Unusual resonators: Plasmonics, metamaterials, and random media

Journal of General Virology (1991), 72, 2129-2141. Printed in Great Britain 2129
Molecular organization of Junin virus S RNA: complete nucleotide sequence, relationship with other members of the Arenaviridae and unusual secondary structures
Pablo D. Ghiringhelli, Rolando V. Rivera-Pomar, Mario E. Lozano, Oscar Grau and Victor Romanowski*
Area de Quimica Biol6gica y Biologia Molecular, Facultad de Ciencias Exactas, Universidad Nacional de la Plata, Calle 47 y 115 (1900), La Plata, Argentina
In this study, overlapping cDNA clones covering the entire S RNA molecule of Junin virus, an arenavirus that causes Argentine haemorrhagic fever, were gener- ated. The complete sequence of this 3400 nucleotide RNA was determined using the dideoxynucleotide chain termination method. The nucleocapsid protein (N) and the glycoprotein precursor (GPC) genes were identified as two non-overlapping open reading frames of opposite polarity, encoding primary translation products of 564 and 481 amino acids, respectively. Intracellular processing of the latter yields the glyco- proteins found in the viral envelope. Comparison of the Junin virus N protein with the homologous proteins of other arenaviruses indicated that amino acid sequences are conserved, the identity ranging from 46 to 76%. The N-terminal half of GPC exhibits an even higher degree of conservation (54 to 82%), whereas the C- terminal half is less conserved (21 to 50%). In all
comparisons the highest level of amino acid sequence identity was seen when Junin virus and Tacaribe virus sequences were aligned. The nucleotide sequence at the 5' end of Junin virus S RNA is not identical to that determined of the other sequenced arenaviruses. How- ever, it is complementary to the 3'-terminal sequences and may form a very stable panhandle structure (AG -242.7 kJ/mol) involving the complete non-coding regions upstream from both the N and GPC genes. In addition, a distinct secondary structure was identified in the intergenic region, downstream from the coding sequences; Junin virus S RNA shows a potential secondary structure consisting of two hairpin loops (AG-163-2 and -239-3 kJ/mol) instead of the single hairpin loop that is usually found in other arenaviruses. The analysis of the arenavirus S RNA nucleotide sequences and their encoded products is discussed in relation to structure and function.
Introduction
Junin virus is the aetiological agent of Argentine haemorrhagic fever, the clinical symptoms of which include haematological, neurological, cardiovascular, renal and immunological alterations. The mortality rate may be as high as 30~, but early treatment with immune plasma reduces this to less than 2 ~ (Maiztegui et al., 1979; Enria et al., 1986). A wide variation in the annual number of cases in Argentina occurs, ranging from 100 to 4000. Since its recognition in the early 1950s, the disease has spread from an area of 16000 km 2 to an area greater than 120000 km 2 of the richest farming land in the country, with a population of approximately 2 million (Maiztegui et al., 1986). The major rodent hosts for Junin virus are Calomys musculinus and C. laucha (Maiztegui, 1975), although infection has been detected on occasion in Mus musculus, Akodon azarae and Orizomys flavescens
(Sabattini et al., 1977). The human population at risk is composed mainly of field workers, infection occurring through cuts or skin abrasions, or inhalation of dust contaminated with the urine and saliva of infected rodents. A high degree of variation in virulence and clinical pattern has been reported for different isolates of Junin virus (Maiztegui, 1975; McKee et al., 1985).
Junin virus is a member of the New World arenavirus group or Tacaribe complex (Johnson et al., 1973; Pfau et al., 1974). Although Junin and Tacaribe viruses have been isolated from different hosts in distant geographical locations, they exhibit a high degree of serological cross- reactivity; other arenaviruses are also serologically related to each other to different extents. All members of the Arenaviridae family share morphological and bio- chemical properties. They are enveloped ssRNA viruses, the genome consisting of two RNA species, large (L, approximately 7 kb) and small (S, approximately 3-5 kb).
0001-0170 © 1991 SGM

2130 P. D. Ghiringhelli and others
The L RNA encodes two proteins, a large L polypeptide presumed to be the RNA polymerase and a small zinc finger-like protein (Salvato & Shimomaye, 1989; Salvato et al., 1989; Iapalucci et al., 1989a, b). The S RNAs of several arenaviruses have been sequenced and shown to have various common features, one being that the nucleocapsid protein (N) and the precursor of the envelope glycoproteins (GPC) are encoded in an ambisense manner (Bishop, 1988).
N (approximately 63K) is translated from a comp- lementary sense (c) mRNA species encoded by the 3' half of the viral S RNA (Auperin et aL, 1984a, b; Romanowski & Bishop, 1985; Clegg & Oram, 1985; Franze-Fernandez et al., 1987). GPC (approximately 57K in the unglycosylated form) is translated from a viral sense (v) mRNA corresponding to the 5' half of the viral S RNA (Auperin et al., 1984c, 1986; Romanowski et al., 1985; Franze-Fernandez et al., 1987).
To characterize the genome of Junin virus and to provide fundamental reagents for detailed molecular, pathogenetic and epidemiological studies, we derived cDNA clones from viral genomic RNA. Here, we report the complete nucleotide sequence of Junin virus S RNA, and analyse its genomic organization and relationship to closely and distantly related arenaviruses.
Methods
Virus and cell lines. Junin virus strain MC2 (from the National Institute of Microbiology, Buenos Aires, Argentina) (De Mitri & Martinez Segovia, 1971) was plaque-cloned in Vero cell monolayers and stocks were grown in BHK-21 cells (both from the ATCC). When 50% confluent, monolayers were infected with 0.1 p.f.u, virus/cell and incubated at 37 °C in Eagle's MEM containing non-essential amino acids and 10% calf serum. The medium was changed to the above containing 2% calf serum 1 day post-infection (p.i.). Virus was recovered and purified from supernatant media collected every 8 h, 3, 4 and 5 days p.i. (Grau et al., 1981 ; Rosas et al., 1988).
Preparation o f viral RNA. RNA was extracted from virions using guanidinium thiocyanate and purified by ultracentrifugation through a 5-7 M-CsCI cushion by the method of Chirgwin et aL (1979). The RNA pellet was resuspended in 0.5% Sarkosyl, phenol-extracted, and reprecipitated with 0.3 M sodium acetate and 2.5 volumes of ethanol. The final pellet was resuspended in water and stored in aliquots at - 7 0 °C.
Synthesis and cloning o f cDNA. A synthetic oligonucleotide comp- lementary to the 19 nucleotide sequence conserved at the 3' terminus of arenavirus S RNA (Auperin et aL, 1982) was phosphorylated and used to prime cDNA synthesis. The procedure was similar to that described by Gubler & Hoffman (1983). The double-stranded cDNA was blunt- ended using T4 DNA polymerase, inserted into the HincII site of the pUC9 plasmid (Vieira & Messing, 1982) and cloned in Escherichia coli strain DH5cc
Screening of recombinant clones was performed by colony hybridiz- ation (Grunstein & Hogness, 1975) using a short copy cDNA probe (Bishop et al., 1982). Plasmid DNA was prepared from hybridization- positive clones, analysed by gel electrophoresis after restriction enzyme digestion and tested by Northern blotting (Maniatis et aL, 1982).
Since full-length cDNA inserts were not obtained, a sequential cloning strategy was employed to generate overlapping clones encompassing the complete S RNA sequence. To this end, the nucleotide sequence information obtained from the first set of clones was used to synthesize an oligonucleotide complementary to their distal end. This specific oligonucleotide was used to further extend the cDN A using Junin virus S RNA as the template. EcoRI linkers were added to this double-stranded cDNA which was ligated into the EcoRI site of pUClY Screening of recombinants was performed using a nick- translated restriction fragment derived from the first group of clones. A third set of clones was generated using the same strategy (see Fig. 2).
Sequence analysis. The nucleotide sequences of the cDNA inserts were determined by the dideoxynucleotide chain termination method of Sanger et al. (1977) using a modified T7 DNA polymerase (Sequenase, USB). The original cDNA inserts were subcloned into M13mpl8 and -mpl9, and the ssDNAs were used as templates for sequencing (Yanisch-Perron et al., 1985). The first 929 nucleotides of Junin virus S RNA were sequenced on both cDNA strands using the chemical cleavage procedure of Maxarn & Gilbert (1980). The 5'end sequence of Junin virus S RNA was confirmed using primer extension with avian myeloblastosis virus reverse transcriptase.
The sequence information was processed on a personal computer using the DNASIS (Hitachi Software Engineering) program and on a VAX computer using the package from the Genetics Computer Group (GCG, Madison, Wis., U.S.A.).
Northern blot analysis. Viral RNA was denatured with 10 mM- CHaHgOH and electrophoresed on a 1% agarose gel according to the method of Bailey & Davidson (1976). The gel was soaked in 14 mM- 2-mercaptoethanol and 0.5 ~tg/ml ethidium bromide to check the quality of the RNA preparation, and transferred onto a GeneScreen nylon membrane (NEN) by capillary blotting. The blot was processed according to the manufacturer's specifications and hybridized to different 3'-P-labeUed cDNA probes prepared by nick translation (Maniatis et aL, 1982) or multipriming (Feinberg & Vogelstein, 1983) of the recombinant plasmid DNAs. Northern blots were used to determine the identity of the cDNA clones, which were analysed further by nucleotide sequencing.
Results
Molecular cloning and nucleotide sequence o f Junin virus S R N A
Using synthetic oligonucleotides as primers for cDNA synthesis, three sets of overlapping clones were obtained in a sequential strategy, as described in Methods.
One set of cDNA clones was generated using the primer 5' CGCACAGTGGATCCTAGGC Y, comp- lementary to the Y-terminal sequence of arenavirus S RNA species (Auperin et al., 1982), and shown to anneal specifically to either S or L RNA when analysed by Northern blot hybridization (Fig. 1).
Based on sequence data reported previously for other arenavirus L and S RNAs (Auperin et al., 1982; Salvato et al., 1989; Iappalucci et al., 1989a) these results probably indicate that the recovery of L RNA cDNA clones was due to the similarity of the 3' end sequences of L and S RNAs (Romanowski & Bishop, 1985).

Junin virus S R N A 2131
1 2 3 4 Junin virus G P C
The first AUG codon of the v S RNA, found at nucleotides 88 to 90, initiates a long ORF that terminates at an in-frame UAA translational termination signal at positions 1531 to 1533. A second A U G is located seven codons downstream from the first in the same reading frame; however, based on the consensus sequences reported by Kozak (1984) (i.e. CCACCAUGG), the first A U G is considered to be the true initiation codon because a G is found at positions + 4 and - 3, and there is also a C at position - 2 . The Mr calculated for the 481 amino acid translation product (55 126) is lower than that estimated for the intracellular GPC, which undergoes cotranslational glycosylation (De Mitri & Martinez Segovia, 1985; Rustici, 1984), by gel electrophoresis.
Eight potential N-glycosylation sites are found in the GPC sequence (Fig. 3). Whether all are used for the attachment of carbohydrate side-chains is not known.
Fig. 1. Northern blot analysis of Junin virus cDNA clones. RNA extracted from purified Junin virus MC2 particles was denatured with 10 mM-CH3HgOH and electrophoresed on a 1 ~ agarose gel (50 ng, lanes l and 3, 500 ng, lanes 2 and 4). The RNA was transferred onto a GeneScreen membrane and hybridized to DNA probes generated by nick translation of plasmids pJUN251 (lanes 1 and 2) and pJUN9 (lanes 3 and 4), representing Junin virus L and S RNA sequences, respectively. Positions of the viral L and S RNAs, as well as the ribosomal RNAs, were visualized by ethidium bromide staining and u.v. illumination prior to transfer onto the membrane.
The nucleotide sequences of some selected S cDNA clones, shown in Fig. 2, were determined using mainly the dideoxynucleotide chain termination method (Sanger et al., 1977). In this analysis all the overlapping regions were identical and the complete sequence of Junin virus S RNA contained 3400 nucleotides (Fig. 3). Primer extension using an oligonucleotide complemen- tary to nucleotides 144 to 195 of the S RNA confirmed the 5' end region of this viral RNA molecule. The size of this RNA species is in agreement with the estimate based on its electrophoretic migration (Afi6n et al., 1976) and coincides with those of other arenaviruses (Auperin et al., 1984; Romanowski et al., 1985; Franze-Fernandez et al., 1987; Auperin & McCormick, 1989). It has a base composition of 26-6~ A, 21.0~o G, 23"8~o C and 28.6~ U.
Analysis of the nucleotide sequence indicated two open reading frames (ORFs), encoding N and GPC, respectively, arranged in an ambisense manner, a characteristic of arenavirus RNAs. These coding assign- ments were confirmed by Western blot analysis of the products generated by each ORF inserted into an expression vector and using anti-Junin virus monoclonal antibodies (MAbs) (data not shown).
Amino acid sequence homology o f arenavirus G P C gene products
The Junin virus GPC amino acid sequence was aligned with the other arenavirus GPCs as shown in Fig. 4. Best- fit alignment showed that amino acid sequence identity is concentrated in two regions: 53 residues at the N terminus and the C-proximal half of GPC. Buchmeier et al. (1987) have demonstrated that in the infected cell lymphocytic choriomeningitis (LCM) virus GPC is cleaved at or near the Arg 262-Arg 263 to yield the proteins G 1 (N-terminal half) and G2 (C-terminal half). By analogy, Junin virus GPC should be cleaved at or near the homologous Arg 243-Arg 244 sequence.
The G1 and G2 regions of GPC defined by the dibasic amino acid sequence between positions 243 to 286, depending on the virus, exhibit quite different degrees of sequence similarity. The amino acid sequences of G l show few clusters of sequence conservation among all the arenaviruses, which are concentrated particularly between positions 1 and 53, and 84 and 97.
This sequence comparison shows that Junin and Yacaribe virus G1 sequences are more similar (50~) than those of the other pairs analysed (Table 1). The 53 N-terminal residues of Junin virus G1 are best aligned with the first 57 residues of the Tacaribe virus G1 sequence. The comparison shows only four non-con- servative amino acid changes and an insertion of four amino acids in the Tacaribe virus sequence (Fig. 4). The sequence similarity is even higher for the G2 poly- peptide, where 8 2 ~ of the amino acids are identical in nature and position (92~o identity when conservative amino acid changes are included). Comparison of the Junin virus G2 sequence with those of the other

2132 P. D. Ghiringhelli and others
1 k b I
2 kb 3 kb
P
vRNA 5' j I Hf P Hf Hf Hf BH
, ~ 1 1 1 Primer extension
pJUN9 t _11
pJUN63 L •
pJUN42 L • ~ D
pJUN433 L •
B D
,p II
J
pJUN58 I II
t I I II
J
~.......~.,...~
Fig. 2. Cloning and sequencing strategy of Junin virus S RNA. The S RNA nucleotide sequence is represented in the viral sense. Some of the overlapping clones, spanning the entire S RNA, are shown as rectangles. Phosphorylated synthetic oligonucleotides used to prime cDNA synthesis are shown as black boxes at the beginning of each clone. Subcloning into M 13mp 18 and -mp 19, using the restriction sites indicated (P, PstI; X, XbaI; H, HinclI; E, EcoRI; EV, EcoRV ; B, BgllI; HF, Hinfl; BH, BamHI), was performed to generate nucleotide sequence data by the method of Sanger et al. (1977). The sequences were obtained using Sequenase as shown by the continuous arrows. A region of the sequence (nucleotides 2472 to 3400) determined by the chemical cleavage method of Maxam & Gilbert (1980) is indicated by broken arrows representing the restriction fragments involved. The thick arrow indicates the 5' end sequence confirmed by primer extension using a synthetic oligonucleotide complementary to Junin virus S RNA nucleotides 143 to 194.
Table 1. Sequence identity* o f arenavirus structural proteins
Virus?
GPC
N G1 G2
TAC PIC LCM LAS TAC PIC LCM LAS TAC PIC LCM LAS
JUN 76 54 49 47 50 20 21 21 82 57 53 57 TAC 54 48 48 24 16 17 51 51 52 PIC 49 49 20 26 52 54 LCM 60 27 69
* The amino acid sequences of all the proteins were aligned and compared pairwise. The figures indicate the percentage of identical amino acid residues in identical positions.
? JUN, Junin virus; TAC, Tacaribe virus; PIC, Pichinde virus; LAS, Lassa virus.
Fig. 3. Nucleotide sequence of Junin virus S RNA. The 3400 nucleotide sequence of the v S RNA of Junin virus is presented. The amino acid sequences of the GPC and N primary translation products are shown above and below the corresponding ORFs. The start and orientation of each ORF are indicated by arrows labelled N and GPC. The translation termination codon of GPC and the corresponding anticodon of N (encoded in the c sequence) are marked by asterisks. Nucleotide numbering starts from the 5' end of the S RNA and the amino acid residue numbering of GPC and N from the N terminus of each protein. The inverted repeats in the intergenic region are boxed.

Junin virus S RNA 2133
GPC M G Q F I S F M Q E I
I UGcAGUAAGGGGAUCCUAG•CGAUUUUGGUAACGCUAUAAGUUGUUACUGcUUUCUAUUUGGACAAcAUcAAACCAUCUAUUGUACAAUGGGGcAAUUcAUCA•cUUCAUGcAAGAAAUA
12 P T F L Q E A L N ! A L V A V S L I A I ! K G V V N L Y K S G C S ! L D L A G R 121 cCUAccUUUUUG•AGGAAGCUcUGAAUAUUGcUCUUGUUGCAGUcAGUCUCAUUGCcAUcAUUAAGGGUGUAGUAAACcUGUAcAAAA•UGGUUGUUCAAUUCUUGAUCUAGCAG•AAGA
52 S C P R A F K I G L H T E V P D C V L L Q W W V S F S N N P H D L P L L C l" L N 241 UcCUGCCCGAGAGcUUUUAAAAUcG•ACUGCACACA•AGGUUCCAGACUGUGUCCUUCUUCAAUGGUGC•]UCUcUUUUUCCAACAAUCCAcAUGACCUGcCUCUGUUGUGUACCUUAAAC
92 K S H L Y I K G G N A S F K I S F D D I A V L L P E Y D V I I Q H P A D M $ W C 361 AAGAGCCAUCUUUACAUUAAGGGGGGCAAUGcUUCAUUcAAGAUcAGCUUUGAUGACAUCGCAGUGUUGUUAcCAGAAUAUGACGUUAUAAUU CA GCAU CC GGCAGAUAUGAGCUGGUGU
132 S K S D D Q I R L S Q W F M N A V G H D W Y L D P P F L C R N R T K T E G F I F 481 U•UAAAAGUGAUGAUCAAAUUAGGCUGUCUCAGUGGUUCAUGAAUGcUGUGGGGCAUGAUUGGUAUCUAGAcCCACCAUUUCUGUGUAGGAACCGUAcAAAGAcAGAAGGcUUCAUCUUU
172 Q V N T S K T G I N E N Y A K K F K T G M H H L Y R E Y P D S C L D G K L C L M
601 CAAGUCAAUA•CUCCAAGA•UGGUAUCAAUGAAAA•UAUGC•AAGAAGUUUAAGACUGGUAUGCACCAUUUAUAUAGAGAAUACCCCGACUCUUGCUUGGAUGGCAAACUGUGUUUGAUG
212 K A Q P T S W P L Q C P L D H V N T L H F L T R G K N I Q L P R R S L K A F F S 721 AA•GcAcAAcCCACCAGUUGGcCUcUCCAAUGUcCACUUGACCAUGUCAACAcAUUACAUUUcCUcACAAGAGGCAAGAACAUUCAGCUUcCAAGGAGGUCUUUAAAAGCAUUCUUUUCc
252 W S L T D S S G K D T P G G Y C L E E &V M L V A A K M K C F G N T A V A K C N L 841 UGGUCUcUGACAGAcUcAUCCGGcAAGGACAcCccUGGAGGCUAUUGUCUAGAAGAGUGGAUGCUCGUUGCAGCCAAAAUGAAGUGUUUUGGCAAUACUGCUGUAGCAAAAUGCAAUCUG
292 ~ H D S E F C D M L R L F D Y N K N A I K T L N D E T K K Q V N L M G Q T I N A 961 AAUCAUGACUCUGAAUUCUGUGACAUGCUGAGGCUUUUUGAUUAcAACAAAAAUGCUAUCAAAACCUUAAAUGAUGAAACUAAGAAACAAGUAAAUCUGAU•GGACAGACAAUCAAUGCG
332 L I S D N L L M K N K ! R E L M $ V P Y C N Y T K F W Y V N H I" L S G Q H S L P 1081 cUGAUAUCUGACAAUUUAUU•AUGAAAAACAAAAUUAGGGAAUUGAUGAGUGUCCCUUACUGCAAUUACACAAAAUUUUSGUAUGUCAACCACACACUUUCAGGACAACACUcAUUACcA
372 R C W L I K N N S Y L N I S D F R N D W I L E S D F L I S E M L S K E Y S D R Q
1201 AGGUGCUGGUUAAUAAAAAACAA•AGCUAUUUGAACAUUUCUGACUU•CGUAAUGACUGGAUACUAGAAAGUGACUUCUUAAUUUCUGAAAUGCUAAGCAAAGAGUAUUCGGACAGGCAG
412 G K T P L T L V D I C F W S T V F F T A S L F L H L V G I P T H R H I R G E A C 1321 GGCAAAACUCCCUUGACUUUAGUUGACAUCUGUUUUUGGAGCACAGUAUUCUUCACAGCGUCCCUCUUCCUUCACUUGGUGGGCAUACCCACCCAUAGGCACAUCAGAGGCGAGGCAUGC
452 P L P H R L N S L G G C R C G K Y P N L K K P T V W R R (3 H * 1441 CCUCUGccCcACAGGCUAAAUAGcUUGGGUGGUUG~AGAUGUGGUAAGUACCCCAAUCUAAAGAAACCAACAGUUUGGCGCAGAG~ACACUAAGACcUCcCGAAGGUCCdC~CCCG
G . . . . . . . . . . . . . . . . . i 1561 GCAUUGCCCGGGCUGG~UGC~CCCCCCAGUCCGCGG~CUGGCCGCGGACUGGGGAGGCACUGCUUACAGUGCAUAGGCUGCCUUCGGGAGGAACAGCAAGCUCGGUGGUAAUAGAGGUG
* L A Y A A K P L F L L S P P L L P T
1681UAA~UUcUUcUUcAUAGAGCUUccCAUCCAACACUGACUGAAAcAUUA~GCAGUCUAGCAGAGCACAGUGUGGCUCACUGGAGGCCAACUUAAAGG~AGCAUCCUUAUCUCUCUUUUUCU 546 L E E E Y L K G D L V S Q F M Y C D L L A C H P E S S A L K F P A D K D R K K K
1801UGCUGACAACCACUCCAUUGU•AUGUUUGCAUAGGUGGcCAAAUUUCUCCCA•ACCUGUUGGUCGAACUGCCUGGCUUGUUCUGAUGUAAGCCUAACAUCAACCAGCUUAAGAUCUCUUC 506 S V V V G N H H K C L H G F K E W V Q Q D F Q R A Q E S R L R V D V L K L D R R
1921UUCCAUGGAGGUCAAACAACUUCCUGAUGUCAUCGGACCCUUGAGUGGUCACAACCAbGUCCGGAGGCAGCAAGCGAAUCACGUAACUAAGAACUCCUGGCAUUGCAUcUUCUAUGUCUU 466 G H L D F L K R I D D S G Q T T V V M D P P L L G I V Y S L V G P M A D E I D K
2041UCAUUAAGAUGCCGUGAGAGUGUcUGCUAcCAUUUUUAAACCCUUUCUCAUCAUGUGGUUUUCUGAAGCAGUGAAUAUAcUUGCUACCUGCAGGCUGGAACAACGCCAUCUcAACAGGGU 426 M L I G H S H R S G N K F G K E D H P K R F C H I Y K S G A P Q F L A M E V P D
2161CAGUAGCUGGUcCUUCAAUGUcGAGCCAAAGGGUAUUGGUGGGGUCGAGUUUCCCCACUGCCUCUcUGAUGAcAGCUU•UUGUAUCUCUGUcAAGUUAGCCAAUcUCAAAUUCUGACCGU 386 T A P G E ] D L W L T N T P D L K G V A E R I V A E Q I E T L N A L R L N Q G N
2281UCUUUUcCGGUUGUCUAGGUCcAGCAACUGGU•IUCCUUGUCAGAUCAAUACUUGUGUUGUCCCAUGACCUGCCUAU•AUUUGUGAUCUGGAACCAAUAUAAGGCCAACcAUcGcCAGAAA 346 K E P Q R P G A V P K R T L D I S T N D W S R G I I Q S R S G I Y P W G D G S L
2401GGCAAAGUUUGUACAGAAGGUUUUcAUAAGGGUUUCUAUUGCCUGGUUUCUCAUCAAUAAACAUGCCUUCUCUUCGUUUAACCUGAAUGGUUGAUUUUAUGAGGGAAGAAAAGUUAUcUG 306 C L K Y L L N E Y P N R N G P K E D 1F M G E R R K V Q 1T S K 1L S S F ~ D P
2521GGGUGACU•UGAUUGU•UCCAACAUAUUUCCAUCAUCAAGAAUGGAUGCACCAGCCUUUACUGCAGCUGAAAGACUAAAGUUGUAGCCAGAAAUGUUGAUGGAGCUUUCAUCCUUAGUCA
266 T V R I T E L M N G 0 D L I S A G A K V A A S L S F N Y G S I N I S S E D K T V
2641CAAUCUGGAGGCAGUCAUGUUCCUGAGUCAAUCUGUCAAGGUCACUCAAGUUUGGAUACUU•ACAGUGUAUAGAAGCCCAAGAGAGGUUAAAGCCUGUAUGACACUGUUCAUUGUCUCAC
226 I Q L C 0 H E Q T L R D L D S L N P Y K V T Y L L G L S T L A Q I V S N M T E G
276! CUCCUUGAACAGUCAUGCAUGCAAUUGUCAAUGCAGGAACAGAACCAAACUGAUUGUUAACUUUUGAAGGAUCUUUAACAUCCCAUACCCUCACCACACCAUUUCCCCCAGUUCCUUGCU
186 G Q V T M C A I T L A P V S G F Q N N L K S P 0 K V 0 W V R V V G N G G T G Q Q
2881GUUGAAAUCCCAGUGUUCUCAAUAUCUCUGAUCUCUUGGCCAGUUGUGACUGAGACAAGUUAC•CAUGUAAACCCCUUGAGAGCCUGUCUCUG•UCUUCUAAACUUGGUUUUUAAAUUCC
146 Q F G L T R L I E S R K A L Q S Q S L N G M Y V G Q S G T E A R R F K T K L N G
3001 •AAGGC•AGACG•CAACUCCAUCCGCUCAACCCUCCCCAGAUCU•CCGCCUUGAAAACCGUGUUUCGUUGAACACUCCUCAUGGACAUGAGUCUGUCAACCU•UUUAUUCAGGUCCCUCA
106 L G S A L E M R E V R G L D G A K F V T N R Q V S R M S M L R D V E K N L D R L
3121ACUUAUUGAGGUCUUCUU•C••C•UUUUAGUCUUUCUGAGUGCCCGCUGCACCUGUGCCACUUGGUUGAAGUCAAUGCUGUCAGCAAUUAGCUUGGCAUCCUUCAGAACAUCCGACUUGA
66 K N L D E E G R K T K R L A R Q V Q A V Q N F D I S 0 A I L K A D K L V D S K V
3241CAGUCUGAGUAAAUUGAcUCAAACCUCUCCUUAAGGACUGAGUCCAUCUAAAGCUUGGAACCUCUUUGGAGUGUGCCAUGCCAGAAGAUCUGGUGGUUUUGAUcUGA•AAAAAAUUGCUc 26 T Q T F Q S L G R R L S Q T W R F S P V E K S H A M
3361 AGUGAAAGUGUUAGACACUAUGCCUAGGAUCCACUGUGCG N
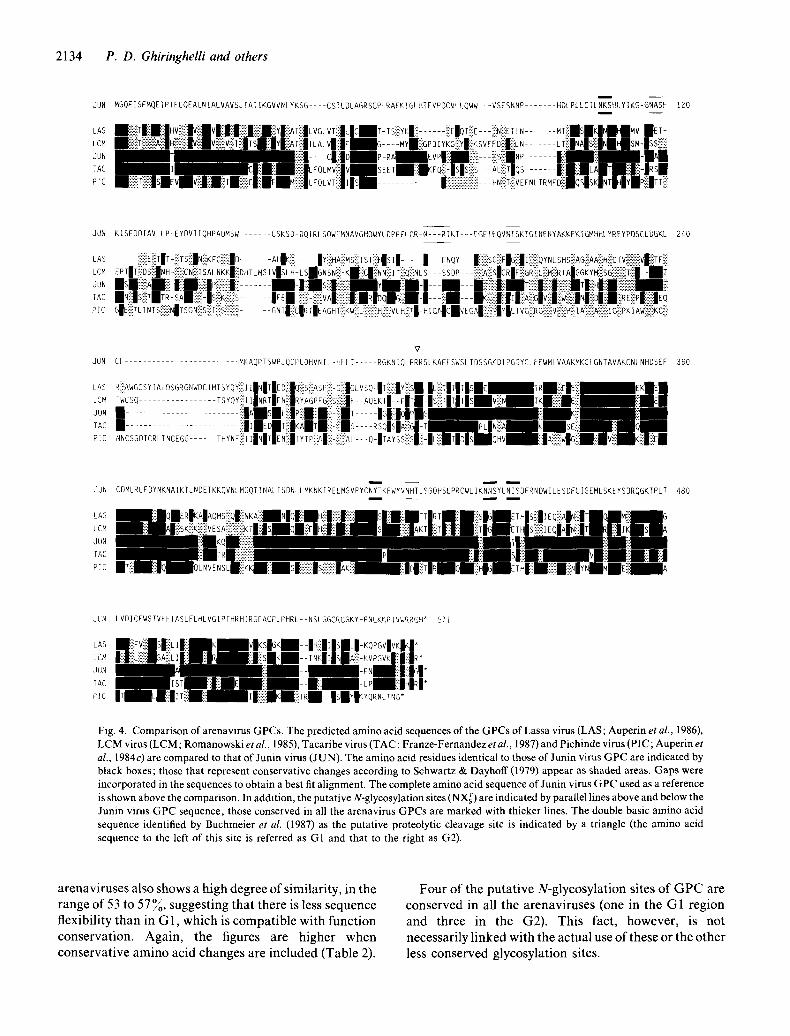
2134 P. D. Ghir inghel l i a n d others
i
JUN MGQFISFMQEIPTFLQEALNIALVAVSL[A[IKGVVNLYKSG-- -CS[LOLAGRSCP~RAFKIGLHIEVPOCVLLQWW --VSFSNNP . . . . HDLPLLCTLNKSHLYIKG-GNASF
LAS ~ : : :::: T !:::: ! i II H.Viiiiii |V : : iV | ii|:::: |::i::::#|iiii::iiii::liiiilY |ii::i~A Tii!::| L V G L V Ti::i:::! L lC ~ T - T S ::ii:i:Y ~ ::i;::: . . . . !i::i::::E |0 T !i:::i: E - - - !::Nii::i::iE T L N . . . . .T::II::ISI4,IHI.v-IE'r: LCM i ~ 4 1 m E : : : T:::::: :::~ ~ : !:!:::::Iv ~ v::::::! :!:v I ::!:i IS :i: y :i:i~ Ti:i:i.:l ILALV I I :!:! F nG-- -MY ~ :i:i:G P D I Y KG!:i:i:Y . . . . . . . . . l;:-::i:i:K S V E ' Di:iiel:.:,: :i:i:L N . . . . . . L Ti:?:i¢.i N ~ S i:i:!!!!i! N • H • s.- I ss::,= ......
JUN ~ T U n l ~ ~ : i l - - c ! ! !onP-~ l~ ' ,P l i l l i i !~ : : - - -~ i~ : i : i l ,P . . . . . . l l n i i : : i - I I TA~ ~ ~ ~ c l ~ I i : : I : # I L r o L . V i i l i v n s ~ T I : : : I G ~ i : I i : : : I s l s : : i i : i S - - A L i : : i i : : T I Q s . . . . . . l i : : ! : : l i l i : : lLAI ITn~i i i - I~s l
n : : : : :T :IIS EV : :I ::: :C ::: F M::::::::::: LFQLVT::: S . . . . . . . . :::::::::::::::::::::::::::::::::---HN::::::T::::::VEFNLTRMFD::: QS SK NT H Y pi:i: TT: P~c ............... I ~ l i , i ! : : : : l ::! I I I . . . . . . . . . . . . . . . . . . . . . . . . . . l I m I I I .! ......
120
m
JUN KISFDD[AVLLP-EYDVIIQHPADMSW - --CSKSD DQIRLSQWFMNAVGHOWYLO#PFLCR N---RIK[---EGFIFQVN~SK%G[NENYAKKFK~GMHHLYRE?PDSCLDGKL
LAS . . . . . . . . . . . . . . . . . ! I ..... I ................... I I I I .............. I .:! .................................................. ! . . . - - -:i:;:i:i:i:Ei:i:i:TIIT ::::::::::::::::::::: D . . . . AH K::: . . . . Y:::HA:NS::::: ST:::H SI . . . . FNQY- ::::SC :F G:: ::::OYNLSHS:!iA~::iAA::Hi:GTV::::V :Trii::
LCM EmTIT!#!OSiiiiilNH-!!iiiiiCN!i!iiiTSAL NK~iiiD TLMS VIsLH-LSIGNS'N ~i:IKii icIi iNN iil Ti:iQi NLS---SSDP---i i i i~i i sIc~Ir~ iGR i!Lii M i RT~GGKYMi S~!i ii!:,!fi i I - i '~N • i~iii H i i;i~i!ii,:'~iii::it:iiii . . . . . ~mt : in~ i i i l : : : : i i i ! i i i i i i nY i l i l - i i -I!ii::~{iiill;~iiii:;l:;iiilTii~:.;ilTlilili.l!il®iiiililil
N!:!:i Si:!:!:T TR-SA :!!:i:i:- S::K::::::S . . . . FE ::::::-::::::VA ::::::: :: R DO G:: - : - K:::: :: I ~::G V: :::~::: N ::D :: ::RE::P : : EQ TAC I . I l i I • . . i I .............. I I ........................ I.:.:.:.:.:.i,:n I • ! I .... • • .:.:,:/:/:,1:.:i ! ........... I .:i ................ I L l i b .......... ~ . . . . . . . . . I ............... i =1 I ..... : . . . . . . . . . . . . . . . . . . . . . . . . . . I I I I::::::::11 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
GIEi:i:i:TLTNTS:!:!:i:i:i:N TSGN;:!:!:Si:i:i:Ii:!:i:S:i:i:i:!:i:i:i:i:- --GNI :::C RT ::::::::::::::::::::::::::::::::::::::::::::::: -H[GA C VEGA ::::::: Y L~VG::::RGi'i#~:V~:~i~£:H'iiA~;#i!~A'!"iG~(;PK]A~i#iKC ~!i:
240
JUN CL . . . . . . . . . . . . . MKAQPTSWPLQCPLOHVNIL- HFLT- - RGKN [QLPRRSLKAFFSWSL TDSSGKDTPGGYCL E EWMLVAAKMKCFGNTAVAKCNLNHDSEF
R!:!:iAWGGSY ALDSGRGNWDCIMTSYQYi:!:!: I N T EDi:i:i Q:::S::ASP:::-G:: GLVSQ- Ti:i:!:!:!:! ¥:i:i:S Li:i:i:T ~ T S E ~R :i~:E E~£ EK E LAS . . . . . . . . . I I I ~1 ............. i l . : : i : . l : : . : l l . : : : l l l l I i : . : . : l ~ . : . ~ K I I TWCSQ . . . . . . TSYOY::II NRT EN: RYAGPFGi:i:i:S':::i:!:! F--AQEKT -F T - S:::T T T S Vi:i:i:N TK :: E i:i:! E
Ju, • . . . . . . . . . . . :- i l i l l s l ~ i : : i i ~ l l i : : - ~ l . . . . H : : i o l ~ ' l ~ ~ i i i / < ! : : ~ i i / :AC l . . . . . . . . . . . . . . . i]::i:IJEDIT::i::IIKJTNI::I-i!IIs -- RS01SI<iGI T I P L | " i j : : i # I K / S E I I i i l i i ] i 0 1 pic N"CSGOTC~LT,CEGG -- T"YN<i::ii~l"lTIE"i::ii:lTYTP::::::i3::;::::-iii::i::iii~L-- Q ~TAYss~s~::!::::.~L::ii~!~T~D~s~Q"v~::::i~A~::ii::::::iiiw~Giiii~i::i::~viii::i~Kiiii~iiiiiE~
360
JUN
LAS
LCM
JUN
TAC
PIC
m - - w m
C DML R L F D YNKNA I K [L N DE T KKOVNL M GQTINALIS D NL L MKNKIR E L MS V P Y C N Y TKFWY V N H T L S GQHS L PRCWLIKNN S Y L N ISDFR N DW i L E S D F L[S E M L S KE Y S DRQGKTPL T 480
JUN LVDICFWSTVFFTASLFLHLVGIPTHRHIRGEACPLPHRL NSLGGCRCGKY-PNLKKPTV,dRRGH * 57~
LAS l i i i i i F V i i i l s l i i i i L ~ l i l . | v l K s l G K I I tH!i!!!I~IslLI-.Q~GvlwI~I* [.~:M iilliiiLi~;ii::iSAiiiiiit- ~IMii i lRIi l i~i~SI"II-T,~I~IsIAi~!~:;-,V'~GwiH~* JU,,, ~ ~ ~ i i l a - ~ - p , / : : i l l G l * TA~ ~ ~ s T l i l E / i : : i l _ l i B _ L , B H , ~ I ~
Fig. 4. Comparison of arenavirus GPCs. The predicted amino acid sequences of the GPCs of Lassa virus (LAS; Auperin et al., 1986), LCM virus (LCM; Romanowski et al., 1985), Tacaribe virus (TAC; Franze-Fernandez et al., 1987) and Pichinde virus (PIC; Auperin et al., 1984c) are compared to that of Junin virus (JUN). The amino acid residues identical to those of Junin virus GPC are indicated by black boxes; those that represent conservative changes according to Schwartz & Dayhoff (1979) appear as shaded areas. Gaps were incorporated in the sequences to obtain a best fit alignment. The complete amino acid sequence of Junin virus GPC used as a reference is shown above the comparison. In addition, the putative N-glycosylation sites (NXs T) are indicated by parallel lines above and below the Junin virus GPC sequence; those conserved in all the arenavirus GPCs are marked with thicker lines. The double basic amino acid sequence identified by Buchmeier et al. (1987) as the putative proteolytic cleavage site is indicated by a triangle (the amino acid sequence to the left of this site is referred as G1 and that to the right as G2).
arenaviruses also shows a high degree o f similarity, in the range of 53 to 57%, suggesting that there is less sequence flexibil ity than in G 1, wh i ch is compat ib le wi th funct ion conservation. Again , the figures are higher when conservat ive amino acid changes are included (Table 2).
Four o f the putat ive N-glycosylat ion sites o f G P C are conserved in all the arenaviruses (one in the G1 region and three in the G2). This fact, however, is not necessari ly l inked with the actual use o f these or the other less conserved glycosylat ion sites.
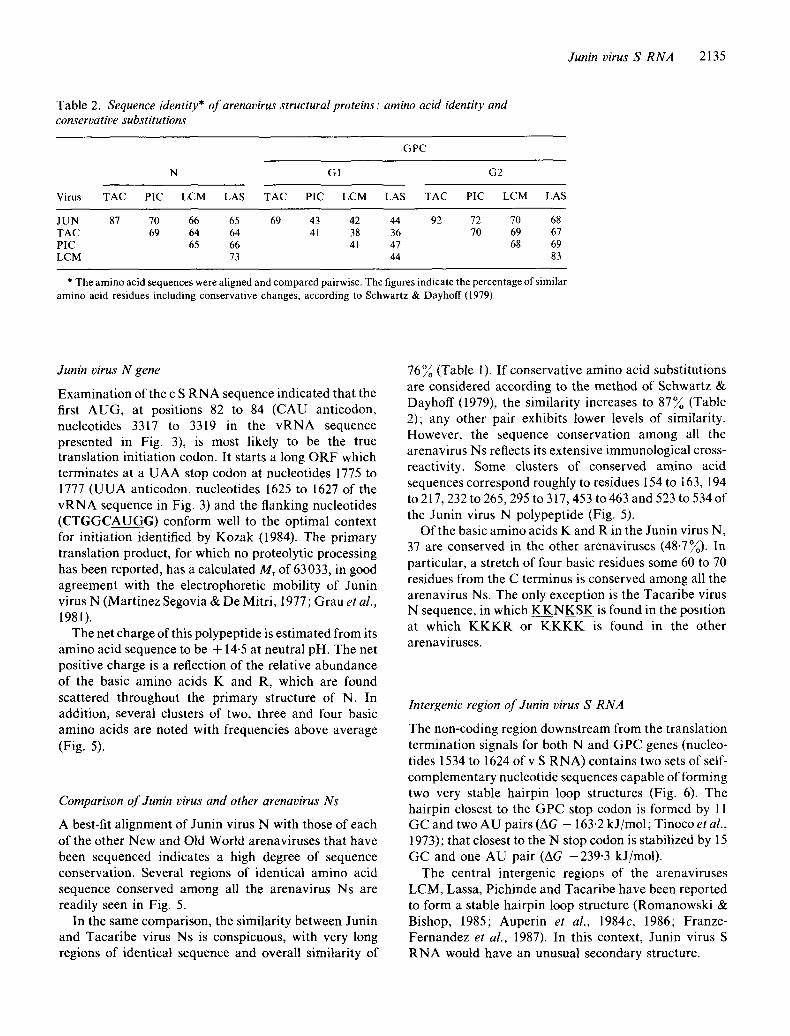
Junin virus S RNA 2135
Table 2. Sequence identity* of arenavirus structural proteins: amino acid identity and conservative substitutions
GPC
N GI G2
Virus TAC PIC LCM LAS TAC PIC LCM LAS TAC PIC LCM LAS
JUN 87 70 66 65 69 43 42 44 92 72 70 68 TAC 69 64 64 41 38 36 70 69 67 PIC 65 66 41 47 68 69 LCM 73 44 83
* The amino acid sequences were aligned and compared pairwise. The figures indicate the percentage of similar amino acid residues including conservative changes, according to Schwartz & Dayhoff (1979).
Junin virus N gene
Examination of the c S RNA sequence indicated that the first AUG, at positions 82 to 84 (CAU anticodon, nucleotides 3317 to 3319 in the vRNA sequence presented in Fig. 3), is most likely to be the true translation initiation codon. It starts a long ORF which terminates at a UAA stop codon at nucleotides 1775 to 1777 (UUA anticodon, nucleotides 1625 to 1627 of the vRNA sequence in Fig. 3) and the flanking nucleotides (CTGGCAUGG) conform well to the optimal context for initiation identified by Kozak (1984). The primary translation product, for which no proteolytic processing has been reported, has a calculated Mr of 63 033, in good agreement with the electrophoretic mobility of Junin virus N (Martinez Segovia & De Mitri, 1977; Grau et al., 1981).
The net charge of this polypeptide is estimated from its amino acid sequence to be + 14-5 at neutral pH. The net positive charge is a reflection of the relative abundance of the basic amino acids K and R, which are found scattered throughout the primary structure of N. In addition, several clusters of two, three and four basic amino acids are noted with frequencies above average (Fig. 5).
Comparison of Junin virus and other arenavirus Ns
A best-fit alignment of Junin virus N with those of each of the other New and Old World arenaviruses that have been sequenced indicates a high degree of sequence conservation. Several regions of identical amino acid sequence conserved among all the arenavirus Ns are readily seen in Fig. 5.
In the same comparison, the similarity between Junin and Tacaribe virus Ns is conspicuous, with very long regions of identical sequence and overall similarity of
7 6 ~ (Table 1). If conservative amino acid substitutions are considered according to the method of Schwartz & Dayhoff (1979), the similarity increases to 8 7 ~ (Table 2); any other pair exhibits lower levels of similarity. However, the sequence conservation among all the arenavirus Ns reflects its extensive immunological cross- reactivity. Some clusters of conserved amino acid sequences correspond roughly to residues 154 to 163, 194 to 217,232 to 265,295 to 317,453 to 463 and 523 to 534 of the Junin virus N polypeptide (Fig. 5).
Of the basic amino acids K and R in the Junin virus N, 37 are conserved in the other arenaviruses (48.7~). In particular, a stretch of four basic residues some 60 to 70 residues from the C terminus is conserved among all the arenavirus Ns. The only exception is the Tacaribe virus N sequence, in which K K N K S K is found in the position at which K K K R or K K K K is found in the other arenaviruses.
Intergenic region of Junin virus S RNA
The non-coding region downstream from the translation termination signals for both N and GPC genes (nucleo- tides 1534 to 1624 o f v S RNA) contains two sets of self- complementary nucleotide sequences capable of forming two very stable hairpin loop structures (Fig. 6). The hairpin closest to the GPC stop codon is formed by 11 GC and two AU pairs (AG - 163.2 kJ/mol; Tinoco et al., 1973); that closest to the N stop codon is stabilized by 15 GC and one AU pair (AG -239 .3 kJ/mol).
The central intergenic regions of the arenaviruses LCM, Lassa, Pichinde and Tacaribe have been reported to form a stable hairpin loop structure (Romanowski & Bishop, 1985; Auperin et al., 1984c, 1986; Franze- Fernandez et al., 1987). In this context, Junin virus S RNA would have an unusual secondary structure.

JUN
JUN MAHS~EvPSF~WTQSL~RGLSQFTQT~S~VL~DA~L~ADS~DFNQvAQvQ;AL~KT~RGEEDLN~L;DLN~E~LMSM;S~Q;NT~F~A~L~;~E;MELAS~LGN~T~F~RAE-T~ 120
LAS IsAi~~l l~ .~S, i i |L~iQAi~i lL"i i i i l l s i ! |S , iLi l lEi l i~ i ! i i i i lKi i i lAI , NliiiE~ilTIQ KS~Iii~IivlTITs ~iiiL~ii' I~Jiii:~lslv ~II~L
.,c i i i , - P~C - - ~ i ! ! o l T i - i ~ i i i i ! i i , l ' - / t ! i i : ' 4 i i ~ l v r l ' r l - ~ L
JUN
SQ-GVYMGNLSQSQLA~RRSEIL~LGF . . . . ~GT~GN~GWRVWD~KDP~KLNNQFGS~PAL~ACM~QGGETMNS~QALT~LG~LYT~YPNLSDLD~L~QEHDCLQ~vT~E~ 240
2136 P. D. Ghiringhelli and others
LAS LCM JUN TAC PIC
S~N~SGYNFSLSAA~A~AS~LDDGNMLET~TPDNFSSL~ST~Q~K~REGMF~DE~PGN~NP~ENLLY~L~LSGDGWP~GS~SQ~G~SWDNT~LT~ ~ --PVAGP~QPE 360
LAS LCM JUN TAC PIC
3UN ~NGQNL~ . . . . LANLTE]QEAv~REA~GKLDPTNTLWLD~EGPATD~EMALFQPAGSKYIHC~KPHDEKGFKNGSRHSHG~LMKD~EDAMPG~LSY~GLLPPD~V~TQGSD~R-~L 480
LAS N S S K S IQ S A G F T IGI 5 51 L M Tiiiiiii!iiiij::::lililL Qiiiill N A K T li!:!IRiiiiiiE lii;l!!::l Si::iiii!::!~l F I E I Z I L IQIQiii::~iiii~ Y I DiiiiiT IiilF A T QliiiilT IAl::!i~Riiiil#|cl PGAAGPP .... QVG SYS TM :3!:!:!:!:!:Li:i G: NAPT :: RFN :: :: QN ::Q :: E T :i:i Q Q~ii :Y :!:i:D!:i:!~A :i:i:Fi:i Q~I~:~:TISIIAI@I:~:~:SC L CM .. I I ........................ I . :1 I . I Ii:l#]ile . . . . . . . . . . I | I H I .:!.:.: • ......... I:.:~ .:.! ........ :.:: : ! i ! i s c ~ l
JUN i ! : : l . . . . INl'iA~|li!IKITliilP~iT~i~iiiiiiK~-- ~ l i i i ~ TAC ::iiii~l .... IslIL~i~IAI~iiEI~I~,Ii~LQLIII~~i::I~I~ P[C ::iiillG S m D . . . . IK Q::.:-..P K E KID Tiii...V S S L. O M I R AI 1 I i . : l T:~.::. m / . i ::,:|1 g TL.. m I : i : I F / . : : . I I i . 0 Ni.~ Y I , i | . . | I j~ l IQl i . . i iLI S!S|R H I I ~ i ~ I F ~ / I I iii|
JUN FD~HGRRD~KLvDvR~T~EQA~QFDQQv~EKFG~L~KHHNGvvv~KKKRDKDAPFK~ASSE~CAL~D~IMFQsV~G~LYE~EEL~L~LFL~AAYA~* 584
LAS i!::iiii::i!i::SQ~;::|:~!!i~i~i|~::;~SK~i::i~s~Ki!i!::::::ii::~!NA~i::::iiQ~::::::iiKD~H~E~::i!i!GKEE~::::::::~-- -T~iii::~::::;~AA::::::;#SIGINT-SVIRAiI::;IIRI~iiiiiEIRTSTI::iRV::::::L** LCM ii::iil s Q N iiii::li::i::! Eiii;iS r-lA S I;ii;i;iiiiiiiiiil;i;ilKIli::iil31ii~MIz I ~ {~l;i!::iiiiii:: . . . . . I Z i ~ i : : | a S Ki;i!::!::ii|P::!iii!L P Ti#a NiiiH D|i;:l. G P N V V r I J~JN i ~ i i i ~ ~ ~ i ~ i i l A l i ! i K L AS S~i l i l v : : i : : i : : i t i i i jY i ; ! i - iT P I P S I I A l l i l ~ TAC ! ~ l ~ ~ i l i L i ~ i l i i l i ~ : : D i ~ i i N ~ i : i : : s l s l P SP S P t ~ ~ : : i | A i i i i s l E I P K IP ] I K E i : i i ' r l i I PIc :::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: . . . . T T A NIP ~ TlI:::::i~ T::ii::::::T G~::::::iiR::::::ii-::::iii::K P MR C I I D T liiiR N N T D L I N L *
Fig. 5. Comparison of the amino acid sequences of the Ns of the Old World arenaviruses Lassa (LAS; Clegg & Oram, 1985) and LCM virus strain WE (LCM; Romanowski & Bishop, 1985), and the New World arenaviruses Tacaribe (TAC; Franze-Fernandez e t al., 1987) and Pichinde (PIC; Auperin e t al., 1984a) with that of Junin virus (JUN; Ghiringhelli et al., 1989). The similarities among the amino acid residues are indicated as in Fig. 4, and the reference Junin virus N sequence is printed above the aligned sequences. The basic amino acid residues K and R are highlighted with thick lines above the sequence of Junin virus N.
5" and 3" ends of Junin virus S RNA
The untranslated upstream sequences of the Junin virus GPC and N genes comprise 87 nudeotides of the 5' terminus of the S RNA and 81 nucleotides complement- ary to the 3' end, respectively.
These two regions can be aligned to form a partially double-stranded structure stabilized by hydrogen bonds
between complementary sequences (Fig. 7). Two alterna- tive structures formed by 54 or 56 hydrogen-bonded base pairs possess the most negative free energy of stabiliz- ation, calculated to be -242-7 kJ/mol according to Tinoco et al. (1973). It should be noted that the actual 3' terminus of Junin virus S RNA has not been directly sequenced. However, in view of the fact that the oligonucleotide 5' CGCACAGTGGATCCTAGGC
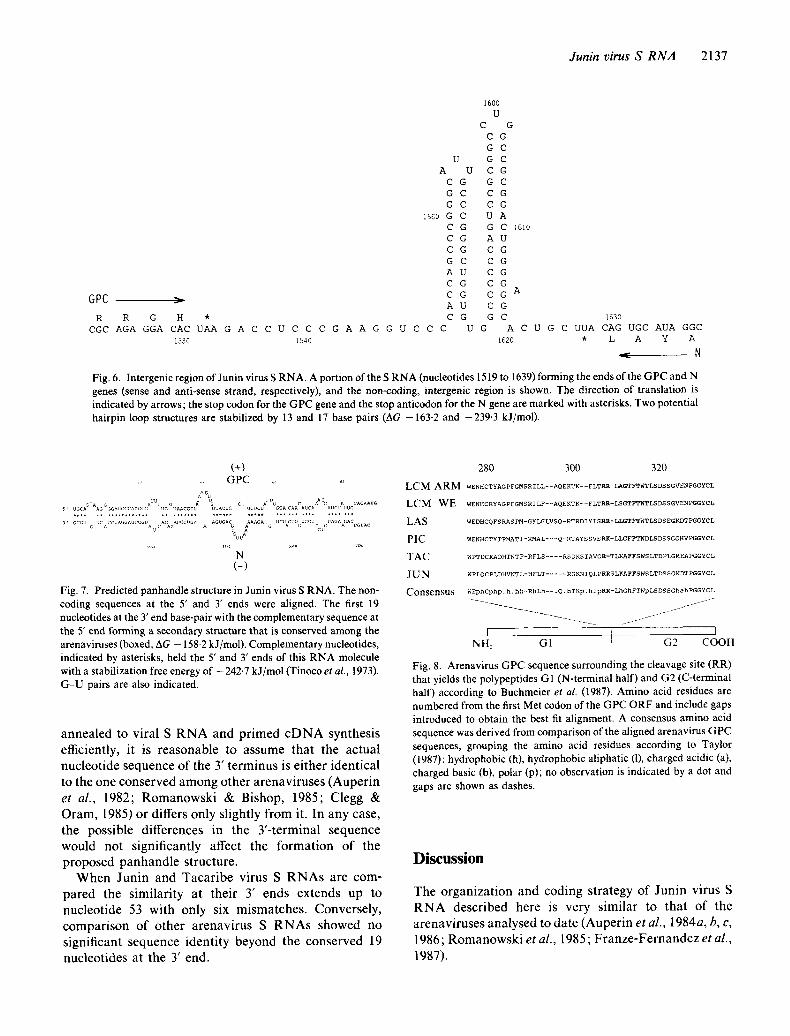
Junin virus S RNA 2137
U
A U
C G
G C
G C
15co G C
C G
C G
C
G
A
C
GPC ~ c A
R R G H * C
CGC AGA GGA CAC UAA G A C C U C C C G A A G G U C C C
1530 1540
1600
u
c G C G G C G C C G G C C G C G U A G C 161o A U
G C G C C G U C G G C G G C G A
U C G G G C 163o
U G A C U G C UUA CAG UGC AUA GGC
1620 * L A Y A
Fig. 6. Intergenic region of Junin virus S RNA. A portion of the S R NA (nucleotides 1519 to 1639) forming the ends of the G PC and N genes (sense and anti-sense strand, respectively), and the non-coding, intergenic region is shown. The direction of translation is indicated by arrows; the stop codon for the GPC gene and the stop anticodon for the N gene are marked with asterisks. Two potential hairpin loop structures are stabilized by 13 and 17 base pairs (AG -163.2 and -239-3 k J/tool).
(+) . . . . . GPC ,,
A a % u uu u u c u u AC ¢ A U C A C A V A C ~ U G A C A U G A
5' UGCA AG GGAUCCUAGGCG UG UAACGCU UUACUG "UUUCU GGA CAA AUCA AUCU UUG
3' GCGU G UCACCUAGGAUCCGU A cACAGAUUGUGA A AGUGAC U AAAGA UCU GUU UCGU UAGA GAC
c U u A
N (-)
Fig. 7. Predicted panhandle structure in Junin virus S RNA. The non- coding sequences at the 5' and 3" ends were aligned. The first 19 nucleotides at the 3' end base-pair with the complementary sequence at the 5' end forming a secondary structure that is conserved among the arenaviruses (boxed, AG - 158.2 kJ/mol). Complementary nucleotides, indicated by asterisks, held the 5' and 3' ends of this RNA molecule with a stabilization free energy of - 242.7 k J/tool (Tinoco et al., 1973). G-U pairs are also indicated.
annealed to viral S RNA and primed cDNA synthesis efficiently, it is reasonable to assume that the actual nucleotide sequence of the 3' terminus is either identical to the one conserved among other arenaviruses (Auperin et al., 1982; Romanowski & Bishop, 1985; Clegg & Oram, 1985) or differs only slightly from it. In any case, the possible differences in the Y-terminal sequence would not significantly affect the formation of the proposed panhandle structure.
When Junin and Tacaribe virus S RNAs are com- pared the similarity at their 3' ends extends up to nucleotide 53 with only six mismatches. Conversely, comparison of other arenavirus S RNAs showed no significant sequence identity beyond the conserved 19 nucleotides at the 3' end.
280 300 320
LCM ARM WEr~HCTyAGprGr~S~LL--AQEKTK--FLrRa-~G~rWrLSDSSGVZ~GYCL
LCM WE WENHCRYAG PFGMS R I LF - -AQEKTK- - F LTRR-LSGTFTWTLS DS SGVEN PGGYCL
L A S WEDHCQFSRAS pM-GYLGLVSQ-RTRDI YI SRR-LLGTFTWTLSDSEGKDTPGGYCL
P I E WENHCTYTPMATI -RMAL- --Q-RTAYSSVS RK-LLGFFTWDLSDSSGGHVPGGYCL
TAC WPTDCKADHTNTF-R FLS .... RSQKS IAVGR-TLKAFFSWS LTDPLGMEAPGG¥ CL
JUN WPLQCPLDHVNTL-H FLT ..... RGKN I QLPRRS LKAFFSWSLTDSSGKDTPGGVCL
C o n s e n s u s WEphCphp. h. hh-RhLh--. Q. bTKp. hl pRR-LhGhFTWpLS DSSGbahPGGYCL
/ /
I I NH2 G1 G2 COOH
Fig. 8. Arenavirus GPC sequence surrounding the cleavage site (RR) that yields the polypeptides G1 (N-terminal half) and G2 (C-terminal half) according to Buchmeier et aL (1987). Amino acid residues are numbered from the first Met codon of the GPC ORF and include gaps introduced to obtain the best fit alignment. A consensus amino acid sequence was derived from comparison of the aligned arenavirus GPC sequences, grouping the amino acid residues according to Taylor (1987): hydrophobic (h), hydrophobic aliphatic (1), charged acidic (a), charged basic (b), polar (p); no observation is indicated by a dot and gaps are shown as dashes.
Discussion
The organization and coding strategy of Junin virus S RNA described here is very similar to that of the arenaviruses analysed to date (Auperin et aL, 1984a, b, c, 1986; Romanowski et al., 1985; Franze-Fernandez et al., 1987).

2138 P. D. Ghiringhelli and others
The AUG codon nearest the 5' end of the v S RNA starts a long ORF encoding GPC. The other ORF starts at the first AUG codon from the 5' end of the c S RNA) and encodes N (Ghiringhelli et al., 1989). Both coding assignments have been confirmed using various pro- karyotic and eukaryotic expression systems, and by analysing the recombinant proteins by Western blotting with MAbs (Sanchez et al., 1989; R. V. Rivera Pomar et al., unpublished results).
Relatively extensive amino acid sequence identity has been noted among the homologous gene products of the arenaviruses, although the sizes of GPC may vary considerably.
Using peptide-specific antibodies, Buchmeier et al. (1987) have defined the proteolytic cleavage site of the GPC of LCM virus (Armstrong strain) which produces the structural glycoproteins GP-1 and GP-2; this cleavage occurs after the Arg 262-Arg 263 sequence. This double basic amino acid sequence is conserved in the other arenaviruses, including Junin virus (Arg 243 Arg 244).
By contrast, alignment of the Tacaribe virus GPC sequence with those of the rest of the arenavirus shows only a single Arg followed by a Thr. Nevertheless, Tacaribe virus GPC is proteolytically processed to give a G protein similar in size to other arenavirus G1 or G2 proteins. This fact, taken together with the existence of other dibasic amino acid sequences in non-conserved regions of GPC (e.g. Lys 186-Lys 187 and Lys 319- Lys 320 of Junin virus GPC) and N that are not known to be targets for proteolytic processing, suggests that the double basic amino acid cluster is not an essential feature of the cleavage specificity. Most likely, the protease involved in the processing of GPC requires only one basic amino acid in a sequence context that makes the particular peptide bond accessible. The sequence requirements might include all or part of the predomi- nantly hydrophobic, 23 amino acid sequence conserved in all the arenaviruses, including Tacaribe virus (Fig. 8). The fact that only a single G protein has been identified in Tacaribe virions remains intriguing, although this might be the result of the other product of GPC being lost during virion purification procedures.
Extending the analysis to the complete GPC sequence, the high level of amino acid identity in the G2 portion should be noted (C-terminal half of GPC); this increases from 51 to 82~o to 67 to 92~o when conservative amino acid changes are included. These data may indicate that the arenavirus G2 sequences have been conserved for functional reasons. Specifically, it has been suggested that LCM virus GP-2 is a transmembrane glycoprotein that interacts with the nucleocapsid complex inside the virion (Buchmeier & Parekh, 1987). It is not known whether this interaction occurs through electrostatic
interactions with the C terminus of G2 (six Arg, three Lys and four His in the 40 C-terminal amino acids). One could hypothesize that multiple interactions with other structures impose more constraints on sequence vari- ation. The sequence conservation in G2 or GP-2 is also reflected by the reactivity of several MAbs that bind to Old and New World arenaviruses in indirect immuno- fluorescence assays (Parekh & Buchmeier, 1986; Weber & Buchmeier, 1988).
Conversely, MAbs directed against GP-1 or G1 (N-terminal half of GPC) are either virus-specific or cross-react only with very closely related, heterologous viruses (Parekh & Buchmeier, 1986; Buchmeier et al., 1981). This is certainly a reflection of the sequence diversity of arenavirus G l s. However, alignment of the Junin virus G1 sequence with its closest relative, Tacaribe virus, reveals 50~o amino acid identity (69~ similarity if conservative amino acid sub- stitutions are considered), which is probably associated with the cross-protection and cross-neutralization of both viruses with either anti-Junin virus or anti- Tacaribe virus convalescent sera (Weissenbacher et al., 1976, 1982).
The Ns of the arenaviruses exhibit extensive sequence conservation, identity ranging from 47 to 76~ and increasing to 64 to 87~o if structurally similar amino acids are also included. The high level of sequence identity is in agreement with the isolation of cross- reacting MAbs and the identification of N as the complement-fixing antigen used to define the Arenaviri- dae family (Rowe et al., 1970; Buchmeier & Oldstone, 1978; De M itri & Martinez Segovia, 1980; Buchmeier et al., 1981).
A common feature of all Ns is the abundance of the basic amino acids Lys and Arg. Junin virus N contains 76 Lys and Arg residues, and 37 of them are conserved in position in the rest of the arenaviruses. This conservation is probably related to structure and function conser- vation, and interaction of the positively charged N with the negatively charged viral RNA.
Based on the observation that in the absence of protein synthesis only the subgenomic N mRNA is transcribed from the S RNA template upon infection (Franze- Fernandez et al., 1987), we and others have suggested that N is required for the transcription of a full-length copy of the genomic S RNA. This model would require N to recognize and bind to the intergenic hairpin struc- tures, i.e. the proposed transcription termination signal. In this respect, Junin virus N contains a basic amino acid-rich sequence (RALRKTKRGE) similar to those found in several RNA-binding proteins such as the N anti-terminators of phages 2, 21 and P22, some ribo- somal proteins, the human immunodeficiency virus Tat and others (Lazinski et al., 1989). We are currently

Junin virus S R N A 2139
investigating the role of N in the transcription/repli- cation process and its regulation.
The non-coding regions of the S R N A sequence of Junin virus exhibit a few interesting features. The Junin virus intergenic region has the ability to form a stable secondary structure consisting of two consecutive hair- pins rather than the single one seen in most of the other arenaviruses. While this manuscript was in preparation, a corrected version of the Tacaribe virus S R N A sequence was made available (M. T. Franze-Fernandez, personal communication); this showed two potential hairpin loop structures in the intergenic region. Simul- taneously, it was also shown that the intergenic region of Mopeia virus S R N A contains two sets of self- complementary sequences capable of forming two hairpin loops separated by 24 non-base-paired nucleo- tides (J. C. S. Clegg, personal communication). This type of hairpin loop structure has been shown to function as a termination signal in the transcription of Tacaribe virus L and S RNAs (M. T. Franze-Fernandez, personal communication).
The 5' and 3' non-coding sequences of Junin virus S R N A have the potential to form a partially double- stranded structure (Fig. 7). The resulting panhandle structure has a stabilization free energy of approximately -242 .7 kJ/mol, which compares well with the values calculated for other arenaviruses (not shown), and is sufficient to hold the 5' and 3' ends of the S R N A to produce circular forms of R N A and nucleocapsids, such as those observed by electron microscopy (Palmer et al., 1977; Vezza et al., 1978 ; Young & Howard, 1983). Other R N A viruses have been shown to contain partially complementary end sequences. In particular, the circular conformation of influenza A and La Crosse virus genomic R N A s has been confirmed experimentally using cross-linking reagents (Hsu et al., 1987; Raju & Kolakofsky, 1989).
The panhandle structure in influenza A virus R N A s has a relatively low stabilization energy (AG - 5 8 - 6 k J/tool) and requires p r o t e i n - R N A interactions to stabilize it. By contrast, the ends of the S R N A of La Crosse virus form a much more stable double-stranded structure (AG -127 . 2 kJ/mol) which has been shown to exist even in naked RNA. The magnitude of the free energy calculated for the base-pairing of the arenavirus S R N A ends favours the assumption that the predicted panhandle structures actually exist and are the chemical basis for the circular conformation observed in both nucleocapsids and isolated virus R N A (Palmer et al., 1977; Vezza et al., 1978; Young & Howard, 1983).
The 5' ends of Pichinde, Lassa, LCM and Tacaribe virus S RNAs have been shown to contain the conserved sequence 5' C G C A C C G G G G A U C C U A G G C , with an extra G in the case of Pichinde and Lassa viruses
(Auperin et al., 1984c, 1986; Romanowski et al., 1985; Franze-Fernandez et al., 1987). Therefore the first portion of the panhandle structures of these four arenaviruses is identical until the end of the sequence shown above; it differs thereafter. On the other hand, the same portion of the 5' end sequence of Junin virus is slightly different from the one described for the other arenaviruses (i.e. 5' U G C A G U A A G G G G A U C C U A - G G C ; differences are shown in bold). Nonetheless, the base-pairing with the 19 conserved nucleotides of the 3' terminus yields a structure similar to that in the other arenaviruses sequenced. Primer extension on viral R N A and sequencing of c D N A clones generated indepen- dently from a distinct strain of Junin virus confirmed the 5' end sequence.
This unexpected difference, found in a region which was presumed to be more conserved, might indicate that the viral R N A polymerase does not recognize an invariant nucleotide sequence at the 3' end when v or c R N A is used as template. In turn, the sequence specificity could be less stringent or the conserved panhandle secondary structure could be recognized as the R N A polymerase docking signal.
It will be possible to address this question using components generated from recombinant D N A as soon as suitable in vitro t ranscription-replication systems become available.
Note. While this manuscript was in the review process, a paper describing the S R N A of Mopeia virus was published (Wilson & Clegg, 1991).
We thank Dr Wim M. Degrave for kindly providing the computer facilities to conduct the DNA sequence analyses. We also thank Silvia A. Moya for manuscript preparation. This research was supported by grants from CONICET, SECYT and CYTED-D. P. D. G. and M. E. L. hold fellowships from CONICET, R.V.R.-P. from CIC BA; O. G. and V. R. are members of the research careers of CIC BA and CONICET, respectively.
References
AI~6N, M. C., GRAU, O., MARTINEZ SEGOVIA, Z. M. & FRANZE- FERNANDEZ, M. T. (1976). RNA composition of Junin virus. Journal of Virology 18, 833-838.
AUPERIN, D. D. & MCCORMICK, J. B. (1989). Nucleotide sequence of the Lassa virus (Josiah strain) S genome RNA and amino acid sequence comparison of the N and GPC proteins to other arenaviruses. Virology 168, 421-425.
AUPERIN, D. D., COMPANS, R. W. & BISHOP, D. H. L. (1982). Nucleotide sequence conservation at the 3" termini of the virion RNA species of New World and Old World arenaviruses. Virology 121, 200-203.
AUPERIN, D. D., GALINSKI, M. & BISHOP, D. H. L. (1984a). The sequences of the N protein gene and intergenic region of the S RNA of Pichinde arenavirus. Virology 134, 208-219.
AUPERIN, D., ROMANOWSKI, V. & BISHOP, D. H. L. (1984b). Genetic analyses of Pichinde and LCM arenaviruses; evidence for a unique organization for Pichinde S RNA. In Segmented Negative Strand Viruses, Arenaviruses, Bunyaviruses and Orthomyxoviruses, pp. 51-57. Edited by R. W. Compans & D. H. L. Bishop. New York : Academic Press.

2140 P. D. Ghiringhelli and others
AUPERIN, D., ROMANOWSKI, V., GALINSKI, M. S . & BISHOP, D. H. L. (1984 c). Sequencing studies of Pichinde arenavirus S RNA indicate a novel coding strategy, an ambisense viral S RNA. Journal of Virology 52, 897-904.
AUPERIN, D. D., SASSO, D. R. & MCCORMICK, J. B. (1986). Nucleotide sequence of the glycoprotein gene and intergenic region of the Lassa virus S genome RNA, Virology 154, 155-167.
BAILEY, J. M. & DAVIDSON, N. (1976). Methylmercury as a reverside denaturing agent for agarose gel electrophoresis. Analytical Bio- chemistry 70, 75 85.
BISHOP, D. H. L. (1988). The ambisense coding strategy of the S RNA of arenaviruses. In Modern Trends in Virology, pp. 99-108. Edited by H. Bauer, H.-D. Klonk & C. Scholtissek. Heidelberg: Springer- Verlag.
BISHOP, D. H. L., GOULD, K. G., AKASHI, H. & CLERX-VAN HAASTER, C. M. (1982). The complete sequence and coding content of snowshoe hare bunyavirus small (S) viral RNA species. Nucleic Acids Research 10, 3703 3713.
BUCHMEIER, M. J. & OLDSTONE, M. B. A. (1978). Identity of the viral protein responsible for serologic cross reactivity among the Tacaribe complex arenaviruses. In Negative Strand Viruses and the Host Cell, pp. 91-97. Edited by B. W. J. Mahy & R. D. Barry. Orlando: Academic Press.
BUCHMEIER, M. J. & PAREKH, B. S. (1987). Protein structure and expression among arenaviruses. Current Topics in Microbiology and Immunology 133, 41-57.
BUCHMEIER, M. J., LEWICKI, H. A., TOMORI, O. & OLDSTONE, M. B. A. ( 1981). Monoclonal antibodies to lymphocytic choriomeningitis and Pichinde viruses: generation, characterizaton and cross-reactivity with other arenaviruses. Virology 113, 73 85.
BUCHME1ER, M. J., SOUTHERN, P. J., PAREKH, B. S., WOODDELL, M. K. & OLDSTONE, M. B. A. (1987). Site-specific antibodies define a cleavage site conserved among arenavirus GPC glycoproteins. Journal of Virology 61, 982 985.
CHIRGWIN, J. M.,PRZYBYLA, A. E., MCDONALD, R. J. & RUTTER, W. J. (1979). Isolation of biologically active ribonucleic acid from sources enriched in ribonuclease. Biochemistry 18, 5294-5299.
CLEGG, J. C. S. & DRAM, J. n . (1985). Molecular cloning of Lassa-virus RNA: nucleotide sequence and expression of the nucleocapsid protein gene. Virology 144, 363-372.
DE MITRI, M. I. & MARTINEZ SEGOVIA, Z. (1971). Phytohemagglutinin unresponsiveness in leukopenia induced by Junin virus in guinea pigs. Acta virologica 16, 234-238.
DE MITRI, M. I. & MARTINEZ SEGOVIA, Z. (1980). Biological activities of Junin virus proteins. II. Complement-fixing polypeptides associated with the soluble antigen and purified particles. Inter- virology 14, 8~90.
DE MITRI, M. I. & MARTINEZ SEGOVIA, Z. (1985). Polypeptide synthesis in Junin virus infected BHK-21 cells. Acta virologica 29, 97 103.
ENRIA, D, A., FRANCO, S. G., AMBROSIO, A., VALLEJOS, D., LEWIS, S. & MAIZTEGUI, J. (1986). Current status of the treatment of Argentine hemorrhagic fever. Medical Microbiology and Immunology 175, 173 176.
FEINBERG, A. P. & VOGELSTEIN, B. (1983). A technique for radiolabelling DNA restriction fragments to high specific activity. Analytical Biochemistry 132, 6-13.
FRANZE-FERNANDEZ, M. T., ZETINA, C., IAPALUCCI, S., LUCERO, M. A., BOlSSOU, C., LOPEZ, R., REY, O., DAHEL1, M., COHEN, G. & ZALEIN, M. (1987). Molecular structure and early events in the replication of Tacaribe arenavirus S RNA. Virus Research 7, 309-324.
GHIRINGHELLI, P. D., RIVERA POMAR, R. V., BARO, N. I., ROSA.S, M. F., GRAU, O. & ROMANOWSKI, V. (1989). Nucleocapsid protein gene of Junin arenavirus (cDNA) sequence. Nucleic" Acids Research 17, 8001.
GRAU, O., FRANZE-FERNANDEZ, M. T., ROMANOWSKI, V., RUSTICI, S M. & ROSAS, M. F. (1981 ). J unin virus structure. In The Replication of Negative Strand Viruses, pp. 11 14. Edited by D. H. L. Bishop & R. W. Compans. Amsterdam: Elsevier/North-Holland.
GRUNSTEIN, M. & HOGNESS, D. S. (1975). Colony hybridization: a method for the isolation of cloned DNAs that contain a specific gene. Proceedings o[' the National Academy of Sciences, U.S.A. 72, 3961-3965.
GUBLER, U. & HOFFMAN, B. J. (1983). A simple and very efticient method for generating cDNA libraries. Gene 25, 263-269.
Hsu, M., PARVlN, J. D., GUIrrA, S., KRYSTAL, M. & PALESE, P. (1987). Genomic RNAs of influenza viruses are held in a circular conformation in virions and in infected cells by a terminal pan handle. Proceedings of the National Academy of Sciences, U.S.A. 84, 8140-8144.
IAPALUCCI, S., LOPEZ, R., REY, O., LOPEZ, N., FRANZE-FERNANDEZ, M. T., COHEN, G. N., LUCERO, M., OCHOA, A. & ZAKIN, M. M. (1989 a). Tacaribe virus L gene encodes a protein of 2210 amino acid residues. Virology 170, 40-47.
IAPALUCCI, S., LOPEZ, N., REY, O., ZAKIN, M. M., COHEN, G. N. & FRANZE-FERNANDEZ, M. T. (1989b). The 5' region of Tacaribe virus L RNA encodes a protein with a potential metal binding domain. Virology 173, 357-361.
JOHNSON, K. M., WEBE, P. A. & JUSTINES, G. (1973). Biology of Tacaribe-complex viruses. In Lymphocytic Chroriomeningitis Virus and Other Arenaviruses, pp. 241-258. Edited by F. Lehmann-Grube. Berlin : Springer-Verlag.
KOZAK, M. (1984). Compilation and analysis of sequences upstream from the translational start in eukaryotic mRNAs. Nucleic Acids Research 12, 857-872.
LAZINSKI, D., GRZADZIELSKA, E. & DAS, A. (1989). Sequence-specific recognition of RNA hairpins by bacteriophage antiterminators requires a conserved arginine-rich motif. Cell 59, 207-218.
MCKEE, K. T., JR, MAHLANDT, B. G., MAIZTEGUI, J. I., GREEN O. E., EDDY, G. A. & PETERS, C. J. (1985). Experimental Argentine haemorrhagic fever in rhesus macaques: virus strain-depen- dent clinical response. Journal of Infectious Diseases 152, 218- 221.
MAIZTEGUI, J. I. 0975). Clinical and epidemiological patterns of Argentine haemorrhagic fever. Bulletin of the World Health Organization 52, 657 675.
MAIZTEGUI, J. I., FERNANDEZ, N. J. & DE DAMILANO, A. J. (1979). Efficacy of immune plasma in treatment of Argentine haemorrhagic fever and association between treatment and a late neurological syndrome. Lancet ii, 1216 1217.
MAIZTEGUI, J. I., FEUILLADE, M. & BRIGGILER, A. (1986). Progressive extension of the endemic area and changing incidence of AHF. Medical Microbiology and Immunology 175, 73 78.
MANIATIS, T., ERITSCH, E. F. & SAMBROOK, J. (1982). Molecular Cloning: A Laboratory Manual. New York: Cold Spring Harbor Laboratory.
MARTINEZ SEGOVlA, Z. M. & DE MITRI, M. I. (1977). Junin virus structural proteins. Journal of Virology 21, 579 583.
MAXAM, A. & GILBERT, M. (1980). Sequencing end-labeled DNA with base-specific chemical cleavages. Methods in Enzymology 65, 499-560.
PALMER, E. L., OmJESKI, J. F., WEBB, P. A. & JOHNSON, K. M. (1977). The circular segmented nucleocapsid of an arenavirus- Tacaribe virus. Journal of General Virology 36, 541 545.
PAREK8, B. S. & BUCHMEIER, M. J. (1986). Proteins of lymphocytic chloriomeningitis virus: antigenic topography of the viral glyco- proteins. Virology 153, 168-178.
PFAU, C. J., BERGOLD, G. H., CASALS, J., JOHNSON K. M., MURPHY, F. A., PEDERSEN, I. R., RAWLS, W. E., ROWE, W. P., WEBB, P. A. & WEISSENBACHER, M. C. (1974). Arenaviruses. lntervirology 4, 207-210.
RAJU, R. & KOLAKOFSKY, D. (1989). The ends of La Crosse virus genome and antigenome RNAs within nucleocapsids are base paired. Journal of Virology 63, 122-128.
ROMANOWSKI, V. & BISHOP, D. H. L. (1985). Conserved sequences and coding of two strains of lymphocytic choriomeningitis virus (WE and ARM) and Pichinde arenavirus. Virus Research 2, 35-51.
ROMANOWSKI, V., MATSUURA, Y. & BISHOP, D. H. L. (1985). Complete sequence of the S RN A of lymphocytic choriomeningitis virus (WE strain) compared to that of Pichinde arenavirus. Virus Research 3, 101-114.
ROSAS, M. F., ROMANOWSKI, V. & GRAU, O. (1988). The phospholipid composition of arenaviruses. Anales de la Asociaci6n quimica argentina 76, 269 283.
ROWE, W. P., MURPHY, F. m., BERGOLD, G. H., CASALS, J., HOTCHIN, J., JOHNSON, K. M., LEHMANN-GRUBE, F., MIMS, C. A., TRAUB, E. &

Junin virus S R N A 2141
WEBB, P. A. (1970). Arenaviruses: proposed name for a newly defined virus group. Journal of Virology 5, 651-652.
RUSTICI, S. M. (1984). Desarrollo "'in vitro" del virus Junin, proteinas intracelulares. Ph.D. Thesis, National University of La Plata.
SABATTINI, M. S., GONZALEZ DE RIOS, L. E., DtAZ, G. & VEGA, V. R. (1977). Infeccion natural y experimental de roedores con virus J unin. Medicina "Buenos Aires 37 (supplement 3), 149 161.
SALVATO, M. ~g. SHIMOMAYE, E. M (1989)i .The complete sequence of lymphocytic choriomeningitis virus reveals a unique RNA structure and a gene for a zinc finger protein., Virology 173, 1-10.
SALVATO, M., SHIMOMAYE, E. ~ OLDSTONE, M. B. A. (1989). The primary structure of the lymphocytic choriomeningitis virus L gene encodes a putative RNA polymerase. Virology 169, 377 384.
SANCHEZ, A., PIFAT, D. Y., KENYON, R. H., PETERS, C. J., McCORMICK, J. B. & KILEY, M. P. (1989). Junin virus monoclonal antibodies: characterization and cross-reactivity with other arena- viruses. Journal of General Virology 70, 1125-1132.
SANGER, F., NICKLEN, S. d~. COULSON, A. R. (1977). DNA sequencing with chain-terminating inhibitors. Proceedings of the National Academy of Sciences, U.S.A. 74, 5463-5467.
SCHWARTZ, R. M. & DAYHOFF, M. O. (1979). Atlas of Protein Sequence and Structure, pp. 353-358. Edited by M. O. Dayhoff. Washington, D.C.: National Biomedical Research Foundation.
TAYLOR, W. R. (1987). Protein structure prediction. In Nucleic Acid and Protein Sequence Analysis, A Practical Approach, pp. 285 322, Edited by M. J. Bishop & C. J. Rawlings. Oxford & Washington D.C. : IRL Press.
TINOCO, I., BORER, P. N., DENGLER, B., LEVINE, M. D., UHLENBECK, O. C., CROTHERS, D. M. & GRALLA, J. (1973). Improved estimation of secondary structure in ribonucleic acids. Nature New Biology 246, 40 41.
VEZZA, A. C., CLEWLEY, J. P., GARD, G. P., ABRAHAM, N. Z., COMPANS, R. W. & BISHOP, D. H. L. (1978). Virion RNA species of the arenaviruses Pichinde, Tacaribe and Tamiami. Journal of Virology 26, 485-497.
VIEIRA, J. & MESSING, J. (1982). The pUC plasmids, an M13mpT- derived system for insertion mutagenesis and sequencing with universal primers. Gene 19, 259-268.
WEBER, E. L. & BUCHME1ER, M. J. (1988). Fine mapping of a peptide sequence containing an antigenic site conserved among arena- viruses. Virology 164, 30-38.
WE1SSENBACHER, M. C., COTO, C. E. ~¢~ CALELLO, M. A. (1976). Cross protection between Tacaribe complex viruses. Presence of neutraliz- ing antibodies against Junin virus (Argentine hemorrhagic fever) in guinea pigs infected with Tacaribe virus. Intert, irology 6, 42-49.
WEISSENBACHER, M. C., COTO, C. E., CALELLO, M. A., RONDINONE, S. N., DAMONTE, E. B. & FRIGERIO, M. J. (1982). Cross-protection in nonhuman primates against Argentine hemorrhagic fever. Injection and Immunity 35, 425 430.
WILSON, S. M. & CLEGG, J. C. S. (1991). Sequence analysis of the S RNA of the African arenavirus Mopeia: an unusual secondary structure feature in the intergenic region. Virology 180, 543-552.
YANISCH-PERRON, C., VIEIRA, J. & MESSING, J. (1985). Improved M I3 phage cloning vectors and host strains: nucleotide sequences of the Ml3mpl8 and pUC19 vectors. Gene 33, 103 119.
YOUNG, P. R. & HOWARD, C. R. (1983). Fine structure analysis of Pichinde virus nucleocapsids. Journal of General Virology 64, 833-842.
(Received 28 January 1991 ; Accepted 22 May I991)
Copyright © 2022 FDOKUMEN