
A hybrid approach to modeling metabolic systems using genetic algorithm and simplex method
19
IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 28, NO. 2, APRIL 1998 173 A Hybrid Approach to Modeling Metabolic Systems Using a Genetic Algorithm and Simplex Method John Yen, Senior Member, IEEE, James C. Liao, Bogju Lee, and David Randolph Abstract—One of the main obstacles in applying genetic algo- rithms (GA’s) to complex problems has been the high computa- tional cost due to their slow convergence rate. We encountered such a difficulty in our attempt to use the classical GA for estimat- ing parameters of a metabolic model. To alleviate this difficulty, we developed a hybrid approach that combines a GA with a stochastic variant of the simplex method in function optimization. Our motivation for developing the stochastic simplex method is to introduce a cost-effective exploration component into the conventional simplex method. In an attempt to make effective use of the simplex operation in a hybrid GA framework, we used an elite-based hybrid architecture that applies one simplex step to a top portion of the ranked population. We compared our ap- proach with five alternative optimization techniques including a simplex–GA hybrid independently developed by Renders–Bersini (R–B) and adaptive simulated annealing (ASA). Our empirical evaluations showed that our hybrid approach for the metabolic modeling problem outperformed all other techniques in terms of accuracy and convergence rate. We used two additional function optimization problems to compare our approach with the five alternative methods. For a sin function maximization problem, our hybrid approach yields the fastest convergence rate without sacrificing the accuracy of the solution found. For De Jong’s F5 function minimization problem, our hybrid approach is the second best (next to ASA). Overall, these tests showed that our hybrid approach is an effective and robust optimization technique. We further conducted an empirical study to iden- tify major factors that affect the performance of the hybrid approach. The study indicated that 1) our elite-based hybrid GA architecture contributes significantly to the performance improvement and 2) the probabilistic simplex is more cost- effective for our hybrid architecture than is the conventional simplex. By analyzing the performance of the hybrid approach for the metabolic modeling problem, we hypothesized that the hybrid approach is particularly suitable for solving complex optimization problems the variables of which vary widely in their sensitivity to the objective function. I. INTRODUCTION G ENETIC algorithms (GA’s) have been demonstrated to be a promising search and optimization technique [1]. GA’s have been successfully applied to system identification [2]–[5] and a wide range of applications including design Manuscript received October 7, 1995; revised July 26, 1996 and February 5, 1997. This work was supported by the NSF under Grant BES 9511737. Part of the research described in the paper was conducted with the support of NSF Young Investigator Awards IRI 92-57293 and BCS-9257351. J. Yen, B. Lee, and D. Randolph are with the Center for Fuzzy Logic, Robotics, and Intelligent Systems Research, Department of Computer Science, Texas A&M University, College Station, TX 77843-3112 USA (e-mail: [email protected]). J. C. Liao is with the University of California, Los Angeles, CA 90095- 1592 USA. Publisher Item Identifier S 1083-4419(98)02188-8. [6], scheduling [7], routing [8], control [9], [10], and others [11]–[13]. One of the main obstacles in applying GA’s to complex problems has often been the high computational cost due to their slow convergence rate. The convergence rate of a GA is typically slower than that of local search techniques (e.g., the steepest descent), because it does not use much local information to determine the most promising search direction. Consequently, a GA explores a wider frontier in the search space in a less directional fashion. The problem of modeling metabolic systems involves the construction of a model of cellular metabolism and effec- tive estimation of model parameters from limited amount of data. In using a GA to estimate parameters of a metabolic model, we found that its slow convergence rate makes the approach much less attractive. This problem is particularly severe for modeling metabolic systems because the evaluation of a candidate model involves simulating the model, which is computationally costly. The GA relies on such evaluations (typically called fitness evaluation) to provide a measure of the fitness of each guess. The result of this evaluation guides GA’s search process. A common strategy in the literature for dealing with the GA’s slow convergence problem is to combine a GA with a complementary local search technique [14]–[17]. The rationale of such a strategy is that such a hybrid approach can combine the merits of the GA with that of a local search technique. Be- cause of the GA, a hybrid approach is less likely to be trapped in a local optimum than a pure local search technique is. Due to its local search, a hybrid approach often converges faster than the pure GA does. Generally speaking, a hybrid approach usually can explore a better tradeoff between computational cost and the global optimality of the solution found. Toward the objective of improving the convergence rate of a GA, we developed a hybrid approach that combines a real- coded GA with a stochastic variant of Nelder–Mead (N–M) simplex method [18], [19]. Our motivation for developing the stochastic simplex method is to introduce a cost-effective exploration component into the conventional simplex method. We compared our hybrid approach extensively with five alter- native optimization methods: 1) a simplex–GA hybrid independently developed by Ren- ders–Bersini (R–B); 2) the G-bit improvement on GA; 3) adaptive simulated annealing (ASA); 4) the real-coded GA; 5) a parallel version of the simplex method. 1083–4419/98$10.00 1998 IEEE
-
Upload
independent -
Category
Documents
-
view
3 -
download
0
Transcript of A hybrid approach to modeling metabolic systems using genetic algorithm and simplex method

IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 28, NO. 2, APRIL 1998 173
A Hybrid Approach to Modeling Metabolic SystemsUsing a Genetic Algorithm and Simplex Method
John Yen,Senior Member, IEEE, James C. Liao, Bogju Lee, and David Randolph
Abstract—One of the main obstacles in applying genetic algo-rithms (GA’s) to complex problems has been the high computa-tional cost due to their slow convergence rate. We encounteredsuch a difficulty in our attempt to use the classical GA for estimat-ing parameters of a metabolic model. To alleviate this difficulty,we developed a hybrid approach that combines a GA with astochastic variant of the simplex method in function optimization.Our motivation for developing the stochastic simplex methodis to introduce a cost-effective exploration component into theconventional simplex method. In an attempt to make effectiveuse of the simplex operation in a hybrid GA framework, we usedan elite-based hybrid architecture that applies one simplex stepto a top portion of the ranked population. We compared our ap-proach with five alternative optimization techniques including asimplex–GA hybrid independently developed by Renders–Bersini(R–B) and adaptive simulated annealing (ASA). Our empiricalevaluations showed that our hybrid approach for the metabolicmodeling problem outperformed all other techniques in terms ofaccuracy and convergence rate. We used two additional functionoptimization problems to compare our approach with the fivealternative methods. For a sin function maximization problem,our hybrid approach yields the fastest convergence rate withoutsacrificing the accuracy of the solution found. For De Jong’sF5 function minimization problem, our hybrid approach is thesecond best (next to ASA). Overall, these tests showed thatour hybrid approach is an effective and robust optimizationtechnique. We further conducted an empirical study to iden-tify major factors that affect the performance of the hybridapproach. The study indicated that 1) our elite-based hybridGA architecture contributes significantly to the performanceimprovement and 2) the probabilistic simplex is more cost-effective for our hybrid architecture than is the conventionalsimplex. By analyzing the performance of the hybrid approachfor the metabolic modeling problem, we hypothesized that thehybrid approach is particularly suitable for solving complexoptimization problems the variables of which vary widely in theirsensitivity to the objective function.
I. INTRODUCTION
GENETIC algorithms (GA’s) have been demonstrated tobe a promising search and optimization technique [1].
GA’s have been successfully applied to system identification[2]–[5] and a wide range of applications including design
Manuscript received October 7, 1995; revised July 26, 1996 and February5, 1997. This work was supported by the NSF under Grant BES 9511737.Part of the research described in the paper was conducted with the support ofNSF Young Investigator Awards IRI 92-57293 and BCS-9257351.
J. Yen, B. Lee, and D. Randolph are with the Center for Fuzzy Logic,Robotics, and Intelligent Systems Research, Department of Computer Science,Texas A&M University, College Station, TX 77843-3112 USA (e-mail:[email protected]).
J. C. Liao is with the University of California, Los Angeles, CA 90095-1592 USA.
Publisher Item Identifier S 1083-4419(98)02188-8.
[6], scheduling [7], routing [8], control [9], [10], and others[11]–[13].
One of the main obstacles in applying GA’s to complexproblems has often been the high computational cost due totheir slow convergence rate. The convergence rate of a GAis typically slower than that of local search techniques (e.g.,the steepest descent), because it does not use much localinformation to determine the most promising search direction.Consequently, a GA explores a wider frontier in the searchspace in a less directional fashion.
The problem of modeling metabolic systems involves theconstruction of a model of cellular metabolism and effec-tive estimation of model parameters from limited amount ofdata. In using a GA to estimate parameters of a metabolicmodel, we found that its slow convergence rate makes theapproach much less attractive. This problem is particularlysevere for modeling metabolic systems because the evaluationof a candidate model involves simulating the model, whichis computationally costly. The GA relies on such evaluations(typically called fitness evaluation) to provide a measure ofthe fitness of each guess. The result of this evaluation guidesGA’s search process.
A common strategy in the literature for dealing with theGA’s slow convergence problem is to combine a GA with acomplementary local search technique [14]–[17]. The rationaleof such a strategy is that such a hybrid approach can combinethe merits of the GA with that of a local search technique. Be-cause of the GA, a hybrid approach is less likely to be trappedin a local optimum than a pure local search technique is. Dueto its local search, a hybrid approach often converges fasterthan the pure GA does. Generally speaking, a hybrid approachusually can explore a better tradeoff between computationalcost and the global optimality of the solution found.
Toward the objective of improving the convergence rate ofa GA, we developed a hybrid approach that combines a real-coded GA with a stochastic variant of Nelder–Mead (N–M)simplex method [18], [19]. Our motivation for developingthe stochastic simplex method is to introduce a cost-effectiveexploration component into the conventional simplex method.We compared our hybrid approach extensively with five alter-native optimization methods:
1) a simplex–GA hybrid independently developed by Ren-ders–Bersini (R–B);
2) the G-bit improvement on GA;3) adaptive simulated annealing (ASA);4) the real-coded GA;5) a parallel version of the simplex method.
1083–4419/98$10.00 1998 IEEE

174 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 28, NO. 2, APRIL 1998
Fig. 1. Pathway of glucose metabolic model.
Section II describes the modeling problem that motivatedour research: the parameter estimation of a system model forthe central metabolism of anEscherichia coli cell. Section IIIbriefly reviews the basics of GA’s, simplex methods, andsimulated annealing which serve as the background for ourdiscussion. A classification of existing hybrid GA approachesis then presented in Section IV to set up the context forintroducing two simplex–GA hybrid approaches: the R–Bapproach and our approach. The performance of applyingour hybrid approach to the metabolic modeling problem iscompared with those of five alternative methods in Section V.To show that our hybrid approach is also useful for solvingother optimization problems, Sections VI and VII empiricallycompare our hybrid approach with these techniques for a func-tion maximization problem and for De Jong’s foxhole function(F5), respectively. In Section VIII, we discuss the results ofadditional experiments designed to gain some insights aboutmajor factors contributing to the effectiveness of the proposedsimplex–GA hybrid approach. Finally, we summarize majorresults of the paper and outline the issues we plan to addressin our future research.
II. THE MODELING OF METABOLIC SYSTEM
Modeling metabolic pathways has long been a desired goalfor biochemists, biochemical engineers, and biotechnologists.The system under consideration here is the central metabolismin Escherichia coli, which includes glycolysis and the tricar-boxylic acid (TCA) cycle. Fig. 1 shows a simplified version ofthe pathway considered in the model.1 Each reaction is shown
1We simplified the pathway for its clarity. Several metabolites are not shownin the figure because the pathway would be too complicated to comprehendotherwise.
TABLE IKINETIC RATE LAWS OF GLUCOSE METABOLIC MODEL
in the pathway as an arrow, which is labeled by the variabledenoting the rate of the reaction.The dynamic mass balance of each metabolite (e.g., GLU,
G6P, PEP, ) is described by an ordinary differential equa-tion with rates of input and output represented by enzymekinetic rate laws,
(1)
where is the vector of metabolite concentrations,andare the kinetic rate laws of enzymes that produce and consume
, respectively. For instance,where is the concentration of glucose-phosphate;is the rate of enzymes that produce , which is a functionof and ; and is the rate of enzymesthat consume , which is a function of and .The kinetic rate laws are typically nonlinear functions of,and they are listed in Table I. Several metabolites such as
in Table I are not shown inthe simplified pathway in Fig. 1 for its clarity. The set ofODE’s is given in Table II.
In the problem given, some key parameters (i.e.,and ) in the rate laws listed in
Table I are unknown and must be estimated from newexperiments involving the whole system with the aid ofparameter estimation methods. These parameters must beidentified by comparing the concentration profiles determinedexperimentally with those predicted by simulation of theODE’s in Table II with proper initial conditions. Theevaluation of a model is usually based on two criteria: 1)

YEN et al.: A HYBRID APPROACH TO MODELING METABOLIC SYSTEMS 175
TABLE IIMODES OF GLUCOSE METABOLIC MODEL
the sum of relative absolute errors between the model outputand the target model behavior obtained experimentally, and2) the convergence of the model output. The second criterionis important because the true model should converge to anequilibrium state. For example, if two metabolic models havethe same accumulative errors and one converges while theother does not, the former model is preferred. To expressthis preference, a penalty should be given a model that doesnot converge to an equilibrium state. When we use a GA toidentify the unknown parameters, these two criteria becomethe basis for designing the GA’s fitness evaluation function,as we shall see later in Section V.
Fig. 2 plots some of landscape of the optimization surfaceof the biomodeling problem at the global optimum. Thesefigures clearly show that many local optima are scattered inthe irregular landscape. Because of the existence of numerouslocal optima in the model, parameter optimization throughgradient techniques fell short of our goal. We instead turnedour attention to the GA, which can avoid entrapment by localoptima. However, applying the pure GA to this problem isdifficult due to its high computational cost. The problem is
(a)
(b)
Fig. 2. Landscape at the global optimum: (a)V2 � V6 and (b)V4 � V2:
attributed to 1) the slow convergence rate of the GA and 2)the inherent computational cost of the evaluation function,which involves simulating metabolic models using sets ofparameter guesses. Since a single simulation could take upto 3 s, evaluating a generation of 150 sets of parametervalues could take more than 12 min. One run of a geneticalgorithm for optimizing six parameters would take about7 h before it converges! In system-level metabolic modeling,the number of parameters that may need to be adjusted canbe very large. Consequently, it is difficult to apply GA’s tolarge-scale biomodeling problems. This scalability problem inapplying the pure GA to metabolic modeling motivated usto investigate a hybrid approach that integrates a GA withother search techniques to improve the GA’s convergence rate.Before describing our hybrid GA approach, we briefly reviewexisting hybrid GA techniques in Section III.
III. B ACKGROUND
Optimization techniques can be classified into two cate-gories: local search methods and global search methods. Alocal search method uses local information about the currentset of data (state) to determine a promising direction formoving some of the data set, which is used to form the next setof data. The advantage of local search techniques is that theyare simple and computationally efficient. But they are easilyentrapped in a local optimum. In contrast, a global searchmethod explores the global search space without using localinformation about promising search direction. Consequently,they are less likely to be trapped in local optima, but theircomputational cost is higher. The distinction between localsearch methods and global search methods is referred to

176 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 28, NO. 2, APRIL 1998
as the “exploitation–exploration” tradeoff in the recent workof Renders [20]. While the global search methods oftenfocus on “exploration,” the local search methods focus on“exploitation.”
Like most global search methods, GA’s are not easilyentrapped in local minima. On the other hand, they typicallyconverge slowly. Many researchers have reported in the liter-ature that combining a GA and a local search technique intoa hybrid approach often produces certain benefits [14]–[16],[21]. This is because a hybrid approach can combine the meritsof the GA with those of a local search technique. Because ofthe GA, a hybrid approach is less likely to be trapped in a localoptimum than a local search technique. Due to its local search,a hybrid approach often converges faster than the GA does.Generally speaking, a hybrid approach usually can explore abetter tradeoff between computational cost and the optimalityof the solution found.
To provide the background necessary for us to introducehybrid approaches, this section briefly reviews the basics ofgenetic algorithm and a local search technique called thesimplex method. We give an overview of various existinghybrid architectures in the next section. Because we willcompare our approach with ASA at a later point, we alsoreview the basics of simulated annealing.
A. Genetic Algorithms
Genetic algorithms are global search and optimization tech-niques modeled from natural genetics, exploring search spaceby incorporating a set of candidate solutions in parallel [22].A GA maintains apopulation of candidate solutions whereeach solution is usually coded as a binary string called achromosome. A chromosome—also referred to as ageno-type—encodes a parameter set (i.e., a candidate solution) fora set of variables being optimized. Each encoded parameter ina chromosome is called agene. A decoded parameter set iscalled aphenotype. A set of chromosomes forms a population,which is evaluated and ranked by afitness evaluationfunction.The initial population is usually generated at random.
The evolution from one generation to the next involves threesteps. First, the current population is first evaluated using thefitness evaluation function, then ranked based on its fitnessvalues. Second, GA’s stochastically select “parents” from thecurrent population with a bias that better chromosomes aremore likely to be selected. This is accomplished using aselection probability that is determined by the fitness valueor the ranking of a chromosome. Third, the GA reproduces“children” from selected “parents” using twogenetic oper-ations: crossover and mutation. This cycle of evaluation,selection, and reproduction terminates when an acceptablesolution is found, when a convergence criterion is met, or whena predetermined limit on the number of iterations is reached.
The crossover operation exchanges information betweentwo chromosomes. First, a randomly selected bit position isused to cut each parent chromosome (i.e., bitstring) into twosubstrings. The parents then exchange their right substringsto produce two new strings (i.e., their children) with the samelength. The mutation operation replaces a randomly chosen bit
of a chromosome with its complement (i.e., changing a “1”with a “0” or a “0” with a “1”). The chances that these twooperations apply to a chromosome is controlled by two proba-bilities: the crossover probability and the mutation probability.Typically, the mutation operation has a low probability toreduce its potential interference with a legitimately progressingsearch.
The GA differs from the conventional optimization tech-niques in that it is inherently parallel. All individuals in apopulation evolve simultaneously without central coordination.They operate on a set of solutions rather than on one solution,hence multiple frontiers are searched simultaneously. Theonly feedback used by the genetic algorithm is the fitnessevaluation. The GA has been shown to be an effective searchtechnique on a wide range of difficult optimization problems[1], [2], [22], [23].
1) Real-coded GA:A real-coded GA is a genetic algorithmrepresentation that uses floating point [24]. A chromosome ina real-coded GA becomes a vector of floating point numbers.With some modifications of genetic operators, real-coded GA’shave resulted in better performance than binary-coded GAfor certain problems [24]. We briefly describe below somemodified genetic operators recommended for real-coded GA.
The crossover operator of a real-coded GA is analogousto that of binary-coded GA except that its crossover pointsfall between genes (i.e., encoded parameters). Two muta-tion operators have been proposed for real-coded GA’s. Arandom mutationchanges a gene with a random numberin the feature’s domain. Adynamic mutationstochasticallychanges a gene within an interval that narrows over time. Forthe two problems we tested (i.e., the biomodeling problemdescribed in Section II and a function maximization problemto be described in Section VI), real-coded GA’s outperformedbinary implementation of GA’s. Therefore, all GA experimentsreported in this paper used real-coded GA’s. To fairly comparehybrid approaches with GA’s, we also used real-coded GA’sto implement the two hybrid approaches that we will describein Section III-B.
B. Simplex Method
Simplex method is a local search technique that uses theevaluation of the current data set to determine the promisingsearch direction. In this section, we first review the basicsimplex method. We then describe two modifications to thebasic simplex method.
Before we elaborate on the simplex method, we will de-scribe another kind of local search method—the gradient-based method—which uses the gradient of the function beingoptimized as the promising search direction [25]. Examplesof common gradient methods include steepest descent [26],Newton strategies [27], Powell’s version of conjugate di-rections [28], and Hooke and Jeeves’ pattern search [27],[29]. Even though these techniques have been widely usedfor many function optimization problems, it is difficult toapply them to the metabolic modeling problem because themathematical relationships between the modeling parametersand the modeling objectives (i.e., close fitness between the

YEN et al.: A HYBRID APPROACH TO MODELING METABOLIC SYSTEMS 177
Fig. 3. An example of two-dimensional simplex.
model prediction and the experimental data) are too complexto be formulated.
1) Basic Simplex Method:The basic simplex method wasfirst introduced by Spendleyet al. [30]. A simplex is definedby a number of points equal to one more than the number ofdimensions of the search space. For an optimization probleminvolving variables, the simplex method searches for anoptimal solution by evaluating a set of points (i.e., pointsforming a simplex), denoted as . The methodcontinually forms new simplices by replacing the worst pointin the simplex, denoted as , with a new point generatedby reflecting over the centroid of the remaining points
(2)
where
The new simplex is then defined by.2 This
cycle of evaluation and reflection iterates until the step size(i.e., ) becomes less than a predetermined valueor the simplex circles around an optimum.
Fig. 3 illustrates how this applies to an optimization probleminvolving two variables. Suppose points and form anoriginal simplex, and point has the worst evaluation. Point
represents the centroid of and . Reflecting pointacross generates , which together with points and ,forms the new simplex.
2) N–M Simplex Method:Nelder and Mead developed amodification to the basic simplex method that allows theprocedure to adjust its search step according to the evaluationresult of the new point generated [19]. This is achieved in threeways. First, if the reflected point is very promising (i.e., betterthan the best point in the current simplex), a new point furtheralong the reflection direction is generated using the equation
(3)
where is the called the expansion coefficient becausethe resulting simplex is expanded. Second, if the reflected point
is worse than the worst point in the original simplex (i.e.,), a new point close to the centroid on the same side ofis generated using the equation
(4)
2If Xr has the worst evaluation in the new simplex, replace the secondworst point in the next cycle instead.
where is called the contraction coefficient be-cause the resulted simplex is contracted. Third, if the reflectedpoint is not worse than but is worse than the secondworst point in the original simplex, a new point close to thecentroid on the opposite side of is generated using thecontraction coefficient
(5)
3) Probabilistic Simplex Method:In order to introduce acost-effective exploration component into the simplex method,we develop a stochastic variant of the simplex method, whichwe call theprobabilistic simplex method. We modify the basicsimplex method to allow the distance between the centroid andthe reflected point to be determined probabilistically. This isachieved by combining (3) and (5) into the following equation:
(6)
where is a random variable taking its value from the interval[0, 2] based on a predetermined probability distribution. Aprobability distribution used in our application is a triangularprobability density function that peaks at 1, and reaches zeroprobability at 0 and 2, respectively. If the reflected pointis worse than the worst point, a probabilistic contractionoperation is applied in a similar way
(7)
where is a random variable taking its value from the interval[0,1] with a triangular probability density function that peaks at0.5. By introducing a stochastic component into the reflectionoperation and the contraction operation, the newly generatedpoint can lie anywhere in a line segment connectingand , rather than constraining to three points in the line.This flexibility allows the probabilistic simplex to explore thesearch space with more freedom. It may also facilitate thefine-tuning of solutions around an optimum.
C. Simulated Annealing
The basic idea of simulated annealing technique is that ittries to avoid being trapped in local minima by making an“uphill” move (for a minimization problem) occasionally [31],[32]. The probability of moving in an “uphill” direction isdetermined by a function in the form of
where is the amount of objective value increase caused bythe uphill move and is a parameter (referred to as “annealingtemperature”) that decreases over time by a schedule. Duringthe initial stage of the simulated annealing search, the systemis more likely to accept uphill moves becauseis high. Asthe search proceeds, the probability of accepting uphill movesgradually decreases becausebecomes lower.
1) Adaptive Simulated Annealing:ASA [33] is a variant ofthe simulated annealing technique where the annealing sched-ule for the temperature decreases exponentially in annealingtime. ASA also introduces re-annealing so that it permitsadaptation to changing sensitivities in the multidimensionalparameter space. ASA attempts to “stretch out” the range

178 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 28, NO. 2, APRIL 1998
over the insensitive parameters. It has been shown that ASAoutperformed GA on De Jong’s test functions [34].
IV. I NTEGRATING GENETIC ALGORITHMS
AND THE SIMPLEX METHOD
While GA’s have shown to be effective for solving a widerange of optimization problems [1], its convergence speed istypically much slower than local optimization techniques. Itcan only recombine good guesses hoping that one recombina-tion will have a better fitness than both of its parents.3 Becauseof this limitation, many researchers have combined GA’swith other optimization techniques to develophybrid geneticalgorithms [14], [15], [17], [20], [35]–[39]. The purpose ofsuch hybrid systems is to speed up the rate of convergencewhile retaining the ability to avoid being easily entrapped at alocal optimum. Although local optimization in a hybrid oftenresults in a faster convergence, it has been shown that too muchlocal optimization can interfere with the search for a globaloptimum by drawing the genetic algorithm’s attention to localoptima too quickly, leading to premature convergence [16].Thus, while local optimization might improve the speed of theanalysis, it may also reduce the quality of the final solutionfound. Thus, designing a hybrid approach for an applicationinvolves a careful analysis of these tradeoffs.
To put our discussion in a larger context, we briefly reviewthe types of hybrid GA architectures before we discuss twospecific hybrid approaches that combine a GA with a simplexmethod.
A. Types of Hybrid Architecture
Hybrid genetic algorithms can be classified into four cate-gories:
1) pipelining hybrids;2) asynchronous hybrids;3) hierarchical hybrids;4) additional operators.4
We briefly review each category below.1) Pipelining Hybrids: Probably the simplest and most
commonly used hybrids are the pipelining hybrids, in whichthe genetic algorithm and some other optimization techniquesare applied sequentially; one generates data (i.e., points inthe search space) used by the other. Typically, pipelininghybrids use the first search algorithm to prune or bias theinitial search space such that the second algorithm will eitherconverge more quickly or more accurately. There are threebasic types of pipelining hybrid GA, as shown in Fig. 4: 1)the GA is applied first, serving as apreprocessor; 2) the GA isapplied last, serving as theprimary search routine; and 3) theGA interleaves with another optimization technique. This hasoften been referred to asstagedhybrid in the literature [16].
G-bit Improvement:G-bit improvement is one of thepipelining hybrids that uses a simple local optimization method
3The underlying foundation of this search strategy is Holland’s SchemaTheory [22].
4These four categories are not mutually exclusive, because a specific hybridapproach can belong to multiple categories. For instance, a pipelining hybridcould introduce additional operators in the GA phase.
(a) (b) (c)
Fig. 4. Three pipelining hybrid GA architectures: (a) preprocessor, (b)primary, and (c) staged pipelining.
by searching the neighbors of the best chromosomes in eachgeneration [2]. The original idea of G-bit improvement onbinary GA is as follows:
1) select one or more of the best strings from the currentpopulation;
2) sweep bit by bit, performing successive one-bit changesto the subject string or strings, retaining the better of thelast two alternatives;
3) at the end of sweep, insert the best structure (or-beststructures) into the population and continue the normalgenetic search.
For a real-coded version of the G-bit improvement algorithm,the process of flipping a bit is replaced by mutating a gene(e.g., through dynamic mutation). In later sections, we willcompare our hybrid approach with G-bit improvement on real-coded GA for the metabolic modeling problem and two otheroptimization problems.
2) Asynchronous Hybrids:An asynchronous hybrid archi-tecture uses a shared population to allow a GA and otheroptimization processes to proceed and cooperate asynchro-nously. One process might work on the problem by itself forseveral iterations before accessing the shared population again.If its findings are better than those in the shared population,it updates the shared population. However, if the process doesnot make any significant improvement after some time, itreturns to the shared population to see if any other processeshave posted any progress.
Two approaches in building asynchronous hybrids are 1)to combine a process that converges slowly with another thatconverges swiftly or 2) to combine multiple processes that areeach suitable for performing search in a subregion of the entiresearch space. The asynchronous teams (A-teams) methodologydescribes the first kind of combination by mating the GA withNewton’s method [14].
3) Hierarchical Hybrids: A hierarchical hybrid GA uses aGA and another optimization technique at two different levelsof an optimization problem. An example of hierarchical hybridis the hybrid of the genetic algorithm and the multivariateadaptive regression splines (MARS) to create the G/SPLINESalgorithm [15]. In this hierarchical hybrid, the GA searches forthe best structure of a spline model at a high level, whereas theparameters of the spline model are computed using regression.

YEN et al.: A HYBRID APPROACH TO MODELING METABOLIC SYSTEMS 179
4) Additional Operators:A genetic algorithm can some-times be improved by introducing additional reproductionoperators that perform one-step (or multistep) local search.Almost all local optimization techniques can be incorporatedinto GA’s this way, since they all can be viewed as an operatorthat generates a “child” from one or multiple parents. Amongthem, the simplex method is particularly suited for this typeof hybrid, since the entire population is already ranked byGA. The computation overhead introduced by a new simplexoperator is thus very low.
Partition-based versus Elite-based Hybrid Architecture:There are at least two hybrid GA architectures for introducinga new operator into GA: 1) thepartition-based hybrid GAarchitecture and 2) theelite-based hybrid GAarchitecture. Ina partition-based hybrid GA architecture, the entire populationis partitioned into disjoint subgroups. A fixed number of childis produced by each subgroup in a generation to replace afixed number of worst chromosomes in the subgroup. Eachchild can be produced by a conventional GA reproductionscheme or by a new operator (i.e., a local search step).Hence, the new operator is associated with a probabilitythat indicates the likelihood that the operator is selected ingenerating a child in the reproduction process. In anelite-based hybrid architecture, the new operator is applied totop-ranking chromosomes to generate a portion of the newpopulation, while the remaining population is generated by aconventional GA reproduction scheme. In both architectures,a fraction of the new generation is created using the newoperator, while a fraction of the remainder is produced by theconventional GA operators. In the first architecture, the newoperator is applied to the entire selected population with afixed probability. In the second architecture, the new operatoris applied to top-ranking chromosomes with probability 1,to lower ranking chromosomes with probability 0. Examplesof elite-based hybrid GA include G-bit improvement on GAand our simplex–GA hybrid. The partition-based hybrid GAwas introduced in R–B’s work, even though they did notgive this architecture a name [35]. As we shall see later inSection VIII, the choice between these two architectures canhave a significant impact on the performance of a hybrid GAsystem.
B. Simplex–GA Hybrid Approaches
In this section, we describe two approaches for incorporatingthe simplex method into the GA as an additional operator.We first describe a simplex–GA hybrid developed by R–B(R–B hybrid). Then, we describe an alternative simplex–GAhybrid we developed independently. Finally, we discuss thedifferences between the two hybrid approaches. The applica-tion of these two hybrid approaches to the metabolic modelingproblem will be reported in the next section.
1) R–B’s Partition-based Simplex–GA Hybrid:R–B re-cently proposed a simplex–GA approach thatpartitions theentire population into groups of chromosomes, where
is the number of variables to be optimized. Therefore, theunderlying hybrid GA architecture ispartition-based, as we
mentioned in the previous section. One of the following threeoperators can be applied to each group.
1) Discrete Crossover: For each gene in a child chromo-some, the operator randomly chooses a parent in thegroup and copy its corresponding gene to the new chro-mosome. This child chromosome replaces the lowestranking parent in the group.
2) Average: Replace the worst parent in the group with theaverage of all parents.
3) Simplex: This is the N–M simplex method describedin Section III with an expansion coefficient 2 and acontraction coefficient 0.5 (i.e., ),with one modification that if the contracted point iseven worse than the worst point, an offspring that is
is generated is the best point in thesimplex). We will refer to this operation “contractiontoward the best” in this paper. In the rest of this paper,we will use this simplex method (referred to as the N–Msimplex or the conventional simplex) to compare withour probabilistic simplex.
Exactly one child is produced by a group in a generation.The chance that a particular operator is applied to a groupis determined by a probability associated with the operator.For the convenience of our discussion, we will refer to theseprobabilities as the crossover probability (denoted), averageprobability (denoted ), and simplex probability (denoted),respectively.
2) Our Elite-based Simplex–GA Hybrid:We developed analternative simplex–GA hybrid independently by applying aconcurrent version of probabilistic simplex operator to topranking chromosomes [18]. Hence, our approach is based onthe elite-based hybrid GA architecture.
Concurrent Simplex:A concurrent simplex is very muchlike the classical simplex methods with one minor difference.Instead of starting with points in the simplex (where
is the number of variables to be optimized), the variantbegins with points, where . Like a classicalsimplex, the best points are selected and theircentroid is calculated. However, instead of reflecting onlyone point across , the concurrent simplex reflects multiplepoints across to produce .All new points are reevaluated and contraction operationsare applied if needed. This process of ranking, selection,reflection, evaluation, contraction, and elimination iterates likethe sequential simplex method. An example of concurrentsimplex in two-dimensional (2-D) space is shown in Fig. 5.The benefit of the concurrent simplex is that it can explore awider search frontier. The main disadvantage is the overheadof evaluating and reflecting more points every iteration.Note also that the concurrent version can incorporate any oneof the three simplex methods described in Section III.
In our simplex–GA hybrid, the concurrent simplex is appliedto the top chromosomes in the population to producechildren. The top chromosomes are copied to the nextgeneration. The remaining chromosomes (i.e., chro-mosomes where is the total population size) are generatedusing GA’s reproduction scheme (i.e., selection, crossover, and

180 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 28, NO. 2, APRIL 1998
Fig. 5. An example of two-dimensional concurrent simplex.
Fig. 6. Reproduction in our elite-based simplex–GA hybrid.
Fig. 7. Our simplex–GA hybrid algorithm.
mutation). Fig. 6 depicts the reproduction stage of this hybridapproach. The algorithm of this simplex–GA hybrid approachis summarized in Fig. 7. The algorithm terminates when itsatisfies a convergence criterion or reaches a predeterminedmaximal number of fitness evaluations (i.e., a maximal trialnumber).
We will refer a specific version of our architecture by thepercentage of population to which the concurrent simplexoperator is applied. For example, a 50% simplex–GA appliesthe concurrent simplex to the top half population. A 100%simplex–GA will mean that no GA reproduction is performed.Obviously, 0% simplex–GA is equivalent to the pure GA.
3) Comparison: Even though both the R–B hybrid and ourhybrid combine the GA and simplex methods, they differ
TABLE IIIA COMPARISON OFR–B HYBRID AND OUR SIMPLEX–GA HYBRID
in two major ways: there are architectural differences anddifferent reproduction operators used. First, the R–B hybrid,which is partition-based, applies simplex reproduction to mul-tiple disjoint subgroups of the population; but our hybrid,which is elite-based, applies simplex reproduction to a topportion of the sorted population. Hence, the rationale ofthe R–B approach is to explore multiple search frontierssimultaneously using both genetic search and simplex localsearch. The R–B approach doesn’t systematically apply thesimplex reproductions. Traditional crossover and mutation isalso applied with some probability. In contrast, the rationaleof our approach is to apply simplex local search to the morepromising points, hoping to speed up the convergence ratewhen they are in the vicinity of an optimum point. In ourhybrid, the GA search is still applied to the entire population togenerate children. Therefore, the more promising pointsin our architecture participate in both the simplex reproductionand the GA reproduction. In R–B hybrid, however, a subgroupcan perform only one kind of reproduction in an iteration.The second difference between the two hybrid approaches liesin the reproduction operators they chose. The R–B approachuses N–M simplex, while our approach uses the probabilisticsimplex. Furthermore, the R–B approach uses multiparentdiscrete crossover and an average operator, while our approachuses two-parent crossover. We summarize the major differ-ences between these two hybrid simplex–GA approaches inTable III.
V. APPLICATION TO METABOLIC MODELING
We have successfully applied our simplex–GA hybrid op-timization approach to the metabolic modeling problem de-scribed in Section II. We implemented the approach by modi-fying the code of GENESIS [40]. In this section, we describethe design of this application and the empirical results ob-tained, which is compared with those of original real-codedGA, concurrent simplex, the R–B hybrid approach, ASA,and the G-bit improvement on real-coded GA. To gain someinsights into the benefits of our approach, we discuss therelationship between the sensitivity of the model parametersand the performance of all these approaches in searchingoptimal parameter values.
A. Design
We describe three major design issues in implementing ofour hybrid simplex–GA for the metabolic modeling problem:

YEN et al.: A HYBRID APPROACH TO MODELING METABOLIC SYSTEMS 181
Fig. 8. Architecture of the fitness evaluation.
Fig. 9. Average best fitness of ten runs for each approach.
1) the encoding scheme, 2) the fitness evaluation, and 3) thechoice of various GA parameters.
1) The Encoding Scheme: The overall objective of themetabolic modeling problem is to construct a modelwhose prediction is consistent with the experimentaldata. The specific objective of our glucose metabolicmodeling problem is to find appropriate values forsix parameters in the model described in Section II(i.e., ). These parameters are chosen be-cause scientists are not very certain about their values.Consequently, a chromosome encodes six genes, eachrepresenting a parameter. Based on the knowledgeabout reasonable values for these parameters, we chosethe actual range of the six parameters to be [0, 800], [0,16 000], [0, 800], [0, 800], [0, 800], and [0, 800].
2) The Fitness Evaluation: To evaluate the fitness of achromosome, we assign the parameter values in thechromosome to their corresponding parameters. We thenevaluate the metabolic model with these parameter as-signment by simulating the model using double pre-cision differential algebraic sensitivity analysis code(DDASAC) [41] with 30 time steps. Even though themetabolic model consists of 44 state variables, only threeof them can actually be observed during experiments(i.e., and ). Consequently, oursystems evaluated a parameter set by comparing thedifference between the prediction and the target valuesof these three observable state variables. We obtainedthe target observations by simulating a target model.In our future research, the target observations will beobtained from actual experiments. The fitness function is
TABLE IVAVERAGE BEST FITNESS FOR TEN RUNS
the sum of two components as mentioned in Section II.The first term is the sum of normalized errors betweenthe model output and the target model behavior onthe three observable state variables. The second termmeasures how well has model output converged sincethe true model should converge to an equilibrium state.Because the convergence of a metabolic model’s outputis a necessary condition of a good model, the secondterm in the fitness function gives an additional penaltyto a model that does not converge to an equilibrium state.The fitness function is as follows:
(8)
where denotes an output variable of the model,denotes a time step, and denote the modeloutput value and the target output value for variable
at time , respectively. The maximum time stepis denoted by . The convergence criteria (i.e., thesecond component) is measured by a weighted sumof the distance between the model outputs during thelast time steps and their final values. Within thesetime steps, higher weights are given to the deviationsoccurred during later time steps using the formula
. Hence, the lower is the fitnessvalue, the better is the model. The architecture of thefitness evaluation is illustrated in Fig. 8.
3) Choice of GA Parameters: We chose GA parametersthat are convenient for designing a fair comparison withthe R–B approach. We used a population size of 147,which can be partitioned into 21 subgroups of sevenchromosomes for the R–B approach. The probabilities ofcrossover and mutation are 0.25 and 0.061, respectively.The selection probability is determined by the rankingof chromosome.
To evaluate the effectiveness of our simplex–GA hybridapproach to the metabolic modeling, we compare the followingapproaches:
1) the pure real-coded GA;2) a 45% simplex–GA hybrid;3) a 100% concurrent probabilistic simplex;

182 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 28, NO. 2, APRIL 1998
TABLE VBEST OVERALL GUESS AFTER 12 000 TRIALS
4) the R–B hybrid;5) the G-bit improvement on real-coded GA;6) ASA
The parameters of R–B hybrid are those reported in theirpaper for a function maximization problem: 0.5 simplex prob-ability, 0.2 crossover probability, and 0.2 average probability[35]. We chose the percentage of simplex reproductions in ourhybrid approach such that the portion of simplex reproductionin the total reproduction is about the same as that of R–B’sapproach
45 hybrid
(9)
R-B hybrid
(10)
where is the population size, is the number of parametersbeing optimized, is the percentage of simplex in our hybrid,and and are the probabilities in R–B hybrid forapplying simplex operator, crossover operator, and averageoperator, respectively.
Each approach was executed ten times, each time startingwith a different initial population generated randomly. Toensure fair comparisons, the ten initial populations used bysix approaches are identical.
B. Empirical Results
Our empirical evaluations showed that our simplex–GAapproach is highly effective for identifying the parametersfor the metabolic modeling problem. Fig. 9 summarizes theperformance of all six approaches by plotting the average ofthe best fitness (average over ten runs) versus the number oftrials (i.e., the number of fitness evaluations).
Table IV lists the average best fitness initially, after 5000trials and after 12 000 trials for each of the six approaches.The figure and the table indicate that the average final bestfitness score found by our hybrid approach is the best amongthe six approaches, followed by ASA. The temperature ratioscale of ASA was 10 and the temperature anneal scalewas 100. In fact, both these top two approaches were able
to find good solutions by 5000 trials. Considering the varianceof the final best fitnesses of ten runs, our hybrid approachalso outperformed all other approaches. This showed therobustness of our approach. The R–B simplex–GA hybridranked third best fitness and convergence rate, which isfollowed by G-bit improvement. The performance of GA isinferior to all other approaches except the 100% concurrentsimplex.
Table V shows the overall best parameter values found byeach approach after 12 000 trials. An interesting phenomenonrevealed by this table is that identifying parametersand is easier than identifying parameters and .A very good guess of and can be found by allsix approaches. However, most approaches had difficulty infinding optimal values of and . In particular, thevalue of in the best final overall guess found by almostall approaches except our 45% simplex–GA are far fromthe optimal value, even though their fitness scores seemreasonably good. This observation motivated us to explorethe relationship between the sensitivity of parameters andthe efforts required by different approaches to find theiroptimal values. By doing this, we hope to gain further insightsabout the benefits of our hybrid approach so that we cangenerate a working hypothesis about the characteristics of theproblems that are most suitable for our simplex–GA hybridapproach.
C. Sensitivity Analysis
The sensitivity of the six parameters in the metabolic modelvary widely. Using DDASAC, we calculated the sensitivityof these parameters at the optimum. Table VI shows thesensitivity and the sensitivity rankings of the parameters.Interestingly, most of them are about ten times more sensitivethan the next parameter in the ranking. Even for the parameterpairs whose sensitivities are closer (i.e., and ),they still differ by about five times. Consequently, the leastsensitive parameters (i.e., ) has a sensitivity that is fourorders of magnitude lower than the most sensitive parameter(i.e., ).
To see how different methods behave differently in search-ing the optimum for the parameter set (which vary widely intheir sensitivities) we record the average of each parameter inthe entire population for each run. These average values are

YEN et al.: A HYBRID APPROACH TO MODELING METABOLIC SYSTEMS 183
TABLE VISENSITIVITY OF PARAMETERS
converted to a normalized error using the following equation:
(11)
where denotes the average value of parameterattrial , and denotes the parameter’s optimal value, whichis shown in Table V. Finally, these errors are averaged overten runs. The results are summarized in Figs. 10–15, orderedby the sensitivity of the parameters. Because ASA doesnot use a population, it is difficult to establish a fair andmeaningful comparison regarding a parameter’s average error.Consequently, ASA does not appear in these figures.
Several important observations can be made from theseresults.
1) Even though GA has less problem in finding close tooptimal values for two of the more sensitive parameters(i.e., and ), it has great difficulties in convergingto the optimal value for the less sensitive parameters(e.g., and ). In fact, the average correctness ofthe three least sensitive parameters almost did not makeany improvement within 12 000 trials. This is becauseGA’s search is guided only by the ranking of fitnessevaluations, which are dominated by the more sensitiveparameters that are not yet converged. In particular,Figs. 10–12 show that the average search behavior ofa GA during the first 3000 trials was dominated by themost sensitive parameter (i.e.,). After 3000 trials, theGA began to improve the next two sensitive parameters(i.e., and ). However, the rate of convergence wasslower for these two parameters. By the end of 12 000trials, the average error score of was still significant.As a result, and dominated the later half of theGA search. The three least sensitive parametersand never had a chance to improve themselves, sincethey could not have much impact on the overall fitnessevaluation due to their low sensitivity.
2) Compared to the GA, our hybrid approach exploredparameters with a wide range of sensitivity much moreeffectively. This can be explained by the search direc-tion provided by the simplex method which not onlyincreased the rate of convergence for finding optimalparameter values, but also enabled optimization formultiple parameters with varying sensitivities. In our ex-periment, our hybrid approach identified optimal valuesfor the three sensitive parameters and within
Fig. 10. Correctness of parameterV3.
Fig. 11. Correctness of parameterV1.
Fig. 12. Correctness of parameterV5.
the first 4000 trials. Between trials 4000 and 7000,the hybrid approach improved the next two insensitiveparameters and significantly. Hence, even theleast sensitive parameter were improved after 4000trials.
3) The R–B simplex–GA hybrid, on the average, convergedfaster than GA’s for and (two of the threemost sensitive parameters). However, some of its searchfor seemed to be trapped in local optimum, whichintroduced an additional difficulty for finding optimumvalues for the three insensitive parameters.
4) The G-bit improvement, on the average, converged to avalue of and that is closer to their global optimumthan what the GA and the R–B simplex–GA found. Itwas able to improve the correctness of after 8000trials. Surprisingly, its average normalized error ofwas the worst. A likely explanation of this phenomena is

184 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 28, NO. 2, APRIL 1998
Fig. 13. Correctness of parameterV4.
Fig. 14. Correctness of parameterV2.
Fig. 15. Correctness of parameterV6.
that the search of G-bit improvement was still dominatedby by the termination time.
5) The concurrent probabilistic simplex had the most dif-ficulties even in converging to the optimum of ,partially because the probabilistic simplex was designedto complement the GA. Without the GA, it is easilytrapped by any local optimum.
VI. A PPLICATION TO A FUNCTION MAXIMIZATION PROBLEM
Because of the success of applying our simplex–GA hybridto the metabolic modeling problem, we decided to furthertest our hybrid approach using two different problems. In thissection, we test it using a function maximization problem. Wetest it using De Jong’s F5 function minimization problem inthe next section. The testbed used in this section is a functionmaximization problem used by R–B [35], which is actuallyan instance of a function family introduced by Michalewicz
in [23]
(12)
where . We chose the function maximizationproblem because there are many (exactly) local minimain this function. As grows, finding maxima of this functionbecomes more and more difficult.
R–B used two instances of this function family to test theirhybrid approach by setting to 10, and to 10 and 100,respectively [35]. These problems are ten-dimensional opti-mization problems. Theoretical maxima of these two functionsare 9.660 (for ) and 9.655 (for ).
We used these two problems to test our hybrid approach(57% simplex–GA) and compare the performance with thoseof GA, 100% concurrent simplex, R–B hybrid, G-bit improve-ment, and ASA. We chose to test 57% simplex–GA because itspercentage of simplex reproductions among all reproductionsis close to that of R–B hybrid
57 hybrid
(13)
R-B hybrid
(14)
This is similar to the reason we chose 45% simplex–GA forthe biomodeling problem.
For each approach, the population size was 44 and themaximum trial number was 1 000 000. Like the biomodelingapplication, we compared the average performance of ten runsfor each approach using a set of ten randomly generated initialpopulations. For the R–B hybrid, we used the parameters thatgave the best performance in their experiments (i.e., 0.2, 0.2,and 0.5 for the crossover probability, the average probability,and the simplex probability, respectively) [35].
Fig. 16 plots the average best fitness versus number oftrials for the two function maximization problems. Because theperformance of the 100% concurrent simplex is much worsethan the other three approaches, they are not included in thefigures. We have also chosen the range of fitness in the figureso that the performance of the three approaches can be clearlydistinguished. Since the performance of the three approachesdiffers mainly in the convergence rate, Table VII compares theaverage trial numbers each approach took to find the optimum.
The following observations are made from the figures andthe table.
1) The real-coded GA, our 57% simplex hybrid, and G-bitimprovement found the theoretical maximum for bothproblems and in every run. TheR–B simplex hybrid found the optimum in eight runsfor each problem.
2) Our hybrid outperformed all other approaches in termsof the convergence rate. The G-bit improvement hasthe second best performance. For the simpler problem

YEN et al.: A HYBRID APPROACH TO MODELING METABOLIC SYSTEMS 185
TABLE VIIAVERAGE TRIALS DIFFERENT APPROACHESTOOK TO FIND THE OPTIMUM
(a)
(b)
Fig. 16. Performance for a function maximization problem: (a)m = 10
and (b)m = 100.
, our hybrid converged about eight times fasterthan the real-coded GA and about 2.5 times faster thanthe G-bit improvement in finding the optimum. For thedifficult problem , our hybrid convergedabout four times faster than the real-coded GA and abouttwice as fast as the G-bit improvement on GA.
3) The performance of real-coded GA was better than thatof the R–B hybrid.
4) The ASA was not robust in that it only found theoptimum in three runs out of ten runs for the difficultproblem .
We need to clarify a few differences between the resultof our experiments and those reported by R–B [35]. TheGA outperformed the R–B hybrid for both problems in ourexperiment, but was outperformed by the R–B hybrid intheir experiment. One of the differences between the twoexperiments is the maximum trials allowed. To take this factorinto consideration, we compared the best fitness value (averageover ten runs) obtained by R–B’s experiment and ours after
TABLE VIIIAVERAGE BEST FITNESS VALUES OBTAINED IN
R–B’S EXPERIMENTS AND OUR EXPERIMENTS
about the same number of trials. This comparison is shownin Table VIII, which indicated that our implementation of theR–B hybrid gave a performance that is similar to their ownimplementation. However, our implementation of the real-coded GA yielded a performance that is much better than thatin R–B’s experiment, especially for the problem whereisset to 100. This may be caused by other differences in thetwo GA implementations (e.g., selection probability, crossoverprobability, mutation probability, etc.). Since we could not findthese details about R–B’s GA implementation in their paper,we cannot analyze these differences further.
The empirical results of applying our hybrid approachto the sin maximization problem suggested that our hybridapproach can be an effective method not only for solvingthe biomodeling problem, but also for solving the complexfunction optimization problems. Our experiments indicatedthat our simplex–GA hybrid is superior to all other fouralternative methods for the sin maximization problem.
VII. A PPLICATION TO DE JONG’S F5FUNCTION MINIMIZATION PROBLEM
We further tested our simplex–GA hybrid using De Jong’sF5 function minimization problem [1]. The function is formu-lated as
(15)
with for andfor as well asfor and

186 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 28, NO. 2, APRIL 1998
TABLE IXAVERAGE TRIAL NUMBERS REACHING THE MINIMUM IN DE JONG’ S F5 FUNCTION
for . The range of is .This function is multimodal and globally minimized at
with the value of 0.998 004. We designedthe GA parameters in both architectures so that the ratioof the update probability of a chromosome by the simplexto the update probability of a chromosome is equal in bothhybrids. In our architecture, the simplex is applied to 28% ofthe population, the crossover probability was 0.25, and themutation probability was 0.389. The mutation probability inR–B’s architecture was 0.59, was 0.8, and were0.1. Table IX summarizes the result of solving the problemusing five approaches. All algorithms converge to the globaloptimum, but their convergence rates were different. Amongthe five algorithms, ASA was the best, followed by our hybridalgorithm. One hypothesis regarding ASA’s performance ondifferent problems is that it is very sensitive on the numberof local optima in the problem. Even though ASA gives asuperior performance in De Jong’s F5 problem, its robustnessis poor in the sin maximization problem (as discussed in theprevious section). Because De Jong’s F5 function has muchless local optima than the sin maximization functions does(25 versus ), we hypothesize that ASA is not as suitablefor optimization problems that have a very large number oflocal optima. However, further research and experiments areneeded to confirm or refine this hypothesis.
VIII. D ISCUSSIONS
After we compared our hybrid approach with R–B’s hy-brid approach for these three problems, we wanted to gainsome empirical insights about factors that contributed tothe differences in their performances. More specifically, wewish to address two questions. How does elitism affect theperformance of our simplex–GA hybrid? How does the choiceof the simplex operator and the choice of the hybrid architec-ture affect the performance of the two simplex–GA hybridapproaches?
To answer these questions, we designed and performedadditional experiments. The rest of this section summarizesthe results of these experiments and describes some plausibleconclusions we drew from these results.
A. The Effect of Elitism
To study the effect of elitism in our simplex–GA hybrid, weapplied a real-coded GA with elites (where is the numberof variables to be optimized) to the biomodeling problemand to the function maximization problem. Table X showsthe average final best fitness for the biomodeling problem.
TABLE XCOMPARING N ELITES GA WITH OTHER
APPROACHES FOR THEBIOMODELING PROBLEM
For ease of comparison, we also included results of threeother alternative approaches: the real-coded GA, our hybrid,and the R–B hybrid. It should be pointed out that the real-coded GA used for comparison in Sections V–VII kept thechromosome ranked first every generation. Therefore, it isin fact a GA with one elite. Table X shows that the real-coded GA with elites improved, on the average, the finalbest fitness of the real-coded GA with 1 elite by 50% forthe biomodeling problem. This is about half of the overallperformance improvement of our 45% hybrid. Fig. 17 plots theaverage best fitness versus trials for the two sin maximizationproblems. The figures clearly show that the GA withelitesdid improve the convergence rate of the original GA (with oneelite). To compare their convergence rates, we summarize theaverage trials required by each approach to find the globaloptimum in Table XI. The GA with elites reduced theaverage trials to find the global optimum by 34% for theproblem with , but by only 5% for the problemwith . It is worth noting that the GA with elitesconverged much faster than the GA did during the first 100 000trials for both problems, as shown in Fig. 17. However, theGA with elites had more difficulty in finding precisely theglobal optimum for the problem with . In fact, it didnot find the optimum precisely in two out of ten runs. Theseempirical analyses suggested that elitism is major contributingfactor to the performance improvement of our hybrid approach,even though it does not account for the entire performanceimprovement.
B. The Effect of the Choice of Simplex Operator
As we have pointed out in Section B, one of the maindifferences between our hybrid and R–B hybrid is the choiceof the simplex operator. We used the probabilistic simplex,while the R–B approach used the N–M simplex. It is thusimportant to understand the effect of different simplex methodon the performance of the two hybrid architectures.
Toward this goal, we implemented both operators for botharchitectures, and applied them to the biomodeling problem,the sin function maximization problems, and De Jong’s F5function. The results are shown in Table XII, Fig. 18, andTable XIII.
We made the following observations from these empiricalcomparisons. First, the probabilistic simplex is more suitablefor our elite-based hybrid architecture. For the biomodelingapplication of our 45% simplex–GA, the average final bestfitness using the N–M simplex was 200 times worse thanthat using the probabilistic simplex. For the sin maximization
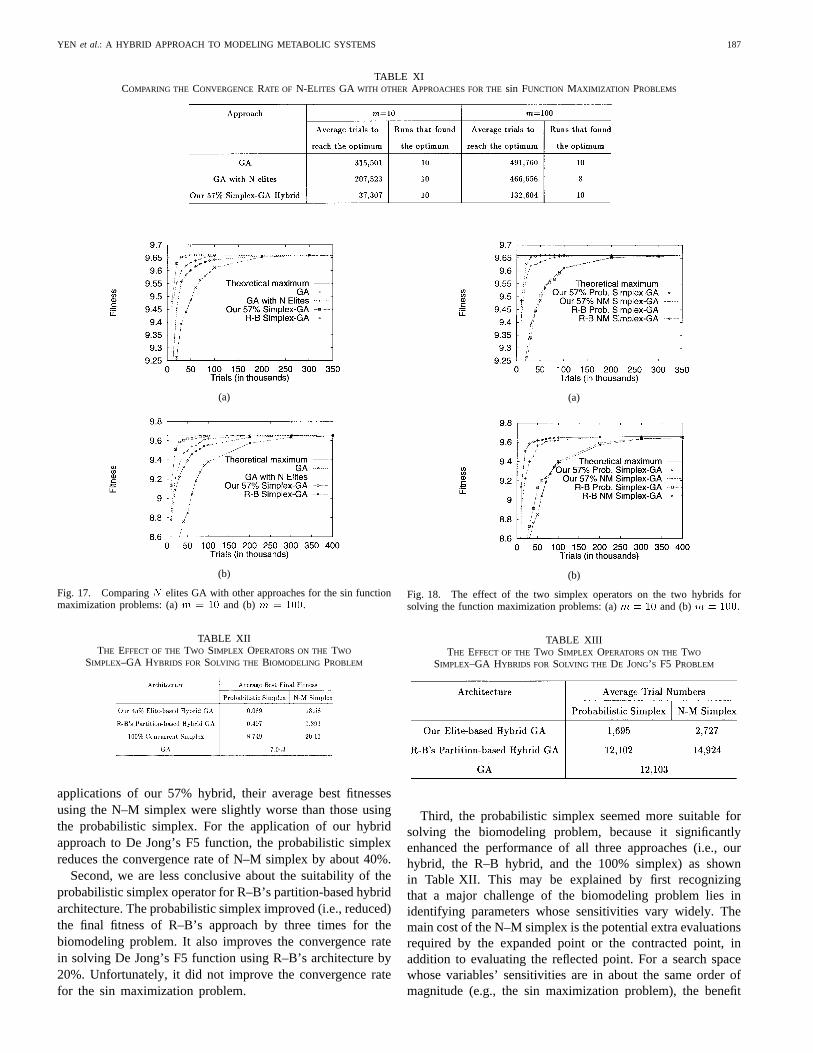
YEN et al.: A HYBRID APPROACH TO MODELING METABOLIC SYSTEMS 187
TABLE XICOMPARING THE CONVERGENCE RATE OF N-ELITES GA WITH OTHER APPROACHES FOR THEsin FUNCTION MAXIMIZATION PROBLEMS
(a)
(b)
Fig. 17. ComparingN elites GA with other approaches for the sin functionmaximization problems: (a)m = 10 and (b)m = 100.
TABLE XIITHE EFFECT OF THETWO SIMPLEX OPERATORS ON THETWO
SIMPLEX–GA HYBRIDS FOR SOLVING THE BIOMODELING PROBLEM
applications of our 57% hybrid, their average best fitnessesusing the N–M simplex were slightly worse than those usingthe probabilistic simplex. For the application of our hybridapproach to De Jong’s F5 function, the probabilistic simplexreduces the convergence rate of N–M simplex by about 40%.
Second, we are less conclusive about the suitability of theprobabilistic simplex operator for R–B’s partition-based hybridarchitecture. The probabilistic simplex improved (i.e., reduced)the final fitness of R–B’s approach by three times for thebiomodeling problem. It also improves the convergence ratein solving De Jong’s F5 function using R–B’s architecture by20%. Unfortunately, it did not improve the convergence ratefor the sin maximization problem.
(a)
(b)
Fig. 18. The effect of the two simplex operators on the two hybrids forsolving the function maximization problems: (a)m = 10 and (b)m = 100.
TABLE XIIITHE EFFECT OF THETWO SIMPLEX OPERATORS ON THETWO
SIMPLEX–GA HYBRIDS FOR SOLVING THE DE JONG’ S F5 PROBLEM
Third, the probabilistic simplex seemed more suitable forsolving the biomodeling problem, because it significantlyenhanced the performance of all three approaches (i.e., ourhybrid, the R–B hybrid, and the 100% simplex) as shownin Table XII. This may be explained by first recognizingthat a major challenge of the biomodeling problem lies inidentifying parameters whose sensitivities vary widely. Themain cost of the N–M simplex is the potential extra evaluationsrequired by the expanded point or the contracted point, inaddition to evaluating the reflected point. For a search spacewhose variables’ sensitivities are in about the same order ofmagnitude (e.g., the sin maximization problem), the benefit

188 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 28, NO. 2, APRIL 1998
Fig. 19. Distribution of operators generating the best chromosomes in thereal-coded GA.
of such additional evaluations may be comparable to thecost. Nevertheless, for a problem whose variables’ sensitivitiesdiffer by several order of magnitude (e.g., the biomodelingproblem), the cost of these evaluations may outweigh theirbenefits. This working hypothesis is in our future research.
C. The Probabilistic Simplex versus the Conventional Simplex
We also have designed two studies to develop a betterunderstanding about the cost-effectiveness tradeoff betweenthe stochastic simplex and the conventional simplex.
1) Study A: Distribution of Reproduction Operators Gener-ating the Best Chromosomes:In the first study, we analyzedthe distribution of reproduction operators that generates thebest chromosomes in each generation for the biomodelingproblem. To do this, we recorded the total number of bestchromosomes (i.e., the chromosome ranks first in a genera-tion) that a particular reproduction operator (e.g., crossover,simplex, or mutation) generates by a particular generationnumber. This information enables us to analyze how often areproduction schemedirectly contributes to the generation of abest chromosome.5 We summarize this information by plottingthe accumulative number of best chromosomes generated byeach reproduction scheme during the entire search process.Such a figure not only shows the frequency a reproductionscheme generates the best chromosome but also shows how thepercentage changes over time. Figs. 19–21 show these plotsfor five optimization approaches to the biomodeling problem:
1) the real-coded GA;2) our elite-based hybrid GA using the probabilistic sim-
plex;3) our elite-based hybrid GA using the N–M simplex;4) the R–B partition-based hybrid GA using the probabilis-
tic simplex;5) the R–B partition-based hybrid GA using the N–M
simplex.
We made the following observations from these figures.
1) In our elite-based hybrid architecture, the simplex op-erator was the main source for generating best chromo-somes, regardless whether which simplex method wasused. In contrast, the simplex operator was rarely a best
5In reality, the best chromosome in a generation is the result of a largecollection of reproductions occurring over a large number of generations.However, it is difficult to study the indirect contributors to the production ofbest chromosomes.
(a)
(b)
Fig. 20. Distribution of operators generating the best chromosomes inour elite-based hybrid GA using (a) the probabilistic simplex and (b) theN–M simplex.
(a)
(b)
Fig. 21. Distribution of operators generating the best chromosomes inR–B’s partition-based hybrid GA using (a) the probabilistic simplex and(b) the N–M simplex.
chromosome generator in R–B’s partition-based hybridGA regardless which simplex method we chose.
2) The probabilistic simplex generated the best chromo-somes more frequently than the N–M simplex did forthe elite-based hybrid GA, especially during the earlystage of the search. By the midpoint of the search

YEN et al.: A HYBRID APPROACH TO MODELING METABOLIC SYSTEMS 189
(i.e., 6000 trials), the probabilistic simplex accounted forabout 70% of the best chromosomes generated, whilethe N–M simplex accounted for only 45% of the bestchromosomes generated.
These observations suggested that our elite-based hybrid ar-chitecture makes more effective use of the simplex operators(for both the conventional simplex and the stochastic simplex)than the partition-based hybrid architecture does. This studyalso indicated that the stochastic simplex contributes more togenerating the best chromosome than the conventional simplexin our elite-based architecture.2) Study B: Cost-Effectiveness of the Probabilistic Simplex
versus the Conventional Simplex:In the second study, weanalyzed the percentage of different operations (e.g., reflection,contraction, expansion, etc.) actually used by the two simplexmethods to obtain some insights about the cost-effectiveness ofthese methods. These operations are associated with differentcosts in terms of number of evaluations required. The costof the reflection operation is the lowest (i.e., one evaluation).The cost of the expansion and the contraction operation aretwo evaluations each. The cost of “contraction to the best” isthe highest (i.e., three evaluations). The probabilistic simplexuses only reflection and contraction, while the R–B simplexwe compare with, which is a minor variant of N–M simplex,uses all four operations mentioned above. Figs. 22 and 23show the accumulated count of these operations in solvingthe biomodeling problem using the four hybrid approachesmentioned in the previous study. The following observationscan be made from these figures.
1) The reflection operation, which has the lowest cost,occurred much more frequent in the elite-based hybridthan it did in the partition-based hybrid. This suggestedthat the elite-based hybrid GA architecture enables thesimplex operator to be more cost-effective.
2) The probabilistic simplex used a higher percentage ofreflection operations than the N–M simplex did in theelite-based hybrid GA. This finding suggested that theprobabilistic simplex is more cost-effective than theN–M simplex in the elite-based GA architecture.
3) For the partition-based hybrid, the percentage of re-flection operations was about the same for the twosimplex methods. However, the significant portion of“contraction to the best” in the conventional simplexintroduced extra cost into the search process.
This study suggested that the elite-based hybrid GA architec-ture uses both simplex methods more cost-effectively than thepartition-based hybrid GA architecture does. It also suggestedthat the probabilistic simplex is more cost-effective than theconventional simplex for the elite-based architecture.
IX. SUMMARY
In this paper, we have introduced an elite-based hybrid GAapproach using a probabilistic simplex method as an addi-tional operator. The motivation of developing the probabilisticsimplex is to introduce a cost-effective exploration componentinto the conventional simplex method. We have successfully
(a)
(b)
Fig. 22. Simplex operators applied in the elite-based hybrid using (a) theprobabilistic simplex and (b) a conventional simplex.
(a)
(b)
Fig. 23. Simplex operators applied in the partition-based hybrid using (a)the probabilistic simplex and (b) a conventional simplex.
applied a real-coded implementation of our simplex–GA hy-brid to a metabolic modeling problem. We have compared ourapproach with
1) an alternative simplex–GA hybrid independently devel-oped by R–B;
2) a pure real-coded GA;3) a G-bit improvement on real-coded GA;4) ASA.

190 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 28, NO. 2, APRIL 1998
In addition to the metabolic modeling problem, two othertestbeds were used: a sin function maximization problem andDe Jong’s F5 function minimization problem. Our hybridapproach outperforms all other approaches for the biomodelingproblem and the sin function maximization problem. Ourapproach gives the second best performance, next to ASA,for De Jong’s F5 function minimization problem. Furtheranalyses also indicated that the performance improvement ofour hybrid approach is partially attributed to the use of elite-based hybrid GA architecture and the cost-effectiveness of theprobabilistic simplex in the elite-based GA architecture. Basedon an observation about the search behavior of our hybridapproach for the biomodeling problem, we conjectured that theproposed partition-based hybrid of probabilistic simplex andGA is particularly suitable for complex optimization problemsthe variables sensitivity of which vary widely.
There are several issues remaining to be addressed in our fu-ture research. First, our working hypothesis regarding suitableapplications of the proposed simplex–GA hybrid needs to beinvestigated through theoretical analysis or further empiricalevaluations. Second, we plan to study the impact of differentprobability distributions for the probabilistic simplex on theperformance of the hybrid system. Third, we need to fullyinvestigate the relationship between the percentage of simplexreproduction and the performance of our hybrid. Finally, weplan to apply the hybrid approach to the identification ofmetabolic models using real experiment data.
ACKNOWLEDGMENT
The authors would like to thank the reviewers for theircomments on an earlier draft of the paper. The softwarepackage for model simulation DDASAC originated from M.Caracotsios and W. E. Stewart. The GENESIS implementationof GA was developed by J. J. Grefenstette [42].
REFERENCES
[1] K. A. Dejong, “Analysis of the behavior of a class of genetic adap-tive systems,” Ph.D. dissertation, Dept. Comput. Commun. Sci., Univ.Michigan, Ann Arbor, 1975.
[2] D. E. Goldberg,Genetic Algorithms in Search, Optimization and Ma-chine Learning. Reading, MA: Addison-Wesley, 1989.
[3] H. Kargupta and R. E. Smith, “System identification with evolvingpolynomial networks,” inProc. 4th Int. Conf. Genetic Algorithms, SanDiego, CA, July 1991.
[4] K. Kristinnson and G. A. Dumont, “System identification and controlusing genetic algorithms,”IEEE Trans. Syst., Man, Cybern., vol. 22, no.5, pp. 1033–1046, 1992.
[5] H. Iba, T. Kurita, H. deGaris, and T. Sato, “System identificationusing structured genetic algorithms,” inProc. 5th Int. Conf. GeneticAlgorithms, Urbana-Champaign, IL, July 1993.
[6] D. M. Etter, M. J. Hicks, and K. H. Cho, “Recursive adaptive filterdesign using an adaptive genetic algorithm,” inProc. IEEE Int. Conf.Acoustics, Speech, Signal Processing (ICASSP ’82), Paris, France, May1982, vol. 2, pp. 635–638.
[7] S. Uckun, S. Bagchi, and K. Kawamura, “Managing genetic search injob shop scheduling,”IEEE Expert, vol. 8, no. 5, pp. 15–24, 1993.
[8] A. B. Conru, “A genetic approach to the cable harness routing problem,”in Proc. 1st IEEE Conf. Evolutionary Computation, Orlando, FL, June1994.
[9] D. P. Kwok and F. Sheng, “Genetic algorithm and simulated annealingfor optimal robot arm pid control,” inProc. 1st IEEE Conf. EvolutionaryComputation, Orlando, FL, June 1994.
[10] D. Park and A. Kandel, “Genetic-based new fuzzy reasoning modelswith application to fuzzy control,”IEEE Trans. Syst., Man, Cybern.,vol. 24, pp. 39–47, Jan. 1994.
[11] T. Smith and K. A. DeJong, “Genetic algorithms applied to the calibra-tion of information driven models of us migration patterns,” inProc.12th Annu. Pittsburgh Conf. Modeling Simulation, Pittsburgh, PA, 1981,pp. 955–959, .
[12] D. J. Janson and J. F. Frenzel, “Training product unit neural networkswith genetic algorithms,”IEEE Expert, vol. 8, no. 5, pp. 26–33, 1993.
[13] M. F. Bramlette, “Finding maximum flow with random and geneticsearch,” inProc. 1st IEEE Conf. Evolutionary Computation, Orlando,FL, June 1994.
[14] P. S. de Souza and S. N. Talukdar, “Genetic algorithm in asynchronousteams,” inProc. 4th Int. Conf. Genetic Algorithms, San Diego, CA, July1991, pp. 392–397.
[15] D. Rogers, “G/SPLINES: A hybrid of Friedman’s multivariate adaptiveregression splines (MARS) algorithm with Holland’s genetic algorithm,”in Proc. 4th Int. Conf. Genetic Algorithms, San Diego, CA, July 1991,pp. 384–391.
[16] K. E. Mathias, L. D. Whitley, C. Stork, and T. Kusuma, “Stagedhybrid genetic search for seismic data imaging,” inProc. 1st IEEE Conf.Evolutionary Computation, Orlando, FL, June 1994, pp. 356–361.
[17] H. Ishibuchi, N. Yamamoto, T. Murata, and H. Tanaka, “Geneticalgorithms and neighborhood search algorithms for fuzzy flowshopscheduling problems,”Fuzzy Sets Syst., vol. 67, no. 1, pp. 81–100, 1994.
[18] J. Yen, J. C. Liao, D. Randolph, and B. Lee, “A hybrid approachto modeling metabolic systems using genetic algorithm and simplexmethod,” in Proc. 11th IEEE Conf. Artificial Intelligence Applications(CAIA95), Los Angeles, CA, Feb. 1995, pp. 277–283.
[19] J. A. Nelder and R. Mead, “A simplex method for function minimiza-tion,” Comput. J., vol. 7, pp. 308–313, 1965.
[20] J. Renders and S. Flasse, “Hybrid methods using genetic algorithms forglobal optimization,”IEEE Trans. Syst., Man, Cybern. B, vol. 26, pp.243–258, Apr. 1996.
[21] D. B. McGarrah and R. S. Judson, “Analysis of the genetic algorithmmethod of molecular conformation determination,”J. Comput. Chem.,vol. 14, no. 11, pp. 1385–1395, 1993.
[22] J. H. Holland, Adaptation in Natural and Artificial Systems. AnnArbor, MI: Univ. Michigan Press, 1975.
[23] Z. Michalewicz, Genetic Algorithms+ Data Structures= EvolutionPrograms. New York: Springer-Verlag, 1992.
[24] C. Z. Janikow and Z. Michalewicz, “An experimental comparison ofbinary and floating point representation in genetic algorithms,” inProc.4th Inte. Conf. Genetic Algorithms, San Diego, CA, July 1991, pp.31–36.
[25] J. Kowalik and M. R. Osborne,Methods for Unconstrained OptimizationProblems. New York: Elsevier, 1968.
[26] R. W. Daniels,An Introduction to Numerical Methods and OptimizationTechniques. New York: North-Holland, 1978.
[27] H. P. Schwefel,Numerical Optimization of Computer Models. NewYork: Wiley, 1981.
[28] M. J. D. Powell, “An efficient method for finding the minimum of afunction of several variables without calculating derivatives,”Comput.J., vol. 7, pp. 155–162, 1964.
[29] R. Hooke and T. A. Jeeves, “Direct search solution of numerical andstatistical problems,”J. ACM, vol. 8, pp. 212–229, 1961.
[30] W. Spendley, G. R. Hext, and F. R. Himsworth, “Sequential applica-tion of simplex designs in optimization and evolutionary operation,”Technometrics, vol. 4, pp. 441–461, 1962.
[31] S. Kirkpatrick, C. D. Galatti, and M. P. Vecchi, “Optimization bysimulated annealing,”Science, vol. 220, pp. 671–680, 1983.
[32] P. J. M. van Laarhoven and E. H. L. Arts,Simulated Annealing: Theoryand Applications. Boston, MA: Kluwer, 1987.
[33] L. Ingber, “Simulated annealing: Practice versus theory,”Math. Comput.Model., vol. 18, no. 11, pp. 29–57, 1993.
[34] L. Ingber and B. Rosen, “Genetic algorithms and very fast simulatedannealing: A comparison,”Math. Comput. Model., vol. 16, no. 11, pp.87–100, 1992.
[35] J. Renders and H. Bersini, “Hybridizing genetic algorithms with hill-climbing methods for global optimization: Two possible ways,” inProc.1st IEEE Conf. Evolutionary Computation, Orlando, FL, June 1994, pp.312–317.
[36] D. H. Ackley, “Stochastic iterated genetic hillclimbing,” Ph.D. disser-tation, Carnegie Mellon Univ., Pittsburgh, PA, 1987.
[37] G. Dozier, J. Bowen, and D. Bahler, “Solving small and large scaleconstraint satisfaction problems using a heuristic-based microgeneticalgorithm,” inProc. 1st IEEE Conf. Evolutionary Computation, Orlando,FL, June 1994.
[38] T. Murata and H. Ishibuchi, “Performance evaluation of genetic al-gorithms for flowshop scheduling problems,” inProc. 1st IEEE Conf.Evolutionary Computation, Orlando, FL, June 1994.

YEN et al.: A HYBRID APPROACH TO MODELING METABOLIC SYSTEMS 191
[39] J. Renders,Algorithmes Genetiques et Reseaux de Neurones: Applica-tions a la Commande de Processus. Paris, France: Hermes, 1994.
[40] J. J. Grefenstette,User’s Guide to GENESIS Version 5.0, 1990.[41] M. Caracotsios and W. E. Stewart, “Sensitivity analysis of initial value
problems with mixed ODE and algebraic equations,”Comput. Chem.Eng., vol. 9, pp. 359–365, 1985.
[42] J. Grefenstette, “GENESIS: A system for using genetic search proce-dures,” inProc. 1984 Conf. Intelligent Systems Machines, pp. 161–165.
John Yen (SM’91) received the B.S. degree inelectrical engineering from National Taiwan Univer-sity, Taipei, Taiwan, R.O.C., in 1980 and the Ph.D.degree in computer science from the University ofCalifornia, Berkeley, in 1986.
Since 1989, he has been an Associate Professorwith the Department of Computer Science and theDirector of Center for Fuzzy Logic, Robotics, andIntelligent Systems, Texas A&M University, Col-lege Station. Previously, he had been conductingartificial intelligence research as a Research Scien-
tist at the Information Sciences Instsitute, University of Southern California,Los Angeles. His research interests include artificial intelligence, fuzzy logic,software engineering, and evolutionary computing. He is an Associate Editorof the IEEE TRANSACTIONS ON FUZZY SYSTEMS.
Dr. Yen is a member of the board of directors of the North American FuzzyInformation Processing Society (NAFIPS), the Secretary of the InternationalFuzzy Systems Association (IFSA), and the Newsletter Editor of the IEEENeural Network Council. He received the National Science Foundation YoungInvestigator Award in 1992 and the K. S. Fu Award from NAFIPS in 1994.
James C. Liao received the B.S. degree in chemi-cal engineering from National Taiwan University,Taipei, Taiwan, R.O.C., in 1980 and the Ph.D.degree in chemical engineering from the Universityof Wisconsin, Madison, in 1987.
He is currently Professor of Chemical Engineer-ing at the University of California, Los Ange-les. Previously, he was on the faculty of TexasA&M University, College Station. Prior to that, hewas a Research Scientist at Eastman Kodak Com-pany, Rochester, NY. His current research includes
metabolic engineering, metabolic control and flux analysis, and regulation inmicorcirculation.
Dr. Liao received the National Science Foundation Young InvestigatorAward in 1992, and is a member of the American Institute of ChemicalEngineers, the American Chemical Society, and the American Society ofMicrobiology.
Bogju Lee received the B.S. degree in computerengineering from Seoul National University, Seoul,Korea, in 1986, the M.S. degree in computer sciencefrom the University of South Carolina, Columbia,in 1992, and the Ph.D. degree in computer sciencefrom Texas A&M University, College Station, in1996.
He is currently a Member of Technical Staff,AT&T Laboratories, Middletown, NJ. His currentresearch includes fuzzy logic, hybrid genetic algo-rithms, and complex system modeling and identifi-
cation using artificial intelligence.Dr. Lee is a member of the American Association for Artificial Intelligence.
David Randolph received the M.S. degree in com-puter science from Texas A&M University, CollegeStation, in 1995, and the B.A. degree in computerscience from Stetson University, De Land, FL, in1990.
He is currently an Engineer at Raytheon, Garland,TX. His area of interest is the optimization ofdistributed systems.




















