
Peer-to-peer semantic coordination
25
See discussions, stats, and author profiles for this publication at: https://www.researchgate.net/publication/222659233 Peer-to-Peer Semantic Coordination Article · October 2003 CITATIONS 46 READS 18 3 authors, including: Paolo Bouquet Università degli Studi di Trento 37 PUBLICATIONS 276 CITATIONS SEE PROFILE Luciano Serafini Fondazione Bruno Kessler 285 PUBLICATIONS 5,544 CITATIONS SEE PROFILE All content following this page was uploaded by Paolo Bouquet on 01 June 2015. The user has requested enhancement of the downloaded file.
Transcript of Peer-to-peer semantic coordination

Seediscussions,stats,andauthorprofilesforthispublicationat:https://www.researchgate.net/publication/222659233
Peer-to-PeerSemanticCoordination
Article·October2003
CITATIONS
46
READS
18
3authors,including:
PaoloBouquet
UniversitàdegliStudidiTrento
37PUBLICATIONS276CITATIONS
SEEPROFILE
LucianoSerafini
FondazioneBrunoKessler
285PUBLICATIONS5,544CITATIONS
SEEPROFILE
AllcontentfollowingthispagewasuploadedbyPaoloBouqueton01June2015.
Theuserhasrequestedenhancementofthedownloadedfile.

Peer-to-Peer Semantic Coordination
P. Bouquet1, L. Serafini2 and S. Zanobini11 Department of Information and Communication Technology – University of Trento
Via Sommarive, 10 – 38050 Trento (Italy)
2ITC-IRST – Istituto per la Ricerca Scientifica e Tecnologica
Via Sommarive, 14 – 38050 Trento (Italy)
[email protected] [email protected] [email protected]
July 13, 2004
Abstract
Semantic coordination, namely the problem of finding an agreement on the meaning ofheterogeneous schemas, is one of the key issues in the development of the Semantic Web.In this paper, we propose a method for discovering semantic mappings across hierarchicalclassifications based on a new approach, which shifts the problem of semantic coordinationfrom the problem of computing linguistic or structural similarities (what most other proposedapproaches do) to the problem of deducing relations between sets of logical formulae thatrepresent the meaning of concepts belonging to different schema. We show how to apply theapproach and the algorithm to an interesting family of schemas, namely hierarchical classi-fications, and present the results of preliminary tests on two types of hierarchical classifica-tions, web directories and catalogs. Finally, we argue why this is a significant improvementon previous approaches.
1 Introduction
One of the key issues in the development of the Semantic Web is the problem of enabling ma-chines to exchange meaningful information/knowledge across applications which (i) may use au-tonomously developed schemas (e.g. taxonomies, classifications, database schemas, data types)for organizing locally available data, and (ii) need to discover relations between schemas toachieve their users’ goals. This problem can be viewed as a problem of coordination, definedas follows: (i) all parties have an interest in finding an agreement on how to map their schemasonto each others, but (ii) there are many possible/plausible solutions (many alternative mappingsacross local schemas) among which they need to select the right, or at least a sufficiently good,one. For this reason, we see this as a problem of semantic coordination1.
1See the introduction of [5] for this notion, and its relation with the notion of meaning negotiation.
1

In environments with more or less well-defined boundaries, like a corporate Intranet, theproblem of semantic coordination can be addressed a priori by defining and using shared schemas(e.g. ontologies) throughout the entire organization2. However, in open environments, like theSemantic Web, this “centralized” approach to semantic coordination is not viable for several rea-sons, such as the difficulty of “negotiating” a shared model that suits the needs of all parties in-volved, the practical impossibility of maintaining such a model in a highly dynamic environment,the problem of finding a satisfactory mapping of pre-existing local schemas onto such a globalmodel. In such a scenario, the problem of exchanging meaningful information across locally de-fined schemas (each possibly presupposing heterogeneous semantic models) seems particularlytough, as we cannot assume an a priori agreement, and therefore its solution requires a moredynamic and flexible form of coordination, which we call “peer-to-peer” semantic coordination.
In this paper, we address an important instance of the problem of peer-to-peer semantic coor-dination, namely the problem of coordinating hierarchical classifications (HCs). HCs are struc-tures having the explicit purpose of organizing/classifying some kind of data (such as documents,records in a database, goods, activities, services). The problem of coordinating HCs is significantfor at least two main reasons:
• first, HCs are widely used in many applications3. Examples are: web directories (seee.g. the GoogleTM Directory or the Yahoo!TMDirectory), content management tools andportals (which often use hierarchical classifications to organize documents and web pages),service registry (web services are typically classified in a hierarchical form, e.g. in UDDI),marketplaces (goods are classified in hierarchical catalogs), PC’s file systems (where filesare typically classified in hierarchical folder structures);
• second, it is an empirical fact that most actual HCs (as most concrete instances of mod-els available on the Semantic Web) are built using structures whose labels are expressionsfrom the language spoken by the community of their users (including technical words, ne-ologisms, proper names, abbreviations, acronyms, whose meaning is shared in that com-munity). In our opinion, recognizing this fact is crucial to go beyond the use of syntactic(or weakly semantic) techniques, as it gives us the chance of exploiting the complex degreeof semantic coordination implicit in the way a community uses the language from whichthe labels of a HC are taken.
The main technical contribution of the paper is a logic–based algorithm, called CTXMATCH,for coordinating HCs. It takes in input two HCs S and S′ and, for each pair of concepts m∈ S andn ∈ S′, returns their semantic relation. The relations we consider in this version of CTXMATCH
are: m is less general than n, m is more general than n, m is equivalent to n, m is compatiblewith (possibly overlappings) n, and m is incompatible with (i.e., disjoint from) n. The formalsemantics of these relations will be made precise in the paper.
With respect to other approaches to semantic coordination proposed in the literature (oftenunder different “headings”, such as schema matching, ontology mapping, semantic integration;
2But see [3] for a discussion of the drawbacks of this approach from the standpoint of Knowledge Managementapplications.
3For an interesting discussion of the central role of classification in human cognition see, e.g., [16, 6].
2

see Section 6 for references and a detailed discussion of some of them), our approach is inno-vative in three main aspects: (1) we introduce a new method for making explicit the meaning ofnodes in a HC (and in general, in structured semantic models) by combining three different typesof knowledge, each of which has a specific role; (2) the result of applying this method is thatwe are able to produce a new representation of a HC, in which all relevant knowledge about thenodes (including their meaning in that specific HC) is encoded as a set of logical formulae; (3)mappings across nodes of two HCs are then deduced via logical reasoning, rather then derivedthrough some more or less complex heuristic procedure, and thus can be assigned a clearly de-fined model-theoretic semantics. As we will show, this leads to a major conceptual shift, as theproblem of semantic coordination between HCs is no longer tackled as a problem of computinglinguistic or structural similarities (possibly with the help of a thesaurus and of other informationabout the type of arcs between nodes), but rather as a problem of deducing relations between for-mulae that represent the meaning of each concept in a given HC. This explains, for example, whyour approach performs much better than other ones when two concepts are intuitively equivalent,but occur in structurally very different HCs.
The paper goes as follows. In Section 2 we introduce the main conceptual assumptionsof the new approach we propose to semantic coordination. In Section 3 we show how thisapproach is instantiated to the problem of coordinating HCs. Then we present the main featuresof CTXMATCH, the proposed algorithm for coordinating HCs (Section 4). In the final part of thepaper, we sum-up the results of testing the algorithm on web directories and catalogs (Section 5)and compare our approach with other proposed approaches for matching schemas (Section 6).
2 Our approach
The method we propose assumes that we deal with a network of physically connected entitieswhich can autonomously decide how to organize locally available data; we call these entitiessemantic peers. Peers organize their data using one or more schemas (e.g., database schemas,directories in a file system, classification schemas, taxonomies, and so on); as we said, in thispaper we focus on classifications. Different peers may use different schemas to classify the samecollection of documents/data, and conversely the same schemas can be used to organize differentcollections of documents/data.
We also assume that semantic peers need to exchange data (in our scenario, this means doc-uments classified under categories belonging to distinct classification schemas). To do this, eachsemantic peer needs to discover ‘mappings’ between its local classification schema(s) and otherpeers’ schemas. Intuitively, a mapping can be viewed as a set of pairwise relations betweenelements of two distinct classification schemas.
The first idea behind our approach is that mappings must represent semantic relations, namelyrelations with a well-defined model-theoretic interpretation. This is an important difference withrespect to approaches based on matching techniques, where a mapping is a measure of (linguistic,structural, . . . ) similarity between schemas (e.g., a real number between 0 and 1). The mainproblem with the latter techniques is that the interpretation of their results is an open problem.For example, how should we interpret a 0.9 similarity? Does it mean that one concept is slightly
3

more general than the other one? Or maybe slightly less general? Or that their meaning 90%overlaps (whatever that means)? Instead, our method returns semantic relations, e.g. that the twoconcepts are (logically) equivalent, or that one is (logically) more/less general, or that they aremutually exclusive. As we will argue, this gives us many advantages, essentially related to theconsequences we can infer from the discovery of such a relation4.
A
B
C D
F
C D
?
A
Figure 1: Mapping abstract schemas
The second idea is that, to discover semantic relations, one must make explicit the meaningimplicit in each element of a schema. The claim is that making explicit the meaning of elementsis the necessary premise for computing semantic relations between elements of distinct schemas,and that this can be done only for schemas in which meaningful labels are used, where “mean-ingful” means that their interpretation is not arbitrary, but is constrained by the conventions ofsome community of speakers/users.
To illustrate the consequences of this idea, consider the difference between the problem ofmapping abstract schemas (like those in Figure 1) and the problem of mapping schemas withmeaningful labels (like those in Figure 2). Nodes in abstract schemas do not have an implicitmeaning, and therefore, whatever technique we use to map them, we will find that there is somerelation between the two nodes D in the two schemas which depends only on the abstract formof the two schemas. The situation is completely different for schemas with meaningful labels.Consider for example the two pairs of structures depicted in Figure 2. Both of them are iso-morphic with the pair of abstract schemas depicted in Figure 1. But, despite this similarity, wecan easily understand that the relation between the two nodes MOUNTAIN is ‘less than’, while therelation between the two nodes FLORENCE is ‘equivalent’. Indeed, for the first pair of nodes, theset of documents we would classify under the node MOUNTAIN on the left hand side is a subsetof the documents we would classify under the node MOUNTAIN on the right; whereas the set ofdocuments which we would classify under the node FLORENCE in the left schema is exactly thesame as the set of documents we would classify under the node FLORENCE on the right hand side.The reason of this difference resides in the presence of meaningful labels which allow us to makeexplicit a lot of information that we have about the terms which appear in the graph, and theirrelations (e.g., that Tuscany is part of Italy, that Florence is in Tuscany, and so on). It’s only
4For a more detailed discussion of the distinction between syntactic and semantic methods, see [14].
4

this information which allows us to understand why the semantic relation between the two nodesMOUNTAIN and the two nodes FLORENCE is different.
MOUNTAINBEACH MOUNTAIN BEACH
ITALY
IMAGES
TUSCANY
ITALY
LUCCA FLORENCELUCCA FLORENCE
TUSCANY
IMAGES
IMAGES
IMAGES
less general than
equivalent
Figure 2: Mapping schemas with meaningful labels
This approach gives us the chance of exploiting the complex degree of semantic coordinationimplicit in the way a community uses the language from which the labels are taken5. The methodis based on the explicitation of the meaning associated with each node in a schema (notice thatschemas such as the two classifications in Figure 2 are not semantic models themselves, as theydo not have the purpose of defining the meaning of terms they contain; however, they presupposea semantic model, and indeed that’s the only reason why we humans can read them quite easily).The explicitation process uses three different levels of knowledge:
Lexical knowledge: knowledge about the words used in the labels. For example, the fact thatthe word ‘Florence’ can be used to indicate ‘a city in Italy’ or ‘a town in northeast SouthCarolina’, and to handle the synonymy;
World knowledge: knowledge about the relation between the concepts expressed by words. Forexample, the fact that ‘Tuscany is part of Italy’, or that ‘Florence is in Italy’;
5Notice that the status of this linguistic coordination at a given time is already ‘codified’ in artifacts (e.g., dictio-naries, but today also ontologies and other formalized models), which provide senses for words (the set of conceptsa word can express) and more complex expressions, relations between concepts, and other important knowledgeabout them. Our aim is to exploit these artifacts as an essential source of constraints on possible/acceptable map-pings across structures.
5

Structural knowledge: knowledge deriving from how labeled nodes are arranged in a givenschema. For example, the fact that the node labeled MOUNTAIN is below a node IMAGEStells us that it classifies images of mountains, and not, say, books about mountains.
As an example of how the three levels are used, consider again the mapping between thetwo nodes MOUNTAIN of Figure 2. Lexical knowledge is used to determine what concepts canbe expressed by each label, e.g. that the word ‘Images’ can denote the concept ‘a visual repre-sentation produced on a surface’. World knowledge tells us, among other things, that ‘Tuscanyis part of Italy’. Finally, structural knowledge tells us that the intended meanings of the twonodes MOUNTAIN is ‘images of Tuscan mountains’ on the left hand side, and ‘images of Italianmountains’ on the right hand side. Using this information, human reasoners (i) understand themeaning expressed by the left hand node, (‘images of Tuscan mountains’, denoted by P), (ii) un-derstand the meaning expressed by the right hand node (‘images of Italian mountains’, denotedby P′), and finally (iii) understand the semantic relation between the meaning of the two nodes,namely that P⊆ P′.
Note that applying the same process for determining the semantic relation holding betweenthe two nodes FLORENCE, which belongs to structurally equivalent structures, leads to differentresult. Indeed, exploiting domain knowledge, we can add the fact that ‘Florence is in Tuscany’(such a relation doesn’t hold between mountains and Italy in the first example). This furtherpiece of domain knowledge allows us to conclude that, beyond structural similarity, the relationis different (namely, ‘equivalent to’).
This analysis of meaning has an important consequence on our approach to semantic coordi-nation. Indeed, unlike all other approaches we know of, we do not use lexical knowledge (and,in our case, domain knowledge) to improve the results of structural matching (e.g., by addingsynonyms for labels, or expanding acronyms). Instead, we combine knowledge from all threelevels to build a new representation of the problem, where the meaning of each node is encodedas a logical formula, and relevant domain knowledge and structural relations between nodes areadded to nodes as sets of axioms that capture background knowledge about them.
This, in turn, introduces the last feature of our approach. Indeed, once the meaning of eachnode, together with all relevant domain and structural knowledge, is encoded as a set of logicalformulae, the problem of discovering the semantic relation between two nodes can be stated notas a matching problem, but as a relatively simple problem of logical deduction. Intuitively, aswe will say in a more technical form in Section 4, determining whether there is an equivalencerelation between the meaning of two nodes becomes a problem of testing whether the first im-plies the second and vice versa (given a suitable collection of axioms, which acts as a sort ofbackground theory); and determining whether one is less general than the other one amounts totesting if the first implies the second. As we will say, in the current version of the algorithm weencode this reasoning problem as a problem of logical satisfiability, and then compute mappingsby feeding the problem to a standard SAT solver.
6

3 P2P coordination of hierarchical classifications
In this section we show how to apply the general approach described in the previous section tothe problem of coordinating HCs. Intuitively, a classification is a grouping of things into classesor categories. When categories are arranged into a hierarchical structure, we have a hierarchicalclassification. Formally, the hierarchical structures we use to build HCs are concept hierarchies,defined as follows in [7]:
Definition 1 (Concept hierarchy) A concept hierarchy is a triple S = 〈N,E, l〉 where N is afinite set of nodes, E is a set of arcs on N, such that 〈N,E〉 is a rooted tree, and l is a functionfrom N to a set L of labels.
Essentially, a concept hierarchy is a rooted tree where categories are nodes of the tree6. Givena concept hierarchy S, a classification can be defined as follows:
Definition 2 (Hierarchical Classification) A hierarchical classification of a set of objects D ina concept hierarchy S = 〈N,E, l〉 is a function µ : N→ 2D.
We assume that the classification function µ in Definition 2 satisfies the following specificityprinciple: an object d ∈D is classified under a node n, if d is about n (according to some criteria,e.g., the semantic intuition of the creator of the classification!) and there isn’t a more specificnode m under which d could be classified7.
Prototypical examples of HCs are the web directories of many search engines, as for examplethe GoogleTM Directory, the Yahoo!TM Directory, or the LooksmartTM web directory, or the PC’sfile–systems. A tiny fraction of the HCs corresponding to the GoogleTM DirectoryTM and to theYahoo!TMDirectory is depicted in Figure 3.
Intuitively, the problem of semantic coordination arises when one needs to find relations be-tween nodes belonging to distinct (and thus typically heterogeneous) HCs. Imagine the followingscenario. You have the left lower classification of Figure 2 and you are interested in finding newdocuments to be classified under the node FLORENCE. So you would like to ask the system to findout for you whether there are nodes in different classifications (e.g., the right lower classificationof Figure 2) which have the same meaning as, or a meaning related to, the node FLORENCE inyour classification8. Formally, we define the problem of semantic coordination as the problemof discovering mappings between nodes in two distinct classifications S and S′:
Definition 3 (Mapping) A mapping M from S = 〈N,E, l〉 to S′ = 〈N′,E ′, l′〉 is a function M :N×N′→ rel, where rel is a set of names of accepted semantic relations.
6Hereafter node, category and classes are used in the same sense.7See for example Yahoo!TM instruction for “Finding an appropriate Category” at
http://docs.yahoo.com/info/suggest/appropriate.html.8Similar examples apply to catalogs. Here we use web directories, as they are well-known to most readers and
easy to understand.
7

www.google.com
Arts
Literature
Chatand
forum
Music
History
Baroque
Arthistory
Organi-zation
Visual arts
Galleries
NorthAmerica
UnitedStates
Arizona
Photo-graphy
www.yahoo.com
Arts &Humanities
Photo-graphy Humanities
Chatand
Forum
Design Art
Architecture
History
Baroque
Arthistory
Organi-zation
Visualarts
Figure 3: Examples of concept hierarchies (source: Google!Directory and Yahoo!Directory)
The set rel of accepted semantic relations depends on the intended use of the structures wewant to map. Indeed, in our experience, the intended use of a structure (e.g., classifying objects)is semantically much more relevant than the type of abstract structures involved (e.g., tree, graph,. . . ) to determine how a structure should be interpreted. As the purpose of mapping HCs isto discover relations between nodes (concepts) that are used to classify objects, four possible
relations can hold between two nodes m and n belonging to different HCs: m⊇−→ n (m is more
general than n); m⊆−→ n (m is less general than n); m
≡−→ n (m is equivalent to n); m
⊥−→ n (m
is disjoint from n). Note that the relations are essentially the set theoretical relations, with theexception of the intersection.
The formal semantics of these expressions is given in terms of compatibility between docu-ments occurring in two different concept hierarchies Ss and St
9:
Definition 4 A mapping function M from Ss = 〈Ns,Es, ls〉 to St = 〈Nt ,Et , lt〉 is extensionally cor-rect with respect to two hierarchical classifications µs and µt of the same set of documents D inSs and St , respectively, if the following conditions hold for any node ns ∈ Ns and nt ∈ Nt:
ns⊇−→ nt ⇒ µs(ns↓)⊇ µt(nt↓)
ns⊆−→ nt ⇒ µs(ns↓)⊆ µt(nt↓)
ns⊥−→ nt ⇒ µs(ns↓)∩µt(nt↓) = /0
ns≡−→ nt ⇒ µs(ns↓) = µt(nt↓)
9The semantics provided in Definition 4 can be viewed as a special case of Local Models Semantic, namely thesemantic provided in [12, 4] to capture the (compatibility) relations between local representations called contexts.Proof-theoretically, compatibility relations are formalized as bridge rules, namely rules whose premise and conclu-sions belong to different theories [13]. CTXMATCH can be viewed as a first attempt of automatically discoveringbridge rules (compatibility relations) across contexts.
8

where µ(c↓) is the union of µ(d) for any d in the subtree rooted at c.
If no relation can be computed, the algorithm returns what we call a compatibility relation(m
∗−→ n, m is compatible with n), which is interpreted as possible intersection: it means that
there is at least one interpretation under which the concepts associated with the two nodes (andtherefore the classified documents) overlap10.
4 The algorithm: CTXMATCH
The CTXMATCH algorithm (see algorithm 1) takes as input two HCs (representing the structuralknowledge), a lexicon L (representing the lexical knowledge) and an ontology O (representingworld knowledge), and returns as output a mapping between the nodes of the two classifications.For the sake of simplicity, in the explanation of the algorithm, we imagine that the two HCs takenas input are the two structures depicted in the lower hand of Figure 2.
The algorithm has essentially the following two main macro steps.
Semantic Explicitation (Steps 2–3): in this phase, the meaning of each node m in a classifica-tion S is made explicit using information from the lexicon L and the ontology O. Explici-tation is performed by generating a formula φ approximating the meaning expressed by anode in a HC, and a set of axioms Θ formalizing the relevant world knowledge. Consider,for example, the node FLORENCE in lower left HC hand of Figure 2: steps 2–3 will gen-erate a formula φ approximating the statement ‘Images of Florence in Tuscany’ and a setof axioms Θ approximating the statement ‘Florence is in Tuscany’. The pair 〈φ,Θ〉, calledcontextualized concept, expresses the meaning of a labeled node in a structure with respectto L and O.
Semantic comparison (Step 4) : In this phase the problem of finding the semantic relation be-tween two nodes m and n is encoded as the problem of finding the semantic relation holdingbetween two contextualized concepts, 〈φ,Θ〉 and 〈ψ,ϒ〉, associated with the nodes m andn respectively in the semantic explicitation phase. To prove that the two nodes FLORENCEin Figure 2 are equivalent, we deduce the logical equivalence between the formulas asso-ciated with the nodes, approximating respectively the statements ‘Images of Florence in
10The reason why we introduced the relation called possible intersection is that we wanted to have a placeholderfor potential relations that we can’t deduce – but we can’t reject either – based on the available knowledge. Forexample, ‘Images of dogs’ and ‘Images of cats’ will be evaluated as compatible unless we have positive informationthat dogs and cats are disjoint. Of course, one might say that this conclusion is wrong, but we need to take intoaccount that in other cases (e.g., ‘Images of churches’ and ‘Images of monuments’) it would be right (for the sakeof argument, let us imagine that there is no explicit connection between churches and monuments in the worldknowledge in use). So the decision is between reasoning under a “closed world assumption” (which would preventus from finding any relation in both cases), or reasoning under an “open world assumption” (which would find arelation of compatibility in both cases). Of course, the open world assumption increases the recall, but decreasesthe precision of the algorithm, whereas the closed world assumption would have the opposite effect. Our decisionwas to go for an open world solution, as most concrete ontologies are not rich enough to support the conjecture thatanything which cannot be deduced is false.
9

Tuscany’ (φ) and ‘Images of Florence in Italy’ (ψ), given some domain axioms, as formu-las approximating the statements ‘Florence is a city of Tuscany’ (Θ), ‘Florence is a city ofItaly’ (ϒ), and ‘Tuscany is a region of Italy’.
Algorithm 1 CTXMATCH(S,S′L,O). Hierarchical Classifications S,S′
. Lexicon L
. Ontology OVarDeclaration:
contextualized concept 〈φ,Θ〉 ,〈ψ,ϒ〉semantic relation rmapping M
1 for each pair of nodes m ∈ S and n ∈ S′ do2 〈φ,Θ〉← SEMANTIC–EXPLICITATION(m,S,L,O);3 〈ψ,ϒ〉← SEMANTIC–EXPLICITATION(n,S′,L,O);4 r← SEMANTIC–COMPARISON(〈φ,Θ〉 ,〈ψ,ϒ〉 ,O);5 M←M∪〈m,n,r〉;6 return M;
Finally, step 5 generates the mapping simply by reiteration of the same process over all pairsof nodes m ∈ S and n ∈ S′ (step 1) and step 6 returns the mapping.
The two following sections describe in detail these two top-level functions SEMANTIC–EXPLICITATION and SEMANTIC–COMPARISON.
In the version of the algorithm presented here, we use WORDNET11 as a source of bothlexical and domain knowledge. However, WORDNET could be replaced by another combinationof a linguistic and a world knowledge resources.
4.1 Semantic explicitation
The function SEMANTIC–EXPLICITATION (algorithm 2) has the main goal of making explicit in aformula the meaning of a labeled node into a structure, by means of lexical and world knowledge.The formula will be expressed in same logical language. The choice of the logical languagedepends on how expressive one wants to be in the approximation of the meaning of nodes, andon the complexity of the NLP techniques used to process labels. In our first implementation, weadopted propositional logic, where each propositional letter corresponds to a concept (synset)provided by WORDNET.
11WORDNET [11] is a well-known Lexical/Ontological repository which contains the set of concepts possiblydenoted by a word (called synsets, i.e. set of synonyms), and a set of relations (essentially Is-A and Part-Of) holdingbetween senses. Hereafter, the notion of sense is used as synonym of concept.
10

Algorithm 2 SEMANTIC–EXPLICITATION(t,S,L,O). t is a node in S. structure S. lexicon L. world knowledge O
VarDeclaration:focus Fset of concepts con[]set of axioms Σset of simple concepts Γformula δ
1 F ← focus(t,S)2 for each node n in F do3 con[n]← EXTRACT–CANDIDATE–CONCEPTS(n,L);4 Σ← EXTRACT–LOCAL-AXIOMS(F,con[],O);5 con[]← FILTER–CONCEPTS(F,Σ,con[]);6 for each node n in the path from t to root in F do7 Γ← Γ ∪ BUILD–SIMPLE–CONCEPT(con[],n);8 δ← BUILD–COMPLEX–CONCEPT(Γ);9 return 〈δ,Σ〉;
Determining the meaning of a node n in a structure is a process that doesn’t require to con-sider all the other nodes. So, we need to concentrate only to the set of nodes relevant for buildingthe meaning of n.
To this end, we introduce the notion of focus of a node n in a classification S, denoted byf (n,S). Intuitively, the focus is the smallest sub-tree of S that one should take into account todetermine the meaning of n in S. In CTXMATCH, the focus is defined as follows:
Definition 5 (Focus) The focus of a node n in a classification S = 〈N,E, l〉, is a finite concepthierarchy f (n,S) = 〈N′,E ′, l′〉 such that: N ′ ⊆ N, and N ′ contains exactly n and its children, itsancestors, and all their children; E ′ ⊆ E is the set of edges between the concepts of N ′; l′ is therestriction of l on N ′.
This definition of focus is motivated by observations on how humans read HCs. When search-ing for documents in a HC, we incrementally construct the meaning of a node n by navigatingthe classification from the root to n. During this navigation, we have access to the labels of theancestors of n, and also to the labels of their siblings. This information is used at each stage tobuild the meaning expressed by a node in a structure12.
Step 1 of function SEMANTIC–EXPLICITATION determines the focus of a node in a structure.
12This definition of focus is appropriate for HCs. With structures used for different purposes, different definitionsof focus should be used. For example, if a concept hierarchy is used to represents data–type, the meaning of a nodeis determined also by the meaning of its sub-nodes, so a more suitable definition of focus f (n,H) would include forexample the sub-tree rooted at n.
11

Steps 2 and 3 exploit lexical knowledge to associate with each word occurring in the nodes ofthe focus all the possible concepts denoted by the word itself. When two or more words in a labelare contained in the Lexicon as a single expression (a so-called multiword), the correspondingsense is selected. Consider the lower left structure of Figure 2. The label ‘Florence’ is associatedwith two concepts (or senses), provided by the lexicon (in this case, WORDNET), correspondingto ‘a city in central Italy on the Arno’ (florence#1) or a ‘a town in northeast South Carolina’(florence#2). In order to maximize the possibility of finding an entry into the Lexicon, we useboth a postagger and a lemmatizator over the labels.
In the step 4, the function EXTRACT–LOCAL–AXIOMS exploits ontology with the aim offinding (possible) ontological relations existing between concepts associated with the words ofthe labels in a focus. Consider again the left lower structure of Figure 2. Imagine that the concept‘a region in central Italy’ (tuscany#1) has been associated with the node TUSCANY in step 3. Thefunction EXTRACT–LOCAL–AXIOMS checks if there exists some relation between the concepttuscany#1 and the concepts associated with other nodes, namely florence#1 and florence#2(associated with node FLORENCE), images#1, . . . , images#8 (associated with node IMAGE), andlucca#1 (associated with node LUCCA)13. For example, exploiting world knowledge, we candiscover, among other things, that ‘florence#1 PartOf tuscany#1’, i.e. that there exists a ‘partof’ relation between the first sense of ‘Florence’ and the first sense of ‘Tuscany’.
World knowledge relations derived from WORDNET are translated into logical axioms, ac-cording to Table 1. So, the relation ‘florence#1 PartOf tuscany#1’ is encoded as ‘florence#1→ tuscany#1’.
WORDNET relation axiom
s#k synonym t#h s#k≡ t#hs#k { hyponym | PartOf }t#h s#k→ t#hs#k { hypernym | HasPart }t#h t#h→ s#k
s#k antonyms t#h ¬(t#k∧s#h)
Table 1: WORDNET relations and their axioms.
To sum up, step 4 tries to discover the relationships holding between concepts expressed bylabels of nodes in the focus f (n,S) of some node n.
Step 5 has the goal of filtering out unlikely senses associated with each node. Going back tothe previous example, we try to discard one of the senses associated with the node FLORENCE.Intuitively, the sense 2 of ‘Florence’, ‘a town in northeast South Carolina’ (florence#2), canbe tentatively discarded, because the node FLORENCE refers clearly to the city in Tuscany. Wereach this result by analyzing the extracted local axioms: the presence of an axiom such as‘florence#1→ tuscany#1’ is used to make the conjecture that the contextually relevant senseof Florence is the city in Tuscany, and not the city in USA. When ambiguity persists (axiomsrelated to different senses or no axioms at all), all the possible senses are left.
Steps 6–7 have the main goal of providing an interpretation of the meaning expressed by(the labels of) the nodes independently from the position they occur into the structure. Let F be
13In this example the focus of the node FLORENCE corresponds to the entire structure.
12

a focus for a node n in a concept hierarchy H. In this phase we associate with each node t inthe path from root to n a logical formula, that we call simple concept, representing all possiblelinguistic interpretations of the label of t allowed by the lexical knowledge available.
Labels are processed by text chunking (via Alembic chunker [9]), and connectives are trans-lated into a logical form according to the following rules:
• coordinating conjunctions and commas are interpreted as disjunctions;
• prepositions, like ‘in’ or ‘of’, are interpreted as a conjunction;
• expressions denoting exclusion, like ‘except’ or ‘but not’, are interpreted as negations.
In the example we provide in Figure 2, the simple concept approximating the meaning ex-pressed by the node IMAGES is the formula image#1∨ . . .∨image#8 (the eight senses providedby WORDNET), the meaning expressed by the node TUSCANY is the atom tuscany#1 (the onlysense provided by WORDNET), while the meaning of the node FLORENCE is approximated bythe atom florence#1 (one of the two senses provided by WORDNET and not discarded by thefiltering).
More complicated cases can be handled. Consider the two classifications depicted in Fig-ure 3. The following simple concepts are found:
• the simple concept expressed by the node Baroque is baroque#1, the unique sense of theword ‘Baroque’ presents in WORDNET;
• the simple concept expressed by the node Arizona is arizona#1, one of the two sensesof ‘Arizona’ (arizona#2 in the sense of ‘glossy snake’ has been discarded because of thepresence of the node UNITED STATES);
• the simple concept expressed by the node Chat and Forum is chat#1∨chat#2∨chat#3∨forum#1∨forum#2∨forum#3, i.e. the disjunction of the meaning of ‘chat’ and ‘forum’taken separately (both ‘chat’ and ‘forum’ have tree senses in WORDNET);
• the simple concept expressed by the node North America is north america#1∨north america#2, the senses associated with the multiword ‘North America’ in Lexicon(WORDNET).
Yahoo
• the simple concept expressed by node the Visual Arts is visual art#1∧¬photography#1: both Visual Arts and Photography are sibling nodes under Arts& Humanities; since in WORDNET the concept photography#1 is in a IsA relationshipwith the concept visual art#1, the node Visual arts is re-interpreted as visual artswith the exception of photography.
13

Step 8 has the goal of building the formula approximating the meaning expressed by a nodeinto a structure, that we call complex concept. In this version of the algorithm, we chose to buildthe complex concept expressed by a node n as the conjunction of the simple concepts associatedwith all of its ancestors (i.e., the path from root to n). So, the complex concept associated withthe node FLORENCE is (image#1∨ . . .∨image#8)∧tuscany#1∧florence#1.
Again, this choice depends on the intended use of the structure. From the specificity prin-ciple of classifications (see section 3) follows that the documents classified under a node n canbe, conceptually, classified also under the ancestors of n (in absence of n). For example, consid-ering the Figure 2, the images classified under the path IMAGES/TUSCANY/FLORENCE could beclassified, in absence of the node FLORENCE, also under the node IMAGES/TUSCANY. This meansthat the meaning associated with a node n, say FLORENCE, that we call φ, must be a subset of themeaning associated with an ancestor node m, say TUSCANY, that we call ψ. So, formally, φ⊆ ψ.Rephrasing this in propositional logics, it means that φ→ ψ. A possible way of formalizing thisaspect in propositional logics is to use conjunctions, so that, for example, if the complex con-cept associated with the node TUSCANY is (image#1∨ . . .∨image#8)∧tuscany#1 (say, ψ), thenthe complex concept associated with the node FLORENCE must be (image#1∨ . . .∨image#8)∧tuscany#1∧florence#1 (say, φ). In this case we have that φ→ ψ.
Finally, step 9 returns the contextualized concept, namely the formula expressing the meaningof the node and the set of local axioms returned by step 4.
4.2 Semantic comparison
After semantic explicitation is performed, the problem of discovering semantic relations betweentwo nodes m and n in two HCs can be reduced to the problem of checking if a logical relationholds between two formulas φ and ψ: this is checked as a problem of propositional satisfiability(SAT), and then computed via a standard SAT solver.
Algorithm 3 SEMANTIC–COMPARISON(〈φ,Θ〉,〈ψ,ϒ〉,O). contextualized concept 〈φ,Θ〉. contextualized concept 〈ψ,ϒ〉. world knowledge O
VarDeclaration:set of formulas Γsemantic relation r
1 Γ← EXTRACT–RELATIONAL–AXIOMS(φ, ψ, O);2 if Θ,ϒ,Γ |= ¬(φ∧ψ) then r← ‘⊥’;3 else if Θ,ϒ,Γ |= (φ≡ ψ) then r← ‘≡’;4 else if Θ,ϒ,Γ |= (φ→ ψ) then r← ‘⊆’;5 else if Θ,ϒ,Γ |= (ψ→ φ) then r← ‘⊇’;6 else r← ‘∗’;7 return r;
In Step 1, the function EXTRACT–RELATIONAL–AXIOMS tries to find axioms which connectconcepts belonging to different HCs. The process is the same as that of the function EXTRACT–
14

LOCAL–AXIOMS, described above, with the only difference that it involves concepts (senses, ifwe use WORDNET) belonging to different HCs. Consider, for example, the senses italy#1 andtuscany#1 associated respectively with nodes ITALY and TUSCANY of Figure 2: the relationalaxioms express the fact that, for example, ‘Tuscany is part of Italy’, and it is translated in theaxiom tuscany#1→ italy#1, according to Table 1.
The problem of finding the semantic relation between two nodes n and m (step 2) is encodedinto a satisfiability problem involving the contextualized concepts associated with two nodes ofdifferent structures and the relational axioms extracted in the previous phases. As we said before,five possible semantic relations are allowed: disjoint (⊥), equivalent (≡), less than (⊆), morethan (⊇) and compatible (∗). Steps 2–6 check which relation holds by running the SAT solver onfive satisfiability problems, where the sets of formulas Θ,ϒ,Γ represent the local axioms of thesource node, the local axioms of the target node and the relational axioms respectively, and φ andψ represent the complex concepts approximating the meaning expressed by the source node andthe target node respectively. Note that the compatibility relation is leaved as default case (step6).
Going back to our example, to prove whether the two nodes labeled FLORENCE in Figure 2 areequivalent, we check the logical equivalence between the formulas approximating the meaningof the two nodes, given the local and the relational axioms. Formally, we have the followingsatisfiability problem:
Θ florence#1→ tuscany#1φ (image#1∨ . . .∨image#8)∧tuscany#1∧florence#1ϒ florence#1→ italy#1ψ (image#1∨ . . .∨image#8)∧italy#1∧florence#1Γ tuscany#1→ italy#1
It is easy to see that the returned relation is ‘≡’. Note that the satisfiability problem for findingthe semantic relation between the nodes MOUNTAIN of Figure 2 is the following:
Θ /0φ (image#1∨ . . .∨image#8)∧tuscany#1∧mountain#1ϒ /0ψ (image#1∨ . . .∨image#8)∧italy#1∧mountain#1Γ tuscany#1→ italy#1
The returned relation is ‘⊆’.The algorithm has been run not only in ad hoc examples, as the classifications depicted in
Figure 2, but also in real world examples. In the following table we present some results obtainedin running CTXMATCH for finding relations between the nodes of the portion of Google andYahoo classifications depicted in Figure 3.
Google node Yahoo node semantic relation found
Baroque Baroque Disjoint (⊥)Visual Arts Visual Arts More general than (⊇)Photography Photography Equivalent (≡)Chat and Forum Chat and Forum Less general than (≡)
15

In the first example, CTXMATCH returns a ‘disjoint’ relation between the two nodes Baroque:the presence of two different ancestors (Music and Architecture) and the related world knowl-edge ‘Music is disjoint with Architecture’ allow us to derive the right semantic relation.
In the second example, CTXMATCH returns the ‘more general than’ relation between thenodes Visual Arts. This is a rather sophisticated result: indeed, world knowledge providesthe information that ‘photography IsA visual art’ (photography#1→ visual art#1). Fromstructural knowledge, we can deduce that, while in the left structure the node Visual Artsdenotes the whole concept (in fact photography is one of its children), in the right structure thenode Visual Arts denotes the concept ‘visual arts except photography’ (in fact photographyis one of its siblings). Given this information, it easy to deduce that, although despite the twonodes lye on the same path, they have different meanings.
The third example shows how the correct relation holding between nodes Photography isreturned (‘equivalence’), despite the presence of different paths, as world knowledge tells us thatphotography#1→ visual art#1.
Finally, between the nodes Chat and Forum a ‘less general than’ relation is found as worldknowledge gives us the axiom ‘literature is a humanities’.
5 Testing the algorithm
In this section, we report from [18] some results of the first test on CTXMATCH on real HCs (i.e.,pre-existing classifications used in real applications).
5.1 Use case Product Re-classification
In order to centrally manage all the company acquisition processes, the headquarter of a wellknown worldwide telecommunication company had realized an e-procurement system14, whichall the company branch-quarters were required to join. Each single office was also requiredto migrate from the product catalogue they used to manage, to this new one managed withinthe platform. This catalogue is extracted from the Universal Standard Products and ServicesClassification (UNSPSC), which is an open global coding system that classifies products andservices. UNSPSC is used extensively around the world in electronic catalogues, search engines,procurement application systems and accounting systems. UNSPSC is a four-level hierarchicalclassification; an extract is reported in the following table:
Level 1 Furniture and FurnishingsLevel 2 Accommodation furnitureLevel 3 FurnitureLevel 4 StandsLevel 4 SofasLevel 4 Coat racks
14An e-procurement system is a technological platform which supports a company in managing its procurementprocesses and, more in general, the re-organization of the value chain on the supply side.
16

The Italian office asked us to apply the matching algorithm to re-classify into UNSPSC (ver-sion 5.0.2) the catalogue of office equipment and accessories they used to classify companysuppliers. The result of running CTXMATCH over UNSPSC and the catalogue can be clearly in-terpreted in terms of re-classification: if the algorithm returns that the item i of the catalogue isequivalent to, or more specific than, the node cUNSPSC of UNSPSC, then i can be classified undercUNSPSC of UNSPSC.
The items to be re-classified are mainly labeled with Italian phrases, but labels also containabbreviations, acronyms, proper names, some English phrases and some typing errors. TheEnglish translation of an extract of this list is reported in the following table. The italic text werecontained in the original labels.
Code DescriptionENT.21.13 cartridge hp desk jet 2000cENR.00.20 magnetic tape cassette exatape 160m xl 7,0gbESA.11.52 hybrid roller pentel red
EVM.00.40 safety scissors, length 25 cm
The item list was matched against two UNSPSC’s segments: Office Equipment and Accessoriesand Supplies (segment 44) and Paper Materials and Products (segment 14).
Notice that the company item catalogue we had to deal with was a plain list of items, eachidentified with a numerical code composed of two numbers, the first referring to a set of moregeneral categories. For example, the number 21 at the beginning of 21.13-cartridge hp desk jet2000c corresponds to printer tapes, cartridge and toner. We first normalized and matched theplain list against UNSPSC. This did not lead us to a satisfactory result. The algorithm performedmuch better when we made explicit the hierarchical classification implicitly contained in theitem codes. This was done by substituting the first numerical code of each item with their textualdescription provided by experts of the company.
After running CTXMATCH, the validation phase of our results was made by comparing themwith the results of a simple keyword-based algorithm. Obviously, in order to establish the cor-rectness of results in terms of precision and recall we must compare them with a correct andcomplete matching list. Not having such a list, we asked a domain expert to manually validatethem.
5.2 Results
This section presents the results of the re-classification phase. Consider first the baseline match-ing process. The baseline was performed by a simple keyword-based matching that workedaccording to the following rule:
for each item description (made up of one or more words) return the set of nodes,and their paths, which maximize the occurrences of the item words
The following tables summarizes the results of the baseline matching:
17

Baselineclassification
Total items 194 100%Rightly classified 75 39%Wrongly classified 92 47%Non classified 27 14%
Given the 193 items to be re-classified, the baseline process found 1945 possible nodes inUNSPSC. This means that for each item the baseline found an average of 6 possible reclassifica-tions. What is crucial is that only 75 out of the 1945 proposed nodes are correct. The percentageof error is quite high (47%) with respect to the one of correctness (39%). The results of thematching algorithm are reported in the following table:
CTXMATCH
classificationTotal items 194 100%Rightly classified 136 70%Wrongly classified 16 8%Non classified 42 22%
In this case, the percentage of success is higher (70%) and, even more relevant, the percentage oferror is minimal (8%)15. This is also confirmed by the values of precision and recall, computedwith respect to the validated list:
Total matches Precision RecallBaseline 1945 4% 39%
CTXMATCH 641 21% 70%
The baseline precision level is quite small, while the matching one is not excellent, but defi-nitely better. The same observations can be made also for the recall values.
Table 2 reports some examples where the algorithm found a correct item for re-classification,while the baseline did not.
If there are not enough information to infer semantic relation, CTXMATCH returns a percent-age, which is intended to represent the degree of compatibility between the two elements. Degreeof compatibility is computed on the basis of a linguistic co-occurrence measures. Examples ofcompatibility relations are contained in the last four rows of Table 2.
As far as the Non Classified items, notice that:
• In some cases, the item to be re-classified were not correctly classified in the companycatalogue. Therefore, CTXMATCH could not compute the relations with the node and itsparent node, in the right way. Examples are: ashtray was classified under tape dispenser;wrapping paper was classified under adhesive labels.
15Notice that the algorithm did not take into account only the UNSPSC level 4 category, since in some casescatalogues items can be matched with UNSPSC level 3 category nodes.
18

ITEMS UNSPSC CLASSES RELATION
drill/drill with 2-4 holes
Office machines, materials and accessories/Supplies for office /
Supplies for writing-desks/Paper staplers
⊆
printing tape, toner, cartridge , printing headOffice machines, materials and accessories/Supplies of printing, telecoping-machine e coping-machine/
Ink cartridges⊆
printing tape, toner, cartridge , printing headOffice machines, materials and accessoriesPrinting forniture, telecoping-machine e coping-machine/
Toner⊆
lampostil pen, marker, highlighter/highlighterSupplies for office/Tools for writing/
Highlighters⊆
ball-point pen, penSupplies for office/Tools for writing/
Assortment of pens and penciles∗
double ruler/double ruler in white plasticAccessories for the office and the writing desk/Accessories for drawing
∗
cleaning kit/PC cleaning kitOffice machines, materials and accessories/Accessories for office machines/
computer cleaning kit∗
cleaning kit //cleaning kit for exatape 4 mm tape heads
Materials for office /Office machines, materials and accessories/
Accessories for office machines/Cleaners of tapes
∗
Table 2: Some examples of matching found by CTXMATCH and not found by the baseline.
• In other cases, semantic coordination was not discovered due to a lack of domain knowl-edge. For instance to match paper for hp with UNSPSC class of printer paper it would havebeen necessary to know that hp stands for Helwett Packard, and that it is a company whichproduces printers.
In a further experiment, we run CTXMATCH between the company catalogue (in Italian) andthe English version of UNSPSC. This was possible because the matching is computed on thebasis of the WORDNET sense IDs, and in the version of WORDNET we used, wordnet-senses IDof Italian and English words are aligned (i.e., the wordnet-sense ID associated with word and itstranslation in the other language is the same). This experiment allows us to find more semanticmatches.
More in general, using aligned lexical sources allows us to approach and manage multi-language environments and to exploit the richness which typically characterizes the English ver-sion of linguistic resources16.
6 Related work
CTXMATCH shifts the problem of semantic coordination from the problem of matching (in amore or less sophisticated way) semantic structures (e.g., schemas) to the problem of deduc-
16The results of this experiment is not reported as they are not comparable with our simple keyword-based base-line, which makes no sense with multiple languages.
19
graphmatching
CUPID / MOMIS GLUE CTXMATCH
Structuralknowledge
• • •
Lexicalknowledge
• • •
Domainknowledge
• •
Instance-basedknowledge
•
Type ofresult
Pairs of nodes Similarity measure ∈[0..1] between pairs ofnodes
Similarity measure ∈[0..1] between pairs ofnodes
Semantic relations be-tween pairs of nodes
Table 3: Comparing CTXMATCH with other methods
ing semantic relations between sets of logical formulae. Under this respect, to the best of ourknowledge, there are no other works to which we can compare ours.
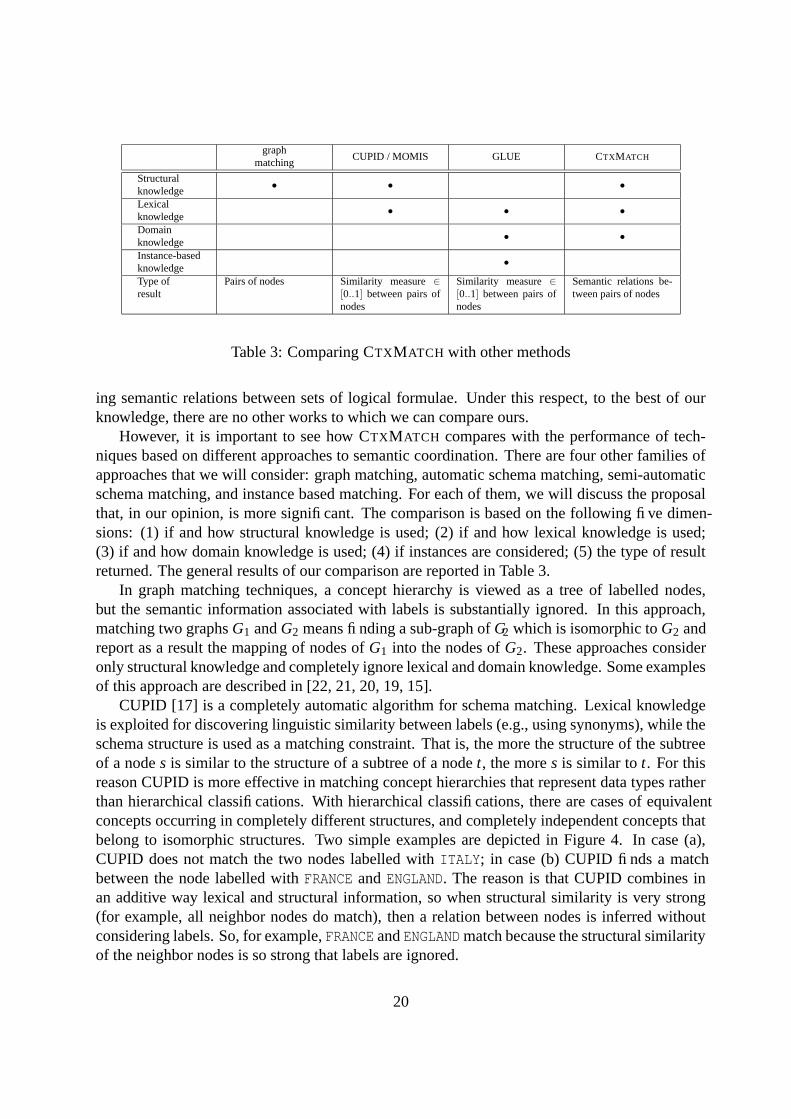
However, it is important to see how CTXMATCH compares with the performance of tech-niques based on different approaches to semantic coordination. There are four other families ofapproaches that we will consider: graph matching, automatic schema matching, semi-automaticschema matching, and instance based matching. For each of them, we will discuss the proposalthat, in our opinion, is more significant. The comparison is based on the following five dimen-sions: (1) if and how structural knowledge is used; (2) if and how lexical knowledge is used;(3) if and how domain knowledge is used; (4) if instances are considered; (5) the type of resultreturned. The general results of our comparison are reported in Table 3.
In graph matching techniques, a concept hierarchy is viewed as a tree of labelled nodes,but the semantic information associated with labels is substantially ignored. In this approach,matching two graphs G1 and G2 means finding a sub-graph of G2 which is isomorphic to G2 andreport as a result the mapping of nodes of G1 into the nodes of G2. These approaches consideronly structural knowledge and completely ignore lexical and domain knowledge. Some examplesof this approach are described in [22, 21, 20, 19, 15].
CUPID [17] is a completely automatic algorithm for schema matching. Lexical knowledgeis exploited for discovering linguistic similarity between labels (e.g., using synonyms), while theschema structure is used as a matching constraint. That is, the more the structure of the subtreeof a node s is similar to the structure of a subtree of a node t, the more s is similar to t. For thisreason CUPID is more effective in matching concept hierarchies that represent data types ratherthan hierarchical classifications. With hierarchical classifications, there are cases of equivalentconcepts occurring in completely different structures, and completely independent concepts thatbelong to isomorphic structures. Two simple examples are depicted in Figure 4. In case (a),CUPID does not match the two nodes labelled with ITALY; in case (b) CUPID finds a matchbetween the node labelled with FRANCE and ENGLAND. The reason is that CUPID combines inan additive way lexical and structural information, so when structural similarity is very strong(for example, all neighbor nodes do match), then a relation between nodes is inferred withoutconsidering labels. So, for example, FRANCE and ENGLAND match because the structural similarityof the neighbor nodes is so strong that labels are ignored.
20

��������
��������
��������������������������
������������
IMAGES
ITALY GERMANYSPAIN FRANCE
EUROPE
� � ��
��������
��������������������
������������ ������������
EUROPE
IMAGES
ITALY GERMANYSPAIN ENGLAND
����
����
����
��
!!""
##$$
IMAGES
ITALY GERMANYSPAIN FRANCE
EUROPE
%�%%�%&�&&�&
'�''�'(�((�(
)�))�)*�**�*
(b)
ITALY
EUROPE
IMAGES(a)
Figure 4: Example of a correct mapping not found by CUPID and of a wrong mapping found byCUPID
MOMIS (Mediator envirOnment for Multiple Information Sources) [1] is a set of tools forinformation integration of (semi-)structured data sources, whose main objective is to define aglobal schema that allow an uniform and transparent access to the data stored in a set of se-mantically heterogeneous sources. One of the key steps of MOMIS is the discovery of overlap-pings (relations) between the different source schemas. This is done by exploiting knowledgein a Common Thesaurus together with a combination of clustering techniques and DescriptionLogics. The approach is very similar to CUPID and presents the same drawbacks in matchinghierarchical classifications. Furthermore, MOMIS includes an interactive process as a step of theintegration procedure, and thus, unlike CTXMATCH, it does not support a fully automatic andrun-time generation of mappings.
GLUE [10] is a taxonomy matcher that builds mappings taking advantage of informationcontained in instances, using machine learning techniques and domain-dependent constraints,manually provided by domain experts. GLUE represents an approach complementary to CTX-MATCH. GLUE is more effective when a large amount of data is available, while CTXMATCH
performs better when less data are available, or the application requires a quick, on-the-fly map-ping between structures. So, for instance, in case of product classification such as UNSPSC orEclss (which are pure hierarchies of concepts with no data attached), GLUE cannot be applied.Combining the two approaches is a challenging research topic, which can probably lead to amore precise and effective methodology for semantic coordination.
7 Conclusions and future work
In this paper we presented a new approach to semantic coordination in open and distributed en-vironments, and an algorithm (called CTXMATCH) that implements this method for hierarchicalclassifications. The algorithm has already been used in a peer-to-peer application for distributedknowledge management (the application is described in [2]), and is going to be applied in apeer-to-peer wireless system for ambient intelligence [8].
An important lesson we learned from this work is that methods for semantic coordinations
21

should not be grouped together on the basis of the type of abstract structure they aim at coordinat-ing (e.g., graphs, concept hierarchies), but on the basis of the intended use of the structures underconsideration. In this paper, we addressed the problem of coordinating concept hierarchies whenused to build hierarchical classifications. Other possible uses of structures are: conceptualizingsome domain (ontologies), describing services (automata), describing data types (schemas). This“pragmatic” level (i.e., the use) is essential to provide the correct interpretation of a structure,and thus to discover the correct mappings with other structures.
The importance we assign to the fact that HCs are labelled with meaningful expressions doesnot mean that we see the problem of semantic coordination as a problem of natural languageprocessing (NLP). On the contrary, the solution we provided is mostly based on knowledgerepresentation and automated reasoning techniques. However, the problem of semantic coordi-nation is a fertile field for collaboration between researchers in knowledge representation and inNLP. Indeed, if in describing the general approach one can assume that some linguistic meaninganalysis for labels is available and ready to use, we must be very clear about the fact that realapplications (like the one we described in Section 4) require a massive use of techniques andtools from NLP, as a good automatic analysis of labels from a linguistic point of view is a nec-essary precondition for applying the algorithm to HC in local applications, and for the quality ofmappings resulting from the application of the algorithm.
The work we presented in this paper is only the first step of a very ambitious scientificproject, namely to investigate the minimal common ground needed to enable communicationbetween autonomous entities (e.g., agents) that cannot “look into each others head”, and thuscan achieve some degree of semantic coordination only through other means, like exchangingmessages or examples, pointing to things, remembering past interactions, generalizing frompast communications, and so on. In this context, we are currently working on the secondversion of the algorithm, which will include the following new features: (i) the extension ofits application beyond hierarchical classifications (namely to structures whose purposes is notto classify things, e.g. service descriptions); (ii) the generalization of the types of structuresthat can be coordinated (e.g., graphs, data type descriptions, . . . ); (iii) the usage of lexicaland world knowledge sources different from WORDNET (our short term goal is to wrap anyOWL-based ontology and link it to WORDNET as a lexical source); (iv) the introduction ofa more expressive logic (e.g., Description Logic) to formalize the concepts associated withnodes (as an example, considering the node MOUNTAIN of the upper right hand structure of Fig-ure 2, we want the SEMANTIC–EXPLICITATION function to extract the following DL concept:‘imageu∃about.(mountainu∃located.italy)’, namely ‘images concerning mountains lo-cated in Italy’); consequently, we plan to move from boolean SAT solvers to DL reasoners; (v)the possibility of using different lexical and/or world knowledge sources for each of the localstructures to be coordinated. The last problem is probably the most challenging one, as it in-troduces asymmetric mappings (if different peers use different lexical and world knowledge, themappings they compute between their classifications may be different). In our opinion, sucha scenario opens a completely new area of research, in which semantic agreements cannot beviewed simply as the result of a coordination process (computation of mappings), but will benegotiated among parties with potentially conflicting interests.
22

References
[1] Sonia Bergamaschi, Silvana Castano, and Maurizio Vincini. Semantic integration ofsemistructured and structured data sources. SIGMOD Record, 28(1):54–59, 1999.
[2] M. Bonifacio, P. Bouquet, G. Mameli, and M. Nori. Kex: a peer-to-peer solution for dis-tributed knowledge management. In D. Karagiannis and U. Reimer, editors, Fourth Interna-tional Conference on Practical Aspects of Knowledge Management (PAKM-2002), Vienna(Austria), 2002.
[3] M. Bonifacio, P. Bouquet, and P. Traverso. Enabling distributed knowledge management.managerial and technological implications. Novatica and Informatik/Informatique, III(1),2002.
[4] A. Borgida and L. Serafini. Distributed description logics: Directed domain correspon-dences in federated information sources. In R. Meersman and Z. Tari, editors, On TheMove to Meaningful Internet Systems 2002: CoopIS, Doa, and ODBase, volume 2519 ofLNCS, pages 36–53. Springer Verlag, 2002.
[5] P. Bouquet, editor. AAAI-02 Workshop on Meaning Negotiation, Edmonton, Canada, July2002. AAAI, AAAI Press.
[6] G. C. Bowker and S. L. Star. Sorting things out: classification and its consequences. MITPress., 1999.
[7] A. Buchner, M. Ranta, J. Hughes, and M. Mantyla. Semantic information mediation amongmultiple product ontologies. In Proc. 4th World Conference on Integrated Design & ProcessTechnology, 1999.
[8] P. Busetta, P. Bouquet, G. Adami, M. Bonifacio, and F. Palmieri. K-Trek: An approach tocontext awareness in large environments. Technical report, Istituto per la Ricerca Scientificae Tecnologica (ITC-IRST), Trento (Italy), April 2003. Submitted to UbiComp’2003.
[9] D. S. Day and M. B. Vilain. Phrase parsing with rule sequence processors: an applicationto the shared CoNLL task. In Proc. of CoNLL-2000 and LLL-2000, Lisbon, Portugal,September 2000.
[10] A. Doan, J. Madhavan, P. Domingos, and A. Halevy. Learning to map between ontologieson the semantic web. In Proceedings of WWW-2002, 11th International WWW Conference,Hawaii, 2002.
[11] Christiane Fellbaum, editor. WordNet: An Electronic Lexical Database. The MIT Press,Cambridge, US, 1998.
[12] C. Ghidini and F. Giunchiglia. Local Models Semantics, or Contextual Reasoning = Local-ity + Compatibility. Artificial Intelligence, 127(2):221–259, April 2001.
23

[13] F. Giunchiglia and L. Serafini. Multilanguage Hierarchical Logics or: how we can dowithout modal logics. Artificial Intelligence, 65(1):29–70, 1994.
[14] F. Giunchiglia and P. Shvaiko. Semantic matching. Proceedings of the ISWC-03 workshopon Semantic Integration, Sanibel Island (Florida), October 2003.
[15] Jeremy Carroll Hewlett-Packard. Matching rdf graphs. In Proc. in the first InternationalSemantic Web Conference - ISWC 2002, pages 5–15, 2002.
[16] G. Lakoff. Women, Fire, and Dangerous Things. Chicago Unversity Press, 1987.
[17] Jayant Madhavan, Philip A. Bernstein, and Erhard Rahm. Generic schema matching withcupid. In The VLDB Journal, pages 49–58, 2001.
[18] B. M. Magnini, L. Serafini, A. Dona, L. Gatti, C. Girardi, , and M. Speranza. Large–scaleevaluation of context matching. Technical Report 0301–07, ITC–IRST, Trento, Italy, 2003.
[19] Tova Milo and Sagit Zohar. Using schema matching to simplify heterogeneous data transla-tion. In Proc. 24th Int. Conf. Very Large Data Bases, VLDB, pages 122–133, 24–27 1998.
[20] Marcello Pelillo, Kaleem Siddiqi, and Steven W. Zucker. Matching hierarchical structuresusing association graphs. Lecture Notes in Computer Science, 1407:3–??, 1998.
[21] Jason Tsong-Li Wang, Kaizhong Zhang, Karpjoo Jeong, and Dennis Shasha. A system forapproximate tree matching. Knowledge and Data Engineering, 6(4):559–571, 1994.
[22] K. Zhang, J. T. L. Wang, and D. Shasha. On the editing distance between undirectedacyclic graphs and related problems. In Z. Galil and E. Ukkonen, editors, Proceedings ofthe 6th Annual Symposium on Combinatorial Pattern Matching, volume 937, pages 395–407, Espoo, Finland, 1995. Springer-Verlag, Berlin.
24




















