
Spatial niches and coexistence: testing theory with tarweeds

IEEE TRANSACTIONS ON EVOLUTIONARY COMPUTATION, VOL. 11, NO. 4, AUGUST 2007 453
Where Are the Niches? Dynamic Fitness SharingAntonio Della Cioppa, Member, IEEE, Claudio De Stefano, and Angelo Marcelli, Member, IEEE
Abstract—The problem of locating all the optima within a multi-modal fitness landscape has been widely addressed in evolutionarycomputation, and many solutions, based on a large variety of dif-ferent techniques, have been proposed in the literature. Amongthem, fitness sharing (FS) is probably the best known and the mostwidely used. The main criticisms to FS concern both the lack ofan explicit mechanism for identifying or providing any informa-tion about the location of the peaks in the fitness landscape, andthe definition of species implicitly assumed by FS. We present amechanism of FS, i.e., dynamic fitness sharing, which has been de-vised in order to overcome these limitations. The proposed methodallows an explicit, dynamic identification of the species discoveredat each generation, their localization on the fitness landscape, theapplication of the sharing mechanism to each species separately,and a species elitist strategy. The proposed method has been testedon a set of standard functions largely adopted in the literature toassess the performance of evolutionary algorithms on multimodalfunctions. Experimental results confirm that our method performssignificantly better than FS and other methods proposed in the lit-erature without requiring any further assumption on the fitnesslandscape than those assumed by the FS itself.
Index Terms—Evolutionary algorithms (EAs), fitness sharing(FS), niching, speciation.
I. INTRODUCTION
THE PROBLEM OF locating all the optima within a fit-ness landscape has been widely studied and for its solution,
many algorithms based on a large variety of different techniqueshave been proposed in the literature [1]–[7]. In this context, evo-lutionary algorithms (EAs) have proved their ability to explorevery large problem spaces and to efficiently approximate the de-sired solution. Nonetheless, EAs have also shown an intrinsicdrawback when dealing with multimodal functions, in that theyhave the property of converging to a population containing justone solution. Such a behavior is the result of the combined ef-fects of both the genetic drift [2], [8], i.e., the tendency of the se-lection mechanism to converge over time toward a uniform dis-tribution of mutants of the fittest individual, and the evaluationmechanism, which computes the fitness of each individual in thepopulation independently of the fitness of the others. Movingfrom these considerations, a relevant research activity has beendevoted for counterbalancing those effects in order to make EAsable to deal with multimodal fitness landscapes [3]. The basicidea most of the methods are based upon, drawn from an analogywith natural ecosystems, is that of preserving genetic diversity
Manuscript received July 18, 2005; revised March 24, 2006.A. Della Cioppa and A. Marcelli are with the Department of Electrical and
Information Engineering, University of Salerno, I 84084 Fisciano (SA), Italy(e-mail: [email protected]).
Claudio De Stefano is with Dipartimento di Automazione, Elettromag-netismo, Ingegneria dell’Informazione e Matematica Industriale, Università diCassino, Cassino (FR), Italy.
Digital Object Identifier 10.1109/TEVC.2006.882433
by encouraging the formation of species or niches, each repre-senting one of the possible solutions [1]–[7], [9]–[11].
In Nature, an ecosystem is typically composed by differentphysical spaces (niches) that exhibit different features and allowboth the formation and the maintenance of different types oflife (species). It is assumed that a species is formed by indi-viduals with similar biological features capable of interbreedingamong themselves, but unable to breed with individuals of otherspecies [12]. As a species adapts to the specific features of theniche in which it lives, natural selection favors the emergence ofspecialized properties within the species that allow its individ-uals to effectively exploit the niche resources. The fitness of anindividual, then, measures its ability to exploit environmentalresources to generate offspring. As a consequence, a naturalecosystem can be characterized by the following properties:
• it is capable of supporting the presence of different species,each occupying a different physical niche;
• the physical resources of a niche are finite and are sharedonly among the individuals populating that niche;
• the density of individuals populating a given niche (nichecarrying capacity) depends on both the amount of re-sources for that niche, and the ability of the species toexploit them.
By analogy, in artificial systems, a niche corresponds to apeak of the fitness landscape, while a species to a subpopu-lation of individuals that, in terms of a given metric, exhibitsimilar features. Following this analogy, niching or speciationmethods have been introduced in evolutionary artificial systemsto promote the formation and the maintenance of stable sub-populations. Among niching methods, fitness sharing (FS) andimplicit fitness sharing are the best known and the most widelyused [3]–[5], [7], [10], [11], [13]–[17]. In the former, the fitnessrepresents the resource for which the individuals belonging tothe same niche compete [3], while in the latter [4], [10], thesharing effects are achieved by means of a sample-and-matchprocedure which resembles the bidding mechanism commonlyused in classifier systems [18].
In FS, subpopulations are formed and maintained by reducingthe probability that the number of individuals populating a peakbecomes larger and larger, so as to cause the disappearance ofthe individuals populating other peaks. This is achieved by re-ducing the fitness of similar individuals as their number grows,with the implicit assumption that similar individuals belong tothe same species and populate the same niche. To this purpose,the definition of both a similarity metric on the search spaceand a threshold (niche radius), representing the maximal dis-tance among individuals to be considered similar and thereforebelonging to the same niche, is required. It has been proved that,when the number of individuals within the population is largeenough and the niche radius is properly set, FS provides as manyspecies in the population as the number of peaks in the fitnesslandscape, thus populating all the niches [19], [20].
1089-778X/$20.00 © 2006 IEEE

454 IEEE TRANSACTIONS ON EVOLUTIONARY COMPUTATION, VOL. 11, NO. 4, AUGUST 2007
In the implicit fitness sharing [4] “each individual’s fitnessis functionally dependent on the rest of the population Thefunctional dependence is introduced through the use of a sim-plified bidding mechanism similar to that of classifier systems
the use of the simple bidding procedure combined with atraditional genetic algorithm is sufficient for the populationto discover and maintain independent subpopulations.” Morespecifically, sharing is accomplished by inducing competitionfor limited and explicit resources. For each environmentalresource, a set of individuals is randomly selected from thepopulation and each individual is matched against the resource.The individual with the highest score is then rewarded. Such aprocedure is repeated a given number of times, through whichthe score of individuals is updated. At each generation, thediscovered niches are obtained by selecting the minimal setof individuals needed to match all the resources. Therefore,niching is implicit in that the number of peaks is determineddynamically and there is no specific limitation on the distancebetween peaks. As a consequence, the method avoids the diffi-culty of appropriately choosing the niche radius, and it is ableto deal with problems in which the peaks are not equally spaced[4], [10], [11]. So, one of the most important limitations ofFS seems to be removed. Actually, the implicit fitness sharingintroduces other parameters to be set, e.g., the size of thesample of individuals that compete, the number of competitioncycles and the definition of a matching procedure. Moreover,the limitation on the population size mentioned above still takesplace. Finally, the method can be applied, at best, on problemsin which explicit and finite resources are available [4], [10],[11], e.g., a training set in a pattern recognition task.
Our main criticism to the FS method, in addition to those re-ported in the literature regarding the difficulty of setting effec-tive values for the niche radius and the population size [21], aswell as the lack of an explicit mechanism for identifying or pro-viding any information about the location of the peaks in thefitness landscape [22], concerns the definition of species implic-itly assumed by the FS method.
As discussed above, in order to ensure that subpopulations aresteadily formed and maintained, only the individuals belongingto the same niche should share the resources of the niche. Thisassumption is not generally true for the FS method [23], becauseeach individual in the population shares its fitness with all theindividuals located at a distance smaller than the niche radius,no matter for the actual peak, i.e., for the niche, to which theybelong. As a consequence, individuals belonging to differentpeaks may share their fitness, while they should not. Only whenthe distance between the borders of neighboring peaks is at leastequal to the niche radius, is it possible to achieve the perfectseparation among niches. Overall, the nonperfect discriminationbetween peaks results in a higher probability of niche loss, thatcan be counterbalanced by an increase of the population sizerequired to solve a multimodal problem. This, in turn, results ina computational time that makes FS impractical as the numberof peaks becomes large.
In order to overcome these drawbacks, we have proposed amethod for estimating the optimal values for the population sizeand the niche radius without any a priori information on thefitness landscape based on an explicit identification of the peaksin the fitness landscape [24].
Here, we propose a sharing method, called dynamic fitnesssharing (DFS), whose foundations were presented in [25],aimed at discovering and populating all the niches in the en-vironment according to their carrying capacity. The proposedmethod is based upon a dynamic, explicit identification of thespecies discovered at each generation and their localization inthe fitness landscape. The application of the FS mechanism,thus, is restricted to individuals belonging to the same species.Eventually, an elitist strategy is applied on the species, bycopying the species masters, i.e., the fittest individuals of thespecies discovered at each generation in the new population.DFS is independent of the EA actually used to search thesolution space, of the values of its internal parameters and,finally, of the particular encoding.
The idea of improving the ability of FS to promote both thepreservation of good individuals through the generations and themaintenance of genetic diversity by adopting an explicit identi-fication of niches has been investigated during the last decade.In fact, since the publication of the first paper on niching byGoldberg and Richardson in 1987, a number of methods havebeen proposed in literature [22], [26]–[29].
The first attempt to dynamically identify the niche in the pop-ulation during the evolution was made by Miller and Shaw in[22]. Their dynamic niche sharing (DNS) adopts a dynamicspecies1 identification and partitions the population by assumingthat the number of niches of the fitness landscape is a prioriknown. The individuals not belonging to any of the previouslyidentified species are grouped into a unique nonspecies class.Moreover, the fitness of the individuals is modified according totwo different sharing mechanisms. The shared fitness of an in-dividual belonging to a species is computed by dividing its rawfitness by the occupation number of the niche, i.e., the number ofindividuals populating that niche. However, the standard FS for-mula is used for individuals belonging to the nonspecies class.The authors motivate this choice in terms of computational cost,in that the occupation number is computed only once for all theindividuals of a species, while the niche count has to be com-puted for each individual in the population. The role played byeach feature (species identification and sharing mechanisms) onthe performance is unclear. It is also unclear how DNS performson complex, deceptive fitness landscape. Moreover, the algo-rithm does not use an elitist strategy on the species, and there-fore it does not tackle the problem of reducing the populationsize needed to solve the problem. The main drawback of thisproposal, however, is that in many applications the number ofniches is not known a priori, and this makes it very hard to applythe DNS successfully.
The method recently proposed by Stanley et al. [26], [27]is interesting in that it uses FS to promote species discoveryand maintenance by combining explicit species identificationwith elitism, but in a quite different context. In particular, theNEAT algorithm deals with problems whose solution requiressearching multiple spaces, because different species in NEAThave a different number of parameters (i.e., dimensions). In sucha context, it would not be realistic to search for all the peaks,
1Note that the authors use the term niche for referring to both the subpopu-lations and the peaks of the fitness landscape. For the sake of coherence withthe terminology used in this paper, we change the term niche into species whenappropriate, while describing their work.

DELLA CIOPPA et al.: WHERE ARE THE NICHES? DYNAMIC FITNESS SHARING 455
because as new dimensions are added the algorithm moves intodifferent spaces where new peaks are located, and to exploitthose new peaks it may have to give up some of the older ones.In other words, NEAT assumes that species will continually dieout and be replaced and uses FS in order to protect innovativespecies in their own niches.
To achieve this goal, NEAT adopts the following strategies:• each species has a representative individual that is ran-
domly chosen among the individuals belonging thespecies;
• if an individual in the population does not belong to anyspecies, then a new species is created with the individualas its representative;
• when a species reproduces, its representative is reproducedif the species is above a minimum size;
• before reproduction, NEAT eliminates the lowest per-forming individuals from the population.
Interestingly, the above strategies are similar to those of DNSand DFS, but NEAT uses FS for different purposes, namely, pro-tecting innovative solutions, while searching multiple spaces.Therefore, it is not directly comparable with any other methodusing FS while searching for all the peaks in a given space.
Species conserving genetic algorithm (SCGA) byBalazs et al. [28] and opt-aiNet by de Castro et al. [29],on the other hand, are particularly interesting in that they donot consider any sharing mechanism. Once a new species isdiscovered, its fittest individual is retained in the next gen-erations until a fitter individual for that species is generated.Both the algorithms upgrade the set of best individuals with thenew ones discovered in the current population, thus realizing asort of elitism with incremental memory. This idea representsthe major novelty of these approaches, allowing to preservegenetic diversity and to maintain species independently onthe fitness of their fittest individuals. Unfortunately, such abehavior implies that each species populating a region of thefitness landscape survives during the entire evolution, whetheror not it corresponds to an actual niche. In addition, the numberof individuals forming a species is not related to the nichecarrying capacity. In particular:
• SCGA is prone to stagnation, as it follows from the au-thors comments to the experimental results reported inSection IV of their paper. As they noticed, the presence inthe final population of species not populating the niches ofthe fitness landscape, requires a method for selecting thedesired solution among the species. This last aim can beachieved only when some a priori knowledge about eitherthe location of the actual niches or their relative fitness isavailable.
• As regards opt-aiNet, the above drawback is tackled byintroducing suppression and genetic diversity mecha-nisms that allow a dynamic population size. This featuremakes opt-aiNet very different from all the other nichingmethods, but it is difficult to estimate the effectiveness ofthose mechanisms on complex problems with a very largenumber of niches. Moreover, in our opinion, it is hard todetermine the influence of such mechanisms on opt-aiNetperformance.
DFS overcomes these drawbacks, because of the followingproperties:
• all the species present in the population at each generationare automatically and explicitly identified;
• its elitist strategy avoids both the premature convergenceand the stagnation usually associated with elitism;
• the adoption of a more biologically plausible definition ofspecies in combination with the suggested elitist strategyensures the convergence of the algorithm towards a popu-lation containing as many species as the number of nichesto be populated;
• the sharing mechanism ensures that each niche will be pop-ulated according to its carrying capacity;
• the population size required to solve the problem is muchsmaller than that required by FS.
The proposed method has been tested on a set of standardmultimodal functions largely adopted in the literature, and theexperimental results were compared with those provided by FS.The performance of the DFS has also been compared with thatof DNS and SCGA, in that those methods introduce a smallernumber of parameters, and the role of such parameters on thesystem performance is clear.
The remainder of this paper is organized as follows: Section IIdescribes the background of the FS method, while Section IIIpresents DFS. The experimental results are illustrated and dis-cussed in Section IV, and our conclusions are eventually left toSection V.
II. FITNESS SHARING (FS)
In artificial evolutionary systems, a population of individualsevolves according to probabilistic transition operators, i.e., se-lection, mutation, and eventually crossover. At each generation,the individuals are selected according to their fitness and manip-ulated by the genetic operators, thus creating offspring. Then,the parents are usually replaced by their offspring in order toobtain a new population.
In a simple EA, the number of individuals whose fitness valueis above the average increases during the evolution, and an in-crease in their number shifts the average fitness value towardseven greater values until a suboptimum is reached, which isequal to the highest fitness among all existing individuals. Then,the system will tend to assume a state of “selective equilibrium,”which is unstable. It will be upset when, as a result of geneticchanges, a new individual appears with a higher fitness value.In such a way, a new state of equilibrium arises, and so on. Atthe end of such evolutionary process, the population consists ofan optimal individual, i.e., the master, with its mutant distribu-tion. The selection mechanism is responsible for the adaptation,allowing the EA to concentrate its efforts in the most promisingarea of the search space and driving the population toward asingle distribution constituted by the fittest individual and itsclose mutants. So, at the end of such evolutionary process, thepopulation consists of a single fittest individual, representing thebest solution found by the algorithm, and its cloud of mutants.There are many cases, however, when the desired solution isnot necessarily the best one, but rather a collection of best, as isthe case, for instance, in multimodal function optimization. Inorder to deal with this class of problem, it is necessary to preventthe species with highest fitness value replacing the competing

456 IEEE TRANSACTIONS ON EVOLUTIONARY COMPUTATION, VOL. 11, NO. 4, AUGUST 2007
species by inducing some kind of restorative pressure to coun-terbalance the convergence pressure of selection. As with nat-ural ecosystems, niching has been suggested as a viable mean tosimultaneously evolve subpopulations exploiting different eco-logical niches by some kind of sharing.
In the FS [3], the peaks in the fitness landscape are consideredas environmental niches with a given amount of environmentalresources proportional to the peak’s height and all the individ-uals populating a given peak have to share the resource of thatpeak. When a peak is overcrowded, the resources of the nicheare overused and the selective pressure is increased by deratingthe fitness of the individuals populating that niche. On the otherhand, less crowded peaks have the fitness of their individualsless derated, thus increasing selective pressure.
The modification of the raw fitness of an individual is accom-plished according to the presence of similar individuals withinthe population, with the implicit assumption that similar indi-viduals populate the same niche. The concept of similarity be-tween two individuals is implemented by defining a metric oneither the genotypic or the phenotypic space and by setting athreshold value which represents the maximal distance be-tween individuals to be considered similar, i.e., belonging to thesame species, and hence populating the same niche.
The shared fitness of an individual at generationis given by
(1)
where is the raw fitness of the individual and isthe niche count which depends on the number and the relativepositions of the individuals within the population with whomthe raw fitness is shared. The niche count is given by
(2)
where is the sharing function which measures the sim-ilarity between two individuals. The most commonly adoptedform of is the following:
(3)
where is the defined distance function, and is theradius of the niches. In general, is computed by usinga metric in the phenotypic space [15], while the choice of thevalues for the parameters and depends on the fitnesslandscape.2 Other definitions of the sharing function can befound in [6].
Let us point out that the basic assumption underlying themethod is that there exists a value of which allows is to as-sociate one and only one niche to each peak of the fitness land-scape (perfect discrimination) [3]. Moreover, as it follows fromformula (3), such a value is the same for all the peaks. Underthis assumption, FS allows the formation and the maintenance ofquasi-stable subpopulations, in that it reduces the effects of the
2In the large majority of studies on the FS, the value of � has been setto 1, yielding to a triangular form for the sharing function. Therefore, in thefollowing, we shall consider only the case � = 1.
genetic drift because the shared fitness of similar individuals isreduced as far as their number increases. Thus, FS allows otherindividuals, with lower raw fitness or belonging to less popu-lated niches, to compete for selection and reproduction. A stateof dynamic equilibrium is eventually reached when the nichesare populated according to their relative fitness.
Although it has been proved that FS provides as many sub-populations as the number of peaks in a multimodal fitness land-scape [20], it suffers from two main drawbacks.
• There is no explicit identification of the niches [6]. Ac-cording to the (2), FS considers each individual in the pop-ulation as the master of a species. Therefore, a given indi-vidual may belong to many species, namely, the species ofwhom it is the master and the species with at least one indi-vidual within its niche radius. As a consequence, the per-fect discrimination hypothesis is not satisfied, and there-fore it is not guaranteed that FS would provide as manysubpopulations as the number of peaks. To accurately de-cide when two individuals belong to the same niche andshould therefore have their fitness shared, we need to knowwhere the niches are.
• The population size required to populate a given number ofniches increases very rapidly with the number of niches,leading to an unbearable computational cost in manyapplications.
III. DYNAMIC FITNESS SHARING (DFS)
Starting from the considerations discussed in the previoussections, we propose a mechanism of FS, which adopts a morebiological plausible definition of species based on the followingcriteria:
• a species consists of a subpopulation of at least twoindividuals;
• each individual in the population belongs to one and onlyone species;
• a species is represented by its species master, i.e., the indi-vidual of the species with the highest raw fitness value.
DFS is based upon explicitly finding the species at each gen-eration, using FS to ensure that each niche will be populatedproportionally to the fitness of its peak, and preserving specieswith few individuals from extinction by elitism. For this pur-pose, DFS embodies an explicit, dynamic identification and lo-calization on the fitness landscape of the species discovered ateach generation, the application of the FS mechanism to eachspecies separately, and a species elitist strategy.
Dynamic species identification is accomplished by assumingonly that effective values for the niche radius and for thepopulation size have been selected in order to achieve theperfect discrimination among the peaks of the fitness landscapeand to maintain the actual number of niches. It should be re-marked here that the above assumptions are equivalent to theassumption that we know a priori the number of perfectly dis-tinguishable niches to be populated and maintained. Obviously,DFS suffers the same drawbacks as FS when wrong values foreither the niche radius or the population size are selected. Deband Goldberg proposed a criterion for estimating the niche ra-dius given the heights of the peaks and their distances [15],while Mahfoud suggested a lower bound for the population size

DELLA CIOPPA et al.: WHERE ARE THE NICHES? DYNAMIC FITNESS SHARING 457
given the number of niches to be maintained [20]. Nonetheless,since in most of the real applications there is very little a prioriknowledge about the fitness landscape, it is generally agreedthat the setting of those parameters remains the main problemwhen using FS [21]. In [24] and [25], we proposed a methodthat can effectively use dynamic species identification mecha-nism for estimating the optimal values for the population sizeand the niche radius without any a priori information on width,number, height, and position of the peaks in the fitness land-scape under examination.
The mechanism for dynamically identifying the species inthe population at each generation is based on the definition ofspecies and exploits the only information available in the popu-lation, i.e., the raw fitness of all the individuals and the similaritymetric defined on either the genotypic or the phenotypic space.The skeleton of the mechanism is outlined in Algorithm 1.
Algorithm 1: Dynamic Species Identification
begin
sort the current population according to the raw fitness;; (number of niches at generation t)
(Dynamic Species Set)
for to do
if the th individual is not marked then
; (number of individuals in thecurrent niche)
for to do
if ( ( th individual is notmarked)) then
mark the th individuals as belonging to theth species;
;
end if
end for
if then
mark the th individual as the species master ofthe th species;
insert the pair ( th individual, ) inDSS;
;
end if
end if
end for
end
Dynamic identification of the species masters is obtained byordering the population at generation according to the rawfitness of the individuals. Then, the best individual is chosen asspecies master candidate. Once a species master candidate has
been selected, its species can be defined as a subsetof individuals in the population which have a distance fromthe species master less than the niche radius and do not belongto other species. If such individuals are found in the currentpopulation, the candidate is assumed as the actual species masterand the individuals belonging to its species marked, otherwise,the candidate is considered an isolated individual. The processis iterated by choosing the first not marked individual of asa master candidate for a new species and terminates when allthe individuals in the current population have been analyzed. Insuch a way, it is possible to partition the population at thetime into a number of species, say , and ina number of isolated individuals
where represents the set of all the isolated individuals.The output provided by this algorithm is then used to im-
plement the species sharing mechanism: for each species, theshared fitness is computed according to the (1), but assumingthat only the individuals belonging to the current species con-tribute to the niche count. In fact, if the individual , itsniche count is computed according to the following formula:
(4)
while is computed according to (3).On the contrary, the fitness of isolated individuals is not mod-
ified, nor they contribute to modify the fitness of any other in-dividual in the population, with the aim to improve the chancefor those individuals to generate a new species.
Summarizing, DFS provides, at each generation, the totalnumber of species, the set of species masters, the distributionof the species in the fitness landscape, and the shared fitnessvalue for each individual in the population. Note that, sincethe population has been ordered according to the raw fitness ofthe individuals, the species masters are ordered according todecreasing values of their raw fitness.
Finally, the species elitist strategy is implemented by copyingthe species masters found at each generation in the next popula-tion. The introduction of this elitist strategy offers two main ad-vantages. The preservation in the next generation of the speciesmasters of all the discovered species avoids the risk that someof them, due to the application of genetic operators, may disap-pear. This strategy also allows for a significant improvement ofthe performance of our method in terms of both the number ofgenerations and the population size needed for discovering andmaintaining the species populating the actual niches of the fit-ness landscape. Moreover, in case of applications for which theactual number of niches to be populated can be estimated, a
-elitist strategy can be implemented by simply copying the firstspecies masters, if present, in the next population. Although it
may be argued that, in general, the use of an elitist strategy fa-vors exploitation rather then exploration, in our case this effectis mitigated by the following properties of DFS:

458 IEEE TRANSACTIONS ON EVOLUTIONARY COMPUTATION, VOL. 11, NO. 4, AUGUST 2007
TABLE ITEST PROBLEMS
• the genetic diversity is preserved because only the speciesmasters are copied in the next population;
• in the worst case of a population in which each speciesmaster has only one individual in its neighborhood, thenumber of species masters copied in the next population isequal to , thus allowing that at most 50% of the popu-lation be replaced by new individuals at each generation.
Finally, the complexity of the proposed algorithm isin the worst case (all the individuals in the population have mu-tual distance greater than ) and in the best case (allthe individuals belong to the same niches), compared with the
complexity of each iteration of the FS.The skeleton of an EA with DFS is outlined in the
Algorithm 2.
Algorithm 2: EA with Dynamic Fitness Sharing (DFS)
begin
;
randomly initialize a population of individuals;
while (not reached the maximum number of generations)do
evaluate the raw fitness of each individual;
apply the Dynamic Species Identification algorithm;
for to do
apply the FS among the individuals belonging tothe th species;
end for
copy the species masters in the new population;
apply the selection mechanism;
apply the crossover operator;
perform mutation on the offsprings;
;
end while
end
IV. EXPERIMENTAL FRAMEWORK
In order to validate the proposed method, we have taken intoaccount the classical functions for testing niching methods,often referred to in literature as , and . Such
problems are widely studied and used in literature [3], so as toallow a reasonable experimental framework.
Table I reports the main features of the test problems em-ployed in terms of number of niches, extraneous peaks, decep-tion, difficulty, and metric. For the sake of comparison, we haveused the same metrics adopted in literature [20].
The EA used for all the experiments is the standard geneticalgorithm described in [30]. For all the problems faced, the en-tire evolution of generations, i.e., the run, has been repeated
times, with different initial populations in order toreduce the well-known effects of randomness embedded in theEAs.
The performance of our method, as well as those of FS, DNS,and SCGA, has been measured in terms of the number of nichesdiscovered and maintained during the evolution with respect tothe actual number of peaks in the fitness landscape. Such a per-formance measure follows the assumption that FS aims at dis-covering and maintaining “stable” subpopulations, each popu-lating a niche of the landscape, and that this is ensured onlywhen a proper niche radius is selected, so as to have the perfectdiscrimination among peaks. If this is not true, as we have shownin [24], the dynamics of the system could be very unstable interms of the number and the location of the niches discoveredand maintained.
In order to evaluate the performance, for each evolution wecompute at each generation the number of niches (the pop-ulation size and niche radius being fixed) and store it inthe element of a niche matrix made of rows (one foreach evolution) and columns (one for each generation). Atthe end of each experiment consisting in runs, we computethe average number of niches discovered at each generation byaveraging the values in all the columns
(5)
Then, the values represent the “averagebehavior” of the algorithm for the assigned values of and .Finally, we compute the standard errors
(6)
of .

DELLA CIOPPA et al.: WHERE ARE THE NICHES? DYNAMIC FITNESS SHARING 459
Fig. 1. (a)M1 and (b)M2 functions.
The specific parameter settings for each test function em-ployed are reported in the following subsections.
A. and Functions
The functions and have been originally proposed byGoldberg and Richardson [3] and are the simplest among theones proposed in the literature for studying the behavior of aniching method. The aim in using such functions is particularlydevoted to analyze the ability of the method to maintain thediscovered niches rather than its searching ability. is definedas it follows:
(7)
with . It exhibits five peaks forand , whose height is equal to 1.0. is the same as
, but the values corresponding to the peaks are 1.0, 0.917,0.707, 0.459, and 0.250, respectively. Its analytical form is thefollowing:
(8)
Fig. 1 shows the plots of and .As regards the experiments, in order to compare our experi-
mental findings with those obtained by Mahfoud [20], for bothfunctions we have used the same parameter setting, i.e., thegenotype has been encoded by using 30 bits, the crossover andthe mutation rates have been set to 0.9 and 0.01, respectively,
has been set equal to 0.1, the FS has been accomplishedby phenotypic comparison, the selection mechanism chosen hasbeen the roulette wheel, and the number of generations hasbeen set equal to 200. Finally, according to Mahfoud [20], wehave computed for both functions the lower bound for thepopulation size able to maintain the desired number of nichesat least for generations with a given probability in case ofpeaks of identical fitness
(9)
and in case of peaks of arbitrary fitness
(10)
where is the ratio between the maximum and the minimumpeak fitness values.
To maintain five niches for generations with prob-ability , it follows from (9) that should be 42 for
, while according to (10), it should be 94 for .As regards the function, Fig. 2 reports the plots of the
average number of niches discovered at each generation ascomputed by means of (5), along with the respective standarderror, for FS, DNS, DFS, and SCGA, respectively. It should benoted that, in comparison to the other considered approaches,FS does not provide any explicit species identification. For thisreason, the number of species discovered at each generationhas been computed by using our dynamic species identificationalgorithm.
The same plots are reported in Fig. 3 for the function . Ouralgorithm outperforms both FS and DNS in terms of number ofniches maintained. In addition, DFS shows better performancethan SCGA in that the latter, maintains a greater number ofniches than the actual one, while DFS does not suffer from thisdrawback. The reason is that, depending on the distribution ofthe individuals on the landscape at a given time, the speciesidentification procedure of SCGA could select a greater numberof species masters than the actual number of species, and thenthe elitist strategy can only upgrade the species set. Our algo-rithm, instead, requires at least two individuals for identifying aspecies and its elitist strategy does not take memory of the pastspecies set. In fact, as it can be simply noted from the figures, thestandard error computed for SCGA is constant and greater thanzero during the entire evolution, while it should be constant onlywhen in all the runs the algorithm discovers the same number ofniches, as with the case of our algorithm. Moreover, it should benoted that both the algorithms require a smaller population sizewith respect to the lower bound found by Mahfoud [20] for dis-covering and maintaining the actual number of niches. In fact,both the algorithms succeed in discovering and maintaining all

460 IEEE TRANSACTIONS ON EVOLUTIONARY COMPUTATION, VOL. 11, NO. 4, AUGUST 2007
Fig. 2. M1: average number of niches and its standard error by (a) FS, (b) DNS, (c) SCGA, and (d) DFS. In all the experiments N = 42.
the niches in the landscape with a population size at least of30 and 50 individuals for and , respectively. Finally,by computing the distance between the species masters and theknown maxima, we can verify that the masters are correctly cen-tered on the peaks.
B. Function
The third function used in our experiment was originally in-troduced by DeJong [2] and it is known as Shekel’s Foxholes. Itis a two-dimensional function , whose landscape ex-hibits 25 equidistant peaks emerging from a flat surface. Therange of variations for the independent variables is the same,namely, , and its peaks are located in corre-spondence of the coordinates , where and are in-teger variables ranging in the interval . The peaks heightsrange in the interval and the highest peak islocated at . The analytical form of the function is thefollowing:
(11)
where and . Aplot of the function is shown in Fig. 4. As the figure shows, thisfunction is far more complex than the previous ones, but it is not
deceptive, in that low order schemata still lead to near-optimalsolutions.
The parameter settings for the experimental findings are thesame as those used by Mahfoud in [20]: the genotype has beenencoded by using 17 bits, the crossover and the mutation rateshave been set to 1.0 and 0.0, respectively, has been setequal to 11.0, the FS has been accomplished by phenotypic com-parison, the selection mechanism chosen has been the roulettewheel, and the number of generations has been set equal to200. As for the previous functions, following Mahfoud [20], wehave computed also for the lower bound for the pop-ulation size able to maintain the desired number of species. Tomaintain 25 niches for at least generations with prob-ability , it follows from (10) that is equal to 266individuals.
As regards the experimental findings, Fig. 5 reports the plotsof the average number of niches discovered at each generationas computed by means of (5), along with the respective standarderror for FS, DNS, DFS, and SCGA, respectively.
Also, in this case, it is evident that the performance of DFS isbetter than all the others. With regards to FS and DNS, DFSexhibits similar performance in discovering the niches at thebeginning of the evolution, but it exhibits better performancein maintaining the discovered niches throughout the remainingevolution. In case of SCGA, DFS is better in both discoveringand maintaining the niches, in that the discovery of the actual
DELLA CIOPPA et al.: WHERE ARE THE NICHES? DYNAMIC FITNESS SHARING 461
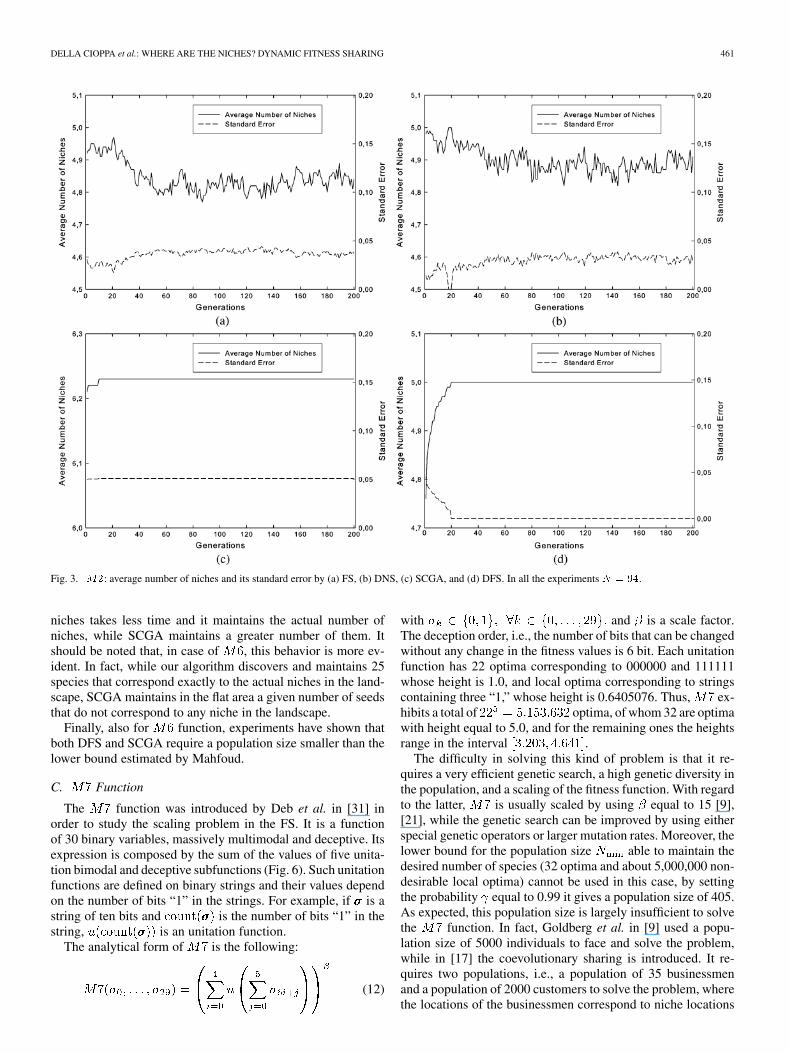
Fig. 3. M2: average number of niches and its standard error by (a) FS, (b) DNS, (c) SCGA, and (d) DFS. In all the experiments N = 94.
niches takes less time and it maintains the actual number ofniches, while SCGA maintains a greater number of them. Itshould be noted that, in case of , this behavior is more ev-ident. In fact, while our algorithm discovers and maintains 25species that correspond exactly to the actual niches in the land-scape, SCGA maintains in the flat area a given number of seedsthat do not correspond to any niche in the landscape.
Finally, also for function, experiments have shown thatboth DFS and SCGA require a population size smaller than thelower bound estimated by Mahfoud.
C. Function
The function was introduced by Deb et al. in [31] inorder to study the scaling problem in the FS. It is a functionof 30 binary variables, massively multimodal and deceptive. Itsexpression is composed by the sum of the values of five unita-tion bimodal and deceptive subfunctions (Fig. 6). Such unitationfunctions are defined on binary strings and their values dependon the number of bits “1” in the strings. For example, if is astring of ten bits and is the number of bits “1” in thestring, is an unitation function.
The analytical form of is the following:
(12)
with and is a scale factor.The deception order, i.e., the number of bits that can be changedwithout any change in the fitness values is 6 bit. Each unitationfunction has 22 optima corresponding to 000000 and 111111whose height is 1.0, and local optima corresponding to stringscontaining three “1,” whose height is 0.6405076. Thus, ex-hibits a total of optima, of whom 32 are optimawith height equal to 5.0, and for the remaining ones the heightsrange in the interval .
The difficulty in solving this kind of problem is that it re-quires a very efficient genetic search, a high genetic diversity inthe population, and a scaling of the fitness function. With regardto the latter, is usually scaled by using equal to 15 [9],[21], while the genetic search can be improved by using eitherspecial genetic operators or larger mutation rates. Moreover, thelower bound for the population size able to maintain thedesired number of species (32 optima and about 5,000,000 non-desirable local optima) cannot be used in this case, by settingthe probability equal to 0.99 it gives a population size of 405.As expected, this population size is largely insufficient to solvethe function. In fact, Goldberg et al. in [9] used a popu-lation size of 5000 individuals to face and solve the problem,while in [17] the coevolutionary sharing is introduced. It re-quires two populations, i.e., a population of 35 businessmenand a population of 2000 customers to solve the problem, wherethe locations of the businessmen correspond to niche locations

462 IEEE TRANSACTIONS ON EVOLUTIONARY COMPUTATION, VOL. 11, NO. 4, AUGUST 2007
Fig. 4. M6 function.
Fig. 5. M6: average number of niches and its standard error by (a) FS, (b) DNS, (c) SCGA, and (d) DFS. In all the experiments N = 266.
and the locations of customers correspond to solutions. Experi-ments not reported here have shown that DNS requires a popu-lation size similar to that used by Goldberg et al. in [9] to solvethe problem.
Keeping these considerations in mind for the problem at hand,in the following we present only the results of DFS and SCGA,in that both FS and DNS require a much larger population size.The parameter settings for both the algorithms are the following:

DELLA CIOPPA et al.: WHERE ARE THE NICHES? DYNAMIC FITNESS SHARING 463
Fig. 6. M7 unitation function.
has been set to 6.0, the FS has been accomplished by geno-typic comparison, has been set to 15, the selection mechanismchosen has been the roulette wheel, the number of generations
has been set to 200, and the crossover rate has been set to1.0. Moreover, to improve the genetic search efficiency, we haveused as mutation the operator [32] with mutation rate of1.0. Such an operator has proved to be more efficient that canon-ical bit-flip mutation in a wide range of applications, and it isbased on simultaneous mutation of small groups of neighboringbits. This choice does not affect the comparison among differentexperiments, because it mainly affects the search ability of thealgorithm, not its ability to maintain the discovered niches. Fi-nally, a population size of 600 individuals has been used.
Fig. 7 reports the plots of the average number of niches dis-covered at each generation as computed by means of (5), alongwith the respective standard error for DFS and SCGA, respec-tively. It should be noted that, while our algorithm is able todiscover and maintain all the 32 desirable species, none of themis discovered by SCGA. Such a poor performance is due to boththe absence of sharing and to the elitist mechanism of SCGAthat drastically reduces the search ability. In fact, about 81% ofthe population is preserved by elitism and only 19% is used forsearching new solutions, while in our algorithm only about 38%of the population is preserved at the end of evolution. Moreover,DFS makes use of the sharing mechanism for populating the dis-covered niches, while SCGA does not. In fact, in the experimentperformed, no explicit upper limit on the number of species mas-ters to be saved has been imposed. As can be simply noted fromFig. 7(b), the total number of species masters saved in the nextgeneration does not reach in any case the upper limit of im-posed by our method. If an explicit limit is imposed, the perfor-mance of DFS gets an improvement in terms of both the conver-gence ability, i.e., the number of generations needed to discoverall the desirable species, and the population size needed to main-tain those species. In fact, Fig. 8 reports the same plot as the pre-vious one for DFS with an upper limit on the number of speciesmasters to be saved equal to 100 and with a population size equalto 400 individuals. Such values have been chosen according topreliminary experimental tuning. As expected, our algorithm isable to discover and maintain all the 32 desired species, thusdrastically reducing the drawback in using the elitist strategy.
Fig. 7. M7: average number of niches and its standard error by (a) SCGA and(b) DFS. In all the experiments N = 600.
Fig. 8. M7: average number of niches and its standard error by DFS with anupper limit on the number of species to be saved equal to 100 and N = 400.
Finally, it should be noted that, the approach of both the al-gorithms can be adopted only when there is a priori knowledgeabout the fitness landscape, i.e., the number of peaks and theirlocations are known, so as to select the desired species from allthe niches maintained. When such information is not available,the number of niches is very large and the landscape is verycomplex as in the case of , something else is needed that

464 IEEE TRANSACTIONS ON EVOLUTIONARY COMPUTATION, VOL. 11, NO. 4, AUGUST 2007
Fig. 9. M7: average number of niches and its standard error by DFS withN =
400 and the threshold on the minimum fitness value set to 4.7.
can help the algorithm to discriminate the “desirable niches”from the “undesirable ones.” Such a discrimination can be ac-complished by introducing in our dynamic species identificationalgorithm a threshold value for the raw fitness. Only the indi-viduals whose raw fitness is greater than the threshold are thenconsidered species masters. This allows us to identify only themost relevant and perfectly discriminable peaks, if any. Obvi-ously, such a method avoids setting an upper limit, other than
, on the number of species masters to be preserved by theelitist strategy.
Fig. 9 reports the results of DFS with no upper limit on thenumber of species masters to be saved and with the thresholdon the minimum fitness value set to 4.7. Such a value has beenchosen according to a preliminary experimental tuning, per-formed as discussed in [24] and [25]. As expected, our algorithmis able to discover and maintain all the 32 niches. It should benoted that only the niche masters of desired niches have beensaved by the elitist strategy, thus drastically reducing the draw-back in using such a technique.
V. CONCLUSION
In this paper, we have proposed a mechanism for FS, i.e.,DFS, which has been devised in order to overcome the limi-tations exhibited by the FS. The proposed method allows:
• an explicit dynamic identification of the species discov-ered at each generation and their localization on the fitnesslandscape;
• the application of the sharing mechanism to each speciesseparately;
• a straightforward implementation of a species elitiststrategy, by copying in the new population the most rep-resentative individuals of the species, i.e., the speciesmasters, discovered at each generation.
Dynamic species identification is accomplished without as-suming any a priori knowledge on the number of niches to bepopulated. The only assumption of our method, as well as ofthe FS and of all the methods employing a single niche radiusto describe all the niches within the search domain, is the perfectdiscrimination hypothesis, according to which the peaks of thefitness landscape are fully distinguishable by means of a propersetting of the niche radius.
Our method is based upon the idea that an explicit identifica-tion of the species at each generation can help both to ensure thateach niche will be populated proportionally to the fitness of itspeak and to preserve species with few individuals from extinc-tion by allowing a species elitist mechanism. As a consequence,the overall performance of any EA adopting such a strategyshould improve in terms of both maintenance and discovery.
The experimental results obtained on a standard set of mul-timodal functions have shown that our method outperforms allother methods proposed in the literature and considered here.They have also shown that DFS is effective, because it providesall the actual species masters when effective values for the nicheradius and for the population size are selected. It shouldalso be noted that the elitist strategy implemented by our methodallows to steadily maintain the actual number of peaks also incase of a population size smaller than the lower bound computedby Mahfoud.
In our opinion, possible improvements for DFS could be thefollowing.
• The definition of a mechanism that allows the use of avariable niche radius. In fact, real-world problems rarelyhave distinct peaks and a single value of the niche radiusshould not be adequate enough to achieve optimal niching.
• A mechanism that allows a dynamic population size sim-ilar to that introduced by opt-aiNet in order to improve thediscover and maintenance ability of our method.
• The estimate of the minimum population size needed byour method for steadily maintaining the actual number ofpeaks in the landscape.
ACKNOWLEDGMENT
The authors gratefully acknowledge the anonymous re-viewers for their insight comments and useful suggestions.
REFERENCES
[1] D. Cavicchio, “Adaptive search using simulated evolution,” Ph.D. dis-sertation, Univ. Michigan, Ann Arbor, MI, 1970.
[2] K. A. De Jong, “An analysis of the behavior of a class of geneticadaptive systems,” Ph.D. dissertation, Univ. Michigan, Ann Arbor, MI,1975, Abstracts International 36(10), 5140B; Univ. Michigan 76–9381.
[3] D. E. Goldberg and J. Richardson, “Genetic algorithms with sharingfor multimodal function optimization,” in Genetic Algorithms andTheir Applications, J. J. Grefenstette, Ed. Hillsdale, NJ: LawrenceErlbaum, 1987, pp. 41–49.
[4] R. E. Smith, S. Forrest, and A. S. Perelson, “Searching for diverse,cooperative populations with genetic algorithms,” Evol. Comput., vol.1, no. 2, pp. 127–149, 1992.
[5] S. W. Mahfoud, “Crowding and preselection revisited,” in LectureNotes in Computer Science, B. M. R. Manner, Ed. : Elsevier Science,1992, Parallel Problem Solving from Nature 2, pp. 27–36, No. IlliGALRep. 92004.
[6] D. Beasley, D. R. Bull, and R. R. Martin, “A sequential niche techniquefor multimodal function optimization,” Evol. Comput., vol. 1, no. 2, pp.101–125, 1993.
[7] J. Horn, D. E. Goldberg, and K. Deb, “Implicit niching in a learningclassifier system: Nature’s way,” Evol. Comput., vol. 2, no. 1, pp.37–66, 1994.
[8] H. Asoh and H. Mühlenbein, “On the mean convergence time ofevolutionary algorithms without selection and mutation,” in ParallelProblem Solving From Nature: PPSN III, Y. Davidor, H.-P. Schwefel,and R. Männer, Eds. Berlin, Germany: Springer-Verlag, 1994, pp.88–97.
[9] C. K. Oei, D. E. Goldberg, and S.-J. Chang, Tournament selec-tion, niching, and the preservation of diversity Univ. Illinois atUrbana–Champaign, Urbana, IL, IlliGAL Rep. 91011, 1991.
[10] S. Forrest, R. E. Smith, B. Javornik, and A. S. Perelson, “Using geneticalgorithms to explore pattern recognition in the immune system,” Evol.Comput., vol. 1, no. 3, pp. 191–211, 1993.

DELLA CIOPPA et al.: WHERE ARE THE NICHES? DYNAMIC FITNESS SHARING 465
[11] P. Darwen and X. Yao, “Every niche method has its niche: Fitnesssharing and implicit sharing compared,” in Lecture Notes in ComputerScience, H.-M. Voigt, W. Ebeling, I. Rechenberg, and H.-P. Schwefel,Eds. Berlin, Germany: Springer-Verlag, 1996, vol. 1141, ParallelProblem Solving From Nature-PPSN IV, pp. 398–407.
[12] E. Mayr, Systematics and the Origin of Species From the Viewpoint ofa Zoologist. New York: Columbia Univ. Press, 1942.
[13] J. Horn, “Finite Markov chain analysis of genetic algorithms withniching,” in Proc. 5th Int. Conf. Genetic Algorithms, S. Forrest, Ed.,1993, pp. 110–117.
[14] ——, GAs (With Sharing) in Search, Optimization and MachineLearning. San Mateo, CA: Morgan Kaufmann, 1997.
[15] K. Deb and D. E. Goldberg, “An investigation of niche and species-for-mation in genetic function optimization,” in Proc. 3rd Int. Conf. Ge-netic Algorithms, J. D. Schaffer, Ed., 1989, pp. 42–50.
[16] J. Horn and D. E. Goldberg, “Natural niching for evolving cooperativeclassifiers,” in Proc. 1st Annu. Conf. Genetic Program., D. B. F. J. R.Koza, D. E. Goldberg, and R. L. Riolo, Eds., 1996, pp. 553–564.
[17] D. E. Goldberg and L. Wang, “Adaptive niching via coevolutionarysharing,” in Genetic Algorithms and Evolution Strategies in Engi-neering and Computer Science. New York: Wiley, 1997, pp. 21–38.
[18] L. B. Booker, D. E. Goldberg, and J. H. Holland, “Classifier systemsand genetic algorithms,” Artif. Intell., vol. 40, pp. 235–282, 1989.
[19] S. Mahfoud, “Genetic drift in sharing methods,” in Proc. 1st IEEEConf. Evol. Comput., 1994, pp. 67–72.
[20] S. W. Mahfoud, “Population size and genetic drift in fitness sharing,” inProc. Foundations Genetic Algorithms, L. D. Whitley and M. D. Vose,Eds., 1995, pp. 185–223.
[21] B. Sareni and L. Krähenbühl, “Fitness sharing and niching methodsrevisited,” IEEE Trans. Evol. Comput., vol. 2, no. 3, pp. 97–106, Sep.1998.
[22] B. L. Miller and M. J. Shaw, “Genetic algorithms with dynamic nichesharing for multimodal function optimization,” in Proc. 1996 IEEE Int.Conf. Evol. Comput., 1996, pp. 786–791.
[23] W. M. Spears, “Simple subpopulation schemes,” in Proc. 4th Annu.Conf. Evol. Program., A. V. Sebald and L. J. Fogel, Eds., 1994, pp.296–307.
[24] A. Della Cioppa, C. De Stefano, and A. Marcelli, “On the role of pop-ulation size and niche radius in fitness sharing,” IEEE Trans. Evol.Comput., vol. 8, no. 6, pp. 580–592, Dec. 2004.
[25] A. Della Cioppa, “Competizione e Cooperazione Negli Algoritmi Evo-lutivi: Il Problema Della Speciazione e i Metodi di Niching,” (in Italian)Ph.D. dissertation, Univ. Naples “Federico II”, Naples, Italy, 1999.
[26] K. O. Stanley and R. Mikkulainen, “Evolving neural networks throughaugmenting topologies,” Evol. Comput., vol. 10, no. 2, pp. 99–127,2002.
[27] ——, “Competitive coevolution through evolutionary complexifica-tion,” J. Artif. Intell. Res., vol. 21, pp. 63–100, 2004.
[28] M. E. Balazs, L. Jianping, G. T. Parks, and P. J. Clarkson, “The effectof distance measure in a GA with species conservation,” IEEE Trans.Evol. Comput., vol. 10, no. 3, pp. 207–234, 2002.
[29] L. N. de Castro and J. Timmins, “An artificial immune network for mul-timodal function optimization,” in Proc. IEEE Congr. Evol. Comput.,IEEE World Congr. Comput. Intell., 2002, vol. 1, pp. 699–704.
[30] D. E. Goldberg, Genetic Algorithms in Search, Optimization, and Ma-chine Learning. Reading, MA: Addison-Wesley, 1989.
[31] D. E. Goldberg, K. Deb, and J. Horn, “Massive multimodality, de-ception, and genetic algorithms,” in Lecture Notes in Computer Sci-ence,. Berlin, Germany: Springer-Verlag, 1992, Proc. 2nd Workshop,Parallel Problem Solving from Nature—PPSN 2, pp. 37–46.
[32] I. De Falco, A. Della Cioppa, A. Iazzetta, and E. Tarantino, “The effec-tiveness of co-mutation in evolutionary algorithms: TheM oper-ator,” in Proc. IEEE Int. Conf. Evol. Comput.—World Congr. Comput.Intell., Anchorage, AK, 1998, pp. 816–821.
Antonio Della Cioppa (M’05) was born in Bellona,Italy, on June 13, 1964. He received the Laurea de-gree in physics and the Ph.D. degree in computer sci-ence, both from University of Naples “Federico II,”Naples, Italy, in 1993 and 1999, respectively.
From 1999 to 2003, he was a Postdoctoral Fellowat the Department of Computer Science and Elec-trical Engineering, University of Salerno, Salerno,Italy. In 2004, he joined the Department of Electricaland Information Engineering, University of Salerno,where he is currently an Assistant Professor of
Computer Science and Artificial Intelligence. He has been active in the fieldsof Artificial Intelligence and Cybernetics. His current research interests arein the fields of theoretical and computational physics (complexity, statisticalmechanics of equilibrium and nonequilibrium phenomena, theory of dynamicalsystems, chaos), prebiotic evolution, Darwinian dynamics and speciation,evolutionary computation, and artificial life.
Dr. Della Cioppa is a member of the Association for Computing Machinery(ACM), the IEEE Computer Society, the IEEE Computational IntelligenceSociety, the European Network of Excellence in Evolutionary Computing(EvoNet), the Machine Learning Network (MLNet), the Knowledge DiscoveryNetwork of Excellence (KDNet), and the AIIA (ECCAI-Italian Chapter). Heserves as Program Committee member of many international conferences suchas the Genetic and Evolutionary Computation Conference and Conference onEvolutionary Computation.
Claudio De Stefano was born in Naples, Italy, onOctober 4, 1961. He received the Laurea degree(Hon.) in electronic engineering and the Ph.D.degree in electronic and computer engineering fromthe University of Naples “Federico II,” Naples, Italy,in 1990 in 1994, respectively
From 1994 to 1996, he was an Assistant Professorof Computer Science at the Department of ComputerScience and Systems, University of Naples “FedericoII.” In 1996, he joined the Faculty of Computer Engi-neering, University of Sannio, Benevento, where he
has been an Assistant Professor of Computer Science. In 2001, he joined the Fac-ulty of Engineering, University of Cassino, where he is currently an AssociateProfessor of Computer Science and Artificial Intelligence. He has authored over70 research papers in international journals and conference proceedings. He hasbeen active in the fields of pattern recognition, image analysis, machine learning,and parallel computing. His current research interests include online and offlinehandwriting recognition, cursive script segmentation, neural networks, and evo-lutionary learning systems.
Dr. De Stefano is a member of the International Association for PatternRecognition (IAPR).
Angelo Marcelli (M’87) received the M.Sc. degreein electronic engineering (cum laude) and the Ph.D.degree in electronic and computer engineering fromthe University of Napoli “Federico II,” Naples, Italy,in 1983 and 1987, respectively.
From 1987 to 1989, he was Chief Researcher ofthe Computer Vision and Artificial Intelligence Lab-oratory, CRIAI, Napoli, Italy, where he also foundedand directed the Italy–Russian Laboratory for ImageAnalysis and Processing. From 1989 to 1992, he hasheld a Researcher position at the Department of Com-
puter and System Engineering, School of Engineering, University of Napoli“Federico II.” From 1992 to 1997, he was appointed a Senior Researcher andAssistant Professor of Computer Engineering at the same department. Since1998, he has been with the Department of Electrical and Information Engi-neering, University of Salerno, where he is currently a Professor of ComputerEngineering. He has been Visiting Scholar of many institutions, such as theInstitute of Engineering Cybernetics, Minsk (BELARUS), the Image AnalysisLaboratory, State University of New York, Stony Brook, Document AnalysisLaboratory, Rensselaer Polytechnic Institute, Troy, NY. His current researchinterest include handwriting recognition, theory and application of evolutionaryalgorithms, active vision model, and natural computation.
Dr. Marcelli is a member of the International Association for Pattern Recog-nition (IAPR) and is the President-Elect of the International GraphonomicsSociety. He serves as Area Editor for the International Journal of DocumentAnalysis and Recognition, as Reviewer for many international journals, such asthe IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE,the IEEE TRANSACTIONS ON CIRCUIT AND SYSTEMS FOR VIDEO TECHNOLOGY,the IEEE TRANSACTIONS ON IMAGE PROCESSING, Pattern Recognition, andPattern Recognition Letters.
Copyright © 2022 FDOKUMEN




















