
Seamless Access to Decentralized Storage Services in Computational Grids via a Virtual File System
10
Cluster Computing 7, 113–122, 2004 2004 Kluwer Academic Publishers. Manufactured in The Netherlands. Seamless Access to Decentralized Storage Services in Computational Grids via a Virtual File System RENATO J. FIGUEIREDO ∗ Department of Electrical and Computer Engineering, University of Florida, Gainesville, FL 32611, USA NIRAV KAPADIA Capital One Services, Inc., Glen Allen, VA 23060, USA JOSÉ A.B. FORTES Department of Electrical and Computer Engineering, University of Florida, Gainesville, FL 32611, USA Abstract. This paper describes a novel technique for establishing a virtual file system that allows data to be transferred user-transparently and on-demand across computing and storage servers of a computational grid. Its implementation is based on extensions to the Network File System (NFS) that are encapsulated in software proxies. A key differentiator between this approach and previous work is the way in which file servers are partitioned: while conventional file systems share a single (logical) server across multiple users, the virtual file system employs multiple proxy servers that are created, customized and terminated dynamically, for the duration of a computing session, on a per- user basis. Furthermore, the solution does not require modifications to standard NFS clients and servers. The described approach has been deployed in the context of the PUNCH network-computing infrastructure, and is unique in its ability to integrate unmodified, interactive applications (even commercial ones) and existing computing infrastructure into a network computing environment. Experimental results show that: (1) the virtual file system performs well in comparison to native NFS in a local-area setup, with mean overheads of 1 and 18%, for the single-client execution of the Andrew benchmark in two representative computing environments, (2) the average overhead for eight clients can be reduced to within 1% of native NFS with the use of concurrent proxies, (3) the wide-area performance is within 1% of the local-area performance for a typical compute-intensive PUNCH application (SimpleScalar), while for the I/O-intensive application Andrew the wide-area performance is 5.5 times worse than the local-area performance. Keywords: file system, computational grid, network-computing, logical account, proxy 1. Introduction Network-centric computing promises to revolutionize the way in which computing services are delivered to the end-user. Analogous to the power grids that distribute electricity today, computational grids will distribute and deliver computing ser- vices to users anytime, anywhere. Corporations and univer- sities will be able to out-source their computing needs, and individual users will be able to access and use software via Web-based computing portals. A computational grid brings together computing nodes, applications, and data distributed across the network to de- liver a network-computing session to an end-user. This paper elaborates on mechanisms by which users, data, and applica- tions can be decoupled from individual computers and admin- istrative domains. The mechanisms, which consist of logical user accounts and a virtual file system, introduce a layer of ab- straction between the physical computing infrastructure and the virtual computational grid perceived by users. This ab- straction converts compute servers into interchangeable parts, allowing a computational grid to assemble computing sys- tems at run time without being limited by the traditional con- ∗ Corresponding author. E-mail: [email protected]fl.edu straints associated with user accounts, file systems, and ad- ministrative domains. Specifically, this paper describes the structure of logical user accounts, and presents a novel implementation of a vir- tual file system that operates with such logical accounts. The virtual file system described in this paper allows data to be transferred on-demand between storage and compute servers for the duration of a computing session, while preserving a logical user account abstraction. It builds on an existing, de- facto standard available for heterogeneous platforms – the Network File System, NFS. The virtual file system is real- ized via extensions to existing NFS implementations that al- low reuse of unmodified clients and servers of conventional operating systems: the proposed modifications are encapsu- lated in software proxies that are configured and controlled by the computational grid middleware. The described approach is unique in its ability to integrate unmodified applications (even commercial ones) and exist- ing computing infrastructure into a heterogeneous, wide-area network computing environment. This work was conducted in the context of PUNCH [8,10], a platform for Internet computing that turns the World Wide Web into a distributed computing portal. It is designed to operate in a distributed, limited-trust environment that spans multiple administrative
Transcript of Seamless Access to Decentralized Storage Services in Computational Grids via a Virtual File System

Cluster Computing 7, 113–122, 2004 2004 Kluwer Academic Publishers. Manufactured in The Netherlands.
Seamless Access to Decentralized Storage Services inComputational Grids via a Virtual File System
RENATO J. FIGUEIREDO ∗Department of Electrical and Computer Engineering, University of Florida, Gainesville, FL 32611, USA
NIRAV KAPADIACapital One Services, Inc., Glen Allen, VA 23060, USA
JOSÉ A.B. FORTESDepartment of Electrical and Computer Engineering, University of Florida, Gainesville, FL 32611, USA
Abstract. This paper describes a novel technique for establishing a virtual file system that allows data to be transferred user-transparentlyand on-demand across computing and storage servers of a computational grid. Its implementation is based on extensions to the NetworkFile System (NFS) that are encapsulated in software proxies. A key differentiator between this approach and previous work is the way inwhich file servers are partitioned: while conventional file systems share a single (logical) server across multiple users, the virtual file systememploys multiple proxy servers that are created, customized and terminated dynamically, for the duration of a computing session, on a per-user basis. Furthermore, the solution does not require modifications to standard NFS clients and servers. The described approach has beendeployed in the context of the PUNCH network-computing infrastructure, and is unique in its ability to integrate unmodified, interactiveapplications (even commercial ones) and existing computing infrastructure into a network computing environment. Experimental resultsshow that: (1) the virtual file system performs well in comparison to native NFS in a local-area setup, with mean overheads of 1 and 18%,for the single-client execution of the Andrew benchmark in two representative computing environments, (2) the average overhead for eightclients can be reduced to within 1% of native NFS with the use of concurrent proxies, (3) the wide-area performance is within 1% of thelocal-area performance for a typical compute-intensive PUNCH application (SimpleScalar), while for the I/O-intensive application Andrewthe wide-area performance is 5.5 times worse than the local-area performance.
Keywords: file system, computational grid, network-computing, logical account, proxy
1. Introduction
Network-centric computing promises to revolutionize the wayin which computing services are delivered to the end-user.Analogous to the power grids that distribute electricity today,computational grids will distribute and deliver computing ser-vices to users anytime, anywhere. Corporations and univer-sities will be able to out-source their computing needs, andindividual users will be able to access and use software viaWeb-based computing portals.
A computational grid brings together computing nodes,applications, and data distributed across the network to de-liver a network-computing session to an end-user. This paperelaborates on mechanisms by which users, data, and applica-tions can be decoupled from individual computers and admin-istrative domains. The mechanisms, which consist of logicaluser accounts and a virtual file system, introduce a layer of ab-straction between the physical computing infrastructure andthe virtual computational grid perceived by users. This ab-straction converts compute servers into interchangeable parts,allowing a computational grid to assemble computing sys-tems at run time without being limited by the traditional con-
∗ Corresponding author.E-mail: [email protected]
straints associated with user accounts, file systems, and ad-ministrative domains.
Specifically, this paper describes the structure of logicaluser accounts, and presents a novel implementation of a vir-tual file system that operates with such logical accounts. Thevirtual file system described in this paper allows data to betransferred on-demand between storage and compute serversfor the duration of a computing session, while preserving alogical user account abstraction. It builds on an existing, de-facto standard available for heterogeneous platforms – theNetwork File System, NFS. The virtual file system is real-ized via extensions to existing NFS implementations that al-low reuse of unmodified clients and servers of conventionaloperating systems: the proposed modifications are encapsu-lated in software proxies that are configured and controlledby the computational grid middleware.
The described approach is unique in its ability to integrateunmodified applications (even commercial ones) and exist-ing computing infrastructure into a heterogeneous, wide-areanetwork computing environment. This work was conductedin the context of PUNCH [8,10], a platform for Internetcomputing that turns the World Wide Web into a distributedcomputing portal. It is designed to operate in a distributed,limited-trust environment that spans multiple administrative

114 FIGUEIREDO, KAPADIA AND FORTES
domains. Users can access and run applications via standardWeb browsers. Applications can be installed “as is” in as lit-tle as thirty minutes. Machines, data, applications, and othercomputing services can be located at different sites and man-aged by different entities. PUNCH has been operational forfive years – today, it is routinely used by about 2000 usersfrom two dozen countries. It provides access to more than 70engineering applications from six vendors, sixteen universi-ties, and four research centers.
The virtual file system of this paper integrates componentsused in both grid computing and traditional file system do-mains in a novel manner. It differs from related work infile-staging techniques for grid computing, e.g., Globus [4]and PBS [2,6], in that it supports user-transparent, on-demandtransfer of data. It differs from related on-demand grid data-access solutions in that it does not require modifications toapplications (e.g., as in Condor [11]) and it does not rely onnon-native file system servers (e.g., as in Legion [5,19]).
A key differentiator between this paper and previous workon traditional distributed file systems is the way in which fileservers are partitioned: while conventional file systems (e.g.,NFS-V2/V3 [14], AFS [13,17]) share a single (logical) serveracross multiple users, the virtual file system employs multipleindependent proxy servers that are created, customized andterminated dynamically, on a per-user basis. The advantagesof a per-user approach include fine-grain authentication, map-ping of user identities without the necessity of global naming,and the possibility of applying user-customized performanceoptimizations such as caching and prefetching. Previous ef-forts on the Ufo [1] and Jade [15] systems have consideredthe advantages of employing per-user agents in the contextof a wide-area file system. However, unlike this paper, Jaderequires that applications be re-linked to dynamic libraries,while Ufo requires low-level process tracing techniques thatare highly O/S-dependent. In addition, both systems requirethe implementation of full NFS client functionality on theagent. The virtual file system of this paper is thus uniquein providing on-demand data access for unmodified applica-tions that work through native clients and servers of existingoperating systems.
In summary, this paper makes the following contributions.First, it describes an implementation of a virtual file systembased on call-forwarding NFS proxies. This implementationhas been in place since the Fall of 2000 and has been ex-tensively exercised during normal use of PUNCH. Second,this paper quantitatively evaluates its performance. The ex-perimental analyses considers two scenarios: virtual file sys-tem sessions within and across administrative domains. Ex-perimental results for the same-domain setup show that theperformance overhead introduced by the virtual file systemis small relative to native NFS: average overheads of 1 and18% are observed for single-client executions of the An-drew benchmark in two different PUNCH computing envi-ronments.
Cross-domain (wide-area) results show that the perfor-mance of the virtual file system is within 1% of the local-area setup for a typical PUNCH compute-intensive applica-
tion (SimpleScalar [3]). However, for an I/O-intensive ap-plication (Andrew) the wide-area execution time is 5.5 timeslarger than the local-area time.
These experimental results are important for two reasons:first, they show that the virtual file system is a effective tech-nique that is currently applicable to compute-intensive appli-cations, even across wide-area networks. Second, they moti-vate future work on performance enhancements for wide-areadeployments that exploit two unique characteristics of the vir-tual file system, namely: (a) middleware-driven migration oflogical user accounts to improve data locality at a coarse gran-ularity, and (b) fine-grain locality techniques (e.g., caching,prefetching) customized on a per-user basis. The first direc-tion is enabled by the underlying abstraction of logical useraccounts, while the second direction is enabled by the imple-mentation of a per-user proxy solution that is controlled bygrid middleware.
The paper is organized as follows. Sections 2 and 3 de-scribe the core concepts behind logical user accounts andvirtual file systems, respectively. Section 4 describes thePUNCH implementation of a virtual file system – PVFS. Sec-tion 5 presents considerations on the security and scalabil-ity of PVFS, and section 6 quantitatively analyzes its per-formance. Section 7 explains how the new paradigm allowscomputational grids to dynamically and transparently managenetwork storage. Section 8 outlines related work and section 9presents concluding remarks.
2. Decoupling users, data, applications, and hardware
Today’s computing systems tightly couple users, data, and ap-plications to the underlying hardware and administrative do-main. For example, users are tied to individual machines byway of user accounts, while data and applications are typi-cally tied to a given administrative domain by way of a localfile system. This causes several problems in the context oflarge computational grids, as outlined below:
• Users need “real” accounts on every single machine towhich they have access. This causes logistical problemsin terms of controlling user access and managing user ac-counts and also increases the complexity of resource man-agement solutions that attempt to automatically allocateresources for users.
• Organizations may add new users, remove existing ones,and change users’ access capabilities at any time. In acomputational grid, this information must be propagatedto a large number of resources distributed across multipleorganizations. Doing this in a timely manner is a difficultproposition at best.
• Policies for sharing resources may change over time – orthey may be tied to dynamic criteria such as system load.Giving users direct access to resources via “permanent”user accounts makes it difficult to implement and enforcesuch policies.

SEAMLESS ACCESS TO DECENTRALIZED STORAGE SERVICES 115
• Data and applications are typically accessible to users viaa local file system, which is often implicitly tied to a sin-gle administrative domain. NFS [14], for example, as-sumes that a given user has the same identity (e.g., theUnix uid) on all machines, making it difficult to scale itacross administrative boundaries. Wide-area file systemsdo exist (e.g., AFS [13,17]), but are not commonly avail-able in standard machine configurations, and hence wouldbe difficult to build upon in grids.
In order to deliver computing as a service in a scalablemanner, it is necessary to effect a fundamental change in themanner in which users, data, and applications are associatedwith computing systems and administrative domains. Thischange can be brought about by introducing a layer of ab-straction between the physical computing infrastructure andthe virtual computational grid perceived by users. The ab-straction layer can be formed by way of two key components:(1) logical user accounts, and (2) a virtual file system. A net-work operating system, in conjunction with an appropriate re-source management system, can then use these components tobuild systems of systems at run-time [9].
This abstraction converts compute servers into inter-changeable parts, thus allowing a computational grid to bro-ker resources among entities such as end users, applica-tion service providers, storage warehouses, and CPU farms.The described approach has been deployed successfully inPUNCH, which employs logical user accounts, a virtual filesystem service that can access remote data on-demand, a net-work operating system, and resource management service thatcan manage computing resources spread across administra-tive domains.
The components of a logical account are traditional sys-tem accounts that are divided into two categories according totheir functionality: shadow accounts, which can be dynami-cally allocated during a computing session, and file accounts,which store user files and directories.
2.1. Shadow accounts
Traditionally, a user account is expressed as a numeric iden-tifier (e.g., the Unix uid) that “belongs” to a given person(i.e., user). Each numeric identifier is permanently assignedto a given person – regardless of whether or not the person isactively making use of any computing resources.
A user account could be conceptualized as a more dynamicentity by treating the numeric identifiers associated with useraccounts on local operating systems as interchangeable enti-ties that can be recycled among users on demand. With thisapproach, a user is allocated a numeric identifier when he/sheattempts to initiate a run (or session); the identifier will be re-claimed by the system after the session is complete. The useraccounts represented by such dynamically recycled numericidentifiers are called shadow accounts.
A logical user account, then, is simply a capability that al-lows a user to “check out” a shadow account on appropriatecomputing resources via the corresponding resource manage-ment systems. Such dynamic capability can be achieved in
a way that preserves the functionality of traditional user ac-counts and achieves high scalability [9].
2.2. File accounts
In today’s computing environments, a user’s files typically re-side in accounts that are directly accessible to the user via alogin name and password, or indirectly accessible via a sharedfile system. In a large, dynamic environment where there is aneed for transparent replication and migration of data (for re-liability or performance reasons), this one-to-one associationof a user’s files with a specific “account” introduces severalconstraints that limit the computing system’s ability to man-age data. The virtual file system approach provides an effec-tive mechanism to decouple this association.
With this approach, files are stored in one or more file ac-counts. A given file account typically stores files for morethan one user, and the computing system may move filesacross file accounts as necessary. Access to the files is bro-kered by the virtual file system; users never directly login toa file account. In the currently deployed PUNCH system, forexample, all user files are multiplexed into a single file ac-count. This file account contains one top-level sub-directoryfor each PUNCH user; the files are associated with users onthe basis of their positions in the directory tree.1
3. Virtual file system
A virtual file system establishes a dynamic mapping betweena user’s data residing in a file account and the shadow accountthat has been allocated for that user. It also guarantees thatany given user will only be able to access files that he/she isauthorized to access.
There are different ways in which a virtual file system canbe implemented. In the context of PUNCH, several alter-natives have been investigated; this section describes previ-ous approaches, highlighting their limitations, and presents anovel virtual file system solution that is currently in use byPUNCH.
3.1. Explicit file transfers
A simple virtual file system could copy all of a user’s filesto a shadow account just before initiating a run (or session)and then copy the files back once the run (or session) is com-plete. This approach has two disadvantages: it is likely toresult in large amounts of unnecessary data transfer, and itwould require a complex coherency protocol to be developedin order to support multiple, simultaneous runs (or sessions).A variation on this theme is to allow (i.e., require) users toexplicitly specify the files that are to be transferred. This ap-proach is commonly referred to as file staging. File stagingworks around some of the issues of redundant data transferand coherency problems (both of which must then be man-ually resolved by the user), but is not suitable for (1) situ-ations in which the user does not know which files will be

116 FIGUEIREDO, KAPADIA AND FORTES
required a priori (e.g., this is true for many CAD and othersession-based applications), or (2) applications that tend toread/write relatively small portions of very large files (e.g.,most database-type applications).
3.2. Implicit file transfers
Another possibility is to transfer data on demand. An ap-proach previously deployed on PUNCH relies on system-calltracing mechanisms such as those found in the context ofUfo [1]. Entire files still need to be transferred, but the processis automated. (The transfer is a side effect of an applicationattempting to open a file.) The disadvantages of this approachare that it is highly O/S-dependent, and it demands extensiveprogramming effort in the development of system-call tracersand customized file system clients.
3.3. Implicit block transfers
The third option is to reuse existing file system capabilities bybuilding on a standard and widely-used file system protocolsuch as NFS. There are three ways to accomplish this goal.One is to enhance the NFS client and/or server code to work ina computational grid environment. This would require kernel-level changes to each version of every operating system onany platform within the grid. The second approach is to usestandard NFS clients in conjunction with custom, user-levelNFS servers. This approach is viable, but involves significantsoftware development. The third possibility is to use NFS callforwarding by way of middle-tier proxies. This approach isattractive for two reasons: it works with standard NFS clientsand servers; and proxies are relatively simple to implement– they only need to receive, modify, and forward standardremote procedure calls (RPC).
4. The PUNCH Virtual File System
The PUNCH Virtual File System – PVFS – is based on a call-forwarding solution that consists of three components: server-side proxies and file service managers, and client-side mountmanagers. The proxies control access to data in the variousfile accounts. The file service managers and mount managerstogether control the setup and shut down of virtual file systemsessions.
Although it is based on a standard protocol, the virtual filesystem approach differs fundamentally from traditional filesystems. For example, with NFS, a file system is establishedonce on behalf of multiple users by system administrators(figure 1(A)). In contrast, the virtual file system creates andterminates dynamic client–server sessions that are managedon a per-user basis by the grid middleware; each session isonly accessible by a given user from a specified client, andthat too only for the duration of the computing session (fig-ure 1(B)). The following discussion outlines the sequence ofsteps involved in the setup of a PVFS session.
When a user attempts to initiate a run (or session), a com-pute server and a shadow account (on the compute server) areallocated for the user by PUNCH’s active yellow pages ser-vice [16]. Next, the file service manager starts a proxy dae-mon in the file account of the server in which the user’s filesare stored. This daemon is configured to only accept requestsfrom one user (Unix uid of shadow account) on a given ma-chine (IP address of compute server). Once the daemon isconfigured, the mount manager employs the standard Unix“mount” command to mount the file system (via the proxy)on the compute server.
After the PVFS session is established, all NFS requestsoriginating from the compute server by a given user (i.e.,shadow account) are processed by the proxy. For valid NFSrequests, the proxy modifies the user and group identifiers ofthe shadow account to the identifiers of the file account in thearguments of NFS remote-procedure calls; it then forwards
Figure 1. Overview of conventional (A) and virtual (B) file systems. There are two clients (C1, C2) and one server (S). In (A), the NFS clients C1, C2 share asingle logical server via a static mount point for all users under /home. In (B), the file account resides in /home/fileA, and two grid users (X, Y) accessthe file system through shadow accounts 1 and 2, respectively. The virtual file system clients connect to two independent (logical) servers and have dynamic
mount points for users inside /home/fileA that are valid only for the duration of a computing session.

SEAMLESS ACCESS TO DECENTRALIZED STORAGE SERVICES 117
Figure 2. Example of shared NFS/PVFS setup currently deployed inPUNCH. In the file server “S”, two user-level proxy daemons (listening toports 10001, 10002) authenticate requests from clients C1, C2. Both dae-mons map shadow1/shadow2 to the uid of the PUNCH file account “fileA”,and forward RPC requests to the kernel-level server via a privileged proxy
(which listens to port 20000).
the requests to the native NFS server. If a request does notmatch the appropriate user-id and IP credentials of the shadowaccount, the request is denied and is not forwarded to the na-tive server.
Figure 1(B) shows the client-side mount commands issuedby the compute servers “C1” and “C2”, under the assump-tion that the PUNCH file account has user accounts laid outas sub-directories of /home/fileA in file server “S”. Thepath exported by the mount proxy ensures that userX cannotaccess the parent directory of /home/fileA/userX (i.e.,this user cannot access files from other users).
4.1. Local-area network setup
A virtual file system server can be configured either as a dedi-cated PVFS server, or as a shared (non-dedicated) PVFS/NFSserver. The current deployment of PVFS is configured to co-exist with a conventional NFS server to a local-area network.In this scenario, the configuration of the native mount daemonis leveraged, and the user-level mount proxy is not used. Fur-thermore, a second proxy, owned by the file account but withaccess to a pre-opened privileged socket, is used to forwardrequests from the user-level proxy to the native NFS daemonvia a secure port.2 Figure 2 depicts an example of the server-side configuration of PVFS in a local-area setup.
Mount proxies are not currently deployed in PUNCH be-cause the setup is contained within a single administrativedomain. Tighter access control can be introduced on theserver side by using a proxy for the mount protocol. Thisproxy negotiates mount requests in the same manner that theNFS proxy negotiates file system transactions. It is pos-sible to support cross-domain PVFS mounts, since authen-tication is dynamically configured by the grid middlewarevia unique combinations of IP addresses and shadow-accountuids.
5. Considerations in scalability and security
The scalability of PVFS can be evaluated in terms of itsability to support a growing number of users (or sessions),clients (i.e., compute servers), and file servers. Since PVFSonly establishes point-to-point connections over TCP/IP, andbecause there is no communication between sessions at the
PVFS level, the system scales simply by replicating thedifferent components of PVFS (file servers and file ac-counts) appropriately. The security implications of PVFS aretied to whether or not it spans multiple administrative do-mains.
When the system is deployed within a single administra-tive domain, it co-exists with the native NFS services. In anon-dedicated PVFS setup, and if login sessions to the fileserver are allowed, it is conceivable for a malicious user withaccess to a NFS file handle to gain access to a file account viathe privileged proxy. Such situation can be avoided by intro-ducing an intra-proxy (i.e., between user-level and privilegedproxies) authentication mechanism. It is possible to imple-ment intra-proxy authentication mechanisms that are trans-parent to the NFS protocol and are managed by the grid mid-dleware. The following is one example: at the beginning ofa computing session, when a user-level proxy is spawned, thegrid middleware records the port assigned to the proxy andadds the port number to a list maintained by the privilegedproxy.3 Then, at the end of the computing session, beforekilling the user-level proxy, the grid middleware removes theport number from the list. This technique ensures that theprivileged proxy only responds to requests from authorizeduser-level proxies.
When PVFS is deployed across administrative domains, itbecomes necessary to preserve the limited-trust relationshipbetween the nodes of the computational grid. For example,when a user belonging to administrative domain ‘A1’ is allo-cated a compute server ‘C2’ in a different domain ‘A2’, PVFSwill map the user’s data from the file server(s) in ‘A1’ to ‘C2’.At this point, ‘C2’ has access to the specific user’s data for theduration of the computing session. To the extent that ‘C2’ hasaccess to user data, and the user has access to ‘C2’, there is atrust relationship between ‘A1’ and ‘A2’. However, this trustbetween ‘A1’ and ‘A2’ is limited in the sense that ‘A2’ cannotgain access to files outside the user’s account or to comput-ing resources in ‘A1’ via PVFS – even if root on ‘C2/A2’ iscompromised. This is a consequence of the fact that ‘A1’ con-trols the mount point and all NFS transactions via the server-side mount and NFS proxies.
When PVFS sessions need to be established across institu-tional firewalls, the grid middleware can start user-level prox-ies on non-privileged ports that are not blocked by the fire-wall; if necessary, the grid middleware can negotiate portswith the firewall. One issue that arises in this context is thatsome NFS mount clients do not allow the specification ofmount ports. Consequently, it becomes necessary for themount client to talk to a port-mapper daemon running on aprivileged port on a file server. Typically, this port will beblocked by firewalls. In such a situation, it is still possibleto deploy the PUNCH virtual file system by relying on a thirdnode – a “file system gateway” – inside the firewall that (1) ac-cepts mount requests from the client via the port-mapper, and(2) forwards NFS requests to the file server across the firewallvia user-level ports managed by the grid middleware. Figure 3shows an example of this configuration.

118 FIGUEIREDO, KAPADIA AND FORTES
Figure 3. Configuration with PVFS file system gateway. Solid lines representkernel-to-PVFS connections that may involve access to the privileged port ofthe gateway’s port-mapper; dashed lines represent PVFS-to-PVFS connec-
tions through user-level ports.
Table 1Configuration of servers (S1, S2, S3, S4) and clients (C1, C2, C3-L, C3-W)used in the performance evaluation. With the exception of C3-W, which isconnected to a wide-area network through a cable-modem link, nodes are
connected by a local-area switched Ethernet network.
Machine #CPUs CPU type Memory Network O/S
S1 2 400 MHz UltraSparc 1 GB 100 Mb/s Solaris 2.7S2 1 167 MHz UltraSparc 256 MB 100 Mb/s Solaris 2.6S3 1 70 MHz Sparc 96 MB 10 Mb/s Solaris 2.6
S4 2 933 MHz P-III 512 MB 100 Mb/s Linux 2.4
C1 4 400 MHz UltraSparc 2 GB 100 Mb/s Solaris 2.7C2 4 480 MHz UltraSparc 4 GB 100 Mb/s Solaris 2.7
C3-L 1 900 MHz P-III 256 MB 100 Mb/s Linux 2.4
C3-W 1 900 MHz P-III 256 MB 1 Mb/s Linux 2.4
6. Performance
The relative performance of PVFS can be measured with re-spect to native NFS in terms of its impact on the number oftransactions per second. PVFS introduces a fixed amount ofoverhead for each file system transaction. This overhead isprimarily a function of RPC handling and context switching;the actual operations performed by the proxy are very simpleand independent of the type of NFS transaction that is for-warded.
The following performance analyses are based on the exe-cution of the Andrew file system benchmark (AB [7]) and theSimpleScalar [3] simulator on directories mounted throughPVFS. Andrew consists of a sequence of Unix commands ofdifferent types (directory creation, file copying, file searching,and compilation) that models a workload typical of a soft-ware development environment. SimpleScalar consists of acycle-accurate simulator of super-scalar microprocessors; itrepresents a typical compute-intensive engineering applica-tion that interfaces with the file system through standard I/Ooperations.
The experimental setup consists of the set of machines de-scribed in table 1. These machines have been chosen to al-low the investigation of three scenarios: one that is typical ofa local-area configuration of PUNCH (section 6.1), one thatemploys previous-generation servers for a sensitivity analysis(section 6.2), and one that captures a wide-area PVFS deploy-
ment (section 6.3). The main objective of the experiment is tocharacterize the performance of PVFS in an existing grid en-vironment, rather than to investigate a wide range of possibledesign points.
6.1. Multiple-client analysis
This first analysis considers the execution of simultaneousinstances of AB on each client machine ‘C1’ and ‘C2’ de-scribed in table 1. For each combination of client, server, andfile system, 200 samples of AB executions were collected at30-minute intervals over a period of four days. The server‘S1’ is a dual-processor machine that is currently the mainPUNCH file server at Purdue University; the clients ‘C1’,‘C2’ are quad-processor machines representative of PUNCHcompute servers. The experiments are performed in a “live”environment where the file server is accessed from both regu-lar PUNCH users and AB.
In the largest experiment, 8 instances of AB are executedconcurrently – i.e., one instance in every CPU of the two4-way multiprocessor clients. The AB benchmark performsboth I/O and computation; thus its execution time is depen-dent on the client’s performance. Since this experiment con-siders clients with different configurations and speeds, perfor-mance results are reported separately for each machine.
The results from the AB experiments are summarized intable 2; NFS refers to the native network file system setup,and PVFS refers to the virtual file system setup with mul-tiple server-side user-level proxies and a single privilegedproxy. Both NFS and PVFS use version 3 of the protocoland 32 KByte read/write buffers.
The results for a single client (AB = 1) show that the over-head introduced by the PVFS proxy is small: the overheadsin mean execution times are 1% (C1) and 18% (C2). Themultiple-client results (AB = 2, 4, 8) indicate a degradationin the performance of PVFS: the average relative overhead in-creases with the number of clients (up to 47%). Furthermore,the standard deviation becomes larger relative to the average(up to 21%), and the ratio between PVFS/NFS maximum ex-ecution times increases to up to 2.2.
This performance degradation is due to the fact that thecurrent implementation of the PVFS proxy is not multi-threaded, causing RPC requests to be serialized by the (sin-gle) privileged proxy. To investigate the impact of the serial-ization overhead, the 8-client experiment was repeated for aconfiguration with 8 user-level and 8 privileged proxies. Theresults from this experiment are shown in table 2 under thelabel PVFS-8. In summary, the results show that the perfor-mance degradation with multiple clients previously observedis indeed due to serialization in the single-threaded privilegedproxy. When multiple proxies are employed, the multiple-client performance of PVFS becomes, on average, within 1%of the performance of native NFS. The virtual file system isthus able to support multiple clients with performance com-parable to the underlying file system.
The setup with a single privileged proxy shown in fig-ure 2 can be extended to one with a fixed number of privi-
SEAMLESS ACCESS TO DECENTRALIZED STORAGE SERVICES 119
Table 2Mean, standard deviation, minimum and maximum execution times (in seconds) of 200 samplesof Andrew benchmark runs for native and virtual file systems (NFS, PVFS) measured at clientsC1 and C2. The file server is S1 (as defined in table 1). The table shows data for 1, 2, 4, and8 concurrent executions of AB (#AB). In all cases, the average load of the 4-processor clients,
measured prior to the execution of AB, is 0.04.
#AB FS Client C1 Client C2
Mean Stdev Min Max Mean Stdev Min Max
1 NFS 18.2 s 1.6 s 16 s 28 s 14.1 s 0.5 s 13 s 17 s1 PVFS 18.4 s 1.9 s 17 s 27 s 16.7 s 1.4 s 15 s 29 s
2 NFS 24.0 s 2.1 s 20 s 30 s 18.7 s 1.4 s 14 s 24 s2 PVFS 22.8 s 3.8 s 20 s 42 s 21.4 s 4.2 s 17 s 43 s
4 NFS 29.8 s 2.4 s 24 s 36 s 25.6 s 2.3 s 21 s 34 s4 PVFS 35.5 s 10.3 s 24 s 85 s 35.0 s 8.3 s 22 s 72 s
8 NFS 43.4 s 4.7 s 31 s 72 s 38.4 s 4.4 s 28 s 53 s8 PVFS 55.4 s 12.5 s 29 s 94 s 56.5 s 12.1 s 29 s 116 s
8 PVFS-8 42.5 s 4.3 s 32 s 57 s 38.8 s 4.8 s 30 s 65 s
leged proxies with little additional complexity to the PUNCHgrid middleware; a simple solution is to map dynamic re-quests onto the privileged proxies in a round-robin fashion.The number of clients supported by PVFS mechanism canalso scale by means of employing multiple servers and fileaccounts, as described in section 5.
6.2. Sensitivity to server performance
This analysis considers three different server configurations:a fast, dual-processor machine (S1), a medium-speed work-station (S2) and a slow workstation (S3). These configura-tions have been chosen to study the impact of server perfor-mance on the overhead introduced by the virtual file-systemproxy.
For each combination of client, server and file-system, 200samples of AB executions have been collected, in 30-minuteintervals. Each sample corresponds to the execution of a sin-gle instance of AB (i.e., a single NFS client). Unlike the ex-periment of section 6.1, where clients were exclusively exe-cuting (one or more copies of) AB, this experiment consid-ers a scenario where the client is shared between AB andother independent PUNCH jobs that compete for the client’sCPUs. This experiment models a typical situation where aPUNCH session competes for resources with other users in acomputing node; i.e. the load at the client machine is high.The recorded average loads show that the 4-processor clientmachine was neither idle nor overloaded in this experiment(table 3).
The results from the sensitivity analysis are summarizedin table 3. For the fast server (S1), the difference between theperformance of NFS and PVFS is small – 3.4% on average.4
The performance overhead of PVFS becomes relatively largerin the slower servers: 9.1% (S2) and 34.6% (S3). This is ex-plained by the fact that the overhead introduced by PVFS isonly on the CPU bound RPC-processing phase of an NFStransaction. With a fast server processor, this overhead issmall with respect to the network and disk I/O componentsof NFS.
Table 3Mean, standard deviation, minimum and maximum execution times (in sec-onds) of 200 samples of Andrew benchmark runs for file-systems mountedfrom servers S1, S2, and S3. “Load” is the average load of the 4-processor
client C1, measured prior to the execution of the benchmark.
Server Mean Stdev Min Max Load
S1, NFS 34.9 s 4.2 s 26 s 48 s 3.9S1, PVFS 36.1 s 4.8 s 27 s 57 s 3.9
S2, NFS 36.1 s 8.3 s 23 s 52 s 2.9S2, PVFS 39.4 s 8.5 s 26 s 56 s 2.9
S3, NFS 41.3 s 7.3 s 29 s 58 s 2.8S3, PVFS 55.6 s 7.5 s 43 s 78 s 2.8
6.3. Wide-area performance
This analysis considers virtual file systems established acrosswide-area networks. The experimental setup consists of aPVFS client (C3) that connects to a server (S4) via two dif-ferent networks: a switched-Ethernet LAN (C3-L) and a resi-dential cable-modem WAN (C3-W, table 1).5
Virtual file systems are established on top of native LinuxNFS-V2 clients and servers with 8 KB read/write transfersizes. The experiments consider results from executions ofAndrew (100 samples) and SimpleScalar (10 samples), col-lected at intervals of 30 or more minutes to avoid possiblecache-induced interference.
Table 4 summarizes the performance data from this exper-iment. The results show that the average wide-area perfor-mance of a compute-intensive application under PVFS is veryclose (within 1%) to the local-area performance. However,for the I/O-intensive application Andrew, the local-area setupdelivers a 5.5 speedup relative to wide-area.
The difference in performance can be attributed to a com-bination of the larger latency and smaller bandwidth of thewide-area setup. About 70% of the RPC requests are latency-sensitive because the amount of data transferred is small (e.g.,NFS lookup, getattr) while the remaining 30% are bandwidth-sensitive (e.g., NFS read, write). It is conceivable to exploit
120 FIGUEIREDO, KAPADIA AND FORTES
Table 4Mean, standard deviation, minimum and maximum execution times of 100samples of Andrew benchmark and 10 samples of SimpleScalar runs onlocal- and wide-area virtual file systems (clients C3-L and C3-W). The fileserver is S4. SimpleScalar simulates the “test” dataset of the Spec95 bench-
mark Tomcatv.
Mean Stdev Min Max
Client C3-LAndrew 25.5 s 3.6 s 22 s 44 sSimpleScalar 2155 s 17 s 2136 s 2183 s
Client C3-WAndrew 141.4 s 7.6 s 132 s 167 sSimpleScalar 2142 s 20 s 2136 s 2148 s
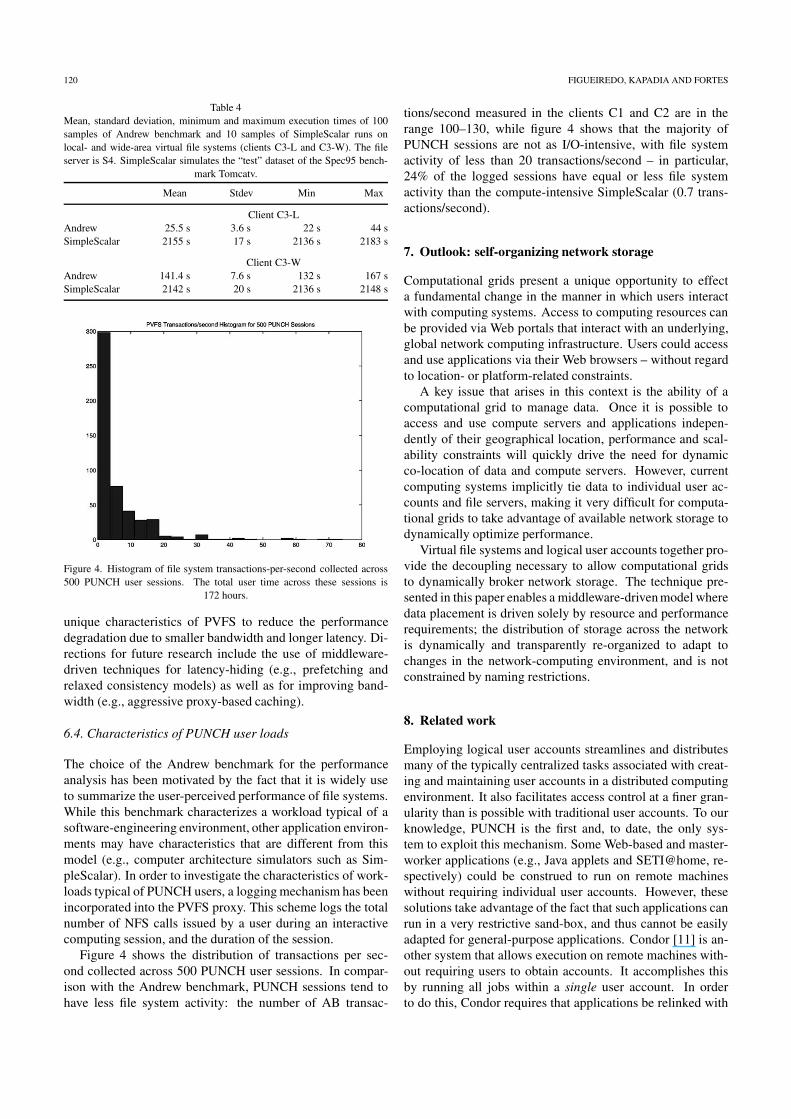
Figure 4. Histogram of file system transactions-per-second collected across500 PUNCH user sessions. The total user time across these sessions is
172 hours.
unique characteristics of PVFS to reduce the performancedegradation due to smaller bandwidth and longer latency. Di-rections for future research include the use of middleware-driven techniques for latency-hiding (e.g., prefetching andrelaxed consistency models) as well as for improving band-width (e.g., aggressive proxy-based caching).
6.4. Characteristics of PUNCH user loads
The choice of the Andrew benchmark for the performanceanalysis has been motivated by the fact that it is widely useto summarize the user-perceived performance of file systems.While this benchmark characterizes a workload typical of asoftware-engineering environment, other application environ-ments may have characteristics that are different from thismodel (e.g., computer architecture simulators such as Sim-pleScalar). In order to investigate the characteristics of work-loads typical of PUNCH users, a logging mechanism has beenincorporated into the PVFS proxy. This scheme logs the totalnumber of NFS calls issued by a user during an interactivecomputing session, and the duration of the session.
Figure 4 shows the distribution of transactions per sec-ond collected across 500 PUNCH user sessions. In compar-ison with the Andrew benchmark, PUNCH sessions tend tohave less file system activity: the number of AB transac-
tions/second measured in the clients C1 and C2 are in therange 100–130, while figure 4 shows that the majority ofPUNCH sessions are not as I/O-intensive, with file systemactivity of less than 20 transactions/second – in particular,24% of the logged sessions have equal or less file systemactivity than the compute-intensive SimpleScalar (0.7 trans-actions/second).
7. Outlook: self-organizing network storage
Computational grids present a unique opportunity to effecta fundamental change in the manner in which users interactwith computing systems. Access to computing resources canbe provided via Web portals that interact with an underlying,global network computing infrastructure. Users could accessand use applications via their Web browsers – without regardto location- or platform-related constraints.
A key issue that arises in this context is the ability of acomputational grid to manage data. Once it is possible toaccess and use compute servers and applications indepen-dently of their geographical location, performance and scal-ability constraints will quickly drive the need for dynamicco-location of data and compute servers. However, currentcomputing systems implicitly tie data to individual user ac-counts and file servers, making it very difficult for computa-tional grids to take advantage of available network storage todynamically optimize performance.
Virtual file systems and logical user accounts together pro-vide the decoupling necessary to allow computational gridsto dynamically broker network storage. The technique pre-sented in this paper enables a middleware-driven model wheredata placement is driven solely by resource and performancerequirements; the distribution of storage across the networkis dynamically and transparently re-organized to adapt tochanges in the network-computing environment, and is notconstrained by naming restrictions.
8. Related work
Employing logical user accounts streamlines and distributesmany of the typically centralized tasks associated with creat-ing and maintaining user accounts in a distributed computingenvironment. It also facilitates access control at a finer gran-ularity than is possible with traditional user accounts. To ourknowledge, PUNCH is the first and, to date, the only sys-tem to exploit this mechanism. Some Web-based and master-worker applications (e.g., Java applets and SETI@home, re-spectively) could be construed to run on remote machineswithout requiring individual user accounts. However, thesesolutions take advantage of the fact that such applications canrun in a very restrictive sand-box, and thus cannot be easilyadapted for general-purpose applications. Condor [11] is an-other system that allows execution on remote machines with-out requiring users to obtain accounts. It accomplishes thisby running all jobs within a single user account. In orderto do this, Condor requires that applications be relinked with

SEAMLESS ACCESS TO DECENTRALIZED STORAGE SERVICES 121
Condor-specific I/O libraries, making this approach unsuit-able for situations where object code is not available (e.g., aswith commercial applications).
Current grid computing solutions typically employ filestaging techniques to transfer files between user accounts inthe absence of a common file system. Examples of these in-clude Globus [4] and PBS [2,6]. As indicated earlier, filestaging approaches require the user to explicitly specify thefiles that need to be transferred, and are often not suitable forsession-based or database-type applications.
Some systems (e.g., Condor [11]) utilize remote I/O mech-anisms (from special libraries) to allow applications to ac-cess remote files. The Kangaroo technique [18] also employsRPC-forwarding agents. However, unlike PVFS, Kangaroodoes not provide full support for the file system semanticscommonly offered by existing NFS/UNIX deployments (e.g.,delete and link operations), and therefore it is not suitable forgeneral-purpose programs that rely on NFS-like file systemsemantics (e.g., database and CAD applications).
Legion [5,19] employs a modified NFS daemon to providea virtual file system.6 From an implementation standpoint,this approach is less appealing than call forwarding: the NFSserver must be modified and extensively tested for complianceand for reliability. Moreover, current user-level NFS servers(including the one employed by Legion) tend to be based onthe older version 2 of the NFS protocol, whereas the call for-warding mechanism described in this paper works with ver-sion 3 (the current version).7 Finally, user-level NFS serversgenerally do not perform as well as the kernel servers that aredeployed with the native operating system.
The Self-certifying File System (SFS) [12] is another ex-ample of a virtual file system that builds on NFS. The primarydifference between SFS and the virtual file system describedhere is that SFS uses a single (logical) proxy to handle all filesystem users. In contrast, PVFS partitions users across mul-tiple, independent proxies. In addition, SFS introduces extraparameters in the NFS remote procedure call semantics.
Previous efforts on the Ufo [1] and Jade [15] systems haveemployed per-user file system agents. However, Jade is notan application-transparent solution – it requires that applica-tions be re-linked to dynamic libraries, while Ufo requireslow-level process tracing techniques that are complex to im-plement and highly O/S-dependent. In addition, both systemsrequire the implementation of full NFS client functionality onthe file system agent. In contrast, PVFS works with unmodi-fied binaries and does not require the implementation of NFS-client functionality – only RPC-level argument modificationand forwarding.
9. Conclusions
This paper proposes a technique for establishing dynamicconnections between computing and data servers of computa-tional grids in a manner that is decoupled from the underlyingsystem accounts. This virtual file system is built on top of ex-isting NFS clients and servers, and achieves performance lev-els comparable to native NFS setups: for the PUNCH server
and client machines considered in this paper, the virtual filesystem introduces an average overhead of 18% or less overthe native NFS for a single instance of AB.
A grid environment leverages the computing power of ex-isting networked machines. Grid-oriented solutions thereforemust be able to work with standard software solutions thatare deployed across its heterogeneous computing nodes. Thevirtual file system described in this paper is well suited fora grid environment because (1) NFS is a “de-facto” standardfor local-area file systems, and (2) PVFS can be deployed ontop of existing configurations, with small administrative over-heads.
Solutions based on existing wide area file systems (e.g.,AFS [13,17]) could be conceived, but would be difficult tobuild upon in grids – wide area file systems are not commonlysupported in today’s standard machine configurations. ThePVFS solution described in this paper has been supported byPUNCH without requiring modifications to the system soft-ware available in its existing nodes. It has been extensivelyexercised during normal use since Fall of 2000; PUNCH hasemployed logical user accounts since early 1998 and a virtualfile system since Fall of 1999.
This paper shows that the user-perceived wide-area per-formance of PVFS is good for a compute-intensive appli-cation, but 5.5 times worse than the local-area performancefor an I/O-intensive application. Future work will investigatewide-area performance enhancements that exploit two uniquecharacteristics of the virtual file system: coarse-grain local-ity enhancement via middleware-driven migration of logicaluser accounts, and fine-grain locality enhancement techniques(e.g., caching, prefetching) customized on a per-user basis.
Acknowledgements
This work was partially funded by the National ScienceFoundation under grants EEC-9700762, ECS-9809520, EIA-9872516, and EIA-9975275, and by an academic reinvest-ment grant from Purdue University. Intel, Purdue, SRC, andHP have provided equipment grants for PUNCH compute-servers. Renato Figueiredo has also been supported by aCAPES fellowship.
Notes
1. The top-level sub-directories are equivalent to “home directories” on Unixfile servers, except for the fact that all files and directories are owned by asingle Unix-level account.
2. In a dedicated PVFS setup, a privileged proxy would not be necessary; theunderlying NFS server can be configured to accept requests only from thelocal host (i.e. the PVFS proxies) via non-secure ports.
3. The PVFS daemon allows dynamic reconfiguration by modifying its inputfile and subsequently notifying the process via a UNIX signal.
4. The absolute AB execution times are larger than the single-AB results oftable 2 due to the larger load of client C1.
5. The cable-modem setup delivers around 1 Mbit/s download and 100 Kbit/supload bandwidths; actual bandwidths vary depending on the number ofnetwork users.
6. This approach has also been investigated on PUNCH.7. The call forwarding mechanism also works with NFS-V2.

122 FIGUEIREDO, KAPADIA AND FORTES
References
[1] A.D. Alexandrov, M. Ibel, K.E. Schauser and C.J. Scheiman, Ufo:A personal global file system based on user-level extensions to the oper-ating system, ACM Transactions on Computer Systems 16(3) (August1998) 207–233.
[2] A. Bayucan, R.L. Henderson, C. Lesiak, B. Mann, T. Proett andD. Tweten, Portable batch system: External reference specification,Technical report, MRJ Technology Solutions (November 1999).
[3] D. Burger and T.M. Austin, The simplescalar tool set, version 2.0,Technical report 1342, Computer Sciences Department, University ofWisconsin at Madison (June 1997).
[4] K. Czajkowski, I. Foster, N. Karonis, C. Kesselman, S. Martin,W. Smith and S. Teucke, A resource management architecture formetacomputing systems, in: Proceedings of the 4th Workshop on JobScheduling Strategies for Parallel Processing (1998). Held in conjunc-tion with the International Parallel and Distributed Processing Sympo-sium.
[5] A.S. Grimshaw, W.A. Wulf et al., The legion vision of a worldwidevirtual computer, Communications of the ACM 40(1) (1997).
[6] R.L. Henderson and D. Tweten, Portable batch system: Requirementspecification, Technical report, NAS Systems Division, NASA AmesResearch Center (August 1998).
[7] J.H. Howard, M.L. Kazar, S.G. Menees, D.A. Nichols, M. Satya-narayanan, R.N. Sidebotham and M.J. West, Scale and performanceof a distributed file system, ACM Transactions on Computer Systems6(1) (February 1988) 51–81.
[8] N.H. Kapadia, R.J.O. Figueiredo and J.A.B. Fortes, PUNCH: Web por-tal for running tools, IEEE Micro (May–June 2000) 38–47.
[9] N.H. Kapadia, R.J.O. Figueiredo and J.A.B. Fortes, Enhancing the scal-ability and usability of computational grids via logical user accountsand virtual file systems, in: Proceedings of the Heterogeneous Com-puting Workshop (HCW) at the International Parallel and DistributedProcessing Symposium (IPDPS), San Francisco, CA (April 2001).
[10] N.H. Kapadia and J.A.B. Fortes, PUNCH: An architecture for web-enabled wide-area network-computing, Cluster Computing: The Jour-nal of Networks, Software Tools and Applications 2(2), Special Issueon High Performance Distributed Computing (September 1999) 153–164.
[11] M. Litzkow, M. Livny and M.W. Mutka, Condor – a hunter of idleworkstations, in: Proceedings of the 8th International Conference onDistributed Computing Systems (June 1988) pp. 104–111.
[12] D. Mazières, M. Kaminsky, M.F. Kaashoek and E. Witchel, Separatingkey management from file system security, in: Proceedings of the 17thACM Symposium on Operating Systems Principles (SOSP), Kiawah Is-land, SC (December 1999).
[13] J.H. Morris, M. Satyanarayanan, M.H. Conner, J.H. Howard, D.S.Rosenthal and F.D. Smith, Andrew: A distributed personal computingenvironment, Communications of the ACM 29(3) (1986) 184–201.
[14] B. Pawlowski, C. Juszczak, P. Staubach, C. Smith, D. Lebel andD. Hitz, NFS version 3 design and implementation, in: Proceedingsof the USENIX Summer Technical Conference (1994).
[15] H.C. Rao and L.L. Peterson, Accessing files on the internet: The jadefile system, IEEE Transactions on Software Engineering 19(6) (1993)613–625.
[16] D. Royo, N.H. Kapadia, J.A.B. Fortes and L. Diaz de Cerio, Ac-tive yellow pages: A pipelined resource management architecture forwide-area network computing, in: Proceedings of the 10th IEEE In-ternational Symposium on High Performance Distributed Computing(HPDC’01), San Francisco, CA (August 2001).
[17] A.Z. Spector and M.L. Kazar, Wide area file service and the AFS ex-perimental system, Unix Review 7(3) (1989).
[18] D. Thain, J. Basney, S.-C. Son and M. Livny, The kangaroo approachto data movement on the grid, in: Proceedings of the 2001 IEEE In-ternational Conference on High-Performance Distributed Computing(HPDC) (August 2001) pp. 325–333.
[19] B.S. White, A.S. Grimshaw and A. Nguyen-Tuong, Grid-based fileaccess: The legion I/O model, in: Proceedings of the 9th IEEE In-ternational Symposium on High Performance Distributed Computing(HPDC’00), Pittsburgh, PA (August 2000) pp. 165–173.
Renato J. Figueiredo received the Ph.D. degreeein computer engineering from Purdue University in2001. He is currently an Assistant Professor in theDepartment of Electrical and Computer Engineeringat Northwestern University. His research interests in-clude computer architecture, high-performance mul-tiprocessors, network-centric grid computing sys-tems, virtual machines and distributed file systems.E-mail: [email protected]
Nirav Kapadia is the Chief Research Scientist atCantiga Systems. His work focuses on network-centric and grid computing. Prior to that, he was Se-nior Research Scientist at Purdue University. Kapa-dia was the primary architect of PUNCH – the Pur-due University Network Computing Hubs. He wasinstrumental in taking the PUNCH technology frominitial concept to a production system that has beenused by thousands of users.E-mail: [email protected]
José A.B. Fortes received the Ph.D. degree in elec-trical engineering from the University of SouthernCalifornia, Los Angeles in 1984. From 1984 until2001 he was on the faculty of the School of Elec-trical and Computer Engineering of Purdue Univer-sity at West Lafayette, Indiana. In 2001 he joinedboth the Department of Electrical and Computer En-gineering and the Department of Computer and In-formation Science and Engineering of the Univer-sity of Florida as Professor and BellSouth EminentScholar. At the University of Florida he is the Found-ing Director of the Advanced Computing and Infor-mation Systems laboratory. He has also served asa Program Director at the National Science Foun-dation and a Visiting Professor at the Computer Ar-chitecture Department of the Universitat Politecnicade Catalunya in Barcelona, Spain. His research in-terests are in the areas of network computing, ad-vanced computing architecture, biologically-inspirednanocomputing and distributed information process-ing systems. His research has been funded by the Na-tional Science Foundation, AT&T Foundation, IBM,General Electric and the Office of Naval Research.José Fortes is a Fellow of the Institute of Electricaland Electronics Engineers (IEEE) professional soci-ety and a former Distinguished Visitor of the IEEEComputer Society.E-mail: [email protected]




















