
Rapport de Stage - MSH Val de Loire |
69
Rapport de Stage Ossant Rémi Réalisé sous la direction de Cécile Boulaire, Maître de conférences à l’université François-Rabelais Jorge Fins, Ingénieur d’étude à la MSH Val-de-Loire Olivier Marlet, Ingénieur d’étude au CNRS Soutenu le 28 juin 2016
-
Upload
khangminh22 -
Category
Documents
-
view
1 -
download
0
Transcript of Rapport de Stage - MSH Val de Loire |

Rapport de Stage
Ossant Rémi
Réalisé sous la direction de
Cécile Boulaire, Maître de conférences à l’université François-Rabelais
Jorge Fins, Ingénieur d’étude à la MSH Val-de-Loire
Olivier Marlet, Ingénieur d’étude au CNRS
Soutenu le 28 juin 2016

1
Résumé
Ce rapport de stage présente le projet OUTAGR de l’équipe de recherche Laboratoire
Archéologie et Territoires au sein duquel j’ai effectué 3 mois de stage sous la direction d’Olivier
Marlet, ingénieur d’étude au CNRS. J’y expose les missions qui m’ont été confiées à savoir :
l’encodage en XML-TEI d’un inventaire des sites comportant de l’outillage agricole daté de la
période gallo-romaine en Gaule, la réalisation d’un instrument de recherche à partir de cet encodage
ainsi que des recommandations pour la réalisation d’autres projets utilisant la TEI.
Summary
This training report presents the OUTAGR project of the research team “Laboratoire
Archéologie et Territoires” within I past 3 months as a part of my training under the direction of
Olivier Marlet, design engineer at CNRS. I outline in this document the missions I had to do, which
were: to encode in XML-TEI an inventory which compiles all the archaeological tools recovered
on archaeological sites of the Gaule, the realisation of a search engine and a list of
recommendations for others projects which could use the TEI technology.

2
Remerciements
Je tiens tout d’abord à remercier Olivier Marlet, ingénieur d’étude au CNRS, qui a été mon
tuteur professionnel durant ce stage, pour m’avoir permis de réaliser ce stage ainsi que pour ses
conseils précieux et sa disponibilité.
J’ai eu l’occasion de rencontrer de nombreuses personnes au cours de ce stage, notamment
toute l’équipe du LAT et les doctorants y travaillant qui se sont montrés accueillants et disponibles
durant toute la durée de mon stage.
Je tiens ensuite à remercier toutes les personnes qui ont trouvé le temps de m’apporter des
conseils, de répondre à mes questionnements ou de m’apporter toute forme d’aide durant cette
période de stage, tout particulièrement Jorge Fins, ingénieur d’étude à la MSH Val-de-Loire, pour
son aide et sa disponibilité, Pierre-Yves Buard, responsable d'édition électronique aux Presses
universitaire de Caen, pour son aide précieuse, ainsi que Mathieu Duboc, ingénieur d’étude au sein
des Bibliothèques Numériques Humanistes, mais également Sandrine Breuil, Ingénieur contractuel
au CNRS, et Guillaume Porte, ingénieur d’étude indépendant.
Je remercie Alain Ferdière, professeur honoraire des universités, et Xavier Rodier, directeur
d’équipe du Laboratoire Archéologie et Territoire, pour m’avoir permis de réaliser ce stage.
J’adresse également mes remerciements à Cécile Boulaire et Laurent Gerbier pour m’avoir
permis de réaliser cette année de master 2 « Patrimoine Écrit et Édition Numérique », ainsi qu’à
toute l’équipe pédagogique du CESR pour leur accompagnement et l’enseignement de qualité qu’ils
m’ont offert tout au long de cette année et pour m’avoir transmis le goût du monde du livre et des
humanités numériques.
Je n’oublie pas enfin pour leur soutien et leurs encouragements constants durant cette année
Adèle, mes parents et mes amis.

3
Sommaire
Résumé 1
Summary 1
Remerciements 2
Sommaire 3
Introduction 5
Abréviations : 6
Chapitre premier : Cadre institutionnel et scientifique du projet 7
I. Le cadre institutionnel 7
1) Le LAT : une équipe de recherche au sein d’une UMR 7
2) Quelques projets de recherche du LAT 9
a. Le projet Marmoutier : archéologie d’un site monastique dans la longue durée 9
b. SOLiDAR : l’utilisation de la technologie LiDAR dans le cadre de la recherche 9
II. Le projet OUTAGR : objectifs et dimensions scientifiques 11
1) Corpus : origine, création et intérêt scientifique 11
2) Description du corpus 12
3) La mission de stage 12
Chapitre deuxième : Le choix et l’utilisation de la TEI et de l’EAD pour le projet OUTAGR 14
I. L’insertion de la TEI au sein du LAT 14
1) Définition et enjeu de la TEI 14
a. Présentation de la TEI 14
b. Avantages et défauts d’une telle technologie dans le cadre du projet 15
2) L’utilisation de la TEI 16
a. Une structure XML adaptée au corpus 16
b. Des balises TEI adaptées au monde de l’archéologie 18
c. La mise en place de l’encodage 19
II. La création d’un instrument de recherche adapté 20
1) L’utilisation de l’EAD : 20

4
a. Définition 20
b. Le passage de la TEI à l’EAD 21
2) Le logiciel libre Pleade dans le cadre du projet 22
a. Présentation du logiciel PLEADE 22
b. Manipulation du logiciel 22
Chapitre troisième : Conduite du projet et perspectives d’exploitation en humanités numériques
24
I. Mise en place d’un calendrier et d’une méthodologie de travail 24
1) État de l’art : la visualisation du but à atteindre 24
2) La mise en place d’un protocole et d’un calendrier 25
II. L’adaptation en cours de projet 26
1) La nécessité d’une autoformation 26
2) L’utilisation d’un réseau d’acteurs des humanités numériques 27
III. Un projet tourné vers de futures activités du laboratoire 29
1) La mise en place d’outils réutilisables 29
2) La rédaction d’un rapport sur le protocole suivi au cours du projet 29
3) La communication autour du projet 30
IV. Bilan et perspectives 31
Conclusion : 34
Table des annexes : 35
Bibliographie et Webographie générale : 66

5
Introduction
Le stage décrit dans ce document, et proposé par Olivier Marle et Alain Ferdière au sein du
LAT, était parfaitement en phase avec mes attentes : la structure était celle d’un laboratoire de
recherche et la mission consistait en un travail alliant à la fois une gestion de projet et une réalisation
technique touchant au thème des humanités numériques.
Au cours de ma première année de master réalisée au sein du CESR, la rédaction d’un
mémoire, portant sur un événement des guerres de Religion en France, m’a permis de découvrir le
monde de la recherche et a conforté mon souhait de poursuivre dans ce domaine. Avant ces deux
années de master, j’ai réalisé une licence Histoire et Archéologie, le fait de pouvoir réaliser un stage
qui touchait à ces domaines me motivait et m’intéressait d’autant plus.
J’ai réalisé un stage de trois mois au sein du Laboratoire Archéologie et Territoire avec pour
charge de mettre en place le projet OUTAGR (Outillages Agricole gallo-romain). Ce rapport
présente le projet ainsi que les missions qui m’ont été confiées à savoir : l’encodage en XML-TEI
d’un inventaire des sites comportant de l’outillage agricole pendant la période gallo-romaine en
Gaule, la réalisation d’une publication électronique à partir de cet encodage ainsi que des
recommandations pour la réalisation d’autres projets utilisant la TEI. L’objectif est ici de présenter,
pour partie et par l’exemple du projet OUTAGR, un premier développement innovant d’édition
XML dans le domaine des humanités numériques au sein d’un laboratoire de recherches
archéologiques. Dans le cadre de mon stage, j’ai réalisé un document présentant le protocole que
j’ai suivi pour mener à bien la mission, il y sera fait régulièrement référence au sein de ce mémoire,
en effet ce document ayant une visée purement technique, il offre parfois des précisions
supplémentaires aux éléments qui sont exposés.
Le rapport s’articule en trois parties, une première présente le cadre institutionnel et
scientifique du projet, la deuxième présente l’aspect technique du projet ainsi que les choix et les
principales difficultés rencontrées, enfin la dernière partie présente l’aspect gestion de projet du
stage réalisé au sein du LAT et les perspectives pour le laboratoire.

6
Abréviations :
: Carte Archéologique de Gaule
: Cités, Territoires, Environnement et Sociétés.
: Centre National de la Recherche Scientifique
: Cascading Style Sheets
: Encoded Archival Description
: Hypertext Markup Language
: Institut National de Recherche Archéologique Préventive
: Laboratoire Archéologie et Territoires
Outillage Agricole Gallo-Romain
PHP Hypertext Preprocessor
Sciences Humaines et Sociales
: Text Encoding Initiative
: Unité Mixte de Recherche
: Unité Propre de Recherche
: Extensive Hypertext Markup Language
: Extensible Markup Language
: Extensive Stylesheet Language Transformation

7
Chapitre premier : Cadre institutionnel et scientifique du projet
Le Laboratoire Archéologie et Territoires est une équipe de recherche dépendant de l’UMR
CITERES et constitue aujourd’hui « l’un des principaux pôles de recherche en archéologie
métropolitaine, de la Préhistoire récente à l’Époque Moderne1 ». Le LAT a été créé en 1992 avec le
statut d’UPR avant d’obtenir son statut d’UMR avec son rattachement à l’Université François
Rabelais en 1994. Son intégration au sein de CITERES a eu lieu lors de la création de cette dernière
en 2004 dans le cadre d’une politique de mutualisation du CNRS. Cette UMR a pour objet
l’étude des villes et des territoires au sens large, cette problématique regroupe à la fois des
recherches sur les zones urbaines, sur la question environnementale, sur les territoires, les sociétés
ainsi que sur les effets des recompositions sociales. Pour pouvoir aborder tous ces thèmes, elle est
composée de quatre équipes de recherche2. La première correspond à l’équipe Construction
politique et Sociale des Territoires (CoST) dirigée par Alain Thalineau qui travaille à une meilleure
connaissance des « effets sociaux et spatiaux » notamment à travers les effets de déterritorialisation
et de (re)territorialisation3. L’équipe Monde arabe et Méditerranée (EMAM) s’intéresse pour sa part
aux relations entre le monde arabe et les autres espaces aux périodes moderne et contemporaine,
elle est dirigée par Nora Semmoud4. L’équipe ingénierie du Projet d’Aménagement, Paysage et
Environnement (IPA-PE), constitue l’une des autres équipes de recherche de CITERES, et travaille
sur les transformations des milieux naturels et des espaces aménagés5.
La dernière équipe de recherche constituant l’UMR CITERES est le « Laboratoire
Archéologie et Territoires » dirigé par Xavier Rodier. Son objet d’étude se subdivise en plusieurs
grands axes de recherche parmi lesquels il est possible de citer : l’analyse de l’inscription des sociétés
dans un environnement et leur propre production d’espaces construits à travers le temps et à partir
d’études archéologiques ou encore l’étude des relations qu’entretenaient les sociétés avec l’espace.
1 http://citeres.univ-tours.fr/spip.php?rubrique82 2 Voir figure 1 3 http://citeres.univ-tours.fr/spip.php?rubrique62 4 http://citeres.univ-tours.fr/spip.php?rubrique63 5 http://citeres.univ-tours.fr/spip.php?rubrique57

8
Ces thèmes sont abordés par le biais de plusieurs branches de l’archéologie, notamment
l’archéologie du bâti, la zoo-archéologie, la céramologie, la géomorphologie mais aussi l’histoire.
Le champ de recherche du LAT concerne la partie occidentale du monde ainsi que le monde
oriental depuis 2004 sur une période allant de la Préhistoire à l’époque moderne. En tant qu’équipe
de recherche, le LAT, comme l’ensemble de l’UMR CITERES, dépend à la fois de l’Université
François-Rabelais de Tours ainsi que du CNRS, elle est également sous la tutelle de l’INRAP et
sera prochainement sous celle du Ministère de la Culture.
Figure 1 : Organigramme de l’UMR CITERES. URL : http://citeres.univ-tours.fr/spip.php?rubrique84

9
Le LAT mène des projets dans plusieurs domaines, par différents biais et bien souvent en
coopération avec d’autres institutions et organismes de recherche. Il m’a semblé intéressant de
présenter les deux principaux afin d’avoir un aperçu de la diversité des projets mis en place par le
LAT à la fois par leurs objectifs mais également par les moyens techniques et scientifiques qu’ils
impliquent dans leurs mises en œuvre.
Ce programme de recherche consacré au site archéologique de Marmoutier a été lancé en
2004 par le LAT et a pour objectif l’étude de l’organisation spatiale d’un établissement monastique
ayant accueilli une communauté religieuse instituée par Saint-Martin au IVeme siècle de notre ère. Le
site archéologique qui fait l’objet de cette étude est localisé à quelques kilomètres de la ville de
Tours1.
Ce projet inclut la fouille d’espaces funéraires, d’espaces bâtis d’époque médiévale et
moderne qui ont composé le monastère, ainsi que d’espaces extérieurs2. Ce projet a également pour
but de fournir un chantier-école aux étudiants d’archéologie, d’histoire et d’histoire de l’art de
l’Université François-Rabelais de Tours au cours de campagnes annuelles de six semaines (entre les
mois de juin et juillet) durant lesquelles ceux-ci peuvent se former à la fouille archéologique ainsi
qu’aux diverses pratiques qu’elle implique. Ce projet donne lieu à une quantité importante de
publications rassemblées dans un rapport annuel d’avancée du chantier3. De nombreux étudiants
en archéologie de Tours travaillent dans le cadre de leur mémoire de recherche sur certains des
éléments constitutifs du site ce qui augmente la quantité de productions scientifiques sur le sujet.
Ce projet de recherche commencé en 2014 porte sur les forêts domaniales de Chambord,
Boulogne, Russy et Blois qui forment un ensemble au sein duquel a été créé le « domaine
Chambord » entre 1522 et 1650. Le but du projet est de mettre en place une télédétection LiDAR4
1 http://www.archearegioncentre.org/Marmoutier.html 2 http://citeres.univ-tours.fr/spip.php?article1305 3 https://hal.archives-ouvertes.fr/halshs-00679740 4 La télédétection LiDAR consiste en l’acquisition de données topographiques et altimétriques par le biais d’un système laser aéroporté associé à un système de localisation par satellite. Ce système permet l’acquisition de données de hautes résolutions (de l’ordre de dix points par mètre carré) et permet de passer au travers de la couverture végétale lors de l’enregistrement des points au sol. Les données obtenues forment des nuages qu’il est possible de transformer en modèles 3D.

10
afin de détecter les microreliefs à travers le massif forestier et ainsi pouvoir observer des structures
archéologiques ou naturelles1. Des prospections pédestres ont permis de mettre en évidence un
nombre important de traces d’occupation en son sein, ce qui a contribué à motiver ce projet.
Une fois mené à terme ce projet permettra à la fois de constituer une base de données
spatiale dans un système d’information géographique afin de pouvoir conduire des analyses fines
de certains secteurs présentant un intérêt archéologique, géographique ou géomorphologique et
dégager des perspectives de recherche pour l’exploitation de ces données2. Par le biais de ce projet,
le LAT a également pour but de mettre en place des protocoles de traitement et d’analyse de
données résultant d’une télédétection LiDAR dans le cadre de projets en laboratoire de recherche.
Le but est également de permettre une valorisation de ces données à destination du grand public
par le biais de la médiation notamment en offrant des représentations virtuelles du domaine
forestier en grande partie inaccessible.
Ce projet est mis en place dans le cadre d’un partenariat avec le laboratoire Intelligence des
Patrimoines3 qui travaille sur ce sujet dans le cadre du « projet Chambord4 », mais également le
Laboratoire Géohydrosystèmes Continentaux Département Géosciences Environnement5 de
l’Université François-Rabelais qui travaille sur « l’étude de l’impact du changement climatique et
des activités anthropiques sur les systèmes fluviaux, les bassins versants et les ressources naturelles
associées6 ».
1 http://citeres.univ-tours.fr/spip.php?article2133 2 Ibid. 3 https://www.intelligencedespatrimoines.fr/ 4 https://www.intelligencedespatrimoines.fr/programme/projets/ 5 https://geosciences.univ-tours.fr/ 6 http://citeres.univ-tours.fr/spip.php?article2133

11
Le corpus de documents qui a été l’objet de travail du stage s’apparente à un inventaire de
l’outillage agricole retrouvé au sein de sites gallo-romains. Cet outillage correspond à différentes
catégories d’objets : des outils aratoires, des outils de charronneries, d’autres utilisés pour
l’harnachement des animaux, des outils dédiés au travail du bois, etc… Du point de vue des bornes
chronologiques, Alain Ferdière a fait le choix de traiter ce sujet sur une période longue puisqu’elle
s’étale de la Tène Finale (IIeme siècle avant J.-C.) jusqu’au début du Haut Moyen-Âge (IVeme siècle
après J.-C.). L’inventaire s’attache donc à donner des informations sur la période dite « romaine »1.
Les sites archéologiques concernés sont ceux des provinces gauloises, germaniques et Alpines, ainsi
il comprend des sites localisés dans les limites géographiques de la France actuelle mais également
sur une partie de l’Allemagne, la Suisse, les Pays-Bas et la Belgique.
Ce travail a été réalisé par Alain Ferdière, notamment au cours de sa thèse2, ainsi que dans
plusieurs ouvrages de synthèse qu’il a écrit ou auquel il a participé, mais également grâce au
dépouillement de la CAG3 et de publications diverses concernant l’outillage antique. Il avait
originellement pour but de documenter une communication présentée au Colloque d’AGER de
Toulouse en 20074. Il a ensuite pris une dimension plus grande et a, aujourd’hui, pour objectif de
fournir un outil de recherche à utiliser à des fins de typologies pour l’une des catégories d’objets
archéologiques. Il permet de donner une vision globale de l’activité des sites ruraux durant la
période d’étude à travers la présence ou l’absence d’un ou de plusieurs types d’outillages. Ce travail,
à la fois du point de vue de son échelle ainsi que de son but d’exhaustivité, est inédit et a pour
ambition de devenir un outil de référence concernant la cartographie de la présence d’outillages
agricoles datant de la période gallo-romaine sur l’intégralité des provinces gauloises, germaniques
et Alpines.
1 La période dite romaine s’étale d’environ 50 avant J.-C. jusqu’à 475 après J.-C. 2 Alain Ferdière, Recherches sur l’habitat rural gallo-romain en Beauce : autour de la fouille de Dambron (1972),
thèse 3e cycle, Université. Paris IV, 6 vol., 946 p. 3 La collection Carte archéologique de Gaule (CAG) correspond à un ensemble de catalogues édités par département français constituant un pré-inventaire archéologique. 4 Alain Ferdière, « Recherche sur les contextes de découverte d’outillage agricole et objets liés au travail et à la production rurale en Gaule romaine », in : Ph. Leveau, C. Raynaud, R. Sablayrolles et F. Trément (dir.) - Les formes de l’habitat rural gallo-romain. Terminologies et typologies à l’épreuve des réalités archéologiques, Actes du Colloque AGER VIII (Toulouse, 2007), Aquitania, Suppl. 17, Bordeaux : 81-107.

12
L’inventaire se présente originellement sous la forme d’un document Word, au format
.docx, de 400 pages1 contenant 2729 entrées, il lui est associé une bibliographie de 200 pages
contenant environ 2700 références. L’auteur a également rédigé plusieurs documents annexes de
quelques pages, notamment une liste des différents outils ainsi que les catégories auxquelles ils
appartiennent, une liste des différents types de sites archéologiques2, une présentation de
l’inventaire ainsi qu’un document concernant les « outils agricoles miniatures en contexte funéraires
et culturels ».
L’inventaire étant le document principal du corpus, il convient d’en donner une description
plus précise. Celui-ci est organisé de manière alphabétique, bien qu’un certain nombre d’entrées
aient été rajoutées par la suite et simplement listées les unes à la suite des autres. Chaque entrée de
l’inventaire porte le nom du site, plusieurs informations quant à la localisation de celui-ci, les
différents outils archéologiques retrouvés en son sein ainsi que les références bibliographiques qui
permettent d’attester de leur présence. L’auteur a parfois ajouté, au sein des entrées, quelques
informations supplémentaires concernant les outils, le contexte de découverte de ceux-ci ou encore
les incertitudes qui perdurent sur certains points.
La mission de stage consistait en l’édition TEI du corpus afin de pouvoir réaliser une édition
électronique mise en ligne avec le logiciel libre PLEADE afin de mettre en place un instrument de
recherche pour le rendre exploitable. L’offre de stage détaillait donc les grandes étapes à réaliser.
Plus précisément, le stage a consisté à mettre en place le protocole d’édition en ligne du corpus, la
gestion du projet et à le réaliser techniquement. La taille du corpus et sa densité nécessitaient la
création d’un instrument de recherche qui soit aisément utilisable tout en permettant une
connexion entre l’inventaire et la bibliographie par le biais des références bibliographiques.
L’un des enjeux du stage était de permettre au LAT une première expérience de l’usage de
la TEI pour la publication en ligne de documents. Jusqu’à présent, l’équipe de recherche n’avait
jamais réalisé de publication en utilisant cette technologie. Dans ce cadre, une documentation
présentant les choix qui ont été faits, les différentes possibilités qui se sont présentées pour mener
1 Voir annexe 1. Elle présente un extrait de l’inventaire au format .docx, réalisé par Alain Ferdière. 2 Les différents types de sites sont au nombre de 52, parmi il peut être cité à titre d’exemple : les camps militaires, les villes, les nécropoles, les sépultures ou encore les villae.

13
à bien les différentes étapes de la mission, a été produite1. Plusieurs fichiers informatiques
spécifiques ont également été créés dans la perspective d’une réutilisation dans d’autres projets,
c’est le cas notamment du teiHeader, c’est-à-dire la partie d’entête du fichier TEI qui contient toutes
les métadonnées le concernant, nous y reviendrons dans une autre partie2.
1 Voir annexe 4. 2 Voir p. 29.

14
Chapitre deuxième : Le choix et l’utilisation de la TEI et de
l’EAD pour le projet OUTAGR
La technologie XML étant innovante au sein du laboratoire Archéologie et Territoires dans
le cadre de projets de recherche, il a été nécessaire de mettre en place à la fois une TEI adaptée au
monde de l’archéologie et de réfléchir à l’insertion de la TEI et de l’EAD dans le cadre du projet
OUTAGR
La TEI est à la fois un langage se basant sur la technologie du XML et un ensemble de
recommandations pour la description et la structuration des textes en sciences humaines1, mise en
place en dans les années 1990 comme un projet au sein d’un mouvement appelé « Humanities
computing » qui allait devenir les Humanités numériques2. Elle s’est depuis beaucoup développée
et est aujourd’hui principalement utilisée pour l’encodage de texte, notamment dans le cadre de
travaux sur des sources primaires mais elle peut aussi bien servir pour des documents numériques
vidéos ou audios. Ce langage s’est aujourd’hui imposé comme le standard de fait de l’édition
numérique et particulièrement concernant la publication des sources primaires3. Dans le cadre
d’une chaîne éditoriale, la TEI a été adoptée par de nombreuses structures de manière systématique,
c’est le cas notamment de la chaîne éditoriale des Presses universitaires de Caen qui a intégré le
XML pour l’ensemble de sa production en mettant en avant la volonté de rationaliser les pratiques
autour du document numérique et en la considérant comme une solution adaptée aux grandes
fonctions de l’édition scientifique4.
1 http://www.unicaen.fr/recherche/mrsh/document_numerique/projets/chaine_editoriale 2 Lou Burnard, Qu’est-ce que la Text Encoding Intiative ? [en ligne], OpenEdition Press, 2015, URL : http://books.openedition.org/oep/1298, consulté le 31/05/2016 3 Emmanuel Château, L’encodage des textes [en ligne], URL : http://www.desgodets.net/edition-des-cours/model, publié le 01/09/2013, consulté le 06/06/2016. 4 www.unicean.fr/recherche/mrsh/document_numerique/projets/chaine_editoriale

15
Comme l’avancent Marjorie Burghart et Nicole Dufournaud dans leur article Édition
électronique de sources : XML et Text Encoding Initiative (TEI) à l’École1, la TEI permet de « dépasser
certaines limites des outils traditionnellement utilisés par les chercheurs, pour répondre aux besoins
des SHS ». La TEI cumule en effet plusieurs avantages qui ont été mis en avant dans l’ouvrage de
Lou Burnard, Qu’est-ce que la Text Encoding Initiative2. La TEI permet de faire ressortir le sens
sémantique de chaînes de caractères mais c’est également un langage qui présentera toujours de la
même manière les informations contenues au sein des fichiers qu’il compose. Ce langage a été créé
par une communauté scientifique pour son propre usage et celle-ci le met à jour régulièrement ce
qui lui assure une grande stabilité et une évolution en fonction des besoins. Ces caractéristiques ont
en fait un choix idéal pour le projet OUTAGR.
Comme nous l’avons déjà évoqué, la TEI est une norme de codage des textes qui repose sur XML,
elle consiste en un balisage descriptif qui permet l’identification explicite de la structure sémantique
sous-jacente d’un document par le biais de balises3. Ce balisage répond à plusieurs contraintes, que
nous ne détaillerons pas dans ce mémoire, les principales étant l’imbrication d’éléments dans
d’autres éléments, le tout formant une structure en arborescence, et l’interdiction de faire se
chevaucher ces éléments. Ce langage comprend également des attributs qui permettent d’ajouter
des propriétés aux éléments, comme le présente l’exemple ci-dessous, issu du travail réalisé au cours
du stage, <placeName> et <rs> sont des éléments tandis que "type" est un attribut :
<placeName type="länder">Bade-Wurtemberg</placeName> <rs
type="harna">hipposandale</rs>
L’utilisation de la TEI dans le cadre de ce projet s’éloigne quelque peu de l’utilisation la plus
répandue de celle-ci dans le cadre de projets de recherche en sciences Humaines puisqu’il ne s’agit
pas d’une source primaire textuelle. Néanmoins ce genre de projet s’inscrit totalement dans un
autre mouvement de la TEI, celui qui tend vers une adaptation et une ouverture de la TEI en
1 Marjorie Burghart et Nicole Dufournaud, « Édition électronique de sources : XML et Text Encoding Initiative (TEI) à l'École », La lettre de L’EHESS [en ligne], n° 38, 2011, URL : http://lettre.ehess.fr/index.php?1530, consulté le 06/06/16 2 Lou Burnard, Qu’est-ce que la Text Intiative Encoding ? [en ligne], URL : http://books.openedition.org/oep/1297, consulté le 30/05/16. 3 Emmanuel Château, L’encodage des textes [en ligne], URL : http://www.desgodets.net/edition-des-cours/model, publié le 01/09/2013, consulté le 06/06/2016.

16
direction de nouveaux domaines1, ici l’archéologie. La TEI ayant été développée principalement
pour la description de textes anciens, son application au domaine de l’archéologie a toutefois
demandé une adaptation particulière notamment dans le choix des balises sur lequel nous
reviendrons plus loin dans ce rapport2. L’utilisation de cette norme d’encodage se justifie en grande
partie par l’apport de la TEI du point de l’enrichissement sémantique des textes, en effet comme
cela a déjà été mis en avant, c’est une des caractéristiques principales de cette grammaire.
Il y a quelques années le LAT a réalisé le projet ICERAMM3 qui ressemble en plusieurs
points au projet OUTAGR dans les buts qui ont été poursuivis, l’objectif était de mettre en ligne
une base de données sur la céramique Médiévale et Moderne et de la rendre consultable via un
instrument de recherche. Afin de réaliser cet instrument de recherche, l’équipe du LAT a choisi
d’utiliser principalement des scripts Jquery4 et des requêtes PHP5 permettant d’appeler des notices
contenues dans la base de données. L’outil de recherche fonctionne parfaitement mais implique un
encodage plus lourd et plus complexe que par le biais du XML. L’utilisation du XML et de la TEI
dans le cadre de ce projet rejoint un autre but qui est celui d’une démonstration des possibilités de
cette technologie dans le cadre d’un projet de recherche, non seulement du point de vue de son
intégration dans une chaîne de travail afin de mettre en place un instrument de recherche mais
également dans l’encodage de textes.
Comme cela a déjà été évoqué précédemment, le LAT n’ayant pas utilisé la technologie
XML-TEI auparavant, il n’a pas été possible de s’appuyer sur une chaîne de travail ou sur certains
fichiers modèles.
Concernant la structure du fichier XML, plusieurs options ont été envisagées, notamment
celle de se baser sur une structure en forme de liste, à l’image de l’encodage réalisé par les
Bibliothèques Virtuelles Humanistes du manuscrit Briefve declaration d’aulcunes dictions plus obscures
1 Lou Burnard, Qu’est-ce que la Text Encoding Intitiative ? [en ligne], OpenEdition Press, 2015 , URL : books.openedition.org/oep/1305, publié le 01/09/2013, consulté le 06/06/2016. 2 Voir p. 18. 3 http://iceramm.univ-tours.fr/bdrechercher.php 4 Le Jquery correspond à une librairie JavaScript, il possède la même puissance que le JavaScrip en utilisant des instructions plus simples, logiques et faciles à maintenir. URL : https://jquery.com/ 5 Le PHP ( PHP : Hypertext Preprocessor) est un langage informatique qui permet de mettre en place des pages web dynamiques.

17
contenües on quatriesme livre des faicts & dicts Heroïcques de Pantagruel 1. En effet la structure de l’inventaire
se présentant sous la forme d’une « liste » d’entrée de site, ce format aurait permis de respecter la
forme du document original, mais cela aurait alourdi le code, puisqu’au sein des entrées de site il
arrive que des listes aient été mises en place. Plus de détails sur ce point ont été donnés dans la
documentation créée au cours du stage2. Il a donc été fait le choix de considérer chacune des entrées
comme un paragraphe à part entière, ce qui a permis de bien les différents sites. Cet aspect est
également plus développé dans la documentation créée au cours du stage3.
Tout fichier TEI contient un TeiHeader, il s’agit de la partie contenant toutes les
métadonnées du fichier. Il est composé de parties principales, une première balisée avec
<fileDesc> qui contient toutes les informations bibliographiques propres au fichier encodé. Dans
le cadre du projet, ont été intégrés dans cette partie : le nom des auteurs, les personnes responsables
de l’encodage et de son contrôle, ou y ayant participé, à savoir mon tuteur de stage, Jorge Fins et
moi-même. Cette partie contient également la liste des institutions qui ont investi des ressources
humaines ou matérielles dans le projet, à savoir le Laboratoire Archéologie et Territoire, l’UMR
CITERES et l’Université François Rabelais. La mention des creatives commons4 pour la publication
d’œuvres en ligne est également présente. A noter qu’il a été choisi de rendre les données produites
dans le cadre du projet OUTAGR libres avec pour condition de ne pas en faire de réutilisation
commerciale et de les partager ou réutiliser dans les mêmes conditions que celles de leur mise en
ligne. Cette partie du header contient également les informations relatives à l’édition du fichier, qui
ont été faibles car cette édition XML-TEI constituait la première du document.
La deuxième partie concerne l’encodage du fichier, elle est balisée par <encodingDesc>,
elle décrit notamment les relations entre le document originel et celui encodé. Peu d’informations
ont été données dans cette partie car le document originel étant un fichier .docx écrit par Alain
Ferdière, peu de détails avaient à être donnés sur des aspects comme le respect des sauts de ligne
ou tout autre aspect éditorial. Cette partie contient également une description du projet.
La troisième partie correspond à la description des aspects non bibliographiques du texte
ainsi que le profil du contenu textuel et est entourée par <profileDesc>. Dans cette partie ont été
déclarées les différentes langues présentes au sein de l’inventaire (français, allemand, latin, anglais,
hongrois et tchèque) ainsi que les sujets qu’il aborde par le biais de la liste de mots-clés
1 http://xtf.bvh.univ-tours.fr/xtf/data/tei/B751131010_FR3370_suppl/B751131010_FR3370_suppl_tei.xml 2 Voir annexe 4, pp. 50-51. 3 Ibid. 4 Les creative commons correspondent à l’exposer des droits de diffusion dans le cadre d’une œuvre intellectuelle en fonction de quatre composantes : l’attribution, l’utilisation commerciale, le partage dans les mêmes conditions et la modification, qui donne 6 licences différentes.

18
correspondant aux autorités matières définies par la Bibliothèque Nationale de France. La dernière
partie concerne les révisions apportées au document au fil du temps, elle ne contient donc pas
beaucoup d’informations puisque, après encodage, il n’a pas été nécessaire de revenir sur ce fichier.
Le header du fichier a été réalisé grâce à la documentation fournie lors du stage XML-TEI
qui a été donnée au M2 PEEN par Jorge Fins, Mathieu Duboc, et Lou Burnard, ainsi que grâce à
la documentation des TEI-guidelines1.
Dans son article l’encodage des textes2, Emanuel Château met en avant que la production d’un
balisage descriptif passe par trois étapes : tout d’abord « la reconnaissance des éléments », qui
consiste à repérer les éléments qu’il sera nécessaire de baliser, puis la « sélection des balises » à
appliquer à ces éléments et enfin la « réalisation du balisage »3.
Dans le cadre de ce projet, les éléments qui ont été sélectionnés sont d’abord les outils
agricoles qui constituent le cœur du fichier à encoder. Puisqu’il n’existe pas de balise TEI servant
spécifiquement à entourer un élément archéologique, il a donc été choisi d’utiliser la balise <rs>
qui correspond à reference string et permet d’entourer « un nom générique ou une chaîne permettant
de s'y référer4 ». Comme cela a été avancé précédemment, Alain Ferdière a classé les différents
outils agricoles en plusieurs catégories, afin de conserver cette information, il a été choisi d’utiliser
un attribut "type" pour caractériser à quelle catégorie appartient chaque outil5. L’autre élément
essentiel qu’il a été nécessaire d’entourer par des balises sont les noms des sites archéologiques. Il
a été choisi une balise <placeName> qui sert à entourer « un nom de lieu absolu ou relatif6 » et,
afin de préciser la nature de ce lieu, un attribut type a été également utilisé. Concernant les autres
éléments de localisation des sites, qu’il s’agisse de villes, départements, länder, région, etc. la même
balise <placeName> a été utilisée ainsi qu’un attribut précisant la nature de l’élément7. Les
expressions latines ont également été traitées, en effet il en existe un certain nombre qui se rapporte
le plus souvent à des structures ou des outils notamment le terme villa ou ascia. Ces expressions
latines ont été entourées par une balise <foreign> qui permet de reconnaître « un mot ou une
expression comme appartenant à une langue différente de celle du contexte8 », la balise a été
1 http://www.tei-c.org/release/doc/tei-p5-doc/fr/html/HD.html 2 Emmanuel Château, op. cit. 3 Ibid. 4 http://www.tei-c.org/release/doc/tei-p5-doc/fr/html/ref-rs.html 5 Le détail des attributs utilisés pour caractériser les outils agricoles est donné dans l’annexe 4, pp. 47-48. 6 http://www.tei-c.org/release/doc/tei-p5-doc/fr/html/ref-placeName.html 7 Le détail des attributs utilisés pour caractériser les 8 http://www.tei-c.org/release/doc/tei-p5-doc/fr/html/ref-foreign.html

19
complétée par un attribut "xml:lang" qui permet de préciser à quelle langue appartient le terme
entouré, ainsi que par un attribut "rend" qui permet de passer l’expression en italique afin de
respecter le choix de l’auteur de mettre ces expressions sous cette police particulière. Enfin les
derniers éléments qui ont été considérés comme assez pertinents pour être entourés de balises sont
les dates et les périodes, qui sont nombreuses dans le cadre de ce projet. C’est la balise <date> qui
a été choisi, elle permet de contenir « une date exprimée dans n'importe quel format1 », ce qui
convient à la fois pour des dates fixes en utilisant un attribut "when" mais également pour des
périodes en utilisant les balises <notBefore> et <notAfter> qui permettent de donner les deux
dates extrêmes de la période. D’autres balises ont été utilisées dans le cadre de l’encodage, elles sont
détaillées dans la quatrième annexe de ce mémoire2.
Afin de gagner du temps dans l’encodage du fichier, il a été choisi de procéder à un pré-
encodage du fichier par le biais du logiciel Odette3. Cet outil mis en place par Frédéric Glorieux,
permet de passer un fichier d’un format .odt à un fichier XML-TEI. Cette opération permet donc
d’avoir un fichier « pré-encodé » en XML-TEI et de gagner un temps précieux pour la partie de
l’encodage. Il a donc suffit de transformer le fichier fourni par Alain Ferdière d’un format .docx à
un format .odt par l’intermédiaire d’un logiciel de traitement de texte pour ensuite pouvoir procéder
à cette étape.
Afin de rendre la partie de l’encodage encore plus efficace, de nombreuses expressions
régulières ont été utilisées. Elles correspondent à « une chaine de caractère permettant de décrire
un ensemble variable par l'utilisation d'une syntaxe précise4 », elles permettent de sélectionner et de
décrire des chaînes avec plusieurs inconnues ou variables en leur sein et sont très utiles pour réaliser
des opérations de « rechercher-remplacer » dans un texte en intégrant des inconnus et des variables
dans les chaînes de caractères à rechercher. C’est à cette fin qu’elles ont été utilisées dans le cadre
de l’encodage notamment pour baliser des outils archéologiques présents à de nombreuses reprises
dans l’inventaire. Néanmoins une grande part de l’encodage a dû être réalisée à la main car
impossible à traiter par le biais d’expressions régulières. De plus lorsque nous avons eu recours à
l’utilisation d’expressions régulières, il a été nécessaire de faire des vérifications sur l’intégralité du
fichier pour prévenir toutes formes d’erreurs. Cette phase d’encodage a été réalisée sur le logiciel
1 http://www.tei-c.org/release/doc/tei-p5-doc/fr/html/ref-date.html 2 Voir annexe 4, pp. 44-48. 3 http://obvil-dev.paris-sorbonne.fr/developpements/Odette/ 4 http://nliautaud.fr/wiki/articles/notepadpp/expreg#notepad_les_expressions_regulieres

20
Oxygen. Afin d’assurer un contrôle des balises utilisées lors de l’encodage le choix a été de fait de
mettre en place un schéma XML par le biais du logiciel Roma1. Un schéma XML permet de définir
une structure de fichier en imposant notamment les éléments et attributs qui sont acceptés au sein
d’un fichier afin que celui-ci soit valide, il est simplement relié au fichier par le biais d’un lien dans
le header. Le fait de créer un schéma permet un contrôle de l’encodage et de prévenir un certain
nombre d’erreurs concomitantes à un encodage manuel.
L’EAD a été utilisée dans le cadre de ce stage pour répondre aux besoins du logiciel Pleade
qui ne permet de traiter que des fichiers dans ce format ou au format EAC2. C’est pour cette raison
qu’il a été nécessaire d’intégrer au projet une procédure permettant le passage de la TEI à l’EAD.
L’EAD a été développée comme une DTD3 pour encoder les instruments de recherches
décrivant les fonds d’archives4. Elle se base sur la grammaire XML ainsi que sur la norme
ISAD(G)5. Ce langage fonctionne principalement sur un système d’emboitement de plusieurs
niveaux archivistiques6, en général un fond d’archives au sein duquel seront présents plusieurs
unités d’archivage et pièces d’archives. Dans le cadre du projet, il a été choisi de ne définir que trois
grandes unités de ce type, la première étant l’inventaire dans sa globalité, la deuxième étant un
ensemble d’entrées regroupées alphabétiquement et enfin une entrée de l’inventaire. La forme du
fichier à traiter dans le cadre du projet n’est pas exactement celle d’un fond d’archives mais elle s’en
rapproche par sa forme, il n’a donc pas été difficile d’adapter l’encodage EAD au fichier, même si
cela a impliqué une perte de données par rapport à la TEI.
1 http://www.tei-c.org/Roma/ 2 L’EAC correspond au format Encoded Archival Context, c’est également une DTD qui repose sur le langage XML au même titre que l’EAD. 3 Une DTD (Document Type Definition) a pour rôle de définir la structure d’un document en imposant un certain nombre de contraintes pour qu’un fichier soit considéré comme valide. 4 http://bonnespratiques-ead.net/guide/intro/autres-normes 5 La norme ISAD(G) correspond à la Norme générale et internationale de description archivistique, elle a été définie par le Conseil international des archives et comprend des règles de description à plusieurs niveaux, des éléments de descriptions, etc. 6 Voir annexe 3, elle présente un extrait de l’encodage de l’inventaire au format EAD.

21
Le passage d’un fichier TEI à un fichier EAD a été réalisé par le biais d’un filtre XSLT1,
cette technologie permet de créer une copie d’un fichier dans un autre format. Cette transformation
se fait de manière choisie et contrôlée dans sa structure et ses éléments. Le fichier de transformation
XSLT se construit sur la base de la grammaire XML en utilisant des templates2 qui vont permettre
de sélectionner les éléments qui vont être transformés en d’autres dans le document « clone ». Ils
permettent également de créer de nouveaux éléments et attributs et de les ajouter ou encore de
supprimer certains éléments du fichier d’origine pour qu’ils ne se retrouvent pas dans le fichier
« clone ».
Dans le cadre de ce projet, il a été choisi de réaliser deux filtres XSLT, l’un pour réaliser le
eadheader, qui a le même rôle que le header d’un fichier TEI mais dans le cas d’un fichier EAD, à
partir du teiHeader et une second concernant le reste du fichier c’est-à-dire la partie « texte » du
fichier TEI. Les deux fichiers EAD obtenus ont ensuite été réunis en un seul qui a constitué le
fichier de l’inventaire encodé en XML-EAD. Les enjeux de cette procédure résidaient dans la
nécessité de perdre le moins de données possibles et d’arriver à mettre en place un fichier EAD
qui soit valide et bien formé sans avoir à recourir à un encodage manuel.
Le langage EAD s’inspire en grande partie du langage TEI, néanmoins il n’a pas la même
précision et la même richesse que ce dernier, ainsi le passage de l’un à l’autre a induit une perte de
données substantielle mais incontournable. Il a notamment été impossible de garder une telle
richesse de données dans le header du fichier EAD tout simplement en raison de l’absence de
balises servant à spécifier certaines informations présentes dans le teiHeader c’est le cas notamment
concernant les métadonnées portant sur l’encodage TEI notamment les acteurs de celui-ci. Dans
le cas du corps du fichier, d’autres informations n’ont également pas pu être gardées au travers de
la transformation c’est particulièrement le cas pour la spécification du type d’outils auquel se
rapportaient les objets archéologiques agricoles entourés par des balises. Néanmoins il convient de
relativiser cette perte de données, en effet elle n’a pas nui à la création de l’outil de recherche, sa
précision et les capacités qui en étaient attendues3.
1 Extensible Stylesheet Language Tranformations 2 Les templates correspondent à des modèles de mises en forme. 3 Voir annexe 4, pp. 56-58. Un tableau a été construit mettant en regard les informations contenus dans le fichier TEI et dans le fichier EAD et précisant quelles informations ont pu être gardées ou non.

22
Le choix de l’utilisation du logiciel Pleade a été réalisé en amont du stage par l’équipe du
Laboratoire Archéologie et Territoire sur les conseils de l’équipe de la MRSH de Caen qui a fourni
une version retravaillée et optimisée du logiciel et qui possédaient une expérience de son utilisation.
Le logiciel Pleade est un logiciel libre permettant de diffuser des instruments de recherches
archivistiques dans une architecture Web1. A partir d’un fichier bien formé et valide au format EAD
ou EAC, le logiciel peut créer une arborescence utilisable dans un instrument de recherche. Pour
pouvoir fonctionner, Pleade s’appuie sur un serveur local, le logiciel SDX ainsi que le logiciel Java.
Conformément au conseil de la MSRH de Caen, il a été choisi d’utiliser Tomcat 7.02 qui est serveur
d’applications Java également libre. Le logiciel propose de nombreuses fonctionnalités qui
permettent de s’adapter à différents projets, notamment un outil de publication d’images
numérisées, la mise ne place d’un entrepôt OAI, la diffusion d’informations statiques sur un site
web3 … Dans le cadre du projet, l’outil de publication d’images numérisées (Navimages) n’a pas
été utilisé mais plusieurs pages statiques ont été ajoutées. Le logiciel Pleade constitue à la fois la
partie back-office et front-office du site, c’est-à-dire que l’interface est la même pour l’utilisateur et
l’administrateur, ainsi les modifications réalisées sur celui-ci notamment concernant l’interface et le
graphisme ont été réalisées directement depuis le logiciel Pleade qui constituera le rendu du site
une fois sa publication réalisée. Dans le cadre du projet il a été choisi la version 3.4 de Pleade qui a
été optimisée par l’équipe de la MRSH de Caen.
Une difficulté a été rencontrée au cours du stage concernant la manipulation du logiciel
Pleade. Il s’agit de l’absence de documentation sur son utilisation, en effet une seule documentation
est accessible sur ce logiciel et concerne la version 2.0 du logiciel, elle est donc obsolète et
inutilisable dans le cas de la manipulation d’une version 3.4 de ce même logiciel. Néanmoins cette
difficulté a pu être contournée par l’utilisation à la fois de listes de diffusion sur le logiciel et l’aide
de la MRSH de Caen, nous reviendrons sur ce point dans le prochain chapitre.
1 http://pleade.org/ 2 http://tomcat.apache.org/ 3 http://pleade.org/fr/documentation/descriptions/index.html

23
La publication de document via le logiciel Pleade est assez simple puisqu’elle se fait de
manière totalement automatique, il est donc très aisé d’arriver à créer un instrument de recherche
fonctionnel1. Néanmoins la personnalisation de l’interface de l’instrument de recherche se fait au
prix de la manipulation des fichiers informatiques en divers langages. La personnalisation des
menus se fait par exemple à partir d’un fichier .xconf qui se base sur une grammaire XML. La
modification de ces fichiers a permis d’intervenir sur le fonctionnement de l’outil de recherche en
personnalisant notamment les menus présents au sein de la page d’accueil, en retirant certains liens
vers des pages présentes par défaut au sein du site et en rajoutant des liens à partir d’entrées du
menu vers de nouvelles pages statiques créées spécifiquement pour le projet.
Nous avons choisi d’ajouter plusieurs pages statiques à l’instrument de recherche afin de le
documenter et de l’enrichir, ces pages statiques correspondent aux fichiers fournis par Alain
Ferdière et concernent la description du but et de l’ambition du travail qu’il a réalisé, ainsi qu’une
annexe portant sur l’outillage agricole miniature retrouvé en contexte funéraire. En plus de cela,
plusieurs autres fichiers ont été rajoutés concernant notamment la création de l’outil de recherche,
des informations sur le projet et le Laboratoire Archéologie et Territoires. Tous ces fichiers ont dû
être encodés au format XHTML2 pour être intégrés à l’instrument de recherche.
Concernant l’aspect purement graphique de l’interface du site, elle a été modifiée en
travaillant les fichiers CSS intégrés au logiciel. Les CSS, Cascading StyleSheet, permettent de définir
l’apparence de documents HTML ou XML3 qui sont donc constitutifs de l’instrument de recherche.
L’aspect général du site a été retravaillé, notamment en ajoutant les logos propres aux institutions
ayant participé au projet.
1 La procédure qui a été suivie pour la publication de document par le biais de Pleade est détaillée au sein de la quatrième annexe aux pages 60 et 61. 2 Le XHTML, Extensive est un format qui consiste en une transposition de l’HTML en XML, il s’écrit donc avec des composants du langage HTML tout en respectant les principes du XML. 3 http://www.w3schools.com/css/

24
Chapitre troisième : Conduite du projet et perspectives
d’exploitation en humanités numériques
La gestion de projet a été un autre élément central du stage réalisé au sein du LAT à côté
de tous les choix techniques et leurs réalisations. Le projet abordant des aspects nouveaux pour
l’équipe de recherche, comme nous l’avons montré précédemment, il était nécessaire de prendre
du recul sur celui-ci, de s’appuyer sur d’autres acteurs des humanités numériques mais également
de laisser un héritage fort de ce projet afin qu’il serve pour d’autres.
Comme nous l’avons déjà présenté plus en amont de ce mémoire, la mission de stage
consistait en l’édition électronique et la mise en ligne de l’inventaire via le logiciel libre PLEADE.
Afin de visualiser l’objectif du stage concernant le rendu qui pouvait être espéré ainsi que
les possibilités du logiciel Pleade, un état de l’art a été réalisé. Plusieurs sites et outils de recherche
réalisés à partir de ce logiciel ont été consultés notamment le programme Nummus1 réalisé par la
MRSH de Caen qui a donné lieu à la mise en place d’un outil de recherche pour consulter une
banque de données portant sur les monnaies découvertes lors de fouilles archéologiques sur le
territoire normand2. Le site europeangardens.eu3 mis en place par la MRSH de Caen et l’Université
de Basse-Normandie, qui a pour but le recensement de toutes les sources d’archives et d’inventaires
publiques et privées relatives à l’art des jardins, a également été relevé lors de cet état de l’art.
Dans le cadre du projet OUTAGR, l’objectif a été fixé d’obtenir un outil utilisable et
fonctionnel, c’est-à-dire un site qui permette à la fois l’accès direct à la base de données sous la
forme d’une arborescence, comme le propose le logiciel, ainsi que la possibilité d’interroger cette
1 https://www.unicaen.fr/crahm/Nummus/pages/fonds.html 2 https://www.unicaen.fr/crahm/Nummus/pages/infos.html 3 http:// http://europeangardens.eu/inventories/fr/

25
base par le biais de requêtes. Ces requêtes se font soit par des recherches simples ou grâce à une
recherche avancée qui nécessite le remplissage d’un formulaire de recherche.
A la suite de l’état de l’art et après avoir eu une vision claire de l’objectif à atteindre dans le
cadre du stage, il a été nécessaire de dégager les différentes étapes nécessaires afin d’atteindre cet
objectif. Une méthodologie de travail par étape avec plusieurs vérifications qui conditionnent le
passage à la suivante a donc été mise en place. Ces étapes ont été dégagées comme suit :
1) Mise en place du cheminement entre le fichier original jusqu’au traitement par PLEADE
2) Choix des balises TEI à utiliser pour l’encodage avec à la fois volonté d’encoder
seulement les informations nécessaires au projet afin de ne pas encoder à outrance le
fichier dans des cas où les informations ne seraient pas utiles.
3) Mise en place d’un header spécifique pour le LAT
4) Mise en place d’un schéma spécifique pour le projet avec l’idée qu’il pourra être réutilisé
par la suite
5) Encodage d’un échantillon de l’inventaire à des fins de test.
6) Choix des balises EAD à utiliser
7) Mise en place d’un filtre XSLT pour passer de la TEI à l’EAD
8) Encodage en TEI de la bibliographie
9) Encodage en TEI de l’inventaire
10) Passage de l’inventaire au format EAD par le biais du filtre XSLT
11) Mise en place du site par le biais du logiciel Pleade
12) Intégration de pages statiques sur le site
13) Travail de l’interface graphique du site
14) Mise en ligne du site sur un serveur de l’université
Plusieurs vérifications et mises en place ont été réalisées, notamment concernant la
vérification du choix des balises TEI et EAD par le biais de rendez-vous avec Jorge Fins, tuteur
pédagogique du stage, des contrôles de l’encodage TEI de la bibliographie et de l’inventaire ainsi
qu’un contrôle de l’inventaire encodé en EAD mais également des contrôles de l’encodage des
fichiers statiques en XHTML grâce à des logiciels vérifiant la validité de ceux-ci.
A ces différentes étapes a été associé un calendrier avec le temps approximatif de chacune
des étapes. Bien que les objectifs du stage aient été remplis, le calendrier prévisionnel n’a pas
toujours été suivi suite notamment en raison de problèmes techniques concernant l’installation d’un
serveur Tomcat et de Pleade, problèmes qui ont allongé certaines étapes, ou encore en raison du
fait qu’il ait été difficile d’estimer le temps nécessaire pour s’auto-former sur plusieurs langages et
outils utilisés durant le stage.

26
Un certain nombre de logiciels et de langages ont été nécessaires à la bonne réalisation de
toutes les étapes du projet, certains étaient déjà maîtrisés avant le début du stage grâce aux
enseignements du M2 PEEN, c’est le cas du langage XML-TEI maitrisé par le biais d’une formation
poussée incluse dans le cours portant sur les humanités numériques réalisé notamment par Jorge
Fins et Mathieu Duboc. C’est pareillement le cas concernant les langages HTML et CSS, qui ont
été appris grâce aux cours d’édition internet dispensé par Alexandre Roulois. Il en va de même
pour la maîtrise du logiciel Oxygen qui a été maitrisé grâce à la formation XML-TEI évoquée
précédemment. Enfin il faut noter que le projet a nécessité l’utilisation du logiciel Tomcat, qui est
un générateur de serveur local, qui a pu être utilisé grâce à la maîtrise de cette technologie à la suite
du cours d’Alexandre Roulois au M2 PEEN.
A l’inverse, plusieurs langages qui ont été utilisés dans le cadre de ce projet n’étaient pas
maîtrisés au début du stage, il a donc été nécessaire de procéder à une autoformation. Ça a été le
cas notamment pour l’EAD, même si comme nous l’avons évoqué précédemment ce langage n’a
pas été utilisé dans le cadre d’un encodage manuel mais simplement comme langage de sortie après
l’utilisation du filtre XLST. Néanmoins il était absolument essentiel de le maîtriser dans sa structure
et son fonctionnement pour être en capacité de choisir les balises de ce langage qui devraient
correspondre à celles utilisées dans le fichier TEI et éventuellement rajouter des éléments qui
viendraient à manquer. Cette autoformation été en grande partie réalisée grâce au site internet
http://bonnespratiques-ead.net/ au sein duquel existe un « guide des bonnes pratiques1 » qui
détaille très précisément et clairement la logique et l’utilisation du langage XML-EAD. Ce site a été
mis en place par un ensemble de professionnels des bibliothèques et des archives et s’adresse aux
professionnels du domaine ayant besoin de cette technologie.
Le langage XSL avait été abordé au cours de la formation XML-TEI dispensé au M2 PEEN
mais sa maîtrise n’était pas suffisante pour répondre au besoin du projet, à savoir réaliser un filtre
XSLT qui soit capable de transformer le fichier de l’inventaire encodé en XML-TEI en un format
XML-EAD. Il a donc été nécessaire de passer par une phase d’autoformation et de
perfectionnement dans ce langage. Cela a été rendu possible grâce à la documentation et aux
exemples fournis au cours de la formation XML-TEI, mais également grâce à plusieurs ressources
1 http://bonnespratiques-ead.net/guide

27
internet, notamment la documentation issue d’une formation dispensée par Lou Burnard à Lyon
en 2011 sur ce sujet, qui a été mise en libre accès1. Plusieurs guides et tutoriels sur le sujet ont
également été utilisés, parmi lesquels il est possible de citer une documentation émanant de
l’université Paris-Diderot2 ou encore une autre réalisée par Emmanuel Lazinier, ingénieur
informatique spécialiste du XML, sur le sujet3.
Concernant le logiciel Pleade, comme cela a été rapidement abordé précédemment, il n’a
pas été possible de se former par le biais de la documentation mise à disposition par les créateurs
du logiciel car celle-ci apparaît être périmée par rapport à la version choisie dans le cadre du stage,
il a fallu s’appuyer sur d’autres acteurs des humanités numériques pour acquérir les compétences
nécessaires à son utilisation.
La mobilisation d’un réseau d’acteurs des humanités numériques a été nécessaire dans le
cadre du projet à la fois pour obtenir des informations sur certaines technologies, comme ce fut le
cas pour Pleade, mais également pour procéder à des vérifications sur les choix effectués ainsi que
pour recevoir des conseils sur les méthodes à adopter. Ces acteurs des humanités numériques
prirent à la fois la forme de personnes appartenant à un réseau de connaissance mais également
celle de communautés en ligne et de listes de diffusions.
Pour reprendre le cas du logiciel Pleade, pour pallier au manque d’informations de la part
des créateurs du logiciels sur son utilisation, il a été nécessaire de contacter et de travailler avec
Pierre-Yves Buard, responsable d’édition électronique aux Presses Universitaires de Caen, qui fait
notamment partie de l’équipe qui nous a fourni une version optimisée du logiciel et qui travaille
avec le LAT sur plusieurs projets. M. Buard a été connu par le biais des cours qu’il a dispensé à la
promotion des masters 2 PEEN de l’année 2015-2016 mais également lors d’un atelier portant sur
le logiciel XMLmind XML Editor4 qui a eu lieu au Centre d’Études Supérieures de la Renaissance
le 26 avril 2016 et auquel j’ai eu l’opportunité de pouvoir participer durant mon stage. Un ensemble
d’échanges ont eu lieu avec Pierre-Yves Buard au sujet de l’utilisation du logiciel Pleade par courrier
électronique mais également par le biais d’un échange téléphonique. Afin de prendre contact avec
1 http://tei.oucs.ox.ac.uk/Talks/2011-05-lyon/xslt-intro.pdf 2 https://www.irif.univ-paris-diderot.fr/~carton/Enseignement/XML/Cours/XSLT/index.html 3 http://xml.chez.com/xslt/ 4 http://www.xmlmind.com/xmleditor/

28
d’autres utilisateurs de Pleade, j’ai également utilisé la liste de diffusion « pleade-users »1 qui m’a
permis de poser des questions à l’ensemble de la communauté d’utilisateurs de ce logiciel.
Dans le cadre du stage, j’ai également procédé à l’inscription à la liste de diffusion des
utilisateurs de l’EAD2 et de la TEI3. Concernant ces deux langages, j’ai également pris contact avec
Jorge Fins, ingénieur à la MSH Val-de-Loire, sur des questions relatives à la TEI et l’EAD,
notamment pour effectuer avec lui des phases de vérification quant au choix des balises dans l’un
et l’autre des langages mais également sur certains aspects techniques quant à l’encodage. M. Fins,
en plus d’être tuteur pédagogique de mon stage, a aussi assuré plusieurs cours durant l’année auprès
des M2 PEEN.
1 https://lists.sourceforge.net/lists/listinfo/pleade-users 2 http://bonnespratiques-ead.net/user/1634/edit 3 https://groupes.renater.fr/sympa/info/tei-fr

29
L’un des objectifs du stage, comme cela a déjà été avancé, était de fournir une expérience
au LAT dans l’utilisation de plusieurs technologies notamment la TEI. Ainsi il a été décidé de la
mise en place de plusieurs livrables, notamment un teiHeader.
Comme nous l’avons évoqué précédemment, l’encodage TEI de l’inventaire a nécessité la
mise en place d’un teiHeader, essentiel à la création de tout fichier utilisant cette grammaire. En
plus de celui qui a été créé et intégré au fichier correspondant à l’inventaire, un second header a été
réalisé durant le stage. Ce second header est identique à celui qui a été utilisé, néanmoins il ne
contient quasiment aucune métadonnée à proprement parler mais seulement les balises qui servent
à les caractériser, mise à part certaines informations concernant l’institution émettrice du fichier qui
correspond donc au LAT. Un certain nombre de commentaires précisant quel type de métadonnées
sont à préciser en fonction de ces balises ont également été incorporées au fichier pour permettre
à un utilisateur qui ne soit pas expert en XML-TEI de pouvoir le manier. Ce fichier a bien sûr pour
ambition d’être un « modèle » pour tout autre projet qui nécessiterait la réalisation de fichier TEI.
A côté de ce header, le schéma XML utilisé dans le cadre du projet a également été réalisé
avec l’idée de pouvoir être réutilisé dans d’autres projets. En plus du fichier contenant ce schéma,
qui est donc au format Relax NG Compact Syntax Schema, un second fichier au format XML a
également été conservé, celui-ci permet de repartir du schéma tel qu’il a été défini dans le logiciel
Roma1. L’idée est que dans le cadre d’un autre projet, il sera possible de réutiliser ce schéma ou de
l’adapter en fonction des besoins du projet en le prenant comme base et en le modifiant en utilisant
le fichier XML et le logiciel Roma.
Afin que le stage que j’ai réalisé ne reste pas qu’un simple travail limité dans le temps mais
qu’il puisse également s’implanter au sein LAT, il m’a été demandé de produire un document
résumant tout le protocole suivi dans le cadre du projet OUTAGR2. Ce livrable est certainement
le plus important, dans le cadre de mon travail ainsi que pour le laboratoire, car il contient à la fois
une expérience mais également des détails techniques sur l’utilisation des technologies dans le cadre
1 http://www.tei-c.org/Roma/ 2 Voir annexe 4.

30
du stage et donne également un aperçu de leurs autres applications potentielles. Il n’a pas pour but
d’être exhaustif sur l’utilisation et le principe des langages informatiques et logiciels qui ont été
utilisés au cours du stage, mais un soin particulier a été apporté au fait de renvoyer à un nombre
important de documentations sur ces différents éléments ainsi qu’à d’autres exemples de projets1.
Ce travail a été construit au fur et à mesure du stage, il présente à la fois les choix qui ont été réalisés
mais également les autres possibilités qui se sont présentées ainsi que les principaux problèmes et
limites qui se sont imposées. Ce rapport a également pour but d’être utilisé comme une base pour
faire évoluer l’application mise en place durant le stage après celui-ci.
Pour communiquer sur la réalisation du projet au sein de l’équipe de recherche, il m’a été
demandé de venir le présenter au cours d’un Conseil d’Équipe réunissant les membres permanents
du LAT, à la fois des chercheurs mais également des ingénieurs et techniciens. Le but était de
présenter à la fois le résultat du projet OUTAGR, à savoir le site et de l’outil de recherche
permettant l’exploitation de l’inventaire mis en ligne sur le serveur de l’université, mais également
les technologies innovantes pour le laboratoire qui ont été employées et à ouvrir sur les autres
possibilités qu’elles offrent dans le cadre de projets en laboratoire de recherche.
Les différents éléments évoqués dans cette partie, à savoir les fichiers réutilisables et la
documentation sur le protocole suivi, vont avoir un impact direct sur le laboratoire puisque
plusieurs de projets incorporant la TEI sont déjà lancés ou en cours de préparation. C’est le cas par
exemple d’une publication portant sur les fouilles de Rigny2 qui est en cours de réalisation au format
TEI par l’équipe de la MRSH de Caen et également concernant le rapport de fouilles du chantier
de Marmoutier de l’année 2016-2017 qui sera publié grâce à une édition XML-TEI en incorporant
un volet webmapping.
1 Voir annexe 4, pp. 63-64. 2 Cette fouille concerne un centre paroissial médiéval, elle a été réalisée entre 1987 et 1999 par le Laboratoire Archéologie et Territoires et a notamment permis la mise au jour de deux églises antérieures en dessous de celle fouillée. URL : http://www.notredamederigny.fr/histoire/

31
Le bilan du projet est globalement très positif puisque les objectifs qui avaient été fixés en
amont de celui-ci ont été remplis. Malgré des difficultés techniques qui ont parfois induit une perte
de temps, le projet a pu s’adapter et remplir les conditions de son succès. Il a permis la mise en
place d’un outil de recherche fonctionnel permettant l’exploitation de la base de données que
constitue l’inventaire d’Alain Ferdière.
Figure 2 : page d’accueil du site publié dans le cadre du projet
La publication du site sur le serveur de l’université a permis de le rendre accessible dans le
cadre d’une première phase de test. Le site donne à la fois accès aux données de l’inventaire sous
forme d’une arborescence1 mais également par le biais d’une barre de recherche simple ainsi qu’un
formulaire de recherche, l’accès aux données est donc parfaitement assuré. Le formulaire de
recherche permet notamment de réaliser des recherches croisées au sein de l’inventaire2, c’est un
des aspects qui a été rendu possible grâce à l’utilisation de la technologie XML.
1 Figure 3 2 Figure 4

32
Figure 3 : présentation de l’arborescence de l’inventaire telle qu’elle est accessible au sein du site
Figure 4 : formulaire de recherche avancée tel qu’il est accessible sur le site

33
Le site comporte plusieurs pages statiques qui correspondent aux fichiers annexes qui ont été
fournis au début du stage concernant la réalisation de l’inventaire1 et une annexe sur l’outillage
miniature en contexte funéraire. Ces deux éléments ont été ajoutés au site afin de l’enrichir au
maximum.
Figure 5 : page statique du site concernant la réalisation de l’inventaire par Alain Ferdière
Cette mise en place est passée par une édition XML-TEI qui a été documentée et qui a
donné lieu à la création de plusieurs livrables : des fichiers informatiques pouvant être intégrés dans
d’autres projets ainsi qu’un fichier présentant le protocole suivi. Le logiciel Pleade a été
correctement intégré dans cette chaîne de production et a permis les résultats escomptés.
Plusieurs éléments pourraient être ajoutés afin d’améliorer l’application, par exemple l’ajout
d’un système de géolocalisation des sites archéologiques par le biais d’une carte interactive ou
encore l’ajout d’un système qui permettrait la recherche de termes archéologiques dans plusieurs
langues puisque le projet concerne des régions dans plusieurs pays d’Europe (notamment
l’Allemagne et la Suisse) et également pour donner une portée plus grande à cet outil. Enfin la
possibilité de Pleade d’intégrer des images et de réaliser une bibliothèque virtuelle pourrait être
l’occasion de réaliser une présentation des différents outils qui sont évoqués dans l’inventaire afin
de fournir aux visiteurs un support visuel.
1 Figure 5

34
Conclusion :
Le stage que j’ai réalisé au Laboratoire Archéologie et Territoires durant trois mois était
totalement en phase avec mes attentes quant à celui-ci, il m’a permis de découvrir le milieu des
laboratoires de recherche en étant confronté à la réalité du travail dans ce type d’institution. Il m’a
permis à la fois de mettre en place un projet innovant, d’en organiser la gestion, de le réaliser et
ainsi d’enrichir les compétences du laboratoire. Il a également rendu possible le fait de parfaire des
connaissances techniques acquises au cours de cette année universitaire dans le cadre du master 2
PEEN mais également d’en acquérir de nouvelles afin de pouvoir mener à bien le projet qui m’a
été confié. Le fait d’avoir réussi à remplir les objectifs du projet a été pour moi une grande réussite
professionnelle et personnelle. La documentation que j’ai produite pendant le stage ainsi que le
teiHeader et le schéma seront réutilisés dans d’autres projets incorporant la TEI. L’une des volontés
du Laboratoire Archéologie et Territoires est de poursuivre le mouvement engagé avec le stage
pour s’ouvrir à l’interopérabilité et d’exploiter cette technologie pour publier plus de
documentations et d’outils.
Le plaisir que j’ai eu à travailler dans le cadre d’un laboratoire de recherche et dans le cadre
des humanités numériques a confirmé mon goût pour ce milieu ainsi que mon projet professionnel
pour la suite.

35
Table des annexes :
Annexe 1 : Extrait de l’inventaire tel qu’il a été fourni par M. Ferdière en format .odt _ p. 36.
Annexe 2 : Extrait de l’inventaire après l’encodage en XML-TEI. _ p. 37.
Annexe 3 : Extrait de l’inventaire après la transformation en XML-EAD par le biais du filtre XSLT.
_ p. 38.
Annexe 4 : Manuel produit dans le cadre du stage. _ pp. 39-64.

36
Annexe 1 : extrait de l’inventaire au format .docx tel que fourni par Alain Ferdière
117 - *Bailleul-sur-Thérain “ Mont de César ” (Oise) : agglomération secondaire GR (?) :
a) - dans une cave GR (fouille Renet en 1878) : 1 clochette en fer (cf. COUTIL 1898-1921 :
185, n. 1) ;
b) - hors contexte, au Musée départemental de l’Oise (coll. Clérambault, inv. 52.178) : 1
mors à quatre anneaux (WOIMANT 1995 : 122).
[118 - *Bailly-en-Rivière (Seine-Maritime) : dépôt métallique de vaisselle de bronze, sans
outillage (WERNER 1938 : 266, n°18 ; cf. KÜNZL 1993 : 490-491, Fig. 8 ; cf. ROGERET 1997 :
117, av. biblio. compl.).]
119 - *Baldenheim (Bas-Rhin) : sépulture “ aristocratique ” de la fin du Ve s. ap. : riche mobilier,
dont 1 cloche en fer (FLOTTÉ et FUCHS 2000 : 162 (av. biblio.)).
120 - Bâle/Basel (BS, Suisse) : oppidum LTF puis agglomération secondaire :
a) - dans l’occupation du Ier s. av. de la « Gasfabrik » : 1 soc d’araire (FURGER-GUNTI et
BERGER 1980 : n°325 ; FELLMANN 1960 ; cf. FEUGÈRE, THAURÉ et VIENNE 1992 :
68, n°134 ; cf. MARBACH 2004b : 18, n°41soc) ; herminette (?) et haches à douille et à
emmanchement à oeil, parmi outils de travail du bois, et clavettes de moyeu (FURGER-
GUNTI et BERGER 1980 : Pl. 15 ; AMREIN et al. 2012 : 176 et Fig. 4.5) ; pour le soc
d’araire alongé, 1 clavette de roue et les outils pour le bois (haches à douille, 1 cognée)
(PERNET 2012 : Fig. 4.5) ;
b) - « Gasfabrik / Usine à Gaz » : dépôt LTF d’objets métalliques et de poterie, dont 1
phalère bombée (et autres pièces de harnachement ?) (HÜGLIN et SPICHTIG 2011) ;
c) - oppidum de « Munsterhügel » : 1 herminette militaire (dolabre) (BERGER et HELMIG
1991 : Fig. 10, 22 ; cf. DESBAT et MAZA 2008 : 246) ; des éléments de harnachement GR,
dt militaire (Katalog… 2008) ;
d) - contexte ? : 1 pendant de harnais (type Bishop 7A) (DESCHLER-ERB 1998b, av.
biblio.) ; et autres éléments de harnachement dont républicains (dont un pendant phalique
en os) (DESCHLER-ERB et al. 2008 : carte, Fig. 5 ; cf. POUX 2008 : 385-386, Fig. 58) ;
e) nécropole BE : 1 éperon (GIESLER 1978 : 46, n°39).
121 - *Balinghem “ Rue du Fort ” (Pas-de-Calais) : en surface : avec des monnaies (Ier-IIIe s.), 1
pendant de harnais, 1 passe-courroie de char (DELMAIRE 1994 : 106).
- Ballan-Miré : voir n° 2197
122 - *Balleray “ Champ d’Artet ” (Nièvre) : bâtiment d’une villa : 1 hipposandale (BIGEARD
1996 : 68).
- Balloy : voir n° 2228
123 - *Bambiderstroff (Moselle) : site indéterminé : 1 paire de force LTF (?) (LINCKENHELD
1933 : 10 ; cf. FLOTTÉ et FUCHS 2004 : 257).
124 - *Bandol “ Le Port ” (Var) : villa maritime, anciennement fouillée : 2 fers de bêches ((BRUN
1999 : 241, av. biblio.).

37
Annexe 2 : extrait de l’inventaire encodé en XML-TEI
<p xml:id="nailleul-sur-Thérain">117 - <placeName type="site_archeo">*Bailleul-sur-
Thérain</placeName> <placeName type="lieu-dit">« Mont de César »</placeName>
(<placeName type="departement">Oise</placeName>) : agglomération secondaire <date
notBefore="-0051" notAfter="0476"><choice><abbr>GR</abbr><expan>gallo-
romain</expan></choice></date> (?) :<lb/>
<list><item>a) - dans une cave <date notBefore="-0051"
notAfter="0476"><choice><abbr>GR</abbr><expan>gallo-romain</expan></choice></date>
(fouille Renet en 1878) : 1 <rs type="ani">clochette</rs> en fer (cf. COUTIL 1898-1921 : 185, n.
1) ;</item>
<item>b) - hors contexte, au Musée départemental de l’Oise (coll. Clérambault, inv. 52.178) :
1 <rs type="harna">mors</rs> à quatre anneaux (WOIMANT 1995 : 122).</item></list></p>
<p xml:id="baillyenriviere">[118 - <placeName type="site_archeo">*Bailly-en-
Rivière</placeName> (<placeName type="departement">Seine-Maritime</placeName>) : dépôt
métallique de vaisselle de bronze, sans outillage (WERNER 1938 : 266, n°18 ; cf. KÜNZL 1993 :
490-491, Fig. 8 ; cf. ROGERET 1997 : 117, av. biblio. compl.).]</p>
<p xml:id="baldenheim">119 - <placeName type="site_archeo">*Baldenheim</placeName>
(<placeName type="departement">Bas-Rhin</placeName>) : sépulture « aristocratique » de la
<date notBefore="0480" notAfter="0499">fin du Ve s. ap.</date> : riche mobilier, dont 1 cloche
en fer (FLOTTÉ et FUCHS 2000 : 162 (av. biblio.)).</p>
<p xml:id="balebasel">120 - <placeName type="site_archeo">Bâle/Basel</placeName>
(<placeName type="länder">BS</placeName>, <placeName
type="pays">Suisse</placeName>) : <foreign rend="i" xml:lang="la">oppidum</foreign> <date
notBefore="-0150" notAfter="-0027"><choice><abbr>LTF</abbr><expan>La Tène
Finale</expan></choice></date> puis agglomération secondaire :<lb/>
<list><item>a) - dans l’occupation du <date notBefore="-0099" notAfter="-0001">I<hi
rend="sup">er</hi> s. av.</date> de la « Gasfabrik » : 1 <rs type="instrAra">soc d’araire</rs>
(FURGER-GUNTI et BERGER 1980 : n°325 ; FELLMANN 1960 ; cf. FEUGÈRE, THAURÉ et
VIENNE 1992 : 68, n°134 ; cf. MARBACH 2004b : 18, n°41soc) ; <rs
type="outAgri">herminette</rs> (?) et <rs type="bois">haches</rs> à <rs
type="outAgri">douille</rs> et à emmanchement à oeil, parmi outils de travail du bois, et <rs
type="charr">clavettes de moyeu</rs> (FURGER-GUNTI et BERGER 1980 : Pl. 15 ; AMREIN
<hi rend="i">et al.</hi> 2012 : 176 et Fig. 4.5) ; pour le <rs type="instrAra">soc d’araire</rs>
alongé, 1 <rs type="charr">clavette de roue</rs> et les outils pour le bois ( <rs
type="bois">haches</rs> à <rs type="outAgri">douille</rs>, 1 <rs type="bois">cognée</rs>)
(PERNET 2012 : Fig. 4.5) ;</item>
<item>b) - « Gasfabrik / Usine à Gaz » : dépôt <date notBefore="-0150" notAfter="-
0027"><choice><abbr>LTF</abbr><expan>La Tène Finale</expan></choice></date> d’objets
métalliques et de poterie, dont 1 <rs type="harna">phalère</rs> bombée (et autres pièces de
harnachement ?) (HÜGLIN et SPICHTIG 2011) ;</item>

38
Annexe 3 : Extrait de l’inventaire encodé en XML-EAD
<p>117 - <name>*Bailleul-sur-Thérain</name>
<geogname>« Mont de César »</geogname> (<geogname>Oise</geogname>) :
agglomération secondaire <date normal="0476/-0051">GR</date> (?) :<lb/>
<list>
<item>a) - dans une cave <date normal="0476/-0051">GR</date> (fouille Renet en 1878) : 1
<subject>clochette</subject> en fer (cf. COUTIL 1898-1921 : 185, n. 1) ;</item>
<item>b) - hors contexte, au Musée départemental de l’Oise (coll. Clérambault, inv. 52.178) :
1 <subject>mors</subject> à quatre anneaux (WOIMANT 1995 : 122).</item>
</list>
</p>
</scopecontent>
</c02>
<c02 id="baillyenriviere">
<did>
<unittitle>*Bailly-en-Rivière</unittitle>
</did>
<scopecontent>
<p>[118 - <name>*Bailly-en-Rivière</name> (<geogname>Seine-Maritime</geogname>) :
dépôt métallique de vaisselle de bronze, sans outillage (WERNER 1938 : 266, n°18 ; cf. KÜNZL
1993 : 490-491, Fig. 8 ; cf. ROGERET 1997 : 117, av. biblio. compl.).]</p>
</scopecontent>
</c02>
<c02 id="baldenheim">
<did>
<unittitle>*Baldenheim</unittitle>
</did>
<scopecontent>
<p>119 - <name>*Baldenheim</name> (<geogname>Bas-Rhin</geogname>) : sépulture
« aristocratique » de la <date normal="0499/0480">fin du Ve s. ap.</date> : riche mobilier, dont
1 cloche en fer (FLOTTÉ et FUCHS 2000 : 162 (av. biblio.)).</p>
</scopecontent>
</c02>
<c02 id="balebasel">
<did>
<unittitle>Bâle/Basel</unittitle>
</did>
<scopecontent>
<p>120 - <name>Bâle/Basel</name> (<geogname>BS</geogname>,
<geogname>Suisse</geogname>) : <emph render="italic">oppidum</emph>
<date normal="-0027/-0150">LTF</date> puis agglomération secondaire :<lb/><list>

39
Annexe 4 : protocole du projet OUTAGR réalisé durant le stage
Réalisé par Rémi Ossant sous la direction d’Olivier Marlet, ingénieur d’étude au CNRS.
mars 2016 – juin 2016

40
Sommaire
I. XML-TEI : choix et mise en place
a) XML-TEI : enjeux et définitions
b) Du document .docx à un fichier primaire en TEI
II. Le balisage en XML-TEI
a) Le choix des balises
b) Structure globale du fichier
c) La création d’un Header et d’un schéma XML adapté au projet
d) L’utilisation des expressions régulières
e) La bibliographie
III. Le passage en EAD
a) Le langage EAD
b) Le choix des balises EAD
c) La mise en place d’un filtre XSLT pour assurer le passage en EAD
IV. Le logiciel PLEADE et son utilisation
a) Intérêt du logiciel
b) Installation
c) Utilisation pour l’édition d’un outil de recherche
1. La publication des fichiers
2. La création de l’outil de recherche, la modification de son interface graphique
Bibliographie :
EAD
Dossiers d’encodage issus d’autres projets
PLEADE
Exemples de site mis en place avec PLEADE
TEI
Dossiers d’encodage issus d’autres projets
XSLT

41
Introduction
Ce document a été créé dans le cadre d’un stage de Master 2 réalisé au sein du Laboratoire
Archéologie de l’UMR CITERES sous la direction d’Olivier Marlet et qui a eu lieu du 7 mars au
10 juin 2016. Sa mission consistait en la création d’un instrument de recherche visant à exploiter
un inventaire des sites de Gaule contenant de l’outillage antique.
Le corpus de document qui a été l’objet de travail du stage a été créé par Alain Ferdière,
professeur honoraire des universités et membre associé du LAT. Cet ensemble de documents se
compose d’un inventaire des sites archéologiques de Gaule comportant de l’outillage agricole, une
bibliographie et plusieurs autres documents annexes de quelques pages notamment un fichier Excel
comportant les différents types d’outils présents dans l’inventaire classés. Le but du stage était de
partir du fichier de l’inventaire, originellement en .docx, de le transformer en un fichier XML-TEI
bien formé et valide puis, par le biais d’un filtre XSLT, de le passer au format XML-EAD et enfin
de traiter ce fichier avec le logiciel PLEADE afin d’en faire un instrument de recherche utilisable.
PLEADE est un logiciel libre qui permet à partir d’un fichier bien formé et valide en XML-EAD
de créer un outil de publication, de consultation et de recherche de documents et d'archives
numériques1.
Dans cette documentation, un certain nombre de langages informatiques seront abordés,
elle n’a pas pour vocation d’être exhaustive sur leurs possibilités et surtout pas sur le moyen de les
manipuler. Nous nous limiterons à une présentation succincte de leurs principes et de leurs
possibilités dans le cadre de ce projet. Ce document contient néanmoins un nombre important de
liens et de références vers des sites ou des documentations en ligne portant sur ces langages ainsi
que leur manipulation. La grande majorité des manipulations qui ont été réalisées et qui sont
décrites dans ce document ont été faites par le biais du logiciel Oxygen XML Editor qui est un
logiciel non-libre mais qui propose néanmoins des licences d’évaluations gratuites2.
Le but de cette documentation est de présenter et d’expliquer le protocole qu’il a été choisi
d’adopter dans le cadre du stage mais également de présenter d’autres possibilités qui auraient pu
être adoptées ainsi que les principales difficultés qui se sont présentées.
1 Pour plus d’informations sur le logiciel et le télécharger : http://pleade.com/ et http://pleade.org/ 2 Pour télécharger le logiciel Oxygen XML Editor et obtenir plus d’informations sur celui-ci : https://www.oxygenxml.com/

42
I. XML-TEI : choix et mise en place
La TEI (Text Encoding Initiative) est une norme de codage de textes qui repose sur le XML
et qui a pour but de faciliter la création l’échange et l’intégration des données textuelles
informatisées. La TEI est un langage descriptif, il consiste donc en un balisage servant à nommer
et caractériser les composants d’une structure textuelle.
C’est un langage riche qui cumule trois avantages principaux qui en font le langage idéal
pour un projet du type de celui d’OUTAGR1. L’un des premiers intérêts de la TEI est qu’elle met
l’accent sur le sens du texte et non pas l’apparence de celui-ci, il permet donc un enrichissement
sémantique, en donnant un sens choisi à des chaînes de caractères. Une prise de décision quant à
l’encodage XML-TEI à utiliser est toujours une activité scientifique, impliquant systématiquement
un choix conscient. Le deuxième point sur lequel il convient d’insister est l’interopérabilité
qu’implique ce langage, un fichier encodé en TEI donnera le même aspect à l’information quel que
soit le logiciel qui est utilisé. Cela représente un avantage à la fois dans le partage des données mais
également dans le fait de pouvoir conserver un encodage à partir duquel il sera possible de partir
afin de publier un document dans un autre format ou pour le mettre à jour dans le cas d’une
évolution des langages informatiques. Enfin la TEI est gérée par une communauté scientifique
pour son propre usage et est développement constant, ce qui lui assure une grande stabilité.
Cette grammaire est plutôt destinée à l’encodage des textes mais elle peut être également
appliquée à toute forme de données numériques, aujourd’hui elle est utilisée dans une majorité de
cas pour l’édition électronique de sources et de textes anciens à l’image du travail réalisé par les
Bibliothèques Virtuelles Humanistes2 ou encore la MSHS de Caen3. De manière générale, la TEI
s’est très largement imposée comme le standard de fait dans le domaine de l’édition numérique à
caractère scientifique, en particulier pour la publication des sources primaires4.
Pour plus d’informations sur la TEI, ses principes et sa manipulation, consulter la bibliographie à
la fin de cette documentation.
La première étape pour passer du document primaire au format .docx, comme celui qui a
été fourni par M. Ferdière dans le cadre de ce projet, jusqu’à un fichier XML-TEI structuré et
encodé, est d’arriver à passer le fichier au format XML-TEI avec pour problématique essentielle
de ne pas perdre d’informations et en essayant d’arriver à un fichier le plus structuré et « pré-
encodé » possible. Quatre solutions ont été envisagées pour répondre à cela.
1 Ces éléments sont principalement tirés de la publication de Lou Burnard : Qu’est-ce que la Text Encoding Initiative [en ligne], URL : http://books.openedition.org/oep/1298, consulté le 30/05/16. 2 http://xtf.bvh.univ-tours.fr/xtf/search?type=tei 3http://www.unicaen.fr/recherche/mrsh/document_numerique/projets 4 http://www.desgodets.net/edition-des-cours/model

43
La première solution consiste simplement en l’import du texte depuis le fichier originel au
sein du logiciel Oxygen puis à procéder à l’encodage. Mais cette solution ne permet aucune
structuration et aucun pré-encodage, son intérêt est donc très limité.
Il est également possible d’utiliser le logiciel 7-zip et de passer le document originel d’un
format .docx au format .odt et ensuite de le décompresser. Un fichier .odt s’apparente à un dossier
composé de plusieurs documents XML zippés dont le fichier « content » qui contient le texte en
XML. Par le biais de cette méthode on obtient un fichier XML-TEI avec quelques balises mais
aucune structuration, ce qui rend le traitement et la lecture du fichier très difficile.
Une autre solution consiste à passer par l’utilisation d’un script XML depuis le logiciel
LibreOffice. Cette solution oblige à créer des feuilles XSLT pour l’import et l’export ainsi que
plusieurs feuilles de styles adaptées. Cette solution implique donc un travail préparatoire assez lourd
mais permettrait un gain de temps par la suite car le stylage aurait permis d’avoir un document
XML-TEI bien encodé et aurait simplement demandé quelques ajustements ainsi qu’une
vérification. Néanmoins le fichier originel étant très homogène dans le cadre du projet OUTAGR,
il aurait été nécessaire de créer des styles de caractères et non pas de paragraphes ce qui aurait
impliqué une opération de stylage longue et aurait certainement occasionné des erreurs qu’il aurait
fallu reprendre depuis le logiciel Oxygen. Il a donc été choisi de ne pas utiliser cette méthode dans
le cadre du projet.
La dernière solution, qui fut celle choisie au cours du projet, est d’utiliser le logiciel Odette,
qui a été développé par Frédéric Glorieux1. Ce logiciel permet de passer d’un fichier .odt à un fichier
XML-TEI de manière automatique. Le fichier qui est obtenu est balisé et structuré de manière très
lisible, un autre avantage est que l’encodage XML-TEI est fait de manière à respecter la mise en
page originale du document. Cette solution implique une reprise pour compléter l’encodage qui
n’est que partiel, mais l’emploi d’expression régulière permet un travail efficace sur le document.
II. Le balisage en XML-TEI
Comme évoqué précédemment, le choix des balises en XML-TEI relève d’un choix
scientifique, c’est grâce à cela que vont pouvoir être identifiés des éléments. Ainsi, avant de se
questionner sur les balises à utiliser, il convient de s’interroger sur les informations qui sont
importantes dans le corpus qui est l’objet de ce travail, afin de ne pas encoder à outrance et alourdir
inutilement le fichier. Dans le cadre du projet OUTAGR, il était important de pouvoir utiliser les
informations se rapportant aux différents outils présents sur les sites (avec la possibilité de pouvoir
différencier les grands types d’outillages), le nom des sites, les éléments de localisation des sites
mais également les éléments se rapportant à des notes, les périodes archéologiques évoquées, etc…
1 http://obvil-dev.paris-sorbonne.fr/developpements/Odette/

44
Concernant la mise en page, il a été choisi de respecter au maximum celle qui a été choisie
par l’auteur, ainsi les retours à la ligne ont été respectés notamment dans les cas où sont listés
plusieurs espaces dans un même site. Il en va de même pour les passages en italiques et en gras.
Par exemple, les renvois vers d’autres références au sein de l’inventaire sont notés sous la forme
« voir n°… », il a donc été choisi de l’entourer avec une balise <hi rend="b">. Le nom des sites
est également en gras, néanmoins il n’est pas nécessaire de l’entourer d’une balise spécifiquement
pour cela, ils sont déjà entourés avec une balise <placeName type="site_archeo"> et on utilisera
les CSS1 pour rendre ces éléments en gras dans le rendu final.
Les balises choisies et utilisées dans le cadre de ce projet sont répertoriées dans le tableau suivant,
il convient de se rapporter à l’index « outillage-vocabulaire.xsl » qui fait partie du dossier fourni par
A. Ferdière auquel il sera fait référence :
Abréviations
<choice><abbr>expressi
on abrégée
</abbr><expan>express
ion développée </expan>
</choice>
Ce balisage concerne les abréviations
utilisées couramment dans le texte (ex :
« frag. » = « fragment »). Cela vaut
également pour les noms de période.
Dates
<date>
@when="…" Cette balise est à utiliser pour des
mentions de dates simples, lorsqu’il s’agit
de baliser des périodes, se référer à cette
catégorie dans le tableau.
Entrée
alphabétique
<head><title>entrée
alphabétique</title></he
ad>
Les entrées alphabétiques de l’inventaire
sont considérées comme des entêtes des
<div>.
Liste
<list>
<item>entrée de liste
</item>
<item>entrée de liste
</item>
</list>
Cet élément <list> est utilisé notamment
pour baliser les énumérations de plusieurs
espaces au sein d’un même site
archéologique.
<placeName>
@type="pays"
Afin d’enrichir les données se rapportant
la localisation d’un site, elles sont balisése
indépendamment en utilisant un attribut
1 Pour plus d’informations sur les CSS, consulter : https://www.w3.org/Style/CSS/learning

45
Localisation
site
@type est utilisé pour spécifier de quel
type d’information de localisation il s’agit.
@type="departeme
nt"
@type="länder" Ce type a également été utilisé pour définir
les provinces suisses.
@type="arrondisse
ment"
Correspond à un arrondissement d’un
länder allemand.
@type="lieu-dit"
mise en
italique ou en
gras d’un
passage
<hi>
@rend="i"
@rend="b"
Cette balise est utilisée seulement pour
respecter la mise en forme de l’auteur sur
certains passages (pour la mise en italique
ou en gras). Néanmoins elle n’est utilisée
que dans le cas où ces éléments ne sont pas
balisés par un autre élément.
Nom du site
<placeName>
@type="site_arche
o"
L’attribut @subtype sert à définir le type
de site archéologique auquel appartient
chaque entrée d’après le fichier produit par
M. Ferdière. Cet attribut n’a pas était
utilisé sur l’intégralité de l’inventaire en
raison du fait que le fichier produit par M.
Ferdière ne concernait qu’une partie des
sites, le type des autres sites
archéologiques n’étant pas spécifié il n’a
pas été possible de procéder à l’encodage.
@subtype="agglo_s
ec"
Pour la catégorie : « Agglomération
secondaire/Agglomération-sanctuaire »
@subtype="arti" Pour la catégorie : « Artisanat (site d’–) »
@subtype="camp_
mili"
Pour la catégorie : « Camp militaire (et
autres sites militaires) »
@subtype="capi" Pour la catégorie : «Capitale de cité »
@subtype="cave" Pour la catégorie : « Cave »
@subtype=" chem" Pour la catégorie : « Chemin »
@subtype="chena" Pour la catégorie : « Chenal aménagé »

46
@subtype="depCul
t"
Pour la catégorie : « Cultuel (dépôt –) »
@subtype="depMet
"
Pour la catégorie : « Dépôt métallique »
@subtype="depSan
s"
Pour la catégorie : « Dépôt (de vaisselle
métallique ou autre) sans outillage »
@subtype="epav" Pour la catégorie : « Épave (de bateau) »
@subtype="etaGr" Pour la catégorie : « Établissement rural
GR »
@subtype="etaLtf" Pour la catégorie : « Établissement rural
LTF »
@subtype="etaSans
"
Pour la catégorie : « Établissement rural
(tous types), sans outillage »
@subtype="fermG
aul"
Pour la catégorie : «Ferme gauloise »
@subtype="fos" Pour la catégorie : « Fosse »
@subtype="foss" Pour la catégorie : « Fossé »
@subtype="grot" Pour la catégorie : « Grotte »
@subtype="gue" Pour la catégorie : « Gué »
@subtype="habit" Pour la catégorie : « Habitat/Habitation
(et voir Maison), dont urbain »
@subtype="mais" Pour la catégorie : « Maison/Domus »
@subtype="mine" Pour la catégorie : « Mine/Carrière »
@subtype="necroG
allo"
Pour la catégorie : « Nécropole (gallo-
romaine) »
@subtype="necro
Mero"
Pour la catégorie : « Nécropole
mérovingienne »
@subtype="oppi" Pour la catégorie : « Oppidum »
@subtype="port" Pour la catégorie : «Port, install. portuaires
»

47
@subtype="puit" Pour la catégorie : «Puits « funéraire » »
@subtype="remp" Pour la catégorie : «Rempart (et fossé
défensif) »
@subtype="rivi" Pour la catégorie : « Rivière (dans le lit de
–)/Fleuve »
@subtype="rue" Pour la catégorie : « Rue urbaine »
@subtype="sanct" Pour la catégorie : «Sanctuaire/Temple »
@subtype="sep" Pour la catégorie : «Sep (d’araire, en bois) »
@subtype="sepu" Pour la catégorie : «Sépulture/Tombe »
@subtype="silo" Pour la catégorie : «Silo »
@subtype="siteHau
t"
Pour la catégorie : «Site de hauteur »
@subtype="thea" Pour la catégorie : «Théâtre »
@subtype="ther" Pour la catégorie : «Thermes »
@subtype="tour" Pour la catégorie : «Tourbe/Tourbière »
@subtype="trouPo
t"
Pour la catégorie : « Trou de poteau (de
bâtiment) »
@subtype="tumu" Pour la catégorie : «Tumulus »
@subtype="villaGr
"
Pour la catégorie : «Villa (GR) »
@subtype="villaSu
b"
Pour la catégorie : «Villa suburbaine, ou
péri-urb. (et établiss. rural –) ; et péri-
agglo »
@subtype="villaVit
"
Pour la catégorie : «Villa viticole »
@subtype=" villLtf
"
Pour la catégorie : «Village LTF »
@subtype="vilChef
"
Pour la catégorie : «Ville/chef-lieu de
cité/capitale de cité »
@subtype="voieRo
m"
Pour la catégorie : « Voie romaine »

48
Nom
institution
<orgName>
Ex : INRAP, etc. Cet élément n’a
finalement pas été utilisé car considéré
comme pas utile dans le cadre du projet.
Noms en
langue
étrangère
<foreign> @lang="code ISO"
@rend="italic"
Ce balisage a été utilisé dans le cadre du
projet seulement pour spécifier les termes
en langue latine.
Outils
retrouvés
parmi le
mobilier
archéologique
des sites
<rs>
Les attributs @type se réfèrent aux
catégories établies par M. Ferdière dans
son fichier Outillage_Vocabulaire.xsl.
@type="instrAra" Pour la catégorie « instrument aratoire »
@type="atteTrai" Pour la catégorie « Attelage/Trait »
@type="outAgri" Pour la catégorie « Outils agricoles »
@type="ani" Pour la catégorie « Pour animaux »
@type="bois" Pour la catégorie « Travail du bois »
@type="charr" Pour la catégorie « Charronnerie »
@type="harna" Pour la catégorie « Harnachement /
ferrure »
@type="instrVete" Pour la catégorie « Instruments
vétérinaires »
Période
<date>
@notBefore
@notAfter
Les attributs @notBefore et @notAfter
correspondent au point de départ et au
terme d’une période (sous forme
normalisée comme suit : aaaa-mm-jj).
Le nom des périodes étant souvent
abrégées la forme complète du balisage
sera la suivante :
<date @notBefore="aaaa-mm-jj" @not
After="aaaa-mm-
jj"><choice><abbr>expression abrégée
</abbr><expan>expression développée
</expan> </choice></date>
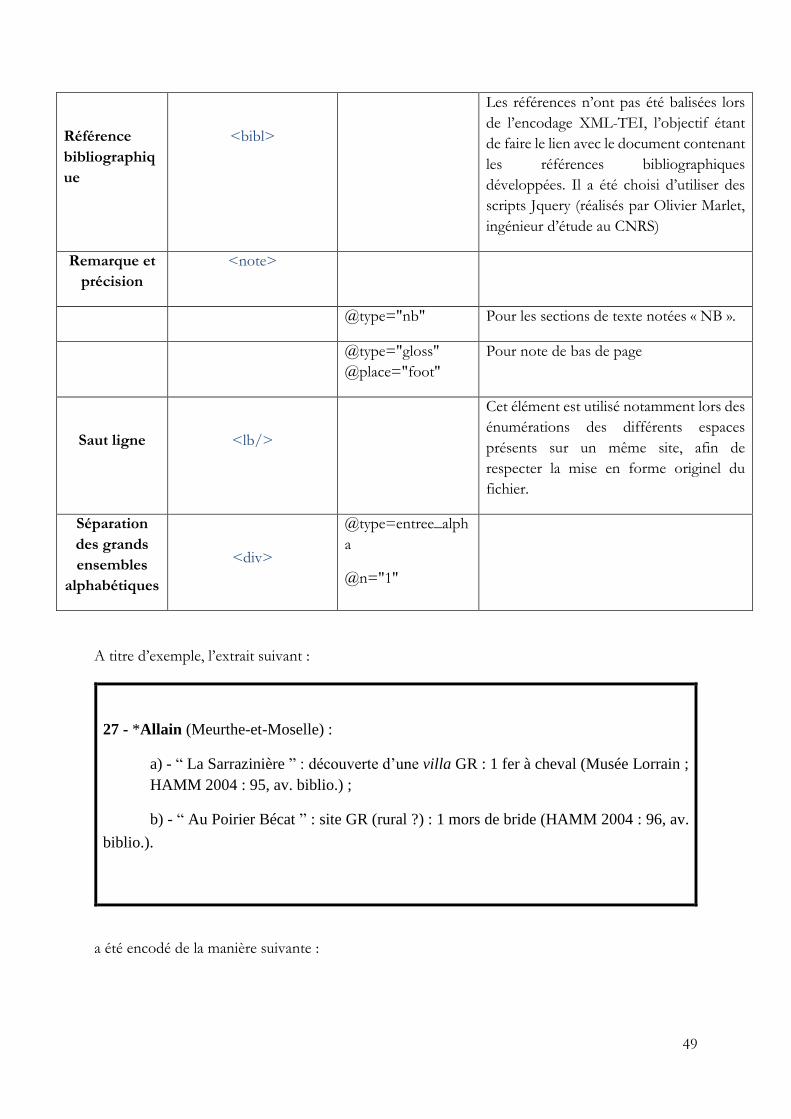
49
Référence
bibliographiq
ue
<bibl>
Les références n’ont pas été balisées lors
de l’encodage XML-TEI, l’objectif étant
de faire le lien avec le document contenant
les références bibliographiques
développées. Il a été choisi d’utiliser des
scripts Jquery (réalisés par Olivier Marlet,
ingénieur d’étude au CNRS)
Remarque et
précision
<note>
@type="nb" Pour les sections de texte notées « NB ».
@type="gloss"
@place="foot"
Pour note de bas de page
Saut ligne
<lb/>
Cet élément est utilisé notamment lors des
énumérations des différents espaces
présents sur un même site, afin de
respecter la mise en forme originel du
fichier.
Séparation
des grands
ensembles
alphabétiques
<div>
@type=entree_alph
a
@n="1"
A titre d’exemple, l’extrait suivant :
27 - *Allain (Meurthe-et-Moselle) :
a) - “ La Sarrazinière ” : découverte d’une villa GR : 1 fer à cheval (Musée Lorrain ;
HAMM 2004 : 95, av. biblio.) ;
b) - “ Au Poirier Bécat ” : site GR (rural ?) : 1 mors de bride (HAMM 2004 : 96, av.
biblio.).
a été encodé de la manière suivante :

50
<p xml:id="allain">27 - <placeName type="site_archeo"
subtype="villaGr">*Allain</placeName>(<placeName type="departement">Meurthe-et-
Moselle</placeName>) :<lb/>
<list><item>a) - <placeName type="lieu-dit">« La Sarrazinière »</placeName> :
découverte d'une <foreign rend="i" xml:lang="la">villa</foreign> <date notBefore="-
0051" notAfter="0476"><choice><abbr>GR</abbr><expan>gallo-
romain</expan></choice></date> : 1 <rs type="harna">fer à cheval</rs> (Musée
Lorrain ; HAMM 2004 : 95, av. biblio.) ;</item>
<item>b) - <placeName type="lieu-dit">« Au Poirier Bécat »</placeName> : site
<choice><abbr>GR</abbr><expan>gallo-romain</expan></choice> (rural ?) : 1 <rs
type="harna">mors de bride</rs> (HAMM 2004 : 96, av. biblio.).</item></list></p>
La structure du fichier respecte les normes XML-TEI1, concernant la structuration globale
du fichier XML-TEI du projet, il a été choisi de procéder en attribuant une <div> incrémentée
avec un attribut @n pour chaque grande lettre de l’inventaire. Chaque entrée au sein de l’inventaire
constituera un paragraphe et sera donc entourée d’une balise <p>.
La structure du fichier aura donc la forme suivante :
<div type="entree_alpha" n="X">
<p>site archéologique 1</p>
<p>site archéologique 2</p>
<p>site archéologique 3</p>
1 Pour plus d’informations sur ce point consulter la bibliographie en fin de documentation

51
…
</div>
<div type="entree_alpha" n="Y">
<p>site archéologique 4</p>
…
</div>
…
Une autre solution aurait été de procéder par le biais d’une balise <list> puisque le
document se présente comme une suite organisée de sites archéologiques, comme cela a été réalisé
par les Bibliothèques Virtuelles Humanistes dans le cadre de l’encodage du manuscrit Briefve
declaration d’aulcunes dictions plus obscures contenües on quatriesme livre des faicts & dicts Heroïcques de
Pantagruel1. L’encodage de ce manuscrit de Rabelais a été fait de sorte que chaque terme du glossaire
a été encadré par la balise <label> après quoi suit la définition qui est encadrée par la balise
<item>. Ce procédé à l’avantage de bien reproduire la forme du texte original, néanmoins dans
le cadre du projet, il a été choisi de ne pas procéder de la sorte car au sein des entrées de sites
archéologiques on trouve parfois des listes (détaillant les différents espaces d’un site archéologique),
et même s’il est tout à fait possible d’intégrer une liste dans une autre au sein d’un encodage XML-
TEI, cela a pour conséquence d’alourdir le code. Ainsi le choix a été fait de procéder par paragraphe
successif dans le cadre de l’encodage de la structure du fichier XML-TEI.
Cette structure sous la forme du liste prendrait la forme suivante :
<list>
<item>site archéologique 1</item>
<item>site archéologique 2</item>
…
</list>
<list>
…
</list>
1 http://xtf.bvh.univ-tours.fr/xtf/data/tei/B751131010_FR3370_suppl/B751131010_FR3370_suppl_tei.xml

52
Le Laboratoire Archéologie et Territoire n’ayant, au moment de la réalisation du projet, pas
produit de document XML-TEI, il a été nécessaire de produire un header1 et un schéma XML2
spécifiquement pour le projet. Ces deux éléments ont été mis en place avec l’idée de pouvoir être
réutilisés dans de futurs projets nécessitant l’utilisation de TEI, moyennant néanmoins quelques
modifications propre à chaque projet surtout concernant le schéma XML.
Il a été choisi de créer un schéma et de ne pas utiliser un schéma TEIall3 en raison de la
taille du document, pour ainsi prévenir des erreurs d’encodage et rendre l’encodage plus léger et
également, dans la même problématique de produire un travail qui pourrait être réutilisé pour un
autre projet. Le header a été réalisé par le biais du logiciel Roma4 du site tei-c.org qui permet de
créer des schémas XML de manière totalement libre et avec une syntaxe correcte. Cela a permis de
réduire le nombre de balises, d’attributs ainsi que de valeurs qui sont autorisées seulement à celles
qui sont nécessaires au projet. Par exemple, toutes les balises se référant à la création de figures et
de tableaux ont été retirées tandis que des attributs @types et @subtypes particuliers ont été ajoutés
à la balise <rs> qui a été choisie pour entourer les outils archéologiques présents dans le fichier à
baliser le mobilier archéologique.
L’un des objectifs du projet était de mettre en relation l’inventaire de l’outillage avec la
bibliographie qui lui correspond. Pour cela, il a d’abord été nécessaire d’encoder la bibliographie
en XML-TEI. Le header et le schéma qui avait été créés précédemment pour l’inventaire ont été
réutilisés dans ce cadre. Cette mise en relation étant le principal objectif, il a été décidé dans un
premier temps de réaliser un encodage minimum sur la bibliographie.
Il a été décidé d’entourer l’ensemble de la référence avec une balise <p> à laquelle a été
ajoutée un attribut @id spécifique vers lequel il sera possible de pointer lors de l’encodage du fichier
principal. La référence à proprement parler a été entourée d’une balise <bibl>, qu’il est possible
de compléter avec un certain nombre d’information complémentaire (<author>, <title>,
etc.). Dans le cadre de ce projet, il n’a pas été jugé nécessaire de le faire car ces informations n’avaient
pas vocation à être utilisées.
Les éléments de bibliographie sont donc encodés sous la forme suivante :
1 Le TeiHeader contient toutes les métadonnées d’un fichier TEI il se situe au début de celui-ci. Pour plus d’informations consulter : http://www.tei-c.org/release/doc/tei-p5-doc/en/html/HD.html 2 Un schéma XML permet de définir un modèle de document, d’imposer un certain nombre de contraintes données. Il a le même principe qu’une DTD. Pour plus d’informations, consulter : https://www.irif.univ-paris-diderot.fr/~carton/Enseignement/XML/Cours/Schemas/ 3 Le schéma TEIall permet d’utiliser toutes les balises et les attributs TEI au sein d’un fichier encodé en XML-TEI. 4 http://www.tei-c.org/Roma/

53
<p xml:id="abauzit2000">°ABAUZIT 2000<lb/>
<bibl>Abauzit P. - Décors d’applique à bordure ajourée de Gaule méridionale,
Instrumentum, 11 (juin) : 16-17.</bibl></p>
Une forme développée comme celle-ci aurait pu être adoptée :
<p xml:id="abauzit2000">°ABAUZIT <date when="2000">2000</date><lb/>
<bibl><author>Abauzit P.</author> - <title type="article">Décors d’applique
à bordure ajourée de Gaule méridionale</title>, <title rend="i"
type="main">Instrumentum</title>,<biblScope>11 <date when="2000-
06">(juin)</date> : 16-17</biblScope>.</bibl></p>
Le procédé qui a été suivi pour le passage de la bibliographie du format natif .docx à un
format XML-TEI est le même que celui qui a été utilisé pour le fichier principal, c’est-à-dire
l’utilisation du logiciel Odette.
D’un point de vue pratique, l’encodage de la bibliographie a été facilité par l’utilisation de
plusieurs expressions régulières, comme par exemple l’une permettant de remplacer une fin de
paragraphe </p> qui suivait la date de parution de la référence par un simple saut de ligne <lb/>,
ce qui permet d’englober l’intégralité de la référence dans le paragraphe possédant un attribut @id.
Pour réaliser le lien entre les deux documents, il a été décidé d’utiliser un script Jquery
(réalisé par Olivier Marlet) qui permet de relier les références abrégées présentes dans l’inventaire
aux références complètes présentes dans la bibliographie. Par ce biais, lorsque la souris passe sur
une référence abrégée de l’inventaire, une fenêtre affiche la référence complète en bas à gauche de
l’écran. Cette solution permet de donner plus d’ergonomie au site et de ne pas avoir à éditer
directement la bibliographie au sein du site, elle est simplement en cache. Ce script étant fait pour
être utilisé sur la version html de l’inventaire, il a été rajouté à la fin du projet lors du développement
de l’outil de recherche.
Une autre solution aurait été de mettre en place le même type de lien entre les références
abrégées et complètes mais seulement en utilisant la technologie XML, notamment par le biais des
balises <xref> et <xptr> ainsi que l’attribut @target. Le principe de cette solution revient à
entourer les références courtes de la bibliographie présentes dans l’inventaire avec une balise xref
et un attribut @target pointant vers l’id de la référence souhaité. Mais cela aurait entraîné une
navigation plus lourde en impliquant un passage de l’inventaire à la bibliographie pour obtenir la

54
référence complète. De plus, cela impliquait également de publier la bibliographie sur le site
directement.
Comme cela a déjà été évoqué auparavant, le choix qui a été fait d’utiliser le logiciel Odette
pour passer du document en .odt à un fichier au format XML-TEI fait qu’une part importante de
l’encodage est à faire directement depuis le logiciel Oxygen. Dans ce cadre, dans un souci d’efficacité
et de gain de temps, l’emploi d’expressions régulières est primordial. L’avantage du document lequel
porté le projet OUTAGR est qu’il est formé avec une rigueur certaine ainsi que selon un schéma
simple qui se répète à chaque entrée, ce qui facilite d’autant plus l’utilisation d’expressions
régulières1. Par exemple dans le cas de l’encodage des grandes périodes archéologiques qui sont
présentes dans l’inventaire, on commence par rechercher le terme dans l’ensemble du document, à
titre d’exemple on peut citer : « LTF » qui correspond à « la Tène Finale ». Ce terme est remplacé
par l’expression suivante :
<date notBefore="-0060" NotAfter="-0027"><choice><abbr>$1</abbr><expan>la Tène
Finale</expan></choice></date>
En reproduisant cette opération pour chacune des périodes qui sont présentes dans le corpus,
cela a permis de gagner une grande quantité de temps sur l’encodage. Cette utilisation des
expressions régulières a également été réalisée pour le balisage des outils archéologiques, certains
lieux qui revenaient régulièrement (notamment les pays) ou encore les mots en latin (comme le
terme villae).
Néanmoins le seul emploi des expressions régulières ne suffit pas, certaines données sont
trop complexes ou inversement trop communes dans leur formation pour que l’emploi
d’expressions régulières soit possible. Pour ce type de données, il est obligatoire de passer par un
encodage manuel, c’est le cas notamment pour une partie des informations concernant la
localisation des sites archéologiques ; ces informations varient d’un site à autre, s’il se trouve à
l’étranger le pays est précisé et pour les sites allemands le länder et l’arrondissement sont précisés,
parfois est ajouté un lieu-dit et parfois non.
1 Pour plus d’informations sur les expressions régulières : https://www.lucaswillems.com/fr/articles/25/tutoriel-pour-maitriser-les-expressions-regulieres

55
Même si un certain nombre de données soient possiblement balisables rapidement par le
biais d’expressions régulières, il est nécessaire de procéder à une vérification systématique de toutes
les données pour prévenir toutes erreurs.
III. Le passage en EAD
L’EAD (Encoded Archival Description) a été développé comme une DTD1 (Document type
Definition) pour encoder les instruments de recherche qui décrivent des fonds d’archives2 en se
basant sur le langage XML, ce langage est compatible avec la norme ISAD(G)3. Sa principale utilité
est l‘indexation et la publication sur le web. Le langage XML-EAD consiste en une imbrication
d’informations de différents niveaux hiérarchiques, typiquement un premier niveau hiérarchique
est constitué par un fond d’archives dans lequel on trouvera plusieurs unités archivistiques
composées par une archive ou un ensemble d’archives.
Dans le cadre de ce projet, même si le corpus ne s’apparente pas à un fond d’archives, il
s’en rapproche par la forme : il s’agit d’un inventaire de sites archéologiques dont chaque entrée est
construite de la même manière, ainsi l’utilisation de l’EAD se justifie dans le cadre du projet.
Comme cela a déjà été avancé précédemment, dans le cadre de ce projet l’instrument de recherche
devait être mis en place à partir du logiciel PLEADE qui accepte seulement le format XML-EAD,
c’est donc la principale raison de son utilisation. Comme nous l’avons déjà évoqué, l’EAD permet
de construire une description hiérarchisée restituant précisément l'imbrication des composants et
sous-composants4, dans le cadre du projet le composant le plus haut de l’inventaire est constitué
par chaque entrée alphabétique, à l’intérieur de celle-ci chaque regroupement alphabétique d’entrées
constitue un sous composant et à l’intérieur de celui-ci, une entrée de site constitue un autre sous-
composant.
Pour plus d’informations sur le format XML-EAD, consulter la bibliographie en fin de
documentation.
Le choix des balises EAD a répondu à deux problématiques : pouvoir convertir les
informations qui ont été d’abord balisées en XML-TEI et axé ce choix sur les éléments qui auront
un intérêt lors de la création de l’outil de recherche, notamment les index de recherche. Les
1 Une DTD sert à construire un ensemble de règles qui vont régir la construction du document XML. Cet ensemble permet de définir l’architecture d’un document XML, les balises et leur hiérarchie. Cet élément a le même rôle qu’un schéma XML. 2 http://bonnespratiques-ead.net/guide/intro/autres-normes 3 L’ISAD(G) correspond à la « Norme générale et internationale de description archivistique » qui a été définie pour la description des fonds et collections conservées dans des services d’archives. 4 http://www.bnf.fr/fr/professionnels/formats_catalogage/a.f_ead.html
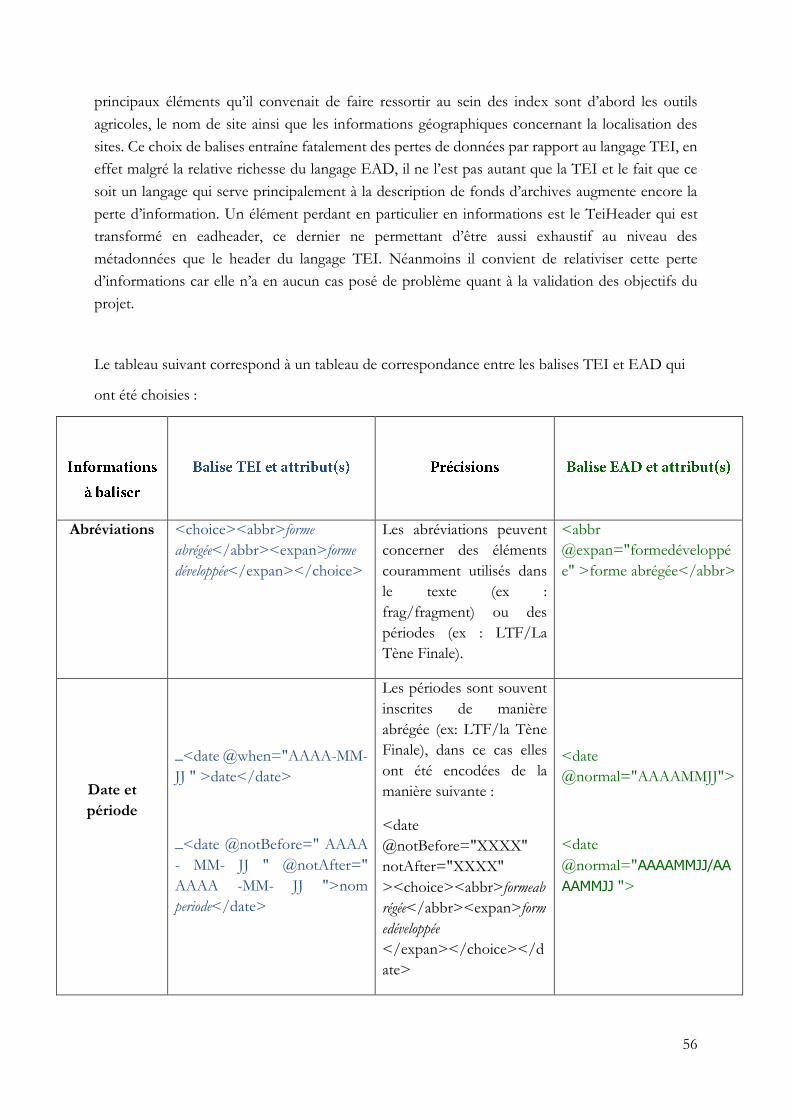
56
principaux éléments qu’il convenait de faire ressortir au sein des index sont d’abord les outils
agricoles, le nom de site ainsi que les informations géographiques concernant la localisation des
sites. Ce choix de balises entraîne fatalement des pertes de données par rapport au langage TEI, en
effet malgré la relative richesse du langage EAD, il ne l’est pas autant que la TEI et le fait que ce
soit un langage qui serve principalement à la description de fonds d’archives augmente encore la
perte d’information. Un élément perdant en particulier en informations est le TeiHeader qui est
transformé en eadheader, ce dernier ne permettant d’être aussi exhaustif au niveau des
métadonnées que le header du langage TEI. Néanmoins il convient de relativiser cette perte
d’informations car elle n’a en aucun cas posé de problème quant à la validation des objectifs du
projet.
Le tableau suivant correspond à un tableau de correspondance entre les balises TEI et EAD qui
ont été choisies :
Abréviations <choice><abbr>forme
abrégée</abbr><expan>forme
développée</expan></choice>
Les abréviations peuvent
concerner des éléments
couramment utilisés dans
le texte (ex :
frag/fragment) ou des
périodes (ex : LTF/La
Tène Finale).
<abbr
@expan="formedéveloppé
e" >forme abrégée</abbr>
Date et
période
_<date @when="AAAA-MM-
JJ " >date</date>
_<date @notBefore=" AAAA
- MM- JJ " @notAfter="
AAAA -MM- JJ ">nom
periode</date>
Les périodes sont souvent
inscrites de manière
abrégée (ex: LTF/la Tène
Finale), dans ce cas elles
ont été encodées de la
manière suivante :
<date
@notBefore="XXXX"
notAfter="XXXX"
><choice><abbr>formeab
régée</abbr><expan>form
edéveloppée
</expan></choice></d
ate>
<date
@normal="AAAAMMJJ">
<date
@normal="AAAAMMJJ/AA
AAMMJJ ">

57
Elément de
localisation
(pays,
département,
…)
<placeName @type="…">
Elément de localisation
</placeName>
<geogname> élément de
localisation </geogname>
Entrée
alphabétique
<head><title>entrée
alphabétique </title></head>
Chaque entrée
alphabétique se situe dans
le <head> des <div> qui
comprennent chacune
l’intégralité des sites
commençant par cette
lettre.
<head>X<head>
Liste
<list>
<item></item>
<item></item>
</list>
Elle apparaît notamment
lorsqu’au sein d’un site, on
trouve plusieurs sous-
localisation différentes
Idem
Mise en
italique et en
gras
<hi @type="i" >terme</hi>
<hi @type="b" >terme</hi>
Certains éléments ont été
mis en gras et en italique
par l’auteur, ces éléments
sont englobés par cette
balise pour respecter les
choix d’édition.
<emph type="italic"
>terme</emph>
<emph type="bold"
>terme</emph>
Mot en
langue
étrangère
<foreign @xml :lang="ISO">
mot</foreign>
Cela concerne des termes
en allemand, anglais, latin,
hongrois et tchèque.
<emph><language
langcode="ISO"
>mot</language></emph>
Nom de site
(entrée)
<placeName
@type="site_archeo"
subtype=" …"
>nomsite</placeName>**
<name>nomsite</name>

58
Note
<note>
parfois
<note @type="nb" >
et
<note @type="gloss">
Il n’est pas possible de
garder l’information de
l’attribut @place qui existe
au sein de la TEI mais non
en EAD.
<note @type="…">
Outil
archéologique
<rs type="…" >outil</rs>***
Un grand nombre de
catégories d’outils existe, il
serait intéressant de
pouvoir garder cette
information pour avoir la
possibilité de pouvoir se
baser sur ces informations
pour des recherches.
<subject>
outil
<subject/>
Paragraphe
(entourant
une entrée)
<p @xml : id="entrée"
>…</p>
Les paragraphes entourent
chacun une entrée.
<c><did
@id=entree>…<did><scop
econtent></scopecontent
></c>
Saut de ligne
<lb/>
Utilisé notamment lors des
listes de sous-locations au
sein d’un site.
Idem
Séparation
des grands
ensembles
alphabétiques
<div type="entree_alpha"
n="X" >
<c @level="series"> <did
id=”entralpha1”><unitid>
A</unitid>…</did></c
>

59
*Parmi les @type de <placeName> on trouve "lieu_dit", "departement", "länder",
"arrondissement" et "pays", il n’a pas été possible de conserver cette information lors du passage
en XML-EAD faute d’équivalence dans ce langage.
** les subtypes sont très nombreux, mais ne pourront pas être exploités dans le document final
faute d’équivalence en XML-EAD.
***les types sont les suivants "instrAra","atteTrai", "outAgri", "ani", "bois", "charr", "harna" et
"instrVete".
Le langage XSLT (Exenstive Style Language Transformations) permet de transformer de manière
automatique un fichier XML en un autre langage informatique, le plus souvent il s’agit d’une
transformation vers un autre langage XML ou en HTML. Ce langage a donc été choisi dans le cadre
de ce projet pour passer d’un fichier XML-TEI à un fichier XML-EAD. Le langage permet de créer
un fichier clone du fichier original dans nouveau format et avec des modifications choisies dans sa
structure et ses composants. XSLT s’appuie sur le XPath1 pour sélectionner les informations à
transformer et respecte la grammaire du XML.
Dans le cadre du projet, il a été choisi de réaliser deux filtres XSLT, l’un portant sur le
« header » et l’autre sur le « body » du fichier pour des raisons de simplicité au niveau de la création
de la structure des filtres. Ainsi le fichier de l’inventaire en XML-TEI a été transformé par le biais
de deux filtres, l’un entraînant la création un fichier XML-EAD avec seulement les éléments de
métadonnées présentes dans le header ainsi que le <frontmatter> et un autre comportant les
données propres de l’inventaire. Ces deux fichiers ont ensuite été reconstitués en un seul qui
constitue l’inventaire complet en XML-EAD.
Pour plus d’informations sur le langage XSLT, son principe et sa mise en place, consulter la
bibliographie en fin de document.
Pour réaliser les transformations, il suffit d’utiliser le bouton « débogueur XSLT » du logiciel
Oxygen XML Editor et de sélectionner ensuite le document à transformer ainsi que le filtre XSLT
voulu.
IV. Le logiciel PLEADE et son utilisation
Le logiciel PLEADE est un outil de publication, de consultation et de recherche de
documents et d'archives numériques (moteur de recherche XML EAD)2. C’est un logiciel libre dont
1 Xpath est un langage d’interrogation des documents XML, il permet de sélectionner certaines parties d’un document XML (attributs, nœuds, sous-arbres, etc.), pour plus d’informations sur le Xpath consulter la bibliographie sur le XSLT en fin de documentation. 2 http://pleade.com/

60
l’objectif se résume à proposer, principalement à destination des services d’archives, un
environnement web dynamique pour publier des instruments de recherche archivistique au format
EAD1. A partir de fichiers EAD bien formés et valides, il est possible de créer un site internet
constituant un instrument de recherche. PLEADE utilise la technologie de Tomcat, SDX ainsi que
Java. PLEADE propose de nombreuses fonctionnalités qui permettent de s’adapter à différents
projets, notamment un outil de publication d’images numérisées, la mise ne place d’un entrepôt
OAI, la diffusion d’informations statiques sur un site web2 …
Afin d’avoir un aperçu des possibilités du logiciel, consulter les liens dans la bibliographie en fin de
document.
L’installation de PLEADE est assez simple mais répond à des contraintes très précises qui
doivent absolument être respectées sous peine de problèmes de fonctionnement ou de non
démarrage du logiciel. Dans le cadre du projet, il a été choisi d’installer une version du logiciel
modifiée par l’équipe de la MSHS de Caen et qui nous a été fourni par l’intermédiaire de Pierre-
Yves Buard. Cette version a été débuguée par les soins de l’équipe et a l’avantage de se présenter
sous la forme d’un fichier contenant à la fois SDX et le logiciel PLEADE en version 4.3. En plus
de SDX et Tomcat, PLEADE s’appuie également sur Java, la version nécessaire à son bon
fonctionnement étant la 1.73.
Comme cela a été avancé plus haut, PLEADE fonctionne en se basant sur SDX et Tomcat,
il convient donc d’installer Tomcat sur le poste de travail en version 7.04, une version supérieure à
celle-ci rendrait impossible l’utilisation du logiciel. Après l’installation de Tomcat, le fichier
« pleade3.4rc3.war » doit être placé dans le dossier webapps située dans le dossier Tomcat 7.0.
Après avoir placé ce document, l’installation se fait automatiquement. Si l’installation c’est bien
déroulé, il suffit d’ouvrir une page internet et de rentrer l’adresse suivante :
http://localhost:8080/pleade3.4rc3 pour atteindre la page du logiciel.
Pour installer une version classique de PLEADE, la procédure est détaillée sur le site officiel du
logiciel5.
L’utilisation de PLEADE pose un certain problème du fait qu’il n’existe pas aujourd’hui de
documentation utilisable sur le logiciel à jour, la seule existante concerne la version 2.0 de PLEADE
1 http://pleade.org/fr/documentation/concepts/index.html 2 http://pleade.org/fr/documentation/descriptions/index.html 3 Cette version est communément appelée Java version 7, elle est téléchargeable à partir du lien suivant : http://www.oracle.com/technetwork/java/javase/downloads/java-archive-downloads-javase7-521261.html 4 La version 7.0 de Tomcat est téléchargeable depuis ce lien : https://tomcat.apache.org/download-70.cgi 5 http://pleade.com/documentation/installation

61
et est donc périmée1. La suite de cette documentation tentera de détailler son utilisation mais ne
doit en aucun être considérée comme exhaustive.
1. La publication des fichiers
Pour mettre en place l’outil de recherche à partir du document EAD, le fichier EAD doit
être placé dans le dossier EAD du dossier exemples2. Une fois placé à cet emplacement, il devient
possible de publier le document à partir de la fenêtre « gestion de contenu » du logiciel PLEADE
dans la section « Publier des documents EAD », une barre permet de « Sélectionner un fichier ou
un dossier à publier », une fois le fichier sélectionner, en appuyant sur le bouton « Valider » le
document est alors publié et accessible dans la section « Gérer les documents EAD publiés » dans
l’onglet « Gestion de contenu ».
2. La modification de l’interface graphique
Le logiciel Pleade fonctionne comme un appareil en back-office et front-office, les
modifications sur le site se font directement sur celui-ci et concernent l’intégralité de l’interface.
Afin de modifier l’interface, il est nécessaire de travailler sur plusieurs fichiers déjà présents au
format xml, html et css, il est donc nécessaire de maîtriser ces langages pour réaliser cette partie de
personnalisation de Pleade.
Concernant l’apparence en tant que tel du site, son application consiste principalement en
la modification en fonction des besoins des pages html correspondant aux différentes pages de
Pleade, elles sont situées dans le dossier « pages3 » dans le cas des pages statiques comme la page
d’accueil. Les pages HTML sont très détaillées, de nombreuses classes et id ont été appliqués à des
balises html <div> et <p>, ces attributs classe et id sont présents également dans des fichiers css,
il est donc possible de se baser sur ce système pour mettre en place l’habillage du site. Les css sont
regroupés dans un dossier au même nom4.
La mise en place des menus, formulaires de recherches ou des rubriques se fait depuis
l’onglet « administration » du logiciel Pleade qui permet de récupérer les fichiers au format .xconf5
qui gèrent ces différents éléments.
1 http://pleade.org/fr/documentation/index.html 2 Apache Software Foundation/Tomcat 7.0/webapps/pleade3.4rc3/exemples/ead 3 Le chemin à suivre pour accéder au dossier « pages » depuis le dossier racine de Tomcat est le suivant : Tomcat 7.0/webapps/pleade3.4rc3/module-eadeac/pages 4 Le chemin à suivre pour accéder au dossier « css » depuis le dosser racine de Tomcat est le suivant : Tomcat 7.0/webapps/pleade3.4rc3/theme/css 5 Un fichier au format .xconf s’appuie sur la grammaire XML.

62
Conclusion :
Il convient de rappeler que les choix qui ont été faits dans le cadre du projet OUTAGR et
qui ont été présentés synthétiquement dans ce document ne constituent qu’un exemple, beaucoup
d’autres solutions auraient pu être choisies pour réaliser un outil de recherche ou traiter un
inventaire du type de celui de Alain Ferdière à des fins de publications électronique. Le choix de la
TEI du passage à l’EAD a été notamment en grande partie conditionné par le choix de réaliser
l’outil de recherche via le logiciel Pleade.
Certaines volontés n’ont pas pu être mises en place dans le cadre du projet principalement
pour des questions de limites techniques. L’un des objectifs étaient notamment de faire
correspondre le nom des outils archéologiques avec leur traduction en anglais, allemand et latin,
cela n’a pas été réalisable faute de possibilités avec le langage XML-EAD et donc impossible à
mettre en place dans le rendu final sur Pleade. Cette correspondance était malgré tout à fait possible
à mettre en place en utilisant la technologie de la TEI. Pleade est un logiciel qui permet la création
d’un outil de recherche de manière simple et en s’épargnant un important travail de programmation,
néanmoins il contient des limites et induit la maîtrise technique d’une certaine quantité de
technologie ainsi qu’une bonne préparation du matériel informatique à son usage.
Dans le cadre de ce projet nous avons été amenés à utiliser plusieurs technologies et
langages informatiques, notamment la TEI et l’EAD, dans un but bien particulier mais leur utilité
s’inscrit dans un cadre beaucoup plus large. Dans le cas de la TEI par exemple, celle-ci peut être
utilisée au sein d’une chaîne d’édition de texte scientifique ou de source primaire.

63
Bibliographie et webographie :
Society of American Archivists, Description Archivistique Encodée : Dictionnaire des balises, traduit de l'anglais par le groupe AFNOR CG46/CN357/GE3, URL :
http://www.archivesdefrance.culture.gouv.fr/static/1066, publié le 01/10/2004, consulté le 30/05/16.
Claire Sibille, EAD : le standard d’encodage pour les descriptions de manuscrits et d’archives, URL :
http://www.enssib.fr/bibliotheque-numerique/documents/1334-ead-le-standard-d-encodage-pour-les-
description-de-manuscrits-et-d-archives.pdf, publié le 19/11/2007, consulté le 30/05/16.
http://www.bnf.fr/fr/professionnels/formats_catalogage/a.f_ead.html
http://bonnespratiques-ead.net/guide
Dossiers d’encodage issus d’autres projets :
http://www.archivistes-experts.fr/reglementation_EAD.pdf
http://www.enssib.fr/bibliotheque-numerique/documents/62240-faire-un-repertoire-ou-un-inventaire-
simple-en-ead-description-archivistique-encodee.pdf
pleade.com
pleade.org
Exemples de sites mis en place à PLEADE :
http://bcmopac.mnhn.fr/expertise/
https://www.unicaen.fr/mrsh/bvma/inventaires/
https://www.unicaen.fr/crahm/Nummus/pages/fonds.html
Lou Burnard, Qu’est-ce que le Text Initiative Encoding ? [en ligne], URL : http://books.openedition.org/oep/1297, consulté le 30/05/16.
http://www.tei-c.org/index.xml
Bernard Barbiche, Conseils pour l’édition des textes de l’époque moderne (XVIe-XVIIIe siècle), URL : http://theleme.enc.sorbonne.fr/cours/edition_epoque_moderne/edition_des_textes, consulté le 30/05/16.
Emmanuel Château, L’encodage des textes, URL : http://www.desgodets.net/edition-des-cours/model, publié le 23/09/13, consulté le 30/05/16.

64
Dossiers d’encodage issus d’autres projets :
http://www.bvh.univ-tours.fr/XML-TEI/index.asp
https://halshs.archives-ouvertes.fr/hal-00718043/document
http://bfm.ens-lyon.fr/IMG/pdf/Manuel_Encodage_TEI.pdf
https://sourceforge.net/p/epidoc/wiki/Home/
https://openclassrooms.com/courses/les-bases-de-la-mise-en-forme-xml-avec-xslt
http://edutechwiki.unige.ch/fr/Tutoriel_XSLT_d%C3%A9butant
https://www.irif.univ-paris-diderot.fr/~carton/Enseignement/XML/Cours/XSLT/index.html
http://xml.chez.com/xslt/

65

66
Bibliographie et Webographie générale :
http://www.w3schools.com/css/
https://www.w3.org/Style/CSS/learning
Alain Ferdière, Recherches sur l’habitat rural gallo-romain en Beauce : autour de la fouille de Dambron (1972),
thèse 3e cycle, Université. Paris IV, 6 vol., 946 p.
Alain Ferdière, « Recherche sur les contextes de découverte d’outillage agricole et objets liés au
travail et à la production rurale en Gaule romaine », in : Ph. Leveau, C. Raynaud, R. Sablayrolles et
F. Trément (dir.) - Les formes de l’habitat rural gallo-romain. Terminologies et typologies à l’épreuve des réalités
archéologiques, Actes du Colloque AGER VIII (Toulouse, 2007), Aquitania, Suppl. 17, Bordeaux : 81-
107.
Gilbert Kaenel, Tène, civilisation de La, Dictionnaire Historique de la Suisse [en ligne], consulté le
06/06/2016. URL : http://www.hls-dhs-dss.ch/textes/f/F8015.php
Claire Sibille, EAD : le standard d’encodage pour les descriptions de manuscrits et d’archives, URL : http://www.enssib.fr/bibliotheque-numerique/documents/1334-ead-le-standard-d-encodage-pour-lesdescription-de-manuscrits-et-d-archives.pdf, publié le 19/11/2007, consulté le 30/05/16.
Society of American Archivists, Description Archivistique Encodée : Dictionnaire des balises, traduit de l'anglais par le groupe AFNOR CG46/CN357/GE3, URL : http://www.archivesdefrance.culture.gouv.fr/static/1066, publié le 01/10/2004, consulté le 30/05/16.
http://www.archivistes-experts.fr/reglementation_EAD.pdf

67
http://www.bnf.fr/fr/professionnels/formats_catalogage/a.f_ead.html http://bonnespratiques-ead.net/guide
http://www.enssib.fr/bibliotheque-numerique/documents/62240-faire-un-repertoire-ou-un-inventairesimple-en-ead-description-archivistique-encodee.pdf
http://nliautaud.fr/wiki/articles/notepadpp/expreg#notepad_les_expressions_regulieres
http://www.archearegioncentre.org/Marmoutier.html
http://citeres.univ-tours.fr/spip.php?article1305
https://hal.archives-ouvertes.fr/halshs-00679740
http://bcmopac.mnhn.fr/expertise/
https://www.unicaen.fr/mrsh/bvma/inventaires/
https://www.unicaen.fr/crahm/Nummus/pages/fonds.html
pleade.com
pleade.org
Bernard Barbiche, Conseils pour l’édition des textes de l’époque moderne (XVIe-XVIIIe siècle), URL : http://theleme.enc.sorbonne.fr/cours/edition_epoque_moderne/edition_des_textes, consulté le 30/05/16.
Lou Burnard, Qu’est-ce que le Text Initiative Encoding ? [en ligne], URL : http://books.openedition.org/oep/1297, consulté le 30/05/16.

68
Emmanuel Château, L’encodage des textes, URL : http://www.desgodets.net/edition-des-cours/model, publié le 23/09/13, consulté le 30/05/16.
http://www.tei-c.org/index.xml
Marjorie Burghart et Nicole Dufournaud, « Édition électronique de sources : XML et Text Encoding Initiative (TEI) à l'École », La lettre de L’EHESS [en ligne], n° 38, 2011, URL : http://lettre.ehess.fr/index.php?1530
http://www.bvh.univ-tours.fr/XML-TEI/index.asp https://halshs.archives-ouvertes.fr/hal-00718043/document http://bfm.ens-lyon.fr/IMG/pdf/Manuel_Encodage_TEI.pdf https://sourceforge.net/p/epidoc/wiki/Home/
https://openclassrooms.com/courses/les-bases-de-la-mise-en-forme-xml-avec-xslt
http://edutechwiki.unige.ch/fr/Tutoriel_XSLT_d%C3%A9butant https://www.irif.univ-paris-
diderot.fr/~carton/Enseignement/XML/Cours/XSLT/index.html http://xml.chez.com/xslt/




















