
User Requirement Elicitation for Cross-Language Information Retrieval
Upload
independentCategory
view
0download
0
Jointly published by Akadémiai Kiadó, Budapest Scientometrics,and Springer, Dordrecht Vol. 65, No. 1 (2005) 131–144
Received April 25, 2005Address for correspondence:KATHERINE W. MCCAINCollege of Information Science & Technology, Drexel University3141 Chestnut Street, Philadelphia, PA 19104, USAE-mail: [email protected]
0138–9130/US $ 20.00Copyright © 2005 Akadémiai Kiadó, BudapestAll rights reserved
The use of bibliometric and knowledge elicitationtechniques to map a knowledge domain:
Software Engineering in the 1990sKATHERINE W. MCCAIN,a JUNE M. VERNER,b GREGORY W. HISLOP,a
WILLIAM EVANCO,a VERA COLEc
a College of Information Science & Technology, Drexel University, Philadelphia, PA (USA)b National ICT Australia, Sydney, NSW (Australia)
c Interlace Corporation, Princeton, NJ (USA)
Parallel mappings of the intellectual and cognitive structure of Software Engineering (SE)were conducted using Author Cocitation Analysis (ACA), PFNet Analysis, and card sorting, aKnowledge Elicitation (KE) method. Cocitation counts for 60 prominent SE authors over theperiod 1990 - 1997 were gathered from SCISEARCH. Forty-six software engineers providedsimilar data by sorting authors’ names into labeled piles. At the 8 cluster level, ACA and KEidentified similar author clusters representing key areas of SE research and application, though theKE labels suggested some differences between the way that the authors’ works were used and howthey were perceived by respondents. In both maps, the clusters were arranged along a horizontalaxis moving from “micro” to “macro” level R&D activities (correlation of X axis coordinates= 0.73). The vertical axis of the two maps differed (correlation of Y axis coordinates = –0.08). TheY axis of the ACA map pointed to a continuum of high to low formal content in published work,whereas the Y axis of the KE map was anchored at the bottom by “generalist” authors and at thetop by authors identified with a single, highly specific and consistent specialty. The PFNet of theraw ACA counts identified Boehm, Basili, and Booch as central figures in subregions of thenetwork with Boehm being connected directly or through a single intervening author with just over50% of the author set. The ACA and KE combination provides a richer picture of the knowledgedomain and provide useful cross-validation.
Introduction
In the study of scholarly fields, Domain Analysis is the study of the field(knowledge domain) as a thought or discourse community. It focuses on such topics asknowledge organization, structure, cooperation patterns, language and communicationforms, information systems, and relevance criteria as a way of understanding thesecommunities (adapted from HJØRLAND & ALBRECHTSEN, 1995). A range ofmethodologies are available to examine different aspects of a knowledge domain,

K. W. MCCAIN et al.: Software Engineering in the 1990s
132 Scientometrics 65 (2005)
including historical investigation, ethnographic and social network analysis,bibliometrics, and knowledge elicitation. Each approach brings its own perspective toDomain Analysis and each has the ability to highlight some features of the Domain,while providing information on others only in passing, if at all. A “multiple indicators”approach, deploying complementary investigational tools, can give a richer picture thancan any one approach by itself.
In this paper, we report on the use of two complementary approaches to DomainAnalysis – Author Cocitation Analysis and Knowledge Elicitation – to elicit somemajor structural features of the domain of Software Engineering (SE). SoftwareEngineering has been defined variously:
• An engineering discipline whose goal is the cost-effective development ofsoftware systems. (SOMMERVILLE, 2001)
• The establishment and use of sound engineering principles in order toobtain economically software that is reliable and works efficiently on realmachines. (BAUER, 1972)
• Software Engineering is the technological and managerial disciplineconcerned with systematic production and maintenance of softwareproducts that are developed and modified on time and within costestimates. (FAIRLEY, 1985)
It is a relatively new discipline, having its roots in a 1968 conference discussing the“software crisis.” According to SOMMERVILLE (2001) the crisis arose as increasingcomputing power mandated larger and more complex software systems. The thencurrent design and management approaches were demonstrably unable to producesoftware that was on time, on budget, performed reliably, and met users’ expectations.A new approach was needed – Software Engineering.
Today, Software Engineering is a well-established field of theoretical and appliedR&D with a substantial scholarly journal literature (MARION & MCCAIN, 2001) and amajor presence in both the Association of Computing Machinery (ACM) and theInstitute of Electrical and Electronics Engineers (IEEE). Its “natural” academic home isstill under debate:
“Many IT professionals still believe that Software Engineering and computerscience are basically the same thing, while others counter that SoftwareEngineering focuses more on engineering process, management and organizationissues than [Computer Science] does. To those engineers who claim thatSoftware Engineering is not a true engineering discipline, since engineeringscience topics such as statics and thermodynamics are not part of its core body ofknowledge, Software Engineering professionals point that the engineeringsciences are not required for the creation of a non-physical product

K. W. MCCAIN et al.: Software Engineering in the 1990s
Scientometrics 65 (2005) 133
(although such knowledge would be needed if software was being developed foran embedded system), and that the Software Engineering process is virtuallyidentical to that in other engineering disciplines.” (BAGERT, 2003)
Indeed, at Drexel University, the MSSE degree has three “tracks”– computerscience, computer engineering, and information systems – offered through the Collegeof Engineering and the College of Information Science and Technology.
We began this domain analysis of Software Engineering in the late 1990s with thegoal of exploring the nature and breadth of the field through the combination ofbibliometric methods (intellectual structure of the SE literature) and knowledgeelicitation methods (cognitive structure based on the perceptions of software engineers).Published studies to date include an exploration of the structure of the core journalliterature of SE, based on both author referencing patterns and index term assignments(MARION & MCCAIN, 2001) and a study of the factors that affect the “visibility” ofSoftware Engineering authors (VERNER et al., 2001) In this report, we examine andvisually map the discourse community of SE through the citation patterns of softwareengineers and through their perceptions of the authors whose works they cite.
Methods
Author Cocitation Analysis (ACA)
Cocited author mapping uses the patterns of co-occurrence of authors’ names inreference lists to examine the intellectual structure of scholarly literatures and, byextension, the fields that produce those literatures. In the citation indexes published byISI (Science Citation Index, Social Science Citation Index, Arts & Humanities CitationIndex), authors’ names represent partial ‘oeuvres’ (the subset of their work in whichthey are first or sole author). ACA techniques are well established and only a briefoutline with specific reference to Software Engineering will be presented here. Thereader is referred to MCCAIN (1990) for general details of data gathering and analysisfor “classical ACA” and WHITE (2003) for an overview and comparison of the use ofPFNets versus standard ACA methods in domain analysis. Two ARIST reviews,BORNER et al. (2003) and WHITE & MCCAIN (1997) place ACA and other citation-based approaches in a broader context of domain analytic visualization techniques.
Selection of authors for analysis. The unit of analysis in our domain analysis ofSoftware Engineering is the publishing author whose body of work is cited by others inSoftware Engineering and related fields. Our goal in developing the author set was toencompass – in a relatively small list of names – a broad cross-section of SoftwareEngineering research. We wanted to develop a manageable set of names that werebroadly representative of the field as a whole.

K. W. MCCAIN et al.: Software Engineering in the 1990s
134 Scientometrics 65 (2005)
We used a combination of sources to establish this representative list. We began byidentifying authors whose publications received 5 or more citations in 8 SoftwareEngineering journals: ACM Transactions on Software Engineering and Methodology,IEEE Transactions on Software Engineering, IEEE Software, IEEE Concurrency(formerly IEEE Parallel and Distributed Technology), IEE Proceedings – SoftwareEngineering (formerly IEE Software Engineering Journal), Information and SoftwareTechnology, Journal of Systems and Software, and Software: Practice & Experience(the “cited” list). Separately, we examined general Software Engineering texts andreference materials, including the editorial boards of prominent journals and identifiedfrequently occurring names (the “text” list). The final set of 60 authors included allnames on both the cited and text lists (50 names). An additional 10 names were selectedfrom the separate list remainders with, as stated earlier, the twin goals ofrepresentativeness and diversity.
Table 1: Authors included in cocitation and card-sorting analysesABDEL-HAMID, TAREK K. GLASS, ROBERT L. PARNAS, DAVID L.ALBRECHT, ALLAN J. GOLDBERG, ADELE PFLEEGER, SHARI L.BASILI, VICTOR R. GOMAA, HASSAN PRESSMAN, ROGER S.BEIZER, BORIS GRADY, ROBERT B. PRIETO-DIAZ, R.BIGGERSTAFF, TED J. HARRISON, W. RAMAMOORTHY, C. V.BOEHM, BARRY W. HOARE, C.A.R ROMBACH, H. D.BOOCH, GRADY HUMPHREY, WATTS S. RUMBAUGH, JAMESBROOKS, FREDERICK P., JR. JACKSON, MICHAEL A. SELBY, R. W.CARD, DAVID N. JACOBSON, IVAR SHAW, MARYCLARKE, LORI A. JONES, T. CAPERS SHEPPERD, M.COAD, PETER KAISER, G. E. SHNEIDERMAN, BENCURTIS, BILL KEMERER, C. F. SOMMERVILLE, IANDAVID, ALLAN M. KERNIGHAN, BRIAN W. TICHY, W. F.DEMARCO, TOM KITCHENHAM, BARBARA A. TRACZ, WILLDIJKSTRA, EDSGER W. LEHNMAN, M. M. WASSERMAN, A. I.FAGAN, M. E. MCCABE, THOMAS J. WEISER, M.FENTON, NORMAN E. MEYER, BERTRAND WEYUKER, ELAINE J.GARLAN, DAVID MILLS, HARLAN D. WING, JEANETTE, M.GHEZZI, CARLO MUSA, JOHN D. YOURDON, EDWARDGILB, TOM MYERS, GLENFORD J. ZAVE, PAMELA
Collection of cocitation data. Two authors are cocited when at least one publishedwork by each is included in the same reference list (with the proviso that the author isfirst or sole author of that work). Cocitation counts are relatively easily obtained by

K. W. MCCAIN et al.: Software Engineering in the 1990s
Scientometrics 65 (2005) 135
searching Science Citation Index online (SCISEARCH–File 34 on Dialog) andspecifying a pair of authors’ names. For instance:
SELECT CA=Booch G AND CA=Rumbaugh Jwill give a count of all the articles in the database that have made at least one referenceto a paper or book by Grady Booch (as first author) and a paper or book by JamesRumbaugh (as first author).∗ Data were gathered for the period 1990–1997 andassembled in a square matrix with off-diagonal cells containing counts of the number ofarticles co-citing each pair of authors. The diagonal cells were treated as missing data.The raw co-citation matrix was converted to a proximity matrix of Pearson correlations,with the off-diagonal cells containing the correlation between the co-citation profiles ofan author pair.
Data analysis. Pathfinder Network Analysis (PFNets) was used to extract the“skeletal” network structure among the co-cited authors from the raw cocitation matrix(WHITE, 2003). In PFNet analysis, the spring-embedder algorithm links nodes (authors)based on their single highest co-occurrence counts. The result is generally a networkstructure with some authors appearing as major foci (many links to others) representingspecialties. Standard ACA methods – hierarchical cluster analysis and multidimensionalscaling – were used to focus on the underlying subject structure and domain dimensionsrepresented in the correlation matrix.
Knowledge Elicitation (KE)
According to COOKE (1994), Knowledge Elicitation is “the process of collectingfrom a human source of knowledge, information that is thought to be relevant to thatknowledge.” The data obtained can provide insight into the subject’s mental models –knowledge, perceptions, and understandings of some part of his or her world. It isfrequently encountered as an initial step in the design of expert systems (as part ofKnowledge Acquisition/Knowledge Engineering). Techniques for eliciting thisinformation include interviews and observation, process tracing (e.g. protocol analysis),and conceptual techniques.
Collection of card-sorting data. The card-sorting technique falls into Cooke’ssubclass of data-gathering conceptual techniques. In a classic experiment (MILLER,1969), Miller had students sort 48 nouns on cards into piles, based on the student’sunderstanding of the words’ meanings. By counting the number of times each pair of
∗ The limitation to “first author only” data is a known problem when using ISI citation data. See, e.g. MCCAIN(1988) and PERSSON (2001) and, for a different view, WHITE (1990). If the interest is in the themes illustratedby authors’ names, the value of the very large data sets may outweigh the inability to see certain perennial co-authors.

K. W. MCCAIN et al.: Software Engineering in the 1990s
136 Scientometrics 65 (2005)
nouns was placed in the same pile, and analyzing the matrix of “co-pile” counts, Millerwas able to discover the students’ perceptions of the relationships between the nounconcepts and dimensions of the cognitive space.
To our knowledge, card-sorting methods have rarely been combined withbibliometric analysis. MCCAIN (1986) used card-sorting and semi-structured interviewstogether with ACA in studies of macroeconomics and Drosophila genetics. The resultsdemonstrated congruence between the perceptions of the macroeconomists and flygeneticists and the structure of their fields as seen through author cocitation patterns.More recently, BUZYDLOWSKI (2003) used card-sorting and telephone interviews in anevaluation of two different interfaces to AUTHORLINK, a real-time ACA-basedvisualization and retrieval system (2002). In his dissertation, Buzydlowski demonstratedthat both PFNet and Kohonen SOM displays were congruent with the perceptions ofscholars across a number of areas in the arts and humanities.
As part of our domain analysis, we contacted a number of members of the SoftwareEngineering community and asked them to participate in a card-sorting exercise similarto those reported in MCCAIN (1986). One major difference was that (for mostrespondents) we sent sets of cards, instructions, and a brief questionnaire to the softwareengineers via postal mail, and they returned their sorted, labeled card piles in the sameway. (A few visitors to the College participated in interviews along with the cardsorting). Willing respondents were provided with 60 cards, each bearing the name ofone of the authors in the cocitation study, along with a number of blank cards. Theywere requested to sort the cards into piles based on their perception of the relatedness ofthe authors’ work, their perceptions of the structure of Software Engineering, or anyother criteria they might like to use and then to label the individual piles using the blankcards. They were permitted to have as many piles as necessary, including pilesconsisting of a single author, and to have piles with such labels as “don’t know thesepeople,” and “not software engineers.”∗
Forty-six respondents returned the sorted and labeled card sets. A matrix ofaggregate “co-pile” counts for the author pairs was assembled, with the value “46”placed in the diagonal, and then converted to a correlation matrix.
Data analysis. When the card-sorting data are aggregated over a reasonably largenumber of respondents, it is possible to analyze these co-occurrence data in the sameway as the cocitation data. In this way, one can compare the structure represented by thescholarly use of published materials (the authors as ‘oeuvres’) and the structure
∗ As part of our data gathering, we asked respondents to suggest additional names that they felt had beenwrongly omitted from the list. A total of 89 different names were suggested, 65 of them only once. Fourauthors – Nancy Leveson, Gerald Weinberg, Steve McConnell, and Richard DeMillo – received more thanthree votes and will be incorporated in an expanded map. This lack of consensus suggests that our list of 60 isa reasonably representative and inclusive one.

K. W. MCCAIN et al.: Software Engineering in the 1990s
Scientometrics 65 (2005) 137
represented by respondents’ perceptions of the authors (the authors as ‘personae’(MCCAIN, 1986) The labels attached to individual authors by their pile placements serveas a subject profile of the author’s perceived contributions and place in the field.
The card sort correlation matrix was subjected to hierarchical cluster analysis andMDS in parallel with the ACA data. In the final analysis, one author (Shneiderman) waseliminated from the map and clusters because he was almost uniformly identified as“not a software engineer,” though he was retained for the QAP (Quadratic AssignmentProblem) analysis of matrix congruence.∗
The similarity of the two data sets was evaluated in two ways. Overall congruencewas assessed based on the QAP statistic (reported as Pearson correlation), a standardprocedure for testing the association between networks (HUBERT & SCHULTZ, 1976;BORGATTI et al., 2002). Similarity of map axes was evaluated based on the correlationbetween the Cartesian coordinates of X-axis and Y-Axis author placement.
Results and discussion
The author cocitation structure of Software Engineering
Figure 1 presents a two-dimensional map of Software Engineering, based on thecocitation pattern correlations among the 60 authors. The 8-cluster solution is imposedon the 2-D point display.∗∗ MDS places points, representing authors, in anapproximation of their “distance” in the correlation matrix; within the constraints of thelow dimensional solution, authors with similar patterns are placed near each other andauthors with patterns similar to many others are placed closer to the center of the map.
The cluster labels are evocative of the authors’ published, cited contributions.Clusters to the left of center represent SE activities in the early stages of thedevelopment process – focusing on the architecture, design, and programming of thesoftware system. Traditional Systems Analysis & Design (modeling the systemgraphically as data flows and transformations) is distinct from the newer Object-Oriented Analysis & Design/Programming (OO approaches focus on objects, classes ofobjects, attributes, and inheritance of attributes). Related to both of these are theconjoined topics of Software Architecture and Software Reuse. “Formal Methods” aremathematically-based techniques for specifying, developing and verifying theproperties of the software system in the early stages of development. Clusters to theright of center include authors focusing on the process of software system development ∗ Shneiderman’s most frequently cited work in SE appears to be the various editions of Designing the UserInterface. While interface design is a topic in the Encyclopedia of Software Engineering, and Curtis, anotherauthor in this study, was a founder of the CHI Conferences, the card sorters made a definite distinctionbetween the two cited authors in terms of their immediate connection to Software Engineering.∗∗ Full dendrograms are available from the first author upon request.

K. W. MCCAIN et al.: Software Engineering in the 1990s
138 Scientometrics 65 (2005)
in terms of Project Management (e.g. Brooks, author of The Mythical Man-Month),general concerns with Software Performance, and research in Software Metrics(measures of the properties of the software system and the software developmentprocess). The two author cluster Software Testing / Reliability spans the break betweenthe two halves of the map.
Figure 1. Cocitation map of 60 highly cited authors in Software Engineering, 1990–1997
The distribution of clusters along the axes of an ACA map highlight key themes inthe knowledge domain under study. In this map, the continuum from left to right alongthe X-axis shows a shift in focus in level – from programming and program design toproject management and post-development software assessment. This continuummirrors the software development life cycle by taking the operating system or majorapplication from initial programming through project management, implementation, andmaintenance. The Y-axis illustrates a common theme in ACA maps, a gradation in thelevel of formal or mathematical content in published research.

K. W. MCCAIN et al.: Software Engineering in the 1990s
Scientometrics 65 (2005) 139
Figure 2. PFNet of 60 cocited authors in Software Engineering, 1992–1997
The PFNet in Figure 2 shifts the representation from groupings based on subjectsimilarity to a focus on a network based on authors with high “centrality” (many linksto other authors) and connections between research specialties (central authors and theirsatellites). The most striking feature of this network is the prominence of Barry Boehmas a focal cited author. Roughly half of the authors in the network are either connecteddirectly to Boehm or are linked by a single intervening point. This points to theimportance of Boehm’s best known contribution to Software Engineering – COCOMO(Constructive Cost Model), an empirically-based non-proprietary software cost andschedule estimating model. To the lower right, Victor Basili connects the area ofsoftware metrics to Boehm and software project management. The author network tothe left of Boehm includes the authors on the left hand side of the map in Figure 1. Keynodal authors include Grady Booch (author of several OO texts) and Hoare (structuredprogramming and formal methods).
The “cognitive” structure of Software Engineering
Figure 3 is a cluster-enhanced MDS map of the card-sorting data. The cluster labelsare a summarization of those provided by the 46 study respondents; at the 8 clusterlevel, the clusters are extremely similar in terms of their authors and subjects to theACA results. In this map, Software Architecture (represented solely by Garlan) iscombined with Formal Methods, leaving Software Reuse as a solo cluster of three

K. W. MCCAIN et al.: Software Engineering in the 1990s
140 Scientometrics 65 (2005)
authors who are recognized for their interest in the design of software based on reusableprogram “modules.” The remaining two authors, Kaiser & Tichy, are in a separatecluster, SW Tools & Environments. The “OO” authors (Booch and colleagues) remainas a distinct cluster, as do the Software Metrics authors. Software Testing/Reliabilityhas expanded to include several authors from the Software Performance ACA cluster.
Figure 3. Card-sorting map of Software Engineering (46 respondents)
The continuum along the X-axis appears to represent the same shift from micro tomacro perspectives on SE. However, the Y-axis no longer points to a strong differencein formal/mathematical orientation. Rather, the card sorters appear to perceive adifference between authors whose work spans a range of issues and interests, and thosewho have a clear primary focus. Somerville, Yourdon, DeMarco, Pressman, and Brookshave all written standard texts or similar publications that have gone into severaleditions and Glass is the editor of a core SE journal (Journal of Systems & Software) aswell as the author of Facts & Fallacies in Software Engineering. The authors in the SEMethodologies/SE Texts cluster were consistently placed in the same pile with labelsreflecting their “foundational” or “generalist” role in Software Engineering. Boehm’splacement at this end of the Y-axis is consistent with his centrality in the ACA PFNet.Authors at the upper end had more consistent labeling in the card sorts.
K. W. MCCAIN et al.: Software Engineering in the 1990s
Scientometrics 65 (2005) 141
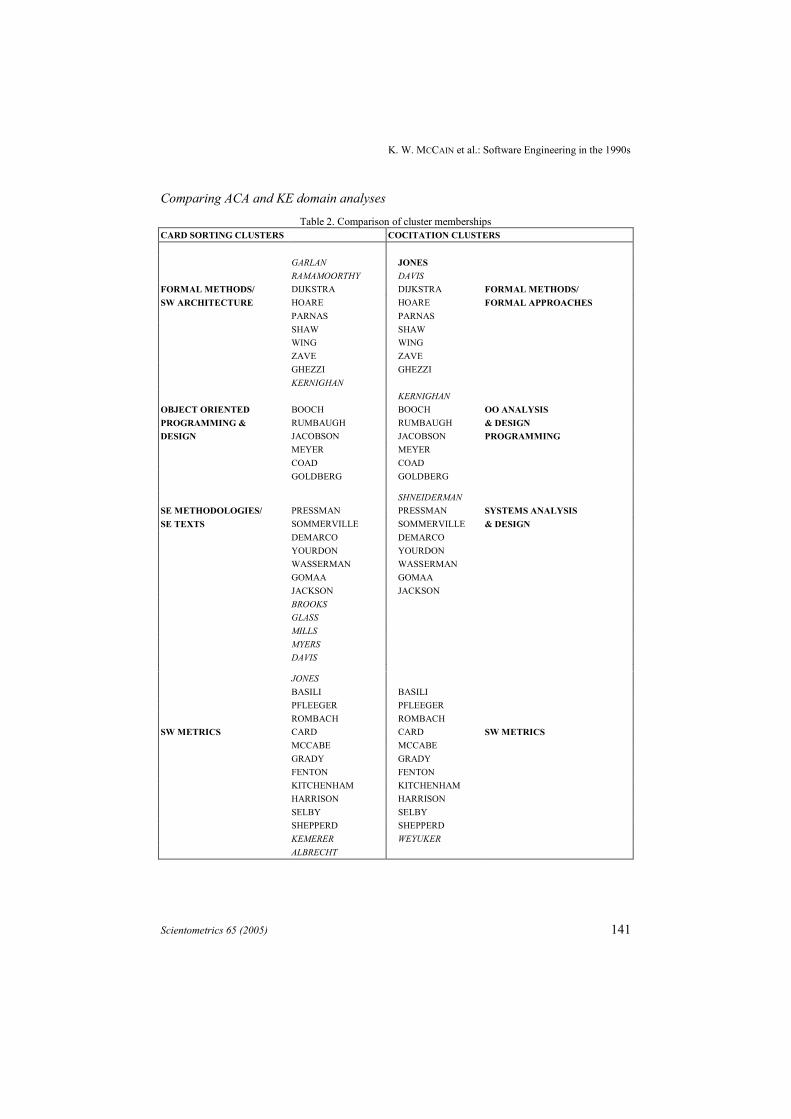
Comparing ACA and KE domain analysesTable 2. Comparison of cluster memberships
CARD SORTING CLUSTERS COCITATION CLUSTERS
GARLAN JONESRAMAMOORTHY DAVIS
FORMAL METHODS/ DIJKSTRA DIJKSTRA FORMAL METHODS/SW ARCHITECTURE HOARE HOARE FORMAL APPROACHES
PARNAS PARNASSHAW SHAWWING WINGZAVE ZAVEGHEZZI GHEZZIKERNIGHAN
KERNIGHANOBJECT ORIENTED BOOCH BOOCH OO ANALYSISPROGRAMMING & RUMBAUGH RUMBAUGH & DESIGNDESIGN JACOBSON JACOBSON PROGRAMMING
MEYER MEYERCOAD COADGOLDBERG GOLDBERG
SHNEIDERMANSE METHODOLOGIES/ PRESSMAN PRESSMAN SYSTEMS ANALYSISSE TEXTS SOMMERVILLE SOMMERVILLE & DESIGN
DEMARCO DEMARCOYOURDON YOURDONWASSERMAN WASSERMANGOMAA GOMAAJACKSON JACKSONBROOKSGLASSMILLSMYERSDAVIS
JONESBASILI BASILIPFLEEGER PFLEEGERROMBACH ROMBACH
SW METRICS CARD CARD SW METRICSMCCABE MCCABEGRADY GRADYFENTON FENTONKITCHENHAM KITCHENHAMHARRISON HARRISONSELBY SELBYSHEPPERD SHEPPERDKEMERER WEYUKERALBRECHT
K. W. MCCAIN et al.: Software Engineering in the 1990s
142 Scientometrics 65 (2005)
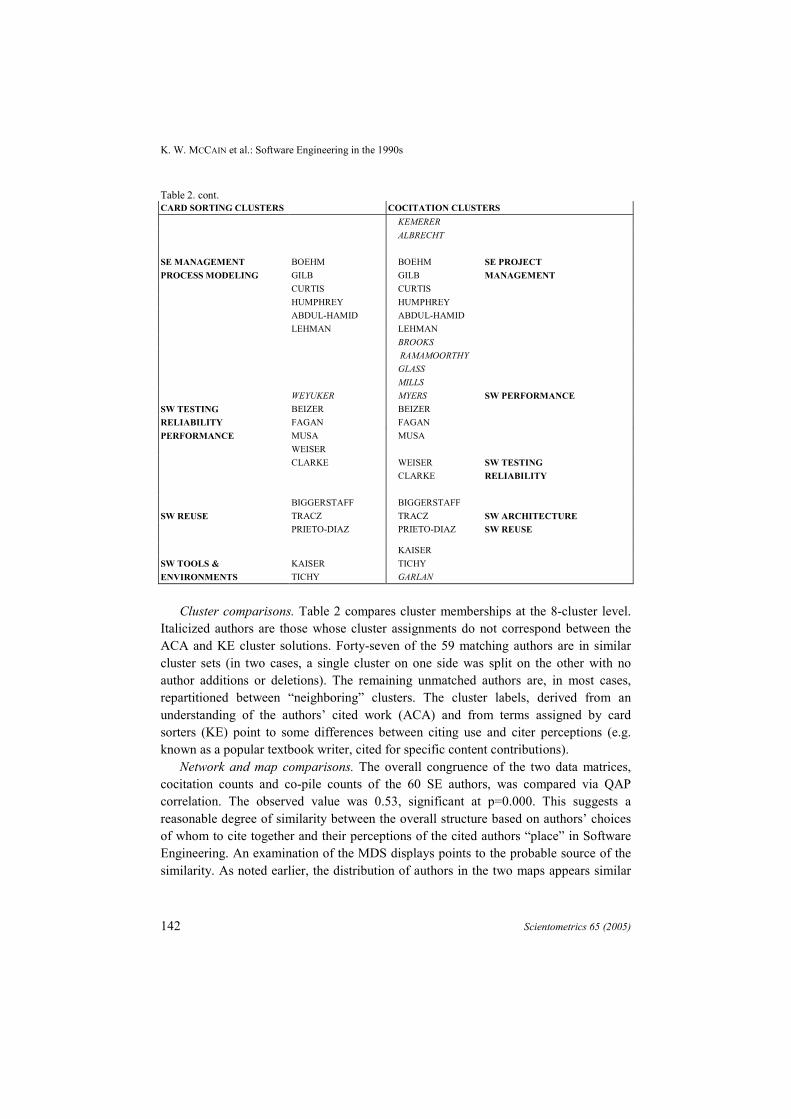
Table 2. cont.CARD SORTING CLUSTERS COCITATION CLUSTERS
KEMERERALBRECHT
SE MANAGEMENT BOEHM BOEHM SE PROJECTPROCESS MODELING GILB GILB MANAGEMENT
CURTIS CURTISHUMPHREY HUMPHREYABDUL-HAMID ABDUL-HAMIDLEHMAN LEHMAN
BROOKSRAMAMOORTHYGLASSMILLS
WEYUKER MYERS SW PERFORMANCESW TESTING BEIZER BEIZERRELIABILITY FAGAN FAGANPERFORMANCE MUSA MUSA
WEISERCLARKE WEISER SW TESTING
CLARKE RELIABILITY
BIGGERSTAFF BIGGERSTAFFSW REUSE TRACZ TRACZ SW ARCHITECTURE
PRIETO-DIAZ PRIETO-DIAZ SW REUSE
KAISERSW TOOLS & KAISER TICHYENVIRONMENTS TICHY GARLAN
Cluster comparisons. Table 2 compares cluster memberships at the 8-cluster level.Italicized authors are those whose cluster assignments do not correspond between theACA and KE cluster solutions. Forty-seven of the 59 matching authors are in similarcluster sets (in two cases, a single cluster on one side was split on the other with noauthor additions or deletions). The remaining unmatched authors are, in most cases,repartitioned between “neighboring” clusters. The cluster labels, derived from anunderstanding of the authors’ cited work (ACA) and from terms assigned by cardsorters (KE) point to some differences between citing use and citer perceptions (e.g.known as a popular textbook writer, cited for specific content contributions).
Network and map comparisons. The overall congruence of the two data matrices,cocitation counts and co-pile counts of the 60 SE authors, was compared via QAPcorrelation. The observed value was 0.53, significant at p=0.000. This suggests areasonable degree of similarity between the overall structure based on authors’ choicesof whom to cite together and their perceptions of the cited authors “place” in SoftwareEngineering. An examination of the MDS displays points to the probable source of thesimilarity. As noted earlier, the distribution of authors in the two maps appears similar

K. W. MCCAIN et al.: Software Engineering in the 1990s
Scientometrics 65 (2005) 143
along the X-axis and strongly dissimilar along the Y-axis. A simple correlation of theauthors’ map coordinates supports this observation: r=0.73 (X-axis) and -0.08 (Y-axis)(a closer fit along the X-axis could probably be obtained through rotation but the defaultconfiguration is sufficient to make the point). The most important structural theme inSoftware Engineering, the “micro � � macro” dimension, exists in both citationpatterns and in perceptions of the field by citing authors. Along the Y-axis, citingpatterns (ACA) focus on the content of authors’ work while general perceptions (KE)include more aspects of the authors’ ‘personae’.
Conclusion
Together, classical Author Cocitation Analysis, PFNet Analysis, and KnowledgeElicitation methods (specifically card sorting) provide complementary views of aknowledge domain. KE methods increase our understanding of the domain by capturingsubjects’ mental models of the domain and providing additional information aboutmapped entities. To a great extent, the two approaches provide useful cross-validation.In Software Engineering as well as other fields, the structure of the literature as seenthrough networks of author indebtedness (citation of previous work) is a good reflectionof their mental models of the field, the place of the (cited) authors, and the relationshipsamong their contributions. We can state with some confidence that Boehm, Basili,Booch, and Hoare are central figures in the Software Engineering R&D literature, basedon their frequent cocitation with substantial numbers of other authors, and we canidentify other authors as probable linkers between research specialties. We can observethat the main organizing principle in the knowledge domain of Software Engineeringappears to be a continuum of activities related to the process of software design,development, and evaluation. This continuum stretches from the programming level(and the use of formal methods to test the validity of program specifications andprogram behavior) through the management of the software development process andthe quantitative evaluation of the completed software system (software metrics). Keyspecialties in Software Engineering (in the decade of the 1990s) included Object-Oriented Programming, Analysis & Design, Formal Methods, Software Reuse,Software Testing & Reliability, Software Process Management, and Software Metrics.We also observe, again, that the cognitive data show that citing authors may distinguishbetween specific contributions (for which an author may be cited) and the more general‘persona’ of an author, which may include attributes not directly related to the rhetoricalvalue of his or her published work. Finally, we note that the congruence of the KE andACA results lend support to the use of ISI “first-author-only” data in such studies. Thesoftware engineers who sorted the cards were certainly taking their full knowledge ofthe authors into account, including their entire ‘oeuvres’ and other attributes.

K. W. MCCAIN et al.: Software Engineering in the 1990s
144 Scientometrics 65 (2005)
∗This research was partially supported by the Kellogg Foundation through their grant to the College of
Information Science & Technology for the development of curricula for information and computingprofessionals. We thank the many software engineers who participated in the card-sorting exercise and Dr.Howard White, professor emeritus of our College, who performed the QAP analysis. Two referees madesuggestions that help to clarify some key points in the methodology. Preliminary versions of this paper weregiven at the Social Networks Conference in New Orleans, LA in February 2002, the Arthur M. SacklerColloquium of the National Academy of Sciences: Mapping Knowledge Domains, May 2003. Irvine, CA.,and the annual meeting of the American Society for Information Science & Technology, Philadelphia, PA,November, 2003.
ReferencesBAGERT, D. J. (2003), What is Software Engineering? Available at:
http://educators.mainfunction.com/Resources/interchange/Preview.asp?PeerID=2448. Accesssed December31, 2004.
BAUER, F. L. (1972), Information Processing 71.BORGATTI, S. P., EVERETT, M. G., FREEMAN, L. C. (2002), Ucinet 6 for Windows, (Harvard, MA, Analytic
Technologies).BORNER, K., CHEN, C. M., BOYACK, K. W. (2003), Visualizing knowledge domains, Annual Review of
Information Science & Technology, 37 : 179–255.BUZYDLOWSKI, J. W. (2003), A Comparison of Self-Organizing Maps and Pathfinder Networks for the
Mapping of Co-Cited Authors, (Ph. D. diss., Drexel University).BUZYDLOWSKI, J. W., WHITE, H. D., LIN, X. (2002), Visual Interfaces to Digital Libraries, Lecture Notes in
Computer Science, 2539 : 133–144.COOKE, N. J. (1994), Knowledge elicitation techniques, International Journal of Human-Computer Studies,
41 : 801–849.FAIRLEY, R. (1985), Software Engineering Concepts, (McGraw-Hill, New York).HJØRLAND, B., ALBRECHTSEN, H. (1995), Toward a new horizon in information science: domain analysis,
Journal of the American Society for Information Science, 46 : 400–425.HUBERT, L., SCHULTZ, J. (1976), Quadratic assignment as a general data analysis strategy, British Journal of
Mathematical &. Statistical Psychology, 29 : 190–241.MARION, L. S., MCCAIN, K. W. (2001), Contrasting views of software engineering journals: Author
cocitation choices and indexer vocabulary assignments, Journal of the American Society for InformationScience, 52 : 297–308.
MCCAIN, K.W. (1986), Cocited author mapping as a valid representation of intellectual structure, Journal ofthe American Society for Information Science, 37 : 111–122.
MCCAIN, K. W. (1988), Evaluating cocited author search performance in a collaborative specialty, Journal ofthe American Society for Information Science, 39 : 428–431.
MCCAIN, K. W. (1990), Mapping authors in intellectual space, Journal of the American Society forInformation Science, 41 : 433–442.
MILLER, G. A. (1969), A psychological method to investigate verbal concepts, Journal of MathematicalPsychology, 6 : 169–191.
SOMMERVILLE, I. (2001), Software Engineering. 6th edition, Addison-Wesley, New York.VERNER, J. M., EVANCO, W. M., MCCAIN, K. W., HISLOP, G. W., COLE, V. (2001), The determinants of
visibility of software engineering researchers, Journal of Systems and Software, 59 : 99–106.WHITE, H. D. (2003), Pathfinder networks and author cocitation analysis: A remapping of paradigmatic information
scientists, Journal of the American Society for Information Science & Technology, 54 : 423–434.WHITE, H. D. (1990), Author co-citation analysis: Overview and defense, In: C. L. BORGMAN (Ed.),
Scholarly Communication and Bibliometrics, Newbury Park, CA: Sage Publications, pp. 84–106.WHITE, H. D., MCCAIN, K. W. (1997), Visualization of literatures, Annual Review of Information Science &
Technology, 32 : 99–168.
Copyright © 2022 FDOKUMEN




















