
Glasgow Pascal Compiler for the Xeon Phi
17
Glasgow Pascal ● Implements Turner’s Vector Pascal. ● SIMD auto parellisation ● MIMD auto parallelisation ● We have implemented it on Intel machine including the Xeon Phi, and earlier on the Sony Cell ● We are using it in the Clopema cloth manipulating robot project
Transcript of Glasgow Pascal Compiler for the Xeon Phi

Glasgow Pascal
● Implements Turner’s Vector Pascal.
● SIMD auto parellisation
● MIMD auto parallelisation
● We have implemented it on Intel
machine including the Xeon Phi, and
earlier on the Sony Cell
● We are using it in the Clopema cloth
manipulating robot project

Stereo Matcher
● We want an implementation that is hardware independent so
that we can upgrade the platform to a 60 core intel Xeon Phi
card
● That requires us to harness both SIMD and multi-core
parallelism
● We have used Vector Pascal a parallel array dialect of Pascal
for this since it auto-parallelises across SIMD and multi-cores
● It can be linked to ROS using a harness in Python ( that is
how our current matcher works with ROS)

listing from file matchlib.pas
+---A 'P' at the start of a line indicates the line has been SIMD parallelised
|+--An 'M' at the start of a line indicates the line has been multi-core parallelised
||
Vv
219 procedure computepolynomialinterpolation(var f_1,a,f1:plane; var x:image;layer:integer);
220 (*! this performs polynomial interpolation and updates all positions
221 in x[layer] where there is a maximum of the polynomial *)
223 var b,c:^plane;
225 BEGIN
...
246 PM b^:= (f1-f_1)/2;
247 PM c^:= f1 - (a+b^);
264 M x[layer]:= if c^<0 then (-b^ *0.5)/c^ else 0.0;
265 PM x[layer]:= (1.0 min(-1.0 max x[layer])) ;
267 x[confidenceplane]:= if c^<epsilon then
268 x[confidenceplane]*(a+b^*x[layer]+c^*x[layer]*x[layer])
269 M else 0.4;
...
272 END;
The parallel interpolation
function
We show this just as an example of the sort of parallelism we use
Variables are images represented as 2d arrays of reals
Operate on whole arrays at a time like MATLAB

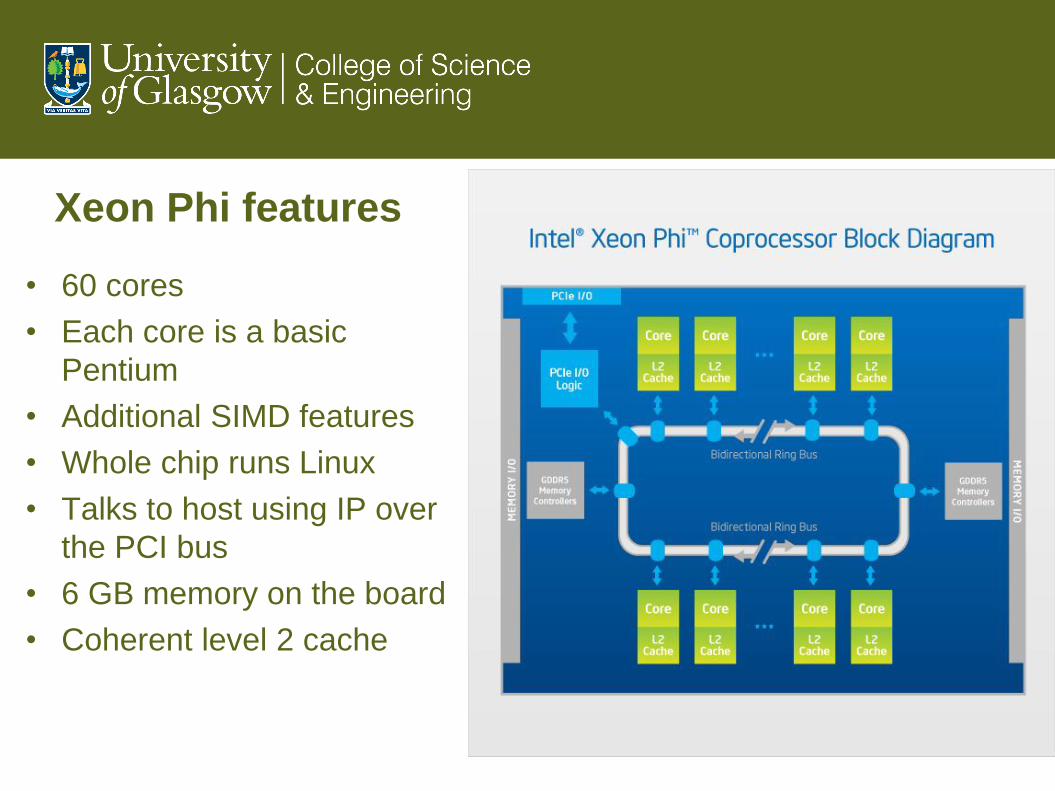
Xeon Phi features
• 60 cores
• Each core is a basic
Pentium
• Additional SIMD features
• Whole chip runs Linux
• Talks to host using IP over
the PCI bus
• 6 GB memory on the board
• Coherent level 2 cache

Vector processor on each core
• Vector registers hold 16 x
32-bit floats
• Vector to vector arithmetic
• K registers allow you to
mask the write to a particular
destination
• K registers set by
comparisons

Multi-core parallelism
• If a statement is a two dimensional array assignment and it
uses only basic arithmetic operations or pure functions (side
effect free) on the right hand side,
• then the work on rows of the array is interleaved between
different n processors so that processor j handles all rows i
such that i mod n = j.

SIMD
• If a statement is an array assignment and the right hand side
contains no function calls and operates on adjacent array
elements,
• then the compiler generates SIMD code.

Parallel IF-expressions
• If the expression on the right is a conditional one with no
function calls
• Then it is evaluated using boolean masks to allow SIMD
execution.

Example of parallel IF-expression
; #substituting in k7 with 2 occurences and score of 17.0 vloadunpacklps ZMM0,[ A] vloadunpackhps ZMM0,[ A+64 ] vloadunpacklps ZMM1,[ B] vloadunpackhps ZMM1,[ B+64]
vcmpps k7, ZMM0, ZMM1,1 ; #substituting in ZMM7 with 2 occurences and score of 6.0
vloadunpacklps ZMM7,[ A] vloadunpackhps ZMM7,[ A+64] vloadunpacklps ZMM0,[ B] vloadunpackhps ZMM0,[ B+64] vmulps ZMM0, ZMM0, ZMM7 vblendmps ZMM0 { k7}, ZMM0, ZMM7 vpackstorelps [ C], ZMM0 vpackstorehps [ C+64], ZMM0
program compvec;
var A,B,C:array[1..16 ]
of real;
begin
A:=iota [0];
B:= 7;
C:= if A<B then A
else A*B;
writeln(a:5,b:5,c:5);
end.
K reg bits select between Zmm0 and Zmm7
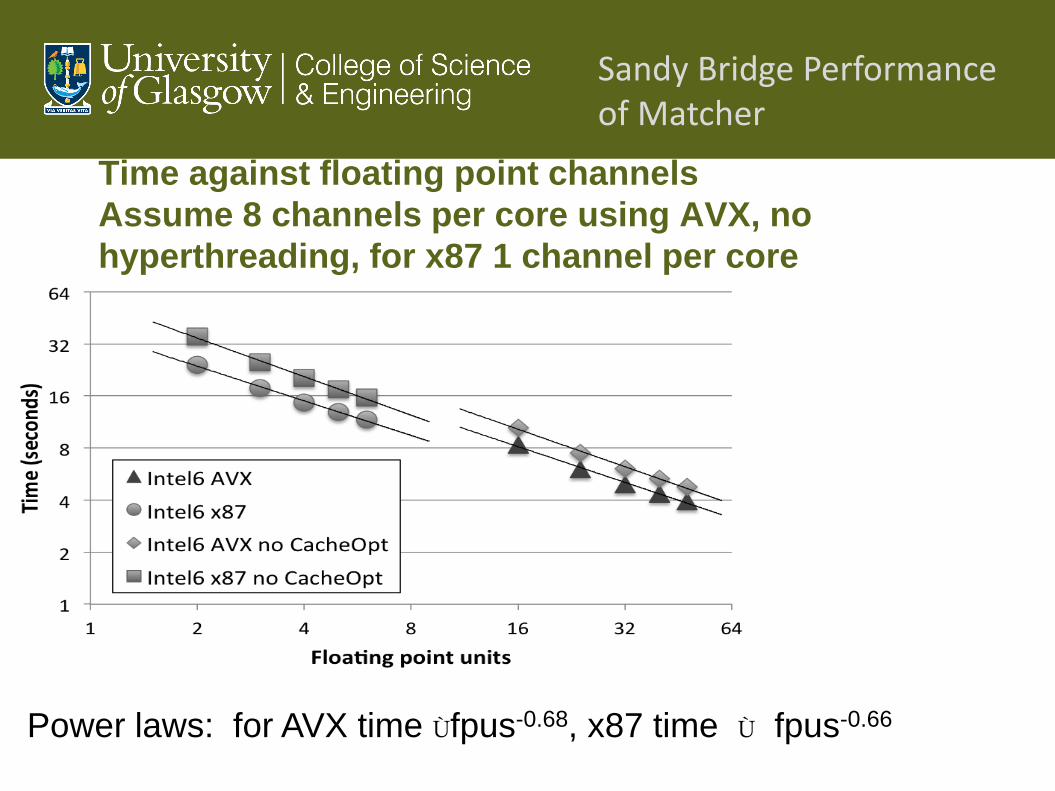
Time against floating point channels
Assume 8 channels per core using AVX, no
hyperthreading, for x87 1 channel per core
Power laws: for AVX time Ùfpus-0.68, x87 time Ù fpus-0.66
Sandy Bridge Performance of Matcher
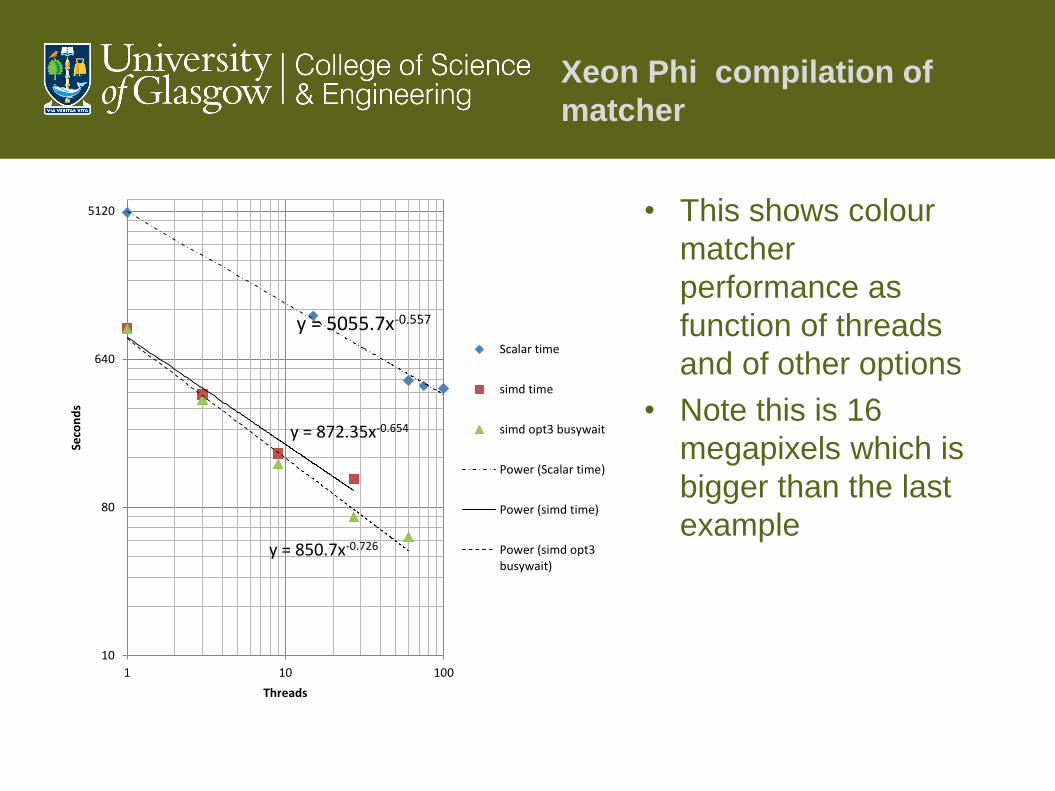
Xeon Phi compilation of
matcher
y = 5055.7x-0.557
y = 872.35x-0.654
y = 850.7x-0.726
10
80
640
5120
1 10 100
Seco
nd
s
Threads
Scalar time
simd time
simd opt3 busywait
Power (Scalar time)
Power (simd time)
Power (simd opt3busywait)
• This shows colour
matcher
performance as
function of threads
and of other options
• Note this is 16
megapixels which is
bigger than the last
example

Gather instructions
• The new instructionset allows a vector register to be loaded with
data spread around memory , ie, at non contiguous locations
• Vgather zmm0, [r12+zmm1]
• R12 is a base register point at an array
• Zmm1 holds a vector of offsets where ZMMO is to be loaded
from
• This can not be handled by current design of code generation
strategy
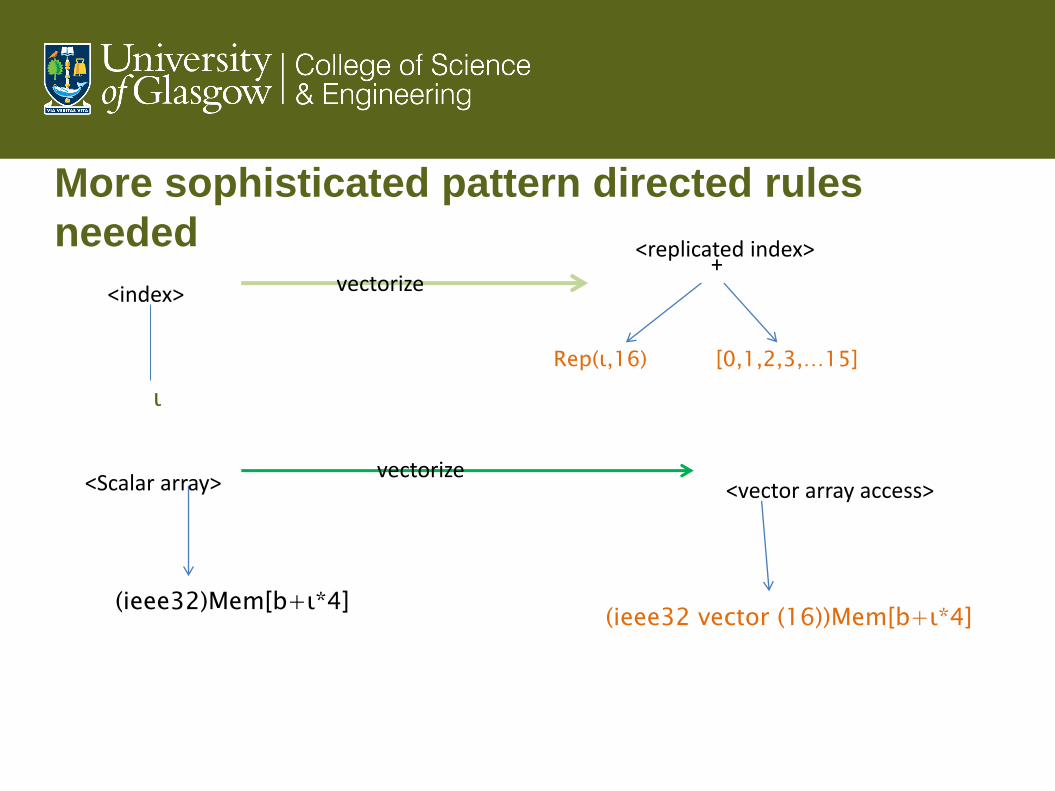
More sophisticated pattern directed rules
needed
ι
Rep(ι,16) [0,1,2,3,…15]
+
(ieee32)Mem[b+ι*4] (ieee32 vector (16))Mem[b+ι*4]
<index>
<Scalar array> <vector array access>
<replicated index>
vectorize
vectorize
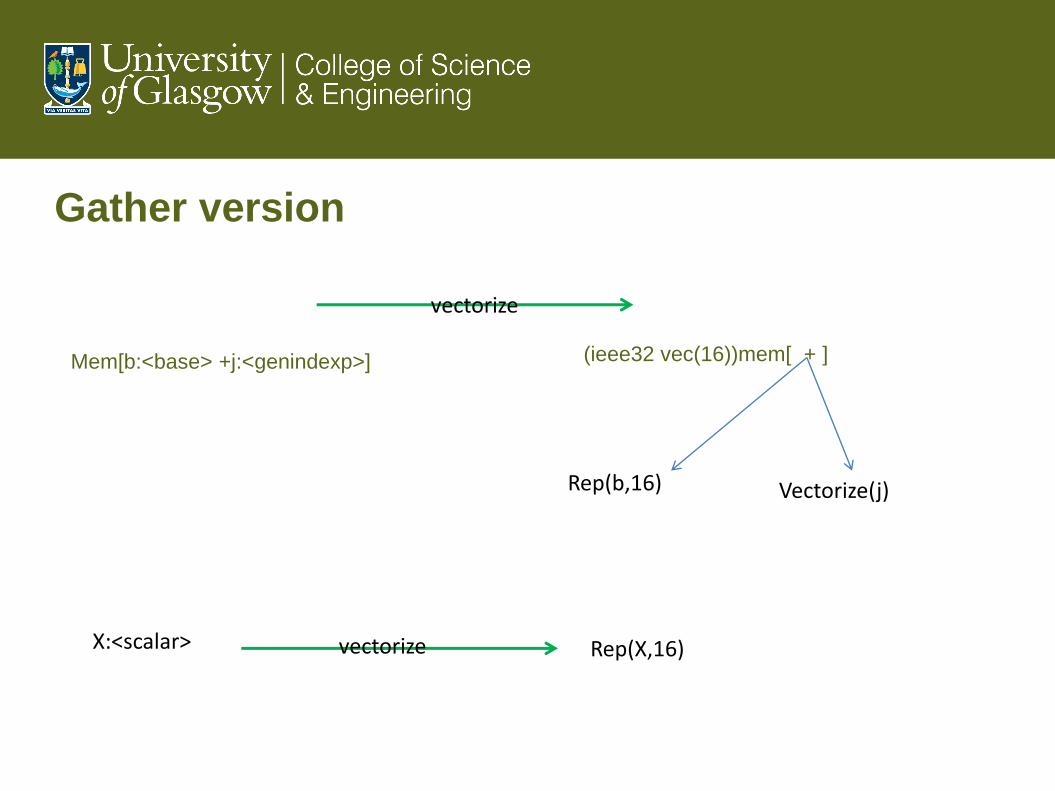
Gather version
Mem[b:<base> +j:<genindexp>] (ieee32 vec(16))mem[ + ]
Rep(b,16) Vectorize(j)
vectorize
X:<scalar> Rep(X,16) vectorize

Approach from now
• Extend the grammar of machine description patterns to allow
machine specific transformation rules on intermediate code
trees.
• Extend the code generator generator to automatically build tree
transformer pass that is applied to code tree before instruction
selection phase.
• Allow named transformation rules to be called by the Java front
end of the compiler.
• lot of design of specification language needed for this.
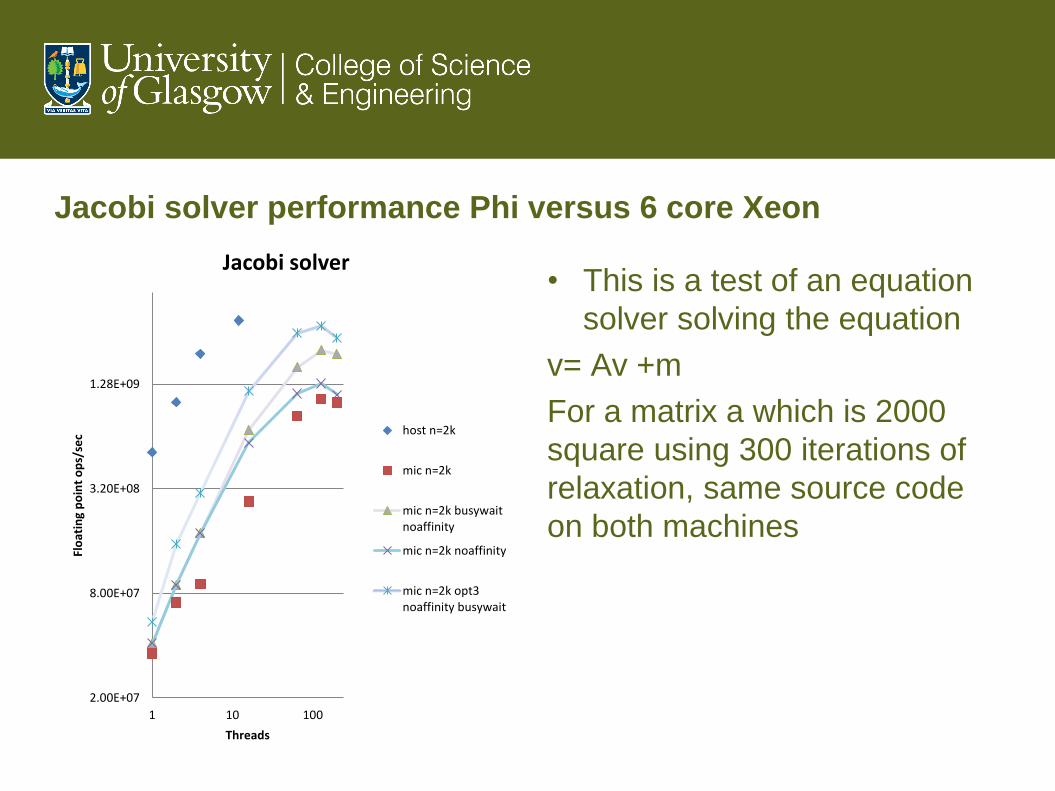
Jacobi solver performance Phi versus 6 core Xeon
2.00E+07
8.00E+07
3.20E+08
1.28E+09
1 10 100
Flo
atin
g p
oin
t o
ps/
sec
Threads
Jacobi solver
host n=2k
mic n=2k
mic n=2k busywaitnoaffinity
mic n=2k noaffinity
mic n=2k opt3noaffinity busywait
• This is a test of an equation
solver solving the equation
v= Av +m
For a matrix a which is 2000
square using 300 iterations of
relaxation, same source code
on both machines




















