
Snapshot II Module No: CS/CC/17 Quadrant 1— e-text - e-PG ...
13
e-PG Pathshala Subject: Computer Science Paper: Cloud Computing Module 17: Snapshot II Module No: CS/CC/17 Quadrant 1— e-text 1. Introduction In the last module we learnt Chandy-Lamport’s global snapshot algorithm for obtaining a consistent and global snapshot in a distributed system. We continue the discussion in this module, take a look at an example and see how this algorithm actually works. This module would also justify the need of obtaining a consistent snapshot by discussing the practical applications of snapshot algorithm in distributed systems, specifically in cloud. 2. Learning Outcome At the end of this module, students will be able to: 1. Understand Chandy-Lamport’s algorithm completely. 2. Be aware about the various applications of distributed snapshot in distributed environment. 3. Appreciate various usages of snapshot in distributed systems. 4. Learn about checkpointing and its use in cloud. 5. Be aware of the challenges of checkpointing. 6. Understand and appreciate the impact of deadlock in a distributed environment. 3. Chandy-Lamport’s Algorithm: An Example To complete our understanding of the algorithm, let us now take an example nd work it out in a step-by-step manner. Although we have learnt the algorithm in the earlier module, let us repeat the algorithm here once more. 3.1. The Chandy-Lamport’s Algorithm Step 1: Initiator Pi records its own state and changes color to red; Step 2: While ∃ an outgoing channel C ij P i sends out a Marker message on outgoing channel C ij ; Step 3:
-
Upload
khangminh22 -
Category
Documents
-
view
1 -
download
0
Transcript of Snapshot II Module No: CS/CC/17 Quadrant 1— e-text - e-PG ...

e-PG Pathshala Subject: Computer Science
Paper: Cloud Computing Module 17: Snapshot II Module No: CS/CC/17 Quadrant 1— e-text
1. Introduction
In the last module we learnt Chandy-Lamport’s global snapshot algorithm for obtaining a consistent and global snapshot in a distributed system. We continue the discussion in this module, take a look at an example and see how this algorithm actually works. This module would also justify the need of obtaining a consistent snapshot by discussing the practical applications of snapshot algorithm in distributed systems, specifically in cloud. 2. Learning Outcome
At the end of this module, students will be able to:
1. Understand Chandy-Lamport’s algorithm completely. 2. Be aware about the various applications of distributed snapshot in distributed
environment. 3. Appreciate various usages of snapshot in distributed systems. 4. Learn about checkpointing and its use in cloud. 5. Be aware of the challenges of checkpointing. 6. Understand and appreciate the impact of deadlock in a distributed environment.
3. Chandy-Lamport’s Algorithm: An Example
To complete our understanding of the algorithm, let us now take an example nd work it out in a step-by-step manner. Although we have learnt the algorithm in the earlier module, let us repeat the algorithm here once more.
3.1. The Chandy-Lamport’s Algorithm
Step 1: Initiator Pi records its own state and changes color to red; Step 2:
While ∃ an outgoing channel Cij Pi sends out a Marker message on outgoing channel Cij; Step 3:

Starts recording the incoming messages on each of the incoming channelsCji
(forall j except i); Stops recording when a Marker is received along a channel
Marks this channel as “empty” and changes channel color to red;
3.2. Chandy-Lamport’s Algorithm: An Example
In this section, let us take an example to understand the algorithm. In our example, there are three processes, P1, P2 and P3. These processes exchange four messages, m1, m2, m3 and m4. The space-time diagram of the system is shown in Figure 17.1. The blue line represents process P1, the magenta line process P2, the orange line process P3 and the green dotted line at the bottom represents the time. This is not the system time. We assume a global time and try and understand the workings of the various processes with respect to this global time, albeit the processes work according to their own clocks. Figure 17.2 shows the pictorial representation of the same system. We will apply the algorithm on this diagram. According to the system model of the algorithm, there are FIFO channels between every pairs of processes. However, in the Figure 17.2 we show only four channels, viz., C12, C21, C13 and C32 that have been used in the system.
Figure 17.1: Example System – Space-Time Diagram
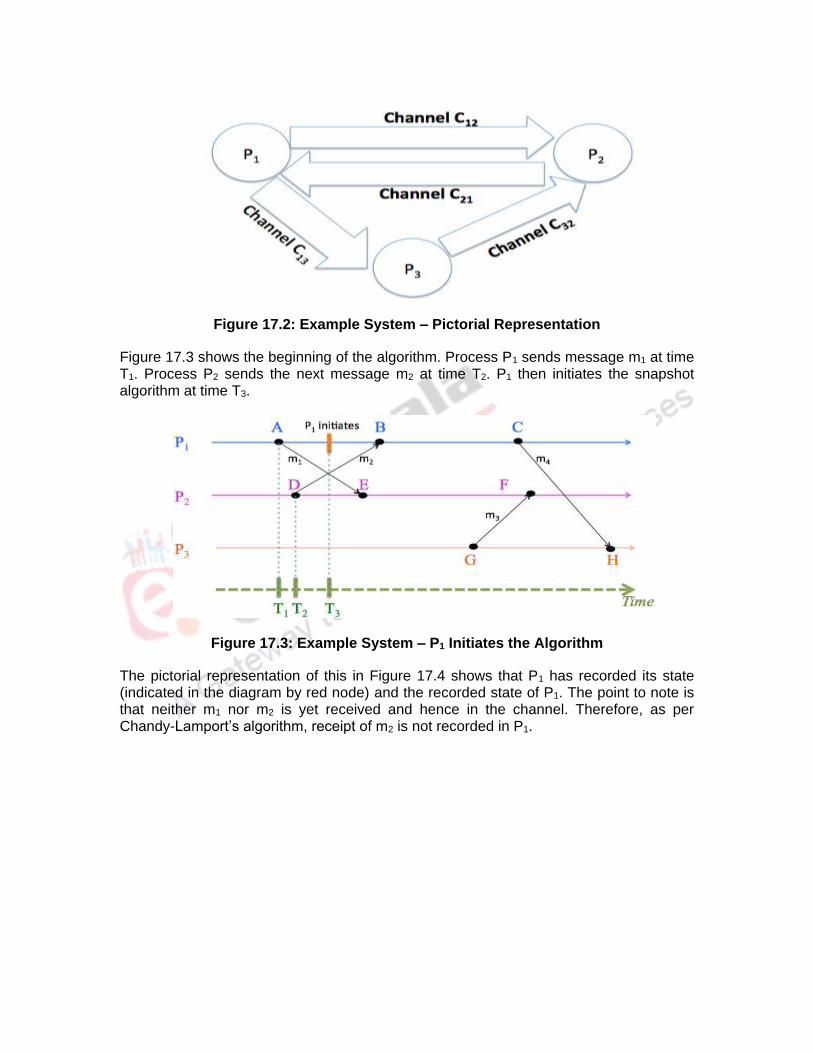
Figure 17.2: Example System – Pictorial Representation
Figure 17.3 shows the beginning of the algorithm. Process P1 sends message m1 at time T1. Process P2 sends the next message m2 at time T2. P1 then initiates the snapshot algorithm at time T3.
Figure 17.3: Example System – P1 Initiates the Algorithm
The pictorial representation of this in Figure 17.4 shows that P1 has recorded its state (indicated in the diagram by red node) and the recorded state of P1. The point to note is that neither m1 nor m2 is yet received and hence in the channel. Therefore, as per Chandy-Lamport’s algorithm, receipt of m2 is not recorded in P1.
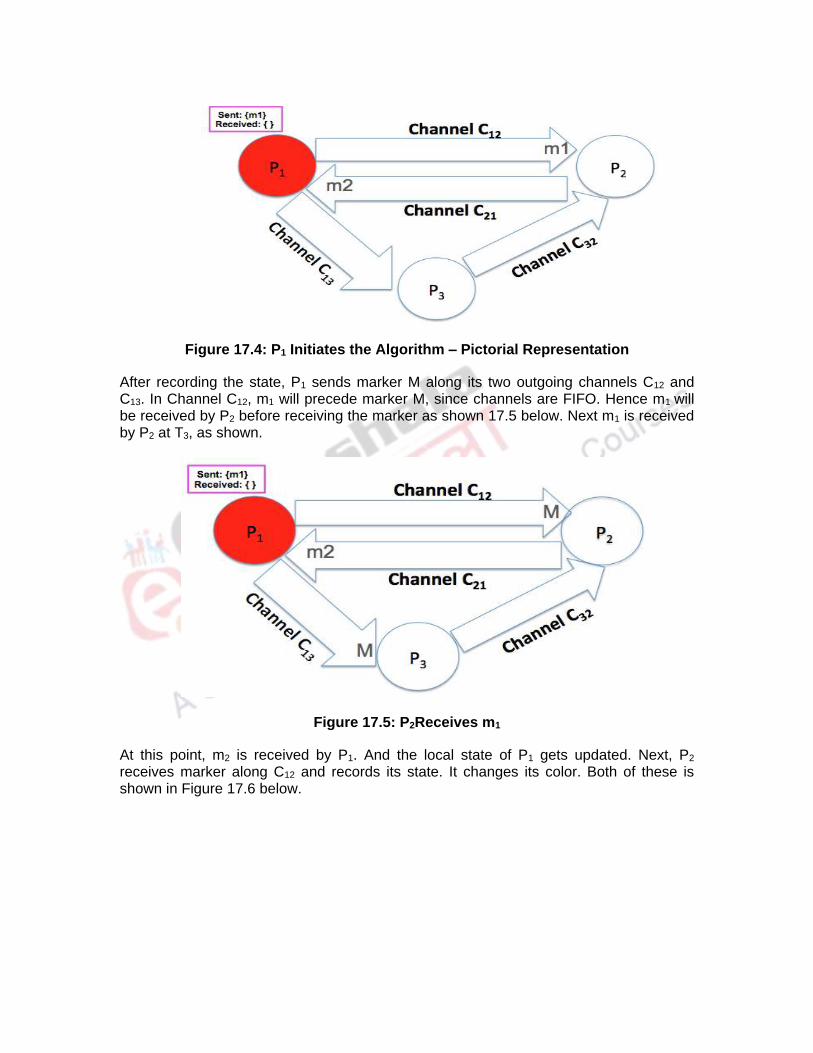
Figure 17.4: P1 Initiates the Algorithm – Pictorial Representation
After recording the state, P1 sends marker M along its two outgoing channels C12 and C13. In Channel C12, m1 will precede marker M, since channels are FIFO. Hence m1 will be received by P2 before receiving the marker as shown 17.5 below. Next m1 is received by P2 at T3, as shown.
Figure 17.5: P2Receives m1
At this point, m2 is received by P1. And the local state of P1 gets updated. Next, P2 receives marker along C12 and records its state. It changes its color. Both of these is shown in Figure 17.6 below.
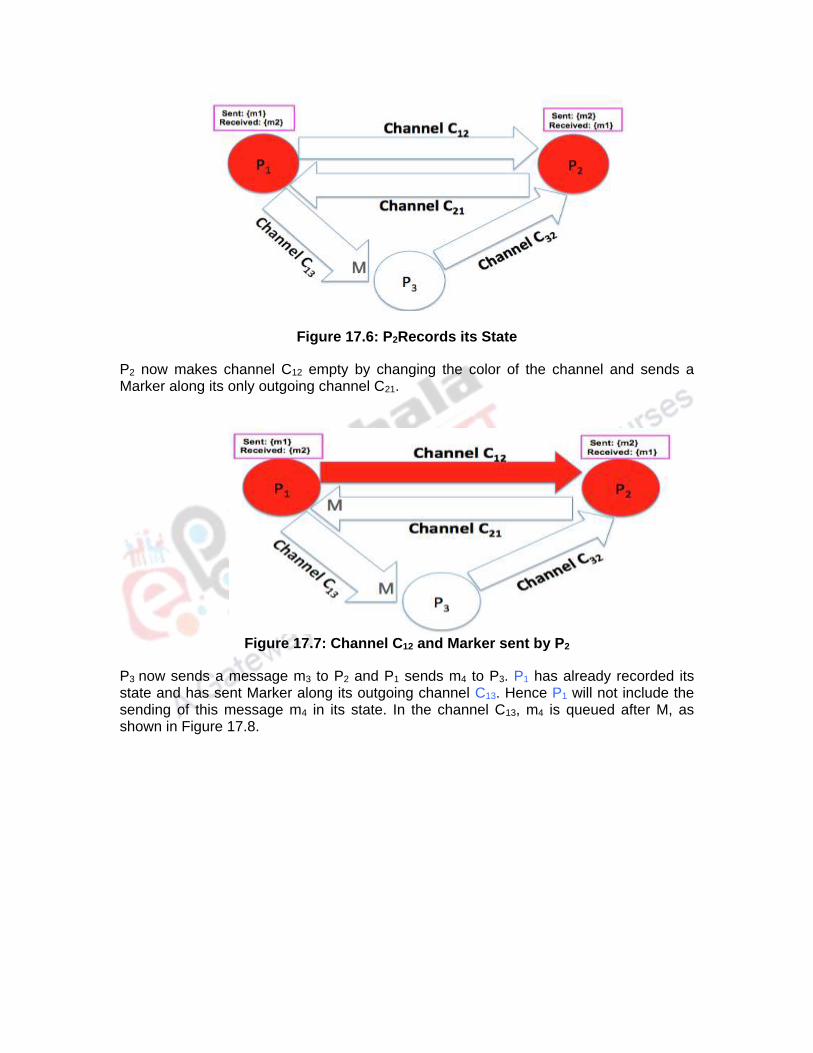
Figure 17.6: P2Records its State
P2 now makes channel C12 empty by changing the color of the channel and sends a Marker along its only outgoing channel C21.
Figure 17.7: Channel C12 and Marker sent by P2
P3 now sends a message m3 to P2 and P1 sends m4 to P3. P1 has already recorded its state and has sent Marker along its outgoing channel C13. Hence P1 will not include the sending of this message m4 in its state. In the channel C13, m4 is queued after M, as shown in Figure 17.8.
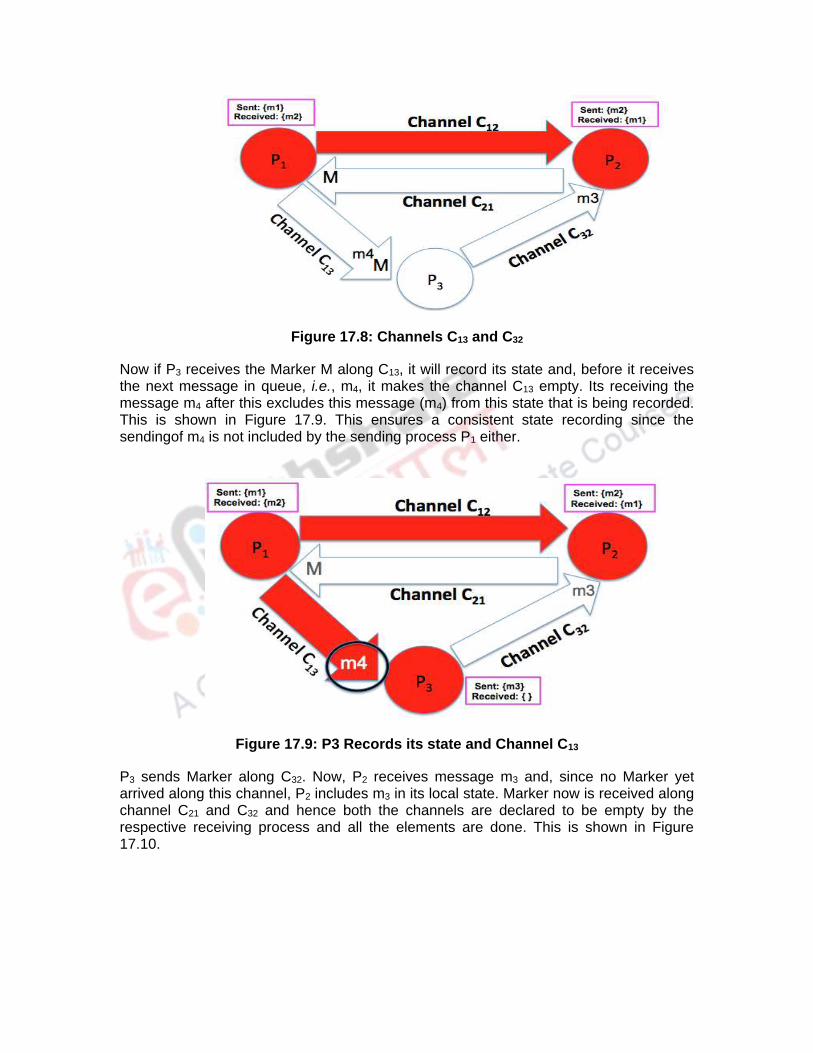
Figure 17.8: Channels C13 and C32
Now if P3 receives the Marker M along C13, it will record its state and, before it receives the next message in queue, i.e., m4, it makes the channel C13 empty. Its receiving the message m4 after this excludes this message (m4) from this state that is being recorded. This is shown in Figure 17.9. This ensures a consistent state recording since the sendingof m4 is not included by the sending process P1 either.
Figure 17.9: P3 Records its state and Channel C13
P3 sends Marker along C32. Now, P2 receives message m3 and, since no Marker yet arrived along this channel, P2 includes m3 in its local state. Marker now is received along channel C21 and C32 and hence both the channels are declared to be empty by the respective receiving process and all the elements are done. This is shown in Figure 17.10.

Figure 17.10: On completion of Recording
Therefore, at the end of the application of Chandy-Lamport’s algorithm, the global state is recorded as follows:
SEND: m1, m2, m3 RECEIVED: m1, m2 and m3.
Hence the state is consistent although the normal exchange of messages did not have to stop for the recording. We further observe that a consistent cut has been obtained by the process, as shown in Figure 17.11 below.
Figure 17.11: Consistent Cut in Chandy-Lamports Algorithm 4. Applications of Snapshot
In this section we will look at various applications that need to use global state or snapshot to realize. These are the followings:
4.1. Checkpointing

Checkpointing is perhaps the most important application of snapshot. It is a method using which recovery of processes and data can be done after a crash in a distributed environment. We will discuss this in the next section.
4.2. Distributed Deadlock Detection
A deadlock is defined to be a state of a set of processes where each process waits for another process to send it a message, and where there is a cycle in the graph of this ‘waits-for’ relationship. Such a system will never make progress.Deadlock is very expensive and needs to be detected if other methods of preventing them are not implemented. While there is no solution to the problem of deadlock in a distributed environment, detecting a deadlock helps. Global state provides an efficient method of deadlock detection.
4.3. Distributed Termination Detection
Since different components of a distributed algorithm execute in many nodes, detecting that such an algorithm has completed its task is challenging. Let us consider an example. Let there be an algorithm running in two nodes as two processes, P1 and P2. Let us consider that these two processes are requesting values from each other. At any point, a process may be active (requesting, sending or receiving values) or passive, that is not engaged in any activity. During the passive period,it may be prepared to respond with a value requested by the other. If, in such an environment, it is observed that both the processes are passive, can we conclude that the algorithm has terminated? The answer to this question is no! The scenario may be such that P1 has sent a request that is in transit, and is waiting, while P2 is idle since the request has not yet arrived. However, this scenario will change and the process P2 will get active when the request reaches P2! Hence, the algorithm has not terminated, even though both P1 and P2 are idle.
The difference between deadlock and termination detection is that, in deadlock the processes involved are inactive by force. In reality these are active. Another difference is that deadlock affects a few nodes/processes of the system, whereas termination is a system-wide concept.
4.4. Distributed Garbage Collection
In a computing environment, programs, or processes, create and use many objects in the memory space. In a single processor environment, these will typically remain inside the address space of the process that create and use these and the memory space will be reused as soon as the process terminates. However, in a distributed environment, this method is not simple. There are many objects that will be created and used by a process in one machine but the objects may reside in any machine in the distributed environment. Many such objects reside in the distributed system that is no longer referencedby any process in the distributed system. Since many of these objects are shared among more than one process, termination of all these processes has to be determined before such an object is declared to be not in use and hence garbage.
Unfortunately, it is not easy to declare an object to be garbage. The memory taken up by that object can be reclaimed only when this is done. An efficient way an object can be identified to be garbage is to take a snapshot of the processes and the channels and

identify if there is any reference to an object. If it is identified to be nil, then the object is garbage and can be reused.
5. Checkpointing in Cloud
Failures are unavoidable in a machine. Large distributed systems like cloud is a cluster of computers in a virtualized environment created using many machines and components to deliver services. Hence it is expected that there will be failures in such an environment. When a failure occurs, the failed process may either be abandoned or restarted. Unfortunately, in a system like cloud, abandoning a process means violating contracts with clients and hence the process cannot be abandoned. Restarting a process that has started recently has low impacts on the clients. However, restarting a long-running process would make the client aware of the delay and hence of the failure. While failures are norms, one of the major characteristics of such a computer cluster has been identified as its ability to recover from such failures transparently. Hence, while accepting that there will be failures, quick recovery from such failures, thereby affecting the clients to as small an extent as possible, is also the need of such systems. It is therefore not surprising that the ability of such systems to recover from failure as transparently to the users as possiblehas been a major point of research. Systems with such abilities are called fault-tolerant systems. Fault tolerant systems employ techniques that enable them to perform tasks in the presence of faults. Fault tolerance can be provided in any system at three different levels: hardware level, architecture level and application level. While it is possible to provide such fault tolerant techniques at the hardware and architecture levels, these are costlier methods that, many times, do not offer flexibility and hence are not much interest to the service providers in a distributed environment. The software solutions, on the other hand, are less costly and are under greater control of the service providers, a desirable trait in a distributed system like cloud. Checkpointing implements software fault tolerance.Along with recovery,checkpointing makes a distributed system fault tolerant.
The basic idea of checkpointing is simple. Stop a running application ensuring that all the relevant data of the application at the point of stoppage is copied in stable storage along with the point of stoppage and then the execution is continued. In case of failure, restart the process from the nearest stoppage point.
Here the question is how often do we stop and save the sates of the application? One way of doing this is to save all the states so that, in case of failure, the application can be restarted immediately from the earlier correct state. But quite obviously, it will be expensive to save all states.Further, saving a state of a running application need the application to stop and hence the performance of the application will suffer if it is stopped too many times.
Instead, checkpointing works by saving the states of a running application at certain intervals in stable storage. In case of a failure, the latest such entry in the stable storage is the point of restart.This way, while a long running application need not restart from the beginning, it also does not suffer from any serious performance issue. In a cloud environment, various parts of an application is expected to run in different machines belonging to different data centers physically distributed over geographically distant regions. In such a system, checkpointing involves several machines located in different parts and hence the checkpointing mechanism needs to be coordinated, ensuring that

saving/restarting points in the different parts of the application in various machines do not give rise to consistency issues.
While all these requirements make checkpointing an expensive operation, its benefits, as provided to a cloud service providers, outweigh the cost and hence it motivates cloud service providers. These are discussed in the next subsection.
5.1. Benefits of Checkpointing in Cloud
There are various benefits of checkpointing in cloud:
1) It provides high availability and hence helps in getting more profit 2) It allows program debugging 3) It helps process migration 4) It helps in load balancing. 5) It helps improved maintenance 6) It makes a cloud environment more energy efficient 7) It helps earn greater profit for the service provider
In the subsections below, we discuss some of these.
5.1.1. Checkpointing Provides Availability in Cloud
One of the major promises of cloud is its availability. To fulfill this promise, fault tolerance is a necessity. A machine that is able to recover from failures quickly and efficiently does not let its users suffer from failures. This is especially true for long tasks running for a long time since there are more prone to suffer from failures in the system. Regular checkpointing saves the states of these applications at certain well-defined intervals. In the event of system failure, they can be restored from their last checkpoint.This way the cloud service provider can safeguard applications and make its services always available. This arrangement also helps all applications in case of catastrophic failures affecting a whole data center. Since stable storages are safe from natural disasters, even when the whole data center gets affected, the applications can be restarted from the last checkpoints.
5.1.2. Checkpointing Provides Greater Profit to Cloud Service Providers
Cloud is a pay-as-you-go model. This means that a client should be able to pay as much as she consumes. To make this model more flexible, an ideal cloud service provider should be able to offer different prioritized services for the similar kind of resource utilization so that a client having a job of lesser priority may choose to pay less since she is willing to wait for the service a littler longer. On the other hand, clients with higher priority jobs must pay more and these jobs must be completed in a much shorter time. Checkpointing is typically used for such an environment.
In this kind of environment, when some resource like CPU cycle is available, a low-priority process may be executed.On arrival of a high priority task, any low-priority application running at that time should be suspended, freeing the resource for the newly arrived high-priority job that has to be served immediately. The low-priority application is suspended by saving its current state in stable storage (using checkpointing). This job will be restored when idle CPU cycles are available at a later time.

This model helps both the service providers as well as the consumers. The providers can make more profit at peak hours and, at the same time saving low-priority jobs for later ensures that the resources are not idle at slack hours. On the other hand, clients can pay less for the same service if there is no deadline for a certain job.
5.1.3. Checkpointing Helps in Process Migration in Cloud
A cloud sometimes may have sudden spike during which the resource requirements go higher than the total resources available with the service provider. Such spikes occur only once in a while and it is very difficult, almost impossible, for a service provider to be prepared for this situation. However, these spikes may cause a service provider not be able to fulfill the customers’ needs thereby violating SLA requirements and leaving a number of clients disgruntled. A typical way to solve this problem is to borrow a similar service/resources from another cloud ready to share such a service/resource. If such a cloud exists, some tasks may be chosen to be migrated to these clouds so that the promised jobs can be completed without having the service provider acquire more resources and without having any problem with the clients. Usually, checkpointing is used to stop a running application and restarting the application after migrating it to another cloud.This way, there is less or no loss of time for the running application that gets migrated. 5.1.4. Checkpointing Helps in Improved Maintenance in Cloud
Sometimes, it is required that a cloud service provider requires to do maintenance operations that need shutting down of all the systems in a data center.However, a cloud is always busy, thereby stopping services completely may prove to be impossible. Further, the availability criterion is violated when a data center gets shut down completely. One way is informing the customers and asking them to wait till such maintenance work is completed. There are many real-time situations where it may even not be possible for applications to wait. A smarter way is to stop all running applications and checkpoint them. Checkpointing is done for two purposes:
(1) Either the applications will wait till the maintenance work is completed and restore these afterwards. However, this may not be possible if either the maintenance work is too long or if there are some high-priority jobs running. (2) The alternative is to migrate them to other clusters or clouds before taking down a cluster for maintenance.
In both the cases, checkpointing is used. 5.1.5. Checkpointing Helps in Rendering Cloud Energy Efficient
A data center runs many servers. However, only during peak hours all these servers are in use. During slack hours, some servers remain completely idle, in which case these can be shut down, thereby saving energy consumption. However, many a time these servers are used only partially. It is quite possible to shut down some of these partially idle servers, after migrating the running applications to other machines. Thus, a reshuffling through migration may result in better utilization of the resources and improved power consumption. And, as we have seen in earlier subsection, reshuffling can be done with the help of checkpointing. Hence checkpointing, indirectly, helps in energy saving.
6. Deadlock Detection using Snapshot

A deadlock is a state where a set of processes request resources that are held by other processes in the set and vice versa.Deadlock is a very serious problem in any computational environment. Handling deadlocks in distributed systems are similar to handling deadlocks in single processor systems.However, there are certain characteristics that make deadlock handling harder in a distributed system in general.
The first is that the processes and resources reside in geographically different locations. This, under certain circumstances, makes it difficult to recognize the fact that deadlock exists. Distributed systems add further dimensions to deadlockdue to the absence of a global clock and the fact that the participating systems may be heterogeneous.A further problem in a distributed system like cloud is the rate at which such systems work and the large number of processes that are involved in any interaction since any deadlock handling mechanism typically requires all the participating nodes to be part of the mechanism.
In general, there can be four strategies for handling deadlocks in a distributed system:
The first is to ignore the deadlock. Many times, due to the vastness and the large number of participating nodes, there may seem to be a deadlock, even in a normal situation. This is called a phantom deadlock. Unnecessarily handling a phantom deadlock is more costly than having an occasional deadlock. This leads to the first option of not taking any action to understand whether there is a deadlock in the system.
The second option is deadlock prevention. Render the system in such a way that deadlock cannot happen. Even in a single processor system prevention makes the system extremely restrictive. Large distributed systems like cloud that handles client requests need greater flexibility and hence prevention-like mechanisms are not suitable.
The third option is to avoid deadlock. In a single processor system this is implemented using what is known as Banker’s algorithm. Such algorithms results in very poor performance in the system and since cloud is performance dependent, avoidance cannot be used in cloud.
The last and the most suitable option is to detect a deadlock and, once detected, such deadlocks may be removed. Deadlock detection requires examination and detection of a cyclic wait. Typically, deadlock detection involves creating and traversing a graph, called a wait for graph (WFG). The state of the system can be modeled by WFG. In a WFG, nodes are processes and there is a directed edge from node P1 to mode P2 if P1 is blocked and is waiting for P2 to release some resource. A system is deadlocked if and only if there exists a directed cycle or knot in the WFG.There are various methods of using WFG to detect deadlock in large distributed systems.One such method, the global state detection based algorithm, detects deadlock by creating and using a snapshot of the system.
A snapshot algorithm exploits the fact that if a stable property holds in the system before the snapshot collection is initiated, this property will still hold in the snapshot. Therefore, distributed deadlocks can be detected by taking a snapshot of the system and examining it for the condition of a deadlock.Global Snapshot algorithm is a method of keeping track of wait-for graph.It periodically examines the WFG for the presence of a cycle. If one or

more cycles are found, a deadlock is detected. Aborting one or more processes would break cycle and hence get rid of the existing deadlock. However, even when an existing deadlock is removed, there is no guarantee that another deadlock is not going to form in recent future. Hence detecting and removing deadlock is a continuous process and hence an expensive one.
The above discussion shows that it is harder to avoid, prevent, or even detect deadlock in cloud. However, of all the methods, detection is the best option.
7. Summary
To summarize this module, we first showed how Chandy-Lamport’s global snapshot algorithm works using an example. We then moved on to the usage of snapshot and showed that there are several in situations cloud where snapshot algorithms are employed. Of these, we discussed in detail one particular application that is popular in a cloud like ambience, i.e. checkpointing. The other popular usage of snapshot is in deadlock detection. We conclude the chapter by observing that even when we detect a deadlock, it is very hard to cure a complex system like cloud of deadlock.
References
1. George Coulouris, Jean Dollimore, Tim Kindberg, Gordon Blair, “Distributed Systems: Concepts and Design”, 5th Edition, Pearson publications, 2011.
2. Tanenbaum, Andrew S., and Maarten Van Steen, “Distributed Systems: Principles and Paradigms”, Prentice-Hall, 2007.
3. D. M. Dhamdhere, “Operating Systems: A Concept based Approach”, Third Edition, Tata McGraw-Hill Education, 2012.
4. Antonopoulos, Nikos, and Lee Gillam (Editors), “Cloud Computing: Principles, Systems and Applications”, Springer Science & Business Media, 2010.
5. Hwang, Kai, Jack Dongarra, and Geoffrey C. Fox, “Distributed and Cloud Computing: From Parallel Processing to the Internet of Things”, Morgan Kaufmann, 2013.
6. Singhal, Mukesh, and Niranjan G. Shivaratri, “Advanced Concepts in Operating Systems” McGraw-Hill, Inc., 1994.
7. Zomaya A. Y. H., “Parallel and Distributed Computing Handbook”, New York: McGraw-Hill, 1996.










![p~ - f\ Cc.-oS] - USAID](https://static.fdokumen.com/doc/165x107/631320b8c72bc2f2dd03ea3e/p-f-cc-os-usaid.jpg)









