Story Tags
93
Story Tags Contar histórias para etiquetar fotografias Nuno Miguel Rochinha Tomás Dissertação para obtenção do Grau de Mestre em Engenharia Informática e de Computadores Júri Presidente: Prof. Joaquim Armando Pires Jorge, Prof. Catedrático, DEI/IST Orientador: Prof. Daniel Jorge Viegas Gonçalves, Prof. Auxiliar, DEI/IST Vogais: Prof. António Rito Silva, Prof. Associado, DEI/IST Outubro de 2009
-
Upload
independent -
Category
Documents
-
view
2 -
download
0
Transcript of Story Tags

Story Tags
Contar histórias para etiquetar fotografias
Nuno Miguel Rochinha Tomás
Dissertação para obtenção do Grau de Mestre em
Engenharia Informática e de Computadores
Júri
Presidente: Prof. Joaquim Armando Pires Jorge, Prof. Catedrático, DEI/IST
Orientador: Prof. Daniel Jorge Viegas Gonçalves, Prof. Auxiliar, DEI/IST
Vogais: Prof. António Rito Silva, Prof. Associado, DEI/IST
Outubro de 2009

i
Sumário Com o aumento de informação multimédia ao longo dos últimos anos, surgiu a necessidade de criar mecanismos que permitam organizar esse conteúdo através de descrições ou palavras-chave. Uma das principais formas de catalogar conteúdos é o tagging. Pode ser encontrado em sites como o Flickr para imagens ou o Del.icio.us para bookmarks. O utilizador é livre de associar tags ao conteúdo com o intuito de obter uma organização que possibilitará uma recuperação mais fácil. No entanto, o tagging é um processo pouco estruturado, podendo tornar difícil a sua utilização generalizada. Se classificar novos items é fácil, nada garante que as tags usadas são as mais indicadas, ou que se usam as mesmas tags em situações semelhantes. Problemas como a polissemia, os sinónimos ou ainda o problema dos níveis básicos da linguagem diminuem a taxa de reutilização de tags e dificultam a posterior recuperação de items.
Para resolver tais problemas, propomos uma solução baseada em narrativas. Todos nós contamos e ouvimos histórias. Numa história, é transmitida muita informação e de forma estruturada. Este trabalho, focado na gestão de fotografias digitais, passou por perceber na fase inicial como é que os utilizadores contam as suas histórias. Com esse fim foi feito um estudo onde foi possível retirar os elementos e estrutura geral das histórias das fotografias dos participantes do estudo. A partir das conclusões desse estudo foi construído um website onde o utilizador estrutura o seu processo de tagging contando histórias sobre as suas fotografias. Em paralelo com o sistema de narrativas foi replicado o sistema de tagging do Flickr no website de modo que na comparação de resultados dos sistemas, não existisse o ruído que poderia advir de interfaces diferentes. Tendo em conta diversos critérios, foram recolhidos e analisados os resultados da utilização do sistema por parte de quarenta pessoas durante um período de tempo. Da análise foi possível concluir que os utilizadores do sistema de narrativas inseriram em média muito mais informação/tags existindo ainda uma grande percentagem de reutilização de tags no sistema de narrativas.
Palavras-Chave Fotografia, Tagging, Narrativas, Reutilização, Interface, Utilizador.

ii
Abstract The increase of multimedia information over the past few years has led to the creation of mechanisms that enable its organization through descriptions or keywords. A popular way of associating such descriptions to content is tagging. It can be found in popular sites such as Flickr (for images) or Delicious (bookmarks), among many others. The user is free to associate several tags to content, richly describing that content, which may lead to an easier retrieval at a later time. This solves several problems with hierarchical organization schemes, where choosing the “correct” classification is often hard. However, tagging is completely unstructured, leading to problems of its own. If cataloguing new items is easy, nothing guarantees that the tags used are most appropriate or the same tags are used in similar situations. Problems such as polysemy, synonyms or the problem of basic levels of language make the reuse of tags lower, and hinder the subsequent recovery of items.
We propose an approach in which narratives are used as an organizing principle for the tagging of photos. We are used to tell and hear stories, making them a natural form of interaction. By inter-relating the information in them as a coherent whole, stories convey much data in a structured way. By resorting to narratives describing their photos, the users are able to convey more information than by using traditional tagging methods. Furthermore this increases tag reuse and minimizes other problems found in tagging. We conducted a user study with 40 users over a period of three months, which shows this to be the case.
Keywords Tagging, Narrative-based interfaces, Digital Photographs

iii
Índice
Sumário.........................................................................................................................................i
Palavras-Chave ............................................................................................................................i
Abstract........................................................................................................................................ii
Keywords.....................................................................................................................................ii
Índice...........................................................................................................................................iii
1. Introdução................................................................................................................................11.1 Objectivo ............................................................................................................. 21.2 Contribuições ..................................................................................................... 21.3 Publicações......................................................................................................... 31.4 Estrutura da Dissertação ................................................................................... 3
2. Trabalho Relacionado.............................................................................................................52.1 Processo cognitivo do tagging ......................................................................... 52.2 Diferentes abordagens ao tagging ................................................................... 6
2.2.1 Sistemas de tagging colaborativo.................................................................. 72.3 Desenho do sistema e Atributos..................................................................... 102.4 Sistemas de tagging......................................................................................... 122.6 Sistemas propostos para melhorar o processo de tagging ......................... 152.5 Discussão.......................................................................................................... 172.6 Conclusão ......................................................................................................... 17
3. Histórias Sobre Fotos...........................................................................................................193.1 Procedimento.................................................................................................... 20
3.1.1 Análises de Entrevistas ............................................................................... 213.2 Resultados ........................................................................................................ 22
3.2.1 Caracterização dos Entrevistados ............................................................... 223.2.2 Elementos das Histórias .............................................................................. 223.2.3 Propriedades Gerais das Histórias .............................................................. 293.2.4 Estruturas das Histórias............................................................................... 313.2.5 Arquitectura das Histórias............................................................................ 373.2.6 Princípios Base............................................................................................ 37
4. Desenho da Interface............................................................................................................394.1 Pré-Requisitos .................................................................................................. 394.2 Interface das Histórias ..................................................................................... 404.3 Diálogos ............................................................................................................ 414.4 O Website “StoryTags”.................................................................................... 424.5 Avaliação Heurística ........................................................................................ 434.6 Arquitectura ...................................................................................................... 45
4.6.1 Linguagens de Programação....................................................................... 464.6.2 Estrutura da Base de Dados........................................................................ 47

iv
4.6.3 Principais componentes e decisões ............................................................ 49
5. Resultados.............................................................................................................................535.1 Caracterização dos utilizadores...................................................................... 545.2 Análise de resultados ...................................................................................... 55
5.2.1 Histórias....................................................................................................... 565.2.2 Tagging........................................................................................................ 65
5.3 Comparando Narrativas com Tagging Tradicional ....................................... 715.4 Conclusão dos resultados............................................................................... 73
6. Conclusão..............................................................................................................................77
Referências................................................................................................................................79
A1 Guia de Entrevista ...............................................................................................................81
A2 Transcrições das Entrevistas ............................................................................................82
A3 Avaliação Heurística ...........................................................................................................85
A4 Interface dos Diálogos ........................................................................................................87

1
1. Introdução Com a Internet deu-se um aumento exponencial na quantidade de informação disponível a todos, e com esse aumento surgiram dificuldades na organização dessa mesma informação. Os sistemas simples, baseados na memorização, têm vindo a ser suplementados por estruturas mais organizadas, que permitem que a informação seja disposta de forma a que a sua recuperação se torne um processo mais simples e eficiente.
A classificação hierárquica é uma das formas mais usuais de organizar a informação. Um dos primeiros trabalhos a referir-se a esta abordagem foi da autoria de Thomas Malone [17]. O autor identificou as categorias mais comuns à organização de documentos nos escritórios: ficheiros, documentos que eram classificados de acordo com o assunto, sendo que documentos semelhantes eram agrupados em pilhas, conjuntos de documentos sem classificação e agrupados sem um critério aparente. Esta era a organização mais comum, uma vez que um problema que advinha da hierarquização era o facto de existirem dificuldades por parte das pessoas em categorizar a informação, porque não sabiam o que abrangia ou representava cada categoria, não conseguindo classificar a informação numa determinada categoria. Desta forma, os utilizadores tentavam, sempre que possível, evitar a classificação de documentos Outro inconveniente nas hierarquias era o facto de que aos documentos só podiam ser colocados num único lugar, o que dificultava ainda mais a escolha de uma classificação [15].
Outras abordagens foram ensaiadas, de forma a contornar os problemas da classificação hierárquica [10]. Ao nível temporal existe um projecto como o “Lifestreams”, uma framework desenvolvida de forma a usar uma ordenação temporal, como metáfora organizacional [7], reconhecendo a importância do tempo como uma particularidade relevante na recuperação de um documento. Existe ainda a abordagem espacial de Rekimoto [25] que propunha que as pessoas ao organizarem os seus documentos no espaço, construíssem estruturas implícitas que lhes permitiam aceder mais facilmente à informação. Rekimoto defendia que as duas abordagens não eram exclusivas e que podiam-se completar, combinando uma distribuição espacial da informação com um mecanismo de navegação cronológico.
Novos sistemas de organização têm sido criados, tendo em conta metáforas lógicas, temporais e mesmo espaciais, seguindo a premissa que os sistemas hierárquicos predominantes são de certa forma inadequados para a gestão de documentos.
Outra forma de classificar documentos que tem vindo emergir e impor-se, tornando-se na abordagem mais popular neste momento, é o tagging que vamos discutir na secção a seguir. Numa primeira fase podemos definir o tagging como uma estratégia utilizada para organizar conteúdos. As pessoas associam palavras-chave livremente ou através de sugestões dadas por um sistema, que surgem como pistas para a informação que está presente no conteúdo que está a ser alvo de tagging.
A estrutura simples que o tagging apresenta, embora tenha as suas vantagens, resulta também em diversos problemas. A forma pouco organizada apresenta problemas ao nível da linguagem, no contexto individual mas que se repercutem exponencialmente num contexto de grupo. Problemas como os sinónimos, polissemia e ainda dos níveis básicos da linguagem, que mais tarde falaremos com maior pormenor, estão presentes nos sistemas de tagging tradicionais.

2
No presente em que somos encarados como pessoas integradas numa sociedade, em que a necessidade de partilhar informação é fundamental, tem de existir sistemas com características únicas, que apresentem melhores índices de desempenho para as necessidades emergentes do novo mundo em que nos encontramos e em que todos os indivíduos gostam de partilhar com os seus pares as suas músicas, as suas notícias e as suas fotografias.
A solução pensada pode passar pela utilização de histórias para associar informação aos conteúdos. Partindo da premissa que todas as pessoas sabem contar histórias, uma vez que está presente no dia-a-dia e é algo natural, tendo conhecimento da estrutura que está presente nas histórias, podemos concluir que poderá ser uma opção viável capaz de ser solução para um sistema de tagging pouco ou nada estruturado.
1.1 Objectivo
O objectivo deste trabalho passa por resolver os problemas identificados nos sistemas de tagging tradicionais, em que o utilizador de forma livre associa conceitos aos seus conteúdos com o objectivo de os identificar e no futuro recuperar. Embora a forma desorganizada e pouco estruturada que é característica do tagging, seja uma possível vantagem, acaba por se apresentar também como uma desvantagem que se torna relevante num ambiente de comunidade em que há partilha de informação.
Estruturando o processo de tagging será possível minimizar ou mesmo resolver os problemas encontrados. Da resolução desses problemas, poderá resultar numa melhoria de outros aspectos relevantes dos sistemas de partilha, como é exemplo a reutilização de informação.
Será analisado um sistema baseado numa forma estruturada e organizada de informação como são as histórias. O objectivo passará por construir um sistema baseado em narrativas e na forma como as pessoas contam as histórias das suas fotografias. A partir desse sistema vamos conseguir retirar resultados e comportamentos dos utilizadores que permitem confrontar o sistema de narrativas que se apresenta como solução, com o sistema tradicional de tagging presente em websites como o Flickr.
A finalidade deste trabalho será apresentar uma alternativa estruturada do processo de tagging capaz de resolver os problemas de linguagem do tagging, conseguindo melhores índices ao nível da reutilização de tagging que poderá resultar num aumento de eficiência na recuperação de conteúdos que estão inseridos numa comunidade.
1.2 Contribuições
Na linha do trabalho desenvolvido com o objectivo de criar um novo sistema de tagging, destacamos as seguinte contribuições:
• Identifição da estrutura geral e elementos que compõem as histórias descrevendo as fotos dos utilizadores. Foi feito um estudo do qual se podem retirar inúmeros aspectos/ características do modo como uma pessoa organiza o seu pensamento para contar a história de uma fotografia.
• A abordagem de utilizar as narrativas como forma de estruturar o processo de tagging tradicional, que por si só possui uma estrutura muito simples quase inexistente e que resulta em problemas quando inserido num ambiente de partilha e de comunidade. Ao utilizar as narrativas consegue-se estruturar o processo de tagging, minimizando alguns dos problemas que os sistemas de tagging tradicionais padecem.

3
• O sistema que resulta do estudo de como as pessoas contam as histórias das suas
fotografias. O sistema é capaz de se adaptar às formas utilizadas pelas pessoas para organizar o seu pensamento. Desde construir uma narrativa que não tenha a estrutura geral como base, ou então conseguir adicionar elementos cada vez mais específicos à sua história, como foi identificada em alguns indivíduos no estudo.
• A comparação de um sistema que utiliza narrativas para estruturar o processo de tagging, demonstrando estruturar o tagging resulta num aumento na informação que uma pessoa associa a um conteúdo, e num aumento de reutilização de tags importante na partilha de conteúdos.
1.3 Publicações
Este trabalho deu origem a uma publicação nacional e uma internacional.
• Tomás, N., Guerreiro, T., Gonçalves, D., Story Tags, Contar histórias para etiquetar fotografias, Procedings of Actas da 3ª Conferência Nacional em Interacção Pessoa-Máquina (Interacção 2008) Évora, Portugal, Outubro 2008
• Tomás, N., Guerreiro, T., Gonçalves, D., Story Tags: once upon a time, there was a photo, Proceeding of Works-in-Progress program at CHI 2009
1.4 Estrutura da Dissertação
Na secção 2 apresentamos o trabalho relacionado com este projecto. Vamos numa primeira fase descrever o que é o tagging, passando a como é utilizado o tagging, e as vantagens e desvantagens da sua utilização. Após essa análise fazemos uma síntese dos sistemas que utilizam o tagging, e um resumo de soluções apresentadas com o mesmo objectivo que o trabalho aqui apresentado, melhorar o processo de tagging.
Na secção 3 é apresentado um estudo sobre a forma como os utilizadores contam as suas histórias. Foi feito um estudo a 20 pessoas, em que cada uma conta 3 histórias de fotografias pessoais. As histórias foram analisadas e retirou-se um conjunto de directrizes de modo a encontrar a estrutura geral para as histórias que as pessoas contam das suas fotografias.
Na secção 4 é apresentada a construção da aplicação, tanto da interface com a apresentação do desenho usado para o utilizador associar informação às suas fotografias sobre a forma de narrativas, como também da interface construída à volta do sistema de narrativa, sendo que este se insere numa rede social em que as pessoas fazem upload das suas fotografias. Também é explicado as decisões tomadas na arquitectura da aplicação, opções de organização, linguagens utilizadas e a forma como foram contornados certas partes da aplicação.
Na secção 5 é descrita a metodologia de avaliação utilizada no projecto, apresentando os critérios de avaliação utilizados para a comparação do sistema baseado nas narrativas com o tradicional. São apresentados os resultados provenientes da utilização do sistema, segundo esses critérios.
Na secção 6 é feita a conclusão da dissertação, revendo os objectivos a que nos propusemos e comparando com os resultados atingidos.

4

5
2. Trabalho Relacionado As tags são palavras-chave que podem ser associadas a um documento ou objecto como forma de meta informação. Tipicamente os utilizadores não possuem a possibilidade de associar relações entre tags, sendo que atribuem símbolos atómicos que são associados ao documento [2]. Aos utilizadores não é facultada uma lista pré-definida de tags, tendo estes a liberdade de escolher qualquer palavra ou expressão para ser usada como tag. A acção de associar uma tag a um documento, tagging, não é um novo conceito, especialmente para bibliotecários ou classificadores profissionais. O que é novo no tagging é o facto de estar a ser feito por todos e não apenas um pequeno grupo experiente e está a ser aplicado na internet a um ritmo bastante elevado, sendo que na actualidade vários sites têm a organização do conteúdo, apoiada no conceito de tagging. Tagging tem por base a simplicidade. O utilizador apenas tem de escolher tags que sejam significativas para ele. Em muitos sites pode apenas ser uma única palavra, mas disso falaremos mais tarde. Uma vez que a tag tenha sido associada ao recurso, vai servir como termo de indexação.
Um dos melhores exemplos da extrema popularidade das tags é a comunidade de partilha de fotografias, o Flickr. A ideia de partilhar tags leva ao conceito de “folksonomia”. A expressão é atribuída a Thomas Vander Wal no Wikipédia. É uma analogia a taxonomia, mas inclui o prefixo folks, palavra inglesa que significa pessoas. Por folksonomia é entendido que a noção do uso e significado correcto de uma tag é determinado por uma comunidade, invés de ser decidido por um conjunto limitado de pessoas. Os defensores da folksonomia referem que ao permitir que o significado de uma tag provenha do uso colectivo de uma comunidade, permite que surja um significado mais correcto do que se este for definido apenas por uma pessoa [2].
Este termo não é aceite por todos, por exemplo, Merholz considera que o termo folksonomia é impreciso, uma vez que a taxonomia tende para hierarquia e controlo, características que tagging tem precisamente o inverso.
É importante reter que neste processo os utilizadores têm uma completa liberdade nas tags, que escolhem e podem associar tags para os seus próprios propósitos organizacionais, sem ter em conta os outros utilizadores.
Deste rápido crescimento do tagging podemos retirar o quão fácil e agradável as pessoas acham o processo de tagging, mas do qual advêm alguns problemas, que abordaremos mais à frente. Numa primeira fase vamos explicar como se desenrola o processo num nível cognitivo.
2.1 Processo cognitivo do tagging
No primeira etapa do processo (figura 2.1), é feita a apresentação de um objecto que é necessário memorizar, numa segunda fase o utilizador analisa semelhanças entre o objecto e conceitos candidatos, ou seja, vocábulos que se podem associar ao objecto. Por exemplo, a uma foto podemos considerar “verão”, “praia”, “Sesimbra” como conceitos semânticos relacionados. Outros conceitos mais pessoais como “férias favoritas”, “melhores amigos”, ou mais relacionados com características físicas, como, “foto digital”, “bom estado”, podem ser associados. Esta é a forma como o tagging é feito, falando cognitivamente uma pessoa ao deparar-se com um determinado objecto associa-lhe conceitos aos quais relacione o objecto. Tal é apoiado por psicólogos cognitivos, que através de alguns métodos, provam que é possível relacionar a activação de conceitos com diferentes fluxos de sangue para diferentes

6
partes do cérebro. O que é relevante reter é que existe consenso sobre a activação de conceitos na psicologia cognitiva [4].
Figura 2.1. Processo cognitivo do tagging [4].
2.2 Diferentes abordagens ao tagging
O tagging está-se a impor na internet a um ritmo alucinante, com sistemas a fazerem do tagging a ferramenta mais importante no apoio à informação que é introduzida na rede todos os dias.
Os elementos a considerar são: quem faz o tagging?; é colaborativo?; tem o propósito de categorização?; que uso é feito das tags?.
Diferentes sites usam o tagging de diferentes formas [14]. O tagging não é sempre feito por utilizadores, em alguns casos poderá ser feito por peritos com os resultados a serem apresentados como uma “tag cloud”, ou seja, uma descrição visual das tags associadas a um recurso. Um exemplo disto é o News.com (http://www.news.com/2243-12_3-0.html) onde os editores do News.com publicam uma história com um ou mais tópicos. Neste site o tagging não é feito por utilizadores mas sim pelos editores. Na “tag cloud” (figura 2.2), os tópicos com mais tags associadas são apresentados com uma letra maior e a cor vermelha, enquanto os outros estão mais pequenos e a cinzento.
Figura 2.2. “Tag cloud”
Quando o tagging é feito pelos utilizadores em actividade num site, diferentes utilizadores vão ter comportamentos diferentes. Alguns utilizadores escolhem tags que querem que sejam públicas com o objectivo de partilhar. Outros utilizadores preferem que as suas tags sejam privadas e as utilizam simplesmente como uma forma de armazenar e organizar informação

7
para as suas próprias finalidades. Um exemplo é no Del.icio.us, um utilizador pode ter uma área privada como forma de organizar os seus “bookmarks”, de forma a poderem ser acedidos de todo o lado, sem existir uma rede social.
Embora a utilização com objectivos privados é uma forma válida de tagging o interesse passa por quando as tags são públicas e partilhadas desenvolvendo folksonomias.
Outros utilizadores podem utilizar tags públicas, mas deliberadamente escolher palavras privadas para que poucos utilizadores as empreguem e assim consigam manter controlo sobre um número de recursos com tags.
2.2.1 Sistemas de tagging colaborativo
Nestes sistemas sociais de tagging devido à escassez de estruturas taxonómicas predefinidas, confiasse na partilha e estruturas sociais e comportamentos emergentes, como estruturas linguísticas e conceptuais da comunidade de utilizadores [19].
Basicamente passa por sites que permitem publicitar tags e partilhar conteúdos onde os utilizadores não classificam a informação apenas para eles próprios, existindo a possibilidade de os utilizadores procurarem informação classificada por outros utilizadores.
Um modelo conceptual representativo dos sistemas de tagging colaborativo [13], poderá ser representado por três entidades que compõem qualquer sistema de tagging:
• Os utilizadores do sistema (quem faz o tagging); • As próprias tags; • Os recursos sobre os quais é feito o tagging.
Cada uma destas entidades podem ser vistas como áreas separadas, cada qual com um conjunto de nós que estão interligados (figura 2.3). O primeiro espaço, “os utilizadores”, consiste no conjunto de utilizadores do sistema de tagging onde cada nó representa um utilizador. O segundo espaço, representa o conjunto de tags, sendo cada nó uma tag distinta. O terceiro espaço, representa o conjunto de recursos, sendo cada nó um recurso único. Uma instância de tagging pode ser vista como uma ligação utilizador>tag(s)->recurso. Podemos observar a partir da figura 2 que as tags são a ligação entre os utilizadores do sistema e os recursos ou conceitos pelos quais procuram.
Figura 2.3. Modelo conceptual dos sistemas de tagging [13]

8
2.2.1.1 Benefícios
Em seguida apresentamos características que podem ser consideradas vantagens.
Os sistemas são multidimensionais, permitindo que os utilizadores associem um grande número de tags que exprimem um conceito e se podem combinar entre eles.
Os utilizadores poderão utilizar a sua própria linguagem, palavras que tenham significado para eles, como individuais, e analisarem os recursos de forma a realçar o mais importante nestes, o que no entanto será um complicação como observaremos mais adiante.
As tags podem ser partilhadas criando conhecimento por agregação, ou seja, é construída uma base partilhada de conhecimento. Os sistemas sociais de tagging promovem o desenvolvimento de comunidades à volta de pontos de vista e interesses comuns.
Permitem que fornecedores e gestores profissionais de informação, de áreas de interesse, estejam a par de como estas estão a ser descritas. É uma janela de observação para os utilizadores que permite ver como estão a pensar e pode fornecer informação sobre os seus hábitos e necessidades.
2.2.1.2 Desvantagens
Estes sistemas têm alguns inconvenientes que advêm do processo de criação de relações entre as tags e os recursos a que ficam associados. Três desses problemas são a polissemia, sinónimos e os chamados níveis básicos de variação [9].
A polissemia ocorre quando uma palavra tem múltiplos sentidos. Um exemplo é a palavra frango, que poderá ser aplicada em vários contextos, como por exemplo: “Eu comi um frango ao jantar” e “O Ricardo comeu um frango no Mundial de Futebol”. Este problema deve-se ao facto que numa procura poderão ser dados resultados que não estarão relacionados com os recursos procurados. Superficialmente, a polissemia é semelhante aos homónimos, onde uma palavra poderá ter múltiplos significados que não estão relacionados uns com os outros. No entanto, os homónimos não constituem um problema tão complexo como a polissemia, uma vez que podem ser largamente excluídos, numa procura por tags, através da adição de conceitos relacionados com os quais os homónimos não desejados não apareceriam.
Os sinónimos apresentam um desafio, sendo que várias palavras poderão ter o mesmo significado ou muito semelhante. É um problema complicado num sistema colaborativo devido à inconsistência dos termos usados no tagging, o que poderá tornar a tarefa da procura muito complicada. A solução passará por os utilizadores chegarem a um consenso ou então terem a percepção de que têm de fazer múltiplas combinações de palavras de forma a terem todos os resultados possíveis.
O problema dos níveis básicos tem a ver com o facto de as pessoas poderem considerar termos de especificidade diferente como sendo os melhores ou mais apropriados para descrever o recurso. Por exemplo, dois especialistas em diferentes áreas, um de peixes e outro de cães. Onde o especialista de cães pode considerar “peixe” um nível básico, onde o especialista de peixe considera “salmão”, e onde o especialista de peixe considera “cão”, o especialista de cães considera “labrador” como nível básico. O nível básico de cada um depende da experiencia que este tem. Um especialista de cães tem de saber diferenciar entre duas raças. Tanto variações no grau de conhecimento, como variações ao nível social e cultural poderão causar variações no nível básico.
Estes sistemas poderão oferecer uma maneira de ultrapassar o problema de vocabulário sem ser necessário utilizar grande poder computacional ou um grande controlo de vocabulários. Com todas as contribuições colectivamente é produzido um sistema de classificação de larga

9
escala que contém todas as categorias que são aceites pelos utilizadores. Os custos totais, para os utilizadores do sistema, em termos de tempo e esforço são pequenos, comparadas com sistemas que confiam em classificações hierárquicas complexas e esquemas de categorização, e segundo um dos criadores do Flickr, Stewart Butterfield, a falta de hierarquia, controlo de sinónimos e precisão semântica é a principal razão para a popularidade do sistema.
A folksonomia nivela por baixo as barreiras da cooperação. Os grupos de utilizadores não têm de concordar na hierarquia de tags ou numa detalhada taxonomia, apenas têm de concordar no significado da tag, de modo a que em conteúdos similares os termos usados tenham valores iguais.
2.2.1.3 Características das tags
Umas das características das tags que vale a pena investigar é o seu uso individual ao longo do tempo. Qual a evolução das tags do utilizador ao longo do tempo? Se estagna ou continua a evoluir ao mesmo tempo que a experiência do utilizador é maior? Golder e Huberman depois de estudarem o Delicious, demonstraram exemplos de certos utilizadores, nos quais os conjuntos de tags distintas aumentam à medida que novos recursos são adicionados. Ainda a lista de tags dos utilizadores aumenta à medida que o tempo passa, novos interesses vão aparecendo, e com estes novas tags para os categorizar e descrever. Numa primeira instância podemos ver um panorama geral comprovativo da convergência para uma folksonomia de um sistema como o Del.icio.us (figura 2.4) em que se pode reparar que o número de tags distintas vai diminuindo drasticamente à medida que o número de utilizadores aumenta, indicando uma concordância no significado das tags usadas pela comunidade e que os utilizadores aplicam tags idênticas a recursos parecidos que vão sendo inseridos no sistema.
Outro estudo, mas este efectuado sobre o sistema lickr (figura 2.5), demonstra o crescimento
Figura 2.4 Tags distintas no Delicious

10
de tags distintas para dez utilizadores escolhidos aleatoriamente. A escolha foi feita a partir de utilizadores que faziam upload de fotos frequentemente (mais de cem fotos) ou eram taggers frequentes (mais de cem tags). O gráfico demonstra o número de tags distintas para cada utilizador depois de um número de fotos. Pode-se verificar a partir do gráfico o número de diferentes comportamentos que emergem destes sistemas sociais de tagging. Em alguns casos, como o utilizador A, novas tags são constantemente adicionadas ao mesmo tempo que o upload de
novas fotos é feito, sugerindo uma fonte de novo vocabulário e um incentivo constante para o uso de tags. Outra situações é o caso do utilizador B, em que apenas algumas tags são utilizadas inicialmente, mas mais tarde nota-se um crescimento repentino, sugerindo que o utilizador ou descobriu novas tags ou novos interesses para o uso destas. Quando os utilizadores que têm poucas tags distintas e o crescimento destas diminui ao longo do tempo, pode-se afirmar que existe uma concordância nas tags usadas ou pouco interesse na sua utilização.
Do gráfico também se pode concluir que a interacção entre utilizador, tags e a utilidade é muito variado.
As tags podem exibir várias taxas de crescimento, reflectindo o desenvolvimento dos interesses dos utilizadores e mudança ao longo do tempo.
Golder e Huberman identificaram ao examinar o sistema Delicious quais os tipos de distinções que são importantes para os utilizadores [9]:
• Identificação do quê (ou quem). Esta parte inclui muitos nomes comuns com vários níveis de especificidade, além de nomes próprios referindo-se a pessoas ou organizações.
• Identificação do que é. Tags podem identificar que tipo de recurso é e sobre o que se trata.
• Identificação de quem o possui. Identificar a quem pertence ou criou o recurso. • Identificar qualidades ou características. Adjectivos são atribuídos aos recursos. • Referência ao próprio. Identificar a relação do utilizador ao recurso. • Organização de tarefas. Quando organiza informação de acordo com uma tarefa,
essa informação pode ter como tag referências à própria tarefa.
2.3 Desenho do sistema e Atributos
Aos estudar os sistemas sociais de tagging podemos ter em conta algumas dimensões chave no desenho dos sistemas, sobre os quais vamos avaliar os sistemas existentes na actualidade [19]:
• Direitos de Tagging. Um dos aspectos chave no desenho do sistema é a restrição ao grupo de utilizadores que podem fazem tagging sobre um recurso. Um sistema de tagging pode ser restrito a só o próprio utilizador poder fazer tagging sobre os seus
Figura 2.5 Número de tags distintas (Flickr)

11
recursos que criara (“self-tagging”), ou permitir que todos os utilizadores possam fazer tagging sobre os recursos (“free-for-all tagging”). Existem ainda, outros níveis de compromisso, como por exemplo, o sistema permitir apenas fazer tagging de um determinado tipo de recurso ou ainda existirem vários níveis de permissão, autorizando somente a família ou amigos a fazerem tagging nos recursos de um utilizador.
• Suporte de Tagging. O mecanismo de entrada das tags pode ter um grande impacto no comportamento do sistema de tagging. Os sistemas podem ser categorizados em três níveis distintos nesta categoria: “blind-tagging”, onde o utilizador que vai associar as tags ao recurso, não conseguindo ver as diferentes tags que foram atribuídas ao mesmo recurso por outros utilizadores; “viewable tagging”, onde o utilizador consegue ver as tags já associadas ao recurso; ou “suggestive tagging”, em que o sistema sugere um número de possíveis tags ao utilizador. Estas poderão ser tags já utilizadas pelo utilizador ou antes associadas ao recurso por outros utilizadores. “Suggestive tagging” poderá implicar uma convergência mais rápida para uma folksonomia.
• Agregação. Outra característica da dinâmica de grupos poderá ser a agregação de tags sobre um recurso. O sistema pode permitir uma multiplicidade de tags para o mesmo recurso, o que poderá implicar tags duplicadas de diferentes utilizadores. Esta abordagem é designada de “bag-model” para a inserção de tags. Em alternativa, os sistemas pedem ao grupo para colectivamente decidirem qual a melhor tag para um recurso em particular.
• Tipo de objecto. O tipo de recurso sobre o qual se faz tagging constitui uma parte importante do sistema. O tipo de objectos mais usuais são paginas Web, material bibliográfico, fotos, vídeos entre outros. Na realidade qualquer tipo de objecto que possa ser representado virtualmente pode ser usado num sistema de tag.
• Origem do material. Recursos sobre o qual se vai fazer o tagging podem ser fornecidos pelos utilizadores, pelo sistema, ou ainda, um sistema poderá receber tagging sobre qualquer recurso da internet. Existe sistemas que restringem a origem do material através da arquitectura, enquanto outros restringem a origem apenas com uso de normas sociais.
• Conectividade dos recursos. Os recursos no sistema podem estar interligados independentemente das tags que lhe estejam associadas. A conectividade pode ser categorizada como “linked”, “grouped” ou “none”. Por exemplo, paginas Web estão interligadas por links, no Flickr as fotos podem estar ligadas por grupos. Implicações para as tags resultantes poderão incluir convergência em tags semelhantes para recursos ligados, principalmente em sistemas com “viewable” ou “suggestive tagging”.
• Conectividade social. Alguns sistemas permitem aos utilizadores estarem ligados entre si. Como a conectividade dos recursos, a conectividade social, poderá estar categorizada como “linked”, “grouped” ou “none”. Implicações da conectividade social estarão focadas em localizar e focar folksonomias baseadas nas estruturas sociais do sistema.

12
2.4 Sistemas de tagging
Flickr
O Flickr é um website de partilha e hospedagem de fotos que tem como base as tags que ajudam na partilha, procura e navegação das contribuições da comunidade de utilizadores. Cada utilizador tem a possibilidade de armazenar as suas fotos pessoais, tornando-as como imagens de apresentação das pessoas. Este desenho de sistema permitiu que a sua popularidade tivesse uma ascensão meteórica ao longo dos anos.
As tags têm um papel crucial neste ambiente, sendo a principal ferramenta de navegação para encontrar recursos semelhantes.
Falando mais detalhadamente de como funciona o sistema de tagging (figura 2.6) e os seus aspectos chave de desenho. Em termos de direitos de tagging, apenas os criadores dos conteúdos o podem fazer, ou existe ainda a possibilidade de delegar direitos sobre outros utilizadores, permitindo que também façam tagging sobre os conteúdos. Na altura da inserção das tags, o sistema não oferece possíveis sugestões de tags que foram dadas a recursos semelhantes. Outra opção de desenho é o facto de em termos de interface, as tags não serem repetidas para o mesmo recurso. Os recursos armazenados são fornecidos pelos utilizadores.
Del.icio.us
O Delicious oferece um serviço na internet que permite que os utilizadores adicionem e pesquisem bookmarks. A ideia por trás deste site da Web baseia-se no facto das pessoas que salvam os seus bookmarks no computador de casa o façam no site, permitindo que estes estejam acessíveis a partir de qualquer local. Além disso, permite que exista uma comunidade de partilha destes bookmarks, possibilitando aos outros utilizadores da comunidade o acesso aos seus bookmarks. Analogamente ao Flickr, a base do sistema de navegação assenta sobre a utilização de tags para identificar os recursos inseridos.
Os direitos de tagging sobre os recursos inseridos nos sites é global, ou seja, qualquer utilizador pode associar uma tag num recurso inserido por outro utilizador. O sistema (figura 2.7) oferece, na altura de associar as tags, sugestões que estão relacionadas com outros recursos semelhantes inseridos no sistema. O sistema aceita uma multiplicidade de tags para o mesmo recurso que pode resultar em tags duplicadas de diferentes utilizadores.
Figura 2.7. Sistema de tagging do Delicious.
Figura 2.6. Sistema de tagging do Flickr.

13
CiteULike
É um serviço grátis que ajuda estudantes a partilhar e armazenar artigos académicos que estão a ler. Permite aos utilizadores terem a sua biblioteca pessoal, a qual pode-se aceder a partir de qualquer computador uma vez que é um serviço Web. O serviço de partilha possibilita saber quem lê os mesmos artigos e através desse sistema poderá ainda descobrir novos artigos relevantes e dos quais o utilizador não tenha conhecimento.
O utilizador depois de se registar pode fazer o upload de artigos. O utilizador dá como argumento o link para o artigo, a partir do qual o site retira informações como o titulo e autores. O site apresenta as informações (figura 2.8) e pede ao utilizador as tags que quer que sejam associadas ao artigo. Qualquer utilizador pode associar tags aos artigos desde que esse mesmo artigo faça parte da sua biblioteca.
Last FM
A Last.FM é um serviço que regista as músicas que o utilizador ouve e a partir das quais, após o processamento das preferências, oferece recursos personalizados ao utilizador, faz ainda, recomendações de artistas e utilizadores com gostos parecidos. Além disso é uma comunidade onde se pode falar com outros utilizadores que partilhem a mesma paixão por um tipo de música.
O direito de tagging no sistema é global, podendo qualquer utilizador fazer tagging sobre um recurso. O sistema apresenta as tags associadas pelos outros utilizadores. Os recursos podem estar agrupados por categorias ou como “playlist”.
YouTube
YouTube é um site amplamente conhecido, em que os utilizadores partilham vídeos. O utilizador pode fazer upload de um vídeo, categorizá-lo , associar tags e uma descrição ao vídeo. É o site mais popular do tipo, devido a poder hospedar quaisquer vídeos (excepto os protegidos com copyright). Permite ainda, que estes recursos sejam embebidos fora do YouTube, em blogs e sites pessoais.
Todos os utilizadores podem fazer tagging (figura 2.9) sobre os recursos inseridos, tendo disponíveis as tags já associadas a recursos. Existe os conceitos de grupos de utilizadores e ainda a possibilidade de ligar recursos entre si.
Figura 2.9. Inserção de vídeos no YouTube
Figura 2.8. Sistema de tagging no CiteULike.

14
ESP Game
É um jogo online (figura 2.10) em que o objectivo é descobrir o conteúdo de imagens, fornecendo tags relevantes. O utilizador regista-se no site como um jogador e depois lança uma java applet. O sistema agrupa dois jogadores aleatoriamente e é apresentada uma imagem de um conjunto delas. O utilizador tem de descobrir o maior número de palavras relevantes para um conjunto de imagens, num determinado tempo, sendo o seu resultado calculado tendo em conta esses factores. O utilizador
começa por escrever tags uma de cada vez para uma imagem. Quando o utilizador e o seu parceiro tiverem escrito a mesma palavra para uma imagem, é referido no programa e passam ao item seguinte [18].
Technorati
O Technorati é um motor de procura de internet especializado na procura de blogs, fazendo concorrência às ferramentas de procura de blogs do Google e Yahoo. O sistema permite que os autores façam tagging sobre os posts do blog, fazendo a agregação de informação nos weblogs e facilitando a sua procura.
Os utilizadores após fazerem o registo no site podem adicionar blogs seus ao Technorati. Após confirmarem a autenticidade como donos do blog, podem adicionar uma descrição e várias tags (figura 2.11) que pensem que estejam relacionadas com o seu blog, que irão servir como palavras-chave para as procuras. Apenas os donos do blog têm direitos de tagging sobre o blog.
Gmail
O Gmail é um serviço gratuito de e-mail criado pelo Google. Foi um serviço revolucionário na medida em que oferecia um armazenamento por utilizador que na altura era imaginável e que nenhum outro serviço na poderia competir. Os utilizadores têm inúmeras funcionalidades presentes, mas a que nos interessa é os marcadores. Estes funcionam como tags que podem ser associadas a mensagens de e-mail pelos utilizadores.
Figura 2.10 ESP Game
Figura 2.11. Technorati.

15
Os marcadores no Gmail vão servir para separar as mensagens/diálogos dos utilizadores. Como é óbvio as tags associadas (figura 2.12) aos e-mails são introduzidas pelo utilizador da conta e só ele terá acesso a elas.
Odeo
O Odeo é uma aplicação online que permite gravar e partilhar podcasts com
uma interface simples feita na tecnologia Flash da Macromedia. Tem ainda, directórios e rádios com canais de podcasts.
Os utilizadores após se registarem no sistema têm a possibilidade de ouvir podcasts de outros utilizadores e fazer tagging sobre esses mesmos recursos. Podem ter a sua própria lista de podcasts e entre outras opções criar uma comunidade que possibilita partilhar as escolhas de cada utilizador.
Going to Meet
O Going to Meet é um site de eventos a um nível global, em que os eventos são registados e onde os utilizadores podem opinar sobre os eventos, permitindo ainda que o utilizador partilhe e promova um evento que conheça ou que esteja a organizar.
O utilizador após se registar tem a oportunidade de adicionar eventos e sobre os quais poderá fazer tagging. Os outros utilizadores não poderão adicionar tags sobre o sistema, apenas poderão deixar uma crítica ao evento.
2.6 Sistemas propostos para melhorar o processo de tagging
Na secção anterior foram apresentados sistemas que utilizam tags para melhorar a experiência dos utilizadores nas aplicações. Ou seja, as tags nas aplicações ajudam o utilizador a organizar o seu conteúdo para no futuro a sua procura consiga ser feita com um maior grau de confiança.
Nesta secção vamos apresentar outros trabalhos que possuem o mesmo objectivo deste projecto, melhorar o processo de tagging. Tendo em consideração que os sistemas de tagging já não são um novidade para os utilizadores, avançou-se para o próximo passo, melhorar os processos de associação de tags à informação.
Um primeiro exemplo, é um sistema de recomendação de tags [27]. Os autores do artigo procederam a uma análise a 52 milhões de fotos do Flickr, das quais retiraram as tags que tinham sido associadas às fotografias. A partir dessa recolha de dados, utilizando o Wordnet para classificar as tags, conseguiram descobrir que conseguiam classificar 52% das tags. Das tags classificadas, a maioria das tags seriam relacionadas com a localização (28%), artefactos ou objectos (16%), pessoas ou grupos (13%), acções ou eventos (9%) e tempo (7%). Desta informação concluiu-se que os utilizadores ao associar informação às fotos vão para lá do que as fotos poderão mostrar, sentindo a necessidade de associar outros tipos de informação às fotografias. Com base nestas informações os autores apresentam um sistema de recomendação de tags. O sistema começa por o utilizador apresentar as suas tags, a partir das quais vão ser geradas, para cada uma, uma lista de seis tags que aparecem associadas a essa
Figura 2.12. Marcadores no Gmail

16
tag. A partir das listas geradas é formada uma lista única de tags ordenadas pelo grau de relevância. O número de elementos da lista é decidido conforme a aplicação.
Outra proposta apresentada, resulta da extracção da semântica das tags [23], mais concretamente na extracção do evento e localização associada às fotos do Flickr. Utilizaram dois métodos de extracção e compararam o desempenho destes. Pretenderam com este sistema depreender que o facto de conseguirem extrair semântica das tags pode melhorar os sistema de tagging actuais, permitindo melhores motores de busca pelas tags e mecanismos e desambiguação.
A utilização de técnicas de clustering com o tagging [1], com o objectivo de agrupar tags semanticamente ligadas, também foi sugerido como solução para melhorar a experiência de associar tags a um conteúdo.
Outra opção baseia-se num algoritmo para sugerir tags para um sistema colaborativo [33]. O algoritmo proposto inclui uma medida de qualidade para tags derivadas de um colectivo de utilizadores eliminando o ruído. Esta medida de qualidade é ajustada dinamicamente com um algoritmo de prémio-penalização que inclui outras fontes de tags.
Outros autores optam por um novo conceito de tagging, “purpose tagging” [28]. Este é direccionado ao facto dos termos utilizados na procura serem diferentes dos utilizados na altura da associação. De forma a contornar tal dificuldade, os autores apresentam um novo tipo de tags, “purpose tags”, que se foca em capturar mais aspectos de intenção do que de conteúdo. Os autores defendem que conseguindo os diferentes propósitos onde um recurso poderá ser utilizado, as purpose tags poderão ser úteis na mediação do vocabulário de intenção com o vocabulário de conteúdo e ainda as tags fornecidas por aplicações de software social.
Outro sistema, reedita a associação de tags com as categorias [22]. É descrito como uma das opções para associar informação a um conteúdo, os sistemas optam por categorias pré-definidas ou então palavras-chave. Os autores criaram um sistema, o Tilkut, que junta as duas possibilidades sendo que os utilizadores podem criar livremente tags ou associar o conteúdo a uma das categorias pré-definidas. Dos resultados retirados, concluiu-se que existem apoiantes para ambas as metodologias. Referiram também, que a um nível mais particular, optam por um tagging livre, enquanto a um nível mais cooperativo essa metodologia de tagging livre poderá tornar-se caótico preferindo optar por um conjunto de categorias pré-definidas.
Outra abordagem ao processo de tagging, ao nível da recomendação de tags num sistema colaborativo, surge tendo em conta a distância semântica entre as tags dos vários utilizadores [26]. A abordagem começa por obter a similaridade das tags recorrendo ao WordNet, sendo utilizada essa métrica de similaridade para obter um conjunto de recomendações que poderá ajudar o utilizador a associar informação ao tagging.
Sistemas automáticos de tagging de imagens também têm vindo a ser explorados no passado, mas sempre com grandes dificuldades para se imporem, devido à elevada capacidade em termos de desempenho e adaptabilidade que apresentam. Tendo em conta essas limitações foi proposto um sistema [24], tagging over time (T/T) , de forma a conseguir-se levar essas aplicações até ao mundo real, onde existe dificuldades de desempenho e adaptabilidade. Esta proposta está assente numa abordagem de meta-aprendizagem. Acreditam que com esta proposta de meta-aprendizagem conseguem recolher informação de um conjunto de estruturas que compõem todo o processo, como dos sistemas de tagging automático, tags que provenham dos utilizadores, fontes exteriores de conhecimento (WordNet) e mesmo o conteúdo visual da imagem. Com esta framework pretende-se conseguir uma base de conhecimento que se apresente capaz de ser utilizada no mundo real com bons desempenhos, capaz de se ser integrada nos sistemas envolventes.

17
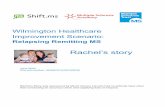
2.5 Discussão
Na tabela 2.1 apresentamos um quadro resumo dos sistemas que analisamos, tendo sido analisados os sistemas conforme as dimensões chave acima descritas. A maioria apresenta os direitos de tagging “free-for-all”, sendo que todos os utilizadores podem fazer tagging sobre recursos que tenham sido inseridos no sistema por outros utilizadores. Aqui poderá advir um dos problemas destes sistemas que é o nível básico das tags atribuídas. Por exemplo, no caso do Flickr, as tags associadas a uma foto poderão divergir radicalmente, dependendo se o tagging é feito pelos fotógrafos, pelos seus amigos ou desconhecidos .
No momento de inserir tags os sistemas estudados apresentam os três tipos de suporte. O Flickr e o Delicious apresentam a “blind-tagging”, ou seja, não apresentam nenhumas tags que estejam já associadas à foto no momento do tagging. A reter é o “suggestive tagging” do site CiteULike, que apresenta sugestões na altura de associar tags aos recursos. Este tipo de suporte poderá ajudar na consolidação da utilização de tags para um recurso, muito mais rapidamente que num sistema de “blind tagging”. Uma folksonomia convergente tem mais possibilidade de acontecer quando o sistema de tagging apresenta opções aos utilizadores. Para os sistemas que apresentam “viewable tagging” as implicações poderão pesar em certas tags que foram associadas ao recurso no inicio, mesmo que não tivessem surgido de outra forma.
Sobre a agregação dos sistemas, onde o “bag-model” é usado, neste caso só o Delicious apresenta um sistema com essa característica, existe a possibilidade de usar estatísticas para um dado recurso, para apresentar aos utilizadores as colecções de opiniões dos taggers. Os dados poderão ser ainda, usados para encontrar relações entre utilizadores, tags e recursos, devido à informação adicional das frequências das tags.
Em sistemas onde existe a conectividade dos recursos, as tags de cada recurso que estão ligados poderão resultar numa convergência mais rápida. Os utilizadores tendem a associar tags parecidas a recursos semelhantes. No LastFM as músicas poderão ser agrupadas por categorias, ou, como no caso do Delicious e do YouTube, os recursos estarem ligados entre si, desde que a partir da página de um recurso exista ligação para recursos semelhantes que abordem os mesmos assuntos. Ou seja, nestes sistemas, nos recursos interligados, as implicações nas tags puderam resultar numa convergência especialmente em cenários que apresentem tags como sugestão ou apresentem as tags já atribuídas aos recursos.
Ao nível da conectividade dos utilizadores temos em casos como o Flickr e outros sistemas estudados, a possibilidade de se formar grupos de utilizadores. Uma das características que poderá resultar do sistema é a formação de folksonomias localizadas, nos grupos, baseadas na estrutura social do sistema.
2.6 Conclusão
Nos sistemas apresentados temos vários problemas em termos de vocabulário, além de existirem também os problemas cognitivos associados ao facto de um utilizador ter de recordar uma determinada tag, a qual associou o recurso que pretende, o que pode ser difícil ao fim de algum tempo. Uma maneira de contornar ou atenuar alguns dos problemas encontrados, é a utilização das narrativas como forma de associar informação aos recursos. É uma abordagem mais natural e estruturada [3]. Contar histórias é algo que é intrínseco à natureza humana, uma vez que crescemos a ouvir as histórias contadas pelos nossos pais e avós. Sendo algo tão natural, as narrativas tornam-se uma hipótese bastante plausível de associar informação aos recursos. Ao contar a história, as pessoas vão associando atributos chave, que estão inerentes a maior parte dos recursos, como “o que é?”, “a quem pertence?”. O individuo forma uma
18
Dire
itos
de
tagg
ing
Supo
rte
de
tagg
ing
Agr
egaç
ão
Tipo
de
obje
cto
Orig
em d
o
Mat
eria
l
Con
ectiv
idad
e do
s re
curs
os
Con
ectiv
idad
e So
cial
Flickr Principalmente “self-tagging”
“blind tagging”
“set model”
Fotos Produzido pelo utilizador
- grouped
Delicious “free-for-all tagging”
“blind tagging”
“bag model” Bookmarks Internet linked -
CiteULike “free-for-all tagging”
“suggestive tagging”
“set model”
Artigos Internet Nenhuma grouped
Last.FM “free-for-all tagging”
“viewable tagging”
“set model”
Músicas Fornecido pelo sistema
grouped grouped
YouTube “self-tagging” “viewable tagging”
“set model” Vídeos
Produzido pelo utilizador
Linked ou grouped grouped
ESP Game “self-tagging” “blind tagging”
“set model”
Fotos Fornecido pelo sistema
Nenhuma grouped
Technorati “self-tagging” “blind tagging”
“set model” Blogs
Produzido pelo utilizador
Nenhuma Nenhuma
Gmail “self-tagging” “blind tagging”
“set model”
E-mails Produzido pelo utilizador
Nenhuma Nenhuma
Odeo “free-for-all tagging”
“viewable tagging”
“set model” Podcasts
Produzido pelo utilizador
Nenhuma grouped
Going to Meet “self-tagging”
“blind tagging”
“set model”
Eventos Produzido pelo utilizador
Nenhuma Nenhuma
Tabela 2.1. Tabela de comparação de sistemas de tagging
estrutura que possui um inicio, um meio e um fim, ao contrário do tagging focado ao longo da pesquisa, em que eram associados atributos aleatórios ao recurso e que tornavam posteriormente a recuperação um processo mais moroso. A narrativa vai tornar obstáculos como a ambiguidade, a polissemia e sinónimos menos óbvios, e poderá disfarçar esses problemas. Tendo em conta as dimensões estudadas dos sistemas podemos admitir que, na narrativa teríamos em conta que o utilizador seria guiado ao longo da história, e em cada palavra-chave que iria completar o sistema apresentaria uma politica de “suggestive-tagging”. Ou seja, antes de completar o campo, seria apresentado ao utilizador um número de termos populares que já tivessem sido inseridos no sistema no âmbito do recurso a ser tratado.

19
3. Histórias Sobre Fotos As narrativas têm como principal característica ,tendo como fundo o objectivo deste trabalho, a estrutura que as identifica. Na mesma medida que a estrutura de uma noticia segue determinadas premissas, como a necessidade de um título, um resumo e um corpo, também as histórias das fotografias contêm um estrutura definida. Os utilizadores ao contar uma história, organizam o seu pensamento sob determinados parâmetros, estruturando os conteúdos da história de modo a conseguir ter algo conciso capaz de ser compreendido por outras pessoas.
Como já foi referido, um dos objectivos do trabalho é organizar o processo de tagging de forma a que se replique esta estrutura das histórias. O objectivo é organizar o processo de tagging incutindo-lhe a estrutura das narrativas, permitindo resolver problemas que o tagging tradicional padece e que se tornam mais complicados num ambiente de comunidade.
Neste capítulo, vamos tentar compreender os processos que as pessoas utilizam para contarem uma história de uma fotografia. Temos de ter em conta que uma história não é apenas um número de elementos interligados sem razão aparente, mas sim elementos que no seu conjunto apresentam uma estrutura com regras bem definidas que os tornam coerentes. Ao desenhar a interface terá de se considerar não só os elementos como um só, mas também a relação entre os mesmos. Ou seja, a estrutura da história terá de ser recriada, para que o utilizador consiga contar a história o mais naturalmente possível e que no final a história contemple os elementos mais importantes das fotografias para o utilizador.
De forma a conseguir recriar o ambiente desejado na interface, foi feito um estudo através da realização de entrevistas. Nas entrevistas foi pedido a cada individuo que contasse a historia de fotos pessoais, que posteriormente foram sujeitas a uma análise, avaliando os elementos que compunham a história, a sua estrutura e o curso lógico que a história seguiu. Os resultados obtidos serviram de base para a construção da interface.
No planeamento do estudo, tendo em conta os objectivos do trabalho, armazenamento e recuperação de fotos, foi criado um grupo de entrevistados, que na sua maioria era composto por utilizadores assíduos da internet, com a característica de serem utilizadores de sites de alojamento de fotos como é o caso do Flickr e o hi5. Foram também inseridos no grupo elementos que, com uma idade mais avançada e por sua vez uma maior experiência de vida, poderão dar outra visão e termo de comparação com os outros elementos do grupo, que numa primeira instância serão o elemento principal e representativo do utilizador do trabalho final.
Ao entrevistado foi pedido para escolher três fotografias pessoais, sobre as quais contaria a sua história. O único requisito obrigatório era que o entrevistado se lembrasse da história da fotografia, de modo a que fosse ser mais benéfico na procura dos padrões das histórias das fotografias. A privacidade do conteúdo das entrevistas seria preservada, excluindo do relato possíveis omissões ou distorções de aspectos da história.
De modo a conseguir, nas entrevistas, histórias mais naturais possível, o papel do entrevistador foi reduzido ao mínimo, só intervindo em situações em que o entrevistado se encontrasse bloqueado, ou a rumar para um caminho que não fosse o pretendido. Com igual objectivo foi utilizado um gravador, com os aspectos da privacidade dos conteúdos a serem salvaguardados antes de começar a gravação, permitiu que não existisse as pausas que seriam prováveis de acontecer, no caso se o entrevistador fosse escrevendo a medida que o

20
entrevistado fosse falando, dando azo a que fosse quebrado o ritmo natural da história, o que não se enquadrava com os aspectos que queríamos reter ao fazer a entrevista.
Nas próximas secções vão ser descritas mais minuciosamente as fases do estudo e de como este foi executado. Serão apresentadas várias análises e sobre as quais vão ser feitas diversas inferências que serão as bases da construção da interface.
3.1 Procedimento
Foram realizadas vinte entrevistas de forma a conseguir uma boa base de informação sobre a qual fosse possível retirar padrões das histórias de forma a conseguir uma base de ideias em que a interface terá de assentar. Se não fosse possível chegar aos padrões, sendo a informação recolhida muito diversificada, seriam realizadas mais entrevistas.
Cada entrevista é composta por duas partes. Numa primeira fase foi descrito aos entrevistados o objectivo do trabalho e o que era esperado do entrevistado, mostrando a importância da sua participação na realização deste projecto. Foi recolhida, ainda, informação relevante do entrevistado para utilização em dados estatísticos (idade, ocupação, género, etc.). Em seguida foi pedida a autorização para gravar a entrevista, garantindo a privacidade dos dados recolhidos. Pedido que todos os entrevistados acederam.
Na segunda parte da entrevista as fotografias foram descritas. Foi solicitado aos entrevistados, no início desta fase, para contar a história da primeira fotografia. Foi indicado as participantes que no momento da escolha das fotografia tivessem em consideração a escolha de fotografias pessoais e das quais se relembrassem bem do contexto em que se inseriam, factor importante para se extrair o máximo de informação das entrevistas. Foi utilizada uma entrevista semi-directiva, de forma a conseguir que o entrevistado tenha liberdade para contar a sua história e o entrevistador tenha a possibilidade de o guiar caso este esteja a desviar-se dos objectivos da entrevista. O entrevistador tinha à sua disposição um número de perguntas guias para os diferentes elementos das histórias das fotografias, que tinham como objectivo recolher informação relevante e se possível permitir ao entrevistador apoiar-se nesse tópico para continuar a sua história. As perguntas foram reduzidas ao mínimo uma vez que não se pretendia um diálogo de pergunta-resposta, mas sim que o entrevistado fosse o único “protagonista”.
Foram feitas duas entrevistas teste, de forma a dar uma ideia inicial do que seria expectável das histórias. Com a informação recolhida das duas entrevistas, foi possível identificar novos elementos que não faziam parte do lista de elementos inicialmente identificados e refinar o conjunto de perguntas de forma a melhor adaptarem-se ao desenrolar das histórias. Serviu ainda como forma de preparação para o entrevistador. A lista dos elementos com as respectivas perguntas permaneceu aberta a novos elementos que aparecessem depois das análises das entrevistas, para que a lista final (Anexo A1) fosse o mais completa possível e que todos os elementos identificados nas histórias ocupassem um lugar na lista. Esta é constituída por 13 elementos, mais tarde vamos detalhar cada um dos elementos explicando a nossa compreensão de cada elemento e o seu papel na história. A lista de elementos é :
1. Tempo 2. Local 3. Autor 4. Propósito 5. Tipo de Fotografia 6. Dimensão 7. Evento

21
8. Dispositivo 9. Descrição 10. Pessoas 11. Paisagens 12. Monumentos 13. Qualidade
3.1.1 Análises de Entrevistas
De forma a recolher todos os elementos que compunham as histórias das fotografias dos utilizadores, a mesmas foram transcritas (Anexo A2) e sujeitas a uma análise de conteúdo. As entrevistas foram analisadas de forma a encontrar os elementos nas histórias. Esta análise foi efectuada à mão, uma vez que seria impossível fazer uma rotina para encontrar os elementos. Embora existam palavras-chave associadas aos elementos, frases também podem aludir aos elementos e para as quais apenas uma função muito complexa capaz de compreender a sintaxe da língua, seria capaz de analisar automaticamente. As análises seguiram o guia que em baixo especificamos, e que explica quais as possíveis representações de cada elemento. Esse guia foi usado em cada uma das entrevistas de forma a conseguir uma análise coerente de todas as entrevistas. Nas frases mais dúbias foi utilizado o bom senso de forma a identificar o elemento que mais se assimilava à frase.
A seguir detalhamos os elementos identificados nas histórias e o guia usado para executar e analisar as entrevistas:
• Tempo: Referências temporais de quando a fotografia foi tirada, incluindo feriados específicos (Natal, Páscoa, etc.) ou estações do ano (Verão, Inverno, etc.). Outras referências temporais deverão ser classificadas como eventos (aniversários, dias em que estava a viajar, etc.);
• Local: Localização de onde foi tirada a fotografia, quer seja localizações geográficas (Lisboa, Suíça, etc.) ou pontos de referência (Instituto Superior técnico, Torre Eiffel, etc.);
• Autor: Pessoa que foi responsável por tirar a foto, poderá ser um nome (Maria, José, etc.) ou poderá ser descrita por um grau de parentesco( um amigo, um transeunte);
• Propósito: Razão invocada para ter sido tirada a foto (porque era uma situação engraçada, para recordar o momento, etc.);
• Tipo de Fotografia: A fotografia é uma imagem de uma ou mais pessoas, retrato, ou é uma imagem que tem apenas teve como objectivo apanhar uma paisagem, uma fotografia que apanha um ambiente natural (cascata, montanha, etc.) ou um ambiente construído como é o caso de obras de arquitectura;
• Dimensão: Referência ao tamanho da fotografia (grande, média, normal, pequena, etc.);
• Evento: Evento da vida pessoal que está de alguma forma ligado à fotografia ou ao detentor da fotografia (viagem a Itália, aniversário do avô, etc.).
• Dispositivo: Referência ao mecanismo tecnológico utilizado para tirar a fotografia (máquina digital/analógica, telemóvel, etc.);
• Descrição: Conteúdo que compõe a fotografia (a minha mão, sol rodeado de nuvens, etc.), ou expressões que estão a ser representadas (estamos com uma cara muito alegre, temos o flash nos olhos, etc.);
• Pessoas: Referência a pessoas que estejam tanto na fotografia, como as que estão referenciadas na história à volta da fotografia;
• Paisagens: Descrição do ambiente natural que seria mostrado na fotografia. • Monumentos: Referências a monumentos que seriam representativos das fotografias. • Qualidade: Referência à qualidade da fotografia (boa, má, etc.);

22
Foi recolhida informação sobre os elementos com base da frequência com que apareciam, podendo-se concluir quais os elementos das fotografias mais facilmente relembrados, considerando-se estes mais importantes.
Na análise foram distinguidos dois tipos de elementos, os induzidos e os espontâneos. Os induzidos ocorrem quando o entrevistador faz uma pergunta ao entrevistado, de forma a tentar que este retome a história a partir desse tópico. Ao analisar as entrevistas, ao encontrar o elemento que se encontrava ligado directamente à pergunta, será automaticamente considerado um elemento induzido. Os outros elementos que foram encontrados e não são induzidos são considerados espontâneos. Respostas negativas às perguntas do entrevistador também foram contadas, ou seja, “não existia mais pessoas” é diferente do não saber se existiam, sendo que esta ideia foi levada em conta na análise das entrevistas.
Como foi dito anteriormente, além de fazer uma análise das ocorrências de cada elemento, também foi feita uma análise relacional, ou seja, foi tido em consideração o número de vezes que um elemento especifico precedia outro, podendo isto revelar a ordem pelo qual os elementos seriam referidos e se alguns elementos estavam interligados entre si. Esta relação só é tida em conta se não abranger elementos induzidos, uma vez que não foi uma relação feita naturalmente pelo utilizador. Não foram consideradas relevantes relações entre elementos que apesar de consecutivos, estão distantes na história, uma vez que o utilizador dispersou nessa parte.
3.2 Resultados
Nas secções seguintes vão ser apresentados os resultados principais que foram extraídos da análise das sessenta histórias das vinte entrevistas.
3.2.1 Caracterização dos Entrevistados
Foram entrevistadas vinte pessoas, das quais treze (65%) são do sexo masculino e sete (35%) do sexo feminino (figura 3.1a). As suas idades estão compreendidas entre os 18 e 57 anos (figura 3.1b). Relativamente às habilitações literárias, são na maioria pessoas que completaram o ensino obrigatório e que hoje em dia frequentam o ensino superior (Tabela 3.1). Cerca de 40% das pessoas já ocupa um lugar no mundo do trabalho, sendo que apenas uma pessoa tem um curso académico mas encontra-se desempregado por opção. A maioria tem contacto com o computador e são utilizadores habituais da internet, sendo que muitas destas pessoas possuem uma conta em sites que armazenam fotografias pessoais. Existem duas pessoas que pertencem a um grupo etário distinto e possuem pouco ou nenhum contacto com computadores. Penso que este grupo, embora não tão diversificado em termos de idade como talvez fosse o pretendido, foca bem os principais utilizadores que o trabalho pretende atingir.
3.2.2 Elementos das Histórias
Nesta secção vamos discutir os elementos que foram encontrados nas histórias recolhidas através das entrevistas. Numa primeira fase vamos fazer uma análise sumária dos elementos. Vamos utilizar o número de vezes que os elementos aparecem na história (frequência) e se estes aparecem nas histórias (ocorrência). Com a análise da frequência podemos ter percepção dos elementos que poderão ser, de alguma forma, complexos de descrever, ou se revelam como fontes importantes de informação, sendo que, o utilizador se refere ao elemento várias vezes na história. Quanto à ocorrência, esta poderá indicar quais os elementos que aparecem em todas as histórias, sendo que todos os utilizadores lhe fazem referência,

23
podendo indicar que é um elemento importante. Distinguimos os elementos em duas classes distintas, espontâneas e induzidas.
(a) Por género (b) Por idade
Figura 3.1. Perfil dos Entrevistados
Número Idade Profissão Habilitações Literárias
1 24 Estudante de Informática 12º Ano 2 23 Estudante de Informática 12º Ano
3 20 Estudante de Biomédica 12º Ano
4 22 Estudante de Matemática 12º Ano
5 26 Mecânico 9º Ano
6 24 Estudante de Mecânica 12º Ano
7 22 Estudante de Psicologia 12º Ano
8 27 Mecânico/Estudante de Mecânica 12º Ano
9 23 Estudante de Electrotecnia 12º Ano
10 24 Estagiário Licenciatura de Engenharia Mecânica 11 23 Estudante de Informática 12º Ano
12 30 Aero-abastecedor 12º Ano
13 25 Estudante de Informática 12º Ano
14 24 Desempregado Licenciatura de Engenharia Mecânica 15 18 Estudante de Electrotecnia 12º Ano
16 23 Engenheiro Civil Mestrado em Engenharia Civil
17 22 Militar da Força Aérea 12º Ano
18 52 Costureira 4º Ano
19 23 Estudante de Electrotecnia 12º Ano
20 57 Aero-mecânico 4º Ano
Tabela 3.1. Profissões e Habilitações Literárias dos Entrevistados
Masculino
Feminino 1
13
31 0 0 0 1 1 00
2468
101214
<20
20‐24
25‐29
30‐34
35‐39
40‐44
45‐49
50‐54
55‐59
>=60
Nr.de
u(lizad
ores
Idade

24
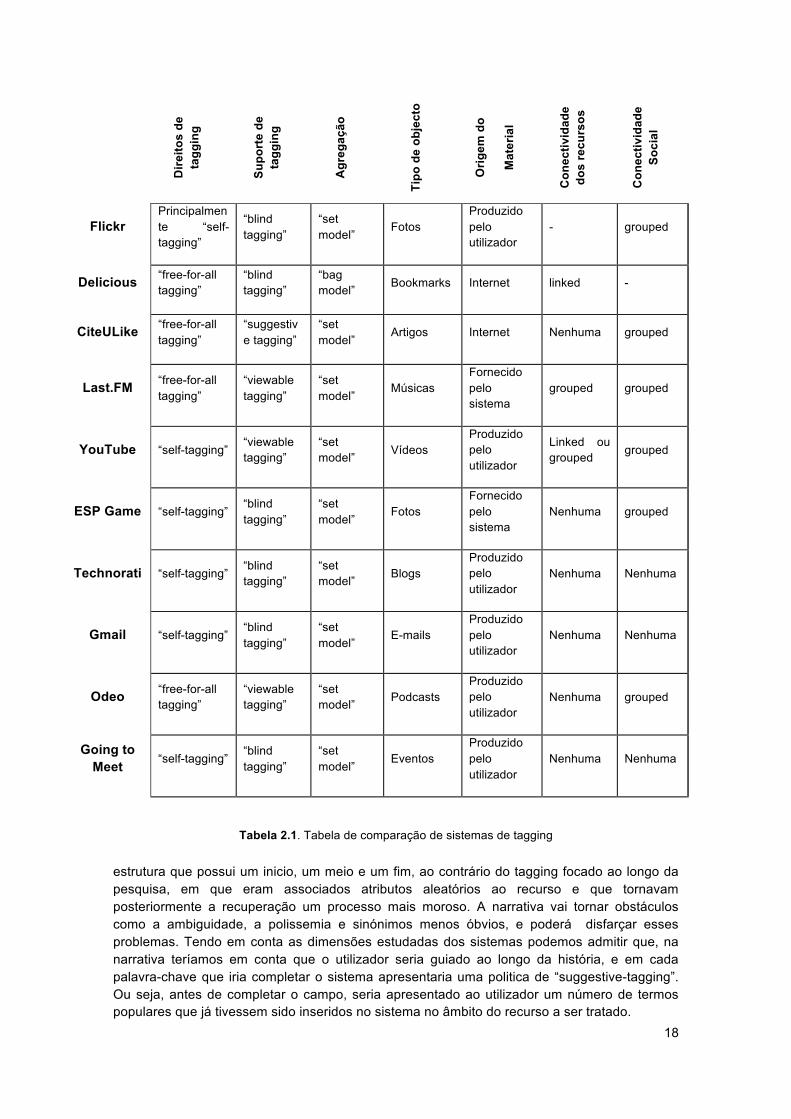
3.2.2.1 Frequência
Na tabela 3.2 mostramos a comparação dos elementos referidos nas histórias contadas em cada uma das três fotografias. Será importante apresentar a relação entre as três fotografias para tentar perceber se existe alguma relação e evolução à medida que o utilizador conta cada uma das histórias.
Será natural constatar que na primeira interacção entre o entrevistador o entrevistado, com este a ser sujeito a uma série de questões, ficaria, de algum modo, com a ideia relativamente aos elementos que deveria referir nas histórias, sendo que na segunda e terceira história o entrevistado já os iria referir espontaneamente. Na tabela podemos notar a evolução das histórias, da primeira à terceira fotografia. O único que demonstrou alguma falta de naturalidade na sua evolução é o elemento “Qualidade” em que o aumento da frequência do elemento induzido da primeira fotografia para a segunda é bastante significativo.
Elemento Foto 1 Foto 2 Foto 3 Total Parcial Total Espontâneo 5 5 7 18 Autor
Induzido 15 13 11 39 57
Espontâneo 25 17 17 59 Local Induzido 4 8 9 21
80
Espontâneo 18 16 18 52 Tempo Induzido 11 11 8 30
82
Espontâneo 6 6 9 21 Propósito Induzido 3 1 1 5
26
Espontâneo 1 2 0 3 Tipo de fotografia Induzido 1 2 1 4
7
Espontâneo 0 3 3 6 Dimensão Induzido 5 1 1 7
13
Espontâneo 14 13 14 41 Evento Induzido 5 5 2 12
53
Espontâneo 3 5 7 15 Dispositivo Induzido 17 15 12 44
59
Espontâneo 18 18 14 50 Descrição Induzido 5 3 4 12
62
Espontâneo 11 13 16 30 Pessoas Induzido 0 1 0 1
31
Espontâneo 3 0 0 3 Paisagens Induzido 2 2 1 5
8
Espontâneo 0 1 2 3 Monumentos Induzido 0 0 0 0
3
Espontâneo 5 14 17 36
36
Qualidade Induzido 13 5 3 21
57
Tabela 3.2. Frequências dos elementos nas histórias
Tendo em consideração que todos os elementos, excepto o elemento “Qualidade”, como indicamos antes, apresentam resultados normais, não será feita uma distinção entre as três fotos e vamos tratar, a partir deste momento, todas sob as mesmas condições. Na figura 3.2 são apresentados as frequências dos elementos nas histórias.
Na lista pré-definida dos elementos, elaborada antes de serem feitas as entrevistas teste, os elementos “Paisagens” e “Monumentos”, não constavam da lista, e não tinham sido

25
considerados. Após as entrevistas teste e face às referências que foram feitas pelos entrevistados, esses elementos ganharam relevância e então foram adicionados à lista. No fim da análise das entrevistas, e pelo que demonstra o gráfico da figura 3.2, esses elementos não representam um número significativo como pontos de referência utilizados pelos entrevistados para recordar a fotografia.
Figura 3.2. Frequência dos Elementos nas Histórias
3.2.2.2 Elementos Espontâneos vs Induzidos
Na figura 3.3 está representada a frequência (%) dos elementos que foram induzidos nas histórias. Como se pode verificar os elementos “Autor”, “Dispositivos”, “Tipo”, “Dimensão” e “Paisagens” foram os elementos com maior frequência nas histórias. como se pode verificar na figura 3.4, por exemplo, o elemento “Autor” ou Dispositivo, são os mais referidos, indicando que poderão ser um elemento importante, mas serão algo que não é associado muito facilmente pelo utilizador sem que exista uma espécie de ajuda ou lembrança ao utilizador.
Os elementos menos induzidos foram os elementos “Propósito”, “Evento”, “Descrição” e “Pessoas” (“Monumentos” é um caso especial). Fora o elemento “Evento”, que deste grupo é dos elementos mais referidos nas histórias, os outros elementos são os que surgem com menos frequência. Sendo que das poucas vezes que estes aparecem nas histórias são referidos espontaneamente, o que poderá indicar que os elementos são importantes ao ponto de não ser necessário qualquer tipo de lembrança, ou então que nenhuma sugestão exterior poderá ajudar o utilizador a lembrar-se deles. No caso do elemento “Evento” e, mais abrangentemente, dos elementos “Local” e “Tempo”, podemos constatar que são considerados importantes e que são lembrados facilmente e mencionados a maioria das vezes espontaneamente.
0102030405060708090
Freq
uência
Elementos
26
Figura 3.3 Percentagem de Elementos Induzidos
Figura 3.4 Frequência Global dos Elementos Induzidos e Espontâneos
3.2.2.3 Frequência Global
No geral, os elementos mais frequentemente mencionados nas histórias e que os utilizadores, de certa forma, consideram mais importantes são o “Autor”, “Local”, “Tempo”, “Evento”, “Dispositivo”, “Descrição” e “Qualidade”. Tendo em conta que foram feitas 60 entrevistas, a maioria dos elementos aparece uma vez em cada história. O caso de elementos como “Local” e “Tempo” ,que apresentam oitenta referências, demonstra o que os utilizadores consideram mais relevante sendo que repetem ou reforçam de modo a demonstrar a sua importância.
O elemento considerado ser o mais importante deverá ser o “Local”, uma vez que apareceu 80 vezes, mas foi apenas induzido em 26% desse número. O grau de precisão deste elemento tende a variar, com os participantes a optar por algo mais geral, ou então um lugar muito específico. No caso mais geral referem-se a lugares como: “(…) para casa… desta amiga nossa.”(E2), “E estamos na bomba (…)”(E10) , “(…)no quarto dela(…)”(E15). Noutras histórias optaram por um local mais preciso: “Foi no jardim da igreja dos em Santa Maria dos
0
10
20
30
40
50
60
70
80
Percen
tagem
Elementos
0102030405060708090
Freq
uência
Elementos
Espontâneos Induzidos

27
Olivais”(E12), “(…)na Estónia, em Talin, capital do país.”(E9), “Foi na cama, em minha casa”(E7).
Outro elemento muito importante foi o “Tempo”. Existiram 82 referências e foi o que teve um melhor rácio entre a frequência e o número de entrevistas, e como o “Local” variam em especificidade: “Foi dia 1 de Outubro deste ano”(E6), “O ano foi 2006, foi assim prai Setembro, Outubro, Novembro… Novembro de 2006. Foi no inverno”(E3), “Tinha à volta dos oito anos”(E10).
O elemento “Descrição” foi outro elemento que foi largamente mencionado, sendo na maioria das vezes de forma espontânea, com os utilizadores a considerarem que ao contarem a história a descrição da foto está particularmente ligada: “Sou eu a fingir… a tentar brincar ao Super-Homem, com uma toalha atada ao pescoço”(E11), “Estávamos vestidos a rigor(…)”(E14), “E a fotografia é eu a apertar o último botão(…)”(E18).
Tal como a “Descrição”, o elemento “Evento” foi na maioria das vezes referido espontaneamente, sendo que os entrevistados associavam a fotografia a eventos como: “num casamento de um amigo meu”(E13), “na passagem de ano”(E17), “quando estava a fazer Erasmus”(E1).
O elemento “Dispositivo” foi várias vezes mencionado, mas a maior parte das vezes foi induzido, talvez pelo facto de ser um elemento que as pessoas têm como certo e não pensam que o necessitam de incluir na história, tendo em conta que todas as vezes que foi induzido os entrevistados tinham uma resposta pronta, sem hesitação. Todas as referências evoluíram em três direcções. As “Máquinas” foram o dispositivo mais utilizado, e alguns juntaram mais pormenores, como se era analógica ou digital. Telemóveis e computadores foram as outras respostas referidas.
A “Qualidade” da fotografia foi mencionada em vários graus qualitativos, e tendo em conta que é uma avaliação que é feita pelo utilizador e não segue um padrão pré-estabelecido e definido pela comunidade, será sempre uma avaliação relativa. A maioria dos entrevistados utilizou adjectivos desde o “mau” até ao “boa”.
A informação do “Autor” da fotografia a maioria das vezes não foi referida espontaneamente pelos entrevistados, pensamos que pelas mesmas razões que o elemento “Dispositivo”. A maioria das referências são os nomes das pessoas que tiraram a fotografia ou o facto de terem sido os próprios a tirarem, o que poderá ser uma razão para omitirem, pois para o entrevistado é uma informação segura que não seria necessário incluir na história.
O elemento “Pessoas” foi referenciado espontaneamente pela maioria, que acharam relevante incluir na história as pessoas que estão a ser fotografadas ou que estariam naquele momento com os próprios entrevistados. Encontramos sempre referências do mesmo tipo: “(…)estou eu, a minha irmã e a minha avó(…)”(E1), “Estava lá com a minha namorada, e os primos dela, o Bastos e a Marília”(E11).
Dos outros elementos existem referências pontuais que alguns entrevistados consideraram que tinham alguma relevância. Sendo elementos com pouca frequência nas histórias, podemos retirar que ou não são facilmente lembrados ou não se apresentam como importantes para os entrevistados.
3.2.2.4 Ocorrências
Algo a ter em consideração, é o facto da análise com recurso frequência não garantir que, por exemplo, o elemento “Tempo” que apareceu 82 vezes, e a sua distribuição não ser por quase

28
todas as histórias e apenas 5 histórias terem muitas referências cada. Nesta parte vamos verificar que a distribuição está feita pela amostra toda.
Figura 3.5 Frequência vs Ocorrências
No gráfico da figura 3.5 podemos comparar a frequência dos elementos com o número de histórias em que o elemento esteve presente. À primeira vista pode verificar-se que apenas os elementos “Tempo” e “Local” possuem uma frequência muito acima do número de ocorrências. Isto poderá querer dizer que os elementos são complicados de descrever e os utilizadores fazem diversas referências de forma a clarificar a informação. Como podemos reparar na figura 3.6, existe muitos elementos que são mencionados apenas uma vez durante uma história, podendo revelarem-se como elementos com informação directa associada e que não têm grandes variações nas repostas.
Figura 3.6 Rácio Ocorrências / Frequências
0102030405060708090
Frequência Ocorrência
00.10.20.30.40.50.60.70.80.91

29
3.2.3 Propriedades Gerais das Histórias
De modo a estudar a estrutura das histórias existem três factores que devemos ter em conta, o tamanho da história, número de transições entre elementos, o número e o tamanho da sequência de elementos sem interrupção.
3.2.3.1 Tamanho da História
Como podemos verificar na tabela 3.3, a média de elementos em cada história é de aproximadamente 9.08 elementos. O desvio padrão calculado foi de 1.74, com tal, consideramos que a variação dos resultados não é muito acentuada. Apenas uma história registou o maior número de elementos encontrados (14), sendo que ainda algumas histórias registaram 7 elementos apenas.
Considerando uma possível dependência entre o tamanho das histórias e a idade do entrevistado, não foi encontrado uma grande relação entre as duas variáveis, sendo que o valor da média das histórias é praticamente igual em todas as faixas etárias em que foram inseridos os entrevistados. Do teste de correlação de Pearson retirou-se um valor de -0.017, que estando muito próximo de 0 revela que as duas variáveis não dependem linearmente uma da outra.
Estudando a possível relação entre o tamanho das histórias, já se encontrou algumas diferenças entre os entrevistados do sexo masculino e feminino. Sendo a diferença não muito abrupta, os indivíduos do sexo masculino na sua média de elementos possuem quase a mais 0.8 elementos em média do que as histórias das entrevistas feitas ao sexo feminino. Ao contrário do que se poderia pensar os homens desta amostra apresentaram capacidades verbais e cognitivas superiores à das mulheres, o que à partida não seria expectável.
(a) Por Idade (b) Por Género
Figura 3.7 Tamanho das Histórias
0.00
2.00
4.00
6.00
8.00
10.00
0.00
2.00
4.00
6.00
8.00
10.00
Masculino Feminino
Fotos
Média 9.08 Desvio Padrão 1.74
Curta 7 Longa 14
Tabela 3.3 Média de elementos em cada história.

30
Masculino Feminino
Média 9.36 8.57
Desvio Padrão 1.81 1.47
Curta 7 7
Longa 14 13
Tabela 3.4 Tamanho das Histórias por Género
3.2.3.2 Número de Transições
Partindo agora para a análise do número de transições por história, este número poderá mostrar quando comparado com o tamanho da história, o quanto de espontaneidade que as histórias possuíram. Uma vez que uma transição é considerada apenas quando o elemento não foi recordado pelo entrevistador e surgiu espontaneamente da parte do entrevistado, o facto de existir poucas transições significa que a maioria dos elementos foi induzida.
Como é possível observar na tabela 3.5, a média de transições é pequena, possui um desvio padrão considerável o que demonstra uma dispersão nos resultados considerável. É importante o facto da relação das transições com o tamanho das histórias representar que 48.26% dos elementos surgem espontaneamente da parte do entrevistado.
Procuramos encontrar uma relação com o género do entrevistado e os resultados encontrados. As entrevistas dos indivíduos do sexo masculino tiveram uma percentagem de 60% de elementos espontâneos nas suas histórias, enquanto nas histórias dos entrevistados do sexo feminino existiu uma percentagem de 51.67%, o que revela e reforça ,o que anteriormente foi afirmado, que o sexo masculino apresentou capacidades cognitivas e verbais superiores.
Em termos da relação da espontaneidade das histórias com a idade dos entrevistados, pelo coeficiente de correlação de Pearson que apresentou um valor de -0,20 podemos concluir que, apesar de uma pequena tendência de as variáveis serem inversamente proporcionais, o valor está mais aproximado de 0, sendo que não existe grande dependência linear entre eles, logo não existindo grande relação entre a idade e a espontaneidade das histórias.
3.2.3.3 Sequências nas Histórias
O número e tamanho das sequências de elementos que não foram interrompidos, ou seja, sequências de elementos referidos espontaneamente pelos entrevistados, dão a ideia de como as histórias foram estruturadas.
Fotos
Média 1.31 Desvio Padrão 0.54
Máximo 3 Mínimo 0
Tabela 3.6 Número de Sequências Ininterruptas
Fotos
Média 3.88 Desvio Padrão 2.37
Máximo 11 Mínimo 0
Transições/Tamanho 57.25%
Tabela 3.5 Transições nas Histórias

31
Figura 3.8 Sequências ininterruptas
As relações com a idade ou género dos entrevistados não são significativas, uma vez que os dados não apresentam grande diversidade. Ou seja, o intervalo de valores é reduzido, sendo as relações da idade e género pouco relevantes.
Tamanho das Sequências nas Histórias Outra estatística a ter em conta, é em vez de número de sequências que compõem a história é o número de elementos que compõem essas sequências de elementos espontâneos. Como está representado na tabela 3.7, podemos constatar que o número médio das sequências é de 2.95 elementos, mas possui um desvio padrão com o valor de 2.26, o que representa um registo algo elevado e denota uma grande diversidade nos dados recolhidos.
Fotos
Média 2.95 Desvio Padrão 2.26
Máximo 12 Mínimo 2
Tabela 3.7 Tamanho das Sequência Ininterruptas
Numa análise aos dados do número de transições nas sequências ininterruptas, podemos retirar que a primeira sequência, com duas excepções, são as sequências que apresentam mais transições, sendo que a sequência a seguir é maioritariamente constituída por uma ou duas transições.
3.2.4 Estruturas das Histórias
Numa narrativa, além dos elementos que constituem a história é importante ter em conta, como estes se relacionam entre eles. Com a finalidade de analisar tal aspecto, foi feita uma análise relacional, registando todas as transições entre os elementos das histórias. Como foi anteriormente referido, apenas transições entre elementos que surgiram espontaneamente na história foram considerados.
05
1015202530354045
0 1 2 3
Nr.de
Histórias
Nr.Elementos

32
Como é expectável, encontramos um número considerável de pares de elementos, em que não existiu nenhuma transição entre os elementos, nas 60 histórias que foram registadas (Figura 3.9 e Tabela 3.8). Tendo em conta a memória associativa que é característica dos humanos, existe elementos pares que não foram mencionados juntos, poderá significar que as pessoas ao estruturar as histórias não associam os dois elementos, não considerando uma relação entre estes.
No sentido contrário existe alguns pares cuja relação é algo forte apresentando frequências de transições consideráveis. Na tabela 3.8 pode-se notar três pares de elementos com transições bastante fortes: “Tempo-Local”, “Local-Evento” e “Dispositivo- Qualidade”. Outras relações a ter em conta são: “Local-Tempo”, “Pessoas-Descrição”, “Local-Pessoas” e “Evento-Tempo” (ordenadas por importância decrescente).
Aut
or
Loca
l
Tem
po
Pro
pósi
to
Tipo
Dim
ensã
o
Eve
nto
Dis
posi
tivo
Des
criç
ão
Pes
soas
Pai
sage
ns
Mon
umen
tos
Qua
lidad
e
Autor 0 2 1 2 0 0 1 2 1 4 0 0 1
Local 4 2 10 3 0 0 13 2 7 8 1 1 0
Tempo 3 15 2 1 1 0 7 0 4 7 0 1 0
Propósito 0 0 0 0 0 0 0 0 6 1 1 0 1
Tipo 0 0 0 0 0 0 0 0 1 0 0 0 0
Dimensão 0 0 0 0 0 0 0 0 0 0 0 0 1
Evento 2 4 8 3 0 0 1 1 6 7 0 0 0
Dispositivo 0 0 0 0 0 0 0 0 1 0 0 0 12
Descrição 6 7 2 2 0 0 2 0 2 6 0 0 1
Pessoas 1 6 4 1 0 0 3 1 9 0 1 0 1
Paisagens 0 0 0 1 0 0 0 0 0 0 0 0 0
Monumentos 0 0 1 0 0 0 0 0 1 0 0 1 0
Qualidade 0 1 1 0 0 5 0 2 2 1 0 0 0
Tabela 3.8 Transições entre Elementos das Histórias

33
Figura 3.9 Transição de Elementos
Podemos verificar os valores normalizados na tabela 3.9 e na figura 3.10. Como podemos observar na tabela as transições com relações mais fortes são “Dipositivo-Qualidade”, “Monumentos-Monumentos”, “Tempo-Local” e “Local-Evento”. Concluímos que, embora os resultados estejam normalizados apresentam resultados muito semelhantes aos valores apresentados quando foram ignoradas as frequências dos elementos. A única diferença é a ordem dos valores em que as diferentes relações se apresentam, que trocam um pouco comparados com os valores não normalizados. A única relação nova é “Monumentos-Monumentos” que embora apresente um valor alto, acaba por não ser muito significativo devido à frequência deste elemento apresentar valores muito baixos, quase irrelevantes.
Outros elementos importantes já verificados, na tabela sem os valores normalizados, possuem igualmente valores consideráveis na tabela 3.9, logo verifica-se que a frequência dos elementos não tem uma relevância significativa quanto à força das relações entre os pares verificadas na tabela 3.8.
Outro aspecto interessante é observar depois de um dado elemento da história qual o elemento que é mais susceptível de surgir posteriormente. De modo a ter essa percepção das histórias foi calculado esse valor que apresentamos na tabela 3.10.
Autor
Local
Tempo
Propósito
Tipo
Dimensão
Evento
DisposiPvo
Descrição
Pessoas
Paisagens
Monumentos
Qualidade
Autor
Local
Tempo
Prop
ósito
Tipo
Dim
ensã
oEven
to
Dispo
siPv
oDescrição
Pessoas
Paisagen
s
Mon
ume
ntos
Qualidad
e
14‐15
13‐14
12‐13
11‐12
10‐11
9‐10
8‐9
7‐8
6‐7
5‐6
4‐5
3‐4

34
Aut
or
Loca
l
Tem
po
Pro
pósi
to
Tipo
Dim
ensã
o
Eve
nto
Dis
posi
tivo
Des
criç
ão
Pes
soas
Pai
sage
ns
Mon
umen
tos
Qua
lidad
e
Autor 0 2.597 1.428 5.128 0 0 1.695 6.06 1.47 6.897 0 0 1.852
Local 5.195 1.695 9.009 3.75 0 0 13 2.703 6.422 8.081 1.613 1.613 0
Tempo 4.286 13.514 1.923 1.37 1.818 0 7.527 0 3.922 7.609 0 1.818 0
Propósito 0 0 0 0 0 0 0 0 8.451 1.639 4.167 0 1.754
Tipo 0 0 0 0 0 0 0 0 1.887 0 0 0 0
Dimensão 0 0 0 0 0 0 0 0 0 0 0 0 2.381
Evento 3.39 4 8.602 4.839 0 0 1.22 1.786 6.593 8.642 0 0 0
Dispositivo 0 0 0 0 0 0 0 0 1.538 0 0 0 23.529
Descrição 8.824 6.422 1.961 2.817 0 0 2.198 0 2 6.667 0 0 1.163
Pessoas 1.724 6.061 4.348 1.639 0 0 3.704 1.818 10 0 2.326 0 1.316
Paisagens 0 0 0 4.167 0 0 0 0 0 0 0 0 0
Monumentos 0 0 1.818 0 0 0 0 0 1.887 0 0 16.667 0
Qualidade 0 1.053 1.136 0 0 11.905 0 3.922 2.326 1.316 0 0 0
Tabela 3.9 Transições Normalizadas entre Elementos das Histórias
Como podemos verificar na tabela 3.9 não existe transições óbvias para além das que apresentam resultados de 1.000 (100%), no entanto são pouco significativos, uma vez que a frequência dos elementos em causa é relativamente pequena, não sendo possível obter resultados que contenham um valor plausível ser tido em conta como referência. Como podemos reparar existe transições com probabilidades aceitáveis como “Dispositivo-Qualidade”, “Propósito-Descrição”,“Qualidade-Dimensão” e “Tempo-Local”. Outras transições prováveis, apesar de menores em termos de valores, mas mesmo assim algo significativas são, por exemplo, “Local-Evento”, “Evento-Tempo” e “Descrição-Local2 com valores perto dos 0.25.
Outro aspecto expressivo é o facto de, por exemplo, o par “Local-Tempo”, que é a quarta maior transição, apresentar apenas 0.196 de probabilidade de acontecer, a explicação é que existem muitas transições a começar com o elemento “Local”, logo entre elas não apresentam diferenças significativas.

35
Figura 3.10 Transição Normalizada de Elementos
Aut
or
Loca
l
Tem
po
Pro
pósi
to
Tipo
Dim
ensã
o
Eve
nto
Dis
posi
tivo
Des
criç
ão
Pes
soas
Pai
sage
ns
Mon
umen
tos
Qua
lidad
e
Autor 0 0.143 0.071 0.143 0 0 0.071 0.143 0.071 0.286 0 0 0.071
Local 0.078 0.039 0.196 0.059 0 0 0.255 0.039 0.137 0.157 0.020 0.020 0
Tempo 0.073 0.366 0.049 0.024 0.024 0 0.171 0 0.098 0.171 0 0.024 0
Propósito 0 0 0 0 0 0 0 0 0.667 0.111 0.111 0 0.111
Tipo 0 0 0 0 0 0 0 0 1.000 0 0 0 0
Dimensão 0 0 0 0 0 0 0 0 0 0 0 0 1.000
Evento 0.063 0.125 0.250 0.094 0 0 0.031 0.031 0.188 0.219 0 0 0
Dispositivo 0 0 0 0 0 0 0 0 0.077 0 0 0 0.923
Descrição 0.214 0.250 0.071 0.071 0 0 0.071 0 0.071 0.214 0 0 0.036
Pessoas 0.037 0.222 0.148 0.037 0 0 0.111 0.037 0.333 0 0.037 0 0.037
Paisagens 0 0 0 1.000 0 0 0 0 0 0 0 0 0
Monumentos 0 0 0.333 0 0 0 0 0 0.333 0 0 0.333 0
Qualidade 0 0.083 0.083 0 0 0.417 0 0.167 0.167 0.083 0 0 0
Tabela 3.10 Probabilidade de Transição entre Elementos das Histórias
AutorLocalTempoPropósitoTipoDimensãoEventoDisposiPvoDescriçãoPessoasPaisagensMonumentosQualidade
Autor
Local
Tempo
Prop
ósito
Tipo
Dim
ensão
Even
to
Dispo
siPvo
Descrição
Pessoas
Paisagen
sMon
umen
tos
Qualidade
22‐24
20‐22
18‐20
16‐18
14‐16
12‐14
10‐12
8‐10
6‐8
4‐6
2‐4
0‐2

36
Nr. Transições (A,B) – Nr. Transições (B,A)
Finalmente, vamos testar se alguns elementos só estão associados a outro elemento numa ordem devida ou se essa ordem não é importante. De forma a obter resultados concretos e calcular uma estimativa da simetria entre elemento, utilizamos a seguinte fórmula para cada par de elementos (A,B) :
O resulta vai variar entre -1 e 1. Esses valores representam a maior assimetria possível, enquanto o mais próximo de 0 representa uma relação mais simétrica.
Aut
or
Loca
l
Tem
po
Pro
pósi
to
Tipo
Dim
ensã
o
Eve
nto
Dis
posi
tivo
Des
criç
ão
Pes
soas
Pai
sage
ns
Mon
umen
tos
Qua
lidad
e
Autor 0
Local 0.33 0
Tempo 0.50 0.20 0
Propósito -1.00 -1.00 -1.00 0
Tipo - - -1.00 - 0
Dimensão - - - - - 0
Evento 0.33 -0.53 0.07 1.00 - - 0
Dispositivo -1.00 -1.00 - - - - -1.00 0
Descrição 0.71 0 -0.33 -0.50 -1.00 - -0.50 -1.00 0
Pessoas -0.60 -0.14 -0.27 0 - - -0.40 1.00 0.20 0
Paisagens - -1.00 - 0 - - - - - -1.00 0
Monumentos - -1.00 0 - - - - - 1.00 - - 0
Qualidade -1.00 1.00 1.00 -1.00 - 0.67 - -0.71 0.33 0 - - 0
Tabela 3.11 Estimativas das Simetrias
Na tabela 3.11, apresentamos os resultados das simetrias encontradas entre os pares de elementos considerados. As células marcadas com o símbolo hífen (-) são pares para os quais não foi possível encontrar uma possível simetria.
Como é possível observar na tabela 3.11, existe para além da diagonal principal pares que apresentam elementos absolutamente simétricos, sendo ainda muito habitual encontrar pares de elementos onde a simetria se limitava a apenas uma direcção.
O mais importante a retirar desta análise é a simetria dos principais pares identificados nas histórias. Tais pares são “Tempo-Local”, “Local-Evento”, “Dispositivo-Qualidade” e “Pessoas-Descrição”. Para o par “Tempo-Local” e “Dispositivo-Qualidade”, podemos observar que apresentam uma relação perto do simétrico (0.2), mas com alguma vantagem
Nr. Transições (A,B) + Nr. Transições (B,A)

37
para o elemento “Tempo” ou “Dispositivo” ser o primeiro a ser referido nos respectivos pares. Os pares “Local-Evento” e “Dispositivo-Qualidade” apresentam relações assimétricas, mas não totais, apresentando valores respectivamente, de 0.53 e 0.71 nas suas relações.
3.2.5 Arquitectura das Histórias
Como foi verificado nas secções anteriores, as histórias das fotografias contêm um padrão, um conjunto de propriedades que está presente em grande parte das entrevistas, como são exemplo as transições que foram analisadas na secção anterior. No entanto, não existe uma maneira fácil de os transpor para a interface de tagging narrativo. Assim, foi necessário analisar as conclusões retiradas para conseguir definir uma estrutura para as histórias. De forma a descobrir a estrutura geral teremos de ter em conta factores como a frequência dos elementos das histórias, a transição entre os elementos e a sua ocorrência.
Uma maneira de organizar a história tendo em consideração todos estes factores é utilizando Modelos de Markov Não-Observáveis (Hidden Markov Model) [32], treinado com as sequências de elementos que retirámos das entrevistas. Os elementos não foram separados entre induzidos e espontâneos uma vez que tal poderá retirar a ideia geral de como a história será composta.
A história geral é composta pelos 11 elementos identificados. O primeiro elemento é o que ocorreu com mais frequência na primeira posição nas histórias utilizadas no treino do algoritmo. Em seguida é utilizada a probabilidade de transição entre elementos para se conseguir encontrar o próximo elemento da história.
A história geral é composta por esta ordem: “Local”, “Tempo”, “Dispositivo”, “Qualidade”, “Dimensão”, “Autor”, “Pessoas”, “Descrição”, “Propósito”, “Tipo”, “Evento”.
3.2.6 Princípios Base
Dos resultados apresentados nas secções anteriores, podemos verificar e retirar alguns princípios base para o desenho da interface e que vamos enunciar em seguida nesta secção.
P1 – Personalização
Não foram encontrados factores relevantes como a idade ou género, que modifiquem em grande escala como as histórias são contadas. Embora algumas estatísticas como o tamanho das histórias ou a razão entre as transições, elementos e o tamanho, apresentarem alguns resultados dos quais se podem tirar algumas conclusões, não se revelam assim tão importantes de modo a que se traduza na necessidade de criar interfaces diferentes para os dois géneros ou para as diferentes faixas etárias.
P2 – Diálogos
Um grande número de frequências de elementos das histórias tive de ser induzido pelo entrevistador. Lembrando o entrevistado utilizando algumas questões, de forma a este conseguir, se possível, evoluir o seu raciocínio e continuar a contar a história. Alguns elementos apresentam uma grande de percentagem de indução, mas não foram alvo de uma resposta negativa e o entrevistado, fora alguma excepção, apresentou sempre uma resposta, associando esse elemento à fotografia. Disto poderá se retirar que alguns elementos sejam dados como certos para o utilizador e não considere necessário referi-los. Isto revela a importância dos diálogos com os utilizadores, permitindo que se consiga retirar toda a informação possível dos mesmos de forma a associar o maior número de elementos às fotografias.

38
P3 – Ambiguidade
Alguma ambiguidade é comum nas histórias, sendo que referencias ao tempo por vezes não são muito precisas, com o utilizador a indicar em vez de datas específicas, um espaço de tempo mais abrangente. Tendo isso em consideração, as narrativas terão de ter alguma tolerância quanto à ambiguidade. Poderão ser usadas técnicas de desambiguação, como utilizar contextos de outros elementos. O utilizador por vezes refere o elemento mais do que uma vez, de forma a reforçar a informação ou tentar clarifica-la. Tal terá de ser tido em conta na interface.
P4 – Elementos e Estrutura
Das histórias analisadas poderá ser retirada uma base em que todas se apoiam. Essa base possibilita que haja um apoio concreto que poderá ser usado para guiar o utilizador pela história, fazendo com que este revele o mais importante, de forma a ser associado às fotografias.
Um das características é o facto da primeira sequência de elementos ser a que se traduz na maior fonte de informação da história. Logo será a mais tida em conta, sendo que as sequências seguintes, que pelos resultados recolhidos costumam ser apenas mais uma, não se apresentem com grande informação. No entanto, terá de ser tida em conta igualmente, uma vez que toda a informação é importante na altura de recuperar as fotografias.
Dos resultados que podemos retirar da secção 3.2.2, verifica-se que alguns elementos são referidos em maior escala que outros, logo poderão ser considerados como elementos mais importantes e que sejam mais facilmente lembrados pelos utilizadores. Outros elementos por serem dados como informação certa ou que os utilizadores consideraram elementos irrelevantes, tiveram de ser induzidos.
P5 – Transições Prováveis
Dos resultados apresentados na secção 3.2.4, podemos retirar um número de transições que acontecem com grande frequência e associando com o elemento com maior probabilidade de ser o próximo a ser lembrado pelo utilizador, poderá ser possível concluir qual o próximo elemento da história, o que ajudará na evolução da história, facilitando a recordação de informação relevante.

39
4. Desenho da Interface
No capítulo anterior foi descrito como é que os utilizadores contam as histórias das suas fotografias. Da análise das transcrições das histórias conseguimos retirar os aspectos principais em que os utilizadores se focam ao contar uma história, tendo esses aspectos de se reflectir no desenho da arquitectura do site. O objectivo a atingir é que no final a aplicação possua uma arquitectura com uma interface capaz de ajudar os utilizadores a organizar o seu raciocínio, tornando o processo de etiquetar fotografias com histórias um processo natural para o utilizador e que o faça com a mesma naturalidade com que conta uma história a outra pessoa.
4.1 Pré-Requisitos
Além das preocupações com a usabilidade, outras preocupações terão de ser tidas em conta. A interface terá de ser desenvolvida tendo em consideração as directivas referenciadas no capítulo anterior. O objectivo é que o processo seja o mais natural possível sendo o mais parecido com o que foi feito nas entrevistas onde era pedido ao utilizador para contar a história. Para tal , a interface terá de permitir que o utilizador aplique essa naturalidade e ajude o utilizador a estruturar todo o processo conseguindo assim atribuir palavras-chave importantes ao conteúdo. Em seguida apresentamos as principais características consideradas na construção da interface.
Algo que ficou do estudo feito e descrito no capítulo anterior, foi a necessidade dos diálogos na interacção com o utilizador. Muitos dos elementos que tiveram frequências bastante aceitáveis, apenas eram referenciados pelos utilizadores após serem lembrados pelo entrevistador. O utilizador apesar de não referir espontaneamente o elemento, quando confrontado com o desafio do entrevistador, foram raras as vezes não apresentou uma resposta positiva. A interface terá assim de ser construída de forma a ajudar o utilizador a estruturar a história, de forma a lembrá-lo de elementos que poderão ser importantes.
Analisando como é que as pessoas contam as histórias das suas fotografias, foi possível retirar uma estrutura geral para as histórias contadas. Esta estrutura foi conseguida recorrendo aos Modelos de Markov não Observáveis [32]. A interface vai ter em conta esta estrutura idealizada de forma a ir ao encontro da naturalidade com que com os utilizadores ligam os elementos da história. A aplicação também vai possuir, tal como os modelos de markov, uma auto-aprendizagem com recurso às histórias contadas anteriormente pelos utilizadores. Ou seja, cada vez que um utilizador vá contar uma história, a estrutura geral vai ser recalculada tendo em conta as histórias já inseridas no sistema por outros utilizadores, conseguindo assim recolher qual a estrutura geral mais indicada.
Embora exista uma estrutura geral identificada, nem todas as pessoas contam a história com o mesmo raciocínio, sendo necessário que a interface esteja preparada para se adaptar ao utilizador. Ou seja, o utilizador poderá pretender em vez de começar a história com o elemento “Local” prefira começar por o elemento “Tempo” ou outro que ache mais importante, ou mesmo no meio de uma história prefira um elemento em detrimento de outro. A interface tem de permitir que tal aconteça. Ao utilizador terão de ser apresentadas soluções, para não ser obrigado a responder quando questionado sobre um elemento para o qual não tem resposta. O utilizador terá ainda a possibilidade de finalizar a sua história no momento que achar oportuno.

40
Como foi característica em algumas das histórias registadas nas entrevistas, o utilizador optou, muitas vezes, por repetir elementos nas suas histórias, fosse pela necessidade de detalhar elementos que talvez tivessem sido mal explicados ou ainda no caso de acharem um elemento tão importante que precisassem de acentuar na sua história. A aplicação nunca dará por terminada a história automaticamente, tendo essa opção partir do utilizador. Os elementos que reconhecemos como importantes para a história serão apresentados numa estrutura circular, permitindo que o utilizador adicione novos elementos até que pretenda finalizar a história.
A aplicação terá ainda de conter um espaço para apresentar o conteúdo ao qual vai ser associado a informação, porque a maioria das informações recolhidas poderá de ser apreendida da visualização das fotografias à procura de elementos visuais, com os quais poderão ser aproveitados para completar a informação textual das fotografias.
4.2 Interface das Histórias
Nesta secção vamos discutir os aspectos da interface escolhida, onde os utilizadores podem associar às suas fotos as narrativas.
Na fase inicial do projecto foi reaproveitada a interface desenvolvida pelo professor Daniel Gonçalves com a aplicação QUILL [11,12]. Embora nem o objectivo final, nem o conteúdo alvo da aplicação seja o mesmo, a interface poderá ser aplicada neste trabalho uma vez que a parte principal, o utilizador contar uma história, é importante para objectivo de ajudar o utilizador a etiquetar eficientemente as suas fotografias.
Na interface do QUILL é apresentada ao utilizador a história à medida que é contada. Os diálogos são apresentados ao utilizador no momento em que é apresentado o elemento para o ajudar a contar a sua história. O utilizador ao se deparar com o “desafio”, responde e vai completando a história com a sua informação. Com o desenrolar da resposta aos diálogos o utilizador vai produzindo uma história. Após algumas modificações ao nível estético, podemos observar o resultado da interface aplicada à realidade deste trabalho na figura 4.1.
Figura 4.1 Interface Story Tags

41
A interface está dividida em 3 partes principais. Na área número 1 temos a parte principal da aplicação, a história à medida que é contada pelo utilizador. O utilizador vai respondendo aos diálogos apresentados pelo sistema e a história vai sendo completada. Temos do lado esquerdo com o número 2 a área onde são apresentadas as possibilidades de resposta aos diálogos que são apresentados na área 1. O utilizador nesta área terá à escolha várias opções que incluem texto livre ou opções pré-definidas que permitirá uma resposta rápida aos utilizadores. O utilizador tem grande liberdade para editar a etiqueta em qualquer momento, carregando no elemento, sendo apresentado a possibilidade de mudar a etiqueta associada ao elemento. Para recriar o mais fielmente possível o acto de contar a história, o utilizador poderá repetir um elemento várias vezes durante a história, uma vez que pode ter a necessidade como aconteceu nas várias entrevistas feitas, repetir elementos, acentuando, ou necessitando de juntar mais informação à história. A Figura 4.2 apresenta um exemplo de uma narrativa de descrição de uma foto. Embora na figura só esteja apresentada um fotografia, um utilizador tem a possibilidade de contar uma história para várias fotografias. Todos temos um conjunto de fotografias tiradas por exemplo numa viagem em que todas as fotografias têm uma história comum. O sistema implementado permite, então, ao utilizador contar uma história para várias fotografias e depois se achar necessário associar histórias únicas à fotografia, ou seja, generaliza uma história para um número de fotografias e depois se pretender contar uma história com pormenores particulares a cada fotografia. Tem ainda disponível três botões na parte inferior que reflectem a opção tomada pelo utilizador. Tem o botão “Done” que implica que o utilizador escolheu ou preencheu umas das opções apresentadas.
O botão “Can’t remember” implica que o utilizador não se lembra da resposta para o diálogo apresentado. Temos ainda o botão “Didn’t happen” que implica que o utilizador não especifica o elemento sendo igualmente relevante para a história. Na área com o número 3 temos as fotografias às quais o utilizador está a associar a história. É importante ser apresentado ao utilizador as fotografias, uma vez que alguns elementos provêm e poderão ser relembrados através da visualização das fotografias. Na próxima secção vamos explicar todas as fases dos diálogos, tanto o texto que é apresentado ao utilizador, como as opções de resposta escolhidas para apresentar ao utilizador.
4.3 Diálogos
Os diálogos que são apresentados aos utilizadores foram desenvolvidos tendo em conta as histórias contadas pelos utilizadores no capitulo 3. Foram retirados das transcrições ideias para cada um dos diálogos que são apresentados aos utilizadores, de forma a desenvolver e orientar a sua resposta no melhor sentido, fornecendo ao utilizador, de certa forma, inspiração para apresentar informação importante nas histórias das fotografias. Cada dialogo é constituído por uma afirmação que ajude o utilizador a lembrar um elemento que poderá ser importante para a sua história. A segunda parte do dialogo contém as possibilidades de resposta a esses elementos. As possibilidades variam conforme o elemento e o que seria expectável como resposta por parte do utilizador. Em alguns diálogos são apresentados campos de texto em que o utilizador poderá dar a resposta livremente, noutros elementos é limitada a resposta do utilizador a um conjunto definido de respostas. Esse conjunto foi criado a partir das entrevistas do utilizador e permite a este agilizar o processo de etiquetagem e de associação de elementos à história. Na tabela 4.1 apresentamos as afirmações dos diálogos utilizados para cada elemento.

42
Autor O autor desta foto foi AUTOR
Descrição A fotografia pode ser descrita como DESCRIÇÃO
Dimensão A dimensão da fotografia é DIMENSÃO
Dispositivo O dispositivo utilizado foi DISPOSITIVO
Evento Foi tirada durante EVENTO
Local Foi tirada em LOCAL
Pessoas PESSOAS estavam presentes
Propósito A fotografia foi tirada porque PROPÓSITO
Qualidade A qualidade da fotografia é QUALIDADE
Tempo Foi tirada TEMPO
Tipo A fotografia representa um(a) TIPO
Tabela 4.1 Diálogos da aplicação
No anexo A4 são expostas todas as possibilidades de resposta que são apresentadas ao utilizador.
4.4 O Website “StoryTags”
Na secção anterior foi apresentada a interface para o núcleo da aplicação, é a secção mais importante, uma vez que é lá que se irá concretizar todo o objectivo da tese. Nesta secção vamos apresentar a interface em redor do núcleo, tendo sido construído uma rede social como tantas outras, com a possibilidade das pessoas poderem fazer o upload das suas fotografias, ter um perfil, ver as histórias dos outros elementos da comunidade, entre outras opções. A seguir vamos apresentar como é que o utilizador interage com o site.
O utilizador regista-se no site preenchendo um formulário com uma série de elementos. No caso de sucesso é direccionado para a sua conta. É apresentado então o ecrã principal do website, a homepage( figura 4.2). O utilizador tem um menu principal na parte superior do ecrã, que está sempre presente e fornece a ligação para as diversas secções do site. Além do menu principal, por cima das fotografias está um conjunto de botões que apresentam acções que o utilizador pode efectuar sobre as fotografias apresentadas. O utilizador poderá visualizar a fotografia em maior pormenor passando o rato por cima da fotografia e carregar na lupa que então aparece. Para ver as histórias associadas às fotografias deverá seguir para o detalhe da fotografia. O utilizador a partir da opção “Upload” poderá carregar as suas fotografias para a sua área. Após o upload ser feito com sucesso, o utilizador é reencaminhado para a subsecção “Photos without Info”, onde estão alocadas as fotografias que não tenham uma história associada. O utilizador só terá as fotos disponíveis na secção “Home” e disponíveis para todos os utilizadores verem após associar uma história às fotografias.

43
Figura 4.2 Página principal
Começando a explicar as diferentes secções, partindo do lado direito temos a secção da comunidade onde são apresentados ao utilizador os outros elementos da comunidade. Neste local o utilizador pode escolher outro utilizador e ver as suas fotos e as respectivas histórias .
Na opção “Search” o utilizador poderá efectuar uma pesquisa pelas fotos de todos os utilizadores, contando uma história. Este processo é idêntico ao que foi descrito para o processo de associação de uma história a fotografias, mas a sua finalidade é a inversa, ou seja, em vez de inserir no sistema, o objectivo é recuperar. À medida que o utilizador vai preenchendo a história vão aparecendo as fotografias que estão relacionadas com informação preenchida. A pesquisa é incremental sendo que à medida que se vai juntando elementos à história, os resultados apresentados estão ordenados por grau de relevância. A primeira fotografia apresentada vai ser então a que está mais próxima da história contada.
O utilizador tem ainda a possibilidade de editar o perfil que foi preenchido no registo, existindo a hipótese de adicionar uma fotografia/retrato ao seu perfil.
4.5 Avaliação Heurística
Após a conclusão da construção do site foi feito uma avaliação heurística de modo a medir a usabilidade da aplicação. Para esta avaliação foram escolhidas 4 pessoas, especialistas em usabilidade, para efectuar uma avaliação rígida e que vai permitir aumentar a qualidade da interface.

44
Para normalizar a avaliação heurística foi criada uma lista de tarefas que os utilizadores teriam de completar, sendo que estas tarefas representam quase na globalidade as funcionalidades do site. Em seguida apresentamos as várias tarefas :
1 – Registar-se no site : O utilizador insere os seus dados pessoais no formulário de registo.
2 – Login no site : É preenchido o formulário com o email e a password.
3 – Fazer upload de uma fotografia : É feito o upload de uma fotografia à escolha do utilizador.
4 – Contar a história da fotografia : Contar a história para a fotografia anteriormente carregada no sistema, inserindo a informação que considerar importante na história.
5 – Ver a história da fotografia.
6 – Editar a história da fotografia: Editar um campo, à escolha do utilizador, da história que está associada à fotografia.
7 – Pesquisar a fotografia : Procurar pela fotografia carregada na secção de pesquisa da aplicação.
8 – Apagar a fotografia.
9 – Fazer logout do site.
Embora exista uma lista de tarefas especificas para o utilizador completar não era pretendido que ficasse preso a esta lista. Era dada completa liberdade ao utilizador para navegar pelo site e fazer as suas observações.
Para a avaliação decorrer sobre uma base foi utilizada as heurísticas de Nielsen [30].
Os utilizadores com base nas heurísticas completaram as tarefas propostas e referidas anteriormente. O objectivo foi que ao realizarem as tarefas fossem bastante críticos e que referissem tudo o que não concordassem e que fosse contra as heurísticas de Nielsen. Aos utilizadores foi pedido uma possível solução para o problema encontrado e que quantificassem a severidade do problema encontrado, num grau de 0 a 4, sendo que 0 é um problema sem importância e 4 é uma catástrofe de usabilidade.
Em seguida vamos apresentar um resumo da avaliação heurística feita pelos utilizadores, com a apresentação dos problemas mais importantes encontrados, as heurísticas em que falhavam e a severidade do problema. Como conclusão de cada problema encontrado é apresentada a solução aplicada no sistema. Esta solução final teve como base a solução proposta pelo utilizador sujeita a uma análise posterior. Todos os problemas podem ser vistos mais em pormenor no anexo A3.
Foram encontrados aproximadamente duas dezenas de problemas. Existiram alguns problemas a nível da interface apontados pelos avaliadores, como por exemplo, o facto de ao passar por cima de um botão, que para além da mudança de cor do botão, os avaliadores pretendiam também uma mudança no tipo de cursor de modo a identificarem melhor o botão, de forma a ir ao encontro da heurística H2-4, ou seja, consistente com as normas identificadas na internet . Outro exemplo, seria o tamanho da lupa quando o utilizador passava por cima de foto que seria pequena e poderia passar despercebida. Estes problemas foram resolvidos utilizando as soluções propostas pelos avaliadores, tendo sido mudado o cursor para uma mão na passagem pelo botão e a lupa foi aumentada de forma a tornar-se mais perceptível ao utilizador.

45
A maioria dos problemas encontrados foram de gravidade média, sendo que a maioria se apresenta como falta de informação por parte do sistema ao utilizador. Seja na altura em que o utilizador faz o upload das fotografias e não é apresentado qualquer estado do sistema, ou então falhas em que o site não apresenta comportamentos consistentes com o que é encontrado na internet e que se poderão apresentar como barreiras à aprendizagem e tornar esta mais complicada para os utilizadores. Outro possível resultado da falta de informação apresentada ao utilizador é a possibilidade de o utilizador cometer possíveis erros, como é exemplo na secção de upload de fotografias em que não era apresentada informação relativa aos tipos de ficheiros e tamanhos destes, que eram permitidos. A omissão da informação poderia levar os utilizadores a cometer erros facilmente evitáveis e está contra a heurística H2-5 de Nielsen. Outro problema identificado pelos avaliadores foi o utilizador não ter a disponibilidade de retornar ao estado anterior. Os avaliadores apresentaram como solução ter um botão de voltar para o estado anterior, sendo a solução implementada no sistema.
Em termos de erros mais graves de usabilidade e seria imperativo a sua resolução, constou-se o facto de algumas funcionalidades apresentarem um funcionamento deficiente que não seria o esperado. Um exemplo era quando o utilizador estava a contar a história a opção “Can't Remember”, para passar para o próximo elemento da história, não funcionava. Outro erro apontado foi que ao editar uma história se o utilizador escolhesse um elemento para editar e não efectuasse nenhuma mudança, este elemento seria perdido, o que não era o comportamento desejado. Outro problema encontrado na avaliação heurística foram caracteres especiais (acentos, cedilhas) que apresentavam uma formatação incorrecta que foi resolvida com a alteração da codificação do site.
Na tabela 4.2 é apresentado uma tabela de consolidação com o resumo da avaliação heurística com número de problemas encontrados na relação entre a severidade e a heurística .
S1 S2 S3 S4 TOTAL H1 - 2 - - 2 H2 1 6 3 1 11 H3 - - - - 0 H4 1 3 1 - 5 H5 - 5 4 1 10 H6 1 - - - 1 H7 - - - - 0 H8 - - - - 0 H9 - - - - 0
H10 - - - - 0 TOTAL 3 16 8 2 29
Tabela 4.2 Consolidação da Avaliação Heurística.
4.6 Arquitectura
Nesta secção vamos apresentar todas as decisões em termos de desenho da arquitectura que foram tomadas de forma a construir o website. Vamos começar pelo nível mais geral vamos utilizar um modelo cliente-servidor. Este modelo computacional define-se basicamente como a separação divisão de clientes e servidores separados por uma rede de computadores. O cliente envia pedidos para um servidor que depois de aceitar o pedido processa-o e retorna um resultado ao cliente.
A razão porque se optou por uma solução cliente-servidor com utilização de uma base de dados, representado na figura 4.3, foi devido às vantagens que tal modelo computacional revela. Uma das vantagens mais importantes foi a capacidade, que este modelo possui, das mudanças do lado do servidor serem transparentes ao cliente, que não é afectado quando são

46
feitas mudanças na aplicação do lado do servidor. Uma vez que os dados são guardados no servidor, poderá significar controlo sobre os dados, permitindo assim a segurança sobre estes.
Figure 4.3 Modelo computacional Cliente-Servidor
O cliente neste modelo computacional preferencialmente utiliza um browser como forma de comunicar com o servidor. O browser serve de plataforma para o cliente fazer os pedidos ao servidor. Ou seja, cada vez que o utilizador carrega num link, o servidor recebe um pedido que executa retornando uma resposta, que na maioria das vezes é uma página de texto com código HTML que o browser interpreta e apresenta ao cliente. Embora grande parte da computação aconteça do lado do servidor, existe também computação feita no cliente (as rotinas de javascript são executadas no lado do cliente). O servidor de forma a guardar informação que necessita de ser persistente, recorre a uma base de dados de forma a guardar todos os dados que necessitam de ficar por mais tempo que a actual sessão do utilizador. Mais a frente é apresentado como está organizada a Base de Dados da aplicação.
Nas próximas subsecções vamos explicar quais as decisões tomadas para toda a aplicação.
4.6.1 Linguagens de Programação
Nesta secção vou apresentar todas as linguagens de programação utilizadas e a explicação pela qual foram utilizadas.
4.6.1.1 HTML (HyperText Markup Language)
Todas as resposta do servidor na comunicação com o cliente é feita utilizando texto. Este texto na maioria das vezes vem sobre uma formatação especifica, ou seja, existe uma estrutura semântica que é introduzida no documento de texto de forma a que o browser do lado do cliente perceba a estrutura e apresente a informação sobre uma determinada forma. A linguagem HTML é escrita sobre a forma de tags que são delimitados por ‘<’ e ‘>’ . O browser interpreta o documento de texto conforme essas tags e atributos que poderão estar associados as mesmas tags. Conforme a tag o browser percebe se terá de apresentar um link, um paragrafo ou o título da página.
4.6.1.2 CSS (Cascate Style Sheets)
Esta linguagem poderá ser escrita dentro do ficheiro de HTML ou num ficheiro à parte e posteriormente incluída na página de HTML. Esta linguagem é utilizada para descrever a apresentação , ou seja, o aspecto e formatação do documento. CSS é utilizado numa primeira fase como forma de separar o conteúdo do documento da sua apresentação. Com esta separação conseguimos um maior controlo sobre a apresentação do documento de HTML, podendo mudar os estilos aplicados à página consoante o que se pretende apresentar, seja uma página para apresentar no browser, seja uma página para impressão.

47
4.6.1.3 Javascript
É uma linguagem de programação que possui uma sintaxe semelhante à de Java, mas é totalmente diferente no conceito e uso. Esta linguagem de script permite que se passe alguma computação para o lado do cliente. Ou seja, utilizando esta linguagem poderá se executar validações de formulários do lado do cliente, sem ser necessário que exista um pedido ao servidor para validar o formulário. Tal permite menos carga no servidor para validações simples. Embora esta seja uma utilização muito habitual, quando não completada com a validação no servidor, poderá apresentar problemas ao nível de segurança. Outra vantagem é a facilidade de manipulação de documentos em árvore como é o caso dos documentos em HTML.
4.6.1.4 PHP
Ao contrário da linguagem Javascript , a linguagem PHP é interpretada no lado do servidor, permitindo a construção de páginas de conteúdo dinâmico. É uma linguagem de script tal como o Javascript que é embebida nas páginas de HTML e que é interpretada pelo servidor, de forma a mudar dinamicamente o conteúdo a ser apresentado. Foi a linguagem utilizada para a ligação à base de dados. Tem como vantagens a sua robustez e velocidade. A programação poderá ser utilizada num paradigma OOP (Object-Oriented programming), ou sobre um estilo procedimental.
4.6.1.5 SQL (Structured Query Language)
É a linguagem utilizada pelo sistema de gestão da base de dados MySQL. É uma linguagem de pesquisa declarativa para a base de dados. É simples e fácil de usar.
4.6.1.6 Ajax
É o uso combinado das tecnologias de Javascript, PHP e HTML, com o objectivo de tornar as páginas de alguma forma mais interactivas, sendo os conteúdos carregados sem a necessidade de ser feito o carregamento da página toda, mas de apenas uma secção. Basicamente o processo é composto por uma chamada feita por javascript a um webservice que está programado em PHP, onde é executado o miolo do processo, sendo feita a computação do lado do servidor. O webservice responde com texto em no formato de HTML que é inserido dinamicamente com auxílio novamente ao javascript.
4.6.2 Estrutura da Base de Dados
Nesta secção vamos apresentar a solução que foi implementada para organizar a base de dados. É apresentada a organização ao nível das tabelas e relações entre elas.
Foram identificados quatro modelos principais, os elementos mais importantes do sistema: Utilizador, Foto, Tag e História.
Na figura 4.4 é apresentada as relações entre os modelos. Como podemos verificar pela figura temos por exemplo a relação entre utilizadores e fotos, ou seja, um utilizador poderá ter 0 ou mais fotografias, mas uma fotografia pertence apenas a um utilizador. Em termos de informação associada às fotografias, temos os modelos tags e histórias. Em ambos os casos uma foto poderá ter várias tags ou histórias, enquanto o inverso uma tag ou história poderá estar associada a uma ou mais fotos. Cada história é composta por vários elementos que a compõem. Logo uma história tem um ou mais elementos, sendo que cada elemento pertence apenas a uma história.
Nas relações N:N foi criada uma tabela intermediária que é composta por duas chaves estrangeiras para as chaves primárias das tabelas das quais se pretende fazer a ligação. Nas

48
relações de 1:N não foi criada uma tabela de ligação, sendo a ligação feita por um atributo, uma chave estrangeira numa tabela. Neste caso, na tabela do modelo que tem muitos elementos com ligação a um elemento da outra tabela.
A tabela “Utilizadores” é composta por todos os campos necessários para a identificação do utilizador, com informação que vai ser necessária para os dados estatísticos pretendidos para analisar os dados consoante idades e sexo. O campo imagem_url é para a localização da fotografia de apresentação do utilizador. O campo sistema difere consoante se ao utilizador foi atribuído a componente de histórias ou de tags.
Figura 4.4 Modelo Relacional
A tabela “Fotos” é apenas composta pelo url onde a foto do utilizador está alojada e o id_utilizador indica qual o utilizador a quem pertence a fotografia.
Na tabela “Tags” são apenas guardadas palavras únicas, sem repetição, sendo que a relação entre as fotos e as tags é guardada na tabela de ligação onde é inserido registos com o id_foto e id_tag, sendo chaves estrangeiras para as chaves primárias das tabelas fotos e tags respectivamente.
A outra variante, e mais importante, do site é a parte das histórias. É tratada numa primeira fase analogamente às tags com uma tabela de ligação entre a tabela de fotos e a de histórias. Tento em consideração que uma história é composta por elementos, existe uma tabela “Elementos” que contém uma chave estrangeira id_história, que indica a que história o elemento pertence. Cada registo é composto pelo tipo de elemento (Autor, Local, Tempo, etc.), a resposta dada a esse elemento (atributo valor), e o tipo_resposta corresponde se o utilizador carregou “Done”, “Can’t Remember” ou “Didn’t Happen”, que será importante de guardar uma vez que indica qual o rumo que o utilizador pretendeu dar à história.

49
4.6.3 Principais componentes e decisões
Nesta secção é apresentado os principais componentes e decisões, que compõem o núcleo do site ao nível de programação.
4.6.3.1 Ligação à BD
Para a ligação à base de dados foi criado um objecto que reduz a complexidade e torna a interacção com a base de dados mais fácil. O objecto tem várias funções de interacção. O construtor da classe cria a ligação à base de dados com dados de acesso e atribui essa ligação a uma variável global do objecto, estando essa variável disponível nas outras funções (adicionar, apagar, procurar, etc.), utilizando-a para fazer os pedidos à BD. Nas funções do objecto é utilizado as funções fornecidas pelo PHP para a interacção com o MySQL.
4.6.3.2 Autenticação e Autorização
A autenticação é feita utilizando um formulário no inicio da interacção do utilizador com o site. É pedido o email e a password recolhidos no registo do utilizador. Se acertar nos campos do login é concedida ao utilizador autorização para navegar pelo site. Na altura do login, no caso de ser feito com sucesso, é escrita no servidor uma variável de sessão com o username do utilizador. Nas páginas em que é necessária autorização para determinadas acções é feito um teste à variável de sessão de modo a saber se a acção poderá ser executada. Se o utilizador tentar entrar numa área restrita e consequentemente falhar o teste de autorização será reencaminhado para a página de login para introduzir os dados de autenticação.
4.6.3.3 Upload de Fotografias
O utilizador pode, como já foi referido, fazer upload das suas fotografias. Tem uma área reservada para escolher as suas fotografias. O utilizador tem a oportunidade de escolher dez fotos de cada vez, de forma a melhorar o processo de upload e torná-lo mais prático . Cada vez que o utilizador escolhe uma fotografia é inserido outro campo para colocar outra fotografia, isto até atingir o máximo de 10 fotografias. O servidor tem um limite de upload de 2 megabytes, tal informação é apresentada ao utilizador, sendo que se o ficheiro for de tamanho superior será apresentado um erro, a informar sobre a situação.
Após serem escolhidas as fotografias e submetido o formulário, o pedido será redireccionado para um script que vai tratar do pedido de upload. Neste script é feito um ciclo para analisar os ficheiros, passá-los por uma bateria de testes.
A bateria de testes é composta pela análise do tamanho e tipo de ficheiro. Neste caso o único interesse é que seja uma imagem e analisada a extensão do ficheiro. Sendo que a extensão poderá não ser a prova absoluta, são feitos testes ao mime type dos ficheiros e com a função getimagesize fornecida pelo PHP tenta-se também recolher informação que só será possível caso o ficheiro seja mesmo uma imagem.
Após os testes é feita a transferência para o servidor e é inserido o registo na base de dados. Ao nome do ficheiro é introduzido um timestamp que torna o nome do ficheiro único e não apresentará problemas ao gravar no disco do servidor, como seria o caso de existir um ficheiro com o mesmo nome.
Antes de ser realizada a transferência é feito um redimensionamento à fotografia de modo a ocupar menos espaço no disco para que na altura da visualização das fotografias seja mais rápido o seu carregamento. O redimensionamento é feito utilizando um modulo, o GD, que permite ao PHP manipular imagens.

50
Se forem encontrados erros nos ficheiro, estes serão inseridos num array que vai compilar todos os erros encontrados no upload dos ficheiros. Em seguida é apresentado ao utilizador todos os erros encontrados.
4.6.3.4 Contar a história
A parte principal do website é a parte em que o utilizador associa informação às suas fotografias, contando uma história.
Todo o processo começa com o sistema a criar uma estrutura geral para a história. Esta estrutura é criada através da análise de todas as histórias que já foram contadas no sistema. Ou seja, o sistema faz uma aprendizagem de forma a conseguir estruturar a história, que siga o raciocínio geral que os utilizadores se baseiam para construir as suas histórias. Como já foi referido, é construída uma matriz com os resultados das probabilidades das transições entre os elementos. Em seguida um algoritmo, tendo em conta essas probabilidades, constrói a história base para a fotografia.
A página é constituída por várias partes. Do lado esquerdo são carregados todos os diálogos que vão ser apresentados ao utilizador, sendo que apenas o actual se encontra visível ao utilizador. Do lado direito são apresentados aos utilizadores os diálogos de forma a “inspirar” o utilizador a responder. Esses diálogos encontram-se escritos em ficheiros de texto, nos diferentes estados ( perguntas/respostas conforme o escolhido pelo utilizador ). Ou seja, cada vez que o utilizador age sobre a história é feito o pedido ajax a uma função de PHP que trata de processar a informação e responder ao pedido. Funções de javascript ao receberem a resposta tratam de apresentá-la ao utilizador.
Por exemplo, no inicio da história é apresentado logo um diálogo para o utilizador apresentar informação sobre o local onde a fotografia foi tirada. O utilizador preenche o espaço de texto correspondente e carrega no botão “Done”. Neste momento é desencadeado um evento de javascript que trata de dizer ao PHP que o utilizador carregou no botão “Done” e com a resposta “Lisboa” ao elemento “Local”. O PHP processa essa informação, procurando pelo texto uma resposta do tipo “Done” para o elemento “Local” e envia de volta para o javascript que constrói a história. Em seguida, faz outro pedido para o PHP para este devolver o próximo diálogo para o elemento seguinte. O PHP processa o pedido e vai procurar no ficheiro de texto que contém os diálogos do próximo elemento e devolve ao javascript o diálogo para a pergunta para esse elemento. Este processo é feito repetidamente ao longo do processo.
No final, quando o utilizador pretende finalizar a história, carrega no botão e começa o processo que finaliza a história. A história é processada e são encontrados todos os elementos que fazem parte da história. É construído para cada elemento um array, com o elemento, o seu valor e o tipo de resposta. Com esse array é feito um pedido ao PHP que trata de retirar todos os elementos e inserir na base de dados, criando uma nova história que é associada às fotografias para as quais o utilizador contou a história.
4.6.3.5 Procurar uma fotografia
Nesta secção o utilizador conta a história da mesma forma que quando associa informação a uma fotografia. A novidade desta secção é o algoritmo de procura. O algoritmo corre todos os elementos já inseridos na história e faz uma procura pelo valor de cada elemento nas histórias das fotografias já inseridas no sistema.
O algoritmo começa na primeira fase por fazer uma divisão de 100 pelo número de elementos que constituem a história. O resultado da divisão é a pontuação que vai ser adicionada cada vez que um elemento da história de uma fotografia corresponder ao inserido na procura. Se o elemento tiver repetido na história, por cada correspondência a mais é adicionado à pontuação da fotografia uma unidade. Desta forma vamos pontuar as fotografias inseridas no sistema e

51
recolher um top de fotografias que vai ao encontro com a história que foi inserida pelo utilizador na procura.
4.6.3.6 Adicionar tags
A outra vertente do site que vai servir de comparação é o sistema de tags. O sistema é idêntico ao utilizado pelo Flickr. O utilizador pode associar tags apenas a uma fotografia de cada vez. Tem uma caixa de texto em que pode adicionar um número de tags, separando-as por espaços. Se quiser pôr como tag uma expressão (mais do que uma palavra) poderá recorrer a aspas. Em termos de programação é utilizado o mesmo sistema de pedido e resposta que foi utilizado nas histórias, com o javascript a fazer pedidos ao PHP, sendo enviado todas as tags inseridas no pedido. Do lado servidor, o PHP processa o pedido, vê quais as tags que não são repetidas e associa-as à fotografia. Quando o processamento termina é enviada a resposta para o lado do cliente e é apresentado ao utilizador as tags novas que foram inseridas.

52

53
5. Resultados Nesta secção vamos apresentar os resultados obtidos da utilização dos sistemas de tagging tradicional e do sistema desenvolvido durante este trabalho, o sistema de narrativas. O objectivo passa por comparar ambas as abordagens tentando perceber se existem vantagens na utilização de um sistema em relação ao outro.
O método para avaliar o sistema de histórias em comparação ao sistema convencional de tagging, passou inicialmente por reunir 40 utilizadores. Consideramos que 40 utilizadores poderão representar uma grande fatia da sociedade, com diferentes idades e experiências de vida, e até mesmo diferentes experiências na utilização da internet.
A primeira fase dos testes foi constituída apenas pelo registo, uma vez que seria importante que todos os utilizadores iniciassem a sua utilização do sistema numa determinada altura, para não existirem discrepâncias sobre o tempo de utilização do sistema. No registo os utilizadores foram distribuídos automaticamente pelos os sistemas de forma aleatória, sendo que o sistema a única regra, manter um nível semelhante de utilizadores em cada sistema, como medida de defesa para que se o número de utilizadores, não atingissem os 40, teríamos à mesma um número nivelado de utilizadores em cada sistema. Após reunir os 40 utilizadores, foi enviado um email para os mesmos agradecendo a sua participação, e explicando em que consistia a utilização do sistema. Dada a incapacidade de reunir com todos os utilizadores de forma a possibilitar a realização de uma formação sobre o sistema, foram enumeradas as acções que o mesmo possibilita. Em seguida apresentamos e detalhamos uma interacção básica com o sistema:
1. Entrar no site e fazer login. 2. Fazer upload de TODAS as fotografias que tiverem. 3. As fotos ficam numa parte do site que pode ser acedida através da Home no link
"photos without info" Se utilizando histórias :
4. Contar uma história para uma ou várias fotos. Podem escolher várias fotos e contarem a mesma história para todas as seleccionadas.
Se utilizando tags:
5. Escolher uma fotografia e associar tags à foto.
Após o inicio da utilização do sistema, as únicas interacções mantidas com os participantes foram através de envios de emails com intervalos de um mês com a intenção de pedir uma maior colaboração se possível aos utilizadores. No final do período de utilização foi feito um agradecimento aos utilizadores pela sua participação no trabalho.
Como já foi referido o sistema de tagging que é utilizado pelo Flickr foi replicado no website que aloja o sistema de histórias, sendo a interface envolvente aos sistemas exactamente igual. Isto permite que os resultados recolhidos não apresentem um possível ruído que poderia advir de interfaces diferentes.
A partir dos resultados obtidos após 4 meses de utilização foi avaliada a utilização dos dois sistemas de tagging segundo seis critérios que em seguida são enumerados.

54
O primeiro critério foi a reutilização das tags. Com isto pretendemos saber se um utilizador ao longo do tempo utilizou conceitos ou expressões semelhantes quando associou informação às fotografias, avaliando se conseguiu agrupar fotos utilizando uma mesma base de informação. Focamos tanto na reutilização a nível pessoal como ao nível da comunidade, para avaliar uma possível folksonomia. A métrica para avaliar este critério baseou-se na utilização do número de vezes que uma tag foi empregue após ser inserida no sistema.
Outra componente será a quantidade de informação associada às fotos em ambos os sistemas. Comparou-se os sistemas à procura no qual os utilizadores associam mais informação às suas fotografias. A métrica utilizada foi o número de elementos/tags que foram inseridos em média pelos utilizados para cada fotografia.
Outro critério é o tempo dispendido para inserir informação. A métrica utilizada foi o tempo médio em segundos que um utilizador levou a classificar uma fotografia em cada um dos sistemas, podendo indicar se a quantidade de tempo dispendido em cada sistema poderá levar as pessoas a escolher o outro sistema, ou então rejeitar qualquer um deles.
Outra componente é o tempo necessário para a recuperação de uma fotografia. Foi pedido ao utilizador para tentar recuperar uma das fotografias mais antigas, sem ter acesso à informação que inseriu na altura em que colocou a fotografia no site. Com isto pretendemos testar se a recuperação da fotografia é feita mais facilmente lembrando da história em que a fotografia decorreu, ou então a partir de conceitos soltos que o utilizador considerou que se identificavam com a foto. A métrica utilizada foi a média de segundos que os utilizadores demoraram a recuperar a fotografia.
É importante analisar também a evolução do tagging feito pelos utilizadores uma vez que durante o tempo de análise o utilizador poderá ter surgido novos interesses na sua vida que resulta num novo conjunto de tags que anteriormente não tinha inserido. Outro aspecto é a familiarização com o sistema, sendo que à medida que se sentem à vontade com o sistema poderão começar a ter um melhor conhecimento e a aproveitar melhor todas as suas características. A métrica utilizada foi o número de elementos/tags que se associou às fotografias à medida que o tempo evoluiu.
Tendo em conta as métricas referidas fizemos uma análise aos resultados recolhidos do site, após alguns meses de utilização por parte de quarenta utilizadores. Como já foi referido os utilizadores foram divididos em dois grupos distintos, separados pelo sistema aleatoriamente no momento do registo. Um grupo é constituído pelos utilizadores do sistema de tagging tradicional e o outro grupo constituído por elementos que utilizaram o sistema desenvolvido para contar histórias de forma a etiquetar fotografias.
Um aspecto a ter em conta na análise dos resultados foi a pouca colaboração por parte dos utilizadores para colocarem fotografias e juntar informação às mesmas quer no sistema de histórias quer no sistema de tagging tradicional. Embora as informações retiradas possam ser consideradas relativamente pequenas, tivemos de optar por finalizar a tese não podendo esperar eternamente pela colaboração dos participantes.
5.1 Caracterização dos utilizadores
Vamos fazer uma caracterização dos utilizadores que se registaram no site, e fazer uma comparação com os utilizadores que foram entrevistados para o estudo de como as pessoas contam as histórias. Existiram 10 utilizadores que participaram em ambas as fases de recolha de dados.

55
Pela análise dos utilizadores podemos verificar que, nos 40 utilizadores, as idades variam entre os 18 e os 33 anos. Todos os utilizadores do website tinham pelo menos o 12º ano de escolaridade completo. Ao nível académico 18 dos 40 utilizadores, completaram uma licenciatura principalmente no ramo de engenharia informática, civil e electrotécnica. 24 participantes já se encontravam a trabalhar distribuindo-se pelo ramos em que se licenciaram, sendo que as outras desempenham cargos como secretários, aero-abastecedores e operadores de call-centers. Ao nível do género dos utilizadores, foram registados 16 pessoas do sexo feminino e 24 do sexo masculino. Podemos observar na figura 5.1 um histograma da organização dos participantes segundo o sistema que estavam a utilizar e o seu género.
Figura 5.1 Organização de pessoas por tipo de sistema e género.
O grupo que foi entrevistado com o intuito de recolher informações de como as pessoas contam as histórias, e o grupo que utilizou o website, possuem características semelhantes. Ambos apresentam aproximadamente a mesma relação nos géneros e em termos de idade a única diferença significativa é que no grupo que utilizou o sistema Web já não houve utilizadores com idades avançadas comparando com os restantes utilizadores.
Ao longo da análise, não iremos apresentar resultados segundo o género e idade dos participantes. Como foi possível concluir do estudo apresentado no capítulo 3, não existem diferenças óbvias nas estruturas das histórias contadas por pessoas de diferentes idades e géneros. A análise vai focar os critérios que referimos anteriormente, importantes para comparar as duas abordagens ao processo de tagging. .
5.2 Análise de resultados
Ao todo foram inseridas 1421 fotografias. Só foram consideradas as fotografias com informação associada (tags ou histórias) uma vez que são as únicas com interesse para o objectivo do trabalho, que resultou num conjunto de 1229 fotografias (86%). Sendo que existiam 40 utilizadores temos uma média de 30,73 fotografias por utilizador. O máximo de fotografias de um utilizador foram cerca de 100 fotografias e o mínimo passou pelas 14. Na tabela 5.1 temos uma análise estatística à participação dos utilizadores ao nível das fotos inseridas no sistema. Na figura 5.2 temos um histograma com o número de fotografias por utilizador.
Média 30,73 Desvio Padrão 15,77 Moda 26
Tabela 5.1 Número de fotos introduzidas por cada utilizador
0
5
10
15
20
25
Histórias Tagging
Nr.de
U(lizad
ores
Sistema
Masculino
Feminino
56
Figura 5.2 Participação de cada utilizador.
As fotografias tendo em conta os utilizadores aos quais estavam associadas estavam distribuídas aproximadamente em 52% (642 fotografias) para o sistema de histórias e os restantes 48% (587 fotografias) para o sistema de tagging tradicional. Não apresentando grande discrepância na distribuição das fotografias pelos dois sistemas, sendo o resultado do t-test sobre os grupos de aproximadamente 0,58 que significa que não existe uma diferença estatísticamente significativa entre os dois grupos. Logo não terá influência na análise dos resultados que poderia acontecer no caso da distribuição não ser próxima dos 50% nos dois sistemas.
5.2.1 Histórias
Nesta secção vamos abordar em pormenor o sistema de histórias. Podemos observar na tabela 5.2 estatísticas sobre a participação dos utilizadores no sistema de histórias. Algo a salientar tendo como comparação as estatísticas a nível global acaba por ser o desvio padrão do número de fotografias, em que existiu uma grande discrepância no que diz respeito ao número de fotografias inseridas pelos utilizadores. Dois utilizadores inseriram um número bem muito maior que todos os outros, do qual se pode retirar que os utilizadores poderão ter-se sentido identificados com o sistema de narrativas e que lhes pode ser útil como ferramenta de organização. Outra hipótese para a discrepância será que os utilizadores têm noção que só inserindo fotos em grande quantidade é que vão ajudar a retirar resultados do sistema e provar a sua utilidade ou não..
Número de Elementos nas Histórias
Vamos agora analisar como são constituídas as histórias dos utilizadores, a partir de estatísticas mais pormenorizadas apresentadas na tabela 5.2.
Ao todo foram adicionadas 656 histórias no sistema. Tendo em conta que as histórias são constituídas por elementos, podemos dizer que ao todo foram adicionados 5363 elementos.
0
50
100
150
200
250
U1 U3 U5 U7 U9 U11U13U15U17U19U21U23U25U27U29U31U33U35U37U39
Nr.de
Fotos
U(lizadores
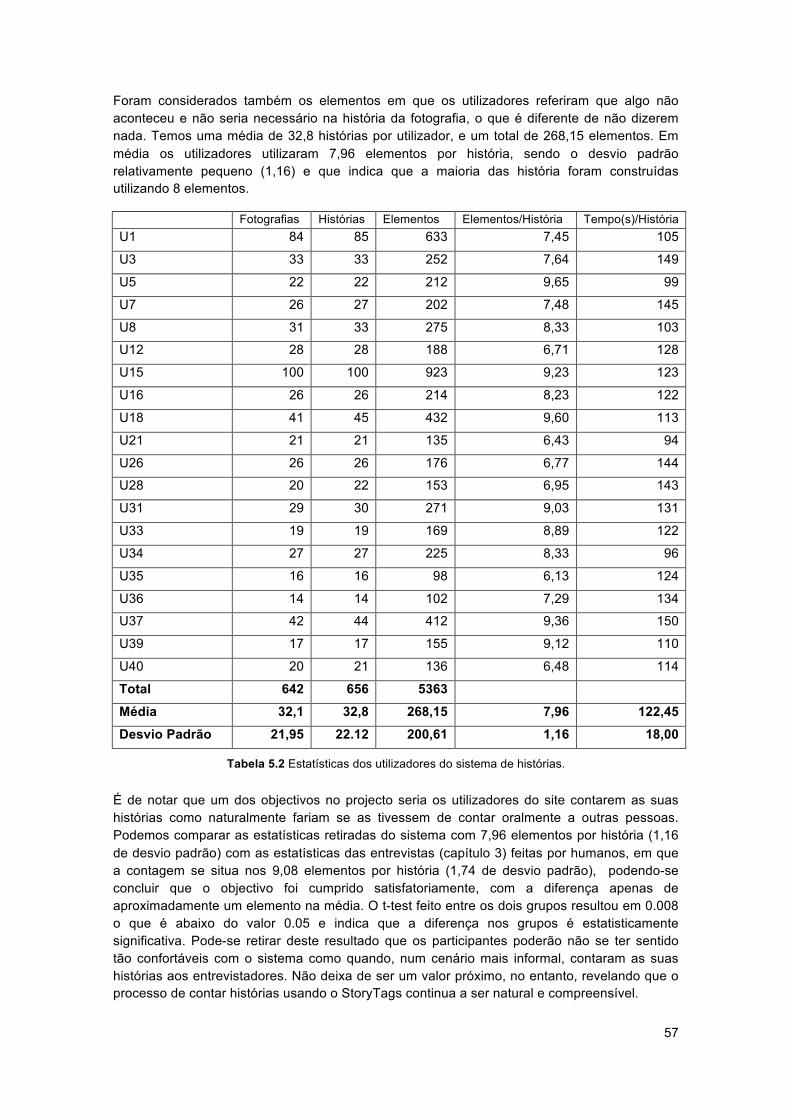
57
Foram considerados também os elementos em que os utilizadores referiram que algo não aconteceu e não seria necessário na história da fotografia, o que é diferente de não dizerem nada. Temos uma média de 32,8 histórias por utilizador, e um total de 268,15 elementos. Em média os utilizadores utilizaram 7,96 elementos por história, sendo o desvio padrão relativamente pequeno (1,16) e que indica que a maioria das história foram construídas utilizando 8 elementos.
Fotografias Histórias Elementos Elementos/História Tempo(s)/História U1 84 85 633 7,45 105
U3 33 33 252 7,64 149
U5 22 22 212 9,65 99
U7 26 27 202 7,48 145
U8 31 33 275 8,33 103
U12 28 28 188 6,71 128
U15 100 100 923 9,23 123
U16 26 26 214 8,23 122
U18 41 45 432 9,60 113
U21 21 21 135 6,43 94
U26 26 26 176 6,77 144
U28 20 22 153 6,95 143
U31 29 30 271 9,03 131
U33 19 19 169 8,89 122
U34 27 27 225 8,33 96
U35 16 16 98 6,13 124
U36 14 14 102 7,29 134
U37 42 44 412 9,36 150
U39 17 17 155 9,12 110
U40 20 21 136 6,48 114
Total 642 656 5363 Média 32,1 32,8 268,15 7,96 122,45 Desvio Padrão 21,95 22.12 200,61 1,16 18,00
Tabela 5.2 Estatísticas dos utilizadores do sistema de histórias.
É de notar que um dos objectivos no projecto seria os utilizadores do site contarem as suas histórias como naturalmente fariam se as tivessem de contar oralmente a outras pessoas. Podemos comparar as estatísticas retiradas do sistema com 7,96 elementos por história (1,16 de desvio padrão) com as estatísticas das entrevistas (capítulo 3) feitas por humanos, em que a contagem se situa nos 9,08 elementos por história (1,74 de desvio padrão), podendo-se concluir que o objectivo foi cumprido satisfatoriamente, com a diferença apenas de aproximadamente um elemento na média. O t-test feito entre os dois grupos resultou em 0.008 o que é abaixo do valor 0.05 e indica que a diferença nos grupos é estatisticamente significativa. Pode-se retirar deste resultado que os participantes poderão não se ter sentido tão confortáveis com o sistema como quando, num cenário mais informal, contaram as suas histórias aos entrevistadores. Não deixa de ser um valor próximo, no entanto, revelando que o processo de contar histórias usando o StoryTags continua a ser natural e compreensível.

58
Na figura 5.3 são apresentadas as distribuições das histórias pelo número de elementos que possuem. Podemos observar que a maioria das histórias se encontra em média como tínhamos calculado anteriormente com 7 ou 8 elementos. Podemos logo neste instante reter a quantidade de informação que o utilizador associou a uma fotografia. Ou seja foi adicionado um número elevado de elementos capaz de identificar a fotografia posteriormente.
Figura 5.3 Distribuição de histórias pelo número de elementos por história
Tempo para inserir as histórias
O factor do tempo também é importante na comparação do sistemas, uma vez que pode ser determinante na escolha de qual o método de tagging a usar. Analisando a correlação entre o número de elementos inseridos e o tempo necessário para o utilizador inserir os elementos em média por história, temos um valor de -0,14, que sendo um valor próximo de 0 indica não existir uma relação que possa ser considerável entre as duas variáveis, existindo uma independência entre elas. Essa relação de independência pode indicar que diferentes pessoas têm diferentes ritmos para inserir as histórias. Poderão existir utilizadores que inserem bastante histórias e como têm bastante prática necessitam de pouco tempo para o fazer. Outro tipo de utilizadores são os que demoram algum tempo a inserir as tags, que poderá resultar da falta de experiência ou do facto do utilizador ter noção que será necessário relembrar a tag num futuro levando o seu tempo a analisar e a procurar a melhor opção.
Informação contida nas histórias
Para analisar com maior pormenor o sistema de narrativas, é necessário aprofundar com maior detalhe as histórias contadas e os elementos escolhidos pelos utilizadores para associarem informação às suas fotografias. Podemos verificar na figura 5.4 que existe um conjunto de 5 elementos que foram referidos em pelo menos 90% das fotografias. Os elementos são o Autor, Dispositivo, Local, Qualidade e Dimensão. O resultado alcançado nestes elementos indica que os utilizadores associam facilmente à fotografia informação relacionada com estes elementos. Os restantes elementos com menor percentagem de utilização apresentam, mesmo assim, uma frequência interessante perto dos 60%. O elemento que apresentou menor percentagem foi o Propósito, que poderá indicar a dificuldade das pessoas em associar essa informação à fotografia ou então que este elemento não é interessante para as pessoas.
Ao observar a figura 5.4 podemos concluir ainda que os utilizadores constroem as histórias com todos os elementos, sendo excepção o Propósito. Pelo resultado podemos concluir que a
11 3 0 07 18
211187
54
80 77
71
0
50
100
150
200
250
1 2 3 4 5 6 7 8 9 10 11 12 13
Nr.de
Histórias
Nr.Elementos

59
escolha dos elementos para a história foi bem sucedida, tendo quase todos apresentado resultados interessantes.
Figura 5.4 Frequência absoluta dos elementos nas histórias
Na comparação com as entrevistas (figura 5.5) que foram utilizadas como base para construir o sistema, podemos retirar algumas ilações. O elemento Tempo, que nas entrevistas foi o elemento mais focado pelos utilizadores, no sistema acabou por ter um resultado bastante abaixo das expectativas, ficando apenas acima do elemento Propósito, que no seu caso não foi uma surpresa, uma vez que a sua relevância para os utilizadores foi semelhante à apresentada nas entrevistas. De resto, os elementos Dimensão e Tipo apresentaram uma importância acima do que a análise às entrevistas sugeriu. Esta situação poderá ter acontecido devido a possibilidades concretas que eram apresentadas ao utilizador, que tornavam a especificação desse elemento fácil de concretizar, podendo ser uma razão para o seu crescimento em relação ao foi observado nas entrevistas. Outro elemento que passou do 3º mais focado nas entrevistas, sendo apenas o 9º mais referido no website foi a descrição. Tal poderá ter acontecido devido a que nas entrevistas sendo que o utilizador tinha mais possibilidade de divagar na história, apresentando no entanto elementos importantes, no sistema não teria tantas facilidade em divagar sendo guiado por uma base que não permitia tanta liberdade ao utilizador. O elemento Autor que foi apenas o 5º elementos mais focado nas entrevistas, no website foi o elemento mais referido pelos utilizadores. Poderá ser resultado do que já foi referido anteriormente, em que nas entrevistas os utilizadores acabam por achar algo tão óbvio que acabam por não referir, mesmo que para estes não deixe de ser um elemento importante. Como no sistema de narrativas já lhe é apresentado o elemento mesmo sendo óbvio, respondem ao diálogo e acabam por inserir essa informação na história.
Outra ilação retirada, é que em apenas 14 das 656 histórias foram inseridas como informação adicional para as respectivamente 14 fotografias. Ou seja existiram utilizadores que além de inserirem uma história por cada foto, em 14 fotografias associaram mais uma história a cada uma. Deste facto, pressupõe-se que a maioria das pessoas necessita apenas de inserir uma história para associar toda a informação à fotografia.
0
100
200
300
400
500
600
700
Freq
uência
Elementos

60
Figura 5.5 Frequência relativa dos elementos nas histórias e estudo.
Da análise dos elementos duplicados nas histórias, em que o utilizador necessitou ou fez questão de enfatizar um elemento numa história, podemos constatar que apenas o elemento Local foi duplicado nas histórias, do qual se retira que as pessoas, por exemplo, numa primeira instância inseriram o país e numa segunda fase sentiram a necessidade de serem mais específicos e indicarem também a cidade onde a foto foi tirada.
Nesta fase podemos apreender que os utilizadores nas histórias conseguem organizar as suas tags em determinados contextos, associando tags a determinados elementos, sugeridos pelos diálogos que são apresentados ao utilizador. Neste sistema, os problemas identificados nos sistemas de tagging tradicionais (capítulo 2), os sinónimos e a polissemia, são reduzidos apenas ao contexto do elemento a qual o utilizador associa a tag.
Reutilização dos elementos
Analisando a reutilização de tags a nível global, e como já foi referido anteriormente, a opção tomada para aumentar a reutilização foi a utilização de uma politica de suggestive-tagging, ou seja, cada vez que o utilizador começa a escrever nos campos apresentados para o efeito é apresentado as tags inseridas pelo o utilizador e por os outros utilizadores para aquele elemento. Desta forma tentamos atingir uma folksonomia, sendo que uma expressão ganhará um significado através do sentido que a comunidade lhe dá. Retirando os resultados a um nível global poderemos ver que os utilizadores inseriram 5363 elementos sendo que 310 são tags distintas. Em termos de percentagem temos portanto, 6% de tags distintas e uma reutilização de 94% das tags inseridas anteriormente.
Tendo em conta que em alguns dos elementos das histórias, são apresentados aos utilizadores elementos pré-definidos, é importante analisar a reutilização retirando todas as tags que estão pré-definidas e foram registadas nas histórias de forma a termos um melhor termo de comparação. Após ter retirado todos esses elementos, obtivemos um total de 294 tags distintas num conjunto de 2269 tags. Calculando o mesmo método que foi utilizado anteriormente chegamos à conclusão que a reulização é de 87%, o que é bastante considerável.
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
Website
Estudo

61
Evolução das tags
Podemos observar na figura 5.6 a evolução do número de tags distintas à medida que os utilizadores introduziam as suas tags no sistema. Como se pode observar, no início foram introduzidas no site, como é natural, um número elevado de tags distintas. Após esse início, o crescimento das tags distintas estagnou mantendo o nível ao longo de quase 3000 tags, o que indica que durante esse período os utilizadores maioritariamente introduziram tags que já teriam sido inseridas no sistema. No final existe novamente um crescimento, que poderá indicar o aparecimento de novos interesses por parte dos utilizadores, resultando num aumento de tags distintas nos conteúdos. Tendo em conta que a altura coincidiu com o Verão, e consequentemente para a maioria dos utilizadores as férias, é fácil perceber o crescimento que foi possível observar no final, uma vez que as férias são uma altura propícia para serem tiradas fotos.
Figura 5.6 Evolução das tags distintas
Recuperação das fotografias
Na parte de recuperação de fotografias, como já foi referido anteriormente, foi pedidos a dois utilizadores do sistema de narrativas para recuperarem duas fotografia antigas. O tempo de recuperação foi medido desde o momento em que o utilizador abre a secção de pesquisa até abrir a fotografia que lhe foi pedida para encontrar.
A tabela 5.4 demonstra a análise à recuperação das fotografias por parte de dois utilizadores. O utilizador 1 necessitou em média de 51 segundos para recuperar a fotografia proposta para ser recuperada. É de notar que o utilizador que na foto número 2 necessitou de reescrever um dos elementos, após se ter lembrado que tinha respondido ao elemento Local a um nível menos especifico, sendo adicionado mais um elemento à contagem de elementos necessários para encontrar a fotografia.
O utilizador 2 apresentou níveis mais satisfatórios que o utilizador 1, tendo demorado em média menos tempo e tendo necessidade de preencher menos elementos para recuperar as suas fotografias. Existiu também, a situação de ter de reescrever um dos elementos após ter-se enganado no elemento Evento.
0
50
100
150
200
250
300
350
0 1000 2000 3000 4000 5000 6000
TagsDis(ntas
Tags

62
Foto 1 Foto 2 Média Tempo 37 segundos 65 segundos 51 segundos Utilizador 1 Nr. elementos 3 elementos 4 elementos * 3,5 elementos Tempo 21 segundos 46 segundos 33,5 segundos Utilizador 2 Nr. elementos 2 elementos 4 elementos * 3 elementos
* reescreveu um dos elementos, sendo feita a contagem de mais um elemento.
Tabela 5.4 Tabela de recuperação de fotografias.
Estudo dos Problemas do tagging
Foi feita uma análise cuidada às tags inseridas no sistema de narrativas, à procura dos problemas referidos anteriormente e que são característicos dos sistemas de tagging tradicionais como a polissemia, sinónimos e os níveis básicos da linguagem. Em seguida vamos apresentar uma análise a cada um.
Sinónimos e Polissemia
Da análise das tags das histórias não foi possível identificar sinónimos. Isto poderá dever-se ao facto que as tags, entendidas aqui como os elementos das histórias, serem compostas por várias palavras, existindo poucas que são constituídas apenas por uma. Sendo as tags bastante descritivas, resultado do utilizador sentir-se motivado a completar o raciocionio do dialogo, torna as tags bastante compostas. Devido a essa completude não foram encontradas semelhanças entre as tags. O mesmo se aplica para as tags polissémicas, em que o contexto é essencial para perceber o significado real da palavra. Como a tag encontrasse ligada ao elemento a que foi associada na história, este contexto contribui para se perceber facilmente o significado das tags, não existindo a ambiguidade que existe nos sistemas de tagging tradicional.
Nível Básico da Linguagem
Esta componente de avaliação foi estudada e implementada no sistema de forma a ser possível medir e comparar ambos os sistemas nesta vertente. Para avaliar a métrica foi criada uma secção no site com fotos de controlo onde seriam postas a cada duas semanas um número de fotos sobre os quais os utilizadores contariam as suas histórias. A avaliação desta componente foi muito aquém do esperado, sendo que uma explicação é que para contar as histórias os utilizadores precisam de se sentir identificados com as fotografias, o que não se reflectia em fotos que não eram pessoais. Como não foi possível retirar os resultados deste componente não foi possível apresentar dados estátisticos para comparar os dois sistemas em análise.
Caso de estudo
Em seguida vamos focar a atenção em um utilizador e analisar de forma a retirar outra percepção do sistema.
Como podemos observar na figura 5.5, temos todo o conjunto de tags distintas, 64 no total, inseridas por um utilizador (a azul) e a frequência com que foram inseridas. Podemos ver que existem algumas tags que são bastante utilizadas. Temos por exemplo, a tag “Me”, indicativa que foi o utilizador que tirou a fotografia, mencionada em cerca de 96 histórias. Temos ainda por exemplo, tags com nomes de cidades, “London”, “Rome” e “Copenhagen” que indicam o nome do local onde a fotografia foi tirada. Temos ainda tags compostas por várias palavras, como por exemplo, “first airplane trip”, onde o utilizador associou à fotografia o evento em que decorreu a fotografia. Outra tag relevante é “Me and Cátia” sendo que indica as pessoas presentes nas fotografias.

63
Como é possível observar na tabela 5.5, em média foram utilizadas 14,42 vezes cada tag durante todo o processo. O número é ilusório, uma vez que existem tags com um número elevado de utilizações, como é o caso da tag “Me” (96 presenças). Tal pode ser conferido no valor do desvio padrão, 23. A moda com valor 1 é indicativa que existem muitas tags que só foram utilizadas uma vez. Isto poderá quer dizer que o utilizador não possuí o hábito de fazer um reutilização de tags, ou então as fotografias representavam situações únicas que não possibilitam a reutilização de tags.
Média 14.42 Desvio Padrão 23
Moda 1
Tabela 5.5 Estatística da utilização das tags de um utilizador
O utilizador no total inseriu 100 fotografias, as quais correspondem 100 histórias. Nessas histórias estão presentes 923 elementos/tags. Resulta numa média de 9.23 tags por história, sendo um valor significativo tendo em conta que a história geral utiliza 11 elementos distintos. Por este valor percebe-se que o utilizador utiliza quase todos os elementos para contar a história das fotografias.
Analisando num panorama global temos 310 tags distintas, e como foi referido anteriormente, 5363 tags no total das histórias contadas pelos utilizadores . Analisando a frequência das tags das histórias (tabela 5.6), podemos ver que as tags foram em média utilizadas 17,3 vezes, mas examinando e equiparando com a situação do utilizador referido anterior, podemos observar que o desvio padrão é significativo, sendo que existem tags que têm uma frequência de utilização bastante elevada. A moda é igualmente demonstrativa das tags únicas que os utilizadores optam por inserir nas suas fotografias.
Média 17,3 Desvio Padrão 61,46
Moda 1
Tabela 5.6 Estatística da utilização das tags de todos os utilizadores
Na figura 5.7 está ainda presente a frequência das tags do utilizador analisando a um nível global no sistema (a vermelho). Podemos verificar que existem algumas tags que foram utilizadas pelo sistema todo. As tags que apresentam frequências elevadas representam tags que são apresentadas pelo sistema para uma rápida escolha do utilizador ou por exemplo, tags com o nome de cidades que foram visitadas pelos utilizadores. Podemos ver que as tags com apenas uma referência são tags únicas ao utilizador e que não apresentam significado para os outros utilizadores.
Em seguida vamos analisar a evolução das tags distintas do utilizador ao longo do tempo e à medida que as fotografias iam sendo inseridas. Como podemos observar na figura 5.8, o utilizador teve logo um crescimento natural nas primeira fotos em que inseriu um conjunto de tags novas, sendo que no decorrendo tempo a curva foi ficando menos acentuada, estagnando nas 62 tags. O utilizador na sua última participação inseriu mais duas tags diferentes das que tinha inserido anteriormente no sistema. Na figura 5.9 é apresentado igualmente a evolução das tags mas à medida que iam sendo inseridas novas fotografias. Podemos ver aqui que o utilizador definiu logo um conjunto de tags distintas nas primeiras 20 fotografias. A partir desse nível a curva estagna, podendo concluir-se que o utilizador fez uma reutilização das tags já inseridas, ou perdeu interesse em fazer tagging dos seus conteúdos ou ainda, não

64
Figura 5.7 Frequência das tags nas histórias (um utilizador a azul, todos os utilizadores a vermelho)
0 100 200 300 400 500 600
LondonOneyearagoCellphoneReasonable
AverageMe
NoonewasthereLondonEyemonumentLandscape
triptolondonLisboa
around...02‐MAY‐2008Guilhermesleeping
thebirthofmynephewPortrait
ParquedasNaçõesBad
RickyandSousaagoodnight
wewerehappyCopenhagen
triptodenmarkIST
theoldestcarIeverseenParis
eiffeltoweritsamazingtriptoparis
notredamecatedralabigbigwaleLondonbridge
DinosFormula1car
visittosciencemuseumOneweekagoDigitalcamerameandfilipe
goodPmeLux
Onemonthagofilipe
filipedrunkitwasfunny
endofthenightinluxExcentricYesterday
excentricphotoSky
GoodVargasCoiote
firstairplanetripBig
romemonumentstriptoromeComputer
RomeMeandCáPa
greattripColiseum
tripsTrevi
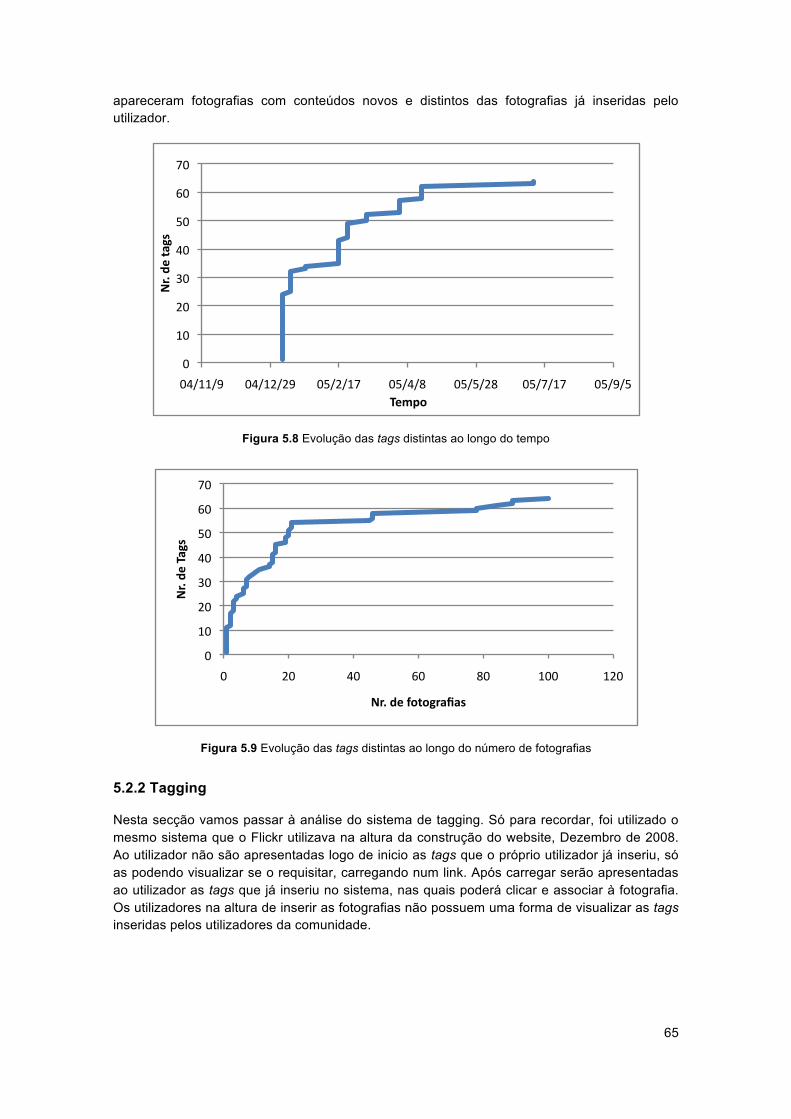
65
apareceram fotografias com conteúdos novos e distintos das fotografias já inseridas pelo utilizador.
Figura 5.8 Evolução das tags distintas ao longo do tempo
Figura 5.9 Evolução das tags distintas ao longo do número de fotografias
5.2.2 Tagging
Nesta secção vamos passar à análise do sistema de tagging. Só para recordar, foi utilizado o mesmo sistema que o Flickr utilizava na altura da construção do website, Dezembro de 2008. Ao utilizador não são apresentadas logo de inicio as tags que o próprio utilizador já inseriu, só as podendo visualizar se o requisitar, carregando num link. Após carregar serão apresentadas ao utilizador as tags que já inseriu no sistema, nas quais poderá clicar e associar à fotografia. Os utilizadores na altura de inserir as fotografias não possuem uma forma de visualizar as tags inseridas pelos utilizadores da comunidade.
0
10
20
30
40
50
60
70
04/11/9 04/12/29 05/2/17 05/4/8 05/5/28 05/7/17 05/9/5
Nr.de
tags
Tempo
0
10
20
30
40
50
60
70
0 20 40 60 80 100 120
Nr.de
Tags
Nr.defotografias

66
Fotografias Tags Tags/Fotografia Tempo(s)/Fotografia U2 30 46 1,53 60
U4 35 105 3,00 53
U6 33 33 1,00 55
U9 31 39 1,26 35
U10 27 45 1,67 40
U11 27 28 1,04 31
U13 30 43 1,43 27
U14 19 21 1,11 64
U17 15 18 1,20 38
U19 30 61 2,03 50
U20 28 34 1,21 54
U22 35 51 1,46 51
U23 33 36 1,09 59
U24 33 38 1,15 46
U25 29 31 1,07 39
U27 32 32 1,00 38
U29 34 40 1,18 39
U30 29 33 1,14 50
U32 30 31 1,03 30
U38 27 28 1,04 53
Total 587 793 Média 29,35 39,65 1,35 45,6 Desvio Padrão 4,97 18,31 0,47 10,79
Tabela 5.7 Estatísticas dos utilizadores do sistema de tagging.
Número de elementos
Na tabela 5.7 podemos observar as estatísticas dos utilizadores no sistema de tagging. Os utilizadores neste sistema associaram 793 tags a 587 fotografias, em média cada utilizador inseriu 29,35 fotografias no sistema, com uma média de 39,65 tags por utilizador, a que equivale 1,35 tags por fotografia. Podemos ver que apenas dois utilizadores passaram a fasquia da média de 2 tags por fotografia que poderá indicar alguma falta de interesse ou falta de mecanismos para o tagging, sendo suficiente, no seu entender, inserir aproximadamente 1 tag por fotografia, fora a excepção em que o utilizador apresentou uma relação de tags por foto de 3 para 1.
Tempo para inserir as tags
Podemos verificar que os utilizadores em média demoraram 45,6 segundos a inserir as tags. Parece valor elevado tendo em conta que os utilizadores na maioria inseriram apenas uma tag nas fotografias. Podemos deduzir deste valor, sendo que não é natural demorarem tanto tempo a escrever uma palavra ou expressão, que a maioria do tempo foi utilizado para pensar numa palavra que descrevesse a fotografia. Analisando se existe alguma relação entre o número de tags por fotografia e o tempo utilizado para fazer o tagging, chegamos à conclusão que a relação é de independência entre ambas, uma vez que a correlação apresentou um

67
resultado 0,17. Como o resultado apresentado é próximo de 0 a relação entre a quantidade de tags inseridas é independente ao tempo utilizado, logo não existe uma relação entre o número de tags inseridas e o tempo perdido a inserir.
Reutilização das tags
Das 793 tags inseridas pelos utilizadores foram encontradas 510 distintas, o que equivale a 64% das tags inseridas pelos utilizadores e que é indicativo que 36% das tags foram reutilizadas pelos utilizadores. A percentagem de tags distintas é indicativa que os utilizadores preferiram quase sempre inserir tags novas para descrever conteúdos inseridos.
Evolução das tags
Como está representado na figura 5.10, a evolução das tags distintas é feita quase numa relação de 1 para 1 com as fotografias, o que pode indicar a falta de mecanismos dos utilizadores para criar tags capazes de agrupar fotografias com conteúdos semelhantes ou envolvência parecida.
Figura 5.10 Evolução das tags distintas globais
Recuperação das fotografias
Outra etapa da análise, semelhante ao que foi feito no sistema de narrativas, foi a recuperação de fotografias, mas com utilizadores do sistema tradicional de tagging. Tendo em conta a tabela 5.9 podemos ver que o utilizador 1, apesar de ter encontrado a primeira fotografia imediatamente, com a segunda fotografia foi o oposto e após 5 tentativas desistiu de a encontrar, não se recordando das palavras-chave que associou ao conteúdo. No caso do utilizador 2, consegui encontrar as duas fotografias, mas foi necessário inserir 4 tags em uma delas(foto 1). Já na segunda fotografia, o utilizador necessitou apenas de empregar duas tags.
Foto 1 Foto 2 Média Tempo 15 segundos Não encontrou - Utilizador 1 Nr. elementos 1 tags 5 tags - Tempo 80 segundos 32 segundos 54 segundos Utilizador 2 Nr. elementos 4 tags 2 tags 3 tags
Tabela 5.9 Tabela de recuperação de fotografias.
0
100
200
300
400
500
600
0 100 200 300 400 500 600 700
Tags
Nr.deFotografias

68
Problemas do tagging
Foi feita uma análise cuidada às tags inseridas, por todos os utilizadores à procura dos problemas referidos anteriormente, polissemia, sinónimos e os níveis básicos da linguagem, que são característicos do tagging. Em seguida vamos apresentar uma análise a cada um.
Sinónimos
Para analisar os sinónimos, foram agrupadas as palavras com o mesmo significado, constituindo grupos de uma palavra, caso não a palavra desse grupo não tivesse nenhuma correspondência com outra, ou grupos de n palavras, caso existisse um número n de sinonimo. O máximo de elementos de um grupo foram três. Na figura 5.11 é apresentado um histograma com a distribuição das palavras pelos respectivos grupos. Como podemos analisar do histograma os utilizados utilizam maioritariamente palavras que não foram usadas por outros utilizadores. Uma vez que o conjunto de resultados é pequeno é normal tal acontecer. Temos no entanto ainda quatro grupos de três sinónimos e dez grupos com dois sinónimos que equivale a dizer que 32 tags possuem sinónimos correspondes no espaço de 587 tags. Ou seja, representa 5,5% de tags que possuem sinónimos. Como foi referido o espaço de resultados é pequeno e é favorável a apresentar resultados ao nível destes. Com um maior número de pessoas a inserir tags a percentagem de sinónimos no conjunto de tags iria naturalmente crescer.
Figura 5.11 Histograma de grupos de sinónimos.
Polissemia
Através da análise do conjunto de tags distintas recolhidas, procurando encontrar palavras que possuíssem mais do que um sentido, encontramos 23 tags nessas condições o que equivale a dizer que em média 4% das palavras possuem mais do que um sentido. Esse sentido só fica definido quando a palavra é inserida em contexto. A palavra solta só por si, não esclarece o seu significado e torna complicado a sua compreensão.
Nível Básico da Linguagem
Como foi referido anteriormente esta componente de avaliação só era possível se todos os utilizadores associassem tags a fotografias definidas como controlo. Tal componente de avaliação foi feita e implementada mas não existiu colaboração por parte dos utilizadores, logo não se pode indagar sobre esta componente.
573
10 40
100
200
300
400
500
600
700
1 2 3
Nr.de
Elemen
tos
Grupos

69
Categorização das Tags
Para uma melhor comparação com o sistema de narrativas foi feito uma análise para categorizar as tags que foram inseridas no sistemas de tagging tradicional. Para as categorias foram utilizadas as identificadas para o sistema de narrativas. Como já referimos as tags não tendo um contexto definido, por vezes mostrou-se impossível determinar a categoria em que se inseriam, ou em alguns casos a tag podia ser categorizada em duas categorias. É o caso das tags que se referiam a nomes próprios, que no âmbito do sistema de narrativas podiam ser categorizados como o autor da fotografia, ou as pessoas se que se encontravam presentes nas fotografias.
Na figura 5.12, é apresentado um histograma com a distribuição das tags por categoria. Podemos retirar do histograma que a maioria das pessoas utiliza tags que descrevem a fotografia, mais concretamente o que constitui a fotografia. A categoria Local é representada por cerca de 130 tags, comprovando que é uma categoria importante tanto no sistema de narrativas como no sistema de tagging tradicional.
Figura 5.12 Categorização das tags
Uma estatística significativa e importante de reter é que aproximadamente 10% das tags não têm uma categoria associada, o que poderá representar tags que se mostram únicas ao utilizador, e que não têm significado para o resto das pessoas. O sistema de tagging tradicional sendo um processo pouco ou nada estruturado, e no qual o utilizador não possui regras que definam o processo de tagging, acaba por incentivar o utilizador a associar informação que lhe é única sem preocupação com uma estrutura e significado que seja útil a outros utilizadores.
Caso de estudo
Em seguida vamos entrar em pormenor no sistema de tagging e tentar perceber comportamentos de um utilizador, analisando as tags por esse inseridas a um nível individual e ainda a um nível global, tentando perceber uma possível relação com a comunidade onde está inserido. O utilizador escolhido foi o que demonstrou melhores relações entre o upload de fotografias e as tags inseridas. Na tabela 5.5 podemos ver as estatísticas de utilização do utilizador tendo em conta que inseriu 35 fotografias no sistemas e um total de 105 tags. A sua média foi de 3 tags por foto que é algo superior à média de todo o conjunto de utilizadores que participaram no sistema de tagging.
74
232
2 1
127
31 36 1 2 59 7 12 2 10
50
100
150
200
250

70
Figura 5.13 Frequência das tags no sistema de tagging tradicional. (um utilizador a azul, todos os utilizadores a vermelho)
0 2 4 6 8 10 12
riramigasparvasparque
dasnações
inêssérgiogala
ISCTEbébeslaranja
FILarteSilvieBarAEAines
8OutubroKatecamsAquárioMaggie
EnterroCaloirochichafumartraje
emblemasbebedeiraSuperBock
parvacorovo
katecassaraainesinesdani
lilianacafé
oceanárioantónio
fototanquecentraljantarNatal
malucossilviamariajoanini
riPPmaryserramirraduduxixa
paláciopenasintrauniãoanel
junhosantos
populareslisboa
marchascasamento
bênçãofinalistasreitoriacidade
universitáriaB‐2
bombardeirolindo
excelentealianças
ourofestaanéis

71
Passando a um nível mais pormenorizado, ao nível das tags inseridas, podemos observar na figura 5.13 a distribuição da utilização para todas as tags inseridas no sistema pelo utilizador, para as suas fotografias. Como podemos ver na tabela 5.8, o utilizador inseriu em média 1.33 cada tag no sistema, com uma moda de 1 indicativa que o utilizador, a maioria das vezes, utilizou uma tag uma única vez para descrever uma das suas fotografias. Desta estatística podemos retirar, como já referimos, a diversidade do âmbito que as fotos revelam ou a falta de mecanismos para fazer tagging agrupando fotografias com âmbitos semelhantes ou idênticos.
Média 1.33 Desvio Padrão 0.81
Moda 1
Tabela 5.8 Estatística da utilização das tags de um utilizador
Como podemos verificar na figura 5.14, o utilizador foi inserindo novas tags à medida que foi inserindo novas fotografias, inserindo sempre novas tags distintas. Poderá constatar-se que o utilizador inseriu 79 tags distintas em 105 tags inseridas, o que equivale a dizer que, 75% das tags inseridas são distintas e apenas 25% das tags foram reutilizadas para descrever outras fotografias.
Figura 5.14 Evolução das tags distintas do utilizador
5.3 Comparando Narrativas com Tagging Tradicional
Após a análise de ambos os sistemas, conseguimos retirar algumas informações e chegar a uma conclusão sobre a comparação do sistema baseado nas narrativas e os sistemas de tagging que hoje em dia estão bastante activos na ajuda ao utilizador para organizar o seu conteúdo. De forma a compararmos os dois sistemas, recorremos a diversas métricas que serão importantes factores de comparação. Temos a reutilização de tags, em que demonstramos se os utilizadores fazem uma reutilização de tags nos seus conteúdos. Com a reutilização de tags numa comunidade, esta tem o poder de criar uma folksonomia, ou seja, um dicionário com palavras que ganham um significado numa comunidade. A quantidade de informação em ambos os sistemas é um factor importante. Se o objectivo é associar informação a um conteúdo, é importante quantificar essa parte do sistema. O tempo é uma métrica importante, quer seja com o objectivo de inserir, como de recuperar os conteúdos, uma vez que pode ser importante no factor de decisão por um ou outro sistema. E por último, a
0
10
20
30
40
50
60
70
80
90
0 5 10 15 20 25 30 35 40
Tags
Fotografias
72
evolução do tagging é outra métrica a reter de forma a analisar os comportamentos dos utilizadores ao longo do tempo em que inseriram as fotografias e as tags.
Sistema de narrativas
Sistema de tagging
Fotografias 642 587
Tags 5363 793
Tags / Fotografia 8,35 1,35
Tabela 5.8 Comparação dos dois sistemas.
Analisando a um nível global a quantidade de informação inserida nos dois sistemas (tabela 5.8), em média os utilizadores no sistema de narrativas inseriram 8,35 elementos de informação para cada fotografia, enquanto no sistema de tagging tradicional os utilizadores apresentaram um resultado de 1,35 tags por fotografia. Isto traduz que os utilizadores do sistema de narrativas introduziram aproximadamente vezes mais informação que os utilizadores do sistema de tagging. É um resultado bastante significativo que indica que os utilizadores conseguiram replicar no sistema o que é natural a eles. Ao contar uma história conseguem transmitir muito mais informação do que quando são deparados com o desafio de arranjar apenas um número de palavras capazes de descrever algo.
Como foi observado anteriormente é importante comparar também o sistema de narrativas com o sistema de tagging sem contar com as tags pré-definidas que existem no sistema de narrativas. Tendo em conta que identificamos 2269 elementos sem contar com os pré-definidos, utilizando as mesmas 642 fotos, temos o resultado de 3,53 tags por fotografia. Comparando com o sistema de tagging continua a ser superior a relação das tags e fotografias no sistema de narrativas.
Dos resultados analisados podemos constatar que nas histórias os problemas que os sistemas de tagging tradicionais apresentam não são tão evidentes. Os problemas de linguagem, no que diz respeito aos sinónimos e a polissemia são reduzidos, uma vez que as tags são inseridas dentro de um contexto, reduzindo o âmbito dos significados de uma palavra.
Outra ilação que pode ser retirada é o facto que grande parte tags que foram inseridas no sistema de narrativas são tags compostas por várias palavras. Os utilizadores do sistema de narrativas tendem ao contar a histórias quando confrontados com os diálogos, a evoluir o texto de forma a conseguir uma história concisa. Por outro lado, os utilizadores do sistema de tagging tradicional tende a utilizar uma única palavra, sendo que existem casos em que o utilizador junta duas palavras sem espaços, como é exemplo a tag “EnterroCaloiro”. O utilizador acaba, de uma forma propositada ou não, por criar uma expressão única e que dificilmente será utilizada por outro utilizador, dificultando a reutilização de tags, diminuindo assim a evolução de uma folksonomia na comunidade.
Sendo as tags do sistema narrativo maioritariamente compostas por várias palavras, poderá existir ainda um maior número de tags inseridas, uma vez que podemos considerar que uma tag composta poderá ser um conjunto de tags, uma vez que o sistema na altura da pesquisa nunca procura por uma tag composta mas sim por palavras únicas. Podemos concluir então, que o sistema de narrativas possibilita aos utilizadores uma maior capacidade de inserir tags às fotografias.
Da análise dos gráficos das figuras 5.6 e 5.8 podemos ver que no sistema de narrativas temos uma maior reutilização das tags. Tal podemos concluir através da linha de evolução, que no caso das narrativas, existe conjuntos consideráveis de fotografias em que não são inseridas

73
muitas tags novas no sistema. No sistema de tagging tradicional já não existem espaços em que é feita uma reutilização das tags já inseridas no sistema e são constantemente inseridas novas tags. Outro dado a ter em conta é o facto de as tags distintas representarem uma quota de 64% das tags inseridas no sistema de tagging tradicional e apenas 6% das tags inseridas no sistema de narrativas (13% no caso de serem retiradas as tags pré-definidas). Destas percentagens concluimos que em termos de reutilização das tags já inseridas existe uma percentagem de 36% no sistema de tagging tradicional e 94% de taxa de reutilização no sistema de narrativas.
Os tempos necessários em cada sistema, para cada utilizador associar informação às fotografias, é bastante diferente. Enquanto que no sistema de narrativas foi necessário em média 122,45 segundos, no sistema de tagging tradicional foi apenas necessário 45,6 segundos. Embora no sistema de narrativas o utilizador tenha demorado sensivelmente o triplo do tempo a inserir informação, em termos da quantidade de informação associada, como foi referido, foi cerca de 6 vezes maior no sistema narrativo que no sistema tradicional de tagging. Logo podemos concluir, que se o factor Tempo não tiver uma importância relativa superior à quantidade de informação associada, o sistema de narrativas demonstra ser uma solução bastante aceitável.
Analisando os problemas encontrados nos sistemas de tagging narrativo, polissemia, sinónimos e os níveis básicos da linguagem pudemos observar que nos sistemas que utilizam narrativas para associar informação às histórias não foram encontrados sinónimos e polissemia, ao contrário do que foi resultado da análise do sistema de tagging tradicional. Os níveis básicos não foi possível verificar uma vez que não existiu colaboração dos utilizadores para a métrica que foi desenvolvida para o efeito.
A categorização feita nos resultados recolhidos do sistema de tagging tradicional veio a revelar que os utilizadores acabam por inserir informação que lhe é única e que não tem significado para outros utilizadores que possam ter contacto com essas mesmas tags. A falta de estrutura das tags no sistema de tagging ajuda os utilizadores a dispersar do objectivo de associar informação relevante ao conteúdo. No caso do sistema de narrativas o utilizador acaba por estruturar o seu tagging definindo tags para elementos espicíficos da história e que possui o mesmo sentido para todos os utilizadores. As narrativas guiam o utilizador, estruturarando o processo de tagging de modo a que o utilizador insira informação importante e relevante. Embora numa primeira fase o utilizador não dê relevância, ficou provado no estudo feito que os elementos que preenche na história são os que são lembrados pelos utilizadores.
5.4 Conclusão dos resultados
Nesta secção pudemos ver e analisar os resultados obtidos da utilização do sistema por parte de 40 pessoas. Foram divididas em dois conjuntos, em que um inseria tags num sistema tradicional de tagging, enquanto o outro inseria no sistema apresentado e estudado neste trabalho, um sistema baseado em narrativas. Segundo um conjunto de métricas compostas pela quantidade de informação que os utilizadores inserem no sistema, pelo tempo que dispensam em cada fotografia para inserir informação relativa a esta e pelo tempo que necessitam para recuperar as fotografias. Foi ainda analisada a evolução das tags ao longo do tempo com um estudo sobre a reutilização de tags tanto a um nível individual como a um nível global.
O conjunto de fotografias que foram utilizadas na análise dos resultados é constituído por 1229 fotografias, sendo distribuídas em 52% para o sistema de histórias e os restantes 48% no sistema de tagging. Em seguida vamos apresentar as conclusões mais importantes retiradas da análise dos dois sistemas de tagging e da comparação entre eles.

74
Através dos resultados retirados da utilização do sistemas de narrativas podemos constatar que os utilizadores em média inseriram 7,96 tags por história, demorando em média 122,45 segundos a contar uma história.
Na análise feita às histórias contadas pelos utilizadores e quais os elementos que utilizam para compor as suas histórias, podemos retirar um número de elementos chave que os utilizadores optaram por mencionar em quase todas as suas histórias. Destes elementos destacam-se os elementos Autor, Dispositivo, Local, Qualidade e Dimensão que foram os elementos que mais ocorrências tiveram nas histórias. Comparando com o estudo feito inicialmente e apresentado no capítulo três, os resultados retirados do sistema foram consistentes com o estudo efectuado. Existiu apenas um elemento cujo resultado retirado do sistema não foi ao encontro do esperado, o Tempo. Sendo um dos elementos mais focados pelos utilizadores nas entrevistas e referido por mais de uma vez em alguma das histórias, não apresentou a mesma importância no sistema. Os utilizadores optaram por não incluir nas histórias o elemento Tempo como parte integrante e informação importante sobre o conteúdo da história.
Os problemas apresentados pelo sistema de tagging tradicional, no que diz respeito aos sinónimos e à polissemia, não são tão graves, uma vez que as narrativas são compostas por um conjunto de elementos aos quais os utilizadores associam as tags. Esses elementos permitem diminuir o âmbito em que se insere o significado da tag.
No sistema de tagging tradicional os utilizadores apresentaram uma média de 1,35 tags por fotografia, com uma média de 45,6 segundos para inserir tags nas fotografias. Podendo ser um valor elevado de tempo para inserir uma ou duas tags, como foi a média, poderá entender-se que os utilizadores utilizaram parte desse tempo para pensar em palavras que associam ao conteúdo e que puderam ajudá-los a recuperar a fotografia no futuro.
Da análise de resultados podemos concluir que com o sistema de narrativas os utilizadores inserem muito mais informação do que num sistema tradicional de tagging. Segundo os resultados, os utilizadores que utilizaram histórias para associar informação às fotografias em média inseriram aproximadamente 6vezes mais informação que os utilizadores do sistema de tagging tradicional. Podemos concluir também que esse aumento de 6 vezes de informação em relação ao sistema tradicional só “custa” ao utilizador o triplo do tempo.
As tags no sistema de histórias foram diferentes do que pudemos observar num sistema tradicional de tagging. No sistema de histórias os utilizadores optaram por completar o diálogo que lhe foi apresentado como desafio, inserindo tags compostas. Estes acabaram por inserir mais informação do que o normal (tags constituídas por uma única palavra) e acabam por melhorar a recuperação das fotografias, uma vez que a pesquisa é feita por palavra e não por uma expressão constituída por várias palavras.
Em termos de reutilização das tags, tendo em conta o número de elementos que foram inseridos pelos utilizadores nos dois sistemas e as tags distintas em cada um dos sistemas, podemos concluir que no sistema de narrativas, utilizando um sistema de sugestive-tagging em que era apresentado aos utilizadores sugestões do que já havia sido inserido no sistema para aquele elemento, levou a uma maior reutilização das tags. No caso do sistema de tagging tradicional o número de tags distintas corresponde a 64% das tags inseridas. As tags distintas no sistema de narrativas representam apenas 6% das tags que foram inseridas. Destes resultados pode-se concluir que o sistema de narrativas, com o sistema de sugestões e as opções pré-definidas apresentadas aos utilizadores, proporciona maiores mecanismos de reutilização de tags, com o sistema de narrativas a atingir os 94% contra os 36% do sistema de tagging tradicional.

75
Na análise à recuperação de fotografias nos dois sistemas, tendo em conta que um dos utilizadores teste do sistema de tagging não conseguiu encontrar a fotografia, não se consegue comparar médias de desempenho. Algo que foi notório, do ponto de vista do observador do comportamento dos utilizadores, é que os que utilizaram o sistema de narrativas sentiram-se menos hesitantes na altura de escrever as tags, sendo guiados através dos diálogos que iam surgindo ao longo do desenrolar da história.
Analisando os problemas característicos dos sistemas de tagging tradicional, foi possível observar que o sistema de tagging apresentou como esperado sinónimos e polissemia nas tags inseridas pelos utilizadores. Dos resultados retirados do sistema de narrativas foi possível observar que as tags não apresentam sinónimos e polissemia entre elas. A explicação é que como as tags são consideradas dentro de um contexto, o elemento a que corresponde na história, sendo a tag específica a esse elemento não apresenta ambiguidade e os problemas dos sinóminos e polissemia não se verificam.

76

77
6. Conclusão Nesta secção vamos apresentar as conclusões a que chegamos neste projecto, sobre uma nova abordagem a uma onda que surgiu na internet há alguns anos e que tem um papel importante para os utilizadores organizarem os seus conteúdos.
Como podemos observar a partir dos resultados retirados na secção anterior, os utilizadores do sistema de narrativas apresentam um aumento bastante significativo, seis vezes mais, na informação associada as suas fotografias pessoais quando comparada com o sistema tradicional do Flickr. Apesar dos utilizadores demorarem em média aproximadamente três vezes mais tempo no sistema de narrativas a completar todo o processo de associação, inseriram cada tag duas vezes mais rápido que o utilizador do sistema tradicional. Tal acontecimento poderá dever-se ao facto do utilizador se sentir guiado pelas histórias e identificar-se com os diálogos apresentados e que não dificuldade em completar.
Um dos principais objectivos seria o sistema de narrativas ajudar a minimizar ou resolver os problemas que os sistemas de tagging tradicional padecem. Através da análise dos resultados apresentados foi possível observar que o sistema de resultados apresentou sinónimos e polissemia nas tags inseridas pelos utilizadores indo ao encontro do esperado. No caso do sistema de narrativas não foi encontrado sinónimos e polissemia nas tags inseridas, uma vez que a tag encontrasse ligada a um elemento da história que lhe atribui o contexto que por vezes falta para perceber o significado das tags. Outro motivo será que a descrição das tags são bastante mais complexas no sistema de narrativas apresentando um outro nível de informação que não é apresentado nos sistemas de tagging tradicionais.
Analisando os resultados concluímos que a nova abordagem apresenta resultados bastante positivos e que demonstram que pode ser uma alternativa bastante fiável aos sistemas de tagging tradicional. A abordagem não tem um factor de construção e aplicação proibitiva para os sistemas existentes, podendo ser adaptada facilmente. A curva de aprendizagem do sistema de narrativas é bastante pequena, uma vez que o sistema é construído a pensar na maneira como as pessoas contam as suas histórias. Tudo estas vertentes acabam por validar esta abordagem como algo que poderá ascender a algo para lá de um protótipo.
Em termos de melhoramento poderá passar por se conseguir pré-preencher alguns dos elementos apresentados nas histórias. Os elementos como a “Qualidade”, “Dimensão” ou mesmo “Local”, poderão ser preenchidos com informação proveniente das máquinas fotográficas, que ao tirar a fotografia associam logo meta-informação aos ficheiros em que as fotos ficam alojadas. Existe ainda trabalhos cujo objectivo é analisar a fotografia e retirar elementos chave, como a presença de pessoas, podendo mesmo as identificar, ou ainda a presença de monumentos que também poderá ajudar a identificar o “Local” da fotografia. Logo através da análise da fotografia conseguimos preencher alguma informação automaticamente nas histórias poupando algum tempo no processo de contar a história da fotografia.
A aplicação da abordagem poderá fazer sentido em sistemas cujos utilizadores sejam essencialmente crianças, uma vez que este sistema se adapta bem às faculdades das crianças. Não tendo estas a capacidade cognitiva de associar um número de palavras soltas a um conteúdo, como terá uma pessoa adulta, o processo de tagging estruturado em narrativas

78
facilita a forma de pensar, facilitando assim o processo de tagging para pessoas mais jovens. Para tal será necessário adaptar o sistema de forma a tornar a interacção acessível a crianças.

79
Referências [1] Begelman, G., Keller, P., Smadja, F., Automated Tag Clustering: Improving search and exploration in the tag space, WWW2006, May 22–26, 2006, Edinburgh, UK.
[2] Brooks, C., Montanez, N., Improved Annotation of the Blogosphere via Autotagging and Hierarchical Clustering, WWW 2006, May 23–26, 2006, Edinburgh, Scotland.
[3] CiteUlike http://www.citeulike.org/
[4] Cognitive Tagging, http://www.rashmisinha.com/archives/05_09/tagging-cognitive.html
[5] Del.icio.us. http://del.icio.us/
[6] Flickr. http://www.flickr.com/
[7] Freeman, E., Gelender, D., Lifestreams: A Storage Model for Personal Data, SIGMOD Record, Vol. 25, No. 1, March 1996
[8] Furnas, G. W., Landauer, T. K., Gomez, L. M., and Dumais, S. T. The vocabulary problem in human-system communication. Commun. ACM 30, 11 (1987), 964-971.
[9] Golder, S., Huberman, B. A. The Structure of Collaborative Tagging Systems, HP Labs technical report,2005.
[10] Gonçalves, D., Jorge, J. Ubiquitous Access to Documents: Using Storytelling to Alleviate Cognitive Problems, Instituto Superior Técnico.
[11] Gonçalves, D., Jorge, J. “Tell me a Story” Issues on the Design of Document Retrieval Systems
[12] Gonçalves, D., Real Stories about Real Documents, Evaluating the Trustworthiness of Document-Describing Stories, March 11, 2005.
[13] Halpin, H., Robu, V, Shepherd, H., The Complex Dynamics of Collaborative Tagging. WWW 2007, May 8–12, 2007, Banff, Alberta, Canada. ACM 978-1-59593-654-7/07/0005.
[14] Hayman, S., Folksonomies and Tagging: New developments in social bookmarking. Ark Group Conference: Developing and Improving Classification Schemes, 27-29 June, 2007, Rydges World Square, Sydney
[15] Jones, W., Phuwanartnurak, A., Gill, R., Bruce, H. Don’t Take My Folders Away! Organizing Personal Information to Get Things Done, CHI 2005, April 2–7, 2005, Portland, Oregon, USA. ACM 1-59593-002-7/05/0004.
[16] Last.fm http://www.lastfm.pt/
[17] Malone, T. How Do People Organize Their Desks? Implications for the Design of Office Information Systems, ACM Transactions on Office Information Systems, Vol. 1, No. 1, January 1983.
[18] MANY2MANY, social consequences of social tagging, http://many.corante.com/archives/2005/01/20/social_consequences_of_social_tagging.php

80
[19] Marlow, C., Naaman, M., Boyd, D., Davis, M., HT06, Tagging Paper, Taxonomy, Flickr, Academic Article, To Read
[20] Mathes, A. Folksonomies - Cooperative Classification and Communication Through Shared Metadata, December 2004.
[21] Odeo, http://odeo.com
[22] Pirjo Näkki, Sari Vainikainen, Asta Bäck, Improved Recommendation based on Collaborative Tagging Behaviors, MindTrek’08, October 7-9, 2008, Tampere, Finland.
[23] Rattenbury, T., Good, N., Naaman, M., Towards Automatic Extraction of Event and Place Semantics from Flickr Tags, SIGIR’07, July 23–27, 2007, Amsterdam, The Netherlands. Copyright 2007 ACM 978-1-59593-597-7/07/0007
[24] Ritendra Datta, Dhiraj Joshi, Jia Li, and James Z. Wang, Tagging over Time: Real-world Image Annotation by Lightweight Meta-learning MM’07, September 23–28, 2007, Augsburg, Bavaria, Germany.
[25] Rekimoto, J., Time-Machine Computing: A Time-centric Approach for the Information Environment, Interaction Laboratory, Sony Computer Science Laboratories,Inc., 1999 ACM 1-58113-075-9/99/11
[26] Shiwan Zhao, Nan Du, Andreas Nauerz, Xiatian Zhang, Quan Yuan , Rongyao Fu, Improved Recommendation based on Collaborative Tagging Behaviors, IUI’08, January 13-16, 2008, Maspalomas, Gran Canaria, Spain.
[27] Sigurbjörnsson, B., van Zwol, R., Flickr Tag Recommendation based on Collective Knowledge , WWW 2008, April 21–25, 2008, Beijing, China. ACM 978-1-60558-085-2/08/04.
[28] Strohmaier, M., Purpose Tagging: Capturing User Intent to Assist Goal-Oriented Social Search, SSM’08, October 30, 2008, Napa Valley, California, USA.
[29] Tesconi, A., Ronzano, M., SemKey, F. : A Semantic Collaborative Tagging System, Marchetti, WWW2007, May 8–12, 2007, Banff, Canada.
[30] Use it, http://www.useit.com/ (Jakob Nielsen's Website)
[31] Whittaker, S. and Sidner, C. (1996). Email Overload: Exploring Personal Information Management of email. Proceedings on Human Factors in Computing Systems, pp 276-283, ACM Press.
[32] Wikipédia, http://en.wikipedia.org/wiki/Hidden_Markov_model
[33] Xu, Z., Fu, Y., Mao, J., Su, D., Towards the Semantic Web: Collaborative Tag Suggestions, Yahoo! Inc.

81
A1 Guia de Entrevista
Foto 1 Foto 2 Foto 3 Elementos Exemplo de perguntas
Autor o “Lembras-te de quem tirou a
fotografia?”
Local o “Recordas-te onde foi tirada a
fotografia?”
Tempo o “E em que altura/data é que
foi tirada?”
Propósito o “Porque foi tirada a
fotografia?”
Tipo de fotografia o “A fotografia é um retrato de
alguém? Uma paisagem?”
Dimensão o “E o tamanho da fotografia?”
Evento
o “Ocorreu em algum evento especial? Um casamento? Uma viagem?”
Dispositivo o “Com aparelho foi tirada a
fotografia?”
Descrição o “Quer dar uma descrição da fotografia?”
Pessoas o “Quem é que está presente na fotografia? Família? Amigos?”
Paisagens o “Tentaste apanhar alguma
paisagem ao tirar a fotografia? O mar? Uma montanha?”
Monumentos
o “Estava perto de algum monumento?”
o “Na fotografia quiseste apanhar algum monumento?”
Qualidade o “E a qualidade com que foi tirada a fotografia?”

82
A2 Transcrições das Entrevistas
Entrevista 1
[Entrevistador]Boa noite! Peço-te que escolhas três fotos tuas e contes a história de cada uma dessas fotos.
*** FOTOGRAFIA 1 ***
[Entrevistado]Esta primeira foto foi tirada em [Abril deste ano]tempo, no [casamento da minha prima]evento … mais velha. [Na foto estou eu, a minha irmã e a minha avó]pessoas … ah, [estou um pouco mais bem vestido do que é normal, camisinha, casaco, calças bege]descrição. Esta foto foi tirada já em [Loures]local no copo de água… [à tarde]tempo. Estava lá bastante gente, foi no [casamento dos primos aqui do lado paterno, foi o casamento do primeiro deles]evento, a mais velha, tem 35 anos.
[Entrevistador]Lembras-te de quem tirou a foto?
[Entrevistado]Foi tirada pelo [meu pai ou pela minha mãe]autor que eram as pessoas que estavam lá comigo.
[Entrevistador] O que utilizaram para tirar a foto?
[Entrevistado] Uma [máquina digital]dispositivo com [4 mega pixéis]qualidade.
**** FOTOGRAFIA 2 ****
[Entrevistado]Falando agora da segunda, esta foto foi tirada [quando estava a fazer Erasmus]evento, em [Estocolmo na Suécia]local. Foi tirada no [dia em que Portugal jogou contra a Holanda no mundial de 2006]evento. Estou [eu e mais 2 colegas meus]pessoas, também portugueses, [equipados a rigor, com t-shirts de Portugal a dizer “Até os comemos!”]descrição, estávamos a ver o jogo [numa esplanada, num sítio em Estocolmo]local que tinha um ecrã gigante para as pessoas verem o jogo. Estava bastante gente a assistir ao jogo, sobretudo suecos como é evidente. Curiosamente a [embaixada holandesa era perto deste local]local. Também vimos alguns holandeses no fim do jogo, e durante. Pelo nosso ar na foto, isto seguramente estava numa parte interessante do jogo, pois [estávamos todos bastante atentos, que nem demos pela foto ser tirada, e com um ar bastante preocupado]descrição. Foi tirada por [colegas nossos, ou um colega nosso suíço, ou uma colega nossa espanhola]autor,pessoas que estavam lá também a ver o jogo connosco, e foi tirado já para [fins de Junho de 2006]tempo.
[Entrevistador] Que dispositivo utilizaram para tirar a foto?
[Entrevistado] Uma [máquina digital]dispositivo... a qualidade é [relativamente boa]qualidade.
**** FOTOGRAFIA 3 ****
[Entrevistado]Quanto a terceira foto, foi tirada também durante o [período de erasmus em Estocolmo]evento, mas uma [visita que eu fiz a Rússia]evento [nos finais de Abril de 2006]tempo. Na foto estou [na praça vermelha… em Moscovo]local, com um colega meu suíço e uma colega minha alemã]pessoas. [Foi tirada bastante cedo, pois chegamos a Moscovo perto… entre as 7 e as 8 da manha]tempo. Viajamos durante a noite, a viagem cerca de 12 horas de São Petersburgo para Moscovo de camioneta. Nesta altura a praça ainda estava fechada, mais tarde tivemos a oportunidade de andar na praça e inclusive visitar o [Kremlin]monumentos. Nesta foto não se vê, mas também tínhamos acabado de passar por uma basílica muito conhecida, que há aqui, a [Saint Basil’s]monumentos que tem umas

83
cúpulas. Não só as cúpulas mas toda ela tem umas cores muito vivas, que até fazem lembrar um pouco uma basílica de brincar. Estava fresquinho, apesar de já ser [fins de Abril]tempo, não dispensamos os nossos casacos de inverno bem quentes. Ah… mas apesar de estar fresco, o tempo estava bom e tivemos sorte nisso, pois o céu até estava limpo. Isto a foto também foi tirada por uma [colega nossa espanhola que fez a viagem connosco]autor, usou uma [máquina digital]dispositivo e a qualidade é [boa]qualidade.
Entrevista 2
[Entrevistador] Boa noite! Peço-te que escolhas três fotos tuas e contes a história de cada uma dessas fotos.
*** FOTOGRAFIA 1 ***
[Entrevistado] Esta foto, foi tirada quando [fui passar [uma semana no verão]tempo em Itália]evento. Foi no [último dia da viagem, na manhã]tempo antes de ir para o aeroporto. Foi em [Milão]local, e é uma fotografia da [parte de dentro do [estádio de San Siro]local]descrição, que [na altura estavam a mudar o relvado]descrição e nós [fomos lá visitar o estádio]propósito. E esta foi [uma das fotografias que tirei]autor. Fui com mais [um amigo meu português, e mais dois amigos meus italianos]pessoas.
[Entrevistador] Foste tu que tiraste a fotografia?
[Entrevistado] Sim, fui eu que tirei a fotografia [das bancadas de San Siro]descrição.
[Entrevistador] Foi durante a viagem a Itália… Quando é que decorreu essa viagem?
[Entrevistado] Esta viagem decorreu [no verão, acho que na segunda semana de Agosto no verão de 2003… acho eu… há 4 anos]tempo.
[Entrevistador] Com que dispositivo a tiraste? Foi uma máquina fotográfica? Um telemóvel?
[Entrevistado] Foi uma [máquina digital da Canon]dispositivo.
[Entrevistador] E a qualidade da fotografia?
[Entrevistado] A fotografia foi tirada com a [qualidade máxima da câmara que é 2 mega pixéis]qualidade.
*** FOTOGRAFIA 2 ***
[Entrevistado] Esta fotografia foi tirada [a 3 anos, creio eu… no fim da primavera, provavelmente em Maio, talvez em Junho]tempo, quando estive [na praia]local com [os meus colegas do técnico]pessoas. Fomos lá [passar um dia a praia]evento, fomos de manha e tivemos lá até a tarde, antes de ter uma aula acho eu. Saímos quando tínhamos uma aula a tarde e voltamos para o técnico. E aqui uma fotografia quando [estávamos a jogar à bola na areia]descrição, quando [estávamos na praia]local.
[Entrevistador] Lembraste de quem tirou a fotografia?
[Entrevistado] Creio que quem tirou a foto, foi um colega nosso chamado [Fitas]autor.
[Entrevistador] E que tipo de fotografia pensa que pretenderam tirar? Foi só as pessoas a jogar a bola? Ou também quiseram apanhar a paisagem…
[Entrevistado] Penso que quis apanhar as duas coisas, tirar não só às pessoas, [os meus colegas e os meus amigos]pessoas, estamos aqui [na praia]local, mas também [o cenário envolvente]paisagem… ficou um [retrato engraçado]tipo.
[Entrevistador] Utilizaste que dispositivo para tirar a foto?
[Entrevistado] Utilizamos uma… acho que foi uma câmara de telemóvel. Foi tirada com um [telemóvel]dispositivo.
[Entrevistador] E a qualidade da fotografia?

84
[Entrevistado] [A qualidade não é tão elevada como tivesse sido tirada por uma câmara digital, mesmo assim para um telemóvel a qualidade é bastante aceitável]qualidade.
*** FOTOGRAFIA 3 ***
[Entrevistado] Esta fotografia foi tirada na [[passagem de ano]evento… de 2003 para 2004]tempo . Foi tirada [em casa de uma amiga de uns amigos meus]local, que resolvemos fazer a [passagem de ano]evento juntos. [E é uma fotografia de [parte do nosso grupo e dois amigos do grupo deles]pessoas que estavam nesta casa]descrição. Nós estávamos noutra casa e fomos fazer a passagem de ano [para casa… desta amiga nossa]local. E esta é [uma fotografia que foi tirada antes da meia-noite, depois de jantar]tempo, [com metade do grupo que lá estava]pessoas.
[Entrevistador] Lembraste de quem tirou a fotografia?
[Entrevistado] [Não me lembro de quem tirou a fotografia… possivelmente foi um amigo meu chamado Gustavo, mas não tenho a certeza de quem a tirou ]autor.
[Entrevistador] E onde se situava a casa onde estavam? Lembraste?
[Entrevistado] [Isto foi numa aldeia no Algarve, não me lembro bem do nome, mas acho que foi ao pé de Lagos, perto de Lagos]local.
[Entrevistador] E o dispositivo utilizado para tirar a fotografia?
[Entrevistado] Foi tirada com uma [máquina digital, não tenho a certeza que máquina foi, mas creio que era uma Fuji ou uma Sony… Foi uma Sony de [3 ou 4 mega pixéis de qualidade]dispositivo. [Tem muito boa qualidade]qualidade a fotografia que foi tirada com o máximo permitido pela máquina.
Nota:
A análise a todas as 20 entrevistas pode ser encontrada no link:
http://web.ist.utl.pt/~ist152386/tese/A2_Entrevistas.pdf

85
A3 Avaliação Heurística Heuristicas Descrição Correcção Severidade H2-5 Campos de nome no registo
não indica qual é o apelido e qual é o nome próprio.
Apresentar apenas um espaço para o nome todo e trocar o nome do campo para Full Name
2
H2-4, H2-5 Após o registo com sucesso o utilizador não fica automaticamente logado no sistema.
Ficar automaticamente logado.
2
H2-1 Please wait não dá feedback suficiente.
Dar feedback através de uma barra de informação ou com mais informação
2
H2-5 Não existe informação dos tamanhos e formatos permitidos
Pôr a informação 2
H2-2, H2-7 O ‘+’ no upload de mais fotos não é muito perceptivel.
Ao inserir uma fotografia, inserir outro campo automaticamente
2
H2-6 A lupa para ver a foto não se vê bem.
Tornar a lupa maior 1
H2-1 Não existe indicação de onde se está depois de se fazer o upload da fotografia.
Indicar onde no sistema se encontra o utilizador
2
H2-2 “Photos without info” não é explicito.
Tornar mais claro o que é e para que serve.
2
H2-5 “Can’t Remember” não funciona
Pôr a funcionar 4
H2-5, H2-2 Acentos e caracteres especiais aparecem mal
Deverá aparecer bem 3
H2-5, H2-2 Passar à frente quando não se quer responder a um elemento não é intuitivo
Tornar mais explicito 2
H2-5 Ao editar um elemento e voltar para outro não apagar automaticamente
Não apagar o que já tinha sido preenchido.
3
H2-2, H2-5 Processo de editar a história algo complicado.
Tornar o processo mais intuitivo.
3
H2-2 A caixa de elementos não é intuitiva
Pôr um titúlo a identificar 2
H2-2 Titulo na secção do search está errado
Pôr o correcto 2
H2-5 Finish no search não é importante e pode conduzir a erros
Retirar o botão 3

86
H2-4 O utilizador na maioria das secção não pode voltar para o estado anterior.
Permitir tal acção ao utilizador
3
H2-5 Ao apagar uma foto não é dado ao utilizador uma hipotese de confirmar a acção
Permitir ao utilizador não continuar.
2
H2-2 Titulo da secção ao ver as fotos de outros membros está incorrecto
Identificar correctamente 2
H2-4 O logo do sistema não tem link para a home.
Adicionar um link. 2
H2-2 Current passord com erro. Escrever bem. 1
H2-2 O sistema aceita um email incorrecto
Preparar o sistema para só aceitar emails correctos
3
H2-2 Não foi possivel editar o elemento.
Resolver erro. 4
H2-4 Registar estár ao pé do login. Pôr um link a seguir do “Forget your password”
2
H2-2 Feedback do registo com sucesso não salta à vista
Apresentar uma mensagem mais explicita.
2
H2-4 No menu apesar de mudar a côr não muda o cursor.
Aparecer a mão para ser mais explicito.
1

87
A4 Interface dos Diálogos
Legenda:
P – Pergunta
N – Resposta
RN – Resposta Negativa
Autor P : O autor desta fotografia foi [o autor] R : O autor desta fotografia foi [%s] RN : Esta fotografia [não foi tirada por ninguém].
Descrição P : A fotografia pode ser descrita como [descrição] R : A fotografia pode ser descrita como [descrição] RN : [Não tem nenhuma descrição a fotografia]
Dimensão P : É de [dimensão] dimensão R : É de [dimensão] dimensão RN : Não sei a dimensão
Dispositivo P : O dispositivo utilizado foi um(a) [dispositivo] R : O dispositivo utilizado foi um(a) [dispositivo] RN : [Não utilizei nenhum dispositivo]
Local P : A fotografia foi tirada em [local] R : A fotografia foi tirada em [%s] RN : Foi tirada em [nenhum local]
Qualidade P : A qualidade é [qualidade] R : A qualidade é [%s] RN : [Não tem uma qualidade específica]
Pessoas P : As pessoas, [pessoas] encontravam-se presentes R : As pessoas, [%s] encontravam-se presentes RN : [Não estava ninguém presente]
Tempo P : Foi tirada por volta de [tempo] R : Foi tirada por volta de [%s] RN : [Foi tirada em nenhum tempo especifico]
Tipo P : A fotografia representa um(a) [tipo] R : A fotografia representa um(a) [%s] RN : [Não tem um tipo específico]
Evento P : Foi tirada durante [evento] R : Foi tirada durante [%s] RN : [A fotografia não tirada durante nenhum evento especifico].

88
Propósito P : A fotografia foi tirada porque [propósito] R : A fotografia foi tirada porque [%s] RN : [Não foi tirada por nenhuma razão particular]