
On Iterative Soft-Decision Decoding of Linear Binary Block Codes and Product Codes
21
276 IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS, VOL. 16, NO. 2, FEBRUARY 1998 On Iterative Soft-Decision Decoding of Linear Binary Block Codes and Product Codes Rainer Lucas, Martin Bossert, Member, IEEE, and Markus Breitbach Abstract— Iterative decoding methods have gained interest, initiated by the results of the so-called “turbo” codes. The theoret- ical description of this decoding, however, seems to be difficult. Therefore, we study the iterative decoding of block codes. First, we discuss the iterative decoding algorithms developed by Gal- lager, Battail et al., and Hagenauer et al. Based on their results, we propose a decoding algorithm which only uses parity check vectors of minimum weight. We give the relation of this iterative decoding to one-step majority-logic decoding, and interpret it as gradient optimization. It is shown that the used parity check set defines the region, where the iterative decoding decides on a particular codeword. We make plausible that, in almost all cases, the iterative decoding converges to a codeword after some iterations. We derive a computationally efficient implementation using the minimal trellis representing the used parity check set. Simulations will illustrate that our algorithm gives results close to soft decision maximum likelihood (SDML) decoding for many code classes like BCH codes, Reed–Muller codes, quadratic residue codes, double circulant codes, and cyclic finite geometry codes. We also present simulation results for product codes and parallel concatenated codes based on block codes. Index Terms— Iterative decoding, linear binary block codes, majority-logic decoding, minimal trellis, product codes, separable (rectangular) codes, soft-decision decoding. I. INTRODUCTION I N digital transmission systems with channel coding, it is well known that the use of reliability information on an additive white Gaussian noise (AWGN) channel gives better performance. In terms of the codeword (block) error probability, soft-decision maximum likelihood (SDML) decod- ing is the optimum decoding principle, provided that all codewords are equiprobable. Given a received sequence, the most likely transmitted codeword is computed. Unfortunately, the computational complexity increases exponentially with the dimension of the block code [5]. As a consequence, its practical application is limited to codes of moderate length with low dimension. On the other hand, it is well known from Shannon theory that increasing the code length leads to a better performance. Consequently, the goal from the viewpoint of decoding is the development of decoding algorithms of low complexity which allow the decoding of long powerful codes with high performance. Manuscript received October 19, 1996; revised February 21, 1997. This paper was presented in part at the 1996 IEEE International Symposium on Information Theory and Its Applications, Victoria, B.C., Canada, September 1996. The authors are with the Department of Information Technology, University of Ulm, D-89081 Ulm, Germany. Publisher Item Identifier S 0733-8716(98)00167-X. One class of decoding algorithms accomplishing this goal constructs a list of candidate codewords on forming variants of the received sequence by erasing coordinates or switching the sign of coordinates with respect to their reliability. These candidate codewords are decoded using algebraic algorithms. Then, that codeword is chosen from the list which has the smallest Euclidean distance to the received vector. Forney’s generalized minimum distance decoding [6], the Chase al- gorithms [7], or the algorithm of Kaneko et al. [8] are representatives of this type. Other algorithms of the same type which do not use an algebraic decoder were suggested, e.g., by Snyders and Be’ery [9], Han et al. [10], or recently by Fossorier and Lin [11], to mention only a few. All of these algorithms can be regarded as branch-and-bound algorithms [12]. Another strategy of decoding is based on the modification of the received channel values by adding an appropriate symbol-by-symbol (s/s) reliability information. It can be used for decoding long codes obtained from concatenated codes, when the decoding is split into steps of moderate complexity and symbol-by-symbol reliability information is transferred between the decoding steps. This symbol-by-symbol soft- input/soft-output decoding also allows a repeated (iterative) decoding of the same sequence. This kind of decoding can be interpreted as gradient optimization [13]. Recently, great success was achieved using this principle for the decoding of parallel concatenated (“turbo”) codes [1]. Thereby, the symbol-by-symbol reliability information is generated with the algorithms of Bahl et al. [14], or Hoeher et al. [15], or the less complex SOVA [16]. The theoretical description of this decoding, however, seems to be difficult. Since concate- nated codes as well as terminated convolutional codes can be interpreted as block codes, this paper is focused on the iterative decoding of linear binary block codes to gain a better understanding of iterative decoding. Prior publications, e.g., by Rudolph et al. [17], Battail et al. [3], Kolesnik [18], or recently Hagenauer et al. [4] and Wiberg [19] are taken into account. We emphasize that we are particularly interested in finding a decoding algorithm providing as good as possible a codeword (block) error rate. Thus, throughout this paper, optimum decoding means SDML decoding with respect to codewords. The organization of the paper is as follows. In Section II, the basic concept of symbol-by-symbol iterative decoding for linear binary block codes is introduced, and the computation of symbol-by-symbol reliability information for block codes is studied. Thereby, we restrict ourselves to algorithms using vectors of the dual code. An approximation of the optimum 0733–8716/98$10.00 1998 IEEE
Transcript of On Iterative Soft-Decision Decoding of Linear Binary Block Codes and Product Codes

276 IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS, VOL. 16, NO. 2, FEBRUARY 1998
On Iterative Soft-Decision Decoding of LinearBinary Block Codes and Product Codes
Rainer Lucas, Martin Bossert,Member, IEEE,and Markus Breitbach
Abstract—Iterative decoding methods have gained interest,initiated by the results of the so-called “turbo” codes. The theoret-ical description of this decoding, however, seems to be difficult.Therefore, we study the iterative decoding of block codes. First,we discuss the iterative decoding algorithms developed by Gal-lager, Battail et al., and Hagenaueret al. Based on their results,we propose a decoding algorithm which only uses parity checkvectors of minimum weight. We give the relation of this iterativedecoding to one-step majority-logic decoding, and interpret it asgradient optimization. It is shown that the used parity checkset defines the region, where the iterative decoding decides ona particular codeword. We make plausible that, in almost allcases, the iterative decoding converges to a codeword after someiterations. We derive a computationally efficient implementationusing the minimal trellis representing the used parity checkset. Simulations will illustrate that our algorithm gives resultsclose to soft decision maximum likelihood (SDML) decoding formany code classes like BCH codes, Reed–Muller codes, quadraticresidue codes, double circulant codes, and cyclic finite geometrycodes. We also present simulation results for product codes andparallel concatenated codes based on block codes.
Index Terms—Iterative decoding, linear binary block codes,majority-logic decoding, minimal trellis, product codes, separable(rectangular) codes, soft-decision decoding.
I. INTRODUCTION
I N digital transmission systems with channel coding, itis well known that the use of reliability information on
an additive white Gaussian noise (AWGN) channel givesbetter performance. In terms of the codeword (block) errorprobability, soft-decision maximum likelihood (SDML) decod-ing is the optimum decoding principle, provided that allcodewords are equiprobable. Given a received sequence, themost likely transmitted codeword is computed. Unfortunately,the computational complexity increases exponentially withthe dimension of the block code [5]. As a consequence, itspractical application is limited to codes of moderate lengthwith low dimension. On the other hand, it is well known fromShannon theory that increasing the code length leads to a betterperformance. Consequently, the goal from the viewpoint ofdecoding is the development of decoding algorithms of lowcomplexity which allow the decoding of long powerful codeswith high performance.
Manuscript received October 19, 1996; revised February 21, 1997. Thispaper was presented in part at the 1996 IEEE International Symposium onInformation Theory and Its Applications, Victoria, B.C., Canada, September1996.
The authors are with the Department of Information Technology, Universityof Ulm, D-89081 Ulm, Germany.
Publisher Item Identifier S 0733-8716(98)00167-X.
One class of decoding algorithms accomplishing this goalconstructs a list of candidate codewords on forming variantsof the received sequence by erasing coordinates or switchingthe sign of coordinates with respect to their reliability. Thesecandidate codewords are decoded using algebraic algorithms.Then, that codeword is chosen from the list which has thesmallest Euclidean distance to the received vector. Forney’sgeneralized minimum distance decoding [6], the Chase al-gorithms [7], or the algorithm of Kanekoet al. [8] arerepresentatives of this type. Other algorithms of the same typewhich do not use an algebraic decoder were suggested, e.g.,by Snyders and Be’ery [9], Hanet al. [10], or recently byFossorier and Lin [11], to mention only a few. All of thesealgorithms can be regarded asbranch-and-boundalgorithms[12].
Another strategy of decoding is based on the modificationof the received channel values by adding an appropriatesymbol-by-symbol (s/s) reliability information. It can be usedfor decoding long codes obtained from concatenated codes,when the decoding is split into steps of moderate complexityand symbol-by-symbol reliability information is transferredbetween the decoding steps. This symbol-by-symbol soft-input/soft-output decoding also allows a repeated (iterative)decoding of the same sequence. This kind of decoding canbe interpreted asgradient optimization[13]. Recently, greatsuccess was achieved using this principle for the decodingof parallel concatenated (“turbo”) codes [1]. Thereby, thesymbol-by-symbol reliability information is generated withthe algorithms of Bahlet al. [14], or Hoeheret al. [15], orthe less complex SOVA [16]. The theoretical description ofthis decoding, however, seems to be difficult. Since concate-nated codes as well as terminated convolutional codes canbe interpreted as block codes, this paper is focused on theiterative decoding of linear binary block codes to gain a betterunderstanding of iterative decoding. Prior publications, e.g.,by Rudolphet al. [17], Battail et al. [3], Kolesnik [18], orrecently Hagenaueret al. [4] and Wiberg [19] are taken intoaccount. We emphasize that we are particularly interested infinding a decoding algorithm providing as good as possiblea codeword (block) error rate. Thus, throughout this paper,optimum decoding means SDML decoding with respect tocodewords.
The organization of the paper is as follows. In Section II,the basic concept of symbol-by-symbol iterative decoding forlinear binary block codes is introduced, and the computationof symbol-by-symbol reliability information for block codesis studied. Thereby, we restrict ourselves to algorithms usingvectors of the dual code. An approximation of the optimum
0733–8716/98$10.00 1998 IEEE

LUCAS et al.: SOFT-DECISION DECODING OF BLOCK AND PRODUCT CODES 277
symbol-by-symbol reliability information which is sufficientfor iterative decoding is proposed. Based on the results ofSection II, we formulate in Section III an iterative decodingalgorithm which only uses the set of minimum weight par-ity check vectors for the computation of symbol-by-symbolreliability information. In Section IV, the convergence of theiterative decoding is analyzed, and its interpretation as gradientoptimization is shown. Section V deals with the computationalcomplexity of our iterative decoding. We develop an efficientimplementation using the minimal trellis representation of theused parity check set, and compare it to optimum decoding.In Section VI, the application of our iterative decoding toproduct codes and parallel concatenated codes is treated.Section VII illustrates the performance achieved with theiterative decoding for several classes of block codes andproduct codes based on them. The performance compared tooptimum decoding is presented. Section VIII gives a briefconclusion.
II. BASIC CONCEPTS
A. Notations
Let denotea codeword of an linear binary block code and
a codeword of the corresponding dual codeThe support of binary vector is
Let be the set of minimum weight codewordsof the dual code with coordinate in their support, andlet We assume BPSK modulation of thecode symbols which maps a codeword into thecorresponding codeword accordingto A codeword is transmitted over achannel with AWGN. The received sequence is Theestimated codeword is denoted by andrespectively. The hard decision of an arbitrary real number
is obtained from the mapping
Let denote the single-sided noise-power spectral den-sity; then, together with the correspondinglog-likelihood ratio of the channel transition probability ofcoordinate is given as
(1)
Using Bayes’ rule, we obtain from (1) the correspondingaposteriori log-likelihood ratio
(2)
denotes thea priori log-likelihood ratio of Notethat the joint log-likelihood ratio is equal to theconditioned log-likelihood ratio since the term
can be canceled out. We assume that the transmittedsymbols are equally likely, and thus, As a result,
we obtain thea posterioriprobability of conditionedon as
(3)
Note that
B. Basic Principles of Symbol-by-Symbol Iterative Decoding
Symbol-by-symbol iterative decoding is based on algo-rithms using symbol-by-symbol soft-input information as wellas generating soft-output information on the decoded symbolswhich is fed back to the decoder input (or to the decoderinput of the next (first) stage in concatenated coding schemes).This enables a repeated (iterative) decoding of the samesequence. In the first iteration, the decoder only uses thechannel output (1) as input, and generates soft output foreach symbol. In subsequent iterations, the soft output can beutilized as input. Well-known algorithms providing symbol-by-symbol soft-output are, e.g., the one of Bahlet al. [14]or the less complex SOVA [16]. In our paper, the case isconsidered only where the additional information is indirect,which means that it is independent of the considered symbol.In the literature, e.g., [4], this indirect informationis calledextrinsic information, while the direct information is calledintrinsic information. The same terminology will be used in thesequel. The repeated decoding is finished if a stop criterion isfulfilled or a maximum number of iterations is exceeded. Thehard decision of the final iteration gives the decoding result.All in all, the general algorithmic structure of a symbol-by-symbol iterative decoding is assumed as follows.
(4)
Note that in (4), the entire sequence is updated in contrastto “turbo” decoding [1], where only information symbols areupdated.
Without going into details, error correction with such analgorithm is based on the following considerations: An errorin position yields an incorrect sign of In this case,
with an opposite sign can correct this error provided thatIf some additional iterations are
required until the sign of the erroneous position is switched oncondition that the sign of the extrinsic is correct also in these

278 IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS, VOL. 16, NO. 2, FEBRUARY 1998
iterations. If has a correct sign and has an incorrectsign, then the hard decision of will be correct as longas for some iterations does not change the sign of
Example 1 illustrates this principle.Example 1:Consider the (3, 2, 2) single parity check code.
Assume, that (0, 0, 0), respectively (1, 1, 1), wastransmitted, and let (0.6, 0.5, 0.8) be the receivedvector. Obviously, (0, 1, 0) is not a codeword.Now, let the extrinsic information in iterationbe computedas follows:
Hence, we obtain after the first iteration
We observe that position 2 is still incorrect, and has attenuatedthe positions 1 and 3. On the other hand, positions 1 and 3have “improved” position 2. After the next iteration, we obtain
Now, (0, 0, 0), i.e., the iterative decoding hascorrected the error in position 2, and has found the transmittedcodeword.
Consequently, the key point of symbol-by-symbol iterativedecoding is to find an algorithm that computes extrinsicinformation with acorrect sign.
C. Optimum Extrinsic Information forSymbol-by-Symbol Iterative Decoding
We restrict ourselves to the computation of extrinsic in-formation using codewords of the dual code.1 The optimumhard decision information on a certain coordinate, sayis given by its maximum a posteriori (MAP)probability. Itcan be computed either using all codewords of the codeor all codewords of the dual code The latter result wasfirst derived by Hartmann–Rudolph [20]. Hagenaueret al. [4]interpreted the MAP probability as an intrinsic part and anextrinsic part, namely
(5)
with
(6)
Clearly, this extrinsic information is optimum with respect toits sign. As noted above, this property is basically required
1The computation of extrinsic information using the codeC is treated, e.g.,in [4].
for the iterative decoding. However, since all codewords ofthe dual code are taken into account, (6) certainly appliesfor decoding high-rate codes only. Similarly, if the extrinsicinformation is computed using all codewords of it can beused for low-rate codes only. Thus, for a practical application,an approximation of (6) is required. A possible approximationis proposed in the following section using the minimum weightcodewords of the dual code.
D. Computation of Extrinsic Information UsingCodewords of the Dual Code
In order to illustrate the principle of computing extrinsicinformation using codewords of the dual code, we first describethe concept ofalgebraic replicasand its extension to softvalues according to Battailet al. [3]. Using an orthogonal setof codewords of the dual code, we get the results of Gallager[2] and Massey [21]. Their results can be applied only to thesmall class of codes with orthogonal parity check sets. We willextend the set of parity check vectors, and with this result, wecan decode a larger class of codes.
1) Algebraic Replicas and Extrinsic Information for Orthog-onal Parity Check Sets:Any codeword of the dual code permitsthe computation of algebraic replicas. An algebraic replica is alinear combination of code symbols generating a certain codesymbol. Let then for all we have
(7)
or, equivalently
(8)
where In the field we canrewrite (8) as
(9)
Assume that hard decisions are considered only, and that (9)is computed using in place of then the right-hand side can be interpreted as hard extrinsic information ofcoordinate with respect to the vector
The soft extrinsic information with respect towas derivedin [2] and [21] using the probability that incoordinates an even (odd) number of ’s are located.However, we get the same result from (6) by assuming thatthe dual code consists of two codewords, namely, the zerocodeword and the parity check vector
(10)
is a real number; its sign gives the hard decision in thefield and its absolute value corresponds to the reliabilityof the hard decision. The extension of (10) to a set of paritycheck vectorsorthogonalon coordinate is straightforward.

LUCAS et al.: SOFT-DECISION DECODING OF BLOCK AND PRODUCT CODES 279
Definition 1: A set of parity check vectors is calledorthogonal on the th coordinateif is an element of thesupport of each vector of the set, but no other coordinateappears more than once in the support of all vectors of the set.
The extrinsic information obtained from the different paritycheck vectors of an orthogonal set is statistically independent.This is why the extrinsic information based on an orthogonalparity check set is simply the sum of the log-likelihood ratio ofeach parity check vector according to (10). Hence, we obtain
(11)
Equation (11) was first derived by Gallager [2] and Massey[21], respectively. It is optimum with respect to the setbut in general, it does not give the MAP log-likelihood ratioof coordinate from (5). A relation between (11) and (6) isgiven by following theorem.
Theorem 1:The result of Gallager/Massey (11) and theresult of Hartmann/Rudolph (6) coincides only for repetitioncodes (RC) and single-parity check codes (SPC).
Proof: See Appendix A.In general, (11) can be regarded as an approximation of (6).
Unfortunately, an arbitrary set of parity check vectors intro-duces statistical dependencies. Therefore, the computation ofsoft extrinsic information is more difficult as for an orthogonalset. However, we will propose an approximation of (6) andgive some plausibility arguments for it.
E. Extrinsic Information Based on the Set ofMinimum Weight Parity Check Vectors
A proper approximation of the optimum extrinsic infor-mation on coordinate should have at least the followingproperty:
(12)
and, of course, it must reduce the computational complexityto realistic values, and should apply to various types of blockcodes. The extrinsic information (6) is optimum with respectto its sign. Thus, requirement (12) ensures that the additionof to coordinate improves this position whenever(6) does. The absolute value of the extrinsic informationis equivalent to the step width of a gradient optimizationalgorithm (see Section IV). Even in the optimization theory,it is in general not clear how to compute an optimum stepwidth, and thus, also not for iterative decoding. Nevertheless,the extrinsic information according to (6) at least provides anoptimum “search direction” for the first iteration.
Next, it will be shown that the extrinsic information obtainedfrom parity check sets depends on the following parameters.
• The Hamming weightof the parity check vectors and thecardinality of the set.
• The combinatorial propertiesof the parity check set.• The demodulation functionused for the channel output.
1) Hamming Weight and Cardinality of the Parity CheckSet: The sums in the numerator and the denominator of (6)can be split into two parts. Letand respectively. Then (6) can berewritten as
(13)
where
(14)
Note that there is the restriction in (13); other-wise, a logarithm domain error will occur. Up to now, no proofhas been known to us that this assumption holds in general.
From (14), we observe that has nodirect influence onposition since Furthermore, since
parity check vectors of low Hamming weighthave a larger contribution than vectors of large Hammingweight. Thus, we suggest to use only parity check vectorsof minimum weight and to neglect
2) Combinatorial Properties of the Parity Check Set:Both(6) and (11) were derived from threshold decoding rules, whichis the same as weighted majority-logic decoding and definedas follows. Let be a set of minimum weight parity checkvectors spanning the dual code.2 Now, let denote a subsetconsisting of parity check vectors with a one at coordinateThen a weighted majority-logic decision on coordinateisdefined as follows. If
(15)
then otherwise, Recall that the hard decisionof a real number is defined as
ifif
Decoding rule (15) coincides with Massey’sa posterioriprobability (APP) threshold decoding [21] if set consists ofparity check vectors orthogonal on coordinateandis computed according to (11). Furthermore, if andthe is computed from (6), then decoding rule (15) isidentical to the optimum threshold decoding rule of Hartmannand Rudolph [20].
Proposition 1: If weighted majority-logic decoding de-codes correctly, then the iterative decoding according to (4)will decode correctly in a single iteration.
2This is an important property because, otherwise, not only the codewordsof C fulfill the constraints according to (7), but also vectors which do notbelong toC:

280 IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS, VOL. 16, NO. 2, FEBRUARY 1998
Proof: See Appendix A.Proposition 1 can be interpreted as follows. It is well
known that the performance ofhard decision majority-logicdecodingdepends on the combinatorial properties of the paritycheck set.Weighted majority-logic decodingadditionally takesinto account the soft output of the channel. Nevertheless,the combinatorial properties of the parity check set are stillof the same importance for the decoding performance. Inparticular, from decoding rule (15), it is observed that errorcorrection with weighted majority-logic decoding presupposesthe computation of extrinsic information with the correctsign, just as required for symbol-by-symbol iterative decoding.Thus, the decoding performance of symbol-by-symbol iterativedecoding depends also on the combinatorial properties of theused parity check set. Consequently, it is concluded fromProposition 1 that the better a parity check set is suited forweighted majority-logic decoding, the better it is suited forsymbol-by-symbol iterative decoding. Well-known sets forweighted majority-logic decoding are those with orthogonalparity check vectors [21], or parity check vectors forming a-design [22]. In general, these sets consists ofminimum weight
codewords of the dual code. Moreover, in [23], it is pointedout that theaverageerror-correction capability of majority-logic decoding based on the minimum weight codewords ofthe dual code can exceed the half minimum distance of thecode. In addition, error correction beyond the half minimumdistance can be achieved, although the minimum weight paritychecks may be neither orthogonal nor form a-design. Asa result, in [23], it is shown that majority-logic decodingbased on the minimum weight parity checks applies not onlyto the well-known majority-logic decodable codes, like finitegeometry codes or Reed–Muller codes, but also to BCH codesand quadratic residue codes. All in all, it is concluded that theextrinsic information computed from a set of minimum weightparity checks, that are suited for majority-logic decoding, hasa correct sign with a high probability, and applies to varioustypes of block codes.
3) Demodulation Functions:Rudolphet al. derived in [17]a weighted majority-logic decoding algorithm that uses thesin( ) function for demodulation of the received symbols. Theyproved for this demodulation function that weighted majority-logic decoding based on orthogonal parity check sets correctsany error provided it is within the half minimum Euclideandistance of the code. In our simulations, the sin( ) functionshowed a better performance in the first iteration compared tothe tanh( ) function.3 However, the performance achieved afterseveral iterations was best when using the tanh( ) function. Thedifference between these two demodulation functions is thatthey generate different absolute values of extrinsic informationfor the same received sequence. In principle, any function ofthe following type may be used for iterative decoding:
ifif
(16)
If we regard the iterative decoding as gradient optimization(what will be shown in Section IV), the use of differentdemodulation functions leads to a different step width for the
3For the tanh( ) function, it can be shown that the correction of all errorswithin the half minimum Euclidean distance is not guaranteed.
TABLE IPERCENTAGE OFCASES WHERE sign(Em(Bm)) = sign(Em(C?))
FOR DIFFERENT TYPES OF CODES
gradient optimization. Due to the different step width, it isclear that the decoding results can be different for the samereceived sequence. It has not been possible to prove whichdemodulation function is optimum for a given parity checkset. However, in our simulations, we obtained the best resultswhen using the tanh( ) function [24].
4) Approximation of the Optimum Extrinsic Information:We will approximate the exact extrinsic information by thefollowing choices of the check set, the demodulation function,and the formula for computation. As parity check set, wechoose the set of minimum weight codewords of the dualcode As demodulation function, we use the tanh( )function, and as a computation formula, we use
(17)
If the set is suited for majority-logic decoding, we statethat this is an approximation which satisfies the requirement(12). To justify our statement, we determined the percentageof cases in which the sign of the above approximation is equalto the sign of the optimum extrinsic information. In Table I,the results for the (15, 7, 5) BCH code, the (31, 21, 5) BCHcode, the (21, 11, 6) difference set cyclic (DSC) code, and the(28, 14, 8) double circulant (DC) code are shown. Note thatfor the (15, 7) BCH code as well as for the (21, 11) DSC code,the set is orthogonal. The minimum weight parity checksof the (31, 21) BCH code form a 2-(31, 12, 44) design, andthose of the (28, 14) DC code form a 1-(28, 8, 156) design.
From Table I, it is observed that at an dB,the percentage of cases in which the sign of approximationis equal to the sign of the optimum extrinsic information isgreater than 71%. At an 4 dB, this number is greaterthan 97%. This corroborates the assumption that (17) satisfiesthe requirement (12), in particular for higher signal-to-noiseratios. Unfortunately, it is not possible to verify the statementfor longer codes because of the computational complexity ofthe optimum extrinsic information. Nevertheless, it is supposedthat it holds for many classes of codes.
The computation formula can be derived from (11) by usingthe following approximations.
• We use (11) even so the parity check vectors are notorthogonal.
• The term is neglected.• Since tanh we can use the approximation ln
Remark: If necessary, we must extend the set of minimumweight parity check vectors by parity check vectors of higherweight in order to span the dual code.

LUCAS et al.: SOFT-DECISION DECODING OF BLOCK AND PRODUCT CODES 281
III. A N ITERATIVE DECODING ALGORITHM (IDA)
Applying (17) to the iterative decoding concept presented inSection II-B yields the following symbol-by-symbol iterativedecoding algorithm.
- -
(18)
(19)
Remark 1:Because of the statistical dependencies withinthe a posteriori values obtained after the first iteration, therepeated decoding is only heuristically motivated even if theoptimum extrinsic information is used. The unsolved problemstill is which extrinsic information is optimum after the firstiteration.
Remark 2: In contrast to Battailet al. [3] and Gallager [2],we propose to use (11) not only for orthogonal parity checksets, but also for nonorthogonal ones.
Remark 3: In our simulations, we found that the iterativedecoding with IDA yields the same performance as using theMAP decision (5, 6) for the codes in Table I, although theresulting signs of both methods are not identical in any case[24] .
Remark 4:The parity check set can berepresented in a minimal trellis that allows an efficient im-plementation of IDA. Such a minimal trellis can be obtainedfrom the corresponding trivial trellis by merging the mergeablevertices of the trivial one. This is treated in Section V in detail.
Remark 5:As already mentioned, IDA is especially suitedfor decoding codes which are majority-logic decodable, e.g.,codes having orthogonal parity check sets or sets buildinga -design [22]. In addition, in [23], it is pointed out thatmajority-logic decoding is not restricted to parity check setsof such type. In the latter case, in fact, no minimum error-correcting radius can be guaranteed, but theaveragenumberof correctable errors can even exceed As an example, theDC code (42, 21) is mentioned.
Remark 6:A parity check set for majority-logic decodinggenerally consists of vectors of minimum weight. However,
in many cases, it is far from being trivial to find these vectorsgiven an arbitrary code. Therefore, we regard the computationof the minimum weight parity check set as a separate researchproblem which is beyond the scope of this paper. Nevertheless,we want to touch on this problem in Section VII, where thesimulation results for different classes of block codes arepresented.
Next, we show that the iterative decoding can be stoppedif a codeword is reached.
Theorem 2:Let be the hard decision of the vectorin iteration Then for all subsequent iterations , the
hard decision of is alsoProof: See Appendix A.
In the next section, we illustrate that IDA provides asuboptimum sequence estimation.
IV. I NTERPRETATION OFITERATIVE
DECODING AS GRADIENT OPTIMIZATION
Given a sequence and a parity check vector theweighted syndrome isThen thegeneralized syndrome weightis defined as follows.
Definition 2: Given the set of parity check vectors ofminimum weight and given that spans the entire dual code.Then, for a sequence the generalized syndrome weight
is defined as
(20)
The relation to IDA becomes obvious by computing thegradient of which is
(21)
(22)
Applying (18) to (21) yields
The partial derivative of coincides with the extrin-sic information used in IDA except for The factorcan be interpreted asstep widthof the gradient optimization.The quality of a gradient optimization depends in particularon a proper computation of the step width and the searchdirection In classical optimizationtheory, line optimizationis a method for calculating an ap-propriate step width, and algorithms likeconjugate gradientmethodsor variable metric methodsare used to determine thesearch direction (see, e.g., [25]). Although these methods areonly optimum for quadratic functions, they are known to givegood results for some nonquadratic ones also. Unfortunately,the application of these methods to IDA yields unsatisfactoryresults [24]. Thus, the computation of a proper step width isstill an open problem. In particular, if the weight of the paritycheck vectors is large and the cardinality of set is small,

282 IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS, VOL. 16, NO. 2, FEBRUARY 1998
it is clear from (18) that the absolute value of is alsosmall. As a result, a large number of iterations is necessaryfor decoding. For some codes, the consideration of theterm during the initialization of IDA remedies this problem.Nevertheless, a proper weighting for the extrinsic informationwhich is generally valid was not found.
Now, the convergence of IDA is investigated. Therefore,consider the following proposition.
Proposition 2: All terms in (20) are positive if andonly if
Proof: See Appendix A.From Proposition 2, it is a reasonable assumption that the
codewords are the maximum points of Consequently, theiteration process will converge to codewords. A tempting con-jecture is that IDA will reach maximum likelihood decoding ifa sufficient number of iterations is performed. This is not truein general, even if the optimum extrinsic information is used.
Theorem 3:Iterative maximuma posterioridecoding is notsoft-decision maximum likelihood decoding in general.
Proof: A counterexample is given in Appendix A.For a given a sequence it was not possible to show to
which codeword the iteration process converges. Moreover,we can describe some points such that, for all coordinates,
, although no codeword wasreached. Let
(23)
and denoteProposition 3: Given a sequence such that
Consequently, In addition, if for all coordinates
(24)
then , although nocodeword was reached.
Proof: A proof is given in Appendix A.Simulations showed that if Proposition 3 is fulfilled for a
sequence then the hard decision of subsequent iterationseither oscillates between noncodewords or stays the same.Fortunately, we found in our simulations that such pointsdo not influence the simulation result significantly since theirprobability of appearance is very small, e.g., for the (31, 21)BCH code, it was less than at dB. In allother cases, the iterative decoding converges to codewords. Weconclude thatIDA provides a suboptimum sequence estimation.In addition, we want to emphasize that this result is contrary to“turbo” decoding, where generally no codewords are reachedsince only the information symbols are updated.
A. Further Results on the Influence of theStructure of the Parity Check Set
The computation of the generalized syndrome weightcanbe decomposed as follows. Assume then the com-putation of the weighted syndromes can be regardedas a nonlinear operator which maps the vector spaceinto i.e.,
Summing up these weighted syndromes, we have a linearfunction that maps into Clearly, the operatorand with it the structure of set determines the properties of
However, is a nonlinear operator, and thus, its completeanalysis is very complicated. For iterative decoding of the (3,1, 3) repetition code using codewords of the (3, 2, 2) single-parity check code, however, we can compute the importanceof the structure of exactly that allows us to draw qualitativeconclusions to other cases.
Denote andFurthermore, the following parity check set is con-
sidered:
In this special case, is a symmetric matrix with realeigenvalues and orthogonal eigenspaces, and the generalizedsyndrome weight can be expressed in terms of a quadraticform, namely
The eigenvalues of are and Theeigenvector corresponding to eigenvalue is
Since eigenvalue has order 2, thecorresponding eigenspace is a plane, namely,Eigenvector is orthogonal to this plane. From the theory ofmatrices, it is known that a quadratic form takes its maximumvalue along that eigenvector that has the largest eigenvalue.Therefore, the maximum values of belong to andare found as and whichcorrespond to the codewords of the (3, 1, 3) repetition code.The eigenspace coincides with the borderof the decision region for SDML decoding of the (3, 1, 3)repetition code. The points wheretakes its minimum valuesbelong to this eigenspace. Therefore, the iterative decodinggives SDML decoding for any received point. The resultinggradient field is shown in Fig. 1. Since our aim is to decreasethe computational complexity, we use now the reduced paritycheck set
for computing Analyzing this case shows that againthe codewords of the repetition code coincide with the max-imum points of However, we have a displaced border ofthe decision region that is given by Asa result, a suboptimum decoding is obtained since the thirdcoordinate has a larger influence than the other ones. This canbe interpreted as a kind of unequal error protection that is notdesirable in our case. The resulting gradient field is shown inFig. 2.
It is not possible to give an exact analysis of IDA withrespect to the used set in general. The above example,however, shows that the parity check set defines the decisionregions for the iterative decoding. Dependent on this set, theydo more or less coincide with the optimum decision regions,but we have no criterion that describes the quality of thisapproximation. Nevertheless, we conclude that the influence

LUCAS et al.: SOFT-DECISION DECODING OF BLOCK AND PRODUCT CODES 283
Fig. 1. Gradient plot with optimum decision regions.
Fig. 2. Gradient plot with nonoptimum decision regions.
of each coordinate for iterative decoding should be the same.This again shows that-designs are well suited for iterativedecoding.
V. COMPUTATIONAL COMPELXITY OF IDA
The estimation of the computational complexity of a decod-ing algorithm depends on its implementation. In the following,we assume that IDA will be implemented on a digital signalprocessor. We estimate the decoding complexity by the numberof floating-point additions and floating-point multiplications,and neglect binary operations.
A. Computational Complexity of the“Straightforward” Implementation
To determine the number of floating-point operations forIDA, we assume that the tanh( ) function is stored in a lookuptable so that it does not require supplementary computations.To compute the extrinsic information on coordinateaccord-ing to (18), multiplications have to be executedfor each of the parity check vectors. In addition, theseextrinsic information values have to be summed up. Accordingto (19), this sum is added to the received value. These stepshave to be repeated for each coordinate. Thus, we obtain forthe number of multiplications and the number of additions
respectively,
B. A Trellis-Based Implementation
A computationally more efficient implementation of IDAis based on a minimal trellis which represents the used paritycheck set. An algorithm for the construction of such a minimaltrellis is proposed. Before arriving at that, we introduce somedefinitions and properties of trellis diagrams for block codes.We closely follow the terminology of [26] and [27].
1) Construction of the Minimal Trellis for the Parity CheckSet : A trellis is an edge-labeled digraph.denotes the set of vertices, the label alphabet, and the setof edges. An edge is an ordered triplet withand The set of vertices is partitioned intodisjoint subsets such that every edge beginningat vertex terminates at a vertex The index
denotes thedepth in The subsets eachconsist of a single vertex called theroot and thetoor byMassey [28]. Consequently, the set of edgesis partitionedinto disjoint subsets where is the set of edgesterminating in An edge is said to haveinitialvertex final vertex and labelFurthermore, the edge is said to beincident fromvertexandincident tovertex The set of edges incident to a vertex
is denoted and the set of edges incident from avertex is denoted A path from the root to thetoor in a sequence of edges definingan tuple overIn the case considered here, such antuple is a vector ofthe set of minimum weight parity check vectors over thealphabet We assume that different paths fromthe root to the toor define different parity check vectors, andthat any path in defines a vector Furthermore, thetrellis is assumed to bereduced[29], i.e., each vertex in thetrellis lies on at least one path fromto Thus, the trellis
represents the setDefinition 3 [30]: A trellis for the set of length
is minimal if it satisfies the following property: for everythe number of vertices in at depth is
less than or equal to the number of vertices at depthin anyother trellis for
Before proposing an algorithm for the construction of theminimal trellis, we have to introduce some definitions. Fora fixed let us split a vector into itshead and its tail Then,according to [27], we define at the depththe tail setas the set of all vectors with the same head
for a fixed (25)
Similarly, thehead set is defined as the set of all vectorswith the same tail
for a fixed (26)
Definition 4 [27]: A set is calledseparableif for everythere is a partition of
such that the following statement holds. Given

284 IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS, VOL. 16, NO. 2, FEBRUARY 1998
(27)
Note that in [29] codes which fulfill the above definition arecalled rectangular. Both terms are synonymous.
The following theorem is proved in [29].Theorem 4: A subset of a separable (rectangular) code4
consisting of all codewords of same Hamming weight isseparable.
As a result, the set of minimum weight parity checkvectors is separable. In [26], [27], it is shown that for separablecodes, the minimal trellis exists and is unique, up toisomorphism.
Definition 5 [27]: Vertices are said to beleftrelativesif they are connected with a vertex by edgeslabeled with the same symbol. Similarly, verticesare said to beright relativesif they are connected with a vertex
by edges labeled with the same symbol.Now, let be an arbitrary trellis representing the setMerging AlgorithmStep F: For merge all left relatives inStep B: For merge all right relatives inTheorem 5: Algorithm generates the minimal trellis
representingProof: See Appendix A.
The expansion index of a trellis is[31]. Then another important property of separable
codes is formulated in the following theorem.Theorem 6 [26], [27]: Let be the minimal
trellis for a separable set, and let be anyother trellis for Then
From Theorem 6, we see that the expansion index is minimumfor a minimal trellis. In the next section, we show that the
is one of two terms describing the computationalcomplexity of IDA, and this is why we obtain a compu-tationally efficient implementation of IDA using a minimaltrellis.
2) Forward–Backward Algorithm:IDA can be imple-mented on a trellis using a forward–backward algorithmsimilar to the one of Bahlet al. [14]. Therefore, we introducean additional labeling for each edge
namely
ifif
Now, for define
(28)
(29)
whereThe values of are computed in a forward recursion
from depth to and the values of are4Note that any binary linear code is separable, e.g., [27].
computed in a backward recursion from depth torespectively. Furthermore, let such that
and let Now theextrinsic information required for IDA is readily computed.We obtain for
(30)
3) Computational Complexity of the Minimal Trellis Imple-mentation: Let the trellis represent a parity check setLet denote the total number of vertices in and let
denote the total number of edges in respectively. Thenumber of expansions in is Since at theroot respectively at the toor no floating-point operationis performed, the total number of floating-point additions ofa forward recursion respectively a backward recursion
is
(31)
Let us denote the total number of edges with labelby Since a floating-point multiplication is only
carried out at edges with label the total numberof floating-point multiplications of a forward recursionrespectively of a backward recursion is
(32)
For computing the extrinsic information on coordinateaccording to (30), we have to take into accountsupplementary additions and supplementary multi-plications. At last, the extrinsic information is added to theintrinsic information which requires a further addition. Allin all, the total number of floating-point multiplications andadditions for a single iteration of IDA is
(33)
(34)
From Theorem 6, we observe that for a minimal trellis, theterm in (33) is minimal. A tempting conjecture is that
and respectively, are also minimal for a minimaltrellis, but up to now, we have no proof for this.
Note that the computation of the optimum extrinsic informa-tion according to (13) on a trellis representing the dual codeis given as
The above formula coincides with the one proposed by Bahlet al. [14], except that it is independent of theth coordinate.

LUCAS et al.: SOFT-DECISION DECODING OF BLOCK AND PRODUCT CODES 285
TABLE IICOMPUTATIONAL COMPLEXITY: “STRAIGHTFORWARD” I MPLEMENTATION
IN COMPARISON WITH MINIMAL TRELLIS IMPLEMENTATION
4) Influence of the Coordinate Ordering on the Computa-tional Complexity: It is well known that codes obtained bypermuting the coordinates of a linear binary block code areequivalent. However, the corresponding minimal trellises ingeneral yield a different vertex complexity, as shown, forinstance, in [32] and [33]. In particular, the vertex complexityof the minimal trellis for a cyclic or its extended code isworst among all equivalent codes [34]. Moreover, in [35], itis proved that the problem of finding a coordinate permutationthat minimizes the number of vertices at a given depth in theminimal trellis is NP complete. An exception are Reed–Mullercodes in standard-bit representation. In [33], the standard-bitrepresentation of Reed–Muller codes is proved to be optimumwith respect to the vertex complexity. For other types of codes,heuristic algorithms to find an efficient coordinate ordering areproposed, e.g., in [36] and [37].
In general, an optimum permutation of the coordinates of alinear binary block code also decreases the vertex complexityof the corresponding trellis for minimum weight parity checkset However, we have to pay attention to the followingtheorem.
Theorem 7:A permutation of the coordinates of a linearbinary block code that yields minimum vertex complexity doesnot, in general, give minimum vertex complexity for a subcodeof constant weight.
Proof: A counterexample is shown in the Appendix.On the other hand, we have the conjecture that for
Reed–Muller codes in standard-bit representation, the vertexcomplexity of a constant weight subcode is also minimum.Furthermore, there are some BCH codes which contain RMcodes as a large subcode. This fact is used in [34] to find an
efficient coordinate ordering for a trellis representing such aBCH code, and consequently, this also leads to an efficientcoordinate ordering for the minimum weight codewords ofsuch a BCH code.
For other types of codes, we applied a slightly modifiedversion of the heuristic algorithm proposed in [37] to find anefficient coordinate ordering for the minimum weight subcodes[24].
C. Comparison of the Computational Complexityof the Trellis-Based Implementation with theStraightforward Implementation
In Table II, the computational complexity in terms ofthe number of floating-point operations per iteration forthe straightforward implementation is compared to theimplentation on a minimal trellis (as well for the cyclicrepresentation as for the best ordering found by the heuristicalgorithm).
We used the abbreviation QR for quadratic residue codes,DC for double circulant codes, RM for Reed–Muller, DSC fordifference-set cyclic codes, and EG for Euclidean geometrycodes. In Section VII, short descriptions of DC codes, DSCcodes, and EG codes are given. As we can see from Table II,the trellis implementation gains a factor in operationscompared to the direct one (for the (63, 37) EG code) upto a factor 32.6 (for the (64, 42) RM code). The large gainobtained for RM codes corroborates the conjecture that thetrellis complexity for constant weight subcodes of RM codesin standard bit representation is minimal.
D. Comparison of the Computational Complexity of IDAwith SDML Decoding on the Syndrome Trellis
1) Preliminary Remarks:Any block code can be SDMLdecoded by Viterbi decoding in the syndrome trellis [38]. Thedecoding complexity in terms of floating-point operations forconventional Viterbi decoding is [26], [27].For the computation of given a generator matrix,refer to [32]. As noted earlier, the vertex complexity of theminimal trellis depends on the coordinate ordering. In thefollowing, the best ordering known to the authors is taken intoaccount for the calculation of the Viterbi decoding complexity.However, for some codes listed in Table III, it was too timeconsuming to use the heuristic algorithm given in [37] to findan efficient coordinate ordering. In such cases, an arbitrarynoncyclic representation is chosen to avoid the cyclic coderepresentation.
In Table III, the computational complexity of IDA is com-pared to Viterbi decoding. Clearly, the number of iterationsused for IDA gives a degree of freedom that balances thecomputational complexity and the performance. We havechosen the maximum number of iterationsin IDA suchthat subsequent iterations did not change the simulation resultssignificantly. Since the number of iterations needed for decod-ing decreases with increasing signal-to-noise-ratio, an upperbound on the floating-point operations istimes the numberof operations per single iteration. This upper bound for thenumber of operations needed for decoding is listed in Table III.

286 IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS, VOL. 16, NO. 2, FEBRUARY 1998
TABLE IIICOMPUTATIONAL COMPLEXITY: IDA IN COMPARISON WITH SDML
The advantages of IDA in terms of computational complex-ity compared to SDML decoding using the syndrome trellisare big for codes of medium rate and large length, e.g., SDMLdecoding of the QR codes, the DSC codes, and the EG codeslisted in Table III is not practicable, whereas the iterativedecoding is possible, and as we will illustrate in Section VII,it is close to SDML decoding. Note that for all codes listed inTable III, the computational complexity of MAP decoding islarger than for SDML decoding [24].
VI. DECODING OF PRODUCT CODES WITH IDA
Since the computational complexity with IDA is low formany block codes, we can apply it for the decoding of productcodes based on powerful codes. This allows the constructionof fairly long codes that can be decoded with moderatecomplexity.
Let and be, respectively, andlinear binary block codes. It is assumed that the informationsymbols are the first symbols of and the first symbolsof
Definition 6: The direct product is anproduct code whose codewords
consist of all arrays constructed by encodinginformation symbols with and the resultingsymbols with (see Fig. 3).
We can also construct a parallel concatenated (“turbo”)code based on systematic block codes by neglecting theredundancy part arising from both codes (see Fig. 4).
The major advantage of a parallel concatenated code is again in code rate. If we assume identical component codes,this gain in decibels is given by( denotes the code rate), and is plotted in Fig. 5.
Fig. 3. Construction of a product code.
Fig. 4. Construction of a parallel concatenated code.
Fig. 5. Code rate gain of a parallel concatenated code.
We observe that the higher the code rate of the componentcode, the less is the gain in code rate for the parallel con-catenated code, as expected. The major disadvantage of theparallel concatenated code is the loss in minimum distance. Itis only compared to for the product code.
For simplicity, we assume in the following that identicalcomponent codes are used. Then, it is possible to decode aproduct code like a nonconcatenated block code sincethe set of minimum weight parity check vectors ofas well as of can be readily determined. These setscan be constructed by either setting a single row or columnin Figs. 3 and 4 to a minimum weight parity check vectorof the component code and filling the remaining coordinateswith zeros. If is the number of minimum weightcodewords of the component code, then the number ofminimum weight codewords of the dual of the product code is
(35)
Accordingly, the number of minimum weight codewordsof the dual of the parallel concatenated code is
(36)
The decoding of ( ) can now be performed such as fora nonconcatenated code. However, in general, it is not clearif the combinatorial properties of ( ) are suited for

LUCAS et al.: SOFT-DECISION DECODING OF BLOCK AND PRODUCT CODES 287
decoding with IDA, even though the combinatorial propertiesof the component codes are well suited for IDA. In that respect,it is shown in [39] that the product of two one-step majority-logic decodable cyclic codes is also one-step majority-logicdecodable. However, simulations showed that the decodingvia the set ( ) achieves worse performance comparedto the alternant decoding of the component codes describedbelow [24].
The decoding of ( ) via the component codes isperformed in two variants as follows. Let the received wordbe represented in an matrix. Furthermore, let us denotethe first component code according to Fig. 3 as horizontalcode and the second component code as vertical code
Both component codes are again assumed to be identical.The extrinsic information obtained from thevertical codes,respectively horizontal codes, are the matrices
...
The soft output computed during the iteration process isrepresented by the matrix
Decoding Variant (a):
Initialization:Set iteration counter and definethe maximum number of iterations
( ) if and(i) For the vertical codes, for
— compute by means of asingle iteration with IDA
— update(ii) For the horizontal codes, for
— compute by means of asingle iterations with IDA
— update(iii) goto ( ).
stop.
In [40], a slightly different decoding is proposed as follows.Decoding Variant (b):• The first iteration is performed according to variant (a).• For subsequent iterations, the algorithmic structure of
variant (a) is retained. However, the decoding result of thefirst iteration is saved, and in subsequent iterations, theextrinsic information is always added to Thus, the updaterule of steps (i) and (ii), respectively, becomes
• For the computation of the extrinsic information of itera-tion the “refined” values are still used.
Note that the entire matrix is updated contrary to [4],where the update is performed on information symbols only.
VII. SIMULATION RESULTS
In this section, we present the simulation results for differentcodes classes obtained with IDA. For some codes consid-ered in the sequel, it is not possible to simulate the SDMLperformance because of the decoding complexity. For thisreason, we determined a lower bound on the SDML blockerror probability (called SDML in the sequel) as follows.
• The zero codeword, respectively the-sequence, is trans-mitted.
• The received sequence is decoded with IDA. Thisyields the vector
• SDML now decides as follows: Given that— estimated codeword—
estimated codeword:
estimated codeword
— If (decoding failure): estimated code-word:
An SDML decoder cannot be better than this bound, andfor an SDML decoder, the bound would coincide. From thebound on the block error rate, the bit-error rate is estimated by
In the figures representing the simulationresults, we refer to as “approximation of the optimumbit error probability.” Note that the application of this boundrequires a considerably low probability for a decoding failure.For a low signal-to-noise ratio, this cannot be guaranteed for allcodes investigated in the following. In these cases, we comparethe performance to good convolutional codes of the same rate.
A. Finite Geometry Codes
The class of finite geometry codes is not as well knownas, e.g., BCH codes. Therefore, we give a short descriptionof these codes before presenting the simulation results. Werestrict ourselves to Euclidean geometry codes and projectivegeometry codes. The exact definition of the Euclidean geom-etry EG and of the projective geometry PG isgiven in Appendix B.
1) Euclidean Geometry Codes:Definition 7 [41]: A th-order binary Euclidean geom-
etry (EG) code of length is the largest cyclic codewhose null space contains the incidence vectors of allflats of the Euclidean geometry EG that do not passthrough the origin.
Note that a subspace of EG is called flat. FromDefinition 7, we know that the dual code of the th-orderEG code contains the incidence vectors of all flatsthat do not pass through the origin. This fact can be used forcomputing parity check vectors for majority-logic decoding(see Appendix B). As a result, it can be shown that a th-order EG code is -step majority-logic decodable [41].In particular, we obtain for a one-step majority-logicdecodable cyclic code. Table IV compares the parameters ofsome th-order EG codes with BCH codes.
The parameters of EG codes get worse compared to BCHcodes with increasing length.

288 IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS, VOL. 16, NO. 2, FEBRUARY 1998
TABLE IVEG CODES COMPARED TO BCH CODES
(255, 175, 17) EG Code:Fig. 6 depicts the simulationsresult for the (255, 175) EG code. We observe that at a bit-errorprobability of , the performance of IDA is 2.1 dB superiorto majority-logic decoding. Furthermore, the performance iscompared with the rate-2/3 convolutional code obtained frompuncturing the rate-1/2 convolutional code with generators
and constraint length [42].The computational complexity for Viterbi decoding of thisconvolutional codes is approximately the same compared tothe iterative decoding of this block code [24]. We observe thatthe iterative decoding of the (255, 175) EG code is slightlybetter at low At a bit-error probability of it is0.3 dB superior to the convolutional code. Note that this EGcode has approximately as good parameters as the (255, 191,17) BCH code, but for the latter one, there exists no soft-decision decoding algorithm of comparable complexity givingthe same performance.
(1023, 781, 33) EG Code:For the decoding of the (1023,781) EG code, we took into account the term according to(1) during the initialization of IDA. This was necessary sincethe cardinality of the set is small and the weight of theparity check vectors is comparatively large, so that IDA needsan unacceptable number of iterations without the term.The simulation result provided in Fig. 7 shows that at a bit-error rate of the performance of IDA is 1.6 dB superiorto majority-logic decoding. Moreover, the performance of IDAis compared to the rate-3/4 punctured convolutional code withgenerators and constraint length[42]. The computational complexity for Viterbi decoding ofthis convolutional code is 20% less compared to the iterativedecoding of the block code [24]. For low signal-to-noiseratios, the performance of the iterative decoding of the (1023,781) EG is superior to the convolutional code, whereas thelatter one has its advantages at medium signal-to-noise ratios.However, at an 4 dB, the performance achieved forthe block code becomes considerably better compared to theconvolutional code. Note that this EG code has approximatelyas good parameters as the (1023, 863) BCH code, but for thelatter one, there exists no soft-decision decoding algorithm ofcomparable complexity giving the same performance.
2) Reed–Muller Codes:Reed–Muller (RM) codes can beregarded as subcodes of Euclidean geometry codes since a
th-order EG code is ath-order Reed–Muller code. As aresult, an RM code is -step majority-logic decodable.The codewords of minimum weight are exactly given by the
flats in EG(64, 22, 16) Reed–Muller Code:The set of the minimum
weight parity check vectors forms a 3-(64, 8, 15) design.Majority-logic decoding based on this set can correct up to fiveerrors, while bounded minimum distance decoding can correct
Fig. 6. Iterative decoding of (255, 175) EG code.
Fig. 7. Iterative decoding of (1023, 781) EG code.
up to seven errors. Fig. 8 provides the simulation results for the(64, 22) RM code. At a block-error rate of 10 the decodingperformance of IDA is 0.1 dB inferior to SDML andthe union bound, respectively. Qualitatively, the same holdsfor the bit-error rate. The computational complexity for theiterative decoding is a factor 3.6 less than SDML decoding inthe syndrome trellis.
(64, 42, 8) Reed–Muller Code:The set of the minimumweight parity check vectors forms a 3-(64, 16, 35) design.Using this set, majority-logic decoding can correct two errors,while bounded minimum distance decoding can correct threeerrors. Fig. 9 shows the simulation results for the (64, 42) RMcode. At a block-error rate of the performance of IDA is0.1 dB inferior to SDML and the union bound is reached.The computational complexity for the iterative decoding is afactor 9.7 less than SDML decoding in the syndrome trellis.
Further simulation results for Reed–Muller codes can befound in [24].
3) Projective Geometry Codes:Definition 8 [41]: A th-order projective geometry
(PG) code of length is definedas the largest subcode whose null space contains the incidentvectors of all flats in PG
Similar to EG codes, the dual code of the th-orderPG code contains the incidence vectors of allflats. Again,

LUCAS et al.: SOFT-DECISION DECODING OF BLOCK AND PRODUCT CODES 289
Fig. 8. Iterative decoding of (64, 22) RM code.
Fig. 9. Iterative decoding of (64, 42) RM code.
TABLE VDSC CODES COMPARED TO BCH CODES
this fact can be used for computing parity check vectors formajority-logic decoding (see Appendix B). As a result, it canbe shown the th-order PG code is -step majority-logicdecodable [41]. In particular, for , we obtain a one-step majority-logic decodable code, and for a (1, 1)PG code becomes adifference-set cyclic (DSC)code. Table Vcompares the parameters of some DSC codes with shortenedBCH codes.
(273, 191, 18) DSC Code:Fig. 10 depicts the performanceof the (273, 191) DSC code compared to Viterbi decoding ofthe rate-2/3 convolutional code with generators
and constraint length The computational com-plexity is approximately the same for both codes [24]. Theperformance achieved for the (273, 191) DSC code comparedto the convolutional code is slightly better at low At abit-error rate of 10 it is 0.5 dB superior to the convolutionalcode. Moreover, at the same bit-error rate, the performance ofIDA is 2.1 dB superior to majority-logic decoding. Note thatthis DSC code has as good parameters as the shortened (273,
Fig. 10. Iterative decoding of (273, 191) DSC code.
Fig. 11. Iterative decoding of (1 057 813) DSC code.
201) BCH code, but for the latter one, there exists no soft-decision decoding algorithm of comparable complexity givingthe same performance.
(1057, 813, 33) DSC Code:For the decoding of the (1057,813) DSC code (Fig. 11), the term according to (1) wastaken into account during the initialization of IDA for the samereasoning as for the (1023, 781) EG code. The performance iscompared with the rate-3/4 punctured convolutional code withgenerators and constraint lengthThe number of floating-point operations required for decodingis 20% less for the convolutional code [24]. For low signal-to-noise ratios, the performance of the (1057, 813) DSC codeis superior to the convolutional code, whereas the latter oneis slightly better at medium signal-to-noise ratios. However,at an 3.5 dB, the performance of the block code isbetter compared to the convolutional code. Moreover, at a bit-error rate of 10 the performance of IDA is 1.8 dB superiorto majority-logic decoding.
B. BCH Codes
For BCH codes, it is more difficult to construct the setof minimum weight codewords than finite geometry codes.However, an algorithm for the construction of minimumweight codewords was proposed recently by Moorthyet al.[43]. It is based on purging the full code trellis to obtain a low-
290 IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS, VOL. 16, NO. 2, FEBRUARY 1998
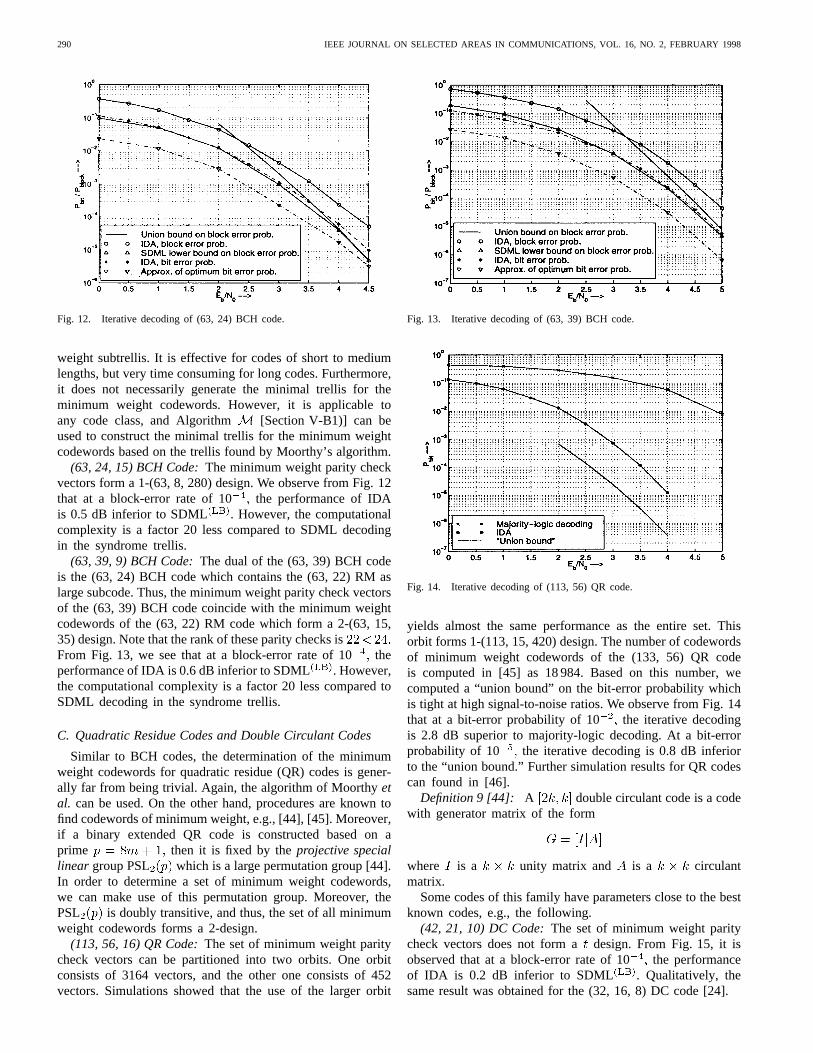
Fig. 12. Iterative decoding of (63, 24) BCH code.
weight subtrellis. It is effective for codes of short to mediumlengths, but very time consuming for long codes. Furthermore,it does not necessarily generate the minimal trellis for theminimum weight codewords. However, it is applicable toany code class, and Algorithm [Section V-B1)] can beused to construct the minimal trellis for the minimum weightcodewords based on the trellis found by Moorthy’s algorithm.
(63, 24, 15) BCH Code:The minimum weight parity checkvectors form a 1-(63, 8, 280) design. We observe from Fig. 12that at a block-error rate of 10 the performance of IDAis 0.5 dB inferior to SDML . However, the computationalcomplexity is a factor 20 less compared to SDML decodingin the syndrome trellis.
(63, 39, 9) BCH Code:The dual of the (63, 39) BCH codeis the (63, 24) BCH code which contains the (63, 22) RM aslarge subcode. Thus, the minimum weight parity check vectorsof the (63, 39) BCH code coincide with the minimum weightcodewords of the (63, 22) RM code which form a 2-(63, 15,35) design. Note that the rank of these parity checks isFrom Fig. 13, we see that at a block-error rate of 10theperformance of IDA is 0.6 dB inferior to SDML . However,the computational complexity is a factor 20 less compared toSDML decoding in the syndrome trellis.
C. Quadratic Residue Codes and Double Circulant Codes
Similar to BCH codes, the determination of the minimumweight codewords for quadratic residue (QR) codes is gener-ally far from being trivial. Again, the algorithm of Moorthyetal. can be used. On the other hand, procedures are known tofind codewords of minimum weight, e.g., [44], [45]. Moreover,if a binary extended QR code is constructed based on aprime then it is fixed by theprojective speciallinear group PSL which is a large permutation group [44].In order to determine a set of minimum weight codewords,we can make use of this permutation group. Moreover, thePSL is doubly transitive, and thus, the set of all minimumweight codewords forms a 2-design.
(113, 56, 16) QR Code:The set of minimum weight paritycheck vectors can be partitioned into two orbits. One orbitconsists of 3164 vectors, and the other one consists of 452vectors. Simulations showed that the use of the larger orbit
Fig. 13. Iterative decoding of (63, 39) BCH code.
Fig. 14. Iterative decoding of (113, 56) QR code.
yields almost the same performance as the entire set. Thisorbit forms 1-(113, 15, 420) design. The number of codewordsof minimum weight codewords of the (133, 56) QR codeis computed in [45] as 18 984. Based on this number, wecomputed a “union bound” on the bit-error probability whichis tight at high signal-to-noise ratios. We observe from Fig. 14that at a bit-error probability of 10 the iterative decodingis 2.8 dB superior to majority-logic decoding. At a bit-errorprobability of 10 the iterative decoding is 0.8 dB inferiorto the “union bound.” Further simulation results for QR codescan found in [46].
Definition 9 [44]: A double circulant code is a codewith generator matrix of the form
where is a unity matrix and is a circulantmatrix.
Some codes of this family have parameters close to the bestknown codes, e.g., the following.
(42, 21, 10) DC Code:The set of minimum weight paritycheck vectors does not form adesign. From Fig. 15, it isobserved that at a block-error rate of 10 the performanceof IDA is 0.2 dB inferior to SDML . Qualitatively, thesame result was obtained for the (32, 16, 8) DC code [24].

LUCAS et al.: SOFT-DECISION DECODING OF BLOCK AND PRODUCT CODES 291
Fig. 15. Iterative decoding of (42, 21) DC code.
D. Product Codes
In this section, we present simulation results for someproduct codes. First, in Fig. 16, we compare the two decodingvariants described in Section VI for the (5329, 2025, 100) DPcode of rate 0.38 and the corresponding (4545, 2025) PC codeof rate 0.45. Both are constructed from the (73, 45, 10) DSCcode. For the DP code, the performance obtained with variant(b) is 0.2 dB superior compared to variant (a) at a bit-errorrate of 10 For the PC code, the performance obtained withvariant (b) is also superior compared to variant (a). Simulationsof other DP (PC) codes showed that decoding variant (b)is better than variant (a) for component codes with orthog-onal parity check sets [24]. For nonorthogonal parity checkvectors, decoding variant (a) achieved in almost all cases abetter performance. However, since an analytical performanceprediction is lacking, we are dependent on simulations in orderto find out which update rule is the best for a particular code.Therefore, it is noted explicitly in the sequel which updaterule is used for decoding. Furthermore, we see that the parallelconcatenated code is better at low signal-to-noise ratios, butinferior at higher signal-to-noise ratios. Such a behavior wasobserved in our simulations in general.
In Fig. 17, the simulation results obtained for the followingcodes are presented. A (441, 121, 36) DP code of rate 0.27is constructed from the (21, 11, 6) DSC code, a (961, 441,25) DP code of rate 0.46 is constructed from the (31, 21, 5)BCH code, and a (3969, 1369, 81) DP code of rate 0.35 isconstructed from the (63, 37, 9) EG code. The performanceof these codes is compared to the rate-1/3 convolutional codewith generators and constraintlength We observe from Fig. 17 that the productcodes have worse performance at low compared to theconvolutional code, whereas at dB, the productcodes are better. For the (3969, 1369) DP code, a bit-errorprobability of 10 is obtained at dB.
VIII. C ONCLUDING REMARKS
Initiated by the results of the so-called “turbo” codes [1],symbol-by-symbol iterative decoding methods have gainedinterest. Their theoretical description, however, is still farfrom being conclusive. Since any concatenated block code or
Fig. 16. Iterative decoding of (5329, 2025) product code and (4545, 2025)parallel concatenated code.
Fig. 17. Iterative decoding of (441, 121) DP code, (961, 441) DP code, and(3969, 1369) DP code.
terminated convolutional code can be regarded as block code,this paper has been devoted to symbol-by-symbol iterativedecoding of block codes in order to get a better understandingof symbol-by-symbol of iterative decoding methods. By ana-lyzing the optimum symbol-by-symbol reliability informationin terms of the dual code, and by deriving the relation toweighted majority-logic decoding, we proposed an iterativedecoding algorithm that uses the parity check vectors ofminimum weight only. We showed that this iterative decodingcan be interpreted as gradient optimization, where the decisionregions are defined by the used parity check set. The existenceof parity check sets giving the SDML decision regions couldbe verified for the trivial codes. For all other codes, we coulddescribe points where the iterative decoding does not convergeinto a codeword. Still an open problem is the computation ofan optimum step width for iterative decoding, as well as thederivation of a tight bound on its performance. Furthermore,we proposed a computationally efficient implementation ofour algorithm using the minimal trellis representing the usedparity check set. Based on this implementation, it was possibleto decode representatives of different classes of block codesclose to the SDML decoding performance. The decoding oflong block codes already showed at dB a better

292 IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS, VOL. 16, NO. 2, FEBRUARY 1998
performance than good convolutional codes of the same rate.In addition, the trellis implementation allowed the decodingof product codes based on these block codes with justifiablecomplexity. The decoding performance of the product codesalready showed at dB a better performancethan SDML decoding of convolutional codes of the same rate.Furthermore, codes with an orthogonal parity check set arewell matched to the iterative decoding. For a fixed lengthand minimum distance of a code, we have obtained betterperformance in comparison with the best known codes ofthese parameters since no efficient decoding is yet availablefor them. We think that the construction of codes matchedto the present algorithm, e.g., Gallager’s low-density paritycheck codes, can be a promising way to obtain good decodingresults, particularly for long codes.
APPENDIX APROOFS
All formal statements such as theorems and propositions ofthis paper are proved in this Appendix.
Proof of Theorem 1
The dual code of an repetition code (RC) is ansingle-parity check (SPC) code and vice versa.
At first, we consider the computation of extrinsic informationusing the repetition code. It consists of the-codeword and the
-codeword, respectively. Thus,and (11) yields
With (6) yields
and, thus,Now, we consider the computation of extrinsic information
by means of an SPC code. The vectors of the set
are orthogonal on coordinate For this set, (11) yields
Since for all the above equation canbe rewritten as
The extrinsic information according to (6) for an SPC codecan be computed by means of the codewords of the repetitioncode, e.g., [24]. This yields
and, thus,Obviously, the rank of the set taken into account in (6) is
A necessary condition that (6) and (11) coincide is thatthe set of vectors orthogonal on coordinatealso has rank
In the binary case, this is fulfilled for the trivial codesonly.
Proof of Proposition 1
Without loss of generality, it is assumed that the-vectorwas transmitted. The received vector is The extrinsicinformation obtained from a parity check set is then
(37)
with If weighted majority-logicdecoding decodes correctly then for we obtainfrom (15)
(38)
Furthermore, we can write
Substituting the above equation into (38) leads to
(39)
Now, the following two cases are considered.1) Coordinate is correct, i.e., From
(39), we obtain

LUCAS et al.: SOFT-DECISION DECODING OF BLOCK AND PRODUCT CODES 293
TABLE VICOUNTEREXAMPLE ILLUSTRATING THAT s/s ITERATIVE DECODING IS NOT EQUIVALENT TO SDML DECODING
or, equivalently
With the above inequality, we get for the iterative decodingrule (4) as required.
2) Coordinate is erroneous, i.e. From(39), we obtain
or, equivalently, With the latter in-equality, we obtain for decoding rule (4)
Proof of Theorem 2
Since we find from (7) mod 2,In terms of the field this is rewritten as
sign This implies
(40)
According to (19), we haveand thus, from (40), it is clear that
Hence, and obviously,
Proof of Proposition 2
Consider the hard decision ofmod 2. Assume that then from (7),
we obtain mod 2, or, equivalently,Assume now that then there is at
least one parity check vectorsuch that mod 2 or,equivalently,
Proof of Proposition 3
Without loss of generality, we assume that the zero code-word, respectively the-sequence, was transmitted. Then wecan write (23) as
According to (24) of Proposition 3, we have
Note that since Hence,
and, thus, although
Proof of Theorem 3
Assume that the zero codeword was transmitted and se-quence was received. This maylook somewhat artificial, but nevertheless, it illustrates thedifference between SDML decoding and symbol-by-symboliterative decoding.
In Table VI, the different decoding results are shown. Wesee that the iterative decoding finds the correct codeword,whereas the SDML codeword does not coincide with thetransmitted codeword in this case.
Proof of Theorem 5
For proving Theorem 5, we have to introduce some defi-nitions. Just as in [29], we define the past subcode and thefuture subcode of a vertex as
is a path from to
is a path from to
Definition 10 [26]: Two distinct vertices and inof a trellis representing set are said to bemergeableifconcatenating the past of one with the future of the otherproduces no paths that are not parity check vectors ofThus,
are mergeable if
For separable codes, the following statements are equivalent[26], [27].
• A trellis for is minimal.• A trellis for is nonmergeable.
We prove Theorem 5 by showing that Algorithm generatesa nonmergeable trellis. Before doing so, consider the thefollowing lemma.

294 IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS, VOL. 16, NO. 2, FEBRUARY 1998
Lemma 1:Let the trellis represent a separable set Iffor a , the past subcodes for all aredisjoint, and additionally the future codes for allare disjoint, then the trellis is nonmergeable at depth
Proof: Assume that at a given depththe past subcodesand the future subcodes are disjoint for all Then,obviously, the future subcode coincides with the tail set
where corresponds to a path from the root toWecannot merge any vertices since codewords with different tailsets must pass through different vertices [27], [29].Hence,the trellis is nonmergeable at depth
Now, consider StepF of Algorithm: Obviously, the past code consists of a single symbol
only and, thus, after merging all left relatives, we obtain twovertices such that for one vertex andfor the other one. Of course,
: After merging all left relatives, we obtain at mostfour vertices such that
Obviously, all pastcodes are disjoint.
: After merging all left relatives, we obtain at mostvertices such that
Hence, after StepF, we have forSimilarly, we obtain after Step
B forNote that after merging the right relatives, we still have theproperty that the past codes of different vertices at any depth
are disjoint. Therefore, after StepB of thealgorithm, we have for
Thus, from the lemma above, the trellis generated by Algo-rithm is nonmergeable and, thus, minimal.
Proof of Theorem 7
Consider the binary (5, 3, 2) code generated by thegenerator matrix
From the above generator matrix, we obtain a minimal trellisrepresenting the codewhich has minimal number of vertices
and minimal number of edges amongall other minimal trellises representing equivalent codes. Thetrellis representing the subcode of minimum weight codewordshas ten vertices and ten edges. The generator matrix
represents an equivalent code The trellis representing theminimum weight subcode of has only nine vertices and nineedges. However, the trellis representinghas 14 vertices and20 edges.
APPENDIX BA BRIEF DESCRIPTION OFFINITE
GEOMETRIES AND FINITE GEOMETRY CODES
This Appendix provides a brief overview of codes-basedfinite geometry. A more extensive description can be found,e.g., in [44], [41], [47].
Definition 11 [44]: A finite projective geometry is a setof points together with a collection of subsets
of called lines, which satisfy the following axioms.
a) There is a unique line passing through any pair of distinctpoints.
b) Every line contains at least three points.c) If distinct lines have a common point and if
are points of not equal to and are points ofnot equal to then the lines and also have acommon point.
d) For any point , there are at least two lines not containingand for any line there are at least two points not
one) A subspace of the projective geometry is a subsetof
such that if are distinct points of then containsall points of the line
A hyperplane is a maximal proper subspace, so thatisthe only subspace which properly contains
Definition 12 [44]: A Euclidean geometry is obtained bydeleting the points of a fixed hyperplane from the sub-spaces of a projective geometry. The resulting sets are calledsubspaces of the affine geometry.
Examples of projective and Euclidean geometries are thoseobtained from finite fields.
The Projective Geometry PG : Consider GFand its subfield GF The points of are taken to bethe nonzero tuplesLet be a primitive element of GF and letbe a primitive element of GF Every element
can be expressed as
where There is a one-to-onecorrespondence between the element and thetuple over GF We may consider asrepresenting a point in Furthermore, let
Then the nonzero elements of GF can be partitionedinto disjoint subsets as follows:
...
Note that the elements ofare considered to be the same point. The elements
are said to form an -dimensional pro-jective geometry PG over GF which satisfies theaxioms of Definition 11.

LUCAS et al.: SOFT-DECISION DECODING OF BLOCK AND PRODUCT CODES 295
Define a flat in PG as follows. A 0 flat is apoint. If are points not all in the sameflat, then all points collinear with and any point definedby form a flat. Thus, a line is a 1 flat,and all other flats are defined recursively. Now, let
be an tuple over GF(2), and let be aprimitive element of GF Then the components ofmay be numbered with the nonzero elements of GFsuch that is numbered
Definition 13: Let be a flat in PG The com-ponents of the incidence vector of the
flat are defined such that
where is the location number of the componentA th-order PG code is then defined as given in
Definition 8.Definition 14 [41]: Let be a nonnegative integer less than
Its expression in radix form is
with Then the weight ofdenoted is defined as
The following theorem characterizes the root of the generatorpolynomial of a th-order PG code.
Theorem 8 [41, p. 243]:Let be a primitive elementof GF Let be a nonnegative integer less than
The generator polynomial of the th-order PG code of length has as aroot if and only if is divisible by and
withThe Euclidean Geometry EG : The Euclidean ge-
ometry EG is obtained from the projective geometryPG by deleting the points of a hyperplane Thereby,it does not matter which one is deleted, but it is convenientto consider the excluded hyperplane as the one consisting ofall points with Then we are left with the pointswhose coordinates can be taken to
Since there are points inPG and the points of a hyperplanewere removed, there remain points which are said toform the Euclidean geometry EG These points canbe labeled by the -tuples withThe zero tuple is called the origin of EG Again, eachpoint can be represented by where is now a primitiveelement of GF Let be a
tuple over GF(2). Then the components ofmaybe numbered with the nonzero elements of GF such that
is numberedDefinition 15: Let be a flat in that does not pass
through the origin The components of the incidencevector of the flat are defined
such that
where is the location number of the componentA th-order EG code is then defined as given in
Definition 7.Theorem 9 [41, p. 229]:Let be a primitive element of
GF Let be a nonnegative integer less thanThe generator polynomial of the th-order EG codeof length has as a root if and only if
Construction of Parity Check Sets for EG Codes:The nullspace of a th-order EG code contains all of theflats of EG not passing through the origin. Let bea flat passing through Then there are
flats which intersect on [41, p. 230]. Since anypoint outside is in one and only one of the flatsthat intersect on in the incidence vectors of these
flats are orthogonal on the digits at locations thatcorrespond to the points in Moreover, let be a
flat passing through Then there are
flats not passing through the origin which intersect onin Again, the incidence vectors of these
flats are orthogonal on the digits at locations correspondingto the points in This process can be continued until
Thus, a th-order EG code is -step majority-logic decodable.
The construction of parity check sets for projective geome-try codes is similar to Euclidean geometry codes. An extensivedescription can be found in [41].
ACKNOWLEDGMENT
The authors wish to thank Prof. Zyablov and Dr. Sidorenkofrom the Russian Academy of Science, Dr. Kotter fromthe University of Linkoping, Sweden, and the anonymousreviewers for helpful suggestions and comments during thepreparation of this work.
REFERENCES
[1] C. Berrou, A. Glavieux, and P. Thitimajshima, “Near Shannon limiterror-correcting coding and decoding: Turbo-codes(1),” inProc. IEEEInt. Conf. Commun., Geneva, Switzerland, 1993, pp. 1064–1079.
[2] R. Gallager, “Low density parity–check codes,”IRE Trans. Inform.Theory, pp. 21–28, Jan. 1962.
[3] G. Battail, M. C. Decouvelaere, and P. Godlewski, “Replication de-coding,” IEEE Trans. Inform. Theory, vol. IT-25, pp. 332–345, May1979.
[4] J. Hagenauer, E. Offer, and L. Papke, “Iterative decoding of binaryblock and convolutional codes,”IEEE Trans. Inform. Theory, vol. 42,pp. 429–446, Mar. 1996.
[5] A. Lafourcade and A. Vardy, “Asymptotically good codes have infinitetrellis complexity,” IEEE Trans. Inform. Theory, vol. 41, pp. 555–559,1995.
[6] G. D. Forney, “Generalized minimum distance decoding,”IEEE Trans.Inform. Theory, vol. IT-12, pp. 125–131, Apr. 1966.
[7] D. Chase, “A class of algorithms for decoding block codes with channelmeasurement information,”IEEE Trans. Inform. Theory, vol. IT-18, pp.170–182, Jan. 1972.

296 IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS, VOL. 16, NO. 2, FEBRUARY 1998
[8] T. Kaneko, T. Nishijima, H. Inazumi, and S. Hirasawa, “An efficientmaximum-likelihood-decoding algorithm for linear block codes withalgebraic decoder,”IEEE Trans. Inform. Theory, vol. 40, pp. 320–327,Mar. 1994.
[9] J. Snyders and Y. Be0ery, “Maximum likelihood soft decoding of binaryblock codes and decoders for the Golay codes,”IEEE Trans. Inform.Theory, vol. 35, pp. 963–975, Sept. 1989.
[10] Y. S. Han, C. R. P. Hartmann, and C. C. Chen, “Efficient priority-first search maximum likelihood soft-decision decoding of linear blockcodes,”IEEE Trans. Inform. Theory, vol. 39, pp. 1514–1523, Sept. 1993.
[11] M. P. Fossorier and S. Lin, “Computationally efficient soft-decisiondecoding of linear block codes based on ordered statistics,”IEEE Trans.Inform. Theory, vol. 42, pp. 738–751, May 1996.
[12] G. L. Nemhauser and L. A. Wolsey,Integer and Combinatorial Opti-mization. New York: Wiley, 1988.
[13] R. Lucas, M. Bossert, and M. Breitbach, “Iterative soft-decision de-coding of linear binary block codes,” inProc. IEEE Int. Symp. Inform.Theory Appl., Sept. 1996, pp. 811–814.
[14] L. R. Bahl, J. Cocke, F. Jelinek, and J. Raviv, “Optimal decoding oflinear codes for minimizing symbol error rate,”IEEE Trans. Inform.Theory, vol. IT-20, pp. 284–287, Mar. 1974.
[15] P. Hoeher, P. Robertson, and E. Villebrun, “Optimal and sub-optimalmaximum a posteriori algorithms suitable for turbo decoding,”Euro-pean Trans. Telecommun., to be published.
[16] J. Hagenauer and P. Hoeher, “A Viterbi algorithm with soft-decisionoutputs and its applications,” inConf. Rec. GLOBECOM 89, Dallas,TX, vol. 3, Nov. 1989, pp. 47.1.1–47.1.7.
[17] L. D. Rudolph, C. R. Hartmann, T. Hwang, and N. Duc, “Algebraicanalog decoding of linear binary codes,”IEEE Trans. Inform. Theory,vol. IT-25, pp. 430–440, July 1979.
[18] V. D. Kolesnik, “Iterative code constructions and multistep decoding,”Sci. Rep., Dec. 1993, DLR, NT, Oberpfaffenhofen, Germany.
[19] N. Wiberg, “Codes and decoding on general graphs,” Ph.D. dissertation,Linkoping Univ., Linkoping, Sweden, 1996.
[20] C. R. P. Hartmann and L. D. Rudolph, “An optimum symbol-by-symboldecoding rule for linear codes,”IEEE Trans. Inform. Theory, vol. IT-22,pp. 514–517, Sept. 1976.
[21] J. L. Massey,Threshold Decoding. Cambridge, MA: MIT Press, 1963.[22] M. Rahman and I. F. Blake, “Majority logic decoding using com-
binatorial designs,”IEEE Trans. Inform. Theory, pp. 585–587, Sept.1975.
[23] M. Bossert and F. Herget, “Hard- and soft-decision decoding beyond thehalf minimum distance—An algorithm for linear codes,”IEEE Trans.Inform. Theory, vol. IT-32, pp. 709–714, Sept. 1986.
[24] R. Lucas, “On iterative soft-decision decoding of linear binary blockcodes,” Ph.D. dissertation, Univ. Ulm, Germany, 1997.
[25] M. Papageorgiou,Optimierung. Munchen/Wien, Germany: R. Olden-burg Verlag, 1996.
[26] A. Vardy and F. Kschischang, “Proof of a conjecture of McElieceregarding the expansion index of the minimal trellis,”IEEE Trans.Inform. Theory, vol. 42, pp. 2027–2034, Nov. 1996.
[27] V. Sidorenko, “The Euler characteristic of the minimal code trellisis maximum,” Probl. Inform. Transm., vol. 33, pp. 87–93, Jan.–Mar.1997.
[28] J. L. Massey, “Foundations and methods of channel encoding,” inInt.Conf. Inform. Theory Syst., vol. 65. Berlin, Germany: NTG Fach-berichte, 1978, pp. 148–157.
[29] F. Kschischang, “The trellis structure of maximal fixed-cost codes,”IEEE Trans. Inform. Theory, vol. 42, pp. 1828–1838, Nov. 1996.
[30] D. J. Muder, “Minimal trellises for block codes,”IEEE Trans. Inform.Theory, vol. 34, pp. 1049–1053, 1988.
[31] R. J. McEliece, “On the B.J.C.R. trellises for linear block codes,”IEEETrans. Inform. Theory, vol. 42, pp. 1072–1092, July 1996.
[32] G. D. Forney, “Dimension/length profiles and trellis complexity of linearblock codes,”IEEE Trans. Inform. Theory, vol. 40, pp. 1741–1752, Nov.1994.
[33] T. Kasami, T. Takata, T. Fuijwara, and S. Lin, “On the optimum bitorders with respect to the state complexity of trellis diagrams for binarylinear block codes,”IEEE Trans. Inform. Theory, vol. 39, pp. 242–245,1993.
[34] , “On complexity of trellis structure of linear block codes,”IEEETrans. Inform. Theory, vol. 39, pp. 1057–1064, 1993.
[35] G. B. Horn and F. Kschischang, “On the intractability of permuting ablock code to minimize trellis complexity,”IEEE Trans. Inform. Theory,vol. 42, pp. 2024–2047, Nov. 1996.
[36] A. Engelhardt, M. Bossert, and J. Maucher, “Heuristic algorithms forordering a linear block code to reduce the number of nodes of a minimaltrellis,” submitted for publication.
[37] F. R. Kschischang and G. B. Horn, “A heuristic for ordering a linearblock code to minimize trellis state complexity,” inProc. 32nd Annu.Allerton Conf. Commun., Contr., Computing, Sept. 1994, pp. 75–84.
[38] J. K. Wolf, “Efficient maximum likelihood decoding of linear blockcodes using a trellis,”IEEE Trans. Inform. Theory, vol. IT-24, pp. 76–80,Jan. 1978.
[39] S. Lin and E. J. Weldon, “Further results on cyclic product codes,”IEEETrans. Inform. Theory, vol. IT-16, pp. 452–459, July 1970.
[40] J. Lodge, R. Young, P. Hoeher, and J. Hagenauer, “Separable MAPfilters for the decoding of product and concatenated codes,” inProc.IEEE Int. Conf. Commun. ICC’93, Geneva, Switzerland, May 1993, pp.1740–1745.
[41] S. Lin and D. J. Costello,Error Control Coding, Fundamentals andApplications. Englewood Cliffs, NJ: Prentice-Hall, 1983.
[42] Y. Yasuda, K. Kashiki, and Y. Hirata, “High rate punctured convolu-tional codes for soft-decision Viterbi decoding,”IEEE Trans. Commun.,vol. 32, pp. 315–319, Mar. 1984.
[43] H. T. Moorthy, S. Lin, and T. Kasami, “Soft decision decoding of binarylinear block codes based on iterative search algorithm,”IEEE Trans.Inform. Theory, vol. 43, pp. 1030–1039, May 1997.
[44] F. J. MacWilliams and N. J. A. Sloane,The Theory of Error-CorrectingCodes. Amsterdam, The Netherlands: North-Holland, 1977.
[45] D. Coppersmith and G. Seroussi, “On the minimum distance of somequadratic residue codes,”IEEE Trans. Inform. Theory, vol. IT-30, pp.407–411, Mar. 1984.
[46] R. Lucas, M. Bossert, M. Breitbach, and H. Griesser, “On iterative soft-decision decoding of binary quadratic residue codes,” inProc. 5th Int.Workshop Algebraic and Combinatorial Coding Theory, June 1996, pp.184–189.
[47] R. E. Blahut,Theory and Practice of Error Control Codes. Reading,MA: Addison-Wesley, 1984.
Rainer Lucas was born in Ulm, Germany, in 1965.He received the Dipl.-Ing. degree in electrical engi-neering from the Technical University of Karlsruhe,Germany, in 1992, and the Ph.D. degree from theUniversity of Ulm, Germany, in 1997.
He is a Research Assistant in the Department ofInformation Technology, University of Ulm, Ger-many. His main research interests lie in the area ofsoft-decision decoding of block codes.
Martin Bossert (M’94) received the Dipl.-Ing. de-gree in electrical engineering from the TechnicalUniversity of Karlsruhe, Germany, in 1981, andthe Ph.D. degree from the Technical University ofDarmstadt, Germany, in 1987.
After a one-year DFG scholarship at LinkopingUniversity, Sweden, he joined AEG Mobile Com-munication, where he was, among others, involvedin the specification and development of the GSMsystem. Since 1993, he has been a Professor in theDepartment of Information Technology, University
of Ulm, Germany. His main research areas concern secure and reliable datatransmission, especially generalized concatenation/coded modulation, codeconstructions for block and convolutional codes, and soft-decision decoding.
Markus Breitbach was born in Andernach, Ger-many, in 1965. He received the Dipl.-Ing. degreein electrical and computer engineering from theAachen University of Technology, Aachen, Ger-many, in 1991, and the Ph.D. degree from theUniversity of Ulm, Germany, in 1997.
He is a Research Assistant in the Departmentof Information Technology, University of Ulm. Hisresearch interests include error-correction coding formultidimensional data transmission media, commu-nication network protocols, and network security.




















