
SQL-Based ETL with Apache Spark on Amazon EKS
51
SQL-Based ETL with Apache Spark on Amazon EKS Implementation Guide
-
Upload
khangminh22 -
Category
Documents
-
view
0 -
download
0
Transcript of SQL-Based ETL with Apache Spark on Amazon EKS

SQL-Based ETL with ApacheSpark on Amazon EKS
Implementation Guide

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
SQL-Based ETL with Apache Spark on Amazon EKS: ImplementationGuideCopyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved.
Amazon's trademarks and trade dress may not be used in connection with any product or service that is notAmazon's, in any manner that is likely to cause confusion among customers, or in any manner that disparages ordiscredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who mayor may not be affiliated with, connected to, or sponsored by Amazon.

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Table of ContentsWelcome .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1Cost ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
Additional cost factors ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5Amazon CloudFront distribution .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5Amazon S3 requests ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
Architecture overview .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6Solution components .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
Amazon Elastic Kubernetes Service .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7Arc data framework .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8Web tools ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
Arc Jupyter ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9Argo Workflows .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
CI/CD pipelines .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10Docker deployment pipeline .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10ETL deployment pipeline .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
Amazon Elastic Container Registry .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10Amazon S3 buckets ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11Sample jobs and datasets ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
Security ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13IAM roles .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13AWS Secrets Manager .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13Amazon CloudFront .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13Security groups .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
Design considerations .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15Change default timeout settings .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15Removing sample resources and optional AWS services .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
AWS CloudFormation template .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18Automated deployment .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
Prerequisites ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19Deployment overview .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19Launch the stack .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20Validate the solution .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
Configure local environment .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22Test the scd2 job in Arc Jupyter ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22(Optional) Develop jobs in local environment .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24Run the quick start job for Argo Workflows .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24Schedule the scd2 job using the Argo CLI ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26Schedule a native Spark job using the Kubernetes Operator for Apache Spark .... . . . . . . . . . . . . . . . . . . . . . . 28
Additional resources .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30Troubleshooting .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31Reference commands .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32Optional tasks for your end-users ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
Self-recovery test ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33Review Spot Instance usage and cost savings .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34Auto scale Spark application with dynamic resource allocation .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
Extending the solution .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37Amazon EMR on Amazon EKS .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37Data Mesh .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
Uninstall the solution .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41Running the uninstallation script ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41Deleting the remaining resources using the AWS Management Console .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41Deleting the Amazon S3 bucket .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
Collection of operational metrics ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43Source code .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
iii

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Revisions .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45Contributors ... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46Notices .... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
iv

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Create meaningful insights usingcodeless ETL capabilities andworkflow orchestration automation
Publication date: July 2021
The SQL-Based ETL with Apache Spark on Amazon EKS solution provides declarative data processingsupport, codeless extract-transform-load (ETL) capabilities, and workflow orchestration automation tohelp your business users (such as analysts and data scientists) access their data and create meaningfulinsights without the need for manual IT processes.
This solution abstracts common ETL activities, including formatting, partitioning, and transformingdatasets, into configurable and productive data processes. This abstraction results in actionable insightsthat is derived more quickly to help you accelerate your data-driven business decisions. Additionally, thissolution uses an open-source Arc data processing framework, run by Amazon Elastic Kubernetes Service(Amazon EKS) and powered by Apache Spark and container technologies, to simplify Spark applicationdevelopment and deployment.
This solution uses GitHub as the source repository to track ETL asset changes, such as Jupyter notebookfile and SQL script updates, allowing for application version control and standardized continuousintegration and continuous delivery (CI/CD) deployments. This solution unifies analytical workloadsand IT operations using standardized and automated processes, providing a simplified ETL deploymentmanagement capability for your organization’s DevOps team. These automated processes help you avoidunintentional human mistakes caused by manual, repetitive tasks.
This solution offers the following features:
• Built, test, and debug ETL jobs in Jupyter: Uses a web-based JupyterHub as an interactive integrateddevelopment environment (IDE). It contains a custom Arc kernel to simplify your ETL applicationdevelopment by allowing you to define each ETL task or stage in separate blocks. The output of eachblock displays data results and a task log. This log captures real-time data processing status andexception messages that can be used if debugging is needed.
• Codeless job orchestration: Schedules jobs and manages complex job dependencies without theneed to code. Argo workflows declaratively defines job implementation target state, orders, andrelationships. It provides a user-friendly graphical dashboard to help you track workflow status andresource usage patterns. The job orchestrator in this solution is a switchable plug-in and can bereplaced by another tool of your choice, for example Apache Airflow or Volcano.
• Docker image auto-deployment: Sets up an AWS continuous improvement and continuousdevelopment (CI/CD) pipeline to securely store the Arc Docker image in Amazon Elastic ContainerRegistry (Amazon ECR).
• ETL CI/CD deployment: Builds a file synchronization process. In this solution, the automated ETLdeployment process integrates the Jupyter IDE with the solution’s GitHub repository to detect sampleETL jobs’ changes. As a one-off setup with your choice of CI/CD tool, a GitHub change activatesa file sync-up process between your Git repository and the artifact S3 bucket. As a result, ArgoWorkflows can refer to the Amazon S3 file assets, such as a Jupyter notebook (job specification file)and automatically orchestrate ETL jobs either on-demand or based on a time or an event.
• SQL-first approach: Uses Spark SQL to implement business logic and data quality checks in ETLpipeline development. You can process and manipulate data in Spark using your existing SQLexpertise.
1

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
This implementation guide describes architectural considerations and configuration steps for deployingSQL-Based ETL with Apache Spark on Amazon EKS in the Amazon Web Services (AWS) Cloud. It includeslinks to an AWS CloudFormation template that launches and configures the AWS services required todeploy this solution using AWS best practices for security and availability.
The guide is intended for IT architects, developers, DevOps, data analysts, data scientists, and any SQLauthors in an organization who have practical experience in the AWS Cloud.
2

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
CostYou are responsible for the cost of the AWS services used while running this solution. As of July 2021,the estimated infrastructure cost to run a two-node Amazon EKS cluster in the US East (N. Virginia) isapproximately $0.63 per hour. Refer to Table 1 for the infrastructure cost breakdown.
Table 1: Infrastructure costs (hourly)
AWS service Dimensions Cost per hour
Amazon EKS cluster (nocompute)
$0.10 per hour per Kubernetescluster
X 1 cluster
$0.1000
Amazon EC2 (On-Demand) m5.xlarge X 1 instance per hour $0.1920
Amazon EC2 (Spot Instances) r4.xlarge X 1 instance per hour
NoteAdditional instancefleet options includer5.xlarge and 5a.xlarge.Amazon EC2 SpotInstance pricing variesbased on the timeperiod your instancesare running. For moreinformation on SpotInstances pricing, referto the Amazon EC2Spot Instances Pricingpage.
$0.0744*
$0.0225 Application LoadBalancer per hour
X 1 hour X 2 load balancers.
$0.0450Elastic Load Balancing
$0.008 per used Applicationload balancer capacity unit perhour (or partial hour) X 1 hour X2 load balancers
$0.0160
$0.045 per NAT Gateway hour $0.0450VPC NAT Gateway
$0.045 per GB Data Processedby NAT Gateways X 1GB perhour
$0.0450
VPC Endpoint Endpoints for Amazon S3,Amazon Athena, AmazonECR, AWS KMS, and AmazonCloudWatch
$0.1000
3

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
AWS service Dimensions Cost per hour
$0.01 per VPC endpoint perAvailability Zone (AZ) X 5endpoints X 2 AZs per hour
$0.01 per GB data processed X 1GB per hour
$0.0100
Total per hour: $0.6274
Additional costs
Amazon S3 (storage) $0.0230 per GB for First 50 TB/month
X 0.8 GB
$0.0184
AWS CodeBuild Free for 100 build minutes ofbuild.general1.small per month
$0.005 per build minute ofgeneral1.small X 2 minutes
$0.0000
AWS CodePipeline Free for the first 30 days aftercreation
$1.00 per active pipeline/month
$0.0000
Total additional costs: $0.0184
If you test the solution using the sample ETL jobs provided, additional costs apply.
• There is no additional cost for running the sample Arc ETL jobs since it is covered by the cost for thetwo-node Amazon EKS cluster listed in Table 1. The Amazon EKS cluster is configured with node-levelauto-scaling. If you run more than two nodes, charges may apply.
• If you run the native wordcount.py PySpark job, it expands the EKS cluster to a larger computeenvironment, which costs approximately $0.15 per run. Refer to Table 2 for the cost breakdown forrunning this sample Spark job.
Table 2: Costs per run for the wordcount PySpark job
AWS service Dimensions Total cost
$0.30 per metric per month X 8metrics X 1 hour
$0.0030Amazon CloudWatch
First 5 GB per month of log dataingested is free X 1 GB
$0.0030
Amazon EC2 (Spot Instances) r4.xlarge ($0.0744/hour) X 6instances X 20 mins
NoteAdditional instancefleet options includer5.xlarge and 5a.xlarge.
$0.1488
4

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Additional cost factors
AWS service Dimensions Total cost
Amazon EKS node-levelauto-scaling charges arecovered in this cost.
Total per run: $0.1518
Additional cost factorsAmazon CloudFront distributionThis solution automatically deploys an Amazon CloudFront distribution to configure a web applicationwith HTTPS. You are responsible for the incurred variable charges from the CloudFront service. However,this service can be removed if you decide to create an SSL/TLS certificate with your own domain. Table 3provides a cost estimate if you use the CloudFront distribution.
Table 3: Amazon CloudFront costs
AWS service Dimensions Total cost
$0.0100 per 10,000 ProxyHTTPS requests
X 70 requests X 2 Web tools
$0.0002
$0.08 per GB for data transfersout Origin X 0.002 GB
$0.0001
Amazon CloudFront
$0.114 per GB for the first 10TB / month data transfer out X0.015 GB
$0.0017
Amazon S3 requestsThe infrastructure cost estimate does not account for Amazon S3 PUT and GET requests, which can varyper scenario. For example, requests by this solution may include the number of data reads by ETL jobs,the number of writes from the VPC log, or an Amazon Athena query result.
We recommend creating a budget through AWS Cost Explorer to help manage costs. Prices are subjectto change. For full details, refer to the pricing web page for each AWS service you will be using in thissolution.
5

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Architecture overviewDeploying this solution with the default parameters builds the following environment in the AWS Cloud.
Figure 1: SQL-based ETL with Apache Spark on Amazon EKS architecture
The AWS CloudFormation template deploys a secure, fault-tolerant, auto-scaling environment to supportyour ETL workloads containing the following components:
1. The user interacts with ETL development and orchestration using Amazon CloudFront and ApplicationLoad Balancer, which secure the connections between the client and the solution’s tools.
2. ETL jobs process batch or stream data via Amazon Virtual Private Cloud (Amazon VPC) endpoints. Thetraffic between ETL processes and data stores does not leave the Amazon network.
3. JupyterHub integrates with the solution’s GitHub repository to track ETL asset changes. The ETLassets include Jupyter notebook (ETL Job specification file) and SQL scripts.
4. The solution deploys sample ETL assets and the Docker build asset from the GitHub repository tothe solution’s artifact Amazon Simple Storage Service (Amazon S3) bucket. The file synchronizationprocess can be done via a CI/CD automated deployment process or manually.
5. The Docker build asset arrives in the solution’s Amazon S3 bucket that activates an AWS CI/CDpipeline, including AWS CodeBuild and AWS CodePipeline, to automatically push the Arc Docker imageto Amazon Elastic Container Registry (Amazon ECR).
6. Argo Workflows initiates on-demand, time-based, or event-based ETL jobs. These jobs automaticallypull the Arc Docker image from Amazon ECR, download ETL assets from the Amazon S3 bucket, andsend application logs to Amazon CloudWatch. These AWS services are activated with VPC endpoints sothat no data traffic leaves the Amazon network.
7. JupyterHub automatically retrieves login credentials from AWS Secrets Manager to validate sign inrequests from users.
6

SQL-Based ETL with Apache Spark onAmazon EKS Implementation GuideAmazon Elastic Kubernetes Service
Solution componentsThis solution contains four distinct design layers providing the following functionalities:
Figure 2: Solution components
1. A customizable and flexible workflow management layer (refer to the Orchestration on Amazon EKSgroup in Figure 2) includes the Argo Workflows plug-in. This plug-in provides a web-based tool toorchestrate your ETL jobs without the need to write code. Optionally, you can use other workflowtools such as Volcano and Apache Airflow.
2. A secure data processing workspace is configured to unify data workloads in the same Amazon EKScluster. This workspace contains a second web-based tool, JupyterHub, for interactive job builds andtesting. You can either develop Jupyter notebook using a declarative approach to specify ETL tasksor programmatically write your ETL steps using PySpark. This workspace also provides Spark jobautomations that are managed by the Argo Workflows tool.
3. A set of security functions are deployed in the solution. Amazon ECR maintains and secures a dataprocessing framework Docker image. The AWS Identity and Access Management (IAM) roles for serviceaccounts (IRSA) feature on Amazon EKS provides token authorization with fine-grained access controlto other AWS services. For example, Amazon EKS integration with Amazon Athena is password-less tomitigate the risk of exposing AWS credentials in a connection string. Jupyter fetches login credentialsfrom AWS Secrets Manager into Amazon EKS on-the-fly. Amazon CloudWatch monitors applicationson Amazon EKS using the activated CloudWatch Container Insights feature.
4. The analytical workloads on the Amazon EKS cluster outputs data results to an Amazon S3 data lake.A data schema entry (metadata) is created in an AWS AWS Glue Data Catalog via Amazon Athena.
Amazon Elastic Kubernetes ServiceThis solution deploys an Amazon EKS cluster that unifies the workflow management process and theSpark ETL automation into a single pane of glass. These processes and automations are implementedin a consistent declarative manner. The builder defines the desired target state without the need to
7
SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Arc data framework
describe the control flow, which is determined by the underlying Spark SQL engine. This unified designsimplifies the management of your infrastructure and the architecture for your data lake.
After deployment and before first use, the Amazon EKS cluster has two pre-launched nodes withthe Cluster Autoscaler activated, which includes an On-Demand and a Spot EC2 instances. Reviewthe Amazon EKS cluster specification in the GitHub repository, which is customizable to meet yourdeployment needs. Additionally, Amazon CloudWatch Container Insights is installed in the Amazon EKScluster to collect, aggregate, and summarize metrics and logs. You can diagnose ETL applications byexamining the /aws/containerinsights/spark-on-eks/application log groups.
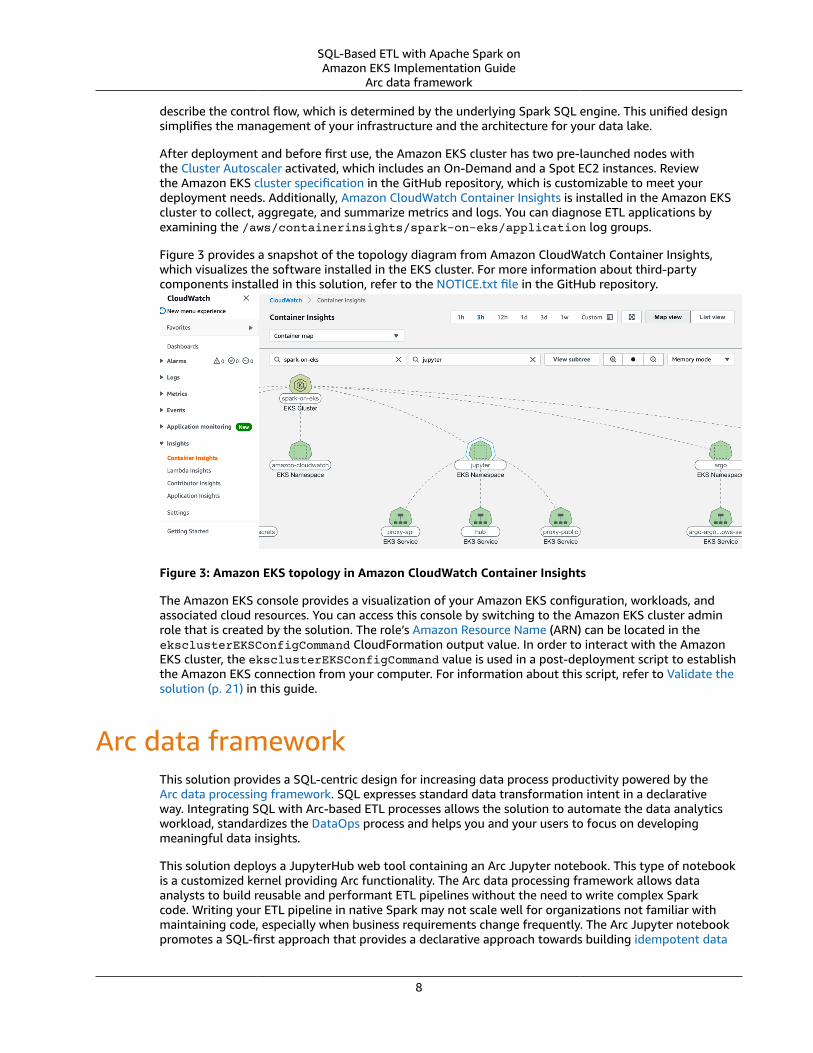
Figure 3 provides a snapshot of the topology diagram from Amazon CloudWatch Container Insights,which visualizes the software installed in the EKS cluster. For more information about third-partycomponents installed in this solution, refer to the NOTICE.txt file in the GitHub repository.
Figure 3: Amazon EKS topology in Amazon CloudWatch Container Insights
The Amazon EKS console provides a visualization of your Amazon EKS configuration, workloads, andassociated cloud resources. You can access this console by switching to the Amazon EKS cluster adminrole that is created by the solution. The role’s Amazon Resource Name (ARN) can be located in theeksclusterEKSConfigCommand CloudFormation output value. In order to interact with the AmazonEKS cluster, the eksclusterEKSConfigCommand value is used in a post-deployment script to establishthe Amazon EKS connection from your computer. For information about this script, refer to Validate thesolution (p. 21) in this guide.
Arc data frameworkThis solution provides a SQL-centric design for increasing data process productivity powered by theArc data processing framework. SQL expresses standard data transformation intent in a declarativeway. Integrating SQL with Arc-based ETL processes allows the solution to automate the data analyticsworkload, standardizes the DataOps process and helps you and your users to focus on developingmeaningful data insights.
This solution deploys a JupyterHub web tool containing an Arc Jupyter notebook. This type of notebookis a customized kernel providing Arc functionality. The Arc data processing framework allows dataanalysts to build reusable and performant ETL pipelines without the need to write complex Sparkcode. Writing your ETL pipeline in native Spark may not scale well for organizations not familiar withmaintaining code, especially when business requirements change frequently. The Arc Jupyter notebookpromotes a SQL-first approach that provides a declarative approach towards building idempotent data
8

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Web tools
pipelines. SQL-driven architectures can be scaled and embedded within your continuous integration andcontinuous delivery (CI/CD) process.
Web toolsThis solution installs two open-source web-based tools on Amazon EKS: Arc Jupyter and Argo Workflowsto automate Spark ETL build and deployment. Arc Jupyter is a custom kernel for JupyterHub thatprovides the Arc data processing functionality.
ImportantBy default, both web tools are configured to time out within 30 minutes for demonstrationpurposes. When you are ready to use these applications with your own datasets, we highlyrecommend you customize these security settings to meet your business requirement. Youcan edit their yaml specification files and adjust the corresponding settings in source/app_resources/jupyter-values.yaml and source/app_resources/argo-values.yaml. Then follow the Customization instruction to generate your CloudFormationstack.
These web-based tools use private IP addresses from Amazon EKS and Application Load Balancers(ALB) as the single point of contact. Two ALBs forward incoming traffics to these private IP addressesrespectively.
Amazon CloudFront uses TLS certificates to encrypt the communication between clients and these webtools. CloudFront serves the HTTPS requests with its default domain name and is placed in front of eachApplication Load Balancer to improve the solution’s network security posture.
NoteAmazon CloudFront is an optional component in this solution. We recommend that yougenerate a TLS certificate containing your own domain, then activate the HTTPS connectionsin these two Application Load Balancers, You can remove CloudFront from the solution bycommenting out or deleting the nested stack lines of code in the source/app.py script.
Arc JupyterThe JupyterHub web tool deploys Arc Jupyter, a custom notebook kernel that helps you interactivelycreate and test Arc ETL data pipelines. This solution provides sample jobs on Arc JupyterHub to help youtest this capability.
ETL assets created for the analytics workload, such as Jupyter notebooks (ETL job specification files) andSQL scripts, must be saved in the solution’s GitHub repository. Additionally, version control for thesenotebooks and the rest of assets must be maintained in the GitHub repository. This repository mustbe your central resource for your ETL development and deployment. However, you have the option tochange the source location from GitHub to your own git-based repository URL by editing the source/app_resources/jupyter-values.yaml file, specifically, the lifecycleHooks section.
ImportantBy default, the JupyterHub web tool is configured to automatically log you out if you are idle for30 minutes. This setting is adjustable. Refer to the previous Note.You must manually save your work to the GitHub repository. Otherwise, if a time out occurs oryou are otherwise logged off JupyterHub, you will lose your unsaved work.
Argo WorkflowsArgo Workflows is a web-based container-native workflow management tool to orchestrate Spark ETLjobs on Amazon EKS. This tool is implemented as a Kubernetes custom resources definition (CRD) inthis solution, allowing you to use declarative language to orchestrate your Spark data workload. This
9

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
CI/CD pipelines
workflow uses a directed acyclic graph (DAG) to show two types of activities: a sequence of tasks andrecords of the dependencies between tasks.
ImportantYour Argo authentication token is refreshed every 15 minutes. If you are logged out of the webapplication, you can regenerate your token and log in using the new token.
CI/CD pipelinesDocker deployment pipelineThis solution deploys continuous integration and continuous delivery (CI/CD) services that use AWSCodeBuild and AWS CodePipeline to automatically push an Arc Docker image to Amazon ECR. The CI/CDpipeline is initiated by an Amazon S3 event when the source code is uploaded to the solution’s default S3bucket.
ETL deployment pipelineTo promote CI/CD, this solution uses the JupyterHub tool as the integrated development environment(IDE). The JupyterHub is configured to synchronize with the latest source code from this solution’sGitHub repository. You can enforce the CI/CD standard by tracking notebook changes and versioning inthe code repository, deploying the data pipeline with minimum manual effort. As shown in the Figure 4,JupyterHub provides the capability to commit notebook changes, and pushes the changes back to thesolution’s Git repository.
Figure 4: Git repository integration in JupyterHub
Amazon Elastic Container RegistryAmazon Elastic Container Registry (Amazon ECR) maintains and secures the Arc framework Dockerimage in your AWS environment. By leveraging AWS CI/CD services, this solution downloadsa public image from the GitHub’s container registry with a specific version. For example,arc_3.10.0_spark_3.0.3_scala_2.12_hadoop_3.2.0 indicates the supported Arc, Spark, Scala, and Hadoopversions. To identify the Arc you are deploying, refer to the NOTICE.txt file in the GitHub repository. The
10

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Amazon S3 buckets
automated ECR build pipeline directly pushes a copy of the Arc image to your Amazon ECR private store.No changes are made to the original public Docker image.
Amazon S3 bucketsThis solution creates a default Amazon S3 bucket with the name prefix <stack-name>-appcode thatis accessed by the Jupyter notebook and ETL jobs. This S3 bucket serves as the storage for your datalake. However, you have the option to use an existing S3 bucket in your AWS account to act as yourdata lake resource. To assign an existing S3 bucket to this solution, enter your S3 bucket name in thedatalakebucket parameter during deployment.
NoteTo secure the access to data in this S3 bucket, the <stack-name>-eksclusterEKSETLSaRoleIAM role controls the S3 bucket access from Jupyter notebook and ETL jobs. This dynamicIAM role template is available from the source/app_resources/etl-iam-role.yamlsource file. Note that there is a limitation for this deployment parameter. It can support onlyone custom S3 bucket. To associate with more than one S3 bucket, you must edit the IAM roletemplate in the source file, then follow the Customization instruction in the GitHub repositoryto generate your CloudFormation template. Ensure these S3 buckets are in the same Region asyour deployment Region.
Sample jobs and datasetsThis solution provides sample ETL jobs and datasets to help you test the solution and become familiarwith the functionalities.
• nyctaxi-job.ipynb: This sample dataset is from the public Registry of Open Data on AWS - New YorkCity Taxi and Limousine Commission Trip Record Data.
• scd2-job.ipynb: This Arc Jupyter notebook is an example that solves a challenging data problem:incremental data processing in a data lake. This job can be tested using both of the solution’s webtools:• In Arc Jupyter, use the scd2-job.ipynb notebook to test and examine the result of each ETL step in
sequential order. This job provides you hands-on experience to working with and debugging an Arc-based ETL pipeline interactively.
• In Argo Workflows, the notebook is broken down into three smaller notebook files without any datalogic changes. Use Argo to orchestrate these ETLs and manage the job dependencies. The notebookfiles include: (1) initial_load.ipynb, which loads the full datasets, (2) delta_load.ipynb,which implements the incremental data load, such as ingest and transform data update, insert ordelete, and (3) scd2_merge.ipynb, which merges the former two job results to implement theType 2 Slowly Changing Dimension (SCD) data operation. For testing purposes, jobs (1) and (2) arescheduled to run in parallel, and job (3) waits until both jobs are successfully finished.
NoteThe scd2-job results in a Delta Lake table that tracks data change history in the SCDType 2 format. Before the job completes, a secure connection is made to Amazon Athenavia the IRSA feature in Amazon EKS. A metadata table is then created and stored in anAWS AWS Glue Data Catalog. You can query the Delta Lake table in Athena the sameway as a regular table. To distinguish these test outputs, the table name in the creationscript is parameterized. From the Arc Jupyter test session, you can pass in the namedefault.deltalake_contact_jhub or any other meaningful name. In the ArgoWorkflows automation, the name is default.contact_snapshot.
• wordcount.py: A native Spark job written in Python script, which counts the frequency of each wordappeared in the Amazon product reviews. The sample dataset is approximately 50 GB, from a publicAmazon Customer Review DatasetAmazon Customer Review Dataset.
11

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Sample jobs and datasets
The example datasets are CSV files stored in the deployment/app_code/data project directory. Theyare automatically deployed to the solution’s default S3 bucket with the name prefix sparkoneks-appcode or <stack-name>-appcode The sample data contains fictitious contact information thatis generated by a python script. For more information about using these sample datasets, refer to therecorded steps in the GitHub repository.
12

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
IAM roles
SecurityWhen you build systems on AWS infrastructure, security responsibilities are shared between you andAWS. This shared model reduces your operational burden because AWS operates, manages, and controlsthe components including the host operating system, the virtualization layer, and the physical securityof the facilities in which the services operate. For more information about AWS security, visit AWS CloudSecurity.
IAM rolesAWS Identity and Access Management (IAM) roles allow customers to assign granular access policiesand permissions to services and users in the AWS Cloud. This solution creates a set of IAM roles forcomponents and add-ins running on Amazon EKS. The sample ETL jobs are controlled by IAM roles thatallows you access to the corresponding source data Amazon S3 bucket.
AWS Secrets ManagerAWS Secrets Manager generates a random password for a user to sign in to the JupyterHub web tool.This password is encrypted by a customer master key (CMK) created by AWS Key Management Service(AWS KMS) that automatically rotates each year.
NoteThis solution does not provide the ability to rotate the Jupyter login password in AWS SecretsManager.
Alternatively, you can remove the need for AWS Secrets Manager by reconfiguring the JupyterHubauthenticator to support Single Sign-On (SSO) or LDAP authentication. For a list of supportedauthenticators, refer to Authenticators in the JupyterHub GitHub repository.
Amazon CloudFrontIn this solution, JupyterHub and Argo Workflows web tools are installed in Amazon EKS. They aresitting behind an Application Load Balancer (ALB) respectively, which forwards incoming requests tothe web tool without an encrypted connection. Amazon CloudFront is placed in front of these ALBs, toactivate the HTTPS protocol between viewers and CloudFront, with a default domain offered by the AWSmanaged service.
We recommend removing CloudFront from the solution, instead generate your SSL/TLS certificate withyour own domain to encrypt the communication between viewers and the Application Load Balancer.Using this approach, you must attach your certificate to the solution’s ALB. For more information, referto How can I associate an ACM SSL/TLS certificate with an Application Load Balancer.
Security groupsThe security groups created in this solution are designed to control and isolate network traffic betweenthe VPC Endpoint, Application Load Balancer, Amazon ECR, and Amazon EKS. We recommend that you
13

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Security groups
review the security groups and further restrict access as needed once your deployment running. Forexample, the VPC Endpoint security group restricts inbound traffic to HTTPS port 443 only.
14

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Change default timeout settings
Design considerationsThis solution uses settings that you may want to adjust, such as the default timeout settings in theJupyterHub and Argo Workflows web tools. This solution also provides sample jobs and optional AWSservices that you can run to test the solution’s functionalities. These resources can be removed to save oncosts.
ImportantAny changes that you make to the solution, such as editing the timeout settings or removing thesample resources requires you to redeploy the AWS CloudFormation stack. This is necessary tomeet CI/CD deployment standards.Follow the Customization procedure to automatically update your CloudFormation template.Alternatively, use the GitHub repository to fork the solution and deploy changes via the AWSCloud Deployment kit (CDK).
Change default timeout settingsThis solution provides the following default timeout settings:
• JupyterHub web tool idle timeout: 30 minutes
• Argo Workflows web tool timeout: 15 minutes
ImportantWhen these timeout limits are reached, you will be logged off the application and unsavedwork will be lost.
Use the following steps to change JupyterHub’s idle timeout setting.
1. Download or fork the solution’s source code from the GitHub repository to your computer, if youhaven’t done so.
2. Open the source/app_resources/jupyter-values.yaml JupyterHub configuration file.
3. Locate the jupyterhub_idle_culler attribute.
4. Adjust the “--timeout=1800” setting. The time unit is in seconds. For information about thissetting, refer to the jupyterhub-idle-culler GitHub repository.
Argo Workflow’s idle timeout is inherited from the underlying Amazon EKS bearer token refreshfrequency, which is not adjustable. However, you can reconfigure the Argo server Authentication mode tosingle-sign on (SSO) mode with a longer and adjustable expiry time (default: 10 hours).
Use the following steps to change the Auth mode:
1. Open the source/app_resources/argo-values.yaml Argo Workflows configuration file.
2. Locate the setting “--auth-mode”.
3. Change the mode from client to SSO mode.
4. Follow the instruction on the Argo Server SSO page to configure the secrets, RBAC and SSO expirytime in Kubernetes environment.
15

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Removing sample resources and optional AWS services
Removing sample resources and optional AWSservices
This solution provides the following resources to help your testing and become familiar with theavailable functionalities. You can remove them at any time.
Sample ETL assets:
• deployment/app_code/data – sample datasets
• deployment/app_code/job – sample jobs
• deployment/app_code/meta – sample metadata definition
• deployment/app_code/sql – sample SQL scripts
• source/example – sample notebooks and job scheduler definitions for testing
Following ETL automation standards for CI/CD deployment, these resources under the deploymentdirectory are automatically uploaded to the solution’s S3 bucket. When you are ready to use your ownresources, you can organize and construct your ETL assets by the same pattern that is provided in thedeployment folder. The layout in the deployment directory is designed to be portable, scalable, andreadable for real-world use cases.
If you choose to remove the automated S3 bucket deployment from the solution:
• Ensure you have an automatic process to upload ETL assets to S3 bucket.
• Open the source/lib/cdk_infra/s3_app_code.py file from your computer, remove code blocksstart with “proj_dir=” and “self.deploy=”, also delete the s3_deploy_contruct propertyblock.
• Search the remaining source code for s3_deploy, delete a line of code associated with the keyword. Ifit appears as one of few parameters referred by a function, modify the code to remove the references.
• Open the solution’s main stack source/lib/spark_on_eks_stack.py file, search forBucketDeployment, then delete the line containing this reference.
Optional AWS services:
• Amazon CloudFront – provides network security for JupyterHub and Argo Workflow
• Amazon CodeBuild and Amazon CodePipeline – provides CI/CD standards to deploy Arc docker imageto Amazon ECR
These AWS services automate and secure the solution and provide a blueprint you can follow whendeploying this solution in your AWS environment. You can remove these resources to save on runningcosts.
If you choose to remove the optional Amazon CloudFront service from the solution:
• Ensure you have your TLS/SSL certificate associated with the solution’s Application Load Balancer.
• Open the solution’s source/app.py entry point file.
• Remove four lines related to the keyword cf_nested_stack, preventing the nested stack from beingactivated during deployment.
• Optionally, search the remaining project source code for the keyword cloudfront and remove theblock of code related to Amazon CloudFront. Note that you can remove the entire source/lib/cloud_front_stack.py file.
16

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Removing sample resources and optional AWS services
If you have existing CI/CD tools or have preferences for the deployment automation, you can remove theoptional Amazon CodeBuild and Amazon CodePipeline services:
• Ensure you have an ECR docker deployment process in place.• Open the solution’s main stack source/lib/spark_on_eks_stack.py file.• Remove three lines from the following section: #2. push docker image to ECR via AWS CICDpipeline so the ECR automation will not be activated during your deployment.
• Change this line "UseAWSCICD": "True" if ecr_image.image_uri else "False" to"UseAWSCICD": "False"
• Optionally, go to the folder source/lib/ecr_build and remove files related to the CI/CD pipeline.Search the remaining source code by the keyword IMAGE_URI,modify the source code to remove thereferences on the ECR docker image URL.
17

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
AWS CloudFormation templateTo automate deployment, this solution uses the following CloudFormation template, which you candownload before deployment:
sql-based-etl-with-apache-spark-on-amazon-eks.template: Use this templateto launch the solution and all associated components. The default configuration deploys AmazonElastic Kubernetes Service, Amazon Simple Storage Service, Amazon Elastic Container Registry, AmazonCloudWatch, AWS Secrets Manager, Amazon Athena, AWS AWS Glue Data Catalog, AWS CodeBuild, andAWS CodePipeline. You can customize the template to meet your specific needs.
NoteAWS CloudFormation resources are created from AWS Cloud Development Kit (CDK) (AWS CDK)constructs.
18

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Prerequisites
Automated deploymentBefore you launch the solution, review the cost, architecture, security, and other considerations discussedin this guide. Follow the step-by-step instructions in this section to configure and deploy the solutioninto your account.
Time to deploy: Approximately 30 minutes
PrerequisitesIn order to configure the solution after the CloudFormation deployment, you must download the sourcecode from the GitHub repository and use AWS Command Line Interface version 1 (AWS CLI) to interactwith AWS remotely from your computer.
If you do not have AWS CLI installed in your environment, refer to the following links to download theappropriate version based on your operating system:
• For Windows OS, download the MSI installer.• For Linux or macOS, download the bundled installer.
Verify that the AWS CLI can communicate with AWS services in your AWS account where this solution willbe deployed, for example, check the S3 bucket connection by running the command:
aws s3 ls
If no connection is found, run the following command to configure your AWS account access. For moredetails, refer to the configuration basics document.
aws configure
The project source code contains a set of application configurations. Download the source code beforelaunching the solution:
git clone https://github.com/awslabs/sql-based-etl-with-apache-spark-on-amazon-eks.gitcd sql-based-etl-with-apache-spark-on-amazon-eks
NoteThe source code is available from the solution’s GitHub repository.
Deployment overviewUse the following steps to deploy this solution on AWS. For detailed instructions, follow the links foreach step.
NoteTo either customize the solution or deploy it using the AWS CDK, refer to the GitHub repository.
Launch the stack (p. 20)
19

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Launch the stack
• Launch the AWS CloudFormation template into your AWS account.• Review the deployment parameters and enter or adjust the default values as needed.
Validate the solution (p. 21)
• Configure local environment• Test the scd2 job in Arc Jupyter• (Optional) Develop jobs in your local environment• Run the quick start job for Argo Workflows• Schedule the scd2 job using the Argo CLI• Schedule a native Spark job using the Kubernetes Operator for Apache Spark
Launch the stackImportantThis solution includes an option to send anonymous operational metrics to AWS. We use thisdata to better understand how customers use this solution and related services and products.AWS owns the data gathered though this survey. Data collection is subject to the AWS PrivacyPolicy.To opt out of this feature, download the template, modify the AWS CloudFormation mappingsection, and then use the AWS CloudFormation console to upload your template and deploy thesolution. For more information, refer to the Collection of operational metrics (p. 43) sectionof this guide.
This automated AWS CloudFormation template deploys the SQL-based ETL with Apache Spark onAmazon EKS solution in AWS Cloud.
NoteYou are responsible for the cost of the AWS services used while running this solution. For moredetails, visit the Cost (p. 3) section in this guide, and refer to the pricing webpage for each AWSservice used in this solution.
1. Sign in to the AWS Management Console and select the button to deploy launch the sql-based-etl-with-apache-spark-on-amazon-eks.template AWS CloudFormation template.
Alternatively, you can download the template as a starting point for your own implementation.2. The template launches in the US East (N. Virginia) by default. To launch the solution in a different AWS
Region, use the Region selector in the console navigation bar.3. On the Quick Create stack page, verify that the correct template URL is in the Amazon S3 URL text
box and choose Next.4. On the Specify stack details page, keep the default Stack name: SparkOnEKS.
NoteIf you decide to change the default name of the stack, you must pass this custom name as aparameter to your post-deployment (p. 21) and delete all clean up (p. 41) scripts afterthe deployment.
5. Under Parameters, review the parameters for this solution template and modify them as necessary.This solution uses the following default values.
20

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Validate the solution
Parameter Default Description
Jhub user sparkoneks JupyterHub username used todynamically create a serviceaccount in Amazon EKS. AnIAM role with least privilegeis assigned to the new serviceaccount, which controls thesolution’s Amazon S3 bucket,access to the datalake S3bucket, Amazon Athena, andAWS Glue permissions. You canchange this value to a differentusername.
Datalake bucket <solution-generated-name> By default, when this fieldis left blank, a new AmazonS3 bucket is created withthe prefix sparkoneks-appcode. The solution S3bucket contains sample sourcedata and ETL assets, such asJupyter notebook job definitionand SQL script files.
You have the option to use yourexisting S3 bucket, if available.To obtain the name of your S3bucket, access the Amazon S3console.
NoteYour S3 bucket mustbe in the same Regionas where this solutionis deployed.
6. Under Capabilities, check the two acknowledgement boxes stating that the template will create AWSIdentity and Access Management (IAM) resources and may require additional capability.
7. Choose Create stack to deploy the stack.
You can view the status of the stack in the AWS CloudFormation console in the Status column. Youshould receive a CREATE_COMPLETE status in approximately 30 minutes.
NoteIf an error occurs during deployment, refer to the Troubleshooting (p. 31) section in thisguide.
Validate the solutionAfter the solution is installed in your AWS account, configure the following validation tasks to testand explore the SQL-based ETL on Amazon EKS capabilities. The Prerequisite (p. 19) steps must becompleted before you can continue.
21

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Configure local environment
Configure local environmentBefore you can interact with Amazon EKS from your local computer, you must install a set of command-line tools. Additionally, the Docker ECR endpoint in each sample job scheduler file must be refreshedbase on the deployment output value IMAGEURI.
Run one of the following shell scripts to automatically install the tools and update the ECR endpoint.
• If you used the default CloudFormation stack name SparkOnEKS provided by the solution, run thefollowing command:
./deployment/post-deployment.sh
• If you created a unique stack name when deploying the solution, replace the <custom-stack-name>with the custom name, run the following command with an additional parameter:
./deployment/post-deployment.sh <custom-stack-name>
NoteThe CloudFormation stack name is case sensitive.
This configuration script outputs the JupyterHub login URL and access credentials. Record them to usewith the following validation tasks or to start your own data analyses.
Test the scd2 job in Arc JupyterArc Jupyter is a custom notebook kernel that helps you to create and test Arc ETL data pipelines in aJupyterHub environment. You can run a test job in the notebook to test and explore solution’s corecapabilities: codeless ETL and SQL-based ETL on Amazon EKS.
ImportantThe Jupyter notebook session times out if it remains idle for 30 minutes. Unsaved work will belost if your session times out. If this happens, you must log in again using the password stored inthe AWS Secrets manager. Note that the timeout setting is configurable (p. 15).This notebook is configured to be downloadable. You have the option to deactivate thiscapability, if needed, to comply with your organization’s data security policies.
Use the following steps to run the test job.
1. Sign in to JupyterHub with your account credentials.
2. On the Server Options page, select the server size. We recommend using the Small default option.
NoteThe server options can be customized in the source/app_resources/jupyter-values.yaml file.
22
SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Test the scd2 job in Arc Jupyter
Figure 5: JupyterHub server options
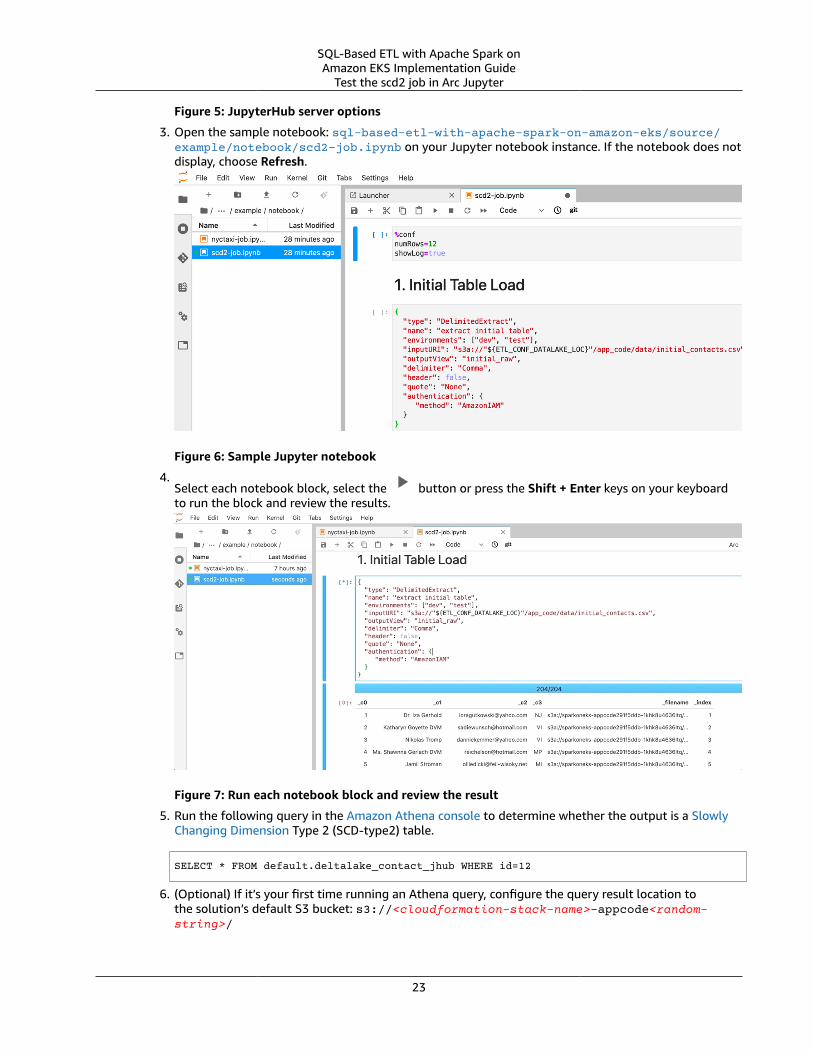
3. Open the sample notebook: sql-based-etl-with-apache-spark-on-amazon-eks/source/example/notebook/scd2-job.ipynb on your Jupyter notebook instance. If the notebook does notdisplay, choose Refresh.
Figure 6: Sample Jupyter notebook
4.Select each notebook block, select the button or press the Shift + Enter keys on your keyboardto run the block and review the results.
Figure 7: Run each notebook block and review the result
5. Run the following query in the Amazon Athena console to determine whether the output is a SlowlyChanging Dimension Type 2 (SCD-type2) table.
SELECT * FROM default.deltalake_contact_jhub WHERE id=12
6. (Optional) If it’s your first time running an Athena query, configure the query result location tothe solution’s default S3 bucket: s3://<cloudformation-stack-name>-appcode<random-string>/
23

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
(Optional) Develop jobs in local environment
Figure 8: Set up Athena query result location
(Optional) Develop jobs in local environmentAn alternative way to run Arc Jupyter is to use the arc-starter tutorial. Use this tutorial when you havedatasets stored in your local environment. This tutorial lets you build your own Arc ETL job in the ArcJupyter IDE at no cost.
If your source data is in AWS, verify that your Jupyter notebook can access it remotely from your localcomputer. For example, run the Jupyter notebook in AWS (p. 22) using Amazon EKS in this solution,which tightly integrates with AWS data stores via a secure channel. Using AWS to run your notebook letsyou leverage IAM-based authentication protocols to mitigate the risk of exposing credentials.
To build an ETL job using the Arc Jupyter Kernel, you can simply follow the Extract-Transform-Load (ETL)concept. For example, to extract data from a database, copy the minimal example from the JDBCExtractdocument to your notebook and update its attributes accordingly. Alternatively, type the key wordextract and press the Tab key on your keyboard to activate the autocomplete (IntelliSense) feature tobuild your job.
Figure 9: Autocomplete in Arc Jupyter notebook
Run the quick start job for Argo WorkflowsTo validate the job scheduling capability, submit a small job to the EKS cluster on the Argo website. Thissolution lets you automate the job orchestration by declaratively specifying the desired state of a jobrun.
24

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Run the quick start job for Argo Workflows
Argo Workflows is an open-source container-native workflow tool to orchestrate parallel jobs onKubernetes. Argo Workflows is implemented as a Kubernetes Custom Resource Definition (CRD).This workflow extends the standard Kubernetes experience by initiating time-based or event-basedworkflows using specification files, which are programming language agnostics.
To schedule the job for a quick start, take the following steps:
1. Run the following command to check the Argo connection from your local computer. If any errorreturns, follow the instruction to configure local environment (p. 21) and run the set up again.
kubectl get svc && argo version --short
2. Sign in to the Argo website using the following command.
NoteArgo’s authentication token refreshes every 15 minutes. Run the command argo auth tokento log in, if you are logged out from the Argo website.
ImportantImportant: For the following command, update the stack_name if you provided a customname for your stack.
stack_name=SparkOnEKSARGO_URL=$(aws cloudformation describe-stacks --stack-name $stack_name --query "Stacks[0].Outputs[?OutputKey=='ARGOURL'].OutputValue" --output text)LOGIN=$(argo auth token)echo -e "\nArgo website:\n$ARGO_URL\n" && echo -e "Login token:\n$LOGIN\n"
3.
Under the Argo icon, select the menu icon ( ) which takes you to the Argo Workflows homepage.
4. From the home page, choose SUBMIT NEW WORKFLOW.
5. From the Submit new workflow page, choose Edit using full workflow options.
6. Choose UPLOAD FILE, locate the nyctaxi job scheduling specification, then choose Create. The filelocation is sql-based-etl-with-apache-spark-on-amazon-eks/source/example/nyctaxi-job-scheduler.yaml.
Figure 10: Schedule the nyctaxi job on Argo
25

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Schedule the scd2 job using the Argo CLI
7.
While the job is running, examine its status and logs by selecting the Step1-query task ( ) on the website, then choose MAIN LOGS.
Schedule the scd2 job using the Argo CLIInstead of scheduling a job on the Argo website, you can use the Argo CLI to automate the workflow. Inorder to demonstrate Argo's advantages, such as workflow templates and job dependencies, the singlescd2 Jupyter notebook was broken down into 3 notebook files, i.e. 3 ETL jobs. They are stored in thedirectory of sql-based-etl-with-apache-spark-on-amazon-eks/deployment/app_code/job.It takes about 5 minutes in total to complete all jobs, which is much faster when running in parallel.
To schedule the scd2 job, take the following steps:
1. Open the source/example/scd2-job-scheduler.yaml file and ensure the ECR image value hasbeen updated with a correct ECR endpoint, which is handled automatically by the post-deploymentscript (p. 21).
Figure 11: Updated ECR image endpoint2. Run the command to schedule the scd2 ETL pipeline from your computer to the Amazon EKS cluster.
The --watch flag shows the job status on the command line console. To exit the watch session, pressctrl+C (this action does not stop the job run).
ImportantFor the following command, update the stack_name if you provided a custom name for yourstack.
stack_name=SparkOnEKS# get the s3 bucket name from CFN outputapp_code_bucket=$(aws cloudformation describe-stacks --stack-name $stack_name --query "Stacks[0].Outputs[?OutputKey=='CODEBUCKET'].OutputValue" --output text)argo submit source/example/scd2-job-scheduler.yaml -n spark --watch -p codeBucket=$app_code_bucket
3. Observe the job’s progress and logs under the spark namespace on the Argo website. Review Run thequick start job for Argo Workflows (p. 24) for sign in guidance to the Argo dashboard.
26

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Schedule the scd2 job using the Argo CLI
Figure 12: scd2 job status on Argo website
4. Run the query in the Amazon Athena console and check if it has the same outcome as your test resultin the Jupyter notebook.
SELECT * FROM default.contact_snapshot WHERE id=12
Figure 13: Query scd2 table in Athena
27
SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Schedule a native Spark job using theKubernetes Operator for Apache Spark
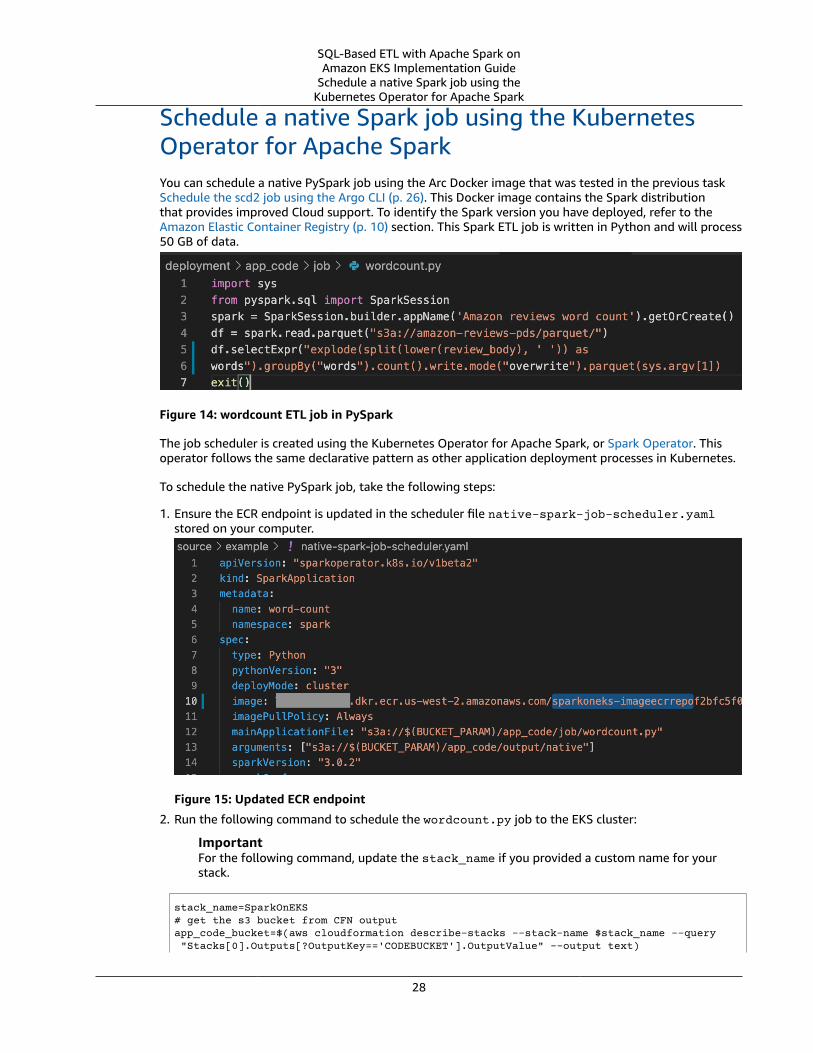
Schedule a native Spark job using the KubernetesOperator for Apache SparkYou can schedule a native PySpark job using the Arc Docker image that was tested in the previous taskSchedule the scd2 job using the Argo CLI (p. 26). This Docker image contains the Spark distributionthat provides improved Cloud support. To identify the Spark version you have deployed, refer to theAmazon Elastic Container Registry (p. 10) section. This Spark ETL job is written in Python and will process50 GB of data.
Figure 14: wordcount ETL job in PySpark
The job scheduler is created using the Kubernetes Operator for Apache Spark, or Spark Operator. Thisoperator follows the same declarative pattern as other application deployment processes in Kubernetes.
To schedule the native PySpark job, take the following steps:
1. Ensure the ECR endpoint is updated in the scheduler file native-spark-job-scheduler.yamlstored on your computer.
Figure 15: Updated ECR endpoint
2. Run the following command to schedule the wordcount.py job to the EKS cluster:
ImportantFor the following command, update the stack_name if you provided a custom name for yourstack.
stack_name=SparkOnEKS# get the s3 bucket from CFN outputapp_code_bucket=$(aws cloudformation describe-stacks --stack-name $stack_name --query "Stacks[0].Outputs[?OutputKey=='CODEBUCKET'].OutputValue" --output text)
28

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Schedule a native Spark job using theKubernetes Operator for Apache Spark
kubectl create -n spark configmap special-config --from-literal=codeBucket=$app_code_bucket# submit the job to EKSkubectl apply -f source/example/native-spark-job-scheduler.yaml
3. To check the job status in your command line tool, run the following command.
kubectl get pod -n spark
4. To observe the job status from the Spark History Server web interface, run the following command.
kubectl port-forward word-count-driver 4040:4040 -n spark# type `localhost:4040` in your web browser
Rerun this Spark job if needed. To rerun, you must delete the current job. Note that job schedulersdefined by Argo Workflows improve the rerun process by preventing the job deletion step. To delete thecurrent job, run the following commands.
kubectl delete -f source/example/native-spark-job-scheduler.yamlkubectl apply -f source/example/native-spark-job-scheduler.yaml
29

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Additional resourcesAWS services
• AWS CloudFormation• Amazon S3• Amazon EKS• Amazon ECR• Amazon CloudFront• Amazon CloudWatch
• AWS Application Load Balancer• AWS CodeBuild• AWS CodePipeline• Amazon Athena• AWS AWS Glue Data Catalog• AWS Secrets Manager
30

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
TroubleshootingIssue: The Amazon ECR container registry with the name prefix <stack-name>-imageecrrepof isempty.
• Reason: The Arc Docker image wasn’t deployed successfully to your AWS account.• Resolution: To redeploy the Docker image, take the following steps:
1. Sign to the AWS CodePipeline console.2. Search for the BuildArcDockerImage pipeline.3. Choose Release change to deploy the Docker image again.
Issue: The Jupyter notebook is either nonresponsive or there are no display outputs.
• Reason: The notebook has timed out after being idle for 30 minutes.• Resolution: Refresh your web browser, log in again with the username and password.
31

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Reference commandsIf you are not familiar with the Kubernetes command tool kubectl, refer to the kubectl cheat sheet.Specifically, the following commands are useful, if you want to experiment with the solution in AmazonEKS:
• kubectl get pod -n spark: display a list of the Spark jobs that are running• kubectl logs word-count-driver -n spark: check the application log of the wordcount job• kubectl delete pod --all -n spark: delete all the running Spark applications• kubectl apply -f source/example/<yaml-filename>: submit a Spark job to Amazon EKS by the
Kubernetes command-line tool
32

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Self-recovery test
Optional tasks for your end-usersYour end-users can run the following optional tasks to gain experience running Apache Spark on AmazonEKS:
• Self-recovery test• Review Spot Instance usage and cost savings• Auto scale Spark application with dynamic resource allocation
Self-recovery testWhen running Apache Spark on Amazon EKS, you can achieve job resiliency using a retry set up. In aSpark application, the driver program is a single point of failure. If a Spark driver fails, the applicationwill not survive. Setting up a job rerun can be challenging when accounting for the capability for self-recovery. However, the process is simplified when using Amazon EKS since the retry declaration consistsof only a few lines, which works for both batch and streaming Spark applications.
Figure 16 shows the retry specification when scheduling the wordcount.py PySpark job. If this job fails,the Spark Operator makes three attempts to submit the job again in ten minute intervals.
Figure 16: Retry setup in the job scheduler
Processing for this native Spark job takes approximately 20 minutes to complete. Run the followingcommands to test the self-recovery capability against the active Spark cluster. If the job is finishedbefore you can perform the test, rerun it by entering the following command:
kubectl delete -f source/example/native-spark-job-scheduler.yamlkubectl apply -f source/example/native-spark-job-scheduler.yaml
To test the Spark driver, manually delete an Amazon EC2 instance that is running the driver program
1. Run the command to identify the EC2 instance that the driver is assigned to.
Kubectl describe pod word-count-driver -n spark
33

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Review Spot Instance usage and cost savings
NoteLook for the following similar message in the output: Successfully assigned spark/word-count-driver to <ip-x-x-x-x>.<region>.compute.internal. The <ip-x-x-x-x>.<region>.compute.internal is the EC2 server name.
2. Next, delete the Amazon EC2 server after replacing the <ec2-server-name> place holder.
kubectl delete node <ec2-server-name>
3. Check whether the driver was recovered.
Kubectl get pod -n spark
Figure 17 demonstrates driver self-recovery when it is running on an interrupted Spot Instance.
Figure 17: Driver on an interrupted Spot Instance
This test result demonstrates the ability for the Spark driver to recover from failure, even after theunderlying EC2 server was intentionally removed. If your job is not time-critical, it is possible to run aSpark driver on a Spot Instance for cost savings.
Next, you can test one of the executors from the same Spark cluster. Delete the Spark executorcontaining the exec-1 suffix.
1. Enter the following command to delete the executor pod:
exec_name=$(kubectl get pod -n spark | grep "exec-1" | awk '{print $1}')kubectl delete -n spark pod $exec_name –-force
2. Run the following command to check whether the deleted executor returns with a different numbersuffix:
kubectl get po -n spark
Review Spot Instance usage and cost savingsInsert text.
34

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Auto scale Spark applicationwith dynamic resource allocation
You can review your Amazon EC2 Spot Instance usage information and a summary of cost savings, as thissolution runs Spark jobs on Spot Instances.
1. Sign in to the Amazon EC2 console and access the Spot Requests page.
2. On the Spot Requests page, choose Savings summary. A dialog box displays showing your usage andcost savings.
Auto scale Spark application with dynamicresource allocation
The example wordcount.py PySpark application processes 50 GB of data in 20 minutes. It dynamicallygrows from zero to 20 Spark executor pods plus a Spark driver pod spread over seven Amazon EC2 SpotInstances.
Initially the Spark application grows from zero to three pods because only one pre-launched SpotInstance is available at the time of the job initiation. As the cluster level autoscaling on Amazon EKSis configured, and Spark’s dynamic resource allocation feature is activated in the job scheduler file,the wordcount.py application automatically increases from three executors up to 20 based on theworkload needs.
To minimize the impact of a Spot Instance interruption or an Amazon EC2 server failure, the autoscalingon the EKS cluster is configured to use two Availability Zones. In a business-critical environment,three Availability Zones should be implemented to maintain the high availability standard. As of July2021, multi-AZ support is available only to Spark applications on Kubernetes or on Amazon EKS inAWS. Running Spark on Amazon EKS can help you meet the high availability, reliability, and resiliencyrequirements for your organization.
Enter the following command to validate that your Spark job is running across multiple AvailabilityZones:
kubectl get node \--label-columns=lifecycle,topology.kubernetes.io/zone
Figure 18: Autoscaling across two availability zones
Run the following command to examine the age of different Spark pods assigned to the job. The outputshould show that these jobs were dynamically allocated to the Spark application to support a growingworkload.
kubectl get pod -n spark
35

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Auto scale Spark applicationwith dynamic resource allocation
Figure 19: Spark’s dynamically resource allocation capability
Optionally, you can limit the job run to one Availability Zone if the increased cost for cross-AZ datatransfer or a longer runtime is a concern. Run the following Spark config setting to your job submittercommand and replace the <availability-zone> placeholder with an Availability Zone of your choice.
--conf spark.kubernetes.node.selector.topology.kubernetes.io/zone=<availability-zone>
In this case, add the Spark config to the source/example/native-spark-job-schedulerspecification file, assigning the Spark pods to a single zone, for example, us-east-1b.
Figure 20: Specify a single AZ in the Spark job scheduler
36

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Amazon EMR on Amazon EKS
Extending the solutionThis solution can be extended in the following ways:
• Support an Amazon EMR on Amazon EKS deployment option
• Support for your data mesh architecture
Amazon EMR on Amazon EKSYou can deploy Spark applications in multiple ways within your AWS environment. This solution supportsthe Amazon EMR on Amazon EKS deployment option. By changing the job scheduling configuration fromdeclarative specification to code-based script, such as python script in the workflow tool Apache Airflowor AWS CLI script in shell, you can use the optimized Spark runtime in EMR to enjoy the faster runningperformance than standard Apache Spark on Amazon EKS.
In this example, AWS CLI is used to interact with Amazon EMR on EKS in order to schedule thewordcount.py Spark job without the need to change the application.
NoteThe Amazon EMR on Amazon EKS feature is not currently available in all AWS Regions. You mustlaunch this solution in an AWS Region where the Amazon EMR on EKS is available. For the mostcurrent availability by Region, refer to the AWS Regional Support List for the Amazon EMR onEKS feature.
Take the following steps to run the job using Amazon EMR on EKS:
1. Run the following code snippet to create an IAM role that Amazon EMR will use for job scheduling.This is the role that EMR jobs will assume when they run on Amazon EKS.
ImportantFor the following command, update the stack_name if you provided a custom name for yourstack.
stack_name=SparkOnEKS
# get the s3 bucket from CFN outputapp_code_bucket=$(aws cloudformation describe-stacks --stack-name $stack_name --query "Stacks[0].Outputs[?OutputKey=='CODEBUCKET'].OutputValue" --output text)
cat <<EoF > ~/environment/emr-trust-policy.json{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "elasticmapreduce.amazonaws.com" }, "Action": "sts:AssumeRole" } ]}EoF
37

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Amazon EMR on Amazon EKS
cat <<EoF > ~/environment/EMRContainers-JobExecutionRole.json{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::amazon-reviews-pds", "arn:aws:s3:::${app_code_bucket}" ] }, { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject" ], "Resource": [ "arn:aws:s3:::amazon-reviews-pds/parquet/*", "arn:aws:s3:::${app_code_bucket}/*"] }, { "Effect": "Allow", "Action": [ "s3:DeleteObject" ], "Resource": [ "arn:aws:s3:::${app_code_bucket}/*" ] }, { "Effect": "Allow", "Action": [ "logs:PutLogEvents", "logs:CreateLogStream", "logs:DescribeLogGroups", "logs:DescribeLogStreams" ], "Resource": [ "arn:aws:logs:*:*:*" ] } ]} EoF
aws iam create-role --role-name EMRContainers-JobExecutionRole --assume-role-policy-document file://~/environment/emr-trust-policy.json
aws iam put-role-policy --role-name EMRContainers-JobExecutionRole --policy-name EMR-Containers-Job-Execution --policy-document file://~/environment/EMRContainers-JobExecutionRole.json
aws emr-containers update-role-trust-policy --cluster-name spark-on-eks --namespace spark --role-name EMRContainers-JobExecutionRole
2. Run the following command and record your IAM user ARN:
aws sts get-caller-identity --query Arn --output text
3. Ask the EKS cluster’s owner or admin to add your IAM user to aws-auth ConfigMap.
38

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Amazon EMR on Amazon EKS
4. To edit the aws-auth config map in the existing Amazon EKS cluster, run the following command:
kubectl edit -n kube-system configmap/aws-auth
5. Replace the placeholder by your user ARN, then add it to the existing EKS cluster as a primary systemuser:
mapUsers: | - groups: - system:masters userarn: arn:aws:iam::<account-id>:user/<your-username> username: admin
6. Register the existing EKS cluster with Amazon EMR by running the command. Ensure you haveinstalled the latest eksctl tool and your current user has permission to take the following action: emr-containers:CreateVirtualCluster.
eksctl create iamidentitymapping --cluster spark-on-eks --namespace spark --service-name "emr-containers"
aws emr-containers create-virtual-cluster \--name emr-demo \--container-provider '{ "id": "spark-on-eks", "type": "EKS", "info": { "eksInfo": { "namespace": "spark" } }}'
7. Submit the wordcount.py PySpark job with Amazon EMR on EKS.
export VIRTUAL_CLUSTER_ID=$(aws emr-containers list-virtual-clusters --query "virtualClusters[?state=='RUNNING'].id" --output text)
export EMR_ROLE_ARN=$(aws iam get-role --role-name EMRContainers-JobExecutionRole --query Role.Arn --output text)
aws emr-containers start-job-run \ --virtual-cluster-id $VIRTUAL_CLUSTER_ID \ --name word_count \ --execution-role-arn $EMR_ROLE_ARN \ --release-label emr-6.2.0-latest \ --job-driver '{ "sparkSubmitJobDriver": { "entryPoint": "s3://'${app_code_bucket}'/app_code/job/wordcount.py","entryPointArguments":["s3://amazon-reviews-pds/parquet/","s3://'${app_code_bucket}'/output/"], "sparkSubmitParameters": "--conf spark.executor.instances=20 --conf spark.executor.memory=3G --conf spark.driver.cores=1 --conf spark.executor.cores=1"}}' \ --configuration-overrides '{"monitoringConfiguration": { "s3MonitoringConfiguration": { "logUri": "s3://'${app_code_bucket}'/emr-eks-logs/"}} }'
For an example deployment of an Arc ETL job using Amazon EMR on EKS, refer to the example using theNYC taxi dataset.
39

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Data Mesh
Data MeshData mesh is a type of data platform architecture that handles the ubiquity of data in the enterprise byleveraging a domain-oriented, self-service design.
This solution simplifies Spark ETL for a diverse range of users: analysts, data scientists, and SQL authorsor business users, allowing them to develop data workflows without the need to write code in aprogramming language, such as Python. You can use the architectural pattern in this solution to driveyour data ownership shift from IT to non-IT, data-focused stakeholders who have a better understandingof your organization’s business operations and needs.
If your organization currently uses a data mesh architecture or is looking to evolve your data platformwith a data mesh, you can leverage this solution to decentralize the monolithic data platform, build aself-serve data infrastructure as a platform, and allow your data consumer and data producer to interactwith the data they own efficiently. To learn more about designing a data mesh in the AWS environment,refer to the example implementation in the consumer packaged goods (CPG) industry.
40

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Running the uninstallation script
Uninstall the solutionThis solution provides a script to help you automatically delete the CloudFormation stack and mostassociated resources. Remaining resources must be manually removed including the Amazon S3 bucketand Amazon VPC.
Running the uninstallation scriptFollow the steps in order to remove the solution from your AWS account:
1. Navigate to the solution’s code repository root folder on your computer.2. Go to the project’s root directory.
cd sql-based-etl-with-apache-spark-on-amazon-eks
3. Do one of the following:• If you used the default stack name SparkOnEKS to deploy the solution, run the script:
./deployment/delete_all.sh
• Otherwise, add the parameter <cloudformation-stack-name> and replace it with your customstack name that was used to deploy the solution.
./deployment/delete_all.sh <cloudformation-stack-name>
Deleting the remaining resources using the AWSManagement Console
Use the following steps to delete the remaining resources from your environment.
1. Sign in to the AWS CloudFormation console.2. Select this solution’s installation stack SparkOnEKS or the stack with your custom name.3. When the SparkOnEKS stack shows the DELETE_FAILED status, choose Delete then Delete Stack to
manually remove the remaining AWS resources.
Deleting the Amazon S3 bucketThis solution is configured to retain the solution-created Amazon S3 bucket if you decide to deletethe AWS CloudFormation stack to prevent accidental data loss. After uninstalling the solution, you canmanually delete this S3 bucket if you do not need to retain the data. Follow these steps to delete theAmazon S3 bucket.
1. Sign in to the Amazon S3 console.2. Search the solution’s default S3 bucket by the keyword appcode.
41

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Deleting the Amazon S3 bucket
3. Select the bucket name, choose Empty, confirm the deletion, then choose Delete to remove thebucket.
42

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Collection of operational metricsThis solution includes an option to send anonymous operational metrics to AWS. We use this data tobetter understand how customers use this solution and related services and products. When invoked, thefollowing information is collected and sent to AWS:
• Solution ID: The AWS solution identifier• Unique ID (UUID): Randomly generated, unique identifier for each SQL-based ETL with Apache Spark
on Amazon EKS deployment• Timestamp: Data-collection timestamp• NoAZs: Count of Availability Zones the solution is deployed to• UseDataLakeBucket: The deployment parameter setting, either a Yes or No value is shared• UseAWSCICD: Identifies whether AWS CI/CD services were used to push a Docker image, either a Yes or
No value is shared
AWS owns the data gathered through this survey. Data collection is subject to the AWS Privacy Policy.To opt out of this feature, complete the following steps before launching the AWS CloudFormationtemplate.
1. Download the AWS CloudFormation template to your local hard drive.2. Open the AWS CloudFormation template with a text editor.3. Modify the AWS CloudFormation template mapping section from:
"Send" : { "SendAnonymousData" : { "Data" : "Yes" }},
to:
"Send" : { "SendAnonymousData" : { "Data" : "No" }},
4. Sign in to the AWS CloudFormation console.5. Select Create stack.6. On the Create stack page, Specify template section, select Upload a template file.7. Under Upload a template file, click Choose file button and select the edited template from your local
drive.8. Choose Next and follow the steps in Launch the stack (p. 20) in the Automated Deployment section of
this guide.
43

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Source codeVisit our GitHub repository to download the source files for this solution and to share yourcustomizations with others. The SQL-based ETL with Apache Spark on Amazon EKS templates aregenerated using the AWS Cloud Development Kit (CDK) (AWS CDK). Refer to the README.md file foradditional information.
44

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
RevisionsDate Change
July 2021 Initial release
45

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
Contributors• Melody Yang• Frank Fan
46

SQL-Based ETL with Apache Spark onAmazon EKS Implementation Guide
NoticesCustomers are responsible for making their own independent assessment of the information in thisdocument. This document: (a) is for informational purposes only, (b) represents AWS current productofferings and practices, which are subject to change without notice, and (c) does not create anycommitments or assurances from AWS and its affiliates, suppliers or licensors. AWS products or servicesare provided “as is” without warranties, representations, or conditions of any kind, whether express orimplied. AWS responsibilities and liabilities to its customers are controlled by AWS agreements, and thisdocument is not part of, nor does it modify, any agreement between AWS and its customers.
SQL-based ETL with Apache Spark on Amazon EKS is licensed under the terms of the of the ApacheLicense Version 2.0 available at The Apache Software Foundation.
47




















