
Multicomponent models for the retention of numbers
18
Psychol. Res. 40, 349-366 (1979) Psychological Research © by Springer-Verlag . 1979 Multicomponent Models for the Retention of Numbers Rainer Schmidt I and Dirk Vorberg 2 1 Fachbereich Psychologie der Universit/tt Giessen, Otto-Behaghel-Str. 10, D-6300 Giessen, Federal Republic of Germany 2 Fachbereich Psychologie und Soziologie der Universit/it Konstanz, Postfach 7733, D-7750 Konstanz, Federal Republic of Germany Summary. Several muhicomponent models of memory (Bower, 1967) are presented and applied to the retention of three-digit numbers. Their applica- tion is based on the notion that both the digits making up a number stimulus and the position in which they appear can be interpreted as the components of a 'memory vector'. The models are fitted to the data obtained in a Peterson- type experiment in which a single three-digit number was shown per trial. During the retention interval the subject engaged in an arithmetical task for either 13.6, 19.6, or 25.6 s. Following this, the subject attempted recall. Con- fidence ratings were also obtained. Twenty-four different types of correctly and incorrectly recalled responses were scored. Their frequency distributions were best predicted at each retention interval by a 'dual encoding' model which relies on the assumption that stimuli are stored both component-wise and by means of a single 'unit code' encoding the entire stimulus number. It is also shown that the confidence ratings may be successfully predicted from estimates of the expected number of components retained. About 80% of the rating vari- ance is predicted by a parameter-free procedure. Introduction More than ten years ago G. Bower made what he called a 'first modest attempt to begin redressing some of the imbalance of facts over theories' in memory research (Bower, p. 230). He has provided a useful framework for studying a basic issue in memory research - that is, the format in which information is encoded and stored. Essentially, * The original experimental study was funded by Grant Ey 4/3, Deutsche Forschungsgemeinschaft, Bad Godesberg. Further developments were made possible by Grant Sch 350/1 to R.S. from the same agency. Part of the theoretical work was done while D.V. was an NSF postdoctoral fellow at the Department of Psychology of New York University, New York. Free computer time was generously supplied by the Courant Institute of Applied Mathematics. We are grateful to Dietrich Albert, Stephanie Kelter, Micha Razel, and Paul Vitz for stimulating discussions. 0340--0727/79/0040/0349/~ 03.60
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of Multicomponent models for the retention of numbers

Psychol. Res. 40, 349-366 (1979) Psychological Research © by Springer-Verlag . 1979
Multicomponent Models for the Retention of Numbers
Rainer Schmidt I and Dirk Vorberg 2
1 Fachbereich Psychologie der Universit/tt Giessen, Otto-Behaghel-Str. 10, D-6300 Giessen, Federal Republic of Germany
2 Fachbereich Psychologie und Soziologie der Universit/it Konstanz, Postfach 7733, D-7750 Konstanz, Federal Republic of Germany
Summary. Several muhicomponent models of memory (Bower, 1967) are
presented and applied to the retention of three-digit numbers. Their applica- tion is based on the notion that both the digits making up a number stimulus
and the position in which they appear can be interpreted as the components of a 'memory vector'. The models are fitted to the data obtained in a Peterson-
type experiment in which a single three-digit number was shown per trial. During the retention interval the subject engaged in an arithmetical task for
either 13.6, 19.6, or 25.6 s. Following this, the subject attempted recall. Con- fidence ratings were also obtained. Twenty-four different types of correctly
and incorrectly recalled responses were scored. Their frequency distributions were best predicted at each retention interval by a 'dual encoding' model which relies on the assumption that stimuli are stored both component-wise and by means of a single 'unit code' encoding the entire stimulus number. It is also shown that the confidence ratings may be successfully predicted from estimates of the expected number of components retained. About 80% of the rating vari- ance is predicted by a parameter-free procedure.
Introduction
More than ten years ago G. Bower made what he called a 'first modest attempt to begin redressing some of the imbalance of facts over theories' in memory research (Bower, p. 230). He has provided a useful framework for studying a basic issue in memory research - that is, the format in which information is encoded and stored. Essentially,
* The original experimental study was funded by Grant Ey 4/3, Deutsche Forschungsgemeinschaft, Bad Godesberg. Further developments were made possible by Grant Sch 350/1 to R.S. from the same agency. Part of the theoretical work was done while D.V. was an NSF postdoctoral fellow at the Department of Psychology of New York University, New York. Free computer time was generously supplied by the Courant Institute of Applied Mathematics. We are grateful to Dietrich Albert, Stephanie Kelter, Micha Razel, and Paul Vitz for stimulating discussions.
0340--0727/79/0040/0349/~ 03.60

350 R. Schmidt and D. Vorberg
Bower conceived of the memory trace as an ordered set - the 'memory vector ' - of elementary attr ibutes or components which are shown to account for a diversity of memory phenomena. Along similar lines, the cognitive approach to psychology which has become popular during recent years has contributed to this author 's work on the complex structure of relatively simple-looking memory items, the overwhelming evi- dence accumulated so far supporting his general mult icomponent theory. For example, explicit models for the representation of single-letter stimuli have been used repeatedly in order to account for the well-known acoustic confusabili ty effects (Estes, 1972; Sperling and Speelman, 1970). There is also evidence on the flexibility, and even the superiority, of the mul t icomponent approach in studies testing the retention of posi- t ional and digit information. Bower (1967) accurately predicted the response patterns obtained under conditions in which simple linear orderings of response-buttons were used as the response terms in a continuous paired-associates task. Similarly, Wickens and Greitzer (1975) demonstrated the usefulness of a mul t icomponent model in a paired-associates task involving simple digits as responses. In their experiment, the accuracy with which 'second guesses' were observed could best be explained by models ascribing a certain amount of structure to. such materials.
The present work is concerned with a mukicomponent interpretat ion of the reten- t ion of three-digit numbers. We shall modify Bower's theory in order to apply it to this kind of material as it is presented in a typical recall task of the Peterson type. The most important feature of our work consists of a comprehensive analysis of the correct and all the incorrect response patterns that are observed in the recall of single three-digit numbers. The usefulness of the general theory will also be demonstrated by a consid- eration of the subject 's confidence in the correctness of his response. It should be intuitively clear that only a detailed data analysis encompassing both the types of response emitted by a subject as well as the confidence he holds in their correctness will enable us to test, and ul t imately to choose among, several different theories of the mukicomponen t trace. At the same time, it should be noted that we do not discuss alternative psychological representations of single digits or positions. Instead, we shall conceive of numbers as simple random sequences of arbitrary, albeit elementary, units. Consequently, our results should also be relevant to studies employing other materials such as letter trigrams.
Moreover, there is compelling experimental evidence of the complexi ty of the rep- resentations of brief sequences of letters or digits in memory, an excellent example being provided by Nelson and Batchelder (1969). They have shown that success in relearning a set of CCCs depends to a large extent on the degree of correctness with which the CCCs are recalled on the first test. Furthermore, recent work by Estes (1972) leaves no doubt that a mul t icomponent representation is necessary if the pat tern of response observed with such materials is to be predicted accurately. More precisely, Estes notes that the memory trace must specify two different kinds of information: the component information proper and the positional information associated with it. Beyond such a description, this author refers to several possibilities for modeling the relationship that must be assumed to hold among these entities; it will be seen that our solution to this problem is quite characteristic of the entire work reported in this paper.

Multicomponent Models 351
Theory
Three types of assumptions will be made: Representation, retention, and response assumptions. This classification parallels that reported in studies on perceptual pheno- mena (Rumelhart , Note 1: Rumelhart and Siple, 1974). In this regard, it should be noted that Bower's ideas have been most influential in perceptual research and, as a matter of fact, our work on memory resembles that cited above in that we also make strong assumptions about the representation of the stimuli occurring in our experiment.
Representation. We assume three-digit and three-position components, one of each kind corresponding to a single place in the stimulus. Digit information is assumed to be primary. If a given digit is lost from memory, the subject can no longer tell at which stimulus position it occurred during presentation. Conversely, positions may be lost without affecting digit information. The theoretical states of the memory vector may
be characterized by triple s X1X2X3, where a) X i = 1 refers to the case in which both digit and position information has been lost from the ith place (i = 1, 2, 3), b) X i = 2 to the case in which only digit information is retained, and c) X i = 3 denotes retention of both kinds of information. For example, if the number 738 is presented in a trial, and the subject retains the digit and the position information associated with the first place, the position information of the second place, and no information at all about the last place, then the corresponding state of the memory vector is coded as 321. There are 27 such states, where 111 refers to the empty vector and 333 to a state of perfect knowledge.
Besides this, the general model includes two special theoretical states 333+ and 111+. 333+, the unit-code, is referred to as a state of perfect knowledge resulting from unitary or 'gestalt '-encoding of the stimulus. In general, either the unit code 333+ or the multi- component trace will be encoded. However, in one interpretation introduced below, the dual-encoding model, both _types of code are assumed to coexist in the memory vector. The other special memory state, 111+, refers to the case in which either the unit code is forgotten or the entire component-trace becomes inaccessible owing to a retrieval failure.
These assumptions extend Bower's theory in several ways. Instead of an abstract dimensional representation, there is explicit identification of the components of the memory vector. Furthermore, it should be noted that different kinds of information may be stored in the memory vector and that it appears necessary to associate different forgetting rates with each kind. Following Bower, our representation may be referred to as partially bierarcbical since position components are nested under their respective digit components, i t may also be related to Estes's (1972) perturbation or 'reverbera- tory loop' model. Estes assumes that ' the loss of order information is primary, and the loss of item information is derivative' (p. 180). His representation was specifically designed to account for transposition errors in recall and it will be of interest to see how our model - it incorporates the converse relationship between order and item information - will handle such phenomena.
Retention. We define retention-probabilit ies for all six attributes of the mult icompon- ent trace. Let Cl, c2, and c 3 denote the probabilities for retaining the first, second, and third digits, and let P l , P2, and P3 be the respective conditional probabilities for retaining the positions in which they were presented. Here the actual probabil i ty values

352 R. Schmidt and D. Vorberg
depend on the retention intervals used in the experiment with no explicit retention- function such as the exponential etc. being postulated. Instead, parameter values will be est imated freely for each retention interval. By this method the representation- assumptions may be examined and tested independently of the specific assumptions concerning memory decay. Much like Bower, we assume that components are forgotten independently of each other. Thus, the retention parameters for the components are assumed to combine multiplicatively, and as a result, the probabilities for the 27 theo-
retical states can be obtained easily. For example, P(l l l ) = (1 - c 1) (1 - c 2) (1 - c3),
P(123) = (1 - Cl)C2(1 - P2)c3P3, etc. It remains to be discussed how the encoding and the retention of the unitary trace
333+ (and of the special no-knowledge state 111 +) relate to the mul t icomponent trace. Our approach to this issue consists in formulating a set of models that incorporate several psychological assumptions found in the literature. Figure 1 represents a general multicomponent tbeory used to derive all the other models considered in the following. Note that it includes two parameters d t and r t. Formally, these parameters serve to weigh the unit code 333+ (and the special state 111+) and the mult icomponent vector. Two instances for which this weighting is of consequence will be considered by way of illustration. First, note that a simple all-or-none model assumes that three-digit numbers are either retained as a unit, or not at all. This case is easily taken care of in the general theory by setting d t equal to zero. Second, note that with a pure muhi- component model, retent ion is only based on the muhicomponent vector, and this leads us to set both d t and r t equal to one, thus effectively removing the unit-code. In general, the parameter d t is interpreted as the probabi l i ty of storing the mult icompo- nent trace (relative to the unit-code), and r t as the probabil i ty of retrieving the unit- code. The uncondit ional probabilit ies for the theoret ical states can in all cases be ob- tained by appropriately multiplying the condit ional probabilit ies indicated on the branches of Figure 1. Again, all encoding and forgetting events are assumed to be statistically independent of each other. The following models will be studied.
1. Simple Code Models
All-or-None Model. By setting d t = 0 Bower's (1961) all-or-none model with states 333+ and 111+ is obtained, i.e., either the three-digit number is completely retained, or
~ 11__!1 +
~'~i 111 11__22_
1 - d t ~ 3 3 3 + Fig. 1. Schematic representation of the gen- eral multicomponent theory

Multicomponent Models 353
no component of it at all. Here r t is assumed to become smaller as the retention interval
is increased.
Simple Multicomponent Model. By setting r t = 1 and d t = 1, the special states are re- moved from the general model, resulting in a mult icomponent model which is similar in spirit to Bower's (1967) model. Again, long retention intervals are expected to be assoc-
iated with small parameter-values c i and Pi-
Simple Multicomponent Model With Retrieval Failures. Same as above. However, a 'short-term-interpretation' of the mult icomponent trace is adopted;access to it may be lost with probabil i ty 1 - r t. This leads to state 111 +. Special assumption: d t = 1.
2. Alternative-Code Models
Simple Alternative-Code Model (AC). Suppose that either a mult icomponent or a unit code is stored at stimulus presentation. Further, suppose that the unit code is inter- preted as a long-term memory trace which cannot be forgotten. The implications re- garding our general model are r t = 1 and d t = d, the latter restriction resulting from the fact that events occurring at presentation cannot be affected by events that occur later in time.
Three further AC-models result if we allow unit-forgetting and/or retrieval failures to affect either kind of code. First, if only the long-term assumption of the unit code is weakened, we obtain an AC-model with unit forgetting (AC-UF). The probabil i ty of forgetting the unit code is assumed to be r t. It is easily proved that this model is equivalent to our general model with r td t = k l , a constant. Secondly, if we adhere to the long-term interpretation of the unit-trace, but allow retrieval failures to affect the component-trace with probabil i ty 1 - rt, we obtain an AC-model with component- vector retrieval failures (AC-CF). This requires rt(1 - d t) = k 2 in the general model. Thirdly, suppose that retrieval failures affect both types of codes with equal probabil i ty r t. This leads to the restriction d t = k 3 for the general model, and defines our AC- model with general retrieval failures (AC-UCF).
3. Dual-Encoding Model
Both a unit and a mult icomponent code are stored in the memory vector with probabil- i ty one at presentation. Here code 333 + denotes an element of the memory vector that is lost with probabil i ty 1 - dt. Accessibility of the entire memory vector is also assumed. This version is equivalent to the restriction of the general model that results from setting
r t = 1. It is impossible to judge the appropriateness of these assumptions and models a
priori. Clearly, the all-or-none model is no strong competitor, merely serving as a baseline against which the mult icomponent models can be evaluated. On the other hand, the alternative-code models extend the original theory considerably, while the dual-code model represents a theoretical alternative for Bower's not ion of ' redundancy in the memory trace' . It should also be noted that this latter model is conceptually similar to Estes's (1973) model for the retention of CCCs, which specifically assumes that there is a short-term memory trace responsible for high acoustic confusability after presentation (our mult icomponent trace?) and another long-term trace that lacks this type of uncertainty (our unit code?).

354 R. Schmidt and D. Vorberg
Response. First, it should be realized that our basic approach requires us to specify two sets of assumptions that serve to predict both the relative frequencies of the re- sponse types and the mean confidence ratings associated with them. These assumptions should be closely related in theory since both performance aspects are supposed to depend on the state of the memory vector at the time of testing. In general, the sub- ject 's recall of a three-digit number will be based on some guessing of the information components that have been lost. At the same time, his confidence in the correctness of a response should bear a strong relationship to the actual amount of guessing that was incurred when giving a full three-digit response. In this section, only the detailed assumptions involved in the prediction of the recall types will be presented, while those referring to the confidence ratings are dealt with in a later section.
The following four types of response assumptions apply to an experimental proce- dure in which the three digits of the stimulus are all different, a) The subject guesses if there are components missing in the memory vector or if the entire vector is not re- trievable. Guesses are 'sophisticated' in the sense that subjects choose three mutually different digits for their response in order to match the characteristics of the stimuli. We code the types o f response observable in the experiment by a set of triples YIY2Y3, where Yi = 1 denotes the case in which the digit presented in the i th place is not given in the response, Yi = 2 if it appears in the wrong position, and Yi = 3 if the i th digit is correctly reproduced in the i th place of the response. For example, if the stimulus presented is the number 749, and if the subject 's response is 792, we code the latter by the three-digit code 312. According to this rule, there are 24 response types ( type 332, 323, and 233 being logically impossible), these representing the smallest units of analysis referred to in this work. The main problem consists in deriving the theoretical probabilities for the response types. Since those for the memory states are easily found, it remains to determine the conditional probabilit ies for guessing the response types
Y1Y2Y 3 given the memory states. These 'guessing probabilities ' P(Y1Y2Y3 /XIX2X 3) are derived by use of elementary combinatorial rules from the assumption stated; two examples are given in the Appendix which show in detail how this was done. b) Regard- ing the choice of a response, states 111 + and 333 + are treated exactly the same as the corresponding states 111 and 333 of the mul t icomponent trace. Thus for the all-or- none model sophisticated guessing is assumed. Regardless of the types of model, if a response is based on 333 +, it will lead to an all-correct response of type 333. c) In the dual-encoding model the unit code 333 + dominates the mul t icomponent trace. If the unit is lost, the response is based on the latter, d) For the simple mul t icomponent model a variation of the first response assumption will be studied. For instance, sup- pose that under certain conditions there is noise in the memory system, for example, with long retention intervals filled with a distractor task involving materials that are similar to those used for the main task. It is possible that this leads the subject to have little confidence in the memory trace retrieved, especially if the information content of the memory vector fell below a certain tbresboM-value. Under such conditions, it would also appear reasonable for a subject to disregard the memory vector and to guess as if there were no information stored at all. This model assumes thai the threshold- value is directly related to the number of components stored in the memory vector. To obtain this value, we simply add the number of digit components to the number of posit ion components available from memory. We assume the threshold to be variable;

Mult icomponent Models 355
a binominal distribution with N = 6 (maximum score) and probabil i ty parameter v t is assumed to account for threshold-variability.
These response assumptions are standard, and little needs to be said to justify them. The notion of a response-threshold was suggested by a similar idea advanced by Rumel- hart (Rumelhart, Note 1; Rumelhart and Siple, 1974) in the context of studies on the perception of single letters and letter trigrams. Rumelhart 's notion of a constant 'candidate set ' of responses - meeting qualitative criteria in order to be evaluated with respect to the sensory information available - is somewhat related to our notion of a variable 'response threshold' . That such work may be referred to at all adds to the potential usefulness of the mult icomponent approach for cognitive psychology in gen- eral - a priori, there appears to be no compelling reason for formulating different response assumptions for mult icomponent traces originating from either the sensory or the memory systems.
Experiment
The theory will be tested on the data provided from a study on the retention of num- bers, performed by the authors some years ago (Schmidt and Vorberg, Note 2). This s tudy was designed so that recognition and recall performance could be compared in a Peterson paradigm. Here however, only the procedural details associated with the recall-tests and the results obtained therewith are reported (cf. Vorberg and Schmidt, 1975, for an analysis of some aspects of the recognition data).
Subject. A single male subject served in the experiment for a period of eight weeks on daily sessions. He was selected from a group of several graduate psychology students at the Technische Hochschule Darmstadt. The subject ul t imately chosen for participa- t ion had performed best both on the recall and on the intervening counting task during training. Payment was on an hourly basis, and the rate conformed to the regulations in use at the University for such and similar services.
Materials. The stimuli for the recall task were randomly generated on a computer sub- ject to a number of restrictions. Only the digits 1 to 9 were used, and all three digits making up a stimulus number were chosen different. Further restrictions were: a) 5 was never shown in the last place; b) successive digits were never repeated (e.g., 558); finally, c) numbers that consisted of digits either increasing or decreasing by either one or two units (e.g., 456, 654, 468 or 864) were excluded.
Design. A Peterson type of procedure was used for presenting and testing single num- ber-stimuli in each trial. Both recognition and recall trials occurred with equal likeli- hood in a pseudo-random sequence. Immediately following the presentation of the stimulus number, the subject began performing a distractor task for either T 1 = 13.6, T 2 = 19.6, or T 3 = 25.6 s. This provided the subject with three retention intervals any one of which was equally likely to appear in any one trial. As previously noted, no further reference will be made to the recognition trials.
Procedure. All trials were initiated by the presentation of the stimulus number which lasted 0.5 s. Immediately following, the distractor task began with the presentation of a random two-digit 'base number ' (0.4 s). The subject 's task was to add and sub- tract single digits continuously, starting with the base number. A random sequence of

356 R. Schmidt and D. Vorberg
ones, twos, and threes was presented, single digits following the base at a rate of 0.4 digits per s. At the shortest retention interval, T1, 20 intervening operations had to be performed, at T 2 there were 35, and at the longest retention interval, T3, there were 50. After the subject had added or subtracted the last digit, the display went blank and this served as a cue for typing the end result of the intervening task (5.2 s). Follow- ing this, on recall trials, a visual cue prompted the subject to type his best guess of the stimulus within an interval of 8 s. The response was displayed on the same display used to present the stimuli. At the end of each trial, the subject judged the correctness of his response on a 10-point rating scale. There Was a pause of 3.4 s separating two trials. No feedback on the correctness of the response and the appropriateness of the rating was given.
A computer program generated the sequence of events and the stimulus materials used throughout the experiment. Two restrictions on the actual sequencing of the stimulus numbers were imposed. First, no repetit ions of stimulus numbers were allowed within three consecutive trials, and second, digits that were repeated on successive trials were shown in different positions.
The subject was trained for a period of approximately two weeks. During training the presentation rate of the digits for the distractor task was progressively increased. For the main experiment 36 daily sessions (Sundays excluded) were held. They con- sisted of one warm-up block with six trials being followed by four main blocks with 20 trials each. On the first two trials of a main block retent ion was randomly tested either by recall or recognition, all retent ion intervals being equally likely. The 18 trials included an equal number of recall and recognition trials, and each retention interval occurred three times with both types of test. At the beginning of a trial, the subject was unaware of whether he would be tested by recognition or recall. Two 5-minute pauses followed after the first and third blocks, and a 10-minute pause after the second. Sessions lasted about one hour.
Apparatus. The sequence of events generated by computer was stored on paper tape. During the sessions the tapes were fed into a digital system (Massey Dickinson) pro- grammed to control the experiment. The subject sat in front of a console containing both the display and a decimal keyboard. Stimuli were displayed on the front screen of three small digit-projectors (Zettler) mounted side by side. Single letters appeared 15 mm in width and 25 mm in height. A separate keyboard consisting of 10 labeled micr0switches was used to obtain the ratings. The experimenter followed the main sequence of events on a control board installed in an adjoining room. All responses were recorded on paper tape and subsequently analysed on a digital computer.
R e s u l t s
The analysis of recall performance is based on data obtained from the last 31 sessions 1. A preliminary analysis of the Overall mean percentage of correct responses scored during each session indicated that performance had become fairly asymptotic after the two- week training period. The percentage of incorrect responses on the distractor task was
1 Data from the other blocks could not be recovered from the paper tapes because of a coding error.

Multicomponent Models 357
relatively low at 3.37%, and a closer examination of these errors revealed that they dif- fered only in a few digits from the correct counting result. Consequently, it seemed safe to combine the data from all trials and sessions irrespective of the success on the dis- tractor. This resulted in a total of 1214 trials being evaluated. There are 415 observa- tions at the shortest retention interval T 1 (13.6 s), 407 observations at the intermediate interval T 2 (19.6 s) and 392 observations at the longest interval T 3 (25.6 s).
The relative frequencies for each of the 24 response types Y1Y2Y3 were computed separately for each retention interval. Since detailed tabulations of the resulting fre- quency distributions are difficult to interpret, they were transformed in several ways in order to bring out the main characteristics of the data. First, position and item- scoring procedures were applied. For position scoring all responses having either O, 1, 2, or 3 correct digit-responses in their correct position were determined. I tem scoring is based on a count of the responses having either 0, 1, 2, or 3 digits correct, irrespec- tive of their position in the response. Figure 2 shows the results. Forgetting is reflected in the decreasing frequency of all-correct responses (type 333, or score 3 by the position scoring procedure): At T 1 78.3% of all responses fall in this class, at T 2 67.6%, and at T 3 55.6%. This tendency is accompanied by a Corresponding increase in all-incorrect responses (type 111, or score 0 by the item-scoring procedure): The respective per- centages for T1, T2, and T 3 are 1.7%, 2.7%, and 6.1% respectively. Taken at face value, item scoring exposes a monotonic relationship between the 'degree of correctness' of the response and the likelihood of its occurrence - this is what would be expected on the basis of a multicomponent interpretation. However, note that position scoring emphasizes an aspect of the data that we would be ready to ascribe to an all-or-none theory; with this procedure high proportions of relatively efficient and poor responses are observed.
Table 1 shows the relative frequencies with which the single-digit positions of the stimulus numbers were recalled correctly (henceforth referred to as 'serial position functions'). One scoring procedure emphasizes digit and another position information. From the top of Table 1, it is seen that a primacy effect is obtained with a position- scoring procedure: The most significant digit is retained best and the least significant
Z ILl -~ .2 o LLI
U.I .8 >
U.I
, !
\ \ i I \ i
, .~ ~ -.:<,
0 1 2 3
T 2
! • t
T 2 } / 0 1 2 3
T 3
/ o o /
T3
,f / i
/ /
0 1 '2 3
NUMBER OF DIGITS RECALLED CORRECTLY
Fig. 2. Obtained and predicted rel- ative frequencies of numbers of correctly recalled digits with posi- tion (top row) and item scoring (bottom row). Predictions by dual-encoding model (solid line) and all-or-none model (broken line)

358 R. Schmidt and D. Vorberg
Table 1. Serial position functions: Relative frequencies of correct digit-responses for digits presented in the i th position. Predictions by dual-coding model in paren- thesis
Presentation position i
Retention interval (in s)
TI: 13.6 T2: 19.6 T3: 25.6
Position scoring
1 0.906 (0.936) 0.807 (0.784) 0.694 (0.674) 2 0.874 (0.853) 0.774 (0.765) 0.676 (0.673) 3 0.821 (0.787) 0.734 (0.721) 0.635 (0.626)
Digit transposed
1 0.011 (0.024) 0.055 (0.070) 0.077 (0.081) 2 0.034 (0.044) 0.083 (0.088) 0.097 (0.099) 3 0.048 (0.063) 0.072 (0.082) 0.071 (0.079)
T 1 entries based on 415, T 2 on 407, and T 3 on 392 observations
worst. This is consistent with all retention intervals used in this study; it is also consis-
tent with results by Bjork and Healy (1974) based on a study using four-letter se-
quences. Transposition errors are reported in the lower part of the table. With the ex- ception of the shortest retention interval, bowed serial-position functions emerge. The
digit in the middle proves to be most susceptible to losing the positional information
associated with it; its transposition rate relative to the extremes is found to be 40% both at T 2 and T 3. This is about the same value as that obtained with CCCs by Nelson and Batchelder (1969, Table 8, p. 104). This corresponds to the fact that relative transposition rates are little affected by relatively large changes in the retention intervals used (also cf. Estes, 1972, Figure 3, p. 169).
An additional method for presenting forgetting effects in our data is available if we rely on the mult icomponent interpretation of the memory trace. In Table 2 the mean confidence ratings obtained are reported both as a function of time and the number of digits correct (position scoring). It is seen that mean confidence increases with the correctness of the response and decreases with the length of the retention interval. Here it would be easy to attribute the latter effect to a changing bias on the part of the sub- ject. However, if Bower's interpretation is correct, confidence ratings should reflect the amount of guessing necessary to issue a certain type of response. According to this theory, the admittedly small but statistically significant larger confidence level associated with correct responses (score 3) at T 1 follows from our assumptions (One- sided large-sample Kolmogoroff-Smirnoff-Test, X 2 [2] = 8.44, p < .025, for the dif- ference between T 2 and T 1. However, X 2 [2] = 1.37, p > .10 for the difference be- tween T 3 and T2.) The interpretation is that subjects will have to guess more frequent- ly after long retention intervals than after short ones in order to perform perfectly correct at a surface level.

Mul t i componen t Models 359
Table 2. Mean confidence ratings
Retention interval (in s) Digits Correct a TI: 13.6 T2: 19.6 T3: 25.6
0 3.71 ( 2 4 ) 2.90 ( 4 8 ) 2.12 ( 7 9 ) 1 4.30 ( 2 7 ) 2.44 ( 3 4 ) 2.67 ( 5 8 ) 2 5.28 ( 3 9 ) 4.73 ( 3 3 ) 4.48 ( 3 7 ) 3 8.54 (325) 8 .32 (275) 8.20 (218)"
Number of observations in parenthesis a Position scoring
General Tbeoretical Analysis. The mul t i componen t models were f i t ted to the relative
frequencies of the 24 response categories by the min imum X 2 method. Chandler 's
(1965) subrout ine STEPIT was used for searching the parameter space of all models.
In general, the parameter values were determined separately for each re tent ion interval;
only the al ternative-code models with restrictive assumptions about rt, tit, and funct ions
thereof , were f i t ted in a single run of the minimizat ion procedure. Table 3 contains
the m i n i m u m X 2 values obtained. An inspection of the first heading in the table reveals
that the two basic single-code models do not fare well. The all-or-none and the simple
m u l t i c o m p o n e n t models lead to to ta l X2s that are decept ively large (1100.91 and
818.34, respectively). However , we must be careful with interpret ing these values in
Table 3. Minimum ×2-values for goodness-of-fit
Retention interval (in s)
Model TI: 13.6 T2:19.6 T3:25.6 Total df
Simple coding All-or-none 574.36 289.39 237.16 1100.91 66 Multicomponent 213.73 256.09 348.52 818.34 51 Multic. with retrieval 147.65 191.48 254.59 593.72 48 Threshold 37.15 26.73 28.36 92.24 48
Alternative coding a AC-U F 52.63 30.48 37.32 120.42 47 AC-Cf 53.67 31.18 37.67 122.52 47 AC-UC F 53.29 30.91 37.64 121.84 47
Dual-coding 47.35 31.07 30.61 109.03 48
General multicomponent 44.91 29.22 29.55 103.68 45 Ordered 46.57 29.65 34.59' 110.50 > 45 b Without positions 73.78 74.18 35.38 183.34 54
a The simple AC model was not evaluated; it implies the dual-encoding model. b Non-linear restrictions on parameter-values with unspecified number of dps.

360 R. Schmidt and D. Vorberg
a formal statistical sense as the number of response categories with low expected fre- quencies is large; e.g., for the all-or-none model 13 response categories out of 24 have expected frequencies smaller than 5 at each retention interval. A better strategy is to relate the goodness-of-fit measure for the alternative-, single-, and multiple-code models informally to that of the general multicomponent model (Total X 2 [45 ] = 103.0). This model, by necessity, yields the smallest x2-estimates of all models (the exception being the threshold version of the simple multicomponent model, which incorporates a totally different response assumption). The reason for this is that all its parameters (r, d, c i, Pi/i = 1, 2, 3) are freely estimated at each retention interval and not subject to any restrictions.
Given the evident failure of the single-code models with the standard sophisticated- guessing assumption, the question arises as to whether a combination of these models leads to a substantial improvement. Furthermore, it is interesting to ask wbicb combin- ation of unit and multicomponent encoding yields a closer approximation to the data: i.e., is the alternative or the dual-encoding model the better? It is readily seen from Table 3 that both types of combinations lead to a substantial reduction in X 2 values. Of the two interpretations the dual-encoding model proves to be superior to all alterna- tive-coding models, its X 2 value closely approaching the reference-x 2 provided by the general model (109.03, as compared to 103.68). We therefore conclude that the dual- encoding model provides the best fit of all our psychologically interpretable models incorporating standard response assumptions.
To illustrate the actual predictive power of the dual-code model its predictions are compared with that of the all-or-none model and the relative frequencies of responses showing a determined number-of-digits-correct. Figure 2 indicates that the model pro- vides a relatively close fit to this data. This holds regardless of the procedure used for scoring the responses. By way of contrast, the discrepancies between the predictions of the all-or-none model and the data are highly systematic. Table 1 compares the serial-position functions predicted by the dual-encoding model with those actually observed. As can be seen, there is a close correspondence for the serial-position func- tions based on the strict position-scoring procedure. It is also interesting to note that the transposition errors closely follow the pattern of vaues observed; however, there is a tendency for the model to over-predict the transposition rate of the digit compo- nents at all retention intervals.
Further results are reported in Table 3. First, models that do not incorporate rep- resentational assumptions about the retention of the positions at which the digits were shown do not provide a satisfactory account of the data. This we conclude from an analysis of the general multicomponent model based on the restriction that all the con- ditional position parameters Pi are equal to one. The resulting X 2 of 183.34 rules out Conrad's pure position-guessing model (Conrad, 1964), at least for the materials used in our study. Second, the interpretation of the component parameters e i and Pi leads us to assume decreasing values for them as the retention interval is increased. Another analysis of the general multicomponent model, with ordinal restrictions imposed on the multicomponent parameters, does not lead to an obvious impairment in goodness- of-fit. Only at T 3 is there a tendency for the monotonicity restriction to have effect. The reason is apparent from Table 4 which contains the actual parameter estimates obtained for the unrestricted dual-encoding model. Observe that the retention

Multicomponent Models 361
Table 4. Parameter estimates for dual-encoding model
Retention interval (in s)
Parameter 13.6 19.6 25.6
Digit components
c 1 0.544 0.445 0.254 c 2 0.518 0.435 0.295 c 3 0.311 0.262 0.111
Position components
P 1 1.000 0.722 0.875 P2 0.776 0.506 0.646 P 3 0.076 0.337 1.000
Unit retrieval
d t 0.715 0.646 0.536
parameters for digit information nicely decrease in value as the retention interval is in- creased from T 1 to T 2 and T 3. Departures from monotonici ty are observed for the positional parameters, especially at the long retention interval T 3. Further studies will
have to show whether this is due to sampling error, or whether it represents a systematic effect.
A final thought applies to the results obtained with the simple multicomponent model with response threshold. It obviously fits the data best of all models, and it cer- tainly is tempting to conclude that it rules out all the elaborate models considered so far. Only by including additional, independent information on the confidence ratings
obtained from our subject shall we be able to discredit the threshold model. The ratio- nale is that this model predicts very little discrimination-in-confidence for the response
types falling below the estimated threshold value. Since the estimated expected-value of the threshold falls between three and four components retained at all retention in- tervals, we would expect our subject to discriminate between responses that are given
conditionally on the theoretical memory states 333, 332, 323, 233, 322, 232, and 223 only. However, the data shows this to be wrong - in fact our subject accurately dis- criminates between responses that are incorrect in all but a few components.
Prediction of Confidence Ratings. In order to evaluate the validity of the models discus- sed so far, it was necessary to derive the guessing probabilities for each response type conditionally on the theoreticalmemory states. However, it is possible to reverse this
procedure and to compute the conditional probabilities of the memory states condition- ally on the observed response types. From these probabilities, it is straightforward to compute the expected number of components retained (0 to 6) given an observable response type. This measure essentially removes the effects of guessing from the re- sponse types and it amounts to a very useful transformation of the data with regard to the following: The expected number of components retained is assumed to be closely related to independent indicators of memory performance not used in the computation of the parameter values themselvesl Examples of such indicators are the confidence
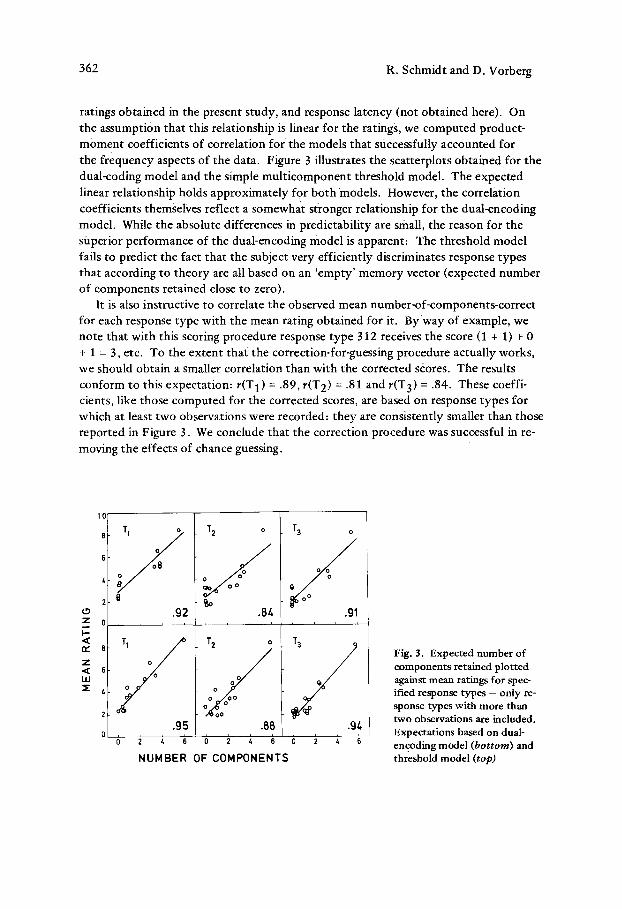
362 R. Schmidt and D. Vorberg
ratings obtained in the present study, and response latency (not obtained here). On the assumption that this relationship is linear for the ratings, we computed product- moment coefficients of correlation for the models that successfully accounted for the frequency aspects of the data. Figure 3 illustrates the scatterplots obtained for the dual-coding model and the simple mul t icomponent threshold model. The expected linear relationship holds approximately for both models. However, the correlation coefficients themselves reflect a somewhat stronger relationship for the dual-encoding model. While the absolute differences in predictabil i ty are small, the reason for the superior performance of the dual-encoding model is apparent: The threshold model fails to predict the fact that the subject very efficiently discriminates response types that according to theory are all based on an 'empty ' memory vector (expected number of components retained close to zero).
It is also instructive to correlate the observed mean number-of-components-correct for each response type with the mean rating obtained for it. By way of example, we note that with this scoring procedure response type 312 receives the score (1 + 1) + 0 + 1 = 3, etc. To the extent that the correction-for-guessing procedure actually works, we should obtain a smaller correlation than with the corrected scores. The results conform to this expectat ion: r(T 1) = .89, r(T 2) = .81 and r(T 3) = .84. These coeffi- cients, like those computed for the corrected scores, are based on response types for which at least two observations were recorded: they are consistently smaller than those reported in Figure 3. We conclude that the correction procedure was successful in re- moving the effects of chance guessing.
10
8
/.
2
f -
r y 8 Z
LLI
TI /
o
@
.92 J
/o .95
0 2 4 6
T 2 o
o ° °
.8/.
T 2 o
/ o o
° o o ° °
.88
T3 o
~ o ° .91
T3 o / .9/.
2 & 6 0 2 ~. 6
NUMBER OF COMPONENTS
Fig. 3. Expected number of components retained plotted against mean ratings for spec- ified response types - only re- sponse types with more than two observations are included. Expectations based on dual- encoding model (bottom) and threshold model (top)

Multicomponent Models 363
Discussion
The main purpose of this paper is to show how Bower's multicomponent theory of the memory trace can be extended to account for detailed aspects in the retention of num- bers. Explicit assumptions about the representation, retention, and the response-genera- tion process serve to raise several theoretical questions. It should be clear that we chose to analyze our data by varying only one basic type of representation that seemed most natural to us; however, other types immediately suggest themselves. For example, the dependency postulated to hold between digit and position information may be reversed along the lines suggested by Estes (1972). Also, inter-item associations might be consid- ered explicitly. Our retention assumptions raise further theoretical issues: What is the function relating component-parameters to the number of digits presented? Is it possible to demonstrate empirically that the retention-parameters remain invariant if only a subset of the digits presented in the experiment may appear at a certain position? (Cf. Bower, 1967, Figure 10, p. 253, for such a result.) Clearly, a comparison among these alternatives and a careful study of the problems involved is beyond the scope of the present investigation.
One aspect of the representation chosen here appears especially debatable: Can the absolute value of a certain digit position actually be neglected? Is the forgetting of digit information truly all-or-none? On the face of information obtained from a study on the internal representation of digits (Shepard, Kilpatrick, and Cunningham, 1975) and with regard to what was said in the introduction about the evidence favoring multi- component representations for very simple items, this assumption may seem unduly restrictive. We would like to point out, however, that very little is known about the actual error committed in different experimental contexts. To illustrate this, consider Nelson and Batchelder's conclusion that 'letters are forgotten in an all-or-none fashion' (Nelson and Batchelder, 1969, p. 96). In their study, experimental conditions appear to have precluded a more than superficial psychological processing of simple letters and digits. Unfortunately, we cannot test the assumptions involved directly in our data as the detailed information needed was lost in the process of data registration. How- ever, further studies are under way that investigate this issue closely.
At an empirical level it is concluded that the dual-encoding model successfully predicts the main features of the data. Recall that this model allows for a redundant encoding of the stimulus: Both a unit-code and a componential representation are assumed to be stored in the memory vector. With this model, the relative frequencies of the response types were fitted accurately enough to allow detailed predictions of summaries of the data, like position- and item-scores, and serial-position functions. This amply demonstrates the internal validity of the model. As regards external valid- ity, an attempt at predicting the mean confidence ratings associated with the response types observed in the experiment was successful. A simple linear relationship holds between the theoretically expected number of components retained and the observed mean ratings. Approximately 80% of the variance was explained by this procedure. We know of no results in the literature with which to compare this finding; however, the simplicity of the functional rule and the strength of the relationship found appear to be very encouraging. When interpreting these findings, it should be kept in mind that rating performance was predicted by means of an entirely parameter-free

364 R. Schmidt and D. Vorberg
procedure. This increases our confidence in the correctness of the basic memory as- sumption adopted in this work, given the fact that very different performance measures strongly support them.
After this positive overall appraisal of the theory, we can now enter into a discussion of certain limitations of the dual-encoding model. From the second data points in the panels of Figure 2 (position scoring) and from Table 1 (bot tom part) it is seen that the model overpredicts the actual transposition rate in the data. Digits somehow stick closely to the positions at which they were presented. This suggests a more general conjecture: It is possible that there is more association among the elements of the stimulus than can be accounted for theoretically. In order to test this, Phi-coefficients of correlation for all pairs of digit-positions in the three-digit numbers (excluding transpositions) were computed. The same procedure was followed with the predicted frequencies of correct and incorrect responses. As might be expected, the average correlation-coefficient (over position-pairs and retention intervals) observed is slightly larger than that predicted: ~0ob s = .49 vs. ~0theo = .41. Both the observed and the pre- dicted mean Phi-coefficients increase with the retention interval due to a relatively rapid increase in the number of incorrect digit pairs. Table 5 contains the details of this correlational analysis. In the data there is a higher correlation associated with the contiguous pairs 1,2 and 2,3 than with the remote pair 1,3. Theory underpredicts the relatively high correlation between the contiguous pairs, and it overpredicts the low one holding for the remote pair. While transpositions were excluded from this analysis, similar considerations apply to them. It may be shown that the theory does not predict very well the fact that transposition rates are relatively high among contiguous positions and relatively low among the remote first and third position. Thus, while patterns of responding reported by Estes (1972) in terms of 'distance functions' are present in our data, our theory does not deal with them in a satisfactory way.
To conclude this discussion, we would like to argue that despite its limitations a variant of our general mul t icomponent theory, the dual-encoding model, was success- ful in predicting the global patterns of responding in a memory task that involved the re tent ion of three-digit numbers. If nothing else, the theory provides us with a deeper understanding of the detailed relationship that holds for all aspects of our data. Further to this, the fact that confidence ratings were successfully related to the mul t icomponent trace should prove encouraging to researchers interested in an approach to human memory that encompasses a variety of performance measures.
Table 5. Correlation among digit-pairs
Retention interval (in s) Digit- pair TI: 13.6 T2:19.6 T3:25.6 Mean
(1, 2.) 0.62 (.26) 0.52 (.36) 0.67 (.43) 0.60 (.35) (2, 3.) 0.45 (.41) 0.49 (.46) 0.63 (.50) 0.52 (.46) (1., 3.) 0.24 (.38) 0.40 (.43) 0.42 (.50) 0.35 (.44) Mean a 0.44 (.35) 0.47 (.42) 0.57 (.48) 0.49 (.41)
Phi-coefficients are based on 390, 362, and 340 observations in T1, T2, and T3, respectively. Pre- dicted values by dual-encoding model in parenthesis a Unweighted arithmetic means

Multicomponent Models 365
Appendix
There foUow two examples of the derivation of the theoretical probabilities of observing response types YIY2Y 3. These derivations are based on the simple multicomponent model. Extensions to the other models are immediate from an examination of Figure 1 and from a consideration of the respective parameter restrictions on r t and d t.
1. P(111). Since the all-incorrect response 111 can only occur with the single state 111, it holds true that P(111) = P(111/111)P(111). To obtain P(111/111) there are (~) possibilities of selecting three~ out of nine possible digits (zeros excluded, and all digits different). There are (~) favorable stimulus selectionsL ,inv°lving only digits not presented in the stimulus. Therefore, P(111/111) equals (~)/(~) i.e. 5/21. P(111) is obtained from the product (5/21)~-1~-273, where ~ = 1 - c.
2. P(122). To obtain the probability of responses in which the digit presented first is missing and the other two appear in positions different from those in which they were initially shown, we first note that there are four multicomponent states leading to this kind of response: 122, 121,112 and 111. We need to know the respective conditional guessing probabilities for response type 122, given these states. P(122/122) is found to be (2/3 !)6/(7), that is 2/7: There are 7 possibilities for guessing a single digit, given that two are known to the subject, and there are six 'favorable' ways of guessing this digit incorrectly. Furthermore, given a set of two correct and a single incorrect digit, there are 2 permutations out of 3! which conform to the observed type 122. On similar considerations, P(122/121) equals (2/3 !)6/(~), or 1/14. Also, P(122/112) equals P(122/121), and P(122/111) is obtained from the expression (2/3!)/ (9), i.e., 1/42. By appropriately weighting these probabilities, an expression for the unconditional probability P(122) is obtained:
P(122) = 2/7 ~1c2~2c3ff 3 + 1/14 (~'1c2P2C 3 + CLC2C3P 3) + 1/42 ClC2C 3
wherec '= 1 - c , ~ = 1-p.
References
Bjork, E.L., Healy, A.F.: Short-term order and item retention. J. Verb. Learn. Verb. Behav. 13, 80--97 (1974)
Bower, G.H.: Application of a model to paired associates learning. Psychometrica 26, 255 -280 (1961)
Bower, G.H.: Multicomponent theory of the memory trace. In: The psychology of learning and motivation, K.W. Spence and J.T. Spence (eds.) pp. 229-235 . New York: Academic Press 1967
Chandler, J.P.: Subroutine Stepit: An algorithm that finds the values of parameters which minimize a given continuous function. Quantum Chemistry Program Ex- change, Indiana University, Bloomington, Ind., 1965
Conrad, R.: Acoustic confusions in immediate memory. Br. J. Psychol. 55, 7 5 - 8 4 (1964)
Estes, W.K.: An associative basis for coding and organization in memory. In: Coding processes in human memory, A.W. Melton and E. Martin (eds.), pp. 161-190. Washington, D.C.: V.H. Winston & Sons 1972

366 R. Schmidt and D. Vorberg
Estes, W.K.: Phonemic coding and rehearsal in short-term memory for letter strings. J. Verb. Learn. Verb. Behav. 12,360--372 (1973)
Jones, G.V.: A fragmentation hypothesis of memory: Cued recall of pictures and of sequential position. J. Exp. Psychol. Gen. 105,277-293 (1976)
Nelson, T.O., Batchelder, W.H.: Forgetting in short-term recall: All-or-none or decre- mental. J. Exp. Psychol. 82, 96-106 (1969)
Rumelhart, D.E.: A multicomponent theory of confusions among briefly exposed alphabetic characters. (Tech. Rep. CHIP - 22). San Diego: University of California, Center for Human Processing 1971
Rumelhart, D.E., Siple, P.: The process of recognizing tachistoscopically presented words. Psycho. Rev. 81, 99--118 (1974)
Schmidt, R., Vorberg, D.: Das Kurzzeitged~ichtnis beim Reproduzieren und Wieder- erkennen (Bericht 69-1) . Darmstadt (West Germany): Technische Hochschule Darmstadt, Institut fiir Psychologie, March 1969
Shepard, R.N., Kilpatric, D.W., Cunningham, J.P.: The internal representation of numbers. Cogn. Psychol. 7, 82-138 (1975)
Sperling, G., Speelman, R.G.: Acoustic similarity and auditory short-term memory experiments and a model. In: Models of human memory, D.A. Norman (ed.) New York: Academic Press 1970
Vorberg, D., Schmidt, R.: A testable property of some discrete state models for recog- nition memory. Psychol. Rev. 82, 316--324 (1975)
Wickens, T.D., Greitzer, F.L.: Second responses in paired-associate learning. J. Math. Psychol. 12, 225-261 (1975)
Received January 2, 1979
Note Added in Proof
The main results presented in this paper were firstly reported at the '16. Tagung ex- perimentell arbeitender Psychologen' in Giessen, 18.--20.3.1974. While there have been only a few contributions to this area lately, we feel that Jones' (1976) idea of the memory trace breaking up into 'fragments' is relevant. Applied to our stimulus material, it leads one to assume intermediary fragment types above those assumed in this paper, i.e. single digit and unitary number codes. Future work might solve the problem of how such a generalization may be parametrized and tested.




















