The Pre-Commercial Procure-
ment (PCP) of HNSciCloud is currently underway [Amsaghrou, 2016]. Mean-
while, Clouds, Grids, and local Clusters are being explored for federation usage
to maximise throughput of their core features. Standardisation will accelerate
federation usage of resources as well as the separation between research groups
and resource provision infrastructures. Standardisation facilitates dynamic re-
source provisioning via open standards without centrally managing a research
group to resource provision infrastructures.
Standardisation and federated resource provisioning require solutions to search
for and mediate resource provisions from different resource providers according
to e-Scientists’ specific demands while also considering resource sharing manage-
ment for the research group. The latter scenario must be considered as the group
may pay for the resources consumed by its members, and a limited budget for
computational resources may require effective spending. An error in a submitted
job, such as an infinite loop, will lead to infinite execution and cost [Calheiros
et al., 2015]. As such, small- and medium-scale research groups may require
fine-grained resource sharing management to manage resource provisioning from
different infrastructures. Also, the solutions should be interoperable with existing
approaches and mechanisms applied by infrastructures. Under these perspectives,
dynamic, customised, and fine-grained accountable resource provisioning from in-
teroperable infrastructures is envisioned.
• Dynamic resource provisioning: Resources are provisioned whenever
required by an e-Scientist.
• Customised resource provisioning: When resources satisfying the fea-
tures required by an e-Scientist are provided.
• Fine-grained accountable resource provisioning: Where resource pro-
visioning is managed by, and resource consumption is known by a group
manager on a per job basis.
A negotiation protocol, which enables the related entities involved in e-Science

32 CHAPTER 1. INTRODUCTION
computational experiments to express their demands and reach a resource pro-
vision agreement, can enable the above features. Hence, this thesis will focus
on negotiable resource provision based on resource sharing rules for e-Scientists
from small- or medium-scale research groups. It will propose solutions that could
realise dynamic, customised, and accountable resource provision.
1.3 Negotiation Entities for e-Science Resource
Provision
As discussed above, the three entities (roles) involved in negotiation for resource
provisions to execute computational experiments include:
E-Scientist: A user of resources who executes computational applications
for research in diverse disciplines and may have limited expertise in computer
science. Software for e-Scientists indicates user access points, i.e. software run-
ning on their machines. E-Scientists may also have specific requirements for their
application execution. Three typical requirements include: (i) limiting the cost or
the consumed CPU time of running a submitted application [Maciej et al., 2012];
(ii) demanding resources with specific features to ensure application execution
performance or throughput [Bosak et al., 2014]; and (iii) ensuring application
execution completes within a specific time [Vecchiola et al., 2012].
Group manager: The manager of a research group focused on resource shar-
ing management. In computing terms, this corresponds to the resource sharing
management software for managing resource distribution and allocation among
group members, mediating resource provisions from infrastructures.
Resource provider: An infrastructure allowing e-Scientists to access and
utilise local resources via network connections. Infrastructure can be built in
different forms, such as Grids, Clouds, and Clusters. Direct access or access via
intermediate web services are two methods enabling remote access from external
domains to local computing resources in an infrastructure. Accordingly, com-
puting resources can be referred to as resources for direct access or services for
access via web services as intermediate layers, respectively. In this thesis, the
term resource represents a general concept in the case that the access mechanism
is not known nor specified.

1.4. RESEARCH MOTIVATIONS AND CHALLENGES 33
1.4 Research Motivations and Challenges
The above discussion shows that different entities in e-Science collaborations and
resource sharing have varied responsibilities and demands. In addition to dy-
namic and customised resource provisioning demands from e-Scientists, short-
term and dynamic resource provisioning collaborations have the following re-
quirements from the group managers and resource providers:
• A group manager will demand: (i) accounting with customised and fine-
grained rules for resource sharing and consumption among the e-Scientists
of the group [Amsaghrou, 2016, Sherif et al., 2014]; and (ii) a single resource
management framework for resource sharing management of group members
and resource provision from different resource providers [Amsaghrou, 2016].
• A resource provider may: (i) require resource provisioning via simple rules;
and (ii) be unwilling to make infrastructure changes (either hardware or
software) to allow e-Scientists access to local resources [Amsaghrou, 2016].
These different views are interpreted and realised in various ways by different
infrastructures. However, no existing infrastructure can meet all these demands.
Combined with on-going technique evolution and standardisation, this thesis con-
siders that dynamic resource provisioning between independent research groups
and infrastructures via open standards can be envisioned. This scenario is the
future of e-Science, as shown in Figure 1.1, and should relate to current mechan-
isms to enable interoperation. The solutions proposed in this thesis can enable
such interoperation and connect the current mechanisms to the future scenario.
Three challenges must be addressed to develop these solutions:
• How to enable resource provisioning that can be interoperable with exist-
ing infrastructures, which can also envision dynamic resource provisioning
collaborations based on open standards.
• How to negotiate resource provisioning that meets the varied demands from
the entities in e-Science collaborations and resource sharing.
• How to verify and evaluate the proposed solutions. As is discussed in
Chapter 2, most production infrastructures and tools are for either large-
scale collaborations or provider lock-in, which makes it challenging to eval-
uate the solutions proposed.

34 CHAPTER 1. INTRODUCTION
Present
isolated infrastructures
Past
technical tweaks; partly via standards
Future dynamic resource provisioning via open standards
Solutions for dynamic, customised, and accountable resource provsioning
Figure 1.1: Research motivations
The scope of this thesis is to find answers to these issues by investigating,
designing, and evaluating a negotiation protocol to support dynamic, customised,
and fine-grained accountable resource provisioning for e-Science collaborations
and resource sharing.
1.5 Research Hypothesis and Objectives
This research hypothesises is that the process of negotiation in e-Science can be
formalised so that it can be formally verified for correctness and experimentally
evaluated.
This idea leads to the following objectives:
1. To investigate and analyse the existing protocols against different entities’
requirements.
2. To build a collaboration model based on an analysis of collaborative struc-
tures in e-Science to represent the relationships and demands of the entities
involved in the proposed negotiation protocol.
3. To establish and evaluate a resource management model to formally rep-
resent the entities’ relationships in the collaboration model to facilitate
accountable resource provisioning and fine-grained resource sharing.
4. To design a negotiation protocol based on the collaboration model from
(2) to: (i) manage the complete resource provisioning lifecycle for e-Science

1.6. METHODOLOGY AND APPROACH 35
collaborations between independent research groups and resource providers;
and (ii) facilitate fine-grained resource sharing in a research group.
5. To build formal models of the negotiation protocol from (4) to verify its
correctness via formal simulations.
6. To build a testbed to implement and evaluate the negotiation protocol from
(4) practically with the resource management model built from (3).
1.6 Methodology and Approach
The following methods are applied to the research presented in this thesis:
• A literature review and analysis of participating entities in e-Science col-
laborations and resource sharing, which contribute to a classification of
e-Science-enabling models.
• The design of a collaboration model to enable small-scale and short-term
e-Science collaborations, which allows for fine-grained resource sharing man-
agement for research groups.
• The establishment of a resource management model for fine-grained resource
sharing management as well as its semantic implementation and software
developed. The resource management model is based on the proposed col-
laboration model.
• The design of a negotiation protocol and theoretical verification of the de-
signed protocol. The theoretical verification serves to verify the correctness
of the protocol. Correctness means that all negotiating entities reach the
same final negotiation states, by communicating with the proposed mes-
sages and following the designed messaging behaviours.
• Testbed implementation using servers to evaluate the functionalities and
performance of the designed experimental evaluation. The functionalit-
ies refer to negotiable dynamic and customised resource provisioning for
e-Scientists and fine-grained accountable resource provisioning for group
managers.

36 CHAPTER 1. INTRODUCTION
This research began with a literature review to investigate the character-
istics of existing infrastructures and their mechanisms. The author compared
the requirements of the entities participating in an e-Science collaboration and
resource sharing for computational application execution. Next, gaps were iden-
tified between these requirements and the services provisioned by existing infra-
structures. This research further investigated the enabling techniques and stand-
ards for resource provisioning and sharing in e-Science as well as authentication
and authorisation mechanisms currently applied in infrastructures. This review
revealed the trends in the approaches to supporting computational application
execution in e-Science. Based on the entities’ demands combined with ongoing de-
velopment, a negotiable contract-oriented resource provisioning based on a novel
collaboration model was proposed. Contract-oriented negotiation allows entities
to express their demands and follow the contracted conditions without binding
the entities together.
With the requirements specified in the literature review, solutions were pro-
posed, designed, and refined by considering input from existing work, which res-
ulted in the proposal of three novel solutions. The first solution is an e-Science
collaboration model, called the Alliance2 model, which extends the existing Alli-
ance model [Parkin, 2007] to include a Resource Manager. It enables fine-grained
resource sharing management for research groups, and focuses on authorisation
and resource usage accounting. The second solution is a resource management
model for e-Science resource provisioning and sharing that reflects the entities’
relationships defined in the Alliance2 model. This model is implemented and
evaluated via a semantic approach by building ontologies and software. The
third contributed solution is a negotiation protocol, called the Alliance2 pro-
tocol, which is based on the Alliance2 model. It allows participating entities
to achieve contract-oriented resource provisioning collaborations via negotiation.
Processes of formal verification and testbed evaluation validated and evaluated
the Alliance2 protocol.
• Formal verification: This models the designed protocol and verifies its cor-
rectness via exhaustive state exploration through formal simulations.
• Testbed evaluation: This builds software to implement the protocol and
apply the developed software for resource provisioning and sharing man-
agement in the selected use cases and production infrastructures.

1.7. RESEARCH CONTRIBUTIONS 37
The testbed evaluation took advantage of the semantic model and software
built based on the Alliance2 resource management model. The Alliance2 resource
management model integrates and processes negotiation requests for customised
and accountable resource provision in e-Science collaborations and resource shar-
ing. Both the Alliance2 resource management model and the testbed were eval-
uated by designing evaluation scenarios for the functions required in fine-grained
accountable resource provisioning via negotiation between independent research
groups and resource providers. Furthermore, the performance of the resource
matchmaking enabled by the Alliance2 resource management model and the auto-
matic negotiation were evaluated. The functions enabled by the testbed were also
compared to some widely-used production tools in e-Science.
1.7 Research Contributions
This section presents the details of novel contributions to state of the art in e-
Science collaborations and resource sharing that result from this research. Based
on the literature review, this thesis extends the Alliance model proposed by [Par-
kin, 2007] for fine-grained accountable resource provisioning between independent
research groups and resource providers.
C1 The Alliance2 model: a novel model for fine-grained accountable
resource provisioning in e-Science collaborations
Alliance2 is a novel collaboration model for (i) managing resource provisions
between a resource requester and a resource provider; and (ii) allowing resource
sharing management within a research group, which may pay for resource usage
by the resource requester. The Alliance2 model provides two important contri-
butions. First, it shifts resource sharing management to the research groups.
To the best of the author’s knowledge, this is the first e-Science collaboration
model that allows research groups to entirely control resource sharing manage-
ment and conduct usage accounting for group members. In this way, the model
contributes to fine-grained resource sharing management for research groups, es-
pecially for small-scale groups that require short-term collaborations for resource
provisioning. Second, the analysis of the Alliance2 model is performed, which
covers: (i) the features contributed by separating research groups from resource
providers and shifting resource sharing management to research groups; and (ii)
comparison between the Alliance2 model and other e-Science enabling models

38 CHAPTER 1. INTRODUCTION
and approaches.
C2 The Alliance2 resource management model: a novel resource
management model with ontologies and software for fine-grained re-
source sharing
The Alliance2 resource management model is a novel model for resource pro-
vision and sharing management and offers the following contributions. First, it
models resource sharing management in a research group, which allows a group
manager to specify and manage resource sharing rules with fine granularity and
conduct accounting for resources consumed by group members. Second, the pro-
posed model is based on a widely-applied information model, the Grid Laborat-
ory Uniform Environment 2.0 (GLUE 2.0) model [Andreozzi et al., 2009]. This
approach contributes to limited changes being required in a great many pro-
duction infrastructures that utilise GLUE 2.0. Third, ontologies are built upon
the proposed resource management model, and software is developed to enable
management of fine-grained resource sharing.
C3 The Alliance2 protocol: a negotiation protocol for fine-grained
accountable resource provisioning
The Alliance2 protocol is a novel negotiation protocol for dynamic, custom-
ised, and fine-grained accountable resource provisioning. It allows a resource
requester and a resource provider to reach a resource provisioning contract, while
the resource provisioning can be managed by fine-grained resource sharing rules
defined by a group manager. The contributions of the Alliance2 protocol include
the following:
1. It makes use of a group manager during resource provisioning negotiation
for contract formation. This mechanism enables resource provisioning to
be managed by resource sharing rules in research groups.
2. It manages the complete resource provisioning lifecycle. This enables a
research group to be independent from resource providers, allowing group
members or the group manager to flexibly form collaborations with multiple
resource providers.
3. The Alliance2 protocol is an extension of the negotiation protocol in [Par-
kin, 2007], by introducing a group manager during resource provisioning
lifecycle. The protocol in [Parkin, 2007] allows a resource requester and
a resource provider to negotiate for a resource provisioning contract based

1.7. RESEARCH CONTRIBUTIONS 39
on contract law. By inheriting the law-based feature, the Alliance2 pro-
tocol enforces the effectiveness of contracts formed via negotiation, which is
especially required by dynamic collaborations between independent entities.
With these contributions, the Alliance2 protocol can mediate for valid nego-
tiation results for fine-grained accountable resource provisioning between inde-
pendent resource requesters and resource providers.
C4 The Alliance2 protocol formal verification models
Formal verification models are built to verify the correctness of the designed
protocol such that the negotiating entities can reach the same negotiation results
if they apply the designed messages and follow the messaging behaviours. The
verification models simulate the negotiating entities and their messaging beha-
viours as designed in the protocol. They verify the correctness of the Alliance2
protocol by exhaustive state exploration, which reveals the state space of the
designed protocol.
C5 The Alliance2 protocol functionality and performance evalu-
ation: a testbed
The testbed uses the proposed Alliance2 protocol, constructed semantic re-
source management model and programs, as well as production use cases, infra-
structures, and gateway. The contributions of the testbed include the following:
1. Negotiable and fine-grained accountable resource provisioning is enabled
by applying the Alliance2 protocol and the proposed resource management
model. To the best of our knowledge, this solution is the first to enable ne-
gotiable customised resource provisioning and fine-grained resource sharing
for computational application execution in e-Science.
2. It demonstrates that the Alliance2 protocol is interoperable with existing e-
Science-enabling infrastructures by using production infrastructures based
on other models.
3. Evaluation of the functionalities and performance has been conducted. The
evaluation demonstrates that: (i) negotiable and fine-grained accountable
resource provisioning is achieved; and (ii) the negotiation procedures do not
extend the resource provisioning lifecycle significantly, compared to the dur-
ation of most computational applications’ execution. The execution time
of different computational applications vary significantly [Deelman et al.,

40 CHAPTER 1. INTRODUCTION
2008, Groen et al., 2016, Voss et al., 2013]. We take executing an astronomy
application, Montage, with Amazon Web Services (AWS) for example [Deel-
man et al., 2008]. Depending on different computational complexities and
the number of processors used, the execution time can vary between 18
minutes (the lowest computational complexity executed on 128 processors)
to 85 hours (the highest computational complexity executed on 1 processor).
As will be presented in Chapter 6, the negotiation will take around 2 seconds
if the first round of negotiation is successful.
1.8 Publications
P1 Zeqian Meng and John Brooke. Negotiation Protocol for Agile Collab-
oration in e-Science. Proceedings of CGW’14 Workshop. Academic Computer
Centre CYFRONET AGH, 2014 ([Meng and Brooke, 2014]).
P2 Zeqian Meng and John Brooke. Negotiation Protocol for Agile and Re-
liable e-Science collaboration. 2015 IEEE 11th International Conference on e-
Science, pages 292-295. IEEE, 2015 ([Meng and Brooke, 2015]).
(This paper was awarded the “Best eScience innovation using eScience tools
outside research” in the 11th IEEE International e-Science Conference student
competition.)
P3 Zeqian Meng, John Brooke, and Rizos Sakellariou. Semantic Accountable
Matchmaking for e-Science Resource Sharing. 2016 IEEE 12th International
Conference on e-Science, pages 282-286. IEEE, 2016 ([Meng et al., 2016]).
P4 Zeqian Meng, John Brooke, Han Junyi, and Rizos Sakellariou. A Negoti-
ation Protocol for Fine-grained Accountable Resource Provisioning and Sharing
in e-Science, In preparation.
P1 introduces C1, C2, and C3, which are discussed in detail in P2 and P3
with changes introduced along with further research. P2 discusses details of
the Alliance2 model (C1), Alliance2 protocol (C3), and formal verification (C4).
P2 presents one formal simulation model developed with the experiment res-
ults, which verified the protocol’s correctness in one scenario. After P2, another
scenario implementing the Alliance2 protocol was identified, so the other formal
simulation model was built to verify that the protocol still behaves as designed.

1.9. THESIS ORGANISATION 41
P3 presents the Alliance2 resource management model (C2) proposed for fine-
grained accountable resource provisioning along with the reasoning and manage-
ment software built and the evaluation results. P3 demonstrates that shifting
resource sharing management to a research group can enable accountable re-
source provisioning on a per job basis. P4 illustrates the testbed established and
the evaluations conducted as C5, presented in this thesis. P4 verifies that the
Alliance2 protocol can facilitate dynamic, customised, and accountable resource
provisioning via negotiation while being interoperable with existing infrastruc-
tures and meeting the real demands of e-Science use cases.
1.9 Thesis Organisation
The remainder of this thesis is structured as shown in Figure 1.2.
Chapter 2 presents a literature review to classify e-Science-enabling models
based on their approaches to forming a collaboration and facilitating accounting
for resource usage. The review also includes current authentication and author-
isation in e-Science. This discussion identifies: (i) e-Scientists’ demands as users;
(ii) a research group’s demands for resource sharing management; and (iii) re-
source providers’ demands for resource provisioning management. The review
reveals why these demands cannot be satisfied by current approaches.
Chapter 3 demonstrates the need for dynamic and accountable resource pro-
visioning demands in e-Science, especially for short-term and small-scale collab-
orations. These needs are discerned from production use cases, and the proposed
Alliance2 model (C1) is presented based on these studies. An analysis of the
features contributed by the Alliance2 model is conducted along with a com-
parison between the Alliance2 model and other e-Science-enabling models and
approaches.
The proposed resource management model (C2) for fine-grained resource shar-
ing management purposes is discussed in Chapter 4. It represents the relation-
ships between participating entities as illustrated in the Alliance2 model. The
software developed for semantic information reasoning and processing is also
presented, which are applied for resource management in the testbed described
in Chapter 6.
Chapter 5 demonstrates the Alliance2 protocol (C3), which is designed based
on the Alliance2 model, with the designed messages and messaging behaviours.

42 CHAPTER 1. INTRODUCTION
IntroductionChapter 1
BackgroundChapter 2
A CollaborationModel:
Alliance2 modelChapter 3
A Resource Manage-ment Model:
Alliance2 resourcemanagement model
Chapter 4
A NegotiationProtocol:
Alliance2 protocolChapter 5
Testbed evaluation ofthe Alliance2 protocol
Chapter 6
ConclusionChapter 7
Contribution:C1: Extended Alliancemodel: Alliance2
Contributions:C3: NegotiationprotocolC4: Spin modelsimulation
Contribution:C2: Semantic implementa-tion with matchmaking &accounting programs
Contribution:C5: Negotiation-enabling broker
Structure
Figure 1.2: A reader’s guide to the thesis structure and dependencies
The solutions for the race conditions are also considered. The approaches that
apply the Alliance2 protocol are discussed, including resource co-allocation and
infrastructures built on different e-Science-enabling models for interoperation.
To verify the properties of the designed protocol, a theoretical verification (C4)
for correctness and a practical evaluation (C5) for functionalities and performance
are presented in Chapter 5 and Chapter 6, respectively. Theoretical verification
is achieved via simulation by building formal models of the proposed protocol.
Practical evaluation is realised by constructing a testbed using the protocol with
production infrastructures, use cases, and gateways.
Finally, Chapter 7 connects conclusions from the proposals, evaluations and
contributions, and recommends an agenda for future work.

Chapter 2
Background
2.1 Introduction
This chapter presents the state of the art solutions supporting e-Science collabor-
ations and resource sharing. Based on the analysis of existing work, a conceptual
classification of the models enabling e-Science collaborations and resource sharing
is illustrated in Section 2.2. Section 1.3 introduced the entities participating in
scientific computational experiments, which offers an outline of how infrastruc-
tures try to meet e-Scientists’ demands. This view illuminates the remaining gaps
between the services supplied and the requirements from e-Scientists. Specific-
ally, authentication and authorisation in existing infrastructures are discussed in
Section 2.3, which reflect the involved entities’ relationships and demands in e-
Science collaborations and resource sharing. These two features are part of the
mechanisms related to supporting dynamic and accountable resource provision-
ing. Authentication demonstrates how e-Scientists access resources in infrastruc-
tures and authorisation shows the mechanisms available to research groups for
resource sharing management.
Then, Section 2.4 reviews the state of the art e-Science resource management
and related techniques for resource sharing from technical and semantic point of
view. This review also highlights the theories and practices that can facilitate
resource provisioning from different e-Science infrastructures for application exe-
cution. From the analysis, the perspectives of interoperation and interoperability
envision dynamic resource provisioning from any infrastructure via negotiation,
which forms the basis for resource provisioning via standards in e-Science. Based
on the background studies, Section 2.5 introduces a solution to fulfil the demands
43

44 CHAPTER 2. BACKGROUND
of different entities in e-Science collaborations and resource sharing. Finally, Sec-
tion 2.6 summarises the chapter.
2.2 Current e-Science Enabling Models and
Lifecycle
As discussed in Section 1.3, e-Scientists, group managers, and resource providers
are three entities involved in collaborations and resource sharing in e-Science. The
e-Science collaboration lifecycle has also been discussed in the previous chapter.
The enabling principles for these lifecycle procedures vary between infrastruc-
tures, which leads to different resource provisioning features and user experiences.
This thesis considers e-Science-enabling infrastructures based on the Grid, Cloud,
Cluster, and Cluster models. This classification covers the e-Science collaboration
lifecycle, including how an e-Scientist or a research group forms a collaboration
with a resource provider for resource provisioning.
Existing research tends to define and compare production e-Science-enabling
models according to the techniques applied. For example, [Sadashiv and Kumar,
2011] presents a thorough comparison between the Cluster computing model,
Grid computing model, and Cloud computing model. This classification is based
on analysing and comparing the enabling techniques and how resources are con-
nected, managed, and allocated. [Sadashiv and Kumar, 2011] also analyses the
features of applications specifically developed for computational experiments that
are supported by these three models. Similarly, [Foster et al., 2008] give a compre-
hensive evaluation and comparison between various aspects of Grids and Clouds.
The aspects identified are the business model, architecture, resource manage-
ment, programming model, and security model. The procedures required for
e-Scientists to access resources of Grids and Clouds are also illustrated in [Foster
et al., 2008]. [Foster et al., 2008] specifies that although the access control of
Grids might be more time-consuming, it adds an extra layer of security to help
prevent unauthorised access. High-Performance Computing (HPC) systems are
classified by [Hussain et al., 2013] into the three categories of Clusters, Grids,
and Clouds. The classification is based on resource management and allocation
mechanisms in HPCs.
These works [Foster et al., 2008, Hussain et al., 2013, Sadashiv and Kumar,
2011] distinguish different e-Science-enabling models from a technical point of

2.2. CURRENT E-SCIENCE ENABLING MODELS AND LIFECYCLE 45
view, i.e. through the techniques and related supporting mechanisms. Alternat-
ively, this thesis establishes a view of e-Science-enabling models as the procedures
to establish and manage resource sharing and provisioning for an e-Science collab-
oration. Resource sharing involves how resources are allocated among e-Scientists
within a group. Resource provisioning concerns the approaches supported by in-
frastructures to enable e-Scientists to access local resources, and decisions for
resource provisioning should obey resource sharing rules within the group. These
procedures consist of the collaboration lifecycle of e-Science computational exper-
iments. This thesis views that an e-Science collaboration lifecycle demonstrates
on-going changes in e-Science infrastructures. These changes are to meet dif-
ferent entities’ demands and enable resources to be provided flexibly along with
the evolution of technology. To enable dynamic and fine-grained accountable re-
source provisioning for e-Science computational experiments, the existing lifecycle
for forming and dissolving a collaboration should be investigated and reviewed.
Accordingly, the mechanisms for resource sharing as applied to a research group
should also be reconsidered.
The analysis of existing e-Science-enabling models in the following sections
focuses on two aspects:
1. The mechanisms to enable e-Scientists or a research group to access a new
resource.
2. The accounting mechanisms and granularity allowed for a group manager
to manage resource sharing among group members.
2.2.1 The Grid Model
Ian Foster and Carl Kesselman define the Grid as an enabler for Virtual Organisa-
tions (VOs) through “an infrastructure that enables flexible, secure, coordinated
resource sharing among dynamic collections of individuals, institutions, and re-
sources” [Foster et al., 2001]. This definition suggests that all entities involved
(e.g. e-Scientists, group managers, and resource providers) should be within the
same VO. More specifically, e-Scientists and resource provision infrastructures
having the same research interests join or establish a VO for resource usage and
sharing, while resources are provisioned from the collaborated infrastructures.

46 CHAPTER 2. BACKGROUND
Grids require new users to gain access to available resources via manual pro-
cedures, including obtaining a digital certificate from relevant authorities [Kran-
zlmuller et al., 2010]. This is to ensure restrictive secure access, which however
may be time-consuming [Foster et al., 2008]. After being assigned a certificate,
an e-Scientist as a user can apply for membership to a VO before a job can be
submitted for execution.
Two access control solutions are supported for an e-Scientist or a research
group to use new resources not available in an existing VO. The first solution is
to establish a new VO via a collaboration with the infrastructure that provides
the needed resources. The second solution is to apply for membership to an
existing VO offering the resources desired. Both solutions are time- and effort-
consuming, especially for short-term collaborations and dynamic resource provi-
sioning demands. So, VO-based access control to Grids is regarded as an obstacle
to cross-Grid interoperation [Riedel et al., 2009]. Compared to cross-VO resource
supplies within an infrastructure, cross-Grid cooperation between two VOs may
require more complex efforts to fill the technical and conceptual gaps among
different established Grids. On the other hand, with the increasing demands
of cross-Grid collaborations, efforts to enable interoperation and interoperability
have been carried out [Riedel et al., 2009]. Before further discussion, definitions
of interoperation and interoperability are provided.
Interoperation: The scenario requiring effort to enable production e-Science
infrastructures to work together as a fast, short-term achievement using as many
existing technologies as are available today via workarounds or tweaks of techno-
logies.
Interoperability: The native capabilities of e-Science technologies and infra-
structures to exchange, understand, share, and use resources directly via common
open standards.
Through the concept of a VO, e-Scientists, group managers and resource pro-
viders rely on centralised management to mediate their requirements and re-
sponsibilities. Resources are supplied after a collaboration (i.e. a VO) is formed
between a research group and resource providers. The collaboration requires the
resource providers to facilitate resource usage authorisation and accounting for
the research group. As a result, the group manager is not aware of the number of
resources required or consumed until job completion. Also, the accounting data
accessible to a group manager is at the VO level, namely the total amount of

2.2. CURRENT E-SCIENCE ENABLING MODELS AND LIFECYCLE 47
resources consumed by all members of the VO.
As an example of an existing authorisation and accounting mechanisms, the
Argus Authorization Service is discussed in detail, which is utilised by the EGI. It
enables resource providers to use authorisation profiles [Ceccanti and Andreetto,
2010a,b, Ceccanti et al., 2010] for access control of available resources. However,
these profiles include the following limitations. First, an authorisation request
does not specify the number of resources required for application execution or
constraints on resource usage per job. Second, the policies applied by resource
provisioning infrastructures for authorisation decisions are at the VO level instead
of per job for a specific user. These issues reveal that the Argus Authorization
Service does not enable traceable resource usage per job for a research group.
The reason is that the centralised resource management in Grids is not aimed at
fine-grained resource sharing management.
To date, two implementations of centralised resource management for VOs
have been widely applied in Grids: the Virtual Organisation Management Sys-
tem (VOMS) [Alfieri et al., 2004] and UNICORE VO Service (UVOS) [Streit
et al., 2010]. UNICORE is a Grid middleware that is built upon a client-server
model to enable e-Scientists to use Grid resources in an integrated and seamless
way. VOMS allocates jobs to available resources in resource provider domains
according to an e-Scientist’s priority and policies specified by the VO. When an
e-Scientist needs to access resources in VOs of which he/she is not a member, the
procedures discussed previously for access to new VOs must be repeated. Such
procedures include manually applying for a new VO membership and new certi-
ficates, if required [Foster et al., 2008, Kranzlmuller et al., 2010]. UVOS considers
such static platform and security credential management to be constraints for e-
Scientists when utilising resources from multiple VOs. As a result, UVOS enable
the management of e-Scientists’ identities in VOs via defining roles and hierarch-
ical groups [Streit et al., 2010]. Access management is achieved by mapping the
attributes applied by VOs to those defined and used globally by UNICORE. In
this way, an e-Scientist can access available resources from different VOs managed
by UVOS. However, as UVOS is still built upon the concept of VO, procedures
for e-Scientists to gain access to new VOs remain the same as by VOMS.
A VO can be very large consisting of hundreds or thousands of members.
Research [Benedyczak and Ba la, 2012] shows that existing support of resource
management from both VOMS and UVOS is static and only includes simple

48 CHAPTER 2. BACKGROUND
complex rela+onships
VO defines complex SLA between members and resources. E.g.: each VO member gets 10k cpuh/month or all members can run up to 10 copies of licensed siDware simutaneously.
Distributed management very hard or impossible
dynamic sta+c
minimal rela+onships
VO does not offer sophis+cated SLAs, etc. VO membership is used mostly to grant access to some resources (which are subject to change)
Distributed management possible
UVOS distributed mgmt
gLite/VOMS No distributed
mgmt
Fine-‐grained resource sharing mgmt for VOs (i.e. research groups)
Figure 2.1: Classification of VOs: the horizontal axis represents the flexibilityof manageable membership for e-Scientists, and the vertical axis represents thecomplexity of manageable granularity of membership.
membership management, as shown in Figure 2.1.
To ensure e-Scientists from a specific VO do not consume more resources than
the amount agreed, an infrastructure can conduct resource consumption manage-
ment. GLUE 2.0 [Andreozzi et al., 2009], for example, is a conceptual information
model for Grid entities. It can specify the rules for resource consumption with
different sets of policies for different sets of users. For instance, the maximum
CPU time that each job consumes can be applied to a group of users. However,
this cannot contribute to more fine-grained resource sharing management for a
research group. Fine-grained resource sharing management is considered by this
thesis as a process that should manage the resource consumption of each job sub-
mitted by a specific user or provide different and dynamic access control for users
in a VO or research group. Such dynamic and fine-grained resource management
should be somewhere in the circled area, as highlighted in Figure 2.1.
Furthermore, infrastructures built upon VOs for e-Science collaborations are
tuned for performance and throughput of the entire infrastructure and e-Scientists’
demands are not their focus. This introduces gaps between e-Scientists’ custom-
ised demands and the services provided. For example, [Venters et al., 2014] re-
veals the tensions between e-Scientists and services provided by WLCG for Large

2.2. CURRENT E-SCIENCE ENABLING MODELS AND LIFECYCLE 49
Hadron Collider (LHC) experiments. Conflicting views and targets of e-Scientists
and the Grid drive physicists to develop custom software on top of existing Grid
software to satisfy specific demands, which affects the Grid’s throughput and
performance. The CMS Remote Analysis Builder (CRAB) [Spiga et al., 2008]
is one such example. CRAB forced resource management systems in WLCG to
exclude particular resources of the Grid from job execution or forced jobs to run
on particular resources within the Grid. This mechanism caused parts of the
Grid to become heavily used and inefficient, while others remained unused. The
research presented in [Venters et al., 2014] stressed the importance of allowing
e-Scientists to request customised resource provision. It also highlighted a need
for a solution to enable e-Scientists and resource providers to resolve different
demands and reach mutual agreements for resource provisioning.
Work in [Bosak et al., 2014] also revealed and, subsequently, resolved a conflict
of interest between e-Scientists and resource provision infrastructures: e-Scientists
want to observe and control their jobs, while infrastructures are concerned about
the overall efficiency. The inefficiency of job execution control may result in long
queuing time. Long queuing time would lead to the total time consumed by a
job execution still being long even though high-performance and high-throughput
computing facilities are applied. This issue also extends e-Scientists’ experiment
lifecycle.
Many tools have been developed to support e-Scientists’ customised resource
provision demands and offer more choices of resources. Such tools supply re-
sources in a dynamic and user-friendly way, such as the Canadian Brain Imaging
Research Platform (CBRAIN) [Sherif et al., 2014]. CBRAIN enables e-Scientists
to access remote data sources and distributed computing sites transparently via
any browser through a graphical interface. CBRAIN also reduces the technical
expertise required from users to conduct analysis using large-scale computing
infrastructures.
Grids are built upon resources distributed across infrastructures. Each re-
source can choose its local job manager, which makes access resource-specific.
This mechanism introduces complexity in interactive job management in a Grid
that allocates workloads of a job to resources, which may be provisioned and man-
aged by different infrastructures. Runtime dynamic resource allocation, which can
be activated by runtime interaction, is time-constrained. This makes it challen-
ging to adapt to different access mechanisms of resources for runtime interaction.

50 CHAPTER 2. BACKGROUND
Pre-Processing Pre-Processing Pre-Processing
Computation
Post-Processing
Time
Figure 2.2: Pipeline of computational steering [Linxweiler et al., 2010]
Pre-Processing
Computation
Post-Processing
Pre-Processing
Computation
Post-Processing
...
Time
Figure 2.3: Traditional computational fluid dynamics process [Linxweiler et al.,2010]
As a result, interactive jobs are converted to batch-based jobs that can be submit-
ted via uniform access points. More specifically, instead of viewing and manipu-
lating generated data during job execution dynamically, as shown in Figure 2.2,
to explore and find usable data, e-Scientists must submit jobs that contain all pos-
sible values they think will be useful. Then, they can only retrieve and examine
results after successful job execution, so a new job submission is required if gener-
ated data are considered worthy for further investigation, as shown in Figure 2.3.
This process extends the research lifecycle [Linxweiler et al., 2010] compared to
interactive job execution. A longer research lifecycle also indicates increased mon-
etary cost if resources and services are consumed via commercialised payment.
The procedure of viewing and manipulating generated data during job execution
dynamically is known as computational steering [Brooke et al., 2003].
To shorten the research lifecycle and meet e-Scientists’ customised demands,
virtualisation has been increasingly applied on top of Grids in the e-Science com-
munity. This virtualisation enables on-demand resource provisioning. For jobs
with short execution time, dynamic resource provisioning avoids the waiting time
in Grids. In addition, for applications that require customised execution envir-
onments, deploying a virtualised execution environment may consume less time
compared to forming a collaboration with a Grid and establishing an execution
environment. Dynamic resource provisioning and customised execution environ-
ments enable interactive computational applications, which further contribute to

2.2. CURRENT E-SCIENCE ENABLING MODELS AND LIFECYCLE 51
shortening the resource lifecycle, as shown in Figure 2.2.
The Federated Cloud (FedCloud) is a virtualisation-enabled Grid [Fernandez-
del Castillo et al., 2015]. It proposes dynamic resource consumption based on real
needs, and immediate resource provisioning upon request [Kranzlmuller et al.,
2010]. To meet the perspective of dynamic resource provisioning via open stand-
ards, the concept of a VO is identified in FedCloud as a group of e-Scientists with
common interests, requirements, and applications, who need to work collabor-
atively and share resources [Solagna, 2015]. Correspondingly, resource providers
are regarded as entities independent from a VO. [Solagna, 2015] also proposes
that the rules for authorisation of a user can be provided by the corresponding
users’ collaboration, which grants the user access to resources. In this way, new
users can be added and removed to enable and disable their access rights without
direct interventions from resource providers. Furthermore, FedCloud considers
interoperability enabled by open standards as the key to resource provisioning
over an open market. However, as a VO still manages resource provisioning, Fed-
Cloud requires the same procedures as a Grid for an e-Scientist to attain a VO’s
membership and security credentials [Kranzlmuller et al., 2010]. Approaches to
resource management and accounting in FedCloud also remain the same. The re-
source provisioning decisions are based on VO-level policies, while coarse-grained
accounting is available for a group manager. Based on these reasons, such in-
frastructures are categorised as infrastructures built on the Grid model in this
thesis.
Following the above discussion of collaborations and resource sharing in Grids,
the Grid model is defined as follows.
Grid model: A design enabling e-Science resource provisioning and sharing
through a VO, which is described as a set of individuals and/or infrastructures
bound by (highly-controlled) resource provisioning and sharing rules [Foster and
Kesselman, 2003]. A VO, i.e. a collaboration, can be formed between a research
group and an infrastructure where the infrastructure acts as a resource provider.
Resources are provisioned for application execution after collaboration formation.
Resource sharing in a VO, i.e. a research group, is managed by coarse-grained
rules. Accounting for resource usage is conducted by the resource provider, and
is available to a group manager with the granularity of a VO as a unit.
In summary, Grids collect available resources from distributed provider do-
mains and share them among e-Scientists who can be from different organisations,

52 CHAPTER 2. BACKGROUND
institutions or companies. Grids maintain a resource provisioning infrastructure’s
domain autonomy and maximise the performance and utilisation of the entire
Grid instead of users’ customised demands. In addition, accessing Grid resources
is time- and effort-consuming. These features result in gaps between the resources
provisioned by Grids and e-Scientists’ demands [Venters et al., 2014]. The ap-
plication of commercial Clouds is intended to fill these gaps.
2.2.2 The Cloud Model
To overcome the effort- and time-consuming procedures to establish VOs and
form collaborations with Grid infrastructures for resource provision, e-Scientists
started to investigate commercial Clouds for computational application execution.
Cloud services initially require only a bank account, which makes them easy to ini-
tiate and saves both equipment and maintenance costs [Beloglazov et al., 2012]
for users. These are two important reasons for e-Scientists to use commercial
Cloud services. The Cloud model is defined by the approaches taken by commer-
cial vendors to offer Cloud services, including such vendors as Amazon [AWS,
2018a] and Google [Google, 2018a]. A private Cloud is exclusively used by a
single organisation, which can be a research group. A hybrid Cloud is an infra-
structure composed of two or more distinct interoperable Clouds, e.g. a public
and a private Cloud [Mell and Grance, 2011]. The reasons for focusing only on
commercial (public) Clouds include:
1. On-premise resource deployment and management require private Clouds
to be facilitated by a research group, making it effort- and time-consuming
for small-scale research groups.
2. Private Clouds are not as cost-effective as public Clouds for small-scale
research groups.
3. Hybrid Clouds are built upon private and public Clouds, indicating that
available functions in hybrid Clouds cannot exceed those supplied by either
private or public Clouds. As a result, the relevant functions of hybrid Clouds
are the same as those available for commercial Clouds.
However, the solutions developed in this thesis (i.e. the Alliance2 model, the
Alliance2 resource management model, and the Alliance2 protocol) can also be

2.2. CURRENT E-SCIENCE ENABLING MODELS AND LIFECYCLE 53
applied to private Clouds and hybrid Clouds. The details of the solutions to such
interoperation will be given in Chapter 3, Chapter 4, and Chapter 5, respectively.
E-Science computational experiments require infrastructure-level deployment
on Clouds with processing, storage, networks, and other fundamental resources.
Accordingly, the discussion of Cloud services will be focused on the infrastructure
level.
Clouds abstract computing power from the underlying hardware, enabling
ubiquitous and on-demand access to a shared pool of resources via networks.
Cloud services are typically enabled by virtualisation techniques and available
for users via internet communication. Virtualisation contributes to dynamic and
customised service provisioning with minimal management efforts or interaction
with service providers [Mell and Grance, 2011]. Dynamic resource provisioning
is achieved by assigning and reassigning resources according to a user’s demands.
Cloud service consumption can be measured as pay-as-you-go with metering in
hours or minutes. Reserved Cloud services can also be measured in years, which
is not applicable for small-scale and short-term collaborations. Cloud services are
typically supplied with a standard Service Level Agreement (SLA) provided by
the provider. Such SLAs contain attributes for Quality of Service (QoS) mandated
by the Cloud provider [Patel et al., 2009]. Changes to standard SLAs are not
favoured by the provider, especially for small- and medium-size organisations [Hon
et al., 2012].
Cloud model: An approach that distinguishes a user’s collaboration (i.e. a
research group in the e-Science scenario) from the Cloud as a resource provider.
Resources are provided by accepting the provider’s standard SLAs, and resource
sharing in a research group can be managed with more fine-grained policies com-
pared to that supported in Grids. However, such policies do not enforce limita-
tions on the number of resources to be consumed. Accounting for resource usage
is conducted by the Cloud provider with the following three approaches currently
available:
1. Based on a user account, if the user in the group has an account in the
same Cloud provider domain.
2. The total amount consumed by a specific service by all users in a group.
3. The total quantity of services consumed by an application where different
Cloud providers supply services. Currently, this option is only available for

54 CHAPTER 2. BACKGROUND
Google Cloud Platform (GCP) and AWS [Google, 2018b].
In a Cloud, a service owner is the individual who establishes an account with
a Cloud provider using a bank account. A service owner can: (i) create groups
with access policies for services; (ii) give access to users as members of groups to
use Cloud services; and (iii) pay for the services consumed by the groups of users.
A service owner can be a group manager in the e-Science scenario. Multiple
e-Scientists can be grouped by a group manager using a payment account. By
enabling a group manager, the Cloud model distinguishes service consumers (i.e.
e-Scientists) from Cloud providers (i.e. resource providers), and service consumers
from a service owner (i.e. a group manager). This mechanism allows a group
manager to manage access to the shared services by creating groups and defining
access policies. If individual e-Scientists have user accounts for the same Cloud
provider domain, accounting details for each e-Scientist are also available to the
group manager. Thus far, in a single Cloud provider domain, a group manager
can create groups with roles for access control and resource management.
Furthermore, a group manager can activate notification for: (i) the cost of an
individual service; and (ii) the total cost of the services consumed by all users
while they are bound with the manager’s account. This indicates there is no
mechanism to control the budget at the level of an individual user or a single job
when services are consumed through one account. A group manager can also view
the total cost consumed by a member, if he/she has an account with the same
Cloud provider. This indicates all the services consumed by this member in a
certain period, which typically is one month. Previously, a Cloud provider cannot
track resource usage within other Cloud providers’ domains when an application
uses services from multiple commercial Clouds. This makes resource sharing
management for a research group even more challenging. However, with the
increasing demands of applying services from multiple Clouds for different service
features, the first monitoring service for applications running across GCP and
AWS is now available. This trend of interoperation between Cloud platforms
is consistent with the core vision of this thesis that a pool of resources can be
provided dynamically over open standards from different infrastructures.
Different from direct access to resources in Grids and Clusters without virtu-
alisation, additional fabrics are needed to enable dynamic resource provisioning
from Clouds. Such fabrics include virtualisation and access via web services in
the application layer. As a result, Clouds have been criticised for inefficient

2.2. CURRENT E-SCIENCE ENABLING MODELS AND LIFECYCLE 55
performance for scientific computational experiments compared with Grids and
Clusters [Sadashiv and Kumar, 2011]. Experiments and evaluation carried out
by [Ostermann et al., 2009] also reveal that the performance and reliability of
a commercial Cloud are not sufficient for large-scale scientific computing. The
characteristics were evaluated by testing: (i) the duration of resource acquisition
and release over short and long periods of time for job execution; and (ii) the dur-
ation of resource acquisition and release over running a single job with a single
instance, with multiple instances with the same type, and with multiple instances
of different instance types. In addition, virtualisation allows more than one user
to share the same physical machine, which presents security and privacy issues
[Pearson, 2013]. These issues are of concern in specific research areas, such as
biology and medicine, that may demand critical confidentiality support.
Despite these disadvantages, dynamic resource provisioning enables Cloud
services to meet e-Scientists’ immediate and temporary resource usage demands.
Clouds are also beneficial as e-Scientists can establish customised application
environments without the time- and effort-consuming manual procedures required
by Grids. Such a customised environment is required by some applications, such
as multi-scale parallel applications and interactive applications.
2.2.3 The Cluster Model
Grids and Clouds can collect available distributed resources and allocate them
to users. A Cluster instead utilises resources available in a geographically local
domain. From a technical point of view, a “Cluster is a collection of paral-
lel or distributed computers which are interconnected among themselves using
high-speed networks” [Sadashiv and Kumar, 2011]. Interconnection ensures high
performance, and redundant computer nodes are reserved in a Cluster for high-
performance purposes to handle node failures. In a Cluster, multiple computers
are linked together and share the computational workload. From the users’ per-
spective, they function as a single virtual machine [Sadashiv and Kumar, 2011].
The computational loads required by a job can be divided into smaller pieces and
distributed to multiple computer nodes in a Cluster.
Clusters can enable fine-grained accounting for resource consumption per job
with policies specified for each user. However, as a Cluster is isolated from other
infrastructures, without extra work for interoperation, it cannot track resource
usage for a job if it requires resources from other infrastructures. This makes

56 CHAPTER 2. BACKGROUND
resource management challenging for a research group if it needs to use resources
provided by a Cluster and other infrastructures. A hybrid infrastructure is presen-
ted in [Belgacem and Chopard, 2015] that applies AWS to complement local
HPC Clusters for a multi-scale application. The application is tightly coupled
and massively parallel, which requires scalable and on-demand resource provision.
This research also conducted an evaluation using the hybrid infrastructure. The
evaluation concluded that Cloud services could be used as a complementary solu-
tion to a local Cluster for such concurrent, multi-scale computational applications
by taking advantage of scalable Cloud resource provisioning. In such a scenario,
a research group may require resource provisioning and sharing management on
the hybrid infrastructure.
According to the features discussed, the characteristics of the Cluster model
are described as follows:
Cluster model: An architecture where a Cluster is maintained and con-
trolled locally in a single administrative domain. Resources are provisioned after
a collaboration has been formed between an e-Scientist or a research group and a
Cluster provider. Accounting is conducted by the provider and can be performed
with fine granularity. Resource management, including accounting, of a Cluster
is isolated from other infrastructures, and interoperation can be enabled.
Clusters may require that the applications submitted for execution must be
explicitly written to incorporate the communication and division of tasks between
nodes. Clusters can be built upon batch-based and queue-based systems. Batch
jobs require e-Scientists to submit all the inputs for application execution during
job submission and do not allow user interaction during job execution [Cap-
pello et al., 2005, Sotomayor et al., 2008]. Queue-based jobs indicate that the
total duration of a job (i.e. queuing and job execution times) depends on an e-
Scientist’s priority and the availability of the required resources [Gog et al., 2016,
Zheng et al., 2016]. E-Scientists may have limited control over job execution in a
Cluster. Consequently, a submitted job can only wait in queues until the required
resources are available, while the user has no awareness when the job can start.
In conclusion, upon an agreement between an e-Scientist or a research group
and a Cluster provider, a limited and specific customised execution environment
can be configured and accessed in Clusters. Dedicated resources ensure high per-
formance and secured resource usage in Clusters. Clusters are not interoperable

2.2. CURRENT E-SCIENCE ENABLING MODELS AND LIFECYCLE 57
with other infrastructures, including solutions for resource management and ac-
counting, which leads to not having any common or widely accepted standards
for Clusters. However, with the growing need for resources that deal with specific
demands, other infrastructures, especially Clouds, are beginning to cooperate
with Clusters.
2.2.4 The Alliance Model
For short-term and lightweight collaborations for resource provisioning, an Al-
liance model was proposed by Parkin [Parkin, 2007]. The Alliance model has
not been implemented in a production environment. In the Alliance model, a
research group is defined as a resource requesting organisation, while an infra-
structure or a collaboration of infrastructures is defined as a resource provisioning
organisation. This highlights the importance of separating the “mechanisms for
forming a collaboration among people from the mechanisms for allocating and
integrating resources in a Grid infrastructure” [Brooke and Parkin, 2010]. The
Alliance model removes the burden of administration of a resource requesting
organisation from the resource provisioning organisation. As was proposed for
dynamic collaborations between independent organisations, the Alliance model
can be interoperable with Grids, Clouds, and Clusters. Interoperation is achieved
by regarding infrastructures based on these models as independent resource pro-
visioning organisations as discussed in [Parkin, 2007].
Alliance model: An Alliance is formed through an agreement between a
resource requesting organisation (i.e. a research group) and a resource provision-
ing organisation (i.e. a resource provider). The resource requesting organisation
manages the administration of its members and the resource provisioning organ-
isation delivers resources under the agreed rules.
Since the Alliance model distinguishes a research group from a resource pro-
vider, it requires different mechanisms for resource management compared to
the models that organise both organisations centrally. This is a key factor in
this thesis to enabling fine-grained resource sharing management for a research
group. The Alliance model was proposed for forming and dissolving dynamic col-
laborations between resource requesting organisations and resource provisioning
organisations. Resource management was not discussed for the Alliance model
in [Parkin, 2007].
Table 2.1 summarises the discussion regarding the enabling models, which

58 CHAPTER 2. BACKGROUND
Table 2.1: Access and accounting mechanisms in e-Science-enabling models
New resourceaccess
The entitythat conducts
accounting
Accountinggranularity forgroup manager
Cross-infrastructure
accounting
Gridmodel
to join a VO or toestablish a VO, toapply for a digital
certificate if required
resourceprovider
per VO not available
Cloudmodel
via bank cardresourceprovider
per account,per service,
per application
only availablebetween GCPand AWS forapplicationexecution
Clustermodel
not availableresourceprovider
per job not available
Alliancemodel
to establish acollaboration
notspecified
notspecified
notspecified
provide resources via infrastructure-specific mechanisms. However, this is chan-
ging to comply with the increasing needs of interoperation and interoperab-
ility, especially in Grids and Clouds. Grids, including virtualisation-enabled
Grids, remain the main infrastructure to assist e-Scientists with computational
experiments. Grids apply restricted access mechanisms (e.g. digital certific-
ates) for e-Scientists to access resources. Clouds are increasingly used to fulfil
e-Scientists’ dynamic and customised resource provisioning demands. However,
neither Grids nor Clouds enable fine-grained resource sharing management for
a research group. Clusters are increasingly combined with other infrastructures
to support e-Scientists’ dynamic and customised resource provisioning demands.
However, Clusters require efforts to interoperate with other infrastructures. Re-
source providers are responsible for management of resource provision and ac-
counting in Grids, Clouds, and Clusters. Overall, infrastructures based on these
three models encounter the challenge of resource management for a job that util-
ises resources from different infrastructures. The independence between research
groups and infrastructures proposed by the Alliance model address this change.
However, accounting for resource sharing management in research groups has not
been discussed by the original Alliance model.

2.3. CURRENT E-SCIENCE AUTHENTICATION AND AUTHORISATION59
2.3 Current e-Science Authentication and
Authorisation
Access control to resources (i.e. authentication and authorisation) for compu-
tational experiments manages the resource provisioning based on management
requirements from both research groups and resource providers. As resource
provision and sharing concerns the members of a research group with varied pri-
orities, authorisation will be the focus of the following discussion. Authentication
will also be discussed briefly to demonstrate the needs of lightweight credentials
for e-Scientists.
Before further review, the authorisation mechanisms required for a resource
provisioning request in e-Science is introduced here. A decision to a resource usage
request from an e-Scientist considers authorisation in two parts: (i) authorisation
within the research group the e-Scientist belongs to; and (ii) authorisation within
the provider domain.
• Authorisation within a research group: A research group manages resource
sharing among its group members. The resource sharing can be managed
by members’ identities, policies defined by the group manager or attributes
allocated to members.
• Authorisation within a provider domain: A resource provider decide which
and how many local resources can be allocated to an e-Scientist if the au-
thentication and authorisation requested by the group manager are success-
ful.
Authentication and authorisation of a resource usage request in e-Science
have experienced continual changes. These changes are driven by the needs of
resource sharing management for research groups, and the need for easy access to
resources for e-Scientists [Bazinet et al., 2014, Piparo et al., 2018]. The variety of
local authentication and authorisation mechanisms utilised by Clusters will not
be discussed here.
Some situations of ad-hoc user collaborations will not be reviewed. Examples
of such situations include that: (i) fire-fighters share data and simulation results
during a fire emergency [Han et al., 2010]; and (ii) data collection and shar-
ing among rescue personnel spread across different locations when a disaster

60 CHAPTER 2. BACKGROUND
occurs [George et al., 2010]. The tools for these situations have different require-
ments compared with those for general computational experiments discussed in
this thesis. For instance, these tools may focus on improving communication
response time or the topology for emergency communication, especially via a
wireless network. Mediating and managing resource provisioning and sharing
between research groups and infrastructures are not their focus. As a result, au-
thentication and authorisation for these ad-hoc user collaborations will not be
discussed in the following sections.
2.3.1 VOMS and Proxy Certificates with Attributes
VOMS [Alfieri et al., 2004] is proposed to: (i) enable more flexible and scalable
VO structures for resource sharing management of a research group; and (ii) allow
resource providers to have total control of local resources. VOMS separates VOs
and Resource Providers (RPs). Under VOMS, a VO is responsible for grouping
users, institutions, and resources (if any) in the same administrative domain.
RPs are responsible for resource provision according to agreements with VOs and
providers’ local resource management policies.
An e-Scientist must obtain an X.509 digital certificate before accessing Grid
resources managed by VOs. An X.509 digital certificate is issued by a Certific-
ation Authority (CA) and is applied for authentication of an e-Scientist. Proxy
certificates can be applied for access delegation on behalf of an e-Scientist, which
are generated from an e-Scientist’s X.509 digital certificate. Proxy certificates in
VOMS are extended via attribute certificates to achieve flexibility and scalability
for authorisation. Attributes included in an attribute certificate are used for au-
thorisation purposes, such as information on an e-Scientist’s group memberships,
roles, and capabilities.
Before sending a request for resource usage to a resource provider, an e-
Scientist needs to attain an attribute certificate from a VOMS server. The attrib-
ute certificate contains credentials of both the e-Scientist and the VOMS server,
the time validity, and the attributes for the e-Scientist, which are all signed by
the VOMS server. After receiving an attribute certificate, the e-Scientist can
generate a proxy certificate with the attribute certificate using his/her X.509 di-
gital certificate, as shown in Figure 2.4. The proxy certificate will then be sent
with resource usage requests to providers. The providers will manage resource
provisioning according to the attributes contained in the attribute certificates

2.3. CURRENT E-SCIENCE AUTHENTICATION AND AUTHORISATION61
VOMS
e-Scientist
1. request 2. attributecertificate
Resourceprovider
3. request +proxy certificate
4. job executiondecision
collaborationagreement
Figure 2.4: Authentication and authorisation in VOMS
and local policies. Figure 2.4 also shows the authentication and authorisation
procedures managed via proxy certificates under VOMS.
2.3.2 Proxy Certificates and Shibboleth: GridShib
GridShib allows for interoperability between the Globus Toolkit [Foster, 2006]
and Shibboleth [Morgan et al., 2004], as a combination of Shibboleth with proxy
certificates. Shibboleth enables a multi-organisational federation to use parti-
cipating organisations’ existing identity management systems for the federation’s
identity management [Morgan et al., 2004]. This allows authentication to be en-
tirely managed by research groups. Proxy certificates are for cross-domain single
sign-on and attribute-based authorisation. GridShib is motivated by allowing a
research group to manage members autonomously and the convergence of Grids
and web services. The primary purpose of GridShib is to allow a resource provider
to attain an e-Scientist’s authorisation attributes from a Shibboleth attribute au-
thority with the e-Scientist’s identity for authorisation purposes. The Shibboleth
attribute authority manages authorisation for a research group. The communica-
tion procedures for the authentication and authorisation enabled by GridShib are
shown in Figure 2.5. The e-Scientist’s identity is extracted from his/her X.509
digital certificate and passed from a resource provider to the GridShib for an
attribute assertion. The returned attribute assertion contains the attributes of
the e-Scientist. The resource provider can then make an authorisation decision
based on these attributes. Such attribute assertion can be embedded in a proxy
certificate for access delegation.

62 CHAPTER 2. BACKGROUND
e-Scientist
VO
Resourceprovider
1. request +digital certificate
4. job executiondecision
GridShib 3.attribute
assertion
2.request
e-Scientist’s
attributes
Figure 2.5: Authentication and authorisation in GridShib
2.3.3 A Cooperative Access Control Model for Ad-hoc
User Collaborations in Grids
The Cooperative Access Control (CAC) model proposed in [Merlo, 2013] is for ad-
hoc collaborations among Grid users. It allows them to share access permissions
to Grid resources without the intervention of Grid administrators. To achieve
this, the CAC model enables a Grid user to create and destroy dynamic groups
within the VOs that he/she belongs to [Merlo, 2013]. The user who creates a
group can define group policies to enable other Grid users to join the group and
share resources. The sharing is based on the user’s existing access priorities in
the Grid.
A created group forms an ad-hoc user collaboration in this scenario. However,
as such collaboration is based on existing Grid identities and corresponding ac-
cess priority, it inherits the authentication and authorisation mechanisms of the
existing Grid infrastructure. As presented in [Merlo, 2013], the CAC model is
implemented into Globus Toolkit 4 (GT4) [Foster, 2006], which uses proxy certi-
ficates for authorisation and access delegation. Accordingly, to share resources in
a dynamic group, an e-Scientist joins or creates a group, specifies the resources
to be shared, and uploads corresponding proxy certificates. GridShib builds an
extra authorisation layer upon a Grid to allow an ad-hoc e-Scientist collabora-
tion, while the CAC model extends an existing VO for resource sharing among
existing Grid users.

2.3. CURRENT E-SCIENCE AUTHENTICATION AND AUTHORISATION63
Administrator(IdP)
e-Scientist
Research group
Resourceprovider
1. request + user name
2. e-Scientist’s user name
3. e-Scientist’s attributes
4. job executiondecision
Figure 2.6: Authentication and authorisation in EGI CheckIn service
2.3.4 Lightweight Credentials and Shibboleth: The EGI
CheckIn Service
The EGI CheckIn service [EGI, 2018a] is proposed for authentication and au-
thorisation for user-friendly and secure access to EGI services. EGI CheckIn also
applies federated authentication and authorisation mechanisms similar to those
of Shibboleth. It is composed of federated Identity Providers (IdPs) and Service
Providers (SPs). EGI focuses on provider federation, so it considers that IdPs
reside outside of the EGI, while the SPs are part of the EGI. Similar to Grid-
Shib, authorisation is conducted by communication between an SP and IdP in
the EGI CheckIn service, as shown in Figure 2.6. A reply from an IdP to an SP
for an authorisation request includes the attributes of the requester. As a result,
SPs still need to store all the authorisation attributes and conduct the actual
authorisation for resource provisioning decisions. The communication procedures
for authentication and authorisation in the EGI CheckIn service are presented in
Figure 2.6.
The key difference between the EGI CheckIn service and GridShib is that the
former enables lightweight credentials for e-Scientists as users to access resources
available in EGI. Such credentials can be a combination of a username and pass-
word. They can be provided by e-Scientists’ home organisations, as well as social
identity providers, or other selected external identity providers.

64 CHAPTER 2. BACKGROUND
2.3.5 AWS Identity and Access Management for Ad-hoc
User Collaborations
Commercial Cloud services enable ad-hoc user collaborations by their nature for
the following two reasons. First, Cloud services can be accessed and used with
only a bank account. Second, a research group can establish an ad-hoc collab-
oration on a Cloud, by taking advantage of available authentication and author-
isation services supplied by the Cloud. AWS enables advanced authentication
and authorisation mechanisms, such as AWS Identity and Access Management
(IAM). IAM is a web service that assists a service owner (e.g. a group manager)
to control who can use the resources (authentication) and what resources they
can use (authorisation), while these resources can be paid for by the owner.
A service owner can create groups and users, and sub-groups are not sup-
ported. A service owner designs and applies policies to grant permissions to
groups and users. Such policies can define which group or user can access which
resources with which actions. AWS IAM enables the integration of an existing
authentication system from an organisation. This is achieved by allowing user
federation through single sign-ons to both an organisation’s site and AWS using
the organisations’ established user identities and credentials. The functionalities
of user federation are required to be developed by customers with the available
AWS APIs.
To date, commercial Clouds implement vendor lock-in. Clouds allow a service
owner to group users and define policies for users for service access and usage.
However, the policies defined by a service owner are maintained within a single
Cloud domain. Resource provisioning decisions do not involve communication
between administratively distributed research groups and resource providers.
2.3.6 Further Discussion
From the above overview, the increasing needs for dynamic resource provision
and autonomous management of a research group can be envisioned. Such needs
push solutions for authentication and authorisation in e-Science to separate re-
search groups from resource providers. Attributes are applied between separated
research groups and resource providers for group members’ authorisation. For au-
thorisation using attributes, like GridShib and the EGI CheckIn service, a com-
mon understanding of attributes is essential for a valid authorisation decision.

2.3. CURRENT E-SCIENCE AUTHENTICATION AND AUTHORISATION65
The vocabulary and semantics applied for attribute description should be clearly
defined and understood by both identity providers (e.g. group managers) and
resource providers.
Even after separating a research group from resource providers, existing au-
thentication and authorisation solutions in e-Science cannot manage complex and
dynamic resource sharing rules for a research group, as shown in Figure 2.1. This
is likely due to the resource providers in these solutions remaining responsible for
processing authorisation of resource provisioning requests, even when a research
group is separated from the resource providers. According to this idea, these
solutions are viewed by this thesis as centralised resource management.
Here, we consider GridShib again as an example of existing centralised re-
source management for a further review. The information passed from a resource
provider to a Shibboleth attribute authority only includes a requester’s identity.
The authorisation attributes of the requester will be returned to and processed
by the resource provider. This is considered a burden for resource providers, es-
pecially in an open market. In an open market, there are a significant number
of users, which results in more management and computing effort from providers
to store and process large quantities of attributes and requests. Also, resource
providers may not be concerned about a requester’s membership or authorisation
attributes in his/her research group. They may be concerned only with if a re-
quester’s request is consistent with his/her group’s policies and any restrictions
placed on the resource consumption. In this scenario, the agreement from the
group indicates that the group confirms it will pay for the resource consumption
if resource provision follows its restrictions.
Different from the resource management solutions discussed above, the Argus
framework separates resource providers from authorisation services and shifts au-
thorisation from resource providers to the Argus authorisation service [Tschopp,
2011]. Resource providers will receive only a positive or negative authorisation
decision for further processing of resource provisioning requests. However, Argus
does not currently support accounting attributes and a complete resource pro-
visioning lifecycle. This leads to the following two results. First, Argus cannot
enforce resource sharing rules defined by a group manager for resource provision-
ing to group members. This means that it cannot support accountable resource
provisioning. Second, Argus cannot be applied for resource provisioning between
independent research groups and resource providers, which makes it unsuitable for

66 CHAPTER 2. BACKGROUND
an open market. A solution to enable accountable resource provisioning through
a complete lifecycle based on the Argus authorisation service and the proposals
of this thesis will be presented in Chapter 7. It gives suggestions for future work
of this research.
2.4 Current e-Science Resource Management:
A Semantic View
This section describes the functional layers applied by existing e-Science infra-
structures for resource sharing and collaboration. This review is is based on the
concepts of interoperation and interoperability, which can expose more resources
for e-Scientists’ use and increase the rates of successful negotiation for dynamic
resource requests [Somasundaram et al., 2014]. Interoperation and interoperabil-
ity are considered the enablers for dynamic and customised resource provisioning
collaborations as well as the basis for an open market.
For investigating interoperation and interoperability of infrastructures, this
chapter provides insights into the fundamental concepts required for a deeper
understanding of resource management in e-Science. In such resource manage-
ment, the resource information can be collected from various infrastructures and
presented in a uniform way for e-Scientists. E-Scientists then select satisfactory
resources for application execution. In this scenario, a common understanding
and shared knowledge for resource provisioning and management are essential.
They enable Interoperation and interoperability. This thesis suggests that inter-
operation and interoperability lower the obstacles for infrastructures to contrib-
ute resources to a worldwide resource pool. They lay the foundation for dynamic
resource provisioning and short-term e-Science collaborations, especially for re-
source provisioning facilitated by virtualisation.
Clusters are built upon localised deployment, and the Alliance model is a
conceptual model that has not been implemented in production. It is difficult
to evaluate the interoperation and interoperability perspectives of Clusters and
Alliances. As a result, only infrastructures based on the Grid model and the Cloud
model will be discussed in this section. Furthermore, discussions in this section
focus on job submission, resource management, and accounting mechanisms in
Grids for the following two reasons. The first reason is that the Grid model is
specially developed for e-Science, such that it can reflect the relationships among

2.4. CURRENT E-SCIENCE RESOURCEMANAGEMENT: A SEMANTIC VIEW67
entities in e-Science collaborations and resource sharing. As a result, the Grid
model is capable of allowing e-Scientists from different institutions, organisations,
or companies to share resources and to collaborate, namely to form a research
group. It also enables a research group to use resources provided from different
infrastructures. The second reason is that Grids, including virtualisation-enabled
Grids, are still considered the main enabler for e-Science collaborations. The
reason is that Clouds are still considered inefficient and have security and privacy
issues, and Clusters are not interoperable with other infrastructures, as discussed
in Section 2.2.
Grid Interoperation Now (GIN) [GIN-CG, 2008] was a Grid community group
for infrastructure standardisation, which aimed for interoperation among produc-
tion Grids. Correspondingly, it was dedicated to providing seamless technical re-
commendations to enable e-Scientists to execute their computational experiments
using existing production infrastructures (built upon the Grid model). GIN sum-
marised five specific areas that should be considered for usable interoperation in
Grids. The five areas are authorisation and identity management, data manage-
ment and movement, job description and submission, information services and
schemas, and pilot test applications [Riedel et al., 2009].
Similarly, to enable interoperation while also considering interoperability, an
infrastructure interoperability reference model tailored to production needs is
proposed in [Riedel, 2013]. This reference model concerns technical reference
architecture, the patterns that can be applied to enable interoperation and inter-
operability, and standards. The functional areas covered by this reference model
proposed by [Riedel, 2013] include security, information, data management, exe-
cution management, and application, which are the same as summarised by GIN.
Based on the proposed reference model, [Riedel, 2013] demonstrates solutions to
sustaining interoperability in production infrastructures. These solutions stress
the importance of applying standards as core building blocks in production. The
research in [Riedel, 2013] also presents the widely-applied standards and recom-
mendations for each functional area in production Grids, as shown in Figure 2.7.
GLUE 2.0 and Usage Record (UR) are highlighted by [Riedel, 2013] (Fig-
ure 2.7) as two key standards in the information area, for resource management
and resource usage tracking, respectively. Furthermore, they are widely applied
in existing Grids, including virtualisation-enabled Grids. With the information
contained by GLUE 2.0, jobs can be submitted to resources via the standards

68 CHAPTER 2. BACKGROUND
GLUE2OGF
UROGF
JSDLOGF
JSDL SPMD Ext.OGF
JSDL HPC Prof. App. Ext.OGF
JSDL Param. Sweep. Ext.OGF
OGSA -BESOGF
SRMOGF
GridFTPOGF
WS-DAIOGF
ByteIOOGF
PKIIETF
SAMLOASIS
XACMLOASIS
ComputeArea
InformationArea
DataArea
SecurityArea
Figure 2.7: Open standards in Grids with their different technical areas [Riedel,2013]
shown in the compute area. Data generated by jobs will be transferred and
stored, following the standards in the data area, while the accounting informa-
tion for job execution can be managed by UR. All these three areas may require
authentication and authorisation of the e-Scientists who submit the jobs. Such
authentication and authorisation can be supported by the security area.
Figure 2.7 also lists the notable organisations that develop common open
standards for infrastructures, including the Open Grid Forum (OGF), the Or-
ganization for the Advancement of Structured Information Standards (OASIS),
and the Internet Engineering Task Force (IETF). Standardisation envisions the
potential to enable: (i) more functioning and stable interconnections between in-
frastructures for collaborative resource provisioning; (ii) and resource provisioning
from any available infrastructures via well-defined rules.
Efforts to integrate different Grid middleware stacks to facilitate interoper-
ability have also been conducted by the European Middleware Initiative (EMI).
EMI endeavours to consolidate and evolve infrastructures from Advanced Re-
source Connector (ARC) [Ellert et al., 2007], dCache [Fuhrmann and Gulzow,
2006], gLite [Laure et al., 2006], and UNICORE [Aiftimiei et al., 2012]. The
implementation in EMI highlights the support of: (i) GLUE 2.0 for interoper-
able information management; and (ii) customised UR implementation to ensure
interoperability between different middleware for accountable data transfer and
processing. A survey also shows that GLUE 2.0 is widely applied in infrastruc-
tures [Riedel et al., 2009].
Taking the Grid model as the dominant model for supporting e-Science and

2.4. CURRENT E-SCIENCE RESOURCEMANAGEMENT: A SEMANTIC VIEW69
to make it comparable, Cloud interoperation will be discussed with reference to
the same five areas proposed by GIN for Grid interoperation. The discussion will
be presented in the following sections.
With the increasing application of virtualisation in Grids, standards are be-
ing established for dynamic resource provisioning in virtualisation-enabled Grids,
such as the Open Cloud Computing Interface (OCCI) [Metsch et al., 2010]. Mean-
while, as discussed in Section 2.2, e-Scientists still have performance and security
concerns when considering moving to Clouds. However, Cloud techniques are
undergoing rapid development and can provide resources with a dynamic and
customised manner. As a result, both Clouds and Grids are regarded as import-
ant sources of support for the e-Science community [Foster et al., 2008]. This
thesis views that Cloud techniques can push the establishment of dynamic re-
source provisioning collaborations between independent research groups and re-
source providers. This can contribute to an open market. The reason is that
Cloud techniques abstract underlying technical differences and supply resources
dynamically with customised execution environment via open standards and well-
defined APIs. With the increasing application of Cloud techniques in Grids, in-
teroperability is an inevitable trend to enlarge the resource pool and enhance
dynamic resource provisioning in virtualisation-enabled Grids [Drescher, 2014].
Interoperation and interoperability can only be enabled based on a common
understanding between participating entities, i.e. e-Scientists, group managers,
and resource providers. Such a common understanding can be achieved by study-
ing and analysing existing techniques with a semantic approach. From the point of
view of QoS support and resource sharing management, two areas closely related
are job description languages and resource information management schemas.
They will be semantically discussed in detail. They present the views of e-
Scientists for job execution support and a research group for resource sharing
management, respectively.
2.4.1 User Requirements: Job Description Languages
A semantic analysis of job description languages and concepts that are widely
applied by existing infrastructures has been carried out. It considers resource
provision via infrastructures based on the Grid model, including virtualisation-
enabled Grids, and the commercial Cloud model. Correspondingly, standards
and specifications for job submission languages have been studied, including

70 CHAPTER 2. BACKGROUND
Job Submission Description Language (JSDL) [Anjomshoaa et al., 2005] applied
by UNICORE [Streit et al., 2010], and OCCI [Metsch et al., 2010] enabled by
EGI [Kranzlmuller et al., 2010] as well as terms used by AWS [AWS, 2018d],
ClassAd [Solomon, 2004] used in HTCondor [Tannenbaum et al., 2001], Resource
Specification Language (RSL) [Globus, 2018] used in Globus [Foster, 2006], and
the extended RSL applied in NorduGrid. These languages and terms are the
typical ones used by infrastructures built on the Grid the Cloud models. While
this study focuses on computing resources, the same methodology can be applied
to other resources, such as storage and networks.
As shown in Table 2.2, JDSL enables e-Scientists to express more require-
ments for application execution compared to other job description languages and
terms. Thus, it is considered more user-oriented and comprehensive than other
job description languages and terms. As also seen in Table 2.2, users of Grids
can describe demands in terms of the application to execute. This is the case
because the software is developed to perform complex job management tasks in
Grids. Such tasks include submitting applications to be executed and specifying
locations to retrieve input files and fetch output files. However, these specific
functions are not available in Clouds. Furthermore, research groups need to es-
tablish customised application execution environments, if required, from scratch
to enable e-Scientists to conduct computational experiments in Clouds. This can
be shown by the attributes described in OCCI, which focus on infrastructure fea-
tures rather than application features. For comparison, Cloud services are also
studied at an infrastructure level, which allow users to choose virtual machines
that satisfy their requirements. By this, the terms analysed for job submission
and resource management for AWS are based on the services’ description for the
Elastic Compute Cloud (EC2) [AWS, 2018d,e]. Considering that Clouds do not
support workflow jobs by default, terms for management purposes, as shown in
Table 2.2, are only for single job execution. Also, Clouds do not support jobs
by nature since terms allowed for Clouds only describe resource features without
features for job execution.
Table 2.2 further shows that Globus RSL considers fewer properties that can
be specified by an e-Scientist for job execution compared to JSDL and the de-
scription enabled by HTCondor. The reason may be that Globus RSL aims to
provide a common set of attributes to describe resources, and implementation
in practice may extend it to compose more complicated resource descriptions.
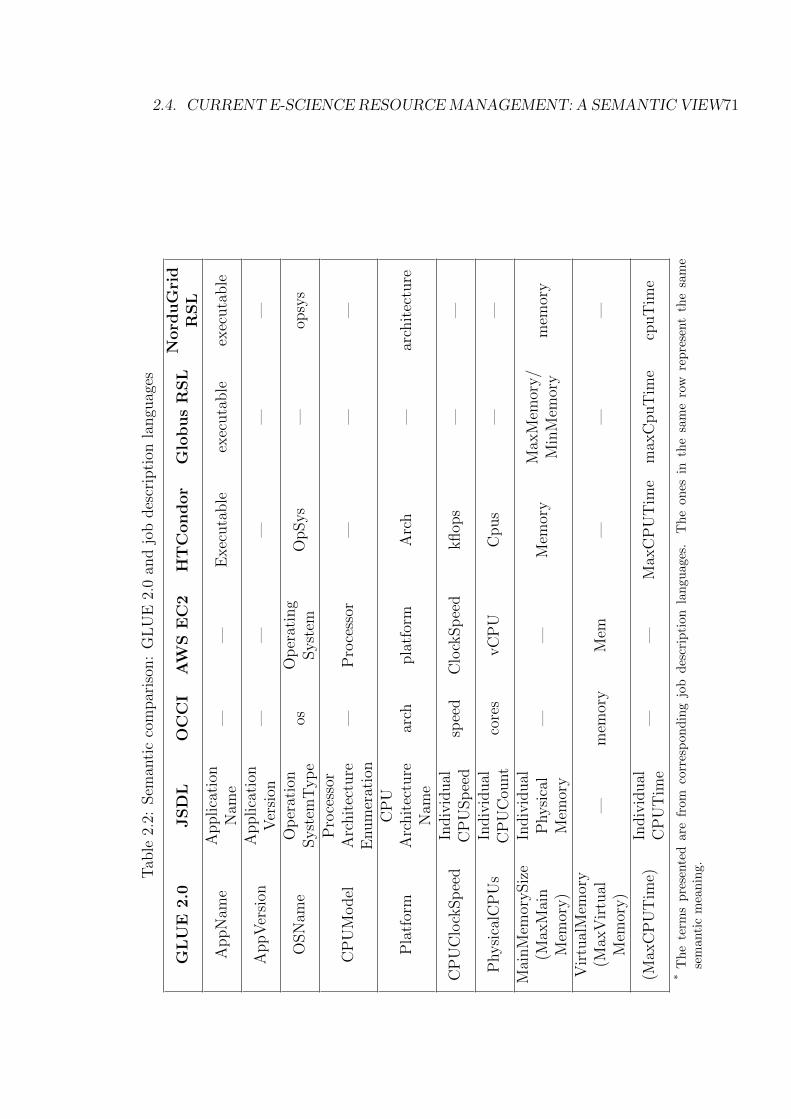
2.4. CURRENT E-SCIENCE RESOURCEMANAGEMENT: A SEMANTIC VIEW71
Tab
le2.
2:Sem
anti
cco
mpar
ison
:G
LU
E2.
0an
djo
bdes
crip
tion
langu
ages
GL
UE
2.0
JS
DL
OC
CI
AW
SE
C2
HT
Condor
Glo
bus
RSL
Nord
uG
rid
RSL
AppN
ame
Applica
tion
Nam
e—
—E
xec
uta
ble
exec
uta
ble
exec
uta
ble
AppV
ersi
onA
pplica
tion
Ver
sion
——
——
—
OSN
ame
Op
erat
ion
Syst
emT
yp
eos
Op
erat
ing
Syst
emO
pSys
—op
sys
CP
UM
odel
Pro
cess
orA
rchit
ectu
reE
num
erat
ion
—P
roce
ssor
——
—
Pla
tfor
mC
PU
Arc
hit
ectu
reN
ame
arch
pla
tfor
mA
rch
—ar
chit
ectu
re
CP
UC
lock
Sp
eed
Indiv
idual
CP
USp
eed
spee
dC
lock
Sp
eed
kflop
s—
—
Physi
calC
PU
sIn
div
idual
CP
UC
ount
core
svC
PU
Cpus
——
Mai
nM
emor
ySiz
e(M
axM
ain
Mem
ory)
Indiv
idual
Physi
cal
Mem
ory
——
Mem
ory
Max
Mem
ory/
Min
Mem
ory
mem
ory
Vir
tual
Mem
ory
(Max
Vir
tual
Mem
ory)
—m
emor
yM
em—
——
(Max
CP
UT
ime)
Indiv
idual
CP
UT
ime
——
Max
CP
UT
ime
max
CpuT
ime
cpuT
ime
*T
he
term
sp
rese
nte
dar
efr
omco
rres
pon
din
gjo
bd
escr
ipti
on
lan
gu
ages
.T
he
on
esin
the
sam
ero
wre
pre
sent
the
sam
ese
man
tic
mea
nin
g.

72 CHAPTER 2. BACKGROUND
NorduGrid RSL is an extension of the Globus RSL [NorduGrid, 2018], which
enables more attributes to be specified by e-Scientists for job submission.
The analysis and comparison of the selected job description languages and
terms reach the following conclusion. Even though the languages and terms
used in different Grids and Clouds vary, fundamentally and semantically they
represent common information regarding resource requirements for application
execution [Riedel et al., 2009]. As shown in Table 2.2, the common resource spe-
cification includes the number of CPUs, disk space, system architecture, memory
size, and operating system. Apart from resource specification, functions to en-
able e-Scientists to specify other experimental requirements are also available in
Grids without virtualisation. This is because that Grids without virtualisation
were originally designed to support e-Science computational experiments. These
functions are supposed to be established by users when utilising Cloud services
from both virtualisation-enabled Grids and commercial Clouds. The comparison
of the job description languages and terms in Table 2.2 also shows that GLUE
2.0 considers a complete set of properties for resource management purposes. As
a result, GLUE 2.0 will be discussed in detail below along with other production
resource management models.
2.4.2 Resource Management: GLUE 2.0
Languages and terms for job description are used by e-Scientists to express their
resource provisioning demands, while a resource management model is concerned
with an e-Science collaboration. Job description and resource management are
closely related, as resource provision and accounting depend on the demands ex-
pressed by job submission languages specified by e-Scientists. A resource manage-
ment model is considered especially important for dynamic resource provisioning
[Elmroth and Tordsson, 2009]. Resource provisioning and sharing are two import-
ant aspects of resource management in e-Science collaborations. Accordingly, the
resource information models discussed in this section focus on possible solutions
to the following:
1. Matching the scenario for resource provisioning management between in-
dependent research groups and resource providers. This indicates that a
resource management model should present the information of concerns to

2.4. CURRENT E-SCIENCE RESOURCEMANAGEMENT: A SEMANTIC VIEW73
e-Scientists, group managers, and resource providers for resource provision-
ing purposes.
2. Assisting group managers with resource sharing management.
To satisfy these two requirements, a resource management model should be
able to: (i) describe the relationships between a research group and a resource
provider for resource provisioning; (ii) manage resource sharing among members
of a research group; (iii) correlate resource sharing rules in a research group with
resource provisioning decisions, if required; and (iv) consider features of resources
provided from different infrastructures, which may be based on different enabling
models.
Different infrastructures may implement varied resource management mod-
els. The ARC information model is proposed by NorduGrid and enabled in the
Advanced Resource Connector (ARC) [Konya and Johansson, 2017]. It models
the information mainly for computing resources with Grid jobs and Grid users,
and briefly for storage resources and metadata catalogues. In other words, the
ARC information model specifies resource information from a provider’s point
of view. Accordingly, it contains large amounts of detailed information on local
resources and job management. Based on this feature, ARC is considered to
be job-oriented, namely for management after job submission. This mechan-
ism cannot be applied to the following two situations: (i) resource provisioning
management, which occurs before job submission; and (ii) distributed application
execution management, where application execution may be divided into multiple
sub-jobs, and sub-jobs are submitted to different resources or providers. Also, the
Grid users specified by the ARC model are authorised users. This does not match
the scenario of resource provisioning via standards where a resource provider may
accept requests from all possible users. Finally, the ARC information model does
not consider Cloud service information.
Another resource management model example is the Common Information
Model (CIM) [DMTF, 2018]. The CIM schema provides a conceptual framework
for describing management data, which includes models for systems, networks,
devices, and applications. It additionally captures the concepts of virtualised
resource management. It does not model the entities that participate. As a
result, it does not manage relationships between participating entities, such as
relationships between entities and applications or between entities and resources.

74 CHAPTER 2. BACKGROUND
However, these two relationships are essential for enabling accountable resource
provisioning, as will be discussed in the next chapter.
Compared to the ARC information model and the CIM, GLUE 2.0 is a com-
prehensive information model, as will be discussed. It can contribute to a solution
that satisfies all the demands discussed above. Also, GLUE 2.0 is the most widely-
applied information model for resource management in Grids. This indicates that
limited changes will be required from infrastructures already implementing GLUE
2.0 to adopt an extended model. Table 2.3 shows that GLUE 2.0 is applied in
production middleware for Grids, including virtualisation-enabled Grids such as
gLite, UNICORE, ARC, and FedCloud [Aiftimiei et al., 2012, Riedel et al., 2009].
Globus currently enables the prior version, GLUE [Schopf et al., 2006]. The re-
source management model in QCG is GLUE 2.0-compliant, and its integration
with GLUE 2.0 has been facilitated. The integration is achieved by a project
collaborating between QCG and EGI infrastructures [Bosak et al., 2014]. The
solutions to mapping ARC to GLUE 2.0 are included in the ARC information
model specification [Konya and Johansson, 2017], and research to interoperate
CIM with GLUE has also been performed [Dıaz et al., 2011]. Based on these
reasons, GLUE 2.0 is chosen as the foundation for the Alliance2 resource man-
agement model proposed in this thesis. The following discussion is focused on
the GLUE 2.0 information model only.
GLUE 2.0 is a conceptual information model for Grid entity description [An-
dreozzi et al., 2009]. GLUE 2.0 has been studied and analysed with job description
languages and terms. Table 2.2 shows that GLUE 2.0 models all information re-
quired for resource management corresponding to job description languages and
terms that can be specified by e-Scientists. GLUE 2.0 also contains definitions
for engaged entities and their roles in e-Science collaborations and resource shar-
ing. For instance, the AdminDomain entity is defined for resource management
administrative roles, and the UserDomain entity is specified for membership man-
agement for a research group. In addition, GLUE 2.0 considers the relationships
among these entities for resource management purposes as well as some account-
ing properties for resource consumption. For these reasons, this thesis concludes
that GLUE 2.0 is a comprehensive specification, and it can provide a resource
management model and information that can be extended for fine-grained ac-
countable resource provision for e-Science computational jobs.

2.4. CURRENT E-SCIENCE RESOURCEMANAGEMENT: A SEMANTIC VIEW75
Tab
le2.
3:Sta
ndar
ds
adop
tion
sfo
rre
sourc
em
anag
emen
tan
dac
counti
ng
inG
rids
gL
ite
Glo
bus
UN
ICO
RE
AR
CQ
CG
FedC
loud
Nord
uG
rid
Res
ourc
em
ana-
gem
ent
model
GL
UE
2.0
GL
UE
GL
UE
2.0
GL
UE
2.0
GL
UE
2.0
com
plian
tG
LU
E2.
0N
orduG
rid
-AR
Cm
odel
Acc
ounti
ng
form
atU
R/C
AR
—U
R/C
AR
UR
/CA
R
Mid
dle
war
e-s
pec
ific
(soon
be
repla
ced
by
CA
R)
Clo
ud
Usa
geR
ecor
d(i
nher
ited
from
UR
)
UR
/CA
R(a
pply
ing
CA
Ris
inan
exp
erim
enta
lst
age)

76 CHAPTER 2. BACKGROUND
Comprehensiveness combined with broad adoption indicates that basing re-
source management upon GLUE 2.0 can contribute the following three advant-
ages. First, it can ease the integration of available resource information from
different infrastructures [Riedel et al., 2009] for resource provisioning, especially
for infrastructures that already implement GLUE 2.0. Second, it makes it easier
to map GLUE 2.0 to resource management models that do not implement GLUE
2.0 for interoperation, as it may contain all the information considered by other
models. Third, it requires less extension to enable the expected functions com-
pared with the other resource management models. These advantages can make
a model based on GLUE 2.0: (i) be easier to interoperate with a large number
of infrastructures that already implement GLUE 2.0; and (ii) can facilitate in-
teroperation between infrastructures for collaborative resource provisioning. The
reason for interoperation is that, as discussed in [Riedel et al., 2009], changing ex-
isting infrastructures to comply with another standard requires non-trivial efforts.
Such changes also require long-term sustained management and improvement by
a standardisation group. These efforts are not realistic for dynamic and small-
or medium-scale collaborations in the short term [Foster et al., 2008, Riedel,
2013]. Additionally, to comply with the increasing usage of Clouds, GLUE 2.0
has included concepts for Cloud services.
Regarding resource management, concepts in GLUE 2.0 apply to e-Science
collaborations and resource sharing. Such concepts include resource, service,
application, and execution environment as well as participating organisations,
projects, and persons. They make GLUE 2.0 suitable to model the complete
resource provisioning lifecycle for e-Science collaborations, including job submis-
sion, authorisation, matchmaking, and accounting. The distinguished definitions
of participating entities make GLUE 2.0 capable of describing e-Science from dif-
ferent angles. This is important for identifying their varied demands in typical
e-Science collaborations for resource sharing [Riedel, 2013].
As an information model for resource management, GLUE 2.0 considers con-
straints on e-Scientists’ consumption of resources. For example, GLUE 2.0 defines
the MaxCPUTime property to limit the maximum CPU time that can be con-
sumed by each job submitted to a specific resource per slot by a user. More
specifically, all jobs submitted to this resource are managed by the same rule.
The properties considered by GLUE 2.0 cannot enable a research group to spe-
cify a limit of a specific amount of resources that a user can consume. Such

2.4. CURRENT E-SCIENCE RESOURCEMANAGEMENT: A SEMANTIC VIEW77
limitation is required by small-scale collaborations and dynamic resource pro-
visioning collaborations in an open market [Amsaghrou, 2016, Hartung et al.,
2010]. Therefore, this thesis considers the resource management modelled by
GLUE 2.0 as coarse-grained. Differently, fine granularity is expected to enable a
research group to define varying quantities of resources that members with dif-
ferent priorities can consume per job for resource sharing management purposes.
To enable the desired fine-grained resource sharing management capability, this
thesis extends GLUE 2.0, as will be detailed in Chapter 4.
GLUE 2.0 is intended for resource management, while job description lan-
guages and terms are used to describe the required resources from a user’s point
of view. Correspondingly, the terms introduced in GLUE 2.0 for management
are consistent with those used by job description languages and terms. Take for
example the property describing the specification of the CPU number for applic-
ation execution. The property PhysicalCPUs defined by GLUE 2.0 represents
the total number of physical CPUs available on a resource or a virtual machine if
a Cloud is utilised. Correspondingly, the IndividualCPUCount property in JSDL
specifies the number of CPUs required to execute the submitted job on each re-
source. The values for these properties can be dynamically updated when their
quantities change. For properties that statically describe resource information,
their definitions in GLUE 2.0 are also consistent with job descriptions applied by
infrastructures. For example, the CPUClockSpeed property in GLUE 2.0 maps to
the IndividualCPUSpeed property in JSDL, semantically, while speed and Clock-
Speed are used in OCCI and AWS, respectively.
The comparison between GLUE 2.0 and different job description languages
and terms aims to identify a common set of properties. Such properties can be
specified by e-Scientists to search for adequate resources for a job and are in-
cluded in GLUE 2.0 for resource management purposes. The semantic analysis
and comparison provided in Table 2.2 include the terms consisting of a common
set of the computing and memory resource information required for application
execution. Values of these terms can be collected by querying corresponding
information from infrastructures for resource provisioning and updated for re-
source management. In this way, resource discovery and management based on
a common understanding can be achieved.
GLUE 2.0 considers not only resource information consistent with job specific-
ations supported by infrastructures but also terms to represent the relationships

78 CHAPTER 2. BACKGROUND
among participating entities. The three typical roles involved in e-Science col-
laborations and resource sharing can be specified by the UserDomain, AdminDo-
main, and Manager entities in GLUE 2.0. UserDomain captures the concept
of VOs for user membership management. AdminDomain contains information
about the identity of a person or a legal entity that pays for the consumption
of services and resources. Manager represents an abstract functional software
component for local resource management in a resource provider domain.
To manage resource sharing within a research group, Member and Level are
defined within UserDomain to indicate a group member’s identity and priority, re-
spectively. Coarse-grained rules can be specified in a MappingPolicy instance for
pre-selection of resources. Resource sharing according to coarse-grained policies
can be achieved by relating a MappingPolicy instance to a UserDomain instance.
Before applying virtualisation to Grids, the Grid model regards resource pro-
viders and e-Scientists as being in the same administrative domain. Since GLUE
2.0 is built upon the Grid model, local resource management software within a
resource provisioning infrastructure is modelled without distinguishing the infra-
structure as a resource provider. Also, GLUE 2.0 specifies “the actual decision
on the service side is performed by an authorisation component that may contain
a finer-grained set of policy rules that in some case may contradict the published
coarse-grained policy rules [Andreozzi et al., 2009].” This indicates that fine-
grained resource provisioning is monitored and managed by provider domains.
However, as large numbers of users exist in a provider domain, fine-grained re-
source management is challenging. As a result, policies for resource management
per job for a specific user are not enabled in Grids or Clouds to date, as discussed
in Section 2.2.
Overall, GLUE 2.0 structures the entities that participate in e-Science col-
laborations and resource sharing and their relationships. It also models the
information for application execution in e-Science. It forms a comprehensive
knowledge underpinning for a general resource management model. However, the
coarse-grained constraints specified by GLUE 2.0 cannot enable the fine-grained
resource sharing management required by research groups. GLUE 2.0 does not
consider constraints for commercial Cloud usage.

2.4. CURRENT E-SCIENCE RESOURCEMANAGEMENT: A SEMANTIC VIEW79
2.4.3 Accounting: Usage Record and Compute
Accounting Record
Accounting is an essential part of resource sharing management. For solutions in-
volving properties for fine-grained accounting, OGF Usage Record (UR) has been
studied. The Compute Accounting Record (CAR) will be discussed briefly for ac-
counting properties for computing resource provisioning. Accounting properties
are researched here not only for after-execution accounting but also for resource
provisioning decisions. For instance, we can consider the maximum CPU time
an e-Scientist or a group manager wants to assign to a job. Such accounting
properties are considered important in this thesis for: (i) fine-grained resource
sharing management in research groups; and (ii) accountable resource provision-
ing between independent research groups and resource providers, which can be
required by an open market. Accordingly, the following discussion will focus on if
an accounting record can present the accounting data accurately for a contract-
oriented collaboration. This is to avoid disputes in a business scenario, which can
be applied to an open market.
The OGF UR is intended to enable the exchange of basic accounting data
regarding different resources between infrastructures. UR accordingly can be
applied to the accounting of resources that are provided collaboratively from
multiple infrastructures for a job. UR focuses on the representation of resource
consumption by outlining the basic building blocks of an accounting record. Ac-
counting properties are categorised into blocks for computing, job, memory, stor-
age, cloud usage, and network. UR also designs a block of properties related to
the identity of the subject accounted for. To meet the increasing application of
Cloud services, UR considers properties related to Cloud usage. For example,
Cloud service consumption can be measured by the Charge property of a corres-
ponding virtual machine type.
The properties specified in UR can be applied to corresponding resource usage
in blocks. However, UR does not discuss the relationships among blocks, that
is, how these resources can be connected and accounted together. Computing
instances supplied by Cloud providers include both computing and storage ser-
vices. In this situation, the Cloud usage and the storage blocks are correlated,
while such relationships cannot be represented in a UR accurately. For example,
an e-Scientist initially requests one AWS m3.large EC2 instance for job executi-

80 CHAPTER 2. BACKGROUND
on1. Each m3.large instance includes 4 virtual CPUs and 4GB storage. During
execution, the job requires an additional 1GB storage, which activates AWS S3
storage services. In this case, the solution to representing the consumption with
a UR is to use a cloud usage block for the m3.large instance used, and a storage
block for the extra 1GB storage consumed. However, the cloud usage record in the
UR does not include detailed service information, such as the 4 virtual CPUs and
4GB storage contained in the m3.large instance. Furthermore, it cannot present
the situations for combined resource consumption, such as both the m3.large
instance and 1GB S3 storage were used to complete this job. These conflicts may
introduce a dispute in a contract-oriented collaboration. In addition, UR does
not specify a Charge property for a cloud usage block instance, which is required
for commercial Cloud usage.
Furthermore, UR only illustrates accounting-related properties for each block
without relating these properties to a specific execution environment. For in-
stance, it specifies CpuDuration for the CPU time consumed by a job without
showing the CPU model and speed that make up the environment to execute
the job. This thesis argues that this not be sufficient for a formal accounting re-
cord for a contract. Alternatively, for resource management purposes, GLUE 2.0
relates an application to its required execution environment and corresponding
management properties. As shown in Table 2.4, GLUE 2.0 can relate an applica-
tion to its required operating system and to the maximum CPU time that can be
allocated to a job instance of this application. This coarse-grained resource man-
agement approach can be extended with the accounting properties learned from
UR and CAR for fine-grained resource sharing management, as will be discussed
in Chapter 4. Table 2.4 only presents a subset of the properties for computing
resources and application execution in both GLUE 2.0 and UR for demonstration
purposes.
The CAR design is based on extending UR with specific properties that can
be applied for accounting purposes. The principal goal of the CAR is to provide
standard definitions for many of the optional accounting record properties of-
ten used in production. For example, UR defines the CpuDuration property to
contain the CPU time consumed by a job. In CAR, this is extended with an
attribute usageType, which specifies the type of CPU time measurement referred
to in the value. The value can be user, system or all (i.e. system+user). CAR
1For the applied instances’ information: https://aws.amazon.com/ec2/instance-types/

2.5. A WAY FORWARD 81
Table 2.4: Application execution properties semantic mapping: GLUE 2.0 & URGLUE 2.0 URAppName —
AppVersion —OSName —
CPUModel —Platform —
CPUClockSpeed —PhysicalCPUs ProcessorsMaxCPUTime CpuDuration
MainMemorySize (VirtualMemorySize)MemoryResourceCapacityRequestedMemoryResourceCapacityAllocated
is for computing resources only. So, for other types of resources, the EMI Stor-
age Accounting Record (StAR) [Jensen et al., 2013], EGI Cloud Usage Record
(CUR) [EGI, 2018b], and Storage Accounting Implementation (SAI) [Cristofori,
2011] can be applied.
For facilitating interoperability, UR and CAR are widely applied for resource
accounting in e-Science infrastructures. The EMI, which aims at Grid interop-
erability of major European middleware providers (ARC, dCache, gLite, UNI-
CORE), adopts UR and CAR for the recording and accounting of resources [Aif-
timiei et al., 2012], as shown in Table 2.3. The table also shows that: (i) the
middleware not having applied UR and CAR are working to enable them now
(i.e. QCG and NorduGrid); and (ii) UR has been adopted for Cloud services
consumption in the virtualisation-enabled Grid FedCloud. The survey in [Riedel
et al., 2009] also reports that UR is widely implemented in e-Science infrastruc-
tures for resource usage tracking and accounting. Furthermore, [Riedel et al.,
2009] stresses that billing and pricing may increase the uptake of Grids in the
commercial scene and support the sustainability of e-Science infrastructures.
2.5 A Way Forward
The previous sections discuss the varied needs of the entities in e-Science col-
laborations and resource sharing. They also present the approaches available in
current e-Science-enabling infrastructures to support such varied demands, espe-
cially for e-Scientists and research group managers. The discussion reveals the
absence of a solution for: (i) enabling dynamic, customised, and reliable resource

82 CHAPTER 2. BACKGROUND
provisioning for e-Scientists; (ii) allowing accountable resource provisioning and
fine-grained resource sharing management for research groups; (iii) imposing no
binding between research groups and infrastructures for dynamic resource provi-
sioning collaborations; and (iv) being interoperable with existing infrastructures
as well as envisioning expanded interoperability.
Contract-oriented negotiation can be a solution for facilitating these missing
features. Accordingly, a negotiation protocol should be capable of the following:
1. Resolving the range of demands from e-Scientists, group managers, and
resource providers.
2. Imposing effectiveness for contract formation.
3. Considering the independence between research groups and resource pro-
viders for the management of the resource provision lifecycle. In this scen-
ario, the main demand of group managers is fine-grained accountable re-
source provisioning for group members.
4. Considering the features of existing infrastructures, primarily the mechan-
isms to allow e-Scientists and research groups to access resources in infra-
structures as well as the mechanisms for research groups to manage resource
sharing among group members.
2.6 Summary
This chapter has introduced the concepts relating to e-Science collaborations and
resource sharing, which form the foundation of this thesis. Work in this chapter
is formulated to express how dynamic resource provision from various infrastruc-
tures can satisfy e-Scientists’ customised demands, while resource sharing within
a research group can be managed at a fine-grained level. With this perspective,
the chapter has presented the state-of-the-art mechanisms for resource provision-
ing and sharing in the enabling models of e-Science, including the Grid, Cloud,
Cluster, and Alliance models. This chapter has also discussed the lifecycle of
these models for e-Science collaborations and resource sharing.
To investigate negotiable resource provisioning, the chapter has researched
the widely-applied terms for resource provisioning and management used by in-
frastructures. From the perspective of supporting e-Scientists’ job execution re-
quirements, job description languages and terms have been analysed. For the

2.6. SUMMARY 83
demand of fine-grained accountable resource provisioning management, GLUE
2.0 and Usage Record have been studied. The studies lay the foundation for: (i)
collaborative resource provisioning of e-Scientists’ demands; and (ii) fine-grained
accountable resource provisioning management of a research group’s demands.
They also illustrate the perspectives of interoperation and interoperability among
infrastructures.
The remainder of this thesis will present the solutions developed for fine-
grained accountable resource provisioning. These solutions enable: (i) e-Scientists
to execute their computational applications with dynamic and customised re-
source provisioning demands; and (ii) group managers to monitor and control
resource provisioning with the policies defined for group members with fine gran-
ularity. This latter scenario allows fine-grained resource sharing management in
a research group.

84 CHAPTER 2. BACKGROUND

Chapter 3
A Collaboration Model: The
Alliance2 Model
3.1 Introduction
This chapter presents a novel collaboration model, the Alliance2 model. The Al-
liance2 model represents the entities and their demands and responsibilities that
considered by the proposed negotiation protocol. It also models the relationships
among those entities. The Alliance2 protocol is based on the Alliance2 model. An
introduction to the Alliance2 model will be a prerequisite for discussing the Alli-
ance2 protocol. As a result, the Alliance2 model will be presented and discussed
in this chapter, before introducing the Alliance2 protocol in the next chapter.
The Alliance2 model aims at enabling dynamic e-Science collaborations while
managing fine-grained accounting for resource sharing for a research group. It
is an extension of the Alliance model proposed by Parkin [Parkin, 2007]. The
Alliance model distinguishes research groups from resource providers for dynamic
e-Science collaborations. Based on that, the Alliance2 model proposes a resource
management entity within a research group to enable fine-grained resource sharing
management. It highlights the importance of re-thinking the ways to enable e-
Science collaborations and resource sharing. The previous chapter has illustrated
the need for dynamic and accountable resource provisioning to:
1. Support e-Scientists’ computational experiments;
2. Assist a research group to manage resource provisioning and sharing with
fine granularity.
85

86CHAPTER 3. A COLLABORATION MODEL: THE ALLIANCE2 MODEL
The goal of this chapter is to develop a solution that meets these demands
placed upon existing infrastructures. The solution should also be able to meet the
needs of the perspective of interoperability, namely to support dynamic resource
provisioning collaborations between independent research groups and resource
providers. To achieve these goals, the proposed Alliance2 model aims to enable
the following four core capabilities:
1. Being able to manage a complete resource provisioning lifecycle, to enable
dynamic collaborations between independent research groups and resource
providers. This is a novel contribution of the Alliance2 model, compared to
the Alliance model;
2. Being able to support fine-grained accountable resource provision, which en-
ables fine-grained resource sharing management for a research group. This
the other novel contribution of the Alliance2 model, compared to the Alli-
ance model;
3. Being interoperable with existing e-Science-enabling models, by being in-
teroperable with the existing mechanisms for e-Science collaborations. This
is contributed by the Alliance model;
4. Being lightweight to facilitate forming or dissolving short-term or dynamic
resource provisioning collaborations, as discussed in Section 1.1, compared
to establishing VOs and accessing resources in Grids. This is contributed
by the Alliance model.
The chapter begins by: (i) investigating real production use cases in the e-
Science community; and (ii) identifying the demands of dynamic and fine-grained
accountable resource provisioning and lightweight collaborations for resource sup-
ply, in Section 3.2. It then presents the Alliance2 model in Section 3.3, which
is proposed in order to meet these demands. It goes on to analyse the features
of the Alliance2 model in Section 3.4.1, and compare the Alliance2 model with
other e-Science-enabling models and approaches in Section 3.4.2. The analysis
and comparison are conducted from the point of view of the enabled collabora-
tion and resource sharing lifecycles. Finally, a summary of the chapter will be
presented in Section 3.5.

3.2. USE CASE STUDIES 87
3.2 Use Case Studies
3.2.1 Interactive Computational Steering
Computational steering is a process that provides e-Scientists with a way to
interact with simulations by modifying program inputs dynamically while the
program is running [Brooke et al., 2003]. It is referred to as interactive computa-
tional steering in this thesis. Compared with executing and analysing programs
in a batch mode, interactive computational steering improves the efficiency of the
feedback loop between users and programs [Linxweiler et al., 2010]. Two differ-
ent implementations of interactive computational steering are being applied in
e-Science: user-interactive computational steering and data-driven computational
steering. User-interactive computational steering enables user interaction to fur-
ther explore data of interest immediately. Data-driven computational steering
allows automatic execution environment changes to ensure the effectiveness of
the generated data during runtime or to control budgets for resource consump-
tion. User-interactive computational steering has been considered as a use case
in Parkin’s work [Parkin, 2007], to highlight the demands for dynamic resource
provisioning. In addition to Parkin’s discussion, fine-grained resource sharing is
also highlighted as a demand of user-interactive computational steering by this
thesis. As a result, user-interactive computational steering will be discussed as a
use case. Data-driven computational steering is a newly proposed approach and
has not been discussed by other work.
User-Interactive Computational Steering
User-interactive computational steering enables e-Scientists to interact with sim-
ulations and visualisations by modifying program inputs during runtime. User-
interactive computational steering can apply visualisation for real-time investiga-
tion of the data generated and collected from the simulation. When an e-Scientist
detects a parameter region of specific interest, he/she may wish to change para-
meters on the fly or to investigate this region further with higher resolution for
visualisation. For further investigation with higher visualisation resolution, all
investigation needs to be rescheduled to resources that have sufficient computing
capability, which is typically facilitated by more CPUs.
At present, user-interactive computational steering is mostly supported by

88CHAPTER 3. A COLLABORATION MODEL: THE ALLIANCE2 MODEL
dedicated computer Clusters. Redundant computing nodes are reserved, for
job re-allocation and performance reasons [Sadashiv and Kumar, 2011], which
leads to low facility utilisation. As user interaction introduces unpredictable
and fluctuating resource usage patterns, it requires supporting mechanisms for
such dynamic resource provisioning. Perhaps because of this extra demand on
resource allocation mechanisms, most extended investigations of the responses
of systems to changes in key parameters have been based on parameter-sweep
methods rather than interactive steering [Mattoso et al., 2013] in most Grids.
Parameter-sweep applications enable running a large number of similar compu-
tations across different combinations of parameter values, requiring the values to
be submitted together for an application’s execution [Volkov and Sukhoroslov,
2015]. Parameter-sweep methods assume that the different ranges of jobs based
on the parameter sweep are known in advance, which makes resource provisioning
predictable. However, from a scientific viewpoint, this assumption will lead to the
following results. First, it prevents efficient identification of areas of particular
interest, as e-Scientists have to wait for all jobs in one submission to complete
before further investigation. In practice, the further investigation can be enabled
by check-pointed job status and re-starting the job with the required resource.
Second, it prevents the concentration of resources at these values, perhaps with
an increased resolution to observe more subtle behaviour.
Dynamic Data-Driven Computational Steering
Typically, computational steering is driven solely by human users. However, in
some scenarios, it is difficult for human users to steer experiments. Such scenarios
include those with large parameter spaces, long run times, and tight steering time
windows. In these scenarios, data-driven computational steering can be utilised
to enable computational experiments to be driven and steered by data collec-
ted from sensors or computer simulation models dynamically and automatically
without user interventions. One example of data-driven computational steering
is the monitoring simulation in a Simulated Water Distribution System (SWDS)
[Hutton et al., 2012]. An SWDS uses the states of a simulation to reflect the states
of the physical water distribution system. In order to do this, model parameters
need to be steered, such as water demands and pipe roughness. Dealing with such
parameters during runtime, even with a small number, is out of the scope of hu-
man ability. Additionally, simulation monitoring is supposed to keep running the

3.2. USE CASE STUDIES 89
whole time, making it impractical for e-Scientists to keep steering the simulation
constantly. Furthermore, an SWDS requires data update frequency to be accur-
ate and high to ensure the effectiveness of the data collected from running water
systems. The data collected in turn can change the requirements of the execu-
tion environment for the system during runtime. If we assume that the updating
frequency of the system is T minutes, then the simulation needs to respond to
the steering update within T minutes. This means that the resources satisfying
the new execution environment need to be determined and new job submission if
required should happen within T minutes. Nevertheless, it is difficult to estimate
the time required by human users to make a steering decision. In order to tackle
these issues raised by human interactions, dynamic data-driven computational
steering aims to automatically make steering decisions using algorithms instead
of having them made by human users. One solution is to assign more computing
resources, typically to increase the number of CPUs, to shorten the execution
time so as to ensure finishing steering in time [Han and Brooke, 2016]. This dy-
namic change of execution environment requires customised resource provisioning
during runtime at short notice. Dynamic and automatic changes to the execution
environment during runtime may also give a group manager concern about the
number of resources consumed by a job.
For both implementations of interactive computation steering, to meet the
demands of dynamic resource provisioning at short notice during runtime, com-
mercial Clouds can be applied as a solution, complementary to Clusters. Mean-
while, pay-as-you-go service consumption of Cloud services pushes e-Scientists to
minimise the use of resources by shortening experiment lifecycles. Runtime inter-
action can shorten research lifecycles and is of potential benefit to e-Scientists to
save the costs of resource consumption [Dias et al., 2011, Linxweiler et al., 2010,
Mattoso et al., 2013], as shown in Figure 2.3.
However, as discussed in the previous chapter, existing Clouds (both commer-
cial Clouds and virtualisation-enabled Grids) cannot track resource consumption
per job, while Clusters are commonly not compatible with external infrastruc-
tures. All these factors may lead to a situation where one of the group members
can easily use all of the group’s resources with the Cloud pay-as-you-go mechan-
ism.
Furthermore, interactive computational steering enables members of a re-
search group to monitor the same simulation during runtime, collaboratively.

90CHAPTER 3. A COLLABORATION MODEL: THE ALLIANCE2 MODEL
This may have the result that two or more members compete for the same re-
sources for further investigation while they are collaborating to monitor a simu-
lation and share the data generated. In such a scenario, access control is critical
for resource sharing and provisioning in the research group.
To summarise, interactive computational steering by a collaboration of e-
Scientists provides scenarios that are good use case drivers for dynamic, custom-
ised, and accountable resource provisioning. Dynamic and customised resource
provisioning is required by e-Scientists during runtime, while the decisions re-
garding access to the shared resources should be authorised and monitored by a
group manager.
3.2.2 VO Group Dynamic Collaborations
Both [Sherif et al., 2014] and [Torres et al., 2012] describe a situation that requires
short-term collaborations under resource management via VOMS. That is when
two or more groups of a specific VO or groups from different VOs seek to col-
laborate on the achievement of a particular objective. This type of collaboration
may require dynamic and reliable access control to the shared resources.
As discussed in [Torres et al., 2012], some e-Scientists from two VOs in the field
of medical imaging need to collaborate for a short period to investigate a medical
problem. This collaboration involves patients’ data and medical images, which
demand critical access control. [Sherif et al., 2014] also points out that in the
BIOMED VO and IBERGRID VO, two in-production VOs for medical research,
the resources within the VOs are normally open to all members, regardless of
which groups they belong to. This access control mechanism exposes critical
authorisation issues for data protection in short-term collaborations. [Sherif et al.,
2014] points out that, to create subgroups within a VO needs to obtain approval
and new membership establishment from the administrator of the VO. It also
requires reconfiguration of the infrastructures involved to support fine-grained
policies among groups. All these demand non-trivial time and effort.
The situations presented in [Sherif et al., 2014] and [Torres et al., 2012] demon-
strate the needs for: (i) short-term and lightweight collaborations; and (ii) fine-
grained access control for existing VO groups to access credential data in the
lightweight collaborations formed.

3.2. USE CASE STUDIES 91
3.2.3 Dynamic Resource Supply for FedCloud
FedCloud, as introduced in Section 2.2.1, claims to build a seamless Grid of
private academic Clouds and virtualised resources. FedCloud is built upon open
standards. It aims to enable e-Scientists to take total control of deployed ap-
plications by dynamic and immediate resource provision based on real needs. In
FedCloud, a collaboration of e-Scientists is regarded as being independent of in-
frastructures as resource providers. To achieve the independence, authorisation in
FedCloud is conducted by Argus [CERN, 2018], which manages authorisation of
research groups. Argus distinguishes a resource provisioning infrastructure as an
authorisation client from an authorisation server. The authorisation server runs
on the Argus nodes as shown in Figure 3.1, making decisions for authorisation
requests for e-Scientists from a research group.
PolicyExecution
Point(PEP
Server)
PolicyDecision
Point(PDP)
PolicyAdministra-tion Point
(PAP)
ManagePolicies
EvaluateAuthorization
Requests
Process ClientRequests and
Responses
PIP
OH
Argus Nodes
C/C++App
JavaApp
PEPClient C
API
PEPClient
Java API
PAPAdminTool
Request Authorizationand Enforce Decision
Request
Response
RequestAuthz.
(XACML)
RetrievePolicies
(XACML)
Edit Policy
Figure 3.1: Argus authorization service framework [CERN, 2018]
The communication procedures for an authorisation decision are presented in
Figure 3.1 and can be described as follows. Before an infrastructure starts to
execute a submitted job from an e-Scientist, the infrastructure requests an au-
thorisation decision from the Argus service by supplying the e-Scientist’s identity.
The e-Scientist’s identity is contained in a digital certificate or a proxy certificate.
A proxy certificate also contains the e-Scientist’s authorisation attributes. Con-
sidering that Argus is also intended for authorisation decisions, this thesis takes
the view that the functions of a proxy certificate and Argus overlap for author-
isation purposes. For access delegation purposes, obtaining a proxy certificate

92CHAPTER 3. A COLLABORATION MODEL: THE ALLIANCE2 MODEL
is not appropriate for resource provisioning from non-collaborating providers.
This scenario can apply to the interoperability scenario, where resources can be
provisioned via negotiation based upon open standards. In such a scenario, an e-
Scientist does not know in advance which resource provisioning infrastructure(s)
will be available. This can result in: (i) the inability to decide the attributes to be
used if the attributes are not globally recognised; and (ii) exposing all attributes
in every request, which holds security risks for e-Scientists.
An Argus authorisation server stores and manages e-Scientists’ attributes for a
group. It is for the Argus authorisation server to make an authorisation decision,
rather than resource providers. This is the important feature that makes Argus
different from GridShib as discussed in the previous chapter or other authorisation
mechanisms that are based on proxy certificates alone. Proxy certificates require
resource providers to make authorisation decisions. As discussed in Section 2.3,
this is not appropriate for dynamic resource provisioning collaborations between
independent research groups and resource providers. Also, this leads to coarse-
grained resource sharing management and accounting for research groups, due
to large numbers of users in a provider domain. Based on these reasons, this
thesis forms the conjecture that to extend Argus with the concepts proposed by
the Alliance2 model can structure dynamic and fine-grained accountable resource
provision in the FedCloud.
To summarise, all the use cases discussed demand dynamic resource provi-
sioning, which may require short-term and lightweight collaborations with infra-
structures. Such collaborations require fine-grained accountable access control to
the shared resources. These use cases illustrate that the e-Science community is
trying to find an innovative solution to facilitating the needs of dynamic and ac-
countable resource provisioning for (short-term and small-scale) resource sharing
and collaboration.
3.3 The Alliance2 Model
As introduced in Section 1.3, the main entities of e-Science collaborations and
resource sharing considered by this work are e-Scientists, a group manager, and
resource providers. These three roles are the typical ones involved in negoti-
able resource provision for computational experiments. They are considered as a
reasonable division for small-scale e-Science collaborations that are aimed at by

3.3. THE ALLIANCE2 MODEL 93
the Alliance2 model. This conceptual structure can be scaled up and extended in
practice. For example, it can be scaled up for a large research group that contains
several sub-groups or extended for a research group with more than one group
manager. These three roles are defined as Resource Requester, Resource Manager,
and Resource Provider in the Alliance2 model, as shown in Figure 3.2. The Alli-
ance2 model extends the Alliance model with a Resource Manager, representing
a group manager.
An e-Scientist collaboration attracts e-Scientists in a specific research area
to collaborate. E-Scientists may come from different universities, organisations,
or companies and have limited IT-related skills. Such a collaboration should be
managed with certain rules, such as members’ priorities to access resources and
limitations for resource consumption, while the resources are shared within the
collaboration. As surveyed in Section 2.2.1, the increasing application of virtual-
isation can make a group manager concerned about resource usage accounting at
the member level [Amsaghrou, 2016]. Different from such management require-
ments, e-Scientists are more concerned about whether the available resources
can satisfy their specific demands, and the quality of the resources or services
supplied [Bosak et al., 2014, Venters et al., 2014]. Based on these two entities’
differing requirements, the Alliance2 model distinguishes a Resource Manager
from Resource Requesters. The Resource Manager plays the role of resource
provisioning and sharing management for a Resource Requester collaboration.
In the Alliance2 model, Resource Requesters and a Resource Manager consti-
tute a resource requesting organisation. E-Scientists can be Resource Requesters,
while a group manager can be represented by a Resource Manager. An infrastruc-
ture can act as a Resource Provider, forming a resource provisioning organisation
to support e-Scientist’ application execution demands. Also, more than one in-
frastructure can collaborate in resource provisioning for one job, forming one
resource provisioning organisation. From the point of view of resource provision
for a single job, a resource provisioning organisation is regarded as a Resource
Provider in the Alliance2 model. The internal management of infrastructures in
a resource provisioning organisation is not considered by the Alliance2 model.
A resource requesting organisation can organise resource sharing among e-
Scientists from different organisations, universities, and companies for short-term
and small-scale collaborations. A resource requesting organisation can be in the
form of a research group. A Resource Manager is defined within a resource

94CHAPTER 3. A COLLABORATION MODEL: THE ALLIANCE2 MODEL
requesting organisation, for the following two reasons. First, a Resource Man-
ager may also request resource provision from Resource Providers, which can be
shared in a resource requesting organisation (i.e. a research group). Second, a Re-
source Manager has closer management relationships with Resource Requesters
(i.e. group members) in the Alliance2 model, compared to models that do not
consider fine-grained resource sharing management. Fine-grained resource shar-
ing management requires more management and communication between group
members and a group manager. A resource requesting organisation is a conceptual
organisational boundary. For implementation, the tools for Resource Requesters
and a Resource Manager are not necessarily bound together.
A resource requesting organisation is a task-forming organisation, gathering
e-Scientists with the same research interest for a collaboration. The e-Scientists
in a resource requesting organisation are experts in a specific research area. They
build applications and establish application execution environments to conduct
experiments specifically for their research area, forming tasks that require re-
source provisioning for execution. To establish rules for resource sharing is also
considered in the task forming process, as task execution should be managed
with resource sharing rules in a resource requesting organisation. A resource
provisioning organisation can represent an infrastructure or a collaboration of
infrastructures, to satisfy the tasks formed in resource requesting organisations
by provisioning the required resources. These relationships are also shown in Fig-
ure 3.2.
Figure 3.2 demonstrates that to conduct computational experiments, Resource
Requesters and a Resource Manager collaborate to set up the execution envir-
onment required by applications, resource sharing policies, and application exe-
cution management, etc. Resource Providers supply resources for the execution
environment set up if required and for application execution. The Resource Re-
questers and Resource Manager are task formulators, and the Resource Providers
are task satisfiers. Resource Requesters and their Resource Manager have a goal
of collaboration in task formation, and tasks are then passed to the Resource
Providers. As discussed in [Brooke and Parkin, 2010, Parkin, 2007], the separa-
tion of task formulators and task satisfiers clearly defines each entity’s role and
responsibility.

3.4. ALLIANCE2 MODEL ANALYSIS 95
Task Formulator (Resource Requester +
Resource Manager)
Task Satisfier (Resource Provider)
Organisational boundaries
Unlimited interaction between the organisations based on the
contents of the agreement between them
Resource Requesting Organisation
Resource Provisioning Organisation
Figure 3.2: Alliance2 Model: extended based on the Alliance model with a Re-source Manager.
3.4 Alliance2 Model Analysis
3.4.1 Features of the Alliance2 Model
The Alliance2 model is based on the Alliance model proposed by Parkin [Parkin,
2007]. As discussed in Section 2.2, the Alliance model distinguishes a resource
requesting organisation from a resource provisioning organisation. This mech-
anism separates a research group (as a resource requesting organisation) from
infrastructures (as resource provisioning organisations). The separation indicates
that a model based on it: (i) can clarify entities’ different requirements, which
makes shifting resource sharing to a research group achievable; (ii) can enable a
research group or an e-Scientists to collaborate with different infrastructures for
resource provisioning; and (iii) should not have a major effect on either the task-
forming entity or the task-satisfying entity, which enables forming and dissolving
of short-term and small-scale collaborations, or even dynamic resource provision-
ing collaborations. These features cannot be envisioned by other enabling models
(i.e. the Grid model, the Cloud model, and the Cluster model), which manage a
research group with infrastructures centrally, including the ad-hoc structures dis-
cussed in Section 2.3. The reasons are as follows. First, these centrally managed
infrastructures or structures require resource providers to conduct accounting

96CHAPTER 3. A COLLABORATION MODEL: THE ALLIANCE2 MODEL
for resource usage, resulting in coarse-grained resource sharing management and
accounting for research groups. Second, centralised resource management will
introduce more work to enable collaborations with new providers, compared with
independent resource management between groups and providers.
By extending a resource requesting organisation with a Resource Manager,
the Alliance2 model enables fine-grained accountable resource provisioning, in
addition to short-term and small-scale collaborations contributed by the Alliance
model. More specifically, the introduction of the Resource Manager allows the
following two features.
1. The Alliance2 model shifts resource sharing management from a resource
provision infrastructure to a research group. This allows fine-grained re-
source sharing management in the group, as the number of members of a
research group is supposed to be smaller than that of an infrastructure,
especially for small or medium groups. This shift also simplifies the access
control and resource provisioning management for a provider, especially for
collaborations between independent research groups and providers. For ex-
ample, role-based resource management can be utilised for such purpose.
It can reduce the mapping complexity between requesters’ identities and a
provider’s local access management [Brooke and Parkin, 2010].
2. The Alliance2 model manages complete resource provisioning lifecycle for
resource provisioning between independent research groups and infrastruc-
tures. In e-Science, it is the group managers who pay for resource consump-
tion by group members, while group managers may also have restrictions on
resource consumption by group members. Including a Resource Manager
for resource provisioning decisions and consumption notifications contrib-
utes to managing complete resource provisioning lifecycle for collaborations
between independent research groups and infrastructures.
As discussed in Section 2.3, authentication and authorisation are two essential
aspects of resource management. Some existing authentication and authorisation
solutions, such as GridShib and the EGI CheckIn service, separate a research
group from resource providers. However, authorisation is mainly conducted by
providers in providers’ domains. The Alliance2 model stresses that authorisa-
tion for resource provisioning should be conducted by a Resource Manager in

3.4. ALLIANCE2 MODEL ANALYSIS 97
a resource requesting organisation. Also, accounting for resource sharing man-
agement within a resource requesting organisation should also be managed by a
Resource Manager. These two mechanisms introduce the following advantages.
1. They require a small set of common attributes used between a Resource
Manager and a Resource Provider for authorisation decisions. These attrib-
utes may only concern themselves with accountable resource provisioning
features, such as the maximum CPU time a job can consume.
2. They meet the perspectives of an open market, where Resource Providers
may only be concerned with: (i) whether a Resource Requester is a member
of a resource requesting organisation assuming that the Resource Manager
will pay for the resources consumed by this Resource Requester; and (ii)
if any restrictions are demanded by the Resource Manager to be imposed
for resource provisioning required by this Resource Requester (if he/she is
a member of the resource requesting organisation).
3. They make fine-grained accountable resource provisioning on a per job basis
achievable, contributing to fine-grained resource sharing management for a
resource requesting organisation, namely a research group.
The solution to shifting resource sharing management to a resource request-
ing organisation is to enable a Resource Manager to make authorisation decisions
and to enforce resource sharing rules for resource provision. More specifically,
a request from a Resource Provider to a Resource Manager for an authorisa-
tion decision includes the attributes or properties that the required resource
provisioning is concerned about. The response includes only an agreement or
disagreement decision and the related information from the Resource Manager
specifically for this resource provisioning. Such information might be the max-
imum amount of resources or the maximum cost this Resource Requester can
consume for this application execution, as shown in Figure 3.3. The proposed
semantic resource management model in Chapter 4 will give details of shifting au-
thorisation and accounting to a resource requesting organisation. The Alliance2
protocol in Chapter 5 will present the solution to mediating the negotiation of
resource provisioning based on this authorisation and accounting shift.
Additionally, distinguishing a Resource Manager from a Resource Requester
enables application of different security mechanisms for communication with a

98CHAPTER 3. A COLLABORATION MODEL: THE ALLIANCE2 MODEL
Resourcemanager
e-Scientist
Research group
Resourceprovider
1. request + user name
2. requester’s user name
3. authorized+max limit/un-authorized
4. resourceprovisioning
decision
Figure 3.3: Authorisation in Alliance2
Resource Provider. For example, the communication between an e-Scientist as a
Resource Requester and an infrastructure as a Resource Provider can require a
username and a password, while the communication between the Resource Man-
ager and the Resource Provider can require digital certificates. This makes it
possible to permit lightweight clients, while still ensuring critical security control
via digital certificates for dynamic resource provisioning collaborations. Light-
weight clients mean that an e-Scientist does not need to apply for and keep
digital certificates. For infrastructures that allow only digital certificates for au-
thentication, two approaches can be taken to enable lightweight clients. First, for
e-Scientists that have attained digital certificates, a mapping between usernames
and certificates is required. Second, for e-Scientists that do not have digital cer-
tificates, a proxy service can be applied. This approach assumes that a group of
e-Scientists may use the same digital certificate, which may introduce the issue
that the priorities allocated to the certificate are higher than a single member
can have. However, as all resource provisioning requests from members need to
be authorised by the Resource Manager, the Resource Manager can define more
fine-grained rules and pass the restrictions for each resource provisioning to Re-
source Providers. In this way, Resource Providers can apply the restrictions for
resource provisioning, rather than the priorities allocated to the certificate. For
infrastructures that already enable authentication with usernames and passwords
for e-Scientists, such as the EGI CheckIn service, no changes are needed to enable
lightweight clients.
The introduction of the Resource Manager also facilitates the management of
a complete resource provisioning lifecycle in a dynamic resource provisioning col-
laboration. Such a lifecycle includes the processing of: (i) resource usage requests;
(ii) resource usage decisions; (iii) job execution; and (iv) resource management

3.4. ALLIANCE2 MODEL ANALYSIS 99
updates according to resource consumption. The Resource Manager is involved
in (ii), (iii) and (iv) in the Alliance2 model. The original Alliance model does
not consider (iv). As a result, it cannot manage a complete resource provision
lifecycle between independent research groups and resource providers.
Also, the independence between a resource requesting organisation and a re-
source provisioning organisation enables resource provisioning from different in-
frastructures as Resource Providers. A resource requesting organisation or a
Resource Requester can elect to collaborate with different infrastructures for re-
source provisioning. Meanwhile, no changes are introduced to the resource re-
questing organisation’s internal organisational structure or management. The
independence also enables interoperation and interoperability. In the Alliance2
model, the Resource Manager is still within a resource requesting organisation. It
does not change the relationship between a resource requesting organisation and
a resource provisioning organisation. Based on this, the methodology in [Parkin,
2007], applied to map the Alliance structure onto Grids, is still suitable to map
the Alliance2 model onto Grids, and onto infrastructures based on the Cloud
model and the Cluster model. This is the interoperation scenario enabled by the
Alliance2 model. The interoperability scenario assumes that dynamic resource
provisioning collaborations can be formed between Resource Requesters and Re-
source Providers, while resource provisioning is managed by the resource sharing
rules in the resource requesting organisations that the Resource Requesters belong
to. It does not require e-Science collaborations to be formed between resource
requesting organisations and resource provisioning organisations in advance.
However, the introduction of Resource Manager also imposes some disadvant-
ages. A single Resource Manager for a research group can be a single point of
failure. Cloud services can be applied to deal with a single point of failure. Im-
ages of the system for Resource Manager can be recorded and updated regularly.
When a failure happens, replicated managers can be created by applying the most
recently recorded image to start the system from the recorded point, to minimise
the loss. Similarly, checkpointing can be implemented by systems that do not use
Cloud services to recover from failures.
A single Resource Manager can also be a focus of attacks, and if it is com-
promised, all the records of the group are open to the attacker. Group members’
resource usage requests need to be authorised by a Resource Manager. Public-
ation of a compromised Resource Manager can avoid malicious resource usage

100CHAPTER 3. A COLLABORATION MODEL: THE ALLIANCE2 MODEL
requests being accepted by providers.
In conclusion, by adding a Resource Manager, the Alliance2 model is cap-
able of enabling the management of the complete resource provisioning lifecycle
for fine-grained resource sharing in dynamic e-Science collaborations. In the Al-
liance2 model, a resource requesting organisation and a resource provisioning
organisation are distinct and independent. This independence makes the Alli-
ance2 model compatible with infrastructures based on other e-Science-enabling
models.
3.4.2 Comparison with Other Enabling Models and
Approaches
A typical e-Science collaboration and resource sharing lifecycle has been presen-
ted in Section 1.1. Here, we map this lifecycle to the Grid model, the Cloud
model, the Cluster model, and the Alliance2 model specifically. We also compare
the functionalities contributed by the approaches available in infrastructures that
are built on the different enabling models and the functionalities contributed by
the Alliance2 model. This discussion gives a hint of the novel functionalities con-
tributed by the Alliance2 model. The detailed comparison between the Alliance2
model and the Alliance model has been discussed above, and need not be repeated
here.
Based on the discussion of the Grid model in Section 2.2.1, the collaboration
and resource sharing lifecycle of Grids can be summarised as follows:
1. A group manager and a Grid form a collaboration for resource provisioning.
The Grid enforces the resource sharing rules of the group and resource
provisioning rules of the Grid with Grid middleware. The Grid plays the
role of a resource provider. Afterwards, the e-Scientists of the group apply
for access to the Grid and obtain digital certificates for resource access.
2. E-Scientists of the group submit jobs to the provider for execution with
specific demands. The provider checks e-Scientists’ access priorities and the
resources’ availability, allocates resources, and commences job execution.
3. After job completion, accounting for the resources consumed by the job
execution is conducted by the provider.

3.4. ALLIANCE2 MODEL ANALYSIS 101
4. The manager of the group can view the accounting data of the whole group
in a specific time period, which is typically one month in existing Grids, as
discussed in Section 2.2.1
Even though accounting data for each job are recorded by Grids, they are not
made visible to a group manager. Fine-grained accounting for resource sharing
in a group can be enabled by taking advantage of available functions offered by
Grid middleware and other tools.
Also, Grids allow a research group to enforce resource sharing rules within
the group for resource provisioning. Such rules are managed by a Grid, i.e. a
Grid manages all the rules for all the e-Scientists that have access to the Grid.
The number of e-Scientists in a Grid can be in the thousands. As discussed in
Section 2.2.1, this has the results that the sharing rules can only be supported in
a coarse-grained manner.
Many gateways and workflow systems have been developed on top of Grids
to assist e-Scientists in accessing resources for computational experiments. Gate-
ways and workflow systems are solutions to easy-to-use entries for e-Scientists
without the intervention of existing VOs or Grid middleware. They can be:
1. Application- or project-specific, to enable best practices according to the
features of the specific application or project;
2. User-friendly, to enable e-Scientists access via lightweight credentials (e.g.
username/password) and web services. Web services are considered more
accessible for e-Scientists, compared to command line interfaces and desktop
applications [Kacsuk et al., 2012, Shahand et al., 2012];
3. User-oriented, to search for satisfactory resources for individual e-Scientists
or to simplify experiment execution procedures, aimed at helping e-Scientists
to focus only on their research questions. Being user-oriented also includes
the scenario that an e-Scientist creates groups and rules to publish and
share the resources that he/she has access to.
AppLes is one of the early works that developed an application management
system to manage distributed resource scheduling of application execution for the
benefit of end-users [Berman et al., 1996]. AppLes proposed scheduling principles
for distributed resource allocation according to specific application execution re-
quirements. Such requirements are application-oriented, such as the amount of

102CHAPTER 3. A COLLABORATION MODEL: THE ALLIANCE2 MODEL
memory required and cost. AppLes stressed that all resources could be evaluated
from the perspective of the application (or user) ultimately based on how much
each benefits the application’s execution. The resources required by application
execution would be mapped with available resources in infrastructures for re-
source allocation decisions. This idea is also taken by this thesis with a semantic
approach, and more discussion will be presented in Chapter 4. AppLes was pro-
posed for application-oriented resource scheduling and can be applied on top of
existing tools, such as Globus, for application-specific resource provisioning.
Some Grid gateways allow individual users access to Grid resources without
establishing VOs. The GARLI 2.0 web service gateway [Bazinet et al., 2014]
is such an example. It was developed for phylogenetic analysis, based on Glo-
bus software to incorporate volunteer computers, traditional Grid resources, and
computer Clusters. The GARLI 2.0 web service enables an e-Scientist to access
computing resources via a username and password only. The web-based user
interface aims to reduce the entry barrier for potential non-technical users.
However, most of the gateways and workflow systems for Grids require digital
certificates and establishment of VOs. They suppose that a research group (i.e.
a VO) has established resource provisioning collaborations with specific Grids,
and e-Scientists as members have obtained access permissions to the Grids. Also,
the resource sharing rules have been enabled in the Grids. Such gateways and
workflow systems do not consider a role of the Resource Manager: (i) to enforce
rules for job submission from e-Scientists; and (ii) to conduct accounting for job
execution required by e-Scientists as group members. As a result, they do not
introduce any difference to the e-Science collaboration and resource sharing li-
fecycle. However, some of them take advantage of available functions in Grids
and facilitate more advanced functions. The WS-PGRADE/gUSE [Kacsuk et al.,
2012] is one of these examples. It enables both workflow-oriented graphical user
interfaces and application-specific science gateways to Grids. It also distinguishes
the varied demands of different types of users in e-Science collaborations and
tailors different functions for them. Five types of users are considered by WS-
PGRADE/gUSE. They are: (i) workflow developers, who develop workflows for
the end-user e-Scientists; (ii) end-user e-Scientists, who are not aware of the fea-
tures of the underlying infrastructures nor of the structure of the workflows that
enables application execution in the underlying infrastructures; (iii) e-Scientists
who require customised workflows for application execution, taking advantage

3.4. ALLIANCE2 MODEL ANALYSIS 103
of APIs provided by WS-PGRADE/gUSE; (iv) e-Scientists who insist on using
existing application APIs; and (v) e-Scientists who prefer to access the gUSE
services via direct API and to run workflows directly via this API.
Similar to WS-PGRADE/gUSE, the e-BioInfra is a gateway that enables Bio-
medical researchers to access Grid resources via web services [Shahand et al.,
2012]. The e-BioInfra gateway applies role-based user authorisation, distinguish-
ing e-Scientists from an administrator (e.g. a group manager). This is the only
authorisation granularity mentioned in [Shahand et al., 2012]. User authentic-
ation of the e-BioInfra gateway is enabled via username/password. However,
access to Grid resources is still granted via a membership of a VO, using X.509
certificates. Proxy certificates are generated and used by functional components
in e-BioInfra for e-Scientists accessing Grid resources.
Many gateways and workflow systems have also been developed for data-
intensive experiments for workflow and data sharing, such as e-Science Cent-
ral [Hiden et al., 2013, Watson et al., 2010]. This e-Science Central enables an
e-Scientist to publish experiment workflows, conduct experiments using Cloud
services, and share experimental data. It allows an e-Scientist to create groups
and policies for workflow and data sharing. However, similar to gateways and
workflow systems for computing-intensive experiments, e-Science Central is also
user-oriented. It helps users to manage computing experiments and share data.
However, the sharing in this scenario is different from the resource sharing for
computational experiments in a research group. It focuses more on managing re-
source publishing and sharing from an individual e-Scientist’ point of view, rather
than a research group. Also, the lifecycle of workflow and data sharing may be
different from the one of resource provision for computational experiments. Thus,
such user-oriented tools are considered to be out the scope of this thesis.
Apart from gateways and workflow systems, another approach to enabling
resource provisioning is brokering. Gateways are usually tailored to specific ap-
plications and infrastructures, while workflow systems focus on managing resource
composing and data transfer for data-intensive experiments. Differently, a broker
is supposed to: (i) gather available resources from different infrastructures to sat-
isfy e-Scientists’ resource usage demands; and (ii) assist e-Scientists from different
disciplines to find out satisfactory resources. Accordingly, a broker may need to
support more general functions for resource provisioning, compared to gateways
and workflow systems.

104CHAPTER 3. A COLLABORATION MODEL: THE ALLIANCE2 MODEL
Nimrod-G is an early effort for brokers. It searched for Grid resources accord-
ing to the deadline and budget constraints specified by e-Scientists [Abramson
et al., 2002]. Nimrod-G aimed at service-oriented Grid resource provisioning in
an economy-driven approach. [Abramson et al., 2002] refers to protocols that
can be applied for negotiating access to resources and choosing the appropriate
ones. However, the protocols referred to only discuss consumers (i.e. e-Scientists)
and providers. They do not consider the situation where a consumer may come
from a research group, where the group wants to enforce resource sharing rules
for resource provisioning to consumers. As a result, they do not consider a role
of Resource Manager as proposed by the Alliance2 model. However, in e-Science
resource sharing, the Resource Manager can be the entity that pays for resource
usage and has constraints for resource consumption by a member.
Similarly, ICENI enabled e-Scientists to access Globus-based resources via web
services [Furmento et al., 2002]. ICENI converged the demands from e-commerce
and e-Science communities. ICENI proposed the idea of providing resources to
a group of users according to a contract formed between the group and the re-
source provider. It also proposed that a member of the group could negotiate
resource usage according to an established contract. This proposal requires that
the restrictions of the new contract be consistent with those established by the
group. However, resource sharing management within research groups was not
the focus of ICENI. Therefore, the contract considered by ICENI focused on ac-
cess restrictions of shared resources, rather than accounting related information
for resource sharing management purposes as proposed by the Alliance2 model.
From the discussion above, we can see that gateways, workflow systems, and
brokers are built upon existing infrastructures and developed for the benefits of
e-Scientists only. They aim to provide user-friendly interfaces for e-Scientists to
focus on and conduct the research of interest or search for available resources.
Some of them consider different roles to enable e-Science experiments, such as
software developers and workflow developers. However, none of them considers
a role of Resource Manager as in the Alliance2 model for resource sharing in an
e-Scientist collaboration.
Even though scientific gateways, workflow systems, and brokers are proposed
with different purposes, they are compatible with the Alliance2 model. For sci-
entific gateways and workflow systems, resource searching occurs before job sub-
mission and accounting occurs after job submission. Correspondingly, extensions

3.4. ALLIANCE2 MODEL ANALYSIS 105
can be built to search for available resources before job submission and to con-
duct accounting after job completion. These solutions assume that individual
e-Scientists have formed a research group and resource searching and provision-
ing obey the resource sharing rules of the group. A solution to extending an
existing Grid gateway as a broker has been implemented and evaluated in this
thesis and will be presented in Chapter 6. The broker developed by this thesis
can also give a hint to how to enable the Alliance2 model by following a brokering
approach.
The lifecycle of the Cloud model and Cluster model is similar to that of
the Grid model, except the following two features. First, Clouds facilitate more
advanced capability of access control and accounting, as discussed in Section 2.2.2.
Second, the access policies and accounting in Clusters can have fine granularity,
namely for each member for each job, as discussed in Section 2.2.3.
The same features of Grid gateways, workflow systems, and brokers apply to
those for Clouds. Differently, the focus of Cloud service searching is on cost and
deadline for execution. Tools have been developed to minimise the cost of service
consumption while satisfying e-Scientists’ resource and deadline demands [Maciej
et al., 2012, Pawluk et al., 2012, Vecchiola et al., 2012]. No group resource sharing
management is likewise considered by these tools, apart from those supplied by
Cloud providers, which have been discussed in Section 2.2.2.
Based on the definition of collaboration lifecycle in Section 1.1, the unique
aspects of the lifecycle contributed by the Alliance2 model can be depicted as
follows.
1. An e-Scientist can be aware of the available resources that can meet specific
demands before job submission. An e-Scientist can choose the resource that
meets his/her demands and/or can offer the most benefits. Meanwhile, the
resource provisioning is based on the resource sharing rules within the group,
which is managed by the group manager and not necessarily known by the
provider. Such rules may include the maximum amount of resources this
e-Scientist can consume for each job. After the provider has confirmed the
resource usage and related restrictions, the job is submitted to the provider
for execution.
2. The group manager is aware of the formation of a resource provisioning
collaboration required by a group member and may update resource sharing
information within the group accordingly.

106CHAPTER 3. A COLLABORATION MODEL: THE ALLIANCE2 MODEL
3. Accounting data for the resources consumed by the job execution is provided
to or calculated by the group manager. The accounting on a per job basis is
not necessarily conducted by the provider. Accounting granularity depends
on the existing accounting mechanisms in provider domains. For Grids
as providers, if the accounting data for a specific job is accessible to a
group manager, this information can be fetched by the manager after job
completion. For Clouds as providers, the duration of resource consumption
can be calculated, and the accounting for the job can be conducted by the
manager. This supposes that the job will be executed immediately after
forming a resource provisioning collaboration and job completion will be
communicated to the group manager.
In summary, the lifecycle contributed by the Alliance2 model is different in
the following aspects when compared to the other enabling models:
1. An e-Scientist can determine which resource(s) will be applied for job exe-
cution according to specific demands before job submission.
2. The group manager is able to enforce rules for resource provisioning and is
aware of resource provisioning decisions. The group manager is also aware
of the number of resources consumed after job completion.
These differences are introduced by the role of Resource Manager. The Re-
source Manager enables: (i) accountable resource provisioning between independ-
ent resource requesting organisation and resource provisioning organisation; and
(ii) fine-grained resource usage accounting for Resource Requesters, who can be
members of the resource requesting organisation.
3.5 Summary
This chapter has discussed the demand for short-term and lightweight collab-
orations, as well as dynamic and fine-grained accountable resource provisioning
with real e-Science use cases. With these use case studies, this chapter high-
lights the different requirements from different entities in e-Science collaborations
and resource sharing. This chapter then presents a novel e-Science collabora-
tion model, the Alliance2 model, for short-term and lightweight collaborations

3.5. SUMMARY 107
between research groups and resource providers. The Alliance2 model shifts re-
source sharing management from resource providers to research groups, contrib-
uting to fine-grained resource sharing management among group members. The
independence between research groups and resource providers enables dynamic
resource provisioning from different providers. It also makes the Alliance2 model
interoperable to existing infrastructures. The introduction of a group manager in
the Alliance2 model enables the management of a complete resource provision-
ing lifecycle for collaborations between independent research groups and resource
providers. Meanwhile, mechanisms are needed to deal with failures or attacks of
the systems for group managers in practice.
The next chapter moves on to the proposed resource management model. The
model is designed to represent and satisfy the different requirements of the entit-
ies designed in the Alliance2 model. It also establishes a common understanding
of resource provisioning and sharing management among the different entities via
negotiation. Built upon the Alliance2 resource management model, a semantic
model for e-Science resource management will be presented in the next chapter.
With the established semantic model, the next chapter will also demonstrate the
development of ontologies and software to enable accountable resource provision-
ing for negotiation.

108CHAPTER 3. A COLLABORATION MODEL: THE ALLIANCE2 MODEL

Chapter 4
A Resource Management Model:
The Alliance2 Resource
Management Model
4.1 Introduction
This chapter proposes a novel resource management model and a semantic imple-
mentation of it. This resource management model is intended to cooperate with
the negotiation protocol proposed in Chapter 5 to enable accountable match-
making and resource consumption for dynamic resource provisioning. Chapter 5
presents a negotiation protocol with designed messages and messaging behaviours,
while this chapter illustrates an information structure and the information con-
tained in the structure. This information can be the contents of messages for
negotiation. The structured information contained in messages can be used to
describe the resources and other features that are the subject of negotiation. Such
structured information will be semantically represented by ontologies, as will be
presented in this chapter.
The established semantic resource management model is able to manage re-
source sharing among e-Scientists of a research group according to access control
policies specified by a group manager. Meanwhile, resource provision from in-
frastructures can follow the resource sharing rules of the group. Based on the
Alliance2 model, this resource management model enables applicable account-
able resource provisioning. For accountable resource provisioning, two aspects
must be achieved: (i) accounting for fine-grained resource sharing management
109

110 CHAPTER 4. A RESOURCE MANAGEMENT MODEL
in a research group; and (ii) accounting for coarse-grained resource provisioning
management for infrastructures as resource providers. Accountable resource pro-
visioning is contributed by two functions: accountable matchmaking for resource
searching and accountable resource consumption for job execution. This means
that a group manager: (i) can inform a resource provider of the restrictions set
for the e-Scientist as a requester, such as the maximum cost for the required
application execution; and (ii) is aware of the e-Scientist’s decisions of resource
selection as well as the amount of resources consumed by the application execu-
tion. Accordingly, the main challenge to be solved in this chapter is establishing
a resource management model to enable the following functions.
1. A common understanding for different entities to describe their demands
and relationships in e-Science collaborations and resource sharing. This
contains the contents that can be negotiated among entities.
2. Fine-grained resource sharing management and accountable resource provi-
sioning for a research group. This can be achieved by defining properties to
establish the relationships required by fine-grained resource management.
The values of the properties developed can be queried and updated during
matchmaking and accounting.
3. Automatic resource matchmaking for negotiation and programs to update
values of accounting properties for matchmaking and resource consumption.
In light of the increasing application of ontologies for semantic information
modelling in e-Science, this chapter begins with a discussion of related work in
Section 4.2. This discussion demonstrates how ontologies can be applied for re-
source matchmaking and management purposes, from a semantic point of view.
Then, an introduction to ontologies is presented in Section 4.3, including a com-
parison with databases for resource management purposes. Section 4.4 goes on
to demonstrate the deployment architecture of the developed ontologies, which
shows the ontologies’ functional relationship. Following this, Section 4.5 intro-
duces the approaches taken to build the proposed resource management model.
To establish the model, a set of common terms has been observed from existing
infrastructures to enable accountable resource provisioning [Raman et al., 1998].
These terms can be used for resource description and management. They also set
the baseline to enable resource information gathering and processing from differ-
ent infrastructure domains. In the process, this chapter identifies the properties

4.2. RELATED WORK 111
required for fine-grained accountable matchmaking and resource sharing. This
chapter then illustrates how the proposed resource management model can sup-
port fine-grained accountable resource provisioning with the identified properties
in Section 4.6.
Section 4.7 evaluates the proposed model with the built ontologies and soft-
ware. Data-driven computational steering (as discussed in Chapter 3) has been
applied as a use case. The implementation follows the same principles applied
in production infrastructures for resource management purposes. It manages in-
formation distribution and processing by using ontologies and developing Java
programs for matchmaking and updating accounting information. This section
goes on to evaluate the functionalities and performance of the ontologies and
software. Finally, Section 4.8 summarises the chapter.
The ontologies and software presented in this chapter have been published in
[Meng et al., 2016].
4.2 Related Work
The related work discussion will focus on semantic information modelling and
matchmaking functions enabled upon the developed semantic model. Other ap-
proaches that enable resource management for computational experiments, such
as database-based systems, will not be discussed here. The discussion attempts
to find out whether existing solutions can meet the demands of: (i) collaborations
between independent research groups and resource providers, and (ii) small-scale
research groups. In other words, whether existing solutions enable fine-grained
resource sharing management for a research group and coarse-grained resource
provisioning management for a resource provider for dynamic resource provision-
ing will be investigated. In addition, the following three aspects will also be
explored. First, inputs from e-Scientists as requesters for job execution, as they
are considered important to make access to resources user-friendly to e-Scientists.
Second, the type of resources or services that can be supplied by providers, i.e.
Grid/Cluster resources or Cloud services, as they may require different mechan-
isms for resource management purposes. Third, the resource management model
applied. This is for the interoperation and interoperability purposes, to figure
out whether a model can collect and process information from different infra-
structures.

112 CHAPTER 4. A RESOURCE MANAGEMENT MODEL
An Ontology-Based Resource Selection Service (OReSS) to search for satis-
factory Cloud services according to an e-Scientist’s requirements has been pro-
posed in [Yoo et al., 2009]. OReSS is established based on a layered architecture,
to collect and integrate distributed resource information for Cloud services. To
search for such services, an e-Scientist has to supply all the details of the required
service, including CPUs, memory size, and network. This is called resource-
oriented matchmaking in this thesis. The ontology developed by [Yoo et al.,
2009] does not consider properties for the participating entities involved, or prop-
erties for resource management purposes. The specification or standard that the
ontology is built upon is not specified in [Yoo et al., 2009]. [Yoo et al., 2009]
enables an e-Scientist to specify a degree of similarity that is acceptable between
the services required and the services provided. This mechanism endeavours to
improve matchmaking throughput and reduce job execution time. The selec-
tion of services is based on the degree of similarity. For instance, an e-Scientist
can specify a similarity degree of 90%. During matchmaking, only services that
have a similarity that is equal to or above 90%, compared to the e-Scientist’s
requirements, can be selected.
The similarity between an e-Scientist’s requirements and available resources is
also calculated and further categorised by the CARE Resource Broker (SeCRB)
[Somasundaram et al., 2014] for resource selection. Three categories are enabled:
exact, high-similarity plug-in and high-similarity subsume. The exact region con-
tains resources that perfectly match the requirements specified in a job request.
The subsume region contains resources that are over-qualified, and the plug-in
region contains resources that do not meet the demands of a request. The match-
making and resource selection in [Somasundaram et al., 2014] consider that the
ability to run a job by a given deadline is important for e-Scientists. Accord-
ingly, resource selection is based on the execution time of applications in SeCRB.
SeCRB aims to discover both Grid and Cloud resources via semantic matchmak-
ing while giving higher matchmaking priority to Grid resources. It is considered
that Grid resources perform better than Cloud resources on HPC application ex-
ecution. As a result, Cloud resources are only selected if Grid resources cannot
meet demands. Resources are supposed to be provisioned based on SLAs, to meet
e-Scientists’ QoS requirements. The information required from an e-Scientist may
include hardware, operating system, and the number of nodes required. Thus,
the matchmaking enabled in [Somasundaram et al., 2014] is considered resource-

4.2. RELATED WORK 113
oriented. The resource information modelling in [Somasundaram et al., 2014] is
achieved by extending the GLUE schema in a broker level for Cloud and Grid
resources.
[Hassan and Abdullah, 2011] illustrates a semantic-based scalable and de-
centralised framework for Grid resource discovery. Different from the work in
[Somasundaram et al., 2014, Yoo et al., 2009], which requires an e-Scientist to
specify resource details, resource discovery in [Hassan and Abdullah, 2011] can be
activated by an e-Scientist’s application execution request. That is, an e-Scientist
only needs to provide an application name for matchmaking. The application is
tagged with information contained in a ontology defining what it requires for
execution. This is called application-oriented matchmaking in this thesis. While
information of Grid resources and applications are represented by an ontology,
an agent is developed to deal with the dynamic changes of the Grid, such as to
update the status of resources. However, the ontology and the agent in [Hassan
and Abdullah, 2011] do not consider properties of the participating entities in-
volved, or properties for resource management purposes. The framework presen-
ted in [Hassan and Abdullah, 2011] also calculates the similarity with regards to
the properties of the requested resource and available resource. The similarity
threshold value is defined by an e-Scientist.
The above work concerns resource matchmaking depending on only require-
ments from e-Scientists. In contrast, the work in [Vouros et al., 2010] also enables
resource providers to register and manage their resources for trading. The estab-
lished matchmaking in [Vouros et al., 2010] is focused on Grid resources. The
matchmaking and information modelling in [Vouros et al., 2010] is based on the
ontology developed in [Vouros et al., 2008]. The ontology presented in [Vouros
et al., 2008] considers properties for the participating entities (i.e. e-Scientists
and providers). It allows both resource- and application-oriented matchmaking.
[Vouros et al., 2010] also enables an e-Scientist to specify the price that he/she is
willing to pay for resource consumption. Accounting-related constraints are con-
sidered by [Vouros et al., 2010] for resource trading, such as the maximum price
allowed for resource consumption on a resource per time-slot. However, such
constraints are specified by e-Scientists, rather than by a group manager. Thus,
it does not consider properties for resource sharing in a research group, which
is the concern of a group manager. In [Vouros et al., 2010], the similarity of an
application-oriented matchmaking result is categorised as Exact, Subsumes, and

114 CHAPTER 4. A RESOURCE MANAGEMENT MODEL
Fail, to describe the level of advertised resources’ fulfilment of demands. This
categorisation applies the same mechanism as used by [Somasundaram et al.,
2014] to decide whether a resource matches exactly, exceeds, or does not match
the requirements specified by an e-Scientist.
The ontology developed by [Ejarque et al., 2010a] is based on Grid resource
information. It specifies entities as requesters and providers and establishes a
relationship between them for resource allocation purposes. The ontology in
[Ejarque et al., 2010a] has been extended and applied in [Ejarque et al., 2010b]
for a multi-agent system for Cloud resource matchmaking and allocation. For
matchmaking based upon the ontology, an e-Scientist can specify resource in-
formation, time constraints, and levels of preferences for resource selection. As
a requester needs to supply resource details for job execution, the matchmaking
enabled by [Ejarque et al., 2010b] is categorised as resource-oriented. Policies for
matchmaking can be specified by both requester and provider. This mechanism
seeks to satisfy both entities’ demands. However, properties considered import-
ant for Cloud resource consumption, such as cost, are not discussed in [Ejarque
et al., 2010b].
[Ma et al., 2011] develops a job allocation system for Cloud resources, where
the allocation is based on requirements specified by e-Scientists. The requirements
include a deadline for job execution, budget, CPU size, type of operating system,
and storage size. Accordingly, the allocation enabled by [Ma et al., 2011] is re-
garded as resource-oriented. QoS parameters can also be specified by e-Scientists,
such as response time and availability. [Ma et al., 2011] aims to handle detailed
user requirements for Cloud resource allocation, to ensure a job will be allocated
to the most suitable candidate. Aimed at resource allocation for e-Scientists, the
only participating entity considered in the ontology developed by [Ma et al., 2011]
is CloudUser.
All the research discussed above applies ontologies to model resource manage-
ment information semantically. Matchmaking programs have also been developed
to search for resources that meet a requester’s customised demands. Some of them
present the terms used to model resource information while the terms are project-
specific. Only one of them builds the ontology based on a standard that has been
widely applied by infrastructures, i.e. the GLUE schema. All of them consider re-
source provisioning management between an e-Scientist and a resource provider.
None of them considers an entity akin to the Resource Manager designed in the

4.3. INTRODUCTION TO ONTOLOGIES 115
Alliance2 model for resource sharing management in a research group. However,
resource sharing management is naturally required by e-Science, to enable col-
laborations among e-Scientists in different places. Without distinguishing the
different demands of a research group and resource providers, all of the related
work discussed applies the same resource management granularity to both re-
search groups and providers. In contrast, the ontologies proposed in this chapter
are based upon a widely-applied and comprehensive information model. The
information model has been extended for: (i) fine-grained accountable match-
making and resource provisioning management for resource sharing in a research
group; and (ii) coarse-grained resource provisioning management for a resource
provider.
4.3 Introduction to Ontologies
Being defined as a “formal, explicit specification of a shared conceptualisation”
[Studer et al., 1998], an ontology is able to describe terms, properties, relation-
ships, and constraints of entities that exist for a particular domain. The concepts
and knowledge within the domain can be presented by description languages. The
Web Ontology Language (OWL) [Bechhofer, 2009] is one of the widely-applied
description languages. In OWL, a class is used to construct abstract knowledge
for concepts with similar characteristics. To depict the constraints of domain
concepts, Object Property and Data Property can be used. An Object Property
relates instances of two classes, and a Data Property relates instances to literal
data (e.g. string, number, datatypes, etc.) [McGuinness and Van Harmelen,
2004].
A semantic presentation is capable of describing the participating entities and
resources, as well as their relationships in e-Science collaborations and resource
sharing. This capability is considered important by the author of this thesis to
convey the novel idea of enabling fine-grained resource sharing and accountable
resource provisioning in e-Science. Apart from static semantic representation, the
reasoning capability equips an ontology with automatic and dynamic information
collection, processing, and generation [Hartung et al., 2010]. This enables applica-
tion of the developed ontologies to software, to verify practically the claimed cap-
abilities. As discussed in [Somasundaram et al., 2014], to coordinate distributed
resources and to share the understanding of terms used in different infrastructures

116 CHAPTER 4. A RESOURCE MANAGEMENT MODEL
to describe resources, integrating semantic technology for resource matchmaking
can be a solution.
Furthermore, user-friendly editors and reasoner libraries are available for on-
tology manipulation. For instance, Protege [Gennari et al., 2003] is a widely-used
ontology editor, while Pellet [Sirin et al., 2007] provides reasoner libraries. They
are especially beneficial for a group manager, who may prefer to focus on me-
diating collaboration and resource management and have limited knowledge of
programming techniques.
Based on these functional capabilities, using ontologies introduces the follow-
ing advantages:
1. The fact that ontologies are rigorously formalised by following logical theor-
ies ensures ontologies’ automated reasoning quality, while they also enable
presentation of semantic features at the same time. The semantic features
include transitivity, reflexivity or inverse, and complement of properties.
These are not supported by non-semantic approaches [Perez et al., 2011].
2. An ontology file is lightweight to exchange and update, compared to man-
aging information in a database. Combined with the inheritance and in-
ference capability, it eases combing and processing information distributed
among different locations. This enables the information to be managed by
different engaged participants. Distributed information processing can be
achieved by inheriting the same common knowledge.
3. An ontology is a widely-used and well-developed method to represent do-
main knowledge. This makes it easy to share and update among different
implementations and deployments [Parkin et al., 2006].
4. An ontology does not describe a specific computer representation for in-
formation and is consequently implementation-independent [Martinez-Cruz
et al., 2012]. This allows different devices for ontology processing, according
to varied demands.
These advantages have contributed to the wide application of ontologies, to
represent resource information and facilitate semantic resource matchmaking.
Apart from the related work discussed, [Ejarque et al., 2010b] utilises ontolo-
gies to achieve semantic interoperability between resource descriptions applied

4.3. INTRODUCTION TO ONTOLOGIES 117
by different public Clouds and e-Scientists’ requests. It aims to search for sat-
isfactory resources via distributed automatic agents. Similarly, the authors of
[Xing et al., 2010] propose an ontology-based information integration system for
generation and maintenance of up-to-date metadata for dynamic and large-scale
Grids. Ontologies have also been applied in [Li and Horrocks, 2004] to support
service advertisement and discovery for e-commerce via intelligent agents.
To take advantage of ontologies’ semantic capability, this thesis applies ontolo-
gies for information modelling in the e-Science domain. The ontologies developed
have been presented with the OWL. The modelled information is focused on the
relationships among e-Scientists, a group manager, and resource providers for
computing resource provisioning in e-Science collaborations and resource shar-
ing. The reasoning capability of ontologies conducts matchmaking to search for
resources according to all involved entities’ demands. Information encoded in
ontologies can be updated for accounting purposes, to manage the complete life-
cycle for resource provisioning for both research groups and resource providers.
Taking these into account, the contributions of the work in this chapter include
the following:
1. The Alliance2 resource management model extended from a widely-applied
and comprehensive Grid information model [Andreozzi et al., 2009]. The
proposed model represents common concepts (including resource, service,
application, resource management, and collaboration management) applied
in various infrastructures. Those infrastructures can be built from different
enabling models, including the Grid, Cloud, and Cluster models. The Alli-
ance2 resource management model also manages the engaged entities with
their relationships and demands, as proposed by the Alliance2 model. The
extensions aim to support accountable resource provisioning for e-Science
collaborations and resource sharing.
2. An implementation of the Alliance2 resource management model that ap-
plies ontologies. The developed ontologies are equipped with fine-grained
accounting properties for authorisation and resource management policies.
These properties can be managed by a research group. They enable match-
making decisions and resource consumption per job in an accountable man-
ner. This implementation is built upon the Alliance2 model proposed in
Chapter 3. Different participating entities’ demands will be managed by
different ontologies.

118 CHAPTER 4. A RESOURCE MANAGEMENT MODEL
3. Software for: (i) application-oriented and resource-oriented resource match-
making utilising automatic reasoning capability of ontologies; and (ii) man-
agement of resource provisioning for resource providers and resource sharing
for group managers by updating values of accounting properties in the on-
tologies developed.
4.4 Overall Ontology Deployment Architecture
According to the roles of entities in e-Science collaborations and resource sharing
(e.g. Resource Requester, Resource Manager, Resource Provider), four ontology
files have been designed and implemented. They are Base, ComputingShare,
MappingPolicy and ComputingService. These ontologies are developed by ex-
tending the specification in GLUE 2.0.
Base ontology (Base.owl): This represents the extended terms and re-
lations as classes and properties respectively. It models participating entities,
resources, and other concepts for e-Science collaborations and resource sharing.
The Base ontology contains the extensions of classes and properties proposed by
this chapter for accountable resource provisioning purposes.
ComputingShare ontology (ComputingShare.owl): This is an instance
of the extended ComputingShare class based on GLUE 2.0. It works as an agree-
ment between an e-Scientist or a group manager and a resource provider. It
specifies the participating entities and the agreed resource provisioning details.
It contains the extensions of accounting attributes for coarse-grained resource
provisioning management for a research group, which may be of concern to a
resource provider.
MappingPolicy ontology (MappingPolicy.owl): This is an instance of
the extended MappingPolicy class based on GLUE 2.0. It targets at specifying
the rules for resource sharing among members of a research group. It contains the
extensions of accounting attributes for fine-grained resource sharing management
for members of the group. It may be of concern to the group’s manager.
ComputingService ontology (ComputingService.owl): This is an in-
stance of the extended ComputingService class based on GLUE 2.0, playing the
role of a resource registry. It can be provisioned by a resource provider to advert-
ise available computing resources. It may contain the extensions of accounting
attributes to define the unit charge or available CPU time of the services.

4.4. OVERALL ONTOLOGY DEPLOYMENT ARCHITECTURE 119
e-‐Scien(st A
Group Management
Mapping Policy.owl
Base.owl
Collaborating Provider AWS
Computing Share.owl
Provider A
Computing Service.owl
Provider B
UserB, group
app resource details
e-‐Scien(st B
e-‐Scien(st C
Computing Service.owl
Figure 4.1: The deployed ontologies’ architecture
The architecture of the deployed ontologies is shown in Figure 4.1. The Com-
putingShare (the ComputerShare.owl) and ComputingService (the Computing-
Service.owl) instances can be deployed and managed in providers’ domains. A
group manager can be responsible for a MappingPolicy instance (the Mapping-
Policy.owl) to manage access control and accounting for resource sharing purposes
within a research group. Values of properties for resource and group membership
management purposes can be updated in instances. Compared to the dynamic
features of instances of ComputingShare, ComputingService, and MappingPolicy,
the Base ontology is more static. It defines the entities and their relations in e-
Science collaborations and resource sharing. The Base ontology (Base.owl) needs
to be inherited (i.e. read) by any instances. It can be deployed anywhere and
allows reading of the information it encodes via the Internet.
The separation of ontology files according to different functional purposes
permits autonomy. It enables entities with different roles to carry out their work
independently and automatically. For example, a matchmaking engine can keep
a ComputingShare ontology locally in a provider domain, to verify requests from
e-Scientists for resource provisioning. The group manager can maintain a Map-
pingPolicy instance for the group’s access control and fine-grained accounting
purposes. Meanwhile, infrastructures as resource providers can have Comput-
ingService ontologies to advertise available resources. The entire procedure of
reasoning upon the architecture imitates resource matchmaking in existing infra-
structures: information advertisement, collection, and processing [Raman et al.,
1998].

120 CHAPTER 4. A RESOURCE MANAGEMENT MODEL
4.5 GLUE 2.0 Extensions and Implementation
4.5.1 Base Ontology: Accounting Property Extensions
The Base ontology extends the main entities in GLUE 2.0 to define fundamental
concepts in e-Science collaborations and resource sharing. To model the concep-
tual entities in the Base ontology, a class ‘framework’ has been constructed. It
follows the approaches applied by [Xing et al., 2006], which developed a Core
Grid Ontology to represent Grid resources semantically. Similarly, three layers
are constructed in the proposed resource management model. The three layers
are for Main Entities, General Classes, and Infrastructure-Specific Classes. Main
Entities and General Classes follow GLUE 2.0 class definition while they are also
constructed with extensions as proposed by this thesis. Figure 4.2 shows the
Main Entities, their relationships defined by GLUE 2.0, and the extensions that
have been constructed on this layer. These extensions will be discussed in detail
in the following sections. The layer for Infrastructure-Specific Classes considers
interoperable translations between GLUE 2.0 and the terms utilised locally in
provider domains. Such terms include job description languages. Extensions
to Infrastructure-Specific Classes can be achieved by defining the relationships
between the Base ontology and the specific knowledge of a resource provisioning
infrastructure.
The classes and properties of GLUE 2.0 have been extended to facilitate fine-
grained accountable resource provisioning, while still obeying the relations among
entities originally defined in GLUE 2.0. All extensions are defined by: (i) con-
sidering the properties applied for job description and resource management in
existing infrastructures, as discussed in Section 2.4; (ii) analysing the relations
between job types supported in infrastructures and corresponding accounting
properties; and (iii) re-using attributes for accounting purposes that are recom-
mended in UR [Cristofori et al., 2013] and CAR [Cristofori et al., 2013]. UR and
CAR have been discussed in Section 2.4.3.
These extensions aim to enable fine-grained resource sharing and accountable
resource provisioning for a research group, and coarse-grained resource provi-
sioning management for resource providers. Fine granularity refers to resource
management for each job request. According to this purpose, class and prop-
erty extensions are focused on the ComputingShare class and the MappingPolicy

4.5. GLUE 2.0 EXTENSIONS AND IMPLEMENTATION 121
UserDomain
<<abstract>> Policy
MappingPolicy AccessPolicy
Endpoint
Activity
<<abstract>> Share
<<abstract>> Resource
<<abstract>> Manager
Service
AdminDomain
<<abstract>> Domain
Location
Contact
ProviderDomain
Main Entities - Relationships
offers defined on
runs mapped into submitted via
offers
manages primary located in
has
primary located in
has
offers
manages
relates to
participates in participates in
participates in
has policies
can be mapped into
can access
exposes
creates
Main Entities – Inheritance
<<abstract>> Entity
<<abstract>> Domain
<<abstract>> Manager
<<abstract>> Policy
<<abstract>> Resource
<<abstract>> Share
Extension
Activity
Location
Contact
Endpoint
Service
Figure 4.2: Extended entities and relationships for the Main Entities: dashedlines highlight the extensions of entities and relationship built upon GLUE 2.0.
class. Corresponding details will be given in the following sections. An example
of such class extensions is the ProviderDomain class and the properties relating it
to the entities and properties originally specified in GLUE 2.0. These extensions
are highlighted in Figure 4.2. We define the ProviderDomain class as follows:

122 CHAPTER 4. A RESOURCE MANAGEMENT MODEL
it represents the entity, which typically can be an infrastructure, to supply re-
sources for computational experiments. The Manager class defined in GLUE
2.0 captures the technical characteristics of local software in a resource provider
domain. Different from this, the extended ProviderDomain class represents an
entity that is willing to provide resources via well-defined interfaces. The exten-
sion is derived from a structural view rather than from a detailed technical view,
to focus on managing related relations. Combined with the AdminDomain class
and the UserDomain class defined by GLUE 2.0, the structural view enabled by
adding a ProviderDomain class can be demonstrated as follows. An infrastructure
presented by a ProviderDomain instance forms a resource provisioning collabor-
ation with a group manager presented by an AdminDomain instance, while the
agreed resources can be accessed and shared by group members included in a
UserDomain instance.
Apart from class extensions, the extended properties for accounting purposes
include:
1. cpuTime Data Property: the remaining CPU time for a research group in
an execution environment (in a ComputingShare instance) or a single user
in a group (in a MappingPolicy instance).
2. balance Data Property: the remaining currency for a research group in an
execution environment (in a ComputingShare instance) or a single user in
a group (in a MappingPolicy instance).
3. charge Data Property: the cost of a specific service for using the CPU(s)
per measurement unit (e.g. per hour or minute) in a ComputingShare
instance or a ComputingService instance.
4. maxCost Data Property: the cost limitation set for a member (in a Map-
pingPolicy instance) or an execution environment (in a ComputingShare
instance) for a job execution per request.
5. maxTotalCost Data Property: the cost limitation of resources that can be
allocated to a job which includes more than one sub-job. This property can
be set for a member (in a MappingPolicy instance) for a job execution per
request.
6. maxCpuTime Data Property: the maximum obtainable CPU time limit that

4.5. GLUE 2.0 EXTENSIONS AND IMPLEMENTATION 123
MappingPolicy
ExecutionEnvironment
ComputingShare
maxCpuTime
UserDomain
Member
maxCpuTime
has
defined on
has
belongTo
has
defined on
defined on
Figure 4.3: The maxCpuTime property extension: the arrows with dashed lineshighlight the extended relations that enable a group to define maxCpuTime foreach member; the arrows with solid lines are the relations defined by GLUE2.0 to enable the same resource management rule to be applied to all the jobssubmitted to a resource.
may be granted to a member (in a MappingPolicy instance) for a job ex-
ecution per request. The extension to maxCpuTime can be illustrated in
Figure 4.3. A UserDomain instance can define values of maxCpuTime for
each member of the group, while the UserDomain instance can be contained
within a MappingPolicy instance. After the coarse-grained properties in a
ComputingShare instance have been verified by a provider, the provider
can require an authorisation decision from the group manager. The de-
cision can be based on the maxCpuTime value defined by the manager for
the requester, which is contained in the MappingPolicy instance. The value
of the maxCpuTime property can be returned to the provider along with a
positive authorisation decision, to enable accountable resource provisioning.
7. maxTotalCpuTime Data Property: the maximum obtainable CPU time limit
that may be granted to a job composed of sub-jobs. This property can be
set for a member (in a MappingPolicy instance) for a job execution per
request.
8. paymentMethod Data Property: the way to calculate the consumption of
resources. Two values have been defined for instantiating this property:
fixed and dynamic. This property can be instantiated in a Computing-
Share instance or a ComputingService instance.

124 CHAPTER 4. A RESOURCE MANAGEMENT MODEL
9. measurement Data Property: the approach of measurement used for quan-
tifying the associated resource consumption, including hour, minute and
second. This property can be instantiated in a ComputingShare instance
or a ComputingService instance.
10. hasJobType Object Property: this indicates how the job should be ex-
ecuted. The defined sub-classes include SingleJob, WorkflowJob, Intera-
ctiveJob.
Take the cpuTime property, for instance, to demonstrate how these exten-
sions can satisfy varied resource management demands in e-Science. As shown in
Listing 4.1, two cases can apply the cpuTime property: for a resource in a Com-
putingShare instance and for a member of a group in a MappingPolicy instance.
The cpuTime instantiated by a ComputingShare instance represents the total re-
maining CPU time on a particular resource available for a research group, while
the resource is instantiated as an ExecutionEnvironment instance. Meanwhile,
it indicates a specific member’s total available CPU time within a group in a
MappingPolicy instance, where the member is an instance of the Member class.
Enabling the assignment of a specific CPU time value to a specific member is the
key to facilitating fine-grained resource sharing in a research group.
Listing 4.1: cpuTime property
<owl :DatatypeProperty rd f : about=”&a l l i a n c e ; cpuTime”>
<rd f s :domain>
<ow l :C la s s>
<owl:unionOf rd f :parseType=” C o l l e c t i o n ”>
<ow l :C la s s rd f : about=”#ExecutionEnvironment ”/>
<ow l :C la s s rd f : about=”#Member”/>
</ owl:unionOf>
</ owl :C la s s>
</ rd f s :domain>
<r d f s : r a n g e r d f : r e s o u r c e=” h t t p : //www. w3 . org /2001/XMLSchema#i n t ”/>
</ owl:DatatypeProperty>
The properties for accountable resource provisioning (i.e. maxCost, maxTotal-
Cost, maxCpuTime, and maxTotalCpuTime) can be defined by a group manager for
a member at the same time. However, for matchmaking and accounting, such a
property will override other properties for accountable resource provisioning pur-
poses, assuming one resource allows only one accounting method. For instance,
maxCost can be used for Cloud services management, while maxCpuTime can be

4.5. GLUE 2.0 EXTENSIONS AND IMPLEMENTATION 125
used for Cluster and Grid resource management. These properties can be inter-
changed with properties for other resources, such as storage. The matchmaking
and accounting programs developed can be adapted or extended for other such
properties easily, as will be discussed in Section 4.6.
The paymentMethod property is constructed as a Data Property with fixed
and dynamic as property values, to distinguish different accounting mechanisms
applied for resource consumption. Fixed is for jobs knowing the number of re-
sources that will be consumed beforehand, which can also be applied to resource
reservation. Dynamic is for jobs that require dynamic resources provisioning. Two
possible cases of such jobs are: (i) jobs enabling interactions with or between pro-
grams during runtime; and (ii) jobs whose execution duration cannot be predicted
during job submission. Interactive computational steering meets both cases, as
it enables users or programs to change resource demands dynamically during
runtime that make execution duration unpredictable. The paymentMethod prop-
erty allows a provider to claim how the supplied resources should be consumed,
while hasJobType enables e-Scientists to express the features of an application to
be executed. Depending on the different accounting metrics used in infrastruc-
tures, three values can be instantiated by the measurement properties: hour,
minute and second. The hour and minute metrics correspond to existing cost
measurement mechanisms of commercial Cloud services, while second is taken
by most Grids and Clusters.
4.5.2 ComputingShare Class Extensions and Ontology
Instance
As defined by GLUE 2.0, the ComputingShare class captures the utilisation tar-
gets for a set of resources. The resources may be supplied according to a re-
quester’s identity, membership in a UserDomain, priority, or the resource charac-
teristics required. Based on this definition, a ComputingShare instance represents
an agreement: (i) between an e-Scientist (as a Resource Requester) and an in-
frastructure (as a Resource Provider); or (ii) between a research group (as a
Resource Manager) and an infrastructure (as a Resource Provider), in this im-
plementation. More specifically, a ComputingShare instance describes the details
agreed for provisioning resources for a member or group, which may be allocated
according to the access control policies for members of the group. The policies

126 CHAPTER 4. A RESOURCE MANAGEMENT MODEL
can be defined by a corresponding MappingPolicy instance in fine granularity. In
this way, the resource provisioning management enabled by the ComputingShare
instance can be at a group or role level. This approach combines the demands
for fine-grained accounting from a research group and coarse-grained accounting
in a provider domain.
To meet such demands, the ComputingShare class is extended with relations
to the following classes: AdminDomain, UserDomain, ProviderDomain, and Ap-
plicationEnvironment, as shown in Figure 4.4. The extended relations, as high-
lighted with dashed lines in Figure 4.4, represent: infrastructure A provides com-
puting resources for users from group B to run application C, which requires D
amount of resources E. The A, B, C, D, E represent information that can be
reasoned about and updated in ontologies for resource management purposes. As
D is literal data, rather than a property, it is not shown in Figure 4.4. Mean-
while, the property hasMappingPolicy in a ComputingShare instance points to
a MappingPolicy instance. The MappingPolicy instance contains fine-grained ac-
cess and consumption control mechanisms within the group. Combined with the
extended properties in the ComputingShare class, the proposed resource man-
agement model can present: infrastructure A provisions computing resources for
user a from group B to run application C, which requires D amount of resource
E and the maximum amount of resource that can be consumed is b. In this
description, properties for a and b are the key properties to enable fine-grained
accountable resource sharing for a research group.
The hasAppEnvironment property specifies the execution environment re-
quired by an application or applications in a workflow, to enable resource match-
making for a specific application. Research group members, a group manager,
and a resource provider can be specified by the hasUserDomain, hasAdminDomain,
and hasProviderDomain properties respectively.
Instances of the ComputingShare and MappingPolicy classes can be dynam-
ically updated by a resource provider and a group manager, for resource provi-
sioning management and resource sharing management, respectively. Take the
cpuTime property in a ComputingShare instance for example. The cpuTime prop-
erty can represent the total remaining CPU time available on a resource for a
research group. After any job from any member of this group is completed, the
value of this property will be updated by the provider. The provider is not con-
cerned about who consumes the amount of CPU time. That is the concern of the

4.5. GLUE 2.0 EXTENSIONS AND IMPLEMENTATION 127
ComputingShare
hasMappingPolicyC:hasAppEnvironment
needLib
hasExeEnvironment
E:
cpuTime
hasOSFamily
hasResource
hasCpuModel
clockSpeed
hasAppB:hasUserDomain
A:hasProviderDomain
hasService
hasAppEnvironment
hasExeEnvironment
hasMiddleware
hasOSFamily
mem
hasResource
hasCpuModel
clockSpeed
measurement
physicalCpus
cpuTime
hasEndpoint
paymentMethod
hasQueue
hasAdminDomain
Fig
ure
4.4:
Pro
per
ties
inth
eC
omputi
ngS
har
ecl
ass:
the
rela
tion
exte
nsi
ons
pro
pos
edby
this
thes
isar
em
arke
dw
ith
das
hed
lines
;th
ere
lati
ons
wit
hso
lid
lines
are
orig
inal
lydefi
ned
inG
LU
E2.
0.

128 CHAPTER 4. A RESOURCE MANAGEMENT MODEL
group manager with a corresponding MappingPolicy instance.
4.5.3 MappingPolicy Class Extensions and Ontology
Instance
GLUE 2.0 defines the MappingPolicy class as an entity that may be used to
express which UserDomain may consume a share of resources. According to
this, an instance of MappingPolicy can be used by a group manager to contain
users’ membership and policies for resource sharing within the group. This can
contribute to resource sharing management and accounting for group members.
However, the MappingPolicy class was originally proposed to include policies
of coarse granularity for collaborations based on the Grid model, as specified in
GLUE 2.0. To enable fine-grained accounting for a resource group, the Mapping-
Policy class is extended with properties for fine-grained accounting, as listed in
Section 2.4.1. These properties can realise resource sharing management for each
member of a group on a per job basis.
The combination of a ComputingShare instance and a corresponding Map-
pingPolicy instance assumes that a resource provisioning collaboration has been
agreed between a requester and an infrastructure. The requester can be a re-
source group or an e-Scientist. This design demonstrates the philosophy applied
for resource management upon ontologies in this work. That is, a Comput-
ingShare instance is for coarse-grained resource provisioning management for a
group from a provider’s point of view, while a related MappingPolicy instance
is for fine-grained resource sharing management from a research group’s point of
view. This feature can also be shown in the extended properties, as discussed in
Section 4.5.1.
4.5.4 ComputingService Class Extensions and Ontology
Instance
A ComputingService instance includes available services’ details, which can be
advertised by a resource provider. By querying service information, e-Scientists or
group managers can establish resource provisioning collaborations with resource
providers dynamically. The combination of a ComputingService instance and
a MappingPolicy instance enables resource provision from new providers, which
follows fine-grained resource sharing policies of a group. So far, two properties

4.5. GLUE 2.0 EXTENSIONS AND IMPLEMENTATION 129
have been extended in the ComputingService class to enable measurement of
resource consumption as specified in Section 4.5.1. They are paymentMethod and
measurement.
4.5.5 Ontology Analysis
Extensions can be achieved by inheriting and inferring their relations with the
established classes and properties in the Base ontology. This mechanism allows
the following features. First, more properties can be extended according to the
resource features supported by infrastructures. Second, concepts and features
of infrastructures can be modelled in Infrastructure-Specific Classes, by introdu-
cing new classes and properties. Third, extensions for other types of resources,
including software resources, network resources, and storage resources, can be
achieved. Take the extension of a specific software available in a provider domain
for visualisation as an example. A subclass VisualisationTools can be built
under the existing Software class. Then, the specific software can be created as
an instance of the VisualisationTools subclass. This extension does not need
to be included in the Base ontology and can be kept by the provider locally. Spe-
cifying that the extension is based on the Base ontology and presenting the URL
to access the Base ontology in an ontology file enable the ontology to fetch and
inherit the Base ontology dynamically. This approach can preserve the stability
of the Base ontology as a common knowledge base while enabling infrastructure-
specific extensions. Combined with the comprehensiveness of GLUE 2.0, this
constructional approach allows representation of any entities and relationships in
e-Science collaborations and resource sharing.
Another approach to information management is using databases. Databases
have been widely implemented for large-scale and centralised resource manage-
ment in infrastructures. For instance, the Berkeley Database Information Index
(BDII) [Field and Schulz, 2005] applies a database for distributed information
management for Grid computing infrastructures. Different from such large-scale
information management, the two main purposes of the resource management
modelling in this thesis are as follows. First, it presents the relationships among
entities to realise the claimed functionalities, namely fine-grained resource shar-
ing management for small- or medium-scale research groups. Second, it makes it
possible for it to be applied to resource sharing management by a group manager,

130 CHAPTER 4. A RESOURCE MANAGEMENT MODEL
who may prefer easy-to-use tools. Considering these requirements, the disadvant-
ages of applying a database, compared to using ontology files, are as follows.
1. A database is not as powerful as an ontology for modelling complex concepts
and knowledge [Martinez-Cruz et al., 2012].
2. A database does not have available tools to directly present and manipulate
the built knowledge in a user-friendly way, as is especially demanded by
group managers.
3. A database cannot be implemented by lightweight platforms. A group man-
ager’s main requirement is to conduct resource management, which is not as
computing-intensive as computational experiments. Group managers would
also demand lightweight tools, such as mobile devices. Ontology files are
lightweight, compared to a database. For example, the largest ontology (i.e.
the Base ontology as presented in Section 4.5.1) developed in this thesis is
102 KB, which includes definitions for 155 classes, 85 object properties,
and 66 data properties. This enables lightweight applications or tools to
be built for group managers to manipulate resource management by using
ontologies. Libraries exist to build such applications or tools, such as Pellet
[Sirin et al., 2007].
One disadvantage of applying ontologies may be inefficiency in managing large
amounts of data. However, as will be discussed in the evaluation section, the
developed ontologies are proposed for resource sharing management in small- or
medium-scale research groups. The amount of data will be relatively small in this
case, making the ontologies’ performance sufficient. When applying the proposed
model for resource management on a large scale, experiences from applying onto-
logies for large-scale information management, for example [Ibrahim et al., 2014,
Vouros et al., 2010], can be learned from. [Ibrahim et al., 2014] uses ontologies
to represent knowledge in the medical and clinical domain, aimed at automat-
ically identifying information in patients’ datasets. [Vouros et al., 2010] applies
ontologies for trading services and resources in Grid e-markets. Alternatively, a
database can be evaluated as another choice for large-scale resource management.
In summary, the design of the ontologies and their deployment architecture
enables dynamic and lightweight information distribution and processing accord-
ing to each entity’s responsibilities and interests. The information for resource

4.6. RESOURCE DISCOVERY AND AGGREGATION 131
sharing and provisioning can be queried, merged, and updated upon distributed
ontology files. These functions can be achieved by the reasoning capability and
dynamic features of ontologies. This information processing mechanism follows
the same principles applied by the Berkeley Database Information Index (BDII)
[Field and Schulz, 2005]. The next section will present the Java programs de-
veloped to realise this mechanism, which are built upon the reasoning capability
and dynamic features of ontologies.
4.6 Resource Discovery and Aggregation
Two types of jobs are allowed by the developed ontology reasoning functions for
e-Science application execution: single jobs and sequential workflow jobs. A se-
quential workflow job can contain multiple single jobs which may be executed in
sequence [Taylor et al., 2014]. Sequential workflow jobs are enabled for resource
matchmaking in the software thus far developed, as it is required by the use case
implemented (i.e. data-driven computational steering). Data-driven computa-
tional steering can apply visualisation after simulation to assist e-Scientists to
visualise runtime results. More details of this use case and the evaluation for the
developed ontologies and programs will be discussed in Section 4.7. Different use
cases may require different types of workflow, which can be developed to extend
existing programs.
Different matchmaking strategies have been developed according to the fea-
tures of e-Science applications and infrastructures. Application-oriented match-
making assumes that a customised environment for application execution has
been established if required [Somasundaram et al., 2014, Zasada et al., 2014]. It
indicates that resource provisioning has been agreed between a requester (i.e. an
e-Scientist or a group manager) and a resource provider, i.e. a collaboration has
been formed. In this case, only performance-related or specific resource-related
features will be investigated. Such features include execution finish time, a cost
limit for resource consumption, and the number of CPUs required. Application-
oriented matchmaking is conducted between a ComputingShare instance and a
MappingPolicy instance. If none of the collaborating providers can fulfil the
requester’s demands and the requester’s balance is sufficient for the required ap-
plication execution, resource-oriented matchmaking will be activated. Resource-

132 CHAPTER 4. A RESOURCE MANAGEMENT MODEL
oriented matchmaking is implemented between a ComputingService instance and
a MappingPolicy instance, searching for satisfactory resources from non-collabora-
ting providers. The matchmaking is carried out with a full package of information
required by application execution. Such information can include the required op-
erating system, CPU model, CPU speed, memory, and storage. Combined with
these two matchmaking scenarios, reasoning algorithms have been designed for
resource allocation and co-allocation, as will be discussed in detail in Section 4.6.2
and Section 4.6.3, respectively.
4.6.1 Reasoning Procedures among Ontologies
This section illustrates the reasoning procedures developed for an application
execution request to demonstrate the functionality of the designed ontologies.
The matchmaking developed assumes that collaborating providers may ensure
good performance, especially when customised application execution settings
are required. For this reason, matchmaking grants higher priority to collabor-
ating providers than new providers. Accordingly, resource searching conducts
application-oriented matchmaking previous to resource-oriented matchmaking.
The reasoning procedures also show the main entities and their relationships in
the constructed conceptual resource management model.
The reasoning logic in Figure 4.5 presents part of the reasoning procedures
enabled for resource- and application-oriented matchmaking. It demonstrates
how matchmaking is achieved for an e-Scientist’s application execution request.
The matchmaking assumes that a ComputingShare instance works as an agree-
ment between a research group and an infrastructure. It contains information
regarding pre-deployed application execution environments if required and the
resources available for this group in each environment. As shown in Figure 4.5,
an e-Scientist can specify his/her username, the name of the application to be
executed, and the research group he/she belongs to for resource matchmaking.
Duration of job execution can also be specified; otherwise, a default value defined
in the ComputingShare ontology will be used. This default value can be set by
the group manager according to the features of applications or the budget control
mechanisms of the group.
The logic in Figure 4.5 demonstrates that when receiving a request, the reas-
oning programs will verify the requester’s identity and membership and, sub-
sequently, whether the requester’s balance is sufficient. This procedure is achieved

4.6. RESOURCE DISCOVERY AND AGGREGATION 133
hasMappingPolicy hasUserDomain
belongToShare belongToUserDomain hasMember
hasAppEnvironment hasApp individualCpuTime
physicalCpus
hasOSFamily
hasResource hasCpuModel
clockSpeed
Access verification
hasComputingService Application-
oriented matchmaking
Resource-oriented
matchmaking
totalCpuTime
cpuTime (balance)
User request UserName, AppName, GroupName
physicalCpus
hasService hasOSFamily
hasResource hasCpuModel
clockSpeed
cpuTime
Step 1
hasAppEnvironment
Step 2
Step 3
hasExeEnvironment
hasExeEnvironment
hasExeEnvironment
Figure 4.5: Reasoning logics among ontologies: rectangles with solid bordersindicate a ComputingShare ontology, rectangles with borders with alternatinglong dashes and dots indicate a MappingPolicy ontology, and rectangles withdashed borders indicate a ComputingService ontology. The block arrays indicatethe common reasoning logic to search for resources in both ComputingShare andComputingService ontologies.
via reasoning an associated MappingPolicy instance, marked as step 1 in Fig-
ure 4.5. It will result in an authorisation decision. To reach an authorisation
decision, the reasoning considers the following two situations:
1. If no specific requirements are specified by the requester such as the number
of CPUs, step 1 in Figure 4.5 will continue to fetch the default required CPU
time and number of CPUs as agreed between the group and the provider in
the ComputingShare instance. Then, these requirements will be passed to
the reasoning of the MappingPolicy instance for an authorisation decision;
2. If specific resource demands are specified, these demands will be passed to
the reasoning of the MappingPolicy instance for an authorisation decision.

134 CHAPTER 4. A RESOURCE MANAGEMENT MODEL
Step 2 in Figure 4.5 will be followed after a positive authorisation decision,
which activates application-oriented matchmaking. Restrictions of concern to
the group manager for resource sharing can be returned together with a positive
authorisation decision, such as the maximum cost allowed. This procedure high-
lights the novelty of the Alliance2 resource management model, which ensures
resource provisioning is manageable on a per job basis for a research group, i.e.
fine-grained resource sharing management. Reasoning on step 2 is also executed
in the ComputingShare instance, which, however, concerns resource provisioning
management on a group basis, i.e. coarse-grained management for a provider.
If none of the collaborating resources within the ComputingShare instance can
meet the demands and the requester’s balance is sufficient, ComputingService on-
tologies will be investigated. This activates the resource-oriented matchmaking
enabled that is shown by step 3 in Figure 4.5. Based on the specific application,
reasoning on ComputingService instances requires a full package of features. The
outcome of a ComputingService instance reasoning is an authorisation decision,
as well as restrictions on resource consumption if the decision is positive.
Figure 4.5 illustrates the generic reasoning logic for both application-oriented
and resource-oriented matchmaking. The reasoning functionalities developed can
be applied to both single jobs and sequential workflow jobs. They can be extended
for jobs of other workflow types.
The information reasoned and the reasoning programs developed, as discussed
above, are based on the specific demands of the use case applied. They can be
project- or application-specific, as well as provider- or user-specific. However,
because CPU time, CPU number, and cost are the common concerns for com-
putational application execution, the software developed can be applied to many
existing cases. Also, it is easy to change or extend existing programs for other
accounting properties. Let us take enabling a property for memory size as an
example. The function to fetch memory size from a ComputingShare or Map-
pingPolicy instance is the same as that to fetch CPU time, requiring only changing
the property cpuTime to memory in the existing function.
The next section demonstrates the algorithms designed and implemented for
resource matchmaking for both single and sequential workflow jobs, based on
features of application execution.

4.6. RESOURCE DISCOVERY AND AGGREGATION 135
4.6.2 Ontology Resource Discovery for Single Jobs
Properties specified in an agreement (i.e. a contract) should be measurable and
quantifiable for resource matchmaking, provisioning, and accounting. These three
procedures are inherently interdependent. For matchmaking based on related
properties, this section defines an agreement in terms of assertions A, where A is a
set of QoS attributes. These QoS attributes are required for resource delivery and
negotiated or agreed between a requester and a provider. A requester must specify
his/her QoS requirements to search for resources that can meet the requirements.
Therefore, our work defines v as the QoS vector consisting of QoS properties, and
R(v) as a set of relationships that exist over v. The set of relations R primarily
specifies the required resources’ properties. These relations can be expressed in
statements that contain logical predicates. They should be measurable and can
be reasoned about, and the predicates can be composed further of properties
and logical operators. Moreover, the assertion A = R(v) must be either TRUE
or FALSE after matchmaking with the attributes described for the relations. So
far, the matchmaking can search for the resources that satisfy the minimum
requirements.
Take the resource-oriented matchmaking activated by this request for ex-
ample: to execute the required application with 3 parallel CPUs each with clock
speed equal or greater than 2.2GHz and with a CPU model as Intel Xeon; each
of these CPUs would be used for 2 hours on a Linux operating system. Given
these specifications, the request for matchmaking is as follows: “At least 3 Intel
Xeon CPUs of clock speed at least 2.2GHz, each available for at least 2 hours.
The program should be run on Linux”. Combined with corresponding properties
defined in ontologies, these QoS specifications can be expressed as an assertion
A of relation R(v) as follows: A = (physicalCpus ≥ 3 ∧ individualCpuTime ≥2 ∧ measurement = hour ∧ clockSpeed ≥ 2.2GHz ∧ CpuModel = Intel Xeon
∧ OSFamily = Linux). This process is similar to the matchmaking enabled by
HPCondor, which develops classads to describe job execution demands [Raman
et al., 1998].
Based on the two matchmaking scenarios (i.e. application- and resource-
oriented matchmaking) set up, different reasoning algorithms to search for re-
sources to satisfy application execution have been designed and implemented.
When a request arrives, resources within formed agreements will be searched for
first by the application-oriented matchmaking, with the demands specified by

136 CHAPTER 4. A RESOURCE MANAGEMENT MODEL
the requester. The demands enabled by this matchmaking process include a spe-
cified deadline or a required number of CPUs. As shown in Algorithm 1, the
application-oriented matchmaking requires the following inputs: a username, a
group name, and an application name. In this algorithm, the properties reasoned
about are: (i) the requester’s membership of the group; (ii) whether the group
has access to execute the application; (iii) the requester’s balance, which will be
compared with the maxCost or maxCpuTime set by the manager; and (iv) the
number of CPUs specified by the requester or the default amount as specified
by a group manager for the application, which is compared with the available
number of CPUs on the provider’s resources. The reasoning of (i) (ii) (iii) can
be conducted by a group manager for an authorisation decision. The authorisa-
tion decision can be returned with the maxCost or maxCpuTime required by the
manager. The reasoning of (iv) can be conducted by a provider to search for
satisfactory resources after receiving a positive authorisation decision.
Algorithm 1 Application-oriented matchmaking applicationInput: username, group name, app nameif the requester is a member of the group then
fetch the requester’s balance, the default CPU number required by the applica-tion, the maxCost or maxTotalCpuTime set by the manager
if the requester has sufficient balance thensearch for execution environments with unit cost at most equal to maxCost,
at least equal to the CPU number as requiredreturn all satisfactory execution environments with resource details
end ifend if
Only when resources within internal collaborating providers cannot meet the
demands, resources available in new provider domains will be searched by the
resource-matchmaking programs developed. The enabled full package of inform-
ation includes the operating system, memory, CPU model, and CPU speed. This
resource-oriented matchmaking algorithm can be illustrated by Algorithm 2. Al-
gorithm 2 shows that, after receiving a positive authorisation decision for the
requester’s request from the group manager, resource-oriented matchmaking is
activated. Algorithm 2 also shows that the authorisation decision during resource-
oriented matchmaking depends on the extended accounting properties only, as the
requester’s membership has been verified during application-oriented matchmak-
ing.
Furthermore, the matchmaking developed enables a combination of sub-offers

4.6. RESOURCE DISCOVERY AND AGGREGATION 137
Algorithm 2 Resource-oriented matchmaking applicationif application-oriented matchmaking failed then
fetch the requester’s balance, the default CPU number required by the applica-tion, the maxCost or maxTotalCpuTime set by the manager
if the requester has sufficient balance thensearch for execution environments with unit cost at most equal to maxCost,
at least equal to the CPU number as required, the required OS and the CPU modelwith at least equal clock speedreturn all satisfactory execution environments with resource details
end ifend if
to form an offer, to satisfy a job request. Sub-offers can be provided by col-
laborating providers or new providers. Both application- and resource-oriented
matchmaking currently return all satisfactory offers. The selection of offers or
sub-offers will depend on demands in practice. In addition, more or other prop-
erties can be included for matchmaking, while such properties are project- or
application-specific. The matchmaking developed can be extended to any other
resources with other features.
4.6.3 Ontology Resource Discovery for Workflow Jobs
The reasoning algorithms for resource matchmaking for single jobs, as illustrated
in the previous section, can also apply to matchmaking for sub-jobs in a workflow
job. This section demonstrates the principles enabled for resource co-allocation
for sequential workflow jobs.
Here we recapitulate previously discussed matchmaking scenarios: (i) match-
making with collaborating resources or with non-collaborating resources; and (ii)
matchmaking with resources within a single domain or within different distributed
domains. Accordingly, the various scheduling scenarios handled by the developed
ontology reasoning programs for workflow jobs are as follows:
• Scenario 1: Application execution requests can be satisfied by collaborating
resources in one execution domain via application-oriented matchmaking.
The matchmaking is conducted in terms of the maximum CPU number
required by sub-jobs and the total CPU time or total cost required for all
sub-jobs.
• Scenario 2: Application execution requests can be satisfied by collaborating

138 CHAPTER 4. A RESOURCE MANAGEMENT MODEL
resources in distributed execution domains (co-allocation) via application-
oriented matchmaking. The matchmaking is conducted in terms of sub-jobs’
CPU number and the total CPU time or total cost required.
• Scenario 3: Application execution requests can be satisfied partly by col-
laborating resources via application-oriented matchmaking, and partly by
resources provided by new providers via resource-oriented matchmaking.
The matchmaking is conducted in terms of some sub-jobs’ CPU number
and the (total) CPU time or (total) cost required; some sub-jobs’ CPU
number, CPU model, CPU speed, operating system, and the (total) CPU
time or (total) cost required.
• Scenario 4: Application execution requests can be satisfied by resources
supplied by only one new provider domain via resource-oriented match-
making. The matchmaking is conducted in terms of sub-jobs’ maximum
CPU number required, CPU model, CPU speed, operating system, and the
total CPU time or total cost required.
• Scenario 5: Application execution requests can be satisfied by resources sup-
plied by more than one new provider domain (co-allocation) via resource-
oriented matchmaking. The matchmaking is conducted in terms of sub-jobs’
CPU number, CPU model, CPU speed, operating system, and the (total)
CPU time or (total) cost required.
The matchmaking algorithm for a sequential workflow job goes through these
five scenarios sequentially to search for satisfactory resources. Matchmaking in
Scenario 3, 4, 5 will only be activated after matchmaking in Scenario 1 and 2 fails.
This is consistent with the principle that application-oriented matchmaking has
higher priority than resource-oriented matchmaking. Apart from the features
of application execution as described above, one more customised matchmaking
demand has also been supported for a workflow job: a deadline to execute the
workflow job.
The above matchmaking algorithm works with Algorithm 1 and Algorithm 2
defined in the previous section to search for satisfactory resources for sequential
workflow jobs. For a sequential workflow job, sub-jobs can be allocated to differ-
ent resources, while resources can be supplied by either collaborating providers

4.6. RESOURCE DISCOVERY AND AGGREGATION 139
or new providers, or both. Offers will only be returned when all sub-jobs are sat-
isfied. Offers contain sub-offers for sub-jobs if sub-jobs are allocated to different
resources.
4.6.4 Access Control for Resource Sharing
Apart from resource features, e-Scientists’ priorities for resource usage are also
considered important for resource provision by a group manager. As a result,
priorities for e-Scientists in a research group to access and use resources are
enabled. Priorities are represented by integer numbers showing different priority
levels in the developed ontologies and programs. A larger number indicates a
higher priority. Priorities can be enabled in different application scenarios for
different purposes. For instance, priorities can be used within a research group
for authorisation management and applied to resources in a provider domain for
coarse-grained resource allocation purposes.
In the developed programs, an e-Scientist’s priority is applied in the follow-
ing two scenarios. The first scenario is when more than one e-Scientist in the
same group competes for the same resource during application-oriented match-
making. The second scenario is when a group manager requires access control to
different application execution approaches (i.e. sequential or parallel) for mem-
bers of the group. Solutions for both scenarios have been enabled for the use
cases implemented in the testbed and will be discussed in detail in Chapter 6.
Combining an e-Scientist’s priority with the matchmaking algorithms developed,
resource-oriented matchmaking will be activated after investigating the following
three cases in this implementation. First, none of the available collaborating re-
sources meets the demands. Second, none of the collaborating resources that are
being negotiated by other e-Scientists with lower priorities meets the demands.
Third, none of the reserved resources negotiated by other e-Scientists with lower
priorities meets the demands.
If still, no resources can meet the demands after resource searching in these
three cases, resources available in new provider domains will be sought. That is,
resource-oriented matchmaking with ComputingService ontology instances will
be activated.
The functions discussed above have been enabled for searching for resources
for both single jobs and sequential workflow jobs. These functions have also been
enabled for distributed resource co-allocation in either a single provider domain or

140 CHAPTER 4. A RESOURCE MANAGEMENT MODEL
multiple provider domains, while the multiple providers satisfy sub-jobs’ demands
for a workflow job.
4.6.5 Accounting for Resource Sharing and Provisioning
Accounting for resource sharing in a research group and for resource provisioning
in a resource provider domain have also been enabled in the developed programs.
The programs have allowed three scenarios for accounting: after successful match-
making, after job completion, and after job termination. A group manager and
a resource provider conduct accounting with different granularity. Accounting
updates for a group manager are activated for a specific member per job, while
for a resource provider they are for resources consumed by a job submitted by
any member of the group.
The use case enabled for evaluation: (i) requires immediate job execution
after successful matchmaking; and (ii) utilises AWS to allow dynamic resource
provisioning when needed. Based on these features, the accounting functionalities
developed assume that resource consumption starts from job submission, and ends
upon receiving job completion or termination notifications from the executed jobs.
Then, they calculate the total amount of the CPU time consumed or the cost and
update resources’ and members’ balances accordingly.
The accounting functionalities manage the complete resource provisioning life-
cycle, complemented by the accountable matchmaking discussed in previous sec-
tions. They also demonstrate that the proposed resource management model can
manage fine-grained resource sharing for a research group, and support coarse-
grained resource provisioning management for resource providers.
4.7 Evaluation
4.7.1 Functionality and Performance Evaluation
The target of the evaluation is to verify that the proposed resource management
model enables fine-grained resource sharing and accountable resource provisioning
for a research group, and coarse-grained resource provisioning management for
a resource provider. The resource management (i.e. accounting) in this process
involves two aspects, for matchmaking and for job execution, respectively. The

4.7. EVALUATION 141
evaluation was conducted on the developed ontologies and programs, by designing
and evaluating scenarios for expected accounting functions.
Data-driven computational steering has been applied as a use case for the
evaluation. As discussed in Section 3.2.1, automatic data-driven steering requires
the system be able to change resource provisioning demands dynamically during
runtime without user intervention. This is to ensure the effectiveness of the data
generated during runtime. However, automatic runtime changes may consume
more resources than a group manager or an e-Scientist will expect or be aware
of, which can be avoided by accountable resource provisioning. Dynamic, cus-
tomised, and accountable resource provision, as required by data-driven compu-
tational steering, makes it a good use case of the proposed resource management
model.
The application of computational steering needs its library to be installed
and configured before steerable job execution, requiring a customised execution
environment. Furthermore, GLUE 2.0 was not designed with commercial Cloud
services in mind, which is considered in the extended resource management model
and needs to be evaluated. Considering these features, we utilised AWS for
resource provisioning in this evaluation.
The developed ComputingShare and ComputingService ontologies have been
instantiated for AWS with corresponding information for the instances used.
Other ontologies do not need changes specifically for this use case. This demon-
strates the generality of the developed ontologies, contributed by GLUE 2.0.
Other Cloud services can be enabled by: (i) changing properties’ values for cor-
responding service, instance, and accounting features in corresponding ontologies
only if no extra features are required; otherwise, (ii) extending the developed on-
tologies and programs for service-specific features, in addition to (i). The values
of the properties and the number of the class instances contained in the developed
ontologies can be edited according to specific cases. All the values applied here
are based on the scenarios designed to model a small-scale research collaboration.
This collaboration scale is as compared with a collaboration on the scale of the
Large Hadron Collider, as discussed in Chapter 2. The definition of a small-scale
research group in this work consists of around 5 to 30 members, as discussed in
Section 1.1. Accordingly, this evaluation assumes that 15 e-Scientists collabor-
ate in a project and form a group, while they use AWS for their computational
application execution.

142 CHAPTER 4. A RESOURCE MANAGEMENT MODEL
To be consistent with the payment method of the AWS EC2 instances used,
service consumption is measured in the unit of hours. The payment method is spe-
cified by the measurement property in the developed ComputingShare ontology.
Accordingly, the properties utilised for service usage constraints for members are
maxCost and balance, to avoid a member of the group consuming an unreason-
able quantity of resources. They are defined in the corresponding MappingPolicy
instance and can be set and updated by a group manager. For demonstration
purposes, the maxCost was set as the cost for one hour of the AWS instance ap-
plied. Both balance values, for the group in each EC2 instance defined in the
ComputingShare ontology and for each member defined in the MappingPolicy on-
tology, are applied for authorisation decisions. They will be checked to see if they
are sufficient to pay at least for job execution for one hour during matchmaking.
The evaluation applied a simple application, which was not computation-
ally intensive. Accordingly, the instance type used was t2.micro for application-
oriented matchmaking. The instances and price information presented here were
obtained from the Amazon Web Services website. Accordingly, service details
were constructed for t2.micro as an execution environment in the Computing-
Share ontology. They included that charge per hour was $0.0131, and CPU
number was 1. For demonstration purposes, the maxCost set for group members
for this instance type was $0.013. Instance type t2.small was also included in the
ComputingShare ontology with group balance as 0. These two settings indic-
ate that only t2.micro should be returned after successful matchmaking and an
application execution will be stopped when it approaches one hour.
Data-driven computational steering enables changes of execution environment
automatically during runtime, which requires matchmaking with a specified num-
ber of CPUs. The running application may require more CPUs than the in-
ternal instances of the collaboration can supply. This scenario would activate the
resource-oriented matchmaking developed. It assumed that the requester still
had sufficient balance, while the existing execution environment could not meet
demands, i.e. instances had fewer CPUs than the required number in this case.
As a result, resource-oriented matchmaking would be activated to search for other
available non-collaborating instances.
The instance types applied for resource-oriented matchmaking were t2.medium,
1The instance information and pricing for this evaluation were observed during July of 2017.

4.7. EVALUATION 143
t2.large, m4.xlarge, and m4.2xlarge. The instances’ features2 and charges3 are
shown in Table 4.1. This information was contained in the developed Computing-
Service ontology. This evaluation scenario assumed that an e-Scientist required
execution of an application with 2 CPUs. Thus, the existing collaborating in-
stances with 1 CPU could not meet demands. As a result, resource-oriented
matchmaking was activated with a detailed specification: operating system as
Linux, CPU model as Intel Xeon, CPU speed as 3.3GHz, and the number of
CPUs as 2. In this case, as the CPU speed required by the application was at
least 3.3GHz, instance information of t2.medium, t2.large would be returned,
including charge per hour.
Table 4.1: Details of the applied AWS instances
InstanceType
OS CPU ModelCPU Speed
(GHz)Number of
CPUs
Chargeper hour
($)t2.micro Linux Intel Xeon 3.3 1 0.013t2.small Linux Intel Xeon 3.3 1 0.026
t2.medium Linux Intel Xeon 3.3 2 0.052t2.large Linux Intel Xeon 3.3 2 0.104m4.large Linux Intel Xeon 2.4 2 0.120m4.xlarge Linux Intel Xeon 2.4 4 0.239
Overall, the scenarios established in AWS for ontology-based resource match-
making and accounting are the following.
1. Application-oriented matchmaking for a single job with the physicalCpus
property. This is activated by an application execution request submitted
by a requester. The CPU number required is at least one.
2. Access control by the balance of an AWS instance. For a job submission
request, the value of the balance property for the requester as a group
member is sufficient to run a job. However, the value of the balance prop-
erty for the group in the satisfying instance is not sufficient to execute the
job for at least one hour.
3. Access control by the balance of a group member. For a job submission
request, the value of the balance property for the requester is not sufficient
to run the job for at least one hour, while other conditions are met.
2For the applied instances’ specification: https://aws.amazon.com/ec2/instance-types/.3For the applied instances’ pricing: https://aws.amazon.com/ec2/pricing/on-demand/.

144 CHAPTER 4. A RESOURCE MANAGEMENT MODEL
4. Access control by the maxCost property. When a job is running after suc-
cessful matchmaking, it will be stopped when the cost of the running job
reaches the maximum amount set by the group manager for the requester.
5. User access control by priority identified with the level property. When
group members with different priorities try to access the same instance, the
request from the member with the highest privilege will be accepted, while
those with lower privileges will be rejected.
6. Resource-oriented matchmaking for a single job with the physicalCpus
required by a running application. This will be activated when application-
oriented matchmaking fails. As required by the running application, the
number of CPUs required is at least 2. During resource-oriented match-
making, the requester’s balance will be checked for job execution for at
least one hour.
The reasoning capability for each property was evaluated by controlling other
properties’ values for the corresponding assumptions as described for each scen-
ario in Table 4.2. The results, as shown in Table 4.2, were delivered by ontology
reasoning enabled by the developed Java programs. They illustrate that the
ontologies and programs developed facilitate application- and resource-oriented
matchmaking based on a requester’s demands, a research group’s expense control
for both members and the group, and the requester’s priority as a group member.
The evaluation shows that the matchmaking and accounting functions developed
support more functions for resource provisioning and sharing than the Related
Work discussed in Section 4.2. [Somasundaram et al., 2014, Yoo et al., 2009] only
considers resource-oriented matchmaking. [Hassan and Abdullah, 2011] considers
both resource- and application-oriented matchmaking. [Hassan and Abdullah,
2011] also considers accountable constraints for matchmaking, which however are
specified by a requester, rather than a group manager. None of the Related Work
considers a role of Resource Manager, indicating that resource sharing manage-
ment of a research group is not considered in these works.
The pure reasoning performance (i.e. excluding network delays) of the de-
veloped ontologies was also evaluated. To measure only the speed of reasoning,
ignoring network delays, all four ontology files were deployed locally. The per-
formance evaluation was run on Mac OS X with 2.8GHz Intel Core i7 and 4GB
memory. The reasoning of each evaluated scenario was repeated 100 times. The

4.7. EVALUATION 145
Table 4.2: AWS single job ontology matchmaking evaluationScenario Result
1. Application-orientedmatchmaking for singlejob with physicalCpus
Assuming that all conditions were satisfied, instancet2.micro was returned with service details. The re-quester’s balance in the MappingPolicy ontology andthe group’s balance in the ComputingShare onto-logy for instance t2.micro were reduced when therequester stopped job execution within the one hourlimit. Also, a stop command was sent to the runninginstance.
2. Matchmaking withinsufficient balance ofAWS instance
Assuming that the group’s balance for instancet2.micro was not sufficient to run an application for 1hour when other conditions were met, no satisfactoryinstance was returned.
3. Matchmaking withinsufficient balance ofgroup member
Assuming that the requester’s balance was not suf-ficient to run an application for 1 hour when otherconditions were met, no satisfactory instance was re-turned.
4. Job executionstopped by maxCost
Assuming that all conditions were met and thejob was executed after successful matchmaking, thejob was stopped when the execution duration ap-proached one hour. The requester’s balance in theMappingPolicy ontology and the group’s balance inthe ComputingShare ontology for instance t2.microwere not reduced, as they had been reduced aftersuccessful matchmaking to avoid over-expenditure.
5. Matchmaking withpriorities identified bylevel
Assuming that UserA and UserB sent requests forthe same instance at the same time and both users’conditions were met and UserA had higher priorityover UserB, UserA was returned with details of in-stance t2.micro as an offer, and UserB was informedthat no satisfactory instance was found.
6. Resource-orientedmatchmaking for singlejob with physicalCpus
required by programs
Assuming that a job required instance type withat least 2 CPUs and the requester had balance of$0.110, instance details of t2.medium and t2.largewere returned.
Table 4.3: AWS job matchmaking performance
Scenario 1 2 3 6Average (ms) 267.1 279.3 272.9 280.8
Standard Deviation (ms) 74.5 74.4 72.5 59.1* ms stands for milliseconds.

146 CHAPTER 4. A RESOURCE MANAGEMENT MODEL
average and standard deviation of the data collected were calculated for the dur-
ation of matchmaking, shown in Table 4.3 as Average and Standard Deviation
respectively.
The reasoning performance of Scenario 1, Scenario 2, Scenario 3, and Scenario
6 are presented in Table 4.3. As shown in Table 4.3, the time to return was only
a fraction of a second. Compared to most Grid or Cloud jobs that require longer
duration, the methods proposed here can be applied where the job duration is
anything over a second. It also indicates that extensions to allow more accounting
properties would not decrease performance, as increasing reasoned elements did
not increase reasoning time significantly. This conclusion is achieved by compar-
ing the performance of Scenario 6 with the other scenarios. In a real distributed
system network, delays would need to be considered. Such delays would be spe-
cific to the network performance between distributed deployed ontologies during
matchmaking.
Performance of Scenario 4 and Scenario 5 was not evaluated, for the following
two reasons:
1. Scenario 4 was designed to verify the functional capability of automatic
ontology updates for accounting attributes, while the reasoning involved is
the same as for Scenario 1.
2. Scenario 5 required manual procedures, which would introduce uncontrol-
lable factors and make it difficult to evaluate the pure performance of auto-
matic reasoning.
There is one scenario that has not been evaluated for its performance, which
has however been facilitated by the developed ontologies. That is matchmaking
for sequential workflow jobs. The reason was that the applied use case has not
hitherto enabled workflow jobs. As a piece of future work, workflow job match-
making can be applied to and evaluated for use cases that have enabled workflow
jobs in existing infrastructures.
4.7.2 Further Analysis
Resource similarity, which has been considered in [Hassan and Abdullah, 2011,
Somasundaram et al., 2014, Vouros et al., 2010, Yoo et al., 2009], has not been
enabled by the software developed. It can facilitate more accurate choices for

4.8. SUMMARY 147
e-Scientists in respect of selecting resources, as well as a higher ratio of successful
matchmaking.
Thus far, the Alliance2 resource management model proposed and ontologies
developed have focused on properties for computational features of application
execution, e.g. features of computing resources. Features of other resources,
including storage, network, and software have not been enabled. Such features
can extend the proposed resource management model to a complete model for all
types of resources. Accordingly, accounting properties for these resources can be
constructed, in addition to the existing ones for CPU time and cost.
The ontology-based approach has been applied and evaluated for small-scale
e-Science collaborations in this chapter. The results show that reasoning per-
formance is efficient for computational applications. This thesis takes the view
that supplying computing resources via open standards is an inevitable trend,
which indicates that the number of users and resources could become very large.
The performance of information storage and matchmaking based upon ontologies
with an immense amount of data should be evaluated. This can be conducted by
comparing resource matchmaking using ontologies with other approaches, such
as databases, for large-scale collaborations.
4.8 Summary
This chapter has presented a novel approach to enable fine-grained accountable re-
source matchmaking semantically for shared resource management in a research
group. It has compared the semantic approach with using a database. It has
also illustrated how the Alliance2 resource management model extended from
GLUE 2.0 for fine-grained accounting purposes has been built. The proposed
model also enables coarse-grained resource provisioning management for resource
providers. The chapter has demonstrated the implementation and evaluation
of the developed ontologies and software. The implementation facilitates auto-
matic resource matchmaking and accounting based on the different requirements
of e-Scientists, a group manager, and resource providers. The performance eval-
uation of the programs has shown that the programs can perform matchmaking
efficiently, considering common Grid or Cloud jobs’ execution time. The chapter
has also discussed further about the disadvantages of the established model, onto-
logies, and software, pointing out the directions for further improvement. Overall,

148 CHAPTER 4. A RESOURCE MANAGEMENT MODEL
the resource management model and ontologies presented have extended an in-
formation model currently widely used for resource matching to provide extra
functionality in the accounting domain.
The next chapter will present the novel negotiation protocol, the Alliance2
protocol. The protocol aims to direct the communication among e-Scientists, a
group manager, and a resource provider to reach a valid negotiation result. The
information negotiated can be presented by the Alliance2 resource management
model in this chapter. The integration of the Alliance2 protocol and the resource
management model facilitates dynamic, customised, and accountable resource
provisioning via negotiation.

Chapter 5
A Negotiation Protocol: The
Alliance2 Protocol
5.1 Introduction
This chapter presents a novel negotiation protocol designed upon the Alliance2
model presented in Chapter 3. The rest of the thesis will illustrate the imple-
mentation and evaluation of the protocol via building formal simulation models
and software, respectively. As this negotiation protocol is specifically proposed
based upon the Alliance2 model, it is named the Alliance2 protocol. The Alli-
ance2 protocol enables an e-Scientist to reach resource provisioning agreements
with resource providers, while agreements can be managed and tracked by the
e-Scientist’s group manager. Accordingly, the goals of the proposed Alliance2
protocol are as follows:
• To manage the complete resource provisioning lifecycle without binding a
research group and resource providers together.
• To enable fine-grained accountable resource provisioning for a research group.
• To enable lightweight but reliable resource provisioning via asymmetric ne-
gotiation. These properties are achieved by inheriting the law-based and
asymmetric negotiation proposed by [Parkin, 2007].
• To be interoperable with existing infrastructures. This is achieved by basing
negotiation upon the Alliance2 model, which inherits the feature of distin-
guishing a resource requesting organisation from a resource provisioning
149

150CHAPTER 5. A NEGOTIATION PROTOCOL: THE ALLIANCE2 PROTOCOL
organisation proposed by [Parkin, 2007].
Taking these goals into account, this chapter begins with a discussion of other
proposals for negotiation protocols that enable dynamic resource provisioning in
e-Science, as will be presented in Section 5.2. The discussion demonstrates the
features required for: (i) contract-oriented negotiation between independent re-
search groups and resource providers; and (ii) interoperation with job submission
mechanisms supported by existing infrastructure. The discussion tries to identify
the advantages and disadvantages of related work based on the features identified.
Based on the discussion, the novelty of the Alliance2 protocol will be presented in
Section 5.3. Then, Section 5.4 introduces the methodology applied for protocol
design. Following this, Section 5.5 presents the terminologies defined and applied
in the Alliance2 protocol and the assumptions followed by the Alliance2 protocol.
Section 5.6 shows the high-level state machine covered by the protocol. Then,
Section 5.7 presents a detailed specification of the messages and messaging beha-
viours designed by the protocol. This section also discusses race conditions that
may happen during a negotiation and identifies the final states that all entities
should reach. Following this, concurrent job submission mechanisms in Grids
will be discussed in Section 5.8.1, to demonstrate the functions available for and
required by e-Scientists for application execution. A further analysis of the Alli-
ance2 protocol and the protocols discussed in the Related Work section will be
presented in Section 5.8.2. To demonstrate the capability of the Alliance2 pro-
tocol, this chapter discusses the approaches to apply it for: (i) negotiating with
more than one resource provider for resource co-allocation, in Section 5.8.3; and
(ii) interoperating with infrastructures based on other e-Science enabling models
as will be described in Section 5.8.4.
This chapter moves on to introduce the theoretical verification of the Alli-
ance2 protocol via formal simulations in Section 5.9. The formal simulations
are applied to verify the correctness of the designed protocol by state space ex-
ploration. This chapter then presents the results and evaluation of the formal
simulation experiments conducted. Finally, a summary of this chapter is given
in Section 5.10.
The proposal of the Alliance2 protocol has been briefly discussed in [Meng
and Brooke, 2014]. The designed negotiation messages, and brief introductions
to negotiation phases and negotiation end states, have been published in [Meng
and Brooke, 2015].

5.2. RELATED WORK 151
5.2 Related Work
The Alliance2 protocol is proposed to meet the scenario of dynamic resource pro-
visioning between independent research groups and resource providers for compu-
tational application execution in e-Science. It should also be interoperable with
existing resource provisioning mechanisms. Accordingly, the following aspects of
the related work will be discussed:
• Does a protocol allow negotiation between independent research groups
and resource providers? This is to investigate whether a protocol manages
a complete resource provisioning lifecycle without centralised management
between research groups and resource providers.
• Does the specification given for a negotiation protocol consider all situations
that will happen during a contract-oriented negotiation? Being contract-
oriented indicates that the negotiation procedures follow requisite legislative
requirements for forming a contract. This is to give confidence to negotiat-
ing entities regarding the effectiveness of the negotiation results. Contract-
oriented negotiation should consider the following situations: (i) to allow
a resource requester to collect information concerning available resources
(invitation to treat); (ii) to allow a resource provider to advertise locally
available resources (advertisement); (iii) to allow a resource requester to
change the contents of an offer during negotiation (revocation); (iv) to al-
low a resource provider to change the contents of an offer (counter-offer); (v)
to allow all entities to terminate a negotiation (negotiation termination);
and (vi) to ensure the acceptance is communicated to the offeree (accept-
ance communication). In addition to these legal requirements, the following
two more situations are considered important in this thesis. First, to allow
all negotiation entities to terminate a formed contract (contract termin-
ation). Second, to allow the involved entities to change the contents of
a formed contract (re-negotiation). These two situations are particularly
true for computational experiments, where both requesters’ and providers’
demands may change dynamically.
• Is a protocol sufficiently formal and effective to enable legally binding con-
tracts? Being sufficiently formal indicates clear definitions of messages and

152CHAPTER 5. A NEGOTIATION PROTOCOL: THE ALLIANCE2 PROTOCOL
messaging behaviours to mediate negotiation between entities without am-
biguity. Being sufficiently effective indicates that a protocol can regulate
all involved entities to reach the same valid result.
• Is a protocol symmetric or asymmetric? This thesis takes the view that
an asymmetric negotiation protocol can demonstrate the varied demands
and responsibilities of entities in e-Science collaboration and resource shar-
ing. Distinguishing different demands and responsibilities of entities also
contributes to dynamic collaborations between independent research groups
and resource providers, without managing them centrally.
One of the early works to enable negotiable resource provisioning is the Ne-
gotiation and Acquisition Protocol (SNAP) [Czajkowski et al., 2002]. SNAP is
an asymmetric agreement protocol. It manages and composes SLAs on a client-
server model. SNAP enables a resource requester as a client to negotiate an SLA
with a resource provider by: (i) sending a request for an identifier for negotiation;
(ii) conducting negotiation for resource provisioning; (iii) setting a termination
time during runtime; and (iv) changing the contents of an agreed SLA. In SNAP,
it is the resource requester who initiates the negotiation, and a resource provider
responds according to the requests received. SNAP also allows a resource re-
quester to terminate or re-negotiate a formed contract. However, SNAP discusses
only two messages for resource negotiation: request and agree. A request can be
sent by a client, when the provider can respond with an agree for acceptance.
These two messages are not sufficient to deal with other negotiation scenarios,
such as negotiation termination initiated by a provider. SNAP focuses on the
aggregation of simple SLAs between a resource requester and a resource provider
to enable a broad range of applications. This is achieved by dynamic combin-
ing a job with distributed resources simultaneously. To explain the combination
procedure, SNAP describes the states and state transitions for job and resource
composition. The states describe the following situations during resource com-
position and job execution: SLAs not yet created; SLAs partially created; SLAs
created; SLAs in effect. The following situations are also discussed: client ter-
mination, failure, and finishing of SLAs. The state representing the finishing of
SLAs indicates that the resource requester will be informed of the completion of
a job, managing the complete resource provisioning lifecycle.
The communication protocol developed in [Ali et al., 2012] enables service se-
lection according to an application’s QoS criteria. The service selection is achieved

5.2. RELATED WORK 153
by hierarchically querying available services. Application QoS manager (AQoS)
is the central communication component for negotiating service allocation. It
exchanges information with software for a Resource Manager module, a Network
Resource Manager module, and a Service module for service allocation. The com-
munication procedures presented in [Ali et al., 2012] illustrate how to coordinate
different types of service for application execution. [Ali et al., 2012] presents two
types of messages during negotiation between a user (as a resource requester) and
AQoS (as a resource provider): “SR: service request, requiring service with QoS
attributes”, and “N: exchanging negotiation documents to establish SLA”. SR
works as an invitation to treat, requiring information on available services and
related attributes. The negotiation presented in [Ali et al., 2012] also allows a re-
source requester to initiate a negotiation, and a resource provider to reply with a
counter-offer. The negotiation procedure shows that the communication protocol
developed by [Ali et al., 2012] is asymmetric. However, detailed information on
how to exchange negotiation documents, i.e. how the negotiation proceeds on
each negotiating entity’s domain, is not given in [Ali et al., 2012].
Different from the asymmetric models used by SNAP and G-QoSM, WS-
Agreement Negotiation [Waeldrich et al., 2011] presents symmetric negotiation
in the specification. WS-Agreement Negotiation also specifies a possible solu-
tion for asymmetric negotiation by implementing existing WS-Agreement Nego-
tiation ports and defining the roles of each entity participating in the negoti-
ation. The asymmetric definition should be specified by the negotiation initiator.
WS-Agreement Negotiation supports distributed web service collaborations by
alternating offer and counter-offer between a resource provider and a resource
requester. It considers that the creation and termination of agreements based on
a negotiated offer are in principle independent from the negotiation process. As
a result, WS-Agreement Negotiation needs to be combined with WS-Agreement
[Andrieux et al., 2011] or WS-Disagreement [Merzky and Papaspyrou, 2012] to
form a contract or terminate a negotiation, respectively. WS-Agreement Negoti-
ation also considers re-negotiation, allowing alteration of an existing agreement
in the Agreement layer. However, it does not discuss the mechanisms to combine
WS-Agreement and WS-Agreement Negotiation for negotiation or re-negotiation.
The EAlternating offer protocol proposed [Adabi et al., 2014] is a revised
version of Rubinstein’s sequential alternating offer protocol [Rubinstein, 1982].
The EAlternating offer protocol is proposed for market-based Grid resource prov-

154CHAPTER 5. A NEGOTIATION PROTOCOL: THE ALLIANCE2 PROTOCOL
isioning. It aims to provide mechanisms to enable users (as resource requesters) to
choose the best proposals received from trading partners (as resource providers)
via two-phase negotiation. To demonstrate the negotiation procedures, the pro-
tocol presents the messaging actions of the two engaged entities. It is the resource
requester who initiates negotiation with proposals in [Adabi et al., 2014]. This
allows the requester to collect all available offers and choose the best offer, as
discussed by [Adabi et al., 2014]. When resource providers receive the proposals,
they can decide to terminate the negotiation or to propose a counter-offer. The
counter-offer discussed in the EAlternating offer protocol is specifically focused
on negotiating the price of resources. It is the resource requester who decides to
accept an offer, while acceptance acknowledgement is required to be replied by
the resource provider to confirm the agreement formation. The EAlternating offer
protocol stresses that acceptance acknowledgement enables a resource requester
to collect available resources and choose the best proposals.
The protocol in [Zasada and Coveney, 2015] utilises a reverse auction al-
gorithm for negotiating access to computational resources. It allows a user (i.e.
resource requester) to select bids (via User Agent), while resource providers (rep-
resented by Resource Agents) need to compete with other providers to be chosen
by the user. Meanwhile, [Zasada and Coveney, 2015] takes advantage of two-
phase commitment, enabling a resource requester: (i) to collect all offers propag-
ated by resource providers before making a decision, as the EAlternating offer
protocol stresses; and (ii) to reserve all the resources required for a job. The
two-phase commit allows distributed resource composition for a workflow job,
where sub-jobs can use different resources. After successful negotiation for access
to resources, a Banking Agent notifies the chosen resource provider(s) to conduct
payment for the agreed resource use. This procedure applies the Reservation No-
tification Protocol in [Zasada and Coveney, 2015]. This thesis argues that this
approach is not suitable for a job whose execution duration cannot be predicted
or known before job execution. In this scenario, the cost of resource consumption
can only be calculated when the job completes. Apart from negotiation messaging
behaviours, [Zasada and Coveney, 2015] also presents the languages designed by
the authors for describing resources and corresponding features. However, as dis-
cussed in the previous chapter, the approach taken by this thesis (i.e. using a
widely-applied standard) can contribute to interoperation and requires limited
changes to existing infrastructures.

5.3. A NOVEL IDEA FOR THE ALLIANCE2 PROTOCOL 155
5.3 A Novel Idea for the Alliance2 Protocol
The Alliance2 protocol is based on the Alliance2 model and designs negotiation
between a Resource Requester, Resource Manager, and Resource Provider for re-
source provisioning. It inherits the law-based feature of the negotiation protocol
proposed by [Parkin, 2007], which follows the European Union (EU) Electronic
Commerce Directive [Lindholm and Maennel, 2000]. This contributes to the fact
that the Alliance2 protocol enables law-based negotiation, which enforces ne-
gotiation results effectively. The key differences that distinguish the Alliance2
protocol from [Parkin, 2007] are as follows. First, the Alliance2 protocol intro-
duces a new role, a Resource Manager, for a group manager. It enables a group
manager to make an authorisation decision during the negotiation between a re-
quester (e.g. an e-Scientist) and a provider. The access decision can be based
on the resource sharing rules within the group. Second, negotiation results are
communicated from a Resource Provider to a Resource Manager to manage the
complete resource provisioning lifecycle. Third, both negotiation termination and
contract termination consider a termination request from a Resource Manager.
To terminate a contract before normal completion in a business scenario may
allow the innocent party to claim a monetary penalty, while to terminate nego-
tiation before contract formation has no legal effects. To distinguish these two
different termination scenarios, the protocol designs different massages and final
states for termination during negotiation and termination of a contract. Four,
formal verification and race conditions, which are not addressed in [Parkin, 2007],
will be discussed.
5.4 Protocol Design Methodology
Based on the Alliance2 model, the Alliance2 protocol aims to facilitate dynamic,
lightweight, and accountable resource provisioning to support e-Scientists’ com-
putational experiments. To achieve this aim, typical entities in e-Science col-
laborations and resource sharing have been analysed, namely e-Scientists, group
managers, and resource providers. The needs and responsibilities of these three
entities have been identified in Section 1.3. Then, this thesis discusses the sup-
porting mechanisms in production infrastructures based on different enabling
models in Section 2.2. It further identifies the gaps between e-Scientists’ needs

156CHAPTER 5. A NEGOTIATION PROTOCOL: THE ALLIANCE2 PROTOCOL
and the resources provided, as well as suggests solutions to filling these gaps.
This thesis proposes that negotiation based on the Alliance2 model, which distin-
guishes the three typical entities in e-Science collaborations and resource sharing,
can be a solution.
Negotiation enables formation and dissolution of collaborations dynamically in
a lightweight manner. As shown in Figure 5.1, resource provisioning applying the
Alliance2 negotiation does not require centralised resource management between
a research group and a resource provider. No centralised resource management
indicates that rules required by a group manager for resource provisioning (i.e.
authorisation) cannot be known in advance. Also, fine-grained resource sharing
management introduces management burden to resource provisioning infrastruc-
tures and can be shifted to a research group, as discussed in Section 3.3. These two
features for dynamic resource provisioning require changing the existing resource
provisioning lifecycle. This change can be: after a resource requester initiates ne-
gotiation with a resource provisioning infrastructure, the infrastructure queries an
authorisation decision with the requester’s group manager, as shown in Figure 5.1.
A positive authorisation decision can be sent with a limitation for the required
resource consumption from the group manager to the infrastructure. In this way,
even through research groups are independent from infrastructures, resource pro-
visioning can still follow the resource sharing rules within the group. This is
a different approach from existing centralised resource management, which can
manage a complete resource provisioning lifecycle between independently engaged
entities. Overall, the proposed negotiation protocol can: (i) meet e-Scientists’
customised and dynamic resource provisioning demands; and (ii) satisfy the dif-
ferent resource management requirements of both a research group and a resource
provisioning infrastructure without a heavyweight centralised management layer.
The design of the protocol refers to [Sharp, 2008] for fundamental principles
that should be followed to design a negotiation protocol. The goal of the Alli-
ance2 protocol is to reach an agreement for resource provisioning among the three
entities in the Alliance2 model. In the e-Science context, negotiation is carried
out on the Application Layer of the OSI model. In the Alliance2 protocol, each
message is communicated between two engaged entities, making an implement-
ation based on a client-server mode possible. Accordingly, the protocol design
takes advantage of the following principles and mechanisms discussed in certain
chapters of [Sharp, 2008]:

5.4. PROTOCOL DESIGN METHODOLOGY 157
e-Scientists
Grids Clouds
Clusters
e-Scienceinfrastructures
Centralised resource management and allocation
1. accessrequest
2. resourcerequest
e-Scientists
Grids Clouds
Clusters
e-Scienceinfrastructures
Resource managementand allocation fora research group
1. accessrequest
2. resourcerequest
e-Scientists
Grids Clouds
Clusters
e-Scienceinfrastructures
Resource managementand allocation fora research group
2. accessrequest
1. resourcerequest
Figure 5.1: The evolution of resource management lifecycle in e-Science: Toenable more dynamic collaborations, some exiting e-Science tools distinguish re-search groups from infrastructures, compared to previous centralised manage-ment. However, they still require infrastructures (i.e. resource providers) toconduct authorisation and accounting for resource consumption by e-Scientists.Authorization decisions are based on the authorisation information attained bye-Scientists from research groups before sending resource requests. The Alliance2protocol proposes that authorisation and accounting of group members should beconducted by research groups, via communication between research groups andinfrastructures, after e-Scientists send resource requests to infrastructures.
1. Protocol and Services [Sharp, 2008, Chapter 3]: for general features of
communication protocols and related concepts.
2. Basic Protocol Mechanisms [Sharp, 2008, Chapter 4]: for detailed basic
protocol mechanisms. More specifically, the following three mechanisms
have been considered when designing and verifying the Alliance2 protocol.
First, messaging sequence control can be realised by a numbering scheme.

158CHAPTER 5. A NEGOTIATION PROTOCOL: THE ALLIANCE2 PROTOCOL
The receiving entity must check that the received message bears the next
number in the agreed sequence and take some suitable action if it is not
the case. Second, retransmission by the sender is a simple cure when the
underlying service loses messages. This is for verification upon a model
checker. An actual implementation of the protocol can take advantage of
a reliable communication protocol in the data transport layer. Third, an
identification in a message, indicating the sequence number of the latest
correctly received message of the sender, makes a protocol resilient to the
following types of error: loss, corruption or duplication of messages, and
loss, corruption or duplication of acknowledgements.
3. Application Support Protocols [Sharp, 2008, Chapter 10]: for the principles
that should be considered when designing and implementing application
protocols. More specifically, the following principles have been referred to:
(i) basic concepts for remote operations via Remote Procedure Call inter-
actions in a client-server system; and (ii) synchronous and asynchronous
Remote Procedure Call on a client-server paradigm.
Furthermore, the scenarios where this protocol is intended to be applied are
e-Science and web services. Accordingly, the approaches to define terms, set
boundaries, and specify relations from previous work [Ali et al., 2012, Czajkowski
et al., 2002, Parkin, 2007, Waeldrich et al., 2011] in negotiating resource supply
for e-Science experiments have been studied.
5.5 Preliminaries
5.5.1 Terminology
Three entities are defined in the Alliance2 protocol. They are Resource Requester,
Resource Manager, and Resource Provider, corresponding to the entities in the
Alliance2 model presented in Chapter 2. A Resource Requester can form a dy-
namic resource provisioning collaboration with a Resource Provider. A Resource
Manager coordinates resource sharing among an e-Scientist collaboration, i.e. a
Resource Requester collaboration. Resource sharing is achieved by managing e-
Scientists’ access to the shared resources and conducting accounting for resource
usage via negotiation. A Resource Manager can also form a collaboration with a

5.5. PRELIMINARIES 159
provider via negotiation for resource supply for computational experiment execu-
tion by members of the group. A Resource Provider is an entity that may obtain
monetary rewards by allowing external users to access local resources. This can
be realised by reaching an agreement for resource provision with a group manager
and/or (subsequently) group members, while it still can keep the autonomy of
the local resources. The lifecycle of accountable resource provisioning considers
not only the negotiation for resource usage but also access control and accounting
between a Resource Manager and a Resource Provider.
Negotiation is a way to resolve difference and reach an agreement among the
entities engaged, usually with multiple rounds of communication. Re-negotiation
is the procedure where an entity of a contracted agreement wants to change
terms in that existing agreement. Re-negotiation will activate new negotiation
for a possible new agreement, and successful re-negotiation will terminate the
existing agreement.
A contract indicates an agreement between a Resource Provider and a Re-
source Requester or Resource Manager, which should also be approved by a Re-
source Manager or privileged manager in the e-Science collaboration scenario. A
privileged manager here means an entity with a higher privilege than a group
manager. In a management hierarchy of e-Science collaborations, this can be a
project manager. A contract describes the resource(s) to be provided and defines
guarantees regarding the level of QoS supplied [Waeldrich et al., 2011]. A contract
for an e-Science collaboration contains both technical elements and non-technical
elements [David and Spence, 2003]. The technical elements consider the practical
effectiveness of the hardware and software infrastructures that are being created
to enable collaborations in e-Science. The non-technical elements may include in-
tellectual property and competition policy. Non-technical elements are out of the
scope of this thesis. Correspondingly, a contract concerns mainly about technical
contents in this protocol. This work also supposes that a contract can be formed
by combining dynamically negotiated contents with a static contract template.
The static contract template can contain the non-technical agreements formed
between a research group and a resource provider. In this case, e-Scientists in
the research group only need to negotiate the properties of interests for applic-
ation execution. This is for the scenario that negotiation is carried out under a
collaboration already formed between a research group and a resource provider.

160CHAPTER 5. A NEGOTIATION PROTOCOL: THE ALLIANCE2 PROTOCOL
5.5.2 Assumptions
The following identifies the boundaries of the designed protocol:
1. It defines negotiating entities, negotiation message types, and different en-
tities’ messaging behaviours.
2. It includes a negotiation protocol and a contract termination protocol.
3. It identifies race conditions that each negotiating entity may encounter dur-
ing negotiation, with corresponding agreed outcomes as solutions.
4. Notification messages during service execution will not be discussed. For
example, messages to inform a requester that the specified input file has
been transferred or deleted are out of the scope of this protocol. In fact,
these features can be provided by existing infrastructures.
5. The protocol does not include mechanisms to deal with concurrent commu-
nication, where an entity has to deal with multiple messages from different
sources at the same time. The Highly-Available Resource Co-allocation
(HARC) [MacLaren, 2007] is one of the works that we can learn from to
deal with concurrent communication. It is proposed for receiving multiple
resources supplied in a coordinated and resilient manner, by replacing a
single coordinator in the classic two-phase commit (2PC) protocol with
multiple coordinators.
6. There is no mechanism to deal with multi-peer consensus, where a group
of requesters wish to reach a negotiation agreement together.
7. The negotiation protocol so far concentrates on negotiation messages and
entities’ messaging behaviours, to enable the features required for contract-
oriented negotiation. The resource provisioning and sharing description
languages as parts of a contract have been discussed in the previous chapter.
The protocol does not consider law-related contract contents. However, the
experience of law-related contract contents can be learned from the contract
templates proposed for scientific Grid or Cloud collaborations, including
commercial Clouds. An example is the FitSM templates used by EGI pay-
by-use experiment [EGI, 2018c]. The FitSM templates are “lightweight
standards, aiming at facilitating service management in IT service provision,
including federated scenarios” [Radecki et al., 2014].

5.6. A HIGH-LEVEL STATE MACHINE 161
Nego%a%on ini%ated nego%a%ng
contracted
uncontracted
Nego%a%on session
successful nego%a%on unsuccessful nego%a%on
terminated
reqTerminated
proTerminated
Termina%on session
completed
Figure 5.2: The high-level state machine for each participant for a completeresource provisioning lifecycle
5.6 A High-Level State Machine
To clearly specify negotiation status, this section presents the negotiation proced-
ures of the Alliance2 protocol with a high-level state machine. This state machine
aims to capture the lifecycle that the Alliance2 protocol covers. The high-level
state machine of each entity in a complete resource provisioning lifecycle is shown
in Figure 5.2. It covers not only the status during negotiation but also the status
of job execution. Accordingly, two high-level sessions are designed: the negoti-
ation session and the termination session. A negotiation session ends with one of
the two final states: contracted and uncontracted. A contracted state indicates
that the negotiation is successful and a contract is formed, while an uncontracted
state means that negotiation ends without forming a contract.
A state negotiating is introduced to complete the negotiation procedures. It
represents the situation where a valid negotiation has been initiated, but no
agreement has been reached. Negotiation termination can be initiated by any of
the three entities before a contract formation, leading to an uncontracted state.
If a contract is formed after successful negotiation, four states have been
designed to capture the results of realisation of formed contracts. They are:
reqTerminated, proTerminated, terminated, completed, and completed.
• proTerminated: This indicates that the Resource Provider terminates a
contract.
• reqTerminated: This indicates that the Resource Requester or Resource

162CHAPTER 5. A NEGOTIATION PROTOCOL: THE ALLIANCE2 PROTOCOL
Manager terminates a contract.
• terminated: This indicates that the Resource Provider and the Resource
Requester or Resource Manager terminate a contract at the same time.
• completed: This indicates that the job has been executed successfully.
These four states are included in a termination session, as shown in Figure 5.2.
As fine-grained resource sharing management for a research group is independ-
ent from resource management in the resource provider domain, the termination
session enables a research group to track the resource usage of each job. The
terminated state is introduced to deal with the scenario where a Resource Re-
quester or Resource Manager and a Resource Provider send termination requests
to terminate a contract at the same time. In this scenario, all entities terminate
the contract with a terminated state. This is to avoid disputes in a business
scenario. To complete the resource provisioning lifecycle, a state completed has
also been introduced in a termination session.
Figure 5.2 shows the states for both the negotiation session and the termina-
tion session. This state machine can also be applied for re-negotiation. While all
the above states are also true for re-negotiating contracts, additional information
is required when re-negotiation is activated. The additional information should
include the original contract identifier and the contents to be re-negotiated. When
a renegotiated contract is successfully created, the state of the original contract
must be changed to a terminated state, to avoid potential disputes.
5.7 Alliance2 Protocol Specification
The messages of the protocol are grouped into different phases of negotiation:
pre-negotiation, negotiation, and termination. The negotiation phase is sub-
sectioned according to functionality: resource negotiation, access negotiation,
and revocation. Negotiation termination is included in the negotiation phase,
while the termination phase discussed here is for contract termination.
The messages designed in the protocol can also be applied for re-negotiation,
while the information contained in messages for re-negotiation may be changed
according to specific application scenarios. Re-negotiation messaging behaviours
remain the same as negotiation.

5.7. ALLIANCE2 PROTOCOL SPECIFICATION 163
Considering that different negotiating entities have varied requirements and
responsibilities, the Alliance2 protocol is designed as an asymmetric protocol.
Accordingly, an Offer message can only be sent from a Resource Requester to a
Resource Provider, and the decision to accept or reject the Offer is made by the
Resource Provider in this protocol. This asymmetric feature makes the Alliance2
protocol compatible with existing infrastructures, which allow only resource pro-
viders to make decisions for resource provisioning. It also allows providers to
make decisions about resource provisioning according to local workload. Mean-
while, QuoteRequest and Quote are designed for a Resource Requester and a Re-
source Provider respectively to express their intention for a collaboration. They
are not legally bound to finalise contracts. If a Resource Requester wants to
change the offer contents before the formation of a contract, revocation can be
activated by sending a revoke request (RevokeReq). Revocation can be accep-
ted via a RevokeAcc message or can be rejected via a RevokeRej message sent
by the corresponding Resource Provider. Access negotiation enables a Resource
Manager to manage accountable resource provisioning, with an AccessSucceed
message or an AccessFailed message. An Accessing message can be sent from a
Resource Provider to a Resource Requester during access negotiation. It informs
that the authorisation is being processed, which can avoid timeouts happening
in the software for the Resource Requester. Negotiation termination enables the
three entities to terminate negotiation via a Terminate message at any time before
forming a contract. The messages for the termination phase, i.e. ReqTerminate
and ProTerminate, allow the three entities to terminate a contract.
Figure 5.3 demonstrates a negotiation case that can be enabled by the pro-
tocol. It shows that a contract (Contract 1 ) is formed after successful negoti-
ation of Offer 1. Before job execution, the Resource Requester wants to change
the contents of Contract 1 and initiates re-negotiation with Offer 2. During
re-negotiation, the Resource Requester wants to change the negotiated contents
again with a RevokeReq message containing Offer 2’. The revocation is accep-
ted by the Resource Provider, and the negotiation forms Contract 2 successfully.
The contract formation is advised to Resource Manager by sending a Contracted
message from the Resource Provider. Then, the job execution is started by the
Resource Provider until a ReqTerminate is sent from the Resource Requester to
terminate the job execution, which also terminates the contract, i.e. Contract 2.
The termination is also advised to the Resource Manager by the Resource Provid-
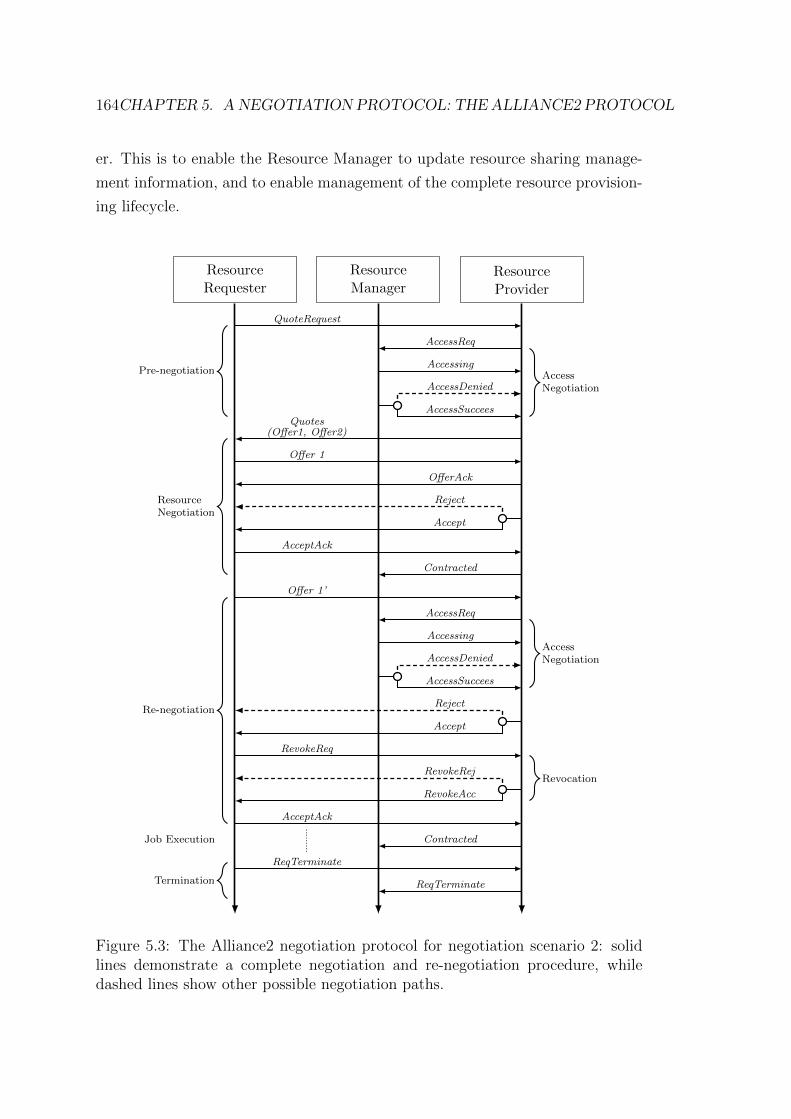
164CHAPTER 5. A NEGOTIATION PROTOCOL: THE ALLIANCE2 PROTOCOL
er. This is to enable the Resource Manager to update resource sharing manage-
ment information, and to enable management of the complete resource provision-
ing lifecycle.
ResourceRequester
ResourceManager
ResourceProvider
QuoteRequest
AccessReq
Accessing
AccessDenied
AccessSuccees
AccessNegotiation
Pre-negotiation
Quotes(Offer1, Offer2)
Offer 1
OfferAck
Reject
Accept
AcceptAck
Contracted
ResourceNegotiation
Offer 1’
AccessReq
Accessing
AccessDenied
AccessSuccees
AccessNegotiation
Reject
Accept
RevokeReq
RevokeRej
RevokeAcc
Revocation
AcceptAck
Re-negotiation
Contracted
ReqTerminate
ReqTerminateTermination
Job Execution
Figure 5.3: The Alliance2 negotiation protocol for negotiation scenario 2: solidlines demonstrate a complete negotiation and re-negotiation procedure, whiledashed lines show other possible negotiation paths.

5.7. ALLIANCE2 PROTOCOL SPECIFICATION 165
The following specification for the Alliance2 protocol will be presented with
corresponding negotiation states. Without being specifically specified, messaging
behaviours will keep the negotiation in a negotiating state during the negotiation
phase.
5.7.1 Pre-negotiation
QuoteRequest: A message from a Resource Requester to a Resource Provider
that asks for a non-binding estimate of available resources.
Quote: A message from a Resource Provider to a Resource Requester to
advise of available resources for a possible collaboration. A Quote is different
from an Offer and cannot be accepted. It indicates an invitation for Offers,
without any legal effects.
5.7.2 Access Negotiation
AccessReq: A message from a Resource Provider to a Resource Manager for a
Resource Requester’s access verification.
Accessing: A message from a Resource Provider to a Resource Requester to
advise that access verification is being processed with the Resource Manager.
AccessDenied: An AccessDenied message can be sent in the following two
situations:
1. From a Resource Manager to a Resource Provider to indicate the denial of
a Resource Requester’s request. Denial reasons may be indicated, such as
no priority or insufficient balance.
2. From a Resource Provider to a Resource Requester with the reason of denial,
indicating that the Resource Manager rejects the Resource Requester’s re-
quest.
AccessDenied leads to an end state of negotiation (e.g. uncontracted). An
AccessDenied message indicates one of the following two situations. First, the
requester is not allowed to access the required resource(s) according to his/her
priority in the group. Second, the requester does not have sufficient balance to
run the job. Both situations make the negotiation unable to proceed further,
reaching the end state of uncontracted.

166CHAPTER 5. A NEGOTIATION PROTOCOL: THE ALLIANCE2 PROTOCOL
AccessSucceed: An AccessSucceed message can be sent in the following
situations:
1. From a Resource Manager to a Resource Provider to confirm the approval
of a Resource Requester’s access.
2. From a Resource Provider to a Resource Requester, to advise that the Re-
source Requester’s access request has been verified by the Resource Man-
ager.
As discussed in the protocol proposed by Parkin [Parkin, 2007], access nego-
tiation is regarded as a stateless simple request-response messaging model. This
indicates that access negotiation can happen at any time during negotiation.
The Alliance2 model presented in Chapter 3 demonstrates that dynamic and ac-
countable resource provisioning requires an authorisation decision for a resource
provisioning decision. It indicates that the access negotiation should happen be-
fore a contract is formed. Based on this, access negotiation can happen in two
possible scenarios in the Alliance2 protocol: during the resource negotiation phase
and during the pre-negotiation phase. These two scenarios are called negotiation
scenario 1 and negotiation scenario 2, respectively, in this thesis. The decision
for implementation should depend on the demands of practice. For instance, if
an access decision depends on complex policies, the process to reach a decision
for access negotiation will take longer than the time consumed by message trans-
portation for the decision. In this scenario, access negotiation that is activated
during resource negotiation is preferable, that is, after a requester has selected an
Offer from all Quotes for further negotiation. This is because that the Offer sent
from the Resource Requester has been preliminarily selected, which can avoid
processing policies of a large number of resources for an access decision. It can
also increase the success rates of negotiation.
5.7.3 Resource Negotiation
Offer: A message from a Resource Requester to a Resource Provider to initiate a
contract negotiation. It may specify the required resource details and performance
requirements.
OfferAck: A message from a Resource Provider to a Resource Requester that
advises of the arrival of an Offer, before making further decisions. This message

5.7. ALLIANCE2 PROTOCOL SPECIFICATION 167
aims to support non-blocking of communication on a Resource Requester’s soft-
ware. It can confirm the arrival of a request and avoid the Resource Requester’s
program keeping waiting. This is especially true in systems where communication
can be executed autonomously.
Accept: A message from a Resource Provider to inform a Resource Requester
that an Offer has been accepted. This message can only be sent after the Resource
Requester’s access has been approved by a corresponding Resource Manager via
access negotiation.
AcceptAck: A message from a Resource Requester to a Resource Provider
to communicate the arrival of an Accept message. This message is essential in
a business scenario, which requires the acceptance to be communicated to the
offeree, namely the Resource Requester in this protocol. Receiving an AcceptAck
can give the provider confidence to supply resources as agreed.
Reject: A message from a Resource Provider to a Resource Requester, in-
dicating that the required resource(s) or performance cannot be satisfied. This
message can only be sent after the Resource Requester’s access has been approved
by a corresponding Resource Manager. Rejection does not indicate the end of a
negotiation, and the Resource Requester can send a new Offer to continue ne-
gotiation. The Reject message may contain reasons for rejection, contributing
to a higher possibility of reaching an agreement in subsequent communication.
The reasons for rejection can be encoded in a computer understandable format
or human readable massage, depending on demands in practice.
Terminate: A message that can be sent by any of the three entities at any
time during negotiation. It ends the negotiation with an uncontracted state. As
this happens before a contract has been formed and no responsibility binds the
negotiating entities yet, there is no need to distinguish which entity terminates
the negotiation. However, it is necessary to ensure that the three entities are
in the same negotiation state, to make a negotiation result valid. A Terminate
message can be sent in the different scenarios as follows:
1. From a Resource Manager to a Resource Provider to end the negotiation
between the Resource Provider and a Resource Requester. In this scenario,
a Terminate message should be sent from the Resource Provider to the
Resource Requester, which may explain that the termination is required by
the Resource Manager.

168CHAPTER 5. A NEGOTIATION PROTOCOL: THE ALLIANCE2 PROTOCOL
2. Either from a Resource Requester to a Resource Provider, or from a Re-
source Provider to a Resource Requester. In both scenarios, the Resource
Provider should inform the corresponding Resource Manager that the nego-
tiation has been terminated, if an AccessReq has been sent to the Resource
Manager.
Contracted: A message from a Resource Provider to a Resource Manager
to advise of successful contract formation. It enables the Resource Manager to
update information for resource sharing management purposes. It closes the
negotiation with a contracted state. This message is important for resource pro-
visioning between independent research groups and resource providers, as there is
no centralised management to communicate a negotiation result and coordinate
resource management updates.
Uncontracted: A message from a Resource Provider to a Resource Manager
to indicate a failed negotiation, after access has been confirmed between the
Resource Provider and the Resource Manager via access negotiation. It closes
the negotiation with an uncontracted state.
5.7.4 Revocation
RevokeReq: A message from a Resource Requester to a Resource Provider. A
Resource Requester can send a RevokeReq after sending an Offer or an Accept,
and before sending an AcceptAck. This allows a Resource Requester to change
contract contents before its formation.
RevokeAcc: A message from a Resource Provider to a Resource Requester,
corresponding to a RevokeReq message sent. It indicates that the RevokeReq sent
by the Resource Requester has been accepted. After receiving a RevokeAcc, the
Resource Requester can propose a new Offer.
RevokeRej: A message from a Resource Provider to a Resource Requester,
corresponding to a RevokeReq message sent. It indicates that the RevokeReq
sent by the Resource Requester has been rejected. After receiving a RevokeRej
message, the Resource Requester may continue negotiation or send a Terminate
message to close the negotiation.

5.7. ALLIANCE2 PROTOCOL SPECIFICATION 169
5.7.5 Contract Termination
Two scenarios will result in the termination of a valid contract before job com-
pletion: termination initiated by any of the three entities; or termination caused
by successful re-negotiation. In a business scenario, the termination of a contract
before its normal completion may introduce benefit conflicts, making it import-
ant to clarify which entity terminates a valid contract. According to this, this
protocol defines additional messages for terminating a contract.
ReqTerminate: A message from either a Resource Requester or a Resource
Manager to a Resource Provider. It should indicate the contract to be termin-
ated and may result in the penalty as agreed in the terminated contract. If a
ReqTerminate is sent from a Resource Requester to a Resource Provider, the
Resource Provider should notify the termination to the Resource Manager, as
shown in Figure 5.3; if a ReqTerminate is sent from a Resource Manager to a
Resource Provider, the Resource Provider should inform the corresponding Re-
source Requester about the termination. In these two termination notification
cases, the Resource Provider can send a ProTerminate, as will be presented below.
The ProTerminate should contain information to clarify that the termination is
initiated by the corresponding Resource Requester or Resource Manager. A Re-
qTerminate may terminate a contract with a reqTerminated state.
ProTerminate: A message from a Resource Provider to both Resource Re-
quester and Resource Manager to terminate a contract. It may include penalty
information as agreed in the terminated contract. A ProTerminate message may
terminate a contract with a proTerminated state.
5.7.6 Race Conditions and Solutions
To complete the specification, race conditions are also discussed for this protocol.
A race condition is a messaging situation where a Resource Requester and a Re-
source Provider, or a Resource Provider and a Resource Manager, send messages
that cross each other on the network. Take the situation shown in Figure 5.4 as an
example: a Resource Requester sends an accept acknowledgement (AcceptAck)
before the current negotiation times out, but the message is not delivered within
the timeout period due to message latency. After the negotiation has timed out
on the provider side, the Resource Provider sends both Resource Requester and
Resource Manager a Terminate message. This results in the AcceptAck message

170CHAPTER 5. A NEGOTIATION PROTOCOL: THE ALLIANCE2 PROTOCOL
ResourceRequester
ResourceProvider
ResourceManager
Offer
AcceptAckTerminate Terminate
race condition
Figure 5.4: A race condition example between Resource Requester and ResourceProvider
from the requester being passed by the Terminate message from the provider,
while these two messages will effect different results of the negotiation. As dis-
cussed in the previous sections, a Terminate message results in an uncontracted
state, while an AcceptAck ends negotiation with a contracted state. As can be
seen from this example, it is very important to discuss race conditions that may
happen during a negotiation and to propose solutions accordingly. This is even
more true for contract-oriented negotiation that may involve monetary payment.
The Alliance2 protocol includes three negotiating entities. The messaging
among the distributed entities during negotiation holds the potentials for race
conditions. Accordingly, this thesis considers this situation for possible race con-
ditions: before an access decision is returned from the Resource Manager, the
Resource Provider receives a RevokeReq message or a Terminate message from
the Resource Requester.
Two cases, where a Resource Requester or a Resource Manager and a Resource
Provider send termination requests to terminate a contract at the same time, have
already been considered in the designed protocol. As discussed in the previous
section, both cases result in a terminated state to avoid benefit conflicts. They
need not be repeated here.
This discussion aims to mediate the messaging behaviours of negotiating en-
tities when a race condition occurs, to enable the negotiating entities to continue
the current negotiation or to reach the same final state. Combined with the
agreed outcomes for negotiation (contracted and uncontracted), the high-level
state machine for each entity during negotiation is shown in Figure 5.5. The
main principle followed when designing solutions to race conditions is to avoid
disputes over negotiation results.

5.7. ALLIANCE2 PROTOCOL SPECIFICATION 171
Nego%a%on ini%ated nego%a%ng
contracted
uncontracted
Nego%a%on session
successful nego%a%on
unsuccessful nego%a%on
Figure 5.5: A high-level state machine for each participant during contract nego-tiation
Before a contract formation or negotiation termination, race conditions occur
for the following three reasons:
1. A Resource Requester can send a RevokeReq message or a Terminate mes-
sage at any time during negotiation;
2. A Resource Provider can send a Terminate message during negotiation at
any time before receiving an AcceptAck message;
3. A Resource Manager can send a Terminate message at any time after re-
ceiving an AccessReq message and before receiving a Contracted message.
For all three entities, after sending a Terminate message before contract form-
ation, they will enter an uncontracted state during negotiation, no matter which
message they may receive afterwards. If the termination is required by the Re-
source Manager, it should be communicated by the Resource Provider to the
Resource Requester.
Revocation is the other main event that may cause race conditions during
negotiation, as a Resource Requester can send a RevokeReq at any time before a
contract formation or negotiation termination. The following proposes solutions,
according to the messages crossed by the RevokeReq message.
1. A Resource Requester sends a RevokeReq message, while the Resource Pro-
vider sends an OfferAck, an Accessing, an AccessSucceed, or an Accept mean-
while. The Resource Requester will stay in a negotiating state and waits
for a following message from the Resource Provider. The following message

172CHAPTER 5. A NEGOTIATION PROTOCOL: THE ALLIANCE2 PROTOCOL
ResourceRequester
ResourceProvider
ResourceManager
Offer
RevokeReqOfferAck
RevokeReqAccessing AccessReq
RevokeReq AccessSucceed AccessSucceed
RevokeReqAccept
Figure 5.6: Some race conditions caused by RevokeReq
can be a RevokeRej, a RevokeAcc, or a Terminate. If a RevokeRej or a Re-
vokeAcc is received, the communication will remain in the negotiating state.
The arrival of a Terminate message ends the negotiation in an uncontracted
state. The Terminate message may contain the reasons for the termination,
such as that the request has been denied by the Resource Provider or it is
requested by the Resource Manager. The race conditions considered for
this scenario are shown in Figure 5.6. All four situations may happen in
negotiation scenario 1, while only the two situations highlighted with blue
circles may happen in negotiation scenario 2.
2. A Resource Requester sends a RevokeReq message, while the Resource Pro-
vider sends a Reject message. The Resource Requester stays in a negotiating
state and may send a new Offer to continue the negotiation.
3. A Resource Requester sends a RevokeReq message, while the Resource Pro-
vider sends an AccessDenied. The negotiation ends in an uncontracted state.
5.8 Protocol Analysis
5.8.1 Job Submission in Grids
Negotiable resource provisioning is not yet available in Grids or infrastructures
based on other enabling models. Existing approaches in Grids allow e-Scientists to

5.8. PROTOCOL ANALYSIS 173
submit jobs with specific demands. Such demands are infrastructure-specific and
may include the start time of job execution, the maximum amount of resources
a job can consume, and specific resource demands (e.g. CPU model, operating
system). It is the infrastructures as resource providers that make the decisions
to accept or reject job execution requests. Before or during job execution: (i)
an e-Scientist as a requester may be able to cancel the job; and (ii) the provider
can cancel or terminate the job. The following discusses existing approaches to
job submission in Grids. It reveals the trends in job management enabled for
e-Scientists in existing Grids.
The glideinWMS is based on the HTCondor (which was named Condor before
2012) batch system [Sfiligoi, 2008]. Job submission is conducted in glideinWMS.
The glideinWMS collects available resources and enables jobs to be scheduled
into resources in provider domains directly. Resource allocation depends on a
VO’s policies and the local policies of provider domains. After job submission
from e-Scientists, the requirements of submitted jobs will be matched with the
available resources. With successful matchmaking, jobs will be submitted to the
selected resource(s) for execution. The Generic Connection Broker (GCB) was
introduced to deal with the network connection in a Grid environment. The
GCB establishes a long TCP connection with a Grid, handling job submission
for execution. E-Scientists can fetch execution results after job completion.
The Globus Toolkit has been developed for distributed resource management
for a Grid. Globus implements the Grid Resource Allocation and Management
(GRAM5) service to provide initiation, monitoring, management, scheduling, and
coordination of remote computations [Vachhani and Atkotiya, 2012]. After job
submission, an e-Scientist can cancel the submitted job. A resource provider can
also cancel a job if the specified demands cannot be met or errors occur during
job execution.
The gLite Workload Management System (WMS) facilitates similar job sub-
mission and management features to the Globus Toolkit [Marco et al., 2009]. In
addition, the gLite WMS allows resubmission when an error occurs before or dur-
ing job execution. It enables e-Scientists to choose the number of times for job
resubmission. If a job fails after having reached the maximum number of retries,
it will be terminally aborted.
In addition to job submission and re-submission, the QCG (previously knows
as QosCosGrid) enables resource reservation [Bosak et al., 2014]. It allows an

174CHAPTER 5. A NEGOTIATION PROTOCOL: THE ALLIANCE2 PROTOCOL
e-Scientist to: (i) specify the time to start job execution, (ii) execute the job no
later than a specified time, and (iii) require the job not to be executed before a
specified time. Reservation can be cancelled. A deadline for job execution can
also be specified by an e-Scientist.
The above discussion shows that customised resource provisioning is increas-
ingly enabled by Grids. It envisions negotiable resource provisioning, accom-
panied with the following two trends. First, the standardisation of Grids allows
resources be collected and allocated dynamically from different infrastructures
to meet a job execution request. Second, Clouds and virtualisation have been
increasingly applied for dynamic and customised resource provisioning. Based
on this perspective, the following will compare the Alliance2 protocol with the
protocols discussed in Section 5.2, for negotiable computational application exe-
cution.
5.8.2 Further Analysis of Related Work
Protocols presented by [Adabi et al., 2014, Ali et al., 2012, Czajkowski et al.,
2002, Waeldrich et al., 2011, Zasada and Coveney, 2015] are proposed to enable
dynamic resource provisioning for e-Scientists to conduct computational exper-
iments. They aim for negotiation between a resource requester and a resource
provider. However, none of them discusses an entity akin to a group manager
and communication with a group manager during negotiation as proposed in the
Alliance2 protocol. This means various things, as discussed below:
1. For [Adabi et al., 2014, Ali et al., 2012, Czajkowski et al., 2002, Waeldrich
et al., 2011], in resource provisioning between independent research group
and resource provider, the manager of the group will be unaware of the
amount of resources contracted between a resource requester and a resource
provider. However, the group manager can be the entity to pay for the con-
tracted resource consumption. One solution for these protocols to achieve
accountable resource provisioning can be to apply existing standards in
combination with the proposed protocols. The Distributed Resource Man-
agement Application API (DRMAA) [Troger et al., 2016] is an example of
such standards. With DRMAA, the number of the resources contracted and
consumed for each job can be queried by a group manager and returned by
a resource provider;

5.8. PROTOCOL ANALYSIS 175
2. [Zasada and Coveney, 2015] proposes a solution to conducting payment for
resource provisioning after successful resource usage negotiation. However,
this solution cannot be applied to situations where the number of resources
to be used cannot be known when negotiating. These situations include
negotiation for: (i) pay-as-you-go resource provisioning from Clouds and
virtualisation-enabled Grids; and (ii) job execution whose execution dur-
ation cannot be known or predicted before job submission, such as user-
interactive computational steering jobs.
As a result, the protocols proposed by [Adabi et al., 2014, Ali et al., 2012,
Czajkowski et al., 2002, Waeldrich et al., 2011, Zasada and Coveney, 2015] in
isolation are not suitable for the scenario of dynamic and accountable resource
provisioning, without binding research groups and resource providers.
The reason may be that [Adabi et al., 2014, Ali et al., 2012, Czajkowski
et al., 2002, Waeldrich et al., 2011, Zasada and Coveney, 2015] are based on
the Grid model. As a result, they restrict the negotiation between a resource
requester and a resource provider. They assume that: (i) a research group has
reached a resource provisioning collaboration with a resource provider; and (ii)
authorisation and accounting are conducted by the provider. These are no longer
true for dynamic resource provisioning collaborations, nor for an open market.
For these two scenarios, resource providers do not concern themselves with and
do not wish to be burdened with a research group’s internal resource sharing
management. Also, these assumptions indicate that previously unused resources
cannot be negotiated dynamically. This resource management lifecycle of the
Grid model has been criticised by [Demchenko et al., 2010]. [Demchenko et al.,
2010] argues that the existing resource management lifecycle should be changed
for on-demand resource provisioning requirements.
Furthermore, none of the protocols discussed above applies formal verification
to validate the protocols’ properties. However, formal verification is critical for
large-scale distributed systems, as it enables a protocol to be checked for desired
properties before implementation [Siegel, 2007]. Also, [Adabi et al., 2014, Ali
et al., 2012, Czajkowski et al., 2002] do not give a detailed specification of the
proposed protocols. Detailed specification can clearly define participating entities’
messages and messaging behaviours, ensuring consistent negotiation states. This
is especially important for contract-oriented negotiation between independent
entities, to force negotiating entities to fulfil contracted conditions.

176CHAPTER 5. A NEGOTIATION PROTOCOL: THE ALLIANCE2 PROTOCOL
Table 5.1 shows a summary of the comparison between the Alliance2 protocols
and the protocols discussed in Section 5.2. The Alliance2 protocol is proposed for
contract-oriented negotiation. As a result, it considers all the functions required
for negotiating a contract [Lindholm and Maennel, 2000] as shown in Table 5.1.
This is achieved by inheriting the law-based features from the protocol proposed
by [Parkin, 2007]. Designed as an asymmetric protocol, proposing counter-offers
is not fully supported by the Alliance2 protocol. However, to enable both a Re-
source Requester and a Resource Provider to change an offer’s contents during
negotiation, messages for revocation purposes can be sent by either entity. A
Resource Requester can send a RevokeReq, and a Resource Provider can send a
Reject message. A Resource Requester can specify the required conditions in a
RevokeReq message, and a Resource Provider can include the reasons for rejec-
tion in a Reject message. These two messages function as counter-offers, which
are required by contract-oriented negotiation [Lindholm and Maennel, 2000]. In
addition to these features contributed by the protocol proposed in [Parkin, 2007],
the Alliance2 protocol introduces communication to enable access negotiation,
negotiation result notification, and job termination notification, as highlighted in
Table 5.1.
Compared to the discussed related work, the Alliance2 protocol considers
all situations that may arise during contract-oriented negotiation, as shown in
Table 5.1. It manages the complete negotiation and resource provisioning life-
cycle between independent research groups and resource providers. It gives a
detailed specification of the designed messages and messaging behaviours, as well
as solutions for some race conditions that may occur during negotiation. The
correctness of the Alliance2 protocol has been verified by the Spin formal model
checker.
Including all the functions required for contract-oriented negotiation indic-
ates that the negotiation procedures consider more messages and messaging be-
haviours than other negotiation protocols, as shown in Table 5.1. This may result
in less efficient negotiation. To ensure efficient negotiation via the Alliance2 pro-
tocol, algorithms and mechanisms to support the proposed functions are essential.
For instance, algorithms can be developed to rank the available offers based on
a requester’s demands. They can help with offer selection and reduce the total
time consumed for negotiation. Such algorithms and mechanisms can be specific
to applications, infrastructures, negotiating entities, etc.

5.8. PROTOCOL ANALYSIS 177
Tab
le5.
1:Sum
mar
yof
neg
otia
tion
pro
toco
ls
SN
AP
G-Q
oSM
WS-A
gree
men
tN
egot
iati
onE
Alt
ernat
ing
Off
erP
roto
col
HP
CN
egot
iati
onP
roto
col
Allia
nce
2P
roto
col
Invit
atio
nto
trea
t—
—X
—X
XA
dve
rtis
emen
t—
——
—X
XA
cces
sneg
otia
tion
X—
——
XX
*R
evoca
tion
——
——
XX
Neg
otia
tion
term
inat
ion
——
—X
(by
pro
vid
er)
X(b
yre
ques
ter
orpro
vid
er)
X(b
yre
ques
ter
orpro
vid
eror
man
ager
)
Cou
nte
roff
er—
XX
XX
par
tly
(only
by
reques
ter
Acc
epta
nce
com
munic
atio
n—
——
—X
X
Con
trac
tte
rmin
atio
nX
(by
reques
ter)
—X
(by
reques
ter
orpro
vid
er)
——
X(b
yre
ques
ter
orpro
vid
eror
man
ager
)R
e-neg
otia
tion
X—
——
—X
Neg
otia
tion
re-
sult
not
ifica
tion
——
——
X(f
orpay
men
t)X
*
Job
term
inat
ion
not
ifica
tion
X—
——
—X
*
Sym
met
ric/
Asy
mm
etri
cas
ym
met
ric
sym
met
ric
sym
met
ric
(can
enab
lesy
mm
etri
c)as
ym
met
ric
asym
met
ric
asym
met
ric
Co-
allo
cati
on—
——
—X
X*
Th
eex
tra
feat
ure
sof
the
All
ian
ce2
pro
toco
l,co
mp
are
dto
the
pro
toco
lp
rop
ose
din
[Park
in,
2007].

178CHAPTER 5. A NEGOTIATION PROTOCOL: THE ALLIANCE2 PROTOCOL
ResourceRequester
ResourceProvider 1
ResourceProvider 2
ResourceManager
QuoteRequest
AccessReq1
AccessSucceed1
Quote1, Quote2
Offer1
Accept1
Offer2
AccessReq2
AccessSucceed2
Accept2
AcceptAck1
Contracted1
AcceptAck2
Contracted2
First-PhaseReservation
Second-PhaseReservation
Figure 5.7: Resource co-allocation based on the Alliance2 negotiation protocol
Take the possible scenarios of rejection and termination from a Resource Pro-
vider for the same request, for instance, to demonstrate that different algorithms
may lead to different negotiation results for the same situation. The example
has the following two assumptions. First, the main targets of negotiation for
application execution by a Resource Requester are to limit cost and meet the
specified execution deadline. Second, the main target of a Resource Provider is
to maximise its profit while still meeting a Resource Requester’s application exe-
cution demands. After receiving an offer, the algorithms applied by the Resource
Provider conclude that the provider can increase the price that will still be within
the price limit set by the Resource Requester. As a result, the Resource Provider
will send a Reject message. The Reject message can include the price that the
provider considers is acceptable. However, if the algorithms applied by the Re-
source Provider conclude that the cost limit proposed by the Resource Requester
is not acceptable, and then a Terminate message will be sent.
5.8.3 Enabling Co-Allocation with Alliance2 Protocol
A single job may require the cooperation of distributed computing resources, stor-
age resources, and data resources, where these resources may be maintained by
different infrastructures in various locations. Such cooperation involves resource
co-allocation [MacLaren, 2007].
The acknowledgement from a Resource Requester is demanded by the final

5.8. PROTOCOL ANALYSIS 179
formation of a contract. It enables the collection of all available offers for dif-
ferent resources before a Resource Requester returns final confirmations to Re-
source Providers. Figure 5.7 demonstrates an approach to applying the Alliance2
protocol to enable negotiation for a job execution conducted by more than one
Resource Provider. The approach shown in Figure 5.7 assumes that a Resource
Requester requires two resources for two sub-jobs in an application execution
request. The Resource Requester first selects two resources that can meet the de-
mands of the two sub-jobs respectively. Only after receiving Accept messages from
both of the selected Resource Providers does the Resource Requester send Ac-
ceptAck messages to the Resource Providers to confirm the contracts’ formation.
This works as a two-phase commit process: offer collection takes place during
the commit-request phase, and sending of acknowledgements happens during the
commit phase [Gray and Reuter, 1992], as shown in Figure 5.7. In this way, the
Alliance2 protocol can not only negotiate resource(s) for a single job but also
form co-allocation among multiple resources required by sub-jobs in a single job.
The same approach can also be applied for resource co-allocation for a workflow
job.
5.8.4 Enabling Alliance2 Protocol for Interoperation
As discussed in Chapter 3, the proposed Alliance2 model can view existing infra-
structures as independent resource providers. This can introduce limited changes
required from an infrastructure for negotiable resource provisioning. Interopera-
tion can be achieved by adding a software component for negotiation purposes,
acting as a Resource Provider on behalf of an infrastructure. Accordingly, infra-
structures are only responsible for application execution. Meanwhile, a software
component for a Resource Manager is also required for access control and resource
sharing management of a research group.
To date, resource provisioning collaborations via negotiation have not been fa-
cilitated by existing infrastructures. One solution to implementing the Alliance2
protocol may be to enable negotiable resource provisioning from collaborating in-
frastructures. This solution assumes that a research group has achieved resource
provisioning collaborations with infrastructures and e-Scientists of the group can
subsequently send job requests with specific execution demands. Every job re-
quest will be authorised by the manager of the group via access negotiation be-
fore job execution. Also, resource consumption by each job will be advised to the

180CHAPTER 5. A NEGOTIATION PROTOCOL: THE ALLIANCE2 PROTOCOL
manager of the group to achieve accountable resource provisioning. These enable
fine-grained resource sharing management in the group. This solution also as-
sumes that e-Scientists have obtained the required digital certificates beforehand
if they are required.
Based on these assumptions, as illustrated in Figure 5.8, resources can be pro-
visioned from an infrastructure, after successful negotiation between an e-Scientist
and a negotiation software component. Successful negotiation indicates that the
request has been authorised by a group manager. The following procedures for
successful negotiation, e.g. job submission, job execution, result collection, and
accounting data collection, remain unchanged as supported by the infrastructures.
Among these procedures, collecting accounting data pre-supposes that providers
support capturing the accounting data and are willing to make it accessible. How-
ever, for Cloud service consumption, the number of resources consumed can be
calculated by a group manager, assuming that a job will be executed immediately
after submission. This assumption is based on the feature that Clouds can sup-
ply resources on demand dynamically. Additionally, communication for resource
management purposes is required to realise the expected accountable resource
provisioning contributed by the Alliance2 protocol. For example, a notification
message can be sent from the negotiation software to the software for a group
manager to advise of a contract formation; and a job completion message can
be sent from the negotiation software, infrastructures, or applications to a group
manager to advise of job completion. These messages allow the group manager
to update resource sharing management information for each job submission.
The testbed presented in Chapter 6 will demonstrate the solutions developed
to enable negotiation upon existing infrastructures (i.e. a Cloud and a Cluster).
The testbed follows the interoperation approach as discussed above.
5.9 Formal Protocol Verification
In this section, a formal method using the Spin model checker [Gerard, 2003] will
be presented. This method is to evaluate the correctness of the Alliance2 protocol.
Correctness means that the negotiating entities can reach the same negotiation
results if they apply the messages and follow the messaging behaviours specified
in the protocol. Apart from the verification purposes, the methodology applied
contributes to a novel approach to verifying the correctness of protocol design in

5.9. FORMAL PROTOCOL VERIFICATION 181
E-ScientistResourceManager
NegotiationAgent
E-Infra-structure
Resource Requesting OrganisationResource Provisioning
Organisation
Offer
AccessReq
AccessSucceed
Accept
AcceptAck
Contracted
Job submission
Figure 5.8: Negotiation with independent providers
a rigorous manner for large-scale distributed communication.
5.9.1 Spin Model Checker
The Spin model checker [Gerard, 2003] is designed for analysing the logical con-
sistency of concurrent or distributed asynchronous software systems. It is espe-
cially focused on verifying the correctness of process interactions [Strunk et al.,
2006]. The Spin model checker can verify properties in a rigorous and mostly auto-
mated manner. As a result, it is a widely-used tool for specifying and verifying
the properties of concurrent and distributed software models. Manual verification
is also available for interactions with a developed model if required, by verifying
the prompt responses from the built model according to inputs from a user. Such
software models can to be written in Promela (Process Meta Language). Promela
supports modelling of asynchronous distributed algorithms as non-deterministic
automata [Gerard, 2003]. Interactive and random simulation can give a developer
basic confidence that the model has the intended properties. To verify the pro-
posed properties upon a model, Spin can search for counterexamples via state
space exploration.
Spin is open-source and widely-used, and has active community maintenance.
Available materials and support can be easily obtained for implementation and
verification. Based on these advantages, various works have utilised Spin for
verification and evaluation purposes. Dury et al. [Dury et al., 2007] use Spin

182CHAPTER 5. A NEGOTIATION PROTOCOL: THE ALLIANCE2 PROTOCOL
to check the compatibility of Role Based Access Control (RBAC) with a given
workflow and validate security properties against the given RBAC constraint
sets and workflow. They stressed the potential for state explosion by applying
a model checker for verification of large-scale systems. [Siegel, 2007] developed
an extension to Spin to facilitate the verification of the correctness properties of
communication using the nonblocking primitives of the Message Passing Interface
(MPI). [Vaz and Ferreira, 2007] modelled and verified the properties of business
workflow patterns upon Spin, by translating generic workflow constructs to a Spin
model.
Spin focuses on verifying the correctness of process interactions. Accordingly,
the emphasis of a built model with Spin is the abstraction of synchronisations and
interactions among concurrent processes. Spin has limited support for internal
sequential computations. As a result, properties that can be specified by Spin
are untimed, or, in other words, of qualitative, not quantitative timing relations.
Typical Spin models attempt to abstract as much as possible from internal se-
quential computations [Strunk et al., 2006]. Other tools dedicated to validating
real-time properties are available, such as KRONOS [Yovine, 1997] and UPPAAL
[Larsen et al., 1997]. While being very accurate, model checking only supports
analysis for a constant number of processes and exhibits poor performance when
analysing more than a few processes. These features also apply to the Spin model
checker. However, the Spin model checker will be applied to verify the negotiation
procedures via three processes, corresponding to the three negotiating entities de-
signed in the Alliance2 protocol. The performance of the built model will not be
impaired in this case.
Additionally, to validate prospective properties by a formal model before im-
plementation enables timely correction [Siegel, 2007], which can save a remarkable
amount of time and effort for implementation. This is even more true for col-
laborations in a large-scale distributed and loosely coupled environment. The
Alliance2 protocol is based on distributed communication among negotiating en-
tities. Accordingly, it can be simulated as a distributed model. As a result, Spin
model checker has been applied as a simulator. Negotiating entities, messages,
and messaging behaviours have been modelled as designed in the protocol. More
details of the established models will be given in the following section. The esta-

5.9. FORMAL PROTOCOL VERIFICATION 183
blished negotiation models built upon Spin are used to examine the logical con-
sistency, i.e. correctness, of the designed protocol. The correctness is verified
by exhaustive exploration of all possible messaging behaviours. The correctness
of the established simulation models means that the designed messages are ex-
changed among the three entities in the designed orders and finally reach the
same final negotiation states.
As discussed in [Kars, 1996], formal methods are only one means to enhance
the quality of a system, and they should be integrated with other measures. The
testbed to verify the other properties of the Alliance2 protocol, i.e. the claimed
functionalities and related performance, will be discussed in Chapter 6.
5.9.2 Implementation
Three processes have been created in the built models for communication of a
Resource Requester, a Resource Manager, and a Resource Provider, respectively.
Negotiation between processes is simulated as sending and receiving messages.
The messaging behaviours of processes are as designed in the Alliance2 protocol.
To simulate the communication in a practical manner, the built models con-
sider and solve issues that may encounter during negotiation, such as livelock and
deadlock. The solutions follow the principles of communication protocol design
[Sharp, 2008] as discussed in Section 5.4. Some issues can be solved by available
techniques in practice, such as TCP for reliable communication. However, any
applied techniques or mechanisms need to be built from scratch when building
models using Spin. This means that the correctness of the techniques or mech-
anisms also needs to be verified, which can introduce more cost than the possible
benefits. As a result, the built models consider the issues that may corrupt ne-
gotiation in practice and apply simple solutions to ensure the negotiation would
not be affected. The solutions that have been implemented when building the
models are as follows:
• Each message includes a message number and a user-identity number. Both
numbers are kept locally, aiming to avoid a global state machine and syn-
chronisation in a distributed environment.
• The message number of a reply message is generated by increasing the
message number of the received message by 1. This mechanism aims to
solve the possible livelock problems via identifying message numbers. A

184CHAPTER 5. A NEGOTIATION PROTOCOL: THE ALLIANCE2 PROTOCOL
livelock happens when a process cannot progress due to the inability to
identify incoming messages.
• A timeout is implemented as an end state to deal with deadlock situations.
A deadlock happens when the communication cannot progress due to mes-
sage loss or corruption.
• Repetition construct is another method to avoid deadlocks in the built
models. To send a reply message repeatedly until the receipt of a response
ensures that a process eventually receives a valid message as designed in
the protocol.
• End-state labels are used to identify valid termination points during nego-
tiation (timeout being a default end state in the Spin model). End states
simulated in the models for the Alliance2 protocol are explained in Table 5.2.
Apart from the end states presented above, two other situations are mod-
elled as end states: agreement on a revocation request and rejection of
an offer. This is to avoid endless recursion in the built models, as both
situations will lead to new rounds of negotiation.
Both scenarios where access negotiation can happen have been simulated in
two models: during pre-negotiation and during resource negotiation. The two
scenarios are represented as a and b respectively in Table 5.2. Cases that are not
marked with a or b apply to both scenarios.
Resource negotiation messages, access request messages and access response
messages contain different information. As a result, three message formats are
defined to represent 17 negotiation messages in the two models built, as shown
in Table 5.3.
Each entity’s messaging channel for negotiation is simulated as an active pro-
cess in the model. A messaging behaviour can be to send or to receive a message.
After sending a message, each process will check for incoming messages or send a
message. For instance, after sending an Accept message, the Resource Requester
process can: (i) send a RevokeReq message to revoke the Offer being negotiated;
or (ii) wait for an AcceptAck message from the Resource Provider process that
confirms contract formation. The decision to send or to receive a message is
simulated as a random choice in the models. This is to ensure that the models
explore all negotiation paths of the Alliance2 protocol.

5.9. FORMAL PROTOCOL VERIFICATION 185
Table 5.2: Negotiation end states
Resource Requester
1. After sending or receiving a Terminate message
2. After receiving an AcceptAck message from theResource Provider process
3. After receiving an AccessDenied message from theResource Provider process
Resource Provider
1a. After sending or receiving a Terminate message
1b. After sending an Uncontracted message to theResource Manager process which is activated by send-ing or receiving a Terminate message from the Re-source Requester process
2. After sending an AcceptAck message to the Re-source Requester process and sending a Contractedmessage to the Resource Manager process
3. After sending an AccessDenied message to theResource Requester process
Resource Manager1. After sending an AccessDenied message to theResource Provider process
2. After receiving a Contracted or an Uncontractedmessage from the Resource Provider process
With the applied mechanisms described above, the built models give confid-
ence regarding the correctness of the designed protocol. Simulation results upon
Spin will return unreached paths, unreached states, and whether conflict mes-
saging behaviours happen between processes during verification. Each entity’s
messaging behaviours that have been simulated are as follows.
Resource Requester Process Messaging Behaviours After a message
has been sent, the incoming message for the Resource Requester process can be
one of the follows:
• A message replying to a previous message from the Resource Provider pro-
cess;
• A Terminate message from the Resource Provider process when the Re-
source Provider process or the Resource Manager process wishes to ter-
minate the negotiation. The scenario of receiving a Terminate from the
Resource Provider process conveying the Resource Manager’s termination

186CHAPTER 5. A NEGOTIATION PROTOCOL: THE ALLIANCE2 PROTOCOL
Table 5.3: Negotiation simulation modelling with SpinMessage Type Message Contents
Resource negotiationmessage
QuoteRequest, Quote, Of-fer, OfferAck, Accessing,Accept, AcceptAck, Reject,RevokeReq, RevokeRej, Re-vokeAcc, Terminate, Con-tracted, Uncontracted
User identity number,message number
Access verificationrequest
AccessReq User identity num-ber, message number,user’s role
Access verificationresponse
AccessDenied, AccessSuc-ceed
User identity number,message number, ac-cess decision
decision can only happen after the Resource Requester process receives an
Accessing from the Resource Provider process.
At the same time, the Resource Requester process may send a RevokeReq or
a Terminate to the Resource Provider process.
Algorithm 3 illustrates part of the negotiation procedures for the Resource
Requester process in the built models. It shows that the Resource Requester
process keeps two local variables: user identity number (uid) and the identity
number of the message it sent previously (sent msg no). After sending an Offer
message, the Resource Requester process may receive an OfferAck or a Terminate
from the Resource Provider process, or it may choose to send a Terminate to end
the conversation or a RevokeReq to change the previously sent Offer. Whenever
the Resource Requester process receives any message from the Resource Provider
process, only when the following two conditions are met, it will proceed to the
next step. The first condition is that the received uid (received uid) matches
the one stored locally. The second condition is that the message identity number
(received msg no) is larger than the locally stored sent msg no by 1.
As shown in Algorithm 3, if the received OfferAck is validated, the Re-
source Requester process proceeds to further negotiation. The received mes-
sage may not be validated. For instance, the received message identity number
(received msg no) does not match that stored locally in the Resource Requester
process. In this case, a new decision needs to be made by the Resource Requester
process between: (i) to keep tracking the incoming messages by applying a loop;

5.9. FORMAL PROTOCOL VERIFICATION 187
or (ii) to send a message. The messages that can be sent by the Resource Re-
quester process are RevokeReq and Terminate. If the process cannot proceed
further, it will timeout and end the current negotiation.
Algorithm 3 Resource Requester messaging behaviourslocal variable uid, sent msg nosend Offer(uid, sent msg no) thenif received OfferAck(received uid, received msg no) then
if (rid == uid) && (received msg no == sent msg no + 1) thenfurther negotiation
else keep checking the incoming message or send a messageend if
end ifif receive Terminate(rid, received msg no) then
if (rid == uid) && (received msg no == sent msg no + 1) thenend state
else keep checking incoming message or send a messageend if
end ifif send Terminate(uid, sent msg no + 1) then
end stateend ifif send RevokeReq(uid, sent msg no + 1) then
further negotiationelse timeoutend if
Resource Provider Process Messaging Behaviours After receiving a
message from the Resource Requester process, the Resource Provider process can
conduct any of the following messaging behaviours:
• To send a message replying to the previous message from the Resource
Requester process.
• To send a Terminate to the Resource Requester process. If the termination
happens after sending an AccessReq to the Resource Manager process, a
Terminate should also be sent to the Resource Manager process.
• To receive a Terminate when the Resource Requester process or the Re-
source Manager process seeks to terminate the negotiation. Receiving a
Terminate from the Resource Manager process can only happen after send-
ing an AccessReq to the Resource Manager process for an access decision.

188CHAPTER 5. A NEGOTIATION PROTOCOL: THE ALLIANCE2 PROTOCOL
• To send an Uncontracted to the Resource Manager process after receiving
or sending a Terminate from or to the Resource Requester process. This
can only happen after successful authorisation via access negotiation.
• To send a Contracted to the Resource Manager process after receiving an
AcceptAck from the Resource Requester process. This can only happen
after successful authorisation via access negotiation.
Resource Manager Process Messaging Behaviour An incoming message
to the Resource Manager process can be an AccessReq, a Terminate, a Contracted,
or an Uncontracted. As discussed above, receiving a Terminate can only occur
after receiving an AccessReq. Also, receiving a Contracted and an Uncontracted
can only occur after successful authorisation via access negotiation. After re-
ceiving an AccessReq and before receiving a Contracted, the Resource Manager
process can send a Terminate to the Resource Provider process. An AccessDenied
and an AccessSucceed are used by the Resource Manager process to inform the
Resource Provider process of access control decisions.
5.9.3 Evaluation
Formal verification has not been applied to other negotiation protocols designed
for e-Science. However, the author of this thesis thinks that it can contribute to a
more efficient implementation, as design errors can be detected and corrected via
simulation before implementation [Siegel, 2007]. Formal verification also enables
property verification before implementing a proposal practically. Furthermore,
formal verification can contribute to interoperation and interoperability evalu-
ation with different systems. This is essential for researchers to evaluate whether
a protocol can be applied to their existing systems. The most important reason
for applying formal verification is that the Alliance2 protocol is law-based. It
requires a rigorous approach to verify the claimed properties, to ensure that ne-
gotiation results are valid to all negotiating entities.
The formal verification is achieved by building simulation models of the de-
signed negotiating entities, messages, and messaging behaviours in the Alliance2
protocol. Both scenarios for access negotiation (access negotiation happening
during pre-negotiation and access negotiation happening during resource nego-
tiation) have been evaluated. The evaluation aims to check whether: (i) each
entity’s messaging behaviours follow the designed procedures; and thus (ii) all

5.10. SUMMARY 189
entities can eventually reach the same valid end state, as designed in the protocol.
There should be no errors during a simulation, even via state space exploration,
because of the following two reasons. First, each message contains information
(i.e. a message number and the message’s type) to avoid exceptional messaging
behaviours. Second, repeated sending and receiving of messages have been im-
plemented to ensure a process can follow the messaging behaviours designed.
The verification results showed that there were no ‘invalid end states’, no
errors, and no messaging conflicts during the implemented simulations. They
matched our expectations and demonstrated that no exception took place. The
total numbers of the states reached were 5980 and 3737 for access negotiation
scenario 1 and access negotiation scenario 2 respectively. The time consumed
for verification of both scenarios was between 0.01-0.02 seconds1. Interactive
simulation has also been conducted. It prompts the user at every execution
step to choose a messaging behaviour. Interactive simulation further verified
the correctness of the designed protocol. The evaluation showed that the three
negotiation processes could reach the same final negotiation states if they apply
the designed messages and follow the designed messaging behaviours.
5.10 Summary
This chapter has presented the Alliance2 protocol, a novel solution to: (i) enabling
fine-grained accountable resource provisioning; and (ii) managing the complete
resource provisioning lifecycle without binding a research group to resource pro-
viders. By inheriting the law-based feature from the protocol in [Parkin, 2007],
the Alliance2 protocol facilitates lightweight but reliable resource provisioning via
negotiation. Based on the Alliance2 model, the Alliance2 protocol is interoper-
able with existing infrastructures, by introducing a software agent for negotiation
purposes. The correctness of the Alliance2 protocol has been verified by the Spin
model checker. The correctness verification ensures that the negotiating entities
can reach the same final negotiation states by negotiating with the proposed mes-
sages and following the proposed messaging behaviours. This chapter has also
reasoned around the importance and usefulness of formal verification for pro-
tocol design and efficient implementation. Furthermore, the comparison between
1The developed models of the proposed negotiation protocol for Spin verification are availableat https://github.com/ZeqianMeng/NegotiationSpin

190CHAPTER 5. A NEGOTIATION PROTOCOL: THE ALLIANCE2 PROTOCOL
the Alliance2 protocol and other negotiation protocols proposed for e-Science
resource provision has been conducted. It shows that the Alliance2 protocol con-
siders all features required by contract-oriented negotiation while others do not.
However, considering more features introduces the possibility of longer duration
of negotiation, which can be improved by related mechanisms in practice.
This chapter has also discussed an approach to implementing the Alliance2
protocol upon existing infrastructures from the perspective of interoperation. An
implementation following the approach will be demonstrated in Chapter 6. The
implementation builds a testbed to evaluate the functionalities and perform-
ance of the Alliance2 protocol. With the ontologies and programs presented
in Chapter 4, the testbed aims to support negotiable and accountable resource
provisioning, as well as fine-grained resource sharing management for a research
group.

Chapter 6
Testbed-Based Protocol
Evaluation
6.1 Introduction
A testbed will be presented in this chapter that evaluates the feasibility, function-
alities, and performance of the designed protocol with production infrastructures
and use cases. The testbed takes advantage of the fine-grained accounting abil-
ity enabled by the ontologies and software shown in Chapter 4, for accountable
resource provisioning.
To enable negotiable resource provisioning, the testbed follows a brokering
mechanism. A broker has been developed to negotiate on behalf of production
infrastructures. The testbed implements the messages and messaging behaviours
designed in the protocol. Accordingly, it will test whether the implemented nego-
tiation functions follow the designed messaging behaviours and reach the expected
negotiation states. Meanwhile, the testbed should support fine-grained account-
able resource provisioning management per job for each member of a research
group. The verification is achieved by designing and evaluating scenarios for
the negotiation and accounting functionalities developed in the testbed. Also,
the performance of the enabled negotiation procedures will also be measured,
without network and with the Internet. The duration of the enabled negotiation
will be compared with computational job execution duration to determine its
efficiency. Furthermore, the mechanisms enabled by the broker to deal with ne-
gotiation exceptions and scalable requests will also be discussed. Moreover, the
application management and resource sharing functions enabled by the broker
191

192 CHAPTER 6. TESTBED-BASED PROTOCOL EVALUATION
will be compared with some widely-used production tools.
This chapter begins by introducing the preliminaries before giving further de-
tails of the testbed in Section 6.2. This is followed by presenting the testbed
architecture, use case implementation, and the main functional software com-
ponents for negotiation and accounting in the testbed in Section 6.3. Then, the
chapter goes on to give details regarding functionality evaluation, performance
evaluation, and further analysis of the testbed in Section 6.4. Finally, Section 6.5
summarise the chapter.
6.2 Preliminaries
6.2.1 Application Hosting Environment 3
Application Hosting Environment 3 (AHE3) [Zasada et al., 2014] is a lightweight
Grid gateway. AHE3 is built upon the Software as a Service concept on top of
infrastructure resources. It is focused on providing an easy-to-use gateway for
e-Scientists in diverse computational application domains with high-performance
service supply. To achieve this, AHE3 is designed to manage job submission and
execution for e-Scientists to various infrastructures based on the demands for the
execution of different applications. Aiming to be user-friendly, AHE3 allows an
e-Scientist to specify only the application to be executed. It will then search
for resources meeting the requirements and submit jobs on behalf of e-Scientists
to corresponding infrastructures. To enable these features, three main functions
have been developed in AHE3 for: (i) managing members to resources in col-
laborating infrastructures; (ii) managing credentials to resources in collaborating
infrastructures; and (iii) mapping resources to applications. So far, AHE3 can
only map general resource information to an application, such as the number of
CPUs and the size of memory required. Support for application-specific paramet-
ers, for example, the number of atoms to be included in a molecular dynamics
application, needs to be extended in AHE3 if required.
Via these functionalities, AHE3 can ease e-Scientists’ work, by hosting tech-
nical details required by applications and infrastructures on behalf of e-Scientists.
It models an application with a high-level concept, by mapping it as a single virtu-
alised job. A single virtualised job may consist of coupled computational sub-jobs
and may be allocated to different resources or infrastructures.

6.2. PRELIMINARIES 193
This underlying philosophy is consistent with the motivation of this test-
bed. The philosophy is that tools supplied for e-Scientists are supposed to be
user-friendly, assisting e-Scientists to focus more on their research domains. User-
friendliness is achieved by abstracting away all the details of underlying hardware
or software systems from the concerns of e-Scientists in AHE3. Taking this ad-
vantage, resource management on top of AHE3 can contribute to a lightweight
client. It indicates that our extension of AHE3 introduces the possibility of al-
lowing e-Scientists to use lightweight clients to manage application execution.
Considering these features, AHE3 has been utilised to enable resource manage-
ment in this testbed.
Resource management in AHE3 maps a resource to a group and does not
relate a job submission to a resource. This mechanism indicates that: (i) AHE3
does not consider resource management for each group member; and (ii) AHE3
does not enable resource management for each job submission. They result in the
fact that AHE3 does not support accountable resource provisioning for members
of a research group. However, accountable resource provisioning for members is
required by e-Science research groups as reported in [Riedel et al., 2009]. It is
especially required by the following two scenarios: (i) when consuming pay-as-
you-go services; and (ii) interactive steering experiments, where job execution can
be manipulated by e-Scientists. Both scenarios make a single member prone to
consuming unreasonable amounts of resources.
6.2.2 Design Principles
To achieve the goals of the Alliance2 protocol presented in Section 5.1, this testbed
provides the following features by implementing the Alliance2 protocol:
1. It demonstrates the feasibility of the protocol: negotiable resource provi-
sioning can be realised by the developed software;
2. It realises dynamic, customised, and fine-grained accountable resource pro-
visioning for e-Scientists as members of a research group, via negotiation;
3. It can cooperate with existing infrastructures and meet real demands of
production use cases.
As [Zasada and Coveney, 2015] argues, to fully realise the implementation of
a negotiation protocol in real e-Science infrastructures is impractical. The reason

194 CHAPTER 6. TESTBED-BASED PROTOCOL EVALUATION
is that root access could be required to enable negotiation with the systems, and
machines need to be taken down. In addition, the required efforts to enable it
are excessive. This is because negotiation-based resource provisioning and collab-
orations are different from the approaches taken by production infrastructures.
Production infrastructures refer to infrastructures that have been established and
are being used to support e-Scientists’ experiments. Production infrastructures
are mostly either based on VOs or single administrative domains. Both cases
have centralised resource management and do not facilitate negotiation for re-
source provisioning by nature. As a result, to achieve the full potential of the
Alliance2 protocol will require changes to or development from scratch of all relev-
ant supporting mechanisms and software, which are out of the scope of this thesis.
Such supporting mechanisms and software include those for resource allocation
and co-allocation, negotiation strategies, and contract selection strategies.
However, the protocol can apply a brokering mechanism [Riedel et al., 2009]
to implement the advantages that it can contribute to production infrastructures.
This can be achieved by developing extra software to negotiate resource provision-
ing on behalf of existing infrastructures. This solution needs to take advantage
of available functions and interfaces provided by infrastructures, relying on the
way the infrastructures make their resources available. It follows the interopera-
tion scenario defined in Chapter 2 and the solutions proposed for interoperation
in Chapter 3. More specifically, it can be realised by developing a broker as an
agent that negotiates on behalf of existing infrastructures for resource provision-
ing. A broker should also be able to translate job submission requests to existing
infrastructures with their processable forms after successful negotiation. Consid-
ering these features, the solution to the testbed implementation can be summar-
ised as follows. When a broker receives an application execution request from
an e-Scientist, negotiation will be activated. The negotiation happens between
the broker, the e-Scientist, and the corresponding software for the manager of
the group to which the e-Scientist belongs. Production infrastructures will ex-
ecute jobs submitted from the broker after contracts are formed. This solution
would introduce limited changes to existing infrastructures. It is similar to how
UNICORE Grid middleware [Erwin and Snelling, 2001] combines resources of
supercomputing centres and makes them available to e-Scientists.
The testbed is set up with a practical execution environment as close as pos-
sible to that of existing production, to ensure that the testbed still can achieve

6.2. PRELIMINARIES 195
valuable experimental experience via the brokering approach. It undertakes the
following approaches:
1. It extends a lightweight Grid gateway, e.g. Application Hosting Environ-
ment 3 (AHE3) [Zasada et al., 2014], to implement the Alliance2 protocol.
2. It follows the same principles applied by production infrastructures to de-
velop functions that are not presently available. Such principles include
those for distributed resource information collection and processing in Berke-
ley Database Information Index (BDII) [Field and Schulz, 2005]. They are
followed for accountable resource provisioning management in the developed
broker.
3. It applies two production use cases that cooperate with infrastructures
based on two different enabling models respectively: the Cloud model and
the Cluster model.
The reasons that infrastructures based on the Grid model are not used are as
follows:
1. For virtualisation-enabled Grids, the same negotiation and resource man-
agement mechanisms that have been developed for the Cloud services util-
ised in the testbed can be used.
2. For Grids without virtualisation or support for resource reservation, as dis-
cussed in Section 2.2.1, an e-Scientist has no control over: (i) how long
the execution will take; (ii) when the job execution will be started; and
(iii) the number of resources the job will consume. These make resource
usage accounting for a job non-trivial with existing Grids, which is out of
the scope of this thesis. However, negotiable resource provisioning can be
realised with the same approach developed for the Cluster model, as will
be discussed in this chapter.
3. Accessing Grids for job submission and job management has been facilitated
and evaluated by AHE3 [Zasada et al., 2014]. AHE3 has enabled applica-
tion execution management upon Grids. Clouds and Clusters have not been
supported and evaluated in AHE3 to date, making them good complement-
ary use cases for this testbed. Additionally, as discussed in Chapter 2, it
is time- and effort-consuming to apply for and establish a VO to enable a

196 CHAPTER 6. TESTBED-BASED PROTOCOL EVALUATION
customised execution environment in Grids. A customised execution en-
vironment is required by one of the implemented use cases. Considering
these reasons, this testbed utilises Cloud services supplied by Amazon and
a Cluster that is managed by the University of Manchester. Both are easy
to start with and allow customised execution environment configuration.
There are many tools and middleware available for Grid job submission and
resource management. The main reasons to apply AHE3 are as follows. First,
AHE3 is application-independent. This means that it can be applied to the chosen
use cases. Second, AHE3 is platform-independent. Platform-independence makes
it possible to be compatible with infrastructures based on different enabling mod-
els. As job submission management in AHE3 can be customised, job submission
to Clusters and Clouds can be built.
By extending AHE3, this testbed demonstrates that the Alliance2 protocol
can interoperate with existing infrastructures while enabling functions that are
not currently available. These functions are for dynamic, customised, and ac-
countable resource provisioning via negotiation.
Apart from negotiation messages and messaging behaviours, other functions
need to be taken into consideration for negotiation and negotiation-based resource
management in practice. They include negotiation decision-making strategies,
resource allocation mechanisms, and concurrent communication management.
They are project-, infrastructure-, or application-specific, and may vary in differ-
ent implementation. The main target of this testbed is to verify the feasibility of
the designed protocol to enable dynamic, customised, and accountable resource
provisioning from infrastructures based on different e-Science enabling models
(the Cloud model and the Cluster model) via negotiation. Focused on this main
target, we have developed simple negotiation decision-making strategies, match-
making strategies, and communication management for this testbed.
The testbed focuses on negotiable contract contents of importance to e-Scientists,
namely specific requirements for application execution or the computing resource(s)
demanded. Such requirements can be a limited time period to run an applica-
tion or the number of CPUs needed. Other elements involved when forming an
e-Science collaboration, for example, intellectual property and competition policy
[David and Spence, 2003], are out of the scope of this work.
Combined with the resource matchmaking for application execution presented
in Chapter 4, the negotiation enabled in this testbed aims at the following two

6.2. PRELIMINARIES 197
functions. First, it searches for satisfactory resources required by applications and
e-Scientists’ customised demands. Second, it enables a group manager to control
and track the resources allocated to and consumed by group members on a per job
basis. This chapter shows how these targets have been approached by requirement
analysis of participating entities in e-Science collaborations and resource sharing,
testbed architecture design, and sophisticated technical implementation.
6.2.3 Use Cases
6.2.3.1 Use Case 1: SWDS on AWS
As discussed in Section 3.2.1, modelling of real-time states of Simulated Wa-
ter Distribution Systems (SWDS) is one of the implementations of data-driven
computational steering. To model a real-time SWDS, the computation has to
be synchronised with data streams that are updated at frequent intervals. This
synchronisation is to ensure the effectiveness of the data collected from real-time
Water Distribution Systems. The data collected in turn can change the require-
ments of the execution environment of the system during runtime. As a result,
the system update should be completed within a limited time frame. Otherwise,
the outdated steering results no longer track the real state of the physical Water
Distribution System. In order to tackle the timing issue of computational steering
driven by run-time collected data, dynamic and customised computing resource
provisioning on a short timescale is required.
Data-driven computational steering enables dynamic resource changes during
runtime and job execution to be controlled by a software component automat-
ically. Also, it was implemented on AWS, which provides resources whenever
required. These two features introduce the possibility of an unreasonable amount
of resources being consumed by a single user. This may make a group manager
concerned about the number of resources or money each e-Scientist in the group
can consume, assuming that the group manager needs to pay for the resources
consumed by group members.
6.2.3.2 Use Case 2: Local Cluster Resource Sharing Management
The local Cluster at the University of Manchester has restricted access control,
meaning that it is not directly accessible from off-campus [Services, 2018a]. This
has the result that the main functionalities required for job submission from the

198 CHAPTER 6. TESTBED-BASED PROTOCOL EVALUATION
broker to the local Cluster are to enable remote connection and communication
with the Cluster via SSH communication. Accordingly, the two main aspects of
interoperation with the Cluster that have been implemented are SSH connection
and message processing for negotiation and accounting purposes. To enable ne-
gotiable and accountable resource provisioning, contract IDs and job IDs should
be tracked. They are managed by message processing programs specifically de-
veloped for this use case in the testbed.
Two types of jobs are supported in the local Cluster: serial jobs and parallel
jobs. As jobs in the Cluster are queue-based, e-Scientists have no control over
the exact time when the application execution will be started and completed.
For applications with timing requirements, a long waiting time in a queue will
mean that the job cannot be completed within the time limit required. This is
even more true for parallel jobs, which require multiple CPUs to execute a job
and can only be started when all the required CPUs become available in the
local Cluster [Services, 2018b]. This mechanism makes parallel jobs submitted
to the local Cluster more prone to delayed execution. This is different from
parallel execution in Clouds, as Clouds can supply resources elastically according
to demands [Belgacem and Chopard, 2015].
Combining with data-driven computational steering and the features of the
two different infrastructures (AWS and the local Cluster), this testbed aims to
verify that the Alliance2 protocol is capable of:
• Enabling data-driven steerable applications to request customised execu-
tion environment during runtime automatically, i.e. to search for resources
dynamically via negotiation and re-negotiation.
• Enabling an e-Scientist to specify a deadline and a job type (e.g. a serial
job or a parallel job) for application execution in the local Cluster via
negotiation.
• Facilitating fine-grained resource sharing and accountable resource provi-
sioning for a research group, for jobs submitted to both AWS and the local
Cluster.
Enabling these capabilities also indicates that the Alliance2 protocol is inter-
operable with existing infrastructures for resource provisioning via negotiation.
The following sections give more details regarding the broker developed, and the
negotiable and accountable resource provisioning enabled.

6.3. IMPLEMENTATION 199
6.3 Implementation
To allow accountable resource provisioning per job for research groups and ne-
gotiable resource provisioning for e-Scientists, AHE3 has been extended in this
thesis with the following three new functions:
1. Resource negotiation and re-negotiation for e-Scientists to conduct compu-
tational experiments in collaborating infrastructures. They are accessible
via the Negotiation APIs in Figure 6.1. Re-negotiation is enabled for Use
Case 1.
2. Accountable resource provisioning on a per job level for fine-grained re-
source sharing management in a research group. This is achieved by re-
source matchmaking and accounting functions developed upon ontologies,
as shown in Figure 6.1.
3. Job submission management for applications to be executed in Clouds and
Clusters. This is to manage job submission after successful negotiation,
namely the processes presented by the arrows for app1 and app2 in Fig-
ure 6.1.
The resulting software, which is a version of the AHE3 extended by the above
three extra functions, is called Service Broker1. More details of the extensions
will be discussed in Section 6.3.3.
6.3.1 Testbed Architecture
As shown in Figure 6.1, the testbed is composed of the following main compon-
ents.
(1) Service Broker: This comprises the functional components for negoti-
ation management and application management. The main functions enabled
include negotiation, user access control, resource matchmaking, accounting, plat-
form credential management, and job submission management. Information is
stored in a database for offer and contract management during negotiation, ter-
mination, and job completion. The database is managed by the Service Broker.
1The source code of Service Broker is available at https://github.com/ZeqianMeng/
ServiceBroker. The developed ontologies are included in the project source under the on-tologies directory.

200 CHAPTER 6. TESTBED-BASED PROTOCOL EVALUATION
Extended Application Hosting Environment 3
Negotiation APIs
Local Cluster
AWS
Service Broker
app1 Client Service steered_app1
scripts app2
Ontologies: resource mgmt. & accounting
Resource matchmaking based on ontologies
e-Scientist
Use Case 1
Use Case 2
Job submission mgmt. app2
2 2
1
1
2
Figure 6.1: Testbed architecture: the modules within the extended AHE3 are theextensions; arrows marked with 1 and 2 show communication for job executionin Use Case 1 and resource provisioning in Use Case 2, respectively.
Accounting data for resource provisioning and sharing management are kept in
ontology files.
(2) AWS is used as a resource provisioning infrastructure in Use Case 1: AWS
has been applied to support dynamic resource provisioning for data-driven compu-
tational steering. It has been pre-installed and pre-configured with computational
steering libraries for application execution2. In addition, the Client Service3
has been developed to enable negotiation on behalf of e-Scientists in this use case.
It is designed to facilitate automatic negotiation for resource provisioning.
(3) A local Cluster is used as a resource provisioning infrastructure in Use
Case 2: A local Cluster facilitated by the University of Manchester has been
used to support customised resource provisioning to meet e-Scientists’ application
execution demands4.
2This use case was achieved by collaborating with Dr Junyi Han via the Water EngineeringKnowledge Transfer Partnership, who had deployed a data-driven steering library on AWS.
3The source code of Client Service is available at https://github.com/ZeqianMeng/
ClientService4This use case was achieved by enabling the control of a particular application in astrophysics
in the local Cluster. The scripts developed by a collaborator, Dr John Brooke, and the scriptsand Java source developed by Zeqian Meng are available at https://github.com/ZeqianMeng/ClusterSource

6.3. IMPLEMENTATION 201
6.3.2 Use Case Implementation
6.3.2.1 Use Case 1 Implementation with Client Service
As discussed in Section 6.2.3.1, Use Case 1 requires a solution to searching for
and assigning more computing resources for a job, which can shorten applica-
tion execution time and make it complete within a given timeframe [Han and
Brooke, 2016]. This dynamic change of execution environment can apply negoti-
ation and re-negotiation for resource provisioning during runtime at short notice.
Accordingly, the main purpose of the Service Broker in this use case is to search
for satisfactory resources and provide the required information regarding the se-
lected resource(s) to the running programs via negotiation and re-negotiation.
Combined with AWS for Cloud service provisioning, the enabled scenario for this
use case is as follows. Instances with a required number of CPUs are needed to
start an application execution, while more CPUs or instances may be demanded
during runtime to shorten execution duration.
The existing programs for SWDS have a function to send requests with the
number of CPUs required. Such requests demand the endpoints of available re-
sources to be returned. To take advantage of this function and introduce limit
changes to existing SWDS programs, the Client Service was developed. The
main purposes of the Client Service are as follows. First, to carry out ne-
gotiation and re-negotiation required by the SWDS programs during runtime,
where the SWDS programs require resources on behalf of e-Scientists. Second,
to shorten the time needed for resource provisioning by automatic negotiation to
ensure the effectiveness of steering results.
For demonstration purposes only, pre-negotiation, resource negotiation, re-
source re-negotiation, and access negotiation have thus far been enabled in the
Client Service. Revocation initiation and termination initiation have not been
enabled in the Client Service (i.e. a Resource Requester). Also, offers and
contracts are selected for e-Scientists randomly to demonstrate the negotiation
procedures enabled by the software. This is because in a real application, only
the e-Scientists would define the criteria for acceptance and this would vary for
different collaborations, e-Scientists, infrastructures, application etc.
Two interfaces are presently available in the Client Service, for negotiation
and re-negotiation respectively. The negotiation service requires the following
inputs: a username, an application name, a group name, and the required number

202 CHAPTER 6. TESTBED-BASED PROTOCOL EVALUATION
of CPUs. Correspondingly, inputs for re-negotiation are a contract number and
the required number of CPUs. The contract number refers to the contract to be
re-negotiated. For re-negotiation, the Service Broker will check whether the
contracted instance has sufficient CPUs as required. This information can be
obtained by reasoning over the corresponding ComputingShare ontology. The
ontology has terms to define the available number of CPUs and balance for the
group in the contracted instance.
The resource management for negotiation, re-negotiation, and job execu-
tion is conducted by the ontologies and programs developed, as presented in
Chapter 4. Here, the ComputingShare ontology acts as a contract between a re-
search group and the Service Broker. The Service Broker acts as a resource
provider. The ComputingShare ontology contains resource information for the
whole group, managing resource provisioning for the Service Broker. The in-
formation contained in the ComputingShare ontology can be updated accordingly
and dynamically during matchmaking, after successful negotiation, and after job
execution. The main properties enabled for this use case for accounting purposes
are physicalCpus, virtualMachine, charge, cost, and balance. For example,
the values for physicalCpus and balance in the ComputingShare instance will
be reasoned upon for matchmaking. They will be reduced after successful negoti-
ation and re-negotiation. After job completion, the value of physicalCpus will be
increased by the number of allocated CPUs, while the value for balance may be
increased. The value for balance will be increased when the consumed amount
is less than the amount that has been reduced after successful negotiation.
With the support of the Client Service, negotiation will be carried out
between the Client Service and the Service Broker. The SWDS deployed in
AWS is only responsible for: (i) application execution after successful negotiation
and re-negotiation; (ii) sending requests with the required number of CPUs; and
(iii) informing the Service Broker when a job execution has been finished. The
complete negotiation and resource management procedures for this use case have
been enabled as follows:
1. An e-Scientist needs to run an application and submits the request to the
Client Service;
2. Negotiation is conducted by the Client Service and the Service Broker
automatically. After a successful negotiation for a resource, the satisfying
resource is returned to the SWDS programs in AWS;

6.3. IMPLEMENTATION 203
3. During application execution, the data-driven steering programs detect
that more CPUs are required to ensure the application can be finished
within a specific time limit. Thus, a request for more CPUs is sent by the
data-driven steering programs on behalf of the e-Scientist to the Client
Service. Then, the Client Service activates re-negotiation with the new
request to the Service Broker;
4. The Service Broker will check if the contracted instance(s) can supply
the extra CPUs via re-negotiation. With unsuccessful re-negotiation, it will
start negotiation for other available instances, and return the satisfying
instance(s) to the running programs;
5. When the Service Broker receives a notification for a job completion from
the SWDS programs, it will update the balance of the e-Scientist and the
balance(s) of the instance(s) that ran the job. It will also update the con-
tract state(s) to completed.
To realise the above procedures, changes have been carried out to the SWDS
programs to enable negotiation with the Service Broker and related accounting
capabilities. These changes are as follows:
1. The SWDS programs will send requests to the Service Broker when more
CPUs are needed and process the returned information. Each piece of
the returned information will contain a contract ID, a job ID, and the
endpoint(s) of the available instance(s);
2. The SWDS programs will track information related to negotiation, namely
contract IDs and job IDs;
3. The SWDS programs will notify the Service Broker when a job is com-
pleted with a corresponding contract ID. In this way, the duration of the job
execution can be calculated by the Service Broker. Then, the balances
for both the e-Scientist and the applied instances can also be updated by
the Service Broker.
6.3.2.2 Use Case 2 Implementation
Envisioning the demand for timely resource provisioning, this testbed allows e-
Scientists to specify a deadline for job execution in the local Cluster. When

204 CHAPTER 6. TESTBED-BASED PROTOCOL EVALUATION
the specified deadline approaches, the Service Broker will check job execution
status with the local Cluster. If the job execution has not been completed, the
Service Broker will terminate the job execution. We assume that checkpointing
and Cloud services can be utilised to continue job execution, making sure the job
can be completed before the deadline required.
In addition, this testbed assumes that only group members with a high pri-
ority can execute parallel jobs, for the following two reasons. First, parallel jobs
may consume more resources than serial jobs. Second, parallel execution may
contribute to shortened execution time, compared to executing all sub-jobs se-
quentially. As a result, three roles are defined for a research group in the Cluster
case:
• Ordinary users: e-Scientists that can execute only serial jobs.
• Prioritised users: e-Scientists that can execute both serial jobs and parallel
jobs.
• A group manager: the entity who allocates priorities to members and defines
resource sharing policies among members of a research group.
The two resource management strategies designed for the Cluster case are as
follows. First, all users within the group can require applications to be executed
serially by one CPU. Second, prioritised users can require jobs to be executed
in parallel with more than one CPU. These policies are supposed to be defined
by a group manager and have been hard-coded in the testbed for demonstration
purposes only. Different policies can be developed according to different imple-
mentation scenarios. This can benefit a research group by defining various rules
for e-Scientists with different priorities or for different application scenarios. The
approaches to developing customised policies have been discussed in Chapter 4.
Resource management for job execution in the local Cluster can also en-
counter this situation: an e-Scientist may submit another application execution
request before the current one is completed. This will introduce the possibility
of over-expenditure caused by follow-up jobs. Correspondingly, to avoid over-
expenditure, the maximum CPU time that can be consumed by the e-Scientist
is used in this case. The balances of a requester and selected resource(s) will
be subtracted from the maximum value after successful negotiation. In the case
that a balance is less than the maximum value, the balance will be reduced to 0.

6.3. IMPLEMENTATION 205
As the local Cluster has defined the maximum CPU time each specific user can
consume per job, these values are set the same as those defined by the Cluster.
This testbed also assumes that the research group has reached an agreement
with the Cluster provider on the total amount of CPU time that can be consumed
by members for both serial jobs and parallel jobs, respectively. In this way, the
Cluster provider only needs to be concerned with the total amount of resources
consumed by any member of the group for serial jobs or parallel jobs. It is for
the group manager to define different priorities and manage fine-grained resource
sharing for group members.
Based on these mechanisms, the complete application execution procedures in
the local Cluster have been enabled as follows. An e-Scientist submits a request
to the Service Broker with a username, a group name, an application name, the
parameters for application execution, the way to execute the application (serial
or parallel), and the deadline for application execution. This request activates
negotiation with the Service Broker. After successful negotiation, the related
balances will be updated, and the application will be submitted to and executed
by the Cluster. When the deadline specified by the e-Scientist is approaching,
and the Service Broker verifies that the submitted job has not been completed,
the job in the Cluster will be terminated. How long before the deadline to verify
the job execution status is infrastructure- and application-specific. It relates to
the scripts and programs built to communicate with a Cluster and to fetch the
required information from the Cluster. In the Service Broker built, it was 23
seconds on average before the deadline specified by an e-Scientist.
The following two features shape the accounting on the local Cluster. First,
the Cluster has facilitated accounting functions, which report the usage of CPUs
in seconds for each job. This is the same as enabled in the Service Broker.
Second, the Cluster has restricted access control, which does not allow programs
running in the Cluster to initiate network connections. According to these two
features, the solution for resource usage accounting in the Use Case 2 is as fol-
lows. The Service Broker fetches accounting data for jobs from the Cluster
over a specific time interval and updates resources’ and requesters’ balances in
corresponding ontologies. The specific time interval can be for each job after the
deadline specified by the requester. Also, the time interval can be relatively long
for all jobs that have been executed in a given period. This is the current solu-
tion enabled in the testbed. The specific time interval can be decided by a group

206 CHAPTER 6. TESTBED-BASED PROTOCOL EVALUATION
manager in practice, according to the needs of resource sharing management in
the group.
6.3.3 Service Broker
The Service Broker has been built upon AHE3 in Java, extending AHE3 with
RESTful web services for negotiation and accounting purposes. The negotiation
service searches for satisfactory resources for job execution. Negotiation takes
place before job submission. Accordingly, the extensions to AHE3 to enable
negotiation have been facilitated as follows. If negotiation succeeds, job submis-
sion will be activated, followed by other existing AHE3 functionalities and the
accounting functionalities extended.
The Service Broker functions as the Resource Provider, as specified in the
Alliance2 protocol. It provides resource details and negotiates on behalf of ex-
isting infrastructures. The Service Broker also enables accountable resource
matchmaking and resource consumption per job for a research group. This is
achieved by the ontologies and software developed, as presented in Chapter 4.
The ontologies and software are responsible for managing resource access control
and sharing policies in fine granularity on behalf of a Resource Manager. They
are independent of the functionalities for matchmaking and resource provisioning
management that are concerned with a Resource Provider. As a result, software
components specifically for a Resource Manager and Resource Providers can be
enabled from existing functions.
Resource management is supported in AHE3 by mapping applications to the
required resources and corresponding platforms. This feature is reserved by the
Service Broker to allow an e-Scientist to interact with the application layer
without being concerned with details of the required resources, aimed at user-
friendly resource provisioning. In this way, an e-Scientist only needs to specify
the application to be executed with expected QoS properties, such as the finish
time for application execution or the required number of CPUs.
Apart from management for accountable resource matchmaking and consump-
tion, the Service Broker enables dynamic and customised application execution
demands from e-Scientists. This is achieved by the negotiation capability enabled
by the Alliance2 protocol. The enabled negotiation and accounting have been
highlighted in Figure 6.2, and have not been facilitated by AHE3 as yet. As
shown in Figure 6.2, functions of negotiation are accessible by the negotiation

6.3. IMPLEMENTATION 207
7. As part of the workflow, the job is submi7ed to contracted
infrastructures
API
AHE Run@me
App Registry
JBPM Workflow, Main Logic and API
5. App-‐State created and workflow ini@ated
Accoun&ng
App-‐Instance
AHE Engine
Connector Module
Storage Module
Security Module
Extension Points
Hibernate ORM
UoM compu@ng Cluster
1. Applica&on Start/Stop/Steer Request
2. Startup/Shutdown
3. Get
4. Prepare
6. Submit (Start job execu@on)
Collaboted Providers
Service Broker Database
Ontology files
8. Data is sent to the designated loca@on once completed
Nego&a&on
Figure 6.2: Architecture of Service Broker: the Negotiation and Accounting mod-ules are extensions in AHE3, with dashed lines to present the related communic-ation and APIs. JBPM is for workflow management; Hibernate ORM allowsobject relational mapping from Java to a database.
web service APIs developed. In the Service Broker, the negotiable contents are
customised to the implemented use cases, but the negotiation procedures can be
taken by all other use cases. Accountable resource provisioning and job execution
are managed by the developed automatic reasoning programs built upon ontolo-
gies, a database, and the web service APIs developed in the Service Broker.
The negotiation APIs assist e-Scientists to search for satisfactory resources
before application execution. After successful negotiation, application execu-
tion will be activated by the Service Broker. During application execution, an
e-Scientist can steer the running application in the data-driven computational
steering use case.

208 CHAPTER 6. TESTBED-BASED PROTOCOL EVALUATION
Functions of accounting are activated in the Service Broker: (i) after suc-
cessful negotiation for both Use Case 1 and Use Case 2; (ii) after successful
re-negotiation in Use Case 1; (iii) by job completion notification from the steer-
ing programs when a job completes in Use Case 1; and (iv) when accounting data
is fetched from the local Cluster in Use Case 2. These accounting functions are
achieved by the combined usage of a database and ontologies. The database man-
ages information for negotiation, offers, contracts, as well as job submission and
execution management. Such information is established as objects in Java and is
managed by the Hibernate Object/Relational Mapping (ORM) framework [King
et al., 2011]. Hibernate ORM maps objects defined by Java to a database. As
discussed in Chapter 4, ontologies manage accounting data for providers and the
group manager.
Overall, in this testbed, the original AHE3 is applied for application man-
agement. Meanwhile, extensions have been built to enable negotiable and fine-
grained accountable resource provisioning, as well as job submission management
for Clouds and Clusters. The following sections give more details of the negoti-
ation and accounting enabled by the Service Broker.
6.3.3.1 Negotiation and Accounting
AHE3 was built with RESTful web services, with the result that communica-
tion can only be paired (i.e. a reply corresponds to a request) [Fielding, 2000].
Considering this feature, the two messages for acknowledgement (OfferAck and
Accessing) were not enabled in this testbed. These two messages do not affect the
validity of contract formation. Also, negotiation termination initiated by a group
manager has not been implemented yet. The reason is that the two use cases
enabled do not need manager termination during negotiation. Apart from that,
other negotiation messages and messaging behaviours as presented in Chapter 5
have been implemented and evaluated. More specifically, pre-negotiation, re-
source negotiation, access negotiation, revocation, negotiation termination initi-
ated by a requester and a provider, contract termination initiated by all three
entities, and re-negotiation have been realised.
The Service Broker has enabled the following situations for negotiation ter-
mination initiated by a provider:
1. When two members of a group compete for the same resource, the ne-
gotiation with the member with lower priority will be terminated by the

6.3. IMPLEMENTATION 209
Service Broker. The termination decision will be returned from the Serv-
ice Broker to the member when the Service Broker receives a further
negotiation message from the member. For instance, a Terminate will be
returned when the Service Broker receives an Accept message from the
member.
2. In Use Case 2, an ordinary user requires the execution of a parallel job.
The termination decision will be returned to the user as a reply to the
Offer received after the Service Broker receives an AccessDenied during
access negotiation. Other scenarios for provider termination can be added,
according to specific strategies for negotiation.
As presented in Chapter 5, access negotiation can be implemented before or
during resource negotiation to verify a requester’s balance and priority for access-
ing resources. This testbed enables access negotiation during the pre-negotiation
phase. Access negotiation during pre-negotiation phase indicates that the poten-
tial offers returned for a request have been filtered by requester’s balance and
priority. Only the resources that the group has sufficient balances on and the
requester has sufficient priority to access will be returned. This can improve the
rate of successful negotiation, which in turn can avoid multiple rounds of ne-
gotiation over networks. For distributed negotiation via the internet, this can
improve performance.
For access negotiation executed during pre-negotiation, the main factor that
can impair negotiation performance is the number of accounting properties to be
evaluated for an access decision for all available resources. As the testbed can only
evaluate the situation of resource provisioning from collaborating infrastructures,
the amount of resources for matchmaking is limited. This introduces limited per-
formance impairment for negotiation. Based on these reasons, it is conjectured
that access negotiation implemented within the pre-negotiation phase could be-
nefit negotiation performance for the use cases enabled in the testbed. The access
negotiation is enabled by an independent function, and it can easily be adapted
for access negotiation with the resource negotiation phase.
The negotiation procedures and related communication developed for account-
ing purposes can be illustrated in Figure 6.3. Figure 6.3 presents the negotiation
and re-negotiation procedures taken by Use Case 1. As shown in Figure 6.3, suc-
cessful negotiation forms a contract (Contract2) between the Client Service

210 CHAPTER 6. TESTBED-BASED PROTOCOL EVALUATION
and the Service Broker. After successful negotiation, the balances of the con-
tracted resource and the requester are reduced, and the job is started in the AWS
domain. When the SWDS programs detect that more CPUs are needed, the
requirement is sent to the Service Broker. Then, the Service Broker verifies
that the contracted instance can provide the extra CPUs required, in addition
to the previously contracted amount. As a result, a new version of Contract2
(Contract3) is formed after successful re-negotiation.
Combined with the use cases applied, the developed negotiation and resource
management procedures are as follows.
Pre-negotiation Pre-negotiation has been taken by both use cases. As high-
lighted in Figure 6.3, when receiving a QuoteRequest message from a requester,
the Service Broker conducts access negotiation with the corresponding Map-
pingPolicy ontologies. The following information will be analysed for an access
negotiation decision: the requester’s membership of the group, the requester’s
balance, and the requester’s priority (only for Use Case 2). These procedures
demonstrate the access negotiation enabled between a Resource Provider and a
Resource Manager. After successful access verification, the Service Broker ac-
tivates matchmaking to search for resources that satisfy the requester’s demands
within ComputingShare ontologies. The matchmaking activated is application-
oriented. Accordingly, only the required resource and application execution fea-
tures are checked by the Service Broker (e.g. the number of CPUs for Use Case
1, and the job type and deadline specified for Use Case 2, in this testbed). The
requester’s balance in the group and the group’s balance available for using the
resources are also evaluated by the Service Broker. This is achieved by compar-
ing them with a default duration or a budget limit that has been agreed between
the research group and the infrastructures. Resources that meet the demands
will be returned as potential offers (Quotes). The information contained in a
Quote can include the available resources, execution environment (type), avail-
able number of CPUs, memory size, and charge per hour for Cloud services when
applicable. The information will vary for different use cases, as different applic-
ations and resource provisioning infrastructures may have different features and
requirements. Other information can also be included according to specific ap-
plication scenarios. Meanwhile, negotiation metadata are stored in the database,
including a unique Quote number, the requester’s identity, the provider’s identity,

6.3. IMPLEMENTATION 211
ClientService
Negotia-tion APIs
Onto-logies
Steerer 1SteeringManager
Steerer 3
Service Broker Resource 1 Resource 3
AWS
app, user,group, CPUs app, user,
group, CPUs
Verified,Resource1,Resource2Offer1: Resource1
Offer2: Resource2
Offer1Contract1:Resource1
RevokeReqRevokeAcc,
Offer2
AcceptAck:Contract2
Reduce balance
Start steeringContract2,
increase n CPUs
Increase n CPUs
Verified,Resource3,Resource4
Offer3: Resource3Offer4: Resource4
AcceptAck:Contract3
Reduce balance
Start steering
Job completes
Update balance
Pre-Negotiation
Negotiation
Re-Negotiation
Figure 6.3: Data-driven steering enabled by negotiation

212 CHAPTER 6. TESTBED-BASED PROTOCOL EVALUATION
the agreed accounting features, the resource’s features, and the negotiation state.
Negotiation Negotiation is demonstrated in both use cases. As presented in
Figure 6.3, upon receiving a requester’s selection of an Offer, the Service Broker
activates resource negotiation procedures. When a resource provisioning confirm-
ation (AcceptAck) is returned from the requester, the negotiation state is updated
in the Service Broker to contracted. Also, the requester’s balance and the bal-
ance of the contracted resource or instance will be reduced by the value set by the
manager in the corresponding ontologies. Afterwards, an application execution
request will be sent to the contracted resource(s) for execution. When receiving
a termination request is sent from a requester, the Service Broker will validate
the required offer. That is to check whether the offer is in a negotiating state.
After validating the negotiation state, the Service Broker will update the state
from negotiating to uncontracted.
Re-negotiation Re-negotiation is demonstrated in Use Case 1. As shown in
Figure 6.3, re-negotiation will be activated when the running SWDS programs
seek to increase the number of CPUs to shorten job execution duration. Re-
negotiation is initiated by the SWDS programs on behalf of a requester. It
attempts to alter the contents of a formed contract, i.e. the number of CPUs, with
the corresponding provider. Accordingly, re-negotiation can only be activated
after the validity of the contract to be re-negotiated has been verified. This
verification has been achieved by checking if the contract is in a contracted state
as established in the previous negotiation phase. If it is, new rounds of negotiation
will be initiated with the same procedures as negotiation. After successful re-
negotiation, the state of the previous contract will be updated to a terminated
state, and the newly formed contract will be in a contracted state. This process
includes the contract termination phase, which is initiated by the requester. In
addition, the accounting functions for re-negotiation are different from those of
negotiation. When applying data-driven computational steering, the application
will keep running when a requester proposes to increase the number of CPUs.
As a result, the budget value to check for re-negotiation is the remaining budget,
which is obtained by reducing the initially set value by the cost consumed so far.
Contract Termination Contract termination may happen in the following
three scenarios. In Use Case 1, it is activated after successful re-negotiation,

6.3. IMPLEMENTATION 213
as described in the re-negotiation scenario. Also, contract termination will be
initiated by a manager when the job execution approaches the maximum cost
allowed. In Use Case 2, it happens when the application execution has not been
completed and the deadline specified by the requester approaches. In the scenario
of Use Case 2, after confirming that the job has not been finished, the Service
Broker will verify that the resource provisioning is in a contracted state first.
Following the verification, a termination request will be sent from the Service
Broker to the local Cluster to terminate the job. Meanwhile, the Service Broker
will update the state of the contract to proTerminated. Balance updates will be
activated when the specified time interval set is reached, and accounting data will
be fetched from the local Cluster.
Revocation Revocation is demonstrated in Use Case 2. Revocation can only
happen during the resource negotiation phase for negotiation and re-negotiation.
Upon receiving a requester’s RevokeReq message, the Service Broker will verify
the current state of the offer to be revoked. If the offer is in a negotiating state,
a revocation decision will be made. In this testbed, the decision for a revocation
request is randomly made by the developed programs.
Apart from the above scenarios that are required by the implemented use cases,
one more function has been considered useful for computational application exe-
cution. That is to allow e-Scientists to stop job execution during runtime. This
function is especially needed for dynamic resource provisioning where e-Scientists
can take charge of job execution. Accordingly, a web service has also been de-
veloped in the Service Broker to receive a request to stop application execution.
This web service has also been evaluated, as will be presented in the evaluation
section.
In addition to the functions of negotiation and accounting, a service to enable
communication of job completion between data-driven steerable applications and
the Service Broker has been developed for Use Case 1. This service is to com-
plete a resource provisioning lifecycle. Via this service, a data-driven steerable
application can inform the Service Broker of the completion of a job with a
corresponding contract ID or job ID. Then, the Service Broker can update the
state of the contract to completed and update all related balances accordingly.

214 CHAPTER 6. TESTBED-BASED PROTOCOL EVALUATION
6.3.3.2 Job Management
AHE3 enables job execution management for jobs submitted to Grids. A full
package of functions supported in Grids includes job submission, file staging, ap-
plication upload, and result fetching. However, Use Case 1 may require changes
to the job execution environment during runtime. This requirement conflicts
with the fixed job execution management workflow and is not supported in most
Grids at present. Furthermore, compared with the mature, developed Grid-based
job submission, to facilitate computational application execution with the same
Grid procedures in Clouds and Clusters, including the local Cluster, needs archi-
tecture design and implementation from scratch. They are still non-trivial and
thus are out of the scope of this research. For all of these reasons, job execu-
tion management in AHE3 is inappropriate for both use cases in this testbed.
Negotiation is carried out between e-Scientists or the Client Service and the
Service Broker, while the workflow in AHE3 is for job management between
the Service Broker and infrastructures. The main aim of the testbed is to eval-
uate the negotiation protocol in practice. A job management workflow is not
related to negotiation procedures and is not the focus of the evaluation. Based
on these reasons, a job submission workflow has been designed and implemented
for the testbed, for both Use Case 1 and Use Case 2. It only considers job sub-
mission procedures. Job re-submission after successful re-negotiation has applied
the same workflow developed for job submission.
As the application management in AHE3 can be related to specific applica-
tions, this job submission workflow has been connected to the use cases enabled.
In this way, the Service Broker can manage not only job execution in Grids but
also job submission to Clusters and Clouds. In addition to job submission man-
agement, job execution and completion management are dealt with the RESTful
web services developed with corresponding APIs, as discussed in the previous
section.
6.3.3.3 Resource Accounting Strategies
The monetary cost of a service (for Use Case 1) and CPU time (for Use Case 2) are
used to measure resource consumption in the testbed, according to the different
measurement mechanisms applied by AWS and the local Cluster. A function
has been developed for both use cases to ensure the throughput of negotiation.

6.4. EVALUATION AND RESULTS 215
That is to compare a requester’s balance with the maximum cost or CPU time
agreed between a research group and providers during negotiation. The reason is
that, in both use cases, the total cost or the total amount of CPU time that will
be consumed cannot be known during negotiation. This function ensures that a
requester would have sufficient balance to run the submitted job.
In Use Case 1, the cost accounted per job for AWS consumption is meas-
ured as the period from starting application execution to completing application
execution. In Use Case 2, for applications to be executed in the local Cluster,
the CPU time consumed is measured when: (i) the deadline set by a requester
approaches, or (ii) the application execution is completed.
This testbed uses hours as the unit for AWS and seconds as the unit for the
local Cluster for duration measurement of application execution. This is con-
sistent with the accounting mechanisms applied by AWS and the local Cluster.
As Grids (including virtualisation-enabled Grids) also measure computing re-
source consumption in seconds [Cristofori et al., 2013], the accounting functions
developed can also be applied to Grids. These accounting strategies work with
the constructed negotiation functionalities, contributing to accountable resource
provisioning. The accounting properties facilitated by the developed ontologies
have been discussed in detail in Chapter 4.
In addition to conducting negotiation and accounting for application execution
demands, functions have also been developed to enable e-Scientists to view their
resource consumption and job execution status. These functions are accessible
via web service APIs for balance querying and job status querying.
6.4 Evaluation and Results
Data-driven computational steering involves dynamic resource changes during
runtime, while the job execution in the local Cluster is queue-based. This leads
to job execution duration for both use cases being unpredictable. As a result,
it is difficult to benchmark and evaluate the duration of the resource provision-
ing lifecycle for the two use cases. Additionally, there is currently no single
accepted benchmark for large-scale scientific computing [Ostermann et al., 2009].
Furthermore, as discussed in Section 6.2.2, negotiation is a different approach
from the existing ways of enabling resource provisioning in e-Science. It is im-
practical to evaluate the full potential for performance of a negotiation protocol

216 CHAPTER 6. TESTBED-BASED PROTOCOL EVALUATION
within existing infrastructures [Zasada and Coveney, 2015]. Theoretical analysis
and comparison between the collaborative formation of a VO and a collaborative
formation via negotiation upon the Alliance model have already been undertaken
in [Parkin, 2007]. For these reasons, only the following two aspects of evaluation
have been conducted in the testbed: (i) functionality evaluation for the enabled
negotiation and related accounting functions with both use cases; and (ii) per-
formance evaluation of the automatic negotiation developed with Use Case 1.
They are evaluated with the designed scenarios as will be presented in the next
section.
The evaluation aims at verifying that the Alliance2 protocol enables not only
dynamic and customised resource provisioning via negotiation as expected, but
also resource sharing management per job for a research group. The definition
of dynamic, customised, and accountable resource provisioning has been given in
Section 1.1.
6.4.1 Negotiation and Accounting Functionality Evaluation
The Service Broker is built upon the interoperation perspective. It applies tech-
nical tweaks to enable resources to be provisioned via negotiation. In this case,
dynamic resource provisioning via a broker can be realised in the following two
situations. First, resource provisioning infrastructures allow dynamic resource
provisioning. Second, the broker manages a sufficient amount of resources, such
that it can find satisfying resources whenever required. In this testbed, dynamic
service provisioning is available from AWS by its very nature for Use Case 1.
Due to the limited amounts of resources allowed in the local Cluster, dynamic
resource provisioning cannot be realised for the Use Case 2 in the testbed.
The testbed has been designed to enable e-Scientists in a research group to
form and dissolve resource provisioning contracts via negotiation with collabor-
ating infrastructures. Meanwhile, resource provisioning is tracked and controlled
by fine-grained policies defined by a group manager, while accounting for resource
usage is on a per job basis. To combine with the two implemented use cases as
discussed in Section 6.2.3, the testbed makes it possible to: (i) search for instances
with sufficient CPUs before and during runtime for steerable applications in Use
Case 1; and (ii) submit jobs with a specified job execution deadline and approach
to the local Cluster in Use Case 2. Collaborating infrastructures indicate the
following two scenarios. First, the total amount of resources to be provisioned by

6.4. EVALUATION AND RESULTS 217
resource provisioning infrastructures to a research group has been agreed. Second,
application-specific execution environments have been established if required.
For functionality evaluation, the Service Broker and the Client Service
were deployed in two separate AWS instances, a t2.medium instance and a t2.micro
instance respectively. The negotiation was activated by:
1. A QuoteRequest sent from the SWDS programs to the Client Service.
Then, the automatic negotiation between the Service Broker and the
Client Service was conducted. Negotiation results would be returned
to the SWDS programs;
2. A QuoteRequest sent from a client program in a local laptop to the Service
Broker. The laptop runs Mac OS X with 2.8GHz Intel Core i7 and 4GB
memory. Negotiation was carried out between the local laptop and the
Service Broker.
Different scenarios have been designed and applied to evaluate the Alliance2
protocol for different expected functions. These scenarios identify all the negoti-
ation and accounting functions proposed by the Alliance2 protocol. Verification
of these scenarios means that negotiation states are updated correctly according
to corresponding negotiation procedures, and accounting functions are activated
and conducted correctly during negotiation and job execution. The verification
can demonstrate that the Alliance2 protocol enables fine-grained accountable re-
source provisioning via negotiation. It also can verify that the Alliance2 protocol
interoperates with existing infrastructures, meeting the interoperation perspect-
ive. The designed and evaluated scenarios are as follows.
• Scenario 1: Successful negotiation is conducted, and the job completes with
both use cases. The requester has sufficient balance to run the specified
application, and the group has sufficient balance for the resources contracted
between the requester and the provider.
• Scenario 2: Successful negotiation is conducted, and the job is stopped by
the deadline specified by the requester with Use Case 2. After success-
ful negotiation and job submission, the Service Broker confirms that the
submitted job has not been completed when the deadline specified by the
requester is approaching.

218 CHAPTER 6. TESTBED-BASED PROTOCOL EVALUATION
• Scenario 3: Successful re-negotiation or new negotiation is conducted with
Use Case 1. After successful negotiation and job submission, the running
application needs to increase the number of CPUs to ensure that the ap-
plication can be completed within a time frame. Also, the balance of the
requester and the balances for the group for the available resources are
sufficient to continue job execution.
• Scenario 4: Negotiation is successfully conducted with rejection as a result
with both use cases. The rejection is caused by insufficient balances in
resources for the group.
• Scenario 5: Negotiation is successfully conducted with rejection as a result
with both use cases. The rejection is caused by insufficient balance of the
requester.
• Scenario 6: Negotiation is successfully conducted with rejection as a result
with Use Case 2. The rejection is caused by a requester requesting a resource
with a higher priority than he/she is allowed to access.
• Scenario 7: Termination is required by the requester during negotiation
before an AcceptAck message is sent with both use cases.
• Scenario 8: Successful negotiation is conducted with a termination request
from the requester after job submission in Use Case 2. The requester sends
a contract termination request to stop application execution.
• Scenario 9: Successful negotiation is conducted, and job execution is con-
trolled by the maximum CPU time or cost set by the group manager with
Use Case 1. This scenario assumes that the application would be executed
immediately after submission. After job submission, the CPU time or cost
of application execution approaches the maximum limit set by the group
manager, or the requester’s balance or the contracted resource’s balance for
the whole group approaches 0.
After evaluating the testbed with the designed scenarios, the corresponding
experiment results were as follows (the screenshots for each Scenario are included
in Appendix A):

6.4. EVALUATION AND RESULTS 219
• Scenario 1: Offers that satisfied the requester’s demands were returned with
resource details. If revocation was demanded by the requester and accepted
by the Service Broker, other satisfying resources were returned. The
required application was activated after receiving an AcceptAck message
from the requester. Moreover, the negotiation state was changed from a
negotiating state to a contracted state for the contracted offer, while other
offers proposed for this negotiation were updated with uncontracted states.
Meanwhile, the requester’s balance and the contracted resource’s balance
were reduced by the CPU time or cost set by the group manager.
Two different accounting mechanisms after job completion have been en-
abled for the two use cases according to their features. Accordingly, different
functions were activated to update corresponding balances with the actual
amount of resources consumed. They are as follows:
1. The Service Broker received a notification for job completion from
the deployed programs in Use Case 1. Then, it updated the requester’s
balance and the contracted instance’s balance in corresponding onto-
logies with the actual resource usage.
2. The CPU time consumed was fetched from the local Cluster by the
Service Broker in Use Case 2. Then, the balances of the requester
and the contracted resource were updated accordingly.
For both use cases, the Service Broker verified that the contracts’ states
were contracted first. Afterwards, it updated the contracts’ states to com-
pleted and updated related balances.
In Use Case 2, the Service Broker detected that the contracted deadline
was approaching and verified that the submitted job had been completed.
Balance updates were realised by fetching the actual execution duration
from the local Cluster.
• Scenario 2: The same procedures for successful negotiation happened. When
the deadline specified by the requester approached, the Service Broker
verified that the job was still running. Thus, the Service Broker sent
a termination request to the Cluster. Moreover, it updated the balance
of the requester and the balance of the resource with the consumed CPU
time. Balance updates were realised by fetching actual execution duration

220 CHAPTER 6. TESTBED-BASED PROTOCOL EVALUATION
from the local Cluster. The Service Broker also updated the state for the
terminated contract from contracted to proTerminated.
• Scenario 3: A contract was formed when the requester required one CPU,
and corresponding balances were updated. When it received the request
to increase the number of CPUs, the Service Broker checked whether
the instance running the job or other instances could meet demands. It
would return offers if satisfactory instances were found. During matchmak-
ing, the requester’s balance was checked against the minimum limit set by
the manager, while instances’ balances were checked against the remaining
maximum value. The remaining maximum value was obtained by reducing
the initial maximum value by the amount consumed. After successful re-
negotiation, the requester’s balance was not reduced. If re-negotiation with
the contracted instance was unsuccessful, negotiation with other instances
for the additional number of CPUs was activated. When a contract was
formed for a new instance, the instance’s balance would be reduced by the
remaining maximum value. In the test, the requester asked for two more
CPUs, and the instances deployed only contained one CPU each. As a
result, the returned contract for negotiation was a combination of two sub-
contracts, each with a unique contract ID. Information for the new contract,
including the sub-contracts, was stored with a contracted state. The sub-
sequent procedures for job submission, application execution, and balance
updates were the same as in Scenario 1.
• Scenario 4: The Service Broker returned a message advising that the
group’s balance for the required resource was not sufficient. It resulted
in negotiation termination from the Service Broker with an uncontracted
state.
• Scenario 5: The Service Broker returned a message advising that the
requester’s balance for the required resource was not sufficient. It resulted
in negotiation termination from the Service Broker with an uncontracted
state.
• Scenario 6: The Service Broker returned a message advising that the
requester did not have the required priority to use the required resource.
This resulted in negotiation termination from the Service Broker with an

6.4. EVALUATION AND RESULTS 221
uncontracted state.
• Scenario 7: The offer proposed by the Service Broker for this negotiation
was updated with an uncontracted state. Upon receiving the termination
request from the requester during negotiation, the Service Broker up-
dated the state to uncontracted after verifying that the offer’s state was
negotiating.
• Scenario 8: The same procedures for successful negotiation occurred. When
it received the stop request, the Service Broker verified the state of the
required contract was contracted. It then updated the contract state to
reqTeminated. It also updated the balances of the requester and the con-
tracted resource with the CPU time consumed.
• Scenario 9: The same procedures for successful negotiation occurred. When
the CPU time or the cost of the service consumed approached the maximum
limit set by the group manager, the Service Broker verified the state of the
contract. When the state was contracted, the Service Broker updated the
state to reqTerminated. As balances for the requester and the contracted
resource had been reduced by the maximum value or reduced to 0 after
successful negotiation, no balance update was carried out in this case.
6.4.2 Automatic Negotiation Performance Evaluation
Both scenarios for negotiation performance evaluation were conducted with Use
Case 1. This is to take advantage of the automatic negotiation capability enabled
in the Client Service and avoid unmeasurable manual procedures. The per-
formance of negotiation has been measured in two situations: without network
in Section 6.4.2.1 and with the Internet in Section 6.4.2.2. Performance evalu-
ation without network deploys all software and ontologies on a laptop, avoiding
fluctuation of network performance. We also measured the time consumed by
negotiation via the Internet, by deploying software and ontologies for different
entities in a distributed manner. This is to give an indication of negotiation
performance in practice.

222 CHAPTER 6. TESTBED-BASED PROTOCOL EVALUATION
6.4.2.1 Negotiation Performance Evaluation without Network
For this evaluation, the laptop runs Mac OS X with 2.8GHz Intel Core i7 and 4GB
memory. The ComputingShare and MappingPolicy ontologies applied during ne-
gotiations were those developed for the data-driven computational steering use
case. The ComputingShare ontology contained 4 instances, which were deployed
and applied for the evaluation of the functionality of negotiation and account-
ing. In addition, two ComputingService ontologies have been created with actual
information from 10 and 50 AWS instances respectively, to measure the scalab-
ility of the negotiation capability of the developed Service Broker. The total
number of members included in the MappingPolicy ontology for a research group
was 15. We considered this a representative size for a small-scale research group,
which is too small to form a VO, as discussed in Section 1.1.
To measure only the duration of negotiation, ignoring network delays, both the
Service Broker and Client Service were deployed on the same local laptop.
These two web services were activated with different ports on the laptop. The
complete negotiation procedures are as follows. A negotiation request is sent
from the laptop to the Client Service. Then, negotiation between the Client
Service and the Service Broker is activated. A reply will be transferred from
the Client Service to the laptop conveying the negotiation result. If the ne-
gotiation succeeds, related information for resources will also be contained in
the reply. The negotiation of each evaluated scenario was repeated 100 times.
Average and standard deviation were then calculated for the duration of the
communication, as shown in Table 6.1.
The performance data shown in Table 6.1 exclude the first enquiry to the
Service Broker. The first enquiry requires initiation of the web services, in-
cluding establishing connections with the database, and it takes longer than sub-
sequent enquiries. This conclusion was formed from experiments, which sent
different enquiries and compared the performance of the corresponding negoti-
ation. The negotiation performance shown in Figure 6.4 was measured with two
different enquiry inputs, applying Scenario 1 as shown in Table 6.1. The enquiry
with the first inputs was repeated 25 times, followed by the enquiry with the
second inputs, which was also repeated 25 times. The whole procedure was then
repeated once in full, making 100 enquiries in total. Conducting the experiment in
two stages rather than repeating each set of inputs 50 times was to avoid any risk
that the performance was influenced by cached data in the machine. In this way,

6.4. EVALUATION AND RESULTS 223
Table 6.1: Automatic negotiation performance without Internet
ScenarioAverage (ms) withStandard Deviation
1. Successful negotiation: all 4 collaborative instancescould satisfy demands and one instance was selected toform one contract
2223±410.6
2. Successful re-negotiation: pure re-negotiationprocedures were measured
1838±390.9
3. Successful negotiation with other collaborativeinstances after failed re-negotiation
5669±313.6
4. Successful negotiation after failed re-negotiation andfailed negotiation with the other 3 collaborativeinstances: this scenario was evaluated with theComputingService ontology with 10 AWS instances
2162±292.5
5. Successful negotiation after failed re-negotiation andfailed negotiation with the other 3 collaborativeinstances: this scenario was evaluated with theComputingService ontology with 50 AWS instances
2220±305.1
6. Successful negotiation with rejection, because ofinsufficient balance for the requester
374±101.1
7. Successful negotiation with rejection, because ofinsufficient balance for all collaborative instances:negotiation with the two ComputingService ontologieswas disabled for this scenario
497±98.3
8. Successful negotiation with rejection, because of nosatisfying instance: none of the contracted 4 instancescan provide the required amount of CPUs; negotiationwith the two ComputingService ontologies was disabledfor this scenario
746±200.9
it contributed to making four enquiries, giving more confidence in the conclusion.
Figure 6.4 shows that after initiation, the duration of negotiation was not affected
by different enquiries. In addition, the duration was around 2000 milliseconds,
consistent with the performance observed for Scenario 1 in Table 6.1.
The scenarios designed in Table 6.1 aim to evaluate all enabled automatic ne-
gotiation procedures. The procedures are: negotiation with contracted instances
that involves application-oriented matchmaking for resource searching; negoti-
ation with un-contracted instances that involves resource-oriented matchmaking;
re-negotiation; and negotiation with rejection as a result. We also evaluated

224 CHAPTER 6. TESTBED-BASED PROTOCOL EVALUATION
Figure 6.4: Negotiation performance
the scalability of the negotiation procedures, by measuring the negotiation per-
formance with different numbers of instances. A detailed discussion is presented
below.
Table 6.1 shows that Scenario 3 consumed more time than the other scenarios.
This result stemmed from the fact that it included three negotiation procedures:
successful negotiation with one collaborative instance, failed re-negotiation with
the contracted instance, and successful negotiation with another collaborative
instance.
Scenario 4 and Scenario 5 measured the negotiation performance, when the
negotiation happened after unsuccessful re-negotiation and negotiation with col-
laborative instances. These two scenarios involved the combination of sub-offers
while negotiating with collaborative instances. The request applied required 5
CPUs, and the 4 collaborative instances each could only provide 1 CPU. As a
result, the matchmaking succeeded in figuring out that the 4 collaborative in-
stances could not collaboratively provide the required 5 CPUs, and activated
resource-oriented matchmaking. Resource-oriented matchmaking searched for
and returned satisfactory services with the designed ComputingService instances.

6.4. EVALUATION AND RESULTS 225
A message would be returned to inform the client if no satisfying services were
found. The algorithms of sub-offer combination can vary, according to specific
demands of applications, projects, e-Scientists, etc. As a result, the actual per-
formance of this scenario can vary in practice. So far, the developed programs
return all satisfactory offers, including all satisfying combinations of sub-offers.
In practice, the offers to return can be determined by specific demands, which
may also contribute to varying performance.
6.4.2.2 Negotiation Performance Evaluation with Internet
For this performance evaluation, the Service Broker and Client Service were
deployed in two different instances on AWS in the EU (Ireland) Region. The
evaluation used a t2.medium instance and a t2.micro instance, for the Service
Broker and Client Service respectively. A t2.medium instance is allocated
with 2 virtual CPUs and 4 GB memory, while a t2.small instance is allocated
with only 1 CPU and 2 GB memory. Both types of instances: (i) have ‘Low to
Moderate’ network performance5; and (ii) use physical processors from the Intel
Xeon family with clock speed up to 3.3 GHz.
Negotiation requests were sent from a client program running on Eclipse using
a laptop. The requests were sent to Client Service, which activated negotiation
procedures. Then, the duration of the automatic negotiation procedures between
Client Service and the Service Broker was measured.
AWS does not provide a benchmark or tools to measure the real-time network
performance of instances applied. Instead, we used the ping command to measure
the real round-trip time for communication between the Client Service and the
Service Broker [Jiang and Dovrolis, 2002]. The network performance of Cloud
services can vary significantly over a day. This measurement aimed at giving
a hint of the network performance during negotiation. In our evaluation, the
ping command was activated in the Client Service before the first negotiation
message was sent to the Service Broker. Each ping command execution was
repeated 10 times. Then, the average duration was obtained, which is shown
as Round-trip Average in Table 6.2. The standard deviation of the round-trip
performance was also obtained, to illustrate the network status during evaluation,
as presented in Table 6.2.
5For detailed information about the applied instances, please refer to https://aws.amazon.
com/ec2/instance-types/#burst

226 CHAPTER 6. TESTBED-BASED PROTOCOL EVALUATION
Table 6.2: Automatic negotiation performance with InternetScenario Negotiation Average (ms) Round-trip Average (ms)
with Standard Deviation with Standard Deviation1 2166± 92.2 0.9 ± 0.12 1778± 171.3 1.0 ± 0.23 4017± 126.5 1.0 ± 0.14 2157± 82.3 0.9 ± 0.15 2166± 76.9 0.9 ± 0.16 348± 31.2 1.0 ± 0.17 440± 26.7 1.0 ± 0.18 586± 148.0 1.0 ± 0.1
The evaluation scenarios were the same as those applied for the negotiation
performance evaluation without internet. The difference is that the negotiation
duration shown in Table 6.2 did not include the transportation of the following
two messages, compared to the communication duration measured in Table 6.1.
The first message is a request transferred from the laptop to the Client Service.
The second message is a reply transferred from the Client Service to the laptop.
This approach was to exclude the variation in performance that may be contrib-
uted by different client devices.
The negotiation of each evaluated scenario was repeated 100 times. Average
and standard deviation were then calculated for the duration of negotiation, as
shown in Table 6.2. The performance data in Table 6.2 also excludes the first
negotiation, for the same reason as discussed for the negotiation performance
evaluation without internet.
Comparison of Table 6.1 and Table 6.2 shows that even though Service
Broker and Client Service were deployed distributed via networks, applying
AWS instances contributed to better performance than evaluating both web ser-
vices locally on a laptop. The reasons include:
1. The negotiation performance evaluation deployed on the laptop included
two more communication procedures: negotiation requests from a client
program running on local Eclipse to the Client Service; and negotiation
result communication from the Client Service to the client program.
2. The two web services (i.e. the Client Service and the Service Broker),
the client program, and the deployed database shared the same resources on
the local laptop. This resulted in that the actual resources that supported

6.4. EVALUATION AND RESULTS 227
the evaluation on the local laptop were fewer than those available in the
AWS instances applied.
3. Both t2.small and t2.medium instances used physical processors from the
Intel Xeon family, which can have a clock speed up to 3.3 GHz. One t2.small
instance is allocated with 1 virtual CPU, while one t2.medium instance is
allocated with 2 virtual CPUs. The laptop used has 1 Intel Core i7 CPU
and 2.8GHz clock speed. This might also contribute to the difference in the
performance evaluated.
4. The round-trip consumed a very short time between the applied AWS EC2
instances, only around 1ms, as shown in Table 6.2. It added little to the
total negotiation time.
The performance data in Table 6.1 and Table 6.2 were consistent. They
demonstrate that: (i) more messaging and reasoning procedures would contribute
to a longer negotiation duration; and (ii) matchmaking with more resources would
not decrease performance significantly.
In summary, as shown in Table 6.1 and Table 6.2, the duration of the complete
automatic negotiation developed was only a few seconds at most. Compared to
most computational application execution, the automatic negotiation developed
can be applied where the job duration is anything over a few seconds. It also
shows that negotiation with more resources did not increase the negotiation time
significantly, by comparing the performance of Scenario 4 and Scenario 5 in both
Table 6.1 and Table 6.2. Also, as shown in Table 6.2, in a real distributed system
network, the negotiation would have minimal impact, compared to the complete
job submission and execution lifecycle of computational applications.
6.4.3 Further Analysis
6.4.3.1 Dealing with Exceptions
The Service Broker is built with RESTful web services and utilises a database
to store negotiation states. When a message arrives, the Service Broker will
verify the received offer ID or contract ID against the locally stored state for the
negotiation before further processing. This mechanism ensures that even if inter-
net interruption happens between the Service Broker and the negotiation client

228 CHAPTER 6. TESTBED-BASED PROTOCOL EVALUATION
during negotiation, whenever the Service Broker receives the re-sent message
from the client, the negotiation can proceed.
However, this mechanism introduces the situation where the database may
be overloaded by large numbers of un-formed contracts. The following two ap-
proaches can be taken to deal with this situation in a specific implementation:
1. The Service Broker checks every negotiation by setting a timer for each
negotiation process. The timer will be terminated when the negotiation
forms a contract. When the timer reaches the end of the time frame set,
it will delete the entry for this negotiation in the database. This approach
will probably introduce an excessive workload to the Service Broker by
tracking every negotiation process.
2. The Service Broker records negotiation start time for every negotiation
process and checks all entries in the database at a specific time interval.
This approach requires setting a time duration by which a negotiation will
be terminated, and the entry for the negotiation in the database will be
deleted by the Service Broker. More specifically, when the time interval is
reached, the Service Broker will go through every entry in the database to
check the negotiation state and the timestamp for when the negotiation was
begun. If the duration of the negotiation has been longer than the duration
set by the Service Broker and the negotiation state is still negotiating,
the Service Broker will delete the entry.
Compared to the first approach, the second approach will introduce a lower
workload, as it does not need to set a timer for every negotiation process. How-
ever, as both approaches require setting timers in the Service Broker, it renders
solutions specific to projects, applications, infrastructures, network performance,
etc. This is because different application scenarios will have differing performance
expectations of the Service Broker and network.
6.4.3.2 Scalability
The Service Broker negotiates on behalf of resource providers for resource pro-
vision. This introduces the possibility of a high quantity of resource provision
requests coming concurrently and requires solutions to dealing with such situ-
ations. As the Service Broker is deployed on Cloud services, instance images
can be utilised to scale up the capability of the Service Broker to deal with

6.4. EVALUATION AND RESULTS 229
high quantities of requests. More instances or more powerful instance(s) can be
instantiated in this situation. Moreover, the Service Broker is built as REST-
ful services and is stateless. This would simplify the process of scaling up or
scaling down, as no state information about the Service Broker itself needs to
be considered. Meanwhile, mechanisms need to be developed to keep track of
many negotiations that might occur simultaneously in large-scale collaborations
and might interfere with each other, which have not been solved in this testbed.
6.4.3.3 Implementation Constraints
As discussed in Section 6.2.2, this testbed is built on top of existing e-Science
gateway and middleware via a brokering approach. It implements workarounds
to enable negotiation with a broker as a resource provider instead of directly
with infrastructures or resources. This limitation can be solved by collaborating
with infrastructures, because direct access to resources and negotiable resource
provisioning are required to be enabled by infrastructures. The Future Work
section will discuss a solution to changing a production authorisation service for
negotiable and accountable resource provisioning.
As pointed out in Section 6.3.2.1, the testbed uses simulations to randomly
choose offers and contracts for users so far. It lacks underlying mechanisms to
support negotiation, such as negotiation strategies, and offer or contract combin-
ation and selection strategies. For mechanisms that are project- or application-
specific, this limitation can be solved by collaborating with use cases that have
specific requirements for such mechanisms. For mechanisms that are general for
negotiation, this limitation can be solved by implementing other research, such
as the strategies proposed in [Sim, 2013] to improve resource utilities, negotiation
success rates, and negotiation speed.
As presented in 6.2.3.2, when a job submitted to the local Cluster cannot be
completed before the deadline specified by the requester, the job will be termin-
ated. To terminate submitted jobs may waste the cost of the resources already
consumed, especially when the execution is close to completion. To improve the
Service Broker in the future can begin with the following two aspects:
1. Checkpointing can be applied to record the status of job execution so that
the un-finished jobs can be submitted to a new provider starting from the
stopped point. Clouds can be enabled as new providers, as they can provi-
sion resources on demand;

230 CHAPTER 6. TESTBED-BASED PROTOCOL EVALUATION
2. More advanced algorithms can be enabled to compare the remaining time
that may be required to complete the job in the local Cluster with the time
required to execute the remaining job on new resources. In this scenario,
the procedures need to be considered to continue job execution on a new
resource include negotiation with the new resource, initiation of job execu-
tion on the new resource, and execution of the un-finished parts of the job
on the new resource.
6.4.3.4 Comparison with Other Approaches
Apart from the presented experimental evaluation, the Service Broker developed
has also been compared with some production tools, as shown in Table 6.3. As
tools in production have not facilitated negotiable resource provisioning as yet,
the comparison is focused on application management and accounting. These
two aspects are considered as the other two main contributions of the testbed.
To give a full picture of the advantages of the Service Broker, the resource
management models applied and the security credentials required from users are
also included in Table 6.3. The discussions of resource management models and
user security credentials have been presented in Chapter 2.
Comparison with available tools for resource provisioning via negotiation has
been discussed in Chapter 5. The tools compared here are some typical ones that
are widely used in production. They are middleware or tools based on the Grid
model, the Cloud model, or portals to Grid resources. The Service Broker is
based on the proposed Alliance2 model. It takes the approach of a broker and is
built upon infrastructures that are based on different enabling models.
As shown in Table 6.3, application management is not supported by the Grid
middleware gLite [Laure et al., 2006]. This means that an e-Scientist needs to
specify the application to be executed, the locations to upload the application, and
perhaps the details of resources for job execution, etc. The same features apply
to other Grid middleware, including ARC [Ellert et al., 2007], Globus [Foster,
2006], and NorduGrid [Eerola et al., 2003]. However, application management
can be realised by developing an additional software layer upon Grid middleware.
Many tools are available for this purpose. The UNICORE Grid gateway is one
example. UNICORE allows an e-Scientist to specify the application for execution
and subsequently select a resource, rather than to give details of resources. This is
similar to AHE3 and the Service Broker. Additionally, a generic web interface
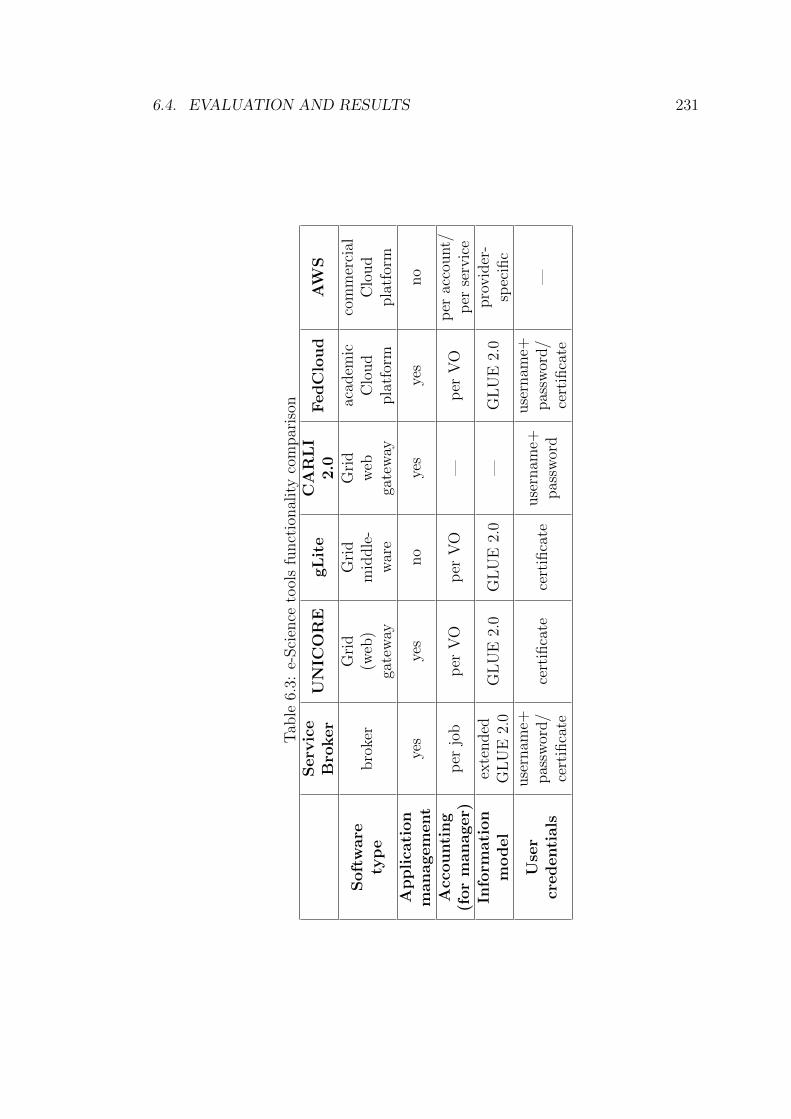
6.4. EVALUATION AND RESULTS 231
Tab
le6.
3:e-
Sci
ence
tool
sfu
nct
ional
ity
com
par
ison
Serv
ice
Bro
ker
UN
ICO
RE
gL
ite
CA
RL
I2.0
FedC
loud
AW
S
Soft
ware
typ
ebro
ker
Gri
d(w
eb)
gate
way
Gri
dm
iddle
-w
are
Gri
dw
ebga
tew
ay
acad
emic
Clo
ud
pla
tfor
m
com
mer
cial
Clo
ud
pla
tfor
mA
pplica
tion
managem
ent
yes
yes
no
yes
yes
no
Acc
ounti
ng
(for
man
ager)
per
job
per
VO
per
VO
—p
erV
Op
erac
count/
per
serv
ice
Info
rmati
on
model
exte
nded
GL
UE
2.0
GL
UE
2.0
GL
UE
2.0
—G
LU
E2.
0pro
vid
er-
spec
ific
Use
rcr
edenti
als
use
rnam
e+pas
swor
d/
cert
ifica
tece
rtifi
cate
cert
ifica
teuse
rnam
e+pas
swor
d
use
rnam
e+pas
swor
d/
cert
ifica
te—

232 CHAPTER 6. TESTBED-BASED PROTOCOL EVALUATION
is also provided by UNICORE to allow e-Scientists access Grid resources in a
lightweight manner, compared to accessing via desktop computers only. The
GARLI 2.0 Grid web gateway is one step further towards facilitating user-friendly
access to Grid resources. It allows an e-Scientist to access Grid resources with a
username and a password as authentication credentials. GARLI 2.0 is not built
upon the concepts of VOs. An e-Scientist only needs to register as a user of
the web gateway to be able to access Grid resources. GARLI 2.0 also supports
application management for e-Scientists as users. Functions of accounting and
the resource management model applied by GARLI 2.0 are not known by the
author of this thesis.
FedCloud is an instance of an academic virtualisation-enabled Grid platform.
It provides application management tools and an application database to help
e-Scientists set up an execution environment efficiently [EGI, 2018d]. Meanwhile,
the functions available in AWS to supply virtual computing infrastructures are
also evaluated. The evaluation reveals that application management is expected
to be realised by software developers manually if it is needed when applying AWS.
As a result, the authentication credentials required for an e-Scientist to access
deployed resources will also be project-specific.
Regarding accounting granularity, all tools upon the Grid model, namely the
gLite middleware, the UNICORE gateway, and the FedCloud platform, support
resource management at a VO level. This means that a report that contains
information as to the total amount of resources consumed by all members of
a VO for a certain time period can be provided by these tools. For instance,
a VO manager in FedCloud can view the total CPU time, the monetary cost
of computation, the memory, etc., that have been consumed by all members of
the VO in units of a month [EGI, 2018e]. Even though AWS aims to provide
detailed accounting information for service usage, it can only show the following
accounting data to a group manager [AWS, 2018b,c]:
• The total cost consumed by a member, if he/she has an AWS account. This
indicates all the services consumed by this member.
• The total cost consumed by a service, which may be contributed by multiple
or all members of the group.
Table 6.3 also shows that, apart from the GARLI 2.0 web gateway and AWS,
the resource management model implemented in all other tools discussed is GLUE

6.5. SUMMARY 233
2.0. As has been presented in Chapter 4, the Alliance2 resource management
model enabled by the Service Broker has been used for resource management
for services supplied by AWS. In consequence, the resource management functions
available in the Service Broker are naturally interoperable with all other tools
in Table 6.3 apart from the GARLI 2.0 web gateway.
The comparison concludes that the Service Broker can realise not only dy-
namic and customised resource provisioning via negotiation, but also accountable
resource provisioning for each job. These functions are not available in existing
infrastructures but are considered by this thesis to be in high demand. The
reasons are: (i) the increasingly growing demands for the use of resources from
different infrastructures according to e-Scientists’ different requirements; and (ii)
the increasing application of virtualisation for dynamic and customised resource
provisioning for computational experiments.
6.5 Summary
The implementation of the Alliance2 protocol has been presented in this chapter.
The implementation cooperates with two use cases enabled in two different infra-
structures. The enabled use cases and infrastructures, combined with the software
developed for negotiation and accounting, contribute to a testbed. The testbed
demonstrates how to establish negotiable and accountable resource provisioning
for application execution via a brokering approach. This chapter discusses the
engineering decisions for each developed software component. The evaluation has
been conducted by verifying the realised negotiation procedures and accounting
functionalities via the designed scenarios. It has compared the expected beha-
viour and working mechanisms of the developed broker with experimental results.
It concludes that the broker facilitates all the proposed functions for negotiable
and accountable resource provisioning for computational application execution.
However, this chapter also points out the constraints introduced by following
a brokering approach to implementing the protocol and the lack of underlying
mechanisms to support negotiation. This chapter has further compared the func-
tionalities of the developed broker with some widely-applied production e-Science
tools. It concludes that the developed broker: (i) realises accountable resource
provisioning for per job execution that has not been facilitated to date; and (ii)
has the potential to be interoperable with existing e-Science infrastructures by

234 CHAPTER 6. TESTBED-BASED PROTOCOL EVALUATION
applying widely-used standards and building well-designed software components.
The next and final chapter draws together conclusions for all the work of this
thesis. It will also propose an agenda for future work.

Chapter 7
Conclusion
7.1 Research Contributions
In this chapter, the work of this thesis is reviewed and set in the context of
the research question formulated in Chapter 1 to understand the identified con-
tributions. The hypothesis presented by this thesis is that negotiation between
an e-Scientist and an infrastructure, where the negotiation decision is communic-
ated to the e-Scientist’s research group, enables accountable resource provisioning
between independent research groups and resource provisioning infrastructures.
Supporting this hypothesis, the following novel contributions are achieved:
1. The design, analysis, and evaluation of a collaboration model called Alli-
ance2, to manage the relationships between entities for dynamic and ac-
countable resource provisioning in e-Science collaborations and resource
sharing. The novelty of the Alliance2 model is that: (i) it separates re-
search groups from resource providers; and (ii) it shifts the resource sharing
management (i.e. authorisation and accounting) of group members from
resource providers to group managers. To the best of the author’s know-
ledge, the Alliance2 model is the first enabling model for e-Science com-
putational experiments to shift resource sharing management to a research
group. This shift allows fine-grained resource sharing management. Com-
parison between the Alliance2 model and other enabling models has been
reviewed. The comparison shows that the Alliance2 model: (i) allows group
managers to take control of resource sharing among group members that
can be in fine granularity; and (ii) enables e-Scientists to have choices on
resource selection.
235

236 CHAPTER 7. CONCLUSION
2. The design, analysis, implementation, and evaluation of a resource man-
agement model to realise fine-grained resource sharing management for a
research group and coarse-grained resource provisioning management for
resource providers. The proposed resource management model is an exten-
sion of a widely-applied Grid information model, GLUE 2.0. This extended
model represents participating entities’ relationships and considers account-
ing properties, including those for commercial Cloud services. It also estab-
lishes a knowledge base for formal contract formation. A semantic model,
ontologies, and software have been built upon the proposed resource man-
agement model to enable searching for satisfactory computing resources to
execute computational applications. They also deal with e-Scientists’ cus-
tomised resource provisioning demands and a research group’s fine-grained
accounting needs. The evaluation of the Alliance2 resource management
model proposed and the programs developed demonstrates that fine-grained
resource sharing and accountable resource provisioning for a research group
are achievable by shifting resource sharing management to the group. The
very short time consumed by the matchmaking programs developed shows
that this solution would add little burden to existing resource management
systems for computational experiments.
3. The design, analysis, and formal evaluation of the Alliance2 protocol. To
the best of the author’s knowledge, the Alliance2 protocol is the first negoti-
ation protocol that considers the role of Resource Manager for e-Science re-
source provisioning. With this role, the Alliance2 protocol: (i) manages the
complete resource provisioning lifecycle with independent resource request-
ing and provisioning organisations; and (ii) tracks resource consumption for
every resource provisioning collaboration formed, i.e. for every job. Also,
the Alliance2 protocol is based on contract law and considers all situations
and functions that should be enabled for contract formation via negotiation.
Race conditions are resolved in the Alliance2 protocol and formal models
are built using the Spin model checker. The formal models verified that the
three negotiating entities (i.e. Resource Requester, Resource Manager, and
Resource Provider) could reach the same negotiation results by applying
the designed messages and following the proposed messaging behaviours.
4. The design, implementation, and evaluation of the Alliance2 protocol in

7.2. FUTURE WORK 237
a testbed, which extends a production e-Science gateway for negotiable
and accountable resource provisioning for application execution. The test-
bed evaluation shows that the Alliance2 protocol contributes the follow-
ing features. First, it can manage the complete resource provisioning li-
fecycle without centralised management of a research group and resource
providers. Second, it enables fine-grained resource sharing for a research
group and accountable dynamic resource provisioning in combination with
the ontologies and programs developed. Third, it is interoperable with ex-
isting infrastructures so that it can be applied to existing infrastructures
for fine-grained accountable resource provisioning for a group manager and
customised resource provisioning for e-Scientists. The testbed verified that
all the scenarios designed for negotiation and accounting function as expec-
ted. Comparison between the developed Service Broker and widely-used
production tools was conducted. The comparison shows that the Service
Broker enables negotiable resource provisioning and accountable resource
sharing on a per job basis. Both are demanded in the e-Science community
but have not thus far been enabled by existing tools. This testbed is a fur-
ther step towards implementing the Alliance2 model, the Alliance2 protocol,
and the Alliance2 resource management model into production.
7.2 Future Work
We present the following recommendations for future work.
Enable the Alliance2 Protocol on a VO and Argus
A solution to applying the Alliance2 protocol using Argus is illustrated in this
section, which aims to facilitate negotiable resource provisioning for the interop-
erability scenario. As discussed in Section 3.2.3, Argus is proposed with the same
principle as the Alliance2 model for authorisation purposes: resource sharing
within a research group should be managed by an authorisation entity independ-
ent of resource providers. However, fine-grained accountable resource provision-
ing is not yet facilitated by Argus. This section constructs a case for future work
where a VO provides a structural organisation of a research group and Argus is
responsible for authorisation. In other words, Argus acts as a Resource Man-
ager. This approach achieves accountable resource provisioning and fine-grained

238 CHAPTER 7. CONCLUSION
VOMS
Client(ResourceRequester)
Argus Nodes(ResourceManager)
VO
Resource RequestingOrganisation
PEP Client
Infrastructure(Resource Provider)
Resource ProvisioningOrganisation
proxycertificate
1. Resourcenegotia
tion
2.Acc
ess
negot
iatio
n
3.N
egot
iatio
nde
cisi
on
Figure 7.1: Negotiation with Argus and a VO
resource sharing by shifting resource sharing management of a group to Argus,
as proposed by the Alliance2 model. Two important aspects considered for the
solution include: (i) how to enable the negotiation procedures; and (ii) how to
enable fine-grained accountable resource provisioning while following the negoti-
ation procedures.
As shown in Figure 7.1, the communication between an e-Scientist (i.e. a
Resource Requester) and an infrastructure (i.e. a Resource Provider) can follow
the resource negotiation procedures according to the Alliance2 protocol. The
authorisation is carried out by Argus components with Argus server nodes be-
ing deployed as a Resource Manager and Argus PEP Client being deployed in
an infrastructure. Access negotiation for authorisation decisions is carried out
between the Argus PEP Client on behalf of the provider and Argus server nodes
on behalf of the group manager. As designed in the Alliance2 protocol, access
negotiation occurs after a provider receives a resource provisioning request from
a requester. The request can contain information for the group that the requester
belongs to, the requester’s identity in the group, and the application to be ex-
ecuted. Based on this information, an authorisation decision can be made by
the group manager. Specific restrictions upon the requester for this application
execution can also be contained in the decision returned from the group man-
ager to the provider if the authorisation is successful. A proxy certificate is used
only for privilege delegation purposes in this case, and the resource provisioning

7.2. FUTURE WORK 239
E-Scientist(ResourceRequester)
Argus Nodes(ResourceManager)
Argus PEPClient
VO Worker Node
Infrastructure(Resource Provider)
QuoteRequest
AccessReq signed byprovider’s certificate
AccessSucceed signedby manager’s certificate
Quote
Offer
Accept
AcceptAck
Contracted
Job execution
Figure 7.2: Negotiation enabled on a VO as a new provider
infrastructure can require it after successful negotiation.
To manage a complete resource provisioning lifecycle between independent
research groups and resource providers, negotiation decisions and resource con-
sumption information are advised by the resource providers to the group manager,
as shown in Figure 7.1.
As discussed in Section 2.2.1, the access control policies enabled by Argus
today cannot enable accountable resource provisioning per job. As a result, the
other main change needed is the support of fine-grained access control policies in
Argus Nodes to meet the fine-grained accountable resource provisioning feature
proposed by the Alliance2 protocol. A solution to enabling fine-grained access
control policies for resource sharing and provisioning management was presented
in Chapter 4.
The solution presented in Figure 7.2 combines the negotiation procedures and
the access control required by the Alliance2 protocol. It can facilitate accountable
resource provisioning via negotiation between a VO and Argus. It illustrates the
use of the Alliance2 protocol for direct negotiation with infrastructures. This
solution requires: (i) negotiation APIs to be extended in the Argus PEP client
for resource negotiation and access negotiation; (ii) fine-grained access control

240 CHAPTER 7. CONCLUSION
policies to be enabled for resource sharing and related processing functions in
the Argus Nodes that work for a group manager; and (iii) extra communication
between the Argus PEP client and Argus Nodes to inform accounting data for
job execution. This solution enables the interoperability perspective with the
following advantages:
1. It enables flexible security mechanisms according to the varied requirements
of infrastructures or negotiation entities. The flexibility is enabled by the
independence between a research group and a resource provider. A research
group can decide the mechanism for group member authentication and the
granularity of resource sharing management. The authentication and re-
source provisioning management between a group manager and a provider
can apply different mechanisms. For instance, authentication of users in a
research group to initiate negotiation can require usernames and passwords,
while authentication between the group manager and a resource provider
for access negotiation can require digital certificates.
2. It does not require a prior contract or collaboration for resource provision-
ing to be formed between a research group and a resource provider. This
presumes that trust between a group (i.e. a resource requester organisation)
and a provider (i.e. a resource provisioning organisation) can be established
by their digital certificates, i.e. that certificates can be applied at the or-
ganisation level. This is compliant with existing certificate-based access
control mechanisms in Grids. It can also expose an unlimited pool of re-
sources to e-Scientists, assuming that certificates owned by group managers
and resource providers are allocated by well-accepted and trusted Certific-
ate Authorities.
In summary, the combination of the Alliance2 protocol with a VO and Argus
can enable dynamic and reliable resource provisioning collaborations. It can also
enable fine-grained and flexible access control according to a research group’s
local authorisation mechanisms and resource sharing policies.
The testbed has focused on the main component that enables negotiation: the
Service Broker. Two other functional components can be considered in future
work that can complete the testbed: a negotiation client for e-Scientists and
resource management interfaces for a group manager.

7.2. FUTURE WORK 241
An Android Client for Resource Requester
In addition to negotiation, software as a client allowing e-Scientists to access
computing resources and execute computational applications can be application-
specific. For computational steering, an important application-specific feature for
a client is that of enabling visualisation. Visualisation allows e-Scientists to view
experimental results, especially for real-time navigation in the user-interactive
computational steering case (as discussed in Section 3.2.1). It enables e-Scientists
to investigate data generated in real time and conduct steering during runtime.
Following the user-oriented principle, the negotiation client is supposed to be
lightweight and easy for e-Scientists to use. To satisfy such demands and utilise
the experiences gained from developing an Android application in the author’s
MSc dissertation [Zeqian, 2012], a client can be developed on the Android plat-
form. The Android platform has a large user base and comprehensive technical
support available. An Android client enables e-Scientists to undertake research
via mobile applications [Deelman, 2015]. This renders job submissions to power-
ful computing resources with lightweight devices for e-Scientists possible. As
a widely-used and open-source platform, Android has been supported by many
visualisation toolkits, including Qt [Fouard et al., 2012, Rathmann and Wilgen,
2016] and OpenViz [AVS, 2018]. This makes it possible to visualise experimental
data on an Android device.
An Android client with visualisation capability is demanded by not only the
applied computational steering use case. For instance, a lightweight client is
essential for real-time forest fire crises, which also require dynamic computing
resource provisioning for simulation and visualisation to predict real fire beha-
viour [Denham et al., 2012].
A Graphical User Interface for Resource Manager
Automatic matchmaking is realised by utilising the developed programs on in-
formation contained in ontologies in the testbed. Such information includes
policies that can be edited and managed by a group manager to manage resource
sharing among group members. Currently, policies contained in ontologies are
edited manually for implementation and evaluation purposes. However, resource
management scientists may be limited in their knowledge of OWL or program-
ming skills. Considering that a group manager would prefer to edit policies using
a graphical user interface (GUI), a resource management tool is envisioned for f-

242 CHAPTER 7. CONCLUSION
uture work. Existing ontology editors, such as Protege, would expose all inform-
ation contained in an ontology, which may result in unexpected changes. So, this
class of tool is not considered a proper tool for resource management, as argued by
this thesis. As a result, a user-friendly editor for ontology manipulation restric-
ted to membership management, resource management, and accounting would be
beneficial.
The GUI should be combined with the main functions that a group manager
requires for resource management. Accordingly, it should be able to: view, add,
delete and edit members’ memberships; view and edit members’ balances; view
and edit members’ priorities; and view and edit resource information, etc. Apart
from resource management, forming resource provisioning collaborations with
resource providers via negotiation can also be enabled, which in turn should be
connected with the resource management functions. This is to enable allocating
and managing the resources obtained from the new collaborations.
The proposed two ideas for future work above are closely related to the test-
bed. The realisation of these proposals, being complementary to the developed
Service Broker, can release the potential of the Alliance2 protocol for resource
provisioning and management via negotiation.

Bibliography
David Abramson, Rajkumar Buyya, and Jonathan Giddy. A computational eco-
nomy for grid computing and its implementation in the Nimrod-G resource
broker. Future Generation Computer Systems, 18(8):1061–1074, 2002.
Sepideh Adabi, Ali Movaghar, Amir Masoud Rahmani, Hamid Beigy, and
Hengameh Dastmalchy-Tabrizi. A new fuzzy negotiation protocol for grid re-
source allocation. Journal of Network and Computer Applications, 37:89–126,
2014.
Cristina Aiftimiei, Alberto Aimar, Andrea Ceccanti, Marco Cecchi, Alberto
Di Meglio, Florida Estrella, Patrick Fuhrmam, Emidio Giorgio, Balazs Konya,
Laurence Field, et al. Towards next generations of software for distributed
infrastructures: the European Middleware Initiative. In 2012 IEEE 8th Inter-
national Conference on e-Science, pages 1–10. IEEE, 2012.
Roberto Alfieri, Roberto Cecchini, Vincenzo Ciaschini, Luca dell’Agnello, Akos
Frohner, Alberto Gianoli, Karoly Lorentey, and Fabio Spataro. VOMS, an
authorization system for virtual organizations. Lecture Notes in Computer
Science, 2970:33–40, 2004.
Rashid J Al Ali, Omer F Rana, David W Walker, Sanjay Jha, and Shaleeza
Sohail. G-QoSM: Grid service discovery using QoS properties. Computing and
Informatics, 21(4):363–382, 2012.
Rachida Amsaghrou. Report on the open market consultation and the results.
Technical report, CERN, 2016. https://doi.org/10.5281/zenodo.51592.
Sergio Andreozzi, Stephen Burke, Felix Ehm, Laurence Field, Gerson Galang,
Balazs Konya, Maarten Litmaath, Paul Millar, and JP Navarro. GLUE
Specification v. 2.0. Technical report, Open Grid Forum, 2009. ht-
tps://www.ogf.org/ogf/doku.php/documents/documents.
243

244 BIBLIOGRAPHY
Alain Andrieux, Karl Czajkowski, Asit Dan, Kate Keahey, Heiko Ludwig, Toshiy-
uki Nakata, Jim Pruyne, John Rofrano, Steve Tuecke, and Ming Xu. Web ser-
vices agreement specification (WS-Agreement). Technical report, Open Grid
Forum, 2011. https://www.ogf.org/ogf/doku.php/documents/documents.
Ali Anjomshoaa, Fred Brisard, Michel Drescher, Donal Fellows, An Ly, Stephen
McGough, Darren Pulsipher, and Andreas Savva. Job submission description
language specification. In Open Grid Forum Informational Document, 2005.
AVS. Data visualization API, software, tool - OpenViz, 2018. [online] Available
at: http://www.avs.com/solutions/openviz/ [Accessed 6 Mar. 2018].
AWS. Amazon Web Services (AWS) - Cloud Computing Services, 2018a. [online]
Available at: http://aws.amazon.com [Accessed 6 Mar. 2018].
AWS. Monitoring Your Usage and Costs - AWS Billing
and Cost Management, 2018b. [online] Available at:
http://docs.aws.amazon.com/awsaccountbilling/latest/aboutv2/monitoring-
costs.html [Accessed 6 Mar. 2018].
AWS. Paying Bills for Multiple Accounts Using Consolidated Billing -
AWS Billing and Cost Management, 2018c. [online] Available at:
http://docs.aws.amazon.com/awsaccountbilling/latest/aboutv2/consolidated-
billing.html [Accessed 6 Mar. 2018].
AWS. Amazon EC2 Instance Types, 2018d. [online] Available at:
https://aws.amazon.com/ec2/instance-types/ [Accessed 6 Mar. 2018].
AWS. EC2 product details - Amazon Web Services, 2018e. [online] Available at:
https://aws.amazon.com/ec2/details/ [Accessed 6 Mar. 2018].
Adam L Bazinet, Derrick J Zwickl, and Michael P Cummings. A gateway for
phylogenetic analysis powered by grid computing featuring GARLI 2.0. Sys-
tematic Biology, 63(5):812–818, 2014.
Sean Bechhofer. OWL: Web Ontology Language, pages 2008–2009. Springer US,
2009.
Mohamed Ben Belgacem and Bastien Chopard. A hybrid HPC/cloud distributed
infrastructure: Coupling EC2 cloud resources with HPC clusters to run large

BIBLIOGRAPHY 245
tightly coupled multiscale applications. Future Generation Computer Systems,
42:11–21, 2015.
Anton Beloglazov, Jemal Abawajy, and Rajkumar Buyya. Energy-aware resource
allocation heuristics for efficient management of data centers for cloud comput-
ing. Future generation computer systems, 28(5):755–768, 2012.
Krzysztof Benedyczak and Piotr Ba la. The next generation of Virtual Organisa-
tions in UNICORE. Unicore Summit, 2012.
Fran Berman, Richard Wolski, Silvia Figueira, Jennifer Schopf, and Gary Shao.
Application-level scheduling on distributed heterogeneous networks. In Pro-
ceedings of the 1996 ACM/IEEE Conference on Supercomputing, pages 39–39.
IEEE, 1996.
Bartosz Bosak, Piotr Kopta, Krzysztof Kurowski, Tomasz Piontek, and Mari-
usz Mamonski. New QosCosGrid Middleware Capabilities and Its Integration
with European e-Infrastructure, pages 34–53. Springer International Publishing,
2014.
John M Brooke and Michael S Parkin. Enabling scientific collaboration on the
grid. Future Generation Computer Systems, 26(3):521–530, 2010.
John M Brooke, Peter V Coveney, Jens Harting, Shantenu Jha, Stephen M
Pickles, Robin L Pinning, and Andrew R Porter. Computational steering in
RealityGrid. In Proceedings of the UK e-Science All Hands Meeting, volume 16,
2003.
Rodrigo N Calheiros, Henry Kasim, Terence Hung, Xiaorong Li, Sifei Lu, Long
Wang, Henry Palit, Gary Lee, Tuan Ngo, and Rajkumar Buyya. Cloud Com-
puting with e-Science Applications, chapter Adaptive execution of scientific
workflow applications on clouds, page 73. CRC Press, 2015.
Franck Cappello, Samir Djilali, Gilles Fedak, Thomas Herault, Frederic Magni-
ette, Vincent Neri, and Oleg Lodygensky. Computing on large-scale distributed
systems: XtremWeb architecture, programming models, security, tests and con-
vergence with grid. Future Generation Computer Systems, 21(3):417–437, 2005.

246 BIBLIOGRAPHY
Andrea Ceccanti and Paolo Andreetto. XACML Grid Computing Element Au-
thorization Profile, Version 1.0. Technical report, CERN Accelerating science,
2010a. https://edms.cern.ch/document/1078881/1.
Andrea Ceccanti and Paolo Andreetto. XACML Grid Worker Node Authoriza-
tion Profile, Version 1.0. Technical report, CERN Accelerating science, 2010b.
https://edms.cern.ch/document/1058175/1.0.1.
Andrea Ceccanti, Valery Tschopp, Michel Jouvin, and Marco Caber-
letti. Simplified Policy Language. EGEE, 2010. http://argus-
documentation.readthedocs.io/en/stable/pap/simplified policy language.html.
CERN. Argus Authorization Service, 2018. [online] Available at:
https://http://argus-documentation.readthedocs.io/en/latest/ [Accessed
6 Mar. 2018].
Jonathan Chin and Peter V Coveney. Towards tractable toolkits for the Grid: a
plea for lightweight, usable middleware. Technical report, 2004. URL http:
//the.earth.li/~jon/junk/lgpaper.html. UK e-Science Technical Report
UKeS-2004-01.
A. Cristofori, J.K. Nilsen, J. Gordon, M. Jones, J.A. Kennedy, and R. Muller-
Pfefferkorn. Usage Record–Format Recommendation. Technical report, Open
Grid Forum, 2013.
Andrea Cristofori. Grid accounting for computing and storage resources towards
standardization. PhD thesis, Universita degli Studi di Ferrara, 2011.
Karl Czajkowski, Ian Foster, Carl Kesselman, Volker Sander, and Steven Tuecke.
SNAP: A protocol for negotiating service level agreements and coordinating
resource management in distributed systems. In Job scheduling strategies for
parallel processing, pages 153–183. Springer Berlin Heidelberg, 2002.
Paul A David and Michael J Spence. Towards institutional infrastructures for
e-Science: The scope of the challenge, 2003. OII Research Report No. 2,
http://dx.doi.org/10.2139/ssrn.1325240.
Ewa Deelman. Challenges of managing scientific workflows in high-throughput
and high-performance computing environments, 2015. Presentation presented
in the 2016 IEEE 12th International Conference on eScience, Munich, Germany.

BIBLIOGRAPHY 247
Ewa Deelman, Gurmeet Singh, Miron Livny, Bruce Berriman, and John Good.
The cost of doing science on the Cloud: The Montage example. In Proceedings
of the 2008 ACM/IEEE Conference on Supercomputing, SC 08, pages 50:1–
50:12. IEEE Press, 2008. ISBN 978-1-4244-2835-9. URL http://dl.acm.org/
citation.cfm?id=1413370.1413421.
Ewa Deelman, Dennis Gannon, Matthew Shields, and Ian Taylor. Workflows and
e-science: An overview of workflow system features and capabilities. Future
Generation Computer Systems, 25(5):528–540, 2009.
Yuri Demchenko, Cees De Laat, Diego R Lopez, and Joan A Garcıa-Espın. Secur-
ity services lifecycle management in on-demand infrastructure services provi-
sioning. In IEEE Second International Conference on Cloud Computing Tech-
nology and Science, pages 644–650. IEEE, 2010.
Monica Denham, Kerstin Wendt, German Bianchini, Ana Cortes, and Tomas
Margalef. Dynamic data-driven genetic algorithm for forest fire spread predic-
tion. Journal of Computational Science, 3(5):398–404, 2012.
Jonas Dias, Eduardo Ogasawara, Daniel de Oliveira, Fabio Porto, Alvaro LGA
Coutinho, and Marta Mattoso. Supporting dynamic parameter sweep in adapt-
ive and user-steered workflow. In Proceedings of the 6th workshop on Workflows
in support of large-scale science, pages 31–36. ACM, 2011.
Ivan Dıaz, G Fern, MJ Martın, J Tourino, et al. Extending the Globus inform-
ation service with the common information model. In IEEE 9th International
Symposium on Parallel and Distributed Processing with Applications (ISPA),
pages 113–119. IEEE, 2011.
DMTF. Common Information Model. Technical report, Distributed Management
Task Force (DMTF), 2018. URL https://www.dmtf.org/standards/cim/
cim_schema_v2500.
Michel Drescher. Interoperability is the key to freedom in the cloud, 2014. EGI
Cloud Position Paper Cloudscape VI.
Arnaud Dury, Sergiy Boroday, Alexandre Petrenko, and Volkmar Lotz. Formal
verification of business workflows and role based access control systems. In
The International Conference on Emerging Security Information, Systems, and
Technologies, 2007. SecureWare 2007, pages 201–210. IEEE, 2007.

248 BIBLIOGRAPHY
Paula Eerola, Balazs Konya, Oxana Smirnova, T Ekelof, Mattias Ellert,
John Renner Hansen, Jakob Langgaard Nielsen, A Waananen, Aleksandr Kon-
stantinov, Juha Herrala, et al. The NorduGrid production Grid infrastructure,
status and plans. In Proceedings of the 4th International Workshop on Grid
Computing, GRID ’03, pages 158–165. IEEE Computer Society, 2003.
EGI. EGI AAI Checkin Service, 2018a. [online] Available at: ht-
tps://wiki.egi.eu/wiki/AAI [Accessed 6 Mar. 2018].
EGI. Cloud usage record for egi federated cloud, 2018b. [online] Available at: ht-
tps://wiki.egi.eu/wiki/Federated Cloud Technology#Accounting [Accessed 28
June. 2018].
EGI. EGI Pay-For-Use PoC - EGIwiki, 2018c. [online] Available at: ht-
tps://wiki.egi.eu/wiki/EGI Pay-for-Use PoC:Home [Accessed 6 Mar. 2018].
EGI. EGI Applications Database, 2018d. [online] Available at: ht-
tps://appdb.egi.eu/ [Accessed 6 Mar. 2018].
EGI. EGI Accounting Portal, 2018e. [online] Available at: ht-
tps://accounting.egi.eu/ [Accessed 29 May. 2018].
EGI. Marketplace - e-Infrastructure Services for Research, 2018f. [online] Avail-
able at: https://marketplace.egi.eu/ [Accessed 28 May. 2018].
Jorge Ejarque, Marc de Palol, Inigo Goiri, Ferran Julia, Jordi Guitart, Rosa M
Badia, and Jordi Torres. Exploiting semantics and virtualization for SLA-
driven resource allocation in service providers. Concurrency and Computation:
Practice and Experience, 22(5):541–572, 2010a.
Jorge Ejarque, Raul Sirvent, and Rosa M Badia. A multi-agent approach for
semantic resource allocation. In 2010 IEEE Second International Conference on
Cloud Computing Technology and Science (CloudCom), pages 335–342. IEEE,
2010b.
Mattias Ellert, Michael Grønager, Aleksandr Konstantinov, Balazs Konya, Jonas
Lindemann, Ilja Livenson, Jakob Langgaard Nielsen, Marko Niinimaki, Oxana
Smirnova, and Anders Waananen. Advanced Resource Connector middleware
for lightweight computational Grids. Future Generation Computer Systems, 23
(2):219–240, 2007.

BIBLIOGRAPHY 249
Erik Elmroth and Johan Tordsson. A standards-based grid resource brokering
service supporting advance reservations, coallocation, and cross-grid interop-
erability. Concurrency and Computation: Practice and Experience, 21(18):
2298–2335, 2009.
Dietmar Erwin and David Snelling. UNICORE: A Grid computing environment.
In Euro-Par 2001 Parallel Processing, pages 825–834. Springer Berlin Heidel-
berg, 2001.
Enol Fernandez-del Castillo, Diego Scardaci, and Alvaro Lopez Garcia. The EGI
federated cloud e-infrastructure. Procedia Computer Science, 68:196–205, 2015.
Laurence Field and M Schulz. Grid deployment experiences: The path to a
production quality LDAP based grid information system. In Computing in
High Energy Physics and Nuclear Physics, pages 723–726, 2005.
Roy Fielding. Architectural styles and the design of network-based software archi-
tectures, chapter Representational state transfer (REST). University of Cali-
fornia, 2000. Ph.D. thesis.
Ian Foster. Globus toolkit version 4: Software for service-oriented systems.
Journal of computer science and technology, 21(4):513–520, 2006.
Ian Foster and Carl Kesselman. The Grid 2: Blueprint for a new computing
infrastructure. Elsevier, 2003.
Ian Foster, Carl Kesselman, and Steven Tuecke. The anatomy of the Grid: En-
abling scalable virtual organizations. The International Journal of High Per-
formance Computing Applications, 15(3):200–222, 2001.
Ian Foster, Yong Zhao, Ioan Raicu, and Shiyong Lu. Cloud Computing and Grid
Computing 360-degree compared. In Grid Computing Environments Workshop,
2008. GCE’08, pages 1–10. IEEE, 2008.
Celine Fouard, Aurelien Deram, Yannick Keraval, and Emmanuel Promayon.
CamiTK: a modular framework integrating visualization, image processing and
biomechanical modeling. In Soft tissue biomechanical modeling for computer
assisted surgery, pages 323–354. Springer, 2012.

250 BIBLIOGRAPHY
Patrick Fuhrmann and Volker Gulzow. dCache, storage system for the future. In
Euro-Par 2006 Parallel Processing, pages 1106–1113. Springer Berlin Heidel-
berg, 2006.
Nathalie Furmento, William Lee, Anthony Mayer, Steven Newhouse, and John
Darlington. ICENI: an open grid service architecture implemented with Jini.
In Proceedings of the 2002 ACM/IEEE conference on Supercomputing, pages
1–10. IEEE Computer Society Press, 2002.
Martin Gasthuber, Helge Meinhard, and Robert Jones. HNSciCloud - Overview
and technical challenges. Journal of Physics: Conference Series, 898(5), 2017.
John H Gennari, Mark A Musen, Ray W Fergerson, William E Grosso, Monica
Crubezy, Henrik Eriksson, Natalya F Noy, and Samson W Tu. The evolution
of Protege: an environment for knowledge-based systems development. Inter-
national Journal of Human-computer studies, 58(1):89–123, 2003.
Stephen M George, Wei Zhou, Harshavardhan Chenji, Myounggyu Won, Yong Oh
Lee, Andria Pazarloglou, Radu Stoleru, and Prabir Barooah. DistressNet: a
wireless ad hoc and sensor network architecture for situation management in
disaster response. IEEE Communications Magazine, 48(3), 2010.
J Holzmann Gerard. The SPIN model checker: Primer and reference manual.
Addison-Wesley Professional, 2003.
GIN-CG. OGF-Grid Interoperation Now Community Group (GIN-CG), 2008.
URL http://forge.ogf.org/sf/projects/gin.
Globus. The Globus Resource Specification Language RSL v1. 1, 2018. URL
http://toolkit.globus.org/toolkit/docs/2.4/gram/rsl_spec1.html.
Ionel Gog, Malte Schwarzkopf, Adam Gleave, Robert Nicholas Watson, and
Steven Hand. Firmament: Fast, centralized cluster scheduling at scale. Usenix,
2016.
Google. Google Cloud Computing, Hosting Services & APIs, 2018a. [online]
Available at: https://cloud.google.com [Accessed 6 Mar. 2018].
Google. Management Tools - Develop, Deploy and Manage Cloud
Apps - Google Cloud Platform, 2018b. [online] Available at: ht-
tps://cloud.google.com/products/management/ [Accessed 6 Mar. 2018].

BIBLIOGRAPHY 251
Jim Gray and Andreas Reuter. Transaction processing: concepts and techniques,
chapter Transactional Resource Manager Concepts. Elsevier, 1992.
Derek Groen, Agastya P Bhati, James Suter, James Hetherington, Stefan J
Zasada, and Peter V Coveney. FabSim: Facilitating computational research
through automation on large-scale and distributed e-infrastructures. Computer
Physics Communications, 207:375–385, 2016.
Junyi Han and John Brooke. Hybrid computational steering for dynamic data-
driven application systems. Procedia Computer Science, 80:407–417, 2016.
Liangxiu Han, Stephen Potter, George Beckett, Gavin Pringle, Stephen Welch,
Sung-Han Koo, Gerhard Wickler, Asif Usmani, Jose L Torero, and Austin Tate.
FireGrid: An e-Infrastructure for next-generation emergency response support.
Journal of Parallel and Distributed Computing, 70(11):1128–1141, 2010.
Michael Hartung, Frank Loebe, Heinrich Herre, and Erhard Rahm. Management
of evolving semantic grid metadata within a collaborative platform. Informa-
tion Sciences, 180(10):1837–1849, 2010.
Mahamat Issa Hassan and Azween Abdullah. A new grid resource discovery
framework. Int. Arab J. Inf. Technol., 8(1):99–107, 2011.
Mark Hayes, Lorna Morris, Rob Crouchley, Daniel Grose, Ties Van Ark, Rob
Allan, and John Kewley. GROWL: A lightweight grid services toolkit and
applications. In Proceedings of the UK e-Science All Hands Meeting.
Hugo Hiden, Simon Woodman, Paul Watson, and Jacek Cala. Developing cloud
applications using the e-Science Central platform. Phil. Trans. R. Soc. A, 371
(1983), 2013.
W Kuan Hon, Christopher Millard, and Ian Walden. Negotiating cloud contracts:
Looking at clouds from both sides now. Stan. Tech. L. Rev., 16:79, 2012.
Hameed Hussain, Saif Ur Rehman Malik, Abdul Hameed, Samee Ullah Khan,
Gage Bickler, Nasro Min-Allah, Muhammad Bilal Qureshi, Limin Zhang, Wang
Yongji, Nasir Ghani, et al. A survey on resource allocation in high performance
distributed computing systems. Parallel Computing, 39(11):709–736, 2013.

252 BIBLIOGRAPHY
Christopher J Hutton, Zoran Kapelan, Lydia Vamvakeridou-Lyroudia, and
Dragan A Savic. Dealing with uncertainty in water distribution system models:
A framework for real-time modeling and data assimilation. Journal of Water
Resources Planning and Management, 140(2):169–183, 2012.
Ahmed Ibrahim, Anca Bucur, Andre Dekker, M Scott Marshall, David Perez-
Rey, Raul Alonso-Calvo, Holger Stenzhorn, Sheng Yu, Cyril Krykwinski, An-
ouar Laarif, et al. Analysis of the suitability of existing medical ontologies
for building a scalable semantic interoperability solution supporting multi-site
collaboration in oncology. In 2014 IEEE International Conference on Bioin-
formatics and Bioengineering (BIBE), pages 204–211. IEEE, 2014.
HT Jensen, JK Nilsen, P Millar, R Muller-Pfefferkorn, Z Molnar, and R Zappi.
Emi star–definition of a storage accounting record. Technical report, 2013.
URL https://www.ogf.org/ogf/doku.php/documents/documents.
Hao Jiang and Constantinos Dovrolis. Passive estimation of TCP round-trip
times. ACM SIGCOMM Computer Communication Review, 32(3):75–88, 2002.
Marina Jirotka, Charlotte P Lee, and Gary M Olson. Supporting scientific collab-
oration: Methods, tools and concepts. Computer Supported Cooperative Work
(CSCW), 22(4-6):667–715, 2013.
Peter Kacsuk, Zoltan Farkas, Miklos Kozlovszky, Gabor Hermann, Akos Balasko,
Krisztian Karoczkai, and Istvan Marton. WS-PGRADE/gUSE generic DCI
gateway framework for a large variety of user communities. Journal of Grid
Computing, pages 1–30, 2012.
Pim Kars. The application of Promela and Spin in the BOS project. In Proceed-
ings of the 2nd SPIN Workshop, 1996.
Gavin King, Christian Bauer, Max Rydahl Andersen, Emmanuel Bernard, Steve
Ebersole, and H Ferentschik. Hibernate Reference Documentation 3.6.10 final.
Technical report, JBoss Community, 2011. URL https://docs.jboss.org/
hibernate/orm/3.6/reference/en-US/html/.
Balazs Konya and Daniel Johansson. The NorduGrid - ARC Information System.
Technical report, The NorduGrid Collaboration, 2017. URL www.nordugrid.
org/documents/arc_infosys.pdf.

BIBLIOGRAPHY 253
D Kranzlmuller, J Marco de Lucas, and P Oster. The European Grid Initiat-
ive (EGI). In Remote Instrumentation and Virtual Laboratories, pages 61–66.
Springer, 2010.
Kim G Larsen, Paul Pettersson, and Wang Yi. UPPAAL in a nutshell. In-
ternational Journal on Software Tools for Technology Transfer (STTT), 1(1):
134–152, 1997.
Erwin Laure, A Edlund, F Pacini, P Buncic, M Barroso, A Di Meglio, F Prelz,
A Frohner, O Mulmo, A Krenek, et al. Programming the Grid with gLite.
Technical report, CERN, 2006.
Lei Li and Ian Horrocks. A software framework for matchmaking based on se-
mantic web technology. International Journal of Electronic Commerce, 8(4):
39–60, 2004.
Pia Lindholm and Frithjof A Maennel. Directive on Electronic Commerce
(2000/31/EC). 2000.
Jan Linxweiler, Manfred Krafczyk, and Jonas Tolke. Highly interactive compu-
tational steering for coupled 3D flow problems utilizing multiple GPUs. Com-
puting and visualization in science, 13(7):299–314, 2010.
Yong Beom Ma, Sung Ho Jang, and Jong Sik Lee. Ontology-based resource man-
agement for cloud computing. In Asian Conference on Intelligent Information
and Database Systems, pages 343–352. Springer, 2011.
Malawski Maciej, Juve Gideon, Deelman Ewa, and Nabrzyski Jarek. Cost-
and deadline-constrained provisioning for scientific workflow ensembles in IaaS
clouds. In Proceedings of the International Conference on High Performance
Computing, Networking, Storage and Analysis. IEEE Computer Society Press,
2012.
Jon MacLaren. HARC: the highly-available resource co-allocator. pages 1385–
1402. Springer Berlin Heidelberg, 2007.
Cecchi Marco, Capannini Fabio, Dorigo Alvise, Ghiselli Antonia, Giacomini
Francesco, Maraschini Alessandro, Marzolla Moreno, Monforte Salvatore, Pa-
cini Fabrizio, Petronzio Luca, et al. The gLite workload management system.

254 BIBLIOGRAPHY
In Advances in Grid and Pervasive Computing, pages 256–268. Springer Berlin
Heidelberg, 2009.
Carmen Martinez-Cruz, Ignacio J Blanco, and M Amparo Vila. Ontologies versus
relational databases: are they so different? A comparison. Artificial Intelligence
Review, pages 1–20, 2012.
Marta Mattoso, Kary Ocana, Felipe Horta, Jonas Dias, Eduardo Ogasawara,
Vitor Silva, Daniel de Oliveira, Flavio Costa, and Igor Araujo. User-steering
of HPC workflows: state-of-the-art and future directions. In Proceedings of the
2nd ACM SIGMOD Workshop on Scalable Workflow Execution Engines and
Technologies, page 4. ACM, 2013.
Deborah L McGuinness and Frank Van Harmelen. OWL Web Ontology Lan-
guage Overview. W3C Recommendation, 2004. https://www.w3.org/TR/owl-
features/.
Peter Mell and Tim Grance. The NIST definition of cloud computing. Computer
Security Division, Information Technology Laboratory, National Institute of
Standards and Technology Gaithersburg, 2011.
Zeqian Meng and John Brooke. Negotiation protocol for Agile collaboration in e-
Science. CGW’14 Workshop, Academic Computer Centre CYFRONET AGH,
2014.
Zeqian Meng and John Brooke. Negotiation protocol for agile and reliable e-
Science collaboration. In 2015 IEEE 11th International Conference on e-
Science, pages 292–295. IEEE, 2015.
Zeqian Meng, John Brooke, and Rizos Sakellariou. Semantic accountable match-
making for e-Science resource sharing. In 2016 IEEE 12th International Con-
ference on e-Science, pages 282–286. IEEE, 2016.
Alessio Merlo. Secure cooperative access control on grid. Future Generation
Computer Systems, 29(2):497–508, 2013.
Andre Merzky and Alexander Papaspyrou. WS-Disagreement. Technical re-
port, Open Grid Forum, 2012. URL https://www.ogf.org/ogf/doku.php/
documents/documents.

BIBLIOGRAPHY 255
Thijs Metsch, Andy Edmonds, et al. Open cloud computing interface-
infrastructure. In Standards Track, no. GFD-R in The Open Grid Forum
Document Series, Open Cloud Computing Interface (OCCI) Working Group,
Muncie (IN), 2010.
RL Morgan, Scott Cantor, Steven Carmody, Walter Hoehn, and Ken Klingen-
stein. Federated security: The Shibboleth approach. Educause Quarterly, 27
(4):12–17, 2004.
NorduGrid. Extended resource specification language. Technical report, 2018.
URL www.nordugrid.org/documents/xrsl.pdf. Reference Manual for ARC
versions 0.8 and above.
Simon Ostermann, Alexandria Iosup, Nezih Yigitbasi, Radu Prodan, Thomas
Fahringer, and Dick Epema. A performance analysis of EC2 cloud comput-
ing services for scientific computing. In International Conference on Cloud
Computing, pages 115–131. Springer, 2009.
Michael Parkin, S Van der Berghe, Oscar Corcho, Dave Snelling, and John
Brooke. The knowledge of the Grid: A Grid Ontology. In Proceedings of
the Cracow Grid Workshop, CGW2006, 2006.
Michael Stephen Parkin. Lightweight client organisations for the computational
grid. PhD thesis, University of Manchester, 2007.
Pankesh Patel, Ajith H Ranabahu, and Amit P Sheth. Service Level Agreement
in cloud computing. 2009.
Przemyslaw Pawluk, Bradley Simmons, Michael Smit, Marin Litoiu, and Serge
Mankovski. Introducing STRATOS: A cloud broker service. In 2012 IEEE
5th International Conference on Cloud Computing (CLOUD), pages 891–898.
IEEE, 2012.
Siani Pearson. Privacy, security and trust in cloud computing. In Privacy and
Security for Cloud Computing, pages 3–42. Springer, 2013.
Juan M Marın Perez, Jorge Bernal Bernabe, Jose M Alcaraz Calero, Felix J Gar-
cia Clemente, Gregorio Martınez Perez, and Antonio F Gomez Skarmeta.
Semantic-based authorization architecture for Grid. Future Generation Com-
puter Systems, 27(1):40–55, 2011.

256 BIBLIOGRAPHY
Danilo Piparo, Enric Tejedor, Pere Mato, Luca Mascetti, Jakub Moscicki, and
Massimo Lamanna. SWAN: a service for interactive analysis in the cloud.
Future Generation Computer Systems, 78:1071–1078, 2018.
Marcin Radecki, Tadeusz Szymocha, Tomasz Szepieniec, and Roksana Rozanska.
Improving PL-Grid Operations Based on FitSM Standard, volume 8500, pages
94–105. Springer, Cham, 2014.
Rajesh Raman, Miron Livny, and Marvin Solomon. Matchmaking: Distributed
resource management for high throughput computing. In Proceedings of The
Seventh International Symposium on High Performance Distributed Comput-
ing, pages 140–146. IEEE, 1998.
Uwe Rathmann and Josef Wilgen. Qwt-Qt Widgets for technical applications,
2016. [online] Available at: http://qwt.sourceforge.net/ [Accessed 24 May.
2018].
RCUK. e-Infrastructure - Research Councils UK, 2018. [online] Available at:
http://www.rcuk.ac.uk/research/xrcprogrammes/otherprogs/einfrastructure/
[Accessed 6 Mar. 2018].
Morris Riedel. Design and Applications of an Interoperability Reference Model
for Production e-Science Infrastructures, volume 16. Forschungszentrum Julich,
2013.
Morris Riedel, Erwin Laure, Th Soddemann, Laurence Field, John-Paul Navarro,
James Casey, Maarten Litmaath, J Ph Baud, Birger Koblitz, Charlie Catlett,
et al. Interoperation of world-wide production e-Science infrastructures. Con-
currency and Computation: Practice and Experience, 21(8):961–990, 2009.
Ariel Rubinstein. Perfect equilibrium in a bargaining model. Econometrica:
Journal of the Econometric Society, pages 97–109, 1982.
Naidila Sadashiv and SM Dilip Kumar. Cluster, grid and cloud computing: A de-
tailed comparison. In 2011 6th International Conference on Computer Science
& Education (ICCSE), pages 477–482. IEEE, 2011.
Jennifer M Schopf, Laura Pearlman, Neill Miller, Carl Kesselman, Ian Foster,
Mike D’Arcy, and Ann Chervenak. Monitoring the grid with the Globus Toolkit
MDS4. Journal of Physics: Conference Series, 46(1):521, 2006.

BIBLIOGRAPHY 257
UoM IT Services. Connecting to the CSF, 2018a. [online] Avail-
able at: http://ri.itservices.manchester.ac.uk/csf/getting-started-on-the-
csf/connecting-to-the-csf/ [Accessed 6 Mar. 2018].
UoM IT Services. Parallel jobs, 2018b. [online] Available at:
http://ri.itservices.manchester.ac.uk/csf/batch/parallel-jobs/ [Accessed 6
Mar. 2018].
Igor Sfiligoi. glideinWMS: a generic pilot-based workload management system.
Journal of Physics: Conference Series, 119(6), 2008.
Shayan Shahand, Mark Santcroos, Antoine HC van Kampen, and Sılvia Delgado
Olabarriaga. A grid-enabled gateway for biomedical data analysis. Journal of
Grid Computing, pages 1–18, 2012.
Robin Sharp. Principles of protocol design. Springer Science & Business Media,
2008.
Tarek Sherif, Pierre Rioux, Marc-Etienne Rousseau, Nicolas Kassis, Natacha
Beck, Reza Adalat, Samir Das, Tristan Glatard, and Alan C Evans. CBRAIN:
a web-based, distributed computing platform for collaborative neuroimaging
research. Frontiers in neuroinformatics, 8, 2014.
Jamie Shiers. The worldwide LHC computing grid (worldwide LCG). Computer
physics communications, 177(1):219–223, 2007.
Stephen Siegel. Model checking nonblocking MPI programs. In Verification,
Model Checking, and Abstract Interpretation, pages 44–58. Springer Berlin
Heidelberg, 2007.
Kwang Mong Sim. Complex and concurrent negotiations for multiple interrelated
e-markets. IEEE transactions on cybernetics, 43(1):230–245, 2013.
Evren Sirin, Bijan Parsia, Bernardo Cuenca Grau, Aditya Kalyanpur, and Yarden
Katz. Pellet: A practical OWL-DL reasoner. Web Semantics: science, services
and agents on the World Wide Web, 5(2):51–53, 2007.
Peter Solagna. AAI in EGI Current Status, 2015. Presenta-
tion presented in the 2015 EGI Conference, Lisbon, Portugal, ht-
tps://documents.egi.eu/public/ShowDocument?docid=2185.

258 BIBLIOGRAPHY
Marvin Solomon. The ClassAd language reference manual, Version 2.4. Technical
report, Computer Sciences Department, University of Wisconsin, 2004.
Thamarai Selvi Somasundaram, Kannan Govindarajan, Usha Kiruthika, and Ra-
jkumar Buyya. Semantic-enabled CARE Resource Broker (SeCRB) for man-
aging grid and cloud environment. The Journal of Supercomputing, 68(2):
509–556, 2014.
Borja Sotomayor, Kate Keahey, and Ian Foster. Combining batch execution and
leasing using virtual machines. In Proceedings of the 17th international sym-
posium on high performance distributed computing, pages 87–96. ACM, 2008.
D Spiga, S Lacaprara, W Bacchi, M Cinquilli, G Codispoti, M Corvo, A Dorigo,
A Fanfani, F Fanzago, F Farina, et al. CRAB: the CMS distributed analysis
tool development and design. Nuclear Physics B - Proceedings Supplements,
177:267–268, 2008. Proceedings of the Hadron Collider Physics Symposium
2007.
Achim Streit, Piotr Bala, Alexander Beck-Ratzka, Krzysztof Benedyczak, Sandra
Bergmann, Rebecca Breu, Jason Milad Daivandy, Bastian Demuth, Anastasia
Eifer, Andre Giesler, et al. UNICORE 6 - recent and future advancements. An-
nals of Telecommunications-annales des Telecommunications, 65(11-12):757–
762, 2010.
Elisabeth A Strunk, M Anthony Aiello, and John C Knight. A survey of tools
for model checking and model-based development, 2006.
Rudi Studer, V Richard Benjamins, and Dieter Fensel. Knowledge engineering:
principles and methods. Data & knowledge engineering, 25(1-2):161–197, 1998.
Todd Tannenbaum, Derek Wright, Karen Miller, and Miron Livny. Condor: a
distributed job scheduler, pages 307–350. MIT press, 2001.
Ian J Taylor, Ewa Deelman, Dennis B Gannon, and Matthew Shields. Workflows
for e-Science: scientific workflows for grids, pages 1–10. Springer Publishing
Company, Incorporated, 2014.
Erik Torres, German Molto, Damia Segrelles, and Ignacio Blanquer. A replicated
information system to enable dynamic collaborations in the grid. Concurrency
and Computation: Practice and Experience, 24(14):1668–1683, 2012.

BIBLIOGRAPHY 259
Peter Troger, Roger Brobst, Daniel Gruber, Mariusz Mamonski, and Daniel
Templeton. Distributed resource management application API Version
2.2 (DRMAA). Technical report, Open Grid Forum, 2016. ht-
tps://www.ogf.org/documents/GFD.230.pdf.
Valery Tschopp. Argus, the EMI authorization service. In 1st EMI Technical
Conference, 2011.
Milan K Vachhani and Kishor H Atkotiya. Globus toolkit 5 (gt5): Introduction
of a tool to develop grid application and middleware. International Journal of
Emerging Technology and Advanced Engineering, 2(7):174–178, 2012.
Catia Vaz and Carla Ferreira. Formal verification of workflow patterns with Spin.
Technical report, Dept. of Electronic and Telecommunications and Computer
Engineering ISEL, Polytechnic Institute of Lisbon, 2007.
Christian Vecchiola, Rodrigo N Calheiros, Dileban Karunamoorthy, and Rajku-
mar Buyya. Deadline-driven provisioning of resources for scientific applications
in hybrid clouds with Aneka. Future Generation Computer Systems, 28(1):58–
65, 2012.
Will Venters, Eivor Oborn, and Michael Barrett. A trichordal temporal approach
to digital coordination: the sociomaterial mangling of the CERN grid. MIS
Quaterly, 38:927–949, 2014.
Sergey Volkov and Oleg Sukhoroslov. A generic web service for running parameter
sweep experiments in distributed computing environment. Procedia Computer
Science, 66:477–486, 2015.
Alex Voss, Adam Barker, Mahboubeh Asgari-Targhi, Adriaan van Ballegooijen,
and Ian Sommerville. An elastic virtual infrastructure for research applications
(ELVIRA). Journal of Cloud Computing: Advances, Systems and Applications,
2(1):20, 2013.
George A Vouros, Andreas Papasalouros, Konstantinos Kotis, Alexandros
Valarakos, Konstantinos Tzonas, Xavier Vilajosana, Ruby Krishnaswamy, and
Nejla Amara-Hachmi. The Grid4All ontology for the retrieval of traded re-
sources in a market-oriented grid. International Journal of Web and Grid
Services, 4(4):418–439, 2008.

260 BIBLIOGRAPHY
George A Vouros, Andreas Papasalouros, Konstantinos Tzonas, Alexandros
Valarakos, Konstantinos Kotis, Jorge-Arnulfo Quiane-Ruiz, Philippe Lamarre,
and Patrick Valduriez. A semantic information system for services and traded
resources in grid e-markets. Future Generation Computer Systems, 26(7):916–
933, 2010.
Oliver Waeldrich, Dominic Battre, Francis Brazier, Kassidy Clark, Michel Oey,
Alexander Papaspyrou, Philipp Wieder, and Wolfgang Ziegler. WS-Agreement
negotiation version 1.0. Technical report, Open Grid Forum, 2011. URL https:
//www.ogf.org/ogf/doku.php/documents/documents.
Paul Watson, Hugo Hiden, and Simon Woodman. e-Science Central for CAR-
MEN: science as a service. Concurrency and computation: Practice and Ex-
perience, 22(17):2369–2380, 2010.
Wei Xing, Marios D Dikaiakos, and Rizos Sakellariou. A core grid ontology for the
semantic grid. In Sixth IEEE International Symposium on Cluster Computing
and the Grid, volume 1, pages 178–184. IEEE, 2006.
Wei Xing, Oscar Corcho, Carole Goble, and Marios D Dikaiakos. An ActOn-based
semantic information service for Grids. Future Generation Computer Systems,
26(3):324–336, 2010.
Hyunjeong Yoo, Cinyoung Hur, Seoyoung Kim, and Yoonhee Kim. An ontology-
based resource selection service on science cloud. Grid and Distributed Com-
puting, pages 221–228, 2009.
Sergio Yovine. Kronos: A verification tool for real-time systems. International
Journal on Software Tools for Technology Transfer (STTT), 1(1):123–133,
1997.
Jia Yu and Rajkumar Buyya. A taxonomy of workflow management systems for
grid computing. Journal of Grid Computing, 3(3-4):171–200, 2005.
Stefan J. Zasada and Peter V. Coveney. A distributed multi-
agent market place for HPC compute cycle resource trading, 2015.
http://arxiv.org/abs/1512.04343.

BIBLIOGRAPHY 261
Stefan J Zasada, David CW Chang, Ali N Haidar, and Peter V Coveney. Flex-
ible composition and execution of large scale applications on distributed e-
Infrastructures. Journal of Computational Science, 5(1):51–62, 2014.
Meng Zeqian. Android application based on web service and cloud computing.
Master’s thesis, University of Manchester, 2012.
Xingwu Zheng, Zhou Zhou, Xu Yang, Zhiling Lan, and Jia Wang. Exploring
plan-based scheduling for large-scale computing systems. In 2016 IEEE Inter-
national Conference on Cluster Computing (CLUSTER), pages 259–268. IEEE,
2016.

262 BIBLIOGRAPHY

Appendix A
Testbed Experiment Screenshots
Section 6.4 has discussed the scenarios designed to evaluate the perspective ne-
gotiation and accounting capabilities enabled by the Alliance2 protocol. Here we
present the screenshots that were taken during the experiment for each designed
scenario, to illustrate the enabled functionalities of the Service Broker.
• Scenario 1: Successful negotiation is conducted and the job completes with
both use cases.
The screenshot shown in Figure A.1 is for a successful negotiation proced-
ure for Use Case 2. As can be seen in the screenshot, the information
contained in the request included the requester’s username, the requester’s
group name, the name of the application to be executed, the type of job
required, and the deadline for the application execution. The Service
Broker verified that:
1. The balance of the required resource for the group that the requester
belonged to and the balance of the requester were equal to or larger
than the maximum CPU time value set by the group manager.
2. The requester’s privilege was proved to be able to run the application
in the way as required in the request (serial or parallel).
After the verification, the information of the Quote message was stored
in the database of the Service Broker. The Quote then was returned to
the requester with this information: the Quote ID, the provider name,
the allocated resource’s privilege level, and the deadline as specified in the
request.
263

264 APPENDIX A. TESTBED EXPERIMENT SCREENSHOTS
Figure A.1: Screenshot: negotiation in Service Broker: the screenshot highlightsthe Quote returned, the default CPU time set by the manager for the requesterSofia for each application execution request, the balance for members with normalprivilege in the ComputingShare ontology and the requester Sofia’s balance in theMappingPolicy ontology.
Figure A.2 presents the balance updates in the Service Broker after the
Service Broker received the acknowledgement from the requester.
Figure A.3 captures the functionality in the Service Broker to verify
whether the submitted job had been completed in the local Cluster when
the deadline specified by the requester approached.
Figure A.4 shows that the Service Broker confirmed that the submitted
job had been completed. Furthermore, Figure A.5 shows that:
1. the Service Broker updated the state for the contract to completed.
2. the Service Broker updated the balance of the requester in the Map-
pingPolicy instance.
3. the Service Broker updated the balance of the contracted resource
in the ComputingShare instance.
Balance updates were realised by fetching the actual execution duration
from the local Cluster.

265
Figure A.2: Screenshot: procedures when Service Broker received contract ac-knowledgement: the screenshot highlights the balance updates for both the re-quester and members with normal privilege in corresponding ontologies.
Figure A.3: Screenshot: the deadline specified detected by Service Broker
Figure A.4: Screenshot: Service Broker verified the completion of the job

266 APPENDIX A. TESTBED EXPERIMENT SCREENSHOTS
Figure A.5: Screenshot: balance updates for resource consumption in Use Case 1
Figure A.6: Screenshot: Service Broker detected that the specified deadline ap-
proached
Figure A.7: Screenshot: Service Broker updated the contract state to reqTermin-
ated
• Scenario 2: Successful negotiation is conducted, and the job is stopped by
the deadline specified by the requester with Use Case 2.
The same procedures as presented for Scenario 1 to fetch the submitted job
status in the local Cluster happened when the Service Broker detected

267
Figure A.8: Screenshot: the contract formation procedures in Service Broker
that the deadline specified by the requester approached. These procedures
are shown in Figure A.6. The Service Broker subsequently found that
the job had not been completed. It then terminated the job execution. The
Service Broker also updated the state for the terminated contract from
contracted to reqTerminated, as shown in Figure A.7. Figure A.8 presents
the confirmation of the successful negotiation.
• Scenario 3: Successful re-negotiation or new negotiation is conducted with
Use Case 1.
Figure A.9 shows that the first contract was formed when the requester
required 1 CPU and corresponding balance updates. When receiving the
requester’s request to increase the number of CPUs, the Service Broker
checked whether the resource running the job or other collaborating re-
sources could meet demands. It would return offers if satisfactory resources
were found. During matchmaking, the requester’s balance was checked
with the minimum limit set by the manager, while resources’ balances were
checked with the remaining maximum value. The remaining maximum
value was obtained by reducing the initial maximum value by the amount
consumed. The reasoning procedures are presented in Figure A.10.
After successful re-negotiation, the requester’s balance was not reduced. If
re-negotiation with the contracted resource was unsuccessful, negotiation
with other collaborating resources for the additional number of CPUs was
activated. When a contract was formed for another resource, the balance
of the contracted resource would be reduced by the remaining maximum

268 APPENDIX A. TESTBED EXPERIMENT SCREENSHOTS
Figure A.9: Screenshot: first contract formation in the re-negotiation scenario
Figure A.10: Screenshot: reasoning procedures during re-negotiation: the screen-shot shows that 3 CPUs were required from the running steerable application. Italso shows the detailed reasoning procedures, which will be activated for everycontract negotiation or re-negotiation request.
value. In the experiment, the requester requested 2 more CPUs and the col-
laborating instances each had only 1 CPU. Thus, the contract returned for
re-negotiation was a combination of two sub-contracts, each with a unique
contract ID, as shown in Figure A.11. Information of the new contract,
including the two sub-contracts, was stored with a contracted state. The
procedures followed for job submission, application execution, and balance
updates were the same as Scenario 1. Figures A.12 to A.14 show the balance
updates activated when the Service Broker received notifications of job
completion for the three contracts.
• Scenario 4: Negotiation is successfully conducted with rejection as a result,

269
Figure A.11: Screenshot: the Quotes returned by Service Broker during re-negotiation: the requester required 3 CPUs. As each instance had only 1 CPUavailable, two more instances were returned, in addition to the contracted one.
Figure A.12: Screenshot: balance updates for the first contract completion inService Broker
Figure A.13: Screenshot: balance updates for the second contract completion inService Broker
because of insufficient balances of resources for the group. This scenario
has been tested with both use cases.
The Service Broker returned a message advising that the group’s balance
of the required resource was insufficient. The result is shown in Figure A.15.
As highlighted in Figure A.15, the balance of the group members with
normal privilege was 0, while the default value set by the manager was

270 APPENDIX A. TESTBED EXPERIMENT SCREENSHOTS
Figure A.14: Screenshot: balance updates for the third contract completion inService Broker
Figure A.15: Screenshot: insufficient balance of the group for the required re-source: the requester Sofia who had a balance of 4913411 seconds of CPU timewas a member with privileged access.
7200. It resulted in rejection from the Service Broker.
• Scenario 5: Negotiation is successfully conducted with rejection as a result,
because of an insufficient balance of the requester. The Service Broker
returned a message advising that the requester’s balance of the required
resource was insufficient, as shown in Figure A.16. This scenario has been
tested with both use cases.
• Scenario 6: Negotiation is successfully conducted with rejection as a res-
ult, because of the requester requesting a resource that requires a higher
privilege than he/she is allowed. This scenario has been tested with Use
Case 2.
The Service Broker returned a message advising that the requester did
not have the privilege required to use the required resource. The result is
shown in Figure A.17.

271
Figure A.16: Screenshot: insufficient balance of the requester: the requester Sofiawho had no balance of CPU time was a member with privileged access.
Figure A.17: Screenshot: the requester had no privilege to the required resource:
the requester Junyi was a user with normal privilege and tried to access privileged
resources for a parallel job.
• Scenario 7: Termination is required by the requester during negotiation
before an AcceptAck message is received. This scenario has been tested
with both use cases. In the evaluation, all offers proposed by the Service
Broker for this negotiation were updated with uncontracted states. Fig-
ure A.18 shows that the Service Broker received an offer and updated
the negotiation state to negotiating. When it received the termination re-
quest from the requester, the Service Broker verified that the offer’s state
was negotiating. It then updated the state to uncontracted, as shown in
Figure A.19.
• Scenario 8: Successful negotiation is conducted, and the job is stopped by

272 APPENDIX A. TESTBED EXPERIMENT SCREENSHOTS
Figure A.18: Screenshot: successful negotiation for the termination scenario: thequestion marks were the values stored in the database.
Figure A.19: Screenshot: successful termination of the required Offer
a request from the requester during runtime. This scenario has been tested
with Use Case 2.
The same procedures for successful negotiation took place. When receiving
the request to stop job execution, the Service Broker verified the state
of the related contract and updated the balances of the requester and the
resource, as presented in Figure A.20. Procedures in Figure A.21 show the
contract formation procedures of the terminated contract.
• Scenario 9: Successful negotiation is conducted, and job execution is con-
trolled by the maximum CPU time or cost set by the group manager for
the requester.
The same procedures for successful negotiation took place. When the CPU
time or the cost consumed was approaching the maximum limit set by the
group manager, the Service Broker verified the state of the contract. If

273
the state was contracted, the Service Broker updated the state to reqTer-
minated. As balances of the requester and the contracted resource had been
reduced by the maximum value or reduced to 0 after successful negotiation,
no balance update was carried out in this case, as shown in Figure A.22.
Procedures in Figure A.23 show the contract formation procedures of the
terminated contract.
Figure A.20: Screenshot: the stop request was received, and balances were up-dated in Service Broker
Figure A.21: Screenshot: successful contract formation for the user-stop scenario

Figure A.22: Screenshot: the maximum CPU time reached, and the contractstate was updated in Service Broker
Figure A.23: Screenshot: successful contract formation for the manager-stopscenario
Copyright © 2022 FDOKUMEN




















