
Supporting Realistic OpenMP Applications on a Commodity Cluster of Workstations

Future Generation Computer Systems 24 (2008) 166–176www.elsevier.com/locate/fgcs
Supporting data management on cluster grids
Franco Frattolillo
Research Centre on Software Technology, Department of Engineering, University of Sannio, Corso Garibaldi 107, Benevento, Italy
Received 29 September 2006; received in revised form 31 March 2007; accepted 6 April 2007Available online 13 April 2007
Abstract
Cluster grid computing is considered a promising alternative to grid computing, since it uses networked computing resources widely availablewithin the so-called “departmental” organizations as high performance/cost ratio computing platforms. ePVM is an extension of the well-knownPVM programming system, and has been purposely developed to run large-scale PVM applications on cluster grids spanning across multidomain,non-routable networks. To this end, ePVM has been also provided with a parallel file system that enables the enormous volumes of data usuallygenerated by large-scale parallel applications to be managed and distributed among the multiple disks available within cluster grids. In particular,the parallel file system, called ePIOUS, is an optimized implementation of the PIOUS parallel file system under ePVM. The implementation hasbeen developed taking into account the two-level physical network topology characterizing the cluster grids built by ePVM. Furthermore, in ordernot to penalize the application performance, ePIOUS has been also provided with a file caching service that is able to speed up file accesses acrossclusters.c© 2007 Elsevier B.V. All rights reserved.
Keywords: Cluster grids; Parallel file systems; Parallel computing
1. Introduction
Cluster grid computing [1,2] can be considered an actualalternative to both grid computing [3–5] and traditionalparallel computing based on supercomputing systems and onclusters of workstations exploited as a unique, coherent, highperformance computing resource. However, while clusters ofworkstations are currently used to build high performance/costratio computing platforms, grid computing still means tointegrate heterogeneous computing resources of widely varyingcapabilities, connected by potentially unreliable, heterogeneousnetworks, and located in different administrative domains. Infact, this can create many problems for programmers, who haveto deal with highly variable communication delays, securitythreats, machine and network failures, and the distributedownership of computing resources, if they want to properlyconfigure and optimize their large-scale applications in a gridcomputational context.
On the other hand, traditional parallel computing, particu-larly that based on clusters of workstations, tends to use net-worked computing resources widely available within the so-called “departmental” organizations, such as research centers,
E-mail address: [email protected].
0167-739X/$ - see front matter c© 2007 Elsevier B.V. All rights reserved.doi:10.1016/j.future.2007.04.002
universities, and business enterprises, where problems concern-ing security, ownership, and configuration of the used net-worked resources are commonly and easily solved within a sin-gle administrative domain [6].
However, it is also worth noting that most of the computingresources existing within departmental organizations are oftenrepresented by computing nodes belonging to non-routable,private networks and connected to the Internet through publiclyaddressable IP front-end nodes [6]. As a consequence, suchresources cannot be considered as actually available to runlarge-scale applications, since they cannot be easily exploitedby widely used, conventional or standard parallel programmingsupports, such as PVM (Parallel Virtual Machine) [7] orMPI (Message Passing Interface) [8], or middlewares for gridcomputing [3,5].
ePVM [6,9] is an extension of PVM [7,10,11], a well-knownprogramming system mainly used by the scientific communityto develop high performance, large-scale parallel applicationson high performance/cost ratio computing platforms, such asclusters of workstations (COWs). The main goal of ePVMis to enable PVM applications to efficiently run on “clustergrids” spanning across multidomain, non-routable networks. Infact, ePVM enables computing nodes, even those not provided

F. Frattolillo / Future Generation Computer Systems 24 (2008) 166–176 167
Fig. 1. The scheme of a generic PVM virtual machine.
with public IP addresses but connected to the Internet throughpublicly addressable IP front-end computing nodes, to be usedas hosts in a unique parallel virtual machine. Therefore, ePVMallows programmers to build and dynamically reconfigure aPVM compliant parallel virtual machine that can be extendedto comprise collections of COWs provided that these aresupplied with publicly addressable IP front-end nodes. As aconsequence, even if all the computing nodes taking part inan ePVM virtual machine result in being actually arrangedaccording to a physical network topology consisting of twohierarchical levels (the level of the publicly addressable IPnodes and the level of the non publicly addressable IPnodes belonging to COWs), they virtually appear as arrangedaccording to a flat logical network topology.
Furthermore, it is also worth noting that large-scalePVM applications often generate enormous volumes of data,which can be efficiently managed and distributed among thecomputing nodes by specific parallel file systems (PFS’s). Tothis end, in the past, a number of PFS’s were developed [12–14].Among them, PIOUS (Parallel Input/Output System) [15–17]was purposely designed to incorporate parallel I/O intoexisting parallel programming systems. It has been widelyused as a normal parallel application within PVM. Therefore,PIOUS could be directly exploited within ePVM. However,the execution of PIOUS under ePVM usually results in itbeing penalized by the two-level physical network topologycharacterizing the cluster grids normally built by ePVM, andthis ends up also penalizing the applications using both ePVMand PIOUS.
This paper presents ePIOUS [18], the optimized implemen-tation of PIOUS under ePVM. The implementation has beencarried out taking into account the basic ideas and architectureof ePVM. Therefore, the implementation fully exploits the two-level physical network topology characterizing the cluster gridsbuilt by ePVM. To this end, ePIOUS has been also providedwith a specific file caching service that can speed up file ac-cesses across clusters.
The outline of the paper is as follows. Section 2 summarizesthe main PVM concepts. Section 3 describes the ePVMapproach, whereas Section 4 briefly presents the ePVMprogramming system. Section 5 describes the ePIOUS parallel
file system. Section 6 reports on some experimental results. InSection 7 a brief conclusion is presented.
2. The PVM programming system
PVM [7,10,11] is a programming system based on theconcept of a “virtual machine”, that is, a software abstractionof a distributed computing platform consisting of a set ofcooperating processes, called “daemons”, that together supplythe services required to run parallel applications as if they wereon a distributed memory parallel computer (see Fig. 1).
Daemons can run on heterogeneous distributed computingnodes connected by a variety of networks. In particular, all thenodes making up a virtual machine are called “hosts”, and PVMrequires that one daemon has to reside on each host.
To run a PVM application, a virtual machine has to be firstcreated by starting one daemon (also called pvmd) on each hostto be used. The first daemon created at application startup (bya command row or by a specific “console” application suppliedby PVM) is designated the “master”, whereas the others startedby the master are called “slaves”. During the computation, alldaemons are considered equal, but only the master can performsome actions, such as dynamically changing the configurationof the virtual machine by starting new slaves.
An application consists of several user processes, called“tasks”, which are executed by the hosts making up the virtualmachine and can obtain the services they need by interactingwith daemons through the software routines belonging to aportable application programming interface (API).
The API is implemented by a library of routines that areneeded for cooperation between the tasks of an application.Therefore, the library essentially contains user-callable routinesfor message passing, spawning and coordinating tasks, anddynamically modifying the virtual machine.
Each PVM task is identified by a 32-bit integer, called“task identifier” (TID), which contains two main fields: theformer, called hostID, identifies the host on which the task runs,whereas the latter, called taskID, identifies the task running onthe host. The hostID is a number relative to the virtual machine,whereas the taskID is a value assigned by a counter tied to thehost.

168 F. Frattolillo / Future Generation Computer Systems 24 (2008) 166–176
Tasks can interact by message passing. Messages are sent toand received from TIDs.
TIDs must be unique across the entire virtual machine, andso they are supplied by the pvmds and are not user-chosen.Although PVM encodes information into each TID, the useris expected to treat the TIDs as opaque integer identifiers. ThePVM library contains several routines that return TID values,so that an application task can identify other tasks in the virtualmachine.
Finally, the configuration of a virtual machine can change,and the number of tasks that make up a parallel computationcan grow and shrink under application control.
3. The ePVM approach
PVM requires that all the hosts making up a virtual machineare IP addressable. In fact, PVM cannot exploit a COWprovided only with one publicly addressable IP front-endcomputing node that hides from the Internet all the othernodes of the cluster. This means that PVM running on hostsoutside such a COW cannot exploit the cluster’s internal nodes.Therefore, PVM appears to be inflexible in many respects,which can be constraining when the main goal of a softwareinfrastructure is to aggregate or cross-access varied computingresources available within different administrative domains,networks, and institutions.
However, it is worth noting that PVM is today widelyused by application programmers and scientists who are notvery experienced in parallel programming, such as chemists,biologists, etc. As a consequence, a number of resourcemanagers, grid software toolkits, and message passing librarieshave been developed to support the execution of PVMapplications within grid computing environments [6]. Amongthem, Condor [19], Globus [20,21], and Beolin [22,23]represent well-known examples.
Condor is a specialized workload management systemfor computing-intensive applications. It acts as a resourcemanager for the PVM daemons. Therefore, it can be used todynamically construct PVM virtual machines from a “pool”of computing nodes available on the Internet. However,Condor provides support only to PVM applications basedon the “master–worker” programming paradigm, and needsto run specific daemons on the harnessed computing nodes.As a consequence, since all daemons communicate throughmechanisms based on TCP/UDP, all the used nodes must bepublicly IP addressable.
Globus is a metacomputing infrastructure that consists ofpredefined and integrated modules pertaining to grid services,such as communication, resource allocation, process manage-ment, data access, etc. Although no parallel programming in-terfaces that have been adapted to use the Globus services in-clude a complete implementation of PVM, the computing re-sources managed by Globus can be exploited by Condor-G [24]users, who can submit PVM applications, that are then auto-matically matched and run on the Globus resources. However,even though Globus supports several communication mecha-nisms and protocols within localized networks, the basic con-
nectivity anyway requires that all the computing resources arepublicly IP addressable.
A different approach is adopted by the Beolin port, whichhas been included in the version 3.4.3 of PVM and has beenmodeled on some other PVM ports involving massively parallelprocessors (MPPs). Beolin can exploit a COW that is providedwith a publicly addressable IP front-end node by enabling PVMto start the pvmd daemon on it. To this end, an environmentvariable set by the user specifies which clustered nodes areavailable for running PVM tasks. Each subsequent request tospawn tasks on the COW front-end node causes tasks to beallocated to the clustered nodes specified as available, with eachtask going on a separate node. As a consequence, no two taskscan share the same node, and if the user attempts to spawn moretasks than there are nodes, PVM returns a runtime error.
Although Beolin hides all the low-level details of a COWand allows users to reuse their PVM applications without codechanges, it is affected by a number of design constraints thatprevent expert programmers from taking full advantage of thecomputing power made available by a COW. In particular, aprogrammer is not allowed to explicitly control task allocationon the clustered nodes, and this does not make it possible toallocate tasks on the basis of the node computational power andto implement load balancing strategies within the cluster.
ePVM supports the execution of large-scale PVM applica-tions in a different way from Condor and Globus. It overcomesthe limitations affecting PVM and Beolin by adopting an ap-proach that succeeds in being more similar to the ones fol-lowed by PACX-MPI (Parallel Computer extension) [25–28]and H2O [29,30] in the context of MPI programming.
PACX-MPI is a library that makes it possible to seamlesslyrun MPI applications on computational grids without anyadaptation of the application code. In fact, MPI applicationscan run on heterogeneous metacomputers made up of clustersof MPPs and computing nodes, connected through highspeed networks or the Internet. To this end, communicationamong MPI processes internal to a single MPP uses thevendor MPI library, whereas communication to the othercomputing nodes of the metacomputer, such as the onesinternal to the other MPPs, is done via standard protocolssupported by the connecting network. To accomplish this,on each MPP taking part in the computation two specificdaemons take care of communication external to the MPP.Such daemons are implemented as additional, local MPIprocesses. Therefore, communication internal to an MPP can behandled using vendor optimized communication software, thusfully exploiting the capacity of the underlying communicationsubsystem, whereas external communication can be managedwithout having thousands of open connections between MPIprocesses. However, PACX-MPI was not specifically designedto exploit computing nodes belonging to multidomain, non-routable networks.
On the contrary, H2O just facilitates the execution ofMPI applications across multidomain clusters, that is, clustershidden behind firewalls or interconnected by non-routablenetworks. It is a distributed metacomputing framework thatimplements complex functions, such as those specifically

F. Frattolillo / Future Generation Computer Systems 24 (2008) 166–176 169
Fig. 2. The architecture of an “extended virtual machine”.
devoted to guarantee fault tolerance in distributed computingenvironments. In fact, MPI applications using H2O have toinstantiate specific agents, called “pluglets”, at selected front-end locations, which serve as proxies that transparently relaymessages between the different domains.
ePVM follows the design approach of PACX-MPI, sincethe latter makes it possible to extend a PVM virtual machineto non publicly addressable IP clustered nodes by usingspecific PVM daemons running on the IP addressable front-endnodes of each cluster involved in the computation. However,ePVM extends the capabilities of PACX-MPI since it canrun PVM applications on multidomain clusters interconnectedby non-routable networks, thus being more similar to H2O.Furthermore, unlike Beolin, ePVM enables any clustered nodeto be shared among multiple tasks, thus being able to explicitlycontrol task allocation within a cluster.
4. The ePVM programming system
ePVM extends PVM by introducing the abstraction of the“cluster” [6]. A cluster is a set of interconnected computingnodes provided with private IP addresses and hidden behind apublicly addressable IP front-end computing node (see Fig. 2).During computation, it is managed as a normal PVM virtualmachine, where a “master” pvmd daemon is started on the front-end node, whereas “slaves” are started on all the other nodesof the cluster. However, the front-end node is also providedwith a specific ePVM daemon, called epvmd, which allowsthe cluster to interact with all other clusters. In fact, epvmdis a multi-process daemon that serves as a message router andworker able to provide a point of contact among distinct PVMvirtual machines, each managing a cluster. Thus, ePVM enablesthe building of “extended virtual machines” (EVMs). Such amachine is made up of:
(i) publicly addressable IP computing nodes, which aregrouped in a first PVM virtual machine, called the “main”machine;
(ii) further PVM virtual machines, one for each clusterprovided with a publicly addressable IP front-endcomputing node (see Fig. 2).
In fact, due to ePVM, both publicly addressable IP nodes andthose belonging to a PVM virtual machine managing a clustercan be directly referred to as hosts. Therefore, even thoughdistinct PVM virtual machines can coexist in an EVM, allthe computing nodes can run PVM tasks as in a single, flatdistributed computing platform.
At application startup, a “master” epvmd daemon is createdon the host, from which the application is started. This daemonmanages the “main” PVM virtual machine, but it can alsomanage another PVM virtual machine, if it is allocated on ahost that is the front-end node of an employed cluster. Then,a “slave” epvmd is started on each front-end node of the otheremployed clusters.
All epvmds perform the same actions, but only the mastercan manage the configuration of the EVM. Such a configurationcomprises information about all the clusters and hosts takingpart in the EVM.
epvmds act in conjunction with an extension of the PVMlibrary, called libepvm [6], which enables tasks within a clusterto interface with epvmd in order to exchange messages withall the other tasks in the EVM, and to perform system servicerequests. Moreover, to support a flat task network, the originalPVM task identification mechanism has been modified. In fact,each task in an EVM is identified by a 32-bit integer, called“virtual task identifier” (VTID), unique across the entire EVM.However, unlike the original TID, which contains only twomain fields (hostID and taskID), a VTID also contains athird field, called “cluster identifier” (CID), which specifies thevirtual machine which the pair (hostID, taskID) belongs to [6].
When a task allocated on a host belonging to a clusterof an EVM invokes a libepvm routine, the software librarydecides whether the actions to be performed can be confinedto the cluster or has to involve other clusters of the EVM.In the former case, the routine is served as in a PVM virtualmachine: the task invoking the routine contacts the pvmdrunning on its host, which takes charge of completing theroutine service. In the latter case, the invoked routine contactsthe epvmd managing its cluster, which serves the routine withinthe EVM. To this end, epvmd has been internally structured asa multi-process daemon composed of a “manager task” (MT),a “dispatcher task” (DT), and a pool of “workers” (Ws) (see

170 F. Frattolillo / Future Generation Computer Systems 24 (2008) 166–176
Fig. 3. The epvmd architecture and the interactions with application tasks.
Fig. 3). All these tasks are implemented as normal PVM tasks,and this enables them and application tasks to communicate byusing the standard routines made available by PVM, such aspvm send and pvm receive.
Whenever a task within a cluster wants to communicatewith a task running on a host belonging to a different clusteror requires a system service involving actions that have to beperformed on a host belonging to a different cluster, it contactsMT, which is the local front-end section of epvmd.
MT is the sole point of contact among application tasksand epvmd, and so it is not allowed to block while waitingfor a libepvm routine, that involves inter-cluster operations, tobe executed. To assure this, epvmd exploits its multi-processimplementation based on multiple Ws, each of which takescharge of performing in parallel the operations needed to servea libepvm routine [6]. In particular, a W can serve a libepvmroutine by contacting the epvmd managing the target cluster. Inthis case, the W interacts with the DT of the remote epvmd,which has the task of receiving the service requests comingfrom remote epvmds and dispatching them to local Ws, whichhave the task of serving libepvm routines (see Fig. 3).
Once a W has served a remote service request, it can alsoreturn a result back to the epvmd originating the request. In thiscase, the W contacts the DT of this epvmd, which, once it hasreceived the result, dispatches it to the MT, which takes chargeof delivering the result to the task that invoked the routine.
Finally, the choice of implementing epvmd as a multi-process daemon rather than, for example, a multithreadeddaemon has been motivated by two main reasons [6]:
• PVM is not “thread safe”, and this would have made theintegration of epvmd in the PVM software difficult;
• thread supports provided by the major operating systems aretypically not standardized.
5. ePIOUS
ePIOUS is the optimized implementation of PIOUS [15–17]under ePVM. It implements a PFS on cluster grids built byusing the ePVM system. However, ePIOUS cannot providethe same performance and functions characterizing commercialPFS’s, such as, for example, GPFS [31], which are availableonly on the specific computing platforms on which the vendor
has implemented them. On the other hand, ePIOUS cannotbe considered a distributed file system, such as NFS [32],which is commonly designed to provide distributed access tofiles from multiple client computing nodes, thus implementinga consistency semantics and a caching behavior designedaccordingly for such access. In fact, file systems developedfor distributed access are not designed for high-bandwidthconcurrent writes that parallel applications typically require.Therefore, ePIOUS can be mainly considered a research PFS,since it is mostly a prototype developed to support clustergrid computing in the context of multidomain, non-routablenetworks.
5.1. The software architecture
ePIOUS preserves as much as possible the original behavior,semantics and software architecture of PIOUS [15–17].Therefore, an ePIOUS file is logically represented by a parafileobject and is physically composed of one or more disjointsegments, which are the data units actually stored by hosts aslinear sequence of bytes.
The number of segments in a file is set at the time of creation.ePIOUS assumes that the segments of a file created by a taskrunning on a host belonging to a cluster are allowed to be storedsolely on the hosts of that cluster. In particular, the segments ofa file are placed on the hosts of a cluster in a round-robin way.
ePIOUS supports coordinated access to parafile objects.Such access is characterized by sequential consistencysemantics and a dynamically-selectable fault tolerance level.To obtain this, ePIOUS has been provided with a softwarearchitecture mainly consisting of a set of parallel data servers(PDS’s), a service coordinator (PSC), a data cache server(CPDS), and a software library, called libepious, linked totasks and comprising all the routines originally implemented byPIOUS. Such architecture is replicated on each cluster takingpart in an EVM and is shown in Fig. 4.
As in ePVM, PDS’s, CPDS and PSC are all implementedas normal PVM tasks, and so they can communicate by usingpvm send and pvm receive.
One PDS has to reside on each host over which files are“declustered”, i.e. over hosts that store physical segments offiles. It provides transaction-based access to its local portionsof files.

F. Frattolillo / Future Generation Computer Systems 24 (2008) 166–176 171
Fig. 4. The ePIOUS software architecture.
On the contrary, a PSC is unique within each cluster of anEVM, and may be allocated on any host of a cluster. It onlyparticipates in the high level operations involving files, suchas open and close operations, while it does not participate ingeneral file access. In fact, PSCs are contacted by tasks uponfile openings to obtain file descriptors and to ensure the correctsemantics in file access.
Like a PSC, a CPDS is unique within each cluster ofan EVM, and may be allocated on any host of a cluster. Itimplements a specific file caching service in order to speedup file accesses that require inter-cluster operations, thustaking into account the particular physical network topologycharacterizing cluster grids. Therefore, a CPDS is alwaysinvolved in “remote” file accesses, which take place whenevera task belonging to a cluster wants to access a file declusteredwithin a different cluster. To this end, as reported above,ePIOUS assumes that files created by tasks belonging to acluster are allowed to be stored only on hosts within that cluster,even though they can be opened and written by tasks running onhosts belonging to any cluster composing the EVM.
To implement the behavior described above, the structureof the original PIOUS file descriptors has been modified.In particular, each descriptor now includes the CID, whichspecifies the cluster whose hosts store the file’s physicalsegments. Therefore, if a task belonging to a cluster wants toopen a file created within a different cluster, it has to specifythe pair (CID, pathname). This pair becomes the filenameparameter in the open routine, and can unambiguously identifythe file within the EVM. However, the task, once the filedescriptor has been obtained, can use it to transparently accessthe file, without having to specify the CID or any otherinformation about the file.
5.2. Operations on files
Parallel operations on files are performed within the contextof transactions, transparently to the user, to provide sequentialconsistency of access and tolerance of system failures. Inparticular, the libepious routines behave as in PIOUS andact as transaction managers for coordinator and data servers
participating in a distributed transaction satisfying a userrequest across the clusters of an EVM.
Two user-selectable transaction types are supported inaccessing files: “stable” and “volatile”. Both transaction typesensure serializability of access. However, the former is a“traditional” transaction that uses a two-phase commit protocolbased on logging and synchronous disk write operations.Therefore, such a transaction can guarantee that coherencein file access is maintained in the event of a system failure.On the contrary, the latter can be considered a “lightweight”transaction that does not guarantee fault-tolerance to the fileaccess, even though it does not incur the overheads of the fileaccess protocol implemented by the “stable” transactions.
Three file access types are supported: “global”, “indepen-dent”, and “segmented”. In particular, tasks accessing a file de-clared as “global” view it as a linear sequence of bytes and sharea single file pointer. By contrast, tasks accessing a file declaredas “independent” view it as a linear sequence of bytes, but main-tain local file pointers. Finally, tasks accessing a file declared as“segmented” view the actual segmented file structure exposedby the associated parafile object, and can access segments vialocal file pointers.
ePIOUS provides tasks with sequentially consistent accessto files opened under any file access type. In particular, bothdata access and file pointer update are guaranteed to be atomicwith respect to concurrency.
Furthermore, ePIOUS implements a further type ofcoordinated file access at the application level, which shouldnot be confused with the transaction mechanisms transparentlyemployed for single file access operations. In fact, such anaccess enables the grouping of read and write operationswithin the context of a single application level transaction, alsocalled user transaction, which can be activated by invokingspecific routines provided by libepious.
A user transaction is implemented as an atomic unitwith respect to concurrency. As a consequence, it guaranteessequential consistency with respect to other user transactionsand single file access operations.
From the point of view of the EVM, two types of fileoperations are supported: those involving PSC and PDS’s, andthose solely involving PDS’s. The former includes the classicopen and close operations as well as the operations thatchange file attributes. The latter includes the read and writeoperations. In fact, both types of operations involve CPDS’swhen they require that inter-cluster actions be performed.
The scheme of PSC-PDS’s operations is depicted in Fig. 5and in Fig. 6. In particular, when a task allocated on a hostbelonging to a cluster of an EVM invokes an ePIOUS routine toperform a PSC-PDS’s operation, the libepious library contactsthe PSC running within the cluster, which decides whether theactions to be performed are “local” or “remote”, i.e. if theactions can be confined to the cluster or involve other clustersof the EVM. In fact, such a decision can be taken by simplyexamining the file descriptor, which specifies the CID of thecluster within which the file has been created.
If the required actions are “local”, the routine is served as inPIOUS (see Fig. 5). Therefore, the task wanting to access the

172 F. Frattolillo / Future Generation Computer Systems 24 (2008) 166–176
Fig. 5. The scheme of a local PSC-PDS’s interaction.
file contacts the PSC server running within the cluster, whichtakes charge of completing the routine service by accessing thePDS’s managing the file.
On the contrary, if the required actions are “remote” (seeFig. 6), the PSC server contacts the local CPDS. If the requireddata are already in cache, the CPDS directly returns them tothe PSC, which delivers them to the task. This means that onlythe interactions 1, 2, 11, and 12 shown in Fig. 6 are actuallyperformed. Otherwise, the CPDS has to contact the epvmdmanaging its cluster, which takes charge of serving the routinewithin the EVM. This means that the epvmd of the local clustersends the file access request to the epvmd of the remote cluster,which serves the request as if it were issued within its cluster.Once the file has been accessed, the required data are returnedto the remote epvmd, which sends them back to the local epvmd.Then, the data are sent to the CPDS, which, after having storedthem in its cache memory, returns them to the PSC, which takescharge of delivering them to the task.
The PDS’s operations follow a scheme similar to PSC-PDS’soperations (see Figs. 7 and 8). In particular, when the file accessrequires “remote” interactions (see Fig. 8), the task wantingto access the file first contacts the CPDS, which can directlyreturn the required data if they are available in its cache. In thiscase, only the interactions 1 and 8 shown in Fig. 8 are actuallyperformed. Otherwise, the CPDS has to start the “remote”interaction scheme by involving the local and remote epvmds.In this case, the remote epvmd behaves as the task wantingto access the file, thus interacting with the PDS’s local to itscluster, as depicted in Fig. 7.
5.3. The file caching service
As reported in the previous sections, ePIOUS provides aspecific file caching service that can speed up file accessesinvolving different clusters of an EVM. Therefore, the serviceis provided to the sole tasks that perform file access operationsrequiring “remote” interactions.
The use of a caching service at task level gives rise toa cache coherence problem determined by the possibility ofhaving shared writing of a file from different tasks, which mightlead to an incoherent view of data [33]. Therefore, to avoid thisproblem, ePIOUS implements a simplified version of the cachecoherence protocol described in [34].
The implemented protocol is executed by the CPDS serverstogether with the PDS servers. In particular, the CPDS’simplement the file caching service, whereas the PDS’s takecharge of maintaining the global state for files and also actas coherence managers [34], thus implementing the functionspurposely defined by the adopted protocol to guarantee cachecoherence.
When a file access request is received by a CPDS from atask, the cache is analyzed to obtain the list of the “present” and“absent” segments of the referred file. The present segments,those found in the cache, are immediately copied to the taskspace, while the absent segments, those not found in the cache,are requested to the remote PDS’s managing them through theepvmds. In fact, the request issued by the CPDS is sent tothe local epvmd, which delivers it to the remote epvmd. Then,the remote epvmd contacts the PDS’s managing the requestedsegments. In particular, the worker that manages the requeston behalf of the remote epvmd implements a synchronizationbarrier for all the involved PDS’s. When all the PDS’s havereached the barrier, the requested segments are returned tothe CPDS, and the event is notified to the PDS’s acting ascoherence managers in order to eventually activate the cachecoherence protocol. To this end, the implemented protocol isbased on the following sub-protocols, which are not describedbecause this is out of the scope of the paper: the “sequentialcoherence protocol” (SCP) and the “concurrent coherenceprotocol” (CCP). The former solves the “sequential write-sharing” (SWS) problem and detects the “concurrent write-sharing” (CWS) on a file. The latter solves the CWS problemafter being activated when the SCP detects a CWS situation ona file [34].
Fig. 6. The scheme of a remote PSC-PDS’s interaction.

F. Frattolillo / Future Generation Computer Systems 24 (2008) 166–176 173
Fig. 7. The scheme of a local PDS’s interaction.
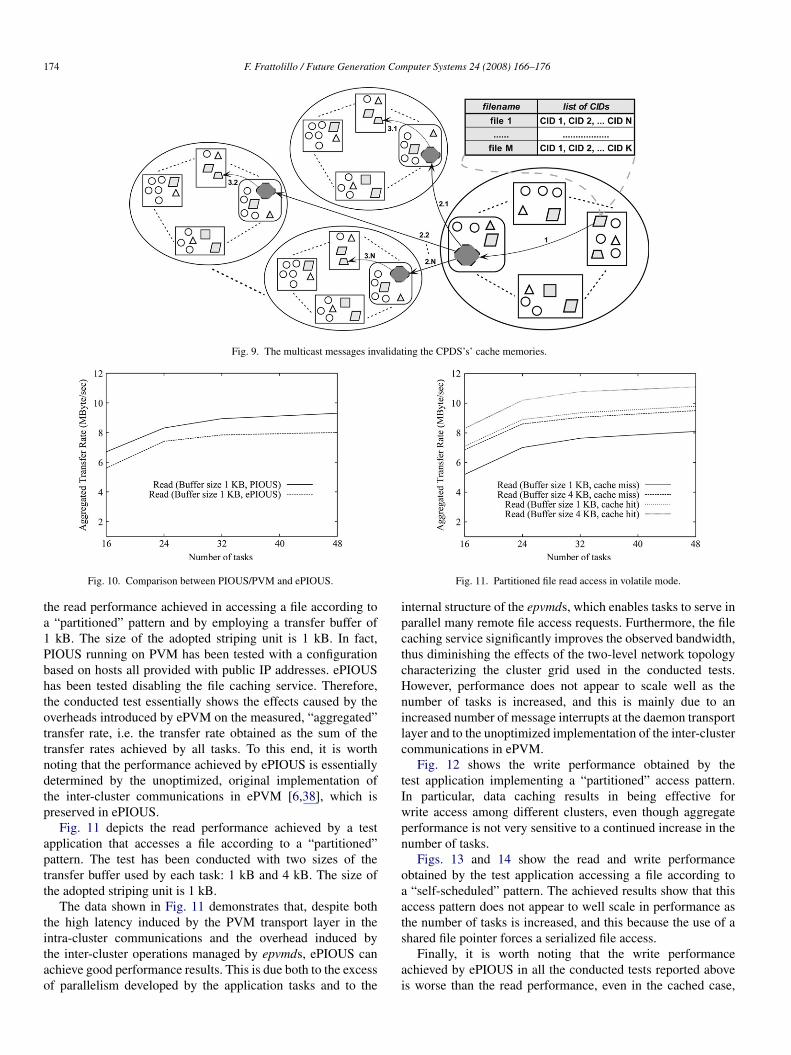
As reported above, both SCP and CCP involve CPDS’s andPDS’s. Furthermore, CCP also implements a specific strategy toinvalidate the cache memories of the CPDS’s. In fact, a CPDShas to update its cache memory whenever:
(i) a cache miss is generated in a remote file access (see Figs. 6and 8);
(ii) a file, declustered within a cluster but whose segments havebeen cached by the CPDS’s of other clusters of an EVM, isupdated.
To easily invalidate the cache memories of the CPDS’s inthe latter case, each PDS manages a table in which each entryis associated to a file locally declustered, and refers to the listof the clusters whose CPDS’s have cached segments of the file.Thus, when a file included in the table is updated by a PDS, aspecific invalidating message can be multicast to all the CPDS’sbelonging to the clusters reported in the list, according to thescheme shown in Fig. 9.
Finally, it is worth noting that a CPDS implements, bydefault, a “segmented least-recently used” caching policy [35].However, it has been purposely designed to easily adoptdifferent caching algorithms.
6. Experimental results
This section reports on a number of tests designed toestimate the performance potential provided by ePIOUS. Thetests mainly measure the aggregated transfer rate in a varietyof configurations, and are intended primarily as an indicatorof how ePIOUS actually performs. However, many other tests
have been conducted on ePIOUS, even if they are not reportedin this section for the sake of brevity. To this end, it is worthnoting that the behavior of ePIOUS is strongly influenced byePVM, whose performance potential is documented in [6].
The software programs used to test ePIOUS have beendeveloped on the basis of some main examples reported inliterature, such as those reported in [13].
All the tests have been conducted on two PC clustersconnected by a Fast Ethernet network. The first cluster iscomposed of 16 PCs interconnected by a Fast Ethernet switchand each equipped with Intel Pentium IV 3 GHz, hard diskEIDE 60 GB, and 1 GB of RAM. The second cluster iscomposed of 8 PCs connected by a Fast Ethernet switch andeach equipped with Intel Xeon 2.8 GHz, hard disk EIDE 80GB, and 1 GB of RAM. All the PCs run Red Hat Linux rel. 9.
The benchmark applications implement two parallelfile access patterns, defined as “partitioned” and “self-scheduled” [36]. The former divides a file into contiguousblocks, with each block accessed sequentially by a differenttask. The latter results when a linear file is accessedsequentially by a group of tasks via a shared file pointer.In fact, “partitioned” and “self-scheduled” access essentiallycorrespond to the ePIOUS “independent” and “global” fileaccess types, respectively.
The files used in the tests are characterized by a numberof segments multiple of the number of the PDS’s employed.As a consequence, the linear file mapping provided by the“independent” and “global” views result in a data distributionpattern that is equivalent to the so-called “disk striping” [37],which is characterized by a linear sequence of fixed size datablocks, called “striping units”, distributed in a round-robin wayacross a number of hosts.
The number of the tasks performing the read and writefile operations may vary from 16 to 48. Furthermore, thetasks are all allocated on the hosts belonging to the firstcluster according to a round-robin strategy, whereas the PDS’saccessed during the tests are allocated on the hosts belongingto the second cluster. Finally, files are always accessed in the“volatile” mode. However, the conducted tests have shown thatthe “stable” mode causes a performance degradation about 16%with respect to the “volatile” mode.
Fig. 10 shows a simple comparison between PIOUS andePIOUS. The test application used in the comparison measures
Fig. 8. The scheme of a remote PDS’s interaction.
174 F. Frattolillo / Future Generation Computer Systems 24 (2008) 166–176
Fig. 9. The multicast messages invalidating the CPDS’s’ cache memories.
Fig. 10. Comparison between PIOUS/PVM and ePIOUS.
the read performance achieved in accessing a file according toa “partitioned” pattern and by employing a transfer buffer of1 kB. The size of the adopted striping unit is 1 kB. In fact,PIOUS running on PVM has been tested with a configurationbased on hosts all provided with public IP addresses. ePIOUShas been tested disabling the file caching service. Therefore,the conducted test essentially shows the effects caused by theoverheads introduced by ePVM on the measured, “aggregated”transfer rate, i.e. the transfer rate obtained as the sum of thetransfer rates achieved by all tasks. To this end, it is worthnoting that the performance achieved by ePIOUS is essentiallydetermined by the unoptimized, original implementation ofthe inter-cluster communications in ePVM [6,38], which ispreserved in ePIOUS.
Fig. 11 depicts the read performance achieved by a testapplication that accesses a file according to a “partitioned”pattern. The test has been conducted with two sizes of thetransfer buffer used by each task: 1 kB and 4 kB. The size ofthe adopted striping unit is 1 kB.
The data shown in Fig. 11 demonstrates that, despite boththe high latency induced by the PVM transport layer in theintra-cluster communications and the overhead induced bythe inter-cluster operations managed by epvmds, ePIOUS canachieve good performance results. This is due both to the excessof parallelism developed by the application tasks and to the
Fig. 11. Partitioned file read access in volatile mode.
internal structure of the epvmds, which enables tasks to serve inparallel many remote file access requests. Furthermore, the filecaching service significantly improves the observed bandwidth,thus diminishing the effects of the two-level network topologycharacterizing the cluster grid used in the conducted tests.However, performance does not appear to scale well as thenumber of tasks is increased, and this is mainly due to anincreased number of message interrupts at the daemon transportlayer and to the unoptimized implementation of the inter-clustercommunications in ePVM.
Fig. 12 shows the write performance obtained by thetest application implementing a “partitioned” access pattern.In particular, data caching results in being effective forwrite access among different clusters, even though aggregateperformance is not very sensitive to a continued increase in thenumber of tasks.
Figs. 13 and 14 show the read and write performanceobtained by the test application accessing a file according toa “self-scheduled” pattern. The achieved results show that thisaccess pattern does not appear to well scale in performance asthe number of tasks is increased, and this because the use of ashared file pointer forces a serialized file access.
Finally, it is worth noting that the write performanceachieved by ePIOUS in all the conducted tests reported aboveis worse than the read performance, even in the cached case,

F. Frattolillo / Future Generation Computer Systems 24 (2008) 166–176 175
Fig. 12. Partitioned file write access in volatile mode.
Fig. 13. Self-scheduled file read access in volatile mode.
Fig. 14. Self-scheduled file write access in volatile mode.
because it reflects the performance behavior characterizingPIOUS and PVM, as documented in [15–17], as well as thelack of specific optimizations in the implementation of theadopted cache coherence protocol, such as the write-before-fullmechanism [34].
7. Conclusions and future work
ePIOUS is the PIOUS implementation under ePVM, a PVMextension that enables large-scale PVM applications to runon cluster grids spanning across multidomain, non-routablenetworks. The limited modifications to the PIOUS library andthe addition of a caching service that can speed up file accesses
involving different clusters have enabled ePIOUS to achieve agood performance in all the executed tests, and this essentiallydemonstrates that existing PVM applications can run on clustergrids without having to be rearranged or penalized by the useof complex software systems for grid computing.
Future work will be mainly focused on the implementationof optimized inter-cluster communications, according to thescheme proposed in [38], and of additional mechanisms toenhance the behavior of the file caching service, such as theread-ahead and write-before-full mechanisms [34].
References
[1] W. Gentzsch, Grid computing, a vendor’s vision, in: Procs of the 2ndIEEE/ACM Int’l Symposium on Cluster Computing and the Grid, Berlin,Germany, 2002, pp. 290–296.
[2] P. Stefan, The hungarian clustergrid project, in: Procs of the Int’lConvention MIPRO 2003, Opatija, Croatia, 2003.
[3] F. Berman, G. Fox, T. Hey (Eds.), Grid Computing: Making the GlobalInfrastructure a Reality, Wiley & Sons, 2003.
[4] J. Joseph, C. Fellenstein, Grid Computing, Prentice Hall PTR, 2003.[5] I. Foster, C. Kesselman (Eds.), The Grid: Blueprint for a New Computing
Infrastructure, 2nd ed., Morgan Kaufmann, 2004.[6] F. Frattolillo, Running large-scale applications on cluster grids,
International Journal of High Performance Computing Applications 19(2) (2005) 157–172.
[7] A. Geist, A. Beguelin, et al., PVM: Parallel Virtual Machine. A Users’Guide and Tutorial for Networked Parallel Computing, The MIT Press,1994.
[8] W. Gropp, E. Lusk, A. Skjellum (Eds.), Using MPI: Portable ParallelProgramming with the Message-Passing Interface, 2nd ed., The MITPress, 1999.
[9] F. Frattolillo, A PVM extension to exploit cluster grids, in: Procs of the11th EuroPVM/MPI Int’l Conference (Budapest, Hungary), in: LectureNotes in Computer Science, vol. 3241, 2004, pp. 362–369.
[10] G. Geist, J. Kohl, R. Manchel, P. Papadopoulos, New features of PVM 3.4and beyond, in: Procs of the 2nd Euro PVM Users’ Group Meeting, Lyon,France, 1995.
[11] A. Beguelin, J. Dongarra, et al., Recent enhancements to PVM, Inter-national Journal of Supercomputer Applications and High PerformanceComputing 9 (2) (1995) 108–127.
[12] T. Ludwig, R. Wismuller, The Tool-Set—An integrated tool environmentfor PVM, in: Procs of the 2nd Euro PVM Users’ Group Meeting, Lyon,France, 1995.
[13] W.B. Ligon III, R.B. Ross, Implementation and performance of a parallelfile system for high performance distributed applications, in: Procs of the5th IEEE Int’l Symposium on High Performance Distributed Computing,Syracuse, NY, USA, 1996, pp. 471–480.
[14] E. Schikuta, T. Fuerle, H. Wanek, ViPIOS: The Vienna parallelinput/output system, in: European Conference on Parallel Processing(Southampton, England), in: Lecture Notes in Computer Science, vol.1470, 1998, pp. 953–958.
[15] S.A. Moyer, V.S. Sunderam, PIOUS: A scalable parallel I/O systemfor distributed computing environments, in: Procs of the Scalable High-Performance Computing Conference, Knoxville, TN, USA, 1994, pp.71–78.
[16] S.A. Moyer, V.S. Sunderam, A parallel I/O system for high-performancedistributed computing, in: Procs of the IFIP WG10.3 Working Conferenceon Programming Environments for Massively Parallel DistributedSystems, Monte Verita, Ascona, Switzerland, 1994.
[17] V.S. Sunderam, S.A. Moyer, Parallel I/O for distributed systems: Issuesand implementation, Future Generation Computer Systems 12 (1) (1996)25–38.
[18] F. Frattolillo, S. D’Onofrio, An efficient parallel file system for clustergrids, in: Procs of the 12th EuroPVM/MPI Int’l Conference (Sorrento,Italy), in: Lecture Notes in Computer Science, vol. 3666, 2005,pp. 94–101.

176 F. Frattolillo / Future Generation Computer Systems 24 (2008) 166–176
[19] T. Tannenbaum, D. Wright, K. Miller, M. Livny, Condor—A distributedjob scheduler, in: T. Sterling (Ed.), Beowulf Cluster Computing withLinux, The MIT Press, 2002.
[20] I. Foster, C. Kesselman, Globus: A metacomputing infrastructuretoolkit, International Journal of Supercomputer Applications and HighPerformance Computing 11 (2) (1997) 115–128.
[21] I. Foster, C. Kesselman, The Globus project: A status report, FutureGeneration Computer Systems 15 (5–6) (1999) 607–621.
[22] P.L. Springer, PVM support for clusters, in: Procs of the 3rd IEEE Int’lConference on Cluster Computing, Newport Beach, CA, USA, 2001, pp.183–186.
[23] P.L. Springer, Enhancements to PVM’s BEOLIN architecture, in: Procsof the 12th EuroPVM/MPI Int’l Conference (Sorrento, Italy), in: LectureNotes in Computer Science, vol. 3666, 2005, pp. 250–257.
[24] J. Frey, T. Tannenbaum, I. Foster, Condor-G: A computation managementagent for multi-institutional grids, in: Procs of the 10th IEEE Int’lSymposium on High Performance Distributed Computing, San Francisco,CA, USA, 2001, p. 0055.
[25] T. Beisel, E. Gabriel, M. Resch, An extension to MPI for distributedcomputing on MPPs, in: Procs of the 4th European PVM/MPI Users’Group Meeting on Recent Advances in Parallel Virtual Machine andMessage Passing Interface (Cracow, Poland), in: Lecture Notes inComputer Science, vol. 1332, 1997, pp. 75–82.
[26] E. Gabriel, M. Resch, T. Beisel, R. Keller, Distributed computing in aheterogeneous computing environment, in: Procs of the 5th EuropeanPVM/MPI Users’ Group Meeting on Recent Advances in Parallel VirtualMachine and Message Passing Interface (Liverpool, UK), in: LectureNotes in Computer Science, vol. 1497, 1998, pp. 180–187.
[27] M.A. Brune, G.E. Fagg, M.M. Resch, Message-passing environments formetacomputing, Future Generation Computer Systems 15 (5–6) (1999)699–712.
[28] S.M. Pickles, J.M. Brooke, F.C. Costen, E. Gabriel, M. Muller,M. Resch, S.M. Ord, Metacomputing across intercontinental networks,Future Generation Computer Systems 17 (8) (2001) 911–918.
[29] D. Kurzyniec, P. Hwang, V. Sunderam, Failure resilient heterogeneousparallel computing across multidomain clusters, International Journal ofHigh Performance Computing Applications 19 (2) (2005) 143–155.
[30] G. Stuer, V. Sunderam, J. Broeckhove, Towards OGSA compatibilityin the H2O metacomputing framework, Future Generation Computer
Systems 21 (1) (2005) 221–226.[31] P.F. Corbett, D.G. Feitelson, et al., Parallel file systems for the IBM SP
computers, IBM Systems Journal 34 (2) (1995) 222–248.[32] H. Stern, Managing NFS and NIS, O’Reilly & Associates, Inc., 1991.[33] M. Nelson, B. Welch, J. Ousterhout, Caching in the Sprite network file
system, ACM Transactions on Computer Systems 6 (1) (1988) 134–154.[34] F. Garcia-Carballeira, J. Carretero, A. Calderon, J.M. Perez, J.D.
Garcia, An adaptive cache coherence protocol specification for parallelinput/output systems, IEEE Transactions on Parallel and DistributedSystems 15 (6) (2004) 533–545.
[35] T. Wong, J. Wilkes, My cache or yours? making storage more exclusive,in: Procs of the USENIX Annual Technical Conference, Monterey, CA,USA, 2002.
[36] T.W. Crockett, File concepts for parallel I/O, in: Procs of the ACM/IEEEInt’l Conference on Supercomputing, Reno, NV, USA, 1989, pp. 574–579.
[37] K. Salem, H. Garcia Molina, Disk striping, in: Procs of the 2nd IEEEInt’l Conference on Data Engineering, Los Angeles, CA, USA, 1986, pp.336–342.
[38] M. Petrone, R. Zarrelli, Utilizing PVM in a multidomain clustersenvironment, in: Procs of the 12th EuroPVM/MPI Int’l Conference(Sorrento, Italy), in: Lecture Notes in Computer Science, vol. 3666, 2005,pp. 241–249.
Franco Frattolillo received his Laurea degree “cumlaude” in electronic engineering from the Universityof Napoli “Federico II”, Italy, in 1989/1990 and hisPh.D. degree in computer engineering, applied electro-magnetics, and telecommunications from University ofSalerno, Italy. He was a researcher with the Depart-ment of Electrical and Information Engineering of theUniversity of Salerno from 1991 to 1998. In 1999 hejoined the Faculty of Engineering of the University ofSannio, Italy, where he currently teaches high perfor-
mance computing systems, advanced topics in computer networks, network se-curity, and system programming. He is also a research leader with the ResearchCentre on Software Technology of the University of Sannio and at the Compe-tence Centre on Information Technologies of the Campania Region, Italy. Hehas written several papers in the areas of parallel programming systems. Hisresearch interests also include metacomputing systems, cluster and grid com-puting, and network security.
Copyright © 2022 FDOKUMEN




















