







Bahasa
Halaman
Hukum


- 23 -
Marek Łukasik
NARZĘDZIA LINGWISTYKI KORPUSOWEJ
W WARSZTACIE TERMINOLOGA, TERMINOGRAFA
I TŁUMACZA TEKSTÓW SPECJALISTYCZNYCH (CZ. I)
1.
Artykuł jest poszerzoną prezentacją zagadnień poruszonych przez
autora w wystąpieniu wygłoszonym podczas zebrania naukowego Katedry
Języków Specjalistycznych, które odbyło się 18 stycznia 2007 roku.
Przedstawiona w niniejszej publikacji problematyka stanowi ogólny wstęp
do lingwistyki korpusowej i ma na celu zapoznanie Czytelnika
z możliwościami wykorzystania wybranych funkcji programów do obróbki danych korpusowych w warsztacie wymienionych w tytule profesji.
Pierwsza część pracy jest krótkim zarysem teoretycznym przedsta-
wiającym definicje, typologię oraz cechy korpusu tekstowego.
W drugiej części artykułu rozważane są techniczne aspekty gromadzenia
danych korpusowych, zaś trzecia część publikacji przedstawia najważniej-
sze funkcje dwóch programów korpusowych i możliwości ich wykorzysta-
nia w badaniach terminologicznych, terminograficznych i przekładowych.
Inne funkcje programów do obróbki danych korpusowych zostaną
omówione w kolejnym artykule.
1.1. Nie trzeba chyba nikogo przekonywać, że rewolucja informatyczna
ułatwiła pracę w większości dziedzin ludzkiej działalności. Technologie
komputerowe są obecne w każdym aspekcie życia codziennego: od
telefonów komórkowych, urządzeń AGD, samochodów – po promy i sondy
kosmiczne. Oczywiście komputer znalazł również zastosowanie w wielu
dyscyplinach językoznawstwa mimo faktu, iż nie wszystkie aspekty
języka da się w łatwy sposób przenieść na algorytmy „zrozumiałe” dla
maszyny. Na szczególną uwagę, ze względu na specyfikę prowadzonych
badań, zasługuje w tym miejscu interdyscyplinarna dziedzina wiedzy
zajmująca się problematyką automatycznej analizy i opisu naturalnych
języków ludzkich, a mianowicie inżynieria lingwistyczna (ang. NLP – Natural Language Processing)1, która z jednej strony opiera się na
1 Skrótowiec NLP może odnosić się również do angielskiego terminu Neurolingu-istic Programming – tzw. programowania neurolingwistycznego, popularnej
ostatnio, acz kontrowersyjnej dyscypliny będącej zestawem strategii (technik, ćwiczeń) mających na celu zmianę wzorców zachowań (w tym motywacji). Ogólnie na temat NLP m.in.: Bandler R.: 1985; na temat zastosowania NLP w glottodydaktyce np.: Revell J. & Norman S.: 1997 oraz tychże: 1999.

- 24 -
badaniach językoznawczych, z drugiej zaś korzysta z osiągnięć informa-
tyki, w tym sztucznej inteligencji. Należy również zauważyć, że jednym
z zagadnień w zakresie NLP jest wykorzystanie rozbudowanych korpusów
tekstowych w analizie języka naturalnego przez maszynę m.in. wynajdywa-
niu schematów językowych oraz wykonywaniu tłumaczenia tzw. maszyno-
wego (ang. machine translation) na podstawie metod statystycznych
i probabilistycznych. Wśród narzędzi NLP znajdują się takie, które nie są
obce użytkownikom programów do obróbki danych korpusowych, np. lista
frekwencyjna wyrazów, wyszukiwanie powtarzalnych połączeń wyrazo-
wych (kolokacji) i in. [zob. m.in. Kay 1997, Young & Bloothooft 1997, Hacken 2001, Hutchins 2005, Wu 2005 i in.].
Z perspektywy niniejszego artykułu na pierwszy plan wysuwa się
natomiast metodologia empirycznych badań lingwistycznych (przez
niektórych uznawana za wyodrębnioną dziedzinę) zwana lingwistyką
korpusową. W najprostszym ujęciu lingwistyka korpusowa (ang. corpus
linguistics) zajmuje się „doborem i elektronicznym przetwarzaniem
określonych zbiorów tekstów, określanych jako korpusy tekstowe” [Grucza
2007: 108]. Warto dodać, że zarówno NLP, w tym tłumaczenie maszynowe,
jak również lingwistyka korpusowa zaliczane są do nadrzędnej dziedziny
językoznawstwa zwanej lingwistyką komputerową (lub informatyczną; ang. computational linguistics).
1.2.
Poniżej zamieszczono kilka definicji korpusu tekstowego:
[korpus to] teksty, dane itp. zgromadzone ze względu na swoją repre-zentatywność, stanowiące podstawę do analizy naukowej [SJP PWN].
Corpus – a collection of materials that has been made for a particular purpose, such as a set of textbooks which are being analyzed and com-pared or a sample of sentences or utterances which are being analyzed for their linguistic features [Richards at al. 1996: 88].
A corpus is a collection of pieces of language that are selected and or-dered according to explicit linguistic criteria in order to be used as a sample of the language [Sinclair 1996].
A large collection of authentic texts that have been gathered in electronic form according to a specific set of criteria [Bowker & Pearson 2002: 9].
The term ‘corpus’ may be defined as a body or collection of linguistic data, especially the one considered complete and representative, from a particular language or languages, in the form of recorded utterances or written texts, which is available for theoretical or/and applied linguistic
investigation [Burkhanov 1998: 50].

- 25 -
Korpus tekstowy to każdy zbiór pisanych lub mówionych tekstów sfor-mułowanych w określonym języku (językach), które zostały zebrane
i wybrane według określonych kryteriów [Grucza 2007: 108].
Na początku warto zwrócić uwagę na przyjętą terminologię. W lin-
gwistyce korpusowej na określenie zbioru tekstów najczęściej przyjmuje się
terminy „korpus”, „korpus językowy” oraz „korpus tekstowy” [ang. corpus,
language corpus, linguistic corpus, text corpus a. corpus of texts].
W niniejszej pracy przyjmiemy ostatni z wymienionych terminów, jako
najbardziej precyzyjny, ponieważ, jak zauważa S. Grucza, „Na pytanie, czy lingwistyka korpusowa zbiera i instrumentalizuje określone języki, trzeba
wyraźnie odpowiedzieć, że nie, ponieważ w tekstach, rozumianych zarówno
jako wyrażenia […], jak i jako denotaty […], nie zawierają się żadne
języki” [podkreślenie moje – MŁ], więc „korpusy tekstowe to zbiory
materialnie zrealizowanych wypowiedzi językowych, a nie języków, nie
zbiorów języków […]” (szerzej na ten temat w: Grucza 2007). Jednak, ze
względów ekonomiki, w niniejszym artykule będziemy również używać
terminu „korpus” w znaczeniu wyrażenia „korpus tekstowy”.
1.3.
Na podstawie powyższych definicji można wymienić podstawowe
cechy korpusu tekstowego. Należą do nich:
a) dobór materiału językowego wg ustalonych kryteriów;
b) reprezentatywność oraz naturalność (autentyczność) materiału języko-
wego (tekstów);
c) objętość korpusu tekstowego; d) elektroniczna postać zgromadzonych danych;
e) cel badawczy.
(a)
Pierwsza z wymienionych cech sugeruje, że korpus tekstowy nie jest przypadkowym zestawem tekstów, a zbiorem powstałym w wyniku
precyzyjnie zaplanowanych działań oraz odpowiednio dobranych wymo-
gów (kryteriów). Oczywiście korpusem tekstowym sensu largo można
nazwać dowolny zbiór tekstów (np. zgromadzony w bibliotece), jednakże
z perspektywy lingwistyki korpusowej taki zbiór nie jest korpusem
tekstowym sensu stricto [Waliński 2005]. Z faktu budowy korpusów na
podstawie różnych kryteriów wynika, że każdy korpus tekstowy jest (może
być) tworzony niejako „na miarę”, w zależności od przyjętego celu
badawczego albo przeznaczenia, zaś same kryteria doboru tekstów mogą
stanowić podstawę typologii korpusów tekstowych.

- 26 -
Wśród wielu takich kryteriów wyróżnić można:
· zakres: korpusy referencyjne, obejmujące wszystkie rodzaje tekstów –
(ang. reference corpora) vs. korpusy specjalne, obejmujące wybrane
rodzaje tekstów np. specjalistyczne – (ang. special/specialized corpora);
· forma tekstów: korpusy tekstów mówionych (transkrybowanych) –
(ang. spoken c.) vs. korpusy tekstów pisanych – (ang. written c.);
· rodzaj lingwalności: korpusy jednojęzyczne (monolingwalne) – (ang.
monoligual c.) vs. korpusy wielojęzyczne (multilingwalne) – (ang.
multilingual c.), które można dalej podzielić na korpusy złożone wy-łącznie z tekstów paralelnych niebędących własnymi translatami – (ang.
comparable c.) oraz złożone z oryginałów i ich translatów w poszcze-
gólnych językach – (ang. parallel c.);
· stopień otwartości: korpusy statyczne (zamknięte), czyli nieposzerzane
o nowe teksty – (ang. closed/ static) vs. korpusy dynamiczne (monitoru-
jące), czyli nieustannie uzupełniane oraz weryfikowane – (ang.
open/monitor c.);
· odniesienie temporalne: korpusy synchroniczne – (ang. synchronic c.)
vs. korpusy diachroniczne – (ang. diachronic c.);
· stopień kompletności: korpusy z pełnymi tekstami – (ang. full-text c.)
vs. korpusy z tekstami o określonej długości, np. zawierające wyłącznie streszczenia, wstępy itd. artykułów naukowych – (ang. sample c.);
· rodzaj opracowania danych: korpusy anotowane – opatrzone
specjalnymi znacznikami (tagami), które mogą definiować dany wyraz
w zakresie informacji gramatycznej (np. części mowy: Part-Of-Speech
tagging), syntagmatycznej czy semantycznej – (ang. annotated/tagged
corpora) vs. korpusy nieanotowane – (ang. raw text/data corpora).
Szczególnym przypadkiem jest tu tzw. korpus lematyzowany – (ang.
lemmatized corpus), w którym wyrazy występujące w tekście w formie
fleksyjnej zostają sprowadzone do postaci podstawowej (słownikowej)
w procesie zwanym lematyzacją (hasłowaniem) [Scherer S. 2006:17
[w:] Grucza S.: 2007: 110-111; Bowker & Pearson 2002; Kuratczyk
2007: 201; Stubbs 2002: 114; Waliński 2005].
(b)
Dany korpus tekstowy nazywamy reprezentatywnym, jeśli wyniki
badań przeprowadzonych na tekstach wchodzących w jego skład można
poddać uogólnieniom w projekcji na cały język. Korpus jest zawsze tylko
„próbką” wszystkich wytworów danego języka, dlatego też warunkiem jego
reprezentatywności jest właściwe zrównoważenie (ang. ballancing) – czyli
dobór odpowiednich (naturalnych) proporcji – różnych typów („gatunków”)
tekstów tworzących korpus. Należy przy tym pamiętać, że proporcje oraz
„gatunki” tekstów będą się zmieniały w zależności od typu korpusu
tekstowego. Ponadto proporcje takie nie zostały nigdzie jednoznacznie

- 27 -
określone i powinny być rozważane wyłącznie w kategoriach względnych
[McEnery 2006: 21]. Dla reprezentatywnego, monitorującego korpusu
tekstów języka ogólnego, np. Brytyjskiego Korpusu Narodowego (ang. BNC
– British National Corpus), którego teksty mają reprezentować dany język
narodowy w całej rozciągłości, ważny będzie (wyrażany procentowo) udział
jak największej liczby różnorodnych typów tekstów, z różnych socjo- oraz
regiolektów, zarówno ogólnych jak i specjalistycznych, pisanych (artykuły,
podręczniki, encyklopedie, słowniki i in.), jak również mówionych (przemó-
wień, wykładów, rozmów telefonicznych i in.)2. W przypadku korpusu
tekstów specjalistycznych, oprócz odpowiedniego doboru materiału ze względu na określoną dziedzinę wiedzy, lub – w przypadku korpusu
interdyscyplinarnego – dziedzin wiedzy, na pierwszy plan wysuwa się
właściwe dobranie proporcji tekstów o różnym stopniu terminologizacji oraz
należących do różnych klas funkcjonalnych, tj. tekstów terminogennych,
tekstów utrwalających terminy, tekstów terminonośnych czy tekstów
popularnonaukowych [Lukszyn 2005: 46].
Korpus uznawany jest za naturalny (autentyczny), jeżeli zebrane tek-
sty stanowią przykłady jak najbardziej naturalnej komunikacji językowej,
przy czym należy podkreślić, że kwestia autentyczności dotyczy zarówno
pisanych, jak i mówionych korpusów tekstowych. W przypadku korpusów tekstów mówionych problemy z naturalnością pojawiają się zarówno na
etapie rejestracji wypowiedzi na nośnik, jak również na etapie późniejszej
ich transkrypcji. Pozyskiwanie materiału badawczego wymaga poinformo-
wania referenta o zamiarze rejestracji (nagrania) jego wypowiedzi.
U niektórych osób informacja taka może negatywnie wpłynąć na jakość
wygłaszanego tekstu, powodując swoistą nienaturalność sytuacji komunika-
cyjnej. Ponadto nawet w przypadku nagrania wideo nie da się oddać
naturalnego kontekstu (konsytuacji). Z kolei transkrypcja nagrania oparta
jest o pewne określone zasady, które dodatkowo ograniczają naturalność
rejestrowanego materiału badawczego.
Co się tyczy tekstów pisanych – należy pamiętać, że już na etapie
projektowania korpusu dokonujemy pewnego doboru tekstów (fragmentów
tekstów). Selekcja taka, przeprowadzona na podstawie subiektywnych
kryteriów, prowadzi do obniżenia jakości próby materiału. Dodatkowym
czynnikiem wpływającym na nieautentyczność zgromadzonych tekstów
jest ich obróbka lingwistyczna (anotacja, lematyzacja itd.). Wymienione
2 Szczegółowe dane liczbowe dotyczące korpusu BNC zawarto na odnośnej stronie internetowej: <http://www.natcorp.ox.ac.uk/corpus/index.xml.ID=numbers>, data dostępu: 20.09.2007.

- 28 -
procedury zmieniają autentyczność choćby o tyle, o ile np. „otagowany”
korpus staje się nieczytelny dla człowieka, a staje się bardziej funkcjonalny
dla maszyny (konkretnego programu/programów komputerowych do
obróbki danych korpusowych). Nie ma wśród badaczy zgody co to tego,
czy większą wartość przedstawiają korpusy tekstów „surowych”, nieanoto-
wanych (nieotagowanych), czy też korpusy anotowane. Należy jednak
zwrócić uwagę na fakt, że automatyczna anotacja może prowadzić do
błędów, które pozostawione „same sobie” z pewnością niekorzystnie
wpłyną na jakość materiału i wyników badań. Z drugiej zaś strony,
komputer nie jest w stanie analizować jednostek języka w zakresie ich znaczeń (jest w stanie wyłącznie badać formy znaków językowych) i tylko
odpowiednie opisanie danych może pomóc w późniejszej szerszej analizie
korpusu tekstowego [Grucza 2007: 112 i n.; McEnery 2006: 30 i n.;
Piotrowski 2004; Stubbs 2004; Waliński 2005 i in.].
(c)
Kolejną cechą korpusu tekstowego, rozważaną w kategoriach
względnych, jest jego objętość. Wielu badaczy podkreśla wymóg zgroma-
dzenia „dużej liczby tekstów” w celu statystycznego wyeliminowania
ewentualnych osobliwości oraz zwiększenia reprezentatywności korpusu
tekstowego. Tymczasem objętość korpusu zależy od liczby kryteriów,
wedle których jest on budowany: im mniej kryteriów doboru tekstów (np. ze względu na ich rodzaje/gatunki), tym potencjalnie większy korpus
(i odwrotnie). Ponadto korpusy tekstowe tworzone są dla realizacji konkret-
nego celu badawczego (pragmatycznego), co dodatkowo może wpływać na
ograniczenia dotyczące gromadzonego materiału [Grucza 2007: 110 i n.].
Znaczna cześć badaczy podkreśla, że na potrzeby własnych badań
korpusowych wystarczy zgromadzić teksty o łącznej objętości od kilkunastu
do kilkudziesięciu tysięcy wyrazów. Natomiast w przypadku korpusów
monitorujących (zob. pkt. b) liczby te wahają się w granicach od kilku do
kilkuset milionów (np. objętość BNC w wersji dostępnej komercyjnie to
100 mln, a w przypadku The Bank of English to 524 mln jednostek leksykalnych)3.
(d)
Potrzeba gromadzenia i przetwarzania danych korpusowych w for-
mie elektronicznej nie dziwi już dziś nikogo. Komputery w zasadniczy
sposób wpłynęły na badania lingwistyczne, w tym korpusowe (mimo, iż
były one niegdyś prowadzone w sposób tradycyjny, np. przy opracowywaniu
3 Szczegóły dotyczące korpusu The Bank of English (COLLINS Cobuild) udostępniono na odnośnej stronie internetowej: <ttp://www.collins.co.uk/books.aspx?group=153>, data dostępu: 10.10.2007.

- 29 -
konkordancji), wykonując zajmujące kiedyś kilka miesięcy lub lat czynności
w kilka chwil. Zasadniczo w dzisiejszej dobie badania z zakresu lingwistyki
korpusowej nie są prowadzone w sposób tradycyjny. W przypadku korpusów
monitorujących oraz korpusów tworzonych na potrzeby leksykografii
(terminografii) na plan pierwszy wysuwa się również aktualność tekstów. Dla
specjalistów wielu dziedzin (szybka) publikacja w wersji elektronicznej jest
warunkiem sine qua non (za)istnienia w społeczności naukowej. Dzięki temu
większość „najbardziej aktualnych” tekstów specjalistycznych dostępna jest
w formie elektronicznej – jeśli nie bezpośrednio w Internecie (zob. np. jedną
z baz artykułów nauk ścisłych: ArXiv.org <http://arxiv.org>), to z pewnością u wydawcy. Warto dodać, że duża część tekstów jest również umieszczana na
nośnikach CD/DVD oraz w tzw. bibliotekach wirtualnych.
(e)
Korpusy tekstowe budowane są dla realizacji określonych celów ba-
dawczych lub pragmatycznych. Ponieważ nie sposób wymienić wszystkich
możliwości wykorzystania korpusów tekstowych, poniżej zamieszczono
skrócony wykaz dziedzin (oraz potencjalnych badań), w których zastosowa-
nie mogą znaleźć metody lingwistyki korpusowej. Do najczęstszych (oprócz
wymienionej już we wstępie inżynierii lingwistycznej) należą:
· lingwistyka: (w szerokim ujęciu), badania zarówno synchroniczne, jak
również diachroniczne: w analizach gramatycznych, syntagmatycznych,
semantycznych, historycznych, porównawczych, socjolingwistycznych,
idiolektalnych, np. „języka” poszczególnych autorów tekstów, stylistycz-nych, w analizie dyskursu, w tym, w badaniach lingwistyki sądowej (ang.
forensic linguistics) i in.;
· terminologia: automatyczna ekscerpcja tekstów standardowych oraz
terminów, półautomatyczne tworzenie baz danych terminologicznych,
wyszukiwanie definicji, kolokacji standardowych, neologizmów i in.;
· leksykografia (terminografia): tworzenie siatki haseł słowników
(leksykonów, glosariuszy) ogólnych, specjalnych (np. gwar, frekwencyj-
nych, cytatów), specjalistycznych (=terminologicznych) – jedno- lub
wielojęzycznych, publikowanie list frekwencyjnych i in.;
· translatoryka: tworzenie baz danych tekstów paralelnych, generowanie
konkordancji równoległych, tworzenie tzw. pamięci tłumaczeniowych (ang. translation memory) wykorzystywanych w programach wspomaga-
jących tłumaczenie (ang. CAT – Computer Assisted/Aided Translation
programs), półautomatyczne wyszukiwanie odpowiedników obcojęzycz-
nych, kontekstów równoległych i in.;
· glottodydaktyka: tworzenie materiałów do nauki języka, np. wyszukiwa-
nie tekstów o określonej zawartości leksykalnej, wyszukiwanie schematów
językowych w układzie paradygmatycznym i syntagmatycznym, monito-
rowanie postępów uczniów przy wykorzystaniu tzw. korpusu uczniow-
skiego (ang. learner’s corpus) i in.

- 30 -
1.4.
Należy zdać sobie sprawę, że analiza danych korpusowych nie jest
w stanie zapewnić badaczom wszystkich informacji o języku, podobnie jak
dane obserwacyjne, choćby w astronomii, nie są w stanie dostarczyć
wszystkich parametrów badanego obiektu. „Podejście korpusowe” jest
metodą obiektywizacji badań, szczególnie w przypadku jakościowo dobrze
dobranych danych spełniających wymogi próby statystycznej. Fakt, że
mamy do czynienia z wytworami językowymi, a nie samym językiem,
(który jest „dostępny” wyłącznie samym mówcom-słuchaczom, gdyż
istnieje wyłącznie w ich umysłach i jest ich inherentną właściwością) oznacza, że nie da się zupełnie wyłączyć introspekcji z badań językoznaw-
czych. Jednak nie da się zaprzeczyć, że w niektórych badaniach stosowanie
metod lingwistyki korpusowej, opartych na reprezentatywnych zbiorach
tekstów i wykorzystujących potencjał obliczeniowy współczesnych
komputerów jest dziś nieodzownym warunkiem.
2.
W kolejnym rozdziale omówione zostaną podstawowe zagadnienia
techniczne związane z gromadzeniem tekstów oraz kompilacją własnego,
jednojęzycznego korpusu tekstowego. O korpusach równoległych (wieloję-
zycznych) będzie mowa w kolejnym artykule, jednak kwestie techniczne związane z tego typu korpusami są niemal identyczne, jak w przypadku
korpusu jednojęzycznego.
2.1.
Przed przystąpieniem do pracy z jakimkolwiek korpusem należy
w pierwszej kolejności określić cel badania. W ten sposób będzie można
adekwatnie ograniczyć zbiór tekstów przeznaczonych do analizy.
W przypadku „gotowych” korpusów opracowanych w sposób profesjonalny
(np. BNC w wydaniu World Edition 2007) istnieje możliwość „preselekcji”
tekstów. Ponadto wykorzystanie takich korpusów rozwiązuje wiele kwestii
natury technicznej, z którymi badacze spotykają się przy gromadzeniu i opracowywaniu danych do własnego korpusu. Tu, oprócz zdefiniowania
celu badania, należy określić wszystkie niezbędne parametry korpusu
tekstów: zakres dziedzin/gatunków oraz rodzaj tekstów (zob. kryteria
doboru tekstów), objętość korpusu dostępność danych (tekstów), sposób
rejestrowania danych, techniczne parametry danych elektronicznych,
sposoby „wzbogacenia” korpusu, czy sposoby weryfikacji tekstów. Ponadto
nie należy zapominać o monitorowaniu „jakości technicznej” już zgroma-
dzonych danych.

- 31 -
Pozyskiwanie tekstów w dobie Internetu i publikacji elektronicz-
nych nie stanowi większego problemu (oczywiście pomijając w tym
miejscu kwestie dotyczące ich jakości merytorycznej). Są one dostępne
zarówno na stronach WWW (mogą być „zbierane” zarówno przez
użytkownika, jak i przez oprogramowanie do automatycznego pozyskiwa-
nia tekstów – tzw. crawlery), jak również – co już podkreślono – udostęp-
niane na nośnikach optycznych CD/DVD (dotyczy to szczególnie wydań
archiwalnych czasopism). Jednakże z bezpośrednim wykorzystaniem takich
materiałów wiążą się pewne problemy techniczne, które uniemożliwiają
przeprowadzanie badań na tym etapie budowy korpusu (np. programy służące analizie korpusów nie są w stanie analizować lub analizują
nieprawidłowo zebrane dane). Zebrany materiał należy w pierwszej
kolejności poddać obróbce technicznej, tj. pliki źródłowe należy odpowied-
nio przygotować (teksty „wyczyścić” z ewentualnego „szumu”, uzgodnić
akapity w korpusie paralelnym – wielojęzycznym itd.) i zapisać do
wybranego formatu pliku docelowego.
2.2.
Jeszcze do niedawna duża część programów do obróbki danych kor-
pusowych wymagała wykorzystania formatu pliku, który niejednokrotnie
mógł być odczytany wyłącznie przez konkretny program korpusowy. Obecnie coraz szerzej stosuje się „uniwersalne” formaty plików, które
w zasadzie mogą być odczytane przez większość programów (przykładowe
rozszerzenia popularnych formatów to np. .xml, .txt). Bardzo istotną kwestią
w przypadku alfabetów języków „wykorzystujących” znaki diakrytyczne
jest zapisanie odpowiedniego dla nich kodowania. Jednym z najbardziej
rozpowszechnionych standardów umożliwiających kodowanie znaków
diakrytycznych jest Unicode, który może być stosowany bez względu na
wykorzystywany system operacyjny, program do obróbki danych czy język.
Najpopularniejszym systemem kodowania w tym standardzie jest UTF-8
(UTF – ang. Unicode Transformation Format), który jest wstecznie
kompatybilny z wcześniejszym standardem ASCII (ang. American Standard Code for Information Interchange) [Waliński 2005: 10]. Programy, takie
jak np. Notatnik pozwalają na bezpośrednie kodowanie plików tekstowych
(rozszerzenie .txt) do standardu Unicode UTF-8.
Pliki źródłowe występują w różnych formatach i dlatego przed
przystąpieniem do pracy z korpusem należy je przekonwenterować do
przyjętego formatu pliku docelowego (np. txt). I tak na przykład teksty
zgromadzone w postaci plików pdf można w prosty sposób zapisać
w formacie tekstowym (funkcja taka jest dostępna bezpośrednio
w programie Acrobat Reader). Jednak, po pierwsze, teksty umieszczone
w kolumnach, zawierające formatowania, ilustracje, wzory matematyczne,

- 32 -
odnośniki internetowe – będą wprowadzały „szum” (tu rozumiany
wyłącznie z punktu widzenia technicznej obróbki tekstu, zob. Ryc. 1) do
pliku docelowego, stanowiąc o obniżeniu jego jakości. Po drugie, nie
wszystkie pliki pdf są plikami z zapisanym tekstem; jeśli są to zeskanowane
strony jakiejś publikacji, program (np. wspomniany Acrobat Reader) „nie
poradzi” sobie z zapisem pliku źródłowego do pliku w formacie tekstowym.
Pozostaje ewentualnie zeskanowanie wydrukowanego dokumentu (lub
zapisanie go w formacie pliku graficznego) i przetworzenie takiego
zeskanowanego obrazu (pliku graficznego) za pomocą oprogramowania
OCR (zob. niżej). Z kolei zapisywanie stron internetowych bezpośrednio z poziomu przeglądarki internetowej do pliku txt (wraz z odpowiednim
kodowaniem znaków diakrytycznych) jest już szeroko dostępną funkcją,
dzięki czemu nie ma potrzeby oczyszczenia dokumentu z wszelkich
znaczników (np. znaczników html w przypadku dostępu wyłącznie do kodu
źródłowego danej strony). Alternatywą jest wykorzystanie komendy
„kopiuj-wklej”, dzięki której możemy przenieść tekst do dowolnego edytora
tekstów, a następnie zapisać w wybranym formacie pliku docelowego.
2.3.
W przypadku dostępu do tekstów występujących jedynie w wersji
drukowanej należy dokonać ich dygitalizacji. Wiąże się to z zeskanowa-niem danego tekstu oraz przetworzeniem go przez odpowiedni program do
rozpoznawania pisma/druku (ang. OCR – Optical Character Recognition).
Procedura taka stwarza jednak sporo problemów, a jej skuteczność zależy
od jakości technicznej zeskanowanego tekstu: jeśli druk jest poplamiony,
wyblakły, nierównomiernie rozłożony, zapisany rzadko występującymi
czcionkami, litery są niewyraźne, tekst zawiera dużo grafiki – wówczas
program OCR popełni znaczną liczbę błędów przy zapisie tekstu w formie
elektronicznej. Dlatego też po każdej takiej operacji należy zapisany tekst
przejrzeć i dokonać (już ręcznie) korekty. Niekiedy liczba błędów dys-
kwalifikuje tę procedurę z powodu czasochłonności przedsięwzięcia. Jeżeli
jednak tekst jest niezbędnym elementem prowadzonych/planowanych badań – a jest np. starodrukiem, rękopisem czy stwarza opisane powyżej problemy
– należy rozważyć wprowadzenie tekstu z klawiatury.
2.4.
Zebrane dane korpusowe należy rejestrować tak, aby móc do nich dotrzeć w łatwy i szybki sposób. Plikom należy nadać czytelne nazwy (np.
en_astron_20102006.txt – tj. tekst w języku angielskim z dziedziny
astronomii zarejestrowany 20 października 2006), należy je pokatalogować
(np. wg typów tekstów, daty wydania itp.) oraz sporządzić kartotekę
(zawierającą takie dane jak np.: nazwa języka, nazwisko autora, tytuł i data
publikacji dzieła, nazwa dziedziny (specjalistycznej), objętość, nazwa pliku

- 33 -
w bazie danych korpusowych). Z technicznego punktu widzenia warto
również przechowywać oryginalne pliki źródłowe, gdyż każde „wzbogace-
nie” tekstów znacznikami (tagami) zmienia jego naturalność. Ponadto
teksty oryginalne mogą zawierać informację pozajęzykową (np. graficzną)
lub zapisaną w innym kodzie (np. w języku matematyki), która może
warunkować poprawną analizę tekstu.
2.5.
Korpus tekstowy wymaga ciągłej weryfikacji. W przypadku tek-
stów specjalistycznych zgromadzonych na potrzeby słownika terminolo-
gicznego (np. ciągle aktualizowanego słownika komputerowego) będzie
to oznaczało usuwanie (archiwizację) plików zawierających teksty
„przestarzałe” lub nieadekwatne w stosunku do bieżącego poziomu
wiedzy przedmiotowej i uzupełnianie korpusu tekstami „nowymi”. Weryfikacja będzie dotyczyła również tekstów, które w wyniku kolejnych
formatowań i „wzbogacania” (np. anotacji, lematyzacji itd.) uległy
znacznemu zniekształceniu (szum). Więcej o metodach „wzbogacania”
korpuów tekstowych w kolejnym artykule.
3. Ostatnia część niniejszej publikacji koncentruje się na zagadnie-
niach, z którymi styka się użytkownik programów do obróbki korpusowej.
Na przykładzie dwóch programów komputerowych przedstawiono tu
podstawowe funkcje takiego oprogramowania i możliwości jego
wykorzystania w pracy terminologa, terminografa oraz tłumacza tekstów
Ryc. 1 Przykład „szumu” w pliku tekstowym (txt) po konwersji
z formatu pdf fragmentu artykułu z dziedziny kosmologii (widoczne
„sklejenie” tekstu oraz „źle” zakodowane działanie matematyczne).

- 34 -
specjalistycznych. Funkcje te zostały zilustrowane zrzutami ekranowymi
dwóch programów korpusowych: nieodpłatnego AntConc w wersji 3.2.1.
oraz odpłatnego MonoConc Pro w wersji 2.2. Ilustracje te zamieszczono za
zgodą autorów odnośnych aplikacji (zob. bibliografia odpowiednio:
AntConc oraz MonoConc Pro). Autor niniejszego artykułu nie podejmuje
się oceny żadnego z prezentowanych programów.
Większość programów komputerowych do obróbki danych korpu-
sowych (niesłużących wzbogacaniu korpusu) można podzielić na dwie
kategorie: programy do analizy frekwencyjnej oraz programy konkor-
dancyjne, tzw. konkordancery (ang. concordancers), z tym, że większość
dostępnych programów łączy w sobie oba powyższe moduły, czego
doskonałym przykładem są omawiane tu programy.
3.1.1.
Programy do analizy frekwencyjnej pozwalają w pierwszej kolejno-ści na generowanie list frekwencyjnych, czyli wykazów częstości
występowania poszczególnych (unikatowych) wyrazów w korpusie (tzw.
typów, ang. types). Część programów jest w stanie również podać liczbę
zdań, średnią liczbę liter w wyrazach, liczbę n-wyrazowych połączeń itp.
Wygenerowane listy frekwencyjne mogą ponadto przedstawiać procentowy
udział poszczególnych typów w stosunku do objętości całego korpusu, czyli
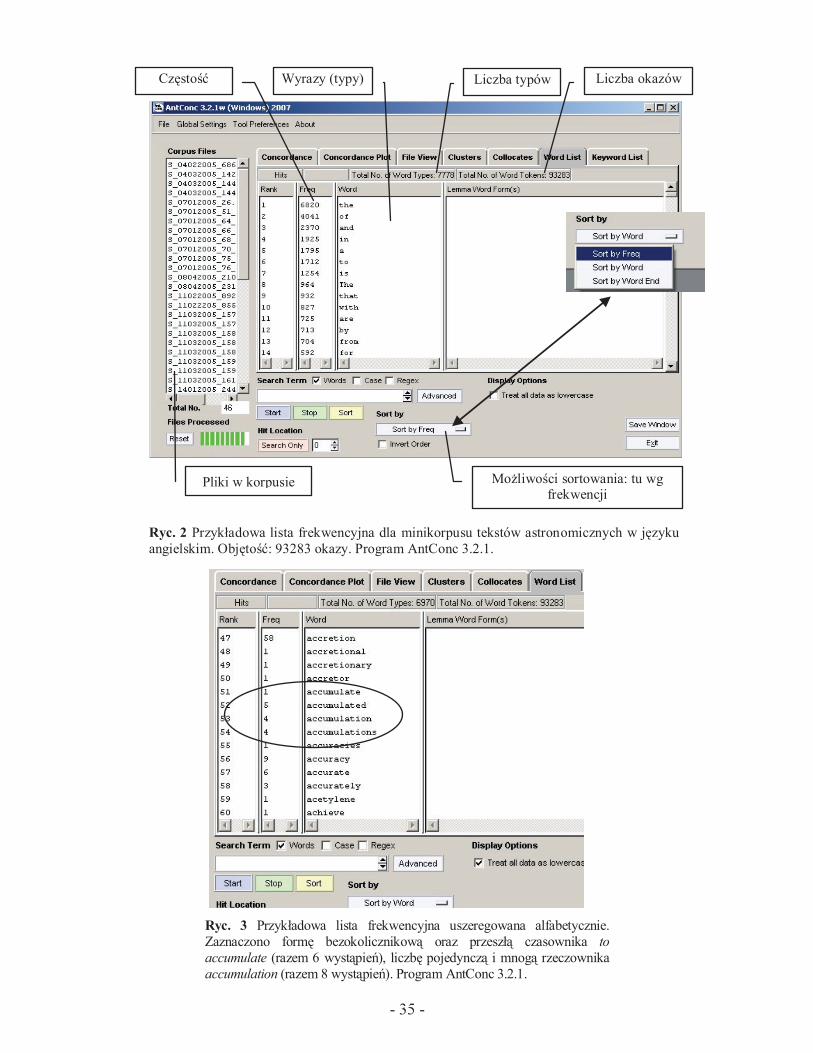
wszystkich wyrazów w tekście (tzw. okazów, ang. tokens). Poniżej (Ryc. 2)
przedstawiono listę frekwencyjną wygenerowaną dla niewielkiego korpusu
składającego się z fragmentów angielskojęzycznych tekstów popularno-
naukowych z dziedziny astronomii.
Listy frekwencyjne można porządkować na wiele sposobów. Lista
przedstawiona poniżej uszeregowana jest wg kolejności częstości występo-
wania wyrazów (frekwencji). Zazwyczaj możliwe jest również uszeregowa-
nie alfabetyczne oraz a tergo wszystkich typów (zob. Ryc. 3 oraz Ryc. 5 i 6).
W niektórych programach można ponadto określić wartość progową
frekwencji (np. 3 wystąpienia), poniżej której wyraz-typ nie znajdzie się na
liście frekwencyjnej.
- 35 -
Liczba okazów
Możliwości sortowania: tu wg frekwencji
Pliki w korpusie
Liczba typów Częstość Wyrazy (typy)
Ryc. 2 Przykładowa lista frekwencyjna dla minikorpusu tekstów astronomicznych w języku
angielskim. Objętość: 93283 okazy. Program AntConc 3.2.1.
Ryc. 3 Przykładowa lista frekwencyjna uszeregowana alfabetycznie.
Zaznaczono formę bezokolicznikową oraz przeszłą czasownika to
accumulate (razem 6 wystąpień), liczbę pojedynczą i mnogą rzeczownika
accumulation (razem 8 wystąpień). Program AntConc 3.2.1.

- 36 -
Z listami frekwencyjnymi wygenerowanymi na podstawie niezlema-
tyzowanych korpusów tekstowych w językach bogatych fleksyjnie (jak np.
języku polskim) wiąże się pewien problem: programy do obróbki korpuso-
wej nie są w stanie odróżnić poszczególnych form fleksyjnych wyrazów
i umieszczają je w różnych miejscach wykazu jako osobne typy (np.
gwiazda, gwiazd, gwiazdy itd.). Dlatego też istotną procedurą wzbogacania
korpusu jest hasłowanie (lematyzacja), w której hasło sprowadzane jest do
postaci słownikowej (bezokolicznika, mianownika liczby pojedynczej itd.).
W przypadku języków analitycznych o nierozbudowanej fleksji (np. język
angielski) brak lematyzacji można częściowo rozwiązać przez zsumowanie wystąpień form fleksyjnych po uporządkowaniu zbioru w kolejności
alfabetycznej (Ryc. 3). Jednak za każdym razem należy postępować
rozważnie i posiłkować się kontekstem, a to za sprawą występującej
homonimii (homografii). Niekiedy kwestia ta może okazać się jeszcze
bardziej skomplikowana, gdyż bez kontekstu nie wiadomo, czy forma –ing
jest pochodną zastosowanego czasu Continuous, formą gerundialną, czy
może rzeczownikiem. W przypadku języków fleksyjnych trudności te
nawarstwiają się – szczególnie w procesie automatycznej lematyzacji
korpusu tekstowego (np. w przypadku formy fleksyjnej gwiazdy nie
wiadomo, czy forma ta jest dopełniaczem liczby pojedynczej czy mianow-
nikiem liczby mnogiej).
Jak wynika z listy frekwencyjnej przedstawionej na Ryc. 2 najczęst-
szymi typami w korpusie tekstowym są wyrazy „gramatyczne”.
W niektórych przypadkach niezbędne jest wyeliminowanie tego typu
wyrazów za pomocą funkcji Stop List, która umożliwia umieszczenie na
oddzielnej liście wyrazów/znaków pomijanych przez program korpusowy
podczas obliczania frekwencji. Funkcja taka pozwala także „oczyścić” tekst
z niepożądanego „szumu”, np. znaków-pozostałości po wzorach matema-
tycznych, chemicznych itp. (zob. poniżej np. „c” – od stałej fizycznej
prędkości światła). W kontekście terminologii funkcja Stop List może
służyć wyłączeniu wyrazów języka ogólnego podczas ekscerpcji jednowy-razowych terminów. Jednak jej zastosowanie jest o wiele szersze. W ciągle
aktualizowanym i weryfikowanym korpusie tekstów specjalistycznych, tzw.
monitorującym (zob. wyżej); funkcja Stop List może być wykorzystana do
wyłączenia wszystkich zarejestrowanych już jednostek leksykalnych w celu
odnalezienia w nowych tekstach jednostek niezarejestrowanych, które mogą
być nowymi terminami lub neologizmami.
Poniżej zamieszczono przykładowy wykaz wyrazów-znaków
umieszczonych na takiej liście (Tabela 1). Z kolei Ryc. 4 przedstawia listę
frekwencyjną minikorpusu tekstów astronomicznych uzyskaną po
zastosowaniu funkcji Stop List.

- 37 -
Tabela 1 Przykładowy (skrócony) wykaz Stop List.
the have its where and an may would in than o e a they more some is or because um that these their however with we most over
by was also b are it within our from has about if s not into at but c as been i this were less on between only be such during which can
3.2.
W kontekście języków specjalistycznych listy frekwencyjne mogą
ponadto okazać się przydatne w badaniu proporcji terminologicznych
(w tym stopnia terminologizacji danego tekstu), przy określaniu zakresu
tematycznego tekstu (tekstów), wyszukiwaniu serii terminologicznych oraz
terminolelementów, a dzięki temu przy budowie słowników jedno- i wielo-
języcznych, przygotowywaniu materiałów dydaktycznych z konkretnego
zakresu dziedzinowego oraz na odpowiednim poziomie leksykalnym (np.
wg częstości występowania: od leksyki występującej często, np. ogólno-
naukowej, po wąskospecjalistyczną) itd.
Ryc. 4 Lista frekwencyjna wygenerowana dla
korpusu tekstów specjalistycznych z wykorzysta-niem funkcji Stop List. Program: AntConc 3.2.1.

- 38 -
Tabela 2 Określenie zakresu tematycznego tekstów za pomocą listy
frekwencyjnej. Wykaz przedstawia 10 pierwszych terminów
pojawiających się na listach frekwencyjnych dwóch porównywalnych
wielkością korpusów (pominięto wyrazy „ogólne”).
3.2.1.
Przy określaniu proporcji terminologicznych czy stopnia terminolo-
gizacji tekstów należy pamiętać, że lista frekwencyjna nie udzieli bezpo-
średniej odpowiedzi na pytanie dotyczące np. stosunku wyrazów ogólnych
do konwencjonalnych. Wynika to choćby z faktu istnienia dużej liczby
wielowyrazowych jednostek terminologicznych, których ekscerpcja
wymaga równoległego zastosowania innych procedur (np. funkcji
kolokacji). Jednak na początkowym etapie prac można dokonać szacunko-
wych obliczeń tego parametru poprzez np. porównanie list frekwencyjnych
tekstów ogólnych, popularnonaukowych oraz wąskospecjalistycznych, które z kolei mogą rzutować na dalszą analizę tych tekstów. Lista frekwen-
cyjna opracowana na podstawie reprezentatywnego korpusu tekstów
specjalistycznych może stanowić swoistą matrycę porównawczą dla
dalszych badań kwantytatywnych kolejnych zestawów tekstów.
3.2.2.
Listy frekwencyjne umożliwiają określenie zakresu tematycznego
zebranego korpusu (lub pojedynczego tekstu). Ponadto w połączeniu
z funkcją dystrybucji (zob. 3.4.3.) ułatwiają właściwe dobranie tekstów do
rozbudowywanego korpusu, dobór tematycznie spójnych materiałów
(tekstów) dydaktycznych i in. Tabela 2 przedstawia porównanie 10 pierwszych terminów pojawiających się w dwóch porównywalnych
wielkością korpusach, które uwidaczniają tematykę zbioru tekstów.
KORPUS 1 KORPUS 2
Nr Termin Nr Termin
1. mass 1. field
2. solar 2. boundary
3. Saturn 3. sound
4. field 4. energy
5. star 5. time
6. planet 6. frequency
7. magnetic 7. acoustic
8. energy 8. noise
9. stars 9. diffraction
10. system 10. wave
Korpus tekstów z zakresu
astronomii
Korpus tekstów z zakresu
akustyki

- 39 -
3.2.3.
Uszeregowanie listy frekwencyjnej w porządku alfabetycznym (lub
a tergo) umożliwia odnalezienie potencjalnych serii terminologicznych,
a na jej podstawie wyekscerpowanie terminoelementów konkretnego
zestawu tekstów. Dzięki jednoczesnemu ukazaniu frekwencji funcja ta staje
się niezastąpionym narzędziem przy ustalaniu klucza terminologicznego
danego korpusu, będącego ważnym elementem pracy terminologów
stanowiącym istotę tworzenia słowników asocjacyjnych. Poniżej zamiesz-
czono materiał ilustrujący serie terminologiczne pojawiające się na listach
frekwencyjnych uszeregowanych alfabetycznie oraz a tergo (Ryc. 5 oraz 6).
3.2.4.
Jak wspomniano, większość jednostek o najwyższej frekwencji
(Ryc. 2) to wyrazy gramatyczne, podstawowe łączniki zdań oraz przyimki.
Kolejne pozycje na liście to czasowniki modalne, posiłkowe oraz zaimki
wskazujące. Dane z listy frekwencyjnej mogą więc być podstawą ustalania
kolejności nauczanych treści w zakresie dydaktyki gramatyki języka obcego
(oraz specjalistycznego) oraz w zakresie dydaktyki leksyki (w tym spec-
jalnej), której kolejność nauczania ma istotne znaczenie z perspektywy
tworzenia nowego systemu pojęciowego w umyśle.
Ryc. 6 Lista frekwencyjna uszeregowana
a tergo. Seria terminologiczna: R+logy. Program AntConc 3.2.1.
Ryc. 5 Lista frekwencyjna uszeregowa-
na alfabetycznie. Seria terminologiczna: exo+R. Program AntConc 3.2.1.
- 40 -
3.3.
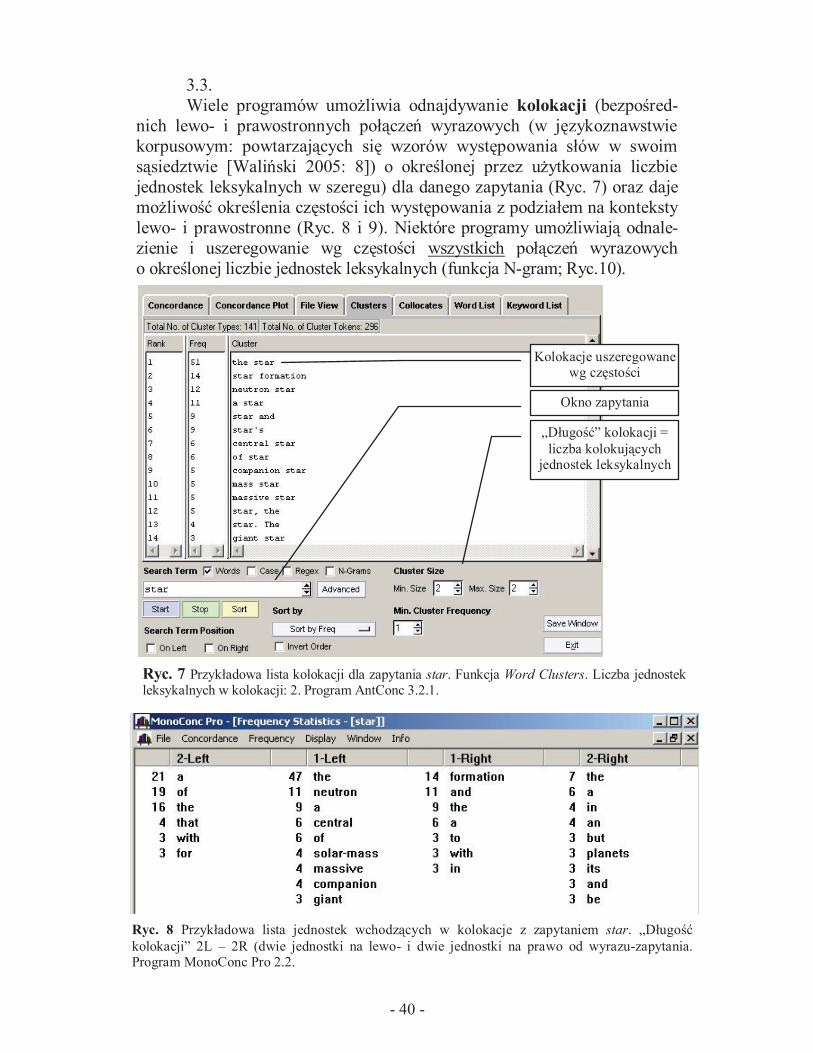
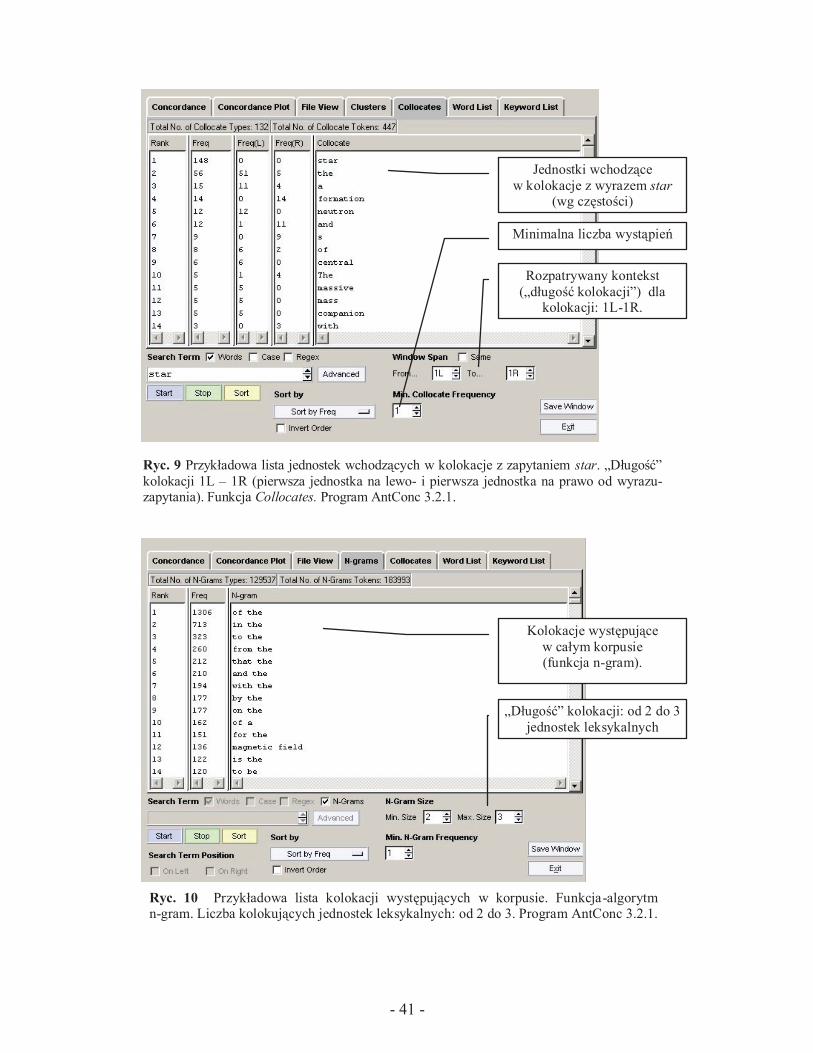
Wiele programów umożliwia odnajdywanie kolokacji (bezpośred-
nich lewo- i prawostronnych połączeń wyrazowych (w językoznawstwie
korpusowym: powtarzających się wzorów występowania słów w swoim
sąsiedztwie [Waliński 2005: 8]) o określonej przez użytkowania liczbie
jednostek leksykalnych w szeregu) dla danego zapytania (Ryc. 7) oraz daje
możliwość określenia częstości ich występowania z podziałem na konteksty
lewo- i prawostronne (Ryc. 8 i 9). Niektóre programy umożliwiają odnale-
zienie i uszeregowanie wg częstości wszystkich połączeń wyrazowych
o określonej liczbie jednostek leksykalnych (funkcja N-gram; Ryc.10).
Ryc. 8 Przykładowa lista jednostek wchodzących w kolokacje z zapytaniem star. „Długość
kolokacji” 2L – 2R (dwie jednostki na lewo- i dwie jednostki na prawo od wyrazu-zapytania. Program MonoConc Pro 2.2.
Ryc. 7 Przykładowa lista kolokacji dla zapytania star. Funkcja Word Clusters. Liczba jednostek leksykalnych w kolokacji: 2. Program AntConc 3.2.1.
Kolokacje uszeregowane wg częstości
Okno zapytania
„Długość” kolokacji =
liczba kolokujących jednostek leksykalnych
- 41 -
Ryc. 10 Przykładowa lista kolokacji występujących w korpusie. Funkcja-algorytm n-gram. Liczba kolokujących jednostek leksykalnych: od 2 do 3. Program AntConc 3.2.1.
Kolokacje występujące
w całym korpusie (funkcja n-gram).
„Długość” kolokacji: od 2 do 3
jednostek leksykalnych
Ryc. 9 Przykładowa lista jednostek wchodzących w kolokacje z zapytaniem star. „Długość”
kolokacji 1L – 1R (pierwsza jednostka na lewo- i pierwsza jednostka na prawo od wyrazu-zapytania). Funkcja Collocates. Program AntConc 3.2.1.
Jednostki wchodzące
w kolokacje z wyrazem star (wg częstości)
Minimalna liczba wystąpień
Rozpatrywany kontekst
(„długość kolokacji”) dla kolokacji: 1L-1R.

- 42 -
3.3.1
Nietrudno wyobrazić sobie możliwości zastosowania funkcji koloka-
cji w terminologii, terminografii czy tłumaczeniu. W pierwszej kolejności
wykazy takie mogą służyć odnalezieniu wielowyrazowych jednostek
terminologicznych (funkcja n-gram). Dzięki możliwości ograniczenia ciągu
można wyszukiwać i opisywać w kategoriach częstości jednostki termino-
logiczne o określonej liczbie elementów składowych (np. terminy
5-wyrazowe). Ponadto wykazy kolokacji (i kolokatów) dla określonego
wyrazu-terminu stanowią podstawowe narzędzie przy budowie słowników
w układzie gniazdowym, a w kontekście terminologii oraz terminografii mogą ujawniać łączliwość terminów z innymi terminami i wyrazami języka
ogólnego, co jest nie bez znaczenia wobec braku na rynku terminologicznych
słowników kolokacji [zob. Łukasik 2007; Michta – w niniejszym tomie].
3.4.
Konkordancje to zbiory przykładów użycia danego wyrazu (zapy-
tania) w jego bezpośrednich lewo- i prawostronnych otoczeniach teksto-
wych (kontekstach = KWIC = ang. Key-Word-In-Context) w całym
korpusie. Jak wspomniano powyżej, programy do wyświetlania konkordan-
cji są bardzo często modułami wielofunkcyjnych programów do obróbki
danych korpusowych. Ryc. 11 ilustruje przykładową konkordancję dla terminu star. Program MonoConc Pro w wersji 2.2. wyświetla niejako
„przy okazji” najczęstsze kolokacje z szukanym wyrazem (tu: kolokacje
zostały podkreślone). Funkcja ta w prezentowanym programie łączy więc w
sobie moduł konkordancyjny z analizą statystyczną kolokacji. Ponadto
konteksty lewo- czy prawostronne można porządkować alfabetycznie (wg
kolejnych lewo- lub prawostronnych miejsc w ciągu – zob. Ryc. 12).
Ryc. 11 Przykładowa konkordancja dla wyrazu star. Podkreślone wyrazy to najczęstsze
kolokacje. „Długosć kolokacji”: 2-L / 2-R. Program MonoConc Pro 2.2.

- 43 -
3.4.1. Dzięki konkordancjom możliwe jest badanie wyrazów w związkach
syntagmatycznych oraz, przy zastosowaniu stałych ram, w związkach
paradygmatycznych. W pracy terminologa, terminografa i tłumacza
umożliwia odszukanie kontekstów (na potrzeby np. tłumaczenia przy
poszukiwaniu wzorca składniowego w języku docelowym), przykładowych
zdań (na potrzeby np. słownika kontekstowego), definicji,
a w przypadku konkordancji dwujęzycznych stosowanych w korpusach
paralelnych – pozwala odnaleźć odpowiedniki i konteksty w dwóch języ-
kach, umożliwiając tym samym korpusowe badania konfrontatywne.
Poniżej przedstawiono przykładowe wykorzystanie omawianej funkcji
w pracy terminologia/terminografa.
3.4.2.
Obligatoryjnym elementem mikrostruktury branżowych słowników
terminologicznych, tworzonych wg obowiązujących zasad pracy termino-
graficznej, jest obecność definicji. „Klasyczne” rodzaje definicji, podające
najbliższe pojęcie nadrzędne, a następnie cechę (cechy) wyróżniające
(Definito fit per genus proximum et differentiam specificam), zawierają
w swojej budowie zazwyczaj tzw. spójki (spójniki) definicyjne, czyli
wyrażenia, których celem jest wykazanie równości między definiendum
(tego co ma być zdefiniowane) a definiensem (wyrażeniem/członem
definiującym). Znajomość tych wyrażeń (np. „jest to”; „to”; „znaczy tyle,
co”, „to tyle co”; ang. An X is a … // Xs are … oraz …is called an X)
Ryc. 12 Przykładowa konkordancja dla wyrazu star z uporządkowanym alfabetycznie
kontekstem lewostronnym 1-L (pierwszy wyraz po lewej stronie od wyrazu-zapytania). Program MonoConc Pro 2.2.

- 44 -
umożliwia odnalezienie potencjalnych definicji w dowolnym korpusie
tekstów specjalistycznych. Narzędziem wspomagającym tego typu pracę
jest konkordancja, dzięki której możliwe staje się dotarcie do istotnych
charakterystyk definiowanego pojęcia. Ryc. 13 przedstawia konkordancję
ukazującą potencjalne definicje (charakterystyki) pojęcia z dziedziny
kosmologii – ciemnej energii, ang. dark energy.
3.4.3.
Z funkcją konkordancji związana jest funkcja dystrybucji (w pro-
gramie AntConc: Concordance plot), czyli częstości i miejsca występo-
wania danego wyrazu-zapytania w poszczególnych tekstach (plikach)
poddanego analizie korpusu tekstowego. Umożliwia ona odnalezienie
tekstów zgodnych tematycznie z danym pojęciem, co nabiera szczególne-
go znaczenia w procesie rozbudowy własnego, dziedzinowego korpusu tekstowego. Poniższy przykład (Ryc. 14) ilustruje możliwość wykorzy-
stania tej funkcji. Dla terminu-zapytania black hole program odnalazł 45
linii konkordancyjnych, z czego 34 pochodzą z pliku o nazwie
S_07012005_76_80.txt o objętości 16908 znaków. Plik taki zostałby
z pewnością włączony do angielskojęzycznego, wąskospecjalistycznego
korpusu tekstów z dziedziny obiektów astronomicznych zwanych
czarnymi dziurami.
Ryc. 13 Przykładowa konkordancja przedstawiającą definicję pojęcia (charakterystyki obiektu) dla zapytania dark energy. Program AntConc 3.2.1.

- 45 -
4. Współczesne podejście korpusowe niewątpliwie zmieniło charakter
pracy językoznawców oraz specjalistów w różnych dziedzinach lingwistyki
stosowanej. Z warsztatu zniknęły kartoteki robocze pełne papierowych
fiszek, które zastąpiono komputerami oraz elektronicznymi bazami danych.
Dostarczyło ono również metod badań ukierunkowanych na obiektywizm,
niemogących zastąpić człowiekaw procesie introspekcji, lecz w ogromnej
mierze przyczyniających się do zautomatyzowania pewnych czynności,
skracając czas ich wykonywania nawet do kilku sekund. Metody lingwisty-
ki korpusowej stały się więc komplementarnym narzędziem w formułowa-
niu sądów o języku.
W niniejszym artykule przedstawiono tylko niektóre z możliwych
funkcji dwóch programów do obróbki danych korpusowych. W następnym
artykule omówione zostaną kolejne funkcje tego typu oprogramowania.
Ryc. 14 Przykładowa lista dystrybucji dla terminu-zapytania black hole w plikach korpusu tekstów astronomicznych. Program AntConc 3.2.1.
Dla zapytania black hole
program wyświetlił 45 linii
z kontekstami.
Termin black hole najczęściej
pojawił się w tekście zapisanym
w pliku S_07012005_76_80.txt.

- 46 -
Bibliografia:
AntConc, wersja 3.2.1., autor programu: Laurence Anthony, dostępny
nieodpłatnie na stronie domowej autora: mmmmmmmmmmm
<http://www.antlab.sci.waseda.ac.jp/>.
Bandler R., 1985, Using Your Brain for a Change, Moab: Real People Press.
Bowker L, Pearson J., 2002, Working with Specialized Language.
A practical guide to Using corpora, London: Routledge.
Burkhanov I., 1998, Lexicography. A Dictionary of Basic Terminology,
Rzeszów: Wydawnictwo Wyższej Szkoły Pedagogicznej. Grucza S., 2007, O konieczności tworzenia korpusów tekstów specjali-
stycznych, [w:] S. Grucza et al. [red.], W kręgu teorii i praktyki lingwi-
stycznej, Warszawa: WUW, s. 103-122.
Hacken T. P., 2001, Has There Been a revolution in Machine Translation,
„Machine Translation”, Vol. 16, Dordrecht: Kluwer Academic
Publishers, s. 1-19.
Hutchins J., 2005, Example-based machine translation: a review and
commentary, „Machine Translation”, Vol. 19, Dordrecht: Kluwer Aca-
demic Publishers, s. 197-211.
Kay M., 1997, The Proper Place of Men and Machines in Language
Translation, „Machine Translation”, Vol. 12, Dordrecht: Kluwer Academic Publishers, s. 3-23.
Kuratczyk M., 2007, Nowe narzędzia w leksykografii dwujęzycznej
(rosyjsko-polskiej i polsko-rozyjskiej), [w:] S. Grucza et al. [red.],
W kręgu teorii i praktyki lingwistycznej, Warszawa: WUW, s. 197-211.
Lukszyn J. [red.], 2005, Języki specjalistyczne. Słownik terminologii
przedmiotowej, Warszawa: KJS.
Łukasik M., 2007, Angielsko-polskie i polsko-angielskie słowniki
terminologiczne (1990-2005) – analiza kwantytatywna, [w:] M. Kornac-
ka [red.], Języki Specjalistyczne 7. Teksty specjalistyczne jako nośniki
wiedzy fachowej, Warszawa: KJS, s. 163-176.
McEnery T. [et al.], 2006, Corpus-Based Language Studies. An advanced resource book, London-New York: Routledge.
MonoConc Pro, wersja 2.2., autor programu: Michael Barlow, program
dostępny za opłatą. Na podanej poniżej stronie internetowej znajduje się
wersja demonstracyjna programu: <http://www.athel.com/mono.html>.
Piotrowski T., 2004, Komputerowe korpusy tekstowe polszczyzny, ze strony
domowej autora:
<http://www.tadeuszpiotrowski.neostrada.pl/krak2004.pdf>, data dostę-
pu: 20 sierpnia 2007.
Revell J., Norman S., 1997, Handling Over: NLP based activities for language
learning, London: Saffire Press.
Revell J., Norman S., 1999, In Your Hands: NLP in ELT, London:
Saffire Press.

- 47 -
Richards J.C., 1996, Longman Dictionary of Language Teaching
& Applied Lingusistics, Harlow: Longman.
Sinclair J., 1996, EAGLES: Preliminary recommendations on Corpus
Typology. EAG-TCWG-CTYP/P. Pisa: ILC-CNR.
SJP PWN – Słownik Języka Polskiego PWN [wersja online]:
<http://sjp.pwn.pl>, data dostępu: 20 września 2007.
Stubbs M., 2004, Language Corpora, [w:] A. Davies, C. Elder [red.],
The handbook of Applied Linguistics, Malden-Oxford-Carlton: Blac-
kwell Publishing.
Young S., Bloothooft G., 1997, Corpus-based Methods in Language and speech Processing, Dordrecht: Kluwer Academic Publishers.
Waliński J., 2005, Typologia korpusów oraz warsztat informatyczny
lingwistyki korpusowej, [w:] B. Lewandowska-Tomaszczyk [red.],
Podstawy językoznawstwa korpusowego, Łódź: Wydawnictwo UŁ;
wersja elektroniczna:mmmmmmmmmmmmmmmmmmmmmmmm
<http://www.filolog.uni.lodz.pl/elise/emodule/files/Typologia_korpusow.doc>
data dostępu: 20 września 2007.
Wu D., 2005, MT model space: statistical versus compositional versus
exxample-based machine translation, „Machine Translation”, Vol. 19,
Dordrecht: Kluwer Academic Publishers, s. 213-227.
Top Related
Copyright © 2022 FDOKUMEN

