
A model of consensus in group decision making under linguistic assessments
24
-
Upload
independent -
Category
Documents
-
view
2 -
download
0
Transcript of A model of consensus in group decision making under linguistic assessments

DECSAI Deparment of Computer Scienceand Arti�cial IntelligenceA Model of Consensusin Group Decision Makingunder Linguistic AssessmentsF. Herrera, E. Herrera-Viedma, J.L. Verdegay
Technical Report #DECSAI-94109.September, 1994To appear in Fuzzy Sets and Systems.ETS de Ingenier��a Inform�atica. Universidad de Granada.18071 Granada - Spain - Phone +34.58.244019, Fax +34.58.243317

A Model of Consensusin Group Decision Makingunder Linguistic AssessmentsF. Herrera, E. Herrera-Viedma, J.L. VerdegayDept. of Computer Science and Arti�cial IntelligenceUniversity of Granada, 18071 - Granada, Spaine-mail: herrera,viedma,[email protected] paper presents a consensus model in group decision making under linguisticassessments. It is based on the use of linguistic preferences to provide individuals'opinions, and on the use of fuzzy majority of consensus, represented by means ofa linguistic quanti�er. Several linguistic consensus degrees and linguistic distancesare de�ned, acting on three levels. The consensus degrees indicate how far a groupof individuals is from the maximum consensus, and linguistic distances indicatehow far each individual is from current consensus labels over the preferences. Thisconsensus model allows to incorporate more human consistency in decision supportsystems.Keywords: Group decision making, linguistic modelling, consensus degree.1. IntroductionDecision making problems basically consist of �nding the best option from a feasibleoption set. As human beings are constantly making decisions in the real world, inmany situations, the use of computerized decision support systems, may be much helpin solving decision making problems. Thus, the designing and building of "intelligent"decision support systems has become a research �eld of high growth in the last fewyears.In these systems the problem is how to introduce intelligence into them, that is, howto incorporate human consistency in decision making models of decision support sys-tems. There are several approaches to the problem by means of fuzzy-logic-based tools.A lot of authors have provided interesting results on multicriteria decision making,multistage decision making, solving methods of group decision making, and measures

for consensus formation in group decision making. In all the cases the fuzzy logic hasplayed an important role.The group decision problem is established in an environment where there is a ques-tion to solve, a set of possible options, and a set of individuals (experts, judgess,...) whopresent their opinions or preferences over the set of possible options. A distinguishedperson may exist, called a moderator, responsible for directing the session until allindividuals reach an agreement on the solution to choose.In a usual framework, there are a �nite set of alternatives X = fx1; : : : ; xng withtheir respective relevance degrees de�ned as a real numbers, such that �R(i) 2 [0; 1]denotes the relevance degree of the alternative xi, and a �nite set of individuals N =f1; : : : ; mg with their respective importance degrees also de�ned as real numbers, suchthat, �G(k) 2 [0; 1] denotes the importance degree of individual "k" . Each individualk 2 N provides his or her opinions on X as a fuzzy preference relation P k � XxX,with pkij 2 [0; 1] denoting the preference degree of the alternative xi over xj . As it isevident, if some vagueness is assumed and coherently �R(i), i = 1; : : : ; n, and �G(k),k 2 N , are de�ned as fuzzy sets, then the considered model becomes indentical to thatone in [11].Sometimes, however an individual could have a vague knowledge about the pref-erence degree of the alternative xi over xj and cannot estimate his preference withan exact numerical value. Then a more realistic approach may be to use linguisticassessments instead of numerical values, that is, to suppose that the variables whichparticipate in the problem are assessed by means of linguistic terms [3, 4, 7, 10, 12, 14].A scale of certainty expressions (linguistically assessed) would be presented to the indi-viduals, who could then use it to describe their degrees of certainty in a preference. Inthis environment we have linguistic preference relations to provide individuals' opinions.On the other hand, assuming a set of alternatives or decisions, the basic question ishow to relate to di�erent decision schemata. According to [2] there are (at least) twopossibilities: a group selection process and a consensus process. The �rst, a calculationof some mean value decision schema of a set of decisions D would imply the choice of analgebraic consensus as a mapping l : DxD =) D, whereas the second, the measure ofdistance between schemata, it could be called topological consensus involving a mappingk : DxD =) L, where L is a complete lattice. In [7, 10] models were proposed to the�rst possibility under linguistic preferences. Here, we will focus on the second posibility,to develop a consensus process under linguistic preferences.Usually, a group of individuals initially have disagreeing opinions. The consensusreaching process is a necessity of all group decision making processes, because to achievea general consensus about selected options is a desirable goal. Consensus is traditionallymeant as a full and unanimous agreement of all individuals' opinions (it is the maximumconsensus). Obviously, this type of consensus is an ideal consensus and very di�cult

to achieve. Therefore, it is quite natural to look for the highest consensus, that is, themaximum possible consensus. This process is viewed as a dynamic process where amoderator, via exchange of information and rational arguments, tries to persuade theindividuals to update their opinions. In each step, the degree of existing consensusand the distance from an ideal consensus is measured. The moderator uses the degreeor measure of consensus to control the process. This is repeated until the group getscloser to a maximum consensus, i.e, either until the distance to the ideal consensus isconsidered su�ciently small, or until individuals' opinions become su�ciently similar.Therefore, the type of consensus obtained in this way is not an absolute consensus inthe ordinary sense, it is a relative and gradual consensus. This is represented in �gure1.INDIVIDUALS
SET
opinions
recomendations
MODERATOR
QUESTION
OPTIONS
SET
CONSENSUS
SOLUTION
GROUP DECISION MAKING ENVIRONMENTFig. 1. Consensus Reaching Process in Group Decision Making.Although this consensus framework has been considered by several authors [2, 5,11], in all the cases the measures used for the Consensus Reaching Process in GroupDecision Making are focused on the expert set and calculated in numerical context,and however, from this point of view, in this paper we develop a new fuzzy logic basedconsensus model in group decision making focused on the alternative set and calculatedin linguistic context. Therefore, the novelty here is on acting in the alternative setassessed linguistically.The proposed model calculates two types of consensus measures in this set, whichare applied in three acting levels: level of preference, level of alternative, andlevel of preference relation. These measures are:1. Consensus Degrees. Used to evaluate the current consensus stage, and consti-tuted by three measures: the preference linguistic consensus degree, thealternative linguistic consensus degree, and the relation linguistic con-sensus degree.2. Linguistic Distances. Used to evaluate the individuals' distance to social opin-ions, and constituted by three measures: the preference linguistic distance,

the alternative linguistic distance, and the relation linguistic distance.These measures are calculated using three processes:1. Counting Process. To count the individuals' opinions over preference values.2. Coincidence Process. To choose the coincidence degree, that is, the pro-portion of individuals, who are in agreement in their preference values, and alsoto calculate the consensus labels, that is, the social opinion over preferencevalues.3. Computing Process. To calculate each one of above measures in its respectivelevel.In the following, section 2 shows the importance of the linguistic assessments andthe linguistic quanti�ers in group decision making. Section 3 presents the consensusmodel. Then, and for the sake of illustrating the consensus reaching process described,section 4 is devoted to develop an easy example, and �nally, in the section 5 someconclusions are pointed out.2. Linguistic Assessments and Linguistic Quanti�ers2.1. Linguistic Assessments in Decision MakingThe linguistic approach considers the variables which participate in the problemassessed by means of linguistic terms instead of numerical values [16]. This approachis appropriate for a lot of problems, since it allows a representation of the individuals'information in a more direct and adequate form whether they are unable of expressingthat with precision.A linguistic variable di�ers from a numerical one in that its values are not numbers,but words or sentences in a natural or arti�cial language. Since words, in general,are less precise than numbers, the concept of a linguistic variable serves the purposeof providing a means of approximated characterization of phenomena, which are toocomplex, or too ill-de�ned to be amenable its description in conventional quantitativeterms.Therefore we need a term set de�ning the uncertainty granularity, that is the levelof distinction among di�erent countings of uncertainty [17]. The elements of the termset will determine the granularity of the uncertainty. In [1] the use of term sets withodd cardinal was studied, representing the middle term an assess of "approximately0.5", being the rest terms placed symmetrically around it and the limit of granularity11 or no more than 13.The semantic of the elements of the term set is given by fuzzy numbers de�ned onthe [0,1] interval, which are described by membership functions. Because the linguistic

assessments are just approximate ones given by the individuals, we can consider thatlinear trapezoidal membership functions are good enough to capture the vagueness ofthose linguistic assessments, since to obtain more accurate values may be impossibleor unnecessary. This representation is achieved by the 4-tuple (ai; bi; �i; �i), the �rsttwo paremeters indicate the interval in which the membership value is 1; the third andfourth parameters indicate the left and right width.For instance the �gure 2 shows an hierarchical structure of linguistic values or labels.MEDIUM
MEDIUM
fuzzy set approx. 0.5
0.5
NONE
LOW
VERY-LOWLOWHIGH
HIGH
VERY-HIGHPERFECT
[0,0.5]fuzzy fuzzy [0.5,1]onsets sets on
[0,0.5]numbers onReal Real numbers on [0.5,1]
LEVEL 2
LEVEL 1
LEVEL 3
LEVEL 4 Fig. 2. Hierarchy of labels.As it is clear, level 1 provides a granularity containing three labels, level 2 a gran-ularity with nine labels, and of course, di�erent granularity levels could be presented.In fact, in this �gure level 4 presents the �nest granularity in a decision process, thenumerical values.Accordingly, to establish what kind of label set to use ought to be the �rst priority.Then, let S = fsig; i 2 H = f0; : : : ; Tg, be a �nite and totally ordered term set on [0,1]in the usual sense [1, 3, 17]. Any label si represents a possible value for a linguistic realvariable, that is, a vague property or constraint on [0,1]. We consider a term set withodd cardinal, where the middle label represents an uncertainty of "approximately 0.5"and the rest terms are placed symmetrically around it. Moreover, the term set musthave the following characteristics:1) The set is ordered: si � sj if i � j.2) There is the negation operator: Neg(si) = sj such that j = T -i.3) Maximization operator: Max(si; sj) = si if si � sj .4) Minimization operator: Min(si; sj) = si if si � sj .For example, this is the case of the following term set of level 2:S = fs6 = P; s5 = VH; s4 = H; s3 =M; s2 = L; s1 = V L; s0 = Ng;

where P = Perfect V H = V ery High H = HighM =Medium L = Low V L = V ery LowN = None2.2. Linguistic Quanti�ers in Decision MakingThe fuzzy linguistic quanti�ers were introduced by Zadeh in 1983 [18]. Linguisticquanti�ers are typi�ed by terms such as most, at least half, all, as many as possibleand assumed a quanti�er Q to be a fuzzy set in [0,1]. Zadeh distinguished betweentwo types of quanti�ers, absolute and proportional or relative. Absolute quanti�ers areused to represent amounts that are absolute in nature. These quanti�ers are closelyrelated to the concepts of the count of number of elements. Zadeh suggested that theseabsolute quanti�ers values can be represented as fuzzy subsets of the non-negative reals,R+. In particular, he suggested that an absolute quanti�er can be represented by afuzzy subset Q, where for any r 2 R+, Q(r) indicates the degree to which the value rsatis�es the concept represented by Q. And, relative quanti�ers represent proportiontype statements. Thus, if Q is a relative quanti�er, then Q can be represented as afuzzy subset of [0; 1] such that for each r 2 [0; 1], Q(r) indicates the degree to which rportion of objects satis�es the concept devoted by Q.An absolute quanti�er Q : R+ ! [0; 1] satis�es:Q(0) = 0; and 9k such that Q(k) = 1:A relative quanti�er, Q : [0; 1]! [0; 1]; satis�es:Q(0) = 0; and 9r 2 [0; 1] such that Q(r) = 1:A non-decreasing quanti�er satis�es:8a; b if a > b then Q(a) � Q(b):The membership function of a non-decreasing relative quanti�er can be representedas Q(r) = 8>><>>: 0 if r < ar�ab�a if a � r � b1 if r > bwith a; b; r 2 [0; 1].
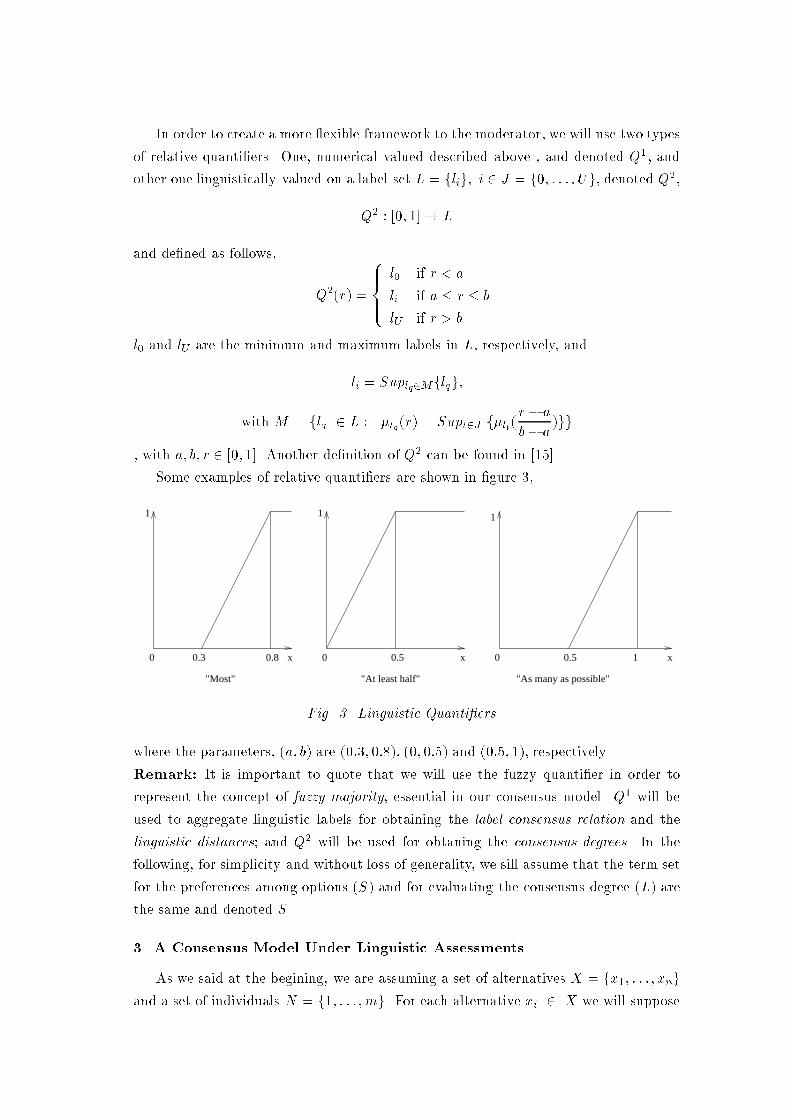
In order to create a more exible framework to the moderator, we will use two typesof relative quanti�ers. One, numerical valued described above , and denoted Q1, andother one linguistically valued on a label set L = flig; i 2 J = f0; : : : ; Ug, denoted Q2,Q2 : [0; 1]! Land de�ned as follows, Q2(r) = 8>><>>: l0 if r < ali if a � r � blU if r > bl0 and lU are the minimum and maximum labels in L, respectively, andli = Suplq2Mflqg;with M = flq 2 L : �lq(r) = Supt2J f�lt(r� ab� a )gg, with a; b; r 2 [0; 1]. Another de�nition of Q2 can be found in [15].Some examples of relative quanti�ers are shown in �gure 3,1
0 0.3 0 0.5 0 0.5 1 xxx0.8
1 1
"Most" "At least half" "As many as possible"Fig. 3. Linguistic Quanti�ers.where the parameters, (a; b) are (0:3; 0:8), (0; 0:5) and (0:5; 1), respectively.Remark: It is important to quote that we will use the fuzzy quanti�er in order torepresent the concept of fuzzy majority, essential in our consensus model. Q1 will beused to aggregate linguistic labels for obtaining the label consensus relation and thelinguistic distances; and Q2 will be used for obtaning the consensus degrees. In thefollowing, for simplicity and without loss of generality, we sill assume that the term setfor the preferences among options (S) and for evaluating the consensus degree (L) arethe same and denoted S.3. A Consensus Model Under Linguistic AssessmentsAs we said at the begining, we are assuming a set of alternatives X = fx1; : : : ; xngand a set of individuals N = f1; : : : ; mg. For each alternative xi 2 X we will suppose

de�ned a relevance degree �R(i) 2 [0; 1], from 0 standing for 'de�nitely irrelevant' and1 standing for 'de�nitely relevant', through all intermediate values. Similarly, for eachindividual k 2 N we will assume known an importance degree �G(k) 2 [0; 1] witha meaning clear enough. Then, the described model consideres that each individualk 2 N provides his or her opinions on X as preference relation linguistically assessedinto the term set, S, �P k : XxX ! S;where �P k (xi; xj) = pkij 2 S represents the linguistically assessed preference degree ofthe alternative xi over xj . We assume that P k is reciprocal in the sense, pkij = Neg(pkji),and by de�nition pkii = s0 (the minimum label in S).As previously was mentioned, we present a consensus model based on the idea ofcounting the number of individuals that are in agreement over the linguistic value as-signed to each preference, and the aggregation of that information under fuzzy majority.Its most important feature is that it incorporates two consensus measure types:(i) linguistic consensus degrees, to evaluate the current consensus existing amongindividuals; and(ii) linguistic distances, to evaluate the distance of individuals' opinions to thecurrent consensus labels of preferences.Both measures, used jointly, describe with a great exactness the current consensussituation, and help the moderator a great deal in the consensus reaching process.Graphically this consensus model is re ected in �gure 4.MODERATOR
SET
COINCIDENCE COMPUTING
PROCESS PROCESSPROCESS PROCESS
RELATIONS
MEASURES
CONSENSUS
LINGUISTIC
RELATIONS
CONSENSUS MODEL UNDER LINGUISTIC ASSESSMENTS
COUNTINGCOINCIDENCE
PREFERENCE
INDIVIDUALS
CONSENSUS
ARRAYS
RECOMMENDATIONS
Fig. 4. Consensus Model.

The consensus model is composed of three parts:1. Counting Process. From linguistic preference relations given by individuals, itis calculated the number of individuals who are in agreement over the preferencevalue of each alternative pair (xi; xj). To do that, we will de�ne two arrays, calledcoincidence arrays.2. Coincidence Process. Using the above information are calculated two relations:(a) Labels Consensus Relation (LCR), which contains the consensus labelsover each preference, and(b) Individuals Consensus Relation (ICR), which contains the coincidencedegrees of each preference.3. Computing Process. Finally, in this process several consensus measuresover the above consensus relations are calculated. These measures enhance themoderator's knowledge upon the current consensus situation, and are used by themoderator to direct the consensus formation process.These processes are repeated periodically, until an aceptable consensus degree is achieved.3.1. Counting ProcessThe main goal of this process is to calculate the number of individuals who havechosen each label assigned as preference value of each alternative pair. This informationis stored in the coincidence arrays, as follows.Previously, from the set of linguistic preference relations P k , k 2 N , we de�ne anarray Vij for the T + 1 possible labels that can be assigned as preference value. Eachcomponent Vij [st]; i; j = 1; : : : ; n; t = 0; : : : ; T; is a set of individuals' identi�cationnumbers, who selected the value st as preference value of the pair (xi; xj). Each Vij iscalculated according to this expression,Vij [st] = fk = pkij = st; k = 1::mg; 8st 2 S:As we have mentioned, we de�ne a pair of arrays, called coincidence arrays, tostore information refered to the number of individuals and their respective importancedegrees:� The �rst, symbolized as V Cij , and called individuals coincidence array, con-tains in each position st the number of individuals, who coincide to assign thelabel st as preference value. The components of this array are obtained asV Cij [st] = ](Vij[st]); 8st 2 S:where # stands for the cardinal of the term set.

� The second, symbolized as V Gij , and called degrees coincidence array, containsin each position st the arithmetic average of individuals' importance degrees, whocoincide to assign the label st as preference value.V Gij [st] = 8>><>>: (Pz2Vij [st] �G(z))=V Cij [st] if V Cij [st] > 1 8st 2 S:0 otherwise3.2. Coincidence ProcessThis process is based on the idea of coincidence of individuals and preferencevalues. We consider that coincidence exists over a label assigned to a preference value,when more than one individual has chosen that label.In this process we pursue two goals:(i) to �nd out the consensus label over the preference value of each alternative pair(xi; xj); thus we will obtain the label consensus relation (LCR),(ii) to calculate the coincidence degree, that is, the number of individuals, who se-lected each one of the above consensus labels; then we will obtain the individualconsensus relation (ICR).Both goals are achieved from the coincidence arrays (V Cij ; V Gij ). The �rst goal is nec-essary for calculating the linguistic distance of each individual, and the second goal isessential to calculate the consensus degrees.The relations are calculated under a consensus policy, called average consensuspolicy, which obtains consensus values (labels or number of individuals) as the averageunder fuzzy majority of the coincidence arrays values. In what follows, we are going toshow how to obtain both relations.3.2.1. Label Consensus Relation (LCR)Each element (i; j) of the label consensus relation, denoted by LCRij, representsthe consensus label over the preference of each alternative pair (xi; xj). It isobtained as the aggregation of linguistic indexes st, of the components of V Cij [st],such that, V Cij [st] > 1. That is, the aggregation of those linguistic labels st, whichhave been chosen by more than one individual to evaluate the preference of thealternative pair (xi; xj).To aggregate linguistic labels, we use an aggregation operator by direct compu-tation on labels, the LOWA operator, de�ned in [6], asF (a1; : : : ; am) = W �BT = Cfwk; bk; k = 1; : : : ; mg == w1 � b1 � (1� w1)�Cf�h; bh; h = 2; : : : ; mg

where W = [w1; : : : ; wn], is a weighting vector, such that, wi 2 [0; 1] and �iwi =1;; �h = wh=�m2 wk; h = 2; : : : ; m, and B is the associated ordered label vector.Each element bi 2 B is the i-th largest label in the collection a1; : : : ; am. If wj = 1and wi = 0 with i 6= j 8i, then the convex combination is de�ned as:Cfwi; bi; i = 1; : : : ; mg = bj :The weights wi are computed according to [13] by means of a nondecreasingrelative quanti�er, Q, which represents the above mentioned concept of fuzzymajority: wi = Q(i=m)�Q((i� 1)=m); i= 1; : : : ; m:In our case, the fuzzy quanti�er is Q1, and we write the LOWA operator, as FQ1to indicate that we calculate the weights by means of Q1.Before calculating LCR, we de�ne the following label setsMij , for each alternativepair (xi; xj), Mij = fsy = V Cij [sy] > 1; sy 2 Sg:which contain linguistic labels which have been chosen by more than one individ-ual to evaluate the preference of the respective alternative pair, according to thecoincidence concept.From the above label sets and using the LOWA operator with a selected quanti�erQ1, we calculate each LCRij, according to the following expression,LCRij = 8>><>>: FQ1(l1; : : : ; lq) if ](Mij) > 1 and lk 2Mij ; k = 1; : : : ; qlq if ](Mij) = 1 and lq 2MijUndefined otherwisewhere q=](Mij).The LOWA operator FQ1 based on the concept of fuzzy majority represented bythe relative quanti�er is applied, to obtain the average of the selected labels.3.2.2. Individuals Consensus Relation (ICR)Each element (i; j) of the individuals consensus relation, denoted by ICRij, rep-resents the proportional number of individuals whose preference values have beenused to calculate the consensus label LCRij. It is obtained as an arithmeticaverage of the components (V Cij [st]; VGij [st]) of the coincidence arrays.Since we are interested to know the average of individuals' importance degrees, wede�ne two components for each ICRij. The �rst ICR1ij containing the propor-tional number of individuals, and the second ICR2ij, containing their respective

average of importance degrees. Each component of ICRij is obtained as follows,ICR1ij = 8><>: Psy2Mij (V Cij [sy ]=m)](Mij) if ](Mij) 6= 00 otherwiseICR2ij = 8><>: Psy2Mij V Gij [sy ]](Mij) if ](Mij) 6= 00 otherwise3.3. Computing ProcessThis process constitutes the last step of our consensus model, where the linguisticconsensus measures are calculated. These measures are moderator's reference pointsto control and to monitor the consensus reaching process. As we mentioned in theintroduction, we de�ne two types of consensus measures:� Linguistic Consensus Degrees. Used to evaluate current consensus existingamong individuals, and therefore the distance existing to the ideal maximumconsensus. This type of measures helps the moderator to decide over the necessityto continue the consensus reaching process. The linguistic consensus degreesthat we de�ne are: preference linguistic consensus degree, alternative linguisticconsensus degree, and relation linguistic consensus degree.� Linguistic Distances. Used to evaluate how far the individuals' opinions arefrom current consensus labels. This type of measure helps the moderator to iden-tify which individuals are furthest from current social consensus labels, and inwhat preferences the distance exits. We de�ne three linguistic distances: pref-erence linguistic distance, alternative linguistic distance, and relation linguisticdistance.The three measures of both types are de�ned distinguishing among three levels ofcomputation: (i) Level of the Preference; (ii) Level of the Alternative; (iii) Level of thePreference Relation.We de�ne one measure of each type in its respective level. This is re ected in the�gure 5.We calculate the linguistic consensus degrees using:� Relevance degrees of alternatives.� Quanti�er Q2, to represent the concept of fuzzy majority.� Individuals consensus relation, ICR.

M E A S U R E S OF C O N S E N S U S
CONSENSUS
DEGREES
LINGUISTIC
DISTANCES
LE
VE
L
1
LE
VE
L
2
L E
V E
L S
OF
C O
M P
U T
A T
I O
N
LE
VE
L
3
L I N G U I S T I C
C O N S E N S U S
D E G R E E
D E G R E E
C O N S E N S U S
L I N G U I S T I C
A L T E R N A T I V E
L I N G U I S T I C
C O N S E N S U S
D E G R E E
L I N G U I S T I C
D I S T A N C E
D I S T A N C E
D I S T A N C E
L I N G U I S T I C
L I N G U I S T I C
A L T E R N A T I V E
PREFERENCE(Xi,Xj)
Xi
ALTERNATIVE
RELATION
PREFERENCE
P
RELATION RELATION
P REFERENCE P REFERENCE
Fig. 5. Linguistic Consensus Measures.We calculate the linguistic distances using:� Preference relations of individuals.� LOWA operator.� Quanti�er Q1, to represent the concept of fuzzy majority.� Labels consensus relation, LCR.The computing process is showed in �gure 6.Next, we de�ne each linguistic consensus measure in its respective level, by meansof the above elements mentioned.3.3.1. Linguistic Consensus DegreesBefore de�ning each degree, we introduce the concept of consensus importanceover preference of pair (xi; xj), abbreviated �I(xij), de�ned using the alternative rele-vance degree and the second component of ICR, as�I (xij) = 8<: �R(i)+�R(j)+ICR2ij3 if ICR2ij 6= 00 otherwise.�I(xij) represents the importance of the consensus degree achieved over each preferencevalue.Besides, we use the linguistic valued quanti�er Q2, which represents a linguisticfuzzy majority of consensus.

P R E F E R E N C E
A L T E R N A T I V E
R E L A T I O N
LEVEL 3
LEVEL 2
LEVEL 1
CONSENSUS
LINGUISTIC
PREFERENCE
CONSENSUS
LINGUISTIC
ALTERNATIVE
DEGREE
CONSENSUS
LINGUISTIC
RELATION
DEGREE
DISTANCE
LINGUISTIC
PREFERENCE
DISTANCE
LINGUISTIC
ALTERNATIVE
DISTANCE
LINGUISTIC
RELATION
DEGREES
CONSENSUS
LINGUISTIC
DISTANCES
LINGUISTIC
CURRENTCONSENSUS MEASURES COMPUTING PROCESS
DEGREE
-CONSENSUS RELATION LCR-QUANTIFIER Q
1
-LOWA OPERATOR F-PREFERENCE RELATIONS P-RELEVANCE DEGREE
-QUANTIFIER Q -CONSENSUS RELATION ICR
2
k
Fig. 6. Computing Process.1. Level 1: Preference Linguistic Consensus DegreeThis degree is de�ned over the labels assigned to the preference of each pair(xi; xj), and it is denoted by PCRij . It indicates the consensus degree existingamong all the m preference values attributed by the m individuals to a concretepreference. If we call PCR to the relation of all PCRij then PCR is calculatedas follows, PCRij = Q2(ICR1ij ^ �I (xij)) i; j = 1; : : : ; n; and i 6= j:2. Level 2: Alternative Linguistic Consensus DegreeThis degree is de�ned over the label set assigned to all the preferences of onealternative xi, and it is denoted by PCRi. It allows us to measure the consensusexisting over all the alternative pairs where one given is present. It is calculatedas PCRi = Q2[ nXj=1i6=j(ICR1ij ^ �I(xij))=(n� 1)] ; i = 1; : : : ; n:

3. Level 3: Relation Linguistic Consensus DegreeThis degree is de�ned over the preference relations of individuals' opinions, and itis denoted by RC. It evaluates the social consensus, that is, the current consensusexisting among all individuals over all preferences. This is calculated as follows,RC = Q2[( nXi nXj=1i6=j(ICR1ij ^ �I(xij))=(n2 � n)]:3.3.2. Linguistic DistancesIn a similar way, the linguistic distances are de�ned, distinguishing the three actinglevels, and using the above cited concepts. The idea is based on the evaluation of theapproximation among individuals' opinions and the current consensus labels of eachpreference.1. Level 1: Preference Linguistic DistanceThis distance is de�ned over the consensus label of the preference of each pair(xi; xj). It measures the distance between the opinions of an individual k over onepreference and its respective consensus label. It is denoted by Dkij , and obtainedas: Dkij = 8>><>>: pkij � LCRij if pkij > LCRijLCRij � pkij if LCRij >= pkij i 6= jsT otherwisewith i; j = 1; : : : ; n, and k = 1; : : : ; m.2. Level 2: Alternative Linguistic DistanceThis distance is de�ned over the consensus labels of the preferences of one alter-native xi. It measures the distance between the preference values of an individualk over an alternative and its respective consensus labels. It is denoted by Dki , andobtained as followsDki = FQ1(Dkij ; j = 1; : : : ; n; j 6= i) k = 1::m; i = 1::n:3. Level 3: Relation Linguistic DistanceThis distance is de�ned over the consensus labels of social preference relationLCR. It measures the distance between the preference values of an individual kover all alternatives and their respective consensus labels. It is denoted by DkRand obtained as follows,DkR = FQ1(Dkij; i; j = 1::n; j 6= i)with ; k = 1::m

In short the main feature of the described model is that of being very complete,because its measures allow the moderator to have plentiful information on the currentconsensus stage. In a direct way: information about the consensus degree by means ofthe linguistic consensus degrees, information about the consensus labels in every pref-erence with the label consensus relation, and the behavior of the individuals during theconsensus process, managing the linguistic distances. In an indirect way: informationabout the individuals, who are less in agreement, and in which preference this occurs,or information about the preferences where the agreement is high.In the following we show the use of this model in one step of the consensus formationprocess, with a theoretical but clear example.4. ExampleTo illustrate from the practical point of view the consensus reaching process pro-posed, consider the following nine linguistic label set with their respective associatedsemantic, [1]: C Certain (1; 1; 0; 0)EL Extremely likely (:98; :99; :05; :01)ML Most likely (:78; :92; :06; :05)MC Meaningfull chance (:63; :80; :05; :06)IM It may (:41; :58; :09; :07)SC Small chance (:22; :36; :05; :06)V LC V ery low chance (:1; :18; :06; :05)EU Extremely unlikely (:01; :02; :01; :05)I Impossible (0; 0; 0; 0)represented graphically as,0.0 1.00.5Fig. 7. Distribution of the nine linguistic labels.

Let four individuals be, whose linguistic preferences using the above label set are:P1 = 2666664 � SC MC V LCMC � IM IMSC IM � V LCML IM ML � 3777775P2 = 2666664 � IM IM V LCIM � MC IMIM SC � V LCML IM ML � 3777775P3 = 2666664 � IM MC IIM � ML IMSC VLC � V LCC IM ML � 3777775P4 = 2666664 � SC MC SCMC � V LC SCSC ML � V LCMC MC ML � 3777775respectively.We shall use the linguistic quanti�er Q = "As least half" with the pair (0:0; 0:5) forthe process with its two versions, numerical and linguistically valued. Let us study theconsensus model with two di�erent importance and relevance degree set.4.1. Example 1The importance and relevance degrees of particular alternatives and individuals are:�R(x1) = 1 �R(x2) = 1 �R(x3) = 1 �R(x4) = 1�G(1) = 1 �G(2) = 1 �G(3) = 1 �G(4) = 1:respectively.Some examples of components of coincidence vectors obtained in the counting pro-cess are:V13[MC] = f1; 3; 4g V23[C] = f�g V24[SC] = f1g V34[V LC] = f1; 2; 3; 4gwith respective components (V Cij [st]; VGij [st]):V C13[MC] = 3 V C23[C] = 0 V C24[SC] = 1 V C34[V LC] = 4V G13[MC] = 1 V G23[C] = 0 V G24[SC] = 1 V G34[V LC] = 1In the coincidence process are obtained the relations:Individuals Consensus Relations (ICR1,ICR2):ICR1 = 2666664 � 0:5 0:75 0:50:5 � 0 0:750:75 0 � 10:5 0:75 1 � 3777775 ICR2 = 2666664 � 1 1 11 � 0 11 0 � 11 1 1 � 3777775

Labels Consensus Relation (LCR):LCR = 2666664 � IM MC VLCMC � ? IMSC ? � V LCML IM ML � 3777775Note that the symbol ? of LCR indicates unde�ned value in LCR23 and LCR32 becausethere is not a label value with coincidence value greater than 1. Note also, that as thepreference relations P k are reciprocal in the sense pkij = Neg(pkji), then the componentsof ICR are symmetric. Therefore, to calculate the consensus degrees we could do itusing only the elements (i,j) i = 1; : : : ; n� 1; j = i+ 1; : : : ; n. However, the reciprocityis not preserved in LCR, because of the LOWA operator.From these consensus relations we obtain the following linguistic consensus degreesand linguistic distances:A. Consensus DegreesA.1 Level of PreferenceThe preference linguistic consensus degree are:PCR = 2666664 � C C CC � I CC I � CC C C � 3777775In this case as �I(xij) = 1; 8i = 1; : : : ; n; j = 1; : : : ; n, i 6= j, then each PCRij =Q2(ICR1ij). As can be observed there are ten preferences where the consensus degreeis total, according to the fuzzy majority of consensus established by the quanti�er "Atleast half". If we use another quanti�er such as "As many as possible", then the resultsare: PCR = 2666664 � I IM II � I IMIM I � CI IM C � 3777775that is, there are only two preferences where the consensus is maximum. Therefore,depending on the more or less strict nature of our idea of consensus, we must choosethe adequate quanti�er.

A.2 Level of AlternativeThe alternative linguistic consensus degrees, fPCRig are:PCR1 = Q2(0:58) = C PCR2 = Q2(0:4167) =MLPCR3 = Q2(0:58) = C PCR4 = Q2(0:75) = C:A.3 Level of RelationThe relation linguistic consensus degree RC isRC = Q2(0:5833) = CRemarks: According to the concept of linguistic fuzzy majority of consensus intro-duced by the linguistically valued quanti�er, Q2, we obtain some conclusions:1. The social consensus degree is total.2. On the preferences of pairs (x2; x3) and (x3; x2) there is no consensus.3. And, the consensus degree over the preferences values of alternative x2 is thesmallest one. The other alternatives present a total consensus degree.B. The linguistic Distances.The linguistic distances of each individual k to social consensus labels, with k =1; : : : ; m, are:B.1. Level of PreferenceThe preference linguistic distances are:D1 = 2666664 � EU I II � C II C � II I I � 3777775D2 = 2666664 � I EU IEU � C IEU C � II I I � 3777775D3 = 2666664 � I I V LCEU � C II C � IV LC I I � 3777775D4 = 2666664 � EU I EUI � C EUI C � IEU EU I � 3777775B.2.Level of AlternativeThe alternative linguistic distances with Q1 are:Individual 1 : D11 = EU D12 =MC D13 =MC D14 = IIndividual 2 : D21 = EU D22 =ML D23 =ML D24 = IIndividual 3 : D31 = EU D32 =ML D33 =MC D34 = EUIndividual 4 : D41 = EU D42 =ML D43 =MC D44 = EU

B.3.Level of RelationThe relation linguistic distances using Q1 are:D1R = EU D2R = SC D3R = SC D4R = SCRemarks: We can draw some conclusions:1. The individual 1 present less distance to the current social cosensus stage.2. All individuals are in disagreement in current preference values of the pairs(x2; x3) and (x3; x2). We must remember that LCR23 =? and LCR32 =?.3. In the preference of the pairs (x1; x4) and (x4; x1), the individual 3 is furthestaway from the social opinion.4. In the preferences of alternatives x2 and x3 there is more disagreement.4.2. Example 2The relevance and importance degrees of particular alternatives and individuals are:�R(x1) = 0:4 �R(x2) = 1 �R(x3) = 0:3 �R(x4) = 0:8�G(1) = 0:9 �G(2) = 0:2 �G(3) = 0:5 �G(4) = 0:7Some examples of components of coincidence vectors obtained in counting processare: V13[MC] = f1; 3; 4g V23[C] = f�g V24[SC] = f1g V34[V LC] = f1; 2; 3; 4g:With their respective components (V Cij [st]; V Gij [st]):V C13[MC] = 3 V C23[C] = 0 V C24[SC] = 1 V C34[V LC] = 4V G13[MC] = 0:7 V G23[C] = 0 V G24[SC] = 0:7 V G34[V LC] = 0:575:The consensus relations are:Individual Consensus RelationsICR1 = 2666664 � 0:5 0:75 0:50:5 � 0 0:750:75 0 � 10:5 0:75 1 � 3777775 ICR2 = 2666664 � 0:575 0:7 0:550:575 � 0 0:5330:7 0 � 0:5750:55 0:533 0:575 � 3777775

Label Consensus RelationLCR = 2666664 � IM MC VLCMC � ? IMSC ? � V LCML IM ML � 3777775As it is observed the LCR does not change, because it does not depend on the impor-tance and relevance degrees.The consensus measures are:A. Consensus DegreesA.1.Level of PreferenceThe importance of consensus of the alternative pairs are:2666664 � �I(x12) = 0:6583 �I (x13) = 0:4667 �I(x14) = 0:5833�I (x21) = 0:6583 � �I (x23) = 0:4333 �I(x24) = 0:7767�I (x31) = 0:4667 �I(x32) = 0:4333 � �I(x34) = 0:5583�I (x41) = 0:5833 �I(x42) = 0:7767 �I (x43) = 0:5583 � 3777775Then PCR is PCRQ2 = 2666664 � C ML CC � I CML I � CC C C � 3777775A.2. Level of AlternativeThe alternative linguistic consensus degrees, PCRi are:PCR1 = Q2(0:4889) = EL PCR2 = Q2(0:4167) =MLPCR3 = Q2(0:34167) =MC PCR4 = Q2(0:602767) = CA.3.Level of RelationThe relation linguistic consensus degree RC isRC = Q2(0:4625) =MLRemarks: As it is possible to observe in this example, because of the in uence ofimportance and relevance degrees:1. The social consensus degree is smaller than the above one.2. The total social consensus degrees over the alternative x1 and x3 are lost. Thealternative x4 conserves the maximum consensus degree, and x2 does not change.

Finally, as the linguistic distances do not change, because the importance and relevancedegree are not used in their computing process, we do not compute them.6. ConclusionsIn this paper we have presented a consensus model in group decision making underlinguistic assessments. All the relevant results are expressed using linguistic labels, amore natural way to comunicate information. This model incorporates human consis-tency in decision making models. The model presents a wide spectrum of consensusmeasures, which allow analysing, controlling and monitoring the consensus reachingprocess describing the current consensus stage.References[1] P.P. Bonissone and K.S. Decker (1986), Selecting Uncertainty Calculi and Gran-ularity: An Experiment in Trading-o� Precision and Complexity. In: L.H. Kanaland J.F. Lemmer (Eds.), Uncertainty in Arti�cial Intelligence, North-Holland,London, 217-247.[2] C. Carlsson, D. Ehrenberg, P. Eklund, M. Fedrizzi, P. Gustafsson, P. Lindholm,G. Merkuryeva and T. Riissanen, A.G.S. Ventre, (1992), Consensus in DistributedSoft Environments. European Journal of Operational Research 61, 165-185.[3] M. Delgado, J.L. Verdegay and M.A. Vila (1993), Linguistic Decision MakingModels. International Journal of Intelligent Systems 7, 479-492.[4] M. Delgado, J.L. Verdegay and M.A. Vila (1994), A model for linguistic partialinformation in decision making problems. To appear in: International Journal ofIntelligent Systems.[5] M. Fedrizzi, J. Kacprzyk and S. Zadrozny (1988), An interactive multi-user de-cision support system for consensus reaching processes using fuzzy logic with lin-guistic quanti�ers. Decisions Support Systems 4, 313-327.[6] F.Herrera and J.L. Verdegay (1993), Linguistic Assessments in group decision.Proc of First European Congress on Fuzzy and Intelligent Technologies, Aachen,941-948.[7] F. Herrera, E. Herrera-Viedma and J.L. Verdegay (1994), A Linguistic DecisionProcess in Group Decision Making. Submitted to Group Decision and Negotiation.[8] F. Herrera and J.L. Verdegay (1994), On Group Decision Making under LinguisticPreferences and Fuzzy Linguistic Quanti�ers. Proc. of Fith Int. Conf. on Infor-mation Processing and Management of Uncertainly in Knowledge-Based Systems,Paris, 418-22.

[9] F. Herrera, E. Herrera-Viedma and J.L. Verdegay (1994), On Dominance Degreesin Group Decision Making with Preferences. Proc. of Fouth International Work-shop, Current Issue in Fuzzy Technologies: Decision Models and Systems, Trento113-117.[10] F. Herrera, E. Herrera-Viedma and J.L. Verdegay (1994), A Sequential SelectionProcess in Group Decision Making with Linguistic Assessment. Accepted in Int.Journal Information Science.[11] J. Kacprzyk and M. Fedrizzi (1988),A 'soft' measure of consensus in the setting ofpartial (fuzzy) preferences. European Journal of Operational Research 34, 316-323.[12] M. Tong and P. P. Bonissone (1980), A Linguistic Approach to Decision Makingwith Fuzzy Sets. IEEE Transactions on Systems, Man and Cybernetics, Vol 10, N.11, 716-723[13] R.R. Yager (1988), On ordered weighted averaging aggregation operators in multi-criteria decision making. IEEE Transactions on Systems, Man, and Cybernetics.Vol 18, N 1, 183-190.[14] R.R. Yager (1992), Fuzzy Screening Systems. In: R. Lowen (Ed.), Fuzzy Logic:State of the Art, (Kluwer Academic Publisers).[15] R.R. Yager (1992), Applications and Extension of OWA aggregation. Int. Journalof Man-Machine Studies 37.[16] L. Zadeh (1975), The Concept of a Linguistic Variable and its Applications to Ap-proximate Reasoning. Part I, Information Sciences 8, 199-249, Part II, InformationSciences 8, 301-357, Part III, Information Sciences 9 43-80.[17] L. Zadeh (1979), Fuzzy Sets and Information Granularity. In: M.M. Gupta et al.(Eds.), Advances in Fuzzy Sets Theory and Applications, North Holland, London,3-18.[18] L. Zadeh (1983) A Computational Approach to Fuzzy Quanti�ers in Natural Lan-guage, Comps & Maths. with Appls. 9, 149-184.




















