
Quicksilver: a quasi-static compiler for Java
17
Quicksilver: A Quasi-Static Compiler for Java Mauricio Serrano Rajesh Bordawekar Sam Midkiff Manish Gupta IBM T. J. Watson Research Center P.O. Box 218, Yorktown Heights, NY 10598 ABSTRACT 1. INTRODUCTION
-
Upload
independent -
Category
Documents
-
view
4 -
download
0
Transcript of Quicksilver: a quasi-static compiler for Java

Quicksilver: A Quasi-Static Compiler for Java
Mauricio Serrano Rajesh Bordawekar Sam Midkiff Manish GuptaIBM T. J. Watson Research Center
P.O. Box 218, Yorktown Heights, NY 10598fmserrano, bordaw, smidkiff, [email protected] paper presents the design and implementation of theQuicksilver1 quasi-static compiler for Java. Quasi-static com-pilation is a new approach that combines the bene�ts ofstatic and dynamic compilation, while maintaining compli-ance with the Java standard, including support of its dy-namic features. A quasi-static compiler relies on the gen-eration and reuse of persistent code images to reduce theoverhead of compilation during program execution, and toprovide identical, testable and reliable binaries over di�erentprogram executions. At runtime, the quasi-static compileradapts pre-compiled binaries to the current JVM instance,and uses dynamic compilation of the code when necessaryto support dynamic Java features. Our system allows in-terprocedural program optimizations to be performed whilemaintaining binary compatibility. Experimental data ob-tained using a preliminary implementation of a quasi-staticcompiler in the Jalape~no JVM clearly demonstrates the ben-e�ts of our approach: we achieve a runtime compilation costcomparable to that of baseline (fast, non-optimizing) compi-lation, and deliver the runtime program performance of thehighest optimization level supported by the Jalape~no opti-mizing compiler. For the SPECjvm98 benchmark suite,we obtain a factor of 104 to 158 reduction in the runtimecompilation overhead relative to the Jalape~no optimizingcompiler. Relative to the better of the baseline and the opti-mizing Jalape~no compilers, the overall performance (takinginto account both runtime compilation and execution costs)is increased by 9.2% to 91.4% for the SPECjvm98 bench-marks with size 100, and by 54% to 356% for the (shorterrunning) SPECjvm98 benchmarks with size 10.1. INTRODUCTION1The name Quicksilver was chosen because, like quicksilver,our compiler easily changes its form in response to externalconditions. Quicksilver is another name for Mercury, the Ro-man god of merchants and merchandise { important serverapplications { and is identi�ed with the Greek god Hermes[17], who, like the Quicksilver compiler, is extremely fast.
The Java Programming Language [20] has become a pop-ular language for a wide spectrum of application domains:from high-end servers [16] to client-side applications, andeven for embedded devices [11, 32]. Java programs are runwithin a virtual machine called the Java Virtual Machine(JVM). The JVM can either interpret the Java bytecode orcompile it into the native code of the target machine. Be-cause interpretation incurs a high runtime overhead, JVMsusually rely on compilation. The most popular compilationapproach is to perform dynamic or just-in-time (JIT) com-pilation, where translation from bytecode to native code isperformed just before a method is executed. Examples ofdynamic compilers available as products include the IBMJIT [39], the Sun JDK and HotSpot [31, 22], and the Mi-crosoft JIT [13]. Several other dynamic compilers have beendeveloped, which include Jalape~no [2], OpenJIT [34], andLaTTe [41]. The other compilation approach is to staticallycompile the bytecodes and then execute the compiled binaryin a Java run-time environment. Examples of static compil-ers include HPCJ [37], Marmot [19], TowerJ [40], JOVE [26],and BulletTrain [23].This paper presents quasi-static compilation, a novel ap-proach that combines the bene�ts of static and dynamiccompilation without sacri�cing compliance with the Javastandard in supporting its dynamic features. Quasi-staticcompilation involves two phases: o�ine generation of opti-mized binaries and runtime \compilation" of these binaries.The o�ine compilation can use either a static or dynamiccompiler to generate these binaries. The optimized binariesgenerated by the o�ine compiler are stored in a reusableformat, called the quasi-static image, or QSI. These imagespersist across multiple JVM instances and allow methodsto be executed from the precompiled classes. The runtimecompiler reads the precompiled code images and performsvalidation checks and on-the- y adaptation, or stitching, ofthe images for that JVM instance. The stitching processperforms a binary-to-binary transformation of code usingrelocation information collected during the o�ine compila-tion. Stitching can be implemented with low runtime over-head and memory footprint. If the precompiled code can-not be reused (e.g., if a class is modi�ed after its QSI isgenerated), the quasi-static compiler performs compilationat runtime to generate the binary for execution. The corre-sponding QSI can optionally be updated to store the newversion along with its relocation information. Thus QSI'smay evolve over time to re ect the changing dynamic envi-ronment.

Quasi-static compilation is useful in scenarios where class�les are invariant over executions of the Java bytecodes indistinct JVM instances and where response time, perfor-mance, testability, reliability, or memory requirements areimportant issues. For example, a transactional server canprecompile an application for a particular workload andreuse the optimized binary for future invocations for a sim-ilar workload. In particular, quasi-static compilation helpsmitigate the following problems with static and dynamiccompilation. The problems with dynamic compilation in-clude:� Performance overhead of compilation at run-time: Theoverhead of compilation is incurred every time the pro-gram is executed and is re ected in the overall execu-tion time. Therefore, dynamic compilers tend to beless aggressive in applying optimizations that requiredeep analysis of the program. Quasi-static compilationcan employ aggressive optimizations in an o�ine man-ner; the runtime overhead of reading the quasi-staticimages and adapting them for use in the JVM is quitelow.� Testability and serviceability problems of the generatedcode: Dynamic compilers that make use of runtimeinformation about data characteristics to drive opti-mizations can lead to a di�erent binary executable be-ing produced each time the program is executed. Thiscan create reliability problems, as the code being exe-cuted may never have been tested. The code generatedby the quasi-static compiler is obtained in an o�inemanner and can be subjected to rigorous testing (anddebugging, if necessary), before being used repeatedlyin production runs. Note that the dynamic nature ofJava requires that a quasi-static compiler be able togenerate new code at runtime in response to events likedynamic class loading (of a class not compiled before)or changes to a class �le after compilation. However,an application programmer can exercise more controlover these events, if having identical binaries acrossexecutions is important.� Large memory footprint : A dynamic compiler is a com-plex software system, particularly if it supports aggres-sive optimizations. Hence, it usually has a large mem-ory footprint. The memory footprint is particularlyimportant for embedded systems, where the memoryavailable on the device is limited. A quasi-static com-piler, however, performs optimizations during an of- ine compilation of the program. The memory foot-print of runtime adaptation of QSI's is quite low, andby using an interpreter or a simple runtime compilerto deal with the (unexpected) case where a methodneeds to be recompiled, the quasi-static compiler canavoid substantially increasing the memory footprint ofthe application program.Some of the problems with static compilation arise out ofthe dynamic nature of Java:� Dynamic class loading: In general, dynamic class load-ing, as de�ned in Java [20], requires the ability to han-dle a sequence of bytecodes representing a class (not
seen earlier by the compiler) at run time. Hence, it isimpossible for a JVM to support Java in its entiretywith a pure static compiler. Fully compliant static sys-tems require an interpreter or a dynamic compiler aswell. The quasi-static compiler can easily handle thissituation by resorting to dynamic compilation.� Dynamic binding: The code for dynamically linkedclass libraries may not be available during static com-pilation of a program, causing opportunities for inter-procedural optimizations to be missed. Furthermore,the rules for runtime binding and binary compatibilityin Java [20] make it illegal to apply even simple inter-class optimizations { e.g., method inlining across classboundaries { unless the system has the ability to undothose optimizations in the event of changes to otherclasses. The quasi-static compiler can perform o�inecompilation of a program using an optimized dynamiccompiler that employs aggressive interprocedural opti-mizations, and generates relocatable binaries. Binarycompatibility in the presence of inter-class optimiza-tions is ensured by recording these dependences whilegenerating the QSI's, performing the necessary checksduring program execution, and recompiling the meth-ods if those checks fail.We describe the design of a quasi-static compiler and presentdetails of our current implementation in the context of theJalape~no JVM [2, 3], being developed at IBM Research.Some of the techniques we have employed in our compilerhave been used individually in other systems. However, theyare unique in the context of Java, and o�er tremendous ad-vantages relative to other Java compilation strategies. Inparticular, our paper makes the following contributions:� It presents a new approach to Java compilation thatcombines the important bene�ts of static and dynamiccompilers. Our approach sharply reduces the runtimecompilation costs and improves performance and re-liability by reusing highly-optimized and more easilytestable binaries.� It introduces stitching as an approach for runtime adap-tation of pre-compiled binaries to a JVM instance. Itdescribes an implementation of stitching in the Jalape~noJVM that is e�cient in both space and time.� It presents a framework for preserving optimizationsacross JVM instances. This framework allows inter-class optimizations (e.g., inlining) to be performed of- ine, with reusable code being produced for execution,without breaking binary compatibility.� It presents experimental results, in the context of astate of the art JVM, that demonstrate the perfor-mance advantages of quasi-static compilation. Ourcompiler achieves a runtime compilation cost compa-rable with that of fast non-optimizing compilation,and delivers the runtime program performance of thehighest optimization level supported by the optimiz-ing compiler, thus delivering the highest overall perfor-mance. Relative to the better of the baseline and theoptimizing compilers of Jalape~no, the overall perfor-mance is increased by 9.2% to 91.4% for the SPECjvm98

benchmarks with size 100, and by 54% to 356% for thesame benchmarks with size 10.The rest of this paper is organized as follows. Section 2presents the design of a quasi-static compiler and an overviewof its implementation in the context of the Jalape~no JVM.Section 3 describes the compilation phase when QSI's aregenerated, and Section 4 describes how pre-existing QSI'sare used during program execution. Section 5 presents ex-perimental results from a preliminary implementation of ourcompiler. Section 6 describes related work. Finally, Sec-tion 7 presents conclusions and plans for future work.2. OVERVIEW OF DESIGNIn this section, we present an overview of the design of thequasi-static compiler and its implementation in the contextof the Jalape~no JVM. Our basic design can be applied toany JVM.2.1 Basic PrinciplesDuring the compilation of a Java class, a quasi-static com-piler saves the executable code and auxiliary informationneeded to reuse that code as a quasi-static image (QSI).Each QSI is closely associated with a single class. At pro-gram execution time, the compiler tries to reuse these QSI'safter verifying their validity and adapting them to the newexecution environment. If, however, a QSI for a class doesnot exist or is invalid, the compiler can compile the classat runtime. This ability clearly distinguishes a quasi-staticcompiler from a purely static compiler, and allows it to sup-port dynamic features of Java like dynamic class loading.This also explains the rationale of our approach in build-ing a quasi-static compiler by extending a dynamic compilerrather than trying to add support for the dynamic featuresby extending a static compiler.The quasi-static compiler can be con�gured in di�erent ways,depending on the attributes of static or dynamic compilationthat are considered important in the system. The defaultapproach presented in this paper attaches high importanceto obtaining the QSI's prior to the production runs. Thiscorresponds more closely to the static compilation model,and enables a sharp reduction in runtime compilation costand better testability of the code to be executed (althoughevents like dynamic class loading may still require previouslyuntested code to be generated and used at run time). Wedesignate the �rst execution of a program as a \compilationrun". The quasi-static compiler is referred to as being in thewrite mode during this run, as it generates QSI's of variousclasses that are instantiated. An alternative to using run-time compilation during the write mode would be to compilethe program statically and generate the QSI's. During nor-mal execution of the program, the quasi-static compiler isin read mode, where it tries to reuse existing QSI's (and at-tempts to avoid invalidation of previously generated QSI's),but does not generate new QSI's.The quasi-static compiler can also be employed in a moredynamic environment, where the main emphasis is on amor-tizing the overhead of compilation over di�erent JVM execu-tions, rather than on obtaining similar binaries across thoseruns or reducing the memory footprint of the dynamic opti-
mizing compiler. The invalidation of a previously generatedQSI is then treated as purely a performance issue. An adap-tive compiler, in such a JVM, could choose to recompile a\hot" method in order to take advantage of runtime char-acteristics during a particular execution. In this system,it is not necessary to make a distinction between the writeand read modes of the quasi-static compiler. A QSI may begenerated during normal execution as a new image or as areplacement for an existing QSI, and the compiler may de-cide at runtime whether or not to reuse an existing QSI. Weshall not discuss such a dynamic environment any further inthis paper.Although some individual components of our quasi-staticapproach (e.g., static compilation, relocatable linking, dy-namic compilation) have been used in other contexts, thecombined e�ectiveness of these components in a system tocompile and execute Java are uniquely powerful. We havemade the following key design decisions that allow the fullpower of this approach to be exploited:1. Dynamic compilation as the base case. Correct behav-ior in the presence of dynamic activity that invalidatesthe correctness of a class's semantics (that were cap-tured in the QSI) can be obtained by using the dy-namic compilation system. This simpli�es the designand implementation of a quasi-static compiler. Fur-thermore, it allows more aggressive optimizations tobe attempted because a safe fall-back position is al-ways available at e�ectively the same performance asif quasi-static compilation had not been used.2. Use of a relocatable binary format. This eliminatesQSI invalidations resulting from changes in the execu-tion environment that are a property of the implemen-tation and JVM environment, but that do not alter thesemantics of the class captured in the QSI.3. Provision for multiple method versions. This allowsspecialization of generated code to accommodate dif-ferent workload characteristics and di�erent constraintson optimizations, allowing quasi-static compiled codeto obtain many of the performance bene�ts that accruefrom dynamic compilation.4. Code generation at a �ner granularity than the whole-program. By generating code in units smaller thana whole program, the number of QSI's that must beinvalidated because of changes to class �les used bythe program, and the opportunities for the use of codein a QSI by many applications, are increased. Both ofthese reduce the overhead associated with compilationand enhance the bene�ts of quasi-static compilation.2.2 Implementation of the Quasi-Static Com-
piler in JalapenoOur quasi-static compiler is implemented within the contextof the Jalape~no JVM [2, 3]. Figure 1 gives a high-leveloverview of the Jalape~no JVM.The Jalape~no JVM supports a variety of compilers. Thebaseline compiler provides fast translation of bytecode tonative code, without any optimizations. The optimizing
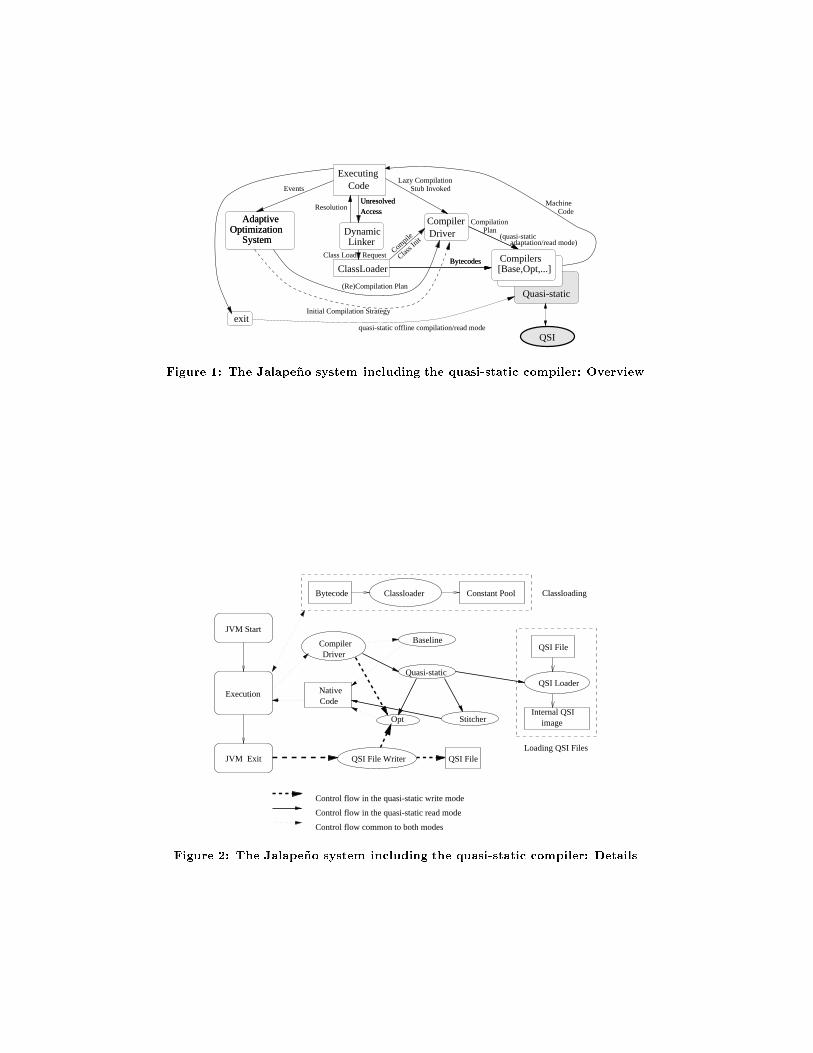
Access
QSI
CompilationPlan
(quasi-staticadaptation/read mode)
MachineCode
Unresolved
Access
Unresolved
quasi-static offline compilation/read mode
Resolution
CodeExecuting
Compil
e
Events
(Re)Compilation Plan
BytecodesClass Load Request Clas
s Init
Lazy CompilationStub Invoked
ClassLoader
Bytecodes
exit
DriverCompiler
DynamicLinker
AdaptiveOptimization
System
AdaptiveOptimization
System
Compilers[Base,Opt,...]
Quasi-static
Initial Compilation StrategyFigure 1: The Jalape~no system including the quasi-static compiler: Overview Code
Internal QSI image
QSI File Writer QSI File
Native
Loading QSI Files
Baseline
Quasi-static
CompilerDriver
StitcherOpt
JVM Start
Execution
JVM Exit
Classloading
QSI File
QSI Loader
Bytecode Classloader Constant Pool
Control flow in the quasi-static write mode
Control flow in the quasi-static read mode
Control flow common to both modesFigure 2: The Jalape~no system including the quasi-static compiler: Details

(Opt) compiler leads to the best program execution times(i.e., the time actually spent in executing the program, ig-noring the runtime compilation cost), but uses more re-sources (both memory and time) in performing the com-pilation. The adaptive compiler [5], being developed con-currently with the quasi-static compiler, initially compilesmethods using the baseline compiler, but methods whoseexecution is a signi�cant part of the program execution timeare recompiled using the Opt compiler. As can be seen inFigure 1, the quasi-static compiler is one of these compilers.We use the lazy method compilation framework [27] ofJalape~no, in which the JVM compiles a method only whenit is actually invoked, rather than compiling each method ofa class when it is linked and resolved. When the Jalape~nosystem determines that a method needs to be compiled, itinvokes the compiler driver. The compiler chosen by theJVM to perform runtime compilation depends on the JVMcon�guration. The JVM used in our system is con�gured toinvoke the quasi-static compiler by default.Figure 2 shows the Jalape~no components that are importantto the quasi-static compiler. Ovals represent JVM compo-nents, squares are data structures, and rounded squares arephases of the JVM execution. Solid directed arcs representread phase control ow, dashed arcs represents write phasecontrol ow, and dotted arcs represent control ow takenby both the read and write phases. As seen in the �gure,the quasi-static compiler currently uses the Opt compiler toperform compilation of the method codes during its writemode. Some of the important optimizations performed bythe Opt compiler (and utilized by the quasi-static compiler)are global constant and non-null value propagation; methodinlining; lock and unlock inlining; ow insensitive elimina-tion of redundant cast checks; null check and constant sizedarrays bounds checks; local bounds check elimination; andcommon subexpression elimination. These optimizations arediscussed further in [2]. In the future, we plan to incorporateadditional optimizations based on interprocedural analysis,that may be too expensive (for the Opt compiler) to performat runtime.During program execution (the read mode), the quasi-staticcompiler attempts to reuse the existing QSI's after readingtheir data, performing the validation checks, and stitchingthe binary code to the current JVM instance. As seen inFigure 2, the native code produced by the stitcher is thenexecuted. If it determines that a method needs to be recom-piled, it uses the Opt compiler (in principle, it could invokethe adaptive or baseline compiler as well).2.3 Digests and QSI security modelsThe quasi-static compiler can use digital signatures for sev-eral purposes, including forming �le names for QSI's, check-ing the integrity of a QSI, and determining that a QSI isthe same as the one generated from a veri�ed class �le. Adigest of the QSI �le is obtained using a secure hashingfunction [18]. A digest of a data stream is a one-way hashfunction of the contents of the data stream that, with avery high probability, yields a di�erent value if there areany changes made to the contents of the data stream [18].We developed a preliminary implementation of our secu-rity mechanism which uses the Secure Hashing Algorithm
(SHA) [36] to form digests. This preliminary implementa-tion is used for measurements of digest overheads reportedin Section 5, and the IBM DK1.1.8 numbers reported inthis section. This preliminary implementation is not fullyintegrated into the Quicksilver prototype because of limita-tions in the Jalape~no JVM support of standard classes thatmake use of non-standard native code interfaces (e.g. Big-Integer). Where appropriate, we describe the design of thequasi-static compiler in terms of digests while also describ-ing what is implemented.If a QSI is not kept in a secure area, the quasi-static com-piler can ensure that it was generated by a trusted compilerfrom a given class �le using the following procedure. Inthe write mode, the trusted compiler forms a digest of boththe class �le and the QSI, and then combines the digests. Adigital signature is then computed using a cryptographicallysound digital signature algorithm, (DSA [36] is used in ourpreliminary implementation), and appended to the QSI. Todetermine that the QSI is valid in read mode, the digestof the class �le is formed and combined with the digest ofthe QSI (computed by excluding the stored the digital sig-nature). The digital signature is then read from the QSIand veri�ed using this combined digest. If either the class�le or QSI has been changed, the combined signature willhave changed, and veri�cation will fail. Thus, veri�cationmakes it highly likely (to the extent allowed by the digestand digital signature algorithms) that the QSI is the QSIproduced by the trusted compiler.Although forming digests is relatively inexpensive (see Sec-tion 5 for detailed numbers) digitally signing and verifying asignature is a more expensive operation. The naive defaultimplementation supplied with the IBM DK1.1.8 requires ap-proximately 30{50 ms per �le to perform a signature veri-�cation on our benchmarking platform (see Section 5 fordetails). We know of other implementations that on compa-rable hardware platforms can perform this operation in 10ms [8].The cost of signature veri�cation can be mitigated by thefollowing:1. System �les are typically not veri�ed by JVM imple-mentations. If the system �les can be maliciously tam-pered with, then there is no reason to believe that thetampering won't also involve the �les performing veri�-cation, making veri�cation pointless. Unsigned digestscan be used to detect non-malicious corruption.2. If non-system QSI �les reside on a secure server, theveri�cation of the �le can be performed once (whenthe QSI is received). Thereafter, the same securitymechanisms used to protect the system �les can beused to protect the QSI �les.3. A secure database of digest pairs (class digest,QSI di-gest) can be maintained, with the digest of the classand QSI being formed at class loading time, and com-pared to the entries in the secure database. This tech-nique relies on the security provided by the database,rather than digital signatures, to ensure that signa-tures generated by the trusted compiler have not been

altered and therefor continue to accurately capture thecontents of the trusted QSI �le. By doing so, it is notnecessary to verify a digital signature each time a classis loaded, thereby allowing veri�cation to be done byonly incurring the cost of forming digests.4. If Java 2 security mechanisms are being enforced withdigital signatures, and the class �le is writable by thetrusted compiler, a digest of the QSI can be placed inthe class �le as an annotation before signing the class�le. Because the Java 2 security mechanism will verifythat the class �le signature is valid, there is no addi-tional cost incurred for verifying the signature for theQSI �le veri�cation. If the class �le signature veri-�es, it is known that the QSI digest contained withinhas not changed. If this digest matches the digest ofthe current QSI �le, then the QSI �le is unchanged.Thus veri�cation of the QSI �le only requires forminga digest of the QSI �le, and not an additional digitalsignature veri�cation.Because of these techniques, we believe that in a server envi-ronment the overall cost of verifying the validity of class �lescan be kept low. Moreover, the ability to inexpensively signmessages and verify signatures has widespread and commer-cially important implications, and is an active research area.Therefore, the cost of performing veri�cation will becomecheaper over time, as the bene�ts of the aggressive analy-sis of programs enabled by quasi-static compilation becomegreater.3. PROGRAM COMPILATION: GENERA-
TION OF QUASI-STATIC IMAGESFor each class that is instantiated during the compilationrun, a QSI is created to record the executable code for com-piled methods in a persistent manner. The QSI is logicallya part of the classfile. However, it is stored in a sepa-rate �le with a .qsi su�x. The decision to store the QSIseparately from the classfile gives the JVM greater exi-bility in determining where to place the QSI. For example,the QSI of a class arriving over the network may be storedlocally. Furthermore, this allows the JVM to create andupdate QSI's for read-only classfiles.The layout of a QSI is shown in Figure 3. In our implemen-tation, a QSI is created, just before the end of JVM exe-cution, for each class with an Opt-compiled method. Anymethod in such a class that was only baseline-compiled dur-ing execution is recompiled with the Opt compiler. In theclass header region for each QSI, the compiler stores infor-mation such as the environment information (JVM and OSversions, target architecture), a digital signature for the QSIand a directory area with pointers to various method coderegions. For each method the compiler records additional in-formation, such as exception tables, garbage collection (GC)maps, dependence and relocation information, as explainedlater in this section.In the remainder of this section, we �rst describe how thecorrespondence is maintained between a class �le and theQSI �le. We then discuss how QSI's are obtained for librarycode. Finally, we describe how dependences on other classes,
Speculative Optimizations Info
Digital Signature
Dependence Information
String Table
Method Descriptor Table Entry
. . . Method Descriptor Table Entry
Method Descriptor Table
Timestamp/Digest
Class Header
Magic Number
Environment InformationMethod Area
Dependence Information
Debug Information
Relocation Area
Extended Constant Pool
Exception Table
GC Map
Binary CodeSpeculative Optimizations InfoFigure 3: Layout of the quasi-static image.information to support speculative optimizations, and relo-cation information are recorded for each QSI, in addition tothe binary code.3.1 Correspondence between class and quasi-
static imageGiven that a QSI is stored separately from a class �le, theJVM needs a mechanism to uniquely identify and locate aQSI corresponding to a runtime class. In Java 2, a runtimeclass is uniquely identi�ed by the pair hC;Di, where C is thefully quali�ed name of the class, and D is the de�ning classloader of that class [29, 31]. All class loaders other than theprimordial class loader (which is regarded as a null classloader) are �rst class Java objects.The location in which the original class �le is stored canbe viewed as having two components: the repository con-taining the class, and the directory structure implied by thefully quali�ed name of the class. For example, consider aclass with fully quali�ed name MyPackage.Foo, stored as/jvm/Jalapeno.classes/MyPackage/Foo.class on an AIXplatform. We refer to /jvm/Jalapeno.classes as the repos-itory of that class.Consider a class hC;Di whose bytecode is stored in reposi-tory R. The quasi-static compiler obtains the name of thecorresponding QSI as an ASCII expanded version of the 160-bit digest of the class bytecode with a .qsi su�x. This �leis given an additional human-readable name in the form ofC D.qsi, which is also the name used in our current imple-mentation.2 The QSI is stored into the repository fr(R;D),where fr can be viewed as a set of class-to-QSI mappingsde�ned for various class loaders. These mapping functionsare chosen to be simple to compute and to not rely informa-tion about class loaders aside from the fully quali�ed nameof their class.Our compiler uses the local �le system to store the QSI'sfor various classes. In principle, the QSI's may be stored in2Our original design involved using the class name as thename of the QSI and storing the digest of the de�ning classloader in each QSI. The simpli�cation, of using the digestof the class as the name of the QSI, was suggested by oneof the anonymous OOPSLA reviewers.

other forms of persistent storage such as a database.3.2 Shared class librariesDuring the compilation of a program, the quasi-static com-piler encounters not only classes that are unique to the pro-gram, but also classes from libraries that are shared acrossprograms. In order to maintain a strict correspondence be-tween a class �le and a QSI �le, we ensure that only a singlecopy of the QSI �le is generated for a class. Our frameworkallows multiple code versions of a method to appear in a sin-gle QSI �le, so, in principle, library code may be specializedfor di�erent applications. Furthermore, since compilationis done in an o�ine manner, the compiler has more free-dom to apply potentially expensive interprocedural analysisto discover opportunities for method specialization. How-ever, we are still in the process of implementing analysis toguide method specialization. We do currently support op-timizations like inlining of methods from class libraries intomethods from the user code.3.3 Security attributesIf security is enforced by signing a digest of the QSI, asdescribed in Section 2.3, a �eld is reserved in the QSI tohold the digital signature. We again note that this, and allfeatures requiring digests, have not yet been implementedin our prototype.3.4 Dependence informationOf particular interest from the point of view of global op-timizations is the dependence information recorded by thecompiler. While compiling a method A.foo(), for each op-timization that exploits some information from a di�erentclass B (e.g., if a method B.moo() is inlined into A.foo()),the compiler adds class B to the set of classes on which thecode for A.foo() is dependent. (This allows the quasi-staticcompiler to perform dependence checks during program ex-ecution to support binary compatibility, as described in thenext section.) Finally, at the time of writing the QSI forclass A, the dependences recorded for various methods ofA are examined. The dependences that are common to allmethods are recorded at the class-level, and the remainingdependences are recorded along with each method. For ex-ample, if a class A has two methods foo() and bar(), whichare dependent, respectively, on classes fB;Cg and fB;Dg, thecompiler would record the dependence of A.qsi as a wholeon B, and additionally, the dependence of foo() on C and ofbar() on D.The dependence information of a method A.foo() or classA on another class C is recorded as a digest of C in the QSIfor A (in either the method-level dependence area associatedwith A.foo() or in the class-level dependence area). Analternative mechanism employed in our current implemen-tation (again, due to problems with the implementation ofdigests) is to simply record the name of the class C in theQSI. The dependence check is performed, as described inthe next section, by comparing the timestamp of the QSIwith the timestamp of the class on which the code in theQSI is dependent.
3.5 Information forSpeculativeOptimizationsThe Jalape~no Opt compiler supports speculative inlining ofvirtual methods when the corresponding object pre-existenceconditions are met [15]. In this case, the compiled code ofa caller method needs to be invalidated if any inlined calleemethod is overridden due to dynamic class loading (the pre-existence conditions ensure that no stack frame rewritingneeds to be done on code invalidation [15, 5]). The Optcompiler maintains an invalidation database which recordsthe inlined callee methods along with corresponding com-piled caller methods. The invalidation database is consultedby the classloader to detect if any inlined method is overrid-den due to the loading of a new class. If an inlined methodis overridden, compiled binaries of the corresponding callermethods are invalidated.The quasi-static compiler stores the invalidation databaseas a method list in the QSI and loads it along with the classdependence list. The invalidation database is resurrectedduring the read mode, and is used by the JVM to invalidateany previous inlining decisions due to dynamic class loadingduring current execution of the program. A similar mech-anism can be used by the quasi-static compiler to supportother speculative optimizations.3.6 Relocation InformationThe binary executable code, the exception table and the GCmap information3 all contain references that are speci�c tothe execution instance in which the QSI is created. Hence,we need to record additional relocation information to allowthose references to be adapted to a new execution instance ata later time. The actual information needed is closely tiedto the details of the JVM implementation. Our compilergenerates relocation entries for the following instructions:� Static �eld and method references: In Jalape~no, theo�sets for �elds and method references are determinedby the Jalape~no class loading process and the order inwhich classes are loaded in a particular execution of aJVM. Due to lazy class loading, classes can be loadedin a di�erent order in di�erent JVM instances, thusrequiring di�erent values of these o�sets in di�erentJVM instances.� Instance �eld and method references: The o�sets usedfor �elds of objects and for virtual methods of a refer-enced class may change if its parent class (from whichthe referenced class is derived) changes between thetime of writing and use of the QSI. Furthermore, theresolution status of those referenced �elds and meth-ods may change in the di�erent JVM instances. Wedo not invalidate a QSI for these reasons, and instead,change the references appropriately via stitching.� String and oating-point constants: These are allo-cated in the global table pointed to by the JTOC reg-ister. Thus these references need the proper o�set inthe current JVM instance.3The GC map for a method invocation site contains theinvoked method's id in addition to GC information. Thismethod id is used for lazy method invocation [27] and mustbe stitched.

� Runtime �eld and method accesses: The Jalape~no bootimage is built with several prede�ned Java classes thatmainly consist of runtime library methods, since Jalape~noitself is written in Java [3]. Thus the boot image is afrozen core, i.e., its classes are always resolved and itso�sets are always the same, independent of the run.Although it is not strictly necessary to provide relo-cation information for runtime references, we provideit to support version compatibility so that quasi-staticimages can be run with new releases of the Jalape~noboot image.Each relocation entry contains the instruction o�set in thebinary code for the method, an access type, and a symbolicreference. The symbolic reference is normally expressed asan index into the constant pool of the given class [30]. We donot have to store the constant pool itself in the QSI, becausethe same constant pool is available during a later executionof the JVM (the quasi-static compiler veri�es that the classhas not changed), and because stitching is performed onlyafter the class has already been loaded. Due to method inlin-ing across class boundaries, a method may contain referencesthat do not appear in the constant pool of its de�ning class.The quasi-static compiler creates an extended constant poolto handle relocation for references that are imported fromother classes. An extended constant pool entry consists ofa fully quali�ed name for a method or a �eld reference (forexample, X:foo(II)I for method foo in class X with twointeger arguments and an integer return type) in a similarway to entries in the constant pool.Example: Consider a method foo() in a class A thatloads a static �eld stats.count). The following PowerPCload instruction is generated to access the �eld:lwz R1=@{JTOC + offset of field stats.count }JTOC is a dedicated register pointing to the table ofglobal variables, and offset of field stats.count is animmediate-signed �eld giving the position of stats.countin that table. The value of the offset is assigned when theclass stats is loaded. The relocation entry for the instruc-tion contains the o�set of the lwz instruction, the accesstype (static �eld access), and the symbolic reference to theconstant pool entry in the class A for stats.count.In addition to method variables, the compiler also generatesrelocation information for exception tables and GC maps.Exception tables contain references to symbolic exceptiontypes. Since Jalape~no supports type-precise garbage collec-tion, the garbage collection (GC) maps contain informationabout registers and stackframe locations containing live ref-erences at program points where garbage collection can oc-cur (See [24] for details). If new instructions are inserted,then the program points for garbage collection need to beupdated (see section 4.2.2).4. PROGRAM EXECUTION: REUSE OF
QUASI-STATIC IMAGESThe quasi-static compiler is invoked by its parent JVM whenthe JVM decides to compile a method. Note that the JVM
ensures that by this time, the declaring class of the methodhas already been loaded and resolved. The quasi-static com-piler checks if aQSI �le exists for that class. If the �le exists,it reads data from that �le and performs the steps describedbelow to check that the QSI �le is not out-of-date and hasnot been tampered with. If these tests show that the �le isvalid, the compiler accesses the code for the given method(if it exists), performs method-speci�c dependence tests, andadapts the code so that it can be used in the current JVMinstance. If any of these steps fails, the quasi-static com-piler simply compiles the method at runtime (using the Optcompiler4 in our current Jalape~no implementation).4.1 Image Loading and Validation ChecksWe now describe the steps involved in loading the QSI �leand performing validation checks on it.4.1.1 Identification of QSI fileThe quasi-static compiler �rst computes a digest of the byte-code for the given class C. It identi�es the de�ning classloader of C, and also the repository from which C wasloaded. Based on the mapping function fr (described inSection 3.1), the compiler identi�es the repository holdingthe QSI �le for C. It checks if a QSI �le with a name match-ing the digest of C exists. If so, the matching of the namewith the new digest for C signi�es that the original class hasnot changed since the generation of the QSI. If no such �leexists, the quasi-static compiler uses dynamic compilation.In lieu of using the digest of the class (see the discussion inSections 2.3 and 3.1), our current implementation recordsthe timestamp (time of last modi�cation) of each QSI. Ifthe timestamp of the QSI �le is smaller than the timestampof the corresponding class5 , it implies that the original classhas changed since the generation (or modi�cation6 ) of theQSI �le, hence the QSI is invalidated.4.1.2 Compatibility checksFirst, the magic number and the execution environmentinformation (such as the JVM version, operating systemversion, and target architecture) stored in the QSI �le ischecked to ensure that it is compatible with the currentJVM.To ensure binary compatibility while supporting global op-timizations like method inlining across class boundaries, thequasi-static compiler performs dependence checks on theQSI. The recorded digest of each class C on which the givenQSI (as a whole) is dependent is compared with the com-puted digest of C. The check fails if any of those digestsdo not match. During this step, if any such class C hasnot been already loaded by the JVM, it is loaded eagerly{ in the event of an exception (or error) being thrown in4We would have used the baseline compiler instead, if thetarget of our JVM was a memory-constrained system.5The timestamp for a class �le is available in Java viastandard methods like java.io.File.lastModified andjava.util.zip.ZipEntry.getTime.6Each time an existing QSI �le is modi�ed, its originaltimestamp is similarly compared with the timestamp of theclass �le, and the QSI is invalidated if it is older than theclass �le.

loading this class, the exception is caught and ignored, butthe dependence check fails. As discussed in Section 4.1.4,similar dependence checks are performed for �ner grain de-pendences recorded with methods that are quasi-staticallycompiled.Our current implementation performs the dependence checksby comparing the timestamps of classes on which a QSI isdependent with the timestamp of the QSI. The check failsif any class on the dependence list has a smaller timestampthan that of the QSI. As described above, a class is loadedeagerly, if it is not already loaded, to allow this check toproceed.4.1.3 Security checkThe validity of the QSI �le can be checked by the quasi-static compiler in a variety of ways, as described in Section2.3. This check allow the quasi-static compiler to detectcorrupted or maliciously altered QSI �les, and maintain theJava security requirements.4.1.4 Method lookup, eager/lazymethod loading, and
checksOnce the validity of the QSI �le has been established, apointer to the method code is obtained by performing alookup over themethod directory area. The reading of methodcode from the QSI �le may be done in a lazy manner (whenresponding to a JVM request to compile that speci�c method)or in an eager manner (when the QSI �le is read for the�rst time, which in turn happens the �rst time that quasi-static compilation is attempted of anymethod in that class).We refer to these alternatives as eager method loading andlazy method loading respectively. To support lazy methodloading conveniently, our implementation uses a random ac-cess �le (java.io.RandomAccessFile) to store a QSI. Eagermethod loading is useful when most (or all) methods storedin the QSI are used during program execution, because se-quential I/O is more e�cient due to bu�er prefetching. Onthe other hand, lazy method loading has the advantage ofavoiding unnecessary I/O if relatively few methods storedin the QSI are needed during program execution. Thiswould become particularly important when we start apply-ing method specialization and keeping multiple method ver-sions in the QSI. Note that even when we perform eagermethod loading, the stitching of method codes is still donein a lazy manner, in accordance with the lazy method com-pilation strategy used in the Jalape~no JVM [27].The �rst item in the method code area is the informationabout the dependence of this method code on other Javaclasses. As described above for class-level dependence checks,the digests of class �les corresponding to classes in this de-pendence list are compared with the recorded digests in theQSI �le to check if the given method code should be con-sidered invalid. (Again, as described above for class-leveldependence checks, our current implementation uses times-tamps of class �les and the QSI for the method-level depen-dence checks as well.) As an optimization, the reading ofthe remainder of the method code can be deferred until theabove validity check is performed.
4.2 Stitching Method InformationStitching is the last step in the runtime adaptation of binarycode. Using relocation information, various references areadapted to the new execution instance. We now describethe details of stitching in the context of our implementationin Jalape~no JVM.We discuss some interesting problems thatstitching needs to handle, with the help of examples.4.2.1 Stitching activitiesThe quasi-static compiler performs the following activitiesas part of stitching.� Updating absolute o�sets: The absolute o�sets usedfor various references, like static �eld and method ref-erences, are changed using the recorded relocation in-formation. The relocation information identi�es theinstruction that needs to be stitched, and also identi-�es the symbolic reference from which the new o�setinformation may be generated. Note that stitchinghappens after the class has already been loaded andresolved. Therefore, the new table o�sets to be usedfor �eld and method references are available from themappings that the JVM maintains for the constantpools.� Monitoring the resolution status of method/�eld vari-ables. We say that a variable is resolved if its corre-sponding class has been loaded and initialized. De-pending on the class loading order, some variables re-solved when the binary code was generated may beunresolved when the code in the QSI is to be exe-cuted. Java semantics [30] require that the �rst time avariable is accessed its de�ning class be loaded and ini-tialized. Thus, the compiler needs to insert extra codefor an access that is resolved during the write modeand is unresolved during the read mode.� Monitoring pre-existing optimizations. Some optimiza-tions, e.g., constant propagation, produce code thatmay be speci�c to a JVM instance and hence, needsto be modi�ed every time it is reused. In this case,instead of invalidating the code and recompiling themethod, we can perform �ne-grain adaptation of thecode without breaking the existing optimizations (seethe last example in Section 4.2.2).Stitching requires only a single pass over the code array, evenin the case where extra instructions are added, because weonly add new code to the end of the method without recom-puting relative branches (see Section 4.2.2). The resultsfrom our implementation in the Jalape~no JVM indicate thatstitching is very fast, taking less than 65 cycles for each in-struction in the method (see Section 5 for details). Thisspeed is important because it is a runtime overhead thatincreases the startup time for a method, and increases theoverall execution time of the program.Stitching is di�erent from backpatching [4] because stitch-ing occurs at link-time (before a method is executed), whilebackpatching occurs during the method execution. We notethat stitching of a method's code occurs only once before themethod is executed for the �rst time. It is not necessary to

update, or backpatch the method's code after execution be-gins. Hence, stitching does not su�er from dynamic linkingproblems which a�ect method backpatching on SMP ma-chines [4].4.2.2 ExamplesThis section presents two examples of stitching static �eldreferences to illustrate the problems that stitching can en-counter. Typically, stitching only involves changing an in-struction o�set for a particular JVM instance. In some rarecases (which were encountered infrequently during the ex-ecution of the benchmarks described in Section 5), furtherprocessing is necessary, as described in the following exam-ples.Consider the following instruction to access a static �eld:lwz R1=@{JTOC + offset of field}At the stitching time, the original offset is changed to thenew o�set of the static �eld. The PowerPC load-immediateinstructions use a signed 16-bit immediate �eld. If the newo�set is too big to �t into the 16-bit immediate �eld usedby the load instruction, we will need two instructions toperform the access:addis R1=JTOC + high(offset)lwz R1=@{R1 + low(offset) }The PowerPC addis instruction adds the content of theJTOC register with the high order bits of the o�set. Then,the load instruction lwz adds the lower order bits of theo�set. In this case, we replace the original instruction bya branch instruction to the end of the code, where we in-sert the two-instruction sequence followed by a branch backto the next instruction after the �eld access. This simpli-�es stitching, at the expense of introducing some ine�ciencyinto the code. Since this case arises quite rarely, we feel thisis a reasonable approach. (Some possible alternatives to thisapproach are: (i) insert the extra instruction in an inlinedmanner into the code and adjust the rest of the code ac-cordingly, or (ii) indicate that stitching is too complicatedin this case, and let the quasi-static compiler compile themethod dynamically.) We may need to add new entries tothe method's garbage collection map and exception table,re ecting the new instructions added at the end of the code.For example, if the original instruction is in a try block,the new instructions inserted at the end of the code as areplacement of the original instruction are also in that tryblock, thus we need to add a new entry in the exception ta-ble. Similarly, if the original instruction is a GC point, thenew instructions contain an extra GC point at a di�erentmachine code o�set.A second complication is that a static �eld access may beunresolved at stitching time, requiring the static �eld loadinstruction to be replaced by the machine instruction se-quence of Figure 4. The �rst instruction loads the o�setof a table used for resolving �elds. The second instructionloads an entry from that table using a unique �eld identi-�cation number as an index. The third instruction tests if
try:lwz R1=@{JTOC + offset of field table} (1)lwz R1=@{R1 + field Id} (2)if (R1 == 0) goto resolve (3)lwz R1=@{JTOC + R1} // field access (4)...resolve:(resolve field) (5)b try // goto try (6)Figure 4: Code inserted by the Jalape~no optimizingcompiler for unresolved �eld accesses.the entry is zero (the value for unresolved �elds), and thefourth instruction performs the �eld access. The code for�eld resolution is placed in line (5), but for brevity is notshown in this example. The �eld resolution can throw anexception if there is an error. As in the previous case, wemay need to add entries to the garbage collection map andexception table for the new instruction inserted at the endof the code.4.3 Preserving optimizations across JVM in-
stancesAs described in Section 2.2, the quasi-static compiler em-ploys the Opt compiler to perform several optimizationsduring the write mode. The quasi-static compiler uses theQSI to propagate information necessary to preserve theseoptimizations across JVM instances. The optimizations, in-cluding speculative optimizations, are currently supportedin two ways in the quasi-static compiler: (i) through check-ing dependence information and recompiling the method ifthere is a dependence violation, or (ii) through stitching,which performs a �ne-grain adaptation at runtime. Stitch-ing is the preferred mechanism as long as it can be donerelatively inexpensively. However, dependence checking isappropriate when dependence violations are infrequent, andwhen stitching would be too expensive.An interesting example of an optimization requiring a com-bination of the above approaches is method inlining. Topreserve method inlining across class boundaries over di�er-ent execution contexts, the quasi-static compiler not onlyrecords the dependence information (Section 3.4), but alsocreates an extended constant pool to support the stitchingof inlined code and stores it in the QSI (Section 3.6). Fur-thermore, to support speculative inlining, it preserves thesupporting data structure (the invalidation database) andstitches it such that the database can be used by the JVMduring the next execution instance.We do not foresee any problem in supporting optimizationsacross execution instances through a combination of stitch-ing and dependence checking. However, the current imple-mentation does not support the following optimizations forsimplicity, although they can be supported in principle:� Inlining of allocation code: A new statement is trans-lated by the Opt compiler into a call into the alloca-tion code; the code is later inlined. The allocation

code comes in two versions, depending on whether theclass was resolved at the time of the compilation ofthe method. If the class was not resolved, then theclass resolution needs to be performed at runtime. Ifthe quasi-static compiler inlines the allocation code,then we potentially need to replace a relatively largesequence of allocation code by di�erent code that ac-counts for the class not being already resolved.� Optimization of static final �eld references. Suchreferences can be considered constants after the classis initialized, as in the Java code example:static final long time = getTime();In this example, time is assigned at class initializa-tion time. The optimizing compiler (during the writemode) will replace the �eld references by the constantvalue of the �eld, if the class is already initialized. Thismay no longer be true when the QSI is loaded. Thisoptimization could be supported in two ways, duringthe read mode:{ Uses of the static �eld can be collected during thewrite mode, and stitched with the correct valueduring read mode.{ A code dependence can be recorded on the as-sumption that the static �eld has a particularvalue, and the QSI invalidated at runtime if thestatic �eld takes a di�erent value or is not initial-ized when the code is run.5. EXPERIMENTAL RESULTSTo evaluate the e�ectiveness of the quasi-static compiler, wecompared it with two di�erent Jalape~no dynamic compilers:baseline and Opt. The Jalape~no baseline compiler is the sim-plest possible compiler { table lookups convert individualbytecodes into the corresponding sequence of machine in-structions. The Opt compiler implements many well-knownoptimizations (Section 2.2). The performance of code gen-erated using the Opt compiler has been shown to be com-parable with that from the JIT used in the IBM DeveloperKit for AIX, Java Technology Edition, Version 1.1.8(IBMDK1.1.8) [2].We ran our experiments on a 4-way SMP with 166 MHzPowerPC 604e processors running AIX 4.3. For report-ing the Opt compiler measurements, we used the highestcompiler optimization level (-O3). In each case, the entireJalape~no framework (i.e., the JVM runtime and compilers,which are themselves written in Java) were compiled usingthe same high optimization level. The Jalape~no classes werepre-compiled and stored in the JVM boot image. We usedthe Jalape~no JVM version with copying garbage collector(the Jalape~no JVM supports several garbage collectors [2]).For experimental evaluation, we chose SPECjvm98, anindustry-standard benchmark suite [14], and pBOB, theportable business object benchmark (version 1.2B4) [7].pBOB follows the business model of the TPC-C benchmarkand measures the scalability and throughput of the JVM.The default problem size for SPECjvm98 is 100. The pBOBapplication was run on 4 processors in a \minimal" mode
which has a two-minute measurement period. pBOB reportsmaximum throughput in terms of number of transactions. Inthis paper, we have reported pBOB results using a di�erentmetric: we used the transaction count from the Opt com-piler run as the reference value, and using the correspondingmeasurement duration (i.e., 120 seconds), we translated thetransaction counts for the baseline and quasi-static compil-ers into time in seconds required to run the same numberof transactions as the Opt compiled run. Using the timemetric (instead of the transaction count) allows us to reportthe compilation times in a more meaningful manner relativeto our other results.For each benchmark, we report execution and compilationtimes for the baseline, Opt, and quasi-static compilers. Forthe baseline and Opt compilers, the runtime compilationtime measures the time required to convert the Java byte-code to machine-dependent native code. For the quasi-staticcompiler, the runtime compilation time measures the timerequired to load the qsi �les, read the relocatable binaries,perform dependence checks and adapt these binaries. It alsoincludes the time required for compiling methods using thebaseline compiler7 . We did not �nd any signi�cant perfor-mance di�erence between eager and lazy method loading ofthe QSI �les. Hence, we have reported measurements onlyfor eager method loading. We have also turned o� supportfor speculative inlining due to a bug. We are currently work-ing on �xing the problem.compress jess db javac mpeg mtrt jack pBOB
Benchmarks
0.0
100.0
200.0
300.0
400.0
500.0
Tim
e (s
ec)
Performance of Specjvm98 and pBOBSpecjvm98 size=100, pBOB (4 processors)
Execution TimeCompilation Time
QS
OP
BL
BL
QS
BL
OP
QS
BL
OPQS
BLOP
QS OP
BL
QSOP
BL
QSOP
BL: BaselineOP: OptimizingQS: Quasi-static
BL
OPQSFigure 5: Performance of the SPECjvm98 andpBOB using the Quasi-static(QS), Baseline(BL),and Opt(OP) compilers. The bottom bar denotesthe execution time and the top bar denotes the com-pilation time.Figures 5 and 6 present the performance of SPECjvm98 andpBOB using the three compilers. Each stacked bar reports7Our current implementation only performs quasi-staticcompilation of methods that are Opt-compiled during thewrite mode.

compress jess db javac mpeg mtrt jackSpecjvm98 Benchmarks
0.0
10.0
20.0
30.0
40.0
50.0
60.0
Tim
e (s
ec)
Performance of Specjvm98 BenchmarksBenchmark size=10
Execution TimeCompilation Time
QS
OP
BLBL
QSBL
OP
QS BL
OP
QSBL
OP
QS
OP
BL
QS
OPBL
QS
OP
BL: BaselineOP: OptimizingQS: Quasi-static
Figure 6: Performance of the SPECjvm98 bench-marks (size=10) using the Quasi-static(QS), Base-line(BL), and Opt(OP) Compilers. The bottom bardenotes the execution time and the top bar denotesthe compilation time.the program execution time and the runtime compilationtime in seconds. The worst program execution time is ob-served when the baseline compiler is used. The Opt andquasi-static compilers provide comparable program execu-tion times. In some cases the Opt compiler leads to betterprogram performance { we believe this results from our cur-rently turning o� the optimization to inline new operations.In the other cases the quasi-static compiler delivers betterprogram performance. We believe this di�erence is due tothe smaller memory footprint of the quasi-static compilersince the Opt compiler is not invoked at runtime (resultingin fewer garbage collections and reduced memory tra�c).The quasi-static compiler obtains the best overall execu-tion times (counting both program execution and runtimecompilation) in all cases. Further, the compilation cost ofthe Opt compiler is the highest among the three compilers.The impact of compilation cost is more pronounced for theSPECjvm98 benchmarks with the smaller size of 10 (Fig-ure 6). In all cases, the compilation costs of the baselineand quasi-static compilers are negligible when compared tothat of the Opt compiler. The runtime compilation cost ofthe quasi-static compiler, when compared to that of the Optcompiler, is lower by a factor of 104 to 158 for SPECjvm98.Further, relative to the better of the baseline and the opti-mizing Jalape~no compilers, the overall performance (takinginto account both runtime compilation and execution costs)is increased by 9.2% to 91.4% for the SPECjvm98 bench-marks with size 100, and by 54% to 356% for the (shorterrunning) SPECjvm98 benchmarks with size 10.Figure 7 presents the comparison between the compilationcosts of the quasi-static read mode and the baseline com-piler (which are too small to show up in Figures 5 and 6).
compress jess db javac mpeg mtrt jack pBOBBenchmarks
0.0
100.0
200.0
300.0
400.0
500.0
Tim
e (m
sec)
Comparison with the Baseline CompilerSpecjvm98 size=100, pBOB (4 processors)
Compilation time
BL
QSBL
BL
BL
BL
BL
BL
QS
QS
QS
QSQS
QS
BL: BaselineQS: Quasi-static
BL
QS
Figure 7: Comparing Compilation costs of theQuasi-static (QS) and Baseline (BL) compilers us-ing the SPECjvm98 benchmarks and pBOB.For most benchmarks, the quasi-static compilation cost isroughly equivalent to that of the baseline compiler. As dis-cussed earlier, the Jalape~no baseline compiler supports nooptimizations and requires the least compilation cost of thedynamic Jalape~no compilers. Figures 5, 6, and 7 demon-strate that our implementation of the quasi-static compilerachieves program performance comparable to the most ag-gressive optimizing compiler while keeping the runtime com-pilation cost extremely low { comparable to the fastest (base-line) compiler.Table 1 gives a breakup of the compilation cost during theread mode of the quasi-static compiler. For each program,the �rst column shows the number of QSI �les that wereused, and the next two columns show the number of meth-ods that were compiled using the baseline and quasi-staticcompilers. The baseline compiler is used for compiling meth-ods before the quasi-static compiler is initialized. The nextfour columns show the respective costs of various compi-lation components: the cost of baseline compilation, theI/O cost associated with accessing the QSI �les, the costof performing dependence checks, and the cost of adaptingthe relocatable binaries, which includes stitching the binarycode and auxiliary data such as GC maps and exception ta-bles. For each program in SPECjvm98, the same number ofmethods are baseline-compiled, before the quasi-static com-piler is initialized. The table illustrates that the runtimequasi-static compilation times, while low in absolute terms,are dominated by I/O times. Tables 2 and 3 present moredetailed measurements of the I/O and stitching costs.Table 2 presents I/O costs associated with the quasi-staticcompilation. For each benchmark, we present the numberof QSI �les that were opened during the read mode, alongwith the minimum, maximum and average �le sizes in bytes.

Table 1: Quasi-static compilation costs.Program # File # Methods Quasi-static Compilation Costs(ms)Baseline QS Baseline I/O Depend. Stitchcompress 43 34 129 12 51 11 6jess 169 34 487 12 183 33 20db 37 34 137 12 51 11 6javac 172 34 743 12 334 56 39mpegaudio 69 34 255 12 92 18 12mtrt 59 34 208 12 81 16 10jack 77 34 246 12 93 18 14pBOB 82 32 422 12 163 29 23Table 2: I/O costs associated with the quasi-static compilation.Program # Files File size(bytes) I/O Costs (ms)Min Max Avg Total File Class Methodcompress 43 178 31460 4254 51 7 22 22jess 169 144 31460 2467 183 39 73 71db 37 178 31460 5127 51 6 21 24javac 172 126 44196 4328 334 39 182 113mpegaudio 69 178 111502 5758 92 13 36 43mtrt 59 152 31460 4433 81 10 38 33jack 77 144 60892 5140 93 13 36 44pBOB 82 144 38338 6396 163 13 90 60In Table 2, the \Total" column denotes the overall I/O timefor each application, the \File" column denotes the aggre-gate time required for opening the �les, the \Class" columndenotes the aggregate time required to read the class header,string table, and method table, and the \Method" columndenotes the aggregate time required to read the relocatablemethod binaries along with relocation tables, GC maps, andexception tables. In our experiments, the number of QSI�les varied from 37 (db) to 172 (javac). The �le sizes variedfrom 126 bytes to 111502 bytes; the maximum average �lesize being 6396 bytes. For all applications, the I/O time wasdominated by the time required to fetch the class data. Theclass I/O time includes time required for reading the classheader, extended constant pool, string table and method de-scriptor table (see Figure 3). Note that these results wereachieved only after extensive tuning of I/O, and in particu-lar, by using unformatted I/O wherever possible.Table 3 shows further details about stitching. Column (a)of Table 3 shows the aggregate code size (i.e., the num-ber of machine instructions) for each benchmark. Column(b) shows the total number of relocation entries for eachprogram. The third column shows the percentage of in-structions that needed stitching. Finally, the last columnpresents the stitching cost per machine code instruction. Ta-ble 3 illustrates that the amount of relocation required forstitching the code is a small fraction of the code size { themaximum being 15.4% for javac (the average is around 8%).Further, the cost of stitching per machine instruction (notper instruction stitched) in the original code is very small{ it varies from 0.17 microseconds (mpegaudio) to 0.39 mi-croseconds (javac). On a 166 MHz PowerPC 604e processor,this amounts to less than 65 cycles per instruction. The to-tal cost of runtime quasi-static compilation per instruction
is also very small { it varies from 1.7 microseconds (mpe-gaudio) to 4.27 microseconds (javac).Table 4 presents the times to create digests for the class andQSI �les for each benchmark. Columns of the table describethe number of application (non-system) class and QSI �lesfor which digests were formed, the total number of bytes inthe class �les the time taken to form the class �le digests,the total number of bytes in theQSI �les, and the time takento form the QSI �le digests. For reasons given in Section2.3, only the cost of forming digests for non-system �leshas been counted. Because the standard digest classes arenot yet supported in the Jalape~no JVM, these numbers havebeen collected under the IBM DK1.1.8, running on the samemachine as the other benchmark results. The numbers werecollected using the default SHA [36] digest implementationin the IBM DK1.1.8 java.security.MessageDigest class.Because the ability to form digests is not currently part ofthe Quicksilver prototype, these times are not included inthe other benchmark results.Although the cost of forming digests exceeds the combinedcost of checking dependences via timestamps and stitching,it is still far less than the compilation costs of the Opt com-piler (see Figure 6). Moreover, because we are using thedefault implementation provided with the IBM DK1.1.8 dis-tribution, rather than the highly optimized implementationsavailable from various providers for an additional fee, andbecause much of the computation occurs in native code andis JVM independent, these numbers represent upper boundson overheads incurred from forming digests.

Table 3: Evaluating the stitching process: Comparing code and relocation table sizes and measuring the costof stitching per machine instruction.Program Code Size(a) Reloc. Size(b) (b/a) Total Cost Cost/intr(# instr) (# reloc instr) (%) (ms) (cycles/instr)compress 26518 2386 9.0 6 38jess 56495 6115 10.8 20 59db 29025 2538 8.7 6 34javac 100359 15440 15.4 39 65mpegaudio 71227 5233 7.3 12 28mtrt 37041 4219 11.4 10 45jack 63236 6509 10.3 14 37pBOB 81599 9234 11.3 23 47Table 4: Costs of creating digests for the application class and QSI �les using the IBM DK1.1.8.Program # class class Files QSI Filessize (bytes) digest time (ms) size (bytes) digest time (ms)compress 24 98623 20 120315 25jess 146 441838 89 315476 80db 16 92194 18 121836 18javac 143 548659 108 636865 137mpeg 50 192451 40 341798 72mtrt 38 139085 20 190397 41jack 57 204401 36 341655 67pBOB 41 228095 47 361126 756. RELATED WORKSeveral groups have developed dynamic compilers for Java,such as the IBM JIT [39], Sun HotSpot [22], Microsoft JIT [13],and the OpenJIT [34]. Several static compilers for Java arealso available, such as HPCJ [37], JOVE [26], Marmot [19],TowerJ [40] and BulletTrain [23]. Our work is di�erent, inthat it attempts to incorporate the advantages of static com-pilation into a dynamic compilation system for Java. TheIBM AS/400 JVM [35] seems to be the closest to our e�orts.The AS/400 JVM supports execution of statically precom-piled code (appearing in the form of a Java program object,which is similar to a dynamically linked library), with fall-back to the JIT compiler. In contrast, our Quicksilver com-piler generates code with more e�cient, direct, referencesto �elds and methods, and relies on stitching to adapt theprecompiled code image to a new execution instance.Azevedo, Nicolau, and Hummel [6] have developed the AJITcompiler. The AJIT compiler annotates the byte-code withmachine independent analysis information that allows theJIT to perform some optimizations without having to dy-namically perform analysis. This system di�ers from oursin that program transformation and code generation stilloccur at application execution time.DyC [21] is a selective dynamic compilation system for Cwhich shares some of our goals. DyC reduces the dynamiccompilation overhead by statically preplanning the dynamicoptimizations. Based on user annotations that identify vari-ables with relatively few runtime values, it applies partialevaluation techniques to partition computations in regionsa�ected by those variables into static and dynamic computa-
tions. DyC also supports automatic caching of dynamicallycompiled code. Many other systems, such as Tempo [12]and Fabius [28] support a similar staging of optimizations,triggered by user annotations. In contrast to these systemswhich target C and ML, we target the Java language, whichpresents new challenges. Our work has so far focussed onbuilding the basic system which can support a wide range ofoptimizations applied by a sophisticated dynamic compilerwith the attendant advantages, like compilation overhead,of a static compiler. In the future, we plan to support codespecialization, although without any user annotations.Recently, researchers have proposed techniques to detect sit-uations where analysis based on a \closed world" view of theprogram continues to be valid for the \open world" scenario,where dynamic class loading may take place. Detlefs andAgesen [15] present techniques to identify opportunities forinlining virtual methods that are not a�ected by dynamicclass loading. Sreedhar et al. [38] present extant analysis,which is a general framework to allow optimizations, thatremain valid in the presence of dynamic class loading, tobe applied based on a static analysis of the program. Thiswork is complementary to the work described in our paper.We plan to build upon these techniques while performinginterprocedural analysis in the quasi-static compiler.Several systems for selective recompilation of programs keeptrack of dependences between modules to reduce the over-head of recompilation [9, 1, 10]. We apply these techniquesin a di�erent context, and also supplement them with ourstitching techniques that allow previously generated code tobe �xed up, rather then invalidated, based on new runtime

conditions.The Forest project [25] at Sun Labs is developing orthogonalpersistence for the Java platform (OPJ). OPJ provides sup-port for checkpointing the state of a Java application. OPJis a programming model that enables generation and reuseof persistent images of the Java application variables includ-ing classes, objects and threads. The quasi-static compilerdoes not store the state of a Java application, rather it storesand reuses method binaries needed for the Java application.Necula has proposed the notion of proof-carrying code for asimple language to allow a host system to determine if it issafe to execute a binary program supplied by an untrustedsource [33]. In the context of our work, the JVM executesan adapted form of the binary executable produced earlierby the same JVM, and not by an untrusted source. Hence,we use the simpler approach of using digital signatures toverify that the code produced by the trusted source has notbeen tampered with. In the future, when the proof-carryingcode methodology is well-developed for languages like Java,it should be possible to integrate it into the quasi-staticcompiler.7. CONCLUSIONSFor performance reasons, JVMs usually rely on compilationinstead of interpretation for executing the Java bytecodes.Two common compilation approaches { dynamic and static{ have their drawbacks and bene�ts. Since static compi-lation is not Java-compliant, most JVMs tend to use dy-namic compilation, even though the compilation time canadversely a�ect the overall program execution time.In this paper, we presented a new approach for compilingJava bytecodes: quasi-static compilation. It performs o�ineoptimizing compilation and stores the relocatable binariesinto persistent code images. During program execution, itreuses previously generated code images after performingon-the- y binary adaptation to the new JVM context, andusing dynamic compilation if the relocatable binaries can-not be used. We presented details of our implementationof the quasi-static compiler using the Jalape~no JVM. Weused the Jalape~no dynamic optimizing compiler for o�inecompilation. We evaluated our implementation using theSPECjvm98 benchmark suite and the pBOB benchmark.We demonstrated that our quasi-static compiler providesthe optimization bene�ts of the highest optimization level(supported by the optimizing dynamic compiler) while in-curring compilation costs comparable to those of the fastest,non-optimizing (baseline) dynamic compiler, thus deliveringthe best overall performance. The runtime compilation costof the quasi-static compiler is lower by a factor of 104 to 158for SPECjvm98 relative to that of the optimizing compiler.Relative to the better of the baseline and the optimizingJalape~no compilers, the overall performance is improved by9.2% to 91.4% for the longer running version, and by 54%to 356% for the shorter running version of the benchmarksuite.In the future, we shall investigate more general strategies forrecording dependence information to explore the trade-o�sbetween the overhead of dependence checking and the like-lihood of QSI invalidation during program execution time.
For example, the compiler may move a dependence itemshared by the important (but not all) methods to a class-level dependence, to reduce the overhead of dependence check-ing. This comes at the expense of possibly invalidating theentire QSI �le rather than invalidating just the quasi-staticcode for a single method. On the other hand, the com-piler may keep dependence information at a �ner granularity(e.g., method-to-method dependence) to reduce the chancesof invalidating a QSI, at the expense of increased overheadof dependence checking.We are currently extending the quasi-static compiler to sup-port global program optimizations that are often not sup-ported by dynamic compilers due to inhibitive compilationcosts. We are building upon the techniques described in [15]and [38] to support optimizations in presence of dynamicclass loading. We plan to support method specializationbased on partial evaluation techniques. As we incorporateoptimizations performed exclusively by the quasi-static com-piler that lead to execution time improvements, we expectto show even greater bene�ts from the quasi-static compila-tion approach.8. ACKNOWLEDGMENTSThe help of the Jalape~no compiler and runtime groups hasbeen invaluable in implementing our prototype. We wouldlike to thank John Field, Vugranam Sreedhar, Chet Murthy,and the anonymous referees for their valuable comments.We would also like to thank Donna Dillenberger, Lee Nack-man, Pratap Pattnaik, and Marc Snir for supporting thiswork.9. REFERENCES[1] R. Adams, W. Tichy, and A. Weinert. The cost ofselective recompilation and environment processing.ACM Transactions on Software Engineering andMethodology, 3(1):3{28, January 1994.[2] B. Alpern, C. Attanasio, J. Barton, M. Burke,P. Cheng, J.-D. Choi, A. Cocchi, S. Fink, D. Grove,M. Hind, S. Hummel, D. Lieber, V. Litvinov,M. Mergen, T. Ngo, J. Russel, V. Sarkar, M. Serrano,J. Shepherd, S. Smith, V. Sreedhar, H. Srinivasan,and J. Whaley. The Jalape~no virtual machine. IBMSystems Journal, 39(1):211{193, 2000. JavaPerformance Issue.[3] B. Alpern, C. Attanasio, J. Barton, A. Cocchi,S. Flynn Hummel, D. Lieber, M. Mergen, T. Ngo,J. Shepherd, and S. Smith. Implementing Jalape~no inJava. In Proceedings of the 1999 ACM SIGPLANConference on Object-Oriented Programming Systems,Languages and Applications (OOPSLA'99), Denver,Colorado, October 1999.[4] B. Alpern, M. Charney, J.-D. Choi, A. Cocchi, andD. Lieber. Dynamic linking on a shared-memorymultiprocessor. In Proceedings of PACT'99, LosAngeles, California, June 1999.[5] M. Arnold, S. Fink, D. Grove, M. Hind, andP. Sweeney. Adaptive optimization in the Jalape~noJVM. In Proc. ACM SIGPLAN Conference onObject-Oriented Programming and Systems,

Languages, and Applications (OOPSLA) 2000,Minneapolis, MN, October 2000.[6] A. Azevedo, A. Nicolau, and J. Hummel. Anannotation aware Java virtual machineimplementation. In Proc. ACM SIGPLAN 1999 JavaGrande Conference, June 1999.[7] S. Baylor, M. Devarakonda, S. Fink, E. Gluzberg,M. Kalantar, P. Muttineni, E. Barsness, R. Arora,R. Dimpsey, and S. Munroe. Java server benchmarks.IBM Systems Journal, 39(1):57{81, 2000. JavaPerformance Issue.[8] Peter Buhler and Thomas Eirich. privatecommunication.[9] M. Burke and L. Torczon. Interproceduraloptimization: Eliminating unnecessary recompilation.ACM Transactions on Programming Languages andSystems, 15(3):367{399, July 1993.[10] C. Chambers, J. Dean, and D. Grove. A framework forselective recompilation in the presence of complexintermodule dependencies. In Proc. 17th InternationalConference on Software Engineering, Seattle, WA,April 1995.[11] Hewlett-Packard Company. Chai products.http://www.hp.com/emso/products/chaivm.[12] C. Consel and F. No�el. A general approach forrun-time specialization and its application to C. In23rd Annual ACM SIGACT-SIGPLAN Symposium onthe Principles of Programming Languages, pages145{156, January 1996.[13] Microsoft Corporation. MS SDK for Java 4.0.http://www.microsoft.com/java/vm.htm.[14] The Standard Performance Evaluation Corporation.SPEC JVM98 Benchmarks, 1998.http://www.spec.org/osg/jvm98.[15] D. Detlefs and O. Agesen. Inlining of virtual methods.In Proc. 13th European Conference on Object-OrientedProgramming, pages 258{278, 1999.[16] D. Dillenberger, R. Bordawekar, C. Clark, D. Durand,D. Emmes, O. Gohda, S. Howard, M. Oliver,F. Samuel, and R. St. John. Building a Java virtualmachine for server applications: The JVM on OS/390.IBM Systems Journal, 39(1):194{210, 2000. JavaPerformance Issue.[17] Encyclopedia Britannica Online. Information availablevia search at http://www.eb.com.[18] Proposed Federal Information Processing Standard forSecure Hash Standard. Federal Register,57(21):3747{3749, 31, January 1992.[19] R. Fitzgerald, T. Knoblock, E. Ruf, B. Steensgard,and D. Tarditi. Marmot: An optimizing compiler forJava. Technical Report 33, Microsoft Research, June1999.[20] J. Gosling, B. Joy, and G. Steele. The Java(TM)Language Speci�cation. Addison-Wesley, 1996.
[21] B. Grant, M. Philipose, M. Mock, C. Chambers, andS. Eggers. An Evaluation of Staged Run-TimeOptimizations in DyC. In SIGPLAN'1999 Conf. onProgramming Language Design and Implementation,pages 293{304. ACM SIGPLAN, May 1999.[22] The Java Hotspot Performance Engine Architecture.http://java.sun.com/products/hotspot/whitepaper.html.[23] NaturalBridge Inc. BulletTrain optimizing compilerand runtime for JVM bytecodes.http://www.naturalbridge.com/bullettrain.html.[24] R. Jones and R. Lins. Garbage Collection: Algorithmsfor Automatic Dynamic Memory Management. JohnWiley and Sons, 1996.[25] M. Jordan and M. Atkinson. Orthogonal Persistencefor the Java Platform: Draft speci�cation, October1999.http://www.sun.com/research/forest/index.html.[26] Jove. Jove, super optimizing deployment environmentfor Java.http://www.instantiations.com/javaspeed/jovereport.htm.[27] C. Krintz, D. Grove, D. Lieber, V. Sarkar, andB. Calder. Reducing the overhead of dynamiccompilation. Technical Report CSE2000-0648,University of California, San Diego, April 2000.[28] M. Leone and P. Lee. Dynamic specialization in theFabius system. In ACM Computing Surveys, pages30(3es):23{28, September 1998.[29] S. Liang and G. Bracha. Dynamic class loading in theJava virtual machine. In Proceedings of the 1998 ACMSIGPLAN Conference on Object-OrientedProgramming Systems, Languages and Applications(OOPSLA'98), Vancouver, Canada, October 1998.[30] T. Lindholm and F. Yellin, editors. The Java VirtualMachine Speci�cation, Second Edition.AddisonWesley, 1998.[31] Sun Microsystems. Java2 Platform, Standard EditionDocumentation. http://java.sun.com/docs/index.html.[32] Sun Microsystems. EmbeddedJava(TM) applicationenvironment.http://java.sun.com/products/embeddedjava/.[33] G. Necula. Proof-carrying code. In 24th Annual ACMSIGACT-SIGPLAN Symposium on the Principles ofProgramming Languages, Paris, France, January 1997.[34] H. Ogawa, K. Shumira, S. Matsuoka, F. Maruyama,Y. Sohda, and F. Kimura. OpenJIT : An open-ended,re ective JIT compiler framework for Java. In Proc.European Conference on Object-OrientedProgramming, Cannes, France, June 2000.[35] P. Richards and D. Hicks. Virtual integration.AS/400, pages 50{56, March 1998.

[36] B. Schneier. Applied Cyptography: Protocols,Algorithms, and Source Code in C. John Wiley andSons, 1996.[37] V. Seshadri. IBM High Performance Compiler forJava. AIXpert Magazine, September 1997.http://www.developer.ibm.com/library/aixpert.[38] V. Sreedhar, M. Burke, and J.-D. Choi. A frameworkfor interprocedural optimization in the presence ofdynamic class loading. In SIGPLAN'2000 Conf. onProgramming Language Design and Implementation,To appear. ACM SIGPLAN, 2000.[39] T. Suganuma, T. Ogasawara, M. Takeuchi, T. Yasue,M. Kawahito, K. Ishizaki, H. Komatsu, andT. Nakatani. Overview of the IBM Java just-in-timecompiler. IBM Systems Journal, 39(1):175{193, 2000.Java Performance Issue.[40] Tower Technology Corporation. TowerJ3 - a newgeneration native Java compiler and runtimeenvironment.http://www.towerj.com/products/whitepapergnj.shtml.[41] B.-S Yang, S.-M Moon, S. Park, J. Lee, S. Lee,J. Park, Y Chung, S. Kim, K. Ebcioglu, andE. Altman. LaTTe: A Java VM Just-in-TimeCompiler with Fast and E�cient Register Allocation.In Proc. 1999 International Conference on ParallelArchitectures and Compilation Techniques (PACT'99),1999.




















