
Psychometric Review of Articulation Tests for Preschool ...
39
Psychometric Review 1 RUNNING HEAD: Psychometric Review Psychometric Review of Speech Tests for Preschool Children: 25 Years Later A Senior Honors Thesis Presented in Partial Fulfillment of the Requirements for graduation with research distinction in Speech and Hearing Science in the Undergraduate Colleges of The Ohio State University By Brook N. Mathias The Ohio State University June, 2010 Project Advisor: Dr. Rebecca McCauley, Department of Speech and Hearing Science
-
Upload
khangminh22 -
Category
Documents
-
view
2 -
download
0
Transcript of Psychometric Review of Articulation Tests for Preschool ...

Psychometric Review
1
RUNNING HEAD: Psychometric Review Psychometric Review of Speech Tests for Preschool Children: 25 Years Later A Senior Honors Thesis Presented in Partial Fulfillment of the Requirements for graduation with research distinction in Speech and Hearing Science in the Undergraduate Colleges of The Ohio State University By Brook N. Mathias The Ohio State University June, 2010 Project Advisor: Dr. Rebecca McCauley, Department of Speech and Hearing Science

Psychometric Review
2

Psychometric Review
3
Abstract
The purposes of this study were to (a) examine the psychometric quality of 9 tests that
help speech-language pathologists assess the speech sound production of preschool
children and (b) compare these results with those obtained since a similar study
conducted 25 years ago (McCauley & Swisher, 1984). To accomplish this, manuals for
these 9 tests were examined using 11 criteria considered important for standardized
norm-referenced tests. All of the current tests met at least 4, and 8 of the 9 tests met at
least 5 of the criteria. On the other hand, reliability was unmet by all the tests. When
compared to previous results, some improvement in the past 25 years can be seen.
Nonetheless, more needs to be done to provide the best possible tools for identification of
speech sound disorders in young children.

Psychometric Review
4
Acknowledgements I would like thank my advisor, Rebecca J. McCauley, for her constant support and
guidance throughout the entire thesis process. Her dedication and experience has proven
to be invaluable and I have grown professionally and academically as a result. I would
like thank Michelle Bourgeois for all of her time, encouragement, and support throughout
the year. Furthermore, I would like to thank Abby Kinsey and Melanie Wollam for their
help in the accuracy procedures as well as their collaboration in the review process.
This project was supported by the Arts and Sciences Undergraduate Scholarship
and the Social and Behavioral Sciences Undergraduate Research Scholarship.

Psychometric Review
5
Table of Contents Abstract………………………………………………………………………………….. 3 Acknowledgements……………………………………………………………………… 4 Chapter 1: Introduction and Literature Review…………………………………………. 6 Chapter 2: Methods…………………………………………………………………….. 17 Chapter 3: Results……………………………………………………………………… 26 Chapter 4: Discussion……………………………………………………………………28 Chapter 5: Summary……………………………………………………………………..29 References………………………………………………………………………………..30 Appendix. Reviewed Tests………………………………………………………………32 Tables ……………………………………………………………………………………33 List of Figures……………………………………………………………………………38 Figures……………………………………………………………………………………39

Psychometric Review
6
Psychometric Review of Speech Tests for Preschool Children: 25 Years Later
Tests of speech sound development have been useful to clinicians in identifying
problems and patterns in a person’s speech and creating an intervention program
applicable to that individual’s needs. However, the clinician must determine which test is
appropriate for a given purpose, which requires the knowledge of the tests’ materials and
the child to whom the test will be administered. Therefore, it is necessary for a clinician
to be familiar with the adequate skills and tools that a test requires (Andersson, 2005).
In the last 25 years, the development of new or updated speech and language tests
has widened the options of tests from which the clinician can choose. Often the clinician
will choose to administer norm-referenced tests based on its ability to compare a client to
levels expected of a child within a similar age group or category to a set of data on
similar children (i.e., to a set of norms). Based on the standards established by the test
developers, a speech-language pathologist is able to answer the question of how their
client compares to the average (Shipley & McAfee, 2009). This gives a basis to
determine whether the client falls within or outside the range of the average children in
that group. If the child’s scores fall outside of the normative sample, the child may be
said to have a speech or language behavior resulting in significant speech or language
behavior differences (McCauley & Swisher, 1984).
Through the use of norm-referenced standardized tests, professionals are able to
rely on these tests to calculate scores without excessive external contributors such as
setting or test instruction errors. Thus, to maximize validity and reliability, test users must
follow the administration directions as they are instructed in the test manual (Shipley &
McAfee, 2009). As a follow up to the Psychometric Review of Language and Articulation

Psychometric Review
7
Tests for Preschool Children (McCauley & Swisher, 1984), this review is intended to
revisit the results of McCauley & Swisher’s original study and re-address currently
available speech sound production tests based on similar criteria. Because McCauley &
Swisher (1984) found that the 30 language and articulation tests reviewed failed to
exhibit many of the psychometric characteristics required of well standardized norm-
referenced tests, redoing this study will evaluate whether or not this situation has
improved.
Since 1984, several reviews of the psychometric characteristics of language tests
are available. In reviews that are available, McCauley & Swisher’s criteria from the 1984
review are often cited and replicated. Researchers often combined McCauley &
Swisher’s criteria alongside their own developed criteria to evaluate specific tests
(Andersson, 2005; Plante & Vance, 1994). But in most reviews the researchers fail to
consider more than a few tests or do not review each test based on a set list of criteria.
However, the review of psychometric information of speech sound production tests is
scarce. Accordingly, this study applies the same 11 criteria to 9 norm-referenced speech
sound production tests for use with preschool children.
The intent of this paper is to revisit the concerns raised by McCauley & Swisher
25 years ago by reviewing test materials that were created following 1984, specifically, in
1998 or after. Discussions stimulated through this paper may benefit speech-language
pathologists who administer speech tests. Also, clinicians can use this information to be
more aware of the psychometric data contained in these tests and become more
knowledgeable of each test’s strengths and weaknesses when making clinical decisions.
Test users can also use this data to conduct an appropriate psychometric review before

Psychometric Review
8
purchasing a test (McCauley & Swisher, 1984). Nonetheless, this study should not be
used as a definitive review but as a basic guideline for clinicians in the area of a test’s
psychometrics.
It is important to understand several concepts when reviewing norm-referenced
standardized tests for their psychometric data. Therefore, prior to discussing the criteria
used in this review, it is necessary to address the following: (a) test validity and reliability
and (b) the normative sample.
Background on Basic Psychometric Concepts
Validity and Reliability
“Most standardized tests published for speech language pathologists include
details concerning the technical quality of the instruments including information
concerning the sample to whom the test was administered, the norming procedures, and
the reliability and validity of the test” (Hutchinson, 1996, p. 109). Clinicians can be
confident in using a measurement instrument when that instrument shows evidence of
validity and reliability. To be considered well developed as well as standardized, tests
must be supported by evidence that they function as intended when used as recommended.
Specifically, they must demonstrate evidence of reliability and validity for intended
purposes and populations. Reviewing a test’s psychometric characteristics entails
critically evaluating evidence that the test functions as intended and consistently for the
purposes and populations for which it was originally developed and is currently used
(McCauley & Strand, 2008).
A test is said to be more valid when the instrument measures what it is designed
to measure and does so accurately. For example, a thermometer is valid measurement

Psychometric Review
9
instrument of temperature to the degree that it accurately measures temperature. In the
case of speech sound production tests, the instrument is valid if it accurately measures a
child’s speech production ability as it is intended to be measured. However, test validity
is largely the product of successful test construction and evaluation (McCauley &
Swisher, 1984). Several approaches to gathering validity evidence should be considered
to ensure the overall accuracy of an instrument. Test validity is addressed by obtaining
multiple sources of evidence that support the use of a test for a particular purpose
(Messick, 1989; Plante & Vance, 1994) Therefore, with regard to validity, three kinds are
considered important to any test that measures the behavior and is used to make
inferences about underlying abilities; these sources have sometimes been referred as-
construct, content, and criterion-related validity (APA, 1974).
Construct validity refers to evidence that a test measures a predetermined
theoretical construct, which is an explanation of a behavior or attribute based on
empirical observation (Shipley & McAfee, 2009). For example, the concept that
children’s speech production improves with age is based on speech development studies.
Therefore, a valid test should show that when a test is administered to preschool aged
children, their scores should progressively improve as they grow older. Construct validity
must be shown through evidence that a test can be used reliably, that individual test items
are sensitive to the intended construct and insensitive to extraneous factors, and that
performance on the test provides the intended information about the test taker (Plante &
Vance, 1994). Because construct validity is important to the overall validity of a test, this
concept was added as the eleventh criterion to McCauley & Swisher’s (1984a) original
ten criteria. It had been initially not included in the review because of concerns about

Psychometric Review
10
difficulties in operationalizing the criterion to be associated with such evidence
(McCauley & Swisher, 1984).
Content validity refers to evidence that a test’s contents are representative of the
content domain of the skill being assessed (Shipley & McAfee, 2009). Content validity is
often the first aspect of validity addressed in a test manual and, in many cases, is the
principal form of validity addressed (Plante & Vance, 1994). In the case of the study,
content validity can be shown if the speech sound production test addresses all phonemes
which are necessary for assessing the entire articulation spectrum. It is important that the
content validity in a test is examined by an individual who possesses expertise on the
behavior being assessed (McCauley & Swisher, 1984).
Criterion-related validity refers to evidence of validity that is established by use
of an external criterion (Shipley & McAfee, 2009). If a new test’s results agree with the
results of tests that users already accept as valid measures of the construct, we can have
increased confidence in the new test. “On the other hand, when the test under review
produces results that are quite different from the accepted test, some analysis and
explanation of the differences in the two tests should be provided” (Hutchinson, 1996, p.
111). Therefore, a valid instrument shows collection of empirical evidence that scores on
the test are related to some other measure of the behavior being assessed. In most cases,
as well as in our review, two types of criterion-related validity are evaluated: concurrent
and predictive validity.
Concurrent validity refers to the validity of a test in comparison to a widely
accepted standard (Shipley & McAfee, 2009). For example, when determining if a
person’s score on an achievement test allows for estimation of that person’s score on a

Psychometric Review
11
criterion measure, the score must be compared to other achievement tests presumed to be
valid and/or judgments of achievement by teachers, parents, and students. “If the person’s
score on the achievement test presents evidence of content validity and elicits test scores
corresponding closely to judgments and scores from other valid achievement tests, we
can conclude that there is evidence of that test’s criterion-related validity” (Salvia,
Ysseldyke, & Bolt, 2010, p. 67).
Predictive validity refers to evidence of the test’s ability to predict performance
(the criterion measure) in another situation or at a later time. It implies that there is a
known relationship between the behaviors the test measures and the skills the exhibited at
some future time (Shipley & McAfee, 2009). Thus, predictive criterion-related validity
refers to the temporal sequence by which a person’s performance on some criterion
measure is estimated on the basis of that person’s current assessment. For example,
reading progress can be assessed by a reading achievement test (presumed to valid) or by
teacher judgments of reading ability. If the reading readiness test has content validity and
produces scores that are highly related to either later teacher judgments of readiness or
validity assessed reading skills, we can conclude that the test is a valid test of reading
readiness and addresses predictive validity accurately (Salvia, Ysseldyke, & Bolt, 2010).
Note that it is primarily tests that would used to think about future outcomes for which
evidence of predictive validity is obtained and would be of great significance in
evaluating test quality.
Any characteristic of a test that causes it to measure something other than the
behavior of interest decreases the validity of the test. “One of the most important
characteristics of a test that limits its validity is its reliability; when a test is unreliable, it

Psychometric Review
12
fails to measure consistently what it is intended to measure and, therefore, it is a less
valid measurement” (McCauley & Swisher, 1984, p. 35). “Unlike validity, which is a
unitary notion (there are different kinds of evidence but not different kinds of validity),
reliability is not unitary. That is, a test's reliability can be classified by the various sources
of error possible: (a) items and subtests. (b) examiners, (c) conditions of time and place,
and (d) test takers and standardization samples” (Hutchinson, 1996, p. 115). Reliability
refers to a test’s results being replicable. Furthermore, when administered properly, a test
gives consistent results on repeated administrations or with different interpreters judging
the same administration (Shipley & McAfee, 2009). For example, if a reliable articulation
test is used to measure speech production ability, a child should receive the same scores if
tested at different times on that test in the same day. For the purposes of this review, two
kinds of reliability will be discussed: test-retest and interexaminer reliability.
Test-retest reliability indicates the relationship between a child’s scores on a
single test when that test is administered to the same child on two occasions
(Andersson, 1995; Linn & Gronlund, 2000). For example, if the same child is tested
once and receives a standard score of 100 and then is tested 2 weeks later and
receives a standard score of 65, something has compromised the accuracy of the
results. It is necessary to provide a long enough time interval between the two
testing periods to allow for the child to minimize his familiarity with the test
materials but a short enough period that his test scores are not affected by
maturation or learning (Andersson, 2005; Linn & Gronlund, 2000). Therefore, a time
interval of 6 months would probably allow a child too much time to progress in their
speech production development and would most likely result is a disagreement

Psychometric Review
13
between scores of the first and second testing. If the child is tested 2 weeks after his
initial testing then the scores should remain similar to assure accuracy.
Interexaminer reliability indicates the relationship between scores received when
two or more independent examiners score the test (Andersson, 2005; Linn & Gronlund,
2000). Therefore, it is important that when the same child is tested by two different
clinicians, the results remain consistent. “Although some variation is expected, large gaps
between two examiners scores can be a reason for concern. For example, it does little
good to administer a test on which the same child might receive a standard score of 100
or a standard score of 65, depending on the conditions under which the test is
administered (e.g., who administers the test)” (Andersson, 2005, p. 214). If there is a
difference between a child’s scores when administered by two clinicians, the clinicans’
administrative and scoring techniques are not matching up and can cause
misinterpretation of the child’s speech sound abilities or diagnosis. To provide adequate
interscorer reliability, it is appropriate for the test publishers to provide the test user’s
with proper training on the test procedures prior to administration.
The Normative Sample
The standardization sample consists of the children to whom the test is
administered when the test is under development; it is usually intended to be
representative of the general population of children. “Selection of children for this
sample is important because the test developer uses the results for these children as
a basis for the test’s normative data (i.e., these data determine the correspondence
between the raw scores and the standard scores), allowing clinicians to compare the
performance of one child to that of the child’s peers” (Andersson, 2005, p. 208;

Psychometric Review
14
Salvia & Ysseldyke, 2004). “The manual should also provide enough details concerning
the standardization sample that a user can judge if the norms are appropriate for use with
a particular child or types of children to be evaluated. Two important criteria are the
reasonable representativeness and adequate size of the sample” (Hutchinson, 1996, p.
117). Therefore, a larger sample provides the normative data with a higher degree of
accuracy and a smaller degree of error. “This number should be large enough to
guarantee stability. In practice, 100 participants in each age or grade is considered
minimum” (Salvia, Ysseldyke, & Bolt, 2010, p. 50). When a wider range of children are
tested during development of the test, the results show more significance in
corresponding to the actual population represented. However, the use of a wider sample
size can also lead to concerns regarding dialect differences in pronunciation; therefore,
these situations must be noted.
It is important for there to be enough information given about the sample used for
clinicians to feel the instrument is adequate to judge their test taker’s speech sound
production abilities. Ideally, this normative data can be used to answer relevant questions
about test takers; however, unfortunately, most tests do not incorporate information to
answer if there is an impairment or not (McCauley & Swisher, 1984). Overall, the
normative sample should provide information to aid the test user in making decisions on
where a child’s abilities are lacking.
“Normative samples usually include individuals who represent the age and
demographic for whom the test is intended. For psychological tests, information
regarding the age, geographic residence, and socioeconomic status of individuals in the
normative sample should be supplied” (APA, 1974; McCauley & Swisher, 1984, p. 49).

Psychometric Review
15
Most often this sample is obtained from the general population; however, specific
populations can be used depending on the intention of the test (Peña, Spaulding, & Plante,
2006). For example, if a test was intended for use with individuals with dementia, the
normative sample would be dependent upon individuals with the diagnosis of memory
loss to assure an appropriate comparison in the results. Therefore, when testing a person
for dementia, it is necessary to have a normative sample that represents that population to
create cutoffs to determine presence of the condition and its severity. Accordingly, tests
involving normative data may potentially be of value to tests that are aimed at speakers
with given accents (i.e. southern speakers or speakers of African American vernacular
English).
However; when testing children for speech sound production ability, clinicians
are often looking for whether an impairment exists rather than for help in quantifying
severity. This calls into question whom that child should be compared with in order to
make this decision. Therefore, it is important to indicate if a test excludes individuals on
basis of disability or nonnormal language ability. Although such exclusions may seem to
make sense when one wants to ask whether a child’s performance is similar or dissimilar
to the performance of “normal” or “normal speaking” children, this approach to choosing
the normative sample presents some difficulties. One such problem is that even the most
deviant scores contained in the normative sample represent normal performance.
Historically, some authors (McCauley & Swisher, 1984; p. 49; Salvia & Ysseldyke, 1981)
have suggested that a child receiving a score below the lowest score received by the
normative sample has received a score with an unknown probability and may or may not
represent nonnormal performance if all of the participants in the norming study were

Psychometric Review
16
thought to have typical speech or language. “In the field of communication disorders, it is
often interpreted to mean that tests should include children with documented language
impairment (LI) in the normative group” (Peña, Spaulding, & Plante, 2006, p. 248).
The desire to look at recent speech sound production tests led to adoption of
methodology assessing major issues visited in an earlier study. Thus, the purposes of this
study were to (a) examine the psychometric quality of 9 tests that help speech-language
pathologists assess the speech sound production of preschool children and (b) compare
these results with those obtained since a similar study conducted 25 years ago (McCauley
& Swisher, 1984).
Methods
Test Search Strategy
Initially, a list of 376 language and speech sound production tests was compiled
as possible candidates for use in the review. These tests were gathered from two primary
sources: the Buros Institute Test Review’s Online (Buros Institute, 2009) as well as
American Speech-Language-Hearing Association Online Catalogue (ASHA, 2009).
Publisher websites were also examined. Key terms used in searching included all of the
following: articulation, phonology, speech, language, apraxia, and oral motor.
We selected tests for review if they (a) were norm-referenced instruments; (b)
included preschool aged children (i.e. children at or below the age of 4 years old); (c)
were not considered a screening instrument, (d) were available in March or April 2010
through a commercial source, and (e) were published in or after 1998. From these, we
excluded tests if more detailed examination revealed any of the following: (a) their
material focused on oral motor skills or apraxia, (b) the test was designed for non-native

Psychometric Review
17
English speakers, or (c) the test was designed for the hearing impaired. These criteria
were used in order to focus on tests most likely to help us answer questions related to the
psychometric characteristics of speech sound production tests for preschool children.
Psychometric Criteria for Review
“The criteria in this review consist of a set of characteristics that should be
considered when a clinician chooses or makes use of a norm-referenced test to evaluate a
child’s speech status. They were chosen due to their recognized importance and relevance
to tests of articulation, and because they could be translated into relatively objective
decision rules” (APA, 1974; McCauley & Swisher, 1984, p. 37; Salvia & Ysseldyke,
1981). The failure of a test to meet these criteria or provide information on them has
serious effects on the merits of a test-no matter how in harmony the content of a given
test is with the test user’s concept of the skill being tested.
Because this study is a replication of McCauley & Swisher (1984), the first 10
criteria are based exactly on what was used in the 1984 study; however, the eleventh
criterion was added due to its significance to identifying an instrument as a valid measure.
In fact, these criteria and the consequences of their not being met are stated exactly as
they were in McCauley and Swisher (1984) and in McCauley and Strand (2008):
Criterion 1. The test manual should clearly define the standardization sample so
that the test user can examine its appropriateness for a particular test taker (APA,
1974, pp. 20-21; McCauley & Swisher, 1984; Weiner & Hoock, 1973). To pass
this criterion, a test needed to give three pieces of information considered
important for speech testing: (a) the normative sample’s geographic residence, (b)
socioeconomic status (family income), (c) the “normalcy” of subject in the same,

Psychometric Review
18
including the number of individuals excluded because they exhibited nonnormal
speech or nonnormal development. If any of the information stated prior was not
present in the test manual, that test did not meet the criterion. It was necessary
that all parts of the standardization sample information be present to meet this
criterion.
Consequences if unmet. Without this information, the test user cannot tell whether
the normative sample is representative of the test author's intended population and
whether it is the population against which the test taker's performance should be
compared. For example, the way in which the standardization sample was chosen
may have resulted in the use of children with a very different language
background from that of the test taker. In such a case, the comparison of the test
taker to the norms would be of little value if the clinician were interested in the
normalcy of the test taker's language, but would be of considerable value if the
clinician were interested in whether the test taker's language differed from that of
the normative group.
Criterion 2. For each subgroup examined during the standardization of the test, an
adequate sample size should be used. In order to pass this criterion, a test needed
to have subgroups with a sample size of 100 or more. This particular value is
consistently referred to by authorities as the lower limit for adequate sample size
(APA, 1974, pp. 27-28, 37; McCauley & Swisher, 1984). Furthermore, it was
necessary to examine if the age intervals in the standardization sample were
consistent with the age intervals in the raw score conversion data in the appendix
of the test manual. If these age intervals did not match and could not be proven to

Psychometric Review
19
provide each subgroup with at least 100 subjects, this criterion was considered
unmet.
Consequences in unmet. If a small sample size is used, the norms are likely to be
less reliable, that is, less stable; therefore, use of a different group of children
might have resulted in different norms. In addition, relatively rare individuals
(e.g., language- or articulation-impaired children) might not have been included in
the sample because of the small number of subjects. This possibility makes the
interpretation of the scores of possibly impaired children difficult. The smaller the
sample size, the greater are the problems (Salvia & Ysseldyke, 1981, p. 123;
Weiner & Hoock, 1973).
Criterion 3. The reliability and validity of the test should be promoted through the
use of systematic item analysis during item construction and selection (Anastasi,
1976, p. 198; McCauley & Swisher, 1984). To pass this criterion, the test manual
needed to report evidence that quantitative methods were used to study and
control item difficulty item validity, or both. Therefore, content validity had to be
present showing item relevance as well as content coverage.
Consequences in unmet. Although the consequences would be less important if all
other criteria to be discussed here were met by a test, that is rarely the case. Few
norm-referenced tests provide adequate evidence that the test measures accurately
what it purports to measure. This criterion, then, serves as an alternative
indication that the test may possess validity and reliability. According to Anastasi
(1976, p. 198), "high reliability and validity can be built into a test in advance
through item analysis."

Psychometric Review
20
Criterion 4. Measures of central tendency and variability of test scores should be
reported in the manual for relevant subgroups examined during the objective
evaluation of the tests (APA, 1974, p. 22; McCauley & Swisher, 1984). To pass
this criterion, both the mean and the standard deviation had to be given for the
total raw scores of all relevant subgroup.
Consequences if unmet. The mean is the average score received by members of
the normative subgroup. The standard deviation gives the test user an estimate of
how much variation was shown by the scores received by subgroup members.
Because these pieces of information can also serve as the basis for other ways of
presenting the norms (e.g., z scores), their absence robs the test user of flexibility
in the use of the test norms.
Criterion 5. Evidence of concurrent validity should be supplied in the test manual
(APA, 1974, pp. 26-27; McCauley & Swisher, 1984). To pass this criterion, the
test manual needed to provide empirical evidence that categorizations of children
as normal or impaired obtained using the test agree closely with categorizations
obtained by other methods that be considered valid, for example, clinician
judgments or scores on other validated tests.
Consequences in unmet. The absence of this kind of evidence calls into question a
test's ability to help with assessment questions related to the existence of
impairment. Because the reason for using a norm-referenced test of language or
articulation is to enable the test user to compare a child's score against the scores
of other children as an aid in the determination of normalcy, the failure of a test
on this criterion should cause the test user to question the usefulness of that test.

Psychometric Review
21
Criterion 6. Evidence of predictive validity should be supplied in the test manual
(APA, 1974, pp. 26-27; McCauley & Swisher, 1984). To pass this criterion, a test
manual needed to include empirical evidence that it could be used to predict later
performance on another, valid criterion of the speech behavior addressed by the
test in question.
Consequences if unmet. Evidence of this kind of predictive validity enables the
test user to use a test to make assessment decisions related to the need for therapy.
Therefore, its absence means that other possibly invalid sources of information
will be weighed more heavily in the decision process.
Criterion 7. An estimate of test-retest reliability for relevant subgroups should be
supplied in the test manual (APA, 1974, pp. 50, 54; McCauley & Swisher, 1984).
To pass this criterion, the test manual needed to supply empirical evidence of test-
retest reliability, including a correlation coefficient of .90 or better (Salvia &
Ysseldyke, 1981, p. 98) that was statistically significant at or beyond the .05 level
(Anastasi, 1976, pp. 108-109). If statistical significance was not addressed in the
test manual, this criterion was marked as unmet.
Consequences in unmet. Without this information, the test user does not know to
what extent test results are stable and to what extent they will fluctuate over time.
If this kind of reliability is low, the test should be viewed with the suspicion one
would have of a rubber ruler. A correlation coefficient of .90 is considered a
minimum standard of reliability when a test is used to make decisions regarding
the existence of a problem (Salvia & Ysseldyke, 1981, p. 98). If in addition to
being relatively high the correlation coefficient is not also statistically significant,

Psychometric Review
22
that fact may be due to the specific characteristics of the individuals chosen as
part of the normative sample, but would not be duplicated if the standardization
process were repeated with other, similar groups.
Criterion 8. Empirical evidence of interexaminer reliability should be given in the
test manual (APA, 1974, p. 50; McCauley & Swisher, 1984). To pass this
criterion, a test manual needed to report evidence of interexaminer reliability that
included a correlation coefficient of .90 or better (Salvia & Ysseldyke, 1981, p.
98) that was statistically significant at or beyond the .05 level (Anastasi, 1976, pp.
108-109). If statistical significance was not addressed in the test manual, this
criterion was marked as unmet.
Consequences if unmet. Without an estimate of interexaminer reliability, the test
user does not know the degree to which a test taker is likely to receive similar
scores if the test is given again by different individuals or if the same test is
scored by different individuals. Neither can it be known whether the tester is
likely to affect the scores of test takers in a way that improperly penalizes or
favors them.
Criterion 9. Test administration procedures should be described in sufficient
detail to enable the test user to duplicate the administration and scoring
procedures used during test standardization (APA, 1974, p. 18; McCauley &
Swisher, 1984). To pass this criterion, the test manual needed to provide sufficient
description so that, after reading the test manual, the reviewer believed she could
administer and score the test without grave doubts about correct procedures.

Psychometric Review
23
Consequences if unmet. Unless the administration process is described in detail,
the test user does not know whether it is reasonable to compare the test taker's
performance to the norms. Information supplied in the test manual should include
specific instructions on how to administer, score, and interpret the test and on the
setting in which testing should be conducted. If a test is administered without
duplicating the procedures followed during standardization, the test taker may be
given an unfair advantage or may be unfairly penalized by differences in
instructions, surroundings, and so forth.
Criterion 10. The test manual should supply information about the special
qualifications required of the test administration or scorer (APA, 1974, p.15;
McCauley & Swisher, 1984; Salvia & Ysseldyke, 1981, p.18). To pass this
criterion, the test manual needed to state both general and specialized training
required for administrators and scorers.
Consequences if unmet. Information of this kind should be given for all tests
because the administration, scoring, and interpretation of test results should only
be done by a qualified person. Moreover, for rating scales this information is
particularly crucial because such scales use observations as test data. Without this
information, it is impossible for the test user to judge the quality of the data
obtained with the test.
Criterion 11. The test manual needed to supply evidence of construct validity in
the test manual. To pass this criterion, the test manual needed to address any of
the following to meet the operational definition: (a) evidence from a factor
analytic study confirming expectations of the test’s internal structure, (b) evidence

Psychometric Review
24
that test performance improves with age, (c) evidence that groups that were
predicted to differ in test performance actually do so. In addition, evidence needed
to be obtained within a study in which statistical methods and participants were
described (McCauley & Strand, 2008).
Consequences if unmet. “Almost any kind of information about a test can
contribute to an understanding of its construct validity, but the contribution
becomes stronger if the degree of fit of the information with the theoretical
rationale underlying score interpretation is explicitly evaluated” (Hutchinson,
1996, p. 111; Messick, 1989, p.17). Therefore, without the evidence of construct
validity present, the test is lacking in its strength to provide clinicians with an
instrument that can feel comfortable with and view as accurate.
The review of each test manual was first carried out by the author using a scoring
sheet that reiterated each of the operational criteria described above. Both the author and
a second reviewer, who was also an undergraduate, conducted a similar study scoring 2
norm-referenced tests that did not address speech sound development before beginning
the review process—by which time they had achieved an agreement of 91%.
Once all of the available tests were reviewed by the author, the second reviewer
randomly selected 20 percent (n=2) of the tests for review to ensure accuracy. The other
undergraduate reviewer was familiar with the criteria and review process of this study as
she was conducting a similar study in which she reviewed 16 norm-referenced language
tests for preschool children prior to reviewing the speech sound production tests for
agreement.

Psychometric Review
25
Results
Only 9 tests were identified through the selection process.
The second examiner’s ratings agreed with those of the first examiner on 95.5%
of the 22 ratings (2 tests x 11 criteria). Percentage agreement was 10 out of 11 criteria
(91%) for one test and 11 out of 11 criteria agreed (100%) on the other. For each rating of
pass or fail on which the examiners disagreed, the test manual was consulted and the
disagreement was reconciled.
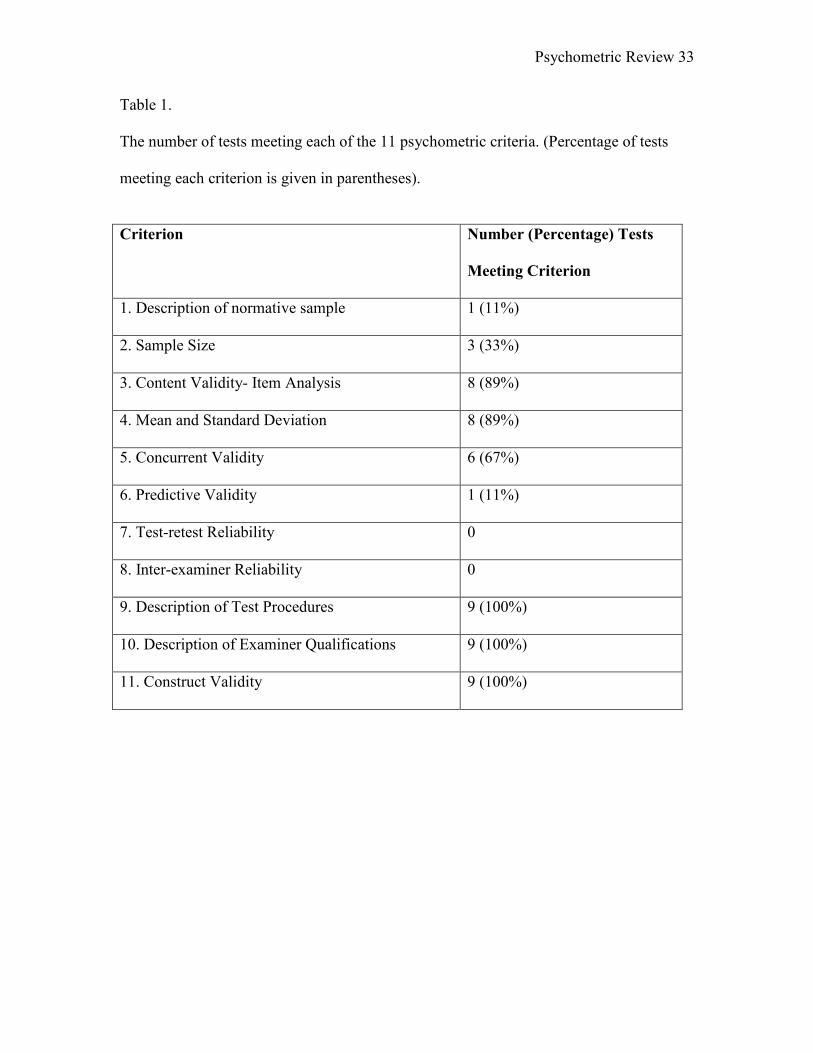
In Table 1, the number of tests meeting each criterion is summarized for the final
rating results. Results for the 9 speech tests results were combined to calculate the
number and percentage of tests meeting that criterion. The majority of the tests met over
half of the 11 psychometric criteria. The criteria that were most frequently met were
description of test procedures (Criterion 9), description of examiner qualifications
(Criterion 10), and evidence of construct validity (Criterion 11). All of the tests met these
criteria. The two criteria related to evidence of content validity (Criterion 3) and reporting
means and standard deviations (Criterion 4) were met by 8 of the reviewed tests.
The criteria that were most frequently unmet dealt with evidence of test-retest
reliability (Criterion 7) and evidence of interexaminer reliability (Criterion 8). None of
the tests met these criteria based on the operational definitions for test-retest and
interexaminer reliability. Although majority of the tests met the correlation coefficient of
at least a .90, these tests did not address the use of statistical significance in their
evidence resulting in failure of those criteria.

Psychometric Review
26
The criteria dealing with description of the normative sample (Criterion 1) and
evidence of predictive validity (Criterion 6) were each only met by one of the tests. Due
to information regarding the samples geographic region, socioeconomic status, and
normalcy needed to pass Criterion 1, many of the tests only provided information on one
of those areas but not all. Many of the reviewed tests used the mother’s educational level
as the socioeconomic status of the sample; however, the family’s income level was
needed to meet the requirements of socioeconomic status in this review.
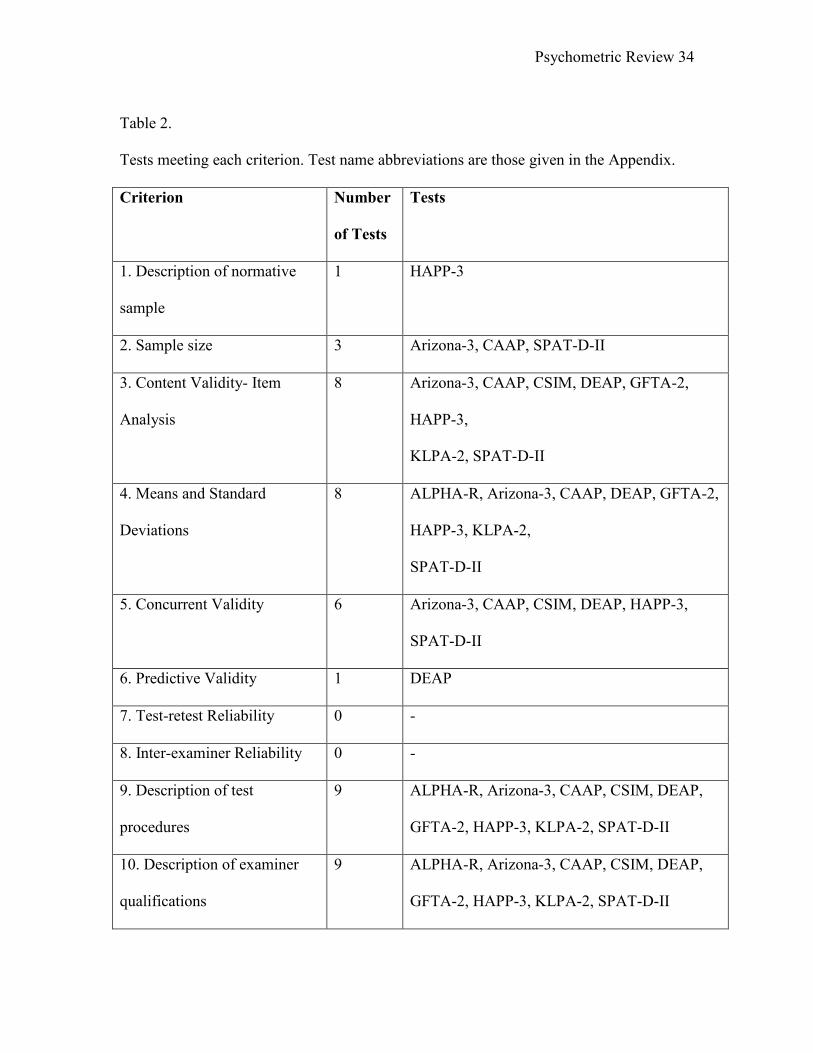
Table 2 lists the names of tests meeting each criterion. Although certain names
appear more often than others, the pattern of met criteria observed in Table 1 is not due to
the existence of a few tests that met almost all criteria while most met none. This fact is
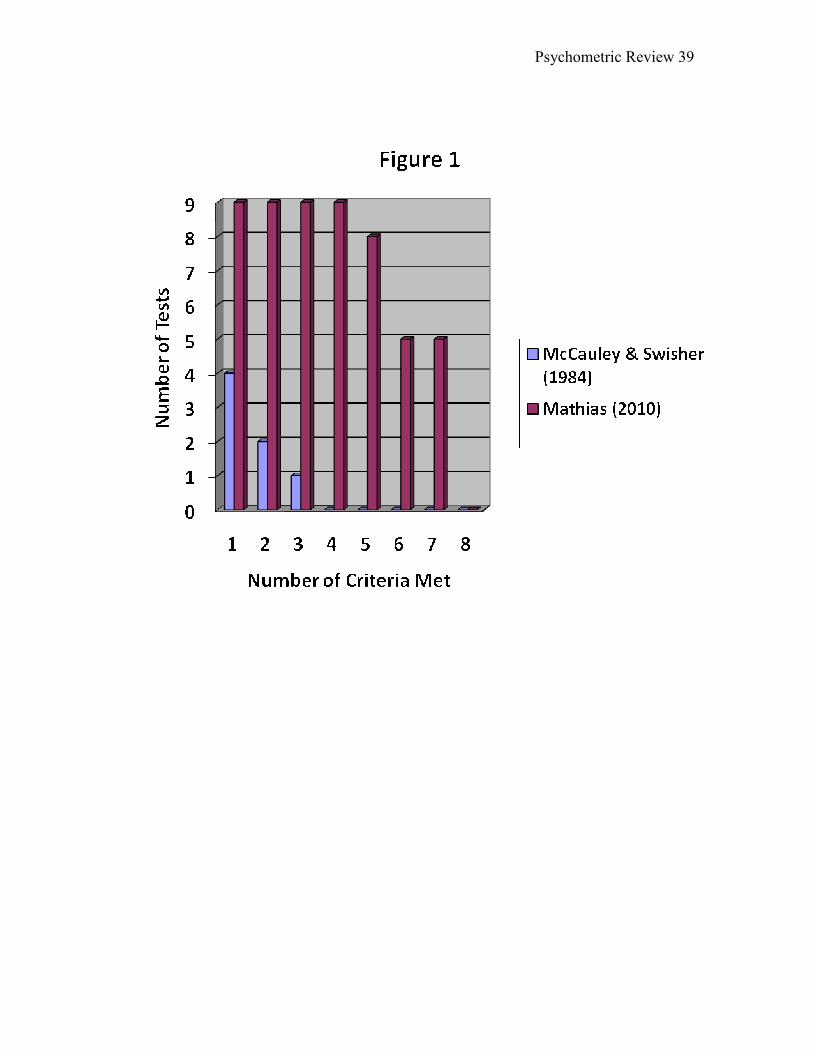
illustrated graphically in Figure 1 which records the number of tests that met one or more
criteria, two or more criteria, and so on. The largest number of criteria met by any test
was 7 criteria which were met by 5 tests. The lowest number of criteria met by one test
was four. The median number of criteria met by all tests was six.
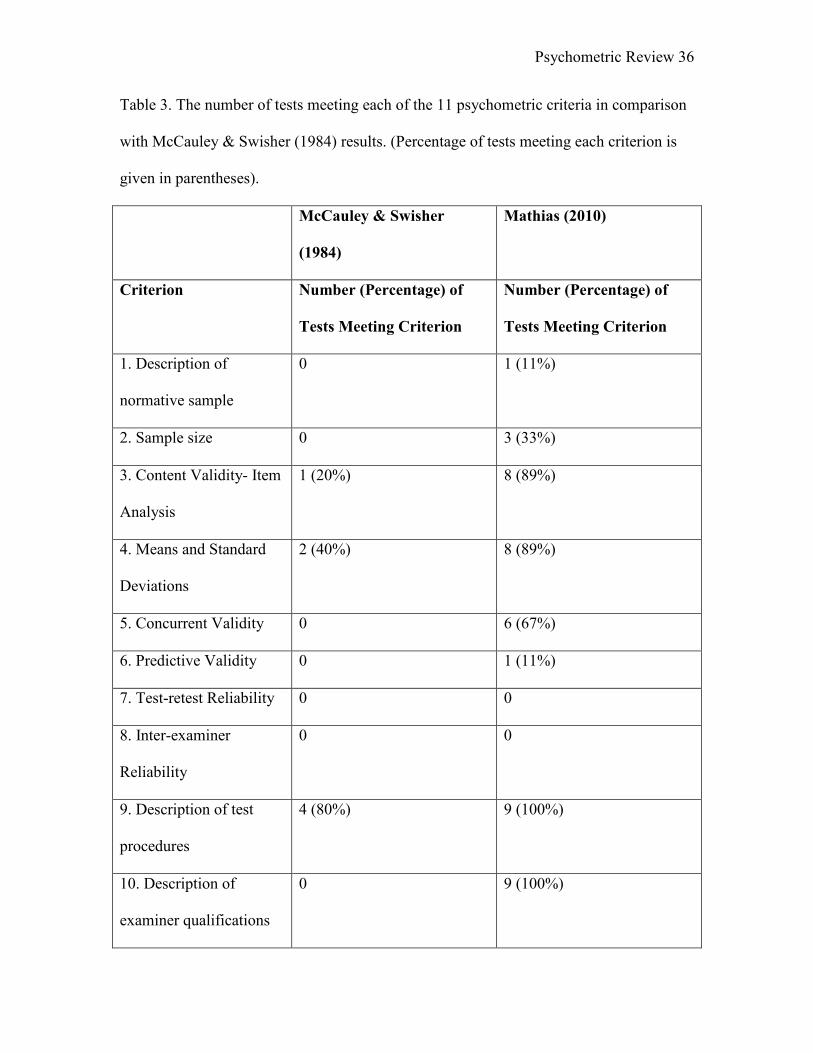
Results Compared to Results from McCauley & Swisher (1984) When comparing the changes that have occurred in the past 25 years as reflected
in the results of this study and those of McCauley and Swisher (1984), one can feel
confident in the progress of speech sound production tests’ inclusion of psychometric
information. Whereas, in 1984 only 5 tests were available for review, that number has
nearly doubled to 9 in 2010. This provides proof to the statement that clinicians have
several more choices available to them when choosing an instrument to assess a child.
The number of criteria met by tests was minimal in the 1984 (McCauley &
Swisher) review; however, these numbers have strengthened according to the results of

Psychometric Review
27
this study. Out of the 5 articulation tests for preschool children reviewed by McCauley &
Swisher (1984), the highest number of criteria by a test was 3 of the 10 (30%). Otherwise,
2 of the tests met at least 2 of the criteria and 4 of tests met at least 1 of the criteria. In
contrast, in this study, the highest number of criteria met by a test was 7 of the 11 (64%)
criteria and this number was met by 5 of the tests. However, all the tests met at least 4 of
the criteria and 8 of the tests reviewed met 5 criteria. These numbers can be interpreted as
good progress on the inclusion of psychometric data of speech sound production tests
over the last 25 years.
Discussion
Readers can compare findings across more than two decades by examining
Figures 1, which show number of tests reviewed that met at least n criteria in McCauley
and Swisher (1984) and the number of criteria met by tests reviewed in this study.
The number of criteria addressed by the tests reviewed in the 1984 (McCauley &
Swisher) study and those in this study have significantly increased. In the 1984
(McCauley & Swisher) review, the results showed that 7 of the 10 (70%) criteria were
not met by any tests. However, in this study, that number had decreased to 2 out of 11
(18%) criteria remaining unmet by the tests. Accordingly, this study reveals that only 3
out of 10 (30%) were met by tests in McCauley & Swisher’s (1984) review while 9 out of
11 (82%) were met by tests in this review. The only criteria that were met in 1984
(McCauley & Swisher), were those dealing with Content Validity and Item Analysis
(Criterion 3), means and standard deviations (Criterion 4), and description of test
procedures (Criterion 9). In this study, those criteria were those addressed most by the
tests reviewed. However, as stated previously, those criteria related to reliability were

Psychometric Review
28
those that still require improvement in speech tests for preschool children. Tables 1 and 3
show the comparison of McCauley and Swisher (1984) and this study as how many of
each criterion was met by the number of tests (percentage).
The pattern that emerges from this review may be somewhat discouraging.
However, in comparison the results of the 1984 study, there have been a significant
improvement in the inclusion of these psychometric criteria in the past 25 years. Similar
to the finding of McCauley & Swisher (1984), the two criteria that would require the
small amount of time and financial resources were met most often- Criterion 9
(description of test procedures) and Criterion 10 (description of examiner qualifications).
This is somewhat predictable based on the knowledge, time, and money that are required
when addressing psychometric data dealing with reliability and validity which were the
criteria most frequently unmet (McCauley & Swisher, 1984, p. 40).
On the other hand, it can be reassuring to speech-language pathologists that
speech sound production test publishers are making an effort to address the psychometric
information appropriate of a norm-referenced test. Although Criterion 11 (evidence of
construct validity) was added to the 10 criteria used in the original study, all of the tests
were able to meet the requirements of that criterion. Due to the operation definition of
construct validity asking for evidence of content, concurrent, and predictive validity, all
of the tests reviewed showed some form of empirical evidence of validity. As for the
continuing failure of reliability, the use of statistical significance may be a given when
calculating test-retest and interexaminer reliability for tests using large standardization
samples and, therefore, is not recorded as a part of the results. However, because this

Psychometric Review
29
cannot be confirmed by the information given, these criteria are still left unmet in all tests
reviewed.
Summary
All of the current 9 commercially available norm-referenced tests of speech sound
production met at least 4 of the 11 criteria examined. Five of them (about half) met 7 of
the 11 criteria used in this study. Criteria that tended to be met by all (n=9) or almost all
(n=8) of the currently available tests related to the description of test procedures,
examiner qualifications, and of the normative data (reporting of means and standard
deviations) as well as to evidence of validity (content and construct). However, test-retest
and inter-examiner reliability were not adequately reported by any of the tests in the
current group.
Whereas in 1984, only 5 tests were available for review, that number has nearly
doubled to 10 in 2010. The number of criteria that were met also essentially doubled.
Whereas in 1984, the maximum percent of criteria met was 30% (3 of 10), which was
met by only one test; for the current group of tests the maximum number of criteria met
was 7 of 11(64%) and more than half of the reviewed tests met that number. A continuing
weakness of tests in this area was the absence of test-retest and inter-examiner
agreement; however, one aspect of the criteria used to review these psychometric
characteristics may have been responsible for this outcome and will require further
investigation.
In short, although speech sound production tests appear to be improving in their
psychometric quality, more can still be done to produce the best possible tools for use
with preschool children.

Psychometric Review
30
References
American Psychological Association. (1974). Standards for educational and
psychological tests. Washington, DC: APA.
American Speech-Language-Hearing Association. (2009). Directory of Speech-Language
Pathology Assessment Instruments. Retrieved November 14, 2009, from
www.asha.org/SLP/assessment/.
Anastasi, A. (1976). Psychological testing (4th ed.). New York: Macmillan.
Andersson, L. (2005). Determining the adequacy of tests of children’s language.
Communication Disorders Quarterly, 26(4), 207-225.
Buros Institute. (2009). Test Reviews Online. Retrieved October, 16, 2009, from
www.unl.edu/buros.
Hutchinson, T. A. (1996). What to look for in the technical manual: Twenty questions for
users. Language, Speech, and Hearing Services in Schools, 27, 109-121.
Linn, R., & Gronlund, N. (2000). Measurement and assessment in teaching.
Upper Saddle River, NJ:Merrill/Prentice Hall.
McCauley, R. J., & Strand, E. A., (2008). A review of standardized tests of nonverbal
oral and speech motor performance in children. American Journal of Speech-
Language Pathology, 17, 81-91.
McCauley, R. J., & Swisher, L. (1984). Psychometric review of language and articulation
tests for preschool children. Journal of Speech and Hearing Disorders, 49, 34-42.
Messik, S. (1989). Meanings and values in test validation: The science and ethics of
assessment. Educational Researcher, 18, 5-11.

Psychometric Review
31
Peña, E. D., Spaulding, T. J., & Plante, E. (2006). The composition of normative groups
and diagnostic decision making: Shooting ourselves in the foot. American Journal
of Speech-Language Pathology, 15, 247-254.
Plante, E., & Vance, R. (1994). Selection of preschool language tests: A data based
approach. Language, Speech, and Hearing Services in Schools, 25, 19-24.
Salvia, J., & Ysseldyke, J. (1981). Assessments in special and remedial education (2nd
ed.). Boston: Houghton Mifflin.
Salvia, J., & Ysseldyke, J. E. (2004). Assessment: In special and inclusive education
(9th ed.). Boston: Houghton Mifflin.
Salvia, J., Ysseldyke, J.E., & Bolt, S. (2010). Assessment in special and inclusive
education (11th Edition). Belmont, CA: Wadsworth Cengage Learning.
Shipley, K. G., & McAfee, J. G. (2009). Assessment in speech-language pathology: A
resource manual (4th ed). New York: Delmar Cengage Learning.
Weiner, P., & Hoock, W. (1973). The standardization of tests: Criteria and criticisms.
Journal of Speech and Hearing Research, 16, 616-626.

Psychometric Review
32
Appendix. Reviewed Tests
Dawson, J.I., & Tattersall, P.J. (2001). Structured Photographic Articulation Test II
(SPAT-D II). DeKalb, IL: Janelle.
Dodd, B., Hua, Z., Crosbie, S., Holm, A., & Ozanne, A. (2006). Diagnostic Evaluation of
Articulation and Phonology (DEAP). San Antonio, CA: Pearson Assessments.
Fudala, J. B., & Reynolds, W. (2000). Arizona Articulation Proficiency Scales- Third
Revision (Arizona-3). Los Angeles: Western Psychological Services.
Goldman, R., & Fristoe, M. (2000). Goldman-Fristoe Test of Articulation- Second
Edition (GFTA-2). Circle Pines, MN: AGS.
Hodson, B. W. (2003). Hodson Assessment of Phonological Patterns- Third Edition
(HAPP-3). Austin, TX: Pro-Ed.
Khan, L. M., & Lewis, N.P. (2002). Khan-Lewis Phonological Analysis- Second Edition
(KLPA-2). Circle Pines, MN: AGS.
Lowe, R. J. (2000). Assessment Link between Phonology and Articulation, Revised
(ALPHA-R). Mifflinville, PA: ALPHA Speech & Language Resources.
Secord, W., & Donohue, J. (1998). Clinical Assessment of Articulation and Phonology
(CAAP). Greenville, SC: Super Duper.
Wilcox, K., & Morris, S. (1999). Children’s Speech Intelligibility Measures (CSIM). San
Antonio, TX: The Psychological Corporation.
Psychometric Review
33
Table 1.
The number of tests meeting each of the 11 psychometric criteria. (Percentage of tests
meeting each criterion is given in parentheses).
Criterion Number (Percentage) Tests
Meeting Criterion
1. Description of normative sample 1 (11%)
2. Sample Size 3 (33%)
3. Content Validity- Item Analysis 8 (89%)
4. Mean and Standard Deviation 8 (89%)
5. Concurrent Validity 6 (67%)
6. Predictive Validity 1 (11%)
7. Test-retest Reliability 0
8. Inter-examiner Reliability 0
9. Description of Test Procedures 9 (100%)
10. Description of Examiner Qualifications 9 (100%)
11. Construct Validity 9 (100%)
Psychometric Review
34
Table 2.
Tests meeting each criterion. Test name abbreviations are those given in the Appendix.
Criterion Number
of Tests
Tests
1. Description of normative
sample
1 HAPP-3
2. Sample size 3 Arizona-3, CAAP, SPAT-D-II
3. Content Validity- Item
Analysis
8 Arizona-3, CAAP, CSIM, DEAP, GFTA-2,
HAPP-3,
KLPA-2, SPAT-D-II
4. Means and Standard
Deviations
8 ALPHA-R, Arizona-3, CAAP, DEAP, GFTA-2,
HAPP-3, KLPA-2,
SPAT-D-II
5. Concurrent Validity 6 Arizona-3, CAAP, CSIM, DEAP, HAPP-3,
SPAT-D-II
6. Predictive Validity 1 DEAP
7. Test-retest Reliability 0 -
8. Inter-examiner Reliability 0 -
9. Description of test
procedures
9 ALPHA-R, Arizona-3, CAAP, CSIM, DEAP,
GFTA-2, HAPP-3, KLPA-2, SPAT-D-II
10. Description of examiner
qualifications
9 ALPHA-R, Arizona-3, CAAP, CSIM, DEAP,
GFTA-2, HAPP-3, KLPA-2, SPAT-D-II

Psychometric Review
35
11. Construct Validity 9 ALPHA-R, Arizona-3, CAAP, CSIM, DEAP,
GFTA-2, HAPP-3, KLPA-2, SPAT-D-II
Psychometric Review
36
Table 3. The number of tests meeting each of the 11 psychometric criteria in comparison
with McCauley & Swisher (1984) results. (Percentage of tests meeting each criterion is
given in parentheses).
McCauley & Swisher
(1984)
Mathias (2010)
Criterion Number (Percentage) of
Tests Meeting Criterion
Number (Percentage) of
Tests Meeting Criterion
1. Description of
normative sample
0 1 (11%)
2. Sample size 0 3 (33%)
3. Content Validity- Item
Analysis
1 (20%) 8 (89%)
4. Means and Standard
Deviations
2 (40%) 8 (89%)
5. Concurrent Validity 0 6 (67%)
6. Predictive Validity 0 1 (11%)
7. Test-retest Reliability 0 0
8. Inter-examiner
Reliability
0 0
9. Description of test
procedures
4 (80%) 9 (100%)
10. Description of
examiner qualifications
0 9 (100%)

Psychometric Review
37
11. Construct Validity n/a 9 (100%)

Psychometric Review
38
List of Figures Figure 1. The number of 9 reviewed tests that met at least n criteria (Mathias, 2010) in
comparison with the number of 5 reviewed tests that met at least n criteria (McCauley &
Swisher, 1984).
Psychometric Review
39




















