
1994 ACM SIGPLAN Workshop on ML and its Applications - CiteSeerX
164
ISSN 0249-6399 apport de recherche 1994
-
Upload
khangminh22 -
Category
Documents
-
view
0 -
download
0
Transcript of 1994 ACM SIGPLAN Workshop on ML and its Applications - CiteSeerX

ISS
N 0
249-
6399
ap por t de r ech er ch e
1 9 9 4
INSTITUT NATIONAL DE RECHERCHE EN INFORMATIQUE ET AUTOMATIQUERecord of the1994ACM SIGPLANWorkshop on ML and its ApplicationsOrlando, Florida (USA)June 25-26, 1994N� 2265Juin 1994PROGRAMME 2Calcul symbolique,programmationet g�enie logiciel

22

Actes du s�eminaire1994ACM-SIGPLANWorkshop on ML and its ApplicationsAvant proposLe langage de programmation ML est devenu �a la fois un outil important et un cadre de travail pourla recherche sur la conception des langages et de leur mise en �uvre. Le but de ce s�eminaire est depr�esenter les d�eveloppements r�ecents autour de ML et de cr�eer un forum pour les id�ees nouvelles.Le th�eme principal est la modularit�e | les syst�emes de modules, la programmation avec objets et larecompilation, mais d'autres sujets importants tels que la compilation, les extensions du langage etdes applications sont �egalement repr�esent�es.Ce volume contient 16 articles pr�esent�es au 1994 ACM SIGPLAN Workshop on ML and its Ap-plications qui a eu lieu les 25 et 26 juin 1994 �a Orlando, Floride, en conjonction avec les conf�erenceset les s�eminaires ACM SIGPLAN '94. C'�etait le cinqui�eme s�eminaire sur ML, et le second organis�eavec la participation de SIGPLAN. Les articles ont �et�e s�electionn�es par le comit�e de lecture parmiun ensemble de 41 r�esum�es de 4 pages soumis par courrier �electronique. Un autre r�esum�e, soumistardivement, n'a pas pu etre consid�er�e. Les r�esum�es n'ont pas �et�e formellement �evalu�es mais ils ont�et�e lus par tous les membres du comit�e de programme.La dur�ee du s�eminaire n'a malheureusement pas permis de retenir tous les articles int�eressants.Le comit�e de lecture tient �a remercier tous les auteurs qui ont soumis un r�esum�e, que celui-ci ait oun'ait pas pu etre retenu. Le grand nombre de soumissions montre l'importance du langage ML etl'enthousiasme qu'il suscite.


ForewordThe ML programming language has evolved as an important tool, as well as a framework forresearch in language design and implementation. The aim of this workshop is to present recentdevelopments and provide a forum for new ideas related to ML. The main theme of the papers ismodularity | module systems, object oriented programming, and recompilation, but other impor-tant topics, such as compilation, language extensions, and applications, are also represented.This volume contains 16 papers presented at the 1994 ACM SIGPLAN Workshop on ML andits Applications, which was held on June 25 and 26, 1994 in Orlando Florida, in conjunction withthe ACM SIGPLAN '94 Conferences and Workshops. This was the �fth workshop on ML, andthe second sponsored by SIGPLAN. The papers were selected by the program committee from acollection of 41 four-page abstracts submitted by electronic mail. One additional abstract could notbe considered since it was submitted after the deadline. The abstracts were not formally refereed,but were reviewed by all members of the program committee.Unfortunately, because of time limitations, we could not accept all of the worthy papers. Wewould like to thank all of the authors who submitted abstracts, regardless of whether they wereaccepted or rejected. The large number of submissions is a testament to the importance andenthusiasm surrounding the ML language.Workshop CommiteeWorkshop ChairJohn H. Reppy (AT&T Bell Laboratories)Program ChairDidier R�emy (INRIA-Rocquencourt)Program CommiteeLennart Augustsson (Chalmers University)Guy Cousineau (Ecole Normale Superieur d'Ulm)Tim Gri�n (AT&T Bell Laboratories)Peter Lee (Carnegie Mellon University)Atsushi Ohori (Kyoto University)i

Author IndexAppel, Andrew W. : : : : : : : : : : : : : : 148Barth�elemy, Fran�cois : : : : : : : : : : : : : 34Bj�rner, Nikolaj Skallerud : : : : : : :120Chailloux, Emmanuel : : : : : : : : : : : : 79Cr�egut, Pierre : : : : : : : : : : : : : : : : 13, 23Danvy, Olivier : : : : : : : : : : : : : : : : : : 112de Rauglaudre, Daniel : : : : : : : : : : : :70Duggan, Dominic : : : : : : : : : : : : : : : : 50Goubault, Jean : : : : : : : : : : : : : : : : : : 62Guzm�an, Juan Carlos : : : : : : : : : : : 127Harper, Robert : : : : : : : : : : : : : : : : : 136Heintze, Nevin : : : : : : : : : : : : : : : : : : 112Inagaki, Yasuyoshi : : : : : : : : : : : : : : : 91Kawaguchi, Nobuo : : : : : : : : : : : : : : : 91Lee, Peter : : : : : : : : : : : : : : : : : : : : : : 136Leroy, Xavier : : : : : : : : : : : : : : : : : : : : : :1MacQueen, Dave : : : : : : : : : : : : : : : : : 13Malmkj�r, Karoline : : : : : : : : : : : : :112Mauny, Michel : : : : : : : : : : : : : : : : : : : 70Pfenning, Frank : : : : : : : : : : : : : : : : :136Rollins, Eugene : : : : : : : : : : : : : : : : : 136Rouaix, Fran�cois : : : : : : : : : : : : : : : : : 34Sakabe, Toshiki : : : : : : : : : : : : : : : : : : 91Serrano, Manuel : : : : : : : : : : : : : : : : 101Su�arez, Asc�ander : : : : : : : : : : : : 79, 127Thorup, Lars : : : : : : : : : : : : : : : : : : : : :41Tofte, Mads : : : : : : : : : : : : : : : : : : : : : : 41Weis, Pierre : : : : : : : : : : : : : : : : : : : : :101
ii

Saturday, June 25Session 1: 9:00{10:30 a.m. ModulesA Syntactic Theory of Type Generativity and Sharing : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 1Xavier Leroy (INRIA-Rocquencourt)An Implementation of Higher-order Functors : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : :13Pierre Cr�egut (CNET-Lannion) and Dave MacQueen (AT&T Bell Laboratories)Safe Dynamic Connection of Distributed Applications : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 23Pierre Cr�egut (CNET-Lannion)Session 2: 11:00 a.m.{12:30 p.m. Object-oriented ProgrammingAbstract Data-types and Operators: An Experiment in Constraint-based Parsing : : : : : : : : : 34Fran�cois Barth�elemy and Fran�cois Rouaix (INRIA-Rocquencourt)Object Oriented Programming and Standard ML : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 41Lars Thorup and Mads Tofte (DIKU)Object Interfaces, Polymorphic Methods and Multi-method Dispatch for ML-likeLanguages : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 50Dominic Duggan (University of Waterloo)Session 3: 2:00{4:00 p.m. Advanced Features and ApplicationsHimML: Standard ML with Fast Sets and Maps : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 62Jean Goubault (Bull)A Complete and Realistic Implementation of Quotations for ML : : : : : : : : : : : : : : : : : : : : : : : : :70Michel Mauny and Daniel de Rauglaudre (INRIA-Rocquencourt)mlP�cTEX, A Picture Environment for LaTEX : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : :79Emmanuel Chailloux (LITP) and Asc�ander Su�arez (Universidad Sim�on Bol��var)TERSE : TErm Rewriting Support Environment : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 91Nobuo Kawaguchi, Toshiki Sakabe and Yasuyoshi Inagaki (Nagoya University)Session 4: 4:00{5:30pm Demonstrations and PostersSunday, June 26Session 5: 9:00{10:30 a.m. Compilation1+1=1: an Optimizing Caml Compiler : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 101Manuel Serrano and Pierre Weis (INRIA-Rocquencourt)ML Partial Evaluation using Set-based Analysis : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 112Karoline Malmkj�r (Aarhus University), Nevin Heintze (Carnegie Mellon University)and Olivier Danvy (Aarhus University)Minimal Typing Derivations : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 120Nikolaj Skallerud Bj�rner (Stanford University)iii

Session 6: 11:00 a.m.{ 12:30 p.m. Security and RecompilationA Type System for Exceptions : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 127Juan Carlos Guzm�an and Asc�ander Su�arez (Universidad Sim�on Bol��var)A Compilation Manager for Standard ML of New Jersey : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 136Robert Harper, Peter Lee, Frank Pfenning and Eugene Rollins (Carnergie Mellon Uni-versity)Axiomatic Bootstrapping: A Guide for the Compiler Hacker : : : : : : : : : : : : : : : : : : : : : : : : : : : :148Andrew W. Appel (Princeton University)
iv

A syntactic theory of type generativity and sharing(extended abstract)Xavier LeroyINRIA Rocquencourt�AbstractThis paper presents a purely syntactic account of typegenerativity and sharing | two key mechanisms in theSML module system | and shows its equivalence withthe traditional stamp-based description of these mecha-nisms. This syntactic description recasts the SML mod-ule system in a more abstract, type-theoretic framework.1 IntroductionFirst introduced to justify a posteriori the use of nameequivalence in typechecker implementations, the notionof type generativity (the fact that, in some languages,data type de�nitions generate \new" types incompatiblewith any other types including data types with similarstructure) has since emerged as a key mechanism to im-plement type abstraction: the important programmingtechnique where a named type t is equipped with op-erations f;g; : : : then the concrete implementation of tis hidden, leaving an abstract type t that can only beaccessed through the operations f;g; : : : [12]. Type gen-erativity plays a crucial role in type abstraction, sincemaking a type t abstract amounts to generating a newtype t incompatible with any other type, including itsconcrete representation and other data types with similarstructure. Generativity ensures that only the operationsprovided over t can access its concrete representation.Type generativity is therefore an essential feature oftype abstraction; unfortunately, it is also one of the mostmysterious and most di�cult to de�ne formally in a typesystem. In simple cases such as Modula-2's modules [21],name equivalence provides a satisfactory notion of gener-ativity: generated types are represented in type expres-sions by their names; uniqueness of names is ensured bysuitable syntactic restrictions or by renamings. Unfor-tunately, this simple approach does not extend easily tomore powerful module and type abstraction systems, inparticular those that feature functors (parameterized ab-stractions) [13, 7]. The main reason is that if the resultof a functor contains a generative type declaration, thena new type must be generated for each application of thefunctor. Otherwise, two di�erent structures obtained byapplying a functor to two di�erent arguments would have�Most of this work was done while the author was visitingStanford University. Current address: projet Cristal, INRIARocquencourt, B.P. 105, 78153 Le Chesnay, France. E-mail:[email protected].
compatible type components and therefore could accesseach other's representations, which violates abstraction.Simple approaches based on name equivalence fail to ac-count for the generation of new types at each functorapplication.Parameterized abstractions such as SML's functorsraise other interesting issues in connection with type gen-erativity. First, not all type components in functor re-sults are generative: in many practical situations, theyare simply inherited from some types in the functor argu-ment, and the compatibility between the argument typeand the result type must be preserved. Second, we shouldalso account for SML's sharing constraints: the mecha-nism by which a functor with several arguments can re-quire that some type components of its arguments areactually the same type, or in other terms that they havebeen generated at the same time [13, 7]. Therefore, atheory for type generativity must not go too far and e.g.systematically generate new types for all functor appli-cations. Instead, it should maintain a suitable notionof type identity, where new types are generated whenthe programmer requires it, but the identities of existingtypes are correctly propagated otherwise.Two approaches to type generativity and sharing havebeen investigated so far. The �rst approach, exempli-�ed by the De�nition of SML [16], formalizes the use ofstamps to represent generative types (a common imple-mentation practice) and extends it to the case of functors.The result is a calculus over stamps that captures the ex-pected behavior of type generativity, but is too low-leveland operational in nature to allow easy formal reason-ing about type abstraction (e.g. proving the fundamentalrepresentation independence properties), and is relativelydi�cult to extend with new features.The second approach to type abstraction relies onname equivalence to account for type generativity: gener-ative types are represented in the type algebra by free orexistentially quanti�ed type variables, which are struc-turally di�erent from any other type expression exceptthemselves; suitable restrictions over variable names en-sure that two types generated at di�erent times will al-ways be represented by di�erent variables. A numberof type systems have been developed along these lines[17, 5, 2, 3], more abstract and type-theoretic in avorthan the stamp-based descriptions. These type systemsare relatively easy to extend and reason about, but gen-erally fail to account for the expected behavior of typegenerativity: new types are generated in situations where1

the identity of an existing type should be preserved [14];moreover, sharing constraints are not accounted for.The purpose of the present paper is to show that asimple extension of the type-theoretic approach | theintroduction of type equalities in signatures, as recentlyproposed in [10, 6] | succeeds in capturing a reasonablenotion of type identity: we will prove that a type sys-tem for modules, derived from [10], expresses exactly thesame notion of type generativity and sharing as the SMLstamp-based static semantics. Assuming that the lattercaptures \the" right notion of type generativity, as sug-gested by the large amount of practical experience gainedwith the SML module system, the equivalence result inthis paper therefore proves that we have �nally obtaineda satisfactory syntactic description of type generativityand sharing.The remainder of this paper is organized as follows.Section 2 introduces a skeletal module language and givesit a stamp-based static semantics in the style of the De�-nition. Section 3 reviews the syntactic approaches to typeabstraction and generativity that have been proposed sofar. As an application of these ideas, section 4 gives atype system (without stamps) for the skeletal modulelanguage, subject to some syntactic restrictions. Sec-tion 5 de�nes a normalization process that circumventsthe syntactic restrictions in a way compatible with thestamp-based static semantics. Section 6 �nally provesthe equivalence of the type system and the static seman-tics on normalized programs.2 A stamp-based static semanticsThe simpli�ed module language TypModL we will use inthis paper is derived from the ModL calculus introducedby Tofte et al. to study the related notions of structuresharing and generativity [7, 19, 20, 1]. TypModL featuresgenerative and non-generative type declarations, struc-tures, and �rst-order functors. The main simpli�cationwith respect to the SML module system is that structureshave no value components, since the presence of values instructures is irrelevant to our study of type generativity.In the following grammar, t ranges over type iden-ti�ers, x over structure identi�ers, and f over functoridenti�ers.Programs:m ::= " the empty programj structure x = s; m structure bindingj functor f(x : S) = s; m functor bindingStructure expressions:s ::= ps access to a structurej struct d end structure constructionj f(s) functor applicationStructure body:d ::= " j c;dDe�nitions:c ::= type t = T type bindingj datatype t type creationj structure x = s structure bindingj open s structure inclusionSignature expressions:S ::= sig D end
Signature body:D ::= " j C;DDeclarations:D ::= type t type declarationj structure x : S structure declarationj sharing pt = p0t sharing constraintType expressions:T ::= pt j T1 ! T2Structure paths:ps ::= x j ps:xType paths:pt ::= t j ps:tA program is a sequence of structure and functor def-initions. A structure contains de�nitions for types andsub-structures. Two kinds of type de�nitions are pro-vided: non-generative, type t = T , which de�nes t asa synonym for the type expression T , and generative,datatype t, which creates a \new" type t. The latter isintended to model the datatype and abstype constructsin SML, which declare new types with associated con-structors or functions. Since we do not have values inthis calculus, the constructors and functions associatedwith datatype and abstype are omitted.The static semantics (compile-time checks) for thiscalculus is a direct adaptation of the static semanticsgiven in the SML de�nition [16, chapter 5]. It uses the\semantic" objects de�ned below to represent types andstructures at compile-time. Stamps, written n, rangeover a countable set of identi�ers.Types: � ::= n j �1 ! �2Signatures: � ::= ft 7! � ; x 7! �; : : :gFunctor signatures: � ::= 8N1: (�1;8N2:�2)(N1, N2 are sets of stamps)Environments: � ::= ft 7! � ; x 7! �; f 7! �; : : :gTypes � are either function types or stamps representinggenerated types. Signatures � are �nite maps from typeidenti�ers to types, and from structure identi�ers to sig-natures. Environments � are similar, but also map func-tor identi�ers to functor signatures. Functor signatures8N1: (�1;8N2:�2) are composed of two signatures andtwo sets of universally quanti�ed names: the signature�1 describes the expected shape for the argument, thesignature �2 describes the result structure, N2 is the setof stamps that must be generated afresh at each applica-tion, and N1 is the set of \ exible" stamps in the functorargument (those that can be instantiated to match thestructure provided as argument). Functor signatures areidenti�ed modulo renaming of bound stamps.The static semantics is de�ned by the in-ference rules in �gure 1. The rules de�neseveral \elaboration judgements" of the form� ` syntactic object ) semantic object, which check thewell-formedness of syntactic objects in the elaborationenvironment � and return their representations assemantic objects.The rules for elaborating type and structure expres-sions (rules 1{10) translate the type and structure pathsaccording to the environment � and build the correspond-ing semantic objects. The rule for datatype declarations(rule 8) assigns a new stamp n to the type being de-clared: n is chosen outside of FS(�), the set of stamps2

Elaboration of paths: �(ps:x) = (�(ps))(x) �(ps:t) = (�(ps))(t)Elaboration of type expressions:� ` pt ) �(pt) (1) � ` T1 ) �1 � ` T2 ) �2� ` (T1 ! T2)) (�1 ! �2) (2)Elaboration of structure expressions:� ` ps ) �(ps) (3) � ` d) �� ` struct d end) � (4)� ` s) � (�1;8N:�2) � �(f) � � �1 N \ FS(�) = ;� ` f(s)) �2 (5)� ` ") fg (6) � ` T ) � �+ ft 7! �g ` d) �� ` (type t = T ; d)) ft 7! �g+ � (7) n =2 FS(�) � + ft 7! ng ` d) �� ` (datatype t; d)) ft 7! ng+ � (8)� ` s) �1 � + fx 7! �1g ` d) �� ` (structure x = s; d)) fx 7! �1g+� (9) � ` s) �1 �+ �1 ` d) �2� ` (open s; d)) �1 +�2 (10)Elaboration of signature expressions:� ` D) �� ` (sig D end)) � (11) � ` ") fg (12) � + ft 7! �g ` D) �� ` (type t; D)) ft 7! �g+� (13)� ` S ) �1 � + fx 7! �1g ` D) �� ` (structure x : S; D)) fx 7! �1g+� (14) �(pt) = �(p0t) � ` D) �� ` (sharing pt = p0t; D)) � (15)Elaboration of programs:� ` ") ok (16) � ` s) � � + fx 7! �g ` m) ok� ` (structure x = s; m)) ok (17)� ` S ) �1 �1 is principal for S in � N1 = FS(�1) n FS(�)� + fx 7! �1g ` s) �2 N2 = FS(�2) n FS(�1) n FS(�)� + ff 7! 8N1: (�1;8N2:�2)g ` m) ok� ` (functor f(x : S) = s; m)) ok (18)Figure 1: Static semantics with stampsoccurring free in the environment �, then bound to t in� for the elaboration of the remainder of the de�nition,which ensures that n will not be assigned later to anotherdatatype declaration.The most interesting rule is the rule for functor appli-cation (rule 5). Matching the structure argument againstthe functor argument signature involves two steps: an in-stantiation step (written �) where the exible stamps inthe argument and result signatures are substituted bytypes matching those in the argument structure, and anenrichment step (written �), which checks that the argu-ment contains all the required components and possiblymore. These two steps are formally de�ned as follows:De�nition 1 (Instantiation relation)(�01;8N 02:�02) � 8N1: (�1;8N2:�2) holds ifthere exists a substitution ' of types for stampssuch that Dom(') � N1 and �01 = '(�1) and8N2:�02 = '(8N 02:�2).De�nition 2 (Enrichment relation) �1 � �2 holdsif Dom(�1) � Dom(�2) and �1(t) = �2(t) for all t 2Dom(�2) and �1(x) � �2(x) for all x 2 Dom(�2).The constraint N \ FS(�) = ; in rule 5 ensures thatnew stamps are assigned to the generative types in thefunctor result.Elaboration of signature expressions (rules 11{15) isstraightforward, except that the rule for type compo-nents (rule 13) allows any type, not only new stamps, tobe assigned to the type identi�er. The goal is to allowsubsequent sharing constraints (rule 15) to be satis�edby suitable choice of these types.As a result, a signature expression can elaborate tomany di�erent signatures. However, some of these sig-natures are principal in the following sense: � is princi-pal for S in � if � ` S ) � and, for all �0 such that� ` S ) �0, there exists a substitution ' of types forstamps such that �0 = '(�) and Dom(')\N = ;. Intu-itively, a signature is principal for S if it captures exactly3

the sharing required by S, but no more. It is easy toprove that any signature expression that elaborates in �admits a principal signature in � [19].The rule for functor declarations (rule 18) representsthe functor argument by its principal signature duringthe elaboration of the structure body. The stamps thatare free in the principal signature but not used in � be-come the exible stamps N1 in the functor signature; thestamps N2 that are free in the functor body signature butnot in � nor in N1 are the stamps N2 that are generatedat each application.3 Type systems for type abstractionIn this section, we review some previously proposed typesystems for type abstraction and progressively introducethe main ingredients of our type system. Unlike the staticsemantics, these systems are purely syntactic in nature:the typing rules involve only structure and signature ex-pressions; no elaboration into richer semantic objects isrequired.3.1 Existential typesMitchell and Plotkin [17] derived the �rst such typesystem from the observation that type abstractionhas strong connections with second-order existentialquanti�cation in logic: a signature sig type t; : : :end is viewed as the existential statement \there existsa type t such that : : : "; a structure struct type t=T;: : : end, as a constructive proof of this statement.To access structure components, the Mitchell-Plotkinapproach does not use projections (s:t to refer to thecomponent t of s) as in the SML modules, but insteada binding construct open s as D in e, modeled after9-elimination in constructive logic. This construct bindsthe components of structure s to the variables declared inD (a signature body), then evaluates the expression e inthe enriched context. For the purpose of type-checkinge, the type variables t1 : : : tn declared in D are treatedas free type variables in the type algebra; hence ti isincompatible with any type except itself. This ensuresthat e is parametric in t1 : : : tn and can safely be executedwith any concrete implementation of t1 : : : tn.Type abstraction is ensured by two crucial syntacticrestrictions on the open construct. First, the type vari-ables t1 : : : tn bound by D in open must not be alreadybound in the current environment, to ensure the unique-ness of the types t1 : : : tn. Second, the variables t1 : : : tnmust not appear free in the type of the body e of theopen construct.This approach provides a simple and elegant treat-ment of type abstraction. Its main weakness is that itdoes not correctly preserve the identity of an abstracttype [4]: if open is applied twice to the same structure,the two sets of type variables thus introduced will notmatch; hence, types are generated when structures areopened, not when they are created. This lack of a unique\witness" for each abstract type makes this approach in-appropriate for modular programming [14].
3.2 The dot notationIn an attempt to address this issue, Cardelli [4, 2] has pro-posed a variant of the Mitchell-Plotkin approach wherethe open elimination construct is replaced by the \dotnotation", that is, a projection-like elimination constructsimilar to SML's long identi�ers and Modula-2's quali-�ed identi�ers: in a type context, s:t refers to the typecomponent t of structure s. Two type expressions of theform s:t and s0:t are compatible if and only if s and s0are syntactically identical.As in Mitchell and Plotkin's approach, type abstrac-tion is here ensured via suitable syntactic restrictions.First, s in s:t cannot be any structure expression, but isrequired to be a structure identi�er x or structure pathx:x1:x2 : : : xn, to ensure that its evaluation cannot gen-erate new types. The following example illustrates whatgoes wrong if this restriction is lifted:functor F(X: sig end) =struct datatype t; ... end;... F(sig end).t ... F(sig end).t ...The two applications of F generate distinct types t, butthe two occurrences of F(sig end).t, which are syntac-tically identical, would be considered as compatible typesaccording to the equivalence rule for type expressions.The other restrictions are similar to those for theopen construct: functor parameters must not appear inthe result signature of the functor (no dependent func-tor types); structure bindings (in structures or as functorparameters) must not rebind an already bound structurename. As an example of incorrect rebinding, assume thecurrent environment isstructure s : (struct type t; val v:t end);val x : s.tand consider the declarationstructure s = struct datatype t endAfter typing, x will appear to have type s.t (the newlygenerated type), which is semantically false. Therefore,rebindings must be avoided by prior renaming of boundvariables, as with the open construct.Projections and renamingsThis necessary renaming of variables is problematic inconjunction with the dot notation. Identi�ers bound in-side a struct ... end should not be renamed, since thedot notation relies on their names to extract a compo-nent of the structure. For instance, if we rename t to t'in the structurestructure s = struct type t = int; ... endthen further references to s.t become invalid. (There isno sensible way to transform them into s.t', since theyare outside the scope of the binding type t=int.)One solution to this problem is to use positions in-stead of names to extract structure components [3], butthis makes signature subsumption problematic.A more general solution is to distinguish betweennames and identi�ers [10, 6]. Each identi�er has a name,but distinct identi�ers may have the same name. Accessin structures is by component name; type equivalence4

and references to bound variables are by identi�er. Wewrite t, x for type and structure names, and ti and xifor type and structure identi�ers (with respective namest and x), where the mark i is taken from a countableset, in order to provide in�nitely many identi�ers witha given name. The general shape of paths is nowxi:y : : : t, referring to the component named t of : : : ofthe component named y of the structure bound to theidenti�er xi.In this approach, renamings are allowed to change themark parts of identi�ers, but must preserve their nameparts. For instance, in the structurestructure xi = struct type tj = int; ... endwe can rename tj to tk without changing the meaning ofxi:t, but renaming tj to sj would be incorrect.This distinction between names and identi�ers is re-quired for type-checking, but can be omitted in the pro-gram source: identi�ers can be recovered before type-checking by associating a di�erent identi�er to each bind-ing occurrence of a name and applying the standard scop-ing rules to names. We will use this convention in theexamples below.Problems with the dot notationUnlike the open notation, the dot notation provides aunique witness for each type component of a structureand is much closer to actual programming languages.However, it still fails to provide a reasonable notion oftype identity. Consider taking a restricted view of astructure by constraining it to a smaller signature, asin structure x =struct datatype t; val f=...; val g=... endstructure y =(x : sig type t; val f: ... end)This restriction generates a new type y.t incompatiblewith x.t, while all views of the same structure shouldhave compatible type components. Similarly, functor ap-plication always generates new types in the result struc-ture, even if these types are actually taken from the func-tor argument:functor f(x: sig type t end) =struct type t = x.t endstructure x = struct datatype t endstructure y = f(x)The type y.t is incompatible with x.t, even though fpropagates the t component of its argument unchanged.Finally, the dot notation as presented above does notaccount for sharing constraints.3.3 Manifest typesIn an attempt to palliate these de�ciencies of the dot no-tation, Harper and Lillibridge [6] and independently theauthor [10] have proposed to enrich signatures with typeequations. The idea is to have two kinds of speci�cationsfor type components:� type t, which matches any implementation of t butabstracts the implementation type;
� type t = T where T is a type expression, whichrequires t to be implemented as a type compatiblewith T , and publicizes that t is compatible with T .We call the latter a manifest type speci�cation, by oppo-sition to the former, which is an abstract type speci�ca-tion. The motivation for this extension is that it is oftenneeded to package a type with some operations withoutgenerating a new type, so that the operations apply topreexisting values of that type. For instance, in the caseof the structurestructure IntOrder =structtype t = int;fun less (x:t) (y:t) = x<yendit is important that IntOrder.t remains compatible withint, so that IntOrder.less can be applied to integer val-ues. More generally, no type abstraction should occurwhen a structure provides additional operations over anexisting type, instead of de�ning a new type with associ-ated operations. Manifest types in speci�cations answerthis need: the structure IntOrder can be given the sig-naturesig type t=int; val less: t->t->bool endfrom which users of the structure can deduceIntOrder:t = int and therefore apply IntOrder.lessto integer values. (See [10] for more examples. Thispropagation of type equalities can also be ensured via acompletely di�erent approach based on strong sums [14],but strong sums raise serious theoretical and practicaldi�culties [8, 9] which are avoided in the \manifesttypes" approach.)Manifest types also palliate most of the de�cienciesof the \dot notation" approach described above. Tak-ing a restricted view of a structure while preserving typecompatibility can now be done as follows:structure x =struct datatype t; val f=...; val g=... endstructure y =(x : sig type t=x.t; val f: ... end)(Checking that x satis�es the signature constraint aboverequires unusual typing rules, as we shall see in section 4.)Similarly, the propagation of types through functors canbe expressed by introducing manifest types that dependon the functor argument in the result signature:functor f(x: sig type t end): sig type t=x.t end= struct type t=x.t endstructure y = struct datatype t endstructure z = f(y)The typing rule assign the signature sig type t=y.t toz, therefore establishing that z.t is compatible with y.tas expected.Finally, manifest types in functor argument positionexpress sharing constraints in the functor argument: thefunctorfunctor f(x: sig type t; ... endy: sig type t=x.t; ... end) = ...5

behaves exactly like the following SML functor with asharing constraint:functor f(x: sig type t; ... endy: sig type t; ... endsharing x.t = y.t) = ...That is, the typing rules guarantee that the functor canonly be applied to structures x and y for which we canprove that the type components x.t and y.t are the sametype. Moreover, x.t and y.t are assumed to be compat-ible when typing the body of the functor.Syntactic restrictionsThe dot notation combined with manifest type speci�ca-tion therefore appears as a promising approach to typegenerativity and sharing. Due to the rather strong syn-tactic restrictions it requires, it is not clear, however,that it o�ers the same expressiveness as the stamp-basedstatic semantics.First restriction: to account for the propagation oftypes through functors, we had to relax the restrictionthat the functor parameter must not occur in the resultsignature, and allow dependent functor types, as infunctor f(x: sig type t end):sig type t=x.t end = ...Dependent functor types alone cause no di�culties; whatis problematic is their combination with the dot notation.Consider the application f(g(y)). If we blindly substi-tute the actual argument for the formal parameter in theresult signature of f, we getf(g(y)) : sig type t = g(y).t endwhich is not a well-formed signature (it violates the re-striction of the dot notation to paths). Functors withdependent types can therefore only be applied to paths,but not to arbitrary structure expressions.Second, some syntactic restrictions also apply to shar-ing constraints. The sharing constraints expressible bymanifest types in contravariant position are of the for-mat type t; sharing t = p, that is, both local (thesharing constraint appears next to the type declaration)and asymmetrical (one side of the constraint must bean identi�er). In contrast, SML's sharing constraints aresymmetrical (the two sides are paths) and not necessarilylocal.In the remainder of this paper, we will prove thatthese syntactic restrictions can be circumvented in a sys-tematic way (section 5) and do not prevent this approachfrom having the same expressiveness as the static seman-tics (section 6).4 A path-based type systemBased on the discussion in the previous section, wenow give a purely syntactic type system for a variantTypModL0 of the module calculus TypModL introducedin section 2. The main di�erences are the use of manifesttypes instead of sharing constraints in signatures, thesyntactic restrictions outlined in section 3.3, and theaddition of higher-order functors, that is, functorsas �rst-class structure expressions. Unlike in the
stamp-based static semantics, higher-order functors areeasily added to the type system; they even simplify thecalculus by obviating the distinction between de�nitionsand programs.Structure expressions:s ::= p access to a structurej struct d end structure constructionj functor(xi : S)s functor abstractionj s(p) functor applicationStructure body:d ::= " j c;dDe�nitions:c ::= type ti = T type bindingj datatype ti type creationj structure xi = s structure bindingj open s structure inclusionSignature expressions:S ::= sig D end simple signaturej functor(xi : S1)S2 functor signatureSignature body:D ::= " j C;DDeclarations:C ::= type ti opaque type declarationj type ti = T manifest type declarationj structure xi : S structure declarationType expressions:T ::= ti j p:t j T1 ! T2Structure paths:p ::= xi j p:xAs explained in section 3.2, x and t stand for structureand type names, while xi and ti are structure and typeidenti�ers, with the i component taken from some count-able set of symbols. All identi�ers bound in a given dec-laration are required to have di�erent names. We writeBV (D) for the set of identi�ers bound (declared) by thedeclaration D.The typing rules for this calculus are given in �gure 2.Rules 19{29 de�ne the familiar typing judgement \underassumptions E, the structure expression s has signatureS", written E ` s : S. We brie y explain the mostunusual rules.Since structures are dependent products, access to astructure component (rules 20 and 38) cannot return thetype of the component as is, leaving dangling referencesto identi�ers bound earlier in the structure. Instead,these identi�er must be pre�xed by the extraction pathp, in order to preserve their meaning. For instance, if phas typesig type t; structure x : sig type u = t end end;then the signature of p:x is sig type u = p:t end, withp:t in place of t.The subtyping relation <: between signatures(rules 30{36) allows two degrees of exibility: extraneoussignature components can be ignored and signaturecomponents reordered via rule 31; type equalities canbe forgotten via rule 33, turning manifest types intoabstract types. The function � : f1; : : : ;mg 7! f1; : : : ; ngin rule 31 injects the components of the more generalsignature into the components of the less general6

Typing of module expressions and de�nitions:E1; structure xi : S; E2 ` xi : S (19) E ` p : sig D1; structure xi : S; D2 endE ` p:x : Sftj p:t; xk p:x j tj 2 BV (D1); xk 2 BV (D1)g (20)E ` S signature xi =2 BV (E) E; structure xi : S ` s : S0E ` functor(xi : S)s : functor(xi : S)S0 (21)E ` s : functor(xi : S0)S E ` p : S00 E ` S00 <: S0E ` s(p) : Sfxi pg (22) E ` p : SE ` p : S=p (23)E ` d : DE ` struct d end : sig D end (24) E ` " : " (25)ti =2 BV (E) E ` T type E; type ti = T ` d : DE ` (type ti = T ; d) : (type ti = T ; D) (26) ti =2 BV (E) E; type ti ` d : DE ` (datatype ti; d) : (type ti; D) (27)xi =2 BV (E) E ` s : S E; structure xi : S ` d : DE ` (structure xi = s; d) : (structure xi : S; D) (28)E ` s : sig D1 end BV (D1) \BV (E) = ; E;D1 ` d : D2E ` (open s;d) : (D1;D2) (29)Module subtyping:E ` S2 <: S1 E; structure xi : S2 ` S01 <: S02E ` functor(xi : S1)S01 <: functor(xi : S2)S02 (30)� : f1; : : : ;mg 7! f1; : : : ; ng E;C1; : : : ;Cn ` C�(i) <: C 0i for i 2 f1; : : : ;mgE ` sig C1; : : : ;Cn end <: sig C 01; : : : ;C 0m end (31)E ` (type ti) <: (type ti) (32) E ` (type ti = T ) <: (type ti) (33)E ` ti � TE ` (type ti) <: (type ti = T ) (34) E ` T1 � T2E ` (type ti = T1) <: (type ti = T2) (35)E ` S1 <: S2E ` (structure xi : S1) <: (structure xi : S2) (36)Type equivalence: (rules for congruence, re exivity, symmetry, transitivity omitted)E1; type ti = T ; E2 ` ti � T (37) E ` p : sig D1; type ti = T ; D2 endE ` p:t � Tftj p:t; xk p:x j tj 2 BV (D1); xk 2 BV (D1)g (38)Well-formedness of types and signatures (E ` T type and E ` S signature): rules omitted.Figure 2: Type system with pathssignature; it is entirely determined by the names of thecomponents of the two signatures.Rule 23 expresses the fact that if a structure boundto a path p has an abstract type component ti, this typeis always equal to p:t. Hence, type ti in the signatureof p can be replaced by type ti = p:t. This replacementoperation, written S=p, is de�ned by:(sig D end)=p = sig D=p end(functor(xi : S1)S2)=p = functor(xi : S1)S2"=p = "(type ti; D)=p = type ti = p:t; D=p(type ti = T ; D)=p = type ti = p:t; D=p(structure xi : S; D)=p = structure xi : S=p:x; D=pRule 23 is essential to prove that some sharing constraintsare satis�ed (see [10] for examples) and also to preservetype compatibility between views of a structure. As anexample of the latter, consider:structure x = struct datatype t; ... end;structure y = (x : sig type t=x.t end);The manifest type in the signature of y is needed to en-sure that x.t and y.t remain compatible. But the signa-ture inferred for x, sig type t; ... end, is not included7

Normalization of structure expressions:struct d1; structure xi = f(s); d2 end a! struct d1; structure yj = s; structure xi = f(yj); d2 endif s is not a path, y =2 BV (d1) [ fxg [BV (d2) and yj =2 FV (d2)Normalization of program expressions:structure xi = f(s); m a! structure yj = s; structure xi = f(yj); mif s is not a path and yj =2 FV (m)functor fi(xj : S) = gk(s); m a! functor fi(xj : S) = (struct structure yl = s; open gk(yl) end); mif s is not a pathFigure 3: Normalization of functor applicationsinto the signature given for y. Rule 23 must be appliedbefore checking signature inclusion to give x the signaturesig type t=x.t; ... end.5 NormalizationIn preparation for an equivalence result between the sys-tems in section 2 and 4, we now show that any TypModLprogram can be rewritten into an equivalent program(with respect to the static semantics in section 2) thatmeets the syntactic restrictions imposed by TypModL0.5.1 Introduction of identi�ersThe �rst step in the rewriting is the addition of marks toidenti�ers in a way consistent with the scoping rules ofTypModL. A simple way to perform this transformationis to add the same mark i to all occurrences of names inthe original program, then consider the resulting programmodulo alpha-conversion of marks.Introducing marks early in the normalization processallows subsequent transformations to rename identi�ersin order to avoid name captures, an operation that is notalways possible in the original TypModL calculus.The static semantics with stamps (�gure 1) easily ex-tends to marked identi�ers: signatures � and environ-ments � are now mappings from identi�ers (names +marks) to types and signatures. Since names are boundat most once in a signature, access by name in signaturesis non-ambiguous: for any name y, there exists at mostone mark i such that yi 2 Dom(�). By abuse of notation,we still write �(y) for �(yi) where i is the mark such thatyi 2 Dom(�).5.2 Normalization of functor applica-tionsIn TypModL0, functor arguments are restricted to paths:f(p), where p is a path, is correct, but f(g(p)) is prohib-ited. In the latter case, an intermediate binding of g(p)to a structure identi�er must be introduced. This trans-formation is expressed by the rewrite rules over structureexpressions and programs shown in �gure 3.These rules are obviously terminating and any pro-gram in normal form with respect to these rules con-tains only applications of functors to paths. It is easy to
show that this transformation preserves the meaning ofthe program according to the static semantics:Proposition 11. If � ` s) � and s a! s0, then there exists a signa-ture �0 � � such that � ` s0 ) �0.2. If � ` m) ok and m a! m0, then � ` m0 ) ok.This transformation is an instance of Sabry andFelleisen's A-normalization [18], which also consistsin naming the results of all function and primitiveapplications, but works in the more general settingof call-by-value �-calculus. A-normalization has beendeveloped as an alternative to continuation-passingstyle for compiler optimizations; it �nds here anunexpected application in the area of type systems. Thisintroduction of new names for each functor applicationcan be viewed as the syntactic counterpart of thecreation of new stamps for the generative components offunctor results.5.3 Normalization of sharing constraintsWe now turn to the other syntactic restriction of thetype system in section 4: it can only express sharingconstraints of the form type ti; sharing ti = por type ti; sharing p = ti. We call these sharingconstraints (where the constraint occurs next to thedeclaration of one of the constrained types) local.The rewrite rules over declarations shown in �gure 4transform arbitrary sharing constraints into local sharingconstraints, by moving constraints towards the left untilthey hit the declaration of one of the types involved inthe constraints.To reduce the number of rules, we have consideredsharing constraints as commutative and identi�edsharing p = q with sharing q = p. We write p, q for\path tails", that is, sequences of names; all type pathscan be written either ti or xi:p. We write p=D for thepath obtained from the path tail p by completing the�rst name of p into an identi�er according to the leftcontext D: t=D = ti if ti 2 BV (D)x:p=D = xi:p if xi 2 BV (D)8

sharing p = p; D s! D (1)type ti; sharing p = q; D s! sharing p = q; type ti; D (2)if ti =2 FV (p) and ti =2 FV (q)structure xi : S; sharing p = q; D s! sharing p = q; structure xi : S; D (3)if xi =2 FV (p) and xi =2 FV (q)type ti; sharing ti = p; sharing q = r; D s! sharing q = r; type ti; sharing ti = p; D (4)structure xi : sig D end; sharing xi:p = xi:q; D0 s! structure xi : sig D; sharing p=D = q=D end; D0(5)structure xi : sig D end; sharing xi:p = q; D0 s! structure xi : sig D; sharing p=D = q end; D0 (6)if xi =2 FV (q)structure xi : sig sharing p = q; D end;D0 s! sharing p = q; structure xi : sig D end; D0 (7)sharing ti = p; sharing ti = q; D s! sharing p = q; sharing ti = p; D (8)Figure 4: Normalization of sharing constraintsIf ti or xi are not bound in D for any i, then the comple-tion is unde�ned and rules 5 and 6 do not apply.Rules 2, 3 and 4 exchange a sharing constraint withthe preceding signature item if this item does not de-�ne any type involved in the constraint. Rule 4 doesnot allow permuting arbitrary independent sharing con-straints, since this would make the rewriting system non-normalizing. Instead, the rule applies only if the leftmostconstraint is local. Rules 5 and 6 shorten the paths in-volved in a constraint by moving the constraint insidethe sub-signature that corresponds to the path. Rule 7handles sharing constraints that occur in a sub-signaturebut do not actually depend on the sub-signature. Fi-nally, rule 8 simpli�es multiple sharing constraints overthe same simple type ti.Proposition 2 The rewriting system s! is normalizing.Proof: Consider the positions of the non-local sharingconstraints in the signature expression being rewritten.Each reduction rules moves one or several non-local con-straint one step to the left and does not change the posi-tions of the other non-local constraints. 2The normalization of a signature expression does nota�ect the outcome of its elaboration:Proposition 3 If D s! D0, then � ` D0 ) � if andonly if � ` D) �. Therefore, if S s! S0, then S and S0admit the same principal signature in �.Proof: by case analysis on the reduction rules, and ex-amination of the elaboration derivations. See [11] for amore complete proof. 2We now show that if a signature expression is in nor-mal form, then all sharing constraints contained in thesignature are either local (type ti; sharing ti = p) orequate two \rigid" paths, that is, two paths referring totypes bound outside the signature. Here is an exampleof the latter case:
structure S = struct datatype t; ... endstructure R = struct type t = S.t; ... end... sig sharing S.t = R.t end ...A sharing constraint between rigid paths is satis�ed inde-pendently of the structure to which the functor is applied:either the two types are di�erent and then the signaturedoes not elaborate at all, or the two types are identical(as in the example above) and then the sharing constraintcan be deleted without changing the result of the elabora-tion. Hence, if a signature expression elaborates, we canassume that it contains no sharing constraints betweentwo rigid paths.Proposition 4 Let S be a signature expression that elab-orates (there exists � and � such that � ` S ) �). If Sis in normal form, then all sharing constraints in S areeither local or rigid.Proof: We show that if S contains a non-local sharingconstraint, then either this constraint is rigid or S is notin normal form. Let sharing p = q be the leftmost non-local sharing constraint in S. Assume p 6= q (otherwise,rule 1 applies). Let S0 be the smallest sub-signature ofS that contains the constraint. Consider the signatureitems that precede the constraint in S0.If S0 = sig sharing p = q; : : : end, then either S0is a proper sub-signature of S and rule 7 apply, or S0 = Sand then p and q are rigid paths (otherwise D would notelaborate).If S0 = sig : : : ; type ti; sharing p = q; : : : end,then ti is not free in p nor q (otherwise, the constraintwould be local), hence rule 2 applies.If S0 = sig : : : ; sharing p0 = q0; sharing p =q; : : : end, then the constraint p0 = q0 is local (otherwise,p = q would not be the leftmost non-local constraint inS), hence either rule 4 or rule 8 apply.If S0 = sig : : : ; structure xi : S00; sharing p =q; : : : end, then one of rules 3, 5 or 6 must apply (thefact that S elaborates guarantees the existence of thecompletions p=D and q=D in rules 5 or 6). 29

Normalized TypModL TypModL0Signature components: type ti; sharing ti = T ! type ti = TProgram components: functor fi(xj : S) = s ! structure fi = functor(xj : S)sPrograms: m ! struct m endFigure 5: Correspondence between TypModL0 and normalized TypModL6 Equivalence of the type system andthe static semanticsThe program expressions from the TypModL calculus ofsection 2, once normalized as described in the previoussection, can be considered as structure expressions fromthe TypModL0 calculus in section 4, modulo the syntacticidenti�cations shown in �gure 5. We have therefore iden-ti�ed TypModL programs in normal form with the �rst-order fragment of TypModL0. Programs in normal formcan therefore be checked at compile-time using either thestatic semantics from section 2 or the type system fromsection 4. We now prove that the two approaches giveexactly the same results:Proposition 5 Letm be a TypModL program in normalform, or, equivalently, a �rst-order TypModL0 de�nition.Then, fg ` m) ok if and only if there exists a declara-tion D such that " ` m : D.To establish this result by induction on thederivations, we need �rst to set up a correspondencebetween the stamp-based semantic objects usedfor elaboration and the signature expressions usedfor type-checking. The idea is that the stamps insemantic objects are in one-to-one correspondencewith equivalence classes of paths for the equivalencerelation between types induced by the manifest typedeclarations in the signature expressions; this one-to-onecorrespondence extends to an isomorphism betweenthe syntactic objects (type and signature expressions)and the syntactic objects. For technical reasons, it iseasier to de�ne the isomorphism directly, and assignstamps to equivalence classes of paths on the y.The translation [T ]� of a type expression T in anenvironment � (mapping type identi�ers to types andstructure identi�ers to signatures or functor signatures)is de�ned by: [ti]� = �(ti)[ps:t]� = �(ps)(t)[T1 ! T2]� = [T1]� ! [T2]�The translation is extended to signature expressions anddeclarations as follows:[sig D end]� = [D]�[functor(xi : S1)S2]� = 8N1: (�1;8N2:�2)where �1 = [S1]� and �2 = [S2]�+fxi �1gand N1 = FS(�1) n FS(�)and N2 = FS(�2) n FS(�1) n FS(�)
["]� = fg[type ti; D]� = fti 7! ng+ [D]�+fti 7!ngwhere n =2 FS(�)[type ti = T ; D]� = fti 7! [T ]�g+ [D]�+fti 7![T ]�g[structure xi : S; D]� = fxi 7! [S]�g+ [D]�+fxi 7![S]�gFinally, the translation of a typing environment E is de-�ned as [E] = [E]fg, where E is viewed as a declaration.The translation de�ned above strongly resembles theelaboration of signature expressions in the static seman-tics (rules 11{15), except that it is completely determin-istic: [S]� is uniquely de�ned up to a renaming of stampsnot free in �. We write =� to denote equality of typesand signatures up to a renaming of stamps not free in �.The elimination of the non-determinism introduced byrule 13 has been made possible by the transformation ofsharing constraints into manifest type declarations. Thefollowing proposition relates precisely the translation [�]with type and signature elaboration:Proposition 61. Let T be a type expression. If [T ]� is de�ned, then� ` T ) [T ]�. Conversely, if there exists � suchthat � ` T ) � , then [T ]� is de�ned and equal to � .2. Let S be a normalized signature expression. If [S]�is de�ned, then � ` S ) [S]�. Conversely, if thereexists � such that � ` S ) �, then [S]� is de�nedand is the principal signature of S in �.Proof: easy structural inductions on T and S. For (2),notice that a type ti declared by type ti; sharing ti =pt can only elaborate to �(pt). In all other cases, there areno sharing constraints over ti and we obtain a principalsignature by assigning a fresh stamp to ti. 2We can now express the main inductive step for theproof of proposition 5:Proposition 7 Let s be a normalized structure expres-sion and d be a normalized de�nition. Assume de�ned� = [E].1. If � ` s) � for some signature�, then there existsa signature expression S such that E ` s : S and[S]� =� �. If � ` d) � for some signature�, thenthere exists a declarationD such that E ` d : D and[D]� =� �.2. Conversely, if E ` s : S for some signature expres-sion S, then [S]� is de�ned and � ` s ) [S=s]�.If E ` d : D for some declaration D, then [D]� isde�ned and � ` d) [D]�.10

In part (2), we have written S=s for S=p if s is a structurepath p, and S otherwise. Notice that in part (2), we donot generally have � ` s ) [S]�, since if s is a path pand S declares abstract types, then the translation [S]�will assign new stamps to these types and therefore willnot be equal to �(p) as expected. In this case, we canonly reason about S=p, which does not contain abstracttypes and therefore which translates without creation ofnew stamps, as expected.The proof of proposition 7 makes use of two key lem-mas: proposition 9, which relates type equivalence andtype elaboration, and proposition 11, which shows thatthe subtyping relation between signatures is equivalent toa combination of instantiation and enrichment. Propo-sitions 8 and 13 are auxiliary results. Most proofs areomitted from this summary; full proofs can be found in[11].Proposition 8 Assume de�ned � = [E]. Let p be astructure path. Then, E ` p : S for some signature ex-pression S if and only if �(p) is de�ned. In this case,[S=p]� is de�ned and [S=p]� = �(p).Proposition 9 Assume de�ned � = [E] and �1 = [T1]�and �2 = [T2]�. Then, E ` T1 � T2 if and only if �1 = �2.Proof: the \only if" part is an easy induction on thederivation of E ` T1 � T2, using proposition 8 in thecase of rule 38. The \if" part is more involving. To atyping environment E, we associate a rewriting relationE! over type expressions de�ned by the following axioms:ti E! T if E = E1; type ti = T ; E2p:t E! Tfti p:t; xj p:x jti 2 BV (D1); xj 2 BV (D1)gif E ` p : sig D1; type ti = T ; D2 endThis rewriting relation has the following properties (theproofs are sketched in parentheses):1. If T E! T 0, we can derive E ` T � T 0. (Applicationsof the �rst rewriting axiom correspond to rule 37,of the second axiom to rule 38.)2. If T E! T 0 and � = [T ]� is de�ned, then � 0 = [T 0]�is de�ned and � = � 0. (Use the \only if" part ofthis proof and property 1 above.)3. If [E] is de�ned, then E! is normalizing. (Followsfrom the fact that since [E] is de�ned, all manifesttype declarations type ti = T in E are such thatall identi�ers and paths contained in T are boundearlier than ti in E.)4. If T 01 and T 02 are in normal form with respect to E!,and if [T 01]� = [T 02]�, then T 01 and T 02 are syntacti-cally identical. (Follows from the fact that a path innormal form corresponds to an abstract type decla-ration, and therefore is assigned a stamp that is dif-ferent from the stamps assigned to any other path.)Now, assume [T1]� = [T2]�. Let T 01 be the normal formof T1 with respect to E!, and T 02 be the normal form of
T2. These normal forms exists by (3). By (2) and thehypothesis [T1]� = [T2]�, we have [T 01]� = [T 02]�. By (4),it follows that T 01 = T 02. By (1), we have derivations ofE ` T1 � T 01 and E ` T2 � T 02. By transitivity andsymmetry, we obtain a derivation of E ` T1 � T2. 2Proposition 10 Let � be an environment and �, �0 betwo signatures such that �0 � '(�) for some substitu-tion ' with Dom(') � FS(�) nFS(�). For all signatureexpressions S, if [S]�+� is de�ned, then so is [S]�+�0 ,moreover [S]�+�0 =� [S]�+�. (The same result holds fora type expression T instead of a signature expression S.)Proof: easy structural induction on T and S. 2Proposition 11 Let S and S0 be two signature expres-sions containing no functor signatures. Assume de�ned� = [E] and � = [S]� and �0 = [S0]�. Then, E ` S0 <: Sif and only if there exists a substitution ' of types forstamps such that Dom(') � FS(�) n FS(�) and �0 �'(�).Proposition 12 Assume de�ned [S]�+fxi �g. Let p bea path. If �(p) = '(�) for some substitution ' withDom(') � FS(�) n FS(�), then [Sfxi pg]� is de�nedand [Sfxi pg]� =� '([S]�+fxi �g):Finally, proposition 5 (the main equivalence result)follows from the proposition below:Proposition 13 Assume de�ned � = [E]. Let m be aTypModL program in normal form. Then, � ` m ) okif and only if there exists a declaration D such that E `m : D.7 Concluding remarksThe work presented here can be summarized as follows:just as type generativity in Modula-2 and similar lan-guages can be described bytype generativity = name equivalence;we have formally shown that type generativity and shar-ing in an SML-like module calculus (with functors andmultiple views) can be described astype generativity and sharing =path equivalence + A-normalization + S-normalizationwhere \path equivalence" refers to the combination ofmanifest types with the dot notation, \A-normalization"is the naming of intermediate functor applications, and\S-normalization" is the attening of sharing constraints.Future work on this topic include extensions of theresults presented here to higher-order functors and tostructure generativity. It is an open problem to accountfor SML's structure generativity and sharing in a typesystem similar to the one presented here. As for higher-order functors, neither the stamp-based static semanticsnor the manifest type-based type system extend straight-forwardly to higher-order functors. Tofte's original exten-sion of the static semantics [20] does not propagate typeand structure sharing as expected. MacQueen and Tofte11

[15] solve this di�culty by partially re-elaborating higher-order functors at each application, but this required amajor rework of the stamp-based static semantics. Thetype system in section 4 has higher-order functors builtin, but again not all expected type equalities are prop-agated through higher-order functors (see [10] for exam-ples). The author is working on extensions of the \man-ifest types" mechanism that could solve this di�culty,but it is unlikely that the equivalence result in this papercarries over to an equivalence between these extensionsand MacQueen and Tofte's static semantics.References[1] Mar��a-Virginia Aponte. Extending record typing totype parametric modules with sharing. In 20th sym-posium Principles of Programming Languages, pages465{478. ACM Press, 1993.[2] Luca Cardelli. Typeful programming. In Erich J.Neuhold and Manfred Paul, editors, Formal De-scription of Programming Concepts, pages 431{507.Springer-Verlag, 1989.[3] Luca Cardelli and Xavier Leroy. Abstract types andthe dot notation. In Proc. IFIP TC2 working confer-ence on programming concepts and methods. North-Holland, 1990.[4] Luca Cardelli and David B. MacQueen. Persistenceand type abstraction. In M. P. Atkinson, P. Bune-man, and R. Morrison, editors, Data types and per-sistence. Springer-Verlag, 1988.[5] Luca Cardelli and Peter Wegner. On understandingtypes, data abstraction, and polymorphism. Com-puting surveys, 17(4):471{522, 1985.[6] Robert Harper and Mark Lillibridge. A type-theoretic approach to higher-order modules withsharing. In 21st symposium Principles of Program-ming Languages, pages 123{137. ACM Press, 1994.[7] Robert Harper, Robin Milner, and Mads Tofte. Atype discipline for program modules. In TAPSOFT87, volume 250 of Lecture Notes in Computer Sci-ence, pages 308{319. Springer-Verlag, 1987.[8] Robert Harper and John C. Mitchell. On the typestructure of Standard ML. ACM Transactions onProgramming Languages and Systems, 15(2):211{252, 1993.[9] Robert Harper, John C. Mitchell, and EugenioMoggi. Higher-order modules and the phase distinc-tion. In 17th symposium Principles of ProgrammingLanguages, pages 341{354. ACM Press, 1990.[10] Xavier Leroy. Manifest types, modules, and separatecompilation. In 21st symposium Principles of Pro-gramming Languages, pages 109{122. ACM Press,1994.[11] Xavier Leroy. A syntactic approach to type genera-tivity and sharing. Draft, available electronically onftp.inria.fr, directory INRIA/Projects/cristal/Xavier.Leroy, 1994.
[12] Barbara Liskov and John Guttag. Abstraction andspeci�cation in program development. MIT Press,1986.[13] David B. MacQueen. Modules for Standard ML. InLisp and Functional Programming 1984, pages 198{207. ACM Press, 1984.[14] David B. MacQueen. Using dependent types to ex-press modular structure. In 13th symposium Prin-ciples of Programming Languages, pages 277{286.ACM Press, 1986.[15] David B. MacQueen and Mads Tofte. A semanticsfor higher-order functors. In European Symposiumon Programming, 1994.[16] Robin Milner, Mads Tofte, and Robert Harper. Thede�nition of Standard ML. The MIT Press, 1990.[17] John C. Mitchell and Gordon D. Plotkin. Abstracttypes have existential type. ACM Transactions onProgramming Languages and Systems, 10(3):470{502, 1988.[18] Amr Sabry and Matthias Felleisen. Reasoning aboutprograms in continuation-passing style. In Lisp andFunctional Programming 1992, pages 288{298, 1992.[19] Mads Tofte. Operational semantics and polymorphictype inference. PhD thesis CST-52-88, University ofEdinburgh, 1988.[20] Mads Tofte. Principal signatures for higher-orderprogram modules. In 19th symposium Principlesof Programming Languages, pages 189{199. ACMPress, 1992.[21] Niklaus Wirth. Programming in Modula-2. Springer-Verlag, 1983.
12

An Implementation of Higher-Order FunctorsPierre Cr�egut David B. MacQueenCNET - France Telecom AT&T Bell LaboratoriesLannion - France Murray Hill - USAAbstractRecently the module language of SML of New Jerseyhas been augmented with higher-order functors. Theirsemantics is described in [Tof94, MT94]. This papersketches how higher-order functors can be implementedwith e�cient static representations. The key idea of theSML/NJ implementation is the sharing of signature en-vironments, and this idea has been carried over to thehigher-order case.1 Introduction1.1 Review of SML modulesBasic ML modules, called structures, are encapsulatedenvironments considered as objects of the language. Weaccess the components of a structure using a dot notationor by \opening" the structure, making all its componentsdirectly accessible in the environment.Signatures are module interfaces and play the role oftypes for structures. They are environments associat-ing speci�cations with component names and are usedboth to describe and to constrain structures. Signaturematching checks that a structure ful�lls the constraintsspeci�ed by a signature, and creates a new structure thatis a restricted \view" of the original structure, allowingaccess only to the speci�ed components. The structureresulting from signature matching is also referred to asan instance of the signature.Finally, functors are functions from structures to struc-tures. The argument is speci�ed by a signature and theresult is given by a structure expression, which may op-tionally be constrained by a result signature.Datatype declarations and most structure declarationsare generative,meaning that each declaration of a datatypeor structure creates a new object with a unique staticidentity (implemented by an internal stamp1). The def-inition of type equality used in type checking rests onthese unique static identities. Sharing constraints in sig-natures can be used to require that several type or struc-ture components in a speci�cation share the same staticidentity.Signature matching is said to be transparent, mean-ing that the static identities of a structure and its com-ponents are not hidden by signature matching. In the1These stamps are analogous to names in the De�nition[MTH90].
instance structure resulting from a signature match, thevisibility of components is determined by the signature,but their identity is inherited from the original structure.1.2 Higher-order functorsHigher-order functors are introduced in the syntax byallowing functors to be de�ned within structures. It isthe interaction of this feature with regular functor de�-nition that increases the expressive power of the modulelanguage and raises implementation problems. A func-tor can now be passed to other functor as a componentof the argument structure, and a functor can return an-other functor as a component of its body structure. Inthe following paragraphs we informally describe the ex-pected behavior in terms of the propagation of stamps.Functors returned by functors. The example belowillustrates a typical situation where a functor F returnsanother functor G. The behavior of G will naturally de-pend on the parameter of F.functor F(X:sig ... end) =structstructure A = struct .... X ... endfunctor G(Y:sig ... A ... X ... end) =struct ... X ... A ... endstructure B = G(...)endstructure S = F(XX)structure T = S.G(YY)The functor G can depend on the argument X eitherdirectly or through the substructure A. This dependencywill derive from occurrences of X and A either in the spec-i�cation of the argument or in the body structure of G,or both. Then this functor G may be applied both insidethe body of F and outside.The way that the structure T depends on XX must bede�ned somehow within the representation of the functorS.G.Functors passed to functors. Here is a �rst orderfunctor F taking a structure G as parameter:functor F(structure G: sig type t end): sig type s end =struct13

type s = G.tendNow we construct a structure Rint by applying F to aparticular structure G.structure Rint =F(structure G = struct type t = int end)The type G.t in the argument is propagated to the result,giving us Rint.s = int.Now consider another functor where the parameter Gis a functor whose result signature is the same as for theprevious structure G. In this case we have to apply theparameter G in the body in order to extract the type t.functor F'(functor G(): sig type t end): sig type s end =structstructure A = G()type s = A.tendNow we apply F' to an actual functor G that de�nes typet as before.structure Rint' =F'(functor G() = struct type t = int end)Again we expect Rint.s = int, as in the case where theparameter was a structure. In other words, if functors areto be \�rst-class," they must be able to propagate typeinformation just as structures do when passed as parame-ters. This means that there is propagation of the stampsin the argument functor body. We will see that this im-plies that the internal application of functor G must bere-evaluated for each application of the functor F'.2 Outline of the implementationThe essential elements of the implementation of the mod-ule system are (1) the static and dynamic representationsof signatures, structures, functors, and environments, and(2) algorithms for the four basic processes involved inelaborating the module constructs: signature matching,signature \instantiation," functor abstraction, and func-tor application.We will concentrate on the static representation ofmodules, but to brie y summarize the dynamic represen-tations, here is the coding of modules in the underlyingenriched lambda-calculus used as input to the back-endof the compiler:� structures are coded by records;� signatures have no dynamic counterpart, but signa-ture matching produces of a small shape coercionfunction called a thinning;� functors are coded by functions from records torecords.The main goal of the implementation is to limit copy-ing of the rather large data structures encoding typesand signatures. It does so by splitting the representa-tion of structures into a stable signature part contain-ing relivized types and dynamic access information and
a \core" part containing the more volatile stamp infor-mation that varies from one instance of a signature toanother. Roughly speaking, the signature part speci�esvisibility and access, while the core speci�es static iden-tity information.In the De�nition, the primitive object is the structureand a signature is a valid structure with a set of stampsconsidered as abstract. In the implementation, the sig-nature is just a skeletal framework for the structure witha set of identity (or sharing) relations that some of thestamped components must satisfy. This representation isclosely related to the one used in [MT94]. It is relativelyeasy to compile the source code of a signature de�nitioninto our internal representation. But compared to theDe�nition's representation it is more di�cult to constructa \free instance" structure matching the signature withminimal sharing. Such free instance structures are usedto verify that the signature is legal and they also play arole in building functors, where the free instance of theparameter signature serves as a dummy argument duringthe elaboration of the body. The process of construct-ing a free instance structure from a signature is called\instantiation."The representation of functors is obtained by extend-ing the previous ideas. A functor is represented by apair of input and output signatures and a higher-orderfunctor core that represents a function transforming thecore of the argument into the core of the result. Con-cretely, this core function is described by a sequence ofsimple instructions, called the \recipe," that construct aresult structure starting the an argument structure in abottom-up fashion.A functor de�nition is elaborated by making a dummyargument by instantiating the parameter signature, bind-ing this argument to the formal parameter identi�er toaugment the environment, and elaborating the body rel-ative to this augmented environment to create a formalresult structure. Then the structure of the formal resultis analyzed relative to the dummy argument to extracta recipe for building the former from the latter. Thisprocess called functor abstraction.Higher-order functors have increased the complexityof this general scheme in the following ways:� A functor can be de�ned inside another functor. Sothe result of its application relies not only on its ar-gument but also on the argument of the outer appli-cation of the containing functor. This means thatthere must be a notion of functor closure, which isimplemented by giving a new implicit argument tothe functor: its \context".� Functors can be passed to other functors and ap-plied inside. We must be able to re-evaluate suchinternal applications with actual argument functorsto extract the static identity information (stamps)that they carry, as in the example of functor F'above.� We must be able to match functors against functorsignatures and instantiate functor signatures. Thisis done by \lifting" regular structure instantiation,structure matching and functor application as willbe explained below.14

2.1 Object representationsWe now consider in more detail the representations of thevarious components used in elaboration. The elaborationphase of the compiler has two main products: a static en-vironment that contains information about bound vari-ables, and a typed abstract syntax data structure thatwill ultimately be used for code generation. Here weconcentrate on the static environment and the represen-tations used for various kinds of bindings.Static environments. Static environments are �nitemaps from identi�ers to objects and are implemented bya mixture of association lists (easy to update to shareand to modify) and hashtables (providing fast accesses).Environments are built like association lists and are thensolidi�ed as hashtables. Identi�ers are partitioned intoseveral \namespaces" (values, types, structures, functors,signatures, etc.), but a single environment contains bind-ings covering all name spaces.Stamps. Stamps represent the identity of componentsin the static semantics. In the implementation, they arepartitioned into local classes and a global one. Localstamps have a \scope" associated with a particular elab-oration process such as the instantiation of a functor pa-rameter signature or the elaboration of a functor body.Global stamps must be unique and persistent, becausethey are used for type-safe linkage of separate compila-tion units (see [AM94]). They are implemented by \in-trinsic persistent identi�ers," which are 128 bit valuescomputed by hashing the static environment data struc-ture for a compilation unit. Stamps are stored in a datastructure called the core that is described in the para-graphs on signatures and structures below.Signatures. A signature can be thought of as a tem-plate for a structure that speci�es an invariant form thatis to be complemented by content, i.e. \core" arrays con-taining static identity information involving stamps. Therepresentation of signatures has three parts:� an environment de�ning the set of visible compo-nents, and for each component (1) its position inthe dynamic representation, (2) the �xed part of itsstatic speci�cation (e.g. its type or signature), and(3) paths in the core arrays to the variable identitypart;� size speci�cations for three arrays (for structures,functors, and types). Those arrays constitute thecore of instance structures and are used to storethe static identity information and, more generally,all the information left unspeci�ed by the signaturebut provided by a matching structure;� two sets of sharing constraints, for structures andtypes respectively. A constraint is a set of paths inthe core arrays with an optional �xed object for thecase of \external" sharing with a previously de�nedstructure or type. 22Type abbreviations in signatures have recently been addedand are treated as a third kind of constraint.
The signature environment is used to interpret the sym-bolic paths appearing in the source code. To obtain thestatic interpretation of the path, each identi�er is trans-lated into an index into the appropriate core array, yield-ing a corresponding index path for navigating the core tothe designated static entity. To obtain the dynamic in-terpretation of the path, each identi�er is translated intothe corresponding dynamic access instruction (a recordselection index to be applied to the corresponding dy-namic structure record). For more details about howidentity-invariant component speci�cations are handledin the environment, see [Mac88], which is still reasonablyaccurate on this point.In the implementation, signatures are stamped forfaster signature comparison and to indicate the \age"of objects during elaboration, but signatures do not havestatic identities in the semantics.Structures. A structure representation consists of:� a signature;� a stamp (or in some cases an indirect reference toa stamp);� a core, consisting of three arrays containing fullstatic representations of the structure, functor, andtype components.There is also a degenerate form of structure represen-tation consisting simply of an environment and a stamp,which is used for toplevel structures de�ned without asignature constraint.The core of a structure is \ attened," in that it cancontain not only its own components, but also compo-nents of some of its substructures (those whose signa-tures are \embedded," or written in-line within the mainsignature), and in this case the core is shared with theseembedded substructures. This avoids the use of back-ward links when a component of a substructure refers toa direct component of the main structure. On the otherhand, if a substructure signature was de�ned previouslyand referred to by name, then that substructure will haveits own core.This method is reminiscent of the closure sharing methodsometimes used in the dynamic representation of func-tions, which allows several functions to share a commonclosure environment record. Figure 1 shows the internalrepresentation of a structure a that is an instance of thesignature S on the left, showing the sharing of the coreamong a, its two direct substructures b and c, and b'ssubstructure d. Note also that there is sharing of signa-tures. For instance, the signature of b is referred to inspecifying b within the signature of a, and it is also partof the structure representation for b referred to from thecommon substructure core array.Functors. A functor is represented by the argumentsignature and a recipe, or sequence of instructions, spec-ifying how to build the result structure when the functoris applied. Each instruction of the recipe explains howto build a single level structure from objects taken fromeither the context, the argument, or components con-structed by previous steps of the recipe.15

signature S = sigtype tstructure b : sigtype uval x : tstructure d :sig endendstructure c :sig endenda
ut
bc d
a
{} {}
a
b: str(0)
c: str (2)
t: type(0)
stamp
core
signature
u:type(1)x:t(0)
d:str(1)Figure 1: Internal representation of structuresFigure 2 gives a simpli�ed summary of the main in-structions used in the recipe for building structure com-ponents. There are also recipes for making types andanother for component functors, but these are a degener-ate cases. The �rst command speci�es that a particularexternal structure from the context be included in theconstruction. The second extracts a component from thefunctor argument, and the third speci�es a list of previ-ously constructed components that are to be combined toform the core of the next component structure in somespeci�ed way (which may involve functor application).An example will be given in �gure 4 and explained inconjunction with the functor abstraction process.The result of a functor depends on its argument. Tocode those links without having to rebuild signatures ateach application, the argument is made an invisible com-ponent of the result. It is by convention stored as the�rst element of the core, but it is not accessible via theresult signature.Dynamic representations. At runtime structures arerecords and functors are function closures mapping recordsto records. Signatures have no runtime representationthemselves, but they contain the dynamic access pathsto the components of corresponding structure records.Static signature matching produces as a byproduct a \thin-ning" translation that is used to coerce the structurerecord to an appropriate \shape" during the dynamicexecution. Figure 3 gives a simple example of such athinning function. This function is executed only once(it may be reused if the thinning appears in a functor)during the \linking" phase to create the new structurerecord. In the lambda language on which the CPS trans-formation is performed, the notion of modules has com-pletely disappeared.2.2 Basic processesSignature matching. Matching a signature with a struc-ture is done by checking that the components speci�edin the signature exist in the structure and satisfy the
respective type or signature constraints. The thinningfunction is generated at the same time. Finally sharingconstraints are checked by comparing the stamps of theequated components, or testing type constructor equalityfor type components.Signature Instantiation. Awell-formed, self-consistentsignature can be matched by some nonempty set of struc-tures. In order to check that a signature is well-formedand consistent, and in order to elaborate functor dec-larations and perform functor signature matching, it isnecessary to be able to derive a \free structure" from asignature to act as a generic representative of the set ofmatching structures. A free structure is a dummy struc-ture that is as general and unconstrained as possible whilestill matching the signature. It has exactly the compo-nents speci�ed in the signature, and has no more sharingamong its components than is directly or indirectly re-quired by the signature's sharing speci�cations. Instan-tiation is the process of constructing such a dummy freestructure for a signature.We try to build a structure from a signature descrip-tion by �rst building the unconstrained structure treecoded by the signature's environment and then unify-ing structures and types as speci�ed by the sharing con-straints of the signature. This entails uni�cation of envi-ronments, which is achieved by taking the union of theircomponents, recursively unifying components having thesame name. The algorithm is based on the Patterson-Wegman linear uni�cation algorithm.Functor abstraction. The elaboration of functor dec-larations builds functor representations using the follow-ing steps:� A dummy argument is created from the speci�ca-tion of the parameter by signature instantiation.� The environment is temporarily augmented by bind-ing the argument identi�er to the dummy argumentstructure.3the item also contains the signature.16

< struct > The item comes from the context and is taken as theexternal structure < struct > with no relocation.ARG[< path >] The item is a component from the argument and the path< path > indicates how to access it from the root of theargument.fi1; :::; ing A new structure is constructed, with its core de�ned interms of items constructed at earlier steps ik of the recipe.A new stamp is created for each application.3Figure 2: Summary of the recipe commands used in a functor body (structure fragment)structure signature thinningsource code structval x = ...val y = ...val z = ...end sigval z : ...val y : ...endrepresentation fx = ; y = ; z = g fz :; y :g (implicitly) fn fx; y; zg => fz; ygFigure 3: Thinning of a structure after coercion� The body is elaborated as a regular structure in theaugmented environment to yield the formal resultof the functor application.� The argument is scanned to extract all the paths toits subcomponents.� The body is scanned to build a recipe for recon-structing instances when the functor is applied. Lo-cal stamps are used as time indicators to determinethe origin and order of creation of the components:{ some come from the context and are kept inthe recipe as constants,{ some come from the argument, the recipe willcontain the path in the argument to accesstheir actual value at the time of the application{ some are locally generated in the body. Therecipe indicates that those stamps must be re-generated at each application.Figure 4 gives an example of functor abstraction. Thecode on the left is expanded internally into a dummyinstance graphically represented in the middle picture.The white triangle is the external structure Y alreadyrepresented in the environment. The black one representsthe argument X. It has been created by instantiating thesignature of the argument. Finally we have the templatebody with a core containing three elements. The �rst onecorresponding to A points to the argument, the second tothe external structure Y and the last de�nes a new emptystructure corresponding to C.All this is expressed in the recipe given in the rightpicture. We use the syntax of �gure 2. The recipe con-tains four actions. Instruction 0 refers to a part of theargument. In fact it is the full argument, so the path toaccess the component is empty (we take the root). In-struction 1 imports structure Y. Instruction 2 creates anew structure, its core is empty but it will have a new
stamp. Finally instruction 3 creates a new structure witha new stamp that will contains the structures resultingfrom the three previous instructions.The creation of the dummy argument by instantiationis an important step: when building the body it is neces-sary to use some actual stamps and type de�nitions fromthe parameter, especially during type checking, and thesemust satisfy the sharing speci�cations of the parametersignature.Functor application. A functor is applied by match-ing the argument against the parameter speci�cation toget the actual parameter instance, and applying the recipe.As components are constructed in a bottom-up fashion,they are saved in a table and reused as necessary toachieve the necessary sharing. To represent relative ref-erences to components of the argument within the bodysignature, the argument is retained as an invisible sub-structure of the result by making it the �rst item in thesubstructure array.3 Higher-order functorsWe are now ready to address the new issues and problemsintroduced by higher-order functors.Functors in structures. To introduce higher-orderfunctors, the essential modi�cation to the module lan-guage is to admit functors as members of structures. Thestatic interface of a functor is given by a functor signa-ture, which consists simply of a pair of signatures for theargument and result. The syntax of functor signaturedeclarations is reminiscent of the syntax of functors4:funsig FF(X:S1) = S2signature S = sig functor Ff:FF end4This syntax may be changed to \funsig F = (X:S1):S2," thesyntax used in [Tof94], in a future release.17

structure Y = ...functor F(X:S) = structstructure A = Xstructure B = Ystructure C =struct endend Y X Body{ A , B , C }
{}
0 := ARG[ ]1 := Y2 := fg3 := f1; 2; 3gFigure 4: Coding functor body elaboration as a recipeSyntactic sugar. We provide some abbreviations forcurried functors:functor F(X:S)(Y:T) = Bstructure A = F(X)(Y)functor G = F(X)stand respectively forfunctor F(X:S) = struct functor $(Y:S) = B endstructure A = let $$ = F(X) in $$.$ (Y) endfunctor G = let $$ = F(X) in $$.$ endwhere let has been extended to functor expressions. $and $$ are two hidden identi�ers used by the system.Context of higher-order functors. A functor de-�ned inside a structure (its context structure) may de-pend on previous components of that structure. As longas the context structure is a �xed top-level structure,there are no new problems. But if the context structureis itself the body of another functor, we must keep trackof which instantiation is used and \close" the embeddedfunctor with respect to this instantiation.functor F(type u) =structtype t = ... u ...functor G (val x:t): sig val y:t * u ... end =struct ... endendThe signature of the parameter of G depends on t and sodoes the body of G. But t is a moving type whose actualde�nition depends on the argument of F, and therefore twill change meaning with each application of F.The required behavior is implemented by passing thecontext structure as a hidden argument of the functor.There are two possible variations:� Pass a small structure that contains exactly the setof components the functor uses.� Pass the full context structure.The second solution simpli�es the building of the embed-ded functor: there is no special structure to elaborate,but on the other hand it creates an intricately loopingobject that is inconvenient to handle in ML5. The functorrecipe of the external functor will contain a pointer to the5Both solutions were tested and the second was kept for his-torical reasons.
recipe of the embedded one (this recipe doesn't dependon the context and so nothing has to be done during theabstraction or the application of the outer functor) and areference to instructions in the structure recipe that willredo the context.The core arrays resulting from the application of Fand G of the previous example are shown schematicallyin �gure 5. In this diagram T[<path>] refers to the typede�ned by following the path <path> through the localcore arrays, starting with structure core arrays and end-ing with the type core array. The context part that hasbeen added to the parameter structure is called the \par-ent."Functor signature instantiation. Functor signatureinstantiation is performed by a kind of \lifting" of reg-ular signature instantiation. We illustrate this with thefollowing functor signature example:funsig F(X:sig structure A:sig end end) =sig structure Y:sig endsharing Y=Aend� A dummy argument is built by instantiating the pa-rameter signature. The result of this is a structureX' that looks like the result of evaluating struct structure A=struct end end.� The \full" argument is the structure containing thecontext and the dummy argument. If the funsig oc-curs within a signature, the context is the result ofinstantiating the containing signature without in-stantiating its functor components. Assuming inthis case that the functor signature is de�ned at toplevel so there is no context, we build the followingstructure that we will call FullArg:structstructure Parent = struct endstructure Argument = X'end� A dummy result is built by instantiating the signa-ture of the body with the knowledge (representedas a sharing constraint) that the full argument isincluded as a hidden substructure. So we get some-thing that intuitively looks like:structlocalstructure FullArg = FullArg18

structure F' = F(Y)structure G' = F'.G(X)y: T[0.0.i] * T[0.0.0.1.j]
G’
Full argument of G’
no parent
Full argument of F
t = ... T[0.1.j]
iF’
parent
parameter
parameter
X
Y
x: T[0.i]
u
j
0 1
0
0 1
0
Figure 5: The tree of cores after a double functor applicationinstructure Y = FullArg.Argument.Aendend� From the dummy argument and the dummy result,abstraction is done as for a regular functor de�-nition and a regular functor representation is ex-tracted. Here we would get the following recipe0 := {1;2}; 1 := ARG[]; 2:=ARG[1,0];where ARG[] corresponds to the path FullArg andARG[1,0] corresponds to the path FullArg.Argument.A.This recipe may look backward (top-down construc-tion rather than bottom up, but it works becausethe instructions are exectuted in a \call-by-need"fashion. Thus we start by trying to �ll slot 0 in thetable, and to do this we have to �rst �ll slots 1 and2, so we go and execute the corresponding instruc-tions. This saves having to do a topological sort ofthe constructions when we de�ne the recipe.In signatures, we can instantiate functor componentsafter the instantiation of the rest of the signature bodybecause while the functor components can depend onstructure components, there are no dependencies on thefunctor components (becuase one can't select from a func-tor, nor apply it in the signature). A functor instance isgiven for each occurrence of a functor speci�cation andno attempt is made to give a meaning to functor shar-ing, because functors do not have static identities of theirown.Functor signature matching. Suppose that we havea functor signature of the form
funsig FS(X: S1): sig ... endand want to match it against a functorfunctor F(Y: S2): sig ... end = struct ... end(We assume that the result signatures are written in-linein both cases to allow for the most general case where theparameter structure is refered to in the result signature.)Let R1 and R2 informally denote the result signatures ofthe functor signature FS and the functor F respectively.How do we match F against FS?The argument signature S1 in the functor signaturerepresents the minimal constraints the matched functorcan expect. So S1 is instantiated to obtain a dummystructure D1 and F is applied to it, thereby checking thatD1 satis�es F's parameter signature S2 (meaning that S1is at least as restrictive as S2). Assume that the functorapplication succeeds and let D2 denote its result. Let R1'be the signature resulting from partially instantiating R1with the sharing identity X = D1, as in:signature R1' =siginclude R1sharing X = D1endNow if D2 matches R1', the functor F has successfullymatched FS. The matching relation is contravariant be-tween the arguments and covariant between the results(see [Tof94] for further discussion), and this matchingprocedure parallels exactly the de�nition in the formalsemantics presented in [MT94].Note that it is necessary to perform a real functor ap-plication during the functor signature matching to propa-gate the additional information that the new speci�cationof the argument can give.19

As far as the dynamic representations are concerned,functor signature matching yields a double thinning: onefor the input and one for the result. So when the F ismatched against FS and if f is the function coding F, s isthe thinning translating an instance of S1 into an instanceof S2 and r is the thinning translating an instance of R2an instance of R1, then the dynamic meaning of F:FS isthe function r � f � s.As an example, consider the following de�nitions:functor F(structure X:Sand Y:S) =structstructure X' = Xand Y' = Yendfunsig FS(structure X:Sand Y:Ssharing X = Y) =sigstructure X' : Sstructure Y' : Ssharing X' = Y'endHere the fact that X' and Y' share comes from the addi-tional constraint put on the argument that its componentshare. This information is transmitted by applying thefunctor to a dummy that will contain the additional in-formation that X and Y have the same stamps. If one onlylooks at the original signature of the functor body, thisis invisible.Replaying functor applications. One fundamentaldi�erence between the �rst-order and higher-order mod-ule systems involves the treatment of functor applicationsappearing within a functor body. In the �rst-order case,a functor application within a functor body only has tobe performed once, formally, when the functor body iselaborated. In the higher-order case, a functor applica-tion involving a parameter functor must be performedformally when the body is elaborated and again with theactual parameter functor when the external functor is ap-plied, in order to extract additional sharing informationcarried by the actual parameter functor.To illustrate this, consider the following example:functor Apply(functor F:S -> Sstructure X:S)= F(X)functor Id(structure X:S) = Xif we don't reapply Id in the structure expression:Apply(functor F = Id structure X = A)we can't infer that the result shares with the argumentA. Now consider the following slightly more complex case:functor F'(functor G(type u):sig type t end): sig type s end =structstructure A = G(type u = int)type s = A.tend
We have three kinds of expected behaviors when F' isapplied to a functor G:� A new type is created:functor G(type u) =struct datatype t = C end� type t is a �xed known typefunctor G(type u) = struct type t = bool end� type u is passed alongfunctor G(type u) = struct type t = u endNote that we need to redo the application only if thefunctor was a parameter of the external application; ifonly the argument of the internal application dependson the outer parameter, its actual value is automaticallypropagated in the result of the application without redo-ing the application. For instance, when elaborating thedeclarationfunctor F() = structstructure X = struct endlocalfunctor F(Y:sig end) = structstructure A=struct endstructure B=Xstructure C=Yendin structure R=F(X) endendthe formal application of the local F produces somethingequivalent to the following expanded code:functor F() = structstructure X = struct endstructure R = structstructure A=struct endstructure B=Xstructure C=XendendTo handle cases where functor applications should beredone, we introduce a third form of structure represen-tation consisting of a triple containing the functor, theargument, and the formal result. The formal result isused for matching and most of the regular operations.The functor and argument parts are used by the abstrac-tion process, which generates a recipe step to redo theapplication.Here are the two new instructions for recipes:App(i1; i2) The item is the result of the applica-tion of the functor built in the itemi1 to the structure built in item i2.i(< path >) The item i should be the result ofa functor application. The item de-�ned is the subcomponent obtainedby following the path < path > initem i.New recipe instructions20

To illustrate this, the body of the following functor:signature S = sig structure R:S' endfunctor F(functor G(X:S''):S) =structstructure A = G(Y)structure B = A.Rendhas the following recipe:0 := {1,2,3}1 := ARG[] (* always the argument *)2 := App(0.1.0, <path of Y>)3 := 2(1) (* A.(0) is the full argument Y *)Finally, abstraction must be done by following the or-der of the de�nition, otherwise a substructure resultingfrom a functor application could be incorrectly taken fora structure created by the functor. For example, if we ab-stract B before A we would infer that B is a new free struc-ture created by F (the recipe would be 3 := { ... })whereas it is the result of the application of G.Dealing with \open." For convenience, some pro-grammers begin their modules with a sequence of \open"declarations that dump the contents of several structuresin the environment and rely on a constraining signatureto avoid re-exporting these bindings. As long as suchstructures are de�ned at toplevel it is easy to strip outthe unwanted bindings, but if they are de�ned inside afunctor, it is more di�cult because we rely on the com-plete history of the elaboration of the body to abstractthe functor.To limit the e�ect on the size of the static environ-ment of this programming style, opened structures areconsidered as a kind of substructure and the environ-ment lookup function implicitly searches for componentsof these substructures.4 ConclusionThe module system implementation used in StandardML of New Jersey has adapted quite well to the addi-tion of higher-order functors. The implementation rep-resentations and processes also relate well to the seman-tic description in [MT94]. It appears that further use-ful features such as parameterized signatures, signaturesin structures, and even parameterization over signaturescould be accommodated naturally in the current imple-mentation framework techniques, and some exploratorywork has been done on these extensions.References[AM94] Andrew Appel and David MacQueen. Sepa-rate compilation for Standard ML. In Proc.1994 ACM Conf. on Programming LanguageDesign and Implementation, New York, 1994.ACM Press.[Mac84] David MacQueen. Modules for Standard ML.In Proc. 1984 ACM Conf. on LISP and Func-tional Programming, pages 198{207, New York,1984. ACM Press.
[Mac88] David B. MacQueen. The implementation ofStandard ML modules. In ACM Conf. on Lispand Functional Programming, pages 212{23,New York, 1988. ACM Press.[MT91] Robin Milner and Mads Tofte. Commentaryon Standard ML. MIT Press, 1991.[MT94] David MacQueen and Mads Tofte. A semanticsfor higher order functors. In Proc. of the 5thEuropean Symposium on Programming (ESOP94), volume LNCS Vol. 788, pages 409{423.Springer Verlag, April 1994.[MTH90] Robin Milner, Mads Tofte, and Robert Harper.The De�nition of Standard ML. MIT Press,1990.[Tof94] Mads Tofte. Principal signatures for higher-order program modules. Journal of FunctionalProgramming, 1994.
21

22

Safe Dynamic Connection of Distributed ApplicationsPierre Cr�egutCNET Lannion - France Telecom �E-mail: [email protected] paper presents a safe way to connect separate appli-cations (i.e compiled completely independently) writtenin Facile, an extension of SML for distributed program-ming. Safe means that once the connection is established,all the links are type safe and no more dynamic checkingis required.This mechanism relies on the ML module system andit provides applications with a mechanism to exchangemodules through servers that act as a kind of modulesdatabases.1 IntroductionA lot of applications have to cooperate with others builtcompletely independently. For example, applications canrely on an existing distant database or delegate part ofthe computation to other softwares on remote comput-ers. Many languages provide supports for programmingconcurrent applications (CML, Ada, etc ...) in a typesafe way, but only a few help the programmer to inter-connect independent distributed applications which havebeen built separately.One would like to guarantee the same level of safetyfor distributed applications as for centralized ones: therisk of unsafe interconnection of applications increaseswith the complexity of the running environment. An ap-plication expects a set of components from its environ-ment and makes some of its own components available tothe rest of the world for further extension and use. Thisstatement is similar to the problem of gathering indepen-dent modules to build a system.In this paper, we present a way to interconnect appli-cations by exchanging modules over the network. Visiblemodules are broadcast on the network and gathered onlibraries. Applications can query a module by sending aninterface matching it.Programs are typechecked at compile-time and areshown correct with respect to the interface used for query-ing the external modules they need. The only necessaryruntime checks are done by the module server when thosemodules are e�ectively queried. These operations usuallyoccur during an initial con�guration phase.This work has been done in the framework of Facile[GMP90] an extension of Standard ML with concurrency,�Work done at ECRC - M�unich.
communications by rendez-vous and facilities for distribut-ing applications over networks of computers. StandardML provides a very powerful module system [Mac84] thatallows the nesting of modules, the manipulation of inter-faces as objects and the parameterization of modules byother modules.1.1 Comparison with other worksThis work is an extension of the import/export mech-anism of Harper [Har86]. The basis is the same but weprovide a semantics ensuring that types are well renamedover the network.A. Appel and Z. Shao in [AS93] propose a smart wayof recompiling modules with incomplete information. Itcould be adapted to work on a network but here we havechosen to give type information explicitly as it is used asa key.DML is another distributed extension of SML [OK93].This work is more general than the DML solution becauseit is not limited to the RPC protocol. RPC has an inher-ent cost as a function call is more expensive on a networkthan locally [BALL84]. Moreover the new solution allowsthe transmission of information on types: in Ohori andKato's paper, the environment used to build an exportedfunction is empty. Finally, the separation between con-�guration and the rest of the execution, and the supportfor organizing the space of shared objects make it safer.Many distributed platforms consider processes as ob-jects [BHJ+87, APML91]. In this setting they can pro-vide safe communications as a communication is sendinga message to an object and objects have well de�ned in-terfaces. CORBA [OMG91] speci�es a standard of objectinterfaces. But there seem to be some weak points:� clients can do dynamic invocation of objects (in factinterfaces) but type-checking becomes completelydynamic.� interfaces are the only information given to clientsabout the implementations and are all put on thesame level. Types and semantics of objects are thenequated which can be dangerous on a wide system.� Mappings of IDL (the language of CORBA) to anon object-oriented languages like C loose all thetype information on objects (coalesced in a typeObject).23

2 The framework2.1 SML module system2.1.1 Structures, signatures and FunctorsAn ML program is a sequence of objects declarations (i.e.bindings of a name to a de�nition) , where objects canbe basic values, functions, exceptions or types.A structure (module) is an object grouping a �nitesequence of declarations. Itself can be declared and beput inside another module. Components of modules canbe accessed by using the dot notation:<module name>.<component name>An interface of a structure speci�es which of its com-ponents are visible and with which speci�cations (typesfor values, interfaces for substructures). An interface isan object by itself, called a signature, and can be de-clared. Coercing a module by a signature means thatone checks that the module ful�lls the speci�cations con-tained in the signature and the result of the coercion isthe module with an interface limited to what was speci-�ed in the signature.Functors are functions taking a module as argumentand de�ning another module by using some of the com-ponents of the argument. Whereas types of functions areinferred in the core language, the parameter of a functormust be completely speci�ed by a signature in the de�-nition of the functor. Whatever argument is supplied atthe application of the functor, only the elements speci�edin the functor can be used to build the result.2.1.2 Semantics of types in SMLWhat makes the paricular nature of the SML type sys-tem is that each type is tagged with a hidden stamp cre-ated during the elaboration of the type declaration. Thisstamp is used to compare types and makes them uniquein the system. Structures are also generative.If a functor contains a type declaration1 , each applica-tion will yield a di�erent type with a new stamp whetherits representation is abstracted or not.In a speci�cation it is possible to require that twotypes or two structures are in fact the same. This is calleda sharing constraint. Constraints are useful to specifyfunctors combining di�erent types and structures. So MLtypes are more powerful than existential types because itis possible to keep track of their origin independently ofthe operations with which they were de�ned.We will see that stamps are a convenient way to repre-sent types in a distributed system. The main task of ourimplementation is maintaining a coherent view of typestamps over the network.2.2 ConcurrencyFacile is an extension of SML providing:� functions creating new processes dynamically. Thecode of a process is just a regular function2 ;1By type we mean a user datatype, other declarations onlyde�ne abbreviations.2Facile uses in fact a more complex syntax but it is not relevantfor this paper.
spawn: (unit ! unit) ! unit� functions creating bidirectional communication chan-nels and communicating by rendez-vous over thosechannels (each communication has one emitter andone receiver):channel: unit ! '1a channelsend: 'a channel � 'a ! unit:receive: 'a channel ! 'aAny kind of value can be transmitted over a channel(functions, other channels). The type given to thechannel ensures that the type of the value sent isthe same as the type of the value expected;� functions to make non deterministic choices accord-ing to guards specifying emissions or receptions ongiven channels or delays.This part of the language is very similar to CML [Rep92].2.3 The connection problemA Facile system is organized in nodes. Each node is aFacile runtime on which one runs a concurrent program.Processes share a single heap and as far as static elabo-ration is concerned, a single environment. It is possibleto spawn processes on new nodes but the emphasis israther put on collaboration between nodes created in-dependently. Nodes communicate through regular chan-nels as described in the previous subsection. The mainproblem is establishing an initial connection between twonodes.In CML, all the processes of an application share acommon ancestor. A link can be established betweentwo processes by creating a channel in a common ances-tor and passing it implicitly to both processes with theenvironment of their body.Facile programs running on di�erent nodes can becompiled separately. There is no more common ancestorand common environment. Facile provides a primitiveunsafe mechanism. One of the applications must createthe channel, and publish it on the network (i.e. give it toa central channel server) with a string that identi�es thechannel, the other application retrieves it by consultingthe server using the same string. Respective functionsfor posting and retrieving a channel on the network are:publish : 'a channel � string ! unit�nd : string ! 'a channelThe following CML-like program:fun concurentSystem () =let val shared channel = channel ()fun process1 () = send(shared channel , 1)fun process2 () = print(receive shared channel)in spawn process1; spawn process2 endcan be translated in the following pair of Facile distributedprograms:(� application 1 �)val channel to post = channel () : int channel;publish(channel to post,"key for channel");send(channel to post,1);24

(� application 2 �)val found channel = �nd "key for channel" : int channel;print (receive found channel);3 Dynamic Connectivity3.1 Requirements of a safe solutionThe previous mechanism has several drawbacks:� It is unsafe. If the publisher and the �nder usedi�erent types, the connection will probably causethe failure of one of the systems (the receiver).� Only channels can be exchanged: the level of ab-straction one can obtain on a single node [Rep92]is broken.� There is a single space of keys. Confusion betweenkeys can be very dangerous as there is no type-checking.The solution should also verify the following points:� It should allow nodes to transmit information abouttypes and in particular �t in the framework of MLgenerative types.� The amount of dynamic checking should be limitedand if possible be isolated from the rest of the exe-cution so that one knows quickly if the environmentis able to provide what the application requires.3.2 Exchanging modulesWe propose to exchange modules instead of channels.Modules can be sent to libraries. A library is a logicallocation on which any number of modules can be stored.A library is attached to a module server which is a spe-cialized application. Servers are either independent MLapplications or are run as a separate process in a node.Each server contains a unique initial library. Libraries areidenti�ed by an SML value of the (new) primitive typelibrary. New libraries can be created at will (by sendinga message to the server). Each call to new_library willcreate a new library independant from the one already inuse.(� launch a new server �)val structure server : string ! unit(� the string identi�es the server �)val initial library : string ! libraryval new library : string ! libraryAn application can post some of its modules on thelibrary by using the following syntax:<declaration> ::= supplying <exp> with <structure exp>Such a declaration belongs to the module languageand must be done at toplevel or inside a structure orfunctor, not inside a core-ML expression. exp must eval-uate to a value of type library. structure exp is thebody of a structure, built for the occasion or already ex-isting.An application can retrieve a module from an identi-�ed library by sending it a signature. The last modulestored on the library that matches the interface is sent
back after coercion by the signature. If there is no mod-ule �lling the requirements, the query is blocked until oneis posted.The module is actually sent as an object and the se-mantics of the exchange is the semantics of transmissionfor ML values on channels.<structure exp> ::=demanding <exp> with <signature exp>Here again exp is an expression of type library.The use of libraries is twofold:� Libraries are used to solve con icts between mod-ules verifying the same interface. It is up to the userto ensure that they are stored on di�erent libraries.As library addresses are values, they can be storedwith whatever information is necessary to chooseone among them, in modules that are published onother libraries.� one can restrict the access to a set of modules byusing a private library whose address is only knownto a small group of processes.Matching provides a mechanism for retrieval by spec-i�cation and libraries for retrieval by names. They areorthogonal as there can be many modules with di�erentspeci�cations on a single library and modules with thesame speci�cations but on di�erent libraries.But at the end, something should make clear whichmodule is accessed, otherwise one must rely on the timeof the supplying to solve the con ict arising: the lastitem posted is chosen. This rule makes the updating ofdatabases possible and is sensible relatively to the staticscoping rules. But on the other hand there is a risk ofnondeterminism in a sequence of supply, demand, supplymade on di�erent node but using a single signature on agiven library. Only the user can avoid it by his own wayof programming. This risk is inherent to the possibilityof updating which we feel necessary on a network.A general view of the mechanism is summarized in �g-ure 1. Search by speci�cation and partitioning in librariesis a good compromise between the extensibility and thepower of expression on one hand and the simplicity of theconcepts on the other.ODULEM
LIBRARY
a librarya module
EMITER
MODULE SERVER
a library
a module
RECEIVER
defining a set of possiblea signature
modules
lastretrieve the
if conflictFigure 1: General view of the module librariesRemark: Exchanging modules does not replace ex-changing channels: it replaces the initial establishmentof the application that was done by exchanging channelsby a safer and more abstract mechanism.25

3.3 Impact on the strati�cation of thelanguageThe proposed solution plays with the strati�cation ofSML between its core and module language.� demand and supply are part of the module languageso are statically typed. They are executed whenmodules are loaded.� library values are regular �rst class values of thecore language. In fact the user could have a biggerset of regular ML functions operating on librariesto help their management.As linking (in the sense of loading modules) and com-putations are intricately mixed in SML, it is possible toquery a module, use it to compute a library value anduse this library value to retrieve another module.One of the main characteristics (and defect) of themodule language is that there is no control structure likeloops or conditionals. This can be a quality as this con-servative approach can ease debugging and fault recovery.But it may be an inconvenience for some applications.In those cases, we need the possibility of using locally astructure (called from the network) inside a regular ex-pression. This extension is considered in the last section.3.4 Examples3.4.1 Channels with modi�ed interfacesThe following functor takes a list channel and put anabstract version in a module on the network. One canuse those channels only to receive.functor ListenChannel(val l:libraryval chan_list:'a channel list) =structstructure M = structabstype 'a listen_channel =CH of 'a channelwithval channels =map (fn c => CH c) chan_listfun listen (CH c) = receive cendendsupplying l with Mend3.4.2 A basic protocolWe can implement RPC. This functor takes a functionand its input and output types and exports a modulecontaining a stub function making the interface with theoriginal application.functor RPC(type source and targetval func: source ! targetval lib: library) =structval input = channel ()fun server () =
let val (v,out)=receive inputin send(out,func v); server () endval = spawn serversupplying lib with structfun func v =let val out = channel () insend(input,(v,out));receive out endendendBecause of its wide usage and due to some limitationswith the use of weak type variables typing the channel (inorder to have a RPC access to a polymorphic function),this functor should be part of the core of Facile.3.4.3 Modules are better than RPCSometimes exchanging modules can be more powerfulthan simple RPC because the RPC call can be wrappedup in the code of an exported function. So we can choosethe better solution: exchange heavy functions and thenreduce network tra�c or just import channels and doregular RPC over them.We want to implement a service translating abbrevia-tions in a document. The database of abbreviations is ac-cessible through the function expand : string ! stringwhich must be used locally. Let us suppose we have afunction substitute(s; subst) that takes a string s and asubstitution subst : string ! string and gives back thetext after substituting each abbreviation a by subst(a).The following implementation transmits only the ab-breviations and their translations instead of the wholestring.val input = channel ()fun server () =let val (v,out)=receive inputin send(out,expand v); server () endval = spawn serversupplying lib with structlocalfun remote expand v =let val out = channel ()in send(input,(v,out)); receive out endinfun translate text =substitute(text, remote expand)endendModules can also be used to import higher-order func-tions instead of using RPC to apply them to a local func-tion, limiting the tra�c on the network as long as thefunctions don't depend on a remote state.3.4.4 Using di�erent librariesThe functors presented here can be used to store andretrieve modules of a given interface S using a string todi�erentiate them. We use a module table on the centrallibraries to store the contents of the archive (here thekeys are strings). The modules are posted on di�erentlibraries. Those library names are created by the emitterand are only accessible through the table. Access for26

writing on the table is here unprotected: the user shouldadd a semaphore to protect this access. This could bewritten in ML but is not the purpose of the paper.val central library = initial library "server"signature TABLE = sigval table : (string � library) listendstructure Table : TABLE =struct val table = [] endsupplying central library with Tablefunctor Post(structure Mod:Sval key:string) = struct(� mutex take (); �)structure Table =demanding central library with TABLEval library = new library "server"supplying library with Modstructure NewTable : TABLE = structval table = (key,library) :: Table.tableendsupplying central library with NewTable(� mutex release (); �)end(� functor to retrieve a module from the server �)functor Retrieve(val key:string) : S =letexception NOT FOUNDstructure Table =demanding central library with TABLE(� table lookup function �)fun assoc k [] = raise NOT FOUNDj assoc k ((k',l) :: r) =if k = k' then l else assoc k rval library = assoc key Table.tablestructure Mod = demanding library with Sin Mod end3.4.5 Abstract types and generativityManaging di�erent con�gurations on an hetero-geneous network We consider a network with hetero-geneous screens all described by a signature SCREEN con-taining a type screen. Each machine contains its screendescription on a local server having the same name as themachine. We also consider a graphical interface server ona library containing functors of interfacefunsig Gr(structure X:SCREEN) = GRAPHICSwhere the signature GRAPHICS can be the description ofa kind of toolkit.The following prelude can start an application:(* The description of the expected toolkit *)signature MOTIF = ...let val machine_name = gethostname ()val machine_library =initial_library machine_nameinstructure Screen =demanding machine_library
with SCREENendstructure InterfaceMotif =demanding graphic_librarywith sigfunctor Interface(structure X:SCREENsharing type X.screen =Screen.screen): MOTIFendstructure Motif =InterfaceMotif.Interface(structure X = Screen)The sharing constraints ensures that the functor retrievedwill be strictly compatible with the signature obtained.The constraint is an information given to the server:no functor would probably match the signature withoutit because all would do some assumptions on the typescreen not mentioned in the query.A toy switch The second example is a small subsetof a demonstration program run at ECRC simulating aswitch 3. It was inspired by an example from [AVW93]and [Pur87]. Lines are grouped in modules called LSM.Those groups are then interconnected to a central ele-ment making the switching. The logic of a call is de-scribed by an automaton on each side that are intercon-nected Their interface with the LSM is �xed by the switchbut the contents of messages exchanged between automa-tons (signaling) can be changed with the release of thesoftware.When the switch is launched, each group loads a struc-ture of signature:sigfunctor Automaton(Lsm:LSM) : AUTOMATONendThe automaton signature contains essentially an abstractdatatype message and communication ports. The groupcreates an actual automaton by instantiating the automa-ton functor with its de�nition of the LSM that must beseen as a device driver and post the structure Automatonon its local library. Then it queries the libraries of theother groups with the following signaturessiginclude AUTOMATONsharing message = Automaton.messageendThis way it obtains a connection with the other systemsusing a protocol compatible with its release. As far asthe code of the switch is concerned, this type is com-pletely abstract, but the code of the automaton uses therepresentation of the type.3The aim of the full program was to use features like signatureexchange and structure exchange declaration in let expressions.Those features are mentionned at the end of the article in theproposed extenstions27

4 SemanticsFor this part, we assume that the reader is familiar withnatural semantics and the De�nition of Standard ML[MTH90, MT91] in particular. We will give a sketch ofthe formal semantics of the new construct. We use thesame formalism as the De�nition for the static part. Forthe dynamic semantics, we use a transition system forthe module language and rely on the natural semanticsfor the core language.Communications and concurrency hard to specify ina natural semantics framework can occur in the core lan-guage. But the purpose of the paper is not to give a fulldynamic semantics of Facile or CML.As we need to transmit the types of structures andsignatures exported to the dynamic semantics, we chooseto annotate the program fragment with the relevant types(in fact demanding and supplying constructs). The clas-sical static semantics is obtained by removing the anno-tations from the text.4.1 Static semanticsA judgement B ` exp ) � states that in a given staticenvironment B, a piece of syntax exp elaborates in a type� . We assume that the type library is de�ned in the initialbasis (see the appendix of the de�nition). We need thetwo following rules for the new constructors :B ` exp) f library ; fgg B ` strexp) SB ` supplying<S>exp with strexp) fgB ` exp) f library ; fgg B ` sigexp) (N)SB ` demanding<N(S)>exp with sigexp) Sand a modi�ed rule for functor application that annotatesthe application. B ` strexp) SB(funid) = ((N 001 )S001 ; (N 01)S01)(S002 ; (N 01)S02) = �(S001 ; (N 01)S01)S002 � S S03 = S02Dom(�) = N 001 Dom( ) = N 01N of B \ (N 01) = ;B ` funid(strexp)< ��> ) S03In the dynamic semantics we need the type obtained forthe instantiation of the body, not the one stored in thetemplate. The functor application has been modi�ed tokeep track of the substitution that transforms the tem-plate body in the result of the application.We recall that the form (N)S can only be used forprincipal signatures, i.e. a signature type that containsexactly what is speci�ed in the signature expression. Thisinsures that S is the type of a template structure �llingthe requirement of sigexp but not more. This trick is alsoused to build a template of the argument of a functorduring the elaboration of the functor. Here the wholeprogram can be seen as a functor applied to the externalenvironment.4.2 Why is stamp renaming necessary ?The most important part of the semantics we present,concerns the renaming in the dynamic semantics of the
MODULE SERVER
execution
staticCOMPILATIONSOURCE CODE supplying lib with s demanding lib with S
+ codeenv static repres of s
renamingstamp
static representation of S
stamp & typeupdate
RUNTIMEstamp
renamingstamp env
template of struct matching S
structurematching SFigure 2: Renaming stampsstamps created in the static semantics. We recall that astamp identi�es a type and is created at the declarationof the type.The �nal solution is sketched in the diagram 2. Thenext paragraph explains what would occur if no renaming(actions in italics) was performed.Not enough stamps are di�erent The resultof a single compilation can be executed more than once.This creates stamp collisions. We assume that applica-tion 1 is run twice, that t is bound to two di�erent re-alizations (for example string and int). After the twoposting, there are two modules on the network using twodi�erent types marked with the same stamp. We supposethat application 2 retrieves the result of the two execu-tions, either because it managed to get the �rst postedstructure before it was overwritten by the second call tothe �rst application or because the �rst application man-ages to use di�erent libraries (if there is a global libraryserver). The call will succeed because when it will com-pare a1.u and a2.u they have the same stamps, but stillg can't be applied on y.
T (XX)
U(YY)
namestamp
real
identity
A TYPE
1st run
DEMAND type T (YY)
SUPPLY type T (YY)
Application 1
2nd run
U(YY)
U(YY)
Application 2
ANOTHER TYPE
T(ZZ)
CLASH !!!Figure 3: Not enough renaming(� application 1 �)structure a = demanding sigtype t val x:t val f: t ! unitendsupplying structtype u = a.t val y = a.x val g= a.f28

end(� application 2 �)structure a1 = demanding sigtype u val y: u and g: u!unitendstructure a2 = demanding sigtype u sharing u=a1.u val y: u and g:u!unitendval = a2.g a1.yThe problem is summarized in �gure 3.Too many stamps are di�erent If we don'tkeep track of the real stamps contained in demandedstructures, we may loose some sharing.DEMAND type T (XX)T(YY)
X: T(YY) DEMAND X:T (XX)
A VALUE OF THIS TYPE
A TYPE
XX
??
NETWORK NODEFigure 4: Too many di�erent stampsstructure a = demanding sig type searched type endstructure b = demanding sigval searched object : a.searched typeendSuch a sentence can succeed, only if the second de-mand looks for an object of the actual type searched_typenot its model used in the elaboration. In �gure 4, the realstamp put in the library is Y Y but the program tries tofetch it with XX created at compile time.4.3 Dynamic semanticsThe dynamic semantics is done on annotated terms. Weconsider the dynamic semantics of an individual program�rst. The state of the abstract machine is made of anenvironment which is a list of partial functions and de-limiters, a code which is a list of program fragments anda function from stamps to stamps used to rename stampsbefore transmitting them on the network.To execute signatures and core language expressions,we use the original, natural style, dynamic semanticswhere the judgement E ` exp ) v states that an ex-pression exp evaluates to a value v in the environmentE. For the sake of clarity, we have merged the distinctenvironments of the dynamic basis in a single environ-ment, the state for side e�ects has been omitted.By comparison with the De�nition, the syntax hasbeen simpli�ed: Only identi�ers are allowed in functorapplications and supplying expressions. This way weavoid the complexity of adding special instructions to rep-resent operations delayed until their arguments are built.We introduce the environment delimiter BIs which meansthat the functions stacked over it should be coalesced in
a single environment function restricted by I and boundto the identi�er s and the instruction R(E) that restoresan environment stack.Finally, we de�ne the application of a substitution toa piece of annotated syntax as the piece of syntax withthe substitution applied to the annotations.Env streamlines an environment stack and transformsit in a single function:Env(f : l) = f +Env(l)Env(Bs : l) = Env(l)Env(nil) = �x:!Intuitively + (S; v; �; f) represents the completion of arequest for a module matching the signature S on libraryv. f is the code given and � is the resulting renaming.In the same way * (S; v; f) represents the completion ofa supplying with the structure of static representation Sand code f on library v.We summarize the interesting transition rules in �gure5. The other can be easily derived from the de�nition.The �rst three rules give the treatment of demand andsupply request and structure de�nition. The two nextrules show how declarations are treated sequentially. Thesemantics depends on the order and the interleaving ofthe demand and supplys. The two last rules explain howa functor application is performed.Finally a system is made of a set of programs repre-sented by their states and a module pool which consti-tutes the module servers. Figure 6 presents the seman-tics of a pool of nodes. Note that as SML has a strati�edmodule language, we do not consider process spawningwhich is done underneath. Elements of the pool are an-notated by the size of the pool to enforce priorities in theretrieval.5 ImplementationWe will sketch the implementation of demanding l withS. Figure 7 sketches this implementation. The case ofsupply is similar.� The abstract tree of S is elaborated. The signatureis transformed into its internal representation.� From this internal representation, we extract a tem-plate structure matching the signature but that con-tains no additional constraints. The stamps are asabstract as possible. This process is called instan-tiation and is a regular part of module elaboration[CM94].� The structure obtained will be the result of de-manding and it is added to the static environment.� From the static representation of the structure weextract the following information:{ the set of paths leading to local stamps,{ the set of stamps that are not local but thatcome from other demanding in the program.� The static representation and the two sets are frozenand given as argument to the code that will performthe demand during the execution of the program.29

Env(E) ` exp) v Env(E) ` sigexp) I(BIs :: E; demanding<(N)S>exp with sigexp :: C; �) +(�((N)S);v;f;�0 )���! (fs 7! f # Ig :: E;C; �0 � �)Env(E) ` exp) v Env(E)(strid) = f(E; supplying<S>exp with strid :: C; �) *(�(S);v;f)���! (E;C; �)Env(E) ` sigexp) I(E; structure strid : sigexp = streexp :: C; �)! (BIstrid :: E; strexp :: C; �)(f1 :: : : : :: fn :: BIs :: E; end :: C; �) ! (fs 7! (f1 + : : :+ fn) # Ig :: E;C; �)(E; struct d1 : : : dn end :: C; �) ! (E;d1 :: : : : :: dn :: end :: C; �)Env(E) ` funid) (strid0 : I; strexp0; E0) Env(E)(strid) = f(BIs :: E;funid(strid)<�0> :: C; �) !([fstrid0 7! f # Ig+ Env(E0);BIs ]; �0(strexp0) ::R(E) :: C; �)(f :: E0;R(E) :: C; �) ! (f + E;C; �)Figure 5: Dynamic semantics for module expressionsST i ! ST 0i(< ST 1; : : :ST i : : :ST n >;MP )! (< ST 1; : : :ST 0i : : :ST n >;MP )ST i +((N)S;v;f;�)���! ST 0i (S0 ; v; f; i) 2MP Dom(�) � N �(S) � S0 i maximal(< ST 1; : : :ST i : : :ST n >;MP )! (< ST 1; : : :ST 0i : : :ST n >;MP )ST i *(S;v;f)�! ST 0i(< ST 1; : : :ST i : : :ST n >;MP )! (< ST 1; : : :ST 0i : : :ST n >; f(S; v; f; card(MP ))g[MP )Figure 6: Dynamic semantics for processesFreezing is done by transforming a data structureinto a string. This support is already provided bySML/NJ to dump runtime objects on �les and bythe marshalling algorithms used by Facile.During the execution of the program, the followingactions are performed:� On the client demanding S:{ the static representation and the sets are un-frozen. All the stamps that come from previ-ous demands are associated to their transla-tion: the node maintains a dynamic environ-ment associating real runtime stamps to tem-plate stamps used during the compilation;{ The structure, the reduced renaming environ-ment for stamps and the paths are sent to theserver.� On the module server:{ the signature of the template structure is spe-cialized: the renaming environment is applied.This is performed on the server because wewant to limit the size of the program presenton each client. The server which is a modi-�ed compiler frontend understands the inter-nal representation of signatures;{ the server searches in the right library if thestatic representation of a module matches thesignature. We assume that it �nds one: s,otherwise the request is delayed;{ The server extracts the local stamps in thetemplate structure and in the structure s byfollowing the transmitted paths. It builds anassociation list of stamps in the template struc-ture and actual stamps in the supplied struc-ture;{ It sends the code of the supplied structure withthe association list to the client node.30

� On the client again:{ The code is added to the dynamic environ-ment. As the interface may restrict the con-tents of the supplied module, it may be nec-essary to reorganize the representation of themodule (a record). The \thinning" functionis computed on the module server and appliedon the client;{ The stamps association list enriches the dy-namic renaming environment.Finally, the implementation of functors must be mod-i�ed. If a functor contains a demand or supply, then thetemplate structure transmitted to the server is not theone used during the elaboration of the functor but theone that can be computed when the functor is applied.For example in the following example:functor F(type t) =demanding l withsig val x:t endstructure Rbool = F(bool)structure Rint = F(int)we expect an object of type bool in the �rst case and intin the second structure.The code of the functor takes a new argument whichis the list of all the actual static representations of thequeried or sent objects. When the functor applicationis elaborated, those static representations are extractedfrom the result, frozen and given to the code of the func-tor. The paths to local stamps are the same, but the listof stamps to modify is passed with the actual structure.Links between the server and the client nodes are reg-ular channels established with the unsafe interface pre-sented at the beginning. But this interface is now hiddenfrom the end-user and its aim is only to stamp links withthe di�erent servers. The code of the server reuses asmuch as possible the SML/NJ compiler front-end. Mod-ules static and dynamic representations are ML objects(a module is coded like a regular record), they can bemade persistent by dumping them on a �le.6 Conclusion6.1 ExtensionsWe have considered the following extensions:reloading modules:As communication links can have failures it may benecessary to fetch new modules to replace damagedcomponents. Allowing local declaration of struc-tures inside functions makes loops on demandingpossible. So the new syntax is just lifting the re-striction that prohibited structure declaration toappear inside regular let. But local structures can'tde�ne types; otherwise those types could break thetype system by escaping 4.4In fact, a solution exists: types in local structures should beconsidered as existential types and implemented as in [LO92].
other policies for exchanging modules: Instead of ac-tually sending the module, we could also provide astub making an RPC interface with the original ver-sion that would remain on the original node (a moreclassical and simpler solution for heterogeneous sys-tems). There would be two kinds of supply but itwould be transparent for demand.higher-order functors and module class signatures:In pure SML, functors and signatures declarationsare restricted to the top-level. But both restrictionscan be lifted. The mechanism can be extended aslong as the following restriction is enforced:A functor containing demand or supplyoperations is called a critical functor. Acritical functor cannot be given as a pa-rameter of a higher order functor or sup-plied to the network.managing libraries:It is necessary to provide some functions to cleanlibraries: we give two functions destroying modulessupplied by a given process or belonging to a givenlibrary.persistent applications:We have studied the possibility of freezing an appli-cation on a core �le and wakening it up when somemodules are touched on the library. In the currentstate, channels must be restarted by an initializa-tion function provided by the user. The moduledoesn't really come from the database but from theapplication itself.In the current status, the system works on a network ofSuns. Some members of the group are studying transmis-sion of functions between heterogeneous hardware. Thesolution should be immediately applicable to our mecha-nism.6.2 Adaptation to other languagesThis mechanism has been written on top of Facile butmakes no assumption on the communication paradigm.It could be adapted to any distributed language providedthere is a real module language and speci�cations areobjects of this language.In a language providing �rst class modules (like Quest[Car91]), the problem of recon�guration would not existas the use of modules is totally unconstrained. On theother hand, generativity gives to SML the power of keep-ing track of the types and express strong sharing relationsbetween syntactically unrelated objects. This would notbe possible in the framework of existential types.6.3 To concludeThe proposed mechanism provides a way to connect in-dependent distributed applications safely and ful�lls therequirement given in section 2. It is powerful and ex-tensible and its best properties are to keep the level ofabstraction one can obtain in centralized systems and tolimit dynamic type-checking to a minimum.31
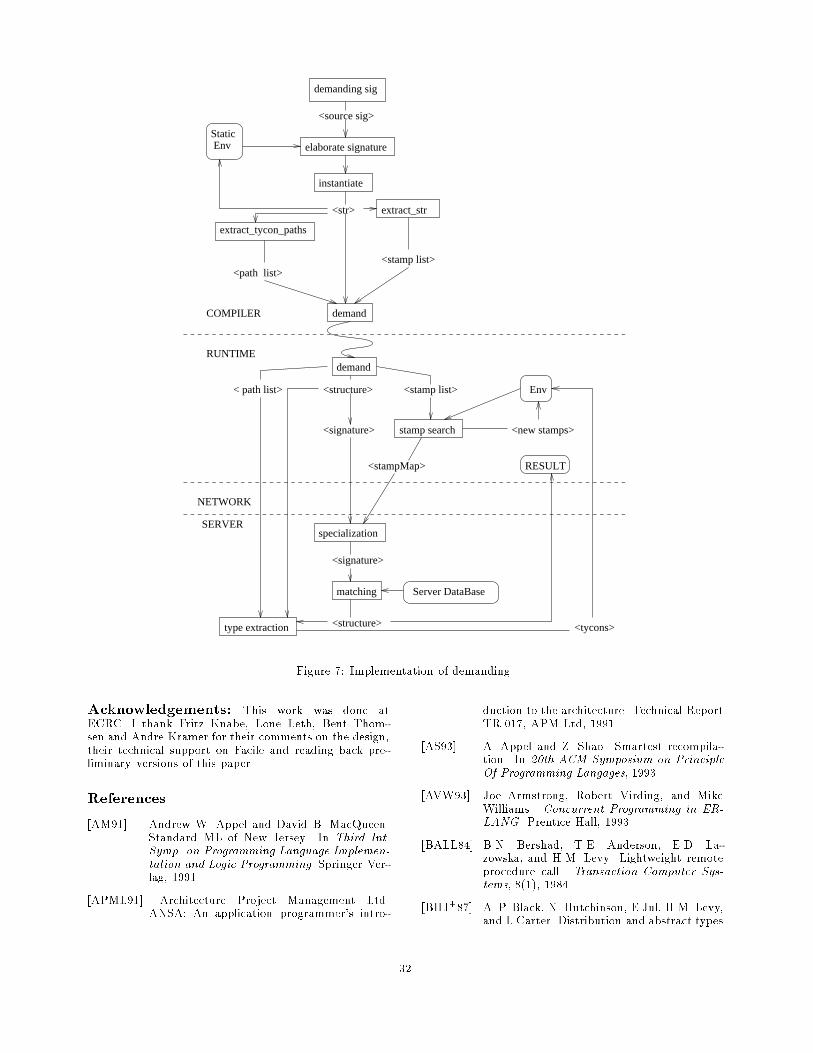
extract_tycon_paths
Static Env
demanding sig
instantiate
specialization
<signature>
matching
<structure>
<stamp list>
<stampMap>
demand
stamp search
Server DataBase
RESULT
<tycons>
Env
<new stamps>
RUNTIME
SERVER
NETWORK
COMPILER demand
elaborate signature
<source sig>
type extraction
<str>
<structure>
<stamp list>
extract_str
< path list>
<signature>
<path list>
Figure 7: Implementation of demandingAcknowledgements: This work was done atECRC. I thank Fritz Knabe, Lone Leth, Bent Thom-sen and Andre Kramer for their comments on the design,their technical support on Facile and reading back pre-liminary versions of this paper.References[AM91] Andrew W. Appel and David B. MacQueen.Standard ML of New Jersey. In Third Int.Symp. on Programming Language Implemen-tation and Logic Programming. Springer Ver-lag, 1991.[APML91] Architecture Project Management Ltd.ANSA: An application programmer's intro-duction to the architecture. Technical ReportTR 017, APM Ltd, 1991.[AS93] A. Appel and Z. Shao. Smartest recompila-tion. In 20th ACM Symposium on PrincipleOf Programming Langages, 1993.[AVW93] Joe Armstrong, Robert Virding, and MikeWilliams. Concurrent Programming in ER-LANG. Prentice Hall, 1993.[BALL84] B.N. Bershad, T.E. Anderson, E.D. La-zowska, and H.M. Levy. Lightweight remoteprocedure call. Transaction Computer Sys-tems, 8(1), 1984.[BHJ+87] A. P. Black, N. Hutchinson, E Jul, H.M. Levy,and L Carter. Distribution and abstract types32

in emerald. IEEE Trans. on Software Eng.,13(1), 1987.[Car91] Luca Cardelli. The Quest Language and Sys-tem. Technical report, DEC-SRC, 1991.[CM94] Pierre Cr�egut and David B. MacQueen. Animplementation of higher-order functors. InACM SIGPLAN Workshop on ML and itsApplications, 1994.[GMP90] A. Giacalone, P. Mishra, and S. Prasad. Op-erational and algebraic semantics for facile: Asymetric integration of concurrent and func-tional programming. In ICALP 1990, LNCS443. Springer Verlag, 1990.[Har86] Robert Harper. Modules and persistence inStandard ML. Technical Report ECS-LFCS-86-11, University of Edinburgh, 1986.[LO92] Konstantin La�ufer and Martin Odersky. Anextension of ML with �rst-class abstracttypes. In ACM SIGPLAN Workshop on MLand its Applications, 1992.[Mac84] David MacQueen. Modules for standard ML.In Lisp and Functional Programming, 1984.[MT91] Robin Milner and Mads Tofte. Commentaryon Standard ML. MIT Press, 1991.[MTH90] Robin Milner, Mads Tofte, and RobertHarper. The De�nition of Standard ML. MITPress, 1990.[OK93] Atsushi Ohori and Kazuhiko Kato. Semanticsfor communication primitives in a polymor-phic language. In 20th ACM Symposium onPrinciple Of Programming Langages, 1993.[OMG91] Object Management Group. Common objectrequest broker architecture and speci�cation.Technical Report 91.12.1, OMG, 1991.[Pur87] Michael Purser. Computers and Telecommu-nications Networks. Blackwell Scienti�c Pub-lications, 1987.[Rep92] John Hamilton Reppy. High-Order Concur-rency. PhD thesis, Cornell University, 1992.33

Abstract Data-Types and Operators: an Experiment in Constraint-BasedParsingFran�cois Barth�elemy � Fran�cois RouaixINRIA RocquencourtBP 10578153 Le [email protected] [email protected] paper presents an experiment of system-building inAlcool{90, a dialect of ML with run-time overloading,abstract data types and operators. The system, whosepurpose is to implement, analyse and compare severalalgorithms for constraint-based parsing, makes a heavyuse of modularity to produce the various algorithms froma con�guration of basic and parameterized components.We describe how abstract types and operators providethis modularity, discuss the experiment, and comparethis approach to more classical modules systems.1 IntroductionMost frequently, software designers use modularity fororganisational purposes: decompose a large piece of soft-ware in smaller units. Modules can be developped in-dependently. Another application of modularity is thecon�guration of the software for producing several ver-sions. A compiler, whose back-end vary from processorto processor is such an example. The various versionsmay also have di�erent semantics, according to the mod-ules they are made of: instead of implementing a singlefunction, as for a compiler, di�erent con�gurations of thesystem produce di�erent algorithms.The adequacy of modularity support for this variouspurposes, in a programming language, is thus an impor-tant issue. We need a su�cient expressive power of themodule facilities, easily accessible by the programmer.The �rst author has written in Alcool{90 a systemimplementing a whole family of parsing algorithms withina single parsing framework, in order to be able to comparethose algorithms in a meaningful way. Alcool{90 is an MLdialect extended with run-time overloading and providesa form of modularity through abstract data types andoperators. This experiment is a large scale test of thesefeatures.Section 2 introduces the relevant Alcool{90 features,that is abstract data types and operators. Section 3 de-scribes a general framework for constraint-based parsing.Section 4 details the construction of the system. Finally,section 5 presents our analysis of the experiment.�Part of the research reported in this abstract was performedwhen this author was visiting the Universidade Nova de Lisboa(Portugal)
2 Introduction to Alcool{90Alcool{90 is an extension of ML (Caml Light dialect) withrun-time overloading. The type system of this languageis described in [10]. We recall here the underlying prin-ciples: the typing of expressions containing overloadedsymbols requires the extension of the well-known para-metric polymorphism of ML to some form of boundedpolymorphism. Bounded polymorphism expresses con-straints necessary to solve overloading at run-time.User-declared \overloading schemes" such asoverload print: 'self -> unit;;introduce bounded type variables in the typing assump-tions (the 'self pseudo-variable indicates in which typethe value of the overloaded symbol will be taken at run-time).Expressions of the form \overload x = M in N" pro-duce run-time overloading. The evaluation of M is de-layed to each occurrence of x in N , thus allowing di�erentchoices of values for overloaded symbols in M accordingto the type of x at the occurrence. Therefore, overload-bound expressions denote abstract values, and are typedwith bounded type schemes:overload double = fun x -> x + x;;double : 'a -> 'a with'a={ + : 'a -> 'a -> 'a}This type scheme ranges over types 'a which possess aprimitive + of type 'a -> 'a -> 'a. Types \possess-ing" primitives are abstract types, characterised by theirsignature (list of primitives with their types). Checkingand inference of bounds are then syntactical operationson signatures (encoded with rational terms, so that usualinstantiation and uni�cation on type expressions are eas-ily de�ned).This approach is di�erent from the one used in Has-kell, where bounds (for equivalent type schemes) are givenby the condition that types must belong to a given class.A type can be proven to belong to a class through user-de�ned rules (instance declarations), which explain howto equip the type with a dictionary to satisfy the classsignature.2.1 Abstract typesHaving introduced the notion of bounds in the type sys-tem, we now present the construction de�ning an abstract34

type T , with primitives xi of types �i:pack8<: x1 =M1...xn =Mn 9=; to T =8<: x1 : �1...xn : �n 9=;This is a simple encapsulation mechanism, producinga dictionary that will be passed at run-time, to allow res-olution of overloading. There is no way to access the rep-resentation (or witness) of an abstract type. For example,here is how the built-in int type would be abstracted asInt1:# pack# zero = 0# and one = 1# and prefix + = add_int# and ...# as implementation Int = {# zero: 'self,# one: 'self,# prefix +: 'self -> 'self -> 'self,# .... };;2.2 OperatorsWe can now go further, and introduce type operators,that is functions mapping abstract types to abstract ty-pes. The point is that operators come for free, since wealready have all the features we need, in the type sys-tem and in the compiler. Consider a pack declarationas above: by typing Mi as abstract values with boundedtype schemes (with a common bound, say S), we get pa-rameterisation of T , thus de�ning an operator rangingover all abstract types matching S. It is easy to see thatfor each abstract type t matching the bound of the typeschemes, we have a set of valid values forming the prim-itives of T(t). We compile this declaration as a functiontaking the dictionary of the parameter, and returning adictionary.The \type" of a Polynomial operator would beimplementation Polynomial ['r] = {list: 'r list -> 'self ,zero : 'self ,one : 'self ,prefix + : 'self -> 'self -> 'self ,prefix - : 'self -> 'self -> 'self ,prefix * : 'self -> 'self -> 'self ,scal : 'self -> 'r -> 'self,print : 'self -> unit}where'r={print: 'r -> unit,prefix * : 'r -> 'r -> 'r,prefix - : 'r -> 'r -> 'r,zero: 'r,prefix +: 'r -> 'r -> 'r,one: 'r};;The parameter 'r corresponds to the implementation ofthe coe�cients of the polynomials. The implementation1'self denotes Int in the signature
of Polynomial, not given here, is a trivial representationwith lists of coe�cients. The list primitive allows the useof the constant list notations to write polynomials (byoverloading the list injection). We can get an imple-mentation of polynomials on any ring by applying thePolynomial operator to the implementation of the coef-�cients. Thus, Polynomial(Int) is a type that has theprimitives described in the signature above.Operator application is not generative, so T (t) is equi-valent to T (t) instead of being incomparable types. Typequanti�cation is simply obtained by using type variablesin signatures. Moreover, when typing the declaration ofan operator, the compiler is able to infer the bound ofthe type parameter (since it is simply the bound in thetype schemes of the primitives).Operators do not interfere with the initial type systemfor programs, for, when infering types for programs, weonly need to manipulate bounds that correspond to basicabstract types. Operators can also appear in type anno-tations of programs. In this case, we have to check thevalidity of operator application, which is easy since it re-lies on the same syntactical operations on signatures thatwere previously de�ned in the type system (signatures foroperators can still be encoded as rational terms).2.3 SearchFinally, as a convenience for the programmer, the com-piler o�ers a search facility, providing a form of semi-automated program con�guration. Given a signature,the search algorithm attempts to �nd all possible ab-stract types matching this signature, including abstracttypes obtained by the application of operators. Thus,when typing a program where some overloading has tobe solved statically, that is, some \unknown" abstracttypes are required to compile the program, the user isprompted with a set of possible con�gurations.The computation of the set of abstract types matchinga bound is only semi-decidable. A simple breadth-�rstexploration of the search tree would produce the set ofsolutions, possibly in�nite, but, without further analysisor precautions, may not terminate if there are no solu-tions. This phenomenon is related to undecidability oftyping in the Wadler/Blott type system for overloadingif no constraints are imposed on instance declarations.In a practical implementation, this di�culty is avoidedby limiting the search to a user-de�ned depth of operatorapplication. Note also that the problem does not a�ecttype inference itself.2.4 ModularityThe form of modularity provided by this type systemrelies on the following identity� simple module = abstract type� parameterised module (functor) = operator� module access = overloading resolution3 A General Framework for ParsingWe used Alcool{90, abstract data types and operators towrite a system. We describe now this system in order to35

show how Alcool{90 is used and why it is especially suit-able. We �rst present the theoretic bases of the system.The technical details of its architecture are presented inthe next section.The aim of the system is to experimentally study pars-ing for constraint-based languages. It must therefore im-plement not only one algorithm, but as many as possible.Furthermore, the system has to be opened to new devel-opments, impossible to predict at the beginning of theproject.Constraint-based Grammars are a family of grammarclasses. It appeared in the �eld of computational linguis-tics as a convenient abstraction of most grammars usedfor natural language as far as an actual computation isintended.Informally, constraint-based grammars are made ofa context-free structure and some additional constraintsthat have to be satis�ed by syntax trees of the language.Di�erent classes of grammars use di�erent kinds of con-straints on di�erent domains (e.g: �rst-order terms, gra-phs, integers), but they share some useful properties givenin [4]. Variable tuples are added to grammar symbols:these variables stand for some attributes of the symbol(e.g.: gender and number of a noun). The constraintsare relations between attributes of symbols appearing ina rule (e.g.: agreement between an article and a nounexpressed by the equality of their gender and number at-tributes).Constraint based-grammars include logic grammars(De�nite Clause Grammars and variants), Uni�cationGrammars, Tree Adjoining Grammars, and, at least par-tially, Lexical-Functional Grammars and Head PhraseStructure Grammars. Of course, there are syntacticaldi�erences between these classes. A simple translation isnecessary from the original syntax to a common form toenlight the convergence of all these formalisms.We present a general framework, derived from a con-text-free scheme by Lang [5], that divides parsing mattersin three di�erent tasks. First, the compilation that trans-lates a grammar into a push-down automaton describinghow a parse-tree is built. The automaton can be non-deterministic if several trees have to be considered whenparsing a string. Second, the interpretation of the push-down automaton that has to deal with non-determinism.Third, the constraint solving, used by both compilationand interpretation to perform operations related to con-straints.Several algorithms can perform each of these threetasks: the compiler can generate either top-down or bot-tom-up automata, the interpreter can make use of back-tracking or of tabulation and the solver has to deal withdi�erent kinds of constraints (�rst-order terms, features,etc).Most of the parsing methods, including all the mostcommon ones, are expressible within our framework.3.1 EPDAsThe separation between the compiler and the interpreteris based on an intermediate representation that describeshow a grammar is used following a given parsing strat-egy. This intermediate representation is a Push-DownAutomaton. It is known that most context-free parserscan be encoded with such a stack machine (stacks are the
proper data structure to perform a top-down traversal ofparse trees). Of course, the usual formalism has to beextended to take constraints into account, and possiblyuse them to disambiguate the parsing. We call ExtendedPush-Down Automaton (EPDA) the extended formalism.We do not give here the formal de�nition of EPDA.Informally, it is a machine using three data structures:a stack containing at each level a stack symbol and itstuple of variables; a representation of the terminal stringthat distinguishes tokens that have already been used andthose that are still to be read; �nally a constraint. A con-�guration of an automaton is a triple of these three data.Transitions are partial functions from con�gurations tocon�gurations. We add some restrictions to these tran-sitions: the only change allowed for the string is that atmost one more token is read; only the top of the stackis accessible and at most one symbol can be added orremoved from it at once. These restrictions are neededto employ directly the generic tabular techniques for au-tomata execution described in [1]. EPDAs may be non-deterministic, i.e. several transitions are applicable on agiven con�guration.Parsing for Constraint-Based Grammars blends twotasks:� The structural part, that consists in building theskeleton of parse trees. This part is similar to acontext-free parsing with the underlying context-free projection of the grammar.� Solving the constraints of this skeleton.The two tasks are related in the following way: con-straints appear at the nodes of the tree; the structureis not a valid syntax tree if the constraint set is unsat-is�able. Each task can be performed in several ways:there are several context-free parsing methods (e.g. LL,LR) and constraints sets can be solved globally or incre-mentally, using various orders, and several ways of mixingthe two tasks are valid. Tree construction involves a stackmechanism, and constraint solving results in a constraint.The di�erent parsing techniques can be described as com-putations on these two data structures. EPDAs are thusable to encode various parsers for Constraint Grammars.Automatic translation of grammars into EPDAs ispossible using extensions of usual context-free techniques[2].3.2 ArchitectureThanks to the intermediate representation (EPDA), pars-ing can be divided into two independent passes: the com-pilation that translates a grammar into an extended au-tomaton; the execution that takes an EPDA and a stringand produces a forest of syntax trees. To achieve theindependence, the compiler is not allowed to make anyassumptions about the way the automata it produces willbe executed, and the interpreter in charge of the execu-tion is not allowed to make assumptions about the au-tomata it executes.We add to this scheme reused from context-free pars-ing a third component: the solver (in an extensive mean-ing) in charge of all the operations related to constraintsand variables. We try to make it as independent from theother two modules (compiler and interpreter) as possible.36

There is not a full independence, since both the com-piler and the interpreter involve constraints and relatedoperations, that are performed by the solver. We justwant to de�ne a clear interface between the solver and theother modules, an interface independent from the kind ofconstraints and from the solving algorithms being used.The same compiler (resp. interpreter) used with di�erentsolvers will work on di�erent classes of grammars. For in-stance, the same compiler can compile Uni�cation Gram-mars and De�nite Clause Grammars, using two solvers,one implementing feature uni�cation, the second one im-plementing �rst-order uni�cation.We can see a complete parsing system as the com-bination of three modules, compiler, interpreter, solver.When each module has several implementations, wewould like to take any combination of three modules.This schematic abstraction captures parsing algorithmswe are interested in. However, actually de�ning interfacesfor a practical system without restricting open-endednessor the abstraction (interchangeability of components) wasthe most di�cult technical task of this work.3.3 SolversThe main problem lies in the de�nition of the solver'sinterface. Some of the required operations are obvious:renaming of constraints and tuples, constraint building,extraction of the variables from a constraint, etc.By the way, remark that constraint solving can behidden within the solver, and thus not appear in the in-terface. There is an equivalence relation between con-straints given by their interpretations. This relation canbe used to replace a constraint by another equivalent one,possibly simpler. The solving can also be explicitly usedto enforce the simpli�cation of constraints at some pointsof the parsing.Unfortunately some special techniques require morespeci�c operations on constraints. For instance, a familyof parsing strategies related to Earley's algorithm makeuse of the restriction operator de�ned by Shieber in [12].Another example: some tabular techniques take bene�tfrom a projection operator that restricts constraints withrespect to a subset of their variables.We could de�ne the solver's interface as the cartesianproduct of all the operations used by at least one tech-nique. There are two reasons to reject such an approach.The �rst one is that some seldom used operations aredi�cult to de�ne on some constraints domains. It is thecase, among others, of the projection. The second rea-son is that it would restrict to the techniques alreadyexisting and known by us at the moment when we de-sign the interface. This contradicts the open-endednessrequirement. A new operation can appear, useful for anew parsing method or for optimizing the old ones.We prefer a exible de�nition of the interface. In-stead of de�ning one single interface, we will allow eachalternative implementation of the solver to de�ne exactlywhat it o�ers and each implementation of the compiler orof the interpreter to de�ne what it demands. The com-bination of modules will involve the checking that theo�er encompasses the demand, that all the needed oper-ations are implemented. This imposes restrictions on thecombination of modules: it is the overhead to obtain anopen-ended system, opened to new developments.
The implementation of our modules (compiler, inter-preter, solver) as Alcool{90 abstract data types is fullyadapted.4 The APOC{II systemThe APOC{II system is a system for constraint-basedparsing written in Alcool{90 following the framework de-scribed in the previous section. It implements more than60 di�erent parsing algorithms for Context-Free Gram-mars, Tree-Adjoining Grammars, and De�nite-ClauseGrammars. The di�erent generated parsers are compara-ble, because they are implemented in the same way, withcommon data structures. Experimental comparison caninvolve more than 20 parsers for a given grammar andgive results independent from the implementation.Furthermore, adding new modules multiplies the num-ber of parsing algorithm. APOC{II is open to new parsingtechniques to such an extent that it can be seen as a li-brary of tools for parsing, including constraint solvers,look-ahead, parsing strategies and control strategies.These tools make prototyping of parsing algorithms eas-ier and quicker.4.1 Architecture of the systemAPOC{II has two levels of modularity: the �rst one is thatof the three main components distinguished above, com-piler, interpreter and solver. Each of these componentsis implemented by several alternative modules, that arecombinable using Alcool{90 discipline.The second level of modularity consist in splittingeach of the three main components into several modules.This makes the sharing of common parts of di�erent im-plementations possible.We give now examples of splitting APOC{II uses at themoment, in order to give an idea of this second level ofmodularity. This splitting has proved convenient so far,but it is not �xed and imposed to further developments:a new implementation can be added even if it uses acompletely di�erent internal structure.A solver is made of:� a module for variables, variable generation and re-naming,� a parser for constraints,� a pretty-printer for constraints,� a constraint builder (creation of abstract syntaxtrees for constraints, e.g. building constraints ex-pressing equality of variables),� a solver in the restrictive meaning, in charge of con-straint reduction,� an interface that encapsulate all the other modules.A compiler includes:� a grammar parser (that uses the constraint parsergiven by the solver),� a module for look-ahead (for computation of look-ahead sets by static analysis of the grammar),37

Solver Context-free Grammars - De�nite Clause Grammars(grammar class) Tree Adjoining Grammars - Uni�cation Grammars : : :parsing strategy top-down - pure bottom-up - Earley - Earley with restriction(transition generator) left-corner - LR - precedence - PLR : : :look-ahead context-free look-ahead of 0 or 1 symbolcontext-free look-ahead of k symbols - context-sensitive look-aheadinterpreter backtracking - Earley-like tabulation - Graph-structured Stacks : : :Agenda management Synchronization - lifo - �fo - various weights : : :(for tabulation only) Figure 2: modules of APOC{IIModules written in bold font are already implemented, whereas modules written in italic are possible extensions to thesystem.� a module for EPDA representation and handling,� a transition generator which translates grammarrules into EPDA transitions therefore determiningthe parsing strategy (cf. �gure 4),� Control code, using previous modules, de�ning the\compile" function, the only one exported.The two interpreters implemented so far have verydi�erent structures. The �rst one uses backtracking andthe second one uses tabulation. They share some moduleshowever, such as a module handling transitions and alexer of input strings.Figure 1 shows the interface of the tabular interpreter.The �le begins by consulting the interface �le \tr sem-form" in which the type stack transition used later isde�ned. The name of the implementation is pd sync. Itis preceded and followed by two type variable lists (thetype variables are pre�xed by a quote). The �rst variables('so, 't, 'it) are free, whereas variables in the second list[('dom, 'lex, 'ag, 'c)] correspond to abstract types, theparameters of the operator pd sync.The operator de�nes only one function, namely exe-cute.The �rst parameters ('dom) is a type de�ning the op-erations on items, i.e. data pieces that are stored in thetable. 'lex is a lexer, 'ag an agenda that handles compu-tation order, 'c a solver. The operations from these typesused by pd sync are given after the where. Note that thefour parameters signatures share some free variables. Forinstance, variable 't (the type of terminal symbols or to-kens) appears in the lexer but also in the domain. Theparameter 'c itself is used by two other parameters. Twokinds of type sharing are thus expressed in our example.Free variables and parameters may also appear in thetype of the functions de�ned by the module, but it is notthe case in that example.4.2 Module combinationThe interest of the modular architecture is in the combi-natorial e�ect of module composition. It leads to manydi�erent parsing algorithms. The �gure 4 summarizesthe di�erent aspects of the parsing algorithms that canvary more or less independently.For example, the built-in parsing method of Prolog forDCGs is obtained by combining the solver for DCGs, the
top-down strategy, 0 symbol of look-ahead and a back-tracking interpreter (and other modules not mentioned in�gure 4 because they do not change the algorithm, butat most its implementation).Some remarks about �gure 4:� we call Earley parsing strategy the way Earley de-duction [8] builds a tree, not the control methodit uses. It di�ers from top-down by the way con-straints are taken into account.� the di�erence between Earley-like tabulation andgraph-structure stacks is the data structure usedfor item storage. Several variants are possible, thatactually change the parser's behavior.� we call synchronization a kind of breadth-�rstsearch where scanning a terminal is performed onlywhen it is needed by all the paths of the search-tree.The search is synchronized with the input string. Itis the order used by Earley's algorithm.� at the moment, only generic look-ahead, that islook-ahead based on the �rst and follow sets, hasbeen considered. Some more accurate look-aheadtechniques such as the ones involved in SLR(k) pars-ing are probably not independent from the parsingstrategy and cannot be an independent module.Building a parsing system with APOC{II consists rou-ghly in choosing one module of each row of �gure 4 andcombining them. Some of the combinations are not pos-sible. Thanks to type-checking, Alcool{90 will detect theincompatibility and provide a type-based explanation ofthe problem.The techniques implemented by APOC{II are not orig-inal. For instance, the LR compilation strategy comesfrom a paper by Nilsson, [7], left-corner parsing has beenused by Matsumoto and Tanaka in [6]. As far as weknow, however, LR and left-corner parsers have not beenproposed for Tree-Adjoining Grammars before.Notice that the modularity is also useful to vary im-plementation of algorithms. For instance, a �rst proto-type may be quickly written by implementing constraintsreduction in a naive way. A re�ned version may be writ-ten later, if needed.38

(* synchronous tabular execution *)#open "tr_sem_form";;implementation('so, 't, 'it) pd_sync [('dom, 'lex, 'ag, 'c)]= {execute: in_channel -> in_channel -> 'self}where 'dom ={dom_get_tr : 'dom -> 'it -> 't list ->('so, 'c, 't) stack_transition list,dom_add_transition : 'dom -> 'it ->('so, 'c, 't) stack_transition -> unit,dom_synchroneous_danger :'dom -> 'it -> bool,dom_get_item_for_pop :'dom -> 'it -> 'it list,dom_print_item : 'dom -> 'it -> unit,dom_subsume_or_install :'dom -> 'it -> bool,dom_initial_item : 'dom -> 'it,dom_apply_trans : 'dom -> 'it list ->('so, 'c, 't) stack_transition ->'t list -> 'it,dom_create : in_channel -> 'dom,dom_same_index : 'dom -> 'it -> 'it -> bool}and 'lex={lexer_next_token : 'lex -> 't,lexer_create : in_channel -> 'c -> 'lex}and 'ag={agenda_step : 'ag -> unit,agenda_next : 'ag -> 'it,agenda_add_futur : 'ag -> 'it -> unit,agenda_add : 'ag -> 'it -> unit,agenda_create : unit -> 'ag}and 'c ={solver_true : 'c};; Figure 1: Interface of a tabular interpreter
4.3 Use of APOC{IIAPOC{II is essentially devoted to comparison betweenparsing algorithms.At the moment, APOC{II o�ers more than 60 di�erentparsing algorithms. Given a grammar, there is a choiceof more than 20 di�erent parsers. Adding one moduledoes not add only one more algorithm, but several newvariants.We used APOC{II for some experiments to evaluateparsers' behavior at run-time. We took basic EPDA com-putation steps, i.e. transition applications, as a unit forexperimental measurements. We think it is signi�cant,although not perfect.We ran several parsers on a collection of small andmiddle-size (50 rules) grammars and several strings (in-cluding incorrect ones).Our approach does not allow a comparison betweenbacktracking and tabular parsers. Both executions applytransitions, but the costs of these applications are incom-parable: tabular execution costs more because of tablemanagement overhead. With backtracking, we soughtonly one solution. With tabulation, we sought all solu-tions. Some examples are given in [3].The results of these preliminary tests must be cau-tiously interpreted. We observed some trends that stillhave to be con�rmed. Two techniques seem more e�-cient than the others: left-corner bottom-up and LR. Fora backtracking execution, one or the other is better, de-pending on the grammar. If left-corner beats LR, thensome other techniques (LL and variants) may run fasterthan LR either. With a tabular execution, left-corneracts better on all the \real life" grammars we consid-ered. However, LR can win with some peculiar gram-mars (mainly the grammars written to show that LR issometimes better than left-corner).APOC{II has several advantages. First of all, it pro-vides comparable implementations of the most commonparsing algorithms. Their e�ciency can be abstractlymeasured, for instance by counting the number of com-putation step (EPDA transition application) performedto compute a tree or a complete forest of parse trees. Wecall this kind of measurements abstract because it doesnot rely neither on the implementation nor on the ma-chine that runs the parser. Other comparisons could bedone statically, on the automaton or on the parse forest(e.g. number of transitions, amount of determinism, sizeof the forest, amount of structure sharing).Otherwise, APOC{II can be used as a toolkit that pro-vides a library of modules useful to implement quicklynew parser generators. For instance, one has only towrite a solver to obtain up to 22 parsing algorithms (per-haps less if the solver provides only basic operations).The library contains tools to deal with some constraints,look-ahead, lexing, tabulation, etc. Reusing these toolswhenever it is possible saves a lot of work.5 AnalysisWe will discuss three aspects of this experiment. First,the objective di�culties encountered during the develop-ment of the system. Then, the practical problems, and�nally, the adequacy of the Alcool{90 language, compared39

to an advanced module system, as proposed by StandardML.The most di�cult point in this experiment, as ex-plained in section 3 was to design the interfaces of thedi�erent components.Among the practical problems, we can point out thedi�culty of grasping the subtle di�erence between thelet in form and the overload in form. Other problemswere essentially due to the raw status of the Alcool{90compiler : all error messages, including module composi-tion and matching are emitted by the type-checker, sincethis particular approach of identifying modules with ab-stract data types moves all compiler veri�cations in therealm of type-checking. It seems here that we would haveneeded some tools in the programming environment.Finally, we may discuss the choice of abstract datatypes with overloading as the basis of modularity, insteadof Standard ML modules. The advantages are :� type inference of module parameters,� implicit access to parameters, by the overloadingresolution mechanism,� sharing constraints are not needed (non-generativeoperator applications, variables in signatures),� true separate compilation,� inference of possible solutions for a component. Agiven parsing algorithm requires about 15 abstracttypes or operators, with a depth of operator appli-cation of around 5,� some basic overloading facilities, such as overload-ing the print primitive.The drawbacks are mostly� some hacks to circumvent the identity \module =abstract data type". Type abstraction was neverconsidered as a limitation when designing the ar-chitecture or writing the code.However, since this system o�ers only the simplestform of modules (a type with interpretive functions),two limitations arose: �rst, there are cases whereseveral types are needed in the module, and theuser has to encode all values in the product or thesum of these types. Then, some component in thearchitecture may not have any \natural" type as-sociated with it, e.g. a \compiler" or a generaltransformation function. In this case, the witnessof the abstract type has to be some arbitrary type,such as unit, and a special value for this type mustbe given, in order to e�ectively use the overloadingmechanism.� performance: the implementation su�ers from theoverhead of run-time overloading as module accessmechanism. However, the purpose of the systemwas to implement several parsing algorithms in aunique framework to analyse them, and not to pro-duce e�cient parsers.One can also remark that a smarter compiler couldremove this overhead by producing specialised ver-sions of primitives de�ning operators instead of shar-ing their code by adding dictionary abstraction.
ConclusionThis experiment has shown how the modularity notionsprovided by abstract types and operators can be suc-cessfully used in the building of a large complex system.The technical details of modularity were not so importantthan the design of the system, especially in this architec-ture supporting several classes of algorithms. The bestoriginal point of the Alcool{90 approach is probably thesearch of solutions matching a given signature.References[1] F. Barth�elemy and E. Villemonte de la Clergerie.Subsumption{oriented push{down automata. InProc. of PLILP'92, pages 100{114, june 1992.[2] Fran�cois Barth�elemy. Outils pour l'analyse synta-xique contextuelle. Th�ese de doctorat, Universit�ed'Orl�eans, 1993.[3] Fran�cois Barth�elemy. A single formalism for a widerange of parsers for dcgs. In Twente Workshop onLanguage Technology - TWLT'6, pages 117{127, de-cember 1993.[4] M. H�ohfeld and G. Smolka. De�nite Relations overConstraint Languages. Technical Report 53, LILOG,IWBS, IBM Deutschland, october 1988.[5] Bernard Lang. Deterministic techniques for e�-cient non-deterministic parsers. In Proc. of the 2ndColloquium on automata, languages and Program-ming, pages 255{269, Saarbr�ucken (Germany), 1974.Springer-Verlag (LNCS 14).[6] Y. Matsumoto and H. Tanaka. Bup: A bottom-upparser embedded in prolog. New Generation Com-puting, 1:145{158, 1983.[7] Ulf Nilsson. Aid: An alternative implementationof DCGs. New Generation Computing, 4:383{399,1986.[8] F. C. N. Pereira and D. H. D. Warren. Parsingas deduction. In Proc. of the 21st Annual Meetingof the Association for Computationnal Linguistic,pages 137{144, Cambridge (Massachussetts), 1983.[9] Fran�cois Rouaix. ALCOOL-90: Typage de la sur-charge dans un langage fonctionnel. Th�ese de doc-torat, Universit�e Paris 7, 1990.[10] Fran�cois Rouaix. Safe run-time overloading. In Pro-ceedings of the 17th ACM Conference on Principlesof Programming Languages, pages 355{366, 1990.[11] Fran�cois Rouaix. The Alcool{90 Report. Prelimi-nary Draft, April 1992.[12] Stuart M. Shieber. Using restriction to extendparsing algorithms for complex{feature{based for-malisms. In Proceedings of the 23rd Annual Meet-ing of the Association for Computational Linguis-tics, pages 145{152, Chicago (Illinois), 1985.40

Object-Oriented Programming and Standard MLLars Thorup and Mads TofteDepartment of Computer Science, University of CopenhagenUniversitetsparken 1, DK - 2100 �, Denmark.AbstractThis paper explores connections betweenobject-oriented programming and StandardML. In particular we show that F -boundedpolymorphism can be expressed using ML'spolymorphism and a programming techniquewe call wrapping. The encoding of F -boundedpolymorphism can be used to encode classes asML modules.1 IntroductionObject-oriented programming provides a rangeof concepts that purportedly facilitate encap-sulation, code reuse and modularity. So doesStandard ML. However, it is not obvious howthe concepts provided by object-oriented pro-gramming (OOP) correspond to concepts infunctional programming languages. In this pa-per we explore the following relationships:OOP Standard MLobject valueobject type recursive (record) typesubtyping coercion functionsF-bounded ML-polymorphismpolymorphism with wrapper typesclasses modulesclass inheritance module dependencyThe relationships of the �rst three lines arewell studied[Car88,Red88,CP89]. The empha-sis of this paper is on an encoding of F -boundedpolymorphism using ML's polymorphism anda technique called wrapping. As evidence forthe existence of the relationships we outline anencoding of object-oriented concepts in Stan-dard ML. Our encoding is not a suggestionof how one should write object-oriented pro-grams in Standard ML | indeed the encodingis not practical in this respect. Nor does the en-coding claim to avoid special treatment of ob-jects in an implementation. The key purpose ofthe paper is to address the following question:
suppose one were to extend SML with object-oriented features; which of these features wouldthen deserve a semantic analysis in their ownright and which features could be understoodas syntactic sugar for features already in thelanguage? This is a useful distinction to make,if one attempts to de�ne such a language for-mally. Somewhat surprisingly, perhaps, it ap-pears that virtually all concepts of staticallytyped object-oriented programming languagescan be encoded in Standard ML and moreover,that the encoding is relatively straightforward.In [Bru93a], Bruce presents a statically typedobject-oriented programming language. Heproves the soundness of the type inference sys-tem with the aid of a denotational semantics,which is presented in terms of a model of theF-bounded second-order lambda calculus. Bycontrast, programs that result from our en-coding are well-typed SML-programs, so wehave reduced the type soundness of the object-oriented features to that of Standard ML.A di�erent approach to typing in object-oriented languages is to use existential types asobject types.[PT93,Rem94]The motivation for F-bounded polymorphismin representing object-oriented concepts is dueto the following fact: sometimes a subclass mustbe able to inherit from a superclass even if thetype of the objects of the subclass is not a sub-type of the type of the objects of the super-class. Such inheritance can be made type-safenevertheless, by making the inherited methodsF-boundedly polymorphic in self [CHC90].In the rest of the paper, we �rst outline asimple representation of objects as ML values.We then de�ne a subtype relation and rules forthe construction of coercion functions. Thenwe present the encoding of F-bounded poly-morphism by ML-polymorphism. Finally, weuse these representations to outline an encodingof classes with static inheritance as modules inStandard ML.It should be stressed that this paper merelyoutlines an encoding. However, the encoding issu�ciently simple that we feel con�dent that itcould be de�ned rigorously. We do provide aprecise de�nition of the construction of wrap-

per functions, since it is the cornerstone of theencoding.This paper is based on the �rst author's M.Sc.thesis[Tho94].2 ObjectsAn object is a run-time value containing a setof encapsulated instance variables and a set ofmethodswhich are allowed to access and updatethe instance variables. When an object receivesamessage, its corresponding method is invoked.In this paper, we regard methods in distinctobjects as being distinct, even though they mayshare code. Thus it makes sense to talk aboutthe receiver of a message, meaning the objectwhich contains the invoked method. A methodhas access to the receiver through the specialname self.We represent an object by a recursive recordwith the instance variables as locally declaredvariables. The record contains a component foreach method, and every method is a function.When the type of the object is recursive, wewrap the record in the constructor of a recur-sive datatype. Access to self is represented byapplying a recursive function, self. (Through-out, we use bold for \object-oriented" syntax,and teletype for ML code.) As an example,here is a declaration of a `point' object, p, writ-ten in pseudo-object-oriented notation:p = objectprivatevar x := 0publicfungetx()return xfunmove(dx)x := x+dxreturn selffundist(p)return x�p :getxendIn ML, we �rst declare the type of p:datatype Point = POINT of {getx: unit -> int,move: int -> Point,dist: Point -> int};We then declare p:val p: Point =letval x = ref 0fun self() = POINT{getx = fn() => !x,move = fn(dx) =>(x := !x + dx; self()),dist = fn(POINT pr) =>!x - (#getx pr)()}inself()end;
Note that every access to self creates a record inthis encoding. This ine�ciency can be avoidedby the use of references.[Tho94]When a message must be sent to an objectcorresponding top1 :dist(p2)we write the following ML-expression:(fn(POINT pr) => (#dist pr)(p2)) p13 SubtypingSubtyping is an organization of types into a hi-erarchy of subtypes and supertypes. In object-oriented programming, subtyping is based onmethod-subsets. Roughly speaking, the type ofan object is considered a subtype of the type ofobjects with fewer methods. With subtyping,any value of some type can be used as a valueof any of the supertypes of this type.Ideally, one might want Standard ML's typesystem fully integrated with a powerful subtyp-ing discipline and automatic type inference. Itturns out that a very simple subtyping disci-pline su�ces, if one is willing to accept the fol-lowing two premises. First, all datatypes thatare to be used as object types must be declaredby the programmer. Second, the programmermust indicate the program points where coer-cion from subtype to supertype must take place.The subtyping rules we use are such that it isstraightforward to determine, for given types �and � 0, whether � is a subtype of � 0 and, if so, tosynthesise a coercion function of type � ! � 0.Our examples all use Standard ML without anyextensions, so we write out coercion functions infull.The subtyping rules that guide the generationof coercion functions are shown in Appendix A.We have aimed for the simplest possible relationon ML types which gives the desired subtypingon those datatypes that represent object types.In particular, our subtyping relation is the iden-tity on all types that contain a datatype namewhose arity is greater than zero. One conse-quence of this restriction is that there will beno subtyping relationship between, say, a list ofpoints and a list of colourpoints, even when it ispossible to coerce every colourpoint to a point.As an example, it follows from our rules, thatPoint is a subtype of the type Shape, declaredby:datatype Shape = SHAPE of {move: int -> Shape};To coerce a value of type Point to a value oftype Shape, representing the same object as theoriginal value, we call the coercion function gen-erated by the applicable rules. It can be writtenas:fun ShapeFromPoint(POINT pr) =SHAPE {move=ShapeFromPoint o (#move pr)}42

Note that, because Shape is recursive, the co-ercion function also becomes recursive. Movinga shape which is really a point can be done bymoving it as a point and then regarding it as ashape!4 F-bounded polymorphismWe start out fromMilner's type discipline[Mi78,DaMi82]. Let � range over a denumerably in�-nite set of type variables and let � range over aset of (basic) type names (e.g. int).Types and type schemes are de�ned by thegrammar� ::= � j � ! � j � type� ::= � j 8�:� type schemeWe now extend the above by introducing, as athird layer, bounded type schemes of the form8� � �:�. The bound \� �" means that thebounded type scheme can only be instantiatedwith subtypes of � .A type function is a function from types totypes. We consider type functions that can bewritten in the form ��:� . If applied to sometype, � 0, this function yields � [� 0=�], i.e. � withall occurrences of � replaced by � 0. Here is anexample of a type function:Fdist = ��:fdist : �! intgIt can be written in ML as:type 'a Fdist = {dist: 'a -> int};(Standard ML uses post�x notation for the ap-plication of type constructors; hence one writese.g. 'a Fdist and not Fdist('a).)Canning et al. have shown that boundedpolymorphism can be generalized to F-boundedpolymorphism, where the bound is expressedwith a type function [CCHOM89]. An exampleof an (F-)bounded type scheme is8� � Fdist(�):�� �� �! � (�)The bound \� Fdist(�)" means that the F-bounded type scheme can only be instantiatedwith a type � , if � � Fdist(�).4.1 Wrapper typesWe represent F-bounded polymorphism by adevice we call wrapped values. A similar device,called adapters, has been discovered indepen-dently by Satish Thatt�e [Tha94], although hedoes not employ it to F-bounded polymorphismdirectly.For any given type function used in an F-bound we introduce a so-called wrapper typescheme. Any object1 which satis�es the F-bound can be wrapped into a value of an in-stance of the wrapper type scheme; the wrapped1F-bounded polymorphism applies to any value, butto simplify the presentation, we talk of those val-ues that represent objects only, and refer to these asobjects.
value can be unwrapped again to reveal theoriginal object with its original type. The mes-sages that are permitted by the F-bound can besent to the wrapped value.We shall now give a formal de�nition ofwrapping. We do so using the terminology ofthe De�nition of Standard ML [MTH90,MT91].Let F be a type function, let conF be a newvalue constructor and let tF be a new typename.2 Consider the type structure:3(��:� tF ; fconF 7! 8�:(F (� tF ) � �)! � tF g)corresponding to the ML-declaration:datatype 'a W = conF of F ('a W) * 'aWe say that this type structure is a wrappertype structure for F , with wrapper type scheme8�:� tF . Notice the strong resemblance be-tween, for every type � , the instance � tF of8�:� tF and the recursive type ��:(F (�)� �).The former is identi�ed by a type name, how-ever, whereas the latter is anonymous. For ex-ample, here is an ML declaration which intro-duces a wrapper type structure for Fdist.datatype 'b Dist =DIST of 'b Dist Fdist * 'b;4.2 Wrapping, unwrapping andviewingLet F be a type function and let (��:� tF ; CE)be a wrapper type structure for F . An object,o, whose type, � , satis�es � � F (�), can bewrapped to a value of the type � tF , which isan instance of the wrapper type scheme. Thiswrapping is done by a wrapper function for F on� ; it has type � ! � tF . The wrapper functiondoes the following: First o is coerced from �to F (�) using the ordinary coercion rules forsubtyping. Then this value is coerced from F (�)to F (� tF ). Finally this value is paired with oitself.A wrapped value of type � tF can be un-wrapped to reveal the original object with itsoriginal type, � , by applying an unwrapper func-tion for F ; it has type 8�:� tF ! �. Theunwrapper function simply extracts the secondcomponent of the wrapped value.To be able to send messages to a wrappedvalue, it must �rst be viewed as an object type.A wrapped value of type � tF can be viewedto a value of the type F (� tF ) by applying aview function for F ; it has type 8�:� tF !F (� tF ). The view function simply extracts the�rst component of the wrapped value.2Type names are \stamps" that uniquely identifydatatypes. We use t to range over type names. Con-structed types are written in post�x notation; henceint list or � t. The De�nition of Standard ML uses theletter � to range over type functions.3A type structure is a pair (F; CE), where F is atype function and CE is a constructor environment,i.e., a map from value constructors to type schemes.43

The general de�nitions of wrapper, unwrap-per and view functions are given in Appendix B.As an example, here follows the declarationof � the wrapper function for wrapping objectsof type Point to wrapped values of typePoint Dist;� the unwrapper function for unwrappingwrapped values of any instance of thewrapper type scheme 8'a.'a Dist; and� the view function for viewing wrapped val-ues of any instance of the wrapper typescheme 8'a.'a Dist:fun unDist(DIST(_,obj)) = objfun viewDist(DIST(r,_)) = rfun DistFromPoint(p as POINT pr) =DIST({dist=(#dist pr) o unDist},p)The types of these functions are:unDist: 'a Dist -> 'aviewDist: 'a Dist -> 'a Dist FdistDistFromPoint: Point -> Point Dist4.3 F-bounded polymorphictypesHere is the essence of wrapping:Every function which has an F-bounded type scheme, 8� � F (�):�,can be represented by a function whichhas the type scheme 8�:�[(� tF )=�]and manipulates wrapped values.As an example, here is a declaration of an F-bounded polymorphic function of the type (*):funnearest(typeT � D(T);a;b; c : T) : Tif a :dist(b) < a :dist(c) thenreturn belsereturn cendendIt can be written in ML as follows, using theview function de�ned above:fun nearest(a:'t Dist, b:'t Dist,c:'t Dist): 't Dist =if (#dist (viewDist a))(b) <(#dist (viewDist a))(c) thenbelsec;When this function must be called with threeobjects corresponding top0 = nearest(Point;p;p;p)we write the following ML-code using the wrap-per and unwrapper functions de�ned above:
val p': Point =unDist(nearest(DistFromPoint p,DistFromPoint p,DistFromPoint p));5 Classes and inheritanceIn object-oriented programming a class is agenerator, which can generate objects contain-ing methods that share code but operate onseparate, mutable instance variables. A classcontains formal initialisation parameters, in-stance variable generators and method gener-ators. (Usually the components of classes aresimply termed instance variables and methods,but we want to be able to distinguish thecomponents of objects from the components ofclasses.)A subclass can inherit instance variable gen-erators and method generators from one ormore superclasses. If a class inherits from morethan one superclass, the class relationship istermed multiple inheritance. A method genera-tor in a subclass can override the correspondingmethod generator in a superclass. An overrid-ing method generator can even generate meth-ods that apply the overridden method genera-tor.In most statically typed object-oriented pro-gramming languages, like C++ and Ei�el,classes are static entities leading to static in-heritance, where the inheritance hierarchy is�xed at compile-time. In other object-orientedprogramming languages, like Smalltalk, classesare �rst-class values, leading to dynamic inher-itance, where the inheritance hierarchy is deter-mined during program execution. Our encodingtreats static inheritance only.When a class is instantiated with actual ini-tialisation values, an object is generated. Theinstance variables of the object are generatedby the instance variable generators of the classand all its superclasses and initialised with theactual initialisation value. The methods of theobject are generated by the method generatorsof the class and the non-overridden method gen-erators of all its superclasses.Instance variables are lexically scoped, in thesense that an instance variable generated by aninstance variable generator of some class canonly be accessed by the methods generated bythe method generators of this class.Some object-oriented languages have a fea-ture which we shall call self-class reference. Theidea is that a method can instantiate the class ofthe object, which contains it (typically by refer-ring to this class as selfclass). Because methodgenerators can be inherited, the class of the ob-ject which contains a method need not be thesame as the class which contains the methodgenerator.44

Point = class(x 0;y 0)privatevar x : int := x 0var y : int := y 0publicfungetx() : intreturn xfungety() : intreturn yprocmove(dx : int;dy : int)x := x+dxy := y + dyfunequal(p : selftype) : boolreturn self :getx() = p :getx()andself :gety() = p :gety()funclone() : selftypereturn selfclass(x;y)endstructure Point = structtype 'a F = {getx: unit -> int, gety: unit -> int,move: int * int -> unit,equal: 'a -> bool,clone: unit -> 'a};datatype Self = SELF of Self F;. . .wrap, unwrap and view: see Appendix C.abstype Vars = VARS of {x: int ref, y: int ref} withfun init(x,y) = VARS {x= ref x, y= ref y};fun getx(VARS iv)() = !(#x iv)and gety(VARS iv)() = !(#y iv);fun move(VARS iv)(dx,dy) = ((#x iv) := !(#x iv) + dx;(#y iv) := !(#y iv) + dy);fun equal(self)(p) =(#getx (view self))() = (#getx (view p))()andalso(#gety (view self))() = (#gety (view p))();fun clone(VARS iv, selfclass)() =(unwrap o selfclass)(!(#x iv),!(#y iv));end;fun new(x, y) =letval iv: Vars = init(x,y)fun self() = SELF {getx= getx(iv), gety= gety(iv),move= move(iv),equal= fn(p) => equal (wrap(self())) (wrap p),clone= clone(iv, wrap o new)}inself()end;end;Figure 1: A (super) classSince we consider static inheritance only, werepresent a class by a module in Standard ML.In particular, non-parameterised classes can berepresented by ML structures. The module con-tains method generators, an instance variablegenerator and an object generator, all repre-sented by functions. The class is instantiatedby calling the object generator with actual ini-tialisation values. We represent static inher-itance by calling instance variable generatorsand method generators of superclasses from theobject generator of the subclass.A method generator f can have parametersthat stand for:1. the instance variables of the object inwhich the method generated by f resides;2. self: the object in which the method gen-erated by f resides, so that the method canaccess this object (the receiver);3. selfclass: the object generator of the classof the object in which the method gener-ated by f resides, so that the method caninstantiate this class by applying the objectgenerator.
In examples, we omit parameters of eitherkind when they are not needed.A method generator must be F -boundedpolymorphic in the self and selfclass param-eters to allow subclasses to inherit the method,even when the type of the objects generated bythe subclass is not a subtype of the type of theobjects generated by the superclass [CHC90].To this end, we use the representation of F-bounded polymorphism by wrapper types. TheF-bound to be used in a particular class is ob-tained by parameterising the type of the in-stances of the class on its self-references; e.g.if the type of the instances of the class is ��:�,the F-bound must be ��:�.As an example, Figure 1 shows the declara-tion of a point-class. The instance variables areencapsulated by abstracting their type, calledVars. The type Self is the type of the objectsgenerated by the point-class. The function initis the instance variable generator. The func-tions getx, gety, move, equal and clone aremethod generators. Finally, new is the objectgenerator.45

ColPoint = class(x 0;y 0)inheritPoint(x 0;y 0)privatevar c : bool := truepublicfungetc() : boolreturn cendfun switch()c := not cendfunequal(p : selftype) : boolreturnSuper : equal(p)andself :getc() = p : getc()endendstructure Colpoint = structstructure Super = Point;type 'a F = {getc: unit -> bool,switch: unit -> unit,getx: unit -> int, gety: unit -> int,move: int * int -> unit,equal: 'a -> bool,clone: unit -> 'a};datatype Self = SELF of Self F;. . .wrap, unwrap, view, wrapSuper, SuperWrapFromWrap:see Appendix Ctype Vars = {c: bool ref, sup: Super.Vars};fun init(x,y) = {c= ref true, sup= Super.init(x,y)};fun getc(iv: Vars)() = !(#c iv);fun switch(iv: Vars)() = (#c iv) := not(!(#c iv));fun equal(self)(p) =Super.equal(SuperWrapFromWrap self)(SuperWrapFromWrap p)andalso (#getc (view self))() =(#getc (view p))();fun new(x,y) =letval iv: Vars = init(x,y)fun self() = SELF {getc= getc(iv),switch= switch(iv),getx= Super.getx(#sup iv),gety= Super.gety(#sup iv),move= Super.move(#sup iv),equal= fn(p) => equal(wrap(self()))(wrap p),clone= Super.clone(#sup iv, wrapSuper o new)}inself()end;end;Figure 2: A subclassAn example of self-reference is the F-boundedpolymorphic method generator equal, whichaccesses self. An example of self-class ref-erence is the F-bounded polymorphic methodgenerator clone, which accesses selfclass.When a class must be instantiated corre-sponding top = newPoint(2; 3)we write the following ML-declaration:val p = Point.new(2, 3)Figure 2 shows the declaration of a colourpointsubclass, which inherits most of its componentsfrom Point, even though Colpoint.Self is nota subtype of Point.Self. The method gen-erator equal overrides the method generatorSuper.equal but calls it as part of its computa-tion; the instance variable generator does like-wise. All the other method generators are eitherinherited directly or are new to the colourpoint-class. For brevity, the instance variable of thecolourpoint-class has not been encapsulated.
Finally, we note that classes that taketypes or classes as parameters can be repre-sented quite naturally by parameterised mod-ules (functors) in Standard ML.6 ConclusionWe have presented an encoding of F -boundedpolymorphism into ML polymorphism andshown that this makes it possible to representclasses with static inheritance by ML modules.The existence and relative simplicity of theencoding suggests that it is possible to inte-grate the concepts of object-oriented program-ming with the concepts of Standard ML withoutcomplicating the semantics greatly.The fact that such an integration appears tobe possible in theory does not imply that it isdesirable in practice. Rather than having a sin-gle well-understood paradigm, one could end upwith a hybrid language which constantly forcesprogrammers to choose between two rather dif-ferent styles of programming.Without programming experience, it is im-possible to tell whether the integration outlinedin this paper is useful in real programming. Itdoes seem, however, that the encoding makes it46

possible to explore an interesting space of pro-gramming styles. One style would be to pro-gram much as though one is programming Stan-dard ML and just treat objects as a subset ofvalues on which certain additional operationsapply. Another style is to regard the object-oriented structuring mechanisms as the primaryones and just use functional programming inthe implementation of methods. The encodingitself does not appear to favour one choice overthe other, nor does it force one to make thesame choice throughout an entire program.7 AcknowledgementThis work was supported by the Danish Re-search Council, as part of the DART project un-der the PIFT programme. Conversations withLuca Cardelli, Michael Schwartzbach and JensPalsberg helped to simplify the subtyping rules.References[AC91] Roberto M. Amadio and LucaCardelli. Subtyping recursive types.In Proceedings of the 18th ACMSymposium on Principles of Pro-gramming Languages, pages 104{118, January 1991.[Bru93a] Kim B. Bruce. Safe Type Check-ing in a Statically-Typed Object-Oriented Programming Language. InProceedings of the 20th ACM Sympo-sium on Principles of ProgrammingLanguages, pages 285{298, January1993.[Car88] Luca Cardelli. A semantics of multi-ple inheritance. In Information andComputation, vol. 76, 1988, pages138-164.[CCHOM89] Peter Canning, William Cook,Walter Hill, Walter Oltho�, John C.Mitchell. F-Bounded Polymorphismfor Object-Oriented Programming.Conference on Functional Program-ming and Computer Architecture,1989, pages 273{280.[CHC90] William R. Cook, Walter L. Hill andPeter S. Canning. Inheritance is notsubtyping. In Proceedings of the 17ACM Symposium on Principles ofProgramming Languages, pages 125{135, January 1990.[CP89] William Cook & Jens Palsberg.A denotational semantics of inheri-tance and its correctness. In OOP-SLA 1989 as SIGPLAN Notices, vol24, nr. 10, October 1989, pages 433{444.
[DaMi82] Louis Damas and Robin Milner.Principal Type Schemes for Func-tional Programs. In Proc. 9th An-nual ACM Symp. on Principles ofProgramming Languages, 1982[KPS93] Dexter Kozen, Jens Palsberg andMichael I. Schwartzbach. E�cientRecursive Subtyping. In Proc. 20thAnnual ACM Symp. on Principles ofProgramming Languages, 1993[Mi78] Robin Milner. A theory of typepolymorphism in programming. InJ. Computer and Systems Sciences,vol. 17, pages 348{375, 1978.[MTH90] Robin Milner, Mads Tofte & RobertHarper: The De�nition of StandardML, MIT Press, 1990.[MT91] Robin Milner and Mads Tofte:Commentary of Standard ML, MITPress, 1991.[PT93] Benjamin C. Pierce and David N.Turner. Object-oriented program-ming without recursive types. InProceedings of the 20th ACM Sympo-sium on Principles of ProgrammingLanguages, January 1993.[Red88] Uday S. Reddy. Objects as Closures:Abstract Semantics of Object Ori-ented Languages. In ACM Confer-ence on LISP and Functional Pro-gramming, 1988, pages 289{297.[Rem94] Didier R�emy. Programming Objectswith ML-ART { An extension to MLwith Abstract and Record Types.To appear in Theoretical Aspects ofComputer Science, 1994.[Tha94] Satish R. Thatt�e. Automated Syn-thesis of Interface Adapters forReusable Classes. In Proceedings ofthe 21st ACM Symposium on Prin-ciples of Programming Languages,pages 174{187, January 1994.[Tho94] Lars Thorup. A Comparative Anal-ysis of Concepts in Object-orientedProgramming, M.Sc. thesis 93-7-11,Dept. of Computer Science, Univer-sity of Copenhagen, Denmark (inDanish).47

A Subtyping rulesThe construction of wrapper, unwrapper and view functions relies on a subtyping relation, de�ned asfollows.A coercion map is a �nite map from pairs of type names to ML value variables. We use C to rangeover coercion maps. The intended reading of C(t; t0) = var is that it has been postulated that varis a coercion function from t to t0. The coercion map serves to give �nite proofs of the existence ofrecursive coercion functions.A type structure set is a well-formed set of type structures[MTH90]. We use T to range over typestructure sets. Intuitively, T consists of the type structures that have been declared so far.The subtyping relation itself takes the form C;T ` � � � 0 ) exp, read: \in coercion map C andtype structure set T , � is a subtype of � 0 via coercion exp." The coercion exp is an ML expression.The rules are:Coercions C;T ` � � � 0 ) expC;T ` �i � � 0i ) expi i = 1::n m;n � 0 var newC;T ` flab1 : �1; . . . ; labn+m : �n+mg� flab1 : �1; . . . ; labn : �ng) (fn var => {lab1=exp1(#lab1 var),. . ., labn=expn(#labn var)}) (1)C;T ` � 0p � �p ) expp C;T ` �r � � 0r ) expr var newC;T ` �p ! �r � � 0p ! � 0r ) (fn var => expr o var o expp) (2)C(t; t0) = varC;T ` t � t0 ) var (3)(t; t0) 62 Dom(C) f and x new(��:�t; fcon 7! 8�:� ! � tg) 2 T(��0:�0 t0; fcon0 7! 8�:� 0 ! � t0g) 2 TC + f(t; t0) 7! fg; T ` � � � 0 ) expC;T ` t � t0 ) let fun f(con x)=con0(exp(x)) in f end (4)Comment: f and x are value variables; t and t0 are type names, ��:�t is a type function, 8�:� ! � tis a type scheme, and the semantic object (��:�t; fcon 7! 8�:� ! � tg) is an example of a typestructure. See [MTH90,MT91] for further explanation of these objects.C;T ` � � �) (fn x => x) (5)Comment: Here � ranges over type variables.� = (�1; . . . ; �n)t n � 1C;T ` � � � ) (fn x => x) (6)Comment: This rule also covers the case where � takes the form � 0 ref, for some � 0.Given T , � and � 0 we say that � is a subtype of � 0 (in T via coercion exp), if there exists a proofof the statement fg; T ` � � � 0 ) exp. Given T , � and � 0, it is straightforward to decide whetherthere exists an exp such that � is a subtype of � 0 in T via exp. (The structure of any proof yieldingconclusion C;T ` � � � 0 ) exp is completely determined by C, T , � and � 0.)Unlike some work on subtyping [AC91,KPS93], the above rules do not yield equivalence of recursivedatatypes that have the same in�nite unfolding but di�erent �nite presentations. Thus we follow theStandard ML approach of using \type name" equivalence rather than \structural" equivalence of types.(Recall that we use the term type name for the internal \stamp" of a datatype, not for an identi�er.)48

B Wrap, unwrap and view functionsLet F be a type function, let (��:�tF ; fconF 7! �g) be a wrapper type structure for F , and let wF;� ,uF and vF be three ML value variables (w for wrap, u for unwrap and v for view, respectively). Thenthe unwrapper function for F and the view function for F are declared as follows:fun uF (conF( ,obj)) = objfun vF(conF(r, )) = rThe type of uF is 8�:�tF ! �, and the type of vF is 8�:�tF ! F (� tF ).Now, let C and T be a coercion set and a type structure set respectively. For any type, � , ifC;T ` � � F (�)) exp2and C + f(t; t0) 7! wF;� ; (t0; t) 7! uF g ` F (t) � F (t0)) exp1where t and t0 have to be new type names, the wrapper function for F on � is declared as follows:fun wF;� x = conF ((exp1 o exp2) x, x)The type of wF;� is � ! � tF . Intuitively, t stands for � , t0 stands for � tF and the coercion exp2 canbe inferred in a constraint map in which it is hypothesised that wF;� and uF really are the desiredwrapper and unwrapper functions.C Extra class codestructure Point = struct...datatype 'a Wrap = WRAP of ('a Wrap) F * 'a;fun unwrap(WRAP(_,obj)) = obj;fun view(WRAP(r,_)) = rfun wrap(p as SELF pr): Self Wrap = WRAP({getx= (#getx pr), gety= (#gety pr),move= (#move pr),equal= (#equal pr) o unwrap,clone= wrap o (#clone pr)},p);...end;structure Colpoint = struct...datatype 'a Wrap = WRAP of ('a Wrap) F * 'a;fun unwrap(WRAP(_,obj)) = obj;fun view(WRAP(r,_)) = r;fun wrap(cp as SELF cpr) = WRAP ({getc= (#getc cpr),switch= (#switch cpr),getx= (#getx cpr), gety= (#gety cpr),move= (#move cpr),equal= (#equal cpr) o unwrap,clone= wrap o (#clone cpr)},cp);fun wrapSuper(cp as SELF cpr) = Super.WRAP ({getx= (#getx cpr), gety= (#gety cpr),move= (#move cpr),equal= (#equal cpr) o Super.unwrap,clone= wrapSuper o (#clone cpr)},cp);fun SuperWrapFromWrap(wcp) = Super.WRAP ({getx= #getx (view wcp), gety= #gety (view wcp),move= #move (view wcp),equal= (#equal (view wcp)) o Super.unwrap,clone= SuperWrapFromWrap o (#clone (view wcp))},wcp);...end; 49

Object interfaces, polymorphic methods and multi-method dispatchingfor ML-like languages
Dominic Duggan�Department of Computer Science
University of WaterlooOntario, Canada N2L [email protected]
1 Introduction
Recent years have seen much attention paid to the foundationsof typed object oriented programming languages. Experienceswith typed object oriented languages, which have either limitedtype systems or in some cases exhibit type holes, has given somemotivation to this work.
In this paperwe presenta moderately novelapproach to defin-ing object types, and show how this may be applied to the MLprogramming language. As motivation for the work on formalfoundations for object oriented type systems, Schwartzbach [29,Page 20] reasons that, since “Smalltalk is inspired by Lisp,” andML can be seen as an improvement on Lisp, some of this workcan be seen as attempting to “create an object oriented languageinspired by ML.” In this paper we show that, in addition to thismotivation, adding object oriented constructs to the ML languagecan extend the power of the ML type system in non-trivial ways.For this reason, we claim that our approach is particularly appro-priate for adding object orientation to ML-like languages.
At first it might appear that adding objects to ML is a particu-larly silly idea. It is well-known that “objects” in ML can be sim-ulated by closures1. Breazu-Tannen et al [3] have shown howmuch of the subtyping machinery of object oriented languages(such as bounded quantification) may be translated into implicitcoercion functions in a core calculus without subtyping.
However the work on formal approaches to object-orientedtyping, including the work targeted particularly at ML, fails toaddress the fundamental limitations imposed by the ML type sys-tem. These limitations make any straightforward addition of ob-jects to ML somewhat wanting. The most important of theselimitations is the commitment of ML to predicative polymorphism[15], which affords a particularly pleasant framework for typeinference2. The limitation of this is to require that polymorphicfunctions be second-class values. As pointed out by Canning etal [4], it is difficult to see how this restriction might be lifted if wewish to add collection objects to ML. Considering that the mainusefulness of ML-style parametric polymorphism is in defininggeneric operations over data structures (lists, trees, etc), an ob-ject oriented dialect of ML without collection objects would ap-pear to be a peculiar proposition.
Consider the example in Fig. 1. This example gives the def-inition of an interface 'a set for set objects (the use of a data-type is necessary because Standard ML does not have circulartypes). setclass defines a constructor for set objects, building�Supported by NSERC Operating Grant 0105568.1In fact some will argue that objects are the “poor person’s closure.”2It has only recently been shown that the type inference problem for System F,the impredicative second-order�-calculus, is undecidable [35].
datatype a set = set of finsert : a �> unit,remove : unit �> a,map : ( a �> a) �> a setg
fun setclass () =let
fun insert self x = ( self := x :: (!self ) )and remove self () =
let val (x::xs) = !self in self := xs; x endand map f [ ] = [ ]j map f (x::xs) = (f x) :: (map f xs)and map self f = mkset (map f (!self ))and mkset self = let val self = ref self in
set f insert=insert self,remove=remove self,map=map self g
endin
mkset [ ]end;
fun insert (set S) = # insert S;fun remove (set S) = # remove S;fun map (set S) = # map S;
val a = setclass () : int set;insert a 1;insert a 10;insert a 100;
val b = map a (fn x => x+1);remove a ();remove b ();
val c = map a (fn x:int => makestring x);
Figure 1: Attempting to define set objects in ML
a closure with internal state given by the instance variable self,and with insert, remove and map methods. The restrictionin this example is to require that, for the map method, the do-main type of the operation being mapped must be the same asthe range type. As a result, for example, we cannot build the ob-ject c which would result from converting the elements of a tostrings.
The obvious way to fix this is to change the type of the mapmethod. The crux of the problem is that we cannot define3:3Steele encounters a similar problem when he attempts to define a Haskell
50

datatype 'a set = set off : : :map : ('a -> 'b) -> ('b set) gEssentially we are trying to define the type constructor:set = �� � f: : : ; map : 8� � (�! �)!(� set)gBut as is well-known, ML-style type inference dependscruciallyon the fact that universal type quantifiers are at the outermostlevel of a type, so that simple first-order unification can be usedto solve equality constraints over the free algebra of the type con-structors.F -bounded quantification is one of the most popular appr-oaches to properly typing implementation inheritance [7], usu-ally formulated as an extension of System F. However type check-ing with F -bounded quantification relies on checking for sub-typing of recursive types. Although algorithms for the latter havebeen provided for simple recursive types, essentially followingsimilar approachesto algorithms for checking for equivalenceofregular tree languages [21], the problem is known to be undecid-able for non-regular recursive type expressions [31] (the modi-fied definition of 'a set above is an example of such a type).
In this paper we propose a new approach to adding objectorientation to ML and languages of its ilk. This approach has ac-tually emerged from our work on parametric overloading, com-bining parametric and ad-hoc polymorphism [18, 33]. Our pointof departure is the idea of basing object interfaces on the useof existential types, and the use of overloaded functions definedover witness types as methods. Our approach is particularly suit-able for adding object orientation to ML because the type sys-tem is essentially predicative (type inference is as in ML, withsome extensions to the unification algorithm), yet first-class ob-jects with polymorphic methods are allowed. There is a pleas-ing analogy here with Modula-3: whereas objects in the latterprovide upward closures in a manner which is supported withextensions to a conventional runtime system for Algol-like lan-guages, in our approach objects provide first-class polymorphicfunctions in a manner which is supported with extensions to theusual Hindley-Milner style type inference.
Pierce and Turnerhave already proposed a “data abstraction”model of object oriented typing based on the use of existentials[28] (as opposed to the “procedural abstraction” model associ-ated with objects-as-closures and F -bounded quantification).There are important differences between the latter proposal andthat presented here. Pierce and Turner work with Girard’sSystemF! extendedwith record types and subtyping, using sub-typing of type operators as an alternative to F -bounded quantifi-cation. Transplanting this approach to ML introduces the sameproblems as mentioned above (the lack of polymorphic meth-ods). Furthermore a serious limitation with the approachof Pierceand Turner is the lack of support for binary methods (one of themajor motivations for the introduction of F -bounded quantifica-tion). Our approach properly supports binary methods througha facility for multi-method dispatching.
Multi-methods solve the problem of contravariance in sub-typing by projecting methods out of a global environment, usingthe types of all of the arguments to resolve the method instance tobe invoked. The most prominent work following this approachhas been that of Castagna et al [6]. Rather than relying on recordtypes as a model of object interfaces, they instead use intersec-tion types to define methods as overloaded functions. Unlikeour work, their calculus does not (yet) support recursively de-fined functions. The multi-method approach to object orienta-
datatype for pseudomonads [32], and for the same reason: his implementation ofpseudomonads requires first-class polymorphic functions.
tion (as exemplified by CLOS [20]) has been criticized for vio-lating encapsulation, since rather than having methods encapsu-lated in objects they are instead projected out of a global environ-ment (using dynamic type discrimination in the case of Castagnaet al). Our approach provides dynamic single-method dispatch-ing and static multi-method dispatching. This latter fact avoidsthe violation of encapsulation criticized by others.
Finally an essential point about this work is that it does notexist in isolation from other desirable aspects of a type systemfor ML. In another paper [9] we consider another extension ofthe basic type system presentedhere, which provides a new modelfor dynamic typing for ML (based on overload dispatch) whichovercomesmany of the practical problems encountered in addingthe type dynamic to ML. An essential aspect of this work con-sists of combining our approach to parametric overloading withthe constructorclassesproposedby Jones for Haskell [17]. Joneshas shown how general monad comprehensions, and more re-cently Steele’s pseudomonads, may be simply and elegantly codedusing constructor classes. Combined with the work presentedhere, this demonstrates the merit of considering the addition oftype constructor overloading to ML.
2 Open kinds for parametric overloading
In this section we review an approach to parametric overload-ing which is an alternative to Haskell type classes [12, 13, 14].The foundations for type classes were originally formulated byWadler and Blott [33] in terms of type predicates (later gener-alized by Jones to qualified types [16]). In earlier work we de-veloped an alternative approach to parametric overloading basedon constraining type variables by open kinds (A comparison ofopen kinds and type predicates may be found in [13]). Openkinds constrain instantiations of type variables to types whichhave certain operations defined over them (in a similar way totype predicates). In addition, an overloaded operation has an as-sociated domain kind which describes the types for which in-stances of that operation are defined.
We use an expository mini-language which can be consid-ered as a kernel language for ML and Haskell. The syntax fortypes and kinds is given by:P ::= e j overload a : � in P jinstance a : � = e in Pe ::= c j x j a j fn x) e j (e1 e2) jfix f(x))e j let x = e1 in e2� ::= � j t(�1; : : : ; �n)� ::= � j 8� : $ � �$ ::= > j Kfa1; : : : ; ang! ::= ? j t(!1; : : : ; !n) j !1 t !2 j $The syntactic class of terms (denoted by e) includes two names-pacesof program variables, non-overloadedvariables x and over-loaded variables a, and some initial set of program constants(ranged over by c). The term constructors include �-abstraction(fn x) e), application, a fixed point operator fix and a letconstruct. The syntax for programs P introduces a construct fordeclaring new overload instances. The constructinstance a : � = e in P is a form of recursive let for defin-ing a recursive overload instance for a. The intention is that theoverloaded symbol a be augmented with the instance e in thecontext of the expressions e and program P . The constructoverload a : � in P is used to introduce a type template fora (as explained below), and is meant to precede any instancedeclarations for a. For the purpose of providing useful examples
51

in this section, we also assume that the expository mini-languagehas the usualmechanismsfor recursive function declarationswithpattern-matching (we use Standard ML syntax throughout).
The class of monomorphic types or monotypes includes typevariables � and compound type expressions t(�1; : : : ; �n) re-sulting from applying an n-ary type constructor t to n type ex-pressions �1; : : : ; �n. Here t ranges over an initial set of typeconstructors, eachwith an associatedarity, with the arity-checkingleft implicit for now. This set of type constructors includes atleast the binary type constructor!. The class of polymorphictypes or polytypes is obtained by universally quantifying overmonotypes; unlike the usual case for ML-style type systems, theuniversal type quantifier includes a kind constraint on the typevariable being quantified over. Our use of the word kind is con-sistent with its usual meaning as the “type” of a type operator.
Kinds intuitively form a lattice of sets of types, with ? and> as the bottom and top of the lattice, respectively, and uniongiven by the join operatort (the meet operatoruis useful mainlywhen reasoning about algorithms [13]). In addition each typeconstructor t has an associated kind constructor t of the same ar-ity; a kind expression t(!1; : : : ; !n) denotes the setof types withoutermost type constructor t applied to types �1 2 !1; : : : ; �n 2!n.
Since kinds intuitively characterize sets of types, we usef!1; : : : ; !ng as an alternative syntax for the expression!1t � � � t!n. Thus int t realt string may be denoted byfint,real,stringg. It should be noted that this notation isnot quite a set-of-types notation. For example the kind expres-sion fint, fint, stringg listg intuitively denotes the setof types fint, int list, string listg.
While kinds have an obvious interpretation as sets of groundmonotypes, the construct Kfa1; : : : ; ang is particular to para-metric overloading. Intuitively Kfag is the domain kind of theoverloaded variable a, in the sense that a has type:a : 8�:Kfag � �for some type template � . The kind expression Kfag denotesthe types of the available instance types for a, and is defined by a(possibly recursive) inequality in a separate context of contain-ment constraints for domain kinds. Since additional overload-ings may change this kind,Kfag is always interpreted relative toa particular kinding context. A kinding context K is a set of in-equalities of the form ! � Kfag. For example, assuming equal-ity = is defined for integers and reals, the full type of = is definedby:Kf=g � fint, realg= : 8�:Kf=g � � � � ! boolIf member is defined in an environment containing this type forequality, then member is given the type:member : 8�:Kf=g � � ! (� list) ! boolThe type of member is given with respect to a kinding contextthat defines the open kind (i.e., the set of possible instances) for=. Consider now if an instance is defined for equality for lists(using the instance construct):instance = :(8�:Kf=g � (� list) � (� list) ! bool) =fn ([], []) ) truej (x::xs, y::ys) ) (x=y) andalso (xs=ys)j ( , ) ) falseAfter this definition, the syntactic types for = and member areunchanged; however the definition of the domain kind for = hasnow been extended to:
Kf=g � fint, real, Kf=g listgThis kind reflects the fact that equality is now defined for lists,provided equality is also defined for the element type of the list.Note that the containment constraint for the domain kind for =is now recursive. Rather than containing the set of two typesfint, realg, the domain kind for = now contains the infiniteset fint, real, int list, real list,int list list, : : : g.
If another instance is defined for equality, for ML-style ref-erences:instance = :(8�:> � (� ref) � (� ref) ! bool) =builtinRefEqThen the resulting domain kind for = isKf=g � fint, real, Kf=g list, > refgThe kind expression> refdenotes the fact that reference equal-ity does not constrain the element type for references.
Throughout all of this process of defining new instances forequality, the syntactic type ofmember remains unchanged. How-ever the fact that member refers to the domain kind of = indi-rectly through the Kf=g construct allows member to rebind in-crementally to this domain kind as it is extended. Thus after theabove definitions for =, member is now applicable to say a list ofreferences.
WhileKfag denotes the domain kind for the overloadedvari-able a, Kfa1; : : : ; ang denotes the intersection of the domainkinds for the corresponding variables a1; : : : ; an . Although in-tersection of kinds (denoted by the meet operator u) is reallyonly necessary when reasoning about algorithms, the followingrule is derivable from the theory given in [13, Sect. 3]:Kfa1; : : : ; amg uKfb1; : : : ; bng =Kfa1; : : : ; am; b1; : : : ; bng
It is also possible to reintroduce type predicates as an abbre-viation for kinded types. For example the type:8� � [?+ : �� �! �][?� : �� �! �]�! �� �can be read as an abbreviation for:8� : Kf+; �g � �! �� �[13] contains further discussionof the relationship between openkinds and type predicates. [13] also contains a formalization ofthe type system summarized here. This type system uses sub-kinding and type judgements of the form:K ` !1 � !2K; �;A `� e : �whereK 2 Kind Context ::= fKfag � !aga� 2 Kind Environment ::= f� : !�g�A 2 Type Environment ::= fx : �xgx [ fa : �aga
52

3 Object Interfaces
In the previous section we saw an approach to constraining thepossible instantiations of a type variable, using a kind to describethe operations which neededto be definedover that variable. Ourapproach to defining object interfaces is a reasonably obviousstep, combining our notion of openkinds with the existential typesoriginally introduced by Mitchell and Plotkin [25]. Laufer andOdersky considered the extension of ML type inference to han-dle existentials [22]. We follow an alternative approach in Sect. 8,based on �0-unification [23]
We extend our syntax as follows:e ::= : : : j h� : $ = �; ei jopen e as h �, x i in e2� ::= : : : j 9� : $ � �An object interface is a type of the form 9� : $ � �. The valuecomponent of a data algebra inhabiting such a type is the selfcomponent of the object, while the type component is the typeof self (referred to as myType in some approaches). The inno-vative aspect here is the fact that methods are represented as in-stances of overloaded operations defined over the type of self.Consider the standard example from object-oriented typing, ofpoint objects4. Considera (single-dimensional)point object withsetX and getXmethods, where these are defined as overloadedoperators with signatures5:getX : 8� : KfgetXg � �! intsetX : 8� : KfsetXg � �! int! �We may define the interfaces for such objects using the existen-tial:type Point = 9� : KfsetX,getXg � �The subkinding theory formalized in [13] includes the rule thatKfa1; : : : ; am; am+1; : : : ; ang � Kfa1; : : : ; amg. If we de-fine coloured points as points having the additional colourmethod:colour : 8� : Kfcolourg � �! Colourtype ColourPoint = 9� : KfsetX,getX,colourg � �then this subkinding rule may be extended to the existential typeconstructor, giving a form of subtyping:K ` $ � $0C `� 9� : $ � � <: 9� : $0 � �Under this subtyping rule, we have that ColourPoint is a sub-type of Point6.
Our intention is to interpret the kind expression 9� : $ � �as the collection of ground types f9� : $0 � � j $0 � $g. Atechnical difficulty here is to reconcile the covariant ordering re-lation on kind expressions with the subtyping relation on object4The reader who feels dissatisfied that we concentrate on point and colour pointobjects should be aware that these have been the canonical examples for object-oriented type systems (as presented at POPL) for the last six years. Mitchell hastermed them “the stacks of object-orientedprogramming.” Abadi and Cardelli [1]consider some fresher examples, which we do not have space to consider here.5Actually one of these types is not quite right. We address this point further inSect. 10.6This subtyping of the object types is possible because point objects in this ex-ample do not contain binary methods which lead to the usual problems with con-travariance in subtyping. Because of the use of existential types, our approachshares the limitation of Pierce and Turner’s approach that it cannot be applied tobinary methods. In Sect. 5 we show how a form of equality multi-method can bedefined in our framework which allows ColourPoint to be a subtype of Point,while allowing point and colour point objects to be compared for equality.
interfaces, which is contr avariant in the arrow type. We split thekind ordering relation into two ordering relations, �+ and��,with: n � mK ` 9� : Kfamg � � �+ 9� : Kfang � �n � mK ` 9� : Kfamg � � �� 9� : Kfang � �K ` !1 �� !01 K ` !2 �+ !02K ` !1 ! !2 �+ !01 ! !02We use� to denote generically�+ and��.
Objects provide proper dynamic dispatching of overloadedoperations. For example we may define a global getX operationas:instance getX : (9� : KfgetXg � �) ! int =fn p ) open p as h myType, self i in getX selfUsing subtyping, this operation may be applied to any object whichhas a getX method, and dynamically dispatches to the methodfor that particular object. Note that this method is not projectedout of the environment. For example if we allow local overloadinstances7, then we may define:localinstance getX : real!int = fn x ) real2int xinval p = h myType:KfgetXg=real, 3.142 iend;getX p; (* Dynamic invocation of p's getX *)4 Polymorphic Methods
We now consider how to extend this framework with polymor-phic methods. The framework presented in Sect. 2 only allowsoverload templates of the form 8� : Kfag � � .
We extend the notion of object interfaces described in theprevious section with constructor arities8, as described by thefollowing grammer:� 2 Arities ::= �1 :! �2 j >� 2 Types ::= 9� : $ � � �1 : : : �nThe grammar also contains a generalization of the form of exis-tentials to allow witness type constructors. The idea is now that(as suggested by Jones [17]) we allow overloaded functions tobe defined over type constructors. For our purposes type con-structors correspond to the witness type constructors for collec-tion objects, while the overloaded functions correspond to theobject methods. Since open kinds Kfang now characterize setsof type constructors rather than simply sets of types, technicallywe need to index these kind expressions by the constructor ar-ity, for example K>f+,*g and K>!>f cons,car,cdrg. Inaddition we need to generalize this to the other kind construc-tors (?�;>�;t� and so on). If list is a type constructor of ar-ity>! >, then list>!> is the corresponding kind construc-tor. We refer to these as (open) constructor kinds; they consti-tute a strict generalization of open kinds. As with Jones’ type-checking algorithm for constructor classes, kind-checking now7A discussion of local overload instances for parametric overloading may befound in [13].8The system of constructor arities is similar to the constructor kinds proposedby Jones for constructorclasses [17]. For examplehis � ! � kind is representablehere as > ! >. We use “constructor kinds” to refer to a generalization of openkinds which relies on constructor arities.
53

overload getX : a �> intoverload setX : a �> int �> aoverload colour : a �> Colouroverload op = : a � a �> bool
type Point = 9 a:KfgetX,setXg. ainstance getX : int �> int = fn x => xinstance op = : Point � Point �> bool =
fn (p,q) => (getX p) = (getX q)
type ColourPoint = 9 a:KfgetX,setX,colourg. adatatype CP = CP of int � Colourinstance getX : CP �> int = fn CP(x, ) => xinstance colour : CP �> Colour = fn CP( ,c) => cinstance op = : ColourPoint � ColourPoint �> bool =
fn (p,q) => (getX p) = (getX q) andalso(colour p) = (colour q)
Figure 2: Defining equality multi-methods for point objects
involves arity checking for these simple kind constructors. Fur-thermore templates are now allowed to be polymorphic (withall type variables constrained to >�), as the following exampleshows. We define the signatures for the set methods as follows9:insert : 8� : K>!>fconsg � 8� : >��(�) ! � ! unitremove : 8� : K>!>fconsg � 8� : > � �(�) ! �map : 8� : K>!>fmapg � 8� : > � 8 : >��(�) ! (� ! ) ! �( )For example an instance of insert for an implementation of setobjects using list references may be implemented as follows:datatype 'a listref = listref of 'a list refinstance map :('b listref) ! ('b ! 'c) ! ('c listref) =fn (listref self) ) fn f )(listref (ref (map' f (!self))))5 Multi-Method Dispatching
Constructor arities introduce the possibility of higher-order typeconstructors, over which we may define overloaded functions.An obvious constructor to consider is the existential 9. Sincethe existential constrains the witness type with an open kind, ingeneral we have the compound type constructors 9[$] of arity(�! >)! > for any kind $ (of arity �)10 . The correspond-ing kind constructor is 9(�!>)!>[$].
We have already glimpsed an example of this, in the defini-tion of a global operation for dispatching the getXmethod of anobject. In that case we have:KfgetXg � f9� : KfgetXg � �g
Since existential types are distinguished by the kind constrainton the witness type, it is reasonable to allow overloadings of dif-ferent forms of the existential. Figure 2 gives an example of this,where equality multi-methods are definedfor points and colouredpoints. Assume for example that p has type Point and cp hastype ColourPoint. There is no equality operation for compar-ing a point and a colour point. With the definitions in Fig. 2, the9The definition of map shares the same limitation as setX in the previous sec-tion. We address this issue in Sect. 10.10In the language of Sect. 7, with explicit �-abstraction in the type language,9� : $� � � is an abbreviation for 9[$�](�� : � � �).
object interface ColourPoint is a subtype of Point. In the ap-plication (cp=p), the cp object may be treated as an argumentof type Point, with the overload instance of = for simple pointobjects invoked to compare cp and p.F -bounded quantification was partly introduced by Cook,Hill and Canning [7] in order to allow such binary methods with-out Eiffel’s type hole. This approach has the asymmetric prop-erty that a point can compare itself with a colour point, but acolour point cannot compare itself with a point. Similarly to us,Castagna et al [6] allow both forms of comparison by project-ing the appropriate implementation of equality out of a globalenvironment. In their approach multi-method dispatching is dy-namic, based on dynamically discriminating against the types ofthemulti-method arguments; single-method dispatching is a specialcase of multi-method dispatching. In our approachsingle-methodand multi-method dispatchingare distinct; the former is dynamic,projecting methods out of an object, whereas the latter is static,projecting multi-methods out of the environment.
Pierce and Turner [28], and Abadi and Cardelli [2], do notsupport binary methods11, and therefore for example do not al-low the equality method to be defined for points.
6 Subtype Constraints
There is one more concept to introduce before giving the formaldefinition of our type system for object interfaces. The problemis with type inference. Consider the following example:fn x ) ( open x as h �, y i in getX y; x )This function has an infinite number of incomparable types:(9� : KfgetXg � �) ! (9� : KfgetXg � �)(9� : KfgetX,setXg � �) ! (9� : KfgetXg � �)(9� : KfgetX,setXg � �) ! (9� : KfgetX,setXg � �): : :On the other hand, a type such as (9� : KfgetXg ��)! (9� :KfgetX,setXg � �) is not valid for this expression.
In order to maintain principal types, we introduce subtypingconstraints into the syntax of polymorphic types [26]. A generalpolymorphic type now has the form 8�n : $n �C ) � , whereC is a set of subtyping constraints of the form � <: � 0. In theexample above, the expression can be given the following prin-cipal type:8� : > � 8� : >�f� <: (9 : KfgetXg � ); � <: �g ) � ! �7 Type Rules
In this section we discuss the formalization of our type system,while the problem of type inference is considered in the next sec-tion. The type system summarized in Sect. 2 is fully formalizedin [13]. We consider here the extension of that type system withconstructor kinds and existential types. For the purposes of typeinference we will consider one further extension to the type sys-tem, allowing �-abstraction in the formation of types. This ex-tension allows the extension of the type system with full existen-tials 9� : $�� . This extension is necessaryonce we considerex-istentials with witness type constructors. The extensions to the11“Binary methods have provenvery hard to handle in general, andwe have littleto contribute” [1].
54

syntax of types and kinds of Sect. 2 are:� ::= � j t j �� : � � � j �1 �2 j (R�1 �2)C ::= f�11 <: �12 ; : : : ; �n1 <: �n2 g� ::= C ) � j 8� : $ � � � �� ::= > j �1 :! �2$ ::= : : : j � :! $! ::= : : : j � :! ! j �We abbreviate fg ) � by � . This syntax strictly generalizesthe syntax presented earlier for constructor kinds and existen-tials. The full existential 9� : $ � � � � is syntactic sugarfor 9[$ � �](�� : � ��). Type-checking for the full existentialrequires the packaging construct h� : $ = � 0; e : �i; we useh� : $ = � 0; ei as an abbreviation for h� : $ = � 0; e : �i.We assume the usual ��-conversion relation on the language oftypes. We denote this by � ! � 0 , and we denote the corre-sponding reduction relation by � �! � 0 . We have:(�� : � � �1) �2 �! f�2=�g�1�� : � � � � ! � where � =2 FV(�)In addition to the application (�1 �2), we also have the uninter-preted application12 (R�1 �2). We term this rigid application,while we term the interpreted application flexible application.The former form of application is necessary in order to keep uni-fication in type inference terminating and unitary. For example,for the types:8� : $� � >! > � 8� : $� � > � 8 : $ � >�(R� �)! (� ! )! (R� )8� : $� � > � 9� : $� � >! > � (� �)8� : $� � >! > � 9� : $� � > � (� �)The applications in the first type must be rigid, otherwise typeinference will in general require higher order unification. Theapplication in the second type can safely be chosen to be flexi-ble, since the head is not affected by substitutions. In fact, wealso require this application to be rigid, for technical reasons todo with �-expansion during unification. For similar reasons weshare Jones’ restriction that type constructors must be fully ap-plied in type expressions [17]. It is perhaps less obvious whythe application in the third type can be flexible, since � may bereplaced during type inference by a “non-generic” type variable.Yet it is absolutely essential that this be allowed in order for typeinference to correctly handle the scoping of types with variable-binding constructs. In the next section we show how this is doneusing Miller’s algorithm for �0-unification [23, 27].�-abstraction and �-conversion in the type language, and ar-ities for such type expressions, are familiar concepts in type sys-tems such as SystemF! . What is novel here is the system ofopen kinds which “refine” these type arities. The open kindssummarized in Sect. 2 refine the arity > of monomorphic types.The open kind expression � :! ! is introduced as a form of de-pendent arrow kind to refine the arity �1 :! �2. In conjunctionwith this, we allow type variables (bound by such arrow kinds)in open kind expressions. Furthermore we have:!> denotes !!�1 :!�2 denotes � :! !�2Kind environments now have the form:� 2 Kind Environment ::= f� : !� � ��g�12In the type system considered by Jones, this is the only form of applicationprovided in the language of types [17]. Jones does not consider�-abstraction or aconvertibility relation in his type language.
TYVAR(� : ! � �) 2 �K; � `� � : ! � �
TYCON
(t : �1 :! � � � :! �n!>) 2 �K; � `� t : (�1 :! � � � :! �n :! t �1 : : : �n)� (�1 :! � � � :! �n!>)TYABS
K; �; � : � � �1 `� � : ! � �2K; � `� (�� : �1 � �) : � :! ! � �1 :! �2TYAPPF
K; � `� �1 : � :! !1 � �2 :! �1K; � `� �2 : !2 � �2K; � `� (�1 �2) : f!2=�g!1 � �1TYAPPR
K; � `� �1 : � :! !1 � �2 :! �1K; � `� �2 : !2 � �2K; � `� (R�1 �2) : f!2=�g!1 � �1TYSUB
K; � `� � : ! � � K `� ! �+ !0 � �K; � `� � : !0 � �TYFORM
K; � `� � ji : !ji � �i for i = 1; : : : ;m, j = 1; 2K; � `� � : $ � >K; � `� f�11 <: �21 ; : : : ; �1m <: �2mg ) � type
TYALLK; �; � : ! � � `� � typeK; � `� 8� : ! � � � � type
Figure 3: Kinding Rules for Type System
INSTTK; � `� � type � ! � 0K; �;C `� � v � 0
INSTCC `� �1 <: �2 for (�1 <: �2) 2 C0K; �;C `� � v � 0K; �;C `� � v C0 ) � 0
INSTPK; � `� � 0 : $ � � K; �;C `� � v f� 0=�g�K; �;C `� � v 8� : $ � � � �
Figure 4: Instance Relation Between Types
Furthermore we now have the kinding judgement for type ex-pressions: K;� `� � : ! � �The kinding rules for types are presented in Fig. 3.
Theorem 1 The following propertieshold for the calculus of well-kinded types:
Church-Rosser If � ��! �1 and � ��! �2 , then there existssome � 0 such that �1 ��! � 0 and �2 ��! � 0 .
Strong Normalization If K;� `� � : ! � �, then there doesnot exist an infinite sequence of reductions � = �0 �!�1 �! � � � �! �i �! �i+1 �! � � �.
Figure 5 gives selected type rules for the language. The omit-ted rules are basically standard. The OVAR rule for using anoverloaded variable uses an instance relation between types de-fined in Fig. 4.
8 Type Inference
In this section we consider the problem of type inference for thetype system presented in the previous section. Figure 6 gives theinteresting cases for the type inference algorithm (details for theother language constructs are similar to for example [13]). The
55

A(x) = 8�n : $m � �m �C ) �(K; Q; A; x; CA; CK; (ST ;ET )) �=)(Q8�m : �m � 8�m : �m � �m � 8� : �� � >; �; CA; CK; �m � $m; (� <: �; C;ST ; ET ))(K; Q; A; e; CA; CK; CT ) �=) (Q0; � 0; C0A; C0K ; C 0T )(K; Q; A; h� : $ � � = �; e : � 00i; CA; CK ; (ST ;ET )) �=)(Q08�� : > � 8� : �� � >; �; C0A; C0K ; (� <: (9� : $ � � � � 00);S 0T ; (� 0 = f�=�g� 00);E 0T ))(K; Q; A; e1; CA; CK; CT ) �=) (Q0; �1; C 0A; C 0K; C0T )(K; Q`; A; e2; C 0A; C0K; C0T ) �=) (Q00; �2; C00A; C00K; (S 00T ; E 00T ))(K; Q; A; (e1 e2); CA; CK; CT ) �=) (Q008�� : > � 8� : �� � >; �; C00A; C 00K; (S 00T ; (�1 = �2 ! �);E 00T ))(K; Q; A; e1; CA; CK; CT ) �=) (Q0; �1; C 0A; C 0K; C0T )(K; Q08" � 8�� : " � 8�� : > � 8� : > � 8� : �� � > � 9� : �� � " � 8 : � � >;A;x : ; e2; CA; CK; (S0T ; (�1 = 9� : �� � " � );E 0T ) �=) (Q00; �2; C 00A; C00K; C00T )(K; Q; A; open e1 as h �, x i in e2; CA; CK; CT ) �=) (Q00; �2; C 00A; C 00K; C00T )(K; Q; A; e1; CA; CK; CT ) �=) (Q0; �1; C 0A; C 0K; C0T )(K; Q0; C0A; C 0K; C0T ) �=) (K; Q00; C 00A; C 00K; C00T )� = U(Q00; C 00A; C00K; C00T ) f�1; : : : ; �mg = UV(Q00; �(�1))� UV(Q00; �(A))C = f(� <: � 0) 2 S 00T j UV(Q00; �(�)) [ UV(Q00; �(� 0)) � f�igig S(3)T = S 00T � C C 00K f�1;:::;�mg=) C(3)K ; �0� = �0�(8�m : ��m � �m � C ) �1)(K; Q00; A;x : �; e2; C00A; C(3)K ; (S(3)T ; E 00T )) �=) (Q(4); �2; C(4)A ; C(4)K ; C(4)T )(K; Q; A; let x = e1 in e2; CA; CK; CT ) �=) (Q(4); �2; C(4)A ; C(4)K ; C(4)T )Figure 6: Type Inference Algorithm
algorithm is presented in natural semantics style. Input to thealgorithm includes a kind context K , type environment A andprogram P . The kind environment � is generalized to a quanti-fier prefix to ensure the proper scoping of substitutions:Q ::= � j Q1Q2 j 8" j 8� : � j8� : ! � � j 9� : ! � �Universally quantified variables correspond to “free” variables,constrainedby equality and inequality constraints. These includetype variables�, kind variables � and arity variables ". Existen-tially quantified type variables correspond to the abstract witnesstypes in opened data algebras. The interleaving of universal andexistential quantifiers captures the scoping restrictions on the al-lowable substitutions for free type variables.
As usual the heart of type inference is in the constraints gen-erated by a walk over the abstract syntax tree of a program, andthe constraint solvers used to simplify those constraints and checkfor consistency. The type inference algorithm keeps track of threecollections of constraints, for arity variables (CA), kind variables(CK) and type variables (CT ). The latter two further decomposeinto equality constraints (EK and ET ) and ordering constraints(SK and ST ). An execution of the type checker therefore con-sists of the transition:(K; Q; A; P ; CA; CK; CT ) �=) (Q0; � ; C0A; C 0K; C0T )
where CA ::= > j CA;C0A j �1 = �2CK ::= (SK; EK)SK ::= > j SK ;S 0K j !1 � !2EK ::= > j EK;E 0K j !1 = !2CT ::= (ST ; ET )ST ::= > j ST ;S 0T j �1 <: �2ET ::= > j ET ;E 0T j �1 = �2ET and ST are lists, while the other constraint collections aremultisets. When we reason about correctness, we use an exten-sion of Miller’s unification logic [24]. In this logic, > is truthand ; (comma) is conjunction, so configurations of the seman-tics may be regarded as formulae in this unification logic. CAis in solved form if it is of the form "1 = �1; : : : ; "n = �n,where no "i occurs in any �j . SK is in solved form if it is of theform �1 � !1; : : : ; �n � $n where each�i is distinct. ST is insolved form if it is of the form �1 <: �1; : : : ; �n <: �n. FinallyET is in solved form if it is of the form �1 = �1; : : : ; �n = �nwhere no �i occurs free in any �j .
One technical complication is that the algorithm may com-pute subkindingconstraints (using the matching procedure,whichlifts subtyping to subkinding) which must then be converted tosubtyping constraints to be exported in the signature of a let-definition. If a subtyping constraint� <: 9� : Kfa1; : : : ; ang �� � � is replaced by the constraints � = 9� : � � � � �;� �Kfa1; : : : ; ang, and this subkinding constraint must later be ex-ported in a type as a subtyping constraint, we must be able tosalvage � from � and export the subtype constraint � <: 9� :Kfa1; : : : ; ang � � � �. We omit the tedious details from thispresentation.
56

OVAR(a : �) 2 A K; �;C `� � v �K; �;C;A `� a : �
OVLD
� = 8� : Kfag � � � 8� : > � � � �fKfag � !g =2 K K; � `� � typeK [ fKfag � ?g; �;C;A [ fa : �g `� P : �K; �;C;A `� (overload a : � in P ) : �INST
K0; �0;C;A `� e : �1 K0 ; �;C;A `� P : �2K; �;C;A `� (instance a : � = e in P ) : �2where
8>>><>>>: A(a) = 8�a : Kfag � � � �a and K(a) = !� = 8�n : $n � �n � �0�0 = f(t �1 : : : �n)=�g�a for some tFV(�0) = f�1; : : : ; �ng�0 = �; �n : $n � �nK0 = K [ fKfag � �0(t �1 : : : �n)gLET
K; �; �n : $n;C [ C0;A `� e1 : �1f�igi � (FV(�1) [ FV(C0))� (FV(A)[ FV(C))K; �;C;A; x : (8�n : $n � �n � C ) �1) `� e2 : �2K; �;C;A `� let x = e1 in e2 : �2PACK
K; � `� � : $ � � K; �;C;A `� e : f�=�g� 0K; �;C;A `� h� : $ � � = �; e : � 0i : 9� : $ � � � � 0OPEN
K; �;C;A `� e : 9� : $ � � � �K; �; � : $ � �;C;A; x : � `� e0 : � 0K; �;C;A `� (open e as h �, x i in e0) : � 0TY
K; �;C;A `� e : � C `� � <: � 0K; �;C;A `� e : � 0TYE
`� $ � $0 � � C `� � <: � 0C `� (9� : $ � � � �) <: (9� : $0 � � � � 0)TYH
(� <: � 0) 2 CC `� � <: � 0TYF
C `� � 01 <: �1 C `� �2 <: � 02C `� �1 ! �2 <: � 01 ! � 02Figure 5: Type Rules for Type System
The type inference algorithm is written in a slightlynon-traditional way. The constraints that are accumulated dur-ing type inference are threaded through the execution of the al-gorithm. The equality constraints correspond to the more usualsubstitution which is computed during Hindley-Milner type in-ference. We prefer to formulate this as a collection of constraintsfor reasoningabout well-typednessof computed substitutions un-der a mixed prefix. In order to simplify the description of the al-gorithm, we only perform constraint solving when the type of alet-definition is being added to the environment.
For type-checking a variable, we assume that the bound typevariables in a polymorphic type have been renamed apart fromthe variables in the quantifier prefix before the type is instanti-ated by type inference. The description of type inference for thelet construct uses several auxiliary notions. Given a constraintconfiguration in solved form, U returns the substitution corre-sponding to the equalities (in solved form) in that configuration.CK f�1;:::;�mg=) C 0K; �0 denotes the removal of all constraints ofthe form ��i � !i from SK and the addition of the equalities��i = !i to EK , for i = 1; : : : ;m, with the corresponding sub-stitution �0 computed as f��1 7! !1; : : : ; ��m 7! !mg. Givena quantifier prefixQ and a type � , UV(Q; �) denotes the free typevariables in � which are universally quantified in Q.
The constraint solver is invoked in type-checking the letconstruct. It is written in structured operational semantics style,using configurations of the form (K; Q; CA; CK; CT ). Asusual the heart of the constraint solver is the unification algo-
rithm, specified in Figs. 7 and 8. The quantifier and unifica-tion transitions preserve the scoping restrictions specified by theinterleaving of the quantifiers [24].
The second stage in the constraint solver is the solver for thesubtyping constraints. This solver checks that types in a subtyp-ing constraint “match” [26], in the process reducing such con-straints to atomic constraints. Atomic constraints are subtyp-ing constraints between variables (� <: �) and subkinding con-straints between kind constraints ($ � $0). Figure 9 givessome of the matching transitions: these carry along a reflexivelytransitively closed partial order PT over type variables, corre-sponding to the subtyping relationships between type variablesrequired by previously processedconstraints. [�]PT denotes theset of all constraints involving variables related to � in the sym-metric transitive closure of PT . Matching transitions are inter-leaved with unification transitions, since the former may gener-ate unification constraints.
The third stage in the constraint solver is arity inference. Thisis simple first-order unification (as in the usual ML type infer-ence algorithm). The fourth stage in the constraint solver in-volves checking that computed type substitutions are well-kinded,in the sense that Q(�) �+ Q(�) for each answer constraint� = � . This is essentially similar to the algorithm provided in[13] (with some complications introduced by the �+ and ��relations). The final stage in constraint solving is to check thatthe subkinding and subtyping constraints are consistent. We relyon an algorithm described by Wand and O’Keefe [34], since oursubtyping system forms a lattice.
We use the following meta-logic to reason about correctnessof the constraint-solving process and the fact that the correspond-ing substitution is the most general well-typed substitution [10]:
Definition 8.1 (Unification Logic with Substitutions) Aformula of the unification logic is of the form:F ::= > j F1;F2 j 8" � F j 8� : � � F j8� : ! � � � F j 9� : ! � � � F j � = �0 j! = !0 j ! � !0 j � = � 0 j � <: � 0A substitution � is a (syntactically well-sorted) mapping over ar-ity, kind and type variables which is the identity on all but a fi-nite number of variables. Define dom(�) to be those variableson which � is not the identity. Define the rules for the judgementform K;� `� � : F as follows:K; � `� � : >K;� `� � : F1 K;� `� � : F2K; � `� � : F1;F2� =2 dom(�) K;�; � : ! � � `� � : FK;� `� � : 9� : ! � � � F� 2 dom(�) K; � `� �(�) : ! � �K;� `� � : f�(�)=�gFK;� `� � : 8� : ! � � � F� 2 dom(�) K; � `� � : f�(�)=�gFK;� `� � : 8� � F" 2 dom(�) K;� `� � : f�(")="gFK; � `� � : 8" � FK;� `� � : � = �K `� ! � � K `� ! = !0 � � K `� !0 � �K;� `� � : ! = !0
57

Q19� : !1 � �18� : !2 � �2Q2 =) Q18� : !2 � �29� : !1 � �1Q2Q18� : !1 � �18� : !2 � �2Q2 =) Q18� : !2 � �28� : !1 � �1Q2Q =) Q0(K; Q; CA; CK; CT ) =) (K; Q0; CA; CK; CT )Figure 7: Quantifier Transitions(Q; (�� : � � � = �� : � � � 0);ET ; CA; EK) =) (Q9� : � � �; � = � 0;ET ; CA; EK)(Q; (�� : � � � = � 0);ET ; CA; EK) =) (Q9� : � � �; (� = � 0 �);ET ; CA; EK)(Q; (t �1 : : : �m = t � 01 : : : � 0m);ET ; CA; EK) =) (Q; �1 = � 01; : : : ; �m = � 0m;ET ; CA; EK)(Q; (9[$ � �]� = 9[$0 � �0]� 0);ET ; CA; EK) =) (Q; � = � 0; ET ; � = �0;CA; $ = $0;EK)(Q; (t �1 : : : �m = t � 01 : : : � 0m);ET ; CA; EK) =) (Q; �1 = � 01; : : : ; �m = � 0m;ET ; CA; EK)(Q19� : ! � �Q2; (� �1 : : : �m = � � 01 : : : � 0m);ET ; CA; EK) =) (Q; �1 = � 01; : : : ; �m = � 0m;ET ; CA; EK)(Q8� : ! � (�1 :! � � � :! �m :! �)Q2; (� �1 : : : �m = t �1 : : : �n);ET ; CA; EK) =)(Q18�8� 1 : (�1 :! � � � :! �m :! �01) � � � � 8� n : (�1 :! � � � :! �m :! �0n) � 8 1 : � 1 � � � 8 n : � n )Q2;f�=�g((� �1 : : : �m = t �1 : : : �n);ET ); � = � ; CA; EK)
where (t : �01 :! � � � :! �0n :! �) 2 � and (9�i : !0i � �i) 2 Q2 for i = 1; : : : ;mand � = ��1 : �1 � � ���m : �m � t ( 1 �1 : : : �m) : : : ( n �1 : : : �m)and � =2 FV(�1) [ � � � [ FV(�n)(Q8� : ! � (�1 :! � � � :! �m :! �)Q2; (� �1 : : : �m = � �1 : : : �n);ET ; CA; EK) =)(Q18�8� 1 : (�1 :! � � � :! �m :! �01) � � � � 8� n : (�1 :! � � � :! �m :! �0n) � 8 1 : � 1 � � � 8 n : � n )Q2;f�=�g((� �1 : : : �m = � �1 : : : �n);ET ); � = � ; CA; EK)where (9� : ! � �01 :! � � � :! �0n :! �) 2 Q1 and (9�i : !0i � �i) 2 Q2 for i = 1; : : : ;mand � = ��1 : �1 � � ���m : �m � � ( 1 �1 : : : �m) : : : ( n �1 : : : �m)and � =2 FV(�1) [ � � � [ FV(�n)(Q8� : ! � (�1 :! � � � :! �m :! �)Q2; (� �1 : : : �m = �k �1 : : : �n);ET ; CA; EK) =)(Q18�8� 1 : (�1 :! � � � :! �m :! �01) � � � � 8� n : (�1 :! � � � :! �m :! �0n) � 8 1 : � 1 � � � 8 n : � n )Q2;f�=�g((� �1 : : : �m = �k �1 : : : �n);ET ); � = � ; CA; EK)where (9�i : !0i � �i) 2 Q2 for i = 1; : : : ;m and �k = �01 :! � � � :! �0n :! �and � = ��1 : �1 � � ���m : �m � �k ( 1 �1 : : : �m) : : : ( n �1 : : : �m)and � =2 FV(�1) [ � � � [ FV(�n)(Q8� : ! � (�1 :! � � � :! �m :! �)Q2; (� 1 : : : m = � 01 : : : 0m);ET ; CA; EK) =)(Q18� � 8�� : (��(1) :! � � � :! ��(p) :! �) � 8� : ��Q2;f�=�g((� 1 : : : m = � 01 : : : 0m);ET ); � = � ; CA; EK)
where (9 i : !i � �i); (9 0j : !0j � �0j) 2 Q2 and p =j fk j k = 0kg jand � is an injective mapping from p into m such that �(k) = 0�(k)and � = � 1 : �1 � � �� m : �m � � �(1) : : : �(p)(Q8� : ! � (�1 :! � � � :! �m :! �)8� : !0 � (�01 :! � � � :! �0n :! �)Q2; (� 1 : : : m = � 01 : : : 0n);ET ; CA; EK)=) (Q18�8� � 8�� : (�001 :! � � � :! �00p :! �) � 8� : ��Q2;f�=�; � 0=�g((� 1 : : : m = � 01 : : : 0n);ET ); � = �; � = � 0; CA; EK)
where (9 i : !i � �i); (9 0j : !0j � �0j) 2 Q2 and f 001 ; : : : ; 00p g = f 1; : : : ; mg \ f 01; : : : ; 0ngand � = � 1 : �1 � � � � m : �m � � 001 : : : 00pand � 0 = � 01 : �01 � � �� 0n : �0n � � 001 : : : 00p(Q; ET ; CA; EK) =) (Q0; E 0T ; C0A; E 0K)(K; Q; CA; (SK; EK); (ST ; ET )) =) (K; Q0; C0A; (SK; E 0K); (ST ; E 0T ))
Figure 8: Unification Transitions
58

K `� ! � � K `� ! � !0 � � K `� !0 � �K;� `� � : ! � !0K;� `� � : ! � � � ! � 0K;� `� � 0 : !0 � �K;� `� � : � = � 0K; � `� � : ! � � `� �1 <: �2K;� `� � 0 : !0 � �K;� `� � : � <: � 0Theorem 2 Any sequence of transitions of the constraint solveris terminating. An type constructed by the unification algorithmis well-kinded. Given constraint solver configurations(K; Q; CA; CK ; CT ) and (K; Q0; C 0A; C0K; C0T ) such that(K; Q; CA; CK ; CT ) �=)(K; Q0; C 0A; C 0K; C0T ), then:
1. If K;� `� � : Q(CA;CK;CT ) then there exists some�0 � � such that K; � `� Q0(C0A;C 0K;C0T ) :.2. If K;� `� �0 : Q0(C0A;C 0K;C0T ) then K;� `� �0 :Q(CA;CK;CT ).
As a corollary, we have that if � = U(K; Q; CA; CK; CT ) fora final configuration in solved form, then � is a most general uni-fier. Given � = �n : !n, let 8(�) = 8�n : !n.
Theorem 3 Given kind contextK , kind environment�, type en-vironmentA, programP . If(K; 8(�); A; P ; >; (>;>); (>;>)) �=)(Q0; � ; C0A; C0K ; C 0T )and K;�0 `� � : Q0(C 0A;C0K; C0T ) for some �0, thenK;�0;S 0T ; �A `� P : �� .
Theorem 4 Given C , K , �, A, P . If K; �0;C; �A `� P : �for some � such that K;�0 `� � : C , then(K; 8(�); A; P ; >; (>;>); (C;>)) �=)(Q0; � 0; C0A; C0K ; C 0T )with �0 = U((K; Q0; C0A; C0K ; C 0T )), �0 = f(� : �0(��) �Q0(�) j � =2 dom(�0)g, then there exists some �00 such that�A = �00�0A and � = �00� .
9 Operational Semantics
In this section we consider the semantics of our mini-languagebased on its translation into an underlying calculus of explicitpolymorphic typing. We denote the original implicitly typed lan-guage presented in earlier sections by MLcore, while we denotethis latter explicitly typed language by MLeval. The details ofMLeval, for the original system of simple open kinds (and alsowith closed kinds), are worked out in [14]. The extension of thiscalculus with existentials and subtyping (and a correspondingnarrowing operation) are provided in [9]. The further extensionof this system with arities and subtyping constraints is straight-forward, and we omit the details.
In the semantics described in [14, Sect. 3], type variables withopen kind are interpreted as type algebras. These are similar todata algebras for existential types, since they bundle up a wit-ness type with a collection of operations over that type. The dif-ference is that type algebras are second-class values and inhabitopen kinds:
Data Algebra h� : $ = �; � 0 : ei 2 9� : $ � � 0Type Algebra (�; fai = eigi) 2 Kfa1; : : : ; ang
For a data algebra inhabiting an existential with an open kindbound on the witness type, the type algebra for the witness typecorresponds to a method table. The syntax for MLeval includesthe constructs:� ::= � j (�; fa1 = e1; : : : ; an = eng)e ::= : : : j Fn � : $ ) e j e[�] jdispatch(a,t) j �:aThe instantiation of an overloaded operation in MLcore is re-placed by two operations, one for statically dispatching out ofthe global environment of the available instances (using thedispatch construct), the other for dynamically dispatching outof the type algebra for a local type variable (using the projectionconstruct �:a).
The transformation from MLcore to MLeval also gives someinsight into how we obtain polymorphic methods without im-predicative polymorphism. If we choose to translate types inthe evaluation language into types in Harper and Mitchell’s XML[15], we see that open kinds correspond to a certain form of thepredicative “strong sum” �. Whereas the translation converts aMLcore kind judgement of the form� 2 Kfa1; : : : ; anginto a MLeval kind judgement of the form(�; fa1 = e1; : : : ; an = eng) 2 Kfa1; : : : ; angtranslating this further into XML gives(�; fa1 = e1; : : : ; an = eng) 2�� : > � fa1 : f�=�a1g�a1 ; : : : ; an : f�=�ang�angThen translating 9� : Kfa1; : : : ; ang � � gives9� : (�� : >�fa1 : f�=�a1g�a1 ; : : : ; an : f�=�ang�ang)��1�10 Typing Constructor Specialization
In Sect. 3 we gave a signature for a setXmethod, and in Sect. 4we gave a signature for a map method, which share the propertythat they return a new object as their result. They also share theproperty that they do not work. Consider for example the defini-tion of setX. Invoking setX in the naive way violates the scop-ing restriction on the use of opened existentials, which in turn iscrucial to maintain the separation between types and values [8].We could fix this by rewrapping the result in an existential, how-ever this has the same limitation as constructor specializationin Modula-3 and C++. We might alternatively define global in-stances of setXwhich perform this wrapping, one for each pos-sible object type. The problem here is with mapping setX overa list of point objects, for example. Using the narrow constructdescribed in [9], the following should evaluate successfully:fun move (p:Point,x) : Point = setX p xcp : ColourPointnarrow[ColourPoint](move(cp,3))
The following approach appears to have promise, and fur-ther motivates our kinded approach to parametric overloadingin this work. We introduce kind variables�1; �2; : : :, and intro-duce bounded kind quantification13:' ::= � j 8� � $ � '13Since we assume polymorphismis predicative, as in ML [15], no foundationalproblems arise here [8]. Our course is basically equivalent to placing a third typeuniverse atop those for types and kinds.
59

(Q8� : ! � (�1 :! � � � :! �m :! �)Q2; (PT ; (� �1 : : : �m) <: (9[$ � �0]�);ST ; ET ); CA; (SK; EK)) =)(Q18� � (8�i)i2I[J[K � (8� i � 8 i : � i )i2I � (8� j � 8 j : � j )j2J � (8� k � 8 k : � k)k2KQ2;(PT � [�]PT [ f i <: j j (�i <: �j) 2 PT g; f�n=�ng((� �1 : : : �m) <: (9[$ � �0]�);ST ); f�=�ngET ; �n = �n);CA; ((�i �+ �)i2I;SK ; EK))where f�igi2I = f�0 j (�0 �: �) 2 PT g and f�jgj2J = f�0 j (� <: �0) 2 PT gand f�kgk2K = FV([�]PT )� (f�igi2I [ f�jgj2J), and n =j I [ J [K jand �i = ��1 : �1 � � ���m : �m � 9[�i � �0]( i �1 : : : �m) for i 2 I [ J [Kand � = �j , = j , � = �j , some j 2 J ,and f�igi2I[J[K \ FV(�) = fg(Q8� : ! � 8� : !0Q2; PT ; (� 1 : : : m <: � 01 : : : 0n);ST ; ET ; CA; (SK ; EK)) =)(Q18�8� � 8��1 : (�001 :! � � � :! �00p :! �) � 8�1 : ��1 � 8��2 : (�001 :! � � � :! �00p :! �) � 8�2 : ��2Q2;(PT [ f�1 <: �2g; f�=�; � 0=�gST ; f�=�; � 0=�gET ; � = �; � = � 0; CA; (SK; EK))
where � = � 1 : �1 � � �� m : �m � �1 001 : : : 00p and � 0 = � 01 : �01 � � �� 0n : �0n � �2 001 : : : 00p(Q; (fg;ST ;ET ); CA; CK) �=) (Q0; (PT ;>;E 0T ); C0A; C0K)(K; Q; CA; CK; (ST ; ET )) �=) (K; Q0; C0A; C 0K ; (PT ; E 0T ))Figure 9: Matching Transitions
We modify the syntax of kind constraints to reflect the fact thatoverload instances may be indexed by a kind parameter as wellas a type parameter. In so doing we also need to introduce anexplicit fixed point operator for kind constraints:$ ::= : : : j � j Kfa1[$1]; : : : ; an[$n]g j �� �$The type signature for setX is now:setX : 8� � (�� �KfsetX[�]g) � 8� : KfsetX[�]g�� ! int ! 9� : � � �Open kinds of the form KfsetXg are now replaced by kinds ofthe form KfsetX[$]g. The definition of the object interfacefor point objects is then:type Point = 9� : (�� �KfgetX,setX[�]g) � �11 Conclusions
We have presented an approach to object-oriented typing in ML-like languageswith parametric overloading. Our approach is mod-erately novel in that it does not involve record types or impred-icative polymorphism, yet it supports objects with polymorphicmethods. Furthermore, because our approach is couched in aframework for overloading, it provides a (static form of) multi-method dispatching.
Some impredicativity appears to be essential for typing object-oriented languageswith some form of parametric polymorphism,if only to support the application of methods to self. This im-predicativity in the object type constructorcan either be obtainedfrom recursive types or existential types. Our analysis showsthat this is the only essential aspect of impredicativity requiredfor object-oriented typing, and for example shows how the pred-icative type system of Standard ML may be extendedwith object-oriented constructs without fundamentally altering the founda-tions of the language (for example, turning it into Quest [5]).Our approach is compatible with the predicative module typesystem of Standard ML [15].
Subtyping is admittedly the least satisfactory aspect of ourtype system, becauseof the complexity of computed types whichresults. Practical experience with a type-checker is required (An
implementation is currently underway in the Standard ML Kit).We have considered subtyping here in order to support multi-method dispatching, and also because it appears to be useful forheterogeneous collections.
In our approach we have used kinded types for parametricoverloading and sets of subtypingconstraints for subtyping. Oth-ers have considered a uniform framework of type predicateswhere these conceptsare combined [30, 19] (See also [16]). Onemay wonder if it is possible for us to provide a similarly uni-form framework? We argue that kinded types are more appro-priate for parametric overloading than type predicates [13]. Fur-thermore formulating overloading constraints as variable kindsprovides us here with objects with polymorphic methods, andin other work with a new model of dynamic typing in ML-likelanguages based on overload dispatching [9]. Kinded types alsoseem the most natural way to combine parametric overloadingwith SML-like modules and interfaces. There are grounds forconsidering a hybrid type system, such as that presented here,which combines kinded types and type predicates. We are cur-rently investigating one alternative, based on constrained arrowtypes.
References
[1] Martin Abadi and Luca Cardelli. A theory of primitive ob-jects. To appear, 1994.
[2] Martin Abadi and Luca Cardelli. A theory of primitiveobjects: Second-order systems. In European Symposiumon Programming, volume 788 of Springer-Verlag LectureNotes in Computer Science, pages 1–25. Springer-Verlag,1994.
[3] Val Breazu-Tannen, Thierry Coquand, Carl Gunter, andAndre Scedrov. Inheritance as implicit coercion. Infor-mation and Computation, 93(1):172–221, 1991.
[4] Peter Canning, William Cook, Walter Hill, and WalterOlthoff. Interfaces for strongly-typed object-oriented pro-gramming. In Proceedingsof ACM Symposium on Object-Oriented Programming: Systems, Languages and Appli-cations, pages 457–467, 1989.
60

[5] Luca Cardelli. Typeful programming. Technical report,DEC Systems Research Center, 1989.
[6] Giuseppe Castagna, Giorgio Ghelli, and Giuseppe Longo.A calculus for overloaded functions with subtyping. InProceedings of ACM Symposium on Lisp and FunctionalProgramming, pages 182–192, 1992.
[7] William Cook, Walter Hill, and Peter Canning. Inheri-tance is not subtyping. In Proceedingsof ACM Symposiumon Principles of ProgrammingLanguages,pages125–135,1990.
[8] Thierry Coquand. An analysis of Girard’s paradox. In Pro-ceedings of IEEE Symposium on Logic in Computer Sci-ence, 1986.
[9] Dominic Duggan. Dynamic types have existential type. 30pages. In preparation., 1994.
[10] Dominic Duggan. Unification with extended patterns.Technical Report CS-93-37, University of Waterloo, 1994.57 pages. Revised March 1994. Submitted for publication.
[11] Dominic Duggan and Frederick Bent. Explaining type in-ference. Technical Report CS-94-14., University of Water-loo, 1994. Submitted for publication.
[12] Dominic Duggan, Gordon Cormack, and John Ophel.Kinded type inference for parameteric overloading. Tech-nical Report CS-93-12, University of Waterloo, 1994. 56pages. Revised March 1994. Accepted subject to revisionin Acta Informatica.
[13] Dominic Duggan and John Ophel. Kinds for parametricoverloading I: A calculus of open kinds. Technical ReportUW TR CS-94-15, University of Waterloo, 1994.
[14] Dominic Duggan and John Ophel. Kinds for paramet-ric overloading II: Closed kinds and semantic soundness.Technical Report UW TR CS-94-16, University of Water-loo, 1994.
[15] Robert Harper and John C. Mitchell. On the type struc-ture of Standard ML. ACM Transactions on ProgrammingLanguages and Systems, 15(2):211–252, 1993.
[16] Mark Jones. Qualified Types: Theory and Practice. PhDthesis, Oxford University Computing Laboratory, 1992.
[17] Mark Jones. A system of constructor classes: Over-loading and implicit higher-order polymorphism. In Pro-ceedings of ACM Symposium on Functional Programmingand Computer Architecture, pages 1–10. Springer-Verlag,1993. Lecture Notes in Computer Science 594.
[18] Stefan Kaes. Parametric overloading in polymorphic pro-gramming languages. In European Symposium on Pro-gramming, pages 131–144. Springer-Verlag, 1988. Lec-ture Notes in Computer Science 300.
[19] Stefan Kaes. Type inference in the presence of overload-ing, subtyping and recursive types. In Proceedingsof ACMSymposium on Lisp and Functional Programming, pages193–204. ACM Press, 1992.
[20] S. C. Keene. Object Oriented Programming in CommonLisp: A Programming Guide in CLOS. Addison-Wesley,1989.
[21] Dexter Kozen, Jens Palsberg, andMichael I. Schwartzbach. Efficient recursive subtyping.In Proceedings of ACM Symposium on Principles of Pro-gramming Languages, pages 419–428. ACM Press, 1993.
[22] Konstantin Laufer and Martin Odersky. An extension ofML with first-class abstract types. In Proceedings of theML Workshop, pages 78–99, 1992.
[23] Dale Miller. A logic programming language with lambda-abstraction, function variables and simple unification.Journal of Logic and Computation, 1(4):497–536, 1991.
[24] Dale Miller. Unification under a mixed prefix. Journal ofSymbolic Computation, 14:321–358, 1992.
[25] John Mitchell and Gordon Plotkin. Abstract types have ex-istential types. ACM Transactions on Programming Lan-guages and Systems, 10(3):470–502, 1988.
[26] John C. Mitchell. Type inference with simple subtypes.Journal of Functional Programming, 1(3):245–286, July1991.
[27] Frank Pfenning. Logic programming in the LF logicalframework. In Gerard Huet and Gordon Plotkin, editors,Logical Frameworks, pages 149–181. Cambridge Univer-sity Press, 1990.
[28] Benjamin Pierce and David Turner. Simple type-theoreticfoundations for object-oriented programming. Journal ofFunctional Programming, 1993. To appear.
[29] Michael I. Schwartzbach. Developments in object-oriented type systems. Tutorial presentation at ACM SIG-PLAN Symposium on Principles of Programming Lan-guages, January 1994.
[30] Geoffry Smith. Combining Overloading and Subtypingwith ParametericPolymorphism. PhD thesis, Cornell Uni-versity, 1991.
[31] Marvin Solomon. Type definitions with parameters. InProceedings of ACM Symposium on Principles of Pro-gramming Languages, pages 31–38. ACM Press, 1978.
[32] Guy Steele. Building interpreters by composing monads.In Proceedings of ACM Symposium on Principles of Pro-gramming Languages, pages 472–492. ACM Press, 1994.
[33] Philip Wadler and Stephen Blott. How to make ad-hocpolymorphism less ad-hoc. In Proceedings of ACM Sym-posium on Principles of Programming Languages, pages60–76. ACM Press, 1989.
[34] Mitchell Wand and Patrick O’Keefe. On the complexity oftype inference with coercion. In Proceedingsof ACM Sym-posium on Functional Programming and Computer Archi-tecture, pages 293–298. ACM Press, 1989.
[35] Joseph B. Wells. Typability and type checking in the sec-ond order �-calculus are equivalent and undecidable. InProceedings of IEEE Symposium on Logic in ComputerScience. IEEE Press, 1994.
61

HimML: Standard ML with Fast Sets and MapsJean GoubaultBull S.A., rue Jean Jaur�es, 78 340 Les Clayes-sous-Bois, FranceTel: (33 1) 30 80 69 [email protected] propose to add sets and maps to Standard ML. Ourimplementation uses hash-tries to code them, yields fastgeneral-purpose set-theoretic operations, and is based ona run-time where all equal objects are shared. We presentevidence that this systematic use of hash-consing, and theuse of hash-tries to code sets, provide good performance.1 IntroductionSets have been an adequate foundation for mathematicsfor nearly a century, and are also an important concep-tual medium in computer science. Modern speci�cationlanguages like VDM [18] and Z [30] are based on sets. Butfew programming languages provide general-purpose setsand maps: although they could be adequate for proto-typing, it is feared that they would be too slow for realapplications.We have designed and implemented an extension ofStandard ML [17], called HimML1 [12] providing fastgeneral (polymorphic) set-theoretic data-structures, anda comprehensive set of e�cient operations on them.After mentioning related work in set-theoretic lan-guages and justifying our choice of Standard ML as atarget language (Section 2), we describe our representa-tion of sets, based on hash-tries (Section 3). We discussthe use of systematic hash-consing to support the kindof allocation needed in this approach, analyze its perfor-mance (Section 4), and examine its consequences on thechoice of garbage collection algorithms and their perfor-mance (Section 5). Section 6 is the conclusion.2 Related Work2.1 Other Set LanguagesFew languages provide a general-purpose set data struc-ture. SETL [29] is a notable exception: in this impera-tive language, all objects, even sets, can be put into sets.Manens [21] and its successor S3L [20] are lambda-calculiapplied to sets. Manens represents them with arrays andindices, and S3L uses partially unfolded trees of continu-ations, allowing for in�nite sets; the tree structure is usedto ensure execution fairness, not for e�ciency.1`Himmel' means `sky' or `heaven' in German; HimML is arecursive acronym for `HimML is a map-oriented ML.
When e�ciency is sought (in�nite sets won't be con-sidered here), special representations are needed. Witha total order on elements, balanced (say, AVL) trees de-crease the complexity for access and update from linear(for lists) to logarithmic [24]; other operations like inter-section and comparison remain expensive. Hash-tablesare better [19], especially with separate chaining. TrabbPardo [32] shows that destructive intersection is then lin-ear in the lower of the cardinals of the two input sets.Hash tables are provided in Common-Lisp [31] or Icon[16] for example, but operations on them are destruc-tive: this is not suited to functional languages like ML. Ifnon-destructiveness is a need, Trabb Pardo showed thathash-tries [19] are good candidates for access, update andintersection (see also [34, 13]).This is the approach we took in HimML [12], an ex-tension of Standard ML [17] with sets and maps. Butthis needs fast polymorphic hash-code and equality func-tions. This is in particular crucial when sets can be putinside sets: Yellin [36] provides sets with constant-timeequality, with a structure reminiscent of based sets �a laSETL [28]; but the more sets there are, the slower hisscheme is. We claim that using hash-consing [2] to shareequal objects, even sets, is a easier and faster solution.2.2 Why Standard ML?Hash-tries and hash-consing are very e�cient, but theydo not mix well with side-e�ects: modifying an object ingeneral involves changing its hash-code and recomputingall data structures containing it, or risking run-time in-consistencies. Moreover, if all equal objects are shared(hash-consed), then modifying one object that happensto be equal to another one also modi�es the latter.This problem was obviated by Goto [10], among oth-ers, by distinguished monocopy (shared) and unsharedobjects. This solves the problem, although at the priceof making the language harder to use.The nice thing about Standard ML is the fact that ob-jects are either immutable or compared by their addresses.For example, references are mutable, but are comparedby their addresses; tuples are compared by their contents,but are immutable. This e�ectively forbids all problemswith side-e�ects. To our knowledge, Standard ML is theonly language with this property (if we except purelyfunctional languages, of course), which made it a targetof choice for our techniques, preferably to SETL or Lispfor instance.62

mapletb b'���0 mapleta a'@@@1branch@@@1���0empty branch���0 @@@1mapletc c'branchFigure 1: The map fa => a',b => b',c => c'g, withh(a) = 010110, h(b) = 111010, h(c) = 100101.3 An E�cient Representation for Setsand MapsWe represent �nite sets by hash-tries [19, 32], also knownas radix-exchange trees. Sets are too poor a structure,though, because no information is attached to elements.We generalize them to �nite (set-theoretic) maps, as inspeci�cation languages like VDM [18] or Z [30]. Notethat most complex data structures in computer scienceare maps [22]: databases, tables, graphs, transition di-agrams, : : : We regard maps as basic: HimML sets aremaps from elements to the 0-tuple ().Hash-tries are built with a hash function h, such thatfor every object x in the system, h(x) is an integer in[0; 2m[ (m � 0). h(x) must characterize x semantically,that is, x and y are equal (in the sense of ML's = pred-icate) if and only if h(x) = h(y). In HimML, h(x) isthe address of x, and hash-consing is used to ensure thatthere is only one copy of any given object: more on thisin Section 4.The type of hash-tries is, in ML notation (this is notvisible to the HimML programmer):datatype ('a,'b) map = empty| maplet of 'a * 'b| branch of ('a,'b) map * ('a,'b) mapempty is the empty map; maplet(x; y) is the cardinal1 map, mapping x to y; branch(g; d) is the disjoint unionof g, the left branch, and d, the right branch; its cardinalis the sum of those of g and d.Write h(x) in binary, as Pn�1i=0 hi(x)2i, i.e. hi(x) isthe ith bit in the address of x: in a node branch(g; d) atdepth i in the trie, g is the submap of the x's such thathi(x) = 0, and d that of the x's such that hi(x) = 1.Moreover, to minimize trie size and ensure canonicity,only maps and submaps with at least two entries usebranch.To illustrate this, look at Figure 1, where a three-element map {a => a',b => b', c => c'} (mapping ato a', b to b', and c to c') is drawn. In this �gure, weassume that a lies at address 010110 in binary, b lies at111010, and c lies at 100101. To �nd whether a is inthe map, for example, we look at its lowest signi�cant(rightmost) bit; this is 0, so go down the left branch ofthe root node. We are now at a branch node again, solook at the second bit from the right; this is 1, so takethe right branch. Again, we are at a branch node, andthe next bit is 1 again, so we take the right branch again,
coming to a maplet node with �rst component a (so aindeed is in the map) and second component a' (so itmaps a to a').Algorithms are straightforward. Applying a map toan element (or testing for set membership), removing anelement from the domain of a map (or from a set), addingan entry to a map (or adding an element to a set) aredone by going down the trie, deciding at each branchnode which edge to follow according to hi(x), i.e., theith bit from the right [32, 13]. These algorithms are non-destructive. In the case of adding or removing elements,the resulting map is built up when we come back up thetrie, building a new branch node at each level. In doingthis, we don't forget to keep the invariant, that is, insteadof building branch(l; r), we return empty when both l andr are empty, we return l when r is empty and l is a maplet,and we return r when l is empty and r is a maplet. Wecall this normalizing the map.Binary operations like intersection, union, symmet-ric di�erence and di�erence of sets, or their analoguesfor maps (restriction to a set, to the complement ofa set, overwriting a map by another, symmetric dif-ference) traverse both maps in parallel. In short, toimplement any of these operations �, we just use thefact that � operates orthogonally to the structure, i.e.,branch(l1; r1) � branch(l2; r2) = branch(l1 � l2; r1 � r2)(and then we normalize the right-hand side). This prop-erty usually does not hold for balanced trees (notably forAVL trees), and this is one reason why the latter are notsuited to computing unions or intersections.Although maps are not balanced, average-case com-plexity is low [32]. Assuming h(x) uniformly distributedover [0; 2m[, and m large enough, a map of cardinaln has average size 2:44n (AVL trees use between 1:5nand 2n), average height 2 log2 n (twice as high as AVLtrees). Computing the cardinal of, accessing an elementin, adding one to, removing one from a map is in O(log n);also, for all practical purposes, all the binary operationswe mentioned are linear in the lower of the cardinals ofthe two input maps [13]. (To be precise, call n1 the lowerone, n2 the higher one, then the complexity is O(1) ifn1 = 0, and O(n1+log(n2=n1)) otherwise.) Finally, notethat the e�ciency of our set algorithms does not dependon the size of elements, since only their address matters.4 Systematic Hash ConsingWe take h(x) as the address of x in memory, which is safeonly if equality-admitting objects have at most one copy.Hash-consing [2] is one solution: it was originally used tosave memory in large programs. It was then used to speedup algorithms, notably in computer algebra [11]. Hash-consing, as other algorithms achieving similar goals likelist condensing, su�ers from two defects: �rst, it is unsafeto modify a sharable structure; and allegedly, managingsharing is costly both in time and space.We have already shown in Section 2.2 why Stan-dard ML provided a unique opportunity to disregard the�rst point. Adding maps coded as hash-tries does notchange the picture, since hash-tries are canonical formsfor maps: semantic equality always agrees with equalityof addresses.As for the second point, our experience is that a goodsharing allocator is ine�cient neither in space, nor in al-63

location time, nor in garbage collection time. Benchmarkresults can be found in [14].To implement sharing with hash-consing, we use aglobal hash-table, with slots containing unsorted lists(sorted lists were actually slower) of colliding entries, toremember previously allocated records, boxed numbers,etc. Its size H is a prime number [19] for a good distribu-tion of data over the slots; we use H = 23227. Then, thehash-table proper does not take up too much memory,but the collision lists use up to as many memory as theshared data. In HimML, this is reduced by inlining thelink �elds of the collision lists in the shared data them-selves. We estimate the swelling due to managing sharingto less than 1.5 on average.4.1 E�ciency of SharingThe major di�culty is speed. In theory, access to the ta-ble is in time O(n=H) (and n can grow much larger than23227). Most authors therefore try to keep n below H,for example by increasing the table size when it becomesalmost full, which yields logarithmic access times, as inthe CaML implementation of hash-tables [35]. We foundthat we didn't need such schemes, provided we maintainso-called optimization bits in the objects: an object a hasits bit set if it is referenced by some shared object. Then,to share (a; b) where a or b has a cleared bit, we do notneed to sweep through the collision list to �nd whether ithas already been allocated, and we can insert the coupleright in front of the list. After sharing, we set the bits ofa and b.This simple trick su�ces to speed allocation consid-erably: preliminary experiments on a �rst version of theallocator, then not yet integrated inside any language im-plementation [13], showed that building and sharing analready recorded couple is as fast as constructing an un-shared couple from a free list, and building and sharingan entirely new couple is at most 2 (on a MIPS 3000)to 2:9 times (on a 68020; 2:6 on a Sparc) times slowerthan building an unshared couple, at least for up to 13collisions per slot on average. This is not to say thathash-consing runs in constant time, but that the ratioof hash-table traversal time to real allocation time re-mains constant: when more and more tuples are allo-cated, cache hits happen more often, which slows downallocation, but does not a�ect accessing the hash-tableso much, since it is so small.More realistic benchmark tests were then conducted[14] to observe the in uence of hash-consing on the per-formance of non-set-theoretic operations; they showedthat this slowdown was actually never attained. To dothese benchmarks, we built two versions of the HimMLevaluator. As it is written in C, it was mainly a matterof using #ifdefs at the right places in the code. The�rst version shares every number, record, tuple or map.In the second one, allocation is rede�ned as non-sharing,and equality is rewritten as the usual recursive descent al-gorithm; it cannot handle sets correctly, but it works onclassical Standard ML programs. We then tested bothversions on standard benchmarks [6]. Results are re-ported in Figure 2.The programs of the benchmark are the following. KBperforms Knuth-Bendix completion on group axioms; it isthe same version by G.Huet as the one used in A.Appel's
benchmarks [3]. boyer checks a tautology by rewriting.church adds 256 to the elements of the list of the �rst10000 reals (in the standard test, they are integers; butat the time these tests were conducted, HimML had onlyboxed reals, because of early design decisions). div e doesthe Euclidean division of 12 by 12, representing integerswith 0 and successor. integre integrates x2 between 0and 1 with 10000 sample points 10 times. sieve is a naivefunctional implementation of the sieve of Eratosthenes,�nding all primes under 20000 (as boxed reals, here).solitaire solves a solitaire board game, using referencesand arrays. sumlist builds the list of numbers (reals) upto 10000 and sums them up, 100 times. tak computesthe sum of 50 computations of tak(18; 12; 6), where takis Gabriel's function; takE does the same, but using ex-ceptions to return results.Most �gures are not impressive in absolute value, andthey should not be, as they show execution times for aninterpreter, and moreover all numbers were handled asboxed reals. However, the results are instructive in thatthey indicate what is changed when we share or don'tshare data.The worst experienced slowdown was by 30% for inte-gre (note that we share reals, too); but, on 10 programs,6 were actually speeded up by systematic hash-consing,including both \real-world" tests of the suite, KB (6%faster) and boyer (82% faster). Surprisingly, we gainedmore in terms of speed than in terms of space: the sizesof the cores were about the same with and without shar-ing for most programs.The tests were done on an interpreted implementa-tion, and interpretation damps the speed ratios, as mostof the execution time is spent in the code of the evaluator,which does not depend on sharing. Moreover, garbagecollections come up rather frequently, because the evalu-ator has to keep trace of all its internal structures. It istherefore to be expected that compiled code should giverise both to increased speed ratios (both speed-ups andslowdowns) and to decreased garbage collection times.These benchmarks don't bene�t directly from shar-ing. KB and boyer bene�t indirectly from sharing in thatthey rather often use the equality function, which is muchfaster in the sharing version, as it is then a simple com-parison of pointers. We could say that sharing memoizes[1] the equality function, i.e. it remembers previous re-sults of equality tests on substructures of the data tocompare. (As an aside, notice also that as an imple-mentation technique for Standard ML, sharing justi�esthat = has polymorphic type ''a * ''a -> bool: in-deed, a claimed property of ML-style polymorphism isthat functions of polymorphic type never have to peekinside substructures of variable type; this holds in ourimplementation, as = only compares the addresses of itstwo arguments, ignoring their structure.)As the benchmarks do not bene�t directly from shar-ing, they cannot be representative of another class ofalgorithms, for which our systematic hash-consing tech-nique provides great rewards. One example comes fromBDDs: BDDs (Binary Decision Diagrams) were rediscov-ered by Bryant in 1986 [5, 4] as a tool for handling propo-sitional formulas and quickly testing whether they aresatis�able; BDDs are shared Shannon trees, i.e. sharednested if{then{else formulas, and yield impressively fastalgorithms [7] in several domains including formal hard-ware veri�cation, where they have since become standard64

Program total time GC time # GC GC time/total core size init+compiletimeKB 85.0 (90.2) s. 29.1 (30.7) s. 92 (93) 34.2% (34.0%) 2.3 (2.3) Mb 3.3 s.boyer 167.1 (303.6) s. 53.4 (56.1) s. 80 (80) 32.0% (18.5%) 2.3 (5.9) Mb 7.0 s.church 573.9 (580.1) s. 81.9 (104.4) s. 174 (291) 14.3% (18.0%) 3.5 (3.1) Mb 0.9 s.div e 184.6 (197.1) s. 85.8 (90.2) s. 645 (655) 46.5% (45.8%) 0.8 (0.8) Mb 1.1 s.integre 36.8 (28.3) s. 7.7 (6.8) s. 23 (23) 20.9% (24.1%) 2.7 (2.7) Mb 0.9 s.sieve 155.1 (128.2) s. 17.1 (17.9) s. 21 (26) 11.0% (13.9%) 8.2 (7.0) Mb 0.9 s.solitaire 562.4 (570.8) s. 105.9 (189.2) s. 691 (1936) 18.8% (33.1%) 0.8 (0.8) Mb 1.3 s.sumlist 313.0 (244.2) s. 75.7 (71.3) s. 158 (173) 24.2% (29.2%) 2.7 (2.7) Mb 0.9 s.tak 617.1 (664.1) s. 195.9 (254.7) s. 2319 (3226) 31.7% (38.4%) 1.6 (1.2) Mb 0.9 s.takE 1228.5 (1298.8) s. 326.0 (375.9) s. 3957 (4630) 26.5% (28.9%) 1.6 (1.6) Mb 0.9 s.Figure 2: Comparative speed of sharing vs. non-sharing implementations (non-sharing time in parentheses)tools. Another example is term uni�cation [27], wherethe naive algorithm takes exponential time and space inthe size of the uni�cands, but becomes quadratic if termsare represented as directed acyclic graphs instead of astrees; smarter methods even achieve a linear bound [25].Such examples occur surprisingly frequently in the do-main of symbolic computation (computer algebra, logic,graph handling, etc.)4.2 Set E�ciencyThe e�ciency of set-theoretic operations has also beenveri�ed in practice. First, the HimML type-checker andtranslator (to an interpreted form) run with symbol ta-bles, substitutions from type variables to types, etc., rep-resented as maps, and can process 200{300 source linesper second on a Sparc 2; this was done deliberately to testwhether a massively set-theoretic approach to coding wasrealistic or not. To give a reference point, we estimate[14] that if the Standard ML of New Jersey compiler [3]did as few work as the HimML system (using the ta-ble on p.199 of [3], we count only the Parse, Semanticsand Translate phases, which account for 7.7% to 14.7%of compilation time), it would process 170{325 lines persecond on the same machine. Of course, these �guresare mere indications, not de�nite evidence. But at least,using sets did not seem to have incurred any particularslowdown.And second, we also implemented a sophisticated3000-line automated theorem prover in HimML, usingquite complicated set-theoretic data structures [15]; notonly is the code fast, but knowing that all operationswould be fast enabled us to think freely in terms of datastructures usually dismissed as too slow, like sets of sets.For example, we generate substitutions � by uni�cation;such substitutions must instantiate unquanti�ed formu-las � to ��, and we look for one that would make ��propositionally unsatis�able. We don't want to considerthe same substitution twice, so we keep and update theset past of all previous substitutions. Substitutions havetype var -m> term (read: map from type var to typeterm), so past naturally has type (var -m> term) set,where � set is an abbreviation for � -m> unit. If thereare n substitutions in past, checking whether � is in pastin HimML takes O(log n) time, independently of the sizej�j of � or the sizes of the elements of past; contrast thiswith any non-sharing implementation of sets, where for
each �0 2 past, we would have to compare � with �0 bysweeping over the variables in their domains.Another example is the connection graph we use inthis prover. A connection graph is a graph whose ver-tices are all atomic formulas (atoms) P (t1; : : : ; tm) of �,and whose unoriented edges link uni�able atoms. Theedges are labeled with the most general uni�ers of theirtwo end points. Because the most frequent operationson this graph are to �nd all labels of edges startingfrom a given end point, and given a label (a uni�er)�, to �nd the equivalence relation it induces on atoms(A �= A0 i� � uni�es A and A0), it was easiest to en-code this graph as two conjugate maps of respective typesatom -m> unif set and unif -m> atom eqvrel, whereunif = var -m> term as before, and we implementedequivalence relations as maps from elements to theirequivalence classes, i.e. ''a eqvrel = ''a -m> ''a set.If the e�ciency of our map data structures dependedon the structure of their elements, operations on sets ofsubstitutions, or worse, on our connection graphs, wouldbe utterly impractical. With hash-tries and hash-consing,and in spite of its high complexity, our prover manages toprove almost all of Pelletier's test problems [26], usuallywithin seconds.To give a taste of the way sets and maps can be prof-itably used in HimML, we have included in the appendixa commented example of a small piece of HimML that im-plements applicative-style Union-Find structures. Thiswill also give a view of the actual syntax (new functions,new syntactic constructs) of HimML.5 Garbage CollectionTo garbage-collect a shared world, it is necessary to cleanup the sharing hash-table. With a mark-and-sweep col-lector, a second sweep phase is added, where the hash-table is traversed, and entries corresponding to freed ob-jects are deleted. In HimML, basically, objects are Lisptagged cons-cells; records of more than 2 �elds have apointer to a heap-allocated vector of �elds. A specialtag is reserved for free objects, i.e, in the free list: ask-ing whether an object has been freed means reading thevalue of a tag.Stop-and-copy algorithms are sometimes preferred tomark-and-sweep, since they compact memory, improvinglocality of reference, and run in time proportional to the65

cells:� � � � � � � � � � � � � � � � � � � � � � � �pointers:� � � � � � � � � � � ���� ��*HHY ���HHY 6 6 6 6 6 6 66P0 6P1 6P2old generation� - new generation� - free cells� -Figure 3: An allocation bucketquantity of live data only. But as they move objects,they are incompatible with our scheme, which identi�esobjects with their addresses. A solution is to use mark-and-sweep for shared objects, and stop-and-copy for oth-ers, like run-time environments (stack frames). Mixingboth approaches, as pioneered in 1990 by V.Delacour [8],is reported to work well in practice. We have compareda pure mark-and-sweep and a mixed-mode garbage col-lector [14], and found that, although the system spent asmaller percentage of its time in garbage collection withmixed-mode (8-15% vs. 10-30%), run times were gener-ally comparable but core sizes were much bigger, by 5 to15 times. This is in accordance to experience in other,non-sharing implementations [37].The allocation policy that we used for doing all bench-marks and measurements until here was to allocate cons-cells from a free list, as this is easy to implement andusually fast enough. We recently changed the allocationand garbage collection policy in a way that enabled usto implement a generation scavenging scheme on a mark-and-sweep-like (non copying) collector. This sped up thegarbage collector (GC cost was reduced to 8-10% of com-putation time, of which 3% are still due to the traversal ofthe global sharing hash-table), and also marginally spedup the allocator, although this was hard to measure, asother optimizations have been brought to the system atthe same time.The idea is the following. Cells are allocated frombuckets, which are arrays of a �xed, high enough numberof cells (currently 512 per bucket). Buckets are linkedtogether, and when there are no more free cells in thecurrent bucket, the allocator switches to the next bucketin the row. Each bucket contains an abstraction of afree list, in the guise of an additional array of pointers tocells (see Figure 3). To allocate a new cell, the allocatorreads o� the cell pointed to by the pointer at address P2,and increments P2. To garbage-collect the bucket, aftermarking all cells, we sweep through the new generationpart of the array of pointers (from P1 to P2), and swappointers along to compact the zone; afterwards, all livecells are pointed by pointers from P1 to some P3 betweenP1 and P2, and cells pointed to by pointers from P3 toP2 are now free: we then set P2 to P3.This way, as in a copying collector, allocation pro-ceeds in a stack-like fashion. Moreover, although cells arenot movable, pointers to cells can be modi�ed to achievemost of the same e�ect. We have not yet implementeda Cheney-style collector based on this analogy, but thislooks promising. This scheme adds an extra indirectionto Cheney-style allocators because we have to go through
pointers to allocate new cells, but no indirection penaltyis to be paid when following links from one cell to an-other (cells still link directly to each other). Generationsthen also become clearly marked in each bucket, so con-ventional generational collection techniques apply.The free-list implementation is more economical interms of space, as the set of free cells is then completelyrepresented through links already present in the cellsthemselves; in our new scheme, we have to allocate anadditional array of pointers. On most machines, cells are16 bytes long (two components, one link in hash-tableslots used for managing sharing, and various tags andbits), and pointers to cells are 4 bytes long. So the spaceoverhead this incurs is roughly 25%, for a reduction ofGC cost to 8-10% of computation time.6 ConclusionSets and maps are powerful conceptual constructs,and deserve an e�cient general-purpose implementation.Representing them by a combination of hash-tries withsystematic sharing by hash-consing has a good theoreticaland practical behavior. We were surprised by the mea-sures of e�ciency we got: �rst, our prototype compiler isabout as fast as the corresponding parts of a well-craftedone; second, the systematic sharing scheme slows downthe system by not much, and actually speeds it up inmore than half the cases tested.It will nonetheless be interesting to specialize the rep-resentation of sets to better-suited ones (like bit-vectorsfor sets of integers, for example), at least for local, non-escaping data inside lexical blocks. Automatic inferenceof representations, as pioneered in [28] for SETL, or asused in [9], might be put to good use in a HimML com-piler.References[1] H. Abelson, G. J. Sussman, and J. Sussman. Struc-ture and Interpretation of Computer Programs. MITPress, 1985.[2] J. Allen. Anatomy of Lisp. McGraw-Hill, 1978.[3] A. Appel. Compiling with Continuations. Cam-bridge University Press, 1992.[4] J.-P. Billon. Perfect normal forms for discrete func-tions. Technical Report 87019, Bull, 1987.66

[5] R. E. Bryant. Graph-based algorithms for booleanfunctions manipulation. IEEE Trans.Comp.,C35(8):677{692, 1986.[6] CAML team. Benchmark suite for CAML and Stan-dard ML. available from the author, or from R�egisCridlig ([email protected]).[7] E. Clarke. Symbolic model checking: 10130 statesand beyond. In CADE-11. LNAI 607, 1992.[8] V. Delacour. Gestion m�emoire automatique pourlangages de programmation de haut niveau. PhD the-sis, Paris VII, 1991.[9] V. Donzeau-Gouge, C. Dubois, and P. Facon.Inf�erence de types et d'implantations pour les ex-pressions ensemblistes. In JFLA'91, pages 21{32,1991.[10] E. Goto. Monocopy and associative algorithms in anextended Lisp. Technical report, U. Tokyo, 1974.[11] E. Goto and Y. Kanada. Recursive hashed datastructures with applications to polynomial manip-ulations. SYMSAC, 1976.[12] J. Goubault. The HimML reference manual. avail-able from the author, 1992.[13] J. Goubault. Implementing functional languageswith fast equality, sets and maps: an exercise in hashconsing. Technical report, Bull, 1992.[14] J. Goubault. Adding sets to ML: design, implemen-tation and experiments. Technical Report 93039,Bull, 1993.[15] J. Goubault. Proving with BDDs and control of in-formation. In CADE-12. Springer, 1994.[16] R. E. Griswold and M. T. Griswold. The Implemen-tation of the Icon Programming Language. PrincetonUniversity Press, 1986.[17] R. Harper, R. Milner, and M. Tofte. The De�nitionof Standard ML. MIT Press, 1990.[18] C. B. Jones. Systematic Software Development UsingVDM. Prentice-Hall, 1990.[19] D. Knuth. Sorting and Searching, volume 3 of TheArt of Computer Programming. Addison-Wesley,1973.[20] J.-J. Lacrampe. S3L �a tire d'ailes. to be published,1992.[21] F. Le Berre. Un langage pour manipuler les ensem-bles : MANENS. PhD thesis, Paris VII, 1982.[22] M. Mac an Airchinnigh. Tutorial lecture notes onthe Irish school of the VDM. In VDM'91, volume552 of LNCS, pages 141{237, 1991.[23] K. Mehlhorn and A. Tsakalidis. Data structures. Invan Leeuwen [33], chapter 6, pages 301{341.[24] M. H. Overmars. The Design of Dynamic DataStructures. LNCS 156, 1983.
[25] M. Paterson and M. Wegman. Linear uni�cation.J.Comp.Sys.Sci., 16:158{167, 1978.[26] F. J. Pelletier. Seventy-�ve problems for testing au-tomatic theorem provers. JAR, 2:191{216, 1986. Er-rata in JAR, 4:235{236, 1988.[27] J. Robinson. A machine-oriented logic based on theresolution principle. JACM, 12(1):23{41, 1965.[28] E. Schonberg, J. Schwartz, and M. Sharir. An auto-matic technique for selection of data representationsin SetL programs. ToPLaS, 3(2):126{143, 1981.[29] J. Schwarz, R. Dewar, E. Dubinski, and E. Schon-berg. Programming with Sets: An Introduction toSETL. Springer, 1986.[30] J. Spivey. An introduction to Z and formal speci�-cations. Soft.Eng.J., 1989.[31] G. L. Steele. Common Lisp. Digital Press, 1984.[32] L. Trabb Pardo. Set Representation and Set Inter-section. PhD thesis, Stanford U., 1978.[33] J. van Leeuwen, editor. Handbook of TheoreticalComputer Science. Elsevier, 1990.[34] J. Vitter and P. Flajolet. Average-case analysis ofalgorithms and data structures. In van Leeuwen [33],chapter 9.[35] P. Weis et al. The CAML reference manual. Tech-nical report, INRIA, 1989. v.2.6.[36] D. M. Yellin. Representing sets with constant timeequality testing. J.Alg., 13:353{373, 1992.[37] B. Zorn. Comparing mark-and-sweep and stop-and-copy garbage collection. In LFP, pages 87{98, 1990.A Applicative Union-Find Structures inHimML: a Taste of Sets and MapsThis appendix is a simple illustration of the use of setsand maps in HimML. The full set of additional syntaxconstructs and primitives, as well as detailed informalexplanations of their semantics can be found in [12].Union-Find structures [23] are well-known data struc-tures for representing equivalence classes of objects,which are endowed with two natural operations: Findcomputes a canonical representative of the equivalenceclass of an object, and Union merges two equivalenceclasses described by their canonical representatives. Im-plicitly, Union modi�es the underlying equivalence class,and is implemented by physically modifying the corre-sponding data structure.Union-Find structures are trees whose nodes (leavesare considered to be nodes as well) are decorated withobjects. Edges are viewed as directed links that pointupward (toward the roots), so that in a sens these treesare turned upside-down. A root of the tree does not pointto any node, and represents a canonical representative ofan equivalence class. All other nodes point to higher inthe tree, and following the links eventually reaches a root:this is how the Find function works.67

To implement Union on two roots r1 and r2, one ofthem is made to point to the other (we assume that r1 6=r2). To keep the structure balanced on average, roots arealso decorated with the numbers of elements in the classthey describe. Then, assuming that r1 has the fewestelements, r1 is made to point to r2, so that r2 becomesthe new root, and its count of elements is incremented bythe count of elements for r1.If x is an element of a class with n elements, Find thentakes roughly O(log n) steps, and Union takes O(1) time.(Notice that, in practice, it means that the time takenby both operations is indistinguishable from constanttime: on a 32-bit computer, no more than 232 objectsare addressable at the same time, so that log n � 32.)This e�ciency is usually seen as coming from the factthat Union is allowed to physically modify the underly-ing data structure, and that non-imperative Union-Findstructures would be too slow, because of the requiredamount of copying.Maps allow us to side-step the di�culty by encodinglinks as maplets in a global map representing the struc-ture. We then lose a logarithmic factor on all operations,but experience (see main text) has always shown this tobe negligible. (Notice, by the way, that side-e�ects havenot disappeared totally, as they are required to main-tain the internal global hash-table that we use to managesharing.)So, a Union-Find structure on objects of type ''a is arecord with �elds link : ''a -m> ''a (mapping sourcesof links to their destinations, going up towards roots)and info : ''a -m> int (mapping roots to the cardi-nal of the associated equivalence class). Notice the dou-ble quotes on the type variable: objects in a Union-Findstructure must indeed have an associated equality func-tion, so that their type must admit equality [17]. In gen-eral, type � -m> � 0 is only legal when � admits equality;this needed a slight amendment of the static semanticsof type declarations in Standard ML, to allow for par-tial type functions ('a -m> 'b is then not legal, whereas''a -m> 'b is, re ecting the domain of de�nition of thetype function -m>).Because we wanted to have curly braces denote setand map expressions, we also had to change the syntaxof record expressions and types to use di�erent delimiters.We chose |[ and ]| to replace { and } in that case. Mak-ing type functions and declarations partial, and changingthis bit of syntax were the only two needed changes in thede�nition of Standard ML, viewed as a subset of HimML.(Other changes were mere additions, to account for setand map operations and various other goodies.)We can now write the type declaration for applicativeUnion-Find structures:type ''a ufind =|[link : ''a -m> ''a,info : ''a -m> int]|We must also provide a new empty Union-Find struc-ture:val empty_equiv = |[link = {}, info = {}]|: ''a ufindwhere {} denotes the empty map, and is a spe-cial case of the notation of maps by enumeration{x1 => y1; : : : ; xn => yn}. In case all yi's are equal to(), the map is a set, and we write {x1; : : : ; xn}.
To implement Find, we use the following HimMLprimitives. If m is a map and x is an object,x inset m tests whether x is in the domain ofm (we have inset : ''a * (''a -m> 'b) -> bool),and ?mx returns its image, or raises the exceptionMapGet if x is not in the domain of m (we have? : ''a -m> 'b -> ''a -> 'b). So we can write a ver-sion of Find, parameterized by a given Union-Find struc-ture:fun Find (|[link,...]|: ''a ufind): ''a -> ''a =let fun f x =if x inset linkthen f (? link x)else xin fendIt then takes O(log n: log n0) time to follow the links,where n is the cardinal of the class of x and n0 is thesize of the structure. (Remember that logarithmic fac-tors are low; in practice, the di�erence is usually hardlynoticeable.)To implement Union, we shall need a few otherHimML operators, whose origin goes back to theVDM speci�cation language [18]. The �rst is++ : (''a -m> 'b) * (''a -m> 'b) -> ''a -m> 'b,the in�x override operator: f ++ g is the map whose do-main is the union of the domains of f and g, and whichmaps x to ?g x if x inset g, or to ?f x otherwise (g\overrides", or takes precedence over f). When f and gare sets, this is just the union operation; HimML givesthe redundant name U to this operation in this restrictedcase.Restriction operators are also needed. f <| g returnsa map whose domain is the intersection of those of f andg, and which coincides with g on this domain (g \re-stricted to" the domain of f). f <-| g does the comple-mentary operation, i.e. it returns a maps whose domainis that of g minus that of f, and which otherwise coin-cides with g (g \restricted by" the domain of f). Onsets, these would be the intersection (& in HimML) andset di�erence (\) operations. HimML provides a wholeslew of other operations, as well as notations for set com-prehensions and quanti�cations over elements and evensubmaps (subsets) of maps and sets; we refer the inter-ested reader to [12].These few operators are enough to de�ne the Unionoperation, which must take a Union-Find structure, tworoots, and return a new Union-Find structure:fun Union (tree as |[link,info]|: ''a ufind)(r1: ''a, r2: ''a): ''a ufind =if r1=r2then treeelse let val n1 = ?info r1 and n2 = ?info r2in if n1 < n2then |[link = link ++ {r1 => r2},info = ({r1} <-| info) ++{r2 => n1+n2}]|else |[link = link ++ {r2 => r1},info = ({r2} <-| info) ++{r1 => n1+n2}]|68

endThen Union takes O(log n0) time.To conclude, why bother with Union-Find structureswhen all we want is �nite equivalence relations? Thefavored style in HimML is to use maps whenever theyprovide a more direct implementation of the mathemati-cal object we wish to code. And a natural representationfor equivalence relations are maps from elements to theirequivalence classes. So, a preferred implementation ofequivalence relations would be:type ''a eqvrel = ''a -m> ''a setval empty_eqvrel = {} : ''a eqvrelfun class_of (r: ''a eqvrel) (x : ''a) =if x inset rthen ?r xelse {x}fun Find r x = choose (class_of r x)fun Union (r: ''a eqvrel) (x: ''a, y: ''a): ''a eqvrel =let val ca = class_of r xand cb = class_of r yin if ca=cbthen relse let val merged = ca U cbin r ++ {x => merged| x in set merged}endendwhere ''a set is an abbreviation for ''a -m> unit,choose : (''a -m> 'b) -> ''a chooses an elementfrom the domain of the map in argument (determinis-tically, i.e. m = m0 ) choose m = choose m0), andthe last signi�cant line shows an example of a map com-prehension computing the constant map that sends everyelement of merged to the set merged itself.Find is then slightly faster, although Union will beslower. But the main bene�t is that this implementationis easily expandable and maintainable: it is as easy tode�ne extra operations, like computing the intersectionof equivalence classes (more exactly, the equivalence re-lation generated by all equalities that hold in both equiv-alence relations in argument), or restricting equivalenceclasses to or by sets of objects given as arguments. (Thelatter, in particular, was needed in our theorem proverfor restricting connection graphs to a given set of atoms.)On the other hand, it is hard to tailor Union-Find struc-tures to accommodate such extensions with reasonablee�ciency.69

A complete and realistic implementation of quotations for MLMichel MaunyINRIA-Rocquencourt� Daniel de RauglaudreINRIA-Rocquencourt�AbstractQuotations have been introduced in the very �rst versions ofML [6] in order to represent propositions in the LCF logicunder a concrete form. ML was themetalanguage of this logic,and the logic was its object language.In this paper, we describe a new implementation of quo-tations in a variant of Caml-Light [8]. We address severalimportant problems, namely the impact of such a mechanismon the design of ML, the problem of separate compilation andthe possibility of implementing support for quotations in com-pilers that do not feature dynamic linking.The novelty of this work is that our implementation is re-alistic, e�cient and complete. It includes arbitrary quotationsand antiquotations, usable as expressions as well as patterns.It is compatible with module systems and preserves separatecompilation. Furthermore, our language is its own object lan-guage, and this allows for manipulating arbitraryML abstractsyntax trees (ASTs, for short) without ever mentioning theirdata constructors.IntroductionQuotations have been introduced in the very �rst versionsof ML [6] in order to represent propositions in the LCFlogic under a concrete form. ML was the metalanguageof this logic, and the logic was its object language. Sucha feature followed the evolution of Edinburgh ML (Cam-bridge, INRIA) and was still present in the Caml [15]system, where several object languages could coexist.Caml quotations are not completely satisfactory forseveral reasons. One is that all object languages areforced to use Caml's lexical analyser, restricting the kindof object languages that can be dealt with. Other reasonsinclude some incompletenesses in the de�nition of Camlas its own object language, and an unclear interactionwith the module system.In this paper, we use a version of ML, derived fromCaml-Light, in the design of which we devoted a par-ticular attention to concrete and abstract syntaxes. Wepresent here only the implementation of quotations, andwe think that the concrete syntax that we use is closeenough to other ML versions for the reader not to beconfused.We start by giving the motivations for this work andthe constraints to be satis�ed by our design (section 1).�Author's address: INRIA, B.P. 105, F-78153 Le ChesnayCedex. Email: fMichel.Mauny,Daniel.de [email protected]
Then, we explain the basic mechanisms of our implemen-tation (section 2). Programming quotation expandersis outlined in section 3. In section 4, we present MLas its own object language together with the impact onthe design of the ML abstract syntax. Problems suchas pretty-printing ML programs containing quotations,or retrieving the source location of a quotation are ad-dressed in section 5. Separate compilation, which wasour original goal, must remain supported, and we showin section 6 how ML programs containing quotations canbe compiled by a batch compiler. Alternative implemen-tations are presented in section 7, for compilers that donot feature dynamic linking. Finally, the interaction withmodule systems is made more precise in section 8. Wegive some examples of usage of quotations in appendix.1 Motivations and constraintsAlthough quotation mechanisms have been proposed be-fore [10, 1, 2, 12], we recall what motivations guided ourwork.1.1 TerminologyIn the following, we call quotation an expression or apattern of the form << e >>, where e denotes a characterstring. The general form of a quotation is <:S< e >>,where S is a syntax name: a legal ML identi�er. Such aquotation is called a named quotation. The former kindof quotations refers to some default syntax name S.When a quotation is used in expression (resp. pat-tern) position, we call it quoted expression (resp. quotedpattern). We call expression (resp. pattern) expander anML function of type String ! MLexpr (resp. String! MLpatt), where MLexpr and MLpatt are the concretetypes of ML ASTs.We call syntax extension a pair of expanders (one forquoted expressions and one for quoted patterns), togetherwith a syntax name S.1.2 The need for quotationsQuotation mechanisms (including antiquotation facilities)developed for ML [10, 1, 2, 12] allow for the manipulationof complex data structures by using a concrete syntax.Typical examples are ASTs: it is by far more pleasant tomanipulate them under a dedicated concrete form rather70

than using directly their representation as ML data struc-tures. A typical example is the direct implementation ofdenotational semantics.The usage of quoted expressions (instead of their MLrepresentations) also o�ers a kind of abstraction in thesense that they allow for a program text (containing quo-tations) to be \parameterised" by the corresponding ex-pander. For example, Pascal constants such as:const MAX=256;can be easily obtained by a quotation mechanism, al-lowing for the textual replacement of <:Macro<MAX>> by256. More importantly, huge sets of constants, such asthe X event names, can be used in ML programs and beexpanded into ML constants (integers in the case of Xevents).Another example is the implementation of assertions�a la C. In a C program, one would write:...; assert(n > 0); ...Using quotations, one would write:...; <:Assert< n > 0 >>; ...assuming the proper de�nition1 for the Assert syntaxextension.More generally, the advantages of C macros can beobtained with quotations.1.3 Independence from data type de�ni-tions and parsing techniquesQuotations do not need to be attached to a �xed parsingtechnology as they are in [1]: when debugging a real-sizecompiler (for a language, say L) implemented in ML, wemust be able to use a variant2 p' of the parser p of Lprograms as a quotation expander. The parser p' can bewritten directly, or generated by a parser generator: wemust be able to use p' as a quotation expander, whatevertechnology it uses.The use of quotations for simulating Pascal constantsimplies that they cannot be systematically attached toa type de�nition as they are in [1]. For representing Xevents, ML integers might be preferable to a dedicatedenumerated type, since events can be passed to or re-ceived from other programs, and coding/decoding inte-gers to/from a dedicated type can be painful.1.4 Locations in source programsAlthough we want a general syntax extension mechanism,we still want to be able to pretty-print an ML programcontaining quotations, and to �nd the location of theoriginal source code of quoted expressions or patterns(for printing error messages or debugging).1Given in appendix.2Such a variant is obtained by replacing the parts of p buildingthe L ASTs|the semantic actions of grammar speci�cation, forinstance|by their ML quotation.
2 Basic mechanismsThe expansion of quotations occurs at parse-time, whichguarantees the absence of run-time penalty for user pro-grams. The basic mechanisms of syntax extensions in MLare extremely simple. We need:� \hooks" in the ML concrete syntax for expressionsand patterns, where quotations may occur;� a mechanism to �ll these hooks with user-de�nedfunctions with named objects (syntax extensions).Let us examine in turn each of these ingredients.2.1 Quotation \hooks"Lexical analysis. Lexical tokens are annotated withsource locations (type Loc). A new token \TquotationString String Loc"3 is introduced.The input <:Sn<str>> at source location loc produces thetoken \Tquotation Sn str loc".From the lexical point of view, quotations are similarto string constants, and inner occurrences of \>>" mustbe escaped.Parsing. The expansion of quotations is the ML parsertask. Given a token \Tquotation Sn str loc", the MLparser checks that the syntax Sn exists, and calls one ofthe Sn expanders (depending on wether we are parsingan expression or a pattern) on the string str. The resultof this call is an ML AST, which is returned as result.Syntaxes. A syntax is a triple composed of a nameS (any legal ML identi�er), an expression quotation ex-pander and a pattern quotation expander. A set of syn-tax extensions can be implemented as an association list(private to the compiler) with syntax names as keys, andpairs of expanders as values.Tools are provided in order to register a new syntaxbinding and change the default syntax name (for anony-mous quotations). The function new syntax is such that\new syntax sname (eexpand,pexpand)" declares a newsyntax extension named sname, and composed of the twoexpanders eexpand and pexpand. The directive \!syntaxS", executed at compile-time, sets the default syntax toS.3 Quotation expandersQuotation expanders are arbitrary functions taking stringsas arguments, and returning ML ASTs. Expanders canbe as simple as the functions used for coding Pascal orC constants mentioned in section 1.2, or as complex asparsing functions generated by sophisticated parser gen-erators.In case an expander raises an exception, that excep-tion is trapped by the ML toplevel parser, and reportedas a syntax error.3Tquotation is the data constructor, and it is followed by thetype of its arguments.71

3.1 Programming quotations expandersIf we come back to the simple example of Pascal con-stants, de�ning quotations expanders can be as simple asfunctions matching the string "MAX", and returning theexpression <:MLexpr<256>>, i.e. the ML AST of the con-stant 256. Besides being types, MLexpr and MLpatt arealso prede�ned syntax extensions (cf. section 4) makingour language its own metalanguage. We �rst de�ne thetwo Macro expanders:#value macro_expr = fun [# "MAX" -> <:MLexpr<256>>#| s -> raise (Failure("Undefined \""^s^"\""))];macro_expr : String -> MLexpr = <fun>#value macro_patt = fun [# "MAX" -> <:MLpatt<256>>#| s -> raise (Failure("Undefined \""^s^"\""))];macro_patt : String -> MLpatt = <fun>Then, we declare the new syntax, and make it the defaultone:#new_syntax "Macro" (macro_expr, macro_patt);- : Unit = ()#!syntax Macro;Finally, we can use our new syntax extension:#<<MAX>> - 1;- : Int = 255#value overflow n = (n >= <<MAX>>);overflow : Int -> Bool = <fun>#value meets_max =# fun [ <<MAX>> -> True | _ -> False];meets_max : Int -> Bool = <fun>One drawback of the string matching solution, is thatquotations such as:#<< MAX >>;> Toplevel input:><< MAX >>;>^^^^^^^^^> Macro syntax failure: Undefined " MAX "fail to expand correctly. This is because of the leading ortrailing blanks occurring in the string that is passed tothe expander. String matching functions are easy to de-�ne but might be too naive. Furthermore, such functionscannot process realistic concrete syntaxes. In these cases,a more sophisticated technology is desirable. Parsers canbe written by hand, or using a parser generator in thestyle of Yacc.A more realistic example is the following syntax ex-tension for pure �-terms producing values and patternsfor the following data type:#type Lambda = [# Var String#| Abs String Lambda#| App Lambda Lambda#];Type Lambda defined.Concrete �-terms follow the usual syntax, excepted forabstractions, where abstracted variables are enclosed insquare brackets. For example we write \[x] x" insteadof the more classical \\x.x". We omit the de�nition ofthe expanders lambdae and lambdap:
# new_syntax "Lambda" (lambdae, lambdap);- : Unit = ()# <:Lambda< [x] [y] y >>;- : Lambda = Abs "x" (Abs "y" (Var "y"))Usually, expanders make heavy use of MLexpr or MLpatt(anti)quotations.3.2 Programming antiquotationsGiven an object language, one can limit oneself to theproduction of closed ML ASTs such as:# value lambda_id = <:Lambda<[x] x>>;lambda_id : Lambda = Abs "x" (Var "x")One can also design \hooks" in the concrete syntax andproduce contexts. We choose pairs of \^" as Lambda an-tiquotation marks.The following function returns the list of sub-terms ofits argument:# value rec subterms = fun [# <:Lambda<[^_^] ^t1^>> as t -> [t :: subterms t1]# | <:Lambda<^t1^ ^t2^>> as t# -> [t :: subterms t1 @ subterms t2]# | v -> [v] (* Variable case *)# ];subterms : Lambda -> List Lambda = <fun># subterms <:Lambda< [x] [y] x y>>;- : List Lambda = [Abs "x" (Abs "y" (App (Var "x") (Var "y"))); Abs "y" (App (Var "x") (Var "y")); App (Var"x") (Var "y"); Var "x"; Var "y"]The lambda x function takes a term and returns the ab-straction of the variable x on it:# value lambda_x = fun term -> <:Lambda<[x] ^term^>>;lambda_x : Lambda -> Lambda = <fun># value delta = lambda_x <:Lambda<x x>>;delta : Lambda = Abs "x" (App (Var "x") (Var "x"))A simple technique for programming such antiquotationsis to parse what appears between antiquotation marks asa string, and to pass this string to the ML parser for ex-pressions (or for patterns), using the ML AST producedfor building the �nal result.4 Prede�ned syntaxes: MLexpr and MLpattTwo prede�ned syntaxes provide a simple way of buildingML ASTs. MLexpr produces ASTs for expressions, andMLpatt for patterns.The simplest form of ML quotations is used to pro-duce constant ASTs. In section 4.2, we introduce an-tiquotations in ML quotations: antiquotations allow forbuilding ML contexts (i.e. expressions with holes).4.1 Closed ASTsArbitrary ASTs may be built using the MLexpr syntax.As a simple example, the following examples evaluate toML ASTs (toplevel responses omitted):# <:MLexpr< 1+2 >>;Quotations may be used recursively, as in:# <:MLexpr< do <:Assert< n > 0 \>>; return n >>;72

4.2 ContextsExpressions with holes are more interesting in that theyallow the extractiion of subexpressions (when used as pat-terns) and holes can be �lled in by actual parameters offunctions. Typically, most values (ML ASTs) returnedby user-programmed expanders are built using ML quo-tations and antiquotations.Simple antiquotations. The \#" character being freein our language, we use it as left and right antiquotationmark. As a �rst example, consider a function extractingarguments from a syntactic addition into two parts. (Thedefault syntax is MLexpr.)#value split_add = fun [# <<#e1# + #e2#>> -> (e1,e2)#| _ -> raise (Failure "Not an addition")];split_add : MLexpr -> MLexpr * MLexpr = <fun>On the other hand, it is possible to use antiquotations inorder to build ASTs:#let f5 = <<fact 5>> and e = <<10>>#in << #f5# + #e# >>;- : MLexpr = MLE_app 0 (MLE_app 0 (MLE_lid 0 "+") (MLE_app 0 (MLE_lid 0 "fact") (MLE_int 0 5))) (MLE_int 0 10)A typical usage of MLexpr and MLpatt antiquotations isthe speci�cation of values returned by a user-de�ned quo-tation expander. For example, the result of parsing anapplication in the expression expander for the syntaxLambda is written <:MLexpr<App #e1# #e2#>>, where e1and e2 are the results of parsing the operator and theoperand of the Lambda application.Named antiquotation marks. For contexts to be re-ally usable, we must be able to build and de-structurearbitrary ML ASTs using only their concrete form (quo-tations).Many constructs pose no problem. For example, theconditional is correctly matched:#fun [# <<if #e1# then #e2# else #e3#>> -> (e1,e2,e3)#| _ -> raise(Failure("Not a conditional")) ];- : MLexpr -> MLexpr * MLexpr * MLexpr = <fun>The if, then and else keywords provide a context whichis su�cient to delimit the holes without ambiguity.Problems arise for constructs that provide no syntac-tic context. For instance, integer constants and identi�ersprovide no context at all. A function such as:#fun [ << #n# >> -> n ];- : a -> a = <fun>intended to match ML ASTs reduced to integers con-stants, matches everything, as shown by its type. An-other occurrence of this problem can be found with ar-rays. The pattern <<[|#e#|]>> could match either thesyntax of arrays with only one element, binding e to thatelement, or match any array and bind e to the list of itssubexpressions.An elegant solution to this problem has been proposedby Aasa [2], but it involves an interaction between parsingand typechecking, which we think is undesirable becausethis solution reduces the possible implementations of the
quotation mechanism (cf. section 7). Furthermore, thereare cases where type information does not help at all(when no type constraint is imposed by the surroundingcontext on variables occurring in such antiquotations).Our solution consists in proposing special antiquota-tion marks (which are equivalent to type constraints inAasa's work). The cases that we have to deal with are:� leaves of ML ASTs, holding base type values, suchas strings (for string constants as well as for identi-�ers), integers, etc.;� optional keywords corresponding to a boolean value,like rec;� constructs C derivable from one of the grammarschemes:C ::= lp S rp or C ::= lp MLexpr S rpS ::= � | MLexpr s S S ::= � | s MLexpr Swhere MLexpr denotes any ML expression, � is the emptyalternative, and lp, rp and s are terminals (standingrespectively for left, right parenthesis, and separator).The last case occurs for lists, tuples, arrays, match cases,records and let bindings.For the leaves of ML ASTs holding base values, weadopt the following antiquotation marks: #:string forstring constants, #:int for integers, and similarly forother base values; #:uid for capitalised identi�ers and#:lid for other identi�ers.For recursive constructs such as tuples, etc., we adopta uniform convention for antiquotations, built from paren-theses (lp and rp above) and the separator s. As anexample, the opening antiquotation mark for arrays is\#:;". Intuitively, it introduces a list of expressions sep-arated by a semicolon. Therefore, the pattern [|#:;e#|] matches any array expression, binding e to its listof subexpressions.For optional keywords, we use the antiquotation mark#:kwd, where kwd is the keyword.We admit that these new antiquotation marks couldhave received less cryptic names, but our goal was to showthat the problem of ambiguous quoted patterns could besolved in a systematic way.We conclude this section by mentioning that the prob-lems addressed above may occur also in user-de�ned ex-panders and types (typically ASTs), and the same kindof solutions may be applied.4.3 Impact on the design of MLWe consider in this section the possible impacts of \MLas its own metalanguage" (i.e. the MLexpr and MLpattsyntax extensions) on the design of ML at the level of itsabstract syntax.Abstract syntax trees are not only an unambiguousway of representing programs: they often carry otherkind of information. In the following, we call purelysyntactic information the information concerning syntax(i.e. the information which is mandatory in order to printa program equivalent to the original one). Other kind ofinformation will be called annotations, and do not inter-fere with the syntactic information.73

ML is a quite complex language, with many syntacticconstructs. In this section, we argue for the ASTs to beas close as possible to their concrete representation.Derived forms. It must be clear, from the de�nition ofthe language, whether a syntactic construct is a derivedor a primitive form. This is the case for SML [11], for in-stance. In such a case, it is desirable to have a one-to-onecorrespondence between ASTs and quotation patterns. Ifthis was not the case (for example, if the conditional wasa primitive form, but expanded to a match construct),one could be tempted to write functions such asfun [ << match #e# with #cases# >> -> ...| << if #test# then #yes# else #no# >> -> ......where the second case is useless, because its pattern isan instance of the �rst one. Note also that some de-rived forms, while being justi�ed from a semantic pointof view, can be counter-intuitive to a programmer. Forexample, the SML De�nition speci�es that the sequenceis a derived form for applications of functions discardingthe value of their argument [11, p. 67]. It may be hardto impose to non-specialists a matching on applicationsin order to catch sequences.Therefore, the notions of derived and primitive formsare not only semantic notions, but have a counterpart inthe representation of ASTs, and a good trade-o� has tobe found for the correspondence between derived formsand primitive ones to be reasonably intuitive.Non-syntactic information should appear as an-notations. Compiler writers tend sometimes to designASTs in such a way that they carry informations usefulat code-generation time. For example, a function appliedto n arguments may lead to application nodes with theoperator on one side, and a list with n elements on theother side. The problem is that in the concrete syntax,there is no notion of arity for functions: applications arejuxtapositions which associate to the left. It can be sur-prising for the user to obtain a list of expressions, insteadof an expression as the result of extracting the operandof an application node.We think that multiple applications should be de-tected later on (at typechecking time, for example), andrepresented as such at the level of the intermediate lan-guage, or at parsing time, but stored under the form ofannotations. In the latter case, these annotations mustbe optional, i.e. the correction of the typing and compi-lation processes must not rely on their presence.Independence of syntax trees from the typing con-text. Since data type declarations are always processed(being in a toplevel session or during a batch compila-tion), it is tempting to encode as soon as possible sometype information in ASTs. At parse time, data type dec-larations can be recorded, allowing the parser to make anearly distinction between data constructors and ordinaryidenti�ers. This way, syntax trees can possess distin-guished data constructors with their type information,simplifying a bit the subsequent typechecking phase.If such information is part of the purely syntactic in-formation, it does not �t well with quotations, since a
typing context is necessary to reconstruct it. The rea-son is simple: quotations (more precisely quotation ex-panders) are compiled once for all in a context di�erentfrom their context of use. Because of this separate com-pilation of expanders, syntax trees built by expanderscannot take advantage of their context of use, unless theML parser \patches" them after the quotation expanderreturns (trees must be copied in this case, because of apossible sharing of the same tree between di�erent ex-pander calls).Here again, there are several design possibilities:� the �rst one has been (sometimes vigorously) dis-cussed for a long time, adopted by the Haskell de-signers, but let aside by ML implementors: dataconstructors must be capitalised. Then, the distinc-tion between value identi�ers and data constructorsis done at the lexical level, and type information canbe added as optional annotations (but not as partof the syntactic information).This is the approach that we adopted in our design,and some other improvements of the ML syntax canbe obtained by pushing further this idea.� the other one consists in having a single syntax nodefor identi�ers (of any kind), and to add categoryand type information under the form of optionalannotations. This latter task can be left to thetype synthetizer, in which case no annotation atall is produced.Again, all type information contained in ASTs must notinterfere with purely syntactic information, and must beoptional (i.e. the typechecker should be able to live with-out them).5 AnnotationsMLexpr data constructors carry an integer value which,when strictly positive, is called the address of the node.Our ML parser generates new unique numbers for eachnode of regular programs. Using these addresses as keys,and hash tables, for example, useful informations calledannotations can be stored and retrieved, provided thatthese integers are unique.All nodes allocated by the toplevel ML parser havea non-null address. All nodes allocated by the MLexprexpanders have no address (i.e. carry the integer 0).Pretty-printing. In our implementation, results of ex-pander calls are copied before being plugged in the cur-rent AST. This allows for a relocation of these nodesto take place: all nodes of the ML AST correspond-ing to the quotation are assigned a unique address. Forpretty-printing quotations correctly, the top node of anexpanded quotation can be annotated with its originalsource text, and such annotations can be checked andretrieved by a carefully written ML pretty-printer.Source location. In the same way as we store pretty-printing information as annotations while relocating asyntax node, we store its source text location (or an ap-proximation thereof). This implies that when the sourceof a typing error is inside a quotation, either the whole74

quotation or a part of it is underlined by the type checkeras being the source of the error.6 Separate compilationSo far, all our examples assumed that we were in an MLinteractive session. Actually, our goal is to propose a quo-tation mechanism compatible with separate compilation,and the introduction of quotations at toplevel is just aconsequence of that. We address the problem of separatecompilation in this section.Even under the toplevel loop, we can think of a syntaxextension as an extension of the compiler. More precisely,we can think of the ML compiler compile as being param-eterised by a list of syntax extensions. At each toplevelphrase, the compiler that is actually invoked is (semanti-cally) the partial application (compile exts), where exts isthe current list of syntax extensions. The declaration ofthe new syntax extension (S,(eexpand,pexpand)) impliesthat the next instance of the compiler to be called willbe (compile ((S,(eexpand,pexpand))::exts)).This view of the toplevel compiler leads to the sameconsiderations for a batch compiler. This led us to:� force syntax extensions to be modules (or sets ofmodules) depending only on the pervasive environ-ment. This allows for linking them with the initialcompiler.� add -L options to the compiler, followed by an ob-ject code �le to be loaded before actually compilingthe source �les. This option can be seen as imple-menting the partial application mentioned above.Of course, this scheme works only because of the possi-bility of dynamic loading of code in the compiler. Thisis not always possible, and we outline below three otherpossible implementations (two of which we actually de-veloped).7 Other possible implementationsWhen dynamic loading of code by the batch compiler isnot possible, we can think of relinking the whole com-piler object �les together with compiled syntax exten-sions. This generally implies that syntax extensions arede�ned in the same language as the compiler itself (for-tunately, this language is usually ML itself). There isnot much to be said about this possibility: it is alwayspossible, but a complete relinking of the compiler can beslow in some ML implementations. We actually testedthis possibility, which is quite close to our �nal imple-mentation (which is bootstrapped).We explore below two other possibilities: the inte-gration in the compiler of an ML interpreter (powerfulenough to interpret syntax extensions), and a more clas-sical solution which consists in preprocessing source �lesas the C preprocessor does.These other possible implementations can be explainedin light of re�ned views of the compiling process. Callcompile a batch compiler including a set of syntax exten-sions. We said above that the compiler could be seen as
parameterised by a list of syntax extensions. In fact, if wego further in this direction, we can parameterise the MLparser only by a parsing process in charge of expandingquotations.Traditionally, an ML batch compiler can be decom-posed as follows:gencode � typecheck � parse| {z }compilewhere parse denotes the ML usual parser enriched witha set of syntax extensions.This parser can be seen as the application of a raw MLparser mlparse parameterised by a mechanism of quota-tion expansion: mlparse quotexpand| {z }parseMoreover, quotexpand itself can decomposed in the appli-cation of an interpreter exti of extension de�nitions to aset of �les containing syntax extension de�nitions:exti ext�les| {z }quotexpandTherefore, a compiler without syntax extensions is:gencode � typecheck � mlparse (exti [ ])| {z }compileFinally, one can suppose that mlparse realises itself theapplication of the interpreter exti to extension �les. Ab-stracting over extension �les, we obtain:gencode � typecheck � (mlparse exti)| {z }compileOur implementation follows this decomposition: exten-sion �les are ML compiled �les, and exti dynamicallyloads these �les. Extension �les typically contain callsto new syntax that extend the current ML parser withnew syntax bindings.This decomposition of the compiling process appearsto be useful for justifying the alternative implementationsof quotation expanders given below.7.1 Quotation interpretersThis implementation follows closely the decompositionabove. It relies in the design of an extension languagetogether with its interpreter exti (the language could beML, but it could also be di�erent). The interpreter islinked once for all with the compiler. Therefore, thereis no need for dynamic loading of code. The resultingcompiler, given a list of extension �les, interprets these�les, and is then able to compile source �les containingquotations.We did experiment with such a solution using a sub-set of ML as extension language, and the results werequite satisfactory, mainly because compilation times areconsidered as being less critical than execution times.Di�erent variants of this solution can be imagined,the most interesting of which would probably be an in-terpreter for simple grammars with ML quotations as se-mantic actions, and antiquotations restricted to singlevariables.75

7.2 Preprocessing source �lesAnother possibility is to consider two applications: a textexpander, acting as a preprocessor, composed of an MLextensible parser and a regular ML printer regmlprint,communicating with a regular ML compiler (i.e. witha regular ML parser regmlparse). The whole process isthen the composition:(gencode � typecheck � regmlparse)| {z }regular ML compiler� (regmlprint � (mlparse exti))| {z }preprocessorBecause regmlparse � regmlprint is the identity functionon ML ASTs, the whole process is functionally equivalentto: gencode � typecheck � (mlparse exti)The preprocessor can either be an ML parser staticallylinked to an inprepreter of syntax de�nitions, or be ob-tained by a complete relinking of an ML parser with com-piled syntax extensions (which is a lighter task than re-linking a whole compiler).This solution is certainly the least elegant of all be-cause the source �le actually compiled is the result ofa preprocessing phase, in which source locations can bedi�erent from locations in the original source �le. Thiscould be avoided by omitting the creation of temporary�les and exchange directly ASTs through a communica-tion channel. This way, there is no need for a pretty-printer, nor for parsing expanded source �les; two trivialprograms for printing and parsing ASTs would su�ce.8 Interaction with module systemsThe interaction with the Caml-Light module system isclear, since the quotation system is orthogonal to mod-ules: quotations belong to the compiler, and the scope ofsyntax extensions is global to a compilation.However, since quotation expanders are compile-timeentities, they could be associated with (or be part of)other compile-time entities, as signatures in the SMLmodule system. This would restrict the scope of syn-tax extensions to the scope of the signature they belongto. It is useful to keep in mind that quotations allow forparameterising only program texts. One cannot think, forinstance, of an SML structure or functor being parame-terised by a syntax extension (i.e. a set of expanders):either the expanders are provided when compiling theimplementation, and the compilation is possible, or theexpanders are not known, and the implementation can-not be parsed, and therefore be compiled.9 Related workCaml quotations [15] were a generalisation to several ob-ject languages of the quotations of the original ML sys-tems. Limited to the Caml lexical analyser, Caml quota-tions were strongly linked to the Yacc interface and Camlmacros to the presence of dynamic types [15, 9]. Here,there are no such constraints: we have complete freedom
in the choice of lexing and parsing techniques, and noneed for dynamic typing.Slind presented in [14] the inclusion of quotations andantiquotations in SML-NJ. If used without antiquota-tions, this system implements quotation expansion justlike a regular call of a user-de�ned parser to a string (i.e.expansion occurs at run-time).Antiquotations are \holes" in quotations that are par-sed like regular ML expressions. Fixed antiquotationmarks (\^" or \^(: : :)") are used to escape from an ob-ject language to ML identi�ers or expressions. Given acall \p `...`", the ML parser produces the ML appli-cation of the parser p to a list of elements belonging aspecial polymorphic data type 'a frag. This list is analternation of QUOTE and UNQUOTE data constructors.The expansion of quotations at run-time forbids theusage of quoted patterns, and implies that a quotation oc-curring in a function body will be parsed at each functioncall, in the general case. Furthermore, all antiquotationsin a frag list must possess the same type.SML-NJ quotations can be easily implemented in oursystem. We omit the code of mk frag, which explodes astring into a list of Quote/Antiquote elements.# type Frag a = [ Quote String | Antiquote a ];Type Frag defined.# value mk_frag = ...;# new_syntax "Quote" (mk_frag, failwith);- : Unit = ()# <:Quote<^(True) /\ ^(False)>>;- : List (Frag Bool) = [Quote ""; Antiquote True; Quote " /\\ "; Antiquote False; Quote ""]Aasa et al. [1, 2] present a general solution to theambiguity problem in quotation patterns. They use thecooperation of a speci�c parsing mechanism (Earley's al-gorithm [5]) with the type synthesizer. In this work,data type de�nitions can occur under a concrete form(in which case data constructors are hidden to the user),and the type de�nition includes precedence informationfor disambiguation. Type de�nitions act therefore as def-initions of concrete syntaxes of quotations and antiquo-tations.Aasa's work has been improved by Petersson and Fritz-son [12], who use a more e�cient parsing algorithm [7].Finally, we must mention that we have no support, inAST manipulation, for avoiding unwanted name clashes,which are frequent in presence of some forms of macroexpansion. In [4], a technique for having extensible syn-taxes preserving lexical scoping is presented. This tech-nique relies on a grammar formalism and presents severaladvantages: it is language independent and allows incre-mentality in the language de�nition.Our technique is much more basic: we do not relyon a particular parsing technique, nor on a particularlanguage de�nition formalism. On the other hand, wecannot obtain the same nice properties (incrementality,parsing always terminates, no need for quotation marks).76

Our work does not have exactly the same goal: weare interested in arbitrary language manipulation in ML,including ML programs themselves. In our opinion, ex-tensibility is another topic: it concerns each of the objectlanguages that we manipulate. Extensibility can be seenas orthogonal to our work, since it concerns parsing tech-niques and language de�nition formalisms.10 ConclusionWe have presented the integration and the implementa-tion of a general quotation mechanism in ML.We have shown that separate compilation can be pre-served and that the interaction with module systems re-mains clear, if there is a clear distinction between thecompiler and the program actually compiled. This dis-tinction is indeed the one between compile-time and run-time objects.Syntax extensions are extensions of the compiler, andmore precisely of its parser. Based on this remark, weproposed several reasonable alternative implementations,in order to accomodate compilers not featuring dynamiccode linking.Finally, quotations provide a reasonable way of in-troducing macro expansion in ML, without needing anydynamic typing [9].References[1] A. Aasa, K. Petersson, and D. Synek. Concrete syn-tax for data objects in functional languages. In Pro-ceedings of the 1988 ACM Conference on Lisp andFunctional Programming, pages 96{105, 1988.[2] Annika Aasa. User De�ned Syntax. PhD thesis,Chalmers University of Technology, 1992.[3] A. Appel and D. MacQueen. A Standard ML com-piler. In G. Kahn, editor, Proceedings of the ACMConference on Functional Programming Languagesand Computer Architecture, 1987.[4] Luca Cardelli, Florian Matthes, and Mart��n Abadi.Extensible syntax with lexical scoping. In Proceed-ings of the Fifth Workshop on Database Program-ming Languages, 1993.[5] Jay Earley. An e�cient context-free parsing algo-rithm. Communications of the ACM, 13(2), 1970.[6] M. Gordon, R. Milner, L. Morris, M. Newey, andC. Wadworth. A metalanguage for interactive proofsin LCF. In Proceedings of ACM Symposium on Prin-ciples of Programming Languages, pages 119{130,1978.[7] Jan Heering, Paul Klint, and Jan Rekers. Incre-mental generation of parsers. ACM Sigplan Notices,24(7), 1989.[8] Xavier Leroy. The Caml Light system, release 0.6{ Documentation and user's manual. INRIA, 1993.Distributed with the Caml Light system.[9] Xavier Leroy and Michel Mauny. Dynamics in ML.Journal of Functional Programming, 3(4), 1993.
[10] M. Mauny. Parsers and printers as stream destruc-tors and constructors embedded in functional lan-guages. In Proceedings of the ACM Conference onFunctional Programming Languages and ComputerArchitecture. Addison-Wesley, 1989.[11] Robin Milner, Mads Tofte, and Robert Harper. Thede�nition of Standard ML. The MIT Press, 1990.[12] Mikael Petersson and Peter Fritzson. A general andpractical approach to concrete syntax objects withinML. In Proceedings of the 1992 Workshop on MLand its Applications, 1992.[13] Tim Sheard and Leonidas Fegaras. Fold for all sea-sons. In Proceedings of the 1993 ACM Conferenceon Functional Programming and Computer Archi-tecture, pages 233{242, 1993.[14] Konrad Slind. Object language embedding in Stan-dard ML of New-Jersey. In Proceedings of the 1991Workshop on ML, 1991.[15] P. Weis, M.V. Aponte, A. Laville, M. Mauny, andA. Su�arez. The CAML reference manual. TechnicalReport 121, INRIA, 1990.The Assert exampleThe Assert syntax extension provides a mechanism forchecking the truth of some boolean expressions, and print-ing an error message allowing to �nd the source locationof the guilty program in case an assertion failed. Thefunction locmsg returns a string indicating the source lo-cation of the assertion. The assert expander is de�nedby:# value assert s =# let e = parse_mlexpr s in <:MLexpr<# if #e# then () else# raise (Assert(#:string (locmsg())^s#))# >>;assert : String -> MLexpr = <fun>Assert has no pattern expander.# new_syntax "Assert" (assert,# (fun _ -> raise(Failure "Assert in a pattern")));- : Unit = ()Compiled with the previous de�nition of the Assert ex-panders, the factorial function checks that its argumentis not negative. With an expander returning the ML ex-pression <:MLexpr< () >>, the compiler would generatea code without assertion checks.# exception Assert String;Exception Assert defined.# value rec fact = fun [# 0 -> 1# | n -> do <:Assert<n>= 0>>;# return n*fact(n-1)# ];fact : Int -> Int = <fun># fact (5+6);- : Int = 39916800In case of failure, the Assert exception carries the �lename (standard input, here) and the character endingthe quotation of the assertion.77

#fact (5-6);Uncaught exception: Assert "std_in, Char 60, n>= 0"#fact (5-7);Uncaught exception: Assert "std_in, Char 60, n>= 0"The Printf exampleML has no equivalent to the C function printf. Oneway to simulate it is to provide a special syntax to gen-erate the correct sequence of printing commands. A syn-tax extension called Printf can therefore be introduced.Quotations consist in a format string, in the style of Cformats, and a sequence of ML expressions in the sameorder as the % characters in the format. In the format,%s denotes a string argument, and %d an integer:#value fname = "fact";fname : String = "fact"#let x = 5 in#<:Printf< "%s(%d+1) is %d\n" fname x (fact(x+1)) >>;fact(5+1) is 720- : Unit = ()The previous quotation expands to the following sequenceof printing commands:do print_string fname; print_string "(";print_int x; print_string "+1) is ";print_int (fact(x+1)); print_string "\n";return ();If the Printf quotation expander is carefully pro-grammed, taking care of the source location of parts ofthe quotation, the typechecker is able to locate correctlythe source of type errors:#<:Printf< "This (%s) is not a string\n" 3 >>;> Toplevel input:><:Printf< "This (%s) is not a string\n" 3 >>;> ^> Expression of type Int> cannot be used with type String#<:Printf< "Ill typed: %d\n" (fact "zero") >>;;> Toplevel input:><:Printf< "Ill typed: %d\n" (fact "zero") >>;> ^^^^^^> Expression of type String> cannot be used with type IntGeneration of \fold" functionsSo far, we mentioned only MLexpr and MLpatt as pre-de�ned syntax extensions, for ML expressions and MLpatterns. ML type expressions possess also their quota-tion expanders:#<:MLtexpr< [ Nil | Cons a (List a) ]>>;- : MLtype_expr = MLTE_sum 0 [("Nil", []); ("Cons", [MLTE_lid 0 "a"; MLTE_app 0 (MLTE_uid 0 "List") (MLTE_lid 0 "a")])]Used as patterns with antiquotation marks, they allow tode-structure arbitrary type expressions.Let us assume the existence of a primitive providedby the compiler returning the type expression to whicha type constructor is bound. It is possible to implementan automatic generator of \fold" functions associated totypes [13]. We implemented a simple version of this, em-bedded it into a syntax extension named Fold. Given atype de�nition for binary trees:
# type Btree a b = [# Leaf a# | Node b (Btree a b) (Btree a b)# ];Type Btree defined.we can produce the following function:# value fold_Btree = <:Fold<Btree>>;fold_Btree : (a -> b) -> (c -> b -> b -> b) -> Btree ac -> b = <fun>The expression produced by the Fold quotation is:fun fLeaf -> fun fNode ->let rec fld = fun [Leaf x1 -> fLeaf x1| Node x1 x2 x3 -> fNode x1 (fld x2) (fld x3)]in fldWe can now use it to produce an arithmetic evaluator:# value compute =# fold_Btree (fun x -> x)# (fun [ "+" -> prefix +# | "*" -> prefix *# | _ -> raise(Failure "Unknown op.")]);compute : Btree Int String -> Int = <fun># compute# (Node "+" (Leaf 1)# (Node "*" (Leaf 2) (Leaf 3)));- : Int = 7
78

mlP�cTEX, a picture environment for LaTEXEmmanuel CHAILLOUXLIENS�- LITPy Asc�ander SU�AREZUSBz- LIENS�Abstract\mlPicTex" is a tool for the design of �gures which mightcontain text composed with LaTEX [8]. These �gures aredescribed by programs in the Caml [9] language enrichedwith a set of primitives for drawing lines, arrows, geo-metrical �gures, trees and graphs. The graphical modelis the same as in PostScript [2]. A Caml library, calledMLgraph [6], de�nes this graphical model in a functionalstyle and generates PostScript �les. The Caml programsdescribing �gures are placed in the LaTEX document in-side an mlPic LaTEX environment in which it is also possi-ble to declare as an mlP�cTEX box, any piece of LaTEX text,including labels and references. mlP�cTEX is compatiblewith the LaTEX macro de�nition mechanism and allowsto parameterize the mlP�cTEX pictures inside macros inorder to easily obtain variations on basic pictures. Camlis used as the algorithmic language to describe picturesthat we call ml pictures.IntroductionThe two main motivations of this work are, �rstly thecreation of technical documents which manipulate com-plex pictures, secondly to test on a real application theadvantages and disadvantages of functional programmingto create pictures. For the �rst one, the following pointsare necessary: automatization of the production line, touse the appropriate models (PostScript for the graphicalmodel and LaTEX for the document composition and forthe management of the fonts), �nally to program in asafe and expressive algorithmic language such as Caml.For the second one, we want to test the capabilities ofCaml to describe and to manipulate pictures, and alsothe facilities of extension of this library.In the �rst section this paper describes the represen-tation of an ml picture and the complete work neededto produce a document. Section 2 presents the new pos-sibilities o�ered by mlP�cTEX to manipulate LaTEX boxeswith some basic examples. Section 3 shows automatic�URA 1327 - Laboratoire d'Informatique de l'�Ecole NormaleSup�erieure - 45 rue d'Ulm, 75230 Paris Cedex 05, France. E-mail:fEmmanuel.Chailloux,[email protected] 248 - Laboratoire d'Informatique Th�eorique et Program-mation - Institut Blaise Pascal - 4, place Jussieu - UPMC - 75252Paris Cedex 05, France. E-mail : [email protected] Sim�on Bol��var - Departamento de Computaci�on- Valle de Sartenejas - Caracas 1080 - Venezuela. E-mail :[email protected]
placements of data structures such as trees and graphs.Section 4 explains how to generalize the construction ofml pictures either by using the LaTEX macro mechanismor by creating ml pictures from Caml. Finally, in the lastsection we discuss some related works.1 General DescriptionThis section contains a general description about the na-ture of pictures which are manipulated by mlP�cTEX, themanner to get informations from LaTEX to mlP�cTEX andthe production line to obtain �nal pictures and the doc-ument.1.1 Picture descriptionAn ml �gure is built from MLgraph primitives and is avalue of type picture de�ned in MLgraph. The LaTEXboxes are viewed as patches of white ink with exactlythe same size of real LaTEX boxes. The Caml programbuilds this picture and produces a PostScript �le wherethe LaTEX boxes will be rightly overlaid. Figure 1 showsthis decomposition.PostScript Part
LaTEX part1 +p 1 + x �PostScript Part
LaTEX part1 +p 1 + x=PostScript Part
LaTEX part1 +p 1 + xFigure 1: Decomposition of picture building by mlP�cTEXOne of the main di�culties during the implementationof mlP�cTEX was to reconcile the coordinate systems ofboth PostScript and TEX. Normally, in an ml �gure thereis no need to give an absolute distance as all distances79

are given default values by mlP�cTEX. However it is alwayspossible to apply an optional distance coe�cient to thehole picture or to a particular component. Working inthis way, it is rather simple to change the style and fontsize of a document and recompute ml pictures withoutmodi�cation of their code. Moreover, changes a�ectingglobally the magni�cation of the document (as in thestyle 2up.sty) does not imply any recomputation of ml�gures at all.1.2 Getting Informations from LaTEX tomlP�cTEXThere are mainly two approaches that can be used to getthe LaTEX information outside. The �rst one is to sim-ulate the behavior of LaTEX and to estimate the dimen-sions of boxes. The drawback of this approach is thatthis estimation depends on the LaTEX environment and,in order to produce a good estimation, it is necessary tore-implement an important part of the TEX algorithms.The second approach, used in this work, is to let LaTEXdo its own work and to retrieve the dimensions of the re-sult. In order to achieve this, we need to manipulate theLaTEX boxes in a special new environment (called mlPic),which captures these exact values and writes them in thelog �le of the execution of LaTEX. A simple example isgiven in Figure 2.nbeginfmlPicgnmlDeffformgfp1 +p1 + x (�g. 2)g]nmlBodyfsqrgfrotate 20.0 (oval (latexBox "form"))gnendfmlPicgp 1 +p 1 + x (�g. 2)Figure 2: An oval frame and its mlP�cTEX code1.3 Processing mlP�cTEX picturesThe production line is really simple. For the simplestcase, three steps are necessary:1. latex myFile produces two main �les myFile.log andmyFile.dvi.The mlPic environment adds to the myFile.log �leCaml programs encountered inside a nmlBody com-mand. Inside the dvi �le no picture appears.2. mlpictex myFile creates a directory myFile.picwhichcontains all the described pictures. For each picturep1 there is a �le p1.ps for the PostScript part of thepicture and a �le p1.tex for its interface to LaTEX.mlpictex is a small unix �lter that processes the log
�le to extract Caml programs. Those Caml pro-grams are evaluated and their execution producethe picture �les to be included in the document.3. latex myFile composes the new document with allml pictures included.1.4 mlP�cTEX, The DetailsThe system mlP�cTEX is implemented in LaTEX, Caml Lightand perl1. In order to use it, you must have these threesoftwares installed in your system. mlP�cTEX can be di-vided into three units:� MLgraph.tex. A set of macros written in LaTEXwhich acts as an output/input communication chan-nel between LaTEX and mlP�cTEX. As an output chan-nel, it stores in the log �le produced by LaTEX theinformation concerning the boxes to be included in�gures and the description of the �gures themselvesas ml programs. As an input channel, it looks for�les produced with mlpictex and include them inthe document output when they exist.� mlpictex. A perl script that scans the output pro-duced by the use of the MLgraph.tex macros insideyour document; With this information mlpictex pro-duces a Caml Light program which uses the primi-tives de�ned in the MLgraph and mlPicTex librariesin order to build the document �gures.� MLgraph and mlPicTex libraries. Called from theprogram produced from the document, they com-pute �gures producing PostScript code and tex codeto be included in the document.Although recent versions of LaTEX allows to create andhandle a process during the composition of the document,we prefered to implement mlP�cTEX as a separate tool justlike bibtex. The actions can however be explained as ifthey were executed synchronously. We will follow nowa detailed execution of the example �le of Figure 3. In1 ndocumentstyle:: :2 ninputfMLgraphg: : :3 nbeginfdocumentg:: : :4 nbeginfmlPicg5 nmlDeffbox1gfx�3g6 : : :7 nmlBodyf�g1gf: : :g8 nendfmlPicg9 nendfdocumentgFigure 3: LaTEX �le with ml picturesline 2, the MLgraph �le is included, this make availableto the rest of the document the following commands:� nbeginfmlPicg : : : nendfmlPicg, This is the environ-ment in which ml �gures are de�ned (see the LaTEXbook [8] for a description of environments). Theusage of the following commands outside this envi-ronment might have unpredictable results.1Perl is an acronym of \Practical Extraction and ReportLanguage".80

� De�nition of boxes:nmlDefflabelgftextg,nmlDefGenfoptionsgflabelgftextgand its variants nmlDefBox and nmlVDef. label isthe name by which the LaTEX text will be known inCaml . options is a list of optional arguments thatmodify the layaout of text. Optional arguments arediscussed in section 3.1. The two other forms areused to de�ne pre-composed horizontal and verticalboxes as ml picture components.� Description of a picture:nmlBodyfpictureNamegfCaml expression describing the picturegThis command is used once in an mlPic environ-ment to describe the picture that the user wants toinclude in its document and to give the name of the�le in which this �gure will be stored.� Directives for the Caml compiler:nmlOpenf"filename"gnmlDirfdirectivegThis two commands are used to pass to Caml anydirective needed for the evaluation of ml �gures inthe right environment. These might include theloading of libraries, the declaration of in�x oper-ators, etc.� nmlPut. This is an extension of the nput commandof LaTEX which applies a linear transformation toits argument. This command is internally used bythe tex code generated with mlP�cTEX for the place-ment of latex boxes into ml pictures. Its variantmlPutGen accepts an additional argument which isused to specify colors, to de�ne a clipping zone, etc.Line 3 of the Figure 3 is the start of an ml picture. Itprints on the log �le of the document a header indicatingthat output to mlpictex starts there.In line 5 of Figure 3, a new box called box1 is de�ned;its contents is the text x�3: The actions performed bythis command are the creation of a new box using the boxcreation policy of TEX �lled with the LaTEX text x�3; andthe output to the log �le of the name and dimensions (butnot the contents) of that box. The nmlDefBox variant ofthis command assumes that its second argument is thenumber of an existing box that will be used and erasedduring the creation of the ml picture.In line 7, the nmlBody command must have as argu-ments a name for a �le to be created in a resource environ-ment and an ml program of type picture. This commandde�nes the function latexBoxwhich associates the namesof de�ned �gures with an empty picture with correspond-ing dimensions. It also pass the result of the user pro-gram de�ning the picture to a function of the MLgraphlibrary that computes a postscript program box1.ps thatdraws the �gure, and a tex �le box1.tex that integratespostscript and LaTEX parts of the �gure.Finally, in line 8, the mlPic environment prints anend of picture trailer in the log �le and then try to loadthe �gure as produced on a previous run. If this �gureis available, it is integrated to the document which canimmediately be transformed into postscript and printedwith the dvips command.Figure 4 shows the corresponding LaTEX �le for Figure6. All the �gures generated with mlP�cTEX are describedinside a LaTEX picture environment.
nbeginfpictureg(203.5037,53.0541)(0,0)nput(0,0)fnspecialfps�le=article.pic/ ip.psggnmlPutGenf(12.2396,35.2589)gf1 0 0 1 gfgfncopy28gnmlPutGenf(12.2396,19.3305)gf1 0 0 -1 gfgfncopy28gnmlPutGenf(189.7286,35.2589)gf-1 0 0 1 gfgfncopy28gnmlPutGenf(189.7286,19.3305)gf-1 0 0 -1 gfgfnbox28gnendfpicturegFigure 4: LaTEX �le for an mlP�cTEX �gureIn order to include ml pictures inside other ml pic-tures you must �rst create internal ml pictures and storethem in boxes; Then, they can be included with the mlprimitive nmlDefBox into more complex pictures. If thisfacility were considered useful, changes in the parser ofthe log �le would allow the explicit inclusion of ml pic-tures in nmlDef declarations.2 The MLgraph Graphical ModelmlP�cTEX is based on the MLgraph graphical library [5].The graphical model used in MLgraph is basically thePostScript one. Various objects can be de�ned on thein�nite Cartesian plane and arbitrarily scaled, translatedand rotated by the application of linear transformations.A type picture is used to represent all printable objects.Pictures have a \frame" and possibly a set of named\handles" that are used for combination operations. Pic-tures are de�ned from more basic objects such as geomet-ric elements (lines, arcs and curves), texts and bitmaps.All operations de�ned on these types are purely func-tional except for pixel editing which is done with bitmapsand handle de�nitions.mlP�cTEX integrates the MLgraph primitives to theLaTEX world, introduces the mechanism of optional argu-ments to its own primitives, introduces some automaticand constrained based placement primitives and allowsthe creation of �gures whose size depends on the size ofthe LaTEX components.We explain now, some basic MLgraph concepts whichare useful in describing ml pictures.MLgraph pictures are de�ned from more basic objectssuch as geometrical elements (lines, arcs and curves),texts and bitmaps.2.1 Transformations and AlignmentsA transformation is represented by a 3� 3 matrix whichhas the form: m11 m12 m13m21 m22 m230 0 1 !and operates on vectors representing points with coordi-nates (x,y) of the form: xy1 ! :Some classical linear transformations, such as rotationsor scaling, are provided in the library. The example of81

Figure 5 shows the application of di�erent rotations on aLaTEX text.The little cat is dead
nbeginfmlPicgnmlDeffThegfThe gnmlDefflittlegflittle gnmlDeffcatgfcat gnmlDeffisgfis gnmlDeffdeadgfdead gnmlBodyfrotgflet l =map2 (fun x y ! rotate x (latexBox y))[60.0; 45.0; 30.0; 15.0; 0.0]["The";"little";"cat";"is";"dead"] inalign horizontally Align Bottom lgnendfmlPicg Figure 5: RotationsIn general, transformations are not completely com-puted in MLgraph; In most of the cases, only the frameof a picture is recomputed when a transformation is ap-plied and the real work is delegated to the PostScriptinterpretor. An exception to this rule is necessary in thecase of mlPutGen declarations were the work has to beperformed directly by mlP�cTEX.Figure 6 shows the use of a frame to align pictures ei-The little cat is deadThe little cat is dead Thelittlecatisdead Thelittlecatisdead
nbeginfmlPicgnmlDeffcatdgfThe little cat is deadgnmlBodyf ipgflet c = rectangle (latexBox "catd") inrectangle (align horizontally Align Center [align vertically Align Center [c ;hflip c];align vertically Align Center[vflip c; vflip (hflip c)]])gnendfmlPicg Figure 6: Symmetriesther horizontally or vertically. The two functions hflipand vflip perform symmetrical transformations with re-spect to vertical and horizontal medians of the frame(rectangles are drawn with the mlP�cTEX rectangle prim-itive explained in section 3.
2.2 LaTEX components of ml PicturesHaving access to the exact size of LaTEX boxes, it is rathersimple for mlP�cTEX to automatically place them in theright way. The next example (Figure 7) shows a place-ment in Caml of the matrix elements to visualize theproduct of two matrices.�1 11 11 1 1 1 11 11 1 12x x x x+ 2 x+ 2x+ 2 x+ 2x+ 2 x+ 2x+ 3x+ 32x+ 2) ) ) )) )Figure 7: Matrix productIn this example, a maximal frame is computed forthe matrix elements. This is done with the primitiveforce picture in frame.2.3 ColorsA color is especi�ed either by its level of gray (Gra n), orby its red, green and blue component values ( Rgb (r,g,b)with 0 � n; r; g; b � 1). There are four di�erent waysto select the color (background and foreground) for aLaTEX box. The �rst one is to use the color.sty a style�le extracted from Leslie Lamport's psslides.sty style �leto color its ink. This possibility does not depends onmlP�cTEX. Another way is to indicate, with the nmlDefGenmacro, background and foreground colors. In this caseall the occurrences of the picture will have the same col-ors and occurrences of the same text in di�erent colorhas to be declared separately. The third way is to de-clare once the LaTEX box and to change its color in Camlwith the latexBoxGen function. Finally, it is also possi-ble to change the background color of a picture with thechange color function of MLgraph.Most of the �gures in this paper where created withcolors. The choice of colors in �gures has been madeaccording to their quality in black and white. In thenext example (Figure 8) colored backgrounds are used toemphasize the selected elements:TOWN (1) (2) (3) (4) (5)Honolulu 0Pearl City 13 13 13Maili 1 1 33 33 33Wahiawa 1 1 25 25Laie 1 35 35 35 35Kaneohe 11 11Figure 8: Distances between cities of the Oahu islandThis small example shows well the good knowledge ofmlP�cTEX about the real size of LaTEX boxes.82

2.4 ClippingA clipping zone determines a portion of the user spacewhere the picture will be drawn. This possibility allowsto mask a part of a picture. The use of clipping zonescombined in picture with handles can produce interestinge�ects on a picture. Figure 9 shows a text, which iscut by a diagonal in two triangle. Each new part hasa color which is di�erent from the original and has thesame handle on the diagonal. The combination of thesetwo parts give an e�ect of boundaries between them.nbeginfmlPicgnmlDeffformgfp1 +p1 + x (�g. 2)gnmlBodyfsqrgfrotate 20.0 (oval (latexBox "form"))gnendfmlPicgnbeginfmlPicgnmlDeffformgfp1 +p1 + x (�g. 2)gnmlBodyfsqrgfrotate 20.0 (oval (latexBox "form"))gnendfmlPicgnbeginfmlPicgnmlDeffformgfp1 +p1 + x (�g. 2)gnmlBodyfsqrgfrotate 20.0 (oval (latexBox "form"))gnendfmlPicgnbeginfmlPicgnmlDeffformgfp1 +p1 + x (�g. 2)gnmlBodyfsqrgfrotate 20.0 (oval (latexBox "form"))gnendfmlPicg� �!Figure 9: Colors and clippingThe interesting part of the Caml program is as follows:let np1 = set picture interfaces(clip picture Eoclip pa1 p1) (po1,po1)and np2 = set picture interfaces(clip picture Eoclip pa2 p2) (po1,po1)inalign vertically Align Center [(align vertically Align Center[np2;plus;np1]);rotate 270. space;rotate 270. (latexBox "eq");rotate 270. space;(align horizontally Align Center[group pictures [np1;np2]])]p1 and p2 are identical LaTEX boxes with di�erent colors.pa1 and pa2 correspond to the two clipping zones (cf.triangles of �gure 9). po1 is the same segment for theinput and output handle of each picture correspondingat the diagonal. The function set pictures interfaceassociates this handle to the pictures and the functionclip picture determines the clipping zone for the pic-tures. Then the function group pictures makes the su-perposition of the input handle of the �rst picture overthe output handle of the second one.3 A Tool for Describing FiguresmlP�cTEX can be viewed as a language for the descriptionof �gures that we call \ml pictures." The meta languageof mlP�cTEX is ML and its primitive values and operations
come from the MLgraph library. In the implementationof mlP�cTEX, ML is used as the language in which place-ment algorithms and constraint solving algorithms arewritten. Those algorithms de�ne the descriptions usedin mlP�cTEX for the speci�cation of its �gures.An ml picture is a description of the �gure, the userwants to create. mlP�cTEX interprets descriptions usinga set of hypothesis, which are the default arguments ofdescriptions. By changing the default values (by givingoptional arguments to descriptions), the user can changethe interpretation of its �gures.Finally, an extension to mlP�cTEX is a collection ofalgorithms written in ML that de�ne new descriptions of�gures.3.1 Optional ArgumentsA complete description of simple �gures like a circle maybe very complex. In addition to its diameter and thecoordinates of its center point, it is necessary to have in-formation about the width, shape and color of the circleline, the shape and color of its surface, etc. A posible so-lution to this problem is the use of default values whichcan be changed when they do not correspond to the de-sired picture. The use of asignments for setting defaultvalues would be an acceptable solution in an imperativelanguage, but for ml, it is more convenient to use a styleof parameter passing to functions that allows an arbi-trary number of optimal arguments and a �xed numberof mandatory arguments.Probably, an extension to the record mechanism ofml would allow such a style of parameter passing, but forour practical purposes, we adopted a simple yet powerfuland extendable convention for writting mlP�cTEX primi-tives: The generic version of a primitive operation re-ceives a �rst argument which is a list of optional argu-ments. The remaining arguments are mandatory. In or-der to implement this convention, we de�ned the typeoption of named optional values, functions float, int,color, etc. that inject di�erent types into named options,and selector functions theFloat, theInt, theColor, etc.that extracts named values from lists of options.For instance, the mlP�cTEX primitive circleGen thatdraws a circle around an ml picture receives one manda-tory argument and accepts more than 10 optional argu-ments which includes colors and coe�cients for the diam-eter and the width of the circle line. A simpler primitivecalled circle describes the same action with all of itsarguments taken by default (In fact circle is de�ned ascircleGen[]).For instance, the two calls of Figure 10 describe acircle around an ml picture p , The �rst one describes itcircle p �circleGen[color "background" yellow] p �Figure 10: Examples of Optional Argumentswith all the default values, while the second one describethis circle with a given color for the background insidethe circle.83

3.2 Surrounding PicturesGiven a picture p, circle p, rectangle p and oval pdescribe the �gure obtained by surrounding p with a cir-cle, a rectangle and an oval respectively.circle prectangle poval pFigure 11: Surrounding picturesThe surrounding primitives are used in Figure 2, 13,14, etc. These descriptions accept all line drawing op-tions which include width, colors and dashes, and the"frameDistanceCoef" option which a�ects the distancebetween the frame of the picture and the surrounding lineand has a default value of 1.3.3 Placement of TreesmlP�cTEX de�nes two primitives for the automatic place-ment of trees: tree and proofTree. The algorithm toplace binary trees in an aesthetic way due to Guy Cousi-neau and presented in [5], has been extended for generaltrees.A tree is a data structure that can contain labels onnodes, leaves and lines. The tree primitive of mlP�cTEXtakes a description of the tree and draws it in a size pro-portional to the size of its labels:type (�,�) tree =Node of (�,�) treeRecord j Niland (�,�) treeRecord =finfo:�;sons:(�,�) tree list;label:� labelgand � label = Nolabel j Label of �In order to cover most of the cases of tree construc-tion and to obtain compact notation, we introduce someauxiliary functions that will be used in the examples ofthis section:let node info lab sons =Nodefinfo=latexBox info;label=if lab= ""then Nolabelelse Label (latexBox lab);sons=sonsglet leaf info lab = node info lab []and spacedLeaf info lab = node info lab [Nil];;The functiontree : (picture,picture) tree -> picture
draws a description of a tree where nodes and labels arepictures. This new picture has a good space occupation.Figure 12 presents some brief examples showing the re-sults of the placement algorithm:leaf "p" "" pleaf "p" "a" panode "p" ""[leaf "q" ""; leaf "r" "";leaf "s" ""] pq r snode "p" ""[leaf "q" "a"; Nil;leaf "s" "b"] pq sa b���������������� �������� ���� � ������ �Figure 12: Examples of TreesFigure 13 shows �-term reduction in a graphical form.Each node corresponds to a LaTEX box. The applicationnode is in green (sic). The sizes of the nodes are di�erentbecause the real sizes of �x and x LaTEX boxes di�er.�x�x �x�x �xxxx xx x� � �(�x:xx)(�x:x) ) (�x:x)(�x:x) ) �x:xFigure 13: �-term reductionText below is part of the description used to draw thisexample. Functions redexNode and otherNode are usedto make a di�erence between redexes and the rest of thenodes. Leaves of trees are drawn with the local functionleaf. (align horizontally Align Top[tree(greenNode "appeff"[whiteNode "lx" [whiteNode "app"[ "x"; leaf "x"]];whiteNode "lx" [leaf "x"]]);(latexBox "space");84

tree( greenNode "appeff"[whiteNode "lx" [leaf "x"];whiteNode "lx" [leaf "x"]]);(latexBox "space");tree( whiteNode "lx" [leaf "x"])])The following example, in Figure 14, describes thesame tree with two di�erent representations. This kind oftree, called trie, is used to recognize words, for exampleinside a dictionary. We use it with the words \this",\tea", \it" and \its". n1 n1n2 n2n3 n3n4 n4n5 n5n6 n6n7 n7n8 n8n9 n9n10 n10tt th hii iiss sse ea a t---- - - - -****Figure 14: Two representations for a trie of the words\this", \tea", \it" and \its"Only the decoration of the information changes be-tween the two versions of tries. In the left version, nodesrepresenting the end of a complete word are marked witha star; The function reFrame is used to give the same sizeto all the information nodes.let reFrame s =force picture in framemax frame (latexBox s)let n (s1,s2) =node (align horizontally Align Center[rectangle (reFrame s1);rectangle (reFrame s2)]) in : : :The call force picture in frame f p creates a pic-ture with the contents of picture p and the frame f . Notransformation on the picture is done, only it's relationwith other primitives that use its frame may change. Thevalue max frame is easily computed with an iterator asfollows:let max frame l =it list compose frames(hd l) (tl l)In the second representation of tries, the drawing nodefunction uses background color to distinguish a possibleend of a word. As a consequence of this superpositionof information inside nodes, the tree becomes more com-pact.
let n (s1,s2) lab l =Node finfo=if s2="*"then grayCircle s1else normalCircle s1;sons=l;label=makeLabel labg in ...Observe, in the last example, that trees do not make anydistinction between left and right sons; when an uniqueson exists, the line between nodes is vertical. To draw abinary tree, with missing nodes it is su�cient to create anempty brother to the unique son to orientate the draw-ing. For example, reusing the two functions white nodeand leaf described in Figure 14, the two following treeshave a di�erent drawing:tree (white node "7" [leaf "5"; Nil]) andtree (white node "7" [Nil; leaf "9"]):7 75 9The height and width of trees are de�ned as a valuethat is proportional to the average size of the subpic-tures used as nodes. Using the two optional argumentstreeHeightCoefand treeWidthCoef, the user can changethis proportion and adapt trees to its particular prob-lem. Other possible options for trees include line draw-ing options and the two arguments treeLabelPos andlabelDistanceCoef for the placement of labels at lines.Proof treesA variant of the tree placement algorithm can be used forproof trees. The proofTree function was called in orderto produce the picture of Fig 15.let leaf info = spacedLeaf info "" inalign vertically Align Center[proofTree(node "fx" "lApp"[node "f1" "lVar" [leaf "a1"];node "x" "lVar" [leaf "b"]]);proofTree(node "lfxffx" "lAbs"[node "lxffx" "lAbs"[node "ffx" "lApp"[node "f2" "lVar" [leaf "a2"];leaf "fx"]]])]` �fx:f (f x) : �! � ! �ff : �g ` �x:f (f x) : � ! �(� =)ff : �;x : �g ` f (f x) : �� ` (f x) : � � ` (f x) : �� ` x : �3� �3 �3� ` f : �3 ! �� �2 �3 ! �� ` f : � ! �� �1 � ! � (App) (App)(Abs)(Abs)(V ar) (V ar)(V ar)Figure 15: An exotic typing proofEach line between the nodes of a proof tree may havea label. For instance, the strings "lxffx" and "lApp"85

correspond respectively to the LaTEX texts ff : �g `�x:f (f x) : � ! � and (App).With a simple rotation of the structure of a proof treeit is possible to produce a hierarchical notation for values,as in the example of Figure 16.ab cde ab cd e abcde abcdeFigure 16: Rotations on trees3.4 Placement of GraphsmlP�cTEX has a primitive automatic placement algorithmfor graphs. It also allows to describe a graph easily, byconstraints, in the style of xypic [11]. The user needsto give the directions for the lines between nodes. Theexample in Figure 17 comes from [3].1 2345 6 1112 131520 2428 HonoluluKaneoheLaiePearl CityMaili WahiawaFigure 17: Map of the Oahu island (Hawai)Graphs are represented by values of type graph, de-�ned as follows:type graph =Graph of stringj PGraph of graph*(string*point)listj LGraph of graph*((string * option) list*geom element list list) listj TGraph of transformation*graphj CGraph of graph*graphand line =GLine of (string*option) list*string listj GCurve of (string*option) list*(string*dir) listj GSCurve of (string*option) list*string*(float*string)listj GHull of (string*option) list*string listand dir = Dn j Ds j De j Dwj Dne j Dnw j Dse j Dswj Deg of float
The type graph completely describes the structure ofgraphs as a set of named edges and a set of lines connect-ing or surrounding edges. In order to obtain a picturefrom a description, it is only necessary to add the pic-tures to be placed at edges and lines. The function graphtakes a graph and a list associating names and picturesand produces the picture of the graph. Its type is:value graph : graph ! (string * picture) list! pictureThere are several primitives in mlP�cTEX that can beused to describe graphs. The simplest one is polyGraphwhich allows to describe graphs with the shape of a reg-ular polygon. polyGraph takes the name of the centralpoint, the name of edges and a list of lines and producethe described graph.� �� � � ��� � � ���� � � ����� �� ����� � � ���� � � ��� � � �� �Figure 18: Graphs based on polygonsThe assembleGraphs function of mlP�cTEX joins a setof graphs and a set of independent nodes with positionalconstraints between nodes. Constraints are pairs of nodeswith an orientation. Without any constraint, each nodeis a graph that is placed at an arbitrary position. A con-straint between two isolated graphs concatenates them inorder to satisfy the constraint with a straight line. Con-straints between nodes of the same graph are solved withsymmetric curves. Constraints a�ecting only one nodeare solved as loops.We develop in detail now example of Figure 19 whichis a typical �nite automata.q0q1 q2q3 q4q5a aaaaabbb bbbFigure 19: Deterministic Finite Automata1. We start with a list of unrelated points which willbe the nodes of the graph. When no constraint on86

their position is given, they are just placed any-where. assembleGraphs []["0";"1";"2";"3";"4";"5";"st"][] 0 1 2 3 4 5 st2. Adding a constraint between non connected partsof the graph will positionate them in order to sat-isfy this constraint with straight lines. Constraintshas the form o; a; d; b where o is a list of options, a isa string denoting the source node, d is the directionof the constraint and b is a string denoting targetnode. assembleGraphs []["0";"1";"2";"3";"4";"5";"st"][[float "lineLengthCoef" 0.5],"st",Ds,"0";[],"0",De,"5";[],"1",Dne,"3"]0 1 2 3 45st3. Constraints between two di�erent points of the samesub-graph are solved with curves. Constraints be-tween the same point are solved as loops.assembleGraphs []["0";"1";"2";"3";"4";"5";"st"][[float "lineLengthCoef" 0.5],"st",Ds,"0";[],"0",De,"5";[],"1",Dne,"3";[],"3",Dnw,"0";[],"4",Dne,"2";[],"2",Dnw,"5";[],"1",Dn,"4";[],"4",Ds,"1";[],"2",De,"2"]01 23 45st4. When all the points in the graph are connected, therest of the constraints are solved with curves. Thesecurves are symmetrical with respect to the perpen-dicular line between the two nodes; their directionis the speci�ed at the source node and the opositeone at the target node. In some cases these curvesmay look like straight lines (see for instance, lines5��4 and 0��1).
assembleGraphs []["0";"1";"2";"3";"4";"5";"st"][� � �;[],"3",De,"3";[],"5",Dn,"5";[],"0",Ds,"1";[],"5",Ds,"4"]01 23 45st5. The arrows in the graph are speci�ed with the op-tion string "arrowDir" "F". This option is addedto each oriented line in the graphassembleGraphs []["0";"1";"2";"3";"4";"5";"st"][� � �;[string "arrowDir" "F"],"5",Ds,"4"]01 23 45st6. The basic graph is completely described. It is possi-ble then to include additional lines or to compose itusing others graph describing primitives. In orderto extend our graph with nodes at label positionsin lines, we use the function addPonts. In our ex-ample, nodes is the list of node names to be addedas line labels. We also apply a transformation tothis graph to avoid the superposition of loops andlines of the previous step.(addPoints [](transformGraph (scaling(1.0,1.3))(assembleGraphs [] points lines))nodes) 01 23 45� ���� ���� ���7. Another extension to this graph is the introductionof two partitions that will represent states of thesame equivalence class. The special line GHull(o,n)draws a continuous line around the sequence n ofnodes in a graph. This line can be modi�ed withthe list o of line options.87

addLines(addPoints [](transformGraph (scaling(1.0,1.3))(assembleGraphs [] points lines))nodes)[GHull([],["0";"5"]);GHull([],["1";"3";"2";"4"])]01 23 45� ���� ���� ���8. Finally, the described graph is drawn with the func-tion graph which also add the labels to it producingthe ml picture of Figure 19.graph g labelsWhen this �le is printed on a PostScript color printer,the background of Figure 17 will present a nice greencolor. There are other placement possibilities for nodes ingraphs, including arrays and arbitrary placement basedon edges. The example in Figure 20 comes from [3]. Thethree �rst automata are in the right picture assembled toproduce a new automaton. A new edge is created (label0) to start the right automaton.0
1 1 2 233
44
55
667
78
8a aa
aaa
bb
bbb
bb
b�� �(a) NDFA for a, abb and a�b+(b) NDFA combinationFigure 20: di�erent automata and their composition4 Flexibility and ExtensibilityFirstly, we describe in this section how we can de�ne newLaTEX macros to parameterize mlP�cTEX pictures. This
feature is convenient to draw small graphs and diagrams.Secondly we give a small example to use new librarieswith mlP�cTEX. Finally, we show on an ml picture (Fig-ure 22) built in Caml for the visualization of a tree ofvalues. In that �gure, all the nmlDef declarations wereautomaticly generated by program. This is an interestingapproach to the visualization of results of programs.4.1 Parameterization of �guresIt is possible to parameterize mlP�cTEX �gures by combin-ing ml pictures and macros in LaTEX. Bellow is the de�-nition of a user-de�ned macro called nisos used to buildsmall oriented graphs. It has eight parameters. The �rstis the name of the picture, the next six parameters arethe labels of the graph and there is another one for theapplication of a scaling factor to the graph.A BfgidA idBnisosf�g1gfAgfBgffgfgg fidAgfidBgf1.0gCCC DDDhiidCCC idDDDnisosf�g2gfCCCgfDDDgfhgfig fidCCCgfidDDDgf0.7gFigure 21: Two calls of the nisos macroThe declaration of nisos is the following:nnewcommandfnisosg[8]fnbeginfmlPicgnmlDeffAgf#2gnmlDeffBgf#3gnmlDefffgf#4gnmlDeffggf#5gnmlDeffidagf#6gnmlDeffidbgf#7gnmlBodyf#1gflet opt l =[string "lineName" l;string "arrowDir" "F"] inlet p1 = assembleGraphs [] ["A";"B"][[option "noLine";float "lineLengthCoef" 1.5],"A",De, "B";opt "F", "A",Dnw,"B";opt "G", "B",Dse,"A";opt "IDA","A",Dw, "A";opt "IDB","B",De, "B"]inlet p2 = addPoints [](addPoints[float "frameDistanceCoef" 0.5] p1["F",("f",0.5);"G",("g",0.5)])["IDA",("ida",0.5);"IDB",("idb",0.5)]in88

graphGen [string "graphStyle" "diagonal"](transformGraph (scaling(#8,#8)) p2)["f",latexBox "f";"g",latexBox "g";"A",oval(latexBox �A");"B",oval(latexBox "B");"ida",latexBox "ida";"idb",latexBox "idb"]gnendfmlPicgggThere are three steps in this macro. The �rst one,builds in p1 the skeleton of the graph from the speci�edconstraints. The second step, adds labels to the edges ofthe graph. The third step, decorates the skeleton withits labels.The parametrization of ml pictures in LaTEX com-mands has been extensively used for the description of�gures in this paper; Figures 1, 8, 12, etc. also use thatfeature.4.2 Creating LibrariesmlP�cTEX allows to include Caml libraries inside the mlPicenvironment. This feature makes it possible to easily ex-tend mlP�cTEX with optional and/or user-de�ned libraries.Consider the following two de�nitions inspired by anexample of [1] (�le nzip.ml):let make h p = set picture interfaces p(One handle (fxc=0.; yc=0.g,fxc=10.; yc=0.g),(One handle (fxc=-1.; yc=0.5g,fxc=9.0; yc=0.5g)))inlet create pict start incr the end name =let rec create gray start incr the end r =if (start <=. the end) then relse create gray (start-.incr) incr the end(attach pictures(r, (make h (latexBoxGen[color "foreground" (Gra (start-.incr))]name))));;attach pictures ((create gray start incr the end(make h (make blank picture (0.0,0.0)))),(make h(latexBoxGen[color "foreground" (Gra 1.0)] name)));;The make h function puts two handles on a picture. Thefunction create pic draws n times the same picture ina di�erent level of gray. The attachment of pictures isrealized by the function attach picture which identi�esthe input handle and the output handle of two pictures.The last sentence to this paper corresponds of thefollowing mlP�cTEX description:nbeginfmlPicgnmlOpenf"nzip"gnmlDeffp1gfThis is the End.gnmlBodyff3gfcreate pict 1.0 0.05 0. "p1"gnendfmlPicg4.3 Building mlP�cTEX from CamlWe try to build a picture, corresponding to a tree, whichrepresents all the integer values which converge in lessthan nine steps for the \Syracuse conjecture". The de�-
nition is as follows:un+1 = 1 if un = 1un+1 = un2 if un is evenun+1 = 3 � un + 1 if un is oddThe Syracuse conjecture is \For all u0 > 0 this seriesconverge to 1".The labels indicate the number of steps needed toconverge to 1. For example the number 3 converges inseven steps to 1. This number list is computed in Caml ,translated to mlP�cTEX, and then processed by mlP�cTEX,which calls once again Caml . This is the way to visualizea Caml value in a LaTEX document (the correspondingpicture is built with the LaTEX fonts). To obtain thishorizontal tree we make a (90) rotation on each nodeand at the end a (270) rotation on the tree.5 Related WorksOne of the �rst works in the domain was the \Pic" [7]language used for drawing simple pictures. It operatesas yet another troff preprocessor. mlP�cTEX implementsthe basic ideas introduced by Pic. In order to use Picin LaTEX, it was necessary to translate it. The transfigprogram [4] translates a Pic drawing, and other pictureformats, into LaTEX. Using trans�g with the drawing ed-itor xfig allows to merge PostScript and LaTEX pictures.The problem is that, in no case during the drawing, thereal size of the LaTEX parts are known, then the result isunpredictable.Other systems for the production of documents con-taining complex pictures for LaTEX de�ne in general aset of macros in LaTEX. For instance, PSTricks [12] addsa collection of PostScript-based TEX macros, but thesemacros do not easily integrate LaTEX boxes to create apicture. Also, most of the pictures has to be completelyspeci�ed in order to get a result. PSTricks could be com-pared with the MLgraph library as both of them providethe necessary primitives for drawing completely speci-�ed pictures. The xypic [11] package also adds a set ofmacros to describe complex diagrams. In this case, it iseasy to manipulate LaTEX boxes in the �gure, but it isnot possible to extend them with picture decorations ormerge them with PostScript pictures. In both cases, itis a prerequisite to be an expert in style �les in order toadd something to those macro libraries. Other systemstry to pre-process the LaTEX �les and to interpret part oftheir contents producing poor results for non trivial in-puts. The LaTEX interface of mlP�cTEX is very simple andwas written as a set of LaTEX macros. The generation of�gures, such as trees and graphs, from their descriptionis done in Caml with the MLgraph library and can beeasily extended to other families of pictures.ConclusionWe have presented in this paper a useful tool, mlP�cTEX,to create technical documents which manipulate complexpictures. The following points are supported: automa-tization of the production line, to use the appropriatemodels (PostScript for the graphical model and LaTEXfor the document composition and for the management89

124816326412825651285 214284 51020408013 3612 0123456789Figure 22: Convergence in at most nine stepsof the fonts), �nally to program in a safe and expres-sive algorithmic language such as Caml . To manipulatecomplex data structures, the type system and the patternmatching of Caml was really useful.The mlP�cTEX program uses the MLgraph library with-out needs to know the MLgraph implementation. hencethe (problematic) impossibility to easily extend a type.But as the graphical model used is very complete, wehope to be general enough. The placement algorithmsproposed can be rewritten for another graphics library asX-window, because they are not completely independentof the PostScript graphical model, they use only a smallpart of this one which can be rewritten for X-window. Fi-nally, it is funny to use Caml as a tool to build pictures forLaTEX, i.e. as a classical development language. We hopethat new applications from ML world (e.g. mlP�cTEX forthe LaTEX community writers ) will obtain an increasingdi�usion. This is the End.This is the End.This is the End.This is the End.This is the End.This is the End.This is the End.This is the End.This is the End.This is the End.This is the End.This is the End.This is the End.This is the End.This is the End.This is the End.This is the End.This is the End.This is the End.This is the End.This is the End.References[1] Adobe. PostScript Language : Tutorial and Cook-book. Addison-Wesley, 1985.[2] Adobe. PostScript Reference Manual. Addison-Wesley, 1985.[3] Aho, A., and Ullman, J. Foundations of Com-puter Science. W. H. Freeman and Company, NewYork, 1992.
[4] Beck, M. TRANSFIG: portable �gures for TEX.Tech. rep., CORNELL UNIVERSITY. Ithaca (NYUS), Feb. 1989.[5] Chailloux, E., and Cousineau, G. Graphics inML. InWorkshop on ML and its Applications (June1992), ACM SIGPLAN.[6] Chailloux, E., and Cousineau, G. The MLgraphPrimer. Tech. Rep. 92-15, LIENS, Sept. 1992.[7] Kernighan, B. W. PIC : a crude graphics languagefor typesetting. Tech. rep., Bell Telephone Labora-tory, Jan. 1981.[8] Lamport, L. LaTeX User's Guide and ReferenceManual. Addison-Wesley, 1986.[9] Leroy, X., and Mauny, M. The Caml Light sys-tem, release 0.5. Documentation and user's manual.Tech. rep., INRIA, Sept. 1992.[10] Leslie Lamport. color style in LaTEX distribution, 1989.[11] Rose, K. H. Typesetting Diagrams with XY-Pic :User's Manual. Technical Report, June 1992.[12] Zandt, T. V. PSTricks : User's Guide. Tech. rep.,Mar. 1993. available by anonymous ftp.90

TERSE: TErm Rewriting Support EnvironmentNobuo KAWAGUCHI Toshiki SAKABE Yasuyoshi INAGAKIDepartment of Information Engineering, Nagoya UniversityFuro-cho, Chikusa-ku, Nagoya, 464-01 JAPANE-mail: [email protected] propose an environment for term rewriting compu-tation with Graphical User Interface. The aim of theenvironment is to support analysis of term rewriting com-putation. The environment allows us to manage multipleterms and rules simultaneously. It also helps us to ana-lyze the structure of a term by providing us with graphi-cal tree representation of the term, through which we caneasily edit the term and select the redex to rewrite.We have successfully used Concurrent ML (CML) witheXene library to implement the environment. CML isa high-performance multi-threaded concurrent languagebased on SML/NJ, and eXene is X-window library forSML/NJ written in CML. The environment is clearly di-vided into three parts. These are the term manipulationpart, the tree representation part and the Graphical UserInterface part. The favor of the higher order functionallanguage, CML makes it easy to modify and extend theimplementation.To implement the environment, we have developed alibrary for basic tree representation on top of CML witheXene. We also developed some basic dialog librarieswhich can be used for selecting �les and colors on eXene.1 IntroductionThe Term Rewriting System (TRS) is one of the sim-plest computation models for functional programminglanguages. It can also be used to model term manipu-lation required in program veri�cation and transforma-tion [1][5][6]. In such applications, an environment forterm rewriting with user friendly graphical interface isstrongly required for analyzing structure of terms andrewriting processes. Most TRS interpreters developed sofar are text-based ones, and hence they do not providesu�cient supports for analyzing structure of terms. Alsothese text-based environments can not handle a big termwhich usually occurs in computation of TRS.This paper shows a new idea for a term visualizationbased on Graphical User Interface (GUI) and explainshow to realize the idea. We �rst propose an environ-ment for term rewriting computation with powerful GUIfacilities called TERSE (TErm Rewriting Support Envi-ronment). TERSE can visualize terms and provide exi-ble operations on multiple TRSs and terms. In addition,TERSE can compile some classes of TRSs to ML pro-grams and they can be executed under the environment.
We then show how we can successfully use Concur-rent ML (CML)[10] with eXene library[11] to implementTERSE. CML is a high-performance concurrent languagebased on SML/NJ, which extends SML/NJ by light-weightprocesses with threads and communication channels. eX-ene is a multi-threaded X-window toolkit for SML/NJwritten in CML, which includes low-level libraries likeXlib as well as high-level toolkit like Xtoolkit. Our imple-mentation of TERSE clearly separates the environmentinto three components which are the term manipulationpart, the tree representation part, the GUI part by ap-plying the module system of SML, so that each part canbe modi�ed or extended independently from the otherparts.In addition, we have developed some basic dialog li-braries such as File Dialog, Color Palette. We give a briefmanual of these libraries in Appendix.Section 2 gives a brief introduction to basic conceptsof term rewriting systems. Section 3 discusses the visu-alization of terms and operations for TRSs. Section 4describes overview of the environment TERSE. Section5 describes the implementation related things. Section 6presents the experience notes obtained through this de-velopment.2 Term Rewriting SystemsWe �rst give a brief introduction to term rewriting sys-tems. See [2] for more details. We assume term rewritingsystems are many sorted. Let V be a countably in�niteset of variable symbols and F be a set of function sym-bols. The set of all terms over F and V is denoted byT (F;V ). Function symbols are divided into de�ned func-tion symbols and constructor symbols. Each functionsymbol has arity which denotes sorts of its argumentsand itself.A rewrite rule is a pair < t; u > of terms in T (F; V )such that t 62 V and V ar(t) � V ar(u), where V ar(t)denotes the set of all variables occurring in it. We writet ! u for a rewrite rule < t; u >. A term rewritingsystem (TRS) R is a set of rewrite rules. A term s iscalled a redex of R if there is t ! u in R such that tmatches s. An occurrence of t is a sequence of naturalnumbers which stands for a position of a subterm of t.A redex can be represented as the pair of the occurrenceand the rule. A strategy determines the redex to rewrite.Outermost and innermost strategies are popular strate-gies which correspond to call-by-name and call-by-value91

Figure 1: Simple Treecomputation respectively.A triple of a TRS R, an input term t and a strategyrepresents a computation. One step of the computationis (1) to �nd redexes in the term t with respect to rules ofR, (2) to determine a redex by the strategy, and then (3)to rewrite the redex. If there is no redex in the term, thecomputation terminates. In this case, the term is calleda normal form.3 VisualizationA TRS interpreter with text-based interface is not su�-cient as a support for analyzing structure of terms sincesome informations of terms are not naturally shown bytext. Moreover, in a computation of TRS, even a fewrules can produce a huge term. With text-based envi-ronment, one cannot understand neither the structure ofsuch a big term nor the rewriting sequence of it. It isdesired that all informations that a term has are graph-ically visualized and that any part of a big term canbe displayed. In this section, we propose an advancedmethod of term visualization and operations for control-ling computation of visualized TRS which satisfy theserequirements.3.1 Visualization of TermsFirst, we discuss visualization of terms. The informationnecessary for analyzing terms are:1. sorts of terms2. occurrences of redexes3. kinds of symbols, i.e., which of constructors, de�ned-functions, and variablesThese informations should be visualized so that one canget them from displayed terms.The visual facilities desired for analyzing terms are:1. to give a view of a huge term at a time in a window
Figure 2: Term VisualizationFigure 3: Global Tree2. to shrink subtree and supertree as one node3. to select tree view models among horizontal andvertical ones, etc.The simple representation of terms by trees like �g-ure 1 does not satisfy all requirements above. We en-hance the simple representation so that all requirementsare satis�ed. We call the enhanced representation as termvisualization.Figure 2 shows a view of term visualization. Con-structors, de�ned-functions, and variables are displayedas ellipses, rectangles and circles, respectively. The topof a redex is drawn with thick border. A redex whichis selected by the current strategy is drawn with thickerborder. A shrunk subtree is shown as a triangle node.A little box with numeral inside on top left corner of anode is an occurrence mark which is used for analysis ofthe occurrences propagation.The tree in �gure 2 is a part of big tree and �gure 3shows the entire tree. The part enclosed with the rect-angle in �gure 3 is actually displayed in �gure 2. Moreinformation can be added by using colors in addition to92

Figure 4: TERSE Main Windowthe visualization. A desired tree view model should beselectable among vertical and horizontal ones.Compared with the simple representation by tree, allsorts of information can be easily read from the visualizedterm. Some high-level term analysis, which is impossibleby the text-based or simple representation, is possible byterm visualization.3.2 Visualization of OperationsSecond, we discuss visualization of operations on terms.The following operations on terms are not easy to performunder usual term representations.1. to select an arbitrary redex to rewrite2. to mark an arbitrary occurrence and trace the prop-agation of the mark through rewriting processes3. to show a sequence of terms for analyzing rewritingprocesses4. to change the strategiesIt is clear that term visualization makes the aboveoperations easy for user to perform. So, term visualiza-tion allows us to �nd the occurrences of redexes and toselect and rewrite an arbitrary redex intuitively. It alsomakes it possible to investigate the propagation of themarked occurrence so as to decide whether the occurrenceis a needed-reduction. Moreover, by visualizing rewriting
processes, it helps to intuitively analyze the computationof TRS.4 Overview of the SystemTErm Rewriting Support Environment (TERSE) is a vi-sual environment for design and analysis of term rewrit-ing systems. We try to realize all requirements describedin the last section on TERSE.4.1 Main WindowFigure 4 shows the "Main Window" of TERSE. Var-ious operations are performed by pushing the buttonson the top of the window. "File" button has submenussuch as load/save TRSs from/to a �le, load/save colordescription of the system, and load/save object-�guretranslation of the system. "Step" button rewrites oncethe displayed term and then redisplays it. "Show" but-ton repeats rewriting and displays the term each timeit is rewritten until reaching a normal form. "Rewrite"silently repeats rewriting and displays only the normalform and how many times the term is rewritten if the nor-mal form is obtained. "Transform" button translates cur-rent selected TRS into more e�ective one with commutative-law transformation method [6] in semi-automatic style.(This is an experimental implementation.) These opera-tions textually show the results such as an obtained term,how many times the term is rewritten, a rewriting se-quence, a transformed TRS in the text �eld. "Clear"93

Figure 5: TERSE Term Viewerclears the text �eld. "Term1" and "Term2" are the ed-itable �elds for users to input terms. "Disp Term" dis-plays the input term in "Term1" �eld in "Term Viewer"window as shown in �gure 5. "Disp Rule" activates thedialog which displays rules. One can edit a rule fromthis dialog. "Option" button has submenus to exchangethe terms in "Term1" and "Term2", to copy a term, toconstruct a rule from two input terms, etc. "Outer" and"Inner" are buttons for selecting the outermost and in-nermost strategies, respectively. The rightmost �eld inTERSE Main Window shows a list of TRSs from whicha TRS is selected. TRS named \a1:m3:f2" means thisTRS is composed of No. 1 of add TRS and No.3 of multTRS and No.2 of fact TRS. These numbers have meaningin commutative-law transformation method.4.2 Term Viewer"Term Viewer" window (�gure 5) displays visually a termas a tree and has several buttons. "Rule" button acti-vates the �le dialog to read a TRS from a �le. "Strategy"button has a submenu which contains 4 strategies suchas leftouter, leftinner, rightouter, and rightinner ones."Rewrite" rewrites once the visualized term with currentrule and strategy, and redisplays the result term. "View"button switches view type between the vertical and hori-zontal tree views. Horizontal tree view is shown in �gure6. "Zoom" and "UnZoom" change the magni�cation ofthe tree. If "Global" button is pushed, a new windowfor the global view of the term appears. "Option" but-ton has submenu such as \sequence" menu to displayrewrite sequences, \write PS" menu to save the currentdisplayed tree as a PostScript �le shown in Figure 7 (Theobtained �le is directly included in LaTEXsource with epsfstyle �le.) , and \send term" menu to send the currentdisplays term to the \Term1" �eld of the main window.Clicking the left mouse button on any node of thetree, one can select the node and rewrite the selected re-dex. The middle mouse button makes any subtree to beshrunk to a triangle node. If a triangle node is selected,
Figure 6: Horizontal Term Viewadd
0
fact
0
0
fact
mult
add 0
add
0
s add
mult
add
0
s
add
s
fact
0
fact
0
0
fact
mult
add 0
add
0
s add
mult
add
0
s
add fact
mult
add1
mult
add
s mult
add
0
s
fact
0
s
0
s
fact
mult
add
0
s
s add
mult
add
0
s
add
0
s
fact
0
s
0
s
fact
mult
add
0
s
s add
mult
add
0
s
add
fact
mult
add mult
add
sFigure 7: PostScript Outputthe subtree will be expanded as a tree again. The rightmouse button can mark or unmark any node of the tree.The marked node has little box with mark number insideon the top left corner. Dragging the vertical or horizon-tal scrollbar changes the viewport of the visualized term.Marks and subtree nodes propagate through rewritingprocess following the concept of residual[3]. So one cansee the movement of a subterm through rewriting.4.3 Sequence ViewerFrom the \option" menu of TermViewer, Sequence Viewerin Figure 8 can be invoked. \Step" button rewrites theterm and displays the new tree. With this viewer, one canintuitively obtain the structural transition of the termthrough the rewriting sequence. Figure 8 shows threerewriting sequences starting from the termadd(s(s(s(0))),s(0)) by the following three TRSs.add1: � add(0; y) ! yadd(s(x); y) ! s(add(x;y))add2: � add(0; y) ! yadd(s(x); y) ! s(add(y; x))add3: � add(y; 0) ! yadd(y; s(x)) ! s(add(y; x))These three TRSs are equivalent in the sense that each94

Figure 8: Rewriting Sequenceterm has the same normal form under these TRSs. Butas easily seen, they di�er from each other in the length ofrewriting sequences. This means the e�ciencies of theseTRSs are di�erent. The �rst sequence (TRS add1) needsfour rewriting steps to obtain the normal form,and thesecond sequence (add2) needs three rewriting steps andthe last(add3) needs two steps for the same initial term.Using Sequence Viewer, one can intuitively under-stand the structural di�erence between these rewritingsequences, while in a text-based environment, it is di�-cult to perform this kind of analysis.4.4 Control PanelFigure 9 shows the Control Panel of TERSE. In this win-dow, one can select the color mapping which maps eachfunction/widgets to a color. \Select" button activates theColor Palette window to select a desired color. Settingsof the mapping can be saved into a �le as a ML program.5 ImplementationTERSE is implemented on top of Concurrent ML(CML)with eXene. CML[10] is a high-level, high-performancefunctional language based on SML/NJ, which extendsSML/NJ by light-weight processes with threads and com-munication channels. eXene[11] is a multi-threaded X-window toolkit for SML/NJ written in CML, which in-cludes low-level libraries like Xlib as well as high-leveltoolkit like Xtoolkit. eXene directly communicates withX-server by using signal facility of SML/NJ.Interactive systems are inherently concurrent, so aconcurrent language is preferable to build a GUI system.Combination of CML and eXene makes GUI program-ming very easy. Since eXene has basic user interface li-braries which are interactive objects such as button, list,text-edit and so on. With CML thread facility, each ofthese window objects(widgets) works as a thread.Implementation of TERSE is carefully modularizedinto three parts. These parts are the term manipula-tion part, the tree representation part and the GUI part.95

Figure 9: Control PanelThe interactive part of TERSE is built on CML and eX-ene, while the term manipulation part is built directlyon SML/NJ. The tree representation part depends on itsoutput domain. Figure 10 shows the structure of TERSEimplementation.AAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
SML/NJ
CML
eXene
TERSE
Termmanipulation
GUI
Tree representation
UNIX kernelFigure 10: the structure of TERSE5.1 Term manipulationTo de�ne term manipulation functions in ML are quiteeasy for its datatype facilities. Basic TRS types we de-�ned for implementing TERSE are as follows:datatype term = Var of string| Fun of string * term listtype rule = term * termtype trs = rule listtype occurrence = int listtype redex = occurrence * ruletype m-strategy = redex list -> redex listtype strategy = redex list -> redexFor example, term fact(s(x)) is represented as:
Fun("fact",[Fun("s",[Var "x"])])The type m-strategy is de�ned as mappings betweenredex lists. The type strategy is de�ned as mappingsfrom redex lists to redexes. TERSE has built-in basicm-strategies such as innermost and outermost, and ba-sic strategies such as leftmost and rightmost ones. Onecan de�ne any function of strategy type by using basicstrategies. For example, the outermost-leftmost strategyis de�ned as the composition of the outermost m-strategyand the leftmost strategy.TRS manipulation functions are de�ned as follows.val findRedex :trs * term -> redex listval reduceRedex:term * redex -> termval rewrite: trs * strategy-> term -> termFunction findRedex takes a trs and a term as argu-ments, and returns all redexes in the term. reduceRedextakes a term and a redex, and returns the term rewrit-ten by the redex. rewrite rewrites a given term with atrs and a strategy , and returns the normal form of theterm if it exists. rewrite is de�ned by findRedex andreduceRedex. Other many utility functions for the termmanipulation are de�ned in this part.5.2 TRS compilationTERSE has a feature that compiles some class of TRSsinto ML. (This is a part of the term manipulation compo-nent.) For example, TRS add1 which is shown in section4.3, is compiled into the following ML programs:datatype TRS_int = TRS_0 | TRS_s of TRS_intfun TRS_add(TRS_0,y) = y| TRS_add(TRS_s(x),y) = TRS_s(TRS_add(x,y));TERSE saves the program into a �le and \use" it.The compiled TRS functions run ten to a hundred timesfaster than interpreted ones.5.3 Tree representationThe design concept of the tree representation part isshown in �gure 11. This �gure means that our draw-tree library is designed to accept multiple input domainsand to handle multiple output devices. To achieve thisconcept, the implementation of the tree representationis divided into four sets of modules. \Abstract Tree"module set de�nes the structure and contents of a tree.\Input Domain"module set has the mappings from an in-put domain to tree structures. \Output Device" moduleset de�nes the way of drawing objects into the output de-vice. \DrawTree" module has the function which drawsthe objects on the device following the input tree struc-ture. The input domain of TERSE is the domain of TRSterms and the output device is X-Window system. Thedependency of these modules is shown in �gure 12. Eachsmall rounded rectangle denotes a structure of SML, anda rectangle denotes a functor. A big rounded rectangledenotes a set of modules.A type tree which is a basic type for the tree repre-sentation de�ned in \Abstract Tree" is:datatype tree = Leaf of object| Node of object * tree list96

DrawTreeLibrary
X-Window System
term2tree
PostScript
PostScript
Multiple Input Domain
AAAAAA
AAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAA
Some Data
Multiplue Output Device
TRS Term
some2treetree
Figure 11: Concept of the tree representationType object holds �gure informations about the nodesuch as label of node, color, border size, and so on.In \Input Domain", mappings from TRS terms totrees are separated into two phases: (1) Structural map-ping to shrink the subtrees of a tree ,(2) node mappingfrom the nodes of a term to objects. Each mapping isperformed by the following functions:val term2tree : trsdef-> mlist-> term-> treeval node2obj : nodedata -> objectFunction term2tree takes three arguments and returnsa tree. First argument trsdef contains the informationabout sorts and function types. Second argument mlistcontains the mark list, shrunk subterm information andredex list. Function node2obj is used in term2tree toget objects of each node taking into account which sortthe node has, whether there is a mark on the node, andwhich of a function, a variable and a shrunk subterm thenode is. Of course, one can easily rede�ne these functionsto change the mappings.\Output Device" is speci�ed by the following signa-ture.signature VISUAL =sigstructure D:DIRstructure G:GEOMstructure F:FIGUREtype scaletype canvasval dispObj: (canvas * scale * D.dir)-> F.object -> G.point -> G.rectend
The structure satis�ed this signature contains displaymethods of drawing target such as X-window or PostScript.We developed two structures which satis�es this signa-ture. Function dispObj takes �ve arguments which de-scribe the drawing canvas, scale, direction, shape of ob-ject and drawing point, respectively, and draws the de-sired object.\DrawTree" module is de�ned by functor application.The functor DrawTree is de�ned as follows.functor DrawTree(Visual:VISUAL) : DRAWTREE =structfun drawTree canvas scaledir mode (point,tree) =...endFunctor argument Visual is a structure speci�ed by thesignature VISUAL. \DrawTree" modules for desired out-put devices are de�ned as follows.structure XDrawTree = DrawTree(XVisual)structure PSDrawTree = DrawTree(PSVisual)After converting a term into a tree, we can apply thefunction XDrawTree.drawTree with suitable argumentsto draw the tree on the desired window.5.4 Resource SettingsIn interactive systems, it is strongly required to changethe resource settings such as color of labels. TERSE hasthe facilities to change and to save/load the resource set-tings. To achieve this, we de�ne these settings as refer-ence values. Thus, just by substituting suitable valuesfor these references, one can easily modify the various re-source settings. We used ML programs directly to savethese resource settings. This idea decreases boring cod-ings for load/save data facility because only \use" thisprogram in the environment can change the settings. Ex-ample of a setting program is as follows.TrsTree.objShape :={con=Ellipse, def=Rectangle, var=Circle}Resource.colorList :=[ ("button",{red=0,green=0, blue=0}),("Title",{red=0.green=100,blue=32000}),("[add]",{red=360,green=5440, blue=0})]5.5 GUIThe implementation of the GUI part is fully depends oneXene library. See [11] for more details. We have de-veloped many widgets such as variable list, event canvas,tree widget, and color palette. These widgets are usedfor construct dialog windows. We give a brief manual ofthese libraries in Appendix.6 Development NotesIn this section, we present experience notes obtained throughthe development. TERSE is a middle size application(about 5000 lines with 400 lines' comments).97

Tree
XVisual
Fig
Geometry
Abstract Tree
OutPut Device (X-Window)
DrawTree
Term TrsTree
Input Domainterm2tree
XDrawTree
Figure 12: Module Dependency� SML is a good tool for prototyping. In the�rst stage of development (prototyping phase) , wealmost did not use the module system. And just uselocal and open declaration. Because using modulesystem in non-concrete domain makes modi�cationof the program di�cult.� Decision of the sharing structure or type iskey point of module design in SML. Moduledesign is not di�cult for almost all parts of the envi-ronment. We however had to rewrite several timesthe whole programs for the tree representation tosatisfy the requirements. One problem is that treedrawing fairly depends on the �gure of tree nodesand the device. That is, input and output for draw-ing a tree have quite strong relationships. We shareTree and Fig structures to solve this problem withsignatures TREE,FIGURE.� Good diagrams for module design are help-ful. There is no well known diagrams for describingSML module dependency. We are also in troublewith describing the module structure. We shoulddevelop good diagrams which can contain the infor-mation about signatures, structures, functors, andsharings. The diagrams used in this paper are notsu�cient.� Interactive programming in CML is stronglyrequired. In the top level environment of SML,one can interactively program any kind of functions.In the top level of CML, however, it is impossibleto program multi-threaded processes because at ini-tial of CML session, calling RunCML.doit is alwaysrequired. This facility decreases e�ciency of pro-gramming processes especially for the interactivesystem.The one new idea obtained through the developmentis the way of preserving resource settings. SML can usu-ally read programs at any time, to store resource settings
as the program is useful idea because the resource savedas a ML program is fairly readable and easy to modify.7 ConclusionsThis paper has proposed TERSE, a visual environmentwith GUI that supports design and analysis of TRSs andpresented its implementation by CML with eXene. Theterm visualization method of this paper is superior to thetext-based or simple tree representation in that all sortsof information of terms can be intuitively obtained fromvisualized terms. TERSE provides various operations onvisualized terms and TRSs such as ones for customizingvisualization style, ones for controlling rewriting steps,ones for analyzing the rewriting process, and so forth.The implementation is clearly modularized into threeparts such as the term manipulation part, the tree rep-resentation part and the GUI part. Libraries we havedeveloped for the tree representation are well organizedfor easy reuse.Future tasks are:1. to incorporate the Knuth-Bendix algorithm2. to implement the decision procedure for termina-tion3. to implement a structural term editor4. to add debugging facilities for TRSs5. to improve drawing and rewriting speed6. to extend tree libraries for graph representationReferences[1] Knuth,D.E.,Bendix,P.B.: \Simple Word Plobremsin Universal Algebras" , Computational ProbremsIn Abstract Algebra , J.Leech ed., Pergamon Press,NewYork, pp.263-297(1970).[2] Huet, G.: \Con uent Reductions:Abstract Proper-ties and Applications to Term Rewriting Systems",J.ACM, Vol.27, No.4, pp797-821 (1980).[3] Huet, G., Levy, J.J.: \Call by need computation innon-ambiguous linear term rewriting systems", Rap-port Laboria 359, IRIA(1979).[4] Dershowitz, N.: \Termination of Rewriting" , J.Symbolic Computation, Vol.3, pp69-116 (1989).[5] Toyama,Y. : \How to prove equivalence of termrewriting systems without induction", TCS, No 90,pp369-390(1991).[6] Kawaguchi, N., Sakabe, T., Inagaki, Y.: \Commu-tative Law Based Transformation for Improving Ef-�ciency of Term Rewriting Systems", IEICE Tech-nical Report Vol.93, No.379, COMP93-64(1993).InJapanese.[7] Kawaguchi, N., Sakabe, T., Inagaki, Y.: \SupportEnvironment for Analysis and Transformation ofTerm Rewriting Systems with Graphical User Inter-face", IEICE Technical Report Vol.93, No.426, SS93-44(1994).In Japanese.98

[8] Wikstrom, Ake: \Functional Programming UsingStandard ML", Prentice Hall(1987).[9] Paulson,L.C.: \ML for the Working Programmer",Cambridge University Press(1991).[10] Reppy,J.H.: \CML: A higer-order concurrent lan-guage", In Proceedings of the ACM SIGPLAN'91on PLDI, pp293-305 (1991).[11] Reppy,J.H., Gansner,E.R.: \The eXene LibraryManual(Version 0.4)", AT&T Bell Laboratories(1993).[12] Adobe Systems: \PostScript Reference Manual",Addison-Wesley Pub.(1988).Appendix A:TERSE LibrariesA.1 Tree representationStructures for tree representation are carefully organizedfor reuse. First, we show the signature of FIGURE andits structure. This signature is used for abstraction ofdrawing objects from output device.signature FIGURE =sigdatatypeshape = Box | Square | Circle | Ellipse| Triangle | RoundBox | Diamondtype object (* shape * obj_resource *)type obj_resval ShapeWid : realval ShapeHei : realval CircleSize : realval TriangleWid : realval TriangleHei : realendstructure Fig : FIGURE=structtype rgb = {red:int,blue:int,green:int};datatype shape = ...val ShapeWid = 60.0val ShapeHei = ......type obj_res ={ label : string,border: int ,fore : rgb,fill : rgb ,mark : int}type object = shape * obj_resendWe provided two ways of the tree representation forXwindow system and PostScript. Structure XVisual isfor X-Window and PSVisual is for PostScript.For example, the function which maps basic logicalformula into tree can be written as:structure BasicLogic =structlocalstructure PSDraw:DRAWTREE=DrawTree(PSVisual)open PSDraw.Tree PSDraw.Tree.F PSDraw.G(* open Tree and Figure *)
P Q
Imply
Not
Q
Not
Imply
Figure 13: Tree Exampleval wht = {red = 65535,blue = 65535,green = 65535};val blk = {red = 0,blue = 0,green = 0};indatatype formula = Var of string| Not of formula| Imply of (formula * formula)fun form2tree (Var x) = Leaf(Circle,{label = x,border =1 ,fore = blk, fill = wht ,mark = 0})| form2tree (Not x) = Node ((Box,{label = "Not",border =1,fore = blk, fill = wht,mark = 0}), [form2tree x])| form2tree (Imply(x,y)) = Node ((Ellipse,{label = "Imply",border =1 ,fore = blk, fill = wht ,mark = 0}),[form2tree x,form2tree y]);fun drawFormPS f =let val tree = form2tree f;(* specify output file *)val stm = open_out "formula.ps"fun canvas x= output(stm,x)val _ = PSDraw.V.visualSetup(canvas,(1.0),Dir.DirX)in(PSDraw.drawTree canvas (1.0) Dir.DirXtrue (PT{x=300,y=200},tree);close_out stm)end(* now output PS file. *)val _ = drawFormPS (Imply(Not (Imply(Var "P",Var "Q")),Not (Var "Q"))) ;end (* local *)end (*struct *)After invoking this program, the �le \formula.ps" is cre-ated on the current directory. Figure 13 shows the con-tents of the �le obtained. Figure 14 shows the moduledependency of this program.99

Tree
PSVisual
Fig
PSGeom
Abstract Tree
OutPut Device (PostScript)
DrawTree
BasicLogic
Input Domainform2tree
PSDrawTree
Figure 14: Module Dependency for PSA.2 File DialogWe developed a standard �le dialog useful for any appli-cation. To use this dialog, just call this library as follows.val fileName = FileDialog.fileDialog root ;root is root value obtained by Widget.mkRoot. Figure15 shows the �le dialog window. Files in the current dirare listed up in the window. \Select" button destroys thedialog and returns selected �lename. If the selected �leis a directory, it changes directory and redisplays �les.A.3 Color PaletteColor Palette dialog is useful to select ordinary color forwindow objects. Figure 16 shows Color Palette dialog.It can be invoked as follows.val rgb = ColorPalette.colPalet root "node";"node" is the label displayed in color box. Return valueis a type rgb described in the structure Fig.A.4 How to obtain TERSETERSE can be obtained via anonymous-ftp from:ftp.nuie.nagoya-u.ac.jp:/nagoya-u/TERSE-1.0.tar.gzThis distribution requires at least SML/NJ 0.93. In orderto run TERSE on X-Window, CML-0.9.8 and eXene-0.4are required. These can be obtained from:research.att.com:/dist/ml/or our mirror site:
Figure 15: File DialogFigure 16: Color Paletteftp.nuie.nagoya-u.ac.jp:/language/sml/research.att.com/Please send any comment or bug-report to:[email protected] of TERSE can also be obtained from follow-ing www server.http://www.nuie.nagoya-u.ac.jp/nuie/person/kawaguti/index.html
100

1 + 1 = 1: an optimizing Caml compilerM. Serrano P. WeisINRIA Rocquencourt �AbstractWe present a new Caml compiler, which was obtainedby an original approach: a simple pipeline between twoexisting compilers, each one devoted to half of the compi-lation process. The �rst compiler is a Caml compiler, it isin charge of the front end, and ensures compatibility. Thesecond compiler is an optimizing Scheme compiler, it con-stitutes the back end, and ensures e�ciency. These areCaml Light 0.6 byte-code compiler and a Scheme com-piler (Bigloo). Using this technology, we were able towrite the optimizing compiler in only two man-months.The new compiler is bootstrapped, fully compatible withthe Caml Light 0.6 compiler, and features interestinginter-module optimizations for curried functions. It pro-duces e�cient code, comparable with the one producedby other ML compilers (including SML/NJ). Our newcompiler, Bigloo, is freely available 1.KEYWORDS: Caml, Scheme, ML, compilation, functionallanguages.IntroductionThe Caml Light compiler is a byte-code compiler.This has many advantages: high level of portability, smallmemory requirements (the core image of the compiler istypically 400 Ko), and very fast code generation. Thesegood properties lead to usable Caml Light versions onpersonal computers. On the other hand, a byte-codecompiler appears to produce slow executable programs(namely from two to twenty times slower than assemblycode programs). Hence the need for an optimizing com-piler.It must be clear that the optimizing compiler willcompile much more slowly than the regular compiler: soin pratice we do want the best of the two technologies,the fast byte-code compiler to develop and test programs,and the optimizing compiler to get e�cient executables,as soon as programs are ready to work. In this view, theoptimizing compiler just performs the -O option of thebyte-code compiler. This has an important implication:this compiler must be fully compatible with the byte-codecompiler.�Author's address: INRIA, BP 105, 78153 Le Chesnay,[email protected], [email protected] ftp on ftp.inria.fr (192.93.2.54), �le lang/caml-light/bcl1.6c.0.2unix.tar.Z.
There have been several attempts to obtain such acompiler: CeML by Emmanuel Chailloux [3], and Cam-lot by R�egis Cridlig [5]. Both share the same compilationstrategy: C code generation, and their performances aregood. CeML was not designed to be fully compatiblewith Caml, it was developed to prove that ML could bee�ciently compiled into C. Thus, CeML has some minordi�erences with the core of the Caml language (for in-stance structural equality). The Camlot compiler treatsthe Caml core language, but does not feature exactly thesame syntactic extensions as the Caml Light system [20](for instance the streams feature is not completely sup-ported). As a consequence, these two compilers failedto be fully compliant with the Caml Light system, andnone can be considered as an alternative to the CamlLight byte-code compiler.We present the design decisions and the methodologythat allow us to get a fully compatible optimizing com-piler for Caml.Section 1 gives an overview of the technology appliedto get the new compiler. Section 2 gives the overall archi-tecture of the compiler. Section 3 describes the back-endcompiler. Sections 4, 5, and 6 detail the remainder ofthe compiler. We conclude by a short comparison withrelated works and �nally give some benchmarks.1 The compiler's technologyTo achieve this compatibility goal we choose a sim-ple scheme: the redirection of compilers. Our optimizingcompiler shares the whole front end of the Caml Lightbyte-code compiler. This trivially ensures full compati-bility for the input source code. To gain e�ciency, we justhave to replace the byte-code execution by machine codeexecution. Our optimizing compiler shares all the backend of a good optimizing compiler: the Bigloo Schemecompiler [12]. This ensures very fast code execution.bigloocamloocamlc
Pipe Scheme compilerCaml compiler Figure 1: 1 + 1 = 1In short, we obtain our new compiler from two exist-ing compilers, hence the title of this paper. We simply101

connect the two compilers by plugging the output of the�rst one to the input of the second, in the spirit of Unixpipes. We slightly modify the front end compiler to stopbefore code generation, but the back end compiler is leftunchanged. The main job has been to implement thepipe which is at least one order of magnitude simplerthan re-engeneering a back-end or a front-end.Thus, we stop the Caml Light compiler at the end ofits compilation process by omitting the byte-code gener-ation. This phase is replaced by a text dump of a �-liketree structure representing the program.The pipe is just a mapping of the �-like tree onto aScheme program (we name this translator Camloo).The implementation e�ort to get the new compilerhas been 3000 source code lines (400 lines of Caml, 2600lines of Scheme).2 The global architectureWe explain how to compile Caml modules, that ishow to compile a module implementation and a moduleinterface.2.1 Compiling implementationsWhen compiling the implementation part of a Camlmodule (a .ml �le), camlc processes it as usual, until theobtention of the semantics of the program: type check-ing, name resolution (quali�cation of identi�ers), patternmatching, production of ��code. This ��code is writteninto a .lam �le.Then Camloo translates the .lam �le into a Scheme�le which is compiled by the regular Bigloo compiler.camlc
- Parsing
- Type Checking
- Pattern Matching
- Dump Lambda
camloo- Rewriting
- Mapping
bigloo
- Parsing
- Inlining
- 0cfa
- Closure Analysis
- ...
- Code Generation
- Curryfication Optimization
.o
Front-end:
Back-end:
Pipe:
.scm file
.lam file
.ml file
Figure 2: Bigloo: compiling a Caml implementationIn the �gures, we write in boldface the passes we addto obtain the new compiler.
2.2 Compiling interfacesFor the interface part of a Caml module (a .mli �le),camlc processes it as usual, generating a compiled inter-face (a .zi �le), and in addition a .sci �le containingimportation clauses for the Bigloo module system. Com-piled interfaces serve as usual to ensure incremental re-compilation of Caml modules, while .sci �les are usedby Bigloo to compile implementations.Front-end:
.mli file
.sci file
.zi file
camlc
- Parsing
- Type Checking
- Dump interfaceFigure 3: Bigloo: compiling a Caml module interface2.3 Compiling Scheme or CamlBigloo has a builtin preprocessing mechanism whichpermits addition of user-de�ned passes to the compilerfront-end. Since the invocation of these preprocessingpasses can be associated to �le su�xes, camlc and Cam-loo are invoked when Bigloo encounters a .ml or .mli�le: seen from Bigloo, the Caml Light front end is justa new pass added before the compilation of Scheme code(in the spirit of macro expansion passes). Then we justhave to invoke Bigloo to compile a Caml module. That'swhy the new compiler is named Bigloo as well, and sinceit automatically turns to Scheme compilation for a .scm�le, the new compiler is a Caml and Scheme compiler.camlc camloo
.o
Scheme (.scm )
object file:
bigloo
source files:
Preprocessing Caml to Scheme
Caml (.ml)Figure 4: Bigloo: a Scheme & Caml compiler3 The Bigloo Scheme compilerBigloo [12, 15] is one of the best Scheme compileravailable. It produces very e�cient code via a Schemeto C translation. It uses many powerful techniques tooptimize functional programs, such as 0cfa analysis [16,13], open coding, common subexpressions elimination,optimized closure allocation, ��lifting, compile-time �-reduction, constant folding, recursive calls optimization.In short, this compiler never allocates structure for control- ow (loops are compiled as C loops, direct calls to globalfunctions are compiled as C function calls, and thereforethe allocation of closures is unfrequent).102

Let us describe some of these optimizations and lookat some examples of produced code. In e�ect, the Bigloocompiler produces readable C code: the code given in thefollowing examples has been obtained by a mere alphaconvertion from the actual code produced by the Bigloocompiler. In this C code, type obj is the C union thatimplements Scheme values and upper-case identi�ers cor-respond to C macros.3.1 Open-codingOpen-coding (or inlining) is a technique which re-places a call to a function by the body of this function.Bigloo inlines functions when some explicit inline di-rectives are written in the source �le or when these func-tions verify some pragmatic properties to prevent codeexplosion: the functions to inline must be de�ned in themodule being compiled, and the size of their bodies mustbe small enough. Let us give some examples to illustratethe transformation.(define (succ x) (+ x 1))(define (successor y)(succ y))the de�nition of successor is translated into:(define (successor y)(let ((x y))(+ x 1)))which is then translated into:(define (successor y)(+ y 1))Even recursive functions can be inlined: to inline therecursive function f into function g, Bigloo de�nes f asa local function inside the body of g. To prevent thecompiler from in�nite inlining, no inlining of a recursivefunction can occur within its own body. For short, pro-grams of the form:(define f (lambda args body))(define g (lambda args : : : ( f : : : ) : : : ))are translated into:(define g (lambda args (letrec (( f args body)): : : ( f : : :) : : : )))For instance, let us de�ne map-succ using the map func-tional:(define (map f l)(if (null? l)'()(cons (f (car l)) (map f (cdr l)))))(define (succ x) (+ x 1))(define (map-succ l)(map succ l))When inlining map into map-succ the compiler discoversthat map is self-recursive, so it inlines it using a localde�nition:
(define (map-succ l)(letrec ((map (lambda (f l)(if (null? l)'()(cons (f (car l))(map f (cdr l)))))))(map succ l)))A further pass of the compiler demonstrates that the for-mal parameter f is a loop invariant, so f is substitutedby its actual value (compile-time ��reduction). We get:(define (map-succ l)(letrec ((map (lambda (l)(if (null? l)'()(cons (succ (car l))(map (cdr l)))))))(map l)))Then inlining of function succ occurs, and we �nally geta very e�cient equivalent piece of code:(define (map-succ l)(letrec ((map (lambda (l)(if (null? l)'()(cons (+ 1 (car l))(map (cdr l)))))))(map l)))3.2 Closure analysisThe main design e�ort for the Bigloo compiler hasbeen to compile functions as well as possible: in ourmind this implies to map Scheme functions to C func-tions (or even to C loops) and to work hard to avoidheap-allocation of closures as much as possible.Compiling functions to C loopsThus, Bigloo usually compiles Scheme functions asmuch as possible into C loops or C functions. Whenfunctions escape, that is when functions are used as �rst-class values, this e�cient scheme does not apply, thus thecompiler allocates heap space for function environments.Bigloo uses at closures: the environment part is a heapblock containing exactly the free variables of the func-tions. Despite the larger heap-allocation needed for atclosures, we do not use linked environments since theylead to memory leaks which cannot be circumvented bythe Scheme user.The closure analysis is able to map functions into Cloops even if they are mutually recursive. For instance:(letrec ((odd? (lambda (n)(if (= n 0)#f(even? (- n 1)))))(even? (lambda (m)(if (= m 0)#t(odd? (- m 1))))))(odd? 10))is compiled into:obj n, m;{ n = 10;103

_odd:if( n == 0 )return FALSE;else{ m = SUB( n, 1 );_even:if( m == 0 )return TRUE;else{ n = SUB( m, 1 );goto _odd;}}}Compiling functions to C functionsFunctions which are not the result of other functionsor which are not passed as arguments (functions whichdon't escape) are mapped to C functions. For examplemap-succ is compiled into:obj map_succ( obj l ){ return map( l );}static obj map( obj l ){ if( NULLP( l ) )return NIL;else{ obj r;r = CAR( l );{ obj obj1;obj obj2;obj1 = ADD( 1, r );obj2 = map( CDR( l ) );return MAKE_PAIR( obj1, obj2 );}}}Heap-allocated closuresOnly the escaping functions are allocated in the heap.For instance, the functional composition of two functionsreturns a ��expression as a value. Bigloo create an heap-allocated closure for the expression of line 2:1: (define (o f g)2: (lambda (x)3: (f (g x))))Asmentioned above, Bigloo's closures are arrays. Moreprecisely, the �rst slot of a closure is a pointer to a C func-tion which re ects the code part of the function. The sec-ond slot stores the function arity, the remainder of thearray is devoted to the free variables of the function. (InML this arity slot is indeed useless since functions haveonly one argument, but we need it in Scheme since thereexist n-ary functions.)Then the preceding example is compiled as:obj o( obj f, obj g ){
obj clo;clo = make_closure( lambda_1, 1, 2 );CLOSURE_ENV_SET( clo, 1, g );CLOSURE_ENV_SET( clo, 0, f );return clo;}obj lambda_1( obj clo, obj x ){ obj f, g;f = CLOSURE_ENV_REF( clo, 0 );g = CLOSURE_ENV_REF( clo, 1 );{ obj aux;aux = CLOSURE_ENTRY( g )( g, x );return CLOSURE_ENTRY( f )( f, aux );}} Even functions used as �rst class values can be com-piled without heap-allocation using the following 0cfa op-timization.3.3 0cfaThe 0cfa is a static analysis which reveals static partsof control ow. The analaysis implemented in Bigloo isclose to the one described by O. Shivers in [16]. Since theBigloo compiler does not use the CPS compiling style,the 0cfa analysis is not devoted to the optimization ofthe CPS style code generated by the compiler: it is usedinstead to minimize the number of heap-allocated closure[14].Computed calls turned to direct callsThe 0cfa approximates for each variable the set ofits possible values. In particular, it computes, for eachfunction call in a program, an approximation of the setof all the functions that can be dynamically invoked atthis application site. When this set is restricted to onlyone function, this function can be called directly. Forinstance, consider a functional F having as parameter afunction f , which is called within the body of F . If the0cfa analysis can prove that there is only one possiblevalue v for f , then v is called instead of f , which is nolonger a parameter for F . This saves one parameter pass-ing and replaces a costy call to an unknown function bya direct jump.Let us illustrate this phenomenon with the de�nitionof a function by functional composition:(define (o f g)(lambda (x)(f (g x))))(define succ (lambda (a) (+ a 1)))(define succ2 (o succ succ))Since succ2 can be used out of this program fragmento creates a closure for succ2. Nevertheless the 0cfa provesthat f and g in the code of o are succ. Thus, the expres-sion (o succ succ) is compiled as (lambda (x) (succ(succ x))). After inlining of succ, we get for succ2 thefollowing C code:104

{ obj clo;clo = make_closure( lambda_1, 1, 0 );succ2 = clo;}obj lambda_1( obj clo, obj x ){ return ADD( ADD( x, 1), 1 );} If the de�nition and uses of succ2 are local, then a callto succ2 is an application of the very lambda expressionreturned by o, and thus there is no need to allocate aclosure. For instance(let ((succ2 (o succ succ)))(succ2 4))is compiled using a dummy closure bound to UNSPECIFIED(the special Bigloo value which represents dummies):{ obj clo;clo = UNSPECIFIED;succ2 = clo;lambda_1( succ2, 4 )}static obj lambda_1( obj clo, obj x ){ return ADD( ADD( x, 1), 1 );}From higher-order to �rst-order codeIn some cases the 0cfa is able to automatically replacean higher-order program by an equivalent �rst-order pro-gram. As an example, we study a Scheme higher-orderde�nition of the factorial function without explicit recur-sion:(define (fact n)(let ((f (lambda (g m)(if (= m 0)1(* m (g g (- m 1)))))))(f f n)))Even in this puzzling program, the 0cfa analysis isable to turn the local higher-order de�nition of f into a�rst-order expression. The 0cfa proves that the formalparameter g is always the actual value f, and obtains:(define (fact n)(letrec ((f (lambda (m)(if (= m 0)1(* m (f (- m 1)))))))(f n)))Optimizing currying0cfa analysis can also remove useless curryings. Forinstance, this analysis is able to avoid the creation ofintermediate closures when calling a curried function withseveral arguments.
(define plus(lambda (x) ;; lambda-1(lambda (y) (+ x y)) ;; lambda-2))(define add (lambda (x y) ((plus x) y)))The 0cfa tells the compiler that the only result of aninvocation to plus is the function lambda-2. So (plus x)could be replaced by a call to lambda-2 (which has been��lifted 2). We eventually get the following equivalentprogram which does not require any closure allocation.(define plus(lambda (x)x))(define lambda-2(lambda (env y)(+ env y)))(define add (lambda (x y) (lambda-2 (plus x) y)))0cfa resctrictionsThe 0cfa analysis is local to a module: when a valuecan be used from outside the current module, then theanalysis cannot keep track of this value usage. Thus,the analysis must be pessimistic and for instance mustallocate a closure for a ��expression, simply because itis impossible to know where this ��expression is applied.3.4 CSEThe common subexpression elimination (CSE) attempsto share computation of pure expressions (expressionswithout side e�ects). In Bigloo this optimization is real-ized in three passes:� Purety analysis: it is a simple annotation on expres-sions giving a rough approximation of the side ef-fects that occur during the evalutation of the givenexpression. These annotations are exact for prim-itives and properly propagated to functions. Thisanalysis is not higher-order and is local to modules(imported functions are considered impure).� Let bindings: this rewriting of the abstract syntaxtree makes explicit the control ow (in the spiritof cps). It binds subexpressions to variables usinglet.� Abstract syntax tree pruning: this pass is a recur-sive descent in the abstract syntax tree, which re-moves pure expressions already computed, replac-ing the expressions by the variable they are boundto. This is achieved using a stack of previously en-countered pure expressions.Consider the following de�nitions:(define (add x y)(+ x y))(define (double-add x y)(+ (add x y) (add x y)))2Local functions are ��lifted when they cannot be compiledas C loops105

The function add is proved to be pure since + is a pureprimitive. After let binding, this program is:(define (add x y)(let ((+-res (+ x y)))+-res))(define (double-add x y)(let ((z1 (add x y)))(let ((z2 (add x y)))(let ((+-res (+ z1 z2)))+-res))))After pruning, we get:(define (add x y)(let ((+-res (+ x y)))+-res))(define (double-add x y)(let ((z1 (add x y)))(let ((+-res (+ z1 z1)))+-res))))This simple �rst-order CSE su�ces to remove manyredundant dynamic type checks. Even more tests canbe eliminated by a special treatment of conditionals in-volving type predicates. (When encountering (if test?then-exp else-exp) the tree walker recursively entersthen-exp remembering that test? is statically known tobe true, and conversely for the else-part expression.)This dynamic type checks elimination is useless whencompiling ML code, but CSE remains a valuable opti-mization since it removes duplicated computations suchas multiple accesses to the same �eld in a data structure.4 Camloo as pipelineAs seen above, the two compilers are connected usingtext �les. The last pass of our modi�ed Caml Light com-piler dumps into a �le a �-like expression representingthe Caml source program. As it is, this �le cannot becompiled by Bigloo since it is not a Scheme source text.Thus a small Scheme program (naturally called Camloo)translates this dump into a compilable Scheme source�le: a Bigloo module. This translation is just a mappingof ML constructions and values to appropriate Schemeconstructions and values. When designing this transla-tion, correctness is relatively easy, since Scheme and MLare not so far from each other. In fact the main di�-culty is to get an e�cient translation. However, in thiscase, e�ciency comes from simplicity: we have to mapML constructs to their natural counterparts in Scheme,without any extra encoding. Otherwise, the e�ciencycould be jeopardized, even if the semantics is preserved,since the back-end compiler cannot optimize this encodedprogram. For instance, it is mandatory to map ML func-tions to Scheme n�ary functions, and not systematicallyto unary ones, in order to bene�t from the optimizationsperformed by the back-end to call functions with multiplearguments.4.1 Mapping ML to Scheme: an exampleLet us start by a simple example: consider the follow-ing len.ml �le de�ning the list length function.
let rec list_length = function[] -> 0| x :: l -> 1 + list_length l;;The ��like representation (��code), as obtained by thecommand camlc -dump len.ml, is the following len.lam�le:(lprim(pset_global(qualifiedident "len" "list_length"))((lfunction(lswitch 2 (lvar 0)(((constrconstant(qualifiedident "builtin" "[]") 0 2)(lshared (lconst (scatom 0)) -1))((constrregular(qualifiedident "builtin" "::") 1 2)(lshared(lprim paddint((lconst (scatom 1))(lapply(lprim(pget_global(qualifiedident "len""list_length"))())((lprim (pfield 1) ((lvar 0)))))))-1)))))))This expression is a bit hard to read: let's just say thatit de�nes the global variable list length from the mod-ule len, that the pattern matching has been expanded(lswitch), constructor names have been explicitized (asin "builtin" "::"), and primitives are quali�ed (paddintinstead of +). As the careful reader may have alreadynoticed, the Caml Light compiler uses the De Brujin'snotation, so that local variable names have disappeared(replaced by indexes to their ��binder).From this ��code the Camloo mapping produces the fol-lowing Scheme �le (len.scm), which is a plausible hand-crafted program.(define list_length@len(lambda (x1)(if (null? x1)0(+fx 1 (list_length@len (cdr x1))))))This example illustrates the direct mapping of functions,lists and integers to their Scheme correspondents. More-over, notice that the Scheme code does not use the genericaddition but the faster integer addition (straightforwardimplementation of the paddint primitive call producedby the Caml Light compiler).4.2 The general mappingWe describe here the general scheme that performsthe mapping. We will see later a few exceptions to thegeneral scheme, used to map even more directly some MLdata structures (e.g. lists) and syntactic constructs (e.g.curried functions).Mapping values� Functional values: there are no di�culties to mapCaml functions to Scheme procedures: both lan-guages are ��languages with higher-order function-ality.106

� Basic Caml values such as integers, strings, charac-ters, arrays, oating point numbers, map to the cor-responding Bigloo basic values. However, a smallproblem arose with characters, since Caml Lightcharacters are directly represented as integers: someprimitives have been changed to re ect the untrivialcoercions between Bigloo integers and Bigloo char-acters.� Constant data constructors map to Bigloo constants(for instance, true and falsemap to Scheme boole-ans #t and #f).� Values built with non-constant data constructorsmap to Bigloo vectors: the application of construc-tor C to arguments x, y, z is translated to theBigloo vector #(x y z). The C constructor is map-ped to the corresponding Bigloo runtime tag at-tached to the vector (8 bits are devoted to this tag).� Exceptional values: values built with \extensible"data constructors are also mapped to vectors.Mapping of exceptional values deserves some expla-nations. Since exceptions are generative, each one mustpossess a unique tag. This tag is allocated during thelink phase of the compilation in Caml Light. FortunatelyScheme o�ers the notion of symbols which are names as-sociated to unique objects. Thus, ML exceptions giveraise to the creation of a Lisp symbol which stands forthe stamp of the exception. The symbol's name is com-pound using the name of the exception, the static stampof the exception de�nition (counting the number of re-de�nition of the exception), and the name of the modulethat de�nes this exception.For instance, the constant exception Out of memoryfrom the library module exc, which is evidently not rede-�ned, has symbolic stamp 'Out of memory1@exc. For nonconstant exceptions, the symbol is stored is the �rst slotof the vector representing the exceptional value: Failure"hd" corresponds to the vector #(Failure1@exc "hd").4.2.1 Mapping try : : :raiseThere is no di�culty for the rest of the Caml languageconstructs (mainly loops and conditionals); the last prob-lem is the exception handling. We could have adopteda trivial implementation of try : : :with : : : and raisewith the powerful Scheme call/cc library function. Itsu�ces to de�ne a try-with macro (the variable raiseis bound to the current handler), as suggested by:(define raise (lambda (x)(error "uncaught exception" x)))(define-macro (try-with computation match-handler)`((call/cc(lambda (return)(let ((previous-raise raise))(set! raise(lambda (exc)(set! raise previous-raise)(return(lambda ()(,match-handler exc)))))(let ((result ,computation))(set! raise previous-raise)(lambda () result)))))))
Unfortunately, Scheme implementations using stacksare known to have a slow call/cc function [10]. Pro-ducing C code using the C stack, Bigloo is no exception.Since Caml code may use heavily try and raise con-structs, we need a more e�cient implementation of ex-ception handling. In C, we classically use setjmp andlongjmp, but once more these functions are not designedto be used as intensively as in the C code generated fromML sources. This results in poor runtime behavior forprograms which heavily use try and raise. Thus, someports of our compiler directly use assembly code to im-plement exception handling (e.g. 19 lines for the Sparcprocessor).Pattern matchingCamloo is not in charge to map Caml pattern match-ing to Scheme expressions. Pattern matching is expandedinto basic switches and conditionals by the Caml Lightcompiler. Camloo just maps these two constructions totheir natural Scheme equivalents.We gave up to map Caml pattern matching to theScheme pattern matching featured by Bigloo for sake ofcompatibility: this way our new compiler o�ers all theCaml Light speci�c extensions such as streams.4.3 ModulesCaml Light modules are mapped by Camloo ontoBigloo modules. Bigloo modules are self contained: inter-face and implementation are in the same �le. When com-piling a Caml Light module interface, Camloo producestwo �les: a regular \.zi" compiled interface �le, and aBigloo module with an empty implementation (\.sci"�le) which contains the de�nitions of primitives foundinto the Caml Light interface. When compiling a CamlLight module implementation, Camloo produces one Bi-gloo module which contains the body of the Caml Lightimplementation, and a Bigloo module header containingthe prototypes of all exported functions and variables.This mapping of Caml Light modules to Bigloo mod-ules obliges to compile only modules having an imple-mentation. This is a restriction to the Caml Light mod-ule language, but every Caml Light executable programis compilable by Bigloo. However, this restriction is of noimportance in our case, since our compiler is designed toproduce e�cient executables for already fully developedprograms.4.4 Optimizing the mappingNatural mapping of curried functionsThe general mapping for Caml functions as describedabove is correct, but such a trivial mapping would beine�cient, since ML curried functions would lead to mul-tiple function invocations, with alloction of intermediateclosures.In e�ect, ML does not possess n-ary functions. This isusually circumvented using either tuples or curried func-tions. From a theoretical point of view, these approachesgive the same expressive power as n-ary functions. Fromthe compiler point of view, it is mandatory to map thoseencoded n-ary functions to truly n-ary functions. Since in107

Caml Light the usual encoding of n-ary functions is cur-rying, Camloo has to map Caml Light curried functionsto Scheme n-ary functions. It would also be worthwhileto map functions using tupled arguments to n-ary func-tions, but this remains to be done.As mentioned above, the 0cfa analysis used by theBigloo compiler already optimizes curried application,but this analysis is not powerful enough, since it onlyworks for local (or local to a module) functions. Thus,it remains of paramount importance to design a generaloptimization that maps Caml Light functions with n cur-ried arguments to Scheme procedures with n arguments,particularly for global functions.This new optimization requires the collaboration ofCamloo and Bigloo. Camloo produces for every global(exported or not) function two entry points: the �rst en-try is devoted to partial application (applications whichbuild closures), and the other one is called directly whenthe function is applied to all its curried arguments (totalapplication).Let us give an example:let rec map f = function[] -> []| x :: l -> f x :: map f l;;map succ [1; 2];;This produces two entry points for map, map and 2-map,and 2-map is called directly without any closure alloca-tion:(define map(lambda (x1)(lambda (x2) (2-map x1 x2))))(define 2-map(lambda (x1 x2)(if (null? x2)'()(let ((obj2 (2-map x1 (cdr x2)))(obj1 (x1 (car x2))))(cons obj1 obj2)))))(2-map succ(let ((obj2 (cons 2 '())))(cons 1 obj2)))Moreover, this mapping of curried functions to n-aryfunctions is not restricted to functions local to a mod-ule: our compiler fully optimizes inter-modules curriedfunctions. When a module exports a curried function,Camloo generates export clauses for its two entry points(map and 2-map in the preceding example). Then when amodule imports a curried function, the Bigloo compilerimports the two entry points, so that it can retrieve thedirect entry point when necessary.Natural mapping of listsWe paid a special attention to map ML lists to Schemelists. The main reason is the compatibility between pureScheme code and Scheme code generated from ML. More-over, \conses" are handled e�ciently by Bigloo's runtime:\conses" have a special tag that authorizes to implementthem with only two words.This optimization is very simple: to allocate Camllists as Scheme lists, it is su�cient to detect applicationsof the constructors ::@builtin and []@builtin. For list
accesses, we remark that these accesses always occur inthe expression part of a clause of some pattern match-ing, whose pattern part reveals that we are accessing alist. We then replace the generic accesses by proper ap-plications of car or cdr. (See the list length exampleabove.)Natural mapping of referencesNaive mapping of references as regular Caml valuesusing Bigloo vectors is ine�cient: ref 0 becomes #(0).The problem with this mapping is that each fetch leadsto a vector access and each modi�cation of the referenceleads to a store into the vector. This is admissible whenthe reference is used as a �rst-class value, which is passedto a function or embedded into a data structure. In prat-ice, a very common case is the mapping of referenceswhich are bound to a variable and only used as usualimperative variable (for instance to control a loop). Inthis case, the natural and more e�cient way to imple-ment variables bound to reference cells is to use Schemevariables updated via set!. In this case, there is no needto allocate space: in most cases the variable simply staysin a register.Let us take as example a simple while loop, using areference as control:let x = ref 10 inwhile !x > 0 do print_int !x; x := !x + 1 done;;The mapping turns the while construct into a recur-sive function, and the ML variable x into an imperativeScheme variable:(let ((x1 10))(letrec ((loop (lambda ()(if (>fx x1 0)(begin(print_int@io x1)(set! x1 (+fx x1 1))(loop))'()))))(loop)))which is then translated into a C variable:{ obj x1;x1 = 10;loop:if( GT( x1, 0 ) ){ print_int__io( x1 );x1 = ADD( x1, 1 );goto loop;}elseBNIL;} When the reference is indeed used as a value, we alsouse the natural Scheme counterpart: a reference cell (abit more compact than a vector, since it needs only twowords).This optimization is done by a simple syntactic anal-ysis of the ��like abstract representation of the Camlprogram: variables bound to references are mapped toScheme imperative variables, except if they are used as108

�rst-order values (the variable appears without explicitfetch: x instead of !x).This program transformation is easy and correct inCamloo, because Caml references which are never usedas �rst-class values have the same semantics as Schemeimperative variables. In particular, the Scheme compilerhandles the heap allocation of those imperative variableswhich are shared between several closures.5 LibrariesAll Caml Light libraries written in Caml were com-piled directly by the new compiler. Other libraries werewritten in C. Among the functions provided by these li-braries we distinguish:� functions already available in Bigloo (arithmetic andbasic data type primitives): nothing has to be donehere.� functions of general interest: they have been writ-ten in Scheme and added as new components tothe Bigloo library. For instance, input and outputof circular values (preserving sharing), a few ad-ditional functions on basic data structures (blitstring and string for read).� functions speci�c to Caml (e.g. input-output func-tions or camlyacc and camllex engines) were kept inC, with a bit of rewriting (essentially the C macros).To conclude, the port of Caml Light libraries was easyand in some cases pro�table to the Bigloo system.6 Modifying the two compilers6.1 Fitting Caml LightThe modi�cations to the Caml Light compiler havebeen minor. Apart from the mandatory \dump pass",which is only an abstract tree printer, the sole other mod-i�cation was added for e�ciency. The Caml Light com-piler forgets the arity and the name of constructors afterpattern matching compilation: these are useless to therest of the compiler. We had to keep these informationsto help the Bigloo compiler to optimize pattern matchingand value representation (e.g. lists).6.2 Fitting BiglooDynamic type checkingFrom the e�ciency point of view, an important prob-lem remains: Scheme is dynamically type checked andperforms many runtime type checks. This is not so im-portant in Bigloo since 0cfa analysis and common subex-pressions elimination remove many of these tests (up to75%). Nevertheless we want to take advantage of thestatic type checking of ML to eliminate all of them. For-tunately, as many Scheme or Lisp compilers, Bigloo hasa compilation option to prevent the generation of thesetests: thus when compiling Caml code we safely use the-unsafe option of the Scheme compiler.
Runtime supportMany of the runtime requirements of ML, such as au-tomatic memory management (GC ) and dynamic alloca-tions of data structures (vectors, closures, strings, : : : )already exist in Scheme, we get them for free since wemap ML values to Scheme values.To extend the Bigloo's runtime to implement the CamlLight speci�c primitives, we intensively used another fa-cility available in Bigloo: the \foreign interface". Thisfacility permits direct calls to C functions (or even callsto C macros) and transparent use of C values by theScheme code, without stub code.To summarize, except for the currying optimization,no modi�cations to the existing Bigloo compiler wereneeded to get the new compiler. Thus our new compilerhas been integrated in the new release of Bigloo: Biglooversion 1.6 compiles both Caml Light and Scheme source�les.7 Related workSome ML compilers have already been designed bythe re-utilization of some existing systems. We com-pare Bigloo with three currently available systems: CamlV3.1, sml2c and camlot.Caml V3.1 This Caml compiler [19] has been devel-opped using the Le-Lisp [4] runtime. To obtainthe compiler, implementors had to write an entirelynew front-end and a code generator. Thanks to theLLM3 virtual machine and Le-Lisp runtime, porta-bility is for free. If the Caml compiled had used theComplice Le-Lisp compiler instead of direct produc-tion of LLM3 code, this approach would have beenvery close to ours (except of course that Bigloo pro-duces C code instead of virtual assembly code).sml2c This compiler is based on the rewriting of theSML/NJ [1] compiler code generator. The CPS rep-resentation of program is compiled into a target ma-chine whose instructions are implemented in C. Onthe other hand, this compiler shares the same run-time and uses the same high-level optimizations asSML/NJ.Due to the methodology of sml2c (generation of Ccode to implement the instructions of a virtual ma-chine) the C code produced is very di�erent fromhand-crafted C implementing the same source pro-gram. This C code is thus very di�cult to optimizeby the C compiler. On the contrary, Bigloo workshard to produce readable C code, as similar as pos-sible to hand written C code. The idea is similar toour \natural translation" from ML to Scheme, andhas the same good properties: \natural translation"from Scheme to C produces highly optimisable Ccode3.The main interest of the sml2c approach is to min-imize the amount of assembly required (on the av-erage, the runtime system uses about 500 lines ofassembly for each port). However, we get the same3Let alone the possibility of reasonable use of C symbolicdebuggers109
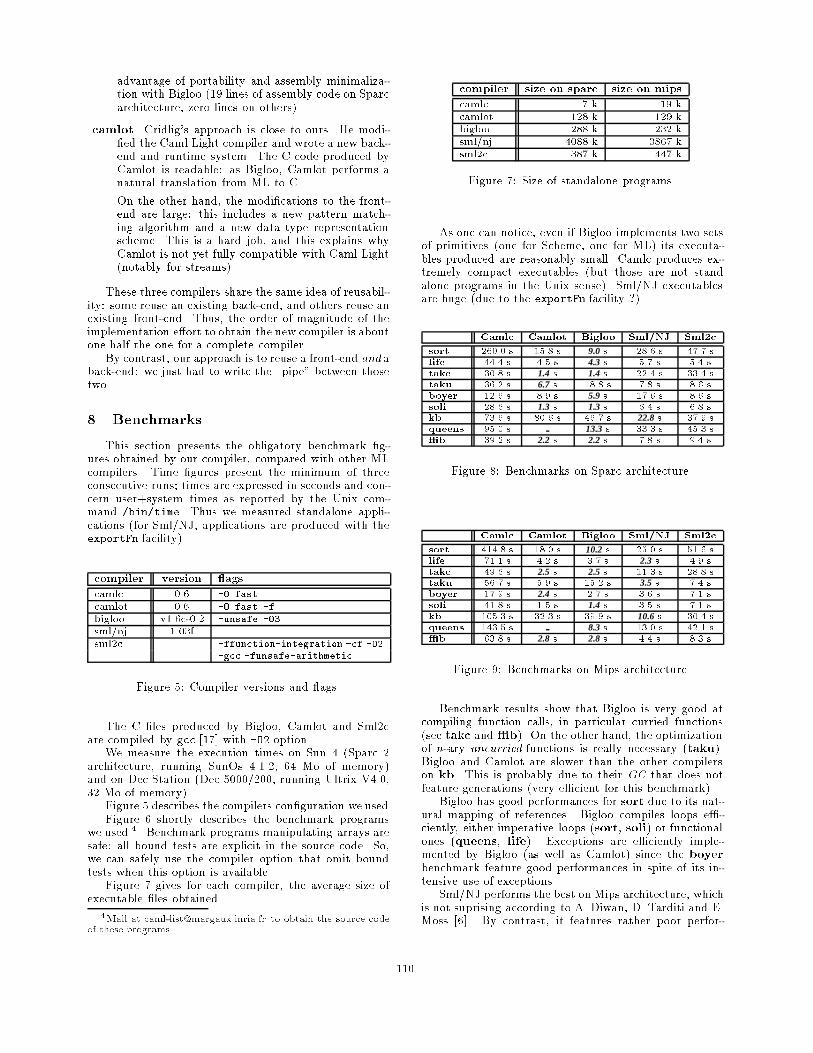
advantage of portability and assembly minimaliza-tion with Bigloo (19 lines of assembly code on Sparcarchitecture, zero lines on others).camlot Cridlig's approach is close to ours. He modi-�ed the Caml Light compiler and wrote a new back-end and runtime system. The C code produced byCamlot is readable: as Bigloo, Camlot performs anatural translation from ML to C.On the other hand, the modi�cations to the front-end are large: this includes a new pattern match-ing algorithm and a new data type representationscheme. This is a hard job, and this explains whyCamlot is not yet fully compatible with Caml Light(notably for streams).These three compilers share the same idea of reusabil-ity: some reuse an existing back-end, and others reuse anexisting front-end. Thus, the order of magnitude of theimplementation e�ort to obtain the new compiler is aboutone half the one for a complete compiler.By contrast, our approach is to reuse a front-end and aback-end: we just had to write the \pipe" between thosetwo.8 BenchmarksThis section presents the obligatory benchmark �g-ures obtained by our compiler, compared with other MLcompilers. Time �gures present the minimum of threeconsecutive runs; times are expressed in seconds and con-cern user+system times as reported by the Unix com-mand /bin/time. Thus we measured standalone appli-cations (for Sml/NJ, applications are produced with theexportFn facility).compiler version agscamlc 0.6 -O fastcamlot 0.6 -O fast -fbigloo v1.6c-0.2 -unsafe -O3sml/nj 1.03fsml2c -ffunction-integration -cf -O2-gcc -funsafe-arithmeticFigure 5: Compiler versions and agsThe C �les produced by Bigloo, Camlot and Sml2care compiled by gcc [17] with -O2 option.We measure the execution times on Sun 4 (Sparc 2architecture, running SunOs 4.1.2, 64 Mo of memory)and on Dec Station (Dec 5000/200, running Ultrix V4.0,32 Mo of memory).Figure 5 describes the compilers con�guration we used.Figure 6 shortly describes the benchmark programswe used 4. Benchmark programs manipulating arrays aresafe: all bound tests are explicit in the source code. So,we can safely use the compiler option that omit boundtests when this option is available.Figure 7 gives for each compiler, the average size ofexecutable �les obtained.4Mail at [email protected] to obtain the source codeof these programs.
compiler size on sparc size on mipscamlc 7 k 19 kcamlot 128 k 129 kbigloo 288 k 232 ksml/nj 4088 k 3867 ksml2c 387 k 447 kFigure 7: Size of standalone programsAs one can notice, even if Bigloo implements two setsof primitives (one for Scheme, one for ML) its executa-bles produced are reasonably small. Camlc produces ex-tremely compact executables (but those are not standalone programs in the Unix sense). Sml/NJ executablesare huge (due to the exportFn facility ?).Camlc Camlot Bigloo Sml/NJ Sml2csort 260.0 s 15.8 s 9.0 s 28.6 s 47.7 slife 44.4 s 4.5 s 4.3 s 5.7 s 5.4 stakc 30.8 s 1.4 s 1.4 s 22.4 s 33.4 staku 36.2 s 6.7 s 18.8 s 7.8 s 8.6 sboyer 12.6 s 8.9 s 5.9 s 17.6 s 8.6 ssoli 28.6 s 1.3 s 1.3 s 6.4 s 6.8 skb 73.6 s 80.6 s 46.7 s 22.8 s 37.9 squeens 95.0 s 13.3 s 33.3 s 45.3 s�b 39.2 s 2.2 s 2.2 s 7.8 s 9.4 sFigure 8: Benchmarks on Sparc architectureCamlc Camlot Bigloo Sml/NJ Sml2csort 414.8 s 18.0 s 10.2 s 25.0 s 51.6 slife 71.1 s 4.2 s 3.7 s 2.3 s 4.9 stakc 49.6 s 2.5 s 2.5 s 11.3 s 28.8 staku 56.7 s 5.9 s 15.2 s 3.5 s 7.4 sboyer 17.9 s 2.4 s 2.7 s 3.6 s 7.1 ssoli 41.8 s 1.5 s 1.4 s 3.5 s 7.1 skb 105.3 s 32.3 s 39.9 s 10.6 s 30.4 squeens 143.5 s 8.3 s 13.0 s 42.1 s�b 63.8 s 2.8 s 2.8 s 4.4 s 8.3 sFigure 9: Benchmarks on Mips architectureBenchmark results show that Bigloo is very good atcompiling function calls, in particular curried functions(see takc and �b). On the other hand, the optimizationof n-ary uncurried functions is really necessary (taku).Bigloo and Camlot are slower than the other compilerson kb. This is probably due to their GC that does notfeature generations (very e�cient for this benchmark).Bigloo has good performances for sort due to its nat-ural mapping of references. Bigloo compiles loops e�-ciently, either imperative loops (sort, soli) or functionalones (queens, life). Exceptions are e�ciently imple-mented by Bigloo (as well as Camlot) since the boyerbenchmark feature good performances in spite of its in-tensive use of exceptions.Sml/NJ performs the best on Mips architecture, whichis not suprising according to A. Diwan, D. Tarditi and E.Moss [6]. By contrast, it features rather poor perfor-110
programs size (lines) description feature testedsort 79 The quicksort algorithm. Loops, array manipulation, references.life 148 The life game. Lists and strings manipulation.takc 11 The Takeuchi function. Curried function call.taku 12 The Takeuchi function. Uncurried function call.boyer 1765 Standard theorem-prover benchmark. Symbolic computation, exception handling.soli 110 The resolution of the solitaire game. Loops, array manipulation.kb 537 The Knuth-Bendix completion algorithm (naive). Symbolic computation, exception handling.queens 71 Ten queens problem solved with lists. Accumulating and mapping on lists.�b 13 A Fibonacci-like higher-order function. Call to closures.Figure 6: Benchmarks descriptionmances on Sparc architecture (not as good as Sml2c forlife and boyer).Di�erences between time �gures on Mips and Sparcare much more similar for compilers producing C code.Camlot and Bigloo have close performances (signi�cantlybetter than Sml2c).ConclusionOur goal was to develop a new fully compatible CamlLight compiler with good performances. Our simple pipe-lining approach leads to an economical realization (only2 man-months). The result is a very good Caml compilerwhich compiles any Caml Light source program: it hasalready been used to compile the entire Coq proof as-sistant system [7]. Furthermore, our compiler is a Camland Scheme compiler: it compiles indi�erently Schemeand ML source �les, and the object codes may live atthe same time in the resulting executable program. Asfar as we know, this degree of integration between twofunctional languages has never been achieved before.This seems to open a new perspective in the relation-ship between Scheme and ML: using our compiler theprogrammer may freely mix Scheme and ML code, andchoose whichever language is more appropriate to developthe algorithm at hand.AcknowledgementWe would like to thank Christian Queinnec for nu-merous encouragements to realize a Scheme and Camlcompiler, and Xavier Leroy and Jean-Marie Ge�roy fortheir careful reading of this paper.References[1] A. W. Appel and D. B. MacQueen. A Standard MLCompiler, in G. Kahn editor, Functional ProgrammingLanguages and Computer Architecture, volume 274,pages 301-324. Springer-Verlag, 1987.[2] H. J. Boehm, Hardware and Operating System Supportfor Conservative Garbage Collection, Proc. of the Inter-national Workshop on Object-Orientation in OperatingSystems, p 61{67, 1991.[3] E. Chailloux, An e�cient way to compile ML to C, ACMSigplan Workshop on ML and its Applications, 1992.[4] J. Chailloux and M. Devin and F. Dupont and J.-M.Hullot and B. Serpette and J. Vuillemin, Le-Lisp version
15.24, le manuel de r�ef�erence, INRIA, Technical Report,1991.[5] R. Cridlig, An optimizing ML to C compiler, ACM Sig-plan Workshop on ML and its Applications, 1992.[6] A. Diwan, D. Tarditi and E. Moss, Memory Subsys-tem Performance of Programs Using Copying GarbagageCollection, Symposium on Principles of ProgrammingLanguages, 1994.[7] G. Dowek, A. Felty, H. Herbelin, G. Huet, The COQproof assistant user's guide, INRIA, Technical Report154, 1993.[8] IEEE Std 1178-1990, Ieee Standard for the Scheme Pro-gramming Language, Institute of Electrical and Elec-tronic Engineers, Inc. New York, NY, 1991.[9] X. Leroy and P. Weis, Manuel de r�ef�erence du langageCAML, InterEditions, Paris, Juillet 1993.[10] Luis Mateu-Brule, Strat�egies avanc�ees de gestion deblocs de controle., Th�ese d'universit�e, Universit�e Pierreet Marie Curie (Paris 6), Paris, F�evrier 1993.[11] R. Milner, M. Tofte, R. Harper, The De�nition of Stan-dard ML, MIT-Press, 1990.[12] M. Serrano, Bigloo user's manual, Technical Report,Inria, to appear.[13] M. Serrano, De l'utilisation des analyses de ots decontroles dans la compilation des langages fonctionnels,Technical Report, LIX/RR/93/05, 1993.[14] M. Serrano, Control ow analysis as an e�cient opti-mization to compile functional langages, unpublished.[15] M. Serrano, Vers une compilation performante des lan-gages fonctionnels, Th�ese d'universit�e, Universit�e Pierreet Marie Curie (Paris 6), Paris, To appear.[16] O. Shivers, Control-Flow Analysis of Higher-Order Lan-guages or Taming Lambda, Carnegie Mellon University,Technical Report, CMU-CS-91-145, 1991.[17] R. M. Stallman, Using and Porting GNU CC, Free Soft-ware Foundation, Inc., April 1989.[18] D. Tarditi, A. Acharya and P. Lee, No assembly re-quired: Compiling Standard ML to C, Carnegie MellonUniversity, Technical Report, CMU-CS-90-187, 1991.[19] P. Weis et al, The CAML reference manual, TechnicalReport, Inria 121, 1991.[20] P. Weis and X. Leroy, Le langage CAML, InterEditions,Paris, Juillet 1993.111

ML Partial Evaluation using Set-Based Analysis �Karoline Malmkj�rAarhus University ��([email protected]) Nevin HeintzeCarnegie Mellon University ���([email protected]) Olivier DanvyAarhus University ��([email protected])AbstractWe describe the design and implementation of an o�-linepartial evaluator for Standard ML programs. Our partialevaluator consists of two phases: analysis and specializa-tion.Analysis: Set-based analysis is used to compute control ow, data ow and binding-time information. Itprovides a combination of speed and accuracy thatis well suited to partial-evaluation applications: theanalysis proceeds at a few hundred lines per sec-ond and is able to deal with higher-order functions,partially-static values, arithmetic, side e�ects andcontrol e�ects.Specialization: To treat the rich static informationsupplied by set-based analysis, continuation-basedspecialization is used in conjunction with a notionof \lightweight" symbolic values. The specializeradapts and improves upon the proven design prin-ciples of o�-line polyvariant partial evaluators.Our system is integrated into the New Jersey compilerfor Standard ML: both input and output languages arethe compiler's intermediate language lambda. As such,our ML partial evaluator is not a source-ML to source-ML program transformer and issues of desugaring andtype checking are avoided.The core part of our implementation, handling higher-order programs with partially-static values, is complete.We are currently working on extensions of the specializerto treat computational e�ects.�Partially supported by the Defense Advanced Research Proj-ects Agency, CSTO, under the title \The Fox Project: AdvancedDevelopment of Systems Software", ARPA Order No. 8313, issuedby ESD/AVS under Contract No. F19628-91-C-0168, and by theDART project funded by the Danish Research Councils.The views and conclusions contained in this document are thoseof the authors and should not be interpreted as representing o�-cial policies, either expressed or implied, of the Defense AdvancedResearch Projects Agency or the U.S. Government.��Computer Science Department, Ny Munkegade, Building540, 8000 Aarhus C, Denmark.���School of Computer Science, 5000 Forbes Ave., Pittsburgh,PA 15213, USA.
1 IntroductionThe last decade has seen substantial advances in partialevaluation [9, 15, 16]. In particular, it now appears fea-sible to build practical large-scale partial evaluators. Atthe same time, much e�ort has been directed towardsbuilding well-structured systems software. Such e�ortsprovide a rich source of motivating examples for partialevaluation.The speci�c context of our work is the CMU FOXproject, which addresses modular systems building inML. Core parts of the standard TCP/IP network protocolsuite have been implemented in an exceptionally struc-tured and modular way [3]. However, the extra modular-ization introduces additional run-time overhead. Partialevaluation provides an appropriate tool for the removalof this overhead.We aim to construct a system that provides practicaland e�ective partial evaluation of systems software writ-ten in ML. Such a system must address all aspects of ML,including side-e�ects, control and arithmetic.Our design uses \polyvariant specialization", which isan aggressive forward constant propagation tightly pairedwith the multiple specialization of selected source pro-gram points and driven by a global, o�-line \binding-time" analysis. Speci�cally:Binding-time analysis: The program is pre-processedto compute information about the structure of val-ues available at partial-evaluation time [7, 15, 20].Specialization: The program is processed to propagatestatic values, perform static computation, and con-struct the residual program.The technique is simple and e�ective.In contemporary o�-line partial evaluators [15], thebinding-time analyzer is designed to meet the needs ofthe specializer. In contrast, we do not have a tai-lored binding-time analyzer. Instead, we obtain binding-time information by enriching an independent and moregeneric source: set-based analysis [12]. Correspondingly,our specializer is designed not only to use the binding-time information but also to exploit set-based informa-tion.Our system is integrated into the New Jersey com-piler for Standard ML [1, 2]. The compiler's lambdaintermediate language is used as both source and targetlanguages. As such, our ML partial evaluator is not asource-ML to source-ML program transformer. Instead,112

it operates on type-checked and syntactically-desugaredprograms. This approach di�ers substantially from thatof Mix-style partial evaluators such as Similix and (toa lesser extent) Schism [5, 8]. Our system also di�ersfrom Birkedal and Welinder's recent SML-Mix, which isa partial-evaluation compiler tailored to generate partialevaluators dedicated to source ML programs [4].ML has a powerful static semantics. For this reasonwe have chosen to partially evaluate programs after thestatic semantics is processed. In this way the partialevaluator can focus on the main goal of partial evaluation| removal of run-time overhead.One could speculate about the properties our partialevaluator should satisfy | besides the de�nitional one,i.e., running the specialized program on the remaininginput must yield the same result as running the sourceprogram on the complete input (modulo termination).For example, should our partial evaluator preserve MLtyping? However, the question is not very meaningfulfor two reasons. First, lambda is not a typed language.Second, the compiler uses transformations that do notpreserve ML typability, e.g., CPS transformation [11] andalso lambda-lifting.The rest of this paper is organized as follows. Section2 gives an overview of the system. Section 3 describes theanalysis and Section 4 describes the specializer. Section5 presents preliminary results.2 System Structure1. The input ML program is parsed, type-checked, andtranslated from abstract syntax into lambda code(this is all performed by the front-end of the NewJersey compiler).2. The lambda code is then pre-processed. Interme-diate results are named and some trivial code sim-pli�cations are performed. The names are used inthe communication between the analyzer and thespecializer.3. The analysis phase of the partial evaluator is ap-plied to the lambda code output by the pre-proc-essing stage. The analyzer constructs a mappingfrom variable identi�ers into control- ow, data- owand binding-time information.4. The mapping from the analysis phase and thelambda code from the pre-processing phase arethen passed to the specializer. The output of thespecializer is another lambda program.5. The output of the specializer is compiled by theback-end of the New Jersey compiler, and madeavailable via a variable binding in the top-level en-vironment.The choice of lambda to represent programs through-out deserves comment. lambda provides a simple repre-sentation of programs (there are only a small numberof di�erent kinds of expressions), and we avoid manyof the issues of syntactic processing and type checkingthat arise in the manipulation of ML source programs.However, lambda is not ideally suited for analysis and
program manipulation for a number of reasons. The pre-processing (stage 2.) addresses some of these problems.Ideally, one would like to have properties such as \eachintermediate result is named" and \operations are onlyapplied to trivial expressions" to be built into the de�-nition of the representation. Sequentialization of inter-mediate computations would also simplify program ma-nipulation. (NB: These properties are all met in nqCPS,A-normal forms, monadic normal forms, and higher-orderthree-address code.)3 AnalysisThe set-based approach to program analysis employs asingle notion of approximation: all inter-variable depen-dencies are ignored [12, 13, 14]. This is achieved by treat-ing variables as sets of values.1 In other words, the envi-ronments encountered at each point in a program are col-lapsed into a single set environment (mapping variablesinto sets). In e�ect, analysis is carried out by extractingrelationships between the sets of values for the programvariables, and then reasoning about these relationships.For example, when set-based analysis is applied to theprogram:let fun append(nil, y') = y'| append(x :: xs, y) = x :: append(xs, y)fun rev nil = nil| rev(z :: zs) = append(rev zs, [z])in rev [1,2,3,4]endthe result of the program is approximated by the set of alllists constructed from 1, 2, 3 and 4. In e�ect, the generalstructure of the list is preserved, but information aboutits order and length are lost.To obtain binding-time information, set-based anal-ysis must be extended to reason about unknown valuesor parameters. These parameters are manipulated andpropagated by the analysis so that the output of theanalysis is correct for all instantiations of the parame-ter. That is, set-based analysis must take into accountall possible behaviours of the parameter. For example,in the context of the de�nition of append, suppose thatwe call append([1,2], dynamic), where the token dynamicis a parameter indicating a dynamic value. Set-basedanalysis yields the following description:X = 1 [ 2L = dynamic [ (X :: L)where L is the set variable describing the results of thecall to append. The structure of the resulting list is pre-served, but information about its order and length arelost.The next example illustrates a combination of poly-variant analysis and parametric reasoning:fun map f nil = nil| map f (x :: l) = (f x) :: (map f l)val t = [1,2,3]1A key di�erence from abstract-interpretation approaches toprogram analysis is that set-based analysis does not use an under-lying abstract domain to approximate program values.113

val d = dynamicval u = map (fn x => (x, d)) tval v = map (fn (x, y) => x) uval w = map (fn (x, y) => y) uFor this program, set-based analysis yields the followinginformation about the variables u, v and w: u is a list ofpairs whose �rst element is either 1, 2 or 3 and whosesecond argument is dynamic; v is a list of 1's, 2's and 3's,and w is a list of dynamic's.We conclude this brief overview by illustrating someimportant issues arising in set-based binding-time analy-sis. Consider the following program fragment:val (v1, v2) = dynamicval w = if dynamic then 1 else 2In the �rst statement, v1 and v2 de-construct the param-eter dynamic. This is modeled by introducing a derivedparameter subterm(dynamic), whose purpose is to denotethe set of all subterms of the parameter dynamic. In thesecond statement, a standard set-based analysis wouldjust compute the set f1; 2g for w; however it is importantto propagate the fact that the value of w is not staticallydetermined. When a test is dependent on a dynamic pa-rameter, we therefore introduce a computation dynamicpa-rameter to the result of the if statement, so that the even-tual set computed for w is f1; 2g [ computation dynamic.4 SpecializationWe use o�-line, polyvariant specialization. It is o�-linebecause most of the control decisions needed in the spe-cializer are determined by information from the analyzer.It is polyvariant because it selects a set of specializationpoints in the source program and produces a residualprogram consisting of multiple variants of these. Further-more, we handle higher-order and partially-static values.Since we want a exible, extensible, and e�cient system,we have aimed for a simple design, re-using concepts thathave proven successful in previous o�-line partial evalu-ators.Since we operate in lambda, we avoid many prob-lems often associated with partial evaluation for typedlanguages. On the other hand, it also imposes some re-strictions. It is for example crucial to be able to processpartially-static values since in lambda, function param-eters are passed as records.The specializer is guided by the information computedby the analyzer. Using the static input, the specializerstarts at the entry point of the source program and prop-agates constant values through the program by unfoldingfunction calls and reducing static expressions. Residualcode is generated whenever parts of the source programcannot be statically evaluated.Some source functions are recursive, and often thereis not enough information to execute their calls statically.Instead we need to construct residual recursive functions.A simple mechanism is to select specialization points inthe source program. When the specializer meets a spe-cialization point, it generates residualized code represent-ing a specialized version of the specialization point. (Thisis referred to as either \polyvariant specialization", \cus-tomization", or \procedure cloning" in the literature.)
We use conditional expressions with dynamic testsas specialization points. Experience suggests that thisis a good choice [15], but further optimization is pos-sible [17, 19, 21]. In a pre-pass through the program,the specialization points are lambda-lifted into a collec-tion of global recursive equations. The free variables ofeach conditional expression are given as parameters tothe corresponding recursive equation. We remark thatwhereas function calls are unfolded, calls to global re-cursive equations (the specialization points) are alwaysresidualized. The residual program is thus a collection ofrecursive equations.E�ective unfolding requires �ner descriptions of val-ues than given by the coarse \known / unknown" distinc-tion. Such descriptions include higher-order and partiallystatic values. Partial evaluators typically represent thesesymbolically. This representation causes problems in thepresence of call unfolding, such as computation duplica-tion, reordering, and loss of dynamic computations. Ourdesign solves this by naming all residual computations.However, naming has the disadvantage of limiting thestatic data ow. This shortcoming can be addressed byusing continuation-based specialization. In e�ect, con-tinuations are used to communicate across naming: thecontinuation accounts for the specialization context, andis sent the name of the residual expression. More de-tail about continuation-based specialization can be foundelsewhere [6, 18] (see also [15, Sec. 10.5]).Since residual computations are named, any dynamicsubpart of a symbolic value is a variable. To simplifythe treatment of symbolic values at specialization points,we represent them as pairs: the actual symbolic value(simple, higher order, or partially static) and the list ofits free dynamic variables. We call this representationlightweight symbolic values.We illustrate elements of our design with the followingdeclaration of and call to a specialization point:let fun foo (x, y, z) = ...in ... foo (a, b, c) ...endSuppose that the call foo (a,b,c) is processed under thefollowing conditions.� The �rst argument a is the partially-static value(CON1(v1,10), [v1]): the construction CON1 of a dy-namic variable v1, and the number 10, paired withthe list of its free variables.� The second argument is the higher-order value(fn x => x + y, (y = (CON2(v2,20), [v2])), [v2]):a closure with one free variable y bound to anotherpartially-static value.� The third argument is a constant string ("helloworld", []).Then we obtain the following residual specialization pointand corresponding residual call:let fun foo' (v1', v2') = ...in ... foo' (v1, v2) ...end114

datatype IntTree = IntLeaf of int| IntNode of IntTree * IntTreedatatype Result = Failure| Success of int listfun aux_reverse [] a= a| aux_reverse (x :: l) a= aux_reverse l (x :: a)fun our_reverse l= aux_reverse l []fun match (IntLeaf(i)) (IntLeaf(j)) l k= if (i = j) then k (i :: l) else Failure| match (IntLeaf(i)) (IntNode(_,_)) l k= Failure| match (IntNode(pl,pr)) (IntLeaf(j)) l k= Failure| match (IntNode(pl,pr)) (IntNode(dl,dr)) l k= match pl dl l (fn l => match pr dr l k)fun pm4 p1 p2= match p1 p2 [] (fn l =>Success (our_reverse l))Figure 1: PM4 | source pattern-matching programwhere foo', v1', and v2' are fresh names. All the staticinformation about the arguments of foo has been propa-gated into the body of foo'. All the dynamic informationhas been �ltered out and residualized in the call to foo'| without traversing any symbolic values. Note that, ingeneral, there is no relationship between the number ofarguments of the specialization point and the number ofarguments of its residualized versions.The specializer is designed to be simple, e�cient, andextensible. Set-based analysis itself provides one possi-ble extension: it yields more information than a typicalbinding-time analysis. Instead of stating that an identi-�er denotes a (partially) static or dynamic value, it de-scribes a set of values for the identi�er. This provides anopportunity for much �ner program specialization. Set-based analysis also provides information about side ef-fects and control e�ects. We are currently extending thespecializer to exploit that information.5 Preliminary resultsCurrently the analysis handles full ML, while the special-izer runs on purely functional programs. We are in theprocess of extending the specializer and the interface tohandle side-e�ects and exceptions.2Since we use an intermediate language, we cannot2Since exceptions are implemented using refs in the New Jerseycompiler, we cannot hope to handle exceptions before side-e�ects,even though they are conceptually easier to add to a functionalstarting point.
datatype IntTree = IntLeaf of int| IntNode of IntTree * IntTreedatatype Result = Failure| Success of int listfun pm4_residual (IntNode(IntNode(IntLeaf 6,IntLeaf 4),IntNode(IntLeaf 5,IntLeaf 8)))= Success [6,4,5,8]| pm4_residual _= FailureFigure 2: PM4 | residual pattern-matching programshow the usual examples of source programs and neatlyspecialized residual programs. Instead, we have run asmall series of benchmarks on a set of pattern matchingprograms.PM1 is a simple matcher on lists. PM2, PM3, andPM4 match on the tree structure de�ned in Figure 1.PM2 uses straightforward recursive descent and returns aboolean. PM3 uses a continuation to linearize the binarydescent. PM4 uses a continuation and returns a Result,as de�ned in Figure 1. It accumulates the list of matchedvalues to return if the entire match succeeds, and throwsaway this list if the match fails.Let us now illustrate the behavior of our system usingthe PM4 program (Figure 1) and the following pattern:val pat = IntNode(IntNode(IntLeaf 6,IntLeaf 4),IntNode(IntLeaf 5,IntLeaf 8))In the context of this pattern, the analysis phase com-putes the following information:� The �rst argument of match is either pat or one ofthe subterms of pat. In particular, this argument isstatic.� The second argument of match is dynamic. More-over, the analysis determines that it is either thevalue passed in at the top-level call to pm4, or somesubterm thereof.� The argument to our reverse is a list whose struc-ture is statically determined. Its elements arecontained in the set f4; 5; 6; 8g. This is alsothe information computed for both arguments ofaux reverse, and the return values of our reverseand aux reverse.� The result of pm4 is a dynamically determined valuethat is either Failure or of the form Success Lwhere L is a list whose structure is statically de-termined and whose elements are contained in theset f4; 5; 6; 8g.Each dynamic conditional expression is then selected as aspecialization point (though again alternative strategiesare possible [19]).115

pro- static source residual an. sp. ratio ratiogram data size comp. run size comp. run time time run size(kb) (sec) (�sec) (kb) (sec) (�sec) (sec) (sec) timepm1 length 3, distinct 3.0 0.4 8.4 3.0 0.3 3.8 0.1 0.06 0.45 1.0length 20, distinct 4.4 0.6 20.7 17.0 0.8 9.2 0.1 0.48 0.44 3.9pm2 full, distinct, depth 4 4.4 0.9 83 18.3 1.2 20.9 0.1 0.53 0.25 4.2sparse, distinct, depth 5 3.4 0.7 32 6.4 0.6 7.4 0.1 0.16 0.23 1.9full, identical, depth 5 6.3 1.3 169 4.6 0.6 54.4 0.1 0.18 0.32 0.7mixed, depth 5 4.9 1.0 110 18.0 2.1 20.4 0.1 0.57 0.19 3.7pm3 full, distinct, depth 4 5.5 1.2 384 23.4 2.6 22.9 0.1 0.80 0.06 4.3sparse, distinct, depth 5 4.4 1.0 147 7.8 0.5 7.1 0.1 0.24 0.05 1.7full, identical, depth 5 7.3 1.6 774 48.9 7.3 31.7 0.1 1.67 0.04 6.7mixed, depth 5 5.7 1.3 475 26.7 3.6 26.6 0.1 0.85 0.06 4.7pm4 full, distinct, depth 4 7.6 2.0 499 24.3 2.7 31.8 0.2 0.93 0.06 3.2sparse, distinct, depth 5 6.5 1.6 183 8.1 0.5 13.3 0.2 0.31 0.07 1.2full, identical, depth 5 9.3 2.2 1031 50.5 7.9 58.2 0.2 2.46 0.06 5.4mixed, depth 5 8.0 1.8 635 30.9 3.9 37.1 0.2 1.24 0.06 3.9map factorial 1.8 0.5 90 0.9 0.4 69 0.1 0.03 0.75 0.5(a) [1,2,3,4,5,8] (factorial) 1.9 0.6 99 0.7 0.3 69 0.1 0.06 0.70 0.4(b) [1,2,3,4,5,8] (double) 1.9 0.5 53 0.7 0.3 29 0.1 0.06 0.55 0.4Figure 3: Pell-mell benchmarks.When specializing PM4 with respect to its �rst ar-gument, the specializer reduces all expressions that onlydepend on the pattern, and reconstructs all the ones thatdepend on the datum.The specialized lambda term corresponds to the MLcode of Figure 2. The specialized code �rst traverses thedatum, and only if it succeeds does it build the resultlist | a nice result considering that PM4 constructs theresult list on the y even if pattern matching fails [10].The actual lambda result of specializing PM4 withrespect to the pattern above is shown in Figures 4 and 5.All variables are represented with numbers. The outer�x-expression declares recursive equations (which havenot been post-unfolded here, for readability). It takes aquadruple: the names of the recursive equations; theirtype tag; their de�nition; and the expression to be evalu-ated in the new (recursive) scope. Each function is passeda record. Each switch statement is a case expression. Itdispatches on the �rst component. The second compo-nent lists the constructors that can be switched on. Thethird component lists the alternative branches (construc-tor and corresponding expression). The fourth compo-nent is the fallthrough branch. Note that there is noimplicit pattern matching in the lambda language: ex-plicit deconstruction (DECON) is needed. Primitive opera-tions are tagged PRIM. The only primitive operation usedhere is integer equality (IEQL).The specializer constructs code where each intermedi-ate result is named and where operations are only appliedto trivial expressions. This makes CPS transformationvery simple | but of course, the rest of the New Jerseycompiler does not know that.The table in Figure 3 gives some benchmarks for thespecialization of the pattern matchers and the usual mapfunction.The size and compilation �gures should be taken witha grain of salt. Sizes are for raw lambda code. For sourceprograms, the sizes refer to the actual (pre-processed)
input to the partial evaluator, including the static datum,rather than to the running program that the the run-timemeasures refer to. For source programs, compilation timeincludes type-checking and de-sugaring.The last two columns give ratios of residual oversource run time, and of residual over source size.PM2, PM3, and PM4 have been specialized with re-spect to four kinds of trees: sparse and full trees with dis-tinct leaves, a full tree with identical leaves and a mixedtree. The �gures given in Table 3 clearly show the di�er-ences between the programs. Generally we see that therun-time gain by specialization is greater when the pro-gram is more complex. As the static data grows, however,the residual program also grows. In PM2, the growth isreduced when the tree has many identical leaves, becauseof the sharing of code inherent in polyvariant special-ization. However, in PM3 and PM4, the continuationinhibits this e�ect, and the residual programs get corre-spondingly larger.The map function was specialized both with respect toits �rst argument (factorial) and its second argument (alist of 6 integers). The corresponding residual programswere run respectively with the list and with factorial (a)and double (b).The benchmarks were run on a SPARC station ELCwith 28 Mb RAM.6 ConclusionWe are building a partial evaluator for Standard ML pro-grams. Our partial evaluator is implemented as an exten-sion of the New Jersey compiler (and is itself written inML). It is structured as an o�-line system consisting of aset-based binding-time analysis and a continuation-basedspecializer.The goals of our design are simplicity, robustness, ande�ciency. It streamlines a number of concepts from pre-vious partial evaluators. Moreover, lightweight symbolic116

FIX ([183784,183790,183819,183797,183809,183825,183835,183804,183815,183831,183840],[BOXEDty,BOXEDty,BOXEDty,BOXEDty,BOXEDty,BOXEDty,BOXEDty,BOXEDty, BOXEDty,BOXEDty,BOXEDty],[FN (183786,BOXEDty,SWITCH (VAR 183786,[TAGGED 0,TAGGED 1],[(DATAcon (prim?,TAGGED 1,BOXEDty),APP (FN (183787,BOXEDty,APP (FN (183788,BOXEDty,APP (FN (183789,BOXEDty,APP (FN (183854,BOXEDty,VAR 183854),APP (APP (VAR 183790,VAR 183789), VAR 183788))),SELECT (1,VAR 183787))),SELECT (0,VAR 183787))),DECON ((prim?,TAGGED 1,BOXEDty),VAR 183786))),(DATAcon (prim?,TAGGED 0,BOXEDty),APP (FN (183855,BOXEDty, CON ((prim?,CONSTANT 0,BOXEDty),RECORD [])),DECON ((prim?,TAGGED 0,BOXEDty),VAR 183786)))],NONE)),FN (183792,BOXEDty,FN (183793,BOXEDty,SWITCH (VAR 183793,[TAGGED 0,TAGGED 1],[(DATAcon (prim?,TAGGED 1,BOXEDty),APP (FN (183794,BOXEDty,APP (FN (183795,BOXEDty,APP (FN (183796,BOXEDty,APP (FN (183852,BOXEDty,VAR 183852),APP (APP (APP (VAR 183797,VAR 183796), VAR 183792),VAR 183795))),SELECT (1,VAR 183794))), SELECT (0,VAR 183794))),DECON ((prim?,TAGGED 1,BOXEDty),VAR 183793))),(DATAcon (prim?,TAGGED 0,BOXEDty),APP (FN (183853,BOXEDty, CON ((prim?,CONSTANT 0,BOXEDty),RECORD [])),DECON ((prim?,TAGGED 0,BOXEDty),VAR 183793)))],NONE))),FN (183821,BOXEDty,SWITCH (VAR 183821,[TAGGED 0,TAGGED 1],[(DATAcon (prim?,TAGGED 1,BOXEDty),APP (FN (183822,BOXEDty,APP (FN (183823,BOXEDty,APP (FN (183824,BOXEDty,APP (FN (183846,BOXEDty,VAR 183846),APP (APP (VAR 183825,VAR 183824), VAR 183823))),SELECT (1,VAR 183822))), SELECT (0,VAR 183822))),DECON ((prim?,TAGGED 1,BOXEDty),VAR 183821))),(DATAcon (prim?,TAGGED 0,BOXEDty),APP (FN (183847,BOXEDty, CON ((prim?,CONSTANT 0,BOXEDty),RECORD [])),DECON ((prim?,TAGGED 0,BOXEDty),VAR 183821)))],NONE)),FN (183799,BOXEDty,FN (183800,BOXEDty,FN (183801,BOXEDty,SWITCH (VAR 183801,[TAGGED 0,TAGGED 1],[(DATAcon (prim?,TAGGED 1,BOXEDty), CON ((prim?,CONSTANT 0,BOXEDty),RECORD [])),(DATAcon (prim?,TAGGED 0,BOXEDty),APP (FN (183802,BOXEDty,APP (FN (183803,BOXEDty,APP (FN (183851,BOXEDty,VAR 183851),APP (APP (APP (VAR 183804,VAR 183799), VAR 183800),VAR 183803))),APP (PRIM (IEQL, ARROWty (RECORDty [INTty,INTty],BOOLty)),RECORD [INT 6,VAR 183802]))),DECON ((prim?,TAGGED 0,BOXEDty),VAR 183801)))], NONE)))),FN (183811,BOXEDty,FN (183812,BOXEDty,SWITCH (VAR 183812,[TAGGED 0,TAGGED 1],[(DATAcon (prim?,TAGGED 1,BOXEDty), CON ((prim?,CONSTANT 0,BOXEDty),RECORD [])),(DATAcon (prim?,TAGGED 0,BOXEDty),APP (FN (183813,BOXEDty,APP (FN (183814,BOXEDty,APP (FN (183849,BOXEDty,VAR 183849),APP (APP (VAR 183815,VAR 183811), VAR 183814))),APP (PRIM (IEQL, ARROWty (RECORDty [INTty,INTty],BOOLty)),RECORD [INT 4,VAR 183813]))),DECON ((prim?,TAGGED 0,BOXEDty),VAR 183812)))],NONE))),Figure 4: Specialized version of PM4 (to be continued)117

FN (183827,BOXEDty,FN (183828,BOXEDty,SWITCH (VAR 183828,[TAGGED 0,TAGGED 1],[(DATAcon (prim?,TAGGED 1,BOXEDty),CON ((prim?,CONSTANT 0,BOXEDty),RECORD [])),(DATAcon (prim?,TAGGED 0,BOXEDty),APP (FN (183829,BOXEDty,APP (FN (183830,BOXEDty,APP (FN (183845,BOXEDty,VAR 183845),APP (APP (VAR 183831,VAR 183827), VAR 183830))),APP (PRIM (IEQL, ARROWty (RECORDty [INTty,INTty],BOOLty)),RECORD [INT 5,VAR 183829]))),DECON ((prim?,TAGGED 0,BOXEDty),VAR 183828)))],NONE))),FN (183837,BOXEDty,SWITCH (VAR 183837,[TAGGED 0,TAGGED 1],[(DATAcon (prim?,TAGGED 1,BOXEDty), CON ((prim?,CONSTANT 0,BOXEDty),RECORD [])),(DATAcon (prim?,TAGGED 0,BOXEDty),APP (FN (183838,BOXEDty,APP (FN (183839,BOXEDty,APP (FN (183843,BOXEDty,VAR 183843),APP (VAR 183840,VAR 183839))),APP (PRIM (IEQL,ARROWty (RECORDty [INTty,INTty],BOOLty)),RECORD [INT 8,VAR 183838]))),DECON ((prim?,TAGGED 0,BOXEDty),VAR 183837)))],NONE)),FN (183806,BOXEDty,FN (183807,BOXEDty,FN (183808,BOXEDty,SWITCH (VAR 183808,[CONSTANT 0,CONSTANT 1],[(DATAcon (prim?,CONSTANT 0,BOXEDty), CON ((prim?,CONSTANT 0,BOXEDty),RECORD [])),(DATAcon (prim?,CONSTANT 1,BOXEDty),APP (FN (183850,BOXEDty,VAR 183850),APP (APP (VAR 183809,VAR 183807),VAR 183806)))], NONE)))),FN (183817,BOXEDty,FN (183818,BOXEDty,SWITCH (VAR 183818,[CONSTANT 0,CONSTANT 1],[(DATAcon (prim?,CONSTANT 0,BOXEDty), CON ((prim?,CONSTANT 0,BOXEDty),RECORD [])),(DATAcon (prim?,CONSTANT 1,BOXEDty),APP (FN (183848,BOXEDty,VAR 183848), APP (VAR 183819,VAR 183817)))],NONE))),FN (183833,BOXEDty,FN (183834,BOXEDty,SWITCH (VAR 183834,[CONSTANT 0,CONSTANT 1],[(DATAcon (prim?,CONSTANT 0,BOXEDty), CON ((prim?,CONSTANT 0,BOXEDty),RECORD [])),(DATAcon (prim?,CONSTANT 1,BOXEDty),APP (FN (183844,BOXEDty,VAR 183844), APP (VAR 183835,VAR 183833)))],NONE))),FN (183842,BOXEDty,SWITCH (VAR 183842,[CONSTANT 0,CONSTANT 1],[(DATAcon (prim?,CONSTANT 0,BOXEDty), CON ((prim?,CONSTANT 0,BOXEDty),RECORD [])),(DATAcon (prim?,CONSTANT 1,BOXEDty),CON ((prim?,UNTAGGED,BOXEDty),CON ((prim?,UNTAGGEDREC 2,BOXEDty),RECORD [INT 6,CON ((prim?,UNTAGGEDREC 2,BOXEDty),RECORD [INT 4,CON ((prim?,UNTAGGEDREC 2,BOXEDty),RECORD [INT 5,CON ((prim?,UNTAGGEDREC 2,BOXEDty),RECORD [INT 8,CON ((prim?,CONSTANT 0,BOXEDty),RECORD [])])])])])))],NONE))],FN (183783,BOXEDty, APP (FN (183856,BOXEDty,VAR 183856),APP (VAR 183784,VAR 183783)))))Figure 5: Specialized version of PM4 (continued and ended)118

values provide an e�cient representation of static values.One of the original motivations for this work is theFOX project [3]. This project uses ML for building sys-tem software, and crucially needs a powerful compile-time optimizer. For various reasons, existing implemen-tations of ML do not use global ow analyses or partialevaluation. Our work is one of the �rst e�orts to em-ploy global analysis for ML program transformation andoptimization.We are currently experimenting with the output of ml-lex and ml-yacc, and with Lal George's code generator.References[1] Andrew W. Appel. Compiling with Continuations.Cambridge University Press, 1992.[2] Andrew W. Appel and David B. MacQueen. Stan-dard ML of New Jersey. In Jan Maluszy�nski andMartin Wirsing, editors, Third International Sym-posium on Programming Language Implementationand Logic Programming, number 528 in LectureNotes in Computer Science, pages 1{13, Passau,Germany, August 1991.[3] Edoardo Biagioni, Robert Harper, Peter Lee, andBrian Milnes. Signatures for a network protocolstack: A systems application of Standard ML. InTalcott [23].[4] Lars Birkedal and Morten Welinder. Partial evalua-tion of Standard ML. Master's thesis, DIKU, Com-puter Science Department, University of Copen-hagen, August 1993.[5] Anders Bondorf. Automatic autoprojection of high-er-order recursive equations. Science of ComputerProgramming, 17(1-3):3{34, 1991. Special issue onESOP'90, the Third European Symposium on Pro-gramming, Copenhagen, May 15-18, 1990.[6] Anders Bondorf. Improving binding times withoutexplicit CPS-conversion. In William Clinger, editor,Proceedings of the 1992 ACM Conference on Lispand Functional Programming, LISP Pointers, Vol. V,No. 1, pages 1{10, San Francisco, California, June1992. ACM Press.[7] Charles Consel. Binding time analysis for higher or-der untyped functional languages. In Mitchell Wand,editor, Proceedings of the 1990 ACM Conference onLisp and Functional Programming, pages 264{272,Nice, France, June 1990. ACM Press.[8] Charles Consel. A tour of Schism: A partial evalu-ation system for higher-order applicative languages.In Schmidt [22], pages 145{154.[9] Charles Consel and Olivier Danvy. Tutorial noteson partial evaluation. In Susan L. Graham, edi-tor, Proceedings of the Twentieth Annual ACM Sym-posium on Principles of Programming Languages,pages 493{501, Charleston, South Carolina, January1993. ACM Press.[10] Olivier Danvy. Semantics-directed compilation ofnon-linear patterns. Information Processing Letters,37:315{322, March 1991.
[11] Bob Harper and Mark Lillibridge. Polymorphic typeassignment and CPS conversion. In Carolyn L. Tal-cott, editor, Special issue on continuations (Part I),LISP and Symbolic Computation, Vol. 6, Nos. 3/4.Kluwer Academic Publishers, December 1993.[12] Nevin Heintze. Set-Based Program Analysis. PhDthesis, School of Computer Science, Carnegie MellonUniversity, Pittsburgh, Pennsylvania, October 1992.[13] Nevin Heintze. Set-based program analysis of MLprograms. In Talcott [23].[14] Nevin Heintze and Joxan Ja�ar. A �nite presenta-tion theorem for approximating logic programs. InPaul Hudak, editor, Proceedings of the SeventeenthAnnual ACM Symposium on Principles of Program-ming Languages, pages 197{209, San Francisco, Cal-ifornia, January 1990. ACM Press.[15] Neil D. Jones, Carsten K. Gomard, and Peter Ses-toft. Partial Evaluation and Automatic ProgramGeneration. Prentice-Hall International, 1993.[16] Neil D. Jones, Peter Sestoft, and Harald S�nder-gaard. An experiment in partial evaluation: Thegeneration of a compiler generator. In Jean-PierreJouannaud, editor, Rewriting Techniques and Appli-cations, number 202 in Lecture Notes in ComputerScience, pages 124{140, Dijon, France, May 1985.[17] Morry Katz and Daniel Weise. Towards a new per-spective on partial evaluation. In Charles Consel,editor, ACM SIGPLAN Workshop on Partial Eval-uation and Semantics-Based Program Manipulation,Research Report 909, Department of Computer Sci-ence, Yale University, pages 29{36, San Francisco,California, June 1992.[18] Julia L. Lawall and Olivier Danvy. Continuation-based partial evaluation. In Talcott [23].[19] Karoline Malmkj�r. Towards e�cient partial evalu-ation. In Schmidt [22], pages 33{43.[20] Flemming Nielson and Hanne Riis Nielson. Two-Level Functional Languages, volume 34 of CambridgeTracts in Theoretical Computer Science. CambridgeUniversity Press, 1992.[21] Erik Ruf. Topics in Online Partial Evaluation.PhD thesis, Stanford University, Stanford, Califor-nia, February 1993. Technical report CSL-TR-93-563.[22] David A. Schmidt, editor. Proceedings of the Sec-ond ACM SIGPLAN Symposium on Partial Evalu-ation and Semantics-Based Program Manipulation,Copenhagen, Denmark, June 1993. ACM Press.[23] Carolyn L. Talcott, editor. Proceedings of the 1994ACM Conference on Lisp and Functional Program-ming, LISP Pointers (to appear), Orlando, Florida,June 1994. ACM Press.119

Minimal Typing DerivationsNikolaj Skallerud Bj�rnerStanford [email protected] present an algorithm which �nds typing derivationsfor ML typeable expressions, such that polymorphic ab-straction is minimized where possible. Consequently, un-necessary boxing or code duplication can be avoided, al-lowing more e�cient ML implementations.1 IntroductionThis paper has been inspired by the use of typing deriva-tions in the analysis of ML programs. In several applica-tions, polymorphism imposes a strong restriction on thekinds of optimizations one can perform. Unboxing anal-ysis [5] is based on typing derivations. It inserts suit-able coercions such that boxed value passing is mostlyavoided. Further boxing can be reduced by avoiding un-necessary polymorphism. In the specialization of ad-hocpolymorphic primitives (such as equality), more e�cientcode can be generated when the types of the primitivesare known at compile-time [1]. Tag-free garbage collec-tion [9] also bene�ts from a typing derivation that avoidspolymorphism. Finally, extensions of the results pre-sented here indicate ways to resolve instances of overload-ing resolution, i.e. determining the types of overloadedoperators (+,�) and resolving ex records. A full versionof this extended abstract is found in [2].The type inference algorithm W presented by [4, 3]generates most general type schemes for ML programs,allowing maximal exibility in program composition. Asa side-e�ect, W also provides a typing derivation or, equiv-alently, a type annotation. However, the type schemes as-sociated with let-bound variables generally will containtype abstractions where they may not be necessary. Forinstance, consider the program:letmkpair = �x:(x;x)in mkpair 3.14Algorithm W would produce the type annotation:letmkpair : 8�:�! �� � =��:�x : �:(x;x)in mkpair [real] 3.14 : real � realinstead of the more re�ned
letmkpair : real ! real � real =�x : real:(x; x)in mkpair 3.14 : real � realThe algorithm M presented in this paper will assign thelatter annotation, so that the polymorphic abstraction isavoided.It turns out that typeable expressions can be conve-niently divided into two classes. One of the classes isthat of programs containing no dead code, i.e. no coderedundant in the evaluation of the expression. For thisclass, we show that there is a unique minimal derivation,in the sense that no other typing derivation of the sameexpression would avoid type abstractions, where the onefound could not.For the other class, consisting of programs contain-ing dead code, or what we will call cut-type variables,unfortunately we can not always �nd a unique minimalderivation. We argue that programs occurring in prac-tice are in the �rst class, and therefore the algorithmproposed here is a practical solution to the problem weformulate.The rest of the paper is organized as follows: In Sec-tion 2 we formalize the problem precisely, and introducethe necessary notation. Section 3 summarizes a gener-alized result on algorithm W's soundness and complete-ness with respect to typing derivations. Section 4 intro-duces algorithm M, which �nds minimal typing deriva-tions. Section 5 discusses soundness and relative com-pleteness with respect to the notion of cut-type variables.In Section 6 we investigate further the role of cut-typevariables. Section 7 discusses applications.2 Problem FormalizationAs in the introductory example, we use type-annotatedexpressions instead of typing derivations. It is simple toestablish the equivalence between these two representa-tions [6].Types and expressions are thus of the form:� ::= � j int j real j bool j � � � 0 j � ! � 0� ::= 8~�:�e ::= x � j (e; e0) j e e0 j�x : �:ejletx : � = �~�:ein e0120

where ~� is a list of type variables and � is an instanti-ation, i.e. a map from type variables to types. Whenthere is no confusion, instantiations are written as listsof types enclosed in square brackets; if the list is empty,it is simply omitted. We will assume that there are nounrelated uses of the same type variable in e. If the typescheme 8~�:� is bound to x, the instantiation � instan-tiates the variables in ~� to types. With the expressione we associate a type environment, TE, containing thetypes of e's free variables and some prede�ned constants,such as the projections �1 and �2. Formally, TE is a �-nite map from variables to type schemes. The statementTE ` �~�:e : �, is called a typing judgement; it assertsthat the type annotations in e are well-formed under TE,and that the derivable type-scheme of �~�:e is �. The toplevel type abstraction �~� is used to abstract variablesbound in �. Type substitution into annotated expres-sions is standard: � e indicates that � is applied to everytype occurring in e, where the usual renaming and scop-ing rules apply to �-abstracted type variables. A gen-eralization of the standard substitution theorem is nowimmediate: If the judgement TE ` e : � is a well-formed,then �TE ` �e : �� is well-formed too.We take e to be the expression where typing informa-tion has been erased, i.e.:e ::= x j (e; e0) j e e0 j�x:e jlet x = e in e0Type schemes are ordered as in [3]: let � = 8~�:� and�0 = 8~�0:� 0 be type schemes, and let � be a substitutionwith dom � � ~�0, then: � <� �0 i� � = �� 0 and ~� doesnot contain variables free in �0.This ordering is generalized to an ordering �� overannotations e; e0 with the same erasure e, and free vari-ables typed by TE and TE0, respectively:(TE ` x �) �� (TE0 ` x �0) i�TE(x)� = � (TE0(x)�0)(TE ` e1 e2) �� (TE0 ` e01 e02) i�(TE ` e1) �� (TE0 ` e01)and (TE ` e2) �� (TE0 ` e02)(TE ` (e1; e2)) �� (TE0 ` (e01; e02)) i�(TE ` e1) �� (TE0 ` e01)and (TE ` e2) �� (TE0 ` e02)(TE ` �x : �:e) �� (TE0 ` �x : � 0:e0) i�(TEx [ fx : �g ` e) �� (TE0x [ fx : � 0g ` e0)and � = � � 0(TE ` letx : � = �~�e1 in e2) ��(TE0 ` letx : �0 = �~�0 e01 in e02) i�(TEx [ fx : �g ` e2) �� (TE0x [ fx : �0g ` e02)and there is a �0 such that dom�0 � ~�0and (TE ` e1) ��0 (�TE0 ` �e01)By a simple induction on the structure of expressions,it follows that in the last rule we furthermore have theconstraint � <�0 ��0. This establishes the connectionbetween the ordering relation on type schemes and theone de�ned here for annotated expressions.When � is clear from the context, or is irelevant, thenwe write � instead of ��.A comparison of two annotations illustrates the mainideas of the ordering:
fx : intg `let id : int! int = �x : int:xin id x�[�7!int]fx : �g ` let id : 8�:� ! � = ���x : �:xin id [�]xThere are 2 places where the top-most annotation is morespeci�c than the lower. The �rst place is in the typesassociated with the free variable x: the type int is asubstitution instance of the type variable �. Secondly thesubstitution �0 introduced in the rule for let-expressions is[� 7! int], thus instantiating the polymorphic abstractedtype variable �.Speaking in more general terms we note that the or-dering relation � re ects the degree of type abstractionin typing derivations. The smaller an annotation is in theordering �, the more re�ned the types are. Ideally, thesmallest annotations would favor type constants (suchas real, int) with �xed-length storage requirements, andthey would introduce polymorphism only where it is re-ally needed.Although the requirements imposed by the orderingrelation may seem overly restrictive (every annotationin e equals the corresponding annotation in e0, modulo auniform substitution �) we show that it captures the trueproperties of principal derivability and minimal derivabil-ity: algorithm W �nds the greatest element in the order-ing, and M will (under certain conditions) �nd the leastelement. More precisely, when M is given e, where edoes not contain dead code, and the type judgement TE` �~�:e : 8~�:� , it �nds the least annotation e0 preservingTE ` �~�:e0 : 8~�:� .In the next section we will shortly motivate the claimabout algorithm W, before treating the dual M in depth.3 Generalized completeness for WWith some trivial modi�cations of W we obtain an algo-rithm which, besides producing most general type schemes,also annotates ground expressions e.W : TypeEnvironment � Expr�! Substitution � Expr � TypeW(TE,x) =let 8�1; : : : ; �n:� 0 = TE(x)�1; : : : ; �n be new type variablesin (id; x [�1; : : : ; �n]; [�i 7! �iji 2 f1; : : : ; ng]� 0)W(TE,�x:e1) =let (S1; e1; �1) = W(TEx [ fx : �g; e1); � is newin (S1; �x : S1�:e1; S1 � ! �1)W(TE,e1e2) =let (S1; e1; �1) = W(TE; e1)(S2; e2; �2) = W(S1TE; e2)V = unify(S2�1; �2 ! �); � is newin (V S2S1; (V S2e1) (V e2); V �)W(TE,(e1; e2)) =let (S1; e1; �1) = W(TE; e1)121

(S2; e2; �2) = W(S1TE; e2)in (S2S1; (S2e1; e2); S2�1 � �2)W(letx = e1 in e2) =let (S1; e1; �1) = W(TE; e1)8~�:�1 = Gen(S1TE; �1)(S2; e2; �2) = W(S1TEx [ fx : 8~�:�1g; e2)in (S2 S1;letx : (S28~�:�1) = (S2�~�e1) ine2; �2)Note: If uni�cation fails, then the entire algorithm fails.The established soundness and completeness proper-ties of the original algorithm W can also be generalizedappropriately to the modi�ed formulation:Theorem 1 (Soundness of W) If W(TE,e) succeedswith (S; e; �) then the type annotation S TE ` e : � iswell formed.The original soundness statement in [3] asserts the ex-istence of a typing derivation. Here this derivation isconstructed explicitly in the form of an annotated ex-pression.When rephrasing the completeness statement, we re-place the original ordering on type schemes by the order-ing on annotated expressions. Thus the principal typingproperty generalizes neatly to principal typing annota-tion.Theorem 2 (Completeness of W) Given TE and e,let TE0 be an instance of TE and e0 be an annotation ofe such that TE0 ` e0 : � 0is a well-formed annotation (with external type � 0). Then(i) W(TE,e) succeeds (ii) If W(TE,e)= (S; e; �) then, forsome substitution R, TE0 = RS (TE) andTE0 ` e0 �R S TE ` eA simple rephrasing of the original proof of W's com-pleteness establishes this theorem. The original proofcan be found in [3] and the detailed rephrasing is foundin [2]. Here, however, we will mainly concentrate on thedevelopment of algorithm M.4 Minimal Derivations via Algorithm MDual to W's dependence on uni�cation, M will heavilyrely on anti-uni�cation. The original algorithms for anti-uni�cation are given in [7, 8]. Here, we assume thatwe are given an algorithm AntiUnify: Type� ! Type� Substitution� , which takes a �nite non-empty list oftypes h�1; : : : ; �ni and returns a type � and substitutionsh�1; : : : ; �ni with the same domains, such that �i = �i� ,and � is the most speci�c generalizer of h�1; : : : ; �ni. Un-like uni�ers, generalizers always exist.The idea underlying M is quite simple: A recursivedescent through the expression e collects for each let-bound variable x : � all the associated type instantiations�1; : : : ; �n. When � is applied to these instantiations, alist of types is formed (�1 = ��1; : : : ; �n = ��n). Usinganti-uni�cation on this list makes it possible to extract aleast general type scheme for x.
M's auxiliary result A collects the instantiations oflet-bound variables. It is a map from variables to listsof instantiations. Two maps A and A0 are merged bythe appending operation A + A0 def= [x 7! A(x)@A0(x)],where we de�ne A(x) def= hi if x 62 dom A. To ensurethat type variables are abstracted appropriately, M alsocollects bound type variables in the set B.The algorithm is described more precisely below:M : Expr ! Expr � InstEnvironment �TyVar�setM(x �) = (e; [x 7! h�i]; f g)M(�x : �:e1) =let (e01; A;B) = M(e1)in (�x : �:e01;A n fxg; B)M(e1 e2) =let (e01; A1;B1) = M(e1)(e02; A2;B2) = M(e2)in (e01 e02;A1 +A2;B1 [B2)M((e1; e2)) =let (e01; A1;B1) = M(e1)(e02; A2;B2) = M(e2)in ((e01; e02);A1 + A2;B1 [B2)M(letx : 8~�:� = �~�e1 in e2) =if x 62 FV (e2) thenlet (e02; A2;B2) = M(e2)(e01; A1;B1) = M(e1)in (letx : 8~�:� = �~�e01 in e02;A1 + (A2 n fxg);B1 [B2 [ ~�)else let(e02; A2;B2) = M(e2)h�1; : : : ; �ni = map (��:(8~�:�) �) A2(x)(� 0; �) = AntiUnifyh�1; : : : ; �nif 1; : : : ; mg= FV(� 0) \ B2 01; : : : ; 0m be new variables.� 00 = [ i 7! 0i]� 0� = unify~�(�; � 00)~� = dom � [ f 01; : : : ; 0mg(e01; A1;B1) = M(� e1)in (letx : 8~�:�� = �~� e01 in subst(x; �; ~�; e02);A1 + (A2 n fxg);B1 [B2 [ ~�)The auxiliary function subst updates the instantiationsof x with respect to the new type-scheme. Hence eachinstantiation � associated with an occurrence of x in e02is changed to the instantiation S [unify~�(� �; �0 �)j� 2dom �], where the subscript ~� indicates which variablesare uni�able. For example let � = [� 7! �], ~� = f�; gand e02 = �y : �:x [� 7! int], then subst(x; �; ~�; e02) = �y :�:x [� 7! int].More formally, we de�ne subst as follows.subst : Var � Substitution � TyVar-set � Expr ! Exprsubst(x; �; ~�; x0 �0) =if x = x0122

then x Sfunify~�(� �; �0 �)j� 2 dom �gelse x0 �0subst(x; �; ~�; �x0 : �:e1) =ifx = x0then �x0 : �:e1else �x0 : �:subst(x; �; ~�; e1)subst(x; �; ~�; e1 e2) = subst(x; �; ~�; e1) subst(x; �; ~�; e2)subst(x; �; ~�; (e1; e2)) = (subst(x; �; ~�; e1), subst(x; �; ~�; e2))subst(x; �; ~�;letx0 : � = �~�e1 in e2) =ifx = x0then letx0 : � = �~� subst(x; �; ~�; e1)in e2elseletx0 : � = �~� subst(x;�; ~�; e1) in subst(x; �; ~�; e2)When applying algorithm M at the top level, thereis no need for the extra results A and B, we thereforewrite M(e) instead of let (e0; A;B) = M(e) in e0 to savenotation.5 Soundness and CompletenessIn this section we will prove the soundness of algorithmM, and identify a class of expressions, for which M iscomplete.5.1 SoundnessAlgorithm M is sound, in the sense that given a wellformed type annotation TE ` �~�:e : � it produces an-other well formed annotation preserving the outer typescheme.Theorem 3 (Soundness of M) Let � be of the form8~�:� . If TE ` �~�:e : �, then TE ` �~�:M(e) : �.The relatively easy proof of soundness uses a moresubtle soundness of subst.Lemma 1 Let � = 8~�:� , �0 = 8~�:� 0 and BV be the setof bound type variables in the expression e. Furthermorelet �1; : : : ; �n be the instantiations of the type-scheme � ofthe variable x in e.If 1. TEx [ fx : �g ` e : �2. FV(�0) is disjoint from BV3. �0 <� � and each of �1� to �n� is an instance of �0then the annotation induced by subst is well formed andTEx [ fx : �0g ` subst(x; �; ~�; e) =id TEx [ fx : �g ` eIn the lemma =id abbreviates �id ^ �id, where id is theidentity substitution.The proof of this lemma is by routine induction overthe structure of e.It is now also routine to prove the soundness of M,similarly over the structure of e. The most involved caseis where e is of the form letx : 8~�:� = �~�e1 in e2, wherex 2 FV (e2), and we have the assumption TE ` e : � .Recursive calls of M produce the expressions e01 and e02,the set ~� = domm and the substitution �.
By the substitution theorem and, the fact that dom�\ FV(TE) = f g, (since dom � = ~� and generalizationupon free variables in the type environment is excluded)we have:TE ` �e1 : ��which by the induction hypothesis givesTE ` e01 : ��The induction hypothesis furthermore ensuresTEx [ fx : 8~�:�g ` e02 : �and the formation of �, BV = B2, �0 = 8~�:�� in M,ensures that the conditions of lemma 2 hold, so:TEx [ fx : 8~�:��g ` subst(x; �; ~�; e02) : �25.2 Cut-type variablesAlgorithm M is complete only for programs not contain-ing dead code. To make this notion precise, we introducethe notion of cut-type variables, which capture formallywhat is meant by dead code.De�ne inductively the (free) type variables of e by:TV(TE,x �) = FV(TE(x) �)TV(TE,e1 e2) = TV(TE,e1) [ TV(TE,e2)TV(TE,(e1; e2)) = TV(TE,e1) [ TV(TE,e2)TV(TE,�x : �:e) = FV(�) [ TV(TEx [ fx : �g,e)TV(TE,letx : 8~�:� = �~�:e1 in e2) =TV(TE,e1)n~�[ TV(TEx [ fx : 8~�:�g; e2)If the judgement TE ` e : � holds, it is trivial toverify that FV(�) � TV(TE; e). The converse inclusionis not always true, as illustrated in Section 6, thus leadingto the notion of cut-type variables. The set of cut-typevariables of TE ` e : � is the set:TV(TE; e) n (FV(�) [ FV(TE)):In words: it is the set of hidden type variables of e, i.e.those free type variables occuring free in the annotatedexpression e, but neither visible in the type environmentTE, nor the resulting type � .It is easy to decide whether a given expression e andtype environment TE have an annotation containing cut-type variables. Since our version of algorithm W gives amost general annotation of an expression e, with typeenvironment TE, any other annotation of e will be asubstitution instance of the one found by W. One maytherefore analyze the result of W for containing cut-typevariables or having unused let-bound variables with as-sociated type-schemes.As the cut-type variables are invisible in e0s type � ,the code associated with these variables represents re-dundant �-redexes, typically of the form of a projection�2(e1; e2), where e1 contains cut-type variables, or of theform letx : � = e1 in e2 where x 62 FV (e2), which istreated as a special case in algorithm M.In proof-theoretic terms, cut-type variables correspondto cuts on formulas which are not in the language of the123

�nal sequent. Similarly, it is easy to show that expres-sions in normal form do not contain cut-type variables.In the formulas-as-types analogy this amounts to the factthat normal form expressions represent cut-free proofs.If it is not possible to annotate an expression e withcut-type variables, then there is only one way to anno-tate the `let-free' subexpressions, i.e. subexpressions e2for which letx = e1 ine2 is a let-free subexpression of e.To make this statement precise, we introduce the equiv-alence relation:TE ` x � � TE0 ` x �0 i�TE(x)� = TE0(x)�0TE ` e1 e2 � TE0 ` e01 e02 i�TE ` e1 � TE0 ` e01and TE ` e2 � TE0 ` e02TE ` (e1; e2) � TE0 ` (e01; e02) i�TE ` e1 � TE0 ` e01and TE ` e2 � TE0 ` e02TE ` �x : �:e � TE0 ` �x : � 0:e0 i�TEx [ fx : �g ` e � TE0x [ fx : � 0g ` e0and � = � 0TE ` letx : � = �~�e1 in e2 �TE0 ` letx : �0 = �~�0 e01 in e02 i�TEx [ fx : �g ` e2 � TE0x [ fx : �0g ` e02Notice that the relation =id = �id ^ �id is �ner than �,that is: TE ` e =id TE0 ` e0 implies TE ` e � TE0 ` e0.A more useful observation is that:Lemma 2 Assume there are no annotations of e underTE containing cut-type variables. Let TE ` e : � and TE` e0 : � be two annotations of e resulting in the same type� . Then: TE ` e � TE ` e0Again the proof is by structural induction on e. Thecases for variables, pairs and �-abstractions are straight-forward. Let-expressions and applications require somecare, so we sketch the principal ideas:Let e = letx : � = �~�e1 in e2; and e0 = letx :�0 = �~� e01 ine02. By the principal typing property thereis a type-scheme �p = 8~�p:�p for e1 under TE that ismore general than � = 8~�:� and �0 = 8~�:�0, i.e. thereare substitutions �1 and �2 satisfying: � = �1�p and �0 =�2�p. It follows that there are annotations e3 and e03 of e2such that subst(x;�1; ~�; e3) = e2 and subst(x; �2; ~�; e03) =e02. Establishing the result is now immediate:TEx [ fx : �g ` e2is by Lemma 1 � to:TEx [ fx : �pg ` e3which by the induction hypothesis is � to:TEx [ fx : �pg ` e03which as again by Lemma 1 is � to:TEx [ fx : �0g ` e02
When e = e1 e2; and e0 = e01 e02 we may assume we aregiven well-formed typing judgements, TE ` e1 : �1 ! �;TE ` e2 : �1; TE ` e01 : � 01 ! � and TE ` e02 : � 01, but�1 and � 01 could be di�erent. We will show that they areequal, so one can apply the induction hypothesis on thesubexpressions to obtain the result.By the principal typing property, there are principalannotations such that TE ` 12 : �1p ! �p and TE `e2 : �1p are well formed judgements. Using the existenceof an most speci�c generalizer �c for �1 and � 01, whichis subsumed by �1p it is possible to conclude that thereis an annotation leading to the well formed judgements:TE ` e1c : �c ! � and TE ` e2c : �c.Now FV(�c)� TV(TE; e2c)� TV(TE; e1c e2c)� FV(TE)[ FV(�), as we apply the hypothesis of the Lemma.Hence, as the substitutions �, and �0 satisfying �(�c !�) = �1 ! � and �0(�c ! �) = � 01 ! � , may not in-volve type variables from FV(TE)[FV(�), it follows that�1 = � 01 = �c.We can now apply the induction hypothesis to e1 ande2 and draw the desired conclusion. 25.3 Relative CompletenessUsing the Lemma 2 above, the relative completeness ofM can now be stated and proved:Theorem 4 (Relative Completeness of M) Supposethat the judgements TE ` �~�:e : � and TE ` �~�:e0 : �hold, and that there are no typing derivations for e = e0that introduce cut-type variables. ThenTE ` M(e) �id TE ` e0Again we sketch the main ideas of the proof, whichproceeds by induction on the structure of e. For variables,abstractions and pairs the induction argument is straight-forward. Lemma 2 is crucial for applications: since TE` e1 e2 � TE ` e01 e02 is given, it follows that e1 and e01,respectively e2 and e02 result in the same types, the casecan therefore be established by a straight forward appli-cation of the induction hypothesis. Let-expressions arethe most elaborate to handle.Thus assume that e = letx : � = �~�e1 in e2 : � ande0 = letx : � = �~�e01 in e02 : � , where � = 8~�:� and �0 =8~ :�0. By the principal typing property a principal type-scheme, say �p = 8~�p:�p, is associated with e1 under TE,such that substitutions and 0 establish � < �p and�0 < 0 �p. Hence instead of using � and �0 to type e2 ande02, one could use �p on expressions e3 and e03 in whichonly the instantiation of x had been changed from e2 ande02 (like done in the proof of the previous theorem). Moreprecisely the expressions would be interrelated as:subst(x; ; ~�; e3) = e2subst(x; 0; ~ ; e03) = e02moreover (�):TEx [ fx : �pg ` M(e3)= TEx [ fx : �g ` subst(x; ; ~�;M(e3))= TEx [ fx : �g ` M(e2)as we use Lemma 1 for the �rst equality and, since e2and e3 only di�er with respect to the type-scheme of x,we can easily justify the second equality.124

Recursive calls of M on e2 also result in the substitu-tion � and the set of type variables ~� used in the resultingexpression, where we can reason:TEx [ fx : 8~�:��g ` subst(x;�; ~�;M(e2)) =by Lemma 2TEx [ fx : �g ` M(e2) =by (�)TEx [ fx : �pg ` M(e3) �idby the induction hypothesisTEx [ fx : �pg ` e03 =by Lemma 2TEx [ fx : �0g ` e02We will now establish the existence of a substitution �0such that 8~�:�� <�0 �0. Let �1; : : : ; �n be the instantiatedtypes of x in subst(x; �; ~�;M(e2)), and � 01; : : : ; � 0n be thecorresponding types of x in e02. The following propertiesnow hold:1. 8i : �i < 8~�:��2. 8i : � 0i < �03. 9�1; : : : �n : 8i : �i = �i� 0i and dom�i \ FV(TEx [fx : �0g) [ FV(�) = ;The �rst two hold, since each �i is an instance of the typescheme associated with the let-bound variable x. The lastholds since we have established subst(x; �; ~�;M(e2)) �ide02. From 2 and 3 we conclude that8i : �i < �0Hence �0 is an upper bound for the �i's. However with theantiuni�cation applied in algorithm M, we constructed8~�:�� to be the least upper bound for the �i's. It followsthat there is a �0, such that 8~�:�� <�0 �0.The last steps in the proof can now be applied:TE ` M(�e1) �id by the induction hypothesisTE ` �0e01 ��0 since dom �0\ FV(TE) = f gTE ` e01In summary we have shown that:TE ` M(e) �id TE ` e0which completes this case, and hereby the proof. 2A direct corollary is that eM = M(e) is the minimaltyping derivation for e when the associated type-schemeof �~�:eM is required to be �.The theorem is stated and proved for an arbitraryderivable type scheme � for e under TE. If in particu-lar we seek the minimal annotation for e supporting theprincipal type-scheme of e, we can �rst apply W, to ob-tain an annotation, and then M to eliminate redundantpolymorphism.6 Presence of Cut-type VariablesThe condition on cut-type variables might have seemednot to play a central role in the completeness proof. Onemight therefore hope to be able to do without it. Howeverthe conditions is really necessary as illustrated by thefollowing examples:
let f = �x:x;g = �x:(x; x)in �2(�x:((f x; f 3); (g x;g true)); 4)In this example there are two minimal but incompatibletyping derivations. The derivation found by W assignspolymorphic types 8�:�! � to f and 8�:� ! � � � tog. A cut-type variable � is introduced in the part:�x : �:((f [�]x; f [int] 3); (g[�] x; g [bool] true))By substituting either int for � or bool for �, one caneither specialize f to the monomorphic type int ! int,or g to bool ! bool� bool, but not both.For an example, where there is no minimal derivationat all, take:let id = �x:x;in �2(�x1:(id x1; id �x2:�1(x1; x2 + 1)); 0)in which id can be typed:8�:�! �> 8�:(int! �)! int! �> 8�:(int! int! �)! int! int! �> 8�:(int! int! int! �)! int! int! int! �> : : :6.1 How to fail minimalityThe two examples above capture precisely the only waysminimality may fail. They correspond closely to the waysuni�cation may fail: by name clash and occurs check.The �rst example illustrates name clash; the latter illus-trates occurs check failure.To illustrate this claim we regard the instantiations�1; : : : ; �n of a type-scheme �, and search for the leastgeneralizer of those. In the algorithm we obtain the gen-eralizer � by applying AntiUnifyh�1 ; : : : ; �ni. However, asthe examples illustrate, the types �1; : : : ; �n may containcut-type variables, which we can instantiate without af-fecting the type at the top level. Hence there could verywell be a substitution � of the cut-type variables, suchthat � > AntiUnifyh��1; : : : ; ��ni.For an example where there is a unique such substi-tution, take the expression annotated by W :let zero : 8�:�! int = ���x : �:0in �2(�x : �:zero [�] x;zero [real] 3:14) : intHere � is a cut-type variable and the type scheme associ-ated with zero is instantiated to �1 = ! int and �2 =real ! int. In algorithm M we �nd AntiUnifyh�1; �2i= � ! int. However, when we instantiate the cut-typevariable by � = [� 7! real], then AntiUnifyh��1; ��2i =real ! int.The two previous examples in this section illustratethat there might not be a unique substitution � yieldingminimal AntiUnifyh��1 ; : : : ��ni.125

The �rst example illustrated name clash. In the at-tempt to �nd a �, (with domain f�g) such that each row� ! �; int! int� ! �; bool! boolwould have least possible generalizers, we failed becausethe type constants int and bool could not be uni�ed.More advanced type systems might be able to optimizeon this case when regarding bool as a subtype of int.By the second example, occurs check failure is illus-trated. We tried to solve the system� ! �; (int! �)! int! �but failed, since we could iterate the substitution [� 7!(int ! �)] and continue getting more and more re�nedinstantiations.In the full paper we attempt to optimize M to treatexamples where proper instantiation of cut-type variablesleads to more re�ned annotations. However the algorithmis quite involved, and it is not clear that we can always�nd optimal solutions there. This contrasts with the easyimplementation of M and its applications.7 ApplicationsAlgorithm M is designed to serve as a back-end to anno-tations produced by any typing algorithm, for instancealgorithm W. Thus it should be relatively easy to add Mto any front end type inference algorithm. This has beendemonstated in the smaller scale, as M has been imple-mented and composed with an implementation of W for asimple, but representative part of core ML. ImplementingM was a trivial programming exercise.The claim that cut-type variables represent dead codeis formally justi�ed by the formulas as types correspon-dence, where cut-type variables represent cutformulas con-taining redundant information. In practice programs ad-mitting cut-type variables simply do not occur. Theclaim is illustrated by a large programming project inSML under current development at Stanford.The simple examples of M's applications given so farillustrate the principal ideas behind the algorithm, butmay not appeal much to applications. In all these sim-pli�ed examples, elementary compile-time partial evalu-ation would provide a more e�cient analysis. A morerealistic example, still somewhat simpli�ed, is the oftenencountered �guration:fun foobar xs =let fun len [] n = n| len ( ::ys) n = len ys (n+1)in map (len xs) xsendBy W len is typed 8�:� list ! int ! int, instead ofint list ! int ! int.Another application indicated in the introduction isto resolve ex records. This aims more at enhancing thetype inference, rather than optimizing the compilation.Examples like
fun flex (mix :fa:int,b:real,c:boolg list) =let fun take r = (#a r,#c r)in map take mixendcannot be compiled by the SML New Jersey compiler ver-sion 0.93. An error \unresolved ex record in let pattern"is reported. To make it compile, the programmer has toprovide the type annotationtake (r:fa:int,b:real,c:boolg) = (#a r,#c r)in the de�nition of take. With minimal typing deriva-tions, the compiler can resolve the record type, since takeis only used for the input mix. This problem was recentlynoted by several developers involved in a programmingproject using SML at Stanford.AcknowledgementsThe author would like to thank Mads Tofte for his consis-tent encouragement, Fritz Henglein for posing the prob-lem, Xavier Leroy for numerous comments and sugges-tions on this paper and Tom�as E. Uribe, Hugh McGuireand Eddie Chang for their proof-reading.References[1] Andrew W. Appel. Compiling with continuations.Cambridge University Press, 1992.[2] Nikolaj S. Bj�rner. Minimal typing derivations.DIKU, 1993. Student Project. Available by ftp fromtheory.stanford.edu. in /pub/nikolaj/mtd.dvi.Z[3] Luis Manuel Martins Damas. Type Assignment inProgramming Languages. PhD thesis, University ofEdinburgh, 1984.[4] Luis Manuel Martins Damas and Robin Milner. Prin-cipal type-schemes for functional programs. In POPL,1982.[5] Xavier Leroy. Unboxed objects for polymorphic typ-ing. In POPL, 1992.[6] John C. Mitchell and Robert Harper. The Essence ofML. In POPL, 1988.[7] G. Plotkin. A note on inductive generalization. Mach.Intell., 5, 1970.[8] J. C. Reynolds. Transformation systems and the al-gebraic structure of atomic formulas. Mach. Intell.,5, 1970.[9] Andrew Tolmach. Tag-free garbage collection usingexplicit type parameters. In Lisp and Functional Pro-gramming, 1994. To appear.126

An Extended Type System for ExceptionsJuan Carlos Guzm�an and Asc�ander Su�arezUniversidad Sim�on Bol��var { Departamento de Computaci�onValle de Sartenejas, Caracas 1080, VenezuelaEmail: fjcguzman,[email protected] present in this paper an extension to the ML typesystem by which it is possible to statically estimate alluntrapped exceptions that can be raised by executinga program. This type system can handle polymorphicinformation on exceptions. A prinicipal extended typeexists and can be computed for any well-typed expression.1 IntroductionSeveral programming languages such as ML[12, 15, 9] fa-cilitate the handling of exceptional computation such asreading past end-of-�le, dividing by zero, or taking thehead of an empty list. The handling of such events can bemore convenient, and more modular by using the raiseand try constructs provided by the language. Ratherthan servicing the exceptional event where it happens(e.g., division by zero) or introducing code to avoid theexecution of such an event, the ML user can escape fromcomputations by raising exceptions which can be caughtin a dynamically enclosing computation.However, ML does not provide any mechanism forcontrolling the universe of possible exceptions that canhappen, and manually keeping track of this at a givenprogram point can prove to be tedious for �rst-order com-putations, and di�cult and error prone for the higher-order case. An uncaught exception aborts the wholecomputation and is usually a result of a programmingbug (failure to catching that exception).Modula 3, another language that facilitates the han-dling of exceptional events accepts annotations in func-tion type signatures for the purpose of identifying the un-treated exceptions within the code segment, but it doesso without any veri�cation of the validity of these anno-tations.We propose in this paper a method for staticly de-termining the uncaught exceptions for ML expressions.This is done as an extension to the Hindley-Milner typesystem of the language. Intuitively, this extension con-sists on annotating the functional type constructor (!)with the set of possible exceptions that may be raised byapplying this function. Also, each expression is taggedwith the set of exceptions it may raise when evaluated.The division function raises the \division by zero" ex-ception (=) if the divisor is zero. The type of the curried
version would be= : hnum! num f=g! num;?ibeing its type the �rst component of the tuple, and its\exceptions when evaluated" the second component|evaluating the division function cannot cause any excep-tion to be raised.Partially applying the function (= 1) still cannot raiseany exception. This fact is re ected in its type:(= 1) : hnum f=g! num;?i:However, fully applying the function may raise the \di-vision by zero" exception:(= 1 0) : hnum; f=gi:If that expression is enclosed within another that cap-tures the \division-by-zero" exception, then the resultingvalue has no exception:try (= 1 0) with =! 0 : hnum;?iWe follow the approach used in in [6], and further de-veloped in [5] for the purpose of controlling mutations ofstate in single-threaded computations. Also, [7] uses thismethod to perform a liveness analysis of functional pro-grams. Following their convention, we will call use, or useto the annotations to the functional constructor, and lia-bility to the exceptions possibly raised by the evaluationof expressions.The proposed technique has the following features:1. simple|just annotations to types,2. intuitive|using types as information carriers makesit easy to comprehend the scope of the annotations,3. reasonably precise for �rst-, as well as for higher-order|is as precise as it can be for an analysis thatdoes not have access to expression values,4. polymorphic on types and annotations|not all theuses of a variable need to have the same annotations|and5. completely reconstructible|the extended type in-ferencer can reconstruct the most general extendedtype without requiring any additional informationfrom the user,127

For presentation purposes, we introduce our technique toa representative subset of the ML language. However,the reader should be assured that the extension to thefull language is straight forward.In Section 2 we establish the working language as wellas its type language. Section 3 presents the inferencerules for the extended type system. In Section 4 we pro-vide several examples of the extended types. In Section 5,we discuss pragmatic issues concerning this type system.In Section 6 we explain how type reconstruction is done.Section 7 surveys other work on the area. Finally, a proofof soundness of the type system can be found in the Ap-pendix.2 PreliminariesIn this paper we limit ourselves to a representative sub-set of the ML language. Each construct included shows aspeci�c feature of the model. We have included the tra-ditional �-calculus constructs, as well as let-expressions,a conditional, a �x point operator, and mechanisms forraising, and capturing exceptions. The syntax for lan-guage follows:De�nition 1 (The Language) Let V and � be a setsof identi�ers used as variable names and exception namesrespectively and C be a set of constants. The set E ofexpressions of the language is de�ned as:E = x x 2 Vj c c 2 Cj e1 e2 e1; e2 2 Ej �x:e x 2 V; e 2 Ej let x = e1 in e2 x 2 V; e1; e2 2 Ej if b then e1 else e2 b; e1; e2 2 Ej �x x = e x 2 V; e 2 Ej raise " " 2 �j try e1 with "! e2 e1; e2 2 E; " 2 �We can safely assume the domains of variable identi�ersand exception names to be disjunct. Also, there is noprovision for \exception variables". All these decisionsare present in ML, and are based on pragmatic consider-ations.In well-typed ML programs, each expression can beassigned a type in such a way that the type of the wholeprogram can be proved from the assertions about thetype of all its constituent expressions. In this paper weextend the notion of type to include the set of all possi-ble exceptions that the program may raise. In order toconsider higher-order expressions, we allow parts of theexception set to be unknown|hence the introduction ofexception set variables. The operations on sets will beunion (notated as \+") and set di�erence (notated as\�"). Union is used to combine the ability to raise excep-tions of subexpressions, while di�erence is used to notethat an exception has been handled.De�nition 2 (Exception Uses) Let UV be a set ofidenti�ers which will be used as use variables. The setU of use expressions is de�ned as:U = s s 2 P(�)j � � 2 UVj u1+u2 u1; u2 2 Uj u� s u 2 U; s 2 P(�)
Note that in set di�erence, the subtrahend must bean enumeration of exceptions. This corresponds to therestriction that an exception must be explicitly named inorder to be caught. Also, the introduction of use variablesonly make sense for the higher-order case. Also note thatthe exception set u1 + u2 is considered equal to u2 + u1since they denote the same set.In order to consider higher-order functions, types offunctions will be decorated in this system with use infor-mation. Notice that this is the only change required tothe type system.De�nition 3 (Types) Let TC be a set of type constantsand TV be a set of type identi�ers. The set T of typeexpressions is de�ned as:T = c c 2 TCj � � 2 TVj (�1; : : : ; �n)c �1; : : : ; �n 2 T; c 2 TCj �1 u! �2 �1; �2 2 T; u 2 UTypes behave as use information carriers. The type �1 u!�2 will read as \a function from �1 to �2 allowing u." Wewrite �1 ! �2 when the use of the type is a variable notoccurring elsewhere in the text.Type schemes are generalizations of types on bothtype variables and use variables.De�nition 4 (Type Schemes) The set S of typeschemes is de�ned as:S = 8�:� � 2 TV; � 2 Sj 8�:� � 2 UV; � 2 Sj � � 2 TType schemes are also called polymorphic types, andspecify a family of types each of which can be obtained byappropriate instantiation of all the quanti�ed variables ofthe scheme. Type schemes are always shallow (all theirquanti�ers appear at the outermost of the expression, sothe relative positions of the type and use variables areirrelevant. Therefore, we will write a type scheme as8�1:::�n�1:::�m:�to denote the scheme whose bound variables are�1; :::; �n; �1; :::;�mDe�nition 5 (Type Environment) A type environ-ment � : V ! (S � U) is a partial mapping from identi-�ers to type schemes. We write�) x : h�; ui if � x = h�; uiThe mapping where all identi�ers are unde�ned is de-noted by ?: ?) x : ?Environments are expanded by using the operator ++ : (V ! (S � U))! (V � S � U)! V ! S(� + fx : h�; uig) x= h�; ui(� + fx1 : h�1; uig) x2=� x2 if x1 6= x2128

�) x : h�; ui Inst(�; �) (Var)� ` x : h�; ui � ` e1 : h�1 u! �2; u1i � ` e2 : h�1; u2i (App)� ` e1 e2 : h�2; u+u1+u2i�+fx : h�1; u1ig ` e : h�2; u2i (Abs)� ` �x:e : h�1 u2! �2; ui �+ ff : h�; u1ig ` e : h�; ui (Fix)� ` �x f = e : h�; ui� ` b : hbool; ui � ` e1 : h�; u1i � ` e2 : h�; u2i (Cond)� ` if b then e1 else e2 : h�; u+u1+u2i � ` e1 : h�; u1i � ` e2 : h�; u2i (Try)� ` try e1 with ""! e2 : h�; (u1 � f"g)+u2i� ` raise " : h�; u+f"gi (Raise)� ` e1 : h�1; u1i Gen(�1;�; u1; �) �+fx : h�; uig ` e2 : h�2; u2i (Let)� ` let x = e1 in e2 : h�2; u1+u2iFigure 1: Type System with UsesDe�nition 6 (Type Substitution) Let � be a typescheme, [�=�] a substitution on type variable �, and [u=�]a substitution on use variable u. Then �[�=�] is the typescheme obtained by replacing all free occurrences of � in� by � . Similarly, �[u=�] is the type scheme obtained byreplacing all free occurrences of � in � by u.De�nition 7 (Type Instantiation) Let� = 8�1:::�n�1:::�m:� 0� is an instance of � if� = � 0[�1=�1; :::; �n=�n; u1=�1; :::; um=�m]for appropriate types �i, and exceptions sets uj , for i =1; :::;n, and j = 1; :::;m.De�nition 8 (Generalization) Let � , �, �, and u bea type, type scheme, type environment, and use, respec-tively. We say that � is a generalization of � accordingto � and u if � is an instance of �, i.e.�= 8�1:::�n�1:::�m:� 0� = � 0[�1=�1; :::; �n=�n; u1=�1; :::; um=�m]and no �i, �j appear free in �, or u for i = 1; :::;n, andj = 1; :::;m.3 Extended Type SystemIn this section we propose an extension based of theHindley-Milner type system for the language ML in whichfunction types are decorated with use information. Fol-lowing is a justi�cation for each rule, detailing the exten-sions while largely ignoring the basics of type inference.The type system rules are shown on Figure 1.Var Like in the standard type system, a variable's typeand use is an instance of the type associated withit in the environment. Due to the fact that ML isstrict, upon reduction of any ML expression, vari-ables are replaced by values, which cannot pro-duce any exception. Note that a use is retrievedfrom the environment. This makes a conservativeassumption.
Abs Evaluating the abstraction does not raise any ex-ception. However any exception that can be raisedin the body of the abstraction can potentially beraised in any context where the abstraction is ap-plied. This is encoded in the system by annotatingthe function type constructor with the potentialuse of the body. Note that the environment of thebody is augmented with a type and use assign-ment for the bound variable (�1 and u1). Further,another use (u) is paired to the type of the ab-straction.Cond Conditionals just require that both branches ofthe decision have the same type. Again, this re-quirement may lead to equalize the extended partsof the types of both branches of the conditional.This construct can have an exceptional behaviorif either of its branches or its condition does.App In a function application, any exception raisedwhen evaluating the function or the argument canbe raised in the application. In addition, any ex-ception that can be raised when the function isapplied (i.e., the use set on top of the function'stype) can also be raised. Note that the require-ment that the function's formal argument's typebe identical to the actual argument's type takesa new meaning for extended types|their use in-formation, if any, must be made equal. This mayseem too restrictive, but, in fact, it is not. It juststates that the information collected on the en-vironment the function is applied can be used torestrict further the type of the function.Fix The �x point operator just enforces that function'sextended type and the body's extended type unify.It can raise any exception that its body can.Try Try catches exception x from its body returninge2 in that case, but cannot catch any exceptionraised while evaluating e2.Raise Raise simply raises an exception, thus its abstractuse re ects that restriction. Also, it does not im-129

pose any restriction on the type of the resultingexpression.Let Let just generalizes the type of e1 during the typ-ing of e2, thus giving the polymorphic behavior ontypes and exception values.There is a proof in the Appendix of the adequacy of thistype system to the problem of statically determining theexceptions that a program can raise.Some of the rules just presented have the ability ofintroducing unrestricted uses, which will typically be ause variable, or the empty set, or a more complex use.Given the partial order introduced by type instantiation,the choice that would lead to a more general type wouldalways be a free variable if possible. Thus, the type ofthe identity function could be8��:� �! �We will omit uses that correspond to variables that ap-pear only once. Therefore, we will write its type as8�:�! �Figure 2 shows the extended types for a selected groupof constants.f+;�; �g: num! num! num=: num! num f=g! numlog: num f�g! numhead: 8�:� list fhdg! �tail: 8�:� list ftlg! � listmap: 8���:(� �! �)! � list �! � listmap2: 8�� �1�2:(� �1! � �2! )! � list! � list �1+�2+fiag! listExceptions:= division by zero� negative numberhd head of an empty listtl tail of an empty listia invalid argumentFigure 2: Extended Type for Selected Constants4 ExamplesThe type system presented in the previous section candiscriminate among expressions of the same base typeaccording to their ability to raise exceptions. To illustratethis fact, let us present two versions of a function thatreceives four parameters: a, b, c, and d, and producesa=bc=dThe �rst version performs the computation only after ithas received all four parameters:F1 � �a b c d:(a=b)=(c=d)
The second version, on the other hand, performs the com-putation a=b as soon as a, and b become available:F2 � �a b:(�v c d:v=(c=d)) (a=b)Both functions have the same base type, but they di�eron where they raise the \divide by zero" exception: F1can raise it only after reading all four arguments, whileF2 can raise the exception after the second, and afterthe fourth argument. This di�erence is re ected in theirextended types:F1 : hnum! num! num! num f=g! num;?iF2 : hnum! num f=g! num! num f=g! num;?iHowever interesting it is to have the type system discrim-inate between them, it is certainly desirable that bothfunctions be somehow \compatible". In fact, they are.The extension to the type system ensures that if two ex-pressions can be given the same base type, then theycan both be given the same extended type. In this case,both funcions can be given the type of F2, shown above.Therefore, expressions such ase1 � [F1;F2] and e2 � if true then F1 else F2have types�1 � hnum! num f=g! num! num f=g! num;?iand(�2 � h(num! num f=g! num! num f=g! num) list;?iBut, in those expressions, the types of F1, and F2 haveto be precisely �2.Further, let F3, and F4 compute a mathematicallyequivalent computation (a=b) � dcin fashions similar to F1, and F2:F3 � �a b c d:(a=b) � d=cF4 � �a b:(�v c:(�w d:w � d) (v=c)) (a=b)Their types areF3 : hnum! num! num! num f=g! num;?iF4 : hnum! num f=g! num f=g! num! num;?iand a type common to F3 and F4 ishnum! num f=g! num f=g! num f=g! num;?iHigher-Order FunctionsHigher-order functions can be polymorphic on their ex-ceptions. Such is the case of the functionF = �f x:f(f x)whose type is h(� �! �)! (� �! �);?i130

�) f : � �! � (F)� ` f : h� �! �;?i�) x : � (Var)� ` x : h�;?i F (App)� ` (f x) : h�;�i F (App)(� =)ff : � �! �;x : �g ` f(f x) : h�;�i (Abs)ff : � �! �g ` �x:f(f x) : h� �! �;?i (Abs)? ` �f x:f(f x) : h(� �! �)! (� �! �);?iFigure 3: Detailed deduction for expression �f x:f(f x)The type of this expression re ects the fact that F doesnot have any knowledge of what exceptions can be pro-duced by the application of f to x. In fact, no such ex-ceptions are handled by F , thus they will remain raisedas a result of F 's application to its arguments. Figure 3shows all the details of the deduction of F 's extendedtype.K : h(� �! � �! �)! �! �! � �+�! �;?iF : h(� �! �)! (� �! �);?i �� �! �=�?=� �KF : h(� �! �)! (� �! �)! � �! �;?iG : hnum f=g! num;?i h num=�f=g+�0=�iKFG : h(num �0! num)! num �0+f=g! num;?iH : hnum f�g! num;?i [f�g=�0]KFGH : hnum f=;�g! num;?iFigure 4: Derivation of a Higher-Order FunctionAnother interesting example that shows how the sys-tem behaves with higher-order functions is the expressionK � �f g h x:f g (f h x)of type h(� �! � �! �)! �! �! � �+�! �;?iWhen applied to all its arguments, K might produce anyof the exceptions of its �rst argument, that is, �+�. Letus now take functionsG � �x:2=x : hnum f=g! num;?iand H � �x: log x : hnum f�g! num;?iIn the derivation of the type of A � K F G H (Figure 4),the types of K, F , G and H have to be respectivelyinstantiated toF : h� ! �;?iG;H: h�;?iK: h(� ! �)! � ! � ! �;?i
where � = num f=;�g! numThe exception set f=;�g represents the only possibleexceptions that can produce expression A.PolymorphismLet-expressions are the means of introducing type poly-morphism to ML. It seems natural to utilize this con-struct to also obtain polymorphism on exceptions. Inparticular, in the example for higher-order functions pre-sented in the previous section. In particular, in the lastexample, we found that in order to correctly type func-tion A, We had to choose particular instances of the typesof F , G, H and K.On the other hand, the following programlet F=�f x:f(f x)and G=�x:2=xand H=�x: log xin (�x:F G x); (�x:F H x)generalizes the types of F , G, and H while instantiatingthe type of each of their occurrences. Therefore, in thisprogram, the type of the body of the let expression ish(num f=g! num)� (num f�g! num)iIf we had not used the let expression the resulting typewould have beenh(num f=;�g! num)� (num f=;�g! num);?iNote that polymorphism on exceptions is just the abil-ity of a function to be able to carry di�erent exceptionsin di�erent occurrences. At each occurrence, however, allthe exceptions that were deduced from its de�nition haveto belong to the exception set.The above example shows that for some higher-orderexpressions, unless they are introduced using a let con-struct, their polymorphism on exceptions|as well as ontypes|is lost. This decision �ts nicely into ML, since thesame construct introduces both kinds of polymorphism.Sharing MorphismsThe handling of exceptions in ML makes it adequate toimplement sharing morphisms in the language. It is usu-ally the case that when homomorphisms such as variablesubstitution is performed on a term, a new term is gener-ated even in the case that the resulting term equals theoriginal one|in this case, the term is completely copied.The function map is an example of such a behavior:let map f = fun [] ! []j (x@l) ! f x@map f lThe function (map i), where i is the identity function,copies its list argument even though its elements are re-turned unchanged. Its extended type (Figure 2) conveysthe information thatmap does not capture any exceptionraised by the application functional argument f .A sharing homomorphism, on the other hand, returnsthe argument|not a copy|if the argument is not alteredby the function. A sharing homomorphism can be imple-mented in either of these techniques:131

� pair the result with a boolean value|e�ectively sig-nalling whether the result is the very argument, or� de�ne an exception, say Id, that is to be raisedwhenever the result of a function is the same asits argument. The calling function then receives aresult if it is di�erent from the argument, and anexception if they are equal.In both cases, the calling function has enough informa-tion to decide whether to return the argument dependingon the results of its calls. However, the latter solution ispreferred because it conveys this information more natu-rally.The implementation of a sharing version of map fol-lows exception Idlet share f a =try f a with Id! alet mapshare f =fun []! raise Idj (x :: xs)!try f x :: share (mapshare f) xswith Id ! x ::mapshare f xslet mapsh f xs = share (mapshare f) xsIn the above programs, share is a function that handlesId by returning the argument|in fact, preventing theexception from escaping further. It is called in contextswhere the result is to be combined in a new structure(althogh the result itself can be shared with the previousstructure). The function mapshare actually processesthe list. Note that the empty list is shared, and notehow (mapshare f) is protected from raising Id|in thiscontext, (f x) did not raise any exception, thus the newstructure needs to be cons'ed to the result of (f x). If, onthe other hand, (f x) raised Id, then (mapshare f) is notprotected, since it would in fact imply that the currentcons cell should be shared. Finally, mapsh just managesthe case when the whole data structure can be shared,e�ectively sharing it.With respect to the typing, the extended type of shareis share : h8��:(� �! �)! � ��fIdg! �;?iwhich indicates that share explicitly handles the Id ex-ception. The extended type of mapshare ismapshare : h8��:(� �! �)! � �+fIdg! �;?isince it can raise Id, and the extended type of mapsh ismapsh : 8��:h(� �! �)! � ��fIdg! �;?isince it handles the Id exception through the call toshare.5 Pragmatic ConsiderationsIn a glance through the CAML-Light documentation [9]the reader will notice that the description of each func-tion includes its type, a short English description of what
it does, and the list of exceptions raised when fully ap-plied. This illustrates the importance of exceptions whendescribing interfaces. Caml allows for modules to bede�ned, along with their interfaces, but, unfortunately,Caml interface mechanism does not allow for the associ-ation of functions to the exceptions they potentially raise.However important the handling of exceptions can bein tyoing programs, or providing interfaces, several issuesneed to be addressed in order to accept a mechanism tohelp us in this regard. Among them are:� is it really necessary to control exceptions?,� how easy is it to read annotated types and under-stand what they mean?,� how easy is it to write annotated types?,� how much overhead does this new analysis impose?As with many other analyses, the real value of theanalysis is not realized from toy programs, such as thosepresented here, but from large programs. Large programstend to have many exceptions. Would it not be annoyingto have a type system report that the main function mayhave a variety of exceptions? On the other hand, excep-tions should be handled, and thus, there should not beany untreaded exceptions. Good programming style in-dicates that exceptions should be treated as soon as theycan be.There are exceptions that the user may choose not tohandle, such as an out of memory exception. In this case,it would certainly be very bothersome to have the typesystem report such an exception for any expression. Tosolve this case, we propose a new ML directive#ignore exc listthat eliminates the list of exceptions exc-list from thereported exceptions.In some cases, there can be exceptions that the user iscertain they will never be raised, therefore, the user doesnot trap them. To illustrate this, consider the functionmap2 whose extended type signature appears in Figure 2.This function is similar to map, but acts on functions oftwo arguments. It requires that the lists of �rst, andsecond arguments be of equal lengths, raising the excep-tion ia otherwise (ia stands for \invalid argument"). Theexpression(fun x ! map2 (prefix �) x x) [1; 2; 3; 4]has type hnum list; fiagi whereas, in practice, the ia ex-ception will not be raised. The type system is unable todetect and/or verify that the exception is bogus in thiscase, and thus, it will report it. In ML, the user maychoose to explicitly handle the expression, but it wouldnot express the fact that the expression should not hap-pen: (fun x! try map2 (prefix �) x xwith ia! :::)[1; 2; 3; 4]has type hnum list;?i (assuming ::: does not raise anyexception)132

Further, the user may use a new exception, such asstop, and write the program as#ignore stop(fun x! try map2 (prefix �) x xwith ia! raise stop)[1; 2; 3; 4]which also has the above type.A more expressive solution is to introduce a new MLexpression exp ignoring exc listto provide a behavior such as the one just presented. Itshould be noted that the compilation of the ignoring-construct should include the raising of another excep-tion that cannot be captured. Otherwise, the expressionwould not be sound. With in mind, the raising of an ig-nored exception should abort the whole program! Thus,the expression((fun x! map2 (prefix �) x x) ignoring ia)[1;2; 3; 4]has type hnum list;?i which is indeed quite reasonable.Another issue that needs to be addressed is about theconcrete syntax of the extension. The syntax presentedso far follows the convention introduced in [4] of annotat-ing the arrows with the abstract use that happens whenthe functional is applied. This is great for pedagogicalpurposes, but cannot be implemented as is in textualprogramming languages. Modula 3 associates exceptionsto types using the keyword raises [1]type raises exc setFX [3] uses the in�x operator \!" to separate the typefrom the e�ect of expressions. We propose to use \." forthis purpose. Thus the extended type signaturee : �:u1+:::+unmeans that e has type � and can raise exceptions u1,...,un(n � 0). The following conventions aid the readability ofthe extension:1. \." has lower operator precedence than \!", butmore precedence than any other type constructor.2. the exceptions clause is optional. Omitting it indi-cates no exceptions are raised.3. For user-generated types, \.." indicates the usermakes no claims on the exceptions raised by theexpression (Computer generated types can alwaysindicate the inferred exceptions).The above conventions favor �rst order types as wellas the types of nested abstractions, that usually appearwhen programming with equational groups. It does notnecessarily favor combinations that raise exceptions andare of functional type.Following the conventions, the type of map can bewritten as (�! �:�)! � list! � list:�The type of fold is(�! �:�1 ! �:�2)! � list! � ! � list:�1+�2The type of fun x y = (fun v z t = v=(z=t))(x=y) isnum! num! num:=! num! num:=
6 Type ReconstructionThe type reconstruction algorithm needed to infer the ex-tended types presented in this paper is a straight-forwardmodi�cation to the Hindley-Milner algorithm. The onlycomplication is how to maintain the set of possible excep-tions handled by any expression, and how to re�ne thosesets with the restrictions implied by the inference rules.As explained in Section 2, the only operations allowedon exception sets are union, and set di�erence where thesubtrahend must be an enumeration of exceptions. Also,it is implied by the rules that any use expression will havea use variable involved in it. Therefore, any use expres-sion u can be expressed as �+u0 where � is a variablenot appearing in u0. The least upper bound of two useexpressions �1+u1 and �2+u2 is the union of sets u1 andu2, which can be obtained with the most general uni-�er (unique modulo equivalence of expressions on sets)s = [�1 �+u01+u02; �2 �+u01+u02] where � is ause variable not appearing in u1 or in u2 and each u0i isobtained by replacing in ui variables � and � with ?.Uni�cation on types is the usual term uni�cation ex-tended with the uni�cation on uses. For instance, themost general uni�er of types(� u+fxg! �)and((� v! �) v! )is the substitutions = 24 (� w+fxg+v! �)=�(� w+fxg+v! �)=�w+v=u;w+fxg=v 35The exceptional behavior of programs is fully recon-structible based solely on the information about the ex-ceptional behavior of the primitives used. For modules,the interface types need to be extended to also conveythe information about the exceptions the typed functionmay raise. Other than this, any currently working MLprogram can be inferred its exceptional behavior. Fur-ther, the system can aid in synthesizing this informa-tion, given that a module module itself can be type-checked, and thus its types|including those belongingto its interface|reconstructed.7 Related WorkThe idea of decorating the arrows with operational prop-erties of expressions was �rst exploited by Gi�ord, Lu-cassen et al in the context of detecting levels of impera-tiveness of expressions in a Scheme-like language. Thiswork was �rst published in [4], and made into an experi-mental programming language called FX [3]. In [8] theyprovide an overview of the FX system, and o�er a recon-struction algorithm for its type system. The FX systemcan detect side-e�ects to user-de�ned regions, which arearbitrary sets of locations where data is allocated. Dataallocated in the same region share the same properties(allocation, mutation, etc.)Guzm�an and Hudak also worked on detecting side-e�ects, this time in the context of lazy functional lan-guages [6, 5]. They extended Gi�ord's work by addingthe notion of liability|an environment that associated133

non-local variables with operational properties. This ex-tension widens the spectrum of possible applications, andmakes it possible to control mutation to data structures|not regions|in single-threaded contexts. Also, in [7],they presented liveness analysis through a de�nition ofan extended type system where not only arrows were alltypes|not only arrows|were annotated.Leroy and Weis have also worked on annotating types.Their work focuses on how to type ML references poly-morphically [10]. Their system very successful in di�er-entiating dangerous references (those whose types cannotbe generalized) from safe ones.8 ConclusionsWe have presented a simple and intuitive yet powerfulmechanism through which the set of potential exceptionsthat can happen in a program can be staticly inferred.The approach used was extending the type system.This provides a simple, clear, and seamless integration ofthis extension to the ML language. We have discussedseveral pragmatic issues concerning this fusion.The type system is polymorphic on the annotations(exceptions that can be raised), as well as on types thusexploiting even further the powerful type system in thelanguage. The type system is fully reconstructible.A Correctness of the Type SystemThe type rules of ML has been adapted in this work tothe handling of information about exceptions. This ex-tension is conservative: Any proof in the original systemcan be decorated in order to obtain a proof in the ex-tended system and thus, the soundness of the type systemfor exceptions is a direct consequence of the soundness ofthe original system. The existence of principal types forexpressions is in the same case. For a proof of soundnessof the type system of ML and of principality of the sys-tem see for instance [2, 14]. We prove in this section thatif an expression evaluates to an exception, this exceptionappears in the use associated to its type.De�nition 9 (Values and Execution Environments)Let C = C�1 [ : : : [ C�n be a set of constants classed bytheir respective types �1; : : : ; �n. An execution environ-ment ' : V ! V al is a partial mapping from identi�ersto values. The set V al of execution values is de�ned asthe disjoint union of constants and closures:V al = c c 2 Cj [�x:e;'] ' is an execution environmentThe expressions of the language are extended to includevalues for which we introduce the typing rules of �gure 6Figure 5 represents the evaluation rules for ML (vari-able w ranges over the the values and exception expres-sions). These rules de�ne the evaluation relation =)'between extended expressions. The normal forms ofthis relation are either values or exceptions of the formraise ".The following theorem states that the type of the re-sult e0 of the evaluation of an expression e is more particu-lar than the type of e. Additionally, the use of expressione contains the use of e0.
c 2 C� (Ctt)� ` c : h�; uify : � j'(y) : �; y 2 FV (e)g ` �x:e : h�1 u! �2; u0i (Cls)� ` [�x:e;'] : h�1 u! �2; u0iFigure 6: Typing Rules for ValuesTheorem 1 Let e; �; u;�; ' be such that for each vari-able x free in e, whenever � ` x : h�; ui we also have'(x) : � . For each expression e0, if there is a deductionfor � ` e : h�; ui and a derivation e =)' e0, there is atype � 0, an use u0 and a derivation for � ` e0 : h� 0; u0isuch that � is more general than � 0 and u0 � u.Proof:The proof is made by induction on the number ofsteps of the derivation e =)' e0 of =)'. Values andexception expression are the normal forms of =)'. Theproperty vacuously hold for values. Expressions of theform raise " has any type and any use containing excep-tion ".Var By de�nition of evaluation environments, '(x) isin normal form and by hypothesis, '(x) : � . Asexceptions are not valid elements of ', we have� ` '(x) : h�;?i:Abs The valuation of an abstraction �x:e is a closure,which is typed exactly as the abstraction it con-tains (with the typing rule (Cls)).App If an application is evaluated using rules (EApp2)or (EApp3), The property is veri�ed by simple useof inductive hypothesis. If the reduction is madewith rule (EApp1), we should explore again thetype of a closure. By inductive hypothesis, thereexist a typing environment �0 verifying �0 y = �for each y free in �x:e with '(y) : � , such that thefollowing diagram holds:�0 + fx : � 01g ` e : h� 02; u03i Abs�0 ` �x:e : h� 01 u03! � 02; u02i Cls� ` [�x:e;'] : h� 01 u03! � 02; u02iAs � 01 u03! � 02 is more general than �1 u3! �2, we haveu03 � u3. Again, by inductive hypothesis, u01 � u1and u02 � u2 which completes the proof of theproperty for applications.Let The polymorphism introduced by let expressionscould also be introduced in a generic type systemby replacing each occurrence of the variable in-troduced in the let by its associated expression(avoiding variable captures by an adequate renam-ing) [13]. The proof of the property for local dec-larations is very similar to the one for applications134

x '=) '(x) (EVar) �x:e '=) [�x:e;'] (EAbs)e1 '=) [�x:e; '] e2 '=) v2 e '0 [v2=x]===========) w (EApp1)(e1 e2) '=) we1 '=) [�x:e;'] e2 '=) raise " (EApp2)(e1 e2) '=) raise " e1 '=) raise " (EApp3)(e1 e2) '=) raise "e1 '=) true e2 '=) w (ECond1)if e1 then e2 else e3 '=) w e1 '=) false e3 '=) w (ECond2)if e1 then e2 else e3 '=) we1 '=) raise " (ECond3)if e1 then e2 else e3 '=) raise " e1 '=) v (ETry1)try e1 with "! e2 '=) ve1 '=) raise " e2 '=) w (ETry2)try e1 with "! e2 '=) w e1 '=) raise "2 x 6= y (ETry2)try e1 with "1 ! e2 '=) raise "2e1 '=) v1 e2 '0[v1=x]===========) w (ELet1)let x = e1 in e2 '=) w e1 '=) raise " (ELet1)let x = e1 in e2 '=) raise "Figure 5: Evaluation Rulesas the polymorphism introduced by local declara-tions is just a particular case of the one introducedby evaluation.Cond, Fix, TryIn these cases, the property is a direct consequenceof the inductive hypothesis.As a consequence of this theorem if there is a deduc-tion for � ` e : h�; ui and a derivation e =)' raise "then exception " is an element of the use u.References[1] L. Cardelli, J. Donahue, L. Glassman, M. Jordan,B. Kalsow, and G. Nelson. Modula-3 language de�nition.27(8):15{42, 8 1992. ACM Sigplan Notices.[2] L. Damas. Type Assignment in Programming Languages.PhD thesis, University of Edinburgh, 5 1985.[3] D.K. Gi�ord, P. Jouvelot, J.M. Lucassen, and M.A. Shel-don. Fx-87 reference manual. Technical Report LCS TR-407, MIT, 9 1987.[4] D.K. Gi�ord and J.M. Lucassen. Integrating functionaland imperative programming. In Proceedings of the 13thACM Symposium on Principles of Programming Lan-guages. ACM, 1986.[5] J.C. Guzm�an. On Expressing the Mutation of State ina Functional Programming Language. PhD thesis, YaleUniversity, May 1993.[6] J.C. Guzm�an and P. Hudak. Single-threaded polymor-phic lambda calculus. In Proceedings of the Fifth AnnualIEEE Symposium on Logic in Computer Science. IEEE,1990.
[7] J.C. Guzm�an and P. Hudak. Liveness analysis via typeinference. In Proceedings of the XVII Latin AmericanInformatics Conference, 1991.[8] P. Jouvelot and D.K. Gi�ord. Algebraic reconstruction oftypes and e�ects. In Proceedings of the 18th ACM Sym-posium on Principles of Programming Languages. ACM,1991.[9] X. Leroy. The caml light system, release 0.6. Technicalreport, INRIA, 1993. Included with the Caml Light 0.6Distribution.[10] X. Leroy and P. Weis. Polymorphic type inference andassignment. In Proceedings of the 18th ACM Symposiumof Principles of Programming Languages. ACM, 1991.[11] J.M. Lucassen and D.K. Gi�ord. Polymorphic e�ect sys-tems. In Proceedings of the 15th ACM Symposium onPrinciples of Programming Languages. ACM, 1988.[12] R. Milner, M. Tofte, and R. Harper. The De�nition ofStandard ML. The MIT Press, 1990.[13] A. Su�arez. Une Implementation de ML en ML. Th�ese dedoctorat, Universit�e Paris VII, 1993.[14] M. Tofte. Operational Semantics and Polymorphic TypeInference. PhD thesis, University of Edinburgh, 1988.[15] P. Weis, M. V. Aponte, A. Laville, M. Mauny, andA. Su�arez. The CAML reference manual. Technical Re-port 121, INRIA, September 1990.135

A Compilation Manager forStandard ML of New Jersey
Robert HarperFrank Pfenning
Peter LeeEugene Rollins �
Abstract
The design and implementation of a compilation manager (CM) for Standard ML of New Jersey(SML/NJ) is described. Truly independent compilation is difficult to implement correctly and efficientlyfor SML because one compilation unit may depend not only on the interface of another, but also onits implementation. In this paper we present an integrated compilation system based on the “visiblecompiler” primitives provided by SML/NJ that supports selective recompilation to minimize systembuild time in most situations. Large systems are presented as hierarchical source groups. An automaticdependency analyzer determines constraints on the order in which sources must be considered. Byabstracting away from the specifics of the SML/NJ compiler, the CM readily generalizes to arbitrary“compilation tools” such as parser generators and embedded languages.
1 Introduction
Large programs are typically built from a collection of independent sources that are repeatedly modified,compiled, and loaded during development and maintenance. The division of programs into separate sourcesis largely motivated by software engineering considerations such as the need to support simultaneousdevelopment by several programers and as an aid to configuration management. Software systems evolveby successive modifications to small collections of sources, after which the system is rebuilt and tested. Itis obviously important in practice to cut down on the time required to rebuild the system, particularly sincethe changes are often of a local nature. Selective recompilation methods seek to reduce system rebuildingtime by compiling less than the entire system after modifications. A variety of such methods have beenproposed, and many have been implemented. Adams, Tichy, and Weiner [1] describe and compare selectiverecompilation methods. Some of these methods are not practical for Standard ML.
Independent compilation allows individual sources to be compiled in complete isolation from the othersources, with dependencies between them resolved at “link time”. Independent compilation is relativelystraightforward for languages with the property that a source may depend only on the interface, and not the�This research was sponsored in part by the Avionics Lab, Wright Research and Development Center, Aeronautical SystemsDivision (AFSC), U. S. Air Force, Wright-Patterson AFB, OH 45433-6543 under Contract F33615-90-C-1465, Arpa Order No.7597. This research was also sponsored in part by the Defense Advanced Research Projects Agency, CSTO, ARPA Order No. 8313,issued by ESD/A VS under Contract No. F19628-91-C-0168. The views and conclusions contained in this document are those ofthe authors and should not be interpreted as representing official policies, either expressed or implied, of the Defense AdvancedResearch Projects Agency or the U.S. Government.
136

implementation, of another source. (This is true of C, for example.) However, Standard ML is unusualin that a source may depend on the implementation of another, rendering truly independent compilationimpossible to achieve without penalty (Shao and Appel [13] sketch an approach based on link-time typechecking and link-time search to resolve identifier references.) MacQueen argues cogently for this languagedesign choice [9, 10]. However, recent work by Harper and Lillibridge [6] and Leroy [8] indicate that it ispossible to eliminate implementation dependencies in favor of interface dependencies without significantlycompromising the flexibility and expressive power of the SML modules system.
Rather than change the language, we consider here an alternative approach that focuses on providing anefficient integrated compilation mechanism through the use of cacheing and automatic dependency analysis.Our approach is a refinement of cutoff recompilation, which compares the previous and current outputfrom compiling a source. If there is no difference, then unmodified dependent sources do not need to berecompiled. In our approach, we do not compare the entire compiler output, rather we only compare theportion of the compiler output that is used as input for further compilation. In our case this portion containsonly type information. Thus, for example, changing a function body without changing its type would notitself cause unmodified sources to be recompiled.
Our method is similar to Tichy’s “smart recompilation” [15] in that we rely on an automatic analyzerto determine the dependency relation among the sources, rather than relying on the programmer to providean explicit “road map” as in the well-known Unix make utility [4]. In order to cope with problems ofre-definition of identifiers (what Tichy calls “overloading”) and to support shared libraries, we provide amechanism for structuring collections of sources into what are called source groups.
The design of the compilation manager (CM) presented here is closely bound to the “visible compiler”primitives of Standard ML of New Jersey, described in a companion paper by Appel and MacQueen [2].In particular we rely on the SML/NJ primitives for manipulating compile- and run-time environments, andfor creating and using compilation units. These primitives provide the fundamental mechanisms neededto build a type-safe CM that does not rely on hidden internal symbol table mechanisms or the creation of“object files” or “load modules”. We gratefully acknowledge the cooperation of Andrew Appel and DavidMacQueen for their development of the visible compiler primitives in conjunction with the design of theCM presented here.
In order to properly expose the issues involved we present the design of the CM in stages, at each steprefining the mechanisms and explaining the issues that arise. In Section 2 we introduce the basic evaluationand environment primitives provided by SML/NJ, and consider their use in building large systems viewedas unstructured sets of sources. In Section 3 we refine the evaluation model into compilation and executionphases, and introduce the caching mechanisms required to avoid redundant recompilation of sources. InSection 4 we introduce the notion of a source group as a means of structuring collections of sources andwe lift the basic compilation and evaluation primitives from the level of individual sources to the level ofsystems. In Section 5 we address the problem of dependency analysis for source groups. Finally, Section 6discusses the generalization of the CM to arbitrary “compilation tools” such as parser generators and stubgenerators.
137

2 Evaluation of Sources
We begin by considering software systems as unstructured collections of sources, each of which provides asequence of signature, structure, and functor bindings.1
Source code may be presented to the SML/NJ system in several different ways. In order to insulate theimplementation from the details of how sources are presented, we introduce an abstract type source withthe following interface:
signature SOURCE = sigtype sourceval sourceFile :string -> sourceval sourceString :string -> sourceval sourceAst :Ast.dec -> source
end
The string argument to sourceFile is the name of a file in an ambient file system. The functionsourceString presents a source as a string, and sourceAst presents a source as an abstract syntax tree(a primitive notion of SML/NJ).
Using the SML/NJ compiler primitives we may define an operation evaluate that evaluates a sourcerelative to an environment, yielding an environment:
val evaluate :source * environment -> environment
The environment argument of evaluate governs the identifiers imported by the source, and the resultenvironment represents the bindings exported by the source. (See The Definition of Standard ML [11] for aprecise explanation of the role of environment in the semantics of SML.)
The followingsignaturesummarizes some importantoperations on environmentsprovided by SML/NJ: [2]
signature ENVIRONMENT = sigtype environmentval layerEnv :environment * environment -> environmentval filterEnv :environment * symbol list -> environmentval pervasives :environmentval topLevel :environment ref
end
The function layerEnv combines two environments by layering the first atop the second, shadowing thebinding of any identifier in the second that is also bound in the first. The function filterEnv eliminatesfrom an environment all but the bindings of the specified list of module-level identifiers (represented inSML/NJ by the type symbol). The variable pervasives is bound to the environment defining the built-inprimitives of the language, and the variable topLevel is bound to a mutable reference cell containing thecurrent set of bindings at top level.
To illustrate the use of these primitives we define a load primitive (called “use” in SML/NJ) thatevaluates a single source file relative to the current top-level bindings, and extends the top-level environmentwith the bindings introduced by the source.
1Admitting arbitrary top-level bindings would not affect the development below in any essential way
138

fun load filename =let val startEnv = layerEnv (!topLevel, pervasives)
val deltaEnv = evaluate (sourceFile filename, startEnv)in
topLevel := layerEnv (deltaEnv, !topLevel)end
Early SML implementations relied on a load-like primitive to build large systems — the system isdescribed by a series of load operations given in a suitable order reflecting the dependencies betweensources. This approach suffers from two major deficiencies. First, it creates pressure on the top-levelenvironment by relying on it both as a temporary “scratch pad” for the interactive loop and as the locus ofthe software system under development. Second, it relies on the programmer to specify the order in whichsources are to be considered. This is problematic because the dependency structure often changes duringdevelopment. Moreover, overuse of the top-level environment tends to obscure the dependency structure byproviding unexpected bindings for free variables.
Our first goal is to eliminate the deficiencies of a load-based approach by generalizing the evaluateprimitive to work with an unordered collection of sources, rather than a single source. The sources of asystem are to be presented in a “declarative” style, without regard to the dependencies between them. Thegeneralized evaluate primitive must determine a suitable order in which to evaluate the sources, andyield the environment resulting from evaluating each source in turn. Thus we seek to satisfy the followingspecification:
val evaluateSourceSet :source list * environment -> environment
For this operation to be well-defined, we must assume that no two sources define the same identifier, andthat no source re-defines an identifier already defined by the environment. The former restriction ensuresthat there is a well-defined order in which the sources may be considered. The latter restriction avoids theambiguity inherent in a situation where one of two sources makes use of an identifier that is defined bothby the other source and the environment of evaluation. We will see how these restrictions can be relaxedthrough the use of source groups in Section 4 below.
Assuming that these restrictions are met, we may implement evaluateSourceSet by evaluating allsources in the set in parallel, synchronizing to ensure that definitions are propagated appropriately. Ifevaluation cannot proceed, then either there is a circular dependency among the sources in the set, or elsesome identifier is undefined. Both of these are errors in SML, and evaluation can be aborted. A simple wayto implement this parallel evaluation strategy is to make use of first-class continuations [5]. The idea is toassociate a continuation with the “undefined identifier” exception that may be invoked to resume evaluationonce the identifier becomes defined. Specifically, the evaluator raises the following exception whenever anundefined identifier is encountered:
exception UndefinedSymbol of symbol * (environment cont)
Evaluation may be resumed by throwing to the packaged continuation an environment that provides adefinition for the packaged symbol.
Although conceptually simple, the parallel evaluation strategy appears to be impractical. A pilot studyindicated that the memory usage of the above implementation is excessive because most evaluations blockearly, holding resources that cannot be used until much later. Furthermore, it is difficult to retrofit theSML/NJ compiler to support the interleaving model sketched above. A natural alternative is to determine
139

statically a schedule of the sources based on the dependencies between them, and to evaluate the sourcesin an order consistent with their mutual dependencies. The difficulty with this approach is that the scopingmechanisms of SML make it impossible to determine the dependencies between sources without performingwhat amounts to a form of elaboration. Moreover, this elaboration process must itself be performed inparallel because modules cannot be elaborated without resolving their free identifiers (e.g., to elaborateopen S we must know the signature of S, and we cannot proceed without this information).
Fortunately it is possible to make do with a limited form of evaluation. This is discussed in more detailin Section 5. For the time being we simply postulate the existence of a function schedule satisfying thefollowing signature:
val schedule :source list * environment -> source list
The intent is that schedule analyses the given list of sources relative to the given environment, and re-orders the list of sources consistently with the dependencies between them. With this in hand we may defineevaluateSourceSet as follows:
fun evaluateSourceSet (sources, baseEnv) =let fun eval (src,env) = layerEnv (evaluate(src,env), env) in
fold eval (schedule(sources,baseEnv)) baseEnvend
That is we build the environment resulting from evaluating each of the sources in the order determined bythe scheduler, with the input environment for each source being the environment resulting from layering theenvironments resulting from evaluating the previous sources atop one another.
It is important note that this evaluation in a sequential order introduces spurious dependencies betweenthe sources. The environment in which a source is evaluated is derived from all preceding sources in theschedule, regardless of whether the source actually depends on them. For example, if both A and B dependon C, but neither depends on the other, we may evaluate these three sources either in the order C, A, B, orC, B, A. Suppose the schedule function gives us the latter, and that the B source is modified. Then there-evaluation of the system will re-evaluate A in an environment reflecting the changes to B, even though Ais insensitive to such changes. We will return to this point in the next section, as it affects the mechanismfor selective recompilation.
3 Selective Recompilation
The evaluation phase of SML/NJ may be divided into compilation and execution phases.2 As we have seenin the previous section, evaluation is performed relative to an environment providing both the types andvalues of the free identifiers of a source. But since the compilation phase requires only the type information,and the execution phase requires only the values, it is natural to split the environment into static and dynamicparts. The compilation and execution phases are linked by a compiledUnit which consists of both thegenerated code for a source and the static environment resulting from elaborating it. These considerationslead to the following specifications:
2The compilation phase may itself be refined into parsing, elaboration, and code generation phases, but we shall not make useof this separation.
140

type environment = staticEnv * dynamicEnvtype compiledUnit = staticEnv * codeUnit
val compile : source * staticEnv -> compiledUnitval execute : compiledUnit * dynamicEnv -> dynamicEnv
Using these primitives we may define evaluate as follows:
fun evaluate (source, (se,de)) =let val (se’,code) = compile (source,se)
val de’ = execute (code, de)in
(se’,de’)end
The environment is decomposed into its static and dynamic parts, the source is compiled relative to the staticpart, and the resulting code is executed relative to the dynamic parts. The static and dynamic results are thenrecombined to form the complete result environment.
Having separated evaluation into compilation and execution phases, it is natural to consider cacheingcompiledUnits to avoid, where possible, redundant compilation. This may be achieved by simplymemoizing the compile function. To do so we must define a suitable notion of equality on staticEnvsand sources.
In principle two sources are equal iff they contain the same SML abstract syntax modulo the names ofbound variables. In practice we rely on an easily checked condition that suffices for true equality of sources.When both sources are files, we rely on the ambient file system to define equality of files; otherwise, twosources are deemed inequivalent. This approximation appears to work well in practice, particularly sincesources in large systems are usually presented as files.
In principle two static environments are equal iff they govern the same set of identifiers, and ascribe thesame type information to each. In practice we rely on a hashing scheme known as an intrinsic stamp [2]to compare static environments. Although it is possible for distinct environments to have identical intrinsicstamps, it is highly improbable that such a clash would occur.
The simple approach to memoization sketched above suffers from a limitation arising from the sequen-tialization of compilation. As discussed at the end of the previous section, the compilation environment fora source may differ solely because previous sources on which it has no dependencies has changed, leading tospurious recompilation. This can be avoided provided that an environment contains sufficient informationabout how it was constructed so that we may determine which portions of the environment have changed,and using only this information to access the cache.
4 Source Groups and Libraries
Up to this point we have considered programs to be given by an unstructured collection of sources whosenamespaces do not conflict. This simplified view is untenable in practice, particularly since we wish tosupport independent development by teams of programmers and the use of libraries of commonly usedprograms. In this section we introduce the concept of a source group which allows for the hierarchicalorganization of sources and relaxes the “no redefinition” restriction imposed above.
A group is defined by a set of sources, a list of subgroups, and an optional list of visible symbols.
141

datatype group = Group offsourceSet :source listsubgroups :group listvisibles :symbol list optiong
A group is evaluated relative to a base environment by recursively evaluating the subgroups relative tothe base environment, then layering the resulting environments on top of the base environment, and finallyevaluating the list of sources according to some schedule. If there is a list of visible symbols, the resultenvironment is filtered to eliminate all but those bindings mentioned in the list. Notice that we assume thatthere are no mutual dependencies between subgroups, and that all free identifiers are resolved either withinthe group or by the base environment.
To avoid unnecessary recompilation during group evaluation, we may use a fine-grained cache currencypredicate as we did for evaluation of source sets. In this case, however, we must also check that eachsymbol imported by a source is defined by the same environment as the cached compilation unit expects.This additional constraint is needed because the same symbol may be defined in different subgroups. If thesubgroups are reordered, or filtered differently, then, even if the sources remain unchanged, a symbol maybe imported from a different environment than it was when the cached compilation unit was generated.
Source groups provide flexibility in structuring the sources of a system, which is important especially forsoftware development teams. However, there are some issues not addressed by groups, specifically havingto do with creating and managing libraries.
1. Firewalls for currency checking. Libraries should be considered stable and a library client is unlikelyto want to check them repeatedly for currency.
2. Demand-driven evaluation. Because of caching of compiled units, compilation of sources is demand-driven for groups. However, all sources (or their cached compiled units) in a group are alwaysexecuted in order to conform to the simple environment layering semantics. Since execution changesstate, this cannot be optimized significantly.3 Libraries, on the other hand, are potentially very large,but only a few modules may be needed by any particular client. Evaluating all cached compilationunits for the library may thus be impractical.
3. Unavailability of sources. In many circumstances the sources for a library will simply be unavailable;in some cases the author of a library might supply only the compiled units.
A library consists of a graph whose nodes are compiled units and whose edges represent dependenciesbetween them. This graph may be used to direct the evaluation of the library to form an environment. Alibrary can be constructed from a group by analyzing the dependencies among sources, compiling them independency order, and building a graph from the resulting compilation units. Thus we have the followingspecification:
type libraryval makeLibrary :group -> library
3Functor bindings would not need to be re-evaluated, but that does not save much, since a functor (essentially) evaluates to itselfin one step.
142

In most circumstances, a library created from a group becomes persistent and is cached as a library archivefile. The graph of compiled units is cached in the file system as a set of pointers to binary files containingthe actual compiled units.
To allow for the use of libraries we extend the notion of a group as follows:
datatype group =Group offsourceSet :source list
subgroups :group listvisibles :symbol list optiong
| Library of library
Libraries are never analyzed for currency; it is assumed that the cached compilation units are always up todate. (Since they have no free identifiers, the compiled code is indepenent of the current environment.)
This approach to libraries is somewhat oversimplified because it assumes that if any portion of a library isto be used, then the entire library must be incorporated. It would be preferable to provide a form of “demand-driven” execution of libraries. This may be achieved by restricting the graph to a given list of symbols priorto executing. This makes sense provided that no library module contains an implicit dependency on anyother. Consider the following example in which each structure is defined in a separate source. Structure A
defines a ref cell called x and does not refer to any other modules. Structure B initializes the value of x. Inthis case, A depends on no other sources, and B depends on A. The evaluation of a group consisting of A andB would first evaluate A then B. If this group is made into a library, and a client only refers to A, then B willnot be evaluated, and the initialization of x will not occur. Of course, it is likely that such a group should bereorganized if it is to be made into a library, for example by not allowing structure A to be visible.
5 Dependency Analysis
We return now to the problem of statically determining the dependencies between a set of sources, whichamounts to determining the set of identifiers imported and exported by each source in the set. As we remarkedearlier, this cannot be done without performing at least some of the work performed by the elaboration phaseof the compiler. The main complication is that the free identifiers of a source are not syntactically evident.For example, consider the following code fragment:
open Nval y = M.x
Whether this code imports structure M depends on whether N defines a structure M. Consequently, adependency analyzer must determine the set of identifiers defined by N before it can determine whether theabove code fragment imports M. This analysis duplicates some of the work performed in compiling eachsource. In particular, every source must be parsed twice, once by the analyzer and once by the compiler. Thisoverhead does not appear to be prohibitive in practice, and in any case can be avoided only by employing a“parallel” elaboration of the sources in a set, using essentially the strategy sketched in Section 2.
The dependency analyzer of the CM maps a source group and a base environment to a source-dependencygraph:
val analyze :group * environment -> sourceGraph
143

A sourceGraph can be traversed to determine a suitable order of evaluation:
val evaluateGraph :sourceGraph * environment -> environment
We may then define evaluateGroup as follows:
fun evaluateGroup (g,e) = evaluateGraph (analyze (g,e), e)
Sources graphs are constructed using the function analyzeSource which constructs the set of symbolsimported and exported by a source. This function satisfies the following specification:
datatype binding = fsymbol :symbol, def :binding listgval analyzeSource :source -> (symbol -> binding) ->fimports :symbol list, exports :binding listg
The type binding represents the definition of a module identifier, recording both the symbol being definedand the bindings contained within it. The function analyzeSource is memoized (in the filesystem) toavoid redundant analysis of sources in a set.
Since the sources in a group are not assumed to be in any useful order (except for the subgroups, whichmust be analyzed before the group itself), we employ a multithreaded strategy similar to the one sketchedearlier for parallel evaluation of sources. The function analyze calls analyzeSource in a separate threadfor each source in the group. When the analysis of one source completes, analyze enters the exportedbindings into a binding table. This table is read by a blocking lookup function which is passed as thesecond argument to each source analyzer thread. The analysis of each source continues as long as symbolslooked up via the lookup function are found. When a lookup fails, the associated analyzeSource thread issuspended. A deadlock occurs if some symbol is not defined in one of the sources or if a circular dependencyexists among some sources in the group. If a deadlock occurs, an error is reported. After the imports andexports of the sources are determined, a sourceGraph can be constructed by creating dependency edgesfrom a source that imports a symbol to the source that exports it.
The dependency analysis of a group is complicated by the fact that the sources in a group may shadowsymbols defined in subgroups. Consider the following group:
Group fsourceSet = [A, B],subgroups = [G],visibles = NONEg
Let us assume that both G and A export a symbol S, whereas B imports S. Care must be taken to ensure thatB imports S from A rather than the subgroup G. In the CM this is accomplished by performing a pre-pass onthe source set to determine only their exported symbols. The result of this pre-pass is then used to filter thesymbols exported by the subgroups for the dependency analysis.
6 Compilation Tools
Thus far we have considered only evaluation of SML sources. However, in practice an SML software systemmay consist of sources that require other forms of processing. This situation arises, for example, when otherlanguages are implemented in SML, or when tools such as parser and lexical analyzer generators are used.In order to support selective recompilation for such languages, we have provided a way to incorporatesource-processing tools into the CM.
144

Our basic assumption is that the ultimate goal of processing a source is the execution of a compiled unit.Thus, a tool can be viewed simply as providing a “compiler” that translates sources into compiled units,which are finally executed in the usual manner. Keeping with the approach described thus far, we continueto make use of dependency analysis before compilation, and thus a tool must also provide two functions tosupport the dependency analyzer.
We provide a structure with the following signature for defining and using tools.
signature TOOL = sigeqtype toolval tool :fexportsFn :source -> symbol list,
analyzeFn :source -> (symbol -> binding)-> fimports :symbol list,
exports :binding listg,compileFn :source * staticEnv -> compiledUnitg-> tool
val exports :source -> symbol listval analyze :source -> (symbol -> binding)
-> fimports :symbol list, exports :binding listgval compile :source * staticEnv -> compiledUnit
end
New tools are introduced to the CM by calling tool. The functions exports, analyze, compile, andstamp each determine the tool for the given source using the toolOf function introduced below, and callthe function appropriate for that tool. The exports and analyze functions provide the necessary supportfor dependency analysis, in the manner described in Section 5. The compile and stamp functions providecompilation and the support for cacheing of compiled units. The compile function is expected to cache itsown intermediate results if any, but the CM caches compiled units.
The signature for abstract type of sources is modified as follows to account for arbitrary compilationtools:
signature SOURCE = sigtype sourceeqtype stampval sourceFile :string * tool -> sourceval sourceString :string * tool -> sourceval sourceAst :Ast.dec * tool -> sourceval toolOf :source -> toolval stamp :source -> stamp
end
Each source object carries along a tool for processing it. The method for determining whether a cachedcompiled unit is current with respect to the source relies on an approximation to source equality. The stampfunction provides a persistent identifier for a source. Stamp equality approximates source equality. A stampfor a file usually will be constructed from the file’s name and modification time, although other schemes arepossible.
As an example, consider the following skeletal definition of a tool for processing sml-yacc [14] grammarfiles.
145

val YaccFileTool =let fun generate (src:source) :source = ...
fun exportsFun src = exports (generate src)fun analyzeFun src = analyze (generate src)fun compileFun (src, se) = compile (generate src, se)
intool fexportsFn = exportsFun,
analyzeFn = analyzeFun,compileFn = compileFung
end
Here, we assume that generate implements the parser generator; that is, it reads a grammar from thegiven source and produces an SML source that implements a parser. In the process, generate cachesthis intermediate output by saving it into a file. Note how compileFun calls compile to compile theintermediate source into a compiled unit.
The actual CM implementation allows more dynamic configuration of tools and sources. For example,the list of possible sources is not fixed as indicated by the signature above, but can be extended by registeringnew types of sources and new tools.
7 Conclusion
We have described a selective recompilation system for Standard ML of New Jersey. It is faithful to thesemantics of Standard ML so that SML programs need not be rewritten in any way in order to be processedby the CM. The system is computationally parsimonious in that it minimizes recomputation of redundantresults. The accuracy of this process is limited only by the conservativeness of the approximations toequality of sources and static environments. Larger systems can be managed, with the ability to structure asoftware system into a hierarchy of subsystems or libraries, each consisting of a set of sources or compiledunits. Finally, the CM is extensible, allowing for compilation tools other than the SML/NJ compiler to beaccommodated.
The design of the CM allows it to be used in many different ways. In practice, different systems havebeen defined on top of the basic CM, each of which implements a particular way of managing incrementalcompilation. For example, Appel defined a structure called Batch that defines operations specific tobootstrapping a new version of the SML/NJ compiler, and is convenient for building cross-compilers. Amore commonly used example is the structure Make that provides a set of operations suitable for use in atypical file-based development environment. This structure provides, among other things, a function
val make :string list -> unit
which, when given the names of the files (in an arbitrary order) containing the sources for a system, createsa source group from the sources and evaluates it relative to the pervasive environment. Similar functionsfor managing a system of source groups are also provided.
Over the past few years, several versions of the CM have been implemented and used daily at anumber of sites. The current implementation is richer in some ways than the CM described here. But,libraries and visible symbols for groups have not yet been implemented. They will be incorporated into theimplementation soon. The CM is provided with the regular distribution of the Standard ML of New Jerseysystem from AT&T.
146

References
[1] Rolf Adams and Walter Tichy and Annette Weinert. The cost of selective recompilation and envi-ronment processing. ACM Transactions on Software Engineering and Methodology, 3(1):3–28, Jan.1994.
[2] Andrew W. Appel and David B. MacQueen. Separate Compilation for Standard ML. In ACMSymposium on Programming Language Design and Implementation, June 1994.
[3] Bruce Duba, Robert Harper, and David MacQueen. Typing first-class continuations in ML. InEighteenth ACM Symposium on Principles of Programming Languages, pages 163-173, Jan. 1991.
[4] Stuart Feldman. Make–a program for maintaining computer programs. Software Practice and Experi-ence, 9(3):255–265, March 1979.
[5] Robert Harper, Bruce Duba, and David MacQueen. Typing first-class continuations in ML. Journal ofFunctional Programming, 3(4):465–484, ? 1993. (See also [3].).
[6] Robert Harper and Mark Lillibridge. A type-theoretic approach to higher-order modules with sharing.In Twenty-first ACM Symposium on Principles of Programming Languages, Jan. 1994.
[7] Robert Harper, David MacQueen, and Robin Milner. Standard ML. Technical Report ECS–LFCS–86–2, Laboratory for the Foundations of Computer Science, Edinburgh University, March 1986.
[8] Xavier Leroy. Manifest types, modules, and separate compilation. In Twenty-first ACM Symposium onPrinciples of Programming Languages, Jan. 1994.
[9] David MacQueen. Modules for Standard ML. In 1984 ACM Conference on LISP and FunctionalProgramming, pages 198–207, 1984. Revised version appears in [7].
[10] David MacQueen. Using dependent types to express modular structure. In Thirteenth ACM Symposiumon Principles of Programming Languages, 1986.
[11] Robin Milner, Mads Tofte, and Robert Harper. The Definition of Standard ML. MIT Press, 1990.
[12] Robert W. Schwanke and Gail E. Kaiser. Smarter recompilation. ACM Transactions on ProgrammingLanguages and Systems, 10(4):627–632, October 1988.
[13] Zhong Shao and Andrew Appel. Smartest recompilation. In Twentieth ACM Symposium on Principlesof Programming Languages, pages 439–450, Charleston, SC, January 1993.
[14] David Tarditi and Andrew W. Appel. ML-YACC, version 2.0. Distributed with Standard ML of NewJersey, April 1990.
[15] Walter F. Tichy. Smart recompilation. ACM Transactions on Programming Languages and Systems,8(3):273–291, July 1986.
147

Axiomatic Bootstrapping:A guide for compiler hackersAndrew W. AppelPrinceton UniversityAbstractIf a compiler for language L is implemented in L, thenit should be able to compile itself. But for systems usedinteractively, commands are compiled and immediatelyexecuted, and these commands may invoke the compiler,there is the question of how ever to cross-compile foranother architecture. Also, where the compiler writesbinary �les of static type information that must then beread in by the bootstrapped interactive compiler, how canone ever change the format of digested type informationin binary �les?Here I attempt an axiomatic clari�cation of the boot-strapping technique. I use the Standard ML of New Jer-sey as a case study. This should be useful to implemen-tors of any self-applicable interactive compiler with non-trivial object-�le and runtime-system compatibility prob-lems.1 IntroductionA conventional C compiler, written in C, is said to be\bootstrapped" if it compiles itself. Now, suppose a newversion of the compiler source is written, that uses dif-ferent registers for passing arguments. The old compilercan compile this source, yielding a new compiler.But look! The executable version cc' of the new com-piler uses the old parameter-passing style, but generatescode that uses the new style. One can use the new com-piler, however, to re-compile all the libraries (and the newcompiler itself) and get a \new new" executable that bothuses and generates the new parameter-passing style.There's not much else to be said about bootstrappingC compilers (though see section 6). But in a languagewith an interactive read-eval-print loop, commands aretyped by the user, compiled immediately, and executed.Such a command, when compiled, may be a recursivecall to the compiler itself, this time to compile a speci-�ed source �le into a binary �le. The compiler process-ing interactive commands is the same one that compilesa source �le; this makes it di�cult to cross-compile fora di�erent target architecture! In fact, in a su�cientlyfeature-laden interactive compilation system, there aremany constraints on the retargeting and bootstrap pro-cess. This paper is a case study of the Standard ML ofNew Jersey (SML/NJ) system, explaining the di�cultiesand how to manage them.
Bin �les. Source �les are transated by SML/NJ into\bin" �les;1 each bin �le contains the executablemachine code for the corresponding source, and theexported static environment for that source [1]. Forexample, if a source �le de�nes two structures S andT , each with several components, then the staticpart of the bin �le is a description of the structuresS and T : the names and types of their componentsand substructures.The static part of the bin �les is an ML data struc-ture, complete with pointers, datatype constructorsetc., created by the compiler and written in binaryform to the bin �le. Ordinarily, when a programis compiled to bin �les by the interactive system,the bin �les (including static part) will be readback into the same version of the system. But inbootstrapping, the compiled program is the \new"compiler, and we want to discard the \old" com-piler. Thus, the new compiler executes, and loadsin static information (from the bin �les) about it-self. For this to work, the representation of staticenvironments in the old and new compilers mustagree. This representation has two parts: the MLdata types E (and their interpretation) chosen bythe programmer; and the representation D of thesedata types as pointers and records in memory. Con-straints on E might occur in any compiler thatstores digested static information; constraints on Dare a consequence of the fact that SML/NJ uses apickler to write relocatable pointer data structuresto the binary �le just as they appear in memory.In-line primops. When the SML/NJ compiler �rst ex-ecutes, it initializes its static environment by con-structing a special primitive basis containing thein-line primitive operations (such as +, :=, etc.).This static environment is built using the same MLdatatypes as ordinary static environments, but itis directly constructed without parsing any input.The primitive environment is then imported andused by the ML code that implements the initialbasis.When compiling a new version of the compiler, onecan augment or change the primitive environment.But one cannot make use of the changed primitivesuntil the new compiler compiles a \new new" com-piler.1This is true of SML/NJ versions since 0.96.148

Initial Basis. ML programs can assume an \initial ba-sis" [5, page 77], an environment in which certaintypes and values are de�ned. The compiler itselfalso relies upon the initial basis. Furthermore, thesource code for the initial basis is part of the sourcecode for the compiler. Finally, the source codefor the initial basis uses, in places, elements of theprimitive basis containing names of specially imple-mented in-line functions.This means that if some new version of the initialbasis is desired, there are potential interactions withthe rest of the system that must be considered.Interactive system. The normal mode of operatingSML/NJ is to compile both interactive input andML programs from source �les, and run the com-piled programs in the same process as the compiler.It is particularly convenient to have an \interactive"compiler during the compiler development process,where individual compiler modules can be replaced\on-the- y." The compiled programs use the sameinitial basis as the compiler. The compiled pro-grams must be callable from the compiler, and mustbe able to call the same initial functions that thecompiler calls; thus, compiled programs must usethe same calling conventions (etc.) as the compileritself. This makes it di�cult to bootstrap a newversion of the compiler that uses di�erent callingconventions.These interactions between the compiler and the ex-ecuting program make for complications when (a newversion of) the compiler is the executing program.ExampleThe terminology of this example will be explained in sec-tion 3, but the point here is to illustrate what can gowrong if one is not careful.Suppose there is a version \1" of the system as a setof ML source �les �1 and bin �les �1. The bin �les arecompiled object �les (like \.o" �les in a C system), andare the result of compiling the source �les using somecompatible version of the compiler.We wish to use �1 to compile �1, yielding a new ver-sion of the executable compiler.First, boot builds an executable �1. This is like alink-loading step in a conventional system, but it mustalso load from �1 the digested description of the initialstatic environment, so that compilations in �1 will haveaccess to library modules (and the compiler itself) sharedwith �1. This sharing is essential, if only so that �1 andthe interactive commands running withinmu1 don't haveseparate copies of runtime-systemmanagement data thatwould trip over each other.boot(�1) = �1Now �1 compiles the source �1 into binary object �les�01: compile(�1; �1) = �01Now we hope that �1 �= �01, whatever that means.
However, suppose one edits the source �les to produce�2, a new version of the compiler that uses a di�erentcalling convention. One might try the following steps:compile(�1; �2) = �2boot(�2) = ?The boot step fails because �2 is not self-consistent.The code generated by �2 from a top-level interactiveexpression (using the new calling conventions) able to callfunctions in the Basis within �2 (compiled using the oldconventions), so the �rst top-level command will dumpcore.On the other hand, some changes are harmless: ifthe only change is a di�erent algorithm for code opti-mization, boot will probably succeed. Finally, some self-inconsistencies will manifest themselves at stages otherthan boot.How can one tell whether a change is harmless? And,since \non-harmless" changes are often necessary, howcan one correctly compile and bootstrap them? The restof the paper addresses these questions.2 CharacterizationI will use the following symbols to describe characteristicsof a \version" of the compiler:A Architecture for which the compiler generates code, oron which it runs.C Calling conventions for which the compiler generatescode: which registers are used for what purpose;how end-of-heap is detected; whether a stack isused; etc.D Datatype layout: how ML data types are laid out inmemory.E Environment representation: how static environmentsare described in terms of ML data types.B Basis: the signature of the initial environment avail-able to ordinary programs (and the compiler) uponstartup.P Primitive Basis: the static environment created bythe compiler, describing in-line primitive operationsand data types. Normally the primitive basis isused only in compiling the source code for the ini-tial basis.2.1 Source characteristicsThese characteristics are now used to describe the sourcecode � for some version of the compiler. The equations inthis section just explain, in informal terms, the meaningof notation that will be used in the axioms of section 3.a 2 Agen(�) The compiler � may contain code generatorsfor several di�erent target architectures; architec-ture a is a member of this set.Cgen(�) = c The compiler � generates code that uses thec calling conventions.149

Dgen(�) = d The compiler � generates code that uses thed datatype layout scheme.Egen(�) = e The compiler � uses (and writes to bin �les)the e static environment representation.Buse(�) = b The non-basis part of the system � (that is,the compiler proper) is a program that makes useof functions in Basis b.Bimp(�) = b The basis part of the system � implementsthe basis b.Puse(�) = p The basis part of the system � is a programthat makes use of the functions in Primitive basisp.Pgen(�) = p The compiler � de�nes a primitive environ-ment p for its compiled code.2.2 Binary �le characteristicsOne can describe these aspects of compiled binary �lesin much the same way:Arun(�) = a The program � runs on architecture a.a 2 Agen(�) The compiler � generates code for the a ar-chitecture.Crun(�) = c The program � follows the c calling conven-tions.Cgen(�) = c The compiler � generates code that uses thec calling conventions.Drun(�) = d The internal data structures of program �obey the d datatype layout scheme.Denv(�) = d The static environments in bin �les � usethe d datatype layout scheme.Dgen(�) = d The compiler � generates code that uses thed datatype layout scheme.Eenv(�) = e The static environment's bin �les � are inthe e environment representation.Egen(�) = e The compiler � uses and generates the e en-vironment representation.Buse(�) = b The non-basis part of � (that is, the com-piler proper) is a program that makes use of func-tions in basis b.Bimp(�) = b The basis part of � implements the basis b.Pgen(�) = p The compiler �1 de�nes a primitive environ-ment p1 for its compiled code.2.3 Executable �le characteristicsThe bin �les are linked with a runtime system (and staticenvironments are read from the bin �les to initialize thecompiler's user-visible \initial basis") to form an exe-cutable �le �, whose characteristics are just like thosefor bin �les �, except that:
� Executable �les do not have separate static envi-ronment sections as bin �les do, so Eenv and Denvdo not apply.� Executable systems generate code for only one ma-chine, so Agen(�) is a single architecture rather thana set of architectures.3 AxiomsI will give axioms describing the procedures of compiling,bootstrapping, retargeting, and elaboration; these axiomswill then be used to prove theorems in section 4.3.1 CompilingTo compile source code, one executes the interactive sys-tem �, and gives commands to compile source �les � intobinary �les �: compile(�; �) = �for which the following equations must hold:Buse(�) v Bimp(�)Puse(�) v Pgen(�)The relation v expresses the ML signature match-ing relation. That is, Puse(�) v Pgen(�) means that thesource �les � can be compiled in a primitive environmentcreated by �: every identi�er looked up will be presentand have an appropriate type. The \basis" (B) part of� de�nes modules that are then used by the \compiler"part of �, so the �rst equation is straightforward. Butthe \primitives" (P ) containing special in-line functionde�nitions must be specially constructed by �.The binary �les (i.e. the �les in the bin directory) �are then characterized by the following equations.Arun(�) = Agen(�)Agen(�) = Agen(�)Crun(�) = Cgen(�)Cgen(�) = Cgen(�)Drun(�) = Dgen(�)Dgen(�) = Dgen(�) These �rst six equations are unre-markable, and would occur in practically any com-piler.Denv(�) = Drun(�) This equation results from the use ofa \pickler" for writing the static type information(pointer data structures) to a �le in the same binaryformat that is used in core.Eenv(�) = Egen(�)Egen(�) = Egen(�) These two equations on E would holdin any compiler that writes digested static type in-formation, with or without the use of a pickler.150

Bimp(�) = I(Bimp(�)) where I is a hash function thatcomputes \persistent identi�ers" from the static en-vironment exported by a source program. The per-sistent identi�ers are then used for linking the ma-chine code of di�erent modules together, in a guar-anteed type-safe way.Buse(�) = Bimp(�) The two equations on B are a con-sequence of sharing library code and data betweenthe interactive system and the compiled user code.Pgen(�) = Pgen(�) True in any compiler that de�nes func-tions that look ordinary to the user but are com-piled specially (e.g., in-line).3.2 BootstrappingThe bootstrapper is a part of the C-language runtime sys-tem. It knows just enough to extract the dynamic part(machine code) from bin �les �; but not the format ofstatic environment representations, which only the com-piler understands. However, the machine code within �is the compiler; once it starts running, it can load thestatic part of � to form an environment (symbol table ofthe initial basis) for compiling user programs. The resultis an interactive compiler �:boot(�) = �:For this to work, the following equations must hold:Arun(�) 2 Agen(�) so that the compiler and top-level in-teractive commands can both run on the same com-puter.Crun(�) = Cgen(�) so that top-level interactive commandscan call and be called by the compiler and initialbasis.Drun(�) = Dgen(�) for the same reason.Denv(�) = Drun(�) so the bootstrapping compiler can readstatic environments from bin �les.Eenv(�) = Egen(�) for the same reason.The remaining equations characterize the output �:Arun(�) = Arun(�) = Agen(�)Crun(�) = Crun(�)Cgen(�) = Cgen(�)Drun(�) = Drun(�)Dgen(�) = Dgen(�)Egen(�) = Egen(�)Buse(�) = Buse(�)Bimp(�) = Bimp(�)Pgen(�) = Pgen(�)Now, for example, one can see that the boot failuredescribed in section 1 is because Crun(�2) 6= Cgen(�2)violating one of the preconditions for boot.
3.3 RetargetingBecause it is impossible to bootstrap using compile andboot if the new compiler uses a new calling sequence orenvironment representation, two special procedures areprovided. The �rst of these is called retarget: Runan interactive compiler �1, and load the bin �les � fora di�erent version of the compiler as a \user program."Since � may include code generators for many machines,one can also specify which target architecture a's codegenerator should be selected from �.retarget(�1; �; a) = �2:The compiler originally present in �1 will be used in�2 for compiling top-level interactive commands, but thecompiler � will be used in �2 for turning source �les intobin �les.Ordinary user programs do not provide their own im-plementation of the initial basis, so the basis portion of �(corresponding to the that implement Bimp(�)) will notbe loaded: Bimp(�) is irrelevant. However, the non-basisportion of the compiler � must be compatible with thebasis already running in �1, so that � can call upon stan-dard I/O functions (etc.) built into �1.As an ordinary user program, the bin �les � executingunder the supervision of �1 can generate code for anyarchitecture or any calling sequence. This is because thecode is not going to be executed in the current process,so it doesn't need to be compatible with the instructionset or calling conventions that �1 itself is using. Thisfreedom is crucial for cross-compilation (compilation fora di�erent target architecture or calling convention).The following restrictions apply:a 2 Agen(�)Arun(�) = Arun(�1)Crun(�) = Crun(�1)Drun(�) = Denv(�) = Drun(�1)Eenv(�) = Egen(�1)Buse(�) = Bimp(�1) This relationship is an exact signa-ture match. In particular, it means that the intrin-sic persistent identi�ers generated from the com-pilation of the initial basis (�les in the src/bootdirectory) in building the bin �les within �1 mustbe identical to the corresponding identi�ers in theinitial basis portion of �. 22This can be guaranteed by producing � and �1 from the samecompiler �0, in the following way:compile(�0; �1) = �1boot(�1) = �1compile(�0; �2) = �where the source codes for the Bimp portions of �1 and �2 areidentical.This works because I is really a function: (x = y) ) (I(x) =I(y)).In versions 0.96{0.98 of the SML/NJ system, the \persistentidenti�ers" were just time stamps, so that I would return di�erentresults at di�erent times. Therefore, with the procedure outlinedat the top of this footnote, B(�) and B(�1) would not exportthe same \persistent identi�ers" even though the source code was151

The following equations characterize the output �2:Arun(�2) = Arun(�1)Agen(�2) = aCrun(�2) = Crun(�1)Cgen(�2) = Cgen(�)Drun(�2) = Drun(�1)Egen(�2) = Egen(�)Buse(�2) = Buse(�1)Bimp(�2) = Bimp(�1)Pgen(�2) = Pgen(�)A funny hybrid indeed.3.4 ElaborationFinally, elab is a special variation on boot that re-parsesthe source �les to build the static environment, insteadof reading it from the bin �les: elab(�; �) = �.Now, given the two stepscompile(�0; �) = �elab(�; �) = �� must satisfy all the equations given for boot aboveexcept for the ones involving Denv(�) and Eenv(�), be-cause the environments will not be read from the bin�les. Another requirement for elab is that � and � mustbe related by the compile command shown.The resulting executable � is de�ned by the sameequations as for boot(�). In fact, with elab there is noneed for boot, except that elab is much slower becauseit re-parses all the source.4 Stable versionsDe�nition: (�; �) form a stable version if the followingequations hold:Arun(�) 2 Agen(�) = Agen(�)Cgen(�) = Crun(�) = Cgen(�)Dgen(�) = Drun(�) = Dgen(�) = Denv(�)Egen(�) = Eenv(�) = Egen(�)Buse(�) v Bimp(�)Bimp(�) = I(Bimp(�))Buse(�) = Bimp(�)Puse(�) v Pgen(�) = Pgen(�)Remark: If compile(boot(�; �0); �) = �0 then (�; �)is a �xed point, a stronger property. But we cannot prove�xed-point properties from the axioms in this paper.Suppose one starts with a stable version (�1; �1) andcreates a new source �2. How can one obtain bin �les �2to make a stable version with the new source?All of the \theorems" in this section are proved usingonly the axioms of section 3 and the de�nition of a stableversion.identical. Instead, one would have to create a new, empty bindirectory; copy just the bin �les for the initial basis from �1 tothe new bin directory �; and then proceed with a compile thatwould use these �les as a starting point.
4.1 New Primitive BasisSuppose Pgen(�2) 6= Pgen(�1), Puse(�2) v Pgen(�2), butall other characteristics (Agen, Cgen, Dgen, Egen, Buse,Bgen, Puse) are identical from one source to another.Then boot(�1) = �1compile(�1; �2) = �2The reader can verify that both of these steps succeed,and that (�2; �2) is stable.4.2 New Initial BasisNow suppose �2 di�ers from �1 in the initial basis (the�les in the boot directory), and perhaps also in Puse, theset of primitives used in the initial basis.boot(�1) = �1compile(�1; �2) = �2The reader can verify that these steps succeed and resultin (�1; �2) stable.4.3 New environmentsSuppose �2 uses a di�erent environment representation(Egen) from �1.The \ordinary" procedure will not work:boot(�1) = �1compile(�1; �2) = �2boot(�2) = ?Now Egen(�2) 6= Eenv(�2), so �2 cannot be used in boot.There are two ways to build a stable version:elab(�2; �2) = �2compile(�2; �2) = �02 orretarget(�1; �2; Arun(�1)) = �02compile(�02; �2) = �002Now, (�2; �02) is stable, and so is (�2; �002 ); �02 and �002are equivalent in all properties.4.4 New datatype layoutIf the new compiler uses a di�erent datatype layout (thatis, Dgen(�2) 6= Dgen(�1)) then the following steps willbuild a stable version: boot(�1) = �1compile(�1; �2) = �2elab(�2; �2) = �2152

Retarget will not do the job; for supposeboot(�1) = �1compile(�1; �2) = �2retarget(�1; �2; a) = �02compile(�02; �2) = �02then Denv(�02) = Dgen(�1), while Drun(�02) = Dgen(�2).Thus �02 cannot be used as input to either boot or retarget.4.5 New calling conventionsSuppose �2 uses new calling conventions: Cgen(�2) 6=Cgen(�1).The procedure is: boot(�1) = �1compile(�1; �2) = �2retarget(�1; �2; Arun(�1)) = �2compile(�01; �2) = �02Now (�2; �02) is stable. The reader can verify thatretarget is necessary, and that elab would not su�ce.4.6 New target architectureGiven (�; �) stable, Arun(�) = a1, suppose one wishes tomake a compiler that runs on architecture a2, for a2 2Agen(�). boot(�) = �1retarget(�1; �; a2) = �2compile(�2; �) = �2Now (�; �2) is a stable compiler running on, and gen-erating code for, architecture a2.4.7 Getting from here to thereSuppose there is a stable version (�1; �1), and a compiler�1 = boot(�1). The programmer makes a new source�2 that di�ers in every characteristic from �1. Let usassume, however, that Puse(�1) v Pgen(�2).There may well exist a �2 such that (�2; �2) is stable,but we do not have such a �2. How is it to be obtained?The �rst problem is that compile is inapplicable, sincewe cannot assume eitherBuse(�2) v Bimp(�2) or Puse(�2) vPgen(�1).The procedures boot, retarget, and elab are not use-ful, since they just take the binary �les �1 that we alreadyhave. elab(�1; �2) is illegal (as the reader may verify),and the author cannot even imagine why it might be use-ful.The trick is to make some intermediate versions of thesource code: �x is like �1 but de�nes augmented primi-tives P ; �y is like �x, but makes use of the augmentedprimitives and provides an augmented basis Bimp.
So, �x is as follows:Agen(�x) = Agen(�1)Cgen(�x) = Cgen(�1)Dgen(�x) = Dgen(�1)Egen(�x) = Egen(�1)Buse(�x) = Buse(�1)Bimp(�x) = Bimp(�1)Puse(�x) = Puse(�1)Pgen(�x) = Pgen(�2)Then compile(�1; �x) = �xboot(�x) = �xNow version �y is another intermediate version:Agen(�y) = Agen(�1)Cgen(�y) = Cgen(�1)Dgen(�y) = Dgen(�1)Egen(�y) = Egen(�1)Buse(�y) = Buse(�2)Bimp(�y) = Bimp(�2)Puse(�y) = Puse(�2)Pgen(�y) = Pgen(�2)Now compile(�x; �y) = �yboot(�y) = �ycompile(�y; �2) = �zretarget(�y; �z) = �zcompile(�z; �2) = �0zelab(�0z; �2) = �2compile(�2; �2) = �2Now (�2; �2) is stable. The proof is just simple (buttedious) equational reasoning, checking that the precon-ditions of each step are satis�ed and characterizing theintermediate results �x; �x; �y; �y; etc.It does seem amazing that �ve compilations are re-quired to get from stable version 1 to stable version 2.But I have not found a shorter sequence.5 GeneralityIn what sense do the \characteristics" A;C;D;E;B; Pform, in any sense, a complete set?The axioms cannot assure the correctness of the com-piler. Specifying that a 50,000 line program faithfullyimplements the 100-page De�nition of Standard ML[5] isnot something that can be done with eight or ten simpleequations in the style shown in this paper. The axioms153

are meant as abstractions of only those aspects of boot-strapping that often prove problematical. Many otheraspects of ML compilation, though di�cult or interest-ing, pose no special problems when bootstrapping andare entirely ignored by the axioms.However, perhaps there are other important issues re-lated to bootstrapping that are not accurately character-ized by any of the axioms.5.1 Runtime systemML requires a runtime system, to do garbage collection,to handle system calls, and to provide various functionsimplemented in C or assembly language. The runtimesystem must know the format of ML data types (to dogarbage collection) and must satisfy other constraints. Aruntime system � has the properties Arun(�), the architec-ture on which it runs; Crun(�), the calling conventions forML-callable entry points; and Drun(�), the ML datatypelayout that it understands.To model runtime systems, we extend boot with aruntime-system argument: boot(�; �) = � with extrapreconditionsArun(�) = Arun(�)Crun(�) = Crun(�)Drun(�) = Drun(�)Elaboration also requires a particular runtime system:elab(�; �; �) with the same three preconditions.The implications of these constraints turn out to bequite trivial; runtime system issues don't cause boot-strapping problems, except as described in the next sub-section.5.2 Structured I/O formatFor example, John Reppy recently rewrote the \pickler"in the runtime system, that writes pointer data structuresto �les (and reads them back). In particular, the picklerwrites static environment representations to bin �les �.Reppy's new pickler uses a di�erent �le format from theold one. The implementation of (either version of) thepickler, and any knowledge about �le format, is entirelywithin the runtime system.We could characterize this as Fgen(�), the format thata given runtime system uses to write ML datatypes toa �le. Then the bin �le � would have a characteristicFenv(�), the format in which static environments havebeen written; and executables � would have the char-acteristic Fgen(�) based on the format that �'s runtimesystem uses.Then we have the following additional axioms. Forcompile(�; �) = � we have Fgen(�) = Fenv(�).For boot(�; �) = � we haveFenv(�) = Fgen(�)Fgen(�) = Fgen(�)(the �rst is a precondition, the second characterizes theoutput �).For retarget(�1; �; a) = �2 we haveFenv(�) = Fgen(�1)Fgen(�2) = Fgen(�1):
And �nally, for elab(�; �; �) = � we have only Fgen(�) =Fgen(�), and Fenv(�) irrelevant.Clearly, Reppy will need to use elab in order to boot-strap his new structure-blaster format, since boot andretarget are too restrictive.This example has illustrated that the axioms of sec-tion 3 do not necessarily form a complete set, but theaxiomatic method is easily extensible to meet new chal-lenges.5.3 New module-�eld layoutOlder versions of SML/NJ sorted the value �elds of asignature into alphabetical order before generating code.This meant that in the translation of this module Sstructure S =structval b = 5val a = 7endwould be as a record in memory in which a (7) appeared�rst, followed by b (5).Current versions of SML/NJ do not sort into alpha-betical order. Thus, bin �les compiled by the new versionshould be incompatible with executables of the old ver-sion.Consider the axiomatization. We say thatGgen(�) is the sorting (nonsorting) technique used forstructure �elds by source code �;Grun(�) is the structure-�eld layout algorithm that hadbeen used in compiling �;Ggen(�1) is the structure-�eld layout algorithm that �uses in generating output code;Grun(�) is analogous to Grun(�);Ggen(�) is analogous to Ggen(�);Grun(�) is the ordering that � uses for interfacing itsown \primitive" structures visible from the ML pro-gram.The next step is to write axioms for G. This is nottrivial, as it involves an understanding of how the com-piler and generated code work. It turns out, however,that the equations for G in the steps compile, boot,retarget, elab are exactly parallel to the equations forC. This implies that G was not necessary at all, and thatC expresses (among other things) the ordering of struc-ture �elds. This is a measure of the robustness of theoriginal axioms.5.4 Record �eld orderingRecord �elds are also sorted by label in SML/NJ. Sort-ing is required by the semantics of the language, but anyconsistent ordering will do. The sorting could, in princi-ple, be done in some nonstandard (i.e. non-alphabetical)order.Since records are used directly in the implementationof static environments, and structures are not, the e�ectof record �elds turns out to be axiomatized exactly like154

datatype layouts D, not like calling sequences C. Thisshould not be surprising, as the record type {a,b} is in-deed a kind of type constructor (just like a datatype) andthe layout into bits of ML data types is exactly what Dwas supposed to characterize.6 Related workLecarme et al. [4] present a good explanation of a theoryof bootstrapping using T-diagrams, a notation inventedby Bratman [2] and formalized by Earley and Sturgis [3].This theory is simple and elegant, and the diagrams arepretty to look at. It is very successful in describing thesteps needed to produce a compiler from source languageSL to object language OL written in implementation lan-guage WL, when one has (for example) a machine exe-cuting instruction set XL, a translator from WL to XLimplemented in XL, an interpreter for OL written in AL,and a translator for AL written in ... and so on. The T-diagrams seem more compact, and easier to read once onelearns how, than the corresponding equational theory.In fact, Earley and Sturgis provide an algorithm toconstruct a bootstrap sequence: Given a set of trans-lators and interpreters (characterized by source, object,and implementation languages), and a desired translator(similarly characterized) their algorithm can either showhow to construct the desired result or prove that it can-not be done. Perhaps an algorithm such as this could bedevised to prove the theorems of sections 4.1{4.6.Lecarme goes further, with a owchart that provideshints about what existing translator should be modi�ed\by hand" (to produce a di�erent target language, or toaccept a di�erent source language, or to run in a di�erentimplementation language) to get to the desired result.Note the similarities with the hand-made intermediateversions �x; �y needed in section 4.7.Why do I abandon T-diagrams? The added prob-lem in SML/NJ (and in similar interactive systems, es-pecially those that have predigested type information) isthat there are extra constraints between the implementa-tion language and the object language that T-diagramsdo not express. Furthermore, the di�erent languages inquestion are all quite similar: executable code describedby (in this case) six characteristics, where many of thecharacteristics are likely to match between any two ver-sions. In using T-diagrams, the similarities between twoexecutables (e.g. identical data type representation) arelost, and would have to be expressed separately in a setof equations.Thompson's Turing award lecture [6] describes howbugs (and viruses) can propagate through the bootstrap-ping process.7 ConclusionWhen compiled code shares important parts of the envi-ronment with the compiler itself, bootstrapping new ver-sions can be complicated, and previous theories of boot-strapping do not seem to extend well. Clearly writtenaxioms can help the poor compiler hacker deal with thecomplexity.Certain choices made in the SML/NJ system compli-cate bootstrap process:
� The SML/NJ system uses a \pickler" to write staticenvironments to binary �les in (almost) exactly thesame format that's used in memory. The result-ing constraints on Denv(�) cause the procedures ofsections 4.4 and 4.7 to take extra elab steps.� The sharing of code and data between the compilerand user programs requires the compiler to load itsown static environments, causing constraints on Eand B.� The use of the same compiler for compiling inter-active commands and source �les for the compileritself requires a special retarget mechanism for re-laxing constraints on A and C.However, each of these features is useful in its own way.The axiomatization of bootstrapping makes it easier totolerate complexity in the process, so that these featurescan be more easily supported.A Command realizationEach of the abstract functions compile, boot, retarget,elab corresponds to a sequence of operating-system com-mands (a shell script) or ML commands. Let � be an in-teractive sml executable with the Compilation Manager(make system) loaded, called sml-cm. Let � be a setof source �les for the compiler in directory src. Thencompile(�; �) is justcd src; echo "Batch.make()" | sml-cmSupposing that the target architecture is sparc (Agen(�) =sparc), this creates a directory � = bin:sparc containingbin �les.Bootstrapping (boot(�; �)) is done by two shell scripts:makeml compiles the runtime system � (written in C andassembly language) from the src/runtime subdirectoryruns it to load the bin �les � to create an executablesml, and makecm executes sml to load the CompilationManager, creating an executable � =sml-cm:cd src; makeml -bin bin.sparc; makecmRetargeting is done by instructing the compilationmanager � = sml � cm to load bin �les for an alternatecompiler in directory � = alt=bin:sparc (for example)and to select the alpha code generator within those �les:echo 'retarget("alt/bin.sparc",".alpha");exportML("sml-a")' | sml-cmThe result of this retarget(�; �; �) is �2 =sml-a.Finally, elaboration is just like boot but with an extracommand-line ag -elab to makeml.References[1] A. W. Appel and D. B. MacQueen. Separate compila-tion for Standard ML. In Proc. SIGPLAN '94 Symp.on Prog. Language Design and Implementation, page(to appear). ACM Press, June 1994.[2] H. Bratman. An alternate form of the UNCOL dia-gram. Commun. ACM, 4(3):142, Mar. 1961. A one-page paper that is half diagrams!155

[3] J. Earley and H. Sturgis. A formalism for translatorinteractions. Commun. ACM, 13(10):607{617, Oct.1970.[4] O. Lecarme, M. Pellissier, and M.-C. Thomas.Computer-aided production of language implementa-tion systems: A review and classi�cation. Software|Practice and Experience, 12(9):785{824, 1982.[5] R. Milner, M. Tofte, and R. Harper. The De�nitionof Standard ML. MIT Press, Cambridge, MA, 1990.[6] K. Thompson. Re ections on trusting trust. Com-mun. ACM, 27(8):761{763, 1984.
156




















