
Systematic Population, Utilization, and Maintenance of a Repository for Comprehensive Reuse
26
Systematic Population, Utilization, and Maintenance of a Repository for Comprehensive Reuse Klaus-Dieter Althoff, Andreas Birk, Susanne Hartkopf, Wolfgang Müller, Markus Nick, Dagmar Surmann, Carsten Tautz Fraunhofer Institute for Experimental Software Engineering, Sauerwiesen 6 67661 Kaiserslautern, Germany {althoff, birk, hartkopf, mueller, nick, surmann, tautz}@iese.fhg.de Abstract. Today’s software developments are faced with steadily increasing expectations: software has to be developed faster, better, and cheaper. At the same time, application complexity increases. Meeting these demands requires fast, continuous learning and the reuse of experience on the part of the project teams. Thus, learning and reuse should be supported by well-defined processes applicable to all kinds of experience which are stored in an organizational mem- ory. In this paper, we introduce a tool architecture supporting continuous learn- ing and reuse of all kinds of experience from the software engineering domain and present the underlying methodology. 1 Introduction The demands on the development of software are steadily increasing: shorter time-to- market, better quality, and better productivity are critical for the competitiveness of today’s software development organizations. To compound matters, the software to be developed increases in its application complexity. To meet these demands, many orga- nizations frequently introduce new software engineering technologies. However, often there is not enough time to train project teams extensively. Experts become a scarce resource. There are three ways to handle scarce resources [11]: automation, better planning, and reuse. The first way is the hardest: Only formalized tasks can be automated, which requires a deep understanding of the task. Unfortunately, in software development, no project is like another. Thus, formalizing tasks is hard. Moreover, many tasks are so complex that they can never be automated completely. This leaves better planning and reuse. Both are similar in the sense that they can be supported by installing an organi- zational memory that is capable of managing all kinds of software engineering experi- ence. It is widely known that an organizational memory must be maintained by an organi- zational unit separate from the project organizations [27, 58]. We base our approach on the experience factory concept [13, 14]. The experience factory (EF) is an organiza- tional unit that supports reuse of experience and collective learning by developing, updating, and providing, on request, clusters of competencies to be used by the project
-
Upload
independent -
Category
Documents
-
view
1 -
download
0
Transcript of Systematic Population, Utilization, and Maintenance of a Repository for Comprehensive Reuse

e-to-s ofto beorga-ften
carce
ning,whicht, no
e sog andgani-peri-
ani-ch onniza-ing,roject
Systematic Population, Utilization, and Maintenance of aRepository for Comprehensive Reuse
Klaus-Dieter Althoff, Andreas Birk, Susanne Hartkopf, Wolfgang Müller,Markus Nick, Dagmar Surmann, Carsten Tautz
Fraunhofer Institute for Experimental Software Engineering, Sauerwiesen 667661 Kaiserslautern, Germany
{althoff, birk, hartkopf, mueller, nick, surmann, tautz}@iese.fhg.de
Abstract. Today’s software developments are faced with steadily increasingexpectations: software has to be developed faster, better, and cheaper. At thesame time, application complexity increases. Meeting these demands requiresfast, continuous learning and the reuse of experience on the part of the projectteams. Thus, learning and reuse should be supported by well-defined processesapplicable to all kinds of experience which are stored in an organizational mem-ory. In this paper, we introduce a tool architecture supporting continuous learn-ing and reuse of all kinds of experience from the software engineering domainand present the underlying methodology.
1 Introduction
The demands on the development of software are steadily increasing: shorter timmarket, better quality, and better productivity are critical for the competitivenestoday’s software development organizations. To compound matters, the softwaredeveloped increases in its application complexity. To meet these demands, manynizations frequently introduce new software engineering technologies. However, othere is not enough time to train project teams extensively. Experts become a sresource.
There are three ways to handle scarce resources [11]: automation, better planand reuse. The first way is the hardest: Only formalized tasks can be automated,requires a deep understanding of the task. Unfortunately, in software developmenproject is like another. Thus, formalizing tasks is hard. Moreover, many tasks arcomplex that they can never be automated completely. This leaves better planninreuse. Both are similar in the sense that they can be supported by installing an orzational memory that is capable of managing all kinds of software engineering exence.
It is widely known that an organizational memory must be maintained by an orgzational unit separate from the project organizations [27, 58]. We base our approathe experience factory concept [13, 14]. The experience factory (EF) is an orgational unit that supports reuse of experience and collective learning by developupdating, and providing, on request, clusters of competencies to be used by the p

hich
n theal-ori-ple-Thisent-
tingustrialarningodol-entstionienceum-
etter,not
codeesign[19,dels
tech-sci-
trievalusects.con-n fur-theto
text)nce,
of theand
-
organizations. The core of the experience factory is the experience base (EB) wacts as the organizational memory.
The experience factory not only selects what experience should be captured iexperience base, but also defines strategies on how to gain such experience (goented knowledge acquisition). Thus, the concept of the experience factory comments existing reuse approaches with a learning component for updating the EB.is operationalized by employing a case-based reasoning [1] strategy [2] for impleming the EB1.
The paper is organized as follows. The next section gives an overview of exisreuse approaches in software engineering. Based on existing approaches and indneeds, we derive an open tool architecture that supports reuse and continuous leof all kinds of experience in Sect. 3. In Sect. 4 and Sect. 5, we present our methogy for reusing and learning, respectively, and show how the architecture implemit. Sect. 6 points out important organizational aspects in the context of the installaof the tool architecture in an organization, whereas Sect. 7 lists some of the experwe gained while implementing the concept in projects. The paper ends with a smary and a conclusion in Sect. 8.
2 State of the Art
Reuse practice exhibits considerable potential for developing software faster, band cheaper [47, 61]. However, the full potential can only be exploited if reuse islimited to code [17, 28]. Examples for software engineering experience besidesinclude requirements, design, and other software documentation as well as dmethod tools [39], software best practices [31], technologies [23], lessons learned46], various models (e.g., resource, product, process, quality [13], and cost mo[15]), measurement plans [26, 60], and data [59].
All this experience has to be stored and retrieved. On the retrieval side, manyniques have been employed. These include classification techniques from libraryence such as enumerated classification, faceted classification, and information re[25]. One of the problems to be dealt with is the fact that artifacts matching the reneeds exactly are rarely found. Therefore, it must be possible to find similar artifaPrieto-Díaz extended the faceted classification as known in library science by thecept of similarity [44]. Case-based reasoning systems extend faceted classificatiother by allowing the facets to have arbitrary types [3, 16, 34]. Maarek et al. tacklesimilarity problem by automatically clustering artifacts and allowing the userbrowse the clusters [35]. For small sets of artifacts, browsing (e.g., using hyperwill suffice [28]. Other techniques are specialized toward specific kinds of experiefor instance, component specifications [36, 41, 42].
There are two basic ways to characterize reusable artifacts: (1) Characteristicsartifact itself (e.g., format, size, origin) and (2) characteristics of its application
1 By “learning” we donotmean “individual learning” but “collective learning” through improving the EB.

). Ide-cs ofele-t triv-
alysisfew
temstem.items
sameaddi-]. A
n thethe
useftwareily onpo-ches
soningoryoft-
ationning54]
epts. A].
f allmongitive
nt isn) and
usage context (e.g., size of project, business domain, experience of project teamally, an artifact is characterized using both kinds of characteristics. Characteristian artifact’s application context can be expected to be most effective for finding rvant reuse candidates. However, finding an appropriate set of characteristics is noial. It requires special techniques known asdomain analysis[10, 37, 43]. Most domainanalysis work has focused on the reuse of software components only. Domain anfor other kinds of software engineering artifacts has been addressed by quite aauthors yet (such as [18, 30]).
If more than one kind of experience is to be reused, either several retrieval sysmay be used (one for each kind of experience) [44] or one generic retrieval sysThe latter can take advantage of the semantic relationships among the experiencefor retrieval, but requires that all kinds of experience are characterized using theformalism. Examples include specialized knowledge-based systems [22, 39]. Intion to semantic relationships, Ostertag et al. consider similarity-based retrieval [40framework for representation and retrieval techniques can be found in [24].
When choosing a representation, one cannot only consider the benefits oretrieval side, but must also consider the cost involved in creating and maintainingEB or “computer-supported learning” in general [24]. However, in contrast to reprocesses, learning processes have not received that much attention in the soengineering community. Research on detailed learning processes focuses primaridentifying reusable components (e.g., [20, 21, 52]) and on building software comnent repositories for a given application domain (e.g., [33, 50]). But these approaare not able to transfer experience (e.g., as lessons learned)across domains [29].
A community that focuses on such learning processes is the case-based reacommunity. It has its roots in Schank´s work on scripts [48] and dynamic mem[49]. An evaluation of current case-based reasoning technology is given in [3]. In sware engineering it has been mainly used for similarity-based retrieval and estimtasks (an overview is given in [4]). [30] and [9] recognized that case-based reasocan be used for implementing continuous learning in an EF-like organization. [53,showed that case-based reasoning and EF are complementary, combinable concfirst architecture for the integration of these concepts has been presented in [4, 6
3 Architecture of a Software Engineering Experience Environment(SEEE)
Our tool architecture is a generic, scalable environment for learning and reuse okinds of software engineering experience. It uses the semantic relationships aexperience items to ensure the consistency of the EB, to allow context-sensretrieval, and to facilitate the understanding of artifacts retrieved. The environmenot restricted to retrieval and storage, but supports the complete reuse (adaptatiolearning processes as defined by our methodology in Sect. 4 and Sect. 5.

onof
ainedthe
col-ctiveIt is
ins”n isickly.e EBemaccur
ed to2, 32,
epre-iencenc-luesser-ructs
teg-
s).
3.1 Knowledge Representation
Storage and retrieval are based on REFSENO, ourrepresentationformalism forsoft-wareengineeringontologies [56, 55]. Pragmatic constraints impose requirementsthe formalism [2]. They concern the responsibility for maintaining different typesknowledge. For example, software engineering artifacts are developed and maintby projects. Thus, project teams should supply information about artifacts (e.g., inform of characterizations). The EF determines what kinds of artifacts should belected, how they are related, and how they should be characterized as to allow effeand efficient retrieval. This conceptual knowledge is captured in the EB schema.used to guide the storage and retrieval of artifacts. Finally, our institute “maintaREFSENO (i.e., the way the conceptual knowledge is specified). This divisioimportant since fast learning can only be realized if experience can be adapted quFast learning is supported by the guidance through the conceptual knowledge. Thschema, on the other hand, evolves slowly in comparison. An evolution of schtakes place after careful analysis of reuse behaviors. More radical changes will oonly if an organization changes its strategic goals. However, REFSENO is expectchange very seldom since it is based on many projects applying the EF concept [45].
REFSENO basically provides constructs to describe concepts (each concept rsents a class of experience items), terminal attributes (typed properties of experitems), nonterminal attributes (typed links to related experience items), similarity futions (for similarity-based retrieval) as well as integrity rules (cardinalities and varanges for attributes, value inferences for automatically computable attributes, ations, and preconditions). The EB schema is specified using REFSENO’s const(Fig. 1 shows an example).
Thus, REFSENO extends the formalism of Ostertag et al. [40] by additional in
Fig. 1.Exemplary schema (not shown: similarity functions, assertions, and precondition
Artifact
Process Model
Technique Description
Code Module
Lesson Learned
Project CharacterizationGranularity: {SW development, requirements phase, …}; card: 1Inputs: {customer req., developer req., design, …, executable
system, customer release}; card: 0..nOutputs: {customer req., developer req., design, …, executable
system, customer release}; card: 0..n…
ProgLang: {Ada, C, C++, …}; card: 1…
Issue: Text; card: 1Guideline: Text; card: 1…
Goal: Text; card: 1…
Name: Text; card: 1Duration: Real [0..100] in “months”; card: 0..1Team size: Integer [0..500]; card: 0..1Type of software: {embedded realtime systems,
integration and test environments, …};card: 1
ProgLang used: {Ada, C, C++, …}; card: 0..n;value := union(([Artifact]=[CodeModule]).[ProgLang])
…
derives
has-part
is-a
is-a
is-a
uses
Name: Text; card: 1…
0..n
1
0..n
1
0..n
0..n

his isdata,ENO
sys-tems)s of ations
com-ed ine sim-nceantems
thecter-d [10,usedue-hus,helingomeby a
ationween
thexpe-d ind ofefore,een
reas-
eno doughand
t dif-
rity rules and by clearly separating the schema definition and characterizations. Tin line with data modeling languages, which distinguish between data models andand enforce the integrity of the database by rules. However, in contrast, REFSallows for similarity-based retrieval.
In projects with our industrial customers we have learned that knowledge-basedtems basing on completely formalized general knowledge (e.g., rule-based sysare not necessary for our objectives. Our queries are restricted to characterizationparticular concept selected by the user. Inferences are limited to value computa(e.g., in Fig. 1 the programming languages used in a project are automaticallyputed by taking the union of the programming languages of all code modules usthe project) that can be performed at the time characterizations are inserted. Thesplifications result in an improvement of retrieval efficiency. The storage of experiein the form of documents (in contrast to codified knowledge) results in a significreduction of the learning effort typically associated with knowledge-based syst[24].
The different attribute types allow to deal with various degrees of formality. Inbeginning of the reuse program, it is often not clear how artifacts should be charaized. Unless a comprehensive pre-study and domain analysis work are preferre37, 43], an initial reuse infrastructure can be built gradually. Text attributes can beto allow the storage of arbitrary information. However, in general, no meaningful qries are possible (though information retrieval techniques are conceivable). Tmainly browsing is possible. However, this may suffice for small collections. Tbrowsing functionality can be enhanced by specifying nonterminal attributes enabnavigation along these semantic relationships. As the information needs becclearer or collections grow in size, text attributes can be supplemented/replacedset of typed attributes that allow meaningful queries (e.g., integer, real, enumertypes). This clearly extends hypertext approaches and allows to distinguish betthe stored experience items.
Moreover, semantic relationships enable context-specific retrieval and facilitateunderstanding of artifacts. Context-specific retrieval allows people to find useful erience they previously were not aware of (e.g., “find all process models appliesmall projects of my organization” might return projects the user has not hearbefore). Using semantic relationships, queries can be stated more precisely. Thereach concept needs to contain only a few terminal attributes to differentiate betwartifacts, because artifacts also differ in theircontext. This feature reduces the effort fosetting up the schema initially because a few characteristic attributes can be foundily by interviewing experts in an organization. After a specific artifact has beretrieved based on its characterization, it has to be evaluated for its applicability. Tso requires understanding of the artifact. Here, context information (provided thronavigation along semantic relationships) helps to quickly identify prerequisitesrationales behind the development of the artifact.
3.2 Scalable SEEE Architecture
The installation of an EB focuses on practical problems and, therefore, has to mee

rowratedf ancess
laterality
three-itec-tionr soft-tems.
spe-oragered inarti-
teriza-in theand
an beerentr each
heseple
sameE tooleling.ase-rver.tool
earch-hing,the
) cannizeserencesareEBtool
r isstor-
ferent requirements. Often, the EB installation starts small, but it must be able to gin size. Frequently, organizations already use specialized tools that must be integinto the EB. The representation of artifact types might change in the course oimprovement program from informal to a more formal representation (e.g., promodels that were represented as simple text documents in the beginning aredeveloped with an advanced process modeling tool). Also additional tool functionmight be supplied as the scope of the reuse program expands.
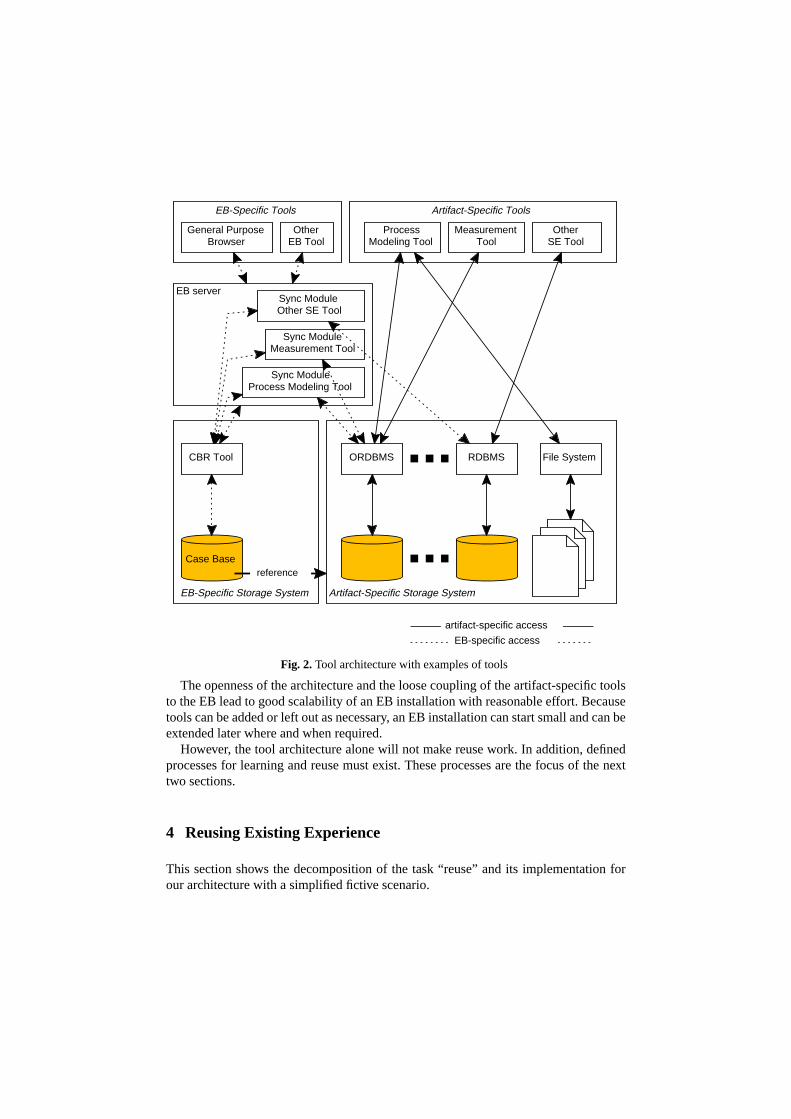
Our solution to these issues is an open architecture – an advancement of thelayer client-server EB architectures presented in [4, 6, 2]. Fig. 2 shows this archture with examples of artifact-specific tools that might already exist in an organizaand must be integrated: a process modeling tool, a measurement tool, and anotheware engineering (SE) tool as well as their respective artifact-specific storage sysThe important aspects of the architecture are described in detail in the following.
The EB data (i.e., artifacts and characterizations) is distributed over an artifact-cific storage system and an EB-specific storage system. In the artifact-specific stsystem, the actual artifact data (e.g., process models, measurement plans) is stoits native format in databases or files. This artifact data consists of all collectedfacts, but not those artifacts (still) under control of a project (project-specific artifacts).The EB-specific storage system consists of a case base where the artifact charactions are stored. Each characterization has a reference to the actual artifact dataartifact-specific storage system. This distribution of the EB data over case baseartifact-specific database systems or files has the advantage that existing tools cinvoked using the reference that is stored in the characterization. Because a diffserver program (i.e., database management system or file system) can be used fotype of artifact according to its needs regarding the representation formalism, tdifferent representation formalisms do not interfere with each other. In the examshown in Fig. 2, the process modeling tool and the measurement tool use theobject-relational database management system (ORDBMS), whereas the other Suses a relational database system (RDBMS) for storing its data. The process modtool also accesses the file system for creating HTML pages for process guidance
Fig. 2 shows our tool architecture. An EB installation has, as its core parts, a cbased reasoning tool (CBR tool) [57], a general purpose browser, and an EB seArtifact-specific tools and storage systems can be added as needed. The CBRstores the artifact characterizations in the case base and allows similarity-based sing via the artifact characterizations. The general purpose browser provides searcviewing, and manipulation of characterizations. The operations are handled byEB server and the CBR tool. Other EB tools (e.g., for special maintenance tasksbe added in parallel to the general purpose browser. The EB server synchroaccess to the case base, the databases, and the files. It also maintains the reffrom the characterizations to the artifacts. All this is only required for objects thatunder the control of the EB. The project-specific artifacts are not in the scope of theand, thus, need not be known by the EB server. To integrate a new artifact-specificinto our architecture, only a small synchronization module for the EB serverequired. Such a module manages access to the EB-specific and artifact-specificage. For our standard tools, synchronization modules are provided.
toolsusean be
nede next
for
The openness of the architecture and the loose coupling of the artifact-specificto the EB lead to good scalability of an EB installation with reasonable effort. Becatools can be added or left out as necessary, an EB installation can start small and cextended later where and when required.
However, the tool architecture alone will not make reuse work. In addition, defiprocesses for learning and reuse must exist. These processes are the focus of thtwo sections.
4 Reusing Existing Experience
This section shows the decomposition of the task “reuse” and its implementationour architecture with a simplified fictive scenario.
Fig. 2.Tool architecture with examples of tools
EB-Specific Tools Artifact-Specific Tools
EB-Specific Storage System Artifact-Specific Storage System
File SystemRDBMSORDBMS
Case Base
CBR Tool
EB server
Sync Module Measurement Tool
Sync Module Process Modeling Tool
Process Modeling Tool
Measurement Tool
Other SE Tool
General Purpose Browser
Sync Module Other SE Tool
Other EB Tool
artifact-specific access
EB-specific access
reference

sitiond.tyacts
the
ence-
at
nt
s) ins
, the
reuses and
facts)n-
ts are
sks:the
ede
4.1 Decomposition of the Task “Reuse”
The task “reuse” is decomposed as shown in Fig. 3 (a refinement of the decompopresented in [15, 2]). In the following, the objectives of the subtasks are describe
The objective ofreusingexperience is to save effort while delivering better qualiin less time. This is done in several ways: First, instead of developing new artiffrom scratch, appropriate reuse candidates areretrieved and utilized. Second, tacitknowledge in a certain context is acquired from experts that are identified usingEB. Third, relevant existing information in a certain context isretrievedfor supportingmanagement in, for example, detecting problems and risks and making experibased decisions.
Theretrieving(objective: to find the most appropriate experience for the problemhand) is decomposed intospecifyingthe needed experience,identifying candidateexperience in the EB,evaluatingthis experience, andselectingthe best-suited experi-ence. The objective ofspecifyingthe needed experience is to determine the importacharacteristics. These characteristics are used during theidentification(objective: tofind a set of objects with the potential to satisfy project-specific reuse requirementone of two ways: Either they are used tobrowsethe EB or they are entered formally aa query (according to the characterization schema) tosearchthe characteristizations ofthe artifacts stored in the EB. Once potentially useful experience has been foundexperience is evaluated in depth regarding its utility. The objective ofevaluatingexpe-rience is to characterize the degree of discrepancies between a given set ofrequirements, and to predict the cost of bridging the gap between reuse candidatereuse requirements. It is decomposed into the automatable taskrecommendwhichcomputes the similarity (based on the query and the characterizations of the artiand the manual taskexamineduring which an expert analyzes the system’s recommedation based on the characterizations of the artifacts. Finally, the evaluation resulused toselectthe best-suited reuse candidate(s).
The best-suited reuse candidate(s) are then utilized. The objective ofutilizing is totake advantage of the existing experience. It is decomposed into the following taCheck-out(optional task; objective: to copy the selected reuse candidate(s) intoproject base2), understand(objective: to find out how to take advantage of the selectreuse candidate(s)),merge artifacts(optional task; objective: to combine several reus
Fig. 3.Decomposition of the task “reuse”.
reuse
specify
utilizeretrieve
identify selectevaluate
browse search recommend examine
check-out
understand
merge artifacts
modify artifact
change
incorporate
givefeedback
constraints

iron-
ndi-
e EBtasks.
arddedr done
-r: asys-
ignt withas a
hstrik-The
-ther-signing theaui”
em ind--urce
candidate(s) to a single artifact),modify artifact(optional task; objective: to bridge thegap between the artifact to be utilized and the needed experience),change constraints(optional task; objective: to adapt a system (set of documents or development envment) so the modified artifact can be incorporated easily),incorporate(objective: toincorporate the (modified) artifact into a given system), andgive feedback(objective:to improve decision making process for future utilizations of the selected reuse cadate(s)).
4.2 Scenario
The following scenario demonstrates the reuse of existing knowledge stored in thand the use of tacit knowledge in the organization. Thus, it exemplifies the reuseof the previous section. The scenario is based on the EB schema shown in Fig. 1
The Project “Maui”. The group “fuel injection” has just signed a contract with a cmanufacturer to develop the software for a new fuel injection system (an embereal-time system). The contract demands a design review, but the group has nevea design review before.
The Planning of the Project “Maui”. The planning of the project starts with a preliminary characterization of the project according to the properties known so faduration of 12 months, a team size of six, the software type “embedded real-timetems”, and the technique “design review”.
The “Maui” project manager needs information on similar projects where a desreview has already been performed because he has never managed a projecdesign reviews before. The preliminary characterization of the project is usedquery (taskspecify) for identifyingsimilar projects in the EB to reuse knowledge fromthese projects (tasksearch). The two most similar projects “Lipari” and “Purace” bothemployed design reviews. Theevaluationshows that these projects did not deal witembedded real-time systems, but experience about design reviews exists. Quiteingly, in both projects the design reviews were combined with design inspections.“Maui” project managerselectsthe first similar project, “Purace”, for getting more indepth, tacit knowledge by interviewing the “owner” of the project experience:“Purace” project manager (taskunderstand). It turns out that the inspections were peformed for preparing the design review. The goal was to eliminate as many dedefects as possible before the customer takes a look at the design, thus, increasconfidence and/or satisfaction of the customer. Based on this discussion, the “Mproject manager decides to employ design inspections as well and prescribes ththe project plan (taskincorporate). The project plan itself is developed using olproject plans from “Lipari” and “Purace” that aremergedand adapted to project-specific needs (taskmodify artifact). While doing so, the “Maui” project manager recognizes that the project cannot be completed in time under the given resso
2 The project base holds all project-specific information and experience.

(task
ppliedodelsthe
-ntlem
ntextsons,Fur-t ofh the
esignjectsi-rded
a-(2)es. Towed
rojecttionsn
k
rcesectslan-onsthat a
constraints. Therefore, he asks for an additional person working for the projectchange constraints).
Furthermore, he decides to check if there are process models that have been afor developing embedded real-time systems, because the development process mthat were used in the projects “Lipari” and “Purace” have not yet been applied todevelopment of such systems. Hence, hespecifiesthe preliminary project characterization as the context foridentifyingprocess models that cover the whole developmeprocess (granularity “SW development”, inputs “customer requirements and probdescription”, and output “customer release”) and have been applied in a similar co(i.e., for the development of embedded real-time systems, with a team of six perand a duration of 12 months). This context-sensitive query is depicted in Fig. 4.therevaluationshows that only one process model is suitable for the developmenembedded real-time systems. This is the process model “Standard 4711”, whicproject manager has already used in several projects. Thus, heselects“Standard 4711”as best-suited reuse candidate and decides toutilize it. To do so, hechecks out“Stan-dard 4711”, invokes the appropriate process modeling tool tounderstandandmodifythe process model to meet the project-specific needs. It is then extended by dinspections and reviews using parts from the process models used in the pro“Lipari” and “Purace” (taskincorporate). The experience gained so far during the utlization (e.g., changes made to “Standard 4711” and effort needed for it) are recoin the EB (taskgive feedback).
The Performance of Project “Maui”. After the performance of the first designinspection, the project manager compares the design error rate of “Maui” (taskspecify)with the lessons learned from theidentifiedsimilar projects “Lipari” and “Purace”,which are also stored in the EB. He finds out the rate is worse than expected. Theeval-uatedandselectedlessons learned for “Lipari” and “Purace” state two potential resons for this (taskunderstand): (1) the design inspection team is less experienced;the design engineers are less experienced. Obviously, the first reason matchcheck the second, the project managers of “Lipari” and “Purace” are intervieregarding the experience of the design engineers involved (taskunderstand). It turnsout that they have almost the same experience as the design engineers in the p“Maui”. Thus, the second reason is rejected and further training for design inspecis arranged (taskincorporate). In the next inspections after the training, the desigerror rate reaches the expected level. This experience is recorded in the EB (tasgivefeedback).
4.3 Benefits of Our Approach
In contrast to [15], our approach also provides knowledge maps for identifying souof tacit knowledge (e.g., the identification of the project managers of the proj“Lipari” and “Purace” who have experience with design reviews), supports the pning and performance of projects by providing relevant information (e.g., lesslearned), and also assists in discovering unexpected knowledge (e.g., the fact

is not, 41,
forrevi-
design review requires a design inspection).Unlike many other approaches, reuse is also comprehensive, that is, reuse
restricted to artifacts of one or a few types (e.g., component specifications [3642]).
5 Learning for Future Projects
This section shows the decomposition of the task “learn” and its implementationour architecture with a simplified scenario that continues the scenario from the pous section.
Fig. 4. Identification of the process model with the general purpose browser.

) toovingmpo-
tnizedture,tored
e theThe
g to
6).e.
t bens,tures cannd/or
ing
5.1 Decomposition of the Task “Learn”
In [15] learning was decomposed into recording and packaging. Because it was (1abstract to be applied systematically in practice and (2) lacking a task for remosuperfluous experience, we developed a more detailed decomposition. This decosition is depicted in Fig. 5 and described in the following.
The objective oflearning is to improve software development by allowing efficienand effective reuse. Therefore, we create a repository of well-specified and orgaexperience. Learning is done by continuously analyzing the technical infrastrucrecording available experience as well as packaging and forgetting already sexperience.
The objective ofanalyzing the technical infrastructure(consisting of the SEEE, itscontents, and the schema underlying the contents) is to find potential to improvtechnical infrastructure regarding its effectiveness and efficiency (see also [8]).analysis can result in various actions: reorganizing existing experience (taskpackage;see Sect. 5.3), removing superfluous experience (taskforget), or recordingnew experi-ence that has been made available through ongoing projects (see next section).
5.2 Recording Newly Available Experience
New experience is added by performing the taskrecord. The objective ofrecordingexperience is to fill the EB with well-specified and organized experience accordinthe needs of the EB’s users. It is decomposed intocollectingthe experience,storing itin the EB, ensuring its reusability byqualifying it, making it available for users’ que-ries (i.e.,publishing it), andinforming interested users about its existence (see Fig.
The objective ofcollectingexperience is to capture new or improved experiencThe EF can do this actively by searching for artifacts and information that mighworth recording for future reuse (in projects and in the world at large). “Worth” meafor example, that the item is the kind of knowledge that is expected to be used in fuprojects, or that the item is regarded useful by the project team. The project teamalso make suggestions for new artifacts or updates of already stored artifacts atheir characterizations.
In general, there is a wide range of ways for collecting experience. The followfour ways are typical:
Fig. 5.Decomposition of the task “learn”.
analyze package
structure adapt aggregate
recordforget
learn
technicalinfrastructure

rd-s for
m-of a
/orcon-
r shortthe
esake
ong;cts
uali-)firstca-
rts it
wlify
g
– Spontaneous collection,where only the scope is defined (e.g., spontaneous recoing of lessons learned during project performance, suggestions by project teamreusable software components)
– Event-driven collectionat milestones of a project (e.g., shipping of a release, copletion of an inspection or review) and at the end of a project (e.g., the analysisproject in a post-mortem meeting with the project team)
– Periodical collection (e.g., periodic checking of projects for new code modules)– Exactly-planned collection,where exactly specified experience is developed and
collected (e.g., an EF-initiated project that develops code modules for reuse, atrolled experiment by the EF for testing a new design inspection method)
Each of these ways has certain advantages and prerequisites. For example: Foprojects it is practicable to collect experience only at the end of the project to keepeffort for learning low. For long-term projects, event-driven collection at milestonmakes new experience available earlier. The periodical collection also allows to martifacts available relatively early when the period of time between milestones is lon the other hand, this could also lead to more effort for qualifying the artifabecause they might not have passed all tests in the project.
All experience collected needs to be stored. The objective ofstoringexperience is tomake a new artifact and its characterization available in the EB so that it can be qfied and published if it is accepted. Experience is stored inexperience packages (EPs[15] that consist of an artifact and its characterization. To store an artifact, it iscopiedfrom the storage system of the project into the EB to avoid further modifitions by the project team. For some artifacts it is appropriate tosplit them into reusableparts (e.g., a program into components). Afterwards, the artifacts or each of the pahas been split into, ischaracterized initially as far as the characteristics are known.
The objective ofqualifyingexperience is to check and modify (if necessary) a neartifact and its characterization to have it “fit” for reuse (or reject it during the quaprocess). Thequality of each EP (or parts thereof) has to beanalyzedto ensure that ithas the required minimal quality. In addition, it ischeckedwhether similar EPs (orparts thereof) alreadyexist. The information about the quality and similar existinexperience is input to the manualreviewprocess. During thereview, thereuse potential
record
qualifycollect store publish inform
characterizesplitcopy analyze review evolve complete
check foranalyze analyze suggest
initially part charaterization
quality existingparts
reusepotential
improvements
Fig. 6.Decomposition of the task “record”

se itsed by
one.
er
il-abletion
alnewbe
d by
ols. Itwn in
-
ctse in
ed asper-
ojectf the
“db-nd itsc-
ola-
ny
db-
of the artifact (or parts thereof) isanalyzedand improvementsare suggestedby thereviewers. Improvement suggestions include how to change the artifact to increareuse potential, which artifacts that are already stored in the EB should be replacthe new artifact (meaning that the taskforgetneeds to be performed after therecord-ing), and which of the already stored artifacts should be merged with the newThen the artifact isevolvedaccording to the improvement suggestions. Also, thechar-acterizationhas to becompleted. Note that evolving an artifact can require anothquality analysis and/or review (depending on the changes).
The objective ofpublishingexperience is to make a stored and qualified EP avaable for its intended users. Before the experience is published, it is only availwithin the context of the recording of the artifact (e.g., for testing the characterizaof the artifacts with some retrievals). Draft versions can bepublished preliminarilywhen useful.
The objective ofinforming is to notify potential users of the new artifacts. Severstrategies can be used, including broadcasting (informing all users about everyartifact), subscribing (users subscribe to the kinds of artifacts they would like toinformed about), and event-driven (e.g., if a checked-out artifact has been improvesomeone else, the person who checked out the artifact is informed).
Scenario.The scenario demonstrates how the learning process is supported by tocontinues the scenario from Sect. 4. The characterization schema of the EB is shoFig. 1.
Planning and Performance of the Project “Maui”.During the planning phase, the preliminary characterization of the project “Maui” isrecorded. The advantages of this arethat the project “Maui” can be notified when, for example, errors are found in artifareused by “Maui”, that the EB can be used as knowledge map on tacit knowledgcurrently running projects, and that the preliminary characterization can be specificontext for all experiences from the project that are recorded during planning andformance of “Maui”. For example, lessons learned cannot be added without a prcharacterization. This is specified in the schema (see Fig. 1) by the cardinality o“derives” relationship between lessons learned and project characterizations.
During project performance, a lesson learned for the reused code moduleaccess” about a problem with a database management system ABC-Access asolution is spontaneouslyrecordedas follows: The lesson learned including its charaterization is provided by the project team as a suggestion for the EB (collectandstore).Thequality analysisregarding the EB standards for lessons learned showed no vitions. Also, no parts similar to those of the lesson learned were found (taskcheck forexisting parts). Afterwards, the lesson learned isreviewed to see whether it is awanted, potentially useful artifact. Except for some editorial changes, noimprove-mentshave beensuggested. Because ABC-Access is expected to be used in mafuture projects, the lesson learned is regarded as useful and, thus,evolvedand pub-lished. Finally, potential users (e.g., all those who checked out the module “access”) are informed about the problem.

lopedwedation
s con-us,
ady
eusewith
r, theng the
sign
n infromor aspe-imple
re are
euse
ser’seus-arti-
, it istch.
Post-Mortem Meeting of Project “Maui”.After the project “Maui” was finished, apost-mortem meeting showed that the new process model, which has been devein the project, is worth being stored in the EB. The post-mortem analysis also shothat instead of six people, seven had been working on the project. The project durwas also prolonged by one month.
The preliminary projectcharacterizationis updated andcompletedbased on theresults of the post-mortem analysis. Then it is validated by areview. Finally, theupdated, validated project characterization ispublished. Note that an analysis of itsreuse potential is not necessary because the project characterization is required atext information for any experience from the project that is stored in the EB. Threcording project characterizations is mandatory for all projects.
The process model iscopied to the EB andinitially characterized. The processmodel is stored as a whole. Thus, it does not have to besplit into parts. Then the pro-cess model and its characterization areanalyzed for their quality. It is noticed that stan-dards regarding names are not fulfilled completely. Moreover, similar artifacts alrestored are identified (taskcheck for existing parts). In this case “Standard 4711” isretrieved to ease the analysis of the reuse potential. For thereview, a process modelingtool is used for viewing the process model. The model isanalyzedregarding itsreusepotential: The process model has been used in a project with a small team. The rscenarios show that process models for projects should be available for projectssmall and large teams. Thus, the process model isevolvedby adding recommendationsabout how the process model can be used in a project with a large team. Moreovenon-standard-compliant names are replaced with standard-compliant names usiprocess modeling tool. Finally, thecharacterization is completed, all project managersare informedabout the new process model, and the EP “Standard 4711 with DeInspections and Review” ispublished (see Fig. 7).
This publishing can even be done remotely with our WWW interface as showFig. 7. The use of WWW-based technology also allows to scale the EB systemuse in a single intranet (e.g., for a small company) up to global networks (e.g., fglobally operating company). For global reuse and learning appropriate artifact-cific storage systems are also required that can deal with world-wide access. Stext or HTML documents can be viewed directly using the WWW browser.
5.3 Organizing and Maintaining Existing Experience
Over time, it may become necessary to reorganize the experience in the EB. Theseveral reasons that can lead to such a reorganization:– The reuse potential was predicted wrong, i.e., an artifact is not as attractive for r
as judged by the reviewers during therecording. This can be “diagnosed” usingaccess statistics (e.g., how often the artifact was returned as the result of a uquery or how often an artifact was actually checked out) [8]. In this case, the rability of the corresponding artifact should be increased, e.g., by modifying thefact.
– The experience may not have been available in the form needed. For instancedifficult to write a handbook on a software engineering technology from scra

tech-eed ton this
, theyge (a)
e ISOEB.
(task
, pro-
sk
ace.
Before a comprehensive and (in practice) useful handbook can be written, thenology needs to be applied in pilot projects, observations and measurements nbe made, and analysis results need to be documented and merged [6, 23]. Icase, many experience items need to be merged to a single new artifact.
– The user requirements may change. As the users of an EB utilize the contentsbegin to better understand their real needs. This may result in requests to chanthe contents and/or (b) the structure of the EB.
– The environment may change. External market pressures (e.g., the need to b9000 conform) may have an impact on both the contents and the structure of the
The reorganization is subject ofpackaging. The objective ofpackagingexperience isto increase its reuse potential. This can be done by, for example, merging artifactsaggregate), improving the EB characterization schema (taskstructure), finding outwhat kinds of packages are required in future projects (new reuse requirementscesses, and scenarios) and acquiring these packages (new criteria forcollecting andquality analysis) or modifying existing EPs to meet these new requirements (taadapt).
Fig. 7.Example for characterizing and publishing a process model using the WWW interf

okeessednaly-efore,n.
geibuteha-
totionulal”).ticu-of
orre-the
ojectsion
Scenario.After the completion of “Maui”, it became evident that many projects tolonger to complete than originally planned (in case of “Maui” one month, sSect. 5.2). It is decided to analyze this further and to find out by how much (expreas a percentage) a project took longer than planned. Unfortunately, this kind of asis was not taken into account at the time the EB schema was developed. Therthe planned duration has not been recorded as part of the project characterizatio
To enable the analysis, the schema needs to be extended (taskstructure): Anattribute “Planned duration” and a concept “Duration Model” (holding the averaovertime of a manually defined set of projects) are added (see Fig. 8). The attr“Overtime factor” of the concept “Duration Model” uses the value inference mecnism of REFSENO. Since all relationships are bidirectional, the formula is ableaccess all “Project Characterizations” that are linked to the particular “DuraModel”. These “Project Characterizations” are referred to as “projects” in the form(see name on arrow connecting “Project Characterization” with “Duration ModeThe formula calculates the average overtime factor of all projects linked to the parlar duration model. If either the attribute “Duration” or “Planned duration” of anythe linked projects is changed, the duration model will be updated automatically.
The next step is to fill the new attribute “Planned duration” with data, i.e.,adaptthecorresponding characterizations of the projects. This is done by retrieving the csponding project plans (invoking a specialized project planning tool) and enteringplanned duration manually. Once all characterizations have been adapted, the prmust beaggregatedfor their duration models (for each group a separate durat
Fig. 8.Extended schema.
Artifact
Process Model
Technique Description
Code Module
Lesson Learned
Project CharacterizationGranularity: {SW development, requirements phase, …}; card: 1Inputs: {customer req., developer req., design, …, executable
system, customer release}; card: 0..nOutputs: {customer req., developer req., design, …, executable
system, customer release}; card: 0..n…
ProgLang: {Ada, C, C++, …}; card: 1…
Issue: Text; card: 1Guideline: Text; card: 1…
Goal: Text; card: 1…
Name: Text; card: 1Planned duration: Real [0..10] in “months”;
card: 0..1Duration: Real [0..100] in “months”; card: 0..1Team size: Integer [0..500]; card: 0..1Type of software: {embedded realtime systems,
integration and test environments, …};card: 1
ProgLang used: {Ada, C, C++, …}; card: 0..n;value := union(([Artifact]=[CodeModule]).[ProgLang])
…
derives
has-part
is-a
is-a
is-auses
Name: Text; card: 1…
0..n
1
0..n
1
0..n
0..n
Duration ModelName: Text; card: 1Overtime factor: Real [-100..500]; card: 1; value inference:
(sum(projects.Duration)/sum(projects.Planned duration)-1)*100…
derives
0..n
1
projects

ed-
nted atings thatiledalsoarac-
ulesse offromted
w-implemoreve-e
ngrests
ranteeto a
sible
con-
rninguiresand
13]
using
model will be constructed). This allows to distinguish between, for example, embded and software development systems which are very different in nature.
5.4 Benefits of Our Approach
So far, learning has often been neglected in reuse approaches. We have presedetailed description of recording, a subtask of learning. For developing and collecexperience, a viable approach has been described. The qualifying actively ensurethe stored artifacts are of high quality and relevant for future (re)use. The detadescription of the recording process allows to support the tasks with tools, whichmakes learning faster, better, and cheaper through, for example, guidance for chterizing new artifacts by the use of schemas, automatically controlled integrity rensuring consistency of the EB, and usage of existing artifact-specific tools. The uWWW-technology for the general purpose browser makes our approach scalablelocal to global use to support world-wide learning in a company that is distribuaround the globe.
The scenario presented also shows a very simplepackagingscenario to give thereader an idea whatpackaging(another subtask of learning) means. The tasks, hoever, can be much more complex than outlined in the scenario. For example, the svalue inference can be replaced by a formula of trend analysis that considersrecent projects with a higher weight than older projects. This would make improments visible in the value of the “Overtime factor” sooner by slowly “forgetting” tholder projects. Also, thestructure task can involve many stakeholders each havitheir own interests in the contents (and therefore schema) of the EB. These inteneed to be prioritized and converted to a schema [51]. Finally, processes that guathe availability of the needed information must be defined. The latter amountsdetailing of therecording task for each kind of artifact stored in the EB.
With the tasks ofanalyzing the technical infrastructure, forgetting, packaging, andrecording(as well as its subtasks), thelearning is not limited to recording and deletingsimple “data sets” as known from traditional database systems. Instead, it is pos(and supported by the flexible SEEE) to also improve the EB itself in agoal-orientedfashion. Value inferences help in keeping maintenance effort low and ensuring thesistency of the EB’s contents.
6 Running an Experience Base
The scenario in the previous sections has shown how the tasks of continuous leaand reuse can be supported by an EB. An actual deployment of an EB also reqthat the EB is embedded into an organizational infrastructure that provides fundingstrategies to consolidate reuse and learning [44].
The organizational infrastructure is divided into project organization and EF [according to the responsibilities of each organizational unit. Theproject organizationconsists of several project teams and focuses on software development while re

dager,
rmines. Theup-lyzesccord-t team
ttingoten-s new
s EPs
tionojectr. Forork,
ct).r the
F) is
experience and gaining it. TheEF provides the technical infrastructure of the EB anrecords and packages experience for future projects. We identified the roles mansupporter, engineer, and librarian within the EF. Themanagerdefines strategic goals,initiates improvement programs, acquires and manages resources. He also detethe structure and contents of the EB (e.g., the schemas) and controls its qualitysupporteris mainly responsible for collecting new experience from projects and sporting the project teams. He collects, stores, and qualifes artifacts (e.g., he anaand reviews a process model and its characterization, evolves a process model) aing to reuse requirements and goals given by the engineer. He assists the projecon request in retrieving and utilizing experience. Theengineeris responsible for ana-lyzing the technical infrastructure as well as for adapting, aggregating, and forgestored experience. He analyzes the technical infrastructure to find improvement ptial. Together with the manager, he identifies new reuse requirements und definegoals for the EB to record EPs according to them. Thelibrarian is responsible for tech-nical tasks like the creation and maintenance of the EB. He stores and publisheand informs potential users of the new EPs.
Fig. 9 shows the elements of the organizational infrastructure and the informaand control flow among them. Here, the supporter is the interface between the prorganization and the EF. For the project organization, he works as a team membethe EF, he collects, characterizes, and qualifies artifacts of the project. For this wthe supporter is paid from the EF (which, in turn, is partly funded by the projeHowever, the border line between the project organization and the EF (i.e., whethetasks of the supporter are mainly performed by the project organization or the E
project organization
reports
instructions
EP, EB infoEP
EB info
EP
query
EP
query
artifacts
(tailored) EP
Fig. 9.Organizational infrastructure for running an experience base
manager
supporter
experience factory
reuse requirementsgoals reports
librarian
reuse
goals
engineer
experience
base
EP
project team
requirements
EP

any to
sonctstart,ht beanduse
ence.onfi-en-
eusetasks.real
s sec-
iquer que-in-ander-
pec-es andts astionscrip-
ail-
s (see
ge ofzingt sug-and
ThisNO.ance, les-
based on the needs and characteristics of a company, and can vary from compcompany [13].
The implementation of the infrastructure can grow incrementally. First, one percan perform all roles of the EF beginning with a single, small project. As more projeparticipate, more people undertake the different roles. However, right from the smanagement commitment is necessary. Elements in convincing management migthe incremental introduction of the infrastructure or reports about the benefitscosts of reuse [28]. A key to create commitment from project teams is training in re[28]. This is done by the supporter who assists the project teams in reusing experiHe also pays attention to the quality of the EPs to strengthen the project teams’ cdence in the reliability of the EPs. Another important point is that the EF gives inctives for recording and reusing experience.
Through the organizational infrastructure the tasks of continuous learning and rare assigned to the above mentioned roles. A role is responsible for its assignedSo, it is ensured that no task is forgotten. Finally, the instantiation of the roles withpersons depends on the specific company.
7 Projects
The approach described in this paper has been applied in several projects. In thition, we present some of them.
In an industrial project, one of the authors was involved in transferring the technof software inspections into a large German company. Various usage scenarios forying information about the technique were identified. They included the initial traing of project teams, providing guidelines during the performance of inspections,providing problem-solution statements for mastering difficult situations during the pformance. The information demands were met by building an EB for software instions. Classes of experience items were (among others) lessons learned (guidelinproblem-solution statements), project characterizations, and auxiliary documenwell as descriptions of intermediate products (defect forms, minutes of inspecmeeting etc.), roles, and process steps. Altogether, they make up the technique detion [23].
Because no complete list of important guidelines and difficult situations was avable a priori, we had to enable the organization tolearn itself. For this purpose, lessonslearned were attached to the process steps and intermediate product descriptionabove) after the performance of an inspection.
Although our technical infrastructure was not deployed at the company, the usaschemas for structuring the description of the technique was very helpful in analythe lessons learned to create guidelines, problem-solution pairs, and improvemengestions. Currently, we are integrating several variants of inspection techniqueslessons learned from various companies into one single EB on inspections.requires the enforcement of the integrity rules using the full capabilities of REFSE
In another project, we have started to deploy parts of a SEEE in a large insurcompany. In that project, we initially developed a schema for the process model

thens, andavenotide-
achwe
ramsthat
andREF-ext)ple-rove-ned
es andions inalityn
initialg ther andtrials
typeowser
ceaboutthate sys-mple
iewed2].e tri-ssen-rieval
beharac-
i-
sons learned, and project characterizations. It is planned to gradually extendschema to also include measurement plans, measurement results, milestone plaproject schedules. Other kinds of experience may follow. Through this project we hlearned that schemas with many text attributes are difficult to fill out because it isalways clear under which attribute a given piece of information must be placed. Gulines for filling out schemas can be devised to alleviate this problem.
Within a publicly funded project we had the opportunity to prove that our approcan be applied to experience handling in other domains, too [5]. In this projectimplemented a prototype of a system that supports continuous improvement progin the health care domain. The EB stores knowledge about improvement ideascomprises not only a context description, but also a diary of the implementationdata that helps to control the improvement program. The schema developed withSENO has a well-balanced number of formalized and not formalized (free tattributes. A thorough elicitation of the vocabulary used in hospitals guided the immentation of taxonomies that are used to create the context description of an impment idea. A trial phase with hospitals in the summer 1999 confirmed the envisioexpressiveness of the schema. Free text attributes are used to record diary entriattach lessons learned to improvement ideas, which are handled as characterizatthe system. The prototype version of the IPQM system (Intelligent Process and QuManagement) is publicly available3. The web interface of this system was built as ainstance of our general purpose browser. In this project we have learned that thestructuring of the experience base can be accelerated by rapid prototyping usingeneral purpose browser. This improves the communication among (EB) manage(experience) engineers during structuring because the prototype can be used forwith existing artifacts.
Apart from the above mentioned projects we have created two other protoapplications that are showcases for our tool architecture (the general purpose brin particular) and serve as publicly available product experience bases.
The first prototype, called CBR-PEB4 (Case-Based Reasoning Product ExperienBase), enables users to search for CBR systems [7]. There are characterizationstwo kinds of CBR systems in the EB: CBR applications (running software systemscan be reused, but must be adapted to new requirements) and CBR tools (softwartems that can be used to generate CBR applications). CBR-PEB is also an exawhere context-sensitive search was rated important by the users that were intervfor the initial definition of the schema (technical criteria and general information) [1
Using this prototype we learned through goal-oriented measurement and usagals that the quality of the artifacts and the accuracy of their characterizations are etial with respect to the perceived usefulness of the experience provided by the retsystem [38]. This means that any artifact stored must exhibit a minimal quality (todefined by the user) and be associated with a complete, correct, and up-to-date cterization [4].
The second prototype, called KM-PEB5 (Knowledge Management Product Exper
3 URL: http://demolab.iese.fhg.de:8080/Project-KVP-EB/4 URL: http://demolab.iese.fhg.de:8080

aboutthe
eful
sup-
forOur
learn-
on ausersthey
suredase.s asualitye fac-
ar-d at
siblecificach
er-roto-
oachver-then
per-
ture
ence Base), has been set-up recently and shall help users retrieve informationknowledge management tools. The comprehensive description of tools allowsusers to perform a context-sensitive search with a high probability to receive usresults even in a rather loosely defined domain.
Both prototypes demonstrate that the architecture presented in this paper canport organizational learning in a globally distributed environment.
8 Conclusion
In this paper we presented our tool architecture and its underlying methodologyreuse and continuous learning of all kinds of software engineering experience.architecture extends existing ones by supporting the whole process of reuse anding for arbitrary experience items.
The retrieval mechanism includes a context-sensitive search and is basedschema that guides the characterizations of experience items. This means thatneed not be knowledge engineers. It also enables them to find useful experiencepreviously were not aware of. The consistency of the experience base is enthrough integrity rules. This reduces the effort for maintaining the experience bThe schema allows a gradual upscaling from informal to formal characterizationcollections grow in size. In addition, the schema ensures helpfulness and good qof service for a diverse set of users (e.g., developers, project managers, experienctory personnel). This has been demonstrated through scenarios.
By allowing arbitrary representations for storing artifacts (in contrast to their chacterizations), new artifacts (and tools to view and edit them) can be incorporateany time. Tools existing in the organization can be integrated easily. It is even posto store earlier versions of an artifact as text files and later versions in a tool-speformat without the need to switch to a new environment. This makes our approflexible with regard to the formality of the artifacts stored. The World Wide Web intface allows to scale up our infrastructure for global use as demonstrated by our ptypes CBR-PEB and KM-PEB.
Currently, we are extending our learning process through an engineering apprfor developing organization-specific schemas. The basic idea is to derive an initialsion from a core set of schemas (the counterparts to our artifact-specific tools) andto iterate this version by monitoring the usefulness (and its influencing factors)ceived by the users.
Acknowledgments
We thank Frank Bomarius for fruitful discussions on the presented tools architecand Sonnhild Namingha for reviewing an earlier version of this paper.
5 URL: http://demolab.iese.fhg.de:8080/KM-PEB/

logical
ningan-
. Post-
autz.Bar-l-er-
e-editor,-
tech--
nt-
ms ’99
andook,
peri-gmann
son-ty of
nd-
n J.
ted
References
1. Agnar Aamodt and Enric Plaza. Case-based reasoning: Foundational issues, methodovariations, and system approaches.AICom - Artificial Intelligence Communications, 7(1):39–59, March 1994.
2. K.-D. Althoff, F. Bomarius, and C. Tautz. Case-based reasoning strategy to build learsoftware organizations.Journal on Intelligent Systems, special issues on "Knowledge Magement and Knowledge Distribution over the Internet", 1999.
3. Klaus-Dieter Althoff. Evaluating case-based reasoning systems: The Inreca case studydoctoral thesis (Habilitationsschrift), University of Kaiserslautern, 1997.
4. Klaus-Dieter Althoff, Andreas Birk, Christiane Gresse von Wangenheim, and Carsten TCase-based reasoning for experimental software engineering. In Mario Lenz, Brigittetsch-Spörl, Hans-Dieter Burkhard, and Stefan Wess, editors,Case-Based Reasoning Technoogy - From Foundations to Applications, number 1400, chapter 9, pages 235–254. SpringVerlag, Berlin, Germany, 1998.
5. Klaus-Dieter Althoff, Frank Bomarius, Wolfgang Müller, and Markus Nick. Using casbased reasoning for supporting continuous improvement processes. In Petra Perner,Proceedings of the Workshop on Machine Learning, pages 54–61, Leipzig, Germany, September 1999. Institute for Image Processing and Applied Informatics.
6. Klaus-Dieter Althoff, Frank Bomarius, and Carsten Tautz. Using case-based reasoningnology to build learning organizations. InProceedings of the the Workshop on Organizational Memories at the European Conference on Artificial Intelligence ’98, Brighton,England, August 1998.
7. Klaus-Dieter Althoff, Markus Nick, and Carsten Tautz. Cbr-peb: An application implemeing reuse concepts of the experience factory for the transfer of cbr system know-how. InPro-ceedings of the Seventh Workshop on Case-Based Reasoning during Expert Syste(XPS-99), Würzburg, Germany, March 1999.
8. Klaus-Dieter Althoff, Markus Nick, and Carsten Tautz. Systematically diagnosingimproving the perceived usefulness of organizational memories. elsewhere in this b1999.
9. Klaus-Dieter Althoff and Wolfgang Wilke. Potential uses of case-based reasoning in exenced based construction of software systems and business process support. In R. Berand W. Wilke, editors,Proceedings of the Fifth German Workshop on Case-Based Reaing, LSA-97-01E, pages 31–38. Centre for Learning Systems and Applications, UniversiKaiserslautern, March 1997.
10. G. Arango.Domain Engineering for Software Reuse. PhD thesis, University of California atIrvine, 1988.
11. Bruce H. Barnes and Terry B. Bollinger. Making reuse cost effective.IEEE Software,8(1):13–24, January 1991.
12. Brigitte Bartsch-Spörl, Klaus-Dieter Althoff, and Alexandre Meissonnier. Learning from areasoning about case-based reasoning systems. InProceedings of the Fourth German Conference on Knowledge-Based Systems (XPS97), March 1997.
13. Victor R. Basili, Gianluigi Caldiera, and H. Dieter Rombach. Experience Factory. In JohMarciniak, editor,Encyclopedia of Software Engineering, volume 1, pages 469–476. JohnWiley & Sons, 1994.
14. Victor R. Basili and H. Dieter Rombach. The TAME Project: Towards improvement–oriensoftware environments.IEEE Transactions on Software Engineering, SE-14(6):758–773,June 1988.
15. Victor R. Basili and H. Dieter Rombach. Support for comprehensive reuse.IEEE Software

ct-ori-
tions.
s. Innce
ach,pro-
.nts.
llard.
ocu-ples,u-f then and
use offt-
start-oto,
s. In’95
ch toare
gani-dge
aim-
Engineering Journal, 6(5):303–316, September 1991.16. R. Bergmann and U. Eisenecker. Case-based reasoning for supporting reuse of obje
ented software: A case study (in German). In M. M. Richter and F. Maurer, editors,Experten-systeme 95, pages 152–169. infix Verlag, 1995.
17. Ted J. Biggerstaff and Charles Richter. Reusability framework, assessment, and direcIEEE Software, 4(2), March 1987.
18. Andreas Birk. Modelling the application domains of software engineering technologieProceedings of the Twelfth IEEE International Automated Software Engineering Confere.IEEE Computer Society Press, 1997.
19. Andreas Birk, Peter Derks, Dirk Hamann, Jorma Hirvensalo, Markku Oivo, Erik RodenbRini van Solingen, and Jorma Taramaa. Applications of measurement in product-focusedcess improvement: A comparative industrial case study. InProceedings of the Fifth Interna-tional Software Metrics Symposium, pages 105–108. IEEE Computer Society Press, 1998
20. Gianluigi Caldiera and Victor R. Basili. Identifying and qualifying reusable componeIEEE Software, 8:61–70, February 1991.
21. A. Cimitile and G. Visaggio. Software salvaging and the call dominance tree.Journal of Sys-tems and Software, 28(2):117–127, February 1995.
22. Premkumar Devanbu, Ronald J. Brachman, Peter G. Selfridge, and Bruce W. BaLaSSIE: a knowledge-based software information system.Communications of the ACM,34(5):34–49, May 1991.
23. Raimund L. Feldmann and Carsten Tautz. Improving Best Practices Through Explicit Dmentation of Experience About Software Technologies. In C. Hawkins, M. Ross, G. Staand J. B. Thompson, editors,INSPIRE III Process Improvement Through Training and Edcation, pages 43–57. The British Computer Society, September 1998. Proceedings oThird International Conference on Software Process Improvement Research, EducatioTraining (INSPIRE’98).
24. W. B. Frakes and P. B. Gandel. Representing reusable software.Information and SoftwareTechnology, 32(10):653–664, December 1990.
25. Wilhelm Gaus.Documentation and Classification Science (in German). Springer-Verlag,Berlin, 1995.
26. C. Gresse von Wangenheim, A. von Wangenheim, and R. M. Barcia. Case-based resoftware engineering measurement plans. InProceedings of the Tenth Conference on Soware Engineering and Knowledge Engineering, San Francisco, 1998.
27. Martin L. Griss. Software reuse experience at Hewlett-Packard. InProceedings of the Six-teenth International Conference on Software Engineering, page 270. IEEE Computer SocietyPress, May 1994.
28. Martin L. Griss, John Favaro, and Paul Walton. Managerial and organizational issues -ing and running a software reuse program. In W. Schäfer, R. Prieto-Diaz, and M. Matsumeditors,Software Reusability, chapter 3, pages 51–78. Ellis Horwood Ltd., 1994.
29. S. Henninger. Developing domain knowledge through the reuse of project experienceMansur Samadzadeh, editor,Proceedings of the Symposium on Software Reusability SSR,pages 186–195, April 1995.
30. S. Henninger, K. Lappala, and A. Raghavendran. An organizational learning approadomain analysis. InProceedings of the Seventeenth International Conference on SoftwEngineering, pages 95–103. ACM Press, 1995.
31. Scott Henninger. Capturing and formalizing best practices in a software development orzation. In Proceedings of the Ninth Conference on Software Engineering and KnowleEngineering, pages 24–31, Madrid, Spain, June 1997.
32. Frank Houdek, Kurt Schneider, and Eva Wieser. Establishing experience factories at D

onety
uh.res.
ploy-
ati-
s:
mpo-
tion
ME
simi-
-
T-95/
lifelity
ion
ler-Benz: An experience report. InProceedings of the Twentieth International ConferenceSoftware Engineering, pages 443–447, Kyoto, Japan, April 1998. IEEE Computer SociPress.
33. Kyo C. Kang, Sajoong Kim, Jaejoon Lee, Kijoo Kim, Euiseob Shin, and Moonhang HFORM: A feature-oriented reuse method with domain-specific reference architectuAnnals of Software Engineering, 5:143–168, 1998.
34. P. Katalagarianos and Y. Vassiliou. On the reuse of software: A case-based approach eming a repository.Automated Software Engineering, 2:55–86, 1995.
35. Y. S. Maarek, D. M. Berry, and G. E. Kaiser. An information retrieval approach for automcally constructing software libraries.IEEE Transactions on Software Engineering,17(8):800–813, August 1991.
36. Rym Mili, Ali Mili, and Roland T. Mittermeir. Storing and retrieving software componentA refinement based system.IEEE Transactions on Software Engineering, 23(7):445–460,July 1997.
37. James M. Neighbors. The draco approach to constructing software from reusable conents.IEEE Transactions on Software Engineering, SE-10(5):564–574, September 1984.
38. Markus Nick, Klaus-Dieter Althoff, and Carsten Tautz. Facilitating the practical evaluaof organizational memories using the goal-question-metric technique. InProceedings of theTwelfth Workshop on Knowledge Acquisition, Modeling and Management, Banff, Alberta,Canada, October 1999.
39. Markku Oivo and Victor R. Basili. Representing software engineering models: The TAgoal oriented approach.IEEE Transactions on Software Engineering, 18(10):886–898, Octo-ber 1992.
40. Eduardo Ostertag, James Hendler, Rubén Prieto-Díaz, and Christine Braun. Computinglarity in a reuse library system: An AI-based approach.ACM Transactions on Software Engi-neering and Methodology, 1(3):205–228, July 1992.
41. John Penix and Perry Alexander. Toward automated component adaptation. InProceedingsof the Ninth Conference on Software Engineering and Knowledge Engineering, pages 535–542, Madrid, Spain, June 1997.
42. Aarthi Prasad and E. K. Park. Reuse systems: An artificial intelligence-based approach.Jour-nal of Systems and Software, 27(3):207–221, December 1994.
43. R. Prieto-Diaz. Domain analysis for reusability. InProceedings of the Eleventh Annual International Computer Software and Application Conference (COMPSAC), pages 23–29, 1987.
44. Rubén Prieto-Díaz. Implementing faceted classification for software reuse.Communicationsof the ACM, 34(5):89–97, May 1991.
45. H. Dieter Rombach. New institute for applied software engineering research.Software Pro-cess Newsletter, pages 12–14, Fall 1996. No. 7.
46. Charisse Sary. Recall prototype lessons learned writing guide. Technical Report 504-SE003, NASA Goddard Space Flight Center, Greenbelt, Maryland, USA, December 1995.
47. Wilhelm Schäfer, Rubén Prieto-Díaz, and Masao Matsumoto.Software Reusability. EllisHorwood, 1994.
48. R. Schank and R. Abelson.Scripts, Plans, Goals, and Understanding. Erlbaum, Northvale,NJ, USA, 1977.
49. Roger C. Schank.Dynamic Memory: A Theory of Learning in Computers and People. Cam-bridge University Press, 1982.
50. M. Simos. Organization domain modeling (odm): Formalizing the core domain modelingcycle. In Mansur Samadzadeh, editor,Proceedings of the Symposium on Software ReusabiSSR’95, pages 196–205, April 1995.
51. Mark Simos, Dick Creps, Carol Klingler, Larry Levine, and Dean Allemang. Organizat

C-996.soft-
tware-
owl-
i-
ormal-8/E,ny),
r sup--s ’99
fe/
nno
-ori-re in
Domain Modeling (ODM) guidebook, version 2.0. Informal Technical Report STARS-VA025/001/00, Lockheed Martin Tactical Defense Systems, Manassas, VA, USA, June 1
52. Guttorm Sindre, Reidar Conradi, and Even-André Karlsson. The REBOOT approach toware reuse.Journal of Systems and Software, 30(201–212), 1995.
53. Carsten Tautz and Klaus-Dieter Althoff. Using case-based reasoning for reusing sofknowledge. In D. Leake and E. Plaza, editors,Proceedings of the Second International Conference on Case-Based Reasoning. Springer Verlag, 1997.
54. Carsten Tautz and Klaus-Dieter Althoff. Operationalizing comprehensive software knedge reuse based on CBR methods. In Lothar Gierl and Mario Lenz, editors,Proceedings ofthe Sixth German Workshop on Case-Based Reasoning, volume 7 ofIMIB Series, pages 89–98, Berlin, Germany, March 1998. Institut für Medizinische Informatik und Biometrik, Unversität Rostock.
55. Carsten Tautz and Christiane Gresse von Wangenheim. REFSENO: A representation fism for software engineering ontologies. Technical Report IESE-Report No. 015.9Fraunhofer Institute for Experimental Software Engineering, Kaiserslautern (Germa1998.
56. Carsten Tautz and Christiane Gresse von Wangenheim. A representation formalism foporting reuse of software engineering knowledge. InProceedings of the Workshop on Knowledge Management, Organizational Memory and Knowledge Reuse during Expert System(XPS-99), Würzburg, Germany, March 1999. http://www.aifb.uni-karlsruhe.de/WBS/dxps99.proc.htm.
57. CBR-Works. URL http://www.tecinno.de/english/products/cbrw_main.htm, 1999. tec:iGmbH, Germany.
58. Will Tracz. International conference on software reuse summary.ACM SIGSOFT SoftwareEngineering Notes, 20(2):21–25, April 1995.
59. Giuseppe Visaggio. Process improvement through data reuse.IEEE Software, 11(4):76–85,July 1994.
60. Christiane Gresse von Wangenheim, Klaus-Dieter Althoff, and Ricardo M. Barcia. Goalented and similarity-based retrieval of software engineering experienceware. elsewhethis book, 1999.
61. Mansour Zand and Mansur Samadzadeh. Software reuse: Current status and trends.Journalof Systems and Software, 30(3):167–170, September 1995.




















