
K3 k4 regresi ganda
51
REGRESI BERGANDA
-
Upload
super-yoni -
Category
Data & Analytics
-
view
140 -
download
3
Transcript of K3 k4 regresi ganda

REGRESI BERGANDA

PENDAHULUAN
Apakah Konsumsi hanya dipengaruhi oleh
Pendapatan saja?
Ada beberapa variabel lain yang berpengaruh,
seperti jumlah anggota keluarga, umur anggota
keluarga, selera pribadi, dan sebagainya.
Bila dianggap variabel lain perlu diakomodasikan
dalam menganalisis konsumsi, maka Regresi
Sederhana dikembangkan menjadi Regresi
Berganda.
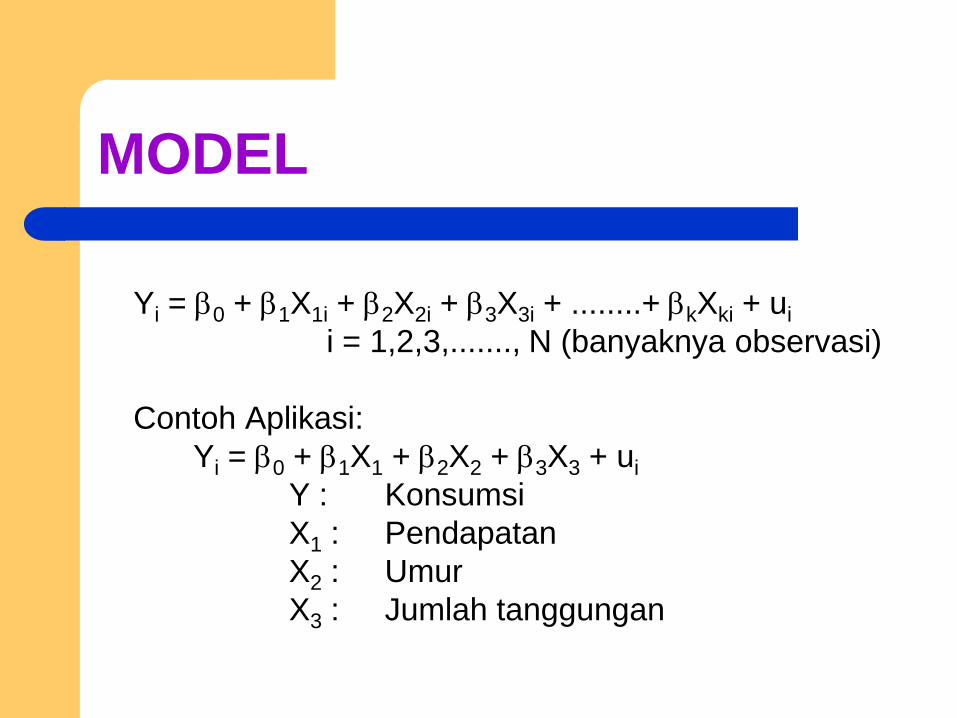
MODEL
Yi = 0 + 1X1i + 2X2i + 3X3i + ........+ kXki + ui
i = 1,2,3,......., N (banyaknya observasi)
Contoh Aplikasi:
Yi = 0 + 1X1 + 2X2 + 3X3 + ui
Y : Konsumsi
X1 : Pendapatan
X2 : Umur
X3 : Jumlah tanggungan

ESTIMASI
Teknik Estimasi: Ordinary Least Square
Estimator:
b = (XTX)-1 XTY
Bentuk tersebut merupakan persamaan matriks,
dimana:
X adalah matriks data variabel bebas
XT adalah bentuk transpose matriks X
(XTX)-1 adalah inverse perkalian matriks XT dan X
Y merupakan vektor data variabel terikat

Pemeriksaan Persamaan Regresi
Standard Error Koefisien
Interval Kepercayaan
Koefisien Determinasi
Nilai-nilai ekstrim
Uji Hipotesis:– Uji t
– Uji F

Uji Hipotesis
Uji-F
Diperuntukkan guna melakukan uji hipotesis koefisien (slop) regresi secara bersamaan.
H0 : 1 = 2 = 3 = 4 =............= k = 0
H1 : Tidak demikian (paling tidak ada satu slop yang 0)
Dimana: k adalah banyaknya variabel bebas.
Regresi sederhana:
H0 : 1 = 0
H1 : 1 0
Pengujian: Tabel ANOVA (Analysis of Variance).

Uji-F
Observasi: Yi = 0 + 1 Xi + ei
Regresi: Ŷi = b0 + b1 Xi (catatan: Ŷi merupakan estimasi dari Yi).
Bila kedua sisi dikurangi maka:
Selanjutnya kedua sisi dikomulatifkan:
SST SSR SSE
SST : Sum of Squared Total
SSR : Sum of Squared Regression
SSE : Sum of Squared Error/Residual
Y Y Y Y ei i
( ) ( )Y Y Y Y ei i i 2 2
( ) ( )Y Y Y Y ei i i 2 2 2
Y

Uji F
Tabel ANOVA
Sumber Sum of Square df Mean Squares F Hitung
Regresi SSR k MSR = SSR/k F = MSR
Error SSE n-k-1 MSE= SSE/(n-k-1) MSE
Total SST n-1
Dimana df adalah degree of freedom, k adalah jumlah variabel bebas (koefisien slop), dan n jumlah observasi (sampel).
Bandingkan F Hit dengan Fα(k,n-k-1)

Asumsi-asumsi yang mendasari OLS
Pendugaan OLS akan bersifat BLUE (Best
Linier Unbiased Estimate) jika memenuhi 3
asumsi utama, yaitu:
– Tidak ada multikolinieritas
– Tidak mengandung Heteroskedastisitas
– Bebas dari otokorelasi

Multikolinieritas
Multikolinieritas: adanya hubungan linier antara regressor.
Misalkan terdapat dua buah regressor, X1
dan X2. Jika X1 dapat dinyatakan sebagai fungsi linier dari X2, misal : X1 = X2, maka ada kolinieritas antara X1 dan X2. Akan tetapi, bila hubungan antara X1 dan X2 tidak linier, misalnya X1 = X22 atau X1 = log X2, maka X1 dan X2 tidak kolinier.

Ilustrasi
Yi = 0 + 1X1 + 2X2 + 3X3 + ui
Y : Konsumsi
X1 : Total Pendapatan
X2 : Pendapatan dari upah
X3 : Pendapatan bukan dari upah
Secara substansi: total pendapatan (X1) = pendapatan dari upah (X2) + pendapatan bukan dari upah (X3). Bila model ini ditaksir menggunakan Ordinary Least Square (OLS), maka itidak dapat diperoleh, karena terjadi perfect multicollinearity.Tidak dapatnya diperoleh karena ( XT X )-1, tidak bisa dicari.

Data Perfect Multikolinieritas
X1 X2 X3
12 48 51
16 64 65
19 76 82
23 92 96
29 116 118
Nilai-nilai yang tertera dalam tabel menunjukan bahwa Antara X1 dan X2
mempunyai hubungan: X2 = 4X1. Hubungan seperti inilah yang disebut
dengan perfect multicollinearity.

Akibat Multikolinieritas
Varians besar (dari taksiran OLS)
Interval kepercayaan lebar (variansi besar
Standar Error besar Interval kepercayaan lebar)
R2 tinggi tetapi tidak banyak variabel yang
signifikan dari uji t.
Terkadang taksiran koefisien yang didapat akan
mempunyai nilai yang tidak sesuai dengan
substansi, sehingga dapat menyesatkan
interpretasi.

Kesalahan Interpretasi
“Interpretasi dari persamaan regresi ganda secara implisit bergantung pada asumsi bahwa variabel-variabel bebas dalam persamaan tersebut tidak saling berkorelasi. Koefisien-koefisien regresi biasanya diinterpretasikan sebagai ukuran perubahan variabel terikat jika salah satu variabel bebasnya naik sebesar satu unit dan seluruh variabel bebas lainnya dianggap tetap. Namun, interpretasi ini menjadi tidak benar apabila terdapat hubungan linier antara variabel bebas”
(Chatterjee and Price, 1977).

Ilustrasi
Konsumsi (Y) Pendapatan (X1) Kekayaan (X2)
40 50 500
50 65 659
65 80 856
90 110 1136
85 100 1023
100 120 1234
110 140 1456
135 190 1954
140 210 2129
160 220 2267

Ilustrasi
Model:
Y = 12,8 – 1,414X1 + 0,202 X2
SE (4,696) (1,199) (0,117)
t (2,726) (-1,179) (1,721)
R2 = 0,982
R2 relatif tinggi, yaitu 98,2%. Artinya?
Uji t tidak signifikan. Artinya?
Koefisien X1 bertanda negatif. Artinya?

Ilustrasi: Model dipecah
Dampak Pendapatan pada Konsumsi
Y = 14,148 + 0,649X1
SE (5,166) (0,037)
t (2,739) (17,659)
R2 = 0,975
R2 tinggi, Uji t signifikan, dan tanda X1 positif.
Dampak Kekayaan pada Konsumsi
Y = 13,587 + 0,0635X2
SE (4,760) (0,003)
t (2,854) (19,280)
R2 = 0,979
R2 tinggi, Uji t signifikan, dan tanda X2 positif.
X1 dan X2 menerangkan variasi yang sama. Bila 1 variabel saja cukup, kenapa harus dua?

Mendeteksi Multikolinieritas dengan Uji Formal
1. Eigenvalues dan Conditional Index
Aturan yang digunakan adalah: Multikolinieritas ditengarai ada didalam persamaan regresi bila nilai Eigenvalues mendekati 0.
Hubungan antara Eigenvalues dan Conditional Index (CI) adalah sebagai berikut:
seigenvalue
seigenvalueCI
min
max
Jika CI berada antara nilai 10 sampai 30: kolinieritas moderat.
Bila CI mempunyai nilai diatas 30: kolinieritas yang kuat.

2. VIF dan Tolerance
)1(
1VIF
2j
jR ; j = 1,2,……,k
k adalah banyaknya variabel bebas
adalah koefisien determinasi antara variabel bebas ke-j dengan
variabel bebas lainnya.
2
jR
2
jR
2
jR
Jika = 0 atau antar variabel bebas tidak berkorelasi, maka nilai VIF = 1.
≠ 0 atau ada korelasi antar variabel bebas, maka nilai VIF > 1. Jika
Oleh karena itu, dapat disimpulkan bahwa kolinieritas tidak ada
jika nilai VIF mendekati angka 1

Tolerance
VIF ini mempunyai hubungan dengan
Tolerance (TOL), dimana hubungannya
adalah sebagai berikut:
2
j 11
TOL jRVIF
Variabel bebas dinyatakan tidak multikolinieritas jika
TOL mendekati 1

Mengatasi kolinieritas
Melihat informasi sejenis yang ada
Tidak mengikutsertakan salah satu variabel yang
kolinier
– Banyak dilakukan.
– Hati-hati, karena dapat menimbulkan specification bias
yaitu salah spesifikasi kalau variabel yang dibuang
merupakan variabel yang sangat penting.
Mentransformasikan variabel
Mencari data tambahan

Heteroskedastisitas (Heteroscedasticity)
Variasi Error tidak konstan. Umumnya terjadi pada data cross
section. Misal data konsumsi dan pendapatan, atau data
keuntungan dan asset perusahaan
0
20
40
60
80
100
120
0 20 40 60
Pola Data Heteroskedastis

Data Heteroskedastisitas
Fakta:– hubungan positif antara X dan Y, dimana nilai Y
meningkat searah dengan nilai X.
– semakin besar nilai variabel bebas (X) dan variabel bebas (Y), semakin jauh koordinat (x,y) dari garis regresi (Error makin membesar)
– besarnya variasi seiring dengan membesarnya nilai X dan Y. Atau dengan kata lain, variasi data yang digunakan untuk membuat model tidak konstan.

Pemeriksaan Heteroskedastisitas
1. Metode Grafik
Prinsip: memeriksa pola residual (ui2)
terhadap taksiran Yi.
Langkah-langkah:
– Run suatu model regresi
– Dari persamaan regresi, hitung ui2
– Buat plot antara ui2 dan taksiran Yi

Pola Grafik
ui2
iY
Pengamatan:
1.Tidak adanya pola yang sistematis.
2.Berapapun nilai Y prediksi, residual kuadratnya relatif sama.
3.Variansi konstan, dan data homoskedastis.
iY
,
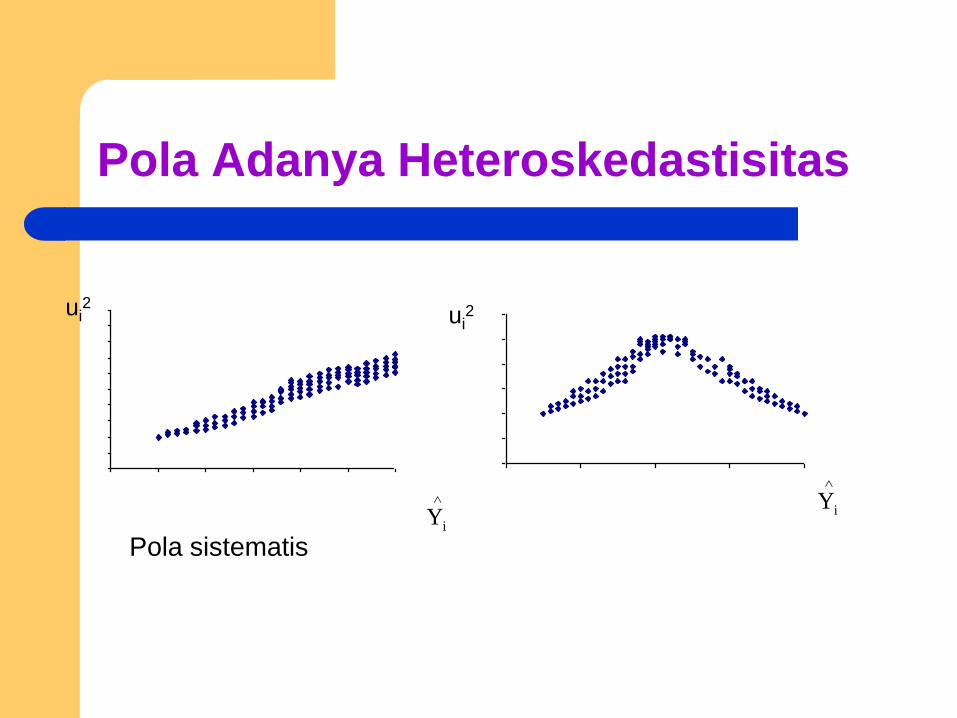
Pola Adanya Heteroskedastisitas
Pola sistematis
ui2ui
2
iY
iY

Uji Park
Prinsip: memanfaatkan bentuk regresi untuk melihat adanya heteroskedastisitas.
Langkah-langkah yang dikenalkan Park:
1. Run regresi Yi = 0 + 0Xi + ui
2. Hitung ln ui2
3. Run regresi ln ui2 = + ln Xi + vi
4. Lakukan uji-t. Bila signifikan, maka ada
heteroskedastisitas dalam data.
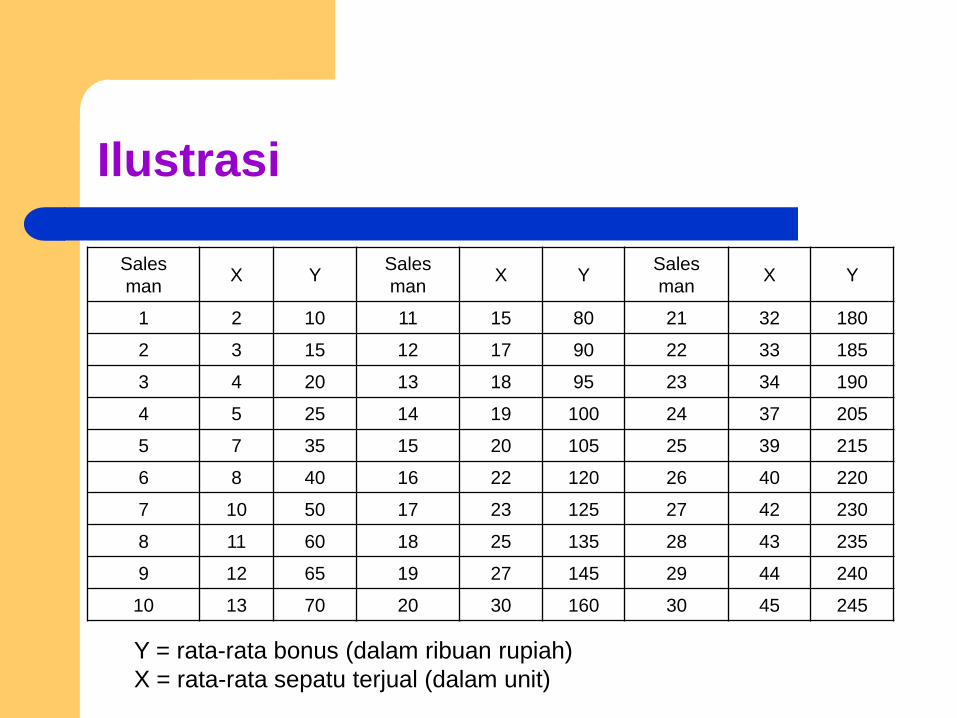
Ilustrasi
Sales
manX Y
Sales
manX Y
Sales
manX Y
1 2 10 11 15 80 21 32 180
2 3 15 12 17 90 22 33 185
3 4 20 13 18 95 23 34 190
4 5 25 14 19 100 24 37 205
5 7 35 15 20 105 25 39 215
6 8 40 16 22 120 26 40 220
7 10 50 17 23 125 27 42 230
8 11 60 18 25 135 28 43 235
9 12 65 19 27 145 29 44 240
10 13 70 20 30 160 30 45 245
Y = rata-rata bonus (dalam ribuan rupiah)
X = rata-rata sepatu terjual (dalam unit)

Ilustrasi
Y = -3,1470 + 5,5653 X
SE (0,0305) R2 = 0,9992
slope signifikan: Bila sepatu terjual naik 1 unit, maka bonus akan naik Rp.5.563.
Apakah ada heteroskedastisitas ?
Run regresi, didapat:
ln ui2 = 6,0393 – 2,1116 ln Xi
SE (0,0090) R2 = 0,9995
Menurut uji t, signifikan sehingga dalam model penjualan sepatu vs bonus di atas ada heteroskedastisitas.

Uji Goldfeld – Quandt
Metode Goldfeld – Quandt sangat populer untuk digunakan, namun agak merepotkan, terutama untuk data yang besar.
Langkah-langkah pada metode ini:– Urutkan nilai X dari kecil ke besar
– Abaikan beberapa pengamatan sekitar median, katakanlah sebanyak c pengamatan. Sisanya, masih ada (N – c) pengamatan
– Lakukan regresi pada pengamatan 1, dan hitung SSE 1
– Lakukan regresi pada pengamatan 2 dan hitung SSE 2.
– Hitung df = jumlah pengamatan dikurangi jumlah parameter
– Lakukan uji F sbb.
11
22
df/RSS
df/RSS
Bila > F tabel, kita tolak hipotesis yang mengatakan data mempunyai variansi
yang homoskedastis

Ilustrasi
Ada 30 pengamatan penjualan sepatu dan bonus. Sebanyak 4 pengamatan yang di tengah diabaikan sehingga tinggal 13 pengamatan pertama (Kelompok I) dan 13 pengamatan kedua (Kelompok II).
Regresi berdasarkan pengamatan pada kelompok I:
Y = -1,7298 + 5,4199 X R2 = 0,9979
RSS1 = 28192,66 df1 = 11
Regresi berdasarkan pengamatan pada kelompok II:
Y = -0,8233 + 5,5110 X R2 = 0,9941
RSS2 = 354397,6 df2 = 11

Ilustrasi
11
22
df/RSS
df/RSS = 354397,6/11
28192,66/11 = 12,5706
Dari tabel F, didapat F = 2,82 sehingga > F
Kesimpukan: ada heteroskedastisitas dalam data

Mengatasi heteroskedastisitas
1. Transformasi dengan Logaritma
Transformasi ini ditujukan untuk memperkecil skala antar variabel bebas. Dengan semakin „sempitnya‟ range nilai observasi, diharapkan variasi error juga tidak akan berbeda besar antar kelompok observasi.
Adapun model yang digunakan adalah:
Ln Yj = β0 + β1 Ln Xj + uj

2. Metode Generalized Least Squares(GLS)
Perhatikan model berikut :
Yj = 1 + 2 Xj + uj dengan Var (uj) = j2
Masing-masing dikalikan 1
j
Y X uj
j j
j
j
j
j
1 2
1
Maka diperoleh transformed model sebagai berikut :
Yi* = 1* + 2Xi* + ui*

GLS
Kita periksa dulu apakah ui* homoskedastis ?
1)(1
)u(E1u
E2
i2
i
2
i2
i
2
i
2
i
E(ui*
2) = konstan

Transformasi
Oleh karena mencari j2 hampir tidak pernah diketahui, maka
biasanya digunakan asumsi untuk mendapat nilai j2. Asumsi
ini dapat dilakukan dengan mentransformasikan variabel. Ada
beberapa jenis, yaitu:
jX
11. Transformasi dengan
Asumsi: j2 = 2
j
22
j XuE
Akibat transformasi, model menjadi:
j
j
jj
j uY
XX
1
X10
atau dapat ditulis dengan: Yi* = 0 X* + 1 + vi

Transformasi
Apakah sudah homoskedastis? Perhatikan bukti berikut:
222
2
2
22
2
)X(X
1)(
X
1
X
j
j
j
jj
juE
uEE(vi
2) = konstan
2. Transformasi denganiX
1
Asumsi: j2 = j
22
j XuE
3. Transformasi dengan E(Yi)
2
j
22
j )][E(YuE Asumsi: j2 =

Otokorelasi
Otokorelasi: korelasi antara variabel itu sendiri, pada pengamatan yang berbeda waktu atau individu. Umumnya kasus otokorelasi banyak terjadi pada data time series Kondisi sekarang dipengaruhi waktu lalu. Misal: Tinggi badan, upah, dsbnya.
Salah satu alat deteksi: melihat pola hubungan antara residual (ui) dan variabel bebas atau waktu (X).

Mendeteksi Otokorelasi
Pola Autokorelasi
ui ui
*
* **
* * * * * *
* * * **
* * * Waktu/X * ** Waktu/X
* * * * ***
*
Gambar nomor (1) menunjukan adanya siklus, sedang nomor (2) menunjukan garis linier. Kedua pola ini menunjukan adanya otokorelasi.

Uji Durbin-Watson ( Uji d)
d
u u
u
t t
t
N
t
t
N
( )
1
2
2
2
1
Statistik Uji
Dalam Paket Program SPSS/EViews Sudah dihitungkan

Aturan main menggunakan uji Durbin-Watson :
Bandingkan nilai d yang dihitung dengan nilai dL
dan dU dari tabel dengan aturan berikut :– Bila d < dL tolak H0; Berarti ada korelasi yang positif
atau kecenderungannya = 1
– Bila dL d dU kita tidak dapat mengambil kesimpulan apa-apa
– Bila dU < d < 4 – dU jangan tolak H0; Artinya tidak ada korelasi positif maupun negatif
– Bila 4 – dU d 4 – dL kita tidak dapat mengambil kesimpulan apa-apa
– Bila d > 4 – dL tolak H0; Berarti ada korelasi negatif

Gambar aturan main menggunakan uji Durbin-Watson
Tidak tahu Tidak tahu
Korelasi positif Tidak ada korelasi Korelasi negatif
0 dL dU 4-dU 4-dL 4

Mengatasi Otokorelasi: Metode Pembedaan Umum (Generalized Differences)
Yt = β0 + β1Xt + ut dan ut = ρ ut-1 + vt
Untuk waktu ke- t-1: Yt-1 = β0 + β1Xt-1 + ut-1
Bila kedua sisi persamaan dikali dengan ρ, maka:
ρ Yt-1 = ρ β0 + ρ β1Xt-1 + ρ ut-1
Sekarang kita kurangkan dengan persamaan Model
Yt - ρ Yt-1 = (β0 - ρ β0) + β1(Xt - ρ Xt-1) + (ut - ρ ut-1)
Persamaan tersebut dapat dituliskan sebagai:
Yt* = β0 (1 - ρ) + β1Xt* + vt
Dimana: Yt* = Yt - ρ Yt-1 dan Xt* = Xt - ρ Xt-1
Idealnya kita
harus dapat
mencari nilai ρ.
Tapi dalam
banyak kasus,
diasumsikan
ρ = 1,
sehingga:
Yt* = Yt - Yt-1
Xt* = Xt - Xt-1

Pemilihan Model
1. R2 Adjusted
Perhatikan Model:
(i) LABA = 5053,712 + 0,049 KREDIT; R2 = 80,6%
(ii) LABA = 45748,484 + 0,0106 ASET + 0,0081 KREDIT; R2= 87,4%.
Model manakah yang lebih baik ditinjau dari koefisien determinasi-nya?.
Sekarang kita perhatikan kembali formula untuk menghitung R2
2
2
2 11SST
SSRR
YY
u
SST
SSE
i
i

R2 Adjusted
SST sama sekali tidak dipengaruhi oleh jumlah variabel bebas, karena formulasinya hanya memperhitungkan variabel terikat
SSE dipengaruhi oleh variabel bebas, dimana semakin banyak variabel bebas, maka nilai SSE cenderung semakin kecil, atau paling tidak tetap. SSE kecil, maka nilai SSR akan besar.
Akibat kedua hal tersebut, maka semakin banyak variabel bebas yang dimasukkan dalam model, maka nilai R2 akan semakin besar.
)1/()(
)/(1
2
2
nYY
knuR
i
i

Pemilihan Model
2. Akaike Information Criterion (AIC)
n
SSEe
n
ueAIC 2k/n
2
i2k/n
n
RSSln
n
2kAICln
Bila kita membandingkan dua buah regresi atau lebih, maka model yang
mempunyai nilai AIC terkecil merupakan model yang lebih baik.

Ilustrasi
LABA = 5053,712 + 0,049 KREDIT; SSE = 3,28E+12
LABA = 58260,461 + 0,013 ASET; SSE = 2,1E+12
LABA = 45748,484 + 0,0106 ASET + 0,0081 KREDIT; SSE =
2,17E+12
9868,2450
123,28Eln
50
2x2
n
RSSln
n
2kAICln (i)
5409,2450
122,1Eln
50
2x2
n
RSSln
n
2kAICln (ii)
6137,2450
122,17Eln
50
2x3
n
RSSln
n
2kAICln (iii)

Pemilihan Model
3. Schwarz Information Criterion (SIC)
n
SSEn
n
unSIC k/n
2
ik/n
n
RSSlnln
n
kSICln n
Sama dengan AIC, model yang mempunyai nilai SIC terkecil merupakan
model yang lebih baik.

Ilustrasi
06,2550
1228,3ln50ln
50
2
n
RSSlnln
n
kSICln (i)
En
62,2450
121,2ln50ln
50
2
n
RSSlnln
n
kSICln (ii)
En
73,2450
1217,2ln50ln
50
3
n
RSSlnln
n
kSICln (iii)
En

Standarisasi Variabel
Kegunaan untuk perbandingan kontribusi antar variabel bebas
untuk menerangkan variabel terikat
Y
i*
iS
YYY
X
i*
iS
XXX
Akibat standarisasi:
Y
i*
iS
YYY
0
Sn
0
Sn
YYY
YY
i*
i
(nilai tengah = 0)=
1
)1/(1)1/(2
2
2
2
2
*
Y
Y
Y
i
YS
nSn
S
nYYS (varian = 1)

Standarisasi Variabel
Model regresi yang menggunakan variabel
yang telah distandarisasi tidak akan
mempunyai intersep
Notasi yang diberikan untuk koefisien
tersebut adalah BETA.
Standarisasi variabel lebih berguna untuk
analisis pada model regresi berganda.




















