Self-repairing adder using fault localization
9
Self-repairing adder using fault localization Muhammad Ali Akbar, Jeong-A Lee ⇑ Computer System Lab, Department of Computer Engineering, Chosun University, South Korea article info Article history: Received 31 October 2013 Received in revised form 20 January 2014 Accepted 20 February 2014 Available online 29 March 2014 Keywords: Self-checking adder Carry-select adder Fault localization Self-repairing adder Multiple faults abstract In this paper we propose an area-efficient self-repairing adder that can repair multiple faults and identify the particular faulty full adder. Fault detection and recovery has been carried out using self-checking full adders that can diagnose the fault based on internal functionality, independent of a fault propagated through carry. The idea was motivated by the common design problem of fault propagation due to carry in various approaches by self-checking adders. Such a fault can create problems in detecting the particular faulty full adder, and we need to replace the entire adder when an error is detected. We apply our self-checking full adder to a carry-select adder (CSeA) and show that the resulting self-checking CSeA consumes 15% less area compared to the previously proposed self-checking CSeA approach without fault localization. After observing fault localization with reduced area overhead, we utilize the self-checking full adder in constructing a self-repairing adder. It has been observed that our proposed self-repairing 16-bit adder can handle up to four faults effectively, with an 80% probability of error recovery compared to triple modular redundancy, which can handle only a single fault at a time. Ó 2014 Elsevier Ltd. All rights reserved. 1. Introduction Advanced microelectronic technologies have allowed current digital systems to become more vulnerable to faults. It has been observed that the problem of single-event upset in digital systems has become more prominent with the increasing complexity of system on a chip, along with decreasing clock cycles to obtain high operating frequency [1,2]. The design of a compact circuit on a chip is advantageous in terms of noise but creates various problems in terms of reliability [3,4]. Researchers agree that reduction in hard- ware size will increase hardware failures in future processors [5]. Thermal cycling, dielectric behavior and biasing of digital inte- grated circuits have also caused many transient and permanent faults [6]. In order to deal with the above-mentioned problems, the con- cepts of self-checking and fault tolerance have been introduced. A system will be fault secure if it remains unaffected by a fault or if it indicates a fault as soon as it occurs [7]. A system will be self-test- ing if it produces a non-coded output in response to every generated fault [8]. A system will be totally self-checking (TSC) if it is both fault secure and self-testing [7]. The concept of TSC is used in different applications, like self-healing networks [9], self-checking arithme- tic logic units (ALUs) [10], etc. Self-checking usually emphasizes the detection of faults and overlooks the overhead associated with fault recovery. Most of the self-checking approaches require re-execution of instructions for fault recovery [11]. However, the re-execution process affects system performance because all operations connected directly or indirectly to the faulty module should be re-executed. Further- more, re-execution cannot guarantee fault recovery, especially if there is a permanent fault or wear-out problem. Therefore, on-line detection and self-repairing is required in a highly dependable sys- tem architecture [12]. In digital system designs, the adder has a wide variety of appli- cations [13]. In the past, many approaches have been adopted to introduce self-checking in adder circuits either by hardware- or time-based redundancy. These approaches can detect an error without indicating its exact location because of fault propagation due to carry. In this paper, we propose a new self-checking and self-repairing full adder in which the faulty full adder module can be identified. Self-checking and repair has been attained using the observed relationship between Sum and Carry-out. The Sum and Carry-out bits of a full adder will be equal to each other when all three inputs are equal. The Sum and Carry-out bits will be com- plemented when any of the three inputs are different. A carry-select adder (CSeA) pre-computes Sum bits using two adders with complemented values of the initial C in , and the final Sum bit will be generated after receiving the actual value of the C in . The presence of two adders is advantageous for introducing a self-checking ability. We first apply our self-checking full adder http://dx.doi.org/10.1016/j.microrel.2014.02.033 0026-2714/Ó 2014 Elsevier Ltd. All rights reserved. ⇑ Corresponding author. Tel.: +82 106851 2207; fax: +82 062 233 6896. E-mail addresses: [email protected] (M.A. Akbar), [email protected] (Jeong-A Lee). Microelectronics Reliability 54 (2014) 1443–1451 Contents lists available at ScienceDirect Microelectronics Reliability journal homepage: www.elsevier.com/locate/microrel
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of Self-repairing adder using fault localization

Microelectronics Reliability 54 (2014) 1443–1451
Contents lists available at ScienceDirect
Microelectronics Reliability
journal homepage: www.elsevier .com/locate /microrel
Self-repairing adder using fault localization
http://dx.doi.org/10.1016/j.microrel.2014.02.0330026-2714/� 2014 Elsevier Ltd. All rights reserved.
⇑ Corresponding author. Tel.: +82 106851 2207; fax: +82 062 233 6896.E-mail addresses: [email protected] (M.A. Akbar), [email protected]
(Jeong-A Lee).
Muhammad Ali Akbar, Jeong-A Lee ⇑Computer System Lab, Department of Computer Engineering, Chosun University, South Korea
a r t i c l e i n f o a b s t r a c t
Article history:Received 31 October 2013Received in revised form 20 January 2014Accepted 20 February 2014Available online 29 March 2014
Keywords:Self-checking adderCarry-select adderFault localizationSelf-repairing adderMultiple faults
In this paper we propose an area-efficient self-repairing adder that can repair multiple faults and identifythe particular faulty full adder. Fault detection and recovery has been carried out using self-checking fulladders that can diagnose the fault based on internal functionality, independent of a fault propagatedthrough carry. The idea was motivated by the common design problem of fault propagation due to carryin various approaches by self-checking adders. Such a fault can create problems in detecting theparticular faulty full adder, and we need to replace the entire adder when an error is detected. We applyour self-checking full adder to a carry-select adder (CSeA) and show that the resulting self-checking CSeAconsumes 15% less area compared to the previously proposed self-checking CSeA approach without faultlocalization. After observing fault localization with reduced area overhead, we utilize the self-checkingfull adder in constructing a self-repairing adder. It has been observed that our proposed self-repairing16-bit adder can handle up to four faults effectively, with an 80% probability of error recovery comparedto triple modular redundancy, which can handle only a single fault at a time.
� 2014 Elsevier Ltd. All rights reserved.
1. Introduction
Advanced microelectronic technologies have allowed currentdigital systems to become more vulnerable to faults. It has beenobserved that the problem of single-event upset in digital systemshas become more prominent with the increasing complexity ofsystem on a chip, along with decreasing clock cycles to obtain highoperating frequency [1,2]. The design of a compact circuit on a chipis advantageous in terms of noise but creates various problems interms of reliability [3,4]. Researchers agree that reduction in hard-ware size will increase hardware failures in future processors [5].Thermal cycling, dielectric behavior and biasing of digital inte-grated circuits have also caused many transient and permanentfaults [6].
In order to deal with the above-mentioned problems, the con-cepts of self-checking and fault tolerance have been introduced. Asystem will be fault secure if it remains unaffected by a fault or ifit indicates a fault as soon as it occurs [7]. A system will be self-test-ing if it produces a non-coded output in response to every generatedfault [8]. A system will be totally self-checking (TSC) if it is both faultsecure and self-testing [7]. The concept of TSC is used in differentapplications, like self-healing networks [9], self-checking arithme-tic logic units (ALUs) [10], etc.
Self-checking usually emphasizes the detection of faults andoverlooks the overhead associated with fault recovery. Most ofthe self-checking approaches require re-execution of instructionsfor fault recovery [11]. However, the re-execution process affectssystem performance because all operations connected directly orindirectly to the faulty module should be re-executed. Further-more, re-execution cannot guarantee fault recovery, especially ifthere is a permanent fault or wear-out problem. Therefore, on-linedetection and self-repairing is required in a highly dependable sys-tem architecture [12].
In digital system designs, the adder has a wide variety of appli-cations [13]. In the past, many approaches have been adopted tointroduce self-checking in adder circuits either by hardware- ortime-based redundancy. These approaches can detect an errorwithout indicating its exact location because of fault propagationdue to carry. In this paper, we propose a new self-checking andself-repairing full adder in which the faulty full adder modulecan be identified. Self-checking and repair has been attained usingthe observed relationship between Sum and Carry-out. The Sumand Carry-out bits of a full adder will be equal to each other whenall three inputs are equal. The Sum and Carry-out bits will be com-plemented when any of the three inputs are different.
A carry-select adder (CSeA) pre-computes Sum bits using twoadders with complemented values of the initial Cin, and the finalSum bit will be generated after receiving the actual value of theCin. The presence of two adders is advantageous for introducing aself-checking ability. We first apply our self-checking full adder

1444 M.A. Akbar, Jeong-A Lee / Microelectronics Reliability 54 (2014) 1443–1451
on CSeA to check the performance and area redundancy of ourproposed approach compared to other self-checking CSeAs. Aftershowing that our approach with fault localization results in areaoverhead reduction, we apply our idea to a self-repairing adderand show that our self-repairing adder can sustain system reliabil-ity for more than one fault with relatively less area overheadcompared to triple modular redundancy (TMR). The proposedself-repairing adder is capable of repairing more than one fault,depending on the adder size. For 16-bit adder design, our proposedself-repairing adder can accommodate up to four faults effectively,with an 80% probability of error recovery.
The paper is organized as follows. Section 2 discusses the previ-ous work and common design problem (i.e., the fault propagationproblem due to carry). In Section 3 we discuss the basic principle,fault coverage, and comparison of our proposed design approachfor a self-checking full adder and its application to CSeA. In Section4 we present the concept and comparison of our proposedself-repairing adder approach. Our research work is concluded inSection 5.
Fault
Fault Cout
Add2
Add1
Add3
Add2
Add3
COMPARATOR
No Fault
FaultCout
Fig. 1. Fault propagation through carry.
2. Previous design approaches
Self-checking systems require redundancy, which can bebroadly classified as time- and hardware-based redundancy. Wewill discuss both of them briefly, along with related works, in thissection.
2.1. Time redundancy
The basic concept of time redundancy is that the same hard-ware will perform a single operation in different intervals of time,and we can detect an error by comparing the two outputs obtainedat different time instances.
Khedhiri et al. [13] designed a self-checking full adder circuitbased on the concept of time variation. The single full adder willwork such that it is used twice to perform the same computationby following different logical paths, and the comparison of the finalresults will indicate the presence of a fault. The key features of theauthors’ design are diversity and a decrease in area overhead byusing different paths for a single operation in each time interval.Moreover, in order for system performance or speed to remainunaffected, it has been argued that the result will be propagatedafter the first computation. Hence, if the first computed result isfaulty, then before detecting the fault, that result will be used forother computations. The propagated fault will also cause faulty re-sults in other modules.
2.2. Hardware redundancy
The basic idea for this approach is to use more than one hard-ware to produce either the same, inverted or coded output. Thecomparison between the outputs of the actual and the redundanthardware will be used to indicate the fault. This approach can befurther classified into duplication of the existing hardware andoutput predictor block. In the duplication of hardware scheme,the two most commonly used approaches are double modularredundancy (DMR) and triple modular redundancy (TMR). In a du-plex system (i.e., DMR) the same hardware is repeated once,whereas TMR requires three modules with which to vote to deter-mine the final output.
The major problem with this concept is that instead of detectingfaults in individual modules, it can detect the overall fault of a sys-tem. This kind of checking creates many complexities in terms offault recovery, because we cannot detect which individual block isfaulty. The other drawback of this approach is that straightforward
implementation will create an area overhead of more than 100%[3,13]. Secondly, it cannot detect a common mode failure in whichboth modules experience the same set of errors [14].
The advantage of TMR over DMR is the probability of obtainingreliable output. It can easily be recognized that by using the TMRtechnique, the area overhead will increase up to 300% comparedto the original design without self-checking. The second problemwith this kind of design approach becomes apparent when twomodules have the same faulty result at the same time, and thenthe correct module is treated as faulty because the output isdependent on a voter circuit that decides on the basis of majority[10].
In a CSeA design, two adders are working in parallel for a com-plemented value of initial carry-input, Cin, and the final output willdepends on the actual value of Cin. The benefit of having two addersat a time was realized by Vasudevan et al. [15], and they intro-duced a fault-tolerant capability without excessive hardware over-head. However, the problems of common mode failure and a higharea overhead requirement for fault recovery still remained un-solved. The fault in carry generation is allowed to propagate andcannot be detected with its first occurrence. Hence, this approachalso suffers in terms of determining the defective full addermodules.
2.3. Common design problem
The common design problem in various approaches for self-checking adders is fault propagation due to carry. Such a faultcan misdirect the system, preventing it from detecting the partic-ular faulty region in a module because a propagated error canmake the correct region of a module appear to be faulty, as well.
A duplex system is shown in Fig. 1, in which each module hasthree full adders. Let us assume that an error occurs in the carrygeneration portion of the first full adder. The propagated error willindicate the second and third full adders as faulty modules,whereas the first full adder will be deemed a fault-free module.Therefore, in order to achieve recovery, we will repair the secondand third modules, and hence, the faulty module is not recovered.Similarly, if we detect that a module having five full adders gener-ates faulty output, then by most of the current approaches we can-not detect which of the five full adders is faulty. Hence, if a fault isindicated in any region of a large module, we need to replace thewhole module in order to accomplish the recovery process. Thiskind of replacement approach will waste resources because theproperly functioning block has also been replaced.
We observed that most design approaches deal with errordetection, but little work has currently been done on the self-repairside. The general consideration for designing a self-checking adder

M.A. Akbar, Jeong-A Lee / Microelectronics Reliability 54 (2014) 1443–1451 1445
is that the recovery process can be feasible after detection of faults.However, the cost for self-repair is too high to be adoptable formost self-checking approaches. If we consider DMR and TMR, theninstead of replacing a single module, we have to replace the wholesystem to achieve recovery. This will introduce a huge area over-head of more than 300% to the actual system, as well as an increasein power consumption. Our proposed design in this paper consid-ers both the facts of self-checking and the recovery. Because of thefault localization property present in our design, the system is onlyrequired to replace the faulty region, without disturbing the wholesystem.
3. Self-checking adder with fault localization
3.1. Basic principle
We utilize the following relations for the full adder:
� The Sum and Carry bits will be equal to each other when allthree inputs are equal.
� The Sum and Carry bits will be complemented when any ofthe three inputs is different.
By using the above two relations, a full adder can be self-checked with only the expense of an equivalence tester (Eqt), asshown in Fig. 2. The purpose of the equivalence tester is to checkthe equivalence of all inputs. Hence, apart from the Sum and Carrybits calculation, we have to compute logic for the equivalence tes-ter, and the expression for that purpose is in Eq. (3.3). The func-tional block Eqt has been designed to produce an active lowoutput so that we can use the fault-secure exclusive nor logicalfunction (XNOR) gate for comparison.
Sum ¼ A� B� Cin ð3:1Þ
Cout ¼ A � Bþ Cin � ðAþ BÞ ð3:2Þ
Equivalence tester ðEqtÞ ¼ NOT ððA�: B�: Cin
�Þ þ ðABCinÞÞ ð3:3Þ
Error ðEf Þ ¼ Sum� Cout � Eqt ð3:4Þ
The final fault is computed by using two XNOR gates. The purposeof the first XNOR gate (G1) is to check whether the Sum and Cout bitsare equal or complemented. We need a second XNOR gate (G2)
Full Adder
A B Cin
Equivalence tester (Eqt)
G1
CoutSum
Error (Ef)
Initial testing(It) G2
Fig. 2. Proposed self-checking full adder.
because of the previously mentioned observation that Sum and Cout
will always complement each other except when all inputs areequal. Thus, the output of G1 will indicate the equality or differenceof Sum and Cout, and G2 will verify the output of G1 by comparing itwith an equivalence tester, and thus generate the final error indica-tion. When Eqt is zero, the output of G1 and G2 should be logic 1 and0, respectively. On the other hand, if Eqt indicates logic 1, then bothXNOR gates should generate logic 0 (i.e., It = 0 and Ef = 0), and in anyother case, a fault will be indicated.
3.2. Self-checking carry select adder
The self-checking CSeA shown in Fig. 3 was proposed by Vasud-evan et al. [15], where two adders and a 2-pair-2-rail checker,along with some combinational logic, are used for self-checking.
We design a self-checking CSeA with single adder, assuming theinitial Cin to be zero and where the individual full adder has beenreplaced by our proposed self-checking full adders. We then gener-ate Sum and Carry output for the initial Cin equal to one using thefollowing relation, where Si
j and Cij represent the jth position of the
Sum and Carry bits, and i is either 0 or 1, indicating the value of theinitial Cin:
(1)
Fig.
S10 is always a complement of S0
0, i.e. S10 ¼ S0
0.
(2) S11 depends on S00, S0
1:
If ðS00 ¼ 0Þ then S1
1 = S01;
If S00 ¼ 1
� �then S1
1 ¼ S0
1.
(3)
C11 depends on C01, S00 and S0
1:
If ðC01 ¼ 1 OR S0
0 � S01 ¼ 1Þ then C1
1 ¼ 1;
The above relationships can be summarized in Eqs. 3.5, 3.6, and3.7. An exclusive OR (XOR) operation is performed in Eq. (3.6) togenerate S1
1 because S11 is not always a complement to S0
1. Moreover,since both C0
1 and S00S0
1 cannot equal 1 at the same time, we usedthe XOR gate in Eq. (3.7) because a self-checking XOR gate was pre-sented by Belgacem et al. [16]. The two-bit proposed self-checking
3. Self-testing carry-select adder [15].

Fig. 5. Designed module required for n-bit extension.
1446 M.A. Akbar, Jeong-A Lee / Microelectronics Reliability 54 (2014) 1443–1451
CSeA is shown in Fig. 4. The design consumes less area compared tothe self-checking CSeA approach of Vasudevan et al. [15], shown inFig. 3.
S10 ¼ S0
0 ð3:5Þ
S11 ¼ S0
0 � S01 ð3:6Þ
C11 ¼ c0
1 � ðS00 � S
01Þ ð3:7Þ
Except for the least significant bit (LSB), S0j and S1
j has the followingrelation:
Except for the LSB, the Sum bit computed when carry-in equals 0will be a complement to the corresponding Sum bit with carry-in equalto 1, only when all the lower Sum bits are equal to logic 1.
In general we can say that:
If S01 � S
02 � S
03 . . . . . . S0
ði�1Þ ¼ 1� �
Then S1j ¼ S0
j
� �;
Else S1j ¼ S0
j
� �;
where j indicates the bit position. Thus, in order to design an n-bitCSeA, the generalized Boolean equations have been shown in Eqs.3.8, 3.9, and 3.10. The design module shown in Fig. 5 will be usedto extend the 2-bit CSeA design to an n-bit CSeA design. All theintermediate Sum bits between the LSB and final Cout can be gener-ated using the module shown in Fig. 5. The LSB and module for finalCout (MOFC) design in Fig. 4 can be used to complete the n-bit self-checking CSeA.
S10 ¼ S0
0 ð3:8Þ
S1n ¼ S0
n � S01 � S
02 � S
03 . . . . . . S0
ðn�1Þ
� �ð3:9Þ
C1n ¼ C0
n � S01 � S
02 � S
03 . . . . . . S0
ðn�1Þ
� �ð3:10Þ
3.3. Fault coverage
The condition for fault coverage of our design has been summa-rized in Table 1. The logic-high of the final error (Ef) will indicate afault. We can easily see that the designed approach guaranteesself-checking only when any one of the Sum, Cout or Eqt lines be-comes faulty. If two of them have a fault at the same time, then
Fig. 4. Proposed design of two-bit self-testing carry-select adder.
that fault cannot be detected. The assumption of having a singlefault at one time becomes valid because the fault-secure propertyassumes that between two consecutive faults, we have enoughtime to detect the error at its first occurrence [16]. Moreover, un-like other techniques, like DMR and TMR, etc., we are testing a verysmall module of a single full adder. The probability of having twofaults at one time in a small module is much lower than with alarge module.
For example: A = 1, B = 0 and Cin = 1 are three respective inputsin our proposed full adder. The corresponding outputs for theseinputs without fault are: Sum = 0, Carry = 1 and Eqt ¼ 1. Let usassume that the Sum bit flips from 0 to 1, and the outputs, afterthe fault, will thus become Sum = 1, Carry = 1 and Eqt ¼ 1. Thiscondition has been indicated as a fault in Table 1.
With our proposed approach for a self-checking adder, a faultgenerated in any full adder can be detected individually. Even ifthe generated carry has a fault, it will not create a fault indicationin subsequent full adders because all the full adders are self-check-ing with respect to their individual functionality and are indepen-dent on their carry input. Hence, the faulty propagated carry willnot create a problem in self-checking in any subsequent full adder.The benefit of this approach is that if we want to recover from thefault, then instead of replacing all full adders present in the com-plete module, we replace only particular full adders.
Moreover, Sum and Cout of a full adder are not sharing any logic,so the problem of transient faults can be overcome. For example,consider a single full adder in which both the final Sum and Cout
share the Sum bit of the first half-adder. Let a, b and Cin be the threeinput bits in the full adder, with values equal to 0, 0 and 1, respec-tively. With these inputs the correct outputs for the final Sum andCout are 1 and 0. Assume that the Sum bit of the first half adder(a � b) flips from 0 to 1. Then this bit flipping can generate a faultin both Sum and Cout because of logic sharing and can thus create aproblem in detection. Therefore, in our proposed idea, the Sum andCout modules work without logic sharing, as shown in Fig. 6, andany fault occurring within the internal logic of an individualmodule will make that particular module faulty, and thus can bedetected easily on comparison.
In addition to a self-checking full adder, we need to have a self-checking XOR gate and multiplexer (MUX). The self-checking XORgate was proposed by Belgacem et al. [16] using a pass-transistor-based differential pair as shown in Fig. 7(a). The self-checking MUXdesign, however, was presented by Vasudevan et al. [15] in whichthe complementary outputs SN and SN will be used to detect thepresence or absence of faults and is shown in Fig. 7(b).

Table 1Conditions for fault coverage.
Conditions Status
If ððEqt ¼¼ 0Þ AND ðSum ¼¼ CoutÞÞ No faultIf ððEqt ¼¼ 1Þ AND ðSum ¼¼ coutÞÞ No faultIf ððEqt ¼¼ 0Þ AND ðSum–CoutÞÞ Fault
If ððEqt ¼¼ 1Þ AND ðSum–CoutÞÞ Fault
Fig. 6. Full adder without logic sharing.
Fig. 7. Self-checking (a) XOR gate [16] and (b) MUX [15].
Table 2Transistor count for individual module implementation.
Modules Required transistorsfor implementation
AND 6XOR 4 [16]MUX 12 [15]Adder 28 [15]Equivalence tester (Eqt) (Eq. (3)) 12Checker (2-XOR) 8Module for final Cout (MOFC) (shown in Fig. 4) 16
Table 3Comparison with time-redundancy based self-checking adder, DMR and TMR.
Individualtransistorcount
Total # oftransistors
Transistoroverhead
Proposed full-adder Adder 28 48 20Eqt 12Checker 8
DMR Adder 56 60 32XOR 4
M.A. Akbar, Jeong-A Lee / Microelectronics Reliability 54 (2014) 1443–1451 1447
3.4. Comparison
The area overhead can be compared in different ways, such astransistor count, gate count and technology dependence. In thissection, we will compare our proposed self-checking full adderwith DMR and TMR. Also, our designed self-checking CSeA willbe compared with the conventional CSeA and self-checking CSeAfrom Vasudevan et al. [15]. The area overhead in both cases wascomputed in terms of transistor count. The transistor count forimplementing a full adder and MUX was taken from Vasudevanet al. [15] while the transistor count for the self-checking XOR gatewas taken from Belgacem et al. [16]. The final transistor count forindividual modules is shown in Table. 2.
TMR Adder 84 124 96Voter[17]
40
Self-checking adder [13] – – 58 30
3.4.1. Area efficiency compared to DMR and TMRSingle-bit adder implementation using DMR required two ad-
ders and a single XOR gate for comparison. For TMR, we need three
adders and one majority voter for selecting the correct output. Inorder to compute transistor count for voter circuitry, we used thefault secure voter design proposed by Kshirsagar and Patrikar [17].
The comparison result of our designed self-checking full adderwith DMR and TMR is shown in Table 3. We see that our designedself-checking full adder requires an overhead of 20 transistorscompared to a full adder without self-checking, whereas DMRand TMR have an overhead of 32 and 96 transistors, respectively.Hence, our designed self-checking full adder requires 25% fewertransistors than DMR and 158% fewer than TMR. Moreover, ourself-checking full adder, without creating a time penalty, has20.8% more area efficiency than a self-checking full adder usingthe time-redundancy approach of Khedhiri et al. [13].
3.4.2. Area efficiency compared to self-checking CSeAThe transistor count for our proposed self-checking CSeA with
multiple bit data is presented in Table 4. The transistor count fora conventional CSeA with and without self-checking was presentedby Vasudevan et al. [15]. It is seen from Table 5 that our designedself-checking CSeA has only negligible area overhead compared toa normal CSeA design and also requires a 15–16% lower transistorcount compared to the self-checking CSeA proposed by Vasudevanet al. [15].
A graphical representation is shown in Fig. 8. We can see thatour proposed self-checking CSeA design shows the same trendcompared to a CSeA without self-checking, whereas the percentageincrease in area overhead of the self-checking CSeA proposed by
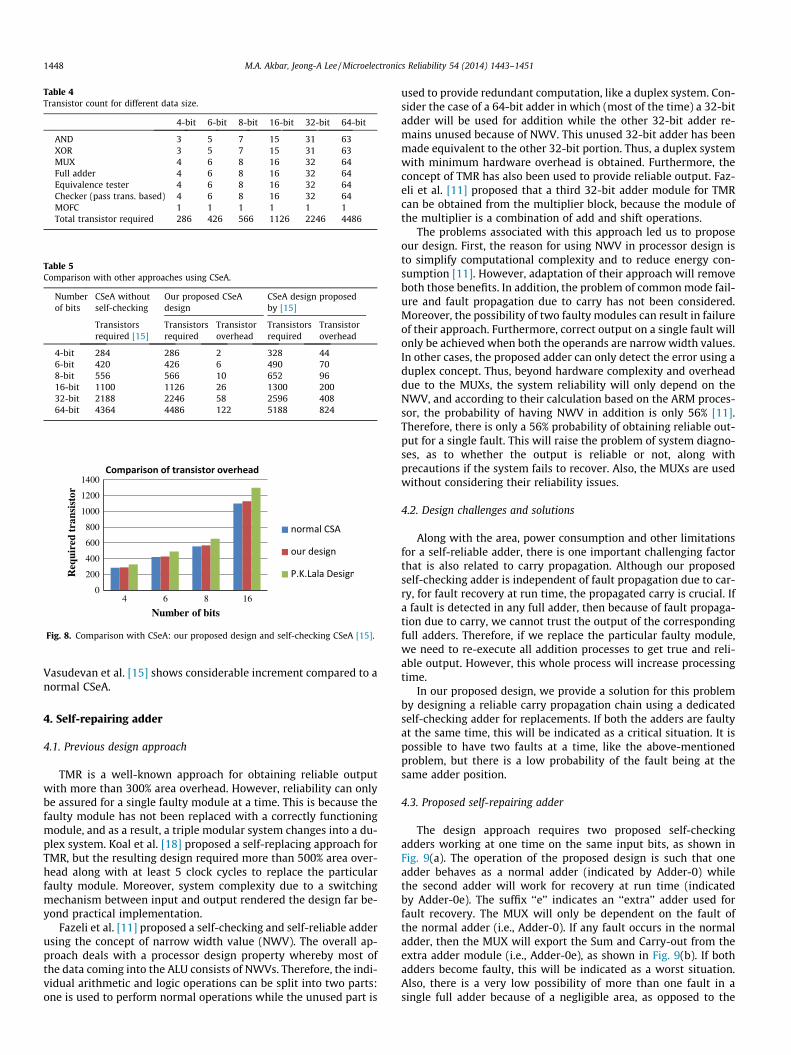
Table 4Transistor count for different data size.
4-bit 6-bit 8-bit 16-bit 32-bit 64-bit
AND 3 5 7 15 31 63XOR 3 5 7 15 31 63MUX 4 6 8 16 32 64Full adder 4 6 8 16 32 64Equivalence tester 4 6 8 16 32 64Checker (pass trans. based) 4 6 8 16 32 64MOFC 1 1 1 1 1 1Total transistor required 286 426 566 1126 2246 4486
Table 5Comparison with other approaches using CSeA.
Numberof bits
CSeA withoutself-checking
Our proposed CSeAdesign
CSeA design proposedby [15]
Transistorsrequired [15]
Transistorsrequired
Transistoroverhead
Transistorsrequired
Transistoroverhead
4-bit 284 286 2 328 446-bit 420 426 6 490 708-bit 556 566 10 652 9616-bit 1100 1126 26 1300 20032-bit 2188 2246 58 2596 40864-bit 4364 4486 122 5188 824
0
200
400
600
800
1000
1200
1400
4 6 8 16
Req
uire
d tr
ansi
stor
Number of bits
Fig. 8. Comparison with CSeA: our proposed design and self-checking CSeA [15].
1448 M.A. Akbar, Jeong-A Lee / Microelectronics Reliability 54 (2014) 1443–1451
Vasudevan et al. [15] shows considerable increment compared to anormal CSeA.
4. Self-repairing adder
4.1. Previous design approach
TMR is a well-known approach for obtaining reliable outputwith more than 300% area overhead. However, reliability can onlybe assured for a single faulty module at a time. This is because thefaulty module has not been replaced with a correctly functioningmodule, and as a result, a triple modular system changes into a du-plex system. Koal et al. [18] proposed a self-replacing approach forTMR, but the resulting design required more than 500% area over-head along with at least 5 clock cycles to replace the particularfaulty module. Moreover, system complexity due to a switchingmechanism between input and output rendered the design far be-yond practical implementation.
Fazeli et al. [11] proposed a self-checking and self-reliable adderusing the concept of narrow width value (NWV). The overall ap-proach deals with a processor design property whereby most ofthe data coming into the ALU consists of NWVs. Therefore, the indi-vidual arithmetic and logic operations can be split into two parts:one is used to perform normal operations while the unused part is
used to provide redundant computation, like a duplex system. Con-sider the case of a 64-bit adder in which (most of the time) a 32-bitadder will be used for addition while the other 32-bit adder re-mains unused because of NWV. This unused 32-bit adder has beenmade equivalent to the other 32-bit portion. Thus, a duplex systemwith minimum hardware overhead is obtained. Furthermore, theconcept of TMR has also been used to provide reliable output. Faz-eli et al. [11] proposed that a third 32-bit adder module for TMRcan be obtained from the multiplier block, because the module ofthe multiplier is a combination of add and shift operations.
The problems associated with this approach led us to proposeour design. First, the reason for using NWV in processor design isto simplify computational complexity and to reduce energy con-sumption [11]. However, adaptation of their approach will removeboth those benefits. In addition, the problem of common mode fail-ure and fault propagation due to carry has not been considered.Moreover, the possibility of two faulty modules can result in failureof their approach. Furthermore, correct output on a single fault willonly be achieved when both the operands are narrow width values.In other cases, the proposed adder can only detect the error using aduplex concept. Thus, beyond hardware complexity and overheaddue to the MUXs, the system reliability will only depend on theNWV, and according to their calculation based on the ARM proces-sor, the probability of having NWV in addition is only 56% [11].Therefore, there is only a 56% probability of obtaining reliable out-put for a single fault. This will raise the problem of system diagno-ses, as to whether the output is reliable or not, along withprecautions if the system fails to recover. Also, the MUXs are usedwithout considering their reliability issues.
4.2. Design challenges and solutions
Along with the area, power consumption and other limitationsfor a self-reliable adder, there is one important challenging factorthat is also related to carry propagation. Although our proposedself-checking adder is independent of fault propagation due to car-ry, for fault recovery at run time, the propagated carry is crucial. Ifa fault is detected in any full adder, then because of fault propaga-tion due to carry, we cannot trust the output of the correspondingfull adders. Therefore, if we replace the particular faulty module,we need to re-execute all addition processes to get true and reli-able output. However, this whole process will increase processingtime.
In our proposed design, we provide a solution for this problemby designing a reliable carry propagation chain using a dedicatedself-checking adder for replacements. If both the adders are faultyat the same time, this will be indicated as a critical situation. It ispossible to have two faults at a time, like the above-mentionedproblem, but there is a low probability of the fault being at thesame adder position.
4.3. Proposed self-repairing adder
The design approach requires two proposed self-checkingadders working at one time on the same input bits, as shown inFig. 9(a). The operation of the proposed design is such that oneadder behaves as a normal adder (indicated by Adder-0) whilethe second adder will work for recovery at run time (indicatedby Adder-0e). The suffix ‘‘e’’ indicates an ‘‘extra’’ adder used forfault recovery. The MUX will only be dependent on the fault ofthe normal adder (i.e., Adder-0). If any fault occurs in the normaladder, then the MUX will export the Sum and Carry-out from theextra adder module (i.e., Adder-0e), as shown in Fig. 9(b). If bothadders become faulty, this will be indicated as a worst situation.Also, there is a very low possibility of more than one fault in asingle full adder because of a negligible area, as opposed to the

Cout
Cout
Cout
Cout
CoutCout
Fig. 9. (a) Proposed design for self-repairing adder and (b) MUX structure.
M.A. Akbar, Jeong-A Lee / Microelectronics Reliability 54 (2014) 1443–1451 1449
complete adder module. Therefore, multiple faults in the individualfull adder have not been considered in this research.
The final Carry-out obtained from the MUX will be fed to bothfull adders present in order to compute the next Sum bit, as shownin Fig. 9(a). The MUX in Fig. 9(a) consists of two internal MUXs, asshown in Fig. 9(b). Both MUXs are designed according to the pro-posed self-checking MUX design by Vasudevan et al. [15].
4.4. Comparison with TMR and NWVA in reliability
The problem associated with TMR reliability is that if two singlefull adders associated with different modules become faulty oneafter the other, then the TMR will fail to provide reliable output.This is due to the absence of self-checking and self-replacementin TMR, because the purpose of the voter circuit is to provide reli-able output based on majority agreement without indicating thepresence of a particular fault in the modules. In order to makeTMR self-checking, we need to increase hardware overhead asmentioned by Majumdar et al. [10]. However, the absence of arecovery process will further increase the probability of more thanone fault. Thus, TMR is sensitive to a single adder of each module.To reduce this sensitivity, we propose the concept of dedicatedreplacement for individual adders, as shown in Fig. 10.
In TMR, all three modules are sensitive with respect to the faultsin the individual full adders. Therefore, we can use the concept ofsimple combinational probability without replacement to computethe probability of fault recovery, as shown in Eq. (4.2). In ourproposed design, all full adders are sensitive with respect to theirindividual replacement full adder modules. If we compute theprobability of a critical situation in which two adders at the sameposition become faulty, then our approach can be the same as twomodules having n full adders. Each module have full adders withnumbers 1 to n sequentially, such that two full adders of the samenumber cannot be present in a single module. If we introduced r
Fig. 10. Our proposed 4-bi
random faults, then the probability of having faults in at least 2 fulladders at the same position without replacement can be computedwith Eq. (4.1), where N is the total number of full adders in bothmodules.
22
� �N � 2r � 2
� �� �� n
N
r
� � ð4:1Þ
In our proposed design, two full adders at the same position becom-ing faulty is the worst situation. Therefore, Eq. (4.1) represents thefailure condition of our adder. Hence, the probability of fault recov-ery in our proposed self-repairing adder can be computed by sub-tracting Eq. (4.1) from 1 as shown in Eq. (4.3).
Pfault recovery in TMR ¼
nr
� �� 3
Nr
� � ð4:2Þ
Pfault recovery in our design ¼ 1�
N � 2r � 2
� �� n
N
r
0B@
1CA
0BBBBBBBB@
1CCCCCCCCA
ð4:3Þ
where n indicates the number of full adders in a single module, andN shows the total number of full adders in all modules. The totalnumber of faults is represented by the term r.
Considering we have three identical modules of 4-bit addersworking in parallel, there is an equal probability of a first fault inany single module. If a second fault occurs, there is a 73% probabil-ity that the fault will occur in any one of the remaining modules
t self-repairing adder.
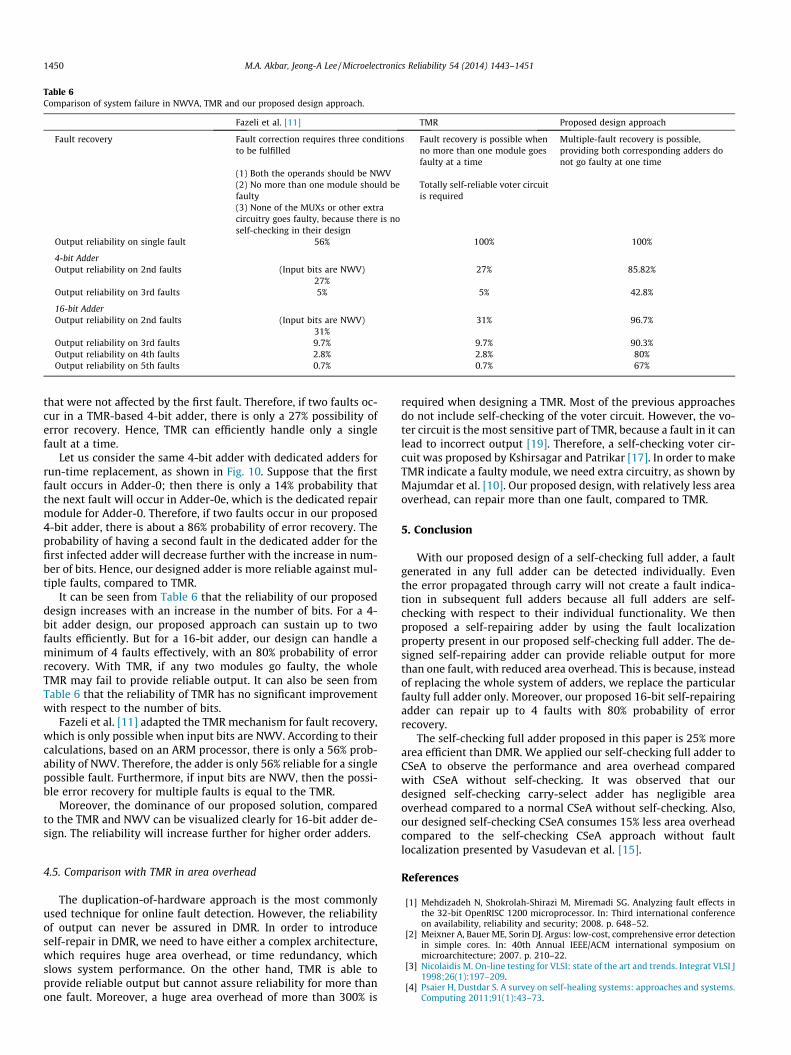
Table 6Comparison of system failure in NWVA, TMR and our proposed design approach.
Fazeli et al. [11] TMR Proposed design approach
Fault recovery Fault correction requires three conditionsto be fulfilled
Fault recovery is possible whenno more than one module goesfaulty at a time
Multiple-fault recovery is possible,providing both corresponding adders donot go faulty at one time
(1) Both the operands should be NWV(2) No more than one module should befaulty
Totally self-reliable voter circuitis required
(3) None of the MUXs or other extracircuitry goes faulty, because there is noself-checking in their design
Output reliability on single fault 56% 100% 100%
4-bit AdderOutput reliability on 2nd faults (Input bits are NWV)
27%27% 85.82%
Output reliability on 3rd faults 5% 5% 42.8%
16-bit AdderOutput reliability on 2nd faults (Input bits are NWV)
31%31% 96.7%
Output reliability on 3rd faults 9.7% 9.7% 90.3%Output reliability on 4th faults 2.8% 2.8% 80%Output reliability on 5th faults 0.7% 0.7% 67%
1450 M.A. Akbar, Jeong-A Lee / Microelectronics Reliability 54 (2014) 1443–1451
that were not affected by the first fault. Therefore, if two faults oc-cur in a TMR-based 4-bit adder, there is only a 27% possibility oferror recovery. Hence, TMR can efficiently handle only a singlefault at a time.
Let us consider the same 4-bit adder with dedicated adders forrun-time replacement, as shown in Fig. 10. Suppose that the firstfault occurs in Adder-0; then there is only a 14% probability thatthe next fault will occur in Adder-0e, which is the dedicated repairmodule for Adder-0. Therefore, if two faults occur in our proposed4-bit adder, there is about a 86% probability of error recovery. Theprobability of having a second fault in the dedicated adder for thefirst infected adder will decrease further with the increase in num-ber of bits. Hence, our designed adder is more reliable against mul-tiple faults, compared to TMR.
It can be seen from Table 6 that the reliability of our proposeddesign increases with an increase in the number of bits. For a 4-bit adder design, our proposed approach can sustain up to twofaults efficiently. But for a 16-bit adder, our design can handle aminimum of 4 faults effectively, with an 80% probability of errorrecovery. With TMR, if any two modules go faulty, the wholeTMR may fail to provide reliable output. It can also be seen fromTable 6 that the reliability of TMR has no significant improvementwith respect to the number of bits.
Fazeli et al. [11] adapted the TMR mechanism for fault recovery,which is only possible when input bits are NWV. According to theircalculations, based on an ARM processor, there is only a 56% prob-ability of NWV. Therefore, the adder is only 56% reliable for a singlepossible fault. Furthermore, if input bits are NWV, then the possi-ble error recovery for multiple faults is equal to the TMR.
Moreover, the dominance of our proposed solution, comparedto the TMR and NWV can be visualized clearly for 16-bit adder de-sign. The reliability will increase further for higher order adders.
4.5. Comparison with TMR in area overhead
The duplication-of-hardware approach is the most commonlyused technique for online fault detection. However, the reliabilityof output can never be assured in DMR. In order to introduceself-repair in DMR, we need to have either a complex architecture,which requires huge area overhead, or time redundancy, whichslows system performance. On the other hand, TMR is able toprovide reliable output but cannot assure reliability for more thanone fault. Moreover, a huge area overhead of more than 300% is
required when designing a TMR. Most of the previous approachesdo not include self-checking of the voter circuit. However, the vo-ter circuit is the most sensitive part of TMR, because a fault in it canlead to incorrect output [19]. Therefore, a self-checking voter cir-cuit was proposed by Kshirsagar and Patrikar [17]. In order to makeTMR indicate a faulty module, we need extra circuitry, as shown byMajumdar et al. [10]. Our proposed design, with relatively less areaoverhead, can repair more than one fault, compared to TMR.
5. Conclusion
With our proposed design of a self-checking full adder, a faultgenerated in any full adder can be detected individually. Eventhe error propagated through carry will not create a fault indica-tion in subsequent full adders because all full adders are self-checking with respect to their individual functionality. We thenproposed a self-repairing adder by using the fault localizationproperty present in our proposed self-checking full adder. The de-signed self-repairing adder can provide reliable output for morethan one fault, with reduced area overhead. This is because, insteadof replacing the whole system of adders, we replace the particularfaulty full adder only. Moreover, our proposed 16-bit self-repairingadder can repair up to 4 faults with 80% probability of errorrecovery.
The self-checking full adder proposed in this paper is 25% morearea efficient than DMR. We applied our self-checking full adder toCSeA to observe the performance and area overhead comparedwith CSeA without self-checking. It was observed that ourdesigned self-checking carry-select adder has negligible areaoverhead compared to a normal CSeA without self-checking. Also,our designed self-checking CSeA consumes 15% less area overheadcompared to the self-checking CSeA approach without faultlocalization presented by Vasudevan et al. [15].
References
[1] Mehdizadeh N, Shokrolah-Shirazi M, Miremadi SG. Analyzing fault effects inthe 32-bit OpenRISC 1200 microprocessor. In: Third international conferenceon availability, reliability and security; 2008. p. 648–52.
[2] Meixner A, Bauer ME, Sorin DJ. Argus: low-cost, comprehensive error detectionin simple cores. In: 40th Annual IEEE/ACM international symposium onmicroarchitecture; 2007. p. 210–22.
[3] Nicolaidis M. On-line testing for VLSI: state of the art and trends. Integrat VLSI J1998;26(1):197–209.
[4] Psaier H, Dustdar S. A survey on self-healing systems: approaches and systems.Computing 2011;91(1):43–73.

M.A. Akbar, Jeong-A Lee / Microelectronics Reliability 54 (2014) 1443–1451 1451
[5] Pellegrini A, Smolinski R, Chen L, Fu X, Hari SKS, Jiang J, et al. CrashTest’ingSWAT: accurate, gate-level evaluation of symptom-based resiliency solutions.In: Proceedings of the conference on design, automation and test in Europe;2012. p. 1106–9.
[6] Hong S, Kim S. Lizard: energy-efficient hard fault detection, diagnosis andisolation in the ALU. In: IEEE international conference on computer design(ICCD); 2010. p. 342–9.
[7] Smith JE, Lam P. A theory of totally self-checking system design. IEEE TransComput 1983;C-32:831–44.
[8] Jha NK, Wang S-J. Design and synthesis of self-checking VLSI circuits. IEEETrans Comput – Aided Des Integr Circ Syst 1993;12:878–87. 6.
[9] Angskun T, Fagg G, Bosilca G, Pjesivac-Grbovic J, Dongarra J. Self-healingnetwork for scalable fault-tolerant runtime environments. Future GeneratComput Syst 2010;26(3):479–85.
[10] Majumdar A, Nayyar S, Sengar JS. Fault tolerant ALU system 2012. In:International conference on computing sciences (ICCS); 2012. p. 255–60.
[11] Fazeli M, Namazi A, Miremadi SG, Haghdoost A. Operand width awarehardware reuse: a low cost fault-tolerant approach to ALU design in embeddedprocessors. Microelectron Reliab 2011;51(12):2374–87.
[12] Koal T, Scheit D, Schölzel M, Vierhaus HT. On the feasibility of built-in selfrepair for logic circuits. In: IEEE international symposium on defect and faulttolerance in VLSI and nanotechnology systems; 2011. p. 316–24.
[13] Khedhiri C, Karmani M, Hamdi B. Concurrent error detection adder based ontwo paths output computation. In: 2011 Ninth IEEE international symposiumon parallel and distributed processing with applications workshops (ISPAW);2011. p. 27–32.
[14] Mitra S, McCluskey EJ. Which concurrent error detection scheme to choose?In: Proceedings IEEE international test conference; 2000. p. 985–94.
[15] Vasudevan DP, Lala PK, Parkerson JP. Self-checking carry-select adder designbased on two-rail encoding. IEEE Trans Circ Syst I, Reg Papers2007;54(12):2696–705.
[16] Belgacem H, Chiraz K, Rached T. Pass transistor based self-checking full adder.Int J Comput Theory Eng 2011;3(5).
[17] Kshirsagar RV, Patrikar RM. Design of a novel fault-tolerant voter circuit forTMR implementation to improve reliability in digital circuits. MicroelectronReliab 2009;49(12):1573–7.
[18] Koal T, Ulbricht M, Vierhaus HT. Vitual TMR scheme combining fault toleranceand self repair. In: 16th Euromicro IEEE conference on digital system design(DSD 2013); 2013. p. 235–42.
[19] Ban T, Naviner L. A simple fault-tolerant digital voter circuit in TMRnanoarchitectures. In: 8th IEEE international northeast workshop on circuitsand systems conference (NEWCAS 2010); 2010. p. 269–72.