
Information Retrieval Selayang Pandang - Komputasi · ij = g(k i, d j) •Pilihan berbeda terhadap...
67
Information Retrieval Selayang Pandang Husni.Trunojoyo.ac.id
Transcript of Information Retrieval Selayang Pandang - Komputasi · ij = g(k i, d j) •Pilihan berbeda terhadap...

Information RetrievalSelayang Pandang
Husni.Trunojoyo.ac.id

Bagian I
Internet (Web) Mutakhir
Apa itu Information Retrieval
Representasi Teks dalam IR
Model Temu-Kembali Boolean
Model Ruang Vektor

Retrieval dan Search
• Temu-Kembali dan Pencarian
• Hal apa yang terpikirkan saat mendengar “information retrieval”?
• Hal apa yang paling dekat dipikiran saat membahas kata “search” atau“search engine”?

Retrieval and Search
Search Engine…

Internet (Web) Mutakhir

Ukuran Internet (per 27 Agustus 2017)
• Web Terindeks: setidaknya 4.59 milyar halaman

Jumlah Website

Pengguna Internet

Pengguna Internet

Update Internet

http://www.internetlivestats.com/


Pertumbuhan Tahunan

Search Engine Market Share

6,586,013,574 Pencarian per-Hari...
Search Engine Pencarian per-Hari
Google 4,464,000,000
Bing 873,964,000
Baidu 583,520,803
Yahoo 536,101,505
Other (AOL, Ask dll.) 128,427,264

Search Engine: Google

Recommender System

Information Retrieval
• Information retrieval (IR) is finding material (usually documents) of an unstructured nature (usually text) that satisfies an information needfrom within large collections (usually stored on computers) [Manning, 2008].
• Information retrieval (IR) is the activity of obtaining informationresources relevant to an information need from a collection of information resources [Wikipedia].

Information Retrieval (IR)
=Temu-Kembali Informasi (TKI)

IR itu…
Arsitektur Search Engine…
Inverted Index
Crawler
Halaman Tersimpan
Statistika Situs & Halaman
Internet
Pembangkit Index
Pengurai Halaman Pembangkit Graf Web Graf Web
Analisa Tautan
Pages
Sisi Offline
Sisi Online
User Interface
Caching
Kemiripan & Ranking
Query
Ranking Halaman
Hal
aman
Taut
an &
An
chor
s
Kata

Web Crawler
Inverted Index
Crawler
Halaman Tersimpan
Statistika Situs & Halaman
Internet
Pembangkit Index
Pengurai Halaman Pembangkit Graf Web Graf Web
Analisa Tautan
Pages
Sisi Offline
Sisi Online
User Interface
Caching
Indexing & Ranking
Query
Ranking Halaman
Hal
aman
Taut
an &
An
chor
s
Kata
➢ Fungsi▪ Mengambil (Fetch) halaman web dengan
mengikuti hyperlink▪ Me-refresh halaman secara periodik
➢Masalah Inti▪ Bandwidth & storage terbatas vs. volume
data sangat besar▪ Frekuensi update halaman
➢ Solusi▪ Prioritaskan crawling berdasarkan pada
ranking halaman dan statistik lain

Page Parser: Pengurai Halaman Web
Inverted Index
Crawler
Halaman Tersimpan
Statistika Situs & Halaman
Internet
Pembangkit Index
Pengurai Halaman Pembangkit Graf Web Graf Web
Analisa Tautan
Pages
Sisi Offline
Sisi Online
User Interface
Caching
Indexing & Ranking
Query
Ranking Halaman
Hal
aman
Taut
an &
An
chor
sKata
➢ Fungsi▪ Mengekstrak aliran data untuk indexing
a. Title: kata-kata dalam <title>…</title>b. URLc. Body
▪ Teks Anchor▪ Teks Plain▪ H1…6▪ Bold, Italic, etc▪ Large, Medium, Small
▪ Membangun peta link parsial▪ Mengirim hyperlink yang ditemukan ke
crawler
➢Masalah Inti▪ Fitur apa yang akan diekstrak?
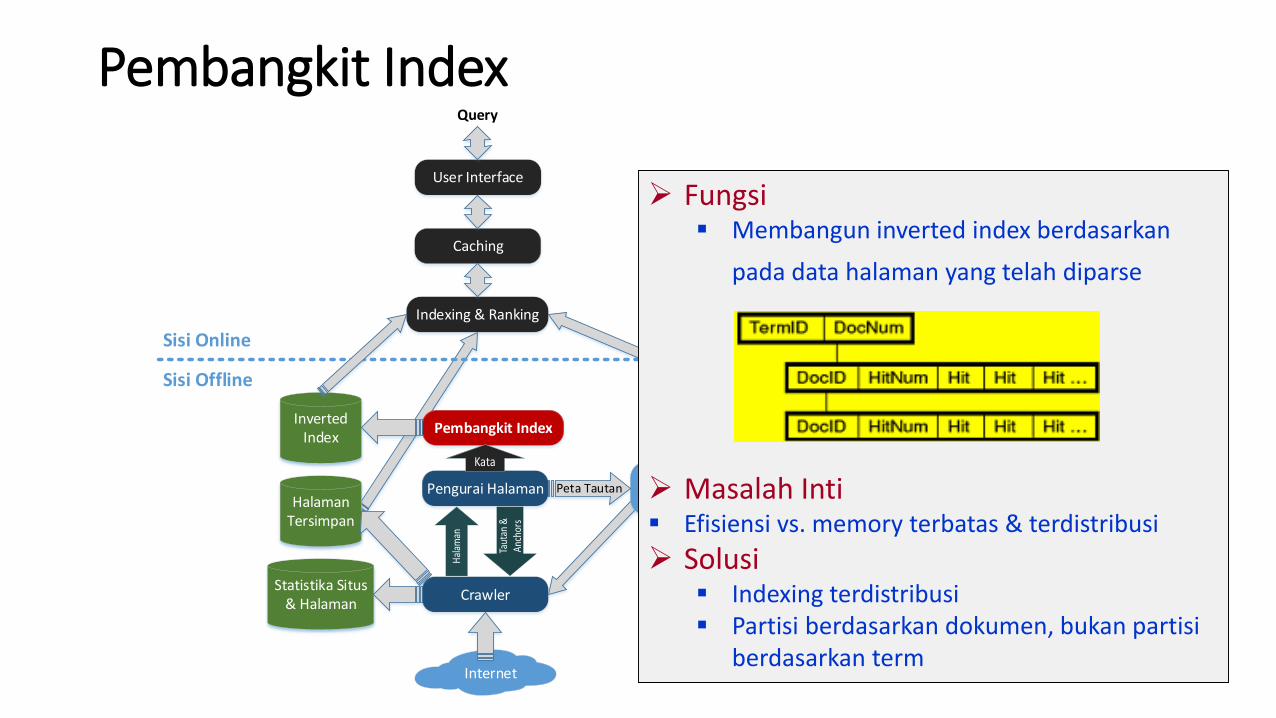
Pembangkit Index
Inverted Index
Crawler
Halaman Tersimpan
Statistika Situs & Halaman
Internet
Pembangkit Index
Pengurai Halaman Pembangkit Graf Web Graf Web
Analisa Tautan
Pages
Sisi Offline
Sisi Online
User Interface
Caching
Indexing & Ranking
Query
Ranking Halaman
Hal
aman
Taut
an &
An
chor
s
Kata
➢ Fungsi▪ Membangun inverted index berdasarkan
pada data halaman yang telah diparse
➢ Masalah Inti▪ Efisiensi vs. memory terbatas & terdistribusi
➢ Solusi▪ Indexing terdistribusi▪ Partisi berdasarkan dokumen, bukan partisi
berdasarkan term

Relevansi & Ranking
Inverted Index
Crawler
Halaman Tersimpan
Statistika Situs & Halaman
Internet
Pembangkit Index
Pengurai Halaman Pembangkit Graf Web Graf Web
Analisa Tautan
Pages
Sisi Offline
Sisi Online
User Interface
Caching
Indexing & Ranking
Query
Ranking Halaman
Hal
aman
Taut
an &
An
chor
sKata
➢ Masalah utama dalam IR dan telah dikajipuluhan tahun
➢ Fungsi▪ Indexing: dengan cepat menemukan halaman yang
mengandung term query▪ Ranking: mengurutkan halaman sesuai dengan
relevansi terhadap query
➢ Masalah Inti▪ Kinerja: inverted list untuk suatu term hot mungkin
ratusan megabyte.▪ Akurasi: fungsi ranking dengan ratusan parameter:
▪ Teks Anchor▪ Ranking halaman▪ Term proximity▪ TF*IDF▪ …
➢ Solusi▪ Kinerja: Top-K query & index pruning▪ Akurasi: Tuning atau learning?

Caching
Inverted Index
Crawler
Halaman Tersimpan
Statistika Situs & Halaman
Internet
Pembangkit Index
Pengurai Halaman Pembangkit Graf Web Graf Web
Analisa Tautan
Pages
Sisi Offline
Sisi Online
User Interface
Caching
Indexing & Ranking
Query
Ranking Halaman
Hal
aman
Taut
an &
An
chor
sKata
➢ Fungsi▪ Men-cache hasil dari query yang sering
untuk menjawab ribuan query per detikdengan waktu respon interaktif
➢Masalah Inti▪ Apa yang dicache?
➢ Solusi▪ Cahing banyak level
▪ Level Query▪ Level Term

Tentang Saya
• Husni• Web site : Husni.trunojoyo.ac.id
• Email : [email protected]
• Ruang kerja: • Lab. SisTer, Teknik Informatika, UTM.
• Bidang Keahlian:• Networking
• Web Application Development
• (Web) Text Mining (Retrieval) & Searching

Setelah Tutorial ini, Anda akan…
1. Memahami pentingnya information retrieval
2. Memperoleh pengetahuan mengenai prinsip-prinsip dari darissistem temu-kembali informasi
3. Memahami proses pembangunan search engine sederhana, mulaidari pre-processing s.d penanganan query pengguna
4. Memperoleh pemahaman dasar dari tiga paradigm IR• Wajib: Model Boolean dan Ruang Vektor

Outline
• Apa itu IR?
• Representasi teks dalam sistem IR
• Model temu-kembali Boolean
• Model ruang vektor
• Temu-kembali Probabilitas klasik
• Pemodelan Bahasa untuk Sistem Temu-Kembali
• Perangkat (tools) IR

Referensi
• C. Manning, P. Raghavan and H. Schutze (2008) Introduction to Information Retrieval, Cambridge University Press• Versi gratis tersedia di: https://nlp.stanford.edu/IR-book/
• Bruce Croft, Donald Metzler, Trevor Strohman (2010) Search Engines: Information Retrieval in Practice, Addison Wesley• Edisi revisi (2015) tersedia gratis di: ciir.cs.umass.edu/downloads/SEIRiP.pdf
• Husni.trunojoyo.ac.id


Apa itu Information Retrieval?

What is IR?
• Information retrieval (Wikipedia)• The activity of obtaining information resources relevant to a user’s
information need from a collection of information resources.
• Elemen dari suatu sistem information retrieval:• Kebutuhan informasi (need, diekspresikan oleh pengguna dalam bentuk
query)
• Sumber daya informasi (resources, biasanya tak terstruktur (unstructured): text, images, video, audio, dll.
• Komponen untuk retrieval sumber daya relevan secara efisien terhadapkebutuhan informasi pengguna, biasanya dari koleksi besar sumber informasi.

Kebutuhan Informasi
• Kebutuhan informasi tersebut diekspreskan melalui query• Kata atau frasa dalam text information retrieval (misal: “serangan ISIS”)
• Citra (image) dalam image content retrieval
Kebutuan informasi adalah kemauan individu atau kelompok untuk mencari dan mendapatkan informasi untuk memenuhi kebutuhan sadar atau bawah sadar. Kebutuhan dan ketertarikan terhadap informasi.(Robert S. Taylor: “The process of asking questions”, 2007)

Mengapa Text Information Retrieval?
• Repositori besar sumber informasi tak-terstruktur• Perusahaan: dokumen teknis, kontrak bisnis
• Pemerintah: dokumentasi, regulasi , undang-undang
• Materi ilmiah: naskah penelitian (seperti di Google Scholar)
• Personal: buku, blog, email, file-file
• World Wide Web: paling membutuhakan IR karena skala terbesar dari semua

Text Information Retrieval
• Sistem yang memerlukan analisis teks fokus pada text information retrieval dimana model-model berlainan:• Dalam merepresetasikan daftar dokumen dan query
• Dalam cara menetapkan relevansi dari dokumen terhadap query• Relevansi dari dokumen adalah skor yang paling sering dijadikan
acuan (bukan keputusan biner)
• Daftar dokumen diranking sesuai dengan skor kedekatan (kemiripan) terhadap query
• Skor relevansi biasanya melibatkan elemen ketidakpastian

Area Kajian Disiplin IR
• Web Crawling: menghimpun data dari Web
• Esktraksi Data: mengambil informasi dan URL dari halaman web
• Preprocessing: menerapkan aturan bahasa untuk memudahkan proses IRdan meningkatkan kualitas relevansi
• Indexing: membuat index (pemetaan term ke daftar dokumen)
• Penanganan Query: mendapatkan dokumen yang relevan dengan Query (kebutuhan informasi pengguna)
• Klasifikasi dan Klasterisasi: kategorisasi secara terpandu dan tidak
• Rekomendasi: memberikan dokumen yang sesuai dengan kebutuhan/profil pengguna, berdasarkan kemiripan dokumen atau kemiripan pengguna
• Evaluasi sistem IR: Presisi, Recall, F-Measure

Representasi Teks dalam IR

Representasi Teks dalam IR
• Representasi Tak-Terstruktur (unstructured)• Teks diwujudkan sebagai suatu himpunan term tak-berurut (sehingga disebut
representasi bag-of-words)• Cukup banyak penyederhanaan: mengabaikan sintaks dan semantik
• Meskipun terlalu sederhana, kinerja retrieval dapat memuaskan
• Representasi Semi Terstruktur• Beberapa term tertentu dianggap lebih penting (term lain diturunkan atau
diabaikan)• Frasa benda (NP), entitas bernama (named entities), dll.
• Representasi Terstruktur• Hampir tidak digunakan dalam konteks IR• Teknik Information extraction (IE) tidak cukup akurat• Model IE dapat makan banyak waktu - tidak dapat diterima di IR

Representasi Dokumen Tak-Terstruktur
One evening Frodo and Sam were walking together in the cool twilight.Both of them felt restless again. On Frodo suddenly the shadow of parting had falling: the time to leave Lothlorien was near.
Potongan dokumen
{(One, 1), (evening, 1), (Frodo, 2), (and, 2), (Sam, 1) (were, 1), (walking, 1), (together, 1), (in, 1), (the, 3), (cool, 1), (twilight, 1), (Both, 1), (of, 2), (them, 1), (felt, 1), (restless, 1), (again, 1), (On, 1), (suddenly, 1), (shadow, 1), (parting, 1), (had, 1), (falling, 1), (time, 1), (to, 1), (leave, 1), (Lothlorien, 1), (was, 1), (near,1)}
Bag of words

Representasi Dokumen Semi-Terstruktur
1. yOne evening Frodo and Sam were walking together in the cool twilight.Both of them felt restless again. On Frodo suddenly the shadow of parting had falling: the time to leave Lothlorien was near.
Potongan dokumen
{(Frodo, 2), (Sam, 1), (Lothlorien, 1)}
Bag of named entity terms
{(evening, 1), (Frodo, 2), (Sam, 1), (twilight, 1), (shadow, 1), (parting,1), (time, 1), (Lothlorien, 1)}
Bag of nouns

Preprocessing
• Dua langkah preprocessing paling umum• Normalisasi morfologis: stemming atau lemmatization• Penghapusan stop-word
• Normalisasi morfologis• Mengubah berbagai bentuk kata yang sama ke bentuk umum• Penting bagi Bahasa yang kaya morfologi, termasuk Indonesia• Stemming (misal automation automat) lebih sering digunakan daripada
lemmatization (misal automation automate). Bahasa lebih sering lemmatization, bukan stemming.
• Penghapusan stop words• Penghapusan term-term yang miskin maknaseperti articles, prepositions,
conjunctions, pronouns, dll.• Cukup menyimpan kata berisi: nouns, verbs, adjectives, adverbs• English stop words: http://www.ranks.nl/resources/stopwords.html
• Kedua metode mereduksi kardinalitas dari himpunan dokumen berbentukbag-of-words dan secara umum meningkatkan kinerja IR

Formalisasi dari Model IR
• Model Retrieval Dasar adalah triple (fd , fq , r) dimana:1. fd adalah fungsi yang memetakan dokumen ke representasi untuk retrieval,
yaitu fd(d) = xd, dimana xd adalah representsi retrieval dari dokumen d,
2. fq adalah fungsi yang memetakan query ke representasi retrievalnya, yaitufq(q) = xq, dimana xq adalah wujud retrieval dari query q,
3. r adalah fungsi ranking (pemeringkatan)
• Melibatkan representasi dokumen pd dan query pq
• Menghitung bilangan real untuk menunjukkan relevansi potensial dari dokumen d untuk query q berdasarkan pd dan pq
relevansi(d, q) = r(fd(d), fq(q))
= r(xd, xq)

Term di Indeks & Bobotnya
• Index term adalah semua term dalam koleksi (atau kamus)
• Himpunan semua term K = {k1, k2, … , kt} , dimana t adalah jumlahdari term
• Untuk setiap dokumen dj , setiap term ki diberikan suatu bobot wij
• Bobot dari term yang tidak muncul dalam dokumen adalah 0
• Dokumen dj direpresentasikan oleh vektor term [w1j ,w2j , : : : ,wtj ]
• Misalnya g adalah fungsi yang menghitung bobot, yaitu wij = g(ki, dj)
• Pilihan berbeda terhadap fungsi komputasi bobot g dan fungsiranking r mendefinisikan model IR berbeda
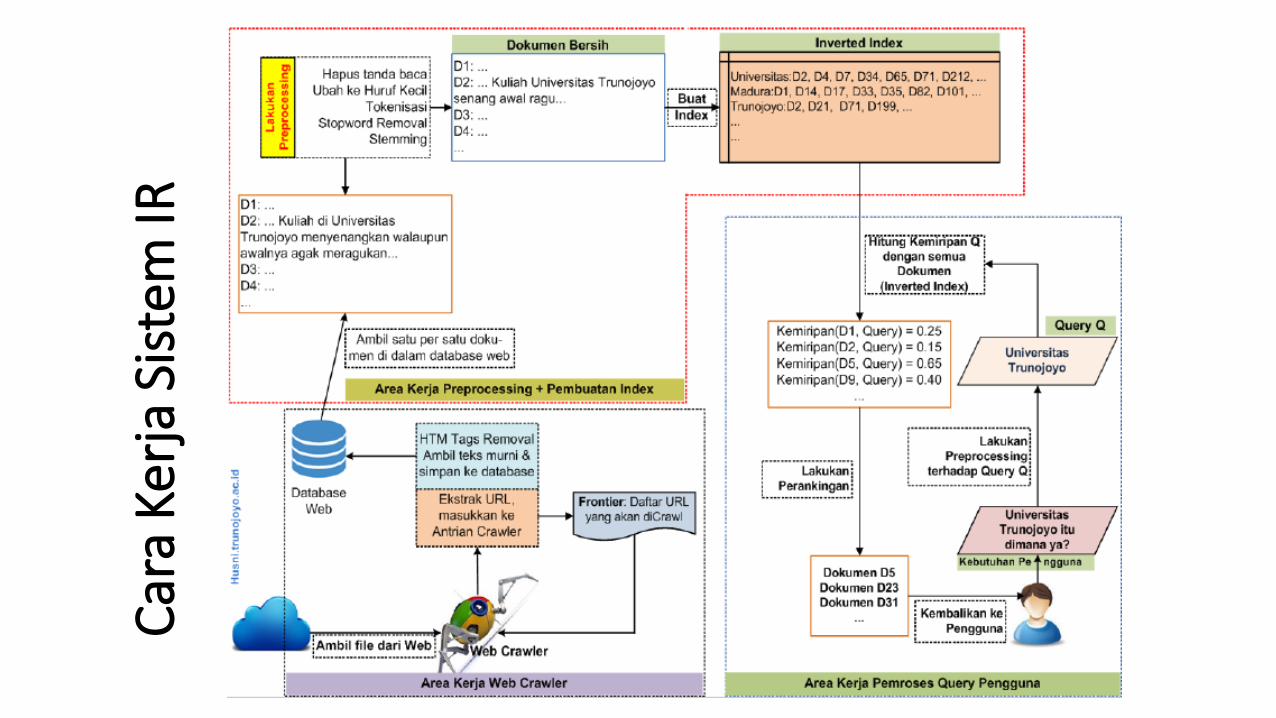
Cara Kerja Sistem IR
Car
a Ke
rja
Sist
emIR
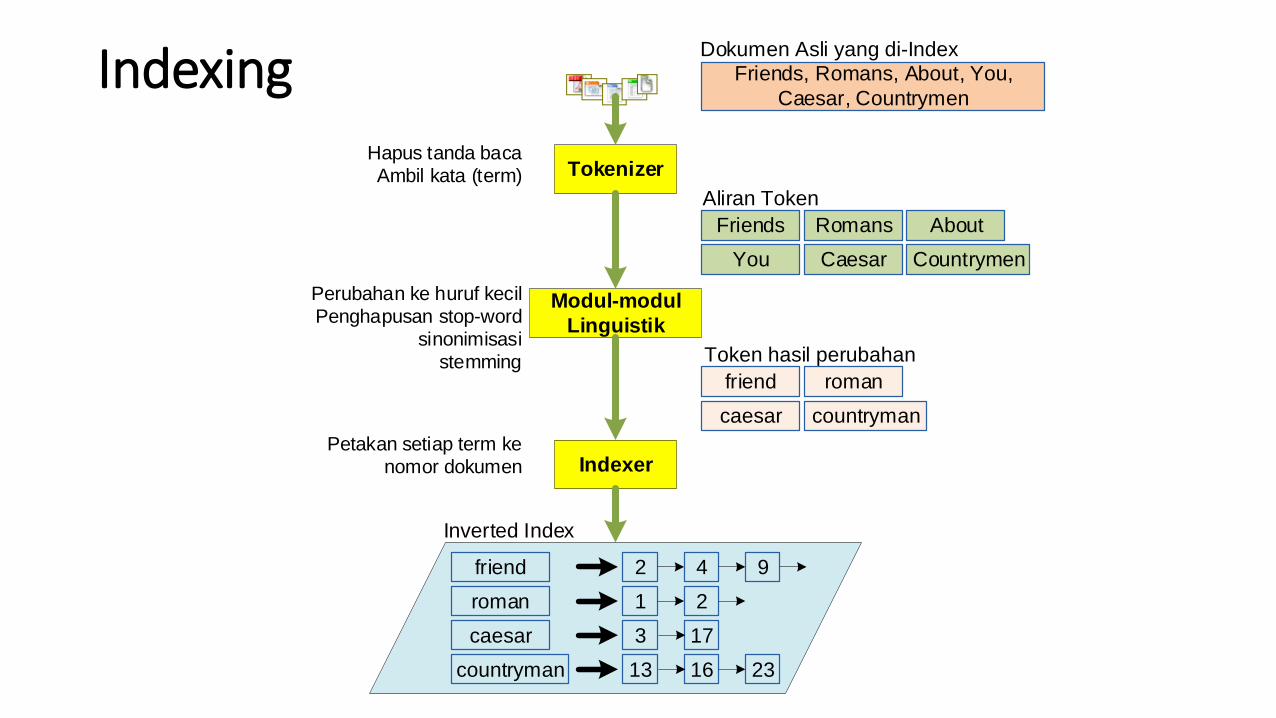
IndexingDokumen Asli yang di-Index
Aliran Token
Token hasil perubahan
Inverted Index
Tokenizer
Modul-modul
Linguistik
Indexer
Friends, Romans, About, You,
Caesar, Countrymen
Friends
You
AboutRomans
Caesar Countrymen
friend roman
caesar countryman
friend
roman
caesar
countryman
2
13
3
21
94
2316
17
Perubahan ke huruf kecil
Penghapusan stop-word
sinonimisasi
stemming
Hapus tanda baca
Ambil kata (term)
Petakan setiap term ke
nomor dokumen

Paradigma IR
• Model Information retrieval secara garis besar dibagi ke dalam 3 paradigma:• Model teori himpunan
• Boolean model• Extended Boolean model
• Model aljabar• Vector space model• Latent semantic indexing
• Model probabilistik• Classic probabilistic model• Language model
• Selain itu, ada model IR yang memanfaatkan algoritma analisis tautan(misalnya PageRank, HITS di Google)• Biasanya digunakan dalam web retrieval yang dokumennya di (hyper)linked

Model Temu-Kembali Boolean

Model Retrieval Boolean
• Dokumen direpresentasikan sebagai bags of words
• Bobot term semuanya biner - wij {0, 1}• wij = 1 iff term ki dapat ditemukan di dalam bag of words dari dokumen dj
• Query q diberikan sebagai formula logika proporsional terhadap term• Term-term dihubungkan oleh operator Boolean (, ), dapat dinegasikan ()
• Setiap query q dapat diubah menjadi disjunctive normal form (DNF), q = qc1 qc2 … qcn, dimana qcl adalah komponen ke-l dari DNF q
• Relevansi dokumen dj terhadap query q dihitung dengan rumus

Contoh Temu-Kembali Boolean
• Perhatikan himpunan term berikut:• K = {Frodo, Sam, blue, sword, orc, Mord}
• Seandainya kita mempunyai dokumen berikut:• d1: “Frodo stabbed the orc with the red sword"
• d2: “Frodo and Sam used the blue lamp to locate orcs"
• d3: “Sam killed many orcs in Mordor with the blue sword"
• Dokumen mana yang relevan dengan query berikut?• q1: (Frodo orc sword) (Frodo blue) {d1, d2}
• q2: (Sam blue) (Sam orc Mordor) {d2, d3}

Boolean Retrieval - Inverted Index
• Struktur data untuk komputasi retrieval yang efisien
• Inverted file berisi daftar rujukan ke dokumen untuk semua term
• Untuk koleksi D berisi dokumen berikut:• d1: “Frodo and Sam stabbed orcs."• d2: “Frodo stabbed the orc with the sword."• d3: “Sam stole Frodo's sword."
• Kita mempunyai inverted index berikut:• L(“Frodo") = {d1, d2, d3}• L(“Sam") = {d1, d3}• L(“orc") = {d1, d2}• L(“stab") = {d1, d2}• L(“sword") = {d2, d3}• L(“stole") = {d3}

Boolean Retrieval - Inverted Index
• Full inverted index juga menyimpan posisi setiap term dalam suatudokumen• Contoh “Frodo": {(d1, 1), (d2, 1), (d3, 3)}
• Inverted index memungkinkan penanganan query Boolean via irisandan gabungan himpunan
• q: (Frodo stab) (Sam orc)• Hasilnya diperoleh dengan kpmputasi:
rel (D, q) = (L(“Frodo") L(“stab")) (L(“Sam") L(“orc"))
= ({d1, d2, d3} {d1, d2}) ({d1, d3} {d1, d2})
= {d1, d2} {d1}
= {d1, d2}

Model Temu-Kembali Boolean
• Kelebihan• Hanya satu: kesederhanaan (efisiensi komputasi)
• Popular di awal sistem IR komersil (seperti Westlaw)
• Kekurangan• Mewujudkan kebutuhan informasi sebagai ekspresi bolean tidak intuitif
• Model murni (asli)
• No ranking: dokumen dihukumi relevan atau tak-relevan
• Kepentingan relative dari term diabaikan
• Model Extended Boolean: varian model Boolean yang melibatkan pengerjaanparsial dari ekspresi Boolean

Model Ruang Vektor(Vector Space Model)

Model Ruang Vektor
• Dokumen dan query direpresentasikan sebagai vektor dari term-term
• Bobot adalah bilangan pecahan > 0dj = [w1j, w2j, …, wtj ]
q = [w1q, w2q,, …, wtq]
• Relevansi dari dokumen terhadap query diestimasi denganmenghitung jarak atau kemiripan antara dua vektor• Metrik jarak: Euclidean, Manhattan, dll.
• Lebih relevan saat jarak semakin kecil
• Metrik kemiripan: Cosine, Dice, dll.
• Lebih relevan ketika kemiripan makin besar

Model Ruang Vektor: Metrik Jarak
1. Euclidean distance
2. Manhattan distance

Model Ruang Vektor: Metrik Kemiripan
3. Cosine similarity
4. Dice similarity

Model Ruang Vektor: Pembobotan Term
• Berapa bobot wij dari term-term untuk dokumen yang dihitung?
• Dua asumsi intuitif:1. Relevansi dari suatu term terhadap dokumen adalah sebanding
dengan frekuensinya dalam dokumen tersebut (komponen term frequency = tf)• Lebih sering lebih relevan
2. Relevansi suatu term terhadap suatu dokumen berbandingterbalik dengan jumlah dokumen dalam koleksi yang dirinyahadir (komponen inverse document frequency = idf)• Makin umum di lintas dokumen makin kurang relevan (contoh stopwords
seperti “the")

VSM: Skema Pembobotan
• Skema pembobotan Biner• Tidak benar-benar sekema pembobotan
• Mengabaikan dua asumsi tersebut
• wij = 1 iff dokumen dj mengandung term ki
• Skema pembobotan TF-IDF• Bobot dihitung sebagai perkalian dari komponen term frequency dan inverse
document frequency-nya
• Salah satu skema popular:

Latihan: Perhitungan Kemiripan dalam SVM
• Koleksi terdiri dari N=3 dokumen:
• d1: “new york times”
• d2: “new york post”
• d3: “los angeles times”
• Suatu saat, ada query: “new new times”.
• Dokumen mana yang paling relevan dengan query tersebut? Rankingkan!
otherwise 0,
0 tfif, tflog 1
10 t,dt,d
t,dw
tt N/df log idf 10

Gunakan Skema Popular
• Pembobotan term:
• Normalisasi panjang:
• Kemiripan query q dengan dokumen d, dalam model ruang vektor, menggunakan cosine similarity:
i ixx 2
2
tdt Ndt
df/log)tflog1(w ,,
••
V
i i
V
i i
V
i ii
dq
dq
d
d
q
q
dq
dqdq
1
2
1
2
1),cos(

Contoh Pencarian Dokumen Relevan
Koleksi dokumen (corpus):
d1 = “Three quarks for Master Mark”
d2 = “The strange history of quark cheese”
d3 = “Strange quark plasmas”
d4 = “Strange Quark XPress problem”

Terbentuk Inverted Index Sederhana
Lexicon dan inverted index:three → {d1}quark → {d1, d2, d3, d4}master → {d1}mark → {d1}strange → {d2, d3, d4}history → {d2}cheese → {d2}plasma → {d3}xpress → {d4}problem → {d4}

Dokumen Mana Paling Relevan
• Jika terdapat Query:
“strange” AND “quark” AND NOT “cheese”
• Himpunan hasil:
{D2, D3, D4} ∩ {D1, D2, D3, D4} ∩ {D1, D3, D4} = {D3, D4}

Latihan Menghitung Bobot Term: tf.idf
• Jika terdapat koleksi 8 dokumen berikut:
d1 = “Introduction to Expert Systems”d2 = “Expert System Software: Engineering and Applications”d3 = “Expert Systems: Principles and Programming”d4 = “The Essence of Expert Systems”d5 = “Knowledge Representation and Reasoning”d6 = “Reasoning About Uncertainty”d7 = “Handbook of Knowledge Representation”d8 = “Expert Python Programming”
• Berapa bobot term “knowledge” dalam dokumen d5?

Contoh VSM: Cosine Similarity
• Q: “gold silver truck”
• D1: “Shipment of gold damaged in a fire”
• D2: “Delivery of silver arrived in a silver truck”
• D3: “Shipment of gold arrived in a truck”





















