
A computer-assisted approach to filtering large numbers of documents for media analyses
20
This article was downloaded by: [The University of British Columbia] On: 03 January 2012, At: 06:59 Publisher: Routledge Informa Ltd Registered in England and Wales Registered Number: 1072954 Registered office: Mortimer House, 37-41 Mortimer Street, London W1T 3JH, UK International Journal of Social Research Methodology Publication details, including instructions for authors and subscription information: http://www.tandfonline.com/loi/tsrm20 A computer-assisted approach to filtering large numbers of documents for media analyses James Voth a , Richard Sawatzky b , Pamela A. Ratner c , Mary Lynn Young d , Robin Repta c , Rebecca Haines-Saah c & Joy L. Johnson c a Intogrey, 41 – 32777 Chilcotin Drive, Abbotsford, British Columbia, Canada, V2T 5W4 b School of Nursing, Trinity Western University, 7600 Glover Road, Langley, British Columbia, Canada, V2Y 1Y1 c School of Nursing, University of British Columbia, 302–6190 Agronomy Road, Vancouver, British Columbia, Canada, V6T 1Z3 d UBC Graduate School of Journalism, University of British Columbia, 6388 Crescent Road, Vancouver, British Columbia, Canada, V6T 1Z2 Available online: 03 Jan 2012 To cite this article: James Voth, Richard Sawatzky, Pamela A. Ratner, Mary Lynn Young, Robin Repta, Rebecca Haines-Saah & Joy L. Johnson (2012): A computer-assisted approach to filtering large numbers of documents for media analyses, International Journal of Social Research Methodology, DOI:10.1080/13645579.2011.645700 To link to this article: http://dx.doi.org/10.1080/13645579.2011.645700 PLEASE SCROLL DOWN FOR ARTICLE Full terms and conditions of use: http://www.tandfonline.com/page/terms-and- conditions
Transcript of A computer-assisted approach to filtering large numbers of documents for media analyses

This article was downloaded by: [The University of British Columbia]On: 03 January 2012, At: 06:59Publisher: RoutledgeInforma Ltd Registered in England and Wales Registered Number: 1072954 Registeredoffice: Mortimer House, 37-41 Mortimer Street, London W1T 3JH, UK
International Journal of SocialResearch MethodologyPublication details, including instructions for authors andsubscription information:http://www.tandfonline.com/loi/tsrm20
A computer-assisted approach tofiltering large numbers of documentsfor media analysesJames Voth a , Richard Sawatzky b , Pamela A. Ratner c , MaryLynn Young d , Robin Repta c , Rebecca Haines-Saah c & Joy L.Johnson ca Intogrey, 41 – 32777 Chilcotin Drive, Abbotsford, BritishColumbia, Canada, V2T 5W4b School of Nursing, Trinity Western University, 7600 Glover Road,Langley, British Columbia, Canada, V2Y 1Y1c School of Nursing, University of British Columbia, 302–6190Agronomy Road, Vancouver, British Columbia, Canada, V6T 1Z3d UBC Graduate School of Journalism, University of BritishColumbia, 6388 Crescent Road, Vancouver, British Columbia,Canada, V6T 1Z2
Available online: 03 Jan 2012
To cite this article: James Voth, Richard Sawatzky, Pamela A. Ratner, Mary Lynn Young, RobinRepta, Rebecca Haines-Saah & Joy L. Johnson (2012): A computer-assisted approach to filteringlarge numbers of documents for media analyses, International Journal of Social ResearchMethodology, DOI:10.1080/13645579.2011.645700
To link to this article: http://dx.doi.org/10.1080/13645579.2011.645700
PLEASE SCROLL DOWN FOR ARTICLE
Full terms and conditions of use: http://www.tandfonline.com/page/terms-and-conditions

This article may be used for research, teaching, and private study purposes. Anysubstantial or systematic reproduction, redistribution, reselling, loan, sub-licensing,systematic supply, or distribution in any form to anyone is expressly forbidden.
The publisher does not give any warranty express or implied or make any representationthat the contents will be complete or accurate or up to date. The accuracy of anyinstructions, formulae, and drug doses should be independently verified with primarysources. The publisher shall not be liable for any loss, actions, claims, proceedings,demand, or costs or damages whatsoever or howsoever caused arising directly orindirectly in connection with or arising out of the use of this material.
Dow
nloa
ded
by [
The
Uni
vers
ity o
f B
ritis
h C
olum
bia]
at 0
6:59
03
Janu
ary
2012

A computer-assisted approach to filtering large numbers ofdocuments for media analyses
James Votha, Richard Sawatzkyb*, Pamela A. Ratnerc, Mary Lynn Youngd, RobinReptac, Rebecca Haines-Saahc and Joy L. Johnsonc
aIntogrey, 41 – 32777 Chilcotin Drive, Abbotsford, British Columbia, Canada V2T 5W4;bSchool of Nursing, Trinity Western University, 7600 Glover Road, Langley, BritishColumbia, Canada V2Y 1Y1; cSchool of Nursing, University of British Columbia, 302–6190Agronomy Road, Vancouver, British Columbia, Canada V6T 1Z3; dUBC Graduate Schoolof Journalism, University of British Columbia, 6388 Crescent Road, Vancouver, BritishColumbia, Canada V6T 1Z2
(Received 4 May 2011; final version received 29 November 2011)
Media analysts are challenged to acquire selections of documents that arerepresentative of their topics of interest. Conventional search and selection pro-cesses are often constrained because of an inability to efficiently filter largeamounts of potentially relevant documents and thus pose the risk of introducingbias. We describe a computer-assisted approach to increase the probability ofidentifying all articles relevant to a topic (in this case, marijuana), and provide anevaluation of its effectiveness in reducing bias while minimizing time expenditure.Using our system, we filtered 23,755 articles in 24.4 h. Relative to conventionalprocesses, a substantial reduction in bias was achieved. Our system significantlyreduced the risk of bias while retaining efficiency and accuracy in documentselection.
Keywords: media analysis; document filtering; selection bias; precision;computer assisted
The number of Canadians, especially youth, who use marijuana is substantial(Elgar, Phillips, & Hammond, 2011), the number of cannabis growing operationshas increased dramatically (Malm & Tita, 2007), and the associated criminal activi-ties appear to be increasingly violent (e.g. gang-related homicides) (Dauvergne,2009; Skelton, 2004). There is a corresponding public debate about the managementof these problems, with a focus on criminal justice, law enforcement, policing, andhealth and safety. There are specific health-related aspects to the debate, includingthe putative salutary effects of marijuana use (i.e. medical marijuana), and thepotential adverse health effects of marijuana production, distribution, and use(Fischer, Rehm, & Hall, 2009; Jones & Hathaway, 2008). Mainstream media have apowerful influence on these debates. To date, we lack a comprehensive analysis ofhow marijuana discourses have been represented in Canadian newspapers. We wereparticularly concerned about the prevailing focus on criminal justice matters and thelimited attention paid to the health-related effects of marijuana use. When health
*Corresponding author. Email: [email protected]
International Journal of Social Research Methodology2011, 1–18, iFirst Article
ISSN 1364-5579 print/ISSN 1464-5300 online� 2011 Taylor & Francishttp://dx.doi.org/10.1080/13645579.2011.645700http://www.tandfonline.com
Dow
nloa
ded
by [
The
Uni
vers
ity o
f B
ritis
h C
olum
bia]
at 0
6:59
03
Janu
ary
2012

effects were the focus, they appeared to be predominantly characterized as salutary(i.e. medical marijuana use), rather than adverse. It became clear that fullappreciation of the subtle and nuanced elements of the discourses would require rel-atively sophisticated methods. We therefore designed a multifaceted project toexplore the representation of marijuana discourses in Canadian newspapers.
Like all media analysts, we were challenged to acquire a comprehensive selectionof articles (or documents or messages) about our topic such that we could be confi-dent that all relevant articles would be included in our analysis. In our initial scan ofnewspaper articles related to marijuana use it became apparent that our analyseswould be biased had we based our identification and selection of relevant articlesexclusively on the use of ‘formal’ language (i.e. marijuana and cannabis vs. pot andweed), limited our selection of articles to those that were predominantly about mari-juana use rather than containing any reference to the topic, or limited our searchingto particular subsections or subjects within newspapers. We specifically sought to beinclusive of content that addressed a variety of topic areas, including criminal justicematters, health, sports, politics, and arts and entertainment. Without doing so, thedominant or typical messages would have been overrepresented and we would nothave been able to meet our goal of capturing the subtleties of the discourses in vari-ous contexts and over time. This paper addresses the methodological approaches wetook, and the system we developed and implemented to identify relevant articles.
The methodological challenge
Ideally, the selection or sampling of articles should be representative of the popula-tion of all relevant articles; in the context of systematic reviews of research litera-ture, this has been conceptualized as the domain of inquiry (Cooper, 2009). Inmany cases, the ‘true’ population of relevant articles is ill-defined because it isembedded within a corpus of relevant and non-relevant materials. Media analystsincreasingly rely on external search and retrieval databases (containing media suchas articles from newspapers, magazines, newsletters, and newswires) that require theuse of search strategies (also known as filtration strategies) to identify an accessiblepopulation that corresponds with their domain of inquiry (Jordan & Manganello,2009; Krippendorff, 2004; Riffe, Aust, & Lacy, 2009; Stryker, Wray, Hornik, &Yanovitzky, 2006). Mismatches between the accessible population and the domainof inquiry may arise because of the inability of analysts to formulate search strate-gies that fully express their intended domain. This includes challenges associatedwith the use of database-specific query syntax, the reliance on controlled vocabular-ies such as subject headings, the use of single-search term strategies, and the ambi-guity of language, in general. Mismatches of this nature could introduce asignificant threat to the external validity (i.e. the generalizability or representative-ness) of the analysis through the bias that arises from unintentionally limiting, andthus redefining, the domain of inquiry.
Some excellent guides to media analysis provide direction for the identificationof relevant articles (e.g. Neuendorf, 2002; Riffe, Lacy, & Fico, 2005) but presup-pose that the population of articles is known and well-defined. In practice, manymedia analyses are constrained by practical considerations and feasibility-drivenapproaches that may limit the representativeness of the sampled articles(Krippendorff, 2004; Riffe, Aust, & Lacy, 2009). Although many researchers haveconsidered the reliability and validity of content analysis procedures, the reliability
2 J. Voth et al.
Dow
nloa
ded
by [
The
Uni
vers
ity o
f B
ritis
h C
olum
bia]
at 0
6:59
03
Janu
ary
2012

and validity of their search strategies have received relatively less attention (Kolbe& Burnett, 1991; Neuendorf, 2002, 2011). Accordingly, there is a risk that theresulting analytical conclusions are biased because of the systematic exclusion ofrelevant articles. The extent to which this is a concern is unknown and depends onthe topic under study. For example, some topics have relatively well-specifiedvocabularies and are typically represented through the use of unambiguous terms(e.g. media analyses about diabetes (Rock, 2005) or the Columbine shootings(Muschert, 2007)). On the other hand, other topics may be more difficult to delin-eate because the related vocabularies are broader in scope; that is, they likely areexpressed through vocabularies that span multiple domains and include manyambiguous terms (often informal) that are not exclusively used with reference to thetopic (Navigli, 2009; Sanderson, 2008; Spasic, Ananiadou, McNaught, & Kumar,2005; Turdakov, 2010).
Herein, we discuss search and article selection strategies designed to minimizebias in the identification of articles about marijuana published in mainstream Cana-dian newspapers. Two approaches could have been taken: (a) we could have nar-rowly defined the domain of inquiry by exclusively using the formal andunambiguous terms marijuana or (marihuana) and cannabis or (b) we could haveattained a broad (inclusive) domain of inquiry by including cultural or less formalterms, such as pot and weed. We speculated that the former approach would likelyhave resulted in a selection of articles that reflected relatively formal criminal jus-tice or medical perspectives, whereas the latter approach would likely have beenmore inclusive of cultural or countercultural perspectives. The latter approach wasmore consistent with our intended domain of inquiry and was therefore preferred.However, the problem with the latter approach is that the terms pot and weed haveseveral meanings, some of which do not refer to marijuana. Their use in a strategydesigned to identify relevant articles creates a significant challenge because of theirambiguity and the resultant demand for significant resources to filter out irrelevantarticles (e.g. articles about cooking and gardening identified through the terms potand weed). The inclusion of informal terms raises questions of feasibility while theirexclusion raises concerns about bias. We therefore set out to develop and validatean approach that would allow for the inclusion of informal search terms to achievea representative sample of articles in a feasible manner.
Our methodological approach
We describe a computer-assisted approach that we developed to facilitate the filter-ing of large numbers of articles and maximize the probability of identifying all arti-cles relevant to our specified domain of inquiry (referred to as high recall Stryker,Wray, Hornik, & Yanovitzky, 2006; White, 2009). Our objectives were to: (a)design a system to accomplish this and (b) evaluate its effectiveness in reducingbias with an acceptable expenditure of resources (namely time). We first describethe development of the system and then provide an example of its application inthe search for Canadian newspaper articles that made reference to, or mention of,marijuana (our domain of inquiry).
We first provide a cursory overview of our approach and the system we devel-oped for searching and identifying relevant articles. We follow this overview withan elaboration of the more technical details of the system and some of the premisesunderlying our approach. It is important to distinguish between terms, words, and
International Journal of Social Research Methodology 3
Dow
nloa
ded
by [
The
Uni
vers
ity o
f B
ritis
h C
olum
bia]
at 0
6:59
03
Janu
ary
2012

their occurrences within articles. We therefore offer some definitions of particularrelevance to our approach in Table 1.
Our first step was to undertake a search of a database that indexes newspaperarticles. We used the Dow Jones Factiva� database. A variety of formal and infor-mal search terms (e.g. marijuana, cannabis, pot and weed) were intentionally usedto query the full text of all articles with the purpose of minimizing the unintentionalexclusion of relevant articles (i.e. maximizing the recall) (our search strategy is fur-ther described in the application section of this manuscript). The search resulted ina large candidate pool of articles (n= 41,348) that included at least one of oursearch terms and was therefore possibly relevant to our domain of inquiry.1 We sub-sequently designed a computer-assisted approach to filter the articles by classifyingeach article as relevant or not relevant based on the identification of terms and theiroccurrences that were indicative of an article’s relevance. The presence of a termcould only be considered indicative of relevance if every occurrence of that term, inthe candidate pool of articles, was found to be unambiguously concerned with thetopic (marijuana). As further elaborated below, ambiguous terms were expanded byadding words found immediately before or after their occurrence within an article,until a high level of confidence about the term’s ‘in context’ meaning was achieved.This process of term expansion continued until all articles were classified as rele-vant or not relevant. A relevant article, thus, was one that contained one or moreoccurrences of a term that unambiguously pertained to marijuana.
Premises underlying the approach
Because of the initial ambiguity of some of the search terms, we required a systemto disambiguate the meaning of their occurrence(s) within a particular article. Thiswas done by adding one or more adjacent words to a term (i.e. expanding the term),thereby increasing its semantic specificity and decreasing its ambiguity (polysemyand homonymy). This approach is based on the premise that, in semantic space, rela-tively less frequently occurring terms (i.e. expanded terms) tend to be more precisein meaning than are terms that occur more frequently (Manin, 2008). This processresulted in a collection of expanded terms whose occurrences overlapped or incorpo-rated other terms’ occurrences that were being disambiguated (for definitions, seeTable 1), as is further explained below. Two rules were applied to analyze thedisambiguated term occurrences within an article to determine the article’s relevance.
Rule number 1
The meaning of an ambiguous term occurrence is superseded by the meaning of anunambiguous term occurrence that incorporates it. Figure 1 provides examples ofthe disambiguation of the search term pot through its expansion into incorporatingterms.
Rule number 2
The ambiguity of a term occurrence persists in instances where it overlaps, ratherthan incorporates, another term occurrence. The ambiguity is reconciled by invokingrule number 1 and identifying an unambiguous expanded term occurrence thatincorporates the two overlapping term occurrences (see Figure 2).
4 J. Voth et al.
Dow
nloa
ded
by [
The
Uni
vers
ity o
f B
ritis
h C
olum
bia]
at 0
6:59
03
Janu
ary
2012

Table1.
Definitio
ns.
Element
Definitio
n(s)
Characteristicsspecificto
ourapproach
Searchterm
Anelem
entof
aqueryused
tosearch
forpossibly
relevant
articlesin
anexternal
database
Aggregatedas
aBoolean
search
usingOR
(e.g.mariju
anaOR
cannabisOR
potOR
weed)
Word
Asequence
ofcharacters
that
hasmeaning(s)
Can
beam
biguous(e.g.potcanreferto
mariju
ana,
acookingvessel,
oraflow
ercontainer)
Term
Anabstract
constructthat
consistsof
asequence
ofoneor
morewords
The
locusof
meaning
that
aids
inthedeterm
inationof
anarticle
beingrelevant
ornot(e.g.‘smoked
weed’
[relevant]or
‘weed
trim
mer’[not
relevant])
Term
-occurrence
Asingle
appearance
ofaterm
with
inaspecificcontext(i.e.
anarticle)
The
relevanceof
anarticle
isdeterm
ined
throughtheanalysisof
the
occurrencesof
term
swith
inthat
article
Expandedterm
Aterm
derivedfrom
anexistin
gterm
byadding
oneor
more
words
before
orafterit
Itisthroughterm
expansionthat
term
occurrencesaredisambiguated
Incorporated
term
-occurrence
Aterm
-occurrencethat
encompasses
anotherterm
-occurrence
inits
entirety
The
meaning
oftheexpanded
term
-occurrencesupersedes
that
ofthe
term
(s)itincorporates
Overlapping
term
-occurrence
Aterm
-occurrencethat
encompasses
only
partof
another
term
-occurrence
Another
expanded
term
that
incorporates
both
overlappingterm
occurrencesisrequired
Article
Anintentionalsequence
ofwords
New
spaper
article
inclusiveof
itsmeta-data
(e.g.headlin
es,errata,
newspaper
section,
subjectindexing
appliedby
thedatabase
provider).Anarticle
canbe
relevant
ornotrelevant
Candidate
article
pool
Asetof
possibly
relevant
articlesretrievedfrom
anexternal
database
throughtheapplicationof
asearch
strategy
Allarticlesretrievedfrom
Dow
JonesFactiv
a�usingoursearch
term
sandcriteria
International Journal of Social Research Methodology 5
Dow
nloa
ded
by [
The
Uni
vers
ity o
f B
ritis
h C
olum
bia]
at 0
6:59
03
Janu
ary
2012

The system architecture
We developed a modularized software system, including a user interface (client),to support our approach. Figure 3 provides a schematic overview. The modulesoperated in concert to handle exploratory queries from the client, article import-ing/conversion, index generation, and term occurrence processing (e.g. term fre-quency counts, positional information, and co-occurrences). Careful attention waspaid to optimize the system to efficiently process a large number of articles andterms. For example, during the filtering process, the system-user could query the
Figure 2. Incorporating two overlapping terms.
Figure 1. Example of search term disambiguation via incorporation. aRelevance withrespect to article selection within this specific candidate article pool. bRemains ambiguous;can only be classified in full context.
6 J. Voth et al.
Dow
nloa
ded
by [
The
Uni
vers
ity o
f B
ritis
h C
olum
bia]
at 0
6:59
03
Janu
ary
2012
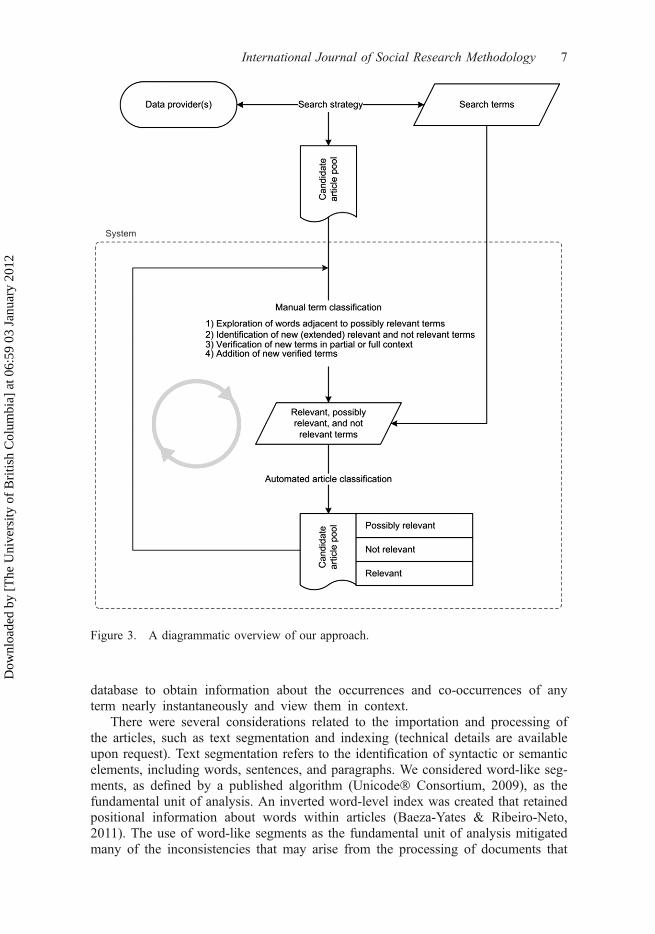
database to obtain information about the occurrences and co-occurrences of anyterm nearly instantaneously and view them in context.
There were several considerations related to the importation and processing ofthe articles, such as text segmentation and indexing (technical details are availableupon request). Text segmentation refers to the identification of syntactic or semanticelements, including words, sentences, and paragraphs. We considered word-like seg-ments, as defined by a published algorithm (Unicode� Consortium, 2009), as thefundamental unit of analysis. An inverted word-level index was created that retainedpositional information about words within articles (Baeza-Yates & Ribeiro-Neto,2011). The use of word-like segments as the fundamental unit of analysis mitigatedmany of the inconsistencies that may arise from the processing of documents that
Figure 3. A diagrammatic overview of our approach.
International Journal of Social Research Methodology 7
Dow
nloa
ded
by [
The
Uni
vers
ity o
f B
ritis
h C
olum
bia]
at 0
6:59
03
Janu
ary
2012

originated in print (e.g. optical character recognition errors that commonly arisewhen printed materials are scanned and converted to text). This was used for theefficient extraction and processing of terms.
Using the system
Once all the candidate articles were imported (n= 41,348), the unambiguous searchterms (e.g. marijuana and cannabis) were applied to identify those articles that couldbe immediately classified as relevant (n= 17,593). The remaining 23,755 articles con-tained only ambiguous search terms. The system-user then chose one of the ambigu-ous search terms (typically the most frequent one) and queried the system to identifythe words that were most commonly found immediately before or after it. The systemallowed the user to explore neighboring terms and the counts of their occurrences.The system-user then constructed an expanded term by choosing a combination ofterms believed to be unambiguous (see Figure 2). These expanded terms were subse-quently validated by viewing their occurrences in the ‘partial context viewer’ (seeFigure 4), which reveals each occurrence with approximately 10 neighboring words,both to the left and to the right. If still in doubt, there was an opportunity for the sys-tem-user to view the term occurrence in ‘full context’ (i.e. read the entire article). Theexpanded term was committed to the database as relevant or not relevant if, and onlyif, all of its occurrences were found to be consistently relevant or not relevant. Theautomated portion of the article classification process was triggered each time a newexpanded term was committed to the system. The articles containing the new term
Figure 4. Rendering of the client interface.
8 J. Voth et al.
Dow
nloa
ded
by [
The
Uni
vers
ity o
f B
ritis
h C
olum
bia]
at 0
6:59
03
Janu
ary
2012

were subsequently reclassified accordingly as relevant or not. This iterative and pro-gressive process was repeated until all possibly relevant articles had been classified.
The application of our approach
The above approach was applied to our particular case of identifying newspaperarticles that referenced marijuana via two sequential steps: (a) implementing asearch strategy to retrieve all potentially relevant articles from the Factiva�database (version: search 2.0) and (b) filtering the retrieved articles to identify thosethat were relevant.
Search and filtering strategies
The Factiva� database was selected because it contains the complete text of majorCanadian newspapers formatted using extensible markup language (XML). We reliedon the Factiva Intelligent Indexing system to identify articles that were: (a) written inEnglish (LA=EN), (b) published within a 10-year interval (publication date = 1 Janu-ary 1997–31 December 2007), (c) published in a Canadian newspaper (RST= sourcecodes of the 157 Canadian sources of which 13 were identified as newspapers), and(d) containing stories about Canada (RE=CANA). We did not use the intelligentindexing subject codes because no subject codes specific to our domain of inquirywere available. For example, the available subject codes, ‘drug/substance abuse’ and‘drug trafficking/dealing’ were not specific enough in that they included all kinds ofdrugs and substances, and yet were perhaps too specific in that they framed the use ofdrugs as a matter of abuse or crime. The following free-text query, consisting of termsthat often refer to marijuana, was used in combination with the above search criteria:(marijuana OR marihuana) OR (cannabis OR canabis) OR (hashish OR hashesh ORhasheesh) OR (reefer) OR (charas) OR (pot) OR (weed). The full-text and the index-ing information of all candidate articles that met the search criteria were retrieved andimported into our system (n= 41,348). Our approach to article filtering was appliedsubsequently to classify each article as relevant or not.
Evaluating efficiency and the reduction of bias
The efficiency of our approach was evaluated by monitoring the process and calcu-lating the aggregate amount of time, in person hours, required to classify the rele-vance of all articles. We defined bias as follows: the extent to which the omission ofrelevant articles is disproportionately distributed across various characteristics ofinterest. That is, bias occurs when relevant articles are not omitted at random. Giventhat we did not know the actual number of relevant articles in Factiva� database, wecould only determine the relative reduction in bias due to the inclusion of ambiguoussearch terms. Accordingly, we evaluated our approach’s capacity to minimize biasby calculating the percentage of the relevant articles that exclusively used one ormore of the ambiguous search terms. That is, we determined the percentage ofarticles that would have been excluded had we ignored the ambiguous search terms(i.e. percent reduction in bias = ((number of all relevant articles� number of relevantarticles with unambiguous terms)/number of all relevant articles)� 100). This rela-tive reduction in bias was evaluated with respect to several characteristics, such asthe year or newspaper in which the article was published, the length of the article(word count), the Canadian provinces or territories that were represented, andselected Factiva� subject headings that were associated with each article.
International Journal of Social Research Methodology 9
Dow
nloa
ded
by [
The
Uni
vers
ity o
f B
ritis
h C
olum
bia]
at 0
6:59
03
Janu
ary
2012

Results
Descriptive statistics
The size of the candidate article pool was 41,348, which included 19,697 (47.6%)articles that were ultimately determined to be relevant. Of the relevant articles,17,593 (89.3%) contained unambiguously relevant search terms and the remaining2104 articles (10.7%) were identified through the disambiguation of possibly rele-vant search terms. An additional 37 articles could not be classified because themeaning of a term occurrence could not be determined without reading the articlein its entirety (i.e. required manual classification). Thus, 23,755 (41,348�17,593)candidate articles had only ambiguous search terms and required processing usingour system. This resulted in an improvement in the recall of 2104 relevant articles(a 12.0% increase relative to the articles with unambiguously relevant search terms).That is, these 2104 articles would not have been identified had we reliedexclusively on unambiguous search terms.
The disambiguation of the terms pot and weed required the addition of 4307expanded terms. The term ‘pot’ was disambiguated using 3195 expanded terms ofwhich 2661 were classified as irrelevant and 534 as relevant. In many cases, multi-ple iterations of expansion were required before the meaning of the term could bedetermined with confidence. For example, the system-user assumed that theexpanded term ‘pot growers’ was relevant. However, through the use of the system,it became apparent that this term could be used in reference to marijuana and,somewhat unexpectedly, in reference to gardeners who grow plants in pots. There-fore, further term expansion was required. Similarly, 1112 expanded terms classifiedas irrelevant (907) or relevant (205) were identified to disambiguate the term‘weed’. The term ‘off the weed,’ for example, needed further disambiguation, andhence term expansion, to distinguish between references to tobacco smoking cessa-tion and marijuana smoking cessation. There were three instances during the devel-opment phase of the system when different system-users undertook theclassification of articles from start to finish. The above numbers were derived fromthe third and final filtering process. Nearly identical classification results wereobtained with a very small number of articles (n= 387) classified inconsistentlyacross the three instances. It is noteworthy that we also manually reviewed andclassified 10,629 of the most ambiguous articles that did not include a relevantsearch term, and then compared the classification with that obtained previously. Ofthese, 158 (1.5%) were classified inconsistently, which resulted in a reliabilityestimate (Cohen’s j) of .93 (95% CI: .92–.94). Given that the manually reviewedarticles were not randomly selected but were systematically selected because theircorrect classification was not obvious, this reliability estimate represents an underes-timation of the degree of precision we achieved and provides strong support for thesemantic validity of the rules described above.
Reduction in bias
To determine the extent to which using ambiguous search terms improved recall ofrelevant articles from the Factiva� database (i.e. reduced bias), we explored the rateat which articles would have been omitted had we relied exclusively on unambigu-ous search terms (i.e. the relevant search terms, marijuana and cannabis). We specif-ically compared the percentage of relevant articles with only ambiguous search
10 J. Voth et al.
Dow
nloa
ded
by [
The
Uni
vers
ity o
f B
ritis
h C
olum
bia]
at 0
6:59
03
Janu
ary
2012

terms (i.e. those that did not contain the terms marijuana or cannabis) across differ-ent newspapers, word counts, subject headings, and geographic regions (Canadianprovinces and territories) about which the article reported, as classified by Factiva�(see Table 2). The results pertaining to the newspapers revealed that recall wasimproved (reduction in bias) to varying degrees ranging from 3.0% of all relevantarticles for the Guelph Mercury (n= 633) to 15.8% for the Edmonton Journal(n= 962). Thus articles with references to marijuana in The Edmonton Journal, TheCambridge Reporter, and The Toronto Star would have been underrepresented rela-tive to those published in other newspapers if we had relied exclusively on unam-biguous search terms. Further analyses could be conducted to explore the possiblereasons for these differences, particularly with respect to the use of formal andinformal terminologies.
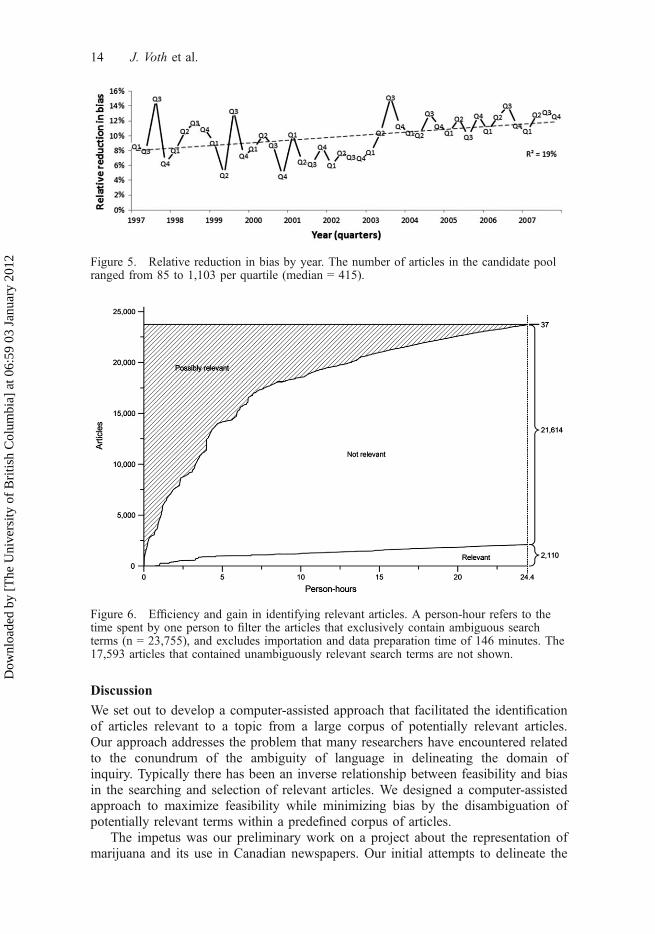
The results similarly revealed that our approach reduced bias in the identifica-tion of relevant articles with respect to their content by region and by subject (asclassified by Factiva�) (see Table 2). The relative reduction in bias ranged from3.9 to 12.2% across various geographic regions within Canada, and from 6.0 to39.4% across various subject headings. The greatest reduction in bias was foundfor articles with an ‘Arts/Entertainment’ subject heading, which suggests that anexclusive reliance on formal terminology would have significantly underrepre-sented stories related to the arts and culture. We also examined the reduction inbias in different years of publication (see Figure 5). On average, there was atrend toward increased use of informal terminology over time. If this wereignored, then bias would have been introduced at a differential rate over time.The articles’ word counts were categorized into quartiles to examine whether thereduction in bias was associated with the length of the article. There was a nota-ble reduction in bias as the articles increased in length (the relative reduction inbias ranged from 7.1% for articles less than 248 words (the first quartile) to18.3% for articles greater than 784 words (the fourth quartile)). Thus, relative toshorter articles, the lengthier articles would have been underrepresented if thesearch terms ‘pot’ and ‘weed’ had been omitted.
Efficiency of our approach in the identification of relevant articles
The time spent by one person to complete the entire process of filtering the arti-cles was 24.4 h. Figure 6 depicts the progress in the classification of the initialset of possibly relevant articles over time (the 23,755 articles that included onlyambiguous search terms). As expected, the greatest progress in article classifica-tion was made during the initial hours. It should be noted that the rate of pro-gress is, to some extent, dependent on the term expansion choices made by thesystem-user. The system-user can maximize efficiency by identifying the most fre-quently occurring expanded terms first. For example, the expanded term ‘a potof’ was identified early on in the process as being not relevant in all of its 1407occurrences. This expanded term contributed to efficiency by directly contributingto the classification of 1103 articles (based on the previously described rules). Incontrast, the expanded term ‘minestrone in the pot’ occurred only once and,although necessary, contributed to the classification of only one article as beingnot relevant.
International Journal of Social Research Methodology 11
Dow
nloa
ded
by [
The
Uni
vers
ity o
f B
ritis
h C
olum
bia]
at 0
6:59
03
Janu
ary
2012
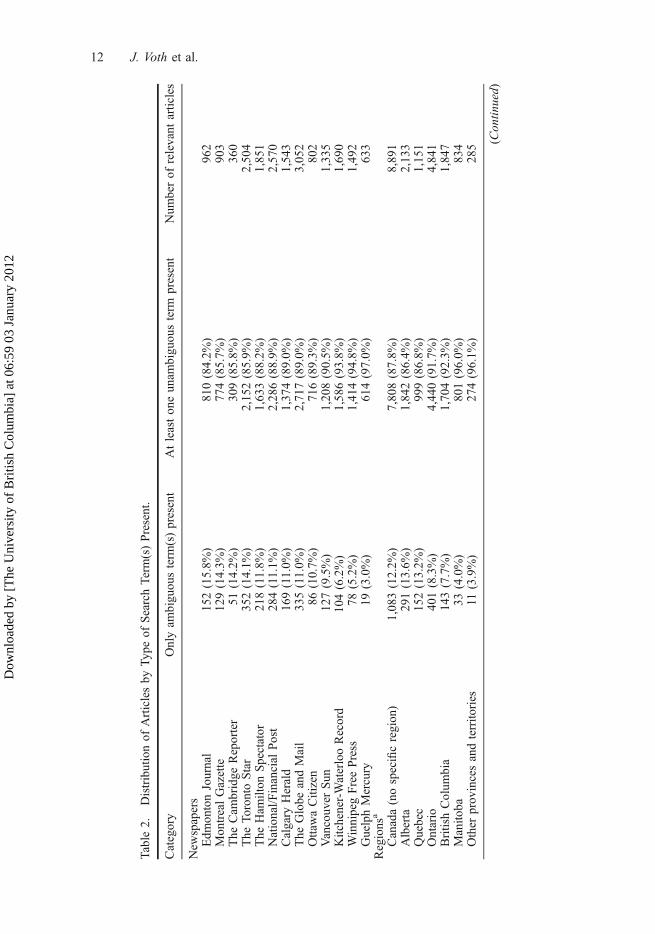
Table
2.Distributionof
Articlesby
Typeof
SearchTerm
(s)Present.
Category
Onlyam
biguousterm
(s)present
Atleastoneunam
biguousterm
present
Num
berof
relevant
articles
New
spapers
Edm
ontonJournal
152(15.8%
)810(84.2%
)962
MontrealGazette
129(14.3%
)774(85.7%
)903
The
Cam
bridge
Reporter
51(14.2%
)309(85.8%
)360
The
TorontoStar
352(14.1%
)2,152(85.9%
)2,504
The
Ham
ilton
Spectator
218(11.8%
)1,633(88.2%
)1,851
National/F
inancial
Post
284(11.1%
)2,286(88.9%
)2,570
Calgary
Herald
169(11.0%
)1,374(89.0%
)1,543
The
Globe
andMail
335(11.0%
)2,717(89.0%
)3,052
OttawaCitizen
86(10.7%
)716(89.3%
)802
Vancouver
Sun
127(9.5%)
1,208(90.5%
)1,335
Kitchener-WaterlooRecord
104(6.2%)
1,586(93.8%
)1,690
WinnipegFreePress
78(5.2%)
1,414(94.8%
)1,492
GuelphMercury
19(3.0%)
614(97.0%
)633
Regions
a
Canada(nospecificregion)
1,083(12.2%
)7,808(87.8%
)8,891
Alberta
291(13.6%
)1,842(86.4%
)2,133
Quebec
152(13.2%
)999(86.8%
)1,151
Ontario
401(8.3%)
4,440(91.7%
)4,841
BritishColum
bia
143(7.7%)
1,704(92.3%
)1,847
Manito
ba33
(4.0%)
801(96.0%
)834
Other
provincesandterrito
ries
11(3.9%)
274(96.1%
)285 (C
ontin
ued)
12 J. Voth et al.
Dow
nloa
ded
by [
The
Uni
vers
ity o
f B
ritis
h C
olum
bia]
at 0
6:59
03
Janu
ary
2012

Table2.
(Contin
ued).
Category
Onlyam
biguousterm
(s)present
Atleastoneunam
biguousterm
present
Num
berof
relevant
articles
Subject
headings
a
Arts/Entertainment
964(39.4%
)1,480(60.6%
)2,444
Politics/Internatio
nalRelations
113(8.5%)
1,215(91.5%
)1,328
Society/Com
munity
/Work
114(8.3%)
1,262(91.7%
)1,376
Fire/RescueServices
1(7.7%)
12(92.3%
)13
Sports/Recreation
95(6.9%)
1,287(93.1%
)1,382
Health
109(6.0%)
1,722(94.0%
)1,831
Wordcount(quartiles)
P785words
900(18.3%
)4,031(81.7%
)4,931
P508and<785words
553(11.2%
)4,383(88.8%
)4,936
P248and<508words
292(6.2%)
4,446(93.8%
)4,738
<248words
359(7.1%)
4,733(92.9%
)5,092
Note.
Categorieshave
been
sorted
bythe%
improv
edrecall(colum
n2).
a These
catego
ries
areno
tmutually
exclusive.
The
coun
tsthereforedo
notcorrespo
ndwith
thetotalnu
mberof
relevant
articles.
International Journal of Social Research Methodology 13
Dow
nloa
ded
by [
The
Uni
vers
ity o
f B
ritis
h C
olum
bia]
at 0
6:59
03
Janu
ary
2012
Discussion
We set out to develop a computer-assisted approach that facilitated the identificationof articles relevant to a topic from a large corpus of potentially relevant articles.Our approach addresses the problem that many researchers have encountered relatedto the conundrum of the ambiguity of language in delineating the domain ofinquiry. Typically there has been an inverse relationship between feasibility and biasin the searching and selection of relevant articles. We designed a computer-assistedapproach to maximize feasibility while minimizing bias by the disambiguation ofpotentially relevant terms within a predefined corpus of articles.
The impetus was our preliminary work on a project about the representation ofmarijuana and its use in Canadian newspapers. Our initial attempts to delineate the
Figure 6. Efficiency and gain in identifying relevant articles. A person-hour refers to thetime spent by one person to filter the articles that exclusively contain ambiguous searchterms (n = 23,755), and excludes importation and data preparation time of 146 minutes. The17,593 articles that contained unambiguously relevant search terms are not shown.
Figure 5. Relative reduction in bias by year. The number of articles in the candidate poolranged from 85 to 1,103 per quartile (median = 415).
14 J. Voth et al.
Dow
nloa
ded
by [
The
Uni
vers
ity o
f B
ritis
h C
olum
bia]
at 0
6:59
03
Janu
ary
2012

target population of all relevant articles indexed in a reference database yielded alarge number of potentially relevant articles. The identification of relevant articleswould have required filtering and thus significant time and other resources had con-ventional methods been applied. The approach that we developed and appliedallowed us to complete this filtering within a reasonable amount of time whilemaintaining a high level of precision (i.e. while minimizing the omission of relevantarticles and maximizing the omission of irrelevant ones). The results demonstratedthat many relevant articles would have been omitted had informal and ambiguouslanguage not been included in our initial search strategy, which would have led to abiased representation of articles related to the topic of interest (i.e. articles usinginformal language would have been underrepresented). We were able to filter23,755 articles in 24.4 h while avoiding such bias.
Notwithstanding the strengths of our approach, several limitations are worthy ofnote. Our approach assumes that it is possible to ascertain the relevance of a termbased on its immediate lexical context. There are instances in which this may notbe the case. For example, the expression ‘gone to pot’ may be used as an adianoeta(or a double entendre) of which the meaning cannot be ascertained with certaintywithin a limited context (i.e. ‘gone to pot’ can refer to something that has gonewrong or does not work, or may have been used as a playful reference to marijuanause). In addition, error could be introduced because of the repetitive nature of thetask which may have led to fatigue or inattention. With respect to our search strat-egy, we acknowledge that we did not include all of the informal search terms per-taining to marijuana use (e.g. idioms such as grass, Mary Jane, ganja, dope, spliff,and 420). The extent to which this is a concern depends on the likelihood of theseterms being used exclusively within an article. Thus one can never be confident ofeliminating bias entirely, or fully defining the domain of inquiry. Nonetheless, ourinclusion of some of the most pertinent informal terms has significantly reducedbias. In addition, other databases could have been included to broaden the search.
Although we have developed a sophisticated software system to implement ourapproach, there are practical aspects of the approach that could be applied feasiblyin the absence of customized software. Our example highlights that exclusive reli-ance on controlled vocabularies, or subject headings, may unintentionally limit ormisrepresent the intended domain of inquiry. For many social science topics, it isimportant to consider a variety of formal and informal terms that may be representa-tive of one’s topic. Some of these terms, especially informal terms, may have multi-ple meanings. To address this problem, term expansion procedures, as demonstratedhere, can be used to identify multi-word terms (phrases) that have greater specific-ity. These, in turn, can be used in the search process to identify relevant or irrele-vant articles with greater precision.
There are other, fully automated, computational systems that employ statisticalmethods to address the ambiguities of language, such as the use of latent-semanticanalysis (Deerwester, Dumais, Furnas, Landauer, & Harshman, 1990) or automatedword-sense disambiguation (Navigli, 2009). These methods have advanced signifi-cantly in recent years, and serve an important function in large scale document anal-ysis; indeed, they have been the focus of most contemporary research in the field ofcomputational linguistics (Jurafsky & Martin, 2009). By design, these methodsapply statistical models that characterize a corpus of documents in terms of its mostdominant patterns. In doing so, there is a risk of obfuscating underlying layers ofmeaning. In media analyses, the subtleties and non-dominant discourses may be as
International Journal of Social Research Methodology 15
Dow
nloa
ded
by [
The
Uni
vers
ity o
f B
ritis
h C
olum
bia]
at 0
6:59
03
Janu
ary
2012

important as are the dominant patterns and are often the focus of study. Ourapproach bridges the benefits of computational approaches, especially efficiency,with the added specificity and sensitivity that can only be accomplished throughhuman intervention. Our computer-assisted approach can be adapted for use in con-junction with model-based statistical approaches.
In addition to the incorporation of model-based statistical methods there areother enhancements that could be considered. For instance, although our approachis currently focused on the classification of relevant and irrelevant articles, it can beexpanded to facilitate other coding purposes or to develop domain-specific lexiconsand dictionaries. While many standardized dictionaries have already been developedand are widely used in content analysis (cf. Neuendorf, 2011), our approach couldbe used when an analysis would benefit from a lexicon derived from the sourcematerials under examination rather than applying one that is assumed to be repre-sentative thereof. It could also be applied to the coding of other units of text, suchas paragraphs or sentences.
In conclusion, we described an approach that addresses several challenges thatarise in using industry reference databases for searching and filtering articles of rele-vance to a particular domain of inquiry. Instead of delineating the domain of inquiryby relying on database-specific subject headings or narrowly defined search queries,our approach provides the means to use more comprehensive search strategies thatminimize bias while retaining considerable efficiency.
AcknowledgementsWe thank employees of Dow Jones Factiva� and of the University of British ColumbiaLibrary for their assistance. Social Sciences and Humanities Research Council of Canada.Grant number: 410-2007-2220.
Note1. The specified search produced a total of 41,461 articles, which included 113 articles that
did not contain any of the search terms in accordance with the Unicode� (2009) wordsegmentation algorithm used in our system. These articles were therefore not consideredin our analysis.
Notes on contributorsJames Voth is the founder of Intogrey, a freelance development, research and consultingcompany that focuses on the application of new media and innovative software development inthe context of social and medical research. He is currently leading the development of acomputer-based patient decision aid platform in conjunction with a Canadian interdisciplinaryresearch team.
Richard Sawatzky is Associate Professor of Nursing at Trinity Western University, Canada.His research program is focused on methods of patient-reported outcomes and quality of lifemeasurement, and the intersections of spirituality, religion, culture and other sources ofdiversity in various health care contexts.
Pamela Ratner is a Professor of Nursing at the University of British Columbia, Canada. Shehas led research initiatives to inform practice and policy through analyses of the socialcontexts that create barriers to health, affect health seeking, and influence health systemresponses. Her research program has focused on cardiovascular risk reduction and thepsychosocial determinants of health risk behaviour.
16 J. Voth et al.
Dow
nloa
ded
by [
The
Uni
vers
ity o
f B
ritis
h C
olum
bia]
at 0
6:59
03
Janu
ary
2012

Mary Lynn Young is an Associate Professor at the University of British Columbia GraduateSchool of Journalism. Her research interests include gender and the media, newsroomsociology, media credibility, and representations of crime.
Robin Repta was a social science researcher at the School of Nursing, University of BritishColumbia (UBC) at the time this paper was written. She is currently a doctoral student inthe UBC Interdisciplinary Studies Graduate Program. Her research interests focus on therelationship between gender and health, health messaging regarding adolescent substanceuse, and the impact of romantic relationships during adolescence on connectedness andhealth.
Rebecca Haines-Saah is a Research Associate at the School of Nursing, University of BritishColumbia where her research focuses on gender, tobacco and substance use.
Joy Johnson is a Professor at the School of Nursing, University of British Columbia and theScientific Director of the Canadian Institutes of Health Research, Institute of Gender andHealth. Her program of research focuses on health promotion and health behaviour change.A major thrust of her work focuses on sex and gender issues in substance use and mentalhealth.
References
Baeza-Yates, R., & Ribeiro-Neto, B. (2011). Modern information retrieval: The conceptsand technology behind search (2nd ed.). New York, NY: Addison Wesley.
Cooper, H. (2009). Research synthesis and meta-analysis. Thousand Oaks, CA: Sage.Dauvergne, M. (2009). Trends in police-reported drug offences in Canada. Juristat, 29(2).Deerwester, S., Dumais, S.T., Furnas, G.W., Landauer, T.K., & Harshman, R. (1990). Index-
ing by latent semantic analysis. Journal of the American Society for Information Science,41(6), 391–407. doi: 10.1002/(sici)1097-4571(199009)41:6<391::aid-asi1>3.0.co;2-9.
Elgar, F.J., Phillips, N., & Hammond, N. (2011). Trends in alcohol and drug use amongCanadian adolescents, 1990–2006. Canadian Journal of Psychiatry, 56(4), 243–247.
Fischer, B., Rehm, J., & Hall, W. (2009). Cannabis use in Canada: The need for a ‘publichealth’ approach. Canadian Journal of Public Health-Revue Canadienne De SantePublique, 100(2), 101–103.
Jones, C., & Hathaway, A.D. (2008). Marijuana medicine and Canadian physicians: Chal-lenges to meaningful drug policy reform. Contemporary Justice Review, 11(2), 165–175.doi: 10.1080/10282580802058429.
Jordan, A.B., & Manganello, J. (2009). Sampling and content analysis: An overview of theissues. In A.B. Jordan, D. Kunkel, J. Manganello, & M. Fishbein (Eds.), Media mes-sages and public health: A decisions approach to content analysis (pp. 53–66). NewYork, NY: Taylor and Francis.
Jurafsky, D., & Martin, J.H. (2009). Speech and language processing: An introduction tonatural language processing, computational linguistics, and speech recognition (2nded.). Upper Saddle River, NJ: Pearson Prentice Hall.
Kolbe, R.H., & Burnett, M.S. (1991). Content-analysis research: An examination ofapplications with directives for improving research reliability and objectivity. Journal ofConsumer Research, 18(2), 243–250.
Krippendorff, K. (2004). Content analysis: An introduction to its methodology (2nd ed).Thousand Oaks, CA: Sage.
Malm, A.E., & Tita, G.E. (2007). A spatial analysis of green teams: A tactical response tomarijuana production in British Columbia. Policy Sciences, 39(4), 361–377. doi:10.1007/s11077-006-9029-0.
Manin, D. (2008). Zipf’s Law and avoidance of excessive synonymy. Cognitive Science, 32(7), 1075–1098. doi: 10.1080/03640210802020003.
Muschert, G.W. (2007). The Columbine victims and the myth of the juvenile superpredator.Youth Violence and Juvenile Justice, 5(4), 351–366. doi: 10.1177/1541204006296173.
International Journal of Social Research Methodology 17
Dow
nloa
ded
by [
The
Uni
vers
ity o
f B
ritis
h C
olum
bia]
at 0
6:59
03
Janu
ary
2012

Navigli, R. (2009). Word sense disambiguation: A survey. ACM Computing Surveys, 41(2),10:11–10:69. doi: 10.1145/1459352.1459355.
Neuendorf, K. (2002). The content analysis guidebook. Thousand Oaks, CA: Sage.Neuendorf, K. (2011). Content analysis: A methodological primer for gender research. Sex
Roles, 64(3), 276–289. doi: 10.1007/s11199-010-9893-0.Riffe, D., Aust, C.F., & Lacy, S.R. (2009). Effectiveness of random, consecutive day and
constructed week sampling. In K. Krippendorff & M.A. Bock (Eds.), The content analy-sis reader (pp. 54–59). Thousand Oaks, CA: Sage.
Riffe, D., Lacy, S., & Fico, F. (2005). Analyzing media messages: Using quantitative contentanalysis in research (2nd ed.). Mahwah, NJ: Lawrence Erlbaum.
Rock, M. (2005). Diabetes portrayals in North American print media: A qualitative andquantitative analysis. American Journal of Public Health, 95, 1832–1838. doi:AJPH.2004.049866.
Sanderson, M. (2008). Ambiguous queries: Test collections need more sense. Paper presentedat the Proceedings of the 31st annual international ACM SIGIR conference on Researchand development in information retrieval, Singapore.
Skelton, C. (2004, September 25). Police fear gang war over pot: Price drop expected toignite violence between crime groups, The Vancouver Sun, p. C2.
Spasic, I., Ananiadou, S., McNaught, J., & Kumar, A. (2005). Text mining and ontologies inbiomedicine: Making sense of raw text. Briefings in Bioinformatics, 6(3), 239–251. doi:10.1093/bib/6.3.239.
Stryker, J.E., Wray, R.J., Hornik, R.C., & Yanovitzky, I. (2006). Validation of databasesearch terms for content analysis: The case of cancer news coverage [Article]. Journal-ism & Mass Communication Quarterly, 83(2), 413–430.
Turdakov, D. (2010). Word sense disambiguation methods. Programming and ComputerSoftware, 36(6), 309–326. doi: 10.1134/s0361768810060010.
Unicode� Consortium. (2009). Unicode� Standard Annex #29: Unicode� Text Segmenta-tion. In M. Davis (Ed.), Mountain view. CA: Author. Retrieved from http://www.uni-code.org/reports/tr29/tr29-15.html
White, H.D. (2009). Scientific communication and literature retrieval. In H. Cooper & L.V.Hedges (Eds.), The handbook of research synthesis (2nd ed., pp. 51–71). New York,NY: Russell Sage.
18 J. Voth et al.
Dow
nloa
ded
by [
The
Uni
vers
ity o
f B
ritis
h C
olum
bia]
at 0
6:59
03
Janu
ary
2012




















