
Turbo codes for Tb/s communications
49
Turbo codes for T b/s communications: code design and hardware architecture Ronald Garzon - Bohorquez , Charbel Abdel Nour, Stefan W eithoffer Catherine Douillard , Norbert Wehn
-
Upload
khangminh22 -
Category
Documents
-
view
0 -
download
0
Transcript of Turbo codes for Tb/s communications

Turbo codes for Tb/s communications:
code design and hardware architecture
Ronald Garzon-Bohorquez, Charbel Abdel Nour, Stefan Weithoffer
Catherine Douillard, Norbert Wehn

1. Introduction
2. Interleaving and puncturing
3. New high throughput architecture
4. Conclusions and future works
OUTLINE

Introduction
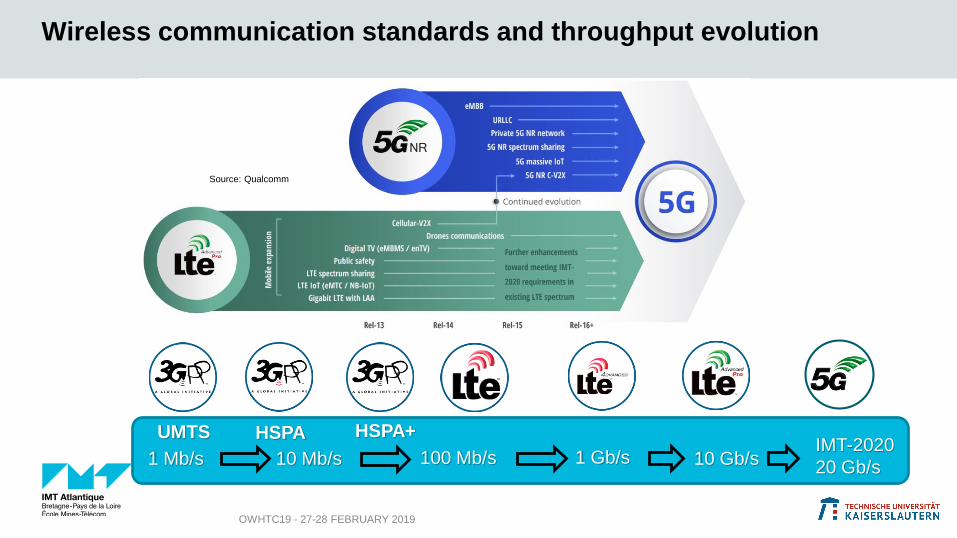
Wireless communication standards and throughput evolution
OWHTC19 - 27-28 FEBRUARY 2019
Source: Qualcomm
UMTS HSPA
1 Mb/s 10 Mb/s 100 Mb/s 1 Gb/s 10 Gb/s
HSPA+IMT-2020
20 Gb/s

Why is LTE FEC code not suitable for B5G communication
systems?
■ Low error rates
LTE turbo code (TC) cannot guarantee frame error rates (FER) lower than
10-5 for high code rates
K = 4032 bits
Scaled Max-Log MAP decoding
8 iterations
AWGN channel
QPSK modulation
1,E-06
1,E-05
1,E-04
1,E-03
1,E-02
1,E-01
1,E+00
0 0,5 1 1,5 2 2,5 3 3,5 4 4,5 5 5,5 6 6,5
FE
R
Eb/N0 (dB)
R=1/3
R=1/2
R=4/7
R=8/13
R=2/3
R=8/11
R=4/5
R=8/9
OWHTC19 - 27-28 FEBRUARY 2019

Why is LTE FEC code not suitable for B5G communication
systems?
■ Low error rates
LTE turbo code (TC) cannot guarantee frame error rates (FER) lower than
10-5 for high code rates
For some rates and sizes, bad interaction between the QPP interleaver
and the rate matching device [1]
Trellis termination: tail bits insertion last bits are less protected
[1] J.-F. Cheng, A. Nimbalker, Y. Blankenship, B. Classon, and T. Blankenship, “Analysis of circular buffer rate
matching for LTE turbo code,” in Proc. IEEE 68th Vehicular Technology Conference (VTC 2008-Fall), Sept.
2008, pp. 1–5.
FEC
EncoderMapper
Rate
Matching
Rate adaptability in LTE
OWHTC19 - 27-28 FEBRUARY 2019

Why is LTE FEC code not suitable for B5G communication
systems?
■ High throughput
QPP interleaver is contention free
Maximum parallelism degree 64
Parallel processing on multiple sub-decoder cores
Throughput: a few Gb/s with nowadays ASIC technologies, a few tens of Gb/s with
next technology nodes (7 nm)
Achieving beyond 100 Gb/s requires
Pipelining the Max-Log-MAP recursions
Unrolling the iterations hardwired interleavers/de-interleavers
Shortcoming of LTE QPP interleaver for very high throughputs:
No common parameters for different block sizes
Issues with place and route of the interleaving network for all sizes
OWHTC19 - 27-28 FEBRUARY 2019

What can make the LTE turbo code suitable for B5G
communication systems?
■ How to lower the error floor?
Adopt tail-biting (circular) termination [2]
Avoid residual errors due to tail bits: same protection in the whole sequence
Avoids rate loss for short blocks
No singularity in the decoding process
[2] C. Weiss, C. Bettstetter, and S. Riedel, “Code construction and decoding of parallel
concatenated tail-biting codes,” IEEE Trans. Inf. Theory, vol. 47, no. 1, pp. 366–386, Jan 2001.

What can make the LTE turbo code suitable for B5G
communication systems?
■ How to lower the error floor?
Adopt tail-biting (circular) termination [2]
Avoid residual errors due to tail bits: same protection in the whole sequence
Avoids rate loss for short blocks
No singularity in the decoding process
Add a precoder or/and a post-encoder
• No change in the TC required
• Introduced in [3]
• Possible convergence improvements
• Extrinsics on parities must be generated
• Example: 3D-TC [4]
PrecoderTurbo Code
(TC)Post-encoder
[4] C. Berrou, A. Graell i Amat, Y. Ould Cheikh Mouhamedou, C. Douillard, and Y. Saouter, “Adding
a rate-1 third dimension to turbo codes,” ITW’07, Sept 2007, pp. 156–161.
[3] S. Tong, H. Zheng, and B. Bai, “Precoded turbo code within 0.1 dB of Shannon limit,” Electron.
Lett., vol. 47, no. 8, pp. 521–522, April 2011.

What can make the LTE turbo code suitable for B5G
communication systems?
■ How to lower the error floor?
Adopt tail-biting (circular) termination [2]
Avoid residual errors due to tail bits: same protection in the whole sequence
Avoids rate loss for short blocks
No singularity in the decoding process
Add a precoder or/and a post-encoder
More complex encoders and decoders
Not suitable for throughput increase
Design enhanced interleavers
Puncture systematic bits for high code rates [5]
Joint design of interleaver parameters and puncturing patterns
[5] S. Crozier, P. Guinand, and A. Hunt, “On designing turbo-codes with data puncturing,”
in Proc. 9th Canadian Workshop of Information Theory (CWIT2005), Montréal, Québec,
Canada, June 2005.

Interleaver design criteria
1 0 0 0 1
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
0 0 0 0 0
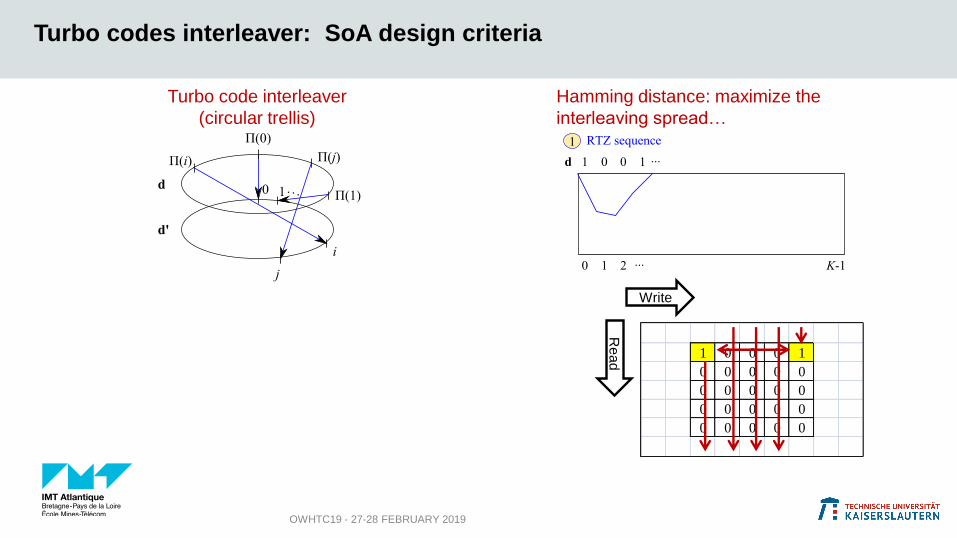
Turbo codes interleaver: SoA design criteria
OWHTC19 - 27-28 FEBRUARY 2019
Turbo code interleaver
(circular trellis)
Hamming distance: maximize the
interleaving spread…
Write
Re
ad

1 0 0 0 1
0 0
0 0
0 0
1 0 0 0 1
1 0 0 0 0 0
0 1 0
0 0
0 0 1
0 1 0 0 0
Hamming distance: maximize the
interleaving spread…
OWHTC19 - 27-28 FEBRUARY 2019
Write
Re
ad
+ add some disorder
Turbo code interleaver
(circular trellis)
Turbo codes interleaver: SoA design criteria
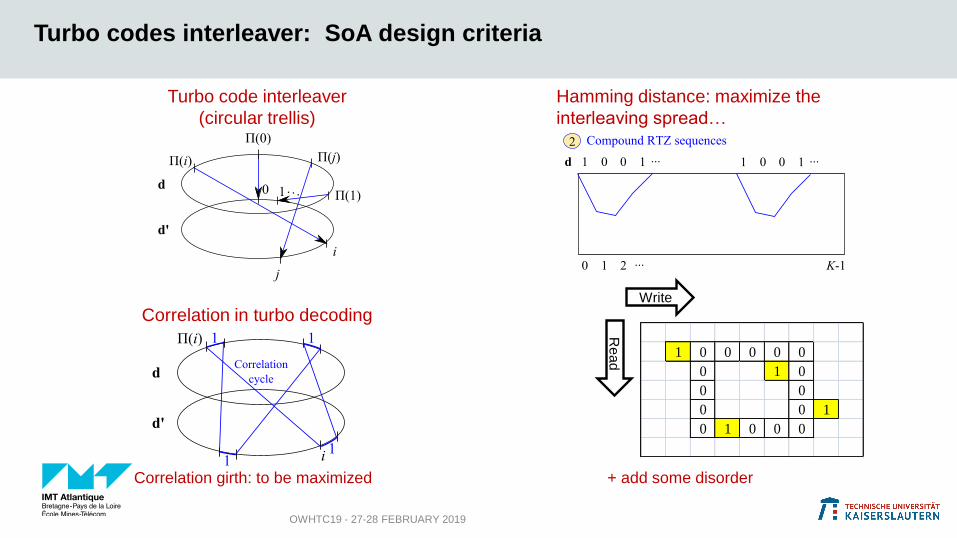
Turbo codes interleaver: SoA design criteria
OWHTC19 - 27-28 FEBRUARY 2019
Turbo code interleaver
(circular trellis)
Correlation in turbo decoding
Correlation girth: to be maximized
1 0 0 0 1
0 0
0 0
0 0
1 0 0 0 1
1 0 0 0 0 0
0 1 0
0 0
0 0 1
0 1 0 0 0
Hamming distance: maximize the
interleaving spread…
Write
Re
ad
+ add some disorder

1. Minimize the multiplicity of the shortest correlation cycles: n(g)
2. Maximize the minimum number of transitions between the two
encoders in the shortest correlation cycles:
=> Maximize the number of distant trellis sections in short cycles
Proposed additional criteria to reduce decoding correlation (1/2)
OWHTC19 - 27-28 FEBRUARY 2019
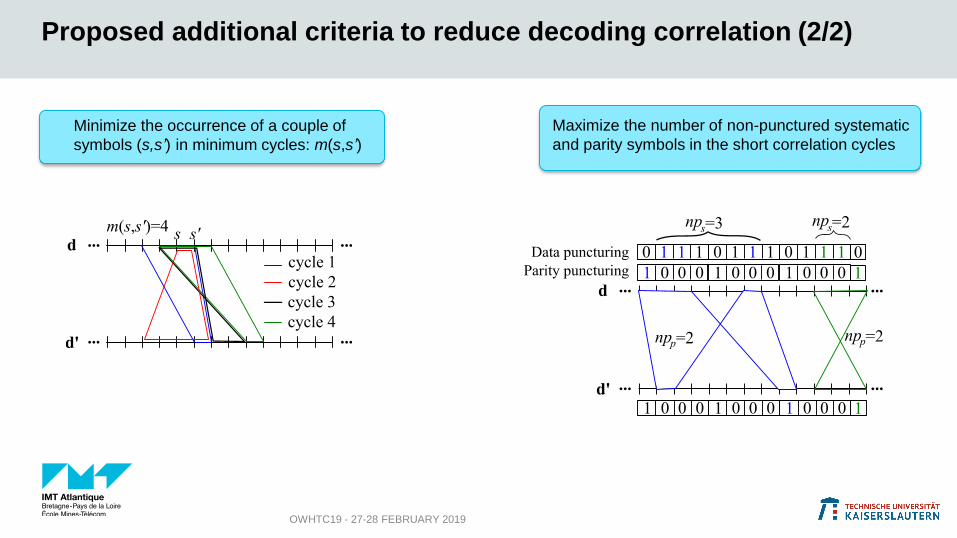
Proposed additional criteria to reduce decoding correlation (2/2)
OWHTC19 - 27-28 FEBRUARY 2019
Minimize the occurrence of a couple of
symbols (s,s’) in minimum cycles: m(s,s’)
Maximize the number of non-punctured systematic
and parity symbols in the short correlation cycles

ΠARP 𝑖 = 𝑃 ∙ 𝑖 + 𝑆(𝑖 mod 𝑄) mod 𝐾
ΠQPP 𝑖 = 𝑓1𝑖 + 𝑓2𝑖2 mod 𝐾
Algebraic interleavers for turbo codes
OWHTC19 - 27-28 FEBRUARY 2019
Almost Regular Permutation (ARP) [8]
Quadratic Permutation Polynomial (QPP) [7]
Dithered Relative Prime (DRP) [6]
[9] R. Garzón Bohórquez, C. Abdel Nour, and C. Douillard. “On the Equivalence of
Interleavers for Turbo Codes,” IEEE Wireless Communication letters, vol. 4, no.1,
Feb. 2015.
ΠDRP 𝑖 = Πa Πb(Πc(𝑖) )
High similarity: • DRP and QPP interleavers can be expressed as ARP interleavers [9]
• Study of ARP interleavers
[6] S. Crozier and P. Guinand, “High-performance low-memory interleaver banks for turbo-
codes,” in Proc. IEEE 54th Vehicular Technology Conference (VTC 2001-Fall), vol. 4,
Atlantic City, NJ, USA, Oct. 2001, pp. 2394–2398.
[7] J. Sun and O. Takeshita, “Interleavers for turbo codes using permutation polynomials
over integer rings,” IEEE Trans. Inf. Theory, vol. 51, no. 1, pp. 101–119, Jan. 2005.
[8] C. Berrou, Y. Saouter, C. Douillard, S. Kerouedan, and M. Jezequel, “Designing good
permutations for turbo codes: towards a single model,” in Proc. IEEE International
Conference on Communications (ICC’04), Paris, France, June 2004, pp. 341–345.
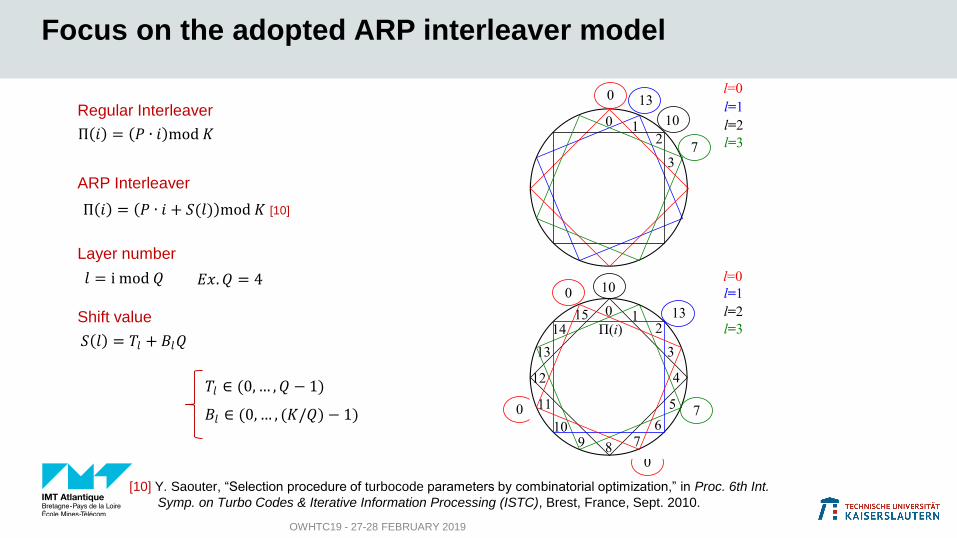
Π 𝑖 = 𝑃 ∙ 𝑖 + 𝑆(𝑙) mod 𝐾
𝐸𝑥. 𝑄 = 4
Focus on the adopted ARP interleaver model
OWHTC19 - 27-28 FEBRUARY 2019
Π 𝑖 = 𝑃 ∙ 𝑖 mod 𝐾
Regular Interleaver
ARP Interleaver
Layer number
Shift value
𝑆 𝑙 = 𝑇𝑙 + 𝐵𝑙𝑄
𝑇𝑙 ∈ (0, … , 𝑄 − 1)
𝐵𝑙 ∈ (0, … , (𝐾/𝑄) − 1)
[10] Y. Saouter, “Selection procedure of turbocode parameters by combinatorial optimization,” in Proc. 6th Int.
Symp. on Turbo Codes & Iterative Information Processing (ISTC), Brest, France, Sept. 2010.
[10]
𝑙 = i mod 𝑄

Joint design of interleaver
parameters and puncturing
patterns

ARP interleavers
respecting
- spread,
- girth,
- puncturing
constraints
Overview of the proposed design method
OWHTC19 - 27-28 FEBRUARY 2019
Selection of
puncturing
pattern
Generation of
candidate
interleavers
Selection of the
best candidate
interleaver
- Systematic
puncturing ratio
- Component code
distance spectrum
- Using uniform
interleaving
According to
the Hamming
distance
spectrum

SELECTION OF THE PUNCTURING PATTERN
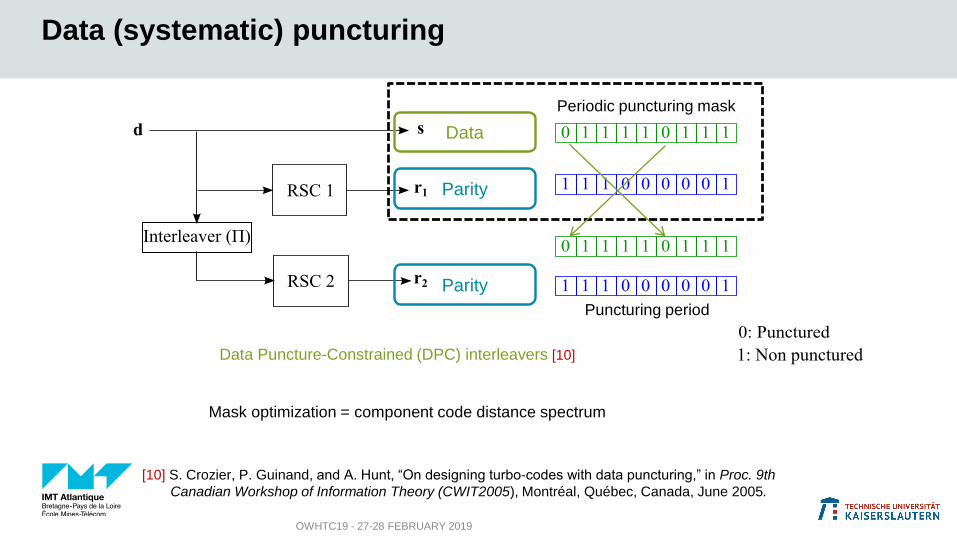
OWHTC19 - 27-28 FEBRUARY 2019
Data (systematic) puncturing
Parity
Parity
Data
Periodic puncturing mask
Data Puncture-Constrained (DPC) interleavers [10]
[10] S. Crozier, P. Guinand, and A. Hunt, “On designing turbo-codes with data puncturing,” in Proc. 9th
Canadian Workshop of Information Theory (CWIT2005), Montréal, Québec, Canada, June 2005.
Puncturing period
Mask optimization = component code distance spectrum

Puncturing mask selection
OWHTC19 - 27-28 FEBRUARY 2019
Description of the selection method Application example: R = 2/3, K=1504
Selection of the best
puncturing mask for the
RSC code for different
data puncturing ratios
Data Puncturing Ratio
(DPR)
Coding rate of
constituent code (Rc)
A0 A1 A2 A3 A4 Puncturing mask:
Data/Parity
0 0.8 0 0 0 9 48 11111111/10001000
2/8 0.88 0 0 3 62 566 01111110/11000001
4/8 1 0 4 38 358 3310 11001100/10011001
Distance spectrum multiplicities
Best pattern for each data puncturing ratio selected according to the distance
spectrum

Selection of the best
puncturing mask for the
RSC code for different
data puncturing ratios
0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.80.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
DPR:0, Uniform
DPR:2/8, DPC uniform
DPR:4/8, DPC uniform
DPR:2/16, DPC uniform
DPR:6/16, DPC uniform
IE1
, IA
2
IA1, IE2
0.70 0.75 0.80 0.850.70
0.75
0.80
0.85
Puncturing mask selection
OWHTC19 - 27-28 FEBRUARY 2019
Description of the selection method
Analysis via modified
EXIT chart
Modified EXIT chart (measured MI) for the
best DPR values
Application example: R = 2/3, K=1504

Selection of the best
puncturing mask for the
RSC code for different
data puncturing ratios
1.00 1.25 1.50 1.75 2.00 2.25 2.50 2.75 3.00 3.2510
-7
10-6
10-5
10-4
10-3
10-2
10-1
100
DPR 0, Uniform
DPR 2/8, DPC uniform
DPR 2/16, DPC uniform
BE
R/F
ER
Eb/N
0 (dB)
Puncturing mask selection
OWHTC19 - 27-28 FEBRUARY 2019
Description of the selection method
Analysis via modified
EXIT chart
Final selection by
simulating the TC error
rate Error rate performance with uniform
interleaving in AWGN channel
Application example: R = 2/3, K=1504

SELECTION OF THE INTERLEAVER PARAMETERS
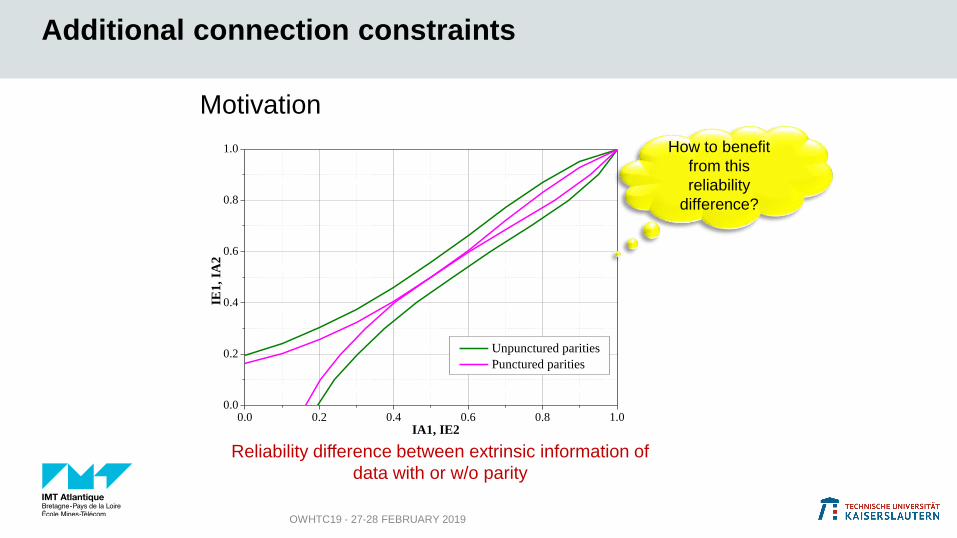
Additional connection constraints
OWHTC19 - 27-28 FEBRUARY 2019
Reliability difference between extrinsic information of
data with or w/o parity
0.0 0.2 0.4 0.6 0.8 1.00.0
0.2
0.4
0.6
0.8
1.0
Unpunctured parities
Punctured parities
IE1
, IA
2
IA1, IE2
Motivation
How to benefit
from this
reliability
difference?
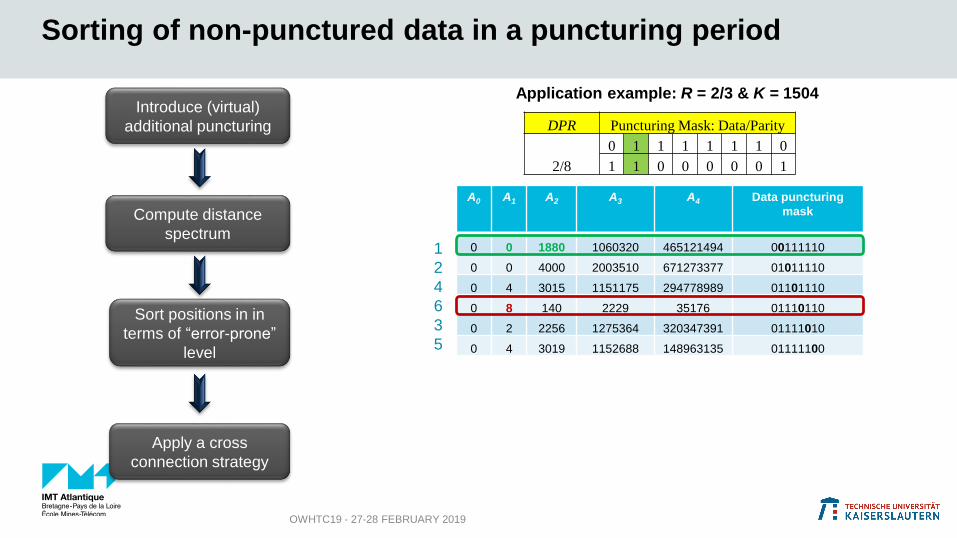
A0 A1 A2 A3 A4 Data puncturing
mask
0 0 1880 1060320 465121494 00111110
0 0 4000 2003510 671273377 01011110
0 4 3015 1151175 294778989 01101110
0 8 140 2229 35176 01110110
0 2 2256 1275364 320347391 01111010
0 4 3019 1152688 148963135 01111100
Sorting of non-punctured data in a puncturing period
OWHTC19 - 27-28 FEBRUARY 2019
Application example: R = 2/3 & K = 1504
DPR Puncturing Mask: Data/Parity
2/8
0 1 1 1 1 1 1 0
1 1 0 0 0 0 0 1
Introduce (virtual)
additional puncturing
Sort positions in in
terms of “error-prone”
level
Apply a cross
connection strategy
Compute distance
spectrum1
2
4
6
3
5
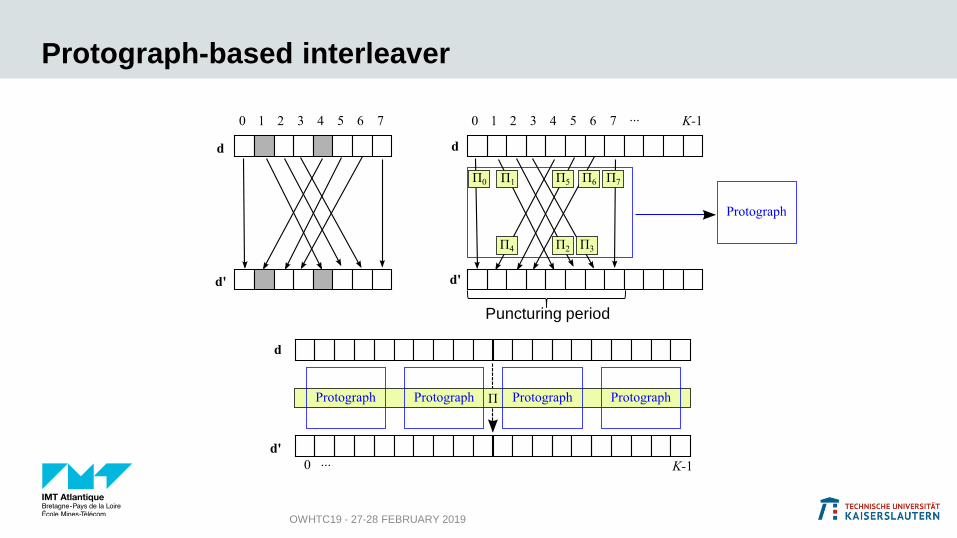
Protograph-based interleaver
OWHTC19 - 27-28 FEBRUARY 2019
Puncturing period

Simulation results (1/2)
OWHTC19 - 27-28 FEBRUARY 2019
1.E-06
1.E-05
1.E-04
1.E-03
1.E-02
1.E-01
1.E+00
-0.5 0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5 5.5
BL
ER
Eb/N0 (dB)
R=1/5
R=1/3
R=2/5
R=1/2
R=2/3
R=3/4
R=5/6
R=8/9
K=8000 bits
8-state turbo code
Scaled Max-Log MAP decoding
8 iterations
AWGN channel
QPSK modulation
Joint protograph interleaving and
puncturing for each code rate
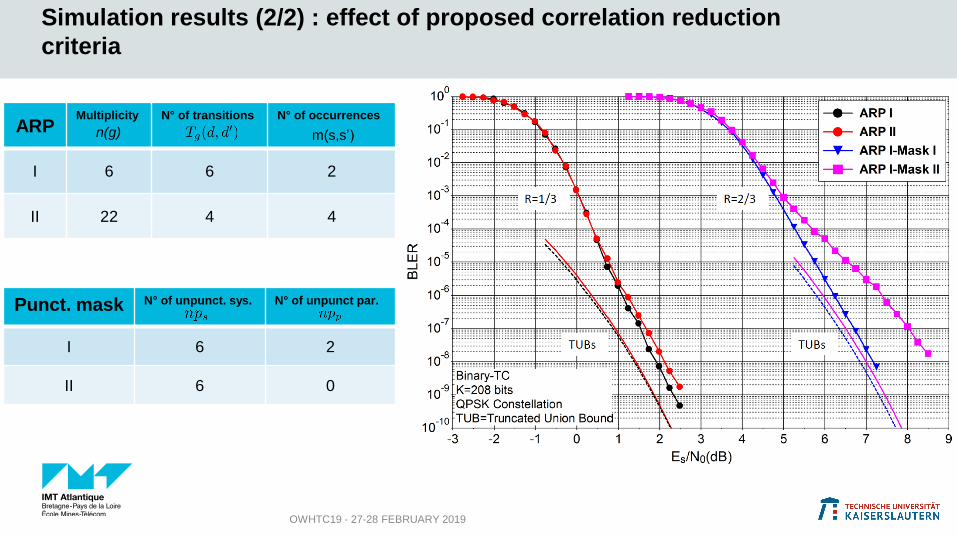
Simulation results (2/2) : effect of proposed correlation reduction
criteria
OWHTC19 - 27-28 FEBRUARY 2019
ARPMultiplicity N° of transitions N° of occurrences
I 6 6 2
II 22 4 4
n(g) m(s,s’)
Punct. mask N° of unpunct. sys. N° of unpunct par.
I 6 2
II 6 0

Support of incremental redundancy

Overview of the design method for rate compatible
TCs
OWHTC19 - 27-28 FEBRUARY 2019
Puncturing pattern
and protograph
design for the
highest code rate
Selection of the best
candidate for PB
interleaver
Definition of
lower coding
rates
incrementally
Based on the
error-prone level
of non-punctured
data positions
According to the
Hamming
distance
spectrum
Best Hamming
distance spectrum
for higher & mother
coding rates.

Protograph construction
OWHTC19 - 27-28 FEBRUARY 2019
Higher coding rate (R=8/9)
Application example: K=4000 bits
Data Puncturing
Rate (DPR)
Coding rate of
constituent code (Rc)
A0 A1 A2 A3 A4 Puncturing mask: Data
Parity
2/16 1 0 16 536 16536 511408 0111111101111111
1010000000000000
Distance spectrum multiplicities
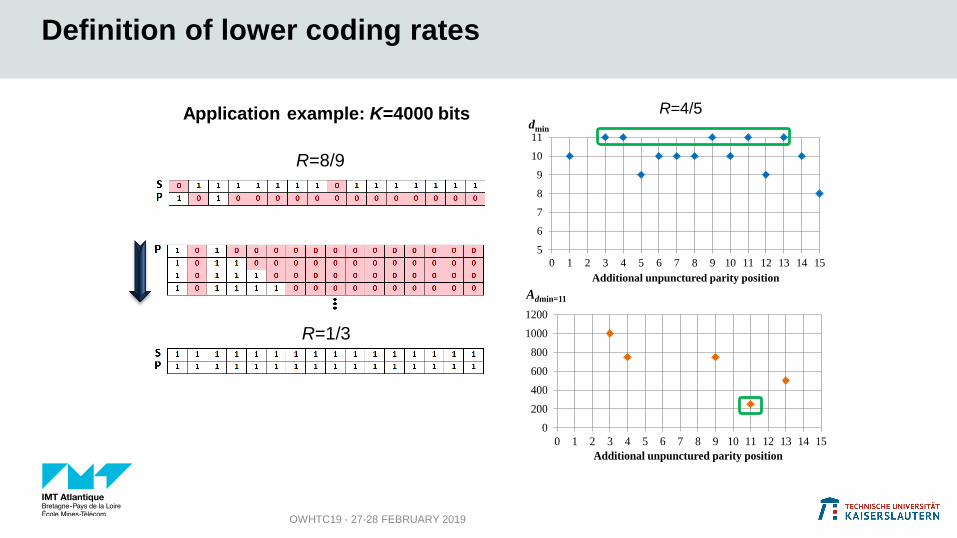
0
200
400
600
800
1000
1200
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
Admin=11
Additional unpunctured parity position
5
6
7
8
9
10
11
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
dmin
Additional unpunctured parity position
Definition of lower coding rates
OWHTC19 - 27-28 FEBRUARY 2019
R=8/9
R=1/3
Application example: K=4000 bits R=4/5
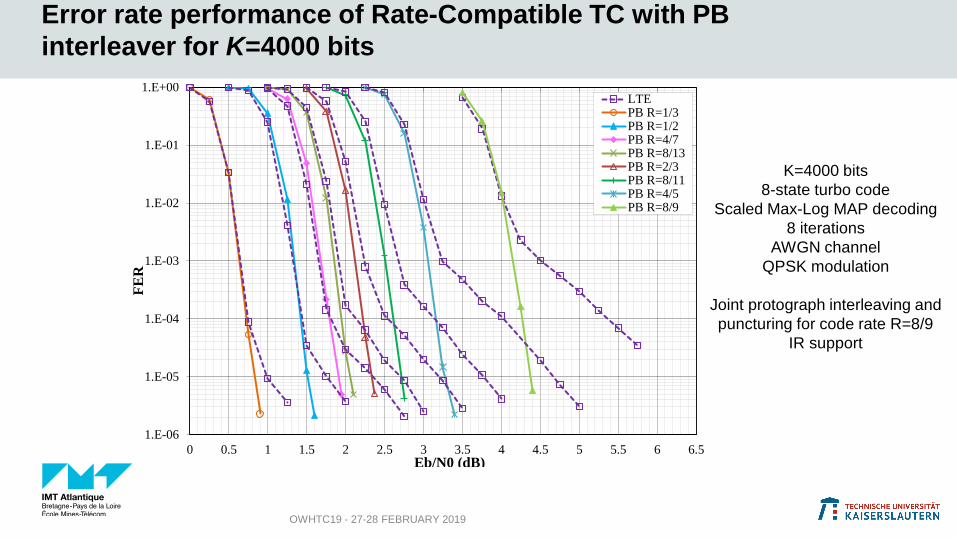
Error rate performance of Rate-Compatible TC with PB
interleaver for K=4000 bits
OWHTC19 - 27-28 FEBRUARY 2019
1.E-06
1.E-05
1.E-04
1.E-03
1.E-02
1.E-01
1.E+00
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5 5.5 6 6.5
FE
R
Eb/N0 (dB)
LTEPB R=1/3PB R=1/2PB R=4/7PB R=8/13PB R=2/3PB R=8/11PB R=4/5PB R=8/9
K=4000 bits
8-state turbo code
Scaled Max-Log MAP decoding
8 iterations
AWGN channel
QPSK modulation
Joint protograph interleaving and
puncturing for code rate R=8/9
IR support

New high throughput architecture

Advantages of the proposed interleaver for high throughput:
Flexible ARP interleavers
ARP Interleaving :
𝜋 𝑖 = 𝑃 ∗ 𝑖 + 𝑆 𝑖 𝑚𝑜𝑑 𝑄 𝑚𝑜𝑑 𝐾
• Let: P = 9, S = [3,13,27,5] and Q = 4
• Information frame size K = 32, 64, 128 bits
• Larger sizes (multiple of) can be constructed from lower sizes with a small overhead
• Regular interleaver for every value of S
OWHTC19 - 27-28 FEBRUARY 2019
Key takeaways:
• Large amount of identical connections
• Simpler interconnect
• Regular structure allows frame size flexibility at minimum hardware cost
• Periodic puncturing
• Improved error correction performance
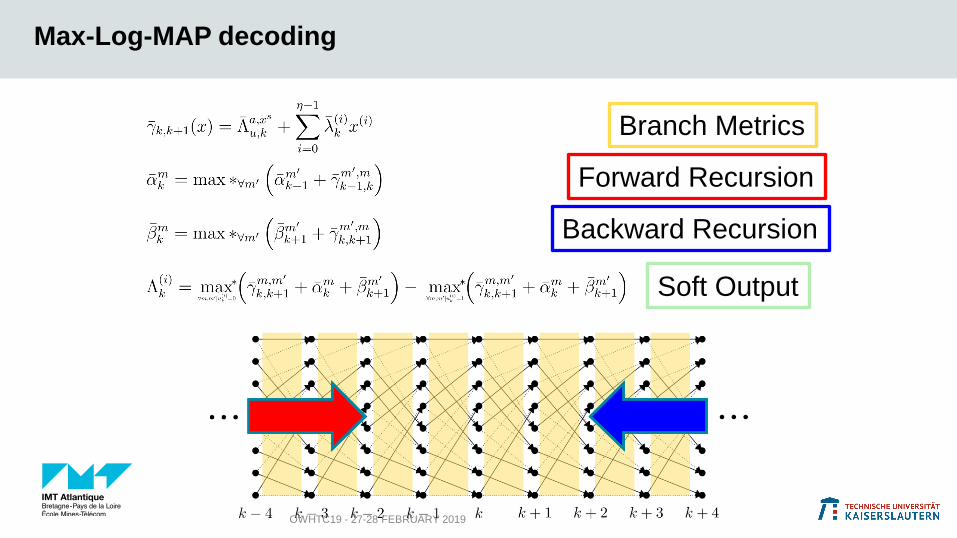
Max-Log-MAP decoding
Branch Metrics
Backward Recursion
Forward Recursion
Soft Output
OWHTC19 - 27-28 FEBRUARY 2019

From Mb/s to Gb/s: Hardware architectures
SMAP
Splitting the
trellis
Recursion
Unrolling
Iteration
Unrolling
Serial MAP (SMAP): One serial max-Log-MAP decoder functioning as Dec1 / Dec2 alternatingly
Mb/s
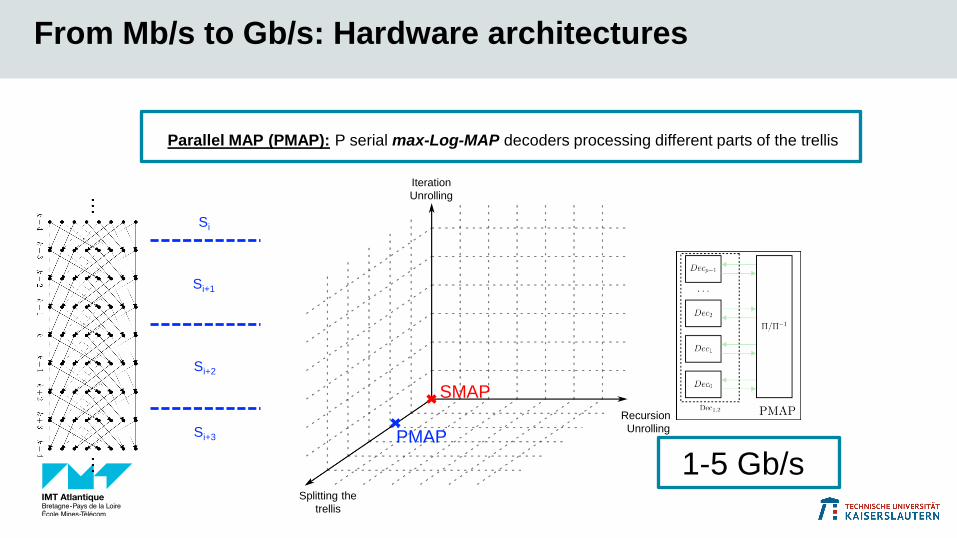
1-5 Gb/s
Parallel MAP (PMAP): P serial max-Log-MAP decoders processing different parts of the trellis
From Mb/s to Gb/s: Hardware architectures
SMAP
PMAP
Splitting the
trellis
Recursion
Unrolling
Iteration
Unrolling
Si
Si+1
Si+2
Si+3

Pipelined MAP (XMAP): Pipelined decoder processing parts of the trellis in a X-shaped pipeline
1-5 Gb/s
From Mb/s to Gb/s: Hardware architectures
SMAP
PMAPXMAP
Splitting the
trellis
Recursion
Unrolling
Iteration
Unrolling
Si+1
Si+2
Si+3
Si+4
Si
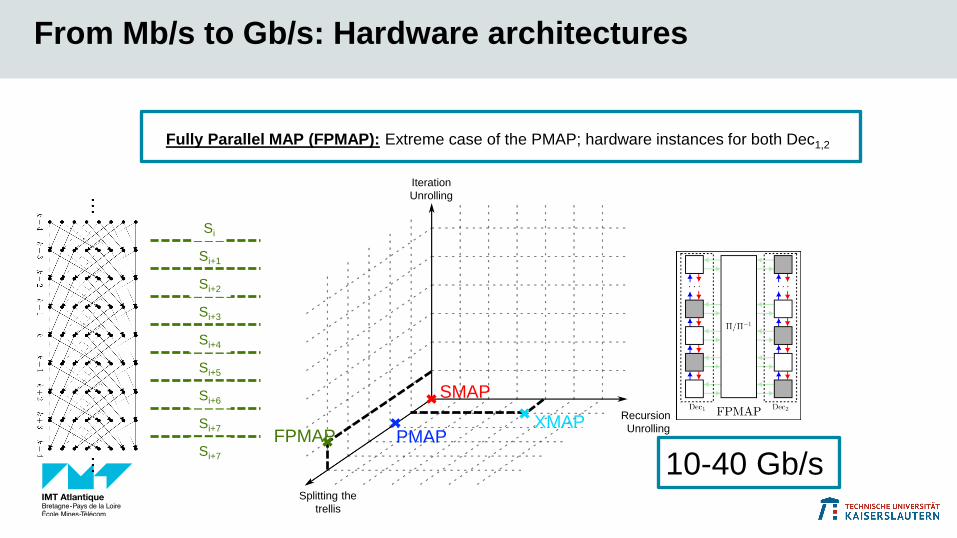
10-40 Gb/s
Fully Parallel MAP (FPMAP): Extreme case of the PMAP; hardware instances for both Dec1,2
From Mb/s to Gb/s: Hardware architectures
SMAP
PMAPFPMAPXMAP
Splitting the
trellis
Recursion
Unrolling
Iteration
Unrolling
Si+1
Si+3
Si+5
Si+7
Si
Si+2
Si+4
Si+6
Si+7
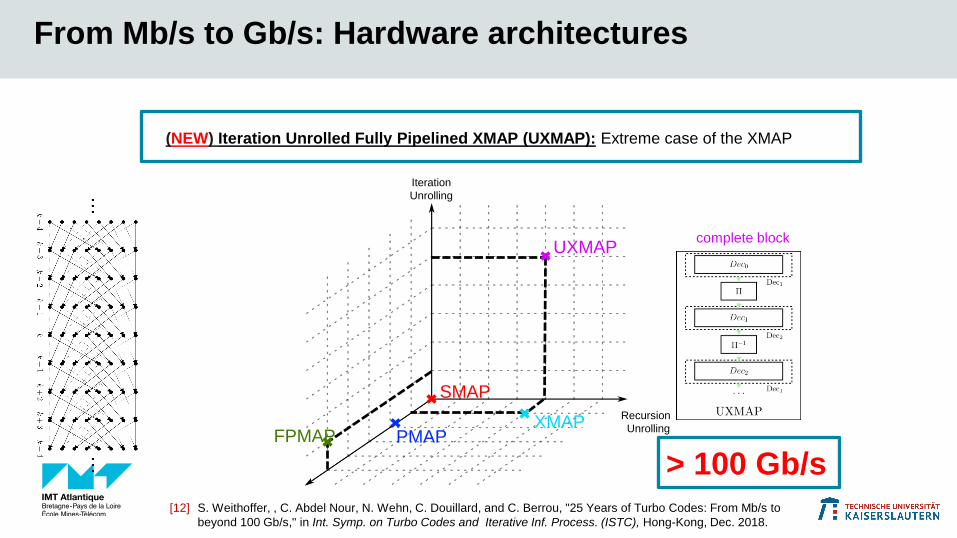
> 100 Gb/s
From Mb/s to Gb/s: Hardware architectures
SMAP
PMAPFPMAPXMAP
UXMAP
Splitting the
trellis
Recursion
Unrolling
Iteration
Unrolling
complete block
[12] S. Weithoffer, , C. Abdel Nour, N. Wehn, C. Douillard, and C. Berrou, "25 Years of Turbo Codes: From Mb/s to
beyond 100 Gb/s," in Int. Symp. on Turbo Codes and Iterative Inf. Process. (ISTC), Hong-Kong, Dec. 2018.
(NEW) Iteration Unrolled Fully Pipelined XMAP (UXMAP): Extreme case of the XMAP
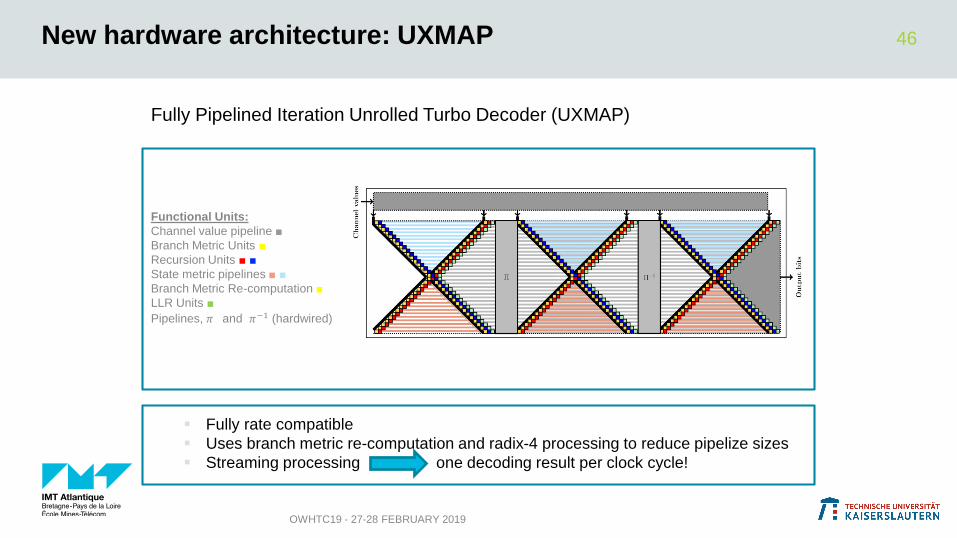
Fully Pipelined Iteration Unrolled Turbo Decoder (UXMAP)
Functional Units:
Channel value pipeline ■
Branch Metric Units ■
Recursion Units ■ ■
State metric pipelines ■ ■
Branch Metric Re-computation ■
LLR Units ■
Pipelines, 𝜋 and 𝜋−1 (hardwired)
New hardware architecture: UXMAP
Fully rate compatible
Uses branch metric re-computation and radix-4 processing to reduce pipelize sizes
Streaming processing one decoding result per clock cycle!
46
OWHTC19 - 27-28 FEBRUARY 2019
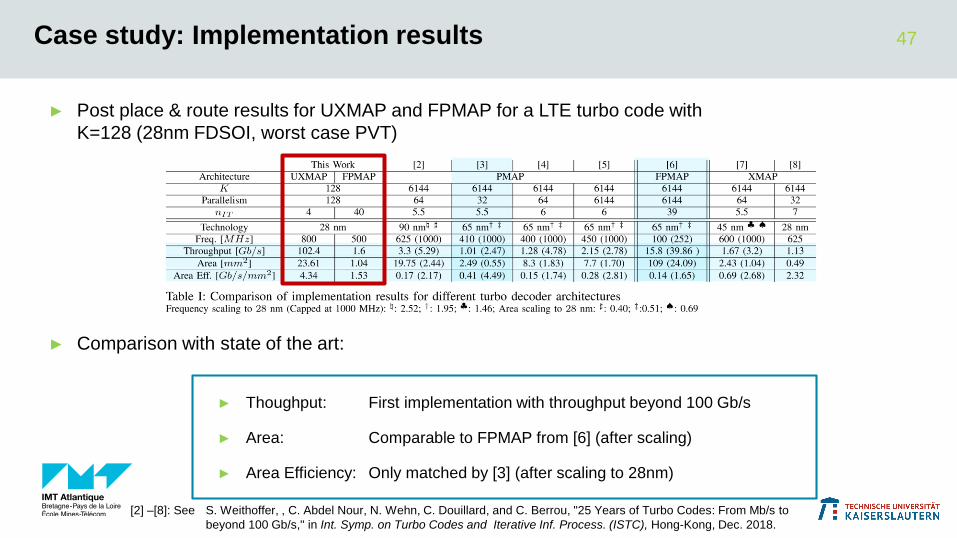
Case study: Implementation results
► Post place & route results for UXMAP and FPMAP for a LTE turbo code with
K=128 (28nm FDSOI, worst case PVT)
► Comparison with state of the art:
► Thoughput: First implementation with throughput beyond 100 Gb/s
► Area: Comparable to FPMAP from [6] (after scaling)
► Area Efficiency: Only matched by [3] (after scaling to 28nm)
[2] –[8]: See S. Weithoffer, , C. Abdel Nour, N. Wehn, C. Douillard, and C. Berrou, "25 Years of Turbo Codes: From Mb/s to
beyond 100 Gb/s," in Int. Symp. on Turbo Codes and Iterative Inf. Process. (ISTC), Hong-Kong, Dec. 2018.
47

Conclusions and future works

Summary and future works
OWHTC19 - 27-28 FEBRUARY 2019
Layout Picture for UXMAP decoder
Contributions:
► New interleaver and puncturing design
► Simpler support of code rate and frame size flexibility
► Introduce periodicity and regularity with simpler interconnect
► Largely improved performance, especially for high rates
► New Turbo Decoder Architecture: UXMAP
► First Turbo Decoder implementation with a throughput of more than 100 Gb/s
Future Work:
► Increase frame size with flexibility support => more relevant for practical use cases
► Reduce area complexity
► Particular interest in simplified decoding algorithms and procedures

What’s next?
► The Max-Log MAP algorithm revisited
- Original new approach dedicated to high radix orders
- Promising initial results:
8-state turbo decoder, radix-8
Computational complexity reduction of 37% in number of ACS units
No performance penalty
Complexity reduction increases with increasing radix order
Favorable conclusions regarding critical path when compared to state-of-the-art high radix decoders
► Hardware architecture refinements
- Original hybrid pipelined / parallel approach
- Initial results halve chip area
OWHTC19 - 27-28 FEBRUARY 2019




















